







Idiomas
Páginas
Jurídico


ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ANÁLISIS Y DESARROLLO DE UNA PLATAFORMA BIG DATA
Autor: Leticia de la Cierva Perreau de Pinninck
Directores: Mario Tenés y Sonia García
Madrid
Julio 2015


Autorizada la entrega del proyecto del alumno/a:
Leticia de la Cierva Perreau de Pinninck
LOS DIRECTORES DEL PROYECTO
Mario Tenés Sonia García
Fdo.: …………………… Fecha: ……/……/……
Vº Bº del Coordinador de Proyectos
David Contreras Bárcena
Fdo.: …………………… Fecha: ……/……/……


AUTORIZACIÓN PARA LA DIGITALIZACIÓN, DEPÓSITO Y DIVULGACIÓN EN
ACCESO ABIERTO (RESTRINGIDO) DE DOCUMENTACIÓN
1º. Declaración de la autoría y acreditación de la misma.
El autor Dña. Leticia de la Cierva Perreau de Pinninck, como alumna de la
UNIVERSIDAD PONTIFICIA COMILLAS (COMILLAS), DECLARA que es el titular de
los derechos de propiedad intelectual, objeto de la presente cesión, en relación con
la obra Trabajo de fin de grado: Análisis y desarrollo de una plataforma Big
Data que ésta es una obra original, y que ostenta la condición de autor en el
sentido que otorga la Ley de Propiedad Intelectual como titular único o cotitular de
la obra.
En caso de ser cotitular, el autor (firmante) declara asimismo que cuenta con el
consentimiento de los restantes titulares para hacer la presente cesión. En caso de
previa cesión a terceros de derechos de explotación de la obra, el autor declara que
tiene la oportuna autorización de dichos titulares de derechos a los fines de esta
cesión o bien que retiene la facultad de ceder estos derechos en la forma prevista
en la presente cesión y así lo acredita.
2º. Objeto y fines de la cesión.
Con el fin de dar la máxima difusión a la obra citada a través del Repositorio
institucional de la Universidad y hacer posible su utilización de forma libre y
gratuita ( con las limitaciones que más adelante se detallan) por todos los usuarios
del repositorio y del portal e-‐ciencia, el autor CEDE a la Universidad Pontificia
Comillas de forma gratuita y no exclusiva, por el máximo plazo legal y con ámbito
universal, los derechos de digitalización, de archivo, de reproducción, de
distribución, de comunicación pública, incluido el derecho de puesta a disposición
electrónica, tal y como se describen en la Ley de Propiedad Intelectual. El derecho
de transformación se cede a los únicos efectos de lo dispuesto en la letra (a) del
apartado siguiente.

3º. Condiciones de la cesión.
Sin perjuicio de la titularidad de la obra, que sigue correspondiendo a su autor, la
cesión de derechos contemplada en esta licencia, el repositorio institucional podrá:
(a) Transformarla para adaptarla a cualquier tecnología susceptible de
incorporarla a internet; realizar adaptaciones para hacer posible la utilización de la
obra en formatos electrónicos, así como incorporar metadatos para realizar el
registro de la obra e incorporar “marcas de agua” o cualquier otro sistema de
seguridad o de protección.
(b) Reproducirla en un soporte digital para su incorporación a una base de datos
electrónica, incluyendo el derecho de reproducir y almacenar la obra en
servidores, a los efectos de garantizar su seguridad, conservación y preservar el
formato. .
(c) Comunicarla y ponerla a disposición del público a través de un archivo abierto
institucional, accesible de modo libre y gratuito a través de internet.1
(d) Distribuir copias electrónicas de la obra a los usuarios en un soporte digital. 2
4º. Derechos del autor.
El autor, en tanto que titular de una obra que cede con carácter no exclusivo a la
Universidad por medio de su registro en el Repositorio Institucional tiene derecho
a:
a) A que la Universidad identifique claramente su nombre como el autor o
propietario de los derechos del documento.
b) Comunicar y dar publicidad a la obra en la versión que ceda y en otras
posteriores a través de cualquier medio.
1 En el supuesto de que el autor opte por el acceso restringido, este apartado quedaría redactado en los siguientes términos: (c) Comunicarla y ponerla a disposición del público a través de un archivo institucional, accesible de modo restringido, en los términos previstos en el Reglamento del Repositorio Institucional 2 En el supuesto de que el autor opte por el acceso restringido, este apartado quedaría eliminado.

c) Solicitar la retirada de la obra del repositorio por causa justificada. A tal fin
deberá ponerse en contacto con el vicerrector/a de investigación
d) Autorizar expresamente a COMILLAS para, en su caso, realizar los trámites
necesarios para la obtención del ISBN.
d) Recibir notificación fehaciente de cualquier reclamación que puedan formular
terceras personas en relación con la obra y, en particular, de reclamaciones
relativas a los derechos de propiedad intelectual sobre ella.
5º. Deberes del autor.
El autor se compromete a:
a) Garantizar que el compromiso que adquiere mediante el presente escrito no
infringe ningún derecho de terceros, ya sean de propiedad industrial, intelectual o
cualquier otro.
b) Garantizar que el contenido de las obras no atenta contra los derechos al honor,
a la intimidad y a la imagen de terceros.
c) Asumir toda reclamación o responsabilidad, incluyendo las indemnizaciones
por daños, que pudieran ejercitarse contra la Universidad por terceros que vieran
infringidos sus derechos e intereses a causa de la cesión.
d) Asumir la responsabilidad en el caso de que las instituciones fueran condenadas
por infracción de derechos derivada de las obras objeto de la cesión.
6º. Fines y funcionamiento del Repositorio Institucional.
La obra se pondrá a disposición de los usuarios para que hagan de ella un uso justo
y respetuoso con los derechos del autor, según lo permitido por la legislación
aplicable, y con fines de estudio, investigación, o cualquier otro fin lícito. Con dicha
finalidad, la Universidad asume los siguientes deberes y se reserva las siguientes
facultades:

a) Deberes del repositorio Institucional:
-‐ La Universidad informará a los usuarios del archivo sobre los usos permitidos, y
no garantiza ni asume responsabilidad alguna por otras formas en que los usuarios
hagan un uso posterior de las obras no conforme con la legislación vigente. El uso
posterior, más allá de la copia privada, requerirá que se cite la fuente y se
reconozca la autoría, que no se obtenga beneficio comercial, y que no se realicen
obras derivadas.
-‐ La Universidad no revisará el contenido de las obras, que en todo caso
permanecerá bajo la responsabilidad exclusiva del autor y no estará obligada a
ejercitar acciones legales en nombre del autor en el supuesto de infracciones a
derechos de propiedad intelectual derivados del depósito y archivo de las obras. El
autor renuncia a cualquier reclamación frente a la Universidad por las formas no
ajustadas a la legislación vigente en que los usuarios hagan uso de las obras.
-‐ La Universidad adoptará las medidas necesarias para la preservación de la obra
en un futuro.
b) Derechos que se reserva el Repositorio institucional respecto de las obras en él
registradas:
-‐ retirar la obra, previa notificación al autor, en supuestos suficientemente
justificados, o en caso de reclamaciones de terceros.
Madrid, a 16 de Julio de 2015
ACEPTA
Fdo.……………………………………………………………



ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ANÁLISIS Y DESARROLLO DE UNA PLATAFORMA BIG DATA
Autor: Leticia de la Cierva Perreau de Pinninck
Directores: Mario Tenés y Sonia García
Madrid
Julio 2015


Agradecimientos
En primer lugar quería agradecer a la empresa VASS por brindarme la
oportunidad de realizar este proyecto, del que tanto he aprendido.
En especial a Mario y a Sonia, por la gran ayuda que me han ofrecido.
Gracias a mis compañeros y amigos por ayudarme en los momentos más críticos.
A mis amigas, porque siempre están ahí cuando las necesito.
A Natalia, porque su compañía y alegría son insustituibles.
A mis padres y hermano, porque gracias a ellos no habría llegado a ser como soy.
A Pablo, siempre.


ANÁLISIS Y DESARROLLO DE UNA PLATAFORMA BIG DATA
Autor: de la Cierva Perreau de Pinninck, Leticia Director: Sonia García, Mario Tenés Entidad Colaboradora: VASS RESUMEN DEL PROYECTO Tras la realización de un estudio de las principales distribuciones open-source de Big
Data- Hortonworks, Cloudera y MapR- se realiza una comparativa entre ellas para
luego seleccionar la que mejor convenga para el desarrollo de una plataforma en
particular. Cloudera será óptima para analizar datos de Twitter con herramientas
Hadoop: Flume para la recolección, HDFS para el almacenamiento, MapReduce para
el procesamiento, Hive para la consulta y Tableau para la visualización.
Palabras clave: Big Data, open-source, Hadoop, Cloudera, Twitter. 1. Introducción
Con el crecimiento exponencial de la cantidad de datos existentes, sumado a la
variedad de sus procedencias, que conlleva una amplia variedad de estructuras o
incluso a la falta de estructura, hace necesaria la existencia de una tecnología capaz de
tratar dichos datos a una velocidad adecuada, de forma que se pueda obtener de dichos
datos una información que proporcione valor a quien la analiza. Es en este contexto en
el que surge la tecnología Big Data.
Los expertos de Forrester definen el Big Data como “un conjunto de técnicas y
tecnologías que permiten manejar datos a una escala extrema y de una forma
asequible”.
Por lo tanto, para que una gran cantidad de datos se considere Big Data, se deben
cumplir los siguientes requisitos, denominados 3Vs:
ü Volumen, que puede ascender hasta los petabytes. ü Velocidad, acercándose lo más que se pueda al procesamiento en streaming. ü Variedad en la estructura de los datos, incluso llegando a la carencia de ella.

Una vez se haya considerado un conjunto de datos como Big Data, será necesario
definir la arquitectura del sistema, basada en las cinco capas típicas de los sistemas de
análisis de información, mostradas en el siguiente diagrama.
Figura 1. Arquitectura Big Data
Dentro de la tecnología que se ha desarrollado para analizar Big Data se encuentra la
más conocida, Hadoop. Se trata de una plataforma software que provee
almacenamiento distribuido y capacidades computacionales bajo una licencia libre.
Hadoop se divide en dos componentes principales: HDFS para almacenamiento
distribuido y MapReduce para capacidades computacionales, ambos basados en un
modelo maestro-esclavo.
Aparte de estas dos herramientas principales, en el ecosistema de Hadoop se han
desarrollado una gran cantidad de herramientas para las distintas capas de la
arquitectura para análisis de datos de Big Data.
2. Definición del proyecto
Con los nuevos desarrollos existentes acerca de la tecnología Big Data, se va a realizar
un análisis de las principales distribuciones de Hadoop open-source existentes en el
mercado según las consideraciones de los expertos.
Según las conclusiones que se obtengan, se desarrollará una plataforma, para un caso
de uso específico, utilizando la distribución que se considere con mejores capacidades
para abordar el mismo y que permita conocer a fondo las tecnologías propias del
ecosistema.

Para poder desarrollar esta plataforma, será necesario en primer lugar definir una
arquitectura que cubra los requisitos necesarios para que el análisis de la información
requerida sea completo, así como el entorno de trabajo que se va a emplear.
Una vez se haya diseñado la plataforma, se procederá a la implementación de la
misma, obteniendo así unos resultados particulares.
3. Descripción de la plataforma
Una vez realizado el análisis de las distribuciones, se considera que cada una de ellas
posee unas características diferentes y que, en función del uso que se le desee dar, esas
características hacen que cada distribución sea óptima.
Para el caso específico que se va a desarrollar, que consiste en la obtención de datos de
la red social Twitter para extraer conclusiones acerca de los datos obtenidos, se
considera que la mejor opción es la distribución Cloudera, ya que se trata de una
distribución que ofrece un alto rendimiento y una gran capacidad para dar soporte
debido a que es la distribución que lleva más tiempo en el mercado y por lo tanto tiene
una comunidad que la respalda mucho mayor; además, los análisis anuales que
realizan los expertos en la materia, la consideran como la mejor distribución del
mercado.
Para el diseño de la plataforma será necesario definir herramientas que cubran todas
las capas de la arquitectura mencionada.
Como se puede observar en el siguiente diagrama, la recolección de datos se realiza
con Flume, que extrae los datos de Twitter, y los deposita en el sistema de ficheros
HDFS. Estos datos se procesan con MapReduce y se vuelven a almacenar para que
Hive, a través de su lenguaje de consultas, sea capaz de crear tablas que puedan ser
representadas en gráficos gracias a Tableau.

4. Resultados
Tras el desarrollo de la plataforma, se observa que se pueden extraer múltiples gráficos
que representen la información obtenida en una gran variedad de formas, por lo que
gracias a esta plataforma se podrán realizar análisis exhaustivos de información
procedente de las redes sociales que permitan extraer patrones y conclusiones que
pueden llegar a ser de gran interés.
Se adjuntan algunos ejemplos de gráficos que se pueden extraer de la plataforma.
Figura 2. Arquitectura del sistema
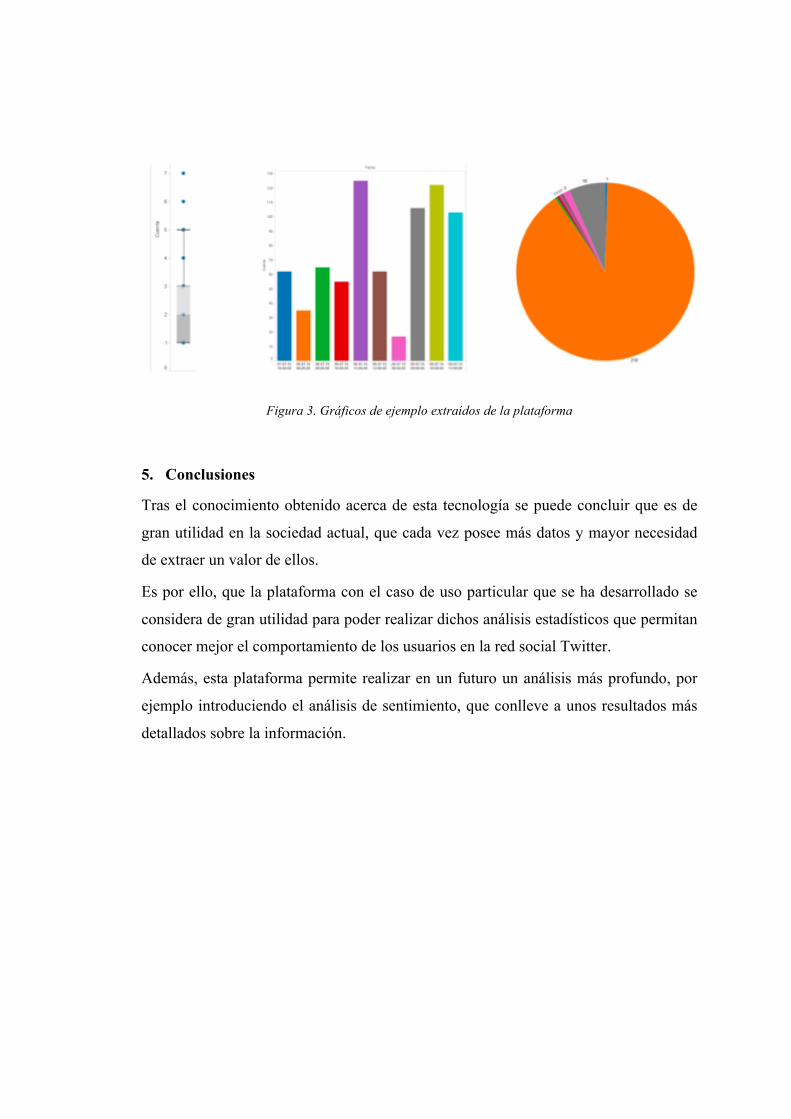
Figura 3. Gráficos de ejemplo extraídos de la plataforma
5. Conclusiones
Tras el conocimiento obtenido acerca de esta tecnología se puede concluir que es de
gran utilidad en la sociedad actual, que cada vez posee más datos y mayor necesidad
de extraer un valor de ellos.
Es por ello, que la plataforma con el caso de uso particular que se ha desarrollado se
considera de gran utilidad para poder realizar dichos análisis estadísticos que permitan
conocer mejor el comportamiento de los usuarios en la red social Twitter.
Además, esta plataforma permite realizar en un futuro un análisis más profundo, por
ejemplo introduciendo el análisis de sentimiento, que conlleve a unos resultados más
detallados sobre la información.

ANALYSIS AND IMPLEMENTATION OF A BIG DATA
PLATFORM
Author: de la Cierva Perreau de Pinninck, Leticia Director: Sonia García, Mario Tenés Collaborative entity: VASS SUMMARY After a study of the best open-source solutions for Big Data in the market-
Hortonworks, Cloudera and MapR-, a comparative between then is done to choose the
best solution for a platform development. Cloudera is chosen to analyze Twitter data
with Hadoop tools: Flume for collection, HDFS for storage, MapReduce for
processing, Hive for querying and Tableau for display.
Key Words: Big Data, open-source, Hadoop, Cloudera, Twitter. 1. Introduction
Taking into account the amounts of data existing and the variety of its sources
(sometimes with different data structures or none at all), it is necessary a technology
able to process these data at a reasonable speed with the objective of getting value out
of the information. This technology is called Big Data.
Experts in Forrester define Big Data as a group of techniques and technologies that
allow handling large amounts of data in a simple way.
For a set of data to be considered Big Data, the following requirements must be met:
• Volume can be up to petabytes. • Velocity is close to streaming processing. • Variety in the data structure.
After a data set is considered as Big Data, defining the systems architecture will be
needed. It will be based in the five common layers used in this kind of system, seen on
the following diagram.

Figure 1. Big Data architecture
The technology used to analyze big data is Hadoop, the most known solution. It is a
software platform that allows parallel processing and storage under an open license.
Hadoop is divided in two main components: HDFS for distributed storage and
MapReduce for processing, both based in a master-slave model.
Apart from these main tools, the Hadoop ecosystem has been completed with a great
variety of tools in different layers that allow Big Data analysis.
2. Project definition
With the new existing developments in Big Data, an analysis is done of the main
Hadoop distributions existing in the market.
The results obtained from this analysis will be used to develop a platform using the
best distribution possible.
In order to develop this platform an architecture definition will be needed, and it must
meet the necessary requirements to allow complete data analysis.
After the design, implementation of the platform will be done obtaining results that
will be analyzed.

3. Platform description
The use case that is going to be developed starts by obtaining Twitter data to extract
conclusions about the data generated. The distribution chosen is Cloudera, since it is
considered the best possible choice for the use case. It offers high performance and a
great capacity to give support since it is the oldest distribution in the market. Experts
consider Cloudera as the best solution in the market.
A set of tools will be needed in the platform to cover all the layers mentioned in the
architecture.
As it can be seen on the following diagram, data collection will be done with Flume,
which extracts the data from Twitter and introduces them into Hadoop file system,
HDFS. This data is processed with MapReduce and is back stored into HDFS, so it
can be queried by Hive and represented in graphs thanks to Tableau.
Figure 2. System architecture

4. Results
After the platform has been developed, multiple data can be obtained and represented
in graphs. Thanks to the platform data can be used to perform analysis in order to
extract patterns and conclusions.
Some examples are shown in the following image:
Figure 3. Graphs extracted from the platform
5. Conclusions
With all the work done it can be concluded that Big Data is a great asset to a society
that has more data every day and more need of obtaining value out of it.
This is why the platform developed with the use case specified is considered of great
utility to perform statistical analysis that allows a better knowledge of user’s behavior.
Besides, this platform allows future deep analysis, resulting in better-detailed results
about the information.


ÍNDICE DE LA MEMORIA
I
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Índice de la memoria Capítulo 1 Introducción .................................................................................................... 3
1.1 Motivación .......................................................................................................................... 5
1.2 Estructura del documento ............................................................................................. 6
1.3 Definición de Big Data ..................................................................................................... 7
1.4 Arquitectura ....................................................................................................................... 8
Capítulo 2 Estado de la tecnología .............................................................................. 13
2.1 Retos del Big Data ........................................................................................................... 13
2.2 Tipos de distribuciones Big Data .............................................................................. 15 2.2.1 Solución Pure Open-‐Source ...................................................................................................................... 15 2.2.2 Solución de Propietario .............................................................................................................................. 16
2.3 Tecnologías sobre las que se apoya el Big Data ................................................... 18 2.3.1 Bases de Datos ............................................................................................................................................... 19 2.3.1.1 NoSQL ....................................................................................................................................................... 19
2.3.2 Hadoop .............................................................................................................................................................. 20 2.3.2.1 Hadoop Distributed File System (HDFS) ................................................................................... 21 2.3.2.2 MapReduce ............................................................................................................................................. 23 2.3.2.3 Limitaciones de Hadoop ................................................................................................................... 25 2.3.2.4 Hadoop 2.0 ............................................................................................................................................. 25 2.3.2.5 Federación HDFS ................................................................................................................................. 26 2.3.2.6 YARN ......................................................................................................................................................... 26 2.3.2.7 Ecosistema de Hadoop ...................................................................................................................... 28
Capítulo 3 Definición del Trabajo ................................................................................ 31
3.1 Objetivos ............................................................................................................................ 31
3.2 Metodología y planificación ........................................................................................ 32
Capítulo 4 Análisis de las Distribuciones .................................................................. 35
4.1 Hortonworks .................................................................................................................... 35 4.1.1 Hadoop Data Platform (HDP) .................................................................................................................. 36 4.1.1.1 Gestión de datos ................................................................................................................................... 37

ÍNDICE DE LA MEMORIA
II
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
4.1.1.2 Acceso de datos .................................................................................................................................... 37 4.1.1.3 Gobernanza de datos e integración ............................................................................................. 38 4.1.1.4 Seguridad ................................................................................................................................................ 39 4.1.1.5 Operaciones ........................................................................................................................................... 40 4.1.1.6 Herramientas HDP .............................................................................................................................. 40
4.2 Cloudera ............................................................................................................................ 41 4.2.1 Cloudera Distribution of Hadoop (CDH) ............................................................................................. 42 4.2.1.1 Cloudera Impala ................................................................................................................................... 45 4.2.1.2 Cloudera Search ................................................................................................................................... 45
4.2.2 Cloudera Manager ........................................................................................................................................ 46 4.2.3 Cloudera Navigator ...................................................................................................................................... 46
4.3 MapR ................................................................................................................................... 47 4.3.1 MapR-‐FS ............................................................................................................................................................ 50 4.3.2 Direct Access NFS ......................................................................................................................................... 51 4.3.3 Heatmap ............................................................................................................................................................ 51
4.4 Comparativa ..................................................................................................................... 52 4.4.1 Comparativa de herramientas ................................................................................................................ 52 4.4.2 Comparativa de productividad ............................................................................................................... 54 4.4.3 Comparativa de tolerancia a fallos ........................................................................................................ 55 4.4.4 Comparativa de rendimiento ................................................................................................................... 56 4.4.5 Comparativa resumen ................................................................................................................................ 57 4.4.6 Otras comparativas ...................................................................................................................................... 59 4.4.7 Conclusiones ................................................................................................................................................... 62
Capítulo 5 Diseño de la plataforma ............................................................................ 65
5.1 Descripción del caso de uso ........................................................................................ 65
5.2 Entorno de trabajo real ................................................................................................ 67
5.3 Entorno de trabajo de laboratorio ........................................................................... 68
5.4 Diseño de la plataforma ............................................................................................... 68
Capítulo 6 Implementación de la plataforma ......................................................... 73
6.1 Recolección de datos ..................................................................................................... 74 6.1.1 Configuración ................................................................................................................................................. 76 6.1.2 Ejecución .......................................................................................................................................................... 77

ÍNDICE DE LA MEMORIA
III
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
6.2 Almacenamiento de datos ........................................................................................... 78
6.3 Procesamiento de datos ............................................................................................... 79 6.3.1 Configuración ................................................................................................................................................. 80 6.3.2 Ejecución .......................................................................................................................................................... 82
6.4 Consulta de datos ........................................................................................................... 83 6.4.1 Configuración ................................................................................................................................................. 84
6.5 Visualización de datos .................................................................................................. 85 6.5.1 Configuración ................................................................................................................................................. 86
Capítulo 7 Análisis de resultados ................................................................................ 93
7.1 Resultados de las ejecuciones de las herramientas ............................................ 93 7.1.1 Resultados de Flume ................................................................................................................................... 93 7.1.2 Resultados de HDFS ..................................................................................................................................... 94 7.1.3 Resultados de MapReduce ........................................................................................................................ 95 7.1.4 Resultados de Hive ....................................................................................................................................... 99
7.2 Visualización de gráficos .......................................................................................... 102
Capítulo 8 Conclusiones y líneas futuras ............................................................... 109
BIBLIOGRAFÍA ..................................................................................................................... 111
ANEXO A 115
8.1 Requisitos previos a la instalación ........................................................................ 115 8.1.1 Sistema operativo ...................................................................................................................................... 116 8.1.2 Nodos .............................................................................................................................................................. 116
8.2 Instalación de Cloudera Manager .......................................................................... 116 8.2.1 Camino A ........................................................................................................................................................ 117
8.3 Configuración Cloudera Manager .......................................................................... 117

ÍNDICE DE LA MEMORIA
IV
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

ÍNDICE DE FIGURAS
V
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Índice de figuras Figura 1. El almacenamiento de información ha crecido significativamente en
los últimos años [1] .................................................................................................................... 4
Figura 2. Hype-‐cycle de Gartner de tecnologías en 2014 .......................................... 4
Figura 3. Arquitectura Big Data ............................................................................................ 9
Figura 4. Tipos de Big Data a recolectar [4] ................................................................... 10
Figura 5. Arquitectura de Hadoop [2] .............................................................................. 21
Figura 7. Funcionamiento MapReduce ............................................................................ 24
Figura 8. Hadoop 1 vs Hadoop 2 [8] .................................................................................. 25
Figura 9. Arquitectura YARN [11] ...................................................................................... 27
Figura 10. Hadoop y su ecosistema [2] ............................................................................ 28
Figura 11. Cronograma ........................................................................................................... 33
Figura 12. Logo Hortonworks [14] .................................................................................... 35
Figura 13. Arquitectura HDP [14] ...................................................................................... 36
Figura 14. Gestión de datos [14] ......................................................................................... 37
Figura 15. Acceso de datos [14] .......................................................................................... 38
Figura 16. Gobernanza de datos e integración [14] ................................................... 39
Figura 17. Seguridad [14] ...................................................................................................... 39
Figura 18. Operaciones [14] ................................................................................................. 40
Figura 19. Hortonworks Data Platform 2.2 [13] .......................................................... 41
Figura 20. Logo Cloudera [15] ............................................................................................. 41
Figura 21. Arquitectura de CDH [16] ................................................................................ 42
Figura 22. Servicios de Cloudera Manager [20] .......................................................... 46
Figura 23. Servicios de Cloudera Navigator [20] ......................................................... 47
Figura 24. Logo MapR [22] .................................................................................................... 47
Figura 25. MapR Heatmap [25] ........................................................................................... 52

ÍNDICE DE FIGURAS
VI
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 26. Cuadrante mágico de Gartner de soluciones de Data Warehouse y
Data Management [26] ........................................................................................................... 61
Figura 27. Forrester Wave sobre soluciones Big Data Hadoop [27] ................... 62
Figura 28. Logo Flume [5] ..................................................................................................... 69
Figura 31. Logo Hive [6] ......................................................................................................... 70
Figura 32. Logo Tableau [7] .................................................................................................. 71
Figura 34. Servicios que gestiona Cloudera Manager ............................................... 74
Figura 35. Sistema de ficheros HDFS ................................................................................ 78
Figura 36. Configuración del sistema DSN para el servidor de Hive .................. 87
Figura 37. Pantalla inicial de Tableau .............................................................................. 88
Figura 38. Tablas de Hive ...................................................................................................... 89
Figura 39. Pantalla de creación de gráficos de Tableau ........................................... 90
Figura 40. Asignación de filas y columnas para el gráfico ....................................... 90
Figura 41. Ejecución del agente de Flume ...................................................................... 93
Figura 42. Sistema de ficheros HDFS conteniendo datos descargados ............. 95
Figura 43. Ejecución del proceso MapReduce (I) ........................................................ 96
Figura 44. Ejecución del proceso MapReduce (II) ...................................................... 96
Figura 45. Interfaz gráfica que muestra el progreso de MapReduce .................. 97
Figura 46. HDFS conteniendo datos de la salida de MapReduce .......................... 97
Figura 47. Contenido fichero part-‐r-‐00000 ................................................................... 98
Figura 48. Contenido fichero part-‐r-‐00001 ................................................................... 99
Figura 49. Tiempo de creación de una tabla en Hive .............................................. 100
Figura 50. Tiempo de carga de datos en una tabla en Hive ................................. 100
Figura 51. Ejemplo de consulta SELECT que produce un MapReduce ........... 101
Figura 52. Ejemplo de consulta SELECT ....................................................................... 101
Figura 53. Sucesión temporal por minutos de los tweets .................................... 103
Figura 54. Diagrama de caja de la evolución por minutos ................................... 104

ÍNDICE DE FIGURAS
VII
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 55. Tabla de colores con la evolución por minutos ................................... 105
Figura 56. Escala de colores para la evolución por minutos ............................... 105
Figura 57. Sucesión temporal por horas de los tweets .......................................... 106
Figura 58. Sucesión temporal por horas de los tweets en horizontal ............. 107
Figura 59. Diagrama circular del idioma de los tweets ......................................... 108
Figura 60. Leyenda del diagrama circular ................................................................... 108
Figura 61. Página de presentación de Cloudera Manager .................................... 118
Figura 62. Detección de nodos de las máquinas virtuales .................................... 119

ÍNDICE DE TABLAS
-‐ VIII -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

ÍNDICE DE TABLAS
-‐ IX -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Índice de tablas
Tabla 1. Pros y contras de la solución open-‐source ................................................... 15
Tabla 3. Pros y contras de la solución propia ............................................................... 17
Tabla 4. Versiones herramientas Cloudera .................................................................... 44
Tabla 5. Funcionalidades Ediciones MapR [22] ........................................................... 49
Tabla 6. Versiones herramientas MapR [25] ................................................................. 50
Tabla 7. Comparativa herramientas Hadoop ................................................................ 53
Tabla 8. Comparativa productividad ................................................................................ 54
Tabla 9. Comparativa tolerancia a fallos ......................................................................... 55
Tabla 10. Comparativa rendimiento ................................................................................. 56
Tabla 11. Comparativa general [28] ................................................................................. 59

ÍNDICE DE TABLAS
-‐ X -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

-‐ 1 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Parte I MEMORIA

-‐ 2 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

Introducción
-‐ 3 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 1 INTRODUCCIÓN
Hoy en día, las organizaciones se enfrentan a grandes cantidades de
información, tanto estructurada como desestructurada3, proveniente de una inmensa
cantidad de fuentes diferentes. El crecimiento del volumen de la información se
produce de una forma exponencial y según la fuente se presenta en diferentes
formatos. Según el IDC, International Data Corporation, más del 90% de la
información de las organizaciones está desestructurada y el volumen de esta
información se duplicará cada 18 meses. Este crecimiento ha hecho que el software de
las bases de datos tradicionales necesite de un nuevo análisis que permita trabajar
con este volumen [1].
Asimismo, el despliegue de la tecnología cloud reduce el tiempo que se tarda
en desplegar productos al mercado y el coste requerido para proveer servicios a los
consumidores de Internet. Esto hace que crezca el número de empresas que buscan
expandir sus negocios por Internet, número añadido a la cantidad de datos que se
generan.
Algunas de las compañías más exitosas del mundo deben este éxito, en parte, a
las estrategias innovadoras que han empleado para acceder, manejar y emplear
porciones de datos que brindar nuevas oportunidades o permiten tomar decisiones
de negocio más rápidamente. Estas estrategias, a día de hoy, se basan en el Big Data.
“Big Data son un conjunto de técnicas y
tecnologías que permiten manejar datos a una
escala extrema de una forma asequible [12]”
3 Los datos desestructurados son aquellos que no están sujetos a un modelo de datos relacional. No se pueden introducir en las tablas de los modelos clásicos debido a que no está definido el número de columnas, sino que varía según la fila.

Introducción
-‐ 4 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 4. El almacenamiento de información ha crecido significativamente en los últimos años [1]
Figura 5. Hype-‐cycle de Gartner de tecnologías en 2014 [34]

Introducción
-‐ 5 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
1.1 MOTIVACIÓN
La iniciativa de desarrollar este proyecto surge en la empresa VASS,
Consultora Tecnológica, en el área del Business Intelligence. El propósito es integrar
en la gama de servicios que ofrece la empresa una plataforma que sea capaz de tratar
Big Data.
Con el paradigma actual de generación de grandes cantidades de información,
será necesario hacer uso de una plataforma que sea capaz de dar soporte,
procesamiento y análisis a todos esos datos. Es aquí donde surge la idea de introducir
esta tecnología en el abanico de servicios que se ofrecen al cliente en VASS.
Según aseguran los informes de la empresa Gartner, especialistas en clasificar
las nuevas tecnologías, el Big Data se encuentra actualmente en fase de desilusión,
como se muestra en la Figura 2, fase en la que está disminuyendo su auge y aún le
queda tiempo para instaurarse por completo, pero se mantiene su nivel de utilidad,
haciéndola incluso necesaria; su nivel de madurez es adolescente, que implica que ya
está instaurado en las empresas visionarias y está empezando a instaurarse en las
empresas que la ven como una oportunidad de negocio; y se considera que va a
proveer un ratio de beneficios transformacional, lo que significa que aporta un nuevo
modelo de negocio en las industrias, que resultará en un gran beneficio económico
debido a todas sus ventajas.
Como opinión personal, esta tecnología será de gran ayuda para las empresas
que ofrezcan servicios, y que probablemente tenga un gran crecimiento en los años
venideros, sobretodo en el ámbito económico. No sólo eso, sino que se trata de una
tecnología que aporta un gran valor a aquellas personas especializadas en ella por el
conocimiento que aporta sobre el tratamiento y análisis de datos.
Por lo tanto, hacer uso de esta tecnología aportará grandes beneficios al
implantarse en el modelo de negocio.

Introducción
-‐ 6 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
1.2 ESTRUCTURA DEL DOCUMENTO
En el presente documento se realiza primero una introducción al Big Data,
definiendo la tecnología y explicando los requisitos básicos para que un conjunto de
información se pueda considerar Big Data. También se hará un resumen del
tratamiento que deben recibir los datos para poder extraer conclusiones útiles sobre
ellas.
A continuación se presentan los retos existentes en esta tecnología, retos que
deben ser solucionados a medida que avanza la tecnología, así como los tipos de
distribuciones que se presentan en el mercado.
En el estado de la tecnología se analiza cómo han avanzado las bases de datos
clásicas hacia nuevos modelos. También se analiza la base de la mayor parte de las
distribuciones presentes en el mercado: Hadoop. Se expone el funcionamiento de esta
plataforma software, así como sus componentes y actualizaciones. Si bien no es la
única plataforma para tratamiento de Big Data existente, el estudio se centrará en
ella, ya que las distribuciones a analizar se basan en Hadoop.
En siguiente lugar se pasa a la fase de análisis, donde se estudiarán en mayor
profundidad las siguientes distribuciones open-‐source: Hortonworks, Cloudera y
MapR. Se presentan los productos y paquetes que ofrecen en el mercado, para poder
realizar las diversas comparativas entre ellas, en cuanto a rendimiento,
productividad, herramientas que permite y tolerancia a fallos.
Una vez se realiza el análisis y la comparativa se llegará a una conclusión que
permita identificar la distribución que se considere más adecuada para el uso que se
le vaya a dar. Es entonces cuando se debe definir la arquitectura del sistema
completo: el entorno de trabajo, donde se especifican los servidores y ordenadores
que serán necesarios, así como sus sistemas operativos; y el diseño de la plataforma,
donde se indican las herramientas propias de Hadoop y específicas de la distribución
seleccionada, que permitirán realizar el tratamiento completo de la información para
obtener así resultados.

Introducción
-‐ 7 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Cuando se tenga el sistema definido, se procederá a implementar la
plataforma.
Finalmente, se probará la plataforma con datos reales que permitan extraer
una serie de conclusiones y así especificar unos trabajos futuros.
1.3 DEFINICIÓN DE BIG DATA
El Big Data se refiere a cantidades masivas de datos, el tamaño y la variedad de
los cuales están muy por encima de la capacidad de procesamiento de las
herramientas de procesado de datos tradicional, sobre todo si se tiene en cuenta el
tiempo que tarda en hacerlo.
Para que una gran cantidad de datos se considere Big Data, por lo tanto, es
necesario que se cumplan tres requisitos, denominados 3Vs [1]:
ü Volumen: como el nombre de Big Data indica, el volumen que los datos pueden
llegar a ocupar puede ascender hasta los terabytes o petabytes. Se ha elevado
tanto como resultado del crecimiento de la demanda de las empresas para
utilizar y analizar más tipos de datos, generalmente desestructurados, que no
encajan en los sistemas de negocios actuales. La cantidad de información está
creciendo con una tasa exponencial; tanto, que el 90% de la información a día
de hoy se ha creado únicamente en los últimos dos años.
ü Velocidad: cada vez más, las empresas necesitan tiempos de respuesta
mínimos, llegando incluso a la respuesta en tiempo real. Cargar la información
en procesos batch no es adecuado para el e-‐commerce, el envío de contenidos
multimedia u otras aplicaciones de tiempo real. Esto hace que se acelere la
velocidad en la carga de datos, sin olvidar su inmenso volumen. El streaming
de datos y la complejidad en el procesado hacen que se tengan que cumplir
una serie de requerimientos de arquitectura nuevos que puedan dar el soporte

Introducción
-‐ 8 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
necesario para ello, es decir, se necesitarán respuestas en tiempo real o lo más
cercano posible.
ü Variedad: tiene que ver con datos de diferentes tipos y que proceden de
distintas fuentes. La mayor parte de los datos actualmente se presentan
desestructurados o semi-‐estructurados, lo que significa que no encajan en las
filas y columnas de las bases de datos relacionales tradicionales.
También se puede hacer referencia a otra serie de términos, como veracidad o
valor de dicha información, que, aunque no son tan relevantes a la hora de definir el
Big Data, ni determinantes a la hora de aplicar su definición, se deben tener en
cuenta:
ü Veracidad: se refiere a la fiabilidad de los datos. Con las muchas formas en las
que se presenta el Big Data, es más difícil controlar la calidad y la precisión del
análisis; si bien, las herramientas que se han desarrollado permiten ahora
trabajar con estos datos.
ü Valor: este término implica que la información, una vez tratada y procesada,
debe aportar algún tipo de valor o se le pueda dar algún uso. Ésta es quizás la V
más importante para las empresas, ya que si no les aporta ningún beneficio, no
es importante la capacidad de procesar los datos.
1.4 ARQUITECTURA
La arquitectura del Big Data se basa en la que tiene cualquier sistema de
análisis de información: basada en cinco capas. De cada capa se encuentran múltiples
herramientas que facilita cada uno de los procesos.

Introducción
-‐ 9 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 6. Arquitectura Big Data
A continuación se especifican las funcionalidades de las capas:
ü Recolección: en esta capa se recopilan los datos que servirán de base para el
análisis que se requiera. La cantidad de datos será muy grande y su formato
será variado. Estos datos pueden proceder de diversas fuentes, por ejemplo
redes sociales, M2M, Big Transaction Data4, biométrica o generado por los
humanos, generalmente procedente de centros de procesado de datos (CPD),
que almacenan por ejemplo las llamadas telefónicas. También, esta
información puede provenir de sistemas de lotes (batch) o de sistemas en
tiempo real (streaming).
Del mismo modo que existen gran variedad de fuentes de información,
también existe una gran cantidad de herramientas encargadas de
recolectarlas. Cada una de ellas con unas funcionalidades específicas
dependiendo de sus características: grandes volúmenes de datos en bases de
datos relacionales, información en streaming o extracción de información de
redes sociales (mediante APIs REST).
La capa de recolección envía los datos a la etapa de almacenamiento, donde se
guardarán los datos que han sido recolectados.
4 Registros de facturación, registros detallados de las llamadas (CDR). Son datos disponibles en formato semiestructurado o no estructurado.

Introducción
-‐ 10 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 7. Tipos de Big Data a recolectar [4]
ü Almacenamiento: en esta capa se encuentran las herramientas que permiten
almacenar la información de gran volumen y variabilidad. Al ser conjuntos de
datos tan grandes, es normal que se trate de herramientas distribuidas y
escalables. Se tienen bases de datos NoSQL, que se explicarán más adelante, y
sistemas de ficheros distribuidos (HDFS).
También se debe destacar que en muchas ocasiones se almacenarán los
resultados del procesamiento de algunos datos de la siguiente capa.
ü Procesamiento y análisis: en esta capa se llevan a cabo todos los análisis y
procesamiento de los datos que han sido almacenados para poder extraer
información de valor. Para poder procesar y analizar los datos, existen
librerías con funciones ya implementadas que facilitan la tarea, que traducen
procesos complejos, paradigmas de procesamiento como MapReduce, etc.
Existen diferentes técnicas de análisis de datos a aplicar según los análisis de
datos requeridos. A continuación indicamos algunas de ellas:
• Asociación: permite encontrar relaciones entre diferentes variables. Se
pretende encontrar una predicción en el comportamiento de las
variables.

Introducción
-‐ 11 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
• Minería de datos (Data Mining): tiene como objetivo encontrar
comportamientos predictivos. Engloba el conjunto de técnicas que
combina métodos estadísticos y de Machine Learning con
almacenamiento en bases de datos.
• Agrupación (Clustering): el análisis de clústeres es un tipo de minería
de datos que divide grandes grupos de individuos en grupos más
pequeños de los cuales no conocíamos su parecido antes del análisis. El
propósito es encontrar similitudes entre estos grupos, y el
descubrimiento de nuevos conociendo cuáles son las cualidades que lo
definen.
• Análisis de texto (Text Analytics): gran parte de los datos generados
por personas son textos, como e-‐mails, búsquedas web o contenidos.
Esta metodología permite extraer información de estos datos y así
modelar temas y asuntos o predecir palabras.
ü Visualización: es la etapa en la que se muestran los resultados de los análisis
que se han realizado sobre los datos almacenados, de forma amigable. Suele
presentarse gráficamente, ya que se puedan extraer conclusiones de una forma
más sencilla y rápida.
ü Administración: esta capa está presente durante todo el proceso anterior. En
esta capa se encuentran todas las herramientas encargadas de administrar y
monitorizar el estado de los sistemas, funcionalidades como comprobar el
estado de los nodos, el modelo de los datos almacenados o ejecutar nuevas
aplicaciones de análisis.

Introducción
-‐ 12 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

Estado de la tecnología
-‐ 13 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 2 ESTADO DE LA TECNOLOGÍA
En este capítulo se va a realizar una introducción a la tecnología que se va a
emplear a lo largo del proyecto, con el fin de introducir en qué estado se encuentra
dicha tecnología para facilitar la comprensión del desarrollo que se realiza
posteriormente.
2.1 RETOS DEL BIG DATA
Con la situación que se presenta respecto a las grandes cantidades de
información generada, se observa que existen una serie de retos en el mercado, de
cara a afrontar el procesamiento, el análisis y el almacenamiento que ello requiere. A
continuación se presentan las características generales que necesita el Big Data para
poder ser implementado y utilizado por una gran mayoría, aunque muchas de ellas ya
se encuentran desarrolladas, mientras que otras necesitan avanzar [1].
ü Se deben desarrollar estándares en la industria. Aunque Hadoop y SQL son
estándares, el desarrollo de nuevos estándares es necesario para satisfacer las
necesidades tanto del cliente como del proveedor.
ü Se deberá soportar el análisis en tiempo real para poder avanzar con las
tecnologías. Los procesos de batch no son suficientes. En este área se ha
desarrollado una nueva tecnología, Spark, que aún tiene un largo camino que
recorrer para llegar a estar completamente implantado en el mercado.
ü Soporte para los metadatos y la catalogación: los datos actualmente se están
recogiendo con información extra, que puede indicar en diferentes capas
información extra, como los elementos del dato, su estructura y la
construcción del fichero.

Estado de la tecnología
-‐ 14 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü Soporte para gobernanza de datos: los datos son un recurso muy importante,
por lo que es primordial mantenerlos seguros y aplicar las políticas de
retención, recuperación, replicación y auditoría en todos los niveles.
ü Soporte para tenencia múltiple: cuando se emplean recursos que comparten
datos, la gobernanza de la seguridad y de los recursos es de vital importancia.
ü Soporte para la seguridad: la seguridad es crítica, así como la autenticación y
autorización para acceder al sistema, ya que la privacidad y la confidencial de
los datos son un verdadero reto con el gran incremento del Big Data.
ü Soporte para el linaje de los datos: se necesita de un servicio que sea capaz
de conseguir una única localización para datos que derivan de otros datos,
ignorando su descendencia, de forma que se conecte a múltiples fuentes de
datos.
ü Soporte para la integración: no existe una plataforma que integre todos estos
datos, por lo que se deben diseñar unos patrones arquitectónicos, así como los
sistemas necesarios para poder unificar todos los datos procedentes de
grandes cantidades de información.
ü Soporte para pruebas: cuando se introduzcan las características básicas del
Big Data en la plataforma oportuna, será necesario realizar una herramienta
que permita hacer pruebas de su efectividad.
Por lo tanto, esto implica que lo que se debe desarrollar para poder llevar un
buen manejo del Big Data serán herramientas de gestión, herramientas de desarrollo
y marcos de trabajo con interfaces para usuarios. Muchas de las categorías
presentadas están ya solucionadas o en proceso; sin embargo, nunca se debe dejar de
avanzar con las tecnologías, ya que siempre existen mejoras a realizar.

Estado de la tecnología
-‐ 15 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
2.2 TIPOS DE DISTRIBUCIONES BIG DATA
A la hora de desarrollar tecnologías que den soporte a datos que cumplan los
tres requisitos del Big Data, se han dado dos soluciones diferentes, en cuanto a quién
ha desarrollado estos sistemas: desde una comunidad abierta hasta las empresas
privadas.
2.2.1 SOLUCIÓN PURE OPEN-‐SOURCE
Donde mejor encaja esta solución es para empresas en las que trabaje un
equipo con los conocimientos técnicos suficientes para poder hacer uso de
desarrollos abiertos.
Pros Contras
ü No necesita licencia
ü Portable
ü Flexible
ü Personalizable
ü Poco soporte
ü Sin servicio de
información
ü Solución de errores
manual
ü Difícil de implementar y
desplegar
Tabla 1. Pros y contras de la solución open-‐source
Apache es el principal proveedor de open-‐source, siendo Apache Hadoop la
implementación abierta del algoritmo MapReduce introducido en 2004 por Google.

Estado de la tecnología
-‐ 16 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Siendo una de las tecnologías de Big Data más conocidas y empleadas, Hadoop
es una plataforma distribuida para procesos paralelos batch que puede desplegar
cientos o miles de nodos de hardware en lo alto del sistema de ficheros. Posee
características, como tolerancia, autocorrección de errores o redundancia, que hacen
que sea una tecnología altamente disponible y segura.
Aunque Hadoop es una tecnología líder en Big Data, también existen otras
tecnologías abiertas que incluyen el despliegue de cloud, herramientas de
estadísticas, acceso a datos, etc. Por ejemplo, Cassandra Project o Apache Accumulo
Project (basado en el diseño de Google BigTable), ambas asociadas a Apache. Algunos
proyectos no distribuidos por Apache son Riak, MongoDB, CouchDB, Redis, etc.,
algunos de los cuales aportan un valor extra a Hadoop, mientras que otros pueden ser
usados en su lugar por algunas características que pueden ser de interés para grupos
específicos. Sobre estos proyectos open-‐source, existen las distribuciones
propiamente dichas. Algunos ejemplos de estas distribuciones son Cloudera o
Hortonworks.
Las soluciones open-‐source ofrecen diversos beneficios, como la ausencia
licencias, portabilidad y flexibilidad. Con esta solución, las empresas no están sujetas
a un único vendedor, por lo que pueden personalizar la solución sin violar patentes o
copyrights. Aun así, la implementación de soluciones open-‐source pueden ser tediosas
para los menos experimentados y ofrecen muy poca formación y soporte, sólo se
encuentra información en los foros de discusión online.
Las soluciones open-‐source se emplean típicamente para empresas con un
personal muy técnico, capaz de encontrar soluciones por su cuenta.
2.2.2 SOLUCIÓN DE PROPIETARIO
Empleada cuando una empresa quiere desarrollar su propio producto porque
al analizar los riesgos, les merece la pena realizar la inversión.

Estado de la tecnología
-‐ 17 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Pros Contras
ü Plataforma de
desarrollo y
mantenimiento
ü Características únicas
y tecnología adicional
ü Fácil despliegue
ü Integración entre
socios y aplicación
ü Formación y soporte
ü Cuotas de licencias
ü Vendedores con
conocimiento
ü Flexibilidad limitada
Tabla 2. Pros y contras de la solución propia
En la mayor parte de los casos, las empresas desarrollan su propia plataforma
de Big Data empleando una combinación de las soluciones anteriores. La ventaja de
esta solución es que el vendedor puede servir de socio a la hora de desarrollar y
mantener la plataforma, e incluso en ocasiones proveyendo formación de desarrollo y
mantenimiento.
Por lo general, las empresas se sienten más cómodas teniendo un camino bien
definido al personal de soporte de acceso, y los vendedores propietarios tienden a ser
muy familiares con su propio producto; por lo tanto, obtener respuestas a preguntas
específicas es más sencillo cuando se trata de una solución propia. Otra posible
ventaja de las soluciones de propietario está relacionada con la similitud de la
integración de socios y aplicación, ya que en el caso de las soluciones abiertas se suele
dar más carga a la integración de la empresa con la plataforma.
A la hora de evaluar la solución propia, la empresa debe considerar el precio y
el coste de las licencias. Aunque más importante, deberían determinar lo que es
distintivamente diferente de las ofertas de open-‐source: en qué es única la solución
del propietario y que valores añade. Por ejemplo, una tecnología adicional o una gran

Estado de la tecnología
-‐ 18 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
sencillez en el despliegue y mantenimiento. Otro tipo de decisiones afectan a la
interoperabilidad, exhaustividad y extensibilidad.
Dado que las soluciones propias dependen de un único vendedor, las empresas
deberían considerar la reputación del vendedor a la hora de proveer lo que es
necesario para este tipo de organizaciones hoy en día o para un futuro previsible.
La elección de la empresa es si el único valor ofrecido merece el riesgo a la
hora de invertir.
Algunas empresas que han desarrollado este tipo de distribuciones son IBM y
Microsoft.
2.3 TECNOLOGÍAS SOBRE LAS QUE SE APOYA EL BIG DATA
A continuación se van a detallar las tecnologías más implantadas para poder
realizar el tratamiento de los datos Big Data.
Por un lado, las bases de datos han avanzado para soportar nuevos formatos o
la falta de formatos, así como el hecho de encontrarse distribuidas. También se
encuentra la principal tecnología del Big Data: Hadoop, que es la tecnología más
implantada en los sistemas de tratamiento de estos datos, así como la base de la
mayor parte de herramientas y distribuciones que se han desarrollado hasta ahora.
Recientemente ha surgido Spark, una alternativa que mejora la gran deficiencia de
Hadoop, que es su procesamiento batch, para pasar a un procesamiento en tiempo
real. Al tratarse de una tecnología tan nueva, aún no tiene un gran soporte ni base, por
lo que no se va a tratar en este proyecto.

Estado de la tecnología
-‐ 19 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
2.3.1 BASES DE DATOS
Debido a la importancia del almacenamiento de la información para poder ser
procesada y analizada, es importante destacar los sistemas de almacenamiento que
han surgido para dar cabida a esta gran cantidad de datos. Se tiene el concepto
NoSQL, bases de datos no relacionales que permiten trabajar con información no
estructurada.
2.3.1.1 NoSQL
A la hora de realizar consultas en las bases de datos con los datos no
estructurados, se observa un problema relacionado con las transacciones, ya que no
es lo único que se analiza, sino que se busca un modelo de consulta horizontal, es
decir, entre bases de datos. Esto no se puede resolver sencillamente, por lo que surge
un nuevo paradigma para solucionarlo, el NoSQL5. No se trata de un sustitutivo de las
bases de datos relacionales (RDBMS), sino que busca otras opciones para escenarios
específicos de datos desestructurados [33].
Existen varias opciones, que según la situación que se presente se puede elegir
una u otra, de forma que se ataquen los problemas de escalamiento, actuación y
modelado de los datos. Estos escenarios son los siguientes:
ü Almacenes clave-‐valor: almacenan una clave y después el valor como conjunto
de bytes. La base de datos no es capaz de interpretar los bytes, por lo que no se
presentan esquemas ni tipos de datos. Básicamente se emplea cuando no
importa la información que se haya almacenado.
ü Bases de datos orientadas a documentos: son una evolución del escenario
anterior. Almacenan una clave y en lugar de guardar la información en forma
de bytes, la almacena en forma de documentos que puedan ser interpretados,
por ejemplo en formato JSON.
5 Not only SQL

Estado de la tecnología
-‐ 20 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü Bases de datos columnares: guardan los datos por columnas. Especialmente
útil para el sector del Business Intelligence por ser muy rápido en operaciones
de lectura. Sin embargo, no es eficiente para la escritura de datos. Su utilidad
se optimiza cuando se calculan datos agregados.
ü Bases de datos orientadas a objetos: se basan en el paradigma de los lenguajes
de programación orientados a objetos. Es decir, se almacenan objetos que
representan relaciones jerárquicas entre ellos. Para acceder de una tabla a otra
se emplean punteros.
ü Bases de datos orientadas a grafos: optimizan las consultas basándose en las
relaciones existentes. Son bases de datos muy eficientes cuando se trata de
conseguir resultados en base a dichas relaciones. Son de gran utilidad cuando
la información se puede representar como una red.
Para el Big Data es muy importante hacer uso del tipo de base de datos que dé
el soporte necesario a la plataforma que se desee emplear. También se debe tener en
cuenta que el sistema debe comprimir la información, ya que el almacenaje de
cantidades tan grandes de información resulta costoso. Algunos de los ejemplos más
reconocidos de estos sistemas de información son MongoDB o Cassandra.
2.3.2 HADOOP
Hadoop es una plataforma software que provee almacenamiento distribuido y
capacidades computacionales bajo una licencia libre. Hadoop surgió para arreglar un
problema de escalabilidad en Nutch, un rastreador open-‐source y un motor de
búsqueda, creado por Doug Cutting. De forma simultánea, Google publicó un nuevo
sistema de ficheros distribuido, Google File System (GFS), y un marco de trabajo para
procesamiento paralelo, MapReduce. La exitosa implementación de los conceptos de
estos desarrollos en el proyecto Nutch resultó en la separación entre dos nuevos
proyectos, uno de los cuales fue Hadoop, un proyecto de primera clase de Apache [2].
Estado de la tecnología
-‐ 21 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
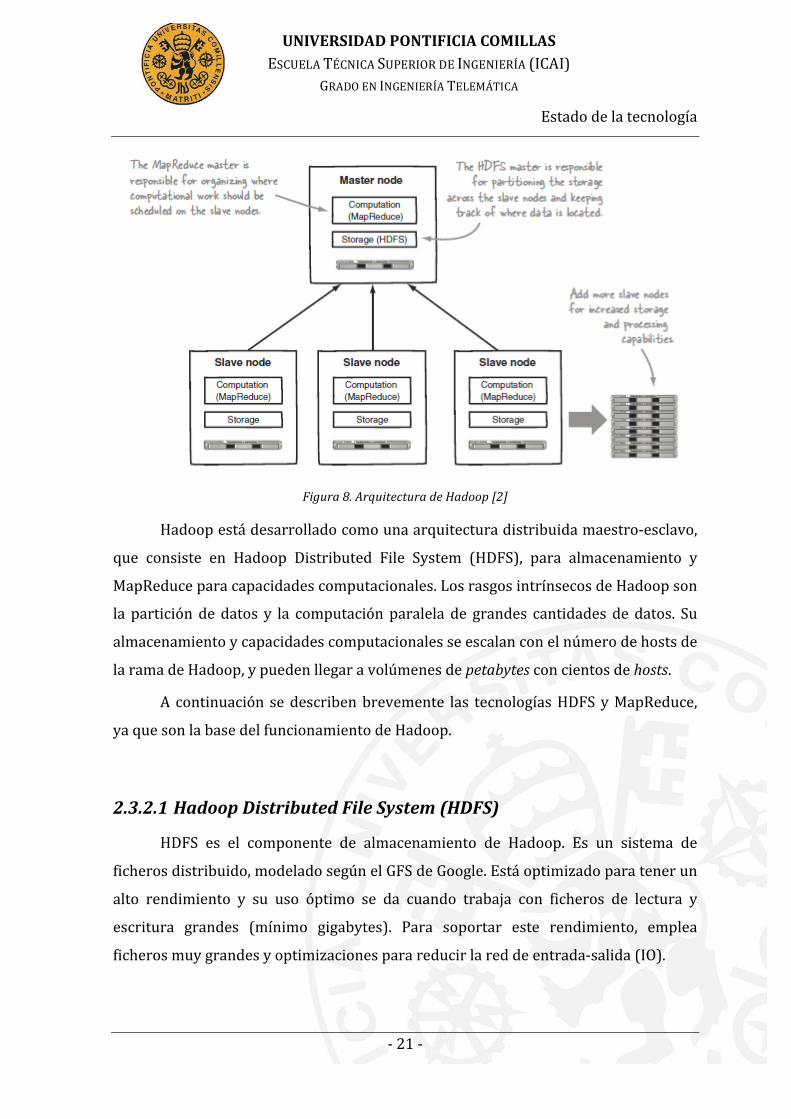
Figura 8. Arquitectura de Hadoop [2]
Hadoop está desarrollado como una arquitectura distribuida maestro-‐esclavo,
que consiste en Hadoop Distributed File System (HDFS), para almacenamiento y
MapReduce para capacidades computacionales. Los rasgos intrínsecos de Hadoop son
la partición de datos y la computación paralela de grandes cantidades de datos. Su
almacenamiento y capacidades computacionales se escalan con el número de hosts de
la rama de Hadoop, y pueden llegar a volúmenes de petabytes con cientos de hosts.
A continuación se describen brevemente las tecnologías HDFS y MapReduce,
ya que son la base del funcionamiento de Hadoop.
2.3.2.1 Hadoop Distributed File System (HDFS)
HDFS es el componente de almacenamiento de Hadoop. Es un sistema de
ficheros distribuido, modelado según el GFS de Google. Está optimizado para tener un
alto rendimiento y su uso óptimo se da cuando trabaja con ficheros de lectura y
escritura grandes (mínimo gigabytes). Para soportar este rendimiento, emplea
ficheros muy grandes y optimizaciones para reducir la red de entrada-‐salida (IO).
Estado de la tecnología
-‐ 22 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
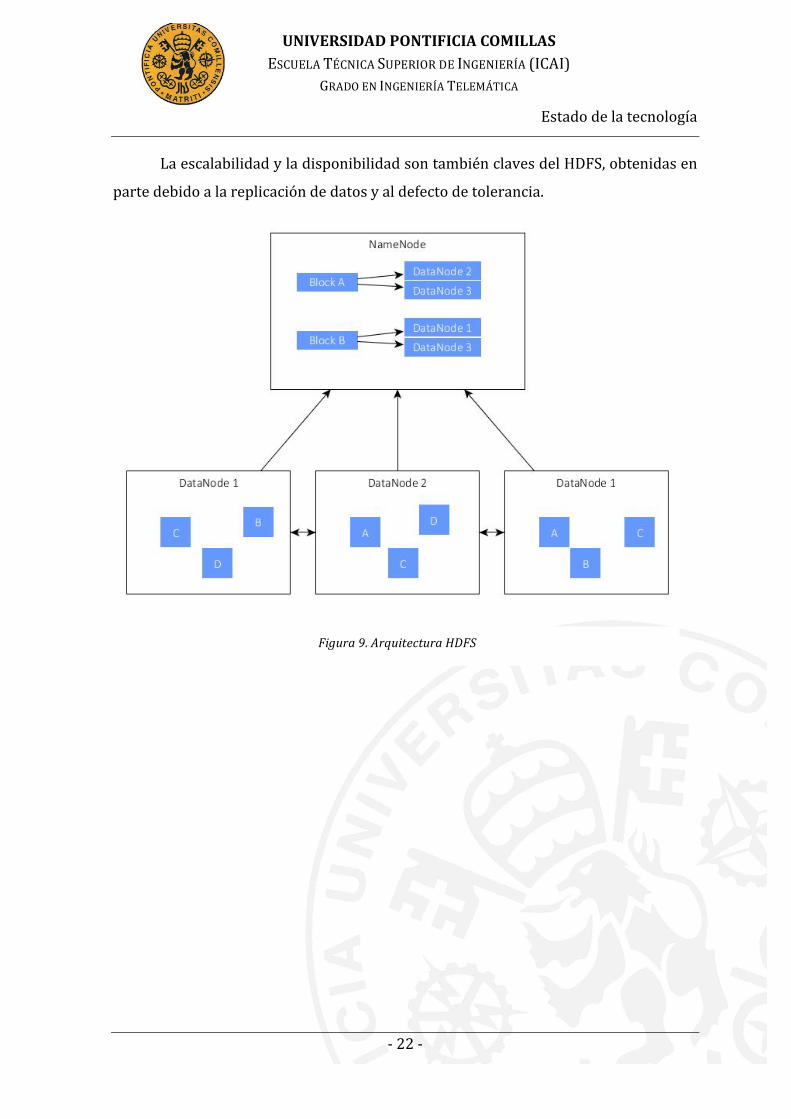
Figura 9. Arquitectura HDFS
La escalabilidad y la disponibilidad son también claves del HDFS, obtenidas en
parte debido a la replicación de datos y al defecto de tolerancia.

Estado de la tecnología
-‐ 23 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
HDFS se compone de nodos, y cada nodo es una instancia Hadoop. Siguiendo el
esquema de maestro-‐esclavo, se configura un nodo maestro o NameNode, que guarda
en memoria lo relacionado con el sistema de ficheros y se encarga de distribuir los
bloques a cada uno de los esclavos para que sean procesados, y un montón de nodos
esclavos o DataNode, que funcionan paralelamente y actúan como si se tratase de un
único nodo. Estos nodos se comunican entre sí a través de TCP/IP.
Sus componentes principales son el NameNode, con el que hablan los clientes
del HDFS para actividades relacionadas con los metadatos, ya que guarda en memoria
lo relacionado con el sistema de ficheros, y el DataNode, que dirige los bloques a cada
fichero, de modo que se encarga de leer y escribir los mencionados ficheros. Los
DataNode se comunican entre sí para las lecturas y escrituras, y están hecho de
bloques, de forma que cada fichero se pueda replicar múltiples veces.
2.3.2.2 MapReduce
El concepto Big Data ha conseguido que se desarrollen nuevas tecnologías para
el almacenado, la consulta y el análisis de la información, tanto estructurada como
desestructurada. Las bases de datos son útiles para trabajar con grandes cantidades
de información cuando lo que importa es la habilidad de almacenaje, no la habilidad
de examinar las relaciones entre elementos de datos. Aquí es donde entra en juego
MapReduce, que reduce este tiempo de procesado de información.
Es un rastreador de trabajo (Job Tracker) distribuido, basado en procesos
batch, modelado según el MapReduce que publicó Google. Permite paralelizar trabajo
a través de una gran cantidad de datos sin tratar, como combinar la información
(logs) de las páginas web con datos relacionales de una base de datos OLTP (OnLine
Transaction Processing) para modelar la forma en que los usuarios interactúan con la
página web. Este tipo de trabajo podría durar días con técnicas de programación
convencional, pero puede ser reducida a minutos empleando MapReduce en un
clúster de Hadoop.

Estado de la tecnología
-‐ 24 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 10. Funcionamiento MapReduce
El modelo MapReduce simplifica el procesamiento paralelo mediante la
abstracción de las complejidades involucradas en trabajar con sistemas distribuidos,
como la computación paralela, la distribución del trabajo, o trabajar con hardware y
software informal.
MapReduce descompone el trabajo de un cliente en pequeños mapas paralelos
(map) y reduce trabajadores (reduce). El mapa y las construcciones reducidas
utilizadas son prestados de aquellas encontradas en el lenguaje de programación
funcional Lisp y usa un modelo shared-‐nothing, en el que se tiene la noción de que
cada nodo es independiente y autosuficiente, para eliminar cualquier
interdependencia de la ejecución paralela que pueda añadir puntos sincronizados no
buscados o compartir estados.

Estado de la tecnología
-‐ 25 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
2.3.2.3 Limitaciones de Hadoop
No obstante, las dos principales limitaciones que rodean Hadoop son la
disponibilidad y la seguridad.
En HDFS se debe destacar la falta de disponibilidad, ya que es ineficiente
manejando ficheros pequeños, y tiene una falta de compresión transparente. HDFS no
está diseñado para trabajar bien con lecturas aleatorias sobre ficheros pequeños
debido a su optimización para un gran rendimiento. No obstante, esto se soluciona
con la nueva versión de HDFS de High Availability.
MapReduce es una arquitectura basada en procesos batch, que implica que no
se presta a sí mismo para usar casos que necesitan acceso a datos en tiempo real. Las
tareas que requieren sincronización global o compartir datos mutables no encajan
bien con MapReduce, debido a que se trata de una arquitectura que no comparte, lo
que produce algunos retos en ciertos algoritmos que emplea. Como alternativa
mejorada a MapReduce, Apache ha desarrollado el proyecto YARN.
2.3.2.4 Hadoop 2.0
Con la aparición de Hadoop 2, se han introducido dos grandes avances en su
funcionamiento: la federación HDFS y YARN.
Figura 11. Hadoop 1 vs Hadoop 2 [8]

Estado de la tecnología
-‐ 26 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
2.3.2.5 Federación HDFS
Anteriormente, un único NameNode manejaba todos los nodos del clúster. Con
la introducción de la federación HDFS, o HDFS de alta disponibilidad (HA), se
configura un clúster exclusivo con múltiples servidores de NameNodes que se
encargan de manejar el resto de nodos, lo que evita que exista un único punto de fallo
en el sistema. También se permite construir clúster de forma independiente pero con
una base común de almacenamiento de datos, que aporta un escalamiento horizontal
[9].
2.3.2.6 YARN
La introducción de YARN (Yet Another Resource Navigator) trae consigo
mejoras significativas en cuanto a la actuación de algunas aplicaciones, da un soporte
adicional para los modelos de procesado e implementa un motor de ejecución más
flexible.
YARN es un gestor de recursos que fue creado para separar el motor de
procesado de las capacidades de gestión de recursos de MapReduce, de Hadoop 1. Es
el responsable de gestionar y monitorizar las cargas de trabajo, manteniendo un
entorno de multitenencia, implementando controles de seguridad y gestionando las
características de alta disponibilidad (HA) de Hadoop [14].
El propósito de YARN era separar MapReduce en entidades separadas, por lo
que su funcionamiento se basa en cuatro elementos:
ü ResourceManager: único y global en el sistema.
ü ApplicationMaster: uno por aplicación.
ü NodeManager: un esclavo por nodo.
ü Container: uno por cada NodeManager.

Estado de la tecnología
-‐ 27 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 12. Arquitectura YARN [11]
De esta forma, el ResourceManager y el NodeManager forman un nuevo
sistema de aplicaciones de gestión de una forma distribuida, donde el gestor de
recursos es la última autoridad que gestiona los recursos en las aplicaciones del
sistema. El ApplicationMaster es una entidad específica de marcos de trabajo que
negocia los recursos del ResourceManager y trabaja con los nodos de gestión para
ejecutar y monitorizar las tareas.
El ResourceManager tiene un programador de tareas, responsable de asignar
recursos a las distintas aplicaciones ejecutándose en el clúster de acuerdo con las
restricciones, como por ejemplo los límites de cada usuario.
Cada ApplicationMaster tiene responsabilidad de negociar los contenedores de
recursos apropiados del programador, rastrear su estado y monitorizar su progreso.
Es como un contenedor normal. El NodeManager es un esclavo, responsable de lanzar
los contenedores de las aplicaciones, monitorizando su uso de recursos y
reportándolo al ResourceManager.
Las mejoras se pueden resumir en:
ü Multitenencia: YARN permite múltiples motores de acceso para utilizar
Hadoop como el estándar común de motores batch, interactivos o en tiempo
real, de forma que se pueda acceder a la misma información simultáneamente.

Estado de la tecnología
-‐ 28 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü Utilización de clúster: la asignación dinámica de los recursos del clúster de
YARN es una mejora respecto a las estáticas reglas de MapReduce.
ü Escalabilidad: la potencia de procesado de los centro de datos se está
expandiendo continuamente. Posee un gestor de recursos que se centra
exclusivamente en programar y mantener los clúster, aunque se expandan a
cientos de nodos.
ü Compatibilidad: las aplicaciones que emplean MapReduce pueden soportar
YARN sin ninguna interrupción en los procesos que están ejecutándose [10].
2.3.2.7 Ecosistema de Hadoop
El ecosistema de Hadoop es diverso y crece constantemente. A continuación se
presenta un cuadro con las tecnologías más destacables que se han desarrollado o las
que más utilizan los usuarios, las cuales comentará la otra parte colaboradora del
proyecto, denominado “Análisis de soluciones para la implementación de una
plataforma Big Data”.
Figura 13. Hadoop y su ecosistema [2]

Estado de la tecnología
-‐ 29 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Algunas de las grandes empresas que utilizan Hadoop u otras tecnologías de su
ecosistema son Facebook, que la emplea junto con Hive y HBase para análisis de
datos; Twitter, que usa Pig y HBase; Yahoo!, eBay y Google, que hace uso de su propia
versión del MapReduce.
Las organizaciones que utilizan Hadoop tienen un crecimiento continuo. Está
claro que mientras Hadoop siga madurando, su adopción seguirá creciendo.

Estado de la tecnología
-‐ 30 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

Definición del Trabajo
-‐ 31 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 3 DEFINICIÓN DEL TRABAJO
En este apartado se define el trabajo que se va a realizar, especificando los
objetivos concretos del desarrollo de este proyecto, así como la planificación y
metodología de trabajo que éste va a conllevar.
3.1 OBJETIVOS
A continuación se presentan los objetivos que se van a desarrollar en el
presente documento. Con la información presentada anteriormente, el propósito es:
1. En primer lugar se hará un estudio de las distribuciones existentes en el
mercado de las plataformas de Big Data. Para ello, se debe tener en cuenta que
existen distribuciones propias de algunas empresas privadas, las cuales
simplemente se analizarán, y distribuciones open-‐source, que se estudiarán
más a fondo, de forma que se presentará una comparativa entre ellas. Las
distribuciones de código abierto que se estudiarán serán:
a. Cloudera
b. Hortonworks
c. MapR
2. Una vez realizada la comparativa entre las distribuciones mencionadas
anteriormente, se va a seleccionar la que obtenga una mejor valoración acorde
al uso que se le vaya a dar a dicha plataforma.
3. Ya seleccionada la distribución óptima, se deberá definir una arquitectura
lógica del sistema que se va a desarrollar. Es decir, del ecosistema del Big Data
se seleccionarán las herramientas necesarias para poder implantar el sistema

Definición del Trabajo
-‐ 32 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
deseado. Por ejemplo, la base de datos de la que se hará uso para almacenar
los datos una vez procesados.
4. Con la distribución seleccionada y las herramientas definidas, se procederá a
implementar una plataforma que sea capaz de dar soporte a los datos de Big
Data que se seleccionen, de forma que se cumpla una funcionalidad particular,
dada por un caso de uso práctico que se definirá en función de los datos a los
que se tenga acceso.
5. Estando ya implementada la plataforma, se realizarán pruebas haciendo uso
de los datos seleccionados, es decir, se llevará a cabo el proceso de Big Data, en
el que se dan los procesos de recopilación, almacenamiento, procesamiento y
análisis de los datos y por último la visualización de los resultados.
3.2 METODOLOGÍA Y PLANIFICACIÓN
A la hora de definir la metodología de trabajo es importante destacar que se
debe dividir el trabajo en tareas más breves y sencillas para así facilitar su desarrollo,
así como la realización de las pruebas pertinentes.
Para este proyecto en particular, se considera que la metodología que mejor
satisface los requisitos que se deben cumplir es la metodología clásica, en la que se
encuentran cuatro fases clave: análisis, diseño, implementación y pruebas.
La fase inicial o de análisis es la base del proyecto, ya que en ella se han de
analizar detalladamente las distribuciones disponibles y más destacadas, para así
obtener una visión general del paradigma situado sobre el proyecto Hadoop y decidir
cuál de todas ellas será la que mejor se adapte el proyecto en cuestión.
En la fase de diseño, que se desarrollará con la otra parte colaboradora del
proyecto, se definirá la arquitectura sobre la que se sustentará la plataforma. En este
diseño se deberá indicar el almacenamiento físico de los datos que se van a procesar,

Definición del Trabajo
-‐ 33 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
así como las herramientas que se van a utilizar, que se han organizado en las
siguientes clases:
ü Recopilación de datos
ü Almacenamiento
ü Administración
ü Procesamiento y análisis
ü Utilidades
ü Seguridad
Una vez se haya definido toda la arquitectura a utilizar, se pasará a la fase de
implementación. En esta fase se desarrollarán los objetivos haciendo uso de la
distribución seleccionada y las correspondientes herramientas que hagan que la
plataforma sea lo más eficiente posible.
En último lugar se llevará a cabo la fase de pruebas, en la que se comprobará el
correcto funcionamiento de la plataforma y así asegurar que se ha cumplido con los
objetivos definidos. Estas pruebas se desarrollarán con datos reales para poder
obtener unos resultados que aporten información útil.
A continuación se incluye un diagrama de GANTT que representa el
cronograma que se llevará a cabo en el desarrollo del proyecto. Como se puede
observar, la fase que más tiempo ocupará será la del desarrollo de la plataforma.
Figura 14. Cronograma

Definición del Trabajo
-‐ 34 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

Análisis de las Distribuciones
-‐ 35 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 4 ANÁLISIS DE LAS DISTRIBUCIONES
Anteriormente se describieron los tipos de distribuciones existentes en el
mercado: hay distribuciones open-‐source y otras que son de propietarios,
generalmente de pago. En este proyecto se van a analizar las distribuciones abiertas
principales para realizar una comparativa entre ellas y así poder seleccionar la
óptima para el caso de uso específico que se quiera desarrollar.
4.1 HORTONWORKS
Hortonworks es una compañía de software centrada en el desarrollo y soporte
de Apache Hadoop. Se formó en junio de 2011 a partir de un grupo de trabajadores
del proyecto Hadoop de Yahoo.
Figura 15. Logo Hortonworks [14]
El producto principal de Hortonworks se llama Hortonworks Data Platform
(HDP), que incluye al proyecto Apache Hadoop, y es utilizada para almacenar,
procesar y analizar grandes cantidades de datos.

Análisis de las Distribuciones
-‐ 36 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
4.1.1 HADOOP DATA PLATFORM (HDP)
Diseñada, desarrollada y construida completamente en abierto, HDP provee
una plataforma de datos que permite a las organizaciones adoptar una arquitectura
de datos moderna: capaz de soportar lo que se conoce como Big Data.
Con YARN como su centro de arquitectura, provee una plataforma de datos
para procesamiento de datos con multicarga a través de una cadena de métodos de
procesamiento – desde batch hasta tiempo real, pasando por interactivo.
Se caracteriza por ser completamente abierta, fundamentalmente versátil y
completamente integrada con las aplicaciones existentes.
Figura 16. Arquitectura HDP [14]
HDP ofrece la más amplia gama de opciones de despliegue para Hadoop: desde
el sistema operativo, donde se puede utilizar Windows o Linux, hasta el despliegue,
que puede ser en la nube o en un servidor físico. Es una distribución altamente
portátil, que permite fácil y confiablemente migrar de un despliegue a otro.

Análisis de las Distribuciones
-‐ 37 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
4.1.1.1 Gestión de datos
Los componentes del núcleo de HDP son YARN y HDFS. YARN es el centro
arquitectónico de Hadoop que permite procesar datos simultáneamente de múltiples
formas. Provee una gestión de recursos y una arquitectura que se puede conectar
para permitir una gran variedad de métodos de acceso de datos. HDFS por otra parte
provee escalabilidad, tolerancia a fallos y almacenamiento rentable para Big Data.
Figura 17. Gestión de datos [14]
4.1.1.2 Acceso de datos
YARN provee la fundación de un intervalo versátil de motores de
procesamiento que potencia la interacción con los mismos datos de una forma
variable y simultánea. Los casos de uso emergentes son soportados por el ecosistema
de Hadoop, que a su vez aporta motores más especializados.
Se han desarrollado algunas herramientas propias de Hortonworks para el
acceso de datos, Tez o Stinger.

Análisis de las Distribuciones
-‐ 38 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 18. Acceso de datos [14]
4.1.1.3 Gobernanza de datos e integración
HDP extiende el acceso de datos y su gestión con herramientas muy potentes
de gobernanza e integración. Proveen un marco de trabajo confiable, replicable y
simple para la gestión del flujo de datos de entrada y salida de Hadoop. Esta
estructura de control es crítica para una integración exitosa de Hadoop en las
arquitecturas de datos modernas.

Análisis de las Distribuciones
-‐ 39 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 19. Gobernanza de datos e integración [14]
4.1.1.4 Seguridad
La seguridad se integra en HDP en múltiples capas. Características críticas,
como la autenticación, autorización y la protección de datos están en orden para que
se pueda securizar HDP con estos requisitos. También se asegura que se pueda
integrar y extender las soluciones de seguridad actuales para proveer una cobertura
completa.
Figura 20. Seguridad [14]

Análisis de las Distribuciones
-‐ 40 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
4.1.1.5 Operaciones
Los equipos de operaciones despliegan, monitorizan y manejan un clúster de
Hadoop dentro de su amplio ecosistema de datos empresariales. HDP ofrece un
equipo completo de capacidades operacionales que provee ambas visibilidades en el
clúster, además de herramientas de configuración de gestión y optimización a través
de los métodos de acceso de datos. Es destacable Ambari: herramienta que integra
sistemas de gestión.
Figura 21. Operaciones [14]
4.1.1.6 Herramientas HDP
Con la última versión de HDP, la 2.2, se presentan las siguientes versiones de
las herramientas que es capaz de soportar esta plataforma en el momento en el que
se redacta el presente documento. Como se puede observar, el número de
herramientas aumenta con cada nueva versión en las diferentes partes de la
arquitectura. Las nuevas que han surgido son: Spark, Slider, Kafka y Ranger. Además,
también soporta la popular base de datos MongoDB, en su versión 3.0.0.

Análisis de las Distribuciones
-‐ 41 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 22. Hortonworks Data Platform 2.2 [13]
4.2 CLOUDERA
Cloudera es una compañía americana de software que trabaja principalmente
con Hadoop. Fue fundada en 2008 por cuatro ingenieros de distintas empresas:
Yahoo, Google, Facebook y Sleepycat Software. Se dedica a ofrecer soluciones Hadoop
para Big Data y ofrece soporte de sus productos.
Figura 23. Logo Cloudera [15]
Cloudera ofrece su producto en tres paquetes diferentes:
ü Cloudera Enterprise: incluye el paquete completo con una suscripción anual,
incluyendo CDH, Cloudera Manager y Cloudera Navigator.
ü Cloudera Express: incluye algunas funcionalidades extras de gestión de
Cloudera Manager, aparte del núcleo.

Análisis de las Distribuciones
-‐ 42 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü CDH: es el conjunto de elementos del núcleo de Hadoop. Es gratuito. Dentro del
paquete gratuito también se incluyen algunas herramientas de gestión:
Cloudera Manager.
4.2.1 CLOUDERA DISTRIBUTION OF HADOOP (CDH)
CDH es una distribución muy completa de Apache Hadoop y otros proyectos
relacionados. Está 100% licenciado por Apache y es capaz de unificar el
procesamiento batch, SQL interactivo, búsqueda interactiva y el control de acceso. Su
última versión es la 5.3.2 [16].
Además de proporcionar los elementos básicos de Hadoop – almacenamiento
escalable y computación distribuida – añade componentes como un interfaz de
usuario, seguridad o integración con una amplia gama de soluciones de hardware y
software.
Figura 24. Arquitectura de CDH [16]
CDH incluye elementos del núcleo de Apache Hadoop, además de muchos
proyectos de código abierto.
Las principales características de CDH son:

Análisis de las Distribuciones
-‐ 43 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü Flexibilidad: almacena cualquier tipo de información y la procesa con una
cadena de diferentes marcos de trabajo computacionales, incluyendo el
procesamiento batch, SQL interactivo, búsqueda de texto gratuita, aprendizaje
de máquinas y computación estadística.
ü Integración: se trata de una plataforma Hadoop completa y empaquetada.
ü Seguridad: es capaz de procesar y controlar datos confidenciales, así como
asegurar multitenencia.
ü Escalabilidad y extensibilidad: habilita una amplia gama de aplicaciones que
son escalables con cada negocio.
ü Alta disponibilidad: ejecuta las cargas de trabajo críticas de una forma
confiable.
ü Abierto: no pertenece a ningún proveedor.
ü Compatibilidad: se puede usar de forma simultánea a las herramientas de IT.
A continuación se presentan las últimas versiones que soporta CDH para las
herramientas del ecosistema de Hadoop [15].

Análisis de las Distribuciones
-‐ 44 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Herramienta Versión
soportada
Apache Hadoop 2.5.0
Apache Avro 1.7.6
Apache Flume 0.11.0
Apache HBase 0.98.6
HBase-‐Solr 1.5
Apache Hive 0.13.1
Hue 3.7.0
Cloudera Impala 2.1
Apache Mahout 0.9
Apache Oozie 4.0.0
Apache Pig 0.12.0
Cloudera Search 1.0.0
Apache Spark 1.2.0
Apache Sqoop 1.4.5
Apache Sqoop2 1.99.4
Apache Whirr 0.9.0
MongoDB 3.0.0
Apache Zookeeper 3.4.5
Tabla 3. Versiones herramientas Cloudera [15]
Aparte de soportar todas estas versiones, Cloudera ha desarrollado también
dos herramientas propias: Cloudera Impala y Cloudera Search.

Análisis de las Distribuciones
-‐ 45 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
4.2.1.1 Cloudera Impala
Cloudera Impala surge como respuesta a un vacío de Hadoop y las
herramientas de su entorno: Hive, al trabajar sobre MapReduce, no es una
herramienta ágil cuando se trata de bases de datos de un tamaño reducido y se
buscan respuestas en tiempo real.
Impala es una base de datos analítica completamente integrada, que ha sido
diseñada para aprovechar la flexibilidad y escalabilidad, punto fuertes de Hadoop.
Trabaja con el lenguaje SQL, que sí que permite realizar consultas en tiempo real. Por
otro lado, se beneficia de los metadatos de Hive, por lo que es compatible con sus
tablas y puede hacer consultas en bases de datos distribuidas [17].
No obstante, Impala no es un sustituto de Hive, sino que se complementan: los
datos se pueden almacenar en una tabla Hive y ser consultados con Impala, de forma
que se obtenga un sistema de procesado en tiempo real, es decir, mucho más rápido
que si se hace uso exclusivamente de Hive.
El funcionamiento de Impala se asemeja mucho al de cualquier herramienta
relacionada con Hadoop. Se tiene un servicio, denominado impalad, que se ejecuta en
todos los nodos. Cuando alguno de los nodos recibe una consulta, pasa a ser un nodo
coordinador: se encarga de distribuir la carga de trabajo sobre los otros nodos y
cuando recibe las respuestas parciales las unifica en una respuesta final.
Este funcionamiento puede ser monitorizado por un servicio adicional,
statestored, que almacena los estados de los nodos impalad para así distribuir la carga
de trabajo sin que se produzcan colapsos o se envíe trabajo a un nodo caído .
4.2.1.2 Cloudera Search
Search permite la búsqueda de forma escalable sobre los datos del clúster a
través de índices. Para esta indexación se apoya en el sistema de la herramienta Solr.
Sin embargo, realiza las búsquedas sobre texto directamente, sin importar que los

Análisis de las Distribuciones
-‐ 46 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
datos estén estructurados o no. Tampoco requiere de la implementación de código, lo
que sí ocurre con MapReduce, por lo que se disminuye el tiempo de respuesta [18].
4.2.2 CLOUDERA MANAGER
Es la herramienta de Cloudera encargada de administrar el clúster. Ofrece una
interfaz web que facilita la instalación del clúster, seleccionar los nodos y servicios y
permite realizar cualquier configuración y monitorización de forma visual para poder
así detectar cualquier fallo del sistema.
Figura 25. Servicios de Cloudera Manager [20]
En la imagen que se muestra aparecen los servicios que ofrece Cloudera
Manager, de los cuales se han destacado los que se ofrecen de forma gratuita.
4.2.3 CLOUDERA NAVIGATOR
Esta herramienta facilita la administración de los datos del clúster. Verifica los
accesos de los usuarios a los ficheros de HDFS en función de los permisos que éstos
presenten.
También sirve para la auditoría de datos al mantener un registro completo de
los accesos realizados, para así llevar un mayor control sobre los accesos y sus
consecuentes estadísticas o evolución [21].
Esta herramienta no se ofrece de forma gratuita.

Análisis de las Distribuciones
-‐ 47 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 26. Servicios de Cloudera Navigator [20]
4.3 MAPR
MapR es una empresa americana fundada en 2009 que desarrolla y vende
software derivado del proyecto Apache Hadoop. Participa en muchos proyectos como
HBase, Pig o Zookeeper.
Figura 27. Logo MapR [22]
Su principal desarrollo se centra en el proyecto Hadoop, de forma que han
desarrollado una plataforma que se presenta como tres ediciones para satisfacer las
diferentes necesidades de los clientes – M3, M5 y M7 – de forma que cada uno aporta
un mayor número de funcionalidades respectivamente: M3 contiene básicamente el
paquete del framework de Hadoop y sus correspondientes herramientas, y es la única
edición gratuita.
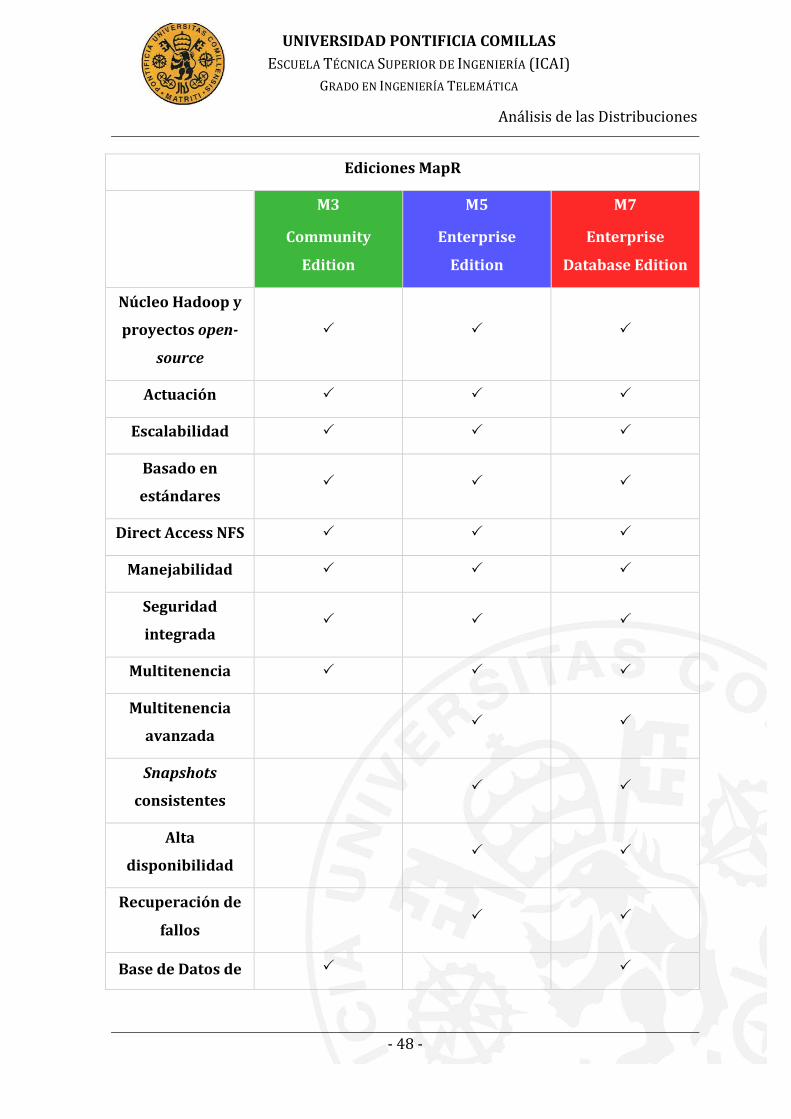
Análisis de las Distribuciones
-‐ 48 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Ediciones MapR
M3
Community
Edition
M5
Enterprise
Edition
M7
Enterprise
Database Edition
Núcleo Hadoop y
proyectos open-‐
source
P P P
Actuación P P P
Escalabilidad P P P
Basado en
estándares P P P
Direct Access NFS P P P
Manejabilidad P P P
Seguridad
integrada P P P
Multitenencia P P P
Multitenencia
avanzada P P
Snapshots
consistentes P P
Alta
disponibilidad P P
Recuperación de
fallos P P
Base de Datos de P P

Análisis de las Distribuciones
-‐ 49 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
MapR integrada
Soporte P P P
Soporte comercial P P
Soporte Drill P P
Soporte Spark P P
Soporte HBase P P
Soporte Solr P P
Soporte Impala P P
Cliente POSIX P P P
Tabla 4. Funcionalidades Ediciones MapR [22]
Independientemente de la edición con la que se trabaje, MapR trabaja con
algunas de las herramientas clásicas del ecosistema de Hadoop, entre las que se
encuentran las siguientes con sus correspondientes versiones:

Análisis de las Distribuciones
-‐ 50 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Herramienta Versión
soportada
Apache Hadoop 2.3.0
Hive 0.13.0
Pig 0.12.0
HBase 0.94.17
Sqoop 1.4.4
Flume 1.4.0
MongoDB 3.0.0
Oozie 4.0.0
Spark 0.9.0
Tez 0.4
Storm 0.9.0
Tabla 5. Versiones herramientas MapR [25]
Como innovación al Big Data, se aportan dos nuevas tecnologías: un sistema de
ficheros – MapR-‐FS –, la capa de acceso Direct Access NFS y el sistema de control de
nodos Heatmap.
4.3.1 MAPR-‐FS
MapR ha desarrollado un nuevo sistema de ficheros distribuido compatible
con HDFS, lo que permite que se trabaje con todas las herramientas de Hadoop y
solucionar algunos problemas inherentes simultáneamente.
La principal ventaja se observa en que es un sistema totalmente distribuido.
En el caso de HDFS existe un nodo que contiene todos los metadatos, nodo que en

Análisis de las Distribuciones
-‐ 51 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
este modelo ha desaparecido. Las ventajas que este sistema de ficheros ofrece son
varias, entre las que se puede destacar la tolerancia a fallos: si se cae un nodo, al
encontrarse los metadatos en todos ellos, se replicarán para no producir una caída en
el sistema. Otra ventaja destacable es que se mejora el rendimiento, ya que el nodo
maestro no produce cuellos de botella para los accesos a los ficheros [23].
4.3.2 DIRECT ACCESS NFS
MapR ha creado una capa de abstracción para facilitar el acceso a su sistema
de ficheros distribuido, MapR-‐FS.
Se trata de un estándar que permite utilizar el navegador de ficheros para
acceder a los datos del sistema de ficheros local, así como a las herramientas sin
necesidad de intermediarios [24].
4.3.3 HEATMAP
Heatmap es la herramienta de gestión de MapR que permite monitorizar y
controlar la actividad y estado de salud del clúster. Es muy sencilla de utilizar y
permite visualizar un gran número de nodos para controlar los posibles errores.
También se añaden algunas facilidades para la administración de los nodos
como conjunto, en lugar de tener que administrarlos de forma individual [25].
A continuación se presenta una imagen del gestor, donde se observa que es
muy intuitivo y sencillo.

Análisis de las Distribuciones
-‐ 52 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 28. MapR Heatmap [25]
4.4 COMPARATIVA
A continuación se va a realizar una comparativa de las tres distribuciones
estudiadas anteriormente. Esta comparativa se va a separar en distintas categorías:
herramientas de Hadoop, productividad, tolerancia a fallos, rendimiento y
administración. A parte de estas categorías también será importante destacar las
opiniones de los expertos, que realizan análisis que incluyen también muchos otros
campos.
4.4.1 COMPARATIVA DE HERRAMIENTAS
Se va a estudiar las versiones que soportan las distribuciones estudiadas de las
distintas herramientas. Para ello, se presenta la siguiente tabla comparativa.
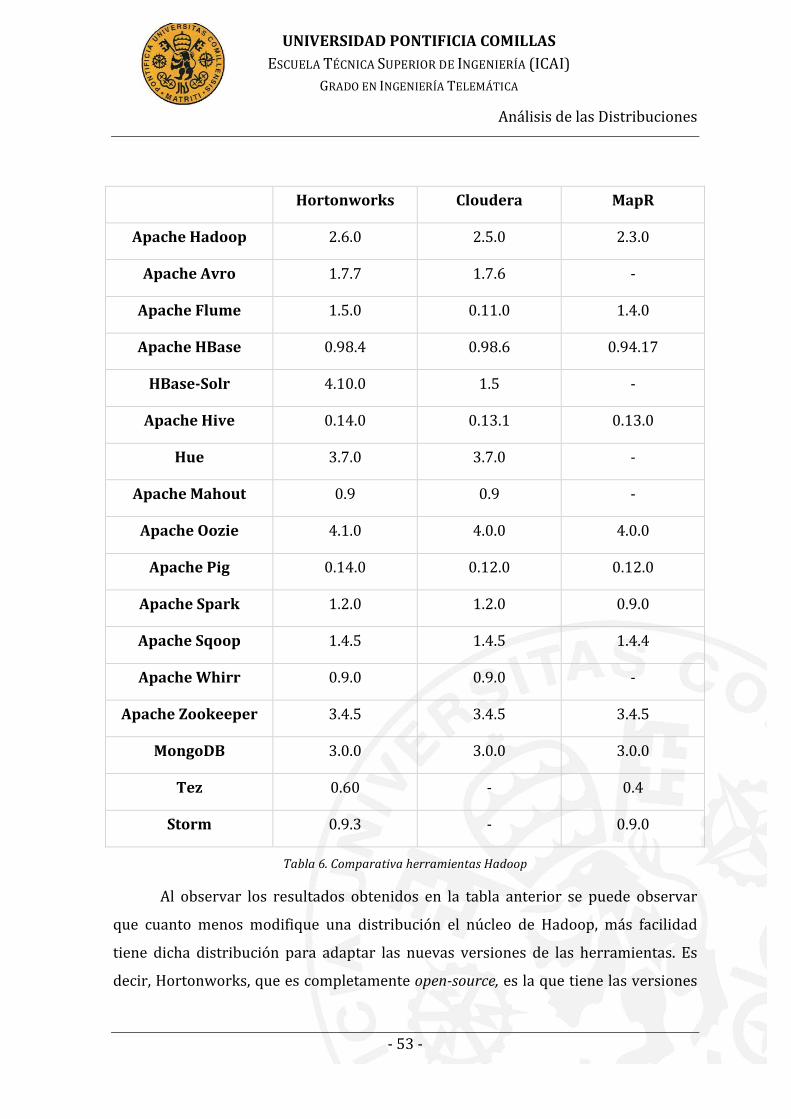
Análisis de las Distribuciones
-‐ 53 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Hortonworks Cloudera MapR
Apache Hadoop 2.6.0 2.5.0 2.3.0
Apache Avro 1.7.7 1.7.6 -‐
Apache Flume 1.5.0 0.11.0 1.4.0
Apache HBase 0.98.4 0.98.6 0.94.17
HBase-‐Solr 4.10.0 1.5 -‐
Apache Hive 0.14.0 0.13.1 0.13.0
Hue 3.7.0 3.7.0 -‐
Apache Mahout 0.9 0.9 -‐
Apache Oozie 4.1.0 4.0.0 4.0.0
Apache Pig 0.14.0 0.12.0 0.12.0
Apache Spark 1.2.0 1.2.0 0.9.0
Apache Sqoop 1.4.5 1.4.5 1.4.4
Apache Whirr 0.9.0 0.9.0 -‐
Apache Zookeeper 3.4.5 3.4.5 3.4.5
MongoDB 3.0.0 3.0.0 3.0.0
Tez 0.60 -‐ 0.4
Storm 0.9.3 -‐ 0.9.0
Tabla 6. Comparativa herramientas Hadoop
Al observar los resultados obtenidos en la tabla anterior se puede observar
que cuanto menos modifique una distribución el núcleo de Hadoop, más facilidad
tiene dicha distribución para adaptar las nuevas versiones de las herramientas. Es
decir, Hortonworks, que es completamente open-‐source, es la que tiene las versiones

Análisis de las Distribuciones
-‐ 54 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
más actualizadas en la mayor parte de las herramientas. También es la distribución
que soporta una mayor variedad de herramientas, si no se tienen en cuenta las
propias que desarrollan algunas distribuciones (Impala de Cloudera o Direct Access
NFS de MapR). Cloudera también soporta una gran cantidad de herramientas, muy
útiles
Aunque en la tabla no se menciona, se debe destacar que las tres
distribuciones soportan el nuevo gestor de recursos YARN. La relevancia de este
hecho reside en que las herramientas que se basen en YARN, podrán ser también
soportadas por estas distribuciones.
4.4.2 COMPARATIVA DE PRODUCTIVIDAD
En este apartado se van a analizar las capacidades que tienen las
distribuciones a la hora de tratar la información, su productividad. Esto es importante
porque hay algunas funcionalidades muy interesantes para las distintas fases del
tratamiento de Big Data.
Hortonworks Cloudera MapR
Análisis de datos
con interfaz gráfica Hue Hue -‐
Uso de HDFS como
sistema de ficheros Fuse DFS Fuse DFS Direct Access DFS
Buscador de
contenido -‐ Search -‐
Consultas de alta
capacidad -‐ Impala -‐
Tabla 7. Comparativa productividad

Análisis de las Distribuciones
-‐ 55 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Como se puede observar en la tabla, Cloudera es la distribución que más
herramientas ha desarrollado con el propósito de mejorar la productividad.
Cloudera ha desarrollado su propia herramienta de consultas interactivas,
Impala, que realiza las consultas prácticamente en tiempo real, mientras que el resto
realizan las búsquedas a través de MapReduce, basado en procesamiento batch,
perdiendo interactividad con el usuario.
También Cloudera es la única que ha desarrollado una herramienta de
búsqueda de contenido a través de índices, Search, que agiliza las consultas.
4.4.3 COMPARATIVA DE TOLERANCIA A FALLOS
En siguiente lugar se va a analizar la tolerancia a fallos que tienen las
distribuciones. Esto es, en caso de ocurrir un fallo, qué distribución es la que tiene un
sistema de recuperación más efectivo o que produce menos pérdidas.
Hortonworks Cloudera MapR
Alta disponibilidad
(HA) de HDFS NameNode NameNode No utiliza HDFS
Replicación de
MapReduce JobTracker JobTracker
JobTracker
mejorado
Anulación de puntos
de entrada únicos -‐ -‐ MapR-‐FS
Mirroring -‐ -‐ Copias de ficheros
y HBase
Snapshots Snapshots HDFS Snapshots HDFS
Snapshots del
sistema de
ficheros y HBase
Tabla 8. Comparativa tolerancia a fallos

Análisis de las Distribuciones
-‐ 56 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Como se puede observar, MapR es la distribución que más se ha ocupado de
solventar los problemas que surgen cuando se producen fallos del sistema. Ha
conseguido esto mediante la eliminación de puntos de entrada únicos de errores del
sistema de ficheros gracias a que se trata de un fichero completamente distribuido,
sin hacer uso de un NameNode.
También permite realizar Mirroring y Snapshots, es decir, copias de los
ficheros en un sistema diferente y capturas del estado en el que se encuentran.
4.4.4 COMPARATIVA DE RENDIMIENTO
En la comparativa de rendimiento, quedarán indicadas qué distribuciones son
mejores a la hora de realizar análisis a mayor velocidad, ya sea por el lenguaje de
bases de datos que se utiliza o por la velocidad de acceso al sistema de ficheros. Se ha
tenido en cuenta mayoritariamente el rendimiento a la hora de realizar las consultas
y acceder a los datos almacenados, ya que se considera que son las fases más críticas
en lo referido al rendimiento, ya que luego la fase de análisis no produce diferencias
demasiado relevantes.
Hortonworks Cloudera MapR
Consultas SQL a
través de Hive y Pig Stinger -‐ -‐
Consultas SQL -‐ Impala -‐
Acceso a ficheros en
almacenamiento -‐ -‐ Direct Access NFS
Recolección de
muchos datos
paralelamente
Sqoop Sqoop Sqoop
Tabla 9. Comparativa rendimiento

Análisis de las Distribuciones
-‐ 57 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
En esta categoría se puede remarcar Stinger, proyecto de Hortonworks que
produce mejoras sobre Hive, aportándole mayor velocidad, escalabilidad aun así
permitiendo las consultas SQL.
También es importante el proyecto Impala que permite las consultas
interactivas, que son lo más parecido a las consultas en tiempo real.
El ya mencionado NFS de MapR acelera el acceso al sistema de ficheros
también muy útil a la hora de tener en cuenta el rendimiento de una distribución.
4.4.5 COMPARATIVA RESUMEN
Por último se presenta una tabla que resume por encima todas las
características básicas de las tres distribuciones.
HORTONWORKS CLOUDERA MAPR
Actuación y escalabilidad
Recolección de
datos Batch Batch
Batch y en tiempo
real
Consultas Batch Tiempo real Batch
Arquitectura de
metadatos Centralizada Centralizada Distribuida
Actuación de
HBase Picos de latencia Picos de latencia
Latencia baja y
consistente
Aplicaciones
NoSQL
Sobretodo
aplicaciones batch
Sobretodo
aplicaciones batch
Aplicaciones batch
y en tiempo real
Dependencia
Alta Recuperación de un Recuperación de un Autocorrección

Análisis de las Distribuciones
-‐ 58 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
disponibilidad único fallo único fallo para múltiples
fallos
MapReduce HA Reinicia los
trabajos Reinicia los trabajos
Continúa sin
reiniciarse
Actualización En tiempo de
inactividad Liberación continua
Liberación
continua
Replicación Datos Datos Datos y metadatos
Copia
instantánea de
volumen
Consistente sólo
para ficheros
cerrados
Consistente sólo
para ficheros
cerrados
Consistente
puntualmente para
todos los ficheros y
tablas
Recuperación de
desastre No
BDR – Copia de
ficheros Mirroring
Manejabilidad
Herramientas de
gestión Ambari Cloudera Manager MapR Heatmap
Soporte de
volumen No No Sí
Heatmap,
alarmas, alertas Sí Sí Sí
Integración con
la API REST Sí Sí Sí
Control de datos
y de trabajo No No Sí
Acceso de datos

Análisis de las Distribuciones
-‐ 59 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Acceso al
sistema de
ficheros
HDFS, NFS sólo en
lectura
HDFS, NFS sólo en
lectura
HDFS, NFS para
lectura y escritura
(POSIX)
Fichero I/O Sólo anexado Sólo anexado Lectura/escritura
ACL para
seguridad Sí Sí Sí
Tabla 10. Comparativa general [3]
Con esta tabla se puede observar de forma general las ventajas y desventajas
de cada una de las distribuciones que se han analizado. Con ella, una vez se presenten
las conclusiones generales, será más sencillo hacerse una idea completa de qué
conceptos son los que aporta cada distribución.
4.4.6 OTRAS COMPARATIVAS
También existen otra serie de factores a tener en cuenta a la hora de
seleccionar la distribución de código abierto con la que se va a trabajar.
Por ejemplo, se debe destacar que las plataformas de Cloudera (CDH) y la de
MapR sólo se pueden implementar en Linux, mientras que Hortonworks, con DHP, se
puede utilizar con Linux y con Windows Server.
También es importante destacar la presencia en el mercado de las
distribuciones. Cloudera es la distribución que lleva mayor tiempo en el mercado y
por lo tanto la más conocida. Esto influye en la comunidad existente, que respalda la
solución y por lo tanto habrá más información y más soporte. En los casos de
Hortonworks y MapR, no se trata de distribuciones tan implantadas en el mercado,
aunque son de las más importantes debido a sus grandes avances que están
realizando recientemente.

Análisis de las Distribuciones
-‐ 60 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Otro aspecto a tener en cuenta es el resultado de los estudios realizados por
empresas como Gartner. Acudiendo al estudio publicado recientemente acerca de las
soluciones de Data Warehouse y Data Management para el análisis, se puede observar
que aparecen varias soluciones, tanto de código abierto como de propietarios. En el
campo de las distribuciones a estudiar, las open-‐source, se observa que aparecen
tanto Cloudera como MapR dentro del cuadro de los “challengers”, donde se
encuentran los vendedores con un mercado significativo que aún tienen que madurar
en sus casos de uso para poder expandirse. Dentro de este cuadro, Cloudera ha
realizado un cambio significativo ya que ha avanzado desde el sector de los
vendedores de nicho a los challengers. MapR se ha introducido por primera vez en
este cuadro.
En el informe aparece también una lista de otros vendedores a tener en cuenta,
en la que aparece también Hortonworks, ya que al participar en la iniciativa Stinger,
se está desarrollando muy rápidamente. A continuación se presenta el cuadrante
mágico del informe mencionado anteriormente.
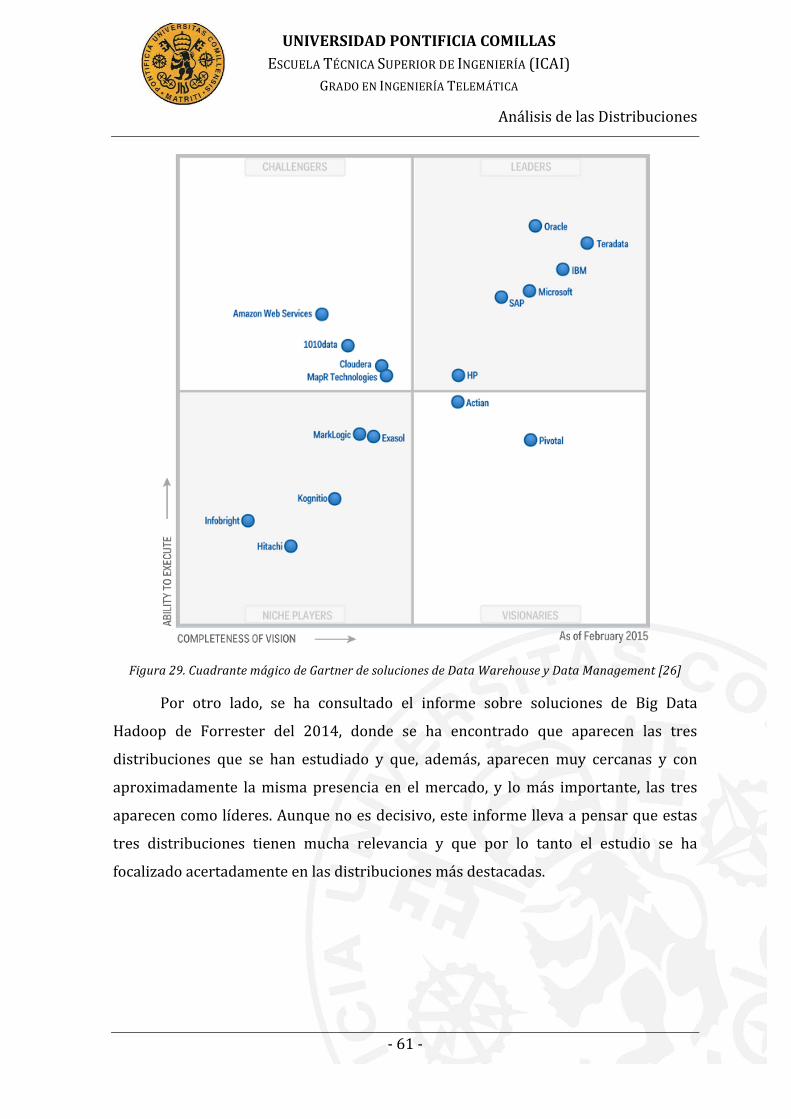
Análisis de las Distribuciones
-‐ 61 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 29. Cuadrante mágico de Gartner de soluciones de Data Warehouse y Data Management [26]
Por otro lado, se ha consultado el informe sobre soluciones de Big Data
Hadoop de Forrester del 2014, donde se ha encontrado que aparecen las tres
distribuciones que se han estudiado y que, además, aparecen muy cercanas y con
aproximadamente la misma presencia en el mercado, y lo más importante, las tres
aparecen como líderes. Aunque no es decisivo, este informe lleva a pensar que estas
tres distribuciones tienen mucha relevancia y que por lo tanto el estudio se ha
focalizado acertadamente en las distribuciones más destacadas.

Análisis de las Distribuciones
-‐ 62 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 30. Forrester Wave sobre soluciones Big Data Hadoop [27]
4.4.7 CONCLUSIONES
Con el estudio realizado, se ha observado que las tres distribuciones en
cuestión tienen sus pros y sus contras.
No obstante, a la hora de discernir cuál se va a utilizar para implementar un
caso de uso específico, se ha tenido muy en cuenta la productividad de la distribución,
que será fundamental para poder realizar las pruebas deseadas. Como se trata de un
estudio a pequeña escala para aprender los posibles usos de esta tecnología que está
en auge, no se ha tenido muy en cuenta la tolerancia a fallos ni las herramientas que
son soportadas por la distribución, ya que son características que no son
especialmente determinantes. Sin embargo, si se tratase de un entorno mayor o con

Análisis de las Distribuciones
-‐ 63 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
datos más críticos, sí que se tendrían que tener más en cuenta las otras
características.
También es destacable en la decisión la presencia en el mercado de la
distribución, ya que al aplicar la distribución en la empresa, se hará uso de este
tratamiento de información con los clientes que lo precisen, y por lo tanto será
necesario hacer uso de una plataforma que sea útil para todas estas empresas.
Atendiendo a estas decisiones, en las que se valora la importancia de cada
factor, se ha llegado a la conclusión de que la distribución que mejor se ajusta a estos
requisitos es Cloudera, por lo que se hará uso de su plataforma CDH para probar el
caso de uso.

Análisis de las Distribuciones
-‐ 64 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

Diseño de la plataforma
-‐ 65 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 5 DISEÑO DE LA PLATAFORMA
En siguiente lugar se va a describir el caso de uso que se va a implementar,
obtenido de la lista de escenarios definidos en el proyecto de Natalia Lizaso, “Análisis
de soluciones para la implementación de una plataforma Big Data”. Para ello, será
necesario especificar la arquitectura sobre la que se apoyará la plataforma a emplear
de Cloudera, CDH, y a continuación se definirá el uso que se hará de la plataforma,
donde se incluirán las herramientas necesarias para el completo tratamiento de la
información.
Este escenario específico se ha considerado óptimo para situaciones en las que
se busca una solución bien posicionada en el mercado y con una amplia experiencia.
Para la implementación del sistema se han planteado dos posibles soluciones:
la primera que se va a desarrollar es la que se debería desarrollar en un entorno de
trabajo real, haciendo uso de varios nodos hospedados en servidores físicos, y un
entorno de laboratorio, en el que se hará uso de un único nodo y es el que se
empleará para el proyecto.
5.1 DESCRIPCIÓN DEL CASO DE USO
Como se ha comentado, el caso de uso que se va a desarrollar está basado en el
proyecto “Análisis de soluciones para la implementación de una plataforma Big
Data”.
Este escenario se considera óptimo para aquellas empresas que buscan una
solución bien posicionada en el mercado, lo que aporta grandes beneficios a la
empresa en cuestión. Esto se debe a que estas soluciones tienen por detrás un gran
respaldo en lo referido a herramientas a emplear, así como una gran comunidad a la

Diseño de la plataforma
-‐ 66 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
que se puedan realizar consultas. Es por tanto que se selecciona la distribución open-‐
source Cloudera, ya que está considerada por los expertos como una de las mejores
distribuciones, ya sea por su rendimiento, por su gran capacidad para dar soporte a
los usuarios y por la gran cantidad de herramientas propias de Hadoop con las que es
compatible.
Para la realización de este proyecto se considera de gran utilidad este
escenario, puesto que se va a desarrollar una plataforma que analice datos de las
redes sociales.
Dentro de las redes sociales más conocidas, como pueden ser Facebook,
Instagram o Twitter, se ha decidido seleccionar esta última debido a que ofrece una
API que permite descargar datos de dicha red social para poder trabajar con ellos
[30].
Entre las varias opciones que presenta esta API, como puede ser el acceso a
una cuenta en función del usuario, de forma que se puedan ver los usuarios o los
seguidores, se encuentra la que se va a desarrollar en este proyecto.
Se trata de buscar tweets que contengan un determinado hashtag. Con ello se
podrá analizar la evolución de dicho hashtag en función del tiempo, determinando
por ejemplo el número de tweets que se generan en función de la franja horaria.
Este análisis permitirá extraer conclusiones acerca del uso de la red social en
función del hashtag.
Para reducir el número de tweets que puedan salir, y conseguir así un análisis
más rápido, se filtrará la localización de dichos tweets en función de coordenadas que
cerrarán la región a tener en cuenta, que en este caso será el territorio español (sin
tener en cuenta los archipiélagos, pero sí Portugal).

Diseño de la plataforma
-‐ 67 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
5.2 ENTORNO DE TRABAJO REAL
Para este entorno de trabajo será necesario definir, en primer lugar, la
arquitectura, o el entorno en el que se desarrollará la plataforma, especificando los
componentes hardware y software que se emplean para el desarrollo.
ü El ordenador portátil del que se hace uso, en el que se realiza el desarrollo de
los componentes, con sistema operativo Windows. Como para hacer uso de la
distribución Cloudera es necesario utilizar Linux, se instala en el equipo una
máquina virtual Linux, en su versión CentOs.
ü En el servidor se instala una plataforma de virtualización, que permite
hospedar los nodos del sistema. Esta plataforma es la propia de VMWare
Player.
ü En esta virtualización se hospedarán los nodos, que serán máquinas virtuales,
con sistema operativo Linux Ubuntu, ya que se trata de un sistema operativo
compatible con Cloudera. Estos nodos son clones de la máquina virtual que se
tiene en el ordenador portátil.
ü Como Hadoop se basa en una arquitectura maestro-‐esclavo, en la que existe un
nodo maestro que se encarga de distribuir la carga de trabajo entre los nodos
esclavos, será necesario que haya un nodo que sea maestro, realizando los
servicios de NameNode de HDFS y Job Tracker en MapReduce. El resto de
nodos serán esclavos, o nodos de trabajo, por lo que se ejecutarán en modo
esclavo, DataNode y TaskTracker. El número de estos nodos será tres, para
poder comprobar el funcionamiento de esta arquitectura. Las máquinas
virtuales mencionadas anteriormente serán las que hagan las funciones de los
distintos nodos. El número de nodos esclavos dependerá de las necesidades
del cliente, buscando siempre el punto óptimo en cuanto a rendimiento.
ü Para gestionar y administrar los nodos que se hospedan en el servidor, se hace
uso de la aplicación Virtual Infrastructure Client, propia de VMWare con una
interfaz gráfica que facilita el proceso. Permite conectarse al servidor,

Diseño de la plataforma
-‐ 68 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
administrar el estado de las máquinas virtuales y acceder a la consola. Este
software se instalará en el ordenador portátil en cuestión.
5.3 ENTORNO DE TRABAJO DE LABORATORIO
Para desarrollar el entorno de trabajo de prueba, se define una arquitectura de
laboratorio, en la que únicamente será necesario un nodo que haga las funciones de
maestro y esclavo, por lo que no es necesario hacer uso de servidores que hospeden
máquinas virtuales.
Para poder hacer uso de la distribución Cloudera, se deberá instalar en un
ordenador que tenga el sistema operativo Windows, la máquina virtual de dicha
distribución, en la que se deberán instalar además las herramientas que se necesiten
emplear.
La máquina virtual que se emplea tiene el sistema operativo Linux, cuya
distribución es CentOs 6.4. Esta máquina virtual permitirá hacer uso del nodo del que
se hará uso para el correcto tratamiento de la información.
5.4 DISEÑO DE LA PLATAFORMA
Una vez se tiene instalada la infraestructura anterior, se puede proceder al
diseño de la plataforma que permita obtener, almacenar y hacer uso de los datos en
cuestión.
Para ello, se debe definir qué herramientas se van a emplear para realizar el
tratamiento completo de la información. Estas herramientas, como se menciona
anteriormente, se distinguen en varias categorías. Será necesario cubrir todas las

Diseño de la plataforma
-‐ 69 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
categorías, seleccionando las herramientas que sean compatibles con Cloudera y que
sean óptimas para el caso a desarrollar.
Las herramientas que se han seleccionado han sido las siguientes:
ü Flume. Se trata de un servicio distribuido, confiable y disponible para colectar,
agregar y mover eficientemente grandes cantidades de datos de una fuente
hacia alguna otra localidad, en este caso a Hadoop. Tiene una arquitectura
simple y flexible, basada en streaming. Es una herramienta robusta y tolerante
a fallos, con mecanismos configurables y de recuperación [5]. Es la
herramienta que se utilizará para la recolección de los datos.
Figura 31. Logo Flume [5]
ü HDFS. Es el sistema de almacenamiento propio de Hadoop, y se trata de un
sistema de almacenamiento distribuido en ficheros que trata de optimizar el
posterior tratamiento que se quiera realizar de la información [2]. Por lo
tanto, esta herramienta se empleará para almacenar los datos obtenidos
mediante Flume.
Figura 32. Logo HDFS

Diseño de la plataforma
-‐ 70 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü MapReduce. Como se ha mencionado anteriormente, MapReduce es un job
tracker que permite reducir las grandes masas de información a un volumen
muy inferior para poder realizar consultas mucho más rápidas y eficientes.
Esta herramienta permitirá que se realicen los análisis a mayor velocidad [2].
ü Hive. Es un software de Apache que facilita la búsqueda y gestión de grandes
cantidades de datos alojados en un almacén distribuido. Provee un mecanismo
para proyectar una estructura en unos datos, a través de un lenguaje similar a
SQL, HiveQL [6]. Se trata por tanto de un lenguaje que da soporte al
almacenamiento.
Figura 34. Logo Hive [6]
ü Finalmente, para mostrar la visualización de datos se hará uso de la
herramienta desarrollada por Tableau, que ofrece una interfaz sencilla e
intuitiva que ofrece gráficos estadísticos acerca de los datos que han sido
analizados [7]. Esta herramienta será especialmente interesante puesto que es
la que mejor conecta con la distribución Cloudera.
Ilustración 33. Logo MapReduce

Diseño de la plataforma
-‐ 71 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 35. Logo Tableau [7]
Por lo tanto, con las herramientas seleccionadas, se puede realizar un análisis
completo de la información.
En el siguiente diagrama se muestra cómo se relacionan las diferentes
herramientas que conforman el sistema, indicando así el flujo que tendrán los datos.
Como se puede observar, los datos se extraerán de Twitter, que ofrece, con una
API REST, acceso a sus datos, de forma que estos se puedan descargar y trabajar con
ellos. Estos tweets se descargan a través de la herramienta Flume, que los almacena
en el sistema de ficheros HDFS.
Figura 36. Flujo de la información

Diseño de la plataforma
-‐ 72 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
En siguiente lugar, los datos se procesarán con MapReduce, que permitirá
obtener una información mucho más simplificada y reducida para que se puedan
realizar consultas lo más óptimas posible con la herramienta Hive, que posee su
propio lenguaje de consultas, que enviará a la herramienta de visualización Tableau
los datos que se deben representar.
Finalmente, gracias a Tableau, se podrán representar una serie de tablas y
estadísticas sobre la información que se descargó inicialmente. Estos gráficos
permitirán obtener conclusiones para así poder buscar posicionarse mejor en el
entorno de las redes sociales, que es el caso de uso que se busca con este análisis de la
información.

Implementación de la plataforma
-‐ 73 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 6 IMPLEMENTACIÓN DE LA PLATAFORMA
A continuación se procede a realizar la implementación de la plataforma
propuesta. Una vez instalado todo el software en el equipo, se procede a recolectar los
tweets para poder realizar el análisis de la información, siguiendo el esquema de la
arquitectura propuesta para Big Data, y haciendo uso de las herramientas
especificadas.
Antes de empezar la implementación, es necesario conocer el entorno de la
máquina virtual con la que se va a trabajar, así como las ventajas que ésta ofrece.
Como se comentó en la descripción de la distribución Cloudera, ésta ofrece un
servicio de gestión denominado Cloudera Manager, gracias al cual se pueden
gestionar todas las herramientas que son compatibles.
Se trata de una interfaz gráfica que permite controlar los nodos con los que se
trabajan en el caso de una implementación multi-‐nodo, así como el estado de los
nodos de las herramientas. En la imagen que se muestra a continuación se pueden
observar las diferentes herramientas que se pueden controlar desde Cloudera
Manager.

Implementación de la plataforma
-‐ 74 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 37. Servicios que gestiona Cloudera Manager
Como se puede observar, en el clúster sólo existe un host, mientras que se
están ejecutando dos procesos de HDFS y uno de Zookeeper. A la izquierda de cada
herramienta aparece el estado en el que se encuentra cada servicio, donde se puede
ver que algunos están parados y otros están esperando a que se acabe de inicializar el
sistema.
6.1 RECOLECCIÓN DE DATOS
La información, procedente de las redes sociales, en este caso Twitter, se va a
recopilar con la herramienta Flume. Esta herramienta, como se mencionó
anteriormente, es de gran utilidad para este caso en particular, ya que a través de una

Implementación de la plataforma
-‐ 75 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
API REST que proporciona la red social Twitter, permite conectarse directamente con
el sistema a emplear en el almacenamiento (HDFS), y volcarlo de una forma muy
sencilla.
Esta herramienta se basa en los siguientes componentes:
ü Los componentes de Flume se ejecutan en un agent, un proceso Java
encargado de almacenar el resto de componentes de Flume, que se lanza para
realizar la funcionalidad que se haya configurado.
ü La información que fluye por el sistema de Flume se denomina event. Es la
carga útil básica de los datos que se transportan. Están formados por el cuerpo
y una serie de cabeceras, que son opcionales e indican decisiones de
enrutamiento u otra información estructurada.
ü El source es el origen del que se extraen los datos, por donde van a entrar los
datos en Flume. Existe una gran variedad de fuentes, pero están limitadas, ya
que el sistema debe entender el tipo de event que se recibe.
ü El área en el que esperan los eventos al salir del source se denomina channel.
Se trata de un almacenamiento temporal para que el componente anterior,
source, y el siguiente, sink, puedan funcionar asíncronamente. Hay dos tipos:
en memoria, que implica que los eventos se almacenan en la memoria
principal, haciéndola más rápida que un disco; y en archivos, que es más lento
pero proporciona un almacenamiento más duradero. Para este caso se
empleará el canal de memoria.
ü El sink es el componente que recibe los eventos del channel. Flume soporta
varios destinos, siendo el más típico el sistema de ficheros distribuido propio
de Hadoop, HDFS. Por lo tanto, su función es volcar los eventos que entran en
el source y se almacenan en el channel sobre un archivo HDFS. Para hacer el
sistema de tratamiento Big Data más eficiente, estos datos se almacenarán en
ficheros de gran tamaño.

Implementación de la plataforma
-‐ 76 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
6.1.1 CONFIGURACIÓN
En siguiente lugar se presentan las partes más relevantes de la configuración
del agente de Flume:
ü En primer lugar se definen los nombres del source, del channel y del sink de este agente en concreto.
twitterAgent.sources = s1 twitterAgent.channels = c1 twitterAgent.sinks = k1
ü Es importante definir el tipo de fuente. Puesto que los datos provienen de
Twitter, será importante establecer la ruta en la que se encuentra el medio de descarga. Esta ruta viene dada por el archivo de java (.jar) en el que se encuentran las librerías de la herramienta. Para tener acceso a datos de Twitter, es necesario crear una aplicación de desarrollador a partir de un usuario de la red social. Esta aplicación aporta al usuario 4 claves secretas que serán necesarias en la propia configuración del agente para permitir dicho acceso (Consumer key, Consumer secret, Access token y Access token secret). Al configurar la fuente se establecen los criterios de búsqueda que se han definido para este caso de uso. En este caso particular se deberán definir unas coordenadas geográficas que limiten el territorio, así como una palabra clave, que será el hashtag de búsqueda de los tweets. También se definen otras características de menor relevancia, como el tamaño de los ficheros de descarga.
twitterAgent.sources.s1.type = com.cloudera.flume.source.TwitterSource
twitterAgent.sources.s1.channels = c1
twitterAgent.sources.s1.consumerKey = <consumer_key>
twitterAgent.sources.s1.consumerSecret = <consumer_secret>
twitterAgent.sources.s1.accessToken = <access_token>
twitterAgent.sources.s1.accessTokenSecret = <access_token_secret>
twitterAgent.sources.s1.keywords = #vacaciones
twitterAgent.sources.s1.swLngLat = -10.129395, 35.790526
twitterAgent.sources.s1.neLngLat = 3.823242, 43.321181

Implementación de la plataforma
-‐ 77 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü En lo referido al canal, tal y como se comentó anteriormente, se define del tipo memoria, indicando además la capacidad que tendrá este canal.
twitterAgent.channels.c1.type=memory twitterAgent.channels.c1.capacity = 10000 twitterAgent.channels.c1.transactionCapacity = 100
ü Finalmente se definirán las características propias del destino en el que se
almacenará la información. Este destino es de tipo HDFS, por lo que se deberá especificar la ruta de destino y algunos otros atributos, como el tipo de fichero del que se trate o el formato en el que se guardará la información.
twitterAgent.sinks.k1.type=hdfs twitterAgent.sinks.k1.channel=c1 twitterAgent.sinks.k1.hdfs.path=/user/cloudera/flume/tweets/%{file} twitterAgent.sinks.k1.hdfs.filePrefix=tweets twitterAgent.sinks.k1.hdfs.fileType=DataStream twitterAgent.sinks.k1.hdfs.writeFormat=Text
6.1.2 EJECUCIÓN
Para ejecutar el agente de Flume se debe ejecutar el siguiente comando, que se
explicará por partes en siguiente lugar.
flume-ng agent -–conf /home/cloudera/ -n twitterAgent –f
/home/cloudera/Agent.conf –Dflume.root.logger=INFO,console
Se observa que se lanza un agente de Flume, cuyo fichero de configuración se
encuentra en la carpeta indicada con ––conf, el nombre del agente que se ejecuta
viene indicado con –n y el fichero en cuestión se referencia con el indicador –f.
Finalmente se añade una indicación para mostrar por la consola información de
proceso.

Implementación de la plataforma
-‐ 78 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
6.2 ALMACENAMIENTO DE DATOS
Para el almacenamiento de los datos se emplea la herramienta HDFS, Hadoop
Distributed File System, es decir, un sistema de ficheros distribuido.
El uso de este sistema es transparente, puesto que no se puede ver cómo
almacena este sistema los ficheros ni los módulos que crea. No obstante, se sabe cómo
es el sistema en sí, teniendo un nodo maestro y varios nodos esclavos que almacenan
los ficheros en partes, de forma que cada parte irá a un nodo diferente, gestionado
por el maestro.
Aún así, gracias al sistema Hadoop, sí que se puede acceder a través del
navegador al sistema de archivos para visualizar qué contenidos se encuentran
almacenados en la ruta que se ha especificado en la configuración del agente de
Flume, como se muestra en la siguiente imagen. El acceso se realiza a través de la URL
localhost:50070/explorer.html/, que muestra las carpetas existentes.
Figura 38. Sistema de ficheros HDFS
Como se menciona en el apartado de recolección de datos, se buscarán ficheros
de gran tamaño para que el sistema sea lo más eficiente posible, si bien este
parámetro se define en la configuración de dicha herramienta.

Implementación de la plataforma
-‐ 79 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Por lo tanto, se considera que los ficheros están almacenados de la forma más
eficiente posible y que se puede acceder a dichos datos de una forma muy sencilla
para trabajar con ellos; sólo es necesario acceder a través de la ruta en la que se
encuentran almacenados. Para trabajar con estos datos, Hadoop se basa en los
comandos de Linux, como –cp para copiarlos o -‐rm para borrarlos.
6.3 PROCESAMIENTO DE DATOS
En este caso, los datos no requieren de un análisis de gran profundidad,
aunque se considera que para trabajar lo más rápidamente posible, se deben procesar
con un sistema de MapReduce. Por lo tanto, los datos se procesan para verse
reducidos.
Un sistema MapReduce funciona a partir de un par de datos: una clave y un
valor. El propósito de esta herramienta es por tanto obtener los datos en el siguiente
formato:
(clave, valor)
En este caso en particular, la clave corresponde a la fecha de creación del tweet
y su hora en un formato que más adelante nos permita ordenarlo y hacer los filtros
oportunos, mientras que el valor representará el número de repeticiones que se
obtenga para dicha clave.
Por lo tanto, un ejemplo que se obtendrá de este proceso será el siguiente:
(09-‐07-‐15 12:30:00, 6)
De donde se interpreta que se han escrito 6 tweets el día 9 de julio de 2015 a
las 12:30 de la mañana, siempre teniendo en cuenta las restricciones geográficas y el
hashtag que se han utilizado como filtro.
La herramienta MapReduce se basa en un código Java que consta de tres
clases:

Implementación de la plataforma
-‐ 80 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ü Driver. Esta clase se encarga de asignar las funcionalidades que realizarán el
proceso de reducción de la información. Es decir, indica qué clase es la
encargada de realizar el mapeo y qué clase reduce el mapeo realizado, así
como otras funcionalidades que se explicarán en más detalle en el apartado de
configuración
ü Mapper. Esta clase, como se ha mencionado, es la encargada de mapear la
información. Es decir, acude al sistema de ficheros en el que están
almacenados los tweets para
ü Reducer. Esta clase es la encargada de coger los pares y reducirlos. En este
caso es muy sencillo, puesto que únicamente tiene que encontrar los que
tienen el primer valor igual e ir sumando aquellos que sean iguales para
obtener el valor total.
6.3.1 CONFIGURACIÓN
En este apartado se comentarán las partes más destacables del código Java del
MapReduce.
ü En el caso de la configuración del Driver, se definirán las clases Mapper y Reducer en sus respectivos campos.
job.setMapperClass(MiMapper.class); job.setReducerClass(MiReducer.class);
Es importante también definir el fichero del que se van a extraer los datos, así como el fichero de destino donde se almacenarán. Estos datos se introducen por línea de comandos al ejecutar el código, por lo que se tienen en cuenta los argumentos introducidos.
FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
También se pueden definir otra serie de funcionalidades, como el número de procesos que se van a utilizar para reducir los datos. En este caso particular se

Implementación de la plataforma
-‐ 81 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
definirán 2, ya que el procesamiento que se va a realizar no es sobre una cantidad demasiado extensa de datos y será un valor suficiente. Más adelante, cuando se observen los resultados de este proceso, se observará que efectivamente se han creado dos ficheros diferentes, cada uno correspondiente a un proceso.
job.setNumReduceTasks(2);
También se deberá definir el formato de las claves y valores con los que se va a trabajar en el proceso de mapeo y reducción, que en este caso será Text para la clave e IntWritable para el valor.
job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
ü Para la configuración del Mapper se debe destacar la existencia de una función
map(), que es la encargada de obtener la información en el formato que entiende MapReduce, con la clave y el valor. En primer lugar, como los datos descargados de Twitter se encuentran en formato JSON, se deberá definir un objeto de este tipo, incluyendo con ello las librerías oportunas, que se descargarán aparte. Gracias a este objeto JSON se puede acceder a todos los campos que contiene, entre ellos “created_at”, que es la fecha de creación de cada tweet, el que será necesario.
JSONObject json = new JSONObject(line); … String date = json.getString("created_at");
Como el formato de la fecha que proporciona Twitter es del tipo “Wed Jul 09
12:38:04 +0000 2015”, y no es el que se necesita, se creará una función que
transformará dicha fecha en la que se necesita (09-‐07-‐15 12:38:04), si bien
como los segundos no son necesarios para analizarlos, se igualarán a cero.
Finalmente, se escribe en el contexto del proceso MapReduce cada clave con
valor 1.
context.write(new Text(clave), new IntWritable(1));

Implementación de la plataforma
-‐ 82 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Esta función map() se ejecuta una vez por cada línea del fichero del que está
leyendo, por lo que se crearán tantas claves como líneas haya, y en este caso
cada línea corresponde a un tweet.
ü Finalmente, la configuración del Reducer debe realizar una suma de todos
aquellos pares que tengan la misma clave. Para ello, con la función reduce(), se
define un bucle que se encarga de sumar todos los pares que tengan la misma
clave, introduciendo el valor obtenido en el segundo elemento del par. for (IntWritable value : values) wordCount += value.get(); context.write(key, new IntWritable(wordCount));
Como se puede observar, los datos se reciben como un objeto Iterable, por lo
que se puede recorrer el vector sin ningún problema.
Finalmente también se escribirán los resultados en el contexto, que es el que
se encarga de copiarlos en último lugar en el sistema de ficheros HDFS de
nuevo, si bien en una ruta diferente.
6.3.2 EJECUCIÓN
Para lanzar el proceso MapReduce será necesario instalar previamente Maven, herramienta de software desarrollada por Apache que sirve para gestionar y construir proyectos Java a partir de un POM (Proyect Object Model), fichero XML que describe el proyecto de software a construir [32]. Gracias a este proyecto resulta mucho más sencillo construir el proyecto y así poder ejecutarlo. Para instalar esta herramienta será necesario ejecutar el siguiente comando dentro de la carpeta donde se encuentra el proyecto:
mvn install
Una vez se ha instalado la herramienta, será necesario construir el proyecto,
indicándole el fichero de entrada, donde están los datos guardados en el HDFS, y el

Implementación de la plataforma
-‐ 83 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
fichero de destino donde se almacenarán una vez se hayan procesado, que también
será el sistema de ficheros. El comando para ejecutarlo será el siguiente:
hadoop jar target/hadoop-java-mrdp-0_wordcount-0.1-job.jar /user/cloudera/flume/tweets/* /user/cloudera/flume/tweets/output/wordcount
Como se puede observar, de entrada se cogen todos los ficheros existentes en
esa ruta, puesto que se analizarán todos los datos descargados de Twitter.
6.4 CONSULTA DE DATOS
Si bien no se trata de una categoría de herramientas que se haya definido, es
fundamental definir una herramienta, que se ha considerado de almacenamiento,
para la consulta.
Una vez que los datos se han reducido y se pueden consultar de una forma
mucho más sencilla, será necesario realizar las consultas oportunas para poder
visualizar los resultados.
Para ello, se emplea la herramienta Hive, que proporciona un lenguaje de
consulta similar al SQL pero aplicable a información desestructurada, llamado
HiveQL.
Hive es un almacén de datos y paquete de análisis de código abierto que se
ejecuta por encima de Hadoop. Hive funciona gracias a HiveQL, un lenguaje basado en
SQL que permite que los usuarios estructuren, resuman y consulten datos. HiveQL es
más que el SQL estándar, ya que incluye una compatibilidad excelente con funciones
map/reduce y tipos de datos complejos y ampliables definidos por el usuario, como
JSON y Thrift. Esta capacidad permite procesar fuentes de datos complejas y
desestructuradas, como documentos de texto y archivos de registro. Hive permite las
extensiones de usuario a través de funciones definidas por el usuario escritas en Java.

Implementación de la plataforma
-‐ 84 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
El funcionamiento de esta herramienta se basa en la creación de tablas de
consulta.
Con esta herramienta se van a crear una serie de tablas con la información que
se considera oportuna para luego poder llevar a cabo un análisis.
Esta herramienta, propia del ecosistema de Hadoop, se diferencia del SQL
clásico por su capacidad para crear tablas a partir de procesos MapReduce, aunque
tiene diversas limitaciones en ciertas consultas más avanzadas. Es por ello que,
aunque se realizarán ejemplos de cómo realiza sus propios procesos MapReduce, el
objetivo principal de este proyecto es emplearla como medio de consulta.
Para el análisis temporal que se va a realizar, el que se extrae de la fase
anterior de procesamiento de datos, se deberá crear una tabla que contenga dos
columnas: en la primera de ellas se almacenará la clave y en la segunda el valor de los
datos obtenidos de MapReduce.
En el ejemplo que se va a presentar, no se precisa de un procesamiento previo
de MapReduce, por lo que los datos serán los que se obtuvieron directamente de
Twitter, en su formato JSON. Como se observará en la presentación de los resultados,
será el propio Hive el que se encargará de hacer un MapReduce sobre esos datos,
obteniendo así una información aprovechable y de un tamaño mucho más reducido.
El caso particular que se va a tomar indica el idioma en el que se presentan los tweets,
que es uno de los campos de la estructura, de forma que se pueda observar qué
resultados se obtienen.
6.4.1 CONFIGURACIÓN
A continuación se van a presentar los pasos necesarios para crear tablas en
Hive. En primer lugar, será necesario acceder a la shell de Hive para luego crear una
base de datos y dentro de ella crear la tabla con las columnas, una de tipo String
denominada fecha y una de tipo Int con la cuenta obtenida del MapReduce.

Implementación de la plataforma
-‐ 85 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
$ hive shell hive > CREATE DATABASE twitter;
De la creación de esta tabla es importante destacar que se debe indicar al
sistema que la separación existente entre las columnas es un tabulador, cuyo código
correspondiente es 011. Finalmente, los datos almacenados en HDFS se cargarán en
la tabla, para que puedan ser consultados.
Se muestra a continuación los comandos necesarios para la creación de la tabla
dentro de la base de datos que se ha denominado twitter.
hive (twitter) > CREATE TABLE tweets1 ( Fecha String, Cuenta Int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\011’ STORED AS TEXTFILE;
Para el caso del ejemplo, y al tratarse de datos en formato JSON, se realizará un
procedimiento diferente. Hive ofrece unas funciones específicas que permiten, a
partir de una tabla, extraer la información en formato JSON. Con esta función
(get_json_object()), se pueden obtener los datos que se consideren oportunos para
realizar cualquier otro tipo de análisis.
En ambos casos, una vez se ha procesado la información, ya se encuentra
preparada par ser mostrada en gráficos.
6.5 VISUALIZACIÓN DE DATOS
Finalmente para la visualización de los datos se empleará la conocida
herramienta Tableau, en su versión Tableau Desktop, puesto que conecta con la
distribución Cloudera y en particular con el servidor de Hive.

Implementación de la plataforma
-‐ 86 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
El uso de esta herramienta es muy sencillo e intuitivo y permite, a través de la
información obtenida de la tabla de consultas de Hive, realizar los gráficos que
muestren la evolución de la información.
6.5.1 CONFIGURACIÓN
Esta herramienta no funciona con sistema operativo Linux, así que se deberá
trabajar en Windows, por lo que para utilizarla será necesario descargarla en este
sistema operativo y a partir de ahí conectarla con el servidor de Hive para que le sirva
los datos.
Una vez se ha descargado el programa y se ha instalado correctamente en la
versión de prueba, para poder conectarlo con Hive, se deberá descargar un driver de
ODBC específico de Cloudera. Gracias a este driver se podrá crear un sistema DSN que
permita la conexión con Hive, configurado como se muestra en la imagen.

Implementación de la plataforma
-‐ 87 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 39. Configuración del sistema DSN para el servidor de Hive
Cuando se haya completado la conexión, en la aplicación Tableau se podrá
conectar a los datos en la opción que permite a través de las bases de datos ODBC,
buscando la conexión que se acaba de crear. A partir de ahí, ya se puede utilizar esta
herramienta.
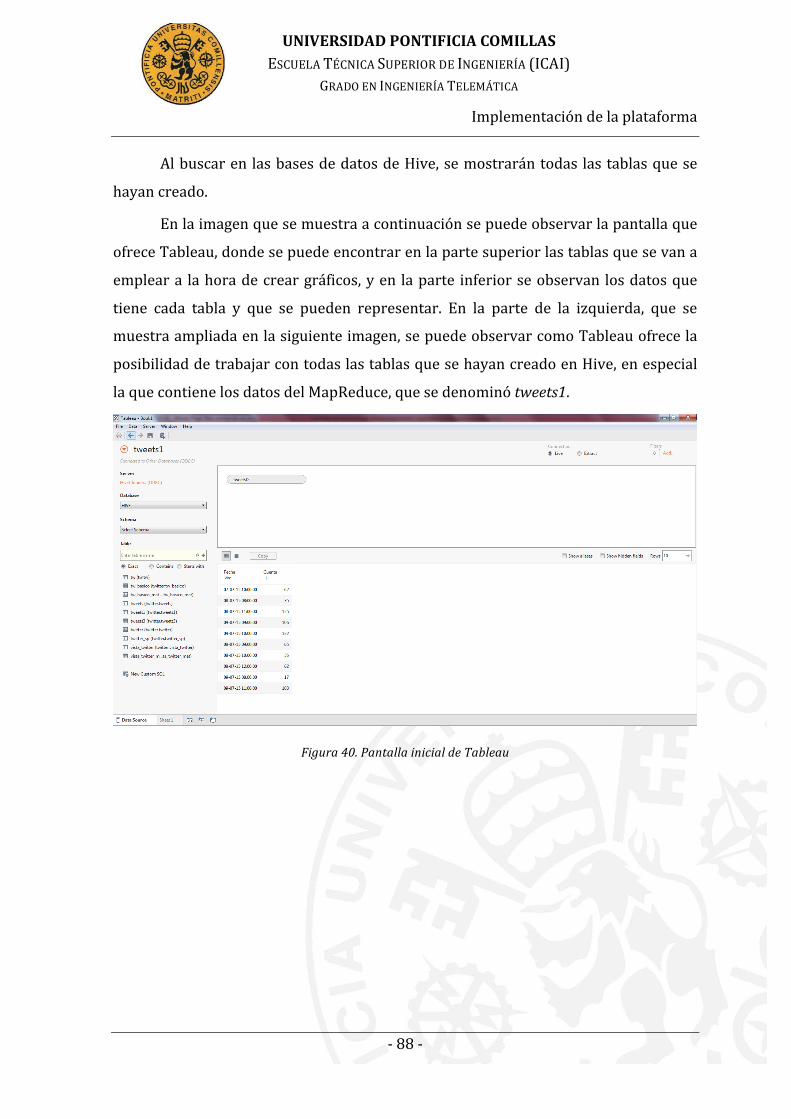
Implementación de la plataforma
-‐ 88 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Al buscar en las bases de datos de Hive, se mostrarán todas las tablas que se
hayan creado.
En la imagen que se muestra a continuación se puede observar la pantalla que
ofrece Tableau, donde se puede encontrar en la parte superior las tablas que se van a
emplear a la hora de crear gráficos, y en la parte inferior se observan los datos que
tiene cada tabla y que se pueden representar. En la parte de la izquierda, que se
muestra ampliada en la siguiente imagen, se puede observar como Tableau ofrece la
posibilidad de trabajar con todas las tablas que se hayan creado en Hive, en especial
la que contiene los datos del MapReduce, que se denominó tweets1.
Figura 40. Pantalla inicial de Tableau

Implementación de la plataforma
-‐ 89 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 41. Tablas de Hive
Por lo tanto, una vez se tiene seleccionada la tabla con la que se desea trabajar,
se procede a seleccionar aquellos atributos que se desean representar. Para ello, en
primer lugar se debe conocer la pantalla que ofrece Tableau para representar
gráficos.

Implementación de la plataforma
-‐ 90 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 42. Pantalla de creación de gráficos de Tableau
Como se puede observar, en la parte izquierda aparecen los nombres de las
columnas de la tabla que se ha seleccionado, situándose en la parte superior en caso
de tratarse de una cadena de caracteres, como es el caso de la fecha, y en la parte
inferior si se trata de números, como es la cuenta.
En la parte superior de la pantalla se debe indicar el contenido de los ejes de la
gráfica, las filas y las columnas; y en la parte de la derecha se indicará el tipo de
gráfico que se desea emplear.
Para el caso que se desea representar, evolución horaria de los tweets, se
colocará en las columnas la fecha y en las filas la cuenta, seleccionando el gráfico de
diagrama de barras, como se muestra a continuación.
Figura 43. Asignación de filas y columnas para el gráfico
Como este caso, se pueden representar todos los gráficos que se deseen. En el
capítulo en el que se analizan los resultados, se mostrarán varios ejemplos que
indican el alcance que tiene esta herramienta de visualización.

Implementación de la plataforma
-‐ 91 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Por ejemplo, también se representará el ejemplo realizado exclusivamente a
partir de Hive, donde se almacenó el idioma de un grupo de tweets. En este caso, se
empleará un diagrama circular y se colocará la columna de idioma en las filas.
Una vez se ha realizado todo este proceso, la herramienta permite editar las
gráficas en cuanto a colores, por ejemplo, o añadir y eliminar algunas etiquetas que
aporten información de utilidad.

Implementación de la plataforma
-‐ 92 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

Análisis de resultados
-‐ 93 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 7 ANÁLISIS DE RESULTADOS
En este capítulo se muestran los resultados obtenidos tras el análisis
presentado.
En primer lugar se mostrarán los resultados obtenidos tras las ejecuciones de
las distintas etapas del análisis, para finalmente mostrar los gráficos obtenidos en la
etapa de visualización y extraer conclusiones de ellos.
7.1 RESULTADOS DE LAS EJECUCIONES DE LAS HERRAMIENTAS
Al ejecutar los diferentes comandos que inician el funcionamiento de las
diferentes herramientas se obtienen diversos resultados.
7.1.1 RESULTADOS DE FLUME
Una vez se ha lanzado el agente de Flume, en la consola aparece información
acerca del proceso que se está ejecutando, de la cual se ha extraído la que se
consideraba importante, mostrada a continuación.
Figura 44. Ejecución del agente de Flume

Análisis de resultados
-‐ 94 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
En la imagen se puede observar cómo se establece correctamente la conexión
con la fuente de la que se extraen los datos, en este caso Twitter, que conlleva a la
descarga de la información.
Esta información que se descarga se almacena en la ruta
/user/cloudera/flume/tweets, en particular en el fichero tweets.1436467134063.
En este momento de la descarga, como aún se está llenando el fichero, se
observa una extensión .tmp, que indica que está en proceso y aún no se puede acceder
a él.
El tiempo de descarga varía en función de la configuración que se haya
establecido para el agente de Flume, puesto que se puede definir el tamaño del
fichero, la capacidad del canal de memoria, así como otros muchos aspectos. Como ya
se mencionó, el tamaño de fichero buscado es de gran tamaño, por lo que el tiempo
que tardará en llenarse cada uno de los ficheros será mayor que si se tratase de
ficheros pequeños.
7.1.2 RESULTADOS DE HDFS
Una vez se haya llenado el fichero que se creó con el agente de Flume, éste
quedará almacenado en el sistema de ficheros HDFS en la ruta especificada, de donde
se podrá descargar y trabajar con él.
Como ya se mostró anteriormente, se puede acceder a los datos que se van
descargando a través del navegador, gracias al buscador que se presenta a
continuación.

Análisis de resultados
-‐ 95 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 45. Sistema de ficheros HDFS conteniendo datos descargados
Se puede observar que cada uno de los ficheros de tweets tiene un tamaño
diferente. Esto se debe a que cada uno se ejecutó realizando diferentes pruebas en las
que se variaba el tamaño del fichero para poder comprobar que efectivamente se
reducía el tiempo de llenado cuando se disminuía el tamaño del fichero.
En cuanto a los permisos que se tienen sobre los ficheros, se observa que
únicamente tiene permiso para escribir el sistema, y que el usuario únicamente tiene
permiso para leer de ellos, lo que permite trabajar con ellos en otros ficheros pero no
modificar los existentes.
7.1.3 RESULTADOS DE MAPREDUCE
Una vez se han descargado los ficheros que contienen los tweets a analizar, se
inicia el proceso de MapReduce. Esto, tal y como se definió en su configuración,
iniciará dos procesos que se encargarán de esta tarea.
En las imágenes que se muestran a continuación, se puede observar la
información que se muestra por consola al ejecutar el proceso.

Análisis de resultados
-‐ 96 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 46. Ejecución del proceso MapReduce (I)
Figura 47. Ejecución del proceso MapReduce (II)

Análisis de resultados
-‐ 97 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
En estas imágenes se puede observar cómo se muestra el progreso del proceso
lanzado, de forma que se realiza primero la tarea de mapear y en siguiente lugar se
observa cómo se reducen los datos.
También se incluye mucha información extra acerca del tamaño del fichero
que se ha procesado, así como de los errores producidos, que en este caso son nulos.
Por otra parte, Cloudera ofrece un servicio a través del cuál se puede visualizar
en el navegador el progreso de los sistemas de MapReduce de forma gráfica, a través
de la URL quickstart.cloudera:8088/proxy/application.
Figura 48. Interfaz gráfica que muestra el progreso de MapReduce
Al finalizar el proceso MapReduce que se lanzó, se puede observar dentro del
sistema de ficheros HDFS cómo se ha creado una carpeta nueva que contiene la
información obtenida, tal como se muestra a continuación.
Figura 49. HDFS conteniendo datos de la salida de MapReduce
Como se puede observar, se han creado tres ficheros. El primero, vacío,
indicando que el proceso se ha completado con éxito. Los dos siguientes son los
correspondientes a los dos procesos paralelos que ejecuta MapReduce. En esta
prueba en particular se hizo con un fichero muy pequeño, por lo que no aparecen
datos en el primero y el segundo está prácticamente vacío. Sin embargo en otras

Análisis de resultados
-‐ 98 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
pruebas con ficheros de mayor tamaño se puede observar que ambos ficheros tienen
aproximadamente el mismo tamaño.
En siguiente lugar se van a mostrar dos ficheros como los mencionados
anteriormente que son salida de un fichero a procesar mucho mayor.
Figura 50. Contenido fichero part-‐r-‐00000

Análisis de resultados
-‐ 99 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 51. Contenido fichero part-‐r-‐00001
Como se puede comprobar si se observa la secuencia de tiempos, el proceso
MapReduce ha dividido el contenido por la mitad, ejecutando cada proceso lanzado la
mitad de los datos en función de su llegada.
7.1.4 RESULTADOS DE HIVE
Al ejecutar las sentencias que crean tablas en Hive, el sistema aporta unos
mensajes indicando el tiempo de ejecución que ha tardado en completar la sentencia,
así como si se ha completado correctamente o no.
Se van a mostrar una serie de capturas de la ejecución de diferentes sentencias
para observar el tiempo que conllevan.
En primer lugar se muestra el tiempo que tarda el sistema en crear una tabla,
que como se puede observar es prácticamente nulo, dado que se trata de un proceso
muy sencillo.

Análisis de resultados
-‐ 100 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 52. Tiempo de creación de una tabla en Hive
Ahora se va a mostrar el tiempo que tarda el sistema en introducir los datos
en la propia tabla. Como se puede observar, el tiempo es claramente superior al
tiempo de creación, pero sigue siendo muy pequeño. Esto se debe a que el contenido
que se ha cargado no ocupa mucho espacio y por lo tanto se puede procesar
rápidamente. Sin embargo, si se tratase de una carga mucho mayor, el rendimiento se
vería bastante afectado.
Figura 53. Tiempo de carga de datos en una tabla en Hive
Además del tiempo de carga, la sentencia muestra otra información, como el
tamaño del fichero o el número de particiones que se realizan.
A continuación se va a visualizar la captura de cuando se realiza una consulta
que necesita ejecutar un proceso MapReduce. Como se mencionó anteriormente, esta
herramienta realiza algunas consultas ejecutando este tipo de procesos, aunque está
bastante limitado. Como se puede observar, se produce una consulta mucho más lenta
que las anteriores, de 27 segundos a pesar de tratarse de una sentencia bastante
básica y de un fichero de un tamaño bastante limitado. Es aquí donde se observa la
deficiencia de este sistema, que pierde mucho rendimiento al tener que realizar estas
consultas.

Análisis de resultados
-‐ 101 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 54. Ejemplo de consulta SELECT que produce un MapReduce
Para compararla con el tiempo que se tarda en ejecutar una consulta que no
necesita de un proceso MapReduce, se muestra un ejemplo muy similar. Se puede
apreciar que el tiempo de esta consulta es mínimo, lo que indica que este
procesamiento MapReduce es, aunque muy útil, muy lento; si bien se podría mejorar
ejecutando más procesos de mapeo, puesto que se ejecutó un único proceso.
Figura 55. Ejemplo de consulta SELECT

Análisis de resultados
-‐ 102 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
7.2 VISUALIZACIÓN DE GRÁFICOS
A continuación se van a mostrar los gráficos obtenidos de los datos de las
tablas creadas en Hive.
La herramienta Tableau es la encargada de representar los datos, y ofrece una
amplia variedad de opciones en cuanto a gráficos y tablas, para poder satisfacer los
requisitos que se puedan necesitar para realizar los análisis oportunos.
En primer lugar se representarán los gráficos obtenidos de los datos que se
han procesado con MapReduce. Estos datos corresponden a una sucesión temporal,
por lo que se estudiará el progreso existente mediante gráficos de diagrama de
barras.
Para poder realizar diferentes análisis, se ha estudiado el comportamiento del
número de tweets en función del minuto en el que se han creado y en función de la
hora.
Para comenzar se estudiará qué sucede con los minutos. Como ya se comentó
anteriormente, sólo se puede obtener una muestra, el 1% de los datos, que es lo que
permite Twitter, por lo que a partir de ello, se puede realizar un análisis aproximado
del comportamiento general de los datos que se generan en la red social.
En la gráfica que se muestra a continuación se puede observar cómo el número
de tweets generados por minuto no sigue ningún tipo particular de sucesión, por lo
que no se ha mostrado todo el espacio temporal que se tenía descargado, sino una
pequeña parte para mostrar el resultado.
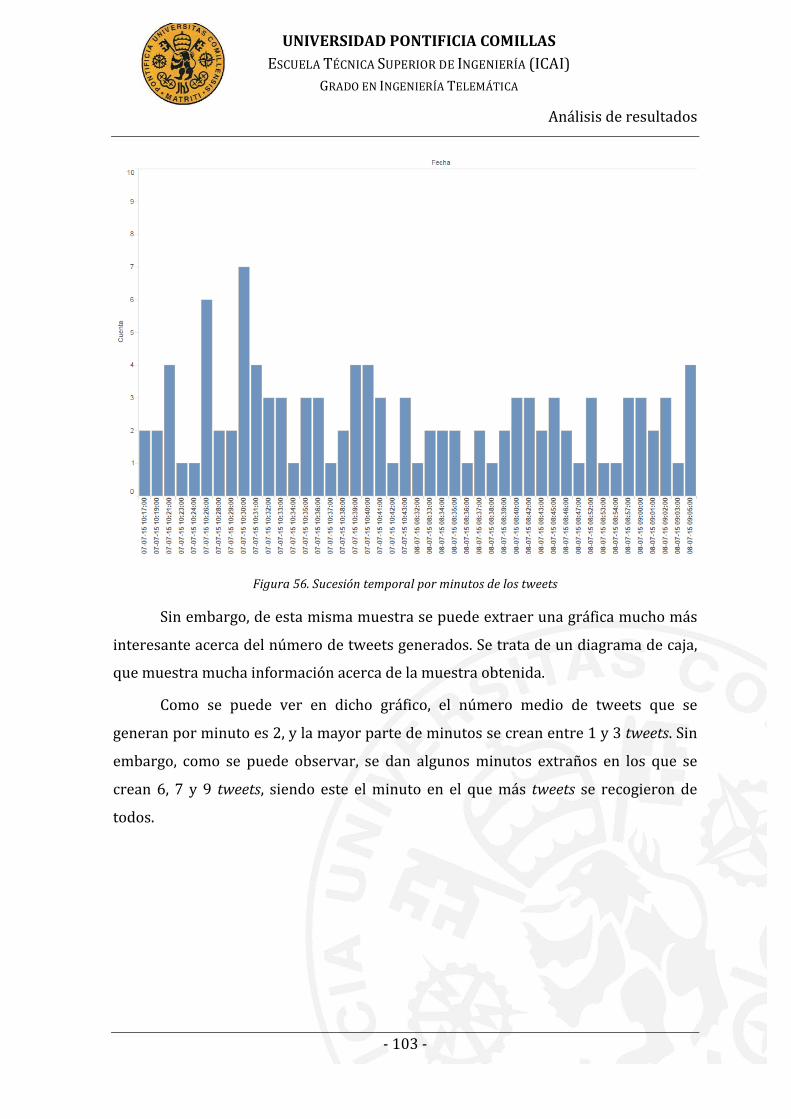
Análisis de resultados
-‐ 103 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 56. Sucesión temporal por minutos de los tweets
Sin embargo, de esta misma muestra se puede extraer una gráfica mucho más
interesante acerca del número de tweets generados. Se trata de un diagrama de caja,
que muestra mucha información acerca de la muestra obtenida.
Como se puede ver en dicho gráfico, el número medio de tweets que se
generan por minuto es 2, y la mayor parte de minutos se crean entre 1 y 3 tweets. Sin
embargo, como se puede observar, se dan algunos minutos extraños en los que se
crean 6, 7 y 9 tweets, siendo este el minuto en el que más tweets se recogieron de
todos.

Análisis de resultados
-‐ 104 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 57. Diagrama de caja de la evolución por minutos
Otra forma que puede ser interesante para analizar los datos es con la
siguiente tabla, que muestra el número de datos que se genera por minuto, de forma
que cada fila se colorea en función de su valor. También se adjunta la escala de color
con su significado, es decir, los minutos en los que se generaron menos tweets se
presentan en gris y cuanto mayor sea dicho número, más azul se coloreará el minuto
correspondiente.
Como se puede observar, la mayor parte de las filas tiene un valor pequeño,
rara vez se superan los cuatro tweets por minuto.

Análisis de resultados
-‐ 105 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 58. Tabla de colores con la evolución por minutos
Figura 59. Escala de colores para la evolución por minutos
A continuación se va a analizar la progresión por horas. En este caso, sí que se
puede observar un ligero patrón en el número de tweets que se han generado. Se
debe destacar que en las horas más tempranas se generan muchos menos tweets,
mientras que a medida que avanza la mañana se generan muchos más.

Análisis de resultados
-‐ 106 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 60. Sucesión temporal por horas de los tweets
También se puede hacer una representación de los datos con un diagrama de
barras horizontal, como el que se muestra a continuación.

Análisis de resultados
-‐ 107 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 61. Sucesión temporal por horas de los tweets en horizontal
Finalmente se van a representar los datos que se obtuvieron al procesarlos
exclusivamente con Hive.
Se va a representar una muestra del número de tweets en función del idioma
en el que están escritos. Como se comentó en la configuración de Flume, los datos
extraídos se han limitado al territorio español, por lo que los datos serán
mayoritariamente en español. Para representarlos se empleará un diagrama circular.
Como se puede observar, la mayor parte de los datos están en español y unos
cuantos tienen el idioma indeterminado.
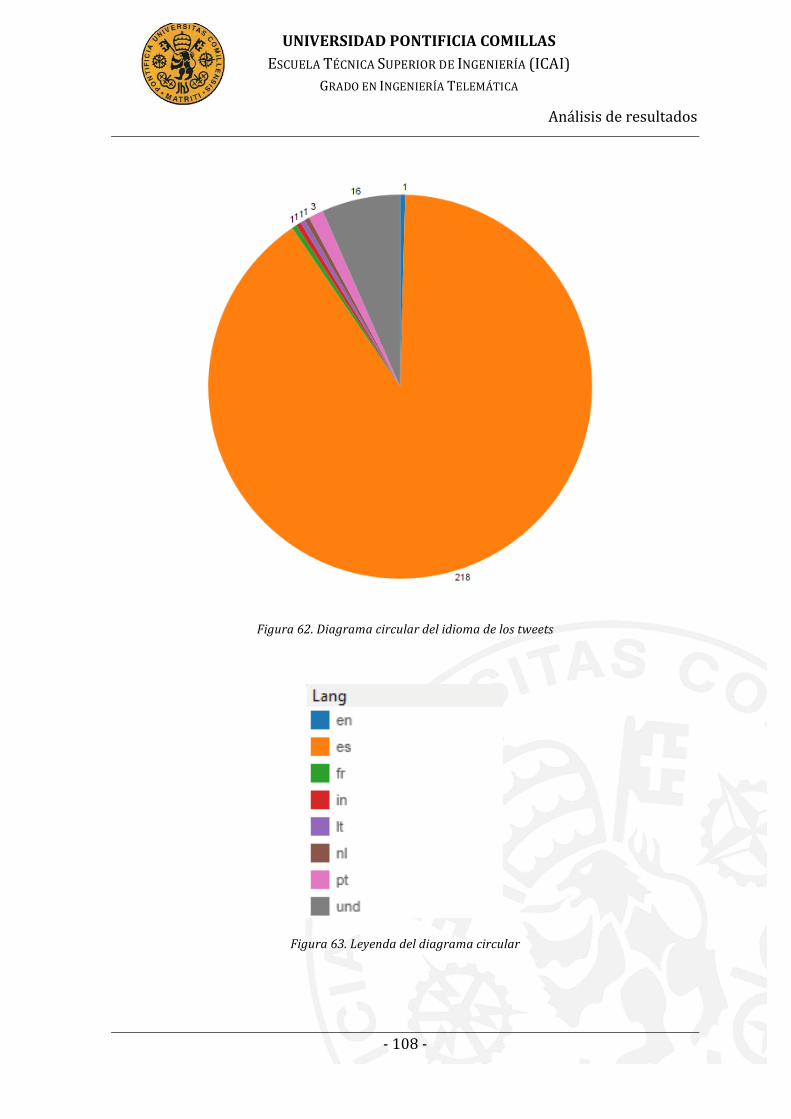
Análisis de resultados
-‐ 108 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Figura 62. Diagrama circular del idioma de los tweets
Figura 63. Leyenda del diagrama circular

Conclusiones y líneas futuras
-‐ 109 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
Capítulo 8 CONCLUSIONES Y LÍNEAS FUTURAS
Vistos los resultados obtenidos del análisis de los datos descargados, se
presentarán las conclusiones obtenidas, así como posibles trabajos a desarrollar a
partir del que se ha realizado.
Como conclusiones generales, y en referencia al Big Data, se destaca que se
trata de un ecosistema muy amplio y que aporta a la sociedad actual, en la que cada
vez se almacenan más y más datos, una nueva forma de analizar dicha información
para que así se pueda obtener un valor añadido a lo que ya se conocía e introducir las
mejoras que sean necesarias acorde a dichos resultados. Es decir, con la introducción
del Big Data en las empresas se podrá obtener una capacidad de análisis muy
superior a la que se obtenía anteriormente para poder así conseguir una información
más detallada de lo que sucede, y relacionarla con otros análisis; es decir, el Big Data
se muestra como una ventaja para el Data Mining. Con esto se pueden analizar
grandes volúmenes de información a una velocidad adecuada para obtener patrones
o comportamientos determinados en ciertos datos, basados en la inteligencia artificial
y la estadística principalmente [31]. Esta tecnología de computación se podrá
emplear, por ejemplo, para detectar anomalías en un sistema antes de que ocurran a
partir de la definición de patrones en su comportamiento.
Como conclusión del análisis de distribuciones open-‐source de Big Data se
extrae que, aunque se hayan estudiado las principales y más reconocidas, se puede
determinar que cada una de ellas aporta una serie de ventajas, que se podrán
aprovechar en función de los objetivos que se deban cumplir en la empresa en
cuestión. Es decir, para cada caso de uso particular habrá una distribución que
satisfaga mejor las necesidades particulares en cuestión.
Del caso de uso particular que se ha desarrollado se puede extraer como
conclusión que hacer uso de las redes sociales para llevar a cabo análisis del
comportamiento de las personas puede suponer muchos beneficios, por ejemplo en lo

Conclusiones y líneas futuras
-‐ 110 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
referido a qué día de la semana se debe sacar al mercado un producto, ya que las
redes sociales son un gran medio de propagación de la información y este análisis
permite saber qué día se utilizan más. En cuanto al análisis de las redes sociales en
función de las horas, se podrá deducir a qué hora tendrá mayor difusión una noticia
en particular o qué eventos tienen un mayor seguimiento.
Como posibles futuros trabajos se puede definir, en primer lugar, el análisis de
los hashtags buscando análisis de sentimiento en los tweets que los contienen. Es
decir, analizando el contenido de los tweets se podría determinar el estado de ánimo
de los usuarios, estudiando si las palabras son negativas (no, mal, ningún…) o
positivas (sí, bien, mejor…), de forma que si el hashtag está relacionado con algún
producto o alguna empresa, ésta pueda tener en cuenta las opiniones del público.
Otro posible trabajo puede ser la relación con la mencionada tecnología Data
Mining. Esta tecnología permite extraer patrones interesantes que hasta el momento
eran desconocidos, para así poder predecir qué sucederá en unas determinadas
condiciones, por ejemplo qué efecto tendrá una noticia o evento, para ofrecer así una
respuesta óptima de servicios en función de la demanda predicha.

BIBLIOGRAFÍA
-‐ 111 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
BIBLIOGRAFÍA
[1] Open Data Center Alliance (ODCA). Big Data Consumer Guide
[2] Alex Holmes. Hadoop in practice
[3] Experfy. Comparativa entre Cloudera, Hortonworks y MapR.
http://www.experfy.com/blog/cloudera-‐vs-‐hortonworks-‐comparing-‐
hadoop-‐distributions/
[4] Gravitar. Big Data.
http://gravitar.biz/bi/big-‐data/
[5] Flume. Flume User Guide.
https://flume.apache.org/FlumeUserGuide.html#twitter-‐1-‐firehose-‐
source-‐experimental
[6] Hive. Información General.
https://hive.apache.org/
[7] Tableau. Información general. http://www.tableau.com/es-‐es/new-‐features/big-‐data-‐0
[8] Dan Sullivan. Getting Started with Hadoop 2.0.
http://www.tomsitpro.com/articles/hadoop-‐2-‐vs-‐1,2-‐718.html
[9] Business Software. Hadoop 2.0, ¿qué trae de nuevo?
http://www.businessoftware.net/big-‐data-‐hadoop-‐2-‐que-‐trae-‐de-‐nuevo/
[10] Hortonworks. YARN.
http://hortonworks.com/hadoop/yarn/
[11] Cloudera. YARN y HA Hadoop.
http://blog.cloudera.com/blog/2014/05/how-‐apache-‐hadoop-‐yarn-‐ha-‐
works/
[12] Forrester. Expand Your Digital Horizon With Big Data (Junio 2013)
[13] Hortonworks. HDP 2.
http://hortonworks.com/blog/announcing-‐hdp-‐2-‐2/

BIBLIOGRAFÍA
-‐ 112 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
[14] Hortonworks. HDP. http://hortonworks.com/hdp/
[15] Cloudera. CDH Packaging information for previous releases.
http://www.cloudera.com/content/cloudera/en/documentation/core/la
test/topics/cdh_vd_cdh_package_previous.html
[16] Cloudera. Cloudera Enterprise.
http://www.cloudera.com/content/cloudera/en/products-‐and-‐
services/cloudera-‐enterprise.html
[17] Cloudera. Impala.
http://www.cloudera.com/content/cloudera/en/products-‐and-‐
services/cdh/impala.html
[18] Cloudera. Cloudera Search.
http://www.cloudera.com/content/cloudera/en/products-‐and-‐
services/cdh/search.html
[19] Cloudera. Cloudera Manager.
http://www.cloudera.com/content/cloudera/en/products-‐and-‐
services/cloudera-‐enterprise/cloudera-‐manager.html
[20] Baoss. Solución Big Data Analytics Cloudera.
http://www.baoss.es/?page_id=4620
[21] Cloudera. Cloudera Navigator.
http://www.cloudera.com/content/cloudera/en/products-‐and-‐
services/cloudera-‐enterprise/cloudera-‐navigator.html
[22] MapR. Características de las distintas ediciones.
https://www.mapr.com/products/hadoop-‐download
[23] MapR. MapR – FS
http://doc.mapr.com/display/MapR/Working+with+MapR-‐FS
[24] MapR. Direct Access NFS.
https://www.mapr.com/resources/videos/mapr-‐nfs
[25] MapR. Heatmap.
https://www.mapr.com/resources/videos/mapr-‐heatmaps

BIBLIOGRAFÍA
-‐ 113 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
[26] Gartner. Magic Quadrant for Data Warehouse and Data Management
Solutions for Analytics (Febrero 2015).
http://www.gartner.com/technology/reprints.do?id=1-‐
29X7GVV&ct=150212&st=sb
[27] Forrester. Forrester Wave: Big Data Hadoop Solutions 2014. [28] Cloudera. Caminos de instalación.
http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cm_ig_install_path_a.html?scroll=cmig_topic_6_5_unique_2
[29] Cloudera. Instalación Cloudera Manager. http://www.cloudera.com/content/cloudera/en/documentation/cloudera-‐manager/v4-‐latest/Cloudera-‐Manager-‐Installation-‐Guide/cmig_install_cm_cdh.html
[30] Twitter. REST API. https://dev.twitter.com/rest/public
[31] Wikipedia. Minería de datos.
https://es.wikipedia.org/wiki/Miner%C3%ADa_de_datos
[32] Maven. What is maven. https://maven.apache.org/what-‐is-‐maven.html
[33] Wikipedia. NoSQL. https://es.wikipedia.org/wiki/NoSQL
[34] Gartner. Gartner's 2014 Hype Cycle for Emerging Technologies Maps
the Journey to Digital Business.
http://www.gartner.com/newsroom/id/2819918

-‐ 114 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA

ANEXO A
-‐ 115 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
ANEXO A
En este anexo se presenta una guía para instalar CDH y el sistema de nodos
necesario.
Como se explicó anteriormente, al describir Cloudera y sus características, esta
distribución cuenta con tres paquetes diferentes: el primero de ellos, gratuito, incluye
el paquete del núcleo Hadoop y alguna herramienta básica de gestión; el segundo
incluye herramientas de gestión y administración, y se trata de una versión de prueba
gratuita durante 60 días; el tercer paquete incluye todas las herramientas disponibles
de Cloudera, y para poder utilizarlo es necesario pagar una cuota anual.
En este proyecto se va a hacer uso del primer paquete, ya que al tratarse de un
entorno de laboratorio, será un sistema pequeño y no será necesario hacer uso de las
herramientas de administración. Sin embargo, en entornos muy grandes será
necesario hacer uso del tercer paquete, que incluye las herramientas de Cloudera
Navigator y facilitarán la tarea de administrar el gran número de nodos presentes.
En este anexo se va a presentar el manual de usuario del primer paquete,
indicando la instalación y la configuración de la herramienta. Previo a la instalación
de este paquete, denominado Cloudera Manager, será necesario explicar la
arquitectura que se va a emplear y su correspondiente implantación.
8.1 REQUISITOS PREVIOS A LA INSTALACIÓN
En primer lugar se va a indicar qué requisitos necesita la plataforma, de modo
que se seleccionen los componentes que sean compatibles con ella.

ANEXO A
-‐ 116 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
8.1.1 SISTEMA OPERATIVO
La plataforma de Cloudera CDH es compatible únicamente con el sistema
operativo Linux, por lo que será necesario poder hacer uso de alguna de sus
versiones. En el caso de la empresa VASS, no hay ordenadores disponibles con ese
sistema operativo, por lo que se instala una máquina virtual compatible con Cloudera
en el ordenador del que se hace uso. La versión instalada es CentOs.
Este sistema operativo es el que se empleará además en los nodos del clúster,
por lo que se realizarán clones de la máquina virtual alojada en el ordenador.
8.1.2 NODOS
Al tratarse de un entorno de prueba, se realizará el desarrollo empleando un
único nodo virtualizado en la propia máquina virtual.
8.2 INSTALACIÓN DE CLOUDERA MANAGER
Una vez se han cumplido los requisitos anteriores, se procede a la instalación
del paquete Cloudera Manager, formado por el núcleo CDH y algunas herramientas de
gestión.
Para instalar este paquete existen tres opciones: camino A, camino B y camino
C. La primera de las opciones se realiza de forma automática y las otras dos son
manuales, por lo que se elige la instalación por el camino A [29].

ANEXO A
-‐ 117 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
8.2.1 CAMINO A
Esta opción [28], aparte de tener la ventaja de tratarse de una instalación
automática de los paquetes del CDH, incluye en el sistema dos requisitos necesarios
para el sistema: instala el Java Development Kit (JDK) de Oracle y configura una base
de datos PostgreSQL para el servidor de Cloudera. PostgreSQL es un sistema de
gestión de bases de datos objeto-‐relacional open-‐source. Utiliza un modelo cliente-‐
servidor y usa multiprocesos en vez de multihilos para garantizar la estabilidad del
sistema.
Para llevar a cabo la instalación del paquete Cloudera Manager, se introducirán
los siguientes comandos en la consola:
$ Sudo wget http://archive.cloudera.com/cm5/installer/latest/cloudera-manager-installer.bin $ sudo chmod u+x cloudera-manager-installer.bin $ sudo ./cloudera-manager-installer.bien
El primero de estos comandos se encarga de coger de internet el directorio que
se va a instalar, el segundo cambia el permiso a ejecución y el tercero realiza la
instalación.
A continuación se empiezan a instalar todos los paquetes necesarios de
Cloudera Manager, incluyendo el JDK y la base de datos. Se pide que se acepten los
términos de la licencia de Cloudera Express, así como los términos del Oracle Binary
Code.
8.3 CONFIGURACIÓN CLOUDERA MANAGER
Cuando se termina la instalación del paquete, se debe acceder en el navegador
a localhost, al puerto número 7180, donde el usuario y la contraseña son admin. Es
aquí donde se accede a Cloudera Manager.

ANEXO A
-‐ 118 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
En primer lugar se muestra la pantalla de inicio que aparece cuando se accede.
Figura 64. Página de presentación de Cloudera Manager
Como se puede observar, Cloudera Manager permite seleccionar diferentes
herramientas para las distintas funcionalidades requeridas por el tratamiento de
datos en Big Data.
En la siguiente pantalla que se muestra, se deben introducir los nombres de las
máquinas virtuales del servidor, que se gestionarán remotamente. Así, se accederá a
ellas para poder definir los nodos (maestro y esclavo) y por lo tanto el clúster. Para
que encuentre los nodos se puede incluir el FQDN (Fully Qualified Domain Name, que
incluye el nombre del equipo y el nombre del dominio al que pertenece) o la dirección

ANEXO A
-‐ 119 -‐
UNIVERSIDAD PONTIFICIA COMILLAS ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
GRADO EN INGENIERÍA TELEMÁTICA
IP de las máquinas virtuales en cuestión, que en este caso al tratarse de un único nodo
virtualizado se deberá especificar la dirección localhost. Cuando se reconoce
correctamente el nodo, se puede acceder a la siguiente pantalla.
Figura 65. Detección de nodos de las máquinas virtuales
Una vez se haya reconocido la dirección especificada, el sistema comienza la
instalación de los agentes y la inicialización de todos los servicios ofrece esta
distribución, por lo que se podrá acceder a ellos.
Top Related