
Universidad Politécnica de Madridoa.upm.es/64465/1/TESIS_MASTER_JOSE_ANTONIO_QUEVEDO... · 2020....
107
Universidad Politécnica de Madrid Máster Universitario en Ciberseguridad Trabajo de Fin de Máster DESARROLLO DE UN MODELO DE CLASIFICACIÓN DE MALWARE LINUX ARM SEGÚN SU FUNCIONALIDAD UTILIZANDO TÉCNICAS DE APRENDIZAJE AUTOMÁTICO Autor: Jose Antonio Quevedo Muñoz Madrid, 29 de junio de 2020
Transcript of Universidad Politécnica de Madridoa.upm.es/64465/1/TESIS_MASTER_JOSE_ANTONIO_QUEVEDO... · 2020....

Universidad Politécnica de Madrid
Máster Universitario en Ciberseguridad
Trabajo de Fin de Máster
DESARROLLO DE UN MODELO DE CLASIFICACIÓN DE MALWARELINUX ARM SEGÚN SU FUNCIONALIDAD UTILIZANDO TÉCNICAS
DE APRENDIZAJE AUTOMÁTICO
Autor: Jose Antonio Quevedo Muñoz
Madrid, 29 de junio de 2020


Trabajo de Fin de Máster
Título: Desarrollo de un modelo de clasificación de malware Linux ARM según su fun-cionalidad utilizando técnicas de aprendizaje automático.
Autor: Jose Antonio Quevedo Muñoz
Director: Luis Miguel Pozo Coronado
Escuela Técnica Superior de Ingenieros de Telecomunicación
Escuela Técnica Superior de Ingeniería y Sistemas de Telecomunicación
Escuela Técnica Superior de Ingenieros Informáticos
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
TRIBUNAL:
PRESIDENTE:
VOCAL:
SECRETARIO:
Fecha de lectura:
Calificación:
Fdo. El secretario del tribunal



Resumen
Resumen —
En este proyecto se han aplicando técnicas de aprendizaje automático supervisado sobre un conjuntode ficheros ejecutables Linux de arquitectura ARM con el objetivo de predecir su funcionalidad partiendode las hipótesis de que las muestras son malware.
Como verdad fundamental se ha tomado el etiquetado obtenido de cada muestra de VirusTotal, queproporciona la interpretación de 63 antivirus, las cuales han sido unificadas con AVClass. Esta verdadfundamental se describe como una variable objetivo discreta multiclase.
Se han generado los informes de análisis estático y dinámico de cada muestra utilizando la herramientaLiSa. Estos informes han sido preprocesados a modo de bolsa de palabras o bag-of-words, elaborandoasí una lista con todas las palabras que aparecen en cada uno de estos informes junto con su número deapariciones.
La selección de características se ha hecho eliminando en primer lugar las palabras con menor númerode apariciones para evitar la identificación individual de las muestras por parte de los modelos y parareducir el coste computacional del procedimiento. Despues se ha aplicado un filtro TFIDF y se hanescogido las k-mejores características utilizando el filtro específico para clasificación χ2. Estos procesosde filtrado de características se han hecho sobre el subconjunto de entrenamiento para evitar fugas dedatos, lo que nos llevaría a resultados irreales.
Con este dataset se han entrenado, medido y comparado 42 combinaciones de técnicas de muestreoy modelos de clasificación. La conclusiones más destacables han sido que ninguna de las técnicas demuestreo ha supuesto una ventaja para clasificar malware en este contexto, y que aunque ninguno delos modelos obtenidos tiene capacidad de aportar información relevante en una aplicación real, el modeloque mejor comportamiento ha mostrado y con mejores posibilidades de obtener resultados satisfactoriosen futuros proyectos es la red neuronal.
Palabras clave — aprendizaje automático supervisado, clasificación de malware, etiquetado,análisis estático, análisis dinámico, LiSa, VirusTotal, AVclass, Linux, Debian, ARM, IoT, selección decaracterísticas, tfidf, sandbox.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
i


Abstract
Abstract —
In this project, supervised machine learning techniques have been applied to a set of Linux executablefiles of ARM architecture with the aim of predicting what type of malware it is based on the initialhypothesis that the samples are malware.
As a fundamental truth, we have taken the labeling obtained from each VirusTotal sample, whichprovides the interpretation of 63 antivirus programs and have been unified with AVClass.
Static and dynamic analysis reports have been generated for each sample using the LiSa tool. Thesereports have been pre-processed as “bag-of-words”, thus compiling a list of all the words that appear ineach of these reports along with their number of occurrences.
Feature selection has been made by first eliminating the words with the fewest occurrences to avoidthe individual identification of the samples by the models and to reduce the computational cost of theprocedure. Then a TFIDF filter has been applied and the k-best characteristics have been chosen usingthe specific filter for classification chi2. These feature filtering processes have been done on the trainingsubset to avoid data leaks, which would lead to unrealistic results.
With this dataset 42 combinations of sampling techniques and classification models have been trained,measured and compared. The most important conclusions have been: no sampling technique has been anadvantage classifying malware in this context, and although none of the obtained models were able toprovide useful information in a real scenario, the algorithm that showed the best behaviour and the bestpossibilities to obtain a satisfaying result in futures projects was the Neural Network.
Key words — supervised machine learning, malware classification, tagging, static analysis, dynamicanalysis, LiSa, VirusTotal, AVClass, Linux, Debian, ARM, IoT, feature selection, tfidf, sandbox.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
iii

iv Trabajo Fin de Máster

Índice general
1. Introducción 11.1. Linux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2. ARM - Internet of Things . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3. Naturaleza del malware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.4. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2. Tecnologías utilizadas 52.1. Debian GNU/Linux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2. LiSa: Linux Sandbox . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3. VirusTotal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3.1. AVClass . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.4. Python 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.5. Scikit-Learn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.6. Pandas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.7. Git . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.7.1. Gitflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.8. Emacs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.9. Latex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.9.1. Texstudio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3. Estado del Arte 113.1. Análisis de malware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1.1. Análisis estático . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.1.2. Análisis dinámico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2. Malware en Linux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2.1. Motores antivirus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3. Lenguajes de programación para aprendizaje automático . . . . . . . . . . . . . . . . . . . 153.4. Estudios previos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4. Marco teórico 194.1. Aprendizaje automático . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1.1. Tipos de aprendizaje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.2. Manejo de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2.1. Fugas de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.3. Selección de características . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.3.1. Filtro de características excesivamente específicas . . . . . . . . . . . . . . . . . . . 244.3.2. Filtro de características duplicadas . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.3.3. Filtro TF-IDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.4. Técnicas de muestreo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264.4.1. Sobremuestreo - Oversampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264.4.2. Submuestreo - Undersampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.4.3. Combinaciones de sobremuestreo y submuestreo . . . . . . . . . . . . . . . . . . . 27
4.5. Modelos algorítmicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
v

ÍNDICE GENERAL
4.5.1. Naïve Bayes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.5.2. KNN - K Nearest Neighbors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.5.3. AdaBoost . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.5.4. Árbol de Decisión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.5.5. Bosque Aleatorio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304.5.6. Red Neuronal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.6. Matriz de Confusión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304.7. Métricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.7.1. Seleccionar la métrica más adecuada . . . . . . . . . . . . . . . . . . . . . . . . . . 314.7.2. Medias para clasificación multiclase . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5. Metodología y diseño 335.1. Requisitos software. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2. Requisitos funcionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.2.1. Obtención de reportes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345.2.2. Cliente de LiSa y VirusTotal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345.2.3. Herramienta de entrenamiento y evaluación de modelos . . . . . . . . . . . . . . . 35
5.3. Proceso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.3.1. Fase 1: Elección del dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.3.2. Fase 2: Herramientas a utilizar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.3.3. Fase 3: Análisis estático y dinámico . . . . . . . . . . . . . . . . . . . . . . . . . . 395.3.4. Fase 4: Preprocesado, particionado de dataset y matriz de características . . . . . 405.3.5. Fase 5: Selección de características - Filtros . . . . . . . . . . . . . . . . . . . . . . 435.3.6. Fase 6: Entrenamiento y validación de modelos . . . . . . . . . . . . . . . . . . . . 455.3.7. Fase 7: Análisis crítico sobre los resultados obtenidos . . . . . . . . . . . . . . . . . 46
6. Manual de uso 476.1. Fase 0: obtención de las muestras ELF ARM. . . . . . . . . . . . . . . . . . . . . . . . . . 476.2. Fase 1: obtención de los informes de los ficheros ELF ARM. . . . . . . . . . . . . . . . . . 48
6.2.1. Envío de muestras a LiSa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 486.2.2. Obtención de reportes malware de LiSa . . . . . . . . . . . . . . . . . . . . . . . . 486.2.3. Envío y obtención de informes VirusTotal . . . . . . . . . . . . . . . . . . . . . . . 49
6.3. Fase 2: obtención de las repeticiones de palabras. . . . . . . . . . . . . . . . . . . . . . . . 496.4. Fase 3: Selección de características. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 496.5. Fase 4: Muestreo, entrenamiento y validación de los modelos. . . . . . . . . . . . . . . . . 50
7. Conclusiones 51
8. Lineas futuras 53
Bibliografía 55
Apéndices 59
A. Anexos 61A.1. Formato de informe LiSa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61A.2. Tablas de resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
A.2.1. Tabla de resultados - media Ponderada . . . . . . . . . . . . . . . . . . . . . . . . 66A.2.2. Tabla de resultados - media Micro . . . . . . . . . . . . . . . . . . . . . . . . . . . 67A.2.3. Tabla de resultados - media Macro . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
A.3. Matrices de confusión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69A.3.1. Muestreo: Ninguno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69A.3.2. Muestreo: Aleatorio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
vi Trabajo Fin de Máster

ÍNDICE GENERAL
A.3.3. Muestreo: SMOTE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75A.3.4. Muestreo: ADASYN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78A.3.5. Muestreo: CondensedNearestNeighbour . . . . . . . . . . . . . . . . . . . . . . . . 81A.3.6. Muestreo: SMOTENN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84A.3.7. Muestreo: SMOTETomek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
A.4. Código fuente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
vii


Índice de figuras
1.1. Causas de los ciberincidentes [4] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2. Cuota de mercado global de Sistemas Operativos [10] . . . . . . . . . . . . . . . . . . . . . 31.3. Histórico de cuota de mercado ARM [11]. . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4. Cuota de mercado de sistemas empotrados en 2017 [12]. . . . . . . . . . . . . . . . . . . . 3
3.1. Productos con mayor número de vulnerabilidades en la historia del software en 2020 [20]. 143.2. Productos con mayor número de vulnerabilidades en 2019 [20]. . . . . . . . . . . . . . . . 143.3. Tabla comparativa de Antivirus [21]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.4. Infografía de lenguajes y librerías de aprendizaje automático [22]. . . . . . . . . . . . . . . 163.5. Precisión reportada por trabajos previos de clusterización [40]. . . . . . . . . . . . . . . . 18
4.1. Forma de una matriz de confusión binaria[48] . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.1. Flujo de trabajo de aprendizaje automático supervisado [50] . . . . . . . . . . . . . . . . . 36
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
ix


Índice de tablas
5.1. Cantidad y proporción de muestras en dataset . . . . . . . . . . . . . . . . . . . . . . . . . 37
A.1. Tabla de resultados - Media: Ponderada . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66A.2. Tabla de resultados - Media: Micro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67A.3. Tabla de resultados - Media: Macro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
xi


1Introducción
Llamamos malware a aquel fichero que al ser utilizado en un computador produce en el sistema efectos
no deseados por el usuario que lo utilizó. El malware es capaz de robar datos, invadir la privacidad,
suplantar la identidad, realizar fraude, extorsión, interrupción de servicios, etc.
Actualmente su principal vía de transmisión es internet. Entre los mecanismos más eficaces de
distribución encontramos el correo electrónico, las redes sociales con ayuda de la ingeniería social, la
interceptación y manipulación de los datos que un usuario pueda intercambiar con una entidad de su
confianza, etc. En definitiva, en la mayoría de los casos a través del engaño al usuario.
La aparición de las redes sociales, el auge de los sistemas distribuidos y el IoT Internet of Things (IoT)
son factores que hacen que la seguridad digital sea una preocupación que afecta a la sociedad a todos
los niveles. Se estima que actualmente hay un 55% de la población con posibilidad de acceso a internet,
un 53% de usuarios activos en la red y un 42% de usuarios activos en redes sociales [1]. El malware
se ha convertido a día de hoy en una de las principales amenazas para gobiernos, empresas e usuarios
individuales debido a la gran penetración que tiene internet en la sociedad a nivel mundial [2] y a las
consecuencias que una vulnerabilidad digital o el descuido de un usuario puede causar.
El número de incidentes de ciberseguridad en el mundo va en aumento y su impacto en la sociedad es
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
1

CAPÍTULO 1. INTRODUCCIÓN
innegable. En España el número de incidentes de ciberseguridad gestionados por el CNI-CERT creció un
43% en 2018 respecto al año anterior. En Europa el coste medio de un ciberataque para una PYME se
estima en 35.000€, lo cual está haciendo que el 60% las empresas europeas que reciben un ciberataque
desaparezcan durante los 6 meses siguientes a haberlo recibido [3]. Y a nivel mundial el coste de los
ciberataques se estima en un 0,85% del PIB anual.
Figura 1.1: Causas de los ciberincidentes [4]
Desde el año 2014 el descenso de la cantidad anual de nuevo malware contrasta con el aumento de los
ataques por malware [5], lo cual indica que el nuevo malware es cada vez más sofisticado y destructivo
[6] [7]. Esto hace necesario anticiparse a estas nuevas amenazas con la aplicación de tecnologías que nos
permitan detectar ataques que se presenten en formas a día de hoy aún desconocidas.
1.1. Linux
El sistema de distribución de software que ofrece Linux goza de una gran reputación debido a la
confiabilidad de sus mecanismos organizativos y criptográficos. Puede que este sea uno de los motivos
por los que haya una idea muy extendida de que en Linux no hay malware, y es que llama la atención el
bajo número de estudios sobre malware de Linux comparado con otros sistemas operativos.
Aunque es cierto que las características de diseño de Linux dificulta la labor de un atacante, pero
tambien es cierto que el kernel de Linux fue en el año 2017 el segundo software con mayor número de
vulnerabilidades críticas sólo por detrás de Adobe Flash, también disponible en esta plataforma.
Según Marketshare, en la historia reciente el sistema operativo más instalado en los ordenadores
domésticos y corporativos de todo el mundo ha sido Microsoft Windows, motivo por el cual puede haber
sido el sistema operativo más atacado, pero en los últimos años se ha visto incrementado el número de
este tipo de ataques sobre sistemas operativos de Linux y macOS. De hecho la cantidad de malware
detectado en 2018 en plataformas Linux ha sido de un 18% [8].
Linux cuenta con poco más del 1% del total de ordenadores activos y de un 2.5% de ordenadores
de escritorio en el mundo. Sin embargo en la actualidad lidera el mercado de supercomputadoras y
servidores de internet, y está aumentando su presencia en computadoras de escritorio, portátiles y equipos
2 Trabajo Fin de Máster

CAPÍTULO 1. INTRODUCCIÓN
empotrados, equipamiento de red, videojuegos, smartphones y tablets [9].
Figura 1.2: Cuota de mercado global de Sistemas Operativos [10]
Con la aparición de los dispositivos móviles, la tendencia ha sido que los servicios se alberguen en la
nube y que cada usuario ejecute las aplicaciones en su móvil, o navegador web en el caso de Sistema
Operativo (SO) de escritorio, mientras que almacena sus datos en la nube.
Si un sistema operativo de un ordenador de escritorio o dispositivo móvil tiene una vulnerabilidad de
seguridad y un usuario malintencionado consigue el control de ese dispositivo, habrá conseguido acceder
a la información de una persona. Pero si un usuario malintencionado toma el control de un servidor o un
supercomputador habrá conseguido acceder a la información de todos los usuarios de todos los servicios
que se encuentren alojados en ese servidor o de un computador realmente potente.
Por lo tanto, dado que cada servidor es utilizado por miles o millones de personas, el impacto que
produce una única vulnerabilidad en estos sistemas los convierte en el primer y más importante punto a
proteger.
1.2. ARM - Internet of Things
Uno de los enfoques tecnológicos que más están llamando la atención en los últimos años es el Internet
de las Cosas o Internet of Things (IoT). Este concepto tecnológico está ligado a la tendencia de conectar
objetos cotidianos a la red para dotar de capacidad de control remoto, monitorizar el dispositivo, o hacer
que reaccione de manera automática a condiciones externas como la cantidad de luz solar, etc.
Figura 1.3: Histórico de cuota de mercado ARM [11].Figura 1.4: Cuota de mercado de sistemas empotra-dos en 2017 [12].
En este paradigma tecnológico son ARM y el sistema operativo Linux quienes dominan el mercado con
una cuota de mercado de un 33% y un 80% respectivamente. Estos son los motivos por los que se ha
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
3

CAPÍTULO 1. INTRODUCCIÓN
elegido este sistemas operativo y esta arquitectura para hacer este estudio.
1.3. Naturaleza del malware
Hasta hace poco la manera habitual de luchar contra el malware ha consistido en mantener un gran
conjunto de ejemplos con los que comparar cada fichero y así identificar los ficheros maliciosos [13]. Una
estrategia útil para no ser infectado por segunda vez pero ineficaz para amenazas de tipo Malware
Polimórfico, Malware Metamórfico y 0-Day. Alrededor del 30% del malware detectado en 2016 fue
clasificado como 0-day [14] y desde finales del 2017 a principios de 2019 se ha observado que el 94%
del malware es de tipo polimórfico [8]. Este dato confirma que la capacidad de los cibercriminales para
reempaquetar y modificar su malware automáticamente ha superado la habilidad de la industria para
conseguir con suficiente velocidad las firmas necesarias para detectar eficazmente el malware.
Ante esta situación contamos con la inteligencia artificial como la técnica que puede ayudar a detectar
malware actualmente desconocido, de manera similar al bloqueo del correo electrónico no deseado, el cual
se ha conseguido reducir en un 99,9% [15].
En el contexto de ataques dirigidos o avanzados, una vez hemos conseguido detectar el malware, lo que
interesa es saber qué pretendía conseguir el atacante para así neutralizar eficazmente la amenaza. Una
muestra detectada de malware solo representa un ataque que puede que haya tenido éxito o no. Esta
información solo podremos obtenerla a través de un análisis forense de malware.
El análisis forense de malware es una tarea de gran complejidad técnica en la que el forense se encuentra
ante la difícil tarea de averiguar qué pretenden hacer unas pocas líneas de código dentro de una ingente
cantidad de código ensamblador. Esto es comparable a buscar una aguja en un pajar que podría no estar
sin saber de antemano qué forma tendrá.
1.4. Objetivos
Con este proyecto pretendemos ahorrarle tiempo a un analista de malware dándole, si no la respuesta
definitiva, al menos sí una pista sobre qué tipo de malware está buscando.
El propósito principal de este proyecto es desarrollar un programa que, a través de la aplicación de
técnicas de aprendizaje automático, proporcione un modelo capaz de clasificar el tipo de malware al que
corresponde un fichero, suponiendo de antemano que dicho fichero es malware.
Somos conscientes de que obtener un modelo de clasificación perfecto es un resultado poco probable,
por lo que un resultado interesante de este trabajo será la validación de los modelos de manera que nos
permita saber cuales son los que mejor resultado ofrecen de cara a futuros proyectos.
4 Trabajo Fin de Máster

2Tecnologías utilizadas
2.1. Debian GNU/Linux
El proyecto Debian [16] es una asociación de personas que han hecho causa común para crear un SO
libre y Debian es el sistema operativo resultante. Los sistemas Debian actualmente usan el núcleo de Linux
o FreeBSD. Aunque lo más común es utilizarlo junto con el kernel Linux, actualmente se está trabajando
para ofrecer la distribución con otros núcleos, en especial Hurd, que consiste en una colección de servidores
que se ejecutan sobre un micronúcleo (como Mach) para implementar las distintas funcionalidades. Hurd
es software libre producido por el proyecto GNU.
Una gran parte de las herramientas básicas que completan el sistema operativo vienen del proyecto
GNU, de ahí los nombres: GNU/Linux, GNU/kFreeBSD, y GNU/Hurd.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
5

CAPÍTULO 2. TECNOLOGÍAS UTILIZADAS
2.2. LiSa: Linux Sandbox
El proyecto LiSa (Linux Sandbox) es un sistema modular de análisis estático y dinámico de malware de
Linux publicado bajo licencia Apache 2.0 y cuyo código está disponible en Github [17]. Sus características
más notables son que: devuelve los resultados en formato json para su posterior análisis manual, con
detección de patrones con herramientas como Yara o con inteligencia artificial para detectar y clasificar
malware de Linux. Soporta las arquitecturas x86_64, i386, arm, mips y aarch64 por medio de emulación
QEMU, cuenta con imágenes de sistema descargables construidas con buildroot, realiza análisis estático
con Radare2 y el análisis dinámico con los módulos de kernel SystemTap: captura de llamadas de sistema,
apertura de ficheros y árboles de procesos. Proporciona estadísticas de red y análisis de DNS, HTTP,
Telnet, e comunicación IRC. Escala utilizando Celery y RabbitMQ y proporciona dos interfaces: un API
REST y un frontend web, y es extensible a través de módulos de análisis e imágenes personalizadas.
2.3. VirusTotal
VirusTotal es una plataforma web que proporciona la posibilidad de analizar ficheros con una gran
cantidad de antivirus de una sola vez.
Es accesible via interfaz web y API REST.
En este proyecto lo hemos utilizado para generar los informes de malware que nos permiten saber qué
tipo de malware es cada muestra según los diferentes motores Antivirus que utiliza VirusTotal.
2.3.1. AVClass
AVClass es una herramienta de etiquetado de malware publicada en 2016 [18].
6 Trabajo Fin de Máster

CAPÍTULO 2. TECNOLOGÍAS UTILIZADAS
Partiendo de una colección de informes de malware procedentes de VirusTotal devuelve el nombre de
la familia de malware más probable para cada muestra que es capaz de extraer de las etiquetas recibidas.
Puede incluso mostrar un ranking de los nombres alternativos que encontró para cada muestra.
AVClass incluye dos funcionalidades: preparación y etiquetado. Aunque para el propósito de este
proyecto la funcionalidad más interesante es el etiquetado, que muestra el nombre de la familia de cada
muestra. La preparación produce una lista de alias y tokens genéricos utilizados por la funcionalidad de
etiquetado.
AVClass es útil porque a menudo los investigadores de seguridad quieren extraer la información de
la familia de malware de las etiquetas AV pero este procedimiento no es tan sencillo como parece,
especialmente para una gran cantidad de muestras.
Entre las ventajas de AVclass encontramos que es automático, independiente de los fabricantes de
antivirus, multiplataforma, no requiere los ejecutables sino únicamente sus informes, cuenta con una
precisión cuantificada y además es software de fuentes abiertas con licencia MIT.
Entre las limitaciones conocidas encontramos que su salida depende de las etiquetas AV recibidas
como entrada en sus informes. AVClass procura compensar el ruido en sus etiquetas de salida pero no
puede identificar el nombre de familia de una muestra si los motores antivirus proporcionan nombres no
genéricos a cada muestra. Concretamente no etiqueta una muestra si no hay al menos 2 motores antivirus
de acuerdo en un nombre de familia. AVClass fue capaz de etiquetar el 81% de las muestras sobre el
conjunto 8 millones de muestras de malware utilizado por sus autores para probar su efectividad.
Sopesando ventajas y limitaciones se ha considerado la combinación de AVClass y VirusTotal como una
opción adecuada para generar el etiquetado del malware que se utiliza en este proyecto por el porcentaje
de cobertura, la variedad de etiquetas, la precisión y concreción mostrada sobre el dataset utilizado.
2.4. Python 3
Python es un lenguaje de programación interpretado, multiparadigma y multiplataforma que usa tipado
dinámico y conteo de referencias para la administración de memoria y cuya filosofía hace hincapié en una
sintaxis que favorece la legibilidad del código.
Es administrado por la Python Software Foundation. Posee una licencia de código abierto denominada
Python Software Foundation License compatible con la GPL de GNU a partir de la versión 2.1.1.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
7

CAPÍTULO 2. TECNOLOGÍAS UTILIZADAS
2.5. Scikit-Learn
Scikit-learn es una librería de aprendizaje automático para el lenguaje de programación Python.
Implementa varios algoritmos de clasificación, regresión y clustering entre los que se incluyen máquinas
de vectores soporte, bosque de árboles aleatorios, k-means y DBSCAN, y ha sido diseñado para operar
con las librerías numéricas y científicas de python NumPy y SciPy.
2.6. Pandas
Pandas es una librería Python que proporciona estructuras de datos diseñadas para trabajar con datos
relacionales o etiquetados de una manera fácil e intuitiva. Su objetivo es ser un bloque funcional para
hacer práctica la utilización de datos reales en Python. El objetivo de sus desarrolladores es convertirse
en la herramienta opensource más potente y flexible de manipulación de datos en cualquier lenguaje.
2.7. Git
Es un software de control de versiones distribuido diseñado por Linus Torvalds, pensando en la eficiencia
y la confiabilidad del mantenimiento de versiones de aplicaciones cuando éstas tienen un gran número de
archivos de código fuente. Su propósito es llevar registro de los cambios en archivos de computadora y
coordinar el trabajo que varias personas realizan sobre archivos compartidos.
8 Trabajo Fin de Máster

CAPÍTULO 2. TECNOLOGÍAS UTILIZADAS
2.7.1. Gitflow
Se ha utilizado Git siguiendo el flujo de trabajo Gitflow, tanto para
la gestión del código como para la redacción de la documentación
de la memoria.
Este flujo de trabajo consiste en crear una rama paralela a Master
llamada Develop.
La rama Develop se utiliza para que el equipo de trabajo mergee
las ramas de cada feature de desarrollo, y una vez que esté
estabilizada, se hayan resuelto los conflictos que pudiera existir y
pase todos los tests, se hace merge con la rama master para,
finalmente, obtener la versión release que se llevará a producción.
2.8. Emacs
Emacs es un editor de texto con una gran cantidad de funciones, muy popular entre programadores
y usuarios técnicos. GNU Emacs es parte del proyecto GNU y la versión más popular de Emacs con
una gran actividad en su desarrollo. El manual de GNU Emacs lo describe como “un editor extensible,
personalizable, auto-documentado y de tiempo real”.
El EMACS original significa, Editor MACroS para el TECO, y fue escrito por Richard Stallman junto
con Guy Steele en 1975.
2.9. Latex
LaTeX es un sistema de preparación de documentos para escritura de alta calidad. En su mayoría es
utilizado para documentos científicos o técnicos de tamaño medio o grande pero puede ser utilizado par
casi cualquier tipo de publicación.
LaTeX no es un procesador de texto. En su lugar anima a los autores a no preocuparse demasiado de
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
9

CAPÍTULO 2. TECNOLOGÍAS UTILIZADAS
la apariencia de sus documentos sino en concentrarse en enriquecer el contenido.
Se basa en la idea de que es mejor dejar el diseño a los diseñadores de documentos, y a los autores el
contenido de los mismos.
2.9.1. Texstudio
TeXstudio es un entorno de escritura integrado de
fuentes abiertas para la creación de documentos
LaTeX. Su objetivo es hacer que la escritura con
LaTeX sea tan fácil y cómoda como sea posible. Por
lo tanto, TexStudio tiene muchas características
como sintaxis resaltada, visor integrado, gestor de
referencias y varios asistentes.
10 Trabajo Fin de Máster

3Estado del Arte
Al revisar el estado del arte de cualquier trabajo de investigación debemos ser cuidadosos a la hora de
elegir las fuentes que utilizamos, ya que son estas las que fijan los conceptos sobre los que basamos el
trabajo. Y es que bien sea porque el artículo de investigación se publicó fuera de fecha sin tener en cuenta
los últimos resultados publicados o porque la metodología aplicada no haya sido del todo exhaustiva, el
resultado puede ser que se genere literatura con conclusiones erróneas [13].
Por eso en este trabajo se ha hecho especial hincapié en explicar qué se ha hecho y por qué. Se espera
que este enfoque resulte útil tanto para el lector novel, desde un punto de vista didáctico, como para el
lector experto para ayudarle a detectar cualquier tipo de error en el que se hubiera podido incurrir en
este estudio.
3.1. Análisis de malware
El análisis de malware es el estudio o proceso para determinar la funcionalidad, el origen y el impacto
potencial de una muestra determinada de malware [19]. Esta información es importante para que el
defensor sea capaz de mitigar el posible ataque que pudiera estar recibiendo en su sistema.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
11

CAPÍTULO 3. ESTADO DEL ARTE
Los métodos de detección de malware se pueden clasificar según el tipo de reconocimiento utilizado en
análisis estático y dinámico.
3.1.1. Análisis estático
El análisis estático se basa en estudiar el fichero sospechoso sin ejecutarlo. Es el tipo de detección de
malware más utilizado por los programas antivirus.
La detección de malware basado en firmas tiene dos métodos fundamentales: basado en extracción de
características binarias y basado en características ensamblador.
En el primer caso existen múltiples herramientas, como por ejemplo Radare2, útiles para extraer esta
información. En el segundo caso existen herramientas como IDA o Ghidra, esta última publicada por la
NSA en el año 2019, la cual permite traducir el código máquina en código ensamblador y, en algunos
casos, en código de alto nivel, el cual puede ser leído y comprendido por los humanos, con el que el
analista de malware puede dar sentido a las instrucciones de ensamblado y hacerse una idea más exacta
de lo que está haciendo el malware analizado. A su vez, para evitar que su malware sea descubierto, los
desarrolladores aplican técnicas para evadir este tipo de análisis, como por ejemplo incrustando errores de
código sintáctico que confundirán a los desensambladores pero que seguirán permitiendo el funcionamiento
del malware durante una ejecución real.
Ventajas
No requiere de una laboratorio especializado.
Las herramientas necesarias son fácilmente accesibles.
El riesgo es mínimo porque el programa no se ejecuta.
Requiere poca potencia de cómputo.
Desventajas del análisis estático
Para el mismo tipo de malware los resultados pueden ser muy distintos según el fichero infectado.
En términos de coste computacional es más económico que el análisis dinámico.
Suele producir una alta tasa de fallo en la detección de malware polimórfico y metamórfico.
Desventajas de las soluciones basadas en firmas
Para el malware conocido, el comportamiento de las soluciones antivirus tradicionales es predecible.
12 Trabajo Fin de Máster

CAPÍTULO 3. ESTADO DEL ARTE
Es poco eficaz contra malware polimórfico y metamórfico.
Es totalmente ineficaz para malware de tipo 0-Day.
A pesar de que la cantidad de nuevos tipos de malware se ha estancado en los últimos años, el alto
grado de polimorfismo y metamorfismo del malware está produciendo un crecimiento exponencial
de las bases de datos de muestras de malware.
3.1.2. Análisis dinámico
El análisis dinámico consiste en ejecutar el fichero y observar cómo se comporta el sistema en el cual
se ha ejecutado.
El malware se ejecuta típicamente en entornos simulados con técnicas de virtualización o similares.
Estos sistemas se caracterízan por estar aislados, controlados y ser replicables.
Una técnica de evasión habitual de este tipo de análisis consiste en detectar el tipo de máquina sobre
la que se está ejecutando el malware. Si el malware detecta que el equipo sobre el que se está ejecutando
cumple con ciertas características, como por ejemplo que es un sistema virtualizado o que posee una baja
cantidad de memoria RAM, disco duro, etc, este puede elegir ocultar su comportamiento maligno, lo que
dará lugar a un falso negativo en el análisis. Este es uno de los motivos por el cual el coste computacional
de este tipo de análisis sea más elevado que el estático, porque que para ser exitoso exige virtualizar un
entorno con todas sus características reales.
Ventajas
Proporciona información detallada sobre el comportamiento del malware.
Es un buen método para detectar malware tipo 0-day y polimórfico.
Desventajas
Requiere un entorno de pruebas especializado y cuidadosamente configurado.
Computacionalmente más caro que el análisis estático.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
13

CAPÍTULO 3. ESTADO DEL ARTE
3.2. Malware en Linux
Figura 3.1: Productos con mayor número de vulnerabilidades en la historia del software en 2020 [20].
A pesar de no ser el sistema operativo con mayor cuota de mercado, hay motivos por los que clasificar
malware para sistemas Linux:
por el crecimiento aumento de cuota de mercado en los últimos años en sistemas de escritorio,
por la importancia que tienen los sistemas que gobierna siendo el líder en servidores en internet y
en supercomputadores,
por la reciente adopción de Microsoft, líder en sistemas de escritorio, del kernel de Linux como
núcleo de sus sistemas,
porque es el sistema más utilizado en sistemas IoT,
porque el kernel de Linux es el productos software con más vulnerabilidades publicadas en la historia
del software.
Como se puede ver en la figura 3.2, las plataformas con mayor número de vulnerabilidad en 2019 han
sido las plataformas Android y la distribución de Debian GNU/Linux [5].
Figura 3.2: Productos con mayor número de vulnerabilidades en 2019 [20].
14 Trabajo Fin de Máster

CAPÍTULO 3. ESTADO DEL ARTE
3.2.1. Motores antivirus
Existe una amplia gama de antivirus para los SO basados en Linux.
Figura 3.3: Tabla comparativa de Antivirus [21].
Uno de las primeros datos que saltan a la vista es que el hecho de utilizar un antivirus de una casa
conocida y con licencia de pago no implica una alta tasa de detección como sucede con F-Prot, Comodo y
McAfee. Por otro lado, el hecho de que la herramienta sea de fuentes abiertas tampoco garantiza excelentes
resultados, ya que ClamAV obtiene un resultado que lo sitúa en la mitad de la tabla comparativa con
un 66% de acierto en la detección. Finalmente encontramos 7 soluciones con maś de un 95% de virus
detectados, de los cuales solo uno, Kaspersky Endpoint Security 8.0 for Linux, consigue el 100% de
detección en malware de Linux.
En el caso de las soluciones comerciales que no son de fuentes abiertas, no sabemos qué estrategia
han seguido para implementar la detección de virus. En el caso de ClamAV, al ser de fuentes abiertas,
sabemos que utiliza un sistema de análisis estático con reconocimiento de malware basado en firmas.
3.3. Lenguajes de programación para aprendizaje automático
Hemos considerado 3 lenguajes que hemos considerado que cuentan con un buen soporte para
aprendizaje automático: R, Python y Scala.
R es un lenguaje específicamente diseñado para el desarrollo estadístico y suele ser el favorito de los
programadores que proceden de entornos matemáticos. Cuenta con un conjunto de herramientas para
investigación reproducible. Es tan específico que puede no ser la elección óptima en caso de ser necesario
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
15

CAPÍTULO 3. ESTADO DEL ARTE
Figura 3.4: Infografía de lenguajes y librerías de aprendizaje automático [22].
resolver un caso de propósito general. Python es un lenguaje de propósito general que suele ser el escogido
por aquellos desarrolladores que provienen de otros entornos de programación. Scala es un lenguaje con
grandes capacidades en entorno clusterizados pero carece de las herramientas de visualización de datos
con las que sí cuentan Python y R. Tanto para Python como para R existe una cantidad de librerías y
un soporte parecido.
Para nuestro caso se ha elegido Python por tres motivos fundamentales: por sus capacidades de
visualización de datos, por contar con una amplia comunidad de desarrolladores y por ser el que ofrece
una curva de aprendizaje más rápida.
3.4. Estudios previos
Etiquetar un ejecutable malicioso como la variante de una familia conocida es importante en
aplicaciones de seguridad como mecanismos de desinfección, identificación de nuevas amenazas mediante
el filtrado de las ya conocidas, la atribución de ataques y linaje del malware [23].
Este etiquetado puede ser realizado manualmente por analistas o automáticamente por aplicaciones
de clasificación de malware utilizando aprendizaje automático supervisado [24] [25] [26], o a través de
aplicaciones de agrupación automática de malware seguido de un etiquetado manual [27] [28] [29] [30].
16 Trabajo Fin de Máster

CAPÍTULO 3. ESTADO DEL ARTE
Una de las aplicaciones del etiquetado de ejecutables es construir conjuntos de datos de referencia
que después son utilizados por investigadores para entrenar y evaluar diferentes modelos supervisados
de clasificación de malware. Esta metodología supone un problema de base ya que los clasificadores de
malware basados en aprendizaje automático supervisado se alimentan del etiquetado de los antivirus. Este
problema se ha pretendido solucionar construyendo conjuntos de datos de referencia usando etiquetas AV
[24] [26] [27] [28] [29]. Pero se sabe que las etiquetas AV son inconsistentes [27] [31] [32] [33].
En particular, distintos motores AV suelen asignar distintas etiquetas a la misma muestra maliciosa,
incluso con distinto código del nombre de familia debido entre otros a los siguientes motivos:
la falta de adherencia por parte de los fabricantes de malware a convenios de nomenclatura estándar
como CARO [34] y CME [35], implica que diferentes motores AV terminen asignando diferentes
nombres a la misma familia de malware,
el objetivo principal de un AV es la detección de malware, mientras que generar una clasificación
precisa y consistente parece ser una prioridad secundaria para este tipo de productos [36] [37],
la utilización de detecciones heurísticas o de comportamiento no específicas de una familia,
Aún a pesar de su conocida inconsistencia, los motores AV siguen siendo la fuente más común para
extraer etiquetas de malware. Esto probablemente ocurre porque en muchas ocasiones no hay otra verdad
fundamental disponible y porque las etiquetas AV suelen contener el nombre de la familia del malware
que el analista está buscando.
Fiabilidad del etiquetado AV
Como acabamos de ver, en el contexto de entrenamiento de modelos supervisados para clasificación
de malware, nos encontramos con que el proceso de extraer información precisa de la familia a la cual
pertenece una muestra maliciosa a partir de las etiquetas AV constituye un problema importante [23].
En primer lugar, algunos enfoques usan las etiquetas AV completas, lo cual es inexacto porque el
nombre de la familia comprende solo una fracción de la etiqueta. Por ejemplo, un motor AV puede usar
diferentes etiquetas para muestras en la misma familia, pero todavía asigne el mismo apellido en esas
etiquetas, como por ejemplo cuando use dos reglas de detección diferentes para la misma familia. Además,
también se da el caso en el que otras obras extraen el apellido de las etiquetas a través de un proceso
manual que no es detallado, y no manejan alias entre los apellidos. Este etiquetado no escala para grandes
cantidades de muestras.
En segundo lugar, se ha demostrado que ningún motor AV detecta todas las muestras y que el número
de motores AV necesarios para lograr una alta corrección en el apellido es mayor que para la detección
[32]. Para abordar estos problemas, es común recurrir al método de voto por mayoría entre un conjunto
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
17

CAPÍTULO 3. ESTADO DEL ARTE
de AV seleccionados, pero esto requiere seleccionar algunos fabricantes AV considerados mejores en el
etiquetado, cuando trabajos previos muestran que algunos fabricantes de AV pueden ser buenos para
etiquetar una familia pero pobre con otras [32]. Además, una mayoría en el voto no se puede alcanzar
en muchos casos, lo que significa que no es posible elegir un apellido para esas muestras y no se pueden
agregar a los datos de evaluación o capacitación [38]. En tercer lugar, cabe notar que centrarse en las
muestras donde la mayoría está de acuerdo puede sesgar los resultados hacia los casos fáciles [39]. Y por
último un comentario crítico en cuanto a otros y también este trabajo, se suele suponer que los resultados
del etiquetado AV corresponden a la verdad fundamental, lo cual no es necesariamente cierto y sería
conveniente evaluar la calidad de dichos datos.
Herramientas existentes
En la actualidad existen en el mercado multitud de herramientas de clasificación de malware, algunas
de las cuales consiguen valoraciones superiores al 90% de precisión y recall entre las que destacaremos
Malheur con una valoración F1 de 95% .
Figura 3.5: Precisión reportada por trabajos previos de clusterización [40].
18 Trabajo Fin de Máster

4Marco teórico
Dado que este proyecto versa sobre clasificación de malware nos centraremos especialmente en modelos
de clasificación.
4.1. Aprendizaje automático
Aprendizaje automático es la rama de la inteligencia artificial que permite a los ordenadores
aprender a hacer una tarea sin haber sido explícitamente programados para realizarla. Esto se consigue
proporcionando datos en forma de muestras a los modelos [41].
4.1.1. Tipos de aprendizaje
Según la salida que proporcionan
El aprendizaje automático puede ser supervisado o no supervisado.
Supervisado: Se caracterizan porque se conocen los valores de la variable respuesta para los datos
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
19

CAPÍTULO 4. MARCO TEÓRICO
de entrenamiento. Este tipo de algoritmos producen una función que establece una correspondencia
entre entradas y salidas del sistema. Parten de una experiencia o conocimiento previo representado
en el conjunto de datos por las características y su resultado conocido, sobre los que nos apoyamos
para hacer predicciones que a su vez nos ayudarán a tomar decisiones.
Ejemplo de este tipo de sistemas es un sistema de control del correo electrónico no deseado en el
cual el usuario indica qué correos electrónicos son spam, gracias a lo cual el sistema puede aprender
de dichas indicaciones para ser capaz de identificar correos similares en un futuro.
En el proceso de aprendizaje automático supervisado se dispone de un dataset formado por registros
o instancias en forma de vectores que describen la información correspondiente a cada muestra. Estos
vectores se agrupan de manera que cada variable o característica se encuentra formando columnas
con la misma variable o característica de cada vector y de esta manera se construye una matriz
cuyo índice de filas estará compuesto por los nombres o identificadores únicos de cada muestra y
su índice de columnas formado por los nombres de las características que describen las muestras.
A continuación se distinguen las variables predictoras X de la variable objetivo Y , y se divide el
conjunto de muestras típicamente en dos subconjuntos: entrenamiento y prueba. El subconjunto de
muestras de entrenamiento se utiliza para entrenar el modelo y el subconjunto de test se utiliza en
la última fase para evaluar la capacidad de clasificación del modelo construido. Las métricas más
comunes para realizar esta evaluación son: Precisión, Exactitud, Exhaustividad y F1.
La selección de características utilizadas para el entrenamiento del algoritmo en un entorno de
aprendizaje automático supervisado es fundamental para el óptimo funcionamiento del modelo.
Una selección inadecuada de las características ralentizará el aprendizaje o incluso hará que no
llegue a producirse nunca.
No supervisado: Es un método de aprendizaje automático donde los resultados del modelo se ajustan
a las observaciones. A diferencia del aprendizaje supervisado, no se parte de un conocimiento a
priori. Se caracteriza porque el algoritmo descubre de manera autónoma las características en los
datos de entrada: regularidades, correlaciones y categorías. Así el aprendizaje no supervisado trata
los objetos de entrada como un conjunto de variables aleatorias, construyendo así un modelo de
densidad para el conjunto de datos.
Un ejemplo de una aplicación interesante de estos algoritmos es la segmentación de clientes, donde
podemos agrupar los clientes en grupos a priori desconocidos de manera automática en función de
ciertas características comunes.
Algunos de los algoritmos de aprendizaje no supervisado más representativos son:
• K-means: es un método de agrupamiento cuyo objetivo es la partición de un conjunto de n
observaciones en k grupos en los que cada observación pertenece al grupo cuyo valor medio es
el más cercano.
20 Trabajo Fin de Máster

CAPÍTULO 4. MARCO TEÓRICO
• Detección de anomalías: consiste en detectar casos que no cumplen una cierta condición
de normalidad. La dificultad que entraña definir esta condición de normalidad hace que
esta técnica tienda a generar falsos positivos fácilmente. Existen dos tipos de detección de
anomalías: estadística y no estadística.
Semisupervisado: combinación de los anteriores, se tiene en cuenta datos marcados y no marcados.
Por refuerzo: su información de entrada es el feedback que obtiene como respuesta a sus acciones.
Se basa en el método de ensayo y error.
Transducción: similar al aprendizaje supervisado pero no construye una función como tal. Trata de
predecir categorías de los futuros ejemplos a partir de ejemplos ya dados.
Multitarea: usan el conocimiento previamente aprendido por el sistema, basándose en enfrentarse
a lo que ya ha visto previamente.
Según el tipo de tarea
Según el tipo de tarea, los tipos de aprendizaje automático se pueden agrupar en: tipo productivo
(clasificación y regresión) o tipo descriptivo (clustering y asociación).
Productivo:
• Clasificación: El objetivo es asignar los valores de clase a registros no clasificados a partir
de ejemplos de entrenamiento. La variable respuesta es de tipo categórica, es decir, toma un
conjunto finito de valores.
• Regresión: El objetivo es asignar un valor real al atributo de un registro a partir de los valores
del resto de los atributos del registro. La variable respuesta es cuantitativa y puede tomar
infinitos valores.
Descriptivo:
• Clustering: consiste en dividir el conjunto de registros en clusters, de manera que los registros
incluidos en cada cluster se caracterizan por su gran similitud o cercanía, mientras que entre
grupos hay una mayor distancia.
• Asociación: consiste en identificar relaciones no explícitas entre atributos categóricos de
registros no clasificados. Se pretende identificar aquellas relaciones que se establecen en función
de la ocurrencia conjunta de varios atributos.
Tipos de modelos
Los modelos creados se pueden clasificar como [42]:
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
21

CAPÍTULO 4. MARCO TEÓRICO
Geométricos: se construyen en el espacio de las instancias y pueden tener múltiples dimensiones.
Pueden tener un borde de decisión lineal entre varias clases.
Probabilísticos: intentan determinar la distribución de probabilidades descriptivas de la función que
relaciona los valores de los nuevos registros con unos valores determinados. Se aplica a aquellos casos
en los que la relación entre el conjunto de atributos y la categoría de la clase no es determinista.
Suele deberse al ruido o a la propia naturaleza de los valores. El más conocido es naïve Bayes,
que almacena como descripción conceptual la previa probabilidad de cada clase y la probabilidad
condicional de cada atributo dado por la clase.
Lógicos: expresan las probabilidades en reglas organizadas en formas de árboles de decisión.
Según su linealidad
Entre los modelos productivos, de clasificación y regresión, se distinguen por su linealidad dos subtipos:
Lineales: La función utilizada para predecir la variable respuesta a partir de las variables predictoras
es una aplicación lineal y las muestras son típicamente descritas por un vector de características.
Destacan por su velocidad de cómputo, especialmente cuando el vector x es disperso, aunque
los árboles de decisión pueden ser más rápidos. Además, los clasificadores lineales con frecuencia
funcionan muy bien cuando el número de dimensiones del vector x es grande, como en clasificación
de documentos, donde típicamente cada elemento en el vector x es el número de apariciones de una
palabra en un documento. En tales casos, el clasificador debe estar bien regularizado.
No lineales: Construyen superficies arbitrarias que permiten separar clusters muy cercanos o que
incluso se solapan.
4.2. Manejo de datos
Una vez tenemos la matriz de características que define las muestras que forman el dataset a analizar,
la manera correcta de manejar los datos es la siguiente:
1. Dividir las características que forman el conjunto de datos en subconjunto de características
predictoras X y características a predecir y.
2. Dividir las muestras que forman el conjunto de datos en subconjunto de muestras de entrenamiento
(Xtrain e ytrain) y subconjunto de muestras de test (Xtest e ytest),
3. El filtro de características se entrena utilizando únicamente las características predictoras del
subconjunto de entrenamiento Xtrain.
22 Trabajo Fin de Máster

CAPÍTULO 4. MARCO TEÓRICO
4. Una vez se ha entrenado el filtro, se aplica la transformación que produce a las características
predictoras de los subconjuntos de entrenamiento y test.
5. Entrenamiento del modelo elegido,
6. Prueba y evaluación del modelo elegido.
4.2.1. Fugas de datos
La fuga de datos, o data leakage, es la creación de información adicional e inesperable en un escenario
real en los datos de entrenamiento, permitiendo así parecer que un modelo de aprendizaje automático
es muy preciso sobre el subconjunto de pruebas, hasta que llega el momento de probarlo en la realidad,
momento en el cual se comprueba que es altamente impreciso. Estas fugas pueden ser producidos tanto
por fallos humanos como mecánicos.
Tipos de fugas de datos
Las fugas de datos suelen producirse tanto por una mala selección de las características predictoras
como por un manejo incorrecto de datos.
Debidas a una incorrecta selección de características predictoras:
Suceden cuando las características utilizadas para predecir los resultados contienen datos con los
que es imposible contar en el momento de hacer la predicción en un escenario real.
Por ejemplo, querer predecir el precio que va a tener un producto con un mes de antelación utilizando
una variable que indica qué precio tendrá ese mismo producto dos semanas antes del momento que
queremos predecir.
Debidas a un incorrecto manejo de datos:
Este tipo de fuga de datos se produce cuando tomamos decisiones en función de los datos de test o
de las predicciones.
Un ejemplo de un manejo incorrecto de datos es entrenar los filtros utilizando el conjunto completo
de datos, es decir, incluyendo el subconjunto de test.
4.3. Selección de características
Una vez hemos dividido el dataset en conjunto de muestras de entrenamiento y conjunto de test,
aplicamos una serie de filtros sobre sobre el conjunto de entrenamiento para seleccionar las características.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
23

CAPÍTULO 4. MARCO TEÓRICO
La estrategia de selección de características consiste en seleccionar aquellas características que sean
relevantes y nos permitan identificar una clase solo por estar ahí. Por lo que procuraremos descartar
tanto aquellas que características demasiado específicas e identificativas de una única muestra, como por
ejemplo el propio nombre de la muestra, como aquellas que sean demasiado comunes, como pudiera ser
en un texto los artículos determinados, conjunciones, etc.
4.3.1. Filtro de características excesivamente específicas
Por este motivo y debido al tamaño del conjunto de palabras que manejamos, empezamos por descartar
las palabras que claramente son demasiado específicas, como son aquellas que aparecen una única vez en
el dataset. Concretamente en este proyecto se eliminan aquellas características que aparecen tantas veces
o menos como muestras tiene la clase más pequeña. Esta manera de proceder puede estar penalizando
la detección de las clases con menos muestras y se debe considerar afinar este filtro en futuros proyectos.
Aún así lo, consideramos este criterio suficientemente bueno como para aplicarlo de esta manera.
4.3.2. Filtro de características duplicadas
Este filtro consiste en eliminar las columnas duplicadas, entendiendo por columnas duplicadas aquellas
que aún pudiéndose tratar de palabras diferentes procedentes de contextos diferentes, se muestren en la
misma cantidad y en las mismas muestras a lo largo del conjunto de entrenamiento. Esta eliminación de
características duplicadas supone una simplificación que pudiera estar haciéndonos perder características
importantes ya que el comportamiento de dichas características podría ser diferente en el conjunto de
entrenamiento que en el conjunto de test. Sin embargo, en este trabajo se ha considerado que la cantidad
de información superflua eliminada con este procedimiento, y por ende la cantidad de ruido eliminado,
supera con creces lo que se pudiera ganar manteniéndolas. Además, esta manera de proceder es lo más
parecido a un escenario real, por lo que finalmente se decide aplicarlo.
4.3.3. Filtro TF-IDF
TF-IDF es un acrónimo del inglés Term Frequency - Inverse Document Frequency, o en castellano
Frecuencia de ocurrencia del término en la frecuencia inversa de un documento. Este término es una
medida numérica que nos permite cuantificar cuán relevante es una palabra para permitir clasificar un
documento dentro de una colección concreta de documentos. Por lo tanto, su valor se calcula para cada
palabra dentro de la colección de documentos teniendo en cuenta todos los documentos de la colección.
Esta medida es normalmente utilizada como factor de ponderación de palabras en minería de texto ya que
aumenta progresivamente cuanto mayor es la frecuencia de aparición de una palabra en un documento y,
al mismo tiempo, es compensada por la frecuencia de dicha palabra dentro de la colección de documentos.
24 Trabajo Fin de Máster

CAPÍTULO 4. MARCO TEÓRICO
El valor TFIDF es el resultado del producto de dos valores: TF e IDF.
TFIDF (t, d) = TF (t, d) ∗ IDF (t,D)
TF: Frecuencia de término
TF representa la frecuencia de un término dentro de un documento. Existen una amplia variedad de
aproximaciones al cálculo de TF. En nuestro caso tomamos la que se ha considerado como la más sencilla.
De este modo tomamos:
t: el término que queremos evaluar,
d: el documento al que pertenece el término t,
D: la colección de documentos,
N: el número total de palabras en el documento d.
Su fórmula matemática es la siguiente:
TF (t) = número apariciones del término t en el documento dnúmero total de palabras en el documento d
IDF: Inversa de la Frecuencia de Documentos
IDF es la inversa de DF, siendo DF la frecuencia de los documentos en los que aparece un término,
siempre dentro de una colección de documentos. La fórmula de DF es la siguiente:
DF (t) = número de documentos en los que aparece el término t
En su versión relativa al número total de documentos en la colección:
DF (t) =número de documentos en los que aparece el término t
número total de documentos en la colección
Quedando su inversa representada de la siguiente manera:
IDF (t,D) =número total de documentos en la colección de documentos D
número de documentos en los que aparece el término t
Existe una gran cantidad de maneras de escalar el valor de IDF. Se ha elegido su escalado logarítmico
para obtener mayor detalle en la cola de distribución. Quedando su fórmula expresada como sigue:
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
25

CAPÍTULO 4. MARCO TEÓRICO
IDF (t,D) = log(número total de documentos en la colección de documentos D
número de documentos en los que aparece el término t)
Para evitar problemas de división por 0 si se diera el caso de que DF fuera nula se da por buena la
siguiente aproximación:
IDF (t,D) = log(número total de documentos en la colección de documentos D(número de documentos en los que aparece el término t)+1 )
4.4. Técnicas de muestreo
La técnicas de muestreo se suelen utilizar cuando el conjunto de datos sobre el que se está trabajando
está desequilibrado, como es nuestro caso. Su objetivo es hacer que el dataset se acerque más a una
situación de equilibrio respecto a la cantidad de muestras de cada clase. Hay dos tipos de técnicas de
muestreo: sobremuestreo y submuestreo.
4.4.1. Sobremuestreo - Oversampling
Las técnicas de sobremuestreo buscan equilibrar el número de muestras de cada clase en el conjunto
de datos de entrenamiento a través de aumentar el número de muestras de las clases menos numerosas.
Random OverSampler: El sobremuestreo aleatorio es uno de los primeros métodos propuestos que
además ha demostrado ser robusto [43]. Consiste en complementar los datos de entrenamiento con
múltiples copias de algunas de las clases minoritarias. Este sobremuestreo se puede hacer más de
una vez sobre los mismos datos. En lugar de duplicar cada muestra en la clase minoritaria, algunas
de ellas pueden elegirse al azar con reemplazo.
ADASYN (Adaptive Synthetic): Utiliza una distribución ponderada para diferentes muestras de
clases minoritarias de acuerdo con su nivel de dificultad en el aprendizaje, donde más datos sintéticos
son generados para muestras de clases minoritarias, las cuales son más difíciles de aprender en
comparación con aquellas muestras minoritarias que son más fáciles de aprender [44]. ADASYN
mejora el aprendizaje con respecto a las distribuciones de datos de dos maneras:
1. reduciendo el sesgo introducido por el desequilibrio de clase, y
2. cambiando adaptativamente el límite de decisión de clasificación hacia los ejemplos difíciles.
Los análisis de simulación en varios conjuntos de datos de aprendizaje automático muestran
la efectividad de este método en cinco métricas de evaluación.
SMOTE (Synthetic Minority Over-sampling Technique) [45]: Para ilustrar cómo funciona esta
técnica consideremos un conjunto de datos de entrenamiento con una cantidad de muestras S y
26 Trabajo Fin de Máster

CAPÍTULO 4. MARCO TEÓRICO
una cantidad de características F en el espacio de características de los datos. Para simplificar
consideraremos estas características continuas. Ahora, como ejemplo, considere un conjunto de
datos de aves para su clasificación. El espacio de características para la clase minoritaria para
la que queremos sobremuestrear podría ser la longitud del pico, la envergadura y el peso (todas
ellas continuas). Para realizar el sobremuestreo tomamos una muestra del conjunto de datos y
consideramos sus k vecinos más cercanos en el espacio de características. Ahora, para crear un
punto de datos sintético tomaremos el vector entre uno de esos k vecinos y el punto de datos actual.
Multiplicaremos este vector por un número aleatorio x entre 0 y 1 y, finalmente, agregamos esto al
punto de datos actual para crear el nuevo punto de datos sintético.
Borderline SMOTE: Es una variante del SMOTE original. Se localizan las muestras límite del
conjunto de datos de entrenamiento para,a partir de ellas, generar nuevas muestras sintéticas.
KMeans-SMOTE: Se realizan agrupaciones por KMeans y se aplica sobremuestreo SMOTE.
SMOTE-NC (SMOTE for Nominal and Continuous): se puede utilizar sobre datasets que contengan
características continuas y categóricas.
SVM-SMOTE: Utiliza el algoritmo SVM para detectar las muestras que se utilizarán para generar
nuevas muestras sintéticas con SMOTE.
4.4.2. Submuestreo - Undersampling
Las técnicas de submuestreo buscan equilibrar el número de muestras de cada clase del conjunto de
datos de entrenamiento reduciendo el número de muestras de las clases más numerosas. En este proyecto
utilizaremos la técnica de condensación de los vecinos más cercanos o Condensed Nearest Neighbour.
4.4.3. Combinaciones de sobremuestreo y submuestreo
SMOTEENN: Sobremuestreo usando SMOTE y limpieza usando ENN.
SMOTE Tomek: Sobremuestreo usando SMOTE y limpieza usando enlaces Tomek.
4.5. Modelos algorítmicos
Un conjunto de datos de entrenamiento con suficiente cantidad y calidad redundarán en un mayor
porcentaje de acierto de los modelos.
Dado que este proyecto consiste en clasificación de malware nos centraremos en modelos de clasificación.
Denotamos:
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
27

CAPÍTULO 4. MARCO TEÓRICO
X a la matriz compuesta por los vectores de variables o características predictoras a cada muestra,
Y al vector predicción o respuesta del modelo, y
Cj a los posibles valores de la variable respuesta.
4.5.1. Naïve Bayes
Naïve Bayes es uno de los clasificadores más utilizados por su simplicidad y rapidez.
Está basada en el Teorema de Bayes, también conocido como teorema de la probabilidad condicionada,
el cual responde a la pregunta de qué probabilidad hay de que suceda un hecho asociado a una probabilidad
que depende de que suceda otro hecho asociado a otra probabilidad.
Presupone que la aparición o no de un atributo en un caso no influye en la aparición del resto de
atributos [46]. Sólo admite variables categóricas, por lo que las variables continuas deben ser categorizadas
previamente a la construcción del modelo. La salida para la etiqueta de cada clase se asigna en función
de una puntuación de probabilidad, normalmente un logaritmo, proporcional a la auténtica probabilidad
estimada.
Algunas aplicaciones habituales de este modelo son la detección de spam, clasificación de textos o la
detección de fraudes en seguros.
4.5.2. KNN - K Nearest Neighbors
Es un método de aprendizaje automático supervisado de clasificación no paramétrica. Sirve para estimar
la función de densidad F (x/Cj) de las características predictoras X por cada clase Cj o directamente
la probabilidad a posteriori de que un elemento x pertenezca a la clase Cj a partir de la información
proporcionada por el conjunto de muestras. En el proceso de aprendizaje no se hace ninguna suposición
acerca de la distribución de las variables predictoras.
Se utiliza en el reconocimiento de patrones como método de clasificación basado en un entrenamiento
mediante ejemplos cercanos en dicho espacio de elementos. KNN es un tipo de aprendizaje conocido como
perezoso (lazy learning), donde la función se aproxima solo localmente y todo el cómputo es referido a
la clasificación. Se establece una distancia en el espacio vectorial de las variables predictoras como por
ejemplo la distancia euclídea. Para clasificar un elemento se buscan los k registros más cercanos y se
clasifica de acuerdo con la clase mayoritaria entre estos k datos.
28 Trabajo Fin de Máster

CAPÍTULO 4. MARCO TEÓRICO
4.5.3. AdaBoost
Boosting es un meta-algoritmo de aprendizaje automático que reduce el sesgo y la varianza en un
contexto de aprendizaje supervisado. Consiste en construir un clasificador robusto a partir de conjunto de
clasificadores débiles. Un clasificador débil es un clasificador débilmente correlacionado con la clasificación
correcta, es decir, que clasifica ligeramente mejor que un clasificador aleatorio. Mientras que un clasificador
robusto es un clasificador con un desempeño cuyas clasificaciones se aproximan más a la realidad [47].
AdaBoost es el algoritmo de boosting más popular, quizá debido a que fue la primera formulación de
un algoritmo que pudo aprender a partir de clasificadores débiles.
AdaBoost para categorización funciona en general de la siguiente manera:
1. Forma un conjunto grande de características sencillas
2. Inicializa pesos para entrenar imágenes
3. Para T iteraciones:
a) Normalización de pesos,
b) Para las características disponibles del conjunto, entrenamiento de un clasificador utilizando
solo una característica y evaluación del error de formación
c) Selección del clasificador con el error más bajo,
d) Actualización los pesos de las imágenes de formación: aumenta el peso si el clasificador clasifica
de forma errónea el objeto, disminuye si lo hace correctamente
4. Formación de un clasificador final robusto como la combinación lineal de los T clasificadores.
4.5.4. Árbol de Decisión
Utiliza un árbol de decisión como un modelo predictivo que mapea observaciones sobre un artículo a
conclusiones sobre el valor objetivo del artículo.
Los modelos de árbol, donde la variable de destino puede tomar un conjunto finito de valores, se
denominan árboles de clasificación. En estas estructuras las hojas representan etiquetas de clase y las
ramas las conjunciones de características que conducen a esas etiquetas de clase. Los árboles de decisión
cuya variable destino puede tomar valores continuos se llaman árboles de regresión.
En análisis de decisión un árbol de decisión se puede utilizar para representar de manera visual y
explícita la toma de decisiones. En minería de datos un árbol de decisión describe datos pero no las
decisiones, más bien el árbol de clasificación resultante se puede usar como entrada para la toma de
decisiones.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
29

CAPÍTULO 4. MARCO TEÓRICO
4.5.5. Bosque Aleatorio
El Bosque Aleatorio, o en inglés Random forest, es una combinación de árboles predictores tal que
cada árbol depende de los valores de un vector aleatorio probado independientemente y con la misma
distribución para cada uno de estos. Es una modificación sustancial del bagging de Breiman que construye
una selección aleatoria de árboles de decisión con una variación controlada y luego los promedia.
En muchos problemas el rendimiento del algoritmo de bosque aleatorio es muy similar a la del boosting,
y es más simple de entrenar y ajustar. Por estos motivos es un algoritmo popular y ampliamente utilizado.
4.5.6. Red Neuronal
Basado en un gran conjunto de unidades neuronales simples (neuronas artificiales), de forma
aproximadamente análoga al comportamiento observado en los axones de las neuronas en los cerebros
biológicos. Cada unidad neuronal está conectada con muchas otras y los enlaces entre ellas pueden
incrementar o inhibir el estado de activación de las neuronas adyacentes empleando funciones de suma.
Cada neurona se comporta como una función cuyo resultado se propaga a las demás neuronas.
4.6. Matriz de Confusión
Los resultados de un modelo de aprendizaje automático se pueden visualizar por medio de lo que se
conoce como matriz de confusión.
Figura 4.1: Forma de una matriz de confusión binaria[48]
En la matriz de confusión binaria de un modelo podemos ver:
Verdaderos positivos: resultados positivos que el modelo ha detectado como positivos.
Verdaderos negativos: resultados negativos que el modelo ha detectado como negativos.
Falsos positivos: resultados negativos que el modelo ha detectado como positivos.
Falsos negativos: resultados positivos que el modelo ha detectado como negativos.
30 Trabajo Fin de Máster

CAPÍTULO 4. MARCO TEÓRICO
En nuestras evaluaciones consideramos el hecho de que se acierte la predicción de la etiqueta del
malware como un resultado positivo, y el fallo en la predicción como un resultado negativo. De ahí que
en las matrices de confusión multietiqueta como las adjuntas en el anexo A.3.7, lo habitual sea encontrar
los verdaderos positivos en la diagonal principal, es decir, en aquella que empieza en la parte superior
izquierda de la matriz y termina en la parte inferior derecha de la misma.
4.7. Métricas
Una vez se ha entrenado un modelo y hecho una clasificación sobre el conjunto de test, nos interesa
medir cómo de buena ha sido esa respuesta. Para ello hay 4 métricas fundamentales [49]: precisión,
exactitud, exhaustividad y F1:
Precisión: representa el porcentaje de instancias evaluadas como verdaderos positivos entre el total
de positivos.
Precision =V erdaderos positivos
V erdaderos positivos+ Falsos positivos
Accuracy (exactitud): representa la fracción de predicciones que el modelo realizó correctamente.
Exactitud =N de predicciones correctas
N total de predicciones
O lo mismo escrito de otra manera:
Exactitud =V P + V N
V P + V N + FP + FN
Exhaustividad, sensibilidad o recall: Representa el porcentaje de instancias de verdaderos positivos
entre el total real de positivos, es decir, verdaderos positivos y falsos negativos.
Recall =V erdaderos Positivos
V erdaderos Positivos+ Falsos Negativos
F1: Es la media armónica de la precisión y la exhaustividad (recall).
F1 = 2 ∗ Precision ∗ Exhausitividad
Precision + Exhausitividad
4.7.1. La métrica más adecuada
Decidir cual es la manera de medir la efectividad de una modelo depende de varios factores.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
31

CAPÍTULO 4. MARCO TEÓRICO
En primer lugar, el contexto del problema. Si hay factores que hacen que un falso positivo nos penalice
más que un falso negativo, entonces querremos una precisión alta. Si lo que penaliza la eficacia del modelo,
y por lo tanto lo que queremos evitar, son los falsos negativos, entonces querremos una exhaustividad
o recall alta. En el caso de que tanto falsos positivos como falsos negativos penalicen igual, entonces la
métrica que más nos podría interesar sería la exactitud o accuracy.
El segundo factor a considerar es el equilibrio del dataset. Y es que si las diferentes clases que lo
componen tienen tamaños muy distintos, la exactitud puede ser una medida engañosa. Para comparar
diferentes clasificadores, uno con exhaustividad alta y otro con precisión alta, si no tenemos más
información sobre el contexto es cuando el f1-score resulta útil porque nos permite valorar ambas métricas.
Además, al afinar un modelo suele suceder que si se hace algo para mejorar la precisión entonces
empeora el recall y viceversa. Por eso lo más conveniente es decidir con argumentos qué valor se va a
utilizar entre estos dos. Sin embargo, en el contexto de la clasificación de malware no encontramos una
clara diferencia que haga decantarnos entre precisión y exhaustividad, por eso tomaremos la métrica F1
que nos ofrece la manera de tener en cuenta al mismo nivel ambas métricas.
4.7.2. Medias para clasificación multiclase
Para problemas de clasificación, la eficacia de un modelo está definido por la matriz de confusión
asociada al modelo. Basándose en las entradas de dicha matriz, es posible calcular las métricas estudiadas
en 4.7. Para evaluar modelos de clasificación binarios es suficiente con evaluar dichas métricas y escoger la
que más convenga para el problema en cuestión. Sin embargo, para los modelos de clasificación multiclase,
dado que puede darse importantes diferencias al predecir cada clase, suele ser conveniente aplicar algún
tipo de media que nos permita ver con más claridad en un único valor cómo está prediciendo el modelo.
Las medias más habituales en clasificación multiclase son micro, macro y ponderada:
micro: le da a cada par muestra-clase una contribución igual a la métrica general (excepto como
resultado del peso de la muestra). En lugar de sumar la métrica por clase, esto suma los dividendos
y divisores que componen las métricas por clase para calcular un cociente global. Se puede preferir
el micro-promedio en entornos de múltiples etiquetas donde se debe ignorar una clase mayoritaria.
macro: simplemente calcula la media de las métricas binarias, dando el mismo peso a cada clase.
En problemas donde las clases poco frecuentes son importantes, la media macro puede ser un
medio para resaltar su desempeño. Por otro lado, la suposición de que todas las clases son
igualmente importantes a menudo es falsa, de modo que el promedio de macro enfatizará en exceso
el rendimiento típicamente bajo en una clase poco frecuente.
ponderada: tiene en cuenta el desequilibrio de clases al calcular el promedio de las métricas binarias
en las que la puntuación de cada clase se pondera por su presencia en la muestra de datos verdaderos.
32 Trabajo Fin de Máster

5Metodología y diseño
Para llevar a cabo el estudio objeto de este proyecto se definen dos tareas a realizar que habrán de
llevarse a cabo de través de dos herramientas: una para manejar los ficheros de malware interactuando
con el API de LiSa y VirusTotal para obtener los informes, y otra para, a partir de dichos informes,
entrenar y evaluar el modelo de clasificación de malware.
5.1. Requisitos software.
La funcionalidad descrita en los requisitos funcionales se consigue con un software que cumple las
siguientes especificaciones:
Lenguaje de programación: Python 3.7,
Podrá hacer uso de las herramientas del sistema que se consideren convenientes.
Ejecución probada en un sistema Debian GNU/Linux 10 Buster.
Contar con documentación para su ejecución.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
33

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Comportamiento configurable por medio de un fichero central de configuración con las siguientes
secciones:
• sección de valores por defecto. Esta sección contiene valores de constantes que normalmente no
requieren modificación por parte del usuario ya que forman parte del funcionamiento interno
del programa.
• sección de configuraciones especificas que el usuario podrá elegir en el momento de ejecutar el
programa a través de un argumento de entrada.
Se evitará el uso de valores mágicos dentro del código.
5.2. Requisitos funcionales
5.2.1. Obtención de reportes
Para la tarea de generación de informes se han utilizado la herramienta de análisis dinámico y estático
LiSa y para su etiquetado se ha utilizado la herramienta AVClass la cual utiliza la información obtenida
de VirusTotal.
Informes LiSa
LiSa proporciona dos interfaces: un frontend web y un API REST. Dado que la interfaz web en la versión
actual solo permite el envío de ficheros de manera individual y dado que en nuestro caso necesitamos un
procesamiento masivo de muestras, necesitaremos interactuar con su interfaz REST, para lo cual vamos
a requerir implementar un cliente que interactue con dicha interfaz.
Informes VirusTotal
Para obtener los informes de VirusTotal nos encontramos con el mismo caso: al tratarse de una interfaz
API necesitamos un cliente para interactuar con él. En este caso existen muchas librerías y clientes que
proporcionan esta funcionalidad.
5.2.2. Cliente de LiSa y VirusTotal
El programa cliente para las API de LiSa y VirusTotal debe ser capaz de:
enviar los ficheros a la interfaz API REST de LiSa,
enviar los ficheros a la interfaz API REST de VirusTotal,
34 Trabajo Fin de Máster

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
recibir los informes de la interfaz API REST De LiSa,
recibir los informes de la interfaz API REST De VirusTotal,
almacenar en disco los informes recibidos del API REST de LiSa,
almacenar en disco los informes recibidos del API REST de VirusTotal,
El programa cumple la anterior funcionalidad siguiendo los siquientes requisitos:
Tener probada su ejecución en un sistema Debian GNU/Linux 10 Buster.
Contar con documentación para su instalación y ejecución.
Comportamiento configurable por medio de un fichero de configuración.
Permitir configurar el comportamiento del programa en función de una etiqueta introducible por
argumento que coincide con una etiqueta del fichero de configuración,
No existen valores mágicos dentro del código, a lo sumo en constantes definidas al principio del
código.
5.2.3. Herramienta de entrenamiento y evaluación de modelos
El programa debe ser capaz de:
Leer los informes almacenados por el cliente API REST De LiSa,
Leer los informes almacenados por el cliente API REST De VirusTotal,
Traducir los informes de análisis LiSa de cada fichero muestra de malware a vectores numéricos,
Aplicar diferentes técnicas de muestreo para balancear el dataset,
Entrenar diferentes modelos de aprendizaje automático supervisado diferentes,
Obtener la predicción de cada modelo,
Medir para cada modelo: precisión, exhaustividad, f1 y recall.
5.3. Proceso
El flujo de un proyecto de aprendizaje automático parte del dato en bruto y termina en el modelo
entrenado y validado tal como se describe en 5.1.
Las fases de este proceso son las siguientes:
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
35

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Figura 5.1: Flujo de trabajo de aprendizaje automático supervisado [50]
1. Elección del dataset.
2. Elección de las herramientas a utilizar.
3. Generación de informes,
4. Preprocesado, particionado de dataset y generación de matriz de características.
5. Filtros de características, (K mejores características para clasificación, TFI-IDF, etc).
6. Entrenamiento de los modelos elegidos, predicción y validación de resultados.
7. Análisis critico sobre los resultados obtenidos.
5.3.1. Fase 1: Elección del dataset
Se ha utilizado un dataset formado por dos conjuntos de muestras de malware procedentes de
VirusShare con ficheros ejecutables de Linux tipo ELF compilados para arquitectura ARM [51] [52].
Contenido del dataset
El dataset utilizado se ha construido a partir de dos datasets procedentes de VirusShare [51] y [52].
Este conjunto consta de 2597 muestras en total, de las cuales se utilizan aquellas que son analizadas con
éxito por LiSa, VirusTotal y AVClass. Esto reduce el conjunto a 2113 muestras.
En el primer filtro que se aplica al dataset eliminamos aquellas muestras que aparecen menos de un
número arbitrario de veces, en este caso hemos fijado este número en 33, lo que nos deja un total de 1974
muestras distribuidas como muestras la tabla 5.3.1.
36 Trabajo Fin de Máster

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Clase Muestras ProporciónMirai 1206 61,09%Gafgyt 535 27,1%Tsunami 87 4,41%Dofloo 52 2,63%Pnscan 33 1,67%Jiagu 7 0,35%
Tabla 5.1: Cantidad y proporción de muestras en dataset
Contamos en este momento con un universo formado por 1974 muestras definidas por 8.062.570 de
características.
Si tenemos en cuenta que el tamaño por defecto del dato del dataframe de Pandas es Float64, si
multiplicamos la cantidad de muestras por la cantidad de características y el tamaño del dato obtenemos
el siguiente tamaño del dataset: 1974 * 8062570 * 64 = 1,01859284352e+12 Bits = 127324105440 Bytes
= 124339946,719 KBytes = 121425,729218 MBytes = 118,579813689 GBytes de RAM.
Como acabamos de ver, a pesar de tratarse de una pequeña cantidad de muestras, la cantidad de
características hace que sea computacionalmente inmanejable por la capacidad computacional de que
disponemos para este proyecto fijado en 24 GB de RAM. Por este motivo procedemos a aplicar un filtro
que va a aplicar una proporción definida por nosotros arbitrariamente que marcará el límite a partir del
cual consideramos que una características no estaría definiendo una clase. Este límite lo definimos de
manera que se eliminarán aquellas características que no aparezcan en al menos un 25% de las muestras
de la clase con menos representantes en el conjunto. Esto implica que se eliminen aquellas características
que aparecen en menos de 6,6 muestras (33*1/4=6.6). Esto reduce en un total de 7.850.091 la cantidad de
características, lo que supone una reducción de un 97,36% de características. Como se ve este filtro aligera
de manera importante el peso computacional del dataset, aunque la manera en la que está planteado es
muy probable que estemos penalizando la detección de las clases menos representadas. Puede que fuera
interesante mejorar este filtro en una próxima iteración de este proyecto para eliminar esta penalización.
Clases de malware
A continuación una breve descripción de cada una de las 7 clases de malware [53] que se han considerado
en este proyecto:
Mirai: es una Botnet. Esta botnet utiliza una amplia variedad de mecanismos para extenderse donde
las más comunes son: infección de ficheros, troyano, adware y riskware.
Gagfyt: Gagfyt es el nombre de la botnet que disemina este malware. Para la expansión de esta
botnet se ha utilizado una diversa variedad de malware. La función principal de este malware es
que da al atacante acceso remoto al equipo infectado.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
37

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Dofloo: está clasificado como un troyano de puerta trasera.
Un troyano de puerta trasera es un tipo de malware que permite a un usuario remoto tener acceso
no autorizado a la computadora infectada. Las capacidades comunes de una puerta trasera incluyen
capturar la entrada del teclado, recopilar información del sistema, descargar o cargar archivos,
realizar ataques de denegación de servicio (DoS) y ejecutar o finalizar procesos.
Lotoor: este tipo de malware utiliza un exploit. Los exploits utilizan vulnerabilidades conocidas del
sistema para obtener acceso al mismo.
Pnscan: Se presenta como malware de tipo troyano y riskware.
Tsunami: Está clasificado como troyano.
Jiagu: Cuando Jiagu se ha presentado en forma de fichero tipo ELF lo ha hecho con funcionalidad de
troyano. Si bien en otras plataformas como Android se ha mostrado con características de Riskware
y Adware. Riskware es cualquier aplicación potencialmente no deseada que no está clasificada
como malware, pero que puede utilizar recursos del sistema de manera no deseable o molesta que
puede desencadenar un riesgo de seguridad. Adware es cualquier paquete de software que muestra
automáticamente anuncios mientras se ejecuta el programa. El adware normalmente no es malicioso,
pero tampoco deseado, y el usuario suele desconocer que está instalado en su equipo.
5.3.2. Fase 2: Herramientas a utilizar
Se ha utilizado la herramienta del sistema file para detectar si el fichero es un fichero binario ejecutable
tipo ELF de arquitectura ARM.
Se ha elegido la herramienta de análisis estático y dinámico LiSa por ser una herramienta de sencilla
configuración, que proporciona un API REST que permite el análisis masivo de ficheros y que incluye
imágenes preconfiguradas para diferentes arquitecturas, entre ellas la arquitectura utilizada en este
proyecto: ARM.
Se ha elegido la herramienta AVClass [40] por ser la única herramienta conocida que en la actualidad
intenta dar una solución al problema de las dificultades de realizar un etiquetado unificado de malware
y por nutrirse de una fuente de información tan potente como es VirusTotal, cuyos informes a día de
hoy incluyen los resultados de 63 antivirus, siendo la información obtenida por esta herramienta la que
utilizaremos como verdad fundamental en relación a las etiquetas de malware, sobre la cual se va a apoyar
nuestro modelo de clasificación.
El lenguaje elegido para la implementación de las herramientas ha sido Python3. Los motivos para
elegir este lenguaje son la agilidad que permite en el desarrollo, su versatilidad y el soporte con que
cuenta para aprendizaje automático.
38 Trabajo Fin de Máster

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Scikit-learn es la librería principal de aprendizaje automático utilizada en este proyecto, la cual utiliza
a su vez librerías bien conocidas para el manejo de datos como son Numpy y Pandas. Esta librería además
cuenta con una muy buena documentación además de soporte para datasets no balanceados que, como
veremos más adelante, es el caso de nuestro conjunto de datos.
5.3.3. Fase 3: Análisis estático y dinámico
Fase 3.1: Filtrado de muestras
Se ha considerado centrar nuestro modelo de detección sobre ficheros binarios ejecutables ARM, por
lo que se hace necesario filtrar las muestras de malware de Linux.
Para seleccionar los ficheros ejecutables Linux ARM se ha ejecutado la herramienta file sobre cada fichero
y a continuación se ha filtrado la salida con grep de manera que se seleccionan solo los ficheros que en su
salida contengan las cadenas ”ARM”, ”ELF”, y no contengan la cadena “not an ELF”.
Una vez seleccionados los ficheros binarios de malware Linux ARM, procederemos a enviarlos a las
plataforma de análisis para generar los diferentes informes.
Fase 3.1: Plataforma LiSa
Se ha elegido la plataforma de análisis estático y dinámico LiSa para generar los informes de los fiche-
ros. Su puesta en marcha es inmediata siguiendo las instrucciones del manual y los entornos de análisis
preconfigurados que incluye para las diferentes arquitecturas. No fue necesario desviarse de las instruc-
ciones de instalación por lo que no entraremos en más detalle en este apartado.
Fase 3.2: Envío de malware y recepción de informes
Para comunicar con las APIs de LiSa y VirusTotal se implementó un programa cliente cuya función
es enviar los ficheros malware a ambas plataformas, obtener sus resultados y almacenarlos en ficheros en
disco duro local.
Todos los informes obtenidos procedentes de LiSa serán utilizados para generar las características por
medio del conteo de palabras, mientras que la información de VirusTotal ha sido tratada con la aplicación
AVClass [40] para extraer de dichos informes la clase a la que pertenece cada fichero de malware.
Se debe tener en cuenta que algunos ficheros del análisis de LiSa dieron error y no pudieron ser
procesados. En un primer momento se consideró parchear la plataforma LiSa de manera que el número
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
39

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
de informes sin analizar se redujera paulatinamente. Se descartó este enfoque porque se decidió priorizar
la homogeneización de la información de entrada al modelo por encima de un mayor número de informes
disponibles.
La aplicación de AVClass, la cual parte de la información de VirusTotal, tampoco consiguió etiquetar
todas las muestras de malware de Linux ARM.
Como resultado, el conjunto de muestras con que contamos para este proyecto está formado por aquellas
muestras de malware ejecutable Linux ARM que hemos podido analizar, estando este conjunto formado
por un total de 13506 muestras.
Al terminar esta fase contamos con ambas informaciones de cada una de los 13506 muestras de malware:
sus informes estático y dinámico de LiSa y el tipo de malware a que corresponde cada fichero procedente
de VirusTotal y AVClass.
Formato de informe LiSa
Los informes LiSa son generados en formato JSON. Estos informes contienen una amplia cantidad de
tipos de informaciones ya que contienen el análisis estático y dinámico, y los diferentes campos que for-
man cada una de estas secciones. En estos informes una misma palabra puede tener diferente significado
dependiendo de en qué sección se encuentre, debido a esto se ha aplicado un mecanismo para diferenciar
las palabras de una sección de las palabras iguales que se encuentran en diferentes secciones. Esta dife-
rencia en los significados según la sección en que se encuentran las hemos llamado contextos, ya que para
cada palabra funcionan como tal dotándolas de una significado presumiblemente diferente.
Se puede consultar el formato de los informes LiSa en el anexo A.1
5.3.4. Fase 4: Preprocesado, particionado de dataset y matriz de caracterís-
ticas
Preprocesado
Los informes LiSa muestran de información distribuida en una gran cantidad y variedad de campos.
Parsear los informes directamente desde el informe json a cadenas de caracteres produciría cadenas empe-
zadas o terminadas por los símbolos ’[],’, y este no es el resultado que buscamos. Además, como se explicó
anteriormente, las palabras que en un contexto tienen un significado, pueden presentar otro distinto en
otro contexto, por lo que debido a esto se ha decidido que lo mejor es realizar un parseado específico para
estos datos.
40 Trabajo Fin de Máster

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Las transformaciones descritas a continuación son ejecutadas por la función ’prepare_master_db’
dentro del script #2 de la herramienta de procesado:
1. La primera transformación consiste en identificar y eliminar aquellos campos que contienen
información que no será útil en próximas fases. Estos campos se pueden clasificar en los siguientes
tipos:
campos cuyo valor es único para cada muestra: ejemplo de este tipo de campos son los
identificadores de los ficheros malware como por ejemplo MD5, SHA256, etc. Estos campos
toman un valor único para cada muestra y por lo tanto no añaden información al dataset ya
que nuestro objetivo es detectar clases, no individuos concretos. Con quedarnos con un campo
de este tipo es suficiente. En nuestro caso eliminamos todos aquellos que identificamos por
medio de la observación manual de muestras excepto el campo ’file_name’.
campos cuyo valor es igual en todas las muestras: este tipo de valores no es necesario eliminarlos
ya que probablemente sean descartados por el filtro TF-IDF que vamos a aplicar a continuación.
Aún así se ha incluido alguno en este apartado. Campos de este son: arquitectura para la cual
fue compilado el binario, tipo de fichero, sistema operativo, etc.
campos con valores de baja probabilidad de repetición: los campos eliminados corresponden
a valores que tienen una muy baja probabilidad de repetirse como es el tamaño total de un
fichero. Sin embargo hay otro tipo de informaciones que sí se han mantenido como es el caso
del tamaño de una sección concreta del binario dentro de su análisis estático. Este segundo
tipo de secciones, aún teniendo una baja probabilidad de repetirse, contienen una información
potencialmente interesante que podría ser aprovechada implementando un procedimiento o
función que generara una o varias características en la cual este tipo de valores fueran asociados
a unos rangos, bien por su propio valor o relacionándolo al valor de otros campos. En un caso
así este tipo de información podría ser de gran utilidad. En este proyecto se ha decidido no
entrar en este enfoque para evitar sesgar el estudio por lo que este tipo de campos se tratarán
del mismo modo que el resto de informaciones. En caso de implementarse una generación de
características de este tipo, esta habrá de hacerse con sumo cuidado.
2. La segunda transformación consiste en dar un formato común a los distintos tipos de datos que
forman cada contexto. Esta transformación implica que cada dato es tratado de manera uniforme
en todos los informes según el tipo de dato que estemos tratando. Los tipos de datos que forman
este informe son: cadena de caracteres, valor entero, valor booleano, diccionario, listas, y otros. Las
listas y diccionarios pueden contener a su vez otras listas y diccionarios, y así sucesivamente hasta
llegar al término básico contenido en cada contexto como son los enteros, las cadenas caracteres, y
los valores nulos. Los valores básicos que no son cadenas de caracteres son traducidos a cadenas de
caracteres.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
41

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
3. La tercera transformación tiene como objetivo poner todas las palabras a un mismo nivel, al mismo
tiempo que se mantiene la información de contexto para cada palabra. Para conseguir esto se genera
un identificador de contexto, el cual se construye a través de la concatenación de los nombres de
los campos que contienen cada palabra, de manera que antes de incluir cada palabra en el conjunto
general de palabras, se concatena el identificador de cada contexto antes de cada palabra. Los iden-
tificadores de contexto son diferentes dentro de cada informe, pero comunes a todos los informes
LiSa. Aunque debemos tener en cuenta que no mantienen la información de contexto a la perfección
en todos los casos. Ejemplo de esta falta de perfección son los casos de las listas de diccionarios.
Dado que los diccionarios que forman parte de una lista no están asociados a un identificador que
los identifique univocamente, dos elementos distintos de una lista tendrán la misma forma y las
variables que los forman estarán precedidos del mismo identificador de contexto, por lo que no se
distinguirá la relación que hay entre las palabras dentro de cada diccionario de esa lista. Aún así,
en este proyecto utilizaremos estos identificadores ya que, a pesar del defecto mencionado, propor-
cionan un mecanismo mejor de mantener la información de contexto que si no los utilizaramos.
Preselección de clases
Antes de realizar el particionado de las muestras en subconjunto de entrenamiento y test, hacemos
una selección previa para eliminar aquellas muestras que no formaran parte del estudio. Las muestras
utilizadas deben formar parte de una clase con un número mínimo de representantes. Toda clase utilizable
contendrá una cantidad mínima de individuos que permita entrenar y probar el modelo con los requisitos
que impongan los diferentes algoritmos y técnicas que se apliquen para obtener el modelo de clasificación.
En este proyecto imponemos 2 requisitos a cada clase:
que haya al menos un individuo de cada clase en cada subconjunto cuando se haga el particionado
estratificado con la proporción 80%-20% de los subconjuntos entrenamiento y test respectivamente.
que la cantidad de muestras en el conjunto de entrenamiento tras el particionado entrenamiento-test
sea capaz de alimentar los algoritmos de undersampling que se decida aplicar.
Particionado de dataset
Antes tomar decisiones de selección de características, se ha procedido a dividir el dataset completo
de manera estratificada en subconjuntos de entrenamiento y test con unas proporciones de 80% y 20%
respectivamente. El motivo se hacer esta separación antes de tomar ninguna decisión sobre el conjunto
de los datos es evitar el efecto de fuga de datos, o en inglés, data leakage.
42 Trabajo Fin de Máster

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Para evitar estas fugas de datos, todas las operaciones de selección de características en este proyecto se
deben hacer, siempre que sea posible, sobre el conjunto de entrenamiento y después aplicar el resultado
del filtro sobre el subconjunto de test.
El reparto de muestras estratificado nos permite mantener la proporción de la cantidad de muestras
de cada clase en cada subconjunto. Esto se hace así por dos motivos:
1. intentar igualar las capacidades de entrenamiento y oportunidades de detección de cada clase, lo
cual no elimina la dificultad intrínseca al hecho de estar tratando un dataset de tipo no balanceado.
2. asegurar de una manera automática que en el conjunto de test siempre haya al menos una muestra
de todas las clases para poder probar su detección. Si no lo hicieramos de manera estratificada, al
repartir las muestras en proporción 80%-20%, resultaría habitual que las clases menos representadas
en el dataset aparecieran solo en el conjunto de entrenamiento, haciendo imposible que se pueda
evaluar su detección.
El aspecto negativo respecto al particionado estratificado es que este tipo de reparto en cierta manera
produce una fuga de información implícita al subconjunto de entrenamiento, de manera que al intentar
detectar una muestra en el conjunto de test, el modelo podría utilizar esa proporción de aparición para
mejorar su detección, lo cual puede implicar que las métricas medidas al validar los resultados sean
mejores que los que nos encontraríamos en un escenario real. Este sería un efecto indeseado.
Para minimizar este efecto, aplicaremos técnicas de oversampling y undersampling las cuales reducirán
este efecto al ser su función equilibrar el número de muestras de cada clase en el conjunto de entrenamiento,
lo cual sucede antes de proceder a entrenar el modelo.
5.3.5. Fase 5: Selección de características - Filtros
Una selección adecuada de las características eliminará ruido en los datos y acelerará el aprendizaje
del modelo de clasificación.
Se han aplicado 4 filtros de características sobre los datos:
filtro de características simple, encargado de eliminar aquellas palabras que aparecen menos de una
cantidad de veces previamente fijada vez en el dataset.
filtro de columnas duplicadas, elimina las características duplicadas,
filtro de valoración TFIDF, selecciona las características con mayor valor TFIDF,
filtro de las K mejores características utilizando el criterio de chi2.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
43

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Filtro de mínimo de apariciones por palabra
Se ha decidido eliminar del conjunto de entrenamiento aquellas palabras que aparezcan menos de una
cantidad de veces prefijada sobre el subconjunto de entrenamiento. El motivo principal para hacer esto
es que el objetivo de un algoritmo de clasificación es, como su propio nombre indica, clasificar muestras.
Esto se consigue detectando la clase a la que pertenece un individuo. La manera correcta de realizar
esta tarea es encontrar aquellas características que hacen que esa muestra pertenezca a una clase. La
manera incorrecta sería identificar uno a uno los individuos, así cuando lo encontráramos, sabríamos que
pertenece a esa clase, no porque pertenezca sino porque es ese individuo. Este último procedimiento no
cumpliría con los objetivos de nuestro proyecto ya que requeriría que conociéramos previamente la clase
de cada individuo, lo cual sería carente de utilidad en un entorno real.
El mínimo número de veces que debe aparecer una palabra para permanecer en el dataset se ha fijado
asegurando que se mantengan todas las palabras que aparezcan al menos una vez en cada muestra de la
clase con menos muestras.
Al aplicar este filtro sobre el conjunto de entrenamiento se reduce de manera sencilla e importante la
cantidad de memoria necesaria para procesar el resto de la información ya que los términos a procesar
disminuyen de una cantidad inicial de 8.319.197 a 223.522, es decir, se reduce la cantidad de términos en
un 97,31%.
Debemos hacer notar un punto de mejora en este proyecto, y es que la manera en la que está definido
el mínimo número de apariciones de un término penaliza la detección de las clases con menos muestras
ya que no está relacionado con la cantidad de muestras de las que consta una clase y, por lo tanto, las
clases que más porcentaje de información pierden son aquellas que cuentan con menos muestras.
Filtro de columnas duplicadas
Una vez hemos convertido el conjunto de datos a matriz de características, eliminamos las características
o columnas duplicadas. Consideramos que dos características están duplicadas cuando ambas tienen
exactamente el mismo valor para cada muestra. Al aplicar este filtro, la matriz resultante tiene un único
representante de cada columna.
Asumimos que es posible que las características que se muestran como duplicadas en el subconjunto de
entrenamiento podrían no comportarse como tal sobre el conjunto completo de datos. Sabemos que esto
redunda en una peor precisión en los resultados que filtrando sobre el conjunto completo, pero se asume
esta pérdida de precisión porque es la manera de proceder para producir resultados reales.
44 Trabajo Fin de Máster

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
Filtro TFIDF
El filtro TFIDF consiste en calcular el valor TFIDF para cada palabra, y a partir de estas valoraciones
se selecciona una cantidad arbitraría de las mejores características según este criterio. La cantidad ha
sido fijada previamente por nosotros en 20.000.
Filtro: Selección de las K mejores características
A la matriz de características actual se le ha aplicado la selección de las K mejores características por
el criterio de Chi2.
El test de Chi2 mide la dependencia entre variables estocásticas, por lo que utilizar esta función
elimina las características que más probablemente sean independientes de la clase y, en consecuencia, las
más irrelevantes para clasificación.
En el filtro por Chi2 se aplican dos hipótesis. Estas son:
H0 (hipótesis nula): El vector de características no es dependiente linealmente del vector de
respuestas y.
H1 (hipótesis alternativa): El vector de características sí es dependiente linealmente del vector de
respuestas y.
Para cada vector de características obtiene su p − valor y las ordena de menor a mayor p − valor. A
menor valor reciba p− valor, mayor dependencia de la variable respuesta y.
En este proyecto hemos decidido quedarnos con las muestras que están por encima del percentil 50.
5.3.6. Fase 6: Entrenamiento y validación de modelos
Una vez hemos seleccionado las características, procedemos a entrenar los modelos, generar una
predicción y validar los resultados.
Para entrenar los modelos utilizamos las matrices Xtrain e ytrain que contienen los vectores de
características y el vector de respuestas esperadas respectivamente.
Para evaluar la predicción utilizamos el subconjunto de test Xtest e ytest. Con estos datos obtenemos
una predicción a partir la cual generamos la matriz de confusión y obtenemos los valores que nos servirán
para medir la efectividad del mismo: precisión, exactitud, exhaustividad y F1.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
45

CAPÍTULO 5. METODOLOGÍA Y DISEÑO
5.3.7. Fase 7: Análisis crítico sobre los resultados obtenidos
Este será el momento de hacer observaciones sobre la eficacia de los algoritmos para discernir cuales
son mejores para nuestro caso concreto.
Para evaluar los modelos tendremos en cuenta toda la información a nuestra disposición que en este
proyecto son las diferentes métricas y las matrices de confusión. Existen otras formas de representación
de la eficacia de los modelos de clasificación como son por ejemplo las curvas ROC y AUC.
46 Trabajo Fin de Máster

6Manual de uso
Al ejecutar el programa podemos ejecutar una fase en concreto. Las fases ejecutadas por el programa
coinciden con las descritas en la sección 5, con la diferencia de que se han organizado de la siguiente
manera:
6.1. Fase 0: obtención de las muestras ELF ARM.
El dataset inicial contiene muestras de diferentes arquitecturas de sistema, por este motivo el primer
paso consiste en obtener los ficheros binarios ejecutables tipo ELF y arquitectura ARM del dataset.
Obtendremos un directorio conteniendo únicamente los ficheros ELF ARM del total de muestras del
dataset inicial tras ejecutar manualmente los siguientes comandos desde la consola bash:
$ for file in *; do file $file | grep -i elf | grep -i arm; done > <
↪→ ruta_del_fichero_conteniendo_la_lista_de_ficheros_ELF_ARM_ >
$ mkdir <directorio_destino_de_los_ficheros_ELF_ARM >
$ cp $(cat <ruta_del_fichero_conteniendo_la_lista_de_ficheros_ELF_ARM_ > | cut -d
↪→ ":" -f1) <directorio_destino_de_los_ficheros_ELF_ARM >
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
47

CAPÍTULO 6. MANUAL DE USO
6.2. Fase 1: obtención de los informes de los ficheros ELF ARM.
En esta fase obtendremos los reportes de los ficheros malware seleccionados procedentes de LiSa y
VirusTotal. Para ello utilizamos el primero de los scripts que se ha llamado 1_lisa_handler.py, que es el
encargado de hacer de cliente con las APIs de LiSa y VirusTotal.
A alto nivel las acciones a realizar son las siguientes:
1. Envío de muestras a LiSa,
2. Obtención de reportes LiSa,
3. Envío y obtención de reportes VirusTotal.
6.2.1. Envío de muestras a LiSa
El envío de muestras al servidor LiSa se realiza con siguiente linea de comandos:
$ ./1 _lisa_handler.py --send_pending_to_sandbox --samples_dir <
↪→ directorio_conteniendo_los_ficheros_ELF_ARM >
Tras ejecutar esta linea se envían a LiSa todas las muestras del directorio de las que aún no se haya
obtenido reporte.
6.2.2. Obtención de reportes malware de LiSa
Tras enviar las muestras de malware a LiSa el servidor necesitará tiempo para procesar las muestras
y generar los informes. La generación de los informes toma varios días con la configuración utilizada por
lo que se ha implementado una opción que permite ejecutar la obtención de informes cada cierto tiempo
obteniendo, además de los informes, el estado del proceso en ese momento.
Internamente esta acción consiste en obtener los informes de la API De LiSa y guardar en disco
los informes en formato JSON. Esta acción se ejecuta a través de la siguiente linea de comandos:
$ ./1 _lisa_handler.py --update_reports_collection
Tras ejecutar esta linea se inicia un proceso de solicitud a LiSa y guardado a disco de los informes no
obtenidos previamente.
48 Trabajo Fin de Máster

CAPÍTULO 6. MANUAL DE USO
6.2.3. Envío y obtención de informes VirusTotal
Esta acción consiste en enviar y obtener de VirusTotal los informes en formato JSON de las muestras
ELF ARM aún no analizadas para su almacenamiento en disco local. Esto se realiza a través de la siguiente
linea de comandos:
$ ./1 _lisa_handler.py --virustotal --samples_dir <
↪→ directorio_conteniendo_los_ficheros_ELF_ARM >
Tras ejecutar esta linea se inicia un proceso de solicitud y obtención de informes al API de VirusTotal.
6.3. Fase 2: obtención de las repeticiones de palabras.
Esta fase es la encargada de:
1. Obtener y contar las palabras contenidas en los reportes LiSa para obtener las características que
llamamos X,
2. analizar con AVClass los informes VirusTotal para obtener la información objetivo, las etiquetas de
cada malware, a lo que llamaremos y,
3. asignación de cada etiqueta y a sus características X, que formará nuestra matriz inicial,
4. particionado de la matriz inicial en subconjuntos disjuntos para entrenamiento y test,
5. aplicación del primer filtro, consistente en eliminar las palabras con pocas apariciones en el dataset
de entrenamiento.
6. obtención del universo de palabras y la cantidad de repeticiones del subconjunto de entrenamiento.
Estas acciones se realizan con el segundo script llamado 2_loader.py ejecutando la siguiente linea de
comandos:
$ ./2 _loader.py
6.4. Fase 3: Selección de características.
En nuestro proyecto, dado que partimos de una cantidad de características superior a los 50 millones,
hacemos la selección de características por medio de filtros.
Los filtros aplicados son los siguientes:
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
49

CAPÍTULO 6. MANUAL DE USO
1. Filtro de características duplicadas, reduce la cantidad de características que contienen la misma
información,
2. Filtro TFIDF, permite saber qué palabras son más relevantes para clasificar un documento dentro
de un conjunto de documentos,
3. Filtro por Chi2, un criterio específico para modelos de clasificación.
6.5. Fase 4: Muestreo, entrenamiento y validación de los modelos.
En primer lugar se ha definido una estrategia de muestreo antes de entrenar los modelos, lo cual
permite hacer ciertos cambios sobre el conjunto de entrenamiento con el fin de mejorar el desempeño de
los modelos de clasificación.
A continuación todos los modelos se entrenan con el subconjunto de entrenamiento (matrices Xtrain e
ytrain), para posteriormente preguntar al modelo ya entrenado qué predicción nos da si le preguntamos
por las muestras contenidas en la matriz Xtest. Finalmente, una vez tenemos la predicción del modelo,
podemos comparar dichos resultados con los esperados, los cuales se encuentra en la matriz ytest, lo cual
nos permite obtener las métricas de exhaustividad, exactitud, precisión y F1 correspondientes a la eficacia
del algoritmo.
El haber obtenido estos valores para todos los modelos en las diferentes condiciones nos permitirá
comparar resultados y ver qué modelos han conseguido mejor empeño.
50 Trabajo Fin de Máster

7Conclusiones
En este proyecto se ha llevado a cabo un estudio de aprendizaje automático utilizando un conjunto
de ficheros malware ELF de arquitectura ARM, lo cual nos ha permitido comparar 42 combinaciones de
técnicas de muestreo y algoritmos de clasificación en el contexto de clasificación de malware.
La realización de este proyecto ha requerido la puesta en marcha de un servicio local LiSa para el
análisis dinámico de malware y la implementación de dos herramientas software: una para el procesado
masivo de malware y otra encargada de realizar el proceso de análisis desde el dato en crudo hasta el
entrenamiento y evaluación de cada modelo de clasificación, pasando por la vectorización de los datos y
la selección de características, procurando en todo momento realizar un buen manejo de la información
para evitar fugas de datos que nos pudieran conducir a predicciones excesivamente optimistas e irreales.
Los modelos obtenidos han sido evaluados considerando la que se ha considerado la métrica más
conveniente para nuestra tarea de clasificación de malware: la media ponderada de F1.
Respecto a los resultados obtenidos, A.2.1 y A.3, observamos lo siguiente:
De las combinaciones estudiadas, de los modelos que mejor F1 han obtenido, ninguno ha aplicado
técnicas de muestreo. Sin embargo se observa un aumento en la variedad de respuestas en los
modelos que sí utilizaron alguna técnica de muestreo, esto tiene sentido ya que el objeto de estas
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
51

CAPÍTULO 7. CONCLUSIONES
técnicas es equilibrar el dataset, por lo que se comprueba que estas técnicas mejoran la capacidad
de clasificación de las clases infrarrepresentadas.
Modelo de clasificación más penalizado por las técnicas de muestreo: Árbol de decisión.
Técnicas de muestreo que menor penalización han producido: Condensación de vecinos más cercanos
y ADASYN.
Modelos de clasificación que han mejorado sus resultados utilizando técnicas de muestreo:
Condensación de vecinos más cercanos con Bosque Aleatorio, Condensación de vecinos más cercanos
con Naive Bayes y ADASYN con Árbol de decisión.
Modelo con muestreo con mejor métrica F1 ponderada: Bosque aleatorio con Condensación de
vecinos más cercanos.
Las clases de malware mejor clasificadas por los modelos han sido Mirai y Gafgyt.
Modelos de clasificación con mejor valoración F1 ponderada: Red neuronal, Árbol de decisión,
AdaBoost y Bosque aleatorio.
Mayor variedad de respuestas: Red Neuronal, Naive Bayes, Nearest Neighbors y AdaBoost.
Por lo tanto, como resultado final, la combinación de muestreo y clasificación obtenida que mejor
métrica y comportamiento ha mostrado en este proyecto la Red Neuronal sin técnicas de muestreo.
Es conveniente, y forma parte de la metodología 5.3, ser críticos con los resultados obtenidos. Por
eso decimos que aunque clasificar dentro de un universo formado por 7 clases como posible respuesta
supone una mayor dificultad que una clasificación binaria, si comparáramos la precisión de este modelo
con el de un hipotético modelo que generara su clasificación apuntando siempre a la clase mayoritaria,
encontraríamos que los modelos obtenidos no proporcionan ninguna mejora respecto a dicho modelo
hipotético porque la clase mayoritaria forma un 58.32% del conjunto de datos y la precisión obtenida por
el mejor modelo, la red neuronal, se encuentra por debajo con un 52.3% de precisión, por lo que debemos
decir que los modelos obtenidos no mejoran la capacidad de predicción que teníamos anteriormente, lo
cual es objetivo fundamental en una aplicación de aprendizaje automático.
Por otro lado, gracias entre otros factores a la metodología aplicada para evitar fugas de datos, el
resultado obtenido puede ser utilizado en el desarrollo de futuros proyectos ya que la comparativa generada
nos indica qué ha funcionado mejor y peor, y qué técnicas tienen más posibilidades de funcionar.
De hecho, el repositorio de muestras de malware utilizado en este proyecto ha recibido cinco veces más
muestras de malware para Linux-ARM en el último año que en toda su historia. Estas muestras no han
sido utilizadas en este proyecto por la limitación de tiempo y capacidad computacional con la que se ha
contado, pero nos hace pensar que será factible conseguir una mejor capacidad de clasificación en futuros
estudios en este campo.
52 Trabajo Fin de Máster

8Lineas futuras
A continuación las acciones que se proponen tomar para mejorar la capacidad de clasificación de los
modelos:
1. Aumentar la capacidad computacional: Como hemos visto, la cantidad de muestras y características
producen una matriz difícilmente manejable con la capacidad de cómputo con que se contaba en
este proyecto. Dado el aumento que se está observando en la cantidad de muestras disponibles, sería
de gran interés aumentar la capacidad de cómputo para mejorar los resultados de futuros modelos
de clasificación. Este aumento de capacidad puede hacerse bien por medio de la utilización de un
cluster local, utilizando computación distribuida o bien utilizando los servicios de nube orientados
a inteligencia artificial con los que actualmente cuentan varias compañías en internet.
2. Dividir el preprocesado: un preprocesado dividido en tareas podría reducir los requisitos
computacionales del proyecto.
3. Refinar la selección de características: esto se puede hacer utilizando una combinación de filtros de
selección de características diferente y afinando los parámetros de los filtros utilizados.
4. Equilibrar los filtros de características para mejorar la detección de clases poco numerosas: se
observa que es habitual que los filtros masivos de características penalizan a las clases con menos
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
53

CAPÍTULO 8. LINEAS FUTURAS
representantes. Concretamente en este proyecto el filtro por número de apariciones es el primero
aplicado al dataset y consiste en la eliminación de palabras aplicando una proporción que depende
únicamente de la cantidad de muestras de la clase más pequeña. Esto redunda en una penalización en
la capacidad de clasificación de las clases con menos muestras. Podría interesar en futuros proyectos
equilibrar este filtro para eliminar esta penalización o bien directamente eliminar las clases que no
disponen de muestras suficientes como para ser clasificadas correctamente.
5. Reenfocar el etiquetado de muestras: la verdad fundamental de la que partimos y el resultado
que buscamos obtener afectan de manera importante al modelo de clasificación de malware que
pretendamos obtener. Como se puede ver en la sección 5.3.1, el etiquetado que nos proporciona la
combinación de VirusTotal y AVClass está centrado en la familia a la que pertenece el malware que
estamos analizando. Sin embargo, la información que más interesa a un analista de malware es qué
funcionalidad exactamente se esconde dentro del malware, más allá de a qué familia pertenece. Es
cierto que conocer la familia y cierta información, como la plataforma a la que está dirigido dicho
malware, nos pueda permitir inferir qué tipo de funcionalidad es más probable que se encuentre
dentro de dicho fichero, pero no es lo ideal. Esto se podría conseguir cambiando la manera en la
que AVClass parsea las etiquetas en el caso de que los motores antivirus de VirusTotal estuvieran
proporcionando la funcionalidad completa, pero no es el caso. Ya que un fichero malware suele
contener varias funcionalidades dentro de sí, se necesitaría un etiquetado detallado o que permita
obtener la funcionalidad concreta asociada a cada fichero conocido, lo cual puede que requiera la
participación de los fabricantes de antivirus. En cualquier caso sería muy conveniente profundizar en
este aspecto si se quiere partir de una verdad fundamental fiable y realmente útil, algo imprescindible
para que un proyecto de aprendizaje automático llegue a un resultado fiable y útil.
6. Añadir otros tipos de informes malware: añadir otras fuentes de información, además de los análisis
estático y dinámico utilizados, como por ejemplo el código desensamblado u otras herramientas que
pudieran generar otra información. Estos informes podrían proporcionar características de calidad
a los modelos lo cual redundará en una mejora de la capacidad de clasificación.
7. Añadir formas de visualización del dataset: siempre es interesante añadir punto de vista de análisis
del dataset, tanto visuales como puramente numéricos, que permitan conocer mejor el dataset con
que estamos trabajando. Esto será de ayuda para elaborar mejores modelos de clasificación.
8. Añadir métricas de evaluación de modelos: como hemos podido ver al final de este proyecto, cada
forma de métrica ha proporcionado una información distinta que no podríamos haber obtenido si
no hubieramos contado con esa métrica concreta. Existen otras métricas además de las vistas en
este proyecto que ayudarán a evaluar los modelos como son las curvas ROC y AUC y que sería
interesante añadir a futuras iteraciones de este proyecto.
54 Trabajo Fin de Máster

Bibliografía
[1] Global Digital Report 2018. 2018. url: https://wearesocial.com/blog/2018/01/global-
digital-report-2018.
[2] Informe mobile en Espania y en el mundo 2017. 2017. url: https://www.amic.media/media/
files/file_352_1289.pdf.
[3] Panorama actual de la ciberseguridad en Espana. Oct. de 2019. url: https://www.ospi.es/
export/sites/ospi/documents/documentos/Seguridad-y-privacidad/Google_Panorama-
actual-de-la-ciberseguridad-en-Espana.pdf.
[4] Allianz Risk Barometer 2020 - Identifying the major business risks for 2020. url: https : / /
www.agcs.allianz.com/content/dam/onemarketing/agcs/agcs/reports/Allianz-Risk-
Barometer-2020.pdf.
[5] Malware: van en aumento los ataques a macOS y Linux. url: https://andro2id.com/malware-
van-aumento-ataques/.
[6] G Data: menos malware pero más complejo y peligroso. 25 de sep. de 2012. url: https://www.
muyseguridad.net/2012/09/25/g-data-menos-malware-pero-mas-complejo-peligroso/.
[7] Allianz Risk Barometer 2017 - Top risks in focus: Cyber incidents. url: https://www.agcs.
allianz.com/insights/expert-risk-articles/allianz-risk-barometer-2017-top-risks-
cyber-incidents/.
[8] Informe de Amenazas y Tendencias. Edición 2019. url: https : / / www. ccn - cert . cni . es /
informes/informes- ccn- cert- publicos/3776- ccn- cert- ia- 13- 19- ciberamenazas- y-
tendencias-edicion-2019-1/file.html.
[9] Aplicaciones GNU/Linux. url: https://es.wikipedia.org/wiki/GNU/Linux\#Aplicaciones.
[10] Android challenges Windows as world’s most popular operating system in terms of internet usage.
2017. url: https://gs.statcounter.com/press/android-challenges-windows-as-worlds-
most-popular-operating-system.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
55

BIBLIOGRAFÍA
[11] ARM 2019 Roadshow slides. 2019. url: https://www.arm.com/- /media/global/company/
investors/PDFs/Arm_SBG_Q1_2019_Roadshow_Slides_FINAL.pdf?revision=9e3e50c9-9b76-
48f1-b02c-a30f5b4f2ee4&la=en.
[12] Linux and Open Source on the Move in Embedded, Says Survey. Ago. de 2017. url: https://www.
linux.com/news/linux-and-open-source-move-embedded-says-survey/.
[13] Alireza Souri y Rahil Hosseini. «A state-of-the-art survey of malware detection approaches using
data mining techniques». En: Human-centric Computing and Information Sciences 8.1 (2018),
pág. 3. issn: 2192-1962. doi: 10.1186/s13673-018-0125-x. url: https://doi.org/10.1186/
s13673-018-0125-x.
[14] WatchGuard Launches New Quarterly Internet Security Report. 30 de mar. de 2017. url: https:
//www.watchguard.com/wgrd-about/press-releases/watchguard-launches-new-quarterly-
internet-security-report.
[15] Pedram Hayati y Vidyasagar Potdar. «Evaluation of spam detection and prevention frameworks
for email and image spam - a state of art». En: (ene. de 2008).
[16] Debian.org. Debian Project. Accedido en 09-06-2020 a urlhttps://www.debian.org/. 2020.
[17] Linux Sandbox github repository. 2020. url: https://github.com/danieluhricek/LiSa.
[18] Alejandro Martín García, Raul Lara-Cabrera y David Camacho. «A new tool for static and dynamic
Android malware analysis». En: sep. de 2018, págs. 509-516. doi: 10.1142/9789813273238_0066.
[19] Análisis de Malware. 2020. url: https://es.wikipedia.org/wiki/An%C3%A1lisis_de_malware.
[20] url: https://www.cvedetails.com.
[21] AV-Test Lab tests 16 Linux antivirus products against Windows and Linux malware. url: https:
//www.csoonline.com/article/2989137/linux/av-test-lab-tests-16-linux-antivirus-
products-against-windows-and-linux-malware.html.
[22] Comparison of top data science libraries for Python, R and Scala [Infographic]. 2018. url: https:
//activewizards.com/blog/comparison-of-top-data-science-libraries-for-python-r-
and-scala-infographic/.
[23] Richard Rivera Guevara. «Tools for the Detection and Analysis of Potentially Unwanted Programs».
Tesis doct. Nov. de 2018. doi: 10.20868/UPM.thesis.53395.
[24] Konrad Rieck y col. «Learning and Classification of Malware Behavior». En: jul. de 2008. doi:
10.1007/978-3-540-70542-0_6.
[25] George Dahl y col. «Large-scale malware classification using random projections and neural
networks». En: oct. de 2013, págs. 3422-3426. doi: 10.1109/ICASSP.2013.6638293.
[26] Konrad Rieck y col. «Automatic analysis of malware behavior using machine learning». En: Journal
of Computer Security 19 (ene. de 2011), págs. 639-668. doi: 10.3233/JCS-2010-0410.
56 Trabajo Fin de Máster

BIBLIOGRAFÍA
[27] Michael Bailey y col. «Automated Classification and Analysis of Internet Malware». En: vol. 4637.
Sep. de 2007, págs. 178-197. doi: 10.1007/978-3-540-74320-0_10.
[28] Ulrich Bayer y col. «Scalable, Behavior-Based Malware Clustering.» En: ene. de 2009.
[29] Roberto Perdisci, Wenke Lee y Nick Feamster. «Behavioral Clustering of HTTP-Based Malware
and Signature Generation Using Malicious Network Traces». En: ene. de 2010, págs. 391-404.
[30] M Zubair Rafique y Juan Caballero. «FIRMA: Malware Clustering and Network Signature
Generation with Mixed Network Behaviors». En: ene. de 2013. doi: 10.1007/978-3-642-41284-
4_8.
[31] Julio Canto y col. «Large scale malware collection: Lessons learned». En: (ene. de 2008).
[32] Aziz Mohaisen y Omar Alrawi. «AV-Meter: An Evaluation of Antivirus Scans and Labels». En:
jul. de 2014, págs. 112-131. isbn: 978-3-319-08508-1. doi: 10.1007/978-3-319-08509-8_7.
[33] Federico Maggi y col. «Finding Non-trivial Malware Naming Inconsistencies». En: vol. 7093. Dic. de
2011, págs. 144-159. doi: 10.1007/978-3-642-25560-1_10.
[34] It’s signed, therefore it’s clean, right? 2010. url: http://citeseerx.ist.psu.edu/viewdoc/
download?doi=10.1.1.169.1531&rep=rep1&type=pdf.
[35] The Common Malware Enumeration Initiative. 2005. url: https://cme.mitre.org/docs/docs-
2005/virusbulletin_cme_sept05.pdf.
[36] P.-M. Bureau y D. Harley. «A dose by any other name». En: (2008). url: http://static4.
esetstatic.com/us/resources/white-papers/Harley-Bureau-VB2008.pdf.
[37] D. Harley. «The Game of the Name: Malware Naming, Shape Shifters and Sympathetic Magic».
En: (2009).
[38] Roberto Perdisci y ManChon U. «VAMO: Towards a fully automated malware clustering validity
analysis». En: dic. de 2012, págs. 329-338. doi: 10.1145/2420950.2420999.
[39] Peng Li y col. «On Challenges in Evaluating Malware Clustering». En: vol. 6307. Sep. de 2010,
págs. 238-255. doi: 10.1007/978-3-642-15512-3_13.
[40] Marcos Sebastián y col. «AVclass: A Tool for Massive Malware Labeling». En: vol. 9854. Sep. de
2016, págs. 230-253. isbn: 978-3-319-45718-5. doi: 10.1007/978-3-319-45719-2_11.
[41] Raquel Noblejas Sampedro. «Estudio de algoritmos de detección de anomalías y su aplicación a
entornos de ciberseguridad». Madrid, 2016. url: http://oa.upm.es/40490/.
[42] An Introduction to Machine Learning Theory and Its Applications: A Visual Tutorial with Examples.
url: http : / / www . toptal . com / machine - learning / machine - learning - theory - an -
introductory-primer.
[43] Charles X. Ling y Chenghui Li. «Data Mining for Direct Marketing: Problems and Solutions». En:
KDD. 1998.
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
57

BIBLIOGRAFÍA
[44] Haibo He y col. «ADASYN: Adaptive synthetic sampling approach for imbalanced learning».
En: 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on
Computational Intelligence). 2008, págs. 1322-1328.
[45] Nitesh Chawla y col. «SMOTE: Synthetic Minority Over-sampling Technique». En: J. Artif. Intell.
Res. (JAIR) 16 (ene. de 2002), págs. 321-357. doi: 10.1613/jair.953.
[46] EMC Education Services. Data Science and Big Data Analytics: Discovering, Analyzing, Visualizing
and Presenting Data. Wiley, 2015. isbn: 9781118876138. url: https://books.google.es/books?
id=QLblBQAAQBAJ.
[47] Boosting. url: https://es.wikipedia.org/wiki/Boosting.
[48] Gene expression programming. url: https://en.wikipedia.org/wiki/Gene_expression_
programming.
[49] Accuracy, Precision, Recall or F1? 15 de mar. de 2018. url: https://towardsdatascience.com/
accuracy-precision-recall-or-f1-331fb37c5cb9.
[50] What I Learned Implementing a Classifier from Scratch in Python. url: http : / / www .
jeannicholashould.com/what-i-learned-implementing-a-classifier-from-scratch.html?
utm_campaign=DataScience_Digest&utm_medium=email&utm_source=Revue%20newsletter.
[51] VirusShare_Linux_20140617. Accedido en 15-03-2019 a url: https://tracker.virusshare.com:7000/
torrents/VirusShare_ELF_20140617.zip.torrent. 2014.
[52] VirusShare_Linux_20160715. Accedido en 15-03-2019 a url: https://tracker.virusshare.com:7000/
torrents/VirusShare_Linux_20160715.zip.torrent. 2016.
[53] Fortiguard encyclopedia. url: https://www.fortiguard.com/encyclopedia/.
58 Trabajo Fin de Máster

Apéndices
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
59


AAnexos
A.1. Formato de informe LiSa
Los informes LiSa siguen el formato JSON con los siguientes campos y tipos:
{
"file_name": <string>,
"type": <string>,
"exec_time": <int>,
"timestamp": <string>,
"md5": <string>,
"sha1": <string>,
"sha256": <string>,
"analysis_start_time": <string>,
"static_analysis": {
"binary_info": {
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas deaprendizaje automático
61

APÉNDICE A. ANEXOS
"arch": <string>,
"endianess": <string>,
"format": <string>,
"machine": <string>,
"type": <string>,
"size": <int>,
"os": <string>,
"static": <boolean>,
"interpret": <string>,
"language": <string>,
"stripped": <boolean>,
"relocations": <boolean>,
"min_opsize": <int>,
"max_opsize": <int>,
"entry_point": [<int>, ..]
},
"imports": [
{
"ordinal": <int>,
"bind": <string>,
"type": <string>,
"name": <string>,
"plt": <int>
},..
],
"exports": [
{
"name": <string>,
"flagname": <string>,
"realname": <string>,
"ordinal": <int>,
"bind": <string>,
"size": <int>,
"type": <string>,
"vaddr": <int>,
"paddr": <int>,
"is_imported": false
62 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
}, ..
],
"libs": [<string>, ..],
"relocations": [],
"symbols": [
{
"name": <string>,
"flagname": <string>,
"realname": <string>,
"ordinal": <int>,
"bind": <string>,
"size": <int>,
"type": <string>,
"vaddr": <int>,
"paddr": <int>,
"is_imported": false
},..
],
"sections": [
{
"name": <string>,
"size": <int>,
"vsize": <int>,
"perm": <string>,
"paddr": <int>,
"vaddr": <int>
},..]
"strings": [ <string>, .. ],
},
"dynamic_analysis": {
"syscalls": [],
"open_files": [],
"processes": [
{
"pid": <int>,
"parent": <int>
}
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
63

APÉNDICE A. ANEXOS
]
},
"network_analysis": {
"anomalies": [],
"irc_messages": [],
"dns_questions": [],
"http_requests": [],
"telnet_data": [],
"port_statistics": {
"TCP": {},
"UDP": {
"67": <int>,
..
}
},
"endpoints": [
{
"ip": <string>,
"ports": [<string>,..],
"blacklisted": false,
"data_in": <int>,
"data_out": <int>
},..
]
},
"view": {
"status": <string>
},
"pcap": <string>,
"machinelog": <string>,
"output": <string>
}
64 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
65

APÉNDICE A. ANEXOS
A.2. Tablas de resultados
A.2.1. Tabla de resultados - media Ponderada
Sampleado Algoritmo F1 Exhaustividad Precisión ExactitudNaive Bayes 0.273 0.213 0.444 0.213Nearest Neighbors 0.450 0.482 0.466 0.482Decision Tree 0.475 0.609 0.510 0.609
Ninguno Random Forest 0.467 0.614 0.614 0.614Neural Net 0.518 0.607 0.523 0.607AdaBoost 0.474 0.607 0.418 0.607Naive Bayes 0.246 0.180 0.467 0.180Nearest Neighbors 0.430 0.421 0.447 0.421Decision Tree 0.011 0.030 0.714 0.030
Aleatorio Random Forest 0.130 0.213 0.383 0.213Neural Net 0.440 0.416 0.474 0.416AdaBoost 0.251 0.198 0.408 0.198Naive Bayes 0.254 0.190 0.433 0.190Nearest Neighbors 0.410 0.388 0.456 0.388Decision Tree 0.110 0.218 0.214 0.218
SMOTE Random Forest 0.425 0.449 0.431 0.449Neural Net 0.435 0.401 0.480 0.401AdaBoost 0.385 0.332 0.471 0.332Naive Bayes 0.258 0.193 0.444 0.193Nearest Neighbors 0.395 0.373 0.436 0.373Decision Tree 0.478 0.599 0.569 0.599
ADASYN Random Forest 0.416 0.437 0.533 0.437Neural Net 0.421 0.393 0.458 0.393AdaBoost 0.394 0.343 0.499 0.343Naive Bayes 0.325 0.294 0.487 0.294
Condensed Nearest Neighbors 0.224 0.226 0.420 0.226Nearest Decision Tree 0.473 0.614 0.601 0.614Neighbour Random Forest 0.504 0.612 0.570 0.612
Neural Net 0.419 0.401 0.449 0.401AdaBoost 0.421 0.398 0.459 0.398Naive Bayes 0.240 0.175 0.512 0.175Nearest Neighbors 0.298 0.266 0.472 0.266Decision Tree 0.004 0.030 0.009 0.030
SMOTENN Random Forest 0.006 0.020 0.043 0.020Neural Net 0.240 0.208 0.439 0.208AdaBoost 0.077 0.063 0.617 0.063Naive Bayes 0.273 0.203 0.470 0.203Nearest Neighbors 0.403 0.378 0.454 0.378
SMOTE Decision Tree 0.033 0.046 0.537 0.046Tomek Random Forest 0.453 0.485 0.553 0.485
Neural Net 0.447 0.404 0.501 0.404AdaBoost 0.210 0.155 0.494 0.155
Tabla A.1: Tabla de resultados - Media: Ponderada66 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
A.2.2. Tabla de resultados - media Micro
Sampleado Algoritmo F1 Exhaustividad Precisión ExactitudNaive Bayes 0.213 0.213 0.213 0.213Nearest Neighbors 0.482 0.482 0.482 0.482Decision Tree 0.609 0.609 0.609 0.609
Ninguno Random Forest 0.614 0.614 0.614 0.614Neural Net 0.607 0.607 0.607 0.607AdaBoost 0.607 0.607 0.607 0.607Naive Bayes 0.180 0.180 0.180 0.180Nearest Neighbors 0.421 0.421 0.421 0.421Decision Tree 0.030 0.030 0.030 0.030
Aleatorio Random Forest 0.213 0.213 0.213 0.213Neural Net 0.416 0.416 0.416 0.416AdaBoost 0.198 0.198 0.198 0.198Naive Bayes 0.190 0.190 0.190 0.190Nearest Neighbors 0.388 0.388 0.388 0.388Decision Tree 0.218 0.218 0.218 0.218
SMOTE Random Forest 0.449 0.449 0.449 0.449Neural Net 0.401 0.401 0.401 0.401AdaBoost 0.332 0.332 0.332 0.332Naive Bayes 0.193 0.193 0.193 0.193Nearest Neighbors 0.373 0.373 0.373 0.373Decision Tree 0.599 0.599 0.599 0.599
ADASYN Random Forest 0.437 0.437 0.437 0.437Neural Net 0.393 0.393 0.393 0.393AdaBoost 0.343 0.343 0.343 0.343Naive Bayes 0.294 0.294 0.294 0.294
Condensed Nearest Neighbors 0.226 0.226 0.226 0.226Nearest Decision Tree 0.614 0.614 0.614 0.614Neighbour Random Forest 0.612 0.612 0.612 0.612
Neural Net 0.401 0.401 0.401 0.401AdaBoost 0.398 0.398 0.398 0.398Naive Bayes 0.175 0.175 0.175 0.175Nearest Neighbors 0.266 0.266 0.266 0.266Decision Tree 0.030 0.030 0.030 0.030
SMOTENN Random Forest 0.020 0.020 0.020 0.020Neural Net 0.208 0.208 0.208 0.208AdaBoost 0.063 0.063 0.063 0.063Naive Bayes 0.203 0.203 0.203 0.203Nearest Neighbors 0.378 0.378 0.378 0.378
SMOTE Decision Tree 0.046 0.046 0.046 0.046Tomek Random Forest 0.485 0.485 0.485 0.485
Neural Net 0.404 0.404 0.404 0.404AdaBoost 0.155 0.155 0.155 0.155
Tabla A.2: Tabla de resultados - Media: Micro
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
67

APÉNDICE A. ANEXOS
A.2.3. Tabla de resultados - media Macro
Sampleado Algoritmo F1 Exhaustividad Precisión ExactitudNaive Bayes 0.139 0.210 0.176 0.213Nearest Neighbors 0.142 0.149 0.271 0.482Decision Tree 0.132 0.167 0.254 0.609
Ninguno Random Forest 0.127 0.167 0.614 0.614Neural Net 0.174 0.185 0.235 0.607AdaBoost 0.171 0.190 0.290 0.607Naive Bayes 0.119 0.169 0.179 0.180Nearest Neighbors 0.155 0.154 0.166 0.421Decision Tree 0.013 0.169 0.255 0.030
Aleatorio Random Forest 0.105 0.204 0.152 0.213Neural Net 0.197 0.202 0.200 0.416AdaBoost 0.109 0.141 0.143 0.198Naive Bayes 0.116 0.166 0.161 0.190Nearest Neighbors 0.171 0.179 0.177 0.388Decision Tree 0.067 0.134 0.067 0.218
SMOTE Random Forest 0.157 0.187 0.159 0.449Neural Net 0.178 0.177 0.196 0.401AdaBoost 0.157 0.177 0.180 0.332Naive Bayes 0.118 0.168 0.166 0.193Nearest Neighbors 0.164 0.170 0.168 0.373Decision Tree 0.135 0.165 0.244 0.599
ADASYN Random Forest 0.174 0.241 0.232 0.437Neural Net 0.198 0.206 0.203 0.393AdaBoost 0.175 0.177 0.236 0.343Naive Bayes 0.165 0.208 0.190 0.294
Condensed Nearest Neighbors 0.101 0.157 0.169 0.226Nearest Decision Tree 0.146 0.176 0.404 0.614Neighbour Random Forest 0.151 0.175 0.538 0.612
Neural Net 0.173 0.180 0.175 0.401AdaBoost 0.223 0.229 0.266 0.398Naive Bayes 0.111 0.152 0.182 0.175Nearest Neighbors 0.157 0.209 0.183 0.266Decision Tree 0.020 0.176 0.018 0.030
SMOTENN Random Forest 0.024 0.111 0.030 0.020Neural Net 0.134 0.185 0.170 0.208AdaBoost 0.038 0.139 0.191 0.063Naive Bayes 0.125 0.173 0.177 0.203Nearest Neighbors 0.169 0.176 0.177 0.378
SMOTE Decision Tree 0.037 0.185 0.238 0.046Tomek Random Forest 0.180 0.221 0.241 0.485
Neural Net 0.196 0.182 0.218 0.404AdaBoost 0.120 0.181 0.194 0.155
Tabla A.3: Tabla de resultados - Media: Macro
68 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
A.3. Matrices de confusión
A.3.1. Muestreo: Ninguno
Modelo: Naive Bayes
Metrica: Ponderada
F1: 0.273
Accuracy: 0.213
Recall: 0.213
Precision: 0.444
Modelo: Nearest Neighbors
Metrica: Ponderada
F1: 0.450
Accuracy: 0.482
Recall: 0.482
Precision: 0.466
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
69
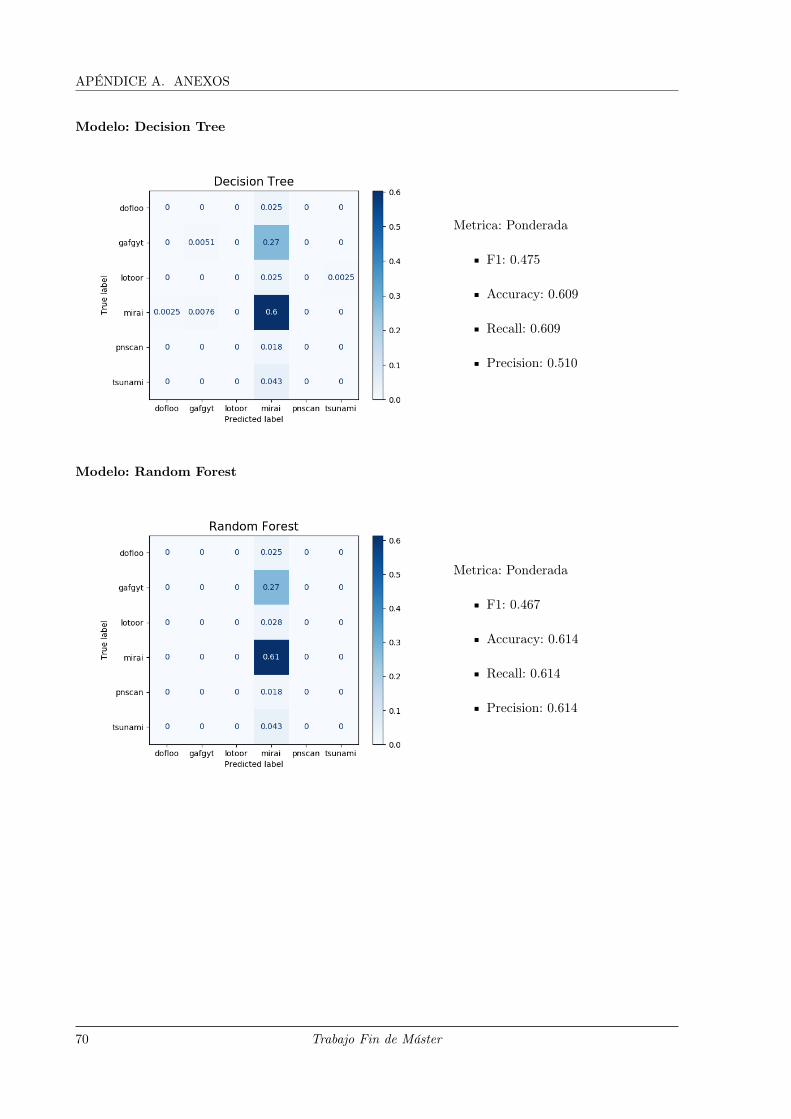
APÉNDICE A. ANEXOS
Modelo: Decision Tree
Metrica: Ponderada
F1: 0.475
Accuracy: 0.609
Recall: 0.609
Precision: 0.510
Modelo: Random Forest
Metrica: Ponderada
F1: 0.467
Accuracy: 0.614
Recall: 0.614
Precision: 0.614
70 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Modelo: Neural Net
Metrica: Ponderada
F1: 0.518
Accuracy: 0.607
Recall: 0.607
Precision: 0.523
Modelo: AdaBoost
Metrica: Ponderada
F1: 0.474
Accuracy: 0.607
Recall: 0.607
Precision: 0.418
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
71

APÉNDICE A. ANEXOS
A.3.2. Muestreo: Aleatorio
Modelo: Naive Bayes
Metrica: Ponderada
F1: 0.246
Accuracy: 0.180
Recall: 0.180
Precision: 0.467
Modelo: Nearest Neighbors
Metrica: Ponderada
F1: 0.430
Accuracy: 0.421
Recall: 0.421
Precision: 0.447
72 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Modelo: Decision Tree
Metrica: Ponderada
F1: 0.011
Accuracy: 0.030
Recall: 0.030
Precision: 0.714
Modelo: Random Forest
Metrica: Ponderada
F1: 0.130
Accuracy: 0.213
Recall: 0.213
Precision: 0.383
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
73

APÉNDICE A. ANEXOS
Modelo: Neural Net
Metrica: Ponderada
F1: 0.440
Accuracy: 0.416
Recall: 0.416
Precision: 0.474
Modelo: AdaBoost
Metrica: Ponderada
F1: 0.251
Accuracy: 0.198
Recall: 0.198
Precision: 0.408
74 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
A.3.3. Muestreo: SMOTE
Modelo: Naive Bayes
Metrica: Ponderada
F1: 0.254
Accuracy: 0.190
Recall: 0.190
Precision: 0.433
Modelo: Nearest Neighbors
Metrica: Ponderada
F1: 0.410
Accuracy: 0.388
Recall: 0.388
Precision: 0.456
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
75

APÉNDICE A. ANEXOS
Modelo: Decision Tree
Metrica: Ponderada
F1: 0.110
Accuracy: 0.218
Recall: 0.218
Precision: 0.214
Modelo: Random Forest
Metrica: Ponderada
F1: 0.425
Accuracy: 0.449
Recall: 0.449
Precision: 0.431
76 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Modelo: Neural Net
Metrica: Ponderada
F1: 0.435
Accuracy: 0.401
Recall: 0.401
Precision: 0.480
Modelo: AdaBoost
Metrica: Ponderada
F1: 0.385
Accuracy: 0.332
Recall: 0.332
Precision: 0.471
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
77

APÉNDICE A. ANEXOS
A.3.4. Muestreo: ADASYN
Modelo: Naive Bayes
Metrica: Ponderada
F1: 0.258
Accuracy: 0.193
Recall: 0.193
Precision: 0.444
Modelo: Nearest Neighbors
Metrica: Ponderada
F1: 0.395
Accuracy: 0.373
Recall: 0.373
Precision: 0.436
78 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Modelo: Decision Tree
Metrica: Ponderada
F1: 0.478
Accuracy: 0.599
Recall: 0.599
Precision: 0.569
Modelo: Random Forest
Metrica: Ponderada
F1: 0.416
Accuracy: 0.437
Recall: 0.437
Precision: 0.533
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
79

APÉNDICE A. ANEXOS
Modelo: Neural Net
Metrica: Ponderada
F1: 0.421
Accuracy: 0.393
Recall: 0.393
Precision: 0.458
Modelo: AdaBoost
Metrica: Ponderada
F1: 0.394
Accuracy: 0.343
Recall: 0.343
Precision: 0.499
80 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
A.3.5. Muestreo: CondensedNearestNeighbour
Modelo: Naive Bayes
Metrica: Ponderada
F1: 0.325
Accuracy: 0.294
Recall: 0.294
Precision: 0.487
Modelo: Nearest Neighbors
Metrica: Ponderada
F1: 0.224
Accuracy: 0.226
Recall: 0.226
Precision: 0.420
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
81

APÉNDICE A. ANEXOS
Modelo: Decision Tree
Metrica: Ponderada
F1: 0.473
Accuracy: 0.614
Recall: 0.614
Precision: 0.601
Modelo: Random Forest
Metrica: Ponderada
F1: 0.504
Accuracy: 0.612
Recall: 0.612
Precision: 0.570
82 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Modelo: Neural Net
Metrica: Ponderada
F1: 0.419
Accuracy: 0.401
Recall: 0.401
Precision: 0.449
Modelo: AdaBoost
Metrica: Ponderada
F1: 0.421
Accuracy: 0.398
Recall: 0.398
Precision: 0.459
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
83

APÉNDICE A. ANEXOS
A.3.6. Muestreo: SMOTENN
Modelo: Naive Bayes
Metrica: Ponderada
F1: 0.240
Accuracy: 0.175
Recall: 0.175
Precision: 0.512
Modelo: Nearest Neighbors
Metrica: Ponderada
F1: 0.298
Accuracy: 0.266
Recall: 0.266
Precision: 0.472
84 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Modelo: Decision Tree
Metrica: Ponderada
F1: 0.004
Accuracy: 0.030
Recall: 0.030
Precision: 0.009
Modelo: Random Forest
Metrica: Ponderada
F1: 0.006
Accuracy: 0.020
Recall: 0.020
Precision: 0.043
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
85

APÉNDICE A. ANEXOS
Modelo: Neural Net
Metrica: Ponderada
F1: 0.240
Accuracy: 0.208
Recall: 0.208
Precision: 0.439
Modelo: AdaBoost
Metrica: Ponderada
F1: 0.077
Accuracy: 0.063
Recall: 0.063
Precision: 0.617
86 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
A.3.7. Muestreo: SMOTETomek
Modelo: Naive Bayes
Metrica: Ponderada
F1: 0.273
Accuracy: 0.203
Recall: 0.203
Precision: 0.470
Modelo: Nearest Neighbors
Metrica: Ponderada
F1: 0.403
Accuracy: 0.378
Recall: 0.378
Precision: 0.454
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
87

APÉNDICE A. ANEXOS
Modelo: Decision Tree
Metrica: Ponderada
F1: 0.033
Accuracy: 0.046
Recall: 0.046
Precision: 0.537
Modelo: Random Forest
Metrica: Ponderada
F1: 0.453
Accuracy: 0.485
Recall: 0.485
Precision: 0.553
88 Trabajo Fin de Máster

APÉNDICE A. ANEXOS
Modelo: Neural Net
Metrica: Ponderada
F1: 0.447
Accuracy: 0.404
Recall: 0.404
Precision: 0.501
Modelo: AdaBoost
Metrica: Ponderada
F1: 0.210
Accuracy: 0.155
Recall: 0.155
Precision: 0.494
Desarrollo de un modelo de clasificación de malware Linux ARM según su funcionalidad utilizando técnicas de aprendizajeautomático
89

APÉNDICE A. ANEXOS
A.4. Código fuente
El código fuente de este proyecto se puede encontrar en el siguiente repositorio:
https://github.com/jaqm/tfm_mlmw
90 Trabajo Fin de Máster


















