
Unidad 1 Conceptos básicos vinculados con la estadística 1 ... · estadística tuvo un importante...
17
Unidad 1 Conceptos básicos vinculados con la estadística 1.1 Reseña histórica de la estadística y la probabilidad, y su importancia en las ciencias sociales. El inicio de la estadística, se da, hace aproximadamente 500 años, a partir de la necesidad del ser humano de llevar un control en sus haberes como forma de ayudar a su propia supervivencia en sus condiciones de vida, se considera por ejemplo, en el pastoreo en el que era necesario llevar el control de cuantos animales integraban un rebaño y cuántos de ellos eran machos y hembras, cuántas de éstas estaban preñadas y con cuantos terminaba al final del día, sea por ganancias a través del nacimiento las crías o pérdidas a través de la pérdida de algún individuo del rebaño. Hace 4000 años al existir asentamientos mejor definidos, se permitió el crecimiento de los poblados, lo que a su vez mejoró la calidad de vida y establecer mayor acercamiento con otras poblaciones sea a través del comercio o el sometimiento fue necesario tener mayor control de las riquezas y el manejo de impuestos. Durante la época de los griegos y romanos al crecer estos imperios se hacen más amplios y complejos los sistemas de control, por lo que la estadística tuvo un importante auge a través de los sistemas de control del estado logrando una avanzada organización y administración de sus dominios a través de los censos en los que se registraban los nacimiento, defunciones y situación legal de las personas, al igual que control de tierras, productos y riquezas. En la Edad Media, se da un impasse en el que no se logra un desarrollo avanzado de la estadística y de la ciencia en general durante un periodo de aproximadamente 1000 años, fue hasta 1545 en que se retoma el proceso de registro más claro y preciso de nacimientos, matrimonios y defunciones. En el renacimiento y con el auge del comercio internacional (descubrimiento de América y nuevas rutas al Asia surgen trabajos científicos importantes, entre los más destacados y solo por mencionar algunos, se encuentran: Copérnico, Galileo, Napier, Bacon y Descartes.
Transcript of Unidad 1 Conceptos básicos vinculados con la estadística 1 ... · estadística tuvo un importante...

Unidad 1 Conceptos básicos vinculados con la estadística
1.1 Reseña histórica de la estadística y la probabilidad, y su importancia en las ciencias sociales.
El inicio de la estadística, se da, hace aproximadamente 500 años, a partir de la
necesidad del ser humano de llevar un control en sus haberes como forma de
ayudar a su propia supervivencia en sus condiciones de vida, se considera por
ejemplo, en el pastoreo en el que era necesario llevar el control de cuantos
animales integraban un rebaño y cuántos de ellos eran machos y hembras,
cuántas de éstas estaban preñadas y con cuantos terminaba al final del día, sea
por ganancias a través del nacimiento las crías o pérdidas a través de la pérdida
de algún individuo del rebaño.
Hace 4000 años al existir asentamientos mejor definidos, se permitió el crecimiento de los
poblados, lo que a su vez mejoró la calidad de vida y establecer mayor acercamiento con
otras poblaciones sea a través del comercio o el sometimiento fue necesario tener mayor
control de las riquezas y el manejo de impuestos.
Durante la época de los griegos y romanos al crecer estos imperios se
hacen más amplios y complejos los sistemas de control, por lo que la
estadística tuvo un importante auge a través de los sistemas de control del
estado logrando una avanzada organización y administración de sus
dominios a través de los censos en los que se registraban los nacimiento,
defunciones y situación legal de las personas, al igual que control de
tierras, productos y riquezas.
En la Edad Media, se da un impasse en el que no se logra un
desarrollo avanzado de la estadística y de la ciencia en
general durante un periodo de aproximadamente 1000 años,
fue hasta 1545 en que se retoma el proceso de registro más
claro y preciso de nacimientos, matrimonios y defunciones.
En el renacimiento y con el auge del comercio internacional (descubrimiento de América y
nuevas rutas al Asia surgen trabajos científicos importantes, entre los más destacados y solo
por mencionar algunos, se encuentran: Copérnico, Galileo, Napier, Bacon y Descartes.

Desarrolla la teoría heliocéntrica, descubriendo que la Tierra giraba alrededor del Sol y no
al revés, como en su época se creía, de igual forma descubrió que la Tierra rotaba
completamente sobre sí misma cada 24 horas y demostró que la Tierra daba una vuelta
completa al Sol en ciclos de un año.
En el campo de la física, Galileo formuló las primeras leyes sobre el movimiento; en el de
la astronomía, confirmó la teoría copernicana con sus observaciones telescópicas. Pero
ninguna de estas valiosas aportaciones tendría tan trascendentales consecuencias como la
introducción de la metodología experimental, logro que le ha valido la consideración de
padre de la ciencia moderna.
Introdujo el concepto de los algoritmos naturales1, publicado en 1614 con el tratado Mirifici
logarithmorum canonis descriptio, fruto de un estudio de dos décadas. Entre las mas
importante esta el logaritmo de base 10.
1Un algoritmo es el conjunto prescrito de instrucciones o reglas bien definidas, ordenadas y finitas que
permiten llevar a cabo una actividad mediante pasos sucesivos que no generen dudas a quien deba hacer dicha
actividad

Consideró que la verdad se puede alcanzar a través de la experiencia y el razonamiento
inductivo. Creó un método del que dio una exposición incompleta en su Novum organum
scientiarum (1620). Su método inductivo pretendía proporcionar un instrumento para
analizar la experiencia, a partir de la recopilación exhaustiva de casos particulares del
fenómeno investigado y la posterior inducción, por analogía, de las características o
propiedades comunes a todos ellos; ese procedimiento había de conducir, gradualmente,
desde las proposiciones más particulares a los enunciados más generales.
El método cartesiano, que Descartes propuso para todas las ciencias y disciplinas, consiste
en descomponer los problemas complejos en partes progresivamente más sencillas hasta
hallar sus elementos básicos, las ideas simples, que se presentan a la razón de un modo
evidente, y proceder a partir de ellas, por síntesis, a reconstruir todo el complejo, exigiendo
a cada nueva relación establecida entre ideas simples la misma evidencia de éstas.
John Graunt en 1663 publicó Natural and Political
Observations Made upon the Bills of Morality
(Observaciones políticas y naturales sobre los
registros de mortalidad) analizando la necesidad de
políticas demográfica y económica fundamentadas
en objetivos. Desarrolla métodos para el censo y
análisis tabular de datos.

Kasper Newmann estudió la tasa de mortalidad en Bresalu realizando
uno de los primeros análisis estadísticos demostrando la falsedad de la
creencia de que las muertes se incrementaban en los años terminados en
siete.
Gottfried Achenwall aplica la estadística para estudiar la agricultura,
manufacturas y comercio de las naciones europeas. Usa por primera
vez el término statistik.
Gerolamo Cardano escribió el Libro de los
Juegos de Azar, en el que presenta los
primeros cálculos de probabilidad.
Pascal formaliza la matemática de una
teoría de la probabilidad.
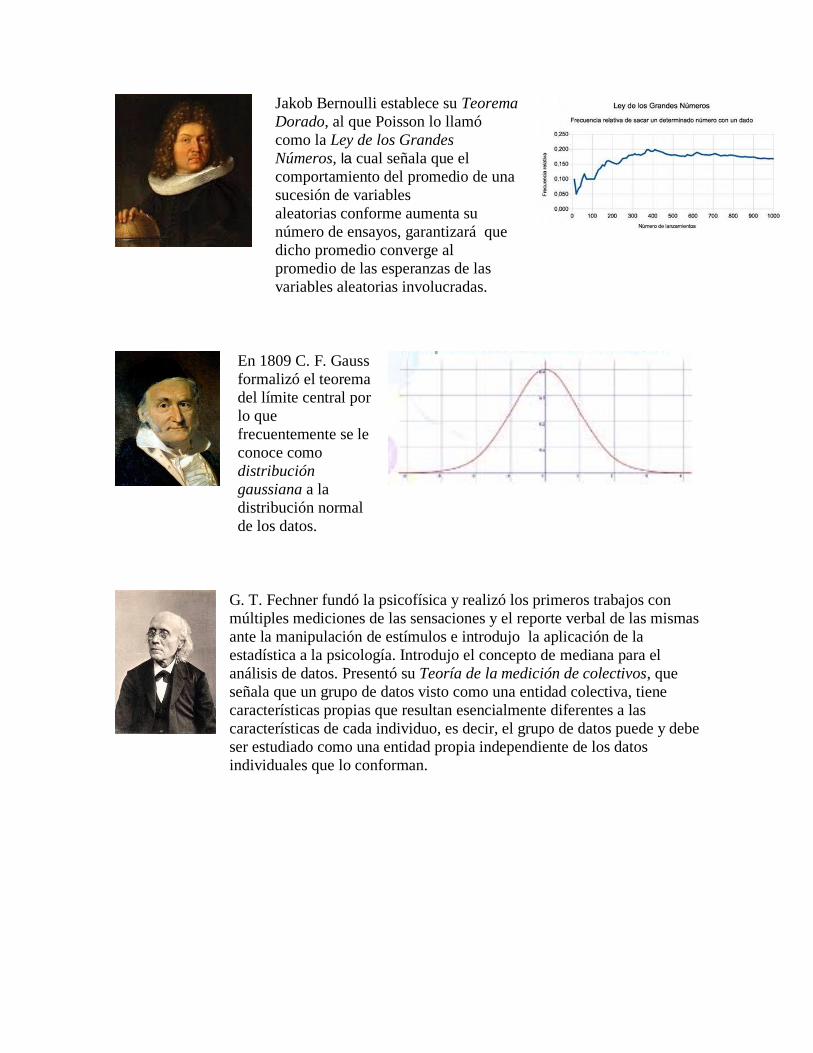
Jakob Bernoulli establece su Teorema
Dorado, al que Poisson lo llamó
como la Ley de los Grandes
Números, la cual señala que el
comportamiento del promedio de una
sucesión de variables
aleatorias conforme aumenta su
número de ensayos, garantizará que
dicho promedio converge al
promedio de las esperanzas de las
variables aleatorias involucradas.
En 1809 C. F. Gauss
formalizó el teorema
del límite central por
lo que
frecuentemente se le
conoce como
distribución
gaussiana a la
distribución normal
de los datos.
G. T. Fechner fundó la psicofísica y realizó los primeros trabajos con
múltiples mediciones de las sensaciones y el reporte verbal de las mismas
ante la manipulación de estímulos e introdujo la aplicación de la
estadística a la psicología. Introdujo el concepto de mediana para el
análisis de datos. Presentó su Teoría de la medición de colectivos, que
señala que un grupo de datos visto como una entidad colectiva, tiene
características propias que resultan esencialmente diferentes a las
características de cada individuo, es decir, el grupo de datos puede y debe
ser estudiado como una entidad propia independiente de los datos
individuales que lo conforman.

Plano Físico Plano Fisiológico Plano Psíquico
Estímulo Físico Excitación (SNC) Sensación
A
B
Wundt en 1879 funda el primer laboratorio
experimental de psicología, partiendo de los
trabajos de Fechner.
F. Galton estableció el estudio de las diferencias individuales,
principalmente en la inteligencia en dotados y estableció los
constructos de la línea de regresión y la correlación. Construyó una
máquina para demostrar el teorema del límite central y es que
siempre que se realiza el experimento, el resultado final se
aproximará a una Campana de Gauss, es decir, conformará una
distribución normal
Caja de Galton

K. Pearson presenta el libro La gramática de la
ciencia, que permite observar el porqué de la
psicología como ciencia y la importancia de
entenderla a la par las ciencias naturales y sociales.
S. S. Stevens formuló la teoría de la
medición en la que establece los
cuatro niveles conocidos (nominal,
ordinal, intervalar y de razón).
R. Fisher desarrolló el análisis de varianza (AVAR o
ANOVA), método que permite probar diferencias de
tendencia central en más de dos grupos. Además creó la
Distribución F, para probar hipótesis en el AVAR.
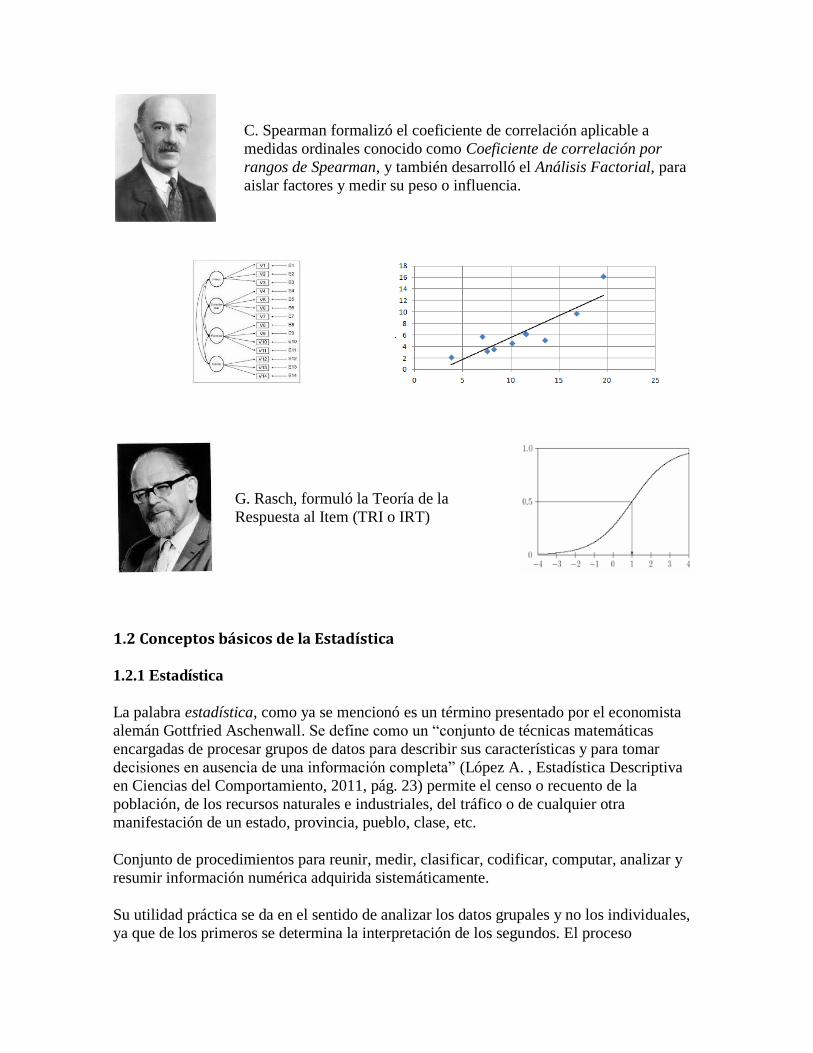
C. Spearman formalizó el coeficiente de correlación aplicable a
medidas ordinales conocido como Coeficiente de correlación por
rangos de Spearman, y también desarrolló el Análisis Factorial, para
aislar factores y medir su peso o influencia.
G. Rasch, formuló la Teoría de la
Respuesta al Item (TRI o IRT)
1.2 Conceptos básicos de la Estadística
1.2.1 Estadística
La palabra estadística, como ya se mencionó es un término presentado por el economista
alemán Gottfried Aschenwall. Se define como un “conjunto de técnicas matemáticas
encargadas de procesar grupos de datos para describir sus características y para tomar
decisiones en ausencia de una información completa” (López A. , Estadística Descriptiva
en Ciencias del Comportamiento, 2011, pág. 23) permite el censo o recuento de la
población, de los recursos naturales e industriales, del tráfico o de cualquier otra
manifestación de un estado, provincia, pueblo, clase, etc.
Conjunto de procedimientos para reunir, medir, clasificar, codificar, computar, analizar y
resumir información numérica adquirida sistemáticamente.
Su utilidad práctica se da en el sentido de analizar los datos grupales y no los individuales,
ya que de los primeros se determina la interpretación de los segundos. El proceso

estadístico se clasifica en tres tipos: Estadística descriptiva, estadística inferencial y
estadística proyectiva.
1.2.2 Estadística descriptiva:
Describe grupos de datos, a partir de su
presentación como datos crudos, es decir, tal como
se obtuvieron, organizándolos, calculando sus
medidas representativas y representándolos a
través de gráficas. Explica cuántas observaciones
fueron registradas y qué tan frecuentemente
ocurrió en los datos cada puntuación o categoría
de observaciones. Recoge, ordena y clasifica los
datos de interés mediante su obtención y análisis
en una muestra de la población considerada para
llegar a resultados veraces y no ambiguos.
1.2.3 Estadística Inferencial:
Extrae conclusiones sobre las relaciones
matemáticas entre las características de un grupo
de personas u objetos. A través de cálculos se
pretende mostrar relaciones causa-efecto, probar
hipótesis y teorías científicas. Trabaja a partir de
las características que se conocen de una muestra
para inferir las características desconocidas de la
población. El inferir o inducir es “sacar
conclusiones sobre algo” (Ritchey, 2002, pág. 15)
1.2.4 Estadística proyectiva:
Utiliza una serie de
observaciones de un
fenómeno observado
obtenidas en un
determinado periodo, para
hacer pronósticos hacia el
futuro, es decir, a través del
comportamiento observado
en el pasado, se pronostica
(o proyecta) el probable
comportamiento del
fenómeno en lo futuro.

1. 3 Variable: Es una característica que puede ser medida en diferentes individuos, y es
susceptible de adoptar diferentes valores. Por ende, las variables deberán ser susceptibles de
medirse, observarse, evaluarse e incluso inferirse a través de la obtención de datos de la
realidad (Hernández, Fernández y Baptista, 2006, p. 148), y cualquier objetivo dentro de la
investigación científica cuantitativa se conforma de variables. Al medir un aspecto
específico de un fenómeno natural se obtiene su medida o magnitud en una escala
determinada. Se llama variable a cualquier magnitud o medida capaz de variar su valor. Y
constante a la magnitud o medida cuyos valores no pueden variar, ejemplo: π = 3.1416.
1.3.1. Clasificación de las variables:
Por la posibilidad de subdivisión
Categórica o
Discretas
Acotada por un extremo
Continua
Acotada por los dos
extremos
No acotada
Por su papel en una correlación Predictor
Criterio
Por su papel en un problema causa-
efecto
Independiente
(VI) Atributiva
Activa
Dependiente
(VD)
Extraña (VE)
Variables continuas y variables discretas:
Variables continuas: Aquellas que pueden variar a lo largo de un continuo. Por tanto, entre
dos puntos cualquiera existe un número infinito de puntos. Ejemplo: estatura, edad,
inteligencia, etc.
Variables discretas: Las variables cuantitativas pueden clasificarse como discretas o
continuas. Un número finito de valores entre dos valores cualesquiera. Una variable
discreta siempre es numérica son aquellas que varían por categorías y entre dos categorías
cualquiera no existe subdivisiones posibles. Ejemplo: sexo, estado civil, etc.
Variables deterministas y variables aleatorias
Fenómeno determinista: aquel que ofrece uno y solo un resultado posible. Ejemplo: ley de
gravedad.

Fenómeno aleatorio: aquel que ofrece dos o más resultados posibles. Ejemplo: una moneda
en un volado.
Variable determinista: aquella que varía conforme a leyes determinista. Ejemplo: velocidad
de caída de un cuerpo, el punto de ebullición el agua.
Variables aleatorias: el resultado del fenómeno aleatorio varía conforme a las leyes de la
probabilidad. Ejemplo: dado, baraja, ruleta, etc.
1.3.2. Evento, concepto y clasificación
Son los posibles resultados de un fenómeno aleatorio. A veces se le llaman sucesos,
acontecimientos, etc.
1.3.3. Clasificaciones de evento
Eventos simples y eventos compuestos
Eventos simples: son aquellos que no pueden descomponerse en eventos más
sencillos. Por ejemplo: si se lanza una moneda y cae sol, éste es un evento simple;
que se trae una carta y aparece el as de diamantes, también lo es.
Eventos compuestos: son aquellas que pueden descomponerse en dos o más eventos
simples. Por ejemplo: una mano de pókar, el resultado del lanzamiento simultáneo
de tres dados, etc.
Eventos excluyentes y eventos inclusivos
Eventos excluyentes: se dice que dos eventos son mutuamente excluyentes cuando
la ocurrencia de uno de ellos impide (o excluye) la ocurrencia del otro o de los
otros. Por ejemplo: si te lanza un dado y aparecen en la cara cuatro, esto excluye la
ocurrencia del resto de caras del dado.
Elementos inclusivos: son aquellos en que la ocurrencia de un evento o implica
(incluye) necesariamente la ocurrencia de otro. Por ejemplo: si se lanzan dos lados y
el resultado es nueve, llegado uno presentó la cara seis, esto implica necesariamente
que el dado dos cayó tres.
Eventos dependientes y eventos independientes
Eventos independientes: se dice que un evento es independiente cuando no es
afectado por la ocurrencia o no ocurrencia de un evento anterior.
Ejemplo: si se lanza una moneda y aparece cara, un segundo lanzamiento será
totalmente independiente de este resultado; supóngase que tenemos una botella con
cinco canicas rojas (R) y tres negras (N), entonces para una primera extracción.

Ahora, en la primera extracción aparece una canica roja, se regresa a la botella y se
aleatoriza. En una siguiente fracción tendremos:
Es decir, no se alteraron las posibilidades y la segunda extracción será
independiente de la primera.
Eventos dependientes: se dice que un evento es dependiente de otro cuando es
afectado por la ocurrencia o no ocurrencia del anterior. Por ejemplo: supóngase
quien el ejemplo anterior no regresamos la canica la botella, entonces:
Ensayo P(R) P(N) Evento Conclusión
0 5/8 3/8 -------- --------
1 4/7 3/7 Roja Disminuye P(R) (5/8) > (4/7)
2 3/6 3/6 Roja Disminuye P(R)
3 3/5 2/5 Negra Disminuye P(N)
1.4. Tipo de Investigación o diseño de investigación, se refiere al “plan o estrategia concebida para obtener la información que se desea” (Hernández, Fernández, & Baptista,
Metodología de la Investigación, 2006, pág. 158).
En la investigación científica cuantitativa se encuentran dos tipos: Experimentales y No
experimentales.
1.4.1 Experimentales: Se realiza una acción y posteriormente observar sus consecuencias;
de manera más particulares un estudio en el que se manipulan intencionalmente una o más
variables independientes (causas), para analizar sus consecuencias en una o más variables
dependientes (efectos), bajo el control del experimentador. Se dividen a la vez en tres
subtipos.
Preexperimentos: Son diseños de un solo grupo con un grado de control mínimo.
Es útil como primer acercamiento al problema de investigación en la realidad
Cuasiexperimentales: Manipulan deliberadamente al menos una variable
independiente para observar su efecto y relación con una o más variables
dependientes, difiriendo de los experimentos “puros” en el grado de seguridad o
confiabilidad que puede tenerse sobre la equivalencia inicial de los grupos.

Experimentales puros: Se realizan sin la manipulación deliberada de las variables
y en las que solo se observan los fenómenos en su ambiente natural para después
analizarlos, tampoco se asignan aleatoriamente a los participantes o los
tratamientos. Las variables independientes ocurren y no es posible manipularlas, por
lo que no se tiene control, ni se puede influir sobre ellas al haber ya ocurrido junto
con sus efectos.
1.4.2 No experimentales
Son estudios que se realizan sin la manipulación deliberada de las variables y en las que
solo se observan los fenómenos en su ambiente natural para después analizarlos, tampoco
se asignan aleatoriamente a los participantes o los tratamientos. Las variables
independientes ocurren y no es posible manipularlas, por lo que no se tiene control, ni se
puede influir sobre ellas al haber ya ocurrido junto con sus efectos.
Transeccionales o transversales: Recolecta datos en un único momento, describe las
variables y analiza su incidencia e interrelación en un momento dado, pudiendo abarcar
varios grupos o subgrupos de indicadores y diferentes situaciones o eventos.
Recolección de datos única
Grupo 1 Grupo 2
Exploratorios: Busca conocer una variable o conjunto de variables, explorando en un
momento específico. Se aplica a problemas de investigación nuevos o poco conocidos,
permitiendo posteriormente el paso a otro tipo de diseños (no experimentales y
experimentales).
Descriptivos: Indagan la incidencia de las modalidades o niveles de una o más variables en
una población. Ubica en una o en diversas variables a un grupo de personas, objetos,
situaciones, contextos, etc. y proporciona una descripción, pudiendo realizar descripciones
comparativas entre grupos o subgrupos.
Correlacionales-causales: Describe la relación entre dos o más variables en un momento
determinado, siendo en términos de correlación o de relación causa-efecto. Se pueden
limitar la relación entre variables sin precisar sentido de causalidad o pretender analizar
relaciones causales. Las relaciones no causales se fundamentan en planteamientos e
hipótesis correlacionales; al evaluar relaciones causales, se hacen planteamientos e
hipótesis causales, en esta modalidad causal, se pueden reconstruir:
A partir de la variable dependiente (investigación causal retrospectiva).
A partir de la variable independiente (investigación causal prospectiva).
A partir de la base de variabilidad amplia de las independientes y dependientes (Causalidad
múltiple).

Los estudios transeccionales causales permiten predecir el comportamiento de una o más
variables a partir de otras, una vez establecida la causalidad, formando a partir de esto
último las variables predictoras.
Longitudinales o evolutivos: Son los estudios que recaban datos de diferentes puntos del
tiempo para realizar inferencias acerca del cambio, sus causas y sus efectos. Los puntos se
especifican de antemano. Se fundamentan en hipótesis de diferentes grupos, correlacionales
y causales.
Diseño de tendencia (trend): Analizan cambios a través del tiempo en las variables, dentro
de una población, centrándose en ésta. Puede medir u observar a toda la población o tan
solo a una muestra, siendo que los sujetos no sean los mismos, pero la población, sí.
Diseño de análisis evolutivo: Se denominan también diseños de evolución de grupos o
cohortes, y se examinan cambios a través del tiempo en subpoblaciones o grupos
específicos. Atiende a grupos divididos (cohortes) identificados por alguna característica en
común. Permite el seguimiento de los grupos a través del tiempo, permitiendo la extracción
de una muestra cada vez que se requiera recolectar datos sobre el grupo o la subpoblación.
Recolección de
datos de una
subpoblación
Recolección de
datos de una
subpoblación
Recolección de
datos de una
subpoblación
Recolección de
datos de una
subpoblación
Muestras distintas, misma subpoblación vinculada por algún criterio o característica
Tiempo 1 Tiempo 2 Tiempo 3 Tiempo 4
Diseño panel: Son similares a los diseños anteriores, solo que el mismo grupo de
participantes es medido u observado en todos los tiempos. Tiene la ventaja que además de
conocer los cambios grupales, se conocen los cambios individuales. Se sabe qué casos
específicos introducen el cambio, siendo su principal desventaja obtener con exactitud los
mismos sujetos para una segunda medición u observación subsecuente.
1.5 Diferencias entre la Estadística Descriptiva y la Estadística Inferencial
Estadística Descriptiva Estadística Inferencial
Recolección, presentación, descripción,
análisis e interpretación de un conjunto de
datos.
Permite el diseño experimental con el fin de
corroborar o descartar una hipótesis.
Analiza, estudia y describe las
características particulares de la totalidad de
los individuos de un grupo.
Permite deducir las propiedades del total de
los elementos de un conjunto a partir del
estudio de una muestra significativa de este
conjunto (Teoría de las Muestras)
Obtiene información, la analiza, elabora y
simplifica para poder interpretarla
rápidamente.
Compara la varianza de dos poblaciones a
partir del análisis de sus respectivas
varianzas (ANOVA).
Ordena datos:
a) A través de tablas de frecuencias, de
Compara más de dos variables entre sí para
comprobar el efecto de las variables y su
interacción, a través del Análisis

valores numéricos, o de clases; ascendentes,
descendentes b) A través de
representaciones gráficas (histogramas,
polígonos de frecuencias, gráficas de series
de tiempos)
multifactorial de varianza (ANCOVA), o
Análisis de Covarianza, analizando los
resultados de investigaciones de tipo
experimental de diseño factorial.
Obtiene Medidas de Tendencia Central
(Media, Mediana y Moda)
Utiliza métodos no paramétricos, para
estudiar modelos estadísticos que tienen una
distribución que no se ajusta a los criterios
paramétricos conocidos.
Obtiene Medidas de Dispersión ((Rango, la
Varianza, la Covarianza y la Desviación
Estándar)
Obtiene Medidas de Asimetría y Curtosis
Hace uso de la probabilidad baynesiana, que
permite que las observaciones y las
evidencias sean utilizadas para actualizar o
inferir la probabilidad y grado de certeza de
una hipótesis.
1.6 Importancia del estudio de la estadística descriptiva2
En una investigación, permite conocer la causalidad y conclusión sobre el efecto
que algunos cambios en las variables independientes tienen sobre las variables dependientes.
Los modelos experimentales requieren medir, manipular y volver a medir para saber
si la manipulación de uno o más factores dentro del modelo experimental han
sufrido modificaciones.
Permite extraer y resumir información útil de las observaciones que se hacen, para
basar las decisiones en datos limitados, dando mayor claridad y precisión a la
investigación psicológica.
Permite el uso de hipótesis, y a través de esta se experimenta y se concluye, luego el
proceso se replica si es necesario.
1.7 Medición
El proceso de medición en psicología va más allá de la concepción física de las
características de la persona, es evidente que existen elementos intrínsecos que se requieren
retomar para conocer realmente al individuo, elementos que conforman sus características
psíquicas y se desglosan en ámbitos como inteligencia, actitudes y valores, por retomar las
de mayor relevancia.
Estos elementos pueden ser medidos de manera más o menos objetiva con base a los
conocimientos que se tengan respecto a estos mismos, la cantidad y sobre todo la calidad de
la información con que se cuenta son imprescindibles para lograr la mayor precisión en el
2 Retomado de: http://albertomendeztorres.blogspot.mx/2009/09/importancia-de-la-estadistica-en-la.html

proceso de medición, de esta manera el hombre a tratado de hallar una forma de medir
aspectos tales como la inteligencia, las actitudes, las habilidades, etc.
Así, en ese sentido se trata de conformar los aspectos que den respaldo a las posibles
mediciones de aquellas características que interesa cuantificar, con la finalidad de
establecer parámetros que permitan darle una utilidad a esa concepción numérica que se da
al fenómeno de estudio en cuestión.
Se debe por principio de cuentas, definir lo que es entendible por medir; en términos
generales, se puede entender el medir como “la descripción de datos en términos de
números” (Guilfor, 1954 en Brown 1980, pág. 8), aunque con mayor precisión se define
como la “asignación de números a objetos o eventos, de acuerdo a reglas explícitas”
(Stevens, 1951 en Brown, 1980, pág. 8).
De igual forma coinciden Siegel y Castellan al definir la medición como “el proceso de
mapear o asignar números a objetos u observaciones” (Siegel & Castellan, 2005, pág. 53)
Carmines y Zeller (1991, citados en Hernández, Fernández, y Baptista, 2010, pág. 276)
definen a la medición como el proceso de vincular conceptos abstractos con indicadores
empíricos a través de un plan explícito, organizado y que permite clasificar y cuantificar
datos disponibles de acuerdo a indicadores
Es decir, la medición “responde a la pregunta ¿cuánto? [y] proporciona una descripción de
la ejecución de la persona; [pero] no nos dice nada sobre el valor de dicha ejecución”
(Brown, 1980, pág. 13).
Se puede observar que se procura otorgar un valor numérico a ciertas características que
interesan en un proceso de investigación, características que no necesariamente han de ser
palpables, sino que se derivan, a decir de Hernández, et al (2006), de abstracciones
formuladas en el desarrollo del conocimiento, es decir, a través de la formulación de
constructos.
1.7 Niveles de Medición
La medición solo es permisible cuando hay cierto grado de isomorfismo entre los sistemas
y sus estructuras, entre el sistema numérico y el sistema y la estructura del objeto que se
está midiendo. Dos sistemas son isomorfos si sus estructuras son idénticas en las relaciones
y operaciones que permiten (Herrans, 2000). Existen cuatro niveles de medición:
Nivel Nominal: Es el nivel más elemental de medición, asigna a las personas a
categorías cualitativamente distintas, y se pretende determinar si existen dos
personas miembros de la misma categoría o clase, es decir, las categorías deben ser
mutuamente excluyente. Esta nivel se caracteriza por la relación de equivalencia
(los sujetos que se agrupan en una categoría específica tienen que ser iguales en
relación con el rasgo que se usó). Permite identificar sujetos como iguales o

diferentes. A variables medidas se les asigna a cada categoría cualquier tipo de
símbolos.
Nivel Ordinal: Clasifican a las personas en alguna dimensión, se tiene la
clasificación y la magnitud, sin tener conocimiento del tamaño de las unidades de la
nivel de medición. Establece relaciones de mayor qué (>) y menor qué (<) (Ej.
Clasificación de los más altos promedios).
Nivel Intervalar: La diferencia de magnitud significa lo mismo en todos los puntos
de la escala. Implica clasificación, magnitud y unidades de tamaños iguales o
estándar y uso un punto cero arbitrario. Su uso en la psicología es importante, ya
que los puntajes se pueden transformar en cualquier clase de calificación lineal;
sumando o restando una constante o multiplicándolas o dividiéndolas por la misma
constante. En este sentido, las calificaciones de una Nivel se pueden convertir a las
de otra que utilice unidades diferentes. Las estadísticas más utilizadas presuponen
una Nivel de intervalos de medición.
Nivel de Razón o Proporción: Posee todas las propiedades de la escala de
intervalos y un punto cero real o verdadero en su origen, llega al nivel de medición
más alto y preciso. La razón entre dos puntos cualesquiera es independiente de la
unidad de medición. Se logra crear una escala de razón cuando cuatro relaciones son
factibles operacionalmente: la relación de equivalencia, la relación de más que, la
razón entre dos intervalos cualesquiera y la razón entre dos valores cualesquiera de
la escala.


















