
UNIVERSITE D'ANTANANARIVO ...
109
N° d’ordre : 18/RS/TCO Année Universitaire : 2012 / 2013 UNIVERSITE D'ANTANANARIVO ------------------------------ ECOLE SUPERIEURE POLYTECHNIQUE ------------------------------- DEPARTEMENT TELECOMMUNICATIONS MEMOIRE DE FIN D'ETUDES en vue de l'obtention du DIPLOME d’INGENIEUR Spécialité : Télécommunication Option : Réseaux et systèmes par : RAMAHAROBANDRO Rahasina Fenomanjato Mariah ETUDE DES PERFORMANCES DES MECANISMES DE QUALITE DE SERVICE DANS UN RESEAU MPLS AVEC TRAFFIC ENGINEERING Soutenu le 19 Décembre 2014 devant la Commission d’Examen composée de : Président : Monsieur RAKOTOMALALA Mamy Alain Examinateurs : Madame RABEHERIMANANA Lyliane Madame ANDRIANTSILAVO Haja Samiarivonjy Monsieur ANDRIAMANALINA Ando Nirina Directeur de mémoire : Monsieur ANDRIAMIASY Zidora
Transcript of UNIVERSITE D'ANTANANARIVO ...

N° d’ordre : 18/RS/TCO Année Universitaire : 2012 / 2013
UNIVERSITE D'ANTANANARIVO
------------------------------
ECOLE SUPERIEURE POLYTECHNIQUE
-------------------------------
DEPARTEMENT TELECOMMUNICATIONS
MEMOIRE DE FIN D'ETUDES
en vue de l'obtention
du DIPLOME d’INGENIEUR
Spécialité : Télécommunication
Option : Réseaux et systèmes
par : RAMAHAROBANDRO Rahasina Fenomanjato Mariah
ETUDE DES PERFORMANCES DES MECANISMES DE
QUALITE DE SERVICE DANS UN RESEAU MPLS AVEC
TRAFFIC ENGINEERING
Soutenu le 19 Décembre 2014 devant la Commission d’Examen composée de :
Président :
Monsieur RAKOTOMALALA Mamy Alain
Examinateurs :
Madame RABEHERIMANANA Lyliane
Madame ANDRIANTSILAVO Haja Samiarivonjy
Monsieur ANDRIAMANALINA Ando Nirina
Directeur de mémoire : Monsieur ANDRIAMIASY Zidora

i
REMERCIEMENTS
Tout d’abord, j’aimerais remercier le Seigneur de m’avoir donné sa bénédiction durant mes
études à l’ESPA et pour la réalisation de ce travail de mémoire de fin d’études.
Je remercie, le Directeur de l’Ecole Supérieure Polytechnique d’Antananarivo, Monsieur
ANDRIANARY Philippe, pour mes cinq années d’études dans cet établissement.
Je suis très reconnaissante envers Monsieur ANDRIAMIASY Zidora, Enseignant au sein du
Département Télécommunication, Directeur de ce mémoire de fin d’études, pour les temps qu’il
m’a accordé, pour son aide et ses précieux conseils durant la préparation de ce travail.
Je suis particulièrement reconnaissante à Monsieur RAKOTOMALALA Mamy Alain, Chef du
Département Télécommunication qui, malgré ses lourdes responsabilités, me fait l’honneur de
présider ce mémoire de fin d’études.
Je témoigne toute ma reconnaissance aux autres membres du jury qui ont bien voulu examiner la
valeur de ce travail :
Madame RABEHERIMANANA Lyliane
Madame ANDRIANTSILAVO Haja Samiarivonjy
Monsieur ANDRIAMANALINA Ando Nirina
Je tiens aussi à exprimer toute ma reconnaissance aux membres de ma famille, pour le soutient
qu’ils m’ont porté tout au long de mes études. Je reconnais les sacrifices que ces longues années
ont représentés et je les remercie d'avoir toujours su m'encourager.
Enfin, je ne saurai oublier toutes les personnes qui m’ont aidée de près ou de loin dans
l’élaboration du présent mémoire.

ii
TABLE DES MATIERES
REMERCIEMENTS ................................................................................................................................... i
TABLE DES MATIERES ............................................................................................................... ii
LISTE DES ABREVIATIONS ....................................................................................................... vi
INTRODUCTION GENERALE ...................................................................................................... 1
CHAPITRE 1 : LE PROTOCOLE INTERNET .............................................................................. 2
1.1 Introduction ......................................................................................................................................... 2
1.2 Caractéristiques du protocole IP ....................................................................................................... 2
1.2.1 Description du protocole IP .......................................................................................................... 2
1.2.2 Format du datagramme IP ........................................................................................................... 2
1.3 L’adressage dans les réseaux IP ........................................................................................................ 5
1.3.1 Principe de l'adressage des machines .......................................................................................... 5
1.3.2 Structure d'adresses IP ................................................................................................................. 5
1.3.3 Classes d'adresses IP .................................................................................................................... 5
1.4 Routage IP ........................................................................................................................................... 7
1.4.1 Les « Autonomous System » ......................................................................................................... 9
1.4.2 Les protocoles de routage IGP ..................................................................................................... 9
1.4.3 Le protocole de routage BGP ..................................................................................................... 12
1.4.4 Différentes phases de routage IP ............................................................................................... 14
1.4.5 Détermination des distances des chemins de réseau à l'aide de métriques .............................. 17
1.5 Résolution d'adresses logiques ......................................................................................................... 18
1.5.1 Le protocole ARP ....................................................................................................................... 18
1.5.2 Le protocole RARP ..................................................................................................................... 19
1.6 Conclusion ......................................................................................................................................... 19
CHAPITRE 2 : MPLS ET INGENIERIE DE TRAFIC ................................................................. 20

iii
2.1 Introduction ....................................................................................................................................... 20
2.2 Etude de la technologie MPLS ......................................................................................................... 20
2.2.1 Principe de fonctionnement de MPLS ....................................................................................... 21
2.2.2 Les labels ..................................................................................................................................... 27
2.2.3 Distribution des labels ................................................................................................................ 29
2.2.4 Les applications de la technologie MPLS .................................................................................. 30
2.2.5 Evolutions MPLS ........................................................................................................................ 32
2.3 Etude de l’ingénierie de trafic avec MPLS ..................................................................................... 33
2.3.1 Définition de l’ingénierie de trafic. ............................................................................................ 33
2.3.2 Principe du «Traffic Engineering » ........................................................................................... 33
2.3.3 Calcul et établissement des "MPLS TE LSP" ........................................................................... 35
2.3.4 Resource ReSerVation Protocol - Traffic Engineering ............................................................ 36
2.4 Conclusion ......................................................................................................................................... 42
CHAPITRE 3 : ETUDE DES DIFFERENTS MECANISMES DE QUALITE DE SERVICE ....... 43
3.1 Introduction ....................................................................................................................................... 43
3.2 Définition de la qualité de service .................................................................................................... 43
3.3 Les paramètres de qualité de service ............................................................................................... 43
3.3.1 La bande passante ....................................................................................................................... 43
3.3.2 Le délai de bout en bout .............................................................................................................. 44
3.3.3 La gigue ....................................................................................................................................... 45
3.3.4 Perte en paquets .......................................................................................................................... 45
3.4 Le modèle à intégration de services : Intserv ................................................................................. 46
3.4.1 Présentation de Intserv .............................................................................................................. 46
3.4.2 Le protocole RSVP ...................................................................................................................... 46
3.4.3 Classes de service de Intserv ....................................................................................................... 47
3.4.4 Architecture de base d'un routeur IntServ ................................................................................ 47
3.4.5 Les modèles de réservation de ressources .................................................................................. 48
3.4.6 Limitations de RSVP ................................................................................................................... 49

iv
3.5 Le modèle à différenciation de services : Diffserv .......................................................................... 49
3.5.1 Présentation de Diffserv ............................................................................................................. 49
3.5.2 Notion de domaine Diffserv ........................................................................................................ 50
3.5.3 Notion de comportement ............................................................................................................. 51
3.5.4 Classes de services de DiffServ ................................................................................................... 51
3.5.5 Architecture Diffserv .................................................................................................................. 53
3.5.6 Architecture des routeurs DiffServ ............................................................................................ 55
3.5.7 L’ordonnancement du trafic ...................................................................................................... 58
3.5.8 Limitations de Diffserv dans les réseaux IP .............................................................................. 60
3.6 Intégration des mécanismes de différenciation de services dans les réseaux MPLS ................... 61
3.6.1 Origine de l’approche DS-TE et ses principales fonctionnalités .............................................. 61
3.6.2 Principe de fonctionnement de Diffserv dans le réseau MPLS ................................................ 62
3.7 Conclusion ......................................................................................................................................... 64
CHAPITRE 4 : SIMULATIONS ET RESULTATS ....................................................................... 65
4.1 Introduction ....................................................................................................................................... 65
4.2 Choix du simulateur.......................................................................................................................... 65
4.3 Présentation du logiciel OPNET Modeler....................................................................................... 65
4.3.1 Les boîtes à outils d’OPNET ...................................................................................................... 66
4.3.2 La conception du réseau sous l’OPNET .................................................................................... 67
4.4 Mise en œuvre .................................................................................................................................... 69
4.4.1 Modélisation d’un réseau MPLS ............................................................................................... 70
4.4.2 Equipements utilisés pour la modélisation du réseau ............................................................... 70
4.4.3 Configurations des trafics .......................................................................................................... 71
4.4.4 Configurations du réseau MPLS avec « Traffic Engineering » ............................................... 74
4.4.5 Analyse des résultats de la simulation ....................................................................................... 78
4.5 Conclusion ......................................................................................................................................... 84
CONCLUSION GENERALE ........................................................................................................ 85

v
ANNEXE 1 LE MODELE OSI .................................................................................................... 86
ANNEXE 2 NOTION SUR LA THEORIE DES FILES D’ATTENTE ........................................ 88
ANNEXE 3 CONFIGURATION DES PARAMETRES PENDANT LA SIMULATION ............. 91
BIBLIOGRAPHIE ........................................................................................................................ 96
FICHE DE RENSEIGNEMENT ................................................................................................... 98
RESUME ....................................................................................................................................... 99
ABSTRACT .................................................................................................................................. 99

vi
LISTE DES ABREVIATIONS
AS Autonomous System
ACL Access Control List
AF Assured Forwarding
ARP Address Resolution Protocol
ATM Asynchronous Transfer Mode
AToM Any Transport over MPLS
BC Bandwidth Constraint
BGP Border gateway Protocol
CL Controlled Load
CoS Class of Services
CPU Central Processing Unit
CQ Custom Queuing
CR-LDP Constraint-based Routing LDP
CSPF Constrained Shortest Path First
CT Class Type
DiffServ Differentiated Services
DSCP Differentiated Services Code Point
DS-TE DiffServ_aware MPLS Traffic Engineering
EGP Exterior Gateway Protocol
E-LSR Egress-LSR
EXP Experimental
FEC Forwarding Equivalent Classes

vii
FF Fixed Filter
FIB Forwarding Information Base
FIFO First In First Out
FR Frame Relay
FTP File Transfer Protocol
GMPLS Generalized Multiprotocol Label Switching
GS Guaranteed Service
IANA Internet Assigned Numbers Authority
ICMP Internet Control Message Protocol
IEEE Institute of Electrical and Electronics Engineers
IETF Internet Engineering Task Force
IGP Interior Gaterway Protocol
IGRP Interior Gaterway Routing Protocol
IHL IP Header Length
I-LSR Ingress-LSR
IntServ Integrated Services
IP Internet Protocol
IS-IS Intermediate System to Intermediate System
ISO International Organisation for Standardization
ISP Internet Service Provider
ITU International Telecommunication Union
LDP Label Distribution Protocol
LER Label Edge Router
LFIB Label Forwarding Information Base
viii
LIB Label Information Base
LSA Link State Advertisement
LSP Label Switching Path
LSR Label Switching Router
MAC Media Access Control
MAM Maximum allocation model
MPLS Multi-Protocol Label Switching
MTU Maximum Transfer Unit
NS-2 Network Simulator-2
OSI Open System Interconection
OSPF Open Shortest Path First
PE Provider Edge
PHB Per Hop Behavior
PIM Protocol Independent Multicast
PPP Point to Point Protocol
PQ Priority Queuing
QoS Quality of Service
RARP Reverse Address Resolution Protocol
RDM Russian Dolls Model
RIP Routing Information Protocol
RSVP Resource Reservation Protocol
SE Shared Explicit
SIP Session Initiation Protocol
SLA Service Level Agreement

ix
SPF Short Path First
TCP Transmission Control Protocol
TDP Tag Distribution Protocol
TE Traffic Engineering
ToS Type of Service
TTL Time To Live
UDP User Datagram Protocol
UIT-T Union Internationale des Télécommunications
VPI/VCI Virtual Path Identifier/ Virtual Channel Identifier
VPLS Virtual Private Lan Service
WF Wildcard Filter
WFQ Weighted Fair Queueing

1
INTRODUCTION GENERALE
La toile Internet connaît actuellement un développement vertigineux. Ce qui a fait de IP un
protocole presque universel. Le succès de ce dernier repose sur sa grande simplicité puisqu'il se
base sur le modèle Best Effort. Toutefois, ce même point qui a fait sa force, constitue actuellement
sa faiblesse. Car le modèle Best Effort a montré ses limites face aux nouveaux besoins des
applications, puisque la demande s'est diversifiée (data, voix, vidéo, etc.) et les services sont de
plus en plus gourmands en ressources. Les nouvelles applications exigent aujourd'hui de
complexifier les réseaux et de prendre en compte les spécifications propres à chacune d'elles pour
qu'elles puissent fonctionner correctement. En d'autres termes, il est primordial d'instaurer la
notion de la Qualité de Service (QoS) dans les réseaux de télécommunications.
D'un autre côté, les réseaux IP ont pris une ampleur tellement grande qu'on ne peut plus envisager
de créer une architecture nouvelle répondant aux besoins de QoS. La solution est alors de définir
des mécanismes complémentaires au fonctionnement de IP de base, permettant de prendre en
compte les exigences propres de chaque type de service. Ceci quitte à introduire une complexité
supplémentaire au fonctionnement de IP.
C'est là que MPLS s'est imposé comme une solution leader. MPLS représente une solution basée
sur le principe de commutation de circuit en remédiant au problème de gaspillage des ressources
par la gestion des priorités dans le trafic à faire circuler. Mais aujourd’hui, l’intérêt de MPLS
réside surtout dans sa capacité à offrir des services tels que le « Traffic Engineering » afin de
garantir l’équilibrage de charge des trafics entre les différents liens. Il surmonte les problèmes de
délai et de pertes de paquets vu dans les réseaux IP en fournissant un contrôle de congestion.
Notre travail consiste à étudier les performances des mécanismes de qualité de service
implémentés sur un réseau MPLS avec « Traffic Engineering » et de voir selon les résultats d’une
simulation faite sur OPNET Modeler le mécanisme le plus performant dont les paramètres de QoS
(gigue, délai de bout en bout) seront les plus optimaux.
Notre mémoire sera divisé en quatre grands chapitres. Dans le premier chapitre, nous présenterons
ce qu’est le protocole IP qui est le protocole le plus utilisé dans les réseaux « Tout IP ». Le
deuxième chapitre fera l’objet d’une étude théorique de la technologie MPLS et de l’ingénierie de
trafic. Le troisième chapitre portera sur l’étude des différents mécanismes de QoS. Et enfin, la
simulation sous OPNET Modeler de notre étude sera traitée dans le quatrième chapitre.

2
CHAPITRE 1
LE PROTOCOLE INTERNET
1.1 Introduction
Avant d’aborder MPLS, il est important d'étudier les fonctionnalités existant dans l'IP classique et
qui ont conduit à l'élaboration de ce protocole. IP signifie « Internet Protocol » ou protocole
Internet. Il représente le protocole réseau le plus répandu. Il permet de découper l'information à
transmettre en paquets, de les adresser, de les transporter indépendamment les uns des autres et de
recomposer le message initial à l'arrivée. Ce protocole utilise ainsi une technique dite de
commutation de paquets. Il apporte l'adressage en couche 3 qui permet la fonction principale de
routage. Il est souvent associé à un protocole de contrôle de la transmission des données appelé
TCP, on parle ainsi du protocole TCP/IP. Au cours de ce premier chapitre nous allons voir les
caractéristiques du protocole IP, l’adressage dans les réseaux IP, le routage IP et enfin la
résolution d’adresse logique. [1]
1.2 Caractéristiques du protocole IP
1.2.1 Description du protocole IP
Comme son nom l'indique « Internet Protocol », le protocole IP a pour rôle de router le trafic à
travers des réseaux. Il a été conçu pour réaliser l'interconnexion de réseaux informatiques et
permettre ainsi les communications entre systèmes. Ce protocole assure la transmission des
paquets de données, appelés datagrammes entre un ordinateur source et un ordinateur destination.
Par exemple, les applications qui tournent sur une machine cliente génèrent des messages qui
doivent être envoyés sur une autre machine d'un autre réseau. IP reçoit ces messages de la couche
transport et les envoie vers sa destination grâce à l'adressage IP.
Le protocole IP multiplexe les protocoles de la couche transport et a la faculté de détruire les
paquets ayant transité trop longtemps sur le réseau. Il permet également de fragmenter et de
rassembler de nouveau les fragments de données. Cependant, il n'effectue ni contrôle d'erreur, ni
contrôle de flux. [1]
1.2.2 Format du datagramme IP
La structure du datagramme IP sera détaillée par la figure 1.01 :

3
Figure 1.01 : Champs d’un datagramme IP
- Ver (version) : indique la version de protocole IP utilisée (4 bits) ;
- IHL (IP header length - Longueur de l’en-tête IP ou LET) : indique la longueur de l'entête
du datagramme en mots de 32 bits (4 octets). Ce champ ne peut prendre une valeur en
dessous de 5 pour être valide ;
- Service (type de service): indique l'importance qui lui a été accordée par un protocole de
couche supérieure donné (8 bits). Il indique au dispositif chargé de l'acheminement des
datagrammes, le routeur, l'attitude à avoir vis-à-vis des datagrammes. Les bits de ce champ
sont répartis comme suit :
Bits 0 - 2 : Priorité ;
Bit 3 : 0 = Retard standard, 1 = Retard faible ;
Bit 4 : 0 = Débit standard, 1 = Haut débit ;
Bits 5 : 0 = Taux d'erreur standard, 1 = Taux d'erreur faible ;
Bit 6 - 7 : Réservé.
Figure 1.02 : Le champ Type of service IP
- Total length (longueur totale): précise la longueur du paquet IP en entier, y compris les
données et l'en-tête, en octets (16 bits). Ce champ ne permet de coder qu'une longueur de
datagramme d'au plus 65.535 octets étant donné qu'il est codé sur 16 bits, comme indiqué
précédemment ;
Priorité R D T 0 0
0 2 3 4 5 6 7

4
- Identification : contient un nombre entier qui identifie le datagramme actuel (16 bits). Il
contient une valeur entière utilisée pour identifier les fragments d'un datagramme. Ce
champ doit être unique pour chaque nouveau datagramme ;
- F ou Flags (indicateurs): un champ de 3 bits dont les 2 bits inférieurs contrôlent la
fragmentation - un bit précise si le paquet peut être fragmenté et le second indique si le
paquet est le dernier fragment d'une série de paquets fragmentés (3 bits).
Bit 0 : réservé, doit être laissé à zéro ;
Bit 1 : (AF) 0 = Fragmentation possible, 1 = Non fractionnable ;
Bit 2 : (DF) 0 = Dernier fragment, 1 = Fragment intermédiaire.
O AF DF
0 1 2
Figure 1.03 : Le champ flag ou indicateur
- Offset ou Fragment Offset (décalage de fragment) : ce champ sert à rassembler les
fragments du datagramme (13 bits). Il indique le décalage du premier octet du fragment
par rapport au datagramme complet. Cette position relative est mesurée en blocs de 8
octets (64 bits). Le décalage du premier fragment vaut zéro ;
- TTL (durée de vie) : un compteur qui décroît graduellement, par incréments, jusqu'à zéro.
A ce moment, le datagramme est supprimé, ce qui empêche les paquets d'être
continuellement en boucle (8 bits) ;
- Protocol (protocole) : précise le protocole de couche supérieure qui recevra les paquets
entrants après la fin du traitement IP (8 bits). Les différentes valeurs admises pour divers
protocoles sont listées dans la RFC 1060. Exemples : 17 pour UDP, 6 pour TCP... ;
- Checksum ou Header checksum (somme de contrôle d'en-tête) : assure l'intégrité de l'en-
tête IP (16 bits). Le Checksum doit être recalculé et vérifié en chaque point du réseau où
l'en-tête est réinterprété puisque certains champs de l'en-tête sont modifiés (ex., durée de
vie) pendant leur transit à travers le réseau ;
- Adresse source ou adresse d'origine : indique le nœud émetteur (32 bits) ;
- Adresse destination : indique le nœud récepteur (32 bits) ;
- Options ou IP Options : cet élément permet au protocole IP de supporter différentes
options, telles que la sécurité (longueur variable) ;

5
Les données contenues dans les datagrammes sont analysées (et éventuellement modifiées) par les
routeurs permettant leur transit. [1] [2]
1.3 L’adressage dans les réseaux IP
1.3.1 Principe de l'adressage des machines
Lorsque nous envoyons des données à travers l'Internet, les données ne sont pas envoyées de
manière brute mais elles sont découpées en messages, puis en segments, en datagrammes et enfin
en trames. Les datagrammes, outre l'information, sont constitués d'en-tête contenant l'adresse IP de
l'expéditeur (votre ordinateur) et celle du destinataire (l'ordinateur que vous voulez atteindre),
ainsi qu'un nombre de contrôles déterminé par l'information emballée dans le paquet : ce nombre
de contrôles, communément appelé en-tête total de contrôles ou « checksum », permet au
destinataire de savoir si le datagramme IP a été "abîmé" pendant son transport. L'adressage joue
donc un rôle très important dans ce processus. [2][4]
1.3.2 Structure d'adresses IP
Chaque machine d'Internet possède une adresse IPv.4 représentée sur un entier de 32 bits, ce qui
lui permet d'être identifiée de manière unique dans le réseau. L'adresse est constituée de deux
parties: un identificateur de réseau (netid) et un identificateur de machine pour ce réseau (hostid).
Il existe quatre classes d'adresses, chacune permettant de coder un nombre différent de réseaux et
de machines. Pour assurer l'unicité des numéros de réseau, les adresses Internet sont attribuées par
un organisme central, l'InterNIC (pour Madagascar, il s'agit du NlC-mg).
Bien qu'IPv.6, la nouvelle génération du protocole IP existe déjà, IPv.4 reste largement le plus
utilisé étant donné que la saturation d'adressage ne semble pas encore être un problème majeur.
Aussi, dans la suite de l'ouvrage, nous nous référerons au protocole IPv4.
IPv6 utilise un adressage utilisant huit groupes de quatre lettres hexadécimales séparés par « : ».
Les enjeux majeurs de l'IPv6, outre l'extension de l'espace d'adressage, sont : un traitement plus
rapide grâce à un en-tête plus simplifié, la sécurité, la notion de flux (qualité de service). [1][2][4]
1.3.3 Classes d'adresses IP
L'adresse réseau est placée sur les bits de poids fort, alors que l'adresse de machine est calculée sur
les bits de poids faible. Il existe plusieurs classes d'adresses. On parle des classes A, B, C, D et E.
Elles sont différenciées par les bits de poids fort qui les composent.

6
Figure 1.04 : Classes d'adresses IP
Une adresse IP est toujours de la forme X1.X2.X3.X4 (les Xi sont des blocs de 8 bits). La
spécification du netid dépend de la classe. Dans le cas d'une classe A, la valeur de X1 permet de
reconnaître ce réseau ; les X2, X3, X4 permettent de constituer des adresses individuelles. On
pourra donc adresser théoriquement 16.777.214 machines. Dans le cas d'une classe B, il est
spécifié par XI et X2. On pourra alors adresser 65.534 machines. Une classe C fixe les valeurs de
XI, X2, X3 pour le netid. On pourra donc adresser 254 machines. La classe D est une classe
quelque peu différente, puisqu'elle est réservée à une utilisation particulière : le multicast. La
classe E est quant à elle une classe non usitée à ce jour. [1] [2]
Le multicast ou multi diffusion est une technique utilisée par les protocoles spéciaux pour
transmettre simultanément des messages à un groupe donné de nœuds différents.
Remarque :
Il y a des adresses spéciales que le public ne peut pas utiliser comme adresse d'identification :
- Adresse machine locale : adresse IP dont le champ réseau (netid) ne contient que des zéros;
- Adresses réseau : adresse IP dont la partie hostid ne comprend que des zéros; => la valeur zéro
ne peut être attribuée à une machine réelle : 192.20.0.0 désigne le réseau de classe B ;
- hostid = 0 (=> tout à zéro), l'adresse est utilisée au démarrage du système afin de connaître
l'adresse IP ;
- hostid = l (=> tout à 1) et netid = l (=> tout à 1) ou hostid = 0 (=> tout à zéro) et netid=0
(=> tout à zéro).
L' I.A.N.A a réservé les trois blocs d'adresses IP suivants pour l'adressage des réseaux privés :

7
- 1 adresse de classe A : 10.0.0.0 - 10.255.255.255 ;
- 16 adresses de classe B : 172.16.0.0 - 172.31.255.255 ;
- 255 adresses de classe C : 192.168.0.0 - 192.168.255.255.
Classe d'adresse IP Minimum Maximum Nombre de réseaux
A 1 126 127
B 128 191 16.383
C 192 223 2.097.151
D 224 239
E 240 247
Tableau 1.01: Comparaison entre les différentes classes d’adresse IP
1.4 Routage IP
Le routage désigne une technique permettant de déterminer le chemin emprunté par un message
ou un paquet de données. C'est une méthode d'acheminement d'informations vers la bonne
destination. Le routage s'opère au niveau de la couche 3 du modèle OSI, c'est-à-dire la couche
réseau ou couche IP. Ainsi, les couches TCP et UDP restent donc à l'écart du concept de routage.
Le système de routage est illustré par la figure 1.05 :
Figure 1.05 : Routage de paquets
Comme nous l'avons dit précédemment les données circulent à travers le réseau sous forme de
paquets ou datagrammes IP. Afin d'atteindre leur destination, ils traversent maints routeurs. [1]
Les routeurs sont des unités d'interconnexion de réseaux qui fonctionnent au niveau de la couche
3 OSI (couche réseau). Ils interconnectent des segments de réseau ou des réseaux entiers. Leur

8
rôle consiste à acheminer les paquets de données entre les réseaux, en fonction des informations
de la couche 3. Ils possèdent l'intelligence nécessaire pour déterminer le meilleur chemin de
transmission des données sur le réseau.
Le routeur assure trois fonctions principales :
- permettre la communication entre des machines n'appartenant pas au même réseau.
- offrir un accès Internet à des utilisateurs d'ordinateurs se trouvant dans un réseau local.
- filtrer les datagrammes IP pouvant avoir accès à un réseau.
Il existe différents niveaux de routeurs, ceux-ci fonctionnent donc avec des protocoles différents:
- Les routeurs noyaux sont les routeurs principaux car ce sont eux qui relient les différents
réseaux ;
- Les routeurs externes permettent une liaison des réseaux autonomes entre eux. Ils
fonctionnent avec un protocole appelé EGP (Exterior Gateway Protocol) qui évolue petit à
petit en gardant la même appellation ;
- Les routeurs internes permettent le routage des informations à l'intérieur d'un réseau
autonome. Ils s'échangent des informations grâce à des protocoles appelés IGP (Interior
Gateway Protocol).
La figure 1.06 représente les différents niveaux de routeurs.
Figure 1.06 : Les différents niveaux de routeurs
Les routeurs possèdent des tables de routage leur permettant de choisir l'interface de sortie d'un
datagramme à partir des informations stockées dans cette dernière. Les routeurs prennent
également des décisions en fonction de la densité du trafic et du débit des liaisons (bande
passante). La sélection du chemin permet à un routeur d'évaluer les chemins disponibles vers une
9
destination donnée et de définir le meilleur chemin pour traiter un datagramme. [1][2]
Dans le cas où le chemin correspondant figurant dans la table de routage est introuvable, IP
supprime le datagramme.
Le tableau 1.02 montre un exemple de table de routage.
Adresse de destination Adresse du prochain routeur directement accessible Interface
194.56.32.124 131.124.51.108 2
110.78.202.15 131.124.51.108 2
53.114.24.239 194.8.212.6 3
187.218.176.54 129.15.64.87 1
Tableau 1.02: Exemple de table de routage
1.4.1 Les « Autonomous System »
Dans le réseau Internet, les routeurs sont organisés de manière hiérarchique. Les domaines dans
l’Internet sont une collection de systèmes autonomes AS ou « Autonomous System ». Un système
autonome est un réseau ou un groupe de réseaux placé sous une autorité administrative de routage
unique.
Les AS utilisent à l’intérieur de leur domaine des protocoles de routage de type IGP tels que OSPF
ou IS-IS. OSPF a été créé par l’IETF (Internet Engineering Task Force) et IS-IS par l’ISO
(International Organization for Standardization). Ces deux protocoles calculent les routes par des
algorithmes de type Link-State basés sur l’algorithme du plus court chemin de Dijkstra. [3]
1.4.2 Les protocoles de routage IGP
Un protocole de routage est un agent capable de modifier les tables de routage dans chaque
routeur afin de rendre possible le transport des paquets de bout en bout, mais aussi de le faire le
plus efficacement possible. Les principaux objectifs à atteindre par un protocole de routage sont:
- Optimisation (sélectionner le meilleur chemin selon les critères choisis),
- Robustesse et souplesse (pour faire face à tout imprévu),
- Convergence rapide (pour faire face rapidement aux boucles et aux pannes réseau),
- Simplicité (pour ne pas surcharger le réseau de données de contrôle).
En échangeant régulièrement des informations, les routeurs construisent une image de la topologie

10
du réseau, qui n’est pas nécessairement connue initialement. Cela permet de créer les tables de
routage. [3]
Il existe deux grands types de protocoles de routage dynamique.
Distance-Vector
Le fonctionnement général d’un algorithme de routage de type distance-vector (vecteur de
distance) est le suivant : Chaque routeur i associe un coût à chacun de ses liens vers un autre
routeur j dans une table di(j). Ce coût peut représenter n’importe quel type de mesure (une
constante, un prix, un délai, ...). Chaque routeur i échange di avec ses voisins, et peut ainsi
construire une nouvelle table Di(i,k) représentant le coût minimum pour atteindre un routeur k non
directement connecté à i. Cette valeur est mise à jour à chaque réception de la table Dj(j,k), pour
toutes les valeurs de k connues par le routeur voisin.
𝐷𝑖 (𝑗, 𝑘) = min𝑗 𝑐𝑜𝑛𝑛𝑒𝑐𝑡é à 𝑖
(𝑑𝑖(𝑗) + 𝐷𝑗(𝑗, 𝑘)) (1.01)
Le choix du lien à emprunter pour aller de i à k est alors le lien (i,j) qui a permis la dernière mise à
jour de la valeur actuelle de Di(i,k).
Ces échanges de tables entre les routeurs se font tant que l’algorithme n’a pas convergé. Une fois
la convergence atteinte, les échanges continuent afin de pouvoir détecter les pannes et reconverger
vers une nouvelle table de routage. Cet algorithme est l’algorithme de Bellman-Ford distribué. [3]
Exemples :
- Le protocole RIP : permet aux routeurs de déterminer le chemin d'envoi des données, sur
la base du concept de vecteur de distance. Lorsque les données passent par un routeur,
elles exécutent un saut. Un chemin comportant quatre sauts indique que les données
empruntant ce chemin doivent passer par quatre routeurs avant d'atteindre leur destination.
S'il existe plusieurs chemins vers une destination, le routeur recourt au protocole RIP pour
sélectionner celui qui comporte le moins de sauts. Toutefois, comme le nombre de sauts est
la seule métrique de routage utilisée par le protocole RIP pour déterminer le meilleur
chemin, il n'est pas certain que le chemin sélectionné soit le plus rapide. Néanmoins,
l'utilisation du protocole RIP est toujours largement répandue. Sa popularité est surtout due
au fait qu'il a été l'un des premiers protocoles de routage à être développé. Le protocole

11
RIP pose un autre problème lorsque la destination choisie ne peut pas être atteinte parce
qu'elle est trop éloignée. Avec le protocole RIP, les données peuvent exécuter 15 sauts au
maximum. Par conséquent, il n'est pas possible d'atteindre un réseau de destination situé à
une distance de plus de 15 routeurs. [1]
- Le protocole IGRP : Le protocole IGRP ou « Interior Gateway Router Protocol » a été
défini par la société Cisco pour ses routeurs. En effet, alors qu'elle utilisait presque
exclusivement à ses débuts le protocole RIP, cette compagnie a été amenée à mettre en
place un routage plus performant, l'IGRP, qui n'est autre qu'une version améliorée de RIP.
Elle intègre le routage multi chemin, la gestion des routes par défaut, la diffusion de
l'information toutes les 90 secondes au lieu de toutes les 30 secondes, la détection des
bouclages, etc. Ce protocole a lui-même été étendu par une meilleure protection contre les
boucles : il s'agit du protocole EIGRP « Extended IGRP ». [1]
Avantages et Inconvénients :
Le problème des algorithmes de routage de type distance-vector est la lenteur de leur convergence
et l’instabilité (boucles de routage) de l’algorithme avant sa convergence. RIP résout cela en
limitant les valeurs possibles de la métrique entre 1 et 15, 16 représentant une distance infinie,
mais cela limite la taille du domaine. IGRP lève cette limitation en introduisant d’autres
techniques. [1]
Link State : OSPF
OSPF ou « Open Shortest Path First » est un protocole de routage dynamique et hiérarchique basé
sur l’adressage IP. C’est un protocole de routage adapté aux grands réseaux à commutation de
paquets (grand nombre de routeurs, redondance sur les chemins) dans lequel chaque routeur a une
vision globale du réseau.
OSPF est un protocole de type Link-State (état de lien) : les données propagées par un routeur sont
uniquement les informations sur ses liens avec ses voisins immédiats du même niveau
hiérarchique. [3]

12
Résumé de l’algorithme du Link-State
Lors de la phase d’initialisation de l’algorithme, chaque routeur découvre et identifie ses voisins
immédiats (les routeurs voisins connectés à ses liens) grâce au protocole Hello. Des informations,
appelées « link-states » sont alors construites. Elles contiennent des informations sur tous les liens
du routeur, et notamment leur métrique. Les LSA « Link-State Advertisement » ou publication
d’état des liens regroupent ces informations pour les diffuser à grande échelle sur l’ensemble du
domaine OSPF, de sorte que chaque routeur ait une vision (décalée dans le temps) de la topologie
du domaine et de sa métrique. Chacun d’eux peut alors appliquer l’algorithme de Dijkstra du plus
court chemin entre lui-même et l’ensemble des autres routeurs, pour construire sa table de routage
IP. [3]
Principes de base d’OSPF
Chaque routeur détermine l’état de ses connections (liens) avec les routeurs voisins. Il diffuse ses
informations à tous les routeurs appartenant à une même zone. Ces informations forment une base
de données qui doit être identique à tous les routeurs de la même zone. Sachant qu’un système
autonome (AS) est constitué de plusieurs zones, l’ensemble de ces bases de données représente la
topologie de l’AS. A partir de cette base de données, chaque routeur va calculer sa table de
routage grâce à l’algorithme SPF (Short Path First).
OSPF est également capable de différencier les classes de service, permettant ainsi un routage
différent selon le type de trafic dans le réseau. Les tables de routages pouvant être différentes
selon les classes de services, une métrique différente peut être utilisée pour chacune d’elle. Le
partage de charge (Load Balancing) entre routes de longueur égales peut également être employé.
[1][3]
1.4.3 Le protocole de routage BGP
Le protocole BGP (Border Gateway Protocol) est un protocole de routage entre systèmes
autonomes. Il est utilisé pour échanger les informations de routage entre AS dans le réseau
Internet. Ces informations de routage se présentent sous la forme de la suite des numéros d'AS à
traverser pour atteindre la destination.
Quand BGP est utilisé entre AS, le protocole est connu sous le nom de e-BGP (exterior BGP). Si
BGP est utilisé à l'intérieur d'un AS pour échanger des routes entre les routeurs de bordure d’un
même AS afin de le traverser, alors le protocole est connu sous le nom de i-BGP (interior BGP).
BGP est un protocole très robuste et très scalable : les tables de routage BGP du réseau Internet

13
comprennent plus de 90000 routes. Si BGP a atteint ce niveau de scalabilité, c'est essentiellement
parce qu'il associe aux routes des attributs permettant de définir des politiques de routage entre
AS. [3]
Figure 1.07 : Exemple d’interconnexion d’AS par BGP
Les routeurs de frontière communiquant par i-BGP doivent être complètement maillés (mais pas
forcément directement connectés) afin de permettre l’échange des informations. Les évolutions de
BGP utilisent cependant des techniques permettant de réduire le nombre de messages à échanger
afin de réduire le trafic de contrôle dans les grands AS.
Les voisins BGP échangent initialement toutes leurs informations de routage par une connexion
TCP. Les routeurs BGP n'envoient ensuite à leur voisins que des mises à jour des tables de routage
lorsqu'un changement de route est détecté ou qu'une nouvelle route est apprise. Ainsi, les routeurs
BGP n'envoient pas de mises à jour périodiques mais ne diffusent que le chemin «optimal» vers un
réseau destination.
BGP peut servir aussi à mettre en commun les tables de routages des différents algorithmes IGP
pouvant exister dans différents sous-domaines d’un même AS, par exemple pour pouvoir router

14
des données d’un sous-domaine à l’autre, sans sortir de l’AS. [3]
Le tableau 1.03 résume les différents types de protocole.
Types de protocole Internet ISO
Intra-domaine (IGP) Entre terminaux ICMP router discovery
ICMP redirect
Distance-Vector :
RIP, RIP II
ES-IS
Entre routeurs Distance-Vector :
RIP, RIP II, IGRP, EIGRP
Link-State :
OSPF
Link-State :
IS-IS
Inter-domaines (EGP) Distance-Vector :
BGP
Tableau 1.03: Protocoles de routage dans internet
1.4.4 Différentes phases de routage IP
Les données utilisateurs se présentant dans le nœud, pour être livrées à sa destination, doivent
passer par différentes phases. [5]
1.4.4.1 Phase d'encapsulation des données
Lors d'une transmission, les données traversent chacune des couches de haut en bas au niveau de
la machine émettrice. A chaque couche, une information est ajoutée au paquet de données, il s'agit
d'un en-tête, ou d'un en-queue, ensemble de données de supervision qui garantit la transmission.
Au niveau de la machine réceptrice, c'est l'opération inverse. Lors du passage dans chaque couche,
l'en-tête ou 1' en-queue est lu, puis supprimé. Ainsi, à la réception, dans la couche de même niveau
que la couche émettrice, le message redevient dans son état originel. [3][5]
Ainsi, à chaque couche, le paquet de données change d'aspect et les appellations changent :
- le paquet de données est appelé message au niveau de la couche application,

15
- le message est ensuite encapsulé sous forme de segment dans la couche transport,
- le segment une fois encapsulé dans la couche Internet prend le nom de datagramme,
- le nom trame est utilisé au niveau de la couche accès réseau.
1.4.4.2 Phase de fragmentation des datagrammes IP
Dans les réseaux à transfert de paquets, les données des utilisateurs sont découpées ou
fragmentées en paquets, ce qui facilite la retransmission. [3]
Fragmenter un datagramme revient à le diviser en plusieurs morceaux. Chaque morceau a le
même format que le datagramme de départ. Chaque nouveau fragment a un en-tête, qui reprend la
plupart des informations de l'en-tête d'origine et il doit tenir dans une seule trame.
Sur Internet, dès qu'un datagramme a été fragmenté, les fragments sont transmis indépendamment
les uns des autres jusqu'à leur destination, où ils doivent être réassemblés. Chaque datagramme
fragmenté porte un numéro de séquencement pour que le récepteur puisse les réassembler dans le
bon ordre.
Si un des fragments est perdu, le datagramme ne peut pas être réassemblé et les autres fragments
doivent être détruits sans être traités. La probabilité de perte d'un datagramme augmente avec la
fragmentation.
Sur toute machine ou passerelle mettant en œuvre TCP/IP, une unité maximale de transfert
(Maximum Transfer Unit ou MTU) définit la taille maximale d'un datagramme véhiculé sur le
réseau physique correspondant.
Lorsque le datagramme est routé vers un réseau physique dont le MTU est supérieur au MTU
courant, la passerelle route les datagrammes tels quels. Par contre, si le MTU est plus petit que le
MTU courant, la passerelle fragmente le datagramme en un certain nombre de fragments,
véhiculés par autant de trames sur le réseau physique correspondant.
Le destinataire final reconstitue le datagramme initial à partir de l'ensemble des fragments reçus,
la taille de ces fragments correspond au plus petit MTU emprunté sur le réseau.
La fragmentation d'un datagramme se fait au niveau des routeurs, c'est-à-dire lors de la transition
d'un réseau dont le MTU est important à un réseau dont le MTU est plus faible.

16
Figure 1.08 : Fragmentation d’un datagramme dans un routeur
Chaque type de réseau a son MTU. Voici quelques exemples de MTU :
Type de réseau MTU(en octets)
Arpanet 1000
Ethernet 1500
FDDI 4470
Tableau 1.04: Exemples de MTU
1.4.4.3 Phase de lecture
Dans le routeur, le processus de couche réseau examine l'en-tête du paquet entrant afin de
déterminer le réseau de destination. Il consulte ensuite la table de routage qui associe les réseaux
aux interfaces sortantes. Le paquet est de nouveau encapsulé dans la trame de liaison de données
appropriée à l'interface sélectionnée, puis il est placé en file d'attente en vue d'être transmis au
nœud suivant le chemin. [3][5]
1.4.4.4 Phase de routage
Dans la phase de routage, deux cas peuvent se présenter.
- Routage direct
C'est le cas où les deux machines qui veulent se communiquer sont rattachées au même réseau,
elles ont donc le même numéro de réseau IP. Il peut s'agir de deux hôtes, ou d'un routeur et d'un
hôte. Il suffit donc de déterminer l'adresse physique destinataire et d'encapsuler le datagramme
dans une trame avant de l'envoyer sur le réseau. [5]
- Routage indirect
Dans ce cas, le routage est plus complexe parce qu'il faut déterminer le routeur auquel les

17
datagrammes doivent être envoyés. Ces derniers peuvent ainsi être transmis de routeur en routeur
jusqu'à ce qu'ils atteignent l'hôte destinataire. La fonction de routage est fondée principalement sur
les tables de routage.
Grâce à la table, le routeur, connaissant l'adresse du destinataire encapsulé dans le message, est
capable de savoir sur quelle interface envoyer le message (cela revient à connaître quelle carte
réseau utilisé) et à quel routeur, directement accessible sur le réseau auquel cette carte est
connectée, remettre le datagramme. Ce mécanisme consistant à ne connaître que l'adresse du
prochain routeur menant à la destination est appelé routage par sauts successifs. [5]
Remarque :
Cependant, il se peut que le destinataire appartienne à un réseau non référencé dans la table de
routage. Dans ce cas, le routeur utilise un routeur par défaut (appelé aussi passerelle par défaut).
Le message est ainsi remis de routeur en routeur par sauts successifs, jusqu'à ce que le destinataire
appartienne à un réseau directement connecté à un routeur. Celui-ci remet alors directement le
message à la machine visée.
1.4.5 Détermination des distances des chemins de réseau à l'aide de métriques
La table de routage est mise à jour dans un intervalle de temps régulier selon les algorithmes
utilisés (à chaque 30s pour RIP). En outre, cette mise à jour est aussi effectuée dès qu'une
modification topologique se produit à savoir : pannes des équipements de routage (routeurs ou
lignes de transmissions), ajout ou suppression des hôtes ou autres modifications.
Lorsqu'un algorithme de routage met à jour une table de routage, son principal objectif est de
déterminer les meilleures informations à présenter dans la table. L'algorithme génère un nombre,
appelé "valeur métrique", pour chaque chemin du réseau.
Nous pouvons calculer les métriques en fonction d'une seule caractéristique de chemin ou en
combinant plusieurs caractéristiques parmi lesquelles :
- le débit : le débit d'une liaison, mesuré en bits par seconde (en règle générale, une liaison
Ethernet à 10 Mbits/s est préférable à une ligne louée de 64 Kbits/s) ;
- le délai : le temps nécessaire à l'acheminement d'un paquet, pour chaque liaison, de la
source à la destination ;

18
- la charge : la quantité de trafics sur une ressource réseau telle qu'un routeur ou une liaison;
- la fiabilité : cette notion indique généralement le taux d'erreurs sur chaque liaison du
réseau ;
- le nombre de sauts : le nombre de routeurs par lesquels un paquet doit passer avant
d'arriver à destination ;
- le coût : une valeur arbitraire, généralement basée sur la bande passante, une dépense
monétaire ou une autre mesure, attribuée à un lien par un administrateur réseau. [3][5]
1.5 Résolution d'adresses logiques
Toute interface du réseau est modélisée par une adresse logique IP. Or, pour la transmission sur
l'interface physique, cette information n'est pas accessible à cause de l'encapsulation dans la trame
qui contient des adresses matérielles, adresses MAC (Media Access Control), qui sont
généralement attribuées par les fabricants de la carte réseau et codées en dur sur la carte. Cela
suppose donc qu’il faut connaître au préalable l'adresse physique du destinataire. Ce qui s'avère
fastidieux pour l'être humain. De plus, nous ne connaissons, au mieux, que l'adresse IP de ce
dernier. Nous devons ainsi mettre en place des techniques de correspondances d'adresses. Ces
techniques sont modélisées par les protocoles ARP et RARP. [1][2][6]
1.5.1 Le protocole ARP
Le protocole ARP (Address Resolution Protocol) permet à un ordinateur de trouver l'adresse
MAC de l'ordinateur associé à une adresse IP. La requête ARP est envoyée avec une adresse
matérielle de diffusion, ou adresse MAC de diffusion, ayant le format FF-FF-FF-FF-FF-FF.
Comme un paquet de données doit contenir une adresse MAC de destination et une adresse IP de
destination, aussi, si l'une ou l'autre manque, les données ne sont pas transmises depuis la couche 3
aux couches supérieures. Ainsi, les adresses MAC et IP se contrôlent et s'équilibrent
mutuellement. Une fois que les équipements ont déterminé les adresses IP des équipements de
destination, ils peuvent ajouter les adresses MAC de destination aux paquets de données.
Les tables ARP, mappent les adresses IP avec les adresses MAC correspondantes. Ces tables sont
des sections de mémoire RAM dans lesquelles la mémoire cache est mise à jour automatiquement
dans chaque équipement. Chaque ordinateur du réseau met à jour sa propre table ARP. Chaque
fois qu'un équipement souhaite envoyer des données sur le réseau, il utilise les informations

19
contenues dans sa table ARP. [6]
1.5.2 Le protocole RARP
Le protocole RARP (Reverse Address Resolution Protocol) est beaucoup moins utilisé, il signifie
Protocole ARP inversé, il s'agit donc d'une sorte d'annuaire inversé des adresses logiques et
physiques. L'utilisateur ne connaît donc pas l'adresse IP de celui à qui il veut correspondre. En
réalité le protocole RARP est essentiellement utilisé pour les stations de travail n'ayant pas de
disque dur et souhaitant connaître leur adresse physique...
Les principaux problèmes de RARP sont : qu'un serveur ne peut servir qu'un LAN et il nécessite
beaucoup de temps d'administration pour maintenir des tables importantes dans les serveurs. Pour
pallier à ces deux problèmes d'administration, le protocole RARP peut être remplacé par le
protocole DRARP (Dynamic RARP), qui en est une version dynamique. [6]
1.6 Conclusion
Le protocole IP est un protocole de niveau 3 fonctionnant en mode non connecté. Ce qui signifie
que la décision de routage d'un paquet est localement effectuée à chaque nœud. On appelle cela le
routage "hop by hop". De ce fait, l'émetteur d'un paquet ne peut pas prévoir le chemin qui sera
emprunté par ce dernier. Il est donc impossible d'avoir la certitude qu'un paquet arrivera à
destination. Enfin, lors du routage, le choix du prochain saut est fait soit en fonction du nombre
de routeurs traversés par le paquet qui doit être minimal, exemple : RIP, soit que la somme des
poids de tous les liens empruntés par le routeur doit être minimale, exemple : OSPF.
Cependant, dans leurs réseaux, les opérateurs ont besoin de plus de "certitude" quant au routage du
trafic
- le routage d'un flux doit emprunter le même chemin : mode connecté ;
- les décisions de routage pour l'établissement d'un chemin doivent prendre en compte
l'utilisation actuelle du débit des liens, afin d'optimiser la bande passante et éviter la
congestion : ingénierie de trafic ;
- un flux doit être acheminé en garantissant le respect de certaines contraintes : qualité de
service.
La technologie MPLS va permettre au réseau IP de pouvoir mettre en œuvre tous ces besoins .
Nous allons donc entamer, dans le deuxième chapitre, l’étude de la technologie MPLS ainsi que
les principes de l’ingénierie de trafic.

20
CHAPITRE 2
MPLS ET INGENIERIE DE TRAFIC
2.1 Introduction
MPLS ou Multi Protocol Label Switching est une technique réseau de commutation en cours de
normalisation dont le rôle principal est de combiner les concepts du routage IP de niveau 3 et les
mécanismes de la commutation de niveau 2 tels que implémentés dans ATM ou Frame Relay.
MPLS doit permettre d’améliorer le rapport performance/prix des équipements de routage,
d’améliorer l’efficacité du routage, en particulier pour les grands réseaux, et d’enrichir les services
de routage.
Le but de MPLS était à l’origine de donner aux routeurs IP une plus grande puissance de
commutation, en basant la décision de routage sur une information de label inséré. La transmission
des paquets était ainsi réalisée en commutant les paquets en fonction du label sans avoir à
consulter l’en-tête de niveau 3 et la table de routage.
Aujourd’hui, l’intérêt de MPLS n’est plus maintenant limité à la rapidité de commutation apportée
mais aussi à l’offre de services qu’il permet, avec notamment les réseaux privés virtuels (VPN) et
le Traffic Engineering (TE), qui ne sont pas réalisables sur des infrastructures IP traditionnelles.
Dans ce chapitre, nous allons voir en première partie les détails de la technologie MPLS ensuite en
deuxième partie faire une étude sur l’ingénierie de trafic.
2.2 Etude de la technologie MPLS
Dans les réseaux IP traditionnels, le routage des paquets se base sur l'adresse de destination
contenue dans l'entête de niveau 3. Chaque routeur doit alors accéder à l'entête réseau puis
consulter sa table de routage, pour déterminer finalement le saut prochain et l'interface de sortie
vers laquelle envoyer ce paquet.
Avec la croissance continue de la taille des réseaux et l'explosion des tailles des tables de routage,
ce mécanisme est devenu de plus en plus consommateur en temps et en mémoire. Une méthode
plus efficace pour l'acheminement des paquets est donc nécessaire à trouver préalablement. C'est
dans cette méthode que s'insère la technologie MPLS. En effet, l'objectif de MPLS est de
combiner en une seule entité l'efficacité des protocoles de routage et la rapidité de commutation de
niveau 2, en basant la transmission des paquets sur la commutation de « labels ». [11]

21
2.2.1 Principe de fonctionnement de MPLS
2.2.1.1 Architecture de MPLS
L'architecture du réseau MPLS utilise des LSR (Label Switch Router) et des LER (Label Edge
Router). [7]
LSR (Label Switch Router)
Le LSR est un équipement de cœur du réseau MPLS de type routeur, ou commutateur qui effectue
la commutation sur les labels et qui participe à la mise en place du chemin par lequel les paquets
sont acheminés. Lorsque le routeur LSR reçoit un paquet labélisé, il le permute avec un autre label
de sortie et expédie le nouveau paquet labélisé sur l'interface de sortie appropriée.
Le routeur LSR, peut jouer plusieurs rôles à savoir :
- l'échange d'informations de routage ;
- l'échange des labels ;
- l'acheminement des paquets.
LER (Label Edge Router)
LER est un LSR qui fait l'interface entre un domaine MPLS et le monde extérieur. En général, une
partie de ses interfaces supportent le protocole MPLS et l'autre un protocole de type IP
traditionnel. Les deux types de LER qui existent sont :
- Ingress LER est un routeur qui gère le trafic qui entre dans un réseau MPLS ;
- Egress LER est un routeur qui gère le trafic qui sort d'un réseau MPLS.
Fonctionnement d’un réseau MPLS
Avant d'examiner le fonctionnement d'un réseau MPLS, on va passer en revue le principe
d'acheminement des paquets dans un réseau IP classique et ainsi pouvoir faire une comparaison
des deux techniques.
Dans un réseau IP classique :
Il y a une mise en œuvre d'un protocole de routage (RIP, OSPF, IS-IS, etc.). Ce protocole sera
exécuté indépendamment par chaque nœud. A la convergence du protocole de routage, chaque
nœud aura une vision plus ou moins complète du réseau et pourra du coup calculer une table de

22
routage contenant l'ensemble des destinations. Chaque destination sera associée à un "prochain
saut" ou "Next Hop". [8]
Dans un réseau MPLS :
La mise en œuvre de MPLS repose sur la détermination de caractéristiques communes à un
ensemble de paquets et dont dépendra l'acheminement de ces derniers. Cette notion de
caractéristiques communes est appelée Forwarding Equivalence Class (FEC).
Une FEC est la représentation d'un ensemble de paquets qui sont transmis de la même manière et
qui suivent le même chemin au sein du réseau en ayant la même priorité.
- Le routage IP classique distingue les paquets en se basant seulement sur les adresses des
réseaux de destination (préfixe d’adresse).
- MPLS constitue les FEC selon de nombreux critères : adresse destination, adresse source,
application, QoS, etc.
Quand un paquet IP arrive à un ingress LER, il sera associé à une FEC. Puis, exactement comme
dans le cas d'un routage IP classique, un protocole de routage sera mis en œuvre pour découvrir un
chemin jusqu'à l'egress LER (voir figure 2.01, les flèches en rouges). Mais à la différence d'un
routage IP classique cette opération ne se réalise qu'une seule fois. Ensuite, tous les paquets
appartenant à la même FEC seront acheminés suivant ce chemin qu'on appellera « «Label
Switched Path » ou LSP.
Ainsi on a eu la séparation entre fonction de routage et fonction de commutation. Le routage se
fait uniquement à la première étape. Ensuite tous les paquets appartenant à la même FEC subiront
une commutation simple à travers ce chemin découvert.
Pour que les LSR puissent commuter correctement les paquets, le Ingress LER affecte une
étiquette appelée aussi « label » à ces paquets, c’est le « label imposition » ou « label pushing ».
Si on prend l'exemple de la figure 2.01, le LSR1 saura en consultant sa table de commutation que
tout paquet entrant ayant le label L=18 appartient à la FEC et doit être commuté sur telle sortie en
lui attribuant un nouveau label L=21, c’est le « label swapping ». Cette opération de commutation
sera exécutée par tous les LSR du LSP jusqu'à aboutir à l'Egress LER qui supprimera le label,
cette opération est le « label popping » ou « label disposition » et routera le paquet de nouveau
dans le monde IP de façon traditionnelle.
L'acheminement des paquets dans le domaine MPLS ne se fait donc pas à base d'adresse IP mais

23
de commutation de label.
Un protocole qui permet de distribuer les labels entre les LSR est mis en œuvre pour que ces
derniers puissent constituer leurs tables de commutation et ainsi exécuter la commutation de label
adéquate à chaque paquet entrant. Cette tâche est effectuée par "un protocole de distribution de
label" tel que LDP ou RSVP TE.
Le « label pushing » et « label popping » peuvent être le résultat d'une classification en FEC aussi
complexe qu'on veut. Ainsi on aura placé toute la complexité aux extrémités du réseau MPLS
alors que le cœur du réseau exécutera seulement la fonction simple de « label swapping » en
consultant la table de commutation. [9]
La figure 2.01 illustre un exemple de réseau MPLS.
Figure 2.01 : Exemple d’un réseau MPLS
2.2.1.2 Structure fonctionnelle MPLS
Le protocole MPLS est fondé sur les deux plans principaux :
Le plan de contrôle
Le plan de contrôle est composé d’un ensemble de protocoles de routage classique et des
protocoles de signalisation. Il est chargé de la construction, du maintien et de la distribution des
tables de routage et des tables de commutations. Pour ce faire, le plan de contrôle utilise des
protocoles de routages classiques, tels qu’IS-IS ou OSPF afin de créer la topologie des nœuds du

24
réseau MPLS, ainsi que des protocoles de signalisation spécialement développés pour le réseau
MPLS comme « Label Distribution Protocol » ou LDP, ou RSVP qui est utilisé par MPLS TE.
Dans un réseau MPLS, il existe deux méthodes pour créer et distribuer les labels. Ces méthodes
sont « Implicit routing » et « Explicit routing ». Ces deux méthodes sont celles utilisées pour
définir les chemins « Label Switching Path » ou LSP dans le réseau MPLS. [9]
- La méthode « implicit routing » est celle du routage implicite, saut par saut (hop by hop)
où chaque paquet contenant un LSP choisit indépendamment le saut suivant pour une FEC
de données.
- Le routage explicite est la méthode « explicit routing » où le premier routeur ELSR
détermine la liste des nœuds ou des routeurs LSR à suivre pour délivrer le paquet.
Le plan de données
Le plan de données permet de transporter les paquets labélisés à travers le réseau MPLS en se
basant sur les tables de commutations. Il correspond à l’acheminement des données en accolant un
entête SHIM aux paquets arrivant dans le domaine MPLS. Le plan de données est indépendant des
algorithmes de routages et d'échanges de Label. Il utilise une table de commutation appelée
« Label Forwarding Information Base » ou LFIB pour transférer les paquets labélisés avec les
bons labels. Cette table est remplie par les protocoles d'échange de label comme le protocole LDP.
A partir des informations de labels apprises par le protocole LDP, les routeurs LSR construisent
deux tables, la LIB et la LFIB. De manière générale, la LIB contient tous les labels appris des
voisins LSR, tandis que la LFIB est utilisée pour la commutation proprement dite des paquets
labélisés. La table LFIB est un sous-ensemble de la base LIB. [7]
La figure 2.02 montre l’architecture d’un routeur LSR.

25
Figure 2.02 : Architecture d’un routeur LSR
2.2.1.3 Structures de données des labels
Le protocole MPLS utilise les trois structures de données LIB, LFIB et FIB pour acheminer les
paquets : [7]
LIB (Label Information Base)
C'est la première table construite par le routeur MPLS est la table LIB. C’est la base de donnée
utilisée par LDP. Elle contient pour chaque sous-réseau IP la liste des labels affectés par les LSR
voisins. Il est possible de connaître les labels affectés à un sous-réseau par chaque LSR voisin et
donc elle contient tous les chemins possibles pour atteindre la destination.
FIB (Forwarding Information Base)
Appartenant au plan de données, elle est la base de données utilisée pour acheminer les paquets
non labellisés (routage IP classique). Un paquet à acheminer est labellisé si le label du saut suivant
est valable pour le réseau de destination IP.
LFIB (Label Forwarding Information Base)
A partir de la table LIB et de la table de routage IP du réseau interne au backbone, chaque routeur
LSR construit une table LFIB qui sera utilisée pour commuter les paquets labélisés. Dans le réseau

26
MPLS, chaque sous-réseau IP est appris par un protocole IGP, qui détermine le prochain saut ou
« next-hop » pour l’atteindre. Donc pour atteindre un sous-réseau IP donné, le routeur LSR
choisit le label d’entrée de la table LIB qui correspond à ce sous-réseau IP et sélectionne comme
label de sortie le label annoncé par le routeur voisin déterminé par le protocole IGP.
2.2.1.4 Construction des structures de données
La construction des structures de données effectuée par chaque routeur LSR doit suivre les étapes
suivantes : [9]
- Élaboration des tables de routages par les protocoles de routage.
- Allocation indépendamment d'un label à chaque destination dans sa table de routage par le
LSR.
- Enregistrement dans la LIB des labels alloués ayant une signification locale.
- Enregistrement dans la table LFIB avec l'action à effectuer sur ces labels et leur prochain
saut.
- Envoi par le LSR les informations sur sa LIB à ces voisins.
- Enregistrement par chaque LSR des informations reçues dans sa LIB.
- Enregistrement des informations reçues des prochains sauts dans la FIB.
Figure 2.03 : Utilisation des structures de données pour l'acheminement

27
2.2.2 Les labels
2.2.2.1 L'encapsulation de label MPLS dans différentes technologies
Le protocole MPLS, basé sur le paradigme de changement de label, dérive directement de
l'expérience acquise avec l'ATM. Ce mécanisme est aussi similaire à celui de Frame Relay ou de
liaisons PPP. L'idée de MPLS est de rajouter un label de couche 2 aux paquets IP dans les routeurs
frontières d'entrée du réseau.
Un label a une signification d'identificateur local d'une FEC entre 2 LSR adjacents et mappe le
flux de trafic entre le LSR amont et le LSR aval. La figure 2.04 illustre la mise en œuvre des
labels dans différentes technologies. Ainsi, MPLS fonctionne indépendamment des protocoles de
niveau 2 (ATM, FR, etc.) et des protocoles de niveau 3 (IP, etc.). C'est ce qui lui vaut son nom de
"MultiProtocol Label Switching". [9]
Figure 2.04 : L'encapsulation MPLS dans différentes technologies
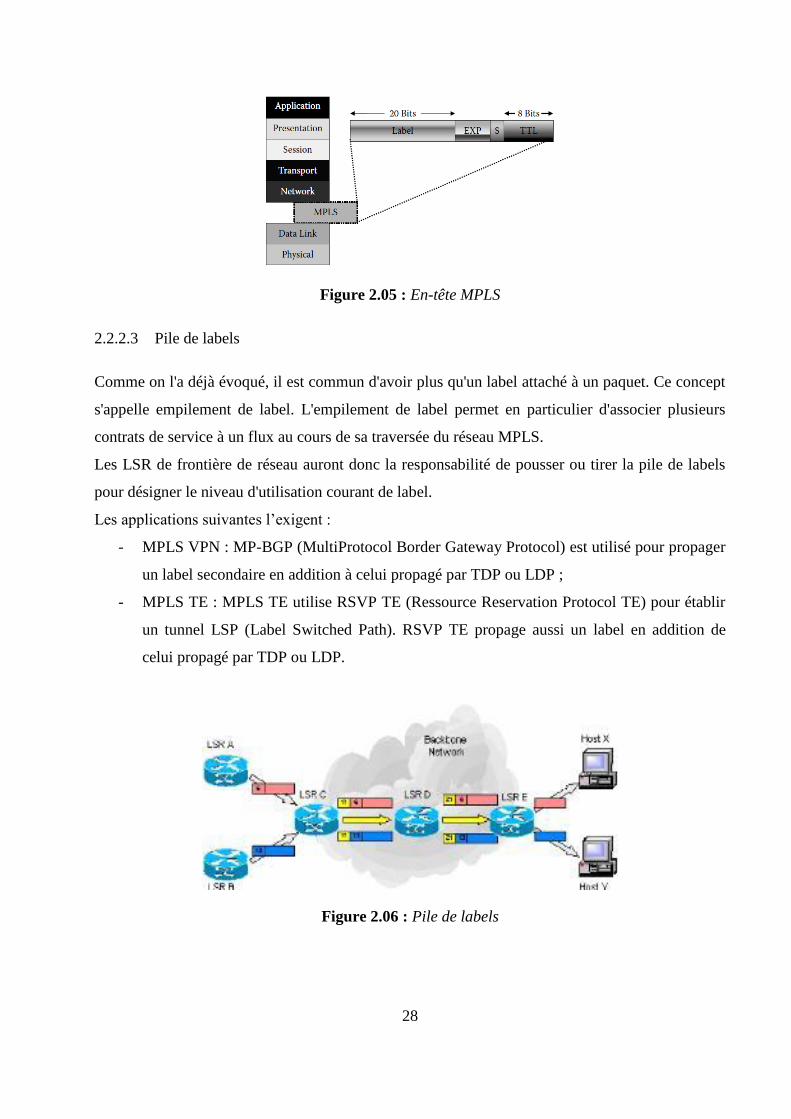
2.2.2.2 L'en-tête MPLS
L'en-tête MPLS se situe entre les en-têtes des couches 2 et 3, où l'en-tête de la couche 2 est celle
du protocole de liaison et celle de la couche 3 est l'en-tête IP. L'entête est composé de quatre
champs :
- Le champ Label (20 bits), valeur représentant le label, il fournit les informations sur le
protocole de la couche 2 et d’autres informations pour transférer les données ;
- Le champ Exp ou CoS (3 bits) pour la classe de service (Class of Service) ;
- Un bit Stack pour supporter un label hiérarchique (empilement de labels) ;
- Et un champ TTL (Time To Live) pour limiter la durée de vie du paquet (8 bits). Ce
champ TTL est le même que pour IP.
28
Figure 2.05 : En-tête MPLS
2.2.2.3 Pile de labels
Comme on l'a déjà évoqué, il est commun d'avoir plus qu'un label attaché à un paquet. Ce concept
s'appelle empilement de label. L'empilement de label permet en particulier d'associer plusieurs
contrats de service à un flux au cours de sa traversée du réseau MPLS.
Les LSR de frontière de réseau auront donc la responsabilité de pousser ou tirer la pile de labels
pour désigner le niveau d'utilisation courant de label.
Les applications suivantes l’exigent :
- MPLS VPN : MP-BGP (MultiProtocol Border Gateway Protocol) est utilisé pour propager
un label secondaire en addition à celui propagé par TDP ou LDP ;
- MPLS TE : MPLS TE utilise RSVP TE (Ressource Reservation Protocol TE) pour établir
un tunnel LSP (Label Switched Path). RSVP TE propage aussi un label en addition de
celui propagé par TDP ou LDP.
Figure 2.06 : Pile de labels

29
2.2.3 Distribution des labels
Les LSR se basent sur l'information de label pour commuter les paquets au travers du cœur de
réseau MPLS. Chaque routeur, lorsqu'il reçoit un paquet taggué, utilise le label pour déterminer
l'interface et le label de sortie. Il est donc nécessaire de propager les informations sur ces labels à
tous les LSR. Pour cela, suivant le type d'architecture utilisée, différents protocoles sont employés
pour l'échange de labels entre LSR.
2.2.3.1 Le protocole LDP
Le protocole LDP est un protocole de signalisation (plus précisément, de distribution des labels)
héritier du protocole propriétaire TDP ou « Tag Distribution Protocol ». Pour en décrire le
fonctionnement, rappelons la notion de l'arbre du plus court chemin : pour un préfixe d'adresse, le
protocole de routage classique définit implicitement un arbre du plus court chemin, arbre ayant
pour racine le LSR de sortie (celui qui a annoncé le préfixe) et pour feuilles les différents routeurs
d'entrée. Le routeur de sortie va annoncer le préfixe à ses voisins, tout y en associant un label. Les
messages de signalisation vont monter jusqu'aux routeurs d'entrée, permettant à chaque LSR
intermédiaire d'associer un label au préfixe.
2.2.3.2 Le protocole CR-LDP
CR-LDP est une version étendue de LDP, où CR correspond à la notion de « routage basé sur les
contraintes des LSP ». Tout comme LDP, CR-LDP utilise des sessions TCP entre les LSR, au
cours desquelles il envoie les messages de distribution des étiquettes. Ceci permet en particulier à
CR-LDP d’assurer une distribution fiable des messages de contrôle.
Les échanges d’informations nécessaires à l’établissement des LSP utilisant CR-LDP sont décrit
dans la figure 2.07. [9]
Figure 2.07 : Etablissement d’un LSP par CR-LDP

30
2.2.3.3 Le protocole RSVP – TE
Le protocole RSVP utilisait initialement un échange de messages pour réserver les ressources des
flux IP à travers un réseau. Une version étendue de ce protocole RSVP-TE, en particulier pour
permettre les tunnels de LSP, autorise actuellement RSVP à être utilisé pour distribuer des
étiquettes MPLS.
RSVP est un protocole complètement séparé de la couche IP, qui utilise des datagrammes IP ou
UDP ou « User Datagram Protocol » pour communiquer entre LSR. RSVP ne requiert pas la
maintenance nécessaire aux connexions TCP, mais doit néanmoins être capable de faire face à la
perte de messages de contrôle.
Les échanges d’informations nécessaires à l’établissement de LSP permettant les tunnels de LSP
et utilisant RSVP sont décrits dans la figure 2.08.
Figure 2.08 : Etablissement LSP par RSVP-TE
2.2.4 Les applications de la technologie MPLS
Il existe aujourd'hui quatre applications majeures de MPLS. Ces applications supposent la mise en
œuvre de composants adaptés aux fonctionnalités recherchées. L'implémentation de
MPLS sera donc différente en fonction des objectifs recherchés. Cela se traduit principalement par
une façon différente d'assigner et de distribuer les labels (Classification, protocoles de distribution
de labels). Le principe d'acheminement des paquets fondé sur l'exploitation des labels étant le
mécanisme de base commun à toutes les approches.

31
Les principales applications de MPLS concernent :
- Any Transport over MPLS (AToM);
- Le support des réseaux privés virtuels (MPLS VPN, Virtual Private Network) ;
- Le support de la qualité de service (MPLS QoS) ;
- Le Traffic Engineering (MPLS TE).
2.2.4.1 Any Transport over MPLS
Ce service traduit l'indépendance de MPLS vis-à-vis des protocoles de couches 2 et 3.
AToM est une application qui facilite le transport du trafic de couche 2, tel que Frame Relay,
Ethernet, PPP et ATM, à travers un nuage MPLS. [10]
2.2.4.2 Le support des réseaux privés virtuels
Pour satisfaire les besoins des opérateurs de services VPN, la gestion de VPN-IP à l’aide des
protocoles MPLS a été définie dans une spécification référencée RFC 2547. Des tunnels sont créés
entre des routeurs MPLS de périphérie appartenant à l’opérateur et dédiés à des groupes fermés
d’usagers particuliers, qui constituent des VPN. Dans l’optique MPLS VPN, un VPN est un
ensemble de sites placés sous la même autorité administrative, ou groupés suivant un intérêt
particulier. [11]
Trois types de VPN sont bâtis autour de MPLS :
- Les VPN de couche 2;
- Les VPN de couche 3 ou BGP-MPLS VPN;
- Les MPLS Virtual Routers.
2.2.4.3 Le support de la qualité de service
MPLS permet d’offrir plusieurs mécanismes de qualité de service à savoir : la classification du
trafic, le marquage de différentes classes suivant des priorités et la gestion de la congestion. Pour
garder la classe de service déjà définie dans un paquet entrant dans un domaine MPLS que ce soit
au niveau du champ IP précédence ou DSCP du modèle Diffserv, la valeur de leurs trois bits du
poids plus fort est copiée au niveau du champ EXP du label MPLS. [12]
2.2.4.4 Le Traffic Engineering
Cette application est en étroite relation avec la qualité de service, puisque son résultat immédiat

32
est l'amélioration de paramètres tels que le délai ou la gigue dans le réseau.
Elle est tout de même considérée comme une application à part entière par la plupart des
industriels. Ceci vient du fait que MPLS TE n'est pas une simple technique de réservation de
ressources pour les applications réseau. C'est un concept plus global qui se veut être une solution
qui vise à augmenter les performances générales du réseau en jouant sur la répartition équilibrée
des charges dans le réseau pour ainsi avoir une utilisation plus optimale des liens.
Le Traffic Engineering va être repris dans la deuxième partie de ce chapitre.
2.2.5 Evolutions MPLS
2.2.5.1 GMPLS
Une première extension du MPLS est le Generalized MPLS. Le concept de cette dernière
technologie est d’étendre la commutation aux réseaux optiques. Le label, en plus de pouvoir être
une valeur numérique peut alors être mappé par une fibre, une longueur d'onde et bien d'autres
paramètres. Le GMPLS met en place une hiérarchie dans les différents supports de réseaux
optiques. GMPLS permet donc de transporter les données sur un ensemble de réseaux hétérogènes
en encapsulant les paquets successivement à chaque entrée dans un nouveau type de réseau. Ainsi,
il est possible d'avoir plusieurs niveaux d'encapsulation selon le nombre de réseaux traversés, le
label correspondant à ce réseau étant conservé jusqu'à la sortie du réseau.
GMPLS reprend le plan de contrôle de MPLS en l'étendant pour prendre en compte les contraintes
liées aux réseaux optiques. En effet, GMPLS va rajouter une brique de gestion des liens à
l'architecture MPLS. Cette brique comprend un ensemble de procédures utilisées pour gérer les
canaux et les erreurs rencontrées sur ceux-ci. [12]
2.2.5.2 VPLS
VPLS ou « Virtual Private LAN Services » définit un service de VPNs au niveau de la couche 2.
Le but est ici de simuler un réseau LAN à travers l'utilisation d'un réseau MPLS classique. Là
encore la plus grande partie des traitements va s'effectuer sur les PE. Chaque PE maintient une
table liée aux adresses MAC. On appelle cette table « Virtual Forwarding Instance » ou VFI. A ce
niveau-là, le mapping des FEC s'effectue directement par rapport aux adresses MAC. Le principe
est similaire à la commutation classique de niveau 2. Une trame arrive sur un PE. Celui-ci consulte
sa table VFI pour vérifier l'existence de l'adresse dans sa table et la commuter s'il le trouve. Le cas
échéant, le PE qui émule ce commutateur va envoyer la trame sur tous les ports logiques relatifs à

33
l'instance VPLS concernée. Le principe est exactement similaire aux VPNs de niveau 3, mise à
part le fait que tout se passe au niveau 2. Le VPLS est encore à l'état de draft à l'IETF, et la norme
spécifiant le protocole de communication et les algorithmes utilisés ne sont donc pas encore
définitifs. [12]
2.3 Etude de l’ingénierie de trafic avec MPLS
2.3.1 Définition de l’ingénierie de trafic.
L’ingénierie de trafic consiste à adapter le trafic à la topologie du réseau. L’expression
« Ingénierie de trafic » désigne l’ensemble des mécanismes de contrôle de l’acheminement du
trafic dans le réseau afin d’optimiser l’utilisation des ressources et de limiter les risques de
congestion. L’objectif de l’ingénierie de trafic est de maximiser la quantité de trafic pouvant
transiter dans le réseau, tout en maintenant la qualité de service (bande passante, délai, …) offerte
aux différents flux.
2.3.2 Principe du «Traffic Engineering »
Figure 2.09 : Le routage classique
Dans la figure 2.09, Il existe deux chemins pour aller de R2 à R6 :
- R2 R5 R6
- R2 R3 R4 R6
En IP classique, Le protocole de routage (OSPF, IS-IS, etc.) va se baser sur le critère du plus
court chemin. Et puisque tous les liens ont le même coût, les paquets venant de R1 ou de R7 et qui
sont destinés à R6 vont tous suivre le même chemin. [8]

34
Ceci peut conduire à quelques problèmes en supposant que tous les liens de la figure 2.09
supportent une bande passante de 150Mbps. Et supposant que R1 envoie en moyenne 90Mbps à
R6, le protocole de routage va faire de sorte que ce trafic utilise le plus court chemin, soit
R2 R5 R6. Si maintenant R7 veut envoyer 100Mbps à R6, la même procédure de routage
fera que ce trafic utilisera aussi le chemin le plus court. Au final, on aura deux trafics de 190Mbps
au total qui veulent tous deux utiliser le chemin le plus court (R2 R5 R6), alors que ce
chemin ne peut supporter que 150Mbps. Ceci va induire des files d'attente et des pertes de paquets.
Cet exemple est un cas explicite de sous-utilisation des ressources du réseau vu que réellement, il
existe un chemin dans le réseau qui n'est pas exploité et que son utilisation aurait permis de
satisfaire les deux trafics.
Contrairement aux solutions IP, MPLS va permettre une simplification radicale de l'intégration de
cette fonctionnalité dans les réseaux.
MPLS TE permet à l'ingress LER de contrôler le chemin que son trafic va emprunter pour
atteindre une destination particulière. Ce concept est connu sous le nom de "Explicit Routing".
Cette méthode est plus flexible que l'acheminement du trafic basé seulement sur l'adresse
destination. MPLS TE réserve de la bande passante en construisant les LSP. Ainsi dans la
topologie de la figure 2.10, LSR2 a la possibilité de construire deux LSP (Tunnel1 et Tunnel2)
relatifs aux chemins :
- LSR2 LSR5 LSR6
- LSR2 LSR3 LSR4 LSR6
Les LSP ainsi construits sont appelés MPLS TE LSP ou TE tunnels.
Figure 2.10 : Le Traffic Engineering selon MPLS

35
La souplesse de l'utilisation des labels dans MPLS TE permet de profiter des avantages suivants :
- Le routage des chemins primaires autour des points de congestion connus dans le réseau
(le contournement de la congestion) ;
- Le contrôle précis du re-routage de trafic, en cas d'incident sur le chemin primaire. On
sous-entend par re-routage : la modification du LSP en cas d'erreur (routeur en panne,
manque de ressources) ;
- Un usage optimal de l'ensemble des liens physiques du réseau, en évitant la surcharge de
certains liens et la sous-utilisation d'autres. C'est ce qu'on appelle l'équilibrage des
charges ou load balancing.
Le Traffic Engineering permet ainsi d'améliorer statistiquement les paramètres de QoS (Taux de
perte, délai, gigue, etc.)
Un exemple concret de Traffic Engineering est qu'il est possible de définir plusieurs LSP entre
chaque couple de LER. Chaque LSP peut être conçu, grâce aux techniques de Traffic
Engineering, pour fournir différentes garanties de bande passante ou de performances. Ainsi,
l'ingress LER pourra placer le trafic prioritaire dans un LSP, le trafic de moyenne priorité dans un
autre LSP et enfin le trafic best effort dans un troisième LSP.
2.3.3 Calcul et établissement des "MPLS TE LSP"
Dans un protocole de routage à état de lien, tel que OSPF ou IS-IS, chaque routeur connaît tous les
routeurs du réseau et les liens qui connectent ces routeurs.
Aussitôt qu'un routeur se fait une idée de la topologie du réseau, il exécute le "Dijkstra Shortest
Path First algorithm" (SPF) pour déterminer le plus court chemin entre lui-même et tous les autres
routeurs du réseau (Construction de la table de routage). Etant donné que tous les routeurs
exécutent le même calcul sur les mêmes données, chaque routeur aura la même image du réseau,
et les paquets seront routés de manière cohérente à chaque saut. [10][13]
Le processus qui génère un chemin pour un "MPLS TE LSP" est différent du SPF classique, mais
pas trop. Il y a deux différences majeures entre le SPF classique, utilisé par les protocoles de
routage, et le CSPF ou « Constrained Shortest Path First », utilisé par MPLS TE :
- Le processus de détermination de chemin n'est pas conçu pour trouver le plus court
chemin, mais il tient compte d'autres contraintes ;

36
- Il y a plus d'une métrique à chaque nœud, au lieu d'une seule comme dans le cas de OSPF
et IS-IS.
A remarquer que l'administrateur n'est pas obligé de passer par CSPF pour calculer un MPTS TE
LSP. Il peut manuellement imposer un chemin explicite à une FEC donnée. Dans certaines
littératures, on appelle les TE LSP calculés par des algorithmes basés sur la situation du trafic des
CR-LSP ou « Constraint-based Routing – LSP », et les TE LSP spécifiés explicitement par
l'administrateur des ER-LSR ou « Explicit Routing – LSP ».
MPLS crée les LSP différemment selon qu'on utilise le Traffic Engineering ou non.
La création d'un "MPLS LSP", dans le cas non TE, suit les deux étapes suivantes :
- Calcul du "MPLS LSP" : Mise en œuvre de l'algorithme SPF (OSPF ou IS-IS) ;
- Etablissement du "MPLS LSP" : Mise en œuvre d'un protocole de distribution de label
Topology-based (LDP, BGP, PIM).
La création d'un "MPLS TE LSP" suit les deux étapes suivantes :
- Calcul du "MPLS TE LSP" : Mise en œuvre de l’algorithme CSPF ou intervention
manuelle de l'administrateur pour imposer une route explicite ;
- Etablissement du "MPLS TE LSP" : Mise en œuvre d'un protocole de distribution de label
Request-based (RSVP TE, CR-LDP).
Après avoir calculé un chemin avec CSPF, ce chemin doit être signalé à travers le réseau, et ceci
pour deux raisons :
- Etablir une chaîne de labels qui représente le chemin ;
- Réserver les ressources nécessaires (bande passante) à travers le chemin.
2.3.4 Resource ReSerVation Protocol - Traffic Engineering
Ce protocole est originalement destiné à être un protocole de signalisation pour IntServ. RSVP
avec quelques extensions a été adapté par MPLS pour être un protocole de signalisation qui
supporte MPLS TE. [13]
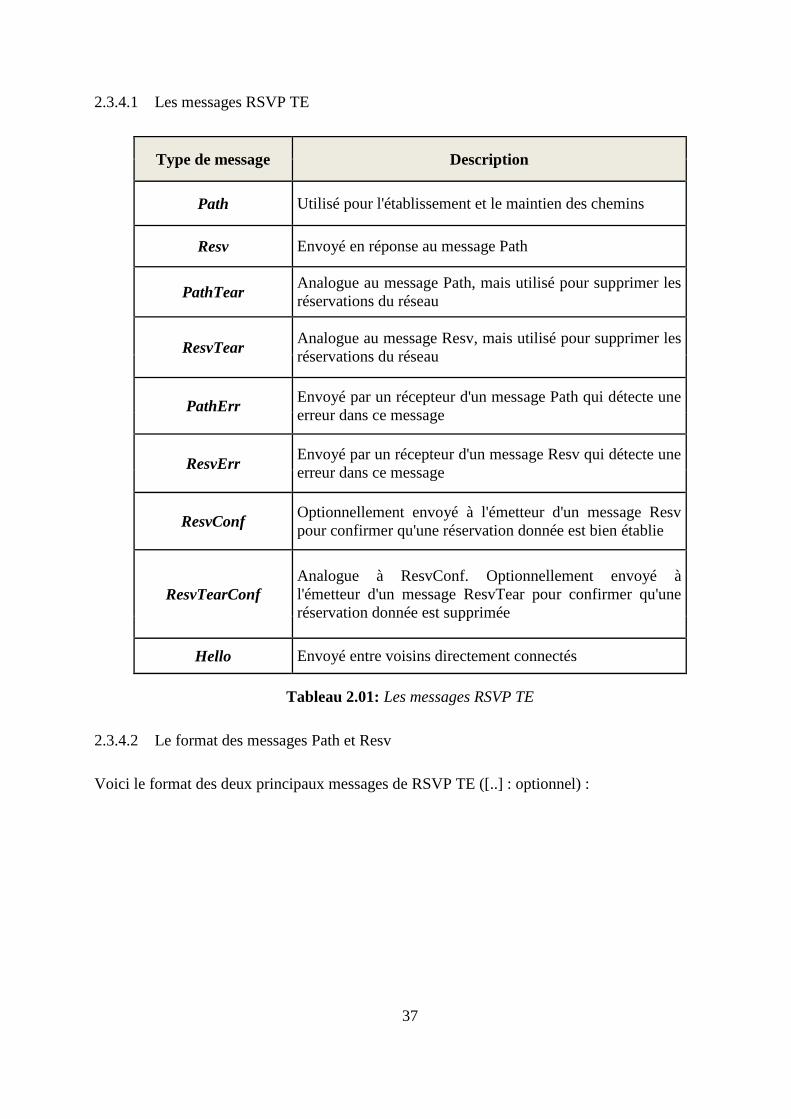
37
2.3.4.1 Les messages RSVP TE
Type de message Description
Path Utilisé pour l'établissement et le maintien des chemins
Resv Envoyé en réponse au message Path
PathTear Analogue au message Path, mais utilisé pour supprimer les
réservations du réseau
ResvTear Analogue au message Resv, mais utilisé pour supprimer les
réservations du réseau
PathErr Envoyé par un récepteur d'un message Path qui détecte une
erreur dans ce message
ResvErr Envoyé par un récepteur d'un message Resv qui détecte une
erreur dans ce message
ResvConf Optionnellement envoyé à l'émetteur d'un message Resv
pour confirmer qu'une réservation donnée est bien établie
ResvTearConf
Analogue à ResvConf. Optionnellement envoyé à
l'émetteur d'un message ResvTear pour confirmer qu'une
réservation donnée est supprimée
Hello Envoyé entre voisins directement connectés
Tableau 2.01: Les messages RSVP TE
2.3.4.2 Le format des messages Path et Resv
Voici le format des deux principaux messages de RSVP TE ([..] : optionnel) :

38
Figure 2.11 : Format du Path message
Figure 2.12 : Format du Resv message
Chacun des objets contenus dans un message RSVP TE remplit une fonction de signalisation
particulière. [13]
2.3.4.3 Le fonctionnement de RSVP TE
RSVP TE est un mécanisme de signalisation utilisé pour réserver des ressources à travers un
réseau. RSVP TE n'est pas un protocole de routage. Toute décision de routage est faite par IGP ou
« Interior Gateway Protocol ». Le seul travail de RSVP TE est de signaler et de maintenir la
réservation de ressources à travers le réseau. [13]
RSVP TE a trois fonctions de base :
- L'établissement et la maintenance des chemins (Path setup and maintenance) ;
- La suppression des chemins (Path teardown) ;
- La signalisation des erreurs (Error signalling).
RSVP TE est un "soft-state protocol". Cela veut dire qu'il a besoin de rafraîchir périodiquement

39
ses réservations dans le réseau. Ceci est différent des "hard-state protocol", qui signalent leurs
requêtes une seule fois et puis supposent qu'elle reste maintenue jusqu'à sa résiliation explicite.
Avec RSVP TE, une requête est résiliée si elle l'est explicitement du réseau par RSVP TE ou si la
durée de réservation expire. [11][13]
L’établissement et la maintenance des chemins
L'établissement d'un LSP avec RSVP-TE passe par deux phases : la phase descendante et la phase
montante. Dans la première phase, le LSR de tête du LSP envoie un message path au LSR de
sortie pour fixer la route et transmettre l'ensemble des paramètres TE (source et destination du
LSP, identifiants du tunnel et du LSP, bande passante, affinités, …). Dans la deuxième phase, un
message Resv est envoyé par le LSR de sortie au LSR de tête afin de réserver les ressources
(bande passante et étiquettes) sur tous les liens du LSP en cours d'établissement. [13]
Message Path :
Afin d'initier l'établissement d'un LSP (dans le sens descendant), le LSR de tête construit un
message Path. Ce message contient des informations concernant la session (identifiant du tunnel et
adresse de la destination), l'émetteur (adresse du LSR de tête et identifiant du LSP), les
caractéristiques du trafic (bande passante et un ensemble de paramètres de classe de service), la
structure de la route choisie et ses propriétés (optionnellement la route explicite et les liens à
inclure ou à exclure) ainsi que le protocole de niveau 3 du modèle ISO acheminé. Ce message path
inclut aussi des informations utiles comme la route sélectionnée qui sera communiquée à tous les
LSR du LSP, la portée des étiquettes allouées (étiquette globale au LSR ou locale à une interface
d'un LSR) et des indications concernant la protection (protection locale fournie ou pas, protection
en cours d'utilisation ou pas,…). Avant d'envoyer le message au prochain LSR permettant
d'atteindre la destination, le LSR de tête crée un état RSVP constitué d'informations déduites du
message path précédent (typiquement les identifiants du LSP et du tunnel RSVP-TE, les adresses
source et destination, le prochain et le précédent nœud, la bande passante réclamée,...).
Le message path transite de proche en proche du LSR de tête jusqu'à atteindre le LSR de sortie.
Chaque LSR de transit qui le reçoit le traite. Si aucune erreur n'est détectée, le LSR créé un état
RSVP déduit du message reçu avant de transmettre le message Path traité au prochain routeur
déterminé à partir de l'objet ERO s'il y en a un, sinon à partir d'informations communiquées par le
protocole de routage. Si par contre, une erreur est détectée, par exemple si la route est invalide, un
message d'erreur (message resvErr) est envoyé à l'émetteur. La propagation du message path ainsi

40
que les états RSVP créés sur les LSR du LSP sont illustrés sur la figure 2.13
Figure 2.13 : Propagation du message Path et création d'états RSVP
Message Resv :
Pour réserver les ressources, le LSR de sortie répond au LSR de tête (après la réception du
message Path) par un message Resv qui transitera de proche en proche, en empruntant le chemin
inverse du message Path correspondant. Pour éviter des traitements supplémentaires, la destination
IP de chaque message Resv sur un LSR est extraite de l'objet RSVP_HOP de l'état RSVP créé lors
de la réception du message Path associé. En conséquence, les routeurs non RSVP parcourus par le
message Resv ne transmettront pas le paquet au driver RSVP.
Tous les routeurs du LSP, sauf le routeur de tête, effectuent un contrôle d'admission sur leur lien
précédent. Si ce contrôle d'admission réussit, de la bande passante et une étiquette MPLS seront
allouées, ce qui induit une mise-à-jour de l'état RSVP associé au LSP, de la table de commutation
MPLS (LFIB) et de la bande passante résiduelle disponible sur le lien. Après traitement et
modification de certains objets (objets ERO, RRO,...) du message Resv reçu, ce dernier est envoyé
au LSR en amont.
Si, par contre, le contrôle d'admission ou l'allocation d'étiquette échoue, un message d'erreur
(message ResvErr) est envoyé au LSR de sortie du LSP. A la réception du message Resv associé
au LSP, le routeur de tête met à jour son état RSVP et ses tables de routage IP et LFIB. A ce
moment, le LSP sera prêt pour acheminer le trafic. La propagation du message Resv ainsi que les
mise à jours des états RSVP sont illustrés sur la figure 2.14.

41
Figure 2.14 : Propagation du message Resv et mise-à-jour des états RSVP
La suppression des chemins
Un LSP peut être supprimé explicitement ou implicitement avec RSVP-TE. Pour supprimer
explicitement un LSP, un message PathTear est envoyé de la source vers la destination. Ce
message permet de détruire l'ensemble des états RSVP sur les LSR du LSP. Un autre message
ResvTear, envoyé de la destination vers la source du LSP, peut aussi détruire le LSP. Cependant et
contrairement au premier message (PathTear), le message ResvTear ne supprime dans les états
RSVP que l'information de réservation de ressources (typiquement, les étiquettes MPLS et les
bandes passantes allouées sur les liens). Afin de détruire complètement le LSP, le message
resvTear doit être suivi d'un message (PathTear) pour effacer totalement les états RSVP associés
au LSP détruit.
La signalisation des erreurs
De temps en temps, des problèmes peuvent avoir lieu dans le réseau (Bande passante non
disponible, boucle de routage, routeur intermédiaire ne prend pas en charge MPLS, message
corrompu, création de label impossible, ...). Ces erreurs sont signalées par PathErr ou ResvErr
messages. Une erreur détectée dans un Path message est traitée par un PathErr message, et une
erreur détectée dans un Resv message est traitée par un ResvErr message.
Les messages d'erreurs sont envoyés vers la source de l'erreur ; le PathErr est envoyé vers le
headend, et un ResvErr est envoyé vers le tail. [13]

42
2.4 Conclusion
Dans ce chapitre, nous nous sommes consacrés, dans la première partie, à l’étude de la technologie
MPLS, le mécanisme de fonctionnement de son architecture et ses éléments les plus importants
(LSR, LSP, FEC,…), leurs différents rôles et les applications que MPLS permet de réaliser.
Nous avons défini, dans la seconde partie, l’ingénierie de trafic. Nous avons commencé par définir
l’ingénierie de trafic et donner son principe. Ensuite, nous avons abordé les mécanismes qui
permettent de mettre en œuvre des solutions MPLS TE dans un réseau et avons terminé par le
fonctionnement du protocole RSVP-TE.
Même si le temps de routage n’est plus l’intérêt de cette technologie, avec l’augmentation de la
puissance des routeurs leur permettant de parcourir largement la table de routage IP à chaque
nouveau paquet, MPLS est toujours très favorable pour s'imposer dans le monde des réseaux. Les
offres MPLS au niveau de la qualité de service et du Traffic Engineering assureront à ce protocole
un succès tant auprès des utilisateurs que des opérateurs et fournisseurs de services.
Dans le troisième chapitre, nous verrons en détails les différents mécanismes de qualité de service
œuvrant dans le réseau MPLS

43
CHAPITRE 3
ETUDE DES DIFFERENTS MECANISMES DE QUALITE DE SERVICE
3.1 Introduction
Bien que, au départ, l’idée du développement de MPLS était la rapidité de la commutation des
paquets, actuellement son principal objectif est le support de l’ingénierie de trafic et de fournir
une qualité de service. Comme le but de l’ingénierie de trafic étant l’optimisation de l’utilisation
des ressources du réseau, MPLS soutient cet objectif en améliorant les caractéristiques de
performance de la circulation du trafic c’est-à-dire que des chemins multiples peuvent être
désormais utilisés simultanément pour améliorer les performances d’une source donnée à une
destination donnée. Comme MPLS utilise la commutation d’étiquettes, les paquets de différents
flux peuvent être étiquetés différemment donc recevant différente qualité de service. MPLS n’a
pas de méthode fonctionnelle pour assurer la qualité de service mais il peut être combiné avec des
services intégrés ou des services différenciés.
Dans ce chapitre nous allons détailler ces mécanismes de qualité de service. Nous verrons tout
d’abord la définition de la qualité de service et ses paramètres, ensuite nous enchaînerons avec le
modèle Intserv et nous terminerons avec le modèle Diffserv.
3.2 Définition de la qualité de service
La qualité de service est un ensemble de caractéristiques de performance de service qui sont
perçues et exprimées par l'utilisateur. Elle se manifeste par des paramètres pouvant prendre des
valeurs qualitatives, c'est à dire qui ne peuvent pas être mesurées directement mais perceptibles
par l'utilisateur ou bien se traduit par des valeurs quantitatives qui sont directement observées et
mesurées aux points d'accès. Il est intéressant de noter qu'on ne parle de la qualité de service que
s'il y a une dégradation de la performance d'un réseau.
3.3 Les paramètres de qualité de service
3.3.1 La bande passante
La bande passante est la quantité maximale de données pouvant être transmise d’une source vers
une destination en une unité de temps. Il s’agit en fait du minimum des bandes passantes
disponibles sur les liens composant le chemin de la source à la destination. La bande passante
disponible sur un chemin dépend donc du support des liaisons, mais aussi du nombre et du débit

44
des flux qui partagent ces liaisons.
A titre d’exemple, les applications vidéo requièrent généralement une bande passante élevée car
d’une part, une image représente une grande quantité d’informations et d’autre part, le nombre
d’images envoyées par unité de temps doit être suffisant pour obtenir une visualisation
satisfaisante. [14][15]
3.3.2 Le délai de bout en bout
Le délai de transmission de bout en bout est le temps écoulé entre l'émission du paquet et sa
réception à l'arrivée. Chaque saut dans le réseau ajoute un délai supplémentaire dû aux trois
facteurs suivant :
- Délai de propagation : C'est le temps que prend la transmission d'un bit via le média de
transmission (paire torsadée, fibre optique, voie radio, etc.) ;
- Délai de traitement : C'est le temps que consomme un routeur pour prendre un paquet de
l'interface d'entrée et le mettre dans la file d'attente de l'interface de sortie ;
- Délai de mise en file d'attente : C'est le temps que le paquet passe dans la file d'attente de
sortie du routeur. Il dépend du nombre et de la taille des paquets déjà dans la file et de la
bande passante de l'interface. Il dépend aussi du mécanisme de file d'attente adopté.
Ping (échos et les réponses ICMP) peut être utilisé pour mesurer le temps d’aller-retour des
paquets IP dans un réseau. Il existe d’autres outils disponibles pour mesurer périodiquement la
réactivité d’un réseau.
Figure 3.01 : Le délai de bout-en-bout

45
Delay = P1 + Q1 + P2 + Q2 + P3 + Q3 + P4 = X ms
Le délai de bout en bout est la somme de tous les délais (propagation, traitement et file d'attente) à
travers le chemin parcouru depuis la source jusqu'à la destination. Le délai de propagation est fixe
(ne dépend que du média de transmission), alors que le délai de traitement et le délai de mise en
file d'attente sont variables (dépendent du trafic). [16][17][18]
3.3.3 La gigue
C’est la variation (en ms) du délai entre les paquets consécutifs. La présence de gigue dans les flux
peut provenir des changements d'intensité de trafic sur les liens de sortie des commutateurs. Plus
globalement, elle dépend du volume de trafic et du nombre d'équipements sur le réseau. La gigue
affecte les applications qui transmettent les paquets à un certain débit fixe et s'attendent à les
recevoir au même débit (par exemple : voix et vidéo). [19]
Figure 3.02 : Illustration du concept de la gigue
3.3.4 Perte en paquets
Généralement, la perte de paquets a lieu lorsque le routeur manque d'espace dans le buffer d'une
interface : ainsi, lorsque la file d'attente de sortie d'une interface particulière est saturée, les
nouveaux paquets qui seront dirigés vers cette interface vont être rejetés.
Les routeurs peuvent rejeter un paquet pour d'autres raisons, par exemple :
- Le CPU (Central Processing Unit) est congestionné et ne peut pas traiter le paquet (la file
d'attente d'entrée est saturée) ;
- Le routeur détecte une erreur dans le paquet (Paquet corrompu) ;
- Le routeur rejette les paquets les moins prioritaires en cas de congestion dans le réseau.
D'autres facteurs peuvent constituer des causes pour la perte de paquets tels que :

46
- L'erreur de routage ;
- La fiabilité du media de transmission.
La perte peut s'exprimer en pourcentage de paquets perdus par rapport aux paquets émis, ou tout
simplement en nombre de paquets perdus par unité de temps. [18]
3.4 Le modèle à intégration de services : Intserv
3.4.1 Présentation de Intserv
Le modèle IntServ a marqué historiquement, en 1994, la volonté de l'IETF de définir une
architecture capable de prendre en charge la qualité de service en temps réel et le contrôle de
partage de la bande passante sur les liens du réseau.
IntServ se repose sur deux principes fondamentaux tels que le contrôle d'admission et le
mécanisme de réservation de ressources.
En effet, le réseau doit être contrôlé et soumis à des mécanismes de contrôle d’admission. Ce
mécanisme détermine si un routeur ou un hôte, est capable de répondre à une nouvelle demande
de QoS, sans gêner les demandes qui ont été déjà accordées. Le contrôle d’admission, est invoqué
dans chaque nœud afin de prendre la décision d'accepter ou de refuser une demande de service en
temps réel le long du chemin entre les utilisateurs finaux.
Afin de pouvoir garantir que la QoS demandée est bien présente, on confie au contrôle
d’admission, d'autres tâches comme l'authentification de ceux qui effectuent des réservations et
l’établissement des rapports concernant ce qui a été fait, qui a demandé quelle réservation, cela
afin d’obtenir une sorte de feedback de l’utilisation des mécanismes de QoS.
Le deuxième mécanisme est la réservation de ressources par un protocole de signalisation
établissant cette réservation (RSVP). Ce dernier est utilisé pour transporter les messages de
réservation de ressources. Ces messages sont ceux qui indiquent aux différents nœuds, la quantité
de bande passante qu'une communication souhaite disposer. [20][21]
3.4.2 Le protocole RSVP
Le protocole RSVP offre une solution intéressante à la gestion d'environnements multi
destinataires. Il autorise plusieurs émetteurs à transmettre vers plusieurs groupes de récepteurs. Il
permet à des récepteurs individuels de passer librement d'un canal à un autre et il optimise la
bande passante utilisée tout en assurant un contrôle de congestion efficace.

47
La réservation dynamique de ressources est fort prometteuse, mais elle est difficile à mettre en
œuvre. Elle nécessite que tous les composants du réseau sachent en exploiter les mécanismes:
- L'application de l'utilisateur doit spécifier ses besoins en termes de QoS ;
- Les systèmes (serveurs/ stations/ périphériques) doivent comprendre les besoins de
l'application et disposer d'une interface de service de QoS ;
- Le protocole de signalisation, RSVP en l'occurrence, doit réserver les ressources dans le
réseau ;
- Les commutateurs et les routeurs du réseau doivent comprendre les requêtes de
réservation et assurer les contrats de QoS auxquels ils s'engagent. [21]
3.4.3 Classes de service de Intserv
Le modèle IntServ définit deux types principaux de services:
- Le service garanti (GS : Guaranteed Service) défini dans le RFC 2212 : ce service émule
au mieux un circuit virtuel dédié. La bande passante est garantie et le délai
d'acheminement limité.
- La charge contrôlée (CL : Controlled Load) définie dans le RFC 2211 : ce service est plus
élaboré que le best effort, mais reste sans garantie.
3.4.4 Architecture de base d'un routeur IntServ
Un routeur prenant en charge les services IntServ doit mettre en œuvre les quatre fonctions
propres à un routeur supportant la QoS à savoir : [20]
- La classification représentée par le classificateur: elle a pour but de classer chaque paquet
entrant dans une classe de flux. La classification réalisée sur chaque routeur du réseau se
fonde sur une classification multichamp ;
- Le contrôle et marquage (control and marking) : il gère la vérification de la conformité
du trafic et le marquage ou l'élimination du trafic non conforme ;
- La gestion des files d'attentes : dans la mesure où chaque flux est normalement affecté à
une file d'attente, les mécanismes de gestion de la congestion pour protéger les flux entre
eux ne sont pas normalemant nécessaires. Dans la pratique, une file d'attente sera affectée à
l'ensemble des flux traités en best effort. Pour les files d'attente assignées aux différents
flux, on peut procéder à leur redimensionnement en fonction précisément de chaque flux ;

48
- L'ordonnancement représenté par l’ordonnanceur ( packet scheduler ) : il a pour but de
gérer les files de sortie pour fournir l'acheminement aux flux de différentes qualités de
service.
Le cas de l'utilisation du protocole de signalisation RSVP (Resource reSerVation Protocol)
implique que le routeur:
- Participe aux échanges de messages RSVP ;
- Calcule les paramètres liés aux objets IntServ ;
- En fonction des demandes issues de RSVP, configure les éléments de QoS du routeur
(classificateur, contrôleur, gestion des files d'attente et ordonnanceur).
Le routeur possédera dans ce cas deux fonctions :
- Une fonction de contrôle d'admission (Admission Control) : elle sert à déterminer si le
routeur à la capacité de traiter la demande du protocole de signalisation.
- Une fonction de contrôle de règles (Policy Control) : elle sert à vérifier si la requête du
protocole de signalisation est légitime par rapport aux règles fixées par l'administrateur
réseau.
La figure 3.03 représente le plan de contrôle d'un routeur IntServ.
Figure 3.03 : Plan de contrôle d'un routeur IntServ
3.4.5 Les modèles de réservation de ressources
Dans RSVP, les réservations de ressources sont faites à l'initiative des récepteurs. On trouve la

49
notion de "style de réservation", qui représente un jeu d'options inclus dans la requête de
réservation de ressources. [20]
Les styles de réservation dépendent de deux options, l'une par le récepteur (mode distinct, mode
partagé), l'autre par l'émetteur (mode explicite, mode ouvert).
On distingue trois styles de réservation :
- Fixed Filter : les ressources sont réservées pour le flot uniquement ;
- Shared Explicit: les ressources sont partagées entre plusieurs flots qui proviennent de
plusieurs émetteurs identifiés ;
- Wildcard Filter : les ressources sont réservées pour un type de flot qui provient de
plusieurs émetteurs, les flots du même type partagent les mêmes ressources.
Sélection Emetteur Sélection Récepteur
Distinct Partagé
Explicite FF SE
Ouvert WF
Tableau 3.01: Style de réservation dans RSVP
3.4.6 Limitations de RSVP
RSVP oblige à maintenir des sessions sur tous les équipements qui sont traversés par les flux. Or
ces sessions nuisent aux performances des équipements et génèrent du trafic sur le réseau (pour
les maintenir, les rafraîchir, etc…). Quand le nombre d’utilisateurs augmente, le nombre de
sessions augmente et les performances de l’architecture diminuent. Ce modèle n’est donc pas
adapté aux réseaux de grande taille. De plus, RSVP est compliqué à mettre en place, et cette
complexité est exponentielle avec la taille du réseau.
Pour ces diverses raisons, RSVP n’est pas beaucoup utilisé dans les réseaux MPLS, le facteur
principal étant sa faible résistance au facteur d’échelle et que les réseaux MPLS sont souvent des
réseaux très étendus. Il est souvent utilisé pour l’ingénierie de trafic avec MPLS-TE, on parle
alors de RSVP-TE. [20][21]
3.5 Le modèle à différenciation de services : Diffserv
3.5.1 Présentation de Diffserv
Le modèle DiffServ a été conçu pour répondre aux limites d’IntServ. L’idée de base est de fournir
une qualité de service non par flux, mais par classe de paquets IP tout en repoussant (le plus

50
possible) la complexité du traitement en bordure du réseau afin de ne pas en surcharger le cœur.
L’intérêt d’un tel modèle est de pouvoir s’occuper du problème d’approvisionnement en qualité de
service à travers une allocation de services basée sur un contrat établi entre un fournisseur de
services et un client.
L’approche de DiffServ permet à des fournisseurs d’offrir différents niveaux de services à
certaines classes de flots de trafic rassemblés.
Ainsi, il est question de supporter un schéma de classification en attribuant des priorités à des
agrégats de trafic. De ce fait, les paquets sont classés grâce à un mécanisme de marquage d’octets
dans l’en-tête des paquets IP, et les services qui sont octroyés par les routeurs à ces paquets
dépendent des classes alors définies. Ce marquage est effectué au niveau de l’étiquette de l’en-tête
du paquet : le DSCP ou « DiffServ Code Point » qui se situe dans le champ DS de l’en-tête IP
réservé à DiffServ.
Grâce à ce marquage, et à l’approche différente de DiffServ par rapport à IntServ, les routeurs
DiffServ gardent une certaine souplesse d’utilisation du point de vue acheminement par rapport à
ceux utilisés dans l’IntServ. [22]
3.5.2 Notion de domaine Diffserv
Un domaine est un ensemble de nœuds (hôtes et routeurs) administrés de façon homogène.
Dans un domaine, on distingue les nœuds internes et les nœuds frontières : les premiers ne sont
entourés que de nœuds appartenant au domaine alors que les seconds sont connectés à des nœuds
frontières d’autres domaines (voir figure 3.04). Si on considère le sens de communication de la
source vers la destination, les nœuds frontières peuvent être d’entrée (ingress) dans le domaine ou
de sortie (egress) dans ce dernier. [22][23]
Figure 3.04 : Distinction des nœuds d’un domaine Diffserv

51
3.5.3 Notion de comportement
Au sein d’un domaine DiffServ, tous les nœuds (hôtes et routeurs) implémentent les mêmes
classes de service et les mêmes comportements PHB ou « Per Hop Behavior » vis-à-vis des
paquets des différentes classes. Un comportement inclut le routage, les politiques de service des
paquets, notamment la priorité de passage ou de rejet en cas de congestion, et éventuellement la
mise en forme du trafic entrant dans le domaine. Les nœuds internes ne doivent pas conserver
d’états en mémoire contrairement à la proposition IntServ ; ils ne font que transmettre les paquets
selon le comportement défini pour leur classe. Les nœuds frontières se chargent de marquer les
paquets selon le code réservé à chaque classe. [22]
La RFC 2475 définit le PHB comme le comportement d’acheminement observable de l’extérieur
qui s’applique aux données dans un nœud DiffServ. Le système marque les paquets conformément
aux codes DSCP et tous les paquets ayant le même code seront agrégés et soumis au même
traitement particulier.
Plusieurs PHB standard ont été définis :
- Le PHB par défaut ;
- Assured Forwarding (AF) PHB ;
- Expedited Forwarding (EF) PHB ;
3.5.4 Classes de services de DiffServ
Dans cette approche, on dispose de trois niveaux de priorité : le service « Best-Effort », le
service « Assured Forwarding », et le service « Expedited Forwarding ».
Le service « Best-Effort »
Le principe du Best Effort se traduit par une simplification à l’extrême des équipements
d’interconnexion. Quand la mémoire d’un routeur est saturée, les paquets sont rejetés.
Les principaux inconvénients de cette politique de contrôle de flux sont un trafic en dents de scie
composé de phases où le débit augmente puis est réduit brutalement et une absence de garantie à
long terme.
La valeur DSCP recommandé pour le PHB par défaut est « 000000 ».

52
Le service « Assured Forwarding »
Il s'agit en fait d'une famille de PHB (PHB group). Quatre classes de "traitement assuré'' sont
définies.
Chacune comporte trois niveaux de priorité (drop precedence) suivant que l'utilisateur : respecte
son contrat, le dépasse légèrement ou est largement en dehors. Les classes sont donc choisies par
l'utilisateur et restent les mêmes tout au long du trajet dans le réseau. Tous les paquets d’un flux
appartiennent à la même classe. A l’intérieur de chaque classe, un algorithme de rejet sélectif
différencie les 3 niveaux de priorité. En cas de congestion dans une classe AF, les paquets de
basse priorité sont détruits en premier. La priorité peut être modifiée dans le réseau par les
opérateurs en fonction du respect ou non des contrats.
Figure 3.05 : Priorité d'acheminement et de rejet.
Un domaine implémentant des services AF doit être, par l’intermédiaire des routeurs de frontière,
capable de contrôler les entrées de trafic AF pour que la qualité de service déterminée pour chaque
classe AF soit satisfaite. Pour cela, les routeurs de frontière doivent mettre en place des
mécanismes de mise en forme de trafic (shaper), de destruction de paquets (dropper),
d’augmentation ou de diminution des pertes de paquets par classe AF et de réassignation de trafics
AF dans d’autres classes AF moins prioritaire.
Le service « Expedited Forwarding »
La classe Expedited Forwarding correspond à la valeur 101110 pour le DSCP. L’objectif est de
fournir un service de transfert équivalent à une ligne virtuelle dédiée à travers le réseau d’un
opérateur.
Le contrat porte sur un débit constant. Les paquets excédentaires sont lissés ou rejetés à l’entrée
pour toujours rester conforme au contrat. L’opérateur s’engage à traiter ce trafic prioritairement.
Pour que le service soit performant, il faut qu’il ne présente qu’une faible partie du trafic total,

53
qu’aucun paquet marqué EF ne soit rejeté dans le cœur du réseau. Pour atteindre ces
performances, les paquets d’un service EF ne doivent pas subir de file d’attente ou passer par des
files de très petite taille et strictement prioritaires.
Le tableau 3.02 résume les différents services selon leur priorité.
Service Priorité
Best Effort Faible
Assured Forwarding Moyenne
Expected Forwarding Forte
Tableau 3.02: Récapitulatif des priorités de services DiffServ
La figure 3.06 montre des exemples d’applications courantes en leur associant les classes de
services de l’architecture DiffServ :
Figure 3.06 : Qualités requises pour des applications sous DiffServ
3.5.5 Architecture Diffserv
Le groupe Diffserv propose donc d'abandonner le traitement du trafic sous forme de flots pour le
caractériser sous forme de classes. On peut aussi parler de « behaviour aggregate » ou BA plutôt
que de classe de trafic.
Le service différencié de l’architecture Diffserv permet de diminuer les informations d’état que

54
chaque nœud du réseau doit mémoriser. Il n’est plus nécessaire de maintenir des états dans les
routeurs pour chacun des flux. Ceci permet son utilisation à grande échelle.
L’idée consiste à diviser le réseau en domaines. On distingue ainsi les routeurs à l’intérieur d’un
domaine (Core router) des routeurs d’accès et de bordure (Edge router). Les routeurs d’accès sont
connectés aux clients, tandis qu’un routeur de bordure est connecté à un autre routeur de bordure
appartenant à un domaine différent. Les routeurs de bordure jouent un rôle différent de ceux qui
sont au cœur du domaine. Ils sont chargés de conditionner le trafic entrant en indiquant
explicitement sur le paquet le service qu’il doit subir. Ainsi, la complexité des routeurs ne dépend
plus du nombre de flux qui passent mais du nombre de classes de service. Chaque classe est
identifiée par une valeur codée dans l'en-tête IP.
Le trafic conditionné est identifié par un champ DS ou un marquage du champ « Type of Service »
ou ToS de l'en-tête de paquet IPv4 ou l’octet « Class Of Service » ou COS d’IPv6. Ce champ
d’entête IP porte l’indice de la Classe de Service DSCP. Sachant que ce travail de marquage est
assez complexe et coûteux en temps de calcul, il vaut mieux limiter au maximum les répétitions.
Les opérations de classification, de contrôle et de marquage sont effectuées par les routeurs
périphériques (Edge Router) tandis que les routeurs centraux (Core Router) traitent les paquets en
fonction de la classe codée dans l'en-tête d'IP (champ DS) et selon un comportement spécifique :
le PHB codé par le DSCP. [23]
La figure 3.07 illustre le champ DSCP de Diffserv.
Figure 3.07 : Le champ DSCP de Diffserv

55
3.5.6 Architecture des routeurs DiffServ
On peut distinguer les routeurs situés dans le cœur de réseau « Core routers » de ceux situés à sa
frontière « Edge routers ». Les routeurs du cœur de réseau du domaine DiffServ réalisent des
opérations simples de bufferisation et d’avancement des paquets de chaque flot en se basant
uniquement sur le marquage fait par les routeurs situés à la frontière du domaine DiffServ. Les
«Core routers » possèdent les deux mécanismes cruciaux du modèle DiffServ, le Scheduling et le
Buffer Management. C’est à ce niveau que la différenciation de service est faite. [23]
Un aspect général d’un réseau Diffserv est donné par la figure 3.08.
Figure 3.08 : Aspect général d’un réseau DiffServ
Les routeurs de bordure ou « edge routers »
Les routeurs « edge » sont responsables de la classification des paquets et du conditionnement du
trafic. L’opération de classification est opérée à l’entrée du réseau, zone où la différenciation de
service est mise en œuvre, le domaine DS, pour assurer le traitement ciblé : celui de pouvoir
différencier les différents flots qui arrivent dans le réseau.
Ces routeurs sont caractérisés par leur gestion des états par flot. Après classification, les paquets
subissent une opération de vérification (module « meter ») qui consiste à déterminer le niveau de
conformité pour chacun des paquets d’un même flot. Ces niveaux de conformité varient en
fonction du conditionnement requis par le service. On peut définir par exemple deux niveaux « in
» et « out » spécifiant si les paquets sont conformes ou non conformes avec le contrat établi.
Cette dernière différenciation est néanmoins utilisée dans l’algorithme d’ordonnancement. L’étape

56
qui suit la vérification du niveau de conformité est de deux types : si les paquets sont conformes,
alors ils sont envoyés pour être étiquetés (nous présenterons cette technique ultérieurement). Dans
le cas contraire, alors il y a trois manières de traiter les paquets non conformes : mise en forme
(shape), marquage (mark) ou élimination (drop) :
- L’opération de mise en forme (shape) a pour but de rendre conforme les paquets qui ne
le sont pas, et ce, par simple retardement de son acheminement. Après un certain temps de
retardement, les paquets deviendront conformes et seront injectés vers le module
d’étiquetage. Cette opération régule les flots suivant les caractéristiques de leur classe. Le
plus souvent cela est fait par la technique du token bucket; des utilitaires de fragmentation
et de compression peuvent y être associés (LFI et RTP de CISCO) ;
- Le processus d’élimination (drop) est nécessaire pour assurer un fonctionnement fiable
du routeur : tous les paquets qui ne sont pas conformes seront forcés à être éliminés. Les
flots pour lesquels il serait préférable d’utiliser cette méthode sont les flots interactifs. En
effet, si on choisit d’appliquer la mise en forme pour ce type de flots, les paquets subiront
un retard significatif et rendront l’interactivité de l’application impossible. C’est pourquoi
il leur est préférable d’être éliminés ;
- Le mécanisme de marquage (mark) a pour effet d’attribuer une priorité aux paquets en
fonction du résultat fourni par l’opération de vérification. C’est à ce niveau qu’est réalisée
l’agrégation des flots en classes. Le Marker détermine le PHB (Per Hop Behavior) du
paquet, et en accord avec les informations transmises par le Meter, positionne le champ
DSCP (marquage de la classe). Il est important de noter que cela n’est pas fait par le
classifier, car un même flot suivant les conditions de trafic peut être marqué différemment.
Avant d’être envoyés vers l’intérieur du réseau, les paquets subissent une dernière opération :
l’étiquetage effectif du champ DSCP. La valeur attribuée au champ correspond au résultat de
toutes les opérations précédentes. Celle-ci peut être modifiée au sein d’autres routeurs de bordure
selon le nouveau conditionnement qui va être appliqué au flot après sa traversée dans les
équipements. La marque qu'un paquet reçu identifie la classe de trafic à laquelle il appartient. Les
paquets ainsi marqués sont alors envoyés dans le réseau avec cette mise en forme.
En bref la fonctionnalité du routeur de bordure est le conditionnement du trafic. Ce dernier peut

57
donc contenir un ensemble d’éléments tels que le vérificateur, le marqueur, le « shaper » et le «
dropper ». En effet, une fois un flot de trafic est choisi par un classificateur, il le dirige vers un
module de conditionnement spécifié pour continuer le processus de traitement. Un conditionneur
de trafic peut ne pas contenir nécessairement chacun des quatre éléments tels que le cas où aucun
profil de traitement n’est présent (les paquets peuvent seulement passer par un classificateur et un
marqueur). [22][23]
Figure 3.09 : Principe de fonctionnement d’un routeur « edge »
Les routeurs de cœur ou « core routers »
Ils sont responsables de l'envoi uniquement. Quand un paquet, marqué de son champ DS, arrive
sur un routeur DS-capable, celui-ci est envoyé au prochain nœud selon ce que l'on appelle son
Per Hop Behaviour (PHB) associé à sa classe. Le PHB influence la façon dont les buffers du
routeur et le lien sont partagés parmi les différentes classes de trafic. Une chose importante dans
l'architecture DS est que les PHB routeurs se basent uniquement sur le marquage de paquet, c'est à
dire la classe de trafic auquel le paquet appartient ; en aucun cas ils ne traiteront différemment des
paquets de sources différentes.
Dans un routeur DiffServ du cœur de réseau, chaque sortie possède un nombre fixe de files
d’attente logiques où le routeur dépose les paquets arrivant sur la base de leur PHB. Les files
d’attente sont servies en accord avec l’algorithme d’ordonnancement.
Le « core router » est constitué de trois éléments principaux. Le routage proprement dit qui
consiste à la détermination du PHB, l’ordonnancement du trafic et la gestion de buffer. [22][23]

58
3.5.7 L’ordonnancement du trafic
Les algorithmes d’ordonnancement sont aussi utilisés pour gérer les ressources sur chaque
élément du réseau. Ils déterminent notamment quels paquets sont choisis pour être transmis, et
quels paquets sont détruits. [22]
- Le « First In First Out » ou FIFO est l’ordonnanceur par défaut le plus simple. Les
paquets sont mis dans la file d’attente et servis dans l’ordre de leur arrivée. C’est la
discipline la plus rapide au point de vue transmission de paquets étant donné qu’elle
n’effectue aucun traitement sur ceux-ci.
Figure 3.10 : First In First Out
- Le « Priority Queuing » est l’ordonnanceur utilisé dans l’architecture Diffserv d’un
réseau. A leur arrivée, les paquets sont mis dans des files d’attente différentes en fonction
de leur classe.

59
Figure 3.11 : Priority queuing
- De la même manière que la discipline Priority queuing, les paquets sont triés par classe
dans les files avec l’ordonnanceur « Round Robin ». Ensuite, un tourniquet alterne les
paquets à servir parmi les files présentes qui sont à priori de même priorité.
Figure 3.12 : Round Robin
- Le « Weighted Fair Queuing » adopte un partage équitable pondéré. Les paquets arrivant
sont classifiés puis mis dans leurs files d’attente respectives de la même manière que pour
le round robin. Les paquets sont servis de façon circulaire. Une autre variante est le « Class
Based Queuing » qui classe d’abord les paquets selon leur service.

60
Figure 3.13 : Weighted Fair Queuing
3.5.8 Limitations de Diffserv dans les réseaux IP
L’architecture Diffserv vise à offrir un service qui pourra répondre aux exigences des applications
temps réels. Pour fournir la QOS demandée, elle s’appuie sur des mécanismes du plan de contrôle.
D’une manière générale, le plan de contrôle définit trois types de mécanismes. Le premier
concerne le contrôle d’admission. Ce dernier décide s’il y a suffisamment de ressources dans le
réseau pour accepter une nouvelle connexion ou non. Le deuxième mécanisme, appelé contrôle de
la politique, spécifie les règles d’accès aux ressources et de service selon des critères
administratifs. Finalement, le troisième se charge d’une gestion des ressources. Cette dernière a
une grande influence sur la QoS de bout en bout.
Les mécanismes qu’assure Diffserv permettent la configuration des routeurs pour assurer que
certains paquets reçoivent un traitement spécial et qu’un certain nombre de règles concernant la
gestion des ressources est bien appliqué. Par conséquent, Diffserv n’assume que les deux premiers
mécanismes du plan de contrôle. Sans l’aide de la gestion des ressources du réseau et des services,
Diffserv ne pourra plus délivrer la QoS de bout en bout.
A titre d’exemple, Diffserv ne permet pas de garantir une bande passante minimale pour certains
flux en cas de congestion. C’est pour cette raison que Diffserv ne semble plus être la solution QoS
du futur réseau Internet. Les efforts se dirigent donc vers de nouvelles approches qui utilisent
Diffserv mais dans un environnement, différent de IP, permettant une réservation effective des
ressources de bout en bout. Ainsi, l’utilisation du protocole MPLS s’impose. [23][24]

61
3.6 Intégration des mécanismes de différenciation de services dans les réseaux MPLS
3.6.1 Origine de l’approche DS-TE et ses principales fonctionnalités
La technologie Diffserv est utilisée par les fournisseurs de services pour réaliser une conception de
réseau évolutif soutenant des classes de services multiples. L’inconvénient de l’architecture
Diffserv est l’absence de contrôle des différents flux de trafic de bout en bout. Ceci rend la
réservation effective des ressources impossible. Dans certains réseaux où l’optimisation des
ressources de transmission est nécessaire, les mécanismes de Diffserv peuvent être complétés par
les mécanismes de la technologie MPLS. Dans ce cas Diffserv et MPLS se complètent en
permettant, chacun de son côté, de répondre à un des objectifs précis. [25]
La combinaison des deux technologies MPLS et Diffserv a donné naissance à une nouvelle
approche nommée en anglais « DiffServ_aware MPLS Traffic Engineering » et notée DS-TE
L’objectif de DS-TE est de permettre la réservation de la bande passante par classe de trafics. DS-
TE consiste à diviser la bande passante réservable en « class type » ou CT : CT0, CT1,... CT7. 8
CT sont définis.
Chaque CT a un pourcentage de la bande passante et un niveau de priorité. Les flux affectés à un
CT utilisent la bande passante associée à celui-ci. Néanmoins, et en cas de saturation de bande
passante, ils peuvent ou ne peuvent pas utiliser la bande passante des autres CT selon le mode de
contrainte de bande passante BC ou « bandwidth constraint ».
Deux modèles de BC sont définis :
- Maximum allocation model (MAM) : une quantité de la bande passante est dédiée à chaque
CT, et il ne peut pas utiliser la bande passante des autres CT même si elle est non utilisée ;
Figure 3.14 : Le modèle d'allocation maximum (MAM).

62
- Russian Dolls Model (RDM) : Chaque classe a sa propre bande passante, mais les classes
de priorité élevée peuvent utiliser la bande non utilisée des classes moins prioritaires.
Figure 3.15 : Le modèle d'allocation Russian Dolls (RDM).
3.6.2 Principe de fonctionnement de Diffserv dans le réseau MPLS
MPLS prend en charge DiffServ mais avec de petits ajustements. MPLS n'introduit aucune
modification à la gestion de trafic et aux concepts de PHB définis dans DiffServ. Les LSR
utilisent les mêmes mécanismes de gestion du trafic (metering, marking, shaping, policing,
queuing ...) pour implémenter les différents PHB.
Le code DSCP de DiffServ contient 6 bits: les 3 premiers bits désignent la classe
d'ordonnancement (PSC : PHB Scheduling Class), à savoir: EF, AF1, AF2, AF3, AF4 et BE, et les
3 derniers désignent la priorité de suppression (Drop Precedence) au sein de la classe comme
AF11, AF12 et AF13 dans AF1. Le standard RFC3270 définit deux manières d'intégrer DiffServ
avec MPLS: [25]
- E-LSP ou « EXP-Inferred PSC LSPs ;
- L-LSP ou « Label-Only-Inferred-PSC LSPs ».
E-LSP
Le champ EXP est utilisé seul pour désigner le PHB. C'est-à-dire seulement 8 PHBs sont
possibles. Le mappage entre DSCP et EXP est défini soit de manière fixe dans tout le domaine,
soit de manière dynamique à l'établissement de chaque LSP par le protocole LDP ou RSVP. La
figure 3.06 montre l'affectation d'EXP suivant la table de mappage DSCP-EXP. [25]

63
Figure 3.16 :
Figure 3.17 : Le mappage DSCP-EXP.
L-LSP
Avec ce mode de LSP, le DSCP est divisé en deux parties de tel sort que les bits représentant les
informations d'ordonnancement PSC sont mappés dans le label et les bits représentant les
informations sur la priorité de suppression (Drop Precedence) sont copiés dans le champ EXP. La
table de correspondance PSC-Label est définie lors de l'établissement de l'LSP. Une modification
a été portée sur les protocoles LDP et RSVP afin de supporter cette signalisation. La figure 3.07
montre l'affectation des labels suivant le PSC et l'EXP suivant le DP. [25]
Figure 3.18 : Affectation de Label-EXP suivant PSC-DP.
3.7 Conclusion
Dans ce chapitre, nous avons parlé des paramètres de qualité de service servant à évaluer la
performance du réseau. Ensuite nous avons aborder le modèle Intserv et avons constaté ses limites

64
dans un réseau MPLS puisque le protocole RSVP est surtout adapté au réseau de petite taille alors
que MPLS est toujours assigné à des réseaux étendus. Enfin, nous avons détaillé le modèle
Diffserv et avons vu son intégration dans le réseau MPLS afin de mieux garantir la qualité de
service au sein du réseau.

65
CHAPITRE 4
SIMULATIONS ET RESULTATS
4.1 Introduction
Afin d’évaluer les paramètres de la QoS d’un réseau MPLS avec « Traffic Engineering » basé sur
la simulation, OPNET® (Optimum Network) Modeler 14.5 a été employé pour mettre en
application différents scénarios. Nous avons employé la version pour étudiant d'OPNET Modeler
14.5. Cet outil a une bonne interface utilisateur et un ensemble riche de modules où les utilisateurs
peuvent efficacement créer les environnements appropriés de simulation en glissant les modules
nécessaires.
Dans ce chapitre, nous allons voir en premier lieu un bref aperçu du logiciel de simulation
OPNET® Modeler 14.5 ; et en deuxième lieu, la simulation du réseau et l’analyse détaillée des
résultats obtenus.
4.2 Choix du simulateur
Il existe plusieurs simulateurs tels que Matlab, Packet Tracer, Opnet, NS2, GNS3. OPNET est un
puissant outil de conception et de simulation de réseau qui a gagné de popularité auprès des
industries et des universités. OPNET possède un module appelé MODELER qui contient un large
éventail de modèles de composants de réseau actuellement disponibles sur le marché. Ces
composants peuvent être configurés de la même manière que dans le cas réel. Cela rend la
simulation de l’environnement du réseau très proche de la réalité.
D’autres caractéristiques de l’OPNET sont : une interface graphique, une librairie de modèles et
protocoles facile à manipuler, de code source pour tous les modèles, des résultats graphiques et
des statistiques, etc.
4.3 Présentation du logiciel OPNET Modeler
OPNET est une famille de logiciels de modélisation et de simulation de réseaux s'adressant à
différent public tel que les entreprises, les opérateurs et la recherche. OPNET Modeler est la
version académique de cette famille, il offre la possibilité de modéliser et d'étudier des réseaux de
communications, des équipements, des protocoles et des applications avec facilité et évolutivité.
OPNET est utilisé par les entreprises technologiques les plus performantes pour accélérer leurs
procédés de recherches et développements.

66
L'approche orientée objet associée à des éditeurs graphiques intégrés d'OPNET simplifie la
composition des réseaux et des équipements. Ceci permet de réaliser facilement une
correspondance entre un système d'informations et le modèle correspondant.
OPNET est basé sur une série d'éditeurs hiérarchisés qui parallélisent la structure du réseau réel
des équipements et des protocoles. [27]
Figure 4.01 : Le logiciel OPNET Modeler (version 14.5)
4.3.1 Les boîtes à outils d’OPNET
4.3.1.1 Les systèmes
OPNET Modeler fournit une librairie de modèles de matériels disponibles dans le commerce. Ces
matériels peuvent être des routeurs, des commutateurs, des stations de travail, et des générateurs
de trames.

67
Figure 4.02 : Exemple de matériels réseaux MPLS
4.3.1.2 Les protocoles
OPNET Modeler fournit des modèles de protocole des différentes couches ISO, tels que http,
TCP, IP, Ethernet, ATM, 802.11, etc…
4.3.2 La conception du réseau sous l’OPNET
Il existe 4 niveaux hiérarchiques dans l’OPNET pour modéliser un réseau. [28]
4.3.2.1 Project level
C’est le niveau de conception le plus élevé. On peut regrouper plusieurs Networks Models dans un
Project. Cela peut faciliter l’analyse ou la comparaison de deux solutions d’ingénierie distinctes.
4.3.2.2 Network level
C’est la représentation du réseau dans son ensemble. C’est-à-dire un ensemble de nœuds ou nodes
reliés par des liens.

68
Figure 4.03 : Exemple de modélisation d’un réseau MPLS sous OPNET
4.3.2.3 Node level
C’est l’ensemble des différentes machines à état et la façon dont ils communiquent via des bus.
Dans ce Node level, on trouve les générateurs de paquets, queue, émetteur point à point, bus, etc.
Figure 4.04 : Exemple de modélisation de nœuds sous OPNET
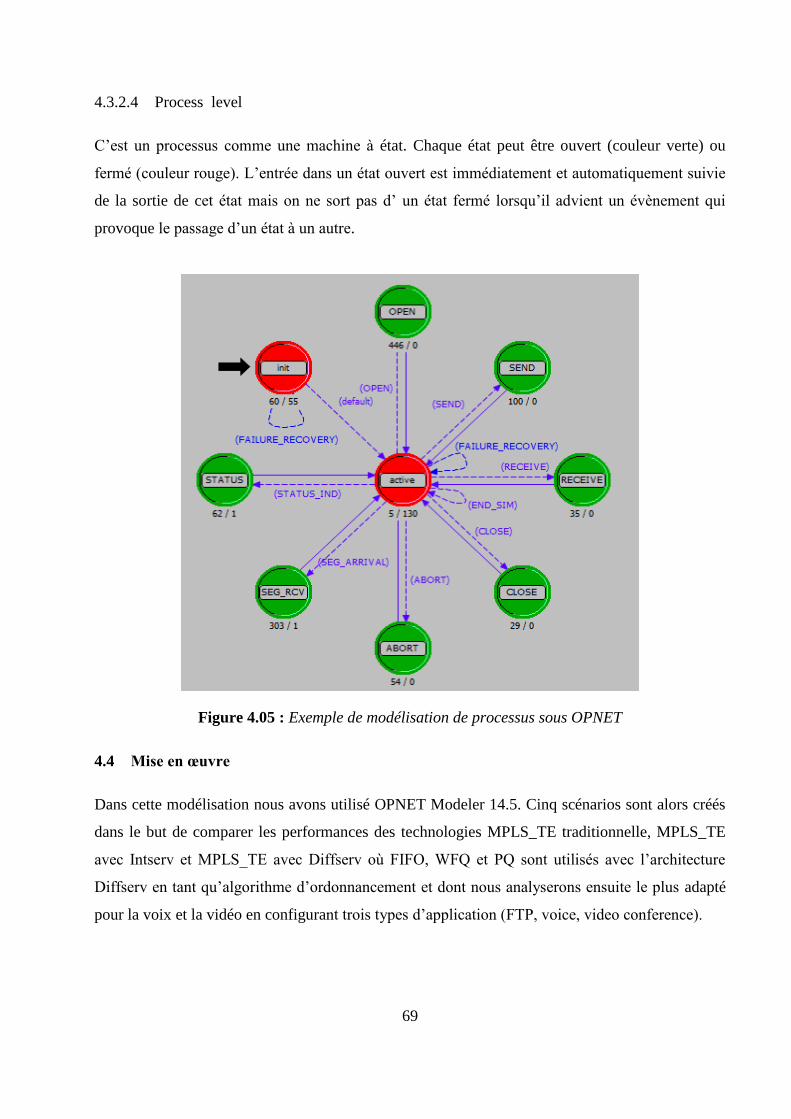
69
4.3.2.4 Process level
C’est un processus comme une machine à état. Chaque état peut être ouvert (couleur verte) ou
fermé (couleur rouge). L’entrée dans un état ouvert est immédiatement et automatiquement suivie
de la sortie de cet état mais on ne sort pas d’ un état fermé lorsqu’il advient un évènement qui
provoque le passage d’un état à un autre.
Figure 4.05 : Exemple de modélisation de processus sous OPNET
4.4 Mise en œuvre
Dans cette modélisation nous avons utilisé OPNET Modeler 14.5. Cinq scénarios sont alors créés
dans le but de comparer les performances des technologies MPLS_TE traditionnelle, MPLS_TE
avec Intserv et MPLS_TE avec Diffserv où FIFO, WFQ et PQ sont utilisés avec l’architecture
Diffserv en tant qu’algorithme d’ordonnancement et dont nous analyserons ensuite le plus adapté
pour la voix et la vidéo en configurant trois types d’application (FTP, voice, video conference).

70
4.4.1 Modélisation d’un réseau MPLS
Pour notre simulation, nous avons implémenté une architecture avec 7 routeurs cœurs du réseau
rattachés avec des liens ppp_DS3 de capacité de 45 Mo et 2 routeurs Edge rattachés au routeur
core avec des liens ppp_DS1 de 2 Mo. Cette architecture est aussi déployée avec le
MPLS_Diffserv et le MPLS_Intserv afin de faire une étude comparative entre les scénarios.
Figure 4.06 : Topologie du réseau à simuler (ici, on a MPLS_diffserv)
4.4.2 Equipements utilisés pour la modélisation du réseau
Notre modèle est composé de plusieurs équipements à savoir :
- Des stations de travail ppp_wkstn : il existe trois types de station à savoir une station de
client FTP, une station pour le client utilisant la vidéo conférence et deux stations pour les
deux clients VoIP ;
- Des serveurs ppp_server à savoir un serveur FTP pour le transfert de données pour la
station FTP et un serveur Vidéo ;
- Des liens ppp_DS3 et ppp_DS1 pour connecter les routeurs ;
- Deux ethernet2_slip8_ler utilisés comme LER (Label Edge Router). Ces LER sont utilisés
comme LER par défaut disponible dans la librairie du modèle MPLS de Opnet ;
- Sept ethernet2_slip_lsr utilisés comme LSR (Label Switch Router). Ce LSR sont utilisés comme
LSR par défaut disponible dans la librairie du modèle MPLS de Opnet ;
- MPLS_E-LSP_Static utilisé pour créer les LSP (Label Switched Path) ;

71
- Application_Config permet de définir et de configurer les types d’application qu’on
souhaite réaliser comme par exemple Video Conferencing, Voice over IP call et File
Transfer ;
- Profile_Config appliqué aux stations de travail et aux serveurs. Il spécifie les applications
utilisées par des groupes particuliers d’utilisateurs ;
- MPLS_Config utilisé pour configurer les Traffic Trunks et les FEC ( Forward Equivalence
Class) ;
- QoS_Config utilisé pour définir les détails de la configuration du QoS.
4.4.3 Configurations des trafics
4.4.3.1 Configuration du trafic FTP
La configuration du trafic FTP est illustrée par la figure 4.07 :
Figure 4.07 : Définition du trafic FTP
Pour le trafic FTP, nous utilisons les attributs suivants :
- Command Mix : Indique le pourcentage des commandes « get » par rapport au total des
commandes FTP. Le pourcentage restant de la commande est la transaction des fichiers
FTP « put ». Ici nous avons utilisé 50% de commande « get » et 50% de commande « put
» ;
- Inter-Request Time (seconds) : indique l’intervalle de temps entre les transferts de fichier.
Le début pour une session de transfert de fichier est compté en ajoutant le « inter-request
time » au temps que le précédent transfert de fichier a commencé. « Constant (50) »

72
indique qu’on envoie deux paquets consécutifs avec un intervalle de temps de 50 s entre
les deux paquets ;
- File Size (bytes) : Définit la taille (en bytes) d’un transfert de fichier. « Constant
(150000) » indique qu’on transmet un paquet de 150000 Kbit à chaque envoi ;
- Symbolic Server Name : indique le serveur de fichier pour le service FTP ;
- Type of Service : Indique le type de service ou le point de code pour les services
différenciés (DSCP) qui est assigné aux paquets à envoyer aux clients. Il représente un
paramètre de session qui autorise les paquets à être envoyés plus rapidement dans une file
IP. L’affectation du type de service chez le client n’est pas affectée par la valeur type de
service spécifié du côté de serveur. Ici, le point de code DSCP assigné au trafic FTP est
AF11 qui correspond à la priorité IP « Background (1) » ;
- RSVP Parameters : Il spécifie les paramètres RSVP (état RSVP, la taille du mémoire
tampon) utilisés par cet équipement. L’utilisateur devrait insérer le nom de « RSVP Flow
Specification » comme défini dans l’objet« QoS Attribute Configuration ».
4.4.3.2 Configuration du trafic voix
La configuration du trafic voix est illustrée par la figure 4.08 :
Figure 4.08 : Définition du trafic voix

73
- Silence Length (seconds) : spécifie le temps passé par la partie appelée (entrant) et la
partie qui émet l’appel (sortant) dans le mode silence dans un cycle speech-silence ;
- Talk Spurt Length (seconds) : spécifie le temps passé par la partie appelée (entrant) et la
partie qui émet l’appel (sortant) dans le mode discours dans un cycle speech-silence ;
- Symbolic Destination Name : c’est le client de destination de l’appel. Il spécifie aussi la
valeur de l’adresse du client si une destination spécifique est à atteindre ;
- Encoder Scheme : c’est un mécanisme de codage à utiliser par les deux parties (appelant et
appelé). Ici, on utilise le codec G.711 ;
- Voice Frames per Packet : cet attribut détermine le nombre de trames de voix codée,
groupées dans un paquet de voix, avant d’être envoyées par l’application à la couche
inférieure ;
- Type of Service : Indique le type de service ou le DSCP qui est assigné aux paquets à
envoyer. Ici, pour la voix, on assigne le point de code DSCP AF31 qui correspond à la
priorité IP « Excellent Effort (3) » ;
- RSVP Parameters : Il spécifie les paramètres RSVP utilisés par cet équipement ;
- Traffic Mix (%) : spécifie le trafic généré comme trafic discret ou trafic « background ou
une partie discrète et une partie background. Le pourcentage spécifié est la partie du trafic
background ;
- Signaling : spécifie les méthodes utilisées pour établir et rompre un appel ;
- Compression Delay (seconds) : cet attribut spécifie le délai de compression d’un paquet ;
- Decompression Delay (seconds) : cet attribut spécifie le délai de décompression d’un
paquet ;
- Conversation Environment : cet attribut est utilisé pour spécifier les environnements de
conversation entrante ou sortante.
4.4.3.3 Configuration du trafic vidéo
La configuration du trafic vidéo est illustrée par la figure 4.09 :

74
Figure 4.09 : Définition du trafic vidéo
Pour la conférence vidéo, nous utilisons les attributs suivants :
- Frame Interarrival Time Information : c’est le débit de la trame (en trames/s) pour la
conférence vidéo entrant et sortant. Pour la conférence vidéo on utilise un débit de 15
trames/s ;
- Frame Size Information : spécifie la taille de la trame vidéo qui est de 128*240 pixels ;
- Symbolic Destination Name : spécifie le serveur distant pour le service de video
conferencing ;
- Type of Service : Indique le type de service ou le DSCP qui est assigné aux paquets à
envoyer. Ici on assigne le point de code DSCP AF41 à la vidéo qui correspond à la priorité
IP 4 « Streaming Multimedia (4) ». C’est une priorité un peu plus élevée pour avoir une
transmission vidéo en bonne qualité ;
- RSVP Parameters : Il spécifie les paramètres RSVP (état RSVP, la taille du mémoire
tampon) utilisés par cet équipement. L’utilisateur devrait insérer le nom de « RSVP Flow
Specification » comme défini dans l’objet« QoS Attribute Configuration » ;
- Traffic Mix : spécifie le trafic généré comme trafic discret ou trafic « background » ou
une partie discrète et une partie background. Le pourcentage spécifié est la partie du trafic
background.
4.4.4 Configurations du réseau MPLS avec « Traffic Engineering »
Une fois le réseau MPLS schématisé, il faut le configurer de telle sorte qu'il soit opérationnel
selon des critères sélectionnés. La configuration du réseau MPLS avec « Traffic Engineering »
doit suivre ces quelques étapes :

75
- la définition des FEC ;
- la définition des « Traffics Trunks » ;
- la définition des LSP pour chaque trafic (FTP,Voice,Video).
4.4.4.1 Définition des FEC
Une FEC se compose d'une ou plusieurs entrées permettant de spécifier un trafic. Pour chaque
entrée, les adresses IP source et destination, les ports de transport source et destination, le type de
protocole transporté ainsi que la valeur du champ ToS peuvent être utilisés pour cette
spécification. Un LER recevant un paquet correspondant à la définition d'une des entrées d'une
FEC acheminera ce paquet sur le LSP correspondant à cette FEC. Pour configurer les FEC qui
seront utilisées dans notre simulation, il faut éditer l'attribut FEC Specification de l'objet MPLS
Configuration. [26]
La figure 4.10 présente la définition des FEC pour chaque trafic.
Figure 4.10 : Définition FEC pour chaque trafic

76
Configuration du champ ToS
Le champ ToS d'un paquet IP est constitué de 8 bits. La valeur de ce champ peut être configurée
selon l'approche telle que définie dans la spécification IP d'origine en utilisant quatre
paramètres. Ces paramètres sont Delay, Throughput, Reliability et Precedence. Le
paramètre Precedence, définissant l'importance du datagramme, peut prendre les 8 valeurs
suivantes : (0) Best Effort, (1) Background, (2) Standard, (3) Excellent Effort, (4) Streaming
Multimedia, (5) Interactive Multimedia, (6) Interactive Voice et (7) Reserved.
Figure 4.11 : Configuration du
champ ToS du trafic FTP
Figure 4.12 : Configuration du
champ ToS du trafic voix
Figure 4.13 : Configuration du
champ ToS du trafic vidéo
Le champ ToS des paquets IP peut également être configuré avec l'approche DSCP
(Differenciated Services Code Point) utilisée avec les réseaux IP supportant l'architecture de
qualité de service Diffserv. Dans ce cas, le champ ToS prend une des valeurs définies pour les
différentes classes de service de cette architecture. La valeur de ce champ peut alors être:
Expedited Forwarding (EF), Assured Forwarding (AFl, AF2, AF3, AF4). Si la classe de service du
paquet est AFl à AF4, il s'ajoute une valeur définissant la priorité d'être supprimé en cas de besoin:
AFxl pour les paquets ayant priorité de ne pas être supprimés, AFx2 pour les paquets pouvant être
supprimés au besoin, AFx3 pour les paquets de la classe x devant être supprimés en premier.

77
4.4.4.2 Définition des « Traffics Trunk »
Un Traffic trunk ne fait pas partie des fondements de la technologie MPLS. Dans un réseau
MPLS sans ingénierie de trafic, les paquets caractérisés par une FEC suivent le LSP
correspondant. Le Traffic Trunk est un concept relié à l'ingénierie de trafic. Pour déplacer le trafic
là où il y a de la bande passante, la FEC n'associe pas le trafic à un autre LSP, c'est le Traffic
Trunk qui est associé à un autre LSP. Lorsque l'ingénierie de trafic est utilisée, la FEC associe un
trafic à un Traffic Trunk qui est lui-même associé à un ou plusieurs LSP. [26]
Pour configurer ceux qui seront utilisés dans notre simulation, il faut éditer 1' attribut Traffic
Trunk Profiles de 1' objet MPLS Configuration. Un profil de Trunk sera configuré pour chaque
trafic FTP, Voix et Vidéo.
Figure 4.14 : Définition des profils de Traffics Trunk
4.4.4.3 Définition des LSP
Chaque type de trafic doit être associé avec le chemin de commutation d'étiquettes spécifiques
(LSP) correspondantes, et qui transporte de trafic jusqu’au routeur LER de destination.
L'association de trafic vers le LSP est effectuée sur le routeur de périphérique LER1 (Traffic
Mapping Configuration). [26]
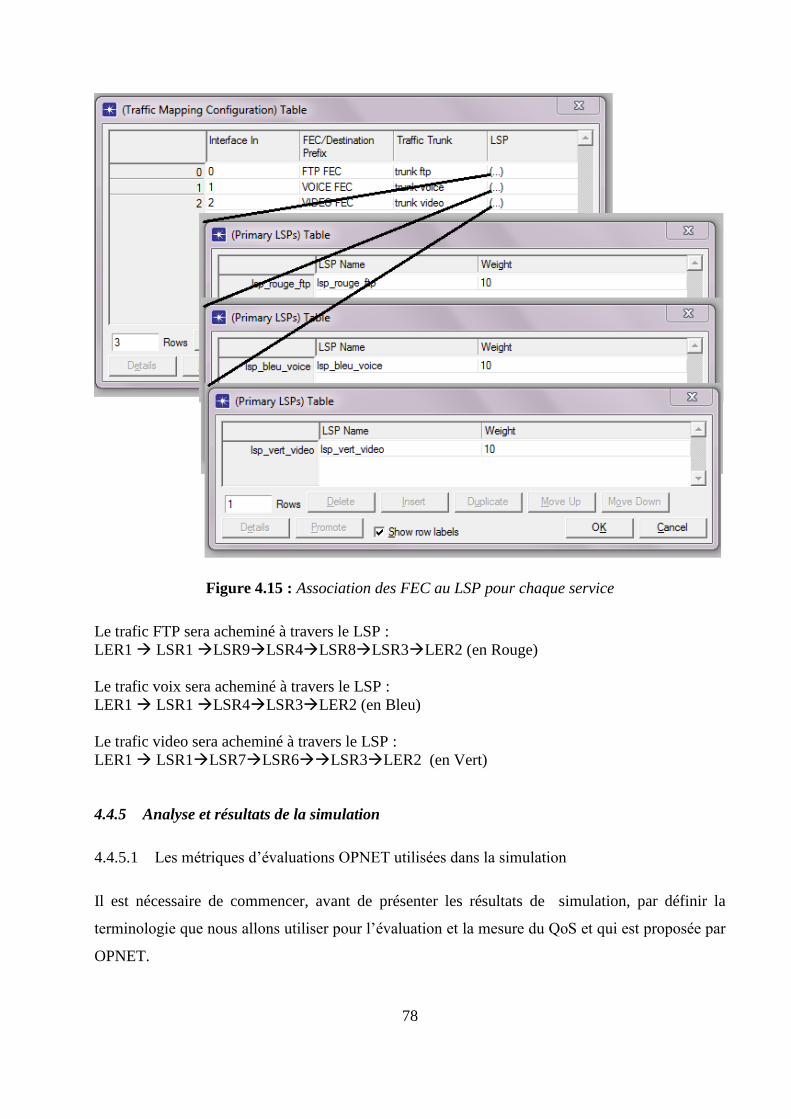
78
Figure 4.15 : Association des FEC au LSP pour chaque service
Le trafic FTP sera acheminé à travers le LSP :
LER1 LSR1 LSR9LSR4LSR8LSR3LER2 (en Rouge)
Le trafic voix sera acheminé à travers le LSP :
LER1 LSR1 LSR4LSR3LER2 (en Bleu)
Le trafic video sera acheminé à travers le LSP :
LER1 LSR1LSR7LSR6LSR3LER2 (en Vert)
4.4.5 Analyse et résultats de la simulation
4.4.5.1 Les métriques d’évaluations OPNET utilisées dans la simulation
Il est nécessaire de commencer, avant de présenter les résultats de simulation, par définir la
terminologie que nous allons utiliser pour l’évaluation et la mesure du QoS et qui est proposée par
OPNET.

79
- Response Time ou temps de réponse : le temps écoulé entre une commande et la
réalisation de cette commande ;
- Packet End to End Delay ou délai de bout en bout : le temps que prend un paquet pour
aller de la couche application de la source à celle de la destination. [8]
Paramètre Réseau Delay
Bon 0 – 150 ms
Moyen 150 – 300 ms
Pauvre > 300ms
Tableau 4.01: Valeurs de délai de
bout en bout pour la voix
Paramètre Réseau Delay
Tolérable < 200 ms
Tableau 4.02: Valeurs de délai de bout en
bout pour la vidéo
- Packet Delay Variation ou gigue: donne la différence entre les délais de transmission.[8]
On peut le définir par la formule :
𝑃𝐷𝑉 = (𝑡4 − 𝑡3) − (𝑡2 − 𝑡1) (4.01)
Si la gigue est négative cela implique que le paquet émis en second arrive en premier.
Paramètre Réseau Packet Delay Variation
Bon 0 – 20ms
Moyen 20 – 50ms
Pauvre > 50ms
Tableau 4.03: Valeurs de gigue pour la voix
Paramètre Réseau Packet Delay Variation
Mauvaise > 5ms
Tableau 4.04: Valeurs de gigue pour la vidéo
4.4.5.2 Analyse des résultats
Pour notre simulation, chaque scénario est simulé pendant une durée de 300s.
- Le scénario MPLS_TE-No QoS (en jaune) donne le résultat produit par le réseau MPLS
avec « Traffic Engineering » sans implémentation de QoS ;
- Le scénario MPLS_TE-Intserv_RSVP (en bleu clair) donne le résultat produit par le réseau
MPLS avec « Traffic Engineering » avec implémentation du service intégré Intserv ;

80
- Les scénarios MPLS_TE-DiffservWFQ (en vert), MPLS_TE-DiffservPQ (en rouge),
MPLS_TE-DiffservFIFO (en bleu foncé) donnent les résultats pour le réseau MPLS avec
« Traffic Engineering », avec implémentation du service différencié et avec utilisation
respectif des algorithmes d’ordonnancement WFQ, PQ, FIFO.
4.4.5.2.1 Analyse du trafic FTP
La figure 4.16 nous montre le résultat du temps de réponse du trafic FTP pour chaque scénario.
Figure 4.16 : Temps de réponse du trafic FTP
D’après ces résultats, le temps de réponse de MPLS_TE sans QoS (en jaune) est nettement plus
élevé, à peu près de 1s, que pour les réseaux MPLS_TE-DiffServ et MPLS_TE-Intserv. Nous
remarquons aussi que MPLS_TE-Intserv(en bleu clair) fournit un meilleur temps de réponse que
pour les scénarios MPLS_TE Diffserv avec utilisation des algorithmes d’ordonnancement PQ,
WFQ, FIFO qui sont confondus à une valeur proche de 200ms.
Puisqu’il est toujours meilleur d’avoir le temps de réponse le plus faible, nous pouvons donc dire
que l’utilisation de MPLS_TE avec implémentation de QoS donne une meilleure performance en
temps de réponse que l’utilisation de MPLS_TE seule.
4.4.5.2.2 Analyse du trafic voix
La figure 4.17 nous montre la variation du délai de retard du trafic voix pour chaque scénario.

81
Figure 4.17 : Variation du délai de retard (gigue) du trafic voix
Nous allons tout d’abord comparer les performances du réseau MPLS_TE sans QoS avec
MPLS_TE avec implémentation de QoS. On remarque que tous les scénarios présentent une
bonne valeur de gigue, inférieure à 20ms. On remarque aussi que le réseau MPLS_TE sans QoS
(en jaune) possède une valeur de gigue beaucoup plus élevée.
Si on compare maintenant les réseaux MPLS_TE avec Diffserv et Intserv, on remarque que
Intserv (en bleu clair) montre de meilleure performance pour la gigue, qui est environ égal à 0, par
rapport à MPLS_TE avec Diffserv implémenté. Cette performance de Intserv s’explique par son
utilisation du protocole RSVP qui maintient des sessions sur tous les équipements qui sont
traversés par les flux.
Si on compare maintenant les performances des algorithmes d’ordonnancement utilisés avec
MPLS_TE-Diffserv, on remarque que WFQ (en vert) n’affiche pas la meilleure performance
même comparé à FIFO (en bleu foncé). Cela est dû au fait qu’il est plus préoccupé par la
prévention de la congestion et le maintien de l’équité. On remarque aussi que PQ (en rouge)
montre la meilleure performance parmi les algorithmes d’ordonnancement utilisés.
La figure 4.18 nous montre le délai de bout en bout pour chaque scénario.

82
Figure 4.18 : Délai de bout en bout du trafic Voix
Tous les scénarios présentent de bonne valeur en ce qui concerne le délai de bout en bout,
inférieur à 150ms. Comme pour la gigue, on remarque que la valeur du Packet End-to-End Delay
est un peu plus élevée pour le réseau MPLS_TE sans QoS (en jaune) par rapport aux autres
scénarios. Les scénarios MPLS_TE-Intserv et MPLS_TE-Diffserv avec les algorithmes
d’ordonnancement sont confondus et ont une valeur près de 60ms.
4.4.5.2.3 Analyse du trafic vidéo
La figure 4.19 nous montre la variation du délai de retard pour la vidéo.
Figure 4.19 : Variation du délai de retard (gigue) du trafic vidéo
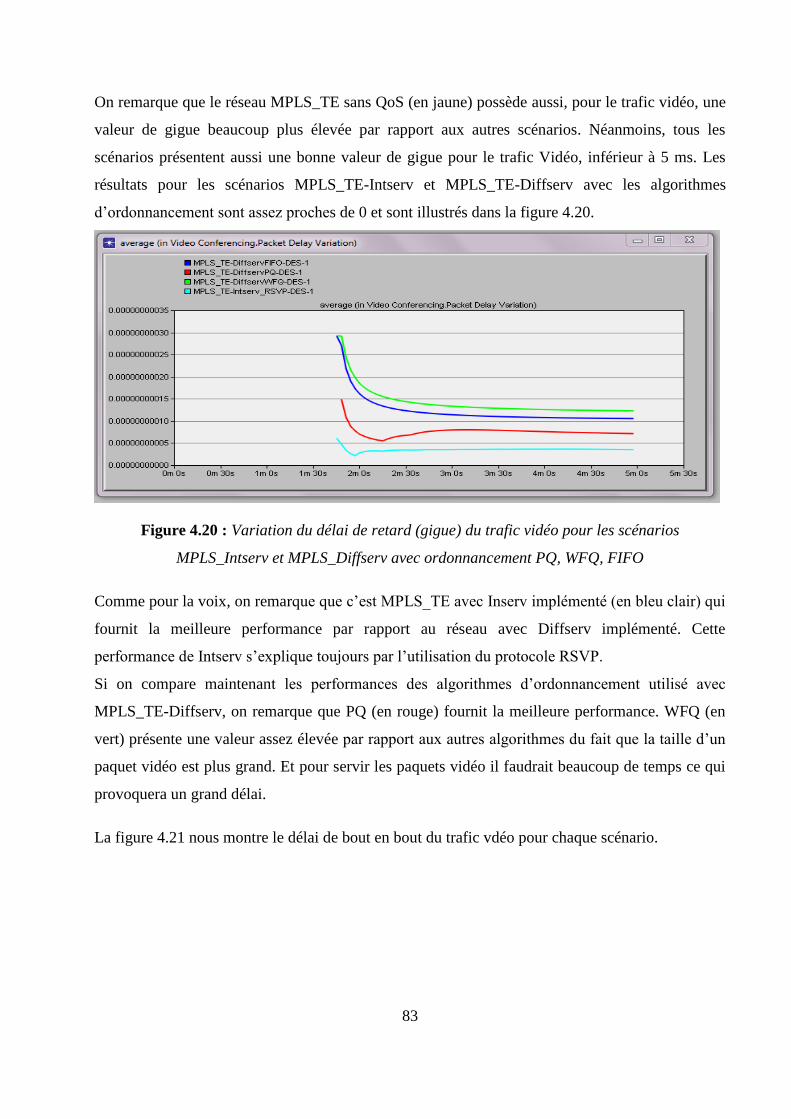
83
On remarque que le réseau MPLS_TE sans QoS (en jaune) possède aussi, pour le trafic vidéo, une
valeur de gigue beaucoup plus élevée par rapport aux autres scénarios. Néanmoins, tous les
scénarios présentent aussi une bonne valeur de gigue pour le trafic Vidéo, inférieur à 5 ms. Les
résultats pour les scénarios MPLS_TE-Intserv et MPLS_TE-Diffserv avec les algorithmes
d’ordonnancement sont assez proches de 0 et sont illustrés dans la figure 4.20.
Figure 4.20 : Variation du délai de retard (gigue) du trafic vidéo pour les scénarios
MPLS_Intserv et MPLS_Diffserv avec ordonnancement PQ, WFQ, FIFO
Comme pour la voix, on remarque que c’est MPLS_TE avec Inserv implémenté (en bleu clair) qui
fournit la meilleure performance par rapport au réseau avec Diffserv implémenté. Cette
performance de Intserv s’explique toujours par l’utilisation du protocole RSVP.
Si on compare maintenant les performances des algorithmes d’ordonnancement utilisé avec
MPLS_TE-Diffserv, on remarque que PQ (en rouge) fournit la meilleure performance. WFQ (en
vert) présente une valeur assez élevée par rapport aux autres algorithmes du fait que la taille d’un
paquet vidéo est plus grand. Et pour servir les paquets vidéo il faudrait beaucoup de temps ce qui
provoquera un grand délai.
La figure 4.21 nous montre le délai de bout en bout du trafic vdéo pour chaque scénario.

84
Figure 4.21 : Délai de bout en bout du trafic vidéo
On remarque que le réseau MPLS_TE sans QoS (en jaune) fournit toujours la plus mauvaise
performance avec un délai de 10 ms. Et MPLS_TE-Intserv (en bleu clair) fournit une plus
meilleure performance que MPLS_TE-Diffserv avec les algorithmes d’ordonnancement dont les
graphes sont confondus à une valeur proche de 2 ms.
4.5 Conclusion
Après l’analyse des résultats de la simulation en observant les délais et ses variantes (gigue et
délai d’attente) pour trois différents services : voix, vidéo conférence, et trafic FTP, nous pouvons
conclure que l’utilisation de la qualité de service dans le réseau MPLS avec « Traffic
Engineering » fournit la meilleure performance, les valeurs de gigue et de délai de bout en bout
sont affaiblies. Et l’utilisation des algorithmes d’ordonnancement FIFO, PQ, WFQ avec
l’architecture Diffserv nous permet de dire que PQ est donc recommandable pour une
transmission vidéo et voix puisqu’il donne des délais faibles par rapport aux autres algorithmes.

85
CONCLUSION GENERALE
De nos jours, les quantités de données transportées sur les réseaux sont de plus en plus
importantes, et le routage IP actuel ne satisfait pas aux contraintes qui sont désormais de l'ordre de
la bande passante et du temps de transmission. MPLS offre indéniablement plusieurs services
intéressants à exploiter, et ne nécessite pas forcément d'investissement conséquent lors de sa mise
en place. L’utilisation des technologies à contrainte temporelle telles que la VoIP ou les
applications vidéo, est de plus en plus fréquente, et le développement de ces dernières requiert
l'utilisation d'un réseau pouvant respecter ses besoins.
MPLS est donc une technologie qui a su prendre une place prépondérante dans les réseaux longue
distance des opérateurs. Son but premier, qui était d'optimiser le temps de traitement des paquets
au sein du cœur de réseau s'est peu à peu effacé pour laisser place aux applications du MPLS
comme le « Traffic Engineering » et le support de la qualité de service.
Le "Traffic Engineering" réalise une répartition plus fine des ressources dans le réseau de
l'opérateur permettant d'un côté d’éviter le recours à une politique de surdimensionnement des
réseaux physiques et d'un autre côté d’associer voix/données sur le même réseau. Et la qualité de
service permet de garantir de bonnes performances aux applications à temps réels.
Notre étude a permis de voir la variation de performance du réseau MPLS-TE avant et après la
mise en œuvre de la qualité de service. L’analyse des résultats de la simulation nous permet de
conclure que l’utilisation des mécanismes de QoS rend le réseau MPLS-TE plus performant pour
les applications FTP, voix et video. Nous avons aussi utilisé des algorithmes d’ordonnancement
avec l’architecture Diffserv, et entre les trois algorithmes FIFO, PQ, WFQ utilisés, nous avons
trouvé que PQ est le plus recommandable pour la transmission voix et vidéo.
Nous n’avons pu couvrir que les algorithmes d’ordonnancement de base. Mais l’étude de tous les
algorithmes d’ordonnancement disponible peut conduire à de meilleure performance.

86
ANNEXE 1
LE MODELE OSI
A1.1 Principe général
Le modèle OSI ou « Open System Interconnexion » a été développé en 1978 par l’ISO ou
« International Standard Organization » afin que soit défini un standard utilisé dans le
développement de système ouvert. Les réseaux s’appuyant sur le modèle OSI parlent le même
langage, ils utilisent des méthodes de communication semblables pour échanger des données.
Le modèle OSI a sept couches : la couche physique, la couche liaison de données, la couche
réseau, la couche transport, la couche session, la couche présentation, et la couche application.
APPLICATION
PRESENTATION
SESSION
TRANSPORT
RESEAU
LIAISON DE DONNEES
PHYSIQUE
Figure A1.1 : Le modèle OSI
Les principes ayant conduit aux sept couches sont les suivantes :
- Une couche ne peut être créée que quand un niveau différent d’abstraction est nécessaire.
- Chaque couche doit fournir une fonction bien définie ;
- Les fonctions de chaque couche doivent être choisies en pensant à la définition de
protocoles normalisés internationaux ;
- Les caractéristiques d’une couche doivent être choisies pour qu’elles réduisent les
informations transmises entre les couches.
Le nombre de couches doit être suffisamment grand pour éviter la cohabitation dans une même
couche de fonctions très différentes et suffisamment petit pour éviter que l’architecture ne
devienne difficile à maîtriser.

87
A1.2 Rôles des couches
La couche physique s’occupe de la transmission des bits de façon brute sur un circuit de
communication. Les bits peuvent être encodés sous forme de 0 ou de 1 ou sous forme analogique.
Elle fait intervenir des interfaces mécaniques et électriques sur le média utilisé.
La couche liaison de données prend les données de la couche physique et fournit ses services à la
couche réseau. Les bits reçus sont groupés en unité logique appelée trame. Les fonctions de
contrôle de flux et d’erreurs y sont éventuellement assurées avec un contrôle d’accès au support.
La couche réseau gère la connexion entre les différents nœuds du réseau. Il comporte trois
fonctions principales : le contrôle de flux, le routage et l’adressage.
La couche transport effectue des contrôles supplémentaires à la couche réseau. Elle réalise le
découpage des messages en paquets pour la couche réseau. Elle doit également gérer les
ressources de communication en gérant un contrôle de flux ou un multiplexage. C’est l’ultime
niveau qui s’occupe de l’acheminement de l’information.
Le rôle de la couche session est de fournir aux entités de présentation les moyens nécessaires à
l’organisation et à la synchronisation de leur dialogue. Elle a pour but d’ouvrir et de fermer des
sessions entre les utilisateurs et possède par conséquent des fonctionnalités nécessaires à
l’ouverture, à la fermeture et au maintien de la connexion. L’insertion de points de
synchronisation est recommandée ; ils permettent, en cas de problèmes, de disposer d’un point
précis à partir duquel l’échange pourra redémarrer.
Pour que deux systèmes puissent se comprendre, ils doivent utiliser le même système de
représentation des données, et cette tâche est assurée par la couche présentation. Elle se charge
donc de la syntaxe des informations, de la représentation des données transférées entre
applications.
Quant à la couche application, elle fournit les fonctions nécessaires aux applications utilisateurs
qui doivent accomplir des tâches de communication. Elle intègre les logiciels qui utilisent les
ressources du réseau.

88
ANNEXE 2
NOTION SUR LA THEORIE DES FILES D’ATTENTE
A2.1 Techniques de gestion des files d’attente
Les réseaux fonctionnant en mode paquet posent un problème particulier pour la qualité de service
car chaque nœud du réseau peut recevoir et analyser chaque paquet de données immédiatement,
mais doit attendre, pour pouvoir le transmettre au nœud suivant, la disponibilité de capacité sur la
ligne de transmission appropriée. Le délai entre la réception et la réémission d’un paquet est par
conséquent variable (cette variation de délai s’appelle la gigue) : le délai peut être très grand
lorsque le réseau est congestionné ou quand un paquet particulièrement long est déjà en cours de
transmission sur l’interface choisie, ou bien très court si le paquet à transmettre trouve toujours de
la capacité disponible immédiatement le long de son chemin de transmission.
Un moyen simple de réduire le délai et la gigue pour un flux de données particulier serait de lui
donner priorité sur tous les autres, mais ceci n’est pas une solution acceptable, car les réseaux de
données sont conçus en général pour traiter équitablement tous les utilisateurs du réseau. Cette
notion d’ « équité » peut être interprétée de nombreuses manières différentes, mais l’idée
directrice est que les flux de données doivent recevoir le même niveau de service, ou bien si le
réseau implémente une notion de priorité, un service d’autant meilleur que la priorité est haute,
tous les flux d’un même niveau de priorité devant être traités de la même manière. Selon
l’interprétation exacte de la notion d’ « équité » dans le réseau, il est possible d’utiliser plusieurs
techniques de gestion de files d’attente dans les nœuds du réseau. Un effort de recherche très
important a été fait pour concevoir des politiques d’ordonnancement qui permettent de minimiser
les délais de transmission tout en donnant à chaque flux une part équitable de la capacité. Sur
chaque file d’attente de sortie correspondant à une ligne de transmission, la politique
d’ordonnancement décide de l’ordre de la transmission des paquets ou éventuellement de leur
destruction et vise pour chaque flux de données à se rapprocher le plus possible de certains
objectifs de vitesse de transmission, de délai, de gigue et de taux de perte de paquets.
Il existe plusieurs technologies, qui peuvent être regroupées en deux catégories.
Dans la première on trouve des algorithmes qui ne visent qu’à ordonner les paquets dans les files
de sortie :

89
- La technique FIFO (First In, First Out, c'est-à-dire « Premier Entré, Premier Sorti »),
parfois appelée FSFS (First Come, First Served, c'est-à-dire « Premier Arrivé, Premier
Servi »). Comme son nom l’indique, cette politique se borne à émettre les paquets sur les
liens de transmission dans l’ordre dans lequel ils ont été reçus ;
- La technique CBQ (Class Based Queuing parfois aussi appelée Custom Queuing) qui
permet de donner aux paquets un traitement différencié selon leur catégorie ;
- Les techniques de partage équitable dites Fair Queuing et Weighted Fair Queuing.
Les techniques de la seconde catégorie définissent des politiques de destruction sélective de
paquet dans les files d’attente, et peuvent être combinées avec les techniques de la première
catégorie :
- Le débordement simple;
- La technique RED (Random Early Detection), WRED (Weighted Random Early
Detection) et ARED (Adaptive Random Early Detection), que l’on pourrait traduire par
respectivement par “ Détection Préventive Aléatoire”, « Détection Préventive Adaptative
Aléatoire »et « Détection Préventive Aléatoire à Coefficient Variables » ;
- La technique BLUE ;
- L’approche IntServ basée sur la réservation statique de ressources (flux par flux) et
DiffServ permettant de fournir des garanties par classe et AQM conçu pour la gestion des
files d’attente au niveau des routeurs.
A2.2 Différents paramètres à étudier
En général, les arrivées des paquets dans un nœud sont indépendantes entres elles. Ces arrivées
sont définies par les processus tels que : Markovien, Poissonnien ou Exponentiel. Ainsi, les
paquets placés dans les mémoires tampons du routeur vont être servis avec un processus de
service selon l'ordre de leurs arrivées et suivant une discipline de service DS appliquée au routeur.
Deux cas peuvent se présenter, s'il y a un serveur libre, alors le paquet est traité immédiatement,
sinon il doit attendre jusqu'à ce qu'il soit traité, c'est le phénomène d'attente.
Une file d'attente est généralement caractérisée par six composantes :
- le processus d'arrivée ;
- le processus de service ;
- le nombre de serveurs ;
- les disciplines de service ;

90
- la capacité de la file ;
- la population des usagers.
A2.3 Types de file d’attente
Il existe plusieurs types de files d'attente telles que : M/M/l, M/M/c, M/M/8, M/M/c/c,
M/M/c/m/K, M/M/c/c/K, M/M/l/K/K et la file M/M/c/K/K. Mais nous n'allons étudier que la file
M/M/1 qui est un standard des files d'attentes.
D'après la notation de Kendall, une file M/M/1 est donc une file avec un processus de Markov en
entrée désigné par le premier M, le deuxième M signifie que le processus de sortie est aussi un
processus de Markov, le nombre 1 indique qu'il n'y a qu'un seul serveur, la discipline de service
appliquée est le FIFO « First In, First Out » ou Premier Arrivé, Premier Servi, une capacité infinie
et un nombre infini de clients qui peuvent entrer dans cette file.
Réseaux de files d'attente M/M/1
Pour arriver à modéliser des systèmes beaucoup plus complexes, une file d'attente simple n'est pas
suffisante, il faut faire appel à des réseaux de files d'attente. Un réseau de files d'attente est
composé d'un ensemble de stations de service (modélisant les ressources, exemple un routeur de
transfert de paquets) et d'un ensemble de clients (paquets). Les files d'attente devant chaque station
contiennent les activités qui ont besoin d'accéder à la ressource. Ce système est caractérisé par les
processus représentant l'arrivée des clients au réseau, les temps de service des clients aux stations,
le cheminement des clients d'une station à l'autre, et les disciplines de service des clients à chaque
station. Il est possible aussi de définir des limitations de la longueur des files, ce qui entraîne des
pertes de clients arrivant à une station déjà pleine, ou le blocage d'une file ne pouvant débiter des
clients vers une file saturée.
Les réseaux à transfert de paquets sont modélisés par des réseaux de files d'attente M/M/l : à l'état
stationnaire, chaque nœud réagit comme une file d'attente M/M/l isolée. Il convient d'adapter les
notations à ces réseaux. La longueur des paquets, en bits, suit une loi exponentielle de paramètre
µ. La moyenne est de 1/µ bit. La capacité de la ième
ligne de communication est notée Ci en bit/s.
Le produit µCi est le taux de service en paquets/s. Le taux d'arrivée pour la ième
ligne est λi
paquets/s.
Pour la ième
ligne, Ti représente le temps d'attente et de transmission, sous la forme :
𝑇𝑖 = 1/(µ𝐶𝑖 + 𝜆𝑖) (A2.01)

91
ANNEXE 3
CONFIGURATION DES PARAMETRES PENDANT LA SIMULATION
A3.1 Configuration des utilisateurs
A3.1.1 client FTP
Figure A3.1 : Configuration du profil FTP
La configuration du profil FTP est illustrée par la figure A3.1. Le profil FTP a donc les paramètres
suivants :
- Operation mode : “Simultaneous” ce qui veut dire que toutes les applications vont tous
commencer en même temps ;
- Start time : “constant(100)” est l’attribut qui définit le début du profil (le profil FTP
commence 100 s après le début de la simulation) ;
- Duration : “End of Simulation” est la durée de la simulation. Le profil se termine à la fin
de la simulation.
Ce profil est utilisé dans le paramètre de la configuration des clients FTP comme illustré dans la
figure A3.2.

92
Figure A3.2 : Configuration du client FTP
A3.1.2 client Vidéo
Figure A3.3 : Configuration du profil vidéo

93
Figure A3.4 : Configuration du client vidéo
La configuration des paramètres du client Vidéo est représentée par les figures A3.3 et A3.4
Les paramètres sont identiques aux paramètres du client FTP.
A3.1.3 client voix
Figure A3.5 : Configuration du profil voix

94
Figure A3.6 : Configuration du client voix
De même pour la voix, les paramètres illustrés par les figures A3.5 et A3.6 sont identiques aux
paramètres configurés pour le FTP.
A3.2 Configuration des serveurs
A3.2.1 serveur FTP
La configuration du serveur FTP est illustrée par la figure A3.7. L’attribut “Application :
Supported Service” indique les paramètres à configurer pour les différents services dans ce
serveur. Les clients peuvent envoyer des trafics à ce serveur pour les applications qui sont
seulement supportées par cet attribut.

95
Figure A3.7 : Configuration du serveur FTP
Pour le serveur FTP l’application supportée est le ftp_app pour le client ftp
A3.2.2 serveur vidéo
La configuration du serveur vidéo est la même que celle du serveur FTP. Elle est représentée par
la figure A3.8.
Figure A3.8 : Configuration du serveur Vidéo
Pour le serveur vidéo l’application supportée est la video_app pour le client Vidéo.

96
BIBLIOGRAPHIE
[1] G. Pujolle, “Les réseaux”, Eyrolles, 2003
[2] C. Servin, “Réseaux et Télécoms”, Dunod, 2003
[3] J. Doyle, “Routing TCP/IP – Volume I”, Cisco Press, 2001
[4] A. Tanenbaum, “Réseaux”, Pearson Education, 2003
[5] C. Huitema, “Le routage dans Internet”, Eyrolles, 1995
[6] W. R. Stevens, A. Wesley, “TCP/IP Illustrated Volume 1, The Protocols ”, 1993
[7] J. Montagnon, T. Huaong, “MPLS et les réseaux d’entreprise”, 2002
[8] J. Mélin, “Qualité de service sur IP”, Eyrolles, 2001
[9] http://www.frameip.com/mpls/index.html
[10] E. Osborne, A. Simha, “Traffic Engineering with MPLS”, Cisco Press, 2002
[11] A. A. Randriamitantsoa, “Planification, Modelisation et Simulation des réseaux par le
protocole MPLS”, Mémoire de fin d’études, Dép.Tél. - ESPA, A.U. : 2000-2001
[12] J. Uzé, “VPLS: Virtual Private LAN Service”, Juniper Networks, 2013
[13] O. Foudhaili, “Analyse des performances de MPLS en terme de "Traffic Engineering" dans
un réseau multiservice ”, école supérieur des communications de Tunis, 2004-2005
[14] N. Simoni, “Des réseaux intelligents à la nouvelle génération de services”, Lavoisier,
2007
[15] K. Mellouk, “Mécanismes du contrôle de la qualité de service”, Lavoisier, 2007

97
[16] M. Marot, “Convergence des Services et Infrastructures Réseaux”, Telecom Paris, 2013
[17] P. Ferguson, G. Huston. J Wiley, “Quality of Service: Delivering QoS in the Internet and
in Corporate Networks”, 1998
[18] G. Fiche, G. Hébuterne, “Trafic et performances des réseaux de télécoms”, Lavoisier,
2003
[19] J. Forouzan, “Data Communications and Networking”, 2003.
[20] R. Braden, D. Clark, S. Shenker, “Integrated services in the internet architecture: an
overview”, United States, 1994
[21] S. Berson, S. Herzog, “Resource reservation protocol (rsvp) – version 1 functional
specification”, 1997
[22] N. Creighton, “QoS IP : Modèles IntServ/DiffServ”, France, 2003
[23] S. Black, “An Architecture for Differentiated Service”, 1998.
[24] A. Samhat, T. Chahed, “La différentiation de service basée sur des mesures”, Marrakech,
2001
[25] S. Davari, P. Vaananen, “Multi-Protocol Label Switching (MPLS) Support of
Differentiated Services”, 2002
[26] M. El Amine, “Planification, ingénierie des réseaux de nouvelle génération-NGN”, 2013
[27] http://www.opnet.com
[28] http://www.opnet.com/university_program/teaching_with_opnet/textbooks_and_materials/

98
FICHE DE RENSEIGNEMENT
Nom : RAMAHAROBANDRO
Prénoms : Rahasina Fenomanjato Mariah
Adresse de l’auteur : Lot MB 552 Andoharanofotsy
Antananarivo 101 – Madagascar
Tel : +261 34 39 993 69
E-Mail: [email protected]
Titre du mémoire :
« ETUDE DES PERFORMANCES DES MECANISMES DE QUALITE DE SERVICE DANS
UN RESEAU MPLS AVEC TRAFFIC ENGINEERING »
Nombre de pages : 99
Nombre de tableaux : 10
Nombre de figures : 69
Mots clés :
MPLS, Traffic Engineering, QoS, INTSERV, DIFFSERV, OPNET Modeler
Directeur de mémoire :
Nom : ANDRIAMIASY
Prénoms : Zidora
Grade : Maître de conférences
Tel : +261 33 11 874 78
E-mail : [email protected]

99
RESUME
Multiprotocol Label Switching (MPLS) est un nouveau paradigme dans les architectures de
routage qui a changé la façon dont le protocole internet (IP) transfert les paquets dans un réseau.
MPLS assure la fiabilité de la communication en minimisant les retards et en améliorant la vitesse
de transfert des paquets. Une caractéristique importante de MPLS est sa capacité à offrir des
services comme le Traffic Engineering (TE) qui joue un rôle important pour minimiser la
congestion par l’équilibrage des charges et la gestion des ressources du réseau. L’évaluation des
performances est faite en considérant les paramètres de gigue et délai de bout en bout.
L’intégration de la qualité de service dans le réseau MPLS-TE peut améliorer la performance du
réseau. Pour implémenter la qualité de service dans un réseau, divers algorithmes
d’ordonnancement peuvent être utilisés. Dans notre étude, la qualité de service a été implémentée
dans le réseau MPLS-TE en utilisant l’architecture du service intégré (Intserv) et du service
différencié (Diffserv). Le résultat de la simulation montre que l’utilisation du Traffic Engineering
avec la qualité de service diminue les paramètres (gigue, délai de bout en bout) de qualité de
service par rapport à l’utilisation seule du TE dans le réseau MPLS.
ABSTRACT
Multiprotocol Label Switching (MPLS) is a new paradigm in routing architectures which has
changed the way Internet Protocol (IP) packet is transferred in a Network. MPLS ensures the
reliability of the communication minimizing the delays and enhancing the speed of packet
transfer. One important feature of MPLS is its capability of providing Traffic Engineering (TE)
which plays a vital role for minimizing the congestion by efficient load, balancing and
management of the network resources. The performance evaluation is done considering the
network parameters latency, jitter, packet end to end delay, and packet delay variation. Integration
of QoS with the MPLS-TE network may enhance the performance of the network. Various
scheduling algorithms can be used for implementing QoS on a network. In our study, QoS is
implemented on top of the MPLS-TE network using Integrated Service (Intserv) and
Differentiated Service (DiffServ) architecture. Performance evaluation is done considering the
network QoS parameters. The simulation result shows that using TE along with QoS in MPLS
network decreases this QoS parameters compared to using TE alone.


















