







Idiomas
Páginas
Jurídico


TEORÍA DE LA INFORMACIÓN - CÓDIGOS 1
TEORÍA DE LA INFORMACIÓN Y
CODIFICACIÓN – CÓDIGOS CANTIDAD DE INFORMACIÓN.
ENTROPÍA.
ENTROPÍA CONDICIONADA.
CANTIDAD DE INFORMACIÓN ENTRE DOS VARIABLES.
LÍMITE DE NYQUIST.
LÍMITE DE SHANNON.
CONSECUENCIAS DE LOS LÍMITES.
TIPOS DE ERRORES.
DETECCIÓN DE ERRORES.
INTRODUCCIÓN A CÓDIGOS.
CÓDIGOS DETECTORES DE ERRORES.
DISTANCIA HAMMING Y DESCODIFICACIÓN POR DISTANCIA MÍNIMA.
CÓDIGOS PERFECTOS.
CÓDIGOS LINEALES.
MATRICES GENERATRICES Y MATRICES DE CONTROL - CÓDIGOS
CORRECTORES.
CÓDIGO DE HAMMING.
CÓDIGO DE GOLAY.
CÓDIGO DE REED-MULLER.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 2
CANTIDAD DE INFORMACIÓN

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 3
CANTIDAD DE INFORMACIÓN
LA CANTIDAD DE INFORMACIÓN ES UNA MEDIDA DE LA
DISMINUCIÓN DE INCERTIDUMBRE ACERCA DE UN SUCESO:
EJ.: SI SE NOS DICE QUE EL NÚMERO QUE HA SALIDO EN UN
DADO ES MENOR QUE DOS, SE NOS DA MÁS INFORMACIÓN QUE
SI SE NOS DICE QUE EL NÚMERO QUE HA SALIDO ES PAR.
LA CANTIDAD DE INFORMACIÓN QUE SE OBTIENE AL CONOCER UN
HECHO ES DIRECTAMENTE PROPORCIONAL AL NÚMERO POSIBLE
DE ESTADOS QUE ESTE TENÍA A PRIORI:
SI INICIALMENTE SE TENÍAN DIEZ POSIBILIDADES, CONOCER
EL HECHO PROPORCIONA MÁS INFORMACIÓN QUE SI
INICIALMENTE SE TUVIERAN DOS.
EJ.: SUPONE MAYOR INFORMACIÓN CONOCER LOS NÚMEROS
GANADORES DEL PRÓXIMO SORTEO DE LA LOTERÍA, QUE
SABER SI UNA MONEDA LANZADA AL AIRE VA A CAER CON
LA CARA O LA CRUZ HACIA ARRIBA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 4
CANTIDAD DE INFORMACIÓN
LA CANTIDAD DE INFORMACIÓN ES PROPORCIONAL A LA
PROBABILIDAD DE UN SUCESO:
SE CONSIDERA LA DISMINUCIÓN DE INCERTIDUMBRE
PROPORCIONAL AL AUMENTO DE CERTEZA.
SI LA PROBABILIDAD DE UN ESTADO FUERA 1 (MÁXIMA):
LA CANTIDAD DE INFORMACIÓN QUE APORTA SERÍA 0.
SI LA PROBABILIDAD SE ACERCARA A 0:
LA CANTIDAD DE INFORMACIÓN TENDERÁ A INFINITO: UN
SUCESO QUE NO PUEDE SUCEDER APORTARÁ UNA CANTIDAD
INFITA DE INFORMACIÓN SI LLEGARA A OCURRIR.
LA CANTIDAD I DE INFORMACIÓN CONTENIDA EN UN MENSAJE, ES
UN VALOR MATEMÁTICO MEDIBLE REFERIDO A LA PROBABILIDAD
p DE QUE UNA INFORMACIÓN EN EL MENSAJE SEA RECIBIDA,
ENTENDIENDO QUE EL VALOR MÁS ALTO SE LE ASIGNA AL
MENSAJE MENOS PROBABLE.
SEGÚN SHANNON:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 5
CANTIDAD DE INFORMACIÓN
EJ.: SE ARROJA UNA MONEDA AL AIRE; SE DEBE CALCULAR LA
CANTIDAD DE INFORMACIÓN CONTENIDA EN LOS MENSAJES CARA
O CRUZ SEPARADAMENTE:
I = log2 [(1/(1/2)] = log2 2 = 1.
I MANIFIESTA LA CANTIDAD DE SÍMBOLOS POSIBLES QUE
REPRESENTAN EL MENSAJE.
SI SE LANZARA UNA MONEDA TRES VECES SEGUIDAS, LOS
OCHO RESULTADOS (O MENSAJES) EQUIPROBABLES PUEDEN
SER:
000, 001, 010, 011, 100, 101, 110, 111.
LA p DE CADA MENSAJE ES DE 1/8, Y SU CANTIDAD DE
INFORMACIÓN ES:
I = log2 [1/(1/8)] = 3.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 6
CANTIDAD DE INFORMACIÓN
LA I DE LOS MENSAJES ES IGUAL A LA CANTIDAD DE BITS DE CADA
MENSAJE.
UNA NOTACIÓN SIMILAR ES LA SIGUIENTE.
SE EMPLEA UNA VARIABLE ALEATORIA V PARA REPRESENTAR LOS
POSIBLES SUCESOS QUE SE PUEDEN ENCONTRAR:
EL SUCESO i-ÉSIMO SE DENOTA COMO xi.
P(xi) SERÁ LA PROBABILIDAD ASOCIADA A DICHO SUCESO.
n SERÁ EL NÚMERO DE SUCESOS POSIBLES.
LA CANTIDAD DE INFORMACIÓN SERÁ:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 7
ENTROPÍA

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 8
ENTROPÍA
LA SUMA PONDERADA DE LAS CANTIDADES DE INFORMACIÓN DE
TODOS LOS POSIBLES ESTADOS DE UNA VARIABLE ALEATORIA V
ES:
LA MAGNITUD H(V) SE CONOCE COMO LA ENTROPÍA DE LA
VARIABLE ALEATORIA V . SUS PROPIEDADES SON LAS SIGUIENTES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 9
ENTROPÍA
LA ENTROPÍA ES PROPORCIONAL A LA LONGITUD MEDIA DE LOS
MENSAJES QUE SE NECESITARÁ PARA CODIFICAR UNA SERIE DE
VALORES DE V:
DE MANERA ÓPTIMA DADO UN ALFABETO CUALQUIERA.
ESTO SIGNIFICA QUE CUANTO MÁS PROBABLE SEA UN VALOR
INDIVIDUAL, APORTARÁ MENOS INFORMACIÓN CUANDO
APAREZCA:
SE PODRÁ CODIFICAR EMPLEANDO UN MENSAJE MÁS CORTO.
SI P(xi) = 1 NO SE NECESITARÍA NINGÚN MENSAJE: SE SABE DE
ANTEMANO QUE V VA A TOMAR EL VALOR xi.
SI P(xi) = 0,9 PARECE MÁS LÓGICO EMPLEAR:
MENSAJES CORTOS PARA REPRESENTAR EL SUCESO xi.
MENSAJES LARGOS PARA LOS xj RESTANTES: EL VALOR
QUE MÁS APARECERÁ EN UNA SECUENCIA DE SUCESOS ES
PRECISAMENTE xi.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 10
ENTROPÍA EJEMPLOS:
ENTROPÍA DE LA VARIABLE ALEATORIA ASOCIADA A LANZAR
UNA MONEDA AL AIRE:
H(M) = -(0,5 log2 (0,5) + 0,5 log2 (0,5)) = 1.
EL SUCESO APORTA EXACTAMENTE UNA UNIDAD DE
INFORMACIÓN.
SI LA MONEDA ESTÁ TRUCADA (60% DE PROBABILIDADES PARA
CARA, 40% PARA CRUZ), SE TIENE:
H(M) = -(0,6 log2 (0,6) + 0,4 log2 (0,4)) = 0,970.
LA CANTIDAD DE INFORMACIÓN ASOCIADA AL SUCESO MÁS SIMPLE:
CONSTA UNICAMENTE DE DOS POSIBILIDADES
EQUIPROBABLES (CASO DE LA MONEDA SIN TRUCAR).
SERÁ LA UNIDAD A LA HORA DE MEDIR ESTA MAGNITUD, Y SE
DENOMINARÁ BIT.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 11
ENTROPÍA SE EMPLEAN LOGARITMOS BASE 2 PARA QUE LA CANTIDAD DE
INFORMACIÓN DEL SUCESO MÁS SIMPLE SEA IGUAL A 1.
LA ENTROPÍA DE UNA VARIABLE ALEATORIA ES EL NÚMERO MEDIO
DE BITS QUE SE NECESITARÁN PARA CODIFICAR C/U DE LOS
ESTADOS DE LA VARIABLE:
SE SUPONE QUE SE EXPRESA C/ SUCESO EMPLEANDO UN
MENSAJE ESCRITO EN UN ALFABETO BINARIO.
SI SE QUIERE REPRESENTAR LOS DIEZ DÍGITOS DECIMALES
USANDO SECUENCIAS DE BITS:
CON 3 BITS NO ES SUFICIENTE, SE NECESITA MÁS.
SI SE USAN 4 BITS TAL VEZ SEA DEMASIADO.
LA ENTROPÍA DE 10 SUCESOS EQUIPROBABLES ES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 12
ENTROPÍA
EL VALOR CALCULADO ES EL LÍMITE TEÓRICO, QUE
NORMALMENTE NO SE PUEDE ALCANZAR.
SE PUEDE DECIR QUE NO EXISTE NINGUNA CODIFICACIÓN QUE
EMPLEE LONGITUDES PROMEDIO DE MENSAJE INFERIORES AL
NÚMERO CALCULADO.
EL MÉTODO DE HUFFMAN PERMITE OBTENER CODIFICACIONES
BINARIAS QUE SE APROXIMAN BASTANTE AL ÓPTIMO TEÓRICO DE
UNA FORMA SENCILLA Y EFICIENTE.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 13
ENTROPÍA LA ENTROPÍA H DE UN SISTEMA DE TRANSMISIÓN ES IGUAL A LA
CANTIDAD DE INFORMACIÓN MEDIA DE SUS MENSAJES, ES DECIR:
H = Imed.
SI EN UN CONJUNTO DE MENSAJES SUS PROBABILIDADES SON
IGUALES, LA ENTROPÍA TOTAL SERÁ:
H = log2 N.
N ES EL NÚMERO DE MENSAJES POSIBLES EN EL CONJUNTO.
EJ.: SE TRANSMITEN MENSAJES BASADOS EN UN ABECEDARIO.
¿CUÁL SERÁ LA ENTROPÍA?:
SE SUPONE QUE LAS COMBINACIONES SON ALEATORIAS Y LOS
MENSAJES SON EQUIPROBABLES.
LA CANTIDAD DE LETRAS ES 26.
LA CANTIDAD DE SIGNOS DE PUNTUACIÓN ES 5.
LA CANTIDAD DE SIGNOS ESPECIALES ES 1 (ESPACIO EN
BLANCO).
LA CANTIDAD TOTAL DE SÍMBOLOS ES ENTONCES 32.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 14
ENTROPÍA
LA ENTROPÍA SERÁ:
H = log2 32 = 5.
DESDE LA ÓPTICA BINARIA ESTO SIGNIFICA QUE SE NECESITAN
5 BITS PARA CODIFICAR CADA SÍMBOLO: 00000, 00001, 00010,
11111, ETC.:
ESTE RESULTADO COINCIDE CON LA RECÍPROCA DE LA
PROBABILIDAD p.
LA ENTROPÍA:
INDICA LA RECÍPROCA DE LA PROBABILIDAD DE OCURRENCIA.
PERMITE VER LA CANTIDAD DE BITS NECESARIOS PARA
REPRESENTAR EL MENSAJE QUE SE VA A TRANSMITIR.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 15
ENTROPÍA CONDICIONADA

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 16
ENTROPÍA CONDICIONADA
SE SUPONE QUE TENEMOS UNA VARIABLE ALEATORIA
BIDIMENSIONAL (X,Y).
LAS DISTRIBUCIONES DE PROBABILIDAD MÁS USUALES QUE SE
PUEDEN DEFINIR SOBRE DICHA VARIABLE, TENIENDO n POSIBLES
CASOS PARA X Y m PARA Y SON:
DISTRIBUCIÓN CONJUNTA DE (X, Y):
DISTRIBUCIONES MARGINALES DE X E Y:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 17
ENTROPÍA CONDICIONADA
DISTRIBUCIONES CONDICIONALES DE X SOBRE Y Y VICEVERSA:
SE DEFINE LA ENTROPÍA DE LAS DISTRIBUCIONES COMO SIGUE:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 18
ENTROPÍA CONDICIONADA
HACIENDO LA SUMA PONDERADA DE LOS H(X/Y = yj) SE OBTIENE
LA EXPRESIÓN DE LA ENTROPÍA CONDICIONADA DE X SOBRE Y:
SE DEFINE LA LEY DE ENTROPÍAS TOTALES:
SI X E Y SON VARIABLES INDEPENDIENTES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 19
CANTIDAD DE INFORMACIÓN ENTRE
DOS VARIABLES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 20
CANTIDAD DE INFORMACIÓN ENTRE
DOS VARIABLES
TEOREMA DE DISMINUCIÓN DE LA ENTROPÍA: LA ENTROPÍA DE
UNA VARIABLE X CONDICIONADA POR OTRA Y ES MENOR O IGUAL
A LA ENTROPÍA DE X:
LA IGUALDAD SE DA SI Y SÓLO SI LAS VARIABLES X E Y SON
INDEPENDIENTES.
IDEA INTUITIVA:
CONOCER ALGO ACERCA DE LA VARIABLE Y PUEDE QUE
AYUDE A SABER MÁS SOBRE X (ES UNA REDUCCIÓN DE SU
ENTROPÍA).
EN NINGÚN CASO PODRÁ HACER QUE AUMENTE LA
INCERTIDUMBRE.
SHANNON PROPUSO UNA MEDIDA PARA LA CANTIDAD DE
INFORMACIÓN QUE APORTA SOBRE UNA VARIABLE EL
CONOCIMIENTO DE OTRA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 21
CANTIDAD DE INFORMACIÓN ENTRE
DOS VARIABLES
SE DEFINE LA CANTIDAD DE INFORMACIÓN DE SHANNON QUE LA
VARIABLE X CONTIENE SOBRE Y COMO:
SIGNIFICA QUE LA CANTIDAD DE INFORMACIÓN QUE APORTA
EL HECHO DE CONOCER X AL MEDIR LA INCERTIDUMBRE
SOBRE Y ES IGUAL A LA DISMINUCIÓN DE ENTROPÍA QUE ESTE
CONOCIMIENTO CONLLEVA.
SUS PROPIEDADES SON LAS SIGUIENTES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 22
LÍMITE DE NYQUIST

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 23
LÍMITE DE NYQUIST
NYQUIST DEMOSTRÓ LA EXISTENCIA DE UNA FRECUENCIA DE MUESTREO LLAMADA FRECUENCIA DE NYQUIST, IGUAL CUANTO MÁS AL DOBLE DE LA FRECUENCIA NATURAL DE ENTRADA (LA FRECUENCIA DE LA SEÑAL QUE SE VA A MUESTREAR).
NYQUIST SOSTIENE QUE SI SE HACE UN MUESTREO CON UNA FRECUENCIA SUPERIOR AL DOBLE:
LA INFORMACIÓN RECUPERADA ES “REDUNDANTE”.
ESTO SE DEBE INTERPRETAR COMO QUE LA CANTIDAD DE INFORMACIÓN OBTENIDA AL RECUPERAR UN MENSAJE QUE SE HA MUESTREADO A UNA FRECUENCIA MAYOR QUE EL DOBLE DE LA NATURAL:
NO DIFIERE DE LA OBTENIDA CUANDO SE MUESTREA A UNA FRECUENCIA DEL DOBLE DE LA NATURAL.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 24
LÍMITE DE NYQUIST
FN ES LA FRECUENCIA DE NYQUIST:
FN = 2 f.
UTILIZANDO EL PASABANDA PARA LOS CANALES DE INFORMACIÓN:
FN ≤ 2 ΔF.
NYQUIST ESTABLECIÓ QUE:
SI LOS CANALES SON SIN RUIDO.
SI LAS SEÑALES SON BINARIAS CON UNA TRANSMISIÓN MONONIVEL.
LA FN COINCIDE CON LA MÁXIMA VELOCIDAD BINARIA:
BPS ≤ 2 ΔF.
ESTO ES UN LÍMITE FÍSICO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 25
LÍMITE DE NYQUIST
ES POSIBLE SUPERAR ESTE MÁXIMO SI LA TRANSMISIÓN ES MULTINIVEL:
POR C/ INSTANTE DE MUESTREO SE TRANSMITIRÁ UN SÍMBOLO QUE CONTIENE MÁS DE DOS BITS Y POR LO TANTO I > 1:
BPS ≤ 2 ΔF log2 m.
m ES LA CANTIDAD DE NIVELES DE LA MODULACIÓN.
ASÍ SE RELACIONA LA MÁXIMA VELOCIDAD BINARIA CON EL ANCHO DE BANDA, LA CANTIDAD DE NIVELES Y LA ENTROPÍA.
A ESTA VELOCIDAD BINARIA SE LA DENOMINA LÍMITE DE NYQUIST:
BPS = 2 ΔF H.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 26
LÍMITE DE NYQUIST
EJ.: EN UN CANAL DE TRANSMISIÓN SE USA UNA MODULACIÓN 64QAM Y ES DEL TIPO “CANAL DE VOZ”. ¿CUÁL SERÁ EL LÍMITE DE NYQUIST?:
MODULACIÓN 64QAM: 64 NIVELES DE MODULACIÓN.
CANAL DE VOZ: 4 KHZ DE PASABANDA.
BPS = 2 ΔF H = 2 x 4 x log2 64 = 8 x 6 = 48 KBPS.
NOTA: COMO LA FRECUENCIA ESTÁ EN KHZ, BPS ESTÁ EN KBPS.
EL LÍMITE ES VÁLIDO EN CANALES SIN RUIDO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 27
LÍMITE DE SHANNON

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 28
LÍMITE DE SHANNON
UN CANAL NO IDEAL ES CONSIDERADO POR SHANNON COMO
RUIDOSO.
EJ.: RUIDO BASE EQUIPARTIDO EXISTENTE EN LOS CANALES DE
COBRE USADOS COMO CANALES DE VOZ:
COINCIDE EN GENERAL CON EL VALOR DE RUIDO TÉRMICO O
LO SUPERA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 29
LÍMITE DE SHANNON
SEGÚN SHANNON EN ESTOS CANALES EXISTE UNA RELACIÓN
ENTRE:
LA CANTIDAD MÁXIMA DE NIVELES QUE EL CANAL PUEDE
ADMITIR.
LA RELACIÓN SEÑAL-A-RUIDO DEL MISMO, QUE ESTÁ DADO
POR:
mmax = (1 + S/N)½.
m ES LA CANTIDAD DE NIVELES.
S Y N SON LOS VALORES DE POTENCIA DE SEÑAL Y DE
POTENCIA DEL RUIDO EXPRESADOS EN UNIDADES DE
POTENCIA.
S/N ES LA RELACIÓN SEÑAL A RUIDO ADIMENSIONAL:
NO ES LA MEDIDA DECIBÉLICA DE LA GANANCIA O LA
PÉRDIDA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 30
LÍMITE DE SHANNON
EL CANAL DEBERÁ ESTAR SUJETO A RUIDO GAUSSIANO LIMITADO
EN BANDA: NO SE CONSIDERA LA PRESENCIA DE RUIDO
IMPULSIVO.
SE BUSCA LA CAPACIDAD MÁXIMA DEL CANAL:
SE DEBE MAXIMIZAR m EN EL LÍMITE DE NYQUIST:
mmax = (1 + S/N) ½.
BPS ≤ 2 ΔF log2 m.
BPS = 2 ΔF log2 (1 + S/N)½.
SIMPLIFICANDO LA ECUACIÓN ANTERIOR, SE OBTIENE LA
MÁXIMA VELOCIDAD DE TRANSMISIÓN EN FUNCIÓN DEL ANCHO DE
BANDA, LA POTENCIA DE LA SEÑAL Y LA DEL RUIDO GAUSSIANO:
BPS = ΔF log2 (1 + S/N).
ES EL LLAMAMOS LÍMITE DE SHANNON DADO POR LA LEY DE
SHANNON-HARTLEY.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 31
CONSECUENCIAS DE LOS LÍMITES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 32
CONSECUENCIAS DE LOS LÍMITES
SE DEBE TENER PRESENTE LO SIGUIENTE:
EN EL CÁLCULO DEL LÍMITE INTERVIENE LA RELACIÓN DE LAS
RESPECTIVAS POTENCIAS EN UNIDADES DE POTENCIA:
S/N ES ADIMENSIONAL, ES DECIR EN VECES.
NO ES LA GANANCIA DEL CIRCUITO NI LA PÉRDIDA DEL MEDIO.
EN EL CANAL SE CONSIDERA EL RUIDO GAUSSIANO.
LA SOLA APLICACIÓN DE LA LEY DE SHANNON:
NO PERMITE DETERMINAR LA MÁXIMA VELOCIDAD DE UN
MODULADOR CUALQUIERA EN UN CANAL REAL.
SI PERMITE DETERMINAR LA MÁXIMA CAPACIDAD DEL CANAL.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 33
CONSECUENCIAS DE LOS LÍMITES
EJ.: SI UN CANAL TIENE UN ANCHO DE BANDA DE 2,7 KHZ Y LA
RELACIÓN ENTRE SEÑAL Y RUIDO ES S/N = 1000:
¿CUÁL SERÁ EL LÍMITE DE SHANNON?.
¿CUÁNTOS ESTADOS DEBERÁ MANEJAR EL MODULADOR?.
BPS = ΔF log2 (1 + S/N) = 2700 log2 (1001) = 26900.
SEGÚN EL LÍMITE DE NYQUIST:
BPS = 2 ΔF log2 m = 2 x 2700 x log2 m = 26900 BPS.
SE REQUERIRÁ AL MENOS UN MODULADOR DE 32 ESTADOS
PARA ALCANZAR ESA TASA DE BITS EN UN CANAL CON ESE
ANCHO DE BANDA.
EL LÍMITE DE SHANNON IMPACTA SOBRE LAS TÉCNICAS DE
MODULACIÓN Y DE TRANSMISIÓN.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 34
CONSECUENCIAS DE LOS LÍMITES
ACTUALMENTE LAS REDES PÚBLICAS DE VOZ TIENEN UN VALOR
TÍPICO S/N DE 35 dB: UNA IMPORTANTE DIFICULTAD PARA
MEJORAR ESTE VALOR ES EL RUIDO DE CUANTIFICACIÓN.
EFECTO DEL RUIDO DE CUANTIZACIÓN:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 35
CONSECUENCIAS DE LOS LÍMITES
EL RUIDO DE CUANTIZACIÓN Nq O ERROR DE CUANTIZACIÓN:
SE PRODUCE EN EL CODEC, A LA ENTRADA DE LA RED
DIGITAL DESDE LA RED ANALÓGICA.
ES PROPORCIONAL A LA DIFERENCIA ENTRE EL VALOR DE LA
AMPLITUD EN LA ENTRADA Y EL VALOR DE LA AMPLITUD A LA
SALIDA DEL CUANTIFICADOR.
ES PRODUCTO DE LA NECESIDAD DE ENCAMINAR LAS SEÑALES
ANALÓGICAS DE ÚLTIMA MILLA HACIA LAS REDES CONMUTADAS
DIGITALES.
SE CONOCE EL VALOR EN dB INDICADO DE 35 Db:
dB = 10 log10 (S/N).
EXPRESANDO S/N EN MODO ADIMENSIONAL EN FUNCIÓN DE Db:
S/N = 10dB/10.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 36
CONSECUENCIAS DE LOS LÍMITES
SUSTITUYENDO ESTE VALOR EN LA ECUACIÓN DEL LÍMITE DE
SHANNON:
bps = ΔF log2 (1 + 10dB/10).
LA MÁXIMA VELOCIDAD EN BPS, SE LOGRA MULTIPLICANDO EL
ANCHO DE BANDA DEL CANAL POR EL log2 DE UNO MÁS DIEZ A LA
DÉCIMA PARTE DE LOS DECIBELES DE LA RED.
PARA UNA RED CON UN ANCHO DE BANDA ESTÁNDAR DE 3 KHZ, SE
OBSERVA QUE:
SI LA RED TIENE UNA RELACIÓN DE 35 DB:
BPS = 34.822 (34 KBPS).
SI LA RED EN CAMBIO MEJORA A 40 DB:
BPS = 39.839 (38,9 KBPS).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 37
TIPOS DE ERRORES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 38
TIPOS DE ERRORES
EN LOS SISTEMAS DE TRANSMISIÓN DIGITAL SE DICE QUE HA HABIDO UN ERROR CUANDO SE ALTERA UN BIT.
EXISTEN DOS TIPOS DE ERRORES:
ERRORES AISLADOS:
ALTERAN A UN SOLO BIT.
ERRORES A RÁFAGAS.
HA HABIDO UNA RÁFAGA DE LONGITUD B CUANDO SE RECIBE UNA SECUENCIA DE B BITS EN LA QUE SON ERRÓNEOS:
• EL PRIMERO.
• EL ÚLTIMO.
• Y CUALQUIER NÚMERO DE BITS INTERMEDIOS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 39
TIPOS DE ERRORES
LA NORMA IEEE 100 DEFINE UNA RÁFAGA DE ERRORES COMO:
• GRUPO DE BITS EN EL QUE DOS BITS ERRÓNEOS CUALQUIERA ESTARÁN SIEMPRE SEPARADOS POR MENOS DE UN NÚMERO X DE BITS CORRECTOS.
• EL ÚLTIMO BIT ERRÓNEO EN UNA RÁFAGA Y EL PRIMER BIT ERRÓNEO DE LA SIGUIENTE ESTARÁN SEPARADOS POR AL MENOS X BITS CORRECTOS.
EN UNA RÁFAGA DE ERRORES HABRÁ UN CONJUNTO DE BITS CON UN NÚMERO DADO DE ERRORES:
NO NECESARIAMENTE TODOS LOS BITS EN EL CONJUNTO SERÁN ERRÓNEOS.
UN ERROR AISLADO SE PUEDE DAR EN PRESENCIA DE RUIDO BLANCO, CUANDO CUALQUIER DETERIORO ALEATORIO EN LA RELACIÓN SEÑAL-RUIDO CONFUNDA AL RECEPTOR EN UN ÚNICO BIT.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 40
TIPOS DE ERRORES
GENERALMENTE LAS RÁFAGAS SON MÁS FRECUENTES Y MÁS DIFÍCILES DE TRATAR:
PUEDEN ESTAR CAUSADAS POR RUIDO IMPULSIVO.
EN LA COMUNICACIÓN MÓVIL OTRA CAUSA PARA LAS RÁFAGAS SON LOS DESVANECIMIENTOS.
LOS EFECTOS DE UNA RÁFAGA SERÁN SIEMPRE MAYORES CUANTO MAYOR SEA LA VELOCIDAD DE TRANSMISIÓN.
EJ.: UN RUIDO IMPULSIVO O UN DESVANECIMIENTO DE 1 µs CAUSARÁ UNA RÁFAGA DE:
10 BITS A UNA VELOCIDAD DE TRANSMISIÓN DE 10 MBPS.
100 BITS A 100 MBPS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 41
DETECCIÓN DE ERRORES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 42
DETECCIÓN DE ERRORES
EN TODO SISTEMA DE TRANSMISIÓN HABRÁ RUIDO:
DARÁ LUGAR A ERRORES QUE MODIFICARÁN UNO O VARIOS BITS DE LA TRAMA.
SE CONSIDERA TRAMA A UNA O VARIAS SECUENCIAS CONTIGUAS DE BITS.
SE CONSIDERAN LAS SIGUIENTES DEFINICIONES DE PROBABILIDADES PARA LOS POSIBLES ERRORES DE TRANSMISIÓN:
Pb: PROBABILIDAD DE QUE UN BIT RECIBIDO SEA ERRÓNEO: TASA DE ERROR POR BIT: BER: BIT ERROR RATE.
P1: PROBABILIDAD DE QUE UNA TRAMA LLEGUE SIN ERRORES.
P2: PROBABILIDAD DE QUE UTILIZANDO UN ALGORITMO PARA LA DETECCIÓN DE ERRORES, UNA TRAMA LLEGUE CON UNO O MÁS ERRORES NO DETECTADOS.
P3: PROBABILIDAD DE QUE UTILIZANDO UN ALGORITMO PARA LA DETECCIÓN DE ERRORES, UNA TRAMA LLEGUE CON UNO O MÁS ERRORES DETECTADOS Y SIN ERRORES INDETECTADOS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 43
DETECCIÓN DE ERRORES
SI NO SE TOMAN MEDIDAS PARA DETECTAR ERRORES:
LA PROBABILIDAD DE ERRORES DETECTADOS: P3 = 0.
SE SUPONE QUE TODOS LOS BITS TIENEN UNA PROBABILIDAD DE ERROR (Pb) CONSTANTE E INDEPENDIENTE:
P1 = (1 - Pb)F.
P2 = (1 – P1).
F: NÚMERO DE BITS POR TRAMA.
LA PROBABILIDAD DE QUE UNA TRAMA LLEGUE SIN NINGÚN BIT ERRÓNEO DISMINUYE AL AUMENTAR LA PROBABILIDAD DE QUE UN BIT SEA ERRÓNEO.
LA PROBABILIDAD DE QUE UNA TRAMA LLEGUE SIN ERRORES DISMINUYE AL AUMENTAR LA LONGITUD DE LA MISMA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 44
DETECCIÓN DE ERRORES
EJ.: UN OBJETIVO EN LAS CONEXIONES RDSI ES QUE LA BER EN UN CANAL DE 64 KBPS DEBE SER MENOR QUE 10-6 PARA POR LO MENOS EL 90% DE LOS INTERVALOS OBSERVADOS DE 1 MINUTO DE DURACIÓN:
SI LOS REQUISITOS SON MENOS EXIGENTES: EN EL MEJOR DE LOS CASOS, UNA TRAMA CON UN BIT ERRÓNEO NO DETECTADO OCURRE POR CADA DÍA DE FUNCIONAMIENTO CONTINUO EN UN CANAL DE 64 KBPS.
SI LA LONGITUD DE LA TRAMA ES DE 1000 BITS.
EL NÚMERO DE TRAMAS QUE SE PUEDEN TRANSMITIR POR DÍA ES 5,529 x 106:
LA TASA DE TRAMAS ERRÓNEAS ES: P2 = 1/(5,529 x 106) = 0,18 x 10-6.
SI Pb = 10-6:
P1 = (0,999999)1000 = 0,999.
P2 = 10-3:
• ESTÁ TRES ÓRDENES DE MAGNITUD POR ENCIMA DE LO REQUERIDO.
ESTO JUSTIFICA USAR TÉCNICAS PARA DETECCIÓN DE ERRORES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 45
DETECCIÓN DE ERRORES
PROCEDIMIENTO PARA DETECTAR ERRORES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 46
DETECCIÓN DE ERRORES
PRINCIPIO GRAL. PARA LAS TÉCNICAS DE DETECCIÓN DE
ERRORES:
DADA UNA TRAMA DE BITS, SE AÑADEN BITS ADICIONALES EN
EL TRANSMISOR FORMANDO UN CÓDIGO DETECTOR DE
ERRORES.
EL CÓDIGO SE CALCULARÁ EN FUNCIÓN DE LOS OTROS BITS
QUE SE VAYAN A TRANSMITIR.
GENERALMENTE, PARA UN BLOQUE DE DATOS DE k BITS, EL
ALGORITMO DE DETECCIÓN DE ERRORES UTILIZA UN CÓDIGO
DE n - k BITS: (n – k) < k.
EL CÓDIGO (CONJUNTO DE BITS) DE DETECCIÓN DE ERRORES,
LLAMADO BITS DE COMPROBACIÓN, SE AÑADE AL BLOQUE DE
DATOS PARA GENERAR LA TRAMA DE n BITS DE LONGITUD
QUE SERÁ TRANSMITIDA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 47
DETECCIÓN DE ERRORES
EL RECEPTOR SEPARARÁ LA TRAMA RECIBIDA:
k BITS DE DATOS.
(n - k) BITS DEL CÓDIGO DE DETECCIÓN DE ERRORES.
EL RECEPTOR REPETIRÁ EL CÁLCULO SOBRE LOS BITS DE
DATOS RECIBIDOS Y COMPARARÁ EL RESULTADO CON LOS BITS
RECIBIDOS EN EL CÓDIGO DE DETECCIÓN DE ERRORES.
SE DETECTARÁ UN ERROR SII LOS DOS RESULTADOS
MENCIONADOS NO COINCIDEN.
P3: PROBABILIDAD DE QUE LA TRAMA CONTENGA ERRORES Y EL
SISTEMA LOS DETECTE.
P2: ES LA TASA DE ERROR RESIDUAL: PROBABILIDAD DE QUE NO SE
DETECTE UN ERROR AUNQUE SE ESTÉ USANDO UN ESQUEMA DE
DETECCIÓN DE ERRORES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 48
DETECCIÓN DE ERRORES
COMPROBACIÓN DE REDUNDANCIA CÍCLIDA (CRC)
UNO DE LOS CÓDIGOS PARA DETECCIÓN DE ERRORES MÁS
HABITUALES Y POTENTES SON LOS DE COMPROBACIÓN DE
REDUNDANCIA CÍCLICA (CRC: CYCLIC REDUNDANCY CHECK).
SE TIENE UN BLOQUE O MENSAJE DE k-BITS.
EL TRANSMISOR GENERA UNA SECUENCIA DE (n - k) BITS:
SECUENCIA DE COMPROBACIÓN DE LA TRAMA: FCS: FRAME
CHECK SEQUENCE.
LA TRAMA RESULTANTE CON n BITS SERÁ DIVISIBLE POR
ALGÚN NÚMERO PREDETERMINADO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 49
DETECCIÓN DE ERRORES
EL RECEPTOR DIVIDIRÁ LA TRAMA RECIBIDA POR ESE NÚMERO Y SI
NO HAY RESTO EN LA DIVISIÓN SUPONDRÁ QUE NO HA HABIDO
ERRORES.
EL RECEPTOR TAMBIÉN PODRÍA DIVIDIR LOS DATOS DE ENTRADA
(IGUAL QUE EL EMISOR) Y COMPARAR EL RESULTADO CON LOS
BITS DE COMPROBACIÓN.
ESTE PROCEDIMIENTO SE PUEDE EXPLICAR USANDO:
ARITMÉTICA MÓDULO 2.
POLINOMIOS.
LÓGICA DIGITAL.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 50
DETECCIÓN DE ERRORES ARITMÉTICA MÓDULO 2
USA SUMAS Y RESTAS BINARIAS SIN ACARREO:
SON IGUALES A LA OPERACIÓN LÓGICA EXCLUSIVE-OR:
1111 1111 11001
+1010 -0101 x 11
0101 1010 11001
11001
101011
T: TRAMA DE n BITS A TRANSMITIR.
M: MENSAJE CON k BITS DE DATOS, CORRESPONDIENTES CON LOS
PRIMEROS k BITS DE T.
F = (n – k) BITS DE FCS: LOS ÚLTIMOS (n – k) BITS DE T.
P: PATRÓN DE n – k + 1 BITS: DIVISOR ELEGIDO.
T / P = 0.
T = 2n-kD + F.
MULTIPLICAR 2n-kD EQUIVALE A DESPLAZAR HACIA LA
IZQUIERDA n – k BITS AÑADIENDO CEROS AL RESULTADO.
SUMAR F SIGNIFICA CONCATENAR D Y F.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 51
DETECCIÓN DE ERRORES
T DEBE SER DIVISIBLE POR P:
(2n-kD) / P = Q + (R / P).
HAY UN COCIENTE Y UN RESTO:
EL RESTO SERÁ AL MENOS 1 BIT MÁS CORTO QUE EL
DIVISOR PORQUE LA DIVISIÓN ES MÓDULO 2.
LA SECUENCIA DE COMPROBACIÓN DE LA TRAMA (FCS) SERÁ
EL RESTO DE LA DIVISIÓN:
T = 2n-kD + R.
R DEBE SATISFACER LA CONDICIÓN DE QUE EL RESTO DE
T/P SEA CERO:
• (T / P) = (2n-kD + R) / P = (2n-kD) / P + (R / P).
• (2n-kD) / P = Q + (R / P).
• (T / P) = Q + (R / P) + (R / P).
CUALQUIER NÚMERO BINARIO SUMADO A MÓDULO 2
CONSIGO MISMO ES 0:
• (T / P) = Q + ((R + R) / P) = Q:
– NO HAY RESTO: T ES DIVISIBLE POR P.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 52
DETECCIÓN DE ERRORES
FCS SE GENERA FÁCILMENTE:
SE DIVIDE (2n-kD) / P Y SE USAN LOS (n – k) BITS DEL RESTO
COMO FCS.
EN EL RECEPTOR SE DIVIDIRÁ (T / P) Y SI NO HA HABIDO ERRORES
EL RESTO SERÁ 0.
EJ.:
MENSAJE D: 1010001101 (10 BITS).
PATRÓN P: 110101 (6 BITS).
FCS R: A CALCULAR (5 BITS).
n: 15; k: 10; (n – k): 5.
MENSAJE x 25: 101000110100000.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 53
DETECCIÓN DE ERRORES
EL RESULTADO ANTERIOR SE DIVIDE POR P:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 54
DETECCIÓN DE ERRORES
T = 2n-kD + R = 25D + R = 101000110101110: ESTO SE TRANSMITE.
SI NO HAY ERRORES EL RECEPTOR RECIBE T:
LA TRAMA RECIBIDA SE DIVIDE POR P Y SI EL RESTO R ES
0 SE SUPONE QUE NO HA HABIDO ERRORES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 55
DETECCIÓN DE ERRORES
EL PATRÓN P:
SE ELIGE CON UN BIT MÁS QUE LA LONGITUD DE LA FCS
DESEADA.
DEPENDERÁ DEL TIPO DE ERROR QUE SE ESPERA SUFRIR.
DEBE TENER COMO MÍNIMO EL BIT MENOS SIGNIFICATIVO Y
EL BIT MÁS SIGNIFICATIVO EN 1.
POLINOMIOS
OTRA POSIBILIDAD DE CRC ES EXPRESAR TODOS LOS VALORES
COMO POLINOMIOS DE UNA VARIABLE MUDA X, CON
COEFICIENTES BINARIOS:
D = 110011; D(X) = X5 + X4 + X + 1.
P = 11001; P(X) = X4 + X3 + 1.
SE USA ARITMÉTICA MÓDULO 2.
EL PROCEDIMIENTO DE CRC ES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 56
DETECCIÓN DE ERRORES
EJEMPLO: SE USA EL EJ. ANTERIOR:
D = 1010001101; D(X) = X9 + X7 + X3 + X2 + 1.
P = 110101; P(X) = X5 + X4 + X2 + 1.
R = 01110; R(X) = X3 + X2 + X.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 57
DETECCIÓN DE ERRORES
DIVISIÓN DE POLINOMIOS DEL EJEMPLO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 58
DETECCIÓN DE ERRORES
UN ERROR E(X) NO SE DETECTARÁ SÓLO SI ES DIVISIBLE POR P(X):
SE DETECTARÁN LOS ERRORES NO DIVISIBLES, SI SE ELIGE
ADECUADAMENTE EL POLINOMIO P(X):
TODOS LOS ERRORES DE UN ÚNICO BIT SI P(X) TIENE MÁS
DE UN TÉRMINO DISTINTO DE CERO.
TODOS LOS ERRORES DOBLES SI P(X) TIENE AL MENOS UN
FACTOR CON TRES TÉRMINOS.
CUALQUIER NÚMERO IMPAR DE ERRORES SI P(X) CONTIENE
EL FACTOR (X + 1).
CUALQUIER RÁFAGA DE ERRORES CON LONGITUD MENOR
O IGUAL QUE n – k: MENOR O IGUAL QUE LA LONGITUD DE
LA FCS.
UNA FRACCIÓN DE LAS RÁFAGAS DE ERRORES CON
LONGITUD IGUAL A n – k + 1:
• LA FRACCIÓN ES 1 – 2-(n-k-1).
UNA FRACCIÓN DE LAS RÁFAGAS DE ERRORES CON
LONGITUDES MAYORES QUE n – k + 1:
• LA FRACCIÓN ES 1 – 2-(n-k).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 59
DETECCIÓN DE ERRORES
SI TODOS LOS PATRONES DE ERROR SON EQUIPROBABLES:
PARA UNA RÁFAGA DE ERRORES DE LONGITUD r + 1 LA
PROBABILIDAD DE QUE NO SE DETECTE UN ERROR ES 1/2r-1.
PARA RÁFAGAS MAYORES LA PROBABILIDAD ES 1/2r.
r ES LA LONGITUD DE LA FCS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 60
DETECCIÓN DE ERRORES
EJ. DE DEFINICIONES DE P(X) USADAS FRECUENTEMENTE:
LA CRC-32 SE USA EN NORMAS IEEE 802 PARA LAN.
LÓGICA DIGITAL
CRC SE PUEDE REPRESENTAR E IMPLEMENTAR CON:
UN CIRCUITO DIVISOR FORMADO POR PUERTAS EXCLUSIVE-OR.
UN REGISTRO DE DESPLAZAMIENTO.
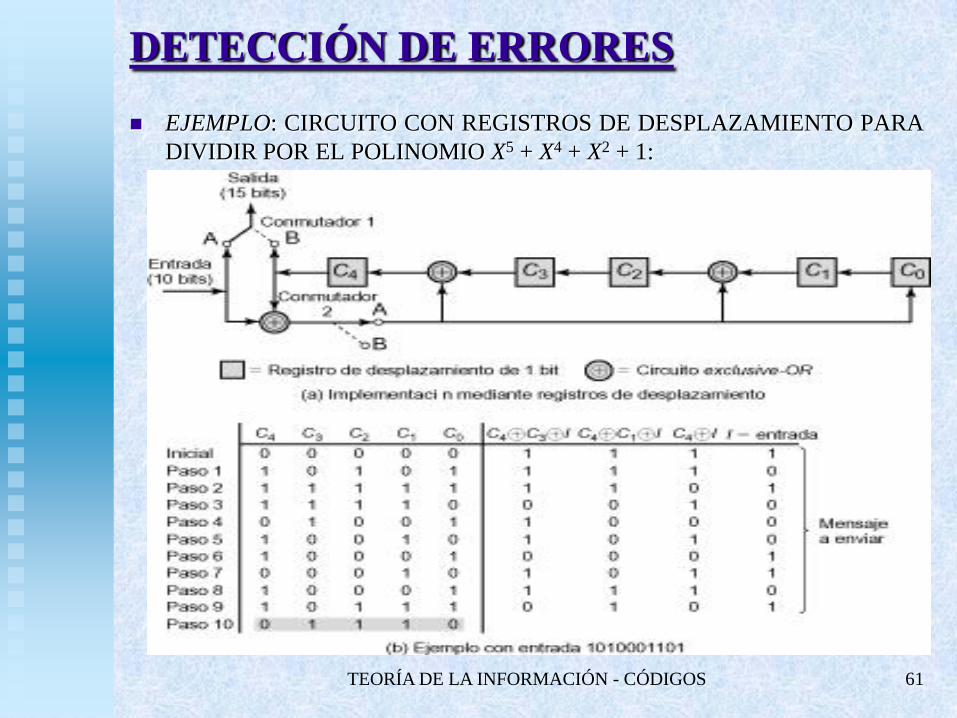
TEORÍA DE LA INFORMACIÓN - CÓDIGOS 61
DETECCIÓN DE ERRORES
EJEMPLO: CIRCUITO CON REGISTROS DE DESPLAZAMIENTO PARA
DIVIDIR POR EL POLINOMIO X5 + X4 + X2 + 1:
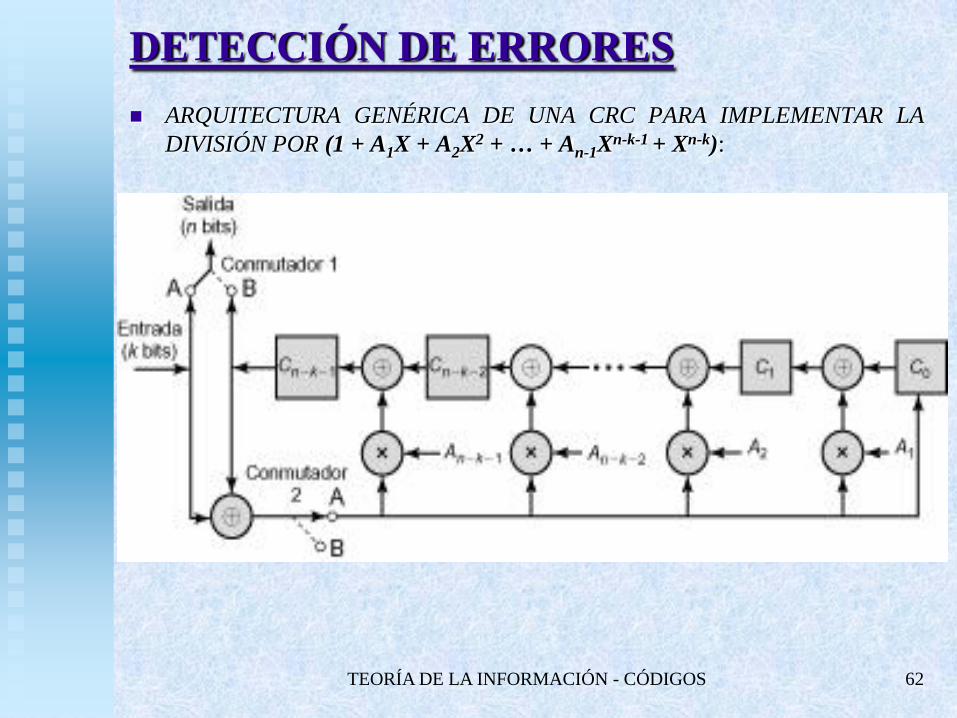
TEORÍA DE LA INFORMACIÓN - CÓDIGOS 62
DETECCIÓN DE ERRORES
ARQUITECTURA GENÉRICA DE UNA CRC PARA IMPLEMENTAR LA
DIVISIÓN POR (1 + A1X + A2X2 + … + An-1X
n-k-1 + Xn-k):

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 63
INTRODUCCIÓN A CÓDIGOS

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 64
INTRODUCCIÓN A CÓDIGOS
DEFINICIÓN: SE CONSIDERA UN CONJUNTO FINITO A={a1, a2, ... aq},
AL QUE SE DENOMINA ALFABETO, A SUS ELEMENTOS, a1, a2, ... aq,
SE LOS LLAMA LETRAS O SÍMBOLOS. LAS SUCESIONES FINITAS
DE ELEMENTOS DE A SE LLAMAN PALABRAS.
LA PALABRA ai1ai2...ain SE DICE QUE TIENE LONGITUD n O BIEN
QUE ES UNA n-PALABRA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 65
INTRODUCCIÓN A CÓDIGOS
EL CONJUNTO DE TODAS LAS PALABRAS SOBRE EL ALFABETO A
SE DENOTARÁ COMO A* (CON INDEPENDENCIA DE LA LONGITUD
DE LAS PALABRAS).
DEFINICIÓN: UN CÓDIGO SOBRE EL ALFABETO A ES UN
SUBCONJUNTO C DE A*, (CONJUNTO FORMADO POR PALABRAS
DEL ALFABETO).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 66
INTRODUCCIÓN A CÓDIGOS
A LOS ELEMENTOS DEL CÓDIGO C SE LES LLAMA PALABRAS DE
CÓDIGO.
EL NÚMERO DE ELEMENTOS DEL CÓDIGO C, QUE NORMALMENTE
SERÁ FINITO, SE DENOTA POR |C| Y SE DENOMINA TAMAÑO DEL
CÓDIGO.
SI C ES UN CÓDIGO SOBRE A Y A TIENE q ELEMENTOS (|A|=q)
ENTONCES SE DICE QUE C ES UN CÓDIGO q-ARIO:
EJEMPLO: A = Z2 = {0,1}: CÓDIGOS BINARIOS.
EJEMPLO DE CÓDIGO BINARIO: C = {0100,0010,0111}.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 67
INTRODUCCIÓN A CÓDIGOS
DEFINICIÓN: SI C ES UN CÓDIGO CUYAS PALABRAS TIENEN TODAS LA MISMA LONGITUD n, SE DICE QUE C ES UN CÓDIGO DE LONGITUD FIJA O UN CÓDIGO DE BLOQUES Y A n SE LE LLAMA LONGITUD DEL CÓDIGO C.
EL CÓDIGO C ANTERIOR ES UN CÓDIGO DE BLOQUES DE LONGITUD 4.
C = {011, 1011, 10} NO ES UN CÓDIGO DE BLOQUES:
NO SE PUEDE HABLAR DE LA LONGITUD DEL CÓDIGO.
SI C ES UN CÓDIGO DE LONGITUD n Y TAMAÑO m SE DICE QUE C ES UN (n,m)-CÓDIGO:
C = {0100,0010,0111} ES (4,3) CÓDIGO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 68
INTRODUCCIÓN A CÓDIGOS
DADO UN ALFABETO S AL QUE DENOMINAREMOS ALFABETO FUENTE Y DADO UN CÓDIGO C SOBRE EL ALFABETO A, SE LLAMA FUNCIÓN DE CODIFICACIÓN A UNA APLICACIÓN BIYECTIVA f:
S ES EL ALFABETO EN EL CUAL ESTÁ LA INFORMACIÓN QUE SE QUIERE CODIFICAR.
UNA APLICACIÓN BIYECTIVA ENTRE 2 CONJUNTOS ES UNA APLICACIÓN:
INYECTIVA: ELEMENTOS DIFERENTES TIENEN IMÁGENES DIFERENTES; Y.
SOBREYECTIVA: LOS ELEMENTOS DEL CONJUNTO C SON IMÁGENES DE ALGÚN ELEMENTO DE S, EN ESTE CASO DE 1 YA QUE LA APLICACIÓN ES INYECTIVA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 69
INTRODUCCIÓN A CÓDIGOS
A VECES f NO SERÁ UNA APLICACIÓN BIYECTIVA; SI f NO FUESE INYECTIVA HABRÍA VARIOS SÍMBOLOS DEL ALFABETO FUENTE QUE SE CODIFICARÍAN DE LA MISMA FORMA:
HARÍA LA DECODIFICACIÓN MUY DIFÍCIL.
CUANDO f ES BIYECTIVA HABLAMOS DE CÓDIGOS DESCIFRABLES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 70
INTRODUCCIÓN A CÓDIGOS
EJEMPLO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 71
INTRODUCCIÓN A CÓDIGOS
POLIVIO O CÓDIGO DE FUEGO GRIEGO (208 A.C.):

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 72
INTRODUCCIÓN A CÓDIGOS
ESTE CÓDIGO NO PERMITE DETECTAR Y/O CORREGIR ERRORES.
CÓDIGO MORSE:
SE USA PARA TRANSMISIONES TELEGRÁFICAS, PARA
CODIFICAR UN MENSAJE FUENTE EN LENGUAJE NATURAL.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 73
INTRODUCCIÓN A CÓDIGOS
ESTE CÓDIGO NO ES DE LONGITUD FIJA:
LAS LETRAS MÁS FRECUENTES SE CODIFICAN CON PALABRAS
CORTAS.
LAS LETRAS MENOS USADAS SE CODIFICAN CON PALABRAS
MÁS LARGAS.
ESTO ES PARA CONSEGUIR MÁS EFICIENCIA.
LOS ESPACIOS SE USAN PARA SEPARAR PALABRAS (6 ESPACIOS).
ESTE CÓDIGO NO PERMITE CORREGIR Y/O DETECTAR ERRORES Y
NO TIENE FINES CRIPTOGRÁFICOS.
CÓDIGO ASCII (AMERICAN STANDARD CODE FOR
INFORMATION INTERCHANGE).
EL ASCII ESTÁNDAR USA PALABRAS DE 7 BITS:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 74
INTRODUCCIÓN A CÓDIGOS
EL CÓDIGO ASCII EXTENDIDO USA PALABRAS DE 8 BITS:
AL CÓDIGO ASCII DE 7 BITS SE LE AÑADE UN BIT DE PARIDAD PARA QUE EL NÚMERO DE 1 DE LA PALABRA SEA PAR:
ESTE ES EL CÓDIGO ASCII ESTÁNDAR CON CONTROL DE PARIDAD.
EL CÓDIGO ASCII ESTÁNDAR:
AL AÑADIR EL BIT DE PARIDAD SI SE CAMBIA UN BIT LA PALABRA QUE SE OBTIENE NO ES VÁLIDA:
EL NÚMERO DE 1 PASA A SER IMPAR CON LO QUE SE DETECTA EL ERROR.
ESTE CÓDIGO SÓLO DETECTA ERRORES, NO PUEDO SABER CUÁL FUE LA PALABRA QUE SE ENVIÓ.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 75
INTRODUCCIÓN A CÓDIGOS
EL ASCII CON CONTROL DE PARIDAD ES UN (8,128) CÓDIGO, MIENTRAS QUE EL ASCII ESTÁNDAR ES UN (7,128) CÓDIGO.
EL CÓDIGO ASCII EXTENDIDO ES UN (8,256) CÓDIGO.
EL CÓDIGO ASCII NO ES MUY EFICIENTE YA QUE ES DE LONGITUD FIJA Y USA EL MISMO NÚMERO DE BITS PARA CODIFICAR CARACTERES FRECUENTES Y POCO FRECUENTES.
EN ESTE CÓDIGO NO HACE FALTA SEPARAR LAS PALABRAS YA QUE CADA PALABRA TIENE UN NÚMERO FIJO DE BITS.
LA VENTAJA DEL ASCII CON BIT DE PARIDAD SOBRE EL ASCII ESTÁNDAR ES QUE PERMITE DETECTAR ERRORES Y SE PUEDE PEDIR REPETIR LA TRANSMISIÓN HASTA QUE ÉSTA SEA CORRECTA.
EL INCONVENIENTE ES QUE ES MENOS EFICIENTE YA QUE PARA TRANSMITIR LA MISMA INFORMACIÓN USA PALABRAS DE 8 BITS EN LUGAR DE PALABRAS DE 7 BITS.
PARA DETECTAR Y CORREGIR ERRORES A LOS CÓDIGOS SE LES AÑADE REDUNDANCIA CON LO QUE SE PIERDE EFICIENCIA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 76
CÓDIGOS DETECTORES DE ERRORES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 77
CÓDIGOS DETECTORES DE ERRORES
SE INTENTA BUSCAR UNA TRANSMISIÓN PRECISA ENTRE DOS PUNTOS.
ESTOS CÓDIGOS SE USAN CUANDO SE REALIZA UNA TRANSMISIÓN POR UN CANAL RUIDOSO:
UN CANAL ES EL MEDIO FÍSICO POR EL CUAL SE REALIZA LA TRANSMISIÓN.
UN CANAL RUIDOSO ES UN CANAL QUE ESTÁ SUJETO A PERTURBACIONES Y QUE GENERA ALTERACIONES EN EL MENSAJE.
LOS CÓDIGOS DETECTORES DE ERRORES SE USAN PARA RECUPERAR LA INFORMACIÓN QUE LLEGÓ INCORRECTAMENTE:
SE USAN TAMBIÉN EN LOS CD, PARA QUE LA INFORMACIÓN SE RECUPERE A PESAR DE QUE EL CD ESTÉ RAYADO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 78
CÓDIGOS DETECTORES DE ERRORES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 79
CÓDIGOS DETECTORES DE ERRORES
LA CODIFICACIÓN Y DECODIFICACIÓN DEBEN SER FÁCILES Y RÁPIDAS.
LA TRANSMISIÓN A TRAVÉS DEL CANAL DEBE SER RÁPIDA.
SE DEBE:
MAXIMIZAR LA CANTIDAD DE INFORMACIÓN TRANSMITIDA POR UNIDAD DE TIEMPO.
DETECTAR Y CORREGIR ERRORES.
ESTA ÚLTIMA CARACTERÍSTICA ENTRA EN CONFLICTO CON LAS ANTERIORES:
HACE QUE AUMENTE EL TAMAÑO DE LO QUE SE TRANSMITE.
EL CÓDIGO DEBE SER LO MÁS EFICIENTE POSIBLE Y DEBE PERMITIR DETECTAR Y CORREGIR ERRORES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 80
CÓDIGOS DETECTORES DE ERRORES
EL CANAL ACEPTA SÍMBOLOS DE UN ALFABETO FINITO A={a1, a2, ... aq} QUE LLAMAREMOS ALFABETO DEL CANAL (EJEMPLO: A = {0, 1}).
PARA SABER QUÉ TAN RUIDOSO ES UN CANAL SE DEBE CONOCER CUÁL ES LA PROBABILIDAD DE QUE SI SE EMITE UN SÍMBOLO SE RECIBA OTRO SÍMBOLO:
P(aj RECIBIDO | ai ENVIADO):
PROBABILIDAD DE QUE SI SE HA ENVIADO ai SE RECIBA aj.
CUANDO ESTE CONJUNTO DE PROBABILIDADES SE CONOCE PARA TODOS LOS VALORES DE i Y j CONOCEMOS LAS CARACTERÍSTICAS DEL CANAL.
EL CANAL PERFECTO SERÍA AQUÉL EN EL QUE:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 81
CÓDIGOS DETECTORES DE ERRORES
A ESTAS PROBABILIDADES SE LES LLAMA PROBABILIDADES DEL CANAL O PROBABILIDADES DE TRANSICIÓN.
EL CANAL PERFECTO NO EXISTE EN LA PRÁCTICA.
DEFINICIÓN: UN CANAL ES UN ALFABETO (DE CANAL) A={a1, a2, ... aq} Y UN CONJUNTO DE PROBABILIDADES DE TRANSICIÓN P(aj RECIBIDO | ai ENVIADO) QUE SATISFACEN:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 82
CÓDIGOS DETECTORES DE ERRORES
EL RUIDO SE DISTRIBUYE ALEATORIAMENTE:
LA PROBABILIDAD DE QUE UN SÍMBOLO SEA CAMBIADO POR OTRO EN LA TRANSMISIÓN ES LA MISMA PARA TODOS LOS SÍMBOLOS.
LA TRANSMISIÓN DE UN SÍMBOLO NO ESTÁ INFLUENCIADA POR LA TRANSMISIÓN DEL SÍMBOLO PRECEDENTE NI DE LOS ANTERIORES:
EL CANAL ES UN CANAL SIN MEMORIA.
EL ERROR EN LA TRANSMISIÓN DE UN SÍMBOLO NO AFECTA A LA TRANSMISIÓN DE LOS SIGUIENTES SÍMBOLOS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 83
CÓDIGOS DETECTORES DE ERRORES
UN CANAL USADO FRECUENTEMENTE ES EL CANAL BINARIO
SIMÉTRICO (BINARY SIMETRIC CHANNEL: BSC). EL ALFABETO
DEL CANAL ES A={0,1}.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 84
CÓDIGOS DETECTORES DE ERRORES
0 p 1.
1-p: PROBABILIDAD DEL CANAL.
p: PROBABILIDAD DEL CRUCE.
p: PROBABILIDAD DE QUE UN 0 SEA RECIBIDO COMO UN 1.
1-p: PROBABILIDAD DE QUE UN 0 SEA RECIBIDO COMO UN 0.
p = 0: CANAL PERFECTO.
p = 1: SIEMPRE SE COMETE ERROR.
EN UN CANAL SIMÉTRICO:
EXISTE LA MISMA PROBABILIDAD DE QUE UN SÍMBOLO SE
RECIBA INCORRECTAMENTE.
SI UN SÍMBOLO SE RECIBE INCORRECTAMENTE HAY LA
MISMA PROBABILIDAD DE QUE SE RECIBA CUALQUIER OTRO
SÍMBOLO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 85
CÓDIGOS DETECTORES DE ERRORES
SI SE QUIERE DETECTAR ERRORES:
SE DEBE DISEÑAR UN CÓDIGO DE TAL FORMA QUE SI A UNA
PALABRA DEL CÓDIGO SE LE CAMBIA UN ÚNICO SÍMBOLO LA
PALABRA RESULTANTE NO SEA UNA PALABRA DEL CÓDIGO
PARA ASÍ PODER SABER QUE SE HA PRODUCIDO UN ERROR.
SI ADEMÁS SE QUIERE CORREGIR ERRORES:
HAY QUE SABER CUÁL ES LA PALABRA ENVIADA.
LA IDEA BÁSICA ES COMPARAR LA PALABRA RECIBIDA CON
TODAS LAS PALABRAS DEL CÓDIGO Y ASIGNARLE LA
PALABRA QUE DIFIERA EN MENOS SÍMBOLOS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 86
CÓDIGOS DETECTORES DE ERRORES
EJEMPLO:
ESTE CÓDIGO NO SERVIRÍA PARA DETECTAR ERRORES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 87
CÓDIGOS DETECTORES DE ERRORES
SI SE PRODUCEN ERRORES LAS PALABRAS QUE SE OBTIENEN SON
PALABRAS DEL CÓDIGO.
PARA DETECTAR ERRORES HAY QUE AÑADIR REDUNDANCIA:
SE MODIFICA EL CÓDIGO PARA CONSEGUIR QUE LAS
PALABRAS DEL CÓDIGO SE PAREZCAN MENOS ENTRE SÍ.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 88
CÓDIGOS DETECTORES DE ERRORES
SE CONSIDERA:
SI SE RECIBE 111010:
SE VE QUE NO ES UNA PALABRA VÁLIDA DEL CÓDIGO Y SE
DETECTA QUE SE HA COMETIDO UN ERROR.
SE COMPARA ESTA PALABRA CON LAS PALABRAS DEL
CÓDIGO Y SE VE EN CUÁNTOS SÍMBOLOS SE DIFERENCIA DE
LAS PALABRAS DEL CÓDIGO.
SE VE QUE LA PALABRA MÁS PRÓXIMA ES LA 101010 YA QUE
SÓLO CAMBIA UN SÍMBOLO, POR LO QUE SE PODRÍA
ASIGNARLE ESTA PALABRA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 89
CÓDIGOS DETECTORES DE ERRORES
ESTE CÓDIGO TIENE LA PROPIEDAD DE QUE SI AL TRANSMITIR
UNA PALABRA SE COMETE UN ÚNICO ERROR SIEMPRE SE PUEDE
RECUPERAR LA PALABRA ORIGINALMENTE TRANSMITIDA YA
QUE DISTA UNO DE UNA PALABRA Y MÁS DE UNO DEL RESTO DE
PALABRAS.
SE DICE QUE ESTE CÓDIGO CORRIGE UN ERROR:
ESTO SE LOGRA A COSTA DE AUMENTAR LA LONGITUD DEL
CÓDIGO.
SE NECESITA EL TRIPLE DE TIEMPO Y ESPACIO PARA
TRANSMITIR LA MISMA INFORMACIÓN: DISMINUYE LA
EFICIENCIA DEL CÓDIGO.
ESTE CÓDIGO SE DENOMINA CÓDIGO DE REPETICIÓN.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 90
CÓDIGOS DETECTORES DE ERRORES
CLASES RESIDUALES MÓDULO n.
DADO:
SEA n Z, n 2. DADOS a, b Z SE DICE QUE a ES CONGRUENTE
CON b MÓDULO n SI:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 91
CÓDIGOS DETECTORES DE ERRORES
LA RELACIÓN DE CONGRUENCIA MÓDULO n ES UNA RELACIÓN
DE EQUIVALENCIA, YA QUE ES REFLEXIVA, SIMÉTRICA Y
TRANSITIVA.
LA RELACIÓN DE EQUIVALENCIA PERMITE DEFINIR LAS CLASES
DE EQUIVALENCIA a Z.
LA CLASE DE EQUIVALENCIA DE a SE DEFINE COMO AQUELLOS
NÚMEROS RELACIONADOS CON a:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 92
CÓDIGOS DETECTORES DE ERRORES
EL CONJUNTO DE TODAS LAS CLASES DE EQUIVALENCIA
FORMAN UNA PARTICIÓN DE Z.
AL CONJUNTO DE TODAS LAS CLASES DE EQUIVALENCIA SE LE
DENOMINA CONJUNTO COCIENTE (SUS ELEMENTOS SON
CLASES).
SEAN a,b Z:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 93
CÓDIGOS DETECTORES DE ERRORES
EN LA DIVISIÓN ENTERA EL RESTO O RESIDUO ES ÚNICO.
CADA ELEMENTO ESTÁ EN LA MISMA CLASE DE EQUIVALENCIA
QUE SU RESTO AL DIVIDIR POR n.
EL NÚMERO DE CLASES ES EL NÚMERO DE POSIBLES RESTOS AL
DIVIDIR POR n (n CLASES).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 94
CÓDIGOS DETECTORES DE ERRORES
DEFINICIÓN: SEA C UN (n,m)-CÓDIGO q-ARIO (|A| = q, SIENDO A EL
ALFABETO). SE DEFINE LA TASA DE INFORMACIÓN (O DE
TRANSMISIÓN) DE C COMO:
EN EL CASO BINARIO SE TIENE:
ESTA DEFINICIÓN EXPRESA LA RELACIÓN QUE HAY ENTRE:
LOS SÍMBOLOS DEL CÓDIGO DEDICADOS A LA INFORMACIÓN.
LOS SÍMBOLOS DEDICADOS A LA REDUNDANCIA (DETECTAR
Y/O CORREGIR ERRORES).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 95
CÓDIGOS DETECTORES DE ERRORES
EJEMPLO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 96
CÓDIGOS DETECTORES DE ERRORES
ESTE CÓDIGO NO CORRIGE NI DETECTA ERRORES:
TODOS LOS SÍMBOLOS ESTÁN DEDICADOS A LA TRANSMISIÓN
DE INFORMACIÓN.
ESTE CÓDIGO TIENE LA MÁXIMA TASA DE TRANSMISIÓN.
PARA CORREGIR UN ERROR SE AÑADE UN BIT DE PARIDAD.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 97
CÓDIGOS DETECTORES DE ERRORES
LA TASA DE INFORMACIÓN DISMINUYE:
SE AÑADIÓ UN BIT PARA DETECTAR ERRORES PERO NO
TRANSMITE INFORMACIÓN.
SE PUEDE VER ESTO COMO EL COCIENTE ENTRE EL NÚMERO
DE SÍMBOLOS DEDICADOS A LA INFORMACIÓN Y EL NÚMERO
TOTAL DE SÍMBOLOS.
DADO R NO PODEMOS DETERMINAR SI EL CÓDIGO PERMITE
DETECTAR Y/O CORREGIR ERRORES.
CONOCIENDO R SABEMOS LA EFICIENCIA DEL CÓDIGO:
LOS CÓDIGOS MÁS EFICIENTES TIENEN R = 1.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 98
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 99
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA SE CONSIDERA:
u ES LA PALABRA TRANSMITIDA Y w ES LA PALABRA RECIBIDA.
PARA DESCODIFICAR SE USA UNA REGLA DE DECISIÓN QUE ES
UNA APLICACIÓN DE An EN C:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 100
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA SI f(w) = u DESCODIFICO w COMO u.
SI w YA ES UNA PALABRA DEL CÓDIGO ENTONCES f(w) = w.
SE TIENE UNA REGLA DE DECISIÓN f: An C QUE VERIFICA:
ESTO SIGNIFICA QUE f(w) TIENE LA PROPIEDAD DE QUE NO HAY
NINGUNA OTRA PALABRA DEL CÓDIGO CON MAYOR
PROBABILIDAD DE HABER SIDO ENVIADA:
SI ESTO SE CUMPLE SE DICE QUE f ES UNA REGLA DE
DECISIÓN DE PROBABILIDAD MÁXIMA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 101
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA SI SE USA UN BSC:
NO CONOCEMOS EL VALOR DE 1-p.
NO SE CALCULAN PROBABILIDADES, SE VE CUÁL ES LA
PALABRA DE CÓDIGO MÁS PRÓXIMA A LA PALABRA
RECIBIDA:
ESTO COINCIDE, PARA UN BSC, CON LA DESCODIFICACIÓN
DE PROBABILIDAD MÁXIMA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 102
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
PROPOSICIÓN: DADO UN BSC CON 0 p ½ LA REGLA DE
DECISIÓN DE PROBABILIDAD MÁXIMA CONSISTE EN ELEGIR LA
PALABRA DE CÓDIGO QUE DIFIERA DE LA PALABRA RECIBIDA EN
EL NÚMERO MÍNIMO DE SÍMBOLOS POSIBLES.
LA PROBABILIDAD DE QUE UNA PALABRA TENGA k ERRORES EN
k POSICIONES DADAS ES pk (1-p)k.
SI SE ENVÍA v Y LA PALABRA RECIBIDA w DIFIERE DE v EN k
LUGARES:
LA PROBABILIDAD P(w RECIBIDO | v ENVIADO) = pk (1-p)k.
PUEDE OCURRIR QUE HAYA VARIAS PALABRAS A DISTANCIA
MÍNIMA (MLD).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 103
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
SE DICE QUE LA DESCODIFICACIÓN ES COMPLETA SI SÓLO HAY
UNA PALABRA POSIBLE CON DISTANCIA MÍNIMA.
SE DICE QUE LA DESCODIFICACIÓN ES INCOMPLETA CUANDO
HAY MÁS DE UNA POSIBLE PALABRA CON DISTANCIA MÍNIMA
Y SE PRODUCE UN ERROR.
DEFINICIÓN: SEA A UN ALFABETO Y u,w An; SE DEFINE LA
DISTANCIA HAMMING d(u,w) COMO EL NÚMERO DE POSICIONES
EN LAS QUE DIFIEREN u Y w.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 104
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
ESTA APLICACIÓN ES UNA MÉTRICA:
ES DEFINIDA POSITIVA:
ES SIMÉTRICA:
PRESENTA DESIGUALDAD TRIANGULAR:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 105
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
DEFINICIÓN: SE LLAMA DISTANCIA MÍNIMA (O DISTANCIA) DE
UN CÓDIGO C A:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 106
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
DEFINICIÓN: UN CÓDIGO C ES t-DETECTOR (DE ERRORES), t Z+,
SI EL NÚMERO DE ERRORES COMETIDOS AL TRANSMITIR UNA
PALABRA ES:
MAYOR O IGUAL QUE 1 Y.
MENOR O IGUAL QUE t.
ENTONCES LA PALABRA RESULTANTE NO ES UNA PALABRA
DEL CÓDIGO.
C SE DICE QUE ES EXACTAMENTE t-DETECTOR CUANDO ES t-
DETECTOR PERO NO ES (t+1)-DETECTOR.
PROPOSICIÓN: UN CÓDIGO C ES EXACTAMENTE t-DETECTOR SI
Y SÓLO SI d(C) = t+1.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 107
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
DEFINICIÓN: UN CÓDIGO C ES t-CORRECTOR DE ERRORES SI:
LA DESCODIFICACIÓN PERMITE CORREGIR TODOS LOS
ERRORES DE TAMAÑO t O MENOR EN UNA PALABRA DEL
CÓDIGO.
SE SUPONE QUE CUANDO HAY VARIAS PALABRAS DEL
CÓDIGO EQUIDISTANTES DE LA PALABRA RECIBIDA EL
PROCESO DE DESCODIFICACIÓN DECLARA UN ERROR Y NO SE
COMPLETA.
UN CÓDIGO C SE DICE QUE ES EXACTAMENTE t-CORRECTOR
CUANDO ES t-CORRECTOR PERO NO ES (t+1)-CORRECTOR.
ERROR DE TAMAÑO t: ERROR EN EL CUAL EL N° DE ERRORES ES
t.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 108
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
PROPOSICIÓN: UN CÓDIGO C ES EXACTAMENTE t-CORRECTOR
SI Y SÓLO SI d(C) = 2t + 1 O 2t + 2.
EJEMPLO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 109
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
LA PALABRA RECIBIDA w DISTA t+1 DE u Y DISTA t DE v, LUEGO
EL CÓDIGO NO CORRIGE t+1 ERRORES.
DEFINICIÓN: UN CÓDIGO DE LONGITUD n, TAMAÑO m Y
DISTANCIA d SE DICE QUE ES UN (n,m,d) – CÓDIGO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 110
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
EJEMPLOS:
CÓDIGO DE REPETICIÓN BINARIA DE LONGITUD n:
ESTE CÓDIGO CORRIGE (n-1) / 2 ERRORES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 111
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
EL MARINER 9 (1979) TOMÓ FOTOS EN BLANCO Y NEGRO DE
MARTE:
LAS IMÁGENES ERAN DE 600X600 Y CON 64 NIVELES DE GRIS.
SE USÓ UN CÓDIGO BINARIO DE TAMAÑO 64; UN (32, 64, 16)-
CÓDIGO (CÓDIGO DE REED-MULLER):
ESTE ERA UN CÓDIGO 7-CORRECTOR.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 112
DISTANCIA HAMMING Y
DESCODIFICACIÓN POR DISTANCIA
MÍNIMA
EL VOYAGER (1979-1981) TOMÓ FOTOS EN COLOR DE JÚPITER Y
SATURNO DE 4096 COLORES:
SE USÓ UN (24, 4096, 8)-CÓDIGO (CÓDIGO DE GOLAY):
ESTE ERA UN CÓDIGO 3-CORRECTOR.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 113
CÓDIGOS PERFECTOS

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 114
CÓDIGOS PERFECTOS
DEFINICIÓN: SEA A UN ALFABETO, |A| = q, v An Y r R, r 0. LA
ESFERA DE RADIO r Y CENTRO v ES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 115
CÓDIGOS PERFECTOS
EL VOLUMEN DE Sq(v,r) ES |Sq(v,r)| Y ESTÁ DADO POR:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 116
CÓDIGOS PERFECTOS
EJEMPLO:
SE TIENE:
A = {0, 1}.
n = 3.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 117
CÓDIGOS PERFECTOS
DEFINICIÓN: SEA C An. EL RADIO DE EMPAQUETAMIENTO DE C ES EL MAYOR ENTERO r TAL QUE TODAS LAS ESFERAS DE RADIO r (Sq (v,r), v C) SON DISJUNTAS.
DEFINICIÓN: EL RADIO DE RECUBRIMIENTO ES EL MENOR ENTERO s TAL QUE LA UNIÓN DE TODAS LAS ESFERAS DE RADIO s ES An.
r = pr(C); s = cr(C).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 118
CÓDIGOS PERFECTOS
PROPOSICIÓN:
UN CÓDIGO C ES t-CORRECTOR SI Y SÓLO SI LAS ESFERAS DE RADIO t Sq (v,t), v C, SON DISJUNTOS.
C ES EXACTAMENTE t-CORRECTOR SI Y SÓLO SI pr(c) = t.
EL RADIO DE EMPAQUETAMIENTO DE UN (n,m,d)-CÓDIGO ES:
DEFINICIÓN: UN CÓDIGO C An SE DICE PERFECTO CUANDO cr(C) = pr(C), ES DECIR, CUANDO EXISTE UN ENTERO r TAL QUE Sq (v,r), v C, SON DISJUNTAS Y RECUBREN An:
EN ESTE CASO LAS ESFERAS DE RADIO r FORMAN UNA PARTICIÓN DE An.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 119
CÓDIGOS PERFECTOS
EJEMPLO:
H2 (3) (HAMMING): ES UN (7,16,3)-CÓDIGO BINARIO.
ESTE ES UN CÓDIGO 1-CORRECTOR.
d = 3 ; t = 1 = pr(H2(3)); m = |H2 (3)| = 16.
VERIFICACIÓN ACERCA DE SI ESTE CÓDIGO ES PERFECTO:
|An| = |Z27| = 27 = 128.
SE DEBE VERIFICAR QUE:
LAS ESFERAS DE RADIO 1 RECUBREN Z27.
LA UNIÓN DE TODAS LAS ESFERAS TIENE 128 ELEMENTOS.
V2(7,1) = |S2(v,1)| = 1 + 7 = 8.
HAY 16 ESFERAS: TIENEN 8·16 PALABRAS = 128.
EL CÓDIGO ES PERFECTO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 120
CÓDIGOS PERFECTOS
PROPOSICIÓN (CONDICIÓN DE EMPAQUETAMIENTO DE
ESFERAS): SEA C UN (n,m,d)-CÓDIGO q-ARIO. C ES PERFECTO SI
Y SÓLO SI d = 2t + 1 ES IMPAR Y ADEMÁS n·Vq(n,t) = qn, ES DECIR:
(n,m,d)-CÓDIGO q-ARIO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 121
CÓDIGOS PERFECTOS
LA EFICIENCIA Y LA CAPACIDAD DE CORREGIR ERRORES SON
INCOMPATIBLES:
PARA CORREGIR ERRORES LAS PALABRAS DEBEN SER
LARGAS, CON LO QUE SE REDUCE LA EFICIENCIA.
SE BUSCAN CÓDIGOS ÓPTIMOS QUE COMBINEN ESTAS DOS
PROPIEDADES.
DEFINICIÓN: LA TASA DE CORRECCIÓN DE ERRORES DE UN
(n,m,d)-CÓDIGO C ES:
ES EL NÚMERO DE ERRORES QUE SE CORRIGEN EN RELACIÓN A LA
LONGITUD DE LAS PALABRAS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 122
CÓDIGOS PERFECTOS
EJEMPLO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 123
CÓDIGOS PERFECTOS
CUANTO MAYOR SEA LA LONGITUD DEL CÓDIGO MÁS AUMENTA
LA TASA DE CORRECCIÓN DE ERRORES (HASTA EL LÍMITE DE 0.5).
NO SE CORRIGEN ERRORES CUANDO TODAS LAS PALABRAS DE An
SON PALABRAS DEL CÓDIGO.
EL PROBLEMA DE CUÁLES SON LOS MEJORES CÓDIGO AÚN NO
ESTÁ RESUELTO.
LA TASA DE CORRECCIÓN DE ERRORES ESTÁ DADA POR d Y n:
SE FIJAN d Y n Y SE TRATA DE OPTIMIZAR m PARA QUE EL
CÓDIGO TENGA R LO MAYOR POSIBLE.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 124
CÓDIGOS PERFECTOS
SE DEFINE:
Aq(n,d) := MAX {m / EXISTE (n,m,d)-CÓDIGO q-ARIO}.
UN (n, Aq(n,d),d)-CÓDIGO SE DICE QUE ES UN CÓDIGO OPTIMABLE.
PROBLEMA PRINCIPAL DE LA TEORÍA DE CÓDIGOS:
DETERMINAR EL VALOR DE Aq(n,d).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 125
CÓDIGOS PERFECTOS
SEGÚN SHANNON EN “A MATHEMATICA THEORY OF
COMMUNICATION”:
TEOREMA DEL CANAL RUIDOSO: ESTE TEOREMA DEMUESTRA
QUE EXISTEN BUENOS CÓDIGOS PERO NO DICE CÓMO
OBTENERLOS.
PARA UN BSC CON PROBABILIDAD DE PASO p LA CAPACIDAD ES:
SE CONSIDERA UN BSC CON CAPACIDAD C(p):
SI R(C) < C(p) ENTONCES PARA CADA > 0 EXISTE UN (n,m)-
CÓDIGO C CUYA TASA DE TRANSMISIÓN ES MAYOR O IGUAL
QUE R Y PARA EL CUAL P(ERROR DE DESCODIFICACIÓN) < .

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 126
CÓDIGOS PERFECTOS
EJEMPLO:
BSC CON p = 0.01; C(p) = 0.919 (CASI 92%).
PODEMOS ENCONTRAR UN CÓDIGO CON R = 0.919 Y CON
PROBABILIDAD DE ERROR ARBITRARIAMENTE BAJA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 127
CÓDIGOS LINEALES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 128
CÓDIGOS LINEALES
LOS CÓDIGOS LINEALES SON ESPACIOS VECTORIALES SOBRE UN CUERPO FINITO.
LOS ALFABETOS QUE USAREMOS SON CUERPOS FINITOS (K).
Zp = {0,1....p-1}.
q = pr: p PRIMO.
Fq: CUERPO FINITO CON q ELEMENTOS.
EN PARTICULAR, SI q = p (PRIMO), ENTONCES Fq = Fp = Zp.
F2 = Z2 = {0,1}.
F3 = {0,1,2}.
F5 = {0,1,2,3,4}.
DEFINICIÓN: UN CÓDIGO LINEAL DE LONGITUD n SOBRE K ES UN K-SUBESPACIO VECTORIAL C DE Kn.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 129
CÓDIGOS LINEALES
K = Z2.
EN EL CASO BINARIO LA SUMA DE DOS PALABRAS DEBE SER UNA PALABRA DEL CÓDIGO.
C = {010}: NO ES UN CÓDIGO LINEAL, YA QUE NO CONTIENE A 000.
C = {000,010,110}: NO ES UN CÓDIGO LINEAL YA QUE 110 + 010 = 100 C.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 130
CÓDIGOS LINEALES
UN CÓDIGO LINEAL BINARIO TIENE UN NÚMERO DE PALABRAS QUE ES POTENCIA DE 2.
UN CÓDIGO LINEAL C SOBRE K DE LONGITUD n Y DIMENSIÓN k SE DICE QUE ES UN [n,k]-CÓDIGO (LINEAL):
SI LA DISTANCIA ES d, SE DICE QUE ES UN [n,k,d]-CÓDIGO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 131
CÓDIGOS LINEALES
DEFINICIÓN: SEA C UN CÓDIGO (NO NECESARIAMENTE LINEAL)
Y v C UNA PALABRA DEL CÓDIGO. SE DEFINE EL PESO DE v
COMO EL NÚMERO w(v) DE SÍMBOLOS NO NULOS DE v:
v = 10010: w(v) = 2.
PROPOSICIÓN: SEA C UN CÓDIGO LINEAL Y u,v C. ENTONCES SE
VERIFICA:
d(u,v) = w(u-v).
w(u) = d(u,0).
DEFINICIÓN: SEA C UN CÓDIGO. SE LLAMA PESO DE C (O PESO
MÍNIMO DE C) A:
PROPOSICIÓN: SI C ES UN CÓDIGO LINEAL ENTONCES d(C) =
w(C).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 132
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 133
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: SEA C UN [n,k]-CÓDIGO LINEAL SOBRE UN CUERPO
K (C Kn). UNA MATRIZ GENERATRIZ DE C ES UNA MATRIZ DE
Mkxn(K) CUYAS FILAS FORMAN UNA BASE DE C.
C = <101101, 011000, 110101, 001010> ES UN [6,3]-CÓDIGO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 134
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
PARA QUE UNA MATRIZ SEA GENERATRIZ SUS FILAS DEBEN SER
UNA BASE DEL CÓDIGO, DEBEN SER UN CONJUNTO LI
(LINEALMENTE INDEPENDIENTE).
LA MATRIZ DEBE TENER RANGO k (= NÚMERO DE FILAS).
PROPOSICIÓN: SI G Mkxn(K) CON k n, G ES MATRIZ
GENERATRIZ DE UN CÓDIGO LINEAL SOBRE K ([n,k]-CÓDIGO) SI Y
SÓLO SI rg(G) = (G) = k.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 135
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
PROPOSICIÓN: SEA C UN [n,k]-CÓDIGO LINEAL SOBRE K Y G
UNA MATRIZ GENERATRIZ DE C:
ENTONCES:
LA SIGUIENTE APLICACIÓN ES UN ISOMORFISMO DE k-
ESPACIOS VECTORIALES.
INTERESA ENCONTRAR MATRICES GENERATRICES LO MÁS
SENCILLAS POSIBLES PARA QUE LA DESCODIFICACIÓN SEA
SENCILLA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 136
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: SEA C UN (n,m,d)-CÓDIGO q-ARIO SOBRE UN
ALFABETO A. SE CONSIDERAN LOS DOS TIPOS DE OPERACIONES
SIGUIENTES:
1) SEA UNA PERMUTACIÓN DEL CONJUNTO DE ÍNDICES {1, 2,
.... N}. ES UNA APLICACIÓN BIYECTIVA DE UN CONJUNTO EN SI
MISMO. EJEMPLO:
PARA CADA PALABRA DEL CÓDIGO u = u1u2 ...un, ui A, SE
SUSTITUYE u POR LA PALABRA u(1) u(2) ... u(n)
(PERMUTACIÓN POSICIONAL).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 137
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
2) SEA PARA CADA ÍNDIDE i {1, 2, ....n}, i: A A UNA
PERMUTACIÓN. SE SUSTITUYE CADA PALABRA DEL CÓDIGO u
= u1u2 ...un POR u1u2 ... i (ui)... un (PERMUTACIÓN DE SÍMBOLOS).
EJEMPLO:
i = 3.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 138
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: EL CÓDIGO C´ ES EQUIVALENTE AL CÓDIGO C
CUANDO C´ SE OBTIENE A PARTIR DE C MEDIANTE UNA
SUCESIÓN FINITA DE OPERACIONES DE LOS 2 TIPOS ANTERIORES.
EJEMPLO:
C’ = {11120, 10221, 21020, 10120, 22011}

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 139
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
AHORA SE APLICA:
SE APLICA 1:
SE APLICA 4:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 140
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
ESTA RELACIÓN ES UNA RELACIÓN DE EQUIVALENCIA, ES
DECIR, CUMPLE LAS PROPIEDADES REFLEXIVA, SIMÉTRICA Y
TRANSITIVA.
ESTAS OPERACIONES CONSERVAN TODOS LOS PARÁMETROS DEL
CÓDIGO (LONGITUD, TAMAÑO Y DISTANCIA ENTRE PALABRAS):
DOS CÓDIGOS EQUIVALENTES TIENEN LOS MISMOS
PARÁMETROS Y LA MISMA DISTANCIA MÍNIMA, CON LO QUE
TIENEN LA MISMA CAPACIDAD DE CORREGIR ERRORES.
PROPOSICIÓN: SEA C UN CÓDIGO DE LONGITUD n SOBRE EL
ALFABETO A Y u An. ENTONCES EXISTE UN CÓDIGO C´
EQUIVALENTE A C Y TAL QUE u C´.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 141
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: UNA MATRIZ GENERATRIZ G DE UN [n,k]-CÓDIGO
SE DICE NORMALIZADA O ESTÁNDAR CUANDO ES DE LA FORMA
SIGUIENTE:
Ik ES LA MATRIZ IDENTIDAD DE Mk(K) (MATRICES
CUADRADAS k X k).
SI UN CÓDIGO C TIENE UNA MATRIZ GENERATRIZ ESTÁNDAR
SE DICE QUE C ES UN CÓDIGO SISTEMÁTICO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 142
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
EJEMPLO:
[5,3]-CÓDIGO.
A: k FILAS Y n-k COLUMNAS.
A Mkx(n-k)(K).
n = k, Kn = C.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 143
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
[n,n]-CÓDIGO.
UN CÓDIGO DE ESTE TIPO ES EL CÓDIGO ASCII ESTÁNDAR.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 144
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
EL CÓDIGO ASCII CON BIT DE PARIDAD:
ES UN (8,128,2)-CÓDIGO.
ES UN CÓDIGO LINEAL YA QUE SI SUMAMOS 2 PALABRAS CON
UN NÚMERO PAR DE UNOS OBTENEMOS UNA PALABRA CON
UN NÚMERO PAR DE UNOS.
ES UN [8,7]-CÓDIGO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 145
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
PROPOSICIÓN: SE VERIFICAN LAS SIGUIENTE PROPIEDADES:
I) TODO CÓDIGO LINEAL ES EQUIVALENTE A UN CÓDIGO
SISTEMÁTICO.
II) UN CÓDIGO SISTEMÁTICO POSEE UNA ÚNICA MATRIZ
GENERATRIZ ESTÁNDAR.
III) SI C ES UN [n,k]-CÓDIGO SISTEMÁTICO ENTONCES PARA
CADA u = u1u2 ...un Kk EXISTE UNA ÚNICA PALABRA DE
CÓDIGO Cu C DE LA FORMA Cu = u1u2 ...uk xk+1...xn.
TOMAMOS TODO Kk Y LE AÑADIMOS n-k SÍMBOLOS DE TAL
FORMA QUE EL CÓDIGO SIGA SIENDO UN EV.
LAS k PRIMERAS COMPONENTES SE LLAMAN SÍMBOLOS DE
INFORMACIÓN Y LAS n-k SIGUIENTES SE LLAMAN SÍMBOLOS
DE CONTROL O SÍMBOLOS DE REDUNDANCIA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 146
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
CÓDIGO ASCII CON BIT DE PARIDAD:
LAS 7 PRIMERAS POSICIONES NO CORRIGEN ERRORES,
FORMAN TODO Z72.
SE AÑADE UN SÍMBOLO DE CONTROL PARA PERMITIR LA
DETECCIÓN DE ERRORES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 147
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DIFERENCIA ENTRE LA DESCODIFICACIÓN DE FUENTE Y LA
DESCODIFICACIÓN DE CANAL:
LA DESCODIFICACIÓN DE CANAL CONSISTE EN:
USAR UN CÓDIGO DETECTOR DE ERRORES.
RECIBIR LAS PALABRAS TRANSMITIDAS.
SI ÉSTAS NO SON PALABRAS DEL CÓDIGO:
POR ALGÚN MÉTODO SUSTITUIR LA PALABRA RECIBIDA
POR UNA PALABRA DEL CÓDIGO.
LA DESCODIFICACIÓN DE LA FUENTE CONSISTE EN:
TOMAR LA INFORMACIÓN Y PASARLA A SU FORMATO
ORIGINAL.
EN EL CASO DE LOS CÓDIGOS LINEALES LA CODIFICACIÓN Y
DESCODIFICACIÓN DE FUENTE ES BASTANTE EFICIENTE.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 148
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
SEA G LA MATRIZ GENERATRIZ DE UN [n,k]-CÓDIGO C SOBRE K.
ESTA APLICACIÓN ES UN ISOMORFISMO DE EV.
PARA CODIFICAR SE CODIFICA POR BLOQUES:
SE CONSTRUYE LA FUENTE COMO ELEMENTOS DE Kk.
SE APLICA EL ISOMORFISMO PASAMOS AL CÓDIGO C.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 149
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
LA DESCODIFICACIÓN DE FUENTE CONSISTE EN:
UNA VEZ QUE SE HA RECIBIDO xG RECUPERAR x.
ESTO SE HACE RESOLVIENDO UN SISTEMA DE ECUACIONES
LINEALES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 150
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
ESTE SISTEMA TIENE RANGO k:
TIENE SOLUCIÓN ÚNICA.
HAY k ECUACIONES LI (LINEALMENTE INDEPENDIENTES):
PODEMOS ELIMINAR n-k ECUACIONES.
EL NÚMERO DE INCÓGNITAS ES IGUAL AL RANGO DEL
SISTEMA.
LA SOLUCIÓN ES ÚNICA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 151
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: SEA C UN [n,k]. EL CÓDIGO DUAL (CÓDIGO
ORTOGONAL) DE C ES EL ESPACIO VECTORIAL ORTOGONAL DE C
CON RESPECTO AL PRODUCTO ESCALAR ORDINARIO DE Kn, ES
DECIR:
PROPOSICIÓN: SI C ES UN [n,k]-CÓDIGO ENTONCES C ES UN [n,n-
k]-CÓDIGO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 152
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
EJEMPLO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 153
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: SE LLAMA MATRIZ DE CONTROL (PARITY-CHECK
MATRIX) DE C A CUALQUIER MATRIZ GENERATRIZ DE C. SI H ES
UNA MATRIZ DE CONTROL DE C ENTONCES:
SI C ES UN [n,k]-CÓDIGO Y H ES UNA MATRIZ DE CONTROL DE C,
H M(n-k)xn(K).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 154
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: UN CÓDIGO LINEAL C SE DICE AUTODUAL
CUANDO COINCIDE CON SU DUAL: C = C .
PROPOSICIÓN: SEA C UN CÓDIGO LINEAL SISTEMÁTICO QUE
TIENE UNA MATRIZ GENERATRIZ ESTÁNDAR G = (Ik | A).
ENTONCES P = (At | -In-k) ES UNA MATRIZ DE CONTROL DE C.
DEFINICIÓN: SE DICE QUE LA MATRIZ DE CONTROL P DEL
CÓDIGO C ES UNA MATRIZ DE CONTROL ESTÁNDAR CUANDO ES
DE LA FORMA P = (B | In-k).
SEA C EL CÓDIGO BINARIO DE MATRIZ GENERATRIZ:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 155
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
SE TIENE C = H2 (3) (CÓDIGO DE HAMMING); HALLAR UNA
MATRIZ DE CONTROL DE C.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 156
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
CARACTERÍSTICAS DE LAS MATRICES GENERATRICES Y LAS MATRICES DE CONTROL:
LA VENTAJA DE LA MATRIZ GENERATRIZ ES QUE A PARTIR DE ELLA ES MÁS FÁCIL OBTENER LAS PALABRAS DEL CÓDIGO (CL (COMBINACIÓN LINEAL) DE SUS FILAS).
PARA EL CÁLCULO DE LA DISTANCIA MÍNIMA ES MEJOR TENER LA MATRIZ DE CONTROL:
A PARTIR DE LA MATRIZ GENERATRIZ NO SE CONOCE NINGÚN MÉTODO DIRECTO PARA OBTENER w(C).
A PARTIR DE LA MATRIZ DE CONTROL SÍ.
PROPOSICIÓN: SEA P UNA MATRIZ DE CONTROL DE UN [n,k,d]-CÓDIGO LINEAL:
ENTONCES LA DISTANCIA MÍNIMA d ES EL MENOR ENTERO POSITIVO r PARA EL CUAL EXISTEN r COLUMNAS LINEALMENTE DEPENDIENTES EN LA MATRIZ P.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 157
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
LOS CÓDIGOS LINEALES TIENEN UN MÉTODO DE DESCODIFICACIÓN (DE CANAL) MUY BUENO.
SEA C UN [n,k]-CÓDIGO LINEAL Y H UNA MATRIZ DE CONTROL DE C, H M(n-k)xn(K). LA MATRIZ H DEFINE UNA APLICACIÓN LINEAL:
DEFINICIÓN: SUPONGAMOS QUE SE TRANSMITE LA PALABRA x C Kn Y QUE LA PALABRA RECIBIDA ES y Kn. ENTONCES A LA DIFERENCIA = y – x Kn SE LE LLAMA PALABRA DE ERROR.
SE PUEDE DEMOSTRAR QUE:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 158
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DEFINICIÓN: SEA C UN [n,k]-CÓDIGO CON MATRIZ DE CONTROL H:
DADO x Kn SE LLAMA SÍNDROME DE x A LA PALABRA h(x) = xHt Kn-k.
x C SI Y SÓLO SI EL SÍNDROME DE x ES 0.
PROPOSICIÓN: SEA C UN [n,k]-CÓDIGO LINEAL CON MATRIZ DE CONTROL H:
SI x,y Kn, x E y TIENEN EL MISMO SÍNDROME SI Y SÓLO SI PERTENECEN A LA MISMA CLASE DEL ESPACIO COCIENTE Kn/C.
LA DESCODIFICACIÓN POR DISTANCIA MÍNIMA CONSISTE EN:
BUSCAR “LA PALABRA DE PESO MÍNIMO ENTRE TODAS LAS QUE TIENEN EL MISMO SÍNDROME QUE LA PALABRA RECIBIDA y”.
CALCULAR x = y - .

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 159
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
ESQUEMA:
SE CALCULA EL SÍNDROME DE LA PALABRA RECIBIDA y, h(y) = yHt.
SE DETERMINA LA CLASE LATERAL ASOCIADA A ESTE SÍNDROME, y+C.
SE BUSCA EN ESTA CLASE LA PALABRA DE PESO MÍNIMO .
SE CALCULA x = y - .
SI C ES UN CÓDIGO t-CORRECTOR Y EN LA TRANSMISIÓN SE HAN COMETIDO t O MENOS ERRORES:
EN LA CLASE y+C HAY UNA ÚNICA PALABRA DE PESO MENOR O IGUAL QUE y QUE ES LA PALABRA DE ERROR .

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 160
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
DESCODIFICACIÓN POR SÍNDROME:
SE CONSTRUYE LA TABLA ESTÁNDAR:
SEA C UN [n,k]-CÓDIGO DE TAMAÑO m(=qk), C Kn.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 161
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
SEA u2 UNA PALABRA DE Kn-C DE PESO MINIMAL. LA 2ª FILA ESTÁ FORMADA POR LAS PALABRAS DE u2+C.
SEA u3 UNA PALABRA DE Kn-C QUE NO PERTENECE A u2+C DE PESO MINIMAL.
SE REPITE ESTO qn-k VECES.
Kn ES LA UNIÓN DISJUNTA DE LAS CLASE u+C.
LAS PALABRAS DE LA 1ª COLUMNA DE LA TABLA ESTÁNDAR SE LLAMAN LÍDERES DE CLASE Y TIENEN PESO MINIMAL DENTRO DE LA CLASE.
SI C ES t-CORRECTOR, CUALQUIER PALABRA DE Kn DE PESO MENOR O IGUAL QUE t ES LÍDER DE CLASE.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 162
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
EN EL CASO BINARIO EL CÁLCULO DEL SÍNDROME SE REALIZA
TOMANDO LA MATRIZ DE CONTROL:
SE CONSIDERAN LAS COMPONENTES NO NULAS DE LA
PALABRA RECIBIDA.
SE SUMAN LAS COLUMNAS DE LA MATRIZ DE CONTROL QUE
OCUPAN LAS POSICIONES NO NULAS DE LA PALABRA
RECIBIDA.
EJEMPLO:
SEA C EL CÓDIGO CON MATRIZ DE CONTROL:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 163
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
CONSTRUIR LA TABLA ESTÁNDAR Y DESCODIFICAR LAS
PALABRAS RECIBIDAS: 11101, 00110 Y 01101.
EN PRIMER LUGAR SE DETERMINA UNA MATRIZ GENERATRIZ
PARA HALLAR LAS PALABRAS DEL CÓDIGO.
C ES UN [5,2]-CÓDIGO. SI SE CALCULA LA MATRIZ DE CONTROL
DEL CÓDIGO DUAL SE OBTIENE UNA MATRIZ GENERATRIZ DEL
DUAL DEL DUAL, QUE ES EL CÓDIGO C.
H ES UNA MATRIZ DE CONTROL ESTÁNDAR ASÍ EL CÓDIGO ES
SISTEMÁTICO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 164
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
LA DISTANCIA MÍNIMA ES EL NÚMERO MÍNIMO DE COLUMNAS
LD (LINEALMENTE DEPENDIENTES) DE LA MATRIZ DE CONTROL.
rg(H) = 3 4 COLUMNAS SERÁN LD.
NO HAY NINGUNA COLUMNA QUE SEA 0, ASÍ d > 1.
DOS COLUMNAS LD, EN EL CASO BINARIO, SERÍAN IGUALES,
COMO NO HAY DOS COLUMNAS IGUALES d > 2.
HAY 3 COLUMNAS LD (1ª = 4ª + 5ª), ASÍ d = 3.
EL CÓDIGO ES 1-CORRECTOR.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 165
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
LA TABLA ESTÁNDAR SE CONSTRUYE COMO SIGUE:
LAS PALABRAS LÍDERES INDICAN CON 1 DÓNDE SE PRODUCE EL ERROR.
LA SEGUNDA Y LA TERCERA COLUMNA SON LAS PALABRAS DEL CÓDIGO MÁS EL LÍDER CORRESPONDIENTE:
ESTO SIGNIFICA QUE ALLÍ ESTARÁN LAS PALABRAS ERRÓNEAS QUE SE PUEDEN ASOCIAR A UNA VÁLIDA, QUE SERÁ LA PRIMERA DE LA COLUMNA.
LOS SÍNDROMES SE CALCULAN MULTIPLICANDO EL LÍDER POR H TRASPUESTA.
LA CUARTA COLUMNA ES LA SUMA DEL LÍDER MÁS LAS PALABRAS DE LAS COLUMNAS SEGUNDA Y TERCERA.
SE PARTE DE LAS PALABRAS 10011 Y 01101 QUE PROVIENEN DE G.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 166
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 167
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
EN UN CÓDIGO t-CORRECTOR TODAS LAS PALABRAS DE PESO MENOR O IGUAL QUE t VAN A SER LÍDERES DE CLASE.
AHORA SE DEBE TOMAR LA PALABRA DE PESO 2 QUE NO SE HAYA PUESTO (HASTA LA 6ª FILA).
SE PONE UNA PALABRA DE PESO 2 Y SE OBTIENE SU SÍNDROME:
SI ÉSTE YA HA SALIDO ES QUE LA PALABRA YA HA SALIDO Y SE DEBE TOMAR OTRA PALABRA.
NO PUEDE HABER OCURRIDO UN ERROR YA QUE SE HA RECIBIDO UNA PALABRA DEL CÓDIGO.
TAMPOCO SE PUEDEN HABER COMETIDO 2 ERRORES, PERO SÍ SE PUDIERON COMETER 3 ERRORES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 168
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
SE BUSCA EL LÍDER DE CLASE DE ESTE SÍNDROME.
ESTA ES LA ÚNICA PALABRA QUE SE PUEDE OBTENER SI SE HA PRODUCIDO UN ÚNICO ERROR.
SI HUBIESEN OCURRIDO 2 ERRORES LA PALABRA REAL PODRÍA SER OTRA PERO ESTE CÓDIGO SÓLO CORRIGE UN ERROR.
h(y) = 011

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 169
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
ESTA PALABRA ES LA PALABRA DE CÓDIGO QUE APARECE EN LA COLUMNA DE LA PALABRA EN LA TABLA.
EL LÍDER DE CLASE ES 11000, QUE TIENE PESO 2:
SI SE HAN COMETIDO AL MENOS 2 ERRORES, COMO EL CÓDIGO ES 1-CORRECTOR NO SE TENDRÁ LA SEGURIDAD DE HACER LA DESCODIFICACIÓN CORRECTA.
SE DESCODIFICARÍA COMO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 170
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
SI SE HAN COMETIDO 2 ERRORES LA PALABRA RECIBIDA PODRÍA HABER SIDO 00000.
SI SE HAN COMETIDO 2 ERRORES CUALQUIERA DE ESTAS DOS PALABRAS PODRÍA HABER SIDO TRANSMITIDA.
ESTE MÉTODO TIENE UN INCONVENIENTE YA QUE LA TABLA ESTÁNDAR PUEDE SER GRANDE:
EN UN CÓDIGO BINARIO DE LONGITUD 100 EN LA TABLA HABRÍA QUE PONER 2100 PALABRAS (SIN CONTAR SÍNDROMES).
ESTO HACE QUE PARA CÓDIGOS DE ESTOS TAMAÑOS LA TABLA SEA INABORDABLE.
EN ESTOS CASOS SE UTILIZARÍA UNA TABLA REDUCIDA CON 2 COLUMNAS, LA COLUMNA DE LOS LÍDERES DE CLASE Y LA DE LOS SÍNDROMES.
SE TENDRÍA LO SIGUIENTE:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 171
MATRICES GENERATRICES Y
MATRICES DE CONTROL – CÓDIGOS
CORRECTORES
EN PRIMER LUGAR SE COLOCAN LAS PALABRAS DE PESO UNO Y
SU SÍNDROME; LUEGO LAS DE PESO 2.
PROPOSICIÓN: SI C ES UN [n,k,d]-CÓDIGO LINEAL ENTONCES d
n-k+1.
DEFINICIÓN: UN [n,k,d]-CÓDIGO LINEAL C SE DICE QUE ES UN
CÓDIGO MDS (MAXIMUN DISTANCE SEPARABLE CODE) CUANDO
d = n-k+1.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 172
CÓDIGO DE HAMMING

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 173
CÓDIGO DE HAMMING
LOS LLAMADOS CÓDIGOS ESPECIALES SON LOS CÓDIGOS DE:
HAMMING.
GOLAY.
REED-MULLER.
ESTOS CÓDIGOS TIENEN UN PROCEDIMIENTO DE
DESCODIFICACIÓN ESPECIAL.
SE TIENE UN [n,k]-CÓDIGO LINEAL; SU DISTANCIA MÍNIMA ES EL
MÍNIMO NÚMERO DE COLUMNAS LD (LINEALMENTE
DEPENDIENTES) DE UNA MATRIZ DE CONTROL.
SEA d LA DISTANCIA MÍNIMA:
SI SE TOMAN d-1 COLUMNAS CUALESQUIERA DE CUALQUIER
MATRIZ DE CONTROL SERÁN LI (LINEALMENTE
INDEPENDIENTES).
HAY UN GRUPO DE d COLUMNAS LD (LINEALMENTE
DEPENDIENTES).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 174
CÓDIGO DE HAMMING
SE CONSTRUIRÁ UN [n,k,3]-CÓDIGO LINEAL DE TAL FORMA QUE
SU MATRIZ DE CONTROL TENGA:
DOS COLUMNAS CUALESQUIERA LI.
TRES COLUMNAS LD.
EL CÓDIGO DE HAMMING q-ARIO DE ORDEN r (r Z, r 2) SERÁ
UN CÓDIGO q-ARIO Hq(r) QUE TIENE UNA MATRIZ DE CONTROL
Hq(r) CON:
r = n – k FILAS.
EL MÁXIMO NÚMERO POSIBLE DE COLUMNAS (SIENDO d = 3).
LAS COLUMNAS DE Hq(r) SON VECTORES DE Frq.
LA MATRIZ DE CONTROL DE Hq(r) ES UNA MATRIZ QUE TIENE r
FILAS Y n = (qr-1)/(q-1) COLUMNAS:
EL CÓDIGO Hq(r) ES UN [n,k,3]-CÓDIGO DONDE k = n – r.
ESTA MATRIZ SE LLAMA MATRIZ DE HAMMING Y NO ES
ÚNICA.
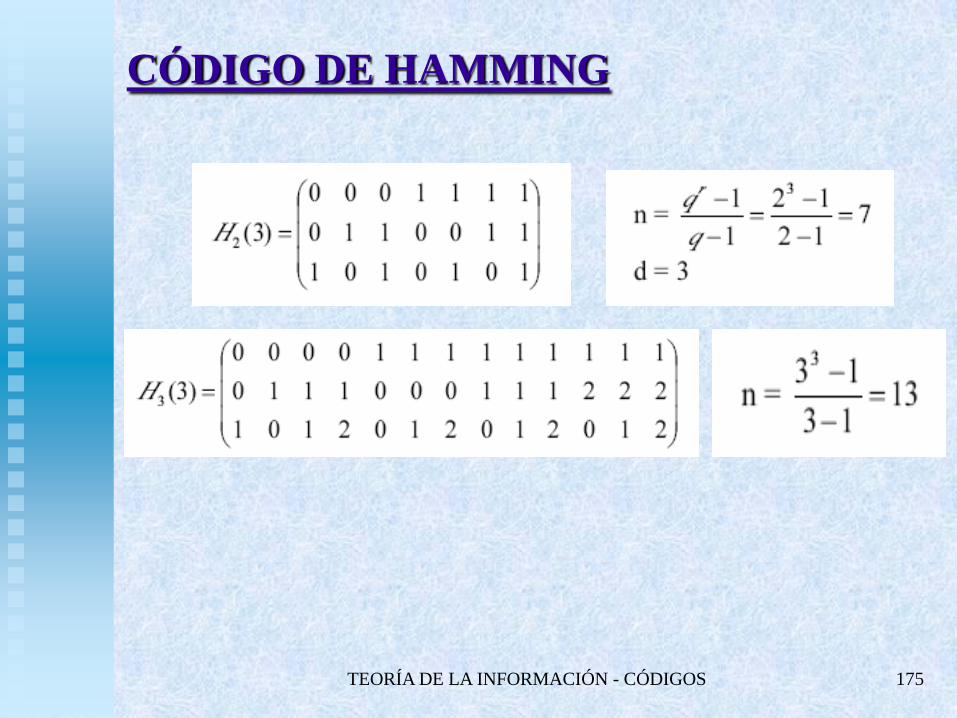
TEORÍA DE LA INFORMACIÓN - CÓDIGOS 175
CÓDIGO DE HAMMING

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 176
CÓDIGO DE HAMMING

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 177
CÓDIGO DE HAMMING
ESTOS FUERON LOS PRIMEROS CÓDIGOS CORRECTORES DE
ERRORES.
PROPOSICIÓN: LOS CÓDIGOS DE HAMMING SON CÓDIGOS
PERFECTOS.
PARA LA DESCODIFICACIÓN DE LOS CÓDIGOS DE HAMMING SE
PARTE DE LA SIGUIENTE PROPOSICIÓN.
PROPOSICIÓN: SI UNA PALABRA x H2(r) SUFRE UN ÚNICO
ERROR RESULTANDO LA PALABRA y, ENTONCES EL SÍNDROME DE
y, h(y), ES LA REPRESENTACIÓN BINARIA DE LA POSICIÓN DEL
ERROR DE LA PALABRA RECIBIDA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 178
CÓDIGO DE HAMMING
SE SUPONE QUE EL ERROR SE HA COMETIDO EN LA POSICIÓN i:
y = x + i,
i = 0 ... 0 1 0 ... 00 ES LA PALABRA DE ERROR.
i SE CORRESPONDE CON EL 1.
ENTONCES:
LA COLUMNA i-ÉSIMA ES LA REPRESENTACIÓN BINARIA DEL
NÚMERO i, i ES LA POSICIÓN DEL ERROR.
CONOCIDO u SE CORRIGE EL ERROR CALCULANDO x = y - i,
CAMBIANDO EL i-ÉSIMO BIT DE y.
[7,4,3]-CÓDIGO.
SE SUPONE QUE SE RECIBE LA PALABRA y = 1101110.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 179
CÓDIGO DE HAMMING

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 180
CÓDIGO DE HAMMING
100 = 4 EL ERROR SE HA COMETIDO EN LA POSICIÓN 4.
LA PALABRA DE ERROR ES e4 = (0001000).
LA PALABRA EMITIDA ES x = y – e4 = 1100110.
A ESTE MÉTODO DE DESCODIFICACIÓN SE LE LLAMA DESCODIFICACIÓN DE HAMMING.
PROPOSICIÓN: SE SUPONE QUE UNA PALABRA x Hq(r) SUFRE UN ÚNICO ERROR, RESULTANDO LA PALABRA RECIBIDA y:
SEA h(y) Kr EL SÍNDROME DE LA PALABRA RECIBIDA Y K EL SÍMBOLO MÁS SIGNIFICATIVO DE h(y).
SI LA COLUMNA DE Hq(r) QUE CONTIENE A -1h(y) ES LA COLUMNA i-ÉSIMA ENTONCES LA PALABRA DE ERROR ES ei = (00 .... 00 .... 0), CON EN LA POSICIÓN i.
SE VERIFICA QUE x = y – ei.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 181
CÓDIGO DE HAMMING
EJEMPLO:
SE SUPONE QUE SE TIENE UN H3(3) Y QUE SE RECIBE LA PALABRA
y = 1101112211201. SE DEBE DESCODIFICAR ESTA PALABRA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 182
CÓDIGO DE HAMMING
h(y) NO ES UNA COLUMNA DE H3(3).
(201) = 2 · (102).
(102) ES LA 7ª COLUMNA DE H3(3):
LA PALABRA DE ERROR ES e7 = 2·(0000001000000).
LA PALABRA EMITIDA ES x = y – 2 e7 = 1101110211201.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 183
CÓDIGO DE GOLAY

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 184
CÓDIGO DE GOLAY
SE CONSIDERA EL CÓDIGO DE GOLAY BINARIO g24.
EL CÓDIGO g24 ES EL CÓDIGO LINEAL BINARIO DE MATRIZ
GENERATRIZ G:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 185
CÓDIGO DE GOLAY
A PARTIR DE LA 3ª FILA LAS FILAS SE OBTIENEN DESPLAZANDO
LA FILA ANTERIOR UNA POSICIÓN A LA IZQUIERDA.
SE CALCULARÁ LA DISTANCIA MÍNIMA DE ESTE CÓDIGO.
PROPOSICIÓN: g24 ES UN CÓDIGO AUTODUAL:
PROPOSICIÓN: LA MATRIZ (A|I12) ES UNA MATRIZ GENERATRIZ
DE g24.
CUANDO UN CÓDIGO ES AUTODUAL LA MATRIZ GENERATRIZ Y
LA MATRIZ DE CONTROL SON IGUALES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 186
CÓDIGO DE GOLAY
PROPOSICIÓN: SI C ES UN CÓDIGO BINARIO Y u,v C, ENTONCES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 187
CÓDIGO DE GOLAY
PROPOSICIÓN: EL PESO DE CADA PALABRA DE g24 ES DIVISIBLE
POR 4.
PROPOSICIÓN: g24 NO TIENE PALABRAS DE PESO 4.
g24 ES UN [24,12,8]-CÓDIGO. ESTE CÓDIGO SE USÓ PARA
TRANSMITIR IMÁGENES DE JÚPITER Y SATURNO (VOYAGER 1979-
1981).
m = 212 = 4096.
SEGÚN VERA PRESS (1968) CUALQUIER [24,12,8]-CÓDIGO LINEAL
BINARIO ES EQUIVALENTE POR MÚLTIPLOS ESCALARES (EN LA
MATRIZ GENERATRIZ SE PUEDEN MULTIPLICAR LAS COLUMNAS
POR UN ESCALAR) AL CÓDIGO g24.
SEGÚN DELSORTE-GOETHOLS (1975) LOS CÓDIGOS DE GOLAY SON
LOS ÚNICOS CÓDIGOS LINEALES CON ESTOS PARÁMETROS.
CUALQUIER (24,212,8)-CÓDIGO BINARIO ES EQUIVALENTE POR
MÚLTIPLOS ESCALARES A g24.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 188
CÓDIGO DE GOLAY
EL CÓDIGO DE GOLAY BINARIO g23:
SE OBTIENE A PARTIR DE g24 “PINCHANDO” UNA COMPONENTE:
USUALMENTE SE ELIMINA EL ÚLTIMO SÍMBOLO DE TODAS
LAS PALABRAS.
n = 23, m = 212.
LA DISTANCIA MÍNIMA O ES LA MISMA O DISMINUYE UNA
UNIDAD:
EN ESTE CASO AL ELIMINAR LA ÚLTIMA COLUMNA DE LA
MATRIZ DE CONTROL DE g24 LA ÚLTIMA FILA TIENEN PESO 7,
ASÍ d = 7.
g23 ES UN [23,12,7]-CÓDIGO.
g23 ES PERFECTO.
g24 SE OBTIENE A PARTIR DE g23 AÑADIÉNDOLE UN BIT DE
PARIDAD.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 189
CÓDIGO DE GOLAY
LOS CÓDIGOS DE GOLAY TERNARIOS:
g12 TIENE POR MATRIZ GENERATRIZ G = (I6|B) DONDE
A PARTIR DE LA 3ª FILA UNA FILA SE OBTIENE A PARTIR DE LA
ANTERIOR DESPLAZÁNDOLA UNA POSICIÓN HACIA LA DERECHA.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 190
CÓDIGO DE GOLAY
PROPIEDADES:
g12 ES AUTODUAL.
B ES SIMÉTRICA.
g12 ES UN [12,6,6]-CÓDIGO.
EL CÓDIGO TERNARIO g11 OBTENIDO PINCHANDO g12 ES UN
[11,6,5]-CÓDIGO PERFECTO.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 191
CÓDIGO DE REED MULLER

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 192
CÓDIGO DE REED MULLER
ESTOS CÓDIGOS SON FÁCILES DE DESCODIFICAR.
DEFINICIÓN: UNA FUNCIÓN DE BOOLE DE m VARIABLES ES UNA
APLICACIÓN:
LAS FUNCIONES DE BOOLE SE SUELEN REPRESENTAR DANDO SU
TABLA DE VERDAD.
m = 3.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 193
CÓDIGO DE REED MULLER
PARA DAR LA FUNCIÓN BOOLEANA BASTA CON QUEDARSE CON
LA ÚLTIMA FILA YA QUE DESCRIBE COMPLETAMENTE LA
FUNCIÓN:
SI SE ASUME QUE SIEMPRE SE TIENE EL MISMO ORDEN.
EXISTE UNA CORRESPONDENCIA BIUNÍVOCA ENTRE FUNCIONES
DE BOOLE DE m VARIABLES Y PALABRAS BINARIAS DE
LONGITUD 2m.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 194
CÓDIGO DE REED MULLER
EN Bm SE DEFINE UNA SUMA:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 195
CÓDIGO DE REED MULLER
SE DEFINE UNA MULTIPLICACIÓN ESCALAR:
SE DEFINEN LOS POLINOMIOS DE BOOLE COMO LOS ELEMENTOS
DEL SIGUIENTE CONJUNTO:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 196
CÓDIGO DE REED MULLER
HAY mk MONOMIOS DE GRADO k EN m VARIABLES.
TODOS LOS POSIBLES MONOMIOS DE m VARIABLES SON:
PROPOSICIÓN: LA APLICACIÓN SIGUIENTE ES UN ISOMORFISMO
DE Z2-ESPACIOS VECTORIALES Y A CADA POLINOMIO DE
BOOLE F(x1,....xm) LE HACE CORRESPONDER LA FUNCIÓN DE
BOOLE f(x1,....xm) DADA POR f(x1,....xm) = F(x1,....xm).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 197
CÓDIGO DE REED MULLER
DEFINICIÓN: SEA m UN ENTERO POSITIVO 0 r m. SE DEFINE EL
CÓDIGO DE REED-MULLER R(r,m), DE LONGITUD 2m Y ORDEN r
COMO EL CONJUNTO DE LAS PALABRAS BINARIAS DE Z2m2
ASOCIADAS A POLINOMIOS DE BOOLE DE Bm QUE TIENEN GRADO
MENOR O IGUAL QUE r.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 198
CÓDIGO DE REED MULLER
EJEMPLOS:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 199
CÓDIGO DE REED MULLER
R(1,3).
LOS POLINOMIOS DE BOOLE DE 3 VARIABLES Y GRADO MENOR O
IGUAL QUE 1 SON DE LA FORMA:
LOS 4 MONOMIOS FORMAN UNA BASE DEL ESPACIO DE LOS
POLINOMIOS.
LA PALABRA DE R(1,3) CORRESPONDIENTE A ESTE POLINOMIO
SERÁ:
LAS PALABRAS ENTRE PARÉNTESIS SON LOS POLINOMIOS QUE
CORRESPONDEN A LOS POLINOMIOS DE BOOLE DE 4 VARIABLES.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 200
CÓDIGO DE REED MULLER

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 201
CÓDIGO DE REED MULLER
EXCEPTO LA PALABRA 1 Y LA 0 TODAS LAS PALABRAS TIENEN 4
UNOS Y 4 CEROS.
EL PESO MÍNIMO ES 4, ASÍ ESTE CÓDIGO TIENE DISTANCIA
MÍNIMA 4.
PROPOSICIÓN: SEA F(x1...xm) = xm + p(x1...xm-1) DONDE p(x1...xm-1) ES
UN POLINOMIO DE BOOLE:
ENTONCES LA FUNCIÓN DE BOOLE INDUCIDA POR F TOMA
LOS VALORES 0 Y 1 EL MISMO NÚMERO DE VECES, ES DECIR,
2m-1 VECES.
PROPOSICIÓN: TODAS LAS PALABRAS DE R(1,m) TIENEN PESO
MÍNIMO 2m-1, EXCEPTO LA PALABRA 00...0 Y LA PALABRA 11...1:
EN CONSECUENCIA LA DISTANCIA MÍNIMA DE R(1,m) ES 2m-1.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 202
CÓDIGO DE REED MULLER
EN LOS CÓDIGOS DE REED-MULLER m NO ES EL TAMAÑO DEL
CÓDIGO SI NO EL NÚMERO DE VARIABLES DEL POLINOMIO DE
BOOLE QUE LE CORRESPONDE.
PROPOSICIÓN: EL CÓDIGO DE REED-MULLER R(r,m) TIENE
LONGITUD 2m Y DIMENSIÓN:
LA TASA DE CÓDIGO ES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 203
CÓDIGO DE REED MULLER
EJEMPLO: DETERMINAR CUÁLES DE LAS SIGUIENTES PALABRAS
PERTENECEN AL CÓDIGO R(2,4):
a) 1101 1110 0001 1001.
b) 0011 0101 0011 1010.
ESTE CÓDIGO TIENE LONGITUD 16; SE DEBE VER QUE LOS
POLINOMIOS DE BOOLE QUE INDUCEN ESTAS PALABRAS TIENEN
GRADO MENOR O IGUAL QUE 2.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 204
CÓDIGO DE REED MULLER
ESTE POLINOMIO DE BOOLE TIENE GRADO 4. LA PALABRA NO
PERTENECE A R(2,4).
ESTA PALABRA PERTENECE A R(2,4).
DEFINICIÓN: SEA C1 UN (n,m1,d1)-CÓDIGO LINEAL Y C2 UN
(n,m2,d2)-CÓDIGO LINEAL SOBRE UN CUERPO K. SE DEFINE UN
CÓDIGO LINEAL SOBRE K:
u(u+v) ES LA YUXTAPOSICIÓN DE LAS PALABRAS u Y u+v.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 205
CÓDIGO DE REED MULLER
PROPOSICIÓN: C1 C2 ES UN (2n,m1m2,d´)-CÓDIGO CON d´=
min{2d1,d2}.
PROPOSICIÓN: SEA 0 < r < m; SE VERIFICA QUE R(r,m) = R(r,m-1)
R(r-1,m-1).

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 206
CÓDIGO DE REED MULLER
COROLARIO: EL CÓDIGO DE REED-MULLER R(m-1,m) ESTÁ
FORMADO POR TODAS LAS PALABRAS BINARIAS DE LONGITUD 2m
Y PESO PAR:
POR TANTO SI r < m R(r,m) SÓLO CONTIENE PALABRAS DE
PESO PAR.
EJEMPLO: R(2,3) ESTÁ FORMADO POR LAS PALABRAS BINARIAS
DE LONGITUD 8 Y PESO PAR; UNA MATRIZ GENERATRIZ ES:

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 207
CÓDIGO DE REED MULLER
ESTA ES LA MATRIZ GENERATRIZ DEL CÓDIGO ASCII CON
PARIDAD.
PROPOSICIÓN: R(r,m) TIENE DISTANCIA MÍNIMA 2m-r POR TANTO
TIENE LOS SIGUIENTES PARÁMETROS:
EJEMPLO: MARINER 4 (1965):
22 FOTOS DE MARTE DE 200 X 200 DE 64 NIVELES.
26 NIVELES 6 Z62 ={000000,...,111111}.
8 · 1/3 BITS/S, 1 FOTO 8 HORAS.

TEORÍA DE LA INFORMACIÓN - CÓDIGOS 208
CÓDIGO DE REED MULLER
EJEMPLO: MARINER 9 (1969-1971):
700 X 832 = 582480 PIXELS, 64 NIVELES.
p = 0.05 , 1-p = 0.95, (0.95)6 0.74.
APROXIMADAMENTE EL 26% DE LA IMAGEN SERÍA ERRÓNEA.
SE INTRODUCEN APROXIMADAMENTE 30 BITS DE REDUNDANCIA.
SI TOMAMOS UN CÓDIGO DE REPETICIÓN TENEMOS d = 5 Y EL
CÓDIGO CORREGIRÍA 2 ERRORES.
PROBABILIDAD DE ERROR = 1%.
SIN CORRECCIÓN DE ERRORES HABRÍA UNOS 150000 PIXELS
ERRÓNEOS POR FOTO:
CON EL CÓDIGO DE REPETICIÓN HABRÍA 5800 PIXELS
ERRÓNEOS POR FOTO.
SE USÓ R(1,5), QUE ES UN [32,6,16]-CÓDIGO, EN ESTE CASO p = 0.01;
CON ESTE CÓDIGO HABRÍA UNOS 58 PIXELS ERRÓNEOS POR FOTO.
16200 BITS/S.
700 X 832 X 32 BITS/PIXEL = 18636800 BITS.
1 IMAGEN 115000 S 32 HORAS.
Top Related