
Tutorial de Minería de Datos - rblanco.orgrblanco.org/TutorialMD.pdf · Programar con Java usando...
22
Tutorial de Minería de Datos Dr. Ricardo Blanco Vega 14 de noviembre de 2016
-
Upload
nguyenkiet -
Category
Documents
-
view
220 -
download
0
Transcript of Tutorial de Minería de Datos - rblanco.orgrblanco.org/TutorialMD.pdf · Programar con Java usando...

Tutorial
de
Minería de Datos
Dr. Ricardo Blanco Vega
14 de noviembre de 2016

2 Tutorial de Minería de Datos
Tabla de Contenido
Minería de Datos en WEKA ........................................................................................................................... 4
Desarrollo Rápido de Sistemas de Predicción ............................................................................................. 14
Aplicación de la metodología CRISP-DM..................................................................................................... 17
Programar con Java usando WEKA ............................................................................................................. 20

3 Tutorial de Minería de Datos
MOTIVACIÓN Aprender de forma práctica la Minería de Datos. Se utiliza WEKA y Java para crear sistemas de predicción. Se enseña cómo aplicar la metodología CRISP-DM en el desarrollo de proyectos de Minería de Datos. Se muestra cómo desarrollar de forma rápida un sistema de predicción. También cómo programar con Java un sistema de predicción tomando como base un modelo de predicción comprensible o incomprensible.
CONTENIDO 1. Minería de Datos en WEKA
2. Desarrollo Rápido de Sistemas de Predicción
3. Aplicación de la metodología CRISP-DM
4. Programar con Java usando WEKA
ESTILO DE EXPOSICIÓN Se imparte una práctica por hora con un total de 4 horas. Las prácticas son frente a computadora. Se debe reservar un laboratorio de cómputo.
PREREQUISITOS Tener conocimientos básicos de Java en especial si conocer el IDE de Netbeans. Si se lleva su propia laptop debe tener instalado Netbeans 8+ con la versión SE y WEKA 3.8+ La sala de laboratorio solamente soporta 40 participantes.
INSTRUCTOR Ricardo Blanco Vega Doctor en Programación Declarativa e Ingeniería de la Programación. Otorgado en 2007 por la Universidad Politécnica de Valencia, España. Maestro en Ciencias en Ciencias Computacionales por el Instituto Tecnológico de Nogales. Docente en la Facultad de Ingeniería de la Universidad Autónoma de Chihuahua (21 años). Maestro Jubilado del Tecnológico de Chihuahua II con 34 años de servicio. Desarrollador de Software en la empresa Tauridas desde 1º. Marzo del 2016 a la fecha. Perfil Deseable PROMEP desde 2007. Primer perfil deseable en el Instituto Tecnológico de Chihuahua II.

4 Tutorial de Minería de Datos
Minería de Datos en WEKA
Se genera un modelo de predicción utilizando el programa explorer de WEKA.
Accediendo al Explorer Suponiendo que WEKA ya está instalado en un ambiente Windows Vista o Windows 7.
1- Dar click en botón inicio
Figura 1. Menú de inicio al seleccionar el botón inicio
2- Se escribe weka (no es sensitivo a minúsculas o mayúsculas).
Figura 2. Escribir weka

5 Tutorial de Minería de Datos
3- Se selecciona Weka 3.7
Figura 3. Elección de Weka 3.7
4- Aparece la interfaz principal de WEKA.
Figura 4. Pantalla principal WEKA
6 Tutorial de Minería de Datos
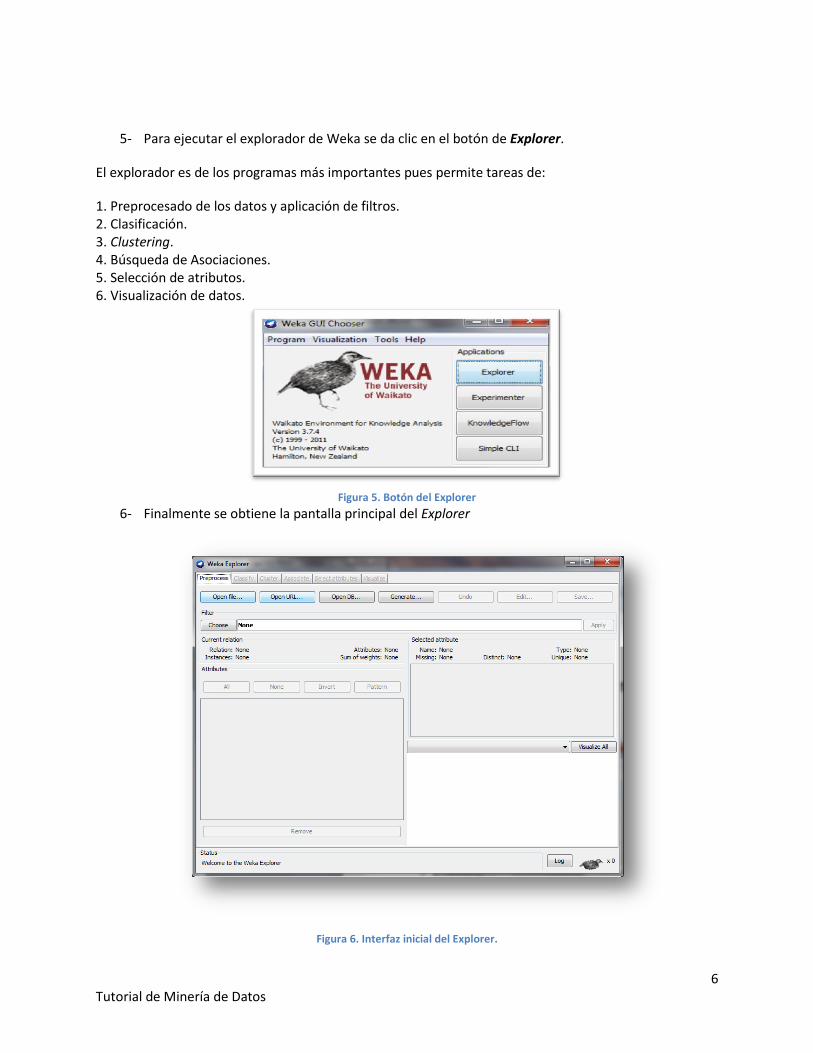
5- Para ejecutar el explorador de Weka se da clic en el botón de Explorer.
El explorador es de los programas más importantes pues permite tareas de:
1. Preprocesado de los datos y aplicación de filtros. 2. Clasificación. 3. Clustering. 4. Búsqueda de Asociaciones. 5. Selección de atributos. 6. Visualización de datos.
Figura 5. Botón del Explorer
6- Finalmente se obtiene la pantalla principal del Explorer
Figura 6. Interfaz inicial del Explorer.

7 Tutorial de Minería de Datos
Creación de un modelo de predicción
Ahora se explica cómo realizar un modelo de clasificación a partir del conjunto de datos weather. Se
sabe, a manera de descripción del problema, que un grupo de personas que les gusta jugar tenis se
levantan temprano, se preparan y trasladan al centro deportivo. Regularmente juegan pero existen
ocasiones en donde no lo hacen. Por lo que están interesados en conocer con anticipación si jugarán o
no en un determinado día. Para ello registran los datos del clima dado que ellos sospechas que esto es lo
que influye de manera significativa sobre la decisión de jugar, aunque siempre juegan cuando está
nublado no saben de forma explícita como se toma la decisión en otros casos. Los valores del clima que
almacenan en el conjunto de datos son: como está el cielo (outlook), la temperatura (temperature), el
porcentaje de humedad (humidity), la presencia o ausencia del viento (windy) y por último si jugaron o
no.
Para abrir el ejemplo se debe dar click en el botón Open file... situado en la parte izquierda superior de la
primera página del programa.
Figura 7. Abrir archivo.
Automáticamente, genera un acceso a archivos donde se debe buscar la ruta donde se encuentran los
conjuntos de datos de ejemplo de WEKA.
Hay que entrar en la carpeta de Weka-3-7 que está en archivos de programa.

8 Tutorial de Minería de Datos
Figura 8. Ubicación de la carpeta de Weka.
Luego a la carpeta de data. Para el ejemplo de este documento se utiliza el archivo weather.
Figura 9. Seleccionando el ejemplo weather
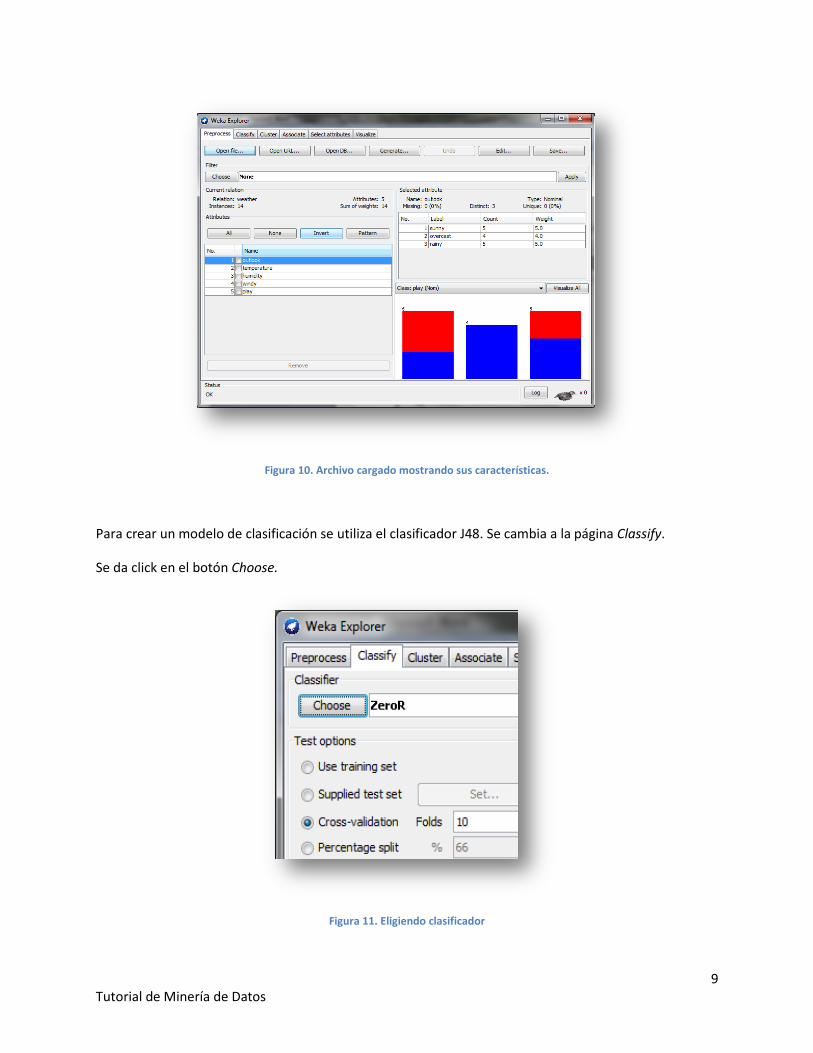
De inmediato, aparece una pantalla con los atributos del ejemplo, su peso, instancias, etc.
9 Tutorial de Minería de Datos
Figura 10. Archivo cargado mostrando sus características.
Para crear un modelo de clasificación se utiliza el clasificador J48. Se cambia a la página Classify.
Se da click en el botón Choose.
Figura 11. Eligiendo clasificador

10 Tutorial de Minería de Datos
Se elige clasificadores, después trees y J48.
Se puede observar que el clasificador ha sido elegido correctamente ya que aparece en el recuadro de
texto que se encuentra enseguida del botón Choose
Figura 12. Clasificador J48 elegido.
Para crear el modelo se debe oprimir el botón Start. En este ejemplo se observa que se tiene una
precisión (instancias correctamente clasificadas) del 64.28% por lo que hay que analizar si es posible una
opción con la que se obtenga un mejor rendimiento.
Figura 13. Numero de instancias clasificadas correctamente
11 Tutorial de Minería de Datos
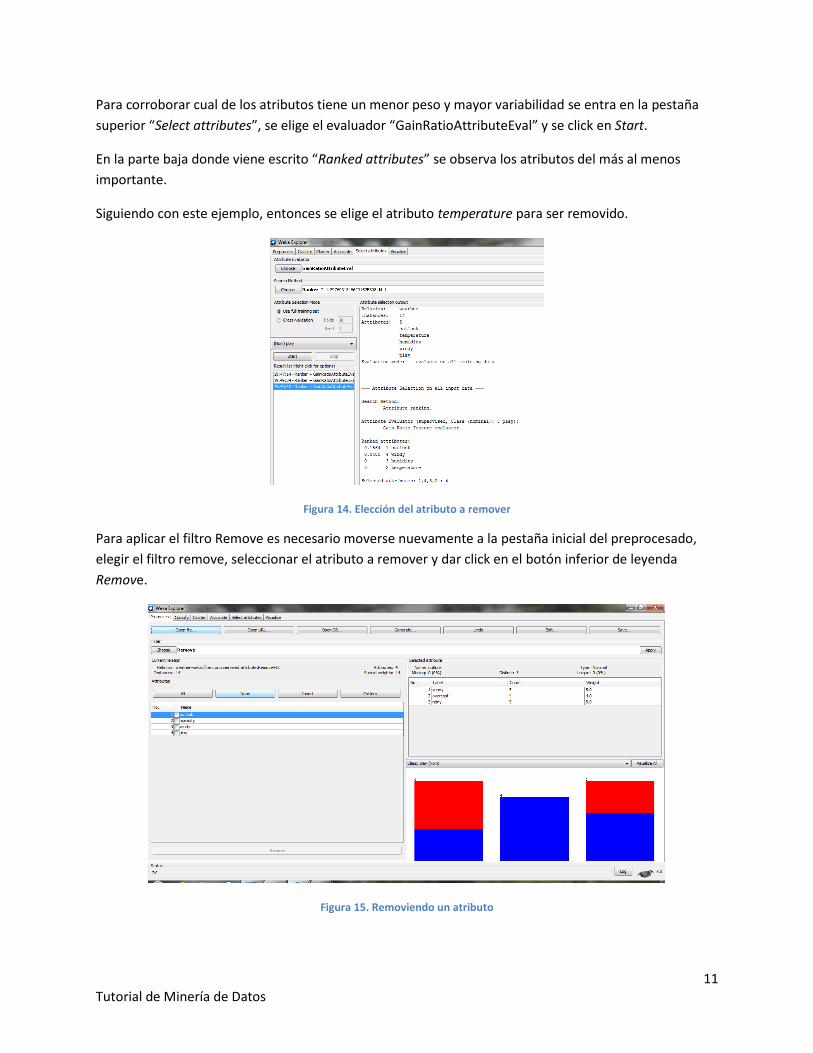
Para corroborar cual de los atributos tiene un menor peso y mayor variabilidad se entra en la pestaña
superior “Select attributes”, se elige el evaluador “GainRatioAttributeEval” y se click en Start.
En la parte baja donde viene escrito “Ranked attributes” se observa los atributos del más al menos
importante.
Siguiendo con este ejemplo, entonces se elige el atributo temperature para ser removido.
Figura 14. Elección del atributo a remover
Para aplicar el filtro Remove es necesario moverse nuevamente a la pestaña inicial del preprocesado,
elegir el filtro remove, seleccionar el atributo a remover y dar click en el botón inferior de leyenda
Remove.
Figura 15. Removiendo un atributo

12 Tutorial de Minería de Datos
Al corroborar nuevamente la precisión se verifica que efectivamente el porcentaje de clasificación
correcto ha llegado a un 71.42%.
Figura 16. Obteniendo mejores resultados.
Al llegar al porcentaje mayor, o que se considere mas efectivo para el ejemplo en cuestión entonces de
procede a guardar los datos y el modelo en una carpeta de trabajo.
El archivo de datos se guarda dando click en el botón derecho superior con la leyenda “Save…”,
tomando en cuenta que los dos archivos a guardar deben estar ubicados dentro de la misma carpeta y
deben tener el mismo nombre para poder correr la aplicación de predicción sin problemas, en nuestro
caso utilizar el nombre de ejemplo.

13 Tutorial de Minería de Datos
Figura 17. Guardando los datos
Para guardar el modelo hay que ubicarse en la pestaña de clasificación, elegir el modelo desarrollado,
dar click derecho y elegir Save model.
Figura 18. Guardando el modelo

14 Tutorial de Minería de Datos
Desarrollo Rápido de Sistemas de Predicción
El presente documento describe cómo realizar el desarrollo de un sistema de predicción utilizando Java
y WEKA (Hall et. al., 2009).
Desarrollo
A continuación se describen los pasos necesarios para primero crear un modelo de predicción y
finalmente como utilizarlo en la construcción de un programa de predicción.
Creación del programa de predicción
Enseguida se procede a copiar la librería y la aplicación predicción.jar (Blanco et. al., 2010). Estos
recursos se obtienen de la carpeta dist del proyecto predicción que se les proporciona en la plataforma.
Se pegan en la carpeta donde se guardaron los archivos anteriores, quedando como lo muestra la Figura
19.
Figura 19. Copiando los archivos de apoyo
Por último, se hace la prueba de la aplicación dando doble click en prediccion.jar.
15 Tutorial de Minería de Datos
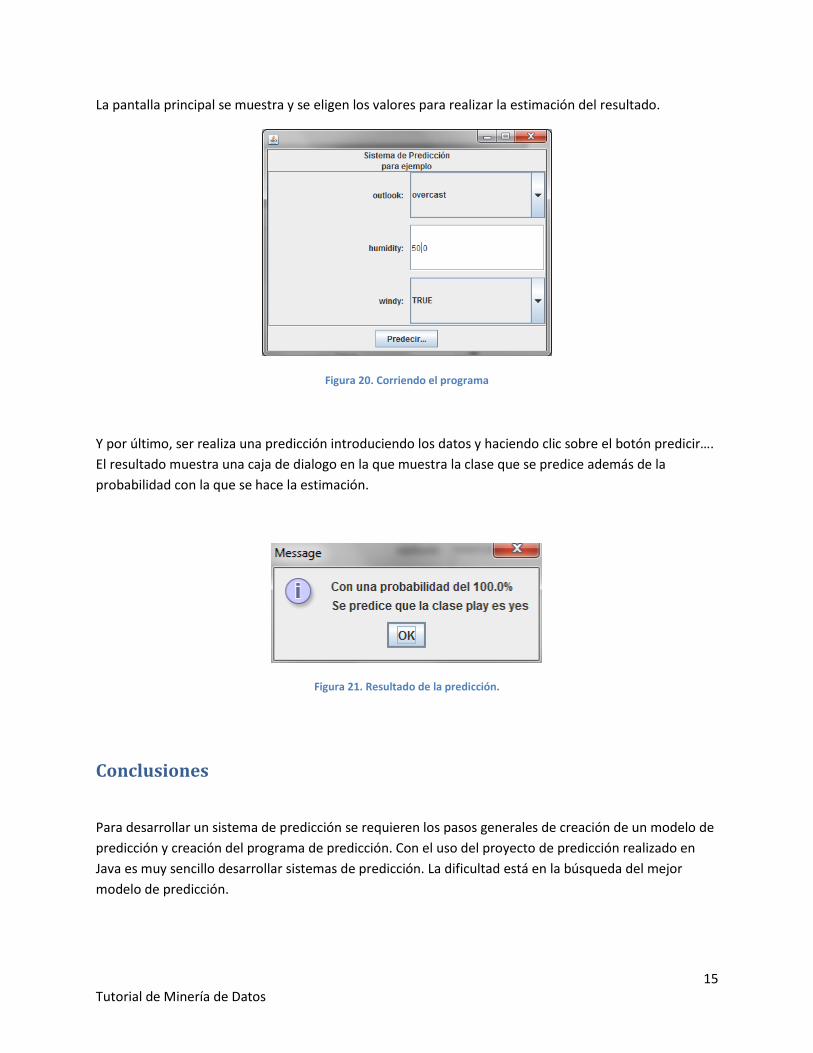
La pantalla principal se muestra y se eligen los valores para realizar la estimación del resultado.
Figura 20. Corriendo el programa
Y por último, ser realiza una predicción introduciendo los datos y haciendo clic sobre el botón predicir….
El resultado muestra una caja de dialogo en la que muestra la clase que se predice además de la
probabilidad con la que se hace la estimación.
Figura 21. Resultado de la predicción.
Conclusiones
Para desarrollar un sistema de predicción se requieren los pasos generales de creación de un modelo de
predicción y creación del programa de predicción. Con el uso del proyecto de predicción realizado en
Java es muy sencillo desarrollar sistemas de predicción. La dificultad está en la búsqueda del mejor
modelo de predicción.

16 Tutorial de Minería de Datos
Recomendaciones
Realice la práctica. Busque encontrar un mejor modelo cambiando de algoritmo de Minería de datos por
ejemplo una red neuronal (en el grupo de functions MultilayerPerceptron). El modelo sálvelo con el
mismo nombre (ejemplo).
Repita la práctica con otro conjunto de datos por ejemplo el de lentes de contacto (contact-lenses.arff).
Por favor, lea el artículo (Blanco et. al., 2010). Posteriormente analice el proyecto predicción realice una
documentación de ese análisis.
Referencias
Hall, Mark; Frank, Eibe; Holmes, Geoffrey; Pfahringer, Bernhard; Reutemann, Peter; Witten, Ian H.
(2009). The WEKA Data Mining Software: An Update; SIGKDD Explorations, Volume 11, Issue 1.
Blanco Vega, Ricardo; Blanco Vega, Humberto; De la Garza Gutiérrez, Hernán; Camacho Ríos, Alberto;
Ibarra Murrieta, Blanca Maricela; Anchondo, Ramón. CREACIÓN AUTOMÁTICA DE PROGRAMAS DE
PREDICCIÓN. 3er Congreso Internacional de Investigación CIPITECH 2010. Parral, Chih., México, 13-15 de
octubre 2010. ISBN 978-607-7912-08-8. Pág 199 a 205

17 Tutorial de Minería de Datos
Aplicación de la metodología CRISP-DM
CRISP-DM (Cross-Industry Standard Process for Data Mining) es un modelo de proceso de minería de datos que describe los enfoques comunes que utilizan los expertos en minería de datos. Incluye un modelo de referencia y una guía para llevar a cabo un proyecto de minería de datos. La guía puede ser muy útil como referencia a la hora de establecer una formulación o planificación de un programa de minería de datos adaptado a las necesidades de cada organización. Como modelo de proceso, CRISP-DM ofrece un resumen del ciclo vital de minería de datos. El modelo y la guía se conforman de seis fases principales, y además existe la realimentación bidireccional entre algunas fases, es decir, algunas fases pueden obligar a revisar parcial o totalmente las fases anteriores.

18 Tutorial de Minería de Datos
Ciclo de Vida en Espiral A continuación, se describen las fases, subfases y subproductos del ciclo de vida del modelo CRISP-DM: 1. Análisis del Problema. La primera fase se centra en conocer los objetivos y requerimientos del proyecto desde una perspectiva de negocio, plantandolo en una definición del problema de minería de datos y un plan preliminar diseñado para obtener objetivos. Consta de cuatro subfases:
Establecimiento de los Objetivos de Negocio: Es fundamental analizar cuáles son los objetivos del negocio para abordar las cuestiones que son realmente importantes y beneficiosas para la organización.
Evaluación de la Situación: Esta tarea involucra una búsqueda detallada de los recursos, restricciones, suposiciones y otros factores al definir el plan del proyecto. La primera salida de esta subfase es un inventario de recursos, incluyendo el personal, los datos y conocimiento previo existente, recursos informáticos, software específico de minería de datos.
Establecimiento de los Objetivos de la Minería de Datos: Deben especificarse en términos de minería de datos, y no en términos de negocio. El productor principal de esta subfase es un listado de los objetivos de minería de datos, otro son los criterios de éxito para los objetivos de minería de datos que ya pueden expresarse en términos de precisión, error cuadrático medio, número de reglas, etc.
Generación del Plan del Proyecto: El plan del proyecto es la salida principal de esta subfase, que implica la comprensión del negocio y debe incluir todas las etapas a desarrollar en el proyecto, junto con la duración, los recursos requeridos, las entradas, las salidas y las dependencias. Este plan de proyecto es dinámico y debe actualizarse a medida que se avanza en el proyecto.
2. Análisis de los Datos: Según este estándar, se trata de recopilar y familiarizarse con los datos, identificar los problemas de calidad de datos y ver las primeras potencialidades o subconjuntos de datos que puede ser interesante analizar, (para ello es importante haber establecido los objetivos de negocio en la fase anterior). Esta fase consta de cuatro subfases:
Recopilación Inicial de Datos: En esta subfase se produce el informe de recopilación.
Descripción de Datos: Aquí se genera el informe de descripción.
Exploración de Datos: En ella se genera el informe de exploración.
Verificación de Calidad de Datos: Se verifica que los datos obtenidos sean adecuados.

19 Tutorial de Minería de Datos
3. Preparación de los Datos: El objetivo de esta fase es obtener la “vista minable”, aunque el estándar no use esta terminología en realidad se habla de dataset y de su descripción. Aquí se incluye la integración, selección, limpieza, y transformación. Esta fase consta de cinco subfases:
Selección de Datos: Razones de inclusión / exclusión.
Limpieza de Datos: Informe de limpieza de datos.
Construcción de Datos: Atributos derivados, registros generados.
Integración de Datos: Datos mezclados.
Formateo de Datos: Datos reformateados. 4. Modelado: Es la aplicación de técnicas de modelado o de minería de datos propiamente dichas a las “vistas minables” anteriores. Esta fase consta de cuatro subfases:
Selección de la Técnica de Modelado: Técnica de modelado, suposiciones de modelado.
Diseño de la Evaluación: Diseño del test.
Construcción del Modelo: Parámetros elegidos, modelos, descripción de los modelos.
Evaluación del Modelo: Medidas del modelo, revisión de los parámetros elegidos.
5. Evaluación: Es necesario evaluar los modelos de la fase anterior, pero ya no solo desde un punto de vista estadístico respecto a los datos, como se realiza en la última subfase de la anterior, sino evaluar si el modelo se ajusta a las necesidades establecidas en la primera fase, es decir, si el modelo nos sirve para responder a algunos de los requerimientos del negocio. Esta fase posee tres subfases:
Evaluación de los Resultados: Evaluación de los resultados de minería de datos, modelos aprobados.
Revisar el Proceso: En esta subfase se inspecciona el proceso.
Establecimiento de los Siguientes Pasos: Lista de posibles acciones, decisión.
6. Despliegue: Busca explotar la utilidad de los modelos, integrándolos en las tareas de toma de decisiones de la organización. Consta de cuatro subfases:
Planificación del Despliegue.
Planificación de la Monitorización y del Mantenimiento.
Generación del Informe Final.
Revisión del Proyecto. Esta metodología para proyectos de minería de datos no es la “más actual” o “la mejor”, pero es muy útil para comprender esta tecnología o extraer ideas para diseñar o revisar métodos de trabajo para proyectos de similares características.

20 Tutorial de Minería de Datos
Programar con Java usando WEKA El objetivo de esta práctica es hacer un sistema de predicción desde 0, tomando en cuenta los
datos de algún caso que vienen por defecto en los datos de WEKA. En este caso se tomaron los
datos de los lentes de contacto.
Desarrollo
Lo primero que debemos de hacer es crear un proyecto nuevo en Java Netbeans, y en los paquetes de fuente crear un formulario Jframe.
Luego colocaremos 2 labels, 2 ComboBox, y dos botones.

21 Tutorial de Minería de Datos
Luego a los labels, les pondremos los nombres de “Porcentaje de Lagrimeo” y “Astigmatismo”.
Un ComboBox tendrá los valores de reducido y normal, y el otro de No y Si.
Un botón tendrá el texto de “¿Qué tipos de lentes debo usar?.
Y el último será el botón de salir.
Le damos click en el botón que dice “¿Qué tipos de lente debo usar?” y escribimos el siguiente código:

22 Tutorial de Minería de Datos
En el botón de salir agregamos la siguiente línea de código para que haga su función.
Y finalmente corremos nuestro sistema de predicción.
Conclusión
Es fácil realizar un sistema de predicción siempre y cuando entendamos los datos y veamos cual es la
problemática que se nos presenta, para así poder desarrollar un sistema entendible, de calidad y sobre
todo útil.
Recomendaciones La recomendación que se hace es que no empiecen el sistema si no han comprendido los datos ni la
problemática que hay que resolver.


















