
Tratamiento estadístico de los datos. Dr. Pedro J. … · el gráfico de probabilidad...
33
Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM). 0 CURSO DE POSTGRADO DEL CSIC: “Tendencias actuales de la investigación en Enología” Módulo: “Tratamiento estadístico de los datos ” Dr. Pedro J. Martín-Álvarez, Instituto de Investigación en Ciencias de la Alimentación (CIAL, CSIC-UAM) Grupo: Biotecnología Enológica Aplicada Madrid, 20-24 de Abril de 2015 ÏNDICE Pág. 1.TRATAMIENTO ESTADÍSTICO DE DATOS UNIVARIANTES............ 1.1 UN SOLO GRUPO DE DATOS ....................................................... 1.2 DOS GRUPOS DE DATOS INDEPENDIENTES ............................ 1.3 DOS GRUPOS DE DATOS RELACIONADOS ............................... 1.4 MAS DE DOS GRUPOS DE DATOS INDEPENDIENTES ....... 1.4.1 Análisis de la Varianza (ANOVA) ............................................ 2. TRATAMIENTO ESTADÍSTICO DE DATOS BIVARIANTES ........... 2.1 ANALISIS DE CORRELACION SIMPLE ....................................... 2.2 ANALISIS DE REGRESION LINEAL SIMPLE ............................. 3. TRATAMIENTO ESTADÍSTICO DATOS MULTIVARIANTES. ....... 3.1 MATRIZ DE DATOS ..................................................................... 3.2 REPRESENTACION GRAFICA DE LOS DATOS........................ 3.3 CLASIFICACION DE LOS METODOS......................................... 3.4 TRATAMIENTO PREVIO DE LOS DATOS ................................... 4. MÉTODOS ESTAD. DATOS MULTIV. NO SUPERVISADOS 4.1 ANALISIS DE COMPONENTES PRINCIPALES............................. 4.2 ANALISIS FACTORIAL .................................................................... 4.3 ANALISIS DE CONGLOMERADOS ....................................... 5. MÉTODOS ESTAD. DATOS MULTIV. SUPERVISADOS ................. 5.1 ANALISIS CANONICO DE VARIABLES (CVA) ............................... 5.2 METODOS DE CLASIFICACION SUPERVISADA .................... 5.2.1 Análisis discriminante ................................................................ 5.2.2 Método SIMCA …….................................................................. 5.2.3 Método kNN ………… ................................................................ 6. MÉTODOS ESTAD. DATOS MULTIV. DE DEPENDENCIA ............ 6.1 ANALISIS DE CORRELACION CANONICA (ACC) ......................... 6.2 MODELOS DE REGRESION MULTIVARIANTE ............................. 6.2.1 Regresión lineal múltiple............................................................ 6.2.2 Diseño de Experimentos ........................................................... 7. BIBLIOGRAFIA .................................................................................. 8. Comandos de los programas SPSS, Statgraphics 5.1 y Statistica 7.1 1 1 2 3 4 5 8 9 10 13 13 14 15 17 17 17 19 20 22 22 22 22 23 23 24 24 24 25 26 28 29
Transcript of Tratamiento estadístico de los datos. Dr. Pedro J. … · el gráfico de probabilidad...

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
0
CURSO DE POSTGRADO DEL CSIC: “Tendencias actuales de la investigación en Enología”
Módulo: “Tratamiento estadístico de los datos”
Dr. Pedro J. Martín-Álvarez, Instituto de Investigación en Ciencias
de la Alimentación (CIAL, CSIC-UAM) Grupo: Biotecnología Enológica Aplicada
Madrid, 20-24 de Abril de 2015
ÏNDICE Pág. 1.TRATAMIENTO ESTADÍSTICO DE DATOS UNIVARIANTES............ 1.1 UN SOLO GRUPO DE DATOS ....................................................... 1.2 DOS GRUPOS DE DATOS INDEPENDIENTES ............................ 1.3 DOS GRUPOS DE DATOS RELACIONADOS ............................... 1.4 MAS DE DOS GRUPOS DE DATOS INDEPENDIENTES ....... 1.4.1 Análisis de la Varianza (ANOVA) ............................................ 2. TRATAMIENTO ESTADÍSTICO DE DATOS BIVARIANTES ........... 2.1 ANALISIS DE CORRELACION SIMPLE ....................................... 2.2 ANALISIS DE REGRESION LINEAL SIMPLE ............................. 3. TRATAMIENTO ESTADÍSTICO DATOS MULTIVARIANTES. ....... 3.1 MATRIZ DE DATOS ..................................................................... 3.2 REPRESENTACION GRAFICA DE LOS DATOS........................ 3.3 CLASIFICACION DE LOS METODOS......................................... 3.4 TRATAMIENTO PREVIO DE LOS DATOS ................................... 4. MÉTODOS ESTAD. DATOS MULTIV. NO SUPERVISADOS 4.1 ANALISIS DE COMPONENTES PRINCIPALES............................. 4.2 ANALISIS FACTORIAL .................................................................... 4.3 ANALISIS DE CONGLOMERADOS ....................................... 5. MÉTODOS ESTAD. DATOS MULTIV. SUPERVISADOS ................. 5.1 ANALISIS CANONICO DE VARIABLES (CVA) ............................... 5.2 METODOS DE CLASIFICACION SUPERVISADA .................... 5.2.1 Análisis discriminante ................................................................ 5.2.2 Método SIMCA …….................................................................. 5.2.3 Método kNN ………… ................................................................ 6. MÉTODOS ESTAD. DATOS MULTIV. DE DEPENDENCIA ............ 6.1 ANALISIS DE CORRELACION CANONICA (ACC) ......................... 6.2 MODELOS DE REGRESION MULTIVARIANTE ............................. 6.2.1 Regresión lineal múltiple............................................................ 6.2.2 Diseño de Experimentos ........................................................... 7. BIBLIOGRAFIA .................................................................................. 8. Comandos de los programas SPSS, Statgraphics 5.1 y Statistica 7.1
1 1 2 3 4 5 8 9
10 13 13 14 15 17 17 17 19 20 22 22 22 22 23 23 24 24 24 25 26 28 29

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
1
1. TRATAMIENTO ESTADÍSTICO DE DATOS UNIVARIANTES
1.1 UN SOLO GRUPO DE DATOS
Datos: disponemos de un conjunto de n datos (observaciones), {x1, x2, x3, ..., xn}, de una única variable aleatoria (v.a.) X, procedentes de una cierta población W. Podríamos calcular:
Medidas de centralización (o de posición), que tienen en cuenta el valor de los datos en la muestra pero no dan idea del agrupamiento de los mismos, como
son: la moda, la media aritmética (n
in
ixx
1/ ) y la mediana que es mas robusta
que la media. También las medias recortadas al 5% (eliminando el 5% de los datos extremos).
Medidas de dispersión o variablididad, que dan idea sobre el agrupamiento de los datos observados en torno a los valores centrales, como son: el intervalo,
amplitud o recorrido ( minmax xx ), la varianza muestral (2
s ), la desviación
estándar (o típica) muestral (n
ii nxxs
1
2 )1/()( ), la desviación estándar
relativa (o coeficiente de variación, xsDER / ), el intervalo intercuartílico
(diferencia entre el primer y tercer cuartíl, IQ = Q3 - Q1), y la MEDA (mediana de las desviaciones entorno a la mediana, MEDA= Mediana |xi – Mediana|) más robusta que la desviación típica.
Momentos y coeficientes de asimetría y apuntamiento, que describen aspectos relevantes de la distribución de frecuencias.
Para la detección de datos anómalos o atípicos, se podría utilizar el intervalo de valores admisibles que se define como: )(5.1),(5.1 133131 QQQQQQ . Una representación
gráfica muy utilizada es el diagrama de caja ("box plot"), que incluye información sobre la mediana, los cuartíles Q1 y Q3, y los extremos del intervalo de valores admisibles (los bigotes). Los datos que están fuera cabría pensar en que son atípicos. Desde un punto de vista inferencial, y aceptando
distribución N( , ) de los datos, que puede comprobarse con el gráfico de probabilidad normal(“Q-Q plot”), o con los test de normalidad (Shapiro y Wilks, Kolmogoroff-Smirnov-Lilliefors,...), podemos utilizar la media aritmética y la desviación estándar muestral como estimadores puntuales de los
parámetros poblacionales , y . Otro estimador puntual de es el valor MEDA/0.675.
Fijado el nivel de significación, normalmente = 0.05, podemos:
calcular el intervalo de confianza para la media poblacional , al 100(1- ,
que vendrá dado por: nstxnstx nn /,/ 1,2/11,2/1 , siendo 1,2/1 nt el valor de la
t-Student con n-1 g.l. tal que F( 1 / 2, 1nt ) = 2/1 ,
calcular el intervalo de confianza para 2, al 100(1- )% que vendrá dado por:
1,2/
2
1,2/1
2/)1(,/)1( nn snsn siendo
2
/2 y 2
1 /2 los valores de la función de
distribución 2con n-1 g.l., tal que F(
2
2/ )= 2/ y F(2
2/1 ) = 2/1 , o
realizar el contraste de hipótesis para la media: 0 0
1 0
H
H donde la
hipótesis nula (H0) puede rechazarse tanto si < 0 como si > 0 (región con 2
VARX
0,70
0,60
0,50
0,40
0,30
0,20
9

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
2
colas). El estadístico utilizado para el contraste es: ns
x
calt
/
0 que sigue una
distribución t-Student con n-1 g.l., si H0 es cierta. Fijado el valor de (p.e. =
0.05), se decide en función del valor de calt : si 1,2/1|| ncal tt , se rechaza la
hipótesis nula y se acepta la hipótesis alternativa (H1); en caso contrario
( 1,2/1|| ncal tt ) no hay motivos para rechazar H0. Utilizando probabilidades
asociadas (facilitadas por los programas estadísticos): si P < se rechaza Ho, en
caso contrario (P > ) se acepta Ho. (“Si P es pequeña → corresponde a un suceso raro → hipótesis de partida incorrecta”). Este test para una media puede utilizarse para "comprobar la exactitud de un
método analítico para una muestra con un valor de referencia 0 " o para
“comprobar si la media de determinados valores es diferente un valor fijo (J.
Pozo-Bayón et al., Agric. Food Chem. 2009, 57, 10784-10792)”.
1.2 DOS GRUPOS DE DATOS INDEPENDIENTES
Datos: Disponemos de dos conjuntos de datos independientes: { x11,x12,x13, ..., x1n1} y {x21, x22, x23, ..., x2n2}, formados por n1 y n2 observaciones, de una misma v.a. X, procedentes de dos poblaciones W1 y W2. Podemos calcular: los valores descriptivos
muestrales: jx y js j=1,2, que serán estimadores, si
existe normalidad, de los correspondientes parámetros
poblacionales j y j. Para el tratamiento gráfico podemos utilizar los diagramas de cajas, o los gráficos de barras de error con los intervalos de confianza para la media, si existe normalidad. Desde un punto de vista inferencial, y aceptando
distribuciones N( i, i) de los datos en cada población, podemos estar interesados en:
obtener los intervalos de confianza para los
parámetros poblacionales j, y j, y también en hacer algún contraste de hipótesis sobre dichos parámetros, o
realizar el test para comparar las dos medias, que
se puede definir como: 211
210
H
H donde la hipótesis
nula (H0) puede ser rechazada tanto si 1< 2 como si 1> 2 (dos colas). Aceptando muestras independientes y varianzas iguales ó no, el estadístico utilizado para el contraste sigue una distribución t-Student con ciertos g.l. (n1 + n2 - 2 en el caso de
igualdad de varianzas). Fijado un valor para el nivel de significación, p. e. = 0.05,
se decide en función de las probabilidades asociadas, y si P < se rechaza Ho, en
caso contrario (P > ) se acepta Ho. Este contraste puede utilizarse para "comparar los resultados obtenidos por dos laboratorios para una misma muestra de referencia", “comparar las concentraciones de un cierto compuesto en vinos elaborados con uvas de 2 variedades”, “comprobar si existen diferencias en la composición de quesos elaborados a partir de leche de vaca o leche de cabra”, “comparar las puntuaciones de un descriptor en quesos procedentes de 2 queserías” ...
BA
grupo
20,00
15,00
10,00
5,00
95%
IC
V
ari
ab
le
BA
grupo
18,00
16,00
14,00
12,00
10,00
Vari
ab
le

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
3
realizar el test para comparar dos varianzas: 2
2
2
11
2
2
2
10
H
H. Aceptando
distribuciones normales en los dos grupos, el estadístico utilizado es: 2
2
2
1 / ssFcal (se
acepta 2
2
2
1 ss ), que sigue una distribución F-Snedecor con n1-1 y n2-2 g.l., si H0 es
cierta. Si 1 21 , 1, 1cal n nF F no hay motivos para rechazar H0. En caso contrario
habría que aceptar que las varianzas no son iguales. La mayoría de los programas estadísticos proporcionan el resultado del test de Levene, para el anterior contraste, utilizando un estadístico con distribución F-Snedecor y 1 y n1+n2-1 g.l. Si la
probabilidad asociada (P) es < se rechaza Ho, en caso contrario (P > ) se acepta Ho. Con muestras independientes y no aceptando distribuciones normales, puede utilizarse el test no paramétrico de Mann-Whitney. Si la probabilidad asociada (P)
es menor que se rechaza Ho. Iglesias M.T., P.J. Martín-Álvarez, M.C. Polo, C. de Lorenzo, E. Pueyo. "Protein analysis of
honeys by Fast protein Liquid Chromatography. Application to the differentiation of floral
honeys and honeydew honeys". J. Agric. Food Chem. 2006, 54, 8322-8327
Statistical Analysis. The statistical methods used for data analysis were a two-sample t-test and
Mann-Whitney U test to determine if there were significant differences between both types of
honey samples and … The STATISTICA program….
Results and discussion
Table 3 shows the mean values and standard deviations of the percentages of peak areas in the
two groups of honeys and the results of the t test for comparison of the two means that coincide
with the obtained by means of the Mann-Whitney U test. It can be observed that the samples of
floral honeys have greater values in the variables P7 and P4 and smaller values in P5, as
compared to the samples of honeydew honeys.
1.3 DOS GRUPOS DE DATOS RELACIONADOS
Datos: disponemos de n parejas de valores de 2 variables procedentes de un misma población W: { (x11 , x12), (x21 , x22), ..., (xn1 , xn2)}. A partir de estas n parejas, podemos calcular las n diferencias entre cada par de valores observados en el mismo individuo, es decir: { d1 = x11 - x12, d2 = x21 - x22 ,..., dn = xn1 - xn2}, así como el valor
medio y la desviación estándar de esta nueva variable d (2
dsyd ).

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
4
Aceptando que esta nueva variable sigue una N( d, d), el contraste de
hipótesis para las dos medias: 0
0
211
210
d
d
H
H, utiliza el estadístico:
/d
dtcal s n
, que sigue una t-Student con n-1 g.l.. Fijado el nivel de significación ,
si 1,2/1|| ncal tt se rechaza la hipótesis nula y se acepta la hipótesis alternativa
(H1); en caso contrario no hay motivos para rechazar H0. Si la probabilidad asociada
(P) es menor que se rechaza Ho. Este contraste puede utilizarse para "comparar los resultados obtenidos con 2 métodos analíticos en n muestras", “comprobar si hay diferencias entre concentraciones antes y después de un proceso”, “comparar las puntuaciones asignadas por 13 jueces a cada una de 10 muestras de quesos antes y después de un tratamiento” ...... En caso de no aceptar distribuciones normales, el test no paramétrico de Wilcoxon puede utilizarse para comparar las dos medias en muestras
relacionadas. Si la probabilidad asociada (P) es menor que se rechaza Ho.
Marcobal, A., M.C. Polo, P.J. Martín-Álvarez, M.V. Moreno-Arribas. "Biogenic amine content
of red spanish wines: Comparison of a direct ELISA and an HPLC method for the
determination of histamine in wines". Food Res. Int., 2005, 38, 387-394
Statistical methods The statistical methods used for analysis were as follows: ...; correlation
analysis and t-test for related samples to compare HPLC and ELISA methods. STATISTICA
(Statsoft Inc., 1998) and SPSS (SPSS Inc., 2001) programs were used for data processing.
Results. … Comparison of the quantitative analysis of histamine by HPLC and ELISA
revealed a good correlation (r = 0.91) between both methods (Fig. 3), although the results of the
t-test for related samples revealed slightly higher results for ELISA (P < 0.05).
1.4 MÁS DE DOS GRUPOS DE DATOS INDEPENDIENTES
Datos: disponemos de k (k > 2) conjuntos de datos: { x1,1, x1,2, x1,3, ..., x1,n1} , { x2,1, x2,2, x2,3, ..., x2,n2} ... {xk,1, xk,2, xk,3, ..., xk,nk}, con nj ( j = 1,2,...k ) observaciones de una misma variable X, procedentes de k poblaciones Wj, y podemos calcular los k
valores medios ( jx ) y las k desviaciones estándar ( js ), estimadores de los
correspondientes parámetros yj j . Para el tratamiento gráfico se pueden utilizar

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
5
los histogramas, los diagramas de cajas y las barras de error. El contraste más utilizado es el siguiente.
Test para comparar las k medias. Desde un punto de vista inferencial, y
aceptando distribuciones normales e igualdad de varianzas ( ,( )jN ), para la
comparación de las k medias: 0
1
i jH i j
H no todas iguales, se utiliza el estadístico:
/( 1)/( )
entre
dentro
SS kF
cal SS n k, que sigue una F-Snedecor con k-1 y n-k g.l. (n= ni), si H0 es
cierta. Fijado el valor del nivel de significación , si 1 , 1,cal k n kF F se rechaza la
hipótesis nula H0 (la dispersión entre los grupos es mayor que la que existe dentro de los grupos); en caso contrario no tenemos motivos para rechazarla. De manera
equivalente, si P < se rechaza H0 y se admite que hay diferencias significativas.
Este contraste puede utilizarse para “comparar las concentraciones de un cierto compuesto en vinos elaborados con uvas de k>2 variedades”, “comprobar si existen diferencias en la composición de quesos elaborados a partir de leche de vaca, o leche de cabra o leche de oveja”, y en general para "comparar los k valores medios obtenidos para k tratamientos", “comparar las puntuaciones de un cierto atributo, asignadas a 12 quesos procedentes de 3 procesos de elaboración, por 12 jueces” y se engloba dentro del tratamiento estadístico: Análisis de la Varianza (ANOVA) de una vía.
Si una vez realizado el anterior contraste hay que aceptar que no todas las medias poblaciones son iguales, se pueden utilizar los test de Schefee, de Tukey, de Student-Newman-Keuls, LSD, ... para averiguar cuáles son las diferentes.
En caso de no aceptar normalidad de las poblaciones se puede utilizar el test no paramétrico de Kruskal-Wallis.
Para comprobar si las k varianzas son iguales, 2 2 2
0 1 2 ...¿ ?kH se puede
utilizar el test de Bartlett, el de Levene, o, si el tamaño de las muestras coincide, el test de Cochran.
Cabezas, L., M.A. González-Viñas, C. Ballesteros,· P.J. Martín-Álvarez. “Application of Partial
Least Squares regression to predict sensory attributes of artisanal and industrial Manchego
cheeses”. Eur. Food Res. Technol., 2006, 222 (3-4), 223-228.
Statistical method: The statistical methods used for analysis were: one-way analysis of
variance to determine if there were significant differences between groups and Student–
Newman–Keuls test for means comparisons, using Statistica program ...
1.4.1 Análisis de la Varianza (ANOVA)
El objetivo fundamental del ANOVA, según Fisher, es descomponer la variabilidad de un experimento, en componentes independientes, que puedan asignarse a causas

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
6
distintas. Según Scheffe, el ANOVA permite analizar medidas, que dependen de varios factores, y que operan simultáneamente, para decidir cuáles tienen un efecto significativo sobre la variable estudiada y cuáles no. Una parte de la variabilidad total de la característica analizada podrá ser justificada por los factores estudiados; y la parte no justificada se acepta que se debe al error y a otros posible factores no controlados. ANOVA de un factor. En el caso de un solo factor con k niveles fijos (o
tratamientos), el modelo matemático aceptado, es: (, , , ,)i j i j i j j i jx e e
, ,i j j i jx e donde ,i jx representa el valor i-ésimo de la variable analizada
en el nivel j-ésimo, /n nj j representa el valor de una media global, n j el
número de medidas en el nivel j-ésimo, j la media de la variable en la población j-
ésima, ( )j j serían k cantidades fijas representando el efecto del nivel j-
ésimo sobre la media global , cumpliéndose 0j jj
n , y , ,( )i j i j je x los
errores, que aceptamos independientes y con distribución ,(0 )N . Para comprobar
si el factor influye sobre la variable analizada, podríamos establecer las hipótesis:
0
1
0 1,2,...,
j
H j kjH no todas las son nulas
, equivalente a la anterior 0
1
i jH i j
H no todas son iguales; si todas
las medias son iguales, entonces todas las j serían nulas, y el factor no tiene efecto
significativo sobre la variable observada. El estadístico para el contraste es el mismo
utilizado anteriormente (1,
/( 1)~
/( )factor
cal k n kerror
SS kF F
SS n k), y los resultados se muestran en
forma de tabla (la tabla ANOVA).
Fuente de Variación
Suma Cuadrados
Grados de libertad
Cuadrado Medio
Valor de la Fcal
Probabilidad asociada
Factor aSS 1k aMSS /a wMSS MSS P
Error wSS ( )n k wMSS
Total tSS 1n
Si el valor de la probabilidad asociada (P) es < se rechaza H0 y se admite que el factor influye. En el caso de un solo factor con k niveles aleatorios, el modelo del análisis de la
varianza viene dado por: , ,i j j i jx a e donde se acepta que los efectos ja son v.a.
independientes con distribución (0, )aN , y los errores ,i je , son independientes y con
distribución (0, )N . Para este modelo interesa comprobar la hipótesis 2
0 0aH , es
decir, no existe variación debida al factor. Para este contraste se utiliza el mismo
estadístico calF utilizado en el modelo de efectos fijos, que sigue una F-Snedecor con
k-1 y n-k g.l.
Simó, C., P.J. Martín-Alvarez, C. Barbas, A. Cifuentes. " Application of stepwise discriminant
analysis to classify commercial orange juices using chiral micellar electrokinetic
chromatography-laser induced fluorescence data of amino acids". Electrophoresis, 2004, 25,
2885 -2891
Statistical analysis. The statistical methods used for the data analysis were: ..; one-way
analysis of variance (ANOVA) to test the effect of the factor studied (processing); Scheffé test
for means comparisons; and ….

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
7
Results:
ANOVA de 2 factores. En el caso de 2 factores, con niveles fijos, se acepta que las diferencias observadas en la variable analizada X se deben: a los diferentes niveles de actuación del factor A, a los diferentes niveles de actuación del factor B, a la posible interacción entre ambos factores A y B, o a otras causas no controladas, que incluiremos en el error experimental. El modelo matemático es
, , , , ,( )i j k i j i j i j kx e con i =1,2,...,a; j =1,2,...,b; k=1,2,...,m
repeticiones; y donde .i i es una cantidad fija, que representa el efecto del
nivel i-ésimo del factor A, .j j es una cantidad fija, que representa el efecto
del nivel j-ésimo del factor B, , . .( )i j ij i j es también una cantidad
fija, que representa el efecto de la interacción entre los niveles i-ésimo del factor A
y j-ésimo del B, y , ,i j ke el error, una v.a., con distribución N(0, ) . Las posibles
hipótesis para contrastar son 3: 1
0 ,
1
1
( ) 0 ,i jH i j
H no todos nulos
, 2
02
1
0iH i
H no todos nulos y
3
0
3
1
0jH j
H no todos nulos
, y los estadísticos utilizados siguen la distribución F-Snedecor, con
diferentes grados de libertad. Los resultados se muestran en la correspondiente tabla ANOVA:
Fuente de Variación
Suma cuadrados
Grados de libertad
Cuadrado Medio
Valor de la Fcal
Probabilidad asociada
Factor A ASS 1a AMSS wA MSSMSS / PA
Factor B BSS 1b BMSS wB MSSMSS / PB
Interacción AB
ABSS )1()1( ba ABMSS
wAB MSSMSS / PAB
Error wSS )1(mba wMSS
Total tSS 1mba
Los estadísticos utilizados son:
1 = /cal AB wF MSS MSS para contrastar si existe interacción ( 1
0H ),
2 = /cal A wF MSS MSS para comprobar el efecto del factor A ( 2
0H ) y
3 = /cal B wF MSS MSS para comprobar si el factor B influye en la respuesta ( 3
0H ).
Si PAB> se acepta 1
0H , y el modelo se dice que es aditivo, no hay interacción. Si
PA> se acepta 2
0H , y se dice que el factor A no influye en la variable analizada. Si se

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
8
cumple PB< hay que rechazar 3
0H y se dice que el factor B si influye. Cuando no
existe interacción entre los factores la influencia de uno de ellos no dependerá de los niveles del otro factor (en el gráfico de las medias las líneas serán paralelas). Cuando sólo existe una observación por celda (m=1), el modelo es:
, ,i j i j i jx e . Esta técnica estadística se puede utilizar para comparar las
puntuaciones asignadas por 10 jueces a una cierta cualidad organoléptica en tres diferentes vinos, con el fin de averiguar si hay diferencias entre las puntuaciones asignadas por los jueces, o entre las puntuaciones de los 3 vinos. Hernández, T., I. Estrella, D. Carlavilla, P.J. Martín-Álvarez, M.V. Moreno-Arribas.“Phenolic
compounds in red wine subjected to industrial malolactic fermentation and ageing on lees”. Anal.
Chim. Acta, 2006, 563 (1-2), 116-125.
Statistical analysis. The statistical methods used for data analysis were: …; two way analysis of
variance (ANOVA) to test the effects of the two factors; Student–Newman–Keuls test for means
comparisons; and …
Results:
2. TRATAMIENTO ESTADÍSTICO DE DATOS BIVARIANTES
Datos: En este caso se dispone de un conjunto de n pares de observaciones de dos variables X1, X2: { (x1,1 , x1,2), (x2,1 , x2,2), ..., (xn,1 , xn,2) }, procedentes de una cierta población bivariante W. En esta situación podemos calcular los valores medios y desviaciones estándar muestrales para cada variable, que serán estimadores de los correspondientes parámetros poblacionales. Pero, al tener dos variables, podemos calcular también, los valores muestrales de la covarianza y del coeficiente de
correlación: )1/())((1
22,11,12 nxxxxsn
iii y
)/( 2112 sssr , que tienen en cuenta la variación
60,0050,0040,0030,0020,0010,00
propanol
14,00
12,00
10,00
8,00
6,00
4,00
me
tan
ol

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
9
conjunta de las dos variables X1 y X2, y que serán estimadores de los correspondientes
parámetros poblacionales: 12 y . El tratamiento gráfico más utilizado es el gráfico, o diagrama, de dispersión. Aceptando distribución conjunta normal bivariante, podríamos conocer la región
de confianza al 100(1- )%, para ( 1, 2) mediante la inecuación matricial:
2
222
11
1
212
1212211 ),(
x
xxx siempre que se conozcan los valores de 1,
2 y 12. Esta región no coincide con el producto cartesiano de los correspondientes intervalos para cada media. Más interesante resulta la elipse de confianza definida
por: 2,2,
22
11
1
2212
12112211
)12
(2
)2(),( nF
xx
xx
ss
ssxxxx
n
nn , que
permite decidir si una observación ),( 21 xx procede o no
de una determinada población con distribución normal bivariante (detección de puntos anómalos). Para el estudio de dependencia entre las dos variables, se recurre al Análisis de Correlación (cuando la muestra ha sido obtenida de forma aleatoria) y/o al Análisis de Regresión (lineal o no lineal), cuando aceptamos que los valores de una de las variables no están sujetos a error, y estamos interesados en expresar la
relación de dependencia mediante un modelo matemático (X2 = f(X1) + ).
2.1 ANALISIS DE CORRELACION SIMPLE
Para el caso de variables cuantitativas, y aceptando distribución normal bivariante, el coeficiente de correlación de Pearson, definido por:
1
2 2
1 1
( )( )
( ) ( )
n
i
n n
i i
x x y yi i
x x y yi i
r , mide la relación lineal entre las dos variables y es estimador
del coeficiente de correlación poblacional . Se puede:
calcular el intervalo de confianza para ( 1 , 2 ), y/o
realizar un test de hipótesis sobre para ver si puede aceptarse que es distinto
de 0 (Ho = 0 ). Si la probabilidad asociada (P) es < se acepta 0. En el caso de no aceptar normalidad en los datos se utiliza el coeficiente correlación de Spearman, que utiliza los rangos de los datos, y el correspondiente test no
paramétrico para el contraste de hipótesis Ho = 0 . Como aplicación de esta técnica: correlación: entre parámetros del color y compuestos fenólicos en vinos, entre descriptotes sensoriales y compuestos químicos, ...
Monagas M., P.J. Martín-Álvarez, B. Bartolomé, C. Gómez-Cordovés. "Statistical
interpretation of the color parameters of red wines in function of their phenolic composition
during aging in bottle". Eur. Food Res. Techn., 2006, 222: 702-709. Statistical analysis: The statistical methods used for the data analysis were: two-way analysis of variance
(ANOVA) to test the influence of the two factors studied, “variety” and “aging time” (the interaction and
error terms were pooled); principal component analysis (PCA) from standardized variables to examine the
relationship between the 20 analyzed variables; and correlation and polynomial regression analysis to
describe the relationship between the color parameters and the phenolic components during aging in
bottle in the different wines…..
22 24 26 28 30 32 34 36 38 40 42 44
Glucosa
26
28
30
32
34
36
38
40
42
44
46
48
50
Fru
cto
sa

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
10
Note. All the regression coefficients (a, b, c) presented are significantly different from zero (p<0.05); R2 = determination coefficient; s = residual standard deviation;
CV(%)=( /s y )100% residual standard deviation expressed as percetange of the mean value
Monagas M., P.J. Martín-Álvarez, C. Gómez-Cordovés, B. Bartolomé. "Time course of the colour of
young red wine from Vitis vinifera L. during aging in the bottle". International Journal of Food Science
and Technology, 2006, 41, 892-899.
Statistical analysis: The statistical methods used for the data analysis were: polynomial regression
analysis, to describe the evolution of the different colour parameters during wine ageing in bottle;
forward stepwise multiple regression analysis, to predict the CIELAB variables using the colorimetric
indices …
2.2 ANALISIS DE REGRESION LINEAL SIMPLE
En el caso de regresión lineal simple, se acepta que las dos variables X e Y están
relacionadas mediante el modelo teórico: 0 1i i iy x . Para este modelo
matemático, se aceptan las siguientes hipótesis: la variable dependiente Y, es una v.a., sujeta a error, la variable independiente X toma valores fijos, y no es una v.a.,
o su error es despreciable frente al de la variable Y, y los errores i son

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
11
independientes y con distribución N(0, ) . El modelo teórico se estima, mediante el
procedimiento de mínimos cuadrados ( 210 )( ii xymin ), por el siguiente
modelo: ii xbby 10ˆ , donde iy es el valor esperado de Y (valor calculado o
predicho por el modelo), para un determinado valor xi de la variable X. Los coeficientes de regresión se calculan mediante las expresiones:
n
i
i
n
i
ii XXYYXXb1
2
1
1 )(/))(( y XbYb 10.
La precisión del ajuste de los datos al modelo, se basa en la siguiente descomposición de la suma de los cuadrados de las desviaciones de los valores de la
variable Y respecto su valor medio: n
iyiy
1
2)(
n
iiiyiy
nyiy
1
2
1
2)ˆ()ˆ( , que
supone dividir la variabilidad total, en una parte explicada por el modelo de regresión, y
otra que aceptamos se debe al error ( resYSSregYSStotYSS )()()( ), y que se presenta
en forma de la siguiente tabla, conocida como tabla ANOVA de la regresión: Fuente de
Variación Suma de
cuadrados Grados
de libertad
Cuadrado Medio
Valor de la Fcal
Valor de P
Mod. Regresión
regYSS )( 1 regMSS resreg MSSMSS / )( 2,1 caln FFprob
Residuo resYSS )( 2n
resMSS
Total totYSS )( 1n
El estadístico /cal reg resF MSS MSS sigue una F-Snedecor con 1 y n-2 g.l., y puede
utilizarse para el contraste: 1 1 10; 0oH H (test de linealidad). Fijado ,
aceptar la hipótesis nula (P > ), es aceptar un modelo constante para Y
( iiY 0 ). Si P < se rechaza la hipótesis nula. Este contraste es equivalente al
que veremos más tarde, basado en la t-Student con n-2 g.l.. Medidas de la precisión son: el coeficiente de determinación:
totreg YSSYSSR )(/)(2
, que informa de la proporción de la variabilidad explicada por el
modelo, y la desviación estándar residual: )2/()( nYSSMSSs resres , que
informa sobre el error medio cometido por el ajuste. En el caso de disponer de repeticiones es posible comprobar si el modelo tiene falta de ajuste, y si es así, habría
que probar otro modelo, por ejemplo el polinómico (2
0 1 2i i i iy x x ).
El estudio de los residuos permite comprobar si se cumplen las hipótesis establecidas para los errores: siguen distribución Normal, son homogéneos e independientes (test Durbin-Watson). Si el modelo se acepta como válido, se pueden calcular los siguientes intervalos de
confianza al 100(1 - )%: intervalo de confianza para 0, intervalo de confianza
para 1, y intervalo de confianza para el valor medio esperado E(Y| X=X0) que permite definir las bandas de confianza para la línea teórica de regresión, al variar
X0, utilizando el valor 1 / 2, 2nt de la t-Student con n-2 g.l.
Fijado el valor de , también se pueden contrastar las siguientes hipótesis:
1 0oH mediante el estadístico: 21 ( )ii
bt X Xcal s
que sigue una t-
Student con n-2 g.l..
Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
12
0o oH mediante el estadístico:
2
2
0( )
ii
i
n X X
X
btcal s
, que sigue una t-Student
con n-2 g.l..
Fijado , si la probabilidad asociada (P) es < se acepta que el parámetro es
distinto de cero ( 0i ).
Como aplicación de esta técnica: calibrado lineal de un método analítico, regresión lineal entre descriptotes sensoriales y compuestos químicos. Marcobal, A., M.C. Polo, P.J. Martín-Álvarez, M.V. Moreno-Arribas. "Biogenic amine content of red spanish
wines: Comparison of a direct ELISA and an HPLC method for the determination of histamine in wines".
Food Res. Int., 2005, 38, 387-394
Statistical methods: The statistical methods used for analysis were as follows: regression analysis for the
calibration curves; ...
Results: Linear regression analysis of area versus concentration of biogenic amines in the standard solution,
using two replicates at five points in the range indicated in Table 2, was used. Regression parameters and
statistical properties can be found in Table 2. In order to judge the adequacy of the linear models, the F-ratio
for lack of fit was calculated (Massart, Vandeginste, Deming, Michotte, & Kaufman, 1988), and when
significant results were obtained, a second-degree polynomial regression was used. As can be seen in Table 2,
the regression lines obtained for all the amines were linear equations that passed through the origin, except for
putrescine, which corresponded to a second-degree polynomial equation. The values of the coefficient of
determination (R2 in Table 2) were higher than 0.99 and indicated that the fits were acceptable, with a
standard deviation of residuals, expressed as a percentage of the mean value of the response, ( / )s y 12%
for the amines quantified. Table 2 also shows the mean values of the recovery results. Recovery has been
estimated as (the amount found in the spiked sample - the amount found in the sample)*100/the amount
added (Massart et al., 1988). The mean values correspond to the individual values obtained from the recovery
experiments and also to the values obtained for two more different wine samples. The mean values of
recovery obtained range from 88% for tyramine to 118% for methylamine.
Detection limits were estimated from the area corresponding to three times the system noise (IUPAC, 1978),
which was calculated as the mean of the area of the noise of seven injections of a 10% ethanol solution. The
values obtained (Table 1) range from 0.006 mg/l for ethylamine to 0.057 mg/l for putrescine.
Quirós, A., M. Ramos, B. Muguerza, M. A. Delgado, P.J. Martín-Álvarez, A. Aleixandre, and I. Recio.
"Determination of the Antihypertensive Peptide LHLPLP in Fermented Milk by High-Performance Liquid
Chromatography–Ion Trap Tandem Mass Spectrometry". Journal of Dairy Science, 2006, 89, 4527-35,
Statistical Methods: Linear and polynomial regression for the calibration curves and nonlinear
regression for studying the evolution of the concentration with the time of fermentation were calculated
with ……………

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
13
3. TRATAMIENTO ESTADÍSTICO DE DATOS MULTIVARIANTES.
El Análisis Multivariante puede definirse como el conjunto de métodos estadísticos y matemáticos para analizar, describir e interpretar observaciones multidimensionales. Como objetivos a conseguir mediante la utilización de estos métodos se pueden citar los siguientes: 1) Reducción de los datos, es decir simplificar la dimensionalidad de los datos sin
perder información valiosa, 2) Buscar agrupamiento de las observaciones o de las variables basada en
alguna medida de semejanza o similitud, 3) Definir reglas de decisión que permitan asignar un individuo con ciertas
características a un grupo determinado, 4) Estudiar medidas de dependencia entre conjuntos de variables, 5) Predecir los valores de las variables a partir de la información aportada por otras,
mediante un modelo matemático, 6) Construir y contrastar hipótesis sobre algunos parámetros poblacionales. Estos métodos pueden ser aplicados en cualquier campo de la Ciencia, y su utilización tuvo un gran crecimiento durante la década de los ochenta como consecuencia: del crecimiento de la utilización de las técnicas analíticas, de la aparición de los microprocesadores, y de la implementación en programas informáticos. Como limitación habría que indicar la necesidad de disponer de los programas de ordenador que generalmente tienen un coste elevado. Como herramientas de trabajo estos métodos utilizan: la Geometría algebraica, el Cálculo matricial, y el Cálculo numérico.
3.1 MATRIZ DE DATOS
Para la aplicación de estos métodos multivariantes necesitamos, como substrato, una tabla de datos donde se recoge la información correspondiente a n muestras, u observaciones, sobre las cuales se han analizado p variables o características, es decir disponemos de datos correspondientes a p variables (X1, X2,...,Xp) analizadas en n muestras procedentes de una cierta población multivariante W. Entre las variables recogidas en la tabla de datos se pueden distinguir dos tipos: las variables cuantitativas que asignan un único valor a cada observación mediante una escala de intervalo o de razón (pueden ser discretas o continuas), y las variables cualitativas o nominales que permiten clasificar las observaciones en grupos mediante una escala nominal. Dentro de las últimas están las variables binarias (o dicotómicas), que solo pueden tomar dos valores. Las variables cualitativas se suelen codificar numéricamente para su tratamiento posterior. Según esta clasificación nuestra tabla de datos estará formada por ambos tipos de variables: cuantitativas y cualitativas codificadas numéricamente.

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
14
Con nuestra tabla de datos, o matriz de datos, podemos pensar en dos posibles modelos geométricos: a) las n observaciones como n puntos en el Espacio Euclídeo p-dimensional de
las p variables. Podríamos definir la matriz de distancias D(n,n) entre las n observaciones, y pensar en elipsoides de concentración de las mismas en el espacio, y
b) las p variables como vectores del espacio Euclídeo n-dimensional de las n observaciones. Podríamos pensar en la matriz de correlación entre las variables a partir de los cosenos entre los correspondientes vectores. De la proyección de un vector en otro, se obtendría la idea de regresión de una variable en otra.
Con vistas a buscar agrupamiento entre las observaciones se definen medidas de semejanza (similitud) y de desemejanza (distancia), relacionadas con la proximidad o lejanía de las mismas. En el caso de variables cuantitativas se pueden definir
diversas distancias entre dos observaciones ),...,( ,1,
'
piii xxx
y ),...,( ,1,
'
pjjj xxx
: la
distancia Euclídea: k kjkiji xxd 2
,,, )( , la distancia ciudad o Manhattan:
k ,,, || kjkiji xxd , la de Chebychev: || ,,, kjkiji xxmaxd ,..., etc, siendo la distancia
Euclídea la más utilizada. Para variable cualitativas se utiliza como medida de distancia el porcentaje de desacuerdo entre los posibles valores:
pxxdeNd kjkiji /)º( ,,,
3.2 REPRESENTACION GRAFICA DE LOS DATOS
Con vistas a detectar posibles patrones en la tabla de datos se recurre a la representación gráfica de las observaciones y de las variables mediante objetos geométricos (puntos, líneas, polígonos, cuerpos, etc.). La semejanza entre los objetos permitirá encontrar los patrones buscados. La mayor limitación estará en que la representación será bidimensional, sobre una hoja de papel o pantalla del ordenador, y por tanto solo aproximada a la realidad. Los métodos de representación bidimensional más utilizados por los métodos multivariantes son:
Métodos directos: En el caso de p variables los se pueden utilizar los diagramas de dispersión matricial, y los iconos a base de histogramas, de perfiles o de estrellas, o de tela araña.
Métodos de aproximación mediante proyección: En este apartado se incluyen las representaciones gráficas más utilizadas en el tratamiento de datos multivariantes. Se trata, en general, de definir nuevas variables (componentes principales, factores, variables canónicas,... ), cumpliendo algún objetivo, y proyectar las muestras sobre estas nuevas variables. La utilización de solo unas pocas variables, permite una visión general de los datos. Así en el caso de componentes principales (o factores) se trata de buscar una nueva variable Y que recoja la máxima variación de la nube de puntos, y en el caso de variables canónicas se trataría de buscar una nueva variable Y para lograr máxima separación entre los valores medios de los grupos, en la proyección. Métodos de aproximación mediante optimización: Consiste en buscar nuevas variables (generalmente dos), con el objetivo de conservar, al máximo, las distancias
absorbanisoamilimetpro12propanolacetetilmetanol
meta
nol
acete
til
pro
panol
metp
ro12
isoam
ili
absorb
an
5
4
3
2
1
marca

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
15
entre las observaciones. Esta técnica, conocida como representación mediante mapas no lineales (“Non-Linear Mapping”), trata de minimizar la función:
ji, jiji ddL 2
,, )ˆ( , siendo jid y ijd las distancias, entre cada dos muestras, en el
espacio de las variables originales y en el espacio bidimensional de las nuevas variables, respectivamente. Representación gráfica de matrices cuadradas: La mejor representación bidimensional de la matriz de distancias entre muestras, o de la matriz de correlaciones entre variables, es el dendrograma, que informa de la similitud de la muestras o de la variables, véase figura adjunta, y que es el resultado, más importante, obtenido mediante la aplicación del Análisis de Conglomerados.
3.3 CLASIFICACION DE LOS METODOS
A la hora de clasificar los métodos para el tratamiento de datos multivariantes se suele hablar de métodos supervisados y no supervisados, según se utilice o no la información de pertenencia de las observaciones a poblaciones o grupos definidos previamente. Si tenemos en cuenta la procedencia de las observaciones y los grupos de variables analizadas en las observaciones, podemos tener distintas matrices de datos. Una clasificación de esta matrices de datos podría ser la siguiente: a) Una única población y un solo grupo de variables Disponemos de una muestra aleatoria de tamaño n, procedente de una única población W, de p variables, con
vector de medias ),...,(' 1 p
y matriz de covarianzas
11 1
1
...... ... ...
...
p
p pp
, que
representamos en la siguiente tabla de datos:
Variables
X1 X2 ... Xp
1 x1,1 x1,2 ... x1,p
Observ. 2 x2,1 x2,2 ... x2,p
3 x3,1 x3,2 ... x3,p
... ... ... ... ...
n xn,1 xn,2 ... xn,p
Podemos calcular los siguientes valores muestrales: el vector de medias
),...,,(' 21 pxxxx
, y las matrices de covarianzas ( S = (sij) ), y de correlaciones ( R =
(rij)) ). Los tratamientos multivariantes para este tipo de matriz de datos, todos ellos no supervisados, podrían ser: - Análisis de Componentes Principales (PCA), y/o el Análisis Factorial (FA) con vistas a reducir la dimensión de los datos y estudiar la interrelación entre variables y entre observaciones, y - Análisis de Conglomerados (CA) para buscar agrupamientos de la observaciones o de las variables. También, con vistas a la representación gráfica de las observaciones, es posible utilizar la representación de mapas no lineales (''no linear mapping'') (LNM). b) Varias poblaciones y un solo grupo de variables: En este caso se dispone de k muestras, con tamaños ni, procedentes de k poblaciones multivariantes Wi en las
mismas p variables, con vectores de medias i
y matrices de covarianzas i , que
representamos en la siguiente tabla de datos:

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
16
Variables X1 X2 ... Xp
1 x1,1,1 x1,2,1 ... x1,p,1
Observ.
2 x2,1,1 x2,2,1 ... x2,p,1
W1 3 x3,1,1 x3,2,1 ... x3,p,1
... ... ... ... ...
n1 xn1,1,1 xn1,2,1 ... xn1,p,1
--- -------------------------------------------------------
--- -------------------------------------------------------
1 x1,1,k x1,2,k ... x1,p,k
Observ.
2 x2,1,k x2,2,k ... x2,p,k
Wk 3 x3,1,k x3,2,k ... x3,p,k
... ... ... ... ...
nk xnk,1,k xnk,2,k ... xnk,p,k
Se pueden calcular los siguientes valores muestrales: los k vectores de medias
),...,,( 21
'
ipiii xxxx
, las k matrices de covarianzas ( Sj ) y las k matrices de
correlaciones ( Rj ). Los métodos de tratamiento a utilizar para este tipo de matriz de datos, todos ellos supervisados, es decir, utilizan la información de la pertenencia de las muestras a los grupos de partida, podrían ser: - Métodos de Clasificación Supervisada: Análisis Lineal Discriminante (DLA) ó Cuadrático (DQA), que son métodos paramétricos que aceptan distribuciones normales de las poblaciones y matrices de covarianza iguales (DLA) o no (DQA)) Método SIMCA, que utiliza el modelo factorial de componentes principales en cada grupos. Método de los k vecinos más próximos (kNN), que es un método no paramétrico. Todos estos métodos permiten obtener reglas de clasificación para asignar nuevas muestras a las poblaciones o grupos de partida, Análisis Canónico de variables (CVA), con vistas a obtener una representación gráfica de las muestras, maximizando las diferencias entre los k grupos, y Análisis Multivariante de la Varianza (MANOVA), para comprobar diferencias entre los grupos.
A la matriz global de datos formada por las n = ni observaciones, también podemos aplicarle los anteriores métodos no supervisados (PCA, FA y CA), siempre que no utilicemos la información sobre la procedencia de las observaciones. c) Una población y dos grupos de variables: Disponemos en este caso de una muestra de tamaño n procedente de una población multivariante W de p+q variables, con vector de medias
, matriz de covarianzas , que recoge la información de un
total de p+q variables analizadas en las mismas n observaciones, y que representamos en la siguiente tabla de datos:
Variables
Variables X1 X2 ... Xp Y1 Y2 ..
.
Yq 1 x1,1 x1,2 ...
... x1,p y1,1 y1,2 ..
.
y1,q
Observ. 2 x2,1 x2,2 ... x2,p y2,1 y2,2 ...
y2,q

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
17
3 x3,1 x3,2 ... x3,p y3,1 y3,2 ...
y3,q
... ... ... ... ... ... ... ...
...
n xn,1 xn,2 ... xn,p yn,1 yn,2 ...
yn,q
Las variables Y's podrían ser características sensoriales de las muestras, mientras que las X's serían las características químicas de las mismas. El objetivo fundamental sería estudiar la relación de dependencia entre ambos grupos de variables. Para cada grupo de variables podemos calcular los correspondientes vectores de medias
),...,( 1 pxx y ),...,( 1 qyy , las matrices de covarianzas (Sx y Sy) y de correlaciones (Rx y
Ry), pero también las matrices de covarianza y correlaciones entre los dos grupos de
variables (Sxy y Rxy). La matriz completa de covarianzas sería: yyx
xyx
SS
SSS , y la de
correlaciones yyx
xyx
RR
RRR . Los métodos de tratamiento a utilizar para este tipo de
matriz de datos, que se incluyen dentro de los métodos para el estudio de dependencia entre los dos conjuntos de variables, podrían ser: Análisis de Correlación Canónica (ACC) para buscar dependencias entre ambos grupos de variables Análisis de Regresión Multivariada que incluye: Regresión Lineal Múltiple (MLR), Regresión por pasos sucesivos (SMLR), Regresión en Componentes Principales (PCR), y la Regresión por mínimos cuadrados parciales (PLS), con vistas a explicar las variables respuestas (variable Y's del segundo grupo) en función de las variables predictoras (variable X's del primer grupo) mediante un modelo matemático que permita predecir los valores de las variables respuesta.
A la matriz global de datos formada por las n observaciones podemos aplicarle también los anteriores métodos no supervisados (PCA, FA y CA).
3.4 TRATAMIENTO PREVIO DE LOS DATOS.
Con vistas a detectar datos anómalos en las matrices de datos anteriores, y antes de aplicar alguna de las distintas técnicas mencionadas, conviene obtener la información descriptiva de todas las variables (valores:
min max, , / , ,x s s x x x ), y los valores mínimo y
máximo de los correspondientes datos estandarizados. Una simple inspección de estos dos últimos valores permitiría detectar posibles datos anómalos. También, para la detección de este tipo de datos, puede utilizarse el rango de valores admisibles:
)13(5.11)13(5.11 QQQxQQQ . La estandarización de las variables, para lograr
0x y 12
s , suele ser utilizada antes de la aplicación de alguno de los métodos
multivariantes.
4. TRATAM. DE DATOS MULTIVARIANTES. METODOS NO SUPERVISADOS
4.1 ANALISIS DE COMPONENTES PRINCIPALES
El principal objetivo de esta técnica del Tratamiento de Datos Multivariantes, es reducir la dimensionalidad de los datos sin perder información valiosa, a partir de la interrelación de las variables analizadas. Se basa en transformar las variables originales en otras nuevas, que llamaremos componentes principales, cumpliendo: 1) cada nueva variable es combinación lineal, normalizada, de las originales, es
decir: 1;... 2,,2,2,1 k ikpipiiii aXaXaXaY
2) las covarianzas entre cada par de estas nueva variables es cero
( cov( , ) 0Y Y i ji j )
3) las nuevas variables tienen varianzas progresivamente decrecientes
( var( ) var( ) ... var( )1 2
Y Y Yp )

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
18
4) la suma de las varianzas de las p nuevas variables coincide con la varianza
total (VT) de las variables originales, es decir: VTXYp
ii
p
ii
11
)var()var(
Se trata, por tanto, de una transformación que podemos representar en forma matricial
de la manera siguiente: ),(),(),( pppnpn AXY . Como resultado de la aplicación de esta
técnica tendremos dos nuevas matrices que recogen toda la información para un
posterior estudio: la matriz ,( )i jY y , de orden (n,p), con las coordenadas de las
observaciones en las nuevas variables, y la matriz ,( )i jA a , de tamaño (p,p), que
tiene en cuenta la interrelación entre las variables originales así como su contribución en la definición de las nuevas variables. Desde un punto de vista geométrico, se trata de una rotación de los ejes de coordenadas, una vez centradas las variables. Determinación de los coeficientes a i,j. Los coeficientes se determinan mediante el cálculo de los valores y vectores propios de la matriz de correlaciones R si las variables están estandarizadas (La mayoría de los programas proceden a estandarizar
previamente las variables). En general, ja
será el vector propio asociado con el j-
ésimo mayor valor propio j y además se cumple que jjYVar )( . La matriz A
tendrá como columnas los vectores propios asociados con los correspondientes valores propios, ordenados de manera decreciente por su valor, y tiene la siguiente
propiedad: 1 tA A , es decir es una matriz ortogonal. Esta propiedad permite
establecer la ecuación matricial: ( , ) ( , ) ( , )
t
n p n p p pX Y A que será muy útil, como veremos
más adelante. Reducción de la dimensionalidad. Teniendo en cuenta que los valores de las
varianzas son progresivamente decrecientes ( jjYVar )( ) y su suma es VT
( VTVar j )( ), podemos considerar:
Y1 explica un 100( 1 /VT)% del total de la varianza de la matriz original de datos,
Y1 + Y2 explican conjuntamente, un 100(( 1 + 2 )/VT)% del total de la varianza de la matriz original de datos, y en general,
Y1 + Y2 +...+ Yq explican conjuntamente, un 100(( 1 + 2 +...+ q )/VT)% del total de la varianza de la matriz original de datos.
En muchas de las aplicaciones, con estas q (q<<p) primeras componentes principales podemos explicar un elevado porcentaje de la varianza total, lo que equivale a considerar que hemos logrado una reducción de la dimensión original de los datos, sin perder más que una parte pequeña que aceptaremos no es muy valiosa. Este nº q de componentes suele corresponder con el número de valores propios >1.
Matricialmente tendremos: ( , ) ( , ) ( , )n q n p p qY X A donde estas q nuevas variables, están
incorrelacionadas, y explican un elevado porcentaje de VT.
Interpretación de las componentes principales. A partir de la observación de la matriz de coeficientes (A(p,q)), podemos descubrir agrupamientos de las variables originales, según su contribución para definir las q nuevas variables. La matriz de coeficientes A se puede transformar
Matriz de componentesa
,960
,952
,934 -,337
,928 -,269
,910 -,280
,902 ,399
,803 -,502
,929
-,376 ,855
,547 ,810
,606 ,760
,949
hexol
m1but2
metanol
propanol
benol
m1but3
etxol
fenol2
terpin
cisol
linol
isol
1 2 3
Componente
Método de extracción: Análisis de compon. princ.
3 componentes extraídosa.
Varianza total explicada
6,682 55,679 55,679
3,092 25,771 81,450
1,556 12,963 94,412
Componente
1
2
3
Total% de lavarianza % acumulado
Autovalores iniciales

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
19
para lograr que sus coeficientes (los “loadings”) sean las correlaciones entre las componentes principales y las variables originales. A partir de esta matriz resulta mas fácil ver las variables que definen las componentes principales, y conocer el agrupamiento de las mismas, utilizando el porcentaje explicado con las primeras q primeras componentes. Representación de las muestras. A partir de la matriz Y, con las puntuaciones (coordenadas) de las muestras (observaciones) en las componentes principales, se puede obtener la representación bidimensional de las muestras en el plano definido por las dos primeras componentes principales. Esta representación de las muestras en función de las dos primeras componentes principales podría utilizarse para: explorar o confirmar posibles agrupamiento de las muestras, y para detectar posibles muestras anómalas (''outliers'').
4.2 ANALISIS FACTORIAL
El objetivo de este método no supervisado, debido a Pearson, es describir la interdependencia entre las variables analizadas a partir de otras, no observadas, llamadas factores. Se acepta que existen k variables (factores) Fi, no observadas, que son responsables de las variables originales Xi. El planteamiento para el modelo factorial ortogonal supone que cada variable original es combinación lineal de los
factores no analizados, es decir: iqqiiiii FbFbFbX ...2211 , donde {F1,
F2,...,Fq} son los factores comunes, { 1 , 2 ,..., p} los específicos de cada una de las p variables, y bij representa las saturaciones (contribuciones o “loadings” de los
factores). En el modelo se acepta que iEFE ii 0)(,0)( , ,)(,)( ICovIFCov ii
{F1, F2,...,Fq} y { 1 , 2 ,..., p} independientes. Se trata, por tanto, de una transformación de los datos, que en forma matricial, se puede expresar de la siguiente
manera: ),(),(),(
*
),( pnpqqnpn EBFX , siendo *
),( pnX la matriz de datos estandarizada.
Desde un punto de vista geométrico se trata de buscar un subespacio, sobre el que se proyectan los n vectores fila 'x
(puntos), correspondientes a las n observaciones de la
matriz X, para hacer mínima la suma de los módulos de los vectores '
(filas de la
matriz E). Una solución para este modelo factorial sería considerar como factores las componentes principales obtenidas a partir de la matriz de correlaciones (para estar estandarizadas), es decir, Fi = Yi , que se conoce como modelo factorial de componentes principales. La solución en q componentes principales, cumple todos
los anteriores requisitos: basta con considerar: ( , ) ( , )n q n qF Y , ( , ) ( , )
t
q p q pB A y
*
( , ) ( , ) ( , ) ( , )
t
n p n q q p n pX Y A E , que es el modelo factorial en componentes principales.
Esto es posible gracias a que la matriz A es una matriz ortogonal. Los resultados con este modelo serían, por tanto, las matrices Y con las coordenadas de las muestras y la matriz A con las contribuciones, o saturaciones, de las variables. La interpretación de los factores se realiza, como antes, a partir de la observación de la matriz B con las saturaciones (o "loadings"). Para una mejor definición de la contribución de los factores en las variables, es posible realizar una rotación de los q factores extraídos. La representación de las muestras (observaciones), como puntos en el plano definido por los dos primeros factores (rotados o no) informa de los posibles agrupamiento de las muestras y de la presencia o no de muestras anómalas (“outliers”).
1,501,000,500,00-0,50-1,00-1,50
PC1
2,00
1,00
0,00
-1,00
PC
2
V+H+SO2
V+H+SO2
V+H
V+H
V+SO2
V+SO2
VC
VC

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
20
4.3 ANALISIS DE CONGLOMERADOS
Es un método no supervisado que tiene como objetivo buscar agrupamientos naturales entre las n observaciones (individuos) o entre las p variables de la tabla de datos. En el caso de agrupamiento de las observaciones, cada una de ellas es considerada como un punto en el espacio p-dimensional, con coordenadas dadas por los p valores de las variables. Existen dos técnicas de agrupamiento: las jerárquicas que ponen de manifiesto la similitud de las observaciones (o variables) entre sí, y que pueden ser divisivas (se parte inicialmente de un solo grupo con todas las observaciones), o aglomerativas (se parte inicialmente de tantos grupos como observaciones), y las no jerárquicas que sólo informan de la pertenencia de las observaciones a cada uno de los grupos. Para la aplicación de esta técnica son necesario las siguientes consideraciones: a) seleccionar una medida de semejanza entre los individuos (observaciones) o entre las variables, según el tipo de datos, b) seleccionar el algoritmo para unir los conglomerados, c) fijar el nº de conglomerados, que se desean formar, en el caso de los métodos no jerárquicos para el agrupamiento de las observaciones, y d) estandarización de las variables si son de distinta naturaleza.
Métodos no jerárquicos. Fijado el número k de conglomerados ( iC ) que
queremos formar, estos métodos permiten obtener una partición de orden k del
conjunto de los n individuos ( W = {1,2,3,...,n} ), es decir: jiji
k
CC
CCCW ...21 .
Cada conglomerado iC estará formado por ni individuos, y tendrá un centroide
cuyas coordenadas serán los valores medios de las p variables en los ni individuos,
es decir: ),...,,( 21 pi xxxc . Para cada conglomerado podemos definir su dispersión
que viene dada como la suma de las distancias al cuadrado de los ni puntos al
centroide, es decir: ),(2ii cjdE . De esta forma es posible definir, para una
determinada partición (C1, C2, ..., Ck), la dispersión total, definida por: k
iikT ECCCD
121 ),...,,( . El objetivo de estas técnicas será buscar la partición de
W, de orden k, que minimice esta dispersión total. Uno de los algoritmos más utilizado es el de las k-medias de McQueen, que consiste en: 1) asignar aleatoriamente los n individuos a los k grupos, 2) calcular los centroides de cada grupo, 3) asignar cada individuo al grupo con centroide más próximo, y 4) repetir los pasos 2) y 3) hasta lograr estabilidad. Aunque está garantizada lograr la estabilidad en un número finito de pasos, este puede disminuirse si se modifica el paso 3) recalculando los centroides después de cada asignación de los individuos. Como resultado de la aplicación de esta técnica, los programas de ordenador suelen proporcionar, además de la descripción de los k conglomerados, los valores medios de las variables en cada uno de los k conglomerados, y la comparación de dichos valores medios (ANOVA). Métodos jerárquicos aglomerativos. La utilización de estos métodos, válidos tanto para agrupar observaciones como variables, permite conocer la interrelación entre los individuos (o variables) mediante una representación gráfica bidimensional llamada dendrograma. Los algoritmos para aplicar estos métodos, en el caso de agrupamiento de observaciones, tienen en común los siguientes pasos: 1) se parte de tantos conglomerados como individuos (C1={1}, C2={2}, ...,Cn={n}), y se calcula la matriz de distancias, normalmente la Euclídea, entre ellos: D = ( d(Ci , Cj) ) = ( dij ) , 2) se buscan los dos conglomerados (Cp y Cq) con menor distancia ( d(Cp , Cq ) = min d(Ci , Cj ) ), 3) se unen los conglomerados Cp y Cq para formar un nuevo grupo y se calcula la nueva matriz de distancias entre los grupos (D = ( d(Ci , Cj)) ), y 4) se repiten los pasos 2) y 3) hasta lograr un único conglomerado formado por todos los n individuos. En general, la

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
21
matriz de distancias del primer paso, suele ser la distancia Euclídea. Las diversas formas de definir la distancia entre dos conglomerados en el paso 3), dan lugar a los distintos métodos de unión:
método del enlace sencillo ( d(Ci , Cj) = mín d(wi,wj) ; wi Ci, wj Cj )
método del enlace completo ( d(Ci , Cj) = máx d(wi,wj) ; wi Ci, wj Cj ) método del centroide ( d(Ci , Cj) = distancia entre los 2 centroides )
método del enlace en media ( d(Ci , Cj) = media { d(wi,wj) ; wi Ci, wj Cj } ) método de Ward que tiene en cuenta, dentro de cada grupo, la dispersión de las
muestras, con respecto al centroide ( j i jjip xxE 2, )( ). La unión de los
conglomerados Cp y Cq, del paso 3), se realiza si qpqp EEE ),( es mínima. Este
método de unión es muy utilizado. Antes de la aplicación de estos métodos jerárquicos la matriz de datos suele ser estandarizada para dar igual importancia a todas las variables. La secuencia de los pasos del algoritmo, se recoge, de forma gráfica, en el dendrograma, que permite observar los grupos obtenidos. En el caso de agrupamiento de las variables, el algoritmo es similar, utilizando como medida de distancia entre variables el valor 1 - el coeficiente de correlación.
Hernández, T., I. Estrella, D. Carlavilla, P.J. Martín-Álvarez, M.V. Moreno-Arribas.“Phenolic
compounds in red wine subjected to industrial malolactic fermentation and ageing on lees”. Anal.
Chim. Acta, 2006, 563 (1-2), 116-125.
Statistical analysis: The statistical methods used for data analysis were: cluster analysis (Ward’s
method from standardized variables), to discover natural groupings of the wine samples in
relation to the two study factors (technological procedure and ageing time); ….
Results: In an attempt to obtain a preliminary view of the main causes for the change in phenolic
compounds during wine ageing, cluster analysis was carried out on the data of the quantified
compounds of the 47 wines studied. Fig. 2 shows the dendrograma obtained. The squared
Euclidean distance was taken as a measure of the proximity between two samples and Ward’s
method was used as the linkage rule. The variables were standardized previously. As can be
observed in this figure, there are two large groups of wines, one corresponding to wines aged for
14 months and the other to the remaining wines. In this second group, the wines are also grouped,
to some extent, according to the time of ageing. As can be observed in Fig. 2, there was no
grouping according to the technological procedure used to manufacture the wines.

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
22
5. TRATAM. DE DATOS MULTIVARIANTES. METODOS SUPERVISADOS
La matriz de datos para la aplicación de estos métodos está formada por k matrices con ni filas y p columnas, que corresponden a k muestras aleatorias, de tamaño ni, procedentes de k poblaciones Wi, en las mismas p variables Xi, con vectores de
medias i
y matrices de covarianzas i .
5.1 ANALISIS CANONICO DE VARIABLES (CVA)
Esta técnica multivariante, tiene como objetivo, obtener la mejor representación gráfica q-dimensional, de las muestras, maximizando las diferencias entre los k grupos estudiados, a partir de la información proporcionada por las p variables Xi analizadas (q = min (p,k-1)). Para lograr este objetivo se obtienen q nuevas variables Yi, llamadas variables canónicas, que son combinación lineal de las originales, están incorrelacionadas entre sí, y maximizan las diferencias entre los k grupos estudiados. Se trata, por tanto, de transformar la matriz X con n =
ni filas y p columnas, en una mueva matriz con n filas y q columnas ( q = mín (p,k-1) ), mediante la transformación matricial Y(n,q) = X(n,p) A(p,q). La representación de las n observaciones en el plano definido por las dos primeras variables canónicas, es el resultado principal de la aplicación de esta técnica multivariante. La distancia euclidea de las muestras a los centroides de cada grupo podría utilizarse como una regla de asignación de las muestras.
5.2 METODOS DE CLASIFICACION SUPERVISADA
Dos son los objetivos fundamentales de estos métodos: a) encontrar reglas de clasificación para lograr una diferenciación de los grupos, y b) utilizar dichas reglas para asignar nuevas observaciones a alguno de los grupos estudiados. Para ello se parte de la información proporcionada por p variables analizadas en las muestras (observaciones) genuinas de los diferentes grupos. La matriz de datos de partida, estará formada por las k matrices, con las muestras de entrenamiento, indicada anteriormente. También se puede disponer de otra matriz de datos,
tnipiii xxx ,...,2,1,2,1, },...,,{ , formada por nt muestras (grupo test), analizadas en las p
variables, a las que queremos aplicar las reglas de asignación obtenidas con el conjunto de entrenamiento, para conocer su procedencia (podrían ser botellas de whisky de la marca A, abiertas, y sometidas a inspección, para verificar su autenticidad).
5.2.1 Análisis Discriminante
Dentro de los métodos de clasificación supervisada, destaca, por su amplia utilización el Análisis Discriminante. Este método paramétrico, acepta que el vector de variables aleatorias (X1, X2,..., Xp) sigue una distribución normal multivariante en
cada uno de los k grupos ( ),( iiN
), y minimiza la probabilidad de clasificación
errónea de las muestras del conjunto de entrenamiento (regla de tipo bayesiano). Si se
acepta que las matrices de covarianzas en los grupos son idénticas ( ),( iN
), el
Análisis Lineal Discriminante (ALD) calcula k funciones lineales de clasificación,
151050-5-10-15
Función 1
6
3
0
-3
-6
-9
Fu
nc
ión
2
4
3
21
Centroide
4
3
2
1
marca
funciones discriminantes canónicas

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
23
Resultados de la clasificación
18 0 0 0 18
0 12 0 0 12
0 0 15 0 15
0 0 0 8 8
100,0 ,0 ,0 ,0 100,0
,0 100,0 ,0 ,0 100,0
,0 ,0 100,0 ,0 100,0
,0 ,0 ,0 100,0 100,0
18 0 0 0 18
0 12 0 0 12
0 0 15 0 15
0 0 0 8 8
100,0 ,0 ,0 ,0 100,0
,0 100,0 ,0 ,0 100,0
,0 ,0 100,0 ,0 100,0
,0 ,0 ,0 100,0 100,0
marca
1
2
3
4
1
2
3
4
1
2
3
4
1
2
3
4
Recuento
%
Recuento
%
Original
Validación cruzada
1 2 3 4
Grupo de pertenencia pronosticado
Total
una para cada grupo, ki
pj
jjijii Xacd
,...,11
, que
permitirán clasificar las muestras del conjunto de entrenamiento con un elevado porcentaje de clasificación correcta, si las p variables tienen un elevado poder discriminante. La regla de asignación
para la muestra ),...,,(' 21 pxxxw
, será: siWwi
kjparawdmaxwd ji ,...,1)()(
. Las
funciones de clasificación y la matriz de clasificación de las muestras del conjunto de entrenamiento, son los resultados más importantes, incluidos en la mayoría de los programas de ordenador, que tienen implementada esta técnica multivariante. El Análisis Lineal Discriminante por pasos sucesivos permite seleccionar, en cada paso, la variable Xi que más ayuda en la discriminación de los k grupos de muestras, definiendo las funciones lineales de clasificación con las variables seleccionadas (subconjunto de las p originales).
Si las matrices de covarianzas son desiguales ( ),( iiN
), el Análisis Cuadrático
Discriminante (AQD) permite obtener k funciones cuadráticas para la clasificación de las muestras (Martín-Álvarez et al 1988, 1991, Herranz et al 1989, 1990).
5.2.2 Método SIMCA
El método SIMCA calcula el modelo factorial de componentes principales en cada grupo, y asigna las muestras a los grupos según su acoplamiento a los modelos teniendo en cuenta el valor del estadístico F para la asignación. Para la representación gráfica utiliza los gráficos de Cooman.
5.2.3 Método kNN
El método de los k vecinos más próximos (kNN), es un método no paramétrico de clasificación que asigna cada muestra al grupo más representado entre los k vecinos más próximos (según la matriz de distancias euclideas)
Hernández, T., I. Estrella, D. Carlavilla, P.J. Martín-Álvarez, M.V. Moreno-Arribas.“Phenolic compounds
in red wine subjected to industrial malolactic fermentation and ageing on lees”. Anal. Chim. Acta, 2006,
563 (1-2), 116-125.
Statistical analysis: The statistical methods used for data analysis were: …; and stepwise discriminant
analysis to select the variables most useful in differentiating the groups. ….
Results: In order to select the phenolic compounds most useful to differentiate the samples of wines aged on
lees (batches A, B, C, D, E and F), stepwise discriminant analysis was applied. Values of 4.0 and 3.9 were
used for F statistics to enter and to remove variables, respectively. Five of the phenolic compounds quantified
(see Table 4) were selected: cis-resveratrol, cis-p-coumaric acid, vanillic acid, (+) catechin and trans-caffeic
acid. A 100% correct assignment of the wines was obtained either by the standard or the leave-one-out cross
Coeficientes de la función de clasificación
16,983 ,055 5,583 1,004
2,895 -,271 2,116 1,364
1,511 -5,266 -4,767 -1,978
,964 2,516 ,874 1,645
4,069 7,384 6,675 4,908
1551,406 2559,752 2321,896 1557,173
-641,801 -904,519 -776,472 -429,555
metanol
acetetil
propanol
metpro12
isoamili
absorban
(Constante)
1 2 3 4
marca
Funciones discriminantes lineales de Fisher
Grupo 1
Grupo 2
k=9; 5 del 1 y 4
del 2
se asigna al 1
21
3 Grupo 1
Grupo 2
k=9; 5 del 1 y 4
del 2
se asigna al 1
21
3 Grupo 1
Grupo 2
k=9; 5 del 1 y 4
del 2
se asigna al 1
21
3

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
24
validation procedures applied to these selected compounds. Fig. 3 shows the wines on the plane defined by
the first two canonical variables, obtained with the five selected phenolic compounds. The population
canonical ellipses for the five types of wines for a 95% confidence limit are also shown in the figure. Again
the wines are grouped by time of ageing but cannot be differentiated according to the technological variable
used in their manufacture. This suggests that during storage, …..
6. TRATAM. DE DATOS MULTIVARIANTES. METODOS DE DEPENDENCIA
Disponemos de una muestra aleatoria de tamaño n, procedente de una población multivariante W en p+q variables (X1, X2,..., Xp, Y1, Y2, ..., Yq), con vector de medias
matriz de covarianzas . Es decir, se dispone de la información de un total de
p+q variables analizadas en las mismas n observaciones.
6.1 ANALISIS DE CORRELACION CANONICA (ACC)
El objetivo de esta técnica multivariante es buscar dependencias lineales entre ambos bloques de variables (bloque X y bloque Y). Para ello se calculan m nuevas variables (m = min(p,q)), llamadas canónicas, en cada bloque (F1, F2, ..., Fm, S1,
S2, ..., Sm), de manera que estén máximamente correlacionadas entre sí (corr(F1,S1)
corr(F2,S2) ... corr(Fm,Sm)). Se trata, por tanto, de obtener las matrices A y B, que permitan las siguientes transformaciones matriciales: F = XA y S = Y B. Los resultados de aplicar esta técnica serían las matrices F, S, A y B, y los valores de las correlaciones canónicas (corr(Fi,Si)). La observación de las sucesivas columnas de las matrices A y B permitirán descubrir las variables más correlacionadas con cada variable canónica. También es posible obtener la representación gráfica de las sucesivas columnas de las matrices F y S (p.e. el diagrama de dispersión de F1 frente a S1). Este método no puede ser utilizado para la predicción de los valores del bloque Y.
6.2 MODELOS DE REGRESION MULTIVARIANTE
Los elementos a considerar a la hora de aplicar estas técnicas de regresión, son:
Variable respuesta, o variable dependiente Y (cada una de las variables del bloque Y), y
Variables predictoras X1, X2,..., Xp. ( o variables independientes). La finalidad de estas técnicas es modelar la variable respuesta Y, mediante un
modelo matemático: ),...,2,1( pXXXfY . Para ello se dispone de un conjunto de n
muestras, conjunto de aprendizaje o calibración: niiipii yxxx ,...,1,,...,2,1 )}{( , para
estimar los parámetros de la función ),...,2,1( pXXXf . En algunos casos, se dispone

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
25
también, de un conjunto de a muestras, grupo evaluación:
ajjjpjj yxxx ,...,1,,...,2,1 )}{( para validar el modelo estimado. Una vez validado el
modelo estimado, mediante el grupo de evaluación, o por validación interna, puede aplicarse para la predicción del valor de la variable Y en las t muestras del grupo
test: tjjpjj xxx ,...,1,,...,2,1 )}{( .
Los datos del conjunto de calibración pueden haber sido seleccionados mediante un diseño fijo de experimentos, cuando el objetivo fundamental es estimar los coeficientes de regresión del modelo con vista a una posible optimización de la respuesta, o mediante un diseño aleatorio, cuando sólo estamos interesados en utilizar el modelo para realizar predicciones
6.2.1 Regresión lineal múltiple
En el caso de regresión lineal múltiple se acepta que los valores de la variable dependiente Y, obedecen al modelo lineal de primer orden
iippiii xxxy ...22110 , que tiene en cuenta, tanto los valores de las p
variables independientes X1, X2,..., Xp, como el error aleatorio de la determinación analítica y de la posible contribución de otras variables no controladas. Para este modelo matemático, se aceptan las siguientes hipótesis: 1) la variable dependiente Y, es una v.a., sujeta a error, 2) las p variables Xi no son variables aleatorias, o su
error es despreciable frente al de Y, y 3) los errores (o residuos) i son
independientes y con distribución ),0(N (lo que implica que ),0(~ ii xNY )
La estimación de los parámetros i del modelo teórico, puede realizarse mediante el
procedimiento de mínimos cuadrados ( yXXXb
')'(1
, siendo X la matriz con los
valores de las p variables en las n muestras del conjunto de calibración y con una primera columna, añadida, de unos), dando lugar al siguiente modelo estimado:
ippiii xbxbxbby ...ˆ22110 . Como medida de precisión del ajuste se utiliza el
coeficiente de determinación múltiple 2
R , que informa de la proporción de la suma de cuadrados de las desviaciones de Y respecto de su valor medio, explicada por el
modelo ( totreg SSSSR /2
siendo errorregtot SSSSSS ), y la desviación estándar
residual s, que informa del tamaño del error cometido ( 2
1
ˆ( ) /( 1)n
i ii
s y y n p ). En el
caso de disponer de repeticiones, varios valores de Y para los mismos valores de las variables X1, ..., Xp, es posible comprobar si el modelo tiene falta de ajuste mediante la descomposición recogida en la correspondiente tabla ANOVA para la regresión
faltaajpuroerrregerrorregtot SSSSSSSSSSSS .
Para validar el modelo es preciso confirmar las hipótesis establecidas sobre los errores
i (si son homogéneos, independientes y siguen distribución Normal). En caso de
aceptar su validez, se podría obtener un valor para estimar el comportamiento en predicción del modelo al aplicarlo a muestras no utilizadas para estimarlo, que puede medirse mediante el error medio en predicción (RMSEP) y que se calcula a partir de los n datos del conjunto de calibración mediante el procedimiento de validación interna
o "leave one out" ( nyyRMSEPn
iii /)ˆ(
1
2)( siendo )(
ˆiy el valor predicho para la
variable Y en la i-ésima observación al utilizar las n -1 restantes en la estimación del modelo).

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
26
Si el modelo es válido, es posible calcular intervalos de confianza para los parámetros
i , así como realizar test de hipótesis sobre los mismos. Como resultados más
importantes que se pueden obtener mediante la aplicación de esta técnica, podemos citar los siguientes:
los valores de los coeficientes de regresión (bi), las desviaciones estándar de los mismos, los valores del estadístico t-Student para confirmar la hipótesis
00 iH , las probabilidades asociadas a este contraste, y a veces, los intervalos
de confianza para los parámetros,
los valores del coeficiente de determinación 2
R , del coeficiente de correlación múltiple R y de la desviación estándar residual (s) que informan de la precisión,
la descomposición de la variabilidad de los valores de la variable Y (tabla ANOVA), y
la tabla con los valores observados, calculados con el modelo, y los residuos de la variable Y.
Como resultado gráfico del ajuste suele utilizarse la representación gráfica de los valores calculados (
iy ) frente a los observados (iy ) .
Si existe multicolinealidad entre las variables Xi, la matriz de inflación (X'X) será casi singular, y su inversión afectará en las estimaciones e intervalos de confianza para los parámetros, y en las predicciones. En este caso se pueden utilizar otros procedimientos: el método de pasos sucesivos para selección de algunas de las p variables, la regresión sesgada, la regresión en componentes principales o la regresión por mínimos cuadrados parciales.
6.2.2 Diseño de Experimentos
El Diseño de Experimentos trata de cómo dirigir y planificar los experimentos, en orden a extraer la máxima cantidad de información a partir de los datos adquiridos en presencia de ruido, con el menor número de ensayos experimentales. La idea fundamental es variar todos los factores importantes simultáneamente en un conjunto de experimentos planificados, y conectar los resultados con la variable respuesta, mediante un modelo matemático. El modelo estimado se utiliza para interpretar, predecir y optimizar. Los objetivos del diseño de experimentos, incluyen: 1) conocer los factores, que de manera individual o en interacción con otros factores, tienen una influencia real en los valores de las variables respuesta (fundamentalmente para el “screening” de los factores), 2) los niveles de los factores que dan lugar a condiciones óptimas, y 3) predecir los valores de las variables respuesta para ciertos niveles de los factores (fundamentalmente para el modelado mediante superficie de respuesta). Los términos empleados en el Diseño de Experimentos son: 1) los factores o variables independientes (Fi), que se cree influyen en la variable respuesta (Y) de un cierto experimento, son controladas por el experimentador, pueden ser de tipo cualitativo o cuantitativo, y pueden tomar diferentes valores (niveles); 2) la variable respuesta o dependiente (Y) que se pretende estudiar, cuyos valores se cree están influidos por los niveles de los factores, y por otras causas que aceptaremos como error experimental, y que son de tipo cuantitativo; 3) el modelo o superficie de respuesta, que es la función matemática con la que se pretende modelizar la variable respuesta analizada, en función de las variables predictoras o independientes, y con parámetros (coeficientes) que hay que estimar; 4) la matriz de experimentos (E), formada por tantas columnas como factores y tantas filas como experimentos a realizar (n), donde figuran los valores reales de los factores en cada experimento; 5)
la matriz del diseño (D) con los valores codificados para los factores ( ( )i iX f F ) y
que tiene tantas columnas como factores y tantas filas como experimentos hay que realizar; 6) la matriz del modelo (X) donde figuran los valores codificados que toman
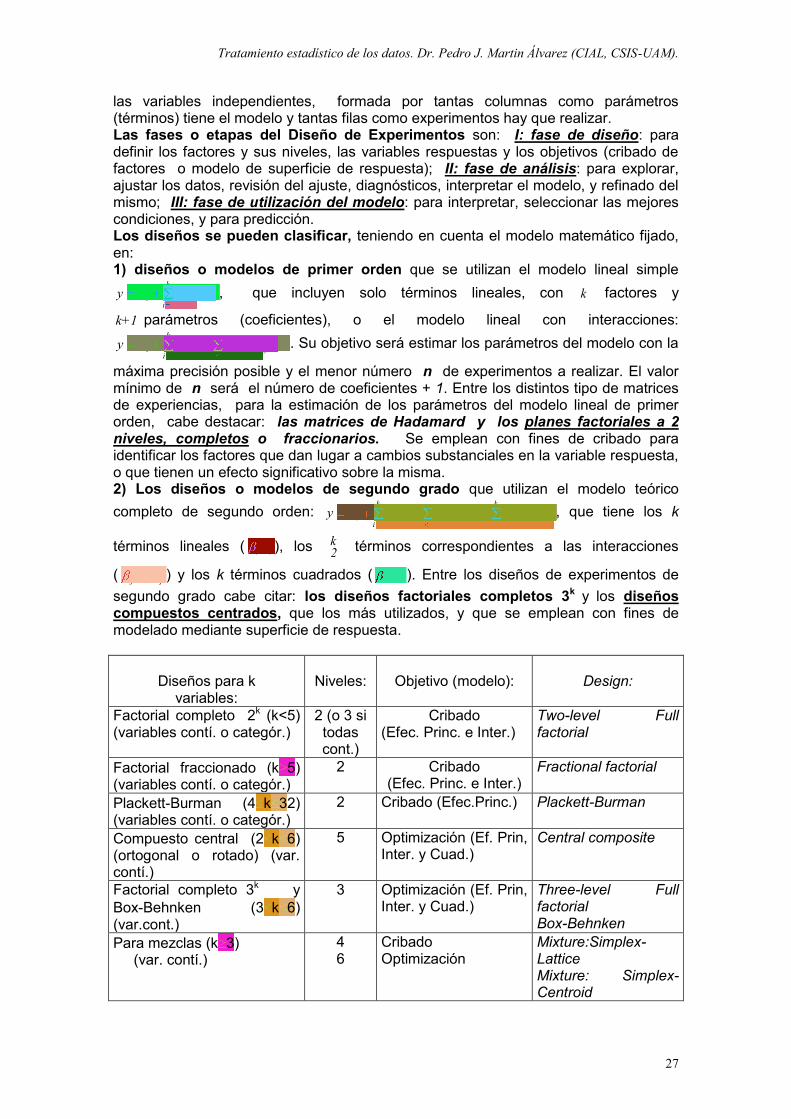
Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
27
las variables independientes, formada por tantas columnas como parámetros (términos) tiene el modelo y tantas filas como experimentos hay que realizar. Las fases o etapas del Diseño de Experimentos son: I: fase de diseño: para definir los factores y sus niveles, las variables respuestas y los objetivos (cribado de factores o modelo de superficie de respuesta); II: fase de análisis: para explorar, ajustar los datos, revisión del ajuste, diagnósticos, interpretar el modelo, y refinado del mismo; III: fase de utilización del modelo: para interpretar, seleccionar las mejores condiciones, y para predicción. Los diseños se pueden clasificar, teniendo en cuenta el modelo matemático fijado, en: 1) diseños o modelos de primer orden que se utilizan el modelo lineal simple
k
0 i ii 1
y x , que incluyen solo términos lineales, con k factores y
k+1 parámetros (coeficientes), o el modelo lineal con interacciones: k
0 i i ij i ji 1 i j
y X X X . Su objetivo será estimar los parámetros del modelo con la
máxima precisión posible y el menor número n de experimentos a realizar. El valor mínimo de n será el número de coeficientes + 1. Entre los distintos tipo de matrices de experiencias, para la estimación de los parámetros del modelo lineal de primer orden, cabe destacar: las matrices de Hadamard y los planes factoriales a 2 niveles, completos o fraccionarios. Se emplean con fines de cribado para identificar los factores que dan lugar a cambios substanciales en la variable respuesta, o que tienen un efecto significativo sobre la misma. 2) Los diseños o modelos de segundo grado que utilizan el modelo teórico
completo de segundo orden: k k
2
0 i i ij i j ii ii 1 i j i 1
y X X X X , que tiene los k
términos lineales ( i iX ), los k2 términos correspondientes a las interacciones
( ij i jX X ) y los k términos cuadrados ( 2
ii iX ). Entre los diseños de experimentos de
segundo grado cabe citar: los diseños factoriales completos 3k y los diseños compuestos centrados, que los más utilizados, y que se emplean con fines de modelado mediante superficie de respuesta.
Diseños para k
variables:
Niveles:
Objetivo (modelo):
Design:
Factorial completo 2k (k<5) (variables contí. o categór.)
2 (o 3 si todas cont.)
Cribado (Efec. Princ. e Inter.)
Two-level Full factorial
Factorial fraccionado (k 5) (variables contí. o categór.)
2 Cribado (Efec. Princ. e Inter.)
Fractional factorial
Plackett-Burman (4 k 32) (variables contí. o categór.)
2 Cribado (Efec.Princ.) Plackett-Burman
Compuesto central (2 k 6) (ortogonal o rotado) (var. contí.)
5 Optimización (Ef. Prin, Inter. y Cuad.)
Central composite
Factorial completo 3k y
Box-Behnken (3 k 6) (var.cont.)
3 Optimización (Ef. Prin, Inter. y Cuad.)
Three-level Full factorial Box-Behnken
Para mezclas (k 3) (var. contí.)
4 6
Cribado Optimización
Mixture:Simplex-Lattice Mixture: Simplex-Centroid

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
28
7. BIBLIOGRAFIA
A.A. Afifi and S.P. Azen."Statistical analysis. A computer oriented ” Academic Press, Inc. (1979) R.G. Brereton "Chemometrics applications of mathematics and statistics to ... ". Ellis Horwood
(1990) R. Cela et al. "Avances en Qimiometría Práctica". Univ.Santiago de Compostela (1994). C.M. Cuadras “Métodos de análisis multivariante” EUNIBAR (1981) N.R. Draper and H.Smith "Applied regression analysys" John Wiley & Sons, Inc. (1981). W.J. Krzanowski “Principles of multivariate analysis. ...” Oxford statistical science series; v.3,
(1988) M. O’Mahoney “Sensory evaluation of food. Statistical methods and procedures”, Marcel Dekker Inc.(1986) A. Martín y J.D. Luna. "Bioestadística para las Ciencias de la Salud", Edic.Norma, Madrid (1989). P.J. Martín Álvarez "Quimiometría Alimentaria". Ediciones de la UAM (2000). P.J. Martín-Álvarez, "PRÁCTICAS DE TRATAMIENTO ESTADÍSTICO DE DATOS CON EL PROGRAMA SPSS PARA WINDOWS. APLICACIONES EN EL ÁREA DE CIENCIA Y TECNOLOGÍA DE ALIMENTOS". Ed.: CSIC, Colec. Biblioteca de Ciencias, nº 27. Madrid, 258 pags., 2006. ISBN: 84-00-08470-5. P.J. Martín-Álvarez “Statistical Techniques for the Interpretation of Analytical Data”, Chapter 13, pages 677-713 in “Wine Chemistry and Biochemistry”. M.Victoria Moreno-Arribas & M. Carmen Polo Editors, Springer (2009). ISBN: 978-0-387-74116-1. P.J. Martín-Álvarez “Guía práctica para la utilización del programa STATISTICA para Windows (versión 7.1) “. P.J. Martín-Alvarez Ed, 2014. ISBN: 978-84-695-9934-1. D.L. Massart, et al. “Chemometrics: A textbook” Elsevier (1990) J.C.Miller and J.N. Miller "Statistics for analytical chemistry. Ellis Horwood Ltd (1984) D.F. Morrison “Multivariate Statistical Methods” McGraw-Hill, Inc. (1976) D. PEÑA. "Estadística: Modelos y métodos. 2. Modelos lineales y ...”. Alianza Editorial S.A.(1992). M.A.Sharaf, D.L. Illman and B.R.Kowalski. "Chemometrics". John Wiley&Sons, Inc.(1986).

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
29
8. Comandos del programa SPSS:
Con el SPSS, para contrastar la hipótesis Ho = 0 = 0.4, elegir en la barra de menús el procedimiento
Analizar, Comparar medias, Prueba T para una muestra, y colocar el nombre de la variable en el cuadro de
Contrastar variables:, y el valor de referencia 0.4 en el cuadro Valor de prueba:, pulsar en Aceptar.
Para contrastar la hipótesis Ho 1 = 2 y conocer los valores descriptivos de la variable en los 2 grupos,
elegir Analizar, Comparar medias, Prueba T para muestras independientes, y colocar el nombre de la
variable en el cuadro Variable a contrastar, y el nombre de la variable de agrupamiento en el cuadro Variable
de agrupación, con los correspondientes valores en la ventana de Definir los grupos, pulsar en Continuar y en
Aceptar. Para contrastar la hipótesis Ho 1 = 2 en el caso de muestras relacionadas, utilizar Analizar,
Comparar medias, Prueba T para muestras relacionadas; seleccionar las dos variables y colocarlas en el
cuadro Variables relacionadas, y pulsar Aceptar.
Para contrastar la hipótesis de igualdad de k medias (Ho 1 = 2 = … = 6) y conocer los valores
descriptivos en cada uno de los grupos, utilizar Analizar, Comparar medias, ANOVA de un factor, y colocar
el nombre de la variable en el cuadro de Dependientes:, y el nombre de la variable de agrupamiento en el
cuadro Factor:. En la ventana de Opciones, elegir en Estadísticos: Descriptivos, Prueba de homogeneidad de
la varianza, Welch, y seleccionar Gráfico de las medias, pulsar Continuar. En la ventana Post Hoc elegir S-N-
K, y Continuar y Aceptar. También se puede utilizar el procedimiento Analizar, Modelo lineal general,
Univariante, y colocar el nombre de la variable en el cuadro Dependiente:, y la variable de agrupamiento en el
cuadro Factores fijos: y pulsar en Aceptar. En el caso de ANOVA de 2 factores se puede utilizar el
procedimiento Analizar, Modelo lineal general, Univariante, y en la ventana de este comando colocar el
nombre de la variable en el cuadro Dependiente:, y los nombre de los factores en el cuadro Factores fijos: (o
Factores aleatorios:) y pulsar en Aceptar.
Para realizar el análisis de regresión lineal simple/múltiple, utilizar el procedimiento Analizar, Regresión,
Lineal, y colocar la/s variable/s independiente/s (xi) en el cuadro Independientes:, y la variable dependiente
(y) en el cuadro Dependiente: En la ventana Estadísticos... seleccionar Estimaciones e Intervalos de confianza
en Coeficientes de regresión, y Ajuste del modelo, pulse Continuar, para obtener los parámetros estimados y
los intervalos de confianza. Para obtener el gráfico de dispersión de los residuos tipificados frente a los valores
observados, y el gráfico de probabilidad normal de los residuos, hay que abrir la ventana Gráficos... y colocar
la variable DEPENDNT en el cuadro del eje X, y la variable ZRESID en el cuadro de la variable Y, y
seleccionar Gráfico de prob. normal en Gráficos de residuos tipificados, y pulsar Continuar. Para guardar,
como nuevas variables, los valores calculados y los residuos, hay que abrir la ventana Guardar... y seleccionar
No tipificados en Valores pronosticados, y No tipificados en Residuos, y pulsar Continuar. En la ventana
Opciones..., compruebe que está seleccionado Incluir constante en la ecuación del modelo teórico, y pulse
Continuar.
Para realizar el análisis de componentes principales (o el factorial) utilizar el comando Analizar,
Reducción de datos, análisis factorial, y colocar las nombres de las variables en el cuadro de Variables. En la
ventana Descriptivos: en Estadísticos elegir Univariados y Solución inicial; en Matriz de correlaciones elegir
Coeficientes y Nivel significación; pulsar Continuar. En la ventana de Extracción: en Método elegir
Componentes principales, en Analizar elegir Matriz de correlaciones, en Extraer elegir Aautovalores >1, y en
Mostrar elegir Solución factorial sin rotar y Gráfico de sedimentación; pulsar Continuar. En la ventana de
Rotación: en Método elegir Ninguno, y en Mostrar elegir Gráficos de saturaciones; pulsar Continuar. En la
ventana de Puntuaciones: señalar Guardar como variables y Método de regresión, pulsar Continuar. Por
último, en la ventana de Opciones: en Valores perdidos elegir excluir casos según lista, y en Formato
visualización de los coeficientes elegir Ordenar por tamaño y Suprimir valores absolutos menores que 0.25;
pulsar Continuar; y pulsar Aceptar en ventana principal.
Para el análisis de conglomerados utilizar el procedimiento Analizar, Clasificar, Conglomerados
jerárquicos. Colocar los nombre de las variables en el cuadro de Variables, en Conglomerar elegir casos, en
Etiquetar casos mediante elegir el nombre de la variable alfabética que se desea utilizar, y en Mostrar elegir
Estadísticos y gráficos. En la ventana de Estadísticos elegir Historial de conglomeración y Matriz de
distancias; Continuar. En la ventana de Gráficos elegir Dendrograma; en Témpanos elegir todos los
conglomerados, y en Orientación elegir Vertical. En la ventana de Método: en Método de conglomeración
elegir el Método de Ward; en Medida elegir Intervalo y Distancia euclídea al cuadrado, en Transformar
valores elegir Estandarizar: Puntuaciones Z por variable; pulsar Continuar y Aceptar.
Para aplicar el análisis lineal discriminante utilizar el procedimiento Analizar, Clasificar, Discriminante,
y colocar los nombres de las variables en el cuadro Independientes:, el nombre de la variable de agrupamiento
con sus valores, en el cuadro Variable de agrupación, y seleccionar Introducir independientes juntas, o Usar
método de inclusión por pasos.
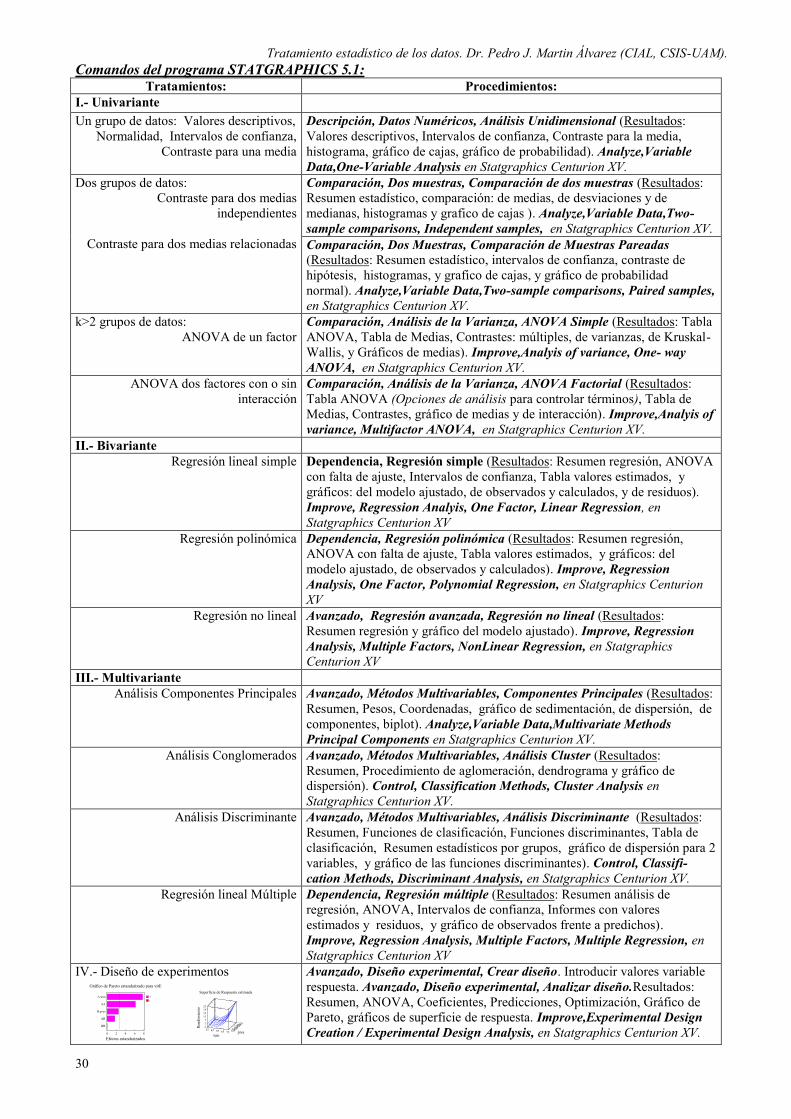
Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
30
Comandos del programa STATGRAPHICS 5.1: Tratamientos: Procedimientos:
I.- Univariante
Un grupo de datos: Valores descriptivos,
Normalidad, Intervalos de confianza,
Contraste para una media
Descripción, Datos Numéricos, Análisis Unidimensional (Resultados:
Valores descriptivos, Intervalos de confianza, Contraste para la media,
histograma, gráfico de cajas, gráfico de probabilidad). Analyze,Variable
Data,One-Variable Analysis en Statgraphics Centurion XV.
Dos grupos de datos:
Contraste para dos medias
independientes
Contraste para dos medias relacionadas
Comparación, Dos muestras, Comparación de dos muestras (Resultados:
Resumen estadístico, comparación: de medias, de desviaciones y de
medianas, histogramas y grafico de cajas ). Analyze,Variable Data,Two-
sample comparisons, Independent samples, en Statgraphics Centurion XV.
Comparación, Dos Muestras, Comparación de Muestras Pareadas (Resultados: Resumen estadístico, intervalos de confianza, contraste de
hipótesis, histogramas, y grafico de cajas, y gráfico de probabilidad
normal). Analyze,Variable Data,Two-sample comparisons, Paired samples,
en Statgraphics Centurion XV.
k>2 grupos de datos:
ANOVA de un factor
Comparación, Análisis de la Varianza, ANOVA Simple (Resultados: Tabla
ANOVA, Tabla de Medias, Contrastes: múltiples, de varianzas, de Kruskal-
Wallis, y Gráficos de medias). Improve,Analyis of variance, One- way
ANOVA, en Statgraphics Centurion XV.
ANOVA dos factores con o sin
interacción
Comparación, Análisis de la Varianza, ANOVA Factorial (Resultados:
Tabla ANOVA (Opciones de análisis para controlar términos), Tabla de
Medias, Contrastes, gráfico de medias y de interacción). Improve,Analyis of
variance, Multifactor ANOVA, en Statgraphics Centurion XV.
II.- Bivariante
Regresión lineal simple Dependencia, Regresión simple (Resultados: Resumen regresión, ANOVA
con falta de ajuste, Intervalos de confianza, Tabla valores estimados, y
gráficos: del modelo ajustado, de observados y calculados, y de residuos).
Improve, Regression Analyis, One Factor, Linear Regression, en
Statgraphics Centurion XV
Regresión polinómica Dependencia, Regresión polinómica (Resultados: Resumen regresión,
ANOVA con falta de ajuste, Tabla valores estimados, y gráficos: del
modelo ajustado, de observados y calculados). Improve, Regression
Analysis, One Factor, Polynomial Regression, en Statgraphics Centurion
XV
Regresión no lineal Avanzado, Regresión avanzada, Regresión no lineal (Resultados:
Resumen regresión y gráfico del modelo ajustado). Improve, Regression
Analysis, Multiple Factors, NonLinear Regression, en Statgraphics
Centurion XV
III.- Multivariante
Análisis Componentes Principales Avanzado, Métodos Multivariables, Componentes Principales (Resultados:
Resumen, Pesos, Coordenadas, gráfico de sedimentación, de dispersión, de
componentes, biplot). Analyze,Variable Data,Multivariate Methods
Principal Components en Statgraphics Centurion XV.
Análisis Conglomerados Avanzado, Métodos Multivariables, Análisis Cluster (Resultados:
Resumen, Procedimiento de aglomeración, dendrograma y gráfico de
dispersión). Control, Classification Methods, Cluster Analysis en
Statgraphics Centurion XV.
Análisis Discriminante Avanzado, Métodos Multivariables, Análisis Discriminante (Resultados:
Resumen, Funciones de clasificación, Funciones discriminantes, Tabla de
clasificación, Resumen estadísticos por grupos, gráfico de dispersión para 2
variables, y gráfico de las funciones discriminantes). Control, Classifi-
cation Methods, Discriminant Analysis, en Statgraphics Centurion XV.
Regresión lineal Múltiple Dependencia, Regresión múltiple (Resultados: Resumen análisis de
regresión, ANOVA, Intervalos de confianza, Informes con valores
estimados y residuos, y gráfico de observados frente a predichos).
Improve, Regression Analysis, Multiple Factors, Multiple Regression, en
Statgraphics Centurion XV
IV.- Diseño de experimentos Gráfico de Pareto estandarizado para vitE
0 2 4 6 8
Efectos estandarizados
BB
AB
B:pres
AA
A:tem +
-
Superficie de Respuesta estimada
tempres
Ren
dim
ien
to
35 45 55 65 75120
160200
240280
320
-1
3
7
11
15
19
23
Avanzado, Diseño experimental, Crear diseño. Introducir valores variable
respuesta. Avanzado, Diseño experimental, Analizar diseño.Resultados:
Resumen, ANOVA, Coeficientes, Predicciones, Optimización, Gráfico de
Pareto, gráficos de superficie de respuesta. Improve,Experimental Design
Creation / Experimental Design Analysis, en Statgraphics Centurion XV.

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
31
Comandos del programa STATISTICA 7.1:
Tratamientos: Procedimientos:
I.- Univariante
Un grupo de datos: Valores descriptivos,
Normalidad, Intervalos de confianza,
Contraste para una media
Statistics, Basic Statistics and Tables, t-test, single sample (Resultados: Valores descriptivos, Intervalos de confianza,
Contraste para la media, histograma, gráfico de cajas, gráfico
de probabilidad)
Dos grupos de datos:
Contraste para dos medias independientes
Contraste para dos medias relacionadas
Statistics, Basic Statistics and Tables, t-test, independent by
groups (Resultados: Resumen estadístico, comparación: de
medias, varianzas, histogramas y grafico de cajas )
Statistics, Basic Statistics and Tables, t-test, dependent
simples (Resultados: Resumen estadístico, contraste de
hipótesis, y grafico de cajas)
Más de 2 grupos de datos:
ANOVA de un factor Statistics, Basic Statistics and Tables,Breakdown & one-way
ANOVA, o Statistics, ANOVA, One-way ANOVA
(Resultados: Tabla ANOVA, Tabla de Medias, Contrastes
múltiples de medias, y Gráficos de medias)
ANOVA dos factores con o sin
interacción
Statistics, ANOVA, Factorial ANOVA or Main effects
ANOVA (Resultados: Tabla ANOVA, Tabla de Medias,
Contrastes, gráfico de medias y de interacción).
II.- Bivariante
Regresión lineal simple Statistics, Multiple regressión (Resultados: Resumen
regresión, Tabla ANOVA, Intervalos de confianza de los
coeficientes, Tabla valores estimados, y gráficos: del modelo
ajustado, de observados y calculados, y de residuos)
Regresión polinómica Statistics, Advanced Linear/Non linear Models, General
Regression Models, Polynomial Regression (Resultados:
Resumen regresión, ANOVA con falta de ajuste, Tabla valores
estimados, y gráficos: del modelo ajustado, de observados y
calculados, y de residuos)
Regresión no lineal Statistics, Advanced Linear/Non linear Models, Nonlinear
Estimation (Resultados: Resumen regresión y gráfico del
modelo ajustado)
III.- Multivariante
Análisis Componentes Principales Statistics, Multivariate Exploratory Techniques. Factor
Analysis (Resultados: Resumen, Loadings, Scores, Scree plot,
salvar scores)
Análisis Conglomerados Statistics, Multivariate Exploratory Techniques. Cluster
Analysis, Joining (Resultados: Dendrograma y matriz de
distancias)
Análisis Discriminante Statistics, Multivariate Exploratory Techniques.
Discriminant Analysis (Resultados: Resumen, Funciones de
clasificación, Funciones discriminantes, Tabla de
clasificación, Resumen estadísticos por grupos, gráfico de
dispersión para 2 variables, y gráfico de las funciones
discriminantes)
Regresión lineal Múltiple Statistics, Multiple regressión (Resultados: Resumen análisis
de regresión, ANOVA, Intervalos de confianza, Informes con
valores estimados y residuos, y gráfico de observados frente
a predichos, y gráfico de residuos)
IV.- Diseño de experimentos
Pareto Chart of Standardized Effects; Variable: VitE
2 factors, 1 Blocks, 10 Runs; MS Residual=7.26911
DV: VitE
-.028251
1.670914
2.480731
6.193008
7.747344
p=.05
Standardized Effect Estimate (Absolute Value)
P(Q)
1Lby2L
(2)P(L)
T(Q)
(1)T(L)
DV: VitE
Statistics, Industrial Statistics, Experimental Design. Analyze
Design. Resultados: Resumen, ANOVA, Coeficientes,
Gráfico de Pareto, Gráfico de efectos, gráficos de superficie de
respuesta, Predicciones, Optimización.

Tratamiento estadístico de los datos. Dr. Pedro J. Martin Álvarez (CIAL, CSIS-UAM).
32
Tratam.
Estadísticos:
Procedimientos con
STATISTICA v7.1:
Proc. con
Statgraphics 5.1
Proc.
con SPSS v.14:
I.- Univariante
Un grupo de datos:
Valores descriptivos,
Normalidad, Int. de
confianza, Contraste
para una media
Statistics, Basic Statistics
and Tables, t-test, single
sample
Descripción, Datos
Numéricos, Análisis
Unidimensional
Analizar, Estadísticos
Descriptivos, Explorar y
Analizar,Comparar
medias, Prueba T para
una muestra
Dos grupos de datos:
Contraste para dos
medias
independientes
Contraste para dos
medias relacionadas
Statistics, Basic Statistics
and Tables, t-test,
independent by groups
Comparación, Dos
muestras, Comparación de
dos muestras)
Analizar, Comparar
medias, Prueba T para
muestras independientes
Statistics, Basic Statistics
and Tables, t-test,
dependent simples
Comparación, Dos
Muestras, Comparación de
Muestras Pareadas
Analizar, Comparar
medias, Prueba T para
muestras relacionadas
k>2 grupos de datos:
ANOVA de un factor Statistics, Basic Statistics
and Tables,Breakdown &
one-way ANOVA, o
Statistics, ANOVA, One-
way ANOVA
Comparación, Análisis de
la Varianza, ANOVA
Simple
Analizar, Comparar
medias, ANOVA de un
factor ó Analizar, Modelo
lineal general, univariante
ANOVA dos factores
con o sin interacción Statistics, ANOVA,
Factorial ANOVA or Main
effects ANOVA
Comparación, Análisis de
la Varianza, ANOVA
Fatorial
Analizar, Modelo lineal
general, Univariante
II.- Bivariante
Regresión lineal
simple Statistics, Multiple
regressión
Dependencia, Regresión
simple. Avanzado,
Regresión Avanzada,
Modelos de Calibración
Analizar, Regresión,
Lineal.
Regresión polinómica Statistics, Advanced
Linear/Non linear Models,
General Regression
Models, Polynomial Regr.
Dependencia, Regresión
polinómica
Analizar, Regresión,
Estimación Curvilínea.
Regresión no lineal Statistics, Advanced
Linear/Non linear Models,
Nonlinear Estimation)
Avanzado, Regresión
avanzada, Regresión no
lineal
Analizar, Regresión, No
Lineal.
III.- Multivariante
Análisis
Componentes
Principales
Statistics, Multivariate
Exploratory Techniques.
Factor Analysis
Avanzado, Métodos
Multivariables,
Componentes Principales
Analizar, Reducción de
datos, análisis factorial.
Análisis
Conglomerados Statistics, Multivariate
Exploratory Techniques.
Cluster Analysis, Joining
Avanzado, Métodos
Multivariables, Análisis
Cluster
Analizar, Clasificar,
Conglomerados
jerárquicos.
Análisis
Discriminante Statistics, Multivariate
Exploratory Techniques.
Discriminant Analysis
Avanzado, Métodos
Multivariables, Análisis
Discriminante
Analizar, Clasificar,
Discriminante.
Regresión lineal
Múltiple Statistics, Multiple
regressión
Dependencia, Regresión
múltiple
Analizar, Regresión,
Lineal.
IV.- Diseño de
experimentos
Statistics, Industrial
Statistics, Experimental
Design. Analyze Design.
1)Avanzado, Diseño
experimental, Crear
diseño. 2)Avanzado,
Diseño experimental,
Analizar diseño.


















