
tics-diseño de sistemas
90
Tecnologías de la Información y Comunicación Sistemas Informáticos 1 LÓGICA DE PROGRAMACIÓN Lenguaje de Programación: Es un conjunto de símbolos, caracteres y reglas que le permiten a las personas comunicarse con la computadora. Los lenguajes de programación tienen un conjunto de instrucciones que nos permiten realizar operaciones de entrada / salida, cálculo, manipulación de textos, comparaciones, almacenamiento y recuperación de información. Definición de Algoritmo: Un algoritmo es una serie de pasos organizados que describe el proceso que se debe seguir, para dar solución a un problema específico. Existen dos tipos de algoritmos: • Gráficos: Es la representación gráfica de las operaciones que realiza un algoritmo (diagrama de flujo). • No Gráficos: Representa en forma descriptiva las operaciones que debe realizar un algoritmo (pseudo código). Dato: Un dato puede ser un simple carácter o un valor entero. El tipo de dato determina el conjunto de valores que puede tomar una variable. Los tipos de datos son los siguientes: Numéricos Simples Lógicos Alfanuméricos (string) Tipos de datos Arreglos (Vectores, Matrices) Estructurados Registros (Def. por el Archivos usuario) Apuntadores Expresiones: Las expresiones son combinaciones de constantes, variables, símbolos de operación, paréntesis y nombres de funciones especiales. Por ejemplo: a + (b + 3)/c. Una expresión consta de operadores y operandos. Según sea el tipo de datos u operandos que manipulan, se clasifican en: • Aritméticas • Relaciónales • Lógicas Operadores Aritméticos Relaciónales Lógicos + Suma - Resta * Multiplicación / División Mod Modulo > Mayor que < Menor que > = Mayor o igual que < = Menor o igual que < > Diferente = Igual And Y OR O Not Negación Prioridad de los Operadores Aritméticos 1. ^ Exponenciación 2. *, /, mod. Multiplicación, división, modulo. 3. +, - Suma y resta Tabla de valores lógicos: AND OR NOT T and T = T T and F = F F and T = F F and F = F T or T = T T or F = T F or T = T F or F = F not T = F not F = T Identificadores: representan los datos de un programa (constantes, variables). Un identificador es una secuencia de caracteres que sirve para identificar una posición en la memoria de la computadora, que nos permite accesar a su contenido. Reglas para formar un identificador • Debe comenzar con una letra (A a Z, mayúsculas o minúsculas) y no deben contener espacios en blanco. • Letras, dígitos y caracteres como la subraya (_) son permitidos después del primer carácter. Constante: Es un dato numérico o alfanumérico que no cambia durante la ejecución del programa.
-
Upload
hardyzofxl1619 -
Category
Documents
-
view
250 -
download
1
Transcript of tics-diseño de sistemas

Tecnologías de la Información y Comunicación Sistemas Informáticos 1
LÓGICA DE PROGRAMACIÓN
Lenguaje de Programación: E s un conjunto de símbolos, caracteres y reglas que le permiten a las personas comunicarse con la computadora. Los lenguajes de programación tienen un conjunto de instrucciones que nos permiten realizar operaciones de entrada / salida, cálculo, manipulación de textos, comparaciones, almacenamiento y recuperación de información. Definición de Algoritmo: Un algoritmo es una serie de pasos organizados que describe el proceso que se debe seguir, para dar solución a un problema específico. Existen dos tipos de algoritmos:
•••• Gráficos: Es la representación gráfica de las operaciones que realiza un algoritmo (diagrama de flujo). •••• No Gráficos: Representa en forma descriptiva las operaciones que debe realizar un algoritmo (pseudo código).
Dato: Un dato puede ser un simple carácter o un valor entero. El tipo de dato determina el conjunto de valores que puede tomar una variable. Los tipos de datos son los siguientes: Numéricos Simples Lógicos Alfanuméricos (string) Tipos de datos Arreglos (Vectores, Matrices) Estructurados Registros (Def. por el Archivos
usuario) Apuntadores
Expresiones: Las expresiones son combinaciones de constantes, variables, símbolos de operación, paréntesis y nombres de funciones especiales. Por ejemplo: a + (b + 3)/c. Una expresión consta de operadores y operandos. Según sea el tipo de datos u operandos que manipulan, se clasifican en:
•••• Aritméticas •••• Relaciónales •••• Lógicas
Operadores Aritméticos Relaciónales Lógicos + Suma - Resta * Multiplicación / División Mod Modulo
> Mayor que < Menor que > = Mayor o igual que < = Menor o igual que < > Diferente = Igual
And Y OR O Not Negación
Prioridad de los Operadores Aritméticos 1. ^ Exponenciación 2. *, /, mod. Multiplicación, división, modulo. 3. +, - Suma y resta
Tabla de valores lógicos:
AND OR NOT T and T = T T and F = F F and T = F F and F = F
T or T = T T or F = T F or T = T F or F = F
not T = F not F = T
Identificadores: representan los datos de un programa (constantes, variables). Un identificador es una secuencia de caracteres que sirve para identificar una posición en la memoria de la computadora, que nos permite accesar a su contenido. Reglas para formar un identificador
•••• Debe comenzar con una letra (A a Z, mayúsculas o minúsculas) y no deben contener espacios en blanco. •••• Letras, dígitos y caracteres como la subraya (_) son permitidos después del primer carácter.
Constante: Es un dato numérico o alfanumérico que no cambia durante la ejecución del programa.

Tecnologías de la Información y Comunicación Sistemas Informáticos 2
Variable: Es un espacio en la memoria de la computadora que permite almacenar temporalmente un dato y éste dato puede cambiar durante la ejecución del programa. Estructuras Algorítmicas: Son formas de trabajo, que permiten, mediante la manipulación de variables, realizar ciertos procesos específicos que nos lleven a la solución de problemas. Estas estructuras se clasifican de acuerdo con su complejidad en: - Asignación Secuenciales - Entrada - Salida - Simples Estructuras Condicionales - Múltiples Algorítmicas - Hacer para Cíclicas - Hacer mientras - Repetir hasta Estructuras Secuenciales: son aquellas en la que una acción (instrucción) sigue a otra en secuencia. Las tareas se ejecutan de tal modo que la salida de una es la entrada de la siguiente y así sucesivamente hasta el fin del proceso. Una estructura secuencial se representa de la siguiente forma: Inicio Accion1 Accion2 . . Acción N Fin Asignación: La asignación consiste, en el paso de valores o resultados a una zona de la memoria. Dicha zona será reconocida con el nombre de la variable que recibe el valor. La asignación se puede clasificar de la siguiente forma:
• Simples: Consiste en pasar un valor constate a una variable (a =15) • Contador: Consiste en usarla como un verificador del numero de veces que se realiza un proceso ( a = a +1) • Acumulador: Consiste en usarla como un sumador en un proceso (a =a +b) • De trabajo: Donde puede recibir el resultado de una operación matemática que involucre muchas variables
(a = c +b *2/4). Lectura: La lectura consiste en recibir desde un dispositivo de entrada (p.ej. el teclado) un valor. Esta operación se representa en un pseudo código como sigue: Leer a, b (Donde “a” y “b” son las variables que recibirán los valores) Escritura: Consiste en mandar por un dispositivo de salida (p.ej. monitor o impresora) un resultado o mensaje. Este proceso se representa en un pseudo código como sigue: Escribe “El resultado es:”, R (Donde “El resultado es:” es un mensaje que se desea que aparezca y R es una variable que contiene un valor y que queremos que éste valor aparezca. Estructuras de Condicionales: Las estructuras condicionales comparan una variable contra otros valores, para que en base al resultado de ésta comparación, se siga un curso de acción dentro del programa. Las comparaciones se pueden hacer contra otra variable o contra una constante. Existen dos tipos básicos, las simples y las dobles.
• Simples: Las estructuras condicionales simples se les conoce como “Tomas de decisión”. Estas tomas de decisión tienen la siguiente forma:
Si <condición> entonces
Acción(es) Fin-si
• Dobles: Las estructuras condicionales dobles permiten elegir entre dos opciones o alternativas posibles en
función del cumplimiento o no de una determinada condición. Se representa de la siguiente forma:

Tecnologías de la Información y Comunicación Sistemas Informáticos 3
Si <condición> entonces Acción(es) si no Acción(es) Fin-si Estructuras Cíclicas: Se llaman problemas repetitivos o cíclicos a aquellos en cuya solución es necesario utilizar un mismo conjunto de acciones que se puedan ejecutar una cantidad específica de veces. Esta cantidad puede ser fija (previamente determinada por el programador) o puede ser variable (estar en función de algún dato dentro del programa).Los ciclos se clasifican en:
• Ciclos con un Numero Determinado de Iteraciones (Ha cer-Para o FOR) Son aquellos en que el número de iteraciones se conoce antes de ejecutarse el ciclo.
• Ciclos con un Numero Indeterminado de Iteraciones ( Hacer-Mientras, Repetir-Hasta o WHILE) Son aquellos
en que el número de iteraciones no se conoce con exactitud, ya que está dado en función de un dato dentro del programa. En otras palabras; ésta es una estructura que repetirá un proceso durante “N” veces, donde “N” puede ser fijo o variable. Para esto, la instrucción se vale de una condición que es la que debe cumplirse para que se siga ejecutando. Cuando la condición ya no se cumple, entonces ya no se ejecuta el proceso.
PROGRAMACIÓN DE COMPUTADORAS Los conceptos básicos del paradigma OO son clase y objeto. Los objetos son simplemente entidades que tienen sentido en el contexto de una aplicación. Todos los objetos son instancias de alguna clase, los términos instancia y objeto son el mismo concepto. Las clases son abstracciones que generalizan dominios de objetos. El estado de un objeto viene dado por el valor de sus características y el comportamiento del objeto por las acciones u operaciones que realiza. Es decir las responsabilidades podemos dividirlas en dos grupos, aquellas que determinan el estado (atributos) y las que determinan el comportamiento (métodos). A los atributos también se les llama: campos, propiedades, variables o atributos; mientras que a los métodos también se les llama rutinas o funciones. El esquema general para la representación de una clase es la siguiente: Nombre de la clase
Estado Responsabilidades Comportamiento
Atributos
Métodos
C# C# es un lenguaje de programación orientado a objetos desarrollado y estandarizado por Microsoft como parte de su plataforma .NET. Su sintaxis básica deriva de C/C++ la cual es similar a la de Java. Tipos de datos más comunes:
Nota: El tipo de dato cadena se llama string . En C# las cadenas son objetos y no una matriz de caracteres, aun así, se puede obtener un carácter arbitrario de una cadena por medio de su índice (mas no modificarlo). Las cadenas son inmutables, una vez creadas no se pueden modificar, solo se pueden copiar total o parcialmente. Se pueden concatenar (unir) dos cadenas mediante el operador +. Las cadenas se pueden usar en las instrucciones switch.

Tecnologías de la Información y Comunicación Sistemas Informáticos 4
El código en C# es una secuencia de símbolos que determinan el conjunto de instrucciones. Dos aspectos determinan si una secuencia de símbolos es correcta en C#: la sintaxis y la semántica . La sintaxis: son reglas que permiten determinar de qué manera los símbolos pueden combinarse para escribir código que por su forma sea correcto. La semántica : permite determinar el significado de la secuencia de símbolos. También a través de las reglas semánticas pueden ser detectados errores de interpretación que no permiten que las acciones o instrucciones puedan ser ejecutadas. Variables: Una variable es una abstracción de una zona de memoria que se utiliza para representar y conservar valores temporalmente de un determinado tipo. Sintaxis: <tipo de dato> <lista de identificadores de variables>; Ejemplo: int unAño; string nombre, apellido; Operadores: La siguiente tabla muestra un resumen de los operadores más importantes.

Tecnologías de la Información y Comunicación Sistemas Informáticos 5
El operador == determina si dos referencias hacen referencia al mismo objeto, pero al usar dicho operador con dos operandos tipo string se prueba la igualdad del contenido de las cadenas y no su referencia. Sin embargo, con el resto de los operadores relacionales, como < o >= se comparan las referencias Comentarios : Un comentario es texto que se incluye en el código fuente con el objetivo de facilitar su legibilidad a los programadores. Los comentarios no tienen significado alguno para la ejecución de una aplicación; esto es equivalente a decir que los comentarios son completamente ignorados por el compilador. Un comentario de una sola línea se determina por los caracteres //. Un comentario con un conjunto de líneas con /* al inicio, y se cierra el bloque con */. Clases y objetos Una clase en C# es una secuencia de símbolos (o caracteres) de un alfabeto básico Sintaxis para la definición de clases class <NombreClase> { <miembros> } Los miembros se definen como los atributos y métodos. Los cuales estarán presentes en cada uno de los objetos o instancias de la clase. Atributos: Son datos comunes a todos los objetos de una determinada clase y su sintaxis de definición es (como la declaración de variable): <TipoDato> <nombreCampo>; El <nombreCampo> puede ser cualquier identificador que cumpla con las reglas establecidas y no coincida con el nombre de otro miembro previamente definido en la clase

Tecnologías de la Información y Comunicación Sistemas Informáticos 6
Métodos: Son un conjunto de instrucciones o acciones que se agrupan a través de un determinado nombre simbólico de tal manera que es posible ejecutarlas en cualquier momento sin tenerlas que volver a escribir. A estas instrucciones se les denomina cuerpo del método, y a su ejecución a través de su nombre se le denomina llamada al método. Los métodos pueden devolver algún valor cuando se ejecutan. En las instrucciones es posible acceder con total libertad a los atributos de la clase a la cual pertenece el método. Su sintaxis es la siguiente: <TipoDevuelto> <identificador del método> ([<Parámetros>]) { <instrucciones> } Ejemplo de la declaración de clase y método: class Persona { // atributos string nombre; int añoNacimiento; // método de consulta o acceso int Edad(int unAño) { // edad aproximada return unAño - añoNacimiento; } } Sobrecarga de métodos: Se denomina así a la posibilidad de disponer de varios métodos con el mismo nombre, pero con diferente lista de parámetros y es posible que cuando se les invoque el compilador podrá determinar a cual llamar a partir de los parámetros pasados en la llamada. Sin embargo, lo que no se permite es definir varios métodos que solamente se diferencien en su valor de retorno, puesto que la forma de invocar a los métodos a través de instancias de la clase es: <objeto>.<nombre del método>([<valores de los parámetros>]) Nota: C# permite la sobrecarga de operadores con la palabra clave operator Encapsulamiento: El mecanismo de encapsulamiento o principio de la ocultación de la información, le permite a los diseñadores de clases determinar qué miembros de estas pueden ser utilizados por otros programadores y cuáles no. A su vez este mecanismo nos permite ocultar todos los detalles relativos a la implementación interna y sólo dejar visibles aquellos que se puedan usar con seguridad y le facilita al creador la posterior modificación. Este mecanismo le permite a las clases proporcionar una interfaz con las responsabilidades que los clientes pueden acceder directamente. El encapsulamiento se consigue añadiendo modificadores de acceso en las definiciones de los métodos y atributos. Estos modificadores son palabras reservadas del lenguaje que indican desde qué código puede accederse a ellos. Los modificadores de C# son los siguientes:
•••• public : indica que la componente puede ser accedida desde cualquier código. Se representa con +. •••• private : sólo puede ser accedido desde el código de la clase a la que pertenece. Es lo considerado. Se
representa con -. •••• protected : permite el acceso desde el código de la clase a la que pertenece o de subclases suyas. Se
representa con #. En caso de no especificarse algún modificador, se considera por defecto u omisión que los miembros de un tipo de dato son private . La creación de un objeto o instancia de clase se realiza por medio de un método constructor. Constructores : Los constructores de una clase son métodos especiales que se definen como componentes de ésta, y que contienen código a ejecutar cada vez que se crea un objeto de ése tipo. Éste código suele utilizarse para la inicialización de los atributos del objeto a crear. La sintaxis básica de definición de constructores consiste en definirlos como cualquier otro método pero dándoles el mismo nombre que la clase a la que pertenecen y no se indicando el tipo de valor de retorno.

Tecnologías de la Información y Comunicación Sistemas Informáticos 7
Sintaxis: <nombreTipo>([<parámetros>]) { <código> }
Nota: Un constructor tiene el mismo nombre que su clase y es sintácticamente similar a un método. Un constructor no regresa ningún valor. Los constructores también pueden ser sobrecargados. Si no se especifica un constructor en una clase, se usa uno por defecto que consiste en asignar a todas las variables el valor de 0 o null según corresponda. La palabra clave this es un apuntador al mismo objeto en el cual se usa. La palabra clave static hace que un miembro pertenezca a una clase en vez de pertenecer a objetos de dicha clase. Se puede tener acceso a dicho miembro antes de que se cree cualquier objeto de su clase y sin referencias a un objeto.
NEW: Se utiliza para crear objetos e invocar constructores. Para crear un nuevo objeto se utiliza la siguiente sintaxis: identificador = new nombre_clase() ;.El operador new también se utiliza para invocar el constructor predeterminado de los tipos de datos. Ejemplo: Class1 o = new Class1(); int i = new int(); Propiedades: Las propiedades son miembros que ofrecen un mecanismo flexible para leer, escribir o calcular los valores de campos privados. Se pueden utilizar las propiedades como si fuesen miembros de datos públicos, aunque en realidad son métodos especiales denominados descriptores de acceso. De este modo, se puede tener acceso a los datos con facilidad, a la vez que proporciona la seguridad y flexibilidad de los métodos Sintaxis: [<modificadores>] <tipoPropiedad> <nombrePropiedad> { get
{ <códigoEscritura>
} set {
<códigoEscritura> }
} Una propiedad definida de esta forma va a ser accedida como si se tratara de un atributo en el cual cada lectura de su valor se ejecutaría el <códigoLectura> y en cada escritura de un valor en ella se ejecutaría <códigoEscritura>. Estructura de control alternativa simple La instrucción if: se evalúa la expresión lógica <condición>, si el resultado de su evaluación es verdadero (true) se ejecuta el <bloque de instrucciones >. Tiene la siguiente sintaxis: if (<condición>) <bloque de instrucciones>; La instrucción if-else: El <bloque de instrucciones 1> se ejecuta en caso de que se cumpla la <condición>, en otro caso se ejecuta entonces el <bloque de instrucciones 2>. La sintaxis es: if (<condición>) <bloque de instrucciones 1>; else <bloque de instrucciones 2>; Estructura de control alternativa múltiple (switch case) La instrucción switch es muy simple: si al evaluarse <expresión> toma <valor 1> entonces se ejecuta <bloque de instrucciones 1>; si al evaluarse <expresión> toma <valor 2> entonces se ejecuta <bloque de instrucciones 2> y así sucesivamente hasta <valor n>. De no coincidir la evaluación con alguno de los valores predeterminados y si existe la opción default (ya que es opcional), entonces se ejecutará <bloque de instrucciones default>. La instrucción break es obligatoria excepto cuando exista una instrucción return en el respectivo bloque de instrucciones. break indica que

Tecnologías de la Información y Comunicación Sistemas Informáticos 8
después de ejecutar el bloque de instrucciones que lo precede se salta a la próxima instrucción después del switch. La sintaxis es la siguiente: switch (<expresión>) {
case <valor 1>: <bloque de instrucciones 1> [break; ]
case <valor 2>: <bloque de instrucciones 2> [break; ]
case <valor n>: <bloque de instrucciones n> [break; ]
[default : <bloque de instrucciones default> [break; ]]
} Estructura de control for: Es uno de los ciclos más conocidos y usados; está controlado por un contador o variable de control. Tiene la siguiente sintaxis: for (<instrucciones 1>; <expresión>; <instrucciones 2>) <instrucciones> La semántica es la siguiente: <instrucciones 1>; se ejecutará una sola vez al inicio del ciclo, generalmente se realizan inicializaciones y declaraciones de variables puesto que como se dijo con anterioridad, esta solo se ejecuta una vez. En caso de que se quiera realizar o ejecutar mas de una instrucción en este momento, dichas instrucciones se deben separar por comas (“,”). <expresión>; es evaluada en cada ciclo y en dependencia del valor que devuelva, dependerá que el bucle continúe ejecutándose (true ) o no (false ). Al no colocarse nada en esta parte, el ciclo tomará como true el valor devuelto por lo que se ejecutará infinitamente. <instrucciones 2>; es ejecutado siempre en cada ciclo al terminar de ejecutar todas las instrucciones que pertenecen al ciclo for en cuestión. Por lo general puede contener alguna actualización para las variables de control. En caso de querer ejecutar en este momento más de una instrucción se deben separar por comas. Estructura de control while: A veces no es posible saber de antemano el número de veces que se va a repetir la ejecución de una porción de código, mientras una condición sea cierta. Para definir este tipo de ciclos condicionales es posible utilizar la estructura de control while, cuya sintaxis es la siguiente: while <condición> <instrucciones> Se ejecuta el bloque (<instrucciones>) mientras la <condición> sea cierta, o dicho de otra manera, el bucle terminará cuando la <condición> sea falsa. En ésta estructura la <condición> se verifica siempre al principio del ciclo por lo que, si la primera vez que se evalúa <condición>, es falsa, el ciclo no llegará nunca a ejecutarse. Estructura de control do-while: La estructura de control do-while es otra sentencia de iteración en la que la condición se evalúa por primera vez después de que las <instrucciones> del ciclo se hayan ejecutado. Esto quiere decir que las sentencias del bucle do-while , al contrario que las del ciclo while , al menos se ejecutan una vez. La sintaxis de esta estructura es la siguiente: do <instrucciones> while <condición>; Estructura de control foreach: El ciclo foreach repite las instrucciones para cada elemento de un arreglo o colección. La finalidad de esta estructura es recorrer todos los elementos de un arreglo o colección, sin necesidad de índices ni valores mínimos o máximos. Sintácticamente, como se muestra a continuación, tras la palabra foreach y entre paréntesis se debe insertar una variable del mismo tipo de datos del arreglo que va tomando el valor de cada uno de los elementos que existan en el arreglo, ejecutando el ciclo para cada uno de ellos. foreach ([<tipo de dato>]<variable> in <arreglo o colección>) <instrucciones> Arreglos Un arreglo unidimensional es un tipo especial de variable que es capaz de almacenar en su interior y de manera ordenada varios elementos de un mismo tipo de datos.

Tecnologías de la Información y Comunicación Sistemas Informáticos 9
<identificador de tipo> [ ] <identificador de variable>; Ejemplo: int [] temperaturas = {28, -5}; // El tamaño del arreglo es 2 y los datos del arreglo son 28 y -5 double [] pesos; // Se declara un arreglo llamado pesos, no se ha definido el tamaño del arreglo. pesos=new double[5]; // crea y define que el tamaño del arreglo pesos es de 5.
PROGRAMACIÓN PARA LA WEB Estructuración de un documento
Las etiquetas mas básicas son las que forman el esqueleto de la página:
<html> Define que se iniciara la construcción de una página web. <head> En esta parte definida como el encabezado, se pueden incluir las funcione de
programación de Java script y las Hojas de Estilo. <title> Define el titulo de nuestra pagina Web <body> Aquí es donde se construirá toda nuestra pagina, es decir todos los elementos
visuales que el usuario observa en la página <HTML> <HEAD> <TITLE>una pagina de ensayo</TITLE> </HEAD> <BODY> Esto es lo que se visualiza en el navegador </BODY> </HTML>
Descripción Etiqueta Atributos Comentarios <!- -> Colores en el Lugar <font color=”#rrggbb”> </font> Párrafos <p></p> Saltos de línea <br> Texto con preformato <pre> </pre> Cabeceras <H1> </H1> hasta
<H6> </H6>
Separadores <HR> ALING=center/left/right alineación SIZE=n ancho de línea, donde n=1 al 10, el 1 es la mas fina WIDTH = n longitud de la línea, NOSHADE línea sin relieve
Tamaño de letra (fuentes)
<FONT SIZE=x></FONT>
Tipos de letras <B> negrita <I> cursiva <u> subrayar <blink> texto intermitente <big> texto grande, el mayor tamaño de fuente <small> texto pequeño, el menor tamaño de la fuente <sup> super indice <sub> subindice <address> bloque de texto cursivo

Tecnologías de la Información y Comunicación Sistemas Informáticos 10
<blockquote> Representar con una tabulación y en cursiva. <cite> muestra el texto como si fuera una cita <code> se utiliza para representar una etiqueta HTML o código de programa <em> presenta el contenido de un bloque de texto enfatizado <strong> texto más enfatizado que el caso anterior. Negrita <strike> texto techado <center> centra el texto en la pantalla
Enlaces <A HREF="xxx"> yyy </A> Listas Ordenadas <OL TYPE= i> </OL> <LH> Titulo de la lista
<LI> Elemento de la lista Listas desordenadas <OL TYPE=” “> </OL> Imágenes <Img src=”.....”>; ALT Asignamos entre comillas un nombre
para la imagen Tablas <table> </table> • Filas • columnas
<tr> </tr> <td> </td>
FRAMES <HTML> <HEAD><TITLE> Titulo </TITLE></HEAD> <FRAMESET COLS=*.*> <!---------CODIGO---------> </FREMESET> </HTML> Veamos que dos asteriscos separados por una coma, nos ayudan a delimitar las zonas de trabajo. En este caso indicamos que ambas ventana son iguales, también es posible sustituir estos asteriscos por números o porcentajes, por ejemplo: <FRAMESET ROW=3*,*> igual a <FRAMESET ROW= 75%,25%>. Formularios <HTML> <HEAD> <TITLE> FORMULARIOS</TITLE> </HEAD> <BODY> <FORM> <P>Nombre completo: <INPUT TYPE="text" NAME="nombre" SIZE="30"> <P>Dirección: <INPUT TYPE="text" NAME="direccion" SIZE="50">
<TABLE>
<TR> <TD>...</TD> <TD>...</TD> <TD>...</TD>
<TD>...</TD> <TD>...</TD> <TD>...</TD>
<TD>...</TD> <TD>...</TD> <TD>...</TD>
</TR>
<TR> </TR>
<TR> </TR>
</TABLE>

Tecnologías de la Información y Comunicación Sistemas Informáticos 11
<P>Ciudad: <INPUT TYPE="text" NAME="ciudad" SIZE="20"> Código Postal: <INPUT TYPE="text" NAME="c.p." SIZE="6" MAXLENGTH="5"> <P>Teléfono: <INPUT TYPE="text" NAME="telefono" SIZE="10" MAXLENGTH="9"> <P>Fax: <INPUT TYPE="text" NAME="FAX" SIZE="10" MAXLENGTH="9"> <P>Email: <INPUT TYPE="text" NAME="email" SIZE="30"> <P>Catálogo: <SELECT> <OPTION VALUE="nacional"> Nacional <OPTION VALUE="internacional" SELECTED> Internacional <OPTION VALUE="completo"> Completo </SELECT> <P> <INPUT TYPE="image" BORDER="0" SRC="img/enviar.jpg" VALUE="Enviar"> </FORM> </BODY> </HTML> JAVASCRIP Javascript es un lenguaje de programación utilizado para crear pequeños programitas encargados de realizar acciones dentro del ámbito de una página web. Con Javascript podemos crear efectos especiales en las páginas y definir interactividades con el usuario. El navegador del cliente es el encargado de interpretar las instrucciones Javascript y ejecutarlas para realizar estos efectos e interactividades, de modo que el mayor recurso, y tal vez el único, con que cuenta este lenguaje es el propio navegador
Queremos que quede claro que Javascript no tiene nada que ver con Java , salvo en sus orígenes, como se ha podido leer hace unas líneas. Actualmente son productos totalmente distintos y no guardan entre si más relación que la sintaxis idéntica y poco más. Algunas diferencias entre estos dos lenguajes son las siguientes:

Tecnologías de la Información y Comunicación Sistemas Informáticos 12
• Compilador . Para programar en Java necesitamos un Kit de desarrollo y un compilador. Sin embargo, Javascript no es un lenguaje que necesite que sus programas se compilen, sino que éstos se interpretan por parte del navegador cuando éste lee la página.
• Orientado a objetos . Java es un lenguaje de programación orientado a objetos. (Más tarde veremos que quiere decir orientado a objetos, para el que no lo sepa todavía) Javascript no es orientado a objetos, esto quiere decir que podremos programar sin necesidad de crear clases, tal como se realiza en los lenguajes de programación estructurada como C o Pascal.
• Propósito . Java es mucho más potente que Javascript, esto es debido a que Java es un lenguaje de propósito general, con el que se pueden hacer aplicaciones de lo más variado, sin embargo, con Javascript sólo podemos escribir programas para que se ejecuten en páginas web.
• Estructuras fuertes . Java es un lenguaje de programación fuertemente tipado, esto quiere decir que al declarar una variable tendremos que indicar su tipo y no podrá cambiar de un tipo a otro automáticamente. Por su parte Javascript no tiene esta característica, y podemos meter en una variable la información que deseemos, independientemente del tipo de ésta. Además, podremos cambiar el tipo de información de una varible cuando queramos.
• Otras características . Como vemos Java es mucho más complejo, aunque también más potente, robusto y seguro. Tiene más funcionalidades que Javascript y las diferencias que los separan son lo suficientemente importantes como para distinguirlos fácilmente.
El lenguaje Javascript tiene una sintaxis muy parecida a la de Java por estar basado en él. También es muy parecida a la del lenguaje C, de modo que si el lector conoce alguno de estos dos lenguajes se podrá manejar con facilidad con el código. De todos modos, en los siguientes capítulos vamos a describir toda la sintaxis con detenimiento, por lo que los novatos no tendrán ningún problema con ella. Comentarios Un comentario es una parte de código que no es interpretada por el navegador y cuya utilidad radica en facilitar la lectura al programador. El programador, a medida que desarrolla el script, va dejando frases o palabras sueltas, llamadas comentarios, que le ayudan a él o a cualquier otro a leer mas fácilmente el script a la hora de modificarlo o depurarlo. Ya se vio anteriormente algún comentario Javascript, pero ahora vamos a contarlos de nuevo. Existen dos tipos de comentarios en el lenguaje. Uno de ellos, la doble barra, sirve para comentar una línea de código. El otro comentario lo podemos utilizar para comentar varias líneas y se indica con los signos /* para empezar el comentario y */ para terminarlo. Veamos unos ejemplos. <SCRIPT> //Este es un comentario de una línea /*Este comentario se puede extender por varias líneas. Las que quieras*/ </SCRIPT> Mayúsculas y minúsculas En javascript se han de respetar las mayúsculas y las minúsculas. Si nos equivocamos al utilizarlas el navegador responderá con un mensaje de error de sintaxis. Por convención los nombres de las cosas se escriben en minúsculas, salvo que se utilice un nombre con más de una palabra, pues en ese caso se escribirán con mayúsculas las iniciales de las palabras siguientes a la primera. También se puede utilizar mayúscula en las iniciales de las primeras palabras en algunos casos, como los nombres de las clases, aunque ya veremos más adelante cuáles son estos casos y qué son las clases. Separación de instrucciones Las distintas instrucciones que contienen nuestros scripts se han de separar convenientemente para que el navegador no indique los correspondientes errores de sintaxis. Javascript tiene dos maneras de separar instrucciones. La primera es a través del carácter punto y coma (;) y la segunda es a través de un salto de línea.

Tecnologías de la Información y Comunicación Sistemas Informáticos 13
Por esta razón Las sentencias Javascript no necesitan acabar en punto y coma a no ser que coloquemos dos instrucciones en la misma línea. No es una mala idea, de todos modos, acostumbrarse a utilizar el punto y coma después de cada instrucción pues otros lenguajes como Java o C obligan a utilizarlas y nos estaremos acostumbrando a realizar una sintaxis más parecida a la habitual en entornos de programación avanzados.
Cómo definir funciones
Las funciones se definen por medio del estatuto function , el cual requiere un nombre para la función, una lista de parámetros o argumentos que se pasarán a la función y un bloque de comandos que define lo que hace la función:
function nombre_de_la_funcion(parametro1, parametro 2, ... , parametroN)
{ linea_de_comando; ... ... linea_de_comando }
Los nombres de las funcines son sensibles a mayúsculas y minúsculas, pueden incluir el guión de subrayado y deben comenzar con una letra. La lista de argumentos se encierra entre parétesis y van separados por comas.
Cómo pasar parámetros
En el ejemplo expuesto arriba vemos que la función AlertBox acepta un parámetro llamado cMens . Dentro de la función, las referencias a cMens aluden al valor pasado a la función. Respecto de los parámetros, hay varios aspectos a considerar:
• Tanto las variables como los literales se pueden pasar como argumentos cuando se llama a una función. • Si se pasa una variable a una función, al cambiar el valor del parámetro dentro de la función, no se estará
alterando el valor de la variable pasada a la función. • Los parámetros existen sólo durante la vida de la función, si llama a una función varias veces, los parámetros se
crean de nuevo cada vez que se llama a la función, y los valores que contienen cuando la función terminó la última vez, no se retienen.
• Si un parámetro de una función tuviere el mismo nombre que una variable externa a la función, la función sólo "verá" el valor del parámetro.
• Tanto los valores de los parámetros de una función como las variables creadas dentro de la misma, son desconocidos por el resto de las funciones del documento.
Variables y literales
Podemos imaginarnos las variables como cajas para guardar cosas que vamos a necesitar mientras ejecutamos JavaScript.
Es habitual declarar variables en la mayoría de los lenguajes de programación. Esto significa que antes de utilizar una variable se le adjudica un nombre con el fin de que, cada vez que se ejecute el programa, se reserve un espacio de memoria para el contenido de la variable. En JavaScript declaramos variables utilizando la palabra clave var :
var nombre_variable;

Tecnologías de la Información y Comunicación Sistemas Informáticos 14
También puede incluirse algun contenido al declarar la variable:
var nombre_variable = contenido ;
A esto se lo llama inicializar la variable. Por ejemplo:
var cEstado = "Buenos Aires"; var nCodPostal = 1000; var oForms = document.forms;
Por otro lado tenemos las literales. Las literales son valores fijos que proporcionan literalmente un valor a un programa. Extisten tre tipos de datos literales: numéricos, cadenas y boleanos.
• Cadenas (strings), "Hola todos" • Números , enteros y decimales • Boleanos (verdadero|true // falso|false)
HOJAS DE ESTILO CSS Las Hojas de estilo son un complemento directo de HTML y conforman un lenguaje con el cual se definen las características formales (apariencia o estilos) de las instrucciones HTML en una página. Con la ayuda de las hojas de estilo se puede definir por ejemplo, que un encabezamiento de 1er. Nivel tenga un tamaño de letra de 18 puntos, usando la fuente “Helvética” sin ser resaltada y a una distancia de 1.75 cm. del párrafo que sigue. Este tipo de descripciones no se pueden hacer en HTML “tradicional”.
Ventajas y desventajas
Ventajas:
• Podemos modificarla la presentación de todos los elementos estándar del documento sin tener que modificar el código HTML estructural.
• Disponemos de comandos y atributos más potentes y precisos con los que podemos maquetar exactamente un documento.
• Es un lenguaje muy sencillo, ya que se basa en el uso de propiedades muy intuitivas, similares a las de un procesador de texto en inglés.
• Podemos general un estilo externo que contenga todas las definiciones de estilo de un documento y modificar éste únicamente para efectuar cambios en una o varias páginas Web.
• Es uno de los pilares del DHTML y puede combinarse con JavaScript, VBScript, ect. • Su uso estructurado y razonado permite ahorrar muchas líneas de código HTML
Desventajas:
• La principal y la única desventaja hasta el momento podemos decir que es la incompatibilidad entre navegadores distintos.
Hay tres navegadores que soportan aceptablemente las CSS; Microsoft Internet Explorer, Netscape y Opera. Aunque todos ellos aseguran la compatibilidad lo cierto es que entre varias versiones de un mismo navegador, ya hay irregularidades. La solución a este inconveniente es conocer las propiedades implementadas en cada versión de navegador, probar nuestros estilos en varios navegadores y pensar que siempre puede haber un navegador visualizando la página sin soporte para CSS, con lo que el HTML será el único código a interpretar.
Las Hojas de estilo tienen una estructura simple, flexible y potente. No es necesario tener grandes conocimientos de programación (más bien ninguno) para trabajar cómodamente con ellas. Dada su fácil estructuración podemos definir la apariencia de cada elemento o grupo de ellos con suma facilidad cambiando posteriormente si diseño si es necesario, de forma simple y rápida.

Tecnologías de la Información y Comunicación Sistemas Informáticos 15
Sintaxis y Reglas
Disponemos de multitud de formas o reglas para definir los estilos dentro de un documento dependiendo de la finalidad a conseguir, podemos definir un estilo de manera global, es decir, especificar las propiedades que van a afectar a todo el documento, aplicar los estilos a un elemento HTML concreto, establecer estilos dependiendo del contexto que rodea el elemento (estar dentro de un tabla, formar parte de una lista) etc.
Una hoja de estilo se define de manera similar a los Scripts de JavaScript o Vbscript. La definición global de un estilo estará delimitada por las etiquetas <style> </style> respectivamente y en su interior podremos establecer los estilos que se utilizan en todo el documento. Para especificar el tipo de sintaxis que se empleará utilizaremos el atributo TYPE. Su valor por defecto es “text/css” y selecciona la sintaxis CSS
<style type=”text/css”>
<!-
P{color: green}
->
</style>
Estilos de etiqueta
A continuación estudiaremos las distintas formas sintácticas de definir estilos en un documento HTML. La sintaxis básica es la siguiente:
Selector {Propiedad: Valor}
El selector es el valor en HTML al que afectar la definición del estilo en función del valor asignado a la propiedad que desea especificar. Al conjunto Propiedad- Valor se le llama: Declaración.
Por ejemplo: P{color:green}
Aquí se indica que todos los párrafos serán de color verde. Si además queremos que todos los párrafos estén justificados, habrá que añadir la propiedad correspondiente, en este caso:
P{text-align: justify}
En el ejemplo anterior ya tenemos dos líneas de código y solo acabamos de empezar, pues bien la sintaxis CSS permite añadir todas las propiedades que queramos para un mismo selector entre sus corchetes separando las mismas por un punto y coma. Así pues, para configurar un párrafo de color verde y justificado, la sintaxis adecuada sería:
P {color:green; text-align: justify}
Si quisiéramos añadir el estilo definido anteriormente a la etiqueta <B> (negrita), no sería necesario volver a escribir toda la declaración, bastaría con separar con una coma un selector de otro. Veamos como:
B, P {color:green; text-align: justify}
Ahora imaginemos que además, el estilo negrita (B) debe aparecer sobre un fondo blanco. En este caso, la solución es añadir una nueva línea ya que es una propiedad que queremos aplicar sólo al selector negrita, Así nuestro estilo tomaría la siguiente forma:
B, P {color:green; text-align: justify}
B {background-color: white}
Otra posibilidad puede ser la de establecer un estilo dependiendo de una condición estructural. Por ejemplo, si el texto en negrita aparece dentro de la celda de una tabla, entonces el fondo debe de ser negro y la letra debe aparecer en cursiva.
TD B { background-color: black; font-style: italic}
Observe como en este caso no sean separado los selectores con una coma. De esta forma, el interprete CSS entiende que esa declaración sólo debe cumplirse para las negritas que estén dentro de la celda.
Finalmente podemos aplicar un estilo concreto a un elemento del documento, bien sea porque de manera puntual se requiere modificar el estilo definido en anteriores declaraciones en el supuesto de que las hubiera o porque sólo queremos que ese elemento modifique sus propiedades de estilo sin afectar a sus semejantes.

Tecnologías de la Información y Comunicación Sistemas Informáticos 16
Así pues, volviendo a nuestro selector de negritas <B>, vamos a indicar en un punto determinado del código HTML un estilo concreto:
El texto en negrita en este punto <B style= “Font-size:12pt; color:”#0000FF”>
Es mas grande y esta en azul. </B> .
Definición de estilos mediante clases
La utilización de clases va a permitirnos especificar distintos estilos para un mismo elementos HTML o bien generar estilos tipo para poder aplicarlos a cualquier etiqueta HTML según sea necesario. Su sintaxis es:
Elemento.nombreclase {propiedad:valor}
Por ejemplo, vamos a definir varios colores de párrafo de la siguiente manera:
P.amarillo {color:yellow}
P.verde {color:green}
P.colorextraño {color:#CA36E1}
Si queremos aplicar los estilos de color definidos anteriormente, el código sería similar al siguiente:
<P> este párrafo no tiene ningún estilo aplicado
<P class=amarillo> este saldrá de color Amarillo
<P class=verde> este seguro que verde
<P class=colorextraño> el color extraño se parece al violeta
Sin embargo, ¿qué pasaría si también se quisiera determinar un estilo de color para todos los encabezados? Evidentemente, no tendríamos que repetir la propiedad color para cada encabezado, bastaría con definir una clase sin asociarla a ningún estilo.
.amarillo {color:yelow}
.verde {color:green}
.colorextraño {color:#ca36e1}
Como puede verse, la sintaxis es la misma, salvo que en este caso, está omitiendo el selector, con lo que está dejando abierta la posibilidad de aplicarlo a cualquiera.
<P class=amarillo>este saldrá de color amarillo
<h1 class=verde>este encabezado saldrá de color verde </h1>
<B class=colorextraño> esta negrita es de color ¿violeta?
BASE DE DATOS
Objetivo : Diseñar bases de datos mediante la utilización de la interfaz de un Sistema Manejador de Base de Datos (SMDB) empleando un modelo de datos así como las restricciones de integridad a un nivel creativo .
Una base de datos es una recopilación de información relativa a un asunto o un propósito particular, como el seguimiento de pedidos de clientes o el mantenimiento de una colección de música.
Definiciones de términos que involucran a las bases de datos:
Datos: Conjunto de caracteres con algún significado, pueden ser numéricos, alfabéticos, o alfanuméricos.
Información: Es un conjunto ordenado de datos los cuales son manejados según la necesidad del usuario, para que un conjunto de datos pueda ser procesado eficientemente y pueda dar lugar a información, primero se debe guardar lógicamente en archivos.
Campo: Unidad básica de una base de datos . Un campo puede ser, por ejemplo, el nombre de una persona. El equivalente a las columnas del modelo relacional.

Tecnologías de la Información y Comunicación Sistemas Informáticos 17
Registro: (También llamado fila o tupla ) Representa un elemento único de datos implícitamente estructurados en una tabla.
Archivo : Colección de registros almacenados siguiendo una estructura homogénea. El equivalente a las tablas del modelo relacional.
Dentro de este marco, otra definición es: “Conjunto o colección de archivos interrelacionados , cuyo contenido engloba a la información concerniente de una organi zación, de tal manera que los datos estén disponibl es para los usuarios, una de las finalidades de las bases d e datos es eliminar la redundancia o por lo menos minimizarla”.
Funciones de los sistemas de bases de datos. Las funciones principales de un sistema de base de datos es disminuir (evitar) los siguientes aspectos:
1. Redundancia e inconsistencia de datos. (originar duplicados de información) 2. Dificultad para tener acceso a los datos. (entorno de datos que no le facilite al usuario el manejo de los mismos) 3. Aislamiento de los datos. (los datos están repartidos en varios archivos) 4. Anomalías del acceso concurrente.(interacción de actualizaciones concurrentes pueden resultar datos inconsistentes 5. Problemas de seguridad. (todos los usuarios pueden visualizar alguna información) 6. Problemas de integridad. (los datos deben satisfacer cierto tipo de restricciones de consistencia)
Niveles de Abstracción: Un objetivo importante de un sistema de base de datos es proporcionar a los usuarios una visión abstracta de los datos , es decir, el sistema esconde ciertos detalles de cómo se alma cenan y mantienen los datos .
Nivel Físico (base de datos física). Es la representación del nivel más bajo de abstracción, en éste se describe en detalle la forma en como se almacenan los datos en los dispositivos de almacenamiento (por ejemplo, mediante señaladores o índices para el acceso aleatorio a los datos).
Nivel Conceptual (base de datos lógica). En este nivel se describe que datos son almacenados realmente en la base de datos y las relaciones que existen entre los mismos, describe la base de datos completa en términos de su estructura de diseño.
Nivel de Visión. Nivel más alto de abstracción, es lo que el usuario final puede visualizar del sistema terminado, describe sólo una parte de la base de datos al usuario acreditado para verla.
Actores en los sistemas de bases de datos:
Administrador de Bases de Datos. (DBA, Database Adm inistrator)
Usuarios de Bases de Datos, se clasifican en:
� Programadores de aplicaciones. Los profesionales en computación que interactúan con el sistema por medio de llamadas en DML (Lenguaje de Manipulación de Datos), las cuales están incorporadas en un programa escrito en un lenguaje de programación (Por ejemplo, COBOL, PL/I, Pascal, C, etc.)
� Usuarios sofisticados. Los usuarios sofisticados interactúan con el sistema sin escribir programas. En cambio explotan la información.
� Usuarios especializados. Algunos usuarios sofisticados escriben aplicaciones de base de datos especializadas que no encajan en el marco tradicional de procesamiento de datos.
� Usuarios ingenuos. Los usuarios no sofisticados interactúan con el sistema invocando a uno de los programas de aplicación permanentes que se han escrito anteriormente en el sistema de base de datos, podemos mencionar al usuario ingenuo como el usuario final que utiliza el sistema de base de datos sin saber nada del diseño interno del mismo por ejemplo: un cajero.

Tecnologías de la Información y Comunicación Sistemas Informáticos 18
Sistemas Gestores de de Bases de datos. El sistema de gestión de la base de datos (SGBD) es una aplicación que permite a los usuarios definir, crear y mantener la base de datos, y proporciona acceso controlado a la misma.
Ventajas de utilizar un SGBD. Existen distintos objetivos que deben cumplir los SGBD, tales como:
� Abstracción de la información .
� Independencia .
� Redundancia mínima .
� Consistencia .
� Seguridad .
� Integridad .
� Respaldo y recuperación . � Control de la concurrencia .
� Tiempo de respuesta .
Estructura Global de un sistema de base de datos: Un sistema de base de datos se encuentra dividido en módulos cada uno de los cuales controla una parte de la responsabilidad total de sistema.
Los componentes funcionales de un sistema de base de datos, son: Gestor de archivos, Manejador de base de datos, Procesador de consultas, Compilador de DDL, Archivo de datos, Diccionario de dato s, Índices.
MODELOS DE BASES DE DATOS. Los modelos de bases de datos son un conjunto de conceptos, reglas y convenciones que nos permiten describir y manipular (consultar y actualizar) los datos de un cierto mundo real que deseamos almacenar en una base de datos. Son un eficaz instrumento en el diseño de Bases de Datos, al proporcionar instrumentos que ayudan a la estructuración, paso a paso, del mundo real hasta llegar a la base de Datos física.
� MODELOS LÓGICOS BASADOS EN OBJETOS. Se usan para describir datos en el nivel conceptual y de visión, es decir, con este modelo representamos los datos como nosotros los percibimos en el mundo real, tienen una capacidad de estructuración bastante flexible y permiten especificar restricciones de datos explícitamente. Entre los modelos que encontramos de este tipo son Modelo Entidad-Relación , Modelo Entidad-Relación Extendido y Modelo Orientado a Objetos.
� MODELOS LÓGICOS BASADOS EN REGISTROS . Se utilizan para describir datos en los niveles conceptual y físico; se utilizan para especificar la estructura lógica completa de las bases de datos y proporcionan una descripción de alto nivel de implementación, tienen un número fijo de campos, atributos y longitud fija, entre estos encontramos el Modelo de Red, Modelo Jerárquico y Modelo Relacional .
MODELO DE DATOS ENTIDAD-RELACIÓN. Denominado por sus siglas como: E-R. Este modelo representa a la realidad a través de entidades , que son objetos que existen y que se distinguen de otros p or sus características , por ejemplo: un alumno se distingue de otro por sus características particulares como lo es el nombre, o el número de control así mismo, un empleado, una materia, etc.
Las características de las entidades en base de datos se llaman atributos , por ejemplo el nombre, dirección teléfono, grado, grupo, etc. son atributos de la entidad alumno. A su vez una entidad se puede asociar o relacionar con más entidades a través de relaciones, Una relación es la asociación que existe entre dos a más entidades.
Símbolo Representa
Entidad
Relación
Atributos

Tecnologías de la Información y Comunicación Sistemas Informáticos 19
TIPOS DE RELACIÓN. Existen 4 tipos de relaciones que pueden establecerse entre entidades, las cuales establecen con cuantas entidades de tipo B se pueden relacionar una entidad de tipo A:
� Relación uno a uno. Se presenta cuando existe una relación como su nombre lo indica uno a uno, denominado también relación de matrimonio. Una entidad del tipo A sólo se puede relacionar con una entidad del tipo B, y viceversa;
� Relación uno a muchos. Significa que una entidad del tipo A puede relacionarse con cualquier cantidad de entidades del tipo B, y una entidad del tipo B sólo puede estar relacionada con una entidad del tipo A.
� Muchos a uno. Indica que una entidad del tipo B puede relacionarse con cualquier cantidad de entidades del tipo A y una entidad del tipo A sólo puede estar relacionada con una entidad del tipo B.
� Muchos a muchos. Establece que cualquier cantidad de entidades del tipo A pueden estar relacionados con cualquier cantidad de entidades del tipo B.
A los tipos de relaciones antes descritos, también se le conoce como cardinalidad.
MODELO DE DATOS RELACIONAL. Modelo relacional. El modelo relacional ofrece una manera única de representar los datos: como una tabla bidimensional denominada relación (tabla), dicha relación (tabla) contiene campos (columnas) y registros (filas) .
Sus elementos son: Campos, Registros, Dominios, Claves.
CLAVES
Clave Primaria (primary key). Columna o combinación de columnas cuyos valores identifican de manera única cada fila de la tabla.
Clave Foránea (foreign key). Las columnas de una tabla cuyos valores coinciden con los de la clave primaria de otra tabla se denominan claves externas o foráneas. Conjuntamente una clave primaria y una clave foránea crean una relación padre/hijo entre las tablas que las contienen.
NORMALIZACIÓN
Proceso durante el cual los esquemas de relación que no cumplen las condiciones se descomponen repartiendo sus atributos entre esquemas de relación más pequeños que cumplen las condiciones establecidas. Un objetivo es garantizar que no ocurran anomalías de actualización. Primera forma normal (1FN). Una relación está en primera forma normal (1FN) si los valores para cada atributo de la relación son atómicos. Esto quiere decir simplemente que cada atributo sólo puede pertenecer a un dominio (es indivisible) y que tiene un valor único para cada fila. Segunda forma normal (2FN). Una relación está es segunda forma normal (2FN) si está en 1FN y todos los atributos no clave dependen de la clave completa y no sólo de una parte de esta. Tercera forma normal (3FN). Una relación está en tercera forma normal si todos los atributos de la relación dependen funcionalmente sólo de la clave y no de ningún otro atributo. LENGUAJE DE CONSULTA ESTRUCTURADO (SQL). El Lenguaje de consulta estructurado (Structured Query Language, por sus siglas en inglés) es un lenguaje declarativo de acceso a bases de datos relacionales que permite especificar diversos tipos de operaciones sobre las mismas. OPTIMIZACION DE CONSULTAS Cláusula GROUP BY. La cláusula GROUP BY se usa para producir valores de agregado para cada fila del conjunto de resultados. Cuando se usan sin una cláusula GROUP BY, las funciones de agregado sólo devuelven un valor de agregado para la instrucción SELECT.
Cláusula HAVING. La cláusula HAVING establece las condiciones de la cláusula GROUP BY de la misma forma que WHERE interactúa con SELECT. Mientras que las condiciones de búsqueda de WHERE se aplican antes de que se produzca la operación de agrupamiento, las condiciones de búsqueda de HAVING se aplican después. La sintaxis de la cláusula HAVING es similar a la de la cláusula WHERE, con la diferencia de que HAVING puede contener funciones de
Ligas

Tecnologías de la Información y Comunicación Sistemas Informáticos 20
agregado . Las cláusulas HAVING pueden hacer referencia a cualquiera de los elementos que aparecen en la lista de selección
Cláusula ORDER BY. La cláusula ORDER BY ordena los resultados de una consulta por una o más columnas. PREDICADOS
CONSULTAS AVANZADAS (LIKE, BETWEEN, IN, NOT IN)
LIKE. La palabra clave LIKE busca valores de cadenas de caracteres, de fecha o de hora, que coincidan con un determinado patrón. BETWEEN. La palabra clave BETWEEN especifica un intervalo inclusivo de búsqueda.
NOT BETWEEN. Busca todas las filas que estén fuera del intervalo que se especifique.
IN. La palabra clave IN permite seleccionar las filas que coincidan con alguno de los valores de una lista.
NOT IN. La palabra clave NOT IN permite seleccionar las filas que no coincidan con alguno de los valores de una lista.
INNER JOIN. Las vinculaciones entre tablas se realiza mediante la cláusula INNER que combina registros de dos tablas siempre que haya concordancia de valores en un campo común.
LEFT JOIN, RIGTHJOIN. Un LEFT JOIN o un RIGHT JOIN puede anidarse dentro de un INNER JOIN, pero un INNER JOIN no puede anidarse dentro de un LEFT JOIN o un RIGHT JOIN.
PROCEDIMIENTOS ALMACENADOS (TRANSACT –SQL). Un procedimiento almacenado es una colección con nombre de instrucciones de Transact-SQL que se almacena en el servidor. Los procedimientos almacenados son un método para encapsular tareas repetitivas. Admiten variables declaradas por el usuario, ejecución condicional y otras características de programación muy eficaces.
Sintaxis general: CREATE PROC nombre_del_procedimiento { @ parametro tipo_de_dato(longitud) } AS Instrucciones_sql
Ejecutar un procedimiento almacenado . Para ejecutar un procedimiento almacenado se utiliza el comando:
EXEC nombre_del_procedimiento ó EXECUTE nombre_del_procedimiento
FUNCIONES DE AGREGADO
COUNT Devuelve el número de de registros de la tabla que se haya especificado.
AVG Calcula el promedio de los valores de un campo determinado.
SUM Devuelve la suma o total de un campo determinado.
MAX Devuelve el valor máximo de un campo determinado.
MIN Devuelve el valor mínimo de un campo determinado.
PREDICADOS ALL Devuelve todos los campos de la tabla. TOP Devuelve un determinado número de registros de la tabla. DISTINCT Omite los registros cuyos campos seleccionados coincidan totalmente.
DISTINCTROW Omite los registros duplicados basándose en la totalidad del registro y no sólo en los campos seleccionados.

Tecnologías de la Información y Comunicación Sistemas Informáticos 21
TRIGGER. Es una clase especial de procedimiento almacenado que se ejecuta automáticamente cuando un usuario intenta la instrucción especificada de modificación de datos en la tabla indicada. Sintaxis general:
CREATE TRIGGER nombre_del_trigger
ON nombre_tabla
FOR COMANDO(S)
AS …
VISTAS. Una vista se puede considerar una tabla virtual o una consulta almacenada. Los datos accesibles a través de una vista no están almacenados en un objeto distinto de la base de datos. Lo que está almacenado en la base de datos es una instrucción SELECT. El resultado de la instrucción SELECT forma la tabla virtual que la vista devuelve.
Sintaxis general:
CREATE VIEW nombre_vista AS SELECT campo(s) FROM tabla
Si ya no necesita una vista, puede quitar su definición de la base de datos con la instrucción DROP VIEW nombre_vista. TRANSACCIONES. Una transacción es la unidad de ejecución de un programa que accede y posiblemente actualiza varios elementos de datos . Sintaxis general: Begin transaction nombre_de_la_transacción Instrucciones sql (select, insert, update, delete) End
COMMIT TRANSACTION. Se utiliza para finalizar una transacción correctamente sino hubo errores. Todas las modificaciones de datos realizadas en la transacción se convierten en partes permanentes de la base de datos.
ROLLBACK TRANSACTION. Deshace una transacción explícita o implícita hasta el inicio de la transacción o hasta un punto de almacenamiento dentro de una transacción.
SEGURIDAD Y OPTIMIZACIÓN
� Seguridad: Se refiere al la protección contra el acceso mal intencionado. � Integridad : Se refiere a la protección contra la pérdida accidental de consistencia (precisión, corrección o
validez de la BD). � Confidencialidad: Tarea del Administrador de la BD de aumentarla.
La información debe estar protegida contra:
� Accesos no autorizados � Destrucción o alteración con fines indebidos � Introducción accidental de Inconsistencia (El mal uso que se haga de la BD puede ser intencional o
accidental) Los tipos de fallos que una BD puede tener son:
� Físicos: De memoria, caídas del sistema, anomalías de acceso concurrente. � Lógicos: De programación, de l Sistema Operativo � Humanos: Mal intencionados o no.
Un DBMS facilita los mecanismos para prevenir los fallos: � Subsistemas de Control: Facilita los mecanismos para prevenir las fallas. � Subsistemas de Detección: Para detectar las fallas una vez que se han producido. � Subsistemas de Recuperación: Para corregir las fallas después de haber sido detectadas.
NIVELES DE SEGURIDAD. Un usuario atraviesa dos fases de seguridad al trabajar en SQL Server: la autenticación y autorización (aprobación de los permisos). La fase de la autenticación identifica al usuario que está usando una cuenta de inicio de sesión y verifica sólo su capacidad para conectarse a una instancia de SQL Server. Si la autenticación tiene

Tecnologías de la Información y Comunicación Sistemas Informáticos 22
éxito, el usuario se conecta a una instancia de SQL Server. El usuario necesita entonces permisos para acceder a las bases de datos en el servidor, lo que se obtiene concediendo acceso a una cuenta en cada base de datos (asociadas al inicio de sesión del usuario).
La implementación en SQL Server abarca los siguientes aspectos:
SEGURIDAD FÍSICA DEL SERVIDOR. Restringir el acceso físico al servidor SQL Server únicamente al personal autorizado. Además, también debemos tener en cuenta la seguridad física del lugar donde está almacenado o dispuesto el servidor, es decir, en un lugar ventilado adecuadamente, un lugar con los dispositivos ante alguna contingencia, como por ejemplo:
� Extintores, antes los incendios o corto circuitos. � Ubicación adecuada del servidor, por ejemplo si existen riesgos de inundación, tal vez podríamos
ubicarlo en un lugar elevado. � El cableado debe estar adecuado al lugar para evitar problemas con el fluido eléctrico. � UPS o sistema de alimentación contínua de energía.
CUENTAS Y CONTRASEÑAS. Nunca usar contraseñas en blanco o escribir las contraseñas en alguna aplicación. Es recomendable tener contraseñas mixtas que comiencen con uno o varios números seguido por una combinación de letras y caracteres especiales para contrarrestar los ataques producidos por los hackers. CONCEDER PERMISOS: SENTENCIA GRANT La sentencia GRANT crea una entrada en el sistema de seguridad que permite a un usuario de la base de datos actual trabajar con datos de la base de datos actual o ejecutar instrucciones Transact-SQL específicas. Para permisos de la instrucción :
GRANT { ALL | statement [ , . . n ] } TO security_account [, . . . n]
DENEGAR PERMISOS: SENTENCIA DENY La sentencia DENY crea una entrada en el sistema de seguridad que deniega un permiso de una cuenta de seguridad en la base de datos actual e impide que la cuenta de seguridad herede los permisos a través de los miembros de su grupo o función. Permisos de la instrucción:
DENY {ALL | statement [ , . . . n ] } TO security_account [ , . . . ]
EVOCAR PERMISOS: SENTENCIA REVOKE Es posible revocar un permiso que previamente se ha otorgado o denegado. La revocación se asemeja a la denegación en que ambas retiran un permiso concedido y en el mismo nivel. No obstante, aunque la revocación retira un permiso concedido, no impide que el usuario, grupo o función lo herede de un nivel superior.. La sintaxis de REVOKE es la siguiente: Permisos de la instrucción:
REVOKE { ALL | statement [ , . . . n ] FROM security_account [ , . . . n ]
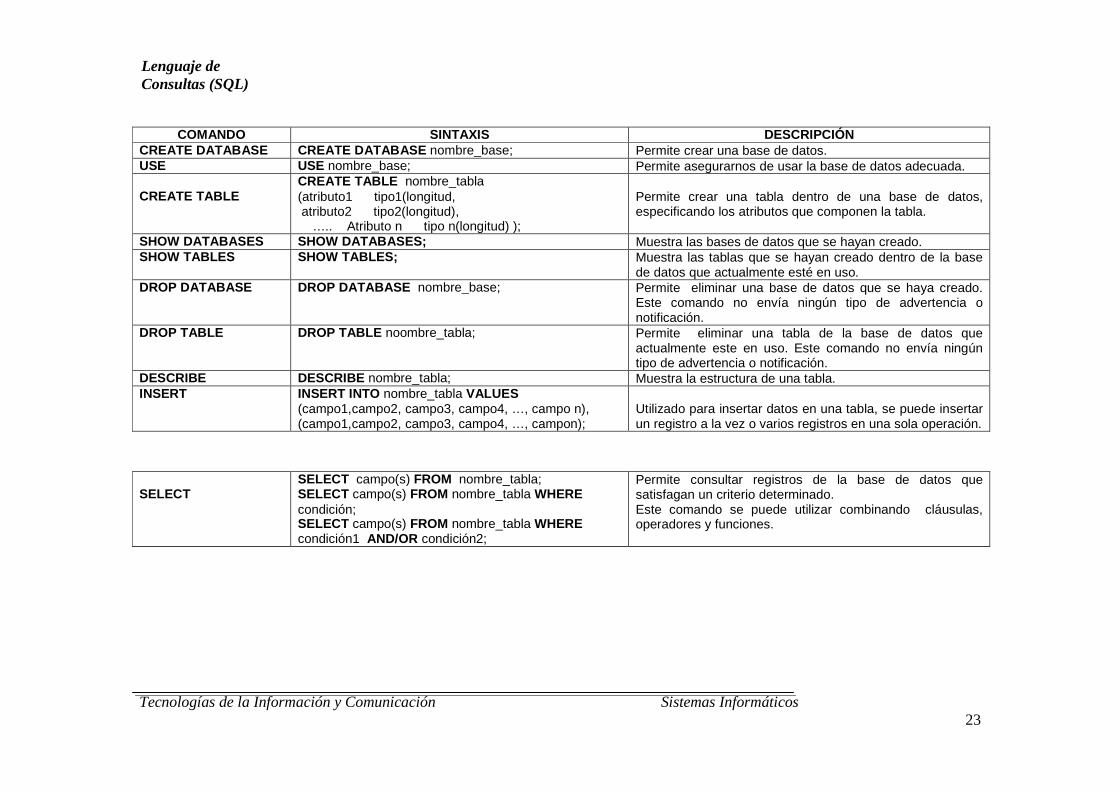
Tecnologías de la Información y Comunicación Sistemas Informáticos 23
COMANDO SINTAXIS DESCRIPCIÓN CREATE DATABASE CREATE DATABASE nombre_base; Permite crear una base de datos. USE USE nombre_base; Permite asegurarnos de usar la base de datos adecuada. CREATE TABLE
CREATE TABLE nombre_tabla (atributo1 tipo1(longitud, atributo2 tipo2(longitud), ….. Atributo n tipo n(longitud) );
Permite crear una tabla dentro de una base de datos, especificando los atributos que componen la tabla.
SHOW DATABASES SHOW DATABASES; Muestra las bases de datos que se hayan creado. SHOW TABLES SHOW TABLES; Muestra las tablas que se hayan creado dentro de la base
de datos que actualmente esté en uso. DROP DATABASE DROP DATABASE nombre_base; Permite eliminar una base de datos que se haya creado.
Este comando no envía ningún tipo de advertencia o notificación.
DROP TABLE
DROP TABLE noombre_tabla; Permite eliminar una tabla de la base de datos que actualmente este en uso. Este comando no envía ningún tipo de advertencia o notificación.
DESCRIBE DESCRIBE nombre_tabla; Muestra la estructura de una tabla. INSERT INSERT INTO nombre_tabla VALUES
(campo1,campo2, campo3, campo4, …, campo n), (campo1,campo2, campo3, campo4, …, campon);
Utilizado para insertar datos en una tabla, se puede insertar un registro a la vez o varios registros en una sola operación.
SELECT
SELECT campo(s) FROM nombre_tabla; SELECT campo(s) FROM nombre_tabla WHERE condición; SELECT campo(s) FROM nombre_tabla WHERE condición1 AND/OR condición2;
Permite consultar registros de la base de datos que satisfagan un criterio determinado. Este comando se puede utilizar combinando cláusulas, operadores y funciones.
Lenguaje de Consultas (SQL)

Tecnologías de la Información y Comunicación Sistemas Informáticos 24
UPDATE
UPDATE nombre_tabla SET campo_a_modificar = nuevo_dato WHERE campo_condición = valor_condición;
Utilizado para modificar los valores de los campos de un registro. Si no se utiliza la cláusula WHERE se modificaran todos los registros de la tabla.
DELETE
DELETE FROM nombre_tabla WHERE condición; Utilizado para eliminar registros de una tabla.Si no se utiliza la cláusula WHERE se borraran todos los registros de la tabla.
OPERADORES DE COMPARACIÓN
>, <, <>, >=, <=, = Se utiliza para establecer una comparación entre números.
LIKE Se utiliza para establecer una comparación con un texto determinado.
CLAÚSULAS
FROM Especifica la tabla de la cuál se van a solicitar los registros.
WHERE Especifica las condiciones que deben de cumplir los registros.
OPERADORES LÓGICOS
AND Evalúa dos condiciones y devuelve un valor de verdad si ambas son ciertas.
OR Es el “O” lógico. Evalúa dos condiciones.

Tecnologías de la Información y Comunicación Sistemas Informáticos 25
COMUNICACIÓN DE DATOS Terminología de networking Redes de datos Las redes de datos se desarrollaron como consecuencia de aplicaciones comerciales diseñadas para microcomputadores. A principios de la década de 1980 networking se expandió enormemente, aun cuando en sus inicios su desarrollo fue desorganizado. Redes de área local (LAN) Las LAN constan de los siguientes componentes:
• Computadores • Tarjetas de interfaz de red • Dispositivos periféricos • Medios de networking • Dispositivos de networking
Algunas de las tecnologías comunes de LAN son:
• Ethernet • Token Ring • FDDI
Redes de área metropolitana (MAN) La MAN es una red que abarca un área metropolitana, como, por ejemplo, una ciudad o una zona suburbana. Una MAN generalmente consta de una o más LAN dentro de un área geográfica común. Redes de área amplia (WAN) Algunas de las tecnologías comunes de WAN son:
• Módems • Red digital de servicios integrados (RDSI) • Línea de suscripción digital (DSL - Digital Subscriber Line) • Frame Relay • Series de portadoras para EE.UU. (T) y Europa (E): T1, E1, T3, E3 • Red óptica síncrona (SONET )
Redes de área de almacenamiento (SAN) Una SAN es una red dedicada, de alto rendimiento, que se utiliza para trasladar datos entre servidores y recursos de almacenamiento. Al tratarse de una red separada y dedicada, evita todo conflicto de tráfico entre clientes y servidores
Red privada virtual (VPN) Una VPN es una red privada que se construye dentro de una infraestructura de red pública, como la Internet global. Ancho de banda El ancho de banda se define como la cantidad de información que puede fluir a través de una conexión de red en un período dado. El ancho de banda analógico se mide en función de la cantidad de espectro magn ético ocupada por cada señal. La unidad de medida básica del ancho de banda analógico es el hercio (Hz), o ciclos por segundo. Las unidades de medida más comúnmente usadas son el kilohercio (KHz), el megahercio (MHz), y el gigahercio (GHz). Estas unidades se utilizan para describir las frecuencias de los teléfonos inalámbricos, que generalmente operan a 900 MHz o a 2,4 GHz. El ancho de banda digital, toda la información se envía como bits, independientemente del tipo de información del cual se trate. Voz, video y datos se convierten todos en corrientes de bits al ser preparados para su transmisión a través de medios digitales. El ancho de banda en redes inalámbricas son las unidades que se usan para describir las frecuencias 802.11a y 802.11b, que operan a 5GHz y 2,4 GHz. Comunicaciones de par a par

Tecnologías de la Información y Comunicación Sistemas Informáticos 26
Para que los datos puedan viajar desde el origen hasta su destino, cada capa del modelo OSI en el origen debe comunicarse con su capa par en el lugar destino. Esta forma de comunicación se conoce como de par-a-par. Durante este proceso, los protocolos de cada capa intercambian información, denominada unidades de datos de protocolo (PDU). Cada capa de comunicación en el computador origen se comunica con un PDU específico de capa, y con su capa par en el computador destino.
Pruebas de encapsulamiento de los datos El proceso de los datos son incorporados al ordenador hasta que se trasmiten al medio se llama encapsulación. Estos datos son formateados, segmentados, identificados con el direccionamiento lógico y físico para finalmente ser enviados al medio. A cada capa del modelo osi le corresponde una PDU “Unidad de datos Posiblemente que la cantidad de los datos sea demasiada, la capa de transporte desde el origen se encarga de segmentarlos para si ser empaquetados debidamente, esta misma capa del destino se encargara de resemblar los datos y colocarlos de forma secuencial, ya que no siempre no llegan a su destino en el orden en que han sido segmentados, así mismo acorde al protocolo que este utilizando habrá corrección de errores. Estos segmentos son empaquetados (paquetes o datagramas) e identificados en la capa de red con la dirección lógica o ip correspondiente al origen y destino. Ocurre lo mismo con la dirección MAC en la capa de enlace de datos formándose las tramas o frames para ser transmitidos a través de una interfaz. Finalmente las tramas son enviadas al medio desde la capa física. ENCAPSULAMIENTOS DE DATOS: DATOS DATOS SEGMENTADOS: DATOS, DATOS, DATOS
ENCABEZADO IP: ENCABEZADO IP, DATOS, FCS ENCABEZADO MAC: ENCABEZADO MAC, ENCABEZADO IP, DATOS FCS.
Dominios de colisión y difusión Ethernet es una tecnología conflictiva, todos los equipos de trabajo que se conectan al mismo medio físico reciben las señales enviadas por otros dispositivos. Si dos estaciones transmiten a la vez, se genera una colisión. Si no existieran mecanismos que detectasen y corrigiesen los errores de estas colisiones, Ethernet no podría funcionar. En el diseño de una red se debe tener especial cuidado con los llamados:
Dominios de Colisión: Grupo de dispositivos conectados al miso medio físico, de tal manera que si dos dispositivos acceden al medio al miso tiempo, el resultado será una colisión entre las dos señales. Se produce un consumo inadecuado de recursos y de ancho de banda. Dominio de difusión (Broadcast): Grupo de dispositivos de la red envía y reciben mensajes de difusión entre ellos. Una cantidad excesiva de estos mensajes de difusión entre ellos. Una cantidad excesiva de estos mensajes de difusión provocara un bajo rendimiento en la red, una cantidad exagerada (tormenta) dará como resultado el mal funcionamiento de la red hasta tal punto de poder dejarla completamente congestionada.
Los hubs tienen un único dominio de colisión, eso quiere decir que si que si dos equipos provocan una colisión en un segmento asociado a un puerto del hubs, todos los equipos provocan una colisión en un segmento asociado a un puerto del hubs, todos los demás dispositivos aun estando en diferentes puertos se verán afectados. Si una estación envía un Broadcast, debido a que un hub también tiene un solo dominio de difusión. CSMA / CD acceso múltiple con detección de portadora (carrier) y detección e colisiones. Varios puestos pueden tener acceso al medio y que, para que un puesto pueda acceder a dicho medio, deberá detectar la portadora para asegurarse de que ningún otro puesto este utilizándolo. Si el medio se encuentra en uso, el puesto procederá a mantener en suspenso el envió de datos. En caso de que haya dos puestos que no detectan ningún otro tráfico, ambos trataran de trasmitir al mismo tiempo, dando como resultado una colisión. A partir esta colisión las estaciones emiten una señal de congestión para asegurase de que existe una colisión y se generas un algoritmo de espera con el que las estaciones retransmitirán aleatoriamente. Modelo OSI

Tecnologías de la Información y Comunicación Sistemas Informáticos 27
El modelo de referencia de Interconexión de Sistemas Abiertos (OSI) lanzado en 1984 fue el modelo de red descriptivo creado por ISO. Proporcionó a los fabricantes un conjunto de estándares que aseguraron una mayor compatibilidad e interoperabilidad entre los distintos tipos de tecnología de red producidos por las empresas a nivel mundial. Ventajas del modelo OSI
� Reduce la complejidad � Estandariza las interfaces � Facilita el diseño modular � Asegura la interoperabilidad de la tecnología
Las capas del modelo OSI.
Dispositivos de networking que se utilizan en las c apas del Modelo OSI

Tecnologías de la Información y Comunicación Sistemas Informáticos 28
Capa Física : Corresponden los medios, (cobre, fibra, RF), los conectores, transeivers (adaptadores), repetidores y hubs. Ninguno de ellos manipula los datos transmitidos si no que solo se encargan de transportarlos y propagarlos por la red. Enlace de Datos : Se diferencia perfectamente los dominios de colisión y los dominios de difusión. Los Puentes y los Switches dividen a la red en segmentos, estos a su vez crean dominios de colisión. Una colisión producida en un segmento conectado a un switch no afectará a los demás segmentos conectados al mismo switch. Sin embargo los dispositivos de capa 2 no crean dominios de broadcast o difusión. Un switch de 12 puertos utilizados tendrá 12 dominios de colisión y 1 de difusión. Capa de Red: Los routers en la capa de red del modelo OSI separando los segmentos en dominios de colisión y difusión únicos. Estos segmentos están identificados por una dirección de red que permitirá alcanzar las estaciones finales. Los routers cumplen dos funciones básicas que son la de enrutar y conmutar los paquetes. Modelo TCP/IP La capa de aplicación La capa de aplicación del modelo TCP/IP maneja protocolos de alto nivel, aspectos de representación, codificación y control de diálogo. Transferencia de archivos: TFTP,FTP,NFS, Correo Electrónico: SMT, Conexión remota: Telnet, rlogin, Administración de red: SNMP*, Gestión de nombres: DNS La capa de transporte La capa de transporte proporciona servicios de transporte desde el host origen hacia el host destino. Esta capa forma una conexión lógica entre los puntos finales de la red, el host transmisor y el host receptor. Los servicios de transporte incluyen Protocolo de control de trasmisión Orientado a conexión (TCP) y Protocolo de Datagrama de Usuario no orientado a conexión (UDP). La capa de Internet El propósito de la capa de Internet es seleccionar la mejor ruta para enviar paquetes por la red.
• El protocolo principal que funciona en esta capa es el Protocolo de Internet (IP). • El IP ejecuta las siguientes operaciones: • Define un paquete y un esquema de direccionamiento. • Transfiere los datos entre la capa Internet y las capas de acceso de red. • Enruta los paquetes hacia los hosts remotos. • El Protocolo de mensajes de control en Internet (ICMP) suministra capacidades de
control y envío de mensajes. • El Protocolo de resolución de direcciones (ARP) determina la MAC, para las direcciones
IP conocidas. • El Protocolo de resolución inversa de direcciones (RARP) determina IP cuando se
conoce la dirección MAC. La capa de acceso de red Capa de host a red maneja todos los aspectos que un paquete IP requiere para efectuar un enlace físico real con los medios de la red. Tecnología LAN y WAN, la capas física y de enlace de datos del modelo OSI. Las funciones de la capa de acceso de red incluyen la asignación de direcciones IP a las direcciones físicas y el encapsulamiento de los paquetes IP en tramas. Dispositivos de networking Los equipos que se conectan de forma directa a un segmento de red; estos dispositivos se clasifican en dos grupos. 1.- Dispositivos de usuario final (Host). Los dispositivos de usuario final incluyen los computadores, impresoras, escáneres, y demás dispositivos que brindan servicios directamente al usuario.

Tecnologías de la Información y Comunicación Sistemas Informáticos 29
2.- Dispositivos de red son todos aquellos que conectan entre sí a los dispositivos de usuario final, posibilitando su intercomunicación.
Topología de red La topología de red define como la estructura física y lógica que forma una red. a).- Topología física, que es la disposición real de los cables o medios. b).- Topología lógica, que define la forma en que los hosts acceden a los medios para enviar datos. Los dos tipos más comunes de topologías lógicas son:
• Broadcast • Transmisión de tokens.
Protocolos de red Un protocolo es un conjunto de reglas y convenciones que rigen un aspecto particular de cómo los dispositivos de una red se comunican entre sí. Los protocolos determinan el formato, la sincronización, la secuenciación y el control de errores en la comunicación de datos. Los protocolos controlan todos los aspectos de la comunicación de datos, que incluye Estas normas de red son creadas y administradas por una serie de diferentes organizaciones y comités. Entre ellos se incluyen el Instituto de Ingeniería Eléctrica y Electrónica (IEEE), el Instituto Nacional Americano de Normalización (ANSI), la Asociación de la Industria de las Telecomunicaciones (TIA), la Asociación de Industrias Electrónicas (EIA) y la Unión Internacional de Telecomunicaciones (UIT), antiguamente conocida como el Comité Consultivo Internacional Telegráfico y Telefónico (CCITT).
Topologías Lógicas Topologías Físicas

Tecnologías de la Información y Comunicación Sistemas Informáticos 30
Medios de Ethernet y requisitos de conector Antes de seleccionar la implementación de Ethernet, tenga en cuenta los requisitos de los conectores y medios para cada una de ellas. También tenga en cuenta el nivel de rendimiento que necesita la red.
DIRECCIONAMIENTO IP Una dirección IP es una secuencia de 1s y 0s de 32 bits, se representa como 4 números decimales separados por puntos. En un DIRECCIONAMIENTO JERÁRQUICO la dirección IP consta de 2 partes, la primera identifica la dirección de la red donde se conecta el sistema y la segunda identifica el sistema en particular de esa red (el hosts, la máquina particular) y contiene diferentes niveles. Las direcciones ip se dividen en clases: CLASE INICIO
DECIMAL INICIO BIN RANGO BINARIO OCTETOS MASCARA DE
SUBRED A 1 - 126 0 00000000-01111111 R.H.H.H 255.0.0.0 B 128 - 191 10 10000000-10111111 R.R.H.H 255.255.0.0 C 192 - 223 110 11000000-11011111 R.R.R.H 255.255.255.0 D 224 - 239 1110 11100000-11101111 USO MULTICAST E 240 - 254 RESERVADO PARA INVESTIGACIÓN IETF LAS SUBREDES se realizan cuando se dividen en redes más pequeñas, para su mayor aprovechamiento y seguridad en bajo nivel en la LAN. DADA LA DIRECCIÓN IP 192.10.8.0 Y SE DESEAN CREAR 6 SUBREDES UTILIZABLES, DETERMINA:
A. determinar la clase, los octetos de red y de host, ya que solo se trabajará con los octetos de host.
B. determina el numero de bits prestados que se requieren, con la formula: 2n-2>subredes requeridas. (de izquierda a derecha en la parte de host).
C. determinar: mascara de subred por default y mascara de subred especifica (a los bits prestados asignarle 1 binario y a los que quedan para host asignarle 0 binario; después convertir a decimal)
D. realiza la tabla mostrando: numero de subred, bits por subred, num de hosts por subred, direcciones de subred, números asignados a los hosts. (determina el rango restando a 256 el resultado del ultimo octeto, decimal del paso c)
E. grafica, indicando los números de: la red, subredes y hosts
A. 192.10.8.0 �CLASE C R . R . R . H B. 2n-2>28 23-2>28 SE PEDIRÁN PRESTADOS 3 BITS:
23=8 SE PUEDEN CREAR 8 SUBREDES

Tecnologías de la Información y Comunicación Sistemas Informáticos 31
23-2=6 DE LAS CUALES 6 SERÁN UTILIZABLES. POR LO TANTO QUEDAN 5 BITS PARA HOST
25=32 SE PUEDEN CONECTAR 32 HOSTS A CADA SUBRED 23-2=30 DE LOS CUALES 30 HOST SERÁN UTILIZABLES
C. MASCARA DE SUBRED POR DEFAULT: = 255.255.255.0 MASCARA DE SUBRED ESPECÍFICA: 192.10.8. 111 00000 = 192.10.8.224 RED SUBRED HOST
D. RANGO = 256-224 = 32
NUM. SUBRED
BITS DE SUBRED
NUM. HOST DECIMAL
DIRECCIÓN DE SUBREDES
NUM. DE HOSTS
0 000 0 - 31 192.10.8.0 ����No se usa 1 001 32 - 63 192.10.8.32 192.10.8 .33 -
.63 2 010 64 - 95 192.10.8.64 192.10.8 .65 -
.95 3 011 96 - 127 192.10.8.96 192.10.8 .97 -
.127 4 100 128 - 159 192.10.8.128 192.10.8 .129 -
.159 5 101 160 - 191 192.10.8.160 192.10.8 .161 -
.191 6 110 192 - 223 192.10.8.192 192.10.8 .193 -
.223 7 111 224 - 255 192.10.8.224 ����No se usa
.
REDES DE CÓMPUTO ENRUTAMIENTO DETERMINACIÓN DE RUTAS IP Para que un dispositivo de 3 capas pueda determinar la ruta hacia un destino debe tener conocimiento de cómo hacerlo. El aprendizaje de las rutas puede ser mediante enrutamiento estático o dinámico. LAS RUTAS DINÁMICAS son aprendidas automáticamente por el router a través de la información enviada por otros routers, una vez que el administrador ha configurado un protocolo de enrutamiento que permite el aprendizaje dinámico de rutas. Para poder enlutar paquetes de información un router debe conocer lo siguiente:
• DIRECCIÓN DE DESTINO: dirección a donde han de ser enviados los paquetes. • FUENTES DE INFORMACIÓN: otros routers de donde el router aprende las rutas hasta los
destinos especificados. • DESCUBRIR LAS POSIBLES RUTAS HACIA EL DESTINO: rutas iniciales posibles hasta los
destinos deseados. • SELECCIONAR LAS MEJORES RUTAS: determinar cual es la mejor ruta hasta el destino
especificado.
192.10.8.32
192.10.8.64 192.10.8.128
192.10.8.96
192.10.8.160
192.10.8.192 192.10.8.0

Tecnologías de la Información y Comunicación Sistemas Informáticos 32
• MANTENER LAS TABLAS DE ENRUTAMIENTO ACTUALIZADAS: mantener conocimiento actualizado de las rutas destino.
La información de enrutamiento que el router aprende desde sus fuentes se coloca en su propia tabla de enrutamiento. El router se vale se esta tabla para determinar los puertos de salida que debe utilizar para retransmitir un paquete hasta su destino. La tabla de enrutamiento es la fuente principal de información del router acerca de las redes. Si la red de destino está conectada directamente, el router debe aprender y calcular la ruta mas óptima a usar para reenviar paquetes. Si las redes de destino esta conectada directamente, el router ya sabrá el puerto que debe usar para reenviar paquetes. Si las redes de destino no están conectadas directamente, el router debe aprender y calcular la ruta mas optima a usar para reenviar paquetes a dichas redes. La tabla de enrutamiento se construye mediante uno de estos dos métodos o ambos:
• Manualmente, por el administrador de la red. • A través de procesos dinámicos que se ejecutan en la red.
LAS RUTAS ESTÁTICAS son aprendidas por el router a través del administrador, que establece dicha ruta manualmente, quien también debe actualizar cuando tenga lugar un cambio de topología. Las rutas estáticas se definen administrativamente y establecen rutas especificas que han de surgir los paquetes para pasar de un puerto destino. Se establece un control preciso del enrutamiento según los parámetros del administrador. Las rutas estáticas por default especifican un gateway (puerta de enlace) de ultimo recurso, a la que el router debe enviar un paquete destinado a una red que no aparece en su tabla de enrutamiento, es decir que desconoce. Las rutas estáticas se utilizan habitualmente desde una red hasta una red de conexión única, ya que existen más que una ruta de entrada y salida de una red de conexión única, evitando de este modo la sobrecarga de tráfico que genera un protocolo de enrutamiento. La ruta estática se configura para seguir conectividad con un enlace de datos que no esta directamente conectado al router. Para conectividad de extremo a extremo es necesario configurar la ruta en ambas direcciones. El comando ip route configura una ruta estática, los parámetros del comando definen la ruta estática. Las entradas creadas en la tabla usando este procedimiento permanecerán en dichas tablas mientras la ruta siga activa. Con la opción permanent, la ruta seguirá en la tabla aunque la ruta en cuestión haya dejado de estar activa. La sintaxis de configuración de una ruta estática es la siguiente:
Router (config) # ip router router {red} {mascara} {dirección ip / interfaz} {distancia} {permanent} Red: es la red o subred de destino. Mascara: es la mascara de subred. Interfaz: es el nombre de la interfaz que debe usarse para llegar a la red de destino.
Distancia: es un parámetro opcional, que se define la distancia administrativa. Permanent: un parámetro opcional que especifica que la ruta no debe se eliminada, aunque la interfaz deje de estar activa. RUTAS ESTÁTICA POR DEFECTO Una ruta estática, predeterminada o de último recurso es un tipo especial de ruta estática que se utiliza cuando no se conoce una ruta hasta un destino determinado, o cuando no es posible almacenar en la tabla de enrutamiento la información relativa a todas las rutas posibles. La sintaxis de configuración de una ruta estática por defecto es la siguiente:
Router (config) # ip route 0.0.0.0 0.0.0.0 {dirección ip / interfaz} {distancia} PROTOCOLOS Los protocolos describen el conjunto de normas y convenciones que rigen la forma en que los dispositivos de una red intercambian información. Algunos de los protocolos más usados, que operan en la capa de Internet, son: *IP: proporciona un enrutamiento de paquetes no orientados a conexión de máximo esfuerzo, no por el contenido de los paquetes, sino, busca una ruta hacia el destino. * ICMP Protocolo de mensajes de control de Internet: suministra capacidades de control y envío de mensajes. Herramientas tales como PING y TRACERT lo utilizan. * ARP Protocolo de resolución de direcciones: determina la dirección de la capa de enlace de datos, la dirección MAC, para direcciones IP conocidas. * RARP Protocolo de resolución inversa de direcciones: determina las direcciones IP cuando se conoce la dirección MAC. UN PROTOCOLO ENRUTADO lleva una completa información de capa3, por ejemplo: TCP/IP, IPX, APPLE TALK y NetBEUI.

Tecnologías de la Información y Comunicación Sistemas Informáticos 33
UN PROTOCOLO DE ENRUTAMIENTO es utilizado por los routers para mantener tablas de enrutamiento y así poder elegir la mejor ruta hacia el destino, por ejemplo: RIP, IGRP, EIGRP y OSPF. Dentro de los protocolos de enrutamiento encontramos dos grandes núcleos:
• PROTOCOLOS DE GATEWAY INTERIOR (IGP): Se usan para intercambiar información de enrutamiento dentro de un sistema autónomo (RIP, IGRP).
• PROTOCOLO DE GATEWAY EXTERIOR (EGP): Se usan para intercambiar información de enrutamiento entre sistemas autónomos.
UN SISTEMA AUTÓNOMO (AS) es un conjunto de redes bajo un dominio administrativo común, se utilizan si el sistema utiliza algún BGP o red pública. LA DISTANCIA ADMINISTRATIVA permite que un protocolo tenga mayor prioridad sobre otro ya que son multiprotocolos. CLASES DE PROTOCOLOS DE ENRUTAMIENTO * Vector distancia: determina la dirección y la distancia a cualquier red (RIP, EIGRP) * Estado de enlace: tiene una idea exacta de la topología de red y no efectúa actualizaciones a menos que ocurra un cambio (OSPF y EIS-EIS) * Híbrido: combina aspectos de los dos anteriores (EIGRP). ENRUTAMIENTO POR VECTOR DISTANCIA Pasa por copias periódicas de la tabla de enrutamiento de un router a otro acumulando vectores de distancia (donde el vector es una dirección y la distancia es una medida de longitud). Cada protocolo utiliza un algoritmo distinto para determinar la ruta óptima, este genera un número llamado “métrica de ruta”. Las métricas más comunes son: Numero de saltos: numero de router por los que pasaron el paquete. Tic tac: el trazo de un enlace de datos usando pulsos de reloj (IBM). Coste: valor arbitrario basado en el ancho de banda. Ancho de banda: capacidad de datos de un enlace. Retraso: tiempo en mover un paquete de un origen a un destino. Carga: cantidad de actividad existente de un recurso de red. Fiabilidad: valor de errores de bit de cada enlace. MTU: unidad máxima de transmisión. LOS BUCLES DE ENRUTAMIENTO se generan si no existe una convergencia rápida y precisa entre los router. La solución a los bucles de enrutamiento son:
• Métricas máximas: solamente permiten la repartición de enrutamiento has ta que la métrica exceda el valor máximo permitido (RIP 16 saltos).
• Horizonte dividido (slip horizont) el router conoce otra ruta viable al destino y no devolverá información por la interfaz donde la recibió.
• Envenenamiento: se asegura que todos los router del segmento hayan recibido información acerca de la ruta envenenada, es una operación complementaria del horizonte dividido.
• Temporizadores: los router no aplican ningún cambio que pudieran afectar las rutas durante un periodo de tiempo determinado.
Los protocolos por vector distancia inundan la red con broadcast de actualizaciones de enrutamiento. LOS PROTOCOLOS DE ENRUTAMIENTO POR ESTADO ENLACE construyen tablas de enrutamiento basándose en una base de datos de la topología. EL ALGORITMO SPF (primero la ruta libre mas corta) usa la base de datos para construir la tabla de enrutamiento. El enrutamiento por estado enlace, utiliza PAQUETES DE ESTADO ENLACE (LSP), una base de datos topológica, el algoritmo SPF, el árbol SPF resultantes y una tabla de enrutamiento con las rutas y puertos de cada red. Existe una visión independiente de la red por cada router por lo que se producen muy pocos errores. No tienen límites de saltos, la métrica se basa en coste, a partir del algoritmo Dijkstra y se basa en la velocidad del enlace. Los protocolos de enrutamiento estado-enlace son protocolos de enrutamiento de gateway interior, que se utilizan dentro de un mismo sistema autónomo y se puede dividir en sectores más pequeños que se llaman áreas, el área principal o backbone de un sistema autónomo es el area0. Los protocolos estado-enlace son más rápidos y escalables que los de vector distancia por:
• Los protocolos de estado enlace solo envían actualizaciones cuando hay cambios de topología. • Las actualizaciones periódicas son menos frecuentes que los protocolos vector distancia. • Puede manejar redes segmentadas en distintas áreas jerárquicamente organizadas, limitando el
alcance de los cambios de rutas. • Las redes de este tipo soportan direccionamiento sin clase. • Las redes de este tipo soportan resumen de ruta.

Tecnologías de la Información y Comunicación Sistemas Informáticos 34
PROTOCOLO RIP IGRP EIGRP IS-IS OSPF VECTOR-DISTANCIA
X X X
ESTADO DE ENLACE
X X
RESUMEN AUTO- MÁTICO DE RUTA
X X X X
RESUMEN MANUAL DE RUTA
X X X X X
SOPORTE VLSM X X X PROPIETARIO DE CISCO
X X
CONVERGENCIA LENTO LENTO MUY RÁPIDO MUY RÁPIDO
MUY RÁPIDO
DISTANCIA ADVA.
120 100 90 115 110
TIEMPO DE ACTUALIZACIÓN
30 90
MÉTRICA SALTOS COMPUESTA COMPUESTA COSTE COSTE CONFIGURACIÓN INICIAL DEL ROUTER Un router es un ordenador construido para desempeñar funciones específicas de capa 3, proporciona hardware y software necesarios para encaminar paquetes entre redes, permite interconectar subreds LAN y establecer conexiones de área amplia entre las subredes. Puede trabajar exclusivamente con redes LAN, exclusivamente con reds WAN o estar en la frontera entre una LAN y una WAN al mismo tiempo. Las dos tareas principales de los routers son:
• CONMUTAR los paquetes desde una interfaz perteneciente a una red hacia otra interfaz de una red diferente y
• ENRUTAR o encontrar el mejor camino hacia la red destino El IOS es el sistema operativo de internetworking que utlizan los routers CISCO. LOS COMPONENTES PRINCIPALES DEL HARDWARE DE UN ROUT ER son:
• CPU: Unidad central de procesamiento, inicializa el sistema, realiza funciones de enrutamiento y control de la interfaz de la red.
• RAM: Memoria de acceso aleatorio, para la información de la tablas de enrutamiento, el cache de conmutación rápida, configuración actual y colas de paquetes.
• MEMORIA FLASH: Almacena una imagen completa del software IOS de cisco. • NVRAM: Memoria de acceso aleatorio no volátil, se utiliza para la configuración de inicio y
retiene sus contenidos al ser apagada la unidad. • BUSES: Bus de sistema se utiliza para la comunicación entre la CPU y las interfaces y/o ranuras
de expansión, transfiere los paquetes hacia y desde las interfaces. • ROM: Memoria de solo lectura que se utiliza para almacenar de forma permanente el código de
diagnóstico de inicio (monitor de rom), diagnostica el hardware y carga el software IOS de cisco desde la memoria flash a la RAM.
• INTERFACES: Son las conexiones de los routers con el exterior. Los tres tipos son:
LAN : De tipo ethernet o token ring, tienen chips controladores para conectar el sistema a los medios.
WAN: Incluyen la CSU o unidad de servicio de canal integrada, la RDSI y la serial. ADMINISTRACIÓN : Los puertos de consola y aux son puertos seriales que se utilizan
principalmente para la configuración inicial del router, no son puertos de networking, realizan sesiones terminales.
• FUENTE DE ALIMENTACIÓN: Brinda la energía necesaria para operar los componentes internos.

Tecnologías de la Información y Comunicación Sistemas Informáticos 35
UN ROUTER O SWITCH PUEDEN SER CONFIGURADOS DESDE DISTINTAS UBICACIONES: • En la instalación inicial, el administrador de red configura desde una terminal de consola,
conectado por medio del puerto de consola. • Con una conexión local por MODEM con el puerto auxiliar del dispositivo, para dispositivos
remotos. • Dispositivos con direcciones IP establecidas para conexiones TELNET. • Descarga de un archivo de configuración de un servidor TFTP. • Configurar un dispositivo por medio del navegador HTTP (Hypertext Transfer Protocol).
Al iniciar por primera vez el router CISCO, no tiene configuración inicial, por lo que el software pide detalles mediante el SETUP. LAS RUTINAS y PUESTA EN MARCHA DEL ROUTER son las siguientes:
1. Asegurarse que el router cuenta con hardware de verificado (POST). 2. Localiza y carga el IOS de CISCO como sistema operativo. 3. Localizar y aplicar las instrucciones de configuración relativas a los atributos específicos del
router, funciones de protocolos y direcciones de interfaz. MODOS DE TRABAJO:
MODO SÍMBOLO ACCESO SALIDA EXEC usuario Router> EXEC privilegiado Router# Eneble Ctl + z exit
disable Configuración global Router(config)# Configure terminal Ctl + z exit Configuración de interfaces
Router(config-if)# Interface [tipo y num] Ctl + z exit
Configuración de router Router(config-router)# Router [protocolo] Ctl + z exit EJEMPLO DE CONFIGURACIÓN
LOS PROTOCOLOS Y ESTÁNDARES DE LA CAPA FISICA DE WAN son:
• EIA / TIA 232 • EIA / TIA 449 • V.24 • V.35 • X.21 • G.703 • EIA 530 • RDSI • T1,T3, E1 Y E3 • xDSL • SONET
LOS PROTOCOLOS Y ESTÁNDARES DE LA CAPA DE ENLACE DE DATOS DE
WAN son: • HDLC control de enlace de datos
de alto nivel • FRAME RELAY
• PPP protocolo punto a punto • SDLC control de enlace de datos
síncrono • SLIP protocolo de internet de
enlace serial • X.25 • ATM • LAPB • LAPD • LAPF

Tecnologías de la Información y Comunicación Sistemas Informáticos 36
Las configuraciones se almacenan en la RAM, que se perderá al apagar el router, por lo que es necesario hacer una copia. Se pueden utilizar los siguientes comandos para realizar copias del archivo de configuración: #copy running-config startup-config #copy startup-config running-config #copy running-config tftp O bien se puede eliminar con el commando #erase startup-config LOS COMANDOS SHOW nos permiten el rápido diagnóstico de fallos, algunos se ejecutan en el modo usuario y otros en el modo privilegiado.
• show interfaces • show controllers serial • show clock • show hosts • show users • show sesions • show history • show flash • show version • show arp • show protocols • show startup-config • show running-conig
Existe una convención para asignar NOMBRES AL IOS DE CISCO , por ejemplo: c4500-js-1_121-5.bin donde: c4500 � Plataforma de hardware js � Conjunto de funciones especiales

Tecnologías de la Información y Comunicación Sistemas Informáticos 37
1 � Formato de archivo 121-5 � Número de versión
LA CONFIGURACIÓN DE ENRUTAMIENTO ESTÁTICO se realiza a través del comando de configuración global de OSI ip route , este utiliza varios parámetros , como: dirección de red, mascara de subred asociada e información del destino, que puede adoptar una de las siguientes formas:
• Dirección ip específica del siguiente router de la ruta. • Dirección de red de otra ruta de la tabla de enrutamiento a la que deben reenviarse los paquetes. • Interfaz conectada directamente en la que se encuentra la red destino.
EL USO DE RUTAS ESTÁTICAS SE ACONSEJA en los siguientes casos:
• Circuito de datos poco fiable y deja de funcionar constantemente. • Red donde existe una sola conexión con un solo ISP. • Cuando se puede acceder a la red a través de una conexión de acceso telefónico. • Cuando un cliente o cualquier otra red vinculada no desean intercambiar información de
enrutamiento dinámico. LA CONFIGURACIÓN DE RUTAS ESTÁTICAS POR DEFECTO se utilizan cuando el destino al que se pretende llegar son múltiples redes o no se conocen, la sintaxis es la siguiente: Router(config)# ip route 0.0.0.0 0.0.0.0 [ip del primer salto/inter faz de salida] [distancia administrativa] LOS PROTOCOLOS DE CONFIGURACIÓN DE ENRUTAMIENTO DIN ÁMICO son algoritmos que permiten que los routers publiquen, o anuncien, la existencia de la información de ruta de red ip necesaria para crear la tabla de enrutamiento, determinan el criterio de selección de ruta que sigue el paquete cuando se le presenta al router, esperando una decisión de conmutar, sus objetivos consisten en proporcionar al usuario la posibilidad de seleccionar la ruta idónea en la red, reaccionar con rapidez a los cambios de la misma y realizar dichas tareas de la manera mas sencilla y con la menor sobrecarga del router posible. Para habilitar un protocolo de enrutamiento dinámico, se realizan las siguientes tareas:
• Seleccionar un protocolo de enrutamiento. • Seleccionar las redes ip a enrutar.
El comando ROUTER es el encargado de iniciar el proceso de enrutamiento, posteriormente se asocian las redes con el comando NETWORK. Router(config)# router [protocolo] [id o sistema autónomo] Router(config-router) # network [num. de red directamente conectada] EL PROTOCOLO DE INFORMACIÓN DE ENRUTAMIENTO (RIP) es uno de los protocolos de enrutamiento mas antiguos utilizado por dispositivos basados en IP. Sus principales características son:
• Es un protocolo basado en vector distancia. • Utiliza la cuenta de saltos del router como métrica • El máximo es 15 saltos, si excede estos saltos se etiqueta como inalcanzable. • Difunde actualizaciones de enrutamiento por medio de la tabla de enrutamiento completa cada
30 segundos, por omisión. • Puede realizar equilibrado de carga en un máximo de seis rutas de igual coste (la especificación
por omisión es de 4). • RIP v1 requiere que se use una sola mascara de red de longitud fija para cada número de red de
clase principal que es anunciado y no contempla actualizaciones desencadenadas. • RIP v2 permiten máscaras de subred de longitud variable (VLSM) en la interconexión,
permite actualizaciones desencadenadas, el número máximo de ritas paralelas permitidas la tabla de enrutamiento faculta a RIP para llevar a cabo el equilibrio de carga.
• En RIP la información de enrutamiento se propaga de un router a los vecinos por medio de una difusión de IP usando el protocolo UDP y el puerto 520 .
CONFIGURACIÓN RIP Router(config) # router rip Router(config-router)# network 192.168.1.0 Router(config-router)# network 200.200.21.0 Router(config-router)# vesion 2 Router(config-router)# maximum-paths 6 LA REDISTRIBUCIÓN ESTÁTICA EN RIP se utiliza para que todos los routers contenidos dentro del mismo sistema autónomo tengan conocimiento de la existencia de esas rutas. Esto se hacer con el comando REDISTRIBUTE STATIC .

Tecnologías de la Información y Comunicación Sistemas Informáticos 38
EL PROTOCOLO DE ENRUTAMIENTO DE GATEWAY INTERIOR (I GRP) es un protocolo vector-distancia, desarrollado por cisco systems a mediados de los 80´s, corrige algunos defectos de RIP y proporciona un mejor soporte para grandes redes con enlaces de diferentes anchos de banda. IGRP calcula su métrica en base a diferentes atributos de ruta de red, como: retraso de red, ancho de banda y retraso basados en velocidad y capacidad, relativas a la interfaz. Los atributos de carga y fiabilidad se calculan según el rendimiento de la interfaz.
• Utiliza publicaciones IP para comunicar información de enrutamiento con vecinos, pero no depende de UDP o TCP.
• Funciona en forma similar a UDP. • Soporta múltiples rutas entre origen y destino, con conmutación automática pueden transportar 2
líneas una misma trama de tráfico de forma cooperativa. • El equilibrio de carga de coste desigual permite distribuir el tráfico hasta entre 6 rutas de distinto
coste, para mayor rendimiento y fiabilidad. LAS MEJORAS SOBRE RIP son:
• ESCALABILIDAD MEJORADA: Admite una red con un número máxima de 255 saltos de router. • MÉTRICA SOFISTICADA: Distingue entre diferentes tipos de medios de conexión y costes
asociados. • SOPORTE DE MÚLTIPLES RUTAS: Ofrece una convergencia de funcionalidad, enviando
información sobre cambios en la red a medida que está disponible. LAS MÉTRICAS IGRP son compuestas, la más baja se considera la óptima, entre estas encontramos:
• ANCHO DE BANDA : valor mínimo de ancho de banda en la ruta. • RETRASO: retraso de interfaz acumulado a lo largo de la ruta. • FIABILIDAD: viabilidad entre el origen y el destino, determinado por el intercambio de mensajes
de actividad. • CARGA : carga de un enlace entre el origen y el destino, medido en bps. • MTU: valor de la unidad máxima de transmisión de la ruta.
La fiabilidad y la carga no tienen unidades propias y pueden tomar valores entre 0 y 255. El ancho de banda puede tomar valores que reflejan velocidades desde 1200 hasta 106 bps. El retaso puede ser cualquier valor entre 1y 2*1023. Por defecto utiliza el ancho de banda y retraso como métrica preestablecida. CONFIGURACIÓN IGRP Router(config) # router igrp 100 Router(config-router)# network 192.168.1.0 Router(config-router)# network 200.200.21.0 Router(config-router)# variance 2 Router(config-router)# traffic-share? CONVERGENCIA es la capacidad de los routers de poseer la misma información de enrutamiento actualizada. IGRP y EIGRP se redistribuyen automáticamente si ambos tienen el mismo número de sistema autónomo. PROCESO DE RECUPERACIÓN DE CONTRASEÑA
• PARA ROUTERS CISCO SERIES 2000,2500,3000,4000 con C PU motorola 680x0 y 7000 ejecutando IOS versión 10.0 o posterior.
PASO 1: Conecte una terminal o PC con software de emulación de terminal al puerto de consola del router.
Acceda físicamente al router, apague y encienda el router. PASO 2: Pulse la tecla de interrupción del terminal durante los primeros 60 segundos del encendido del router. En el caso de hyperterminal la combinación del control control+pausa dará la señal de interrupción en el router. Aparecerá el símbolo rommon> sin nombre del router. Si no aparece el símbolo, la terminal no esta enviando la señal de interrupción correcta. PASO 3: Introduzca el comando orden de registro 0x2142 para arrancar desde flash e ignorar NVRAM. PASO 4: En el símbolo rommon> introduzca el comando i (initialize) para reiniciar el router, ignorando la configuración grabada en la NVRAM. PASO 5: Siga los pasos de arranque normales. Aparecerá el símbolo router>. PASO 6: La memoria RAM estará vacía, copie el contenido de la NVRAM a la RAM, para recuperar la configuración y contraseña no deseada. El nombre del router volverá a ser el original. PASO 7: Cambie la contraseña no deseada por una conocida.

Tecnologías de la Información y Comunicación Sistemas Informáticos 39
PASO 8: Guarde su nueva contraseña en la NVRAM y si fuera necesario levante administrativamente las interfaces con el comando no shutdown. PASO 9: Introduzca desde el modo global el comando config-register 0x2102 . PASO 10: Introduzca el comando reload en el símbolo del nivel exec privilegiado, responda yes al guardado de registro de configuración y confirme el reinicio. El router arrancará con la configuración y la contraseña conocida.
• PARA ROUTERS CISCO SERIES 1700,2600,4500,7200 y 750 0 Siga los pasos anteriores, el único cambio es en el PASO 4, donde se introducirá el comando reset, en lugar del comando i. LOS COMANDOS BOOT SYSTEM especifican el nombre y la ubicación de la imagen IOS que se debe cargar: COMANDO PARA ARRANCAR
DESDE… Router(config)#boot system flash [nombre_archivo] IOS de memoria flash
Router(config)#boot system rom IOS de memoria rom
Router(config)#boot system tftp [nombre_archivo] [dirección_servidor]
IOS de memoria tftp
Si no existen comandos de boot system en la coanfiguración, por omisión el router carga el primer archivo encontrado en la memoria flash y la ejecuta.
• PARA SWITCHES SERIES 2900 / 2950 PASO 1: Apage el switch, vuelva a encenderlo mientras presiona el botón “MODE” en la parte delantera del switch, deje de presionarlo una vez que se apage el led “STAT”. PASO 2: Para iniciar el sistema de archivos y terminar de cargar el sistema operativo, introduzca los comandos: flash_init load_helper dir flash: PASO 3: Escriba rename flash:config.txt flash:config.old para cambiar el nombre del archive de configuración. Este archivo contiene la definición de contraseña PASO 4: Escriba boot para arrancar el sistema, responda NO a la continuación de diálogos de configuración. PASO 5: En el indicador de exec privilegiado escriba rename flash config.old flash:config.txt para cambiar el nombre del archivo de configuración al nombre original. PASO 6: Copie el archivo de configuración a la memoria , cambie la contraseña anterior (desconocida) con
los siguientes comandos: switch # configure Terminal switch(config)# no enable secret switch(config)# enable password [password Nuevo] switch(config)# enable secret [password Nuevo] switch(config)# line console 0 switch(config-line)# password [password Nuevo] switch(config-line)# exit switch(config)# line vty 0 15 switch(config-line)# password [password Nuevo] switch(config-line)# exit switch(config)# exit switch(config)# copy running-config startup-config
LAS LISTAS DE CONTROL DE ACCESO sirven para identificar el tráfico, después se filtra y se consigue una mejor administración del tráfico global de la red. Una lista de control de acceso IP es un listado secuencial de condiciones de permiso o prohibición que se aplican a las direcciones IP o a protocolos IP de capa superior.
• Identifican el tráfico que ha de ser filtrado en su tránsito por el router, pero no pueden filtrar el tráfico originado por el propio router.
• Se aplican a los puertos de líneas de Terminal virtual para permitir y denegar tráfico TELNET entrante o saliente.
• Establecen un control mas fino o a la hora de separar el tráfico en diferentes colas de prioridades y personalizadas.
• Identifica el tráfico interesante , para activar las llamadas del enrutamiento por llamada telefónica bajo demanda DDR.

Tecnologías de la Información y Comunicación Sistemas Informáticos 40
Para las listas salientes : Un permit significa enviar el buffer de salida. Un deny descarta un paquete. Para las listas entrantes : Un permit significa continuar el procesamiento del
paquete tras su recepción en una interfaz. Un deny significa descartar el paquete.
Las instrucciones de una ACL operan en orden lógico secuencial, se evalúan los paquetes de principio a fin, en lugar de salir por alguna interfaz, todos los paquetes que no satisfacen las instrucciones de las ACL son descartados y devuelve en paquete especial notificando al remitente que el destino ha sido inalcanzable. TIPOS DE ACL LAS LISTAS DE ACCESO ESTÁNDAR comprueban las direcciones de origen de paquetes que solicitan enrutamiento, el resultado es el permiso o negación de la salida del paquete por parte del protocolo, basándose en la dirección IP de la red-subred-host de origen. Las lista de acceso IP estándar verifican sólo la dirección de origen en la cabecera del paquete (capa 3). LAS LISTA DE ACCESO EXTENDIDAS comprueban tanto la dirección origen como la del destino de cada paquete, verifican los protocolos especificados, números de puerto y otros parámetros. Las listas de acceso IP extendidas pueden verificar muchos elementos, incluyendo opciones de la cabecera del segmento (capa 4), como números de puerto TCP y UDP, direcciones IP de origen y destino; así como protocolos específicos. LISTA DE ACCESO NUMERADAS A las ACL se les asigna un número dentro de los siguientes rangos de lista de acceso numeradas:
ACL RANGO RANGO EXTENDIDO
IP estándar 1-99 1300-1999
IP extendida 100-199 2000-2699
Prot, type code 200-299
DECnet 300-399
XNS estándar 400-499
XNS extendida 500-599
Apple talk 600-699
IPX estándar 800-899
IPX extendida 900-999
Filtro SAP 1000-1099
CONFIGURACIÓN DE ACL ESTÁNDAR Router# configure terminal Router(config)# access-list [1-99] [permit/deny][dirección origen] [ mascara comodín] Router(config)# interface [ tipo y no. de interfaz] Router(config-if)# ip access-group [no. de ACL] [in/out]
CONFIGURACIÓN DE ACL EXTENDIDA Router# configure terminal Router(config)# access-list [1-99] [permit/deny] [protocolo] [direc ción origen] [ mascara comodín] [dirección destino] [máscara comodín] [puerto] [e stablished] [log] Router(config)# interface [ tipo y no. de interfaz] Router(config-if)# ip access-group [no. de ACL] [in/out]
APLICACIÓN DE UNA ACL A LINEA TELNET Router# configure terminal Router(config)# line vty 0 4 Router(config-line)# access-class [no. de ACL] [ in / out ]
Para eliminar ACLs , se antepone la palabra no a las instrucciones principales, de esta forma:
Router(config)# no access-list [1-99] [permit/deny][dirección origen] [ mascara comodín] Router(config-if)#no ip access-group [no. de ACL] [in/out]

Tecnologías de la Información y Comunicación Sistemas Informáticos 41
De igual forma es posible la CONFIGURACIÓN DE LISTA DE ACCESO NOMBRADAS , en vez de asignarle un número, se le asigna un nombre: Router# configure terminal Router(config)# ip access-list [Standard / extended] [nombre] Router(config [std/ext] nac1)# [permit/deny] [condiciones de prueba] Router(config [std/ext] nac1)# no [permit/deny] [condiciones de prueba] Router(config)# interface de asociación de ACL Router(config-if)# ip access-group [nombre] [in/out] Para VERIFICACIÓN DE ACLs se pueden utilizar los siguientes comados: Show ip interface [tipo de interfaz] [no. de interfaz] Show access-list Show access-lists
• Una lista de acceso puede ser aplicada a múltiples interfaces • Solo puede haber una ALC por protocolo, por dirección y por interfaz. • A menos que termine una ACL con una condición de permiso implícito en toso, se denegará todo
el tráfico que no cumpla ninguna de las condiciones establecidas en la lista ya que existe un deny implícito al final de cada lista.
• Las ACLs extendidazas deben colocarse normalmente lo mas cerca posible de l origen del
tráfico que será denegado, mientras que las estándar lo mas cerca posible del destino ANALISIS Y DISEÑO DE SISTEMAS DE INFORMACIÓN
REPRESENTACIÓN DE SISTEMAS CON UML, USO Y CICLO ITE RATIVO E INCREMENTAL
INTRODUCCIÓN AL UML El lenguaje de modelado unificado UML, es un lenguaje gráfico el cual nos permite visualizar, especificar, construir y documentar todos los objetos/elementos de un sistema. UML nos proporciona una lenguaje estándar para construir el mapa/plano de un sistema, cubriendo cosas conceptuales como los procesos de los negocios y las funciones del sistema, así como cosas concretas como clases escritas en un lenguaje especifico de programación, esquemas de base de datos y componentes de software reutilizable. UML es un estándar ampliamente utilizado que representa las mejores practicas y lecciones aprendidas durante una década de experiencia en el modelado de sistemas de software complejos.
Sin embargo, hay que tener en cuenta un aspecto importante: no pretende definir un modelo estándar de desarrollo, sino únicamente un lenguaje de modelado. Otros métodos de modelaje como OMT (Object Modeling Technique) o Booch sí definen procesos concretos. En UML los procesos de desarrollo son diferentes según los distintos dominios de trabajo; no puede ser el mismo el proceso para crear una aplicación en tiempo real, que el proceso de desarrollo de una aplicación orientada a gestión, por poner un ejemplo. Las diferencias son muy marcadas y afectan a todas las fases del proceso. El método del UML recomienda utilizar los procesos que otras metodologías tienen definidos. Con la creación del UML se persigue obtener un lenguaje que sea capaz de abstraer cualquier tipo de sistema, sea informático o no, mediante los diagramas, es decir, mediante representaciones gráficas que contienen toda la información relevante del sistema. Un diagrama es una representación gráfica de una colección de elementos del modelo, que habitualmente toma forma de grafo donde los arcos que conectan sus vértices son las relaciones entre los objetos y los vértices se corresponden con los elementos del modelo. Los distintos puntos de vista de un sistema real que se quieren representar para obtener el modelo se dibujan de forma que se resaltan los detalles necesarios para entender el sistema. Lo que se intenta es lograr con esto es que los lenguajes que se aplican siguiendo los métodos más utilizados sigan evolucionando en conjunto y no por separado. Y además, unificar las perspectivas entre diferentes tipos de sistemas (no sólo software, sino también en el ámbito de los negocios), al aclarar las fases de desarrollo, los requerimientos de análisis, el diseño, la implementación y los conceptos internos de la OO. ESTEREOTIPOS, COMENTARIOS Y RESTRICCIONES EN UML

Tecnologías de la Información y Comunicación
Los sistemas actuales tienen como característica que son complejos y generalmente contienen muchas clases. Estas clases deben ser organizadas de alguna forma de tal forma que puedan ser vistas por muchos grupos de persodonde cada uno de estos grupos esta interesado en ver cierto nivel de detalle. El modelado visual permite mostrar el modelo de muchas formas, de tal manera que cada vista muestre un cierto nivel de abstracción que le sea de interés a cierto grupo de DIAGRAMAS PARA REPRESENTAR LOS REQUERIMIENTOS DEL S ISTEMA
Diagramas de Casos de Uso:
Un caso de uso es una secuencia de transacciones que son desarrolladas por un sistema en respuesta a un evento que inicia un actor sobre el propio sistemael comportamiento de un sistema mediante su interacción con los usuarios y/o otros sistemas. O lo que es igual , un diagrama que muestra la relación entre los actores y los casos de uso entre los elementos del modelo, por ejemplo la relación y la generalización son relaciones. Los diagramas de casos de uso se utilizan para ilustrar los requerimientos del sistema al mostrar como reacciona una respuesta a eventos que se producen en el mismo. En este tipo de diagrama intervienen algunos conceptos nuevos: un actor es una entidad externa al sistema que se modela y que puede interactuar con él; un ejemplo de actor podría ser un usuario o cualquier otro sistema. Las relaciones entre casos de uso y actores pueden ser las siguientes:
Se muestra como ilustración los casos de uso de la máquina de café.
DIAGRAMAS PARA REPRESENTAR LA ESTRUCTURA ESTÁTICA D EL SISTEMA
as de la Información y Comunicación Sistemas Informáticos
Los sistemas actuales tienen como característica que son complejos y generalmente contienen muchas clases. Estas clases deben ser organizadas de alguna forma de tal forma que puedan ser vistas por muchos grupos de persodonde cada uno de estos grupos esta interesado en ver cierto nivel de detalle.
El modelado visual permite mostrar el modelo de muchas formas, de tal manera que cada vista muestre un cierto nivel de abstracción que le sea de interés a cierto grupo de personas.
DIAGRAMAS PARA REPRESENTAR LOS REQUERIMIENTOS DEL S ISTEMA
una secuencia de transacciones que son desarrolladas por un sistema en respuesta a un evento que inicia un actor sobre el propio sistema. Los diagramas de casos de uso sirven para especificar la funcionalidad y el comportamiento de un sistema mediante su interacción con los usuarios y/o otros sistemas. O lo que es igual , un diagrama que muestra la relación entre los actores y los casos de uso en un sistema. Una relación es una conexión entre los elementos del modelo, por ejemplo la relación y la generalización son relaciones.
Los diagramas de casos de uso se utilizan para ilustrar los requerimientos del sistema al mostrar como reacciona una spuesta a eventos que se producen en el mismo. En este tipo de diagrama intervienen algunos conceptos nuevos:
es una entidad externa al sistema que se modela y que puede interactuar con él; un ejemplo de actor podría o sistema. Las relaciones entre casos de uso y actores pueden ser las siguientes:
• Un actor se comunica con un caso de uso.
• Un caso de uso extiende otro caso de uso.
• Un caso de uso usa otro caso de uso.
ilustración los casos de uso de la máquina de café.
DIAGRAMAS PARA REPRESENTAR LA ESTRUCTURA ESTÁTICA D EL SISTEMA
Sistemas Informáticos 42
Los sistemas actuales tienen como característica que son complejos y generalmente contienen muchas clases. Estas clases deben ser organizadas de alguna forma de tal forma que puedan ser vistas por muchos grupos de personas,
El modelado visual permite mostrar el modelo de muchas formas, de tal manera que cada vista muestre un cierto
una secuencia de transacciones que son desarrolladas por un sistema en respuesta a un evento diagramas de casos de uso sirven para especificar la funcionalidad y
el comportamiento de un sistema mediante su interacción con los usuarios y/o otros sistemas. O lo que es igual , un en un sistema. Una relación es una conexión
entre los elementos del modelo, por ejemplo la relación y la generalización son relaciones.
Los diagramas de casos de uso se utilizan para ilustrar los requerimientos del sistema al mostrar como reacciona una spuesta a eventos que se producen en el mismo. En este tipo de diagrama intervienen algunos conceptos nuevos:
es una entidad externa al sistema que se modela y que puede interactuar con él; un ejemplo de actor podría o sistema. Las relaciones entre casos de uso y actores pueden ser las siguientes:
Un actor se comunica con un caso de
Un caso de uso extiende otro caso de
Un caso de uso usa otro caso de uso.

Tecnologías de la Información y Comunicación Sistemas Informáticos 43
a) Diagramas de Clases En UML, una clase aparece en un diagrama de clases como un rectángulo con su nombre, como en la figura 1
Figura 1 Un modelo de Clases muy sencillo Identificación de objetos y clases.
La construcción de un modelo de clases incluye la identificación de las clases que debería existir en nuestro sistema: ésta es una parte fundamental del trabajo de diseñar un sistema orientado a objetos. Antes de tratar cómo identificar objetos y clases, discutamos los criterios para tener éxito. ¿Qué hace que un modelo de clases sea bueno? Hay dos objetivos que se pretenden alcanzar:
• Construir, lo más rápido y barato posible, un sistema que satisfaga nuestros requisitos actuales. • Construir un sistema que sea fácil de mantener y adaptar a futuros requisitos.
Estos objetivos, muchas veces se encuentran enfrentados; una razón del éxito de las técnicas orientadas a
objetos, y especialmente de las técnicas de diseño basadas en componentes que permiten dar un paso hacia su reconciliación.
Para cumplir el segundo objetivo habría que construir un sistema compuesto por módulos encapsulados, con acoplamiento débil y cohesión fuerte Además: Cada comportamiento que requiera el sistema debe ser proporcionado por los objetos de las clases que elijamos.
Un buen modelo de clases está formado (dentro de lo posible) por clases que representan clases permanentes de los objetos del dominio, las cuales no dependen de la funcionalidad requerida en este momento. La naturaleza estática de los sistemas se representa a través de los diagramas de clase, los cuales muestran las relaciones entre las clases involucradas.
Los diagramas de clases representan un conjunto de elementos del modelo que son estáticos, como las clases y los tipos, sus contenidos y las relaciones que se establecen entre ellos.
Libro

Tecnologías de la Información y Comunicación Sistemas Informáticos 44
Algunos de los elementos que se pueden clasificar como estáticos son los siguientes:
Paquete : Es el mecanismo de que dispone UML para organizar sus elementos en grupos, se representa un grupo de elementos del modelo. Un sistema es un único paquete que contiene el resto del sistema, por lo tanto, un paquete debe poder anidarse, permitiéndose que un paquete contenga otro paquete. Clases : Una clase representa un conjunto de objetos que tienen una estructura, un comportamiento y unas relaciones con propiedades parecidas. Describe un conjunto de objetos que comparte los mismos atributos, operaciones, métodos, relaciones y significado. En UML una clase es una implementación de un tipo. Los componentes de una clase son:
Atributo . Se corresponde con las propiedades de una clase o un tipo. Se identifica mediante un nombre. Existen atributos simples y complejos.
Operación . También conocido como método, es un servicio proporcionado por la clase que puede ser solicitado por otras clases y que produce un comportamiento en ellas cuando se realiza.
Las clases pueden tener varios parámetros formales, son las clases denominadas plantillas. Sus atributos y
operaciones vendrán definidas según sus parámetros formales. Las plantillas pueden tener especificados los valores reales para los parámetros formales, entonces reciben el nombre de clase parametrizada instanciada. Se puede usar en cualquier lugar en el que se podría aparecer su plantilla.
Metaclase : Es una clase cuyas instancias son clases. Sirven como depósito para mantener las variables de clase y proporcionan operaciones (método de clase) para inicializar estas variables. Se utilizan para construir metamodelos (modelos que se utilizan para definir otros modelos). Tipos : Es un descriptor de objetos que tiene un estado abstracto y especificaciones de operaciones pero no su implementación. Un tipo establece una especificación de comportamiento para las clases. Interfaz : Representa el uso de un tipo para describir el comportamiento visible externamente de cualquier elemento del modelo. Relación entre clases : Las relaciones proveen unan forma de establecer la comunicación entre los objetos y se representa dibujando una línea recta entre las clases.
Las clases se relacionan entre sí de distintas formas, que marcan los tipos de relaciones existentes:
Asociación :
Es una relación que describe un conjunto de vínculos entre clases. Pueden ser binarias o n-arias, según se implican a dos clases o más. Las relaciones de asociación vienen identificadas por los roles, que son los nombres que indican el comportamiento que tienen los tipos o las clases, en el caso del rol de asociación (existen otros tipos de roles según la relación a la que identifiquen). Indican la información más importante de las asociaciones.

Tecnologías de la Información y Comunicación Sistemas Informáticos 45
Existe una forma especial de asociación, la agregación, que especifica una relación entre las clases donde el llamado "agregado" indica el todo y el "componente" es una parte del mismo.
En el ejemplo la clase “TradeLeg” pertenece o es parte de la clase “Trade”.
Todas estas relaciones de asociación y agregación son por default bidireccionales, mas sin embargo es deseable restringir la navegación en una sola dirección. Para establecer la dirección de navegación se utiliza una cabeza de flecha.
Composición :
Es un tipo de agregación donde la relación de posesión es tan fuerte como para marcar otro tipo de relación. Las clases en UML tienen un tiempo de vida determinado, en las relaciones de composición, el tiempo de vida de la clase que es parte del todo (o agregado) viene determinado por el tiempo de vida de la clase que representa el todo, por tanto es equivalente a un atributo, aunque no lo es porque es una clase y puede funcionar como tal en otros casos.
Generalización : “herencia”
Cuando se establece una relación de este tipo entre dos clases, una es una Superclase y la otra es una Subclase. La subclase comparte la estructura y el comportamiento de la superclase. Puede haber más de una clase que se comporte como subclase
.

Tecnologías de la Información y Comunicación Sistemas Informáticos 46
Dependencia :
Una relación de dependencia se establece entre clases (u objetos) cuando un cambio en el elemento independiente del modelo puede requerir un cambio en el elemento dependiente.
Relación de Refinamiento:
Es una relación entre dos elementos donde uno de ellos especifica de forma completa al otro que ya ha sido especificado con cierto detalle.
Multiplicidades Es posible especificar: . Un número exacto simplemente escribiéndolo. . Un rango de números utilizando dos puntos entre un par de números. . Un número arbitrario, no especificado utilizando *.
Aproximadamente, puede pensar en el * de UML como un símbolo de infinito, por lo que la multiplicidad 1 . . * expresa que el número de copias puede ser cualquier cosa entre 1 e infinito. Por supuesto, cada vez habrá en realidad un número finito de objetos en nuestro sistema completo, por lo que esto realmente indica que puede haber cualquier número de copias de un libro, a condición de que haya al menos uno.
Se puede también especificar una posible multiplicidad mediante una lista de multiplicidades separadas por comas: por ejemplo 3, 12..15, 901 . . * es una multiplicidad improbable que se dé, que indica que puede haber exactamente 3, o bien entre 12 y 15 (inclusive) o bien al menos 901, de 10 que sea. DIAGRAMAS PARA REPRESENTAR LA ESTRUCTURA DINÁMICA D EL SISTEMA
a) Diagrama de secuencia
Muestran las interacciones entre un conjunto de objetos, ordenadas según el tiempo en que tienen lugar. En los diagramas de este tipo intervienen objetos, que tienen un significado parecido al de los objetos representados en los diagramas de colaboración, es decir son instancias concretas de una clase que participa en la interacción.
Los diagramas de secuencia permiten indicar cuál es el momento en el que se envía o se completa un mensaje
mediante el tiempo de transición, que se especifica en el diagrama.

Tecnologías de la Información y Comunicación
Ejemplo de un diagrama: Los rectángulos representan los objetos y las líneas punteadas debajo de ellos el tiempo, así como la serie de eventos que pueden ocurrir entre los objetos. Las flechas horizontales representan A continuación se muestra un ejemplo de diagrama de secuencia, que da detalle al caso de uso PedirProducto del ejemplo de la cafetera
b) Diagrama de colaboración
Muestra la interacción entre varios objetos y
entre objetos organizadas alrededor de los objetos y sus vinculaciones. A diferencia de un diagrama de secuencias, un diagrama de colaboraciones muestra las relaciones entre los objetos, nolos mensajes. Los diagramas de secuencias y los diagramas de colaboraciones expresan información similar, pero en una forma diferente.
Un enlace es una instancia de una asociación que conecta dos objetos de unenlace puede ser reflexivo si conecta a un elemento consigo mismo. La existencia de un enlace entre dos objetos indica que puede existir un intercambio de mensajes entre los objetos conectados.
as de la Información y Comunicación Sistemas Informáticos
Los rectángulos representan los objetos y las líneas punteadas debajo de ellos el tiempo, así como la serie de eventos que pueden ocurrir entre los objetos. Las flechas horizontales representan mensajes entre los objetos participantes.
A continuación se muestra un ejemplo de diagrama de secuencia, que da detalle al caso de uso PedirProducto del
Muestra la interacción entre varios objetos y los enlaces que existen entre ellos. Representa las interacciones entre objetos organizadas alrededor de los objetos y sus vinculaciones. A diferencia de un diagrama de secuencias, un diagrama de colaboraciones muestra las relaciones entre los objetos, no la secuencia en el tiempo en que se producen los mensajes. Los diagramas de secuencias y los diagramas de colaboraciones expresan información similar, pero en
es una instancia de una asociación que conecta dos objetos de un enlace puede ser reflexivo si conecta a un elemento consigo mismo. La existencia de un enlace entre dos objetos indica que puede existir un intercambio de mensajes entre los objetos conectados.
Sistemas Informáticos 47
Los rectángulos representan los objetos y las líneas punteadas debajo de ellos el tiempo, así como la serie de eventos mensajes entre los objetos participantes.
A continuación se muestra un ejemplo de diagrama de secuencia, que da detalle al caso de uso PedirProducto del
los enlaces que existen entre ellos. Representa las interacciones entre objetos organizadas alrededor de los objetos y sus vinculaciones. A diferencia de un diagrama de secuencias, un
la secuencia en el tiempo en que se producen los mensajes. Los diagramas de secuencias y los diagramas de colaboraciones expresan información similar, pero en
diagrama de colaboración. El enlace puede ser reflexivo si conecta a un elemento consigo mismo. La existencia de un enlace entre dos objetos

Tecnologías de la Información y Comunicación
Los diagramas de interacción inrepresenta el envío de un mensaje desde un objeto a otro si entre ellos existe un enlace. Los mensajes que se envían entre objetos pueden ser de distintos tipos, también según comosincrónicos, balking, timeout y asíncronos. Ejemplo de un diagrama:
El Diagrama de Colaboración ofrece una mejor visión del escenario cuando el analista está intentando comprender la participación de un objeto en el sistema. Ver el ejemplo siguiente:
DIAGRAMAS PARA REPRESENTAR EL COMPORTAMIENTO DEL SISTEMA
a) Diagramas de actividad
Son similares a los diagramas de flujo de otras metodologías OO. En realidad se corresponden con un caso
especial de los diagramas de estado donde los estados son más transiciones que suceden al finalizar esta acción, o lo que es lo mismo, un paso en la ejecución de lo que será un procedimiento) y las transiciones vienen provocadas por la finalización de las acciones que tienen lugade origen. Siempre van unidos a una clase o a la implementación de un caso de uso o de un método (que tiene el
as de la Información y Comunicación Sistemas Informáticos
Los diagramas de interacción indican el flujo de mensajes entre elementos del modelo, el flujo de mensajes representa el envío de un mensaje desde un objeto a otro si entre ellos existe un enlace. Los mensajes que se envían entre objetos pueden ser de distintos tipos, también según como se producen en el tiempo; existen mensajes simples,
y asíncronos.
El Diagrama de Colaboración ofrece una mejor visión del escenario cuando el analista está intentando comprender la participación de un objeto en el sistema. Ver el ejemplo siguiente:
REPRESENTAR EL COMPORTAMIENTO DEL SISTEMA
Son similares a los diagramas de flujo de otras metodologías OO. En realidad se corresponden con un caso especial de los diagramas de estado donde los estados son estados de acción (estados con una acción interna y una o más transiciones que suceden al finalizar esta acción, o lo que es lo mismo, un paso en la ejecución de lo que será un procedimiento) y las transiciones vienen provocadas por la finalización de las acciones que tienen lugade origen. Siempre van unidos a una clase o a la implementación de un caso de uso o de un método (que tiene el
Sistemas Informáticos 48
entre elementos del modelo, el flujo de mensajes representa el envío de un mensaje desde un objeto a otro si entre ellos existe un enlace. Los mensajes que se envían
se producen en el tiempo; existen mensajes simples,
El Diagrama de Colaboración ofrece una mejor visión del escenario cuando el analista está intentando
Son similares a los diagramas de flujo de otras metodologías OO. En realidad se corresponden con un caso os con una acción interna y una o
más transiciones que suceden al finalizar esta acción, o lo que es lo mismo, un paso en la ejecución de lo que será un procedimiento) y las transiciones vienen provocadas por la finalización de las acciones que tienen lugar en los estados de origen. Siempre van unidos a una clase o a la implementación de un caso de uso o de un método (que tiene el

Tecnologías de la Información y Comunicación Sistemas Informáticos 49
mismo significado que en cualquier otra metodología OO). Los diagramas de actividad se utilizan para mostrar el flujo de operaciones que se desencadenan en un procedimiento interno del sistema. Ejemplo de un diagrama.
MODELADO DEL CASE, REINGENIERÍA DE SOFTWARE E INGENIERÍA DE REVERSA QUÉ SON LAS HERRAMIENTAS CASE Se puede definir a las Herramientas CASE como un conjunto de programas y ayudas que dan asistencia a los analistas, ingenieros de software y desarrolladores, durante todos los pasos del Ciclo de Vida de desarrollo de un Software. La mejor razón para la creación de estas herramientas fue el incremento en la velocidad de desarrollo de los sistemas. Por esto, las compañías pudieron desarrollar sistemas sin encarar el problema de tener cambios en las necesidades del negocio, antes de finalizar el proceso de desarrollo. Beneficios en todas las etapas del proceso de desarrollo de software:
• Verificar el uso de todos los elementos en el sistema diseñado. • Automatizar el dibujo de diagramas. • Ayudar en la documentación del sistema. • Ayudar en la creación de relaciones en la Base de Datos. • Generar estructuras de código.
La principal ventaja de la utilización de una herramienta CASE, es la mejora de la calidad de los desarrollos realizados y, en segundo término, el aumento de la productividad.

Tecnologías de la Información y Comunicación Sistemas Informáticos 50
Etapas del método CASE.
Especificaciones de EasyCASE Profesional La adopción de herramientas CASE debe incluir los siguientes procesos principales:
# Preparación # Evaluación y Selección # Proyecto Piloto # Transición
Estrategias de Implantación de una Herramienta CASE
1. Identificar la magnitud de problemas a resolver en la Institución. 2. Identificar el nivel estratégico que deben tener los sistemas. 3. Evaluar los recursos de hardware y software disponibles en la Institución y el medio. 4. Evaluar el nivel del personal. 5. Efectuar un estudio de costo-beneficio definiendo metas a lograr. 6. Elegir las herramientas apropiadas para la Institución. 7. Establecer un programa de capacitación de personal de sistemas y usuarios.
8. Elegir una aplicación que reúna la mayor parte de los siguientes requisitos:
CALIDAD EN EL DESARROLLO DE SOFTWARE

Tecnologías de la Información y Comunicación Sistemas Informáticos 51
Calidad del software.- se define como la concordancia con los requisitos funcionales y de rendimiento explícitamente establecidos, con los estándares de desarrollo explícitamente documentados y con las características implícitas que se espera de todo software desarrollado profesionalmente. Objetivos de la ingeniería de software
En la construcción y desarrollo de proyectos se aplican métodos y técnicas para resolver los problemas, la informática aporta herramientas y procedimientos sobre los que se apoya la ingeniería de software.
• Mejorar la calidad de los productos de software • Aumentar la productividad y trabajo de los ingenieros del software. • Facilitar el control del proceso de desarrollo de software. • Suministrar a los desarrolladores las bases para construir software de alta calidad en una forma
eficiente. • Definir una disciplina que garantice la producción y el mantenimiento de los productos software
desarrollados en el plazo fijado y dentro del costo estimado.
Objetivos de los proyectos de sistemas
Para que los objetivos se cumplan las empresas emprenden proyectos por las siguientes razones: "Las cinco C "
Capacidad: Las actividades de la organización están influenciadas por la capacidad de ésta para procesar transacciones con rapidez y eficiencia.
Los sistemas de información mejoran esta capacidad en tres formas.
* Aumentan la velocidad de procesamiento
*Aumento en el volumen
* Recuperación más rápida de la información
Costo
* Vigilancia de los costos
* Reducción de costos
Control
*Mayor seguridad de información
*Menor margen de error: (mejora de la exactitud y la consistencia)
Comunicación
* Interconexión: ( aumento en la comunicación)
* Integración de áreas en las empresas:
Beneficios de la ingeniería de software
• Facilita a los desarrolladores el probar sus ideas • Facilita descubrir los errores con mayor agilidad • Proporciona información sobre el estado del sistema de software

Tecnologías de la Información y Comunicación Sistemas Informáticos 52
• Evita la reutilización • Genera nuevas alternativas
Reingeniería
Hammer y Champy definen a la reingeniería de procesos como “la reconcepción fundamental y el
rediseño radical de los procesos de negocios para lograr mejoras dramáticas en medidas de desempeño
tales como en costos, calidad, servicio y rapidez” (Fuente: Institute of Industrial Engineers, "Más allá de
la Reingeniería", CECSA, México, 1995, p.4) Factores correspondientes a la reingeniería FACTOR.- Por lo que a continuación se escriben los factores relevantes de reingeniería:
• Costo de mantenimiento y operaciones • Duración de los procesos de reingeniería o nuevo desarrollo • Reingeniería de software • Cambio radical
Lógica para el desarrollo de prototipos ordenadamen te Un cliente, a menudo, define un conjunto de objetivos generales para el software, pero no identifica los requisitos detallados de entrada proceso o salida. El paradigma de construcción de prototipos comienza con la recolección de requisitos. El desarrollador y el cliente encuentran y definen los objetivos globales para el software, identifican los requisitos conocidos y las áreas del esquema en donde es obligatoria más definición. Entonces aparece un diseño rápido que se centra en una representación de esos aspectos del software que serán visibles para el usuario/cliente. El diseño rápido lleva a la construcción de un prototipo, el prototipo lo evalúa el cliente/usuario (uso del prototipo) y se utiliza para refinar los requisitos del software a desarrollar (revisión y mejoramiento del prototipo). Modelo de calidad para el desarrollo de software
Para resolver los problemas reales de una industria, un ingeniero (o equipo) de software debe incorporar una estrategia de desarrollo que acompañe al proceso. Estas estrategias a menudo se llama modelo de proceso o paradigmas de la ingeniería del software o modelos de calidad para el desarrollo de software. La estrategia de desarrollo puede ser de diferentes tipos:
• Modelo Lineal Secuencial o de cascada • Modelo de construcción de prototipos • Modelo DRA
Definición de conceptos importantes GESTIONADO.- significa que la responsabilidad del mantenimiento y de la operativa de los procesos no recae sobre el cliente sino sobre el personal administrativo correspondiente. INICIAL.- quiere decir que hay que tomar en cuenta los factores de calidad en el software, desde que se empieza a programar. OPTIMIZADO.- insuperable hasta ese momento. DEFINIDO.- Explicar su significado con palabras simples.

Tecnologías de la Información y Comunicación Sistemas Informáticos 53
ADMINISTRADO CUANTITATIVAMENTE.- hay que cumplir con todos los requisitos de los anteriores y, además, los procesos deben estar controlados a través de estadísticas u otras técnicas cuantitativas.
Principios del PSP
El diseño de PSP se basa en los siguientes principios de planeación y de calidad [HUMPHREY; 95]
• Cada ingeniero es esencialmente diferente; para ser más precisos, los ingenieros deben planear su trabajo y basar sus planes en sus propios datos personales.
• Para mejorar constantemente su funcionamiento, los ingenieros deben utilizar personalmente procesos bien definidos y medidos.
• Para desarrollar productos de calidad, los ingenieros deben sentirse personalmente comprometidos con la calidad de sus productos.
• Cuesta menos encontrar y arreglar errores en la etapa inicial del proyecto que encontrarlos en las etapas subsecuentes.
• Es más eficiente prevenir defectos que encontrarlos y arreglarlos. • La manera correcta de hacer las cosas es siempre la manera más rápida y más barata de hacer un trabajo.
Pasos del PSP
Pasos Involucrados
Los pasos que se necesitan para llevar a cabo un trabajo utilizando PSP son: Medición Personal (PSP0) Planificación Personal (PSP1) Calidad Personal (PSP2) Proceso Personal Cíclico (PSP3) Todos los niveles PSP, a excepción de PSP3, presentan a su vez tres etapas durante su tiempo de vida, estas son Planificación, Desarrollo y Fin de ciclo.
Figura 2.6 Medición personal de PSP 0 y PSP 0.1

Tecnologías de la Información y Comunicación Sistemas Informáticos 54
SISTEMAS OPERATIVOS
GENERALIDADES DE LOS SISTEMAS OPERATIVOS MULTIUSUARIOS Existen diversos programas que se manejan en una computadora. De todos los programas y aplicaciones comerciales que se conocen hoy en día, los más importantes son los llamados programas del sistema, que son programas que controlan el hardware de manera directa o indirecta.
Entre ellos existen: editores, compiladores, traductores, ligadores, etc,. Sin embargo el más importante de todos es el Sistema Operativo.
Definición (de Sistema Operativo): Software de Sistema que se encarga de la gestión de recursos y su administración tanto de software como de hardware, ocultando los detalles al usuario, permitiéndole una interacción más cómoda con los mismos.
Así existen dos formas de visualizar a los sistemas operativos: Top-Down (Arriba-Abajo): Como un software capaz de comunicarse con los recursos de hardware de la computadora sin mostrar los detalles al usuario. Bottom-Up (Abajo-Arriba): Visto como un software gestor de recursos de hardware y su control para que el usuario obtenga la información de forma rápida y correcta.
Un sistema operativo tradicional se puede ver como un modelo en capas superpuestas(capas de cebolla) desde la mas interna, que esta pegada con el hardware de la computadora, y la mas externa que esta en interacción directa con el usuario.
Estos componentes son: Kernel o Núcleo . Es el programa medular que ejecuta programas y gestiona dispositivos de
hardware tales como los discos y las impresoras. Shell. Proporciona una interfaz para el usuario. Recibe ordenes del usuario y las envía al núcleo
para ser ejecutadas. Sistema de archivos. Organiza la forma en que se almacenan los archivos en dispositivos de
almacenamiento tales como los discos. Aplicaciones Son programas especializados, tales como editores, compiladores y programas de
comunicaciones, que realizan operaciones de computación estándar. Una de las aplicaciones más utilizadas es la interfaz gráfica que facilita enormemente la interacción humano computadora.
PROCESOS Y ARCHIVOS
Ahora bien dentro de los sistemas operativos existen dos paradigmas ó definiciones fundamentales con las que un sistema operativo opera. Proceso: Cualquier programa en ejecución Archivo: Secuencia de bytes almacenados en cualquier dispositivo de memoria secundaria De manera principal los sistemas operativos se apoyan en estos conceptos para poder ofrecer los servicios adecuados. En base a esta forma de trabajo los sistemas operativos pueden clasificarse como sigue:
• Monousuarios Los SO monousuarios son aquellos que soportan a un usuario a la vez, sin importar el número de procesadores que tenga la computadora o el número de procesos o tareas que el usuario pueda ejecutar en un mismo instante de tiempo. Las computadoras personales típicamente se han clasificado en este renglón.
• Multiusuarios

Tecnologías de la Información y Comunicación Sistemas Informáticos 55
Los SO multiusuarios son capaces de dar servicio a más de un usuario a la vez, ya sea por medio de varias terminales conectadas a la computadora o por medio de sesiones remotas en una red de comunicaciones. No importa el número de procesadores en la máquina ni el número de procesos que cada usuario puede ejecutar simultáneamente.
En otras palabras consiste en el fraccionamiento del tiempo (timesharing). El tiempo compartido en ordenadores o computadoras consiste en el uso de un sistema por más de una persona al mismo tiempo, ejecutando programas separados de forma concurrente, intercambiando porciones de tiempo asignadas a cada programa (usuario). En este aspecto, es similar a la capacidad de multitareas que es común en la mayoría de los microordenadores o las microcomputadoras. Sin embargo el tiempo compartido se asocia generalmente con el acceso de varios usuarios a computadoras más grandes y a organizaciones de servicios, mientras que la multitarea relacionada con las microcomputadoras implica la realización de múltiples tareas por un solo usuario
Esto facilita la reducción de tiempo ocioso en el procesador, e indirectamente implica reducción de los costos de energía y equipamiento para resolver las necesidades de cómputo de los usuarios. Ejemplos de sistemas operativos con característica de multiusuario son VMS y Unix en sus múltiples derivaciones (e.g. IRIX, Solaris, etc.) y los sistemas "clones de Unix" como Linux y FreeBSD.
En la familia de los sistemas operativos Microsoft Windows, las versiones domésticas y para clientes de Windows 2000, Windows XP y Windows Vista proveen soporte para ambientes personalizados por usuario, pero no admiten múltiples usuarios usando el escritorio del sistema concurrentemente, las versiones de servidor de Windows 2000 y Windows 2003 (así como la futura versión de Vista "Longhorn") proveen servicio de escritorio a múltiples usuarios de forma concurrente a través de Terminal Services.
Un sistema operativo multiusuario, a diferencia de uno monousuario, debe resolver una serie de complejos problemas de administración de recursos, memoria, acceso al sistema de archivos, etc. Multitarea Es una característica de un sistema operativo moderno. Permite que varios procesos sean ejecutados al mismo tiempo compartiendo uno o más procesadores. Tipos de multitarea:
• Nula: El sistema operativo carece de multitarea. Aun así puede lograrse a veces algo parecido a una multitarea implementándola en espacio de usuario, o usando trucos como los TSR de MS-DOS. Un ejemplo típico de un sistema no multitarea es MS-DOS y sus clones.
• Cooperativa: Los procesos de usuario son quienes ceden la CPU al sistema operativo a intervalos regulares. Muy problemática, puesto que si el proceso de usuario se interrumpe y no cede la CPU al sistema operativo, todo el sistema estará trabado, es decir, sin poder hacer nada. Da lugar también a latencias muy irregulares, y la imposibilidad de tener en cuenta este esquema en sistemas operativos de tiempo real. Un ejemplo sería Windows hasta la versión 95.
• Preferente: El sistema operativo es el encargado de administrar el/los procesador(es), repartiendo el tiempo de uso de este entre los procesos que estén esperando para utilizarlo. Cada proceso utiliza el procesador durante cortos períodos de tiempo, pero el resultado final es prácticamente igual que si estuviesen ejecutándose al mismo tiempo. Ejemplos de sistemas de este tipo serían Unix y sus clones (FreeBSD, Linux...), Windows NT...
• Real: Sólo se da en sistemas multiprocesador. Es aquella en la que varios procesos se ejecutan realmente al mismo tiempo, en distintos microprocesadores. Suele ser también preferente. Ejemplos de sistemas operativos con esa capacidad: variantes Unix, Linux, Windows NT, etc.
Sistema Operativo Linux En un sentido estricto, sólo se puede hablar de una versión de Linux en un momento determinado: la última versión actualizada del núcleo. El núcleo es el dominio particular de Torvalds en el desarrollo de Linux, dejando todas las aplicaciones y servicios que actúan sobre el núcleo para los miles de desarrolladores que hay en el mundo. En el sentido genérico de Linux, que se refiere a las colecciones de aplicaciones que se ejecutan sobre el núcleo, hay muchas versiones de Linux. Cada distribución tiene características específicas, que incluyen métodos de instalación, ampliaciones y características especiales.

Tecnologías de la Información y Comunicación Sistemas Informáticos 56
Lo interesante de la forma dual de usar el término Linux es que ocurre lo mismo con el término SO. En un sentido comercial, un SO es una gran colección de aplicaciones que complementan el núcleo. Esto es lo que son Windows 95 y Windows 98, Windows NT, Windows 2000, o Mac OS. Desde un punto de vista técnico, un SO es el núcleo principal que proporciona funciones básicas para desarrollar y ejecutar aplicaciones. Un Sistema Operativo multiusuario Más importante que sus capacidades multitarea son sus características como SO multiusuario, características que comparte con todas las versiones de Unís y otros sistemas clónicos de Unix.
Linux permite varios usuarios simultáneos, permitiendo aprovechar al máximo las capacidades multitarea del SO. La gran ventaja de esto es que permite utilizar Linux como servidor de aplicaciones. Desde sus terminales, los usuarios pueden conectarse a través de una red con el servidor y ejecutar las aplicaciones directamente en él, en lugar de hacerlo en su propio ordenador.
Linux es un sistema que trabaja propiamente de dos formas:
• Línea de Comandos • Interfaz Gráfica
El shell o línea de comandos trabaja con comandos diversos que cumplen las siguientes
funciones, entre muchas otras:
• Sobre los archivos y directorios • Tratamiento de Archivos • Permisos y Espacio de Disco Duro • Monitoreo de procesos • Redireccionamiento y Tuberías
Además trabaja con un super usuario o administrador del sistema que es capaz de manejar las características anteriores y muchas otras. LÍNEA DE COMANDO COMANDOS SOBRE ARCHIVOS Y DIRECTORIOS Comando : mkdir Formato: mkdir [opciones] directorio Descripción: Crea directorios. Ejemplo: mkdir –p /home/juan/documentos/cartas Crea el directorio cartas y todos los directorios anteriores necesarios. Comando: rmdir Formato: rmdir directorio Descripción: Borra el directorio especificado. Siempre y cuando este vacío. Ejemplo: rmdir cartas Comando: pwd Formato: pwd Descripción: Informa sobre cuál es el directorio actual en el que nos encontramos, no tiene ningún tipo de parámetro. Comando: cd Formato: cd nombre_del_directorio

Tecnologías de la Información y Comunicación Sistemas Informáticos 57
Descripción: Cambia del directorio actual al indicado en nombre_del_directorio. Si no se indica ningún directorio cambiara al directorio raíz del usuario que lo invoca. Admite los directorios . y .. correspondientes al actual y al padre del actual para indicar los caminos relativos al directorio destino. Ejemplos: cd cartas Cambia al directorio cartas. Comando : ls Formato: ls [opciones] archivos Descripción: Lista los archivos indicados mostrando información sobre ellos. Si no se pasa como parámetro ningún nombre de archivo, lista los archivos del directorio actual. Las opciones son:
-a -l -t -r Archivos
Muestra todos los archivos del directorio actual incluyendo los archivos ocultos, que en LINUX son los que comienza su nombre por punto. Muestra los directorios como archivos en lugar de mostrar sus contenidos.
Ejemplos: ls –l Muestra los archivos del directorio actual con el formato extendido dando toda la información. ls –la *.c Muestra todos los archivos en formato extenso cuyo nombre termine en .c y que comiencen por cualquier cadena de carácter, mostrará también los que se consideran ocultos, que comprenden por .., y cumplan en resto de las condiciones. COMANDOS BÁSICOS PARA EL MANEJO DE ARCHIVOS Comando : cat Formato: cat [opciones] archivos Descripción: Concatena la lista de archivos que se le facilita en la salida estándar. Ejemplos: cat hola.txt Comando: rm Formato: rm [opciones] archivos Descripción: Elimina archivos y directorios del sistema de ficheros. Se utiliza tanto para borrar archivos, enlaces y directorios. Para eliminar directorios es necesaria la opción –r. Hay que tener mucho cuidado con la utilización de este comando pues sus acciones son irreparables. Las opciones son: Ejemplos: rm * Borra todos los archivos del directorio actual pidiendo permiso para cada archivo que va a borrar. Comando: cp Formato: cp [opciones] fuente destino Descripción: Copia archivos y directorios. Copiará fuente a destino, fuente puede ser una lista de archivos que copiará a un directorio indicado en destino. También puede copiar un archivo sobre otro archivo. Ejemplos: cp /usr/bin/joe . Copia el archivo joe del directorio /usr/bin al directorio actual. cp joe joe.old Copia el contenido de joe a joe.old, es decir, respalda joe. Comando: mv Formato: mv [opciones] origen destino Descripción: Mueve archivos y directorios. También es el comando que se utiliza para renombrado de archivos y directorios por ser similar el efecto que se produce. Ejemplos: mv carta.txt carta.doc Cambia de nombre el archivo carta.txt a carta.doc. Comando: ln Formato: ln [-s] origen destino

Tecnologías de la Información y Comunicación Sistemas Informáticos 58
Descripción: Crea un enlace a un archivo, con el fin de poder acceder a un archivo con más de un nombre. Ejemplos: ln –s documento.txt trabajo.txt Crea un enlace simbólico o ligadura simbólica del archivo documento.txt en el enlace trabajo.txt. Comando: file Formato: file archivo Descripción: Realiza una exploración del archivo tratando de clasificarlo. Al final imprime en pantalla la descripción del archivo e información relevante. Ejemplo : carta.doc Clasifica a carta.doc como un documento de Microsoft Office Document Comando: find Formato: find directorio(s) [criterios_de_seleccion] [opcion_de_comando] nom arch Descripción: El comando find se utiliza para examinar la jerarquía de directorios en búsqueda de archivos. Para esta búsqueda pueden indicarse ciertos criterios. Además, también puede aparecer el nombre del archivo encontrado en pantalla o ejecutarse con un comando. Ejemplo: find . –name jose –print En este caso busca en el directorio actual . el archivo con nombre jose e imprime los lugares o búsquedas exitosas. TRATAMIENTO DE ARCHIVOS Comando: cat Formato: cat [opciones] archivo [archivo1]…[archivon] Descripción: Despliega el contenido de un archivo sin paginación y sin formato hacia la pantalla ó consola. Concatena dos o más archivos en uno sólo. Ejemplo: cat numero.c Despliega el contenido del archivo numero.c a la pantalla sin formato y sin pausas ó paginación. Comando : more Formato: more [opciones] archivo Descripción: Se utiliza para paginar texto que no cabe en la pantalla y, por tanto, se desplaza sin poderlo ver. Se utiliza a través de un redireccionamiento o una pipe para formatear el resultado de otro comando. Para salir de more antes de terminar pulse q y para avanzar barra espaciadora. Ejemplos: ls –l | more Lista los archivos del directorio actual y se los pasa al comando more para que lo pagine y lo muestre página a página. more cartas.txt Pagina el contenido de cartas.txt Comando: less Formato: less [-cmsCM] [-xtab] [+comando] [archivo...] Descripción: Al igual que more, less es un programa de paginación. Una de sus principales ventajas es que hace fácil desplazarse hacia atrás o hacia adelante de un archivo.Los datos se despliegan pantalla por pantalla. Con las flechas de dirección regresa o avanza. Ejemplo: less hola.txt Muestra el contenido de hola.txt paginado y con formato. Con la posibilidad de ir hacia delante y hacia atrás del texto. Comando: tail Formato: tail [opciones] archivo Descripción: Muestra las últimas líneas del archivo que se le pasan como parámetro. Por defecto muestra las diez últimas líneas. Ejemplo: tail archivo_largo.txt Muestra las 10 últimas líneas del archivo_largo.txt. Comando: head Formato: head [opciones] archivo

Tecnologías de la Información y Comunicación Sistemas Informáticos 59
Descripción: Muestra las primeras líneas del archivo que se le pasan como parámetro. Por defecto muestra las diez primeras líneas. Ejemplo: head archivo_largo.txt Muestra las 10 primeras líneas del archivo_largo.txt. Comando: grep Formato: grep [opciones] patrón [archivo(s)] Descripción: Permite buscar cadenas de caracteres en los archivos que le indiquemos. grep toma el patrón que deseamos buscar como primer argumento y el resto de los argumentos los toma como nombres de archivos. En caso de que el elemento que deseemos buscar se componga de más de una palabra, ese elemento deberemos incluirlo entre comillas dobles. Una vez buscado el patrón, se visualizan todos los archivos que lo contienen. Ejemplos: grep NULL * En este caso, grep busca el patrón NULL en todos los archivos del directorio actual. Recordemos que el asterisco sustituye a cualquier cadena de caracteres, y en este caso a todos los archivos del directorio en el que estemos situados.
grep –n main /home/chan/spro/*.c En el caso anterior, al colocar la opción –n se visualiza el número de línea del archivo donde
se encuentra el patrón buscado. PERMISOS Y ESPACIO DE DISCO DURO Comando: chgrp Formato: chgrp [opciones] grupo archivos Descripción: Permite el cambio del grupo propietario de un archivo ó directorio. Para cambiar la propiedad de grupo de un archivo o directorio hay que ser el propietario de dicho archivo o ser el usuario root. Ejemplo: chgrp invitados p* Cambia el grupo propietario a invitados de todos los archivos que comiencen por la letra p dentro del directorio actual. Comando: chmod Formato: chmod [opciones] modo archivos Descripción: Permite el cambio de los permisos o modo de los archivos y directorios. Los permisos de un archivo o directorio permiten controlar el acceso a los mismos. Existen tres niveles de permisos, los de propietario, grupo y otros. Así los permisos de propietario afectan al propietario del archivo o directorio, los permisos de grupo afectan al grupo propietario y, por último, otros afectan al resto de usuarios del sistema.
Dentro de cada nivel de permisos existen tres tipos de derechos de lectura r de escritura w y de ejecución x. En archivos, los derechos de lectura y escritura permitirán leer y escribir el archivo respectivamente y el derecho de ejecución ejecutar si se trata de un fichero que contiene código ejecutable. Ejemplo: chmod rwx,r,r archivo.txt Comando: chown Formato: chown [opciones] usuario archivos Descripción: Permite el cambio de usuario propietario de un archivo o directorio. Para cambiar el propietario de un archivo o directorios hay que ser el propietario de dicho archivo o ser el usuario root. Si se cambia la propiedad de un archivo sin ser el root ya no se podrá volver a obtener dicha propiedad, esta acción la tendrá que hacer el nuevo propietario o el root. Ejemplos: chown jdalanis tabla.txt Cambia el propietario de tabla.txt al usuario jdalanis Comando: du Formato: du [opciones] archivos Descripción: Informa sobre la cantidad de espacio que ocupan en disco los archivos y directorios indicados como parámetros. Si no se da ningún parámetro se da la información del directorio actual. Las opciones más utiles son: -k -s
Muestra los tamaños en kilobytes. Muestra el tamaño que ocupa cada subdirectorio en conjunto con la suma de todo lo que ocupa

Tecnologías de la Información y Comunicación Sistemas Informáticos 60
-h
su contenido. Muestra el tamaño que ocupa la partición para que sea entendible para los humanos.
Ejemplos: du –s /var Muestra el tamaño total ocupado por el directorio /var y todo su contenido. Comando: df Descripción: Muestra información acerca de las particiones y el porcentaje que cada partición ocupa sobre el disco duro o unidad. Si por el contrario se introduce un directorio, se mostrarán sólo las estadísticas de la unidad de disco que incluye dicho directorio. Además muestra donde esta montada la partición, cual es su tamaño. Las principales opciones para usar con df son: -h -t -k
Nos enseña el número de bloques ocupados en gigabytes, megabytes o kilobytes ? de forma legible para el ser humano human readable Tipo de unidad (ext2, nfs, etc.). Muestra los resultados en i-bloques para cada sistema de archivos
MONITOREO DE PROCESOS Comando: ps Formato: ps [opciones] Descripción: Informa acerca de los procesos que en ese momento se están ejecutando en el sistema. Si no le pasamos ninguna opción, sólo nos ofrecerá un pequeño informe de los procesos asociados a nuestra terminal. En el sistema BSD, esta orden funciona de forma diferente como lo hace en UNIX System V. Las opciones más comunes para este último son: -e Informa de todos los procesos que hay en el sistema. -f Proporciona una lista completa de cada proceso, incluyendo el identificador de cada uno de ellos
(PID) y el identificador del proceso padre (PPID). -l Da listados largos y completos que contiene muchos detalles de los procesos de los que informa,
incluyendo prioridad, valor nice y tamaño de la memoria. Ejemplo: ps –ef UID PID PPID C STIME TTY TIME COMMAND
Root 0 0 0 12:04:19 ? 0:00 swapper
Root 1 0 0 12:04:19 ? 0:00 /etc/init
Root 2 0 0 12:04:19 ? 0:00 /pagedaemon
Root 4 0 0 12:04:19 ? 0:00 netisr
Root 3332 0 0 12:04:46 ? 0:00 /etc/vtdaemon
Root 3288 1 0 12:04:33 ? 0:00 /etc/rlbdaemon
Chan 4025 1 0 12:23:22 Tyy0 0:02 ksh
Analicemos cada uno de los campos anteriores: UID Nombre del usuario propietario del proceso. PID Identificador del proceso. PPID Identificador del proceso padre. C Índica la cantidad de recursos de CPU que el proceso ha utilizado recientemente. El núcleo
utiliza esta información para calcular la prioridad. Este campo puede ser modificado con la orden nice.
STIME Instante de comienzo del proceso.

Tecnologías de la Información y Comunicación Sistemas Informáticos 61
TTY Terminal asociado al proceso. Es el terminal usado por el proceso para operaciones de lectura y escritura estándar. Algunos procesos no están asociados a ningún terminal, en cuyo caso la columna de TTY de la salida contiene el símbolo de interrogación, ?.
TIME Tiempo de CPU asignado al proceso. COMMAND Nombre del programa que contiene la imagen del proceso. Comando: kill Formato: kill [-señal] PID [PID...] Descripción: La orden kill, como hemos dicho, se utiliza para enviar señales. El que envía la señal debe ser el propietario de los procesos o el administrador del sistema. Por defecto, kill envía la señal número 15 al proceso especificado, con intención de terminar su ejecución. Esta señal número 15 lo máximo que hace es avisar al proceso que termine por si mismo, pero el proceso puede ignorarla. Si queremos eliminar el proceso definitivamente, lo mejor es enviarla la señal número 9, que no se puede ignorar. Ejemplo: Imaginemos que queremos eliminar el proceso tail cuyo PID es el 1809. La forma de hacerlo sería: kill –9 1809 COMANDOS VARIOS Comando: finger Formato: finger [opciones] usuarios Descripción: Este comando se utiliza para obtener información sobre los usuarios del sistema, muestra toda la información referente a un usuario que hay registrada en el sistema. Si solo se invoca el comando sin ninguna opción ni nombre de usuario nos da información referente a los usuarios actualmente conectados al sistema. Podemos pedir información sobre usuarios de otras computadoras conectadas en red poniendo:[email protected]. Ejemplo: finger jdalanis Nos devolverá la información almacenada referente al usuario jdalanis Comando: clear Formato: clear Descripción: Borra la pantalla completamente de la terminal en la que se este trabajando. Comando: man Formato: man [comando] Descripción: Localiza y muestra la(s) página(s) del manual del comando especificado. Ejemplo: man date El manual en línea man contiene páginas del manual para cada comando y otras páginas acerca de las funciones internas que los progrmadores utilizan, formatos para diferentes tipos de sistema de archivo, descripciones de hardware que puede conectarse a su Sistema Operativo. Comando: cal Formato: cal [-j] [-y] [mes] [año] Descripción: Muestra en pantalla el calendario del año indicado, o del mes indicado. Ejemplos: cal Muestra en pantalla el calendario del mes actual. cal 4 1974 Muestra el calendario de abril de 1974. cal 2010 Muestra el calendario del año 2010. Comando: who Formato: who [opciones] [archivo] who am i Descripción: Informa sobre quién está en el sistema. Lista el nombre de conexión, el nombre de la terminal y el momento de conexión para cada usuario conectado al sistema LINUX. También puede escribir who am i y sólo se imprimirá la línea de la terminal en la cual se escribió el comando.

Tecnologías de la Información y Comunicación Sistemas Informáticos 62
Ejemplos: who El comando who se ocupa para saber quien se encuentra en el sistema con la finalidad de: mandar mensajes, conocer la carga del sistema o para verificar la actividad en el sistema antes de su cierre. Comando: passwd Formato: passwd [nombre del usuario] Descripción: Cambia la contraseña del usuario (password), siempre que ya se haya registrado. Una contraseña sólo puede ser cambiada por el propietario de la misma, passwd pedirá que escriba la contraseña actual para probar que aún es la misma persona que cuando se llevo a cabo el registro. Posteriormente el programa. passwd pide la nueva contraseña dos veces para asegurarse de que sea correcta. Si se ha introducido la misma contraseña las dos veces, la orden passwd cambiará la idea de que el sistema tiene la contraseña y regresará luego al shell de la forma usual para aceptar la siguiente orden. Si se comete un error, el programa passwd acabará volviendo al shell para que se pueda intentar de nuevo. Si se cancela la ejecución del comando passwd, acabará dejando la vieja contraseña todavía en activo. Si olvidara la contraseña, no hay manera de recuperarla, ni aún el administrador del sistema puede hacerlo. Puede asignarle una nueva. El administrador del sistema podrá crear una contraseña nula o variar las contraseñas de los distintos usuarios. Comando: shutdown Formato: /sbin/shutdown [-t segundos] [-rkhncf] tiempo [mensaje] Descripción: Termina todos los procesos que se estén ejecutando en el sistema de manera ordenada. Cierra el sistema, parando todas las conexiones y esperando antes de detenerse mientras lanza mensajes de aviso. Cuando se especifica una hora, el cierre se realizará a la hora indicada. Sólo el superusuario o un usuario con autorización pueden ejecutar la orden shutdown. Las opciones son: -r Reinicia después de cerrar. -h Se detiene después de hacer el shutdown. mensaje Envía el mensaje a todos los usuarios. Ejemplos: shutdown –h +10 El sistema se cierra al cabo de 10 minutos. shutdown –r now Cierra el sistema inmediatamente y después lo vuelve a arrancar. shutdown –h +5 “El sistema necesita un descanso” Advierte a los usuarios del cierre del sistema para darles tiempo a terminar lo que estén haciendo. El comando shutdown forma parte del procedimiento de desconexión, que tiene como finalidad mantener la sanidad del sistema cuando se arranque de nuevo. shutdown trata de evitar que los procesos en ejecución no se vean afectados o alterados por la caída o desconexión del sistema Comando: exit Formato: exit Descripción: Indica que se ha terminado la sesión y libera a la terminal para ser utilizada por alguien más o para ingresar con un identificador distinto. La terminación o despedida impide que gente extraña utilice la terminal y el identificador para provocar perjuicios potenciales. REDIRECCIONAMIENTO Y TUBERÍAS
Símbolo Significado <
Se usa para redireccionar la entrada en un comando o programa a fin de que provenga de un archivo y no de la terminal, es decir, en vez de que la entrada provenga del teclado de la terminal, viene de un archivo. Por ejemplo, el siguiente comando envia por correo electrónico el archivo info al usuario jdalanis mail jdalanisu < info En vez de volver a escribir el contenido del archivo info hacia el comando mail, se utiliza
dicho archivo como la entrada (stdin) hacia el comando mail. > Se emplea para redireccionar la salida de un programa hacia un archivo, es decir, en vez
de que la salida vaya a la pantalla de la terminal, se coloca en un archivo. Por ejemplo, el siguiente comando guarda la hora y fecha actuales en el archivo fecha: date > fecha

Tecnologías de la Información y Comunicación Sistemas Informáticos 63
En lugar de que el comando date despliegue la hora y fecha actuales en la pantalla de la terminal las envía al archivo fecha. Linux crea o sobreescribe el archivo a la derecha del símbolo >, por lo que debe tenerse cuidado de no destruir información útil de esta manera.
>> Se usa para añadir información a un archivo existente. Por ejemplo, el siguiente comando agrega la fecha actual a un archivo llamado reporte: date >> reporte
Tuberías
Con frecuencia es necesario utilizar la salida de un proceso como entrada de otro, o dicho de otra manera, un proceso podría generar cierta salida que fuera utilizada por otro. Por ejemplo, en el comando: cat cartas.txt | grep amor el primer proceso, que ejecuta cat, y muestra el archivo cartas.txt. El segundo proceso, que ejecuta grep, selecciona e imprime en la salida estándar todas las líneas que contienen la palabra “amor” desde la salida generada por el primer proceso.
En vez de introducir cada comando por separado y guardar los resultados en archivos intermedios, puede conectar una secuencia de comandos por medio de una tubería . El carácter de tubería de Linux es una barra vertical ( | ).
PROGRAMACIÓN AVANZADA
APLICACIONES EN MODO GRÁFICO EN C# 1. Introducción y fundamentos para el manejo de grá ficos
El sistema operativo Windows proporciona una interface compuesta de muchos controles gráficos que permiten la interacción con el usuario final. Las aplicaciones desarrolladas en la plataforma .NET se consideran también como aplicaciones gráficas. Justificación: Es necesario que se tenga una forma de acceso a los recursos gráficos del sistema operativo, sobre todo cuando la información que va a manejar una aplicación requiere de una representación gráfica personalizada y que va cambiando con respecto al comportamiento de la información. GDI+ • Antes de .NET: Fuerte dependencia entre el lenguaje y el Hardware de generación de gráficos. • La tecnología GDI+ se encarga de proporcionar una programación independiente del dispositivo
físico sobre el que se van a generar los gráficos. • GDI+ divide su campo de trabajo en tres áreas principales.
� Generación de gráficos vectoriales 2D � Manipulación de imágenes en los formatos gráficos más habituales. � Visualización de texto en un amplio abanico de tipos de letra.
Evolución en el desarrollo de gráficos
1.1 Primitivas de Graficación Tres acciones para la creación de un gráfico:
1. Definir un objeto en donde se va a crear la gráfica (como una hoja de papel o lienzo). 2. Establecer el objeto con el cual se va a graficar (como un lápiz o un lapicero)

Tecnologías de la Información y Comunicación Sistemas Informáticos 64
3. Elegir que control va a servir como contenedor de la gráfica, ya que como la programación es independiente al dispositivo, una gráfica ya creada, se puede visualizar en cualquier control de la aplicación.
Instancias de clases que se encuentran dentro del namespace System.Draw 1. El objeto para definir donde se va a realizar la gráfica es una instancia de la clase Graphics, para
definir 2. el lapicero o brocha para pintar se usan instancias de la clase Pen o SolidBrush y para
establecer en que 3. control se va a visualizar el dibujo se puede usar cualquier control que contenga el método
CreateGraphics. Primera primitiva de graficación: Línea
Graphics hoja; Pen pluma = new Pen(Color.MidnightBlue , 2); hoja = panel1.CreateGraphics(); hoja.Clear(Color.Blue); int x1, y1, x2, y2; x1 = panel1.Width / 2; y1 = panel1.Height / 2; x2 = x1; y2 = panel1.Height; hoja.DrawLine(pluma, x1, y1, x2, y2);
1.2 clases y métodos para graficar clase Graphics clase pen clase brush
Métodos más comunes : DrawLine DrawRectangle, DrawEllipse DrawPolygon DrawCurve DrawBezier DrawPie
DrawLine
hoja.DrawLine(pluma, x1, y1, x2, y2); Donde X1,Y1 representan el punto inicial de la línea y X2, Y2 representan el punto final de la línea. Point punto1= new Point() ;
Point punto2= new Point (); punto1.X = panel1.Width / 2; punto1.Y = panel1.Height / 2; punto2.X = punto1.X; punto2.Y = panel1.Height; hoja.DrawLine(pluma, punto1, punto2); Point punto1 = new Point(panel1.Width / 2, panel1.Height / 2); Point punto2 = new Point(punto1.X, panel1.Height); hoja.DrawLine(pluma, punto1, punto2); hoja.DrawLine(pluma, new Point(panel1.Width / 2, panel1.Height / 2), new Point(panel1.Width / 2, panel1.Height));
DRAWRECTANGLE: Este método permite crear un rectángulo en la posición y longitudes indicadas, su sintaxis tiene dos formas que son:
• hoja.DrawRectangle(pluma ,new Rectangle (10,10,20,40)); • hoja.DrawRectangle(pluma,10,10,40,50);

Tecnologías de la Información y Comunicación Sistemas Informáticos 65
La primera hace uso de una instancia de la clase rectangle, que es una clase con los parámetros siguientes:
• Rectangle(X1,Y1, width, height) • Donde X1,Y1 representan su esquina superior izquierda del rectángulo y width su longitud sobre
el eje x a partir de la coordenada X1 y height su longitud sobre el eje y a partir de y1.
DRAWELLIPSE: Una elipse es un ovalo o forma circular, determinada por el rectángulo que la encierra. Las dos dimensiones de este rectángulo son los diámetros de la elipse. La sintaxis de este método tiene dos formas que son:
• hoja.DrawEllipse(pluma,new Rectangle (10,10, 80,90)); • hoja.DrawEllipse(pluma, 10, 10, 90, 90);
DRAWPOLYGON: Este método dibuja un polígono arbitrario, solo sigue el orden de los puntos (point) que se le pasan como argumento y el punto final lo enlaza automáticamente con el punto inicial, para cerrar la figura y dejar el polígono correspondiente. Su sintaxis general es la siguiente:
Graphics.DrawPolygon(pen, points()); Donde points() es un arreglo de instancias de la clase point. Point[] puntos = new Point[] { new Point(230, 190), new Point(125, 60),
new Point(250, 140),new Point(260, 250),new Point(310, 190), new Point(330, 220), new Point(310, 300),new Point(270, 390), new Point(190, 360), new Point(250, 330),new Point(190, 300), new Point(230, 270), new Point(230, 190)};
hoja.DrawPolygon(pluma, puntos); DRAWCURVE: Como su nombre lo indica, este método permite crear curvas a través de una serie de puntos dados. Cada punto que se agregue es por donde va a pasar la curva, por lo tanto entre más puntos se tengan, la curva tendrá mayor resolución y definición. Este tipo de curvas es similar a crear una curva con una cuerda que va a pasar por varios clavos en una pared, como la cuerda es un material no rígido y muy manejable, necesita una determinada tensión para la generación de la curva, si la tensión es muy grande en lugar de una curva parecerá un conjunto de rectas unidas, y si la tensión es mínima la cuerda puede quedar demasiado suelta y hacer más curvas de las esperadas. La sintaxis general de este método es la siguiente:
Graphics.DrawCurve(pen, points, tension) Donde points es un arreglo de instancias point que contiene los “clavos” por donde va a pasar la cuerda y tension es un valor flotante donde 0 representa la mayor tensión. Una curva se define bien con una tensión de 0.5 o 0.8, tensiones mayores a 1 hacen curvas inesperadas. Point[] clavos = new Point[] { new Point(20, 50), new Point(220, 190), new Point(330, 80), new Point(450, 280) }; hoja.DrawCurve(pluma,clavos,0);
DRAWBEZIER: Con este método se puede generar una curva de Bezier, la cual es más suavizada y solo se define a través de cuatro puntos,
– el punto inicial, – el punto de control 1, – el punto de control 2 y – el punto final.
• La curva no pasa a través de los puntos de control, solo sirven para darle una orientación a la curva.
• Semejando con el mundo real, es como si se estuviera creando una curva con un alambre y los puntos de control son dos imanes que marcan el sentido de la misma.
• hoja.DrawBezier(pluma, new Point(120, 150), new Point(200, 90), new Point(330, 30), new Point(410, 110));
DRAWPIE: Este método dibuja un pie, similar a una porción de pastel, es decir, es un arco unido por dos segmentos de línea que se conectan al centro de un círculo, o una elipse.
• Graphics.DrawPie(pen, X, Y, width, height, start, sweep); – Donde X, Y, width y height representan el rectángulo de la elipse,

Tecnologías de la Información y Comunicación Sistemas Informáticos 66
– start es el ángulo donde inicia el pie y – sweep representa el desplazamiento en grados a partir del ángulo inicial.
• hoja.DrawPie(pluma,40,80,70,70,0,90);
1.3 Programación de Aplicaciones
La aplicación de los métodos de graficación va a depender de las necesidades del programador. Uso común: la animación de objetos. Ir dibujando y borrando un mismo elemento gráfico desde distintas posiciones creando un efecto de movimiento.
Ejemplo: Hacer un programa que permita la animación de cinco círculos que comiencen en el centro del área de dibujo y se vayan moviendo en distintas direcciones hasta los límites superiores del área de dibujo. • Diseño del Formulario • Botón que activa la animación y, • Area de dibujo que es un control label con el tamaño suficiente (AutoSize-False) y con su estilo de
bordes definido para visualizar el cuadro correspondiente (BorderStyle-Fixed3D)
Graphics hoja; Pen plu = new Pen(Color.Red, 2); Pen plu2 = new Pen(Color.White, 2); hoja = label1.CreateGraphics(); hoja.Clear(Color.White); int x1, y1, longi; Rectangle cuadrito = new Rectangle (); Rectangle cuad2 = new Rectangle(); Rectangle cuad3 = new Rectangle(); Rectangle cuad4 = new Rectangle(); Rectangle cuad5 = new Rectangle(); x1 = (label1.Width / 2) - 20; y1 = (label1.Height / 2) - 20; longi = 40; cuadrito.X = x1; cuadrito.Y = y1; cuadrito.Width = longi; cuadrito.Height = longi; cuad2 = cuadrito; cuad3 = cuad2; cuad4 = cuad3; cuad5 = cuad4; for (int z=1; z<=y1; z+=4) { hoja.DrawEllipse(plu, cuadrito); hoja.DrawEllipse(plu, cuad2); hoja.DrawEllipse(plu, cuad3); hoja.DrawEllipse(plu, cuad4); hoja.DrawEllipse(plu, cuad5); for (int a = 0; a <= 15000; a++) { for (int b = 0; b <= 1000; b++) { } }

Tecnologías de la Información y Comunicación Sistemas Informáticos 67
hoja.DrawEllipse(plu2, cuadrito); hoja.DrawEllipse(plu2, cuad2); hoja.DrawEllipse(plu2, cuad3); hoja.DrawEllipse(plu2, cuad4); hoja.DrawEllipse(plu2, cuad5); cuadrito.Y -= 4; cuad2.X -= 4; cuad3.X += 4; cuad4.X -= 3; cuad4.Y -= 3; cuad5.X += 3; cuad5.Y -= 3; } hoja.DrawEllipse(plu, cuadrito); hoja.DrawEllipse(plu, cuad2); hoja.DrawEllipse(plu, cuad3); hoja.DrawEllipse(plu, cuad4); hoja.DrawEllipse(plu, cuad5); MANEJO DE ERRORES CON EXCEPCIONES Los errores causados por un programa de computadora pueden ser clasificados dentro de tres grupos principales:
� Tiempo de diseño, � Ejecución, y � lógico.
• El error en tiempo de diseño es el más fácil de encontrar y arreglar. • Un error de este tipo ocurre cuando se escribe código no siguiendo las reglas del lenguaje de
programación. • Son fáciles de encontrar debido a que Visual Estudio .NET no solo indica donde esta, sino que parte
de la línea es incompresible para el lenguaje. • Los errores en tiempo de ejecución son más difíciles de ubicar, debido a que Visual Studio no
proporciona una ayuda para encontrar el error hasta que este ocurre en la ejecución del programa. • Estos errores ocurren cuando un programa intenta alguna cosa ilegal, como acceder a datos que no
existen o recursos para los cuales no se tienen los permisos adecuados. • Este tipo de errores puede causar que el programa se cuelgue a menos que sean manejados
adecuadamente. • El tercer tipo de error, el error lógico, es frecuentemente el más insidioso para ubicar, debido a que
por si mismo puede no manifestarse como un problema en todo el programa. • Un programa con un error lógico simplemente significa que la salida u operación del programa no es
exactamente como se esperaba. • Lo anterior puede ser ocasionado por un cálculo incorrecto o tener una opción de menú habilitada
cuando se quería deshabilitar, etc. • Excepciones integradas • Un error en tiempo de ejecución en C#.NET genera una exception. • Una excepción es una respuesta a una condición de error que el programa ha generado. • El manejo de un error es una sección de código de C#.NET que permite detectar excepciones y
ejecutar los pasos necesarios para recuperar el control después del error. Considere el siguiente bloque de código dentro del evento clic de un botón. private void button1_Click(object sender, EventArgs e) { string cadena = "cochinos"; button1.Text = cadena.Substring (10,1); } El código esta intentando desplegar el onceavo caracter en la cadena “cochinos”. La cadena sólo contiene ochos caracteres y una excepción es generada al momento de ejecutar el evento, como lo muestra la siguiente imagen.

Tecnologías de la Información y Comunicación Sistemas Informáticos 68
• Lo primero que debe notarse es el hecho de que el mensaje ocurre en tiempo de ejecución como un
tipo de excepción no controlada. • Esto significa que la línea de código que ha generado el error no esta contenida dentro de un bloque
de manejo de excepción. • La segunda pieza de información es que la excepción es del tipo ArgumentOutOfRangeException. • Los errores pueden ser clasificados en grupos, en el caso anterior el mensaje indica que el objeto
excepción generado es de dicha clase, la cual es descendiente de la clase Exception. • La información adicional indica algunas notas específicas sobre la naturaleza del error, para el
ejemplo, el índice –startIndex no puede ser mayor que la longitud de la cadena. Estructura de una excepción El siguiente código contiene el mismo problema que en la sección anterior pero contiene una forma simple de atrapar el error que se produce.
private void button1_Click(object sender, EventArgs e) { string cadena = "cochinos"; try { button1.Text = cadena.Substring(10, 1); } catch { button1.Text = "Error"; } } • El código intenta hacer lo mismo que el código anterior, pero esta vez la sentencia de la cadena
“defectuosa” es envuelta entre el bloque try … Catch … • Este bloque representa el manejo básico de una excepción. Si algún código después de la sentencia
Try genera una excepción, el control del programa automáticamente salta al código después de la sentencia Catch.
• Si excepciones no son generadas en el código bajo la sentencia Try, entonces el bloque Catch es pasado por alto.
• Cuando el código es ejecutado, ArgumentOutOfRangeException se genera y el código no termina con un mensaje. En su lugar, la propiedad text del botón establece la palabra “Error”, y el programa continúa con su ejecución.
Una variación en el manejo de excepciones es el siguiente:
private void button1_Click(object sender, EventArgs e) { string cadena = "cochinos"; try { button1.Text = cadena.Substring(10, 1); } catch (Exception oEx)

Tecnologías de la Información y Comunicación Sistemas Informáticos 69
{ button1.Text = oEx.Message; } } • En esta ocasión, la excepción genera una instancia de la clase Exception y localiza dicha instancia
en una variable llamada oEX. • Tener la variable de una instancia de excepción es útil debido a que ofrece el texto del problema, que
es desplegado en un mensaje. • De hecho, desplegar el mensaje de la excepción dentro de una ventana es mucho mejor que hacerlo
durante la ejecución del programa con una excepción no controlada. • Note que el control de la excepción anterior no diferencia entre los diferentes tipos de errores, si
alguna excepción es generada dentro del bloque Try, entonces el bloque Catch es ejecutada. • Es posible escribir un control de excepción que maneje diferentes clases de errores, por ejemplo vea
el siguiente código. private void button2_Click(object sender, EventArgs e) { try { button2.Text = listBox1.SelectedItem.ToString(); } catch (NullReferenceException oEx) { MessageBox.Show("Por favor selecciona un elemento del ListBox"); MessageBox.Show(oEx.Message); } catch (Exception oEx) { MessageBox.Show("Otro error" + oEx.Message); } } • Este código intenta tomar el item seleccionado en un ListBox y lo despliega en el texto de un botón.
Si ningún item es seleccionado en el ListBox, entonces NullReferenceException será generada, y se usa la información para indicarle al usuario que debe hacer una selección de item en el ListBox. Si algún otro tipo de excepción es generada, el código despliega el texto del mensaje de error.
• Observe que, el control de excepción más específico se encuentra primero y el control de excepción más general posteriormente.
• El programador debe tener cuidado en el orden de establecer el control de las excepciones. • Además la variable oEX es reutilizada en cada bloque de excepción. • Lo anterior es posible debido a que la sentencia Catch en realidad sirve como una declaración de la
variable y la variable oEX tiene un alcance local sólo dentro del bloque Catch. • Finalmente, la instancia de la excepción es declarada en cada bloque Catch con alcance también
dentro de su bloque. • Cuando una excepción es generada y manejada por una sentencia Catch, la ejecución del código es
transferida inmediatamente al primer bloque de control de excepción Catch relevante y entonces continua fuera del bloque Try … Catch …
• Algunas veces, puede ser necesario ejecutar algún tipo de limpieza antes de moverse fuera del bloque de control de excepción.
• Considere el siguiente código: private void LeerArchivoTexto(string nombreArchivo) { StreamReader flujoLectura; string linea; Boolean valorB = false; listBox1.Items.Clear(); flujoLectura = new StreamReader(nombreArchivo); try { while (!valorB) { linea = flujoLectura.ReadLine(); if (linea == null) valorB = true;

Tecnologías de la Información y Comunicación Sistemas Informáticos 70
else listBox1.Items.Add(linea); } flujoLectura.Close(); } catch (Exception oEx) { MessageBox.Show(oEx.Message); } } • Este método intenta leer el contenido de un archivo de texto y colocar el resultado dentro de un
ListBox, línea por línea. • Mucho del código de lectura es envuelto dentro de un controlador de excepción genérico. Si alguna
excepción es encontrada en el ciclo principal, entonces la línea flujoLectura.Close( ) dentro del vecindario nunca será ejecutada.
• Lo anterior significa que el flujo del archivo nunca será apropiadamente cerrado, posiblemente conduciendo a una fuga de recurso.
• Afortunadamente, existe un tipo adicional de bloque disponible en el control de una excepción que específicamente permite evitar este tipo de problema.
• Este nuevo bloque es llamado el bloque Finally. El código dentro de un bloque Finally siempre se ejecuta, si alguna excepción es generada o no.
• Considere el siguiente código modificado respecto al anterior: private void LeerArchivoTexto(string nombreArchivo) { StreamReader flujoLectura; string linea; Boolean valorB = false; listBox1.Items.Clear(); flujoLectura = new StreamReader(nombreArchivo); try { while (!valorB) { linea = flujoLectura.ReadLine(); if (linea == null) valorB = true; else listBox1.Items.Add(linea); } } catch (Exception oEx) { MessageBox.Show(oEx.Message); } finally { flujoLectura.Close(); } } • En este caso, si alguna excepción dentro del ciclo de lectura del archivo ocurre será manejada con
una ventana de mensaje, y entonces el objeto StreamReader es cerrado dentro del bloque Finally. • La sentencia de cerrar se ejecuta si el código dentro del bloque Try … Catch se ejecuta o falla. • Esto permite garantizar que ciertos recursos o controles son apropiadamente dispuestos cuando ya
no son necesitados. Tipos de excepciones • Existen cientos de clases de excepción construidas dentro del entorno .NET, la figura siguiente
muestra la ventana de diálogo de excepciones que se encuentra en el menú Depurar.

Tecnologías de la Información y Comunicación Sistemas Informáticos 71
• Buscando en el árbol mostrado por la ventana se pueden encontrar eventualmente todas las clases
que generan excepciones del entorno .NET que pueden ser usadas en las sentencias Catch según el tipo de error que se desea controlar en un orden específico o genérico.
Excepciones personalizadas • Conforme se es más hábil en la escritura de clases, probablemente se encuentre uno con la
necesidad crear excepciones propias. • Imagine escribir el código para una propiedad de cierta clase de tipo entero que tiene un cierto
rango. • Si un desarrollador esta usando la clase e intenta configurar la propiedad a un valor mas allá del
rango, es posible que se quiera informar al desarrollador que ha proporcionado un valor inválido. • La mejor forma para informarle de este problema es enviándole una excepción. • Suponga escribir la clase CtaCredito, para llevar el control de cuentas bancarias. • Se introduce el titular de la cuenta y un importe para el crédito que necesita asignar. • No obstante, dicho crédito no podrá sobrepasar el valor de 2500; así que, para controlar tal
circunstancia, se crea adicionalmente, la clase CreditoException, que heredando de Exception, contendrá información en uno de sus miembros, sobre la excepción producida en cuanto al importe que se intentó asignar a la cuenta.
// esta clase contiene la información sobre un error // producido en un objeto CtaCredito class CreditoException : Exception { private readonly String mDescription; public CreditoException(String lsDescription) { mDescription = lsDescription; } public string Descripsion { get { return mDescription; } } } class CtaCredito { private string mTitular; private readonly double mDisponible; //propiedad Titular public string Titular { get {

Tecnologías de la Información y Comunicación Sistemas Informáticos 72
return mTitular; } set { mTitular = value; } } //propiedad Credito de solo lectura public double Credito { get { return mDisponible; } } /* en este método, si se intenta asignar un importe superior al permitido, se lanza una excepción, utilizando un objeto de la clase CreditoException, heredado de Exception */ public void AsignarCredito(double ldbCredito) { if (ldbCredito > 2500 ) throw new CreditoException("Límite disponible: 2500 - se intento asignar " + Convert .ToString (ldbCredito )); else mDisponible = ldbCredito; } } • El esquema del proceso es el siguiente: cuando al método AsignarCredito( ), de un objeto
CtaCredito, se intente asignar un valor no permitido, se genera un nuevo objeto CreditoException y se lanza a través de la palabra clave throw, que es la encargada de emitir las excepciones en el entorno de ejecución. � El uso de estas clases sería:
� Agregar un botón con el texto: Uso de Exception Personalizada. � Agregar un label con el texto: Mensajes.
Evento clic del botón //crear un objeto de la nueva clase CtaCredito CtaCredito oCredito = new CtaCredito(); try { //asignar valores a propiedades oCredito.Titular = "Nancy lopez"; oCredito.AsignarCredito(1000); //no hay error en la expresion anterior label1.Text = "El crédito actual de: " + oCredito.Titular + " es de: " + Convert.ToString(oCredito.Credito); //la siguiente instruccion produce un error oCredito.AsignarCredito(5000); } catch (CreditoException oExep) { //manipulador para las excepciones producidas sobre un objeto CtaCredito label1.Text = oExep.Descripsion; } finally { MessageBox.Show("El controlador de errores ha finalizado"); }

Tecnologías de la Información y Comunicación Sistemas Informáticos 73
ESTRUCTURA DE DATOS Aplicará las clases de la biblioteca estándar STL del lenguaje C++ y será capaz de manejar las estructuras de datos dinámicas para la elaboración de programas, utilizando la Programación Orientada a Objetos. INTRODUCCIÓN A LA ORIENTACIÓN A OBJETOS Y A LOS TIP OS DE DATOS ABSTRACTOS (TDA) Las Técnicas Orientadas a Objetos (TOO) brindan la posibilidad de construir objetos complejos a partir de objetos existentes, lo que permite un alto grado de reutilización, ahorro de tiempo y dinero y confiabilidad. Además, ofrecen soporte para encapsular datos y comportamiento, estructurar los objetos en clases y organizar las clases en jerarquías, permitiendo compartir comportamiento a través de la herencia.
El concepto orientado a objetos se puede definir de la siguiente manera:
Orientación a Objetos (OO) = Objetos + Clasificació n + Herencia + Comunicación Las ventajas que ofrece la tecnología orientada a objetos son: Encapsulado u ocultamiento de información , Reutilización, Estabilidad, Consistencia.
Una clase es la implementación de un tipo de objeto. Especifica las estructuras de datos y los métodos operativos permisibles que se aplican a cada uno de sus objetos. Una clase puede tener muchas subclases.
Por ejemplo, los atributos de un estudiante son, entre otros, registro o matrícula, nombre, dirección y teléfono, todos de tipo cadena (string). Algunas de las operaciones que pueden implementarse mediante la creación de la clase Estudiante se presentan a continuación.

Tecnologías de la Información y Comunicación Sistemas Informáticos 74
Nombre del método Operación o función que realiza el método estEstudiante Establece las propiedades del estudiante a un estado consistente a
partir de los datos o cadenas de entrada registro, nombre, dirección y teléfono proporcionados como argumentos durante el llamado a este método.
obtRegistro Lee y devuelve el registro del estudiante. obtNombre Lee y devuelve el nombre del estudiante. obtDirección Lee y regresa la dirección del estudiante. Veamos otro ejemplo, un rectángulo se caracteriza por tener sus lados opuestos paralelos dos a dos. Si se considera la construcción de la clase Rectángulo , ésta tiene los atributos base y altura, cuyos valores predeterminados son 1. Tiene métodos que implementan las operaciones que calculan y devuelven el perímetro y el área del rectángulo, además de las operaciones que establecen y obtienen los valores de la base y la altura. Los métodos que establecen las propiedades del rectángulo verifican que la base y la altura sean números reales mayores que 0.0 y menores que 20.0.
A continuación se menciona como se podrían utilizar la herencia y el polimorfismo para crear una clase base abstracta llamada Paralelogramo y derivar a partir de ésta las subclases Rectángulo y Cuadrado . Un Rectángulo es un Paralelogramo porque sus lados opuestos son paralelos dos a dos; es decir, el concepto de paralelogramo se aplica al objeto rectángulo y por lo tanto éste se clasifica como miembro o instancia de la clase Paralelogramo . Los cuadrados, romboides y rombos también son clasificados como paralelogramos. Todos, Rectángulos , Cuadrados , Romboides y Rombos , son instancias de la clase Paralelogramo porque tienen la propiedad de que sus lados opuestos son paralelos dos a dos. Sin embargo, debe observarse que los rectángulos, cuadrados, romboides y rombos tienen, a su vez, atributos y comportamientos propios (los rectángulos tienen los cuatro ángulos iguales y los lados contiguos desiguales, los cuadrados tienen los cuatro ángulos iguales y los cuatro lados iguales, los romboides tienen los lados y los ángulos contiguos desiguales, y los rombos tienen los cuatro lados iguales y los ángulos contiguos desiguales), por lo que éstos pueden ser definidos como subclases de la clase paralelogramo. Cada una de estas subclases tendrá sus estructuras de datos y métodos propios, además de los que herede de su clase padre.
La herencia en una forma de reutilización del software en la que se crean clases nuevas a partir de clases ya existentes por medio de la absorción se sus atributos y comportamientos, sobreponiéndolos o mejorándolos con capacidades que las clases nuevas requieran. Mediante la herencia se logra compartir el comportamiento y los atributos de las clases de objetos definidas previamente con extensiones de clases de objetos que reciben el nombre de subclases. Se dice que las subclases heredan las estructuras de datos y las operaciones de la clase de objetos a partir de la cual se derivan.
El hecho de que un tipo de objeto de alto nivel pueda especializarse en tipos de objeto de bajo nivel, permite la creación de una jerarquía de clases, subclases, sub-subclases, etc. Una clase permite la implementación de un tipo de objeto. Una subclase hereda propiedades de su clase padre, una sub-subclase hereda propiedades de las subclases, etc. Una subclase puede heredar las estructuras de datos y los métodos de su superclase; también puede tener sus propios métodos e incluso tipos de datos propios.

Tecnologías de la Información y Comunicación Sistemas Informáticos 75
De manera más específica se tienen las siguientes definiciones. Una subclase es una clase que hereda las propiedades y los métodos de una clase existente. Una superclase es una clase de la cual otra clase hereda propiedades y métodos. Herencia simple es cuando una clase se deriva de una superclase. Herencia múltiple es cuando una clase se deriva de más de una superclase. El polimorfismo se define como la habilidad de los objetos de diferentes clases, que están relacionados mediante la herencia, para responder en forma diferente al mismo mensaje; es decir, al llamado o solicitud de una operación implementada por un método de manera diferente para cada tipo de objeto. Aún así, aunque los métodos sean distintos, llevan a cabo el mismo propósito operativo. La palabra polimorfismo se aplica a una operación que adopta varias formas de implementación. La herencia y el polimorfismo, dan la posibilidad de que una clase pase por alto el comportamiento heredado de un tipo a un subtipo, al permitir la redefinición del método de una operación heredada en el subtipo. Por ejemplo, si las clases Rectángulo , Cuadrado , Romboide y Rombo se derivan de la clase base Paralelogramo (cuadrilátero o polígono de cuatro lados con los lados opuestos paralelos dos a dos), entonces cada instancia de las clases derivadas también son instancias de la clase base y por lo tanto no tendrían que repetir el comportamiento heredado de Paralelogramo . Si dentro de las estructuras de datos de la clase Paralelogramo se define un arreglo de cuatro puntos para almacenar las coordenadas de los vértices del paralelogramo y la operación exhibir se implementa mediante un método que conecte los cuatro vértices del paralelogramo y lo muestre en pantalla, entonces dicha operación también se aplicaría a los rectángulos, cuadrados, romboides y rombos; es decir, las clases Rectángulo , Cuadrado , Romboide y Rombo heredan la operación exhibir de la clase Paralelogramo y no tienen que repetirla o redefinirla. Sin embargo, aunque todas las operaciones de Paralelogramo se aplican a sus subclases, el método operativo puede ser diferente; por ejemplo, el método para calcular el perímetro de un paralelogramo, un romboide o un rectángulo podría definirse como dos veces la suma de la longitud de sus lados adyacentes, pero el método para calcular el perímetro de un cuadrado o un rombo podría definirse como cuatro veces la longitud de cualquiera de sus lados. En este caso es necesario redefinir la operación que calcula el perímetro en las subclases Cuadrado y Rombo . DEFINICIÓN DE ESTRUCTURA DE DATOS Las estructuras de datos, también conocidas como tipos de datos, establecen una relación entre las distintas formas de representación de los datos, que se caracterizan por su organización y por las operaciones que se pueden realizar con ellas. Las estructuras de datos dictan la organización, los métodos de acceso y las alternativas de procesamiento para la información. Debido a que la estructura de la información afectará el diseño de los programas, las estructuras de datos juegan un papel muy importante. La organización y complejidad de las estructuras de datos tan sólo está limitada por el ingenio del diseñador; sin embargo, hay un número reducido de estructuras de datos clásicas (elemento escalar, arreglos, listas, pilas, colas y árboles), que constituyen los bloques con los que se construyen estructuras más sofisticadas. Es importante tener en cuenta que las estructuras de datos se pueden representar a diferentes niveles de abstracción. Por ejemplo, una pila es un modelo conceptual de una estructura de datos, que puede implementarse como un arreglo (vector secuencial) o como una lista ligada. TIPOS DE DATOS ABSTRACTOS (TDA) Un TDA es un tipo de dato definido por el programador (por ejemplo, una clase) que se puede manipular de un modo similar a los tipos de datos definidos por el sistema. Está formado por un conjunto válido de elementos y un número de operaciones primitivas que se pueden realizar sobre ellos. Ejemplo: Definición del tipo (representación):
Numero racional: Conjunto de pares de elementos (a, b) de tipo entero, con b<>0.
Operaciones (interfaz de uso):
• CrearRacional: a, b = (a,b) • Suma: (a,b) + (c,d) = (a*d+b*c , b*d) • Resta: (a,b) - (c,d) = (a*d-b*c , b*d) • Producto: (a,b) * (c,d) = (a*c , b*d)

Tecnologías de la Información y Comunicación Sistemas Informáticos 76
• División: (a,b) / (c,d) = (a*d , b*c) • Numerador: (a,b) = a • Denominador: (a,b) = b • ValorReal: (a,b) = a/b • MCD: (a,b) ... • Potencia: (a,b)^c = (a^c , b^c) • Simplifica: (a,b) = ( a/mcd(a,b) , b/mcd(a,b) )
Una vez definido el TDA (o clase) se podrán declarar variables (objetos o instancias) de ese tipo para utilizar (llamar o invocar) los métodos (operaciones) que aporta la clase. Ejemplo: TRacional r1,r2, rsuma; // declara tres objetos de tipo TRacional r1.CrearRacional(4,7); // llama al método CrearRacional del objeto r1 r2.CrearRacional(5,8); // llama al método CrearRacional del objeto r2 // el valor devuelto por el método Suma del objeto r1 lo asigna al objeto rsuma rsuma = r1.Suma(r1, r2); printf(“El valor real es %f”, rsuma.ValorReal() ); // imprime el valor real del objeto rsuma LA BIBLIOTECA STL (Standard Template Library – Bibl ioteca estándar de plantillas) La STL está formada por contenedores (estructuras de datos comunes organizadas como plantillas), iteradores y algoritmos. Es decir, la STL es una biblioteca estándar de contenedores de objetos organizados en platillas. Su uso puede ahorrar considerable tiempo y esfuerzo, y da como resultado programas de más alta calidad. Las clases de contendores de la STL más importantes son:
1. vector : Para inserciones y eliminaciones rápidas al final. Permite el acceso directo a cualquier elemento. Archivo de encabezado <vector> .
2. list : Lista de enlace doble que permite la inserción y eliminación rápidas en cualquier lugar. Archivo de encabezado <list> .
3. stack : LIFO (Last In First Out – ultimo en entrar, primero en salir). Archivo de encabezado <stack> .
4. queue : FIFO (First In First Out – primero en entrar, primero en salir). Archivo de encabezado <queue> .
Nota: El contenido de todos los archivos de encabezado está en namespace std . La STL fue diseñada a fin de que los contenedores proporcionen funcionalidad similar, por lo que hay muchas operaciones genéricas, tales como la función size , que se aplican a todos los contenedores, y otras que sólo se aplican a subconjuntos de contenedores similares. Las funciones más comunes para todos los contenedores de la STL son:
1. constructor predeterminado : Proporciona una inicialización predeterminada del contenedor. Cada contenedor puede tener varios constructores que proporcionan una variedad de métodos de inicialización para dicho contenedor.
2. constructor de copia : Inicializa al contenedor para que sea una copia de un contenedor existente del mismo tipo.
3. destructor : Destruye un contenedor cuando ya no es necesario. 4. empty : Devuelve trae si no hay elementos en el contenedor y false en caso contrario. 5. max_size : Devuelve la cantidad máxima de elementos de un contenedor. 6. size : Devuelve la cantidad de elementos que hay actualmente en el contenedor. 7. operator= : Asigna un contenedor a otro. 8. operator< : Devuelve true si el primer contenedor es menor que el segundo y false en caso
contrario. 9. operator<= : Devuelve true si el primer contenedor es menor o igual que el segundo y false en
caso contrario. 10. operator> : Devuelve true si el primer contenedor es mayor que el segundo y false en caso
contrario.

Tecnologías de la Información y Comunicación Sistemas Informáticos 77
11. operator>= : Devuelve true si el primer contenedor es mayor o igual que el segundo y false en caso contrario.
12. operator== : Devuelve true si el primer contenedor es igual al segundo y false en caso contrario. 13. operator !=: Devuelve true si el primer contenedor no es igual que el segundo y false en caso
contrario. 14. swap : Intercambia los elementos de dos contenedores.
ITERADORES Los iteradotes se utilizan para apuntar hacia los elementos de contenedores. Éstos guardan información de estado que es sensible a los contenedores particulares sobre los que operan y, por lo tanto, dichos iteradotes están implementados en forma adecuada para cada tipo de contenedor. Sin embargo, algunas operaciones de los iteradotes son uniformes entre los contenedores. Por ejemplo, el operador * desreferencia a un iterador para que se pueda utilizar el elemento hacia el que apunta. La operación ++ sobre un iterador devuelve un iterador al siguiente elemento del contenedor (en forma muy similar a como el incremento de un apuntador a un arreglo coloca al apuntador en el siguiente elemento de dicho arreglo). Si el iterador i apunta a un elemento en particular, ++i apunta al siguiente elemento y *i hace referencia al elemento al que apunta i. Se usa un objeto de tipo iterator para referirse a un elemento de contenedor que puede modificarse. Se usa un objeto de tipo const_iterator para referirnos a un elemento de contendor que no puede modificarse. ARREGLOS: CONTENEDOR vector La clase vector proporciona una estructura de datos con localidades de memoria contiguas, lo que permite un acceso directo y eficiente a cualquier elemento de un vector por medio del operador de subíndice [ ] , exactamente como se hace con un arreglo de C o C++. Un objeto de tipo vector puede cambiar su tamaño dinámicamente y soporta iteradores de acceso aleatorio. En el siguiente programa de ejemplo se usan varios métodos de la clase vector . #include "stdafx.h" #include <iostream> #include <vector> using namespace std; // Requerido int _tmain(int argc, _TCHAR* argv[]) { const int TAM = 6; // definición del arreglo a de 6 enteros al estilo C o C++ int a[TAM] = {1, 2, 3, 4, 5, 6}; // Declaración de un objeto v de tipo vector (uso de STL) que // almacena valores de tipo entero, cuya capacidad y tamaño son 0. vector<int> v; // Asigna en la variable tamv es valor devuelto por el método size() // del objeto v, dicho valor es el número de elementos que están // actualmente almacenados en el contenedor. int tamv = v.size(); cout << "El tamaño inicial de v es: " << tamv << endl; // Asigna en la variable capv el valor devuelto po el método // capacity() del objeto v, dicho valor es el número de elementos // que se pueden almacenar en el vector v antes de que éste reajuste // dinámicamente su tamaño para acomodar elementos. int capv = v.capacity(); cout << "La capacidad inicial de v es: " << capv << endl; // Agrega los enteros del 0 al 9 al final del vector v for(int i=0; i<10; i++){ v.push_back(i); // agrega el entero i al final del vector v // Nota: El método push_back del objeto v agrega un elemento

Tecnologías de la Información y Comunicación Sistemas Informáticos 78
// al final del vector v. Si se agrega un elemento a un vector // lleno, éste incrementa su tamaño automáticamente. } // Mostrar el nuevo tamaño y capacidad del vector v después de // ejecutar push_back. cout << "El tamaño de v es: " << v.size() << endl; cout << "La capacidad de v es: " << v.capacity() << endl; cout << "\nContenido del arreglo a utilizando la notación de apuntador:" << endl; for(int *ptr = a; ptr!=a+TAM; ++ptr){ cout << *ptr << ' ' << endl; } cout << "\n Contenido del arreglo o vector v utilizando la notación de iterador:" << endl; // Declaración de un iterador constante llamado p para iterar a // través del vector v. vector<int>::const_iterator p; // El método begin() del objeto v devuelve un iterador constante al // primer elemento del objeto v. El ciclo continúa mientras p no pase // del final del vector v, lo cual se determina comparando a p con el // resultado de v.end(), que devuelve un iterador constante el cual // indica la localidad que está después del último elemento del vector v. // La expresión p++ coloca al iterador en el siguiente elemento de // dicho objeto. for(p=v.begin(); p!=v.end(); p++){ cout << *p << ' ' << endl; } // Probar algunos métodos de la clase vector: // v.front() - Devuelve el primer elemento del vector v // v.back() - Devuelve el último elemento del vector v cout << "Primer elemento de v: " << v.front() << endl; cout << "Último elemento de v: " << v.back() << endl; // Establece a 7 el primer elemento v[0] = 7; // Establece a 10 el elemento que está en la localidad 2 del vector v v.at(2) = 10; // inserta 22 como segundo elemento del vector v v.insert(v.begin() + 1, 22); // elimina el primer elemento del vector v v.erase(v.begin()); // borra todos los elementos del vector v v.erase(v.begin(), v.end()); // clear llama a erase para vaciar el vector v v.clear(); getchar(); return 0; } LISTAS: CONTENEDOR list Una lista es una estructura de datos que representa una colección homogénea y dinámica de elementos con una relación lineal entre ellos. Es decir, cada elemento de la lista (excepto el primero) tiene un único elemento predecesor y cada elemento (excepto el último) tienen un elemento sucesor. La representación escogida dependerá de la utilización que se le vaya a dar al tipo. Lo normal es implementarlas como listas de elementos enlazados mediante apuntadores. Los elementos serán objetos con uno o varios campos de datos y un campo de tipo puntero que hará referencia al siguiente elemento.

Tecnologías de la Información y Comunicación Sistemas Informáticos 79
El contenedor list proporciona una implementación eficiente para las operaciones de inserción y eliminación en cualquier localidad del contenedor. La clase list está implementada como una lista de enlace doble, es decir, cada nodo de un objeto list contiene un apuntador al nodo anterior de dicho objeto y otro al hacia el siguiente nodo del mismo, lo que permite que la clase list soporte iteradotes bidireccionales que permiten que el contenedor sea recorrido tanto hacia delante como hacia atrás. Muchas de las funciones miembro de la clase list manipulan los elementos del contenedor como un conjunto de elementos ordenados. En el siguiente programa de ejemplo se usan los métodos más usuales de la clase list . #include "stdafx.h" #include <iostream> #include <list> using namespace std; int _tmain(int argc, _TCHAR* argv[]) { // Crea un objeto llamado lista de tipo list que puede // almacenar valores de tipo entero. list<int> lista; // Declaración de un iterador constante llamado p para // iterar a través de la lista de enteros. list<int>::const_iterator p; int i; // Agrega a la lista de enteros los valores: 1, 2, 3 y 4. // Después del ciclo la lista de enteros contendrá: // 4, 3, 2 y 1, dado que cada elemento insertado se // agrega al inicio de la lista. for(i=1; i<5; i++){ // El método push_front(i) agrega el valor de i al // inicio de la lista de enteros. lista.push_front(i); } // Agrega a la lista de enteros los valores: 5, 6, 7, 8 // y 9. Después del ciclo la lista de enteros contendrá: // 4, 3, 2, 1, 5, 6, 7, 8 y 9 dado que cada elemento // insertado se agrega al final de la lista. for(i=5; i<10; i++){ // El método push_back(i) agrega el valor de i al // final de la lista de enteros. lista.push_back(i); } // El método empty() devuelve true si la lista está // vacía y false en caso contrario. bool vacia = lista.empty(); if(vacia){ // si la lista está vacía cout << "La lista está vacía."; } else{ // de lo contrario (si la lista no está vacía) lista.sort(); // ordena los elementos de la lista // Después de ejecutar el método sort() la lista // contiene: 1, 2, 3, 4, 5, 6, 7, 8 y 9. // Elimina el elemento del inicio de la lista. lista.pop_front(); // En este punto la lista contiene: 2,3,4,5,6,7,8 y 9 // Elimina el elemento del final de la lista. lista.pop_back(); // En este punto la lista contiene: 2,3,4,5,6,7 y 8

Tecnologías de la Información y Comunicación Sistemas Informáticos 80
// El método begin() del objeto lista devuelve un iterador // constante al primer elemento del objeto lista. El ciclo // continúa mientras p no pase del último nodo de la lista, // lo cual se determina comparando a p con el resultado // de lista.end(), que devuelve un iterador constante que // indica la localidad que está después del último elemento // de la lista. La expresión p++ coloca al iterador en el // siguiente elemento de dicho objeto. for(p=lista.begin(); p!=lista.end(); p++){ cout << *p << ' '; } // Al finalizar el ciclo, los elementos de la lista // impresos son: // 2 3 4 5 6 7 8 } getchar(); return 0; } PILAS: ADAPTADOR DE CONTENEDOR stack Una pila es una estructura de datos LIFO (Last In, First Out – último en entrar, primer en salir) que permite almacenar una colección lineal, dinámica y homogénea de elementos, en la que los elementos de insertan y se extraen por el mismo extremo.
Nota : Un adaptador de contenedor no soporta iteradotes. El beneficio de una clase de adaptador es que el programador pueda elegir una estructura de datos subyacente adecuada. Las clases de adaptador proporcionan funciones miembro push y pop que implementan los métodos adecuados de insertar y eliminar un elemento de cada estructura de datos de adaptador. La clase stack (pila) proporciona la funcionalidad que permite inserciones y eliminaciones de un extremo de la estructura de datos subyacente del tipo LIFO. Un objeto stack puede implementarse con cualquier contenedor se secuencia: vector , list y deque . En el ejemplo que se presenta a continuación se crean dos pilas de enteros utilizando los contenedores vector y list . #include "stdafx.h" #include <iostream> #include <stack> #include <vector> #include <list> using namespace std; int _tmain(int argc, _TCHAR* argv[]) { // pilaVector es un objeto de tipo stack de enteros que utiliza // un objeto de tipo vector de enteros como estructura de datos // subyacente. stack<int, vector<int>> pilaVector; // pilaLista es un objeto de tipo stack de enteros que utiliza // un objeto de tipo list de enteros como estructura de datos // subyacente. stack<int, list<int>> pilaLista; // Coloca 10 enteros en el stack pilaVector y

Tecnologías de la Información y Comunicación Sistemas Informáticos 81
// 10 enteros en el stack pilaLista. for(int i=0; i<10; i++){ // Coloca el entero i en la parte superior de las pilas // pilaVector y pilaLista. pilaVector.push(i); pilaLista.push(i); } // Asigna a la variable entera tampila el valor devuelto por el // método size del stack pilaVector. El método size() devuelve // el número de elementos que se encuentran en la pila. int tampila = pilaVector.size(); cout << "El número de elementos de la pilaVector es: " << tampila << endl; // Asigna a la variable entera tampila el valor devuelto por el // método size del stack pilaLista. El método size() devuelve // el número de elementos que se encuentran en la pila. tampila = pilaLista.size(); cout << "El número de elementos de la pilaLista es: " << tampila << endl; // Mientras el stack pilaVector no se encuentre vacía: // a) imprimir el elemento que se encuentra en la parte superior // del stack pilaVector. // b) eliminar el elemento superior del stack pilaVector. while(!pilaVector.empty()){ cout << pilaVector.top() << ' '; pilaVector.pop(); } getchar(); return 0; } COLAS: ADAPTADOR DE CONTENEDOR queue La clase queue (cola) proporciona funcionalidad que permite inserciones al final de la estructura de datos subyacente y eliminaciones al inicio de ésta, por eso a este tipo de estructura se le conoce como FIFO (First In, First Out – primero en entrar, primero en salir). Un objeto tipo queue se puede implementar con las estructuras de datos de la STL list y deque . En el ejemplo que se presenta a continuación se crea una cola de número reales utilizando el contenedor list . #include "stdafx.h" #include <iostream> #include <queue> #include <list> using namespace std; int _tmain(int argc, _TCHAR* argv[]) { // cola es un objeto de tipo queue de número reales que utiliza // un objeto de tipo list de número reales como estructura de datos // subyacente. queue<double, list<double>> cola; // Agrega 10 enteros en la cola. for(int i=0; i<10; i++) { // Coloca el entero i al final de la cola. cola.push(i); } // Asigna a la variable entera tamcola el valor devuelto por el // método size de la cola. El método size() devuelve el número // de elementos que se encuentran en la cola. int tamcola = cola.size(); cout << "El número de elementos de la cola es: " << tamcola << endl; // El método front del objeto cola devuelve el elemento // que se encuantra al inicio de la cola.

Tecnologías de la Información y Comunicación Sistemas Informáticos 82
cout << "El elemento del frente de la cola es " << cola.front() << endl; // Mientras la cola no se encuentre vacía: // a) imprimir el elemento que se encuentra al inicio de la cola. // b) eliminar el elemento que se encuentra al inicio de la cola. while(!cola.empty()) { cout << cola.front() << ' '; cola.pop(); } getchar(); return 0; } ÁRBOLES Un árbol es una estructura de datos no lineal que establece una estructura jerárquica entre los objetos. Los árboles genealógicos y los organigramas son ejemplos comunes de árboles. Un árbol es una colección de elementos llamados NODOS, uno de los cuales se distingue del resto y se le llama la RAÍZ, junto con una relación que impone una estructura jerárquica entre los nodos.
Ejemplo de un árbol.
A
B C D
HG IFE
Raíz
Hojas
Los términos más importantes de un árbol son:
• Grado de un nodo : es el número de subárboles que tienen como raíz ese nodo (nodos que cuelgan del nodo).
• Nodo terminal u hoja : nodo con grado 0. No tiene subárboles. • Grado de un árbol : grado máximo de los nodos de un árbol. • Hijos de un nodo : nodos que dependen directamente de ese nodo, es decir, las raíces de sus
subárboles. • Padre de un nodo : antecesor directo de un nodo del cual depende directamente.
• Nodos hermanos : nodos hijos del mismo nodo padre. • Camino : sucesión de nodos del árbol: n(1), n(2), .. n(k), tal que n(i) es el padre de n(i+1). • Antecesores de un nodo : todos los nodos en el camino desde la raíz del árbol hasta ese nodo. • Nivel de un nodo : longitud del camino desde la raíz hasta el nodo. El nodo raíz tiene nivel 1. • Altura o profundidad de un árbol : nivel máximo de un nodo en un árbol

Tecnologías de la Información y Comunicación Sistemas Informáticos 83
Ejemplo de un árbol binario.
• En general en el lado izquierdo van los subárboles menores al nodo actual y en la rama derecha van los subárboles mayores.
4
2 6
531 7
Se debe de definir la forma en como se pueden recorrer todos los nodos de un determinado árbol, en general existen tres formas de recorrer un árbol que son: 1)Prefijo, 2)Infijo, 3)Posfijo Que obedecen a las reglas:
1) nodo – subárbol izq. – subárbol der. 2) subárbol izq. – nodo – subárbol der.
3) subárbol izq. – subárbol der. – nodo
ADMINISTRACIÓN DE LA FUNCIÓN INFORMÁTICA Administración : proceso de crear, diseñar y mantener un ambiente en el que las personas al laborar o trabajar en grupos, alcancen con eficiencia metas seleccionadas. Proceso administrativo: el proceso metodológico que implica una serie de actividades que llevará a una mejor consecución de los objetivos, en un periodo más corto y con una mayor productividad. Elementos del proceso administrativo: Planeación. Determinación racional de adónde queremos ir y cómo llegar allá Niveles de planeación de un centro de cómputo Planeación de recursos: Instalaciones acorde a las necesidades informáticas, equipo de cómputo y materiales de producción. Planeación operativa. Análisis de necesidades para definir una plataforma tecnológica con una infraestructura en hardware, software, personal operativo etc. Planeación de instalación física y ubicación física . Los factores que como mínimo hay que cubrir son: Espacio físico, movilidad de equipos, iluminación, tratamiento acústico, seguridad física del local y suministro eléctrico.
Criterios para seleccionar software : � Verificar el tipo de Software de programa, existen dos niveles: básico. Sistema Operativo y soporte:
Base de datos � Proveedor. Debe cubrir ciertos requisitos: prestigio, soporte técnico, personal especializado,
comunicación rápida, capacitación, cartera de clientes de software iguales al adquirido. � Costos: Se considerarán condición de pago, local, inclusión de entrenamiento, costos de
mantenimiento.
Criterios para seleccionar Hardware � Equipos: La configuración de acuerdo a la carga de trabajo, crecimiento vertical y horizontal,
garantía, tecnología de punta.

Tecnologías de la Información y Comunicación Sistemas Informáticos 84
� Proveedor. prestigio, soporte técnico, personal especializado, comunicación rápida, capacitación, cartera de clientes de software iguales al adquirido
� Precios: Condiciones de pago, descuentos, costos de mantenimiento
Proceso general para la Adquisición de Software y Hardware.
� Solicitud de propuesta. Partiendo de los objetivos establecidos en la etapa de planeación � Evaluación de propuesta. Verificar operatividad � Financiamiento. Ver fuentes de financiamiento � Negociación de Contrato. Por escrito e incluir todos los aspectos de hardware y software
Principales problemas de un centro de cómputo
Hardware
� Defectos de fabricación y ó daños físicos que puedan tener durante su transporte. � Que el manual de uso este en otro idioma ajeno al que manejamos � las piezas que pudiera ser dañadas no son muy comunes y por tanto difíciles de conseguir. � Cuando se trabaja con conexión a red, es muy común que por falta de conocimiento den órdenes
que la puedan bloquear o provocar que esta se caiga. � Que las impresoras deben recibir trato especial por que la configuración de estas es muy especifica.
Software � Los archivos necesarios para su instalación no están contenidos en el CD de instalación. � El ambiente en que se desarrolla no es compatible con el sistema operativo que esta siendo usado
por el PC. � El idioma, no siempre esta en el que nosotros hablamos y por tanto nos es difícil su manejo. � Algunas ordenes, comandos ú operaciones son muy complejos y puede producir que al darlas de
manera equivoca bloquee el equipo. �
Sistemas y empresas con mayor riesgo En sistemas donde se manejan nominas o control de valores, se pueden realizar transacciones fraudulentas de dinero y sacarlo de la empresa. Los sistemas mecanizados son susceptibles de pérdidas o fraudes debido a que: • Manejan grandes volúmenes de datos e interviene poco personal, lo que impide verificar todas las
partidas. • En los registros magnéticos transitorios menos que se realicen pruebas dentro de un período de
tiempo corto, podrían perderse los detalles de lo que sucedió, quedando sólo los efectos. • Los sistemas son impersonales, aparecen en un formato ilegible y están controlados parcialmente por
personas cuya principal preocupación son los aspectos técnicos del equipo y del sistema y que no comprenden, o no les afecta, el significado de los datos que manipulan.
• En el diseño de un sistema importante es difícil asegurar que se han previsto todas las situaciones posibles y es probable que en las previsiones que se hayan hecho queden <<agujeros>> sin cubrir.
• Cuando existe personal muy inteligente, que trabaja por iniciativa propia la mayoría del tiempo, resultar difícil implantar unos niveles normales de control y supervisión.
• El error y el fraude son difíciles de equiparar. A menudo, los errores no son iguales al fraude. Se tiende a empezar buscando errores de programación y del sistema. Si falla esta operación, se buscan fallos técnicos y operativos. Sólo cuando todas estas averiguaciones han dado resultados negativos, acaba pensándose en que la causa podría ser un fraude.
Tipificación de los delitos informáticos, Clasifica ción Según la Actividad Informática
• Conductas dirigidas a causar daños físicos: Destrucción «física» del hardware y el software de un sistema. Estas conductas pueden ser analizadas jurídicamente
• Copia ilegal de software y espionaje informático: Obtener datos en forma ilegítima o sustracción del sistema si tiene valor comercial.
• Infracción de los derechos de autor: conductas que supongan la copia o el plagio de las obras protegidas, donde concurran dos circunstancias: el ánimo de lucro y el perjuicio de tercero

Tecnologías de la Información y Comunicación Sistemas Informáticos 85
• Infracción del Copyright de bases de datos: No existe una protección uniforme de las bases de datos en los países que tienen acceso a Internet. En general se protegen los datos pero no el sistema
• Uso ilegítimo de sistemas informáticos ajenos: Empleados utilizan los sistemas de las empresas para fines privados.
• Delitos informáticos contra la privacidad: Utilización indebida o modificación de datos personales de registro público o privado
• Pornografía infantil. Utilización de sistemas informáticos para su distribución Clasificación Según el Instrumento, Medio o Fin u O bjetivo Como instrumento o medio :
• Falsificación de documentos vía computarizada (tarjetas de crédito, cheques, etc.) • Variación de los activos y pasivos en la situación contable de las empresas. • Lectura, sustracción o copiado de información confidencial. • Modificación de datos de entrada y salida • Aprovechamiento indebido o violación de un código para penetrar a un sistema introduciendo
instrucciones inapropiadas. • Variación en cuanto al destino de pequeñas cantidades de dinero hacia una cuenta bancaria apócrifa. • Uso no autorizado de programas de cómputo. • Introducción de instrucciones que provocan «interrupciones » en la lógica interna de los programas. • Alteración en el funcionamiento de los sistemas, a través de los virus informáticos. • Obtención de información residual impresa en papel luego de la ejecución de trabajos. • Acceso a áreas informatizadas en forma no autorizada. • Intervención en las líneas de comunicación de datos o teleproceso.
Como fin u objetivo . Conductas criminales que van dirigidas contra las computadoras, accesorios o programas como entidad física:
• Programación de instrucciones que producen un bloqueo total al sistema. • Destrucción de programas por cualquier método. • Daño a la memoria. • Atentado físico contra la máquina o sus accesorios. • Sabotaje político o terrorismo en que se destruya o surja un apoderamiento de los centros neurálgicos
computarizados. • Secuestro de soportes magnéticos entre los que figure información valiosa con fines de chantaje
Ley de Derechos de Autor (FRAGMENTOS IMPORTANTES)
Artículo 101 .- Se entiende por programa de computación la expresión original en cualquier forma, lenguaje o código, de un conjunto de instrucciones que, con una secuencia, estructura y organización determinada, tiene como propósito que una computadora o dispositivo realice una tarea o función específica. Artículo 102 .- Los programas de computación se protegen en los mismos términos que las obras literarias. Dicha protección se extiende tanto a los programas operativos como a los programas aplicativos, ya sea en forma de código fuente o de código objeto. Se exceptúan aquellos programas de cómputo que tengan por objeto causar efectos nocivos a otros programas o equipos. Artículo 103 .- Salvo pacto en contrario, los derechos patrimoniales sobre un programa de computación y su documentación, cuando hayan sido creados por uno o varios empleados en el ejercicio de sus funciones o siguiendo las instrucciones del empleador, corresponden a éste. Como excepción a lo previsto por el artículo 33 de la presente Ley, el plazo de la cesión de derechos en materia de programas de computación no está sujeto a limitación alguna. Artículo 104 .-Como excepción a lo previsto en el artículo 27 fracción IV, el titular de los derechos de autor sobre un programa de computación o sobre una base de datos conservará, aún después de la venta de ejemplares de los mismos, el derecho de autorizar o prohibir el arrendamiento de dichos ejemplares. Este precepto no se aplicará cuando el ejemplar del programa de computación no constituya en sí mismo un objeto esencial de la licencia de uso. Artículo 105 .- El usuario legítimo de un programa de computación podrá realizar el número de copias que le autorice la licencia concedida por el titular de los derechos de autor, o una sola copia de dicho programa siempre y cuando:

Tecnologías de la Información y Comunicación Sistemas Informáticos 86
I. Sea indispensable para la utilización del programa, o II. Sea destinada exclusivamente como resguardo para sustituir la copia legítimamente adquirida, cuando ésta no pueda utilizarse por daño o pérdida. La copia de respaldo deberá ser destruida cuando cese el derecho del usuario para utilizar el programa de computación.
Artículo 106 .- El derecho patrimonial sobre un programa de computación comprende la facultad de autorizar o prohibir: I. La reproducción permanente o provisional del programa en todo o en parte, por cualquier medio y forma: II. La traducción, la adaptación, el arreglo o cualquier otra modificación de un programa y la reproducción del programa resultante III. Cualquier forma de distribución del programa o de una copia del mismo, incluido el alquiler, y IV. La de compilación, los procesos para revertir la ingeniería de un programa de computación y el desensamblaje. Artículo 107 .- Las bases de datos o de otros materiales legibles por medio de máquinas o en otra forma, que por razones de selección y disposición de su contenido constituyan creaciones intelectuales, quedarán protegidas como compilaciones. Dicha protección no se extenderá a los datos y materiales en sí mismos. Artículo 108 .- Las bases de datos que no sean originales quedan, sin embargo, protegidas en su uso exclusivo por quien las haya elaborado, durante un lapso de 5 años. Artículo 109 .- El acceso a información de carácter privado relativa a las personas contenidas en las bases de datos a que se refiere el artículo anterior, así como la publicación, reproducción, divulgación, comunicación pública y transmisión de dicha información, requerirá la autorización previa de las personas de que se trate. Quedan exceptuados de lo anterior, las investigaciones de las autoridades encargadas de la procuración e impartición de justicia, de acuerdo con la legislación respectiva, así como el acceso a archivos públicos por las personas autorizadas por la ley, siempre que la consulta sea realizada conforme a los procedimientos respectivos. Artículo 110 .- El titular del derecho patrimonial sobre una base de datos tendrá el derecho exclusivo, respecto de la forma de expresión de la estructura de dicha base, de autorizar o prohibir: I. Su reproducción permanente o temporal, total o parcial, por Cualquier medio y de cualquier forma; II. Su traducción, adaptación, reordenación y cualquier otra modificación; III. La distribución del original o copias de la base de datos; IV. La comunicación al público, y V. La reproducción, distribución o comunicación pública de los resultados de las operaciones mencionadas en la fracción II del presente artículo. Artículo 111 .- Los programas efectuados electrónicamente que contengan elementos visuales, sonoros, tridimensionales o animados quedan protegidos por esta Ley en los elementos primigenios que contengan. Artículo 112 .- Queda prohibida la importación, fabricación, distribución y utilización de aparatos o la prestación de servicios destinados a eliminar la protección técnica de los programas de cómputo, de las transmisiones a través del espectro electromagnético y de redes de telecomunicaciones y de los programas de elementos electrónicos señalados en el artículo anterior. Artículo 113 .- Las obras e interpretaciones o ejecuciones transmitidas por medios electrónicos a través del espectro electromagnético y de redes de telecomunicaciones y el resultado que se obtenga de esta transmisión estarán protegidas por esta Ley. Artículo 114 .- La transmisión de obras protegidas por esta Ley mediante cable, ondas radioeléctricas, satélite u otras similares, deberán adecuarse, en lo conducente, a la legislación mexicana y respetar en todo caso y en todo tiempo las disposiciones sobre la materia. Artículo 164 .- El Registro Público del Derecho de Autor tiene las siguientes obligaciones: I. Inscribir, cuando proceda, las obras y documentos que le sean presentados II. Proporcionar a las personas que lo soliciten la información de las inscripciones y, salvo lo dispuesto en los párrafos siguientes, de los documentos que obran en el Registro. Tratándose de programas de computación, de contratos de edición y de obras inéditas, la obtención de copias sólo se permitirá mediante autorización del titular del derecho patrimonial o por mandamiento judicial.

Tecnologías de la Información y Comunicación Sistemas Informáticos 87
CALIDAD Sistemas de Gestión de Calidad Calidad.- Es asegurarse de que un producto o servicio sea consistente (no variable), confiable (que haga las cosas de forma fiable todo el tiempo) y esté libre de errores y defectos.
Las etapas para resolver un problema computacional son:
• Diseño • Análisis • Desarrollo • Pruebas • Mantenimiento
NOTA.- Estas etapas corresponde al modelo de análisis y diseño de sistemas de información denominado CASCADA o modelo lineal Bases del Control Estadístico del Proceso
La historia japonesa nos dice que el Samurai, el guerrero japonés, usaba siete herramientas o armas en su actividad militar. Inspirado en su tradición, el doctor Kaoru Ishikawa estableció las siete herramientas básicas, denominadas herramientas de control estadístico :
• Diagrama de Causa – Efecto (o de Ishikawa) • Hojas de Verificación y/o Recopilación de Datos • Histograma • Diagrama de Pareto • Diagrama de Flujo • Diagrama de Dispersión • Gráficas de Control
Las herramientas no pretenden sustituir la experiencia, intuición, autoridad o determinación del
empleado o trabajador experto, sino auxiliarlo en la recopilación y el análisis de datos para tomar decisiones con base a ellos, y así resolver la mayoría de los problemas en las áreas productivas. Diagrama Causa – Efecto. El Diagrama de Causa – Efecto, también conocido como Diagrama de Pescado o Ishikawa, sirve para ordenar las causas que afectan o influyen en la calidad de un proceso, producto o servicio. De acuerdo con la lógica, todo efecto (evento, problema, desviación, etc.) tiene cuando menos una causa, y el uso de este diagrama facilitará el entendimiento y comprensión de un proceso, aún en situaciones complicadas. Así seguimos ampliando el Diagrama de Causa-Efecto hasta que contenga todas las causas posibles de dispersión. El siguiente diagrama es aplicado a la creación de la mayonesa.
Tecnologías de la Información y Comunicación Sistemas Informáticos 88
Histograma
Un histograma es un gráfico o diagrama que muestra el número de veces que se repiten cada uno de los resultados cuando se realizan mediciones sucesivas. Esto permite ver alrededor de que valor se agrupan las mediciones (Tendencia central) y cual es la dispersión alrededor de ese valor central.
Supongamos que un médico dietista desea estudiar el peso de personas adultas de sexo
masculino y recopila una gran cantidad de datos midiendo el peso en kilogramos de sus pacientes varones:
Así como están los datos es muy difícil sacar conclusiones acerca de ellos.
Entonces, lo primero que hace el médico es agrupar los datos en intervalos contando cuantos resultados de mediciones de peso hay dentro de cada intervalo (Esta es la frecuencia). Por ejemplo, ¿Cuántos pacientes pesan entre 60 y 65 kilos? ¿Cuántos pacientes pesan entre 65 y 70 kilos?:

Tecnologías de la Información y Comunicación Sistemas Informáticos 89
Diagrama de Pareto
El Diagrama de Pareto es un histograma especial, en el cual las frecuencias de ciertos eventos
aparecen ordenadas de mayor a menor. Vamos a explicarlo con un ejemplo.
Supongamos que un fabricante de heladeras desea analizar cuales son los defectos más frecuentes que aparecen en las unidades al salir de la línea de producción. Para esto, empezó por clasificar todos los defectos posibles en sus diversos tipos:

Tecnologías de la Información y Comunicación Sistemas Informáticos 90
Diagrama de Dispersión.
Los Diagramas de Dispersión o Gráficos de Correlación permiten estudiar la relación entre 2 variables. Dadas 2 variables X e Y, se dice que existe una correlación entre ambas si cada vez que aumenta el valor de X aumenta proporcionalmente el valor de Y (Correlación positiva) o si cada vez que aumenta el valor de X disminuye en igual proporción el valor de Y (Correlación negativa).


















