
UNIVERSIDAD PONTIFICIA DE...
88
UNIVERSIDAD DISTRITAL “FRANCISCO JOSE DE CALDAS” TESIS ESPECIALIZACION EN INGENIERIA DE SOFTWARE ANÁLISIS DE FLUJOS DE INFORMACIÓN DE LA RED SOCIAL TWITTER Caso de Estudio: “Impacto de las tendencias en redes sociales para las operaciones del mercado de acciones de la empresa ECOPETROL” Autores: Ing. Edgar Leonardo Sarmiento Pacanchique Ing. Diego Camilo Silva Téllez Director: Ing. Sandro Javier Bolaños, PhD Revisor: Ing. Jorge Mario Calvo, PhD Bogotá 2017
Transcript of UNIVERSIDAD PONTIFICIA DE...

UNIVERSIDAD DISTRITAL “FRANCISCO JOSE DE CALDAS”
TESIS
ESPECIALIZACION EN INGENIERIA DE SOFTWARE
ANÁLISIS DE FLUJOS DE INFORMACIÓN DE LA RED SOCIAL TWITTER
Caso de Estudio: “Impacto de las tendencias en redes sociales para las operaciones del mercado de acciones de la empresa ECOPETROL”
Autores: Ing. Edgar Leonardo Sarmiento Pacanchique Ing. Diego Camilo Silva Téllez
Director: Ing. Sandro Javier Bolaños, PhD
Revisor: Ing. Jorge Mario Calvo, PhD
Bogotá 2017


Resumen
La proliferación de las redes sociales ha generado nuevas fuentes de información con
millones de datos de usuarios de todo el mundo [1], sin embargo estos datos se caracterizan
principalmente por dos aspectos, el primero es que no cuentan con una estructura bien
definida, y el segundo es que al ser opiniones personales de los internautas su nivel de
confiabilidad sin un contexto es bajo [2]. La generación de grandes volúmenes de datos ha
traído consigo el desarrollo de herramientas para el procesamiento de los mismos, con
máquinas cada vez más potentes y la utilización de técnicas de análisis y extracción de
información [3].
Las TIC se han convertido en un área transversal para el desarrollo de cualquier sector debido
a que la implementación de herramientas tecnológicas influye en gran medida para alcanzar
el éxito o fracaso de una organización [4]; por lo tanto, el desaprovechamiento de la
información presente en los flujos de datos de una red social puede impactar el desarrollo de
un determinado sector al no contar con reportes objetivos de tendencias del mercado en
fuentes alternativas de información.
El desarrollo de este proyecto se enfoca en la construcción de un modelo de datos para
realizar clasificación de tweets que permita identificar las tendencias de opinión en la red
social Twitter frente al comportamiento accionario de una marca.
Palabras Clave
Redes sociales, minería de textos, análisis de sentimientos, algoritmos de clasificación,
procesamiento de lenguaje natural, SVM, Twitter, streaming, transformación de datos,
operaciones del mercado, bolsa de valores, tendencias, minería de opinión, conjunto
supervisado, lenguaje R, Python.


Abstract
The proliferation of social networks has generated new data sources with millions of data
from users of worldwide, however these data are mainly characterized by two aspects: the
first is that lack a well-defined structure, and the second is that being the personal opinions
of netizens the level of reliability without a context is low. The generation of large volumes
of data has led to the development of tools for processing them, with increasingly powerful
machines and the use of techniques of analysis and information extraction.
TIC has become a cross-sectional area for the development of any sector because the
implementation of technological tools greatly influences for success or failure of an
organization; therefore the waste of the information in the data streams of a social network
can impact the development of a special sector by not having objective reports of market
trends in alternative sources of information.
The development of this project focuses on the construction of a data model to perform the
classification of tweets that allow to identify the tendencies of opinion in the social red
Twitter against the behavior of the actions of an organization.
Keywords
Social networks, Text mining, Analysis of feelings, classification algorithms, Natural
language processing, SVM, Twitter, streaming, data transformation, market operations,
stock exchange, trends, mining opinion, Supervised set, R language, Python.


7
Agradecimientos
Damos las gracias a nuestros padres, familiares y amigos quienes apoyaron nuestro esfuerzo
en la culminación de este ciclo de formación, su paciencia y aliento han sido la motivación
para llegar a este punto.
También ofrecemos un agradecimiento a la Universidad Distrital Francisco José de Caldas
en cabeza de sus maestros de la especialización y en especial a nuestro director y revisor del
proyecto de investigación, sus enseñanzas y aportes nos han permitido crecer personal y
profesionalmente.


9
Tabla de Contenidos
INTRODUCCIÓN .................................................................................................................. 1 PARTE I. FUNDAMENTACIÓN DE LA INVESTIGACIÓN ............................................. 3
CAPÍTULO 1. DESCRIPCIÓN DE LA INVESTIGACIÓN ................................................ 5 1.1 Planteamiento del problema ........................................................................................ 6
1.2 Justificación ................................................................................................................. 7 1.3 Hipótesis ...................................................................................................................... 8
1.4 Objetivos ...................................................................................................................... 9 1.5 Metodología seguida durante la investigación .......................................................... 10
1.6 Organización del trabajo ............................................................................................ 11 PARTE II. ESTADO DEL ARTE ........................................................................................ 12 CAPÍTULO 2. MARCO REFERENCIAL DEL PROYECTO ............................................ 13
1.1 Marco Teórico ........................................................................................................... 14 1.1.1 Antecedentes del procesamiento de textos ............................................................ 14
1.1.1.1 Historia y estado del arte del Procesamiento de Lenguaje Natural .................... 14 1.1.1.2 Sistemas de información de texto....................................................................... 14 1.1.1.3 Representación de textos .................................................................................... 15
1.1.2 Acceso a datos de texto .......................................................................................... 16 1.1.2.1 Modos de acceso: Pull vs Push .......................................................................... 16
1.1.2.2 Acceso interactivo multimodal........................................................................... 17 1.1.2.3 Modelos de captura de textos ............................................................................. 18 1.1.3 Información estructurada vs no estructurada ......................................................... 19
1.1.3.1 Clasificación de los datos no estructurados........................................................ 19 1.1.3.2 Tratamiento de datos no estructurados ............................................................... 19 1.1.4 Análisis de textos ................................................................................................... 20 1.1.4.1 Aplicaciones de análisis de textos ...................................................................... 20 1.1.4.2 Alcance del análisis de textos............................................................................. 21
1.1.5 Minería de asociación de palabras ......................................................................... 21 1.1.6 Categorización de textos ........................................................................................ 22 1.1.6.1 Características de la categorización de textos .................................................... 22
1.1.6.2 Algoritmos de categorización............................................................................. 22 1.1.7 Minería de opinión/análisis de sentimientos .......................................................... 24

1.1.8 Procesamiento del lenguaje natural ....................................................................... 25 1.1.9 Arquitectura empresarial ........................................................................................ 25 1.1.9.1 Archimate ........................................................................................................... 26
1.2 Marco conceptual ...................................................................................................... 37 1.2.1 Twitter .................................................................................................................... 37 1.2.2 Mercado bursátil .................................................................................................... 37 1.2.3 Ecopetrol S.A ......................................................................................................... 37 1.2.3.1 Streaming ........................................................................................................... 38
1.2.4 Tecnología de la Información y Comunicaciones (TIC) ....................................... 38 1.2.5 Inteligencia Computacional ................................................................................... 39 1.2.6 Lenguaje natural .................................................................................................... 39
1.2.7 Lingüística computacional ..................................................................................... 39 1.2.8 R Data Analysis ..................................................................................................... 40 1.2.9 Paquete caret .......................................................................................................... 40 1.2.10 Tweepy ................................................................................................................... 40
1.2.11 Pymongo ................................................................................................................ 41
PARTE III. DESARROLLO DE LA INVESTIGACIÓN ................................................... 43 Capítulo 3. Desarrollo de la propuesta de investigación ...................................................... 45 3.1 Fase 1: comprensión del negocio .............................................................................. 46
3.1.1 Objetivos del negocio ............................................................................................ 46 3.1.2 Situación actual y alcance ...................................................................................... 47
3.2 Fase 2: comprensión de los datos .............................................................................. 49 3.2.1 Recolección de los datos ........................................................................................ 50
3.2.2 Exploración de datos .............................................................................................. 51 3.3 Fase 3: preparación de los datos ................................................................................ 52
3.3.1 Estructuración de los datos .................................................................................... 52 3.3.2 Formateo de los datos ............................................................................................ 53 3.4 Fase 4: modelado ....................................................................................................... 54
3.4.1 Selección de la técnica de modelado ..................................................................... 54 3.4.2 Construcción del modelo ....................................................................................... 55
3.5 Fase 5: evaluación ..................................................................................................... 55 3.5.1 Evaluación de resultados ....................................................................................... 55
3.5.2 Revisión e integración ........................................................................................... 56 3.5.3 Presentación de resultados ..................................................................................... 59
3.5.3.1 Menú principal ................................................................................................... 60 3.5.3.2 Módulo de Clasificación de sentimientos .......................................................... 60 3.5.3.3 Módulo de Análisis de mercado ......................................................................... 62 PARTE IV. Conclusiones .................................................................................................... 63 Capítulo 4. Conclusiones ...................................................................................................... 65
4.1 Verificación, contraste y evaluación de los objetivos ............................................... 66 4.2 Aportes originales ...................................................................................................... 67 4.3 Líneas de investigación futuras ................................................................................. 68 4.4 Conclusiones .............................................................................................................. 69 BIBLIOGRAFÍA .................................................................................................................. 70


IV
Tabla de Figuras
Figura 1 Comparación entre aplicaciones de profundidad para PLN ................................... 15 Figura 2. Niveles de representación en texto ........................................................................ 15
Figura 3. Modos de acceso a la información de textos ......................................................... 16 Figura 4. Interfaz de búsqueda simple con mapa de tópicos ................................................ 18
Figura 5. Analogía del ser humano como sensor para la percepción de su entorno ............. 21 Figura 6. Tareas en la categorización de textos .................................................................... 22 Figura 7. Representación del algoritmo KNN ...................................................................... 23
Figura 8. Hiperplanos del algoritmo SVM ........................................................................... 23 Figura 9. Perceptrón Multicapa ............................................................................................ 24
Figura 10. Tareas de minería de opinión .............................................................................. 24 Figura 11 Arquitectura de sistema de Procesamiento de Lenguaje Natural ......................... 25
Figura 12. Componentes de la Arquitectura Empresarial .................................................... 26 Figura 13. Conceptos core de Archimate ............................................................................. 27 Figura 14. Framework Archimate ....................................................................................... 28
Figura 15. Metamodelo de Organización ............................................................................. 29 Figura 16. Metamodelo de Cooperación de Actor ............................................................... 29
Figura 17. Metamodelo de Función del Negocio ................................................................. 30 Figura 18. Metamodelo de Proceso de Negocio ................................................................... 30 Figura 19. Metamodelo de Cooperación de Proceso de Negocio......................................... 31
Figura 20. Metamodelo de Producto .................................................................................... 31
Figura 21. Metamodelo de Comportamiento de Aplicación ................................................ 32 Figura 22. Metamodelo de Cooperación de Aplicación ....................................................... 33 Figura 23. Metamodelo de Estructura de Aplicación ........................................................... 33
Figura 24. Metamodelo de Uso de Aplicación ..................................................................... 34 Figura 25. Metamodelo de Infraestructura ........................................................................... 34 Figura 26. Metamodelo de Uso de Infraestructura ............................................................... 35 Figura 27. Metamodelo de Implementación y Despliegue ................................................... 35 Figura 28. Metamodelo de Estructura de la Información ..................................................... 36
Figura 29. Metamodelode Realización del Servicio ............................................................. 36 Figura 30. Punto de vista de Cooperación de Actor ............................................................. 46 Figura 31.Punto de vista de proceso de Negocio ................................................................. 47 Figura 32. Punto de vista de Producto .................................................................................. 47
Figura 33. Punto de vista de Comportamiento de Aplicación .............................................. 48

Figura 34. Punto de vista de Organización e Implementación ............................................. 49 Figura 35. Punto de vista de Infraestructura ......................................................................... 50 Figura 36. Autenticación OAuth con Python-Twitter .......................................................... 51
Figura 37. Punto de vista de Estructura de la Información .................................................. 52 Figura 38. Conjunto de conocimiento supervisado .............................................................. 53 Figura 39. Modelo SVM construido para el caso de estudio................................................ 55 Figura 40. Matriz de confusión del modelo .......................................................................... 56 Figura 41. Cooperación de Aplicación ................................................................................. 57
Figura 42. Punto de vista de Niveles .................................................................................... 57 Figura 43. Punto de vista de Migración e Implementación .................................................. 58 Figura 44. Punto de vista de Stakeholder ............................................................................. 59
Figura 45. Punto de vista de Principios ................................................................................ 59 Figura 46. Presentación de resultados .................................................................................. 60 Figura 47. Flujo de actividades BackOffice módulo de Tendencias en tiempo real ............ 61 Figura 48. Diseño del Grafico de Tendencias ...................................................................... 61
Figura 49. Diseño del Grafico de Relevancia ....................................................................... 62


Índice de Tablas
Tabla 1. Principales atributos del Tweet .............................................................................. 51
Tabla 2. Pre procesamiento de datos .................................................................................... 54 Tabla 3. Componentes y funcionalidad TrendSoft ............................................................... 56


INTRODUCCIÓN
Vivimos bajo un verdadero tsunami de datos y el mundo de los negocios ha implementado
varias técnicas de análisis para generar información relevante que apoye la toma de
decisiones. Estas técnicas consisten en un proceso de inspección, limpieza, transformación y
modelado de petabytes y exabytes de datos que a diario se generan desde múltiples fuentes
como sistemas de facturación, sensores, satélites, teléfonos móviles, posts en las redes
sociales, entre muchas otras.
Las técnicas de análisis permiten procesar información estructurada y no estructurada; la
primera corresponde a información tradicional, como cifras de ventas, estados contables y
reportes financieros, que ha sido la fuente de datos más usual en el mundo de los negocios, y
para los que se aplica técnicas de análisis tradicional. Pero ahora, gracias a tecnologías
disruptivas, se suman las comunicaciones humanas que transcurren en las redes sociales, las
llamadas que reciben los Call Center, la información de los GPS o los videos que se publican
en Youtube, todo convertido en datos no estructurados que alimentan la toma de decisiones
en la empresa de nuestros días.
El desarrollo de esta investigación busca extraer datos de la red social Twitter utilizando un
API de captura de flujos de información y procesar la misma con el fin de realizar análisis y
categorizaciones cuantificables del contenido, en favor de la toma de decisiones para la
operación de valores en el mercado del grupo de acciones de la empresa Ecopetrol S.A.


PARTE I. FUNDAMENTACIÓN DE LA INVESTIGACIÓN


5
CAPÍTULO 1. DESCRIPCIÓN DE LA INVESTIGACIÓN
En este capítulo se abordarán los conceptos preliminares y antecedentes que dieron pie al
desarrollo de la investigación.

6
1.1 Planteamiento del problema
La proliferación de las redes sociales ha generado nuevas fuentes de información con
millones de datos de usuarios de todo el mundo, sin embargo estos datos se caracterizan
principalmente por dos aspectos, el primero es que no cuentan con una estructura bien
definida, y el segundo es que al ser opiniones personales de los internautas su nivel de
confiabilidad sin un contexto es bajo. La generación de grandes volúmenes de datos ha traído
consigo el desarrollo de herramientas para el procesamiento de los mismos, con máquinas
cada vez más potentes y la utilización de técnicas de análisis y extracción de información.
El mercado accionario se caracteriza por ser altamente dinámico debido a que depende de
tendencias, donde cualquier evento puede impactar positiva o negativamente un sector
económico de una región o del mundo entero, como sucede con las acciones del grupo
Ecopetrol que se ven afectadas cuando un factor externo al negocio genera impacto en la
sociedad. A lo largo del tiempo, este mercado ha implementado herramientas TIC para
mejorar su desempeño, pero se han quedan cortas debido a la exigencia del mismo. A pesar
de la existencia de frameworks de procesamiento de datos en tiempo real, estos no han sido
puestos en marcha para extraer, procesar y reportar información a partir de los flujos de datos
de una red social en favor de la toma de decisiones para un sector del mercado bursátil.
Las TIC se han convertido en un área transversal para el desarrollo de cualquier sector debido
a que la implementación de herramientas tecnológicas influye en gran medida para alcanzar
el éxito o fracaso de una organización; por lo tanto el desaprovechamiento de la información
presente en los flujos de datos de una red social puede impactar el desarrollo de un
determinado sector al no contar con reportes objetivos de tendencias del mercado en fuentes
alternativas de información.
La articulación de la academia con la empresa pública y privada se convertiría en una alianza
estratégica relevante, que permitiría impulsar la innovación y el crecimiento de los sectores
participantes; de manera que un estudio investigativo que permita extraer la información no
estructurada de redes sociales a las que se aplicaran técnicas de procesamiento de textos como
análisis de sentimientos y procesamiento en lenguaje natural expone una oportunidad de
negocio que permite aprovechar fuentes de información alternativa.

7
1.2 Justificación
La modificación orgánica de Ecopetrol en el 2003 permitió su incursión en la bolsa de valores
en el año 2008, lo que implica que las acciones del grupo se mueven positiva o negativamente
de acuerdo a las tendencias del mercado, y mucho más cuando actividades petroleras generan
impacto ambiental. Por otra parte, la academia y el sector TI en su propósito de extraer
conocimiento de fuentes de información, ha impulso el desarrollo de herramientas y
metodologías para procesar grandes volúmenes de datos, pero estas investigaciones la
mayoría de veces queda únicamente en el ámbito académico porque las organizaciones no se
preocupan por invertir en investigación e innovación con tecnología vanguardista, que
permita medir la percepción que tiene la sociedad y el sector económico frente a la compañía,
utilizando fuentes alternativas de información, tal como las redes sociales.
De esta manera es importante realizar una investigación en la cual utilizando un marco de
trabajo para el análisis de textos, se extraiga y procese información de la red social Twitter,
para determinar la relevancia en la toma de decisiones relacionadas con las tendencias
sociales de interés, usando como caso de estudio las acciones en el mercado del grupo
empresarial Ecopetrol S.A

8
1.3 Hipótesis
¿Un marco de trabajo para el análisis de textos aplicado al procesamiento de información no
estructurada de la red social Twitter, permite identificar aspectos relevantes sobre las
tendencias del mercado de valores de la empresa Ecopetrol y la polaridad de los usuarios en
fuentes alternativas de información?

9
1.4 Objetivos
1.4.1 Objetivo general
Analizar los flujos de información de la red social Twitter mediante un marco de trabajo para
el análisis de textos con el fin de determinar su influencia en la operación de acciones de
Ecopetrol.
1.4.2 Objetivos específicos
Capturar los datos de la red social utilizando un API de Twitter para preparar y
disponer la información que será utilizada en el proceso de análisis de texto.
Seleccionar las técnicas de análisis de textos a partir de la caracterización y evaluación
de tecnologías existentes, que permita la categorización y cuantificación de la información
no estructurada de la red social Twitter.
Reportar la información obtenida en el análisis de flujos de datos de la red social por
medio de informes gráficos que apoyen la toma de decisiones en las operaciones del mercado
para las acciones de Ecopetrol

10
1.5 Metodología seguida durante la investigación
1.5.1 Tipo de estudio
El desarrollo de esta investigación está basada en un estudio de tipo analítico, donde se
pretende a través de la confrontación de diversas tecnologías de análisis de textos determinar
aquella que por sus características ofrezca las mejores cualidades para la categorización de
información no estructurada de la red social Twitter.
1.5.2 Método de investigación
El desarrollo del proyecto se basa en el método de medición, el cual busca obtener
información numérica acerca de las propiedades de varias herramientas de análisis de texto,
con el fin de comparar magnitudes medibles y conocidas, y establecer una base teórica que
permita seleccionar aquella que ofrezca mejores cualidades para el estudio de información
de la red social Twitter.
1.5.3 Fuentes y técnicas para la recolección de la información
Las principales fuentes de investigación de este proyecto se basan en documentación técnica
y manuales referentes al marco de trabajo para el análisis de textos, los estudios hechos por
investigadores sobre la temática propuesta y los estándares y normas generados por las
comunidades académicas especializadas.
1.5.4 Tratamiento de la información
El tratamiento de la información durante el desarrollo de este proyecto se realiza aplicando
los conceptos básicos de Extracción, Transformación y Carga (ETL, por sus siglas en inglés):
Extracción: fase en la que se define las características, herramientas y medios de
captura y almacenamiento de datos.
Transformación: fase que permite aplicar los procesos de limpieza e integración de
los datos recolectados.
Carga: fase que utiliza los datos capturados para montarlos en un modelo de
clasificación y transformarlos en conocimiento útil.

11
1.6 Organización del trabajo
El desarrollo de la investigación está compuesto por 5 capítulos que abordan las actividades
utilizadas para llevar a cabo el cumplimiento de los objetivos propuestos, a continuación de
describe el contenido de cada uno de estos:
Parte I. Fundamentación de la investigación: contiene información referente al
planteamiento del problema, los objetivos y la justificación investigación.
Parte II. Estado del Arte: información de las teorías que soportan el desarrollo de
la investigación.
Parte III. Desarrollo de la investigación: contiene fases utilizadas para la
construcción del modelo de datos de clasificación y la construcción de la aplicación cliente
para el caso de estudio.
Parte IV. Resultados y Conclusiones de la investigación: Se describen los
resultados obtenidos y los aprendizajes dados en el proceso de investigación.
Parte V. Líneas de Investigación Futura: describe los trabajos futuros que pueden
realizarse para ampliar el alcance de la investigación.

PARTE II. ESTADO DEL ARTE

CAPÍTULO 2. MARCO REFERENCIAL DEL PROYECTO
Este capítulo presenta las fuentes conceptuales y el estado del arte de las investigaciones
realizadas por autores que han contribuido con la construcción de la base de conocimiento,
las teorías y los conceptos que sustentan el desarrollo de este proyecto.

1.1 Marco Teórico
1.1.1 Antecedentes del procesamiento de textos
Una gran cantidad de información que actualmente se encuentra en la nube corresponde a
información textual (textos en lenguaje natural) proveniente de periódicos, revistas,
documentos ofimáticos, entre otros; que se convierte en un activo importante por las
siguientes razones: los textos en lenguaje natural es la forma más importante de descubrir el
conocimiento humano, el tipo más común de información encontrado por la gente y el tipo
más expresivo de información en el sentido que puede ser usada para describir otro medio de
comunicación como vídeos o imágenes [5].
1.1.1.1 Historia y estado del arte del Procesamiento de Lenguaje Natural
Desde el nacimiento de las computadoras, el hombre se ha querido comunicar con estas
utilizando diferentes lenguajes a través del tiempo, en la actualidad busca mediante técnicas
comunicarse con las máquinas por medio de lenguaje natural [6].
Las investigaciones de procesamiento de textos, después de 1980 pasaron de estudiar los
enfoques de la simbología tradicional al procesamiento de lenguaje natural, el cual es menos
robusto para ser desarrollado en aplicaciones reales y se centra más en enfoques estadísticos.
Es así que las primeras investigaciones se hicieron en reconocimiento de voz, pasando al
conocimiento lingüístico, reconocimiento facial, entre otros. Sin embargo, el tratamiento de
estructuras en el lenguaje de procesamiento natural es un tema complejo debido a la
ambigüedad del lenguaje porque el análisis semántico es satisfactorio solamente para algunos
casos, mientras que en otros, el significado puede ser completamente diferente [5].
1.1.1.2 Sistemas de información de texto
Las técnicas de PLN que están compuestas por una estructura robusta pero poco profunda
tienden a ser más empleada, que aquellas de análisis a profundidad, lo que puede perjudicar
el rendimiento de la aplicación debido a errores causados por la dificultad general de las
técnicas de PLN utilizadas, tal como se puede visualizar en la figura 1. La tarea más difícil
en el desarrollo de una investigación de procesamiento de textos es entender con precisión el
significado del texto en lenguaje natural y optimizar directamente el rendimiento del modelo
de clasificación o categorización construido [5].
El procesamiento de Lenguaje natural no es exclusivo del uso de técnicas con enfoque
estadístico porque estas son más útiles a la hora de cuantificar la incertidumbre asociada con
el uso de lenguaje natural [5].

15
Figura 1 Comparación entre aplicaciones de profundidad para PLN
Fuente: Tomado de Text Data Management and Analysis [5]
1.1.1.3 Representación de textos
Las técnicas de PNL permiten diseñar diferentes tipos de caracterizaciones informativas para
objetos de texto, la primera consiste en la representación de la oración como una cadena de
caracteres (la forma más general de representar el texto), pero su principal desventaja radica
en que no permite realizar análisis semántico. La siguiente versión de la representación del
texto se caracteriza por realizar la segmentación de la oración para obtener una secuencia de
palabras y mediante la identificación de las palabras puede descubrir información estadística
de la composición del texto analizar [5].
Figura 2. Niveles de representación en texto
Fuente: Tomado de Text Data Management and Analysis [5]

1.1.2 Acceso a datos de texto
El acceso a los datos de texto debe tener en cuenta dos aspectos importantes, primero se debe
habilitar la recuperación de los datos relevantes para el análisis de un problema evitando la
una sobrecarga innecesaria de información con datos que no son relevantes para la solución,
segundo, la interpretación de cualquier resultado o descubrimiento en el contexto apropiado
provee la procedencia de los datos (origen de los datos)[5].
La meta del acceso a los datos de texto es conectar a los usuarios con la información correcta
en el momento adecuado, esta conexión se puede realizar de dos modos: Pull donde el usuario
tiene la iniciativa y puede realizar la búsqueda de información relevante fuera del sistema, y
Push donde el sistema toma la iniciativa para ofrecer información relevante al usuario [5].
1.1.2.1 Modos de acceso: Pull vs Push
Los seres humanos son productores y consumidores de datos de texto, por lo tanto se
convierten en una herramienta importante para seleccionar los datos más relevantes de un
problema de aplicación en particular, lo que es beneficioso, ya que permite evitar el
procesamiento de la gran cantidad de datos de texto en bruto y centrarse en analizar la parte
más relevante. La selección de datos de texto relevantes de una gran colección es la tarea
básica del acceso de texto, la cual se basa en la especificación de la necesidad de información
de un usuario. La figura 3 describe los modos de extracción Push y Pull.
Figura 3. Modos de acceso a la información de textos
Fuente: autores
En el modo de extracción, el usuario inicia el proceso de acceso para encontrar los datos de
texto relevantes, normalmente mediante un motor de búsqueda. Este modo de acceso al texto
es esencial cuando un usuario tiene una necesidad de información ad hoc, es decir, una

17
necesidad de información temporal que puede desaparecer una vez que se satisface la
necesidad [5].
En el modo de extracción, la navegación es otra forma complementaria de acceder a los datos
porque puede ser útil para el usuario cuando no conoce la sintaxis para formular una consulta
eficaz, no encuentra información relevante del caso de estudio, es inconveniente introducir
una consulta de palabras clave o simplemente cuando se desea explorar un tema sin objetivo
fijo [5].
Los tipos de necesidades de información se pueden clasificar [5]:
Necesidades a corto plazo: es temporal y usualmente se satisface mediante la
búsqueda o navegación en el ámbito de la información. Asocian con mayor frecuencia al
modo Pull.
Necesidades a largo plazo: son satisfechas mediante el filtrado o las asignaciones
dadas al sistema cuando este tome la iniciativa de iniciar la información relevante a un
usuario. Asocian con el modo Push.
La recuperación ad hoc es extremadamente importante porque las necesidades ad hoc de
información aparecen más frecuentemente que las necesidades de información a largo plazo.
1.1.2.2 Acceso interactivo multimodal
Los sistemas de procesamiento de texto deben proporcionar acceso multimodal a los datos
para que los modos Pull y Push estén integrados con el entorno de acceso, y de esta forma
proporcionar mayor flexibilidad a los usuarios para consultar o navegar a voluntad [5].
La figura 4 permite identificar el rastreo en la navegación de un usuario, que inicio consultado
una mesa, luego busco la mesa de comedor asiática, busco la mesa de comedor, se dirigió
primero a la silla de comedor y luego a los muebles de comedor, para finalmente buscar los
muebles como tema general. Si este usuario se da cuenta que necesita una "nueva búsqueda”,
él puede usar una nueva consulta para lograrlo. Así, podemos ver cómo un sistema de acceso
de texto puede combinar múltiples modos de acceso a la información para satisfacer las
necesidades de un usuario [5].

Figura 4. Interfaz de búsqueda simple con mapa de tópicos
Fuente: tomado de SocialSurfing@UIUC
1.1.2.3 Modelos de captura de textos
Durante muchas décadas, los investigadores han diseñado varios tipos diferentes de modelos
de captura que se ubican en diferentes categorías[5], en primer lugar, una familia de modelos
se basados en la idea de similitud, que considera que si un documento es más similar a la
consulta que otro documento, se podría deducir que el primer documento es más relevante
que el segundo, en este caso, la función de clasificación se define como la similitud entre la
consulta y el documento [7]. El segundo conjunto de modelos se denominan modelos de
recuperación probabilística, los cuales asumen que las consultas y los documentos son todas
observaciones de variables aleatorias, y que hay una variable aleatoria binaria llamada R para
indicar si un documento es relevante para una consulta o no. El tercer tipo de modelo es la
inferencia probabilística, el cual busca asociar la incertidumbre a las reglas de inferencia, lo
que permite cuantificar la probabilidad de que se pueda demostrar que la consulta sigue al
documento. Esta familia de modelos es teóricamente apropiada, pero en la práctica, a menudo
se reducen a modelos esencialmente similares al modelo de espacio vectorial o un modelo de
recuperación probabilística regular [8]. Finalmente, también existe una familia de modelos
que utilizan el pensamiento axiomático, que se caracterizan por definir un conjunto de
restricciones que satisfaga la buena función de recuperación, en este caso el problema es
encontrar la función de clasificación adecuada para satisfacer las restricciones deseadas. A
pesar de que los modelos descritos se basan en diferentes formas de pensamiento, al final las
funciones de recuperación tienden a ser muy similares e involucran variables similares.

19
1.1.3 Información estructurada vs no estructurada
La información estructurada corresponde a los datos concretamente definidos y sujetos
a un formato muy concreto. A nivel de base de datos, la información estructurada
corresponde a los campos con una definición específica, por ejemplo una fecha, un valor
numérico en una factura, el tipo de IVA, el apellido de un cliente [9]. Este tipo de
información funciona como una red troncal de ideas de negocio que permite sacar el máximo
provecho de la analítica avanzada para mejorar las relaciones con los clientes, ahorrar costes,
tomar las mejores decisiones, minimizar riesgos y avanzar hacia un futuro prometedor de la
mano de la tecnología [10].
La información no estructurada no cumple con la estructura definida por una base de datos
tradicional sino que tienen múltiples formas de representación (texto, audio, imágenes), y
para ser almacenada requiere estructuras específicas. Las principales características de los
datos no estructurados son [11]:
Volumen y crecimiento: los niveles de volumen y crecimiento son superiores a datos
estructurados.
Orígenes de datos: los datos proveen de redes sociales, foros, emails, datos extraídos
de la web, entre otros.
Almacenamiento: estructuras de almacenamiento no estructuradas, por ejemplo
bases de datos no relacionales.
Terminología: los datos son de tipo texto.
Seguridad: no existe certeza de que la información que se procese sea cierta, debido
a que esta corresponde a opinión de los usuarios.
1.1.3.1 Clasificación de los datos no estructurados
La información no estructurada se divide en dos clasificaciones [11]:
Datos no estructurados y semi estructurados. los datos semi estructurados
corresponden a aquellos que no residen en bases de datos relacionales, pero presentan una
organización interna que facilita su tratamiento, tales como documentos XML y datos
almacenados en bases de datos NoSQL.
Datos de tipo texto y no-texto. Los datos no estructurados de tipo texto son los
generados en las redes sociales, foros, e-mails, presentaciones de Power Point o documentos
Word, mientras que datos no-texto agrupa las imágenes, ficheros de audio o ficheros de video
tipo flash.
1.1.3.2 TRATAMIENTO DE DATOS NO ESTRUCTURADOS
Los aspectos que se deben considerar cuando se realice tratamiento de información no
estructurada son los siguientes [11]:

Crear una plataforma escalable (infraestructura y procesos): que permita tratar
grandes cantidades de datos, con una capacidad de almacenamiento y de procesamiento
escalable.
Añadir información/estructura complementaria a los datos no estructurados: la
información no estructurada trae consigo un conjunto de datos de estructurados, los cuales
deben ser tenidos en cuenta a la hora de procesar la información.
Crear conjuntos reducidos de datos que sean representativos: dado el volumen
de información, es importante extraer una muestra de datos que sean estadísticamente
representativos sobre los datos a analizar.
Desarrollo de algoritmos: la aplicación de algún algoritmo de análisis de datos que
permita descubrir patrones sobre múltiples dimensiones.
Procesos de depuración/limpiado de datos: debido al volumen de datos se debe
contar con una correcta gestión del histórico de datos y detección de datos no usados con el
objetivo de limpiar la información y liberar espacio.
1.1.4 Análisis de textos
1.1.4.1 Aplicaciones de análisis de textos
En el transcurrir de la vida cotidiana, todas las personas procesan gran cantidad de datos de
texto, sim embargo con el surgimiento del Internet y la masificación de las computadoras, se
construyeron motores de búsqueda, los cuales son utilizados para encontrar documentos
relevantes, mientras que el procesamiento posterior es realizado manualmente. Tal proceso
es aceptable cuando la cantidad de datos de texto a procesar es pequeña, sin embargo, a
medida que aumenta la cantidad de datos de texto, el procesamiento manual de estos datos
no sería factible ni aceptable, especialmente para aplicaciones que requieren un tiempo de
respuesta crítico, por lo tanto, resulta cada vez más importante desarrollar herramientas que
apoyen el análisis de texto [5].
En general, se pueden distinguir dos tipos de aplicaciones de análisis de texto, un tipo son las
que pueden reemplazar el trabajo manual realizado por un usuario en el análisis de contenidos
de texto, por ejemplo, la clasificación automática de correos electrónicos en una compañía.
El otro tipo son aquellas que pueden descubrir el conocimiento que los seres humanos no
pueden ser capaces de descubrir, a través del procesamiento y aprendizaje de grandes
volúmenes de contenido [12].
Un campo de aplicación importante para el análisis de textos es la inteligencia de negocios,
donde utilizando y dominando técnicas de minería de texto se puede aprovechar la fuente de
información de los clientes para extraer el conocimiento a partir de las opiniones de las
personas acerca de un producto [13].

21
1.1.4.2 Alcance del análisis de textos
Los seres humanos se comportan como sensores subjetivos que observan el mundo real desde
su propia perspectiva y expresan lo que han observado en forma de datos de texto. Al tratar
los datos de texto como datos observados por los sensores humanos, se puede examinar todos
estos datos juntos en el mismo marco de referencia. El problema de la minería de datos puede
definirse entonces en cómo transformar todos esos datos en conocimiento práctico que
permita cambiar el mundo y mejorarlo. Por supuesto, para diferentes tipos de datos,
generalmente necesitamos diferentes algoritmos, cada uno adecuado para la extracción de un
determinado tipo de datos.
Existen muchos algoritmos generales que son aplicables a todo tipo de datos; los cuales son
útiles pero para realizar un análisis particular de datos, se tendría que desarrollar un algoritmo
especializado.
Figura 5. Analogía del ser humano como sensor para la percepción de su entorno
Fuente: autores
1.1.5 Minería de asociación de palabras
En la búsqueda y recuperación de textos, se puede usar las asociaciones de palabras para
modificar una consulta y de esta forma retroalimentar los datos obtenidos, haciendo que la
búsqueda sea más efectiva; este proceso se conoce como expansión de consultas, la cual
puede ser complementada usando palabras relacionadas para sugerir consultas relativas al
interés de un usuario y de esta forma explorar el espacio de la información [5].
Otra aplicación de la minería de asociación de palabras es la construcción automática de una
jerarquía para navegar, la cual puede estar constituido por palabras como nodos y
asociaciones como aristas, permitiendo al usuario navegar de una palabra a otra para
encontrar información. Finalmente, estas asociaciones de palabras pueden usarse para

comparar y resumir opiniones, que sería determinadas por medio de relaciones sintácticas
sobre comentarios del producto [5].
1.1.6 Categorización de textos
La categorización de textos se propone dos metas específicas en el análisis de textos: la
primera busca enriquecer la representación de textos en múltiples niveles como palabras
clave y categorías, y la segunda meta permite inferir las propiedades de las entidades, de este
modo mientras una entidad pueda ser asociada con el texto, de alguna manera se puede
asociar las demás entidades relacionadas a ese texto.
Figura 6. Tareas en la categorización de textos
Fuente: tomado de Text Data Management and Analysis [5]
1.1.6.1 Características de la categorización de textos
A través de los resultados obtenidos en el desarrollo de proyectos de análisis de texto, se
generó una estrategia para la categorización de textos que demuestra que las características
léxicas de bajo nivel combinadas con características sintácticas de alto nivel dan el mejor
rendimiento en un clasificador de texto. Tener un conjunto diverso de características permite
al clasificador dar una amplia gama de espacio en el que puede tomar una decisión que
delimite entre las diferentes clases de etiquetas [14].
1.1.6.2 Algoritmos de categorización
El objetivo de los algoritmos de categorización es extraer conocimiento a partir del
procesamiento de texto no estructurado [15]. A continuación se describe los tres algoritmos
de categorización más utilizados:
Algoritmo KNN (K-Nearest Neighbor): los clasificadores basados en este
algoritmo no construyen una representación declarativa explícita de las categorías sino que
computan directamente la similitud entre el documento a ser clasificado y los documentos de
entrenamiento. El entrenamiento para estos clasificadores consiste simplemente en
almacenar representaciones de los documentos de entrenamiento junto con sus categorías
[16] [5].
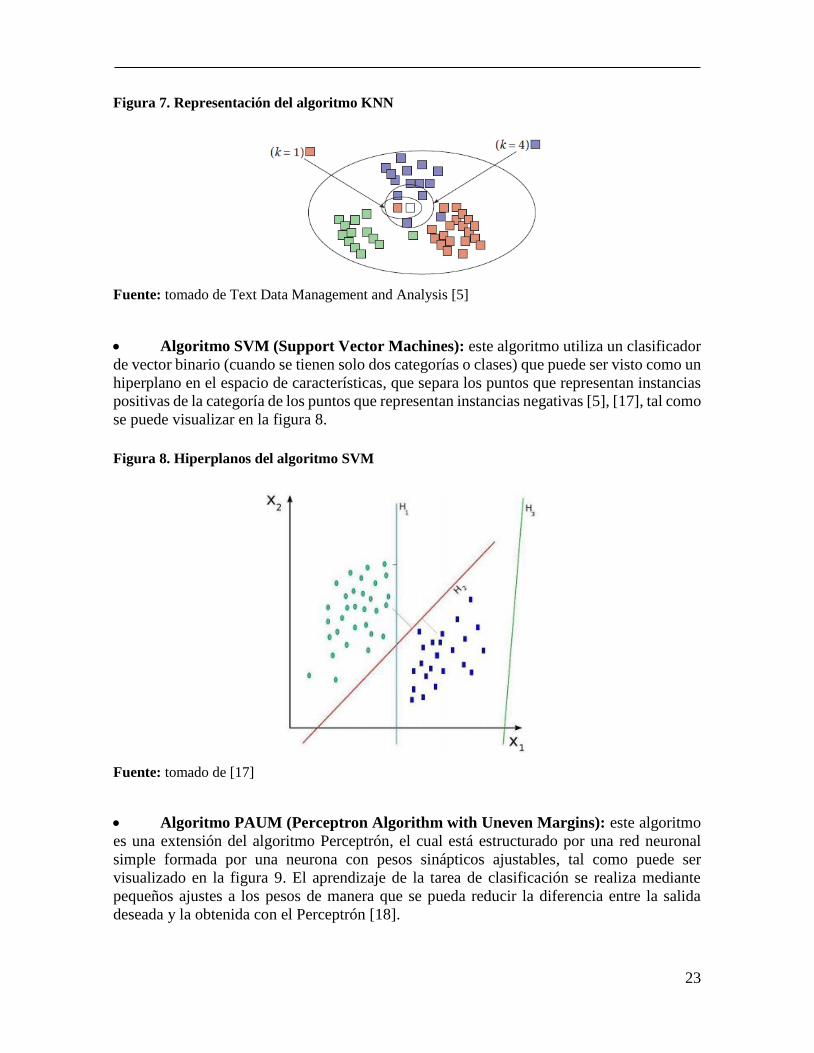
23
Figura 7. Representación del algoritmo KNN
Fuente: tomado de Text Data Management and Analysis [5]
Algoritmo SVM (Support Vector Machines): este algoritmo utiliza un clasificador
de vector binario (cuando se tienen solo dos categorías o clases) que puede ser visto como un
hiperplano en el espacio de características, que separa los puntos que representan instancias
positivas de la categoría de los puntos que representan instancias negativas [5], [17], tal como
se puede visualizar en la figura 8.
Figura 8. Hiperplanos del algoritmo SVM
Fuente: tomado de [17]
Algoritmo PAUM (Perceptron Algorithm with Uneven Margins): este algoritmo
es una extensión del algoritmo Perceptrón, el cual está estructurado por una red neuronal
simple formada por una neurona con pesos sinápticos ajustables, tal como puede ser
visualizado en la figura 9. El aprendizaje de la tarea de clasificación se realiza mediante
pequeños ajustes a los pesos de manera que se pueda reducir la diferencia entre la salida
deseada y la obtenida con el Perceptrón [18].

Figura 9. Perceptrón Multicapa
Fuente: tomado de [19]
1.1.7 Minería de opinión/análisis de sentimientos
El análisis de sentimientos, también conocido como minería de opiniones, consiste en
clasificar automáticamente un texto escrito en un lenguaje natural, en un sentimiento positivo
o negativo, de opinión o subjetividad [5]. Con la evolución tecnológica de los últimos años,
la minería de opinión ha tomado importancia porque permite el tratamiento de datos de redes
sociales, foros, correo electrónico, blogs, utilizando técnicas de clasificación y categorización
de textos en función de la semántica expresada por el autor [20].
Figura 10. Tareas de minería de opinión
Fuente: Tomado de Text Data Management and Analysis [5]
La clasificación de sentimientos está constituida dos componentes, el primero corresponde a
la entrada de un objeto de texto para ser analizado, y la segunda es la etiqueta de sentimiento.
El análisis de polaridad está conformado por dos categorías como positivo, negativo o neutro,
mientras tanto, el análisis emocional puede ir más allá de la polaridad para caracterizar el
sentimiento preciso del titular de la opinión. Una calificación de cinco es la más positiva, y
una calificación de uno es la más negativa. En el análisis de la emoción también hay

25
diferentes maneras de diseñar las categorías, dentro de las que se destacan son: felicidad,
tristeza, incertidumbre, enfado, sorpresa y disgusto [20].
1.1.8 Procesamiento del lenguaje natural
El Procesamiento del Lenguaje Natural (PLN) es la disciplina encargada de producir sistemas
informáticos que posibiliten la comunicación entre el hombre y la computadora, por medio
del lenguaje humano, la voz o del texto. Se trata de una disciplina tan antigua como el uso de
las computadoras, de gran profundidad, y con aplicaciones importantes en la traducción
automática o la búsqueda de información en Internet [21].
Figura 11 Arquitectura de sistema de Procesamiento de Lenguaje Natural
Fuente: tomado de [21].
1.1.9 Arquitectura empresarial
La arquitectura empresarial es una disciplina que ha venido evolucionando desde los modelos
administrativos y de gestión, la teoría administrativa y de sistemas, y que propone la
estructura de una organización en tres niveles [22]:
Estratégico: definición del mercado, productos, servicios y metas organizaciones.
Procesos: operaciones de negocio de acuerdo a los objetivos empresariales.
Sistemas de información: automatización de los procesos de negocio establecidos.
Los diferentes frameworks de Arquitectura Empresarial han definido varios puntos de vista
que permiten alinear los procesos, datos, aplicaciones e infraestructura del negocio para
enfocar sus esfuerzos en función de alcanzar los objetivos estratégicos de la organización
[22]. El éxito de la Arquitectura empresarial radica en la integración de los diferentes
componentes de la organización. Los componentes de la Arquitectura Empresarial son:
estrategia, gobierno de TI, información, sistemas de información, servicios de Tecnología,
uso y apropiación [23], tal como son presentados en la figura 12.

Figura 12. Componentes de la Arquitectura Empresarial
Fuente: tomada de Colombia Digital [23]
1.1.9.1 Archimate
ArchiMate nace como un lenguaje de modelado de arquitecturas empresariales que tiene
como objetivo, proveer una representación uniforme de los diagramas que describen la
arquitectura empresarial de una organización, permitiendo comprender las diferentes áreas o
capas empresariales: estrategia, negocio, información, aplicaciones e infraestructura
tecnológica. El principal elemento en esta metodología es el servicio, que está definido como
una unidad de funcionalidad que un actor (sistema o una organización) pone a disposición
del ambiente de trabajo [24].
La arquitectura es una descripción formal de un sistema, organizado en una manera tal que
soporta las propiedades estructurales y de comportamiento de un sistema y su evolución. El
lenguaje de modelado de arquitectura empresarial Archimate fue desarrollado para proveer
una representación uniforme de diagramas, que ofrece un enfoque arquitectónico integrado
para describir y visualizar los dominios, relaciones y dependencias de la arquitectura [24].
Archimate es un lenguaje de peso ligero y escalable en varios aspectos [24]:

27
El framework de arquitectura es simple pero comprensible para proveer buenos
mecanismos de estructuración para los dominios, capas y aspectos de la arquitectura.
El lenguaje incorpora el concepto del paradigma “orientado a servicios” que
promueve un nuevo principio de organización en términos de (negocio, aplicación e
infraestructura) servicios para la organización.
El rol del estándar Archimate es proveer un lenguaje gráfico para la representación de la
arquitectura empresarial en todo tiempo, que permita alcanzar una inequívoca especificación
y descripción de los componentes de la misma, especialmente de sus relaciones. El lenguaje
Archimate está compuesto de tres tipos de elementos, que son descritos a continuación y
pueden verse relacionados en la [24]:
Elementos estructurales activos: conformado por actores del negocio, componentes
de la aplicación y dispositivos que muestran el comportamiento real.
Elementos de comportamiento: los conceptos de estructura activa se asignan a los
de comportamiento, para mostrar quien o que realiza el comportamiento.
Elementos estructurales pasivos: representa los objetos sobre los que sea realiza el
comportamiento.
Figura 13. Conceptos core de Archimate
Fuente: tomado de [24]
Con base en los conceptos mencionados, Archimate propone tres capas para el lenguaje de
arquitectura empresarial [24]:
Capa del negocio: ofrece productos y servicios a clientes externos, los cuales son
realizado en la organización por actores de los procesos de negocio.
Capa de aplicación: soporta la capa de negocio ofreciendo aplicaciones de servicio.
Capa de tecnología: ofrece la infraestructura necesaria para ejecutar las aplicaciones.

Los elementos y capas propuestos pueden ser organizados como un framework de 9 celdas,
que permite modelar diferentes puntos de vista empresariales, donde la posición dentro de la
celda resalta las preocupaciones de los interesados. Ver figura 14.
Figura 14. Framework Archimate
Fuente: tomado de [24]
Capa de Negocio: esta capa tiene como objetivo ilustrar las entidades del negocio frente a
tres dimensiones de comportamiento: procesos, servicios y producto. El modelamiento de la
capa del negocio involucra los conceptos activos, pasivos e informacionales necesarios para
alcanzar el dominio de la información, del producto, del proceso y de la organización:
Conceptos activos: proceso, servicio, función, Interacción, Evento.
Conceptos pasivos: actor, rol, colaboración, interfaz, localización, objeto.
Conceptos informacionales: producto, contrato, servicio, valor, significado,
representación.
A continuación se presentan los puntos de vista que componen la capa de negocio, cada uno
cuenta con una breve descripción:
Organización: se centra en la organización interna de una compañía, un
departamento, una red de empresas o una entidad organizativa. Este es útil para identificar
competencias, autoridad y responsabilidad dentro de una organización. La figura 15 muestra
el metamodelo propuesto.
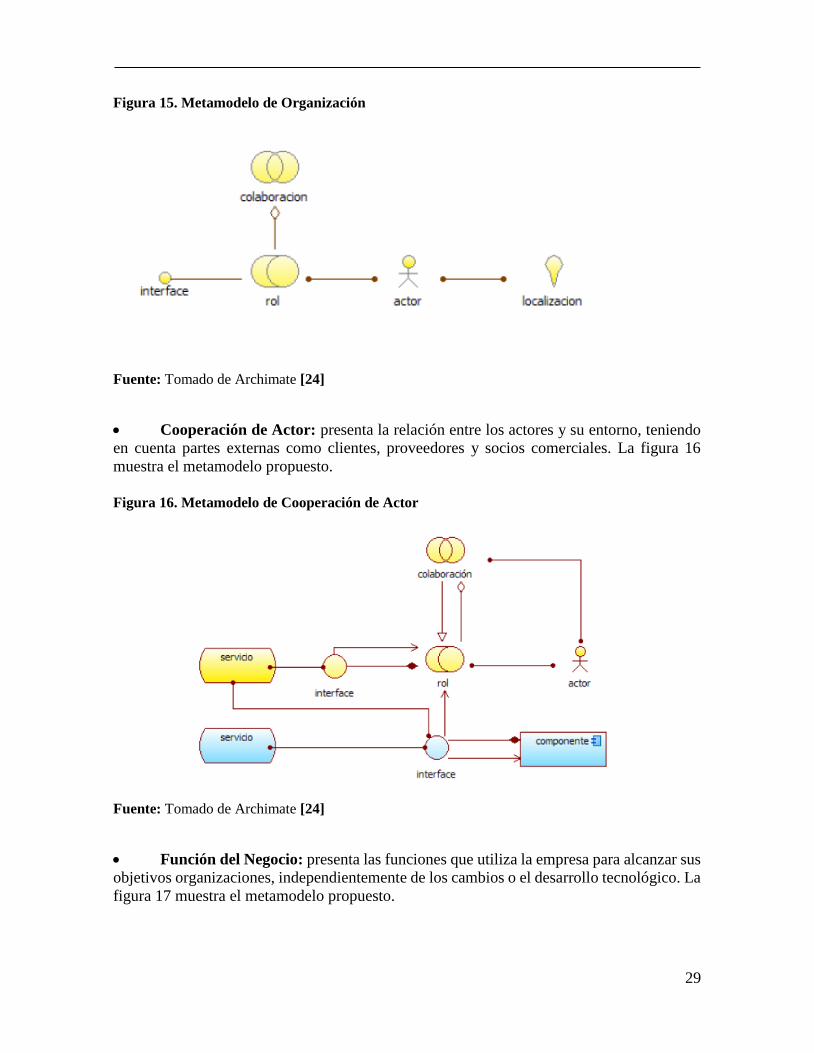
29
Figura 15. Metamodelo de Organización
Fuente: Tomado de Archimate [24]
Cooperación de Actor: presenta la relación entre los actores y su entorno, teniendo
en cuenta partes externas como clientes, proveedores y socios comerciales. La figura 16
muestra el metamodelo propuesto.
Figura 16. Metamodelo de Cooperación de Actor
Fuente: Tomado de Archimate [24]
Función del Negocio: presenta las funciones que utiliza la empresa para alcanzar sus
objetivos organizaciones, independientemente de los cambios o el desarrollo tecnológico. La
figura 17 muestra el metamodelo propuesto.
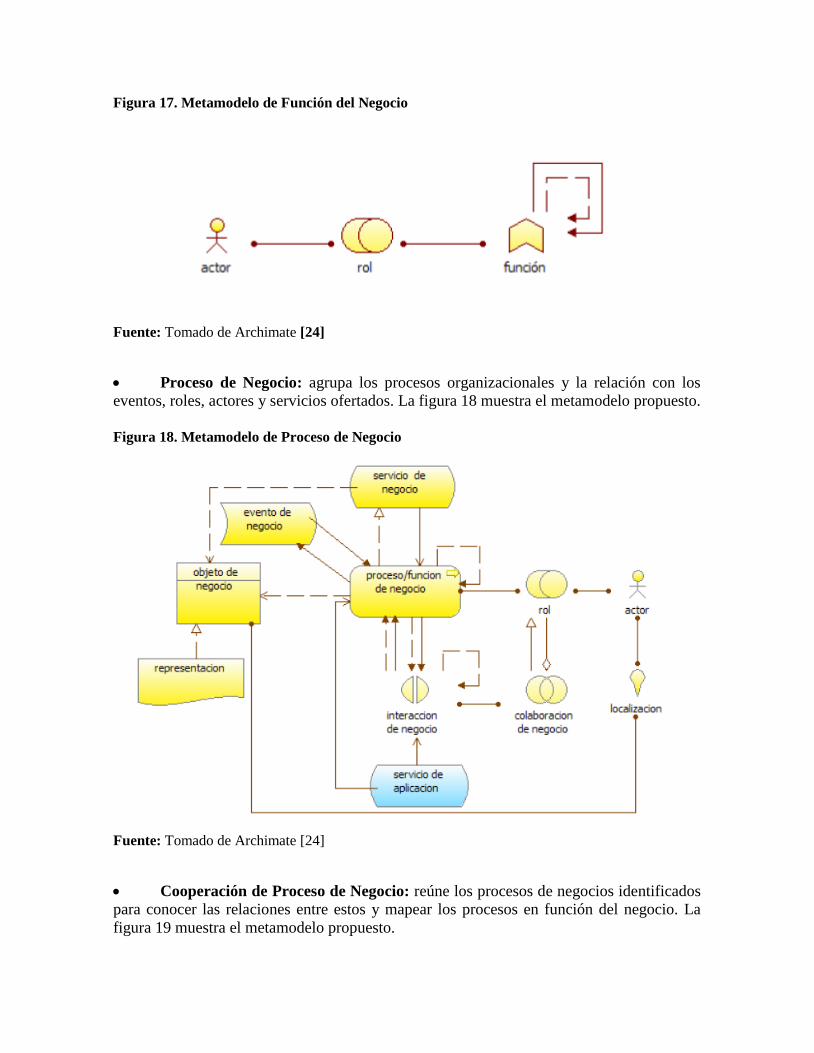
Figura 17. Metamodelo de Función del Negocio
Fuente: Tomado de Archimate [24]
Proceso de Negocio: agrupa los procesos organizacionales y la relación con los
eventos, roles, actores y servicios ofertados. La figura 18 muestra el metamodelo propuesto.
Figura 18. Metamodelo de Proceso de Negocio
Fuente: Tomado de Archimate [24]
Cooperación de Proceso de Negocio: reúne los procesos de negocios identificados
para conocer las relaciones entre estos y mapear los procesos en función del negocio. La
figura 19 muestra el metamodelo propuesto.
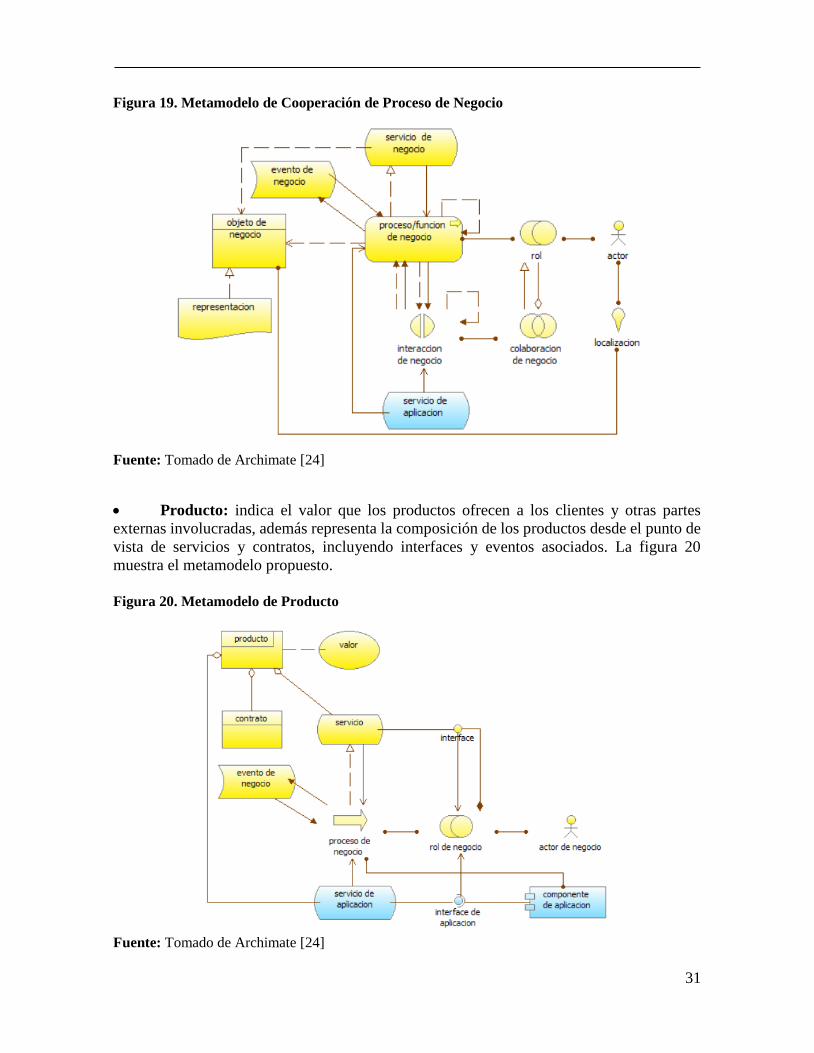
31
Figura 19. Metamodelo de Cooperación de Proceso de Negocio
Fuente: Tomado de Archimate [24]
Producto: indica el valor que los productos ofrecen a los clientes y otras partes
externas involucradas, además representa la composición de los productos desde el punto de
vista de servicios y contratos, incluyendo interfaces y eventos asociados. La figura 20
muestra el metamodelo propuesto.
Figura 20. Metamodelo de Producto
Fuente: Tomado de Archimate [24]
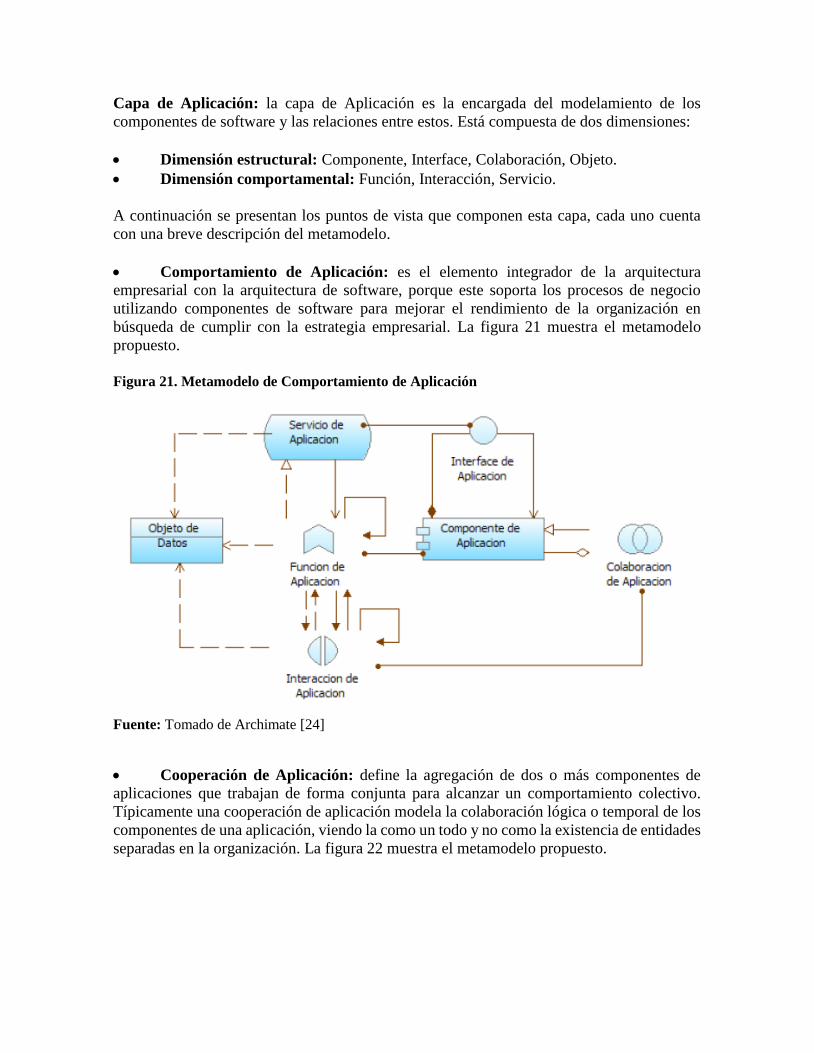
Capa de Aplicación: la capa de Aplicación es la encargada del modelamiento de los
componentes de software y las relaciones entre estos. Está compuesta de dos dimensiones:
Dimensión estructural: Componente, Interface, Colaboración, Objeto.
Dimensión comportamental: Función, Interacción, Servicio.
A continuación se presentan los puntos de vista que componen esta capa, cada uno cuenta
con una breve descripción del metamodelo.
Comportamiento de Aplicación: es el elemento integrador de la arquitectura
empresarial con la arquitectura de software, porque este soporta los procesos de negocio
utilizando componentes de software para mejorar el rendimiento de la organización en
búsqueda de cumplir con la estrategia empresarial. La figura 21 muestra el metamodelo
propuesto.
Figura 21. Metamodelo de Comportamiento de Aplicación
Fuente: Tomado de Archimate [24]
Cooperación de Aplicación: define la agregación de dos o más componentes de
aplicaciones que trabajan de forma conjunta para alcanzar un comportamiento colectivo.
Típicamente una cooperación de aplicación modela la colaboración lógica o temporal de los
componentes de una aplicación, viendo la como un todo y no como la existencia de entidades
separadas en la organización. La figura 22 muestra el metamodelo propuesto.
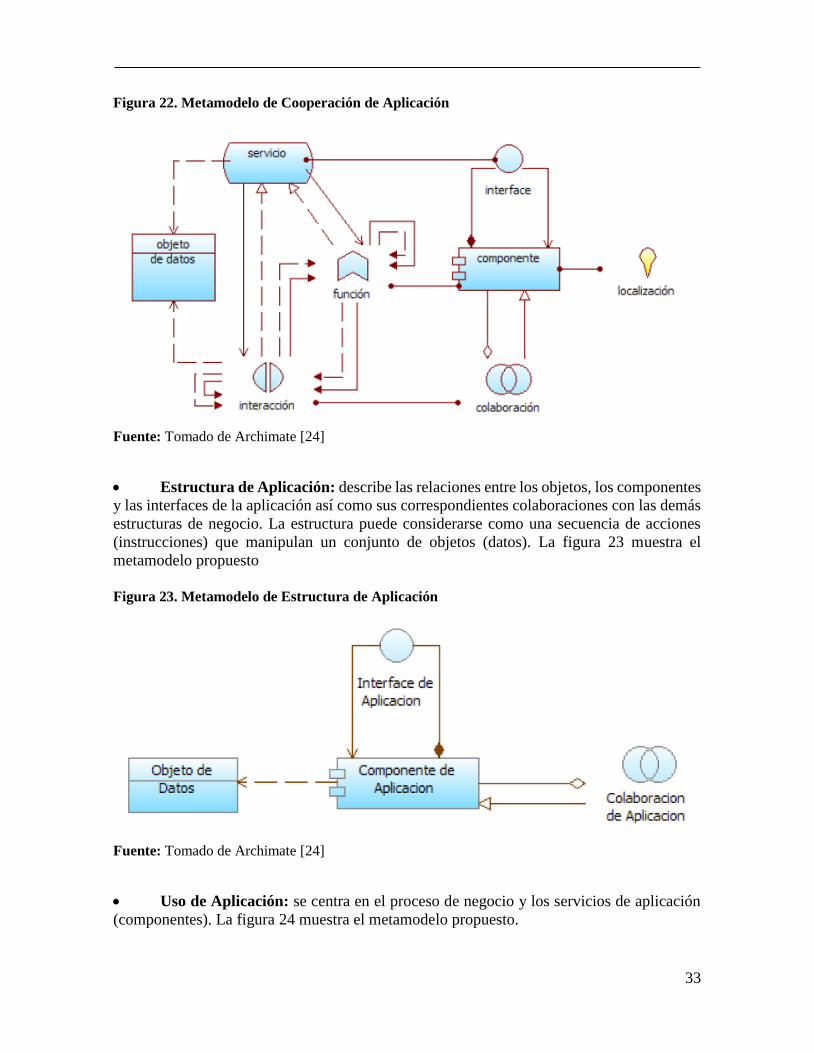
33
Figura 22. Metamodelo de Cooperación de Aplicación
Fuente: Tomado de Archimate [24]
Estructura de Aplicación: describe las relaciones entre los objetos, los componentes
y las interfaces de la aplicación así como sus correspondientes colaboraciones con las demás
estructuras de negocio. La estructura puede considerarse como una secuencia de acciones
(instrucciones) que manipulan un conjunto de objetos (datos). La figura 23 muestra el
metamodelo propuesto
Figura 23. Metamodelo de Estructura de Aplicación
Fuente: Tomado de Archimate [24]
Uso de Aplicación: se centra en el proceso de negocio y los servicios de aplicación
(componentes). La figura 24 muestra el metamodelo propuesto.
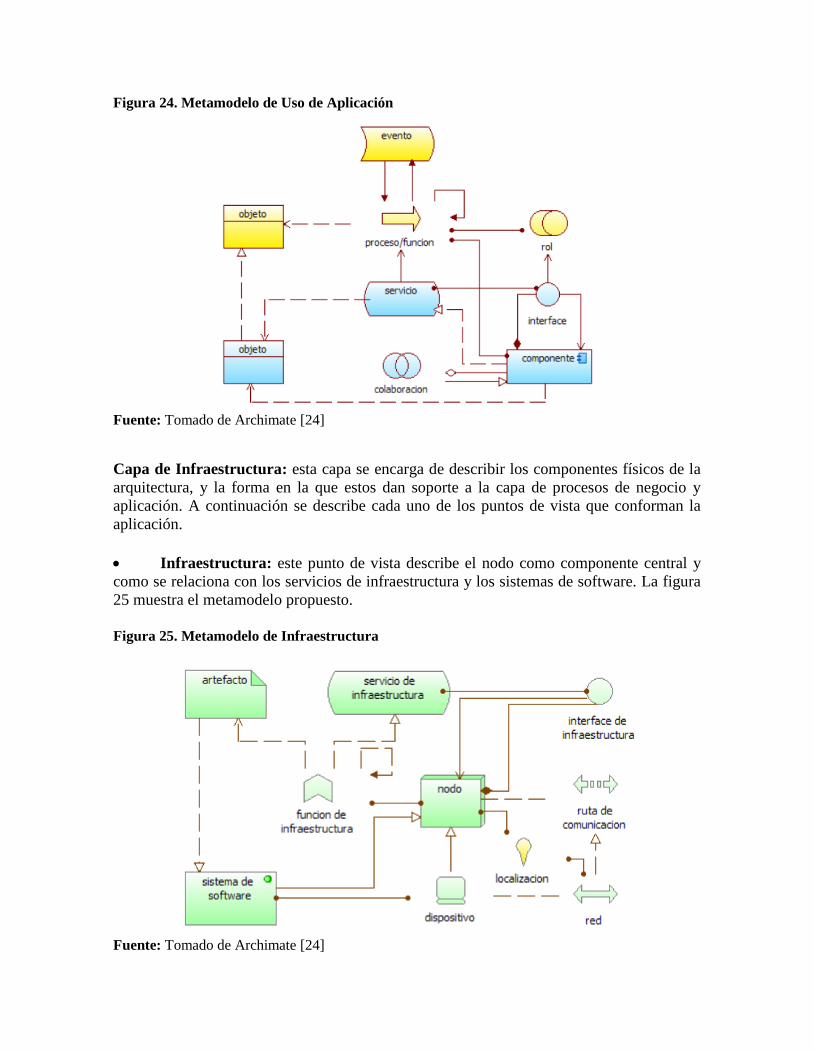
Figura 24. Metamodelo de Uso de Aplicación
Fuente: Tomado de Archimate [24]
Capa de Infraestructura: esta capa se encarga de describir los componentes físicos de la
arquitectura, y la forma en la que estos dan soporte a la capa de procesos de negocio y
aplicación. A continuación se describe cada uno de los puntos de vista que conforman la
aplicación.
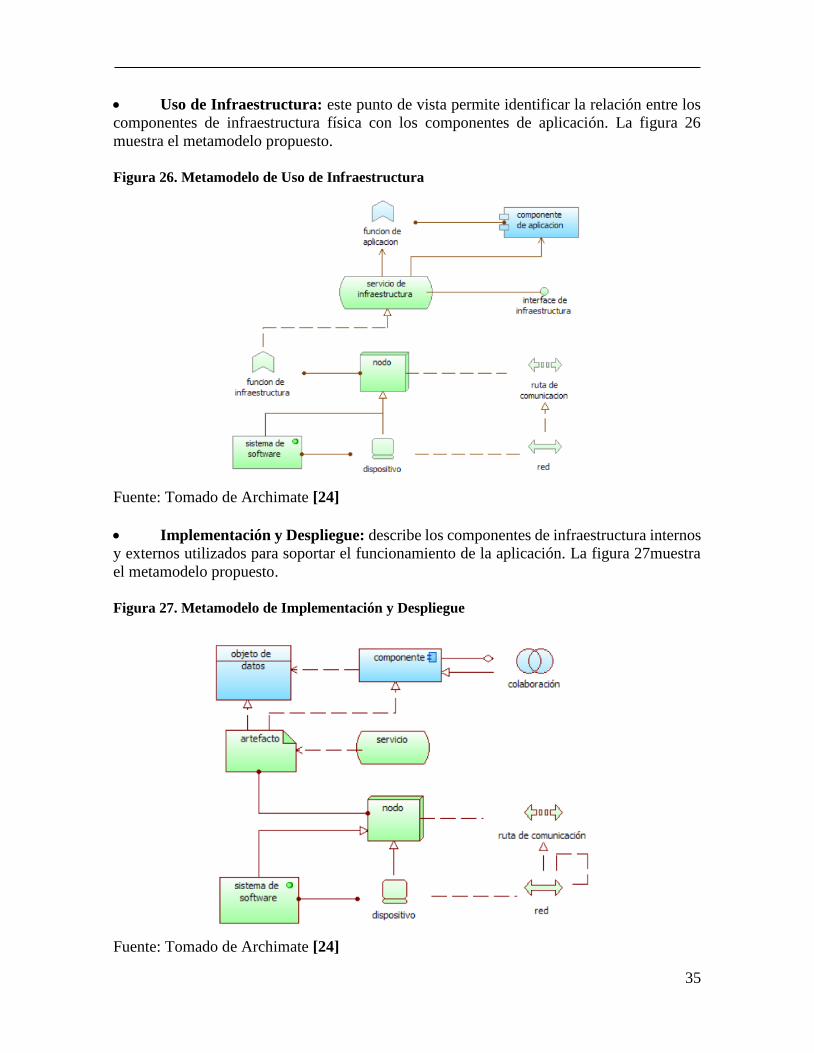
Infraestructura: este punto de vista describe el nodo como componente central y
como se relaciona con los servicios de infraestructura y los sistemas de software. La figura
25 muestra el metamodelo propuesto.
Figura 25. Metamodelo de Infraestructura
Fuente: Tomado de Archimate [24]
35
Uso de Infraestructura: este punto de vista permite identificar la relación entre los
componentes de infraestructura física con los componentes de aplicación. La figura 26
muestra el metamodelo propuesto.
Figura 26. Metamodelo de Uso de Infraestructura
Fuente: Tomado de Archimate [24]
Implementación y Despliegue: describe los componentes de infraestructura internos
y externos utilizados para soportar el funcionamiento de la aplicación. La figura 27muestra
el metamodelo propuesto.
Figura 27. Metamodelo de Implementación y Despliegue
Fuente: Tomado de Archimate [24]
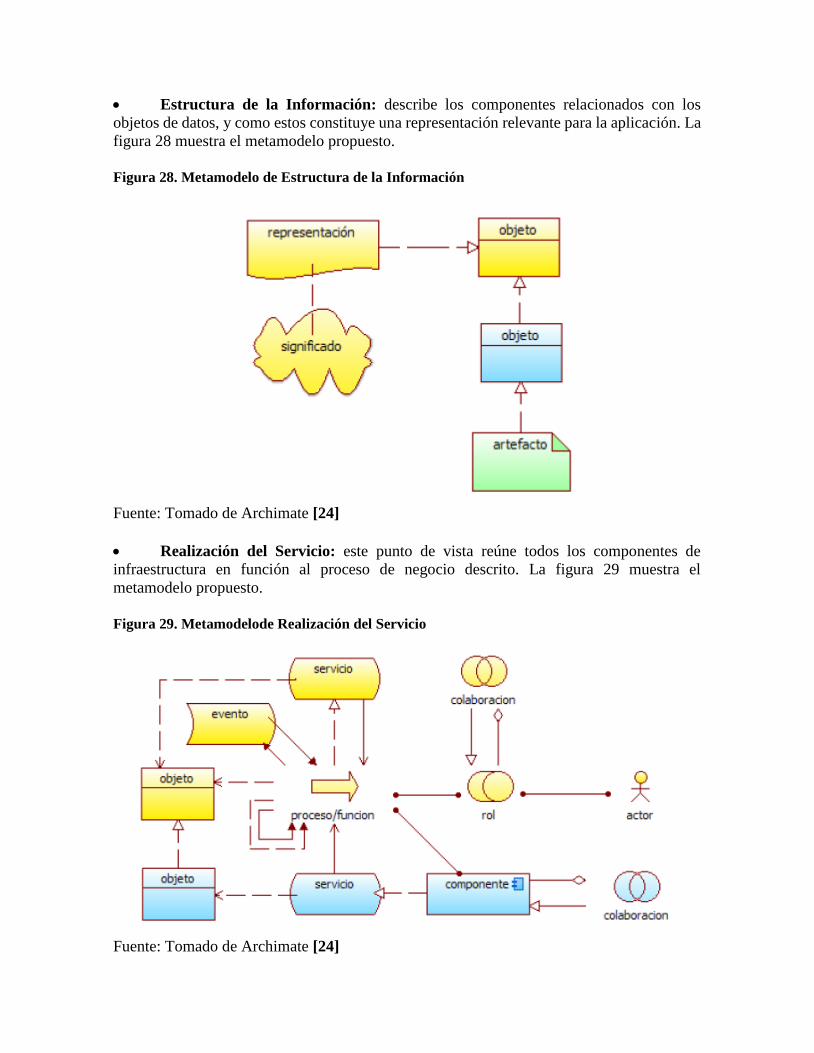
Estructura de la Información: describe los componentes relacionados con los
objetos de datos, y como estos constituye una representación relevante para la aplicación. La
figura 28 muestra el metamodelo propuesto.
Figura 28. Metamodelo de Estructura de la Información
Fuente: Tomado de Archimate [24]
Realización del Servicio: este punto de vista reúne todos los componentes de
infraestructura en función al proceso de negocio descrito. La figura 29 muestra el
metamodelo propuesto.
Figura 29. Metamodelode Realización del Servicio
Fuente: Tomado de Archimate [24]

37
Existe dos capas adicionales, la primera corresponde a la Motivacional que está conformada
por los stakeholder, principios, requerimientos y restricciones del sistema, y la segunda
corresponde a la de Proyecto, la cual se encarga de presentar un concepto general de los
entregables.
1.2 Marco conceptual
1.2.1 Twitter
Twitter es una red social que tiene como misión “darle a todos el poder de generar y
compartir ideas e información al instante y sin obstáculos”, en mensajes cortos de hasta 140
caracteres [25]. Esta red social cuenta con 313 millones de usuarios activos, y se basa en la
publicación y visualización de contenidos de usuarios a los cuales ‘sigue’ dentro de la
aplicación. Según cifras de [26] reporta que el 65,8% de las empresas de Estados Unidos con
más de 100 empleados utiliza Twitter para hacer Marketing, lo que conlleva a que el 80% de
usuarios alguna vez ha mencionado una marca en la red social. Por esta razón Twitter ha
implementado políticas y lineamientos para apoyar el uso de redes sociales dentro del
contenido web de las organizaciones, mediante herramientas de análisis y estadística de datos
compartidos en la red.
1.2.2 Mercado bursátil
El mercado es el espacio, la situación o el contexto en el cual se lleva a cabo la venta o
compra de bienes, servicios o mercancía por parte de unos compradores que demandan esas
mercancías, y unos vendedores que las ofrecen. El mercado bursátil está relacionado con las
operaciones o transacciones que se realizan en diferentes bolsas alrededor del mundo. Las
bolsas según su reglamento, permiten que en los mercados bursátiles intervengan y realicen
operaciones tanto personas como empresas u organizaciones que deseen invertir. La demanda
y oferta de productos y servicios actúa como fuerza para establecer el precio de los mismos,
por lo que se considera al mercado bursátil un mercado centralizado y regulado.
El desempeño, la evolución y las tendencias del mercado bursátil se miden a través de índices
que reflejan los movimientos que, por efectos de demanda y oferta, tienen los precios de
diferentes productos, activos o títulos que se intercambian en las bolsas [27].
1.2.3 Ecopetrol S.A
Ecopetrol fue fundado en 1951 para encargarse de administrar el recurso hidrocarburífero de
la nación, y fue creciendo a medida que otras concesiones revirtieron e incorporó su
operación. En 1970 adoptó su primer estatuto orgánico que ratificó su naturaleza de empresa
industrial y comercial del estado, adscrita al Ministerio de Minas y Energía, y cuya vigilancia
fiscal es ejercida por la Controlaría General de la Nación [28].

El decreto 1760 del 26 de junio de 2003 modificó la estructura orgánica de la compañía, y la
convirtió en una sociedad pública por acciones, ciento por ciento estatal. A partir del 2003,
Ecopetrol S.A inició una era con mayor autonomía, lo que permitió acelerar sus actividades
de explotación y su capacidad de obtener resultados con visión empresarial y comercial en el
mercado petrolero mundial [28].
Actualmente Ecopetrol S.A es la empresa más grande del país con una utilidad neta de $15,4
billones registrados en el 2011, y la principal compañía petrolera en Colombia [28].
1.2.3.1 Streaming
En este modo de acceso, al hacer la petición inicial Twitter abre una conexión entre el
solicitante y su servidor, y enviará por ella tweets que sean publicados a partir de ese
momento y que cumplan los filtros que se hayan establecido en el momento de iniciar la
conexión. Se recibirán nuevos tweets ininterrumpidamente hasta que se decida cerrar la
conexión. Este proceso es en tiempo real: desde que alguien crea un tweet hasta que llega a
los usuarios con una conexión a la Streaming API abierta sólo pasan aproximadamente 350
milisegundos [29].
Es importante destacar que mientras la API Rest proporciona acceso a la información ya
existente en Twitter en el momento de hacer la llamada, mediante la Streaming API sólo
recibiremos información creada posteriormente a la creación del canal de comunicación entre
nosotros y Twitter
1.2.4 Tecnología de la Información y Comunicaciones (TIC)
Son un conjunto de medios de comunicación y aplicaciones de información que permiten la
extracción, producción, almacenamiento, tratamiento y visualización de contenidos en forma
de voz, imágenes y datos. Las tecnologías de la Información han sido conceptualizadas como
la integración y convergencia de la computación, microelectrónica, las telecomunicaciones y
las técnicas de procesamiento de datos. Los principales componentes son el factor humano,
los contenidos de información, el equipamiento, la infraestructura física, el software y los
mecanismos electrónicos de intercambio de información [30].
El desarrollo de la sociedad actual se debe en gran medida al papel que han desempeñado las
TIC como núcleo central de la transformación económica y social. Los factores claves que
se han desempeñado un rol importante en la evolución de las TICs son [30]:
El desarrollo de la microelectrónica que ha posibilitado el avance en la potencia y
capacidad de cómputo de los dispositivos.
El avance en las telecomunicaciones que ha generado una mayor exposición de datos
a nivel local y global.
El desarrollo acelerado de sistemas de información.

39
1.2.5 Inteligencia Computacional
Es una disciplina que asocia una serie de algoritmos inspirados en procesos biológicos de
alta complejidad que buscan resolver problemas que la computación tradicional no es capaz
de abordar con razonamiento clásico. Dentro de las técnicas de Inteligencia Computacional
se destacan las redes neuronales artificiales (RNA), la computacional evolutiva, la lógica
difusa, la inteligencia de enjambre y los sistemas inmunes artificiales [31].
La inteligencia computacional es un área multidisciplinaria que utiliza ciencias como la
computación, la matemática, la lógica y la filosofía para estudiar la creación y diseño de
sistemas capaces de resolver problemas complejos de situaciones cotidianas, utilizando un
paradigma de inteligencia humana. Esta área se caracteriza por combinar elementos de
aprendizaje, adaptación, evolución y lógica difusa, no siendo restrictiva de métodos
estadísticos, los cuales son utilizados como complementos [32].
1.2.6 Lenguaje natural
El lenguaje es la función que permite a las personas expresar sentimientos y comunicarse con
otros individuos del entorno, la cual puede realizarse utilizando signos escritos mediante
señales o vocales; por lo tanto, el lenguaje natural es el medio que utilizan las personas para
establecer comunicación a partir de la experiencia y que permite ser utilizado para analizar
situaciones altamente complejas y razonar sutilmente [21].
Los lenguajes naturales tienen alto poder expresivo y sirven de herramienta para analizar
situaciones altamente complejas, además su sintaxis puede ser modelada en un lenguaje
formal, similar a los utilizados en la matemática y lógica [21].
1.2.7 Lingüística computacional
El procesamiento del lenguaje natural dio origen la rama de investigación conocida como
lingüística computacional, la cual se encargaba de desarrollar técnicas a través de la
introspectiva e intuición reflejadas en diccionarios y reglas detalladas en las que los lingüistas
buscan proveer a las computadoras la capacidad de entender el lenguaje humano. Pero esta
perspectiva cambio con la aparición del internet porque se hizo disponible grandes
volúmenes de textos para ser procesados con técnicas estadísticas para el procesamiento de
datos. La lingüística computacional dejo de ser una rama de la lingüística y se convirtió en
la disciplina que se conoce hoy como aprendizaje automático [33].
El aprendizaje automático busca descubrir las regularidades y relaciones existentes entre los
datos, utilizando algoritmos de aprendizaje [33]. Los sistemas que soportan las técnicas de
aprendizaje automático deben contener las siguientes características: determinación de
contenido, planificación del documento, generación de expresiones de referencia,
agregación, lexicalización y realización superficial, que deben estar incluidas en los
siguientes niveles básicos de representación [34]:

Nivel conceptual: conocimiento no lingüístico.
Nivel semántico: representación del significado desde el punto de vista lingüístico.
Nivel retórico: organización de las estructuras guiada por la retórica para dotar de
coherencia al texto.
Nivel de documento: estructuración del discurso en una jerarquía de funciones
textuales.
Nivel sintáctico: comprende el procesamiento sintáctico de los elementos generados.
1.2.8 R Data Analysis
R es un lenguaje y ambiente para realizar procesos de computación estadística y gráfica, con
una amplia gama de técnicas estadísticas (modelamiento lineal y no lineal, pruebas
estadísticas clásicas, análisis de series de tiempo, clasificación, Clustering, entre otras) y
gráficas [35].
R es una suite integrada de software que proveer herramientas para facilitar la manipulación
de datos y el cálculo y visualización de resultados, incluyendo [35]:
Un manejo efectivo de datos y facilidad de almacenamiento
Una suite para la operación de cálculos sobre vectores y matrices
Una colección integrada y coherente de herramientas para el análisis de datos
Complementos gráficos para el análisis de datos y la presentación de resultados
Un lenguaje de programación simple y efectivo que incluye condicionales, bucles,
variables, funciones, entre otros.
1.2.9 PAQUETE CARET
El paquete Caret es un conjunto de funciones que buscan simular el proceso de creación de
modelos de predicción. El paquete contiene las siguientes herramientas [36]:
División de datos (Data Splitting)
Pre – procesamiento
Selección de características
Personalización de modelos utilizando re muestreo
Estimación de la importancia de variables
El paquete inició como una forma de proveer una interface uniforme de sus funciones para
la estandarización de tareas comunes [36].
1.2.10 Tweepy
Tweepy es una librería de código abierto disponible que permite comunicar Python con la
plataforma Twitter. Tweepy soporta el acceso a Twitter utilizando los métodos de Basic
Authentication y OAuth [37]. Tweepy facilita el uso de la API de streaming de Twitter al

41
manejar la autenticación, la conexión, la creación y la destrucción de la sesión, la lectura de
los mensajes entrantes y los mensajes de enrutamiento parcial[38].
1.2.11 Pymongo
Pymongo es una distribución Python que contiene herramientas para trabajar con la base de
datos MongoDB [39].


PARTE III. DESARROLLO DE LA INVESTIGACIÓN


Capítulo 3. Desarrollo de la propuesta de investigación
En este capítulo se describen las actividades y tareas que fueron desarrolladas para dar
cumplimiento a los objetivos de la investigación, partiendo de la construcción de un modelo
de clasificación para determinar el sentimiento de tweets asociados a Ecopetrol, para
finalmente implantar ese modelo en una aplicación cliente que permita visualizar el forma
gráfica la correlación entre las tendencias de opinión en Twitter contra el comportamiento
de mercado.
La metodología utilizada en el desarrollo de la investigación corresponde a CRISP-DM [40],
la cual está dividida en 6 fases que abarcan las actividades utilizadas en la construcción de
proyectos de Data Mining; la fase de implementación no aplica al desarrollo de esta
investigación por tratarse de un proyecto académico. Los procesos empleados para el
desarrollo de cada fase se describen a continuación:
3.1 Fase 1: comprensión del negocio
La comprensión del negocio es una de las tareas más importantes del proyecto porque permite
entender los objetivos y requisitos del proyecto, y de esta forma plantear el alcance de la
investigación. El desarrollo de esta fase permitió identificar los objetivos del negocio
mediante los modelos de la capa de negocio propuesta por Archimate [24], y a partir de estos
desarrollar el plan de proyecto que presente una perspectiva empresarial del proyecto.
3.1.1 Objetivos del negocio
La primera actividad en el desarrollo de la investigación corresponde a la identificación de
los objetivos del negocio, la cual se hizo utilizando los siguientes puntos de vista de la capa
de Negocio:
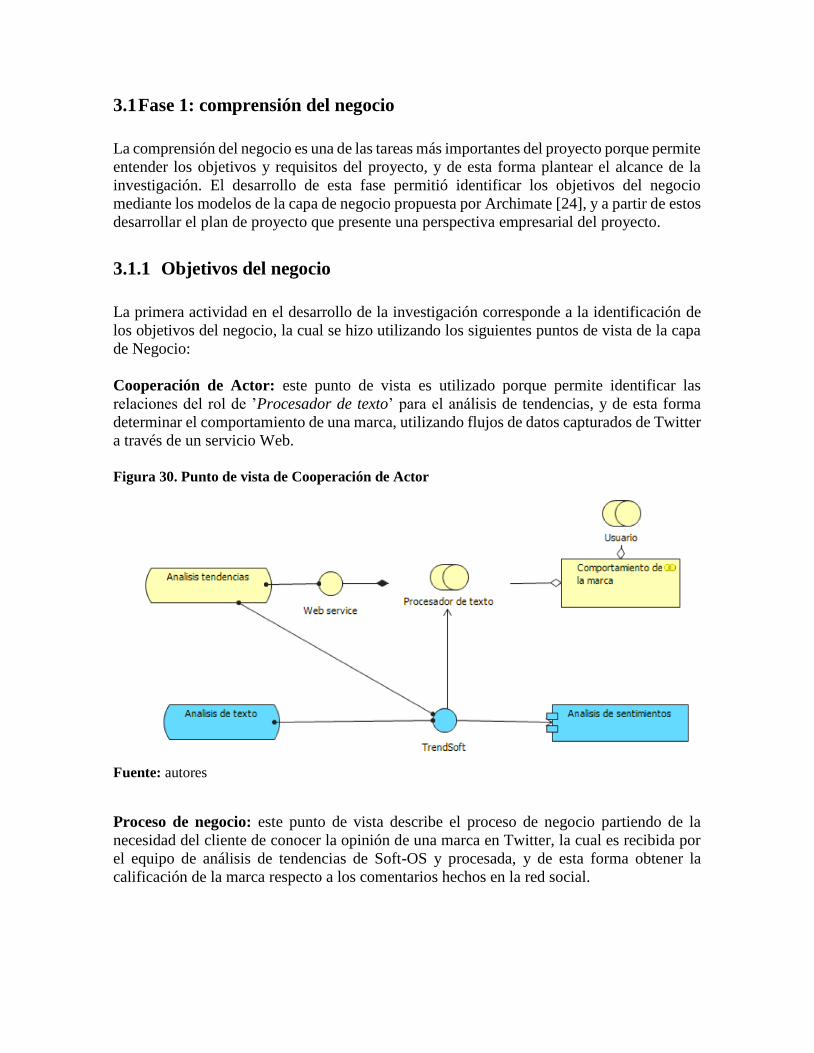
Cooperación de Actor: este punto de vista es utilizado porque permite identificar las
relaciones del rol de ’Procesador de texto’ para el análisis de tendencias, y de esta forma
determinar el comportamiento de una marca, utilizando flujos de datos capturados de Twitter
a través de un servicio Web.
Figura 30. Punto de vista de Cooperación de Actor
Fuente: autores
Proceso de negocio: este punto de vista describe el proceso de negocio partiendo de la
necesidad del cliente de conocer la opinión de una marca en Twitter, la cual es recibida por
el equipo de análisis de tendencias de Soft-OS y procesada, y de esta forma obtener la
calificación de la marca respecto a los comentarios hechos en la red social.

47
Figura 31.Punto de vista de proceso de Negocio
Fuente: autores
Producto: el punto de vista de producto se encarga de realizar la clasificación de tweets y su
respectiva calificación del sentimiento, ofreciendo al usuario la posibilidad de realizar un
análisis del comportamiento de una marca en particular. Además el usuario puede establecer
una relación entre el comportamiento en las redes sociales respecto al comportamiento real
de la marca en el mercado.
Figura 32. Punto de vista de Producto
Fuente: autores
3.1.2 Situación actual y alcance
El interés creciente en temas de inteligencia computacional y análisis de datos ha traído
consigo el surgimiento de técnicas y herramientas para la clasificación y categorización de
datos estructurados y no estructurados. Además, los datos públicos provenientes de las redes

sociales pueden ser accedidos de forma gratuita por medio de APIs de captura en tiempo real,
y a su vez procesados utilizando aplicaciones de análisis de datos. Es así que este proyecto
utilizará la información no estructurados de la red social Twitter y las herramientas
procesamiento de datos para evaluar los comentarios de los usuarios de esta red social y
mostrar el comportamiento de la opinión de una marca (Ecopetrol, como caso de estudio).
Asimismo permite relacionar el comportamiento del mercado de la marca frente a las
tendencias de Twitter. Para alcanzar estos objetivos se debe construir las funcionalidades
descritas en el punto de vista de Comportamiento de Aplicación (ver figura 33) y relacionadas
a continuación.
Figura 33. Punto de vista de Comportamiento de Aplicación
Fuente: autores
Un módulo de captura de datos provenientes de Twitter, tomando como criterio un
diccionario de campos.
Una base de datos no relacional para el almacenamiento de datos.
Una herramienta de procesamiento de datos que permita la limpieza y estructuración
de la información.
Un módulo de calificación de opinión que evalúe la semántica de un Tweet y
determine si este es positivo o negativo.
Un módulo de relación mercado – opinión de la marca.
Un módulo de reportes que permita descargar informes de los análisis aplicados en
una ventana de tiempo.
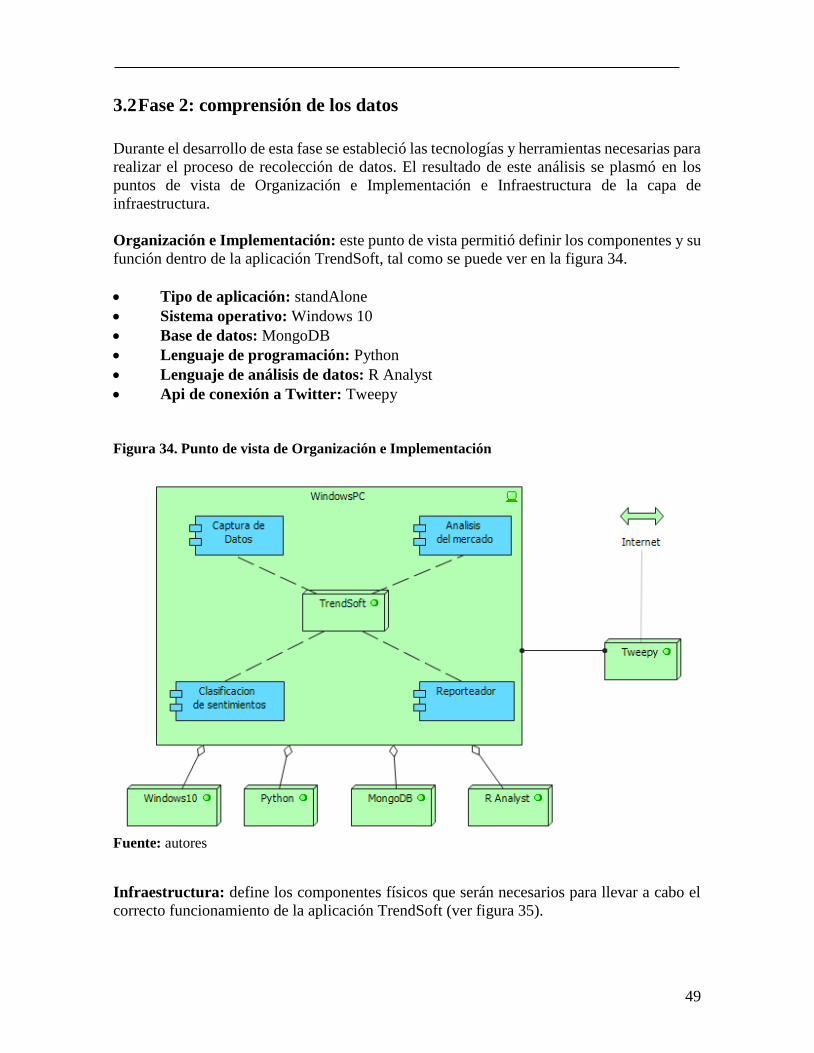
49
3.2 Fase 2: comprensión de los datos
Durante el desarrollo de esta fase se estableció las tecnologías y herramientas necesarias para
realizar el proceso de recolección de datos. El resultado de este análisis se plasmó en los
puntos de vista de Organización e Implementación e Infraestructura de la capa de
infraestructura.
Organización e Implementación: este punto de vista permitió definir los componentes y su
función dentro de la aplicación TrendSoft, tal como se puede ver en la figura 34.
Tipo de aplicación: standAlone
Sistema operativo: Windows 10
Base de datos: MongoDB
Lenguaje de programación: Python
Lenguaje de análisis de datos: R Analyst
Api de conexión a Twitter: Tweepy
Figura 34. Punto de vista de Organización e Implementación
Fuente: autores
Infraestructura: define los componentes físicos que serán necesarios para llevar a cabo el
correcto funcionamiento de la aplicación TrendSoft (ver figura 35).

Figura 35. Punto de vista de Infraestructura
Fuente: autores
3.2.1 Recolección de los datos
El proceso de captura de datos se hizo utilizando la API de Twitter para Python Tweepy bajo
el método de Streaming, a partir de la definición de un diccionario de campos relacionado
con el caso de estudio. Dicho diccionario inicialmente se hizo teniendo en cuenta palabras
claves relacionadas con el procesamiento de petróleo, Ecopetrol y sus filiales, pero una vez
iniciada la captura, este se redujo para evitar basura en la información recolectada; El
diccionario de campos definido es: {'ecopetrol', 'petroleo', 'oleoducto', ‘refineria’}
El script de captura se construyó utilizando las librerías OAuthHandler y API del lenguaje
de programación Python, y la información es persistida en una base de datos MongoDB, la
cual permite almacenar 27 atributos de cada tweet. La ventana de captura se estableció entre
las 9 am y las 4 pm, tiempo según el cual [41] se presenta mayor interactividad de los usuarios
de Twitter, y a su vez coincide con el horario de operación de la Bolsa de Valores de
Colombia (BVC), factor importante para la relación entre el comportamiento del mercado y
las tendencias en Twitter.
Los flujos de información de la red ofrecen muestras de los datos públicos que fluyen a través
de Twitter. Una vez que las aplicaciones externas establecen una conexión a un punto final
de transmisión, se entrega un feed de Tweets, sin tener que preocuparse por los límites de las
tasas como en el REST API.
Los clientes que realizan excesivos intentos de conexión (tanto con éxito como sin éxito)
corren el riesgo de que su IP sea bloqueada automáticamente[42].

51
Figura 36. Autenticación OAuth con Python-Twitter
Fuente: autores
La captura de datos se hizo utilizando las librerías de Python Python-twitter y Tweepy, bajo
el IDE de programación Eclipse. Twitter expone una API de servicios web para ser
consultada de forma gratuita, que retornara es una instancia de clase de modelo Tweepy con
los flujos de información suministrados.
Los controladores en MongoDB se utilizan para la conectividad entre las aplicaciones cliente
y la base de datos [43]. Para el desarrollo del proyecto, se tiene un programa Python que se
conecta a la base de datos MongoDB, utilizando el controlador Python.
3.2.2 Exploración de datos
La recolección de datos realizada inicialmente contenía mucha información basura que no
aportaba ninguna relevancia al caso de estudio, esto debido a que el tema de Ecopetrol ha
venido siendo politizado por investigaciones de corrupción. Por lo tanto, se ajustó el
diccionario de campos a un dominio más corto y conciso porque la amplitud del mismo no
era garantía de calidad en la información capturada.
Teniendo en cuenta la ventana de tiempo y el diccionario de campos establecidos, el volumen
de captura es aproximadamente 500 tweet por hora, lo que significa 3500 tweet al día;
cantidad necesaria para poder evaluar y establecer una tendencia de acuerdo a la opinión de
los usuarios. La tabla 1 muestra los atributos más relevantes de cada tweet utilizados para el
análisis de datos, teniendo en cuenta que existen otros que no contienen información válida.
Tabla 1. Principales atributos del Tweet
Atributo Descripción
Id Número de identificación del registro
Text Contenido del tweet
Id Id de Twitter
Favorite_count Número de favoritos
Retweeted Si es RT
Timestamp_ms Fecha y hora de captura
User Información del usuario
Geo Ubicación geográfica de publicación
Lang Lenguaje

Created_at Fecha de publicación
Fuente: autores
El punto de vista Estructura de Información de la capa de Infraestructura permite identificar
la relación entre los objetos de datos y los objetos del negocio; para el caso de estudio se
cuenta con un objeto de datos tweet que apoya la interpretación semántica del mismo para
verse reflejada en reportes sobre tendencias y opinión.
Figura 37. Punto de vista de Estructura de la Información
Fuente: autores
3.3 Fase 3: preparación de los datos
La captura de datos realizada en la fase 2 tenía el propósito de brindar un acercamiento a la
estructura de los flujos de información provenientes de Twitter, para determinar de forma
adecuada las técnicas de pre procesamiento y el modelo de datos que mejor se ajuste a los a
objetivos del caso de estudio. La fase de preparación de los datos tuvo en cuenta dos
actividades principales, las cuales se describen a continuación:
3.3.1 Estructuración de los datos
La construcción de un modelo de análisis de datos requiere de un conjunto de datos de
conocimiento supervisado, el cual está compuesto por una clasificación manual de la
información para enseñar al modelo la forma correcta de evaluar la información. Partiendo
de esta premisa, se realizó la captura de datos de la red social Twitter por 3 semanas para
obtener un total de 45458 tweet. La evaluación manual de la totalidad de datos es un tarea
compleja, por lo que se tomó una muestra más reducida de 1479 tweet, a los cuales se realizó
una valoración positiva (1) o negativa (-1) del sentimiento del tweet, de acuerdo al criterio
de los autores. Este conjunto supervisado se montó en un archivo .csv, que luego fue cargado
al modelo, tal como se puede visualizar en la figura 38.

53
Figura 38. Conjunto de conocimiento supervisado
Fuente: autores
La calificación manual del sentimiento de los tweet fue un proceso complejo que involucró
tiempo y conocimiento de la situación petrolera en Colombia y en el mundo, para dar un
criterio acertado de la semántica del tweet.
3.3.2 Formateo de los datos
Los procesos de pre procesamiento de datos son tan importantes como la misma captura e
involucran gran cantidad de recursos para llevar a cabo esta actividad, es por esto que se
evaluaron diferentes técnicas y herramientas para limpiar y formatear la información del
conjunto de conocimiento supervisado, y los nuevos tweets que serán evaluados una vez esté
construido el modelo. Después de revisar las ventajas y desventajas, se optó por realizar este
proceso utilizando las librerías tm y SnowballC del lenguaje R, las cuales permiten aplicar
varias técnicas de limpieza a partir de un corpus de conocimiento. En la tabla 2 se muestra
los procesos aplicados sobre cada tweet:

Tabla 2. Pre procesamiento de datos
Proceso Resultado
Tweet original “RT @: PETROLEO WTI sigue bajando acercandose a $48. Exceso
de inventarios de crudo se mantiene mientras la OPEP pierde cuota
de?”
Convertir a
minúscula
“rt @: petroleo wti sigue bajando acercandose a $48. exceso de
inventarios de crudo se mantiene mientras la opep pierde cuota de?”
Eliminar
puntuación
“rt petroleo wti sigue bajando acercandose a 48 exceso de inventarios
de crudo se mantiene mientras la opep pierde cuota de”
Eliminar números “rt petroleo wti sigue bajando acercandose a exceso de inventarios de
crudo se mantiene mientras la opep pierde cuota de”
Eliminar
pronombres
“rt petroleo wti sigue bajando acercandose exceso inventarios crudo
mantiene mientras opep pierde cuota”
Eliminar palabras
del diccionario
“rt wti sigue bajando acercandose exceso inventarios crudo mantiene
mientras opep pierde cuota”
Eliminar palabra
RT
“wti sigue bajando acercandose exceso inventarios crudo mantiene
mientras opep pierde cuota”
Palabras a la raíz “wti sigue bajand acercandose exces inventarios crud mantiene
mientras opep pierd cuot”
Fuente: autores
3.4 Fase 4: modelado
El objetivo del análisis de datos realizado en el proyecto es determinar el sentimiento positivo
o negativo de tweet referente a una marca en específico (Ecopetrol, como caso de estudio),
por lo tanto se seleccionó la técnica de Maquina de Soporte de Vectores (SVM, por sus siglas
en inglés) porque esta se enfoca en procesos de clasificación y regresión, partir de un conjunto
de datos de supervisados para entrenar el modelo y de esta forma por predecir
comportamientos de nuevos datos, ajustándose a los objetivos propuestos en esta
investigación.
3.4.1 Selección de la técnica de modelado
La SVM es una de las técnicas más importantes de Machine Learning que trabaja bajo un
enfoque probabilístico y buscar arrojar resultados de clasificación y predicción. Debido a la
popularidad de esta técnica, se ha desarrollado librerías en diferentes plataformas que apoyan
este proceso, para el caso de estudio se utilizan las librerías Caret, e1071 y plyr del lenguaje
R que permiten la construcción del modelo de análisis propuesto para este caso de estudio.
La construcción del modelo de clasificación a partir de la técnica de SVM ofrece una serie
de ventajas respecto al bajo tiempo de implementación y los niveles satisfactorios de
precisión del mismo.

55
3.4.2 Construcción del modelo
La construcción del modelo se hizo utilizando la técnica de SVM y un conjunto de datos de
entrenamiento, tal como se puede observar en la figura 39.
Figura 39. Modelo SVM construido para el caso de estudio
Fuente: autores
El modelo toma como factor clave el sentimiento del tweet presente en el conjunto de datos
y arroja un número total de 753 vectores clasificados en dos clases (positiva y negativa). La
estructura de este modelo es robusta, de tal forma que permita clasificar textos en un grado
significativo de precisión.
3.5 Fase 5: evaluación
La fase de evaluación permitió contrastar los resultados arrojados por el modelo con un
conjunto de prueba y de esta forma establecer el nivel de precisión utilizando una matriz de
confusión.
3.5.1 Evaluación de resultados
Del total de la muestra establecida como conjunto de datos supervisados se estableció dedicar
el 90% de la misma como conjunto de entrenamiento, y el 10% restante como conjunto de
prueba. Una vez finalizado este proceso se evaluación se tuvo la matriz de confusión que se
presenta en la figura 40.

Figura 40. Matriz de confusión del modelo
Fuente: autores
La matriz de confusión fue aplicada sobre el conjunto de prueba y arroja resultados
satisfactorios de 86% de precisión, que permiten determinar la validez del modelo construido
y la aplicación de este para la clasificación de nuevos flujos de información.
3.5.2 Revisión e integración
Una vez construido el modelo de análisis de datos, realizada la validación y aprobado el uso
del mismo en caso de estudio, se procede a construir la aplicación cliente que soporte el
modelo y permita a los usuarios visualizar las tendencias con la opinión de una marca.
La delimitación de los componentes de la aplicación y su ubicación en una determinada
localización, se hizo por medio del punto de vista de Cooperación de aplicación (ver figura
41), el cual permitió identificar la necesidad de construir 4 componentes con las
características descritas en la tabla 3:
Tabla 3. Componentes y funcionalidad TrendSoft
Componente Ubicación Funcionalidad
Reporteador Front Office Mostar de forma gráfica al usuario las tendencias
de opiniones y el comportamiento del mercado
Captura de datos Back Office Realizar la captura y almacenamiento de tweets.
Clasificación de
Sentimientos
Back Office Asignar una clasificación positiva o negativa,
teniendo en cuenta la semántica del tweet.
Análisis de
Mercado
Back Office Correlacionar la opinión de la marca con el
comportamiento del mercado Fuente: autores
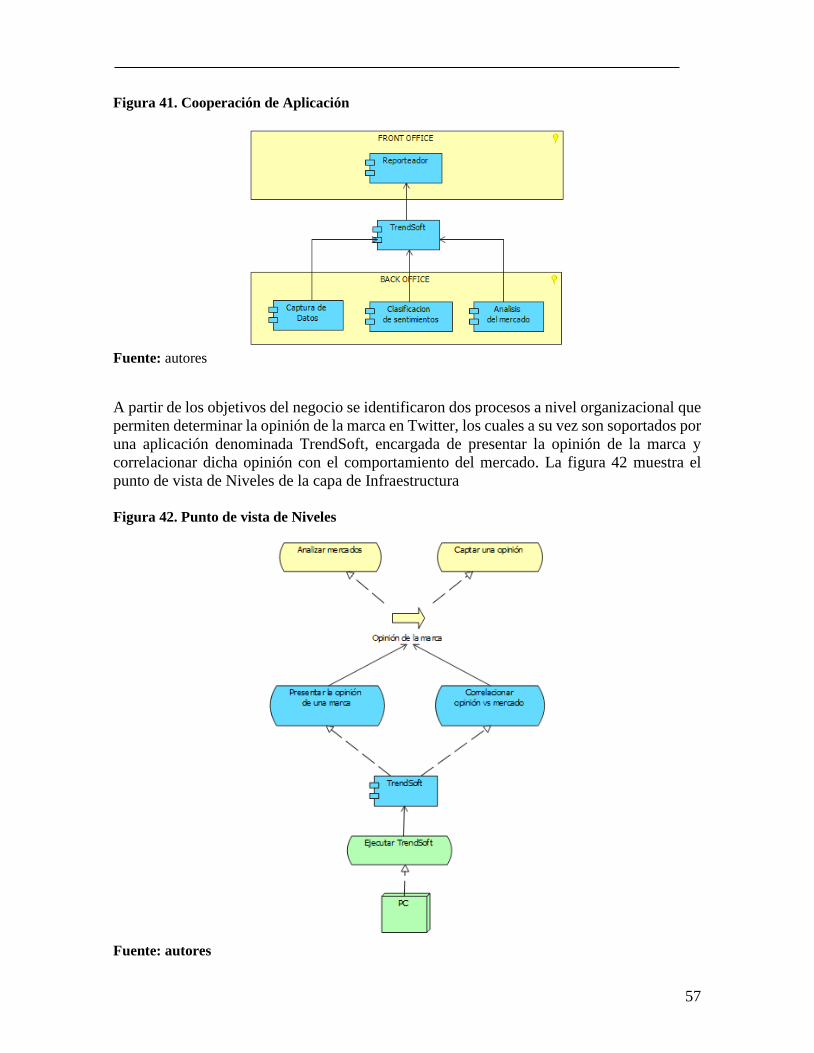
57
Figura 41. Cooperación de Aplicación
Fuente: autores
A partir de los objetivos del negocio se identificaron dos procesos a nivel organizacional que
permiten determinar la opinión de la marca en Twitter, los cuales a su vez son soportados por
una aplicación denominada TrendSoft, encargada de presentar la opinión de la marca y
correlacionar dicha opinión con el comportamiento del mercado. La figura 42 muestra el
punto de vista de Niveles de la capa de Infraestructura
Figura 42. Punto de vista de Niveles
Fuente: autores

El punto de vista de Migración e Implementación presenta un resumen de los componentes
y la relación de estos, que conforman los entregables arquitectónicos del proyecto. El
producto relaciona las tendencias de Twitter con el comportamiento del mercado para
determinar la opinión de la marca en la red social, y de esta forma ofrecer al Trader mayor
asertividad al realizar operaciones bursátiles.
Figura 43. Punto de vista de Migración e Implementación
Fuente: autores
La capa de motivación se vale de los puntos de vista de Stakeholder y Principios para modelar
el comportamiento deseado de la aplicación desarrollada, a continuación se describe la
importancia de los modelos propuestos:
Stakeholder: la aplicación desarrollada le permite al Trader correlacionar la opinión de la
marca con las tendencias del mercado y de esta forma ofrecer un mayor grado de asertividad
al realizar operaciones bursátiles.
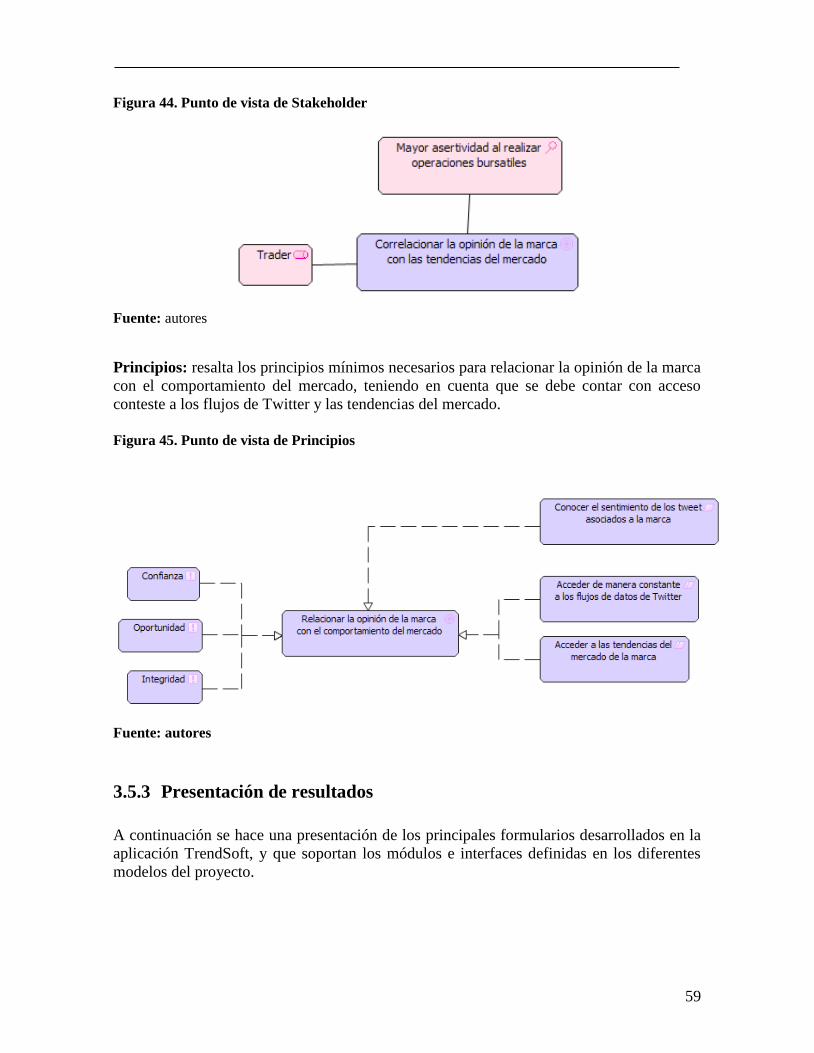
59
Figura 44. Punto de vista de Stakeholder
Fuente: autores
Principios: resalta los principios mínimos necesarios para relacionar la opinión de la marca
con el comportamiento del mercado, teniendo en cuenta que se debe contar con acceso
conteste a los flujos de Twitter y las tendencias del mercado.
Figura 45. Punto de vista de Principios
Fuente: autores
3.5.3 Presentación de resultados
A continuación se hace una presentación de los principales formularios desarrollados en la
aplicación TrendSoft, y que soportan los módulos e interfaces definidas en los diferentes
modelos del proyecto.

3.5.3.1 Menú principal
El menú principal permite seleccionar el módulo que el usuario va a ejecutar, el primer
módulo permite la visualización de las tendencias de opinión en tiempo real, mientras que el
segundo permite correlacionar las tendencias contra el comportamiento del mercado, tal
como se puede visualizar en la figura 46.
Figura 46. Presentación de resultados
Fuente: autores
3.5.3.2 Módulo de Clasificación de sentimientos
Este módulo cuenta con la función más importante de la aplicación que corresponde a la
clasificación de tweets (positivo o negativo) de acuerdo al modelo de análisis construido. Los
pasos seguidos en BackOffice del módulo para alcanzar este objetivo se describen en la figura
47.
Para la construcción de las gráficas del módulo se utilizaron las librerías NumPy y Matplotlib
de Python, cuyo uso se enfoca en la construcción de aplicaciones de ciencias matemáticas e
ingeniería, porque aprovechan la velocidad de procesamiento generada por el alto nivel de
acoplamiento de las librerías numpy para números y las librerías Matplotlib para la
representación gráfica.
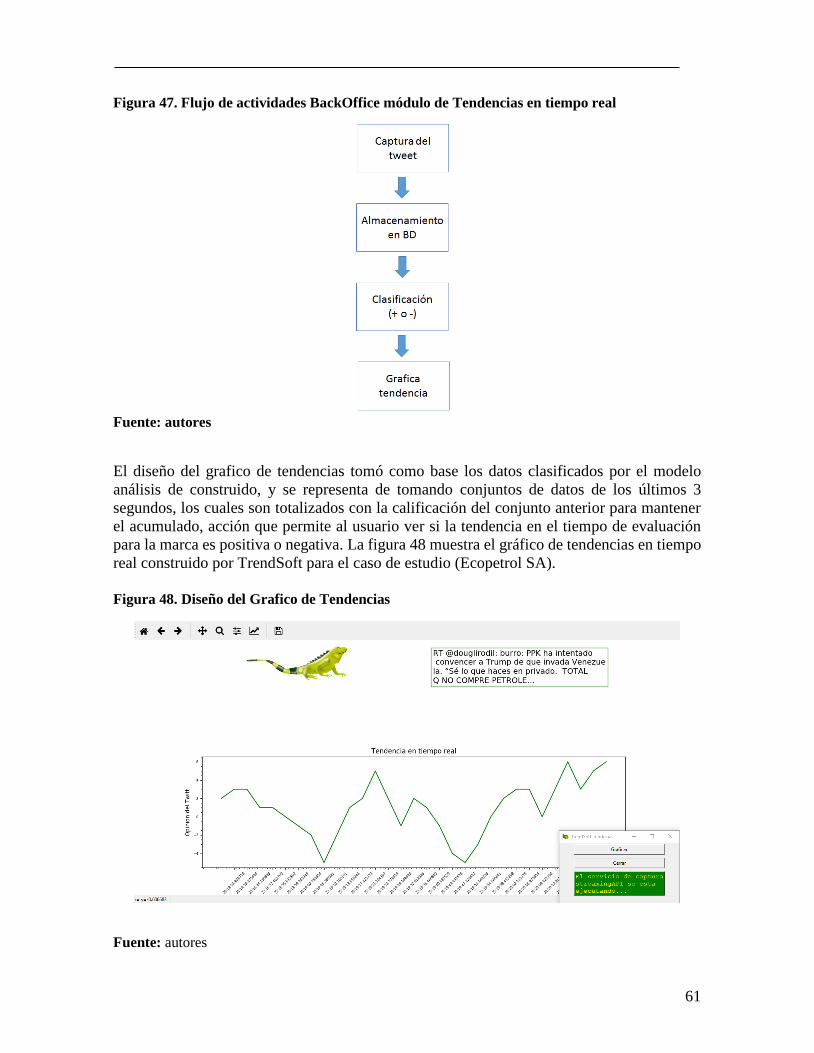
61
Figura 47. Flujo de actividades BackOffice módulo de Tendencias en tiempo real
Fuente: autores
El diseño del grafico de tendencias tomó como base los datos clasificados por el modelo
análisis de construido, y se representa de tomando conjuntos de datos de los últimos 3
segundos, los cuales son totalizados con la calificación del conjunto anterior para mantener
el acumulado, acción que permite al usuario ver si la tendencia en el tiempo de evaluación
para la marca es positiva o negativa. La figura 48 muestra el gráfico de tendencias en tiempo
real construido por TrendSoft para el caso de estudio (Ecopetrol SA).
Figura 48. Diseño del Grafico de Tendencias
Fuente: autores
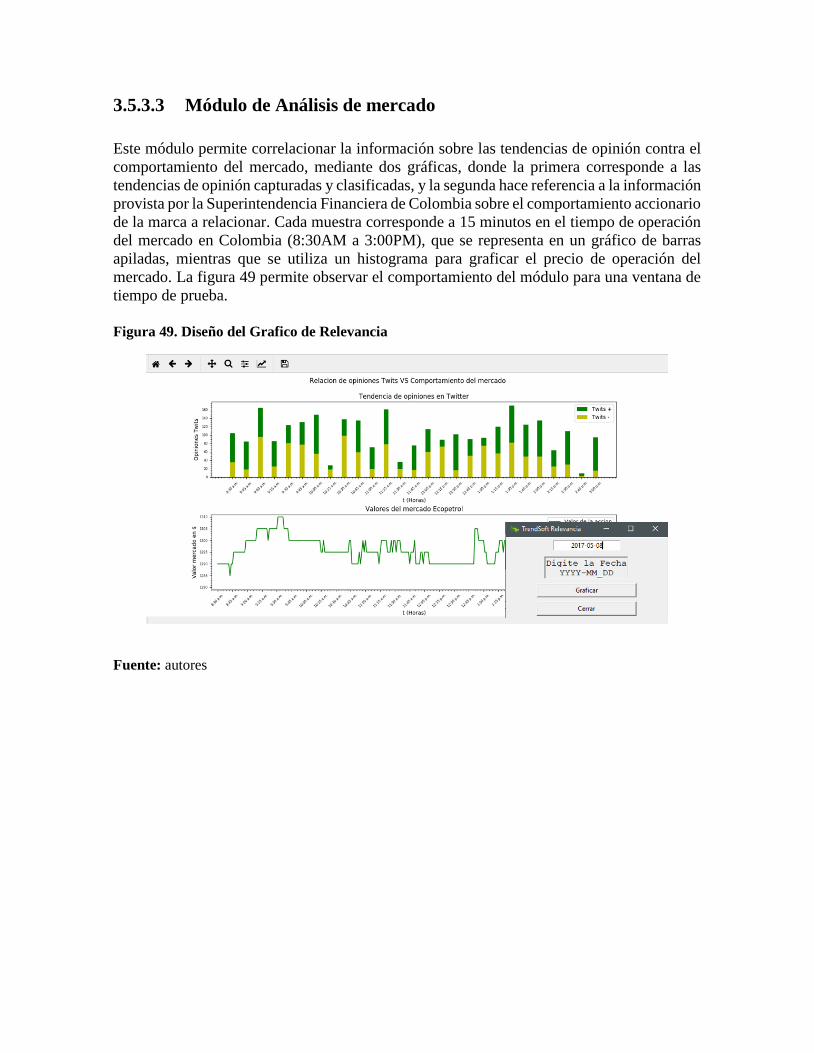
3.5.3.3 Módulo de Análisis de mercado
Este módulo permite correlacionar la información sobre las tendencias de opinión contra el
comportamiento del mercado, mediante dos gráficas, donde la primera corresponde a las
tendencias de opinión capturadas y clasificadas, y la segunda hace referencia a la información
provista por la Superintendencia Financiera de Colombia sobre el comportamiento accionario
de la marca a relacionar. Cada muestra corresponde a 15 minutos en el tiempo de operación
del mercado en Colombia (8:30AM a 3:00PM), que se representa en un gráfico de barras
apiladas, mientras que se utiliza un histograma para graficar el precio de operación del
mercado. La figura 49 permite observar el comportamiento del módulo para una ventana de
tiempo de prueba.
Figura 49. Diseño del Grafico de Relevancia
Fuente: autores

63
PARTE IV. Conclusiones


65
Capítulo 4. Conclusiones
En este capítulo se presenta de manera reflexiva los aprendizajes alcanzados en el desarrollo
de la investigación así como los posibles aportes a la construcción de ciencia y conocimiento
en el país.

66
4.1 Verificación, contraste y evaluación de los objetivos
La investigación tuvo como resultado la aplicación TrendSoft, la cual permite la clasificación
de sentimientos de tweets asociados a Ecopetrol en tiempo real, utilizando una técnica de
Text Data Mining. Esta herramienta está compuesta por un componente de captura de datos
encargada de la extracción, la limpieza y adecuación de los mismos, un componente de
clasificación que utiliza un modelo construido en R para determinar el sentimiento de un
tweet, y un componente de tendencias del mercado, el cuál utiliza la información obtenida
en la clasificación y el comportamiento accionario en una ventana de tiempo, para presentar
al usuario de forma gráfica la correlación de la variable de opinión vs la variable de mercado
y de esta forma ofrecer al usuario soporte para determinar la influencia de la opinión en la
operación de acciones de Ecopetrol.
El marco de trabajo propuesto cumple los objetivos de la investigación porque utiliza reportes
gráficos para correlacionar las variables de opinión y de mercado de Ecopetrol, teniendo en
cuenta la aplicación del modelo de Data Text Mining desarrollado sobre los flujos de
información capturada.

67
4.2 Aportes originales
Una herramienta de análisis de datos que permite capturar, almacenar, clasificar y presentar
el sentimiento de un tweets frente a la opinión de una marca en tiempo real, y utilizar esta
información para construir un gráfica de tendencias que sea comparable como el
comportamiento de mercado en una ventana de tiempo.

68
4.3 Líneas de investigación futuras
A lo largo del desarrollo de la investigación observamos funcionalidades que pueden ser
implementadas en una segunda fase del proyecto, tales como:
La generación de módulos para el estudio de diferentes mercados aplicado al
Community Management, usando la información de redes sociales como Twitter es posible
determinar la opinión de los internautas aplicada a cualquier tipo de marca lo que permitirá
a los mercados analizados adaptarse a la tendencia social siendo más competitivos.
Diseñar un módulo con técnicas de análisis lineal que permita contrastar la opinión
de los internautas en redes sociales, esto permitiría darle un enfoque de interés a las áreas de
BI en el mercado de las organizaciones.
Implementar una versión móvil de los módulos de análisis de datos que permita
soportar el proceso de toma de decisiones de negocio de forma portable.
Utilizar un conjunto de palabras positivas y negativas para clasificar el conjunto de
datos supervisados de otras marcas diferentes al caso de estudio.

69
4.4 Conclusiones
El desarrollo de la investigación permitió identificar que las técnicas de Data Text Mining, y
Clasificación aplicadas al análisis de datos no estructurados, son disciplinas promisorias en
el campo de las TIC y de un gran interés para las organizaciones que buscan aprovechar los
volúmenes de información presente en redes sociales porque permite aplicar algoritmos para
el descubrimiento de conocimiento que apoye la toma de decisiones.
La proliferación de técnicas y algoritmos para el procesamiento, clasificación, categorización
y predicción de datos ha llevado a que estos estén accesibles a profesionales TI y personas
interesadas en la temática, aspecto que facilitó la implementación de los mismos en la
construcción del modelo de procesamiento de datos propuesto sin contar con conocimientos
especializados en inteligencia computacional, herramientas privativas y/o dispositivos de alto
rendimiento.
Contar con una aplicación de análisis de datos para relacionar las tendencias de redes sociales
con el comportamiento accionario del mercado de una marca, se convierte en una herramienta
importante para el sector financiero y para la comunidad en general porque permite tener una
perspectiva de las opiniones de los internautas en tiempo real, utilizando fuentes alternativas
de información como redes sociales, para descubrir conocimiento y aplicarlo en la operación
bursátil de una organización.

70
BIBLIOGRAFÍA
[1] M. Gómez-Aguilar, S. Roses-Campos, and P. Farias-Batlle, “El uso académico de las
redes sociales en universitarios,” Comun. Rev. Científica Comun. y Educ., vol. 19, no.
38, pp. 131–138, 2012.
[2] M. del F. García, A. J. Daly, and J. Supovitz, “Desvelando climas de opinión por
medio del Social Media Mining y Análisis de Redes Sociales en Twitter. El caso de
los Common Core State Standards,” Redes. Rev. Hisp. para el análisis redes Soc., vol.
26, no. 1, pp. 53–75, 2015.
[3] M. Del-Fresno-García, “Haciendo visible lo invisible: Visualización de la estructura
de las relaciones en red en Twitter por medio del Análisis de Redes Sociales,” El Prof.
la Inf., vol. 23, no. 3, pp. 1386–6710, 2014.
[4] M. Slusarczyk Antosz and N. H. Morales Merchán, “ANÁLISIS DE LAS
ESTRATEGIAS EMPRESARIALES Y DE LAS TIC.,” 3C Empres., vol. 5, no. 1,
2016.
[5] C. Zhai and S. Massung, Text Data Management and Analysis: A Practical
Introduction to Information Retrieval and Text Mining. ACM, 2016.
[6] F. Friedrich, J. Mendling, and F. Puhlmann, “Process model generation from natural
language text,” in International Conference on Advanced Information Systems
Engineering, 2011, pp. 482–496.
[7] G. Salton, a. Wong, and C. S. Yang, “A vector space model for automatic indexing,”
Commun. ACM, vol. 18, no. 11, pp. 613–620, 1975.
[8] H. Turtle and W. B. Croft, “Inference networks for document retrieval,” Proc. 13th
Annu. Int. ACM SIGIR Conf. Res. Dev. Inf. Retr. - SIGIR ’90, pp. 1–24, 1990.
[9] J. M. Cotelo, F. Cruz, F. J. Ortega, and J. A. Troyano, “Explorando Twitter mediante
la integración de información estructurada y no estructurada,” Proces. del Leng. Nat.,
vol. 55, pp. 75–82, 2015.
[10] D. Zeng, H. Chen, R. Lusch, and S. H. Li, “Social media analytics and intelligence,”
IEEE Intelligent Systems, vol. 25, no. 6, pp. 13–16, 2010.
[11] J. Vidal, “Big data: Gestión de datos no estructurados,” 214AD. [Online]. Available:
https://goo.gl/BafCNL.
[12] A. K. Noor, “Potential of cognitive computing and cognitive systems,” Open
Engineering, vol. 5, no. 1. 2015.

<Título Anexo>
71
[13] A. A. R. Gómez and D. W. R. Bautista, “Inteligencia de negocios: Estado del arte,”
Sci. Tech., vol. 1, no. 44, pp. 321–326, 2010.
[14] E. Stamatatos, N. Fakotakis, and G. Kokkinakis, “Automatic Text Categorization in
Terms of Genre and Author,” Comput. Linguist., vol. 26, no. 4, pp. 471–495, Dec.
2000.
[15] M. A. P. Abelleira and C. A. Cardoso, “Minería de texto para la categorización
automática de documentos,” PhD Comput. Sci. por Carnegie Mellon Univ. Madrid,
España, 2010.
[16] C. G. Cambronero and I. G. Moreno, “Algoritmos de aprendizaje: knn & kmeans,”
Intelgencia en Redes Comun. Univ. Carlos III Madrid, 2006.
[17] Y. Gala García, “Algoritmos SVM para problemas sobre big data.” 2013.
[18] P. R. Santana, R. Costaguta, and D. Missio, “Aplicación de Algoritmos de
Clasificación de Minería de Textos para el Reconocimiento de Habilidades de E-
tutores Colaborativos,” Intel. Artif. Rev. Iberoam. Intel. Artif., vol. 17, no. 53, pp. 57–
67, 2014.
[19] H. Vivas, “Optimización en entrenamiento del perceptrón multicapa.” Tesis de
Maestría. Universidad del Cauca, Popayán, Colombia.[Links], 2014.
[20] E. Martínez Cámara, M. T. Martín Valdivia, J. M. Perea Ortega, and L. A. Ureña
López, “Técnicas de clasificación de opiniones aplicadas a un corpus en español,”
2011.
[21] A. C. Vásquez, J. P. Quispe, and A. M. Huayna, “Procesamiento de lenguaje natural,”
Rev. Investig. Sist. e Informática, vol. 6, no. 2, pp. 45–54, 2009.
[22] M. D. Arango Serna, J. E. Londoño Salazar, and J. A. Zapata Cortés, “Arquitectura
empresarial: una visión general,” Rev. Ing. Univ. Medellín, vol. 9, no. 16, pp. 101–
111, 2010.
[23] Colombia Digital, “¿Qué es Arquitectura Empresarial?,” 2018. [Online]. Available:
https://goo.gl/bhF7St.
[24] ArchiMate, “ArchiMate® 2,” The Open Group, 2013. [Online]. Available:
http://pubs.opengroup.org/architecture/archimate2-doc/chap08.html.
[25] Twitter, “Twitter,” 2016. [Online]. Available: https://about.twitter.com/es/company.
[26] Brandwatch, “Estadísticas de Twitter para el 2016,” 2016.
[27] Subgerencia Cultural del Banco de la República, “Mercado Bursátil,” 2015. [Online].
Available:
http://admin.banrepcultural.org/blaavirtual/ayudadetareas/economia/mercado_bursati
l.
[28] Ecopetrol S.A, “Ecopetrol,” 2016. [Online]. Available:
http://www.ecopetrol.com.co/wps/portal/es/ecopetrol-web.
[29] A. Bifet and E. Frank, “Sentiment knowledge discovery in twitter streaming data,” in
International Conference on Discovery Science, 2010, pp. 1–15.
[30] EcuRed, “Tecnologías de la Información y las Comunicaciones,” 2015. [Online].
Available:
https://www.ecured.cu/Tecnologías_de_la_información_y_las_comunicaciones.
[31] Grupo Integrado de Ingeniería GII, “Inteligencia Computacional,” 2017. [Online].
Available: http://www.gii.udc.es/investigacion/detalle/3.
[32] S. Acosta, “Inteligencia Computacional,” 2016. [Online]. Available:
http://computacional.webcindario.com.
[33] A. Gelbukh, “Procesamiento de lenguaje natural,” S. d. Virtual, Ed, 2010.

Anexo A
72
[34] C. G. Ibáñez, R. H. Ballesteros, and P. Gervás, “Una arquitectura software para el
desarrollo de aplicaciones de generación de lenguaje natural,” Proces. del Leng. Nat.,
vol. 33, 2004.
[35] T. R. Foundation, “What is R?,” 2017. [Online]. Available: https://www.r-
project.org/about.html.
[36] M. Kuhn, “The Caret package,” 2016. [Online]. Available: https://goo.gl/7IBgwT.
[37] Python Central, “Introduction to tweepy, Twitter for Python,” 2013. [Online].
Available: https://goo.gl/gBeu4N.
[38] Python, “Welcome to python-twitter’s documentation! — python-twitter 3.2.1
documentation,” 2016. .
[39] MongoDB, “PyMongo 3.4.0 Documentation,” 2015. [Online]. Available:
https://goo.gl/DOZBir.
[40] O. NCR (Dinamarca), AG(Alemania), SPSS (Inglaterra) and y D.-C. (Holanda),
Teradata, SPSS, “Metodología para el Desarrollo de Proyectos en Minería de Datos
CRISP-DM,” 2000.
[41] El tiempo, “Así usan las redes sociales los jóvenes en Colombia,” 2016. [Online].
Available: https://goo.gl/3sNGD0.
[42] Twitter, “Twitter Developer Documentation,” 2016. .
[43] MongoDB, “PyMongo 3.4.0 Documentation — PyMongo 3.4.0 documentation,”
2016. .


















