
UN ALGORITMO DE ESTI MACIÓN DE DISTRIBU CIÓN …
138
Guanajuato, Gto., 9 de septiembre de 2019 UN ALGORITMO DE ESTIMACIÓN DE DISTRIBUCIÓN BASADO EN T-CHERRY JUNCTION TREE T E S I S Que para obtener el grado de Maestro en Ciencias con Orientación en Computación y Matemáticas Industriales Presenta Juan Bosco Robledo Muñoz Director de Tesis: Dr. Arturo Hernández Aguirre Autorización de la versión final
Transcript of UN ALGORITMO DE ESTI MACIÓN DE DISTRIBU CIÓN …

Guanajuato, Gto., 9 de septiembre de 2019
UN ALGORITMO DE ESTIMACIÓN
DE DISTRIBUCIÓN BASADO EN
T-CHERRY JUNCTION TREE
T E S I S Que para obtener el grado de
Maestro en Ciencias
con Orientación en
Computación y Matemáticas Industriales
Presenta
Juan Bosco Robledo Muñoz
Director de Tesis:
Dr. Arturo Hernández Aguirre
Autorización de la versión final


Reconocimientos
Nuestra familia nos acompana siempre, brindandonos apoyo incondicional, aliento yconsejos; no importa a donde vamos ni que es lo que hagamos. Deseo expresar a ellosmi profundo agradecimiento por esto. De manera muy especial a Izabel; a mis padres,Guadalupe y Adela; y a mis hermanos Mary, Miguel, Ubaldo, Cruz y Lupita.
Expreso mi gratitud de manera sincera hacia mi asesor de tesis, el Doctor ArturoHernandez Aguirre por su constante apoyo, comprension y paciencia. Siempre estuvo dis-puesto a orientarme y compartir su conocimiento, lo cual fue fundamental para la realiza-cion de este trabajo.
Quisiera agradecer tambien a los Doctores Ignacio Segovia Domınguez y Carlos SeguraGonzalez sus valiosas observaciones y sugerencias para mejorar este trabajo.
El apoyo de los amigos y companeros que conocı en CIMAT, en especial de Ricardoy Andrei, fue muy importante durante mi residencia en Guanajuato. Es algo por lo quesiento un sincero agradecimiento.
Agradezco a los investigadores con los que convivı en CIMAT ya que siempre encontreen ellos disposicion para compartir saberes y resolver dudas.
Por ultimo, y no por ello con menos gratitud, quisiera afirmar que estoy en deuda conCIMAT y CONACYT como instituciones. La beca CONACYT hizo posible mi estanciaen Guanajuato y CIMAT me proveyo con una calidad excelente de todo lo necesario parael desarrollo de este trabajo.
iii


Resumen
Existe una familia de Algoritmos Evolutivos que ajustan un modelo de la distribucion deprobabilidad de los mejores individuos de la poblacion con el fin de utilizar la informaciondel espacio de busqueda contenida en ellos de manera explıcita para guiar el proceso deoptimizacion. Son los llamados Algoritmos Evolutivos Basados en Modelos. Entre estosdestacan los Algoritmos de Estimacion de Distribucion, los cuales hacen simulaciones des-de el modelo para generar nuevos individuos. Una buena parte de estos algoritmos usanModelos Graficos Probabilısticos, que consisten en una estructura dada por un grafo y susparametros; donde los vertices del grafo son las variables del problema y una arista indicaque hay dependencia entre las variables que conecta. El costo computacional de manejareste tipo de modelos esta en funcion de la densidad del grafo. Se suelen usar grafos dis-persos ya que es necesario construir el modelo varias veces durante el proceso evolutivo.
En este trabajo buscamos hacer uso de manera eficiente de un modelo mas denso, locual nos permitira tomar en cuenta mas dependencias entre las variables del problema.Se propone para esto la construccion de un t-Cherry Junction Tree de orden k (donde kindica la densidad del modelo) usando el algoritmo propuesto por Proulx y Zhang, conuna mejora en cuestion de eficiencia en la metrica de calidad del ajuste a la distribucionde probabilidad de los individuos. Se aplica este modelo en un Algoritmo de Estimacionde Distribucion, que llamamos t-Cherry EDA, y se hace un analisis experimental de surendimiento en funciones de benchmark comunmente usadas en la literatura para distintasdensidades del grafo.
Los resultados muestran que un valor de k adecuado respecto a las propiedades dedependencia de las variables obtiene buenos resultados. Al usar una densidad menor omayor a la adecuada el rendimiento del algoritmo baja, por lo que una estrategia deadaptacion de este valor surge como trabajo futuro. El modelo muestra ser robusto, puesademas de las propiedades usadas en este trabajo podemos mencionar que su entropıa esun buen indicador de convergencia; y los individuos simulados desde el pueden ser usadoscomo vectores de mutacion correlacionados. Es por esto que sus posibles aplicaciones seextienden a otras familias de Algoritmos Evolutivos Basados en Modelos.
v


Indice general
Indice de figuras XI
Indice de tablas XIII
1. Introduccion 11.1. Algoritmos Evolutivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2. Algoritmo Genetico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.1. Seleccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.2. Recombinacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.3. Mutacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3. Motivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.4. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.5. Estructura de la tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2. Algoritmos Evolutivos basados en Modelos 112.1. Algoritmos de Estimacion de Distribucion. . . . . . . . . . . . . . . . . . . . 11
2.1.1. Seleccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.1.2. Reemplazo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.1.3. Construccion y uso del modelo para la generacion de nuevos individuos 12
2.2. Estrategias evolutivas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.1. Seleccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.2. Reemplazo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.3. Uso del modelo para la mutacion . . . . . . . . . . . . . . . . . . . . 16
3. Modelos graficos y su uso en los EDAs 193.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1.1. Notacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.1.1.1. Probabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2. Breve introduccion a los Modelos Graficos Probabilısticos . . . . . . . . . . 213.2.1. Definicion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2.2. Grafos dirigidos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
vii

INDICE GENERAL
3.2.2.1. Caso discreto . . . . . . . . . . . . . . . . . . . . . . . . . . 223.2.2.2. Caso Gaussiano . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.3. Grafos no dirigidos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.2.4. Construccion del Modelo . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.4.1. Score + Search . . . . . . . . . . . . . . . . . . . . . . . . . 293.2.4.1.1. Metricas . . . . . . . . . . . . . . . . . . . . . . . 293.2.4.1.2. Estrategias de busqueda . . . . . . . . . . . . . . . 31
3.2.4.2. Deteccion de independencias . . . . . . . . . . . . . . . . . 323.2.5. Simulacion desde el Modelo Grafico Probabilıstico . . . . . . . . . . 32
3.3. Aplicacion en Algoritmos Evolutivos . . . . . . . . . . . . . . . . . . . . . . 333.3.1. Sin dependencias: Grafos desconectados . . . . . . . . . . . . . . . . 333.3.2. Dependencias por pares . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.3.2.1. Cadena . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.3.2.2. Arbol de dependencias . . . . . . . . . . . . . . . . . . . . 37
3.3.3. Multiples interdependencias . . . . . . . . . . . . . . . . . . . . . . . 393.3.3.1. Polytree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.3.3.2. Redes Bayesianas/Gaussianas . . . . . . . . . . . . . . . . 403.3.3.3. Redes de Markov . . . . . . . . . . . . . . . . . . . . . . . . 413.3.3.4. Grafo completo . . . . . . . . . . . . . . . . . . . . . . . . . 42
4. El t-Cherry Junction Tree de orden k 434.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.1.1. Presentando los grafos . . . . . . . . . . . . . . . . . . . . . . . . . . 434.2. Definiciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.2.1. t-Cherry Tree de orden k . . . . . . . . . . . . . . . . . . . . . . . . 484.2.2. Junction Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.2.2.1. El peso del Junction Tree . . . . . . . . . . . . . . . . . . . 514.2.3. t-Cherry Junction Tree de orden k . . . . . . . . . . . . . . . . . . . 52
4.3. Construccion del modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544.3.1. Algoritmos de construccion en la literatura . . . . . . . . . . . . . . 554.3.2. La actualizacion de orden . . . . . . . . . . . . . . . . . . . . . . . . 59
4.3.2.1. Notacion y terminologıa . . . . . . . . . . . . . . . . . . . . 594.3.2.2. La actualizacion de clusters . . . . . . . . . . . . . . . . . . 60
4.3.2.2.1. Escenarios de actualizacion de cluster . . . . . . . 604.3.2.2.2. Order Update Process . . . . . . . . . . . . . . . . 63
4.3.2.3. Bud Conversion . . . . . . . . . . . . . . . . . . . . . . . . 664.3.2.3.1. t-Cherry Bud Conversion Algorithm . . . . . . . . 66
4.3.3. Actualizacion de Orden . . . . . . . . . . . . . . . . . . . . . . . . . 684.3.3.1. Complejidad computacional . . . . . . . . . . . . . . . . . . 68
4.4. Construccion de un t-Cherry Junction Tree de orden k Gaussiano . . . . . . 694.4.1. Simplificacion de la expresion de incremento en el peso del arbol . . 704.4.2. Complejidad computacional . . . . . . . . . . . . . . . . . . . . . . . 72
viii

INDICE GENERAL
5. Un EDA para optimizacion numerica basado en t-Cherry Junction Treede orden k 735.1. Del t-Cherry Junction Tree de orden k a una Red Gaussiana . . . . . . . . 745.2. El t-Cherry EDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.2.1. Construccion del modelo usando un archivo de individuos . . . . . . 775.2.2. Generacion de nuevos individuos . . . . . . . . . . . . . . . . . . . . 795.2.3. Estrategia de reemplazo inspirada en ES . . . . . . . . . . . . . . . . 79
5.3. Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 795.3.1. Benchmark de funciones . . . . . . . . . . . . . . . . . . . . . . . . . 805.3.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.3.2.1. Tablas de resultados, d=20 . . . . . . . . . . . . . . . . . . 825.3.2.2. Graficas de resultados, d=20 . . . . . . . . . . . . . . . . . 855.3.2.3. Graficas de datos relevantes durante el proceso evolutivo,
d=20 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 905.3.2.4. Tablas de resultados, d=30 . . . . . . . . . . . . . . . . . . 945.3.2.5. Graficas de resultados, d=30 . . . . . . . . . . . . . . . . . 975.3.2.6. Graficas de datos relevantes durante el proceso evolutivo,
d=30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6. Conclusiones 1056.1. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6.1.1. Uso del t-Cherry Junction Tree de orden k en Algoritmos Evolutivos 1066.1.2. t-Cherry EDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
A. Teorıa de la informacion 109A.1. Contenido de informacion de una variable aleatoria . . . . . . . . . . . . . . 109A.2. Entropıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
A.2.1. Entropıa diferencial . . . . . . . . . . . . . . . . . . . . . . . . . . . 110A.2.2. Divergencia de Kullback-Leibler . . . . . . . . . . . . . . . . . . . . 110
A.3. Informacion Mutua . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
B. Algoritmos sobre grafos 113B.1. Recorrido en amplitud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113B.2. Recorrido en profundidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114B.3. Arbol de Expansion de Peso Maximo . . . . . . . . . . . . . . . . . . . . . . 115
Bibliografıa 119
ix


Indice de figuras
2.1. Ejecucion de un EDA sobre un problema en un espacio continuo unidimen-sional . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2. Normales bivariadas usadas para la generacion de mutaciones en ESs . . . . 16
3.1. PGM con estructura dada por un DAG . . . . . . . . . . . . . . . . . . . . 233.2. PGM con estructura dada por un grafo no dirigido . . . . . . . . . . . . . . 283.3. PGM usado en el UMDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.4. PGM usado en el MIMIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.5. PGM con estructura de Arbol de Chow-Liu . . . . . . . . . . . . . . . . . . 383.6. Direccionamiento de aristas para el PGM en la figura 3.5 . . . . . . . . . . 383.7. PGM con estructura de Polytree . . . . . . . . . . . . . . . . . . . . . . . . 403.8. Red Bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.1. Proceso de construccion de un Cherry Tree de 6 vertices . . . . . . . . . . . 444.2. Ejemplo de un Cherry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444.3. Proceso de construccion de un t-Cherry Tree. . . . . . . . . . . . . . . . . . 454.4. Ejemplo de un t-Cherry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.5. MRF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.6. Junction Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.7. t-Cherry Tree MRF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.8. t-Cherry Junction Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.9. t-Cherry Tree de orden k = 4 . . . . . . . . . . . . . . . . . . . . . . . . . . 494.10. t-Cherry Junction Tree de orden k = 4 . . . . . . . . . . . . . . . . . . . . . 544.11. Actualizacion de un cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . 614.12. Actualizacion de orden. Caso 4 . . . . . . . . . . . . . . . . . . . . . . . . . 614.13. Actualizacion de orden. Caso 2 . . . . . . . . . . . . . . . . . . . . . . . . . 624.14. Bud con separador de tamano k − 1 . . . . . . . . . . . . . . . . . . . . . . 664.15. Bud Conversion aplicado sobre el bud mostrado en la figura 4.14 . . . . . . 67
5.1. Un t-Cherry Junction Tree de orden k = 4 y la MN representada en este . . 745.2. Ejemplos de DAG obtenidos desde la MN en el cluster raız . . . . . . . . . 75
xi

INDICE DE FIGURAS
5.3. Ejemplo de DAG obtenidos desde la MN representada en el t-Cherry Jun-ction Tree de orden k . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.4. Leyendas de las graficas presentadas . . . . . . . . . . . . . . . . . . . . . . 865.5. Mınimo error encontrado para f5, f6, f7, d = 20 . . . . . . . . . . . . . . . . 875.6. Evaluaciones de funcion para f1, f2, f9, d = 20 . . . . . . . . . . . . . . . . 885.7. Evaluaciones de funcion para f5, f6, f7, d = 20. . . . . . . . . . . . . . . . . 895.8. Logplots de la evolucion la mediana del error mınimo encontrado, d = 20. . 915.9. Evolucion de la mediana de la razon de exitos, d = 20. . . . . . . . . . . . . 925.10. Evolucion de la mediana del peso del arbol en funciones separables, d = 20 935.11. Evolucion de la mediana del peso del arbol en funciones no separables, d = 20 945.12. Mınimo error encontrado para f5, f6, f7, d = 30 . . . . . . . . . . . . . . . . 985.13. Evaluaciones de funcion para f1, f2, f9, d = 30 . . . . . . . . . . . . . . . . 995.14. Evaluaciones de funcion para f5, f6, f7, d = 30 . . . . . . . . . . . . . . . . 1005.15. Evolucion de la mediana del peso del arbol en funciones no separables, d = 301015.16. Logplots de la evolucion la mediana del error mınimo encontrado, d = 30 . . 1025.17. Evolucion de la mediana de la razon de exitos, d = 30 . . . . . . . . . . . . 1035.18. Evolucion de la mediana del peso del arbol en funciones separables, d = 30 104
B.1. Grafo de ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113B.2. MWST del grafo de ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
xii

Indice de tablas
3.1. Variables y su conjunto de padres asociados representados en la figura 3.1 . 233.2. Tabla de probabilidades para la BN en la figura 3.1 . . . . . . . . . . . . . . 243.3. Tabla de parametros para la GN en la figura 3.1 . . . . . . . . . . . . . . . 273.4. Cliques y parametros de MN ilustrada en la figura 3.2 . . . . . . . . . . . . 28
5.1. Caracterısticas de las funciones del experimento . . . . . . . . . . . . . . . . 805.2. Definicion de las funciones del experimento . . . . . . . . . . . . . . . . . . 815.3. Resultados. d = 20, n = 200, h = 2 . . . . . . . . . . . . . . . . . . . . . . . 835.4. Resultados. d = 20, n = 200, h = 0 . . . . . . . . . . . . . . . . . . . . . . . 845.5. Wilcoxon Rank Sum Test para d = 20 . . . . . . . . . . . . . . . . . . . . . 855.6. Resultados. d = 30, n = 300, h = 2 . . . . . . . . . . . . . . . . . . . . . . . 955.7. Resultados. d = 30, n = 300, h = 0 . . . . . . . . . . . . . . . . . . . . . . . 965.8. Wilcoxon Rank Sum Test para d = 20 . . . . . . . . . . . . . . . . . . . . . 97
xiii


Indice de Algoritmos
1. EA Generico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42. GA Generico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63. EDA Generico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124. ES Generica: (µ/ρ, κ, λ)-ES . . . . . . . . . . . . . . . . . . . . . . . . . . . 155. Probabilistic Logic Sampling . . . . . . . . . . . . . . . . . . . . . . . . . . 326. Construccion de un t-Cherry Tree (2) . . . . . . . . . . . . . . . . . . . . . 497. Representacion de un t-Cherry Tree de orden k como Junction Tree . . . . 538. Greedy Puzzling Algorithm (33) . . . . . . . . . . . . . . . . . . . . . . . . 5710. Agregar una actualizacion potencial a la cola de prioridad . . . . . . . . . . 649. Order Update Process (33) . . . . . . . . . . . . . . . . . . . . . . . . . . . 6511. t-Cherry Bud Conversion Algorithm (33) . . . . . . . . . . . . . . . . . . . 6812. Construccion del t-Cherry Junction Tree de orden k (33) . . . . . . . . . . . 6913. Algoritmo de direccionamiento de aristas . . . . . . . . . . . . . . . . . . . . 7714. Pseudocodigo del t-Cherry EDA . . . . . . . . . . . . . . . . . . . . . . . . 7815. Pseudocodigo de implementacion de un BFS . . . . . . . . . . . . . . . . . . 11416. Pseudocodigo de implementacion de un DFS . . . . . . . . . . . . . . . . . 11517. Pseudocodigo de implementacion del algoritmo de Kruskal para encontrar
un MWST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
xv


Capıtulo 1
Introduccion
Cuando hablamos de optimizacion de un problema podemos decir de manera simpleque esta consiste en escoger de entre un conjunto de opciones de solucion la mejor, mi-diendo la calidad de las soluciones usando un criterio definido (30). Por ejemplo, en laciudad de Guanajuato, queremos ir del CIMAT a la alhondiga de granaditas caminando.Podemos usar varias rutas pasando entre calles, callejones, carreteras, caminos y veredasen el campo. Si nuestro criterio es distancia, pasaremos sobre todo por callejones y veredas.Pero tal vez por la noche nuestro criterio sea seguridad, y optemos sobre todo por calles ycarreteras. Cuando somos recien llegados, preferimos pasar por las zonas que conocemos,como Valenciana o San Javier. Escogemos dentro de estas localidades la mejor de las ru-tas. Aquı estamos resolviendo un problema de optimizacion local, es decir, encontramosla mejor opcion dentro de una zona cercana a donde nos encontramos. Con el paso deltiempo habremos explorado mas zonas en la ciudad, y nos daremos cuenta que existenmejores rutas por zonas que antes no habıamos siquiera tomado en cuenta, como los ca-minos vecinales que bajan por la mina de la Valenciana. Llegado el momento conoceremosla ciudad completa y tendremos la certeza de conocer la mejor ruta de todas. Habremosresuelto entonces el problema de optimizacion global de la ruta para ir del CIMAT a laalhondiga.
Este tipo de problemas son muy comunes en nuestras vidas, y aprendemos con eltiempo a resolverlos en cierta medida. Ası tambien en diversos campos de las ciencias eingenierıas se presentan, aunque en general son mucho mas complejos, por lo que aprenderde manera empırica como resolverlos toma muchısimo tiempo. Esto ha motivado que seanun campo bastante prolıfico de investigacion.
Con el fin de dar formalidad a lo antes planteado haremos a continuacion una seriede definiciones al respecto del problema de optimizacion global en espacios continuos sinrestricciones, pues es el campo de investigacion especıfico en el que de desarrolla estetrabajo.
1

1. INTRODUCCION
X1, . . . , Xd son las variables del problema, donde Xi ∈ IR; ∀i ∈ 1, . . . , d.
x1, . . . , xd, donde xi es un valor de Xi, representa a un punto de busqueda. Sele da el nombre de solucion candidata. xi es valido en cierto intervalo, es decir,li ≤ xi ≤ ui,∀i ∈ 1, . . . , d. Al conjunto SS que contiene a todas las solucionescandidatas se le llama espacio de busqueda.
La funcion objetivo f(x1, . . . , xd) es una funcion de valores reales f : Ω ⊂ IRd → IRque mapea una solucion candidata a un valor escalar que nos permite cuantificar sucalidad.
Entonces, resolver el problema de optimizacion global se puede definir como encontrarla solucion candidata x1, . . . , xd∗ ∈ SS tal que
f(x1, . . . , xd∗) ≤ f(x1, . . . , xd) (1.1)
∀x1, . . . , xd ∈ SS (1.2)
A x1, . . . , xd∗ se le llama mınimo global (30).
En los problemas de optimizacion de caja negra, del termino en ingles Black BoxOptimization (BBO) no se considera la definicion de f(x1, . . . , xd) pero tenemos la po-sibilidad de medir la calidad de una solucion candidata. Tambien hay problemas dondef(x1, . . . , xd) no se puede resolver de manera analıtica. En estos casos podemos encon-trar o aproximarnos al mınimo global haciendo una exploracion en el espacio de busqueda,el cual suele ser enorme; por lo que estos problemas suelen ser muy difıciles de resolver yprecisan de una gran cantidad de recursos computacionales para ello (32). Ası que en lapractica se hace imposible recorrer por completo del espacio de busqueda, por lo que seefectua una exploracion parcial. Podemos hacer esto de manera ingenua (ya sea generandolas soluciones en cierto orden o buscando uniformemente de manera aleatoria) pero nose suelen obtener buenos resultados ası. Tenemos que usar estrategias de busqueda masinteligentes. Una buena idea es usar la informacion del espacio de busqueda contenida enlas soluciones candidatas que hemos evaluado hasta ahora durante la exploracion, con elfin de encontrar patrones y usarlos para guiar la busqueda.
1.1. Algoritmos Evolutivos
Con base en esta idea, a mediados de los 60 se comienza a investigar sobre algoritmosque hacen la exploracion con estrategias inspiradas en la evolucion de las especies en elmundo natural: Los Algoritmos Evolutivos, del termino en ingles Evolutionary Algorithm(EA)(20). Estos algoritmos mantienen un conjunto de soluciones candidatas durante su
2

1.1 Algoritmos Evolutivos
ejecucion, y sobre estas aplican de manera iterativa operaciones de recombinacion, muta-cion y seleccion (ver algoritmo 1).
En la teorıa de EAs hay algunos terminos que es importante definir por cuestiones declaridad.
En este trabajo estaremos hablando siempre de problemas de minimizacion, a menosde que se mencione explıcitamente lo contrario.
Las variables del problema se denominan tambien variables de decision.
Las soluciones candidatas se representan en un vector x = (x1, . . . , xd)T de instancias
de las variables de decision.
Los individuos q tendran dos componentes al menos, el vector de variables de decisionq.x y un fitness o valor de aptitud q.f , que es el valor de funcion objetivo f(q.x).
Un conjunto de individuos forma una poblacion Q.
Cuando decimos que qi es mejor o mas apto que qj es porque se cumple que qi.f <qj .f
Se le llama generacion a una iteracion del algoritmo.
A los individuos creados en la generacion actual se les llama hijos, a aquellos indivi-duos desde los cuales se recombinaron se les llama padres.
La dimensionalidad del problema (numero de variables de decision) se representaracon d, y el tamano de la poblacion con n.
Analicemos ahora el algoritmo 1 y veamos la analogıa con respecto a la evolucion delos individuos en el mundo natural.
En la operacion de recombinacion (paso 6), los hijos en Qtoffs heredan caracterısticas
sus padres, provenientes de Qt−1. Esto nos permite aprovechar de manera implıcita la in-formacion del espacio de busqueda contenida en los individuos de generaciones anteriores(para mas informacion sobre esto, vea la hipotesis de los bloques constructores de Goldbergen (13)). Dentro de esta operacion se hace una seleccion, pues existe preferencia para quelos mejores individuos en Qt−1 sean seleccionados como padres para recombinarse. Estopermite ir moviendo a la poblacion hacia zonas mas promisorias. De manera analoga, enla naturaleza la recombinacion permite el paso de informacion genetica de los individuosmas aptos de generacion en generacion.
Las mutaciones son un cambio aleatorio en el codigo genetico de las especies que enalgunos casos permite una mejor adaptacion a su entorno. Cuando es ası, los individuos
3

1. INTRODUCCION
Algorithm 1 EA Generico
1: procedure EA(n)
2: t← 0
3: Qt ← n nuevos individuos generados desde una distribucion uniforme
4: repeat
5: t← t+ 1
6: Qtoffs ← conjunto de hijos recombinados desde Qt−1
7: Qt′offs ← conjunto de individuos en Qtoffs a los que se le aplico una mutacion.
8: Obtener el fitness q.f ; ∀q ∈ Qt′offs.
9: Qt ← n individuos seleccionados de Qt−1 ∪ Qt′offs mediante una estrategia
definida con base en su fitness.
10: until Criterio de terminacion se cumpla
return Individuo de fitness mınimo en Qt
11: end procedure
mutados pasan su informacion genetica a las siguientes generaciones, por lo que esta mu-tacion perdura. Aunque estas se dan con una frecuencia muy baja, con el paso del tiempohan hecho posible la biodiversidad que existe en el mundo. En los algoritmos evolutivosla mutacion (paso 7) tiene la misma funcion, a la vez que la diversidad promovida por lamisma hace posible la exploracion de zonas del espacio de busqueda alejadas de donde seencuentran los individuos en la generacion actual Qtoffs, aumentando ası la probabilidadde escapar de mınimos locales (20).
La operacion de reemplazo (paso 9) esta inspirada en el hecho que en la naturalezageneralmente los individuos mejor adaptados prevalecen. Durante el proceso evolutivo lossobrevivientes generan en su mayorıa individuos parecidos a ellos en la siguiente genera-cion, lo que va provocando que las poblaciones se parezcan. Esto provoca que los individuossean cada vez mas aptos y sus caracterısticas se vayan unificando. Haciendo la analogıaen los EAs, la seleccion y la estrategia de reemplazo permiten que la poblacion se vayamoviendo hacia un mınimo mientras los individuos agrupan en una zona cada vez mas pe-quena. A este fenomeno se le llama convergencia. (20) El tiempo en que tarda este eventoen darse dependera de la estrategia de seleccion y reemplazo definida, de los parametrosde recombinacion y mutacion usados y de las caracterısticas del espacio de busqueda.
Una estrategia de seleccion agresiva que asegure la permanencia siempre de los mejoresacelera la convergencia, a la vez que una estrategia mas relajada permite explorar durante
4

1.2 Algoritmo Genetico
mas generaciones. Llamamos presion de seleccion a la preferencia por escoger a los indivi-duos mas aptos de una poblacion para recombinarse o pasar a la siguiente generacion. Demanera intuitiva, nos conviene usar estrategias con una alta presion de seleccion en fun-ciones de un solo mınimo (llamadas unimodales) y estrategias mas relajadas en funcionesde varios mınimos (multimodales) (20).
1.2. Algoritmo Genetico
Uno de los primeros EAs y de uso mas extendido es el Algoritmo Genetico, del terminoen ingles Genetic Algorithm (GA). Se puede citar como trabajo seminal el libro de Holland(16). Su definicion se ajusta bastante bien a lo visto para los EAs en general (ver algoritmo2) con individuos cuyas variables son representadas en forma binaria, de manera que q.xes un vector de cadenas de bits.
En el GA se introducen nuevos parametros para sus operadores.
noffs es el numero de nuevos individuos a generar.
pm, pc define la probabilidad de mutacion y recombinacion de una variable respecti-vamente.
En su version generica, los operadores del GA se definen de la siguiente manera:
1.2.1. Seleccion
Lıneas 8 y 14 del algoritmo. Como se puede apreciar en el pseudocodigo 2, se ejecutauna operacion de seleccion en dos momentos: Para obtener a los individuos padres desdelos cuales se generara uno hijo mediante la operacion de recombinacion (lınea 8) y paraescoger a los individuos que pasan a la siguiente generacion desde la poblacion de padrese hijos en conjunto (lınea 14). A esta operacion se le llama reemplazo.
Existen varias estrategias para ejecutar una operacion de seleccion de n individuos, lasmas populares son:
Torneo binario. Se toman dos individuos desde la poblacion y se selecciona al demejor fitness. Se repite n veces.
Truncamiento. Se ordenan los individuos de mejor a peor fitness y se seleccionan losn primeros.
Ruleta. Cada individuo tiene una probabilidad de ser seleccionado proporcional a sufitness. Se hacen entonces n selecciones aleatorias.
5

1. INTRODUCCION
Algorithm 2 GA Generico
1: procedure GA(n, noffs, pc, pm)
2: t← 0
3: Qt ← n individuos con variables binarias generadas desde una bernoulli con p=0.5
4: repeat
5: t← t+ 1
6: Qtoffs ← ∅
7: for i ∈ 1, . . . , noffs do
8: parent1, parent2 ← seleccionados desde Qt−1
9: qoffs.x← recombinacion(parent1.x, parent2.x, pc)
10: qoffs.x← mutacion(qoffs.x, pm)
11: qoffs.f ← f(qoffs.x)
12: Qtoffs ← Qtoffs ∪ qoffs13: end for
14: Qt ← n individuos seleccionados de Qt−1 ∪ Qtoffs mediante una estrategia
definida con base en su fitness.
15: until Criterio de terminacion se cumpla
return Individuo de fitness mınimo en Qt
16: end procedure
6

1.2 Algoritmo Genetico
1.2.2. Recombinacion
Lınea 9 del algoritmo 2. Consiste en la generacion de un nuevo individuo q.xt a partirde un conjunto de individuos seleccionados como padres.
Se suele usar el operador de cruza uniforme, en este se usa una probabilidad pc paradecidir desde cual padre se toma el i-esimo valor. De manera mas formal:
∀i ∈ 1, . . . , d : q.xti ← parent1.xi si rand() ≤ pc, e.o.c q.xti ← parent2.xi
1.2.3. Mutacion
Lınea 10 del algoritmo 2. La mutacion consiste en cambiar cada valor binario en xtoffscon cierta probabilidad pm, es decir:
∀i ∈ 1, . . . , d : q.xti ← not q.xti si rand() ≤ pm
Se ha hecho mucha investigacion sobre GAs por lo que existe una gran variedad de algo-ritmos existentes en esta familia, los cuales definen operadores de recombinacion, mutaciony seleccion diferentes con el fin de mejorar su rendimiento en cierto tipo de problemas (20).Muchos de estos operadores tienen ademas parametros extras o diferentes a los menciona-dos en el parrafo anterior, ası que escoger un GA con los parametros adecuados para unproblema en particular se torna un tanto difıcil en la practica ya que en general tenemospoco conocimiento del problema a optimizar o bien este es un BBO.
Existen ademas otras metaheurısticas inspiradas en la relacion que existe entre los in-dividuos que coexisten en grupos. Podemos mencionar entre estas a los algoritmos basadosen la inteligencia de enjambres, como el de Optimizacion por enjambre de partıculas, deltermino en ingles Particle Swarm Optimization (PSO) o el de Optimizacion por colonia dehormigas, del termino en ingles Ant Colony Optimization (ACO). Para saber mas sobreeste tema, remitimos al lector a (45).
Al igual que los GAs, la mayorıa de estos algoritmos necesitan varios parametros pa-ra sus operadores y su rendimiento depende mucho del problema que se ataca. Entoncessurge una pregunta: ¿Podrıamos aliviar estas desventajas usando de manera explıcita lainformacion del espacio de busqueda usando a los individuos que hemos generado durantela ejecucion del algoritmo?
Con esta motivacion surgio una familia dentro de los EAs: los Algoritmos Evolutivosbasados en Modelos, del termino en ingles Model Based Evolutionary Algorithm (MBEAs),termino acunado recientemente en (46); aunque las raıces de esta familia se pueden ras-trear hasta el origen de las Estrategias Evolutivas, del termino en ingles EvolutionaryStrategies (ES) (1).
7

1. INTRODUCCION
El funcionamiento de los MBEAs se basa en la construccion de un modelo de la dis-tribucion de probabilidad sobre los mejores individuos generados durante el proceso evo-lutivo, con el fin de hacer uso de manera explıcita la informacion del espacio de busquedacontenida en estos individuos.
Ası, desde este modelo, podemos generar hijos que hereden caracterısticas de sus pa-dres y crear mutaciones de acuerdo a sus propiedades. Entonces podemos prescindir de latarea de encontrar los operadores adecuados y sus parametros para cada tipo de problema.En el siguiente capıtulo se abordara esto con detalle.
1.3. Motivacion
Los MBEAs obtienen el modelo de distribucion de probabilidad calculando los parame-tros de una distribucion definida para el algoritmo, o construyendo y calculando losparametros de un modelo grafico (para una definicion formal de esto ultimo vea la seccion3.2). La finalidad es que este modelo se aproxime a la distribucion de los mejores indivi-duos en cierta generacion con la finalidad de que describa caracterısticas del espacio debusqueda utiles en el proceso de optimizacion (23).
En el caso de los modelos graficos la cantidad de recursos computacionales para cons-truir las estructuras que describen la distribucion depende de la densidad deseada en lasmismas. Esto aunado a que durante el proceso evolutivo es necesario construir el modeloun gran numero de veces provoca que sean muy populares en los MBEAs los modeloscuyos grafos son desconectados, arboles o cadenas. Las dos operaciones que dependende la densidad del grafo y que pueden llegar a consumir una gran cantidad de recursoscomputacionales son:
Busqueda del grafo que represente un modelo de distribucion de probabilidad quemejor se aproxime a la distribucion de los mejores individuos. El espacio de posiblesestructuras es enorme.
Medicion de la calidad de esta aproximacion.
Todo esto se aborda con detalle en el capitulo 3. Existen en la literatura algunos algorit-mos que construyen grafos mas densos ((23), (38)) usando diversas estrategias para hacermenos costosa la construccion del modelo y/o la medicion de la calidad de la aproximacion.Esto motiva a investigar sobre el uso en MBEAs de otras estructuras que ya existen en elestado del arte de los modelos graficos.
Por otro lado, en los MBEAs para optimizacion global continua por cuestiones practi-cas se suelen utilizar modelos Gaussianos. Se han utilizado: (a) distribucion de d modelos
8

1.4 Objetivos
univariados, (b) distribuciones Normales Multivariadas de d variables y (c) factorizacio-nes de esta descritas en un modelo grafico (23). Al usar (a) no tomamos en cuenta lasdependencias que pueden existir entre las variables. Al utilizar (b), si existen variables enel problema que no estan correlacionadas, es posible que tomemos en cuenta dependenciasque perjudiquen la busqueda. En el caso (c), el construir un modelo grafico Gaussiano conuna densidad adecuada puede capturar las dependencias de una mejor manera. Esto setiene que hacer de manera eficiente para que sea factible su uso en MBEAs.
1.4. Objetivos
Este trabajo tiene como objetivo principal proponer el uso de una red Gaussiana comomodelo en MBEAs para optimizacion global continua cuya estructura se obtiene desde unt-Cherry Junction Tree de orden k (42) asumiendo que las variables del problema siguenuna Distribucion Normal Multivariada
Como objetivo adicional se busca implementar el t-Cherry Junction Tree de ordenk como modelo en un Algoritmo de Estimacion de Distribucion, del termino en inglesEstimation of Distribution Algorithm (EDA), al que llamamos t-Cherry EDA, y analizarsu rendimiento al variar el parametro k, que indica la densidad de la estructura del modeloy con ello la cantidad de dependencias representadas en este.
1.5. Estructura de la tesis
Este trabajo se organiza de la manera siguiente.
En el capıtulo 2 repasamos las generalidades de los dos principales tipos de MBEAsque existen en la literatura: Los EDAs y las ESs.
En el capıtulo 3 revisamos brevemente la teorıa de modelos graficos necesaria paraabordar el tema de los MBEAs. Despues hacemos una revision el estado del arte de losEDAs para optimizacion continua y discreta que usan modelos graficos probabilısticospara representar la distribucion de los individuos seleccionados.
En el capıtulo siguiente 4 presentamos al t-Cherry Junction Tree de orden k, listamossus propiedades mas importantes y describimos el algoritmo de construccion propuesto en(33). Este consiste en aplicar k− 2 veces una actualizacion de orden, empezando desde unt-Cherry Junction Tree de orden 2. La actualizacion de orden es un algoritmo greedy quepermite construir uno de orden κ desde otro de orden κ − 1. Se propone usar la metricade calidad de ajuste para un t-Cherry Junction Tree de orden k que presentan Szantai yKovacs en (19), y se presenta una simplificacion del calculo de esta metrica para el modeloGaussiano.
9

1. INTRODUCCION
En el capıtulo 5 se propone una estrategia simple de direccionamiento de las aristasdel grafo representado por el t-Cherry Junction Tree de orden k con el fin de obteneruna red Gaussiana, la cual es el modelo implementado en el t-Cherry EDA. Se presentantambien resultados en problemas clasicos de benchmark para optimizacion continua globalsin restricciones, ademas de otras graficas de interes.
Por ultimo en el capıtulo 6 se presentan las conclusiones acerca del t-Cherry JunctionTree de orden k y su desempeno en el t-Cherry EDA. Se discuten ademas los posiblesusos de este modelo en otros MBEAs y el trabajo que se puede hacer para mejorar eldesempeno del t-Cherry EDA.
10

Capıtulo 2
Algoritmos Evolutivos basados en Modelos
Como ya mencionamos en la introduccion, los MBEAs construyen un modelo de pro-babilidad de los individuos con el fin de dirigir la busqueda. Para esto ultimo hay dosenfoques principales:
Mediante la generacion directa de los nuevos individuos desde el modelo. Los EDAsson la familia de algoritmos que usan esta tecnica. El modelo se puede construirsobre variables discretas o continuas, por lo que se pueden abordar problemas deambos casos.
Mediante la generacion de mutaciones desde el modelo que se aplican despues enlos individuos. Estas mutaciones contienen informacion de las dependencias entrelas variables. Las ESs son la familia de algoritmos que usan esta tecnica. Atacansolamente problemas de variables continuas.
En las siguientes dos secciones se hace una breve revision de la teorıa de estas dosfamilias de algoritmos.
2.1. Algoritmos de Estimacion de Distribucion.
Los EDAs fueron introducidos a mediados de los 90 por Muhlenbein y Paaß(28). Comose puede apreciar en el algoritmo 3 un EDA y un GA tienen en comun las operaciones deseleccion y reemplazo de individuos, vistas en la seccion 1.1. Lo que caracteriza al EDAes que la generacion de nuevos individuos se realiza mediante simulacion desde un modelode distribucion de probabilidad construido desde la poblacion (lıneas 7 y 8), usando asıde manera explıcita la informacion de dependencia entre variables para guiar la busqueda.Esto es muy importante, pues en problemas de optimizacion del mundo real son muy rarosaquellos cuyas variables son independientes entre sı.
11

2. ALGORITMOS EVOLUTIVOS BASADOS EN MODELOS
Algorithm 3 EDA Generico
1: procedure EDA(n, ns)
2: Q0 ← n individuos de una distribucion uniforme
3: ∀q0 ∈ Q0 : q0.f = f(q0.x)
4: t← 1
5: repeat
6: Qts ← ns individuos seleccionados desde Qt−1 mediante un criterio definido
7: pt(x)← estimacion de modelo de probabilidad desde qts.x ∈ Qts8: Qt ← n individuos generados desde pt(x)
9: ∀qt ∈ Qt : qt.f = f(qt.x)
10: t← t+ 1
11: until Criterio de terminacion se cumpla
12: end procedure
2.1.1. Seleccion
Como estrategia de seleccion (lınea 6 del algoritmo 3) se puede usar cualquiera de lasexistentes en el estado del arte para GAs, como las mencionadas en la seccion 1.2.1, aunquela mas comun es la seleccion por truncamiento. El parametro ns nos permite controlar lapresion de seleccion.
2.1.2. Reemplazo
En la lınea 8 del algoritmo 3 podemos notar que se reemplazan por completo los nindividuos de la generacion anterior. Para manejar elitismo podemos sustituir n por unparametro de usuario noffs, de manera que conservamos los mejores n− noffs individuosde la generacion anterior.
2.1.3. Construccion y uso del modelo para la generacion de nuevos in-
dividuos
El modelo que se usa y el aprendizaje de sus parametros son la parte central de unEDA (ver la lınea 7 del algoritmo 3), de hecho estas caracterısticas son usadas para darles
12
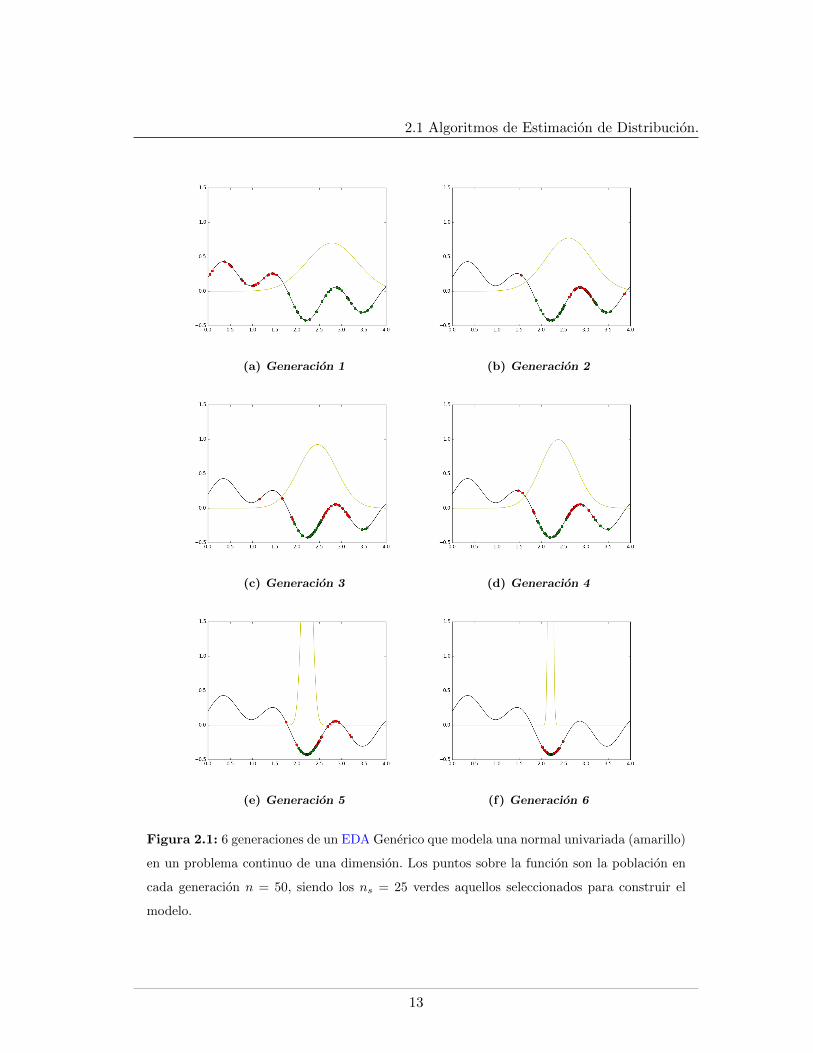
2.1 Algoritmos de Estimacion de Distribucion.
(a) Generacion 1 (b) Generacion 2
(c) Generacion 3 (d) Generacion 4
(e) Generacion 5 (f) Generacion 6
Figura 2.1: 6 generaciones de un EDA Generico que modela una normal univariada (amarillo)
en un problema continuo de una dimension. Los puntos sobre la funcion son la poblacion en
cada generacion n = 50, siendo los ns = 25 verdes aquellos seleccionados para construir el
modelo.
13

2. ALGORITMOS EVOLUTIVOS BASADOS EN MODELOS
nombre y clasificarlos (23). El modelo puede estar definido de manera fija o construidomediante el ajuste a la distribucion de probabilidad de las variables de decision de unconjunto de individuos seleccionados. Se calculan despues sus parametros de manera queeste ajuste sea optimo, o bien, que la aproximacion sea de calidad. Se suelen construirmodelos con grafos dispersos (lo que implica tomar en cuenta pocas dependencias entrelas variables) pues son menos los recursos computacionales necesarios para manejarlos.Cabe mencionar que en algunos de los EDAs que atacan problemas de optimizacion globalcontinua se define una distribucion a usar (casi siempre Normales Multivariadas o Uni-variadas) y solo se calculan desde los individuos seleccionados sus parametros mediantelos estimadores de maxima verosimilitud. Como la lınea 8 del algoritmo 3 describe, pa-ra obtener nuevos individuos simplemente se hacen simulaciones desde el modelo ajustado.
En el capıtulo siguiente se hace un repaso de los EDAs mas representativos que usanmodelos graficos tomando como criterio el nivel de dispersion del grafo que se construye.
2.2. Estrategias evolutivas.
Las ESs son una familia de EA disenadas para atacar problemas de optimizacion globalcontinua. La idea central es guiar la busqueda mediante la aplicacion de mutaciones a losindividuos, las cuales son obtenidas desde un modelo de probabilidad cuyos parametros seadaptan usando un conjunto de padres seleccionados. Esto quiere decir, que a diferenciade los EDAs, se define una distribucion (generalmente Normales Univariadas y Multivaria-das) y se van buscando valores optimos para sus parametros durante el proceso evolutivo.En el algoritmo 4 se muestra la Estrategia Evolutiva (µ/ρ, κ, λ)-ES, que se considera laES generica (4).
En la notacion estandar de las ESs µ es el tamano de la poblacion, ρ ≤ µ es el numerode padres que se usan para adaptar los valores de los parametros necesarios para obteneruna mutacion, λ es el numero de hijos a generar en cada generacion y κ es el lımite de edad(generaciones que han pasado desde que se crearon) que pueden alcanzar los individuos,valor que se representa en cada uno con qt.Ψ.α. Estos parametros son requeridos al usuarioy en el algoritmo existen algunos mas que son adaptados durante el proceso evolutivo. Losreferentes al algoritmo se agrupan en un conjunto Ψalg y los referentes a cada individuoen q.Ψ.
2.2.1. Seleccion
En la lınea 7 del algoritmo 4 observamos que no existe presion de seleccion al escogerlos padres en Qs ya que son seleccionados de manera aleatoria y uniforme. Lo que haceavanzar la busqueda es el reemplazo. (4)
14

2.2 Estrategias evolutivas.
Algorithm 4 ES Generica: (µ/ρ, κ, λ)-ES
1: procedure ES(µ, ρ, κ, λ,Ψalg)
2: t← 0
3: Qt ← µ individuos de una distribucion uniforme
4: ∀qt ∈ Qt : qt.Ψ.α← 1, qt.f = f(qt.x)
5: repeat
6: Qoffs ← ∅
7: for i ∈ 1, 2, . . . , λ do
8: Qs ← ρ individuos seleccionados de manera aleatoria uniformemente desde
Qt
9: qmut.x← mutacion(recombinacion(Qs), Ψalg)
10: qoffs.x← qoffs.x + qmut.x
11: qoffs.Ψ.α← 0, qoffs.f ← f(qoffs.x)
12: Qtoffs ← Qtoffs ∪ qoffs13: end for
14: Qt+1 ← los µ mejores individuos en Qoffs ∪ qt ∈ Qt : qt.Ψ.α < κ
15: ∀qt+1 ∈ Qt+1 : qt.Ψ.α← qt.Ψ.α+ 1
16: Adaptar Ψalg y q.Ψ∀q ∈ Qt+1
17: t← t+ 1
18: until Criterio de terminacion se cumpla
19: end procedure
2.2.2. Reemplazo
En las ESs se usa como estrategia de reemplazo el truncamiento de un conjunto deindividuos de tamano menor o igual a λ+µ compuesto por padres e hijos con edad menora κ. Consideremos que κ = ∞. Esta estrategia se llama plus-selection y las ESs que lausan se clasifican como (µ/ρ+ λ)-ES. Aquı existe elitismo pues usamos la totalidad de lapoblacion formada por padres e hijos. Consideremos ahora que κ = 1. Esta estrategia sellama comma-selection y las ESs que la usan se clasifican como (µ/ρ, λ)-ES. Aquı se seseleccionaran los mejores µ hijos, entonces no existe elitismo y se debe asegurar que λ ≥ µ.
15

2. ALGORITMOS EVOLUTIVOS BASADOS EN MODELOS
2.2.3. Uso del modelo para la mutacion
Como ya hemos mencionado en una buena parte de las ESs se usan distribucionesNormales (Univariadas o Multivariadas) para la generacion de mutaciones, pues estasdistribuciones permiten con probabilidad mayor a cero generar cualquiera de los puntosdentro del espacio de busqueda (4). Entonces, mediante estrategias definidas por cadaES, se usan los individuos en Qs para encontrar un valor optimo para los valores de losparametros del modelo, generalmente de la matriz de covarianzas. Es comun tambien quese usen los valores de los parametros de generaciones anteriores en la adaptacion, hacien-do que la participacion en la adaptacion de un individuo sea inversamente proporcionala su edad. Estos parametros pueden ser globales (contenidos en Ψalg) o unicos para cadaindividuo (contenidos en q.Ψ). Para una explicacion mas detallada de esto y un analisismuy interesante de la relacion de la matriz de covarianzas con el Hessiano remitimos allector a (4).
Dentro de las ESs podemos encontrar algoritmos que generan mutaciones con algunaestrategia de las tres mostradas en la imagen 2.2:
(a) δ ∗N(0, I) (b) δ ∗N(0,D) (c) δ ∗N(0,C)
Figura 2.2: Elipsoides representando normales bivariadas usadas para generar mutaciones en
un problema bidimensional. Su tamano esta ponderado por el tamano de paso δ
Se puede inferir que los algoritmos que usan mutaciones como en la figura 2.2-(a) solotienen que adaptar a δ, por lo que la complejidad en el numero de parametros a adaptar esO(1). Aquellos que generan mutaciones como en la figura 2.2-(B) adaptan una varianza Dii
por cada variable de decision, ademas del tamano de paso. Aquı la complejidad es O(d).Estas dos estrategias generan mutaciones que no toman en cuenta dependencias entre lasvariables por lo que estamos en realidad adaptando d varianzas de Normales Univariadas.
Por ultimo, en la estrategia que se aprecia en la figura 2.2-(c) se generan mutaciones
16

2.2 Estrategias evolutivas.
correlacionadas, lo cual es deseable en funciones donde sı hay dependencias entre variables.Sin embargo es evidente que la cantidad de parametros a adaptar ahora crece de formacuadratica en funcion del numero de variables del problema.
Se puede concluir que las ESs se diferencıan dentro de los Algoritmos Evolutivos porlas siguientes caracterısticas (4):
Los individuos estan formados por las variables de decision, su fitness y parametrosde estrategia individuales.
La seleccion de individuos usados para la recombinacion se hace de forma aleatoriay uniforme.
Los parametros de los operadores de mutacion se adaptan durante el proceso evolu-tivo.
En pocas palabras, los parametros del modelo se obtienen recombinando a los indi-viduos y las mutaciones simulando desde el modelo.
17


Capıtulo 3
Modelos graficos y su uso en los EDAs
3.1. Introduccion
En este capıtulo se hace una breve revision de la teorıa de Modelos Graficos Proba-bilısticos para hacer luego un repaso de sus aplicaciones mas representativas en MBEAsdel estado del arte.
3.1.1. Notacion
En este capıtulo y en los dos siguientes se abordaran temas de Modelos Graficos Pro-babilısticos. Es por ello que definimos desde este momento la notacion a usar.
Para conjuntos se usan letras mayusculas. Durante el desarrollo de este trabajo losconjuntos contendran sobre todo variables aleatorias. Por ejemplo C = X1, X3, X5 esun conjunto de 3 variables aleatorias.
Para conjuntos de conjuntos se usan letras en cursiva, por ejemplo C.
Por cuestiones de claridad al referirnos a los elementos de un conjunto C = Xi, Xj , . . . , Xnpodemos hacer referencia a las variables aleatorias o a sus ındices, siendo util estoultimo al definir subconjuntos de elementos relacionados a las variables aleatoriasmediante sus ındices.
Para vectores se usan negritas. Por ejemplo x ∈ IRd es una instancia de un vectoraleatorio.
Los elementos de un vector se especifican con la misma letra pero sin negrita eindizados: xi es el valor i-esimo en x.
Se define un subvector mediante un conjunto de ındices. Por ejemplo, si C =X1, X3, X5 entonces xC = (x1, x3, x5)T es un subvector de x = (x1, . . . , x7)T .
19

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
Para matrices se usan letras griegas mayusculas. Ejemplo: Matriz de covarianzas Σ ∈IRd×d.
Λ(i,) se usa para referirse al i-esimo vector fila de la matriz Λ, y Λ(,j) para su j-esimovector columna .
Λ(i,j) se usa para referirse al elemento de la matriz en la posicion j de la fila i. Conel fin de hacer mas facil la lectura de los temas referentes a la Distribucion NormalMultivariada, en esta se indizaran los elementos de la matriz de covarianzas o decorrelacion con minusculas griegas: Σ(i,j) , σij .
Al igual que con los vectores, se define una submatriz mediante un conjunto deındices. Sea Λ ∈ IRd×d una matriz y C un conjunto de ındices de tamano m ≤ d.Entonces ΛC ∈ IRm×m es una submatriz de Λ. Por ejemplo, si C = X1, X3, X5 yd = 7 entonces
Λ =
Λ(1,1) Λ(1,2) . . . Λ(1,7)
Λ(2,1) Λ(2,2) . . . Λ(2,7)
......
. . ....
Λ(7,1) Λ(7,2) . . . Λ(7,7)
ΛC =
Λ(1,1) Λ(1,3) Λ(1,5)
Λ(3,1) Λ(3,3) Λ(3,5)
Λ(5,1) Λ(5,3) Λ(5,5)
3.1.1.1. Probabilidad
Dado un problema de d variables aleatorias, tenemos que X = (X1, X2, . . . , Xd)T es el
vector aleatorio del problema, y x = (x1, x2, . . . , xd)T una cierta instancia de valores de es-
te vector. Cada variable Xi puede depender de un conjunto de variables. A este conjunto sele llamara Pai. Podemos asociar un vector aleatorio Pai = (Xj : j ∈ Pai)T a este conjunto.
Abordemos el caso de que Xi sea de naturaleza discreta.
Xi puede tomar ri valores diferentes, y sus padres en conjunto pueden tomar qivalores diferentes.
La funcion de probabilidad conjunta para X se abreviara como P (X = x) , P (x).
De manera analoga, la funcion de probabilidad condicional se abreviara como P (Xi =xi |Pai = pai) , P (xi | pai).
Sea C ⊆ X. Entonces XC = (Xi : i ∈ C)T y la funcion de probabilidad conjunta seabrevia como P (XC = xC) , P (xC).
20

3.2 Breve introduccion a los Modelos Graficos Probabilısticos
Para variables aleatorias continuas se toma en cuenta el mismo criterio, teniendo encuenta que se hara referencia a la funcion de densidad conjunta como f(x).
3.2. Breve introduccion a los Modelos Graficos Probabilısti-
cos
Antes de dar paso a la revision de algunos de los modelos graficos usados en EDAsqueremos presentar de manera muy breve que es un modelo grafico y como se puedeconstruir desde el subconjunto de individuos seleccionados.
3.2.1. Definicion
Un Modelo Grafico Probabilıstico, del termino en ingles Probabilistic Graphical Model(PGM) es una herramienta muy usada en Estadıstica y Machine Learning para describirde manera efectiva y simple las propiedades de dependencia entre las variables de un pro-blema. Un PGM M = (S,Θ) esta formado por una estructura S y ciertos parametrosde la distribucion Θ (17). S esta representada en un grafo, sus vertices representan a lasvariables del problema y una arista entre dos de ellas indica dependencia. Estos grafospueden ser dirigidos o no dirigidos.
En el PGM se encuentran tambien las propiedades de independencia condicional delproblema, aunque no de manera tan evidente. Si hacemos una separacion del grafo (d -separacion en el caso de grafos dirigidos) usando las variables sobre las cuales se condiciona,las variables de uno de los subgrafos resultantes de la separacion son independientes con-dicionalmente de las del otro.
Al tener esta informacion de (in)dependencias se puede reducir el costo de ajustar ycalcular los parametros del modelo. Esto es muy importante, pues a menudo la complejidadcomputacional de los problemas hace que no sea factible trabajar con una distribucion deprobabilidad conjunta completa.
3.2.2. Grafos dirigidos
Hablando de grafos dirigidos en un PGM, nos referiremos a la variable origen de laarista como variable padre y a la variable destino como variable hija.
Es evidente que el grafo tiene que ser un Grafo Dirigido Acıclico, del termino en inglesDirected Acyclic Graph (DAG) para que S sea una estructura valida. En este caso lasdirecciones de las aristas indican influencia directa de la variable padre en la hija. En
21

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
la figura 3.1 se muestra un ejemplo de un DAG como estructura valida de un PGM. Ladefinicion de los parametros Θ depende de la naturaleza de las variables.
En el grafo se muestra cada variable Xi y su conjunto de padres Pai, es decir, el con-junto de variables que tienen una arista que incide en Xi (Ver tabla 3.1). Se le asociaademas a Xi un vector aleatorio de sus padres Pai = (Xj : j ∈ Pai)T . Esto quiere decirhay dependencia entre Xi y las variables en Pai, y que hay independencia en el otro caso.
Entonces, dado un problema de d variables cuya Funcion de Masa de ProbabilidadConjunta, del termino en ingles Joint Probability Mass Function (JPMF) esta dada por
ρ(x) = ρ(x1)ρ(x2 | x1)ρ(x3 | x2, x1) . . . ρ(xi | x1, . . . , xi−1) . . . ρ(xd | x1, . . . , xd−1) (3.1)
se pueden representar sus propiedades de dependencia en un PGM que tiene un DAGcomo estructura y usando este ultimo se puede factorizar la funcion 3.1 de esta manera:
ρ(x) = ρ(x1 | pa1)ρ(x2 | pa2) . . . ρ(xd | pad) =d∏i=1
ρ(xi | pai) (3.2)
Por ejemplo, la factorizacion de la JPMF representada por el grafo en la figura 3.1 es
ρ(x) = ρ(x1)ρ(x2 | x1)ρ(x3 | x1, x2)ρ(x4)ρ(x5 | x3)ρ(x6 | x4, x5) (3.3)
Es importante mencionar que el uso de un DAG como estructura en un EDA ayuda aque la simulacion de datos durante el proceso evolutivo sea eficiente y sencilla. Para cadavariable Xi esta definido su conjunto de padres Pai, de manera que podemos empezar porsimular las variables Xi : Pai = ∅ que son vertices raız y continuar en orden con aquellascuyos padres ya hayan sido simulados en su totalidad. Esta operacion de simulacion sepuede completar de manera eficiente. En la seccion 3.2.5 se explica esto con detalle.
3.2.2.1. Caso discreto
Sea M = (S,Θ) un PGM con S representada por un DAG, cuyos vertices son a su vezvariables aleatorias de naturaleza discreta. Entonces M es una Red Bayesiana, del terminoen ingles Bayesian Network (BN) (29). La factorizacion de la JPMF P (x) representada enla BN esta definida como el producto de las probabilidades condicionales para cada valorxi dados los valores de sus padres pai.
P (x) =d∏i=1
P (xi | pai) (3.4)
22

3.2 Breve introduccion a los Modelos Graficos Probabilısticos
X2
X5
X3
X1
X4
X6
Figura 3.1: Ejemplo de un DAG valido
como estructura de un PGM para un
problema de 6 variables.
Xi Pai
X1 ∅
X2 X1
X3 X1, X2
X4 ∅
X5 X3
X6 X4, X5
Tabla 3.1: Variables y su conjunto de
padres asociados representados en la fi-
gura 3.1
Si suponemos que las variables del grafo mostrado en la figura 3.1 son discretas, en-tonces la JPMF representada ahı es
P (x) = P (x1)P (x2 | x1)P (x3 | x1, x2)P (x4)P (x5 | x3)P (x6 | x4, x5) (3.5)
Los parametros Θ de una BN son justamente el conjunto de probabilidades condicionalesθijk = P (xji | paki ), ∀i = 1, . . . d; ∀j = 1, . . . ri; ∀k = 1, . . . qi. Esto es, una probabilidadcondicional para cada uno de los ri valores que puede tomar la variable xi, dados cadauno de las qi posibles combinaciones de valores de sus padres, aunque se puede ahorrarun poco de espacio y especificar en los parametros solo ri−1 probabilidades condicionalespara cada xi, dado que
∑rij=1 P (xji | paki ) = 1. Con todas ellas se construye una tabla de
probabilidades.
Supongamos que las d = 6 variables en el DAG mostrado en la figura 3.1 son binarias.Entonces X3 puede tomar r3 = 2 valores distintos 0, 1 y sus padres Pa3 = X1, X2pueden tomar q3 = 4 valores diferentes 0, 0; 0, 1; 1, 0; 1, 1. De la misma manera para X5
tenemos que r5 = 2, q5 = 2 y para X4 tenemos que r4 = 2, q4 = 0. Esto se muestra en latabla 3.2.
Notemos que el numero de parametros de la distribucion crece de manera exponencialcon el numero de variables en el problema. A esta caracterıstica de las distribuciones devariables discretas se le llama complejidad representacional. Es por esto que usar modelos
23

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
graficos supone una ventaja, pues las propiedades de independencia condicional descritaspermiten reducir el numero de parametros a usar. Para representar la distribucion deprobabilidad conjunta completa de 6 variables binarias
P (x) = P (X1)P (X2 |X1)P (X3 |X1, X2) . . . P (X6 |X1, X2, X3, X4, X5)
se necesitarıan 1 + 2 + 4 + 8 + 16 + 32 = 63 entradas en la tabla de probabilidades, contralas 14 entradas que se muestran en la tabla 3.2 para el ejemplo mostrado en la figura 3.1.
Factor Entradas en TP
P (x1) θ1;0;∅
P (x2 | x1) θ2;0;0, θ2;0;1
P (x3 | x1, x2) θ3;0;0,0, θ3;0;0,1, θ3;0;1,0, θ3;0;1,1
P (x4) θ4;0;∅
P (x5 | x3) θ5;0;0, θ5;0;1
P (x6 | x4, x5) θ6;0;0,0, θ6;0;0,1, θ6;0;1,0, θ6;0;1,1
Total de entradas 14
Tabla 3.2: Entradas en la tabla de probabilidades para cada factor de la JPMF 3.5
3.2.2.2. Caso Gaussiano
En esta seccion abordaremos el caso particular de las redes Gaussianas, las cuales seusan frecuentemente como modelo en EDAs que trabajan en espacios continuos. Comen-cemos primero por presentar la Distribucion Normal Multivariada, del termino en inglesMultivariate Normal Distribution (MVND) y una factorizacion de la misma.
Sea X = (X1, . . . , Xd)T un vector aleatorio de variables continuas, este sigue una
MVND si y solo si su funcion de densidad esta definida como
N(x;µ,Σ) , f(x) = (2π)−d2 detΣ−
12 e−
12
(x−µ)TΣ−1(x−µ) (3.6)
Donde µ = (µ1, . . . , µd)T es el vector de medias no condicionales de las variablesX1, . . . , Xd
y Σ ∈ IRd×d es su matriz de covarianzas. Esta Funcion de Densidad Conjunta, del termino
24

3.2 Breve introduccion a los Modelos Graficos Probabilısticos
en ingles Joint Density Function (JDF) se puede descomponer a su vez en un producto dedensidades Gaussianas univariadas condicionales (10)
f(x) =
d∏i=1
f(xi | x1, . . . , xi−1) (3.7)
Donde cada densidad Gaussiana condicional esta definida como
f(xi | x1, . . . xi−1) , N(xi;µi +
i−1∑j=1
bij(xj − µj), vi) (3.8)
Aquı µi es el la media no condicional de la variable Xi, bij es el coeficiente de regresionlineal de Xi sobre Xj y vi es la varianza condicional de Xi dados los valores xj para j ∈ Pai.
La expresion µi +∑i−1
j=1 bij(xj − µj) es un desarrollo de la esperanza condicional paravariables Gaussianas que se muestra en la ecuacion 3.9. Para hacer mas facil la notacion,sea Pai = X1, . . . , Xi−1 el conjunto de variables sobre las cuales se condiciona Xi yPai = (X1, . . . , Xi−1)T un vector aleatorio de esas variables
E(Xi |Pai) = µi +Σi,PaiΣ−1Pai
(pai − µPai) = µi + bi(pai − µPai) (3.9)
Donde Σi,Pai = (σi,1, . . . , σi,i−1) es un vector fila con las covarianzas entre la variable Xi ylas variables en Pai, ΣPai es la matriz de covarianzas de estas ultimas y bi = Σi,PaiΣ
−1Pai
es el vector de coeficientes de regresion de Xi sobre las variables en Pai.
Desarrollando tambien la expresion para la varianza condicional de variables gaussianastenemos que
vi = σ2i −Σi,PaiΣ
−1Pai
ΣTi,Pai = σ2
i − biΣTi,Pai (3.10)
Es importante notar que la funcion 3.7 requiere que toda variable Xi este condicio-nada sobre y solo sobre las variables Xj que cumplen con j = 1, . . . , i − 1. En ca-so de que esto no se cumpla es necesario que exista una permutacion de ındices π =π1, π2, . . . , πd, tal que para toda Xπi las variables sobre las que esta condicionada seansolamente Xπ1 , . . . , Xπi−1. Entonces en este caso se podrıa reescribir la expresion 3.8como
f(xπi | xπ1 , . . . xπi−1) , N(xπi ;µπi +
i−1∑j=1
bπiπj (xπj − µπj ), vπi) (3.11)
A π se le llama orden ancestral, y es un requisito definirlo para que una funcion den-sidad representada en la forma 3.7 sea valida. Este concepto en general es importantehablando de PGMs dirigidos pues notemos que el DAG en estos tiene al menos un ordenancestral, es decir, un orden donde para toda Xi las variables en Pai le preceden. Este se
25

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
puede obtener de manera eficiente con un algoritmo basado en Recorrido en profundidad,del termino en ingles Depth-First Search (DFS) sobre el DAG (14) (ver seccion B.2 enel apendice B). En adelante se describiran los PGMs obviando este concepto, pero no sedebe de olvidar a la hora de hacer la implementacion de los algoritmos.
Hasta ahora se ha hecho un breve repaso de la MVND, su funcion de densidad 3.6 y surepresentacion como un producto de densidades univariadas Gaussianas 3.7. Al analizaresta ultima podemos formular una pregunta:
¿Y si Xi no estuviera condicionada sobre todas las variables X1, . . . , Xi−1?
Es decir, tenemos ahora que cada Xi esta condicionada sobre un conjunto de variablespadre Pai. Entonces, de manera analoga a lo que se hace en las redes Bayesianas, podemosrepresentar esto en un grafo, asociar a cada Xi un vector aleatorio Pai y factorizar la JDF3.7 en un producto de la funciones de densidad univariadas Gaussianas, que estarıan dadaspor
f(xi | pai) , N(xi;µi +i−1∑j=1
bij(xj − µj), vi) (3.12)
Donde bij = 0 cuando Xj /∈ Pai, es decir, donde no haya una arista en el grafo entre lasvariables Xi y Xj ; y vi es la varianza condicional de Xi dados los valores pai. El resultadode esto es una Red Gaussiana, del termino en ingles Gaussian Network (GN) (37). Cabemencionar que una GN es una red Bayesiana tambien, aunque en este trabajo lo abrevia-remos ası por cuestiones de claridad.
Por ejemplo, si suponemos que el DAG en la figura 3.1 es una estructura de una GN,entonces la factorizacion de la JDF representada ahı es:
f(x) =
d∏i=1
f(xi | pai) = f(x1)f(x2 | x1)f(x3 | x1, x2)f(x4)f(x5 | x3)f(x6 | x4, x5)
y usando la funcion de densidad condicional 3.8 al final tenemos que
f(x) = (1√
2πv1e− (x1−µ1)
2
2v1 )(1√
2πv2e−
(x2−(µ2+b2,1(x1−µ1)))2
2v2 )
(1√
2πv3e−
(x3−(µ3+b3,1(x1−µ1)+b3,2(x2−µ2)))2
2v3 )
(1√
2πv4e− (x4−µ4)
2
2v4 )(1√
2πv5e−
(x5−(µ5+b5,3(x3−µ3)))2
2v5 )
(1√
2πv6e−
(x6−(µ6+b6,4(x4−µ4)+b6,5(x5−µ5)))2
2v6 )
(3.13)
26

3.2 Breve introduccion a los Modelos Graficos Probabilısticos
Entonces, en una GN M = (S,Θ) la estructura esta dada por un DAG y permiteel manejo de las propiedades de (in)dependencia entre las variables de manera analo-ga a una red Bayesiana. Sus parametros Θ estan dados para cada variable Xi comoθi ≡ µi,bi = (bij , . . . )
T∀j ∈ Pai, vi. Para el ejemplo en la figura 3.1 los parametrosserıan los mostrados en la tabla 3.3.
Es importante recordar el orden ancestral se debe definir para todo PGM con estruc-tura representada en un DAG (este es el caso) y que las expresiones para el calculo de losparametros bij y vi estan dadas en las ecuaciones 3.9 y 3.10 respectivamente.
En el caso de la MVND la complejidad representacional es cuadratica, ası que usarmodelos graficos cuando el tamano del problema es pequeno no supone un ahorro signifi-cativo de recursos computacionales.La ventaja en este sentido se da en caso de que el problema que estemos manejando seamuy grande (d >> 100) ya que un bajo nivel de densidad del grafo en la GN permi-tira hacer la simulacion mediante PLS (ver seccion 3.2.5) evitando hacerlo mediante lafactorizacion Cholesky de la matriz de covarianzas de complejidad O(d3).
Variable Parametros
X1 θ1 = µ1,−, v1
X2 θ2 = µ2, (b21), v2
X3 θ2 = µ3, (b31, b32), v3
X4 θ4 = µ4,−, v4
X5 θ5 = µ5, (b53), v5
X6 θ6 = µ6, (b64, b65), v6
Tabla 3.3: Parametros para la JDF factorizada 3.13
Es importante mencionar desde ahora que el resultado final del algoritmo que se pro-pone en este trabajo es una Red Gaussiana.
3.2.3. Grafos no dirigidos
Un PGM M = (S,Θ) tambien puede tener como estructura a un grafo no dirigido. Aeste tipo de modelo grafico se le llama Red de Markov, del termino en ingles Markov Net-
27

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
work (MN). Aquı las aristas representan influencia simetrica entre variables. Un ejemplose visualiza en la figura 3.2.
Los parametros de la MN son funciones no negativas Ψc(xc) cada una definida sobreun clique c (subgrafo completo) del grafo. A estas funciones se les llama potenciales, y esimportante senalar que no tienen interpretacion probabilıstica para un tamano de cliquek > 3. Solo se puede tomar en cuenta el hecho de que si Ψ(xc1) > Ψ(xc2), entonces xc1 esmas probable que xc2 .
Sea C = c1, c2, . . . el conjunto de cliques en el grafo no dirigido de una MN. Entoncesla distribucion de Gibbs (12)
ρΨC (x) =1
Z
∏c∈C
ψc(xc) (3.14)
es la funcion de probabilidad conjunta de la distribucion representada en esa red, y sedefine por el producto normalizado de potenciales de sus cliques.Consideremos una MN con la estructura que se muestra en la figura 3.2. Sus cliques yparametros se muestran en la tabla 3.4, la distribucion de Gibbs representada allı estadada por
ρΨC (x) =1
Zψc1(x1, x2, x3)ψc2(x1, x3, x4)ψc3(x3, x5)ψc4(x5, x6) (3.15)
X2
X4
X3
X1
X5
X6
Figura 3.2: Ejemplo de estructura S de
una MN para un problema de 6 varia-
bles.
Clique Potencial
c1 = X1, X2, X3 ψc1(x1, x2, x3)
c2 = X1, X3, X4 ψc2(x1, x3, x4)
c3 = X3, X5 ψc3(x3, x5)
c4 = X5, X6 ψc4(x5, x6)
Tabla 3.4: Cliques y parametros de la
MN ilustrada en la figura 3.2
Esta familia de PGM se usa de manera extensa en inferencia estadıstica pues sonuna herramienta muy eficiente para ello. Sin embargo, debido en gran parte a la alta
28

3.2 Breve introduccion a los Modelos Graficos Probabilısticos
complejidad computacional de simular datos desde este tipo de modelos graficos no sehan usado de manera extensa en los EDAs. Algunos algoritmos como el EDA de arbolde dependencias de Chow & Liu o el Polytree de variables Gaussianas (que se veran masadelante), ademas del algoritmo que se presenta en este trabajo, construyen este tipode grafos, para luego dar direccion a las aristas y con ello hacer factible la simulacionindividuos. En la siguiente seccion se hace un repaso del estado del arte, y se aborda estocon detalle.
3.2.4. Construccion del Modelo
En los ultimos anos se han desarrollado una gran cantidad de algoritmos para cons-truir la estructura S y aprender los parametros Θ desde los datos del problema. Parasu aplicacion en EAs se necesita que estos algoritmos sean computacionalmente eficientes(pues se tiene que realizar varias veces la construccion y aprendizaje durante el procesoevolutivo, en la mayorıa de los casos en cada generacion) sacrificando con ello frecuente-mente exactitud en el ajuste del modelo. Este intercambio de precision por eficiencia sueleser benefico en ambos sentidos, ya que dada la naturaleza estocastica de los AlgoritmosEvolutivos el construir un modelo de probabilidad muy ajustado del conjunto Qts sesga labusqueda hacia las zonas ocupadas por los mejores individuos en el tiempo t, cuando eloptimo global no se encuentra necesariamente en esas zonas o en los alrededores.
Se hace a continuacion un repaso de algunos de estos algoritmos y tecnicas para cons-truir modelos graficos. Reiteramos que casi todos los algoritmos aplicados en los EDAsusan DAGs, es por eso que practicamente todos los algoritmos aquı presentados tienencomo resultado un PGM con estructura de DAG.
Podemos clasificar estos algoritmos de acuerdo a la naturaleza del modelado (23) enmetodos de deteccion de independencias condicionales y metodos de Score + Search.
3.2.4.1. Score + Search
Como su nombre lo indica estos algoritmos se basan en la realizacion de una busqueda(Search) en el espacio de las estructuras validas (DAGs) de un PGM. Se necesita definiruna metrica de la calidad del ajuste de cierto modelo a los datos (Score), con el fin derealizar esta busqueda de manera inteligente.
3.2.4.1.1 Metricas
Las metricas mas usadas se pueden clasificar en dos grupos:
Metricas basadas en verosimilitud. Se trata de encontrar la pareja de estructura S yestimadores de maxima verosimilitud θi para los parametros θi que maximicen la logverosimilitud log p(Q | S, Θ). Es decir, se busca establecer una metrica de que tanto
29

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
el Modelo Grafico M = (S,Θ) describe los datos Q.Ejemplo para una red Bayesiana: Penalized Maximum Likelihood
logP (Q | S,Θ) = logn∏l=1
d∏i=1
P (xli | pai) =d∑i=1
ri∑j=1
qi∑k=1
log(θijk)nijk
y dado que el estimador de maxima verosimilitud es θijk =nijknik
, donde nijk es elnumero de veces que en la base de datos la variable Xi tiene su valor j-esimo y suspadres la combinacion de valores k-esimo. Entonces
logP (Q | S, Θ) =d∑i=1
ri∑j=1
qi∑k=1
nijk lognijknik
es la log verosimilitud de la red Bayesiana para los datos contenidos en Q. Solohace falta agregar una funcion de penalizacion f(n, |Θ|) que depende del numero deobservaciones en los datos y del numero de parametros de la red, esta ultima con elfin de mitigar el error que se puede dar por el numero n de observaciones (puedenser pocas) y por la complejidad del modelo, ya que |Θ| puede llegar a ser bastantegrande. Al final, la metrica Penalized Maximum Likelihood queda definida como
d∑i=1
ri∑j=1
qi∑k=1
nijk lognijknik− f(n, |Θ|) (3.16)
Ejemplo para una red Gaussiana. Sea L(Q | S,Θ) la verosimilitud de los datos dadala GN. Entonces, la log verosimilitud es
lnL(Q | S,Θ) = ln
n∏l=1
d∏i=1
f(xli | pai)
Usando la definicion 3.12 y agregando una funcion de penalizacion analoga al casodiscreto definimos entonces la metrica como:
n∑l=1
d∑i=1
[− ln(√
2πvi)−1
2vi(xli − µi −
∑xj∈pai
bij(xlj − µj))2]− f(n, |Θ|) (3.17)
Metricas basadas en Teorıa de la informacion. Se trata de medir la diferencia entrela distribucion de probabilidad de los individuos Q ∼ ρ(x) y la aproximacion ρg(x)representada en el PGM. Para ello se usa la Divergencia de Kullback-Leibler, deltermino en ingles Kullback-Leibler Divergence (KLD) como medida de la diferenciaentre las dos distribuciones. En resumen, mientras menor sea la DKL(ρ(x), ρg(x)),mejor es el modelo construido.
30

3.2 Breve introduccion a los Modelos Graficos Probabilısticos
Ejemplo: Peso de un arbol de dependencias (7). Mediante el desarrollo de la KLD(ver definicion A.6 en el apendice A) entre la JPMF de la distribucion original yla del PGM cuya estructura es un arbol, con funciones de probabilidad P (x) yP t(x) = P (xr)
∏di=1,i 6=r P (xi | xpai) respectivamente, se obtiene que
DKL(P (x), P t(x)) = −H(X) +d∑i=1
H(Xi)−d∑
i=1,i 6=rI(Xi, Xpai)
Siendo las entropıas H(Xi) y H(X) independientes de la estructura del grafo sepueden ignorar, por lo que la metrica se define como la suma de las informacionesmutuas de los pares de variables formados por padres e hijas:
d∑i=1,i 6=r
I(Xi, Xpai) (3.18)
En la seccion 3.3 se abordan de manera mas extensa algunas de estas metricas.
3.2.4.1.2 Estrategias de busqueda
El tamano del espacio de busqueda de estructuras validas es enorme. Para un problemade n variables esta dado por la formula recursiva (23):
f(n) =n∑i=1
(−1)i+1
(n
i
)2i(n− i)f(n− i)
f(1) = 1, f(0) = 1
Se ha probado en (6) que el problema de encontrar la estructura optima donde cadavertice tenga un grado de entrada k > 1 es NP-Hard. Para k = 1 se puede resolver conel algoritmo de Arbol de Expansion de Peso Maximo, del termino en ingles MaximumWeight Spanning Tree (MWST) (7) (ver seccion B.3 en el apendice B). Ası que podemosdescribir a la busqueda como un problema de optimizacion por sı mismo. En principioes evidente que no es posible hacer una busqueda exhaustiva en el espacio de estructurasvalidas, entonces otras estrategias se han usado para el caso k > 1 como:
Algoritmos greedy. Se comienza con un grafo sin aristas o muy disperso. Entoncesse prueba conectar algunas aristas agregando la que mejore en mayor magnitud lametrica definida en cada paso.
Algoritmos de busqueda local. Dado un grafo inicial, se buscan y evaluan distintosgrafos en una vecindad de radio definido. Se toma el mejor de los encontrados. Elresultado depende en gran medida de la estructura inicial.
Metaheurısticas. Se han usado algoritmos geneticos, simulated annealing, entre otrasmetaheurısticas, usando como funcion de fitness la metrica definida.
31

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
3.2.4.2. Deteccion de independencias
Estos algoritmos comienzan tıpicamente con un grafo completo o uno bastante densocomo estructura inicial. Se escogen dos vertices adyacentes del grafo y se ejecutan prue-bas estadısticas de independencia condicional dado un subconjunto de vertices del grafo,comunmente vecinos de los vertices a los cuales se les ejecuta la prueba. Si esta es satisfac-toria, se podan las aristas correspondientes y se continua, hasta que se no se encuentranmas pares de variables que pasen la prueba o se llega al nivel deseado de dispersion en elgrafo. Un ejemplo de estos algoritmos es el PC, propuesto por Spirtes en 1991 (40).
3.2.5. Simulacion desde el Modelo Grafico Probabilıstico
Entre los algoritmos de simulacion desde un PGM hay uno que destaca por su sen-cillez y eficiencia: el Muestreo Logico Probabilıstico, del termino en ingles ProbabilisticLogic Sampling (PLS) (15). Vea el algoritmo 5. Se simulan las variables con su funcion deprobabilidad condicional ρπi(xπi | paπi), dado un orden ancestral π del grafo. Es decir, secomienza por las variables que no tienen padres (vertices raız en el grafo) y se continua conaquellas que ya tengan el vector de valores de padres paπi simulado en su totalidad. Estose puede hacer en tiempo lineal con respecto a la suma de la cantidad de vertices y aristasusando un algoritmo basado en el DFS sobre el grafo, explicado de manera sencilla y claraen (14). Esta forma de simulacion se puede efectuar en redes Bayesianas y Gaussianas,por lo que en este trabajo se adopta este algoritmo como estrategia para la simulacion denuevos individuos.
Algorithm 5 Probabilistic Logic Sampling
1: procedure PLS(π, d,M)
2: for i = 1, . . . , d do
3: xπi ← simular valor desde ρπi(xπi | paπi)
4: end for
5: return x
6: end procedure
Por ejemplo, para simular datos desde la BN cuya estructura esta ilustrada en la figura3.1 se sigue el siguiente procedimiento:
1. x1 ← desde N(µ1, σ21)
2. x4 ← desde N(µ4, σ41)
32

3.3 Aplicacion en Algoritmos Evolutivos
3. x2 ← desde N(µ2 + b21(x1 − µ1), v2)
4. x3 ← desde N(µ3 + b31(x1 − µ1) + b32(x2 − µ2), v3)
5. x5 ← desde N(µ5 + b53(x3 − µ3), v5)
6. x6 ← desde N(µ6 + b64(x4 − µ4) + b65(x5 − µ5), v6)
Por otro lado, para simular observaciones desde una MN se usa muestreo de Gibbs(12), un algoritmo iterativo que partiendo de una observacion inicial x0 = (x0
1, . . . , x0d),
obtiene en cada iteracion una nueva observacion xt mediante la simulacion de cada unade las xti condicionada sobre los valores xtj , Xj ∈ Pai, j < i ∪ xt−1
j , Xj ∈ Pai, j > i.Se considera que es un metodo de Montecarlo. La cantidad de recursos computacionalesdel que hace uso de este algoritmo es mucho mayor que la de el PLS, por el hecho de quese tienen que descartar un buen numero de las primeras muestras por ser muy semejantesa la observacion inicial x0; ademas de que dos muestras consecutivas o muy cercanas sonidenticamente distribuidas pero no son independientes, por lo que se deben de descartartambien.
3.3. Aplicacion en Algoritmos Evolutivos
A continuacion se hace un repaso de los principales PGM que se usan como modelo enEDAs, clasificados como se hace en (23). Tambien se mencionan algunos EDAs sencillosrepresentativos para el caso discreto y el caso continuo que usan estos PGMs. Todos ellosconstruyen DAGs, por la razon dada en el parrafo anterior. La clasificacion de los PGMsse hace usando como criterio el nivel de densidad del grafo que construyen, dada por elmaximo de variables sobre las cuales se condiciona a cada Xi, es decir, cuantos padrespuede tener cada variable.
Sin dependencias. Los grafos en este tipo de algoritmos son desconectados.
Con dependencias por pares. Es decir, que cada variable tiene a lo mas un padre.Los grafos pueden ser cadenas, arboles o bosques.
Con multiples interdependencias. Cada variable tiene puede tener hasta d−1 padres.En esta clasificacion estan los polytrees y otras redes Bayesianas o Gaussianas masdensas.
3.3.1. Sin dependencias: Grafos desconectados
El UMDA (siglas en ingles para Univariate Marginal Distribution Algorithm) es pre-sentado por Heinz Muhlenbein en 1998 (27). La inspiracion para este algoritmo la toma delos estudios que se hacen de la crıa de ganado, y de como al lograr el Linkage equilibrium;
33

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
las frecuencias del genotipo son el producto de frecuencias univariadas marginales. Poresta razon el algoritmo esta basado en la estimacion de probabilidades marginales P (xi),estando la JPMF dada por
P (x) =d∏i=1
P (xi) (3.19)
El aprendizaje de los parametros P (xi) se hace mediante un conteo de frecuencias. Estealgoritmo es el mas sencillo entre los EDAs pues no hay construccion del modelo grafico(se define siempre como un grafo completamente desconectado, ver figura 3.3). Ademas,al manejar solo probabilidades marginales univariadas la complejidad computacional esbastante baja.
La version para espacios continuos del UMDA, llamado UMDAc (24) efectua pruebasestadısticas para identificar la funcion de densidad f(xi) de cada variable que mejor des-cribe su distribucion. Una vez identificadas se aprenden sus parametros por medio de susestimadores de maxima verosimilitud, por lo que al final la funcion de densidad conjuntaesta dada por el producto de estas.
f(x) =d∏i=1
f(xi)
En la practica por cuestiones de factibilidad se hace el supuesto de que cada una delas variables en el problema siguen una distribucion Gaussiana. Este algoritmo se llamaUMDAG
c (24).
X1
X4
X3
X2
X5
X6
Figura 3.3: Ejemplo de un grafo que representa al modelo de distribucion que se usa en el
UMDA
34

3.3 Aplicacion en Algoritmos Evolutivos
3.3.2. Dependencias por pares
3.3.2.1. Cadena
El MIMIC (Siglas para Mutual Information Maximization for Input Clustering) es unalgoritmo presentado por (9) para la construccion de un grafo en forma de cadena, comoen el ejemplo de la figura 3.4. Para la explicacion de este abordaremos el caso discreto.Como es evidente, en una cadena cada variable tiene un solo padre, a excepcion de laprimera variable, que no esta condicionada. La distribucion de probabilidad conjunta quese representa esta dada por el producto de probabilidades condicionales
P π(x) = P (xπ1)
d∏i=2
P (xπi | xπi−1) (3.20)
X1
X4
X3
X2
X5
X6
Figura 3.4: Ejemplo de una cadena para seis variables. En este caso π = 2, 1, 3, 6, 5, 4.
Si X1, . . . , X6 son discretas, la factorizacion de la funcion de probabilidad es P (x) =
P (x2)P (x1 | x2)P (x3 | x1)P (x6 | x3)P (x5 | x6)P (x4 | x5)
Donde π = π1, π2, . . . , πd es una permutacion de los ındices de las variables del pro-blema. Es evidente que para un problema de d variables hay d! estructuras diferentes.
La KLD entre la distribucion real de los individuos y la representada por la cadena
35

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
dada por cierta permutacion π es
DKL(P (x), P π(x)) =∑x
(P (x) logP (x)− P (x) logP π(x))
= −H(X)−∑x
P (x) log
(P (xπ1)
d∏i=2
P (xπi | xπi−1)
)
= −H(X)−∑x
P (x) logP (xπ1) +d∑i=2
P (x) logP (xπi | xπi−1)
= −H(X) +H(Xπ1) +
d∑i=2
H(Xπi |Xπi−1)
Ya que la entropıa H(X) no varıa dependiendo de la estructura, se busca entonces lacadena representada por la permutacion π que minimice a
H(Xπ1) +d∑i=2
H(Xπi |Xπi−1) (3.21)
Se sugiere para esto un algoritmo greedy. En un inicio se toma como Xπ1 a la variablecon menor entropıa estimada. Luego se toma como Xπ2 a la variable con menor entropıacondicional dada Xπ1 y que aun no se encuentre en el grafo, esto con el fin de conservarla estructura de cadena (Ver en el apendice A las definiciones A.2 y A.3). Se repite esteultimo paso esto para π3, . . . , πd.En el caso de que las variables sean de naturaleza continua, si suponemos que siguen unaMVND los autores en (24) usan el concepto de entropıa diferencial mostrado en el apendiceA.4 para definir la medida de la aproximacion del modelo como
h(Xπ1) +d∑i=2
h(Xπi |Xπi−1) (3.22)
donde h(Xi) es la entropıa diferencial de la variable Gaussiana Xi y h(Xi|Xj) es la entropıadiferencial condicional Gaussiana de Xi dado Xi (ver las definicion A.5 en el apendice A).Esta version del algoritmo se llama MIMICG
c y usa el mismo algoritmo greedy para laconstruccion de la estructura.Con respecto al aprendizaje de los parametros, la cadena es en sı misma una red Bayesianao Gaussiana (dependiendo del tipo de variables), por lo que se aprenden los parametroscomo se explico en la seccion 3.2. De igual manera, para la simulacion de individuos, seusa el PLS.
36

3.3 Aplicacion en Algoritmos Evolutivos
3.3.2.2. Arbol de dependencias
Para la explicacion de este algoritmo tambien abordaremos el caso discreto. Chow yLiu presentan en (7) el arbol de dependencias, el cual es un grafo donde cada variable Xi
depende de una variable padre Xpai excepto por aquella que funge como raız. Esto nosrecuerda a las caracterısticas de la cadena del MIMIC. La diferencia es que en el MIMICexiste la restriccion de que cada variable puede tener un grado de salida a lo mas de 1(lo que preserva la forma de cadena), y en este algoritmo esa restriccion no existe (lo quepermite que se formen arboles). La distribucion conjunta representada por el arbol tienecomo funcion de probabilidad
P t(x) = P (xr)
d∏i=1,i 6=r
P (xi | xpai)
donde Xr es la variable raız del arbol. De lo que se trata es de encontrar el arbol para ladistribucion mas cercana a la distribucion real de un conjunto de observaciones Q. Paraello se utiliza la KLD
DKL(P (x), P t(x)) =∑x
P (x) logP (x)−∑x
P (x) logP t(x)
= −H(X)−d∑i=1
∑x
P (x) logP (xi)−d∑
i=1,i 6=r
∑x
P (x) logP (xi, xpai)
P (xi)P (xpai)
= −H(X) +
d∑i=1
H(Xi)−d∑
i=1,i 6=rI(Xi, Xpai)
Este fue el ejemplo que se explico en la seccion 3.2, en la parte de metricas basadasen Teorıa de la Informacion. Como se dijo ya −H(X) y
∑di=1H(Xi) no dependen de la
estructura del grafo, por lo que es posible definir la metrica de la calidad en el ajuste decierto arbol como
d∑i=1,i 6=r
I(Xi, Xpai) =d∑i=1
ri∑j=1
rPai∑k=1
P (xji , xkPai) log
P (xji , xkPai
)
P (xji )P (xkPai)(3.23)
A la expresion 3.23 se le llama peso del arbol, el cual esta dado por la suma de lasinformaciones mutuas (ver la definicion A.8 en el apendice A) de padres e hijas. El arboloptimo es aquel entre todos los nn−2 arboles posibles que tiene la menor KLD, es decir,mayor peso. Es con base en esto que Chow y Liu demuestran en (7) que se puede encontrarel arbol optimo mediante el algoritmo MWST, usando como peso de arista la informacionmutua entre las variables que conecta. De manera breve, el algoritmo consiste primero enordenar las d(d−1)
2 aristas que pueden existir en el grafo por su peso. Luego, comenzando
37

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
con un grafo desconectado, se van agregando las aristas en orden descendente siempre ycuando no formen un ciclo, hasta que todas las variables hayan sido conectadas.Es importante senalar que las aristas que se agregan en este algoritmo no tienen direccion,por lo que el resultado es un grafo no dirigido (ver ejemplo en la figura 3.5).
X1
X4
X3
X2
X5
X6
Figura 3.5: Ejemplo de un arbol
de Chow-Liu para 6 variables
X1
X4
X3
X2
X5
X6
Figura 3.6: Ejemplo de un direccionamiento
de las aristas para la estructura en la figura
3.5 Si X1, . . . , X6 son discretas, la factoriza-
cion de la funcion de probabilidad es P (x) =
P (x3)P (x1|x3)P (x4|x3)P (x2|x4)P (x6|x3)P (x5|x6)
Para usarse en un EDA, se tiene que convertir en un DAG usando una estrategia sim-ple. Se escoge como raız Xr la variable con menor entropıa del par de variables de mayorinformacion mutua (Es decir, de las que conecta la primer arista que se agrego al arbol).Al hacer un DFS (ver la seccion B.2 en el apendice B) sobre el arbol comenzando en Xr
podemos establecer las direcciones de las aristas y a la vez su orden ancestral para estecaso en especıfico. Un ejemplo se muestra en la figura 3.6 con raız r = 3.
Si las variables son de naturaleza continua y suponemos que siguen una MVND en-tonces podemos usar la misma expresion del peso de arbol 3.23, usando la definicion deinformacion mutua para variables Gaussianas (ver definicion A.11 en el apendice A). Parasimplificar las cosas, se puede establecer como peso de la arista la correlacion −1 < ρij < 1,pues por su rango de posibles valores al maximizar esta se maximiza I(Xi, Xj) (24). Seaprenden los parametros como se explica en la seccion 3.2 para redes Bayesianas y Gaus-sianas, dependiendo del caso.
38

3.3 Aplicacion en Algoritmos Evolutivos
3.3.3. Multiples interdependencias
3.3.3.1. Polytree
El polytree es un grafo dirigido donde cada vertice puede tener de 0 a d − 1 padres,con la condicion de que no haya aristas entre estos. Si les quitamos las direcciones a lasaristas, nos quedamos con un arbol. Otra caracterıstica es que hay un solo camino entredos vertices. Si consideramos a un polytree como la estructura de un PGM M(S,Θ), ladistribucion conjunta representada por este tiene como funcion de probabilidad
P t(x) =
(∏r∈R
P (xr)
)d∏
i=1,i/∈R
P (xi | xpai)
donde R es el conjunto de ındices de las variables que son raız en el polytree. En (39) seexplora su uso como PGM para usarse en un EDA de espacios discretos llamandolo PADA(Polytree Approximation of Distribution Algorithm).
En este trabajo se aborda la construccion del polytree comenzando con un grafo com-pletamente desconectado, y se hacen pruebas de dependencia usando informacion mutuaI(Xi, Xj) para trazar aristas. Se obliga que I(Xi, Xj) > ε1 para evitar sobreajustes ydesechar las dependencias debiles. Se usa tambien como prueba de dependencia la in-formacion mutua condicional I(Xi, Xj |Xk) (ver definicion A.12 en el apendice A). SiI(Xi, Xj) > I(Xi, Xj |Xk) siempre y cuando I(Xi, Xj) − I(Xi, Xj |Xk) > ε2, entoncesdecimos que saber Xk incrementa la informacion mutua entre Xi y Xj , por lo que noson condicionalmente independientes dado Xk. Esto forma una conexion head to headXi → Xk ← Xj en el grafo, en el ejemplo mostrado en la figura 3.7 se ve esta conexionentre X4, X1, X3. Este tipo de conexiones son las que permiten que haya vertices congrado de entrada mayor a 1.
En otros trabajos (36) se considera construir primero un arbol de dependencias median-te el algoritmo de Chow-Liu, y luego hacer pruebas de dependencia del tipo I(Xi, Xj) >I(Xi, Xj | Xk) para darle direccion a las aristas. En ese trabajo se propone el GaussianPolytree para espacios continuos, usando la definicion de informacion mutua Gaussiana yla informacion mutua condicional Gaussiana como medidas de dependencia.
39

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
X1
X4
X3
X2
X5
X6
Figura 3.7: Ejemplo de un polytree para 6 variables. Si quitamos las direccio-
nes de las aristas, nos quedamos con el arbol de dependencias mostrado en 3.5. Si
X1, . . . , X6 son discretas, la factorizacion de la funcion de probabilidad es P (x) =
P (x4)P (x1)P (x2 | x4)P (x3 | x1, x4)P (x6 | x3)P (x5 | x6)
3.3.3.2. Redes Bayesianas/Gaussianas
Aunque las cadenas, arboles y polytrees son redes Bayesianas tambien, se suele iden-tificar a los PGM con DAGs que no pertenecen a ninguna de las tres subclasificacionesanteriores como red Bayesiana. Las variables dentro de estas suelen tener mas de un padre,y los padres suelen tener conexiones entre ellos por lo que los modelos construidos suelenser mas complejos. Podemos ver un ejemplo en la figura 3.8.
Los EDAs para espacios discretos que usan redes Bayesianas son la familia de los EBNA(siglas para Estimation of Bayesian Network Algorithm) (21) y usan tecnicas de Score +Search (23) para construirlas. Lo que los distingue entre ellos es la metrica de calidad delgrafo que usan, por ejemplo el EBNABIC usa una metrica Penalized Maximum Likelihoodllamada Bayesian Information Criterion (34).
d∑i=1
ri∑j=1
qi∑k=1
nijk lognijknik− 1
2log n
d∑i=1
qi(ri − 1) (3.24)
40

3.3 Aplicacion en Algoritmos Evolutivos
X1
X4
X3
X2
X5
X6
Figura 3.8: Ejemplo de una Red Bayesiana para 6 variables. La factorizacion de la funcion
de probabilidad es P (x) = P (x4)P (x2 | x4)P (x1 | x4)P (x3 | x1, x4)P (x6 | x2, x3)P (x5 | x6). Un
orden ancestral de esta red es π = 4, 2, 1, 3, 6, 5
Recordemos que qi es el numero de las posibles combinaciones de valores para el con-junto de padres Pai y ri el numero de distintos valores que puede tomar la variable Xi.
Usan estrategias greedy de busqueda, en algunos casos combinada con busquedas loca-les (se toma el grafo de la generacion anterior como estructura inicial) con el fin de hacermas eficiente la construccion.
Para el caso continuo se supone, al igual que en los algoritmos vistos hasta el momento,que las variables siguen una MVND. Los algoritmos estan agrupados tambien en la familiade los EGNA (siglas para Estimation of Gaussian Network Algorithm). Tambien los distin-gue la metrica usada en la construccion del grafo, por ejemplo el EGNABIC usa tambienla version Gaussiana de Penalized Maximum Likelihood 3.17 con funcion de penalizacion
f(d, |Θ|) = 12 log d
(2d+
∑di=1 |Pai|
)3.3.3.3. Redes de Markov
Varios EDAs que usan como modelo redes de Markov regularizadas de orden k, lla-mados MNEDA (siglas para Markov Network Estimation of Distribution Algorithm) sonpropuestos por Santana en varios trabajos, de los cuales presenta un resumen en (38).Entre las estrategias de construccion del modelo presentadas ahı destaca la optimizacionde la agrupacion de variables en clusters, donde la informacion mutua es utilizada comomedida de distancia entre dos variables. Cada cluster representa un subgrafo completo enla red de Markov. Es importante hacer notar que el algoritmo de construccion usado en
41

3. MODELOS GRAFICOS Y SU USO EN LOS EDAS
este trabajo (abordado con detalle en el siguiente capıtulo) tambien crea clusters formandouna red de Markov representada como un t-Cherry Junction Tree de orden k, usando unametrica de calidad en funcion de la informacion mutua.
En los MNEDAs, el hecho de no conocer con certeza el numero de clusters a formarhace mas complejo al algoritmo de agrupacion, por lo que se adoptan diversas estrategiaspara aliviar este problema, como busquedas locales y greedys a partir de una estructurapreviamente construida, con un orden k definido.
3.3.3.4. Grafo completo
Si suponemos que las variables del problema siguen una MVND podemos manejar ladistribucion conjunta completa gracias a la complejidad de calculo O(d3) y almacenamientoO(d2), Con base en 3.7 podemos decir que la distribucion esta representada por un grafocompleto. Para variables discretas no es factible hacer esto, por las razones mencionadasen la seccion anterior. El EMNAglobal (22) es un algoritmo que estima los parametros µ,Σde una MVND desde la poblacion Q en cada generacion mediante sus estimadores demaxima verosimilitud:
µi =1
N
N∑k=1
xik
σij =1
N
N∑k=1
(xik − µi)(xjk − µj)
.En este algoritmo podemos notar, al igual que en UMDA, que no hay construccion del
grafo pues se da una estructura fija. Solo se aprenden sus parametros.
42

Capıtulo 4
El t -Cherry Junction Tree de orden k
Recordando lo mencionado en el capıtulo 1, este trabajo tiene como objetivo proponerel uso del t-Cherry Junction Tree de orden k como PGM a usar en un EDA para optimi-zacion global sin restricciones. La finalidad de este capıtulo es describir la estructura deeste PGM y un algoritmo eficiente para su construccion.Los temas en este capıtulo se organizan de la manera siguiente:En la seccion 4.1 se presentan de manera breve los grafos que hay que conocer para enten-der que es un t-Cherry Junction Tree de orden k. En la siguiente seccion 4.2 se generalizalo visto en la introduccion y se definen formalmente estos grafos, y se aborda su uso comoestructuras en PGMs. A continuacion, en 4.3 se explica el algoritmo para construirlo. Alfinal, en la seccion 4.4 se explica en detalle como construir de manera eficiente un t-CherryJunction Tree de orden k donde suponemos que las variables siguen una MVND.
4.1. Introduccion
El orden k de un grafo no dirigido se define como el tamano de su clique maximo.Entonces, dentro de un grafo de orden k = 4 hay 1 o mas cliques de tamano 4. De maneraanaloga en un Junction Tree el orden es el tamano del cluster mas grande.En esta seccion por cuestiones de claridad en las figuras ilustramos los diferentes tiposde grafos no dirigidos mediante ejemplos de orden 3. Cabe mencionar que en este casoen particular los nombres prescinden del orden. Por ejemplo, un t-Cherry Tree de ordenk = 3 es llamado simplemente t-Cherry Tree.
4.1.1. Presentando los grafos
El Cherry Tree (3) es un grafo no dirigido (no es un arbol, a pesar de lo que su nombresugiere) que se construye mediante el siguiente algoritmo:
1. Se conectan dos vertices cualesquiera.
43
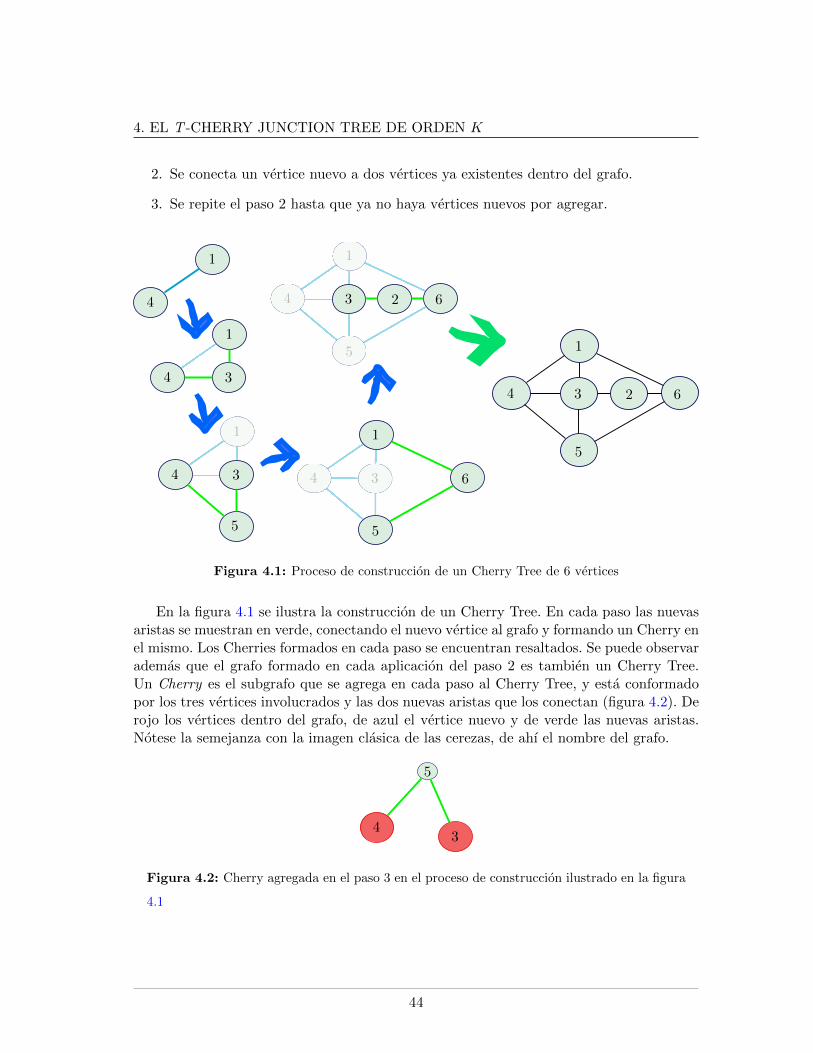
4. EL T -CHERRY JUNCTION TREE DE ORDEN K
2. Se conecta un vertice nuevo a dos vertices ya existentes dentro del grafo.
3. Se repite el paso 2 hasta que ya no haya vertices nuevos por agregar.
1
3 2 64
5
1
4
1
34
1
34
5
1
3 64
5
1
3 2 64
5
Figura 4.1: Proceso de construccion de un Cherry Tree de 6 vertices
En la figura 4.1 se ilustra la construccion de un Cherry Tree. En cada paso las nuevasaristas se muestran en verde, conectando el nuevo vertice al grafo y formando un Cherry enel mismo. Los Cherries formados en cada paso se encuentran resaltados. Se puede observarademas que el grafo formado en cada aplicacion del paso 2 es tambien un Cherry Tree.Un Cherry es el subgrafo que se agrega en cada paso al Cherry Tree, y esta conformadopor los tres vertices involucrados y las dos nuevas aristas que los conectan (figura 4.2). Derojo los vertices dentro del grafo, de azul el vertice nuevo y de verde las nuevas aristas.Notese la semejanza con la imagen clasica de las cerezas, de ahı el nombre del grafo.
34
5
Figura 4.2: Cherry agregada en el paso 3 en el proceso de construccion ilustrado en la figura
4.1
44
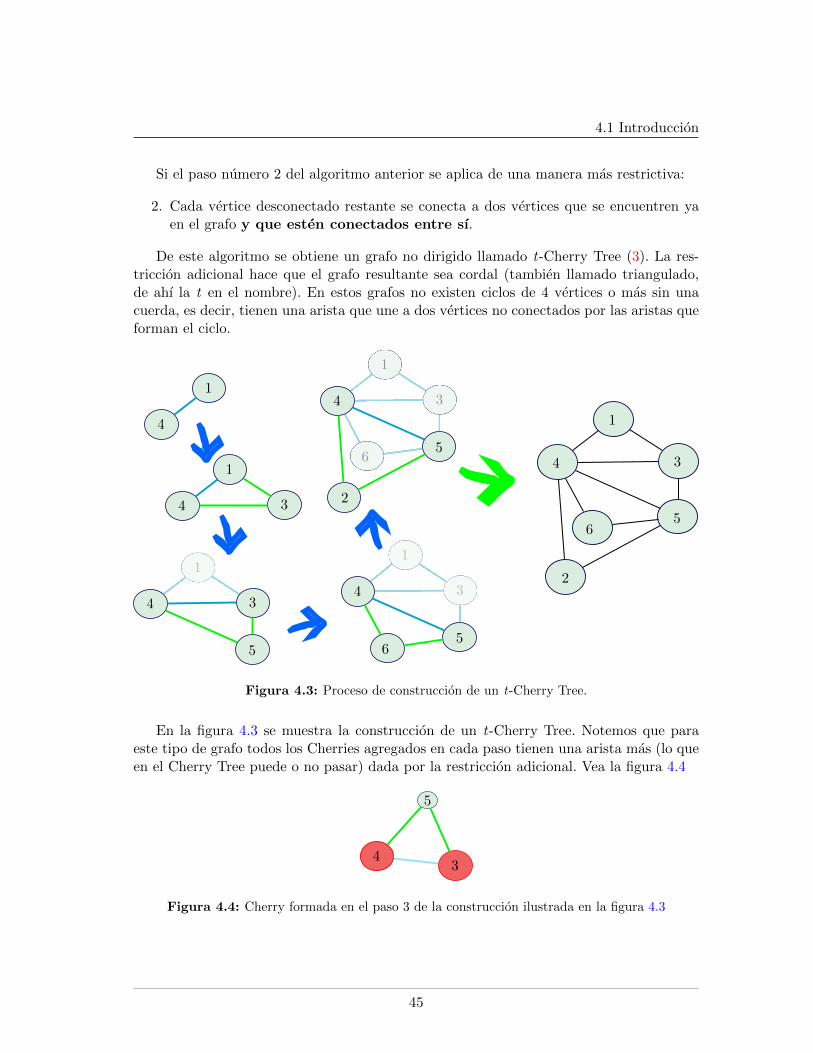
4.1 Introduccion
Si el paso numero 2 del algoritmo anterior se aplica de una manera mas restrictiva:
2. Cada vertice desconectado restante se conecta a dos vertices que se encuentren yaen el grafo y que esten conectados entre sı.
De este algoritmo se obtiene un grafo no dirigido llamado t-Cherry Tree (3). La res-triccion adicional hace que el grafo resultante sea cordal (tambien llamado triangulado,de ahı la t en el nombre). En estos grafos no existen ciclos de 4 vertices o mas sin unacuerda, es decir, tienen una arista que une a dos vertices no conectados por las aristas queforman el ciclo.
1
4
1
34
1
34
5
1
3
6
4
5
1
3
2
6
4
5
1
3
2
6
4
5
Figura 4.3: Proceso de construccion de un t-Cherry Tree.
En la figura 4.3 se muestra la construccion de un t-Cherry Tree. Notemos que paraeste tipo de grafo todos los Cherries agregados en cada paso tienen una arista mas (lo queen el Cherry Tree puede o no pasar) dada por la restriccion adicional. Vea la figura 4.4
34
5
Figura 4.4: Cherry formada en el paso 3 de la construccion ilustrada en la figura 4.3
45

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
Para llegar al t-Cherry Junction Tree, primero presentaremos al Junction Tree (18), elcual es una representacion de un PGM con estructura no dirigida en forma de arbol, usadode manera amplia en inferencia estadıstica. Cumple con las siguientes caracterısticas:
1. Cada vertice del arbol es un subconjunto de variables aleatorias del problema, lla-mado cluster.
2. Cada arista del arbol que conecta dos clusters es otro subconjunto de variablesaleatorias, dadas por la interseccion de los clusters que une. Es llamada separador.
3. Cumple con la propiedad Running Intersection: Si existe una variable aleatoria endos clusters, tiene que existir en todos los clusters que hay en el camino entre losprimeros dos.
4. La union de todos los clusters en el Junction Tree es un conjunto que contiene atodas las variables aleatorias del problema.
Pero, ¿cual es la relacion entre un Junction Tree y un t-Cherry Tree?Debemos notar primero que un t-Cherry Tree puede ser una estructura valida para unPGM no dirigido o red de Markov. Hay en el area de inferencia estadıstica un algorit-mo llamado Node Elimination (8), que permite representar una de estas en un JunctionTree. De manera breve, este consiste en que cada uno de los cliques maximos del grafose convierte en un nodo del arbol, y se escogen las aristas mediante un algoritmo paraencontrar un MWST, donde los pesos de las mismas estan definidas por el numero devariables contenidas en la interseccion de las variables en los cliques que unen.Las figuras 4.5 y 4.6 muestran un ejemplo de esta representacion.
X1
X3
X2
X6
X4
X5X7
X1
X4
X2
X6
X4
X5
X3
X5X7
X3X4
X5
Figura 4.5: Ejemplo de una MN y sus cliques maximos
46
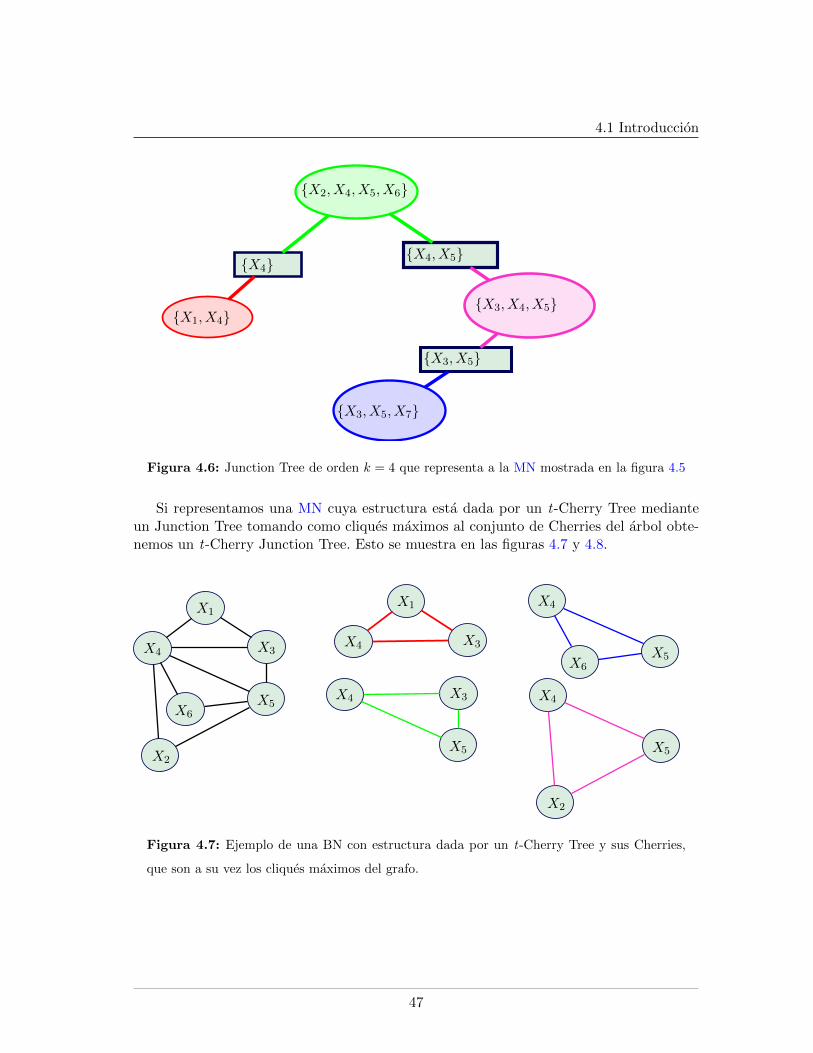
4.1 Introduccion
X1, X4X3, X4, X5
X3, X5, X7
X2, X4, X5, X6
X4
X3, X5
X4, X5
Figura 4.6: Junction Tree de orden k = 4 que representa a la MN mostrada en la figura 4.5
Si representamos una MN cuya estructura esta dada por un t-Cherry Tree medianteun Junction Tree tomando como cliques maximos al conjunto de Cherries del arbol obte-nemos un t-Cherry Junction Tree. Esto se muestra en las figuras 4.7 y 4.8.
X1
X3
X2
X6
X4
X5
X1
X3X4
X3X4
X5
X6
X4
X5
X2
X4
X5
Figura 4.7: Ejemplo de una BN con estructura dada por un t-Cherry Tree y sus Cherries,
que son a su vez los cliques maximos del grafo.
47

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
X1, X3, X4 X2, X4, X5
X4, X5, X6
X3, X4, X5
X3, X4
X4, X5
X4, X5
Figura 4.8: t-Cherry Junction Tree que representa a la MN mostrada en la figura 4.7
Es importante tener en cuenta la relacion entre un PGM con estructura dada por unt-Cherry Tree de orden k y su representacion como t-Cherry Junction Tree de orden k,pues en este trabajo se usa este ultimo como estructura en el proceso de construccion delPGM de la poblacion seleccionada en el MBEA, debido a las ventajas de visualizaciony manejo que implica usar esta representacion. Finalizada la construccion, se toma elt-Cherry Tree de orden k representado en el t-Cherry Junction Tree de orden k y sedireccionan sus aristas, con el fin de obtener una GN y poder generar nuevos individuosde manera eficiente.
4.2. Definiciones
En el desarrollo de esta seccion y la siguiente se abordara el caso de que el vectoraleatorio X contiene d variables aleatorias discretas. Ası entonces, se hablara de funcionesde probabilidad P (x) y se retomara la notacion definida en el capıtulo anterior para elmanejo de estas variables.
4.2.1. t-Cherry Tree de orden k
En la introduccion se ilustraron de manera simple por cuestiones de claridad el CherryTree y el t-Cherry Tree. En (2) se generaliza este ultimo concepto y se presenta el SimplexMultitree de orden k, tambien llamado t-Cherry Tree de orden k. Entre otros nombresque se le dan a esta estructura estan el Elementary Model de orden k (26) y Fractal Treede orden k (31). Se define como un grafo no dirigido construido mediante el algoritmo 6.
48

4.2 Definiciones
Algorithm 6 Construccion de un t-Cherry Tree (2)
Require: k, V, d . V es un conjunto de d vertices
1: Construir grafo completo de k − 1 vertices
2: while Existan vertices por agregar do
3: Conectar un vertice nuevo a k − 1 vertices que ya estan en el grafo y
4: que el subgrafo inducido por estos sea un clique.
5: end while
En la i-esima repeticion del ciclo en el algoritmo 6 se hace referencia a un clique in-ducido por k − 1 vertices Vi1 , . . . , Vik−1
, el cual es llamado hyperedge (hiper-arista) y serepresenta con εi. A este clique se le agrega un vertice Vik conectandose mediante k − 1aristas a todos los vertices dentro del hyperedge, formando otro clique al cual se llamahypercherry. Se le representa como ζi = εi, Vik = Vi1 , . . . , Vik−1
, Vik.Entonces un t-Cherry Tree de orden k se define como ∆k = (V, ζ, ε), donde ζ es el conjuntode hypercherries del grafo, y ε el conjunto de hyperedges. Es importante hacer notar quecuando k = 2 se tiene un arbol, cuando k = 3 se tiene un t-Cherry Tree, y en formageneral para k > 3 se tiene un t-Cherry Tree de orden k. Tambien notemos que un mismohyperedge puede ser usado varias veces para conectar vertices nuevos.
1
34
5
1
34
5
1
34 6
5
1
34 6
2
5
1
34 6
2
Figura 4.9: Proceso de construccion de un t-Cherry Tree de orden k = 4 para 6 variables
En la figura 4.9 podemos ver en cada paso el hyperedge usado esta formado por las3 aristas en azul y los vertices a las que conecta, y el hypercherry creado es el cliqueformado por el hyperedge junto con el vertice que se agrega y las aristas nuevas (en
49

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
verde). Se ilustran los hypercherries en la figura como el subgrafo resaltado en cada paso.
4.2.2. Junction Tree
Ya se ha ilustrado en la introduccion tambien lo que es un Junction Tree. En la presentesubseccion profundizaremos en el tema un poco mas, pues al ser el t-Cherry Junction Treede orden k un caso particular de Junction Tree de orden k es importante definir a esteultimo de manera completa y enlistar algunas de sus propiedades.Un Junction Tree (18) es un modelo grafico con estructura de arbol sobre X que cumplecon las siguientes propiedades:
1. Cada vertice del arbol es un subconjunto de variables aleatorias C ⊂ X. Se le llamacluster y se le asocia un vector aleatorio XC y una distribucion marginal conjuntadada por P (xC).
2. Cada arista del arbol que conecta dos clusters C1 y C2 contiene a un subconjuntode variables aleatorias S = C1 ∩ C2. Se le llama separador y se le asocia un vectoraleatorio XS y una distribucion marginal conjunta dada por P (xS).
3. Cumple con la propiedad Running Intersection: Sea Xi una variable aleatoria talque Xi ∈ C1 y Xi ∈ C2. Sea A el conjunto de clusters existentes en el camino entreC1 y C2. Entonces Xi ∈ A,∀A ∈ A. Es decir, si una variable esta en dos clusters,entonces tiene que estar en todos aquellos que estan en el camino entre los dos.
4.⋂C∈CC = X. Donde C es el conjunto de los clusters del Junction Tree. Es decir,
todas las variables aleatorias en X estan en al menos un cluster.
Completando la notacion, C es el conjunto de clusters del Junction Tree, y S el conjuntode separadores sin repeticion (porque pueden haber separadores iguales). Entonces, unJunction Tree JT (C, S,Θ) es un PGM cuya estructura esta dada por C y S. Al igualque con los demas modelos graficos revisados hasta ahora la estructura del Junction Treecodifica propiedades de dependencia e independencia entre las variables del problema, ypor ende representa a una distribucion conjunta con JPMF como (25)
P JT (x) =
∏XC∈C P (xC)∏
XS∈S P (xS)vS−1(4.1)
Donde vS es el numero clusters que contienen a cierto separador S. Por la segunda pro-piedad del Junction Tree, se entiende que si hay vS clusters tal que S ⊂ C, entonces Sesta presente vS − 1 veces en el arbol.
Por ejemplo, la funcion de probabilidad conjunta de la distribucion representada por elJunction Tree mostrado en la figura 4.6 es:
P JT (x) =P (x1, x4)P (x2, x4, x5, x6)P (x3, x4, x5)P (x3, x5, x7)
P (x4)P (x4, x5)P (x3, x5)
50

4.2 Definiciones
4.2.2.1. El peso del Junction Tree
Dada la factorizacion de la JPMF en la ecuacion 4.1 de un vector aleatorio X se puedeestablecer una metrica de la calidad del ajuste de un PGM con estructura de JunctionTree sobre X a la distribucion de X usando la KLD, generalizando lo desarrollado para elArbol de Chow-Liu (41). A esta medida se le denomina en la literatura el peso del JunctionTree.
DKL(P (x), P JT (x)) =∑x
P (x) logP (x)
P JT (x)
=∑x
P (x) logP (x)−∑x
P (x) logP JT (x)
= −H(X)−∑x
P (x) log
∏XC∈C P (xC)∏
XS∈S P (xS)vS−1
= −H(X)−∑x
P (x) log∏
XC∈CP (xC) +
∑x
P (x) log∏
XS∈SP (xS)vS−1
Si agregamos el siguiente termino:∑x
P (x) log∏
XC∈CP (xC1)P (xC2) . . . P (xCk)−
∑x
P (x) log∏
XC∈CP (xC1)P (xC2) . . . P (xCk)
Entonces tenemos:
DKL(P (x), P JT (x)) =
−H(X)−∑x
P (x) log∏
XC∈CP (xC) +
∑x
P (x) log∏
XC∈CP (xC1)P (xC2) . . . P (xCk)
+∑x
P (x) log∏
XS∈SP (xS)vS−1 −
∑x
P (x) log∏
XC∈CP (xC1)P (xC2) . . . P (xCk)
= −H(X)−∑x
P (x)
log∏
XC∈CP (xC)− log
∏XC∈C
P (xC1)P (xC2) . . . P (xCk)
+∑x
P (x)
log∏
XS∈SP (xS)vS−1 − log
∏XC∈C
P (xC1)P (xC2) . . . P (xCk)
= −H(X)−
∑x
P (x) log
∏XC∈C P (xC)∏
XC∈C P (xC1)P (xC2) . . . P (xCk)
+∑x
P (x) log
∏XS∈S P (xS)vS−1∏
XC∈C P (xC1)P (xC2) . . . P (xCk)
Por el hecho de que en la union de los clusters del Junction Tree estan todas lasvariables Xi existentes en X repetidas vi ≥ 2 veces, y en los separadores estan vi−1 veces,
51

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
la fraccion en el ultimo sumando del desarrollo anterior se puede factorizar dando comoresultado:
DKL(P (x), P JT (x)) = −H(X)−∑x
P (x) log
∏XC∈C P (xC)∏
XC∈C P (xC1)P (xC2) . . . P (xCk)
+∑x
P (x) log
∏XS∈S P (xS)vS−1∏
XS∈S (P (xS1)P (xCS ) . . . P (xSk))vS−1−∑x
P (x) logn∏i=1
P (xi)
Dado que XC es marginal de X tenemos que:∑x
P (x) log
∏XC∈C P (xC)∏
XC∈C P (xC1)P (xC2) . . . P (xCk)
=∑x
P (x)∑
XC∈Clog
P (xC)
P (xC1)P (xC2) . . . P (xCk)
=∑
XC∈C
∑xC
P (xC) logP (xC)
P (xC1)P (xC2) . . . P (xCk)
Si aplicamos el mismo principio a XS y Xi, usando la definicion de Correlacion Total,del termino en ingles Total Correlation (TC) de un vector aleatorio (ver definicion A.13en el apendice A) tenemos que al final la divergencia esta dada por
DKL(P (x), P JT (x)) = −H(X)−
∑XC∈C
I(XC)−∑XS∈S
(vS − 1)I(XS)
+d∑i=1
H(Xi)
(4.2)Notese que los terminos −H(X) y
∑di=1H(Xi) no dependen de la estructura del Jun-
ction Tree, por lo que su peso esta definido como:
wJT =∑
XC∈CI(XC)−
∑XS∈S
(vS − 1)I(XS) (4.3)
En pocas palabras el peso del Junction Tree es la suma de las TC de los vectoresaleatorios XC asociados a los clusters menos la suma de las TC de los vectores aleatoriosXS asociados a los separadores.Decimos entonces entre mas peso tiene un arbol, mejor es su ajuste, es decir, minimizarla KLD supone maximizar wJT .
4.2.3. t-Cherry Junction Tree de orden k
El t-Cherry Junction Tree de orden k, JT∆k(C, S,Θ) es un Junction Tree cuya es-
tructura C, S representa a un t-Cherry Tree de orden k.
52

4.2 Definiciones
Dado ∆k = (V, ζ, ε), podemos representarlo en forma de Junction Tree con el siguientealgoritmo.
Algorithm 7 Representacion de un t-Cherry Tree de orden k mediante un t-Cherry
Junction Tree del mismo orden
Require: ∆k
1: C← C ∪ Xi : i ∈ ζ1
2: for j = 2, . . . , d− k + 1 do
3: C← C ∪ Xi : i ∈ ζj
4: S← S ∪ Xi : i ∈ εj−1
5: end for
return C, S
Recordemos que definimos a S como el conjunto de separadores sin repeticion, aunqueen este algoritmo por cuestiones de claridad suponemos que tenemos los separadores talcual estan en el t-Cherry Tree de orden k. Ası entonces el primer hypercherry del arboldefine a las variables del primer cluster del Junction Tree. Luego, cada una de las hyper-cherries forma otro cluster, y se conecta al Junction Tree mediante el hyperedge asociado.En (41) demuestran que debido a la naturaleza recursiva de la construccion del t-CherryTree de orden k, se preserva la propiedad Running Intersection, por lo que el arbol formadopor el algoritmo 7 es un Junction Tree. En la figura 4.10 se muestra un ejemplo.
Como caracterısticas especıficas de un t-Cherry Junction Tree podemos mencionar:
Tiene d− k + 1 clusters y d− k separadores
Todos los clusters tienen k variables
Todos los separadores tienen k − 1 variables
Tambien en (41) se demuestra que para todo Junction Tree de orden k que se construyepara aproximar cierta distribucion de probabilidad, hay un t-Cherry Junction Tree deorden k que da una aproximacion igual o mejor. Se demuestra allı que hacer clusters yseparadores de mayor tamano implica que el ajuste mejorara o se mantendra igual.Es por esto que, dado un Junction Tree de orden k se pueden agregar variables a todossus clusters para que sean de tamano k + 1 y a sus separadores para que sean de tamanok, dando como resultado un t-Cherry Junction Tree de orden k+ 1 con una mejor o igualaproximacion.Esta es la razon por la que en este trabajo, como en la mayorıa de los relacionados en
53

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
la literatura, dado cierto orden k deseado, se busca construir este tipo de estructuras enlugar de Junction Trees.
X1, X2, X3, X4 X1, X3, X5, X6
X1, X3, X4, X5
X1, X3, X4 X1, X3, X5
Figura 4.10: t-Cherry Junction Tree de orden k = 4 que representa al t-Cherry Tree de
orden k = 4 mostrado en la figura 4.9
4.3. Construccion del modelo
El algoritmo que se usa en este trabajo para la construccion del t-Cherry JunctionTree de orden k consiste en una aplicacion sucesiva de actualizaciones de orden, como sepropone en (33). Esto se abordara con detalle en la seccion 4.3.2. Como unica modificaciona este algoritmo proponemos el uso de una metrica de mejora para el algoritmo greedy enfuncion del peso wJT definido en la ecuacion 4.3 en lugar de la propuesta por los autoresen (33) que esta en funcion de la entropıa conjunta de clusters y separadores. Esta metricaes calculada a partir de un conjunto de observaciones Q, que en el caso de los algoritmosevolutivos es la poblacion seleccionada.
A manera de introduccion explicamos brevemente en que consiste el algoritmo a usarpara la construccion del modelo:
1. Construir un arbol de Chow-Liu.
2. Representar este ultimo como un t-Cherry Junction Tree de orden k = 2, dondeel par de variables en cada cluster son las parejas de informacion mutua maximaencontradas en el proceso de construccion del arbol de Chow-Liu.
3. Ejecutar una actualizacion de orden desde el t-Cherry Junction Tree de orden k paraobtener uno de orden k + 1.
54

4.3 Construccion del modelo
3.1. Agregar en todos los clusters una variable de manera que la metrica de mejorase maximice, y actualizar sus separadores.
3.2. Asegurarse el resultado es un t-Cherry Junction Tree de orden k + 1.
4. Repetir el paso 3 hasta que lleguemos al orden esperado.
La razon de tomar una estrategia incremental y greedy es evidente. Hacer una busquedaexhaustiva en el espacio de busqueda de los t-Cherry Junction Trees de orden k no esfactible pues el tamano de este crece exponencialmente con el numero de variables delproblema (19). Como ya lo hemos mencionado, en (41) se comprueba que la complejidadde este problema es NP-Hard.
Cabe senalar que buscar solo t-Cherry Junction Trees de orden k en lugar de Jun-ction Trees de orden k permite simplificar el algoritmo, mas no reduce la complejidadcomputacional de la busqueda.
4.3.1. Algoritmos de construccion en la literatura
Antes de pasar a la descripcion del algoritmo que usamos en este trabajo haremos unbreve repaso de algunos otros utilizados para la construccion de PGMs con estructurasdescritas por grafos triangulados o su representacion en Junction Trees. Cabe mencionarque el objetivo de algunos de estos trabajos es obtener una extension natural del algoritmode Chow-Liu para modelos de orden k.
El primer trabajo que se hizo en el tema es el de Malvestuto (26) donde se presentanlos modelos elementales de rango k. Siendo breves, decimos que estos son modelos graficoscon estructura dada por un t-Cherry Tree de orden k, que tambien son representados enforma de Junction Tree. Se remite al lector a la referencia para entender estos modelosmediante los teoremas y pruebas que el autor plantea. En el mismo trabajo se da unadefinicion de entropıa del modelo
HJT =∑
XC∈CH(XC)−
∑XS∈S
(vS − 1)H(XS) (4.4)
que se presenta como una metrica de calidad de su ajuste a los datos, ya que se demuestraque minimizar HJT equivale a minimizar la KLD entre el modelo completo y el modelo re-presentado por el elementary model (26). Se busca entonces mediante un algoritmo greedyinspirado en el algoritmo de Chow-Liu obtener una estructura que minimice la entropıadel modelo. Se demuestra que este algoritmo obtiene la estructura de menor HJT en loscasos k = 2 y k = d − 1. En trabajos posteriores de Szantai y Kovacks (19),(42) se desa-rrollan las mismas ideas pero partiendo de un t-Cherry Tree de orden k y representandolocomo t-Cherry Junction Tree de orden k, proponiendo como metrica de calidad del ajustedel modelo el peso del Junction Tree como se define en la ecuacion 4.3. Se propone allıun algoritmo greedy basado en el propuesto por Malvestuto, el cual consiste en definir
55

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
como raız el cluster de tamano k de mayor TC, e ir agregando de manera greedy pares decluster-separador que maximicen el peso del arbol en cada paso manteniendo una estruc-tura valida. Los pares de cluster-separador B = C, S que se van agregando se llamansimple-buds (41). Tienen un peso asociado dado por wbud = I(XC)−I(XS) y una variabledominante Xd = C ∩ S.
En (33) se presenta una mejora para este algoritmo, que consiste en la paralelizaciondel calculo de los pesos wbud y una verificacion eficiente de la validez de la estructura.Esto se muestra en el algoritmo 8. Γ es una cola de prioridad que contiene a los k
(dk
)posibles simple-buds que podrıan existir en un t-Cherry Junction Tree de orden k paraun problema de d variables. Como valor de prioridad se establece a wbud. V es un vectorusado para la validacion eficiente de la estructura que indica si vi = 1 entonces Xi ya estacontenida en algun cluster, entonces ya no puede ser variable dominante de ningun otro.Vea (33) para la demostracion de esta afirmacion.
Es evidente que la complejidad del algoritmo 8 es de O(k(dk
)), dada por la tarea de
calcular todos los pesos de los simple-buds posibles, por lo que su uso solo es factibleen problemas de baja dimensionalidad, o bien para k muy pequena o bastante cercanaa d. Se complica aun mas al construir el modelo desde un conjunto de observaciones Q,pues la complejidad arriba mencionada supone que el costo de calcular la TC de cadauno de los clusters y separadores es constante, por lo que en la practica falta el factorque define la complejidad del costo del calculo de la TC. Esto aunado a que aun con lagran complejidad computacional de estos algoritmos no se garantiza que el PGM que dancomo resultado sea el de mejor ajuste para cierta k dada, provoco que se buscaran otrasestrategias de construccion eficientes que aunque tampoco garantizan el mejor ajuste sonfactibles computacionalmente hablando.
El primer trabajo que aborda la construccion de manera incremental es (11), donde sepresenta un algoritmo para construir PGMs con estructura de grafos no dirigidos triangu-lados llamandoles modelos factorizables. Se sugiere comenzar con un grafo completamentedesconectado y luego aplicar de manera sucesiva la siguiente operacion hasta obtener cier-ta densidad en el grafo:
Sea Gt un grafo en la iteracion t. Se hace una lista de las aristas elegibles, es decir,aristas que se pueden agregar de manera que el grafo siga siendo factorizable. Entoncestomamos de manera greedy una de esas aristas Xv, Xu, y la agregamos al grafo, dandocomo resultado G′t = Gt ∪ Xv, Xu. Se hace Gt+1 = G′t y se pasa a la siguiente iteracion.Se usa como metrica de mejorıa la entropıa del modelo dada en la ecuacion 4.4.
Se presenta en el artıculo tambien un algoritmo eficiente de complejidad O(d2) paraidentificar a las aristas elegibles y un teorema acerca del decremento en la entropıa del
56

4.3 Construccion del modelo
Algorithm 8 Greedy Puzzling Algorithm (33)
Require: k,Γ
1: JT∆k.C← ∅
2: JT∆k.S← ∅ . Se inicia con una estructura vacıa
3: V ← ~0
4: C ← cluster que maximiza I(XC)
5: JT∆k.C← JT∆
k.C ∪ C . La raız es el cluster de mayor TC
6: vΓ.top.C ← 1
7: Γ.pop
8: while ∃vj ∈ V, vj = 0 do . Mientras haya variables fuera del Junction Tree
9: if vΓ.top.d = 0 then . Si la variable dominante no esta en el Junction Tree
10: for all Ci ∈ JT∆k.C do
11: if Γ.top.S ⊂ Ci then . Si hay un cluster valido
12: JT∆k.C← JT∆
k.C ∪ Γ.top.C
13: JT∆k.S← JT∆
k.S ∪ Γ.top.S . Agregar cluster y separador
14: vΓ.top.d ← 1
15: exit for
16: end if
17: end for
18: end if
19: Γ.pop
20: end while
return JT∆k
57

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
modelo al agregar una arista, el cual esta dado por:
∆wJTH (Sij , Xv, Xu) = −H(Sij ∪Xv ∪Xu) +H(Sij ∪Xv) + (Sij ∪Xu)−H(Sij) (4.5)
Donde Sij es el conjunto de vertices que estan en el separador maximo del grafo que po-ne a Xv y Xu en diferentes componentes conectados. Este teorema es importante, puesdemuestra que el cambio en la entropıa del modelo al agregar una arista solo dependede las dos variables que se unen y del separador ya existente entre ellas. Esto motiva suuso como metrica en algoritmos de construccion que van haciendo el grafo cada vez masdenso, comenzado de uno muy disperso, tıpicamente un arbol de Chow-Liu. Estas ideasson retomadas en la actualizacion de orden (33).
En un trabajo mas reciente (31) se adopta una estrategia de divide y venceras paraconstruir Fractal Trees de orden k, que son lo mismo que los t-Cherry Trees de ordenk. Al igual que la actualizacion de orden, se comienza con un arbol de Chow-Liu comoestructura inicial. De ahı se obtiene un Fractal Tree de orden k = 3 mediante la aplicacionde este algoritmo. Se sigue aplicando este hasta llegar al orden deseado. Se hacen allıalgunas definiciones importantes para entender el algoritmo como:
Vecinos comunes N(Vs) de un conjunto de vertices Vs. Son aquellos vertices queestan conectados a todos los vertices en Vs.
Mantle G[N(Vs)] de Vs. Es el subgrafo inducido por los vecinos comunes de Vs.
El algoritmo se trata de dividir el problema de obtener un modelo de orden k en unode k + 1 en d − k subproblemas, uno por cada separador existente en el grafo. Estossubproblemas consisten en agregar aristas en los mantles de cada separador. Primero setoma a este como Vs. Se obtiene entonces G[N(Vs)], el cual sera siempre un bosque. Seejecuta un algoritmo de Chow-Liu generalizado en este subgrafo con el fin de obtener unarbol. Las aristas obtenidas por este algoritmo son las elegibles a agregar. Se demuestraque con esta operacion se garantiza que al agregar las aristas eligibles en el grafo siguesiendo factorizable y a la vez se va minimizando HJT , pues el algoritmo de Chow-Liugeneralizado se ejecuta tomando como valor de aristas la informacion mutua condicionalentre las variables que une Xv, Xu condicionada por aquellas en el separador XSij .
I(Xv, Xu |XSij )
Se proponen dos algoritmos, uno que hace estas d− k operaciones en paralelo, y otrosecuencial que toma en cuenta los cambios en las aristas eligibles provocados al agregar unaarista en el modelo, ya que al hacer esta operacion cambian los cliques en el grafo, y puedencambiar por lo tanto los separadores dentro de este, invalidando algunas aristas elegibles ycreando otras. Cabe mencionar que en los resultados de este trabajo el algoritmo secuencialda como resultado un mejor ajuste del modelo a los datos que el algoritmo paralelo.
58

4.3 Construccion del modelo
4.3.2. La actualizacion de orden
Como ya hemos mencionado, en (19) se propone construir un t-Cherry Junction Tree(k = 3) a partir de un arbol de Chow-Liu (que se puede representar como un t-CherryJunction Tree de orden k = 2). En ese artıculo se hace un DFS en el arbol de Chow-Liu.El orden de visita determina cual es la variable dominante del simple Bud a agregar encada paso.
En (33) se generaliza esta idea, proponiendo una metodologıa llamada actualizacionde orden. Esta consiste en dos fases las cuales se han descrito de manera breve en el pasonumero 3 del algoritmo presentado en la introduccion de esta seccion 4.3 y que se reiterana continuacion:
1. Order Update Process. Dado un t-Cherry Junction Tree de orden k se puede construirun Junction Tree de orden k+ 1 al actualizar todos los clusters, es decir, agregarlesuna variable a cada uno.
2. Bud Conversion. Del Junction Tree construido en el paso anterior se obtiene un t-Cherry Junction Tree de orden k + 1 expandiendo los clusters que hayan quedadoconectados con separadores de tamano k − 1.
En los apartados siguientes se aborda con detalle esta metodologıa.
4.3.2.1. Notacion y terminologıa
Cluster activo CA. El que en la actualizacion recibe una variable Xv desde un clustervecino CD.
Cluster donante CD. En la actualizacion es el vecino de CA que contiene a Xv.
Separador SAD = CA ∩ CD.
Actualizacion. Accion de agregar la variable Xv al cluster CA y al separador SAD,es decir CA = CA ∪Xv y SAD = SAD ∪Xv
Cluster actualizado. Cualquiera de tamano k + 1.
Cluster actualizable. Cualquiera de tamano k.
Actualizacion potencial. Probable adicion en CA de Xv desde CD.
59

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
4.3.2.2. La actualizacion de clusters
Es importante recalcar algunos hechos sobre la actualizacion de clusters.
El agregar una variable a todos los clusters para que queden de tamano k + 1 noimplica que todos los separadores vayan a quedar de tamano k.
La restriccion de vecindad necesaria en la actualizacion se necesita para cumplircon la propiedad Running Intersection y se refiere a lo mismo a lo que en los otrostrabajos se llama eligibilidad de la arista.
Una actualizacion equivale a agregar una arista entre Xv y Xu = CA \CD en la MNrepresentada en el Junction Tree como se explica en (11) (ver figura 4.11).
Cada una de estas actualizaciones provoca un cambio en la estructura del JunctionTree y por lo tanto un cambio en su peso.
∆wJT = wJT′ − wJT
Aquı wJT′
es el Junction Tree con el cluster actualizado y wJT es el Junction Treeoriginal. El Order Update Process propuesto por Proulx y Zhang en (33) es un algoritmogreedy que actualiza todos los clusters buscando maximizar ∆wJT en cada operacion.
4.3.2.2.1 Escenarios de actualizacion de cluster
Antes de dar paso a la explicacion del Order Update Process, queremos explicar endetalle los tres diferentes escenarios de actualizacion de cluster que se pueden dar. Dadosdos clusters vecinos Ci, Cj , puede ser que los dos sean de tamano k (a), ambos de tamanok + 1 (b) o que uno sea de tamano k y el otro de tamano k + 1 (c). En el escenario (b) esevidente que no hay mas que hacer, pues los dos clusters estan ya actualizados.Consideremos el escenario (a) en dos clusters vecinos Ci, Cj . Ambos clusters pueden donaruna variable al otro, por lo que hay dos actualizaciones potenciales:
CA CD Xv Xu
Cj Ci Cj \ Ci Ci \ CjCi Cj Ci \ Cj Cj \ Ci
Notemos que al realizar cualquiera de las dos actualizaciones potenciales se va a cumplirque CD = SAD y que CD ⊂ CA. Esto se muestra en la figura 4.11. Se pueden quitarentonces del Junction Tree CD y SAD, y conectar a los vecinos de CD a CA. Por lo tanto,el resultado en este escenario es solamente el cluster CA = CA∪Xv = CA∪CD. Es evidentetambien que hay una sola actualizacion potencial en realidad, por lo que no es necesariotomar en cuenta las dos listadas en la tabla de arriba en la construccion.
60
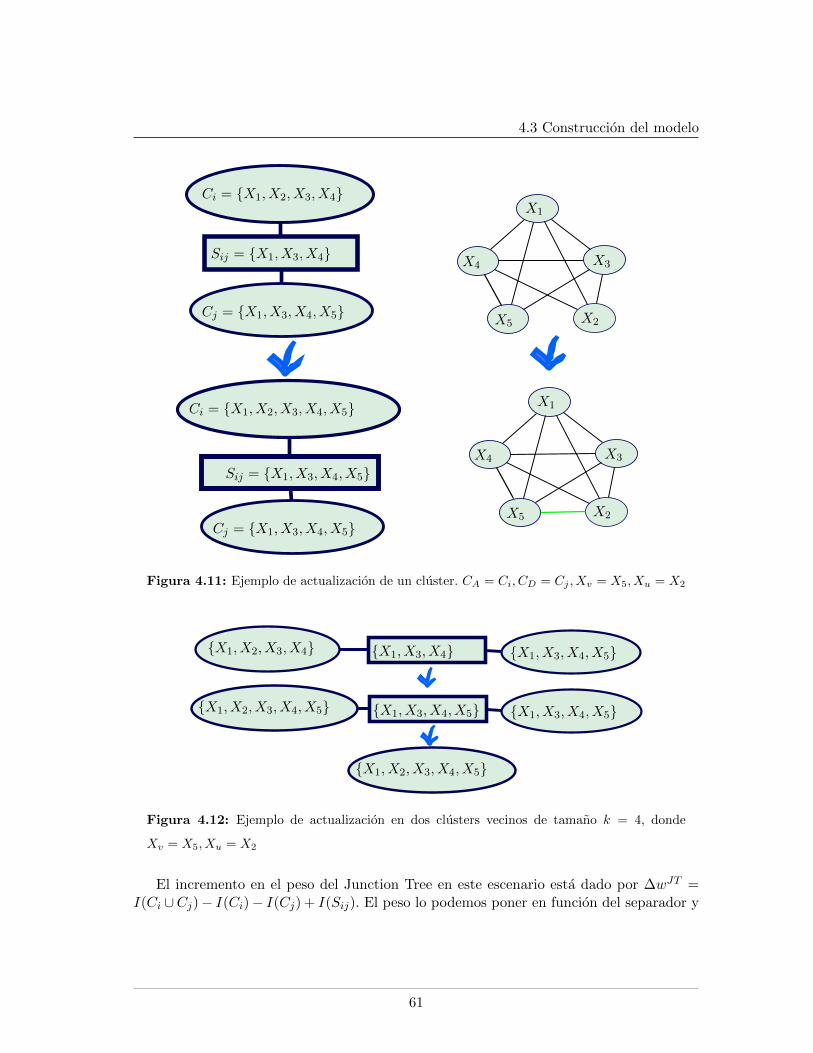
4.3 Construccion del modelo
Cj = X1, X3, X4, X5
Ci = X1, X2, X3, X4
Sij = X1, X3, X4
Cj = X1, X3, X4, X5
Ci = X1, X2, X3, X4, X5
Sij = X1, X3, X4, X5
X5
X1
X3X4
X2
X5
X1
X3X4
X2
Figura 4.11: Ejemplo de actualizacion de un cluster. CA = Ci, CD = Cj , Xv = X5, Xu = X2
X1, X3, X4, X5X1, X2, X3, X4 X1, X3, X4
X1, X3, X4, X5X1, X2, X3, X4, X5 X1, X3, X4, X5
X1, X2, X3, X4, X5
Figura 4.12: Ejemplo de actualizacion en dos clusters vecinos de tamano k = 4, donde
Xv = X5, Xu = X2
El incremento en el peso del Junction Tree en este escenario esta dado por ∆wJT =I(Ci ∪Cj)− I(Ci)− I(Cj) + I(Sij). El peso lo podemos poner en funcion del separador y
61

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
las variables que se conectan en la red de Markov representada en el Junction Tree
∆wJT (Sij , Xv, Xu) = I(Sij ∪Xv ∪Xu)− I(Sij ∪Xv)− I(Sij ∪Xu) + I(Sij)
Consideremos ahora el escenario (c). Ahora solo el cluster de tamano k es actuali-zable. Supongamos que |Ci| = k y que |Cj | = k + 1. Entonces CA = Ci, CD = Cj yXv1 , Xv2 = CD \ CA. Ya que hay dos variables en CD que no existen en CA, hay dosactualizaciones potenciales
CA CD Xv Xu
Ci Cj Xv1 Ci \ CjCi Cj Xv2 Ci \ Cj
Supongamos que se hace una operacion de actualizacion con Xv1 . En este caso solo se haceCA = CA ∪Xv1 y SAD = SAD ∪Xv1 .
X1, X3, X4, X5X1, X2, X3, X4, X6 X1, X3, X4
X1, X2, X3, X4, X5X1, X2, X3, X4, X6 X1, X2, X3, X4
Figura 4.13: Ejemplo de dos actualizacion en clusters vecinos, de tamano k = 4 y k = 5. En
este caso Xv = X2, Xu = X5.
Entonces, el incremento en el peso de esta operacion de actualizacion esta dado por∆wJT = I(Ci ∪Xv1) − I(Sij ∪Xv1) − I(Ci) + I(Sij). Al igual que en el caso anterior, elpeso lo podemos poner en funcion del separador y las variables que se conectan
∆wJT (Sij , Xv1 , Xu) = I(Sij ∪Xv1 ∪Xu)− I(Sij ∪Xv1)− I(Sij ∪Xu) + I(Sij)
Como se puede observar, no importando el escenario de actualizacion, el incremento enel peso del arbol esta dado en funcion del separador Sij de los clusters involucrados y lasvariables Xv, Xu
∆wJT (Sij , Xv, Xu) = I(Sij ∪Xv ∪Xu)− I(Sij ∪Xv)− I(Sij ∪Xu) + I(Sij) (4.6)
Esta misma conclusion se demuestra en (11), pero a partir de la entropıa del modelo,dando como resultado lo mostrado en la ecuacion 4.5. De hecho, los casos (a) y (c) ex-plicados arriba para un t-Cherry Junction Tree de orden k son casos particulares de losdescritos en el teorema 4.1 del mismo artıculo para grafos no dirigidos triangulados (casos4 y 2 respectivamente). Cabe aquı recordar que la expresion 4.5 es usada como medida de
62

4.3 Construccion del modelo
mejora para el Order Update Process en (33).En este trabajo usamos la definicion 4.6 pues la expresion de peso del Junction Tree dadaen (41) esta en funcion de TC.
4.3.2.2.2 Order Update Process
El Order Update Process consiste en la aplicacion sucesiva de cuatro pasos, hasta quetodos los clusters en el Junction Tree sean de tamano k + 1. Como entrada del algorit-mo necesitamos un t-Cherry Junction Tree de orden k y una tabla Γ de actualizacionespotenciales cuyos elementos se definen como γ = CA, CD, Xv, Xu,∆w
JT . Esta tabla esconstruida recorriendo el t-Cherry Junction Tree de orden k inicial mediante un DFS,siendo CA el nodo actual y CD el nodo padre. Los cuatro pasos del Order Update Processse enumeran a continuacion:
1. Obtener SAD, Xv, Xu = argmax(∆wJT (SAD, Xv, Xu))
2. Ejecutar el proceso de actualizacion. CA = CA ∪Xv, SAD = SAD ∪Xv.
3. En el escenario (c) a los clusters actualizables vecinos de CA con excepcion de CDahora podemos agregarles Xv. En el escenario (a) tambien podemos hacer esto,ademas de que a los clusters actualizables vecinos de CD les podemos agregar ahoraXu. Hay que agregar entonces estas actualizaciones potenciales a la tabla.
4. En el escenario (a) hay que recorrer las entradas de la tabla, y asignar CD = CA encada entrada que tenga a CD como cluster donador. ¿Porque debemos de hacer esto?Tomemos a cierta actualizacion potencial agregada a la tabla en pasos anteriores quecontiene a CD como cluster donador. CD ya no existe mas ya que ahora esta contenidoen CA y por lo tanto no es el mismo cluster con el que se calculo la actualizacionpotencial en su momento. Aun ası, la entrada es valida, ya que el incremento en elpeso ∆wJT (ver ecuacion 4.6) no depende de CA ni CD, sino del separador y de lasvariables Xv, Xu, que para clusters actualizables, siguen siendo los mismos.
La tabla de actualizaciones potenciales la podemos manejar con una cola de priori-dad siendo ∆wJT el valor de prioridad. Notemos que en el comienzo del algoritmo hayexactamente d− k = |C| − 1 actualizaciones potenciales, pues todas estan en el escenario(a).
Complejidad computacional Asumiremos para este apartado que el costo de cal-cular el incremento en el peso del Junction Tree es w. Entonces durante una ejecucion delOrder Update Process, dado un problema de tamano d y un t-Cherry Junction Tree deorden k, se haran las siguientes operaciones:
63

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
Construir Γ inicial. Se calculan d − k actualizaciones potenciales y se guardan enuna cola de prioridad en ambos sentidos. Aquı se hacen entonces w(d − k) + 2(d −k) log2 2(d− k) operaciones.
Ciclo principal. El numero de actualizaciones de cluster que se efectuan tiene comocota superior el numero de clusters (d−k). En cada una de estas se hacen recorridossobre los conjuntos neighbors(CA)\CD y neighbors(CD)\CA calculando una nuevaactualizacion potencial de costo w en cada visita. Para los (d− k) clusters se hacenen total 2(d − k) recorridos en sus vecindades por lo que el numero de operacionesesta acotado por 2w(d− k).
Actualizacion de la cola de prioridad. Con base en el punto anterior, a lo mas seagregaran 2(d − k) actualizaciones potenciales a la cola de prioridad durante lasiteraciones del ciclo principal, por lo que al final su tamano maximo sera de 4(d−k).Por lo tanto para recorrerla con el fin de actualizar la informacion acerca de clustersque se han eliminado del arbol se hacen 4(d− k) log2 4(d− k) operaciones.
Entonces, el numero maximo de operaciones total esta acotado por 3w(d− k) + 2(d−k) log2 2(d − k) + 4(d − k) log2 4(d − k). En la gran mayorıa de los caso tendremos quew(d − k) > (d − k) log2(d − k), por lo que podemos concluir que la complejidad de unaejecucion del algoritmo Order Update Process en funcion de d,k y w es de
O (w(d− k)) (4.7)
Cabe senalar que en este analisis se omitieron algunas operaciones de complejidadconstante o muy baja, como por ejemplo las operaciones inherentes al DFS o la obtenciondel elemento superior de la cola de prioridad.
Algorithm 10 Agregar una actualizacion potencial a la cola de prioridad
1: procedure pushPU(Γ, CA, CD, Xv, Xu)
2: γ.CA ← CA
3: γ.CD ← CD
4: γ.Xv ← Xv
5: γ.Xu ← Xu
6: γ.∆w ← ∆wJT (CA ∩ CD, Xv, Xu) . Usar la ecuacion 4.6
7: Γ.push(γ)
8: end procedure
64

4.3 Construccion del modelo
Algorithm 9 Order Update Process (33)
1: procedure OrderUpdateProcess(JT∆k,Γ)
2: while ∃C ∈ JT∆k .C | C.updated= 0 do
3: γ ← Γ.top
4: CA ← γ.CA
5: if CA.updated= 0 then
6: CD ← γ.CD
7: CA ← CA ∪ γ.Xv, SAD ← SAD ∪ γ.Xv . Ejecutar actualizacion
8: CA.updated= 1
9: for all Ci ∈ (neighbors(CA) \ CD) do
10: if Ci.updated= 0 then . Agregar AP a los vecinos de CA
11: pushPU(Ci, CA, γ.Xv, Ci \ CA)
12: end if
13: end for
14: if CD ⊂ CA then . Escenario a)
15: for all Ci ∈ (neighbors(CD) \ CA) do
16: link(Ci, CA)
17: if Ci.updated= 0 then . Agregar AP a los vecinos de CD
18: pushPU(Ci, CA, γ.Xu, Ci \ CA)
19: end if
20: end for
21: for all γi ∈ Γ do . Cambiar referencia en Γ
22: if γi.CD = CD then
23: γi.CD = CA
24: end if
25: end for
26: JT∆k.C← JT∆
k.C \ CD, JT∆
k.S← JT∆
k.S \ SAD . Eliminar CD
27: end if
28: end if
29: Γ.pop
30: end while
31: end procedure
65

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
4.3.2.3. Bud Conversion
Durante la actualizacion de orden puede suceder que algunos separadores queden detamano k− 1, es decir, que haya en el arbol clusters de tamano k+ 1 que solo tienen k− 1variables en comun. Esto sucede cuando, siendo C1 y C2 vecinos, C1 agrega una variabledesde un vecino que no es C2 y de manera analoga C2 agrega una variable desde un vecinoque no es C1. Se ilustra esto en la figura 4.14. Esta es la razon por la que no se puedeasegurar que el resultado del algoritmo 9 sea un t-Cherry Junction Tree de orden k + 1,sino un Junction Tree de orden k + 1.
X1, X3, X4
X1, X2, X3
X1, X3
X4, X5, X6
X4, X5
X3, X4, X5X3, X4
X1, X2, X3, X4
X4, X5, X6
X4, X5
X3, X4, X5X3, X4
X1, X2, X3, X4 X3, X4, X5, X6X3, X4
CA
CD
CA
CD
Figura 4.14: Generacion de un bud con separador de tamano k − 1.
4.3.2.3.1 t-Cherry Bud Conversion Algorithm
Para marcar como convertibles las tripletas cluster-separador-cluster (llamadas buds)que esten en el escenario descrito en la figura 4.14 hacemos un DFS el Junction Treede orden k + 1 resultado del algoritmo 9. En cada uno de estos buds convertibles hay|S|+ |C1 \S|+ |C2 \S| = k− 1 + 2 + 2 = k+ 3 variables involucradas, por lo que, segun laprimera propiedad de los t-Cherry Junction Tree de orden k enunciada en la seccion 4.2.3,tendra que haber entonces d− (k + 1) + 1 = k + 3− k = 3 clusters y dos separadores quecubran esas variables. Al proceso de reemplazar los buds etiquetados como convertiblescon 3 clusters y dos separadores nuevos se le llama Bud Conversion (33). Dos de los tresclusters ya estan definidos, son C1 y C2, ya que si los cambiamos podrıamos violar lapropiedad Running Intersection. Entonces, el problema se reduce a encontrar un clusterC3 = S ∪Xf ∪Xd, donde Xd ∈ C1 \S y Xf ∈ C2 \S, y los separadores S ∪Xd y S ∪Xf
que los unan a C1 y C2, de manera que se maximice cambio en el peso del arbol dado porla conversion del bud:
∆wbud(S,Xd, Xf ) = I(S ∪Xd ∪Xf )− I(S ∪Xd)− I(S ∪Xf ) + I(S) (4.8)
66
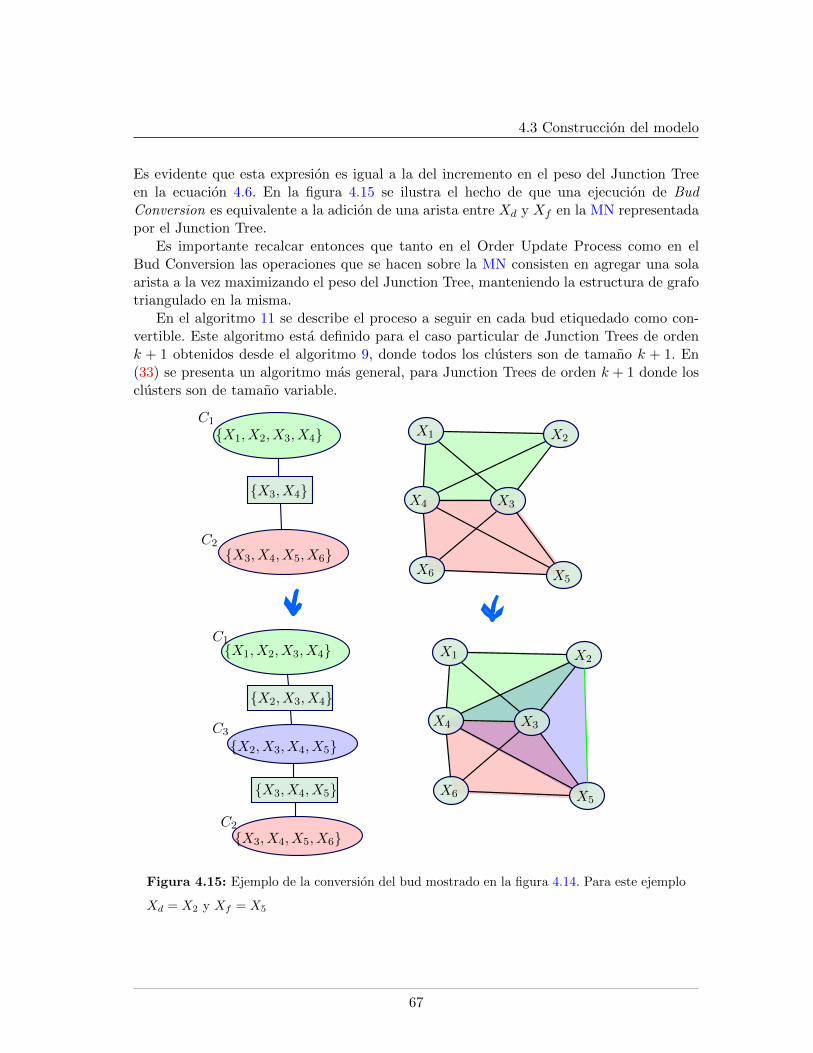
4.3 Construccion del modelo
Es evidente que esta expresion es igual a la del incremento en el peso del Junction Treeen la ecuacion 4.6. En la figura 4.15 se ilustra el hecho de que una ejecucion de BudConversion es equivalente a la adicion de una arista entre Xd y Xf en la MN representadapor el Junction Tree.
Es importante recalcar entonces que tanto en el Order Update Process como en elBud Conversion las operaciones que se hacen sobre la MN consisten en agregar una solaarista a la vez maximizando el peso del Junction Tree, manteniendo la estructura de grafotriangulado en la misma.
En el algoritmo 11 se describe el proceso a seguir en cada bud etiquedado como con-vertible. Este algoritmo esta definido para el caso particular de Junction Trees de ordenk + 1 obtenidos desde el algoritmo 9, donde todos los clusters son de tamano k + 1. En(33) se presenta un algoritmo mas general, para Junction Trees de orden k + 1 donde losclusters son de tamano variable.
X1, X2, X3, X4
X3, X4, X5, X6
X3, X4
X5
X1 X2
X4 X3
X6
X1, X2, X3, X4
X2, X3, X4, X5
X2, X3, X4
X3, X4, X5, X6
X3, X4, X5 X5
X1 X2
X4 X3
X6
C1
C2
C1
C2
C3
Figura 4.15: Ejemplo de la conversion del bud mostrado en la figura 4.14. Para este ejemplo
Xd = X2 y Xf = X5
67

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
Complejidad computacional Dado que |C1\S| = 2 y |C2\S| = 2, tenemos siempreentonces cuatro clusters C3 posibles, por lo que la busqueda del maximo se puede haceren tiempo constante. En terminos de d,k y w en el peor de los casos se hacen (d − k)/2ejecuciones de Bud Conversion, cada una con un costo de 4w, por lo que la complejidadqueda tambien como
O (w(d− k)) (4.9)
Algorithm 11 t-Cherry Bud Conversion Algorithm (33)
1: procedure BudConversion(JT k, C1, C2, S = C1 \ C2)
2: D ← C1 \ S
3: F ← C2 \ S
4: X∗d , X∗f ← argmaxXd∈D,Xf∈F
(∆wJT (S,Xd, Xf )
). Usar la ecuacion 4.6
5: JT k.S← JT k.S \ S
6: JT k.C← JT k.C ∪ S ∪X∗d ∪X∗f
7: JT k.S← JT k.S ∪ S ∪X∗d ∪ S ∪X∗f
8: end procedure
4.3.3. Actualizacion de Orden
Ya definidas las dos operaciones necesarias para ejecutar una actualizacion de orden,el algoritmo de construccion del t-Cherry Junction Tree de orden k queda como:
4.3.3.1. Complejidad computacional
Omitiendo las operaciones de construccion del arbol de Chow-Liu y su representacionen un t-Cherry Junction Tree de orden 2, la complejidad computacional del algoritmo 12es
O (kw(d− k)) (4.10)
68

4.4 Construccion de un t-Cherry Junction Tree de orden k Gaussiano
Algorithm 12 Construccion del t-Cherry Junction Tree de orden k (33)
1: procedure BuildTCherryJunctionTree(Φ, k)
2: MCHL ←MWST(Φ) . Construir un arbol de Chow-Liu
3: JT∆2 ← BuildJTFromChowLiu(MCHL) . Representarlo en un t-Cherry
Junction Tree de orden 2
4: for κ = 3 . . . k do . Ejecutar k − 2 Actualizaciones de orden
5: Γ← cola de prioridad vacıa
6: for all neighbors Ci, Cj ∈ JT∆κ
do
7: pushPU(Γ, Ci, Cj , Cj \ Ci, Ci \ Cj)
8: end for
9: OrderUpdateProcess(JT∆κ,Γ)
10: for all buds Ci, Cj , Sij ∈ JT κ where |Sij | = κ− 1 do
11: BudConversion(JT κ, Ci, Cj , Sij)
12: end for
13: end for
14: end procedure
Aquı Φ es una matriz de informacion mutua por pares de las variables.
4.4. Construccion de un t-Cherry Junction Tree de orden k
Gaussiano
Hasta ahora la definicion del t-Cherry Junction Tree de orden k y en la explicacionde un algoritmo para su construccion se ha hecho para variables aleatorias discretas. Paratrabajar con MBEAs en espacios continuos asumiremos que las variables del problemasiguen una MVND. Entonces la construccion del t-Cherry Junction Tree de orden k sehara mediante el algoritmo 12 y para el incremento en el peso del arbol usaremos la TCcomo esta definida para MVND (ver definicion A.14 en el apendice A).
La TC de un cluster o separador esta en funcion del determinante de la matriz decorrelacion de las variables que contiene. Hemos definido una estrategia para evitar resolverestos determinantes y ası hacer menos costoso el calculo del incremento del peso del arbol,
69

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
aprovechando la naturaleza incremental del algoritmo. En esta seccion desarrollamos estaestrategia y describimos una interpretacion geometrica de la expresion de incremento enel peso del arbol simplificada.
4.4.1. Simplificacion de la expresion de incremento en el peso del arbol
Podemos definir la funcion de incremento en el peso de un Junction Tree para variablesGaussianas como:
∆wJT (Sij , Xv, Xu) = I(Sij ∪Xv ∪Xu)− I(Sij ∪Xv)− I(Sij ∪Xu) + I(Sij)
= −1
2ln(detΦSij∪Xv∪Xu) +
1
2ln(detΦSij∪Xv) +
1
2ln (detΦSij∪Xu)− 1
2ln (detΦSij )
=1
2ln
(detΦSij∪Xv detΦSij∪XudetΦSij∪Xv∪Xu detΦSij
)(4.11)
Donde Φ es la matriz de correlacion. Es evidente que maximizar a wJT (Sij , Xv, Xu) esequivalente a maximizar a la expresion dentro del logaritmo, por lo que la expresion delpeso simplificado queda como
∆wJTs (Sij , Xv, Xu) =detΦSij∪Xv detΦSij∪XudetΦSij∪Xv∪Xu detΦSij
(4.12)
Podemos deshacernos de los determinantes en esta expresion. Consideremos de ahoraen adelante que se comenzara a construir un t-Cherry Junction Tree de orden k+ 1 desdeuno de orden k.
Como se puede observar en la ecuacion 4.11, se deben calcular determinantes de sub-matrices de Φ: dos submatrices de tamano k, una de tamano k−1 y otra de tamano k+1.El determinante de una matriz Φ ∈ IRk×k definida positiva, como es el caso de Φ se puedecalcular como
detΦ =k∏l=1
Λ2(l,l) (4.13)
donde Λ es una matriz triangular resultado de la factorizacion de Cholesky ΛΛT = Φ. En-tonces, podemos afirmar que la complejidad de calcular ∆wJTs (Sij , Xv, Xu) es de O(k3),que es la complejidad de la factorizacion Cholesky en la ecuacion 4.13.
Tenemos que hacer entonces una factorizacion Cholesky de las cuatro submatrices deΦ. Por ejemplo: ΦSij∪Xv = ΛSij∪XvΛ
TSij∪Xv . Ahora bien, aquı es importante notar que
ΦSij∪Xv es a su vez una submatriz de ΦSij∪Xv∪Xu y que ΦSij es submatriz de ΦSij∪Xu . Masimportante aun, tenemos tambien que ΛSij∪Xv es submatriz de ΛSij∪Xv∪Xu y que ΛSij es
70

4.4 Construccion de un t-Cherry Junction Tree de orden k Gaussiano
submatriz de ΛSij∪Xu . Es por esta razon que podemos reducir la complejidad de calcular∆wJTs (Sij , Xv, Xu) para cada actualizacion potencial a O(k2). Si en cada separador Sijalmacenamos una matriz triangular ΛSij podemos continuar la factorizacion de Choleskyen la ultima iteracion del ciclo externo para obtener ΛSij∪Xu y ΛSij∪Xv y usando estaultima calculamos de la misma manera ΦSij∪Xv∪Xu .
Tomando en cuenta lo expuesto en el parrafo anterior y yendo un poco mas lejos,podemos reducir la expresion de peso simplificado para el t-Cherry Junction Tree deorden k Gaussiano a
∆wJTs (Sij , Xv, Xu) =detΦSij∪Xv detΦSij∪XudetΦSij∪Xv∪Xu detΦSij
=
∏kl=1 Λ
2Sij∪Xv(l,l)
∏kl=1 Λ
2Sij∪Xu(l,l)∏k+1
l=1 Λ2Sij∪Xv∪Xu(l,l)
∏k−1l=1 Λ
2Sij(l,l)
=Λ2Sij∪Xu(k,k)
Λ2Sij∪Xv∪Xu(k+1,k+1)
(4.14)
Entonces ya no es necesario calcular determinantes, sino, a partir de la matriz ΛSijcontinuar con la factorizacion de las matrices ΦSij∪Xu y ΦSij∪Xv∪Xu y con ello calcular∆wJTs (Sij , Xv, Xu). Entonces la ecuacion 4.14 se usa en este trabajo como medida de me-jora para la actualizacion de orden. Aquı cabe hacer la siguiente observacion.
Maximizar 4.14 supone que el denominador sea pequeno y el numerador grande encierto grado, de manera que esta razon se maximice. El numerador es el ultimo elementoal cuadrado de la diagonal de la matriz triangular ΛSij∪Xu y el denominador es el ultimoelemento al cuadrado en la diagonal de ΛSij∪Xv∪Xu .Recordemos lo mostrado en la definicion A.14 de TC de variables que siguen una MVND.Dado un conjunto de muestras Q de un vector aleatorio X ∈ IRd, el determinante de lamatriz de correlacion ΦX esta relacionado con el hipervolumen de espacio ocupado por lasobservaciones estandarizadas en el espacio d-dimensional. Si todas las correlaciones entrelas variables en X valen 0, el determinante sera 1. De otra manera, el determinante seramenor a 1, tendiendo a cero mientras haya una mayor correlacion entre las variables. Estotambien tiene relacion con la entropıa conjunta de las variables, pues a mayor volumenocupado por las observaciones, mayor es la entropıa conjunta en ellas.
Sea entonces Sij cierto separador de tamano k − 1. Entonces detΦSij =∏k−1l=1 Λ
2Sij(l,l)
es el volumen ocupado por las observaciones estandarizadas de las variables en Sij en suespacio k−1 dimensional. Sea ahora Sij∪Xu un cluster actualizable de tamano k. Entonces
detΦSij∪Xu =∏kl=1 Λ
2Sij∪Xu(l,l) es el volumen ocupado por las observaciones normalizadas
de las variables en Sij ∪Xu en su espacio k dimensional. Como se puede observar, hay uncambio en el volumen al agregar Xu en Sij , y este cambio esta ponderado por el ultimo
71

4. EL T -CHERRY JUNCTION TREE DE ORDEN K
factor Λ2Sij∪Xu(k,k), que resulta ser el numerador en la ecuacion 4.14. Podemos decir lo
mismo para ΦSij∪Xv y ΦSij∪Xv∪Xu , lo cual da como resultado el denominador.Entonces podemos concluir que maximizar ∆wJTs (Sij , Xv, Xu) significa encontrar en elJunction Tree un separador Sij y un cluster activo conectado a este con una variable do-minante Xu, de manera que el factor Λ2
Sij∪Xu(k,k) que mide el cambio de volumen desde
detΦSij a detΦSij∪Xu sea grande, y encontrar un cluster conectado a Sij (esto es, vecino deSij∪Xu) con variable dominante Xv de manera que el factor Λ2
Sij∪Xv∪Xu(k+1,k+1) que mide
el cambio de volumen desde detΦSij∪Xv detΦSij∪Xv∪Xu sea pequeno. En pocas palabras,encontrar un cluster cuya variable dominante Xu implique un cambio grande en el volu-men con respecto al separador Sij y encontrar un cluster donante con variable dominanteXv de manera que al agregar esta al primero implique un cambio pequeno en el volumen.
Dicho esto, al final construimos el t-Cherry Junction Tree de orden k usando el algo-ritmo 12 y para el valor de prioridad en la cola usamos 4.14.
4.4.2. Complejidad computacional
Como se menciono en la subseccion anterior el costo w de calcular el incremento en elpeso del Junction Tree Gaussiano 4.14 tiene complejidad O(k2), por lo que la complejidaddel algoritmo que se usa en este trabajo en funcion de k y d es:
O(k3(d− k)
)(4.15)
72

Capıtulo 5
Un EDA para optimizacion numerica
basado en t -Cherry Junction Tree de
orden k
Una buena parte de los EDAs para optimizacion global continua sin restricciones queusan PGMs asumen que la distribucion de los individuos como conjunto de observacionessigue una MVND. Reiteramos que en este trabajo hacemos lo mismo, por lo que el modeloque construiremos es una red Gaussiana de ciertas caracterısticas. Para ello tenemos quehacer varias operaciones que podemos resumir en dos pasos principales:
1. Construir un t-Cherry Junction Tree de orden k Gaussiano desde el conjunto deindividuos Q. Se usa el algoritmo 12 para ello.
2. Obtener una GN usando como base la estructura de la MN representada en el t-Cherry Junction Tree de orden k.
En el capıtulo anterior se explico ya en detalle como llevar a cabo el paso 1. Eneste capıtulo comenzamos explicando en la seccion 5.1 como ejecutar el paso 2, lo quenos permitira obtener una estructura factible para su uso en MBEAs. Esto nos servirade preambulo ademas para presentar en la seccion 5.2 al t-Cherry EDA, un algoritmo deestimacion de distribucion para optimizacion global continua sin restricciones. En la ultimaseccion se hace un analisis experimental del rendimiento del algoritmo en un benchmarkde funciones comunmente usadas en la literatura.
73

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
5.1. Del t-Cherry Junction Tree de orden k a una Red Gaus-
siana
De manera breve y practica, para completar el paso 1 comenzamos calculando desdeel conjunto Q de n individuos el vector de medias µ y las matrices de covarianza Σ ycorrelacion Φ, con el fin de hacer este calculo una sola vez y desde estas obtener lassubmatrices necesarias durante la construccion, ası como para simulacion de datos que sehara posteriormente. Una vez hecho esto construimos el t-Cherry Junction Tree de ordenk con el algoritmo 12, siendo la matriz de correlacion Φ y el orden k los parametros deentrada.
X5
X3X6
X2X1, X2, X3, X4
X1, X3, X5, X6
X1, X3, X4, X5
X1, X3, X4
X1, X3, X5
X7X3, X4, X5, X7
X3, X4, X5
X1
X4
Figura 5.1: Ejemplo de resultado del paso 1. Un t-Cherry Junction Tree de orden k = 4 y la
MN representada en este.
Una vez completado el paso 1, usaremos un procedimiento simple para ejecutar el paso2. El orden de visita de los clusters en un DFS sobre el t-Cherry Junction Tree de orden knos dara las direcciones de las aristas de un DAG que trazaremos sobre el grafo no dirigidoque describe a la MN, de manera que obtendremos un grafo dirigido que usaremos a lavez como estructura para la GN.
Para ejecutar el DFS necesitamos escoger un cluster como raız, por lo que tomamos elaquel con menor TC. Antes de comenzar con el DFS, daremos direccion a las aristas delsubgrafo dentro del clique de k vertices de la MN representado en este cluster raız. Surgela pregunta: ¿Cual es la mejor manera de darle direccion? Observemos primero que, dadauna permutacion π de los ındices de las variables en el clique de tamano k, debe de haberaristas dirigidas hacia Xπi solo desde Xπ1 . . . Xπi−1 , ∀i ∈ 1, . . . , k de manera que el grafo
74

5.1 Del t-Cherry Junction Tree de orden k a una Red Gaussiana
dirigido sea valido para una GN (es decir, que sea un DAG). Es facil ver que existen k!maneras de ordenar las variables en el clique.
En la figura 5.2 se aprecia un ejemplo de lo que se explica en el parrafo anterior. Comose puede observar se tomo como raız el cluster del t-Cherry Junction Tree de orden k enla imagen 5.1, la cual nos servira de ejemplo para las demas operaciones del algoritmo quedescribiremos en esta seccion.
X3
X2
X1, X2, X3, X4
X1
X4
X3
X2
X1
X4
X3
X2
X1
X4
Figura 5.2: A la izquierda se observan dos ejemplos de GN cuyos DAG se obtuvieron con las
permutaciones 1, 2, 3, 4 y 4, 2, 1, 3 desde el cluster X1, X2, X3, X4 mostrado en la parte
superior derecha. La MN representada en el cluster se aprecia debajo de este.
Entonces podemos reformular la pregunta anterior como: ¿Cual es la permutacion quenos permite tener un mejor ajuste a los datos dentro de este subgrafo? La respuesta escualquiera. Para demostrarlo usaremos la definicion de la log-verosimilitud negativa paracierto PGM dirigido M
− ll(M) =
d∑i=1
H(Xi |Pai) =
d∑i=1
[H(Xi,Pai)−H(Pai)] (5.1)
Sea C un clique de k vertices en una GN y π cierta permutacion que describe el ordende sus aristas. La log-verosimilitud negativa del clique es
−ll(C) = H(Xπ1) +H(Xπ2 , Xπ1)−H(Xπ1) +H(Xπ3 , Xπ2 , Xπ1)
−H(Xπ2 , Xπ1) + · · ·+H(Xπk , Xπk−1, . . . , Xπ1)−H(Xπk−1
, . . . , Xπ1) =
H(Xπk , Xπk−1, . . . , Xπ1)
(5.2)
75

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Notemos que el resultado de la ecuacion 5.2 es la entropıa conjunta de las variables enel cluster. Se puede entonces establecer cualquier orden ancestral para este subgrafo, porejemplo el mismo en el que se fueron agregando las variables a este cluster durante laactualizacion de orden, ya que cualquier permutacion de las variables como parametros dela entropıa conjunta no cambia su valor.
Una vez definido el DAG, desde el cluster raız hacemos el DFS en el t-Cherry JunctionTree de orden k. En cada visita al cluster CN desde el cluster CO trazamos k − 1 aristasdesde las variables que se encuentran en el separador que los conecta hasta la variabledominante en CN . En la figura 5.3 se muestra a la izquierda el recorrido DFS del arbolde ejemplo en la figura 5.1, suponiendo que el cluster de menor TC es X1, X2, X3, X4.A la derecha se va mostrando el DAG que trazamos sobre la MN.
Una vez trazado el DAG, tenemos construida la estructura de nuestra GN. Solo tenemosque calcular ahora sus parametros, tal como se explica en la seccion 3.2.2.2.
El algoritmo 13 describe la obtencion de la GN partiendo del t-Cherry Junction Treede orden k.
X5
X3X6
X2
X7
X1
X4
X5
X3X6
X2
X7
X1
X4
X5
X3X6
X2
X7
X1
X4
X5
X3X6
X2
X7
X1
X4
Figura 5.3: Ejemplo de DAG obtenidos desde la MN representada en el t-Cherry Junction
Tree de orden k.
76

5.2 El t-Cherry EDA
Algorithm 13 Algoritmo de direccionamiento de aristas de una MN representada en un
t-Cherry Junction Tree de orden k
1: procedure BuildGN(JT∆k)
2: M∆k ← ∅
3: Croot ← ArgMaxC∈CI(XC)
4: M∆k ←M∆k∪ DAG sobre Croot con alguna permutacion π
5: for CN visitado en un DFS(Croot) do
6: M∆k ←M∆k ∪Xv = CN \ SN∪ aristas desde variables en SN hacia Xv
7: end for
8: Calcular parametros para M∆k
return M∆k
9: end procedure
5.2. El t-Cherry EDA
Se describe el t-Cherry EDA en el algoritmo 14. Como se puede observar, este esuna implementacion del EDA Generico que se muestra en el algoritmo 3. A continuaciondescribimos como se definieron las operaciones de generacion, seleccion y reemplazo deindividuos, y las particularidades de la construccion del modelo.
5.2.1. Construccion del modelo usando un archivo de individuos
La construccion del modelo se da al principio de cada generacion y se describe en laslıneas 7, 8 y 9 del algoritmo 14. Para ello se calculan el vector de medias µ y las matrices decovarianza Σ y correlacion Φ desde la union de la poblacion y un conjunto H de individuosdescartados en generaciones pasadas, de tamano maximo h. Para mantener |H| ≤ h sevan eliminando del archivo los individuos de mas edad, es decir, aquellos que se crearonen las generaciones mas antiguas.
Se construye entonces un t-Cherry Junction Tree de orden k usando Φ y se obtienedesde este una GN M∆k
que vamos a usar para la generacion de nuevos individuos.El construir el modelo usando tambien los individuos en H en lugar de solo usar la
poblacion Q tiene como finalidad aliviar en cierta medida la perdida de diversidad en lapoblacion provocada por ajustar el modelo a muestras pequenas de individuos aptos.
77

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Algorithm 14 Pseudocodigo del t-Cherry EDA
1: procedure t-Cherry EDA(n, d, k, h)
2: Q0 ← n individuos de una distribucion uniforme
3: ∀q0 ∈ Q0 : q0.f = f(q0.x)
4: t← 1
5: repeat
6: Obtener µt,Σt, Φt desde H ∪Qt−1
7: JT∆k
t ← BuildTCherryJunctionTree(Φt, k)
8: M∆k
t ← BuildGN(JT∆k
t )
9: Qtoffs ← n individuos desde PLS(ancestralOrder(M∆k
t ), d,M∆k
t , µt,Σt)
10: ∀qtoffs ∈ Qtoffs : qtoffs.f = f(qtoffs.x)
11: Qt ← seleccionar los mejores n individuos de Qt−1 ∪Qtoffs12: H ← H ∪Qt−1 ∪Qtoffs \Qt
13: Truncar H a tamano h
14: t← t+ 1
15: until Criterio de terminacion se cumpla
16: end procedure
78

5.3 Experimentos
5.2.2. Generacion de nuevos individuos
Los n nuevos individuos se simulan desde M∆kusando el algoritmo 5 PLS. Es impor-
tante notar que para toda variable Xi en la BN resultante del algoritmo 13 el subgrafoinducido por sus variables padres es completo, por lo que para simular el vector pai nece-sario para hacer la simulacion de xi se usa la submatriz de covarianzas ΣPai y el vector de
medias µPai . Decimos entonces que los parametros de M∆k(ver seccion 3.2.2.2) son ob-
tenidos desde µ y Σ sin necesidad de hacer calculos adicionales. Recordemos tambien quees necesario tener la permutacion π de ındices de las variables del problema, que describeel orden ancestral de M∆k
.
5.2.3. Estrategia de reemplazo inspirada en ES
La estrategia de reemplazo esta fuertemente basada en la utilizada en las estrategiasevolutivas µ/ρ + λ (ver seccion 2.2.2). De hecho podemos decir que es la misma, conµ = λ = n. En cada generacion t se junta la poblacion de padres Qt−1 y la de hijos Qtoffsy se forma la poblacion Qt con los mejores n individuos de las dos poblaciones. Cabesenalar que se tiene entonces el grado mas alto de elitismo, ya que un individuo q no sepierde en el transcurso de las generaciones hasta que se encuentren n mejores que el.
5.3. Experimentos
Con el fin de evaluar de manera experimental el desempeno del t-Cherry EDA este seutilizo para optimizar 12 funciones de variables de naturaleza continua comunmente usadasen la literatura para hacer comparaciones de desempeno entre algoritmos de optimizacionglobal sin restricciones (32). Estos experimentos se hicieron con distintos parametros, cadaconfiguracion se ejecuto 51 veces.
La evaluacion del desempeno va enfocada a analizar mediante los resultados del ex-perimento las ventajas que brinda al t-Cherry EDA el incrementar el orden del t-CherryJunction Tree, construyendo con esto GNs mas densas, lo que implica tomar en cuentamas posibles dependencias entre las variables. Entonces el analisis comparativo se mos-trara sobre varias versiones del t-Cherry EDA, con k = 4, k = 6 y k = 8, el EDA de arbolde dependencias de Chow & Liu en su version Gaussiana (en adelante Chow & Lui EDAc)y el UMDAcG . Estos ultimos se pueden comparar como las versiones de t-Cherry EDAcon k = 2 y k = 1 respectivamente. Se presentan ademas resultados de los algoritmos cony sin archivo de individuos.
79

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Funcion Nombre Separable Modalidad Caracterısticas relevantes
f1 Sphere Sı Unimodal
f2 Ellipsoid Sı Unimodal Mal condicionada
f3 Cigar Tablet Sı Unimodal Mınimo en region plana
f4 Different Powers Sı Unimodal Mal condicionada
f5 Schwefel 1.2 No Unimodal
f6 Zakharov No Unimodal Mınimo en region plana
f7 Trid No Unimodal
f8 Ackley Sı Multimodal Gran cantidad de mınimos locales
f9 Griewank Sı Multimodal Gran cantidad de mınimos locales
f10 Rastrigin Sı Multimodal Gran cantidad de mınimos locales
f11 Levy 8 Sı Multimodal Gran cantidad de mınimos locales
f12 Rosenbrock No Multimodal Mınimo en region muy estrecha
Tabla 5.1: Funciones usadas en el experimento y algunas caracterısticas de interes para el
analisis
5.3.1. Benchmark de funciones
De las funciones descritas en (32) se escogieron varias de manera que hubiera en elconjunto funciones con numero de dimensiones generalizable, con y sin dependencia entrevariables, modales y multimodales. Las primeras once funciones se usan en (36), agregamosen este trabajo la funcion Rosenbrock generalizada f12.
En la tablas 5.1 y 5.2 se muestran las funciones usadas en el experimento, con algunasde sus caracterısticas.
80

5.3 Experimentos
Funcion Definicion f(x∗) x∗ Lımites comunes
i = 1, . . . , d
f1
d∑i=1
x2i 0 xi = 0 −5.12 ≤ xi ≤ 5.12
f2
d∑i=1
106 i−1d−1x2
i 0 xi = 0 −65.536 ≤ xi ≤ 65.536
f3 x21 +
d−1∑i=2
104x2i + 108x2
d 0 xi = 0 −5 ≤ xi ≤ 5
f4
d∑i=1
|xi|2+10 i−1d−1 0 xi = 0 −5 ≤ xi ≤ 5
f5
d∑i=1
i∑j=1
xj
2
0 xi = 0 −5 ≤ xi ≤ 5
f6
d∑i=1
x2i +
(d∑i=1
0.5ixi
)2
+
(d∑i=1
0.5ixi
)4
0 xi = 0 −5 ≤ xi ≤ 5
f7
d∑i=1
(xi − 1)2 −d∑i=1
xixi−1−d(d+ 4)(d− 1)
6xi = i(d+ 1− i) −d2 ≤ xi ≤ d2
f8 − exp
(1
d
d∑i=1
cos(2πxi)
)+ 20 + e 0 xi = 0 −32.768 ≤ xi ≤ 32.768
f9
d∑i=1
x2i
4000−
d∏i=1
cos
(xi√i
)+ 1 0 xi = 0 −600 ≤ xi ≤ 600
f10 10d+d∑i=1
[x2i − 10 cos(2πxi)
]0 xi = 0 −5.12 ≤ xi ≤ 5.12
f11
d−1∑i=1
(yi − 1)2 [1 + 10 sin2(πyi+1)]
+ sin2(πy1) + (yd − 1)2; yi = 1 +1
4(x1 + 1)
0 xi = −1 −10 ≤ xi ≤ 10
f12
d−1∑i=1
[100
(xi+1 − x2
i
)2+ (xj − 1)2
]0 xi = 1 −2.048 ≤ xi ≤ 2.048
Tabla 5.2: Definicion de las funciones usadas en el experimento. Los lımites comunes son
usados solo en la creacion de los individuos en la primera generacion, no se obliga durante el
proceso evolutivo a que los valores esten dentro de los lımites.
5.3.2. Resultados
Los siguientes puntos describen los experimentos que se realizaron.
Se ejecutaron los algoritmos UMDAcG , el Chow & Lui EDAc y tres versiones delt-Cherry EDA: k = 4, 6, 8.
81

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Se ejecutaron cuatro configuraciones por algoritmo, combinando la dimensionalidady el uso de archivo de historial: d = 20, 30 y h = 0, 2.
Cada configuracion se ejecuto 51 veces.
Se establecio que n = 10d y que el maximo numero de evaluaciones de funcion sea10000d
Se toma como criterio de paro el que el error mınimo encontrado sea menor o iguala 1E − 6 (es decir, una ejecucion exitosa), o bien, llegar al numero maximo deevaluaciones de funcion (una ejecucion fallida).
El mınimo de las primeras diez funciones se encuentra en el centro del espacio debusqueda si lo acotamos mediante los lımites comunes del espacio de busqueda mos-trados en la tabla 5.2, esto supondrıa una ventaja para un EDA que difıcilmente seda en escenarios reales. Por esta razon los lımites de todas las funciones se definieroncomo lii
1.2 ≤ xi ≤ 1.2lsi, i = 1, . . . , d.
Separamos la presentacion de los resultados usando como criterio su dimensionalidad.En las tablas de resultados se muestran para cada funcion dos renglones, en el primero sevisualizan datos sobre el error mınimo alcanzado y en el segundo datos sobre el numerode evaluaciones de funcion que realizaron las ejecuciones exitosas.
Es importante hacer enfasis en el hecho de que no se hizo una busqueda de valoresoptimos para los parametros h y n para cada valor de k y d. Se usa n = 10d que esuna configuracion ingenua para el tamano de poblacion y h = 2 para usar archivo dehistorial, se ejecutaron los experimentos ası con el fin de no sesgar los resultados de maneraintencional hacia alguna version del algoritmo. Es por ello que es posible que los resultadosaquı mostrados sean mejorados haciendo una busqueda de parametros adecuados para cadaversion del algoritmo.
5.3.2.1. Tablas de resultados, d=20
En las tablas 5.4 y 5.3 se muestran los resultados de las diferentes configuraciones dealgoritmos para los problemas en 20 dimensiones. En el primer renglon de las tablas semuestran datos estadısticos del mejor error encontrado en las ejecuciones de cada con-figuracion, con formato mediana (desviacion estandar). En el segundo renglon se puedenvisualizar datos de las evaluaciones de funcion realizadas hasta cumplir con el criteriode paro, con formato mediana (desviacion estandar) Porcentaje de exitos. En negritas seencuentran resaltados los mejores resultados.
82

5.3 Experimentos
UMDAcG Chow & Liu EDA2nc t-Cherry4 EDA2n t-Cherry6 EDA2n t-Cherry8 EDA2n
f1 8.797E-07 (1.25E-07) 8.809E-07 (1.20E-07) 8.635E-07 (1.17E-07) 8.313E-07 (1.27E-07) 8.707E-07 (1.19E-07)
1.62E+4 (2.06E+2) 100 2.47E+4 (2.99E+2) 100 2.45E+4 (2.46E+2) 100 2.43E+4 (2.76E+2) 100 2.43E+4 (2.67E+2) 100
f2 8.419E-07 (1.24E-07) 8.563E-07 (1.21E-07) 8.946E-07 (1.19E-07) 8.854E-07 (9.22E-08) 8.395E-07 (1.10E-07)
2.81E+4 (2.22E+2) 100 4.27E+4 (3.01E+2) 100 4.23E+4 (3.65E+2) 100 4.22E+4 (3.39E+2) 100 4.20E+4 (3.77E+2) 100
f3 8.501E-07 (1.10E-07) 8.710E-07 (1.28E-07) 8.552E-07 (1.27E-07) 8.613E-07 (1.21E-07) 8.718E-07 (1.22E-07)
2.50E+4 (2.24E+2) 100 3.80E+4 (3.51E+2) 100 3.78E+4 (3.06E+2) 100 3.78E+4 (3.15E+2) 100 3.75E+4 (3.47E+2) 100
f4 8.054E-07 (1.49E-07) 7.921E-07 (1.71E-07) 8.226E-07 (1.57E-07) 8.615E-07 (1.51E-07) 8.151E-07 (1.54E-07)
9.57E+3 (2.51E+2) 100 1.44E+4 (3.14E+2) 100 1.42E+4 (3.17E+2) 100 1.42E+4 (3.02E+2) 100 1.41E+4 (2.94E+2) 100
f5 5.717E-03 (8.52E-03) 6.469E-04 (2.75E-03) 4.279E-06 (3.04E-03) 9.965E-07 (9.10E-05) 9.776E-07 (4.42E-05)
2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (7.36E+4) 31.4 4.35E+4 (8.23E+4) 54.9 3.30E+4 (7.66E+4) 70.6
f6 8.736E-07 (1.06E-07) 9.757E-07 (1.78E-04) 1.473E-04 (4.72E-03) 1.084E-04 (3.82E-03) 1.067E-04 (1.37E-03)
1.19E+5 (2.60E+3) 100 1.14E+5 (4.61E+4) 56.9 2.00E+5 (4.03E+4) 15.7 2.00E+5 (4.28E+4) 17.6 2.00E+5 (4.11E+4) 11.8
f7 3.571E+3 (5.87E+2) 8.598E-07 (1.21E-07) 8.509E-07 (1.82E+0) 8.459E-07 (6.61E-02) 9.050E-07 (4.13E-01)
2.00E+5 (0.00E+0) 3.66E+4 (2.56E+2) 100 3.63E+4 (2.29E+4) 98 3.61E+4 (2.30E+4) 98 3.59E+4 (3.22E+4) 96.1
f8 9.340E-07 (7.08E-08) 9.329E-07 (6.81E-08) 9.125E-07 (7.17E-08) 9.086E-07 (7.45E-08) 9.416E-07 (5.45E-08)
3.21E+4 (2.12E+2) 100 4.88E+4 (3.74E+2) 100 4.84E+4 (3.37E+2) 100 4.82E+4 (3.20E+2) 100 4.80E+4 (3.07E+2) 100
f9 8.391E-07 (1.28E-07) 8.438E-07 (1.04E-07) 8.724E-07 (1.25E-07) 9.105E-07 (1.24E-07) 8.305E-07 (1.11E-07)
2.29E+4 (3.13E+2) 100 3.48E+4 (3.51E+2) 100 3.45E+4 (4.17E+2) 100 3.44E+4 (3.65E+2) 100 3.41E+4 (2.83E+2) 100
f10 8.123E+1 (7.24E+0) 7.940E+1 (6.68E+0) 7.974E+1 (8.82E+0) 7.823E+1 (7.40E+0) 7.616E+1 (5.96E+0)
2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0)
f11 8.773E-07 (1.31E-07) 8.998E-07 (1.41E-07) 8.787E-07 (1.28E-07) 8.584E-07 (1.15E-07) 8.685E-07 (1.20E-07)
1.62E+4 (2.66E+2) 100 2.46E+4 (3.01E+2) 100 2.44E+4 (2.98E+2) 100 2.43E+4 (3.19E+2) 100 2.41E+4 (3.39E+2) 100
f12 1.803E+1 (6.30E-02) 1.748E+1 (2.43E-01) 1.751E+1 (2.42E-01) 1.751E+1 (2.51E-01) 1.749E+1 (3.37E-01)
2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0)
Tabla 5.3: Resultados obtenidos para d = 20 usando un archivo de individuos de tamano 2n.
En el analisis vamos a omitir el rendimiento de los algoritmos en las funciones f10 yf12 pues no fueron capaces de resolverlas en ningun caso, aunque cabe senalar que se notauna mejora muy pequena al ir aumentando el valor de k para el modelo, esto dado por unamejor explotacion en la zona del espacio de busqueda donde se queda atrapado el algoritmo.
En los resultados del mınimo error encontrado observamos que el comportamiento escongruente con lo que se espera al ir agregando al modelo dependencias entre variables.Notemos primero entonces que el UMDAcG tiene un buen desempeno en funciones sepa-rables, ya que las resuelve todas al igual que el t-Cherry EDA.
En el caso de las no separables el t-Cherry EDA en alguna de las versiones tiene elmejor desempeno, aunque observemos en los resultados de la funcion f6 que no siempreun grafo mas denso da mejores resultados.
Por ultimo, observamos tambien que usar un archivo de individuos le da robustez al
83

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
algoritmo pues aumenta significativamente el porcentaje de exito. Podemos atribuir estoal retraso en la convergencia que da el hecho de ajustar el modelo a una poblacion masgrande y diversa.
UMDAcG Chow & Liu EDAc t-Cherry4 EDA t-Cherry6 EDA t-Cherry8 EDA
f1 8.517E-07 (1.21E-07) 8.586E-07 (1.18E-07) 8.473E-07 (1.40E-07) 8.496E-07 (1.24E-07) 7.926E-07 (1.69E-07)
1.63E+4 (1.91E+2) 100 1.57E+4 (2.39E+2) 100 1.56E+4 (2.26E+2) 100 1.55E+4 (2.32E+2) 100 1.53E+4 (2.22E+2) 100
f2 8.400E-07 (1.16E-07) 8.934E-07 (1.36E-07) 8.287E-07 (9.98E-08) 8.520E-07 (1.12E-07) 8.670E-07 (2.46E+0)
2.80E+4 (2.40E+2) 100 2.73E+4 (2.61E+2) 100 2.70E+4 (2.22E+2) 100 2.68E+4 (2.79E+2) 100 2.67E+4 (6.02E+4) 86.3
f3 8.750E-07 (9.17E-08) 8.485E-07 (1.45E-07) 8.752E-07 (3.98E-02) 8.447E-07 (2.62E-02) 8.612E-07 (2.58E-02)
2.49E+4 (2.62E+2) 100 2.43E+4 (2.16E+2) 100 2.40E+4 (2.46E+4) 98 2.39E+4 (4.78E+4) 92.2 2.37E+4 (5.29E+4) 90.2
f4 7.721E-07 (1.65E-07) 7.992E-07 (1.41E-07) 8.158E-07 (1.70E-07) 7.591E-07 (2.27E-07) 7.881E-07 (1.81E-07)
9.59E+3 (2.28E+2) 100 9.27E+3 (1.93E+2) 100 9.21E+3 (1.89E+2) 100 9.21E+3 (2.11E+2) 100 9.15E+3 (2.27E+2) 100
f5 3.982E-03 (6.24E-03) 2.363E-03 (2.25E-02) 5.666E-04 (8.49E-03) 2.606E-04 (1.05E-02) 3.996E-05 (6.13E-03)
2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (3.31E+4) 3.9 2.00E+5 (6.98E+4) 19.6 2.00E+5 (8.14E+4) 29.4
f6 8.692E-07 (1.20E-07) 1.537E-05 (7.80E-04) 2.151E-04 (3.07E-02) 2.497E-04 (1.16E-02) 6.338E-04 (4.74E-03)
1.19E+5 (2.50E+3) 100 2.00E+5 (4.55E+4) 23.5 2.00E+5 (3.74E+4) 9.8 2.00E+5 (3.11E+4) 5.9 2.00E+5 (2.73E+4) 3.9
f7 3.859E+3 (4.73E+2) 8.337E-07 (1.62E+0) 1.000E-01 (1.41E+1) 7.476E-01 (3.15E+1) 3.765E+0 (4.19E+1)
2.00E+5 (0.00E+0) 2.36E+4 (4.19E+4) 94.1 2.00E+5 (8.79E+4) 41.2 2.00E+5 (7.59E+4) 23.5 2.00E+5 (6.82E+4) 17.6
f8 9.353E-07 (6.16E-08) 9.254E-07 (6.56E-08) 9.263E-07 (7.29E-08) 9.364E-07 (6.32E-08) 9.335E-07 (8.50E-08)
3.19E+4 (2.58E+2) 100 3.11E+4 (2.77E+2) 100 3.07E+4 (2.98E+2) 100 3.05E+4 (2.27E+2) 100 3.03E+4 (2.92E+2) 100
f9 8.432E-07 (1.06E-07) 8.652E-07 (1.22E-07) 8.579E-07 (1.38E-07) 8.476E-07 (1.13E-07) 8.596E-07 (1.26E-07)
2.29E+4 (3.47E+2) 100 2.22E+4 (3.30E+2) 100 2.20E+4 (2.64E+2) 100 2.18E+4 (2.10E+2) 100 2.17E+4 (2.94E+2) 100
f10 8.091E+1 (6.30E+0) 7.705E+1 (6.89E+0) 7.657E+1 (6.10E+0) 7.667E+1 (6.18E+0) 7.575E+1 (6.95E+0)
2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0)
f11 8.499E-07 (1.05E-07) 8.392E-07 (1.20E-07) 8.753E-07 (1.07E-07) 8.714E-07 (1.16E-07) 8.475E-07 (1.25E-07)
1.62E+4 (2.22E+2) 100 1.59E+4 (2.21E+2) 100 1.56E+4 (2.21E+2) 100 1.55E+4 (2.15E+2) 100 1.53E+4 (2.25E+2) 100
f12 1.803E+1 (5.02E-02) 1.757E+1 (2.60E-01) 1.764E+1 (2.67E-01) 1.769E+1 (3.77E-01) 1.781E+1 (3.11E-01)
2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0) 2.00E+5 (0.00E+0)
Tabla 5.4: Resultados obtenidos para d = 20.
En lo que respecta a los resultados de las evaluaciones de funcion ejecutadas podemosver que el archivo de individuos da robustez pero retrasa la convergencia, por lo que im-pacta negativamente en el numero de evaluaciones de funcion que se deben de realizar.Si observamos los resultados de la tabla 5.4, podemos ver que incluso en las funcionesseparables el construir un modelo mas denso ayuda en la convergencia y con ello en elrendimiento en cuanto a numero de evaluaciones de funcion se refiere.
En la tabla 5.5 se muestra un ranking para los algoritmos por funcion. Note en elencabezado de la tabla que CLEDAh
c es el Chow & Lui EDAc y que tCkEDAh es elt-CherrykEDAh.
84
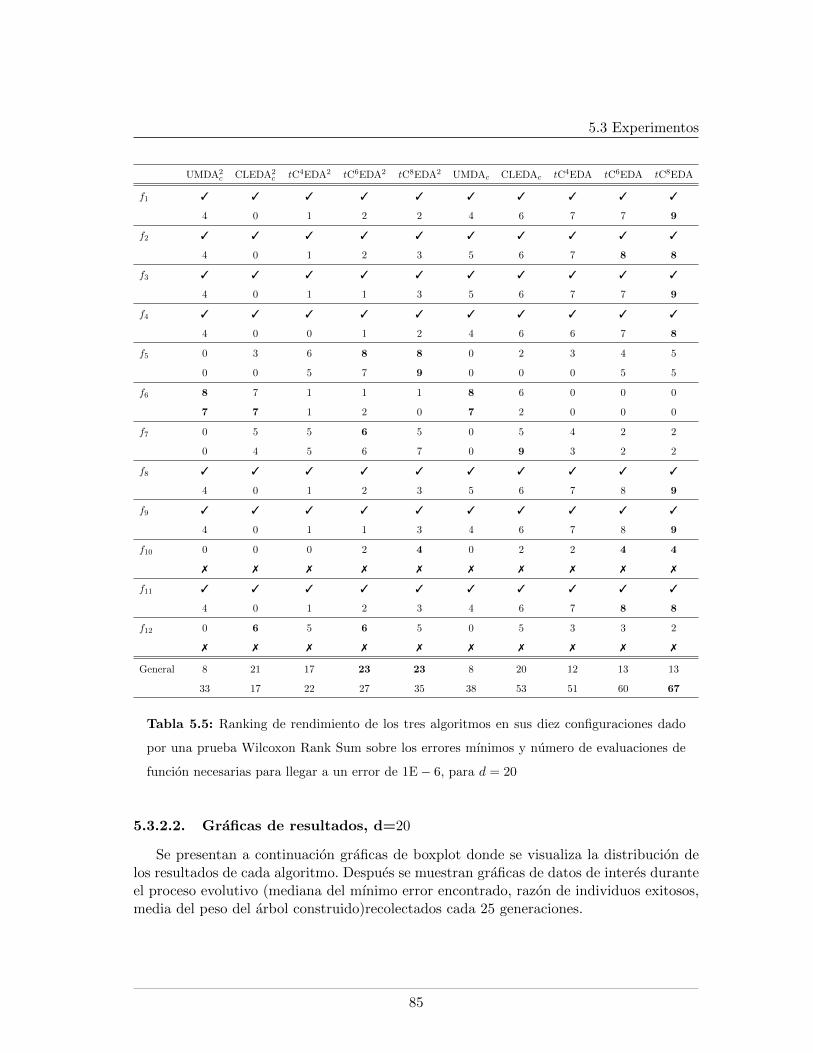
5.3 Experimentos
UMDA2c CLEDA2
c tC4EDA2 tC6EDA2 tC8EDA2 UMDAc CLEDAc tC4EDA tC6EDA tC8EDA
f1 3 3 3 3 3 3 3 3 3 3
4 0 1 2 2 4 6 7 7 9
f2 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 5 6 7 8 8
f3 3 3 3 3 3 3 3 3 3 3
4 0 1 1 3 5 6 7 7 9
f4 3 3 3 3 3 3 3 3 3 3
4 0 0 1 2 4 6 6 7 8
f5 0 3 6 8 8 0 2 3 4 5
0 0 5 7 9 0 0 0 5 5
f6 8 7 1 1 1 8 6 0 0 0
7 7 1 2 0 7 2 0 0 0
f7 0 5 5 6 5 0 5 4 2 2
0 4 5 6 7 0 9 3 2 2
f8 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 5 6 7 8 9
f9 3 3 3 3 3 3 3 3 3 3
4 0 1 1 3 4 6 7 8 9
f10 0 0 0 2 4 0 2 2 4 4
7 7 7 7 7 7 7 7 7 7
f11 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 4 6 7 8 8
f12 0 6 5 6 5 0 5 3 3 2
7 7 7 7 7 7 7 7 7 7
General 8 21 17 23 23 8 20 12 13 13
33 17 22 27 35 38 53 51 60 67
Tabla 5.5: Ranking de rendimiento de los tres algoritmos en sus diez configuraciones dado
por una prueba Wilcoxon Rank Sum sobre los errores mınimos y numero de evaluaciones de
funcion necesarias para llegar a un error de 1E− 6, para d = 20
5.3.2.2. Graficas de resultados, d=20
Se presentan a continuacion graficas de boxplot donde se visualiza la distribucion delos resultados de cada algoritmo. Despues se muestran graficas de datos de interes duranteel proceso evolutivo (mediana del mınimo error encontrado, razon de individuos exitosos,media del peso del arbol construido)recolectados cada 25 generaciones.
85

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Con el fin de facilitar la visualizacion se asigno un color a cada orden de algoritmo: rosaal UMDAcG , amarillo al Chow & Liu EDAc y verde, rojo y azul para los el t-Cherry EDAde ordenes 4, 6 y 8 respectivamente; la tonalidad mas oscura indica el uso del archivo deindividuos. Tambien es importante notar que en el caso de las graficas del proceso evolutivose trazan lıneas con puntos cuya forma se asigno tambien a cada orden de algoritmo: cruzal UMDAcG, triangulo al Chow & Liu EDAc y rombo, cuadrado y cırculo para los el t-Cherry EDA de ordenes 4, 6 y 8 respectivamente; el relleno solido indica el uso del archivode individuos. Todo esto se observa en la figura 5.4.
Figura 5.4: Leyendas usadas para las graficas presentadas en este capıtulo.
Observando la variacion de los errores mınimos encontrados en la figura 5.5 se puedeapreciar que usar archivo de individuos hace al algoritmo mas robusto, ademas de queobtiene mejores resultados. No se presentan graficas de errores mınimos para las funcionesseparables, pues todas fueron resueltas en su totalidad para 20 dimensiones. En la figura5.6 se muestra la desventaja de usar archivo de individuos en cuanto a velocidad de con-vergencia se refiere. Podemos observar tambien que no importa si se usa o no un archivo,al incrementar k se converge mas rapido. Por ultimo, en la figura 5.7 se puede observarque al incrementar k va mejorando la razon de exitos, aunque estas funciones en especıficonecesitaron el uso archivo de individuos para que la mejora fuera significativa.
86
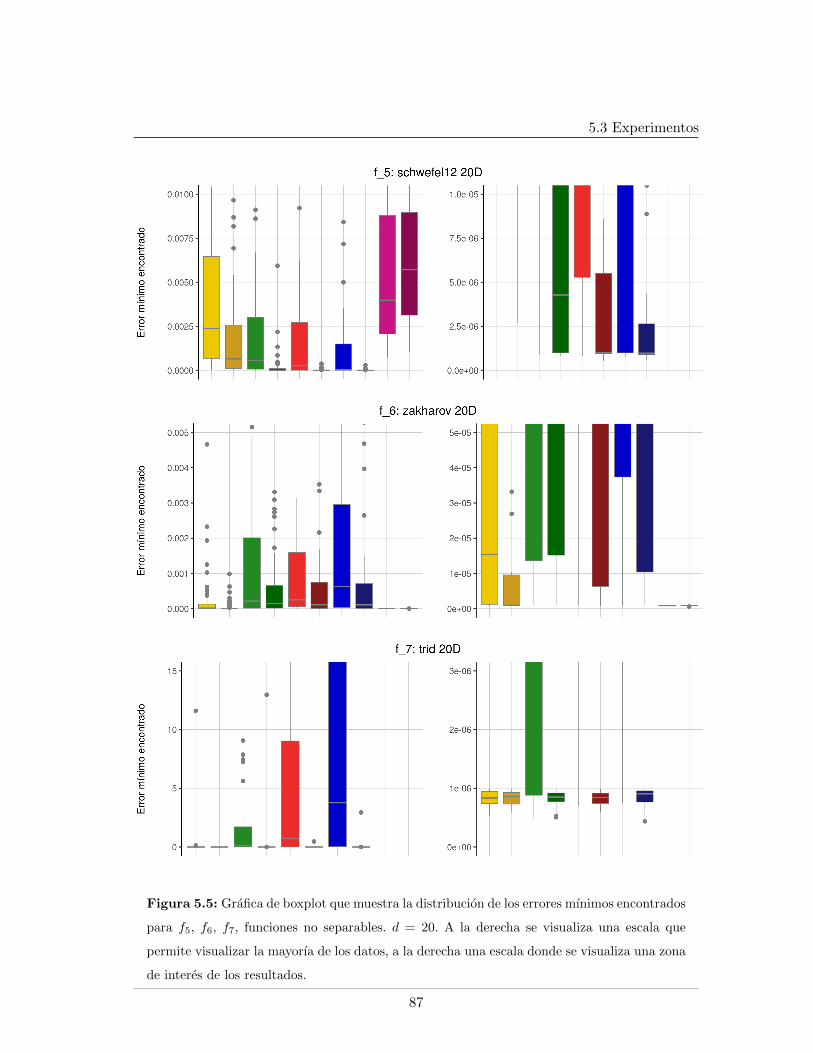
5.3 Experimentos
Figura 5.5: Grafica de boxplot que muestra la distribucion de los errores mınimos encontrados
para f5, f6, f7, funciones no separables. d = 20. A la derecha se visualiza una escala que
permite visualizar la mayorıa de los datos, a la derecha una escala donde se visualiza una zona
de interes de los resultados.
87
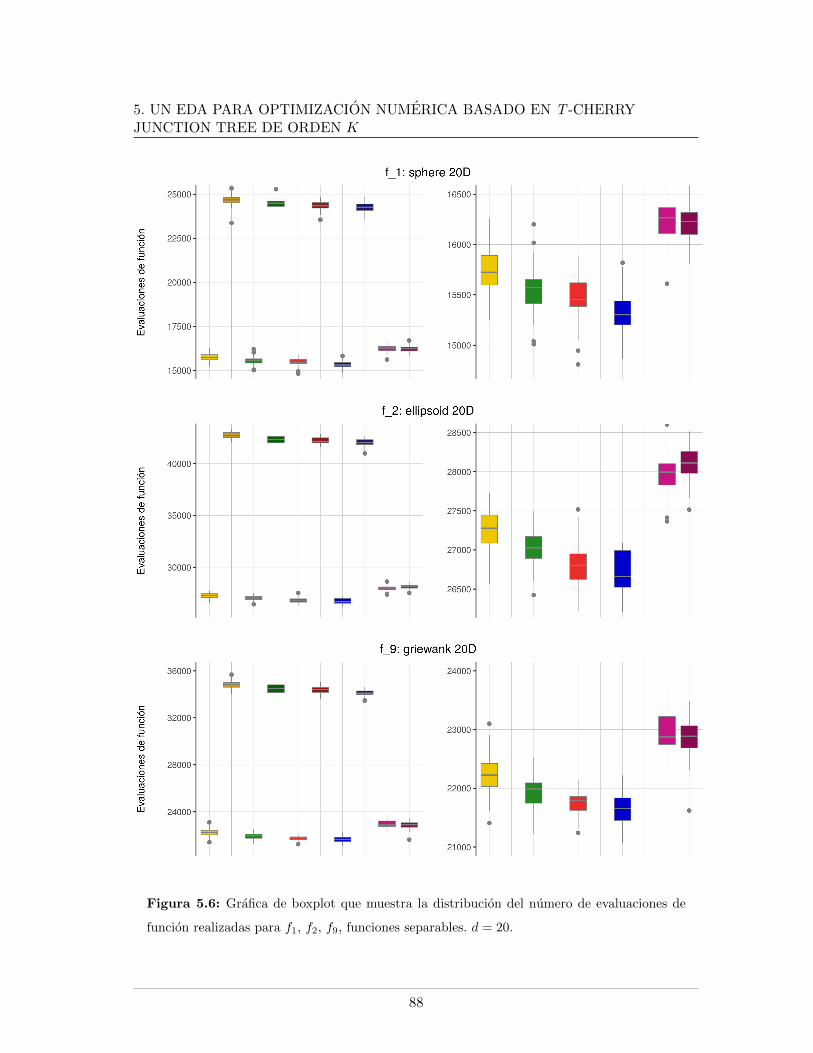
5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Figura 5.6: Grafica de boxplot que muestra la distribucion del numero de evaluaciones de
funcion realizadas para f1, f2, f9, funciones separables. d = 20.
88
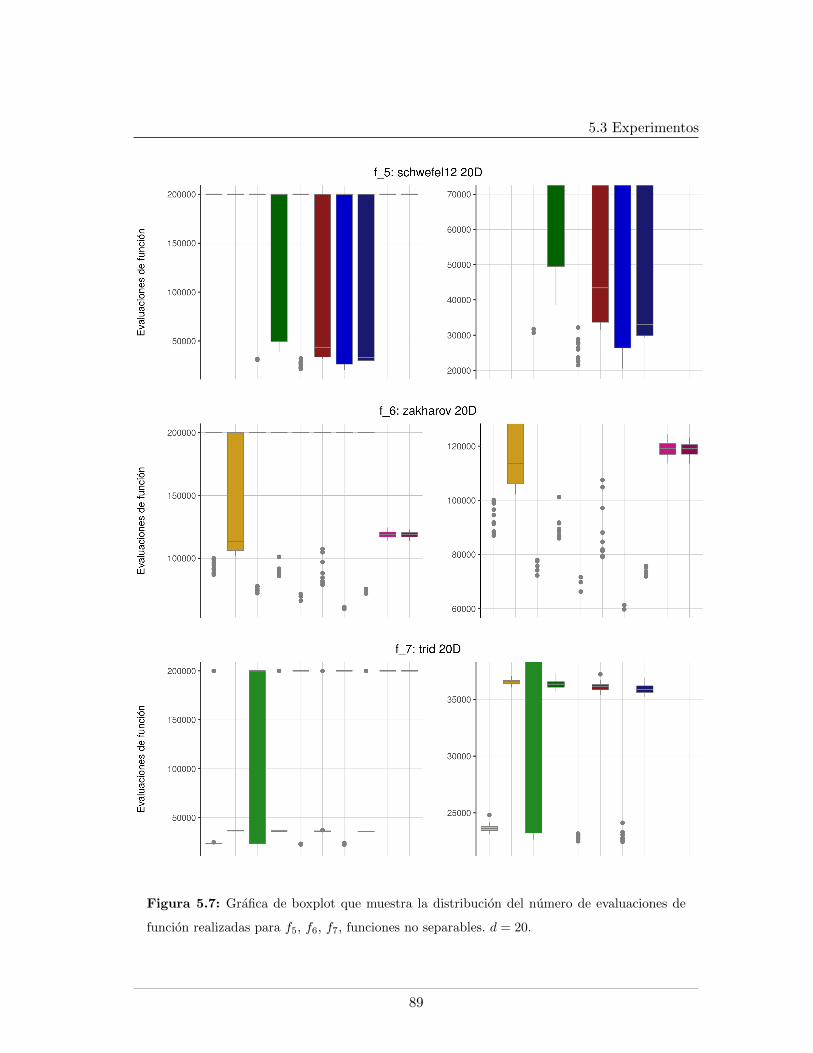
5.3 Experimentos
Figura 5.7: Grafica de boxplot que muestra la distribucion del numero de evaluaciones de
funcion realizadas para f5, f6, f7, funciones no separables. d = 20.
89

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
5.3.2.3. Graficas de datos relevantes durante el proceso evolutivo, d=20
En las graficas (a) (b) (c) de la figura 5.8 se aprecia la evolucion de la mediana del errormınimo encontrado en funciones separables. Se observa un comportamiento muy pareci-do para las diferentes funciones, a pesar de sus diferentes caracterısticas de modalidad ocondicionamiento, ademas de que es notorio que los algoritmos con k mayor convergen unpoco mas rapido. Las graficas (d) (e) (f) muestran la evolucion en funciones no separables.Al no apreciar patrones aquı se puede concluir que para estas funciones las caracterısti-cas adicionales a la dependencia entre variables impacta en el rendimiento del algoritmo,siendo las versiones con archivo de individuos las mejores en este sentido.
En lo que respecta a la razon de individuos exitosos por generacion notemos que en lasfunciones separables esta alrededor de 0.55 con las versiones de los algoritmos que usan unarchivo de individuos y de 0.45 para aquellas que no (graficas (a), (b), (c) y (g) en la figura5.9). La separacion entre estas dos clasificaciones esta muy bien definida. En las funcionesno separables (graficas (d), (e), (f) y (h) en la misma figura) el comportamiento es muchomas erratico, pero si observamos con atencion veremos que al final de la ejecucion la razonde individuos exitosos se aproxima tambien a estos valores. Se espera que el numero deindividuos exitosos sea menor en las versiones con archivo de individuos por la gananciaen la diversidad que se obtiene, implicando una menor velocidad de convergencia. Lo quees por lo menos curioso son los valores tan parecidos en este aspecto, dada la diversidadde funciones que se estan resolviendo.
Las graficas en las figuras 5.10 y 5.11 muestran que, como es de esperarse, el pesodel arbol es una medida de la dependencia de las variables. Observemos la diferencia enel comportamiento en las funciones separables en la primera figura (la media del peso semantiene en valores cercanos a 0 dentro del orden de 1E1) y en las no separables en lasegunda (la media del peso suele subir por encima de ese orden). Notemos que en funcionesseparables, en etapas avanzadas de la evolucion, la poblacion puede haber convergido demanera que exista correlacion entre las variables en sus individuos, por lo que el arboltendra un peso no despreciable. Observemos para esto las graficas (c) y (d) de la figura5.10 que en las ejecuciones no resueltas el peso del arbol fue creciendo mientras pasabanlas generaciones, cosa que no se observa en la funcion rastrigin (grafica (g) en la mismafigura) que aunque no hubo ejecuciones exitosas el peso se mantuvo estable hasta el final.Entonces para tomar el peso del arbol como una medida definitiva de dependencia setendra que combinar con una medida de la diversidad de la poblacion, como la entropıapor ejemplo; con el fin de tener en cuenta el estado de convergencia del algoritmo.
90
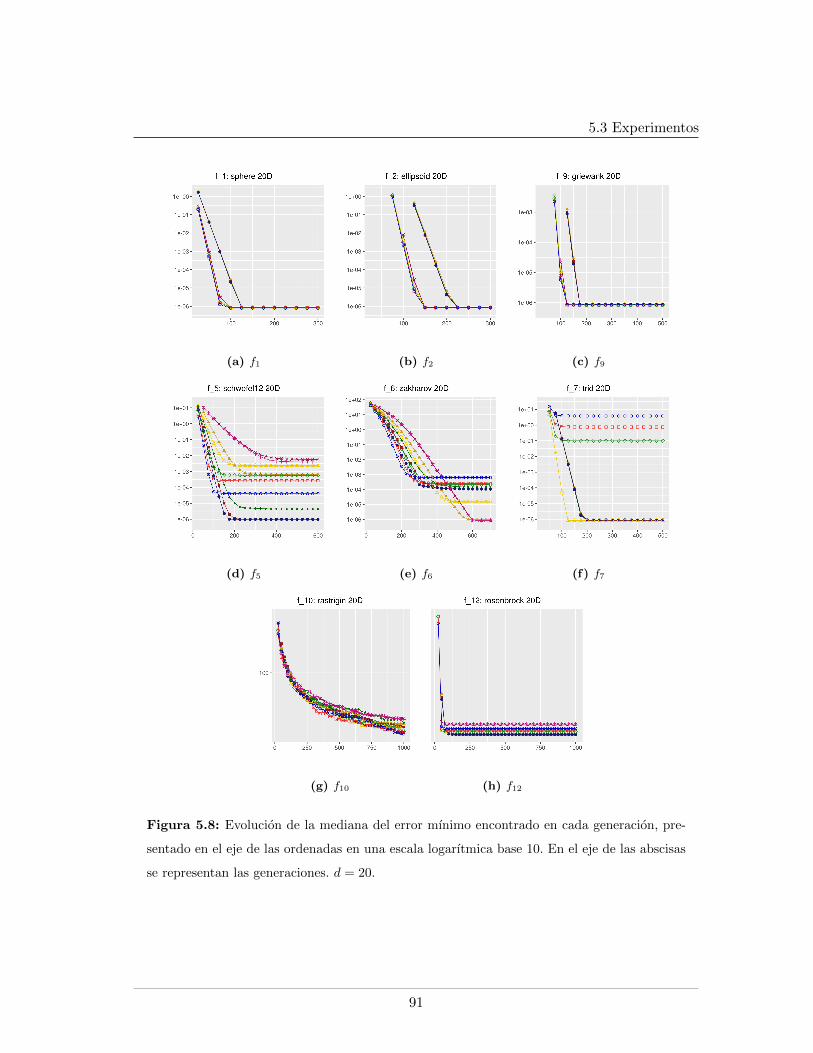
5.3 Experimentos
(a) f1 (b) f2 (c) f9
(d) f5 (e) f6 (f) f7
(g) f10 (h) f12
Figura 5.8: Evolucion de la mediana del error mınimo encontrado en cada generacion, pre-
sentado en el eje de las ordenadas en una escala logarıtmica base 10. En el eje de las abscisas
se representan las generaciones. d = 20.
91
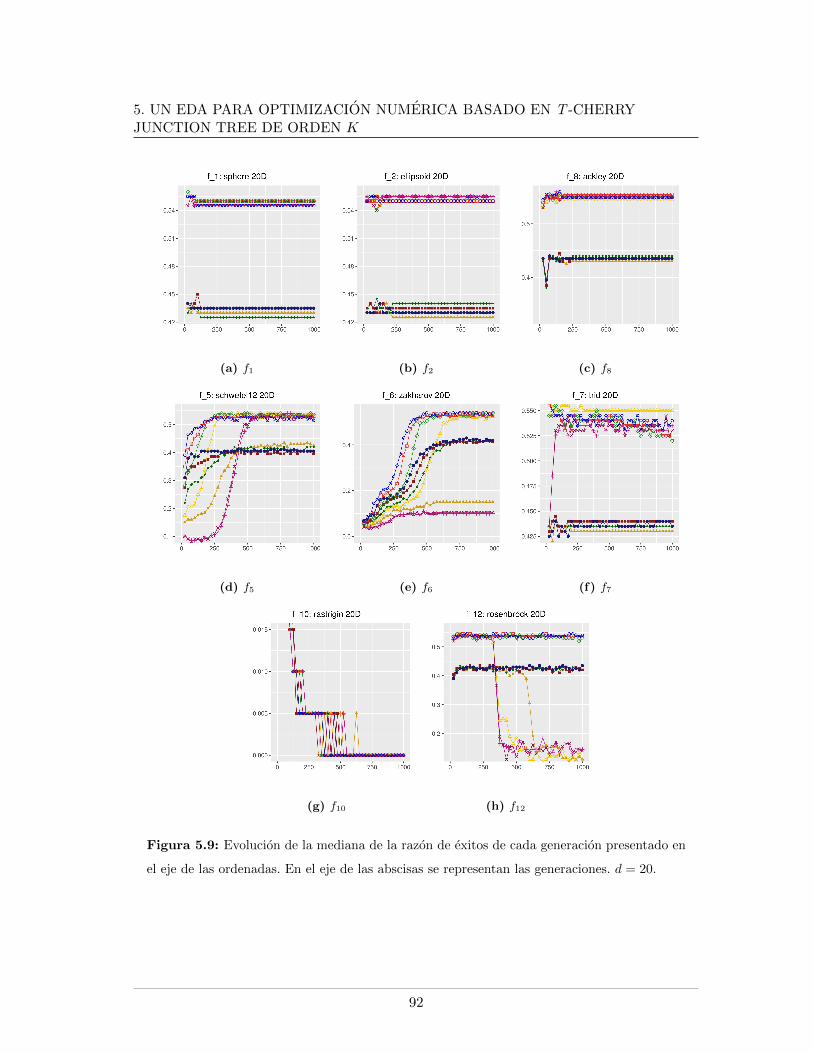
5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
(a) f1 (b) f2 (c) f8
(d) f5 (e) f6 (f) f7
(g) f10 (h) f12
Figura 5.9: Evolucion de la mediana de la razon de exitos de cada generacion presentado en
el eje de las ordenadas. En el eje de las abscisas se representan las generaciones. d = 20.
92
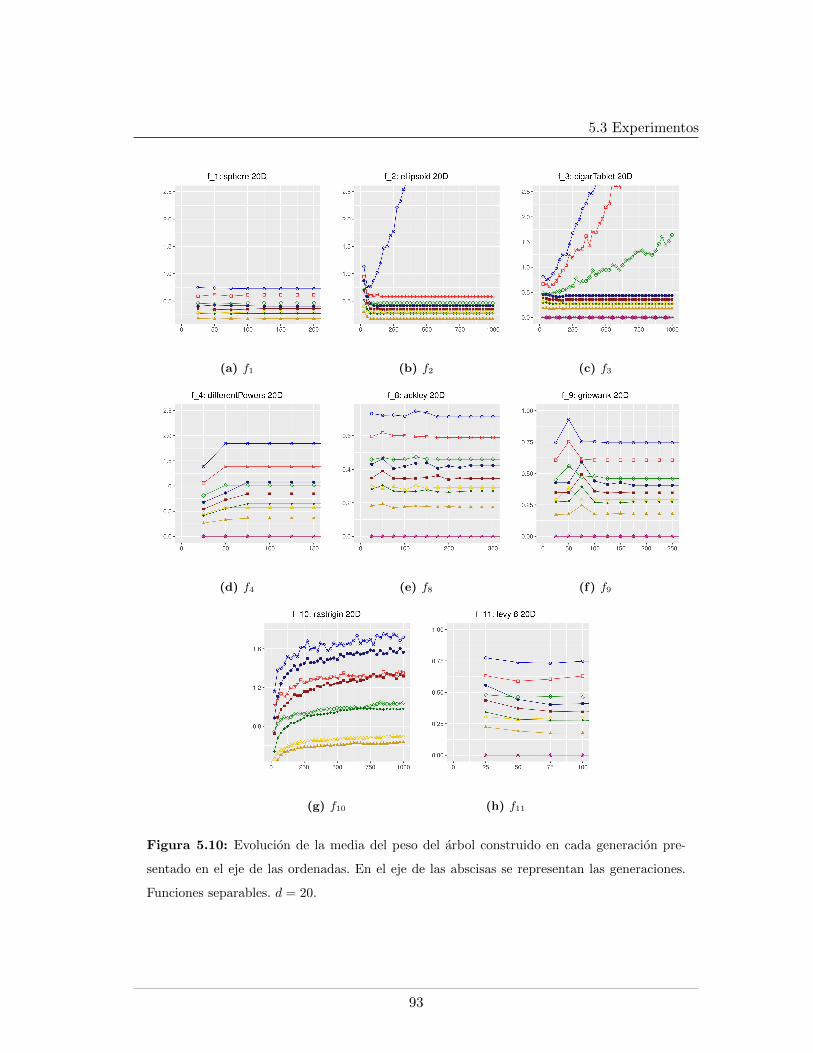
5.3 Experimentos
(a) f1 (b) f2 (c) f3
(d) f4 (e) f8 (f) f9
(g) f10 (h) f11
Figura 5.10: Evolucion de la media del peso del arbol construido en cada generacion pre-
sentado en el eje de las ordenadas. En el eje de las abscisas se representan las generaciones.
Funciones separables. d = 20.
93
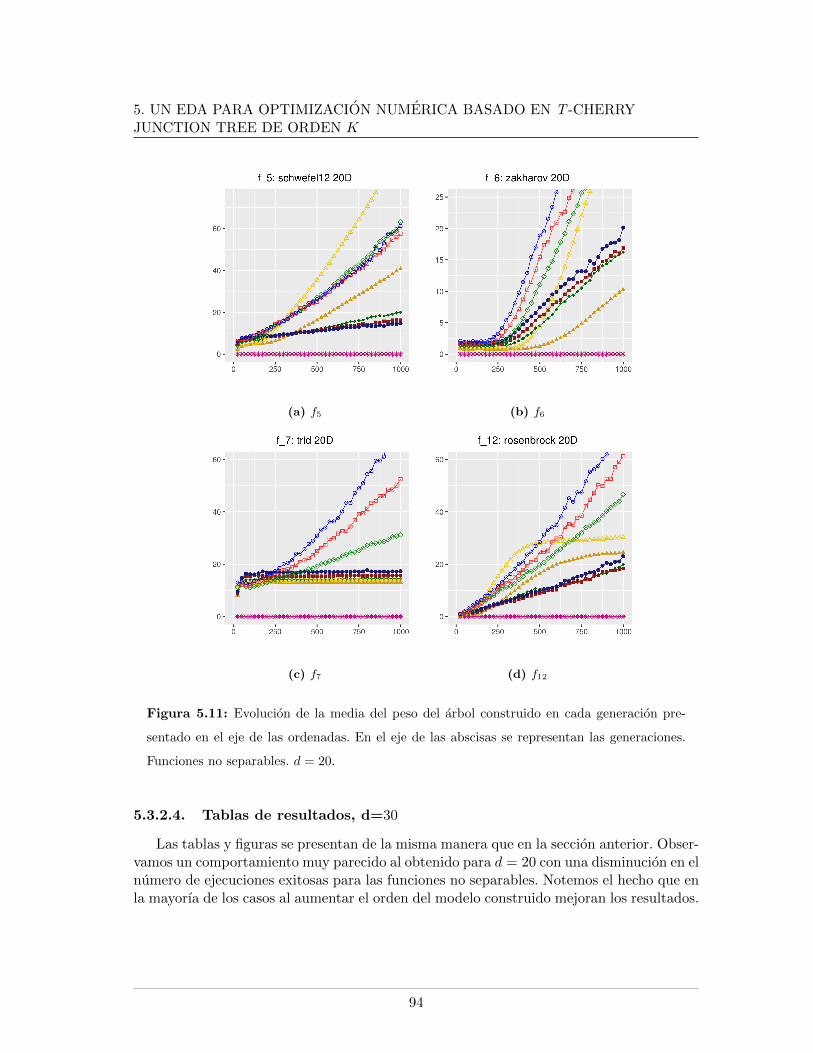
5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
(a) f5 (b) f6
(c) f7 (d) f12
Figura 5.11: Evolucion de la media del peso del arbol construido en cada generacion pre-
sentado en el eje de las ordenadas. En el eje de las abscisas se representan las generaciones.
Funciones no separables. d = 20.
5.3.2.4. Tablas de resultados, d=30
Las tablas y figuras se presentan de la misma manera que en la seccion anterior. Obser-vamos un comportamiento muy parecido al obtenido para d = 20 con una disminucion en elnumero de ejecuciones exitosas para las funciones no separables. Notemos el hecho que enla mayorıa de los casos al aumentar el orden del modelo construido mejoran los resultados.
94

5.3 Experimentos
Mencion aparte merece el comportamiento de los algoritmos en la funcion no separablef6 zakharov pues en dimension 20 se resolvio usando el UMDAcG y el Chow & Liu EDAc,y en dimension 30 se obtuvieron mejores resultados con los EDAs de modelo mas denso.
Con la tendencia observada de mejorıa en los resultados construyendo un modelo masdenso pero tomando en cuenta las excepciones que hemos mencionado podemos intuir quees importante definir una estrategia de adaptacion de k para el t-Cherry EDA. Esta sepodrıa definir en funcion del peso del arbol, la razon de individuos exitosos y la mejora enfitness.
UMDAcG Chow & Liu EDA2nc t-Cherry4 EDA2n t-Cherry6 EDA2n t-Cherry8 EDA2n
f1 8.706E-07 (1.08E-07) 9.082E-07 (1.00E-07) 9.192E-07 (9.43E-08) 9.057E-07 (1.06E-07) 8.946E-07 (1.02E-07)
3.15E+4 (3.24E+2) 100 4.78E+4 (4.15E+2) 100 4.75E+4 (4.01E+2) 100 4.73E+4 (3.78E+2) 100 4.70E+4 (3.87E+2) 100
f2 8.844E-07 (9.83E-08) 9.216E-07 (9.95E-08) 9.080E-07 (8.75E-08) 8.775E-07 (9.08E-08) 8.999E-07 (9.89E-08)
5.39E+4 (3.45E+2) 100 8.20E+4 (4.94E+2) 100 8.15E+4 (3.86E+2) 100 8.13E+4 (4.34E+2) 100 8.09E+4 (4.50E+2) 100
f3 8.579E-07 (1.02E-07) 9.162E-07 (8.37E-08) 8.935E-07 (9.38E-08) 9.046E-07 (8.24E-08) 8.952E-07 (1.11E-07)
4.78E+4 (3.23E+2) 100 7.29E+4 (4.12E+2) 100 7.24E+4 (4.01E+2) 100 7.21E+4 (4.24E+2) 100 7.17E+4 (4.21E+2) 100
f4 8.231E-07 (1.44E-07) 8.702E-07 (1.44E-07) 8.379E-07 (1.40E-07) 8.441E-07 (1.30E-07) 8.475E-07 (1.29E-07)
1.89E+4 (2.77E+2) 100 2.81E+4 (4.24E+2) 100 2.82E+4 (4.04E+2) 100 2.79E+4 (3.46E+2) 100 2.80E+4 (4.58E+2) 100
f5 1.274E-02 (7.71E-03) 4.096E-03 (6.71E-03) 8.129E-04 (8.12E-03) 2.779E-04 (6.24E-03) 1.012E-04 (3.60E-03)
3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (5.56E+4) 7.8 3.00E+5 (7.95E+4) 15.7
f6 2.437E-04 (8.56E-05) 1.186E-05 (5.26E-05) 1.977E-06 (8.38E-05) 6.732E-06 (6.11E-04) 4.617E-06 (3.27E-04)
3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (6.54E+3) 37.3 3.00E+5 (1.35E+4) 37.3 3.00E+5 (2.03E+4) 29.4
f7 1.572E+4 (1.74E+3) 8.894E-07 (1.09E-07) 8.992E-07 (1.01E-07) 9.331E-07 (2.97E-02) 8.744E-07 (4.78E+0)
3.00E+5 (0.00E+0) 7.43E+4 (4.46E+2) 100 7.38E+4 (5.58E+2) 100 7.36E+4 (3.17E+4) 98 7.32E+4 (8.73E+4) 82.4
f8 9.449E-07 (5.03E-08) 9.644E-07 (5.11E-08) 9.582E-07 (5.73E-08) 9.517E-07 (4.37E-08) 9.680E-07 (5.01E-08)
6.06E+4 (4.04E+2) 100 9.22E+4 (4.64E+2) 100 9.17E+4 (5.12E+2) 100 9.13E+4 (3.68E+2) 100 9.07E+4 (5.09E+2) 100
f9 9.031E-07 (9.74E-08) 9.009E-07 (9.44E-08) 8.867E-07 (9.48E-08) 8.855E-07 (9.96E-08) 9.258E-07 (8.39E-08)
4.29E+4 (3.53E+2) 100 6.48E+4 (5.29E+2) 100 6.47E+4 (3.59E+2) 100 6.45E+4 (5.56E+2) 100 6.42E+4 (4.68E+2) 100
f10 1.522E+2 (8.55E+0) 1.516E+2 (7.19E+0) 1.483E+2 (8.78E+0) 1.493E+2 (9.05E+0) 1.468E+2 (9.23E+0)
3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0)
f11 8.821E-07 (1.04E-07) 8.936E-07 (1.04E-07) 8.861E-07 (9.38E-08) 8.970E-07 (9.26E-08) 8.947E-07 (1.02E-07)
3.15E+4 (3.76E+2) 100 4.79E+4 (4.17E+2) 100 4.74E+4 (5.16E+2) 100 4.71E+4 (3.97E+2) 100 4.69E+4 (4.71E+2) 100
f12 2.795E+1 (4.95E-02) 2.731E+1 (1.91E-01) 2.740E+1 (1.87E-01) 2.733E+1 (1.79E-01) 2.736E+1 (2.56E-01)
3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0)
Tabla 5.6: Resultados obtenidos para d = 30 usando un archivo de individuos.
95

5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
UMDAcG Chow & Liu EDA2nc t-Cherry4 EDA2n t-Cherry6 EDA2n t-Cherry8 EDA2n
f1 8.861E-07 (1.19E-07) 9.041E-07 (1.17E-07) 8.665E-07 (1.16E-07) 8.760E-07 (1.03E-07) 8.601E-07 (1.09E-07)
3.15E+4 (3.18E+2) 100 3.06E+4 (3.55E+2) 100 3.03E+4 (2.96E+2) 100 3.01E+4 (3.37E+2) 100 2.99E+4 (2.81E+2) 100
f2 8.902E-07 (9.99E-08) 8.533E-07 (1.10E-07) 8.800E-07 (1.05E-07) 8.701E-07 (1.21E-07) 8.617E-07 (1.07E-07)
5.38E+4 (3.82E+2) 100 5.25E+4 (3.11E+2) 100 5.19E+4 (3.32E+2) 100 5.16E+4 (3.97E+2) 100 5.13E+4 (3.33E+2) 100
f3 8.757E-07 (9.21E-08) 8.993E-07 (1.02E-07) 8.705E-07 (1.14E-07) 8.770E-07 (3.53E-04) 9.038E-07 (2.03E-02)
4.78E+4 (3.53E+2) 100 4.65E+4 (3.54E+2) 100 4.62E+4 (3.38E+2) 100 4.57E+4 (3.56E+4) 98 4.54E+4 (3.56E+4) 98
f4 8.207E-07 (1.37E-07) 8.643E-07 (1.27E-07) 8.222E-07 (1.36E-07) 8.261E-07 (1.45E-07) 7.930E-07 (1.62E-07)
1.89E+4 (2.90E+2) 100 1.83E+4 (2.33E+2) 100 1.81E+4 (3.00E+2) 100 1.80E+4 (2.58E+2) 100 1.80E+4 (2.82E+2) 100
f5 1.302E-02 (1.08E-02) 1.177E-02 (2.43E-02) 3.196E-03 (1.27E-02) 2.298E-03 (1.29E-02) 2.634E-03 (2.57E-02)
3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (3.19E+4) 2 3.00E+5 (3.48E+4) 2
f6 2.454E-04 (8.65E-05) 1.743E-06 (5.46E-04) 1.492E-05 (3.55E-03) 2.889E-05 (1.47E-03) 5.155E-06 (1.39E-03)
3.00E+5 (0.00E+0) 3.00E+5 (1.04E+3) 9.8 3.00E+5 (1.10E+4) 17.6 3.00E+5 (2.43E+4) 25.5 3.00E+5 (3.29E+4) 33.3
f7 1.623E+4 (1.44E+3) 9.226E-07 (8.24E+1) 5.269E+0 (1.20E+2) 3.245E+1 (1.77E+2) 7.111E+1 (2.53E+2)
3.00E+5 (0.00E+0) 4.85E+4 (1.11E+5) 74.5 3.00E+5 (1.05E+5) 21.6 3.00E+5 (6.86E+4) 7.8 3.00E+5 (4.97E+4) 3.9
f8 9.470E-07 (5.36E-08) 9.387E-07 (6.39E-08) 9.213E-07 (6.62E-08) 9.607E-07 (6.19E-08) 9.235E-07 (4.81E-08)
6.05E+4 (3.74E+2) 100 5.91E+4 (3.77E+2) 100 5.85E+4 (3.65E+2) 100 5.79E+4 (3.54E+2) 100 5.76E+4 (3.08E+2) 100
f9 8.744E-07 (1.06E-07) 8.603E-07 (1.04E-07) 8.403E-07 (1.12E-07) 8.615E-07 (1.22E-07) 8.932E-07 (9.68E-08)
4.27E+4 (3.40E+2) 100 4.17E+4 (3.53E+2) 100 4.13E+4 (3.52E+2) 100 4.10E+4 (2.68E+2) 100 4.06E+4 (3.64E+2) 100
f10 1.510E+2 (9.18E+0) 1.513E+2 (1.09E+1) 1.492E+2 (8.11E+0) 1.516E+2 (9.31E+0) 1.501E+2 (1.31E+1)
3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0)
f11 8.654E-07 (9.95E-08) 9.005E-07 (9.35E-08) 8.747E-07 (9.62E-08) 8.851E-07 (8.23E-08) 8.342E-07 (1.13E-07)
3.15E+4 (3.06E+2) 100 3.07E+4 (3.21E+2) 100 3.03E+4 (3.31E+2) 100 3.00E+4 (2.41E+2) 100 2.98E+4 (3.01E+2) 100
f12 2.796E+1 (5.10E-02) 2.756E+1 (2.24E-01) 2.756E+1 (2.02E-01) 2.762E+1 (2.48E-01) 2.757E+1 (2.58E-01)
3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0) 3.00E+5 (0.00E+0)
Tabla 5.7: Resultados obtenidos para d = 30 sin archivo de individuos
Como en el caso d = 20, observamos que la version de t-Cherry EDA probada en esteexperimento con mejor resultado en la prueba de Wilcoxon Rank Sum es para k = 8, esdecir, para el modelo mas denso construido (vea la tabla 5.8). Sin embargo, si analizamosde manera global los resultados del experimento se fortalece el argumento de que k es unparametro fundamental en el rendimiento del algoritmo y que no siempre es mejor usarvalores grandes para k.
96
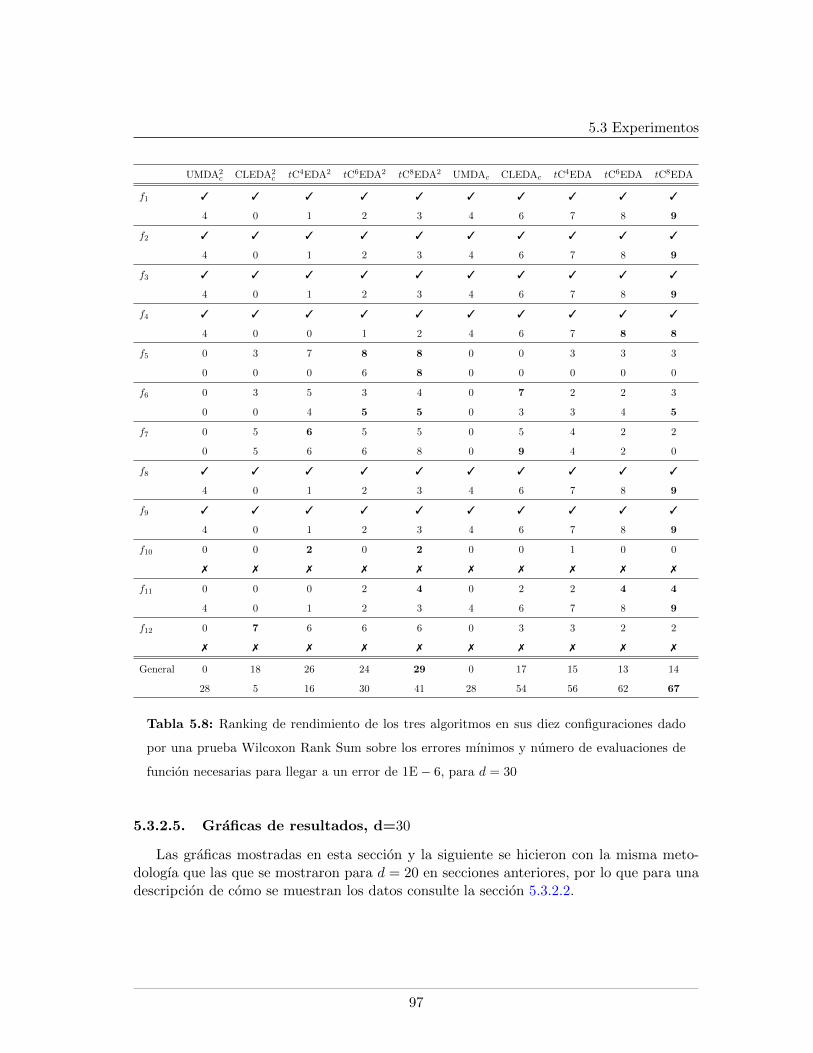
5.3 Experimentos
UMDA2c CLEDA2
c tC4EDA2 tC6EDA2 tC8EDA2 UMDAc CLEDAc tC4EDA tC6EDA tC8EDA
f1 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 4 6 7 8 9
f2 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 4 6 7 8 9
f3 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 4 6 7 8 9
f4 3 3 3 3 3 3 3 3 3 3
4 0 0 1 2 4 6 7 8 8
f5 0 3 7 8 8 0 0 3 3 3
0 0 0 6 8 0 0 0 0 0
f6 0 3 5 3 4 0 7 2 2 3
0 0 4 5 5 0 3 3 4 5
f7 0 5 6 5 5 0 5 4 2 2
0 5 6 6 8 0 9 4 2 0
f8 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 4 6 7 8 9
f9 3 3 3 3 3 3 3 3 3 3
4 0 1 2 3 4 6 7 8 9
f10 0 0 2 0 2 0 0 1 0 0
7 7 7 7 7 7 7 7 7 7
f11 0 0 0 2 4 0 2 2 4 4
4 0 1 2 3 4 6 7 8 9
f12 0 7 6 6 6 0 3 3 2 2
7 7 7 7 7 7 7 7 7 7
General 0 18 26 24 29 0 17 15 13 14
28 5 16 30 41 28 54 56 62 67
Tabla 5.8: Ranking de rendimiento de los tres algoritmos en sus diez configuraciones dado
por una prueba Wilcoxon Rank Sum sobre los errores mınimos y numero de evaluaciones de
funcion necesarias para llegar a un error de 1E− 6, para d = 30
5.3.2.5. Graficas de resultados, d=30
Las graficas mostradas en esta seccion y la siguiente se hicieron con la misma meto-dologıa que las que se mostraron para d = 20 en secciones anteriores, por lo que para unadescripcion de como se muestran los datos consulte la seccion 5.3.2.2.
97
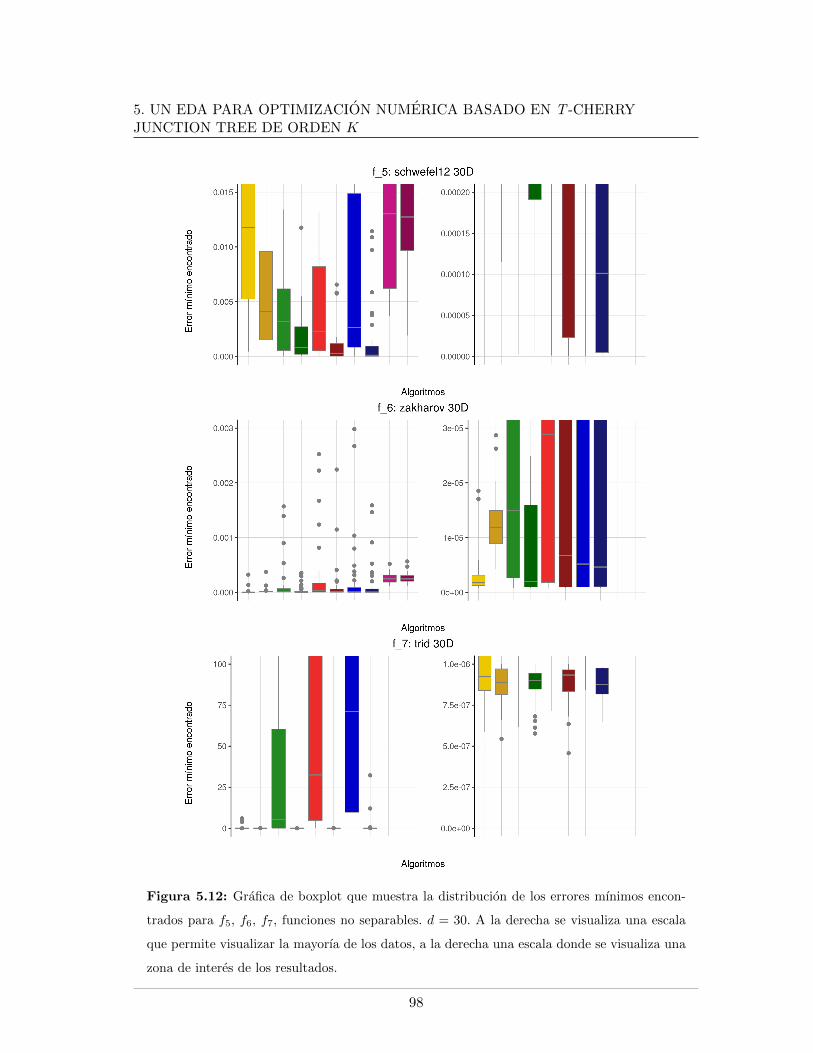
5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Figura 5.12: Grafica de boxplot que muestra la distribucion de los errores mınimos encon-
trados para f5, f6, f7, funciones no separables. d = 30. A la derecha se visualiza una escala
que permite visualizar la mayorıa de los datos, a la derecha una escala donde se visualiza una
zona de interes de los resultados.
98
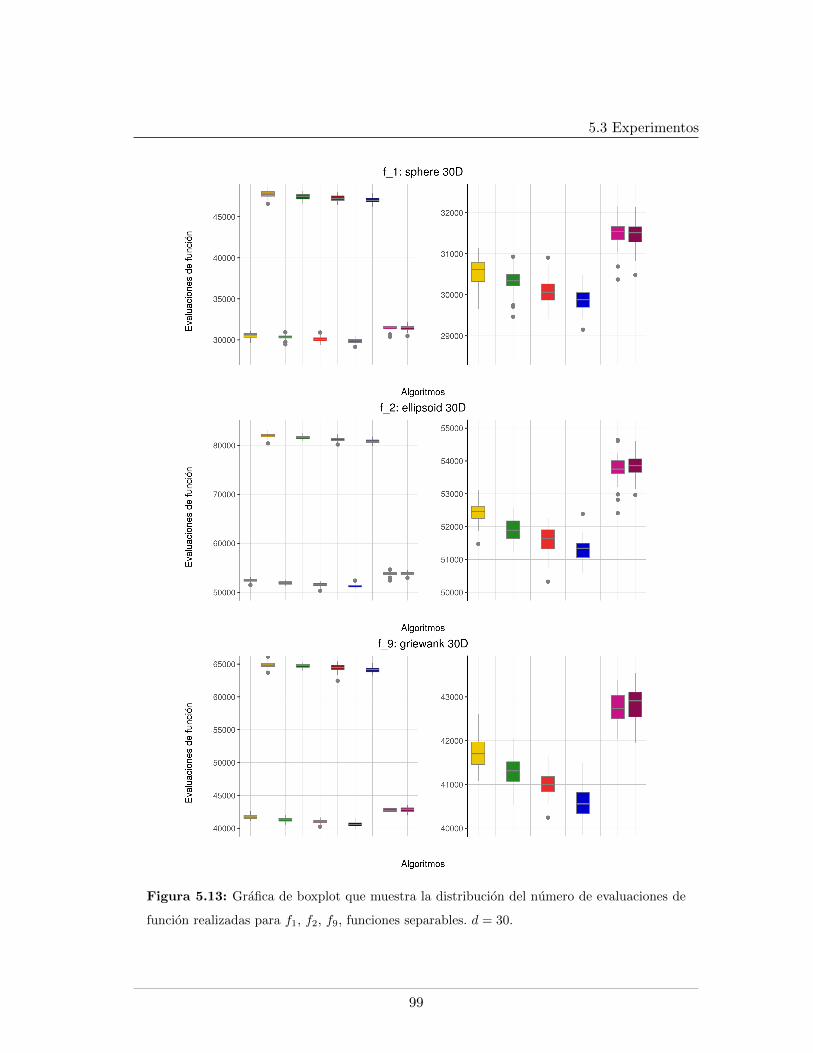
5.3 Experimentos
Figura 5.13: Grafica de boxplot que muestra la distribucion del numero de evaluaciones de
funcion realizadas para f1, f2, f9, funciones separables. d = 30.
99
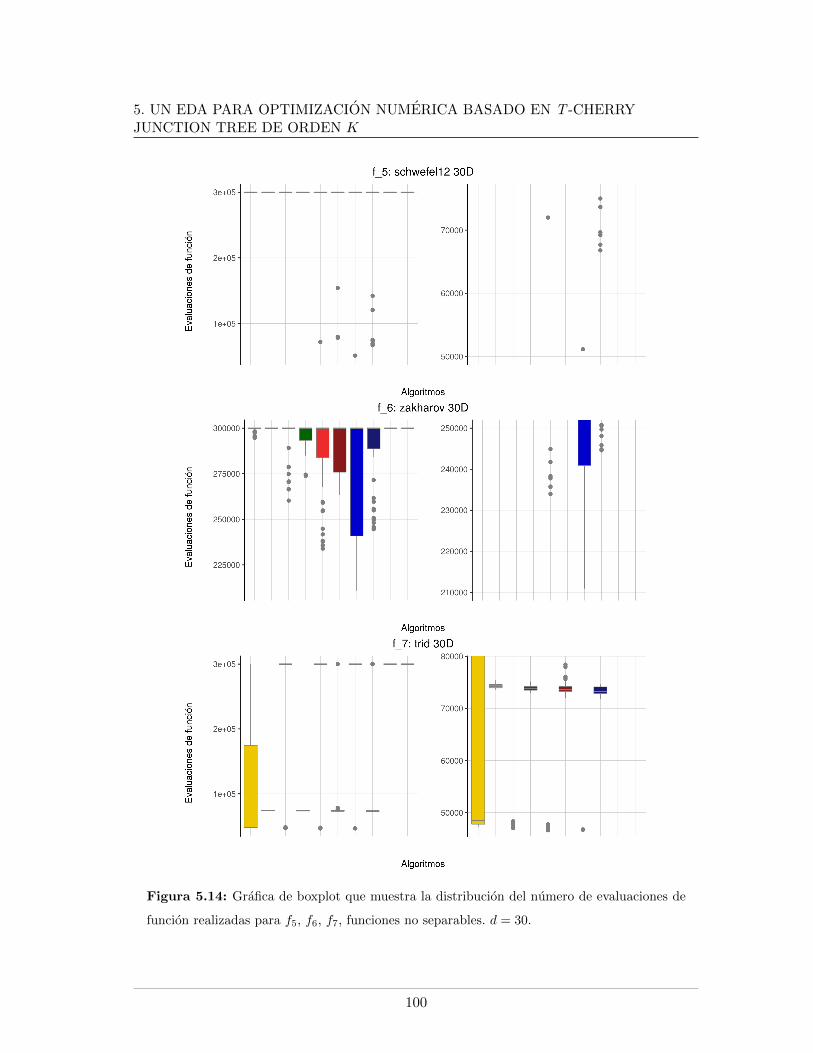
5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
Figura 5.14: Grafica de boxplot que muestra la distribucion del numero de evaluaciones de
funcion realizadas para f5, f6, f7, funciones no separables. d = 30.
100
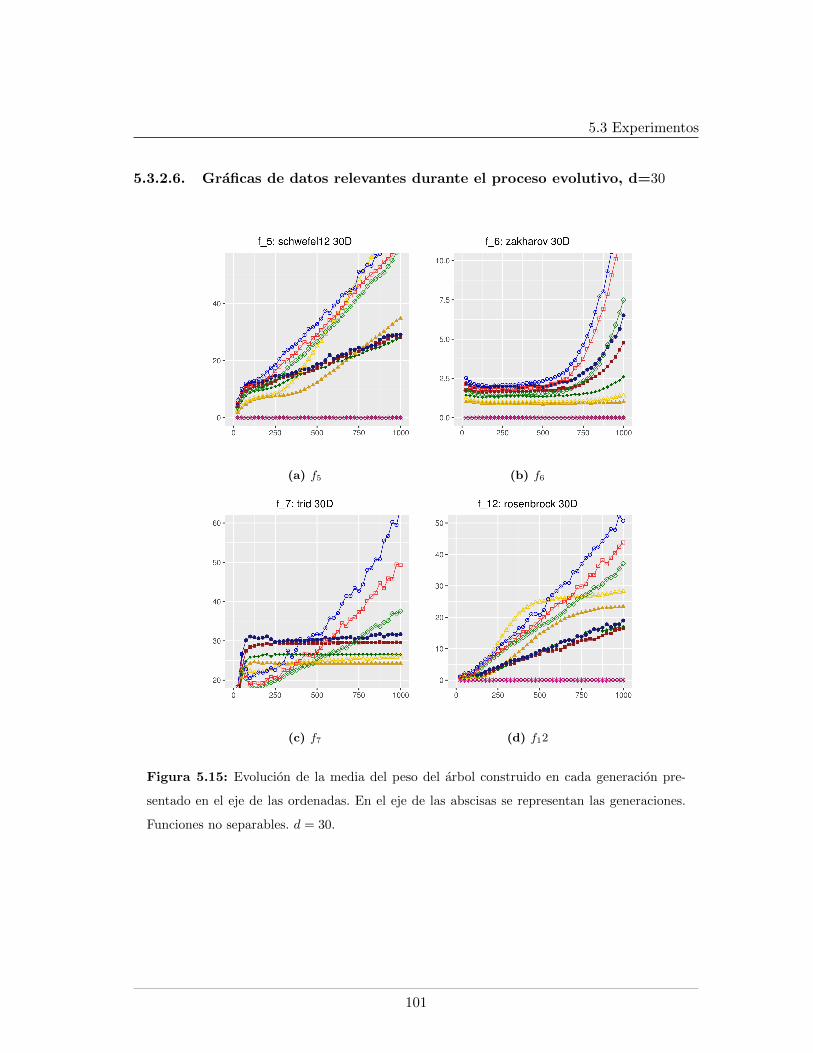
5.3 Experimentos
5.3.2.6. Graficas de datos relevantes durante el proceso evolutivo, d=30
(a) f5 (b) f6
(c) f7 (d) f12
Figura 5.15: Evolucion de la media del peso del arbol construido en cada generacion pre-
sentado en el eje de las ordenadas. En el eje de las abscisas se representan las generaciones.
Funciones no separables. d = 30.
101
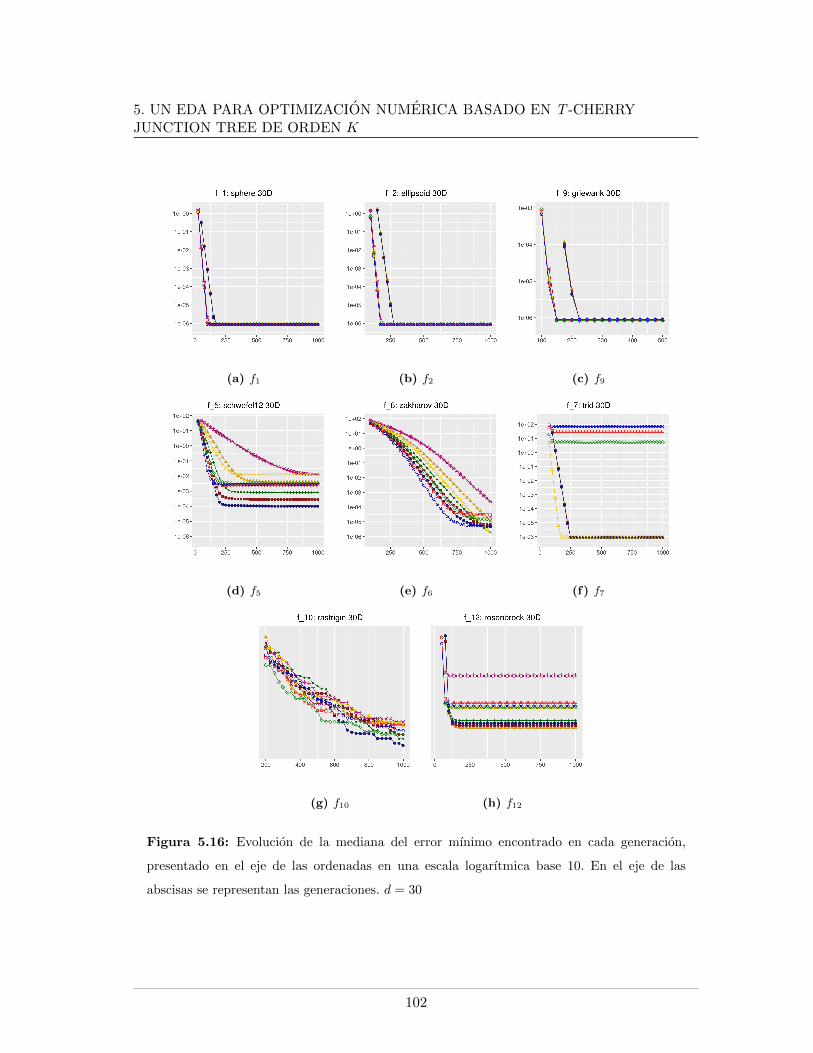
5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
(a) f1 (b) f2 (c) f9
(d) f5 (e) f6 (f) f7
(g) f10 (h) f12
Figura 5.16: Evolucion de la mediana del error mınimo encontrado en cada generacion,
presentado en el eje de las ordenadas en una escala logarıtmica base 10. En el eje de las
abscisas se representan las generaciones. d = 30
102
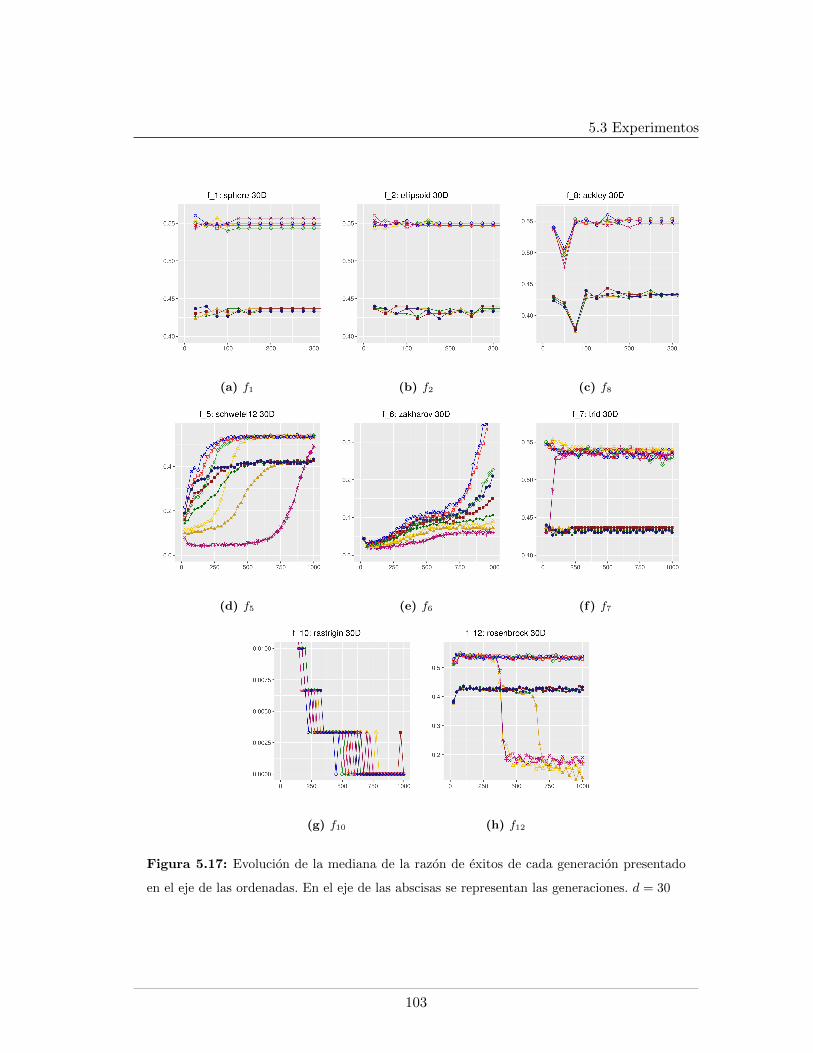
5.3 Experimentos
(a) f1 (b) f2 (c) f8
(d) f5 (e) f6 (f) f7
(g) f10 (h) f12
Figura 5.17: Evolucion de la mediana de la razon de exitos de cada generacion presentado
en el eje de las ordenadas. En el eje de las abscisas se representan las generaciones. d = 30
103
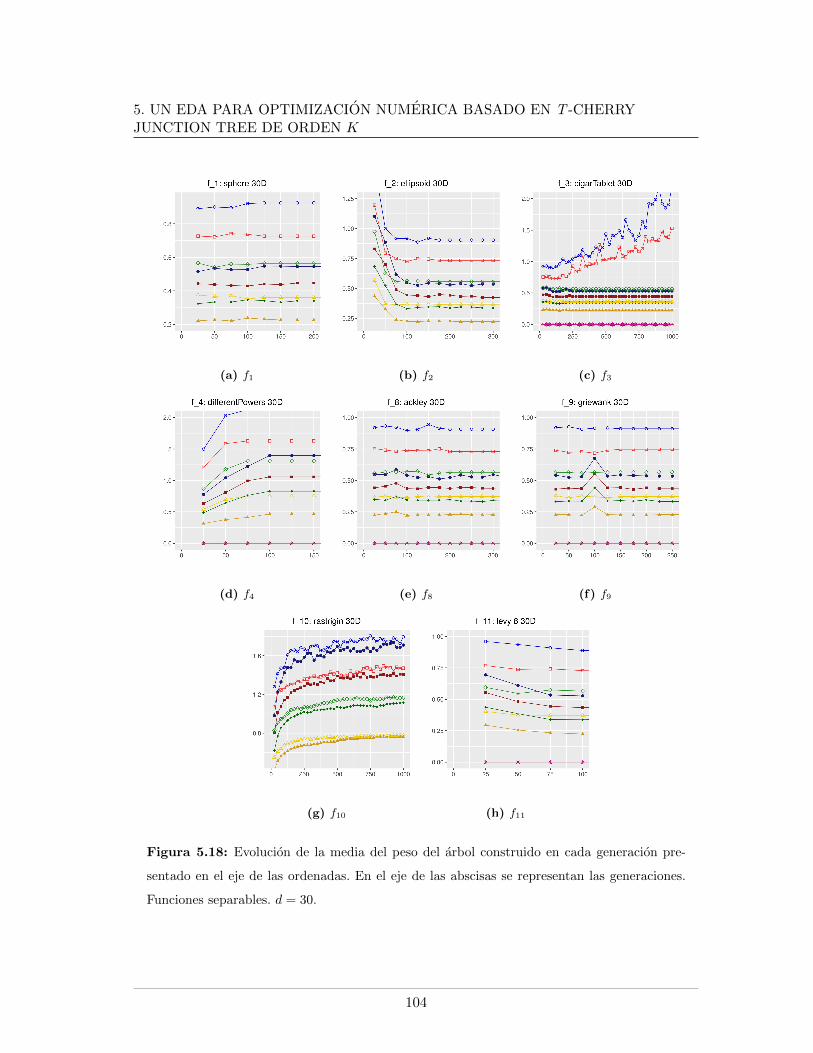
5. UN EDA PARA OPTIMIZACION NUMERICA BASADO EN T -CHERRYJUNCTION TREE DE ORDEN K
(a) f1 (b) f2 (c) f3
(d) f4 (e) f8 (f) f9
(g) f10 (h) f11
Figura 5.18: Evolucion de la media del peso del arbol construido en cada generacion pre-
sentado en el eje de las ordenadas. En el eje de las abscisas se representan las generaciones.
Funciones separables. d = 30.
104

Capıtulo 6
Conclusiones
Este trabajo busca proponer el uso de un PGM en MBEAs, que de manera factible per-mita la modelacion de las dependencias entre las variables del problema en una estructurade cierta densidad. Este modelo es el t-Cherry Junction Tree de orden k. Hemos logradosimplificar la ecuacion que mide la calidad en el ajuste del modelo usando una metricadiferente a la de los autores del algoritmo de construccion; de esta manera disminuimossu complejidad computacional en un orden de magnitud respecto a k, aportando tambienuna interpretacion de la expresion que mide el incremento en el ajuste.
Se busco tambien aplicar esta propuesta en un EDA que llamamos t-Cherry EDA.Se sometio a un analisis experimental con el fin de evaluar el rendimiento para distintosvalores de orden k en un benchmark de funciones comunmente usadas en la literatura.Los resultados de los experimentos muestran que el tomar en cuenta mas dependenciasmejora los resultados en funciones no separables siempre y cuando k tenga un valor ade-cuado conforme a sus caracterısticas de dependencia entre variables. Por ejemplo, en lafuncion f5 Schwefel todas las variables tienen dependencia entre sı, por lo que valores dek mas grandes dan mejores resultados. Por el contrario, en la funcion f7 Trid se observaque k = 2 suele dar buenos resultados, por lo que se puede intuir que en esta funcion haydependencias entre pares de variables. En el caso de las funciones separables el valor de kno parece tener un impacto significativo en el rendimiento, solo ocasionalmente en la ro-bustez debido a un posible sobreajuste y convergencia prematura en valores de k mayoresa 1.
Es por esto que a partir de los experimentos concluimos que el uso de este modelocontribuye a la mejora de resultados de los EDAs que usan modelos Gaussianos parafunciones no separables. Sin embargo, los resultados sugieren que el encontrar el valor dek adecuado a las caracterısticas de dependencia entre variables en el problema es necesariopara asegurar un buen rendimiento del algoritmo. En la practica una buena cantidad deproblemas que se abordan con los EAs son de BBO por lo que no tenemos el conocimiento
105

6. CONCLUSIONES
suficiente como para establecer un valor de k adecuado.En los mismos experimentos pudimos observar que el peso del arbol es una buena medidade dependencia entre variables siempre y cuando no nos encontremos en etapas avanzadasde convergencia. Esto ultimo se puede medir con la entropıa del mismo t-Cherry JunctionTree de orden k.Entonces este modelo nos permite al mismo tiempo tomar en cuenta de manera explıcitalas dependencias entre las variables del problema, tener metricas de esto (el peso del arbol)y de la diversidad en la poblacion (la entropıa del modelo). Ademas permitirıa obtenervectores de variables correlacionadas para operadores de mutacion. Son estas las razonespor las que concluimos que es un buen modelo a construir para MBEAs, y en los EAsque puedan necesitar de estas funcionalidades. Se profundiza un poco en estos temas enla siguiente seccion.
6.1. Trabajo futuro
Se pueden intuir un buen numero de aplicaciones del t-Cherry Junction Tree de ordenk y de la red Gaussiana obtenida desde este en EAs. Algunas de las ideas que fueronsaltando a la vista durante la realizacion de este trabajo se enuncian a continuacion.
6.1.1. Uso del t-Cherry Junction Tree de orden k en Algoritmos Evolu-
tivos
En los MBEAs de optimizacion global continua que encuentran los parametros de unaMVND (vector de medias y matriz de covarianzas) se puede sustituir esta con la GNobtenida desde un t-Cherry Junction Tree de orden k (ver seccion 5.1). Bajo esta ideapodemos considerar que el t-Cherry EDA es el algoritmo resultante de sustituir la MVNDen el EMNA.
Se puede usar la misma idea en los algoritmos que encuentran el vector de medias ymatriz de covarianzas para una MVND de manera que se aproxime de manera optima ala distribucion Boltzmann de los individuos seleccionados, como lo son el BEMNA (35)y el BGEDA (5). La entrada del algoritmo de construccion del t-Cherry Junction Treede orden k serıa la matriz de correlacion calculada desde la matriz de covarianzas de laaproximacion. Es importante senalar que al sustituir la MVND por una GN construidacon la metodologıa usada en este trabajo ya no estamos haciendo uso de la distribucion deaproximacion optima, si no de una obtenida desde de esta, por lo que de manera estrictala idea de aproximacion a la Boltzmann se rompe.
Es preciso tambien senalar que la matriz de precision de la GN se puede obtener demanera eficiente, y es rala de manera inversamente proporcional a k, por lo puede ser util
106

6.1 Trabajo futuro
en dimensionalidades grandes. Los vectores propios de esta matriz son iguales a los de lamatriz de covarianzas de la MVND representada en la GN. Uno de los posibles usos deesto es la rotacion del sistema de coordenadas del problema para aliviar dependencia entrevariables, como se usa en el CoBiDE (43).
Tambien se puede construir un t-Cherry Junction Tree de orden k desde la poblacionseleccionada de EAs que tengan operadores de cruza, de manera que se cruce intercam-biando bloques completos de variables definidos por los clusters en el arbol. Esto con elfin de conservar juntas las variables que tienen dependencia entre ellas.
6.1.2. t-Cherry EDA
Tambien surgieron varias ideas para mejorar el t-Cherry EDA, el cual forma partedel segundo objetivo de este trabajo. Al respecto consideramos que la investigacion puedecontinuar en los siguientes temas:
Busqueda de mejores parametros. Los valores para los parametros k, h, n usadosen este trabajo se escogieron de forma ingenua con el fin de no sesgar de maneraintencional los resultados hacia alguna version del algoritmo, por lo que es posibleque existan otros valores para estos parametros que mejoren el rendimiento en losdiversos tipos de problemas.
Adopcion de otra estrategia de reemplazo. Recordemos en el t-Cherry EDA se im-plemento la estrategia de reemplazo plus-selection µ/ρ + λ (ver seccion 2.2.2) conµ = λ = n y ρ = n+ hn. Se puede entonces buscar valores adecuados tambien paraµ, ρ, λ.
La eleccion de un valor adecuado para el parametro k. Esto es crıtico pues tieneuna influencia importante en el rendimiento del algoritmo al definir la densidad dela Red Gaussiana que se construye, ası como en su tiempo de ejecucion ya que lacomplejidad computacional de la construccion del modelo esta en funcion de esteparametro (ecuacion 4.15). Es por ello que se puede disenar una estrategia para suadaptacion en funcion del peso del arbol como medida de dependencia y calidad deajuste, de la entropıa del modelo construido como medida de diversidad, y de lamejora en el fitness. Ası se podrıa obtener una version del algoritmo adaptable alas propiedades de dependencia del problema a optimizar y con pocos parametros:h, n y de manera opcional λ, µ, ρ. Una segunda idea de adaptacion de la densidad delmodelo es usar estrategias de penalizacion al momento de calcular las actualizacionespotenciales durante el Order Update Process de manera que, si el incremento en elpeso de la mejor actualizacion potencial en la cola de prioridad es menor a la medidade penalizacion, detenemos el algoritmo. Podemos usar estrategias de penalizacionya existentes en la literatura como las revisadas en la seccion 3.2.4.1.1, por ejemplola Penalized Maximum Likelihood (ver ecuacion 3.17).
107

6. CONCLUSIONES
Implementacion de un operador de mutacion. En las graficas de los datos relevantesdurante el proceso evolutivo se observa que el algoritmo converge en etapas tem-pranas de la ejecucion, y el uso de un archivo de individuos, aunque mejora losresultados, no retrasa la convergencia de manera significativa. Es por ello que puedeimplementarse un operador de mutacion como el que esta definido en Evolucion Di-ferencial o en las ESs. De manera breve, la idea es que en la operacion de generacionde individuos, con cierta probabilidad, aplicar sobre un individuo qt−1 una mutacionusando al recien simulado q′.x como un vector de mutacion; obteniendo un nuevoindividuo qtoffs de la siguiente manera:
qtoffs.x← qtrand2 .x + F (qtrand1 .x− qoffs.x)
Donde F es un nuevo parametro que indica el tamano de paso y para el cual existenya en la literatura una vasta cantidad de trabajos para su adaptacion durante elproceso evolutivo. La ventaja de hacerlo de esta manera es que se construirıa soloun modelo para la generacion de nuevos individuos y para las mutaciones.
108

Apendice A
Teorıa de la informacion
En este apendice se hace un breve repaso sobre conceptos de teorıa de la informacionque se usan en el desarrollo de este trabajo. Se definen algunos conceptos para variablesaleatorias por razones de simplicidad, omitiendo su definicion para vectores aleatorios.
A.1. Contenido de informacion de una variable aleatoria
Dada una variable aleatoria X con cierta funcion de masa de probabilidad P (x), elcontenido de informacion sobre X que nos da una observacion x es
IX(x) = log1
P (x)(A.1)
La base del logaritmo se suele escoger dependiendo de las unidades de informacion quequeramos medir. De manera intuitiva, una observacion con poca probabilidad nos da masinformacion que una que es mas probable que aparezca.
A.2. Entropıa
Sea X una variable aleatoria discreta y P (x) su funcion de masa de probabilidad.Entonces la entropıa de Shannon se define como la esperanza del contenido de informacionde la variable aleatoria:
H(X) = −∑x
P (x) logP (x) (A.2)
Entre mas alta la entropıa, mayor es la incertidumbre sobre los r distintos valores quepuede tomar X. En el caso de que todos los valores tengan la misma probabilidad 1
r deocurrir la entropıa es maxima.
109

A. TEORIA DE LA INFORMACION
La entropıa de variables aleatorias discretas se tambien se puede interpretar como unamedida no negativa de la incertidumbre de una fuente de informacion estocastica.
Es tambien util definir el valor esperado del contenido de informacion de la varia-ble aleatoria X una vez que tenemos conocimiento sobre la variable Y como la entropıacondicional de X dada Y
H(X|Y ) = −∑x,y
P (x, y) logP (x, y)
P (y)(A.3)
A.2.1. Entropıa diferencial
Es una expresion propuesta desde la definicion A.2 pensando en que serıa su analo-ga para distribuciones de variables continuas. Sea entonces X una variable aleatoria denaturaleza continua y f(x) su funcion de densidad, entonces su entropıa diferencial es
h(X) = −∫xf(x) log f(x)dx (A.4)
Despues se comprobo que esta no conserva algunas de las interpretaciones y propiedadesimportantes de la entropıa de Shannon, por ejemplo la entropıa diferencial no es no nega-tiva. Sin embargo, en la literatura de MBEA se ha usado la entropıa diferencial Gaussianaen las medidas de calidad de ajuste de los modelos. La entropıa diferencial de una variablealeatoria Gaussiana X esta definida como:
h(X) =1
2ln 2πeσ2 (A.5)
A.2.2. Divergencia de Kullback-Leibler
La KLD o entropıa relativa es una medida de la diferencia entre dos distribuciones deprobabilidad. Es asimetrica y generalmente se usa para medir el ajuste o aproximacionde cierto modelo a la distribucion de un conjunto de datos o a una distribucion teorica.Se establece entonces que P (x) es la funcion de masa de probabilidad a aproximar y queQ(x) es la funcion de masa de probabilidad del modelo o aproximacion.
Para variables discretas se define como:
DKL(P (x), Q(x)) =∑x
P (x) logP (x)
Q(x)(A.6)
Y para variables continuas se define de manera analoga, siendo f(x) y g(x) funciones dedensidad de una variable aleatoria continua X:
DKL(f(x), g(x)) =
∫xf(x) log
f(x)
g(x)(A.7)
110

A.3 Informacion Mutua
A.3. Informacion Mutua
La informacion mutua es una medida de la reduccion de incertidumbre sobre unavariable aleatoria X dado que tenemos conocimiento de otra variable Y . Es decir, mideque tanto nos dice Y sobre X. Se define entonces como la KLD entre la JPMF P (x, y) deX y Y y la JPMF de ambas P (x)P (y) suponiendo que son independientes :
I(X;Y ) =∑x
∑y
P (x, y) logP (x, y)
P (x)P (y)(A.8)
Usando la descripcion en el parrafo anterior se puede definir de manera intuitiva a lainformacion mutua en funcion de entropıas como
I(X;Y ) = H(X)−H(X|Y ) (A.9)
Es importante mencionar que a diferencia de la entropıa y la entropıa diferencial, al definirla informacion mutua para variables aleatorias continuas de manera analoga como
I(X;Y ) =
∫x
∫yf(x, y) log
f(x, y)
f(x)f(y)(A.10)
esta conserva sus propiedades y se puede interpretar de la misma manera. Para el caso devariables Gaussianas haciendo el desarrollo se llega a la definicion siguiente:
I(X,Y ) = −1
2ln(1− ρ2
XY ) (A.11)
Esta ultima se usa para construir arboles de Chow & Liu sobre variables Gaussianas.Tambien se ha revisado en este trabajo el algoritmo para construir un polytree sobrevariables Gaussianas, por lo que es util definir la informacion mutua condicional como
I(X,Y | Z) =1
2log
σ2Xσ
2Y σ
2Z(1− ρ2
XZ)(1− ρ2Y Z)
detΣXY Z(A.12)
donde ΣXY Z es la matriz de covarianzas de las tres variables y ρXY es la correlacion entreX y Y .
Se han propuesto algunas generalizaciones de la informacion mutua para distribucio-nes multivariadas. En este trabajo se adopta la TC (44), la cual es una medida de ladependencia entre dos o mas variables aleatorias. De manera mas formal, para un con-junto de d variables aleatorias X1, X2, . . . , Xd contenidas en un vector aleatorio X lacorrelacion total I(X) esta definida como la KLD de la distribucion conjunta con JPMFP (x) y la distribucion suponiendo que todas las variables son independientes entre sı, conP (x1)P (x2) . . . P (xd)
I(X) =∑x1
∑x2
· · ·∑xd
P (x) logP (x)
P (x1)P (x2) . . . P (xd)(A.13)
111

A. TEORIA DE LA INFORMACION
Este concepto es importante en este trabajo pues esta presente en el unico termino quedepende de la estructura del PGM en la KLD de una distribucion y su aproximacion me-diante un Junction Tree (ver ecuacion 4.2).
En el caso continuo se define de manera analoga, solo usando integrales en lugar desumas. En el caso especıfico de la TC Gaussiana, haciendo el desarrollo se llega a lasiguiente expresion
I(X) = −1
2ln det ρX (A.14)
donde ρX es la matriz de correlacion. Aquı es importante notar que esta medida esta enfuncion del determinante de la matriz de correlacion, cuya interpretacion se describe acontinuacion:
Sea X ∈ IRd un vector aleatorio cuya distribucion es una MVND y Q un conjunto de Nobservaciones x ∈ IRd del mismo. Si estandarizamos las variables aleatorias (y por tanto susobservaciones tambien) el volumen ocupado por los puntos x en el espacio d-dimensionalesta dado por det ρX. Si todas las variables en X son independientes, el espacio ocupadoes una esfera cuyo volumen es de 1. Si hay correlacion en alguna medida, el espacio esocupado es una elipsoide cuyo volumen es ≤ 1, tendiendo a 0 mientras la correlacion entrealgunas de las variables sea mas fuerte.
112

Apendice B
Algoritmos sobre grafos
A continuacion se hace una breve explicacion de los algoritmos sobre grafos que seusaron en este trabajo. Con el fin de ejemplificarlos se usara el grafo mostrado en la figuraB.1. Para una revision mas extensa el lector es remitido a la referencia (14).
1
3
2
6
4
5
7
0.20.1
0.8
0.2
0.5
0.22
0.3
0.750.01
Figura B.1: Ejemplo de un grafo no dirigido con pesos en las aristas
B.1. Recorrido en amplitud
El Recorrido en amplitud, del termino en ingles Breadth-First Search (BFS) es unalgoritmo que recorre el grafo visitando cada vez todos los vecinos no visitados de unvertice dado Va, repitiendo esta operacion para todos los vertices en orden de visita. Siempezamos desde un vertice raız Vr, entonces los siguientes en ser visitados seran todos
113

B. ALGORITMOS SOBRE GRAFOS
los vecinos de Vr. Despues se visitan todos los vecinos no visitados de los vecinos de Vr,y ası sucesivamente. Se suele implementar con una cola de vertices, donde por cada Vaque sale de la cola se insertan sus vecinos no visitados. Entonces, comenzamos con la colavacıa, donde se inserta Vr. Lo sacamos e insertamos sus vecinos. Sacamos el primer vecinoe insertamos los vecinos de este no visitados. Repetimos esto hasta haber terminado contodos los vertices. El algoritmo 15 describe su implementacion.
Algorithm 15 Pseudocodigo de implementacion de un BFS
1: procedure BFS(G(V,E), Vr)
2: q ← ∅
3: q.push(Vr)
4: while |q| > 0 do
5: Va ← q.pop()
6: for all Vn ← vecino no visitado de Va do
7: q.push(Vn)
8: end for
9: end while
10: end procedure
Por ejemplo, un BFS sobre el grafo en la figura B.1 tomando el vertice 4 como Vrse puede representar como (4); 4 ← (2, 3, 1); 2 ← (3, 1, 7, 5); 3 ← (1, 7, 5); 1 ← (7, 5); 7 ←(5, 6); 5← (6); 6, dando como resultado un orden de visita 4, 3, 2, 1, 7, 5, 6
B.2. Recorrido en profundidad
El DFS es un algoritmo que recorre el grafo visitando un vertice Va a la vez. Si elVa tiene vecinos no visitados, se visita cada uno de estos a la vez siendo ahora estos Va,por lo que esta operacion se aplica de forma recursiva. Cuando Va no tiene vecinos novisitados, se regresa hasta el ultimo Va en la pila de llamadas recursivas que tiene vecinosaun sin visitar, para continuar allı. A esta operacion se le llama backtracking. Podemoscomenzar a hacer las llamadas recursivas desde un nodo raız Vr. El algoritmo 16 describesu implementacion.
114

B.3 Arbol de Expansion de Peso Maximo
Algorithm 16 Pseudocodigo de implementacion de un DFS
1: procedure DFS(G(V,E), Va)
2: for all Vn ← vecino no visitado de Va do
3: DFS(G(V,E), Vn)
4: end for
5: end procedure
Por ejemplo, un DFS sobre el grafo en la figura B.1 tomando el vertice 5 como Vr sepuede representar como 5 → 2 → 7 → 6 − backtrack − 5 → 3 → 1 → 4, dando comoresultado un orden de visita 5, 2, 7, 6, 3, 1, 4.
B.3. Arbol de Expansion de Peso Maximo
Observemos el grafo G(V,E) en la figura B.1. Es un grafo no dirigido, conectado y conpesos en las aristas. Queremos encontrar un subconjunto de las aristas E′ ∈ E de maneraque el grafo G(V,E′) este aun conectado y la suma de los pesos en las aristas sea maximo.Entonces el grafo G(V,E′) serıa un MWST del grafo original.
Se usa en este trabajo el algoritmo de kruskal (descrito en el algoritmo 17) para encon-trar el MWST de un grafo conectado, no dirigido y con pesos en las aristas. Este consisteen comenzar con un grafo sin aristas, e ir agregando aquellas de peso maximo siempre ycuando no se formen ciclos. Se pueden usar estructuras de datos de manejo eficiente, comouna cola de prioridad para ordenar las aristas usando su peso como valor de prioridad yun Union-Find disjoint set para verificar si se forman ciclos.
115

B. ALGORITMOS SOBRE GRAFOS
Algorithm 17 Pseudocodigo de implementacion del algoritmo de Kruskal para encontrar
un MWST
1: procedure MWST(G(V,E))
2: E′ ← ∅
3: pq ← ∅
4: for all Ea ∈ E do
5: pq.push(Ea)
6: end for
7: for all Ea ∈ E do
8: if No se forma un ciclo then
9: E′ ← Ea
10: end if
11: end forreturn G(V,E′)
12: end procedure
1
3
2
6
4
5
7
0.2
0.8
0.5
0.22
0.3
0.75
Figura B.2: MWST del grafo mostrado en la figura B.1
116

Siglas
ACO Optimizacion por colonia de hormigas, del termino en ingles Ant Colony Optimi-zation. 7
BBO optimizacion de caja negra, del termino en ingles Black Box Optimization. 2, 6, 105
BFS Recorrido en amplitud, del termino en ingles Breadth-First Search. 113, 114
BN Red Bayesiana, del termino en ingles Bayesian Network. 23, 32, 79
DAG Grafo Dirigido Acıclico, del termino en ingles Directed Acyclic Graph. 21–23, 25–27,29, 33, 38, 39, 74–76
DFS Recorrido en profundidad, del termino en ingles Depth-First Search. 25, 32, 38, 59,63, 64, 67, 74, 76, 114, 115
EA Algoritmos Evolutivos, del termino en ingles Evolutionary Algorithm. 2, 4, 5, 7, 14,29, 105–107
EDA Algoritmo de Estimacion de Distribucion, del termino en ingles Estimation of Dis-tribution Algorithm. 8, 9, 11, 13, 14, 21, 22, 24, 28, 29, 33, 38–40, 43, 73, 77, 82, 95,105
ES Estrategias Evolutivas, del termino en ingles Evolutionary Strategies. 7, 9, 11, 14–17,108
GA Algoritmo Genetico, del termino en ingles Genetic Algorithm. 5–7, 11, 12
GN Red Gaussiana, del termino en ingles Gaussian Network. 26, 27, 30, 48, 73–77, 79,106
JDF Funcion de Densidad Conjunta, del termino en ingles Joint Density Function. 24,26, 27
117

Siglas
JPMF Funcion de Masa de Probabilidad Conjunta, del termino en ingles Joint Probabi-lity Mass Function. 22–24, 30, 33, 51, 111
KLD Divergencia de Kullback-Leibler, del termino en ingles Kullback-Leibler Divergence.30, 35–37, 51, 53, 56, 110–112
MBEA Algoritmo Evolutivo basado en Modelo, del termino en ingles Model Based Evo-lutionary Algorithm. 7–9, 11, 19, 48, 70, 73, 105, 106, 110
MN Red de Markov, del termino en ingles Markov Network. 27, 28, 32, 47, 48, 60, 67,73–77
MVND Distribucion Normal Multivariada, del termino en ingles Multivariate NormalDistribution. 24, 26, 27, 36, 38, 40, 41, 43, 70, 71, 73, 106, 112
MWST Arbol de Expansion de Peso Maximo, del termino en ingles Maximum WeightSpanning Tree. 31, 37, 46, 115, 116
PGM Modelo Grafico Probabilıstico, del termino en ingles Probabilistic Graphical Model.21–23, 25, 27–31, 33, 38, 39, 43, 46, 48, 51, 55, 58, 73, 75, 105, 112
PLS Muestreo Logico Probabilıstico, del termino en ingles Probabilistic Logic Sampling.31, 32, 36, 79
PSO Optimizacion por enjambre de partıculas, del termino en ingles Particle SwarmOptimization. 7
TC Correlacion Total, del termino en ingles Total Correlation. 52, 53, 56, 58, 63, 70, 71,74, 111, 112
118

Bibliografıa
[1] Bck, T., Foussette, C., and Krause, P. (2013). Contemporary Evolution Strategies.Springer Publishing Company, Incorporated. 7
[2] Bukszar, J. (2001). Upper bounds for the probability of a union by multitrees. Adv.in Appl. Probab., 33(2):437–452. xv, 48, 49
[3] Bukszar, J. and Prekopa, A. (2001). Probability bounds with cherry trees. Mathematicsof Operations Research, 26(1):174–192. 43, 45
[4] Back, T., Foussette, C., and Krause, P. (2013). Contemporary Evolution Strategies.Springer Publishing Company, Incorporated. 14, 16, 17
[5] Cai, Y., Sun, X., and Jia, P. (2006). Probabilistic modeling for continuous eda withboltzmann selection and kullback-leibeler divergence. GECCO 2006 - Genetic and Evo-lutionary Computation Conference, 1:389–396. 106
[6] Chickering, D. M., Geiger, D., and Heckerman, D. (2000). Learning bayesian networks:Search methods and experimental results. In IEEE Transanctions Pattern Anal. Mach.Intell. 31
[7] Chow, C. and Liu, C. (1968). Approximating discrete probability distributions withdependence trees. IEEE Trans. Inf. Theor., 14(3):462–467. 31, 37
[8] Cowell, R. G., Dawid, A. P., Lauritzen, S. L., and Spiegelhalter, D. J. (2007). Pro-babilistic Networks and Expert Systems: Exact Computational Methods for BayesianNetworks. Springer Publishing Company, Incorporated, 1st edition. 46
[9] De Bonet, J. S., Isbell, Jr., C. L., and Viola, P. (1996). Mimic: Finding optima byestimating probability densities. In Proceedings of the 9th International Conferenceon Neural Information Processing Systems, NIPS’96, pages 424–430, Cambridge, MA,USA. MIT Press. 35
[10] DeGroot, M. H. (2005). Some Special Multivariate Distributions, pages 48–66. JohnWiley and Sons, Inc. 25
119

BIBLIOGRAFIA
[11] Deshpande, A., Garofalakis, M., and Jordan, M. I. (2001). Efficient stepwise selectionin decomposable models. In Proceedings of the Seventeenth Conference on Uncertaintyin Artificial Intelligence, UAI’01, pages 128–135, San Francisco, CA, USA. MorganKaufmann Publishers Inc. 56, 60, 62
[12] Geman, S. and Geman, D. (1984). Stochastic relaxation, gibbs distributions, and thebayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell., 6(6):721–741.28, 33
[13] Goldberg, D. E. (1989). Genetic Algorithms in Search, Optimization and MachineLearning. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1st edition.3
[14] Halim, S. and Halim, F. (2013). Competitive Programming 3: The New Lower Boundof Programming Contests : Handbook for ACM ICPC and IOI Contestants. Lulu.com.26, 32, 113
[15] Henrion, M. (1986). Propagating uncertainty in bayesian networks by probabilisticlogic sampling. In UAI. 32
[16] Holland, J. H. (1975). Adaptation in Natural and Artificial Systems. University ofMichigan Press, Ann Arbor, MI. second edition, 1992. 5
[17] Howard, R. A. and Matheson, J. E. (2005). Influence diagrams. Decision Analysis,2(3):127–143. 21
[18] Jensen, F., Lauritzen, S., and Olesen, K. (1990). Bayesian updating in causal proba-bilistic networks by local computations. Computational Statistics Quarterly, 4:269–282.46, 50
[19] Kovacs, E. and Szantai, T. (2010). On the Approximation of a Discrete MultivariateProbability Distribution Using the New Concept of t-Cherry Junction Tree, pages 39–56.Springer Berlin Heidelberg, Berlin, Heidelberg. 9, 55, 59
[20] Kumar, M., Husain, M., Upreti, N., and Gupta, D. (2010). Genetic algorithm: Reviewand application. Journal of Information and Knowledge Management. 2, 4, 5, 7
[21] Larranaga, P., Etxeberria, R., Lozano, J. A., and Pena, J. M. (2000). Combinatorialoptimization by learning and simulation of bayesian networks. In Proceedings of theSixteenth Conference on Uncertainty in Artificial Intelligence, UAI’00, pages 343–352,San Francisco, CA, USA. Morgan Kaufmann Publishers Inc. 40
[22] Larranaga, P., Lozano, J. A., and Bengoetxea, E. (2001). Estimation of distributionalgorithms based on multivariate normal distributions and Gaussian networks. TechnicalReport KZZA-IK-1-01, Dept. of Computer Science and Artificial Intelligence, Universityof Basque Country. 42
120

BIBLIOGRAFIA
[23] Larranaga, P. and Lozano, J. A. (2001). Estimation of Distribution Algorithms: ANew Tool for Evolutionary Computation. Kluwer Academic Publishers, Norwell, MA,USA. 8, 9, 14, 29, 31, 33, 40
[24] Larranaga, P., Etxeberria, R., Lozano, J. A., and Pena, J. (1999). Optimization bylearning and simulation of bayesian and gaussian networks. 34, 36, 38
[25] Lauritzen, S. L. and Spiegelhalter, D. J. (1990). Readings in uncertain reasoning.In Shafer, G. and Pearl, J., editors, Readings in Uncertain Reasoning, chapter LocalComputations with Probabilities on Graphical Structures and Their Application toExpert Systems, pages 415–448. Morgan Kaufmann Publishers Inc., San Francisco, CA,USA. 50
[26] Malvestuto, F. M. (1991). Approximating discrete probability distributions withdecomposable models. IEEE Trans. Systems, Man, and Cybernetics, 21:1287–1294. 48,55
[27] Muhlenbein, H. (1997). The equation for response to selection and its use for predic-tion. Evol. Comput., 5(3):303–346. 33
[28] Muhlenbein, H. and Paass, G. (1996). From recombination of genes to the estimationof distributions i. binary parameters. In Proceedings of the 4th International Conferenceon Parallel Problem Solving from Nature, PPSN IV, pages 178–187, London, UK, UK.Springer-Verlag. 11
[29] Neapolitan, R. E. (1990). Probabilistic Reasoning in Expert Systems: Theory andAlgorithms. John Wiley and Sons, Inc., New York, NY, USA. 22
[30] Nocedal, J. and Wright, S. J. (2006). Numerical Optimization. Springer, New York,NY, USA, second edition. 1, 2
[31] Perez, A., Inza, I. n., and Lozano, J. A. (2016). Efficient approximation of probabilitydistributions with k-order decomposable models. Int. J. Approx. Reasoning, 74(C):58–87. 48, 58
[32] Price, K., Storn, R., and Lampinen, J. (2005). Differential Evolution: A PracticalApproach to Global Optimization. Natural Computing Series. Springer. 2, 79, 80
[33] Proulx, B. and Zhang, J. (2014). Modeling social network relationships via t-cherryjunction trees. In IEEE INFOCOM 2014 - IEEE Conference on Computer Communi-cations, pages 2229–2237. xv, xv, xv, xv, 9, 54, 56, 57, 58, 59, 60, 63, 65, 66, 67, 68,69
[34] Schwarz, G. (1978). Estimating the dimension of a model. Annals of Statisic,6(2):461–464. 40
121

BIBLIOGRAFIA
[35] Segovia-Domınguez, I., Hernandez-Aguirre, A., and Valdez, S. I. (2015). Designing theboltzmann estimation of multivariate normal distribution: Issues, goals and solutions.In 2015 IEEE Congress on Evolutionary Computation (CEC), pages 2082–2089. 106
[36] Segovia Domınguez, I., Hernandez-Aguirre, A., and Villa Diharce, E. (2011). Globaloptimization with the gaussian polytree eda. In ”Sidorov, G. and Batyrshin, I., editors,Advances on Soft Computing. Proceedings of the 10th Mexican International Conferenceon Artificial Intelligence, LNAI 7095, pages 165–175, Berlin Heidelberg. Springer-Verlag.39, 80
[37] Shachter, R. D. and Kenley, C. R. (1989). Gaussian influence diagrams. ManagementScience, 35(5):527–550. 26
[38] Siddhartha, S. and Roberto, S. (2012). Markov Networks in Evolutionary Compu-tation. Springer-Verlag Berlin Heidelberg. Adaptation, Learning and Optimization. 8,41
[39] Soto, M., Ochoa, A., Acid, S., and de Campos, L. (1999). Introducing the polytreeapproximation of distribution algorithm. In Proceedings of the Second Symposium onArtificial Intelligence in International Conference CIMAF ’99, pages 360–367. 39
[40] Spirtes, P. and Glymour, C. (1991). An algorithm for fast recovery of sparse causalgraphs. Social Science Computer Review, 9(1):62–72. 32
[41] Szantai, T. and Kovacs, E. (2012). Hypergraphs as a mean of discovering the depen-dence structure of a discrete multivariate probability distribution. Annals of OperationsResearch, 193(1):71–90. 51, 53, 55, 56, 63
[42] Szantai, T. and Kovacs, E. (2013). Discovering a junction tree behind a markovnetwork by a greedy algorithm. Optimization and Engineering, 14(4):503–518. 9, 55
[43] Wang, Y., Li, H.-X., Huang, T., and Li, L. (2014). Differential evolution based oncovariance matrix learning and bimodal distribution parameter setting. Appl. Soft Com-put., 18(C):232–247. 107
[44] Watanabe, S. (1960). Information theoretical analysis of multivariate correlation.IBM Journal of Research and Development, 4(1):66–82. 111
[45] Yang, X.-S. (2008). Nature-Inspired Metaheuristic Algorithms. Luniver Press. 7
[46] Zlochin, M. (2004). Model-based search for combinatorial optimization: A criticalsurvey. Annals of Operations Research, 131:373–395. 7
122


















