
4. fragmentación vertical
24
FRAGMENTACIÓN VERTICAL
-
Upload
janoe-antonio-gonzalez-reyes -
Category
Education
-
view
107 -
download
0
Transcript of 4. fragmentación vertical
FRAGMENTACIÓN VERTICAL

FRAGMENTACIÓN VERTICAL
Cada fragmento vertical de una relación R produce los fragmentos R1, R2, …, Rn donde cada uno de ellos contiene un subconjunto de atributos de R así como la llave primaria.
Objetivo: Particionar la relación en partes más pequeñas para que las aplicaciones de usuario corran sobre un solo fragmento.

FRAGMENTACIÓN VERTICAL
Existen dos acercamientos heurísticos para la fragmentación vertical de relaciones globales: Agrupar: Asignar cada atributo a algún
fragmento, y en cada paso, reunir algunos fragmentos hasta que algún tipo de condición sea satisfecha.
Dividir: Comienza con una relación y decide particionar basándose en el comportamiento de accesos de aplicaciones a los atributos.
Dividir sólo se aplica a aquellos atributos que no son llave.

REQUERIMIENTOS DE INFORMACIÓN Necesitamos algún valor que pueda medir la noción
de “pertenencia” entre los atributos que son accedidos con mayor frecuencia (afinidad de atributos).
El principal requerimiento de información es la frecuencia de acceso.
Sea Q={q1, q2, …, qq} un conjunto de consultas que acceden a la relación R(A1, A2, …, An). Entonces para consulta qi y cada atributo Aj, asociamos un valor de uso de atributo, denotado por uso(qi, Aj) y definido como:
1 si el atributo Aj es referenciado por la uso(qi, Aj)= consulta qi
0 de otra manera

REQUERIMIENTOS DE INFORMACIÓN
Ejemplo: Considere la relación PROJ. Asuma que las siguientes relaciones están definidas para correr en esta relación.
q1: Encontrar el presupuesto de un proyecto, dado su número de identificaciónq2: Encontrar los nombres y presupuestos de todos los proyectos.q3: Encontrar los nombres de proyectos localizados en una cierta ciudad.q4: Encontrar el total del presupuesto de un proyecto dada una ciudad.

REQUERIMIENTOS DE INFORMACIÓN
Matriz de uso de atributos

REQUERIMIENTOS DE INFORMACIÓN
Necesitamos, además, la medida de frecuencia que mide el vínculo entre dos atributos de una relación y como son accedidos por las aplicaciones.
La medida de afinidad entre dos atributos Ai y Aj de una relación R(A1, A2, …, An) con respecto al conjunto de aplicaciones Q={q1, q2, …, qq} es definida por:

REQUERIMIENTOS DE INFORMACIÓN
donde refl(qk) es el número de accesos a los atributos (Ai, Aj) para cada ejecución de la aplicación qk en el sitio Sl y accl(qk) es la medida de la frecuencia de acceso de la aplicación previamente definida y modificada para incluir frecuencias en diferentes sitios.

REQUERIMIENTOS DE INFORMACIÓN
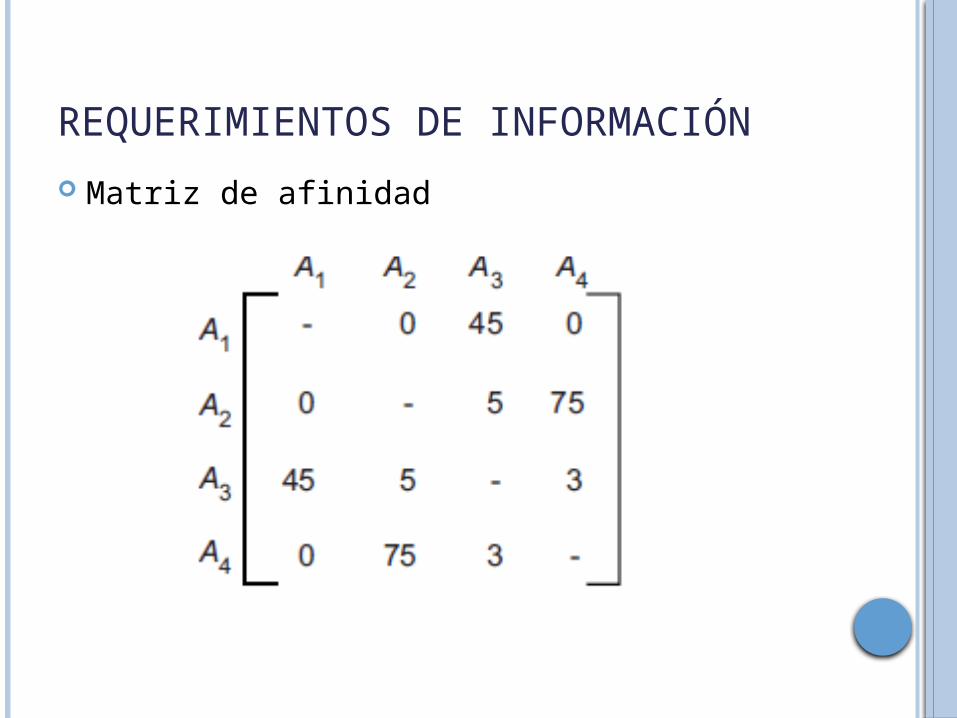
Continuemos con el ejemplo anterior. Por simplicidad, asumamos que refl(qk)=1 para toda qk y Sl. Si las frecuencias de aplicación son:
entonces la medida de afinidad entre los atributos A1 y A3 puede ser medida como:
REQUERIMIENTOS DE INFORMACIÓN
Matriz de afinidad

ALGORITMO DE AGRUPACIÓN
La tarea principal en el diseño de un algoritmo de fragmentación vertical es encontrar alguna característica para agrupar los atributos de una relación basada en los valores de afinidad de atributos (AA).
Lo que se pretende es maximizar la siguiente medida de afinidad global (AM):

ALGORITMO DE AGRUPACIÓN
Como la matriz de afinidad de atributos (AA) es simétrica, la función objetivo se reduce a:
donde

ALGORITMO DE AGRUPACIÓN

ALGORITMO BEA
1. Inicialización: Posicionar una de las columnas de AA arbitrariamente en CA.
2. Iteración: Escoger una de las columnas restantes y tratar de establecerla en alguna de las posiciones restantes de la matriz CA.
3. Orden de las filas: Una vez que el orden de las columnas esté definido, la posición de las filas debe cambiar de tal manera que sus posiciones concuerden con las posiciones de las columnas.

ALGORITMO BEA
Para la segunda parte del algoritmo definimos
Pero también debemos definir el vínculo entre dos atributos como

ALGORITMO BEA
Por tanto, la función objetivo a optimizar queda de la siguiente manera

ALGORITMO BEA
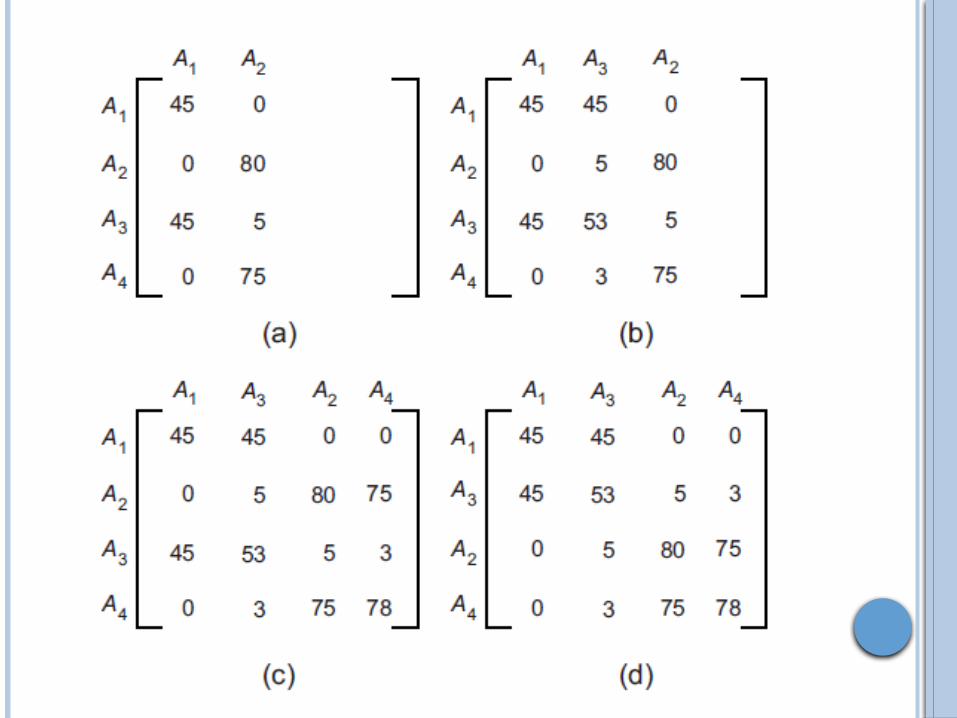
Consideremos el ejemplo anterior y estudiemos la contribución de mover el atributo A4 entre los atributos A1 y A2, dado por la fórmula
Cont(A1, A4, A2) =
2bond(A1, A4)+2bond(A4, A2) – 2bond(A1, A2)
bond(A1, A4)=135
bond(A4, A2)=11865
bond(A1, A2)=225
Cont(A1, A4, A2)=23550

ALGORITMO BEA
Cuando se desarrolla el algoritmo utilizando la fórmula Cont es necesario determinar las características inherentes de posicionar un atributo lo más a la derecha o lo más a la izquierda posible dentro de la matriz de agrupamiento. Para el ejemplo el primer paso es posicionar el atributo A1 en la primera columna, a partir de aquí podemos establecer A2 tanto a la izquierda como a la derecha de A1, sin embargo su vínculo es independiente de la posición en la que se encuentren. Por tanto continuamos con el atributo A3, el cual podemos poner a la izquierda de A1, entre A1 y A2, o a la derecha de A2.

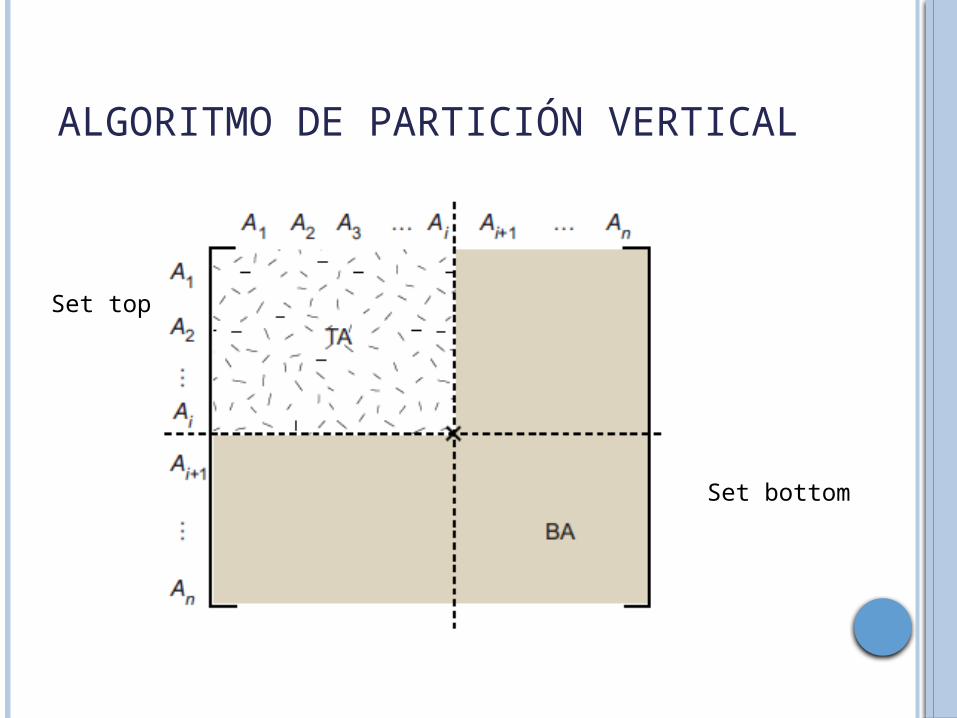
ALGORITMO DE PARTICIÓN VERTICAL
El objetivo de la división es encontrar conjuntos de atributos que sean accedidos únicamente, o para la mayoría de las partes, por distintos conjuntos de aplicaciones.
ALGORITMO DE PARTICIÓN VERTICAL
Set top
Set bottom

ALGORITMO DE PARTICIÓN VERTICAL

ALGORITMO DE PARTICIÓN VERTICAL
Maximizar el acceso a un solo fragmento y minimizar el acceso a varios (ambos).



















