
1. Introducción al método científico · 2013-09-20 · Introducción al método científico ......
38
1 Método científico. Teoría de la probabilidad. Variables. Evaluación de la asociación. Medidas de Riesgo e Impacto. Muestra y Población. 1. Introducción al método científico Ejemplo 1 En un estudio transversal, llevado a cabo en 1997, se deseaba conocer la prevalencia de diabetes mellitus en sujetos de edad mayor o igual a 20 años en la ciudad de Venado Tuerto (sur de la Provincia de Santa Fe, Argentina; población en ese año 38200). Con este propósito se obtiene una muestra que representa la distribución por edad y sexo de la población de Venado Tuerto (n=540), a través de una técnica de muestreo multietápico, aleatorizado de las viviendas y de los individuos dentro de las viviendas seleccionadas. Se emplearon los datos del último censo nacional. Se obtiene una prevalencia de 7.9%.
Transcript of 1. Introducción al método científico · 2013-09-20 · Introducción al método científico ......

1
Método científico. Teoría de la probabilidad. Variables. Evaluación de la
asociación. Medidas de Riesgo e Impacto. Muestra y Población.
1. Introducción al método científico
Ejemplo 1
En un estudio transversal, llevado a cabo en 1997, se
deseaba conocer la prevalencia de diabetes mellitus en
sujetos de edad mayor o igual a 20 años en la ciudad de
Venado Tuerto (sur de la Provincia de Santa Fe, Argentina;
población en ese año 38200). Con este propósito se obtiene
una muestra que representa la distribución por edad y sexo
de la población de Venado Tuerto (n=540), a través de una
técnica de muestreo multietápico, aleatorizado de las
viviendas y de los individuos dentro de las viviendas
seleccionadas. Se emplearon los datos del último censo
nacional. Se obtiene una prevalencia de 7.9%.

2
Ejemplo 2
Se intenta conocer el efecto de dos tratamientos en
pacientes con diabetes mellitus tipo 2 de reciente
diagnóstico, respecto del desarrollo o empeoramiento
de ciertas complicaciones microvasculares (nefropatía,
retinopatía, neuropatía). Para ello, 3200 pacientes, que
reúnen los criterios de inclusión y exclusión
establecidos en el protocolo, son asignados
aleatoriamente a dos grupos: el primero, a tratar
intensivamente (esto es, procurar el logro de glucemias
de ayunas inferiores a los 106 mg/dl) y el segundo a
tratar de manera convencional (esto es, procurando el
logro de valores glucémicos de ayunas inferiores a los
270 mg/dl). El seguimiento mediano es de 10.7 años.
Como resultado, el tratamiento intensivo reduce el
riesgo de desarrollo de complicaciones microvasculares
en un 25% respecto del tratamiento convencional.
Visto de un modo muy simple, el método científico consiste en un conjunto de
pasos a través de los que pretendemos validar una forma particular de
conocimiento al que hemos de llamar “científico”. Antes de abordarlo de un modo
más formal, conviene que tengamos en cuenta algunos aspectos preliminares:

3
1. En ciencias fácticas, trabajamos con muestras que deben ser representativas
de la población a la que pertenecen. En efecto, seleccionar una muestra (un
subconjunto de la población) que la represente no siempre es sencillo y resulta de
importancia fundamental para la correcta aplicación del método científico en
investigación clínica y epidemiológica. Cada problema planteado y propuesto para
su investigación exige una cuidadosa consideración acerca de la selección de la
muestra más apropiada. En el ejemplo 1, los autores procuran conocer la
prevalencia (esto es, el número de casos de una enfermedad sobre la población
en riesgo de padecerla, en un momento determinado) de diabetes en mayores de
20 años en Venado Tuerto, y para ello seleccionan al azar una muestra que
representa la distribución de la población general de Venado Tuerto en términos
de edad y sexo.
En el ejemplo 2, en cambio, dado que los autores procuran estudiar los efectos de
dos tratamientos para la diabetes mellitus tipo 2 (uno “intensivo” y otro
“convencional”), se seleccionan pacientes con diabetes tipo 2 de reciente
comienzo que cumplen con ciertos criterios de inclusión y exclusión (“criterios de
selección”), establecidos en el protocolo de investigación. Como vemos, en el caso
del ejemplo 1 se ha seleccionado una muestra que pretende representar a la
población general de Venado Tuerto, en tanto que en el ejemplo 2 se ha debido
obtener una muestra de sujetos perteneciente a la “población infinita” de
diabéticos tipo 2 de reciente comienzo. Ambos ejemplos tienen en común el
interés puesto de manifiesto en obtener muestras que representen a una
población a la que pertenecen.
2. Teniendo en cuenta la naturaleza y los objetivos de nuestro estudio, hemos de
identificar las variables que han de estar en el foco de nuestro interés. De manera
intuitiva, por variables entenderemos a las cualidades, atributos o magnitudes que

4
hemos de identificar en el contexto de nuestro estudio, y que serán objeto de
nuestra atención. Una propiedad importante de las variables es, precisamente, su
capacidad de “variar”, esto es, de asumir más de un valor posible. Por ejemplo, la
variable “sexo” (cualidad o atributo) puede asumir los valores “femenino” o
“masculino”; la variable “diabetes mellitus” puede asumir los valores “sí” o “no”; la
variable “glucemia” puede asumir infinitos valores dentro de unos límites (ejemplo,
101 mg/dl, 105 mg/dl, 106.7 mg/dl). Cada uno de estos valores constituye un
“dato”. Así, pues, “femenino” es uno de los datos posibles para la variable sexo.
3. Un proceso crucial en el contexto del método científico consiste en la
descripción de las variables en estudio. Debemos diferenciar los términos
“descripción” de “definición”. Definir una variable implica enunciar las
características que hacen que una variable sea esa y no otra. Consiste en apuntar
lo que la variable es. Podemos, por ejemplo, definir a la variable diabetes mellitus
diciendo: “se trata de una enfermedad crónica, progresiva e incurable,
caracterizada por hiperglucemia y debida a una insuficiente actividad de la
insulina”. Esta definición, correcta en principio y aceptable como “definición
general”, resulta poco operativa; con ella, será difícil diagnosticar o aun reconocer
a un diabético. Por ello, existen otras formas de definición, como, por ejemplo:
“hiperglucemia entendida como valores de glucemia iguales o superiores a los 126
mg/dl, o iguales o superiores a 200 mg/dl dos horas tras una carga oral de 75
gramos de glucosa en agua, o iguales o superiores a los 200 mg/dl en cualquier
momento del día, al azar, cuando se acompañe de síntomas tales como poliuria,
polidipsia o pérdida de peso”. Ahora bien; hemos dicho que definir no es describir.
En nuestro contexto, describir es dar de la variable una o más medidas. Cuando
digamos, por ejemplo, que “el 7% de los argentinos mayores de 20 años padece
diabetes mellitus”, estaremos describiendo a la variable diabetes. Cuando digamos
que la glucemia media de los varones mayores de 60 años es 98 mg/dl, estaremos

5
describiendo la variable “glucemia de varones mayores de 60 años”. Como se
comprenderá, la modificación de una definición operativa puede acarrear un
cambio en el valor medido. Si en lugar de definir diabetes sobre la base de una
glucemia de ayunas mayor o igual a 126 mg/dl lo hiciéramos tomando como punto
de corte una glucemia de 140 mg/dl, la proporción de personas con diabetes
podría verse modificada.
4. A menudo es de nuestro interés verificar si entre dos o más variables bajo
estudio existe asociación. No hemos de profundizar en el análisis de los aspectos
epistemológicos que involucra el concepto, ni hemos de discutir las variadas
formas en que puede ser entendida la asociación entre variables. Simplemente
diremos que, en su forma más simple, el término puede ser comprendido de la
siguiente forma: “dos variables están asociadas cuando, al variar una, la otra
también varía”. Esta forma de comprender la asociación entre variables (desde la
óptica de la “variación concomitante”) no pretende agotar otras interpretaciones,
pero procura introducirnos de manera sencilla a la comprensión de uno de los
aspectos más interesantes del método.
5. El que dos variables se encuentren asociadas no necesariamente implica que
la una sea la causa de la otra. En efecto, asociación no implica causalidad.
Veamos: a) “valores elevados de colesterolemia se asocian con una mayor
frecuencia de enfermedad coronaria”; b) “niveles altos de creatininemia se asocian
con una mayor frecuencia de complicaciones en los pacientes con insuficiencia
renal”. Respecto del enunciado a), con toda la provisionalidad que las ideas que
conforman el conocimiento científico en un momento de nuestra historia, podemos
afirmar con razonable convicción que la asociación es causal. Ello no implica que
todos los casos de enfermedad coronaria sean atribuibles a la hipercolesterolemia
y sólo a ella. Pero sí podemos aceptar que la hipercolesterolemia es una causa

6
importante (no la única) de enfermedad coronaria. Sin embargo, en el enunciado
b), la asociación no parece causal. En efecto, no es la creatininemia la causa de
las complicaciones de la insuficiencia renal crónica; la creatinina se acumula en la
falla renal y, junto con ella, dejan de eliminarse otras sustancias que son las
verdaderas responsables de las complicaciones que pueden hallarse en los
pacientes. En el caso de la hipercolesterolemia, la disminución de los niveles
séricos de colesterol ha de conducir a una disminución del riesgo de enfermedad
coronaria; en el segundo enunciado, la reducción exclusiva de la creatininemia de
ha de modificar el curso de la enfermedad, dado que no es la causa de las
complicaciones. No siempre es sencillo definir si una asociación es causal; por
ello, emplearemos el término causa de una manera sumamente cuidadosa,
reconociendo que la determinación de la causalidad de una asociación es uno de
los procesos más complejos y debatidos de la metodología en ciencias fácticas.
2. El método experimental.
Las consideraciones efectuadas anteriormente nos permitirán comprender mejor
las características de cada uno de los pasos del método.
Clásicamente, el primer escalón es el constituido por la observación. Por tal
entenderemos un “mirar con intención científica”. En efecto, la misma observación
en ciencias fácticas se optimiza cuando se desarrolla siguiendo un “plan”, que es
la manifestación de esta intención científica. La observación implica, además, que
el observador NO deber intervenir (al menos de manera deliberada) sobre el
sistema observado. Esta es una característica central en la observación científica:
el observador no debe manipular variables de manera intencional, no debe
modificar el curso de la naturaleza en lo que respecta al sistema bajo estudio.
¿Cuáles son los propósitos de la observación? Por un lado, podemos observar
con el propósito de describir. En efecto, pongamos por caso el del ejemplo 1. El

7
objetivo de los autores consistió en conocer la prevalencia de diabetes mellitus
tipo 2 en Venado Tuerto. El propósito fue descriptivo; aun así, se trató de un
estudio de observación. Los autores tenían un plan, no modificaron el curso de la
naturaleza, y obtuvieron una medida de la variable en estudio.
Sin embargo, otros estudios de observación procuran generar hipótesis. Por
hipótesis entendemos una “explicación preliminar de los hechos observados”.
Preliminar, en el sentido de que estas hipótesis serán confirmadas o rechazadas
en el terreno experimental. Estarán sujetas al contraste experimental, siempre
que sea posible.
Veamos el caso del “estudio Framingham”. Se trata de uno de los estudios de
observación que ha resultado clave en la epidemiología cardiovascular moderna.
Sus autores se instalaron en una comunidad relativamente pequeña en Nueva
Inglaterra (Estados Unidos), Framingham, con el plan de estudiar la asociación
entre diversas variables antropométricas, de la historia personal y familiar,
bioquímicas, etc. con la morbimortalidad cardiovascular. Entre las conclusiones
relevantes del estudio figuran afirmaciones tales como: “La colesterolemia guarda
una relación concentración/respuesta con la morbimortalidad cardiovascular”.
¿De qué se trata esta afirmación? Los autores no modificaron deliberadamente las
variables bajo estudio; no recomendaron, por ejemplo, cambios en el estilo de vida
ni prescribieron medicamento alguno. Solo observaron el comportamiento de un
número suficientemente grande de sujetos durante un tiempo suficientemente
prolongado. Al final, emitieron sus hipótesis: en efecto, a través de enunciados
tales como “la colesterolemia guarda una relación concentración/respuesta con la
morbimortalidad cardiovascular” los autores proponen una explicación preliminar,
anterior a todo experimento, al menos parcial del fenómeno “morbimortalidad

8
cardiovascular”. No excluyen otras posibles explicaciones, pero observan una
asociación digna de ser contrastada experimentalmente. Han pues emitido una
hipótesis. Muchos años más tarde, tomando sujetos hipercolesterolémicos,
dividiéndolos en dos grupos, uno tratado con placebo y otro con un agente
reductor de la colesterolemia, se comprobó que la manipulación experimental de
las concentraciones de colesterol, esto es, su reducción farmacológica, era
seguida de una disminución de la morbimortalidad cardiovascular. Ello no sucedía
con igual intensidad en los tratados con placebo. La hipótesis surgida en
Framingham era comprobada y verificada en el experimento.
Resumamos, pues; los diseños en investigación clínica
pueden ser clasificados en:
a) De observación
b) De intervención (o experimentales)
Dado que la observación tiene dos propósitos fundamentales, esto es, descripción
o generación de hipótesis, los estudios de observación de dividen en descriptivos
y analíticos. Así, tenemos:

9
Un reporte de caso describe las características más importantes de la historia
clínica de un paciente, casi siempre refiriéndose a un desorden raro o bien un
curso clínico de interés particular. Comunicar un caso ilustrativo, o tal vez un
posible caso índice de alguna entidad peculiar puede ser de interés para la
comunidad médica.
En una serie de casos se comunican los hallazgos de un número de sujetos que
tienen en común cierta característica digna de remarcar.
Los estudios transversales son estudios descriptivos en los que se trata de
establecer estado de una muestra en un momento puntual, determinado. Se trata
de una “fotografía” de nuestra muestra en estudio. Suelen ser empleados en el
estudio de la prevalencia de una entidad clínica o bien en la descripción de una
enfermedad.
Los estudios analíticos de cohortes y de casos y controles procuran
demostrar la existencia de asociaciones entre exposiciones y eventos. En los
estudios de cohortes, un grupo de sujetos expuestos a un determinado factor es

10
seguido en forma longitudinal, a lo largo del tiempo, a efectos de verificar la
frecuencia con que se desarrolla un evento de interés. Esta frecuencia se compara
con la obtenida en un grupo de no expuestos seguidos a lo largo del mismo
tiempo.
SI
EVENTO
NO
SI
EXPOSICIÓN
NO SI
EVENTO
NO
Por ejemplo, podríamos estar interesados en comprobar si la exposición al
cigarrillo guarda asociación con el desarrollo de carcinoma de pulmón. Así,
tomaremos una cohorte de expuestos al cigarrillo (fumadores) y los seguiremos
unos años a efectos de verificar la frecuencia (incidencia) con la que desarrollan
carcinoma. Del mismo modo, seguiremos una cohorte de no fumadores durante
ese tiempo a efectos de conocer la frecuencia (incidencia) con la que desarrollan
cáncer de pulmón.
Cuando la frecuencia de un evento es muy baja, el diseño de cohortes puede
resultar sumamente ineficiente; podemos seguir la evolución de muchas personas
muchos años sin observar el desarrollo de un caso entre los expuestos ni entre los
no expuestos. En esas condiciones, podría ser mejor emplear un diseño del tipo

11
casos y controles. Supongamos que creemos que una entidad rara, la cirrosis
biliar primaria, guarda relación con el consumo de anticonceptivos bucales. Si
optáramos por un diseño de cohortes, deberíamos seguir a muchas mujeres
expuestas a anticonceptivos, durante muchos años, con el riesgo de no verificar el
desarrollo de ningún caso de cirrosis biliar. Por ello, podría ser más conveniente
recurrir a un diseño de casos y controles: iríamos a un centro hospitalario en el
que se concentren casos de cirrosis biliar, y encuestaríamos a estas mujeres
respecto del consumo de anticonceptivos. Luego, tomaríamos controles (mujeres
de igual edad que los casos, similar medio social, laboral, etc) e intentaríamos
conocer el antecedente de consumo de anticonceptivos.
Entonces…
SI
EXPUESTOS
NO
CASOS (presentan el evento)
CONTROLES (no presentan el evento)
SI
NO EXPUESTOS
NO
Los ensayos clínicos son experimentos, llevados a cabo en seres humanos,
éticamente justificados. Entonces, en un ensayo clínico el observador ha de
intervenir sobre el sistema observado, manipulando variables y modificando el
curso de la naturaleza.

12
Los ensayos clínicos se rigen por tres principios:
1. Principio de comparación: el tratamiento bajo estudio (intervención) ¿es
diferente que otro tratamiento o que un placebo?
2. Principio de significación: suponiendo que el tratamiento bajo estudio sea
diferente que otro, esta diferencia, ¿puede ser meramente casual?
3. Principio de causalidad: si es poco probable que la diferencia hallada entre
el tratamiento en estudio y otro tratamiento sea casual, ¿es el tratamiento
bajo estudio la causa de la diferencia, o puede deberse a error –sesgo-?
Esta presentación de los diseños más comunes en
investigación clínica sólo tiene la pretensión de introducir al
tema, que será mejor desarrollado en el próximo módulo.
3. Variables en la investigación científica.
De un modo simplificado, es común clasificar a las variables en:
a) Variables deterministas
b) Variables aleatorias
Hemos aprendido a conocer las variables deterministas en nuestros cursos de
Física, específicamente al estudiar la mecánica clásica, la mecánica “newtoniana”.

13
En efecto, veamos el siguiente ejemplo: dejemos caer un objeto desde una
posición A hasta una B. Separa A de B una altura h.
h
Supongamos ahora que se nos pide calcular el tiempo en que el cuerpo alcanza B
en su caída desde A. Supongamos que tarda 0.2 segundos. Volvamos a repetir la
experiencia, lanzando el cuerpo desde A, sin modificar h. El tiempo volverá a ser
0.2 segundos. ¿Y si repetimos la experiencia “n” veces? Pues seguramente, si no
modificamos h ni cambiamos de posición en nuestro planeta, el tiempo seguirá
siendo 0.2 segundos. A lo sumo, hemos de asumir cierto error que podemos
cometer en la medida del tiempo (error de reloj) o al medir la altura h. Pero eso es
todo; el tiempo t es una función de h y de la aceleración de la gravedad (g). Estas
variables deterministas nos han sido presentadas tempranamente en nuestra vida
escolar, y a través de ellas, hemos aprendido a creer que todo en la naturaleza es
predecible, con la única condición de conocer las leyes que rigen los fenómenos,
sólidamente constituidas y expresadas por fórmulas indiscutibles y “eternas”.
Lamentablemente para nuestra “sensación de seguridad”, muchos sucesos en el
universo parecen comportarse de una manera distinta.
Veamos el siguiente caso:
A B

14
Ejemplo 3
Nos encontramos en presencia de un paciente varón de 80
años, cuyos padres han muerto a los 50 años de edad a
causa de infarto de miocardio. El paciente es diabético,
hipertenso, hipercolesterolémico, fumador y obeso. Ha
padecido ya dos infartos de miocardio y un accidente
cerebrovascular. Nuestra pregunta es: ¿estará vivo aun
dentro de tres años?
Si pensamos con detenimiento la pregunta, veremos que no es demasiado
diferente de la formulada en el problema de caída libre. Allí preguntábamos por el
tiempo que tardaría en alcanzar la posición B, y sin dudas, y con pequeño error,
podíamos afirmar que 0.2 segundos.
Ahora bien; aquí se nos pregunta que nuestro paciente sobrevivirá unos años
dada la presencia de unas ciertas variables... ¿Podríamos responder de un modo
definitivo; SI o NO? ¿Estamos seguros que vivirá o que, por el contrario, ha de
estar muerto? La respuesta más apropiada, tal vez, sería: “es probable que no
sobreviva los tres años”. Incluso, quizás, podría decirse: “es muy probable que no
sobreviva”. Y hasta: “es más probable que este paciente fallezca que lo haga un
joven de 20 años en perfecto estado de salud que habita un barrio rico de
Copenhague”. Vemos que no podemos afirmar con total certidumbre en un sentido
determinado (que persista vivo o que muera), pero podemos tomar en
consideración una cierta probabilidad de que el hecho suceda. Es que, a
diferencia del problema de caída libre, estamos aquí en presencia de variables
aleatorias, esto es, variables que asumen ciertos valores con una cierta
probabilidad.

15
Ello nos obliga, pues, a introducirnos en el concepto de probabilidad y algunas de
sus propiedades y consecuencias. Más adelante en este módulo volveremos
sobre este tema, para enfocarnos en la manera en que se pueden describir los
diferentes tipos de variables.
4. Introducción al concepto de probabilidad.
¿Cuál es la probabilidad de obtener un tres arrojando una única vez un dado?
La respuesta a esta pregunta es relativamente simple: 1/6, es decir, 0.166.
¿Cuáles son los fundamentos a través de los cuales arribamos a este resultado?
Bien, pues, hagamos algo de historia. Pierre-Simón de Laplace (1749-1827) fue
sin duda uno de los matemáticos más importantes de la historia. Interesado en las
leyes que rigen los juegos de azar, publicó su “Ensayo Filosófico sobre las
Posibilidades”, y en él enunció de manera formal el concepto de probabilidad. Para
comprenderlo, conviene apelar a algunas definiciones previas. Por evento
entendemos al resultado de una observación o de una experiencia. Como una
consecuencia de esta definición, comprenderemos inmediatamente que un evento
se da o no se da, sucede o no. Y Laplace nos ofrece la siguiente fórmula que
define la probabilidad de un evento o suceso:
Probabilidad del evento = casos favorables al mismo / casos posibles
Volvamos al ejemplo del lanzamiento del dado. En él, sólo una cara lleva impresa
el número tres, y existen en él seis caras. Por tanto, sólo existe un caso favorable
por cada seis posibles.

16
Laplace nos dice: “la probabilidad de un suceso es un número comprendido entre
0 (que es la probabilidad del suceso imposible) y 1 (que es la probabilidad del
suceso seguro)”. Desde luego, si no existiera ninguna cara con el número tres, la
probabilidad de obtener un tres en un único lanzamiento del dado sería igual a 0;
si, en cambio, todas las caras llevaran impresas el número tres, la probabilidad
sería 1. De todos modos, a efectos de simplificar la comunicación, solemos
expresar la probabilidad en términos porcentuales, o por mil, o por diez o cien mil,
etc. En el caso del lanzamiento del dado, la probabilidad de obtener un “tres” en
un único lanzamiento es 0.166 ó 16.6%.
Si bien el llamado “Axioma de Laplace” (o, de manera incorrecta, “Primera Ley de
la Probabilidad”), resulta fácil de comprender, debemos señalar que el mismo
autor nos advierte que para conocer la probabilidad de un suceso, la experiencia
debe reiterarse un “número suficientemente grande de veces”, y, agregaremos, en
condiciones lo más parecidas posible. Desafortunadamente, poco nos dice
Laplace acerca del mejor modo de conocer ese “número suficientemente grande
de veces”. Por otra parte, la fórmula de Laplace resulta fácil de concebir y aplicar
cuando se trabaja con instrumentos simples, tales como un dado, o una moneda.
En una moneda, sabemos que existe sólo una cara y una seca, de modo de
conocer los “casos favorables” y los “posibles” no resulta particularmente difícil.
Pero, ¿qué tal si se nos pregunta “cuál es la probabilidad de morir de una forma
rara de neumonía”? Una posible respuesta es: “debo observar un número
suficientemente grande de casos de esa forma de neumonía, y contar las muertes
entre esos casos”. Pero ¿cuántos casos debo observar?
Tratemos de facilitar las cosas aplicando los mismos principios de Laplace al caso
de la moneda. Dado que se trata de un instrumento simple, fácilmente podemos
calcular que la probabilidad de obtener “cara” en un solo lanzamiento de la
moneda es 0.5 ó 50%. Pero por un momento olvidemos este resultado. Lancemos
la moneda, digamos, 10 veces. Es posible que, aun sin que nadie nos haga

17
ninguna trampa, obtengamos, por ejemplo, 6 caras. Por tanto, la frecuencia
relativa de caras es 6/10 = 0.60 ó 60% y, si aplicara la fórmula de Laplace (otra
vez, olvidando que ya conozco lo que debiera dar), tendría: 6 casos favorables
sobre 10 posibles, esto es 0.60 ó 60%.
¿Por qué no obtuve 50% de caras? Tal vez porque no lancé la moneda un número
suficientemente grande de veces. De hecho, si hubiera lanzado la moneda sólo 5
veces, ¡jamás podría obtener un 50% de caras!. Digamos que lanzo la moneda,
ahora, 100 veces; obtengo 57 caras. En número absolutos es sacado 7 caras más
que las requeridas para lograr el 50%; sin embargo, el cociente “casos favorables
/ casos posibles” dará: 57%, más cerca del 50% que cuando obtuve 6 caras
lanzando 10 veces la moneda. Veamos un ejemplo en la Tabla 1:
TABLA 1. NUMERO DE REPETICIONES DE LA EXPERIENCIA Y EL
COCIENTE DE LAPLACE
Arrojo “n” veces
la moneda
Obtengo “m”
caras
Frecuencia
relativa de caras
“Casos
favorables /
Casos posibles”
10 6 0.6 ó 60% 0.6 ó 60%
100 57 0.57 ó 57% 0.57 ó 57%
1000 509 0.509 ó 50.9% 0.509 ó 50.9%
10000 5015 0.5015 ó 50.15% 0.5015 ó 50.15%
............. ............. ............. .............
Como vemos, el cociente “casos favorables / casos posibles” equivale al concepto
de frecuencia relativa. Y como vemos, al aumentar el número de veces que se
repite la experiencia (lanzamiento de la moneda) acumulando sus resultados, más
cerca se estará de conocer la probabilidad de un evento.
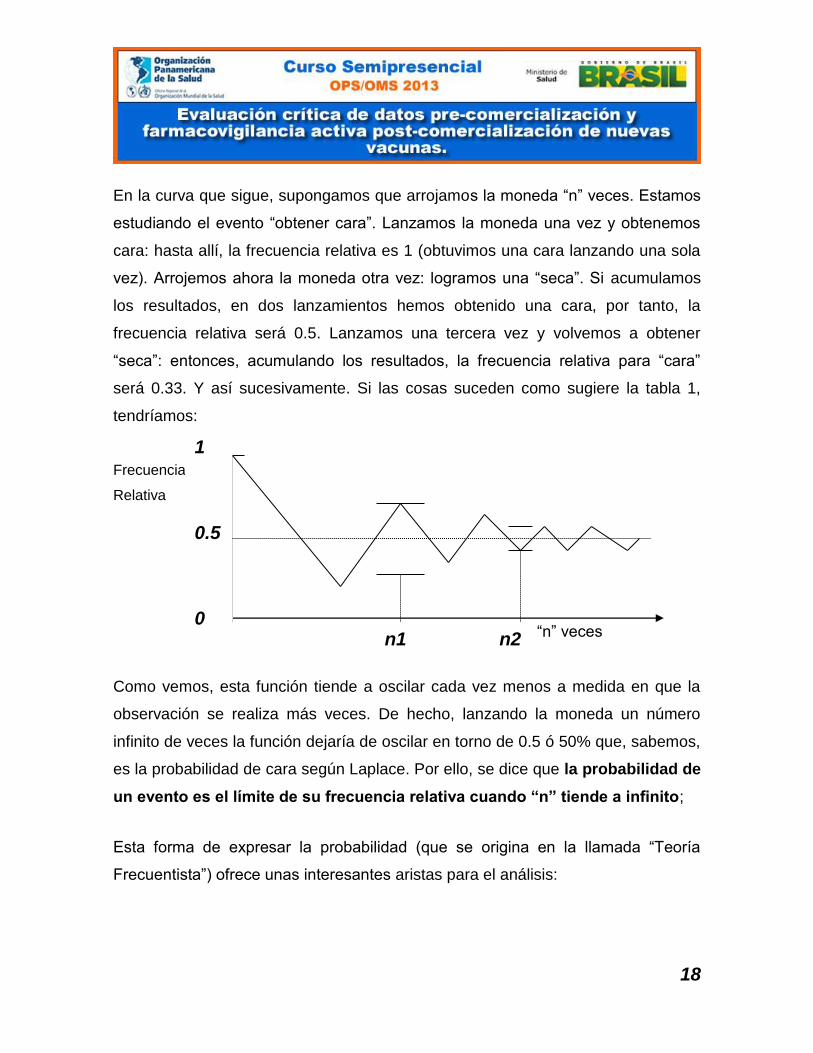
18
En la curva que sigue, supongamos que arrojamos la moneda “n” veces. Estamos
estudiando el evento “obtener cara”. Lanzamos la moneda una vez y obtenemos
cara: hasta allí, la frecuencia relativa es 1 (obtuvimos una cara lanzando una sola
vez). Arrojemos ahora la moneda otra vez: logramos una “seca”. Si acumulamos
los resultados, en dos lanzamientos hemos obtenido una cara, por tanto, la
frecuencia relativa será 0.5. Lanzamos una tercera vez y volvemos a obtener
“seca”: entonces, acumulando los resultados, la frecuencia relativa para “cara”
será 0.33. Y así sucesivamente. Si las cosas suceden como sugiere la tabla 1,
tendríamos:
Frecuencia
Relativa
“n” veces
Como vemos, esta función tiende a oscilar cada vez menos a medida en que la
observación se realiza más veces. De hecho, lanzando la moneda un número
infinito de veces la función dejaría de oscilar en torno de 0.5 ó 50% que, sabemos,
es la probabilidad de cara según Laplace. Por ello, se dice que la probabilidad de
un evento es el límite de su frecuencia relativa cuando “n” tiende a infinito;
Esta forma de expresar la probabilidad (que se origina en la llamada “Teoría
Frecuentista”) ofrece unas interesantes aristas para el análisis:
1 0.5 0 n1 n2

19
1. Si Ud desea conocer la probabilidad de un suceso, puede trabajar con un
“n” que dependerá de cuánta oscilación esté dispuesto a aceptar. Con un
tamaño muestral n1, Ud conocerá la probabilidad con una cierta “precisión”,
menor que aquella con la que podrá conocer la probabilidad con el tamaño
n2.
2. Esa oscilación es una forma de error, conocido como error aleatorio (o
“imprecisión” o error “no sistemático”).
3. El error aleatorio se reduce cuando se incrementa el “n” o tamaño muestral.
Como podemos comprender, a partir de esta concepción es posible definir un
tamaño muestral que nos permita conocer la probabilidad, sabiendo que hemos de
cometer un cierto error aleatorio. Así, podremos calcular un tamaño razonable con
el objeto de conocer la probabilidad de morir de una forma rara de neumonía,
sabiendo que no hallaremos la probabilidad “puntual” de ese suceso, sino que lo la
estimaremos con cierto error aleatorio (tanto menor cuanto mayor el tamaño
muestral).
5. Descripción de variables aleatorias
Ya hemos definido lo que es una variable aleatoria, nos ocuparemos ahora de
cómo describir los diferentes tipos de variables aleatorias.
Comencemos con un ejemplo…

20
Ejemplo 4
Un grupo de investigadores quiere llevar adelante un estudio
de acerca del tipo de eventos adversos reportados luego de la
vacunación antisarampionosa. Si bien, como hemos discutido
previamente, desde el punto de vista metodológico se debería
seleccionar una muestra representativa en relación al tamaño
de la población, daremos ejemplos con números pequeños
para facilitar los cálculos. Así, imaginaremos que realizamos
este estudio sobre un total de 10 pacientes.
Debido a que interesa incluir en esta evaluación niños sanos y
sin otras patologías asociadas, se realiza una medición de
frecuencia cardiaca basal.
A continuación se presentan los datos:
Niño Fcard
1 100
2 89
3 95
4 110
5 115
6 118
7 90
8 95
9 92
10 100

21
Un fenómeno interesante que se observa al analizar estos datos es que, si bien
se trata de 10 niños de edad similar, y asumiendo que las mediciones se
realizaron con la misma técnica, el número correspondiente a la variable
frecuencia cardiaca que se registra es distinto para cada uno!!!
Este fenómeno que estamos tratando de describir se denomina variabilidad. La
variabilidad es una característica de la naturaleza y de los seres vivos.
Supongamos que en esta muestra de pacientes hubiera un niño con una
frecuencia cardiaca de 60 por minuto. Observando los datos queda claro que 60
es un valor que se aleja llamativamente de los demás. La pregunta que
intuitivamente nos formularíamos es ¿tiene este niño alguna condición en
particular? como por ejemplo un trastorno en la frecuencia cardiaca,
alternativamente, podemos pensar que este valor se registró como producto de la
variabilidad de la naturaleza. Como veremos más adelante, los métodos
estadísticos no hacen otra cosa que tratar de discernir si esta diferencia se
corresponde con una señal (es decir a un valor que indica que éste bebé
corresponde a una población de niños distinta, en este caso con trastornos de la
frecuencia cardiaca) o con la propia variabilidad implícita en naturaleza aleatoria
de las variables con las que trabajamos (lo que no es señal, sino simplemente,
“ruido”).
Los métodos estadísticos constituyen una manera de lidiar
con la variabilidad, tratando de diferenciar “ruidos” en la
naturaleza de “señales verdaderas”.

22
Retomando la definición que hemos enunciado antes, se define como variable a
una característica cuyo valor puede variar entre los sujetos de una muestra o de
una población.
Claro está que esta definición es genérica (es decir, aplica a todas las variables)
pero es insuficiente a la hora de caracterizar los atributos de cada una de las
diferentes variables en las que nos podemos interesar. Continuando con nuestro
estudio de investigación, interesa ahora tomar otras variables tales como:
Sexo
Temperatura
Presencia de erupciones
Número de plaquetas
Nótese que al listar de esta manera a las variables, la definición de algunas tales
como sexo no necesita mayores aclaraciones, pero éste no es necesariamente el
caso para las otras. Tomemos el ejemplo de temperatura y, para recordar todas
las aclaraciones que hay que hacer con respecto a la misma, tenga presente
siempre el concepto de reproducibilidad; es decir que la interpretación de la
variable temperatura debe ser la misma para todos los lectores del trabajo de
investigación.
Entonces podrían surgir las siguientes preguntas:
a) Dónde se tomará, por ejemplo ¿axilar o rectal?
b) ¿En qué momento o momentos del estudio se tomará? Esto abre un segundo
interrogante, es decir si en realidad no hay que definir más de una variable
relacionada con la temperatura tales como: temperatura basal, 24 horas luego
de la aplicación de una vacuna y 48 horas luego de su administración;

23
c) Si se define temperatura basal, por ejemplo 1 hora antes de realizar el
procedimiento de vacunación, ¿cuántas tomas de temperatura se realizarán:
una sola, 2, 3?
d) ¿Con qué instrumento se tomará a la temperatura, con termómetro de mercurio
o digital?
Si bien muchos de estos procedimientos pueden estar detallados en los métodos
del estudio, es recomendable que cada variable tenga lo que se denomina una
definición operativa que implica definir exactamente a la misma.
Por ejemplo, la temperatura definida como temperatura axilar, tomada con
termómetro de mercurio durante al menos 3 minutos.
Clasificación de las variables.
Una vez que hemos seleccionado las variables de interés del estudio y que las
hemos definido operativamente, deberemos pensar en la escala de medición de
dicha variable. Pero, ¿a qué nos referimos con escala de medición?
Para responder a este interrogante, continuemos definiendo la variable
temperatura. Al confeccionar la planilla de recolección de datos, podemos
consignar la información de la siguiente manera,
Niño Temperatura
1 37.3
2 36.3
3 35.8
… …
Pero también podemos registrarla de la siguiente (Ejemplo II),

24
Temperatura menor 37.5 30 niños
Temperatura entre 37.5 y 38.5 12 niños
Temperatura mayor a 38.5 5 niños
Si bien la variable es la misma, lo que cambia de un ejemplo a otro es la escala de
medición. Debido a que la elección del análisis estadístico para analizar una
variable depende de la escala de medición de la misma, clasificarlas siguiendo
esta característica es de suma importancia. En forma general podemos decir que
las variables se clasifican en cuantitativas y cualitativas
Las variables cuantitativas son aquellas cuyos datos pueden ser medidos en
forma numérica. Por ejemplo en el primer caso, medimos la temperatura y ésta
medición la representamos con un número.
A su vez la escala numérica a utilizar puede ser continua o discreta,
Variables numéricas continuas: son aquellas que pueden tomar como valores
posibles a números reales y que entre dos valores numéricos hay infinitos valores
posibles.
Variables numéricas discretas: son aquellas variables numéricas que no
cumplen con la propiedad de continuidad.
Por ejemplo, la edad es una variable numérica continua debido a que entre dos
valores, como 4 y 5 años, puede haber infinitos valores intermedios. Es decir que
es posible escribir edad en todos sus valores potenciales, por ejemplo 4,567326
años. En cambio número de hijos es una variable numérica discreta dado que
entre 1 hijo y 2 no están definidos valores intermedios (por ejemplo 1, 5 hijos).

25
Las variables cualitativas son aquellas cuyos valores revelan la pertenencia de
los sujetos u objetos en estudio a un cierto grupo, y pueden ser subclasificadas en
nominales u ordinales. Las variables nominales son aquellas en las que la
medición corresponde a un conjunto de categorías que no tienen un orden
determinado. Por ejemplo, imaginemos que en la ficha de recolección de datos de
nuestro estudio, interesa consignar la procedencia.
Procedencia:
Salta :
Capital Federal:
Provincia de Buenos Aires:
Tierra del Fuego:
¿Por qué decimos que ésta variable es cualitativa y no cuantitativa?
Sencillamente porque lo que diferencia a las categorías de esta variable no es un
valor numérico, sino una cualidad, en este caso el lugar de donde proviene el
paciente. Queda claro también que, en este caso, no se pueden establecer
relaciones de orden (es decir vivir en Salta no es ni más ni menos –en términos
jerárquicos- que vivir en Tierra del Fuego).
Por otro lado, las variables cualitativas son ordinales cuando es posible
establecer cierto sentido de orden entre las categorías relevadas. En éste caso,
podríamos interesarnos por el nivel educativo de la madre del niño, consignándolo
de ésta manera,

26
Nivel de educación de la madre:
Ninguno
Primario completo
Secundario completo
Terciario completo
Si bien esta variable es similar en cuanto a sus características a las nominales,
cada categoría de la misma implica un cierto orden debido a que, si se completó la
educación secundaria, se deberían tener más conocimientos que si sólo se tiene
educación primaria. Sin embargo, no se puede establecer una distancia
cuantitativa entre cada categoría, es decir, el hecho de tener educación
secundaria completa no implica que se sepa 2 veces más que los que tienen
educación primaria completa.
Estamos en condiciones ahora de resumir los tipos de variables que hemos
analizado,
Variables
Cualitativas Cuantitativas
Continuas Discretas
Ordinales Nominales
Nos ocuparemos ahora de la manera de describir las variables, entendiendo por
este término, la acción de dar de las variables dimensiones o atributos numéricos.

27
En otras palabras, la descripción de una variable está relacionada con la forma de
resumir los datos correspondientes a la misma.
Pero… ¿qué significa esto? Pensemos en la planilla de recolección de datos que
hemos ido construyendo a lo largo de éste texto, y tratemos de resumirla en un
formulario de ejemplo
N° de Formulario:
Nombre y Apellido:
Edad .......
Temperatura ..... ºC
Frecuencia Cardíaca ....... latidos/min
N° de Hermanos.....
Educación de la madre:
Ninguna
Primaria
Secundaria
Terciaria
El registro de datos de éste estudio se lleva adelante completando un formulario
por paciente.
En éste caso, la información de las variables numéricas se consignará con un
número (por ejemplo edad, número de hermanos, frecuencia cardiaca), en tanto
que en el caso de las variables categóricas se consignará a qué categoría
pertenece el paciente. Por ejemplo se indicará mediante una cruz el período
educativo completado por la mamá.
Ahora, una vez registrada la información de por ejemplo 10 pacientes, se deberán
reportar los datos correspondientes a cada variable. Una opción sería mostrar los

28
pacientes uno por uno, pero esto es poco práctico (imagínelos en una casuística
de 1000 pacientes) y además ¡es muy difícil realizar análisis estadísticos de ésta
manera! No sintetizaríamos la información ni podríamos hacer un uso práctico de
la misma.
Convendría entonces buscar medidas que resuman en forma conveniente,
sintética e informativa, a los datos de dicha variables, es decir buscar medidas que
representen en un solo valor a la mayoría de los datos consignados en
determinada variable. Las medidas de resumen difieren según la clase a la que
pertenece cada variable.
Para las variables cualitativas se pueden emplear las siguientes herramientas,
Distribución de frecuencias: consiste en describir la lista de las categorías
posibles de la variable y consignar el número de observaciones correspondientes
a cada categoría
Por ejemplo la variable “Educación de la madre”:
Ninguna: 1
Primaria: 4
Secundaria: 3
Terciaria: 2
Cada categoría debe ser mutuamente excluyente (es decir que los pacientes
deben pertenecer a sólo una categoría) y la suma total de las categorías debe ser
igual al total de los pacientes de la muestra (hay 10 madres, una sin educación
formal, cuatro que han recibido educación primaria, etc: total= 10)
Sin embargo, las distribuciones de frecuencia son mucho más útiles cuando se las
acopla con el cálculo de las frecuencias relativas de cada categoria, que ya hemos
estudiado en el transcurso del módulo.

29
Continuemos con el ejemplo, los datos consignados en la distribución de
frecuencias describen correctamente a la variable, pero dificultan la posibilidad de
hacer comparaciones. Por ejemplo supongamos que queremos comparar el nivel
educativo de las madres de ésta casuística de pacientes vs. otro estudio hecho en
el Chaco.
Educación de las madres (n 10) Madres en el Chaco (n=50)
Ninguna: 1 Ninguna: 5
Primaria: 4 Primaria: 15
Secundaria: 3 Secundaria: 25
Terciaria: 2 Terciaria: 5
Si miramos los datos de la categoría primaria en nuestro estudio y en el estudio
del Chaco, parecería que hay muchas más madres que completaron la categoría
primaria (n=15) en el Chaco que en nuestro estudio (n=4). Sin embargo, nótese
que el n total de nuestra casuística es de 10 pacientes, en tanto que el que
corresponde al estudio del Chaco es de 50. Queda claro entonces que es
importante hallar una medida que permita comparar a ambos grupos. Esto será
posible mediante el cálculo de las frecuencias relativas para las distintas
categorías en ambos grupos.
Entendemos por frecuencia relativa para un intervalo a la proporción de las
observaciones de la muestra que corresponde ¡en cada intervalo. Se calcula
dividiendo el número de observaciones (en éste caso madres) que corresponden a
cada intervalo por el número total de la muestra. En el caso de educación primaria
sería:

30
Estudio I
Educación Primaria: 4/10=0.4
Estudio de Chaco:
Educación Primaria: 15/50= 0.3
Nótese entonces que al realizar la comparación correctamente, observamos que el
nivel de educación primaria completa fue mayor en nuestro estudio que en el del
Chaco. En este caso, la suma de todas las categorías debe ser igual a 1. Muchas
veces la frecuencia relativa se expresa en porcentaje, es decir multiplicando la
frecuencia relativa por 100. En ese caso, la suma de todas las frecuencias debe
ser igual a 100. Si la distribución de frecuencias se va a consignar de esta manera,
es importante informar el n total de la muestra. A continuación ejemplificaremos
una forma de mostrar estos datos en una tabla.
Variable Estudio I
(n=10)
Frecuencia
Relativa
Estudio II
(n= 50)
Frecuencia
Relativa
Estudio I
(n=10)
Porcentaje
Estudio II
(n=50)
Porcentaje
Sin Educación 0.1 0.1 10% 10%
Primario completo 0.4 0.3 40% 30%
Secundario Completo 0.3 0.5 30% 50%
Terciario Completo 0.2 0.1 20% 10%
Total 1 1 100% 100%
Como observamos en esta tabla, la distribución de frecuencias relativas permite la
comparabilidad de la misma variable entre dos muestras con denominadores
distintos

31
Las medidas de frecuencia que acabamos describir no son otra cosa que tasas,
es decir, relaciones que describen la frecuencia de sucesos en la que el
numerador es parte del denominador. En el ejemplo anterior, el numerador es el
número de madres que cumplieron con determinada categoría (por ejemplo
completar la educación terciaria) y el denominador es el total de la muestra
estudiada.
Si bien acabamos de ver que las tasas se pueden expresar como proporciones,
cabe destacar que no todo lo que en medicina se expresa como porcentaje
corresponde a una tasa correctamente concebida. Dos casos de gran interés, son
la tasa de prevalencia y la tasa de incidencia.
Comencemos con un ejemplo.
Ejemplo 5
Supongamos que un hospital reporta que se han registrado
un 3% de erupciones cutáneas asociadas a la aplicación de la
vacuna del sarampión. La siguiente pregunta será ¿se trata
de nuevos casos o del total de casos registrados en el
periodo de interés?
Esto definirá las tasas de prevalencia o incidencia.
Prevalencia: Es la relación entre el número total de individuos que tienen un
atributo o enfermedad en un momento en particular y la población en riesgo de
tener ese atributo o enfermedad en ese punto de tiempo.
Incidencia: Representa la relación entre los nuevos eventos en un período de
tiempo en relación a los sujetos expuestos en ese período de tiempo

32
Si quisiéramos medir por ejemplo la prevalencia de encefalitis en los niños
vacunados por vacuna antisarampionosa en la Argentina deberíamos evaluar,
1) Los casos de encefalitis en niños con vacuna antisarampionosa en un
período de tiempo
2) Todos los niños vacunados con vacuna antisarampionosa en dicho período
de tiempo
3) Obtener el cociente de ambos números
Si quisiéramos medir la incidencia, habría que seleccionar sólo a los niños
vacunados que no presentaron encefalitis y calcular:
Casos nuevos de encefalitis en niños con vacuna antisarampionosa en un período
de tiempo
Todos los niños vacunados con vacuna antisarampionosa en dicho período de
tiempo
Nos ocuparemos ahora de la descripción de las variables continuas. Para ello
continuaremos con otro ejemplo. Supongamos que se quiere evaluar el registro de
temperatura a las 4 horas de administrada la vacuna antisarampionosa. Para
facilitar el ejercicio, asumiremos que sólo interesa este registro (Ejemplo I),
Paciente Temperatura
1 37.5
2 37
3 36.5
4 38

33
5 38
6 36
7 37
8 37
9 36
10 36
Como en el caso de las variables categóricas, interesa presentar medidas que
resuman esta información en forma representativa. Así como en las variables
categórica, la distribución de frecuencias relativas (es decir la proporción de
individuos que tienen el evento del total de la muestra en cada categoría) daba
una idea general de los valores que puede tomar dicha variable, para describir las
variables continuas, necesitamos no sólo una medida de promedio sino una de
dispersión. A continuación presentaremos las medidas sumarias y de dispersión
correspondientes a las variables cuantitativas,
Media:
Es una “medida de tendencia central”, corresponde al promedio de observaciones
de la muestra y se calcula como la suma de las mediciones dividido el número
de los sujetos.
Sin embargo, la utilización de la media no puede aplicarse a todos los casos.
Veamos un ejemplo, supongamos que deseamos comparar la temperatura en 2
grupos de sujetos:
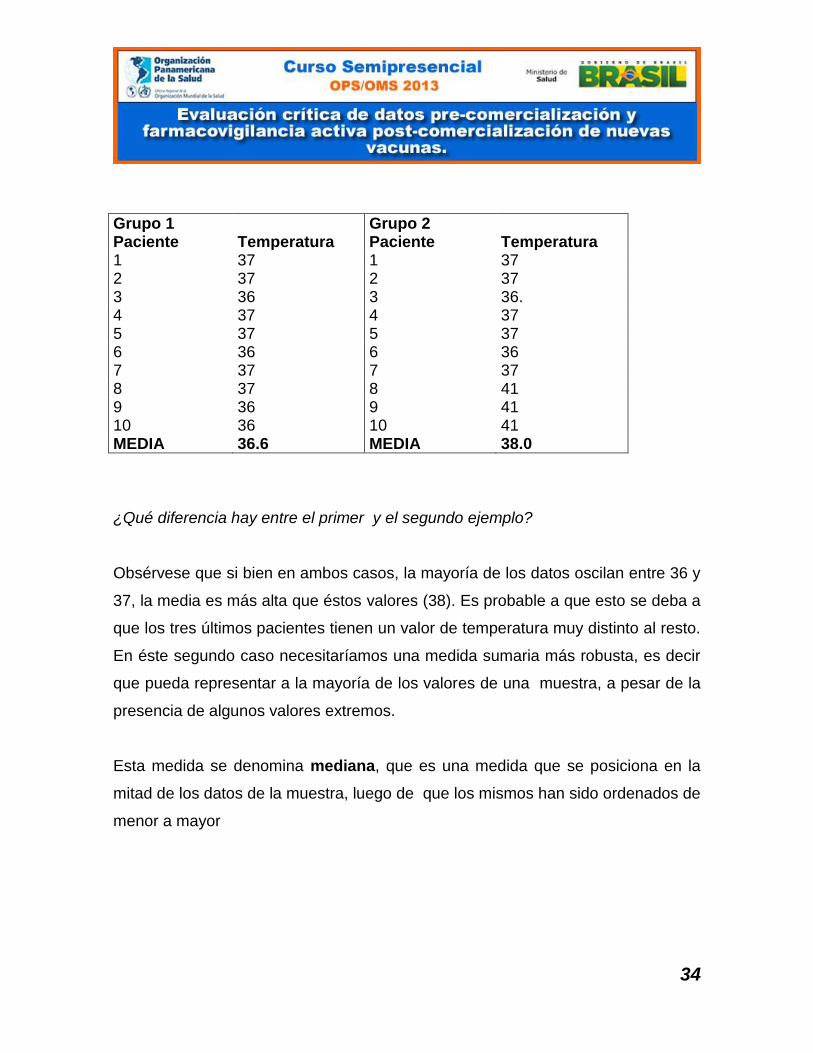
34
Grupo 1 Grupo 2 Paciente Temperatura Paciente Temperatura 1 37 1 37 2 37 2 37 3 36 3 36. 4 37 4 37 5 37 5 37 6 36 6 36 7 37 7 37 8 37 8 41 9 36 9 41 10 36 10 41 MEDIA 36.6 MEDIA 38.0
¿Qué diferencia hay entre el primer y el segundo ejemplo?
Obsérvese que si bien en ambos casos, la mayoría de los datos oscilan entre 36 y
37, la media es más alta que éstos valores (38). Es probable a que esto se deba a
que los tres últimos pacientes tienen un valor de temperatura muy distinto al resto.
En éste segundo caso necesitaríamos una medida sumaria más robusta, es decir
que pueda representar a la mayoría de los valores de una muestra, a pesar de la
presencia de algunos valores extremos.
Esta medida se denomina mediana, que es una medida que se posiciona en la
mitad de los datos de la muestra, luego de que los mismos han sido ordenados de
menor a mayor

35
En el Grupo 2, ordenemos para ello los datos de menor a mayor:
N Temperatura
1 36
2 36
3 37
4 37
5 37
6 37
7 37
8 41
9 41
10 41
Si tuviéramos 9 datos, la observación número 5 dejaría las observaciones 1,2,3 y
4 por debajo y la 6,7,8 y 9 por encima y por lo tanto la mediana sería claramente
37.
En el caso de n par, el cálculo se hace sumando los valores asignados a las dos
observaciones del medio, y se promedian
En este caso:
Observación 5=37
Observación 6= 37
(37+37)/2= 37. Por lo tanto, la mediana es 37.

36
Si hubiéramos considerado la media en los dos ejemplos, hubiéramos llegado a la
conclusión de que los niños del grupo 2 en general han tenido más temperatura
que los del grupo 1. Dado que cuando no hay datos extremos (como en el grupo
1), los valores de media y mediana coinciden, entonces para comparar éstos dos
ejemplos entre sí conviene tomar las medianas.
Hagamos un resumen entonces de las medidas sumarias en ambos ejemplos,
Ejemplo 1 (sin datos extremos)
Media Mediana
36.6 37
Ejemplo 2 (con datos extremos)
Media Mediana
38 37
En el primer caso vemos que la media y la mediana no difieren en gran medida,
por lo que podemos asumir que la mayoría de los datos corresponden a éstos
valores. En el segundo caso, vemos que -al registrarse valores extremos- la
media y la mediana difieren, siendo la mediana la medida más representativa de
los datos.
Asimismo, debemos hacer notar que con registrar la media o la mediana no
alcanza para dar una descripción completa de las variables cuantitativas. Las
mismas dan una idea de los valores medios, pero no nos dicen cuánto se alejan
los valores registrados de dicho valor medio. Para completar la descripción de una
variable cuantativa, tenemos que empelar las medidas de dispersión. Dichas
medidas nos dan una idea de la variabilidad de los datos alrededor de los valores

37
medios, evaluados ya sea mediante la media o la mediana. Si bien existen
diversas medidas de dispersión, en esta sección nos ocuparemos del desvío
estándar y del rango.
El desvío estándar (DE) es una medida de la variabilidad de la muestra, basada
en la medición del desvío o la distancia existente entre cada dato y su medida de
tendencia central, por ejemplo, la media. No nos ocuparemos de la fórmula, ya
que esta medida es calculada por todos los programas informáticos de estadística
e incluso por las planillas de cálculo utilizadas corrientemente como por ejemplo el
Microsoft Excel® o el OpenOffice®.
El desvío estándar es una medida representativa de la dispersión de los datos
cuando no hay datos extremos. Por lo tanto, es la medida de dispersión que
acompaña a la media.
Volviendo al ejemplo anterior, los datos del Grupo1 se resumirían como
Temperatura axilar: Media 36.6; DE= 0.51
En el caso de que los datos no se distribuyan en forma simétrica alrededor de la
media, es conveniente usar medidas de dispersión que no sean sensibles a los
datos extremos. Tal es el caso del rango y de los valores máximos y mínimos.
El rango es la diferencia entre la observación más grande y la más pequeña.
En el caso del ejemplo 2, la forma correcta de reportar la medida sumaria y de
dispersión es,
Mediana: 37, Mínimo y Máximo: 36-41, Rango: 5
38
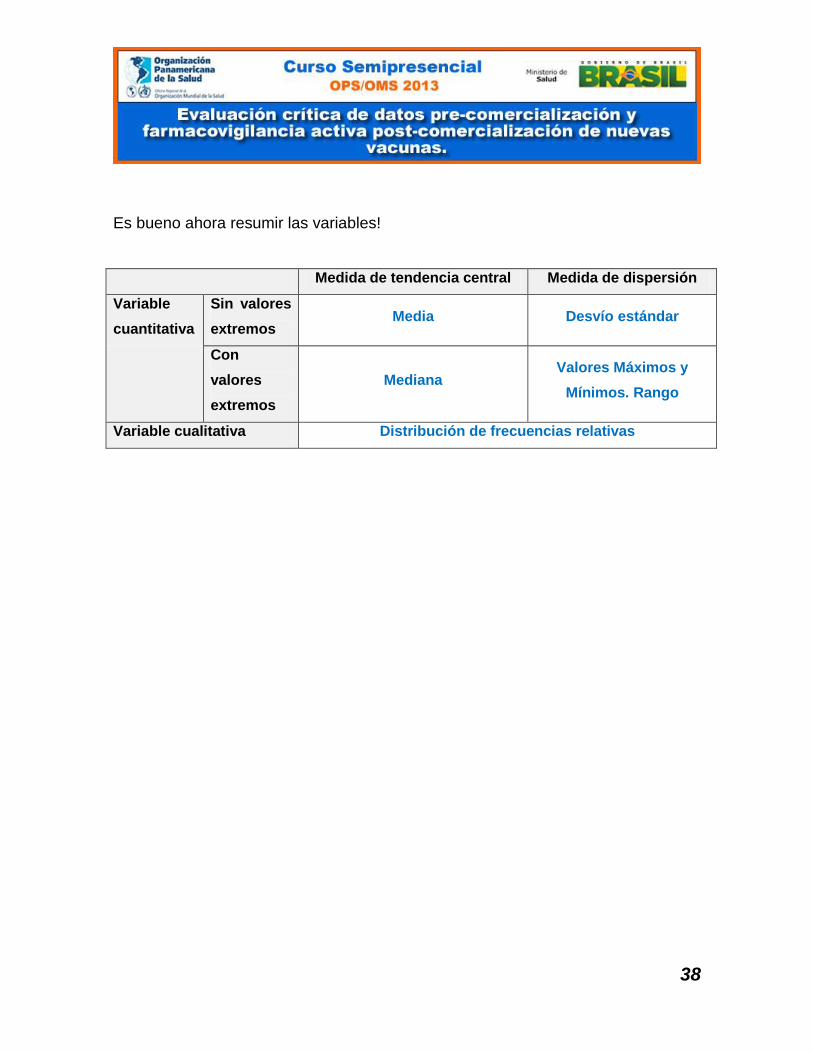
Es bueno ahora resumir las variables!
Medida de tendencia central Medida de dispersión
Variable
cuantitativa
Sin valores
extremos Media Desvío estándar
Con
valores
extremos
Mediana Valores Máximos y
Mínimos. Rango
Variable cualitativa Distribución de frecuencias relativas














