
Tesis Doctoral - Dpto. de Sistemas Informáticos y ... · Resolución de Ecuaciones Diferenciales....
344
Departamento de Sistemas Informáticos y Computación Universidad Politécnica de Valencia Tesis Doctoral Computación de Altas Prestaciones para el Cálculo de Funciones de Matrices y su Aplicación a la Resolución de Ecuaciones Diferenciales presentado por: J. Javier Ibáñez González Director: Dr. D. Vicente Hernández García Valencia, 2006
-
Upload
truongthuy -
Category
Documents
-
view
214 -
download
0
Transcript of Tesis Doctoral - Dpto. de Sistemas Informáticos y ... · Resolución de Ecuaciones Diferenciales....

Departamento de Sistemas Informáticos y Computación
Universidad Politécnica de Valencia
Tesis Doctoral
Computación de Altas Prestaciones para el Cálculo de Funciones de Matrices y su Aplicación a la
Resolución de Ecuaciones Diferenciales
presentado por:
J. Javier Ibáñez González
Director:
Dr. D. Vicente Hernández García
Valencia, 2006


Resumen
La presente memoria se enmarca dentro de la línea de investigación de Computación de Altas Prestaciones para el Cálculo de Funciones de Matrices y su Aplicación a la Resolución de Ecuaciones Diferenciales. Este campo de investigación está teniendo un gran auge en los últimos años, ya que proporciona soluciones a cuestiones muy diversas como son la simulación de fenómenos físicos o la resolución de problemas de control.
La tesis se centra, fundamentalmente, en el desarrollo de métodos y la implementación de algoritmos que calculan Funciones de Matrices, y su aplicación a la resolución de Ecuaciones Diferenciales Ordinarias (EDOs) y Ecuaciones Diferenciales Matriciales de Riccati (EDMRs).
El punto de partida del trabajo desarrollado ha sido el estudio del estado del arte de cada una de esas áreas, proponiéndose nuevos métodos y algoritmos que, de algún modo, mejoran los ya existentes.
También se han explorado diversos campos de aplicación de este tipo de aproximaciones. Uno de ellos, la propagación de rayos luminosos en fibras de cristal fotónico y la posibilidad de controlar su comportamiento usando medios periódicos, está siendo una de las perspectivas más prometedoras en la búsqueda de alternativas a la tecnología de los semiconductores. En este sentido, la Computación de Altas Prestaciones permite, mediante la simulación, conocer el comportamiento de la luz en esos medios, dando soporte experimental a las cuestiones teóricas que en la actualidad se están investigando.
Para obtener un software de calidad, se ha utilizado un paradigma de ciclo de vida de tipo semiautomático. Además, se han realizado numerosas pruebas que han permitido determinar, por un parte, los parámetros óptimos de los algoritmos implementados y, por otra, analizar la precisión y eficiencia del código implementado.

Resum
La present memòria s’emmarca dins la línia d’investigació de Computació d’Altes Prestacions per al Càlcul de Funcions de Matrius i la seua Aplicació a la Resolució d’Equacions Diferencials. Este camp d’investigació està tenint una gran expansió en els últims anys, ja que proporciona solucions a qüestions molt diverses com són la simulació de fenòmens físics o la resolució de problemes de control.
La tesi se centra, fonamentalment, en el desenvolupament de mètodes i la implementació de algoritmes que calculen Funcions de Matrius, i la seua aplicació a la resolució d’Equacions Diferencials Ordinàries (EDOs) i Equacions Diferencials Matricials de Riccati (EDMRs).
El punt de partida del treball realitzat ha sigut l’estudi de l’estat de l’art de cada una d’eixes àrees, proposant-se nous mètodes i algoritmes que, d’alguna manera, milloren els ja existents.
També s’han explorat diversos camps d’aplicació d’esta tipus d’aproximacions. Un d’ells, la propagació de rajos lluminosos en fibres de cristall fotònic i la possibilitat de controlar el seu comportament usant medis periòdics, està sent una de les perspectives més prometedores en la busca d’alternatives a la tecnologia dels semiconductors. En este sentit, la Computació d’Altes Prestacions permet, per mitjà de la simulació, conéixer el comportament de la llum en eixos medis, donant suport experimental a les qüestions teòriques que en l’actualitat s’estan investigant.
Per a obtindre un software de qualitat, s’ha utilitzat un paradigma de cicle de vida de tipus semiautomàtic. A més, s’han realitzat nombroses proves que han permés determinar, per una part, els paràmetres òptims dels algoritmes implementats i, d’una altra, analitzar la precisió i eficiència del codi implementat.

Abstract
The present memory is framed in the research field of High-Performance Computing of Matrix Functions and its Application to the Solution of Differential Equations. This research field is having an important growth in the last years, since it provides solutions to very diverse questions, such the simulation of physical phenomena or the treatment of control problems.
The thesis is focused, fundamentally, on the development of methods and the implementation of algorithms that compute Matrix Functions, and its application to the solution of Ordinary Differential Equations (ODEs) and Differential Matrix Riccati Equations (DMREs).
The starting point of the developed work has been the study of the state-of-the-art of each one of those areas, setting out new methods and algorithms that, in some way, improve the existing ones.
Diverse fields of application of this type of approaches have also been explored. One of them, the propagation of light beams in photonic crystal fibers and the possibility of controlling their behaviour using periodic means, is one of the most promising perspectives in the search of alternatives to the semiconductors technology. In this sense, the High-Performance Computing allows, by means of the simulation, to know the behaviour of the light in those means, giving experimental support to the theoretical questions that at the present time are the subject of research.
In order to obtain quality software, a semiautomatic life cycle has been used. In addition, numerous tests have been carried out, which have allowed, on the one hand, to the determine optimal values for the parameters of the implemented algorithms and, on the other hand, to analyze the precision and efficiency of the implemented code.

Agradecimientos
Al llegar al final de un largo viaje, uno contempla todo el camino recorrido, y recuerda cada una de las etapas por las que ha ido pasando; en especial, suele recordar como comenzó y como ha llegado a esa meta final. Todo ese trayecto ha trascurrido por numerosas dificultades, pero gracias a la familia, amigos y compañeros de trabajo, ha llegado a buen término. Por todo ello quiero expresar mi más profundo agradecimiento a todos aquellos, que de alguna manera, han contribuido a este feliz desenlace.
En primer lugar quiero agradecer especialmente toda la ayuda y apoyo que he recibido durante todo este tiempo a mi director de tesis Dr. Vicente Hernández García. De él quiero destacar su profundo conocimiento de las materias desarrolladas en la tesis, su rigurosidad científica, su clara visión de los aspectos que pudieran ser novedosos y sobre todo por la paciencia y confianza que siempre ha depositado en mí.
Agradezco también a mis compañeros de viaje Enrique Arias y Jesús Peinado, por sus constantes apoyos y compartir con ellos tareas de investigación; a mi compañero de despacho Juan Garayoa, por todo lo compartido en los muchos años que nos conocemos y por la ayuda que siempre he tenido de él; a Pedro López, por su constante apoyo y sabios consejos; a Pedro Ruiz, por el camino que hemos iniciado y el que nos queda por recorrer; a mis compañeros de la asignatura de CNU Victor García e Ignacio Blanquer, por toda la ayuda que en numerosas ocasiones me han brindado. Tampoco quiero olvidar a mis compañeros del grupo de investigación Antonio Vidal, Vicente Vidal, José E. Román, David Guerrero, José Miguel Alonso, Fernando Alvarruiz, Gabriel García, Germán Vidal, etc., por todos los consejos y ayudas que en muchas ocasiones he recibido de ellos. En general, quiero agradecer a todos los compañeros del Departamento de Sistemas Informáticos y Computación de la Universidad Politécnica de Valencia por la ayuda que en algún momento me hayan podido dar.
Quiero agradecer también toda la ayuda y colaboración de Albert Ferrando, Pedro Fernández de Córdoba y Mario Zacarés, que me ha permitido conocer un área de investigación tan importante como la Fotónica en la que aplicar los algoritmos de cálculo de Funciones de Matrices desarrollados en esta Tesis .
Muchas gracias, como no podía ser menos, a mis amigos Dolores, Javier, Neri, Amalia, Miguel, Rosa, Pablo, José, Laura, Vicente, Juan, Manoli, Abelardo, Gloria, etc., por esos momentos que hemos compartido juntos y que espero sigamos disfrutando.
Muchas gracias a mis padres Jacinto y Gloria por darme la vida, y todo el cariño y afecto que, de manera desinteresada, siempre me han mostrado. Gracias también a mi hermana Gloria, por todas las cosas compartidas y por el mutuo afecto que nos tenemos. Agradezco también la comprensión y ánimo que siempre me ha dado mi familia más cercana Pepe, Emilia, Pepe, Eli, Miguel, Cristina, Carlos, Lourdes, Carol, Toni, Andrés, Ani, Maria Jesús, Guillermo, Miguel Ángel, Maria José, Marivi, Silvia, Bernabé, etc., y mis sobrinos Isabel, Carlos, Patricia, Victor, Adrián, Javier, Maria Jesús, Guillermo.
Por último, gracias a Mari, amiga, esposa y compañera por todo el cariño compartido desde nuestra adolescencia, y por todo el apoyo, paciencia y comprensión que siempre ha tenido conmigo, y a mis hijos Jorge y Álvaro, por el cariño que siempre recibo de ellos.

VII
ÍNDICE GENERAL
Capítulo 1 Introducción......................................................................... 1
1.1 Resumen de Contenidos.................................................................................... 1
1.2 Objetivos y Aportaciones de la Tesis................................................................ 1
1.3 Metodología...................................................................................................... 4
1.4 Estructura de la Tesis ....................................................................................... 7
Capítulo 2 Estado del Arte .................................................................. 11
2.1 Resumen de Contenidos.................................................................................. 11
2.2 Funciones de Matrices ................................................................................... 11 2.2.1 Definiciones y Propiedades ................................................................................................11 2.2.2 Funciones de Matrices más Usuales ...................................................................................14
2.2.2.1 Función Exponencial.................................................................................................14 2.2.2.2 Función Signo ...........................................................................................................15 2.2.2.3 Función Raíz Cuadrada.............................................................................................16 2.2.2.4 Función Raíz p-ésima................................................................................................19 2.2.2.5 Función Logaritmo....................................................................................................21 2.2.2.6 Funciones Seno y Coseno .........................................................................................22
2.2.3 Métodos Numéricos para el Cálculo de Funciones de Matrices .........................................23 2.2.3.1 Función Exponencial.................................................................................................23
2.2.3.1.1 Métodos Basados en las Series de Taylor ............................................................23 2.2.3.1.2 Métodos Basados en los Aproximantes de Padé ..................................................23 2.2.3.1.3 Métodos Basados en Integración Numérica .........................................................27 2.2.3.1.4 Métodos Polinomiales ..........................................................................................29 2.2.3.1.5 Métodos Basados en la Descomposición de Matrices ..........................................32 2.2.3.1.6 Métodos Basados en los Subespacios de Krylov..................................................36
2.2.3.2 Función Signo ...........................................................................................................37 2.2.3.3 Función Raíz Cuadrada.............................................................................................39 2.2.3.4 Función Raíz p-ésima de una Matriz.........................................................................41 2.2.3.5 Función Logaritmo....................................................................................................43 2.2.3.6 Función Coseno.........................................................................................................45 2.2.3.7 Caso General .............................................................................................................46
2.2.4 Software de Funciones de Matrices ....................................................................................47 2.2.4.1 Expokit......................................................................................................................47 2.2.4.2 Proyecto “Parallel Computation of Matrix Functions” .............................................47 2.2.4.3 Proyecto “Numerical Analysis of Matrix Functions” ...............................................48
2.3 Ecuaciones Diferenciales Ordinarias (EDOs) ............................................... 48 2.3.1 Definiciones y Propiedades ................................................................................................48 2.3.2 Métodos Numéricos para la Resolución de EDOs..............................................................49 2.3.3 Métodos de un solo Paso ....................................................................................................49
2.3.3.1 Métodos Basados en las Series de Taylor .................................................................49 2.3.3.2 Métodos de Runge-Kutta ..........................................................................................50 2.3.3.3 Métodos Multipaso Lineales .....................................................................................52
2.3.3.3.1 Métodos de Adams...............................................................................................52 2.3.3.3.2 Métodos BDF .......................................................................................................54
2.3.4 Linealización a Trozos de EDOs ........................................................................................55 2.3.5 Software para la Resolución de EDOs................................................................................56
2.4 Ecuaciones Diferenciales Matriciales de Riccati (EDMRs) .......................... 58 2.4.1 Definiciones y Propiedades ................................................................................................58 2.4.2 Métodos de Resolución de EDMRs....................................................................................60
2.4.2.1 Integración Directa....................................................................................................60 2.4.2.2 Métodos de Linealización .........................................................................................60

VIII
2.4.2.2.1 Método de Davison-Maki.....................................................................................61 2.4.2.2.2 Procedimiento Iterativo Matricial ASP (Automatic Synthesis Program) .............62
2.4.2.3 Método BDF .............................................................................................................62 2.4.3 Métodos de Resolución de EDMRs Simétricas ..................................................................64
2.4.3.1 Métodos de Linealización .........................................................................................64 2.4.3.1.1 Método de la Exponencial no Negativa................................................................64 2.4.3.1.2 Método de Schur ..................................................................................................65
2.4.3.2 Método de Chandrasekhar.........................................................................................66 2.4.3.3 Algoritmo de Particionado Numérico (APN)............................................................68 2.4.3.4 Método Basado en la Ecuación Algebraica de Riccati (EAR) ..................................70 2.4.3.5 Método de Leipnik ....................................................................................................71 2.4.3.6 Método de la Raíz Cuadrada .....................................................................................72 2.4.3.7 Método de Rusnak ....................................................................................................73 2.4.3.8 Métodos Conservativos y Métodos Simplécticos .....................................................74 2.4.3.9 Métodos BDF para EDMRs de gran Escala..............................................................76
2.4.4 Aplicaciones .......................................................................................................................78 2.4.4.1 Problemas del Control Óptimo..................................................................................78 2.4.4.2 Problemas de Filtrado y Estimación..........................................................................79 2.4.4.3 Sistemas de Parámetros Distribuidos ........................................................................80 2.4.4.4 Reducción de Orden y Desacoplamiento ..................................................................81 2.4.4.5 Resolución de Problemas de Contorno .....................................................................82
2.4.5 Software para la Resolución de EDMRs ............................................................................83 2.5 Conclusiones................................................................................................... 84
Capítulo 3 Cálculo de Funciones de Matrices ................................... 87
3.1 Resumen de Contenidos.................................................................................. 87
3.2 Algoritmos Basados en los Aproximantes Diagonales de Padé..................... 90 3.2.1 Esquema General................................................................................................................90 3.2.2 Determinación de los Polinomios de la Aproximación Diagonal de Padé .........................92 3.2.3 Funciones Polinómicas y Racionales..................................................................................94 3.2.4 Cálculo de Funciones de Matrices ......................................................................................96
3.2.4.1 Función Exponencial.................................................................................................97 3.2.4.2 Función Potencia Fraccionaria ..................................................................................99 3.2.4.3 Función Logaritmo..................................................................................................102 3.2.4.4 Función Coseno.......................................................................................................104 3.2.4.5 Función Seno ..........................................................................................................106
3.3 Algoritmos Basados Descomposición Real de Schur de una matriz ............ 108 3.3.1 Esquema General..............................................................................................................108 3.3.2 Algoritmo Basado en la Reducción a una Forma Diagonal por Bloques..........................109 3.3.3 Algoritmos Basados en la Resolución de la Ecuación Conmutante .................................112
3.3.3.1 Algoritmos Orientados a Columnas y a Diagonales................................................113 3.3.3.1.1 Algoritmo Orientado a Columnas ......................................................................117 3.3.3.1.2 Algoritmo Orientado a Diagonales.....................................................................118
3.3.3.2 Algoritmos Orientados a Bloques ...........................................................................119 3.3.3.3 Algoritmo con Agrupación de Valores Propios Cercanos ......................................121
3.3.4 Algoritmo Basado en los Aproximantes Diagonales de Padé...........................................124 3.4 Conclusiones................................................................................................. 125
Capítulo 4 Linealización a Trozos .................................................... 129
4.1 Resumen de Contenidos................................................................................ 129
4.2 Métodos de Linealización a Trozos para EDOs........................................... 131 4.2.1 EDOs no Autónomas ........................................................................................................131
4.2.1.1 Método Basado en los Aproximantes Diagonales de Padé .....................................135 4.2.1.2 Método Basado en la Ecuación Conmutante...........................................................142

IX
4.2.1.3 Método Basado en los Subespacios de Krylov .......................................................145 4.2.2 EDOs Autónomas .............................................................................................................149
4.2.2.1 Método Basado en los Aproximantes Diagonales de Padé .....................................151 4.2.2.2 Método Basado en la Ecuación Conmutante...........................................................153 4.2.2.3 Método Basado en los Subespacios de Krylov .......................................................155
4.3 Métodos de Linealización a Trozos de EDMRs ........................................... 158 4.3.1 Resolución de EDMRs con Coeficientes Variables..........................................................158
4.3.1.1 Método Basado en los Aproximantes Diagonales de Padé .....................................160 4.3.1.2 Método Basado en la Ecuación Conmutante...........................................................167 4.3.1.3 Método Basado en los Subespacios de Krylov .......................................................172
4.3.2 Resolución de EDMRs con Coeficientes Constantes .......................................................175 4.3.2.1 Método Basado en los Aproximantes Diagonales de Padé .....................................177 4.3.2.2 Método Basado en la Ecuación Conmutante...........................................................181 4.3.2.3 Método Basado en los Subespacios de Krylov .......................................................184
4.4 Conclusiones................................................................................................. 186
Capítulo 5 Resultados Experimentales ............................................ 189
5.1 Resumen de Contenidos................................................................................ 189
5.2 Cálculo de Funciones de Matrices ............................................................... 190 5.2.1 Funciones Polinómicas y Racionales................................................................................190
5.2.1.1 Resultados Funciones Polinómicas .........................................................................191 5.2.1.2 Resultados Funciones Racionales ...........................................................................194
5.2.2 Rutinas Basadas en los Aproximantes Diagonales de Padé..............................................200 5.2.3 Rutinas Basadas en la Descomposición real de Schur de una matriz ...............................210
5.3 Propagación de Ondas Monocromáticas en Fibras de Cristal Fotónico .... 214 5.3.1 Algoritmo Basado en la Diagonalización de una Matriz ..................................................216 5.3.2 Algoritmo Basado en los Aproximantes Diagonales de Padé...........................................217 5.3.3 Algoritmo Basado en la Iteración DB y en los Aproximantes Diagonales de Padé .........218 5.3.4 Resultados.........................................................................................................................218
5.4 Resolución de EDOs..................................................................................... 220 5.4.1 EDOs Autónomas .............................................................................................................222 5.4.2 EDOs no autónomas .........................................................................................................237
5.5 Resolución de EDMRs.................................................................................. 246 5.5.1 EDMRs con Coeficientes Constantes ...............................................................................249 5.5.2 EDMRs con Coeficientes Variables .................................................................................266
5.6 Conclusiones................................................................................................. 280
Capítulo 6 Conclusiones y Líneas Futuras de Investigación ......... 285
6.1 Resumen de Contenidos................................................................................ 285
6.2 Conclusiones Finales.................................................................................... 285 6.2.1 Funciones de Matrices ......................................................................................................285 6.2.2 Aplicación de las Funciones de Matrices .........................................................................286 6.2.3 Resolución de EDOs.........................................................................................................287 6.2.4 Resolución de EDMRs .....................................................................................................288
6.3 Publicaciones en el Marco de la Tesis ......................................................... 290
6.4 Líneas Futuras de Investigación .................................................................. 292
Apéndice A. Conceptos Básicos y Notaciones ................................. 295
Apéndice B. MATLAB...................................................................... 307

X
Resolución de EDOs.......................................................................................................................307 Funciones de Matrices ....................................................................................................................308
Apéndice C. BLAS y LAPACK........................................................ 311 BLAS 312
Convenciones en el BLAS .........................................................................................................312 Estructura del BLAS ..................................................................................................................313
LAPACK ........................................................................................................................................315 Estructura del LAPACK ............................................................................................................315 Tratamiento de Errores en el LAPACK .....................................................................................316 Equilibrado y Condicionamiento en LAPACK..........................................................................319 Proyector Espectral y Separación de Matrices ...........................................................................320 Otras Características del LAPACK............................................................................................322
Argumentos Matriciales ........................................................................................................322 Matrices de Trabajo...............................................................................................................322 Argumento Info .....................................................................................................................322 Determinación del Tamaño de Bloque Óptimo .....................................................................322
Prestaciones del LAPACK.........................................................................................................323
Apéndice D. SGI Altix 3700.............................................................. 325 Arquitectura ....................................................................................................................................325 Software..........................................................................................................................................325
Compiladores .............................................................................................................................326 Librerías .....................................................................................................................................326
Bibliografía .............................................................................................. 327

Capítulo 1: Introducción
1
Capítulo 1 Introducción
1.1 Resumen de Contenidos Esta memoria se enmarca dentro de la línea de investigación de Computación de Altas Prestaciones para el Cálculo de Funciones de Matrices y su aplicación a la resolución de problemas que aparecen en ingeniería y en otras áreas de aplicación. Entre los problemas tratados en esta tesis se encuentran la Resolución de Ecuaciones Diferenciales Ordinarias (EDO), la Resolución de Ecuaciones Diferenciales Matriciales de Riccati (EDMRs) y la Simulación de la Propagación de Ondas en Fibras de Cristal Fotónico. Para ello, se han diseñado nuevos métodos y algoritmos, escritos en MATLAB y FORTRAN, que resuelven los problemas citados. La implementación de dichos algoritmos se ha realizado de manera eficiente y portable, desde un punto de vista computacional, al haber utilizado librerías optimizadas de BLAS (Basic Linear Algebra Subroutines) y LAPACK (Linear Algebra PACKage), hoy por hoy, los estándares más ampliamente utilizados en el desarrollo de software numérico de Altas Prestaciones.
Este capítulo está estructurado en cuatro secciones. En la segunda sección se enumeran los objetivos que han servido de guía en el desarrollo de la tesis, describiendo además las aportaciones más relevantes de la misma.
La tercera sección describe la metodología utilizada en el desarrollo del software. Para obtener un software de calidad es necesario utilizar metodologías procedentes de la Ingeniería del Software. Para ello se han aplicado métodos y técnicas que proceden de dicha disciplina, adaptándolos convenientemente para el desarrollo de Software de Computación Numérica de Altas Prestaciones.
La última sección está dedicada a detallar el contenido de cada uno de los capítulos que conforman esta tesis, describiendo brevemente el contenido de los mismos.
1.2 Objetivos y Aportaciones de la Tesis Los objetivos generales que se han pretendido alcanzar al desarrollar esta tesis han sido:
• Estudiar las propiedades numéricas de las Funciones de Matrices más usuales y así desarrollar nuevos algoritmos para su cálculo.
• Resolver EDOs y EDMRs mediante técnicas que involucran Funciones de Matrices, desarrollando nuevos métodos y algoritmos.
• Análisis y resolución de problemas reales en los que es necesario el cálculo de Funciones de Matrices.
• Desarrollar un software de computación numérica de calidad, es decir, eficiente, de altas prestaciones, portable, robusto y correcto, para la resolución de los problemas citados.
Todos estos objetivos se han alcanzado, como a continuación se detalla.

Capítulo 1: Introducción
2
La necesidad de calcular Funciones de Matrices aparece en una gran variedad de aplicaciones, constituyendo una herramienta básica en el diseño de sistemas de control, problemas de convección difusión, estudio de fluidos, etc. En algunas de estas aplicaciones se requiere un tiempo de cálculo muy elevado, al aparecer en la resolución del problema matrices de gran dimensión, mientras que en otras es necesario realizar muchos cálculos por unidad de tiempo para, por ejemplo, poder interactuar sobre un sistema físico en tiempo real. En esta tesis se ha realizado un estudio completo de las funciones matriciales más utilizadas, proponiéndose la utilización de metodologías generales para el cálculo de las mismas. En la actualidad el paquete de software MATLAB tiene implementadas un amplio conjunto de Funciones de Matrices; sin embargo, únicamente se dispone de un reducido número de rutinas escritas en lenguajes de alto nivel que calculan algunas de las funciones matriciales más usuales. Entre las contribuciones de esta tesis para el cálculo de Funciones de Matrices se encuentran las siguientes:
• Desarrollo de algoritmos, basados en metodologías generales, para el cálculo de Funciones de Matrices: algoritmos basados en los aproximantes diagonales de Padé de una función y algoritmos basados en la descomposición real de Schur de una matriz.
• Se ha diseñado nuevos algoritmos basados en los aproximantes diagonales de Padé que permiten el cálculo eficiente de Funciones de Matrices como, por ejemplo, la potencia fraccionaria de una matriz (Algoritmo 3.7) o la función seno matricial (Algoritmo 3.10).
• Se han diseñado nuevos algoritmos que utilizan la descomposición real de Schur de una matriz para calcular Funciones de Matrices. Entre estos algoritmos se encuentran el basado en la forma diagonal a bloques (Algoritmo 3.13 ), los basados en la Ecuación Conmutante (Algoritmo 3.15, Algoritmo 3.16, Algoritmo 3.17, Algoritmo 3.18), el basado en la agrupación en clusters de los valores propios cercanos de un matriz (Algoritmo 3.22) y el basado en los aproximantes diagonales de Padé (Algoritmo 3.23).
• Diseño e implementación de funciones/rutinas escritas en MATLAB y FORTRAN, para el cálculo de Funciones de Matrices, basadas en las rutinas anteriores.
• Estudio, diseño e implementación de rutinas de altas prestaciones que permiten la simulación de la propagación de ondas en fibras de cristal fotónico.
Para la mayoría de las EDOs no lineales se desconoce su solución analítica y hay que utilizar técnicas numéricas para obtener soluciones aproximadas. Estas técnicas se basan en la transformación, mediante fórmulas de diferenciación o de integración numérica, de un problema continuo en otro discreto, siendo hasta ahora los métodos Runge-Kutta o BDF (Backward Differentiation Formulae) los más ampliamente utilizados. En esta tesis se propone resolver EDOs mediante la técnica de linealización a trozos. Esta técnica consiste en dividir el intervalo considerado en subintervalos más pequeños, de manera que en cada uno de ellos se realiza una aproximación lineal de la función que define a la EDO. Entre las aportaciones realizadas en esta tesis para la resolución de EDOs se encuentran las siguientes:
• Demostración del Teorema 4.1 que permite resolver EDOs mediante la técnica de linealización a trozos de la función que define a la EDO, y en donde no se requiere que la matriz Jacobiana sea invertible.

Capítulo 1: Introducción
3
• Desarrollo de dos nuevos métodos, basados en el teorema anterior, para la resolución de EDOs:
− Método basado en el cálculo de la exponencial de una matriz a bloques, asociada al problema, mediante aproximantes diagonales de Padé.
− Método basado en el cálculo del producto de la exponencial de una matriz a bloques por un vector mediante una aproximación basada en subespacios de Krylov.
• Desarrollo de un método para la resolución de EDOs basado en la linealización a trozos y en la Ecuación Conmutante. En esta aproximación es necesario que la matriz Jacobiana sea invertible.
• Para cada uno de los métodos anteriores se han desarrollo algoritmos para la resolución de EDOs no autónomas (Algoritmo 4.5, Algoritmo 4.7, Algoritmo 4.11) y para la resolución de EDOs autónomas (Algoritmo 4.14, Algoritmo 4.16 y Algoritmo 4.18).
• Implementación de los algoritmos anteriores en MATLAB y FORTRAN, determinando los parámetros característicos de los diferentes métodos y optimizando sus costes espacial y temporal.
Una de las ecuaciones diferenciales no lineales más usadas en el ámbito científico es la Ecuación Diferencial Matricial de Riccati (EDMR). Esta ecuación juega un papel fundamental en problemas de control óptimo y filtrado. Una de las técnicas ampliamente utilizadas para resolver dicha ecuación consiste en aplicar el método BDF. Este método está especialmente indicado para resolver EDMRs de tipo rígido. Otro de los métodos que se pueden aplicar en la resolución de EDMRs consiste en la vectorización de ecuaciones diferenciales matriciales, que permite convertir una EDMR en una EDO. En esta tesis se han desarrollado varios métodos de resolución de EDMRs que consisten en aplicar la linealización a trozos a la EDO anterior, utilizando técnicas especiales para la resolución eficiente de la misma. Entre las aportaciones relativas a la resolución de EDMRs se encuentran las siguientes:
• Desarrollo de una nueva metodolgía para la resolución de EDMRs basada en la técnica de linealización a trozos. Esta metodología consiste, básicamente, en transformar la EDMR en una EDO de gran dimensión y aplicarle la linealización a trozos.
• Desarrollo de tres métodos basados en la linealización a trozos.
− Método basado en los aproximantes diagonales de Padé. El primer método consiste en calcular la solución aproximada de una EDMR en un instante determinado mediante el cálculo de dos exponenciales de matrices definidas a bloques. De este modo, se pasa de un problema vectorial de gran dimensión a otro matricial de menor dimensión. Este método está basado en dos teoremas desarrollados en el ámbito de esta tesis, Teorema 4.3 y Teorema 4.5, que se aplican, respectivamente, a EDMRs con coeficientes variables y a EDMRs con coeficientes constantes.
− Método basado en la Ecuación Conmutante. Para el segundo método se han demostrado dos teoremas, uno para EDMRs con coeficientes variables (Teorema 4.4) y otro para EDMRs con coeficientes constantes (Teorema 4.6), que permiten transformar un problema vectorial de resolución de una

Capítulo 1: Introducción
4
EDO de gran dimensión en otro matricial, consistente en resolver ecuaciones matriciales de Sylvester.
− Método basado en los subespacios de Krylov. El tercer método está basado en el cálculo del producto de la exponencial de una matriz definida a bloques, obtenida en el proceso de vectorización, por un vector, utilizando para ello los subespacios de Krylov.
• A partir de los métodos anteriores se han desarrollado seis nuevos algoritmos (Algoritmo 4.21, Algoritmo 4.23, Algoritmo 4.26, Algoritmo 4.29, Algoritmo 4.31, Algoritmo 4.33) y sus correspondientes implementaciones.
A partir de las pruebas realizadas en el Capítulo 5, se puede comprobar que el coste computacional de las implementaciones basadas en los métodos de linealización a trozos resultan ser menores que las implementaciones basadas en el método BDF ([Diec92]), siendo además algo más precisas. Además, tienen un buen comportamiento cuando se aplican a EDMRs de tipo rígido.
Hay que destacar que actualmente no se dispone de funciones escritas en MATLAB que resuelvan EDMRs y, en el caso de rutinas escritas en FORTRAN, tan sólo se dispone del paquete DRSOL (), pero únicamente para datos en simple precisión.
Debido al gran número de algoritmos desarrollados e implementados, ha sido necesario utilizar una notación que permitiese conocer a partir del nombre de un algoritmo la finalidad del mismo y el método empleado. La nomenclatura utilizada para los algoritmos es txxyyyzzz, donde t indica el tipo de dato utilizado, xx indica el tipo de matriz, yyy indica el problema que se resuelve y zzz el método utilizado. Los valores de los tres primeros caracteres son:
• t: tipo de dato utilizado.
− t=s, datos reales de simple precisión;
− t=d, datos reales de doble precisión;
− t=c, datos complejos de simple precisión;
− t=z, datos complejos de doble precisión.
• xx: tipo de matriz.
− xx=ge, indica matrices generales;
− xx=ct, indica matrices casi triangulares superiores.
La misma nomenclatura ha sido utilizada para nombrar a las funciones de MATLAB y a las rutinas en FORTRAN, de manera que para cada algoritmo se tiene una función en MATLAB y una rutina en FORTRAN con el mismo nombre.
1.3 Metodología Así como las metodologías para el desarrollo del software de gestión están muy avanzadas, el software científico adolece en la actualidad de herramientas que cubran todas las etapas para el desarrollo completo de una aplicación. Las técnicas más empleadas para el desarrollo del software de gestión no se pueden aplicar debido, fundamentalmente, a la propia naturaleza de las aplicaciones del cálculo científico que, en general, poseen muy pocas características en común. En esta tesis se aboga por

Capítulo 1: Introducción
5
utilizar un ciclo de vida semiautomático consistente, básicamente, en dos etapas que a continuación se describen.
Para la primera etapa se utiliza MATLAB pues dispone de un lenguaje de programación que permite expresar y desarrollar, de forma sencilla, algoritmos numéricos, disponiendo además de numerosas funciones del algebra matricial y de una potente herramienta de depuración de código que facilita el desarrollo de los mismos.
En la segunda etapa se utiliza un lenguaje de alto nivel (FORTRAN) junto con las librerías BLAS y LAPACK. Estas librerías implementan, por una parte, las operaciones más comunes entre vectores y matrices y, por otra, disponen de numerosas rutinas que resuelven los problemas más comunes que aparecen en el algebra matricial. Esto posibilita escribir los programas en FORTRAN (o C) de forma modular, centrando la atención en los aspectos algorítmicos y no en los detalles del propio lenguaje utilizado. Otra ventaja adicional es que la mayor parte de los sistemas informáticos utilizados en computación disponen de librerías optimizadas de BLAS y LAPACK, con el consiguiente rendimiento de los códigos que utilizan a esas rutinas.
De este modo, la combinación de estas herramientas posibilita la creación de software numérico robusto y de altas prestaciones de forma sistemática y sencilla. En la siguiente figura se muestra el ciclo de vida utilizado en el desarrollo del software numérico.
Figura 1.1: Ciclo de vida utilizado en el desarrollo del software.
En (1) se tiene claramente definido el problema que se quiere resolver. En (2) se realiza una descripción matemática del método que se va a implementar, partiendo de un estudio teórico de la viabilidad del mismo. En (3) se realiza un primer algoritmo, escrito en MATLAB, que implementa el método desarrollado en (2). A través de sucesivas pruebas se determinan, mediante (4), los valores óptimos de los parámetros característicos del método aplicado. Una vez se ha realizado este ajuste, se tiene un primer algoritmo escrito en MATLAB. Como paso intermedio para la codificación del algoritmo anterior en un lenguaje de alto nivel, se desarrolla un segundo algoritmo en (5) mediante la traducción del primer algoritmo, de manera que las operaciones que aparecen en él corresponden a operaciones básicas del BLAS y del LAPACK. En (6) se hace una codificación en un lenguaje de alto nivel en el que se hace una traducción del algoritmo desarrollado en (5) utilizando llamadas a BLAS o a LAPACK. La etapa (7) es necesaria, fundamentalmente, cuando se usan algoritmos orientados a bloques, en los que es necesario optimizar los accesos a memoria.
Formulación del problema (1)
Algoritmo 1
MATLAB (3)
Ajuste de los parámetros del algoritmo 1 (4)
Descripción matemática del
método (2)
Algoritmo 2
MATLAB (5)
Código en lenguaje de alto nivel (6)
Ajuste de los parámetros del
código (7)

Capítulo 1: Introducción
6
En la siguiente figura se muestra un ejemplo en el que aparece la codificación de un fragmento de un algoritmo según la metodología considerada.
Figura 1.2: Codificación de un fragmento de un algoritmo en las etapas (3), (5) y (6).
Como se puede observar, el código de la etapa (3) se desglosa en varias líneas de código correspondiente al algoritmo de la etapa (5). El código obtenido en (6) es una traducción, línea a línea, del código de la etapa (5).
Para las etapas (3) y (6) se ha dispuesto de un numeroso conjunto de pruebas que permiten validar el código desarrollado. Estas baterías de pruebas provienen, en algunos casos, de problemas reales y, en otros, de pruebas especiales que permiten comprobar la bondad de los algoritmos desarrollados. Entre las baterías de pruebas utilizadas se encuentran las siguientes:
• Cálculo de Funciones de Matrices.
− The Matrix Computation Toolbox for MATLAB ([High02]). Contiene una colección de funciones escritas en MATLAB para la generación de matrices de prueba, el cálculo de factorizaciones matriciales, la visualización de matrices, etc.
− Además del anterior paquete, se han diseñado y utilizado, dentro del marco de la tesis, numerosas funciones/rutinas escritas en MATLAB y FORTRAN que
(3) G= A21+A22*X-X*A11-X*A12*X;
(5) G=A21; G=A22*X+G; G=-X*A11+G; W=X*A12; G=-W*X+G;
(6) C G=A21 CALL DCOPY(MN,WORK(NA21),1,WORK(NG),1) C G=A22*X+G CALL DGEMM('N','N',M,N,M,ONE,WORK(NA22),M,X,M, $ ONE,WORK(NG),M) C G=-X*A11+G CALL DGEMM('N','N',M,N,N,-ONE,X,M,WORK(NA11),N, $ ONE,WORK(NG),M) C W=X*A12; CALL DGEMM('N','N',M,M,N,ONE,X,M,WORK(NA12),N, $ ZERO,WORK(NWORK),M) C G=-W*X+G; CALL DGEMM('N','N',M,N,M,-ONE,WORK(NWORK),M,X,M, $ ONE,WORK(NG),M)

Capítulo 1: Introducción
7
generan matrices especiales, idóneas para el estudio de Funciones de Matrices como, por ejemplo, matrices casi triangulares superiores, matrices de Hessenberg, matrices con valores propios múltiples, etc.
• Resolución de EDOs.
− Test Set for Initial Value Problems Solvers ([LiSw98]). Contiene una colección de problemas de valores iniciales para EDOs, Ecuaciones Diferenciales Implícitas (EDIs) y Ecuaciones Diferenciales Algebraicas (EDAs), escritos en FORTRAN y procedentes de problemas reales.
• Resolución de EDMRs.
− Time-Varying Riccati Differential Equations with Known Analytic Solutions ([Choi92]). Se trata de un artículo aparecido en la revista IEEE Transactions on Automatic Control, en el que se definen problemas de EDMRs con solución analítica conocida, ideales para su utilización en pruebas.
− Numerical Integration of the Differential Riccati Equation and Some Related Issues ([Diec92]). Contiene una recopilación de varios problemas de EDMRs que provienen de problemas reales, además de una de las aproximaciones del método de resolución BDF más ampliamente utilizada.
1.4 Estructura de la Tesis El contenido de esta tesis se estructura en seis capítulos. El primero corresponde al actual capítulo, en el que se ha realizado una breve descripción de los objetivos planteados en esta tesis, se han enumerado las aportaciones realizadas y se ha explicado la metodología utilizada en el desarrollo e implementación de los algoritmos desarrollados.
En el segundo capítulo se realiza una descripción del estado del arte correspondiente al cálculo de Funciones de Matrices y a la resolución de EDOs y EDMRs. En el caso de las Funciones de Matrices se describen algunas de las definiciones de función de una matriz, se enumeran sus propiedades más importantes y se describen los métodos más usuales para su cálculo. Para la resolución de EDOs se detallan únicamente aquellos aspectos de interés que posteriormente se utilizarán en el desarrollo e implementación de los nuevos métodos basados en la linealización a trozos. Por último, se realiza una descripción detallada del estado del arte correspondiente a la resolución de EDMRs, haciendo una breve exposición de sus principales propiedades, describiendo los métodos numéricos más destacados que se han ido utilizando a lo largo del tiempo y enumerando algunas de sus aplicaciones.
El tercer capítulo está dedicado a describir los algoritmos desarrollados en esta tesis para el cálculo de Funciones de Matrices. Para ello se han desarrollado dos metodologías generales: una basada en los aproximantes diagonales de Padé y otra que utiliza la reducción a la forma real de Schur de una matriz. La primera metodología consiste, básicamente, en las siguientes etapas: 1.- minimizar la norma de la matriz considerada; 2.-determinar un polinomio de Taylor apropiado de la función; 3.- calcular, a partir del polinomio de Taylor, los polinomios de la aproximación diagonal de Padé de la función; 4.- obtener la aproximación diagonal de Padé de la función; y 5.- calcular la función de la matriz, teniendo en cuenta la reducción de la norma realizada en la primera etapa. Una vez realizada esta descripción se particulariza, dicho algoritmo general, al cálculo de algunas Funciones de Matrices: exponencial, logarítmica, potencia

Capítulo 1: Introducción
8
fraccionaria, seno y coseno. La segunda metodología utiliza la forma real de Schur de una matriz para calcular, a partir de ella, la función de la matriz original. Los algoritmos que utilizan esta metodología suelen ser muy precisos y razonablemente eficientes. Entre estos algoritmos se encuentran los basados en la Ecuación Conmutante sin agrupación de valores propios (algoritmos orientados a columnas, a diagonales y a bloques), el algoritmo basado en la agrupación de valores propios cercanos, el algoritmo basado en la diagonalización a bloques de una matriz y el basado en el cálculo de Funciones de Matrices casi triangulares superiores mediante los aproximantes diagonales de Padé.
El cuarto capítulo está dedicado a la resolución de EDOs y EDMRs mediante la técnica de linealización a trozos. En el caso de EDOs se demuestra el Teorema 4.1 y se presentan tres métodos, basados en él, que permiten resolver eficientemente EDOs: Método basado en los aproximantes diagonales de Padé, método basado en la Ecuación Conmutante y método basado en los subespacios de Krylov.
Para la resolución de EDMRS se ha desarrollado una metodología consistente en transformar la EDMR en una EDO y aplicar a esta ecuación diferencial la técnica de linealización a trozos desarrollada para EDOs. Al aplicar la linealización a trozos, se obtiene una Ecuación Diferencial Lineal (EDL) de gran dimensión en cada subintervalo, por lo que se hace necesaria la aplicación de métodos especiales para su resolución. En este caso, en lugar de aplicar los métodos desarrollados para EDOs, se han desarrollado tres nuevos métodos: Método basado en los aproximantes diagonales de Padé, método basado en la Ecuación Conmutante y método basado en los subespacios de Krylov Todos los anteriores métodos se han particularizado para resolver EDOs autónomas y EDMRs con coeficientes constantes de modo que se han reducido los costes computacionales y de almacenamiento.
En el quinto capítulo se detallan y analizan todas las pruebas realizadas. En primer lugar se describen brevemente los componentes software y hardware que, de algún modo, se han utilizado en el desarrollo e implementación de los algoritmos descritos en esta tesis. A continuación se describen las pruebas realizadas para el cálculo de Funciones de Matrices, comenzando con el cálculo de funciones polinómicas y racionales, continuando con el cálculo de funciones trascendentes mediante los aproximantes diagonales de Padé y mediante la descomposición real de Schur de una matriz. Para cada prueba se determinan los valores óptimos de los parámetros característicos de cada implementación. En tercer lugar se presenta un problema consistente en la simulación de la propagación de ondas monocromáticas en fibras de cristal fotónico. El interés del estudio es analizar dicha propagación sin hacer uso de experimentos reales con las consiguientes ventajas que esto supone. Para ello se analizan e implementan los métodos numéricos más adecuados para su simulación. A continuación se describen las pruebas realizadas para la resolución de EDOs, presentando el problema a resolver y sus orígenes. Para cada problema se comparan las funciones/rutinas implementadas, habiendo determinado previamente los valores óptimos de los parámetros característicos de cada función/rutina. Para esa comparación, se han realizado diversas pruebas en las que se varía el incremento de tiempo utilizado en la linealización a trozos, el tiempo final y el tamaño de problema. Del mismo modo, se realiza un estudio similar para la resolución de EDMRs.
En el sexto capítulo se exponen las conclusiones de todo el trabajo realizado, se enumeran las publicaciones realizadas en el marco de esta tesis y se perfilan las posibles líneas de investigación futuras que se abren con la misma.

Capítulo 1: Introducción
9
Al final de la tesis se han añadido cuatro apéndices que a continuación se detallan. En el primer apéndice se describen las definiciones, propiedades y teoremas que, de algún modo, se han utilizado en esta tesis, así como la notación empleada en la misma. En el segundo apéndice se realiza una descripción de MATLAB, como entorno de desarrollo y programación de algoritmos. En el tercer apéndice se describen BLAS y LAPACK, por ser las librerías utilizadas en el desarrollo eficiente y portable de software numérico de altas prestaciones. En el cuarto anexo se describen los componentes software y hardware que se han utilizado en el desarrollo e implementación de los algoritmos descritos en esta tesis: la máquina SGI Altix 3700, el compilador FORTRAN de Intel y las librerías SGI SCL (Scientific Computing Software Library) que contienen el BLAS y el LAPACK.


Capítulo 2: Estado del Arte
11
Capítulo 2 Estado del Arte
2.1 Resumen de Contenidos En este capítulo se hace una revisión de las propiedades y métodos más relevantes para el cálculo de Funciones de Matrices, y la resolución de Ecuaciones Diferenciales Ordinarias (EDOs) y Ecuaciones Diferencial Matriciales de Riccati (EDMRs).
Este capítulo se ha estructurado en cinco secciones. La segunda sección comienza con un estudio completo de las funciones matriciales más utilizadas, indicando sus orígenes y aplicaciones, haciendo además una breve descripción de los métodos que se han ido utilizando desde sus comienzos hasta nuestros días. Junto a la descripción de estos métodos se realiza un estudio comparativo de los mismos, para deducir cuáles son las mejores estrategias para el cálculo de Funciones de Matrices. La finalidad de este estudio es encontrar metodologías generales que permitan calcular eficientemente Funciones de Matrices, sin dejar de lado cada caso particular (tipo de función y matriz).
En la tercera sección se describen únicamente aquellos aspectos de interés en la resolución de EDOs que, de alguna manera, se utilizan en los siguientes capítulos, especialmente los relacionados con el desarrollo e implementación de los nuevos métodos basados en la linealización a trozos.
En la cuarta sección se comienza con una breve descripción de las principales propiedades de las EDMRs, detallando a continuación los métodos de resolución de EDMRs más conocidos, para finalizar con algunos ejemplos de aplicaciones de las mismas.
En la última sección se exponen las conclusiones de este capítulo.
2.2 Funciones de Matrices
2.2.1 Definiciones y Propiedades De una manera informal, dada una función compleja de variable compleja )(zf definida sobre el espectro de una matriz cuadrada A , la matriz )(Af se puede obtener sustituyendo la variable z por la matriz A en la expresión que define a )(zf . Desde un punto de vista formal, )(Af se puede definir utilizando diferentes aproximaciones. En [Rine78], Rinehart demostró la equivalencia entre ocho definiciones de funciones de matrices; quizás la más elegante de ellas, aunque no la más útil desde el punto de vista computacional, es la que se presenta en primer lugar.
Definición 2.1 ([GoVa96], capítulo11).
Sea A una matriz cuadrada definida en el conjunto de los números complejos C y )(zf una función analítica definida en un abierto C⊂U que contiene al espectro de
A . Si U⊂Γ es una curva rectificable que rodea al espectro de A , entonces la matriz )(Af se puede definir como

Capítulo 2: Estado del Arte
12
∫Γ
−−= dzAIzzfi
Af 1))((21)(π
.
Según esta definición, el elemento ),( jk de la matriz )(Af viene dado por
( )∫Γ
−−= dzeAIzezfi
f jTkkj
1)(21π
,
siendo ke y je , respectivamente, la k-ésima y la j-ésima columna de la matriz identidad I . Esta definición proviene del teorema integral de Cauchy, por lo que se trata de una definición independiente de la curva Γ .
Una de las definiciones más utilizadas ([Gant90], [LaMi85]) es la basada en la forma canónica de Jordan de una matriz y en el polinomio de interpolación de grado mínimo de una función.
Definición 2.2 ([Gant90], capítulo 5).
Dada una función analítica )(zf definida en un abierto C⊂U que contiene al espectro de nxnA C∈ , se define la matriz )(Af como
)()( ApAf = ,
siendo )(zp el polinomio de grado mínimo que interpola a la función )(zf en el espectro de la matriz A ; es decir,
)()( )()(i
ji
j fp λλ = , 1,,1,0 −= inj L , si ,,2,1 L= ,
con s el número de valores propios distintos de A y in la mayor de las dimensiones de los bloques de Jordan que contienen al valor propio iλ .
A partir de estas definiciones se pueden demostrar propiedades que permiten calcular y definir, de otras formas, las funciones de matrices.
Propiedad 2.1
Dada nxnA C∈ y )(zf función analítica definida en un abierto C⊂U que contiene al espectro de A , entonces )(Af es solución de la ecuación
( 2.1 ) XAAX = ,
denominada ecuación conmutante.
Propiedad 2.2
Sea nxnA C∈ y )(zf función analítica definida en un abierto C⊂U que contiene al espectro de A . Si 1−= XBXA entonces
1)()( −= XBXfAf .

Capítulo 2: Estado del Arte
13
Propiedad 2.3
Sea nxnA C∈ y )(zf función analítica definida en un abierto C⊂U que contiene al
espectro de A . Si ),,,(diag 21 rAAAA L= , con ii xnni CA ∈ , ri ,,2,1 L= , ∑
=
=r
ii nn
1
,
entonces
))(,),(),(diag()( 21 rAfAfAfAf L= .
Corolario 2.1.
Sea nxnA C∈ y )(zf una función analítica definida en un abierto C⊂U que contiene al espectro de A . Si
*QSQA =
es la descomposición de Schur de A , entonces *)()( QSQfAf = .
Corolario 2.2.
Sea nxnA C∈ y )(zf una función analítica definida en un abierto C⊂U que contiene al espectro de A . Si
( 2.2 ) 1),,,diag(21
−= XJJJXArλλλ L
es la descomposición canónica de Jordan de la matriz A , entonces
( 2.3 ) 1))(,),(),(diag()(21
−= XJfJfJfXAfrλλλ L ,
siendo
( 2.4 ) ( ) ii
ii
ii
i
xnn
i
ii
i
in
i
in
i
i
in
i
in
ii
f
ff
nf
nf
f
nf
nff
f
Jf C∈
⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−
=
−−
−−
)(00!1
)()(0
)!2()(
)!3()(
)(0
)!1()(
)!2()(
!1)(
)(
)1(
)2()3(
)1()2()1(
λ
λλ
λλλ
λλλλ
λ
LL
OL
MMOOM
L
L
, ri ,,2,1 L= .
Otros autores definen las funciones de matrices a partir del concepto de función matricial primaria.
Definición 2.3 ([HoJo91]).
Sea nxnA C∈ y )(zf una función analítica definida en un abierto C⊂U que contiene al espectro de A . Si ( 2.2 ) es la descomposición canónica de Jordan de la matriz A , se define la función matricial primaria de la matriz A como la matriz )(Af obtenida a partir de las expresiones ( 2.3 ) y ( 2.4 ).

Capítulo 2: Estado del Arte
14
Una última aproximación proviene de la definición de una función como suma de una serie de potencias. El siguiente teorema muestra la manera de definir funciones de matrices a partir de sumas de series de potencias de matrices.
Teorema 2.1.
Dada una matriz nxnA C∈ y )(zf una función analítica definida en un abierto C⊂U que contiene al espectro de A , definida por
∑∞
=
=0
)(k
kk zczf ,
entonces la serie de potencias
∑∞
=0k
kk Ac ,
es convergente, cumpliéndose además ([Rine78] que
∑∞
=
=0
)(k
kk AcAf .
2.2.2 Funciones de Matrices más Usuales
2.2.2.1 Función Exponencial Entre las diferentes funciones de matrices, la función exponencial tiene una especial importancia debido a su relación con la resolución de sistemas de ecuaciones diferenciales lineales ([Bell83], [MoVa78]) que aparecen en la resolución de diversos modelos asociados a fenómenos físicos, químicos, biológicos, económicos, etc. ([Karl59], [Varg62]). Por ejemplo, la solución de la Ecuación Diferencial Lineal (EDL) ([Bell53])
)()()( tbtAxdt
tdx+= , 0≥t
con 0)0( xx = , siendo nxnA ℜ∈ y nb ℜ∈ , viene dada por
∫ −+=t
stAAt dssbexetv0
)( )()0()( .
Una forma sencilla de definir la exponencial de una matriz consiste en considerar la serie de potencias
∑∞
=
=0 !
1k
kz zk
e ,
y definir la exponencial de la matriz A como
∑∞
=
=0 !
1k
kA Ak
e .
Esta serie resulta ser convergente para cualquier matriz cuadrada A .

Capítulo 2: Estado del Arte
15
2.2.2.2 Función Signo La función signo matricial, junto a la exponencial de una matriz, resulta ser una de las funciones matriciales que durante más tiempo y con mayor profundidad se ha investigado. Una de las primeras referencias acerca de la función signo matricial se encuentra en el trabajo realizado por Zolotarjov en el año 1877, en el que se caracterizaban las mejores aproximaciones racionales de la función signo escalar mediante el uso de funciones del tipo seno elíptico. Si embargo, el verdadero auge de esta función se encuentra en el trabajo desarrollado por Roberts. En 1971 Roberts realizó un informe técnico ([Robe71]) en el que se definía esta función y se describían sencillos algoritmos para el cálculo de la misma. En este trabajo también se desarrolló el escalado y la estimación del número de condición asociados a la función signo matricial. Este informe técnico no fue muy conocido por la comunidad científica hasta su publicación como artículo, en el año 1980, en la revista International Journal of Control [Robe80].
En 1971 Abramov ([Abra71]) también utilizó un método basado en el cálculo de la función signo matricial para revolver ciertos problemas de contorno asociados a la resolución de EDOs.
Fruto del trabajo pionero de Roberts ha sido el desarrollo de numerosos campos de investigación relacionados con la función signo matricial:
• Aproximación y condicionamiento de las funciones de matrices.
• Aplicaciones en control como, por ejemplo, la resolución de la Ecuación Algebraica Matricial de Lyapunov (EAML) y la resolución de la Ecuación Algebraica Matricial de Riccati (EAMR).
• Teoría de sistemas y cálculo matricial, aplicándose, por ejemplo, en el cálculo de subespacios invariantes.
• Descomposiciones que aparecen en el cálculo de valores propios de una matriz.
• Cálculo de la raíz cuadrada de una matriz.
• Cálculo de la función sector de una matriz.
A continuación se define la función signo matricial tal como aparece en [Robe80]. La función signo escalar se define como
⎩⎨⎧
<−>+
=0)Re( si10)Re( si1
)(signzz
z .
Si nxnA C∈ no tiene valores propios imaginarios puros, entonces existe la función signo matricial de A y se puede definir a partir de la descomposición canónica de Jordan de A , como a continuación se detalla.
Si 1),,,diag(
21
−= XJJJXArλλλ L
es la descomposición canónica de Jordan de la matriz A , entonces la función signo matricial de A se define como
1))sign(,),sign(,)diag(sign()(sign21
−= XJJJXArλλλ L .
Al cumplirse que

Capítulo 2: Estado del Arte
16
( ) 0)(sign == iz
zdzd
λ
,
y teniendo en cuenta ( 2.4), entonces
( )
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
)(sign0000)(sign00
00)(sign0000)(sign
sign
i
i
i
i
iJ
λλ
λλ
λ
L
MMOMM
L
L
, ri ,,2,1 L= .
Es fácil comprobar que la función signo matricial cumple las siguientes propiedades.
Propiedad 2.4.
Si nxnA C∈ , entonces nIA =2)](sign[ .
Propiedad 2.5.
Si nxnA C∈ , entonces )(sign)(sign)(sign AccA = .
Propiedad 2.6.
Los valores propios de la matriz )(sign A , nxnA C∈ , son 1± .
2.2.2.3 Función Raíz Cuadrada Uno de los métodos más usuales para calcular funciones de matrices consiste en realizar un escalado previo de la matriz, pues permite reducir su norma y así se pueden aplicar técnicas generales para el cálculo de funciones de matrices como, por ejemplo, las aproximaciones de tipo polinómico (aproximaciones de Taylor) o las aproximaciones de tipo racional (aproximantes de Padé). Por ejemplo, el escalado utilizado en el cálculo de la función logarítmica, se puede realizar utilizando la identidad
j
AA j 2/1log2log = , L,2,1=j ,
en la que aparecen raíces cuadradas de matrices.
Para definir la raíz cuadrada de una matriz es necesario que sea consistente con la definición correspondiente al caso escalar. Dada una matriz nxnA C∈ , una solución
nxnX C∈ de la ecuación matricial cuadrática
AX =2 ,
se llama raíz cuadrada de A .
Por ejemplo, fácilmente se puede comprobar que la matriz
⎥⎦
⎤⎢⎣
⎡=
0010
A
no tiene raíces cuadradas, sin embargo, la matriz

Capítulo 2: Estado del Arte
17
⎥⎦
⎤⎢⎣
⎡=
0001
A
admite como raíces cuadradas a las matrices
⎥⎦
⎤⎢⎣
⎡=
0001
1X , ⎥⎦
⎤⎢⎣
⎡−=
0001
2X .
Según esto, puede no existir la raíz cuadrada de A , o existir una o más raíces de ella.
El siguiente teorema caracteriza las raíces cuadradas de una matriz cuadrada compleja y determina cuáles de ellas corresponden a funciones de matrices en el sentido de la Definición 2.2.
Lema 2.1 ([Hig287]).
Si C∈iλ es distinto de cero, entonces el bloque de Jordan
ii
i
xnn
i
i
i
i
J C∈
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
λλ
λλ
λ
000100
000001
L
L
MOOMM
O
L
,
tiene precisamente dos raíces cuadradas que son funciones de i
Jλ en el sentido de la Definición 2.2,
( 2.5 ) ( ) ii
inin
inin
i
xnn
ij
ijij
i
ij
i
iji
i
ij
i
ijijij
j
f
ff
nf
nf
f
nf
nff
f
Jf C∈
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−
=
−−
−−
)(000!1
)()(00
)!2()(
)!3()(
)(0
)!1()(
)!2()(
!1)(
)(
)1(
)2()3(
)1()2()1(
λ
λλ
λλλ
λλλλ
λ
L
L
MMOOM
L
L
, 2,1=j ,
donde λλ =)(jf denota una de las dos ramas de la función raíz cuadrada en el entorno de iλ .
Teorema 2.2 ([Hig287]).
Sea nxnA C∈ una matriz no singular con la descomposición de Jordan 11 ),,,diag(
21
−− == XJJJXXJXArλλλ L ,
donde ii
i
xnnJ C∈λ , ∑=
=r
ii nn
1
, y s ( rs ≤ ) el número de valores propios distintos de A .
Se verifican entonces las siguientes propiedades:

Capítulo 2: Estado del Arte
18
1. A tiene precisamente s2 raíces cuadradas que son funciones de A en el sentido de la Definición 2.2, dadas por
1))(,),(),(diag(2211
−= XJfJfJfXFrrjjjj λλλ L , sj 2,,2,1 L= ,
correspondientes a todas las posibles elecciones de rjjj ,,, 21 L ( { }2,1∈ij , ri ,,2,1 L= ), sujetas a la restricción de que lk jj = si lk λλ = .
2. Si rs < , entonces A tiene raíces cuadradas que no son funciones de A en el sentido de la Definición 2.2. Estas raíces forman familias parametrizadas
11))(,),(),(diag()(2211
−−= XUJfJfJfXUUFrrjjjj λλλ L ,
ri
s j 212 ≤≤+ , ri ,,2,1 L= , siendo U una matriz no singular arbitraria que conmuta con ),,,(diag
21 rJJJ λλλ L , y para cada j existen unos índices k y l ,
dependientes de j , de manera que lk λλ = y lk jj ≠ .
Corolario 2.3 ([Hig287]).
Si C∈kλ es distinto de cero, entonces las únicas raíces cuadradas de la matriz k
Jλ del Lema 2.1 son las que aparecen en ( 2.5 ).
Corolario 2.4 ([Hig287]).
Si cada valor propio de nxnA C∈ aparece en un solo bloque de Jordan de la forma canónica de Jordan de A , entonces A tiene precisamente r2 raíces cuadradas, todas ellas funciones de A en el sentido de la Definición 2.2.
Corolario 2.5 ([Hig287]).
Toda matriz hermítica y definida positiva tiene una única raíz cuadrada hermítica y definida positiva.
A continuación se detallan varios teoremas acerca de la existencia de raíces de matrices cuadradas reales.
Teorema 2.3 ([HoJo91], página 473).
Sea una matriz nxnA ℜ∈ . Existe una matriz nxnB ℜ∈ , raíz cuadrada de A , si y solo si se cumplen las siguientes condiciones:
1. Dados los enteros nr =0 , )( kk Arangor = , para L,2,1,0=k , entonces la
secuencia }{ 1+− kk rr para L,2,1,0=k , no contiene dos apariciones consecutivas del mismo entero par y si además 10 rr − es par, entonces 12 210 ≥+− rrr .
2. Si
ii
i
xnn
i
i
i
i
J C∈
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
λλ
λλ
λ
000100
000001
L
L
MOOMM
O
L

Capítulo 2: Estado del Arte
19
es un bloque de Jordan de A , con iλ un valor propio real negativo de A , entonces A tiene un número par de bloques de Jordan de igual tamaño in incluido
iJλ .
Teorema 2.4 ([High87]).
Sea nxnA ℜ∈ una matriz no singular. Existe una matriz nxnB ℜ∈ , raíz cuadrada real de la matriz A , si y solo si cada bloque de Jordan de la matriz A correspondiente a un valor propio real negativo, aparece un número impar de veces.
La comprobación de la existencia de raíces cuadradas de una matriz, a partir de los teoremas anteriores, es complicada de manejar, fundamentalmente porque es necesario conocer la descomposición canónica de Jordan de la matriz considerada. El siguiente teorema, cuya demostración está basada en la descomposición real de Schur de una matriz, permite una comprobación más sencilla de la existencia de raíces cuadradas de matrices reales.
Teorema 2.5 ([High87]).
Sea nxnA ℜ∈ una matriz no singular. Si A tiene un valor propio real negativo, entonces A no tiene raíces cuadradas que son funciones de A en el sentido de la Definición 2.2. Si A no tiene valores propios reales negativos, entonces existen exactamente cr+2 raíces cuadradas reales que son funciones de A en el sentido de la Definición 2.2, siendo r el número de valores propios reales de A y c el número de pares de valores propios complejos conjugados.
2.2.2.4 Función Raíz p-ésima
Dada una matriz nxnA C∈ , se dice que la matriz nxnX C∈ es una raíz p-ésima de la matriz A si cumple
AX p = .
Entre las aplicaciones que requieren el cálculo de las raíces p-ésimas de una matriz se encuentra el cálculo de la función sector definida por
AAA pp /1)()sec( −= ([KoBa95], [ShTs84]).
Otra posible aplicación aparece en el escalado de una matriz para el cálculo del logaritmo de una matriz. En este caso, se determina un entero positivo p de manera que
pApA /1loglog = ,
con |||| /1 pA menor que un cierto valor ([ChHi01], [KeL289]).
Al igual que ocurre en el caso particular de raíces cuadradas, la raíz p-ésima de una matriz puede no existir o tener una o más soluciones. Si A es no singular, entonces admite al menos una raíz p-ésima; en caso contrario, la matriz A admite raíces p-ésimas dependiendo de la estructura de los divisores elementales de A correspondientes a los valores propios nulos ([Gant90], sección 8.7).

Capítulo 2: Estado del Arte
20
Definición 2.4 ([Smit03]).
Sea nxnA C∈ una matriz no singular con valores propios iλ , ni ,,1L= , de manera que πλ ≠)arg( i , ni ,,1L= . La raíz p-ésima principal de A , denotada por
nxnpA C∈/1 , se define como la matriz que satisface las dos condiciones siguientes:
1. AA pp =)( /1 .
2. Los argumentos de los valores propios de la matriz pA /1 se encuentran en el intervalo [/,/] pp ππ− .
El siguiente teorema, generalización del Teorema 2.2, permite caracterizar las raíces p-ésimas de una matriz cuadrada compleja a partir de su descomposición de Jordan, y determina cuáles de ellas corresponden a funciones de matrices según la Definición 2.2.
Lema 2.2 ([Smit03]).
Si C∈iλ es distinto de cero, entonces el bloque de Jordan
ii
i
xnn
i
i
i
i
J C∈
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
λλ
λλ
λ
000100
000001
L
L
MOOMM
O
L
,
tiene precisamente p raíces p-ésimas que son funciones de i
Jλ , definidas como
( ) ii
inin
inin
i
xnn
ij
ijij
i
ij
i
iji
i
ij
i
ijijij
j
f
ff
nf
nf
f
nf
nff
f
Jf C∈
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−
=
−−
−−
)(000!1
)()(00
)!2()(
)!3()(
)(0
)!1()(
)!2()(
!1)(
)(
)1(
)2()3(
)1()2()1(
λ
λλ
λλλ
λλλλ
λ
L
L
MMOOM
L
L
, pj ,,2,1 L= ,
donde pjf λλ =)( denota una de las p ramas de la función raíz p-ésima en el entorno
de iλ .
Teorema 2.6 ([Smit03]).
Sea nxnA C∈ una matriz no singular con la descomposición de Jordan
( ) 1,,,diag21
−= XJJJXArλλλ L ,
donde ii
i
xnnJ C∈λ , ∑=
=r
ii nn
1
, y s ( rs ≤ ) el número de valores propios distintos de A
Se verifican entonces las siguientes propiedades:

Capítulo 2: Estado del Arte
21
1. A tiene precisamente sp raíces de índice p , dadas por 1))(,),(),(diag(
2211
−= XJfJfJfXFrrjjjj λλλ L , spj ,,2,1 L= ,
correspondientes a todas las posibles elecciones de rjjj ,,, 21 L , { }pji ,,2,1 L∈ , ri ,,2,1 L= , sujetas a la restricción de que lk jj = si lk λλ = .
2. Si rs < , entonces A tiene raíces p-ésimas que no son funciones de A . Estas raíces forman familias parametrizadas
11))(,),(),(diag()(2211
−−= XUJfJfJfXUUFrrjjjj λλλ L ,
ri
s pjp ≤≤+1 ,
donde { }pji ,,2,1 L∈ , ri ,,2,1 L= , siendo U una matriz no singular arbitraria que conmuta con ( )
rJJJ λλλ ,,,diag
21L , y para cada j existen k y l ,
dependientes de j , de manera que lk λλ = y lk jj ≠ .
2.2.2.5 Función Logaritmo Los logaritmos de matrices aparecen en algunos campos de la ingeniería, como los relacionados con la teoría de control. Por ejemplo, para un sistema físico gobernado por la EDL
)()( tAxtx =& , 0)0( xx = ,
en la que nxnA ℜ∈ es una matriz desconocida, es posible determinar esta matriz A a partir de n observaciones, nxxx ,,, 21 L , del vector de estados )(tx , producidas por n vectores de condiciones iniciales ([AlPr81], [SiSp76]). Puesto que la solución de la ecuación diferencial anterior es
0)( xetx At= ,
particularizando esta expresión para 1=t y considerando como estados iniciales las columnas de la matriz identidad, se obtiene que
AeB = ,
y, por tanto, BA log= , siendo ],,,[ 21 nxxxB L= .
El siguiente teorema caracteriza las condiciones de existencia del logaritmo de una matriz.
Teorema 2.7 ([HoJo91], página 475).
1. Si nxnA C∈ es no singular, entonces existe al menos un matriz nxnX C∈ que verifica Ae X = y es polinomial en A ; es decir, existe un polinomio )(zp de manera que )(ApX = .
2. Si nxnA C∈ es singular, entonces no existe ninguna matriz nxnX C∈ tal que Ae X = .
3. Si nxnA ℜ∈ , entonces existe nxnX ℜ∈ de manera que Ae X = si y solo si se cumplen las dos condiciones siguientes:

Capítulo 2: Estado del Arte
22
a. A es no singular.
b. Si
ii
i
xnn
i
i
i
i
CJ ∈
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
λλ
λλ
λ
000100
000001
L
L
MOOMM
O
L
,
es un bloque de Jordan de A , con iλ un valor propio real negativo de A , entonces A tiene un número par de bloques de Jordan de igual tamaño in , incluido
iJλ .
4. Si nxnA ℜ∈ tiene algún valor propio real negativo, entonces ninguna solución real de Ae X = puede ser polinomial en A o función matricial primaria de A .
Como consecuencia de este teorema se tiene que si nxnA ℜ∈ no tiene valores propios reales negativos, entonces tiene un logaritmo real; es decir, existe una matriz nxnL ℜ∈ de manera que AeL = . Pueden existir diferentes matrices que proporcionen el logaritmo de una matriz, pero sólo una de ellas tiene las partes imaginarias de sus valores propios en el intervalo [,] ππ− . Esta matriz se denomina logaritmo principal de A y se denota con Alog .
2.2.2.6 Funciones Seno y Coseno Las funciones matriciales trigonométricas juegan un papel fundamental en los sistemas diferenciales lineales de segundo orden. Por ejemplo, el problema
02
2
=+ Axdt
xd , 0)0( xx = , '0)0(' xx = ,
con nxnA ℜ∈ , tiene como solución '0
10 )(sen)()cos()( xtAtAytAtx −+= .
Problemas más generales de este tipo, en los que aparece un término )(tf en la parte derecha de la ecuación diferencial, proceden de la semidiscretización de la ecuación de ondas y de los sistemas mecánicos sin amortiguamiento. En tales casos, las soluciones pueden expresarse en función de términos que involucran senos y cosenos de matrices ([Serb79]).
Las definiciones más usuales de la funciones seno y coseno de una matriz están basadas en las series de Taylor
∑∞
=
+
+−=
0
12
)!12()1(sen
k
kk
kAA
y
∑∞
=
−=0
2
)!2()1(cos
k
kk
kAA .

Capítulo 2: Estado del Arte
23
2.2.3 Métodos Numéricos para el Cálculo de Funciones de Matrices
2.2.3.1 Función Exponencial
2.2.3.1.1 Métodos Basados en las Series de Taylor
Sea )(zf una función analítica definida sobre el espectro de nxnA C∈
k
kk zczf ∑
∞
=
=0
)( .
Según el Teorema 2.1, la matriz )(Af se puede hallar mediante la expresión
∑∞
=
=0
)(k
kk AcAf .
El valor aproximado de )(Af se puede obtener truncando adecuadamente la serie anterior. Para ello se calculan los términos de la serie hasta que se encuentra un número natural L , de manera que la representación en coma flotante de la matriz LS sea igual a la representación en coma flotante de 1+LS ; es decir, )()( 1+= LL SflSfl , siendo
∑=
=L
k
kkL AcS
0.
El valor aproximado de )(Af será, por lo tanto, )( LSfl .
Este método puede producir un resultado inexacto debido, fundamentalmente, a los errores de redondeo causados cuando se desprecian los términos de la serie a partir de un cierto orden, y al problema de la cancelación de dígitos significativos que se produce cuando se suman y restan números del mismo orden de magnitud. Además, a medida que A es mayor o la dispersión de los valores propios de la matriz A aumenta, se tiene que los errores de redondeo y los costes computacionales aumentan.
Se han diseñado diversos algoritmos basados en las aproximaciones de Taylor ([PChK91], [GoVa96]), que intentan evitar esos problemas, haciendo uso de la identidad
( )mmAA ee /= .
El método de escalado y potenciación consiste en seleccionar un valor m como potencia de 2, jm 2= , de manera que mAe / pueda calcularse con precisión y eficiencia, y entonces calcular ( )mmAe / mediante potenciación repetida.
2.2.3.1.2 Métodos Basados en los Aproximantes de Padé
Los aproximantes de Padé de orden ),( qp de zezf =)( son funciones racionales definidas como
)(/)()( zDzNzR pqpqpq = ,
donde

Capítulo 2: Estado del Arte
24
kp
kpq z
kpkqppkqpzN ∑
= −+−+
=0 )!(!)!(
!)!()(
y
.)()!(!)!(
!)!()(0
kq
kpq z
kqkqpqkqpzD ∑
=
−−+
−+=
En particular, )(0 zRp coincide con el polinomio de Taylor de grado p de la función ze .
Los aproximantes de Padé permiten calcular aproximadamente la exponencial de una matriz nxnA C∈ mediante la expresión
[ ] [ ])()()( 1 ANADARe pqpqpqA −=≅ .
El problema es que únicamente proporcionan buenas aproximaciones en un entorno del origen, tal como revela la igualdad
dueuuADAqp
ARe uAqppq
qpq
pqA )1(
1
0
11 )1()()!(
)1()( −−++ −+
−+= ∫ ([GoVa96], capítulo 11).
Una manera de evitar el problema anterior consiste en utilizar el método de escalado y potenciación, eligiendo para ello el menor entero positivo j de manera que
1/|||| <mA , siendo jm 2= .
Con este criterio, mAe / puede calcularse mediante los aproximantes de Taylor o de Padé. Esta última aproximación ha sido tratada por numerosos autores entre los que cabe destacar, por su análisis de errores, a Ward [Ward77], Kammler [Kamm76], Kallstrom [Kall73], Scraton [Scra71] y Shah [Shah71].
En [MoVa78] Moler y Van Loan demostraron que si
21
2||||
≤∞j
A ,
siendo nxnA C∈ , entonces existe nxnE C∈ tal que EA
pq eR += ,
EAAE = ,
∞∞ ≤ ||||),(|||| AqpE ε ,
.)!1()!(
!!2),( )(3
+++= +−
qpqpqpqp qpε
Estos resultados permiten controlar el error que se puede cometer al calcular Ae pues
∞∞
∞
∞ ≤− ||||),(||||),(
|||||||| Aqp
Apq
A
eAqpe
Re εε .
Existen varias razones para utilizar los aproximantes diagonales de Padé ( qp = ) en lugar de los no diagonales ( qp ≠ ). Si qp < , entonces, aproximadamente, 32qn flops

Capítulo 2: Estado del Arte
25
son necesarios para calcular la aproximación de Padé de orden qp + , )(ARpq . Sin embargo, la misma cantidad de flops son necesarios para calcular la aproximación de orden qpq +>2 , )(ARqq . La conclusión es análoga para qp > .
Existen otros motivos para la utilización de aproximantes diagonales de Padé. Por ejemplo, si todos los valores propios de A están en el semiplano 0)Re( <z , entonces los aproximantes calculados con qp > suelen tener errores de redondeo más elevados debido a problemas de cancelación, mientras que con qp < se suelen producir mayores errores de redondeo debido al mal condicionamiento del denominador )(ADpq .
Existen ciertas aplicaciones donde la determinación de p y q se basan en el comportamiento de
).(lim tARpqt ∞→
Si todos los valores propios de A están en el semiplano complejo izquierdo abierto, entonces
0lim =∞→
At
te ,
y también
0)(lim =→∞
tARpqt, si .pq >
Cuando pq < (incluyendo el caso 0=q ) resulta que los aproximantes de Padé están acotados para valores de t elevados. Si qp = entonces los aproximantes están acotados cuando t tiende a infinito.
En [MoVa78] se proponen los valores óptimos de q ( qp = ) y j en las aproximaciones de Padé y Taylor, en función de la norma de la matriz A . Esos valores están representados en la tabla que se presenta a continuación.
Tabla 2.1: Parámetros óptimos de escalado y potenciación, en los aproximaciones de Padé y Taylor.
(p,q) ε=10-3 ε=10-6 ε=10-9 ε=10-12 ε=10-15
|| A ||∞=10-2 (1,0) (3,0)
(2,0) (4,0)
(3,0) (4,2)
(4,0) (4,4)
(4,0) (5,4)
|| A ||∞=10-1 (2,1) (5,1)
(3,1) (7,1)
(4,1) (6,3)
(5,1) (8,3)
(6,1) (7,5)
|| A ||∞=100 (2,5) (4,5)
(3,5) (6,5)
(4,5) (8,5)
(5,5) (7,7)
(6,5) (9,7)
|| A ||∞=101 (2,8) (4,8)
(3,8) (5,9)
(4,8) (7,9)
(5,8) (9,9)
(6,8) (10,10)
|| A ||∞=102 (2,11) (5,11)
(3,11) (7,11)
(4,11) (6,13)
(5,11) (8,13)
(6,11) (8,14)
|| A ||∞=103 (1,0) (3,0)
(2,0) (4,0)
(3,0) (4,2)
(4,0) (4,4)
(4,0) (5,4)

Capítulo 2: Estado del Arte
26
Dada un pareja de valores ε y ∞|||| A , entonces el par de arriba muestra los valores ),( jq óptimos asociados a la aproximación de Padé
( )[ ] jj
qq AR 22/ ,
y el de abajo especifica la elección más eficiente de ),( jk correspondiente a la aproximación de Taylor
( )[ ] jj
k AT 22/ .
A continuación se presenta un algoritmo ([GoVa96]) que calcula la exponencial de una matriz mediante aproximantes diagonales de Padé.
),( δAdgeexpF = .
Entradas: Matriz nxnA ℜ∈ , tolerancia +ℜ∈δ . Salida: Matriz nxnEAeF ℜ∈= + de manera que ∞∞ ≤ |||||||| AE δ .
1 ))||||(logfloor1,0max( 2 ∞+= Aj 2 jAA 2/= 3 Calcular q de manera que sea el menor entero positivo tal que
δε ≤+++
= +−
)!1()!(!!2),( )(3
qpqpqpqp qp
4 nID = ; nIN = ; nIX = ; 1=c 5 Para qk :1=
5.1 kkq
kqcc)12()1(
+−+−
=
5.2 AXX = ; cXNN += ; cXDD k)1(−+= 6 Para jk :1=
6.1 2FF =
Algoritmo 2.1: Calcula la exponencial de una matriz mediante aproximantes diagonales de Padé.
El coste del algoritmo anterior es 3)3/1(2 njq ++ flops.
En el capítulo 11 de [GoVa96] se señala la necesidad de utilizar técnicas especiales, basadas en el método de Horner y variantes, que permiten reducir el coste computacional de este método. Si, por ejemplo, 8=q y se define )(ADD qq= y
)(ANN qq= , entonces
AVUANqq +=)( y AVUADqq −=)( ,
donde 44
82
642
20 )( AAcAcIcAcIcU nn ++++= ,
y 42
752
31 )( AAcIcAcIcV nn +++= ,

Capítulo 2: Estado del Arte
27
siendo ic , 80 ≤≤ i , los coeficientes del polinomio N .
Recientemente, Higham ([High04]) ha realizado una revisión del cálculo de exponenciales de matrices mediante aproximantes de Padé. En ese artículo Higham argumenta y justifica que la mejor elección del valor de los aproximantes de Padé es el de 13== qp , en lugar de los valores de 6 y 8 que otros autores anteriormente habían señalado. Además, para reducir el coste computacional, Higham utiliza técnicas de anidamiento para el cálculo de las matrices U y V ([PaSt73]).
2.2.3.1.3 Métodos Basados en Integración Numérica
Como Ate y 0xe At son soluciones de la EDL que tiene a la matriz A como matriz de coeficientes, es natural considerar métodos basados en la integración numérica. Los algoritmos de este tipo pueden tener un control del tamaño del paso automático, variando automáticamente el orden de la aproximación. Los métodos basados en fórmulas de un solo paso, fórmulas multipaso y fórmulas multipaso implícito (apartado 2.3.2) presentan ciertas ventajas. Son fáciles de utilizar para el cálculo de Ate , sin embargo, requieren un alto coste computacional.
Puesto que la ecuación de estados de un sistema dinámico lineal continuo es un caso particular de la EDO no lineal,
0)0( )),(),(,()(' xxtutxtftx == ,
su solución puede hallarse mediante métodos de integración numérica para este tipo de ecuaciones.
Una desventaja de esta aproximación es la gran cantidad de operaciones necesarias, pues no hacen uso de la naturaleza especial del problema. Sin embargo, la implementación de un algoritmo que resuelva una EDO es necesaria en el caso de ecuaciones de estado o de problemas control con coeficientes variables. Los métodos numéricos para resolver la EDO
0)0( )),(,()(' xxtxtftx == ,
son discretos; es decir, son métodos que calculan una secuencia de aproximaciones )( kk txx = para un conjunto de puntos
kkk ttt ∆+=+1 , 1,,1,0 −= nk L ,
en donde el tamaño de paso kt∆ puede variar. En general, la aproximación 1+kx se calcula a partir de los valores previos 01 ,,, xxx kk L− .
Los errores en la solución numérica de una EDO son el resultado del proceso de discretización (llamado error de truncamiento) y de los errores de redondeo. El error de discretización local es el error producido en un paso dado, considerando que son exactos los valores previos y que no hay errores de redondeo en los cálculos. Este error se puede determinar de la siguiente forma. Sea la función )(tyk que satisface
kkkkk xtytytfty == )(,))(,()(' .
Entonces el error local kd está dado por
)( 11 ++ −= kkkk tyxd .

Capítulo 2: Estado del Arte
28
De esta forma el error local es la diferencia entre la aproximación calculada y la solución teórica definida por la misma condición inicial en el instante 1+kt .
El error de discretización global ke en el paso k es la diferencia entre la aproximación calculada kx (sin tener en cuenta los errores de redondeo) y la solución exacta )( ktx determinada por la condición inicial 0x , es decir,
)( kkk txxe −= .
Claramente, el error global depende de todos los errores locales producidos en los pasos previos.
Prácticamente, todos los códigos actuales que resuelven EDOs controlan el error local en cada instante, y no intentan controlar directamente el error global. Sin embargo, las propiedades de los errores de redondeo no son estudiadas en profundidad, en parte porque la exactitud requerida en el algoritmo de resolución de la EDO es menor que la precisión de la máquina.
Métodos de Propósito General
Muchas librerías que resuelven problemas de valores iniciales en EDOs, permiten calcular Ate , para diferentes valores de ℜ∈t . El problema de utilizar estas librerías es que no se aprovecha la linealidad de la ecuación asociada al problema del cálculo de
Ate , y que los coeficientes que aparecen en ella son constantes.
Métodos de Paso Único Dos técnicas clásicas para la resolución de ecuaciones diferenciales son los métodos de Taylor y Runge-Kutta de cuarto orden. Si se considera un tamaño de paso t∆ constante, entonces para la aproximación de Taylor de orden cuatro, se obtienen las ecuaciones
iii xtATxAttAIx )(!4
... 44
4
1 ∆=⎟⎟⎠
⎞⎜⎜⎝
⎛ ∆++∆+=+ ,
y para el método de Runge-Kutta de orden cuatro
43211 61
31
31
61 kkkkxx ii ++++=+ ,
siendo
)2/( , 121 kxtAktAxk ii +∆=∆= ,
( )3423 ),2/( kxtAkkxtAk ii +∆=+∆= .
En este caso, se puede comprobar que los dos métodos producirían idénticos resultados, si no fuese por los errores de redondeo. Como el tamaño del paso es fijo, la matriz
)(4 tAT ∆ únicamente se calcula una vez. En tal caso, 1+ix se puede obtener a partir de ix con solo realizar un producto matriz-vector. El método de Runge-Kutta requiere cuatro de estos productos por paso.
Considérese )(tx para un valor particular de t , por ejemplo 1=t . Si mt /1=∆ , entonces
[ ] 04 )()()1( xtATxtmxx mm ∆=≅∆= .

Capítulo 2: Estado del Arte
29
Consecuentemente, existe una conexión cercana entre este método y la aproximación de Taylor con escalado y potenciación antes comentada ([Mast69], [Whit69]). El escalado de tA∆ y su exponencial están aproximados por )(4 tAT ∆ . Sin embargo, incluso si m es una potencia de 2, [ ]mtAT )(4 ∆ no se obtiene normalmente mediante potenciación repetida.
Métodos Multipaso Como es sabido, la posibilidad de aplicar métodos específicos multipaso para resolver problemas lineales con coeficientes constantes, tal como los basados en las fórmulas de Adams-Bashforth, no ha sido estudiada con detalle. Estos métodos no equivalen a los métodos que utilizan escalado y potenciación, puesto que la solución aproximada, para un tiempo dado, está definida en términos de soluciones aproximadas de varios tiempos anteriores. El algoritmo dependería de cómo se obtuviesen los vectores de comienzo y de cómo se determinasen el tamaño del paso y el orden.
2.2.3.1.4 Métodos Polinomiales
Sea
∑−
=
−=−=1
0)det()(
n
k
kk
n zczAzIzc ,
el polinomio característico de la matriz nxnA C∈ .
Según el teorema de Cayley-Hamilton, se tiene que 0)( =Ac , y por lo tanto 1
110−
−+++= nn
n AcAcIcA L .
Luego cualquier potencia de A puede expresarse en términos de 1,,, −nAAI L ,
∑−
=
=1
0
n
j
jkj
k AA β ,
por lo que Ate es polinomial en A con coeficientes analíticos que dependen de t ,
( 2.6 ) ∑∑ ∑∑ ∑∑−
=
−
=
∞
=
∞
=
−
=
∞
=
=⎟⎟⎠
⎞⎜⎜⎝
⎛=⎟⎟
⎠
⎞⎜⎜⎝
⎛==
1
0
1
0 00
1
00 !!!
n
j
jj
n
j
j
k
k
kjk
n
j
jkj
k
k
kkAt AA
ktA
kt
kAte αββ .
Los siguientes métodos utilizan el polinomio característico para calcular la exponencial de una matriz.
Método de Cayley-Hamilton Si se calcula una aproximación de
( 2.7 ) ∑∞
=
=0 !
)(k
k
kjj ktt βα ,
entonces Ate se puede obtener, de manera aproximada, a partir de la expresión ( 2.6 ). Los coeficientes kjβ de ( 2.7 ) se pueden calcular del siguiente modo,

Capítulo 2: Estado del Arte
30
⎪⎪⎩
⎪⎪⎨
⎧
>>+=>
=<
=
−−−−
−−
.0,si,0,si
,si,si
1111
110
,,
,
jnkcjnkcnkcnk
jknkj
nk
j
kj
kj
βββ
δ
β
Una dificultad es que estas fórmulas recursivas son muy propensas a errores de redondeo. Por ejemplo, si ( )α=A es una matriz de orden 1, entonces
kk αβ =0
y
∑∞
=
=0
0 !)(
k
k
ktαα
resulta ser el desarrollo de Taylor de teα , con lo cual existen los mismos problemas que se comentaron en el método de aproximaciones de Taylor.
Otra dificultad de este método es que se debe conocer el polinomio característico de la matriz. Si nλλλ ,,, 21 L son los valores propios de una matriz cuadrada A , entonces el polinomio característico )(zc se puede calcular a partir de
∏=
−=n
iizzc
1
)()( λ .
Aunque los valores propios pueden calcularse de forma estable, no está claro si los coeficientes ic son aceptables. Otros métodos para el cálculo de )(zc están descritos por Wilkinson en [Wilk92]. En este artículo, Wilkinson afirma que los métodos basados en fórmulas que obtienen los coeficientes ic a partir de funciones simétricas son inestables y costosos de implementar. Las técnicas basadas en transformaciones de semejanza fallan cuando A está próxima a ser derogatoria.
En el método de Cayley-Hamilton, Ate se expande en función de las matrices 1,,, −nAAI L . Si { }nAAA ,,, 10 L es un conjunto de matrices que generan el mismo
subespacio, entonces existen funciones analíticas )(tjβ tales que
∑−
=
=1
0)(
n
jjj
At Ate β .
La viabilidad de esta aproximación depende de la facilidad de generar jA y )(tjβ .
Si se conocen los valores propios nλλλ ,,, 21 L de A , entonces se pueden aplicar cualquiera de los métodos que se presentan a continuación.
Método de Interpolación de Lagrange
Se basa en la expresión
∑ ∏= =
≠−
−=
n
j
n
k kj
nktAt
jk
IAee j
1 1 λλλλ .

Capítulo 2: Estado del Arte
31
Método de Interpolación de Newton En este método la expresión utilizada es
( )∑ ∏=
−
=
−+=n
j
j
knkjn
tAt IAIee2
1
121 ] ,,,[1 λλλλλ L .
Las diferencias ] ,,,[ 21 jλλλ L dependen de t y se definen recursivamente mediante las expresiones
2121
21
],[λλ
λλλλ
−−
=tt ee ,
2 ,] ,, ,[] ,, ,[], ,,[1
11
1322121 ≥
−−
=+
++ k
k
kkk λλ
λλλλλλλλλ LLL .
En [Macd56] se analizan estas fórmulas cuando la matriz A tiene valores propios múltiples.
Método de Vandermonde Existen otros métodos para calcular las matrices
∏≠= −
−=
n
k kj
nkj
jk
IAA1 λλ
λ , nj ,,2,1 L= ,
que son necesarias en el método de interpolación de Lagrange. Uno de estos métodos se basa en la determinación de la matriz de Vandermonde
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
−−
−−
−−−
−−
−
111
11
121
12
22
1
121
1111
nn
nn
nn
nn
nn
nn
nn
V
λλλλλλλλ
λλλλ
L
MMOMM
L
L
.
Si jkv es el elemento ),( kj de 1−V , entonces
∑=
−=n
k
kjkj AvA
1
1
y
( 2.8 ) ∑=
=n
jj
tAt Aee j
1
λ .
Cuando A tiene valores propios múltiples se puede utilizar la correspondiente matriz de Vandermonde para el cálculo de las matrices jA que aparecen en la expresión ( 2.8 ).
Estos métodos polinomiales tienen un coste computacional elevado, )( 4nO , por lo que no son apropiados a menos que el valor de n sea pequeño. Si se almacenan las matrices
nAAA ,,, 21 L , entonces el coste de almacenamiento es del orden )( 3nO , mayor que el coste de almacenamiento necesario en los métodos no polinomiales.

Capítulo 2: Estado del Arte
32
Los siguientes métodos no requieren el uso de los valores propios de A y, por lo tanto, desaparece el problema asociado a la multiplicidad de los mismos. Sin embargo, otras dificultades de la misma importancia aparecen en los algoritmos basados en estos métodos.
Método Basado en Transformaciones Inversas de Laplace
Si ][L representa a la transformada de Laplace, entonces los elementos de la matriz 1)(][ −−= AsIeL n
At ,
son funciones racionales de s . En efecto,
k
n
k
kn
n Asc
sAsI ∑−
=
−−− =−
1
0
11
)()( ,
donde
∑−
=
−=−=1
0)det()(
n
k
kk
nn scsAsIsc ,
siendo
kAAc k
kn)(traza 1−
−
−= , nk ,,2,1 L= ,
nknkk IcAAA −− −= 1 , nk ,,2,1 L= ,
nIA =0 .
Estas recurrencias, demostradas por Leverrier y Faddeeva [Fadd59], pueden utilizarse para evaluar Ate mediante la expresión
k
n
k
knAt A
scsLe ∑
−
=
−−−
⎥⎦
⎤⎢⎣
⎡=
1
0
11
)(,
donde las trasformadas inversas
⎥⎦
⎤⎢⎣
⎡ −−−
)(
11
scsL
kn
pueden expresarse como series de potencias en t .
Los problemas de este método son su elevado coste computacional, )( 4nO , y la gran influencia que tienen en él los errores de redondeo.
2.2.3.1.5 Métodos Basados en la Descomposición de Matrices
Todos los métodos de descomposición están basados en hallar transformaciones de semejanza
1−= XBXA ,
de manera que el cálculo de )(Bf sea más sencillo que el de )(Af , puesto que entonces, al aplicar la Propiedad 2.2, se tiene que
1)()( −= XBXfAf .

Capítulo 2: Estado del Arte
33
Estos métodos resultan ser muy eficientes en problemas que involucran a matrices de dimensión elevada; además, si A es una matriz simétrica, entonces estos métodos proporcionan algoritmos simples y efectivos. El problema de estos métodos es que si la matriz X está mal condicionada, entonces se pueden producir errores de redondeo considerables.
Métodos Basados en la Diagonalización de una Matriz
Si nxnA C∈ tiene un conjunto de vectores propios },,,{ 21 nvvv L linealmente independientes y se considera la matriz ],,,[ 21 nvvvV L= , entonces se verifica la ecuación matricial
VDAV = ,
siendo
),,,(diag 21 nD λλλ L= ,
con nλλλ ,,, 21 L los n valores propios de la matriz A . Por lo tanto, 1),,,(diag 21 −= VeeeVe nA λλλ L .
Si A es defectiva o está cerca de serlo, entonces cualquier error en A , incluyendo los errores de redondeo producidos en su cálculo y los errores de redondeo producidos en el cálculo de los vectores propios, pueden conducir a errores elevados en el cálculo de Ate . Una forma de medir la cercanía a la defectividad es el cálculo del número de condición asociado a la matriz de vectores propios V
||||||||)(cond 1−= VVV .
Cuanto mayor sea este número más cerca se encuentra A de ser defectiva.
Como el conjunto de matrices simples es un subconjunto denso del conjunto de matrices cuadradas, la mayoría de las matrices que aparecen en problemas de control o en otras áreas suelen ser simples. Además, se puede equilibrar la matriz A de manera que se minimice )(cond V , con lo cual este método no es demasiado restrictivo.
Si A tiene valores propios complejos y se desea evitar la aritmética compleja, es posible obtener la descomposición
121 ),,,(diag −= VDDDVA rL ,
siendo iD , ri ,,2,1 L= , bloques diagonales de dimensión 1x1 o 2x2 correspondientes a valores propios reales o a valores propios complejos conjugados, respectivamente. Aplicando la Propiedad 2.2 y la Propiedad 2.3, se tiene que
1),,,(diag 21 −= VeeeVe rDDDA L .
Método de la Matriz Compañera
Sea nxnA ℜ∈ y nxnB ℜ∈ la matriz compañera asociado al polinomio característico de A . Al ser B dispersa (véase Propiedad 6.2), pequeñas potencias de B tienen un coste menor que los usuales 3n flops. Consecuentemente, se podría implementar el algoritmo de escalado y potenciación con un reducido coste computacional.
Por otra parte, si A no es derogatoria, entonces se tiene que

Capítulo 2: Estado del Arte
34
1−= YBYA ,
por lo que al aplicar la Propiedad 2.2, se tiene 1−= YYee BA .
El problema de este método es que los algoritmos utilizados en la reducción de la matriz A a la forma compañera son extremadamente inestables y se deben evitar [Wilk92].
Si la ecuación diferencial original consiste en una sola ecuación lineal de orden n , escrita como un sistema lineal de ecuaciones de primer orden, entonces la matriz coeficiente del sistema está en la forma de matriz compañera. Consecuentemente, la reducción anterior no es necesaria. Por lo tanto, se podría utilizar eficazmente el método de la matriz compañera.
A continuación se detalla un método para calcular He , con H una matriz de Hessenberg inferior (las matrices compañeras son un caso particular de este tipo de matrices). Puesto que toda matriz A es similar a una matriz de Hessenberg inferior mediante una transformación ortogonal
nTT IQQQHQA == , ,
entonces THA QQee = .
Para cualquier función analítica )(zf definida sobre el espectro de una matriz A , se tiene que A y )(Af conmutan, en particular
HeHe HH = .
Igualando las columnas k-ésimas en la igualdad anterior, se tiene que
2 ,1
≥= ∑−=
kfhHfn
kiiikk ,
donde kf representa la columna k-ésima de He . Si ninguno de los elementos superdiagonales de la matriz H es cero, entonces una vez se conoce nf las otras columnas se obtienen a partir de la expresión
⎥⎦
⎤⎢⎣
⎡−= ∑
=−−
n
kiiikk
kkk fhHf
hf
11
1 , nk ,,3,2 L= .
Puesto que nf es igual a )1(x , siendo )(tx la solución de la EDO TxtHxtx ]1,0,,0,0[)0( ),()(' L== ,
entonces se puede utilizar uno de los métodos basados en la resolución de EDOs, comentados en 2.2.3.1.3, para el cálculo de nf .
El problema de este método se presenta cuando se tiene un valor pequeño pero no despreciable de kkh 1− . En este caso, los errores de redondeo producidos en el cálculo de
kkh 1/1 − pueden producir un cálculo inexacto de He .
En resumen, los métodos para calcular Ae que involucran la reducción de A a las formas de matriz compañera o de Hessenberg no resultan ser eficientes.

Capítulo 2: Estado del Arte
35
Método Basado en la Forma Canónica de Jordan
Según el Corolario 2.2, si una matriz nxnA C∈ admite la descomposición canónica de Jordan
1),,,diag(21
−= XJJJXArλλλ L ,
entonces 1),,diag( 21 −= XeeeXe rJJJA λλλ L .
La dificultad de este método es que la forma canónica de Jordan no se puede calcular utilizando aritmética en coma flotante. Un simple error de redondeo puede producir que algunos valores propios múltiples se conviertan en distintos, o viceversa, alterando toda la estructura de ),,,diag(
21 rJJJ λλλ L y de X . En [GoWi76] y [KaRu74] se describen
éstas y otras dificultades del método.
Un algoritmo eficiente que calcula la forma canónica de Jordan de una matriz cuadrada compleja, se puede encontrar en [KaRu74]. En este artículo se modifica la definición de forma canónica de Jordan para que sea aplicable en el caso de trabajar con aritmética de precisión finita. Con esta definición se muestra la manera de realizar un algoritmo preciso y estable que calcule valores propios y cadenas de vectores principales asociados. Este algoritmo está basado en el cálculo de una secuencia de transformaciones de semejanza y sucesivas separaciones de rangos de subespacios nulos.
Métodos Basados en la Descomposición real de Schur de una matriz
Sea nxnA ℜ∈ . Según el Teorema 6.7, A admite la descomposición real de Schur TQSQA = ,
siendo nxnQ ℜ∈ matriz ortogonal y nxnS ℜ∈ una matriz casi triangular superior. Aplicando la Propiedad 2.2, se tiene que )(Af se puede obtener a partir de la expresión
TQSQfAf )()( = .
El problema ahora es el cálculo de )(Sf . Diversos métodos se pueden utilizar para dicho cálculo como, por ejemplo, los basados en la ecuación conmutante ( 2.1 ) (véanse [MaHI92], [Ibañ97]). Estos métodos se pueden aplicar de manera inmediata para
nxnA C∈ ([DaH103]).
Método Basado en la Diagonalización a Bloques de una Matriz Este método consiste en encontrar una transformación de semejanza de la matriz
nxnA ℜ∈ 1−= XBXA ,
siendo nxnX ℜ∈ una matriz bien condicionada y nxnB ℜ∈ una matriz diagonal por bloques, en la que cada bloque diagonal es casi triangular superior con valores propios cercanos o incluso múltiples. El tamaño de cada bloque debe ser tan pequeño como sea posible, manteniendo alguna cota superior para )(cond S como, por ejemplo,
100)(cond <S .

Capítulo 2: Estado del Arte
36
En este caso resulta que 1)()( −= XBXfAf ,
donde la matriz )(Bf tiene una estructura diagonal por bloques, tal como se representa en la Figura 2.1. Cada bloque diagonal de )(Bf se puede obtener a partir del correspondiente bloque de B , aplicando cualquiera de los métodos vistos anteriormente.
Figura 2.1: Estructura a bloques de la matriz )(Bf .
Métodos de Separación
Es conocido que la propiedad aditiva de la función exponencial no se verifica en el caso matricial, a menos que las matrices conmuten, es decir,
CBBCeee tCBCtBt =⇔= + )( .
Sin embargo, las exponenciales de las matrices B y C están relacionadas con la exponencial de la matriz CB + mediante, por ejemplo, la fórmula de Trotter [Trot59]
( )mmCmB
m
CB eee //lim∞→
+ = .
Si las exponenciales de las matrices B y C se pueden calcular eficientemente, entonces se puede utilizar la aproximación
( )mmCmBA eee //≅
para obtener la exponencial de la matriz CBA += . Por ejemplo, si se definen la matrices 2/)( TAAB += y 2/)( TAAC −= , entonces B es simétrica y C antisimétrica, por lo que se pueden calcular eficientemente Be y Ce .
2.2.3.1.6 Métodos Basados en los Subespacios de Krylov
Como se describió en el subapartado 2.2.2.1, la solución del problema de valores iniciales
( 2.9 ) )()( tAxtx =& , 0)0( xx = ,
está dada por
0)( xetx At= .

Capítulo 2: Estado del Arte
37
En muchas ocasiones puede ser interesante calcular el producto 0xe At sin hallar expresamente la matriz Ate . A menudo, la matriz A es de gran dimensión y dispersa, como puede ocurrir, por ejemplo, en la discretización espacial de una ecuación en derivadas parciales.
Una serie de métodos que calculan el producto ve At , nxnA ℜ∈ y nv ℜ∈ , están basados en los denominados subespacios de Krylov. Estos métodos consisten, básicamente, en obtener una aproximación de ve At a partir del subespacio de Krylov generado por los vectores },,,,{ 12 vAvAAvv p−L , siendo p un número entero positivo relativamente pequeño con relación a la dimensión de la matriz A . Entre estos métodos se encuentran el método de Lanczos, para el caso en que A sea simétrica, y el método de Arnoldi, para el caso en que A no sea simétrica. En este último método los valores propios de la matriz se aproximan mediante los valores propios de una matriz de Hessenberg de dimensión p . A partir del vector v se obtiene la reducción parcial de Hessenberg
Tppppppp evhHVAV 1,1 +++= ,
donde pV tiene p columnas ortonormales, pH es una matriz de Hessenberg superior de dimensión p , pe es la columna p-ésima de la matriz nI , y 1+pv es un vector unitario
que satisface 01 =+pTp vV . La aproximación que se realiza es
TtHp
At eeVve p1β≅ ,
siendo 2|||| v=β y 1e la primera columna de la matriz nI .
Se pueden obtener muy buenas aproximaciones con valores de p relativamente pequeños, incluso se pueden disponer de cotas del error cometido en la aproximación. Por lo tanto, un problema de gran dimensión y disperso (cálculo de Ate ), se reemplaza por un problema denso de pequeña dimensión (cálculo de tH pe ).
Existen diversos artículos en los que se analizan estos métodos, entre los que cabe destacar [Kniz91] ,[GaSa92], [Saad92], [StLe96], [HoLS97] y [DrGr98].
2.2.3.2 Función Signo La Propiedad 2.4 indica que la función signo matricial de una matriz coincide con la raíz cuadrada de la matriz identidad del mismo orden. Esta observación permitió a Roberts ([Robe71]) calcular el valor de la función signo matricial aplicando el método de Newton a la ecuación matricial
02 =− IX .
Al aplicar este método, se obtiene la iteración
AX =0 ,
)(5.0 11
−+ += kkk XXX , L,2,1,0=k ,
la cual converge cuadráticamente a la matriz )(sign A , siempre que la matriz A no tenga valores propios imaginarios puros y la iteración anterior esté bien definida.
Resultados más precisos pueden obtenerse si en lugar de utilizar la iteración anterior se utiliza la iteración

Capítulo 2: Estado del Arte
38
AX =0 ,
)(5.0 11
−+ −−= kkkk XXXX , L,2,1,0=k .
Higham y Schreiber ([HiSh90]) sugieren utilizar una iteración que evita el cálculo de inversas. Esta iteración se obtiene a partir de la iteración anterior y de la aproximación de Schulz
kknkk XXIXX )( 21 −+≅− .
La iteración que se obtiene es
)3(5.0 21 knkk XIXX −=+ , L,2,1,0=k ,
la cual converge cuadráticamente a la matriz )(sign A siempre que 1|||| 2 <− AIn y se cumplan además las condiciones necesarias de existencia de dicha función matricial.
Pandey, Kenney y Laub ([PaKL90]) deducen una iteración, basada en una forma fraccionaria parcial explícita, definida por
( 2.10 ) ∑=
−+ +=
p
inik
ikk IXX
pX
1
1221 )(11 α
ξ, AX =0 ,
siendo
⎟⎟⎠
⎞⎜⎜⎝
⎛ −+=
pi
i 2)12(cos15.0 πξ , 112 −=
ii ξ
α , pi ,,1L= .
Kenney y Laub presentan en [KeLa91] una familia de iteraciones, basadas en la aproximación de Padé de la función escalar ( ) 2/11)( −−= xxf , definidas mediante la expresión
1221 )()( −
+ = kskrkk XqXpXX , AX =0 ,
donde rp y sq son polinomios de grados r y s , respectivamente.
Aunque los métodos anteriores convergen cuadráticamente, esta convergencia no está asegurada en la práctica a causa de los errores cometidos en cada una de las iteraciones. Una técnica que mejora las iteraciones anteriores consiste en el escalado de las matrices que aparecen en cada iteración. Kenney y Laub presentan en [KeLa92] varios tipos de escalado que permiten mejorar las iteraciones del método de Newton sin escalado si y solo si los factores de escalado se encuentran entre el cuadrado del factor de escalado óptimo y 1. A continuación se presenta una definición del factor de escalado óptimo y una breve explicación de estas técnicas.
La finalidad del método de Newton con escalado consiste en encontrar LL ,,,1 kγγ , de manera que la iteración
AX =0 ,
])([5.0 11
−+ += kkkkk XXX γγ , L,2,1,0=k .
converja hacia una matriz con valores propios 1± (véase [Balz80]). Los valores óptimos de escalado, llamados factores de escalado óptimos, se obtienen a partir del siguiente teorema.

Capítulo 2: Estado del Arte
39
Teorema 2.8 ([KeLa92]).
Sean { })()(1 ,, k
mk λλ L los valores propios de la matriz kX . Si ji
jkj e θρλ ±=)( , donde
0>jρ , 2/πθ <j , mj ≤≤1 , entonces el factor de escalado óptimo *kγ verifica
( 2.11 ) ( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛
−
−=
ijji
jjii
jik θρθρ
θρθρρρ
γcoscoscoscos12* ,
para una cierta pareja de valores i y j .
El problema de encontrar los factores de escalado óptimos del Teorema 2.8 es que es necesario el conocimiento completo de los valores propios de la matriz kX , para
L,2,1,0=k , y además conocer la pareja de índices ),( ji de la expresión ( 2.11 ). Por este motivo, Kenney y Laub desarrollaron en [KeLa92] una familia de métodos de escalado que son óptimos con respecto a una información incompleta de los valores propios de una matriz. Esta familia incluye métodos de escalado óptimos y semióptimos basados en la estimación de los valores propios dominantes de la matriz kX y de su inversa, vía el método de potencias ([GoVa96], página 330) y seleccionando los valores de escalado óptimo para esos valores propios según la expresión ( 2.11 ).
Otras estrategias para la determinación de factores de escalado se basan en la determinación de factores de escalado en la descomposición polar de una matriz ([HoJo91], capítulo 6). Entre ellas cabe destacar
• ⎟⎟⎠
⎞⎜⎜⎝
⎛=
−
2
21
||||||||
k
kBk X
Xγ ([Barr79]),
• 4/1
1
11
1,1
||||||||||||||||
⎟⎟⎠
⎞⎜⎜⎝
⎛=
∞
∞−−
∞
kk
kkk XX
XXγ ([High86]),
• ( ) nkk X /1det −=γ , siendo n la dimensión de la matriz kX ([Byer87]),
• 2/11
||||||||
⎟⎟⎠
⎞⎜⎜⎝
⎛=
−
Fk
FkFk X
Xγ , siendo F|||| norma de Frobenius ([KeLa92]).
2.2.3.3 Función Raíz Cuadrada Uno de los primeros intentos para el cálculo de raíces cuadradas de un matriz aparece en [BjHa83]. En este artículo Björck y Hammarling describen un método rápido y estable que calcula la raíz cuadrada de una matriz compleja mediante la descomposición real de Schur de una matriz. Aunque este método se puede aplicar a matrices reales con únicamente valores propios reales, fracasa cuando la matriz real tiene valores propios complejos.
Higham propone en [Hig287] extender el método de Björck y Hammarling para matrices reales con valores propios reales o complejos que evita la aritmética compleja.
Varios autores han utilizado el método de Newton para implementar algoritmos que calculan raíces cuadradas de una matriz. A continuación se describen algunos de ellos.
Sea nxnCA∈ y la ecuación matricial

Capítulo 2: Estado del Arte
40
0)( 2 =−= AXXF .
Aplicando el método de Newton, se obtiene la recurrencia
)()(' 11 kkkk XFXFXX −
+ −= , ,...2,1,0=k ,
donde 'F es la derivada de Fréchet ([Grif81]) de la función F . Mediante el cálculo de la derivada de Fréchet se llega a la recurrencia
L,2,1,0,1
2
=⎭⎬⎫
+=−=+
+
kHXX
XAXHHX
kkk
kkkkk ,
siendo 0X una matriz previamente seleccionada que suele coincidir con la propia matriz A o con la matriz identidad. Esta iteración converge cuadráticamente a una raíz cuadrada de A siempre que |||| 0XX − sea suficientemente pequeño y la transformación lineal )(' XF sea no singular.
El problema de la iteración anterior es que en cada iteración es necesario resolver una ecuación matricial de Sylvester para matrices densas, lo cual requiere la utilización del método de Bartels-Stewart ([BaSt71]) con el consiguiente alto coste computacional.
Una posible mejora consiste en suponer que las matrices kH y kX conmutan, con lo que se pueden deducir las iteraciones
)(5.0 11 AYYY kkk
−+ += ,
)(5.0 11
−+ += kkk AZZZ ,
las cuales, en caso de converger, lo hacen hacia una raíz cuadrada de la matriz A .
El problema de estas dos iteraciones es que son numéricamente inestables tal como se demuestra en [High84]. En este mismo artículo Higham demuestra que si se utilizan las iteraciones acopladas
AY =0 , nIZ =0 ,
L,2,1,0,)(5.0
)(5.01
1
11 =
⎪⎭
⎪⎬⎫
+=
+=−
+
−+ k
YZZ
ZYY
kkk
kkk ,
basadas en las iteraciones de Denman-Beavers (DB) ([DeBe76]), entonces se obtiene un algoritmo numéricamente estable. Si la matriz A no tiene valores propios reales negativos y todas las iteraciones están bien definidas, se puede demostrar que
2/1AYk → , 2/1−→ AZk , cuando ∞→k .
Posteriormente en [Hig297], Higham establece nuevas iteraciones basadas en iteraciones utilizadas para la función signo matricial:
• Un par de esas iteraciones acopladas, basadas en la iteración de Schulz de la función signo matricial, evitan el cálculo de inversas. Estas iteraciones se definen mediante las expresiones
AY =0 , nIZ =0 ,

Capítulo 2: Estado del Arte
41
( )( ) L,2,1,0,35.0
35.0
1
1 =⎭⎬⎫
+=+=
+
+ kYYZIZ
YZIYY
kkknk
kknkk .
Si 1||),diag(|| <−− nn IAIA , entonces kY y kZ convergen cuadráticamente a 2/1A y 2/1−A , respectivamente.
• Otro par de iteraciones acopladas están basadas en la iteración ( 2.10 ). Estas iteraciones son
AY =0 , nIZ =0 ,
( 2.12 ) ( )
( ) ⎪⎪⎭
⎪⎪⎬
⎫
+=
+=
∑
∑
=
−
+
=
−
+
p
inikk
ikk
p
inikk
ikk
IZYZp
Z
IYZYp
Y
1
121
1
121
11
11
αξ
αξ
, .,2,1,0 L=k
Si A no tiene valores propios reales negativos, entonces las iteraciones kY y kZ definidas en ( 2.12 ) convergen a 2/1A y 2/1−A , respectivamente.
Al igual que ocurre con la función signo matricial, es conveniente utilizar técnicas de escalado que aceleren la convergencia de los métodos descritos anteriormente. Estas técnicas aplicadas a la iteración DB se pueden expresar como
L,2,1,0,)]([5.0
])([5.01
1
11 =
⎪⎭
⎪⎬⎫
+=
+=−
+
−+ k
YZZ
ZYY
kkkkk
kkkkk
γγ
γγ.
De igual modo, se pueden utilizar técnicas del escalado para las iteraciones ( 2.12 ).
Basándose en la técnica de escalado de la función signo matricial descrita en [Byer87], Higham, en ([Hig294], determina factores de escalado para el cálculo de raíces cuadradas de una matriz. En este artículo propone utilizar el factor de escalado
)2/(1)det()det( nkkk ZY −=γ ,
De este modo, la descomposición LU se puede utilizar tanto para hallar las inversas de las matrices kY y kZ como para determinar el factor kγ .
Otra estrategia utilizada por Hoskins y D. J. Walton en [HoWa78] consiste en estimar el radio espectral ([HoJo91], capítulo 1) de las matrices kP , 1−
kP , kQ y 1−kQ .
2.2.3.4 Función Raíz p-ésima de una Matriz En [HoWa79], Hoskins y Walton proponen la iteración
AX =0 ,
])1[(1 11
pkkk AXXp
pX −
+ +−= ,
basada en el método de Newton, que permite calcular la raíz p-ésima de una matriz A simétrica y definida positiva. Sin embargo, como se demuestra en [Smit03], dicha iteración es inestable, a menos que A esté extremadamente bien condicionada. Además,

Capítulo 2: Estado del Arte
42
esa iteración generalmente no converge para otros tipos de matrices que admiten raíces p-ésimas.
En [TsSY88], Tsai, Shieh y Yates definen iteraciones cuya velocidad de convergencia es un parámetro. Las iteraciones acopladas que permiten una convergencia cuadrática a una raíz p-ésima se definen mediante las expresiones
AG =0 , nIR =0 ,
⎪⎭
⎪⎬⎫
−+−+=
−+−+=−
+
−+
))1(())2(2(
]))1()()2(2[(1
1
11
knknkk
pknknkk
GpIGpIRR
GpIGpIGG, L,2,1,0=k ,
cumpliéndose que
nk IG → y pk AR /1→ , cuando ∞→k .
La expresión integral
( )∫∞
−+=
0
1/1 )/(sen dxAxAppA pp
ππ ,
puede deducirse a partir de una identidad estándar en el campo complejo ([Bhat97], [MaHI92]). En [HaHS00], M. Hasan, J. Hasan y L. Scharenroich proponen calcular aproximadamente la integral anterior mediante cuadratura Gaussiana.
En [Smit03], Smith muestra un método basado en la descomposición real de Schur de una matriz para el cálculo de raíces p-ésimas de una matriz que es estable numéricamente. A continuación se detalla ese método. Según el Teorema 6.7, dada una matriz nxnA ℜ∈ , entonces existe una matriz casi triangular superior nxnS ℜ∈ y una matriz ortogonal nxnQ ℜ∈ de manera que
TQSQA = .
Para calcular la raíz p-ésima nxnU ℜ∈ de la matriz S , se siguen los siguientes pasos:
1 Determinar iiU y )(qiiR ( mi ,,2,1 L= , 2,,2,1 −= pq L ) mediante las siguientes
expresiones 1)2(2)1(/1 ,,, −− === p
iip
iiiiiip
iiii URURSU L , mi ,,2,1 L= .
2 Para 1:1 −= nk 2.1 Para kni −= :1
2.1.1 Calcular kiiU +, , resolviendo las ecuaciones
∑∑−
=
−−−
=
−− +=2
0
)(21
0
1p
m
mij
mpii
p
h
hjjij
hpiiij BUUUUS ,
siendo ∑−
+=
=1
1
)()(j
ik
mijik
mij RUB .
2.1.2 Calcular )(,q
kiiR + , 2,,2,1 −= pq L mediante las expresiones
∑∑−
=
−−
=
− +=1
0
)(1
0
)(q
m
mij
mqii
q
h
hjjij
hqii
qij BUUUUR .

Capítulo 2: Estado del Arte
43
Una vez se ha determinado la matriz nxnU ℜ∈ , la raíz p-ésima X se obtiene a partir de la expresión
TQUQX = .
Recientemente en [BiHM04], Bini, Higham y Meini han presentado una variedad de fórmulas que permiten calcular la raíz p-ésima de una matriz mediante técnicas de integración numérica.
2.2.3.5 Función Logaritmo
El logaritmo de una matriz nxnA C∈ cercana a la matriz identidad de orden n , puede encontrarse fácilmente utilizando la serie de Taylor
L−−−−=−= 3/2/)log(log 32 BBBBIA n ,
siendo AIB n −= . Desafortunadamente, si A no se encuentra cerca de la matriz identidad, entonces los métodos basados en esta serie o no convergen o lo hacen muy lentamente.
Una forma de solucionar este problema consiste en utilizar la igualdad
( 2.13 ) k
AA k 2/1log2log = ,
pues al hacer ∞→k se tiene que nIAk
→2/1 , y así se evita el problema comentado anteriormente. Este método, desarrollado por Kenney y Laub ([KeL289]), tiene como nombre “método inverso de escalado y potenciación”, puesto que se trata del proceso inverso al método de escalado y potenciación utilizado en el cálculo de la exponencial de una matriz. En ese artículo Kenney y Laub proponen calcular las raíces cuadradas mediante el método basado en la descomposición real de Schur de una matriz que se describe en [BjHa83] y [Hig287].
Los métodos de cálculo de funciones de matrices basados en la descomposición real de Schur de una matriz tienen el problema de no funcionar bien cuando los valores propios de la matriz están cercanos entre sí ([BjHa83], [Parl76]). En [KeLa98] Kenney y Laub presentan un método, basado en esa descomposición, que evita este problema utilizando para ello una nueva expresión de la derivada de Fréchet ([Grif81]) del logaritmo en términos de la función xxx /)tanh()( =τ , junto a una aproximación de Padé de la función τ .
En [ChHi01], Cheng, Higham, Kenney y Laub utilizan una variante del método inverso de escalado y potenciación en la que las raíces cuadradas se aproximan mediante una iteración matricial y ciertos parámetros se eligen dinámicamente para minimizar el coste computacional, y de este modo alcanzar la precisión necesaria. Para ello utilizan la fórmula
ssss EEEYA 1
21)( 22log2log −−−−−= L , )()(log ii
i ZYE = ,
donde )(iY y )(iZ son los valores finales de una iteración del tipo DB aplicada a )1( −iY . Esta iteración está definida por las expresiones
)](5.0[5.0 11
−+ ++= kknk MMIM , )1(
0−= iYM
)(5.0 11
−+ += knkk MIYY , )1(
0−= iYY ,

Capítulo 2: Estado del Arte
44
)(5.0 11
−+ += knkk MIZZ , IZ =0 ,
siendo kkk ZYM = .
Tanto el método descrito en [KeL289] como el descrito en [ChHi01] deben evaluar un aproximante diagonal de Padé
)()1log()(/)()( 12 +++== mmmm xOxxqxpxr ,
sobre matrices cuadradas A que cumplen la condición 1|||| <A , siendo 16≤m y ||.|| cualquier norma matricial subordinada.
En los dos métodos anteriores la forma de calcular )(xrm está basada en el método de Horner modificado para el caso de funciones matriciales racionales. Sin embargo, varias alternativas se han realizado a la hora de calcular )(xrm , como las propuestas por Dieci y Papini en [DiPa00]. Estos autores argumentan que para calcular aproximantes diagonales de Padé es preferible utilizar fórmulas de cuadratura, y de este modo evitar el mal condicionamiento que tienen las matrices que aparecen en el denominador de la expresión matricial de los aproximantes de Padé.
Más recientemente Higham ([High01]) ha realizado un estudio de diversos métodos basados en los aproximantes de Padé, en las fracciones continuas y en las fracciones parciales:
• Para los aproximantes de Padé, Higham analiza los métodos de Horner, Paterson-Stockmeyer-Van Loan ([Pate73]) y Van Loan ([VanL79]).
• Para las fracciones continuas, Higham considera la fracción continua ([BaGr96])
xcxc
xcxc
xcxr
m
m
m
2
12
3
2
1
11
11
)(
++
++
=
−L
,
donde
11 =c , )12(22 −
=jjc j ,
)12(212 +=+ j
jc j , L,2,1=j .
• Para fracciones parciales, Higham define
∑= +
=m
jm
j
mj
m xx
xr1
)(
)(
1)(
βα
,
siendo )(mjα los pesos y )(m
jβ los nodos de la regla de cuadratura de Gauss-Legendre en el intervalo ]1,0[ .
Los resultados de este estudio confirman que los métodos basados en los aproximantes de Padé y el método basado en fracciones continuas sufren de una cierta inestabilidad cuando la norma de la matriz tiene un valor cercano a 1 y m es grande.
Desde el punto de vista computacional, las mejores elecciones corresponden a las aproximaciones basadas en Padé y la correspondiente a la expansión en fracciones

Capítulo 2: Estado del Arte
45
parciales; pero esta última implementación, junto con la versión de los aproximantes de Padé vía Paterson-Stockmeyer-Van Loan, son más ricas en operaciones del nivel 3 de BLAS. Desde el punto de vista de coste de almacenamiento, la elección del método de Padé vía Paterson-Stockmeyer-Van Loan es el peor, aunque para valores habituales de m ( 16≤m ) el coste de almacenamiento puede ser admisible. El método basado en la expansión en fracciones parciales es fácilmente paralelizable y además no sufre de la inestabilidad cuando se tienen matrices con norma cercana a 1 y valores de m grandes.
Finalmente, Higham concluye que, en términos generales, el mejor método es el de expansión en fracciones parciales, aunque en casos especiales, como por ejemplo cuando se utilizan máquinas de altas prestaciones en las que los productos de matrices son más rápidos que las inversiones y se dispone de suficiente memoria, el método de Paterson-Stockmeyer-Van Loan puede ser la mejor elección, siempre que |||| A sea significativamente menor que uno.
2.2.3.6 Función Coseno
El siguiente método calcula el coseno de una matriz nxnA C∈ mediante la aproximación de Padé. Aunque el algoritmo original se encuentra en [SeBl80], en este subapartado se describe una mejora de él ([Hig203]). Este algoritmo consta, básicamente, de cuatro etapas:
Etapa 1: Reducir la norma de la matriz.
Se aplican sucesivamente tres técnicas para reducir la norma de la matriz A :
• En primer lugar se aplica una transformación de bajo coste que explota la relación de periodicidad de la función coseno,
)cos()1()cos( AqIA qn −=− π , Zq ∈ .
El entero q se elige de manera que minimice el valor de |||| nqIA π− . Este valor no es sencillo de calcular, a menos que se haga algún tipo de aproximación como la que se apunta en el citado artículo. Esta aproximación consiste en determinar el entero q más cercano a nA /)(trazat = que minimice el valor de |||| 1A , siendo
nqIAA π−=1 .
• A continuación se aplican técnicas de equilibrado sobre la matriz 1A obtenida en el paso anterior. El equilibrado de 1A consiste en encontrar una matriz diagonal D , de manera que la matriz DADA 1
12
−= cumpla que para cada valor i , ni ,,2,1 L= , la 1-norma de su i-ésima fila y la 1-norma de su i-ésima columna
sean de magnitud semejante.
• Por último, se realiza el escalado de la matriz 2A . Para ello se determina el valor de un entero j que cumpla
∞+−
∞− <≤ ||||21||||2 2
12 AA jj ,
y se define la matriz
mAA /23 = ,
siendo jm 2= .

Capítulo 2: Estado del Arte
46
Etapa 2: Calcular la aproximación de Padé. El cálculo de los coeficientes de los polinomios que aparecen en la aproximación de Padé se realiza utilizando computación simbólica (Maple y Matemática). Con los valores calculados se obtiene la matriz
333 cos)( AARB pq ≅= .
Etapa 3: Aplicar las transformaciones inversas a las realizadas en la primera etapa.
La transformación inversa del escalado consiste en determinar 22 cos AB = a partir de
33 cos AB = . Para ello, se utiliza el siguiente código:
1 32 BB = 2 Para 1:0 −= ji
2.1 nIBB −= 222 2 .
Como se puede observar, el cálculo realizado en el bucle está basado en la identidad
nIBB −= 2cos22cos , nxnB C∈ .
Las otras dos transformaciones inversas consisten en determinar 1B a partir de 2B y B a partir de 1B , utilizando para ello las expresiones
121
−= DDBB
y
1)1( BB q−= .
Esta última fórmula está basada en la identidad
)cos()1(cos nq qIAA π−−= , nxnA C∈ .
2.2.3.7 Caso General En ([DaH103]), se detalla un método general para calcular funciones de matrices complejas basado en la forma de Schur. Este método utiliza la siguiente propiedad.
Propiedad 2.7 ([Parl74]).
Si ][ ijSS = tiene una estructura triangular superior por bloques, entonces )(SfF = tiene la misma estructura por bloques ][ ijFF = , cumpliéndose que para ji < ,
( 2.14 ) ∑∑+=
−
=
−=−j
ikkjik
j
ikkjikjjijijii FSSFSFFS
1
1
.
El algoritmo básicamente se divide en cuatro etapas:
• Obtener la descomposición de Schur de la matriz A , *QSQA = ,
con nxnS C∈ triangular superior y nxnQ C∈ unitaria.

Capítulo 2: Estado del Arte
47
• Reordenar la forma de Schur de la matriz A , agrupando los valores propios cercanos. Para ello se calcula una transformación bien condicionada definida por una matriz nxnCV ∈ de manera que la matriz 1−= VSVS tenga los valores propios cercanos en el mismo cluster. Esta matriz puede estructurarse en bloques ( mxmijFF ][= ) de tal modo que los bloques diagonales correspondan a los clusters de valores propios cercanos.
• Calcular )(SfF = , hallando los bloques diagonales, )( iiii SfF = mediante la aproximación de Taylor adaptada a matrices triangulares superiores con valores propios cercanos, y los bloques no diagonales mediante la expresión ( 2.14 ).
• Hallar )(AfB = , calculando *1FVQQVB −= .
A continuación se presenta el algoritmo de Schur-Parlet aparecido en [DaH103].
Entradas: Matriz nxnA C∈ y )(zf función analítica.
Salida: Matriz nxnAfB C∈= )( .
1 )(schur],[ ASQ = 2 )(reorschur],[ SSV = 3 Calcular )(SfF = :
3.1 Para mi :1= 3.1.1 )( iiii SfF = 3.1.2 Para 1:1:1 −−= ij
3.1.2.1 Calcular ijF resolviendo la ecuación matricial de Sylvester
∑∑+=
−
=
−=−j
ikkjik
j
ikkjikjjijijii SFFSSFFS
1
1
4 *1FVQQVB −=
Algoritmo 2.2: Algoritmo de Schur-Parlett.
2.2.4 Software de Funciones de Matrices El software disponible para el cálculo de funciones de matrices es escaso, salvo el disponible en entornos comerciales de desarrollo como MATLAB.
2.2.4.1 Expokit Se trata de un paquete de software numérico para el cálculo de exponenciales de matrices densas o dispersas, reales o complejas, escrito en FORTRAN y MATLAB, y disponible en http://www.maths.uq.edu.au/expokit/. Más concretamente, Expokit permite calcular exponenciales de matrices de pequeño tamaño, mediante aproximaciones de Chebyshev y de Padé, y productos de la forma ve At para A matriz dispersa y v vector, mediante un algoritmo basado en los subespacios de Krylov (procesos de Arnoldi y Lanczos).
2.2.4.2 Proyecto “Parallel Computation of Matrix Functions” Fruto de un proyecto de investigación denominado “Parallel Computation of Matrix Functions”, y desarrollado durante los años 1998 y 2001, se publicaron diversos

Capítulo 2: Estado del Arte
48
artículos y se desarrollaron un conjunto de rutinas escritas en FORTRAN, denominado “LogPack”, que calculan logaritmos de matrices basados en el método de escalado inverso y potenciación ([ChHi01]). Estas rutinas se encuentran disponibles en la dirección de Internet http://www.ma.man.ac.uk/~higham/PCMF/.
2.2.4.3 Proyecto “Numerical Analysis of Matrix Functions” El proyecto de investigación “Numerical Analysis of Matrix Functions”, desarrollado durante los años 2001 y 2004, y auspiciado por la agencia de investigación “Engineering and Physical Sciences Research Council” (EPSRC), ha permitido un notable desarrollo teórico y práctico del cálculo de funciones de matrices:
• Método general para el cálculo de funciones de matrices complejas ([DaH103]).
• Métodos para calcular funciones trascendentes y raíces p-ésimas.
• Técnicas que permiten obtener bAf )( , siendo )(zf función analítica, A matriz cuadrada y b vector, sin calcular explícitamente )(Af ([DaH203]).
• Teoría de la perturbación y números de condición asociados al cálculo de funciones de matrices ([Davi04]).
• Teoría y métodos para las funciones matriciales no primarias ([HiMN03], [HiMN03], [DaSm02]).
El software disponible (http://www.maths.man.ac.uk/~higham/NAMF/), consiste en un conjunto de ficheros de tipo “M” y de tipo “MEX” de MATLAB, para el cálculo de funciones de matrices basados en el Algoritmo 2.2.
2.3 Ecuaciones Diferenciales Ordinarias (EDOs)
2.3.1 Definiciones y Propiedades La forma general de una EDO con valores iniciales es
( 2.15 ) ))(,()(' txtftx = , fttt ≤≤0 ,
00 )( xtx = ,
siendo ntx ℜ∈)( y f una función vectorial.
Definición 2.5
Se dice que una función ),( xtf satisface la condición de Lipschitz con respecto a la variable x en el dominio n
f xtt ℜ],[ 0 , si verifica que existe una constante 0>K , denominada constante de Lipschitz de la función ),( xtf , de manera que
||||||),(),(|| 2121 xxKxtfxtf −≤− , nf xttxt ℜ∈∀ ],[),( 0 .
Teorema 2.9 [Flet80])
Sea ),( xtf continua y lipschitziana en el dominio nf xtt ℜ],[ 0 , entonces la EDO de
valores iniciales ( 2.15 ) tiene una única solución en nf xtt ℜ],[ 0 .

Capítulo 2: Estado del Arte
49
Cuando se aplican métodos numéricos para la resolución de EDOs es necesario, en ocasiones, exigir a ),( xtf condiciones más fuertes que la continuidad y ser lipschitziana. Por ejemplo, exigir que ),( xtf sea analítica o que sea diferenciable hasta un cierto orden.
Un concepto muy utilizado en la resolución numérica de EDOs es el de problemas de tipo rígido (“stiff” en inglés). Aunque no existe una definición de tal concepto, cada autor sugiere una aproximación de su significado intuitivo. Esto es así porque, aún no siendo posible dar su definición rigurosa y que ésta sea aplicada en teoremas o propiedades, su uso es muy útil cuando se trata de analizar las propiedades numéricas de un determinado método de resolución de EDOs. Dos aproximaciones se presentan a continuación. Una de ellas fue la primera que introdujo este concepto aplicado a cualquier tipo de ecuaciones diferenciales y la segunda a EDOs.
• “Las ecuaciones diferenciales de tipo rígido son aquellas ecuaciones donde ciertos métodos implícitos, en particular los métodos BDF, funcionan mejor, normalmente mucho mejor, que los métodos explícitos” (Curtiss y Hirschfelder, 1985).
• “Se dice que una EDO es rígida si su solución numérica para algunos métodos requiere (quizás en una porción del intervalo donde está definida la solución) una disminución del tamaño de paso para evitar la inestabilidad” ([Iser98]).
2.3.2 Métodos Numéricos para la Resolución de EDOs Los métodos numéricos más utilizados para la resolución de la EDO ( 2.15 ) se suelen clasificar en dos grandes grupos (véase [AsPe91]): métodos de un solo paso, como el método de Euler, los θ-métodos y los métodos de Runge-Kutta, y métodos de varios pasos o multipaso como los métodos de Adams-Basforth, Adams-Moulton y BDF. Estos métodos conducen a una ecuación en diferencias, representada por un sistema de ecuaciones algebraicas, cuya solución permite obtener valores aproximados a la solución del problema original en un conjunto discreto de puntos. Si se desean aproximaciones continuas en un intervalo, la solución en los puntos discretos puede ser interpolada, aunque también se han desarrollado métodos de Runge-Kutta continuos capaces de proporcionar soluciones aproximadas en los puntos intermedios.
2.3.3 Métodos de un solo Paso Estos métodos se caracterizan por utilizar únicamente información del paso anterior. Un paso típico de estos métodos consiste en obtener una aproximación )( nn txx ≅ a partir de la aproximación 1−nx obtenida en el paso anterior.
2.3.3.1 Métodos Basados en las Series de Taylor Si se trunca el desarrollo en serie de Taylor de la función )(tx alrededor del punto 1−nt , se tiene
( 2.16 ) )1
''1
2'
11 !!2pn
p
nnnn xphxhhxxx −−−− ++++= L ,
siendo 1−−= nn tth .
Si las derivadas parciales con respecto a x y a t se evalúan en el punto ),( 11 −− nn yt , entonces

Capítulo 2: Estado del Arte
50
fxtfx nnn ≡= −−− ),( 11'
1 ,
fffx ytn +=−''
1 ,
fffffffffx yyytytyttn22'''
1 2 ++++=− , etc.
La sustitución de las expresiones anteriores en ( 2.16 ) permite obtener el valor de nx .
Aunque el error cometido en un paso puede ser muy pequeño, el problema es que se deben conocer las derivadas parciales de la función ),( xtf hasta un cierto orden.
2.3.3.2 Métodos de Runge-Kutta
Definición 2.6
Un método de Runge-Kutta de s etapas se define a partir de las siguientes expresiones
),( 11
1 jjn
s
jijni XhctfahxX ++= −
=− ∑ , si ≤≤1 ,
),( 11
1 iin
s
iinn Xhctfbhxx ++= −
=− ∑ .
Los métodos de Runge-Kutta se pueden representar a partir de los coeficientes ija y ib , como
s
sssss
s
s
bbbaaac
aaacaaac
L
L
MOMMM
L
L
21
21
222212
112111
,
siendo
∑=
=s
jiji ac
1, si ,,2,1 L= .
Definición 2.7
El método de Runge-Kutta se dice explícito si 0=ija para todo ij ≥ .
Algunos ejemplos clásicos de los métodos de Runge-Kutta se muestran a continuación.
• Método de Euler hacia adelante.
100
.
• Familia uniparamétrica de métodos de segundo orden.
αα
αα
21
211
0000
−
.

Capítulo 2: Estado del Arte
51
• Método trapezoidal explícito ( 1=α ).
• Método del punto medio explícito ( 2/1=α ).
• Familia uniparamétrica de métodos de tercer orden de tres etapas.
αααα−
−
43
41
041
41
32
32
0032
32
0000
.
• Método de Runge-Kutta clásico de cuarto orden.
61
31
31
61
01001
00210
21
00021
21
00000
.
Definición 2.8
El método de Runge-Kutta se dice implícito si 0≠ija para algún ij ≥ .
La mayor parte de los métodos de Runge-Kutta implícitos provienen de métodos basados en fórmulas de cuadratura, algunos de los cuales se presentan a continuación.
• Métodos de Gauss.
• Método del punto medio implícito.
121
21
.
• Métodos de Radau: Corresponden a fórmulas de orden 12 −s que provienen de fórmulas de cuadratura donde uno de los extremos está incluido ( 01 =c o 0=sc ).
• Método de Euler hacia atrás.
111
.
• Método de Lobatto: Corresponden a fórmulas de orden 22 −s que provienen de fórmulas de cuadratura en las que la función es muestreada en ambos lados del intervalo.
• Método trapezoidal.

Capítulo 2: Estado del Arte
52
21
21
21
211
000.
• Método de Lobatto para 3=s .
61
32
61
61
32
611
241
31
245
21
0000−
.
2.3.3.3 Métodos Multipaso Lineales
Definición 2.9
Un método multipaso lineal de k pasos se define a partir de la expresión
( 2.17 ) ∑∑=
−=
− =k
jjnj
k
jjnj fhx
00βα ,
siendo
),( jnjnjn xtff −−− = ,
y jα y jβ , para kj ,,1,0 L= , parámetros característicos del método.
En la expresión anterior se supone que 00 ≠α (para evitar el escalado se elige 10 =α ) y 0|||| ≠+ kk βα .
Definición 2.10
Un método multipaso se dice explícito si 00 =β . En caso contrario, se dice que el método es implícito.
2.3.3.3.1 Métodos de Adams
Si se integra la EDO ( 2.15 ), se tiene que
∫−
+= −
n
n
t
tnn dttxtftxtx
1
))(,()()( 1 .
En estos métodos, el integrando ))(,( txtf se aproxima mediante un polinomio interpolador utilizando como puntos base algunos valores ),( ii xtf calculados previamente. Según esto, los valores de los parámetros jα en los métodos Adams son
10 =α , 11 −=α y 0=jα para 1>j .

Capítulo 2: Estado del Arte
53
Los métodos de Adams explícitos, denominados también métodos de Adams-Bashforth, se obtienen interpolando ),( xtf a partir de los valores previos de ),( xtf en los instantes knnn ttt −−− ,,, 21 L . Estos métodos se definen a partir de la fórmula
∑=
−− +=k
jjnjnn fhxx
11 β ,
donde
∑−
−=
−⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=1
1
1
1)1(
k
jii
jj j
iγβ ,
dsisi
i ∫ ⎟⎟⎠
⎞⎜⎜⎝
⎛−−=
1
0
)1(γ .
Esta fórmula corresponde a un método de k pasos puesto que utiliza información de los k instantes anteriores knnn ttt −−− ,,, 21 L .
El método de Adams-Bashforth de un paso corresponde al método de Euler hacia delante. Si se considera 2=k , 10 =γ y 2/11 =γ , se obtiene la fórmula de Adams-Bashforth de dos pasos
⎟⎠⎞
⎜⎝⎛ −+= −−− 211 2
123
nnnn ffhxx .
La fórmula de Adams-Bashforth de tres pasos viene dada por
⎟⎠⎞
⎜⎝⎛ +−+= −−−− 3211 12
51216
1223
nnnnn fffhxx .
En la siguiente tabla vienen reflejados los valores característicos de las fórmulas de Adams-Bashforth hasta seis pasos.
k β=1 β=2 β=3 β=4 β=5 β=6
1 1
2 3/2 -1/2
3 23/12 -16/12 5/12
4 55/24 -59/24 37/24 -9/24
5 1901/720 -2774/720 2616/720 -1274/720 251/720
6 4277/1440 -7923/1440 9982/1440 -7298/1440 2877/1440 -475/1440
Tabla 2.2: Coeficientes del método de Adams-Bashforth.
Los métodos de Adams implícitos, denominados también métodos de Adams-Moulton, se caracterizan por interpolar la función ),( xtf en puntos base de instantes anteriores, y

Capítulo 2: Estado del Arte
54
por tanto con valores conocidos, y en el correspondiente al instante nt , con valor desconocido. La fórmula que los define viene dada por
∑=
−− +=k
jjnjnn fhxx
01 β .
En la siguiente tabla vienen reflejados los valores característicos de las fórmulas de Adams-Moulton hasta seis pasos.
β1 β2 β3 β4 β5 β6
r=1 k=1 1
r=2 k=1 1/2 1/2
r=3 k=2 5/12 8/12 -1/12
r=4 k=3 9/24 19/24 -5/24 1/24
r=5 k=4 251/720 646/720 -264/720 106/720 -19/720
r=6 k=5 475/1440 1427/1440 -798/1440 -482/1440 -173/1440 27/1440
Tabla 2.3: Coeficientes del método de Adams-Moulton, siendo r el orden del método.
2.3.3.3.2 Métodos BDF
Se trata de la familia de métodos más utilizada para problemas de tipo rígido. Los métodos BDF se caracterizan porque ),( xtf se evalúa únicamente en el extremo de la derecha del paso ),( nn xt . Estos métodos se obtienen al derivar el polinomio que interpola los valores anteriores de x , e igualar la derivada de x en nt a ),( nn xtf . La fórmula que define al método BDF de orden 1≥r es
( 2.18 ) ),(1
nn
r
jjnjn xtfhxx βα += ∑
=− .
Los coeficientes jα , para rj ,,2,1 L= , y β se muestran en la siguiente tabla.

Capítulo 2: Estado del Arte
55
β 1α 2α 3α 4α 5α
1=r 1 1
2=r 2/3 4/3 -1/3
3=r 6/11 18/11 -9/11 2/11
4=r 12/25 48/25 -36/25 16/25 -3/25
5=r 60/137 300/137 -300/137 200/137 -75/137 12/137
Tabla 2.4: Coeficientes del método BDF.
2.3.4 Linealización a Trozos de EDOs La resolución de EDOs que se presenta en este apartado ([Garc98]), se basa en la aproximación, en cada subintervalo, de la ecuación diferencial no lineal por una Ecuación Diferencial Lineal (EDL).
Sea la EDO con valores iniciales
( 2.19 ) ))(,()(' txtftx = , ],[ 0 fttt ∈ ,
nxtx ℜ∈= 00 )( ,
cumpliendo ),( xtf las condiciones necesarias para que el problema anterior tenga solución y además sea única.
Dada una partición fll ttttt =<<<< −110 L , es posible aproximar la EDO ( 2.19 ) mediante el conjunto de EDLs resultantes de la aproximación lineal de ))(,( txtf en cada subintervalo, es decir,
( 2.20 ) )())(()(' iiiii ttgytyJfty −+−+= , ],[ 1+∈ ii ttt , ii yty =)( , 1,,1,0 −= li L ,
siendo n
iii ytff ℜ∈= ),( ,
nxniii yt
xfJ ℜ∈
∂∂
= ),( la matriz Jacobiana de la función ),( xtf evaluada en ),( ii yt ,
niii yt
tfg ℜ∈
∂∂
= ),( el vector gradiente de la función ),( xtf evaluado en ),( ii yt .
Para resolver la EDO ( 2.19 ), en primer lugar se resuelve la EDL asociada al primer subintervalo
)())(()(' 00000 ttgytyJfty −+−+= , ],[ 10 ttt ∈ ,
con valor inicial 0000 )()( xtxyty === .
La solución viene dada por

Capítulo 2: Estado del Arte
56
∫ −++= −t
t
tJ dtgfeyty0
0 )]([)( 000)(
0 τττ , ],[ 10 ttt ∈ ,
lo que permite calcular )( 11 tyy = .
A continuación se resuelve la EDL asociada al segundo subintervalo
)())(()(' 11111 ttgytyJfty −+−+= , ],[ 21 ttt ∈ ,
con valor inicial 11)( yty = , obteniéndose la solución
∫ −++= −t
t
tJ dtgfeyty1
1 )]([)( 111)(
1 τττ , ],[ 21 ttt ∈ .
En general, la solución de la EDL asociada al i-ésimo subintervalo
( 2.21 ) )())(()(' iiiii ttgytyJfty −+−+= , ],[ 1+∈ ii ttt , li <≤0 ,
con valor inicial ii yty =)( , resulta ser
( 2.22 ) ∫ −++= −t
tiii
tJi
i
i dtgfeyty τττ )]([)( )( , ],[ 1+∈ ii ttt .
Si iJ es invertible, entonces )(ty se puede obtener mediante la expresión
( 2.23 ) )]()([)( 21)(21iiii
ttJiiiiiii gJfJegJttgfJyty ii −−−−− ++−−+−= .
Teorema 2.10 ([Garc98]).
Dada la EDO con valores iniciales
))(,()(' txtftx = ,
00 )( xtx = ,
con ntxx ℜ∈= )( , ],[ 0 fttt ∈ . Si las derivadas parciales de segundo orden de ),( xtf
están acotadas en nf xtt ℜ],[ 0 , entonces el método de linealización a trozos es
convergente, verificándose además que
[ ]1)(2
−∆
≤− ∆tKnnn e
KtCytx ,
siendo ny la solución aproximada obtenida mediante el método de linealización a trozos en el instante nt , )(max
0 ilitt ∆=∆
<≤, iii ttt −=∆ +1 , con K y C constantes
dependientes del problema.
2.3.5 Software para la Resolución de EDOs Existe en la actualidad una gran cantidad de software que permite resolver EDOs para problemas rígidos y no rígidos, así como para problemas de pequeña y gran dimensión. Este software se puede dividir en cuatro grupos:
• Entornos de programación comerciales como MATLAB (www.mathworks.com), Mathematica (www.wolfram.com) y Maple (www.maplesoft.com). La ventaja de

Capítulo 2: Estado del Arte
57
estos programas es su fiabilidad, facilidad de uso, el disponer de numerosas herramientas y tener un excelente control de calidad y soporte.
• Entornos de programación de dominio público como Scilab (www.scilab.org) y Octave (www.octave.org). Se trata de paquetes de software con algunas de las ventajas anteriores, siendo además gratuitos.
• Librerías de software numérico, como el desarrollado por la empresa NAG (Numerical Algorithms Group, www.nag.co.uk) o IMSL de la empresa Absoft Corporation (www.absoft.com). Estas librerías, escritas en FORTRAN y en C, contienen numerosas rutinas que permiten resolver problemas numéricos muy diversos entre los que se encuentra la resolución de EDOs. Las ventajas de estos códigos son su fiabilidad, rapidez y el control de calidad y soporte que supone tener el respaldo de dos grandes empresas.
• Colecciones de códigos de libre distribución. En este grupo se encuentran varios paquetes disponibles en www.netlib.org/ode (NETLIB) como los que a continuación se describen.
• ODEPACK. Es uno de los paquetes de software más difundido para la resolución de EDOs. Desarrollado por Alan C. Hindmarsh ([Hind83], [RaHi93], [BrHi89]), este paquete tiene sus orígenes en 1976 fruto del esfuerzo por obtener una colección de rutinas que resolviesen EDOs con valores iniciales, y la finalidad de establecer un estándar para este tipo de problemas. Consta de un código básico, llamado LSODE, y ocho variantes de él, denominados LSODES, LSODA, LSODAR, LSODPK, LSODKR, LSODI, LSOIBT, y LSODIS, que permiten resolver problemas rígidos o no rígidos de EDOs, tanto en forma explícita ( ),()(' xtftx = ), como en forma lineal implícita ( ),()('),( xtftxxtA = ). LSODE utiliza métodos de Adams, para la resolución de EDOs de tipo no rígido, y métodos BDF y Gear, para la resolución de EDOs rígidas.
• RKSUITE. Desarrollado por R. W. Brankin, I. Gladwell y L. F. Shampine, contiene un conjunto de rutinas escritas en FORTRAN basadas en métodos Runge-Kutta ([BrGS92]).
• Rutinas epsode.f, vode.f, svode, svodpk.f, vode.f y vodpk.f. Rutinas escritas en FORTRAN y desarrolladas por Peter N. Brown y Alan C. Hindmarsh, que resuelven problemas de valores iniciales de EDOs de tipo rígido o no rígido mediante algoritmos basados en el método BDF ([ByHi75], [HiBy75], [Hind74]).
• Rutinas ode.f, sderoot.f y sode.f. Desarrolladas por Shampine y Gordon, resuelven problemas de valores iniciales de EDOs mediante métodos de Adams ([ShGo75]).
• Rutinas rkf45.f y srkf45.f. Rutinas desarrolladas por H. A. Watts y L. F. Shampine, resuelven problemas de valores iniciales de EDOs mediante el método Runge-Kutta-Fehlberg (4,5) ([Fehl69], [ShWD76].

Capítulo 2: Estado del Arte
58
2.4 Ecuaciones Diferenciales Matriciales de Riccati (EDMRs)
2.4.1 Definiciones y Propiedades Se conoce con el nombre de Ecuación Diferencial Matricial de Riccati (EDMR) a una ecuación diferencial matricial cuadrática de primer orden
( 2.24 ) )()()()()()()()()(' tXtRtXtXtBtAtXtQtX −++= , fttt ≤≤0 ,
mxnXtX ℜ∈= 00 )( ,
siendo nxntA ℜ∈)( , mxmtB ℜ∈)( , mxntQ ℜ∈)( , nxmtR ℜ∈)( y mxntX ℜ∈)( .
Teorema 2.11: Existencia y unicidad de la solución.
Sea ))(,( tXtF la función definida por la parte derecha de la EDMR ( 2.24 ),
( 2.25 ) )()()()()()()()())(,( tXtRtXtXtBtAtXtQtXtF −++= ,
y los vectores ))(()( tXvectx = y )))(,(())(,( tXtFvectxtf = , entonces si
ijf y pq
ij
xf
∂∂
, para mpi ,,2,1, L= y nqj ,,2,1, L= ,
son funciones continuas en la región ℜ×],[ 0 ftt , entonces la EDMR ( 2.24 ) tiene una
única solución en una cierta región incluida en mxnftt ℜ×],[ 0 que contiene al punto
),( 00 Xt .
Existe una importante conexión entre las EDMRs y las Ecuaciones Diferenciales Matriciales Lineales (EDMLs), como lo demuestra el siguiente teorema.
Teorema 2.12 ([AnMo71]).
Sea la EDMR
( 2.26 ) )()()()()()()()()(' tXtRtXtXtBtAtXtQtX −++= , fttt ≤≤0 ,
con la condición inicial 1000 )( −= UVtX ,
y la EDML
( 2.27 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−=⎥
⎦
⎤⎢⎣
⎡)()(
)()()()(
)()(
tVtU
tBtQtRtA
tVtU
dtd , fttt ≤≤0 ,
con condición inicial
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡
0
0
0
0
)()(
VU
tVtU
,
siendo nxntUU ℜ∈)(,0 ( 0U invertible) y mxntVV ℜ∈)(,0 .
Suponiendo que la solución de ( 2.26 ) existe y es única en el intervalo ],[ 0 ftt , entonces la solución de ( 2.27 ) tiene la propiedad de que )(tU es invertible y que

Capítulo 2: Estado del Arte
59
( 2.28 ) )()()( 1 tUtVtX −= , ],[ 0 fttt ∈ .
Recíprocamente, si la solución de ( 2.27 ) tiene la propiedad de que )(tU es invertible en el intervalo ],[ 0 ftt , entonces la única solución de ( 2.26 ) está dada por ( 2.28 ).
Un tipo especial de EDMRs son las denominadas EDMRs simétricas que se presentan a continuación.
Definición 2.11
Una EDMR se dice simétrica, si se puede expresar como
( 2.29 ) )()()()()()()()()(' tXtRtXtXtAtAtXtQtX T −++= , fttt ≤≤0 ,
00 )( XtX = ,
siendo nxntRtAtQ ℜ∈)(),(),( , con )(tQ y )(tR simétricas.
Algunos de los métodos de resolución de EDMRs se basan en el siguiente teorema.
Teorema 2.13 ([Lain76])
Sea la EDMR simétrica
( 2.30 ) ),()(),(),()()(),()(),(0000
0 ttXtRttXttXtAtAttXtQt
ttX T −++=∂
∂ , fttt ≤≤0 ,
),( 000nxnXttX ℜ∈= .
La solución de la EDMR simétrica ( 2.30 ) puede obtenerse a partir de la resolución del Sistema de Ecuaciones en Derivadas Parciales (SEDP)
( 2.31 ) ),(),(),(),(0000
0
0 ttttXttt
ttX TΦΦ−=∂
∂ , 000 ),( XttX = , 0tt ≥ ,
y
( 2.32 ) [ ] ),()(),()(),(00
0 tttRttXtAt
tt T Φ−=∂
Φ∂ , nItt =Φ ),( 00 ,
donde
( 2.33 ) 000000000
000 )()()()(),(),(
0
XtRXXtAtAXtQt
ttXttX T
tt
−++=∂
∂=
=
.
Para EDMRs con coeficientes constantes, se cumple que
)()(),( 00 tXttXttX =−= ,
)()(),( 00 ttttt Φ=−Φ=Φ ,
y el sistema formado por las ecuaciones ( 2.31 ) y ( 2.32 ) se reduce al Sistema de Ecuaciones Diferenciales Ordinarias (SEDO)
)(),()()(00 tttXt
dttdX TΦΦ= , 00 )( XtX = , 0tt ≥ ,

Capítulo 2: Estado del Arte
60
[ ] )()()()( tRtXtAdt
td T Φ−=Φ , nIt =Φ )( 0 , 0tt ≥ .
El siguiente teorema demuestra que la solución de la EDMR simétrica ( 2.30 ) se expresa en términos de la solución de la misma EDMR pero con una condición inicial diferente. La solución ),( 0ttX cuando se expresa en términos de otra EDMR se denomina solución particionada generalizada.
Teorema 2.14 ([Lain76])
La solución ),( 0ttX de la EDMR ( 2.30 ) se puede expresar como
( 2.34 ) [ ] ),(),(),(),(),( 011
0000 ttXttttttXttX Tnrnnn Φ+ΟΦ+=
−− ,
donde
),()(),(),(00
0 tttRttt
ttn
Tn
n ΦΦ=∂
Ο∂ , 0),( 00 =Ο ttn ,
[ ] ),()(),()(),(00
0 tttRttXtAt
ttnn
Tn Φ−=∂
Φ∂ , nn Itt =Φ ),( 00 ,
siendo
rn XXttX +=),( 00 .
La matriz ),( 0ttX n es la solución de la EDMR ( 2.30 ) pero con una condición inicial distinta, es decir, ),( 0ttX n es la solución de la EDMR
),()(),(),()()(),()(),(0000
0 ttXtRttXttXtAtAttXtQt
ttXnnn
Tn
n −++=∂
∂ ,
nn XttX =),( 00 .
2.4.2 Métodos de Resolución de EDMRs
2.4.2.1 Integración Directa La forma más simple de resolver EDMRs consiste en convertir la ecuación ( 2.24 ) en el sistema de ecuaciones diferenciales vectoriales de tamaño mn
( 2.35 ) ji
ji
jiijij RXXXBAXqx −++=' , para mi ,,1L= y nj ,,1L= ,
donde iX y iB representan, respectivamente, las filas i-ésimas de las matrices X y B , y jX y jA , las columnas j-ésimas de las matrices X y A .
El problema de este método es que el tamaño de este sistema de ecuaciones diferenciales es excesivamente grande cuando m y n son elevados; además, si el sistema es rígido, entonces la complejidad computacional es muy elevada.
2.4.2.2 Métodos de Linealización Estos métodos se basan en el Teorema 2.12 para convertir una EDMR en una EDML. Si en la fórmula ( 2.28 ) se consideran 00 )( XtX = , nIU =0 y 00 XV = , y la matriz fundamental Φ de la EDMR se divide a bloques

Capítulo 2: Estado del Arte
61
⎥⎦
⎤⎢⎣
⎡ΦΦΦΦ
=Φ),(),(),(),(
),(022021
0120110 tttt
tttttt ,
conforme a la matriz
⎥⎦
⎤⎢⎣
⎡−=
)()()()(
tBtQtRtA
M ,
entonces, según el Teorema 2.12, se tiene que la solución de la EDMR ( 2.24 ) es
( 2.36 ) [ ][ ] 100120110022021 ),(),(),(),()( −Φ+ΦΦ+Φ= XttttXtttttX .
2.4.2.2.1 Método de Davison-Maki
En el caso de EDMRs con coeficientes constantes se puede considerar, sin pérdida de generalidad, que 00 =t . En tal caso, la solución )(tX de la expresión ( 2.36 ) puede obtenerse fácilmente teniendo en cuenta que matriz fundamental )(tΦ coincide con la exponencial de la matriz Mt .
En [DaMa73], Davison y Maki proponen calcular )(tX utilizando un tamaño de paso constante
kft
t2
=∆ , Nk ∈ ,
de manera que se produzca un error de truncamiento menor que una cierta cota positiva elegida previamente, siguiendo el siguiente esquema:
• Calcular la exponencial matricial tMet ∆=∆Φ )( mediante, por ejemplo, las aproximaciones de Padé.
• En los siguientes pasos, se calcula )2( 1 ti ∆Φ + a partir de )2( ti ∆Φ mediante las expresiones
)2()2()2( 1 ttt iii ∆Φ∆Φ=∆Φ + , 1,,1,0 −= ki L .
En [KeLe85], Kenney y Leipnik proponen utilizar un tamaño de paso constante
kt
t f=∆ , Nk ∈ ,
de manera que se produzca un error de truncamiento menor que una cierta cota positiva elegida previamente, siguiendo el siguiente esquema:
• Calcular la exponencial matricial tMet ∆=∆Φ )( mediante, por ejemplo, las aproximaciones de Padé.
• En los siguientes pasos, se calcula ))1(( ti ∆+Φ a partir de )( ti∆Φ mediante las expresiones
)()())1(( ttiti ∆Φ∆Φ=∆+Φ , 1,,2,1 −= ki L .

Capítulo 2: Estado del Arte
62
2.4.2.2.2 Procedimiento Iterativo Matricial ASP (Automatic Synthesis Program)
Este método, debido a Kalman y Englar ([KaEn66]), fue posteriormente utilizado por Kenney y Leipnik (KeLe85]), bajo el nombre de método de Davison-Maki modificado, para resolver EDMRs con 00 =t . Como la matriz fundamental tiene estructura de semigrupo con el producto de matrices, entonces
)0,(),()0,( 11 kkkk tttt ΦΦ=Φ ++ ,
por lo que
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡ΦΦΦΦ
=⎥⎦
⎤⎢⎣
⎡ΦΦ=⎥
⎦
⎤⎢⎣
⎡Φ=⎥
⎦
⎤⎢⎣
⎡
++
++++
+
+
)()(
),(),(),(),(
)0,(),()0,()()(
122121
112111
01
01
1
1
k
k
kkkk
kkkknkkk
nk
k
k
tVtU
tttttttt
XI
tttXI
ttVtU
.
Por lo tanto,
(2.37) .)](),(),()][(),(),([
)()()(1
112111122121
11
11−
++++
+−
++
Φ+ΦΦ+Φ=
=
kkkkkkkkkk
kkk
tXtttttXtttt
tUtVtX
Si la EDMR tiene coeficientes constantes y se considera un tamaño de paso constante t∆ , entonces )( 1+ktX se puede obtener fácilmente puesto que los valores de ),( 1 kkij tt +Φ
son independientes de k .
En este método se pueden destacar las siguientes cuestiones:
• Al contrario de lo que ocurre con el método de Davison-Maki, en el método ASP no hace falta actualizar la exponencial matricial.
• Para pequeños valores de t∆ , se tiene que
nI→Φ (.,.)11 , nxm0(.,.)12 →Φ ,
mxn0(.,.)21 →Φ , mI→Φ (.,.)22 ;
por lo tanto, la matriz )(),(),( 112111 kkkkk tXtttt ++ Φ+Φ está bien condicionada.
• Aunque en principio hay que calcular la exponencial de una matriz de orden n2 , se puede modificar el método para que sólo hagan falta calcular exponenciales de matrices de orden igual a n (véase subapartado 2.4.3.5).
2.4.2.3 Método BDF En el subapartado 2.3.3.3.2 se comentó la resolución de EDOs mediante el método BDF. Este método se puede adaptar para resolver eficientemente EDMRs, resultando ser especialmente útil cuando se trata de resolver problemas de tipo rígido. Existen varios algoritmos basados en este método entre los que cabe destacar el desarrollado en [Diec92]. Si en la ecuación ( 2.24 ) se define ),( XtF como la parte derecha de la misma, es decir,
XtXRXtBtXAtQXtF )()()()(),( −++= ,
y se realiza una partición del intervalo de tiempo ],[ 0 ftt , entonces la solución aproximada en el instante kt ( kX ) se obtiene mediante la resolución de la ecuación implícita

Capítulo 2: Estado del Arte
63
( 2.38 ) ),(1
kk
r
jjkjk XtFhXX βα += ∑
=− ,
donde jα , rj ,,2,1 L= , y β son los coeficientes que aparecen en la Tabla 2.4, siendo r el orden del método BDF.
Si se sustituye el valor de ),( XtF en la ecuación ( 2.38 ), entonces se obtiene la Ecuación Algebraica Matricial de Riccati (EAMR)
( 2.39 ) ])()()()([1
kkkkkkkk
r
jjkjk XtRXXtBtAXtQhXX −++++− ∑
=− βα .
Aplicando el método de Newton a la ecuación anterior, se tiene que
( 2.40 ) ∑=
−+ ++−=−
r
jjkj
lkk
lk
lk
lkl XXtFhXXXG
1
)()()()1(')( ),()(ˆ αβ ,
donde ')(
ˆlG es una aproximación de la derivada de Fréchet ([Grif81], página 310) '
)(lG .
A partir de la ecuación ( 2.40 ), se obtiene la ecuación matricial de Sylvester
( 2.41 ) )(11
)1()1(22
ˆˆ lk
lk
lk HCYYC =− ++ ,
con mxml
k RCXCC ∈−= 12)(
2222ˆ ,
nxnlk RXCCC ∈+= )(
121111ˆ ,
mxnr
jjkj
lkk
lk
lk RXXtFhXH ∈++−= ∑
=−
1
)()()( ),( αβ ,
y mxnl
kl
kl
k RXXY ∈−= ++ )()1()1( ,
siendo
nk ItAhC 5.0)(11 +−= β ,
)(12 ktRhC β= ,
∑=
−+=r
jjkjk XtQhC
121 )( αβ ,
mk ItBhC 5.0)(22 −= β .
Por lo tanto, para encontrar la solución en un cierto instante es necesario resolver varias veces la ecuación ( 2.41 ) hasta que se alcance la convergencia de )(l
kY . Esta ecuación se puede resolver mediante el algoritmo de Bartels-Stewart [BaSt72].

Capítulo 2: Estado del Arte
64
2.4.3 Métodos de Resolución de EDMRs Simétricas
2.4.3.1 Métodos de Linealización
2.4.3.1.1 Método de la Exponencial no Negativa
En [Vaug69], Vaughan señala que el cálculo de )(tX mediante la expresión ( 2.36 ) puede dar lugar a un método inestable para valores elevados de t , proponiendo un método que puede evitar ese problema para el caso de EDMRs simétricas con coeficientes constantes. La EDML asociada a la EDMR simétrica ( 2.29 ) es
( 2.42 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−=⎥
⎦
⎤⎢⎣
⎡)()(
)()(
tVtU
AQRA
tVtU
dtd
T , fttt ≤≤0 ,
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡
00
0
)()(
XI
tVtU n ,
siendo
( 2.43 ) ⎥⎦
⎤⎢⎣
⎡−= TAQ
RAM ,
una matriz Hamiltoniana (Definición 6.24). Por lo tanto, si λ es un valor propio de M , entonces λ− también lo es. Sea W la matriz no singular que diagonaliza a la matriz M ,
⎥⎦
⎤⎢⎣
⎡−
=−
DD
MWW0
01 ,
donde D es la forma canónica de Jordan correspondiente a los valores propios que se encuentran en el semiplano complejo derecho.
Realizando el cambio de variable
( 2.44 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡VU
WWWW
VU
WVU
2221
1211 ,
la ecuación ( 2.42 ) se convierte en
( 2.45 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
=⎥⎦
⎤⎢⎣
⎡)()(
00
)()(
tVtU
DD
tVtU
dtd , ⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡ −
0
1
0
0
)()(
XI
WtVtU n .
Las soluciones de este sistema desacoplado son
)()( 0tUetU Dt= , )()( 0tVetV Dt−= .
A partir de la condición inicial de ( 2.45 ), se tiene que
)()( 012011 tVWtUWIn += ,
)()( 0220210 tVWtUWX += ,
por lo que
)()( 00 tURtV = ,

Capítulo 2: Estado del Arte
65
donde
[ ] [ ]110211
12022 WXWWXWR −−−= − ,
por lo tanto DtDtetUtV −−− = Re)()( 1 .
De la ecuación ( 2.44 ), se tiene que
)()()( 1211 tVWtUWtU += ,
)()()( 2221 tVWtUWtV += ,
y por lo tanto
.]Re][Re[
)]()()][()([)()()(1
12112221
111211
12221
1
−−−−−
−−−−
++=
++==DtDttDtD eWWeWW
tUtVWWtUtVWWtUtVtX
De este método se pueden destacar los siguientes aspectos:
• Al tender t a infinito, no hay crecimiento exponencial en la fórmula que define a )(tX y, por tanto, se evita los problemas que aparecen en el método de Davison-
Maki.
• La solución estable puede obtenerse fácilmente pues resulta ser igual a 11121
−WW .
• Un problema de este método es que el cálculo de la matriz de trasformación W puede estar mal condicionado.
2.4.3.1.2 Método de Schur
Este método es aplicable a EDMRs simétricas con coeficientes constantes. La matriz Hamiltoniana M de la expresión ( 2.43 ) se puede reducir, mediante transformaciones de semejanza ortogonales definidas por una matriz K , a una forma triangular superior a bloques
⎥⎦
⎤⎢⎣
⎡=
22
1211
0 SSS
MKK T ,
de manera que los valores propios 11S se encuentran en el semiplano complejo derecho, y los valores propios de 22S en el semiplano complejo izquierdo.
Si se considera la transformación
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡)()(
)()(
tVtU
KtVtU
,
entonces la EDML ( 2.42 ) queda como
( 2.46 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡)()(
0)()(
22
1211
tVtU
SSS
tVtU
dtd , ⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡
00
0
)()(
XI
KtVtU nT .
A partir de ( 2.46 ) se obtiene la EDML

Capítulo 2: Estado del Arte
66
)()(22 tVS
dttVd
= ,
cuya solución es
( 2.47 ) )()( 022 tVetV tS= ,
así como la EDML
)()()(01211
22 tVeStUSdt
tUd tS+= ,
cuya solución viene dada por
( 2.48 ) τττ dtVeSetUetU St
t
tStS )()()( 012)(
022
0
1111 ∫ −+= .
Si se realiza una división a bloques de la matriz K , conforme a la división a bloques de la matriz M , entonces K se puede expresar como
⎥⎦
⎤⎢⎣
⎡=
2221
1211
KKKK
K .
Teniendo en cuenta la EDML ( 2.46 ), se tiene que
( 2.49 ) )()( 00 tURtV = ,
siendo
][][ 110211
12022 KXKKXKR −−−= − .
Teniendo en cuenta las expresiones ( 2.47 ), ( 2.48 ) y ( 2.49 ), se deduce que
( 2.50 ) tSSt
t
tSn
tS RedeSeRIetUtVtX 1122
0
1122
1
12)(1)()()( −
−
−−
⎥⎥⎦
⎤
⎢⎢⎣
⎡+== ∫ τττ ,
por lo que )(tX se obtiene a partir de )(tX mediante la expresión 1
121122211 )]()][([)()()( −− ++== tXKKtXKKtUtVtX .
De este método se pueden destacar los siguientes aspectos:
• La ventaja de este método es que la matriz ortogonal K se puede calcular mediante un método estable.
• Una forma efectiva de calcular la integral que aparece en ( 2.50 ) puede encontrarse en [VanL78].
2.4.3.2 Método de Chandrasekhar Este método es particularmente útil en problemas de control óptimo y filtrado puesto que, en estos casos, la matriz )(tR de la EDMR simétrica ( 2.29 ) se expresa como el producto
)()()()( 11 tHtRtHtR T −= ,

Capítulo 2: Estado del Arte
67
donde pxntH ℜ∈)( , pxptR ℜ∈)(1 .
El método de Chandrasekhar se basa en el Teorema 2.13 y en el lema que aparece a continuación.
Lema 3 ([Lain76]).
Si nxnW ℜ∈ es una matriz simétrica de rango r , entonces existen unas matrices nxlL ℜ∈1 y )(
2lrnxL −ℜ∈ , siendo l el número de valores propios positivos de la matriz
W , de manera que TT LLLLW 2211 −= .
Si se aplica el lema anterior a la matriz simétrica ),( 00 ttX de la ecuación ( 2.33 ), se tiene que
( 2.51 ) [ ] [ ] )()()()(0
0)()(),( 000201020100 tSLtLtLtL
II
tLtLttX TT
mr
m =⎥⎦
⎤⎢⎣
⎡−
=−
,
donde r es el rango de ),( 00 ttX , nxltL ℜ∈)( 01 y )(02 )( lrnxtL −ℜ∈ .
Sustituyendo ( 2.51 ) en ( 2.31 ) y multiplicando a la derecha de esta ecuación por )()( 1
1 tRtH T − , se tiene que
( 2.52 ) )()(),(),(),( 1100
0
0 tRtHttSYttt
ttK TTKK
−Υ−=∂
∂ ,
)()(),( 01
10000 tRtHXttK T −= ,
donde nxpT tRtHttXttK ℜ∈= − )()(),(),( 1
100 ,
( 2.53 ) nxrkK tLtttt ℜ∈Φ=Υ )(),(),( 000 .
Derivando la ecuación anterior respecto de t y haciendo uso de la ecuación ( 2.32 ), se obtiene
( 2.54 ) ),()](),()([),(00
0 tttHttKtAt
ttK
TK Υ−=∂
Υ∂ ,
)(),( 000 tLttK =Υ .
Por lo tanto, las matrices ),( 0ttK y ),( 0ttKΥ se pueden calcular resolviendo las ecuaciones diferenciales ( 2.52 ) y ( 2.54 ).
La solución ),( 0ttX puede obtenerse a partir de ( 2.31 ) utilizando una fórmula de cuadratura en la ecuación diferencial
( 2.55 ) ),(),(),(
000
0 ttSttt
ttX TKK ΥΥ−=
∂∂
.
Las ecuaciones en derivadas parciales dadas en ( 2.52 ) y ( 2.54 ) no se pueden resolver con facilidad para EDMRs con coeficientes variables, incluso en el caso en que el

Capítulo 2: Estado del Arte
68
número de ecuaciones sea significativamente pequeño. Para el caso de EDMRs con coeficientes constantes, las EDPs se reducen a EDOs puesto que K y KΥ se pueden considerar funciones de 0tt − . Por lo tanto,
dttdK
tttK
tttK
tttK )()()(),( 0
0
0
0
0 −=∂
−∂−=
∂−∂
=∂
∂ ,
luego ( 2.52 ) y ( 2.54 ) se convierten en
1)()()( −Υ= RHtSYtdt
tdK TTKK , 1
00 )( −= RHPtK T ,
[ ] )()()( tHtKAdt
tdK
TK Υ−=Υ , )()( 00 tLtK =Υ ,
y )(tX se puede obtener integrando )()( tSYt TKKΥ .
En este método se puede destacar que:
• Si 00 =X , entonces la matriz QttX =),( 00 es semidefinida positiva y la matriz S de la ecuación ( 2.55 ) es igual a la matriz identidad de rango r , siendo r el rango de la matriz Q .
• Si se utiliza un método directo de integración, entonces el número total de ecuaciones a integrar es )( rpn + puesto que nxpK ℜ∈ y nxr
K ℜ∈Υ . Si 2/)1( +<<+ nrp , entonces el número de ecuaciones en este método es mucho
menor que los obtenidos mediante un método directo de integración. La desigualdad es satisfecha si tanto el parámetro p como el parámetro r son pequeños comparados con n . De este modo, sólo para algunas clases especiales de EDMRs es interesante utilizar este método.
• En la implementación de un filtro de Kalman únicamente es necesario conocer la matriz de ganancia ),( 0ttK , no siendo imprescindible calcular la matriz ),( 0ttX .
2.4.3.3 Algoritmo de Particionado Numérico (APN) Este método, basado en el Teorema 2.14, fue sugerido por Lainiotis ([Lain76]) para resolver EDMRs simétricas. Supóngase que el intervalo de integración se divide en k subintervalos ],[,],,[ 110 fk tttt −L . Las soluciones en los nodos están dadas por las siguientes fórmulas recursivas obtenidas a partir de la ecuación ( 2.34 ):
( 2.56 ) ),()],(),()[,(),(),( 11
011
11101 iiTniriiniiniini ttttXttttttXttX +
−+
−++++ Φ+ΟΦ+= .
De acuerdo con el Teorema 2.14, ),( 1 iin ttX + , ),( 1 iin tt +Φ y ),( 1 iin tt +Ο se obtienen mediante la integración de las siguientes ecuaciones diferenciales
( 2.57 ) ),()(),(),(
iniTn
in tttRttt
ttΦΦ=
∂Ο∂
, niin tt 0),( =Ο ,
( 2.58 ) ),()](),()([),(inin
Tin tttRttXtAt
ttΦ−=
∂Φ∂ , niin Itt =Φ ),( ,
( 2.59 ) ),,()(),(),()()(),()(),(ininin
Tin
i
in ttXtRttXttXtAtAttXtQt
ttX−++=
∂∂

Capítulo 2: Estado del Arte
69
niiin XttX =),( ,
en cada uno de los subintervalos ],[ 1+ii tt .
La condición inicial niX en la última ecuación se elige de manera que la matriz
niiir XttXttX −= ),(),( 00
sea no singular.
Para calcular eficientemente las matrices ),( 1 iin ttX + , ),( 1 iin tt +Φ y ),( 1 iin tt +Ο se puede aplicar el Teorema 2.13 a ),( in ttX y ),( in ttΦ . En cuyo caso, ( 2.57 ), ( 2.58 ) y ( 2.59 ) se convierten en las ecuaciones
),()(),(),(ini
Tn
in tttRttt
ttΦΦ=
∂Ο∂ , 0),( =Ο iin tt ,
),()](),()([),(inin
Tin tttRttXtAt
ttΦ−=
∂Φ∂ , niin Itt =Φ ),( ,
),(),(),(),(i
Tniinin
i
in ttttXttt
ttXΦΦ=
∂∂ , niiin XttX =),( ,
donde
).,()(),(),()()(),()(
),(),(
iiniiiniiniT
iiini
tti
iniin
ttXtRttXttXtAtAttXtQ
tttXttX
i
−++=
∂∂
==
Si se elige convenientemente la condición inicial niX , entonces las ecuaciones anteriores pueden resolverse mediante el método de Chandrasekhar.
Respecto de este método se pueden destacar las siguientes cuestiones:
• La integración en cada subintervalo ],[ 1+ii tt es independiente de la integración en los otros subintervalos; por lo tanto, estas integraciones se pueden realizar en paralelo. Las soluciones vienen dadas por las operaciones recursivas de las soluciones elementales de la ecuación ( 2.56 ).
• Este método se puede aplicar a EDMRs con coeficientes periódicos ([SpGu79]). Si la longitud de los subintervalos es múltiplo del periodo y se elige la misma condición inicial niX para cada subintervalo, entonces únicamente es necesario calcular ),( in ttX , ),( in ttΦ y ),( in ttΟ en el primer subintervalo. La solución en los siguientes subintervalos están dados por la siguiente fórmula recursiva
( 2.60 ) ( ) ( ) ( ) ( )[ ] ( ) )()()1( 1 ∆Φ∆∆Ο∆+∆Φ+∆=∆+ − Tnnnn iXiXIXiX ,
siendo ( ) ( )0,kXkX =∆ y kk tt −=∆ +1 .
• La ecuación anterior se puede aplicar también a EDMRs con coeficientes constantes.

Capítulo 2: Estado del Arte
70
• Desde un punto de vista computacional, el cálculo de ),( in ttX , ),( in ttΦ y ),( in ttΟ es costoso puesto que se debe resolver un sistema de ecuaciones en derivadas parciales no lineal.
2.4.3.4 Método Basado en la Ecuación Algebraica de Riccati (EAR) Este método ([AnMo71]) se aplica a la EDMR simétrica
( 2.61 ) XXHHXAXAGGX TTT −++=' , 0≥t ,
0)0( XX = ,
siendo ),( HA estabilizable, ),( AG observable y 0X matriz definida positiva.
Lema 4 ([Wonh68])
Si ),( HA es estabilizable y ),( AG es completamente observable, entonces la EAR
( 2.62 ) 0=−++ XRXXAXAQ T
tiene una única solución definida positiva de manera que el sistema en bucle cerrado definido por
RXAK −= es asintóticamente estable.
Si se aplica el lema anterior, considerando X la solución definida positiva de la EAR
( 2.63 ) 0=−++ XHHXXAAXGG TTT ,
entonces, utilizando las ecuaciones ( 2.61 ) y ( 2.63 ) y llamando XHHAA T−= , se tiene que
( 2.64 ) )()()()()( XXHHXXXXAAXXXXdxd TT −−−−+−=− .
Si XX − es no singular y se define 1)()( −−= XXtZ , entonces
11 )()()(' −− −⎥⎦⎤
⎢⎣⎡ −−−= XXXXdxdXXZ ,
por lo que la ecuación ( 2.64 ) se reduce a
( 2.65 ) TT HHAZZAZ −+=− ' , 10 )()0( −−= XXZ , 0>t .
Puesto que A es estable, entonces existe una única solución definida positiva de la Ecuación Algebraica Matricial de Lyapunov (EAML)
( 2.66 ) TT HHAZZA −+=0 .
Restando las ecuaciones ( 2.66 ) y ( 2.65 ), se obtiene la Ecuación Diferencial Matricial de Lyapunov (EDML)
TAZZZZAZZdtd )()()( −+−=−− , 0>t
con ZXX −− −10 )( como condición inicial. Por lo tanto,

Capítulo 2: Estado del Arte
71
[ ] tAtA T
eZXXeZZ −−− −−=− 10 )( ,
luego
( 2.67 ) [ ]( )
( ) .)(
)(11
0
110
tAtAtAtA
tAtA
eZXXeZeeX
eZXXeZXXTT
T
−−
−−−−
−−++=
−−++=
Una desventaja de este método es el elevado coste computacional del cálculo de X , Z y de la exponencial matricial que aparece en la ecuación ( 2.67 ). Una versión de este método puede encontrase en [Laub82].
2.4.3.5 Método de Leipnik Este método, debido a Leipnik ([Leip85]), permite resolver EDMRs simétricas con coeficientes constantes.
Lema 5 ([Leip85])
Sean C y D matrices cuadradas y
⎥⎦
⎤⎢⎣
⎡=
CDDC
N ( N matriz bisimétrica),
entonces
⎥⎦
⎤⎢⎣
⎡=
EFFE
N n ,
siendo
])()[(5.0 nn DCDCE −++= ,
])()[(5.0 nn DCDCF −−+= .
Sea la EDMR simétrica con coeficientes constantes
( 2.68 ) XRXXAXAQX T −++=' , 0)0( XX = , 0≥t ,
siendo 0X matriz definida positiva.
Si se realiza la transformación
( 2.69 ) HZXZX T += 1 ,
siendo H simétrica, entonces ( 2.68 ) queda como
( 2.70 ) 11111111'1 XRXXAAXQX T −++= , 1
01 )()0( −− −= ZHXZX T , 0>t .
siendo 1
1 )( −−= ZRHAZA , TZRZR =1 ,
11 )( −− −++= ZHRHHAHAQZQ TT .

Capítulo 2: Estado del Arte
72
Como consecuencia de una propiedad descrita en [Copp74], se tiene que si el par ),( RA es controlable, entonces existen la solución maximal +X y la solución minimal −X de la EAR asociada a la EDMR ( 2.68 ). Eligiendo Z y H de manera que
)(21
−+ −= XXZZ T ,
)(21
−+ += XXH ,
entonces
11 AAT −= , 11 QR = .
Por lo tanto, la ecuación ( 2.70 ) se reduce a
( 2.71 ) 1111111'1 XRXAXXAX −+−= , 1
01 )()0( −− −= ZHXZX T , 0>t .
Utilizando el Teorema 2.12, se tiene que el EDML asociado a la EDMR anterior es
( 2.72 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
−=⎥
⎦
⎤⎢⎣
⎡VU
ARRA
VU
dtd
11
11 ,
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡)0()0(
)0(
1XI
VU n .
Puesto que la matriz coeficiente de la ecuación ( 2.72 ) es bisimétrica, entonces se puede aplicar el Lema 5, con lo que
⎥⎦
⎤⎢⎣
⎡=
⎥⎦
⎤⎢⎣
⎡−
−
)()()()(
12
2111
11
tEtEtEtE
et
ARRA
,
donde
[ ]tRAtRA eetE )()(1
1111
21)( −+ += ,
[ ]tRAtRA eetE )()(2
1111
21)( +− −= .
La solución 1X se obtiene a partir de la fórmula ( 2.28 ) y X a partir de ( 2.69 ).
Una ventaja de este método es que la solución X se puede obtener calculando exponenciales de matrices de tamaño n . Sin embargo, este método requiere el cálculo de las soluciones maximal y minimal de una EAR. Además, si estas soluciones están cercanas entre sí, entonces la matriz Z puede estar mal condicionada.
2.4.3.6 Método de la Raíz Cuadrada Este método, debido a Morf, Ley y Kailath ([MoLK78]), es aplicable a la EDMR con coeficientes variables
( 2.73 ) )()()()()()()()()()()(' tXtHtHtXtXtAtAtXtGtGtX TTT −++= , fttt ≤≤0 ,
0)0( XX = ,

Capítulo 2: Estado del Arte
73
siendo 0X matriz definida positiva. En tal caso, la solución )(tX se puede comprobar que es definida positiva (véase subapartado 2.4.3.8). Luego dicha solución se puede expresar como
( 2.74 ) )()()( tStStX T= ,
y la condición inicial como
)()()( 000 tStStX T= ,
donde )(tS (no singular) se puede elegir de manera que sea triangular inferior con elementos positivos en la diagonal principal (factorización de Cholesky).
La EDMR ( 2.73 ) se convierte entonces en la ecuación
).()()()()()()()()()()()()()()(')()()(')('
tStStHtHtStStStStAtAtStStGtGtStStStStX
TTTTTTT
TT
−++=
+=
Multiplicando la ecuación anterior a la izquierda por )(tS T− y a la derecha por )(1 tS − , se obtiene
)()()(')(')( 1 tCtStStStS TT =+ −− ,
donde
)()()()()()()( tHtHtAtAtGtGtC TTT +++= ,
siendo
)()()()( 1 tStAtStA −= , )()()( tHtStH = , )()()( 1 tStGtG −= .
Puesto que )(tS es triangular inferior, entonces )()(' 1 tStS − se puede elegir de manera que coincida con la parte triangular inferior de la matriz )(tC , es decir,
)()(21)()(' tStCtCtS DL ⎥⎦
⎤⎢⎣⎡ += , 00)( StS = ,
siendo )(tCL la parte estrictamente triangular inferior de la matriz )(tC y )(tCD la diagonal de la matriz )(tC .
Una vez se ha calculado )(tS , por ejemplo, mediante integración directa, )(tX se puede calcular a partir de la expresión ( 2.74 ).
Este método puede mejorar el condicionamiento del la EDMR ( 2.73 ), sin embargo, puede tener problemas si la matriz )(tS está mal condicionada.
2.4.3.7 Método de Rusnak Este método, debido a Rusnak ([Rusn88]), se aplica a la EDMR con coeficientes constantes definida por ( 2.61 ), suponiendo que ),( HA es estabilizable y ),( AG detectable. La solución analítica de la ecuación ( 2.61 ) viene dada por la expresión
( 2.75 ) )(
1
0)()(
0)( )(Re)()(
0
00 oT
oT ttK
t
t
tKtKn
ttK eXXdeIXXeXtX −
−
−−−
⎥⎥⎦
⎤
⎢⎢⎣
⎡−+−+= ∫ τττ , 0tt ≥ ,

Capítulo 2: Estado del Arte
74
donde X es la única solución semidefinida positiva de la EAR ( 2.63 ) y XRAK −= . Si se considera un tamaño de paso constante e igual a t∆ , entonces, teniendo en cuenta ( 2.75 ), se obtiene la siguiente fórmula recursiva
tKlnl
tKl eXDIXeX
T ∆−∆+ += 1
1 )ˆ(ˆˆ , L,2,1,0=l ,
siendo
XXX −= 00ˆ ,
XtXX nn −= )(ˆ
y
∫∆
=t
KK deDT
0
Re τττ .
Respecto de este método se pueden realizar dos puntualizaciones:
• Puesto que la matriz 0→D a medida que 0→∆t , entonces la matriz ln XDI ˆ+ está bien condicionada para pequeños valores de t∆ .
• Es necesario calcular la solución X de la EAMR ( 2.63 ) para poder obtener la solución )(tX de la ecuación ( 2.61 ).
2.4.3.8 Métodos Conservativos y Métodos Simplécticos Más que un método, se trata de una familia de métodos que tienen en común la conservación de la simetría y el carácter semidefinido positivo de la solución.
Teorema 2.15 ([DiEi94])
Sea la EDMR simétrica
( 2.76 ) )()()()()()()()()(' tCtXtBtXtAtXtXtAtX T +−+= , 0)0( XX = , 0≥t ,
en donde la condición inicial 0X es una matriz simétrica semidefinida positiva, entonces la solución )(tX es simétrica y semidefinida positiva para todo 0>t . Además, si )(sX o )(sC son definidas positivas para un cierto 0≥s , entonces )(tX es definida positiva para todo st ≥ .
Lo que se busca en estos métodos es aplicar algoritmos que preserven la propiedad de que las soluciones encontradas para instantes de tiempo 0>t conserven la propiedad de ser definidas o semidefinidas positivas. En [DiEi94] se proponen varios de estos métodos. El primero de ellos está basado en el método de linealización de EDMRs. Por el Teorema 2.12, se tiene que la EDML asociada a la EDMR ( 2.76 ) es
( 2.77 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
=⎥⎦
⎤⎢⎣
⎡)()(
)()()()(
)(')('
tZtY
tAtBtCtA
tZtY
T , ⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡I
XZY 0
)0()0(
,
con
( 2.78 ) )()()( 1 tZtYtX −= ,
la solución de la EDMR ( 2.76 ).

Capítulo 2: Estado del Arte
75
Una aproximación consiste en utilizar métodos de discretización para resolver la EDML ( 2.77 ), y calcular entonces )(tX mediante la expresión ( 2.78 ). Por ejemplo, si se utilizan métodos de Gauss (aproximantes diagonales de Padé), entonces sus coeficientes satisfacen ([Sanz92])
( 2.79 ) 0=−+= jijijijiij bbababM , kji ,,1, L=∀ ,
por lo que se trata de métodos Runge-Kutta simplécticos, siendo 0≥jb .
Teorema 2.16 ([DiEi94])
La aplicación de un método Runge-Kutta que satisfaga ( 2.79 ) con 0≥jb a la EDML definida en ( 2.77 ) produce soluciones aproximadas que son simétricas y semidefinidas positivas.
Otro método que se encuentra en [DiEi94] consiste en expresar la EDMR ( 2.76 ) como
)()]()(5.0)()[()()]()(5.0)([)(' tCtBtXtAtXtXtBtXtAtX T +−+−= .
La solución de la ecuación anterior es
( 2.80 ) ττττ dtCtstsXsttX Tt
s
T ),()(),(),()(),()( ΦΦ+ΦΦ= ∫ ,
siendo ),( τtΦ la solución de la EDML
( 2.81 ) [ ] ),()()(5.0)(),( ττ ttBtXtAtt
Φ−=∂
Φ∂ , nI=Φ ),( ττ .
Para obtener una solución aproximada 1+kX que sea definida positiva, a partir de otra
kX que sea definida positiva, se pueden seguir los siguientes pasos:
• Aplicar cualquier método para resolver ( 2.81 ). • Obtener las correspondientes soluciones, utilizando cualquier otro método. • Utilizar una fórmula en la que los pesos para la integración de ( 2.80 ) sean
positivos.
Si se resuelve la ecuación ( 2.81 ) por la regla implícita del punto medio y se utiliza la regla trapezoidal para calcular )(tX en ( 2.80 ), se obtiene un método de segundo grado. La regla del punto medio para ( 2.81 ) requiere una aproximación de )( 2hΟ para
)2/( htX k + . El esquema resultante es
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −+⎥
⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −−=Φ
−
+ knknkkkk XBAhIXBAhI21
421
4
1
2/1 ,
2/12/12/12/1 44 ++++ +Φ⎥⎦⎤
⎢⎣⎡ +Φ= k
Tkkkkk ChChXX ,
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −+⎥
⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −−=Φ +++
−
+++ 2/12/12/1
1
2/12/12/1 21
221
2 kkkkkkk XBAhIXBAhI ,

Capítulo 2: Estado del Arte
76
11 42 ++ +Φ⎥⎦⎤
⎢⎣⎡ +Φ= k
Tkkkkk ChChXX .
Un estudio más completo sobre métodos simplécticos y su aplicación a la resolución de EDMRs que conserven la simetría y la positividad de la solución pueden encontrarse en [SaCa94] o [Mart99].
2.4.3.9 Métodos BDF para EDMRs de gran Escala En [BeMe04] se sugiere resolver EDMRs de gran escala mediante el método Newton-ADI (Alternating Directions Implicit) de rango pequeño ([Benn02], [Benn02]). Estas ecuaciones proceden de la semidiscretización de problemas de control óptimo de ecuaciones en derivadas parciales de tipo parabólico hiperbólico como, por ejemplo, la ecuación de calor, la ecuación de ondas, etc.
Sea la EDMR simétrica
)()()()()()()()(' tRXtXtXtAtAtXtQtX T −++= , fttt ≤≤0 ,
00 )( XtX = .
Aplicando el método BDF y reagrupando adecuadamente los términos de la ecuación, se tiene obtiene la EAMR
( 2.82 ) 0)()5.0()5.0(1
=−−+−++ ∑=
− kkknkkkT
nk
r
jjkjk XRhXIAhXXIAhXQh βββαβ .
Suponiendo que
kTkk CCQ = , pxn
kC ℜ∈ , Tkkk BBR = , nxm
kB ℜ∈ , Tkkk ZZX = , knxz
kB ℜ∈ ,
la EAMR ( 2.82 ) se puede escribir como
( 2.83 ) 0ˆˆˆˆˆˆˆˆˆˆˆˆˆˆ =−++ Tkk
Tkk
Tkkk
Tkk
Tkk
Tkk
Tk ZZBBZZAZZZZACC ,
siendo
nkk IAhA 5.0ˆ −= β ,
kk BhB β=ˆ ,
],,,[ˆ11 rkrkkk ZZChC −−= ααβ L .
Si, por simplicidad de notación, la ecuación ( 2.83 ) se escribe como
0)(0 =−++== PPBBPAPACCPF TTT ,
y se aplica el método de Newton, se tiene que
lll NXX +=+1 ,
siendo
)()'( 1lPl PFFN
l
−= ,

Capítulo 2: Estado del Arte
77
con lPF ' la derivada de Fréchet en la dirección lP , definida como
TTTP PBBAQQPBBAQF )()(:' −+−⎯→⎯ .
Un paso de la iteración de Newton, partiendo de una matriz 0P , quedaría como
1 lT
l PBBAA −= . 2 Calcular lN resolviendo la ecuación de Lyapunov )( llll
Tl PFANNA −=+ .
3 lll NPP +=+1 .
Eligiendo un valor suficientemente pequeño del incremento de tiempo y eligiendo 10 −= kXP , se puede conseguir que iA , 0≥i , sean estables y que lP converja
cuadráticamente a )( 11* ++ ≅= kk tXXP .
Para que este método sea aplicable en problemas de gran escala es necesario utilizar un método que resuelva ecuaciones de Lyapunov, de manera que explote la estructura dispersa y de rango pequeño de las matrices lA .
En primer lugar, la ecuación de Lyapunov del paso se puede escribir como T
lllT
lT
lllTl WWPBBPCCAPPA −=−−=+ ++ :11 .
Suponiendo Tlll ZZP = para nZl <<)(rango y observando que npmWl <<+≤)(rango ,
entonces basta utilizar un método numérico que resuelva la ecuación de Lyapunov anterior como, por ejemplo, una versión modificada del método ADI para ecuaciones de Lyapunov que tengan la forma
TT WWQFFQ −=+ ,
con F estable y wnxnW ℜ∈ .
La iteración ADI se puede escribir como ([Wach88])
)()( 12
1 njjT
jnjT IpFQWWQIpF −−−=+ −− ,
)()(2
1 njjTT
jnjT IpFQWWQIpF −−−=+ − ,
donde p denota el complejo conjugado de C∈p . Si los parámetros jp se eligen de manera apropiada, entonces
QQjj=
∞→lim
con un razón de convergencia superlineal.
Comenzando la iteración anterior con nQ 00 = y observando que para F estable, entonces Q es semidefinida positiva, se tiene que
Tjjj YYQ =
para una cierta matriz jnxrjY ℜ∈ .
Sustituyendo esta factorización en la iteración anterior, reagrupando los términos y combinando los dos pasos de la iteración, se obtiene una iteración ADI factorizada de

Capítulo 2: Estado del Arte
78
manera que en cada paso de la iteración se obtienen wn columnas de un factor de rango completo Q , como a continuación se muestra:
1 WIpFpV nT 1
111 )()(real2 −+−= ; 11 VY = 2 Para ,....3,2=j
2.1 11
11
]))(([)(real
)(real−
−−
−
++−= jnjT
jjnj
jj VIpFppI
p
pV
2.2 ][ 1 jjj VYY −= .
Si en la iteración anterior se alcanza la convergencia después de maxj pasos, entonces
wnnxjjj VVVY max
maxmax],,,[ 21 ℜ∈= L ,
donde wnxnjV ℜ∈ .
Para un valor grande de n y uno pequeño de wn , se puede esperar que nnjr wj <<= max , de manera que se ha obtenido una aproximación
maxjY de rango pequeño de un factor Y
de la solución, es decir, Tjj
T YYYYQmaxmax
≈= . En el caso en que wj njr max= sea grande, se puede aplicar técnicas de compresión ([GuSA03]) para reducir el número de columnas de la matriz
maxjY , sin añadir un error significativo.
2.4.4 Aplicaciones Las EDMRs tienen numerosas aplicaciones en ingeniería y en ciencias aplicadas como, por ejemplo, control óptimo, filtrado óptimo, problemas de valores de contorno, perturbaciones singulares, etc. En este apartado se describen algunas de ellas.
2.4.4.1 Problemas del Control Óptimo En este subapartado se describe la aplicación de EDMRs al problema del sistema de regulador óptimo lineal cuadrático.
Sea la EDL de orden n
)()()()()(' tutBtxtAtx += , 00 )( xtx = , fttt ≤≤0 ,
y el índice de coste cuadrático
)()(21)]()()()()()([
21
0
ffT
t
t
TT tSxtxdttutRtutxtQtxJf
++= ∫ ,
siendo
• ntx ℜ∈)( , el vector de estados;
• nxntA ℜ∈)( , la matriz de estados;
• nxmtB ℜ∈)( , la matriz de entradas (controles);
• mtu ℜ∈)( , el vector de entradas (controles);
• ℜ∈J , el índice de coste;

Capítulo 2: Estado del Arte
79
• nxntQ ℜ∈)( semidefinida positiva, la matriz de pesos correspondientes a los estados;
• mxmtR ℜ∈)( definida positiva, la matriz de pesos correspondientes a los controles;
y
• nxnS ℜ∈ semidefinida positiva, la matriz de pesos correspondientes al valor final.
El objetivo es determinar el control óptimo )(tu que minimice el valor de J . Puede demostrarse ([Kalm61]) que la ley de control óptimo )(tu viene dada por
( 2.84 ) )()()()()( 1 txtPtBtRtu T−−= , fttt ≤≤0 ,
y que la matriz del sistema en bucle cerrado resulta ser
( 2.85 ) )()()()()()( 1 tPtBtRtBtAtK T−−= , fttt ≤≤0 ,
donde )(tP satisface la EDMR
( 2.86 ) )()()()()()()()()()()(' 1 tQtPtBtRtBtPtAtPtPtAtP TT −+−−= − , fttt ≤≤0
StP f =)( .
2.4.4.2 Problemas de Filtrado y Estimación En este subapartado se describe la aplicación de EDMRs al problema de estimación de mínimos cuadrados de sistemas lineales en tiempo continuo. En este caso ntx ℜ∈)( es un vector generado aleatoriamente por la EDL
)()()()()(' tutGtxtFtx += , [ ] 00 )( xtxE = ,
siendo [ ]xE el valor esperado de )(tx , y la señal observada ptz ℜ∈)( viene dada por
)()()()( tvtxtHtz += .
Los vectores mtu ℜ∈)( y ptv ℜ∈)( corresponden a ruidos blancos independientes con medias igual a 0 y matrices de covarianza definidas por las expresiones
[ ] )()()(),(cov τδτ −= ttQutu ,
[ ] )()()(),(cov τδτ −= ttRvtv ,
[ ] 0)(),(cov =τvtu ,
para todo t y τ , siendo nxntQ ℜ∈)( semidefinida positiva y nxntR ℜ∈)( definida positiva. El objetivo es encontrar una estimación )|(~
1 ttx de )( 1tx a partir de los datos observados { }tttz ≤≤0),(τ , de manera que
]||)|(~)([|| 2211 ttxtxE − , tt ≥1 ,
tenga un valor mínimo.

Capítulo 2: Estado del Arte
80
Para tt =1 puede demostrarse ([KaBu61]) que la estimación óptima )|(~ ttx está generada por el sistema lineal dinámico
)|(~)()|(~)()|(~ttztKttxtF
dtttxd
+= , 000 )|(~ xttx = ,
)|(~)()()|(~ ttxtHtzttz −= .
La matriz de ganancias )(tK viene dada por la expresión
)()()()( 1 tRtHtPtK T −= ,
siendo
[ ])|(~)(),|(~)(cov)( ttxtxttxtxtP −−=
la solución de la EDMR
)()()()()()()()()()()()()(' 1 tGtQtGtPtHtRtHtPtFtPtPtFtP TTT +−−= − ,
[ ]000000 )(,)(cov)( xtxxtxPtP −−== , 0tt ≥ .
2.4.4.3 Sistemas de Parámetros Distribuidos El siguiente ejemplo muestra la aplicación de EDMRs al problema de control óptimo en sistemas de parámetros distribuidos ([Hunt79]). Sea el sistema parabólico de parámetros distribuidos
),(),(),(2
2
tyuy
tyxy
tyx+
∂∂
=∂
∂ , fttt ≤≤0 , Ly ≤≤0 ,
con condiciones de contorno
0),0(=
∂∂
ttx , 0),(
=∂
∂y
tLx ,
y la condición inicial
)()0,( yfyx = .
El objetivo es encontrar un control óptimo )(tu de manera que el funcional
( )∫ ∫ +=ft L
dydttyrutyqxJ0 0
22 ),(),(21 ,
tenga un valor mínimo.
Si se utiliza una fórmula en diferencias centrales que aproxime 2
2
yx
∂∂ y se considera
)1/( +=∆ nLy , se obtiene la EDL
( 2.87 ) )()()(' tutAxtx += ,
donde

Capítulo 2: Estado del Arte
81
)2()2(2
220000121000012000
000210000121000022
)(1 ++ℜ∈
⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−
−−
−
∆= nxn
yA
L
L
L
MMOOMMM
O
L
.
El vector de estados )(tx es igual a T
n txtxtx )](,),(),([ 110 +L ,
donde ),()( tyixtxi ∆= , 1,,1,0 += ni L .
El vector de control )(tu es igual a T
n tututu )](,),(),([ 110 +L ,
donde ),()( tyiutui ∆= , 1,,1,0 += ni L .
Con la aproximación anterior y utilizando la regla trapezoidal para la integración de y , el funcional de coste se convierte en
( 2.88 ) ∫ +∆
=ft
TT dttRututQxtxyJ0
)]()()()([2
,
donde
)5.0,1,,1,5.0( LdiagrR
== .
El procedimiento estándar de optimización para ( 2.87 ) y ( 2.88 ) consiste en resolver hacia atrás la EDMR ( 2.86 ), siendo 0)( =ftP . El control óptimo y la trayectoria de estado óptima están gobernados por las ecuaciones ( 2.84 ) y ( 2.85 ), respectivamente.
2.4.4.4 Reducción de Orden y Desacoplamiento La reducción de orden y desacoplamiento de sistemas lineales, vía transformaciones de Riccati ([Chan69], [Sibu66], [SBIK76]), ha demostrado ser una potente herramienta analítica utilizada en matemáticas e ingeniería. Sea la EDL
( 2.89 ) ⎥⎦
⎤⎢⎣
⎡+⎥
⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−=⎥
⎦
⎤⎢⎣
⎡)()(
)()(
)()()()(
)()(
tgtf
tvtu
tBtQtRtA
tvtu
dtd , ⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡
0
0
0
0
)()(
vu
tvtu
, 0tt ≥ ,
donde ntu ℜ∈)( , mtv ℜ∈)( , ntf ℜ∈)( , mtg ℜ∈)( , nxntA ℜ∈)( , nxmtR ℜ∈)( , mxntQ ℜ∈)( y mxmtB ℜ∈)( .
Esta ecuación se puede reducir a un sistema triangular superior a bloques
( 2.90 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡+⎥
⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
−=⎥
⎦
⎤⎢⎣
⎡)()(
)(0
)(ˆ)(ˆ
)()()(0)()()()(
)(ˆ)(ˆ
tgtf
ItXI
tvtu
tRtXtBtRtAtXtR
tvtu
dtd
m
nxmn ,

Capítulo 2: Estado del Arte
82
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
=⎥⎦
⎤⎢⎣
⎡
0
0
00
0
)(0
)(ˆ)(ˆ
vu
ItXI
tvtu
m
nxmn , 0tt ≥ ,
mediante la transformación
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡)(ˆ)(ˆ
)(0
)()(
tvtu
ItXI
tvtu
m
nxmn ,
siendo )(tX la solución de la EDMR
)()()()()()()()()(' tXtRtXtXtBtAtXtQtX −++= , fttt ≤≤0 ,
00 )( XtX = ,
donde la condición inicial 0X se puede elegir arbitrariamente.
Por otra parte, la ecuación ( 2.90 ) puede reducirse a la ecuación
( 2.91 ) ,,
)()(
)()()()(
)()(
)()()(00)()()(
)()(
0tttgtf
ItXtStXtSI
tvtu
tRtXtBtAtXtR
tvtu
dtd
m
n
mxn
nxm
≥⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
−++
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
−=⎥
⎦
⎤⎢⎣
⎡
( 2.92 ) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡−
−+=⎥
⎦
⎤⎢⎣
⎡
0
0
0
000
0
0
)()()()(
)()(
vu
ItXtStXtSI
tvtu
n
m ,
mediante la transformación
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡)()(
0)(
)(ˆ)(ˆ
tvtu
ItSI
tvtu
mmxn
n .
La matriz )(tS resulta ser la solución de la Ecuación Diferencial Matricial de Sylvester (EDMS)
)]()()()[()()]()()([)()(' tRtXtBtStStXtRtAtRtS −−+−+= , fttt ≤≤0 ,
00 )( StS = ,
donde 0S puede elegirse de manera arbitraria. Este proceso puede adicionalmente llevarse a cabo desacoplando los sistemas diagonales a bloques individuales del sistema desacoplado ( 2.91 ). El precio pagado por esta reducción es el cálculo de la solución de las anteriores ecuaciones matriciales diferenciales de Sylvester y Riccati.
2.4.4.5 Resolución de Problemas de Contorno Sea el problema de contorno definido como
( 2.93) ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡)()(
)()(
2
1
2221
1211'2
'1
tyty
AAAA
tyty
, fttt ≤≤0 ,
[ ] 102
011211 )(
)(β=⎥
⎦
⎤⎢⎣
⎡tyty
BB ,

Capítulo 2: Estado del Arte
83
donde nxnA ℜ∈11 , nxmA ℜ∈12 , mxnA ℜ∈21 , mxmA ℜ∈22 , mxnB ℜ∈11 , mxmB ℜ∈12 , nxnB ℜ∈21 , nxmB ℜ∈22 , mℜ∈1β , nℜ∈2β , ny ℜ∈1 y my ℜ∈2 .
Este problema de contorno se puede desacoplar en un problema de valores iniciales y otro de valores finales mediante el cambio de variable definido como
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡ −
)()(
)()()(
2
11
2
1
tyty
tStwtw
,
siendo
)()(
)(0
)( mnxmn
m
nxmn
ItXI
tS ++ℜ∈⎥⎦
⎤⎢⎣
⎡= , mxntX ℜ∈)( ,
de manera que
( 2.94 ) ⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡)()(
)()()(
2
1'2
'1
twtw
tAtwtw
,
con
⎥⎦
⎤⎢⎣
⎡−
+=−= −−
1222
12121111
)(0)(
)(')()()()(AtXA
AtXAAtStStAStStA
mxn
.
Para que esto sea posible (véase [KeLe82], [DESS82]) es necesario que )(tX sea la solución de la EDMR
( 2.95 ) )()()()()(' 12112221 tXAtXAtXtXAAtX −−+= , fttt ≤≤0 ,
111
1200 )( BBtXX −−== ,
siendo
( 2.96 ) 1012 )(]0[ β=twB , 2222221 )(])([ β=+ ff twBtXBB .
Por lo tanto, para resolver el problema de contorno ( 2.93 ) se siguen los siguientes pasos:
1. Resolver la EDMR ( 2.95 ). 2. A partir de ( 2.94 ) se tiene las EDOs
)(])([)( 21222'2 twAtXAtw −= ,
)()()]([)( 21211211'1 twAtwtXAAtw ++= .
Teniendo en cuenta las condiciones dadas en (2.97), se calcularía 2w desde 0t hasta ft y, a continuación, )(2 tw desde ft hasta 0t .
3. Calcular )()()( twtSty = .
2.4.5 Software para la Resolución de EDMRs En la actualidad, el único paquete de dominio público disponible para la resolución de EDMRs es DRESOL (Differential Riccati Equations SOLver).

Capítulo 2: Estado del Arte
84
DRESOL se compone de un conjunto de subrutinas escritas en FORTRAN 77 para datos de simple precisión. Básicamente, utiliza el método BDF ([Diec92]) de manera que en cada paso del mismo se resuelve una Ecuación Algebraica Matricial de Riccati (EAMR) mediante el método de Newton. Al utilizar el método de Newton es necesario resolver una Ecuación Algebraica Matricial de Lyapunov (EAML) o de Sylvester (EAMS), según sea simétrica o no simétrica la EDMR considerada. Basado en el paquete LSODE ([Hind83]), DRSOL presenta mejoras sobre el anterior, respetando algunos aspectos del mismo, como los heurísticos utilizados a la hora de elegir el orden del método, la estimación del error local o la elección automática del tamaño de paso.
Este paquete data del año 1992, por lo que, en cierto modo, se encuentra actualmente desfasado al utilizar la librería EISPACK ([SBDG76]) en lugar de la librería LAPACK, sucesora de la anterior y con notables mejoras sobre la primera. En esta tesis se ha realizado una implementación basada en este paquete ([AHIP05]), que aunque no presenta los heurísticos anteriormente comentados en cuanto a la selección del orden del método y del tamaño del paso, presenta notables mejoras al utilizar los núcleos computaciones BLAS y LAPACK (véanse el Algoritmo 5.6 y el Algoritmo 5.7).
2.5 Conclusiones En este capítulo se ha realizado una revisión del estado del arte concerniente, fundamentalmente, a las tres áreas de investigación tratadas en esta tesis: cálculo de Funciones de Matrices, resolución de EDOs y resolución de EDMRs.
En la primera sección se han descrito los métodos más relevantes para el cálculo de las funciones matriciales más usuales. Posiblemente pueden existir otros métodos pero no tienen la importancia de los descritos en esa sección. No se puede asegurar cual es el mejor método, pues la eficiencia y precisión de cualquiera de ellos depende de la matriz y de la función considerada. Como se puede fácilmente observar, los métodos son muy dependientes de la función considerada aunque emergen dos métodos que se aplican en muchas ocasiones y que, en general, suelen presentar buenas cualidades numéricas: métodos basados en la descomposición real de Schur de una matriz y métodos basados en las aproximaciones racionales de Padé. Se puede constatar, por todo el estudio realizado, que en la actualidad se dispone de un número muy reducido de rutinas que implementan funciones de matrices, a excepción de las funciones incorporadas en MATLAB.
En la segunda sección se ha descrito brevemente la resolución de EDOs. Más que un estado del arte se ha pretendido dar una visión general de su problemática, describiendo aquellos métodos más usuales en la resolución de EDOs. Además, se ha presentado una metodología de resolución de EDOs, basada en la linealización a trozos, que no siendo muy utilizada en la actualidad parece que puede llegar a ser una alternativa fiable a los métodos clásicos de resolución de EDOs. En la actualidad se dispone de numeroso software para la resolución de EDOs tanto de dominio público como comercial.
En la última sección se ha realizado un exhaustivo estudio de los métodos de resolución de EDMRs. Entre ellos se pueden destacar los métodos BDF, que pueden utilizarse tanto en el caso general como en el caso de EDMRs simétricas, y los métodos simplécticos, que solo se pueden utilizar para EDMRs simétricas. De hecho, las aportaciones en los últimos años se dirigen, fundamentalmente, en esos dos caminos aunque no hay que descartar las modificaciones de métodos clásicos de resolución de EDMRs, sobre todo los que utilizan la linealización de EDMRs. No se dispone apenas

Capítulo 2: Estado del Arte
85
de software para la resolución de EDMRs, a pesar de que existen numerosos métodos dedicados a ellas.
Es razonable pensar, por todo lo comentado en este capítulo, que es posible desarrollar un software de calidad y de altas prestaciones que cubra las numerosas lagunas que en la actualidad existen en relación al cálculo de Funciones de Matrices y la resolución de EDOs y EDMRs.


Capítulo 3: Cálculo de Funciones de Matrices
87
Capítulo 3 Cálculo de Funciones de Matrices
3.1 Resumen de Contenidos En este capítulo se describen los algoritmos desarrollados en esta tesis para el cálculo de Funciones de Matrices. Estos algoritmos se basan en las dos metodologías más utilizadas para abordar este tipo de problemas: aproximaciones de Padé y la descomposición real de Schur de una matriz. El interés de aplicar metodologías generales de resolución de problemas computacionales reside en utilizar el mismo código para diferentes tipos de problemas; en nuestro caso, utilizar el mismo código para el cálculo de diferentes Funciones de Matrices. Por tanto, es necesario diseñar algoritmos, basados en estas metodologías, que permitan calcular Funciones de Matrices cualesquiera.
Como se ha descrito en el Capítulo 2, las aproximaciones de Padé son muy utilizadas en el cálculo de Funciones de Matrices: función exponencial, función logarítmica y función coseno. El algoritmo general basado en esta metodología consiste, básicamente, en reducir adecuadamente la norma de la matriz, determinar el polinomio de Taylor de grado 12 +l de la función, determinar los polinomios de grado l asociados a la aproximación diagonal de Padé, aplicar el algoritmo básico de Padé a la matriz obtenida en el primer paso y, por último, aplicar las transformaciones inversas de las aplicadas en la primera etapa. Se podría pensar que lo que es apropiado, desde un punto de vista computacional, para unas funciones (o matrices) también lo es para otras. Esto es así en numerosas ocasiones pero no siempre. Por ello, es necesario adecuar algunas de las etapas de estos algoritmos a la función (o matriz) considerada.
La otra metodología se basa en la forma real de Schur de una matriz. Los algoritmos basados en esta metodología se caracterizan por ser, en general, muy precisos y razonablemente eficientes. Estos algoritmos constan básicamente de dos etapas: determinación de la descomposición real de Schur de la matriz y el cálculo de la función de la matriz considerada a partir de su forma real de Schur.
Los algoritmos que se describen en este capítulo se han desarrollado para matrices reales. La adaptación de los algoritmos basados en las aproximaciones diagonales de Padé para matrices complejas es inmediata. La formulación de los algoritmos basados en la forma de Schur de una matriz compleja es más sencilla que la correspondiente a la forma real de Schur de matrices reales, pues en la primera se obtiene una matriz triangular superior y en la segunda una matriz casi triangular superior.
Este capítulo está estructurado en cuatro secciones. En la segunda sección se describe, en primer lugar, un algoritmo general para el cálculo de Funciones de Matrices basado en los aproximantes diagonales de Padé. En segundo lugar se muestra la manera de obtener los polinomios de la aproximación diagonal de Padé a partir del polinomio de Taylor de grado 12 +l de la función considerada. En tercer lugar se analizan los métodos más eficientes para calcular funciones racionales de matrices. Esta etapa corresponde a una de las partes más costosas del algoritmo. Entre estos métodos se analizan versiones de los métodos de Horner y Paterson-Stockmeyer-Van Loan. Se

Capítulo 3: Cálculo de Funciones de Matrices
88
utilizan dos descomposiciones de matrices para resolver el sistema lineal que aparece en esos métodos: la descomposición LU y la descomposición QR. En cuarto lugar se aplica el algoritmo general para el cálculo de las funciones matriciales exponencial, logarítmica, potencia fraccionaria, seno y coseno. Para cada una de ellas se adapta adecuadamente cada una de las etapas de algoritmo general.
En la tercera sección se describen los algoritmos para el cálculo de Funciones de Matrices basados en la descomposición real de Schur de una matriz. Se comienza describiendo un esquema genérico de los algoritmos basados en esa metodología. Estos algoritmos obtienen )(Af , con A matriz cuadrada real, realizando la descomposición real de Schur de la matriz A y calculando a continuación )(Af a partir de )(Sf , siendo S la forma real de Schur de A . Los algoritmos desarrollados para esa metodología han sido:
• Algoritmo basado en la forma diagonal por bloques. Obtiene, a partir de la forma real de Schur de la matriz A , una matriz B , diagonal por bloques, de manera que los valores propios de bloques diagonales distintos están suficientemente separados. La matriz )(Bf se obtiene calculando el valor de f sobre cada uno de los bloques diagonales de B siendo, por tanto, )(Bf también diagonal por bloques. Finalmente, el valor de )(Af se obtiene a partir de )(Bf .
• Algoritmos basados en la Ecuación Conmutante orientados a columnas y a diagonales. Estos algoritmos calculan )(Sf columna a columna o diagonal a diagonal, determinando, por una parte, los bloques diagonales )( iiSf a partir de los correspondientes iiS , y los no diagonales )( ijSf mediante la resolución de una ecuación matricial de Sylvester.
• Algoritmos basados en la Ecuación Conmutante orientados a bloques. En este caso se realiza una división a bloques de la matriz S utilizando esquemas similares a los descritos en el caso anterior, pero teniendo en cuenta que los bloques pueden tener ahora cualquier dimensión.
• Algoritmo basado en la agrupación en cluster de los valores propios de la matriz. Cuando la matriz A , y por tanto la matriz S , tienen valores propios cercanos entre sí, es conveniente agruparlos de manera que la resolución de la Ecuación Conmutante se realice con precisión. Este algoritmo realiza reordenaciones en los elementos de la matriz S , mediante transformaciones ortogonales de semejanza, de manera que los valores propios cercanos se encuentren en un mismo bloque diagonal. De este modo, la matriz S se puede estructurar por bloques y aplicar un esquema semejante al utilizado en los algoritmos orientados a bloques.
• Algoritmo basado en los aproximantes diagonales de Padé. En este algoritmo se calcula )(Sf mediante la adaptación de los aproximantes diagonales de Padé a matrices casi triangulares superiores.
La última sección está dedicada a resaltar los aspectos de mayor interés de los algoritmos descritos, comentando brevemente las características de los mismos y comparándolos de manera teórica.
Como ya se mencionó en la sección 1.1 del tema de introducción, la nomenclatura utilizada para los algoritmos desarrollados en esta tesis es txxyyyzzz, donde t indica el tipo de dato utilizado, xx indica el tipo de matriz, yyy indica el problema que resuelve y

Capítulo 3: Cálculo de Funciones de Matrices
89
zzz el método utilizado. El significado de los seis últimos caracteres para los algoritmos que calculan Funciones de Matrices es:
• yyy: función considerada.
− Para los algoritmos que resuelven la Ecuación Conmutante por columnas, diagonales, bloques de columnas y bloques de diagonales se tiene que yyy=fun de manera que la función es pasada como argumento de entrada de la rutina.
− Para el resto de algoritmos se utiliza la siguiente nomenclatura:
yyy=fex, indica la función Ae ;
yyy=fax, indica la función Aa ;
yyy=fcs, indica la función Acos ;
yyy=fsn, indica la función Asen ;
yyy=fln, indica la función Aln ;
yyy=flg, indica la función Aalog ;
yyy=fpt, indica la función aA ;
yyy=fpf, indica la función p qA , 2/1/ ≠pq ;
yyy=frc, indica la función A .
• zzz: método utilizado.
− dbe: indica que se utiliza el método DB (Denman and Beavers) con escalado optimizado para el cálculo de la raíz cuadrada de una matriz;
− psv: indica que se utiliza el método de Paterson-Stockmeyer-Van Loan para el cálculo de la aproximación diagonal de Padé;
− hlu: indica que se utiliza el método de Horner y la descomposición LU con pivotamiento parcial de filas para la resolución del sistema de ecuaciones lineales que aparece en la aproximación diagonal de Padé;
− hqr: indica que se utiliza el método de Horner y la descomposición QR para la resolución del sistema de ecuaciones lineales que aparece en la aproximación diagonal de Padé;
− plu: indica que se utiliza el método de Paterson-Stockmeyer-Van Loan y la descomposición LU con pivotamiento parcial de filas para la resolución del sistema de ecuaciones lineales que aparece en la aproximación diagonal de Padé;
− pqr: indica que se utiliza el método de Paterson-Stockmeyer-Van Loan y la descomposición QR para la resolución del sistema de ecuaciones lineales que aparece en la aproximación diagonal de Padé.
− scc: algoritmo basado en la descomposición real de Schur de una matriz y en la resolución de la ecuación conmutante orientada a columnas;
− scd: algoritmo basado en la descomposición real de Schur de una matriz y en la resolución de la ecuación conmutante orientada a diagonales;

Capítulo 3: Cálculo de Funciones de Matrices
90
− sbc: algoritmo basado en la descomposición real de Schur de una matriz y en la resolución de la ecuación conmutante orientada a bloques de columnas;
− sbd: algoritmo basado en la descomposición real de Schur de una matriz y en la resolución de la ecuación conmutante orientada a bloques de diagonales;
− scl: algoritmo basado en la descomposición real de Schur de una matriz y en la resolución de la ecuación conmutante, con agrupación de valores propios en clusters;
− sph: algoritmo basado en la descomposición real de Schur de una matriz y en los aproximantes diagonales de Padé, utilizando el método de Horner;
− spp: algoritmo basado en la descomposición real de Schur de una matriz y en los aproximantes diagonales de Padé, utilizando el método de Paterson-Stockmeyer-Van Loan;
− sdb: algoritmo basado en la descomposición real de Schur de una matriz y en la diagonalización a bloques de la matriz.
3.2 Algoritmos Basados en los Aproximantes Diagonales de Padé
3.2.1 Esquema General En este apartado se describe un esquema general, basado en los aproximantes diagonales de Padé, que permite calcular funciones de matrices )(Af , siendo nxnA ℜ∈ y )(zf una función analítica definida sobre el espectro de A . Esta metodología se puede aplicar a funciones analíticas entre las que se encuentran las siguientes:
• función exponencial,
• función logarítmica,
• potencias de exponente fraccionario,
• funciones trigonométricas seno y coseno.
Las etapas básicas de ese esquema se presentan a continuación:
1. Reducir la norma de la matriz. Cuando se utilizan aproximantes de Padé es conveniente transformar la matriz A en otra matriz A de norma más pequeña. Esto está motivado por el hecho de que los desarrollos en serie de Taylor de la función y, por consiguiente, el desarrollo correspondiente de Padé, están centrados en cero. En el caso de funciones de matrices, los aproximantes diagonales de Padé permiten buenas aproximaciones siempre y cuando la norma de la matriz A sea pequeña. Existen numerosos artículos en los que se utiliza esta técnica:
• Exponencial: [MoVa78], [MoVa03].
• Logaritmo: [KeL289], [High01].
• Coseno: [SeBl80].

Capítulo 3: Cálculo de Funciones de Matrices
91
2. Determinar los coeficientes del desarrollo de Taylor de la función. En esta etapa se determina el polinomio de Taylor correspondiente a la función considerada. Si se desea obtener una aproximación diagonal de Padé de orden ),( ll , entonces el grado del polinomio de Taylor debe ser 12 +l .
3. Determinar los polinomios de la aproximación diagonal de Padé.
Hay muchos motivos que justifican el interés de utilizar aproximantes diagonales de Padé ([MoVa78], [KeL289], [High01]), fundamentalmente porque permiten calcular funciones de matrices con una precisión semejante a la de otros métodos pero con un menor coste computacional. Aunque hay ciertos estudios sobre cuál puede ser el grado óptimo de los polinomios de la aproximación de Padé, éste depende de la matriz y de la función considerada. Como se comentó en el Capítulo 2, recientemente se han revisado criterios teóricos, que hace algunos años se consideraban válidos, en cuanto a la elección de ese grado para la exponencial de una matriz. Por ello, se ha considerado más apropiado hacer variable ese grado para poder determinar de manera experimental cuál puede ser su valor óptimo.
4. Aplicar el algoritmo básico de Padé a la matriz A obtenida en la primera etapa. En esta etapa se aplica el método clásico de aproximantes de Padé, utilizando técnicas que minimizan el número de operaciones (véase por ejemplo [PaSt73] o [VanL79]). El aproximante diagonal de Padé aplicado a la matriz A se define como
)()]([)( 1 ApAqAr −= ,
siendo p y q los polinomios de grado l obtenidos a partir del polinomio de Taylor )(xa de la función )(xf . En definitiva, )(Af se puede calcular aproximadamente
mediante la expresión
)()]([)()( 1 ApAqArAf −=≅ .
5. Aplicar las transformaciones inversas de las aplicadas en la primera etapa. En esta etapa se aplican las transformaciones necesarias a la matriz obtenida en la cuarta etapa, de manera que se tengan en cuenta las transformaciones aplicadas sobre la matriz A .
A continuación se presenta el algoritmo general que calcula funciones de matrices mediante aproximantes diagonales de Padé. Para cada etapa del algoritmo se detalla la el resultado obtenido después de haber aplicado los pasos necesarios.

Capítulo 3: Cálculo de Funciones de Matrices
92
Entradas: Matriz nxnA ℜ∈ , grado +∈ Zl de los polinomios de la aproximación diagonal de Padé, función analítica )(xf .
Salida: Matriz nxnAfB ℜ∈= )( .
1 Aplicar transformaciones que disminuyan |||| A : A . 2 Encontrar el polinomio de Taylor de grado 12 +l de la función )(xf : )(xa . 3 Encontrar los polinomios de grado l de la aproximación diagonal de Padé:
)(xp , )(xq . 4 Calcular la aproximación de Padé )(/)()( xqxpxr = sobre la matriz A :
)(ArB = . 5 Aplicar las transformaciones inversas de las aplicadas en la etapa 1 sobre la
matriz B : B .
Algoritmo 3.1: Algoritmo general para el cálculo de funciones de matrices basado en los aproximantes diagonales de Padé.
3.2.2 Determinación de los Polinomios de la Aproximación Diagonal de Padé
En este apartado se describe la manera de calcular los polinomios de grado l de la aproximación diagonal de Padé de una función analítica )(xf . Sea )(xf una función real que admite el desarrollo en series de potencias
∑∞
=
=0
)(k
kk xaxf
con radio de convergencia R , y la aproximación racional de )(xf
)()()(
xqxpxr = ,
siendo
∑=
=+++=l
i
ii
ll xpxpxppxp
010)( L ,
∑=
=+++=l
j
jj
ll xqxqxqqxq
010)( L
y
)0()0( )) kk rf = , lk 2,,1,0 L= .
Considerando la función
,)(
)(
)()()()(
012
00
2
0
0012
2
0
∑∑∑∑
∑∑∑
=+
===
==+
=
+−⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛=
=−⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛+=
=−=
l
j
jjl
l
i
ii
l
j
jj
l
k
kk
l
i
ii
l
j
jjl
l
k
kk
xqxsxpxqxa
xpxqxsxa
xpxqxfxz

Capítulo 3: Cálculo de Funciones de Matrices
93
se obtiene la expresión
( 3.1 ) )()(0
1200
2
0xzxqxsxpxqxa
l
j
jjl
l
i
ii
l
j
jj
l
k
kk =+−⎟⎟
⎠
⎞⎜⎜⎝
⎛⎟⎠
⎞⎜⎝
⎛ ∑∑∑∑=
+===
,
cumpliéndose además que 0)0() =kz , lk 2,,1,0 L= .
Sustituyendo x por 0, se obtiene la ecuación
( 3.2 ) 0000 =− pqa .
Derivando la expresión ( 3.1 ) l veces y sustituyendo x por 0, se obtienen las ecuaciones
( 3.3 )
.0,0
,0
011110
110211201
11001
=−++++=−++++
=−+
−−
−−−−−
lllll
lllll
pqaqaqaqapqaqaqaqa
pqaqa
L
L
M
La ecuación ( 3.2 ) y las ecuaciones ( 3.3 ) se pueden expresar en forma matricial como
( 3.4 )
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−
−
−−−
l
l
ll
ll
l
l
aaaaaaa
aaa
pp
pp
1
1
0
011
021
01
0
1
1
0
0
00000
M
L
L
MMOMM
L
L
M .
Hallando las derivadas de órdenes ll 2,,1L+ de la expresión ( 3.1 ) y sustituyendo x por 0, se tiene el sistema de ecuaciones lineales
⎪⎪⎪
⎭
⎪⎪⎪
⎬
⎫
=+++++=+++++
=+++++=+++++
−+−−
−−−−−
−++
−−+
00
00
1122211202
11232122012
21321102
11221101
lllllll
lllllll
lllll
lllll
qaqaqaqaqaqaqaqaqaqa
qaqaqaqaqaqaqaqaqaqa
L
L
M
L
L
.
Como se tienen l ecuaciones con 1+l incógnitas, es necesario dar un valor a una de las incógnitas. Tomando 10 =q , entonces el sistema anterior se expresa en forma matricial como
( 3.5 )
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−
=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−
+
+
−
+−−
−−−
+
−
l
l
l
l
l
l
llll
llll
ll
ll
aa
aa
aaaaaaaa
aaaaaaaa
2
12
2
1
1
2
1
12212
13222
231
121
MM
L
L
MMOMM
L
L
.
Por lo tanto, los coeficientes de los polinomios )(xp y )(xq se obtienen resolviendo la ecuación matricial ( 3.5 ) y realizando el producto que aparece en la expresión ( 3.4 ). El algoritmo correspondiente a esta etapa se presenta a continuación.

Capítulo 3: Cálculo de Funciones de Matrices
94
)(],[ adlacpqp =
Entrada: Vector 12 +ℜ∈ la que contienen a los coeficientes del polinomio de Taylor )(xa de grado 12 +l de )(xf .
Salidas: Vectores 1, +ℜ∈ lqp que contienen a los coeficientes de los polinomios )(xp y )(xq , de grados igual a l , del aproximante diagonal de Padé de )(xf .
1 Resolver la ecuación ( 3.5 ) para encontrar los coeficientes del polinomio )(xq . 2 Calcular el producto matriz por vector que aparece en la expresión ( 3.4 ) para
encontrar los coeficientes del polinomio )(xp .
Algoritmo 3.2: Cálculo de los polinomios de la aproximación diagonal de Padé de una función analítica )(xf .
El coste aproximado del algoritmo anterior es
23
38 ll
+ flops.
3.2.3 Funciones Polinómicas y Racionales En este apartado se detallan dos métodos que permiten calcular funciones racionales de matrices. Esto es necesario para el cálculo de funciones de matrices basado en los aproximantes de Padé (cuarta etapa del Algoritmo 3.1). Aunque la descripción se va a realizar para funciones racionales, es fácil ver su extensión para el caso de funciones polinómicas.
El primero se obtiene aplicando el método de Horner para funciones racionales.
),,( AqpdgefrahorB = .
Entradas: Matriz nxnA ℜ∈ , polinomios )(xp y )(xq de grado +∈ Zl .
Salida: Matriz )(ArB = , con )(/)()( xqxpxr = .
1 nl IpP = 2 nl IqQ = 3 Para 0:1:1 −−= li
3.1 ni IpPAP += 3.2 ni IqQAQ +=
4 Calcular B resolviendo la ecuación PQB =
Algoritmo 3.3: Cálculo de la función racional de una matriz mediante el método de Horner.
El coste aproximado del algoritmo anterior es
3
38)1(2 nl ⎥⎦
⎤⎢⎣⎡ +− flops.
El segundo método está basado en el anidamiento de productos, denominado método de Paterson-Stockmeyer-Van Loan, ([PaSt73], [VanL79]).

Capítulo 3: Cálculo de Funciones de Matrices
95
Si
∑=
=l
i
ii ApAp
0)( ,
entonces realizando agrupamientos de s términos, se tiene que
( 3.6 ) ∑∑==
==c
k
ksk
l
i
ii ABApAp
00)()( ,
con )/int( slc = y
⎪⎩
⎪⎨⎧
=+++
−=+++=
−−−−
−−++
ckApApIp
ckApApIpB
scll
scllnsc
sssksknsk
k ,
1,,1,0,1
1
111
L
LL.
Por ejemplo, para 7=l y 3=s se tiene la siguiente expresión
.])([
][
)(
3376
2543
2210
347
36
2543
2210
77
66
55
44
33
2210
AAApIpApAppApApIp
AApApApAppApApIp
ApApApApApApApIpAp
nn
n
n
+++++++=
+++++++=
+++++++=
De igual modo, para
∑=
=l
i
ii AqAq
0)(
se obtiene una expresión similar a ( 3.6 ).
El algoritmo asociado a este método es el siguiente.

Capítulo 3: Cálculo de Funciones de Matrices
96
),,,( AqpsdgefrapsvB = .
Entradas: Factor +∈ Zs de agrupamiento, polinomios )(xp y )(xq de grados iguales a +∈ Zl , matriz nxnA ℜ∈ .
Salida: Matriz )(Ar , con )(/)()( xqxpxr = .
1 )/int( slc = 2 ),mod( slr = 3 AY =1 4 Para sk :2=
4.1 1−= kk YAY 5 Si 0≠r
5.1 rlrlnrl YpYpIpP +++= +−− L11 5.2 rlrlnrl YqYqIqQ +++= +−− L11
6 Si No 6.1 nP 0= 6.2 nQ 0=
7 Para ck :1= 7.1 PYYpIpP ssskcsnkcs +++= −−+−− 11)()( L 7.2 QYYqIqQ ssskcsnkcs +++= −−+−− 11)()( L
8 Calcular )(Ar resolviendo la ecuación PAQr =)( .
Algoritmo 3.4: Cálculo de la función racional de una matriz mediante el método de Paterson-Stockmeyer-Van Loan.
Para calcular kY , sk ,,3,2 L= , son necesarios 3)1(2 ns − flops.
Si se supone que s divide a l , entonces el coste del bucle 7 es
[ ] ⎥⎦⎤
⎢⎣⎡ +=+ 222222 223
snlnsnn
sl .
Por lo tanto, el coste aproximado del algoritmo anterior es
⎥⎦⎤
⎢⎣⎡ ++−=⎥⎦
⎤⎢⎣⎡ ++−= l
snlnsn
snlnnssC 22)1(2222)1(2)( 223 flops.
El valor mínimo de la expresión anterior se obtiene cuando ls 2= .
Si se elige convenientemente el factor s de agrupamiento, se tiene que el algoritmo basado en el método de Paterson-Stockmeyer-Van Loan tiene un menor coste computacional que el algoritmo basado en el método de Horner, a costa de aumentar el coste espacial
3.2.4 Cálculo de Funciones de Matrices En este apartado se describe la aplicación del esquema descrito en el apartado 3.2.13.1 a varias funciones de matrices.

Capítulo 3: Cálculo de Funciones de Matrices
97
3.2.4.1 Función Exponencial
Etapa 1: Reducir la norma de la matriz. Las técnicas de reducción de la norma de una matriz, además de ser eficientes, deben poderse corregir al final del algoritmo, para así obtener la exponencial de la matriz inicial. Para la exponencial de una matriz se pueden aplicar tres técnicas que se pueden utilizar conjuntamente:
• Minimizar la norma de la matriz A ante traslaciones del tipo ntIA − ([Ward77]).
• Equilibrar la matriz ([Ward77]).
• Escalar la matriz ([MoVa78], [MoVa03]).
La primera técnica consiste en minimizar la norma de la matriz A ante todas las posibles traslaciones del tipo ntIA − . El cálculo que conduce a la obtención de la traslación que minimiza a la norma de la matriz no es sencillo; sin embargo, se puede aproximar dicha traslación calculando la media de los valores propios de la matriz. Como la suma de los valores propios de una matriz coincide con la traza de la matriz, entonces la media de los valores propios coincide con nA /)(traza , por lo que se puede considerar la transformación definida por la matriz ntIAA −=1 , siendo
nAt )(traza
= .
La segunda técnica consiste en minimizar la 1-norma de la matriz 1A , ante todas las posibles transformaciones de semejanza diagonales. Esta técnica, conocida con el nombre de equilibrado de la matriz, consiste en encontrar una matriz diagonal D invertible de manera que la 1-norma de la matriz
DADA 11
2−=
tenga el menor valor posible.
La tercera técnica consiste en el escalado de la matriz. Para ello se elige un valor de m que sea potencia de 2 ( jm 2= ), de manera que mAe /2 pueda calcularse con precisión y eficiencia. Un criterio, comúnmente utilizado, consiste en elegir m de manera que la matriz
mAA /2=
tenga una norma menor que una cierta cantidad, por ejemplo, menor que 1.
En resumen, en esta etapa se aplican las siguientes transformaciones:
mAADADAtIAAA n /211
21 =⇒=⇒−=⇒ − .
Etapa 2: Calcular el polinomio de Taylor.
Si se desea obtener una aproximación diagonal de Padé de orden ),( ll , es necesario que el polinomio de Taylor sea de grado 12 +l . En el caso de la función exponencial resulta ser el polinomio
( 3.7 ) 1232
)!12(1
!31
!211)( +
++++++= lx
lxxxxa L .

Capítulo 3: Cálculo de Funciones de Matrices
98
Etapa 3: Calcular los polinomios de la aproximación diagonal de Padé. Se aplica el Algoritmo 3.2 para encontrar, a partir del polinomio de Taylor de la segunda etapa, los polinomios )(xp y )(xq de la función racional de Padé
)(/)()( xqxpxr = .
Etapa 4: Calcular la aproximación diagonal de Padé de la matriz A .
Se calcula )(ArB = utilizando, por ejemplo, el Algoritmo 3.4.
Etapa 5: Aplicar las transformaciones inversas de las realizadas en la etapa 1. Los pasos que se deben realizar en esta etapa corresponden a las transformaciones inversas de las aplicadas en la primera etapa; así pues, habrá que determinar las siguientes transformaciones:
AAAA eBeBeBeB =⇒=⇒=⇒= 1212 .
La primera transformación consiste en calcular 2B a partir de B :
( ) mmAAmA BeeeB ==== 22 , jm 2= .
La segunda transformación consiste en calcular 1B a partir de 2B :
12
11
21
21 −− ====−
DDBDDeeeB ADDAA .
Por último, la tercera transformación consiste en calcular B a partir de 1B :
111 BeeeeeB tAttIAA n ==== + , nAt /)(traza= .
El algoritmo que calcula la exponencial de una matriz mediante aproximantes diagonales de Padé aparece a continuación.

Capítulo 3: Cálculo de Funciones de Matrices
99
),,( AlsdgefexpsvB = .
Entradas: Factor de agrupamiento +∈ Zs , grado +∈ Zl de los polinomios de la aproximación diagonal de Padé, matriz nxnA ℜ∈ .
Salida: Matriz nxnAeB ℜ∈= . 1 Reducir la norma de la matriz A :
1.1 nAt /)(traza= 1.2 ntIAA −=1 1.3 )(],[ 12 AdgebalDA = (equilibrado de la matriz 1A ) 1.4 ))||||(logfloor1,0max( 2 ∞+= Aj 1.5 jAA 2/2=
2 )(ldlaexpa = (determina los coeficientes del polinomio de Taylor según la expresión ( 3.7 ))
3 )(],[ adlacpqp = (determina los polinomios de la aproximación diagonal de Padé mediante el Algoritmo 3.2)
4 ),,,( AqpsdgefrapsvB = (calcula la aproximación diagonal de Padé mediante el Algoritmo 3.4)
5 Aplicar las transformaciones inversas a las aplicadas en la primera etapa: 5.1 Calcular mBB =2 , jm 2= , mediante potenciación sucesiva:
5.1.1 BB =2 5.1.2 Para jk :1=
5.1.2.1 222 BB =
5.2 121
−= DDBB 5.3 1BeB t=
Algoritmo 3.5: Cálculo de la exponencial de una matriz mediante los aproximantes diagonales de Padé.
El coste aproximado del algoritmo anterior es
23
2
3822)1(2 llnjl
snlnsn ++⎥⎦
⎤⎢⎣⎡ +++− flops.
3.2.4.2 Función Potencia Fraccionaria En este subapartado se particulariza el Algoritmo 3.1 a la función
d cdc xxxf == /)( ,
con Zdc ∈, .
Etapa 1: Reducir la norma de la matriz.
Para reducir la norma de nxnA ℜ∈ se determina un entero positivo j de manera que la matriz mAA /1
1 = , jm 2= , tenga una norma cercana a 1. De este modo,
( ) ( ) ( ) ( ) dcm
nd cm
nd cm
nnd cmd cmmd cdc AIAIIAIAAAA +=+=−+==== 11
/1/ ,

Capítulo 3: Cálculo de Funciones de Matrices
100
siendo nIAA −= 1 .
La matriz 1A se puede obtener mediante el cálculo sucesivo de raíces cuadradas,
AAAAj
m j (2/1/1
1 L=== ,
utilizando la iteración DB con escalado descrita en el subapartado 2.2.3.3.
Resumiendo, en esta etapa se realizan las transformaciones siguientes:
nm IAAAAA −=⇒=⇒ 1
/11 .
Etapa 2: Calcular el polinomio de Taylor.
El polinomio de Taylor de grado 12 +l , que permite calcular la aproximación diagonal
de Padé de orden ),( ll , de la función ( ) dkd k xx /)1(1 +=+ , con cmk = , es
( 3.8 ) .221)!12(
1!2!1
1)( 122 +⎟⎠⎞
⎜⎝⎛ −⎟
⎠⎞
⎜⎝⎛ −⎟
⎠⎞
⎜⎝⎛ −
+++⎟
⎠⎞
⎜⎝⎛ −++= lxl
dk
dk
dk
dlkx
dk
dkx
dkxa LL
Etapa 3: Calcular los polinomios de la aproximación diagonal de Padé.
Se aplica el Algoritmo 3.2 para encontrar los polinomios )(xp y )(xq de la aproximación diagonal de Padé )(/)()( xqxpxr = .
Etapa 4: Calcular la aproximación diagonal de Padé de la matriz A .
Se calcula )(ArB = utilizando, por ejemplo, el Algoritmo 3.4.
Etapa 5: Aplicar las transformaciones inversas de las realizadas en la etapa 1.
Los pasos que se deben realizar en esta etapa deben corresponder a las transformaciones inversas de las aplicadas en la primera etapa. Para la potencia fraccionaria se calcula
d cAB = a partir de d cmn AIB )( += , utilizando las transformaciones BBB ⇒⇒ 1 .
La primera transformación consiste en calcular 1B a partir de B :
BAIAB d cmn
d cm =+== )(11 .
La segunda transformación consiste en calcular B a partir de 1B :
( ) 11/1 BAAAB d cmd cmmd c ==== .
Por lo tanto, se puede eliminar la quinta etapa pues BB = .
En primer lugar se presenta un algoritmo que calcula la raíz cuadrada de una matriz mediante una variante de la iteración DB con escalado. Este algoritmo se ha optimizado al resolver un sistema lineal en lugar de calcular las dos matrices inversas que aparecen en el método DB.

Capítulo 3: Cálculo de Funciones de Matrices
101
),,( maxitertolAdgefrcdbeB = .
Entradas: Matriz nxnA ℜ∈ , tolerancia +ℜ∈tol , número máximo de iteraciones +∈ Zmaxiter .
Salida: Matriz AB = . 1 AM = 2 AY = 3 nIZ = 4 1=cont 5 1=k 6 Mientras 1==cont
6.1 )2/(1)det( nM −=γ
6.2 nIWγ1
=
6.3 Calcular X resolviendo la ecuación WMX = 6.4 XW =
6.5 ⎟⎟⎠
⎞⎜⎜⎝
⎛++= WMIM n γ
γ 1225.0 2
6.6 WIW n += γ 6.7 YWY 5.0= 6.8 ZWZ 5.0= 6.9 nIMW −= 6.10 1+= kk 6.11 Si tolW <1|||| o maxiterk >
6.11.1 0=cont
Algoritmo 3.6: Calcula la raíz cuadrada de una matriz mediante el método DB con escalado optimizado.
El coste aproximado del algoritmo anterior es
3
320 kn flops,
donde k es el número de iteraciones necesarias para alcanzar la convergencia.
El algoritmo que calcula la potencia fraccionaria de una matriz mediante aproximantes diagonales de Padé aparece a continuación.

Capítulo 3: Cálculo de Funciones de Matrices
102
),,,,( AdclsdgefpfpsvB = .
Entradas: Factor de agrupamiento +∈ Zs , grado +∈ Zl de los polinomios de la aproximación diagonal de Padé, Zdc ∈, que definen la potencia fraccionaria de exponente dc / , matriz nxnA ℜ∈ .
Salida: Matriz d cAB = . 1 Reducir la norma de la matriz A :
1.1 ))||||(logfloor1,0max( 2 ∞+= Aj
1.2 j
AA 2/11 = :
1.2.1 AA =1 1.2.2 Para ji :1=
1.2.2.1 )100,10,( 1511
−= AdgefrcdbeA (calcula 11 AA = mediante el Algoritmo 3.6)
2 )(ldlafrpa = (determina los coeficientes del polinomio de Taylor según la expresión ( 3.8))
3 )(],[ adlacpqp = (determina los polinomios de la aproximación diagonal de Padé mediante el Algoritmo 3.2)
4 ),,,( 1AqpsdgefrapsvB = (calcula la aproximación diagonal de Padé mediante el Algoritmo 3.4)
Algoritmo 3.7: Cálculo de la potencia fraccionaria de una matriz mediante los aproximantes diagonales de Padé.
El coste aproximado del algoritmo anterior es
232
38
31022)1(2 llKnl
snlnsn j ++⎥⎦
⎤⎢⎣⎡ +++− flops,
siendo jK el número total de iteraciones necesarias para calcular las j raíces cuadradas del bucle 1.2.2.
3.2.4.3 Función Logaritmo
Etapa 1: Reducir la norma de la matriz.
Para reducir la norma de nxnA ℜ∈ se determina un entero positivo j de manera que la matriz mAA /1
1 = , jm 2= , tenga una norma cercana 1. De este modo,
( ) ( ) ( ) ( )AImIAImAmAmA nnnm +=−+=== logloglogloglog 11
/1 ,
siendo nIAA −= 1 .
La matriz 1A se puede obtener mediante el cálculo sucesivo de raíces cuadradas, ya que
AAAAj
m j (2/1/1
1 L=== .
Resumiendo, en esta etapa se realizan las transformaciones siguientes:
nm IAAAAA −=⇒=⇒ 1
/11 .

Capítulo 3: Cálculo de Funciones de Matrices
103
Etapa 2: Calcular el polinomio de Taylor.
El polinomio de Taylor de grado 12 +l , que permite calcular el aproximante diagonal de Padé de orden ),( ll , de la función )1log( x+ es
( 3.9 ) 12432
121
41
31
211)( +
+++−+−+= lx
lxxxxxa L .
Etapa 3: Calcular los polinomios de la aproximación diagonal de Padé.
Se aplica el Algoritmo 3.2 para encontrar los polinomios )(xp y )(xq de la aproximación diagonal de Padé )(/)()( xqxpxr = .
Etapa 4: Calcular la aproximación diagonal de Padé de la matriz A .
Se calcula )(ArB = utilizando, por ejemplo, el Algoritmo 3.4.
Etapa 5: Aplicar las transformaciones inversas de las realizadas en la etapa 1. Los pasos que se deben realizar en esta etapa corresponden a las transformaciones inversas de las aplicadas en la primera etapa. En primer lugar se calcula AB log= a partir de )log( AIB n += , utilizando las transformaciones BBB ⇒⇒ 1 .
La primera transformación consiste en calcular 1B a partir de B :
BAIAB n =+== )log(log 11 .
La segunda transformación consiste en calcular B a partir de 1B :
11/1 logloglog mBAmAmAB m ==== .
El algoritmo para el cálculo del logaritmo de una matriz aparece a continuación.

Capítulo 3: Cálculo de Funciones de Matrices
104
),,( AlsdgeflgpsvB = .
Entradas: Factor de agrupamiento +∈ Zs , grado +∈ Zl de los polinomios de la aproximación diagonal de Padé, matriz nxnA ℜ∈ .
Salida: Matriz nxnAB ℜ∈= log .
1 Reducir la norma de la matriz A : 1.1 ))||||(logfloor1,0max( 2 ∞+= Aj
1.2 j
AA 2/11 = :
1.2.1 AA =1 1.2.2 Para ji :1=
1.2.2.1 )100,10,( 1511
−= AdgefrcdbeA (calcula 11 AA = mediante el Algoritmo 3.6)
1.3 nIAA −= 1 . 2 )(ldlaloga = (determina los coeficientes del polinomio de Taylor según la
expresión ( 3.9 )) 3 )(],[ adlacpqp = (determina los polinomios de la aproximación diagonal de
Padé mediante el Algoritmo 3.2) 4 ),,,( AqpsdgefrapsvB = (calcula la aproximación diagonal de Padé mediante el
Algoritmo 3.4) 5 Aplicar las transformaciones inversas a las aplicadas en la primera etapa:
5.1 BmB =
Algoritmo 3.8: Cálculo del logaritmo de una matriz mediante los aproximantes diagonales de Padé.
El coste aproximado del algoritmo anterior es
232
38222)1(2 llnKl
snlnsn j ++⎟
⎠⎞
⎜⎝⎛ +++− flops,
siendo jK el número total de iteraciones necesarias para calcular las j raíces cuadradas del bucle 1.2.2.
3.2.4.4 Función Coseno El cálculo del coseno de una matriz que se describe a continuación está basado, fundamentalmente, en el método descrito en el subapartado 2.2.3.6.
Etapa 1: Reducir la norma de la matriz. Para reducir la norma de la matriz A , mediante transformaciones de bajo coste, se explota la relación de periodicidad de la función coseno
AqIA qn cos)1()cos( −=− π , Zq ∈ ,
siendo q el entero más cercano a nA /)(traza que hace menor el valor de |||| 1A , donde
nqIAA π−=1 .
A continuación se determina una matriz diagonal D de manera que DADA 11
2−= esté
equilibrada.

Capítulo 3: Cálculo de Funciones de Matrices
105
Por último, se elige jm 2= tal que la matriz
mAA /2=
tenga una norma menor que 1.
Resumiendo, en esta etapa se realizan las transformaciones siguientes
mAADADAqIAAA n /211
21 =⇒=⇒−=⇒ −π .
Etapa 2: Cálculo del polinomio de Taylor.
El polinomio de Taylor de grado 12 +l que permite calcular el aproximante diagonal de Padé de orden ),( ll de la función xcos , es
( 3.10 ) 1222 0)!2(
1)1(!2
11)( +⋅+−++−= lll xxl
xxa L .
Etapa 3: Cálculo de los polinomios de la aproximación diagonal de Padé.
Se aplica el Algoritmo 3.2 para encontrar los polinomios )(xp y )(xq de la función racional de Padé )(/)()( xqxpxr = .
Etapa 4: Cálculo de la aproximación diagonal de Padé de la matriz A .
Se calcula )(ArB = aplicando, por ejemplo, el Algoritmo 3.4.
Etapa 5: Aplicación de las transformaciones inversas de las realizadas en la primera etapa.
Las transformaciones que se deben aplicar en esta etapa son:
ABABABAB coscoscoscos 1122 =⇒=⇒=⇒= .
Como
)2cos(cos 22 AAB j== ,
entonces 2B se puede obtener aplicando j veces la fórmula del coseno del ángulo doble para matrices:
BB =2 Para ji :1=
nIBB −= 222 2 .
En la segunda transformación se debe calcular 11 cos AB = a partir de 22 cos AB = : 1
21
21
211 )cos()cos(cos −−− ==== DDBDADDDAAB .
En la tercera transformación se debe calcular AB cos= a partir de 11 cos AB = :
111 )1(cos)1()cos(cos BAqIAAB qqn −=−=+== π .

Capítulo 3: Cálculo de Funciones de Matrices
106
),,( AlsdgefcspsvB = .
Entradas: Factor de agrupamiento +∈ Zs , grado +∈ Zl de los polinomios de la aproximación diagonal de Padé, matriz nxnA ℜ∈ .
Salida: Matriz AB cos= . 1 Reducir la norma de la matriz A :
1.1 Determinar el entero q más cercano a nA /)(traza que minimice
1nqIA π− 1.2 nqIAA π−=1 1.3 )(],[ 12 AdgebalDA = (equilibrado de la matriz 1A ) 1.4 ))||||(logfloor1,0max( 22 ∞+= Aj 1.5 jAA 2/2=
2 )(ldlacosa = (determina los coeficientes del polinomio de Taylor según la expresión ( 3.10 ))
3 )(],[ adlacpqp = (determina los polinomios de la aproximación diagonal de Padé mediante el Algoritmo 3.2)
4 ),,,( AqpsdgefrapsvB = (calcula la aproximación diagonal de Padé mediante el Algoritmo 3.4)
5 Aplicar transformaciones inversas a las aplicadas en la primera etapa: 5.1 )2cos(2 AB j= :
5.1.1 BB =2 5.1.2 Para ji :1=
5.1.2.1 nIBB −= 222 2
5.2 121
−= DDBB 5.3 1)1( BB q−=
Algoritmo 3.9: Cálculo del coseno de una matriz mediante los aproximantes diagonales de Padé.
El coste aproximado del algoritmo anterior es
232
3822)1(2 llnjl
snlnsn ++⎥⎦
⎤⎢⎣⎡ +++− flops.
3.2.4.5 Función Seno
La aplicación del Algoritmo 3.1 a la función seno resulta complicada debido a que en la quinta etapa es necesario aplicar la identidad
AAA cossen22sen = .
En lugar de ello, se puede calcular el seno de una matriz como a continuación se muestra. Puesto que las matrices
nI2π y A
conmutan, entonces

Capítulo 3: Cálculo de Funciones de Matrices
107
.sen
sen2
sencos2
cossen2
sencos2
cos2
cos
A
AIAIIAIAI nnnnn
=
⎟⎠⎞
⎜⎝⎛+⎟
⎠⎞
⎜⎝⎛=⎟
⎠⎞
⎜⎝⎛+⎟
⎠⎞
⎜⎝⎛=⎟
⎠⎞
⎜⎝⎛ −
πππππ
Por lo tanto, Asen se puede obtener mediante una adaptación del Algoritmo 3.9.
),,( AlsdgefsnpsvB = .
Entradas: Factor de agrupamiento +∈ Zs , grado +∈ Zl de los polinomios de la aproximación diagonal de Padé, matriz nxnA ℜ∈ .
Salida: Matriz AB sen= .
1 AIA n −=2π
2 Reducir la norma de la matriz A : 2.1 Determinar q entero más cercano a nA /)(traza que minimice
1nqIA π− 2.2 nqIAA π−=1 2.3 )(],[ 12 AdgebalDA = (equilibrado de la matriz 1A ) 2.4 ))||||(logfloor1,0max( 22 ∞+= Aj 2.5 jAA 2/2=
3 )(ldlacosa = (determina los coeficientes del polinomio de Taylor según la expresión ( 3.10 ))
4 )(],[ adlacpqp = (determina los polinomios de la aproximación diagonal de Padé mediante el Algoritmo 3.2)
5 ),,,( AqpsdgefrapsvB = (calcula la aproximación diagonal de Padé mediante el Algoritmo 3.4)
6 Aplicar transformaciones inversas a las aplicadas en la primera etapa: 6.1 ( )22 cos AB = :
6.1.1 BB =2 6.1.2 Para ji :1=
6.1.2.1 nIBB −= 222 2
6.2 121
−= DDBB 6.3 1)1( BB q−=
Algoritmo 3.10: Cálculo del seno de una matriz mediante los aproximantes diagonales de Padé.
El coste aproximado del algoritmo anterior es
232
3822)1(2 llnjl
snlnsn ++⎥⎦
⎤⎢⎣⎡ +++− flops.

Capítulo 3: Cálculo de Funciones de Matrices
108
3.3 Algoritmos Basados Descomposición Real de Schur de una matriz
3.3.1 Esquema General Se pueden desarrollar varios algoritmos a partir de la descomposición real de Schur de una matriz nxnA ℜ∈ . Conocida dicha descomposición, se determina el valor de la función sobre la forma real de Schur de la matriz considerada y se calcula )(Af a partir de la matriz anterior. A continuación se describe detalladamente el esquema correspondiente.
Según el Teorema 6.7, A se puede descomponer como TQSQA = ,
siendo nxnQ ℜ∈ ortogonal y nxnS ℜ∈ casi triangular superior. Por la Propiedad 2.2, se tiene que si )(zf es analítica sobre un abierto que contiene al espectro de A , entonces
)(Af se puede calcular como TQSQfAf )()( = .
El algoritmo general que calcula funciones de matrices mediante la forma real de Schur de una matriz se muestra a continuación.
Entrada: Matriz nxnA ℜ∈ . Salida: Matriz nxnAfB ℜ∈= )( .
1 )(],[ AschurSQ = (obtiene la matriz ortogonal nxnQ ℜ∈ y la matriz casi triangular nxnS ℜ∈ de la descomposición real de Schur de la matriz A ).
2 Calcular )(SfF = . 3 Calcular TQFQB = .
Algoritmo 3.11: Algoritmo general para el cálculo de funciones de matrices basado en la descomposición real de Schur de una matriz.
El coste del algoritmo anterior es:
• Primera etapa: El cálculo de la forma real de Schur está basado en el algoritmo iterativo QR de coste estimado de 325n flops (véase [BlDo99]), siendo n la dimensión de la matriz A . Este coste se ha determinado de forma heurística, puesto que al ser un método iterativo el número de flops depende de la velocidad de convergencia de la forma Hessenberg superior a la forma casi triangular superior de la matriz A .
• Segunda etapa: El coste computacional de )(SfF = depende del método usado para su cálculo.
• Tercera etapa: Para obtener B es necesario realizar el producto de una matriz densa por una matriz casi triangular superior ( QFB = ) y el producto de dos matrices densas ( TBQB = ). El coste aproximado de esta etapa es
3
38 n flops.

Capítulo 3: Cálculo de Funciones de Matrices
109
Diversos métodos se pueden utilizar para el cálculo de )(Sf , algunos se pueden encontrar en [Iba97] y [High03], y otros se introducen en este capítulo.
3.3.2 Algoritmo Basado en la Reducción a una Forma Diagonal por Bloques
Una primera estrategia para calcular )(Sf consiste en reducir la matriz S a una matriz diagonal por bloques D , utilizando para ello una transformación no ortogonal de semejanza definida por una matriz invertible nxnY ℜ∈ bien condicionada de manera que los valores propios cercanos se encuentren en el mismo bloque diagonal, y tal que la separación entre bloques diagonales distintos sea lo suficientemente grande. De esta forma, se tiene que
( 3.11 ) 1−= YDYS , ),,,(diag 21 pDDDD L= , ii xnniD ℜ∈ , pi ≤≤1 , ∑
=
=p
ii nn
1,
y entonces )(Sf se puede calcular mediante la expresión 1
11 ))(,),((diag)()( −− == YDfDfYYDYfSf pL ,
donde cada bloque diagonal )( iDf , pi ,,2,1 L= , se puede obtener utilizando, por ejemplo, aproximantes de Padé.
Si la matriz S se puede dividir en bloques,
( 3.12 )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
pp
p
p
S
SSSSS
S
L
MOMM
L
L
00
0 222
11211
, ji xnnijS ℜ∈ , pji ≤≤≤1 , ∑
=
=p
ii nn
1,
de manera que los conjuntos de valores propios de los bloques diagonales, ( ) ( ) ( )ppSSS λλλ ,,, 2211 L , sean disjuntos dos a dos, entonces existe una transformación de
semejanza, definida mediante una matriz invertible nxnY ℜ∈ , de manera que
( 3.13 ) ),,,(diag 22111
ppSSSSYY L=− ([GoVa96], Teorema 7.1.6).
La forma de obtener la matriz Y se describe a continuación.
En primer lugar, la matriz identidad de orden n se divide en bloques ],,,[ 21 pn EEEI L= , inxn
iE ℜ∈ , pi ,,1L= , y se definen las matrices nxnijY ℜ∈ , como
Tjijinij EZEIY += , pji ≤<≤1 ,
siendo ji xnnijZ ℜ∈ matrices a determinar.
Si se fijan los valores de i y de j , entonces la matriz ijY coincide con la matriz identidad excepto que su bloque ),( ji es igual a ijZ , es decir,

Capítulo 3: Cálculo de Funciones de Matrices
110
⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=
p
j
i
n
n
ijn
n
ij
I
I
ZI
I
Y
LLL
MOMOMOM
LLL
MOMOMOM
LLL
MOMOMOM
LLL
000
000
00
0001
.
Si se define ijij SYYS 1−= , entonces se tiene que ijij SYSY = , es decir,
⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
pp
jpjj
ipijii
pji
n
n
ijn
n
S
SS
SSS
SSSS
I
I
ZI
I
p
j
i
LLL
MOMOMOM
LLL
MOMOMOM
LLL
MOMOMOM
LLL
LLL
MOMOMOM
LLL
MOMOMOM
LLL
MOMOMOM
LLL
000
00
0
000
000
00
000 111111
⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=
p
j
i
n
n
ijn
n
pp
jpjj
ipijii
pji
I
I
ZI
I
S
SS
SSS
SSSS
LLL
MOMOMOM
LLL
MOMOMOM
LLL
MOMOMOM
LLL
LLL
MOMOMOM
LLL
MOMOMOM
LLL
MOMOMOM
LLL
000
000
00
000
000
00
0
111111
.
Por tanto, los bloques de las matrices S y S , se relacionan entre sí mediante las siguientes igualdades:
• Bloques diagonales,
kkkk SS = , pk ,,2,1 L= .
• Bloques no diagonales,
ijjjijijiiij SSZZSS +−= , pji ≤<≤1 ,
kjijkikj SZSS += , 1,,2,1 −= ik L ,
jkijikik SZSS −= , pjjk ,,2,1 L++= .
De este modo, el bloque ijS se puede anular si ijZ es solución de la ecuación matricial de Sylvester
ijjjijijii SSZZS −=− ,
donde ii xnniiS ℜ∈ y jj xnn
jjS ℜ∈ son matrices casi triangulares superiores y ji xnnijS ℜ∈ .

Capítulo 3: Cálculo de Funciones de Matrices
111
Por lo tanto, definiendo la matriz Y como
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
== ∏∏= >
pn
pn
pn
p
i
p
ijij
I
ZIZZI
YY
L
MOMM
L
L
00
0 2
112
1
2
1
,
se puede comprobar que ),,,diag( 22111
ppSSSSYY L=− .
A continuación se detalla el algoritmo que permite obtener la transformación de semejanza definida por la matriz Y .
),(],[ SQdlasbdSQ = .
Entradas: Matriz casi triangular superior nxnS ℜ∈ y matriz ortogonal nxnQ ℜ∈ procedentes de la descomposición real de Schur de la matriz nxnA ℜ∈ .
Salidas: Q es sobrescrita por la matriz QY y S es sobrescrita por la matriz ),,,diag( 2211 ppSSS L , de manera que ),,,diag( 2211
1ppSSSSQQ L=− .
1 Para pj :2= 1.1 Para 1:1 −= ji
1.1.1 Calcular Z resolviendo la ecuación matricial de Sylvester ijjjii SZSZS −=−
1.1.2 Para pjk :1+= 1.1.2.1 jkikik ZSSS −= 1.1.2.2 Para pk :1=
1.1.2.2.1 kjkikj QZQQ +=
Algoritmo 3.12: Reducción a la forma diagonal por bloques de una matriz casi triangular superior.
El número de flops de este algoritmo depende de los tamaños de los bloques diagonales de la matriz S .
La elección de la división en bloques de la matriz S determina la sensibilidad de las ecuaciones matriciales de Sylvester que aparecen en el Algoritmo 3.12. Esto afecta al número de condición de la matriz Y y a la estabilidad numérica del proceso de diagonalización por bloques de la matriz S . Esto es debido a que el error relativo de la solución Z~ obtenida al resolver la ecuación matricial de Sylvester
( 3.14 ) ijjjii SZSZS −=− ,
satisface que
( 3.15 ) ),sep(
||||||||
||~||
jjii
F
F
F
SSSu
ZZZ
≅− ([GoNV79]),
siendo

Capítulo 3: Cálculo de Funciones de Matrices
112
F
Fjjii
Xjjii XXSXS
SS||||
||||min),sep(
0
−=
≠ ([Varah79]),
la separación que existe entre los bloques diagonales iiS y jjS , y u el error de redondeo unidad ([GoVa96], página 61).
Si los conjuntos )( iiSλ y )( jjSλ están muy cercanos, entonces se pueden producir grandes errores en la obtención de la diagonalización por bloques, puesto que al cumplirse que
( )( )
||min||||
||||min),sep(
0µλ
λµλλ
−≤−
=∈∈≠
jjii
TT
F
Fjjii
Xjjii XXSXS
SS ,
se tiene que ),sep( jjii SS puede ser pequeña, por lo que si ijZ es la solución de la ecuación ( 3.14 ), entonces ijZ tendrá una gran norma, con lo que la matriz Y estará mal condicionada por ser el producto de matrices de la forma
⎥⎦
⎤⎢⎣
⎡=
IZI
Y ijij 0
.
Puesto que en la forma real de Schur de una matriz A los valores propios cercanos no están necesariamente en el mismo bloque diagonal, es necesario reordenar los bloques diagonales 1x1 o 2x2 mediante transformaciones de semejanza ([NgPa87]) de manera que los valores propios cercanos estén agrupados. De este modo, la separación entre bloques será suficientemente grande con la consiguiente disminución del error cometido.
El siguiente algoritmo calcula funciones de matrices mediante la diagonalización a bloques de una matriz.
),( AfdgefunsbdB = .
Entrada: Función )(xf , matriz nxnA ℜ∈ .
Salida: Matriz nxnAfB ℜ∈= )( .
1 )(],[ AschurSQ = (obtiene las matrices Q y S de la descomposición real de Schur de la matriz A )
2 ),(],[ SQdlasbdSQ = (Algoritmo 3.12) 3 Calcular ))(,),(diag( 11 ppSfSfF L=
4 Calcular 1−= QFQB
Algoritmo 3.13: Cálculo de funciones de matrices basado en la descomposición real de Schur de una matriz y en la forma diagonal a bloques.
3.3.3 Algoritmos Basados en la Resolución de la Ecuación Conmutante
En este apartado se describen varios algoritmos basados en la descomposición real de Schur de una matriz y en la ecuación conmutante.

Capítulo 3: Cálculo de Funciones de Matrices
113
3.3.3.1 Algoritmos Orientados a Columnas y a Diagonales Sea
( 3.16 ) nxn
mm
m
m
S
SSSSS
S ℜ∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
L
MOMM
L
L
00
0 222
11211
, ℜ∈jjS ó 22xjjS ℜ∈ , mj ,,2,1 L= ,
la forma real de Schur de la matriz A y
( 3.17 ) nxn
mm
m
m
F
FFFFF
SfF ℜ∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
==
L
MOMM
L
L
00
0)( 222
11211
, ℜ∈jjF ó 22xjjF ℜ∈ , mj ,,2,1 L= ,
con igual estructura por bloques que la matriz S .
Teniendo en cuenta que las matrices S y F conmutan (Propiedad 2.1), se tienen que los bloques diagonales jjF , mj ,,2,1 L= , se pueden calcular mediante la expresión
( 3.18 ) )( jjjj SfF = ,
y el resto de bloques ijF , nji ≤<≤1 , resolviendo las ecuaciones matriciales de Sylvester
( 3.19 ) ∑∑+=
−
=
−=−j
ikkjik
j
ikkjikjjijijii FSSFSFFS
1
1
.
Para calcular el bloque ijF es necesario haber calculado previamente los bloques que se encuentran a su izquierda y debajo de él, tal como se indica en la siguiente figura.
Figura 3.1: Dependencia de datos en el cálculo de ijF , mji ≤<≤1 .
En los algoritmos orientados a columnas, filas o diagonales es necesario determinar los bloques diagonales de orden 22x de la matriz F , correspondientes a valores propios conjugados de la matriz S (expresión ( 3.18)). A continuación se describe un método
Fik, i ≤k<j
F
Fkj, i<k≤j
Fij

Capítulo 3: Cálculo de Funciones de Matrices
114
descrito en [Ibañ97] que permite calcular la matriz )( jjjj SfF = , siendo jjS un bloque diagonal de orden 22x .
Sea
⎥⎦
⎤⎢⎣
⎡=
+++
+
1,1,1
1,,
kkkk
kkkkjj ss
ssS ,
y
⎟⎟⎠
⎞⎜⎜⎝
⎛⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡=
+++
+
+++
+
1,1,1
1,,
1,1,1
1,,
kkkk
kkkk
kkkk
kkkkjj ss
ssf
ffff
F
el correspondiente bloque de la matriz F .
Sin pérdida de generalidad, se puede suponer que los bloques diagonales 22x tienen los elementos diagonales iguales y los no diagonales de igual valor absoluto pero con distinto signo (véase la función schur de MATLAB y la rutina dgees de LAPACK), es decir,
kkkk ss ,1,1 =++ , |||| 1,,1 ++ = kkkk ss , 01,,1 <++ kkkk ss .
Si se definen kksa ,≡ , 1, +≡ kksb , kksc ,1+≡ y se considera la descomposición en valores propios
⎥⎦
⎤⎢⎣
⎡
−⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡
−=⎥
⎦
⎤⎢⎣
⎡−
bccbbc
zz
bccbbc
acba
00
1
,
donde bcaz += y z el complejo conjugado de z , entonces se cumple que
⎥⎦
⎤⎢⎣
⎡
−⎟⎟⎠
⎞⎜⎜⎝
⎛⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡
−=⎟⎟
⎠
⎞⎜⎜⎝
⎛⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡−
+++
+
bccbbc
zz
fbcc
bbcacba
fffff
kkkk
kkkk
00
1
1,1,1
1,,
y
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡=⎟⎟
⎠
⎞⎜⎜⎝
⎛⎥⎦
⎤⎢⎣
⎡)(0
0)()(0
0)(0
0zf
zfzf
zfz
zf .
Luego
⎥⎦
⎤⎢⎣
⎡
−⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡
−=⎥
⎦
⎤⎢⎣
⎡
+++
+
bccbbc
zfzf
bccbbc
bcffff
kkkk
kkkk
)(00)(1
1,1,1
1,, ,
( 3.20 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−
−=⎥
⎦
⎤⎢⎣
⎡
+++
+
))(Re())(Im(||1
))(Im(||1))(Re(
1,1,1
1,,
zfzfbcb
zfbcc
zf
ffff
kkkk
kkkk .
Para determinar los bloques no diagonales de la matriz F que aparecen en los algoritmos orientados a columnas y diagonales que se presentan en este subapartado, es necesario resolver ecuaciones matriciales casi triangulares superiores de Sylvester. Estas

Capítulo 3: Cálculo de Funciones de Matrices
115
ecuaciones se pueden resolver mediante el método que se presenta a continuación. Sea la ecuación matricial de Sylvester
( 3.21 ) CXBAX =− ,
donde
mxm
rr
r
r
A
AAAAA
A ℜ∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
L
MOMM
L
L
00
0 222
11211
,
ji xmmijA ℜ∈ , para rji ,,1, L= , y im y jm iguales a 1 o 2;
y
nxn
ss
s
s
B
BBBBB
B ℜ∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
L
MOMM
L
L
00
0 222
11211
,
ji xnnijB ℜ∈ , para sji ,,1, L= , y in y jn iguales a 1 o 2; y mxnC ℜ∈ .
Las matrices C y X se dividen en rxs bloques de tamaños 1x1 o 2x2 de acuerdo a la división por bloques de las matrices A y B ,
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
rsrr
s
s
CCC
CCCCCC
C
L
MOMM
L
L
21
22221
11211
,
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
rsrr
s
s
XXX
XXXXXX
X
L
MOMM
L
L
21
22221
11211
,
siendo ji xnmijij XC ℜ∈, , para si ,,1L= , rj ,,1L= .
El bloque ijX se puede obtener igualando los bloques ),( ji de la ecuación ( 3.21 ) tal y como se muestra a continuación.
ij
s
kkjik
r
kkjik CBXXA =+ ∑∑
== 11,
ij
j
kkjik
r
ikkjik CBXXA =+ ∑∑
== 1,
ij
j
kkjikjjij
r
ikkjikijii CBXBXXAXA =+++ ∑∑
−
=+=
1
11
,

Capítulo 3: Cálculo de Funciones de Matrices
116
( 3.22 ) ∑∑−
=+=
−−=+1
11
j
kkjik
r
ikkjikijjjijijii BXXACBXXA .
Aplicando la función vec , se tiene
⎟⎟⎠
⎞⎜⎜⎝
⎛−−=+ ∑∑
−
=+=
1
11vec)vec(
j
kkjik
r
ikkjikijjjijijii BXXACBXXA ,
( 3.23 ) ⎟⎟⎠
⎞⎜⎜⎝
⎛−−=⊗+⊗ ∑∑
−
=+=
1
11vec)()vec(
j
kkjik
r
ikkjikijiji
Tjjiij BXXACXIBAI ,
donde iI e jI representan las matrices identidad de dimensiones, respectivamente, iguales a las de las matrices iiA y jjB .
Basta resolver la ecuación ( 3.23 ) y calcular ijX como
))(vec(mat ijxnmij XXji
= .
A continuación se muestra el algoritmo que resuelve la ecuación casi triangular de Sylvester ( 3.21 ).
),,( CBAdtrsylX = .
Entradas: Matrices casi triangulares superiores mxmA ℜ∈ y nxnB ℜ∈ , matriz mxnC ℜ∈ .
Salida: Matriz mxnX ℜ∈ solución de la ecuación matricial casi triangular de Sylvester CXBAX =+ .
1 Dividir la matriz A en rr × bloques de tamaños 1x1 o 2x2 en función de que los valores propios sean reales o complejos conjugados:
][ ijAA = , ( ℜ∈ijA o 22xijA ℜ∈ )
2 Dividir la matriz B en ss × bloques de tamaños 1x1 o 2x2 en función de que los valores propios sean reales o complejos conjugados:
][ ijBB = , ( ℜ∈ijB o 22xijB ℜ∈ )
3 Dividir la matriz C y X en sr × bloques de tamaños 1x1 o 2x2 en función de la división por bloques de las matrices A y B :
][ ijCC = , ][ ijXX = 4 Para 1:1: −= ri
4.1 Para sj :1=
4.1.1 ∑∑−
=+=
−−=1
11
j
kkjik
r
ikkjikijij BXXACC
4.1.2 )(vec ijij Cc =
4.1.3 iTjjiijij IBAIM ⊗+⊗=
4.1.4 Calcular ijx resolviendo la ecuación ijij cMx = 4.1.5 )(mat ijxnmij xX
ji=
Algoritmo 3.14: Resolución de la ecuación casi triangular de Sylvester.

Capítulo 3: Cálculo de Funciones de Matrices
117
El coste computacional aproximado del algoritmo anterior está comprendido entre
)(21 22 nmmn + y )(
32 22 nmmn + flops.
3.3.3.1.1 Algoritmo Orientado a Columnas
En este algoritmo se calcula, en primer lugar, el bloque diagonal de la primera columna, continuando con los bloques que se encuentran en los sucesivos bloques de columnas. Para cada bloque de columnas se calcula, en primer lugar, el bloque diagonal y, a continuación, los bloques que se encuentran por encima en sentido ascendente tal como se indica en la siguiente figura.
Figura 3.2: Orden de cálculo de los bloques de la matriz F .
Los bloques de la diagonal principal se obtienen a partir de la expresión ( 3.18 ) y el resto de los bloques resolviendo la ecuación matricial de Sylvester ( 3.19 ). Para este algoritmo se puede, o bien calcular el miembro de la derecha en el momento en que se va a resolver la ecuación matricial de Sylvester, o bien haberlo calculado previamente. En el algoritmo que se presenta a continuación se ha elegido la primera estrategia.
)(SdqtfunsccF = .
Entradas: Matriz casi triangular superior nxnS ℜ∈ . Salida: Matriz casi triangular superior nxnSfF ℜ∈= )( .
1 Dividir la matriz S en mxm bloques, de manera que los bloques diagonales sean 11x o 22x , correspondientes a valores propios reales o complejos conjugados,
respectivamente. 2 Para mj :1=
2.1 )( jjjj SfF = 2.2 Para 1:1:1 −−= ji
2.2.1 ∑∑+=
−
=
−=j
ikkjik
j
ikkjikij FSSFF
1
1
2.2.2 ),,( ijjjiiij FSSdtrsylF −= (Algoritmo 3.14)
Algoritmo 3.15: Cálculo de la función de una matriz casi triangular superior basado en la resolución de la ecuación conmutante orientado a columnas.
F

Capítulo 3: Cálculo de Funciones de Matrices
118
El coste computacional aproximado del algoritmo anterior se encuentra entre
23
3nn
+ y 22
23 nn+ flops.
3.3.3.1.2 Algoritmo Orientado a Diagonales
En este caso los bloques se calculan por diagonales. Se comienza con la diagonal principal y se continúa con las diagonales que se encuentran encima de ella. Para cada diagonal los bloques se calculan de arriba hacia abajo.
Figura 3.3: Orden de cálculo de los bloques de la matriz F .
Los bloques de la diagonal principal se calculan utilizando la expresión ( 3.18 ). Los bloques del resto de las diagonales se calculan mediante la resolución de la ecuación matricial de Sylvester ( 3.19 ). Al igual que en el caso anterior, se puede, o bien calcular el miembro de la derecha en el momento en que se va a resolver la ecuación matricial de Sylvester, o haberlo calculado previamente. En el algoritmo que se presenta a continuación se ha elegido esa segunda estrategia. En la siguiente figura se muestra el bloque que se ha calculado y los bloques que se actualizan a partir de él.
Figura 3.4: Bloques ikF y kjF que se actualizan a partir de ijF .
A continuación se presenta el algoritmo que calcula funciones de matrices casi triangulares superiores basado en la resolución de la ecuación conmutante orientada a diagonales.
Fij
Fkj, 1≤k<i
Fik, j<k≤m
1
F
2 3 4 5
F

Capítulo 3: Cálculo de Funciones de Matrices
119
)(SdqtfunscdF = .
Entradas: Matriz casi triangular superior nxnS ℜ∈ . Salida: Matriz casi triangular superior nxnSfF ℜ∈= )( .
1 Dividir la matriz S en mxm bloques, de manera que los bloques diagonales sean 11x o 22x , correspondientes a valores propios reales o complejos conjugados,
respectivamente. 2 Para mk :1=
2.1 Para mkj := 2.1.1 1+−= kji 2.1.2 Si 1>k
2.1.2.1 ),,( ijjjiiij FSSdtrsylF −= (Algoritmo 3.14) 2.1.3 Si no
2.1.3.1 )( jjjj SfF = 2.1.4 Actualizar los bloques jij FF 11 ,, −L 2.1.5 Actualizar los bloques imij FF ,,1 L+
Algoritmo 3.16: Cálculo de la función de una matriz casi triangular superior basado en la resolución de la ecuación conmutante orientado a diagonales.
El coste computacional aproximado del algoritmo anterior se encuentra entre
22
23 nn+ y 2
3
3nn
+ flops.
3.3.3.2 Algoritmos Orientados a Bloques Sea r el tamaño de bloque elegido. Debido a la presencia de elementos subdiagonales no nulos en la forma real de Schur de la matriz S , los tamaños de los bloques diagonales no serán uniformes; es decir, los bloques diagonales de la matriz S podrán tener dimensiones rxr o )1()1( ++ rxr , salvo el bloque diagonal situado en la última fila y columna de bloques que puede tener una dimensión distinta, como resultado del encaje final de la división por bloques con la dimensión de la matriz inicial. El resto de bloques de S se obtienen dividiendo la matriz en bloques rectangulares de acuerdo a los bloques diagonales; de este modo, la matriz S queda dividida sxs bloques. Para la matriz F se utiliza la misma estructura de bloques.
Si se identifican los bloques diagonales en la ecuación SFFS = , se obtiene
)( jjjj SfF = , sj ,,2,1 L= .
Esta ecuación puede resolverse utilizando cualquiera de los algoritmos comentados anteriormente (orientados a columnas u orientados a diagonales).
Los bloques no diagonales se obtienen resolviendo la ecuación casi triangular superior de Sylvester
∑∑+=
−
=
−=−j
ikkjik
j
ikkjikjjijijii FSSFTSFS
1
1
.

Capítulo 3: Cálculo de Funciones de Matrices
120
Razonando como en el subapartado anterior, se pueden deducir varios algoritmos: orientados a filas, orientados a columnas y orientados a diagonales. A continuación se presenta el algoritmo orientado a columnas de bloques.
),( SrdqtfunscbF = .
Entradas: Tamaño de bloque +∈ Zr , matriz casi triangular superior nxnS ℜ∈ . Salida: Matriz casi triangular superior nxnSfF ℜ∈= )( .
1 Dividir S y F en sxs bloques de tamaños rxr o )1()1( ++ rxr (salvo los bloques ssS y ssF que tendrán las dimensiones adecuadas)
2 Para sj :1= 2.1 )( jjjj SdqtfunscF = (Algoritmo 3.15) 2.2 Para 1:1:1 −−= ji
2.2.1 ∑∑+=
−
=
−=j
ikkjik
j
ikkjikij FSSFF
1
1
2.2.2 ),,( ijjjiiij FSSdtrsylF −= (Algoritmo 3.14)
Algoritmo 3.17: Calcula la función de una matriz casi triangular superior mediante la resolución de la ecuación conmutante orientado a columnas de bloques.
El coste computacional aproximado del algoritmo anterior es
3132 n
s⎟⎠⎞
⎜⎝⎛ + flops.
El algoritmo orientado a diagonales de bloques se presenta a continuación.
)(SdqtfunsdbF = .
Entradas: Tamaño de bloque +∈ Zr , matriz casi triangular superior nxnS ℜ∈ . Salida: Matriz casi triangular superior nxnSfF ℜ∈= )( .
1 Dividir S y F en sxs bloques de tamaños rxr o )1()1( ++ rxr (salvo los bloques ssS y ssF que tendrán las dimensiones adecuadas)
2 Para sk :1= 2.1 Para skj :=
2.1.1 1+−= kji 2.1.2 Si 1>k
2.1.2.1 ),,( ijjjiiij FSSdtrsylF −= (Algoritmo 3.14) 2.1.3 Si no
2.1.3.1 )( jjjj SdtrfunscF = (Algoritmo 3.15) 2.1.4 Actualizar los bloques jij FF 11 ,, −L 2.1.5 Actualizar los bloques isij FF ,,1 L+
Algoritmo 3.18: Algoritmo para el cálculo de la función de una matriz casi triangular superior basado en la resolución de la ecuación conmutante orientado a diagonales de bloques.

Capítulo 3: Cálculo de Funciones de Matrices
121
El coste computacional aproximado del algoritmo anterior es
3132 n
s⎟⎠⎞
⎜⎝⎛ + flops.
3.3.3.3 Algoritmo con Agrupación de Valores Propios Cercanos En este subapartado se describe el algoritmo que consiste en agrupar en clusters los valores propios cercanos de la forma real de Schur de una matriz, realizando a continuación las reordenaciones necesarias de manera que la matriz obtenida quede dividida en bloques, estando los valores del mismo cluster en el mismo bloque diagonal. A partir de ahí, se pueden utilizar estrategias similares a las utilizadas en los algoritmos a bloques descritos en el subapartado 3.3.3.2.
El siguiente algoritmo determina un vector g que contiene los índices de comienzo de los bloques diagonales de la forma real de Schur S de la matriz nxnA ℜ∈ .
),( vivrdlagbsg =
Entradas: Vectores nvivr ℜ∈, que contienen, respectivamente, la parte real y la parte imaginaria de los valores propios de la forma real de Schur nxnS ℜ∈ de la matriz nxnA ℜ∈ .
Salida: Vector mg ℜ∈ que contiene los índices de los bloques 1x1 o 2x2 de la matriz S .
1 0=m 2 11 =i 3 112 += ii 4 Mientras ni ≤1
4.1 1+= mm 4.2 1)( img = 4.3 Si 0)( 2 ≠ivi
4.3.1 121 += ii 4.4 Si no
4.4.1 21 ii = 4.5 121 += ii
5 Si ni ≤1 5.1 1+= mm 5.2 1)( img =
Algoritmo 3.19: Determina los bloques diagonales de la forma real de Schur de una matriz.
Una vez se conoce el vector g , se deben determinar los clusters de valores propios. Estas agrupaciones en clusters se realizan de manera que dos valores propios se encuentran en el mismo cluster, siempre que disten entre sí un valor menor que un valor de tolerancia predefinido, no necesariamente pequeño. En el siguiente algoritmo se

Capítulo 3: Cálculo de Funciones de Matrices
122
determina un vector de enteros positivos pZc ∈ de manera que )(kc , pk ≤≤1 , indica a qué cluster pertenece el grupo de valores propios definidos por )(kg .
),,,( tolgvivrdlagcc = .
Entradas: Vectores nvivr ℜ∈, que contienen, respectivamente, la parte real y la parte imaginaria de los valores propios de la matriz casi triangular superior
nxnS ℜ∈ , vector mg ℜ∈ que contiene los índices de los bloques de la expresión ( 6.2 ) y la tolerancia +ℜ∈tol .
Salida: Vector de enteros positivos pZc ∈ que contiene los índices de los clusters. 1 0=p 2 Para mk :1=
2.1 Si 0)( =kc 2.1.1 1+= pp 2.1.2 pkc =)(
2.2 ikgvikgvrvk ))(((abs))(( += 2.3 Para mkj :1+=
2.3.1 ijgvijgvrvj ))(((abs))(( += 2.3.2 Si tolvjvk <− )(abs
2.3.2.1 )()( kcjc =
Algoritmo 3.20: Determina los cluster de la forma real de Schur de una matriz.
Conocida la división en clusters de los valores propios de la matriz S , se realizan los intercambios necesarios de bloques diagonales de manera que los valores propios con el mismo índice de cluster se encuentren en el mismo bloque diagonal. Estos intercambios se realizan utilizando transformaciones de semejanza ortogonales. Al final de este proceso se obtiene una matriz S , divida en bloques conforme a la división en clusters de los valores propios de S , y una matriz ortogonal Q de modo que TQSQS = .
El siguiente algoritmo lleva a cabo el proceso descrito en el párrafo anterior.

Capítulo 3: Cálculo de Funciones de Matrices
123
),,,(],,,[ cgQSdlabexcgQS = .
Entradas: Matriz casi triangular superior nxnS ℜ∈ , matriz ortogonal nxnQ ℜ∈ , vector mg ℜ∈ que contiene los índices de los bloques de la matriz S , vector pc ℜ∈ que contiene los índices de los clusters.
Salidas: Matriz casi triangular superior nxnS ℜ∈ con los bloques diagonales correspondientes a valores propios en el mismo cluster, matriz ortogonal
nxnQ ℜ∈ ( TQSQS = ), vector mg ℜ∈ que contiene los índices de los bloques de la matriz S , vector pc ℜ∈ que contiene los índices de los clusters de la matriz S .
1. SS = 2. nIQ = 3. truecont = 4. Mientras cont
4.1 falsecont = 4.2 Para 1:1 −= mk
4.2.1 Si )1()( +> kckc 4.2.1.1 Intercambiar los bloques diagonales de la matriz S
apuntados por )(kg y )1( +kg actualizando adecuadamente la matriz Q y el vector g
4.2.1.2 )(kccaux = 4.2.1.3 )1()( += kckc 4.2.1.4 cauxkc =+ )1( 4.2.1.5 truecont =
5 1=k 6 Para mj :2=
6.1 Si )()( kcjc ≠ 6.1.1 1+= kk 6.1.2 )()( jgkg = 6.1.3 )()( jckc =
Algoritmo 3.21: Reordenación de la forma real de Schur para la agrupación en clusters de los valores propios cercanos.
Una vez se han determinado S y Q se aplica un esquema semejante al utilizado en el Algoritmo 3.17 o en el Algoritmo 3.18. A continuación se presenta el algoritmo completo.

Capítulo 3: Cálculo de Funciones de Matrices
124
),,,(],[ tolfQSdqtfunsccQF = .
Entradas: Matriz casi triangular superior nxnS ℜ∈ y matriz ortogonal nxnQ ℜ∈ procedentes de descomposición real de Schur de la matriz nxnA ℜ∈ , función )(zf , tolerancia +ℜ∈tol .
Salida: Matriz casi triangular superior nxnSfF ℜ∈= )( , matriz ortogonal actualizada nxnQ ℜ∈ .
1 ),( vivrdlagbsg = (Algoritmo 3.19) 2 ),,,( tolgvivrdlagcc = (Algoritmo 3.20) 3 ),,,(],,,[ cgQSdlabexcgQS = (Algoritmo 3.21) 4 Para pk :1=
4.1 Para pkj := 4.1.1 1+−= kji 4.1.2 Si 1>k
4.1.2.1 ),,( ijjjiiij FSSdtrsylF −= (Algoritmo 3.14) 4.1.3 Si no
4.1.3.1 Calcular )( jjjj SfF = (se puede utilizar, por ejemplo, cualquier algoritmo basado en los aproximantes diagonales de Padé)
4.1.4 Actualizar los bloques jij FF 11 ,, −L 4.1.5 Actualizar los bloques ipij FF ,,1 L+
Algoritmo 3.22: Calcula funciones de matrices mediante la agrupación en cluster de los valores propios cercanos de un matriz.
El coste computacional depende del número de reordenaciones realizadas. Si no hubiese reordenaciones, el coste computacional coincidiría con el correspondiente al algoritmo orientado a bloques.
3.3.4 Algoritmo Basado en los Aproximantes Diagonales de Padé
Este método consiste en calcular )(Sf mediante una variante del método de los aproximantes diagonales de Padé para matrices casi triangulares superiores. El algoritmo resultante se presenta a continuación.

Capítulo 3: Cálculo de Funciones de Matrices
125
)(AdqtfunsppB = .
Entrada: Matriz nxnA ℜ∈ y función )(xf .
Salida: Matriz nxnAfB ℜ∈= )( .
1 )(],[ AschurSQ = (obtiene la matriz casi triangular superior nxnS ℜ∈ y matriz ortogonal nxnQ ℜ∈ procedentes de descomposición real de Schur de la matriz
nxnA ℜ∈ ) 2 )(SfF = (se puede utilizar, por ejemplo, cualquier algoritmo basado en los
aproximantes diagonales de Padé adaptado a matrices casi triangulares superiores)
3 TQFQB =
Algoritmo 3.23: Algoritmo para el cálculo de funciones de matrices basado en la descomposición real de Schur de una matriz y en los aproximantes diagonales de Padé.
3.4 Conclusiones La primera aportación de este capítulo es la implementación de un algoritmo general, basado en los aproximantes diagonales de Padé, que permite calcular funciones analíticas de matrices. Aunque hay dos etapas que dependen de la función y de la matriz considerada (reducción de la norma de la matriz y aplicación de las transformaciones inversas), siempre es posible utilizar estrategias que lo permitan; por ejemplo, el escalado y potenciación para las exponenciales, escalado para las funciones logarítmicas y con radicales, etc. Basta conocer el desarrollo en serie de Taylor de la función, para así determinar la aproximación diagonal de Padé y de ahí calcular la función matricial correspondiente.
Esto permite aplicar el método de los aproximantes diagonales de Padé a otras funciones matriciales distintas de las mencionadas en el Capítulo 2. Por ejemplo, se ha presentado una forma de calcular potencias fraccionarias de una matriz basada en los aproximantes diagonales de Padé. También se ha demostrado una fórmula que permite calcular el seno de una matriz mediante un nuevo algoritmo basado en los aproximantes diagonales de Padé.
La segunda aportación de este capítulo ha sido el diseño de varios algoritmos para el cálculo de Funciones de Matrices basados en la forma real de Schur S de una matriz cuadrada. Las estrategias utilizadas han sido:
1. Diagonalización a bloques de la matriz.
Consiste en obtener una forma diagonal a bloques de la matriz A de manera que cada bloque contiene a los valores propios que se encuentran próximos entre sí. En este caso el valor )(AfF = se obtiene a partir del valor de la función sobre su forma diagonal a bloques.
2. Ecuación Conmutante.
a. Sin agrupación de valores propios.
Algoritmo orientado a columnas: De izquierda a derecha, se obtienen sucesivamente las columnas de bloques de la matriz F . Para cada columna se calcula, en primer lugar, el bloque diagonal jjF utilizando la expresión

Capítulo 3: Cálculo de Funciones de Matrices
126
)( jjjj SfF = , continuando con los bloques que se encuentran por encima de jjF , resolviendo para ello ecuaciones matriciales de Sylvester.
Algoritmo orientado a filas: De abajo hacia arriba, se obtienen sucesivamente las filas de bloques de la matriz F . Para cada fila de bloques se calcula, en primer lugar, el bloque diagonal jjF utilizando la expresión )( jjjj SfF = , continuando con los bloques que se encuentran a la derecha de jjF , resolviendo para ello ecuaciones matriciales de Sylvester.
Algoritmo orientado a diagonales: En primer lugar se determinan los bloques diagonales jjF utilizando la expresión )( jjjj SfF = , calculando a continuación las superdiagonales de abajo hacia arriba resolviendo para ello ecuaciones matriciales de Sylvester.
Algoritmos orientados a bloques: A partir de un tamaño dado r , la matriz S se divide en bloques de manera que los valores propios conjugados se deben encontrar en el mismo bloque diagonal. De este modo, los bloques diagonales son de tamaño rxr o )1()1( ++ rxr , salvo el último bloque que tendrá la dimensión adecuada. A continuación se obtienen los bloques diagonales
)( jjjj SfF = utilizando para ello otros algoritmos para el cálculo de Funciones de Matrices como, por ejemplo, los aproximantes de Padé o los algoritmos orientados a columnas o diagonales. Según la forma de calcular los bloques de la matriz F , se pueden utilizar tres algoritmos: algoritmo orientado a columnas de bloques, algoritmo orientado a filas de bloques y algoritmo orientado a diagonales de bloques.
b. Con agrupación de valores propios.
En aquellas ocasiones en que la matriz S tiene valores propios cercanos entre sí, es conveniente agruparlos de manera que la resolución de la Ecuación Conmutante se realice con precisión. Para ello se deben realizar reordenaciones en la matriz S , utilizando transformaciones ortogonales de semejanza, de manera que los valores propios cercanos se encuentren en un mismo bloque diagonal. De este modo, la matriz S se puede estructurar por bloques de manera que los bloques diagonales se encuentren suficientemente separados entre sí. Estas agrupaciones se deben realizar teniendo en cuenta que el maximizar la separación entre los bloques diagonales puede conducir a obtener grandes bloques con valores propios cercanos, con el consiguiente aumento de las reordenaciones de los valores propios sobre la diagonal de S .
Una vez se ha realizado la división en bloques de la matriz S , los bloques diagonales )( jjjj SfF = se pueden calcular utilizando, por ejemplo, los algoritmos basados en la aproximación diagonal de Padé.
Según el orden utilizado en el cálculo de bloques, se pueden obtener tres algoritmos: algoritmo orientado a columnas de bloques, algoritmo orientado a filas de bloques o algoritmo orientado a diagonales de bloques.
3. Aproximantes de Padé
Este método consiste en calcular )(Sf mediante una variante del método de los aproximantes diagonales de Padé para matrices casi triangulares superiores.

Capítulo 3: Cálculo de Funciones de Matrices
127
Los algoritmos basados en la descomposición real de Schur de una matriz son computacionalmente más costosos que los basados en los aproximantes diagonales de Padé, aunque en muchas ocasiones son más precisos que estos últimos. A continuación se comparan los algoritmos basados en la descomposición real de Schur de una matriz.
• Aunque los algoritmos orientados a filas y a columnas tienen una formulación similar, la forma de acceder a los datos es distinta. Como cabe esperar ([Ibañ97]), si se utiliza el lenguaje de programación FORTRAN se obtienen mejores prestaciones al utilizar un algoritmo orientado a columnas, y si el lenguaje utilizado es C las mejores prestaciones se obtienen un algoritmo orientado a filas. En este capítulo se han descrito únicamente los algoritmos orientados a columnas puesto que en las implementaciones se ha utilizado el lenguaje FORTRAN.
• Los algoritmos orientados a bloques resultan ser habitualmente más eficientes que los orientados a filas o columnas, pues hacen uso de la memoria caché de los ordenadores. De este modo, si se elige convenientemente el tamaño de bloque, se produce una mayor localidad de datos y, por tanto, un menor intercambio de datos entre la memoria principal y la memoria secundaria.
• Los algoritmos con un menor coste computacional corresponden a los basados en la Ecuación Conmutante sin reordenación de valores propios y al basado en los aproximantes diagonales de Padé. El problema de los primeros es que no se pueden utilizar si la matriz tiene valores propios cercanos. Para el segundo método es necesario adaptar, convenientemente, los algoritmos basados en las aproximaciones de Padé para el caso de matrices casi triangulares superiores.
3. Los algoritmos que tienen un mayor coste computacional corresponden al basado en diagonalización a bloques de la matriz y al basado en la Ecuación Conmutante con agrupación en clusters de los valores propios. La ventaja de estos algoritmos, frente al resto de los algoritmos basados en la Ecuación Conmutante, es que se pueden aplicar para cualquier matriz incluso si sus valores propios están muy próximos entre sí.


Capítulo 4: Linealización a Trozos
129
Capítulo 4 Linealización a Trozos
4.1 Resumen de Contenidos En la formulación de modelos de muchos problemas científicos y técnicos aparecen EDOs cuya solución analítica no es conocida. Es por ello que la comunidad investigadora asociada a este campo viene realizando, desde hace tiempo, un gran esfuerzo en el estudio de métodos numéricos que permitan la resolución aproximada de las mismas. En los últimos años un gran número de libros y artículos se han ocupado del estudio de métodos numéricos para la integración de EDOs, especialmente las de tipo rígido. Los más usados en la práctica son los de tipo implícito, especialmente los basados en métodos lineales multipaso, como por ejemplo los métodos Backward Differentiation Formulae (BDF),[HaWa96], por ser muy eficientes para un gran número de problemas de tipo rígido.
La Ecuación Diferencial Matricial de Riccati (EDMR) aparece frecuentemente en las ciencias aplicadas y en la ingeniería. Esta ecuación juega un papel fundamental en problemas de control óptimo, filtrado, estimación, y en la resolución de ciertos problemas de contorno de ecuaciones diferenciales. Una de las técnicas, ampliamente utilizadas para resolver dicha ecuación, consiste en aplicar el método BDF. Este método está especialmente indicado para resolver EDMRs de tipo rígido. Otro de los métodos que se pueden aplicar en la resolución de EDMRs consiste en la vectorización de ecuaciones diferenciales matriciales que consiste en convertir una EDMR en otra de tipo vectorial y aplicar un método de resolución de EDOs. El problema que se plantea en este caso es la gran dimensión de la EDO vectorial obtenida.
En este capítulo se describen nuevos métodos para la resolución de EDOs y EDMRs. En esta tesis se ha optado por profundizar en la metodología basada en la linealización a trozos para el desarrollo de nuevos algoritmos que sean competitivos, en términos computacionales, frente a otros que se han venido utilizando tradicionalmente
En el caso de EDOs se demuestra un nuevo teorema (Teorema 4.1) que permite utilizar la técnica de linealización a trozos, aunque la matriz Jacobiana sea singular. Como consecuencia de este teorema se desarrollan tres nuevos métodos: método basado en los aproximantes diagonales de Padé, método basado en la Ecuación Conmutante y método basado en los subespacios de Krylov.
En el caso de EDMRs se ha desarrollado una nueva metodología, no realizada hasta ahora, basada en la técnica de linealización a trozos. Esta metodología consiste, básicamente, en transformar la EDMR en una EDO de gran dimensión y aplicarle la linealización a trozos. Debido a la gran complejidad computacional y la gran cantidad de memoria necesaria, se han desarrollado métodos especiales para la resolución de la EDO anterior.
El primero de ellos está basado en un un nuevo teorema (Teorema 4.3) que permite transformar un problema vectorial de gran dimensión en otro matricial consistente en el cálculo de una expresión en la que aparecen bloques de las exponenciales de dos

Capítulo 4: Linealización a Trozos
130
matrices. Adaptando convenientemente el método de los aproximantes de Padé para matrices definidas a bloques, se obtiene un algoritmo eficiente en términos de costes computacionales y de almacenamiento.
El segundo método es consecuencia de un teorema basado en la Ecuación Conmutante (Teorema 4.4) que permite transformar el problema vectorial de gran dimensión en otro matricial consistente la resolución de tres ecuaciones matriciales de Sylvester.
El tercer método consiste en calcular la aproximación de la solución en un cierto instante de tiempo mediante el producto de la exponencial de una matriz definida a bloques por un vector, utilizando para ello una adaptación basado en el método de los subespacios de Krylov.
La naturaleza especial de los métodos de linealización a trozos ha hecho necesario modificar, adecuadamente, los algoritmos desarrollados para utilizarlos en la resolución de EDOs autónomas y de EDMRs con coeficientes constantes, explotando las características de este tipo de ecuaciones para así disminuir los costes computacionales y de almacenamiento necesarios.
El contenido de este capítulo está estructurado en cuatro secciones. En la segunda sección se describen los tres métodos de linealización a trozos, anteriormente comentados, para la resolución de EDOs y la adaptación de los mismos en la resolución de EDOs autónomas.
De igual modo, en la tercera sección se detallan los tres métodos de resolución de EDMRs basados en la linealización a trozos y su adaptación a la resolución de EDMRs con coeficientes constantes.
En la última sección se exponen las conclusiones de este capítulo.
Como se describió en la sección 1.1, la nomenclatura utilizada para los algoritmos desarrollados en esta tesis es: txxyyyzzz, siendo t el tipo de dato utilizado, xx el tipo de matriz, yyy el problema que resuelve y zzz el método utilizado. El significado de los seis últimos caracteres para los algoritmos que resuelven EDOs y EDMRs es:
• yyy: función considerada.
− yyy=edo para los algoritmos que resuelven EDOs;
− yyy=dmr para los algoritmos que resuelven EDMRs.
• zzz: método utilizado.
− bdf: indica que se utiliza el método BDF para la resolución de EDOs;
− lpn: indica que se utiliza el método de linealización a trozos basado en los aproximantes diagonales de Padé para la resolución de EDOs no autónomas;
− lcn: indica que se utiliza el método de linealización a trozos basado en la Ecuación Conmutante para la resolución de EDOs no autónomas;
− lkn: indica que se utiliza el método de linealización a trozos basado en los subespacios de Krylov para la resolución de EDOs no autónomas;
− lpa: indica que se utiliza el método de linealización a trozos basado en los aproximantes diagonales de Padé para la resolución de EDOs autónomas;
− lca: indica que se utiliza el método de linealización a trozos basado en la Ecuación Conmutante para la resolución de EDOs autónomas;

Capítulo 4: Linealización a Trozos
131
− lka: indica que se utiliza el método de linealización a trozos basado en los subespacios de Krylov para la resolución de EDOs autónomas;
− bdv: indica que se utiliza el método BDF para la resolución de EDMRs con coeficientes variables;
− lpv: indica que se utiliza el método de linealización a trozos basado en los aproximantes diagonales de Padé para la resolución de EDMRs con coeficientes variables;
− lcv: indica que se utiliza el método de linealización a trozos basado en la Ecuación Conmutante para la resolución de EDMRs con coeficientes variables;
− lkv: indica que se utiliza el método de linealización a trozos basado en los subespacios de Krylov para la resolución de EDMRs con coeficientes variables;
− bdc: indica que se utiliza el método BDF para la resolución de EDMRs con coeficientes constantes;
− lpc: indica que se utiliza el método de linealización a trozos basado en los aproximantes diagonales de Padé para la resolución de EDMRs con coeficientes constantes;
− lcc: indica que se utiliza el método de linealización a trozos basado en la Ecuación Conmutante para la resolución de EDMRs con coeficientes constantes;
− lkc: indica que se utiliza el método de linealización a trozos basado en los subespacios de Krylov para la resolución de EDMRs con coeficientes constantes.
4.2 Métodos de Linealización a Trozos para EDOs
4.2.1 EDOs no Autónomas
Sea la EDO con valores iniciales
( 4.1 ) ))(,()(' txtftx = , ],[ 0 fttt ∈ ,
nxtx ℜ∈= 00 )( ,
cumpliendo ),( xtf las hipótesis del Teorema 2.10 (página 56).
Aplicando la técnica de linealización a trozos descrita en el apartado 2.3.4, se tiene que dada una partición fll ttttt =<<<< −110 L , es posible aproximar la EDO ( 4.1 ) mediante el conjunto de EDLs resultantes de la aproximación lineal de ))(,( txtf en cada subintervalo, es decir,
( 4.2 ) )())(()(' iiiii ttgytyJfty −+−+= , ],[ 1+∈ ii ttt , ii yty =)( , 1,,1,0 −= li L ,
siendo n
iii ytff ℜ∈= ),( ,

Capítulo 4: Linealización a Trozos
132
nxniii yt
xfJ ℜ∈
∂∂
= ),( ,
niii yt
tfg ℜ∈
∂∂
= ),( .
Si iJ es invertible, entonces la solución de la EDL ( 4.2 ) es
)]()([)( 21)(21iiii
ttJiiiiiii gJfJegJttgfJyty ii −−−−− ++−−+−= .
A continuación se enuncia y demuestra un teorema que permite obtener la solución de la EDL ( 4.2 ) aunque iJ no sea invertible.
Teorema 4.1.
La solución de la EDL ( 4.2 ) se puede expresar como
iii
iii
i gttFfttFyty )()()( )(13
)(12 −+−+= ,
donde )()(12 i
i ttF − y )()(13 i
i ttF − son, respectivamente, los bloques (1,2) y (1,3) de la matriz )( ii ttCe − , con
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
i IIJ
C000
000
.
Demostración.
La solución de la EDL ( 4.2 ) es
∫ −++= −t
tiii
tJi
i
i dtgfeyty τττ )]([)( )( .
Si en la expresión anterior se realiza el cambio de variable
its −= τ ,
y se define
itt −=θ ,
entonces
τdds = ,
ststt i −=−−=− θτ ,
por lo tanto
( 4.3 ) isJ
isJ
iiisJ
i gsdsefdseydssgfeyty iii ∫∫∫ −−− ++=++=θ
θθ
θθ
θ
0
)(
0
)(
0
)( ][)( .
Si se considera la matriz triangular superior a bloques definida por

Capítulo 4: Linealización a Trozos
133
( 4.4 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
i IIJ
C000
000
,
entonces la exponencial de la matriz θiC , tiene la forma
( 4.5 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=)(00)()(0)()()(
)(33
)(23
)(22
)(13
)(12
)(11
θθθθθθ
θ
inn
iin
iii
C
FFFFFF
e i ,
siendo )()( θijkF , 31 ≤≤≤ kj , matrices cuadradas de orden n dependientes del
parámetro θ .
Como
θθ
θi
iC
i
C
eCd
de= , n
C Ie i30
==θ
θ ,
entonces
.000
)(00)()()()()(
)(00)()(0)()()(
00000
0
)(00
)()(0
)()()(
)(33
)(23
)(13
)(22
)(12
)(11
)(33
)(23
)(22
)(13
)(12
)(11
)(33
)(23
)(22
)(13
)(12
)(11
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ ++=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
nnn
inn
iii
iii
ii
inn
iin
iii
nnn
nnn
nni
i
nn
ii
n
iii
FFFJFFJFJ
FFFFFF
IIJ
ddF
ddF
ddF
ddF
ddF
ddF
θθθθθθ
θθθθθθ
θθ
θθ
θθ
θθ
θθ
θθ
Igualando los bloques correspondientes en ambos miembros de la expresión anterior, se obtienen las EDMLs
( 4.6 ) )()(11
)(11 θθ
ii
i
FJd
dF= , n
i IF =)0()(11 ,
( 4.7 ) 0)()(22 =
θθ
ddF i
, ni IF =)0()(
22 ,
( 4.8 ) 0)()(33 =
θθ
ddF i
, ni IF =)0()(
33 ,
( 4.9 ) )()( )(33
)(23 θ
θθ i
i
Fd
dF= , n
iF 0)0()(23 = ,
( 4.10 ) )()()( )(22
)(12
)(12 θθ
θθ ii
i
i
FFJd
dF+= , n
iF 0)0()(12 = ,
( 4.11 ) )()()( )(23
)(13
)(13 θθ
θθ ii
i
i
FFJd
dF+= , n
iF 0)0()(13 = ,

Capítulo 4: Linealización a Trozos
134
Resolviendo las EDMLs ( 4.6 ), ( 4.7 ) y ( 4.8 ), se tiene que θθ iJi eF =)()(
11 ,
ni IF =)()(
22 θ ,
ni IF =)()(
33 θ .
Resolviendo las EDMLs ( 4.9 ) ( 4.10 ) y ( 4.11 ), resulta que
ni IF θθ =)()(
23 ,
( 4.12 ) ∫ −=θ
θθ0
)()(12 )( dseF sJi i ,
( 4.13 ) ∫ −=θ
θθ0
)()(13 )( sdseF sJi i ,
y por lo tanto
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
∫∫ −−
nnn
nnn
sJsJJ
C
III
sdsedsee
e
iii
i
000
0
)(
0
)(
θ
θθ
θθθ
θ .
Teniendo en cuenta las expresiones ( 4.3 ), ( 4.12 ) y ( 4.13 ) se deduce que la solución de la EDL ( 4.2 ) viene dada por
ii
ii
i gFfFyty )()()( )(13
)(12 θθ ++= .
Como itt −=θ , entonces
iii
iii
i gttFfttFyty )()()( )(13
)(12 −+−+= ,
con lo que queda demostrado el teorema.
Según el teorema anterior, la solución aproximada en el instante 1+it de la EDO ( 4.1 ) se puede obtener a partir de la solución aproximada en it , utilizando la expresión
( 4.14 ) iii
iii
ii gtFftFyy )()( )(13
)(121 ∆+∆+=+ ,
con iii ttt −=∆ +1 , siendo )()(12 i
i tF ∆ y )()(13 i
i tF ∆ , respectivamente, los bloques (1,2) y (1,3) de la matriz ii tCe ∆ , donde
( 4.15 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
i IIJ
C000
000
.
El siguiente algoritmo calcula, aproximadamente, la solución de la EDO ( 4.1 ) mediante el método de linealización a trozos basado en el cálculo de la exponencial de la matriz definida a bloques ii tC ∆ .

Capítulo 4: Linealización a Trozos
135
),,( 0xdatatdgeedolgny =
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nxnxtJ ℜ∈),( , nxtf ℜ∈),( y nxtg ℜ∈),( , vector inicial nx ℜ∈0 .
Salidas: Matriz )1(10 ],,,[ +ℜ∈= lnx
lyyyY L , niy ℜ∈ , li ,,1,0 L= .
1 00 xy = 2 Para 1:0 −= li
2.1 ),(],,[ ii ytdatagfJ = . 2.2 ii ttt −=∆ +1
2.3 ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nn
IIJ
C000
000
2.4 tCeF ∆= 2.5 gFfFyy ii 13121 ++=+
Algoritmo 4.1: Resolución de EDOs mediante el método de linealización a trozos basado en el cálculo de la exponencial de una matriz.
El problema de calcular 1+iy en el Algoritmo 4.1 son los elevados costes computacionales y de almacenamiento necesarios para obtener tCe ∆ .
4.2.1.1 Método Basado en los Aproximantes Diagonales de Padé En este subapartado se describe la manera de obtener la aproximación 1+iy de la expresión ( 4.14 ) sin el cálculo explícito de la exponencial de la matriz ii tC ∆ , utilizando para ello una adaptación a bloques del método de los aproximantes diagonales de Padé.
Puesto que el cálculo de la exponencial de una matriz se debe realizar muchas veces, no hace falta calcular cada vez los coeficientes de los polinomios de la aproximación diagonal de Padé de la función exponencial. Además, ya que los coeficientes de los términos de grado cero de los polinomios de la aproximación diagonal de Padé son iguales a 1, tan sólo hace falta calcular los correspondientes a los términos de grado mayor que cero. En el siguiente algoritmo se calculan dichos coeficientes.

Capítulo 4: Linealización a Trozos
136
)(],[ 21 qdlapexcc =
Entrada: Grado +∈ Zq de los polinomios de la aproximación diagonal de Padé.
Salida: Vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor que 0 correspondientes a los polinomios de la aproximación diagonal de Padé de la función exponencial.
1 5.0)1(1 =c 2 5.0)1(2 −=c 3 Para qk :2=
3.1 )1()12(
1)( 11 −+−+−
= kckkq
kqkc
3.2 )()1()( 12 kckc k−=
Algoritmo 4.2: Obtiene los polinomios de la aproximación diagonal de Padé de la función exponencial.
A continuación se presenta una modificación del Algoritmo 2.1 en el que se dan, como datos de entrada, los coeficientes de los términos de grado mayor que cero de los polinomios que definen la aproximación diagonal de Padé de la función exponencial.
),,( 21 ccAdlaexpF = .
Entradas: Matriz nxnA ℜ∈ , vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor que cero de los polinomios que definen la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz nxnAeF ℜ∈= . 1 ∞= |||| Anor 2 )))(int(log1,0max( 2 norjA +=
3 Aj
s21
=
4 sAA = 5 AX = 6 AcIN n )1(1+= 7 AcID n )1(2+= 8 Para qk :2=
8.1 XAX = 8.2 XkcNN )(1+= 8.3 XkcDD )(2+=
9 Calcular F resolviendo la ecuación NDF = 10 Para Ajk :1=
10.1 2FF =
Algoritmo 4.3: Calcula la exponencial de una matriz, a partir de los polinomios de la aproximación diagonal de Padé de la función exponencial.
El coste aproximado del algoritmo anterior es

Capítulo 4: Linealización a Trozos
137
3)3/1(2 njq A ++ flops,
siendo )))||(||int(log1,0max( 2 ∞+= AjA .
A continuación se describe la manera de adaptar el algoritmo anterior para calcular únicamente los bloques (1,2) y (1,3) de la exponencial de la matriz
( 4.16 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
IIJ
A000
000
.
Sean
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
33
2322
131211
000
XXXXXX
X
nn
n ,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
33
2322
131211
000
NNNNNN
N
nn
n ,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
33
2322
131211
000
DDDDDD
D
nn
n ,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
33
2322
131211
000
EEEEEE
E
nn
n ,
las matrices que aparecen en el Algoritmo 4.3, cuando éste se aplica a la matriz definida en ( 4.16 ).
4 sAA = .
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡==
nnn
nnn
nni
sIsIsJ
sAA000
000
.
Haciendo ii sJJ = , se tiene después de este paso
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
sIsIJ
A000
000
.
5 AX = .
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
sIsIJ
X000
000
.

Capítulo 4: Linealización a Trozos
138
6 AcIN n )1(1+= .
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ +=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
nnn
nnn
nnin
nn
n
IsIcI
sIcJcI
NNNNNN
00)1(0
0)1()1(
000 1
11
33
2322
131211
,
luego
in JcIN )1(111 += ,
nsIcN )1(112 = ,
nN 013 = ,
nIN =22 ,
nsIcN )1(123 = ,
nIN =33 .
7 AcID n )1(2+= .
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ +=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
nnn
nnn
nnin
nn
n
IsIcI
sIcJcI
DDDDDD
00)1(0
0)1()1(
000 2
22
33
2322
131211
,
luego
in JcID )1(211 += ,
nsIcD )1(212 = ,
nD 013 = ,
nID =22 ,
nsIcD )1(223 = ,
nID =33 .
8.1 XAX = .
.000000
00000
0
000
000
121111
33
2322
131211
33
2322
131211
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
nnn
nnn
i
nnn
nnn
nni
nn
n
nn
n
sXsXJXsI
sIJ
XXXXXX
XXXXXX
Teniendo en cuenta las dependencias de datos, la forma de calcular ijX , 31 ≤≤≤ ji , dentro del bucle 8 es
1213 sXX = ,
1112 sXX = ,
iJXX 1111 = ,

Capítulo 4: Linealización a Trozos
139
siendo 22X , 23X y 33X matrices nulas. 8.2. XkcNN )(1+= .
.00
0)()()(
000
33
2322
131131211211111
33
2322
131211
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ +++=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
NNN
XkcNXkcNXkcN
NNNNNN
nn
n
nn
n
Por lo tanto, las matrices 22N , 23N y 33N no variaran dentro del bucle, conteniendo el valor previo
nIN =22 ,
nsIcN )1(123 = ,
nIN =33 .
8.3. XkcDD )(2+= .
.00
0)()()(
000
33
2322
132131221211211
33
2322
131211
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ +++=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
DDD
XkcDXkcDXkcD
DDDDDD
nn
n
nn
n
Por lo tanto, las matrices 22D , 23D y 33D no variaran dentro del bucle, conteniendo el valor previo,
nID =22 ,
nsIcD )1(223 = ,
nID =33 .
9 Calcular F resolviendo ecuación NDF = .
.00
)1(000
000
)1(0 1
131211
33
2322
131211
2
131211
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
nnn
nnn
nn
n
nnn
nnn
IsIcI
NNN
FFFFFF
IsIcI
DDD
luego
111111 NFD = ,
1222121211 NFDFD =+ ,
13331323121311 NFDFDFD =++ ,
nIF =22 ,
nsIcsFcF )1()1( 133223 =+ ,
nIF =33 .

Capítulo 4: Linealización a Trozos
140
Teniendo en cuenta que 5.0)1(1 =c y 5.0)1(2 −=c , entonces nsIF =23 . Por lo tanto, las matrices 11F , 12F y 13F se pueden obtener resolviendo las
ecuaciones
111111 NFD = ,
12121211 DNFD −= ,
1312131311 DsDNFD −−= .
Luego sólo basta conocer de los pasos anteriores 11N , 12N , 13N , 11D , 12D y
13D , para determinar 11F , 12F y 13F en el paso 9. 10.1. 2FF = Realizando el producto por bloques
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
33
2322
131211
33
2322
131211
33
2322
131211
000
000
000
FFFFFF
FFFFFF
FFFFFF
nn
n
nn
n
nn
n ,
e igualando los bloques correspondientes se tiene 2
1111 FF = ,
2212121112 FFFFF += ,
33132312131113 FFFFFFF ++= , 2
2222 FF = ,
3323232223 FFFFF += , 2
3333 FF = .
Teniendo en cuenta que antes de entrar en el bucle nIF =22 y
nIF =33 , entonces en cualquier paso del bucle se tiene que nIF =22 y
nIF =33 . Según esto, el valor de 23F es
23232323 2FFFF =+= ,
Sabiendo que nsIF =23 antes de entrar en el bucle, entonces al cabo de k iteraciones resulta
nk sIF 223 = .
Atendiendo a la dependencia de datos, la forma de calcular 11F , 12F y
13F es
132312131113 FFFFFF ++= ,
12121112 FFFF += , 2
1111 FF = .

Capítulo 4: Linealización a Trozos
141
A continuación se muestra la correspondiente adaptación a bloques del Algoritmo 4.3, según los pasos anteriormente desarrollados.
),,,,,,(3 211 cctygfJdlaopy ii ∆=+ .
Entradas: Matriz nxnJ ℜ∈ , vector nf ℜ∈ , vector ng ℜ∈ , vector niy ℜ∈ ,
incremento de tiempo ℜ∈∆t , vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación de Padé de la función exponencial.
Salida: Vector niy ℜ∈+1 de la expresión ( 4.14 ).
1 ∞∆= |||| Jtnor
2 )))(int(log1,0max( 2 norj tJ +=∆ ; tJj
ts∆
∆=
2; sJJi =
3 JX =11 ; nsIX =12 ; nX 013 = 4 JcIN n )1(111 += ; nsIcN )1(112 = ; nN 013 = 5 JcID n )1(211 += ; nsIcD )1(212 = ; nD 013 = 6 Para qk :2=
6.1 1213 sXX = ; 1112 sXX = ; iJXX 1111 = 6.2 1111111 )( XkcNN += ; 1211212 )( XkcNN += ; 1311313 )( XkcNN += 6.3 1121111 )( XkcDD += ; 1221212 )( XkcDD += ; 1321313 )( XkcDD +=
7 Calcular 11F , 12F y 13F , resolviendo las ecuaciones: 7.1 111111 NFD = 7.2 12121211 DNFD −= 7.3 1312131311 DsDNFD −−=
8 Para tJjk ∆= :1 8.1 1312131113 FsFFFF ++= ; 12121112 FFFF += ; 2
1111 FF = 8.2 ss 2=
9 gFfFyy ii 13121 ++=+
Algoritmo 4.4: Calcula la solución aproximada en el instante 1+it de una EDO no autónoma mediante la modificación a bloques del Algoritmo 4.3.
El coste aproximado del algoritmo anterior es
3
3132 njq tJ ⎟
⎠⎞
⎜⎝⎛ ++ ∆ flops,
siendo )))||(||int(log1,0max( 2 ∞∆ ∆+= tJj tJ .
A continuación se presenta el algoritmo que resuelve EDOs mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé.

Capítulo 4: Linealización a Trozos
142
),( qxdata,t,dgeedolpny 0= .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nxtf ℜ∈),( , nxnxtJ ℜ∈),( y nxtg ℜ∈),( , vector inicial nx ℜ∈0 , grado +∈ Zq de los
polinomios de la aproximación diagonal de Padé de la función exponencial.
Salidas: Matriz )1(10 ],,,[ +ℜ∈= lnx
lyyyY L , niy ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 xy = 3 Para 1:0 −= li
3.1 ),(],,[ ii ytdatagfJ = 3.2 ii ttt −=∆ +1 3.3 ),,,,,,(3 211 cctygfJdlaopy ii ∆=+ (Algoritmo 4.4)
Algoritmo 4.5: Resolución de EDOs no autónomas mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé.
4.2.1.2 Método Basado en la Ecuación Conmutante
En este subapartado se describe la forma de obtener la solución aproximada 1+iy de la expresión ( 4.14 ) mediante la ecuación conmutante.
Por la Propiedad 2.1, se tiene que las matrices
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
i IIJ
C000
000
y
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∆∆∆
=
∆
∆
nnn
innn
ii
iitJ
tC
ItIItFtFe
e
ii
ii
000
)()( )(13
)(12
conmutan, por lo que
.000
000
000
)()(
000
)()(
00000
0
)(13
)(12
)(13
)(12
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∆∆∆
=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∆∆∆
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∆
∆
nnn
nnn
nni
nnn
innn
ii
iitJ
nnn
innn
ii
iitJ
nnn
nnn
nni
IIJ
ItIItFtFe
ItIItFtFe
IIJ
ii
ii
Igualando los bloques (1,2) y (1,3) de la expresión anterior, se tiene que ii tJ
nii
i eItFJ ∆=+∆ )()(12 ,

Capítulo 4: Linealización a Trozos
143
)()( )(12
)(13 i
iini
ii tFtItFJ ∆=∆+∆ ,
y de aquí las expresiones
( 4.17 ) intJ
iii
i fIeftFJ ii )()()(12 −=∆ ∆ ,
( 4.18 ) intJ
iii
i gIegtFJ ii )()()(12 −=∆ ∆ ,
( 4.19 ) iiiii
iinii
iii
i gtgtFgtItFgtFJ ∆−∆=∆−∆=∆ )())(()( )(12
)(12
)(13 ,
Por lo tanto,
iii
iii
ii gtFftFyy )()( )(13
)(121 ∆+∆+=+
se puede calcular del siguiente modo:
• Calcular iii
i ftFx )()(12 ∆= resolviendo la ecuación
intJ
ii fIexJ ii )( −= ∆ .
• Calcular iii
i gtFz )()(12 ∆= resolviendo la ecuación,
intJ
ii gIezJ ii )( −= ∆ .
• Calcular iii
i gtFw )()(13 ∆= resolviendo la ecuación
iiiii gtzwJ ∆−= .
• Calcular iiii wxyy ++=+1 .
Supóngase que iJ sea invertible. Puesto que se deben resolver tres sistemas de ecuaciones lineales con la misma matriz de coeficientes, se puede utilizar la descomposición LU sin pivotamiento, para reducir el coste computacional del cálculo de 1+iy , tal como se muestra en el siguiente algoritmo. Si iJ fuese singular cabría la posibilidad de realizar una aproximación basada en la descomposición en valores singulares (Teorema 6.8) de la matriz iJ .

Capítulo 4: Linealización a Trozos
144
),,,,,,(3 211 cctygfJdlaocy ii ∆=+ .
Entradas: Matriz nxnJ ℜ∈ , vector nf ℜ∈ , vector ng ℜ∈ , vector niy ℜ∈ ,
incremento de tiempo ℜ∈∆t , vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación de Padé de la función exponencial.
Salida: Vector niy ℜ∈+1 de la expresión ( 4.14 ).
1 ),,( 21 cctJdlaexpE ∆= (Algoritmo 4.3) 2 )(],[ JluUL = 3 Calcular x resolviendo el sistema lineal triangular inferior fIExL n )( −= 4 Calcular x resolviendo el sistema lineal triangular superior xUx = 5 Calcular z resolviendo el sistema lineal triangular inferior gIEzL n )( −= 6 Calcular z resolviendo el sistema lineal triangular superior zUz = 7 Calcular w resolviendo el sistema lineal triangular inferior tgzwL ∆−= 8 Calcular w resolviendo el sistema lineal triangular superior wUw = 9 wxyy ii ++=+1
Algoritmo 4.6: Calcula la solución aproximada en el instante 1+it de una EDO no autónoma mediante la ecuación conmutante.
El coste computacional aproximado del algoritmo anterior es
3
322 njq tJ ⎟
⎠⎞
⎜⎝⎛ ++ ∆ flops,
siendo )))||(||int(log1,0max( 2 ∞∆ ∆+= tJj tJ .
A continuación se muestra el algoritmo que resuelve EDOs no autónomas mediante el método de linealización a trozos basado en la ecuación conmutante
),( qxdata,t,dgeedolcny 0= .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nxtf ℜ∈),( , nxnxtJ ℜ∈),( y nxtg ℜ∈),( , vector inicial nx ℜ∈0 , grado +∈ Zq de los
polinomios de la aproximación diagonal de Padé de la función exponencial.
Salidas: Matriz )1(10 ],,,[ +ℜ∈= lnx
lyyyY L , niy ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 xy = 3 Para 1:0 −= li
3.1 ),(],,[ ii ytdatagfJ = . 3.2 ii ttt −=∆ +1 3.3 ),,,,,,(3 211 cctygfJdlaocy ii ∆=+ (Algoritmo 4.6)
Algoritmo 4.7: Resolución de EDOs no autónomas mediante el método de linealización a trozos basado en la ecuación conmutante.

Capítulo 4: Linealización a Trozos
145
4.2.1.3 Método Basado en los Subespacios de Krylov
El vector 1+iy que aparece en ( 4.14 ), solución aproximada en el instante 1+it de la EDO ( 4.1 ), se puede expresar como
( 4.20 ) itC
iiii
iii
ii veygtFftFyy ii∆+ +=∆+∆+= )()( )(
13)(
121 ,
siendo
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
nnn
nni
i IIJ
C000
000
,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
i
i
nx
i
gfv
10.
El producto itC ve ii∆ de la expresión ( 4.20 ) se puede obtener mediante una modificación
del método basado en los subespacios de Krylov que se describe a continuación.
Dados nxnA ℜ∈ y nv ℜ∈ , se pretende calcular, de manera aproximada, el vector ve A . Para ello se trata de obtener una aproximación del tipo
vAPve pA )(1−≈ ,
siendo 1−pP un polinomio de grado 1−p , con np << .
Si se considera el subespacio de Krylov pK generado por los vectores vAAvv p 1,,, −L ,
entonces se puede obtener una base ortonormal },,,{ 21 pvvv L de pK aplicando el método de Arnoldi.
Entradas: Matriz nxnA ℜ∈ , vector nv ℜ∈ , dimensión +∈ Zp del subespacio de Krylov .
Salida: Base ortonormal },,,{ 21 pvvv L .
1 21 v/||v||v = 2 Para pj :1=
2.1 jAvw = 2.2 Para ji :1=
2.2.1 iT
ij vwh = 2.2.2 iijvhww −=
2.3 21 wh jj =+
2.4 11 / ++ = jj hwv
Algoritmo 4.8: Método de Arnoldi.

Capítulo 4: Linealización a Trozos
146
Sea pV la matriz cuyas columnas son los vectores de la base ortonormal },,,{ 21 pvvv L
obtenida en el algoritmo anterior, es decir, nxppp vvvV ℜ∈= ],,,[ 21 L . Si optpopt xVv = es
la mejor aproximación a ve A de un vector perteneciente a pK , entonces se cumple que
22 ||||min|||| veyvev A
y
Aopt n
−=−ℜ∈
,
por lo que optx es la solución del sistema de ecuaciones normales
veVxVV ATpoptp
Tp = .
La solución del sistema anterior viene dada por
veVveVVVx ATp
ATpp
Tpopt == −1)( ,
por lo tanto
veVVxVv ATppoptpopt == .
Si se define 2|||| v=β , entonces
1eVv pβ= ,
siendo pTe ℜ∈= ]0,,0,1[1 L ,
por lo que
( 4.21 ) 1eVeVVv pAT
ppopt β= .
Por otra parte, si se considera la matriz ][ ijhH = obtenida a partir del método de Arnoldi, entonces se cumple la siguiente relación
Tppppppp evhHVAV 11 +++= ,
siendo pH la matriz de Hessenberg obtenida al considerar las p primeras columnas y p primeras filas de la matriz H .
Además, por la ortogonalidad de las columnas de la matriz pV , se tiene
pTpp AVVH = ,
por lo que
( 4.22 ) pAT
pH VeVe p = .
Finalmente, teniendo en cuenta las expresiones ( 4.21 ) y ( 4.22 ), se obtiene que
1eeVvve pHpopt
A β=≅ .
Este resultado conduce al siguiente algoritmo.

Capítulo 4: Linealización a Trozos
147
),,( 21 ccA,v,p,toldlaexpkryw = .
Entradas: Matriz nxnA ℜ∈ , vector nv ℜ∈ , dimensión +∈ Zp del subespacio de Krylov, tolerancia +ℜ∈tol , vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor que cero de los polinomios que definen la aproximación diagonal de Padé de la función exponencial.
Salida: Vector nAvew ℜ∈= . 1 2||v||=β 2 Si 0==β
2.1 0=w 2.2 Salir del Algoritmo
3 βv/V =)1(:, 4 Para pj :1=
4.1 )(:, jAVw = 4.2 Para ji :1=
4.2.1 )(:,),( iVwjiH T= 4.2.2 )(:,),( iVjiHww −=
4.3 2
ws = 4.4 Si tols <
4.4.1 jp = 4.4.2 Salir del bucle
4.5 sjjH =+ ),1( 4.6 swjV /)1(:, =+
5 ),),:1,:1(():1,:1( 21 ccppHdlaexpppH = (Algoritmo 4.3) 6 )1,:1():1(:, pHpVw β=
Algoritmo 4.9: Calcula el producto de la exponencial de una matriz por un vector, mediante los subespacios de Krylov.
El siguiente algoritmo permite calcular el vector 1+iy de la expresión ( 4.20 ) mediante una adaptación a bloques del Algoritmo 4.9, minimizando los costes computacionales y de almacenamiento.

Capítulo 4: Linealización a Trozos
148
),,,,,,,,(3 211 cctolptygfJdlaoky ii ∆=+ .
Entradas: Matriz nxnJ ℜ∈ , vector nf ℜ∈ , vector ng ℜ∈ , vector niy ℜ∈ ,
incremento de tiempo ℜ∈∆t , dimensión +∈ Zp del subespacio de Krylov, tolerancia +ℜ∈tol , vectores qcc ℜ∈21, que contienen a los coeficientes de los términos de grado mayor que cero de los polinomios que definen la aproximación diagonal de Padé de la función exponencial.
Salida: Vector niy ℜ∈+1 de la expresión ( 4.20 ).
1 nnV 0)1,:1( = ; fnnV =+ )1,2:1( ; gnnV =+ )1,3:12( 2 2||)1,3:1(|| nnV +=β 3 Si 0==β
3.1 Salir 4 β/)1,3:12()1,3:12( nnVnnV +=+ 5 Para pj :1=
5.1 ),2:1(),:1():1( jnnVjnJVnw ++= ; ),3:12()2:1( jnnVnnw +=+ 5.2 )2:1()2:1( ntwnw ∆= ; nnnw 0)3:12( =+ 5.3 Para ji :1=
5.3.1 ),3:1(),( inVwjiH T= 5.3.2 ),3:1(),( inVjiHww −=
5.4 2
ws = 5.5 Si tols <
5.5.1 jp = 5.5.2 Salir del bucle
5.6 sjjH =+ ),1( 5.7 swjnV /)1,3:1( =+
6 ),),:1,:1(():1,:1( 21 ccppHdlaexpppH = (Algoritmo 4.2) 7 )1,:1():1,:1(1 pHpnVyy ii β+=+
Algoritmo 4.10: Calcula la solución aproximada en el instante 1+it de una EDO no autónoma mediante la modificación a bloques del Algoritmo 4.9.
El coste computacional aproximado del algoritmo anterior es 32 )3/1(2)1(62 pjqpnppn
pH +++++ flops,
siendo ||)))(||int(log1,0max( 2 pH Hjp
+= .
A continuación se presenta el algoritmo completo para la resolución de EDOs no autónomas basado en el método de linealización a trozos mediante los subespacios de Krylov.

Capítulo 4: Linealización a Trozos
149
),,,( qtolpxdata,t,dgeedolkny 0= .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nxtf ℜ∈),( , nxnxtJ ℜ∈),( y nxtg ℜ∈),( , vector inicial nx ℜ∈0 , dimensión +∈ Zp
del subespacio de Krylov, tolerancia +ℜ∈tol , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salidas: Matriz )1(10 ],,,[ +ℜ∈= lnx
lyyyY L , niy ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 xy = 3 Para 1:0 −= li
3.1 ),(],,[ ii ytdatagfJ = . 3.2 ii ttt −=∆ +1 3.3 ),,,,,,,(3 211 cctoltygfJdlaoky ii ∆=+ (Algoritmo 4.10)
Algoritmo 4.11: Resolución de EDOs no autónomas mediante el método de linealización a trozos basado en los subespacios de Krylov.
4.2.2 EDOs Autónomas
Sea la EDO con valores iniciales
( 4.23 ) ))(()(' txftx = , ],[ 0 fttt ∈ ,
nxtx ℜ∈= 00 )( ,
cumpliendo )(xf las hipótesis del Teorema 2.10 (página 56), es decir, las derivadas parciales de segundo orden de )(xf están acotadas en nℜ .
Dada una partición fll ttttt =<<<< −110 L , entonces la ecuación anterior se puede aproximar mediante el conjunto de EDLs resultantes de la aproximación lineal de
))(( txf en cada subintervalo, es decir,
( 4.24 ) ))(()(' iii ytyJfty −+= , ],[ 1+∈ ii ttt , ii yty =)( , 1,,1,0 −= li L ,
siendo n
ii yff ℜ∈= )( ,
nxnii y
xfJ ℜ∈
∂∂
= )( .
La solución analítica de la EDL
))(()(' iii ytyJfty −+= , ],[ 1+∈ ii ttt , li <≤0 ,
con valor inicial ii yty =)( , resulta ser
( 4.25 ) ∫ −+=t
ti
tJi
i
i dfeyty ττ )()( , ],[ 1+∈ ii ttt ,

Capítulo 4: Linealización a Trozos
150
por lo que se pueden obtener las soluciones aproximadas lyyy ,,, 10 L resolviendo, sucesivamente, las EDLs en cada uno de los subintervalos ],[ 1+ii tt , 1,,1,0 −= li L .
Teorema 4.2.
La solución de la EDL de valores iniciales
( 4.26 ) ))(()(' iii ytyJfty −+= , ],[ 1+∈ ii ttt , ii yty =)( ,
es
( 4.27 ) iii
i fttFyty )()( )(12 −+= ,
donde )()(12 i
i ttF − es el bloque (1,2) de la matriz )( ii ttCe − , con
( 4.28 ) ⎥⎦
⎤⎢⎣
⎡=
nn
nii
IJC
00.
Demostración.
Basta aplicar el Teorema 4.1, para el caso particular en que nnxig ℜ∈= 10 .
Según el teorema anterior, la solución aproximada en el instante 1+it de la EDO ( 4.23 ) se puede obtener a partir de la solución aproximada en it utilizando la expresión
( 4.29 ) iii
ii ftFyy )()(121 ∆+=+ ,
donde iii ttt −=∆ +1 , siendo )()(12 i
i tF ∆ el bloque (1,2) de la matriz
ii tCe ∆ ,
con
⎥⎦
⎤⎢⎣
⎡=
nn
nii
IJC
00.
El siguiente algoritmo calcula la solución de la EDO ( 4.23 ) mediante el método de linealización a trozos basado en el cálculo de la exponencial de una matriz.

Capítulo 4: Linealización a Trozos
151
)0xdata,t,dgeedolga(y = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nxtf ℜ∈),( y nxnxtJ ℜ∈),( , vector inicial nx ℜ∈0 .
Salidas: Matriz )1(10 ],,,[ +ℜ∈= lnx
lyyyY L , niy ℜ∈ , li ,,1,0 L= .
1 00 xy = 2 Para 1:0 −= li
2.1 ),(],[ ii ytdatafJ =
2.2 ⎥⎦
⎤⎢⎣
⎡=
nn
nIJC
00
2.3 ii ttt −=∆ +1 2.4 tCeF ∆= 2.5 Calcular fFyy ii 121 +=+ (expresión ( 4.29))
Algoritmo 4.12: Algoritmo básico para la resolución de EDOs autónomas mediante el método de linealización a trozos basado en el cálculo de la exponencial de una matriz.
El problema de calcular 1+iy son los elevados costes computacionales y de almacenamiento necesarios para realizar el producto de la exponencial de una matriz de dimensión n2 por un vector de dimensión n2 .
4.2.2.1 Método Basado en los Aproximantes Diagonales de Padé El vector 1+iy de la expresión ( 4.29 ), solución aproximada en el instante 1+it de la EDO ( 4.23 ), se puede calcular sin obtener explícitamente la exponencial de la matriz
ii tC ∆ mediante una adaptación a bloques del método de los aproximantes diagonales de Padé. Razonando del mismo modo que el utilizado en la obtención del Algoritmo 4.4, se tiene el siguiente algoritmo.

Capítulo 4: Linealización a Trozos
152
),,,,,(2 211 cctyfJdlaopy ii ∆=+ .
Entradas: Matriz nxnJ ℜ∈ , vector nf ℜ∈ , vector niy ℜ∈ , incremento de tiempo
ℜ∈∆t , vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación de Padé de la función exponencial.
Salida: Vector mxniy ℜ∈+1 de la expresión ( 4.29 ).
1 ∞∆= |||| Jtnor
2 )))(int(log1,0max( 2 norj tJ +=∆ ; jts
2∆
= ; sJJ =
3 JX =11 ; nsIX =12 4 JcIN n )1(111 += ; nsIcN )1(112 = 5 JcID n )1(211 += ; nsIcD )1(212 = 6 Para qk :2=
6.1 1112 sXX = ; JXX 1111 = 6.2 1111111 )( XkcNN += ; 1211212 )( XkcNN += 6.3 1121111 )( XkcDD += ; 1221212 )( XkcDD +=
7 Calcular 11F y 12F resolviendo las ecuaciones (mediante descomposición LU de
11D ): 7.1 111111 NFD = 7.2 12121211 DNFD −=
8 Para jk :1= 8.1 12121112 FFFF += ; 2
1111 FF = 8.2 ss 2=
9 fFyy ii 121 +=+
Algoritmo 4.13: Calcula la solución aproximada en el instante 1+it de una EDO autónoma mediante la modificación a bloques del método de los aproximantes diagonales de Padé.
El coste aproximado del algoritmo anterior es
3
3122 njq tJ ⎟
⎠⎞
⎜⎝⎛ ++ ∆ flops,
siendo )))||(||int(log1,0max( 2 ∞∆ ∆+= tJj tJ .
A continuación se presenta el algoritmo que resuelve EDOs autónomas mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé.

Capítulo 4: Linealización a Trozos
153
),( qxdata,t,dgeedolpay 0= .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nxtf ℜ∈),( y nxnxtJ ℜ∈),( , vector inicial nx ℜ∈0 , grado +∈ Zq de los polinomios de
la aproximación diagonal de Padé de la función exponencial. Salidas: Matriz )1(
10 ],,,[ +ℜ∈= lnxlyyyY L , n
iy ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 xy = 3 Para 1:0 −= li
3.1 ),(],[ ii ytdatafJ = 3.2 ii ttt −=∆ +1 3.3 ),,,,,(2 211 cctyfJdlaopy ii ∆=+ (Algoritmo 4.13)
Algoritmo 4.14: Resolución de EDOs autónomas mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé.
4.2.2.2 Método Basado en la Ecuación Conmutante
En este subapartado se describe la manera de obtener la solución aproximada 1+iy de la expresión ( 4.29 ) mediante la ecuación conmutante.
Por la Propiedad 2.1, se tiene que las matrices
⎥⎦
⎤⎢⎣
⎡=
nn
nii
IJC
00
y
⎥⎦
⎤⎢⎣
⎡ ∆=
∆∆
nn
iitJ
tC
ItFe
eii
ii
0)()(
12
conmutan, por lo que
.000
)(0
)(00
)(12
)(12
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡ ∆=⎥
⎦
⎤⎢⎣
⎡ ∆⎥⎦
⎤⎢⎣
⎡ ∆∆
nn
ni
nn
iitJ
nn
iitJ
nn
ni IJI
tFeI
tFeIJ iiii
Igualando los bloques (1,2) de la expresión anterior, se tiene que ii tJ
nii
i eItFJ ∆=+∆ )()(12 ,
o bien
( 4.30 ) intJ
iii
i fIeftFJ ii )()()(12 −=∆ ∆ .
Si iJ es invertible, entonces 1+iy se puede calcular del siguiente modo:
• Calcular iii
i ftFx )()(12 ∆= resolviendo la ecuación
intJ
ii fIexJ ii )( −= ∆ .
• Calcular iii xyy +=+1 .

Capítulo 4: Linealización a Trozos
154
A continuación se muestra un algoritmo que calcula el vector 1+iy mediante la ecuación conmutante.
),,,,,(2 211 cctyfJdlaocy ii ∆=+ .
Entradas: Matriz nxnJ ℜ∈ , vector nf ℜ∈ , vector niy ℜ∈ , incremento de tiempo
ℜ∈∆t , vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación de Padé de la función exponencial.
Salida: Vector niy ℜ∈+1 de la expresión ( 4.29 ).
1 ),,( 21 cctJdlaexpE ∆= (Algoritmo 4.3) 2 )(],[ JluUL = 3 Calcular x resolviendo el sistema lineal triangular inferior fIExL n )( −= 4 Calcular x resolviendo el sistema lineal triangular superior xUx = 5 xyy ii +=+1
Algoritmo 4.15: Calcula la solución aproximada en el instante 1+it de una EDO autónoma mediante la ecuación conmutante.
El coste computacional aproximado del algoritmo anterior es
3
322 njq tJ ⎟
⎠⎞
⎜⎝⎛ ++ ∆ flops,
siendo )))||(||int(log1,0max( 2 ∞∆ ∆+= tJj tJ .
A continuación se presenta el algoritmo que resuelve EDOs mediante el método de linealización a trozos basado en la ecuación conmutante.
),( qxdata,t,dgeedolcay 0= .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nxtf ℜ∈),( y nxnxtJ ℜ∈),( , vector inicial nx ℜ∈0 , grado +∈ Zq de los polinomios de
la aproximación diagonal de Padé de la función exponencial. Salidas: Matriz )1(
10 ],,,[ +ℜ∈= lnxlyyyY L , n
iy ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 xy = 3 Para 1:0 −= li
3.1 ),(],[ ii ytdatafJ = 3.2 ii ttt −=∆ +1 3.3 ),,,,,(2 211 cctyfJdlaocy ii ∆=+ (Algoritmo 4.15)
Algoritmo 4.16: Resolución de EDOs autónomas mediante el método de linealización a trozos basado en la ecuación conmutante.

Capítulo 4: Linealización a Trozos
155
4.2.2.3 Método Basado en los Subespacios de Krylov
El vector 1+iy de la expresión ( 4.29 ), solución aproximada en el instante 1+it de la EDO ( 4.23 ), se puede expresar como
( 4.31 ) itC
iiii
ii veyftFyy ii∆+ +=∆+= )()(
121 ,
donde
⎥⎦
⎤⎢⎣
⎡=
nn
nii
IJC
00,
⎥⎦
⎤⎢⎣
⎡=
i
nxi f
v 10.
Para calcular 1+iy , según la expresión anterior, es necesario calcular el producto de la exponencial de una matriz por un vector.
Para calcular itC ve ii∆ de forma eficiente se realiza la siguiente adaptación a bloques del
Algoritmo 4.9:
⎥⎦
⎤⎢⎣
⎡ ∆=⎥
⎦
⎤⎢⎣
⎡ ∆∆=∆⎥
⎦
⎤⎢⎣
⎡=
nn
in
nn
iniii
nn
ni tIJtItJt
IJA
000000, ⎥
⎦
⎤⎢⎣
⎡=
i
nx
fv 10
.
1 2||v||=β .
2||||f i=β .
3 βv/V =)1(:, .
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡+ β/
0)1,2:1(
)1,:1( 1
i
nx
fnnVnV
.
4.1 )1(:,AVw = .
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡∆=⎥
⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡ ∆=⎥
⎦
⎤⎢⎣
⎡+
1
1
0/0
00)2:1():1(
nx
i
i
nx
nn
n ft
ftIJ
nnwnw
ββ.
4.2.1 )1(:,)1,1( VwH T= .
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡∆==
1
111 0
0/
00)1(:,)1,1(
nx
nx
i
nxnx
TT
fftVwH
ββ.
4.2.2 )1(:,)1,1( VHww −= (no se modifica el vector w ).
4.3 2|||| ws = .
ttftws i ∆=∆
=∆
== βββ 22 |||||||| .
4.5 sH =)1,2( . tH ∆=)1,2( .
4.6 swV /)2(:, = .

Capítulo 4: Linealización a Trozos
156
⎥⎦
⎤⎢⎣
⎡=∆
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡∆==⎥
⎦
⎤⎢⎣
⎡+ 1
10
//
0/
)2,2:1()2,:1(
nx
i
nx
i ftft
swnnV
nV ββ .
4.1 )(:, jAVw = , 1>j .
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡ ∆=⎥
⎦
⎤⎢⎣
⎡+ 11 0
),;1(0
),;1(00)2:1(
):1(
nxnxnn
n jnJVjnVtIJnnw
nw.
4.2.1 )(:,),1( jVwjH T= , 1>j .
[ ] 0)1,:1():1(0
)1,:1(0):1(),1(
11 ==⎥
⎦
⎤⎢⎣
⎡= nVnw
nVnwjH T
nxxn
T .
4.2.2 )1(:,),1( VjHww −= , 1>j (no se modifica el vector w ).
4.2.1 )(:,),( jVwjiH T= , 1>i , 1>j .
[ ] ),:1():1(0
),:1(0):1(),(
11 inVnw
inVnwjiH T
nxxn
T =⎥⎦
⎤⎢⎣
⎡= .
4.2.2 )(:,),( iVjiHww −= 1>i , 1>j .
⎥⎦
⎤⎢⎣
⎡ −=⎥
⎦
⎤⎢⎣
⎡−⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡+ 11 0
),:1(),():1(0
),:1(),(
0):1(
)2:1():1(
nxnxn
jnJVjiHnwinVjiH
nwnnw
nw.
4.3 2|||| ws = .
22 ||):1(|||||| nwws == . 4.5 sjjH =+ ),1( , 1>j . 4.6 swjV /)1(:, =+ , 1>j .
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡++
+
nn
snws
nwjnnV
jnV0
/):1(/
0):1(
)1,2:1()1,:1(
.
El siguiente algoritmo calcula el vector 1+iy de la expresión ( 4.31 ) mediante una adaptación a bloques del Algoritmo 4.9, minimizando los costes computacionales y de almacenamiento.

Capítulo 4: Linealización a Trozos
157
),,,,,,,(2 211 cctolptyfJdlaoky ii ∆=+ .
Entradas: Matriz nxnJ ℜ∈ , vector nf ℜ∈ , niy ℜ∈ , incremento de tiempo ℜ∈∆t ,
dimensión +∈ Zp del subespacio de Krylov, tolerancia +ℜ∈tol , vectores qcc ℜ∈21, que contienen los coeficientes de los términos de grado mayor
que cero de los polinomios de la aproximación de Padé de la función exponencial.
Salida: Vector niy ℜ∈+1 de la expresión ( 4.31 ).
1 2|||| f=β 2 Si 0==β
2.1 Salir 3 nnV 0)1,:1( = 4 β/)2,:1( fnV = 5 0)1,1( =H ; tH ∆=)1,2( 6 tJJ ∆= 7 Para pj :2=
7.1 ),:1( jnJVw = 7.2 0),1( =jH 7.3 Para ji :2=
7.3.1 ),:1(),( inVwjiH T= 7.3.2 ),:1(),( inVjiHww −=
7.4 2|||| ws = 7.5 Si tols <
7.5.1 jp = 7.5.2 Salir del bucle
7.6 sjjH =+ ),1( 7.7 swjnV /)1,:1( =+
8 ),),:1,:1(():1,:1( 21 ccppHdlaexpppH = (Algoritmo 4.3) 9 )1,:1():1,:1(1 pHpnVyy ii β+=+
Algoritmo 4.17: Calcula la solución aproximada en el instante 1+it de una EDO autónoma mediante la modificación a bloques del Algoritmo 4.9.
El coste computacional aproximado del algoritmo anterior es 3)3/1(2))(1(2 pjqpnpn
pH ++++− flops,
siendo ||)))(||int(log1,0max( 2 pH Hjp
+= .
A continuación se presenta el algoritmo completo que resuelve EDOs autónomas basada en la linealización a trozos mediante los subespacios de Krylov.

Capítulo 4: Linealización a Trozos
158
),,,( qtolpxdata,t,dgeedolkay 0= .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que calcula nyf ℜ∈)( y nxnytJ ℜ∈),( , vector inicial nx ℜ∈0 , dimensión +∈ Zp del subespacio de
Krylov, tolerancia +ℜ∈tol , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salidas: Matriz )1(10 ],,,[ +ℜ∈= lnx
lyyyY L , niy ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 xy = 3 Para 1:0 −= li
3.1 ),(],[ ii ytdatafJ = 3.2 ii ttt −=∆ +1 3.3 ),,,,,,(2 211 cctoltyfJdlaoky ii ∆=+ (Algoritmo 4.17)
Algoritmo 4.18. Resolución de EDOs autónomas mediante el método de linealización a trozos basado en los subespacios de Krylov.
4.3 Métodos de Linealización a Trozos de EDMRs
4.3.1 Resolución de EDMRs con Coeficientes Variables Sea la EDMR
( 4.32 ) )()()()()()()()()(' 12112221 tXtAtXtAtXtXtAtAtX −−+= , fttt ≤≤0 ,
con valor inicial
,)( 00mxnXtX ℜ∈=
donde nxntA ℜ∈)(11 , nxmtA ℜ∈)(12 , mxntA ℜ∈)(21 y mxmtA ℜ∈)(22 .
Al aplicar la función vec a la EDMR ( 4.32 ), se obtiene la EDO
( 4.33 ) ),(' xtfx = , )( 00 Xvecx = , mntxx ℜ∈= )( ,
siendo
( 4.34 ) ))()()()((vec),( 12112221 XtXAtXAXtAtAxtf −−+= ,
o bien, utilizando la Propiedad 6.7 y la Propiedad 6.8 del producto de Kronecker,
( 4.35 ) xtXAIxItAtAItAxtf nmT
n ))](([])()([))((vec),( 12112221 ⊗−⊗−⊗+=
o
( 4.36 ) xIXtAxItAtAItAxtf mT
mT
n ]))([(])()([))((vec),( 12112221 ⊗−⊗−⊗+= .
Supóngase que las segundas derivadas de las funciones de matrices )(tAij , para 2,1, =ji , están acotadas en ],[ 0 ftt . Considerando la partición fll ttttt =<<<< −110 L
y aplicando la linealización a trozos, se obtiene el conjunto de EDLs resultantes de la aproximación lineal de ),( xtf en cada subintervalo,

Capítulo 4: Linealización a Trozos
159
( 4.37 ) )())(()(' iiiii ttgytyJfty −+−+= , ],[ 1+∈ ii ttt , ii yty =)( , 1,,1,0 −= li L ,
siendo
( 4.38 ) ))()()()((vec 12112221 iiiiiiiii YtAYtAYYtAtAf −−+= ,
( 4.39 ) ( )iiiiiiiii YtAYtAYYtAtAg )()()()(vec '12
'11
'22
'21 −−+= ,
itt
ijij dt
tdAtA
=
=)(
)(' , 2,1, =ji .
Según el Teorema 2.10 (página 56), la solución de la EDL ( 4.37 ) es
( 4.40 ) iii
iii
ii gtFftFyy )()( )(13
)(121 ∆+∆+=+ ,
donde )()(12 i
i tF ∆ y )()(13 i
i tF ∆ son, respectivamente, los bloques (1,2) y (1,3) de la exponencial de la matriz ii tCe ∆ , siendo
( 4.41 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
mnmnmn
mnmnmn
mnmni
i IIJ
C000
000
,
con
( 4.42 ) mTiiniii IBAIyt
xfJ ⊗−⊗=
∂∂
= ),( ,
)()( 1222 iiii tAYtAA −= ,
iiii YtAtAB )()( 1211 += .
Aplicando el operador mxnmat en la expresión ( 4.40 ), se tiene que la solución aproximada en el instante 1+it de la EDMR ( 4.32 ) se puede obtener como
( 4.43 ) ))()((mat )(13
)(121 ii
iii
imxnii gtFftFYY ∆+∆+=+ .
A continuación se presenta un algoritmo básico que resuelve EDMRs con coeficientes variables basado en la linealización a trozos.

Capítulo 4: Linealización a Trozos
160
),,,( 0XdataddatatlgvdgedmrY =
Entradas: Vector de tiempos 1+ℜ∈ lt , matrices coeficiente de la EDMR nxntA ℜ∈)(11 , nxmtA ℜ∈)(12 , mxntA ℜ∈)(21 , mxmtA ℜ∈)(22 , derivadas de las
matrices coeficiente de la EDMR nxntA ℜ∈)('11 , nxmtA ℜ∈)('
12 , mxntA ℜ∈)('
21 , mxmtA ℜ∈)('22 , matriz inicial mxnX ℜ∈0 .
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 00 XY = 2 Para 1:0 −= li
2.1 ))()()()((vec 12112221 iiiiiiii YtAYtAYYtAtAf −−+= 2.2 ))()()()((vec '
12'11
'22
'21 iiiiiiii YtAYtAYYtAtAg −−+=
2.3 )()( 1222 iii tAYtAA −= 2.4 iii YtAtAB )()( 1211 += 2.5 m
Tn IBAIJ ⊗−⊗=
2.6 ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
mnmnmn
mnmnmn
mnmn
IIJ
C000
000
2.7 iii ttt −=∆ +1 2.8 itCeF ∆= 2.9 )(mat 13121 iimxnii gFfFYY ++=+ (véase ( 4.43 ))
Algoritmo 4.19: Resolución de EDMRs con coeficientes variables basada en la linealización a trozos.
El problema del algoritmo anterior son los elevados costes computacionales y de almacenamiento necesarios para realizarlo. En los siguientes subapartados se presentan tres métodos que calculan la matriz 1+iY de la expresión ( 4.43 ), reduciendo dichos costes.
4.3.1.1 Método Basado en los Aproximantes Diagonales de Padé Una forma de resolver la EDMR ( 4.32 ) se basa en el teorema que aparece en este subapartado.
Lema 4.1 ([Bern05], página 422])
Sean mxmA ℜ∈ y nxnB ℜ∈ , entonces ABIBAI eee mn ⊗=⊗+⊗ .
Teorema 4.3.
La matriz 1+iY que aparece en la expresión ( 4.43 ), solución aproximada en el instante
1+it de la EDMR ( 4.32 ), se puede calcular como
( 4.44 ) 1)(22
)(13
)(121 ))())(()(( −
+ ∆∆+∆+= ii
ii
ii
ii tFtHtFYY ,

Capítulo 4: Linealización a Trozos
161
donde )()(12 i
i tF ∆ y )()(22 i
i tF ∆ son, respectivamente, los bloques (1,2) y (2,2) de la matriz ii tCe ∆ , con
( 4.45 ) ⎥⎦
⎤⎢⎣
⎡=
inxm
iii B
FAC
0,
y )()(13 i
i tH ∆ el bloque (1,3) de la matriz ii tDe ∆ , con
( 4.46 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
inxnnxm
ninxm
mxnii
i
BIB
GAD
000
0,
siendo
iiiiiiiii YtAYtAYYtAtAF )()()()( 12112221 −−+= ,
iiiiiiiii YtAYtAYYtAtAG )()()()( '12
'11
'22
'21 −−+= ,
)()( 1222 iiii tAYtAA −= ,
iiii YtAtAB )()( 1211 += .
Demostración.
Al aplicar la linealización a trozos a la EDMR ( 4.32 ) se obtiene en ],[ 1+ii tt la EDL
)())(()(' iiiii ttgytyJfty −+−+= , ii yty =)(
que tiene como solución analítica
[ ]∫ −++= −t
tiii
tJi
i
i dtgfeyty τττ )()( )( .
Si se realiza el cambio de variable
its −= τ ,
y se define
itt −=θ ,
entonces
τdds = ,
ststt i −=−−=− θτ ,
por lo que, aplicando el lema anterior, se tiene que

Capítulo 4: Linealización a Trozos
162
( ) ( ) .
)(
0
)()(
0
)()(
0
))((
0
))((
0
)(
0
)(
∫∫
∫∫
∫∫
−−−−−−
−⊗−⊗−⊗−⊗
−−
⊗+⊗+=
++=
++=
θθθ
θθθ
θθ
θθ
θθ
θθ
sdsgeedsfeey
sdsgedsfey
sdsgedsfeyty
isAsB
isAsB
i
isIBAI
isIBAI
i
isJ
isJ
i
iT
iiT
i
mT
iinmT
iin
ii
Por tanto, si se define )(mat imxni fF = y )(mat imxni gG = , entonces, según la Propiedad 6.8, se tiene
( 4.47 ) ∫∫ −−−−−− ++=θ
θθθ
θθ
0
)()(
0
)()()( sdseGedseFeYtY sBi
sAsBi
sAi
iiii .
Para calcular la primera integral de la expresión anterior, se considera la matriz triangular superior a bloques definida en ( 4.45 ),
⎥⎦
⎤⎢⎣
⎡=
inxm
iii B
FAC
0,
y la exponencial de la matriz θiC ,
⎥⎦
⎤⎢⎣
⎡=
)(0)()(
)(22
)(12
)(11
θθθθ
inxm
iiC
FFF
e i .
Derivando respecto de θ en ambos miembros de la igualdad anterior, se tiene que
θθ
θi
iC
C
Ced
de= ,
por lo que
( 4.48 )
.)(0
)()()(
)(0)()(
0)(0
)()(
)(22
)(22
)(12
)(11
)(22
)(12
)(11
)(22
)(12
)(11
⎥⎦
⎤⎢⎣
⎡ +=
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
θθθθ
θθθ
θθ
θθ
θθ
iinxm
ii
ii
ii
inxm
ii
inxm
iii
nxm
ii
FBFFFAFA
FFF
BFA
ddF
ddF
ddF
Igualando los bloques (1,1), (1,2) y (2,2) de ambos miembros de la ecuación anterior, y teniendo en cuenta que
nmC Ie +=
=0θ
θ ,
se obtienen las siguientes EDMLs
( 4.49 ) )()( )(11
)(11 θ
θθ i
i
i
FAd
dF= , m
i IF =)0()(11 ,
( 4.50 ) )()( )(22
)(22 θ
θθ i
i
i
FBd
dF= , n
i IF =)0()(22 ,

Capítulo 4: Linealización a Trozos
163
( 4.51 ) )()()( )(22
)(12
)(12 θθ
θθ i
ii
i
i
FFFAd
dF+= , mxn
iF 0)0()(12 = .
Resolviendo en primer lugar las EDMLs ( 4.49 ) y ( 4.50 ), se tiene que θθ iAi eF =)()(
11 , θθ iBi eF =)()(
22 .
Sustituyendo θθ iBi eF =)()(22 en ( 4.51 ), se obtiene la EDML
θθθ
θiB
ii
i
i
eFFAd
dF+= )()( )(
12
)(12 , mxn
iF 0)0()(12 = ,
por lo tanto
( 4.52 ) dseFeF sBi
sAi ii∫ −=θ
θθ0
)()(12 )( .
Para calcular la segunda integral que aparece en la expresión ( 4.47 ), se considera la matriz triangular superior a bloques definida en ( 4.46 ),
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
inxnnxm
ninxm
mxnii
i
BIB
GAD
000
0,
y la exponencial de la matriz θiD ,
( 4.53 ) ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=)(00)()(0)()()(
)(33
)(23
)(22
)(13
)(12
)(11
θθθθθθ
θ
inxnnxm
iinxm
iii
D
HHHHHH
e i ,
siendo )()( θijkH , 31 ≤≤≤ kj , matrices de dimensiones conformes a la expresión
anterior, dependientes del parámetro θ .
Como
θθ
θi
iD
D
Ced
de= , nm
D Ie i20 +=
=θ
θ ,
entonces
.)(00
)()()(0)()()()()(
)(00)()(0)()()(
000
0
)(00
)()(0
)()()(
)(33
)(33
)(23
)(22
)(23
)(13
)(22
)(12
)(11
)(33
)(23
)(22
)(13
)(12
)(11
)(33
)(23
)(22
)(13
)(12
)(11
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
+++
=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
θθθθθθθθθ
θθθθθθ
θθ
θθ
θθ
θθ
θθ
θθ
iinxnnxm
iii
iinxm
ii
ii
ii
ii
ii
inxnnxm
iinxm
iii
inxnnxm
ninxm
mxnii
i
nxnnxm
ii
nxm
iii
HBHHBHBHGHAHGHAHA
HHHHHH
BIB
GA
ddH
ddH
ddH
ddH
ddH
ddH

Capítulo 4: Linealización a Trozos
164
Igualando los bloques correspondientes de ambos miembros de la ecuación anterior, se tienen las EDMLs
( 4.54 ) )()( )(11
)(11 θθ
θ ii
i
HAd
dH= , m
i IH =)0()(11 ,
( 4.55 ) )()( )(22
)(22 θθ
θ ii
i
HBd
dH= , n
i IH =)0()(22 ,
( 4.56 ) )()( )(33
)(33 θθ
θ ii
i
HBd
dH= , n
i IH =)0()(33 ,
( 4.57 ) )()()( )(22
)(12
)(12 θθθ
θ ii
ii
i
HGHAd
dH+= , mxn
iH 0)0()(12 = ,
( 4.58 ) )()()( )(33
)(23
)(23 θθθ
θ iii
i
HHBd
dH+= , nxn
iH 0)0()(23 = ,
( 4.59 ) )()()( )(23
)(13
)(13 θθθ
θ ii
ii
i
HGHAd
dH+= , mxn
iH 0)0()(13 = .
Resolviendo las EDMLs ( 4.54 ), ( 4.55 ) y ( 4.56 ), se tiene que θθ iAi eH =)()(
11 , θθ iBi eH =)()(
22 , θθ iBi eH =)()(
33 .
Sustituyendo θθ iBi eH =)()(22 en ( 4.57 ), se obtiene la EDML
θθθ
θiB
ii
i
i
eGHAd
dH+= )()( )(
12
)(12 , mxn
iH 0)0()(12 = ,
por lo tanto,
dseGeHo
sBi
sAi ii∫ −=θ
θθ )()(12 )( .
Sustituyendo θθ iBi eH =)()(33 en ( 4.58 ), se obtiene la EDML
θθθ
θiBi
i
i
eHBd
dH+= )()( )(
23
)(23 , nxn
iH 0)()(23 =θ ,
por lo que resolviéndola se tiene que
θθ θiBi eH =)()(23 .
Por último, sustituyendo θθ θiBi eH =)()(23 en ( 4.59 ), se obtiene la EDML
θθθ
θ θiBi
ii
i
eGHAd
dH+= )()( )(
13
)(13 , mxn
iH 0)0()(13 = ,
cuya solución viene dada por

Capítulo 4: Linealización a Trozos
165
( 4.60 ) dsseGeH sBi
sAi ii∫ −=θ
θθ0
)()(13 )( .
Teniendo en cuenta las expresiones ( 4.47 ), ( 4.52 ) y( 4.60 ), se tiene que
( 4.61 ) 1)(22
)(13
1)(22
)(12 )]()[()]()[()( −− ++= θθθθ iiii
i HHFFYtY ,
y como además θθθ iBii eFH == )()( )(
22)(
22 ,
entonces 1)(
22)(
13)(
12 )]()][()([)( −++= θθθ iiii FHFYtY .
Por último, si en la expresión ( 4.44 ) se sustituye t por 1+it , resulta
( 4.62 ) 1)(22
)(13
)(121 )]()][()([ −
+ ∆∆+∆+= ii
ii
ii
ii tFtHtFYY ,
siendo iii ttt −=∆ +1 , con lo que queda demostrado el teorema.
Puesto que los bloques diagonales (1,1) y (2,2) de las matrices iC y iD que aparecen en las expresiones ( 4.45 ) y ( 4.46 ) son iguales, entonces los bloques diagonales (1,1) y (2,2) de las matrices tCie ∆ y tDie ∆ son iguales, por lo que es posible una adaptación a bloques del Algoritmo 4.3 que permita calcular a la vez )()(
12 ii tF ∆ y )()(
13 ii tH ∆ .
Realizando un razonamiento semejante al utilizado en la obtención del Algoritmo 4.4, se deduce el siguiente algoritmo.

Capítulo 4: Linealización a Trozos
166
),,,,,,,(3 211 cctYGFBAdlabpY ii ∆=+ .
Entradas: Matriz mxmA ℜ∈ , matriz nxnB ℜ∈ , matriz mxnF ℜ∈ , matriz mxnG ℜ∈ , matriz mxn
iY ℜ∈ , incremento de tiempo ℜ∈∆t , vectores qcc ℜ∈21, coeficientes de los términos de grado mayor que 0 de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz mxniY ℜ∈+1 de la expresión ( 4.44 ).
1 ∞= |||| AnorA ; ∞= |||| BnorB ; ∞= |||| FnorF ; ∞= |||| GnorG 2 )1,max( ++= norBnorGnorAnor ; ),max( norFnorAnortnor +∆=
3 )))(int(log1,0max( 2 norj += ; jts
2∆
=
4 sAA = ; sBB = ; sFF = ; sGG = 5 AX =11 ; GX =12 ; FY =12 ; BX =22 ; mxnX 013 = ; nsIX =23 6 11111 )1( XcIN m += ; 12112 )1( XcN = ; 12112 )1( YcM = 7 13113 )1( XcN = ; 22122 )1( XcIN n += ; 23123 )1( XcN = 8 11211 )1( XcID m += ; 12212 )1( XcD = ; 12212 )1( YcP = 9 13213 )1( XcD = ; 22222 )1( XcID n += ; 23223 )1( XcD = 10 Para qk :2=
10.1 1111 AXX = ; 221212 GXAXX += ; 221212 FXAXY += 10.2 231313 GXAXX += ; 222323 sXBXX += ; 2222 BXX = 10.3 1111111 )( XkcNN += ; 1211212 )( XkcNN += ; 1211212 )( XkcMM += 10.4 1311313 )( XkcNN += ; 2212222 )( XkcNN += ; 2312323 )( XkcNN += 10.5 1121111 )( XkcDD += ; 1221212 )( XkcDD += ; 1221212 )( XkcPP += 10.6 1321313 )( XkcDD += ; 2222222 )( XkcDD += ; 2322323 )( XkcDD +=
11 Calcular 11F resolviendo la ecuación 111111 NFD = 12 Calcular 22F resolviendo la ecuación 222222 NFD = 13 Calcular 12F resolviendo la ecuación 2212121211 FDNFD −= 14 Calcular 12G resolviendo la ecuación 2212121211 FEMGD −= 15 Calcular 23F resolviendo la ecuación 2223232322 FDNFD −= 16 Calcular 13F resolviendo la ecuación 22132312131311 FDFDNFD −−= 17 Para jk :1=
17.1 22132312131113 FFFFFFF ++= ; 2212121121 FFFFF +=
17.2 2212121121 XGGXG += ; 2223232223 FFFFF += ; 21111 FF = ; 2
2222 FF = 18 Calcular 1+iY resolviendo la ecuación 1312122 FGYF i +=+ 19 iii YYY += ++ 11
Algoritmo 4.20: Calcula la solución aproximada en el instante 1+it de una EDMR con coeficientes variables mediante la modificación a bloques del Algoritmo 4.3.
El coste computacional aproximado del algoritmo anterior es

Capítulo 4: Linealización a Trozos
167
flops.3462
32
)6832()4842(
3223
32233223
mmnnmm
jnmnnmmqnmnnmm
+−++
+++++++
El siguiente algoritmo resuelve EDMRs con coeficientes variables mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé.
),,,,( 0 qXdataddatatdgedmrlpvY = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función )(tdata que calcula las matrices coeficiente de la EDMR nxntA ℜ∈)(11 , nxmtA ℜ∈)(12 , mxntA ℜ∈)(21 ,
mxmtA ℜ∈)(22 , función )(tdatad que calcula las derivadas de las matrices coeficiente de la EDMR nxntA ℜ∈)('
11 , nxmtA ℜ∈)('12 , mxntA ℜ∈)('
21 , mxmtA ℜ∈)('
22 , matriz inicial mxnX ℜ∈0 , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé.
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 XY = 3 Para 1:0 −= li
3.1 )(],,,[ 22211211 tdataAAAA = 3.2 122222 AYAA i−= 3.3 iYAAG 2221 += 3.4 11AYGG i−= 3.5 )(],,,[ 22211211 tdatadAAAA = 3.6 122222 AYAA i−= 3.7 iYAAF 2221 += 3.8 11AYFF i−= 3.9 iYAAA 121111 += 3.10 ii ttt −=∆ +1 3.11 ),,,,,,,(3 2111221 cctYGFAAdlabpY ii ∆=+ .
Algoritmo 4.21: Resolución de EDMRs con coeficientes variables mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé.
El coste aproximado por iteración del algoritmo anterior es 22 68 mnnm + +coste( data )+coste( datad )+coste(Algoritmo 4.20) flops.
4.3.1.2 Método Basado en la Ecuación Conmutante El método que se presenta en este subapartado es consecuencia del siguiente teorema, cuya demostración está basada en la ecuación conmutante.

Capítulo 4: Linealización a Trozos
168
Teorema 4.4.
Si las matrices iA y iB que aparecen en ( 4.42 ) no tienen valores propios en común, entonces la matriz 1+iY que aparece en la expresión ( 4.43 ), solución aproximada en el instante 1+it de la EDMR ( 4.32 ), se puede calcular como
( 4.63 ) gfii WWYY ++=+1 ,
siendo fW la solución de la ecuación matricial de Sylvester
( 4.64 ) itB
itA
iffi FeFeBWWA iiii −=− ∆−∆
y gW la solución de la ecuación matricial de Sylvester
( 4.65 ) iiiiggi tGWBWWA ∆−=− ,
donde iW es la solución de la ecuación matricial de Sylvester
( 4.66 ) itB
itA
iiii GeGeBWWA iiii −=− ∆−∆ .
Demostración.
Por la Propiedad 2.1, las matrices ii tC ∆ (expresión ( 4.41 )) y ii tCe ∆ conmutan, luego
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∆=⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∆⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ ∆∆
mnmnmn
mnmnmn
mnmni
mnmnmn
imnmnmn
iitJ
mnmnmn
imnmnmn
iitJ
mnmnmn
mnmnmn
mnmni
IIJ
ItII
FFe
ItII
FFeI
IJ iiii
00000
0
000
000
00000
0 )(13
)(12
)(13
)(12
,
en donde se ha simplificado la notación escribiendo )(12
iF y )(13
iF , en lugar de )()(12 i
i tF ∆ y )()(
13 ii tF ∆ , respectivamente.
Igualando los bloques (1,2) de ambos miembros de la ecuación, se obtiene ii tJ
mni
i eIFJ ∆=+)(12 ,
mntJi
i IeFJ ii −= ∆)(12 ,
y de aquí
( 4.67 ) iitJ
ii
i ffefFJ ii −= ∆)(12 .
De igual modo, igualando los bloques (1,3), resulta que )(
12)(
13i
imni
i FtIFJ =∆+ ,
imnii
i tIFFJ ∆−= )(12
)(13 ,
o bien
( 4.68 ) iiii
ii
i gtgFgFJ ∆−= )(12
)(13 .
Si se definen
( 4.69 ) ii
f fFw )(12= y )(mat fmxnf wW = ,

Capítulo 4: Linealización a Trozos
169
y se desarrolla la parte izquierda de la ecuación ( 4.67 ) se deduce, por la Propiedad 6.8, que
( 4.70 ) ( ) ( )iffifmTiinfii
ii BWWAwIBAIwJfFJ −=⊗−⊗== vec)(
12 ,
Desarrollando la parte derecha de la ecuación ( 4.67 ), y teniendo en cuenta el Lema 4.1 y la Propiedad 6.8, se obtiene
( 4.71 ) ( ) ( )
( ),itB
itA
iitAtB
iitIBAI
iitJ
FeFevec
ffeeffeffeiiii
iiiTiim
Tiinii
−=
−⊗=−=−∆−∆
∆∆−∆⊗−⊗∆
siendo
)(mat imxni fF = .
Teniendo en cuenta ( 4.67 ) y las igualdades ( 4.70 ) y ( 4.71 ), se tiene
( ) ( )itB
itA
iffi FeFeBWWAvec iiii −=− ∆−∆vec ,
por lo que fW se puede calcular resolviendo la ecuación matricial de Sylvester ( 4.64),
itB
itA
iffi FeFeBWWA iiii −=− ∆−∆ .
De igual modo, si se definen
ii
i gFw )(12= y )(mat imxni wW = ,
entonces la matriz iW se puede calcular mediante la resolución de la ecuación matricial de Sylvester ( 4.66 ),
itB
itA
iiii GeGeBWWA iiii −=− ∆−∆ ,
siendo
)(mat imxni gG = .
Realizando un desarrollo similar para la expresión ( 4.68 ), se tiene que si se definen
( 4.72 ) ii
g gFw )(13= y )(mat gmxng wW = ,
entonces gW se puede obtener resolviendo la ecuación matricial de Sylvester ( 4.65 ),
( 4.73 ) iiiiggi tGWBWWA ∆−=− .
Teniendo en cuenta las expresiones ( 4.43 ), ( 4.69 ) y ( 4.72 ), se tiene
gfiii
mxnii
mxnii WWYgFfFYY ++=++=+ )(mat)(mat )(13
)(121 ,
con lo que queda demostrado el teorema.
Obsérvese que para calcular la matriz 1+iY del teorema anterior es necesario resolver las ecuaciones matriciales de Sylvester ( 4.64 ), ( 4.65 ) y ( 4.66 ) con las mismas matrices coeficiente iA y iB . Teniendo en cuenta este hecho, se puede reducir el coste computacional para calcular 1+iY del modo que a continuación se muestra.
Sean

Capítulo 4: Linealización a Trozos
170
Taiai QAQA = , Tbibi QBQB = ,
respectivamente, las descomposiciones reales de Schur de las matrices iA y iB , con aQ y bQ matrices ortogonales, y iA y iB matrices casi triangulares superiores. Sustituyendo las expresiones anteriores en la ecuación ( 4.64 ), resulta
iTb
tBbi
Ta
tAa
Tbibff
Taia FQeQFQeQQBQWWQAQ iiii −=− ∆−∆ ,
por lo que
biTa
tBbi
Ta
tAibf
Tabf
Tai QFQeQFQeBQWQQWQA iiii −=− ∆−∆ .
Llamando
bfTa QWQX = ,
biTa QFQF = ,
ii tAa eE ∆= ,
ii tBb eE ∆−= .
se obtiene la ecuación casi triangular superior de Sylvester
( 4.74 ) FFEEBXXA baii −=− .
Aplicando los mismos pasos a la ecuación ( 4.66 ), se deduce que
iTb
tBbi
Ta
tAa
Tbibii
Taia GQeQGQeQQBQWWQAQ iiii −=− ∆−∆ ,
biTa
tBbi
Ta
tAibi
Tabi
Tai QGQeQGQeBQWQQWQA iii −=− ∆−∆1 ,
GGEEBZZA baii −=− ,
siendo
biTa QWQZ = ,
biTa QGQG = ,
ii tAa eE ∆= ,
ii tBb eE ∆−= .
Por último, la ecuación matricial de Sylvester ( 4.65 ) queda como
iiiTbibgg
Taia tGWQBQWWQAQ ∆−=− ,
ibiTabi
Taibg
Tabg
Tai tQGQQWQBQWQQWQA ∆−=− ,
( 4.75 ) iii tGZBYYA ∆−=− ,
siendo

Capítulo 4: Linealización a Trozos
171
bgTa QWQY = ,
biTa QWQZ = ,
biTa QGQG = .
Por lo tanto
( ) Tbai
Tba
Tbaigfii QYXQYYQQXQQYWWYY ++=++=++=+1 .
El siguiente algoritmo calcula la matriz 1+iY de la expresión ( 4.63), según el método descrito en los párrafos anteriores.
),,,,,,,(3 211 cctYGFBAdlabcY ii ∆=+ .
Entradas: Matriz mxmA ℜ∈ , matriz nxnB ℜ∈ , matriz mxnF ℜ∈ , matriz mxnG ℜ∈ , matriz mxn
iY ℜ∈ , incremento de tiempo ℜ∈∆t , vectores qcc ℜ∈21, que contienen a los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz mxniY ℜ∈+1 (véase expresión ( 4.63)).
1 )(],[ AschurAQa = ( descomposición real de Schur de la matriz A ) 2 )(],[ BschurBQb = (descomposición real de Schur de la matriz B ) 3 ),,( 21 cctAdqtexppadEa ∆= (modificación del Algoritmo 2.1) 4 ),,( 21 cctBdqtexppadEb ∆= (modificación del Algoritmo 2.1) 5 b
Ta FQQF = ; FFEEF ba −=
6 ),,( FBAdtrsylF −= (Algoritmo 3.14) 7 b
Ta GQQG = ; GW = ; GGEEG ba −=
8 ),,( GBAdtrsylG −= (Algoritmo 3.14) 9 tWGG ∆−= 10 ),,( GBAdtrsylG −= (Algoritmo 3.14) 11 ( ) T
baii QGFQYY ++=+1
Algoritmo 4.22: Calcula la solución aproximada en el instante 1+it de una EDMR con coeficientes variables mediante la ecuación conmutante.
Notas:
• La exponencial de una matriz casi triangular superior ( dqtexppad ) se puede obtener mediante una modificación del Algoritmo 2.1 para el caso de matrices casi triangulares superiores. Para optimizar el código anterior es necesario que las operaciones con matrices se hagan de tal modo que se explote la estructura casi triangular superior de las mismas. De este modo, el coste del cálculo de la exponencial de una matriz se puede reducir aproximadamente a la mitad, por lo que el coste aproximado del algoritmo anterior es
3223 27111127 nnmnmm +++ +coste(Algoritmo 2.1) flops.

Capítulo 4: Linealización a Trozos
172
• Si las matrices A y B del algoritmo anterior son nulas, entonces 2
1 )(5.0 tGtFYY ii ∆+∆+=+ .
• Si las matrices A y B del algoritmo anterior tienen algún valor propio muy cercano, entonces sería conveniente utilizar el Algoritmo 4.20 o el Algoritmo 4.25 que se describe en el siguiente subapartado.
A continuación se muestra el algoritmo completo que resuelve EDMRs mediante el método de linealización a trozos basado en la ecuación conmutante.
),,,,( 0 qXdataddatatdgedmrlcvY = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función )(tdata que calcula las matrices coeficiente de la EDMR nxntA ℜ∈)(11 , nxmtA ℜ∈)(12 , mxntA ℜ∈)(21 ,
mxmtA ℜ∈)(22 , función )(tdatad que calcula las derivadas de las matrices coeficiente de la EDMR nxntA ℜ∈)('
11 , nxmtA ℜ∈)('12 , mxntA ℜ∈)('
21 , mxmtA ℜ∈)('
22 , matriz inicial mxnX ℜ∈0 , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé.
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 XY = 3 Para 1:0 −= li
3.1 )(],,,[ 22211211 itdataAAAA = 3.2 122222 AYAA i−= 3.3 iYAAG 2221 += 3.4 11AYGG i−= 3.5 )(],,,[ 22211211 itdatadAAAA = 3.6 122222 AYAA i−= 3.7 iYAAF 2221 += 3.8 11AYFF i−= 3.9 iYAAA 121111 += 3.10 ii ttt −=∆ +1 3.11 ),,,,,,,(3 2111221 cctYGFAAdlabcY ii ∆=+ (Algoritmo 4.22)
Algoritmo 4.23: Resolución de EDMRs con coeficientes variables mediante el método de linealización a trozos basado en la ecuación conmutante.
El coste computacional aproximado por iteración del algoritmo anterior es 22 68 mnnm + +coste( data )+coste( datad )+coste(Algoritmo 4.22) flops.
4.3.1.3 Método Basado en los Subespacios de Krylov
La matriz 1+iY de la expresión ( 4.43 ), solución aproximada en el instante 1+it de la EDMR ( 4.32 ), se puede expresar como
( 4.76 ) )(mat))()((mat )(13
)(121 i
tCmxniii
iii
imxnii veYgtFftFYY ii∆
+ +=∆+∆+= ,

Capítulo 4: Linealización a Trozos
173
siendo
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
mnmnmn
mnmnmn
mnmni
i IIJ
C000
000
y
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
i
i
mnx
i
gfv
10.
El coste de almacenamiento de la matriz Jacobiana iJ (véase expresión ( 4.42 ) es excesivamente alto, del orden de 2)(mn números en coma flotante. Teniendo en cuenta que dicha matriz únicamente es necesaria para calcular el producto matriz por vector que aparece en los algoritmos basados en los subespacios de Krylov, sería interesante realizar dicho cálculo sin la formación explícita de la matriz Jacobiana, reduciendo de esta forma el coste de almacenamiento. El algoritmo que se muestra a continuación calcula el producto iivJ , con mn
iv ℜ∈ , sin formar explícitamente la matriz Jacobiana.
),,( vBAdlapkvw = .
Entradas: Matriz mxmA ℜ∈ , matriz nxnB ℜ∈ , vector mnv ℜ∈ . Salida: Vector ( ) mn
mT
n vIBAIw ℜ∈⊗−⊗= .
1 Para ni :1= 1.1 1)1(1 +−= mii 1.2 imi =2 1.3 ):():( 2121 iiAviiw = 1.4 Para nj :1=
1.4.1 1)1(1 +−= mjj 1.4.2 jmj =2 1.4.3 ):():(),():( 212121 iiwjjvijBiiw +−=
Algoritmo 4.24: Cálculo del producto de la matriz Jacobiana de una EDMR por un vector.
El coste computacional aproximado del algoritmo anterior es 22 22 mnnm + flops.
El siguiente algoritmo calcula la matriz 1+iY de la expresión ( 4.76 ) mediante una adaptación a bloques del Algoritmo 4.9, minimizando con ello los costes computacionales y de almacenamiento.

Capítulo 4: Linealización a Trozos
174
),,,,,,,,,(3 211 cctolptYGFBAdlabkY ii ∆=+ .
Entradas: Matriz mxmA ℜ∈ , matriz nxnB ℜ∈ , matriz mxnF ℜ∈ , matriz mnG ℜ∈ , matriz mn
iY ℜ∈ , incremento de tiempo ℜ∈∆t , dimensión +∈ Zp del subespacio de Krylov, tolerancia +ℜ∈tol , vectores qcc ℜ∈21, que contienen a los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz mxniY ℜ∈+1 de la expresión ( 4.76 ).
1 )(vec Ff = ; )(vec Gg = 2 nmmnV 0)1,:1( = ; fmnmnV =+ )1,2:1( ; gmnmnV =+ )1,3:12( 3 2||)1(:,||V=β 4 Si 0==β Salir del algoritmo 5 β/)3:1()3:1( mnmnVmnmnV +=+ 6 Para pj :1=
6.1 )),:1(,,():1( jmnVBAdlapkvmnw = (Algoritmo 4.24) 6.2 ),2:1():1():1( jmnmnVmnwmnw ++= 6.3 ),3:12()2:1( jmnmnVmnmnw +=+ 6.4 nmmnmnw 0)3:12( =+ ; )2:1()2:1( mntwmnw ∆= 6.5 Para ji :1=
6.5.1 ),3:1(),( imnVwjiH T= ; ),3:1(),( imnVjiHww −= 6.6 |||| 2ws = 6.7 Si tols <
6.7.1 jp = 6.7.2 Salir del bucle
6.8 sjjH =+ ),1( 6.9 ),1(/)1,3:1( jjHwjmnV +=+
7 ),),:1,:1(():1,:1( 21 ccppHdlaexpppH = (Algoritmo 4.3) 8 ))1,:1():1,:1((mat1 pHpmnVYY mxnii β+=+
Algoritmo 4.25: Calcula la solución aproximada en el instante 1+it de una EDMR con coeficientes variables mediante la modificación a bloques del Algoritmo 4.9.
El coste computacional aproximado del algoritmo anterior es
)1(622 22 +++ pmnppmnnpm +coste(Algoritmo 4.3) flops.
El algoritmo completo que resuelve EDMRs con coeficientes variables basado en los subespacios de Krylov se muestra a continuación.

Capítulo 4: Linealización a Trozos
175
),,,,,,( 0 qtolpXdataddatatdgedmrlkvY = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función )(tdata que calcula las matrices coeficiente de la EDMR nxntA ℜ∈)(11 , nxmtA ℜ∈)(12 , mxntA ℜ∈)(21 ,
mxmtA ℜ∈)(22 , función )(tdatad que calcula las derivadas de las matrices coeficiente de la EDMR nxntA ℜ∈)('
11 , nxmtA ℜ∈)('12 , mxntA ℜ∈)('
21 , mxmtA ℜ∈)('
22 , matriz inicial mxnX ℜ∈0 , dimensión +∈ Zp del subespacio de Krylov, tolerancia +ℜ∈tol , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé.
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 00 XY = 3 Para 1:0 −= li
3.1 )(],,,[ 22211211 itdataAAAA = 3.2 122222 AYAA i−= 3.3 iYAAG 2221 += 3.4 11AYGG i−= 3.5 )(],,,[ 22211211 itdatadAAAA = 3.6 122222 AYAA i−= 3.7 iYAAF 2221 += 3.8 11AYFF i−= 3.9 iYAAA 121111 += 3.10 ii ttt −=∆ +1 3.11 ),,,,,,,,,(3 2111221 cctolptYGFAAdlabkY ii ∆=+
Algoritmo 4.26: Resolución de EDMRs con coeficientes variables mediante el método de linealización a trozos basado en los subespacios de Krylov.
El coste computacional aproximado por iteración del algoritmo anterior es 22 68 mnnm + +coste( data )+coste( datad )+coste(Algoritmo 4.25) flops.
4.3.2 Resolución de EDMRs con Coeficientes Constantes Sea la EDMR con coeficientes constantes
( 4.77 ) fttttXAtXAtXtXAAtX ≤≤−−+= 012112221 ),()()()()(' ,
mxnXtX ℜ∈= 00 )( ,
siendo nxnRA ∈11 , nxmRA ∈12 , mxnRA ∈21 , mxmRA ∈22 .
Aplicando la función vec a la EDMR ( 4.77 ), se obtiene la EDO autónoma
( 4.78 ) ))(()(' txftx = , )( 00 Xvecx = , )(txx = ,
siendo

Capítulo 4: Linealización a Trozos
176
( 4.79 ) )(vec)( 12112221 XXAXAXAAxf −−+= ,
o bien, utilizando la Propiedad 6.7 y la Propiedad 6.8 del producto de Kronecker,
( 4.80 ) xXAIxIAAIAxf nmT
n )]([][)(vec)( 12112221 ⊗−⊗−⊗+=
o bien
( 4.81 ) xIXAxIAAIAxf mT
mT
n ])[(][)(vec)( 12112221 ⊗−⊗−⊗+= .
Como se cumplen las hipótesis del Teorema 2.10 (página 56), considerando la partición fll ttttt =<<<< −110 L y aplicando la linealización a trozos, se obtiene el conjunto de
EDLs resultantes de la aproximación lineal de ),( xtf en cada subintervalo,
( 4.82 ) ))(()(' iii ytyJfty −+= , ],[ 1+∈ ii ttt , ii yty =)( , 1,,1,0 −= li L .
siendo
( 4.83 ) )( 12112221 iiiii YAYAYYAAvecf −−+= ,
( 4.84 ) ,)( mTiinii IBAIy
xfJ ⊗−⊗=
∂∂
=
donde
( 4.85 ) 1222 AYAA ii −= , ii YAAB 1211 += .
Aplicando el Teorema 4.2, se tiene que la solución de la EDL ( 4.82 ) es
( 4.86 ) iii
i fttFyty )()( )(12 −+= ,
siendo )(12
iF el bloque (1,2) de la matriz θiCe , donde
( 4.87 ) ⎥⎦
⎤⎢⎣
⎡=
mnmn
mnii
IJC
00.
En particular,
( 4.88 ) iii
ii ftFyy )()(121 ∆+=+ ,
siendo iii ttt −=∆ +1 .
Por lo tanto, la solución aproximada en el instante 1+it de la EDMR ( 4.77 ) en el instante 1+it se puede expresar como
( 4.89 ) ))(vec)((mat )(121 FtFYY i
mxnii ∆+=+ .
A continuación se presenta un algoritmo, basado en la linealización a trozos, que resuelve EDMRs con coeficientes constantes.

Capítulo 4: Linealización a Trozos
177
),,( 0XdatatdgedmrlgcY = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que obtiene las matrices coeficiente de la EDMR nxnA ℜ∈11 , nxmA ℜ∈12 , mxnA ℜ∈21 , mxmA ℜ∈22 , matriz inicial mxnX ℜ∈0 .
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 ()],,,[ 22211211 dataAAAA = 2 00 XY = 3 Para 1:0 −= li
3.1 122222 AYAA i−= 3.2 iYAAF 2221 += 3.3 11AYFF i−= 4.4 iYAAA 121111 += 3.5 ii ttt −=∆ +1 3.6 ))(vec)((mat )(
121 FtFYY imxnii ∆+=+ (expresión ( 4.89 ))
Algoritmo 4.27: Resolución de EDMRs con coeficientes constantes mediante la linealización a trozos.
4.3.2.1 Método Basado en los Aproximantes Diagonales de Padé Una forma de calcular la matriz 1+iY de la expresión ( 4.89 ) se basa en el teorema que se presenta a continuación.
Teorema 4.5.
La matriz 1+iY que aparece en la expresión ( 4.89 ), solución aproximada en el instante
1+it de la EDMR con coeficientes constantes ( 4.77 ), se puede calcular utilizando la expresión
( 4.90 ) 1)(22
)(121 )]()[( −
+ ∆∆+= ii
ii
ii tFtFYY ,
donde )()(12 i
i tF ∆ y )()(22 i
i tF ∆ son, respectivamente, los bloques (1,2) y (2,2) de la matriz ii tCe ∆ , con
( 4.91 ) ⎥⎦
⎤⎢⎣
⎡=
inxm
iii B
FAC
0,
siendo
iiiii YAYAYYAAF 12112221 −−+= ,
1222 AYAA ii −= ,
ii YAAB 1211 += .
Demostración.
Al aplicar la linealización a trozos a la EDMR ( 4.77 ) se obtiene en ],[ 1+ii tt la EDL

Capítulo 4: Linealización a Trozos
178
))(()(' iii ytyJfty −+= , ii yty =)(
que tiene como solución analítica
( 4.92 ) ∫ −+=t
ti
tJi
i
i dfeyty ττ )()( .
Si se realiza el cambio de variable
its −= τ
y se define
itt −=θ ,
entonces
τdds = ,
ststt i −=−−=− θτ ,
por lo que, aplicando el Lema 4.1, se tiene que la expresión ( 4.92 ) queda como
( ) .
)(
0
)()(
0
))((
0
)()(
∫
∫∫∫
−−−
−⊗−⊗−−
⊗+=
+=+=+=
θθθ
θθ
θθτ τ
dsfeey
dsfeydsfeyfdeyty
isAsB
i
isIBAI
iisJ
ii
t
t
tJi
iT
i
mT
iini
i
i
Por tanto, si se define )( imxni fmatF = , entonces, según la Propiedad 6.8,
( 4.93 ) ∫ −−−+=θ
θθ
0
)()()( dseFeYtY sBi
sAi
ii
es la solución aproximada de la EDMR ( 4.77 ) en el intervalo ],[ 1+ii tt .
Para calcular la integral que aparece en la expresión ( 4.93 ), se considera la matriz triangular superior a bloques definida en ( 4.91 ),
⎥⎦
⎤⎢⎣
⎡=
imxn
iii B
FAC
0,
y la exponencial de la matriz θiC ,
⎥⎦
⎤⎢⎣
⎡=
)(0)()(
)(22
)(12
)(11
θθθθ
inxm
iiC
FFF
e i .
Derivando respecto de θ en ambos miembros de la igualdad anterior, se tiene que
θθ
θi
iC
C
Ced
de= ,
por lo que

Capítulo 4: Linealización a Trozos
179
( 4.94 )
.)(0
)()()(
)(0)()(
0)(0
)()(
)(22
)(22
)(12
)(11
)(22
)(12
)(11
)(22
)(12
)(11
⎥⎦
⎤⎢⎣
⎡ +=
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
θθθθ
θθθ
θθ
θθ
θθ
iinxm
ii
ii
ii
inxm
ii
inxm
iii
nxm
ii
FBFFFAFA
FFF
BFA
ddF
ddF
ddF
Igualando los bloques (1,1), (1,2) y (2,2) de ambos miembros de la ecuación anterior y teniendo en cuenta que
nmC Ie +=
=0θ
θ ,
se obtienen las siguientes EDMLs con valores iniciales:
( 4.95 ) )()( )(11
)(11 θ
θθ i
i
i
FAd
dF= , m
i IF =)0()(11 ,
( 4.96 ) )()( )(22
)(22 θ
θθ i
i
i
FBd
dF= , n
i IF =)0()(22 ,
( 4.97 ) )()()( )(22
)(12
)(12 θθ
θθ i
ii
i
i
FFFAd
dF+= , mxn
iF 0)0()(12 = .
Resolviendo en primer lugar las EDMLs( 4.95 ) y ( 4.96 ), se tiene que θθ iAi eF =)()(
11 ,
( 4.98 ) θθ iBi eF =)()(22 .
Sustituyendo θθ iBi eF =)()(22 en ( 4.97 ), se obtiene la EDML
θθθ
θiB
ii
i
i
eFFAd
dF+= )()( )(
12
)(12 , mxn
iF 0)0()(12 = ,
por lo tanto,
( 4.99 ) dseFeFo
sBi
sAi ii∫ −=θ
θθ )()(12 )( .
Teniendo en cuenta las expresiones ( 4.93 ), ( 4.98 ) y ( 4.99 ), se tiene que
( ) 1)(22
)(12
0
)(
0
)()( )()()( −−−−−− +=+=+= ∫∫ θθθθ
θθ
θθ iii
BsBi
sAi
sBi
sAi FFYedseFeYdseFeYtY iiiii .
Por último, si en la anterior expresión se sustituye t por 1+it , resulta
( 4.100 ) ( ) 1)(22
)(121 )()( −
+ ∆∆+= ii
ii
ii tFtFYY ,
siendo iii ttt −=∆ +1 , con lo que queda demostrado el teorema.
El siguiente algoritmo calcula la matriz 1+iY de la expresión ( 4.90 ), utilizando una adaptación a bloques del Algoritmo 4.3.

Capítulo 4: Linealización a Trozos
180
),,,,,,(2 211 cctYFBAdlabpY ii ∆=+ .
Entradas: Matriz mxmA ℜ∈ , matriz nxnB ℜ∈ , matriz mxnF ℜ∈ , matriz mxniY ℜ∈ ,
incremento de tiempo ℜ∈∆t , vectores qcc ℜ∈21, que contienen a los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz mxniY ℜ∈+1 de la expresión ( 4.100 ).
1 ∞
= ][ FAnor ; ( )∞
∆= ][,max nIBnortnor 2 )))(int(log1,0max( 2 norj +=
3 jts
2∆
=
4 sAA = ; sBB = ; sFF = 5 AX =11 ; FX =12 ; BX =22 6 11111 )1( XcIN m += ; 12112 )1( XcN = ; 22122 )1( XcIN n += 7 11211 )1( XcID m += ; 12212 )1( XcD = ; 22222 )1( XcID n += 8 Para qk :2=
8.1 221212 FXAXX += ; 1111 AXX = ; 2222 BXX = 8.2 1111111 )( XkcNN += ; 1211212 )( XkcNN += ; 2212222 )( XkcNN += 8.3 1121111 )( XkcDD += ; 1221212 )( XkcDD += ; 2222222 )( XkcDD +=
9 Calcular 11X resolviendo la ecuación 111111 NXD = 10 Calcular 22X resolviendo la ecuación 222222 NXD = 11 Calcular 12X resolviendo la ecuación 2212121211 XDNXD −= 12 Para jk :1=
12.1 2212121121 XXXXX += 12.2 2
1111 XX = ; 22222 XX =
13 Calcular 1+iY resolviendo la ecuación 12122 XYX i =+ 14 iii YYY += ++ 11
Algoritmo 4.28: Calcula la solución aproximada en el instante 1+it de una EDMR con coeficientes constantes mediante la modificación a bloques del Algoritmo 4.3.
El coste computacional aproximado en flops del algoritmo anterior es
( 4.101 ) 32233223
3422
32))(2222( nmnnmmjqnmnnmm ++−+++++ flops.
El siguiente algoritmo resuelve EDMRs con coeficientes constantes mediante el método de linealización a trozos con aproximantes diagonales de Padé.

Capítulo 4: Linealización a Trozos
181
),,,( 0 qXdatatdgedmrlpcY = .
Entradas: Instantes de tiempo it ( li ≤≤0 ), función data que obtiene las matrices coeficiente de la EDMR nxnA ℜ∈11 , nxmA ℜ∈12 , mxnA ℜ∈21 , mxmA ℜ∈22 , matriz inicial mxnX ℜ∈0 , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 ()],,,[ 22211211 dataAAAA = 3 00 XY = 4 Para 1:0 −= li
4.1 122222 AYAA i−= 4.2 iYAAF 2221 += 4.3 11AYFF i−= 4.4 iYAAA 121111 += 4.5 ii ttt −=∆ +1 4.6 ),,,,,,(2 2111221 cctYFAAdlabpY ii ∆=+ (Algoritmo 4.28)
Algoritmo 4.29: Resolución de EDMRs con coeficientes constantes mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé.
El coste en flops por iteración es 22 44 mnnm + +coste(Algoritmo 4.28) flops.
4.3.2.2 Método Basado en la Ecuación Conmutante El método que se describe en este subapartado es consecuencia del siguiente teorema, cuya demostración está basada en la ecuación conmutante.
Teorema 4.6.
Si las matrices iA y iB que aparecen en ( 4.85 ) no tienen valores propios en común, entonces la matriz 1+iY que aparece en la expresión ( 4.89 ), solución aproximada en el instante 1+it de la EDMR con coeficientes ( 4.77 ), se puede calcular como
( 4.102 ) iii WYY +=+1 ,
siendo iW la solución de la ecuación matricial de Sylvester
( 4.103 ) itB
itA
iiii FeFeBWWA iiii −=− ∆−∆ .
Demostración.
Según la Propiedad 2.1, la matriz iC de la expresión ( 4.87 ) conmuta con la matriz ii tCe ∆ , por lo que

Capítulo 4: Linealización a Trozos
182
⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡ ∆∆
mnmn
mni
mnmn
itJ
mnmn
itJ
mnmn
mni IJIFe
IFeIJ iiii
000000
)(12
)(12 ,
en donde se ha simplificado la notación escribiendo )(12
iF en lugar de )()(12 i
i tF ∆ .
Igualando los bloques (1,2) de los dos miembros de la ecuación anterior, se tiene que ii tJ
mni
i eIFJ ∆=+)(12 ,
con lo que
mntJi
i IeFJ ii −= ∆)(12 ,
o bien
( 4.104 ) iitJ
ii
i ffefFJ ii −= ∆)(12 .
Desarrollando el miembro izquierdo de la ecuación ( 4.104 ), y teniendo en cuenta la Propiedad 6.8, se tiene que
( 4.105 ) ( ) ( )iiiiimTiiniii
ii BWWAwIBAIwJfFJ −=⊗−⊗== vec)(
12 ,
siendo
)(mat imxni wW = .
Desarrollando el miembro derecho de la ecuación ( 4.104 ), y tendiendo en cuenta el Lema 4.1 y la Propiedad 6.8, se tiene que
( 4.106 ) ( )
( ) ( ),vec itB
itA
iitAtB
iitIBAI
iitJ
FeFeffee
ffeffeiiiii
Ti
imTiinii
−=−⊗=
−=−∆−∆∆∆−
∆⊗−⊗∆
siendo
)(mat imxni fF = .
A partir de ( 4.104 ) y teniendo en cuenta las expresiones ( 4.105 ) y ( 4.106 ), se tiene
( ) ( )itB
itA
iiii FeFeBWWA iiii −=− ∆−∆vecvec ,
por lo que iW se obtiene resolviendo la ecuación matricial de Sylvester ( 4.103),
itB
itA
iiii FeFeBWWA iiii −=− ∆−∆ ,
con lo que queda demostrado el teorema.
La ecuación matricial de Sylvester ( 4.103) se puede resolver como a continuación se muestra. Sean
Taiai QAQA = , Tbibi QBQB = ,
respectivamente, las descomposiciones reales de Schur de las matrices iA y iB , con aQ y bQ matrices ortogonales, y iA y iB matrices casi triangulares superiores. Sustituyendo las expresiones anteriores en la ecuación ( 4.103 ), se tiene que

Capítulo 4: Linealización a Trozos
183
iTb
tBbi
Ta
tAa
Tbibii
Taia FQeQFQeQQBQWWQAQ iiii −=− ∆−∆ ,
y multiplicando la ecuación anterior a la izquierda por TaQ y a la derecha bQ , se tiene
biTa
tBbi
Ta
tAibi
Tabi
Tai QFQeQFQeBQWQQWQA iiii −=− ∆−∆ .
Llamando
biTa
tBbi
Ta
tA QFQeQFQeC iiii −= ∆−∆ ,
biTa QWQW =1 ,
se obtiene la ecuación casi triangular de Sylvester
CBWWA ii =− 11 ,
con lo que iW se puede obtener resolviendo la ecuación anterior mediante el Algoritmo 3.14, y calculando
Tbai QWQW 1= .
El siguiente algoritmo calcula la matriz 1+iY de la expresión ( 4.102 ), según el método descrito en los párrafos anteriores.
),,,,,,(2 211 cctYFBAdlabcY ii ∆=+ .
Entradas: Matriz mxmA ℜ∈ , matriz nxnB ℜ∈ , matriz mxnF ℜ∈ , matriz mxniY ℜ∈ ,
incremento de tiempo ℜ∈∆t , vectores qcc ℜ∈21, que contienen a los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz mxniY ℜ∈+1 (véase expresión ( 4.102 )).
1 )(],[ AschurAQa = ( descomposición real de Schur de la matriz A ) 2 )(],[ BschurBQb = ( descomposición real de Schur de la matriz B ) 3 ),,( 21 cctAdqtexppadEa ∆= (modificación del Algoritmo 2.1) 4 ),,( 21 cctBdqtexppadEb ∆= (modificación del Algoritmo 2.1) 5 b
Ta FQQF =
6 FFEEF ba −= 7 ),,( FBAdtrsylF −= (Algoritmo 3.14) 8 T
baii FQQYY +=+1
Algoritmo 4.30: Calcula la solución aproximada en el instante 1+it de una EDMR con coeficientes constantes mediante la ecuación conmutante.
Notas:
• La exponencial de una matriz casi triangular superior ( dqtexppad ) se puede obtener mediante una modificación del Algoritmo 2.1 para el caso de matrices casi triangulares superiores. El coste aproximado del algoritmo anterior es
3223 256229 nmnnmm +++ +coste(Algoritmo 2.1) flops.

Capítulo 4: Linealización a Trozos
184
• Si las matrices A y B del algoritmo anterior son nulas, entonces tFYY ii ∆+=+1 .
• Si las matrices A y B del algoritmo anterior tienen algún valor propio muy cercano, entonces sería conveniente utilizar el Algoritmo 4.28 o el Algoritmo 4.32 que se describe en el siguiente subapartado.
),,,( 0 qXdatatdgedmrlccY = .
Entradas: Instantes de tiempo it ( li ≤≤0 ), función data que obtiene las matrices coeficiente de la EDMR nxnA ℜ∈11 , nxmA ℜ∈12 , mxnA ℜ∈21 , mxmA ℜ∈22 , matriz inicial mxnX ℜ∈0 , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 ()],,,[ 22211211 dataAAAA = 3 00 XY = 4 Para 1:0 −= li
4.1 122222 AYAA i−= 4.2 iYAAF 2221 += 4.3 11AYFF i−= 4.4 iYAAA 121111 += 4.5 ii ttt −=∆ +1 4.6 ),,,,,,(2 2111221 cctYFAAdlabcY ii ∆=+ (Algoritmo 4.30)
Algoritmo 4.31: Resolución de EDMRs con coeficientes constantes mediante el método de linealización a trozos basado en la ecuación conmutante.
El coste aproximado por iteración del algoritmo anterior es 22 44 mnnm + +coste(Algoritmo 4.30) flops.
4.3.2.3 Método Basado en los Subespacios de Krylov
La matriz 1+iY de la expresión ( 4.89 ), solución aproximada en el instante 1+it de la EDMR ( 4.77 ), se puede expresar como
( 4.107 ) )(mat))(vec)((mat )(121 i
tCmxni
imxnii veYFtFYY ii∆
+ +=∆+= ,
siendo
⎥⎦
⎤⎢⎣
⎡=
mnmn
mnii
IJC
00
y
⎥⎦
⎤⎢⎣
⎡=
i
mnxi f
v 10.

Capítulo 4: Linealización a Trozos
185
El siguiente algoritmo calcula la matriz 1+iY de la expresión ( 4.107 ) mediante una adaptación a bloques del Algoritmo 4.9, minimizando con ello los costes computacionales y de almacenamiento.
),,,,,,,,(2 211 cctolptYFBAdlabkY ii ∆=+ .
Entradas: Matriz mxmA ℜ∈ , matriz nxnB ℜ∈ , matriz mxnF ℜ∈ , matriz mxniY ℜ∈ ,
incremento de tiempo ℜ∈∆t , dimensión +∈ Zp de los subespacios de Krylov, tolerancia +ℜ∈tol , vectores qcc ℜ∈21, que contienen a los coeficientes de los términos de grado mayor que cero de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Salida: Matriz mxniY ℜ∈+1 de la expresión ( 4.107 ).
1 )(Fvecf = 2 2|||| f=β 3 Si 0==β
3.1 Salir del algoritmo. 4 0)1,1( =H ; tH ∆=)1,2( 5 mnV 0)1(:, = ; β/)2(:, fV = ; tAA ∆= ; tBB ∆= 6 Para pj :2=
6.1 ))(:,,,( jVBAdlapkvw = (Algoritmo 4.24) 6.2 0),( =jiH 6.3 Para ji :2=
6.3.1 )(:,),( iVwjiH T= 6.3.2 )(:,),( iVjiHww −=
6.4 2|||| ws = 6.5 Si tols <
6.5.1 jp = 6.5.2 Salir del bucle
6.6 sjjH =+ ),1( 6.7 swjV /)1(:, =+
7 ),),:1,:1(():1,:1( 21 ccppHdlaexpppH = (Algoritmo 4.3) 8 ))1,:1():1(:,(mat1 pHpVYY mxnii β+=+
Algoritmo 4.32: Calcula la solución aproximada en el instante 1+it de una EDMR con coeficientes constantes mediante la modificación a bloques del Algoritmo 4.9.
El coste computacional aproximado en flops del algoritmo anterior es
)1(222 22 +++ pmnpmpnpmn +coste(Algoritmo 2.1) flops.
Por último, se presenta el algoritmo que resuelve EDMRs con coeficientes constantes mediante el método de linealización a trozos basado en los subespacios de Krylov.

Capítulo 4: Linealización a Trozos
186
),,,,,( 0 qtolpXdatatdgedmrlkcY = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función data que obtiene las matrices coeficiente de la EDMR nxnA ℜ∈11 , nxmA ℜ∈12 , mxnA ℜ∈21 , mxmA ℜ∈22 , matriz inicial mxnX ℜ∈0 , dimensión +∈ Zp del subespacio de Krylov, tolerancia +ℜ∈tol , grado +∈ Zq de los polinomios de la aproximación diagonal de Padé.
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 )(],[ 21 qdlapexcc = (Algoritmo 4.2) 2 ()],,,[ 22211211 dataAAAA = 3 00 XY = 4 Para 1:0 −= li
4.1 1222 AYAA i−= 4.2 iAYAF += 21 4.3 11AYFF i−= 4.4 iYAAB 1211 += 4.5 ii ttt −=∆ +1 4.6 ),,,,,,,,(2 211 cctolptYFBAdlabkY ii ∆=+ (Algoritmo 4.32)
Algoritmo 4.33: Resolución de EDMRs con coeficientes constantes mediante el método de linealización a trozos basado en los subespacios de Krylov.
El coste aproximado por iteración del algoritmo anterior es 22 44 mnnm + +coste(Algoritmo 4.32) flops.
4.4 Conclusiones En este capitulo se han desarrollado nuevos métodos y algoritmos que resuelven EDOs y EDMRs basados en la técnica de linealización a trozos.
Para la resolución de EDOs se han desarrollado tres métodos basados en la linealización a trozos comentada en el apartado 2.3.4. En dos de los métodos desarrollados no es necesario que la matriz Jacobiana sea invertible. Estos métodos se basan en el Teorema 4.1 que permite obtener la solución aproximada de la EDO en cada subintervalo mediante el cálculo de la exponencial de la matriz definida a bloques que aparece en dicho teorema. El primero de ellos está basado en los aproximantes diagonales de Padé y el segundo en los subespacios de Krylov. Para cada uno de ellos se ha diseñado un algoritmo que permite resolver eficientemente, en términos de almacenamiento y coste, EDOs. A partir del Teorema 4.1 también se ha presentado otro método, basado en la Ecuación Conmutante, que es formalmente equivalente al cálculo de la solución analítica en cada subintervalo, pero realizando dicho cálculo de manera que se reduce su coste computacional. En este método es necesario que la matriz Jacobiana sea invertible.
Para la resolución de EDMRs se ha desarrollado una nueva metodología basada en la técnica de linealización a trozos. Esta metodología consiste, básicamente, en transformar la EDMR en una EDO y aplicar a esta ecuación la técnica de linealización a

Capítulo 4: Linealización a Trozos
187
trozos de EDOs. Puesto que la EDL así obtenida es de gran dimensión, se hace necesaria la aplicación de métodos especiales para su resolución.
El primer método está basado en el Teorema 4.3 que permite transformar el problema vectorial de gran dimensión en uno de tipo matricial. Este teorema muestra la manera de calcular la aproximación de la solución en un cierto instante, a partir de la aproximación en el instante anterior, mediante el cálculo de las dos exponenciales de matrices definidas a bloques que aparecen en dicho teorema. Por lo tanto, ha sido necesario desarrollar un algoritmo que calculase, de manera eficiente, dicha aproximación, realizando para ello una modificación del método de los aproximantes diagonales de Padé para el cálculo simultáneo de ciertos bloques de las exponenciales de las dos matrices mencionadas anteriormente.
El segundo método consiste en aplicar la Ecuación Conmutante a la matriz que aparece al aplicar el Teorema 4.1 tras el proceso de vectorización. Al aplicar la citada ecuación, se demuestra que, para poder determinar la solución aproximada en un instante de tiempo, es necesario resolver ecuaciones del tipo Sylvester; de este modo, se ha trasformado un problema vectorial de gran dimensión a otro de tipo matricial. Correspondientemente, se ha desarrollado un algoritmo que permite calcular eficientemente la solución en un cierto instante mediante la resolución de tres ecuaciones matriciales de Sylvester, reduciendo las matrices coeficiente de estas ecuaciones matriciales a la forma real de Schur y aplicando, a continuación, una adaptación del método de Bartels-Stewart.
El tercer y último método calcula el producto de la exponencial de una matriz definida a bloques, obtenida en el proceso de vectorización, por un vector, aplicando para ello una adaptación a bloques del método de proyección basado en los subespacios de Krylov.
Tanto para EDOs autónomas como para EDMRs con coeficientes constantes ha sido necesario adaptar, convenientemente, los anteriores algoritmos, optimizando con ello los costes computacionales y de almacenamiento.
El coste computacional de los métodos desarrollados (tanto para la resolución de EDOs como para la resolución de EDMRs) y la precisión de los mismos dependen de ciertos parámetros característicos que a continuación se citan.
• Métodos basados en los aproximantes diagonales de Padé: grado de los polinomios de la aproximación diagonal de Padé.
• Métodos basados en Ecuación Conmutante: grado de los polinomios de la aproximación diagonal de Padé.
• Métodos basados en los subespacios de Krylov: dimensión de los subespacios de Krylov, grado de los polinomios de la aproximación diagonal de Padé y la tolerancia.
Como los valores óptimos de los citados parámetros dependen del problema considerado, es difícil pronosticar, a priori, cuál es el mejor método y cuáles son los valores óptimos de sus parámetros característicos.
Otro aspecto de interés, nada trivial, es que es posible diseñar una rutina/función “inteligente” capaz de elegir, en función del problema, el mejor de los tres métodos desarrollados incluidos los valores adecuados de sus parámetros característicos. Esto es posible ya que los algoritmos desarrollados tienen la misma estructura, cosa obvia pues parten de una misma metodología, diferenciándose únicamente en la manera de calcular la correspondiente aproximación en un cierto instante.

Capítulo 4: Linealización a Trozos
188
Por todo ello, es necesario establecer y realizar una serie de pruebas que permitan “dar respuesta” a varias de las cuestiones surgidas con estos nuevos métodos.

Capítulo 5: Resultados Experimentales
189
Capítulo 5 Resultados Experimentales
5.1 Resumen de Contenidos En este capítulo se presentan los resultados experimentales obtenidos en la resolución de diferentes problemas de test con los algoritmos descritos en el Capítulo 3 y en el Capítulo 4. Las implementaciones de los algoritmos se han realizado tanto en MATLAB como en FORTRAN.
Las implementaciones en MATLAB se han realizado sobre un ordenador portátil Toshiba con procesador Intel Movile a 2Ghz y 512 Mb de memoria. En las pruebas realizadas se han utilizado la versión 7, por poseer potentes herramientas de depuración de código, y la versión 5.3, por disponer de una función que permite calcular el número de flops de los códigos escritos en MATLAB. Las implementaciones en FORTRAN se han realizado sobre un nodo de un SGI Altix 3700 [SGIAltix], utilizando la versión 8.1 del compilador FORTRAN de Intel y la versión 1.5.1 de la librería SCSL para las llamadas a BLAS y LAPACK, todo ello incluido en el software de esa máquina.
Para cada tipo de prueba se han elegido ejemplos característicos que permitiesen determinar, por una parte, la precisión de los algoritmos implementados y, por otra, determinar la eficiencia de los mismos. Hay que destacar tanto la gran cantidad de pruebas realizadas como la amplia gama de las mismas. Por ejemplo, se han analizado casos de estudio en los que la solución analítica es conocida y así probar la precisión de los algoritmos implementados. Se han seleccionado también problemas con altos costes computacionales eligiendo para ello problemas de gran dimensión. En el caso de la resolución de EDOs y EDMRs se han utilizado casos de estudio que corresponden a problemas de tipo rígido y no rígido, comparándolos con métodos establecidos y muy usados como los basados en el método BDF. Además, para cada prueba realizada se han determinado los valores óptimos, en cuanto a precisión y eficiencia, de los parámetros característicos de cada una de las implementaciones de manera que la comparación reflejase, lo más fielmente posible, el comportamiento de cada uno de los algoritmos implementados.
El contenido de este capítulo está estructurado en seis secciones. En la segunda sección se comparan las diferentes implementaciones realizadas en FORTRAN para el cálculo de Funciones de Matrices. En la tercera sección se analizan los resultados obtenidos en la simulación de la propagación de ondas en fibras de cristal fotónico. En las secciones cuarta y quinta se comparan las prestaciones obtenidas por las funciones y rutinas que resuelven EDOs y EDMRs, tanto a nivel de costes en flops, utilizando MATLAB, como de tiempos de ejecución, utilizando las implementaciones en FORTRAN. En la sexta sección se resumen los resultados más destacados de las pruebas realizadas.
La nomenclatura utilizada para las funciones implementadas en MATLAB y las rutinas implementadas en FORTRAN están descritas en las secciones 1.1, 3.1 y 4.1.

Capítulo 5: Resultados Experimentales
190
5.2 Cálculo de Funciones de Matrices En esta sección se presentan los resultados correspondientes a las implementaciones en MATLAB y FORTRAN de los algoritmos que calculan funciones de matrices.
Sea nxnA ℜ∈ y f una función matricial. Si nxnB ℜ∈ es la matriz obtenida al utilizar un algoritmo que calcula )(Af , se define el error relativo asociado a la 1-norma como
1
1
||)(||||)(||
AfBAfEr −
= .
En la mayoría de las ocasiones no es posible determinar dicho error puesto que )(Af no es conocida. Por ello, en lugar de obtener dicho error, se considerará el error relativo cometido en la ecuación conmutante
1
1
||)||||||
ABBAABEc −
= .
Este error, como se pone de manifiesto en los resultados obtenidos, guarda una relación cercana con el error relativo Er .
5.2.1 Funciones Polinómicas y Racionales En este apartado se muestran los resultados correspondientes a las implementaciones de en MATLAB y FORTRAN correspondientes a los algoritmos del Capítulo 3 que calculan funciones polinómicas y racionales de matrices. Para estas implementaciones se han utilizado los métodos de Horner y Paterson-Stockmeyer-Van Loan. En el caso de las funciones racionales aparece un sistema lineal )()( ApXAq = (siendo p y q los polinomios que definen la función racional), que se resuelve utilizando la descomposición LU con pivotamiento parcial de filas o la descomposición QR. Las rutinas que se van analizar son:
• dgefpohor: Calcula )(ApB = con p polinomio y nxnA ℜ∈ mediante el método de Horner.
• dgefpopsv: Calcula )(ApB = con p polinomio y nxnA ℜ∈ mediante el método de Paterson-Stockmeyer-Van Loan.
• dgefrahlu: Calcula )(/)( AqAp con p y q polinomios y nxnA ℜ∈ mediante el método de Horner, utilizando la descomposición LU con pivotamiento parcial de filas para la resolución del sistema de ecuaciones lineales )()( ApXAq = .
• dgefrahqr: Calcula )(/)( AqAp con p y q polinomios y nxnA ℜ∈ mediante el método de Horner, utilizando la descomposición QR para la resolución del sistema de ecuaciones lineales )()( ApXAq = .
• dgefraplu: Calcula )(/)( AqAp con p y q polinomios y nxnA ℜ∈ mediante el método de Paterson-Stockmeyer-Van Loan, utilizando la descomposición LU con pivotamiento parcial de filas para la resolución del sistema de ecuaciones lineales
)()( ApXAq = .

Capítulo 5: Resultados Experimentales
191
• dgefrapqr: Calcula )(/)( AqAp con p y q polinomios y nxnA ℜ∈ mediante el método de Paterson-Stockmeyer-Van Loan, utilizando la descomposición QR para la resolución del sistema de ecuaciones lineales )()( ApXAq = .
Puesto que el coste computacional y de almacenamiento en los algoritmos basados en el método de Paterson-Stockmeyer-Van Loan dependen del factor de agrupamiento s y del grado de los polinomios de la aproximación diagonal de Padé, se ha considerado conveniente variar esos valores y de este modo comprobar experimentalmente cuáles son sus valores óptimos en función del tamaño de la matriz.
5.2.1.1 Resultados Funciones Polinómicas En las pruebas realizadas se ha variado el grado g de los polinomios entre 5 y 14, el factor de agrupamiento s entre 2 y 8, y la dimensión de la matriz n entre 100 y 1000 en pasos de 100. Además, los coeficientes de la matriz y del polinomio se han generado aleatoriamente en el intervalo [-1,1].
Debido a la gran cantidad de resultados obtenidos únicamente se muestran los tiempos de ejecución correspondientes a matrices aleatorias de dimensiones 500 y 1000. Las precisiones obtenidas en todos los casos para la ecuación conmutante han sido del orden de 1410− . En la siguiente tabla se presentan los tiempos de ejecución de las rutinas dgefpohor y dgefpopsv.
Te g=5 g=6 g=7 g=8 g=9
dgefpohor 0.508 0.508 0.51 0.51 0.513
dgefpopsv s=2 0.444 0.444 0.447 0.449 0.449
dgefpopsv s=3 0.378 0.38 0.382 0.382 0.385
dgefpopsv s=4 0.437 0.439 0.441 0.444 0.446
dgefpopsv s=5 0.435 0.435 0.438 0.44 0.442
dgefpopsv s=6 0.494 0.496 0.496 0.499 0.501
dgefpopsv s=7 0.49 0.493 0.495 0.495 0.497
dgefpopsv s=8 0.549 0.552 0.554 0.556 0.556
Tabla 5.1: Tiempos de ejecución, en segundos, de las rutinas dgefpohor y dgefpopsv, para una matriz aleatoria de dimensión igual a 500, variando el grado g del polinomio entre 5 y 9, y el factor s de agrupamiento entre 2 y 8.

Capítulo 5: Resultados Experimentales
192
Te g=10 g=11 g=12 g=13 g=14
dgefpohor 0.513 0.515 0.515 0.518 0.518
dgefpopsv s=2 0.451 0.453 0.453 0.456 0.458
dgefpopsv s=3 0.387 0.389 0.389 0.392 0.394
dgefpopsv s=4 0.446 0.448 0.45 0.453 0.455
dgefpopsv s=5 0.444 0.447 0.447 0.449 0.451
dgefpopsv s=6 0.503 0.506 0.508 0.51 0.51
dgefpopsv s=7 0.5 0.502 0.504 0.507 0.509
dgefpopsv s=8 0.559 0.561 0.563 0.566 0.568
Tabla 5.2: Tiempos de ejecución, en segundos, de las rutinas dgefpohor y dgefpopsv, para una matriz aleatoria de dimensión igual a 500, variando el grado g del polinomio entre 10 y 14, y el factor s de agrupamiento entre 2 y 8.
Te g=5 g=6 g=7 g=8 g=9
dgefpohor 3.6434 3.6437 3.6436 3.6431 3.6435
dgefpopsv s=2 3.1991 3.1983 3.199 3.1983 3.1986
dgefpopsv s=3 2.7534 2.7537 2.7536 2.7537 2.7532
dgefpopsv s=4 3.1946 3.1941 3.1943 3.1944 3.1946
dgefpopsv s=5 3.1925 3.1924 3.1923 3.1921 3.1922
dgefpopsv s=6 3.6333 3.6334 3.6333 3.633 3.6336
dgefpopsv s=7 3.6311 3.6311 3.6314 3.6314 3.6313
dgefpopsv s=8 4.0722 4.0723 4.0722 4.0719 4.0721
Tabla 5.3: Tiempos de ejecución, en segundos, de las rutinas dgefpohor y dgefpopsv, para una matriz aleatoria de dimensión igual a 1000, variando el grado g del polinomio entre 5 y 9, y el factor s de agrupamiento entre 2 y 8.

Capítulo 5: Resultados Experimentales
193
Te g=10 g=11 g=12 g=13 g=14
dgefpohor 3.6435 3.6434 3.6435 3.6432 3.6433
dgefpopsv s=2 3.1986 3.1983 3.1987 3.1984 3.1988
dgefpopsv s=3 2.7532 2.7537 2.7537 2.7538 2.7535
dgefpopsv s=4 3.1946 3.1945 3.1943 3.1941 3.1945
dgefpopsv s=5 3.1922 3.1924 3.1923 3.1921 3.1924
dgefpopsv s=6 3.6336 3.6334 3.6334 3.633 3.6329
dgefpopsv s=7 3.6313 3.6309 3.6309 3.6314 3.6316
dgefpopsv s=8 4.0721 4.0725 4.0723 4.072 4.0723
Tabla 5.4: Tiempos de ejecución, en segundos, de las rutinas dgefpohor y dgefpopsv, para una matriz aleatoria de dimensión igual a 1000, variando el grado g del polinomio entre 10 y 14, y el factor s de agrupamiento entre 2 y 8.
De las anteriores tablas se pueden extraer las siguientes conclusiones:
• Los menores tiempos de ejecución corresponden a la rutina dgefpopsv con un factor de agrupamiento igual a 3.
• El tiempo de ejecución no varía apenas cuando se aumenta el grado del polinomio.
En la siguientes figuras se muestran los tiempos de ejecución de las rutinas dgefpohor y dgefpopsv (s=3), para matrices de dimensiones 500 y 1000, variando el grado g del polinomio entre 5 y 14.

Capítulo 5: Resultados Experimentales
194
5 6 7 8 9 10 11 12 13 140.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7Dimensión de la matriz n=500
Grado g
Tiem
po (s
egun
dos)
dgefpohordgefpopsv (s=3)
Figura 5.1: Tiempos de ejecución, en segundos, de las rutinas
dgefpohor y dgefpopsv (s=3), para una matriz aleatoria de dimensión igual a 500, variando el grado g del polinomio entre 5 y 14.
5 6 7 8 9 10 11 12 13 142
2.5
3
3.5
4
4.5
5Dimensión de la matriz n=500
Grado g
Tiem
po (s
egun
dos)
dgefpohordgefpopsv (s=3)
Figura 5.2: Tiempos de ejecución, en segundos, de las rutinas
dgefpohor y dgefpopsv (s=3), para una matriz aleatoria de dimensión igual a 1000, variando el grado g del polinomio entre 5 y 14.
5.2.1.2 Resultados Funciones Racionales En este estudio se han considerado sólo funciones racionales donde los polinomios del numerador y del denominador tienen grados iguales. El grado g de los polinomios se ha variado entre 5 y 9, el factor de agrupamiento s entre 2 y 8 y la dimensión de la matriz

Capítulo 5: Resultados Experimentales
195
entre 100 y 1000 en pasos de 100. Además, los coeficientes de la matriz y de los polinomios se han generado aleatoriamente en el intervalo [-1,1].
En primer lugar se presentan dos tablas en las que se muestran los errores relativos de la ecuación conmutante para tamaños de matrices 500 y 1000, correspondientes a las rutinas dgefrahqr, dgefrahlu, dgefrapqr y dgefraplu.
Ec g=5 g=6 g=7 g=8 g=9
dgefrahqr 8.29e-10 1.21e-09 2.59e-07 2.44e-06 9.24e-06
dgefrahlu 2.88e-10 1.30e-09 1.76e-07 1.51e-06 2.16e-05
dgefrapqr s=2 8.59e-10 4.14e-09 1.95e-07 4.37e-06 3.59e-06
dgefraplu s=2 1.32e-09 6.99e-09 2.41e-07 4.37e-06 4.25e-06
dgefrapqr s=3 7.72e-10 3.45e-09 3.8e-07 3.68e-06 1.15e-06
dgefraplu s=3 1.12e-09 4.90e-09 3.27e-07 4.46e-06 2.64e-06
dgefrapqr s=4 7.21e-10 4.99e-09 2.32e-07 3.18e-06 6.28e-06
dgefraplu s=4 1.51e-09 5.06e-09 2.94e-07 3.24e-06 3.17e-06
dgefrapqr s=5 5.66e-10 3.23e-09 2.11e-07 2.51e-06 2.20e-06
dgefraplu s=5 9.66e-10 5.12e-09 2.87e-07 3.63e-06 5.80e-06
dgefrapqr s=6 5.54e-10 2.93e-09 3.18e-07 3.05e-06 5.84e-06
dgefraplu s=6 1.00e-09 4.53e-09 3.61e-07 3.76e-06 4.97e-06
dgefrapqr s=7 5.54e-10 2.51e-09 1.96e-07 3.05e-06 8.5e-06
dgefraplu s=7 1.00e-09 5.31e-09 0.20e-07 3.91e-06 3.18e-06
dgefrapqr s=8 5.54e-10 2.51e-09 1.45e-07 2.31e-06 2.53e-06
dgefraplu s=8 1.00e-09 5.31e-09 4.32e-07 3.27e-06 4.67e-06
Tabla 5.5: Errores relativos cometidos en la ecuación conmutante, correspondientes a las rutinas dgefrahqr, dgefrahlu, dgefrapqr y dgefraplu, para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios entre 5 y 9, y el factor s de agrupamiento entre 2 y 8.

Capítulo 5: Resultados Experimentales
196
Ec g=5 g=6 g=7 g=8 g=9
dgefrahqr 6.93e-09 2.58e-07 1.84e-07 1.42e-4 2.54e-3
dgefrahlu 1.01e-08 6.71e-07 2.12e-07 1.33e-4 4.11e-3
dgefrapqr s=2 5.17e-09 2.22e-07 5.63e-07 2.25e-4 2.82e-3
dgefraplu s=2 1.45e-08 5.37e-07 1.36e-06 3.66e-4 3.63e-03
dgefrapqr s=3 5.25e-09 2.05e-07 5.62e-07 1.74 e-4 1.93e-03
dgefraplu s=3 1.34e-08 4.99e-07 8.71e-07 3.26e-4 3.40e-03
dgefrapqr s=4 5.46e-09 1.89e-07 4.17e-07 1.43e-4 2.12e-03
dgefraplu s=4 1.47e-08 4.75e-07 1.2e-06 2.89e-4 3.57e-03
dgefrapqr s=5 4.51e-09 1.71e-07 4.21e-07 1.36e-4 1.47e-03
dgefraplu s=5 1.47e-08 4.28e-07 1.47e-06 3.07e-4 3.59e-03
dgefrapqr s=6 4.77e-09 1.42e-07 3.61e-07 1.59e-4 1.93e-03
dgefraplu s=6 1.3e-08 4.83e-07 9.97e-07 3.41e-4 2.83e-03
dgefrapqr s=7 4.77e-09 1.41e-07 3.42e-07 1.25e-4 1.55e-03
dgefraplu s=7 1.3e-08 4.85e-07 7.88e-07 3.26e-4 4.23e-03
dgefrapqr s=8 4.77e-09 1.41e-07 3.62e-07 7.98e-05 1.66e-03
dgefraplu s=8 1.3e-08 4.85e-07 1e-06 2.69e-4 3.30e-03
Tabla 5.6: Errores cometidos en la ecuación conmutante correspondientes a las rutinas dgefrahqr, dgefrahlu, dgefrapqr y dgefraplu, para una matriz aleatoria de dimensión igual a 1000, variando el grado g del polinomio entre 5 y 9, y el factor s de agrupamiento entre 2 y 8.
A continuación se presentan dos tablas y dos gráficas en las que aparecen los tiempos de ejecución correspondientes a las rutinas dgefrahqr, dgefrahlu, dgefrapqr y dgefraplu, considerando matrices aleatorias de dimensiones 500 y 1000, variando el grado g de los polinomios entre 5 y 9, y el factor s de agrupamiento entre 2 y 8.

Capítulo 5: Resultados Experimentales
197
Te g=5 g=6 g=7 g=8 g=9
dgefrahqr 0.934 1.060 1.190 1.320 1.440
dgefrahlu 0.787 0.914 1.040 1.170 1.300
dgefrapqr s=2 0.561 0.685 0.690 0.813 0.818
dgefraplu s=2 0.414 0.537 0.543 0.666 0.671
dgefrapqr s=3 0.503 0.626 0.631 0.636 0.759
dgefraplu s=3 0.355 0.478 0.483 0.488 0.611
dgefrapqr s=4 0.560 0.565 0.569 0.693 0.698
dgefraplu s=4 0.413 0.417 0.422 0.546 0.551
dgefrapqr s=5 0.618 0.624 0.628 0.633 0.638
dgefraplu s=5 0.471 0.476 0.481 0.486 0.491
dgefrapqr s=6 0.558 0.682 0.687 0.692 0.696
dgefraplu s=6 0.411 0.534 0.54 0.545 0.549
dgefrapqr s=7 0.617 0.622 0.745 0.750 0.755
dgefraplu s=7 0.470 0.474 0.598 0.603 0.608
dgefrapqr s=8 0.676 0.681 0.686 0.809 0.814
dgefraplu s=8 0.529 0.533 0.538 0.662 0.667
Tabla 5.7: Tiempos de ejecución, en segundos, de las rutinas dgefrahqr, dgefrahlu, dgefrapqr y dgefraplu, para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios entre 5 y 9, y el factor s de agrupamiento entre 2 y 8.

Capítulo 5: Resultados Experimentales
198
Te g=5 g=6 g=7 g=8 g=9
dgefrahqr 0.934 1.06 1.19 1.32 1.44
dgefrahlu 0.787 0.914 1.04 1.17 1.30
dgefrapqr s=2 0.561 0.685 0.69 0.813 0.818
dgefraplu s=2 0.414 0.537 0.543 0.666 0.671
dgefrapqr s=3 0.503 0.626 0.631 0.636 0.759
dgefraplu s=3 0.355 0.478 0.483 0.488 0.611
dgefrapqr s=4 0.56 0.565 0.569 0.693 0.698
dgefraplu s=4 0.413 0.417 0.422 0.546 0.551
dgefrapqr s=5 0.618 0.624 0.628 0.633 0.638
dgefraplu s=5 0.471 0.476 0.481 0.486 0.491
dgefrapqr s=6 0.558 0.682 0.687 0.692 0.696
dgefraplu s=6 0.411 0.534 0.54 0.545 0.549
dgefrapqr s=7 0.617 0.622 0.745 0.75 0.755
dgefraplu s=7 0.47 0.474 0.598 0.603 0.608
dgefrapqr s=8 0.676 0.681 0.686 0.809 0.814
dgefraplu s=8 0.529 0.533 0.538 0.662 0.667
Tabla 5.8: Tiempos de ejecución, en segundos, de las rutinas dgefrahqr, dgefrahlu, dgefrapqr y dgefraplu, para una matriz aleatoria de dimensión igual a 1000, variando el grado g de los polinomios entre 5 y 9, y el factor s de agrupamiento entre 2 y 8.
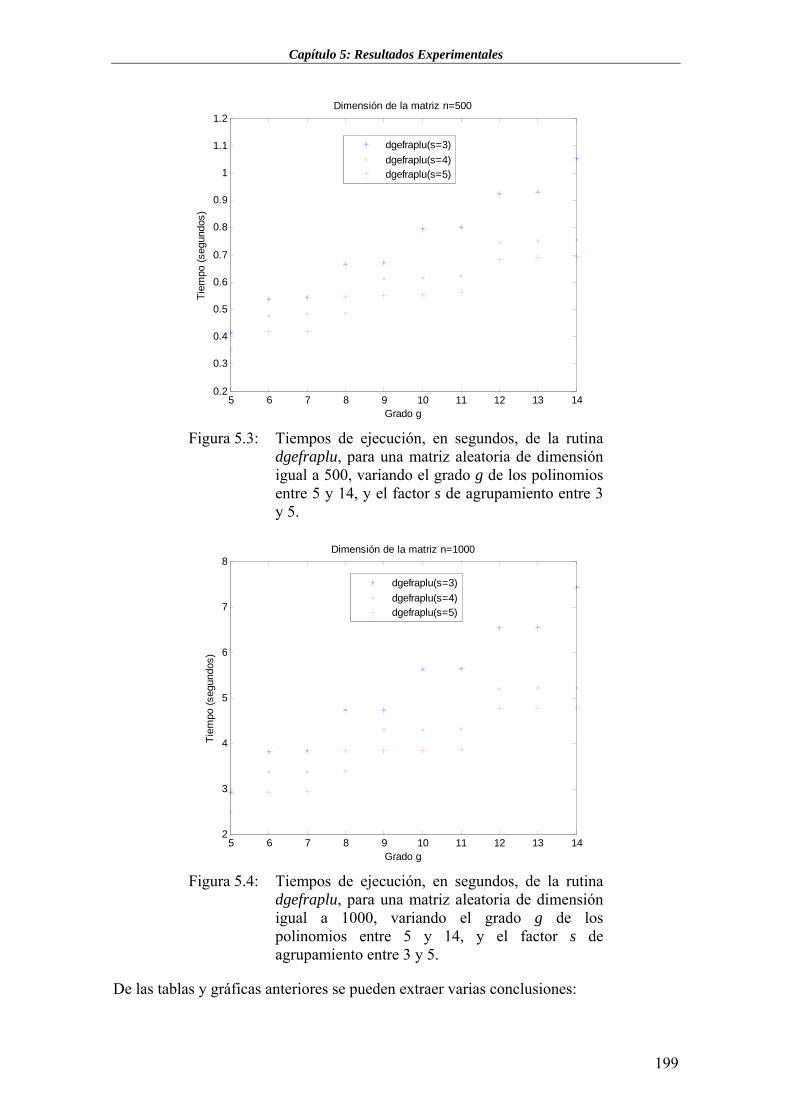
Capítulo 5: Resultados Experimentales
199
5 6 7 8 9 10 11 12 13 140.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2Dimensión de la matriz n=500
Grado g
Tiem
po (s
egun
dos)
dgefraplu(s=3)dgefraplu(s=4)dgefraplu(s=5)
Figura 5.3: Tiempos de ejecución, en segundos, de la rutina
dgefraplu, para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios entre 5 y 14, y el factor s de agrupamiento entre 3 y 5.
5 6 7 8 9 10 11 12 13 142
3
4
5
6
7
8Dimensión de la matriz n=1000
Grado g
Tiem
po (s
egun
dos)
dgefraplu(s=3)dgefraplu(s=4)dgefraplu(s=5)
Figura 5.4: Tiempos de ejecución, en segundos, de la rutina
dgefraplu, para una matriz aleatoria de dimensión igual a 1000, variando el grado g de los polinomios entre 5 y 14, y el factor s de agrupamiento entre 3 y 5.
De las tablas y gráficas anteriores se pueden extraer varias conclusiones:

Capítulo 5: Resultados Experimentales
200
• Se produce una pérdida de precisión a medida que aumenta el grado del polinomio y la dimensión de la matriz.
• Las rutinas que utilizan la descomposición QR tienen un error algo menor que las rutinas que utilizan la descomposición LU con pivotamiento parcial de filas, aunque estas últimas son más rápidas que las primeras.
• Las rutinas basadas en el método de Paterson-Stockmeyer-Van Loan tienen, en general, un tiempo de ejecución menor que las rutinas que utilizan el método de Horner, siendo la rutina dgefraplu la que presenta mejores resultados cuando se eligen factores de agrupamiento s comprendidos entre 3 y 5.
5.2.2 Rutinas Basadas en los Aproximantes Diagonales de Padé Para el cálculo de funciones de matrices basadas en la aproximación diagonal de Padé, se han utilizado las siguientes variantes:
• Resolución del sistema de ecuaciones lineales, que aparece en la aproximación diagonal de Padé mediante la descomposición LU con pivotamiento parcial de filas o mediante la descomposición QR.
• Utilización del método de Horner o del método de Paterson-Stockmeyer-Van Loan.
En función de estas variantes se han obtenido 4 rutinas que implementan la misma función matricial. En la siguiente figura aparecen las citadas aproximaciones.
⎪⎪
⎩
⎪⎪
⎨
⎧
⎩⎨⎧
⎩⎨⎧
QRción DescomposiLUción Descomposi
Horner de Método
QRción DescomposiLUción Descomposi
LoanVan -Stockmeyer-Paterson de Métodof(A) de Cálculo
Figura 5.5: Rutinas que calculan funciones de matrices mediante los aproximantes diagonales de Padé.
Se han realizado pruebas para todas las implementaciones de los algoritmos descritos en el Capítulo 3, pero únicamente se presentan los resultados correspondientes a la función exponencial y a la potencia fraccionaria de una matriz.
El grado g de los polinomios de la aproximación diagonal de Padé se ha variado entre 5 y 14, y el factor s de agrupamiento entre 2 y 8. Los coeficientes de las matrices se han generado aleatoriamente en el intervalo ]10,10[− , y sus dimensiones se han variado entre 100 y 1000 en pasos de 100.
Los errores que se han calculado para cada prueba han sido:
• Error relativo (Er), comparando la solución obtenida con los métodos basados en los aproximantes diagonales de Padé con la solución obtenida utilizando un método basado en la descomposición real de Schur de una matriz (estos métodos son más precisos que los basados en la aproximación de Padé).
• Error relativo en la ecuación conmutante (Ec).
En las siguientes tablas se muestran los errores Er y Ec para tamaños de matrices 100, 500 y 1000 correspondientes a las rutinas dgefexhlu. Únicamente se ha tenido en cuenta el valor de agrupamiento s=2, pues para los otros valores los resultados son semejantes.

Capítulo 5: Resultados Experimentales
201
g=5 g=6 g=7 g=8 g=9
Er .337e-12 .277e-12 .335e-12 .169e-12 .261e-12
Ec .297e-13 .260e-13 .150e-13 .182e-13 .202e-13
Tabla 5.9: Errores relativos de la rutina dgefexhlu para una matriz aleatoria de dimensión igual a 100, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9.
g=10 g=11 g=12 g=13 g=14
Er .177e-12 .384e-12 .101e-12 .291e-12 .259e-12
Ec .252e-13 .204e-13 .150e-13 .146e-13 .234e-13
Tabla 5.10: Errores relativos de la rutina dgefexhlu para una matriz aleatoria de dimensión igual a 100, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 10 y 14.
g=5 g=6 g=7 g=8 g=9
Er .834e-12 .595e-12 .607e-12 .125e-11 .334e-12
Ec .657e-13 .856e-13 .688e-13 .495e-13 .517e-13
Tabla 5.11: Errores relativos de la rutina dgefexhlu para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9.
g=10 g=11 g=12 g=13 g=14
Er .647e-12 .306e-12 .232e-12 .150e-11 .830e-12
Ec .557e-13 .624e-13 .620e-13 .651e-13 .953e-13
Tabla 5.12: Errores relativos de la rutina dgefexhlu para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 10 y 14.

Capítulo 5: Resultados Experimentales
202
g=5 g=6 g=7 g=8 g=9
Er .104e-11 .178e-11 .556e-12 .709e-12 .145e-11
Ec .730e-13 .154e-12 .102e-12 .107e-12 .186e-12
Tabla 5.13: Errores relativos de la rutina dgefexhlu para una matriz aleatoria de dimensión igual a 1000, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9.
g=10 g=11 g=12 g=13 g=14
Er .818e-12 .812e-12 .102e-11 .718e-12 .130e-12
Ec .162e-12 .861e-13 .112e-12 .915e-13 .126e-12
Tabla 5.14: Errores relativos de la rutina dgefexhlu para una matriz aleatoria de dimensión igual a 1000, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 10 y 14.
De las tablas anteriores se desprenden las siguientes conclusiones:
• Los errores relativos Er y Ec aumentan moderadamente a medida que aumenta la dimensión de la matriz.
• Los errores relativos Er y Ec son similares, siendo estos últimos algo menores.
• Con un valor del grado g de la aproximación diagonal igual a 7 se obtiene una precisión aceptable.
En las siguientes tablas se muestran los tiempos de ejecución de las rutinas dgefexhlu, dgefexhqr, dgefexplu y dgefexpqr, para tamaños de matrices iguales a 500 y 1000. Estas rutinas se describen a continuación.
• dgefexhlu: Calcula la exponencial de una matriz mediante aproximantes diagonales de Padé, utilizando el método de Horner y la descomposición LU con pivotamiento parcial de filas en la resolución del sistema de ecuaciones lineales asociado.
• dgefexhqr: Calcula la exponencial de una matriz mediante aproximantes diagonales de Padé, utilizando el método de Horner y la descomposición QR en la resolución del sistema de ecuaciones lineales que aparece en el método anterior.
• dgefexplu: calcula la exponencial de una matriz mediante aproximantes diagonales de Padé, utilizando el método de Paterson-Stockmeyer-Van Loan y la descomposición LU con pivotamiento parcial de filas en la resolución del sistema de ecuaciones lineales asociado.
dgefexpqr: Calcula la exponencial de una matriz mediante aproximantes diagonales de Padé, utilizando el método de Paterson-Stockmeyer-Van Loan y la descomposición QR en la resolución del sistema de ecuaciones lineales asociado.

Capítulo 5: Resultados Experimentales
203
Te g=5 g=6 g=7 g=8 g=9
dgefexhlu 1.45 1.57 1.7 1.82 1.96
dgefexhqr 1.6 1.73 1.85 1.98 2.16
dgefexplu s=2 1.15 1.32 1.28 1.41 1.41
dgefexpqr s=2 1.3 1.46 1.44 1.58 1.57
dgefexplu s=3 1.09 1.22 1.22 1.28 1.35
dgefexpqr s=3 1.25 1.37 1.37 1.38 1.5
dgefexplu s=4 1.15 1.15 1.16 1.28 1.29
dgefexpqr s=4 1.3 1.31 1.36 1.44 1.45
dgefexplu s=5 1.21 1.21 1.23 1.22 1.23
dgefexpqr s=5 1.36 1.36 1.37 1.37 1.38
dgefexplu s=6 1.14 1.27 1.28 1.29 1.28
dgefexpqr s=6 1.29 1.42 1.43 1.44 1.44
dgefexplu s=7 1.2 1.21 1.33 1.34 1.34
dgefexpqr s=7 1.36 1.36 1.49 1.49 1.5
dgefexplu s=8 1.33 1.27 1.27 1.4 1.47
dgefexpqr s=8 1.42 1.42 1.42 1.55 1.55
Tabla 5.15: Tiempos de ejecución, en segundos, de las rutinas dgefexhlu, dgefexhqr, dgefexplu y dgefexpqr, para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9, y el factor de agrupamiento s entre 2 y 8.

Capítulo 5: Resultados Experimentales
204
Te g=10 g=11 g=12 g=13 g=14
dgefexhlu 2.07 2.2 2.32 2.49 2.59
dgefexhqr 2.23 2.34 2.48 2.59 2.76
dgefexplu s=2 1.55 1.54 1.67 1.67 1.8
dgefexpqr s=2 1.69 1.7 1.82 1.83 1.96
dgefexplu s=3 1.36 1.36 1.49 1.49 1.5
dgefexpqr s=3 1.51 1.52 1.64 1.64 1.65
dgefexplu s=4 1.29 1.3 1.43 1.43 1.43
dgefexpqr s=4 1.45 1.45 1.58 1.58 1.59
dgefexplu s=5 1.35 1.36 1.36 1.37 1.37
dgefexpqr s=5 1.51 1.51 1.51 1.52 1.53
dgefexplu s=6 1.29 1.29 1.42 1.42 1.43
dgefexpqr s=6 1.46 1.49 1.57 1.58 1.59
dgefexplu s=7 1.4 1.36 1.41 1.36 1.56
dgefexpqr s=7 1.5 1.51 1.52 1.51 1.64
dgefexplu s=8 1.41 1.41 1.42 1.42 1.42
dgefexpqr s=8 1.56 1.57 1.57 1.66 1.58
Tabla 5.16: Tiempos de ejecución, en segundos, de las rutinas dgefexhlu, dgefexhqr, dgefexplu y dgefexpqr, para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 10 y 14, y el factor de agrupamiento s entre 2 y 8..

Capítulo 5: Resultados Experimentales
205
Te g=5 g=6 g=7 g=8 g=9
dgefexhlu 11.2 12 13 13.9 14.9
dgefexhqr 12.3 13.2 14.2 14.9 16
dgefexplu s=2 8.95 9.76 9.84 10.7 10.7
dgefexpqr s=2 10 10.9 11 11.8 11.8
dgefexplu s=3 8.47 9.3 9.37 9.34 10.3
dgefexpqr s=3 9.55 10.4 10.5 10.5 11.5
dgefexplu s=4 8.89 8.84 8.93 9.77 9.86
dgefexpqr s=4 10.1 10.1 10.1 10.9 11
dgefexplu s=5 9.35 9.31 9.37 9.33 9.39
dgefexpqr s=5 10.6 10.5 10.5 10.5 10.5
dgefexplu s=6 8.9 9.73 9.82 9.76 9.84
dgefexpqr s=6 10 10.9 10.9 10.9 10.9
dgefexplu s=7 9.34 9.27 10.3 10.2 10.3
dgefexpqr s=7 10.4 10.4 11.4 11.3 11.4
dgefexplu s=8 9.79 9.71 9.81 10.6 10.8
dgefexpqr s=8 10.9 10.8 11 11.8 11.8
Tabla 5.17: Tiempos de ejecución, en segundos, de las rutinas dgefexhlu, dgefexhqr, dgefexplu y dgefexpqr, para una matriz aleatoria de dimensión igual a 1000, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9, y el factor de agrupamiento s entre 2 y 8..

Capítulo 5: Resultados Experimentales
206
Te g=10 g=11 g=12 g=13 g=14
dgefexhlu 15.6 16.7 17.3 18.4 19.1
dgefexhqr 16.8 17.8 18.4 19.5 20.2
dgefexplu s=2 11.6 11.7 12.4 12.5 13.3
dgefexpqr s=2 12.7 12.8 13.5 13.6 14.4
dgefexplu s=3 10.2 10.3 11.1 11.2 11.1
dgefexpqr s=3 11.3 11.4 12.1 12.2 12.2
dgefexplu s=4 9.77 9.82 10.6 10.7 10.6
dgefexpqr s=4 11 10.9 11.7 11.8 11.7
dgefexplu s=5 10.2 10.2 10.2 10.3 10.2
dgefexpqr s=5 11.4 11.3 11.2 11.3 11.3
dgefexplu s=6 9.78 9.79 10.6 10.7 10.6
dgefexpqr s=6 10.9 10.9 11.7 11.8 11.7
dgefexplu s=7 10.3 10.2 10.2 10.3 11.1
dgefexpqr s=7 11.3 11.3 11.2 11.3 12.1
dgefexplu s=8 10.7 10.7 10.6 10.7 10.6
dgefexpqr s=8 11.8 11.7 11.7 11.8 11.7
Tabla 5.18: Tiempos de ejecución, en segundos, de las rutinas dgefexhlu, dgefexhqr, dgefexplu y dgefexpqr, para una matriz aleatoria de dimensión igual a 1000, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 10 y 14, y el factor de agrupamiento s entre 2 y 8.
La rutina más rápida es dgefexplu, siempre que se elija un valor adecuado para su factor de agrupamiento s (por ejemplo, entre 3 y 6). A continuación se muestran dos gráficas en las que aparecen los tiempos de ejecución, en segundos, de la rutina dgefexplu, para matrices aleatorias de dimensiones 500 y 1000, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 14, y el factor de agrupamiento s entre 3 y 6.

Capítulo 5: Resultados Experimentales
207
5 6 7 8 9 10 11 12 13 141
1.05
1.1
1.15
1.2
1.25
1.3
1.35
1.4
1.45
1.5Dimensión de la matriz n=500
Grado g
Tiem
po (s
egun
dos)
dgefexplu(s=3)dgefexplu(s=4)dgefexplu(s=5)dgefexplu(s=6)
Figura 5.6: Tiempos de ejecución, en segundos, de la rutina
dgefexplu para una matriz aleatoria de dimensión igual a 500, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 14, y el factor s de agrupamiento entre 3 y 6.
5 6 7 8 9 10 11 12 13 148
8.5
9
9.5
10
10.5
11
11.5
12Dimensión de la matriz n=1000
Grado g
Tiem
po (s
egun
dos)
dgefexplu(s=3)dgefexplu(s=4)dgefexplu(s=5)dgefexplu(s=6)
Figura 5.7: Tiempos de ejecución, en segundos, de la rutina
dgefexplu para una matriz aleatoria de dimensión igual a 1000, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 14, y el factor s de agrupamiento entre 3 y 6.
De las tablas y gráficas anteriores se desprenden las siguientes conclusiones:

Capítulo 5: Resultados Experimentales
208
• Para un mismo valor de s, el tiempo de ejecución menor corresponde a la rutina dgefexplu.
• Los valores de s con menores tiempos de ejecución se encuentran entre 3 y 6.
Por último, se presentan los resultados correspondientes a la rutina dgefpfplu. Esta rutina calcula potencias fraccionarias de una matriz mediante aproximantes diagonales de Padé, utilizando el método Paterson-Stockmeyer-Van Loan y la descomposición LU con pivotamiento parcial de filas en la resolución del sistema de ecuaciones lineales que aparece en el método. En los resultados que se presentan a continuación se ha considerado el caso particular de calcular la raíz cúbica de una matriz.
En la siguiente tabla se muestran el error
1
13
||||||||
AABEr −
=
y el error Ec correspondiente a la ecuación conmutante.
g=5 g=6 g=7 g=8 g=9
Er 0.544e-07 0.266e-09 0.893e-12 0.194e-12 0.195e-12
Ec 0.241e-12 0.241e-12 0.241e-12 0.240e-12 0.245e-12
Tabla 5.19: Errores Er y Ec de la rutina dgefpfhlu para una matriz aleatoria de dimensión igual a 100, considerando un factor de agrupamiento s igual a 2 y variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9.
g=10 g=11 g=12 g=13 g=14
Er 0.195e-12 0.195e-12 0.195e-12 0.195e-12 0.194e-12
Ec 0.241e-12 0.240e-12 0.241e-12 0.242e-12 0.241e-12
Tabla 5.20: Errores Er y Ec de la rutina dgefpfhlu para una matriz aleatoria de dimensión igual a 100, considerando un factor de agrupamiento s igual a 2 y variando el grado g de los polinomios de la aproximación diagonal de Padé entre 10 y 14.
En las siguientes tablas se muestran los tiempos de ejecución de la rutina dgefpfhlu para una matriz aleatoria de dimensión igual a 100, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9, y el factor de agrupamiento s entre 2 y 8.

Capítulo 5: Resultados Experimentales
209
Te g=5 g=6 g=7 g=8 g=9
dgefpfplu s=2 3.2186 3.2317 3.2335 3.2162 3.3020
dgefpfplu s=3 3.2170 3.2147 3.2160 3.2155 3.2168
dgefpfplu s=4 3.3049 3.2177 3.2143 3.2947 3.2157
dgefpfplu s=5 3.2174 3.2497 3.2757 3.2169 3.2378
dgefpfplu s=6 3.2310 3.2354 3.2143 3.2892
dgefpfplu s=7 3.2339 3.2322 3.2592
dgefpfplu s=8 3.2190 3.2244
Tabla 5.21: Tiempos de ejecución de la rutina dgefpfhlu, para una matriz aleatoria de dimensión igual a 100, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 5 y 9, y el factor de agrupamiento s entre 2 y 8.
g=10 g=11 g=12 g=13 g=14
dgefpfplu s=2 3.2500 3.2206 3.2194 3.2202 3.2764
dgefpfplu s=3 3.2327 3.2322 3.2310 3.2352 3.2780
dgefpfplu s=4 3.2298 3.2190 3.2169 3.2177 3.2565
dgefpfplu s=5 3.2608 3.2144 3.2157 3.3472 3.2166
dgefpfplu s=6 3.2164 3.2879 3.5763 3.2243 3.2343
dgefpfplu s=7 3.2725 3.2746 3.2620 3.2612 3.2157
dgefpfplu s=8 3.2540 3.2169 3.2306 3.2347 3.2661
Tabla 5.22: Tiempos de ejecución de la rutina dgefpfhlu , para una matriz aleatoria de dimensión igual a 100, variando el grado g de los polinomios de la aproximación diagonal de Padé entre 10 y 14, y el factor de agrupamiento s entre 2 y 8.
Varias conclusiones se pueden extraer de estas cuatro últimas tablas:
• La precisión obtenida es algo menor que la obtenida en el cálculo de la exponencial de una matriz.
• Se obtiene una precisión aceptable a partir de los aproximantes diagonales de Padé de grado 7.

Capítulo 5: Resultados Experimentales
210
• Los tiempos de ejecución son similares, independientemente del grado de los polinomios del aproximante diagonal de Padé y del factor de agrupamiento.
• Los tiempos de ejecución de la rutina dgefpfplu para un tamaño de matriz igual a 100 son mayores que los tiempos de ejecución de la rutina dgefexhlu para un tamaño de matriz igual a 500.
Las dos últimas conclusiones son consecuencia del mayor coste computacional de la rutina dgefpfplu, asociado al cálculo de la raíz cuadrada de una matriz, etapa necesaria para la reducción inicial de la norma de la matriz.
5.2.3 Rutinas Basadas en la Descomposición real de Schur de una matriz
En este apartado se muestran las pruebas realizadas sobre las rutinas anteriores, salvo las correspondientes a las rutinas basadas en la agrupación de valores propios (rutinas dgeyyyscl), debido a que se ha comprobado que a partir de dimensiones de orden superior a 20, se comete un gran error a menos que se elija una agrupación mayor, coincidente en la mayoría de los casos con un único bloque. En tales casos es más eficiente utilizar directamente las rutinas basadas en los aproximantes diagonales de Padé (rutinas dgeyyysph y dgeyyyspp), puesto que estas rutinas no necesitan reordenaciones. La justificación de este comportamiento se encuentra en que el error cometido al resolver una ecuación matricial de Sylvester
ijjjii FTXXT =− ,
satisface que
),(||||
|||||~||
jjii
Fij
F
F
TTsepF
uX
XX≅
− .
Por lo tanto, para dimensiones grandes y en funciones del tipo exponencial, el error puede ser muy grande debido tanto al valor de ),( jjii TTsep como al valor de FijF |||| .
Las pruebas se han realizado para la función exponencial. El motivo es que la precisión y las prestaciones obtenidas para otras funciones son semejantes, dadas las características de los algoritmos basados en la descomposición real de Schur de una matriz, con la única excepción del basado en los aproximantes diagonales de Padé. En las pruebas realizadas se ha utilizado la rutina dgefexplu (s=3, g=7) para compararla con las rutinas anteriormente mencionadas.
Una de las medidas utilizadas para determinar la precisión de los algoritmos implementados es el error relativo cometido. Esto no siempre es posible, puesto que la solución exacta únicamente se puede conocer en determinados casos y para matrices de pequeña dimensión, exceptuando, evidentemente, el caso de exponenciales de matrices diagonales. Por ello, en algunas de las pruebas se han utilizado matrices cuya exponencial es conocida.
En primer lugar se presentan los resultados obtenidos en cuanto a precisión, determinando el error relativo en el cálculo de la exponencial y el error relativo en la ecuación conmutante. Para ello se han generado matrices de la mayor dimensión posible que pudieran ser calculadas de manera exacta por MATLAB, utilizando las funciones de MATLAB sym y double que permiten pasar, respectivamente, datos de doble

Capítulo 5: Resultados Experimentales
211
precisión a forma simbólica y datos de forma simbólica a doble precisión. Se han considerado las matrices
⎪⎩
⎪⎨
⎧
<−==
>=
ℜ∈jia
ia
jia
A
ij
ii
ijx
,1,
,04040
40
y
⎪⎩
⎪⎨
⎧
<−==
>=
ℜ∈jia
a
jia
A
ij
ii
ijx
,1,1
,07070
70 .
Aunque se han realizado pruebas en las que los parámetros característicos de cada una de ellas se han variado, únicamente se van a presentar aquellos que han obtenido buenos resultados en cuanto a precisión y coste computacional. Según esto, para las rutinas orientadas a bloques, dgefunsbc y dgefunsbd, se ha elegido un tamaño de bloque tb igual a 6 mientras que para las rutinas basadas en los aproximantes diagonales de Padé, dgefunsph y dgefunspp, se ha elegido un grado g=7 de los polinomios de la aproximación diagonal de Padé y un factor de agrupamiento s=4 para la rutina dgefunspp.
En las siguiente tablas se muestran los errores Er y Ec al calcular )( 40Af y )( 70Af .
Er Ec
dgefexplu: g=7, s=3 0.31100e-15 0.22725e-13
dgefunscd 0.47810e-16 0.10017e-15
dgefunscc 0.33498e-16 0.50839e-16
dgefunsbd: tb= 6 0.44342e-16 0.93251e-16
dgefunsbc: tb= 6 0.35363e-16 0.48357e-16
dgeexpsdb 0.24563e-16 0.33250e-14
dgeexpsph: g=7 0.17226e-15 0.13560e-13
dgeexpspp: g=7, s=4 0.50249e-15 0.22583e-13
Tabla 5.23: Errores correspondientes al cálculo de )( 40Af mediante las rutinas dgefexplu, dgefunscd, dgefunscc, dgefunsbd, dgefunsbc, dgefunsdb, dgeexpsph y dgeexpspp.

Capítulo 5: Resultados Experimentales
212
Er Ec
dgefexplu: g=7, s=3 0.21248e-15 0.45270e-13
dgefunscd Error Error
dgefunscc Error Error
dgefunsbd: tb= 6 Error Error
dgefunsbc: tb= 6 Error Error
dgeexpsdb 0.33016e-15 0.10266e-13
dgeexpsph: g=7 0.33016e-15 0.10266e-13
dgeexpspp: g=7, s=4 0.31550e-15 0.19864e-13
Tabla 5.24: Errores correspondientes al cálculo de )( 70Af mediante las rutinas dgefexplu, dgefunscd, dgefunscc, dgefunsbd, dgefunsbc, dgefunsdb, dgeexpsph y dgeexpspp.
A continuación se presentan los errores relativos cometidos en la ecuación conmutante correspondientes a las rutinas que calculan la exponencial de matrices aleatorias de tamaños 500 y 1000.
Ec 500 1000
dgefexplu: g=7, s=3 0.12378e-13 0.80748e-13
dgefunscd 0.59172e-14 0.98738e-14
dgefunscc 0.59172e-14 0.98738e-14
dgefunsbd: tb= 6 0.59369e-14 0.98059e-14
dgefunsbc: tb= 6 0.59381e-14 0.98646e-14
dgeexpsdb 0.68640e-14 0.15640e-13
dgeexpsph: g=7 0.67320e-14 0.12915e-13
dgeexpspp: g=7, s=4 0.75899e-14 0.15556e-13
Tabla 5.25: Errores cometidos (ecuación conmutante) por las rutinas dgefexplu, dgefunscd, dgefunscc, dgefunsbd, dgefunsbc, dgefunsdb, dgeexpsph y dgeexpspp en el cálculo de la exponencial de dos matrices aleatorias de dimensiones 500 y 1000.

Capítulo 5: Resultados Experimentales
213
Los algoritmos se pueden clasificar, según su precisión, en tres grupos:
• Grupo 1: rutina dgefexplu, basada en los aproximantes diagonales de Padé, y rutinas dgeexpsph y dgefunspp, basadas en la descomposición real de Schur de una matriz y en los aproximantes diagonales de Padé.
• Grupo 2: rutinas dgefunscd, dgefunscc, dgefunsbd y dgefunsbc, basadas en la descomposición real de Schur de una matriz y en la ecuación conmutante.
• Grupo 3: rutina dgeexpsdb, basada en la diagonalización por bloques de una matriz.
A partir de las tablas anteriores se pueden extraer las siguientes conclusiones:
• Los errores relativos cometidos en el cálculo de la función de una matriz y en la ecuación conmutante son similares, aunque este último es algo mayor que el primero. Esto es especialmente útil cuando no es conocido el valor exacto de la solución, pues permite conocer, aproximadamente, el error relativo cometido en el cálculo de funciones de matrices a partir del error cometido en la ecuación conmutante.
• Las rutinas del grupo 2 son algo más precisas que las restantes siempre y cuando las matrices no presenten valores propios cercanos.
• La rutina del grupo 3 es algo más precisa que las rutinas del grupo 1.
• Para matrices con valores propios separados, los errores relativos cometidos por las rutinas de los grupos 2 y 3 son de magnitudes semejantes.
• Para matrices con valores propios cercanos, las rutinas del grupo 2 presentan un elevado error.
A continuación se muestran los tiempos de ejecución de las rutinas analizadas.
Te 500 1000
dgefexplu g=7, s=3 1.0618 9.5562
dgefunscd 5.2754 108.28
dgefunscc 5.5376 119.61
dgefunsbd, tb= 6 4.8406 94.051
dgefunsbc, tb= 6 4.9379 98.215
dgefunsdb 5.5266 120.32
dgefunsph,g=7 4.9282 120.10
dgefunspp,g=7,s=4 6.0002 116.56
Tabla 5.26: Tiempos de ejecución, en segundos, de las rutinas dgefexplu, dgefunscd, dgefunscc, dgefunsbd, dgefunsbc, dgefunsdb, dgeexpsph y dgeexpspp, aplicadas al cálculo de la exponencial de dos matrices aleatorias de dimensiones 500 y 1000.

Capítulo 5: Resultados Experimentales
214
De la tabla anterior se pueden extraer las siguientes conclusiones en cuanto a tiempos de ejecución:
• La rutina dgefexplu, basada en los aproximantes diagonales de Padé, es la más rápida.
• Las rutinas basadas en la resolución de la ecuación conmutante por bloques (dgefunsbd, dgefunsbc) se encuentran en segundo lugar.
• Las rutinas basadas en la resolución de la ecuación conmutante por diagonales y columnas (dgefunscd, dgefunscc), junto con las rutinas basadas en la descomposición real de Schur de una matriz y en los aproximantes diagonales de Padé (dgeexpsph, dgeexpspp) se encuentran en tercer lugar.
• La rutina basada en la diagonalización por bloques (dgefunsdb) es la más lenta.
La justificación de estos resultados es que los algoritmos basados en los aproximantes diagonales de Padé son menos costosos que los basados en la descomposición real de Schur de una matriz y, siempre que se utilizan algoritmos orientados a bloques se obtienen tiempos de ejecución menores que los correspondientes a columnas o diagonales, debido a la localidad de los datos.
5.3 Propagación de Ondas Monocromáticas en Fibras de Cristal Fotónico
En esta sección se desarrolla un estudio completo del uso de funciones de matrices en la simulación de la propagación de ondas en fibras de cristal fotónico.
Las Fibras de Cristal Fotónico (FCF) fueron propuestas y fabricadas por primera vez en 1996 ([RuBi95]). Desde entonces, el interés sobre esta nueva tecnología ha ido creciendo debido a sus fascinantes propiedades. Las especiales características de guiado de la luz de las FCF como son, entre otras, la propagación monomodo o la dispersión ultraplana en un amplio rango de longitudes de onda, tienen potenciales aplicaciones en una gran variedad de campos que van desde las comunicaciones ópticas hasta la fabricación de dispositivos optoelectrónicos. Las propiedades de propagación del campo electromagnético en estos sistemas vienen determinadas por la configuración particular de la estructura dieléctrica transversal.
Una FCF está constituida por una fibra delgada de sílice que presenta una distribución periódica de agujeros de aire que se extienden a lo largo de toda su longitud. Tal y como se muestra en la siguiente figura, la periodicidad transversal se pierde, en general, por la ausencia de uno de estos agujeros, lo que conlleva la aparición de un defecto. La ruptura de la periodicidad genera la localización de la luz en la región del defecto.

Capítulo 5: Resultados Experimentales
215
Figura 5.8: Fibra de cristal fotónico.
La estructura de agujeros de aire constituye una red caracterizada geométricamente por la separación entre agujeros Λ y el radio a de los mismos. Típicamente Λ oscila entre 2 µm y 3 µm y el radio a entre 0,2 µm y 1,0 µm.
Cuando la potencia incidente en la fibra es suficientemente alta, las propiedades de propagación se ven modificadas por la presencia de fenómenos de carácter no lineal. Bajo estas condiciones, las propiedades ya no dependen exclusivamente de las características de la fibra, sino que también entra en juego el propio campo propagante. Este régimen de propagación es intrínsecamente más complejo, y en el caso de las FCC, da lugar a espectaculares fenómenos como la generación de supercontínuo ([Coen01]), consistente en la formación de un amplio espectro al propagarse pulsos de alta potencia por el interior de la FCC, o la propagación de solitones espaciales (FeZF03], [FeZF04]), que consisten en estructuras espaciales localizadas que se propagan no linealmente sin deformarse.
El problema consiste en modelizar la propagación no lineal de un campo monocromático en un medio inhomogéneo (la inhomogeneidad se debe a la estructura periódica de agujeros de aire). La evolución no lineal del campo eléctrico a lo largo de la fibra, viene descrita por la ecuación diferencial
( 5.1 ) ),,()),,((),,( zyxzyxLzyxz
i φφφ =∂
− ,
donde 2)3(2
020
20
2 |),,(|),(3),( zyxyxkyxnkL t φγ ∆Χ++∇= ,
siendo
• 2
2
2
22
yxt ∂∂
+∂∂
=∇ ,
• λπ /20 =k ( mµλ 1≈ longitud de onda),
• 3)3( 10−≈Χγ ,
Aire
Sílice
Defecto

Capítulo 5: Resultados Experimentales
216
• ⎩⎨⎧
aire1sílice45.1
),(0 yxn (índices de refracción),
• ⎩⎨⎧
=∆aire0sílice1
),( yx .
Las soluciones estacionarias, o solitones espaciales, de la ecuación diferencial anterior, vienen dados por la expresión
zieyxzyx βφ ),(),,( Φ= .
Mediante técnicas iterativas de resolución de problemas de autovalores no lineales, se ha comprobado que existen dichas soluciones para diversas geometrías de la fibra. Una propiedad fundamental de estas soluciones es su estabilidad, entendiendo ésta como la robustez de la estructura espacial frente a perturbaciones. La solución es estable, si tras perturbar ligeramente el campo y dejarlo evolucionar a través de la fibra, vuelve asintóticamente al estado estacionario. Así pues, para comprobar la estabilidad, se ha de simular numéricamente la propagación a lo largo de la fibra mediante la ecuación ( 5.1 ) de la solución solitónica ligeramente perturbada, tanto en amplitud como en fase
Φ+Φ= δφ ),()0,,( yxyx S .
Realizando una aproximación de grado 0 en la ecuación diferencial ( 5.1 ), se tiene que el valor aproximado de φ en hz + es
),,(),,( )),,(( zyxehzyx hzyxLi φφ φ=+ ,
lo que permite analizar la evolución de φ a lo largo del eje z.
Se trata pues de diseñar algoritmos estables y eficientes que permitan calcular la matriz hAie ,
siendo )(φLA = una matriz compleja densa, no necesariamente simétrica, de elevada norma, con valores propios múltiples, y donde h muy pequeño del orden 910− .
5.3.1 Algoritmo Basado en la Diagonalización de una Matriz Se trata de obtener la descomposición
1−= VDVA ,
siendo
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
n
D
λ
λλ
L
MOMM
L
L
00
0000
2
1
,
una matriz diagonal, iλ , ni ,,2,1 L= , los valores propios de la matriz A y V matriz no singular cuyas columnas coinciden con los vectores propios de A .
A partir de la descomposición anterior se calcula 1−= VVee hDihAi ,

Capítulo 5: Resultados Experimentales
217
siendo
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
hi
hi
hi
hDi
ne
ee
e
λ
λ
λ
L
MOMM
L
L
00
0000
2
1
.
A continuación se presenta el algoritmo que calcula hAie mediante la diagonalización de la matriz A .
), hAig(ezgeferB = .
Entradas: Matriz nxnA C∈ , tamaño del paso +ℜ∈h .
Salida: Matriz nxnhAieB C∈= .
1 Obtener la matriz V y el vector nℜ∈λ de valores propios de la matriz A de manera que 1−= VDVA :
1.1 )(],[ AzgeevV =λ
2 Calcular ),,,( 21 hihihi neeeVdiagV λλλ L= : 2.1 Para nj :1=
2.1.1 hi jejnVjnV λ),:1(),:1( = 3 Calcular B resolviendo el sistema de ecuaciones lineales VBV =
Algoritmo 5.1: Cálculo de la función hAieAf =)( mediante la diagonalización de una matriz.
5.3.2 Algoritmo Basado en los Aproximantes Diagonales de Padé Este algoritmo calcula
hAieAf =)(
mediante el Algoritmo 3.1 particularizado a la función hziezf =)( .

Capítulo 5: Resultados Experimentales
218
),,( lhAzgeferpadB = .
Entradas: Matriz nxnA C∈ , tamaño del paso +ℜ∈h , grado +∈ Zl de los polinomios de la aproximación diagonal de Padé.
Salida: Matriz nxnhAieB C∈= . 1 Aplicar transformaciones que disminuyan |||| A :
1.1 Determinar +ℜ∈1h de manera que la matriz 11 AhA = tenga una norma aproximadamente igual a 1, de este modo se tiene que
1212 AihAhihhAi eee == , siendo 12 / hhh = . 2 Encontrar el polinomio de Taylor )(xa de grado 12 +l de la función
2)( hziezf = . 3 Encontrar los polinomios )(xp y )(xq del aproximante diagonal de Padé de
grado l a partir del polinomio de Taylor )(xa . 4 Calcular la aproximación de Padé )(/)()( 111 AqApArB == .
Algoritmo 5.2: Cálculo de la función hAieAf =)( mediante aproximantes diagonales de Padé.
5.3.3 Algoritmo Basado en la Iteración DB y en los Aproximantes Diagonales de Padé
Este algoritmo consta de dos etapas. En la primera etapa se calcula AB = mediante el método iterativo DB con escalado (véase subapartado 2.2.3.3). En la segunda etapa se calcula hiAeC 1= mediante los aproximantes diagonales de Padé. A continuación se muestra este algoritmo completo.
),,( lhAzgeferdbpB = .
Entradas: Matriz nxnA C∈ , tamaño del paso +ℜ∈h , grado +∈ Zl de los polinomios del aproximante diagonal de Padé.
Salida: Matriz nxnhAieB C∈= .
1 )100,10,( 151
−= AdgefrcdbeA (calcula AA =1 mediante Algoritmo 3.6 de la página 101)
2 )(AzgfexppsvB = (calcula hiAeB 1= mediante la adaptación para matrices complejas del Algoritmo 3.5 de la página 99)
Algoritmo 5.3: Cálculo de la función hAieAf =)( mediante la iteración DB con escalado y los aproximantes diagonales de Padé.
5.3.4 Resultados Las matrices utilizadas en la pruebas se han obtenido a partir de los datos del problema planteado, siendo sus tamaños iguales a 127, 271, 331, 721, 1027, 1261, 1387 y 1951.
Las mejores prestaciones del algoritmo basado en los aproximantes diagonales de Padé (zgeferpad) se obtienen cuando el grado de los polinomios de la aproximación diagonal de Padé es igual a 9. En el caso del algoritmo basado en la iteración DB con escalado y

Capítulo 5: Resultados Experimentales
219
en los aproximantes diagonales de Padé (zgeferdbp), las mejoras prestaciones se obtienen para un grado igual a 3.
Como medida del error cometido en el cálculo de hAie se ha considerado el error relativo correspondiente a la ecuación conmutante, ya que la solución exacta no es conocida. De las pruebas realizadas se puede concluir que los algoritmos más precisos han resultado ser el Algoritmo 5.1 (zgefereig) y el Algoritmo 5.3 (zgeferdbp).
En la siguiente tabla se muestran los tiempos de ejecución de las rutinas implementadas.
Te n=127 n=271 n=331 n=721 n=1027 n=1261 n=1387 n=1951
zgefereig 0.093 0,163 1.469 22.15 64.847 114.53 156.37 402.90
zgeferpad 0.031 0.083 1.417 17.70 51.527 94.32 122.30 331.57
zgeferdbp 0.027 0.064 1.007 10.96 29.703 54.66 70.68 194.25
Tabla 5.27: Tiempos de ejecución, en segundos, de las rutinas zgefereig, zgeferpad y zgeferdbp.
Como se puede observar en la tabla anterior, la rutina más rápida corresponde al Algoritmo 5.3 (zgeferdbp).
A continuación se muestran la relación entre los tiempos de ejecución, en segundos, de las rutinas zgeferpad y zgeferdbp frente a la rutina zgefereig. Para ello se ha dividido el tiempo de ejecución de la rutina zgefereig (T) entre los tiempos de ejecución de las rutinas zgeferpad y zgeferdbp (Ti).
T/Ti n=127 n=271 n=331 n=721 n=1027 n=1261 n=1387 n=1951
zgeferpad 3.000 1,964 1.037 1.251 1.259 1.214 1.279 1.215
zgeferdbp 3.444 2,547 1.459 2.021 2.183 2.095 2.212 2.074
Tabla 5.28: Relación entre el tiempo de ejecución de la rutina zgefereig (T) y los tiempos de ejecución (Ti) de las rutinas zgeferpad y zgeferdbp.

Capítulo 5: Resultados Experimentales
220
0,0000,5001,0001,5002,0002,5003,0003,5004,000
n=127 n=271 n=331 n=721 n=1027 n=1261 n=1387 n=1951
Dimensión
T/Ti
zgeferpadzgeferdbp
Figura 5.9: Relación entre el tiempo de ejecución de la rutina
zgefereig (T) y los tiempos de ejecución (Ti) de las rutinas zgeferpad y zgeferdbp.
Como conclusión, se puede decir que la rutina que presenta un mejor comportamiento, en cuanto a precisión y menores tiempos de ejecución, es la correspondiente al algoritmo basado en la iteración DB con escalado y en los aproximantes diagonales de Padé (zgeferdbp).
5.4 Resolución de EDOs En las pruebas realizadas se han comparado los algoritmos descritos en la sección 4.2 con un algoritmo basado en el método BDF (véase subapartado 2.3.3.3.2). Este algoritmo se muestra continuación.

Capítulo 5: Resultados Experimentales
221
),,,,,( 0 axitermtolrxtdatadgeedobdfY = .
Entradas: Función ),( xtdata que devuelve la matriz Jacobiana nxnxtJ ℜ∈),( y el vector nxtf ℜ∈),( , vector de tiempos 1+ℜ∈ lt , vector inicial nx ℜ∈0 , orden +∈ Zr del método BDF, tolerancia +ℜ∈tol del método BDF, número máximo de iteraciones +∈ Zaxiterm del método BDF.
Salida: Matriz )1(10 ],,,[ +ℜ∈= lnx
lyyyY L , niy ℜ∈ , li ,,1,0 L= .
1 Inicializar α y β con los valores dados en la Tabla 2.4 (página 55) 2 00 xy = ; 0=j 3 Para 1:0 −= li
3.1 ii ttt −=∆ +1 3.2 1+= jj ; ),min( jrp = 3.3 Para 2:1: −= pk
3.3.1 )1,:1(),:1( −= knXknX 3.4 iynX =)1,:1( ; )1,:1(10 nXf pα= 3.5 Para pk :2=
3.5.1 ),:1(00 knXff pkα+= 3.6 ii yy =+1 3.7 1=k 3.8 Mientras axitermk ≤ (método de Newton)
3.8.1 ),(],[ 1+= ii ytdatafJ 3.8.2 ffyy pi β01 +−= + 3.8.3 JtIJ pn β∆−= 3.8.4 Determinar y∆ resolviendo la ecuación yyJ =∆ 3.8.5 Si toly <∆ )(norm
3.8.5.1 Salir fuera del bucle 3.8.6 yyy ii ∆+=+1 3.8.7 1+= kk
3.9 Si axitermk == 3.9.1 error (no hay convergencia)
Algoritmo 5.4: Resolución de EDOs mediante el método BDF.
Una breve descripción de los algoritmos implementados y de sus parámetros característicos aparece a continuación.
• dgeedobdf: Resuelve EDOs mediante el método BDF.
− r: orden del método BDF.
− tol: tolerancia utilizada en el método de Newton.
− maxiter: Número máximo de iteraciones utilizado en el método de Newton.
• dgeedolpn y dgeedolpa : Resuelven EDOs, no autónomas y autónomas, mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé de la función exponencial.

Capítulo 5: Resultados Experimentales
222
− q: grado de los polinomios de la aproximación diagonal de Padé de la función exponencial.
• dgeedolcn y dgeedolca: Resuelven EDOs, no autónomas y autónomas, mediante el método de linealización a trozos basado en la ecuación conmutante.
− q: grado de los polinomios de la aproximación diagonal de Padé de la función exponencial.
• dgeedolkn y dgeedolka: Resuelven EDOs, no autónomas y autónomas, mediante el método de linealización a trozos basado en los subespacios de Krylov.
− p: dimensión del subespacios de Krylov.
− tol: tolerancia en el método de los subespacios de Krylov.
− q: grado de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Para cada caso de estudio se han determinado los valores de los parámetros característicos que ofrecen mayor precisión con un menor coste computacional, habiéndose realizado hasta tres tipos de pruebas:
• Fijar el tamaño del problema y el instante de tiempo, variando el incremento de tiempo.
• Fijar el tamaño del problema y el incremento de tiempo, variando el instante de tiempo.
• Fijar el instante de tiempo y el incremento de tiempo, variando el tamaño del problema.
Para cada prueba se muestran:
• Tabla que contiene los errores relativos cometidos.
• Tabla con los costes computacionales en flops.
• Tabla en la que se muestra la relación entre el coste computacional, en flops, del algoritmo basado en el método BDF y los costes computacionales, en flops, de los algoritmos basados en la linealización a trozos.
• Gráfica que muestra la relación entre el coste computacional, en flops, del algoritmo basado en el método BDF y los costes computacionales, en flops, de los algoritmos basados en la linealización a trozos.
En los casos de estudio que no tienen solución analítica conocida se ha considerado como solución exacta, en un instante determinado, la obtenida a partir de la función de MATLAB ode15s (véase Tabla 6.1, página 308).
5.4.1 EDOs Autónomas Problema 5.1: El primer caso de estudio de una EDO autónoma ([Garc98]), corresponde a una EDO definida como
2'
3xx −= , 0≥t ,
con la condición inicial

Capítulo 5: Resultados Experimentales
223
1)0( =x .
La solución de esta EDO es
ttx
+=
11)( .
Los valores elegidos para los parámetros característicos se muestran a continuación.
• dgeedobdf: r=2, tol=1e-6, maxiter=100.
• dgeedolpa: q=1.
• dgeedolca: q=1.
• dgeedolpa: p=2, tol=1e-6, q=1.
En la primera prueba se considera t=5 y se varía el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 3.883e-05 1.306e-05 6.563e-07 1.688e-07 6.905e-09 1.731e-09
dgeedolpa 4.467e-05 1.101e-05 4.353e-07 1.087e-07 4.342e-09 1.085e-09
dgeedolca 4.467e-05 1.101e-05 4.353e-07 1.087e-07 4.342e-09 1.085e-09
dgeedolka 4.467e-05 1.101e-05 4.353e-07 1.087e-07 4.342e-09 1.085e-09
Tabla 5.29: Errores relativos en el instante de tiempo t=5, variando ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 2958 5058 21998 43998 219998 439998
dgeedolpa 1351 2701 13501 27001 135001 270001
dgeedolca 1051 2101 10501 21001 105001 210001
dgeedolka 3600 7200 36001 72001 360001 720001
Tabla 5.30: Número de flops en el instante de tiempo t=5, variando ∆t.

Capítulo 5: Resultados Experimentales
224
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedolpa 2.189 1.873 1.629 1.629 1.630 1.630
dgeedolca 2.814 2.407 2.095 2.095 2.095 2.095
dgeedolka 0.822 0.703 0.611 0.611 0.611 0.611
Tabla 5.31: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.
0.1 0.05 0.01 0.005 0.001 0.00050.5
1
1.5
2
2.5
∆t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolca)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.10: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.
En la segunda prueba se considera ∆t=0.1 y se varía el tiempo t.

Capítulo 5: Resultados Experimentales
225
Er t=10 t=20 t=30 t=40 t=50 t=60
dgeedobdf 2.343e-05 2.540e-05 2.034e-05 1.659e-05 1.392e-05 1.197e-05
dgeedolpa 2.653e-05 1.454e-05 1.001e-05 7.626e-06 6.160e-06 5.167e-06
dgeedolca 2.653e-05 1.454e-05 1.001e-05 7.626e-06 6.160e-06 5.167e-06
dgeedolka 2.653e-05 1.454e-05 1.001e-05 7.626e-06 6.160e-06 5.167e-06
Tabla 5.32: Errores relativos al considerar ∆t=0.1 y variar el tiempo t.
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgeedobdf 5158 9558 13958 18358 22758 27158
dgeedolpa 2701 5401 8101 10801 13501 16201
dgeedolca 2101 4201 6301 8401 10501 12601
dgeedolka 7200 14400 21600 28800 36000 43200
Tabla 5.33: Número de flops al considerar ∆t=0.1 y variar el tiempo t.
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgeedolpa 1.910 1.770 1.723 1.700 1.686 1.676
dgeedolca 2.455 2.275 2.215 2.185 2.167 2.155
dgeedolka 0.716 0.664 0.646 0.637 0.632 0.629
Tabla 5.34: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
226
5 10 15 20 25 30
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolca)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.11: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• A medida que se incrementa el tiempo, los errores relativos cometidos por los algoritmos basados en la linealización a trozos son algo menores que los cometidos por el algoritmo basado en el método BDF (dgeedobdf).
• Los algoritmos de linealización a trozos basados en los aproximantes diagonales de Padé (dgeedolpa) y en la ecuación conmutante (dgeedolca) tienen un coste computacional menor que el algoritmo basado en el método BDF (dgeedobdf).
• El mayor coste computacional corresponde al algoritmo de linealización a trozos basado en los subespacios de Krylov (dgeedolka).
Problema 5.2: El segundo caso de estudio de una EDO autónoma corresponde a la ecuación logística ([Garc98]) definida como
)1(' xxx −= λ , 0≥t ,
con la condición inicial
0)0( xx = .
La solución de esta EDO es
00
0
)1()(
xexx
tx t +−= −λ .
En las pruebas realizadas se ha considerado 2=λ y 20 =x . Los valores elegidos para los parámetros característicos se muestran a continuación.
• dgeedobdf: r=2, tol=1e-6, maxiter=100.

Capítulo 5: Resultados Experimentales
227
• dgeedolpa: q=1.
• dgeedolca: q=1.
• dgeedolpa: p=2, tol=1e-6, q=1.
En la primera prueba se considera t=5 y se varía el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 3.397e-06 7.848e-07 2.876e-08 7.096e-09 2.807e-10 7.013e-11
dgeedolpa 7.486e-07 1.887e-07 7.566e-09 1.892e-09 7.567e-11 1.892e-11
dgeedolca 7.486e-07 1.887e-07 7.566e-09 1.892e-09 7.567e-11 1.892e-11
dgeedolka 7.486e-07 1.887e-07 7.566e-09 1.892e-09 7.567e-11 1.892e-11
Tabla 5.35: Errores relativos en el instante de tiempo t=5, variando ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 2598 4918 21898 41398 189078 364338
dgeedolpa 1351 2701 13501 27001 135001 270001
dgeedolca 1051 2101 10501 21001 105001 210001
dgeedolka 3601 7201 36001 72001 360001 720001
Tabla 5.36: Número de flops en el instante de tiempo t=5, variando ∆t.
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedolpa 1.923 1.821 1.622 1.533 1.401 1.349
dgeedolca 2.472 2.341 2.085 1.971 1.801 1.735
dgeedolka 0.721 0.683 0.608 0.575 0.525 0.506
Tabla 5.37: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.

Capítulo 5: Resultados Experimentales
228
0.1 0.05 0.01 0.005 0.001 0.00050.5
1
1.5
2
∆t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolca)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.12: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.
En la segunda prueba se considera ∆t=0.1 y se varía el tiempo t.
Er t=3 t=6 t=9 t=12 t=15 t=18
dgeedobdf 1.142e-04 5.437e-07 1.933e-09 6.109e-12 1.887e-14 2.220e-16
dgeedolpa 2.472e-05 1.212e-07 4.461e-10 1.460e-12 4.441e-15 2.220e-16
dgeedolca 2.472e-05 1.212e-07 4.461e-10 1.460e-12 4.441e-15 2.220e-16
dgeedolka 2.472e-05 1.212e-07 4.461e-10 1.460e-12 4.441e-15 2.220e-16
Tabla 5.38: Errores relativos al considerar ∆t =0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
229
Flops t=3 t=6 t=9 t=12 t=15 t=18
dgeedobdf 1718 2978 3698 4418 5138 5858
dgeedolpa 811 1621 2431 3241 4051 4861
dgeedolca 631 1261 1891 2521 3151 3781
dgeedolka 2161 4321 6481 8641 10801 12961
Tabla 5.39: Número de flops al considerar ∆t=0.1 y variar el tiempo t.
F/Fi t=3 t=6 t=9 t=12 t=15 t=18
dgeedolpa 2.118 1.837 1.521 1.363 1.268 1.205
dgeedolca 2.723 2.362 1.956 1.752 1.631 1.549
dgeedolka 0.795 0.689 0.571 0.511 0.476 0.452
Tabla 5.40: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.
2 4 6 8 10 12 14 16 180
0.5
1
1.5
2
2.5
3
t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolca)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.13: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
230
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• Los errores relativos cometidos por los algoritmos basados en el método de linealización son algo menores que los cometidos por el algoritmo basado en el método BDF (dgeedobdf).
• Los algoritmos de linealización a trozos basados en los aproximantes diagonales de Padé (dgeedolpa) y en la ecuación conmutante (dgeedolca) tienen costes computacionales menores que el algoritmo basado en el método BDF (dgeedobdf).
• El mayor coste computacional corresponde al algoritmo basado en la linealización a trozos mediante los subespacios de Krylov (dgeedolka).
Problema 5.3: El tercer caso de estudio corresponde a una EDO autónoma no lineal de orden seis de tipo rígido ([LiSw98]) definida como
)(' xfx = , 0≥t , 6)( ℜ∈= txx , 1800 ≤≤ t ,
con la condición inicial Tx ]367.0,0,0,0,00123.0,437.0[)0( = ,
siendo
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
−+−−−−+−
+−−−−−+−
=
5
532
432
321
541
4321
22
5.05.02
)(
rrrrrrr
rrrFrrr
rrrr
xf
in
,
donde ir , 5,4,3,2,1=i , y inF son variables auxiliares dadas por 5.0
24111 yykr = ,
4322 yykr = ,
512
3 yyKkr = ,
24134 yykr = , 5.0
26645 yykr = ,
⎟⎠⎞
⎜⎝⎛= 2
2 )( yHCOpklAFin .
Los valores de los parámetros 1k , 2k , 3k , 4k , K , KlA , )( 2COp y H son
.737,42.03.3)(,09.0
,3.3,58.0,4.34,7.18
4
23
2
1
====
====
HkCOpkklAkKk

Capítulo 5: Resultados Experimentales
231
El problema proviene del centro de investigación Akzo Novel Central Research de Arnhem, en el que se modela un proceso químico (para más detalles, véase [LiSw98]).
Puesto que la matriz Jacobiana es en ocasiones singular, no se puede utilizar el método de linealización a trozos basado en la ecuación conmutante (dgeedolca). En las pruebas realizadas se comparan los otros tres métodos, siendo los valores elegidos para los parámetros característicos los que se muestran a continuación.
• dgeedobdf: r=2, tol=1e-6, maxiter=100.
• dgeedolpa: q=1.
• dgeedolka: p=3, tol=1e-6, q=1.
En la primera prueba se considera t=5 y se varía el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 7.418e-05 2.369e-05 1.235e-06 3.239e-07 1.254e-08 2.384e-09
dgeedolpa 1.348e-04 3.640e-05 9.074e-07 2.351e-07 8.720e-09 1.445e-09
dgeedolka 4.615e-04 9.971e-05 4.416e-06 1.130e-06 4.511e-08 1.054e-08
Tabla 5.41: Errores relativos en el instante de tiempo t=5, variando ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 68915 134645 651012 1302056 6510424 13020896
dgeedolpa 231607 373113 964537 1929081 9645449 19290913
dgeedolka 33832 66898 332848 665698 3328477 6656950
Tabla 5.42: Número de flops en el instante de tiempo t=5, variando ∆t.
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedolpa 0.298 0.361 0.675 0.675 0.675 0.675
dgeedolka 2.037 2.013 1.956 1.956 1.956 1.956
Tabla 5.43: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.

Capítulo 5: Resultados Experimentales
232
0.1 0.05 0.01 0.005 0.001 0.0005
0.5
1
1.5
2
∆t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.14: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.
En la segunda prueba se considera ∆t=0.01 y se varía el tiempo t.
Er t=5 t=10 t=15 t=20 t=25 t=30
dgeedobdf 1.236e-06 1.218e-06 1.080e-06 9.033e-07 7.314e-07 5.838e-07
dgeedolpa 9.084e-07 9.398e-07 8.524e-07 7.170e-07 5.791e-07 4.585e-07
dgeedolka 4.417e-06 4.625e-06 4.350e-06 3.961e-06 3.169e-06 2.508e-06
Tabla 5.44: Errores relativos al considerar ∆t=0.01 y variar el tiempo t.
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgeedobdf 651012 1301512 1952012 2602668 3253168 3903668
dgeedolpa 964537 1928537 2892537 3856693 4820693 5784693
dgeedolka 332848 665848 998848 1331848 1664848 1997848
Tabla 5.45: Número de flops al considerar ∆t=0.01 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
233
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgeedolpa 0.675 0.675 0.675 0.675 0.675 0.675
dgeedolka 1.956 1.955 1.954 1.954 1.954 1.954
Tabla 5.46: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.01 y variar el tiempo t.
5 10 15 20 25 30
0.8
1
1.2
1.4
1.6
1.8
2
t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.15: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.01 y variar el tiempo t.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• No se puede utilizar el algoritmo de linealización a trozos basado en la ecuación conmutante (dgeedolca), por ser la matriz jacobiana no singular.
• Los errores relativos cometidos por los otros tres algoritmos son semejantes, aunque algo mayores en el caso del algoritmo de linealización a trozos basado en los subespacios de Krylov (dgeedolka).
• El algoritmo con menor coste computacional es el de linealización a trozos basado en los subespacios de Krylov (dgeedolka) y el de mayor coste computacional el de linealización a trozos basado en los aproximantes diagonales de Padé (dgeedolpa).
Problema 5.4: El cuarto caso de estudio proviene de una EDO autónoma no lineal de tipo rígido ([LiSw98]) definida como

Capítulo 5: Resultados Experimentales
234
)(' xfx = , 0≥t , 8)( ℜ∈= txx , 8122.3210 ≤≤ t ,
con la condición inicial Tx ]0057.0,0,0,0,0,0,0,1[)0( = ,
siendo
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
+−−
+−++−++−
−+++−
−+++−
=
786
786
765486
765
432
543
21
321
81.128081.1280
69.043.071.169.028043.043.0745.1
12.171.132.8035.043.003.10
75.871.10007.032.843.071.1
)(
yyyyyy
yyyyyyyyy
yyyyyy
yyyyy
xf .
El problema describe la manera en que la luz se ve envuelta en un proceso de morfogénesis (para más detalles, véase [LiSw98]).
Puesto que la matriz Jacobiana es en ocasiones singular, no se puede utilizar el método de linealización a trozos basado en la ecuación conmutante (dgeedolca). En las pruebas realizadas se comparan los otros tres métodos, siendo los valores elegidos para los parámetros característicos los que se muestran a continuación.
• dgeedobdf: r=3, tol=1e-6, maxiter=100.
• dgeedolpa: q=1.
• dgeedolka: p=4, tol=1e-6, q=1.
En la primera prueba se considera t=5 y se varía el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 4.247e-04 1.060e-04 4.104e-06 1.021e-06 4.066e-08 1.015e-08
dgeedolpa 4.357e-05 1.526e-05 4.833e-07 1.464e-07 5.852e-09 1.460e-09
dgeedolka 5.783e-05 1.040e-05 5.151e-07 1.366e-07 5.767e-09 1.450e-09
Tabla 5.47: Errores relativos en el instante de tiempo t=5, variando ∆t.

Capítulo 5: Resultados Experimentales
235
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 103407 198194 903502 1807166 9036520 18073278
dgeedolpa 563229 919485 2320075 3237239 16186679 32373499
dgeedolka 87281 158617 628419 1256679 6281415 12562747
Tabla 5.48: Número de flops en el instante de tiempo t=5, variando ∆t.
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedolpa 0.184 0.216 0.389 0.558 0.558 0.558
dgeedolka 1.185 1.250 1.438 1.438 1.439 1.439
Tabla 5.49: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.
0.1 0.05 0.01 0.005 0.001 0.00050
0.5
1
∆t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.16: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar ∆t.
En la segunda prueba se considera ∆t=0.01 y se varía el tiempo t.

Capítulo 5: Resultados Experimentales
236
Er t=50 t=100 t=150 t=200 t=250 t=300
dgeedobdf 1.860e-06 2.294e-06 2.989e-06 4.276e-06 7.425e-06 2.406e-05
dgeedolpa 7.245e-07 8.936e-07 1.164e-06 1.665e-06 2.892e-06 9.380e-06
dgeedolka 9.694e-07 1.195e-06 1.556e-06 2.221e-06 3.806e-06 9.309e-06
Tabla 5.50: Errores relativos al considerar ∆t=0.01 y variar el tiempo t.
Flops t=50 t=100 t=150 t=200 t=250 t=300
dgeedobdf 9039384 18079194 27118984 36158864 45198754 54238534
dgeedolpa 31963104 58718104 85473104 106785016 122975016 139165016
dgeedolka 3260055 5465055 7670055 9875055 12080055 14285055
Tabla 5.51: Número de flops al considerar ∆t=0.01 y variar el tiempo t.
F/Fi t=50 t=100 t=150 t=200 t=250 t=300
dgeedolpa 0.283 0.308 0.317 0.339 0.368 0.390
dgeedolka 2.773 3.308 3.536 3.662 3.742 3.797
Tabla 5.52: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.01 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
237
50 100 150 200 250 3000
0.5
1
1.5
2
2.5
3
3.5
4
t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpa)Flops(dgeedobdf)/Flops(dgeedolka)
Figura 5.17: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.01 y variar el tiempo t.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• No se puede utilizar el algoritmo de linealización a trozos basado en la ecuación conmutante (dgeedolca), por ser la matriz jacobiana no singular.
• Los errores relativos cometidos por los otros tres algoritmos son semejantes, aunque algo mayores en el caso del algoritmo basado en el método BDF (dgeedobdf).
• El algoritmo con menor coste computacional es el de linealización a trozos basado en los subespacios de Krylov (dgeedolka), y el de mayor coste computacional el de linealización a trozos basado en los aproximantes diagonales de Padé (dgeedolpa).
5.4.2 EDOs no autónomas Problema 5.5: El primer caso de estudio de una EDO no autónoma ([Garc98]) corresponde a una EDO definida como
1)(' 2 +−= xtx , 3≥t ,
con la condición inicial
2)3( =x .

Capítulo 5: Resultados Experimentales
238
La solución de esta EDO es
tttx
−+=
21)( .
Los valores elegidos para los parámetros característicos se muestran a continuación.
• dgeedobdf: r=2, tol=1e-6, maxiter=100.
• dgeedolpn: q=1.
• dgeedolcn: q=1.
• dgeedolkn: p=3, tol=1e-6, q=1.
En la primera prueba se considera t=4 y se varia el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 3.694e-04 8.889e-05 3.557e-06 8.908e-07 3.570e-08 8.926e-09
dgeedolpn 1.269e-16 1.269e-16 1.269e-16 2.538e-16 1.269e-16 6.344e-16
dgeedolcn 1.269e-16 1.269e-16 7.613e-16 0 3.806e-16 6.344e-16
dgeedolkn 1.269e-16 1.269e-16 0 1.269e-16 7.613e-16 6.344e-16
Tabla 5.53: Errores relativos en el instante de tiempo t=4, variando ∆t.
Puesto que para un incremento de tiempo igual a 0.1 los métodos de linealización a trozos presentan un error muy pequeño, solo se van a representar lo resultados obtenidos para este incremento.
Flops ∆t=0.1
dgeedobdf 2958
dgeedolpn 1351
dgeedolcn 1051
dgeedolkn 3600
Tabla 5.54: Número de flops para t=4 y ∆t=0.1.

Capítulo 5: Resultados Experimentales
239
F/Fi ∆t=0.1
dgeedolpn 2.189
dgeedolcn 2.814
dgeedolkn 0.822
Tabla 5.55: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=4 y ∆t=0.1.
En la segunda prueba se considera ∆t=0.1 y se varía el tiempo t.
Er t=3.5 t=4 t=4.5 t=5 t=5.5 t=6
dgeedobdf 1.463e-03 3.694e-04 1.081e-04 2.951e-05 2.748e-06 6.608e-06
dgeedolpn 0 1.269e-16 0 0 0 1.545e-16
dgeedolcn 1.567e-16 1.269e-16 0 1.903e-16 3.407e-16 1.545e-16
dgeedolkn 1.567e-16 1.269e-16 0 0 0 1.545e-16
Tabla 5.56: Errores relativos al considerar ∆t=0.1 y variar el tiempo t.
Flops t=3.5 t=4 t=4.5 t=5 t=5.5 t=6
dgeedobdf 318 638 958 1278 1598 1918
dgeedolpn 166 330 495 660 824 989
dgeedolcn 136 271 406 541 676 811
dgeedolkn 1736 3471 5206 6956 8706 10456
Tabla 5.57: Número de flops al considerar ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
240
F/Fi t=3.5 t=4 t=4.5 t=5 t=5.5 t=6
dgeedolpn 1.916 1.933 1.935 1.936 1.939 1.939
dgeedolcn 2.338 2.354 2.360 2.362 2.364 2.365
dgeedolkn 0.183 0.184 0.184 0.184 0.184 0.183
Tabla 5.58: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.
3.5 4 4.5 5 5.5 60
0.5
1
1.5
2
2.5
t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpn)Flops(dgeedobdf)/Flops(dgeedolcn)Flops(dgeedobdf)/Flops(dgeedolkn)
Figura 5.18: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• Los errores relativos cometidos por los algoritmos de linealización a trozos son mucho menores que los cometidos por el algoritmo basado en el método BDF (dgeedobdf).
• Los algoritmos de linealización a trozos basados en los aproximantes diagonales de Padé (dgeedolpn) y en la ecuación conmutante (dgeedolcn) tienen un coste computacional menor que el algoritmo basado en el método BDF (dgeedobdf).
• El mayor coste computacional corresponde al algoritmo de linealización a trozos basado en los subespacios de Krylov (dgeedolkn).

Capítulo 5: Resultados Experimentales
241
Problema 5.6: El segundo caso de estudio de una EDO no autónoma ([AsPe91], página 153) corresponde a una EDO definida como
ttxx cos)sen(' +−= λ , 0≥t ,
con la condición inicial
1)0( =x ,
cuya solución viene dada por la expresión
tetx t sen)( += λ .
En las pruebas realizadas se ha considerado 2=λ , siendo los valores elegidos para los parámetros característicos los que se muestran a continuación.
• dgeedobdf: r=3, tol=1e-6, maxiter=100.
• dgeedolpn: q=1.
• dgeedolcn: q=1.
• dgeedolkn: p=3, tol=1e-6, q=1.
En la primera prueba se considera t=5 y se varía el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 4.705e-02 9.254e-03 2.803e-04 6.702e-05 1.996e-03 6.421e-07
dgeedolpn 3.380e-02 8.302e-03 3.301e-04 8.251e-05 1.995e-03 8.250e-07
dgeedolcn 3.380e-02 8.302e-03 3.301e-04 8.251e-05 1.995e-03 8.250e-07
dgeedolkn 3.380e-02 8.302e-03 3.301e-04 8.251e-05 1.995e-03 8.250e-07
Tabla 5.59: Errores relativos en el instante de tiempo t=5, variando el incremento de tiempo ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedobdf 2543 5093 25493 50993 254942 509993
dgeedolpn 1851 3701 18501 37001 184964 370001
dgeedolcn 1301 2601 13001 26001 129975 260001
dgeedolkn 15136 28126 133379 264460 1292732 2555052
Tabla 5.60: Número de flops en el instante de tiempo t=5, variando el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
242
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgeedolpn 1.374 1.376 1.378 1.378 1.378 1.378
dgeedolcn 1.955 1.958 1.961 1.961 1.961 1.962
dgeedolkn 0.168 0.181 0.191 0.193 0.197 0.200
Tabla 5.61: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar el incremento de tiempo ∆t.
0.1 0.05 0.01 0.005 0.001 0.00050
0.5
1
1.5
∆t
F/F i Flops(dgeedobdf)/Flops(dgeedolpn)
Flops(dgeedobdf)/Flops(dgeedolcn)Flops(dgeedobdf)/Flops(dgeedolkn)
Figura 5.19: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=5 y variar el incremento de tiempo ∆t.
En la segunda prueba se varía el tiempo t entre 5 y 30. Por problemas de convergencia en el método BDF, se ha aumentado el número de iteraciones maxiter a 10000. Se ha comprobado que aunque el incremento de tiempo se disminuyera, el método BDF no converge para valores de tiempo mayores que 15. En las siguientes tablas se muestran los resultados obtenidos al considerar ∆t=0.1.

Capítulo 5: Resultados Experimentales
243
Er t=5 t=10 t=15 t=20 t=25 t=30
dgeedobdf 4.705e-02 6.383e-02 8.542e-01 Error Error Error
dgeedolpn 3.380e-02 6.906e-02 1.055e-01 6.464e-02 3.274e-02 2.452e-04
dgeedolcn 3.380e-02 6.906e-02 1.055e-01 6.464e-02 3.274e-02 2.452e-04
dgeedolkn 3.380e-02 6.906e-02 1.055e-01 6.464e-02 3.274e-02 2.444e-04
Tabla 5.62: Errores relativos al considerar ∆t=0.1 y variar el tiempo t.
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgeedobdf 2542 5092 217069 217069 217069 217069
dgeedolpn 1901 3801 5701 7563 9463 11363
dgeedolcn 1351 2701 4051 5374 6724 8074
dgeedolkn 12553 22939 33325 43510 53860 64210
Tabla 5.63: Número de flops al considerar ∆t=0.1 y variar el tiempo t.
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgeedolpn 1.337 1.340 38.076 28.701 22.939 19.103
dgeedolcn 1.882 1.885 53.584 40.392 32.283 26.885
dgeedolkn 0.203 0.222 6.514 4.989 4.030 3.381
Tabla 5.64: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
244
5 10 15 20 25 300
10
20
30
40
50
60
t
F/F i
Flops(dgeedobdf)/Flops(dgeedolpn)Flops(dgeedobdf)/Flops(dgeedolcn)Flops(dgeedobdf)/Flops(dgeedolkn)
Figura 5.20: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgeedobdf) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• El algoritmo basado en el método BDF (dgeedobdf) tiene problemas de convergencia. En caso de convergencia del método BDF, los errores relativos cometidos por los cuatro algoritmos son similares.
• Los algoritmos con menor coste computacional corresponden al de linealización a trozos basado en los aproximante diagonales de Padé (dgeedolpn) y al de linealización a trozos basado en la ecuación conmutante (dgeedolcn). El algoritmo con mayor coste computacional corresponde al de linealización a trozos basado en los subespacios de Krylov (dgeedolkn).
Problema 5.7: El tercer caso de estudio de una EDO no autónoma ([LiSw98]), corresponde a una EDO de tipo rígido definida como
),(' xtfx = , Ntxx 2)( ℜ∈= , 200 ≤≤ t ,
con la condición inicial NTvvvx 2
000 ],0,,,0,,0[)0( ℜ∈= L ,
siendo 200=N .
La función f está definida como
jjjjj
jjj
jj ykyyyyyy
f 21221212323212
12 )(2
2 −+−−−+
− −∆
+−+
∆−
=ς
βς
α ,
1222 −−= jjj ykyf ,

Capítulo 5: Resultados Experimentales
245
siendo
2
3)1(2c
jj
−∆=
ςα ,
2
4)1(c
jj
−∆=
ςβ ,
Los valores de j se encuentran comprendidos entre 1 y N , N/1=∆ς . )()(1 tty φ=− ,
1212 −+ = NN yy , siendo
⎩⎨⎧
∈∈
=]20,5(,0
]5,0(,2)(
tt
tφ .
Este problema proviene del estudio de la penetración de anticuerpos irradiados en un tejido que está infectado por un tumor, procedente de los laboratorios de investigación Akzo Nobel.
Los valores elegidos de k , 0v y c han sido 100, 1 y 4, respectivamente.
Este caso de estudio es interesante pues permite comparar los algoritmos para EDOs de gran dimensión. Puesto que la solución analítica no es conocida, se presentan únicamente los resultados correspondientes a los tiempos de ejecución de las implementaciones realizadas en FORTRAN, aunque se ha comprobado que las soluciones dadas por las implementaciones han sido similares. Al ser la matriz Jacobiana singular, el algoritmo basado en la linealización a trozos mediante la ecuación conmutante (dgeedolpn) no se puede utilizar. Los valores elegidos para los parámetros característicos son los siguientes:
• dgeedobdf: r=2, tol=1e-14, maxiter=100.
• dgeedolpn: q=1.
• dgeedolkn: p=2, tol=1e-14, q=1.
En la siguiente tabla se muestran los tiempos de ejecución, en segundos, de las tres implementaciones en FORTRAN al considerar ∆t=1.0e-6 y variar el tiempo.
Te t=1.0e-5 t=1.0e-4 t=1.0e-3 t=1.0e-2 t=1.0e-1
dgeedobdf 0.85619 8.5590 74.806 734.80 7333.9
dgeedolpn 0.79621 7.9022 78.901 783.92 7908.3
dgeedolkn 0.45720e-02 0.45450e-01 .45433 4.5451 45.468
Tabla 5.65: Tiempos de ejecución, en segundos, al considerar ∆t=1.0e-6 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
246
Te/Tei t=1.0e-5 t=1.0e-4 t=1.0e-3 t=1.0e-2 t=1.0e-1
dgeedolpn 1.08 1.08 0.95 0.94 0.93
dgeedolkn 187.27 188.32 164.65 161.67 161.30
Tabla 5.66: Relación entre el tiempo de ejecución (Te) de la implementación basada en el método BDF (dgeedobdf) y el tiempo de ejecución (Tei) de las implementaciones basadas en la linealización a trozos, al considerar ∆t=1.0e-6 y variar el tiempo t.
De los resultados obtenidos se deduce que la rutina de linealización a trozos basada en los subespacios de Krylov ha resultado ser, aproximadamente, 160 veces más rápida que las otras dos rutinas. Este resultado reafirma el hecho de que para problemas de mediana o gran dimensión, el algoritmo basado en la linealización a trozos mediante los subespacios de Krylov tiene un coste computacional menor o mucho menor que los correspondientes al resto de los algoritmos.
5.5 Resolución de EDMRs En las pruebas realizadas se han comparado los algoritmos descritos en el 4.3 con dos algoritmos basados en el método BDF (véase subapartado 2.4.2.3, página 62). En estos algoritmos se debe resolver la ecuación matricial de Sylvester. Aunque MATLAB dispone de la función lyap, que permite resolver ecuaciones matriciales de Sylvester y ecuaciones de matriciales Lyapunov, en las pruebas se ha utilizado la función dgesyl, que a continuación se muestra, por tener un coste computacional menor que la función lyap.
),,( CBAdgesylX = .
Entradas: Matrices mxmA ℜ∈ , nxnB ℜ∈ y mxnC ℜ∈ . Salida: Matriz mxnX ℜ∈ solución de la ecuación matricial de Sylvester
CXBAX =+ . 1 )(],[ AschurAQa = 2 )(],[ BschurBQb = 3 b
Ta CQQC =
4 ),,( CBAdtrsylC = (Algoritmo 3.14, página 116) 5 T
baCQQC =
Algoritmo 5.5: Resolución de la ecuación matricial de Sylvester.
A continuación se presentan dos algoritmos que resuelven EDMRs, uno para coeficientes variables y otro para coeficientes constantes, mediante el método BDF.

Capítulo 5: Resultados Experimentales
247
),,,,,( 0 axitermtolrXdatatdgedmrbdvY = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función )(tdata que calcula las matrices coeficiente de la EDMR nxntA ℜ∈)(11 , nxmtA ℜ∈)(12 , mxntA ℜ∈)(21 ,
mxmtA ℜ∈)(22 , matriz inicial mxnX ℜ∈0 , orden +∈ Zr del método BDF, tolerancia +ℜ∈tol del método BDF, número máximo de iteraciones
+∈ Zaxiterm del método BDF. Salida: Matriz a bloques )1()(
10 ],,,[ +××ℜ∈= lnmlYYYY L , mxn
iY ℜ∈ , li ,,1,0 L= .
1 Inicializar α y β con los valores dados en la Tabla 2.4 2 00 XY = ; 0=j 3 Para 1:0 −= li
3.1 ii ttt −=∆ +1 ; 1+= jj ; ),min( jrp = 3.2 Para 2:1: −= pk
3.2.1 ),:1,:1(),:1,:1( knmXknmX = 3.3 iYnmX =)1,:1,:1( ; )1,:1,:1(10 nmXC pα= 3.4 Para pk :2=
3.4.1 ),:1,:1(00 knmXCC pkα+= 3.5 )(],,,[ 22211211 itdataAAAA = 3.6 nr IAtC 5.01111 +∆= β ; 1212 AtC rβ∆= ; nr IAtC 5.02222 −∆= β 3.7 0=k 3.8 Mientras axitermk < (método de Newton)
3.8.1 1+= kk 3.8.2 1222 CYCA i−= 3.8.3 ))(( 1211222110 iiiii YAYAYYAArtYCB −−+∆−+−= β 3.8.4 ),,( CBAdgesylY =∆ 3.8.5 Si tolY <∆ )(norm
3.8.5.1 Salir fuera del bucle 3.8.6 YYY ii ∆+=+1
3.9 Si axitermk == 3.9.1 error (no hay convergencia)
Algoritmo 5.6: Resolución de EDMRs con coeficientes variables mediante el método BDF.

Capítulo 5: Resultados Experimentales
248
),,,,,( 0 axitermtolrXdatatdgedmrbdcY = .
Entradas: Vector de tiempos 1+ℜ∈ lt , función )(tdata que devuelve las matrices coeficiente de la EDMR nxnA ℜ∈11 , nxmA ℜ∈12 , mxnA ℜ∈21 , mxmA ℜ∈22 , matriz inicial mxnX ℜ∈0 , orden +∈ Zr del método BDF, tolerancia
+ℜ∈tol del método BDF, número máximo de iteraciones +∈ Zaxiterm del método BDF.
Salida: Matriz a bloques )1()(10 ],,,[ +××ℜ∈= lnm
lYYYY L , mxniY ℜ∈ , li ,,1,0 L= .
1 Inicializar α y β con los valores dados en la Tabla 2.4 (página 55) 2 )(],,,[ 22211211 tdataAAAA = ; 00 XY = ; 0=j 3 Para 1:0 −= li
3.1 ii ttt −=∆ +1 3.2 1+= jj ; ),min( jrp = 3.3 Para 2:1: −= pk
3.3.1 ),:1,:1(),:1,:1( knmXknmX = 3.4 iYnmX =)1,:1,:1( ; )1,:1,:1(10 nmXC pα= 3.5 Para pk :2=
3.5.1 ),:1,:1(00 knmXCC pkα+= 3.6 nr IAtC 5.01111 +∆= β ; 1212 AtC rβ∆= ; nr IAtC 5.02222 −∆= β 3.7 0=k 3.8 Mientras axitermk < (método de Newton)
3.8.1 1+= kk 3.8.2 1222 CYCA i−= 3.8.3 ))(( 1211222110 iiiii YAYAYYAArtYCB −−+∆−+−= β 3.8.4 ),,( CBAdgesylY =∆ 3.8.5 Si tolY <∆ )(norm
3.8.5.1 Salir fuera del bucle 3.8.6 YYY ii ∆+=+1
3.9 Si axitermk == 3.9.1 error (no hay convergencia)
Algoritmo 5.7: Resolución de EDMRs con coeficientes constantes mediante el método BDF.
Una breve descripción de los algoritmos implementados y de sus parámetros característicos aparece a continuación.
• dgedmrbdv y dgedmrbdc: Resuelven EDMRs mediante el método BDF.
− r: orden del método BDF.
− tol: tolerancia utilizada en el método de Newton.
− maxiter: número máximo de iteraciones utilizado en el método Newton.
• dgedmrlpv y dgedmrlpc: Resuelven EDMRs, de coeficientes variables y de coeficientes constantes, mediante el método de linealización a trozos basado en los aproximantes diagonales de Padé de la función exponencial.

Capítulo 5: Resultados Experimentales
249
− q: grado de los polinomios de la aproximación diagonal de Padé de la función exponencial.
• dgedmrlcv y dgedmrlcc: Resuelven EDMRs, de coeficientes variables y de coeficientes constantes, mediante el método de linealización a trozos basado en la ecuación conmutante.
− q: grado de los polinomios de la aproximación diagonal de Padé de la función exponencial.
• dgedmrlkv y dgedmrlkc: Resuelven EDMRs, de coeficientes variables y de coeficientes constantes, mediante el método de linealización a trozos basado en los subespacios de Krylov.
− p: dimensión del subespacio de Krylov.
− tol: tolerancia en el método de los subespacio de Krylov.
− q: grado de los polinomios de la aproximación diagonal de Padé de la función exponencial.
Para cada caso de estudio se han determinado los valores de los parámetros característicos que ofrecen mayor precisión con un menor coste computacional, habiéndose realizado tres tipos de pruebas:
• Fijar el tamaño del problema y el instante de tiempo, variando el incremento de tiempo.
• Fijar el tamaño del problema y el incremento de tiempo, variando el instante de tiempo.
• Fijar el instante de tiempo y el incremento de tiempo, variando el tamaño del problema.
Para cada prueba se muestran:
• Tabla que contiene los errores relativos cometidos.
• Tabla con los costes computacionales en flops o tiempos de ejecución en segundos.
• Tabla en la que se presentan la relación entre el coste computacional del algoritmo basado en el método BDF y los correspondientes a los algoritmos basados en la linealización a trozos.
• Gráfica que muestra la relación entre el coste computacional del algoritmo basado en el método BDF y los correspondientes a los algoritmos basados en la linealización a trozos.
5.5.1 EDMRs con Coeficientes Constantes Problema 5.8: El primer caso de estudio de EDMRs con coeficientes constantes proviene de un problema de ecuaciones diferenciales con condiciones de contorno que puede verse en [Prue86]. La EDMR está definida para 0≥t mediante las matrices coeficiente
⎥⎦
⎤⎢⎣
⎡−−
=1100
0011A , ⎥
⎦
⎤⎢⎣
⎡=
010010
12A , ⎥⎦
⎤⎢⎣
⎡=
01010
21A , ⎥⎦
⎤⎢⎣
⎡−−
=110
0022A ,

Capítulo 5: Resultados Experimentales
250
y la condición inicial
⎥⎦
⎤⎢⎣
⎡−
=0100
)0(X .
La solución aproximada de la EDMR es
( 5.2 ) ⎥⎦
⎤⎢⎣
⎡−
=1.00
110.01X ,
siempre que el valor de t sea elevado.
Los valores elegidos para los parámetros característicos se muestran a continuación.
• dgedmrbdc: r=3, tol=1e-6, maxiter=100.
• dgedmrlpc: q=1.
• dgedmrlcc: q=1.
• dgedmrlkc: p=3, tol=1e-6, q=1.
En la primera prueba se considera t=1 y se varía el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdc 2.450e-01 9.783e-02 5.439e-03 1.399e-03 1.338e-04 1.803e-04
dgedmrlpc 1.243e-01 3.284e-02 1.076e-03 2.694e-04 3.883e-05 3.817e-05
dgedmrlcc 1.229e-01 2.857e-02 8.464e-04 2.694e-04 3.883e-05 3.817e-05
dgedmrlkc 7.258e-02 1.727e-02 7.122e-04 1.810e-04 3.831e-05 3.821e-05
Tabla 5.67: Errores relativos en el instante de tiempo t=1, variando el incremento de tiempo ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdc 30498 38816 150240 287912 1214363 2335679
dgedmrlpc 4667 8101 36995 73981 370423 740975
dgedmrlcc 9171 17517 87948 173892 872894 1740458
dgedmrlkc 5899 10705 52840 105742 526430 1037864
Tabla 5.68: Número de flops en el instante de tiempo t=1, variando el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
251
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrlpc 6.535 4.792 4.061 3.892 3.278 3.152
dgedmrlcc 3.325 2.216 1.708 1.656 1.391 1.342
dgedmrlkc 5.170 3.626 2.843 2.723 2.307 2.250
Tabla 5.69: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1 y variar el incremento de tiempo ∆t.
0.1 0.05 0.01 0.005 0.001 0.00051
1.5
2
2.5
3
3.5
4
4.5
5
5.5
6
6.5
∆t
F/F i
Flops(dgedmrbdc)/Flops(dgedmrlpc)Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.21: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1 y variar ∆t.
En la segunda prueba se considera ∆t=0.1 y se varía el tiempo t.

Capítulo 5: Resultados Experimentales
252
Er t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdc 5.727e-03 3.884e-05 9.581e-06 9.581e-06 9.581e-06 9.581e-06
dgedmrlpc 2.556e-03 1.724e-05 1.161e-07 7.812e-10 5.258e-12 3.561e-14
dgedmrlcc 2.523e-03 1.702e-05 1.146e-07 7.713e-10 5.191e-12 3.498e-14
dgedmrlkc 1.417e-03 9.520e-06 6.389e-08 4.290e-10 2.887e-12 1.972e-14
Tabla 5.70: Errores relativos al considerar ∆t=0.1 y variar el tiempo t.
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdc 94799 159837 200219 231569 262919 294269
dgedmrlpc 22187 44087 65987 87887 109787 131687
dgedmrlcc 44074 88043 132908 176516 219373 262641
dgedmrlkc 20057 35407 50407 68071 97279 126703
Tabla 5.71: Número de flops al considerar ∆t=0.1 y variar el tiempo t.
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgedmrlpc 4.273 3.625 3.034 2.635 2.395 2.235
dgedmrlcc 2.151 1.815 1.506 1.312 1.199 1.120
dgedmrlkc 4.726 4.514 3.972 3.402 2.703 2.323
Tabla 5.72: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
253
5 10 15 20 25 301
1.5
2
2.5
3
3.5
4
4.5
5
t
F/F i
Flops(dgedmrbdc)/Flops(dgedmrlpc)Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.22: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• A medida que se incrementa el tiempo, los errores relativos cometidos por los algoritmos basados en la linealización son menores que el correspondiente al algoritmo basado en el método BDF (dgedmrbdc).
• Los algoritmos basados en la linealización a trozos tienen un coste computacional menor que el correspondiente al método BDF (dgedmrbdc), destacando entre ellos el basado en los subespacios de Krylov (dgedmrlpc), seguido por el basado en los aproximantes diagonales de Padé (dgedmrlpc).
Problema 5.9: El segundo caso de estudio de EDMRs con coeficientes constantes ([Meyer73]) consiste en la EDMR definida por
nAA 02211 == , nIAA α== 2112 , nX 00 = ,
donde el tamaño del problema puede hacerse tan grande como se quiera, siendo 0>α un parámetro característico del problema.
La solución a este problema está dada por
[ ] [ ]tttt eIXeIXeIXeIXtX αααα αααα −−− −++−−+= )()()()()( 001
00 ,
lo que permite determinar los errores cometidos en la resolución de la ecuación.
Los valores elegidos para los parámetros característicos en este caso de estudio se muestran a continuación.
• dgedmrbdc: r=2, tol=1e-6, maxiter=100.
• dgedmrlpc: q=1.

Capítulo 5: Resultados Experimentales
254
• dgedmrlcc: q=1.
• dgedmrlkc: p=2, tol=1e-6, q=1.
En la primera prueba se comparan los cuatro algoritmos al considerar n=2 y t=1, variando el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdc 1.551e-03 3.241e-04 3.137e-05 7.862e-06 3.151e-07 7.880e-08
dgedmrlpc 1.552e-03 3.825e-04 1.513e-05 3.779e-06 1.510e-07 3.774e-08
dgedmrlcc 1.552e-03 3.825e-04 1.513e-05 3.779e-06 1.510e-07 3.774e-08
dgedmrlkc 1.845e-03 4.599e-04 1.838e-05 4.595e-06 1.838e-07 4.595e-08
Tabla 5.73: Errores relativos para n=2 y t=1, variando el incremento de tiempo ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdc 13519 26147 87427 174827 874027 1748027
dgedmrlpc 2385 4765 23805 47605 238005 476005
dgedmrlcc 4853 10123 52283 104983 526583 1053583
dgedmrlkc 2874 5734 28614 57214 286014 572014
Tabla 5.74: Número de flops para n=2 y t=1, variando el incremento de tiempo ∆t.
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrlpc 5.668 5.487 3.673 3.672 3.672 3.672
dgedmrlcc 2.786 2.583 1.672 1.665 1.660 1.659
dgedmrlkc 4.704 4.560 3.055 3.056 3.056 3.056
Tabla 5.75: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, t=1 y variar el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
255
0.1 0.05 0.01 0.005 0.001 0.00051.5
2
2.5
3
3.5
4
4.5
5
5.5
∆t
F/F i
Flops(dgedmrbdc)/Flops(dgedmrlpc)Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.23: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.
En la segunda prueba se comparan los cuatro algoritmos para n=2 y ∆t=0.1, variando el instante t de tiempo.
Er t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdc 9.511e-06 4.718e-06 4.722e-06 4.722e-06 4.722e-06 4.722e-06
dgedmrlpc 1.228e-06 8.956e-11 5.662e-15 2.220e-16 2.220e-16 2.220e-16
dgedmrlcc 1.228e-06 8.956e-11 5.662e-15 2.220e-16 2.220e-16 2.220e-16
dgedmrlkc 2.994e-06 2.674e-10 1.799e-14 2.220e-16 2.220e-16 2.220e-16
Tabla 5.76: Errores relativos para n=2 y ∆t=0.1, variando el tiempo t.

Capítulo 5: Resultados Experimentales
256
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdc 54095 82243 104343 126443 148543 170643
dgedmrlpc 11905 23805 35705 47605 59505 71405
dgedmrlcc 25933 52283 78633 104983 131333 157683
dgedmrlkc 14314 28614 42914 57214 71514 85814
Tabla 5.77: Número de flops para n=2 y ∆t=0.1, variando el tiempo t.
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgedmrlpc 4.544 3.455 2.922 2.656 2.496 2.390
dgedmrlcc 2.086 1.573 1.327 1.204 1.131 1.082
dgedmrlkc 3.779 2.874 2.431 2.210 2.077 1.989
Tabla 5.78: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.1 y variar el tiempo t.
5 10 15 20 25 301
1.5
2
2.5
3
3.5
4
4.5
5
t
F/F i
Flops(dgedmrbdc)/Flops(dgedmrlpc)Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.24: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.1 y variar el tiempo.

Capítulo 5: Resultados Experimentales
257
En la tercera prueba se comparan los cuatro algoritmos considerando t=1, ∆t=0.1, y variar el tamaño n del problema.
Er n=5 n=10 n=15 n=20 n=25 n=30
dgedmrbdc 1.551e-03 1.551e-03 1.551e-03 1.551e-03 1.551e-03 1.551e-03
dgedmrlpc 1.552e-03 1.552e-03 1.552e-03 1.552e-03 1.552e-03 1.552e-03
dgedmrlcc 1.552e-03 1.552e-03 1.552e-03 1.552e-03 1.552e-03 1.552e-03
dgedmrlkc 1.845e-03 1.845e-03 1.845e-03 1.845e-03 1.845e-03 1.845e-03
Tabla 5.79: Errores relativos para t=1 y ∆t=0.1, variando el tamaño n del problema.
Flops n=5 n=10 n=15 n=20 n=25 n=30
dgedmrbdc 138530 906335 2830190 6437095 12254050 20808055
dgedmrlpc 25086 170161 540286 1240461 2375686 4050961
dgedmrlcc 48962 314197 972482 2200817 4176202 7075637
dgedmrlkc 23907 153402 478947 1090542 2078187 3531882
Tabla 5.80: Número de flops para t=1 y ∆t=0.1, variando el tamaño n del problema.
F/Fi n=5 n=10 n=15 n=20 n=25 n=30
dgedmrlpc 5.84 5.69 5.63 5.60 5.58 5.57
dgedmrlcc 3.16 3.21 3.23 3.23 3.24 3.24
dgedmrlkc 6.48 6.47 6.46 6.45 6.45 6.44
Tabla 5.81: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1, ∆t=0.1 y variar el tamaño n del problema.

Capítulo 5: Resultados Experimentales
258
5 10 15 20 25 302.5
3
3.5
4
4.5
5
5.5
6
n
F/F i
Flops(dgedmrbdc)/Flops(dgedmrlpc)Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.25: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.1 y variar el tamaño n del problema.
Para comprobar el comportamiento de los algoritmos cuando el tamaño de la matriz es elevado, se han realizado pruebas con las implementaciones FORTRAN para tamaños del problema 500 y 1000. A continuación se presentan los resultados obtenidos en cuanto a precisión y tiempos de ejecución en segundos.
Er n=500 n=1000
dgedmrbdc 2.1568E-05 2.1568E-05
dgedmrlpc 1.2019E-05 1.2019E-05
dgedmrlcc 1.2019E-05 1.2019E-05
dgedmrlkc 1.9543E-05 1.9543E-05
Tabla 5.82: Errores relativos para t=1 y ∆t=0.01, variando el tamaño n del problema.

Capítulo 5: Resultados Experimentales
259
Te n=500 n=1000
dgedmrbdc 449.07 6544
dgedmrlpc 73.335 498.42
dgedmrlcc 189.91 3128.5
dgedmrlkc 42.062 350.02
Tabla 5.83: Tiempos de ejecución, en segundos, al considerar t=1, ∆t=0.01 y variar el tamaño n del problema.
Te/Tei n=500 n=1000
dgedmrlpc 6,12 13,13
dgedmrlcc 2,36 2,09
dgedmrlkc 10,68 18,70
Tabla 5.84: Relación entre el tiempo de ejecución (Te) de la implementación basada en el método BDF (dgedmrbdc) y el tiempo de ejecución (Tei) de las implementaciones basadas en la linealización a trozos, al considerar t=1, ∆t=0.01 y variar el tamaño n del problema.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• A medida que se incrementa el tiempo, los errores relativos cometidos por los algoritmos basados en la linealización a trozos se hacen más pequeños que el correspondiente al método BDF (dgedmrbdc).
• Los algoritmos que utilizan linealización a trozos tienen un coste computacional menor que el correspondiente al método BDF (dgedmrbdc).
− Cuando se disminuye el incremento de tiempo ∆t, la razón de flops de esos algoritmos respecto al basado en el método BDF va disminuyendo hasta llegar a un incremento de 0.01, a partir del cual dicha razón apenas varía.
− Cuando se aumenta el tiempo, la razón de flops de esos algoritmos respecto al basado en el método BDF va disminuyendo, a costa de alcanzar una mayor precisión.
− Cuando se aumenta el tamaño del problema, la razón de flops de esos algoritmos respecto al basado en el método BDF es prácticamente constante.
− Para tamaños elevados del problema, los algoritmos que utilizan la linealización a trozos tienen tiempos de ejecución menores que el correspondiente al método BDF.
• El menor coste computacional corresponde al algoritmo basado en la linealización a trozos mediante los subespacios de Krylov (dgedmrlkc), seguido de cerca por el

Capítulo 5: Resultados Experimentales
260
algoritmo basado en la linealización a trozos mediante los aproximantes diagonales de Padé (dgedmrlpc).
• El menor tiempo de ejecución corresponde a la implementación basada en linealización a trozos mediante los subespacios de Krylov (dgedmrlkc), seguida muy de cerca por la implementación basada en la linealización a trozos mediante los aproximantes diagonales de Padé (dgedmrlpc). Los tiempos de ejecución de dichas rutinas han sido mucho menores que el tiempo de ejecución de la implementación basada en el método BDF (dgedmrbdc).
Problema 5.10: El tercer caso de estudio de EDMRs con coeficientes constantes ([ChAL90]) corresponde a una EDMR no simétrica definida como
0. t,)0( ;)()()()()('22
222
≥=+−+= kkkk IXTktXTtXtXTtXtX
siendo kkTtX 2
2 , )( ℜ∈ y ℜ∈a . La matriz kT2
se define inductivamente
⎥⎦
⎤⎢⎣
⎡−=
111
22 aT ,
⎥⎦
⎤⎢⎣
⎡−=
−−
−−
11
11
222
222
kk
kk
k TTaTT
T , 2≥k .
La solución analítica de la ecuación anterior es
kk TtaItX2
2
2)tanh()1()( ω
ω+
+= ,
donde 21
2 )1(+
+=k
aω .
Los valores elegidos para los parámetros característicos se muestran a continuación.
• dgedmrbdc: r=2, tol=1e-6, maxiter=100.
• dgedmrlpc: q=1.
• dgedmrlcc: q=1.
• dgedmrlkc: p=2, tol=1e-6, q=2.
En la primera prueba se comparan los cuatro algoritmos al considerar n=2, t=1 y variar el incremento de tiempo ∆t.
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdc 3.547e-04 2.993e-05 1.545e-07 1.029e-08 4.109e-09 1.043e-09
dgedmrlpc 2.657e-05 7.145e-06 2.846e-07 7.088e-08 2.825e-09 7.060e-10
dgedmrlcc 2.755e-05 7.190e-06 2.846e-07 7.088e-08 2.825e-09 7.060e-10
dgedmrlkc 3.139e-05 1.649e-05 7.038e-07 1.763e-07 7.057e-09 1.764e-09
Tabla 5.85: Errores relativos para n=2 y t=1, variando el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
261
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdc 19664 29578 120215 228289 992986 1985986
dgedmrlpc 2790 5102 27035 57801 321771 648317
dgedmrlcc 4940 10228 53422 117426 653121 1285987
dgedmrlkc 2987 5735 28615 57215 286015 572015
Tabla 5.86: Número de flops para n=2 y t=1, variando el incremento de tiempo ∆t.
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrlpc 7.048 5.797 4.447 3.950 3.086 3.063
dgedmrlcc 3.981 2.892 2.250 1.944 1.520 1.544
dgedmrlkc 6.583 5.157 4.201 3.990 3.472 3.472
Tabla 5.87: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, t=1 y variar el incremento de tiempo ∆t.
0.1 0.05 0.01 0.005 0.001 0.00051
1.5
2
2.5
3
3.5
4
4.5
5
5.5
6
6.5
7
∆t
F/F i
Flops(dgedmrbdc)/Flops(dgedmrlpc)Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.26: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
262
En la segunda prueba se comparan los cuatro algoritmos al considerar n=2 y ∆t=0.1, y variar el tiempo t.
Er t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdc 1.067e-07 1.067e-07 1.067e-07 1.067e-07 1.067e-07 1.067e-07
dgedmrlpc 9.233e-18 9.233e-18 9.233e-18 9.233e-18 9.233e-18 9.233e-18
dgedmrlcc 7.648e-18 7.648e-18 7.648e-18 7.648e-18 7.648e-18 7.648e-18
dgedmrlkc 3.376e-18 3.376e-18 3.376e-18 3.376e-18 3.376e-18 3.376e-18
Tabla 5.88: Errores relativos para n=2 y ∆t=0.1, variando el tiempo t.
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdc 43800 69100 94400 119700 145000 170300
dgedmrlpc 12692 24542 36392 48242 60092 71942
dgedmrlcc 26198 52548 78898 105248 131598 157948
dgedmrlkc 12703 17953 23203 28453 33703 38953
Tabla 5.89: Número de flops para n=2 y ∆t=0.1, variando el tiempo t.
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgedmrlpc 3.451 2.816 2.594 2.481 2.413 2.367
dgedmrlcc 1.672 1.315 1.196 1.137 1.102 1.078
dgedmrlkc 3.448 3.849 4.068 4.207 4.302 4.372
Tabla 5.90: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
263
5 10 15 20 25 301
1.5
2
2.5
3
3.5
4
4.5
t
F/F i
Flops(dgedmrbdc)/Flops(dgedmrlpc)Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.27: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.1 y variar el tiempo.
En la tercera prueba se comparan los cuatro algoritmos al considerar t=1 y ∆t=0.1, y variar el tamaño n del problema.
Er n=2 n=4 n=8 n=16 n=32
dgedmrbdc 3.547e-04 7.562e-05 1.749e-05 8.870e-06 1.197e-08
dgedmrlpc 2.657e-05 5.455e-10 7.497e-18 2.057e-17 5.686e-17
dgedmrlcc 2.755e-05 5.377e-10 3.193e-17 2.010e-17 5.395e-17
dgedmrlkc 3.139e-05 5.377e-10 3.192e-17 2.000e-17 5.542e-17
Tabla 5.91: Errores relativos para t=1 y ∆t=0.1, variando el tamaño n del problema.

Capítulo 5: Resultados Experimentales
264
Flops n=2 n=4 n=8 n=16 n=32
dgedmrbdc 19664 161923 1426730 13748067 124472608
dgedmrlpc 2790 23548 273024 3062132 32756918
dgedmrlcc 4940 30462 224468 1646839 13805349
dgedmrlkc 2987 13907 83587 576243 4265235
Tabla 5.92: Número de flops para t=1 y ∆t=0.1, variando el tamaño n del problema.
F/Fi n=2 n=4 n=8 n=16 n=32
dgedmrlpc 7.048 6.876 5.226 4.490 3.800
dgedmrlcc 3.981 5.316 6.356 8.348 9.016
dgedmrlkc 6.583 11.643 17.069 23.858 29.183
Tabla 5.93: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1, ∆t=0.1 y variar el tamaño n del problema.
0 5 10 15 20 25 30 350
5
10
15
20
25
30
n
F/F i Flops(dgedmrbdc)/Flops(dgedmrlpc)
Flops(dgedmrbdc)/Flops(dgedmrlcc)Flops(dgedmrbdc)/Flops(dgedmrlkc)
Figura 5.28: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdc) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.1 y variar el tamaño n del problema.

Capítulo 5: Resultados Experimentales
265
Para comprobar el comportamiento de las implementaciones en FORTRAN cuando el tamaño de la matriz es elevado, se han realizado pruebas con un tamaño del problema igual a 512. A continuación se presentan los resultados obtenidos en cuanto a precisión y tiempos de ejecución en segundos.
Er n=512
dgedmrbdc 5.8356e-07
dgedmrlpc 1.9944e-15
dgedmrlcc 9.6766e-15
dgedmrlkc 9.9517e-15
Tabla 5.94: Errores relativos para t=1, ∆t=0.1 y n=512.
Te n=512
dgedmrbdc 47870.00
dgedmrlpc 579.98
dgedmrlcc 456.08
dgedmrlkc 136.17
Tabla 5.95: Tiempos de ejecución en segundos, considerando t=1, ∆t=0.1 y n=512.
Te/Tei n=512
dgedmrlpc 82,54
dgedmrlcc 104,96
dgedmrlkc 351,55
Tabla 5.96: Relación entre el tiempo de ejecución (Te) de la implementación basada en el método BDF (dgedmrbdc) y el tiempo de ejecución (Tei) de las implementaciones basadas en la linealización a trozos, al considerar t=1, ∆t=0.01 y n=512.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• Los errores relativos cometidos por algoritmos basados en la linealización a trozos, son mucho menores que los errores relativos cometidos por el algoritmo basado en el método BDF (dgedmrbdc).

Capítulo 5: Resultados Experimentales
266
− A medida que se incrementa el tiempo, los errores relativos cometidos por los algoritmos basados en la linealización a trozos se hacen más pequeños que los errores relativos cometidos por el algoritmo basado en el método BDF (dgedmrbdc).
− A medida que se aumenta el tamaño del problema, los errores relativos cometidos por los algoritmos basados en la linealización a trozos se hacen más pequeños que los errores relativos cometidos por el algoritmo basado en el método BDF (dgedmrbdc).
• Los algoritmos que utilizan linealización a trozos tienen un coste computacional menor que el correspondiente al método BDF (dgedmrbdc).
− Cuando se disminuye el incremento de tiempo, la razón de flops de esos algoritmos respecto al basado en el método BDF, va disminuyendo hasta llegar a un incremento de 0.001, a partir del cual dicha razón apenas varía.
− Cuando se aumenta el tiempo, la razón de flops del algoritmo de linealización basado en los subespacios de Krylov con respecto al basado en el método BDF, aumenta. Para los otros dos algoritmos de linealización esa razón disminuye ligeramente.
− Cuando se aumenta el tamaño del problema, la razón de flops de los algoritmos de linealización basados en los subespacios de Krylov (dgedmrlkc) y en la ecuación conmutante (dgedmrlpc), con respecto al basado en el método BDF, aumentan. Para el otro algoritmo de linealización (dgedmrlcc) esa razón disminuye ligeramente.
• Los tiempos de ejecución de las implementaciones basadas en la técnica de linealización a trozos han sido mucho menores que el tiempo de ejecución de la implementación basada en el método BDF (dgedmrbdc). Entre estas implementaciones destaca la basada en los subespacios de Krylov (dgedmrlkc), pues su tiempo de ejecución es mucho menor que la implementación del método BDF (la relación de tiempos es aproximadamente igual a 351 para una dimensión igual a 512).
5.5.2 EDMRs con Coeficientes Variables Problema 5.11: El primer caso de estudio de EDMRs con coeficientes variables corresponde a un problema de tipo test, ampliamente utilizado, conocido como “knee problem” ([DEES82]). Se trata de una EDMR definida como
2' xtxx +−= εε , 10 <<< ε , 1)1( −=−x ,
asociada a la matriz de coeficientes variables
⎥⎦
⎤⎢⎣
⎡ −=⎥
⎦
⎤⎢⎣
⎡=
01/1/
)()()()(
)(2221
1211 εεttatatata
tA , 1== mn , 11 ≤≤− t .
La solución tx = es estable para valores anteriores a 0 y la solución 0≅x es estable a partir de tiempos mayores o iguales a 0.
En las pruebas realizadas se ha considerado un valor ε igual a 1e-4. Los valores de los parámetros característicos de cada método aparecen a continuación.
• dgedmrbdv: r=2, tol=1.0e-6, maxiter=100.

Capítulo 5: Resultados Experimentales
267
• dgedmrlpv: q=1.
• dgedmrlcv: q=1.
• dgedmrlkv: p=3, tol=1.0e-5, q=1.
En la primera prueba se comparan los cuatro algoritmos considerando t=1 y variando el incremento de tiempo entre 0.1 y 0.05, ya que para valores menores la precisión obtenida es la misma.
Er ∆t=0.1 ∆t=0.05
dgedmrbdv 5.001e-05 5.001e-05
dgedmrlpv Error 4.917e-05
dgedmrlcv 4.391e-05 4.988e-05
dgedmrlkv 4.326e-05 4.988e-05
Tabla 5.97: Errores relativos para t=1, variando el incremento de tiempo ∆t.
Flops ∆t=0.1 ∆t=0.05
dgedmrbdv 7203 12140
dgedmrlpv 3426 8145
dgedmrlcv 5049 9704
dgedmrlkv 18728 35018
Tabla 5.98: Número de flops para t=1, variando el incremento de tiempo ∆t.
F/Fi ∆t=0.1 ∆t=0.05
dgedmrlpv 2.102 1.490
dgedmrlcv 1.427 1.251
dgedmrlkv 0.385 0.347
Tabla 5.99: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1 y variar el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
268
0.1 0.05
0.5
1
1.5
2
∆t
F/F i
Flops(dgedmrbdv)/Flops(dgedmrlpv)Flops(dgedmrbdv)/Flops(dgedmrlcv)Flops(dgedmrbdv)/Flops(dgedmrlkv)
Figura 5.29: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1 y variar el incremento de tiempo ∆t.
En la segunda prueba se comparan los cuatro algoritmos para ∆t=0.001, variando el instante t de tiempo.
Er t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdv 1.054e-05 5.538e-06 3.538e-06 2.538e-06 2.538e-06 2.538e-06
dgedmrlpv 1.000e-05 5.000e-06 3.333e-06 2.500e-06 2.000e-06 1.667e-06
dgedmrlcv 1.000e-05 5.000e-06 3.333e-06 2.500e-06 2.000e-06 1.667e-06
dgedmrlkv 1.000e-05 5.000e-06 3.333e-06 2.500e-06 2.000e-06 1.667e-06
Tabla 5.100: Errores relativos considerando ∆t=0.001 y variando el tiempo t.

Capítulo 5: Resultados Experimentales
269
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdv 767164 1252569 1737731 2222812 2707812 3192812
dgedmrlpv 830433 1698033 2623233 3593233 4563233 5603633
dgedmrlcv 1380595 2566392 3762989 4967989 6172989 7391186
dgedmrlkv 2700889 5365589 8127489 10964989 14303381 17818899
Tabla 5.101: Número de flops considerando ∆t=0.001 y variando el tiempo t.
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgedmrlpv 0.924 0.738 0.662 0.619 0.593 0.570
dgedmrlcv 0.556 0.488 0.462 0.447 0.439 0.432
dgedmrlkv 0.284 0.233 0.214 0.203 0.189 0.179
Tabla 5.102: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.001 y variar el tiempo t.
5 10 15 20 25 300.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
t
F/F i
Flops(dgedmrbdv)/Flops(dgedmrlpv)Flops(dgedmrbdv)/Flops(dgedmrlcv)Flops(dgedmrbdv)/Flops(dgedmrlkv)
Figura 5.30: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar ∆t=0.001 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
270
A partir de las tablas anteriores se pueden extraer las siguientes conclusiones:
• Los algoritmos con menor error relativo corresponden al algoritmo basado en el método BDF (dgedmrbdv), y a los algoritmos basados en la linealización a trozos mediante los subespacios de Krylov (dgedmrlkv) y mediante la ecuación conmutante (dgedmrlcv). En el algoritmo basado en la linealización a trozos mediante los aproximantes diagonales de Padé (dgedmrlpv) se produce un error cuando el incremento de tiempo considerado es igual a 0.1.
• Los menores costes computacionales corresponden al algoritmo basado en el método BDF (dgedmrbdv).
• Los algoritmos más rápidos corresponden a los basados en la linealización a trozos mediante los aproximantes diagonales de Padé (dgedmrlpv) y mediante la educación conmutante (dgedmrlcv).
Problema 5.12: El segundo caso de estudio de EDMRs con coeficientes variables ([BrLo87]) proviene de un problema de tipo rígido con valores de contorno. La correspondiente EDMR tiene como matrices coeficiente a
⎥⎦
⎤⎢⎣
⎡−=
0002/
)(11
εttA , ⎥
⎦
⎤⎢⎣
⎡=
εε
/100/1
)(12 tA , ⎥⎦
⎤⎢⎣
⎡=
1012/1
)(21 tA , ⎥⎦
⎤⎢⎣
⎡=
002/0
)(22
εttA ,
siendo 10 <<< ε , 1−≥t , con valor inicial
⎥⎦
⎤⎢⎣
⎡=
0000
0X .
A medida que t se aleja del cero, la solución se aproxima a la matriz
⎥⎦
⎤⎢⎣
⎡=
εε
02/)( ttX .
En las pruebas realizadas se ha considerado un valor ε igual a 1e-4. Los valores de los parámetros característicos de cada método aparecen a continuación.
• dgedmrbdv: r=3, tol=1.0e-14, maxiter=100.
• dgedmrlpv: q=3.
• dgedmrlcv: q=1.
• dgedmrlkv: p=5, tol=1.0e-14, q=1.
En la primera prueba se comparan los cuatro algoritmos al considerar t=1 y variar el incremento de tiempo.

Capítulo 5: Resultados Experimentales
271
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdv 1.414 1.414 2.221e-16 1.112e-16 9.811e-18 2.088e-14
dgedmrlpv Error Error 1.511e-07 7.592e-08 9.814e-09 5.285e-09
dgedmrlcv 6.296e-08 2.220e-16 1.110e-16 1.110e-16 1.112e-16 1.119e-16
dgedmrlkv 6.283e-08 4.577e-16 0 2.047e-16 3.261e-16 7.625e-16
Tabla 5.103: Errores relativos para t=1, variando el incremento de tiempo ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdv 429587 789544 3587274 6860624
dgedmrlpv 324533 570077 1982885 3257621
dgedmrlcv 23235 46671 229231 454631 2240655 4453399
dgedmrlkv 95517 168559 575794 1068339 3986117 7035878
Tabla 5.104: Número de flops para t=1, variando el incremento de tiempo ∆t.
F/Fi ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrlpv 1.324 1.385 1.809 2.106
dgedmrlcv 1.874 1.737 1.601 1.541
dgedmrlkv 0.746 0.739 0.900 0.975
Tabla 5.105: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1 y variar el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
272
0.01 0.005 0.001 0.0005
1
1.5
2
∆t
F/F i
Flops(dgedmrbdv)/Flops(dgedmrlpv)Flops(dgedmrbdv)/Flops(dgedmrlcv)Flops(dgedmrbdv)/Flops(dgedmrlkv)
Figura 5.31: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1 y variar el incremento de tiempo ∆t.
En la segunda prueba se comparan los cuatro algoritmos al considerar n=2, ∆t=0.001 y variar el tiempo t.
Er t=0.1 t=0.2 t=0.3 t=0.4 t=0.5 t=0.6
dgedmrbdv 1.776e-06 1.693e-15 1.693e-15 2.772e-16 1.964e-14 5.013e-15
dgedmrlpv 8.942e-05 1.971e-06 1.971e-06 1.490e-06 1.197e-06 2.502e-07
dgedmrlcv 4.671e-12 0 0 1.386e-16 6.933e-18 1.849e-16
dgedmrlkv 3.226e-12 1.154e-16 1.154e-16 1.059e-15 2.220e-16 3.706e-15
Tabla 5.106: Errores relativos para n=2 y ∆t=0.001, variando el tiempo t.

Capítulo 5: Resultados Experimentales
273
Flops t=0.1 t=0.2 t=0.3 t=0.4 t=0.5 t=0.6
dgedmrbdv 246065 292485 292485 315695 336187 354867
dgedmrlpv 170291 199275 199275 215825 232375 250493
dgedmrlcv 125493 148329 148329 159835 171357 182879
dgedmrlkv 388879 428862 428862 447606 469102 487842
Tabla 5.107: Número de flops para n=2 y ∆t=0.001, variando el tiempo t.
F/Fi t=0.1 t=0.2 t=0.3 t=0.4 t=0.5 t=0.6
dgedmrlpv 1.445 1.468 1.468 1.463 1.447 1.417
dgedmrlcv 1.961 1.972 1.972 1.975 1.962 1.940
dgedmrlkv 0.633 0.682 0.682 0.705 0.717 0.727
Tabla 5.108: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considera n=2, ∆t=0.001 y variar el tiempo t.
0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6
0.8
1
1.2
1.4
1.6
1.8
2
t
F/F i
Flops(dgedmrbdv)/Flops(dgedmrlpv)Flops(dgedmrbdv)/Flops(dgedmrlcv)Flops(dgedmrbdv)/Flops(dgedmrbkv)
Figura 5.32: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.001 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
274
A partir de las tablas anteriores se pueden extraer las siguientes conclusiones:
• Los algoritmos con menor error relativo corresponden a los basados en la linealización a trozos mediante los subespacios de Krylov (dgedmrlkv) y mediante la ecuación conmutante (dgedmrlcv).
− En el algoritmo basado en el método BDF (dgedmrbdv) se producen grandes errores para incrementos de tiempo iguales a 0.1 y a 0.05.
− En el método de linealización a trozos basado en los aproximantes diagonales de Padé (dgedmrlpv) se producen elevados errores cuando los incrementos de tiempo son iguales a 0.1 y a 0.05, debido a que la norma de la matriz Jacobiana es elevada, por lo que el cálculo de su exponencial produce un error de overflow.
• Los algoritmos con menores costes corresponden a los basados en la linealización a trozos mediante la ecuación conmutante (dgedmrlcv) y mediante los aproximantes diagonales de Padé (dgedmrlpv).
• El algoritmo basado en la linealización a trozos mediante los subespacios de Krylov (dgedmrlkv) tiene un coste computacional mayor que el basado en el método BDF (dgedmrbdv).
Problema 5.13: El tercer caso de estudio de EDMRs con coeficientes variables ([Choi92]), corresponde a una EDMR definida como
0. t,)0( ;)()()()()()()()('22
222
≥=−−+−= kkkk IXItbtXtbtXtTtTtXtX
donde k
tX 2 )( ℜ∈ , y k
kT 22
ℜ∈ está definida como
⎥⎦
⎤⎢⎣
⎡−
=)()()()(
2 tatbtbta
T ,
11 22222 −− ⊗+⊗= kkk TIITT , 2≥k ,
siendo tta cos)( = y tsentb =)( .
La solución analítica de la ecuación anterior es
kItttX 2)1tan(cos1
)1tan(cos1)(−−−+
= .
Los valores de los parámetros característicos de cada método aparecen a continuación.
• dgedmrbdv: r=3, tol=1.0e-14, maxiter=100.
• dgedmrlpv: q=2.
• dgedmrlcv: q=2.
• dgedmrlkv: p=3, tol=1.0e-14, q=1.
En la primera prueba se comparan los cuatro algoritmos al considerar n=4 (k=2), t=1 y variar el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
275
Er ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdv 2.018e-02 4.726e-03 2.066e-04 5.217e-05 2.103e-06 5.269e-07
dgedmrlpv 5.335e-03 1.174e-03 5.061e-05 1.277e-05 5.147e-07 1.289e-07
dgedmrlcv 7.419e-02 2.240e-02 1.554e-03 4.563e-04 2.437e-05 6.751e-06
dgedmrlkv 4.718e-03 1.023e-03 4.386e-05 1.106e-05 4.457e-07 1.117e-07
Tabla 5.109: Errores relativos para n=2 y t=1, variando el incremento de tiempo ∆t.
Flops ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrbdv 433518 744608 2817685 5650073 28126108 55959494
dgedmrlpv 57102 109554 575795 1158595 5820995 11654823
dgedmrlcv 119068 226544 1254024 2529762 12931608 26110356
dgedmrlkv 48163 91570 477419 959731 4818236 9646194
Tabla 5.110: Número de flops para n=4 y t=1, variando el incremento de tiempo ∆t.
F/Fi ∆t=0.1 ∆t=0.05 ∆t=0.01 ∆t=0.005 ∆t=0.001 ∆t=0.0005
dgedmrlpv 7.592 6.797 4.894 4.877 4.832 4.801
dgedmrlcv 3.641 3.287 2.247 2.233 2.175 2.143
dgedmrlkv 9.001 8.132 5.902 5.887 5.837 5.801
Tabla 5.111: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=4, t=1 y variar el incremento de tiempo ∆t.

Capítulo 5: Resultados Experimentales
276
0.1 0.05 0.01 0.005 0.001 0.00052
2.5
33.5
4
4.55
5.56
6.57
7.5
88.5
9
∆t
F/F i
Flops(dgedmrbdv)/Flops(dgedmrlpv)Flops(dgedmrbdv)/Flops(dgedmrlcv)Flops(dgedmrbdv)/Flops(dgedmrlkv)
Figura 5.33: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=4, ∆t=0.1 y variar el incremento de tiempo ∆t.
En la segunda prueba se comparan los cuatro algoritmos para n=4 (k=2), ∆t=0.1, variando el instante t de tiempo.
Er t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdv 7.687e-02 1.466e-02 1.245e-02 1.836e-02 9.549e-03 2.215e-02
dgedmrlpv 1.153e-02 1.081e-03 7.964e-04 3.157e-04 4.040e-03 1.190e-02
dgedmrlcv 5.057e-01 2.223e-01 2.455e-01 8.954e-01 3.474e-01 7.782e-01
dgedmrlkv 8.781e-03 2.464e-03 5.066e-04 4.081e-05 3.526e-03 1.072e-02
Tabla 5.112: Errores relativos para n=4 y ∆t=0.1, variando el tiempo t.

Capítulo 5: Resultados Experimentales
277
Flops t=5 t=10 t=15 t=20 t=25 t=30
dgedmrbdv 1934113 3797375 5680701 7503707 9382353 11245258
dgedmrlpv 296418 594418 885286 1178658 1477726 1776762
dgedmrlcv 584064 1078179 1505781 1938668 2438424 2957326
dgedmrlkv 241197 482487 723781 960212 1201523 1442843
Tabla 5.113: Número de flops para n=4 y ∆t=0.1, variando el tiempo t.
F/Fi t=5 t=10 t=15 t=20 t=25 t=30
dgedmrlpv 6.525 6.388 6.417 6.366 6.349 6.329
dgedmrlcv 3.311 3.522 3.773 3.871 3.848 3.803
dgedmrlkv 8.019 7.870 7.849 7.815 7.809 7.794
Tabla 5.114: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=2, ∆t=0.1 y variar el tiempo t.
5 10 15 20 25 303
4
5
6
7
8
9
t
F/F i
Flops(dgedmrbdv)/Flops(dgedmrlpv)Flops(dgedmrbdv)/Flops(dgedmrlcv)Flops(dgedmrbdv)/Flops(dgedmrlkv)
Figura 5.34: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar n=4, ∆t=0.1 y variar el tiempo t.

Capítulo 5: Resultados Experimentales
278
En la tercera prueba se comparan los cuatro algoritmos considerando t=1 y ∆t=0.1, variando el tamaño n del problema.
Er n=2 n=4 n=8 n=16 n=32 n=64
dgedmrbdv 2.018e-02 2.018e-02 2.018e-02 2.018e-02 2.018e-02 2.018e-02
dgedmrlpv 5.374e-03 5.335e-03 5.303e-03 5.326e-03 5.497e-03 4.523e-03
dgedmrlcv 3.004e-02 7.419e-02 1.359e-01 2.153e-01 3.126e-01 4.283e-01
dgedmrlkv 4.718e-03 4.718e-03 4.718e-03 4.718e-03 4.718e-03 4.718e-03
Tabla 5.115: Errores relativos para t=1 y ∆t=0.1, variando el tamaño n del problema.
Flops n=2 n=4 n=8 n=16 n=32 n=64
dgedmrbdv 28919 433518 1331590 8717740 61494024 463083648
dgedmrlpv 10027 57102 376523 2714671 20575955 194870615
dgedmrlcv 15390 119068 480837 2834634 20135747 149904917
dgedmrlkv 11863 48163 250743 1525323 10347743 75449843
Tabla 5.116: Número de flops para t=1 y ∆t=0.1, variando el tamaño n del problema.
F/Fi n=2 n=4 n=8 n=16 n=32 n=64
dgedmrlpv 2.884 7.592 3.537 3.211 2.989 2.376
dgedmrlcv 1.879 3.641 2.769 3.075 3.054 3.089
dgedmrlkv 2.438 9.001 5.311 5.715 5.943 6.138
Tabla 5.117: Relación entre el número de flops (F) del algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1, ∆t=0.1 y variar el tamaño n del problema.

Capítulo 5: Resultados Experimentales
279
0 10 20 30 40 50 60 701
2
3
4
5
6
7
8
9
10
n
F/F i
Flops(dgedmrbdv)/Flops(dgedmrlpv)Flops(dgedmrbdv)/Flops(dgedmrlcv)Flops(dgedmrbdv)/Flops(dgedmrlkv)
Figura 5.35: Relación entre el número de flops (F) del
algoritmo basado en el método BDF (dgedmrbdv) y el número de flops (Fi) de los algoritmos basados en la linealización a trozos, al considerar t=1, ∆t=0.1 y variar el tamaño n del problema.
Para comprobar el comportamiento de las rutinas implementadas cuando el tamaño de la matriz es elevado, se han realizado pruebas con las implementaciones FORTRAN para tamaños del problema 512 y 1024.
Los valores elegidos para los parámetros característicos se muestran a continuación.
• dgedmrbdv: r=2, tol=1e-13, maxiter=100.
• dgedmrlpv: q=2.
• dgedmrlcv: q=3.
• dgedmrlkv: p=3, tol=1e-13, q=1.
A continuación se presentan los resultados obtenidos en cuanto a precisión y tiempos de ejecución en segundos.
Er n=512 n=1024
dgedmrbdv 1.1616E-04 1.1616E-04
dgedmrlpv 5.3723E-05 5.4718E-05
dgedmrlcv 5.2306E-03 5.4516E-03
dgedmrlkv 4.4898E-04 44898E-05
Tabla 5.118: Errores relativos para t=1 y ∆t=0.01, variando el tamaño n del problema.

Capítulo 5: Resultados Experimentales
280
Te n=512 n=1024
dgedmrbdv 1666.5 65757
dgedmrlpv 194.61 1501.4
dgedmrlcv 2834.5 29099
dgedmrlkv 181.12 1460.3
Tabla 5.119: Tiempos de ejecución en segundos, considerando t=1, ∆t=0.01 y variar el tamaño n del problema.
Te/Tei n=512 n=1024
dgedmrlpc 8.56 43.80
dgedmrlcc 0.59 2.26
dgedmrlkc 9.20 45.03
Tabla 5.120: Relación entre el tiempo de ejecución (Te) de la implementación basada en el método BDF (dgedmrbdv) y el tiempo de ejecución (Tei) de las implementaciones basadas en la linealización a trozos, al considerar t=1, ∆t=0.01 y variar el tamaño n del problema.
De los resultados obtenidos se pueden extraer las siguientes conclusiones:
• Los algoritmos con menor error relativo corresponden a los algoritmos basados en la linealización a trozos mediante los subespacios de Krylov (dgedmrlkv) y mediante aproximantes diagonales de Padé, seguidos muy de cerca por el algoritmo basado en el método BDF (dgedmrbdv). Los peores resultados se obtienen para el caso de linealización a trozos mediante la ecuación conmutante (dgedmrlcv).
• Los menores costes computacionales corresponden al método de linealización a trozos basado en los subespacios de krylov (dgedmrlkv), seguido muy de cerca por el basado en los aproximantes diagonales de Padé (dgedmrlpv). Los mayores costes computacionales corresponden al algoritmo basado en el método BDF (dgedmrbdv).
• Para tamaños elevados del problema, las implementaciones basadas en los algoritmos que utilizan la linealización a trozos tienen tiempos de ejecución mucho menores que la implementación basada en el método BDF (dgedmrbdv), destacando la basada en los subespacios de krylov (dgedmrlkv) y la basada los aproximantes diagonales de Padé (dgedmrlpv).
5.6 Conclusiones Como se ha podido comprobar a lo largo del desarrollo de este capítulo, se han realizado un gran número de pruebas para comparar los algoritmos implementados,

Capítulo 5: Resultados Experimentales
281
determinando para cada algoritmo los valores óptimos de sus parámetros característicos. A continuación se sintetizan los resultados más destacables de las pruebas realizadas.
• Funciones de matrices.
− Los algoritmos basados en los aproximantes diagonales de Padé presentan una buena precisión. En cuanto a eficiencia destacan las implementaciones basadas en el método de Paterson-Stockmeyer-Van Loan, eligiendo para ello un factor adecuado de agrupamiento comprendido entre 3 y 5.
− Los algoritmos basados en la descomposición real de Schur de una matriz son, en general, más precisos que los métodos basados en aproximantes diagonales de Padé. En cuanto a eficiencia destacan la implementación que utiliza los aproximantes diagonales de Padé y la implementación basada en la resolución por bloques de la Ecuación Conmutante.
− Las implementaciones basadas en los aproximantes diagonales de Padé son más rápidas que las implementaciones basadas en la descomposición real de Schur de una matriz.
• Resolución de EDOs.
− Los valores óptimos de los parámetros característicos han sido, en la mayoría de los casos, valores pequeños. A modo de resumen, se citan a continuación los valores más habituales.
dgeedobdf: r=2, 3; tol=1e-6; maxiter=100. dgeedolpa-dgeedolpn: q=1. dgeedolca-dgeedolcn: q=1. dgeedolpa- dgeedolpn: p=2, 3, 4; tol=1e-6; q=1.
− En las pruebas realizadas sobre EDOs autónomas se ha podido comprobar que los errores relativos cometidos por los algoritmos basados en los métodos de linealización a trozos son similares a los cometidos por el algoritmo basado en el método BDF, aunque en el caso del algoritmo basado en la linealización a trozos mediante la Ecuación Conmutante este sólo se puede utilizar si la matriz Jacobiana es invertible y está bien condicionada.
− En las pruebas realizadas sobre EDOs autónomas siempre ha sido posible encontrar un algoritmo basado en la linealización a trozos que tuviese un coste computacional menor que el basado en el método BDF. Para problemas de pequeña dimensión destacan los algoritmos basados en los aproximantes diagonales de Padé y en la Ecuación Conmutante. Para problemas de mayor dimensión destaca la implementación basada en los subespacios de Krylov, por tener un coste computacional menor que los costes computacionales correspondientes al resto de algoritmos.
− En las pruebas realizadas sobre EDOs no autónomas, se tiene que los errores relativos cometidos por los algoritmos basados en los métodos de linealización a trozos son algo menores que los cometidos por el algoritmo basado en el método BDF, exceptuando el caso del algoritmo basado en el método de linealización a trozos mediante la Ecuación Conmutante, por necesitar que la matriz Jacobiana sea invertible y esté bien condicionada.

Capítulo 5: Resultados Experimentales
282
− En las pruebas realizadas sobre EDOs no autónomas siempre ha sido posible encontrar un método basado en la linealización a trozos que tuviese un coste computacional menor que el basado en el método BDF. Para problemas de pequeña dimensión destacan el algoritmo basado en los aproximantes diagonales de Padé y el basado en la Ecuación Conmutante. Para problemas de mayor dimensión destaca el algoritmo basado en los subespacios de Krylov. Cabe destacar, en este sentido, los resultados obtenidos en el tercer caso de estudio de EDOs no autónomas, al tener que el tiempo de ejecución de la implementación basada en los subespacios de Krylov es mucho menor que la implementación basada en los otros métodos.
− Tanto los algoritmos basados en los métodos de linealización a trozos como el basado en el método BDF presentan un buen comportamiento en problemas de tipo rígido.
• Resolución de EDMRs.
− Los valores óptimos de los parámetros característicos han sido, en la mayoría de los casos, valores pequeños. A modo de resumen, se citan a continuación los valores más habituales.
dgedmrbdc: r=2, 3; tol=1e-6, 1e-14; maxiter=100. dgedmrlpc-dgedmrlpv: q=1,2. dgedmrlcc-dgedmrlcv: q=1,2,3. dgedmrlpc-dgedmrlpv: p=2, 3, 5; tol=1e-6, 1e-14; q=1,2.
− En las pruebas realizadas sobre EDMRs con coeficientes constantes se tiene que los errores relativos cometidos por los cuatro algoritmos son similares, salvo el segundo caso de estudio en el que el algoritmo basado en el método BDF y el basado en la linealización a trozos mediante los aproximantes diagonales de Padé presentan grandes errores, si el incremento de tiempo es del orden de décimas.
− En las pruebas realizadas sobre EDMRs con coeficientes constantes ha resultado que los algoritmos basados en la linealización a trozos tienen un coste computacional menor que el basado en el método BDF. Entre ellos destacan los algoritmos basados en los aproximantes diagonales de Padé y en los subespacios de Krilov, sobresaliendo este último cuando se consideran problemas de gran dimensión.
− El tiempo de ejecución del método de linealización a trozos basado en los subespacios de Krylov, cuando se aplica sobre EDMRs con coeficientes constantes de mediana o gran dimensión, es menor que el tiempo de ejecución del resto de las implementaciones. Cabe destacar, en este sentido, los resultados obtenidos en el segundo y tercer caso de estudio (Problema 5.9, Problema 5.10) cuando se considera un tamaño del problema elevado, al tener que el tiempo de ejecución de la implementación basada en los subespacios de Krylov ha sido mucho menor que la implementación basada en el método BDF.
− En las pruebas realizadas sobre EDMRs con coeficientes variables, salvo un caso de estudio de pequeña dimensión (Problema 5.11), los algoritmos basados en la linealización a trozos tienen un coste computacional menor que el basado en el método BDF.

Capítulo 5: Resultados Experimentales
283
Para problemas de pequeña dimensión destacan los basados en los aproximantes diagonales de Padé y en la Ecuación Conmutante.
Para problemas de mayor dimensión destaca el método basado en los subespacios de Krylov. En este sentido se pueden resaltar los resultados obtenidos en el tercer caso de estudio de EDMRs con coeficientes variables cuando se consideran tamaños del problema igual 1024, al tener que el tiempo de ejecución de la implementación basada en los subespacios de Krylov ha resultado ser unas cuarenta y cinco veces menor que el tiempo de ejecución de la implementación basada en el método BDF.
− Tanto los algoritmos basados en la linealización a trozos como los basados en el método BDF presentan un buen comportamiento en problemas de tipo rígido.


Capítulo 6: Conclusiones y Líneas Futuras de Investigación
285
Capítulo 6 Conclusiones y Líneas Futuras de Investigación
6.1 Resumen de Contenidos En este capítulo se resume el trabajo realizado en esta tesis, describiendo brevemente los resultados más destacados y perfilando las futuras líneas de investigación. La segunda sección está dedicada a resumir las aportaciones realizadas en el marco de esta tesis y los excelentes resultados obtenidos en las diferentes implementaciones. En la tercera sección se detallan las publicaciones realizadas durante el periodo de realización de la tesis, muchas de las cuales han servido como base de la misma. En la cuarta sección se enumeran las posibles líneas de investigación que se pueden abrir a partir de este trabajo.
6.2 Conclusiones Finales En el marco de esta tesis se han desarrollado nuevos métodos y algoritmos para el cálculo de Funciones de Matrices y la aplicación de Funciones de Matrices a la simulación y la resolución de EDOs y EDMRs.
Para cada algoritmo desarrollado se ha implementado una función en MATLAB y una rutina en FORTRAN. De este modo se dispone en la actualidad de tres librerías, escritas en MATLAB y FORTRAN, que permiten calcular Funciones de Matrices y resolver EDOs y EDMRs.
Las librerías obtenidas tienen las características propias de un software de computación numérica de calidad: eficientes, de altas prestaciones, portables, robustas y correctas. Esto ha sido posible al utilizar un ciclo de vida que permite automatizar el desarrollo de software numérico y disponer de herramientas que lo posibilitan como el entorno MATLAB y las librerías de computación numérica de altas prestaciones BLAS y LAPACK.
6.2.1 Funciones de Matrices Para el cálculo de Funciones de Matrices se han desarrollado dos metodologías generales, basadas en los aproximantes diagonales de Padé y en la descomposición real de Schur de una matriz, que calculan eficientemente Funciones de Matrices.
La metodología basada en los aproximantes diagonales de Padé ha permitido poder calcular funciones especiales de matrices, como las potencias fraccionarias, de una manera nunca realizada hasta ahora. También se puede destacar, como aspecto novedoso, el cálculo de la función seno matricial mediante esta metodología. En general, esta metodología permite calcular funciones analíticas de matrices de manera eficiente. Esto ha sido posible porque la parte más costosa de los algoritmos basados en esta metodología (cálculo de la aproximación de Padé) se ha realizado de la manera más eficiente posible (método de Paterson-Stockmeyer-Van Loan).

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
286
Se han diseñado nuevos algoritmos para el cálculo de Funciones de Matrices que utilizan la descomposición real de Schur de una matriz como, por ejemplo, el basado en la diagonalización a bloques de una matriz, los basados en la Ecuación Conmutante (orientados a columnas, diagonales y a bloques), los basados en la agrupación en cluster de los valores propios cercanos y el basado en los aproximantes diagonales de Padé.
El diseño de estos nuevos algoritmos ha conducido a la implementación de funciones/rutinas basadas en dichas metodologías, escritas en MATLAB y FORTRAN, que calculan Funciones de Matrices. Las rutinas implementadas en FORTRAN utilizan las librerías de computación numérica BLAS y LAPACK, con la consiguiente portabilidad y eficiencia del código implementado. En este sentido cabe destacar el hueco cubierto por este software desarrollado, ya que en la actualidad se dispone de un número muy limitado de rutinas que calculan Funciones de Matrices.
Para analizar las prestaciones de los algoritmos implementados se han realizado una gran cantidad de pruebas que han permitido comprobar la eficiencia y la precisión de las rutias implementas. Estas pruebas además han permitido determinar los valores de los parámetros característicos de algunas de las implementaciones. También se ha podido comprobar cuáles pueden ser las mejores implementaciones para una determinada función y una matriz dada. Por lo tanto, se puede diseñar un algoritmo que determine, a partir de la función y de la matriz considerada, cuál es el mejor método y cuáles los valores óptimos de sus parámetros característicos.
En cuanto a los resultados obtenidos se puede afirmar que se han desarrollado implementaciones muy eficientes, en términos de almacenamiento y coste computacional, destacando las basadas en los aproximantes diagonales de Padé por su rapidez y las basadas en la descomposición real de Schur de una matriz por su precisión.
6.2.2 Aplicación de las Funciones de Matrices Se ha realizado un estudio completo del uso de Funciones de Matrices en la simulación de la propagación de ondas en fibras de cristal fotónico. Las especiales características de guiado de la luz de las fibras de cristal fotónico tienen potenciales aplicaciones en una gran variedad de campos que van desde las comunicaciones ópticas hasta la fabricación de dispositivos optoelectrónicos. Las propiedades de propagación del campo electromagnético en estos sistemas vienen determinadas por la configuración particular de la estructura dieléctrica transversal. A partir de un modelo que representa la propagación no lineal de un campo monocromático en un medio inhomogéneo, se analiza la evolución no lineal del campo eléctrico a lo largo de la fibra. Esta evolución consiste en un proceso iterativo en el que en cada paso se calcula la exponencial de la raíz cuadrada de una matriz de gran dimensión obtenida a partir del paso anterior. Esto supone un alto coste computacional que puede acarrear semanas o incluso meses de simulaciones. Se trataba, pues, de implementar un algoritmo que, manteniendo la precisión adecuada, tuviese un tiempo de ejecución lo menor posible. Partiendo de una implementación previa, basada en la diagonalización de una matriz, se realizó un estudio en profundidad determinando otras posibilidades: método basado en los aproximantes diagonales de Padé y método basado en la iteración DB con aproximantes diagonales de Padé. Tal como muestran los resultados, la implementación basada en la iteración DB con aproximantes diagonales de Padé resultó tener un tiempo de ejecución aproximadamente igual a la mitad del tiempo de ejecución de la primera implementación basada en la diagonalización de la matriz.

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
287
6.2.3 Resolución de EDOs En esta tesis se ha aplicado la técnica de linealización a trozos para resolver EDOs con una nueva aproximación basada en el Teorema 4.1, desarrollado en el ámbito de esta tesis, el cual permite resolver EDOs aunque la matriz Jacobiana que aparece en cada iteración sea singular. Consecuencia de este teorema ha sido el desarrollo de nuevos método de resolución de EDOs. Estos métodos se basan en calcular en cada iteración una expresión en la que aparecen dos bloques de la exponencial de una matriz. Estos métodos se describen a continuación:
• Método basado en los aproximantes diagonales de Padé. En este método se calculan los bloques que aparecen en la expresión que define la nueva aproximación, sin el cálculo explicito de la exponencial que los contiene. Para ello se realiza una adaptación de los aproximantes diagonales de Padé. Para reducir los costes computacionales y de almacenamiento, se ha adaptado adecuadamente el método anterior cuando se aplica sobre EDOs autónomas.
• Método basado en los subespacios de Krylov. En este método se trasforma la expresión que define a la nueva aproximación en el producto de la exponencial de una matriz definida a bloques por un vector. Para calcular eficientemente dicho producto, se utiliza una aproximación basada en subespacios de Krylov. Es posible adaptar el método anterior para resolver EDOs autónomas, reduciendo con ello los costes computacionales y de almacenamiento.
• Método basado en la Ecuación Conmutante En este método se aplica la Ecuación Conmutante a la matriz Jacobiana, para encontrar los bloques que aparecen en la expresión que define la nueva aproximación. En este caso es necesario que la matriz Jacobiana sea invertible. Al igual que ocurre en los otros dos métodos, se han reducido los costes computacionales y de almacenamiento cuando se resuelven EDOs autónomas, adaptando para ello el método anterior.
Para cada uno de los métodos anteriores se ha desarrollo un algoritmo que permite resolver EDOs:
• EDOs no autónomas: Algoritmo 4.5, Algoritmo 4.7 y Algoritmo 4.11.
• EDOs autónomas: Algoritmo 4.14, Algoritmo 4.16 y Algoritmo 4.18.
Además, se han implementado los algoritmos anteriores en MATLAB y FORTRAN, determinando los parámetros característicos de cada uno de ellos y optimizando sus costes espaciales y temporales.
Se han presentado siete casos de estudio, realizando una gran variedad de pruebas sobre ellos. Los resultados obtenidos han mostrado por una parte, cuáles suelen ser los valores óptimos de los parámetros característicos y, por otra, las ventajas que tienen frente a un método clásico de resolución de EDOs (método BDF). Hay que resaltar dos aspectos en este sentido:
• Se han elegido algunos casos de estudio que corresponden a problemas de tipo rígido.
• Se han seleccionado algunos casos de estudios en los que la solución analítica es conocida, y así poder comprobar la precisión de los algoritmos implementados.

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
288
• Se ha elegido un caso de estudio que corresponde a un problema de gran dimensión, y así comprobar la eficiencia de los métodos implementados para este tipo de problemas.
• Para cada caso de estudio se han determinado los valores óptimos de los parámetros característicos de todos los códigos implementados para, de este modo, no favorecer a uno de ellos frente al resto.
• Aunque se han analizado más casos de estudio que los presentados en esta tesis, se ha podido constatar que los resultados obtenidos en estos otros casos han resultado ser similares.
A continuación se hace un breve resumen de los resultados obtenidos:
• Para un mismo incremento de tiempo, la precisión obtenida en los algoritmos basados en la linealización a trozos de EDOs ha resultado ser similar e incluso mayor que la obtenida en el algoritmo basado en el método BDF.
• Los algoritmos basados en los métodos de linealización tienen un excelente comportamiento en la resolución de EDOs de tipo rígido.
• Para cada uno de los caso de estudios considerados, al menos uno de los algoritmos basados en la linealización a trozos ha tenido un coste computacional menor que el correspondiente al método BDF.
• Para problemas de pequeña dimensión han destacado, en cuanto coste computacional, los algoritmos basados en la linealización a trozos mediante los aproximantes diagonales de Padé y mediante la Ecuación Conmutante.
• Para problemas de mediano y gran tamaño, destaca la implementación basada en la linealización a trozos mediante los subespacios de Krylov, por tener un tiempo de ejecución mucho menor que los tiempos de ejecución correspondientes a las otras implementaciones.
6.2.4 Resolución de EDMRs Se ha desarrollado una nueva metodología para la resolución de EDMRs que consiste en la vectorización y posterior aplicación de la linealización a trozos de EDOs. Debido al enorme coste computacional y de almacenamiento necesarios, se han desarrollado tres nuevos métodos de resolución de EDMRs. Entre las aportaciones de esta tesis en relación a la resolución de EDMRs se encuentran las siguientes:
− Demostración de cuatro teoremas (Teorema 4.3, Teorema 4.4, Teorema 4.5, Teorema 4.6) que permiten, mediante su aplicación, resolver EDMRs tal como a continuación se detalla.
• Desarrollo de tres nuevos métodos, basados en la linealización a trozos, para la resolución de EDMRs:
− Método basado en los aproximantes diagonales de Padé. En cada iteración se calculan ciertos bloques de dos exponenciales matriciales, utilizando para ello aproximaciones diagonales de Padé. Este método está basado en el Teorema 4.3, el cual permite transformar un problema vectorial de gran dimensión, problema que aparece al aplicar la linealización a trozos a la EDO obtenida por vectorización de la EDMR, en un problema matricial. Para EDMRs con coeficientes constantes es necesario reducir tanto el número de operaciones como la memoria necesaria. Por ello se demuestra una adaptación del

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
289
Teorema 4.3 para EDMRs con coeficientes constantes (Teorema 4.5). En este caso sólo se calculan dos bloques de una exponencial matricial.
− Método basado en la Ecuación Conmutante. Este método se basa en el Teorema 4.4, el cual permite trasformar un problema vectorial de gran dimensión en un problema matricial consistente en resolver tres ecuaciones matriciales de Sylvester. Para EDMRs con coeficientes constantes se demuestra el Teorema 4.6, el cual permite reducir el número de operaciones y la memoria necesaria, pues en este caso sólo hace falta resolver una ecuación matricial de Sylvester.
− Método basado en los subespacios de Krylov. Al igual que en los métodos anteriores, se aplica el método de linealización a trozos a la EDO obtenida tras la vectorización de la EDMR. En este caso la solución aproximada en un instante de tiempo se obtiene al multiplicar la exponencial de una matriz a bloques de gran dimensión por un vector. Para calcular el producto anterior se realiza una adaptación del método de los subespacios de Krylov aplicado a matrices definidas a bloques. Para reducir el número de operaciones y la memoria necesaria, se realiza también una adaptación de este método para el caso de EDMRs con coeficientes constantes.
• Desarrollo de seis algoritmos basados en los métodos anteriores:
− EDMRs con coeficientes variables: Algoritmo 4.21, Algoritmo 4.23 y Algoritmo 4.26.
− EDMRs con coeficientes constantes: Algoritmo 4.27, Algoritmo 4.29 y Algoritmo 4.31.
• Desarrollo de funciones/rutinas escritas en MATLAB y FORTRAN que permiten resolver EDMRs. Hay que destacar que actualmente no se dispone de funciones escritas en MATLAB que resuelvan EDMRs y, en el caso de rutinas escritas en FORTRAN, tan sólo se dispone del paquete DRSOL, pero únicamente para datos en simple precisión.
En esta tesis se han presentado seis casos de estudio, realizando una gran variedad de pruebas sobre ellos. Los resultados obtenidos han mostrado, por una parte, cuáles suelen ser los valores óptimos de los parámetros característicos de cada uno de los métodos y, por otra, las ventajas que tienen frente a un método BDF. Cabe mencionar también que se han elegido los valores óptimos de parámetros característicos, de manera que no se ha favorecido a uno de los algoritmos (o implementaciones) frente a los demás. Aunque en la tesis se han reflejado seis casos de estudio, se han analizado más casos, habiéndose obtenido resultados similares. En cuanto a los casos de estudio cabe destacar:
• Se han elegido algunos casos de estudio que corresponden a problemas de tipo rígido.
• Se han seleccionado algunos casos de estudios en los que la solución analítica es conocida, y así poder comprobar la precisión de los algoritmos implementados.
• Se han elegido tres casos de estudio que corresponden a problemas de gran dimensión, y así comprobar la eficiencia de los métodos implementados para este tipo de problemas. Dos de ellos corresponde a EDMRs con coeficientes constantes y otro a EDMRs con coeficientes variables.
A continuación se resumen brevemente los resultados obtenidos:

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
290
• Los algoritmos basados en la linealización a trozos tienen una precisión similar e incluso mayor que los algoritmos basados en el método BDF. En un caso de estudio (Problema 5.12), se ha podido comprobar que para incrementos de tiempo del orden de una décima se ha producido error en la implementación del método BDF, no así en dos implementaciones de los métodos de linealización a trozos (implementación basada en la Ecuación Conmutante e implementación basada en los subespacios de Krylov).
• Los algoritmos basados en los métodos de linealización tienen un excelente comportamiento en la resolución de EDMRs de tipo rígido.
• El coste computacional de los algoritmos basados en la linealización a trozos es menor que el coste computacional de los algoritmos basados en el método BDF. Este es un aspecto a destacar, puesto que los algoritmos basados en el método BDF se encuentran entre los más utilizados, actualmente, en la resolución de EDMRs.
• Para EDMRs con coeficientes constantes, los algoritmos basados en los métodos de linealización tienen un coste computacional menor que el algoritmo basado en el método BDF. Entre ellos destacan el basado en los subespacios de Krylov, fundamentalmente por su buen comportamiento a medida que el tamaño del problema se va haciendo mayor, y el basado en los aproximantes diagonales de Padé. En este sentido, se ha comprobado que para tamaños elevados de un problema, el tiempo de ejecución de la implementación basada en los subespacios de Krylov ha sido mucho menor que la implementación basada en el método BDF.
• Para EDMRs con coeficientes variables, el algoritmo basado en el método de linealización a trozos mediante los subespacios de Krylov, presenta, en general, menores errores que los otros algoritmos. Los algoritmos basados en los métodos de linealización a trozos presentan costes computacionales menores que el basado en el método BDF, destacando el basado en la Ecuación Conmutante y el basado en los subespacios de Krylov. Para tamaños elevados de un problema, el tiempo de ejecución de la implementación basada en los subespacios de Krylov ha sido mucho menor que la implementación basada en el método BDF.
6.3 Publicaciones en el Marco de la Tesis • M. Marqués, Vicente Hernández García, J. Javier Ibáñez González, “Parallel
Algorithms for Computing Functions of Matrices on Shared Memory Multiprocessors”. Parallel Computing and Transputer Applications, IO Press, pp. 157-166, 1992.
• Vicente Hernández García, J. Javier Ibáñez González, G. Quintana, A.M. Vidal, V. Vidal, “Experiencias Docentes Sobre el Uso del LAPACK en Multiprocesadores con Memoria Compartida”. Jornadas sobre Nuevas Tecnologías en la Enseñanza de las Matemáticas en la Universidad. E.T.S.I. de Telecomunicación Universidad Politécnica de Valencia, pp. 163-178, 1993.
• Vicente Hernández García, J. Javier Ibáñez González, “Calculo de la Exponencial de una Matriz: Algoritmos Paralelos Basados en la Descomposición Real de Schur”. Informe Técnico/Technical Report DSIC-II-36/93, Departamento de Sistemas Informáticos y Computación, Universidad Politécnica de Valencia, Valencia 1993.

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
291
• Juan Carlos Fernández, Enrique S. Quintana, Vicente Hernández, Javier Ibáñez, “Algoritmos Paralelos para la Resolución de la Ecuación Conmutante Sobre Multiprocesadores con Memoria Distribuida". Informe Técnico/Technical Report DSIC-II-12/95, Departamento de Sistemas Informáticos y Computación, Universidad Politécnica de Valencia, Valencia 1995.
• Enrique Arias Antúnez, Vicente Hernández García, J. Javier Ibáñez González, “Discretization of Continuous-Time Linear Control Systems: A High Performance Computing Approach”. 3rd Portuguese Conference on Automatic Control: CONTROLO’98, pp. 47-51, 1998.
• Enrique Arias Antúnez, Vicente Hernández García, J. Javier Ibáñez González, “Algoritmos Secuencial y Paralelo para la Resolución del Problema de la Discretización de Sistemas Lineales Continuos”. Informe Técnico/Technical Report DSIC-II-45/98, Departamento de Sistemas Informáticos y Computación, Universidad Politécnica de Valencia, Valencia 1998.
• Enrique Arias Antúnez, Vicente Hernández García, J. Javier Ibáñez González, “Distributed Memory Parallel Algoritms for Computing Integrals Involving the Matrix Exponential”. First Niconet Workshop on Numerical Software in Control Engineering, Universidad Politécnica de Valencia, Diciembre de1998.
• Enrique Arias Antúnez, Vicente Hernández García, J. Javier Ibáñez González, “Un Algoritmo Paralelo para el Cálculo de Exponenciales de Matrices e Integrales con Exponenciales de Matrices”. X Jornadas de Paralelismo, La Manga del Mar Menor, pp. 55-60, Septiembre de 1999.
• Enrique Arias Antúnez, Vicente Hernández García, J. Javier Ibáñez González, “Algoritmos Paralelos para el Cálculo de Integrales con Exponenciales de Matrices”. Informe Técnico/Technical Report DSIC-II-20/99, Departamento de Sistemas Informáticos y Computación, Universidad Politécnica de Valencia, Valencia 1999.
• Enrique Arias Antúnez, Vicente Hernández García, Ignacio Blanquer Espert, J. Javier Ibáñez González, “Nonsingular Jacobian Free Piecewise Linearization of Ordinary Differential Equations (EDO)”. Second Niconet Workshop on Numerical Software in Control Engineering, Institut National de Recherche en Informatique et en Automatique, pp. 1-5, Diciembre de1999.
• E. Arias, V. Hernández, J. J. Ibáñez, “Non Singular Jacobian Free Piecewise Linealization of the State Equation”. Controlo’2000: 4th Portuguese Conference on Automatic Control, pp. 630-635, October of 2000.
• E. Arias, V. Hernández, J. J. Ibáñez, “Algoritmos de Altas Prestaciones para la Resolución de Ecuaciones Diferenciales Ordinarias y Algebraicas”. XII Jornadas de Paralelismo. Valencia, pp. 205-209, Septiembre del 2001.
• E. Arias, V. Hernández, J. J. Ibáñez, “High Performance Algorithms for Computing Nonsingular Jacobian Free Piecewise Linealization of Differential Algebraic Equations”. Integral Methods in Science and Engineering, Analytic and Numerical Techniques, Birkhäuser Boston, pp. 7-12, 2004.
• E. Arias, V. Hernández, J. J. Ibáñez and J. Peinado, “Solving Differential Riccati Equations by Using BDF Methods”. Technical Report, DSIC-II/05/05, Universidad Politécnica de Valencia, 2005.

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
292
6.4 Líneas Futuras de Investigación Las líneas futuras de investigación se centrarán en la aplicación del cálculo de Funciones de Matrices en la resolución de problemas de ingeniería, la aplicación de la linealización a trozos y de otras metodologías para la resolución de ecuaciones diferenciales vectoriales y matriciales, y, fundamentalmente, el desarrollo e implementación de los algoritmos paralelos correspondientes a los métodos desarrollados en esta tesis.
Aplicación del cálculo de Funciones de Matrices a la resolución de problemas de ingeniería.
Se trata de abordar el análisis de problemas reales en los que aparece la necesidad de calcular Funciones de Matrices. Para cada problema de este tipo se debe realizar un estudio de cuál es el algoritmo óptimo para ese problema y su posterior implementación. En la actualidad se han realizado diversas implementaciones en este sentido: simulación de la propagación de ondas en fibras de cristal fotónico o ajuste dinámico de los parámetros de control para cambios en los periodos de muestreo en sistemas de control.
Aplicación del cálculo de Funciones de Matrices a la resolución de problemas de ingeniería en los que aparezca la necesidad de resolver EDOs con valores iniciales o valores de contorno.
Se trata de resolver nuevos o antiguos problemas en los que es necesario resolver EDOs, aplicando para ello las técnicas desarrolladas en esta tesis. En particular, para problemas de valores de contorno se puede aplicar la técnica que consiste en desacoplar la ecuación diferencial en dos problemas, uno de valores iniciales y otro de valores finales, mediante la resolución de una EDMR (véase subapartado 2.4.4.5).
Aplicación de la linealización a trozos para la resolución de ecuaciones diferenciales.
Por una parte, se trataría de mejorar los algoritmos ya desarrollados, en cuanto a la elección de un tamaño variable del incremento de tiempo, aprovechar la estructura dispersa de muchos de estos problemas, para diseñar adaptaciones de los algoritmos desarrollados, etc. Por otra parte, se trataría de aplicar técnicas similares, pero para la resolución de otros tipos de ecuaciones diferenciales como:
Ecuaciones Diferenciales Matriciales de Sylvester (EDMSs).
Ecuaciones Diferenciales Matriciales Lineales (EDMLs).
Ecuaciones Diferenciales Algebraicas (EDAs).
Etc.
Desarrollo de nuevos métodos de resolución de EDOs y EDMOs basados en aproximaciones cuadráticas.
Se trataría de realizar una aproximación cuadrática a trozos de la función vectorial/matricial que define a la EDO/EDMO. En este caso la complejidad matemática y computacional es mayor, al aparecer términos cuadráticos, en donde además de la matriz Jacobiana aparece la matriz Hessiana de la función que define a la EDO/EDMO. Es por ello que, quizás, su aplicación esté más limitada que el caso de linealización a trozos, pero las ventajas, en cuanto a precisión, pueden resultar interesantes para el desarrollo de nuevos métodos de resolución de ecuaciones diferenciales.

Capítulo 6: Conclusiones y Líneas Futuras de Investigación
293
Implementaciones paralelas de los algoritmos. Es indudable que los procesadores secuenciales actuales más rápidos, aún utilizando técnicas de segmentación o de computación vectorial, están limitados por su velocidad de reloj. La única manera posible de incrementar la capacidad de procesamiento es utilizar sistemas multiprocesador, de memoria compartida o distribuida, al poder utilizar de manera “cooperativa” varios procesadores. En la actualidad, existen numerosos sistemas multiprocesador muy rápidos y a un precio muy asequible. Por otra parte, en los últimos tiempos se ha desarrollado software estándar para la programación paralela de esos sistemas entre los que destaca el ScaLapack ([ScLA97]). Una línea de investigación claramente definida es el desarrollo e implementación de algoritmos paralelos para la resolución de todos los problemas planteados en esta tesis:
• En el caso de Funciones de Matrices hay que destacar el potencial de los algoritmos paralelos basados en los aproximantes diagonales de Padé, aunque no hay que descartar los basados en la descomposición real de Schur de una matriz. El código que aparece en los algoritmos basados en los aproximantes diagonales de Padé corresponde a operaciones básicas del tipo matriz-matriz o matriz-vector, y a la resolución de sistemas de ecuaciones lineales. En el caso de los algoritmos basados en la descomposición real de Schur de una matriz, además de las operaciones antes mencionadas, necesitan del cálculo de la descomposición real de Schur de una matriz. Con las herramientas actualmente disponibles para el desarrollo de software paralelo, como es el caso del ScaLapack, los códigos que contienen operaciones básicas de matrices y vectores y la resolución de sistemas de ecuaciones lineales, suelen ser muy eficientes en sistemas multiprocesador. En el caso de la obtención de la forma real de Schur, los códigos no son tan eficientes debido a las características del algoritmo iterativo QR que utiliza. Hay que mencionar al respecto que, aunque no se han incluido en esta tesis implementaciones paralelas, se han realizado algunas implementaciones de algoritmos paralelos basados, tanto en la descomposición real de Schur de una matriz, como en los aproximantes diagonales de Padé.
• En el caso de la resolución de EDOs y EDMRs, destacan los métodos basados en los subespacios de Krylov y en los aproximantes diagonales de Padé, pues contienen operaciones básicas del tipo matriz-matriz o matriz-vector, y la resolución de sistemas de ecuaciones lineales. En el caso de los métodos BDF existentes y el método de linealización a trozos basado en la Ecuación Conmutante, la paralelización de los códigos no será tan eficiente, por tener que utilizar la descomposición real de Schur de una matriz a la hora de resolver la ecuación matricial de Sylvester.


Apéndice A: Conceptos Básicos y Notaciones
295
Apéndice A. Conceptos Básicos y Notaciones
Las matrices y vectores que aparecen en esta tesis, se encuentran definidas sobre un cuerpo F , que puede ser el cuerpo de los números complejos C o el cuerpo de los números reales ℜ .
Un vector de dimensión n de sobre el cuerpo F se denotará como n
ivv F∈= ][ ,
o bien como
n
nv
vv
v F∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=M2
1
.
Una matriz A de orden mxn sobre un cuerpo F se denotará como mxn
ijaA F∈= ][ ,
o bien
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
mnmm
n
n
aaa
aaaaaa
A
L
MOMM
L
L
21
22221
11211
.
Con nI se representa a la matriz identidad de orden n ,
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
100
010001
L
MOMM
L
L
nI .
Con mxnmxn F∈0 se representa a la matriz nula de dimensión mxn ,
mxnmxn F∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
000
000000
0
L
MOMM
L
L
,
en particular, nxnn F∈0 representa a la matriz nula de orden n .
Una notación muy usada en computación numérica es la notación de los “dos puntos”. Esta notación permite referenciar fácilmente submatrices, y en particular filas o columnas de una matriz, como a continuación se detalla.

Apéndice A: Conceptos Básicos y Notaciones
296
Dada una matriz mxnijaA F∈= ][ , se denota con ):,:( 2121 jjiiA , para mii ≤≤≤ 211 y
njj ≤≤≤ 211 , a la submatriz de A que consiste en seleccionar los elementos de A cuyos índices de filas se encuentran entre 1i e 2i , y cuyos índices de columnas se encuentran entre 1j y 2j , es decir,
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=
2212
2111
):,:( 2121
jiji
jiji
aa
aajjiiA
L
MOM
L
.
De este modo, ),:1( jmA denota a la columna j-ésima de la matriz A y ):1,( niA la fila i-ésima de la matriz A .
A continuación se presentan algunos conceptos básicos del algebra matricial que se utilizarán en esta tesis, junto con algunas de sus propiedades.
Definición 6.1.
Se denomina traza de una matriz nxnijaA F∈= ][ , a
F∈+++= nnaaaA L2211)(traza .
Definición 6.2. nxn
ijaA F∈= ][ es una matriz diagonal si
0=ija , ji ≠∀ , para nji ,,2,1, L= .
Definición 6.3. nxnA F∈ es diagonal por bloques si es de la forma
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
rA
AA
A
L
MOMM
L
L
00
0000
2
1
,
donde ii xnniA F∈ , ri ,,2,1 L= , siendo nn
r
ii =∑
=1
.
Para expresar que nxnA F∈ es una matriz diagonal por bloques se suelen utilizar las siguientes notaciones:
),,,(diag 21 rAAAA L=
o
rAAAA ⊕⊕⊕= L21 ,
indicando que A es la denominada suma directa de las matrices rAAA ,,, 21 L .

Apéndice A: Conceptos Básicos y Notaciones
297
Definición 6.4. nxn
ijaA F∈= ][ es una matriz triangular superior si
0=ija , ji >∀ , nji ,,2,1, L= .
Definición 6.5. nxn
ijaA F∈= ][ es una matriz casi triangular superior si tiene la forma
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
rr
r
r
A
AAAAA
A
L
MOMM
L
L
00
0 222
11211
,
donde ji xnnijA F∈ , para rji ,,1, L= , siendo }2,1{, ∈ji nn .
Definición 6.6. nxn
ijaA F∈= ][ es una matriz triangular inferior si
0=ija , ji <∀ ; nji ,,2,1, L= .
Si además, 1=iia , ni ,,2,1 L= , se dice que A es triangular inferior unidad.
Definición 6.7. nxn
ijaA F∈= ][ es una matriz superior de Hessenberg si
0=ija , 1+>∀ ji ; nji ,,2,1, L= .
Definición 6.8. nxn
ijaA F∈= ][ es una matriz inferior de Hessenberg si
0=ija , 1+>∀ ij ; nji ,,2,1, L= .
Definición 6.9.
Dada una matriz mxnijaA F∈= ][ , se define la matriz traspuesta de A como
nxmij
T bA F∈= ][ ,
siendo jiij ab = , ni ,,2,1 L= , mj ,,2,1 L= .
Según esto, un vector se puede representar como
[ ] nTnvvvv F∈= ,,, 21 L ,
siendo F∈iv , ni ,,2,1 L= .
Definición 6.10.
Una matriz nxnijaA F∈= ][ se dice que es simétrica si

Apéndice A: Conceptos Básicos y Notaciones
298
AAT = .
Definición 6.11.
Dada una matriz mxnijaA C∈= ][ , la matriz conjugada de A se define como
mxnijaA C∈= ][ ,
donde ija , mi ,,2,1 L= , nj ,,2,1 L= , es el complejo conjugado de ija .
Definición 6.12.
Dada una matriz mxnA C∈ , se define la matriz conjugada traspuesta de A como mxnTAA C∈=* .
Definición 6.13.
Una matriz mxnA C∈ , se dice que es hermítica si
AA =* .
Definición 6.14.
Una matriz nxnA ℜ∈ se dice ortogonal si TAA =−1 .
Definición 6.15.
Una matriz nxnA C∈ se dice unitaria si *1 AA =− .
Definición 6.16.
Se define la matriz de Vandermonde asociada a F∈− nn cccc ,,,, 121 L , como
nxn
nn
nn
nn
nn
nn
nn
nn
cccccccc
ccccV F∈
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
−−
−−
−−−
−−
−
111
11
121
12
22
1
121
1111
L
MMOMM
L
L
.
Definición 6.17 ([HoJo99], página 38).
Se denomina polinomio característico de mxnA F∈ , al polinomio
∑−
=
−=−=1
0
)det()(n
k
kk
nn cAIp λλλλ .
Definición 6.18.
A cada una de las raíces del polinomio característico de la matriz nxnA F∈ se le denomina valor propio de A . Si λ es un valor propio de A , entonces existe al menos

Apéndice A: Conceptos Básicos y Notaciones
299
un vector no nulo nx F∈ , denominado vector propio de A asociado a λ , de manera que
xAx λ= .
Definición 6.19.
Dada una matriz nxnA F∈ , se denomina espectro A al conjunto )(Aλ de todos sus valores propios.
Propiedad 6.1 ([BaSa98], página 313).
Si nxnA F∈ , entonces los coeficientes del polinomio característico de A son
)(traza 1 Ac kk += , 1,,1 −= nk L ,
),det(0 Ac =
siendo )(traza 1 Ak+ la suma de todos los menores principal de orden 1+k de A que contienen en su diagonal principal 1+k elementos de la diagonal principal de A .
Definición 6.20.
Se dice que la matriz nxnB F∈ es semejante a la matriz nxnA F∈ , si existe una matriz no singular nxnX F∈ de manera que
1−= XAXB .
Definición 6.21.
Se dice que una función )(xf es analítica en un abierto U del cuerpo F , si se puede expresar en la forma
∑∞
=
=0
)(k
kk xcxf , Ux ∈ ,
siendo F∈kc , 0≥k .
Teorema 6.1 (descomposición canónica de Jordan).
Si nxnA F∈ , entonces existe una matriz no singular nxnX F∈ de manera que
( 6.1 ) ),,,diag(21
1r
JJJAXX λλλ L=− ,
donde i
Jλ denota al i-ésimo bloque de Jordan de A,
ii
i
xnn
i
i
i
i
J F∈
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
λλ
λλ
λ
000100
000001
L
L
MOOMM
O
L
,
ri ,,2,1 L= , ∑=
=r
ii nn
1.

Apéndice A: Conceptos Básicos y Notaciones
300
La matriz ),,,diag(21 r
JJJ λλλ L se denomina forma canónica de Jordan de la matriz A .
Definición 6.22.
Una matriz nxnA F∈ es derogatoria si existe un valor propio λ de A , que aparece, al menos, en dos bloques distintos de la forma canónica de Jordan de A.
Definición 6.23.
Sean nxnA F∈ y
∑−
=
−=1
0)(
n
k
kk
n cp λλλ ,
su polinomio característico. Se define la matriz compañera asociada a )(λp , como
nxn
nn cccc
B C∈
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
−− 120
1000
00000010
L
L
MOOMM
O
L
1
.
Si n es elevado, entonces la matriz B es dispersa pues tiene un porcentaje alto de elementos nulos
Propiedad 6.2
Dadas las matrices A y B de la Definición 6.23, entonces A y B tienen el mismo polinomio característico.
Propiedad 6.3
Sean A y B las matrices de la Definición 6.23. Si V es la matriz de Vandermonde correspondiente a los valores propios de B , entonces BVV 1− está en la forma de Jordan.
Propiedad 6.4
Sean A y B las matrices de la Definición 6.23. Si A no es derogatoria, entonces A es semejante a una matriz compañera; en caso contrario, A es semejante a una suma directa de matrices compañeras.
Definición 6.24
Se dice que la matriz
nnx
MMMM
M 22
2221
1211 ℜ∈⎥⎦
⎤⎢⎣
⎡= ,
nxnMMMM ℜ∈22211211 ,,, ,
es Hamiltoniana si cumple que
MJMJ T −=−1 ,

Apéndice A: Conceptos Básicos y Notaciones
301
siendo
⎥⎦
⎤⎢⎣
⎡−
=nn
nn
II
J0
0.
Definición 6.25
Se dice que la matriz
nnx
MMMM
M 22
2221
1211 ℜ∈⎥⎦
⎤⎢⎣
⎡= ,
nxnMMMM ℜ∈22211211 ,,, ,
es simpléctica si cumple que 11 −− = MJMJ T ,
siendo
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=nn
nn
II
J0
0.
Definición 6.26.
Se define la función nxnn FF ⎯→⎯:diag ,
de manera que dado [ ] nTnvvvv F∈= ,,, 21 L , entonces
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
nv
vv
v
L
MOMM
L
L
00
0000
)(diag 2
1
.
Teorema 6.2 (Descomposición LU sin pivotamiento).
Si la matriz nxnijaA F∈= ][ verifica que 0)):1,:1(det( ≠iiA , ni ,,2,1 L= , entonces
existe una matriz triangular inferior unidad nxnL F∈ y una matriz triangular superior nxnU F∈ de manera que
LUA = ,
siendo esta descomposición única.
Definición 6.27.
Se dice que nxnP ℜ∈ es una matriz permutación, si cada columna (o fila) de P , contiene un solo elemento igual a 1, siendo el resto de los elementos de dicha fila (o columna) iguales a 0. Esto es, si ),,,( 21 nααα L es una permutación de ),,2,1( nL , entonces
],,,[21
TTTn
eeeP ααα L= ,

Apéndice A: Conceptos Básicos y Notaciones
302
siendo Ti
eα , ni ,,2,1 L= , la columna de índice iα de la matriz identidad nI .
Teorema 6.3 (Descomposición LU con pivotamiento parcial de filas).
Si la matriz nxnA F∈ es invertible, entonces existe una matriz de permutación nxnP ℜ∈ , una matriz triangular inferior unidad nxnL F∈ y una matriz triangular
superior nxnU F∈ , de manera que
LUPA = ,
siendo esta descomposición única.
Teorema 6.4 (Descomposición QR).
Dada una matriz nxnA C∈ , existe una matriz unitaria nxnQ C∈ y una matriz triangular superior nxnR C∈ , de manera que
QRA = .
Si además A es no singular, entonces R puede elegirse de manera que todos sus elementos diagonales sean positivos y, por tanto, dicha descomposición será única.
Teorema 6.5 (Descomposición real QR).
Dada una matriz nxnA ℜ∈ , existe una matriz ortogonal nxnQ ℜ∈ y una matriz triangular superior nxnR ℜ∈ , de manera que
QRA = .
Si además A es no singular, entonces R puede elegirse de manera que todos sus elementos diagonales sean positivos y, por tanto, dicha descomposición será única.
Teorema 6.6 (Descomposición de Schur).
Dada una matriz nxnA C∈ , existe una matriz unitaria nxnQ C∈ y una matriz triangular superior nxnT C∈ , denominada forma de Schur de A , de manera que
*QTQA = ,
donde los elementos de la diagonal de la matriz T coinciden con los valores propios de la matriz A .
Teorema 6.7 (Descomposición real de Schur de una matriz).
Dada una matriz nxnA ℜ∈ , existe una matriz ortogonal nxnQ ℜ∈ y una matriz casi triangular superior nxnS ℜ∈ , denominada forma real de Schur de A , de manera que
( 6.2 ) T
mm
m
m
T Q
S
SSSSS
QQSQA
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
==
L
MOMM
L
L
00
0 222
11211
,

Apéndice A: Conceptos Básicos y Notaciones
303
donde cada bloque diagonal iiS , para mi ,,2,1 L= , es de orden 11x ó 22x . Los bloques diagonales de orden 11x corresponden a valores propios reales de A y los de orden 22x a un par de valores propios complejos conjugados de A .
Teorema 6.8 (Descomposición en Valores Singulares).
Si mxnA ℜ∈ , entonces existen dos matrices ortogonales mxmU ℜ∈ y nxnV ℜ∈ de manera que
pxpp
T AVU ℜ∈= ),,,(diag 21 σσσ L , ),min( nmp = ,
siendo 021 ≥≥≥≥ pσσσ L los llamados valores singulares de la matriz A .
Como consecuencia de este teorema, se define la Descomposición en Valores Singulares (DVS) de la matriz A , como
TVUA Σ= ,
siendo pxp
p ℜ∈=Σ ),,,(diag 21 σσσ L .
Definición 6.28.
Dadas las matrices mxnijaA F∈= ][ y pxq
ijbB F∈= ][ , se define la matriz producto de Kronecker de A por B como
mpxnq
mnmm
n
n
BaBaBa
BaBaBaBaBaBa
BA F∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=⊗
L
MOMM
L
L
21
22221
11211
.
Propiedad 6.5.
Si mxnA F∈ y pxqCB F∈, , entonces
CABACBA ⊗+⊗=+⊗ )( .
Propiedad 6.6.
Si mxnBA F∈, y pxqDC F∈, , entonces
BDACDCBA ⊗=⊗⊗ ))(( .
Definición 6.29.
Una norma vectorial en nF es una función
ℜ⎯→⎯nF ,
que verifica las siguientes propiedades:
1. nxx F∈∀≥ ,0|||| ,
2. 0|||| =x si y solo si x es el vector nulo,

Apéndice A: Conceptos Básicos y Notaciones
304
3. |||||||||| xx αα = , F∈∀α , nx F∈∀ ,
4. |||||||||||| yxyx +≤+ , nyx F∈∀ , .
Definición 6.30.
Dado un entero positivo p , se define la p-norma vectorial en nF como
p pn
ppp xxxx |||||||||| 21 +++= L ,
siendo nTnxxxx F∈= ],,,[ 21 L .
En particular, se define la ∞-norma como
( )||max||||||lim||||1
21 ini
p pn
pp
pxxxxx
≤≤∞→∞ =+++= L .
Definición 6.31.
Una norma matricial en mxnF es una función
ℜ⎯→⎯nxnF ,
que verifica las siguientes propiedades:
1. 0|||| ≥A , mxnA F∈∀ .
2. 0|||| =A si y solo si mxnA 0= .
3. |||||||||| AA αα = , F∈∀α , mxnA F∈∀ .
4. |||||||||||| BABA +≤+ , mxnBA F∈∀ , .
Definición 6.32.
Se define la norma matricial subordinada M|||| a la norma vectorial v|||| , como
( )vxM AxAv
||||max||||1|||| =
= , mxnA F∈ ,
siendo nx F∈ .
Definición 6.33.
Dado un entero positivo p , se define la p-norma matricial sobre mxnF como
( )pxp AxAp
||||max||||1|||| =
= , mxnA F∈ ,
siendo nx F∈ .
Definición 6.34.
Se define la norma de Frobenius de una matriz mxnijaA F∈= ][ como
∑∑= =
=m
i
n
jijF aA
1 1
2|||||| .

Apéndice A: Conceptos Básicos y Notaciones
305
Definición 6.35.
Se denomina número de condición de una matriz invertible nxnA F∈ relativo a la norma matricial subordinada |||| , al número real
||||||||)(cond 1||||
−= AAA .
En particular, con )(cond Ap se designa al número de condición de la matriz A asociado a la p-norma matricial.
Definición 6.36.
Se define la función vec , mnmxn FF ⎯→⎯:vec ,
como la aplicación que a una matriz mxnijaA F∈= ][ , le asocia como imagen el vector
mnA F∈)(vec que se obtiene colocando las columnas de A una a continuación de otra en el orden natural, es decir,
Tmnnnmm aaaaaaaaaA ],,,,,,,,,,,,[)(vec 212221212111 LLLL= .
Propiedad 6.7
Si mxnBA F∈, , entonces
)(vec)(vec)(vec BABA +=+ .
Propiedad 6.8
Si mxnA F∈ , nxpB F∈ y pxqC F∈ , entonces
)(vec)()(vec BACABC T ⊗= .
Definición 6.37.
Dados dos enteros positivos m y n , se define la función mxnmat , mxnmn
mn FF ⎯→⎯:mat ,
como la aplicación que a un vector de tamaño mn mnT
mnmmnmmnmmmm vvvvvvvvvv F∈= +−+−++ ],,,,,,,,,,,,[ 2122121 LLLL ,
le asocia como imagen la matriz mxn que se obtiene colocando las componentes de v, una a continuación de otra en el orden natural, en columnas de tamaño m, es decir,
mxn
mnmm
nmnm
nmnm
mxn
vvv
vvvvvv
v ℜ∈
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
= −+
−−+
2
22
111
)(matOM
L
.

Apéndice A: Conceptos Básicos y Notaciones
306
Definición 6.38.
Un flop es el tiempo necesario para realizar una operación aritmética (suma, resta, producto o división) en coma flotante.

Apéndice B: Rutinas Auxiliares
307
Apéndice B. MATLAB
MATLAB (MAThematical LABoratory) es un entorno de programación que permite realizar cálculos científicos y de ingeniería basados en vectores y matrices. Se puede trabajar con él de forma interactiva o utilizando un intérprete de un lenguaje propio que lleva incorporado. Se distingue de otros lenguajes, como FORTRAN o C, porque opera en un nivel superior, pues permite realizar operaciones básicas entre vectores y matrices, incorporando además un gran número de funciones cuyos argumentos son vectores y matrices. Por otra parte, MATLAB dispone de numerosas herramientas de desarrollo y depuración de código que lo hacen muy útil en el desarrollo de algoritmos.
En la actualidad MATLAB se ha convertido en el estándar de desarrollo de algoritmos en computación numérica. Trefethen llega a afirmar en la introducción de [Tref00] que “con MATLAB ha nacido una nueva era en la computación científica porque puede hacer una cantidad astronómica de cálculos con muy pocas líneas de programa y en unos pocos segundo de tiempo”. Charles F. Van Loan en [VanL00] afirma que “MATLAB ha cambiado la forma de calcular e investigar en las ciencias de la computación”. J. Higham, inminente investigador de funciones matrices, ha utilizado extensamente este software en todos sus trabajos, habiendo publicado recientemente un libro sobre MATLAB ([HiHi00]). MATLAB se ha convertido en una poderosa herramienta para investigar y resolver problemas prácticos sobre todo con el desarrollo de las Toolbox. Las Toolbox contienen funciones de MATLAB que resuelven problemas aplicados a diferentes áreas.
Resolución de EDOs MATLAB es capaz de calcular la evolución en el tiempo de la solución de EDOs lineales y no lineales con valores iniciales
( 6.3 ) ))(,()(' txtftx = , fttt ≤≤0 ,
00 )( xtx = ,
siendo ntx ℜ∈)( y ),( xtf una función vectorial.
La sintaxis básica de las funciones que resuelven EDOs en MATLAB es la siguiente:
),,'('],[ 0ytspanFsolvernameYt = .
• solvername : nombre de la función de MATLAB que resuelve la EDO.
• F : nombre del fichero que contiene la definición de la función ),( txf .
• tspan : vector que indica los instantes en los que se va a evaluar la función. Si contiene sólo dos números, éstos representan el comienzo y el final del intervalo de integración. Si contiene más de dos elementos, indica en qué instantes se quiere obtener la solución,
• 0y : vector columna con el valor inicial.

Apéndice B: Rutinas Auxiliares
308
• Y : matriz con tantas filas como tiempos de salida y tantas columnas como dimensión del vector 0y .
• t : vector que contiene los instantes en los que se obtiene la solución.
En la siguiente tabla se muestran las funciones que resuelven EDOs en MATLAB.
Función Tipo de problema Método utilizado
ode45 no rígido Runge-Kutta de orden 4 y 5
ode23 no rígido Runge-Kutta de orden 2 y 3
ode113 no rígido Métodos lineales multipaso de órdenes 1 a 13
ode15s rígido BDF de órdenes 1 a 5
ode23s rígido Rosembrock modificados de orden 2 y 3
ode23t poco rígido Regla de los trapecios
ode23tb rígido Runge-Kutta implícito de orden 2 y 3
Tabla 6.1: Funciones de MATLAB para la resolución de EDOs.
MATLAB permite utilizar una sintaxis más completa para la resolución de EDOs:
),,,'('],,[ 0 optionsytspanFsolvernamesYt = .
• s : vector que contiene ciertos resultados estadísticos de la integración.
• options : estructura definida por la función odeset, que permite definir ciertas características del método utilizado en la función.
La sintaxis de odeset es
),,'',,'(' 2211 Lvalparamvalparamodesetoptions =
o bien
),,'',,'',( 2211 Lvalparamvalparamoldoptodesetoptions = .
Entre los parámetros más importantes de esta función se encuentran los siguientes:
• Tratamiento del error: RelTol , AbsTol . El test de error está acotado por
|))(|,max()( ixRelTolAbsTolierr ≤ .
• Para el paso: pInitialSte , MaxStep .
• Matriz Jacobiana: Jacobian , JConstant , JPattern , Vectorized .
• Especificación de la salida: OutputFcn , OutputSel , Refine , Stats .
Funciones de Matrices MATLAB posee numerosas funciones de matrices, las cuales se detallan a continuación:

Apéndice B: Rutinas Auxiliares
309
• Función exponencial.
B = expm(A) calcula AeB = . Esta función utiliza la aproximación de Padé con escalado y potenciación.
• Función logaritmo.
B = logm(A) calcula el logaritmo principal de la matriz A , utilizando para ello el Algoritmo 2.2. Si la matriz A es singular o tiene algún valor propio en el semieje real negativo, entonces B no se puede calcular, devolviendo logm un mensaje de error.
La función logm también admite la sintaxis
[B, exitflag] = logm(A),
devolviendo, además del logaritmo principal en caso de existir, el entero exitflag que describe la condición de salida de logm:
• Si exitflag = 0, el logaritmo principal se ha podido calcular.
• Si exitflag = 1, alguna evaluación de la serie de Taylor, utilizada en el cálculo de )( iiii TfF = mediante el Algoritmo 2.2, no converge. Incluso en este caso, el
valor devuelto puede ser exacto.
• Función raíz cuadrada.
B = sqrtm(A) calcula la raíz cuadrada principal de la matriz A . Si A tiene algún valor propio con parte real negativa entonces la matriz devuelta en B es compleja. Si A es singular entonces A no puede tener una raíz cuadrada, mostrando sqrtm un mensaje de error.
La función sqrtm también admite otras sintaxis.
• )(],[ AsqrtmrX = .
En este caso no se muestran mensajes de error, devolviendo en r el valor del residuo
F
F
AXA||||
|||| 2− .
• )(],,[ AsqrtmcX =α .
En este caso en α se devuelve un factor de estabilidad y en c una estimación del número de condición asociado a la raíz cuadrada X . El residuo está acotado aproximadamente por εαn y el error relativo cometido al calcular la raíz cuadrada está acotado aproximadamente por εnc , siendo n la dimensión de la matriz A y ε el redondeo unidad ([GoVa96], página 61).
Si X es real, simétrica y definida positiva, o compleja, hermítica y definida positiva, entonces también es posible calcular su raíz cuadrada.
• Funciones en general.
funm(A,fun) calcula )(Af para una función dada en el argumento fun. La implementación de esta función está basada en el Algoritmo 2.2. Esta función debe admitir un desarrollo en serie de Taylor con un radio de convergencia infinito, excepto para fun = @log, la cuál es tratada de forma especial. Los posibles valores de fun son

Apéndice B: Rutinas Auxiliares
310
@exp, @log, @sin, @cos, @sinh y @cosh. Admite además otras sintaxis que permiten controlar ciertos parámetros para el cálculo de la función matricial.

Apéndice C: BLAS y LAPACK
311
Apéndice C. BLAS y LAPACK
La clave para utilizar eficientemente ordenadores de altas prestaciones es evitar referencias innecesarias a memoria. En la mayoría de los ordenadores, los datos fluyen desde memoria a registros de la máquina o viceversa. Este flujo de datos puede ser más costoso que las operaciones aritméticas entre los datos. Por lo tanto, las prestaciones de los algoritmos pueden estar determinadas por la cantidad de tráfico hacia memoria más que por el número de operaciones en coma flotante realizadas. Este coste motiva la reestructuración de los algoritmos existentes en base a diseñar otros nuevos que minimicen dicho movimiento.
Una forma de conseguir eficiencia en la solución de problemas del álgebra lineal es utilizar BLAS (Basic Linear Algebra Subroutines). En 1973, Hanson, Krogh y Lawson describieron las ventajas de utilizar un conjunto de rutinas básicas para problemas del álgebra lineal. El BLAS ha tenido mucho éxito en este sentido y se ha utilizado en una gran diversidad de software numérico y muchos de los algoritmos publicados por ACM Transactions on Mathematical Software. Las rutinas del BLAS ayudan a la claridad, portabilidad, modularidad y mantenimiento del software, y, además, se ha convertido en un estándar en lo referente a operaciones vectoriales y matriciales.
El deseo de obtener software numérico que pueda ser utilizado por una gran variedad de sistemas informáticos ha culminado en la disponibilidad comercial de una variedad de librerías (por ejemplo, NAG e IMSL) y también de software de dominio público (por ejemplo, LINPACK, EISPACK, NETLIB). Un intento de obtener un software numérico que fuera portable en sistemas MIMD (Multiple Instruction Multiple Data) fue la creación del LAPACK. El desarrollo del LAPACK ha sido un paso natural después de que las especificaciones de los niveles BLAS 2 y BLAS 3 fueran diseñadas entre 1984-86 y 1987-88. La investigación de algoritmos numéricos paralelos continuó varios años, haciendo posible la construcción de un nuevo paquete de software que sustituyese al LINPACK y EISPACK, permitiendo una mayor eficiencia en el uso de las nuevas computadoras de altas prestaciones. La propuesta inicial del LAPACK fue especificada, aunque todavía el BLAS 3 se estaba desarrollando, en un proyecto financiado por la National Science Foundation (USA).
El LAPACK, escrito en FORTRAN 77 estándar para datos en simple y en doble precisión de números reales y complejos, implementa un gran número de algoritmos que resuelven problemas típicos del álgebra lineal entre los que se encuentran: la resolución de sistemas lineales de ecuaciones, las descomposiciones matriciales (LU, Cholesky, QR), el cálculo de valores propios y singulares de una matriz, etc. Las matrices utilizadas en dichos algoritmos se subdividen en bloques de tamaño adecuado y se utilizan rutinas del BLAS para la realización de operaciones básicas entre ellos. Para obtener una alta eficiencia en la ejecución de las rutinas del LAPACK sobre máquinas paralelas, ya sea sobre procesadores vectoriales o multiprocesadores con o sin registros vectoriales, es necesario disponer de una versión optimizada del BLAS que permita el uso eficaz del hardware. Por lo tanto, el paralelismo en la ejecución de dichas rutinas se encuentra en las llamadas al BLAS, estando oculto este paralelismo a los ojos del usuario.

Apéndice C: BLAS y LAPACK
312
Inicialmente las rutinas del LAPACK se diseñaron específicamente para que se ejecutaran eficientemente sobre multiprocesadores con memoria compartida. Por ello, se basan en algoritmos orientados a bloques, es decir, las matrices se dividen en bloques, y las operaciones básicas que aparecen en los algoritmos son productos y actualizaciones de matrices y vectores. Estas operaciones utilizan llamadas al BLAS 2 (operaciones del tipo matriz-vector) o al BLAS 3 (operaciones del tipo matriz-matriz). El uso de tamaños adecuados de bloques es fundamental para el rendimiento de las rutinas. Estos tamaños dependen, fundamentalmente, de la máquina sobre la que se utilizan.
En www.netlib.org/lapack/ se puede encontrar el manual completo de LAPACK en formato html, los códigos fuentes de BLAS y LAPACK, algunas librerías compiladas para varias arquitecturas y sistemas operativos, etc.
Una forma sistemática de obtener software de altas prestaciones consiste en implementar los algoritmos, expresados por ejemplo en MATLAB, en un lenguaje de alto nivel, utilizando núcleos computacionales de altas prestaciones como BLAS y LAPACK. Si se dispone de librerías optimizadas para una determinada arquitectura de BLAS y LAPACK se obtiene un software eficiente y de altas prestaciones. Además, se posibilita el posterior desarrollo de implementaciones paralelas utilizando, por ejemplo, la librería SCALAPACK ([ScLA97]) con la consiguiente ganancia en velocidad.
BLAS
Convenciones en el BLAS Los nombres de las rutinas del BLAS tienen la forma xyyzz. La primera letra del nombre (x) indica el tipo de dato utilizado y su precisión:
S: real en simple precisión.
D: real en doble precisión.
C: complejo en simple precisión.
Z: complejo en doble precisión.
En BLAS 2 y BLAS 3, las dos siguientes letras (yy) indican el tipo de matriz utilizada y las dos últimas el problema que resuelven; así por ejemplo, MM indica producto de dos matrices, MV producto de matriz por un vector, SM resolución de un sistema lineal triangular múltiple, SV resolución de un sistema lineal triangular, etc. El BLAS 1 suele tener una notación propia para todas las letras (salvo la primera).
GE: general GB: general banda
SY: simétrica SB: simétrica banda SP: simétrica empaquetada
HE: hermitiana HB: hermitiana banda HP: hermitiana empaquetada
TR: triangular TB: triangular banda TP: triangular empaquetada
Tabla 6.2: Valores de yy en los nombres de las rutinas del BLAS2 y del BLAS3.

Apéndice C: BLAS y LAPACK
313
Estructura del BLAS
BLAS 1. El conjunto de rutinas de este nivel resuelven problemas básicos de complejidad lineal como, por ejemplo, las operaciones el producto escalar de vectores, la actualización de un vector a partir de otro, generación de rotaciones, cálculo de normas vectoriales, etc.
Las principales subrutinas y funciones son:
_AXPY : yxy += α ,
_SCAL : xx α= ,
_SWAP : intercambia x e y ,
_COPY : xy = ,
_DOT : realiza el producto escalar yxT ,
_NRM2 : calcula la 2-norma de x ,
_ROT : genera una rotación en el plano,
donde x e y son vectores y α un escalar.
BLAS 2. Versiones especiales del BLAS 1, en algunos casos versiones en código máquina, se han implementado sobre un gran número de máquinas, por lo que se ha mejorado la eficiencia del BLAS 1. Sin embargo, en algunas arquitecturas modernas, el uso del BLAS 1 no es el mejor camino para mejorar la eficiencia de códigos de alto nivel. Por ejemplo, en máquinas vectoriales se necesita optimizar operaciones del tipo matriz-vector para aprovechar la potencial eficiencia de la máquina, sin embargo, el uso del BLAS 1 inhibe esta optimización, puesto que el BLAS 1 oculta al compilador la naturaleza de estas operaciones.
Para resolver esta problemática se diseñó el BLAS 2, el cual implementa un conjunto reducido de operaciones matriz-vector que aparecen muy a menudo en la implementación de muchos algoritmos del álgebra lineal. Las operaciones que implementan estas subrutinas tienen un coste cuadrático.
Los tres siguientes tipos de operaciones básicas son implementados en este nivel:
• Operaciones del tipo matriz-vector.
• _GEMV : yxAopy βα += )( .
• _TRMV : xAopx )(= ( A triangular).
• Actualizaciones de rango uno o rango dos.
• _GER : AxyA T += α .
• _SYR2 : AyxxyA TT ++= αα ( A simétrica).
• Resolución de sistemas de ecuaciones lineales triangulares.
• _TRSV : xAopx )( 1−= ( A triangular).

Apéndice C: BLAS y LAPACK
314
En las expresiones anteriores A es una matriz, x e y vectores, α y β escalares y *,,)( XXXXop T= .
BLAS 3. Muchos algoritmos pueden codificarse de manera que la mayor parte del cálculo vectorial o matricial se realice mediante llamadas al BLAS 2. Cuando se trabaja con máquinas vectoriales es aconsejable utilizar longitudes de vectores tan grandes, como sea posible, y así los resultados son calculados sobre un vector (fila o columna) de una sola vez, de manera que las prestaciones aumentan al reutilizar los registros vectoriales en lugar de devolver sus valores a memoria.
Desafortunadamente la aproximación anterior no es apropiada en los ordenadores con una jerarquía de memorias o en ordenadores con procesamiento en paralelo. Para estas arquitecturas es preferible dividir la matriz o matrices en bloques y realizar las operaciones de tipo matriz-matriz sobre bloques. Organizando los cálculos de este modo, se posibilita la completa reutilización de los datos de aquellos bloques que se encuentran en la memoria caché. Esta aproximación evita el excesivo movimiento de datos desde y hacia la memoria. Sobre arquitecturas que permiten el procesamiento en paralelo, el paralelismo se puede explotar de dos formas: (1) las operaciones sobre diferentes bloques puede realizarse en paralelo (concurrencia), y (2) las operaciones vectoriales y escalares en cada bloque pueden realizarse sobre los registros vectoriales (vectorización).
El BLAS 3 se diseñó con el objeto de llevar a cabo operaciones matriz-matriz y así diseñar algoritmos por bloques que permitiesen la realización de un número mayor de operaciones sobre las memoria caché. Las rutinas se han desarrollado de forma similar a la realizada en los niveles 1 y 2 del BLAS, reemplazando los vectores x e y por matrices A , B y C . La ventaja de diseñar el software de manera consistente con el nivel 2 del BLAS es que es más fácil recordar las secuencias de llamadas y las convenciones en los parámetros.
Las principales subrutinas de BLAS 3 son las siguientes:
• Producto matriz-matriz.
• _GEMM: CBopAopC βα += )()( .
• _TRMM: CBAopC βα += )( , BAopC )(α= ( A triangular).
• Actualizaciones de rango k de una matriz simétrica.
• _SYRK: CAAC T βα += , CC βα += AAT (C simétrica).
• _SYRK2: CBAABC TT βαα ++= (C simétrica).
• Resolución de múltiples sistemas lineales triangulares de ecuaciones.
• )( ,)( :_ 11 −− == ABopBBAopBTRSM α ( A triangular).
En las expresiones anteriores A , B y C son matrices, α y β escalares y *,,)( XXXXop T= .

Apéndice C: BLAS y LAPACK
315
LAPACK
Estructura del LAPACK Las rutinas del LAPACK se clasifican en:
• Rutinas driver: Estas rutinas resuelven un problema completo, por ejemplo, la resolución de un sistema lineal de ecuaciones o el cálculo de los valores propios de una matriz real simétrica.
• Rutinas computacionales: Estas rutinas resuelven diferentes tareas computacionales, por ejemplo, la factorización LU, la reducción de una matriz simétrica a la forma tridiagonal, etc. Cada rutina driver llama a una secuencia de rutinas computacionales para realizar su función.
• Rutinas auxiliares. Estas rutinas se clasifican como sigue:
• Rutinas que realizan subtareas de algoritmos orientados a bloques, en particular, rutinas que implementan versiones de algoritmos no orientadas a bloques.
• Rutinas que realizan algunos cálculos computacionales muy comunes de bajo nivel, por ejemplo, el escalado de una matriz, el cálculo de normas matriciales, la generación de matrices elementales de Householder, etc. Algunas de estas rutinas pueden tener interés para los analistas numéricos o desarrolladores del software, y pueden considerarse como futuras ampliaciones del BLAS.
• Rutinas que amplían al BLAS como, por ejemplo, rutinas que realizan rotaciones en el plano complejo u operaciones del tipo matriz-vector que involucran matrices complejas simétricas (no existen rutinas en el BLAS que realicen estas funciones).
El LAPACK dispone de rutinas que trabajan con datos en simple y en doble precisión de números reales y complejos. En la mayoría de los casos hay rutinas semejantes para los diferentes tipos de datos, pero existen algunas excepciones. Por ejemplo, para la resolución de sistemas lineales de ecuaciones indefinidos y simétricos, existen rutinas que resuelven sistemas simétricos complejos y hermíticos complejos, puesto que ambos tipos de sistemas complejos aparecen en aplicaciones prácticas. Sin embargo, no hay un caso complejo análogo al de la rutina que calcula los valores propios de una matriz tridiagonal simétrica, puesto que toda matriz hermitiana compleja se puede reducir a una matriz real tridiagonal simétrica.
Las rutinas que realizan la misma función para datos reales y complejos, siempre que esto sea posible, han sido codificadas para mantener una correspondencia cercana entre ellas. Sin embargo, en algunas áreas, especialmente en problemas de valores propios no simétricos, la correspondencia es necesariamente más lejana.
Las versiones en doble precisión se han generado automáticamente, utilizando el Toolpack/1 (véase [Poll89]). Las rutinas de doble precisión para matrices complejas requieren el tipo de datos no estándar COMPLEX*16, el cual se encuentra disponible para la mayoría de máquinas.
Los nombres de las rutinas driver y computacionales tienen la forma xyyzzz, siendo el sexto carácter un blanco para ciertas rutinas driver. Las tres primeras letras tienen el mismo significado que el utilizado en la denominación de las rutinas del BLAS 2 y del BLAS 3; la primera letra (x) para indicar el tipo de dato y las dos siguientes (yy) para indicar el tipo de matriz, apareciendo otros tipos de matrices, además de los que

Apéndice C: BLAS y LAPACK
316
aparecen en la Tabla 6.2 (véase [ABBD92], página 9). Las siguientes tres letras (zzz) indican la función o algoritmo que implementan. Por ejemplo, con xyySVX se referencian a todas las rutinas driver “expertas“ para la resolución de sistemas lineales de ecuaciones, y con xyySV a todas las rutinas driver “simples” que resuelven sistemas lineales de ecuaciones.
Los nombres de rutinas auxiliares siguen un esquema similar excepto que las letras yy son normalmente LA. Hay dos tipos de excepciones a esta regla. Las rutinas que implementan versiones no orientadas a bloques de un algoritmo orientado a bloques, tienen nombres similares a las rutinas que implementan los algoritmos orientados a bloques, con el sexto carácter igual a 2. Por ejemplo, la rutina SGETF2 es una versión no orientada a bloques de la rutina SGETRF (esta rutina calcula la descomposición LU con pivotamiento parcial de filas de una matriz). La otra excepción la presentan ciertas rutinas que pueden ser vistas como extensiones del BLAS utilizando, en este caso, un esquema similar al usado en las rutinas del BLAS.
A continuación se detallan los problemas resueltos por algunas de las rutinas del LAPACK.
Rutinas driver.
• Resolución de múltiples sistemas lineales de ecuaciones.
• Resolución del problema lineal de mínimos cuadrados.
• Obtención de los valores propios (factorización de Schur) y singulares (descomposición en valores singulares) de una matriz.
• Obtención de los valores propios generalizados de una matriz.
Rutinas computacionales:
• Resolución de un sistema lineal de ecuaciones.
• Factorizaciones ortogonales de una matriz: QR, RQ, LQ y QL.
• Resolución de problemas parciales relacionados con el cálculo de valores propios y singulares: equilibrado de una matriz, cálculo de números de condición y subespacios invariantes de una matriz, etc.
Tratamiento de Errores en el LAPACK Además de proporcionar rutinas más rápidas que las que se tenían anteriormente, el LAPACK añade, al software de computación numérica anterior, unas cotas de error más precisas y comprensibles.
Las cotas de error tradicionales están basadas en el hecho de que los algoritmos en el LAPACK, al igual que los de sus predecesores LINPACK y EISPACK, son estables “hacia atrás”. Las cotas de error dadas por algunas rutinas del LAPACK dependen de algoritmos que satisfacen una condición más fuerte de estabilidad, llamada estabilidad hacia atrás relativa a las componentes.
La rutina del LAPACK _LAMCH permite calcular toda una serie de parámetros característicos de la máquina sobre la que se implementa el LAPACK.
A continuación se presenta un análisis de errores estándar para la evaluación de una función escalar )(zfy = . Sea )alg(z la salida de una rutina que implementa a )(zf ,

Apéndice C: BLAS y LAPACK
317
incluyendo los errores de redondeo. Si )()alg( δ+= zfz , con δ pequeño, entonces se dice que alg es un algoritmo estable hacia atrás para )(zf o que el error hacia atrás δ es pequeño. En otras palabras, )alg(z es el valor exacto de )(zf para una entrada ligeramente perturbada δ+z (algunas veces los algoritmos satisfacen únicamente
νδ ++= )()alg( zfz , donde δ y ν son pequeños, aunque esto no cambia significativamente el análisis de error).
Si se supone que )(zf es derivable, entonces se puede realizar la aproximación
δδ )()()( zfzfzf ′+≈+ ,
por lo que se puede estimar el error cometido a partir de la expresión .)()()()()(alg δδ zfzfzfzfz ′≈−+=−
Por lo tanto, si δ es pequeño y la derivada )(' zf no es elevada, entonces el error )()(alg zfz − será pequeño. En general, solo es necesario que se cumpla la condición
de Lipschitz, para utilizar la constante de Lipschitz en lugar de )(' zf en la obtención de la cota del error.
El error relativo cometido será
|/|),()()(
)()()(alg zzf
zzfzzf
zfzfz δκδ
≡′
≤− ,
donde ),( zfκ es el número de condición de )(zf y |/| zδ el error relativo regresivo de z . Por lo tanto, se puede obtener una cota del error multiplicando el número de condición por el error regresivo. El problema está mal condicionado si su número de condición es grande, y mal formulado si su número de condición es infinito (o no existe).
Si )(zf es una función vectorial, entonces )(' zf es la matriz Jacobiana, de manera que los valores absolutos anteriores se sustituyen por p-normas vectoriales y matriciales. En este caso, se puede hablar de estabilidad regresiva. Por ejemplo, un método estable para resolver sistemas de ecuaciones lineales
bAx = ,
permite obtener una solución 'x que satisface
fbxEA +=+ ')(
siendo
∞
∞
||||||||
AE
y
∞
∞
||||||||
bf
valores cercanos a la precisión de la máquina ε .
La mayor parte de los algoritmos en el LAPACK son estables en el sentido descrito: cuando se aplican sobre una matriz A , producen resultados exactos para una matriz ligeramente perturbada EA + , donde el cociente

Apéndice C: BLAS y LAPACK
318
∞
∞
||||||||
AE
está cercano a ε . Hay algunas matizaciones a esta afirmación. Cuando se calcula la inversa de una matriz, la matriz de error regresivo E es pequeña considerando que las columnas de la matriz inversa se calculan una a una, con una E diferente para cada columna. Esto mismo es cierto en el cálculo de vectores propios de una matriz no simétrica. Cuando se calculan los valores y vectores propios de
BA λ− , IAB λ− ,
con A simétrica y B simétrica y definida positiva (utilizando las rutinas xSYGV o xHEGV), entonces el método puede no ser estable hacia atrás, si B tiene un número de condición elevado, aunque también se tengan cotas de error útiles. La resolución de la ecuación matricial de Sylvester
CXBAX =+ ,
puede no ser estable hacia atrás, aunque otra vez se obtengan cotas del error útiles para X .
El cálculo de números de condición puede ser a veces muy costoso. Por ejemplo, el coste aritmético de resolver el sistema bAx = es de orden 3n y el del cálculo de )(A∞κ es exactamente tres veces mayor. En este caso, )(A∞κ puede ser estimado con un coste de orden 2n . En general, los números de condición y las cotas de error se basan en la estimación de números de condición ([Hage84], [High873], [High882]). El precio pagado por utilizar estimadores es que el error puede ser subestimado en algunas ocasiones. Años de experiencia confirman la exactitud de los estimadores utilizados, aunque se pueden construir ejemplos en los que no ocurre esto ([High902]).
El anterior análisis de errores tiene un inconveniente: Si se utiliza la ∞-norma para medir el error regresivo, entonces entradas de igual magnitud en δ contribuyen de igual manera a la cota del error final
.||||||||),(
zzf δκ =
Esto indica que si z es disperso o tiene algunas entradas pequeñas, entonces un algoritmo estable hacia atrás puede producir grandes cambios comparados con los valores originales. Si estos valores son conocidos exactamente por el usuario, puede ocurrir que estos errores sean inaceptables o que las cotas de error sean inaceptablemente elevadas.
Sea, por ejemplo, bAx =
un sistema diagonal de ecuaciones lineales.
Cada componente de la solución del sistema anterior se puede calcular mediante eliminación Gaussiana
ii
ii a
bx = .
La cota de error usual es aproximadamente igual a

Apéndice C: BLAS y LAPACK
319
||min||max)(
iii
iii
aaA εεκ = ,
la cual puede sobrestimar el error verdadero.
El LAPACK resuelve este problema utilizando algunos algoritmos cuyo error regresivo δ es un pequeño cambio relativo en cada componente de z ( ||)(|| ii zO εδ = ). Este error regresivo tiene en cuenta tanto la estructura dispersa de z como la información de las pequeñas entradas. Estos algoritmos son estables hacia atrás relativos a las componentes. Además, las cotas del error reflejan estos errores regresivos más pequeños.
Si los datos de entrada tienen una incertidumbre independiente en cada componente, cada componente debe tener al menos una incertidumbre relativa pequeña, puesto que cada una ellas es un número en coma flotante. En este caso, el algoritmo contribuye a una incertidumbre extra que no es mucho peor que la incertidumbre de los datos de entrada, de manera que se podría decir que la respuesta dada por un algoritmo estable hacia atrás relativo a las componentes es tan exacta como la que garantiza el dato.
Cuando se resuelve el sistema lineal bAx =
utilizando, por ejemplo, la rutina driver “experta” xyySVX o la rutina computacional xyyRFS, se calcula una solución 'x que satisface
fbxEA +=+ ')( ,
siendo ije pequeños cambios relativos en ija y if un pequeño cambio en ib . En particular, si A es diagonal, entonces la correspondiente cota de error es siempre pequeña, como cabría esperar.
El LAPACK alcanza esta exactitud en la resolución de sistemas de ecuaciones lineales, en la descomposición bidiagonal en valores singulares de una matriz o en el problema tridiagonal y simétrico de los valores propios, dando facilidades para alcanzar esta exactitud en problemas de mínimos cuadrados.
Equilibrado y Condicionamiento en LAPACK Existen dos pasos previos que permiten un cálculo más sencillo de los valores propios de una matriz.
El primer paso consiste en una permutación de filas y columnas de la matriz A de manera que la matriz 'A esté más cerca de una estructura triangular superior (más cercana a la forma Schur):
TPAPA =' ,
siendo P una matriz de permutación.
El segundo paso consiste en escalar la matriz 'A por medio de una matriz diagonal D que permite que las filas y las columnas de ''A estén entre sí más cercanas en norma:
1''' −= DDAA .
El escalado puede reducir la norma de la matriz A con respecto a los valores propios, posibilitando la disminución de los errores de redondeo ([WiRe71]).

Apéndice C: BLAS y LAPACK
320
El equilibrado de una matriz se realiza mediante la rutina driver xGEEVX, la cual realiza una llamada a la rutina computacional xGEBAL. El usuario puede indicar a xGEEVX si desea permutar, escalar, realizar ambas o no hacer ninguna de las dos operaciones; esto se especifica mediante el parámetro de entrada BALANC. La permutación no tiene efecto sobre los números de condición o su interpretación como se ha descrito anteriormente. Sin embargo, el escalado cambia su interpretación, como a continuación se detalla.
Los parámetros de salida de xGEEVX, SCALE (vector real de longitud n ), ILO(entero), IHI(entero) y ABNRM(real) describen el resultado de equilibrar una matriz A de dimensión n , obteniéndose una matriz ''A . La matriz ''A es triangular superior por bloques con al menos tres bloques: de 1 a ILO-1, de ILO a IHI, y de IHI+1 a n . El primer y último bloque son triangulares superiores. Estos bloques no están escalados; solo el bloque que se encuentra entre ILO a IHO está escalado. La uno norma de ''A es devuelta en la variable ABNRM.
Los números de condición descritos en anteriormente son calculados para la matriz equilibrada ''A y, por lo tanto, es necesario realizar alguna interpretación para aplicarlos a los valores y vectores propios de la matriz original A . Para poder utilizar las cotas destinadas a los valores propios de las tablas anteriores se deben reemplazar
2|||| E y FE |||| por ABNRM)(||''||)( εε OAO = . Para poder utilizar las cotas de los vectores propios, se debe tener en cuenta que las cotas sobre rotaciones de vectores propios son las dadas por los vectores propios ''x de ''A , los cuales están relacionados con los vectores propios x de A mediante
''xDPx = , xDPx T 1−= .
Proyector Espectral y Separación de Matrices
Sea nxnA ℜ∈ en la forma de Schur. Si se considera un grupo de 1≥m valores propios de A , incluyendo sus multiplicidades, entonces A se puede descomponer como
( 6.4 ) ⎥⎦
⎤⎢⎣
⎡=
22
1211
0 AAA
A ,
donde los valores propios de la submatriz nxnA ℜ∈11 son exactamente los correspondientes al grupo elegido. En la práctica, si los valores propios sobre la diagonal de A están en otro orden, la rutina xTREXC permite desplazarlos al primer bloque diagonal.
Se define el proyector espectral, o simplemente el proyector P correspondiente a los valores propios de 11A ([Stew73], [Karl59]), como
⎥⎦
⎤⎢⎣
⎡=
00RI
P m ,
donde R satisface la ecuación matricial de Sylvester
( 6.5 ) 122211 ARARA =−
que puede resolverse utilizando la rutina xTRSYL.
Asociado al proyector espectral se encuentra el número

Apéndice C: BLAS y LAPACK
321
.||||1
1||||
1222 RP
s+
==
Puesto que el valor de s es difícil calcular, se utiliza una estimación del mismo definida como
2||||11
FR+.
Esta aproximación difiere como mucho de su valor correcto en un factor igual a ),min( mnm − .
La estimación de ),(sep 2211 AA se realiza con la rutina xLACON (véase [Hage84], [Hig187] y [High882]), la cual estima la norma de un operador lineal
∑=i ijj tT ||max|||| 1 ,
mediante el cálculo de Tx y xT T , para cualquier vector arbitrario x . En este caso, la multiplicación de T por un vector arbitrario x , se obtiene resolviendo la ecuación matricial de Sylvester ( 6.5 ) mediante la rutina xTRSYL con un miembro derecho arbitrario, y el producto de TT por un vector arbitrario x , resolviendo la misma ecuación, pero reemplazando 11A por TA11 y 22A por .22
TA El coste aritmético necesario para resolver cualquiera de las ecuaciones es )( 3nO o como poco )( 2nO , si nm << . Puesto que al utilizar 1|||| T en lugar del valor verdadero de sep, que es 2|||| T , entonces la estimación de sep puede diferir del valor verdadero como mucho en un factor
)( mnm − .
Otra formulación que permite, en principio, calcular exactamente el valor de ),(sep 2211 AA es
)(),(sep 2211min2211 mT
mn IAAIAA ⊗−⊗= −σ .
Este método es generalmente impracticable, puesto que hay que calcular el menor valor singular de una matriz de orden )( mnm − . Por lo tanto, se requiere un espacio de trabajo extra del orden 4n y del orden de 6n operaciones, valores mucho mayores que los obtenidos en el método de estimación del anterior párrafo.
La expresión ),(sep 2211 AA mide la “separación” del espectro de 11A y 22A en el siguiente sentido. Este valor es cero si y solo si las matrices 11A y 22A tienen un valor propio común, y es pequeño si existe una pequeña perturbación de cualquiera de ellas que haga que tengan en común un valor propio. Si 11A y 22A son matrices hermitianas, entonces ),(sep 2211 AA es precisamente el intervalo o mínima distancia entre un valor propio de 11A y otro de 22A . Por otra parte, si 11A y 22A no son hermitianas, entonces
),(sep 2211 AA puede ser mucho mayor que esta distancia.

Apéndice C: BLAS y LAPACK
322
Otras Características del LAPACK
Argumentos Matriciales
Cada argumento de tipo matricial de dos dimensiones se encuentra seguido, en la lista de argumentos, por su dimensión principal (LDA), cuyo nombre viene expresado por LD<nombre de la matriz>. Los argumentos de una matriz están declarados normalmente como matrices de tamaño supuesto (segunda dimensión igual a *). Así por ejemplo, una matriz A se puede declarar como
REAL A(LDA,*)
INTEGER LDA,
aunque las líneas comentadas de la rutina indican que A es dimensión (LDA,N), indicando con ello que el valor mínimo requerido para la segunda dimensión es N. Esta declaración se utiliza para superar algunas limitaciones en el FORTRAN 77 estándar. En particular, permite que la rutina pueda ser invocada cuando la dimensión relevante (N, en este caso) sea igual cero. Sin embargo, las dimensiones de la matriz actual en el programa que llama debe ser al menos 1 (LDA en este ejemplo).
Matrices de Trabajo
Muchas de las rutinas del LAPACK requieren que una o más matrices de trabajo sean pasadas como argumentos. Estas matrices suelen representarse con el nombre WORK y, algunas veces, como IWORK, RWORK o BWORK, para distinguir entre las matrices de trabajo de tipo entero, real o lógico.
Muchas rutinas que implementan algoritmos orientados a bloques necesitan un espacio de trabajo suficiente para contener un bloque de filas o columnas de la matriz. En tales casos, la longitud declarada para la matriz de trabajo debe ser pasada mediante un argumento separado LWORK, el cual se encuentra a continuación del argumento WORK en la lista de argumentos.
Argumento Info
Todas las rutinas documentadas tienen un argumento de diagnóstico INFO que indica el éxito o fallo en la ejecución de la rutina, como a continuación se detalla:
• INFO=0: indica una finalización con éxito.
• INFO<0: valor ilegal de uno o varios argumentos.
• INFO>0: fallo en la realización de cálculos.
Todas las rutinas driver y auxiliares comprueban que los argumentos de entrada, tales como N o LDA, o los argumentos de opción tengan valores adecuados. Si se encuentra un valor ilegal en el i-ésimo argumento, la rutina pone INF con valor –i, llamando a continuación a la rutina de tratamientos de errores XERBLA. La versión estándar de XERBLA da un mensaje de error y finaliza la ejecución de la rutina.
Determinación del Tamaño de Bloque Óptimo
Las rutinas del LAPACK que implementan algoritmos orientados a bloques necesitan determinar el tamaño de bloque óptimo. El diseño del LAPACK está realizado de manera que la elección del tamaño de bloque esté oculta, tanto como sea posible, a la vista de los usuarios, pero al mismo tiempo sea fácilmente accesible para los

Apéndice C: BLAS y LAPACK
323
instaladores del software, puesto que optimizan el LAPACK para una determinada máquina.
Las rutinas del LAPACK llaman a la función ILAENV para obtener, entre otros valores, el tamaño óptimo de bloque. Esta rutina contiene valores por defecto que conducen a un buen comportamiento sobre un gran número de máquinas pero, para poder obtener rendimientos óptimos, es necesario modificar ILAENV para cada máquina en particular. El tamaño de bloque puede depender también de la rutina de llamada, de la combinación de argumentos opcionales (si los hay) y de las dimensiones del problema.
Si ILAENV devuelve un tamaño de bloque igual a 1, entonces la rutina ejecuta el algoritmo no orientado a bloques, llamando a rutinas del nivel 2 del BLAS y nunca a las del nivel 3.
Las rutinas que utilizan a la rutina ILAENV realizan los siguientes pasos:
1. Determinación del tamaño de bloque óptimo usando ILAENV.
2. Si el valor de LWORK indica que se ha proporcionado suficiente espacio de trabajo, entonces la rutina usa el tamaño óptimo; de otro modo, la rutina determina el bloque de mayor tamaño que puede utilizarse con la cantidad de espacio de trabajo proporcionada.
3. Si el nuevo tamaño de bloque no es inferior a un valor umbral (también devuelto por ILAENV), la rutina utiliza este nuevo valor; de otro modo, la rutina utiliza la versión no orientada a bloques del algoritmo.
El mínimo valor de LWORK, que puede necesitarse para utilizar el tamaño de bloque óptimo, se devuelve en WORK(1). Por lo tanto, la rutina utiliza el mayor tamaño de bloque posible del espacio de trabajo proporcionado.
La especificación de LWORK da el valor mínimo necesario para obtener resultados correctos. Este valor coincide con el espacio de trabajo necesario para ejecutar la versión no orientada a bloques del algoritmo. Si el valor proporcionado es menor que ese valor mínimo, entonces se producirá un error en el argumento LWORK.
Si hay duda del espacio de trabajo necesario, los usuarios deben suministrar una cantidad suficiente de memoria y examinar a continuación el valor de WORK(1) en la salida.
Prestaciones del LAPACK El LAPACK fue diseñado inicialmente para obtener buenas prestaciones sobre máquinas vectoriales de un solo procesador o sobre multiprocesadores con memoria compartida. El software del LAPACK también ha sido usado posteriormente sobre nuevas máquinas obteniéndose también buenos resultados (estaciones de trabajo superescalares de altas prestaciones). A continuación se comentan los principales factores que afectan a las prestaciones del LAPACK sobre diferentes tipos de máquinas.
• Vectorización: Diseñar algoritmos vectorizables en álgebra lineal es normalmente sencillo. Sin embargo, para muchos cálculos computacionales existen diversas variantes, todas ellas vectorizables, pero con prestaciones diferentes. Las prestaciones dependen de las características de la máquina, tales como el encadenamiento de sumas y productos vectoriales. Sin embargo, cuando los algoritmos se escriben en un código FORTRAN 77 estándar, las prestaciones pueden disminuir, debido normalmente a que los compiladores del lenguaje

Apéndice C: BLAS y LAPACK
324
FORTRAN no optimizan el número de accesos a memoria, es decir, se produce un número excesivo de carga y almacenamiento de vectores en memoria.
• Movimiento de datos: La causa principal de la limitación del rendimiento de una unidad en coma flotante escalar o vectorial es la velocidad de transferencia entre los diferentes niveles de memoria en una máquina. Por ejemplo, la transferencia de operandos vectoriales entre registros vectoriales, la transferencia de operandos escalares en un procesador escalar, el movimiento de datos entre la memoria principal y la memoria local o memoria caché, y la paginación entre la memoria actual y la del disco en sistemas con memoria virtual. Es deseable maximizar la razón entre la realización de operaciones en coma flotante y los accesos a memoria, así como reutilizar datos, tanto como sea posible, mientras son almacenados en los niveles más altos de la jerarquía de memoria (por ejemplo, registros vectoriales o memoria caché de alta velocidad). El programador de FORTRAN no tiene un control explícito sobre estos tipos de movimientos de datos, aunque puede a menudo influir sobre ellos imponiendo al algoritmo una determinada estructura.
• Paralelismo: La estructuras de bucles anidados que aparecen en los algoritmos del álgebra lineal ofrecen la posibilidad de ser paralelizados cuando se implementan sobre multiprocesadores con memoria compartida. Este es el principal tipo de paralelismo que se explota en el LAPACK. Este paralelismo puede ser automáticamente generado por un compilador, aunque habitualmente es necesario utilizar directivas de compilación que lo permitan.
La clave para obtener en el LAPACK eficiencia y portabilidad es construir el software haciendo uso, tanto como sea posible, de llamadas al BLAS. La eficiencia del LAPACK depende de la eficiencia de la implementación del BLAS en la máquina. Por lo tanto, el BLAS es un interfaz de bajo nivel entre el software del LAPACK y la arquitectura de la máquina. La portabilidad en el LAPACK se obtiene, por tanto, haciendo uso de llamadas al BLAS.
El BLAS 1 se utiliza en el LAPACK más por conveniencia que por prestaciones. Las llamadas del LAPACK a rutinas del BLAS 1 corresponden a una fracción insignificante de los cálculos computacionales que se realizan, no pudiéndose alcanzar una alta eficiencia sobre la mayor parte de las supercomputadoras modernas.
El BLAS 2 puede alcanzar las prestaciones máximas en muchos de los procesadores vectoriales. Sin embargo, sobre otros procesadores vectoriales las prestaciones del LAPACK se encuentran limitadas por la velocidad de movimientos de datos entre los diferentes niveles de memoria.
Esta limitación es superada en el BLAS 3, al realizar operaciones en coma flotante de orden cúbico sobre conjuntos de datos de cardinalidad cuadrática.

Apéndice D: SGI Altix 3700
325
Apéndice D. SGI Altix 3700
El componente hardware constituye una parte fundamental de un computador puesto que, de alguna forma, indica el máximo rendimiento que un equipo será capaz de ofrecer. Complementariamente, será preciso disponer de un sistema operativo eficaz y versátil que permita manejarlo de manera cómoda y simple y, por otra parte, que los compiladores y utilidades de desarrollo permitan acercar el rendimiento real al máximo impuesto por el hardware.
Arquitectura EL SGI 3700 es un sistema multiprocesador con arquitectura NUMA (Non Uniform Memory Access) perteneciente a la serie SGI 3000 [SGIA03]. En esta máquina la memoria está físicamente distribuida sobre todos los procesadores, pero la combinación del sistema operativo y unos controladores hardware especiales mantienen una imagen de memoria compartida a nivel de usuario.
Figura 6.1.
Los procesadores corresponden al Intel Itanium II CPU [SGIA03] trabajando a 1.3Ghz, con 3MB de memoria caché (conocida como “Madison”). La memoria total es de 44 Gb. El hardware se haya dispuesto en forma modular mediante la división en “bricks”: C-Bricks (Computational bricks), R-bricks (Router bricks), IX-Bricks (Peripheral bricks) y M-Bricks( Memory bricks). Cada C-Brick contiene un total de 4 procesadores con un ancho de banda total de 3.2Gb/s.
Software El servidor SGI Altix 3000 funciona bajo el sistema operativo Linux de 64 bits Red Hat 7.2 con el kernel de Linux 2.4.19. Para mejorar las prestaciones, SGI incluye un entorno de desarrollo optimizado para la arquitectura Altix 3000, denominado SGI ProPack, que permite obtener el máximo rendimiento del sistema.
Red Hat es una de las distribuciones de LINUX más popular del mercado hoy en día, siendo emulada por muchas otras. Es muy sencilla de instalar e incluye la detección automática de dispositivos, un instalador gráfico y un excelente conjunto de aplicaciones comerciales en su distribución oficial.

Apéndice D: SGI Altix 3700
326
Compiladores La serie SGI 3000 dispone en la actualidad de varias versiones de los compiladores GNU (gcc, g77 y g++) e Intel. Los compiladores de Intel se han diseñado para sacar el máximo partido posible de las prestaciones teóricas máximas del hardware (tanto del procesador como del resto de la arquitectura) de los servidores Altix 3000. La última versión instalada corresponde a la versión 9. Los compiladores de Intel soportan los lenguajes C, C++ y los estándares de FORTRAN 77, 90 y 95.
El compilador de C y C++ cumple las siguientes características:
• Compatible con el estándar Ansi C y C++.
• Compatible binario con GNU gcc.
• Soporta la mayoría de las extensiones de lenguaje GNU C y C++.
• Compatibilidad con C99 (subconjunto).
• Se pueden mezclar binarios de código C con gcc 3.x e Intel 7.0.
• Ficheros objetos C pueden ser enlazados con el compilador de Intel o con gcc.
Si se comparan el código generado por los compiladores de Intel con los de GNU, el primero resulta ser varias veces más rápido que el correspondiente a GNU.
Librerías Para el Altix 3700 se disponen de dos librerías optimizadas del BLAS y LAPACK: Intel MKL [IMKL03] versión 8.0, y el SGI SCSL (Scientific Computing Software Library), versión 1.5.1. En las implementaciones realizadas se ha utilizado las librerías SCSL, pues contiene al BLAS y al LAPACK totalmente optimizados y paralelizados para la arquitectura de SGI. La documentación de las rutinas de estas librerías se encuentra disponible en la página http://techpubs.sgi.com.

Bibliografía
327
Bibliografía [ABBD92] E. Anderson, Z. Bai, C. Bischof, J. Demmel and others, “LAPACK Users’s Guide”. SIAM,
1992. [ABHI00] E. Arias, I. Blanquer, V. Hernández y J. Ibáñez, “Nonsingular Jacobian Free Piecewise
Linealization of State Equation”. Controlo 2000, Portuguese Association of Automatic Control, 2000.
[Abra71] A. A. Abramov, “On the Boundary Conditions at a Singular Point for Linear Ordinary Differentials Equations”, U.S.S.R. Computational Mathematics and Mathematical Physics, vol. 11, pp. 363-367, 1971.
[AHBI99] E. Arias Antúnez, V. Hernández García, I. Blanquer Espert and J. Ibáñez González, “Nonsingular Jacobian Free Piecewise Linearization of Ordinary Differential Equations (EDO)”. Second Workshop Niconet on: Numerical Control Software: SILICOT, Rocquencourt, France, 1999.
[AHIP05] E. Arias, V. Hernández, J. J. Ibáñez and J. Peinado, “Solving Differential Riccati Equations by Using BDF Methods”. Technical Report DSIC-II/05/05, UPV, Valencia, 2005.
[AlPr81] R. C. Allen and S. A. Pruess, “An Analysis of an Inverse Problem in Ordinary Differential Equations”. SIAM J. Sci. Statist. Comput., 2, pp. 176–185, 1981.
[AnDo92] E. Anderson, J. Dongarra and S. Ostrouchov, “LAPACK Working Note 41 Installation Guide for LAPACK”. Department of Computer Science University of Tennessee Knoxville, Tennessee, 1992.
[AnMo71] B. D. Anderson and J. B. Moore, “Linear Optimal Control”. Prentice Hall, Englewood Cliffs, N.J., 1971.
[ArCa76] E. S. Armstron and A. K. Caglayan, “An Algorithm for the Weighting Matrices in the Sampled-Data Optimal Linear Regulator Problem”. NASA Langley Res. Ctr., Hampton, VA, NASA Tech. Note NASA TN D-8372, 1976.
[AsPe91] U. M. Ascher, L.R. Petzold, “Computer Methods for Ordinary Differential Equations and Differential-Algebraic Equations”. SIAM, 1998.
[BaGr96] G. A. Baker, Jr. and P. Graves-Morris, “Padé Approximants”. 2nd ed., Encyclopedia Math. Appl., Cambridge University Press, Cambridge, UK, 1996.
[Balz80] L. A. Balzer, “Accelerated Convergence of the Matriz Sign Function Method of Solving Lyapunov, Riccati, and other Matriz Equations”. Internat. J. Control, Vol. 32, pp. 1057-1078, 1980.
[Barr79] A. Y. Barraud, “Investigations Autor de la Function Signe d’une Matrice-Application à l’Équation de Riccati”. R.A.I.R.O. Automat. Syst. Anal. Control, Vol. 13, pp. 335-368, 1979.
[BaSt71] R. H. Bartels and G. W. Stewart, “Algorithm 432, Solution of the Matrix Equation AX+XB=C”, Communications of the ACM, Vol. 15, Nº 9, pp. 820-913, 1972.
[BaSt72] R.H. Bartels and G.W. Stewart, “Solution of the Matrix Equation AX + XB = C: Algorithm 432”. Comm. ACM, 15, pp. 820–826, 1972.
[BeDo91] A. Beguelin, J. Dongarra, et al., “A user’s Guide to PVM: Parallel Virtual Machine”. Tech. Report TM-11826, Oak Ridge National Laboratory, 1991.
[Bell53] R. Bellman, “Stability Theory of Differential Equations”. McGraw-Hill Book Co. Inc., New York, 1953.
[Bell83] R. Bellman, “On the Calculation of Matrix Exponential”. Linear and Multilinear Algebra, 41, pp. 73-79, 1983.
[BeMe04] P. Benner and H. Mena, “BDF Methods for Large-Scale Differential Riccati Equations”. Fakultät für Mathematik Technische Universität Chemnitz, D-09107 Chemnitz, Germany, 2004.
[Benn02] P. Benner, “Efficient Algorithms for Large-Scale Quadratic Matrix Equations”. Proc. Appl. Math. Mech., 1(1), 492–495, 2002.
[Benn04] P. Benner, “Solving Large-Scale Control Problems”. IEEE Control Systems Magazine, 14(1), pp. 44–59, 2004.
[Bern05] D. S. Bernstein, “Matrix Mathematics”. Pricenton University Press, 2005. [Bhat97] R. Bhatia, “Matrix Analysis”, Springer-Verlag, New York, 1997. [BiHM04] D. A. Bini, N. J. Higham, And Beatrice Meini, “Algorithms for the Matrix pth Root”.
Numerical Analysis Report 454, Manchester Centre for Computational Mathematics, University of Manchester, 2004.

Bibliografía
328
[BjHa83] A. Björck and S. Hammarling, “A Schur Method for the Square Root of a Matrix”. Linear Algebra Appl. 52/53, pp. 127-140, 1983.
[BlDo99] S. Blackford, J. Dongarra, “LAPACK Working Note 41 Installation Guide for LAPACK, Version 3.0”. Department of Computer Science University of Tennessee Knoxville, Tennessee, 1999.
[Brew78] J. W. Brewer, “Kronecker Product and Matrix Calculus in System Theory”. IEEE Transactions on Circuits and Systems, 25 (9), pp. 772-781, September, 1978.
[BrGS92] R.W. Brankin, I. Gladwell, and L.F. Shampine, “RKSUITE: a suite of Runge-Kutta codes for the initial value problem for ODEs”. Softreport 92-S1, Department of Mathematics, Southern Methodist University, Dallas, Texas, U.S.A, 1992.
[BrHi89] P. N. Brown and A. C. Hindmarsh, “Reduced Storage Matrix Methods in Stiff ODE Systems”. J. Appl. Math. & Comp., 31, pp.40-91, 1989.
[BrLo87] D. Brown and J. Lorenz, “A High-Order Method for Stiff BVPs with Turning Points”. SIAM J. Sci. Statist. Comput., pp. 790-805, 1987.
[Butc87] J. C. Butcher, “The Numerical Analysis of Ordinary Differential Equations: Runge-Kutta and General Linear Methods”. Wiley, Chichester, 1987.
[Byer87] R. Byers, “Solving the Algebraic Riccati Equation with the Matrix Sign Function”. Linear Algebra Appl., Vol. 85, pp. 267–279, 1987.
[ByHi75] G. D. Byrne and A. C. Hindmarsh, “A Polyalgorithm for the Numerical Solution of Ordinary Differential Equations”. ACM Transactions on Mathematical Software, 1, pp. 71-96, 1975.
[CDOP95] J. Choi, J. Dongarra, S. Ostrouchov, A. Petitet, D. Walker, and R. C. WHALEY, “A Proposal for a Set of Parallel Basic Linear Algebra Subprograms”. Computer Science Dept. Technical Report CS-95-292, University of Tennessee, Knoxville, TN, May 1995.
[ChAL90] C. H. Choi and A. J. Laub, “Efficient Matrix-valued Algorithms for Solving Stiff Riccati Differential Equations”. IEEE Trans. on Automatic Control, 35(7), pp. 770–776, 1990.
[Chan69] K. W. Chang, “Remarks on a Certain Hypothesis in Singular Perturbations”. Proc. American Math. Soc., 23 , pp. 41-45, 1969.
[ChHi01] S. H. Cheng, N. J. Higham, C. S. Kenney, and A. J. Laub, “Approximating the Logarithm of a Matrix to Specified Accuracy”. SIAM J. Matrix Anal. Appl., 22, pp. 1112–1125, 2001.
[ChLa87] C. H. Choi and A.J. Laub, “Improving the Efficiency of Matrix Operations in the Numerical Solution of Large Implicit Systems of Linear Differential Equations”. Int. J. Control, 46, pp. 991-100, 1987.
[Choi90] C. H. Choi, “Efficient Algorithms for Solving Stiff Matrix-valued Riccati differential equations”. Phd., 1988.
[Choi92] C. H. Choi, “Time-Varyng Riccati Differential Equations with Known Analytic Solutions”. IEEE Trans. on Automatic Control, 37(5), pp. 642–645, 1992.
[Coen01] Stéphane Coen et al., “White-light Supercontinuum Generation with 60-ps Pump Pulses in a Photonic Crystal Fiber”. Opt. Lett 26, 1356 (2001).
[Copp74] W. A. Coppel., “Matrix Quadratic Equations”. Bull. Australian Math. Soc., 10 pp 377-401, 1974.
[DaH103] P. I. Davies and N. J. Higham, “A Schur-Parlett Algorithm for Computing Matrix Functions”. SIAM J. Matrix Analysis Appl., Vol. 25, No. 2, pp 464-485, 2003.
[DaH203] P. I. Davies and N. J. Higham, “Computing f(A)b for Matrix Functions f”. Numerical Analysis Report No. 436, Manchester Centre for Computational Mathematics, Manchester, England, November 2003. Submitted to Proceedings of the Third International Workshop on QCD and Numerical Analysis, Edinburgh, 2003.
[Dahl63] G. Dahlquist, “A Special Stability Problem for Linear Multistep Methods”. BIT 3, pp. 27-43, 1963.
[DaMa73] E. J. Davison and M. C. Maki, “The Numerical Solution of the Matrix Riccati Differential Equation”. IEEE Trans. on Automatic Control, AC-18, pp. 71-73, 1973.
[DaSm02] P. I. Davies and M. I. Smith, “Updating the Singular Value Decomposition”. Numerical Analysis Report No. 405, Manchester Centre for Computational Mathematics, Manchester, England, August 2002. To appear in J. Comput. Appl. Math.
[Davi04] P. I. Davies, “Structured Conditioning of Matrix Functions”. Numerical Analysis Report No. 441, Manchester Centre for Computational Mathematics, Manchester, England, January 2004.

Bibliografía
329
[DBMS79] J. J. Dongarra, J. R. Bunch, C. B. Moler and G. W. Stewart, “LINPACK Users’ Guide”. SIAM, Philadelphia, PA, 1979.
[DDHH90] J. J. Dongarra, J. Du Croz, S. Hammerling, and R. J. Hanson, “A Set of Level 3 Basic Linear Algebra Subprograms”. ACM Trans. Math. Soft, 16(90), 1990.
[DeBe76] E. D. Denman and A. N. Beavers, “The Matrix Sign Function and Computations in Systems”. Appl. Math. Comp., vol. 2, pp. 63-94, 1976.
[DEES82] G. Dahlquist, L. Edsberg, G. Skollermo and G. Soderlind, ”Are the Numerical Methods and Software Satisfactory for Chemical Kinetecs?”. Numerical Integration of DE and Large Linear Systems, J. Hinze, ed. Springer-Verlag, pp. 149-164, 1982.
[DeHi90] J. W. Demmel and N. J. Higham, ”Improved Error Bounds for Undetermined Systems Solvers”. Computer Science Dept. Technical Report CS-90-113, University of Tennesse, Knoxville, 1990.
[DeSc83] J. E. Dennis and R. B. Schnabel, “Numerical Methods for Unconstrained Optimization and Nonlinear Equations”. Prentice-Hall, Englewood Cliffs, NJ, 1983.
[Diec92] L. Dieci, “Numerical Integration of the Differential Riccati Equation and some Related Issues”. SIAM, 29(3), pp. 781–815, 1992.
[DiEi94] L. Dieci and T. Eirola, “Positive Definitess in the Numerical Solution of Riccati Differential Equations”. Numerical Math, 67, pp. 303–313, 1994.
[DiPa00] L. Dieci and A. Papini, “Conditioning and Padé Approximation of the Logarithm of a Matrix”. SIAM J. Matrix Anal. Appl., Vol. 21, pp. 913–930, 2000.
[DoLe76] P. Dorato and A. Levis, “Optimal Linear Regulators: The Discrete Time Case”. IEEE Trans. Automat. Control, col AC-16, 1971.
[DoVan92] J. Dongarra, R. Van De Geijn and D. W. Walter, “A Look at Scalable Dense Linear Algebra Libraries”. Proceedings of the Scalable High-Performance Computing Conference, IEEE Publishers, pp. 372-379, 1992.
[DoWhS95] J. Dongarra and R. C. Whaley, “A User's Guide to the BLACS v1.1”. Computer Science Dept. Technical Report CS-95-281, University of Tennessee, Knoxville, TN, 1995.
[DrGr98] V. Druskin, A. Greenbaum and L. Knizhnerman, “Using Nonorthogonal Lanczos Vectors in the Computation of Matrix Functions”. SIAM J. Sci. Comput. 19, pp. 38-54, 1998.
[Fadd59] V. N. Faddeeva, “Computational Methods of Linear Algebra”. Dover Publications, New York, 1959.
[Fehl69] E. Fehlberg, “Low-order Classical Runge-Kutta Formulas with Step-size Control and their Application to some Heat Transfer Problems. NASA Rept TR R-315, Huntsville, AL, April 15, 1969.
[FeZF03] A. Ferrando, M. Zacarés, P. Fernández de Córdoba, D. Binosi y J.A. Monsoriu, “Spatial Soliton Formation in Photonic Crystal Fibers”. Optics Express 11, 452, 2003.
[FeZF04] A. Ferrando, M. Zacarés, P. Fernández de Córdoba, D. Binosi y J.A. Monsoriu, “Vortex Solitons in Photonic Crystal Fibers”. Optics Express 12, 817, 2004.
[Gant90] F. R. Gantmacher, “The Theory of Matrices”. Vol. I, Chelsey, New York, 1990. [Garc98] Carmen García López, “Métodos de Linealización para la Resolución Numérica de
Ecuaciones Diferenciales”. Tesis Doctoral, Málaga, 1998. [GaSa92] E. Gallopoulos and Saad, “Efficient Solution of Parabolic Equations by Krylov
Approximation Methods”. SIAM J. Sci. Statist. Comput., 13, pp. 1236-1264, 1992. [GoLR82] I. Gohberg, P. Lancaster and L. Rodman., “Matrix Polinomials”. Academic Press, New
York, 1982. [GoNV79] G. H. Golub, S. Nash and C. F. Van Loan, “A Hessenberg-Schur Method for the Matrix
Problem AX+XB=C”. IEEE Trans. Auto. Cont., AC-24, pp. 909-913, 1979. [GoVa96] G. H. Golub and C. F. Van Loan, “Matrix Computations”. Third Edition, Johns Hopkins
University Press, Baltimore, Maryland, 1996. [GoWi76] G. H. Golub and J. H. Wilkinson, “Ill-Conditioned Eigensystems and the Computation of
the Jordan Canonical Form”. SIAM Review 18, 1976. [Grif81] D. H. Griffel, “Applied Functional Analysis”. Ellis Hordwood Series, Mathematics and its
applications, 1981. [GrLS94] W. Group, E. Lusk, A. Skjellum, “Using MPI: Portable Parallel Programming with the
Message-Passing Interface”. MIT Press, Cambridge, Massachusetts, 1994. [GuSA03] S. Gugercin, D.C. Sorensen, and A.C. Antoulas, “A Modified Low-rank Smith Method for
Large-scale Lyapunov Equations”. Numerical Algorithms, 32(1), pp. 27–55, 2003. [Hage84] W. W. Hager, “Condition estimators”. SIAM J. Sci Stat. Comput., 5, pp. 311-316, 1984.

Bibliografía
330
[HaHS00] M. A. Hasan, J. A. K. Hasan, and L. Scharenroich, “New Integral Representations and Algorithms for Computing nth Roots and the Matrix Sector Function of Nonsingular Complex Matrices”. Proceedings of the 39th IEEE Conference on Decision and Control, Sydney, Australia, pp. 4247–4252, 2000.
[HaNW87] E. Hairer, S. P. Norsett and G. Wanner, “Solving ODE. Nonstiff Problems”. Springer Verlag, 1987.
[HaWa91] E. Harier and G. Wanner, “Computer Methods for Ordinary Differential Equations and Differential Algebraic Equations”, SIAM, 1998.
[HaWa96] E. Hairer and G. Wanner, “Solving Ordinary Differential Equations II: Stiff and Differential-Algebraic Problems”. Springer-Verlag, 1996.
[HiBy75] A. C. Hindmarsh and G. D. Byrne, “Episode, an Experimental Package for the Integration Of Systems Of Ordinary Differential Equations, Ucid-30112, L.L.L., May, 1975.
[Hig103] N. J. Higham, “A Schur-Parlett Algorithm for Computing Matrix Functions”. SIAM J. Matrix Anal. Appl., Vol. 25, No. 2, pp. 464-485, 2003.
[Hig187] N. J. Higham, “A Survey of Condition Number Estimation for Triangular Matrices”. SIAM Review, 29, pp. 575-596, 1987.
[Hig194] N. J. Higham, “The Matrix Sign Decomposition and its Relation to the Polar Decomposition”. Linear Algebra and Appl., 212/213:3-20, 1994.
[Hig203] N. J. Higham, “Computing the Matrix Cosine”. Kluwer Academic Publishers, Numerical Algorithms 34, pp. 13–26, 2003.
[Hig287] N. J. Higham, “Computing Real Square Roots of a Real Matrix”. Linear Algebra and Appl.,88/89, pp. 405-430, 1987.
[Hig297] N. J. Higham, “Stable Iterations for the Matrix Square Root”. Numerical Algorithms, Vol. 15, pp. 227-242, 1997.
[High01] N. J. Higham, “Evaluating Padé Approximants of the Matrix Logarithm”. SIAM J. Matrix Anal. App., Vol. 22, Nº 4, pp. 1126-1135, 2001.
[High02] Nicholas J. Higham, “The Matrix Computation Toolbox for MATLAB”. Department of Mathematics, University of Manchester, Manchester, 2002.
[High04] N. J. Higham, “The Scaling and Squaring Method for the Matrix Exponential Revisited”. Numerical Analysis Report 452, Manchester Centre for Computational Mathematics, 2004.
[High84] N. J. Higham, “Newton’s Method for the Matrix Square Root”. Numerical Analysis Report No. 91, Univ. of Manchester, 1984.
[High86] N. J. Higham, “Computing the Polar Decomposition with Applications”. SIAM J. Sci. Stat. Comput., Vol. 7, pp. 1160-1174, 1986.
[High873] N. J. Higham, “A Survey of Condition Number Estimation for Triangular Matrices”. SIAM Review, 29, pp. 575-596, 1987.
[High88] N. J. Higham, “FORTRAN Codes for Estimating the One-Norm of a Real or Complex Matrix, with Applications to Condition Estimation”. ACM Trans. Math. Soft., 14, pp. 381-396, 1988.
[High882] N. J. Higham, “FORTRAN Codes for Estimating the One-norm of a Real or Complex Matrix, with Applications to Condition Estimation”. ACM Trans. Math. Soft., 14, pp. 381-396, 1988.
[High90] N. J. Higham, “Experience with a Matrix Norm Estimator”. SIAM J. Sci. Stat. Comput.,11, pp. 804-809,1990.
[HiHi00] D. J. Higham and N. J. Higham, “MATLAB Guide”. Society for Industrial and Applied Mathematics (SIAM), Philadelphia 2000.
[HiMN03] N. J. Higham, D. S. Mackey, N. Mackey and F. Tisseur, “Computing the Polar Decomposition and the Matrix Sign Decomposition in Matrix Groups”. Numerical Analysis Report No. 426, Manchester Centre for Computational Mathematics, Manchester, England, April 2003. Revised November 2003. To appear in SIAM J. Matrix Anal. Appl.
[HiMN04] N. J. Higham, D. S. Mackey, N. Mackey, and F. Tisseur, “Functions Preserving Matrix Groups and Iterations for the Matrix Square Root”. Numerical Analysis Report 446, Manchester Centre for Computational Mathematics, Manchester, England, March 2004.
[Hind74] A. C. Hindmarsh, “Gear, Ordinary differential Equation System Solver”. Ucid-30001, rev. 3, l.l.l., December, 1974.
[Hind83] A. C. Hindmarsh, “ODEPACK, a Systematized Collection of ODE Solvers”. Scientific Computing, R. S. Stepleman et al. (eds.), North-Holland, Amsterdam, Vol. 1 of IMACS Transactions on Scientific Computation, pp. 55-64, 1983.

Bibliografía
331
[HiSh90] N. J. Higham and R. S. Schreiber, “Fast Polar Decomposition of an Arbitrary Matrix”. SIAM J. Sci. Stat. Comput., 11, pp. 648-655,1990.
[HoJo91] R. A. Horn and C. R. Johnson, “Topics in Matrix Analysis”. Cambridge University Press, London, 1991.
[HoLS97] M. Hochbruck, C. Lubich and H. Selhofer, “Exponential Integrators for Large Systems of Differential Equations”. SIAM J. Numer. Anal. 34, pp. 1911-1925, 1997.
[HoWa78] W. D. Hoskins and D. J. Walton, “A Faster Method of Computing the Square Root of a Matrix”. IEEE Trans. Automat. Control. AC-23(3), pp. 494–495, 1978.
[Hunt79] E. Huntley, “A Note on the Application of the Matrix Riccati Equation to the Optimal Control of Distributed Parameter Systems”. IEEE Trans. On Automatic Control, AC-24, pp. 487-489, 1979.
[Ibañ97] J. Javier Ibáñez González, “Algoritmos Paralelos para el Cálculo de la Exponencial de una Matriz sobre Multiprocesadores de Memoria Compartida”. Proyecto Fin de Carrera UPV, 1997.
[IMKL03] Intel Corporation, “Intel® Math Kernel Library, Reference Manual”. 2003. [Iser98] A. Iserles, “A First Course in the Numerical Analysis of Differential Equations”.
Cambridge Texts in Applied Mathematics, University of Cambridge, 1988. [KaBu61] R. E. Kalman and R. S. Bucy, “New Results in Linear Filtering and Prediction Theory”.
Trans. ASME, J. Basic Eng., 83, Series D , pp. 95-108, 1961. [KaEn66] R. E. Kalman and T. S. Englar, “A User's Manual for the Automatic Synthesis Program”.
NASA Report CR-475, 1966. [Kall73] C. Kallstrom, “Computing Exp(A) and Exp(As)”. Report 7309, Division of Automatic
Control, Lund Institute of Technology, Lund, Sweden, 1973. [Kalm61] R. E. Kalman, “Contributions to the Theory of Optimal Control”. Bol. Soc. Mat. Mex., 5,
pp. 102-119, 1961. [Kamm76] D. W. Kammler, “Numerical Evaluation of Exp(At) when A is a Companion Matrix”.
unpublished manuscript, University of Southern Illinois, Carbondale, IL,1976. [Karl59] S. Karlin, “Mathematical Methods and Theory in Games, Programming, and Economics”.
Addison-Wedsley Pub. Co., Mass., 1959. [KaRu74] B. Kågström and A. Ruhe, “An algorithm for Numerical Computation of the Jordan
Normal Form of a Complex Matrix”. Report UMONF 51.74, Department of Information Processing, University of Umea, Umea, Sweden, 1974.
[KeL189] C. S. Kenney and A. J. Laub, “Padé Error Estimates for the Logarithm of a Matrix”. International J. Control, 50, pp. 707–730, 1989.
[KeL289] C. S. Kenney and A. J. Laub, “Condition Estimates for Matrix Functions”. SIAM J. Matrix Anal. Appl., Vol. 10, pp. 191–209, 1989.
[KeLa91] C. S. Kenney and A. J. Laub, “Rational Iterative Methods for the Matrix Sign Function”. SIAM J. Matrix Anal. Appl., 12(2):273-291, 1991.
[KeLa92] C. S. Kenney and A. J. Laub, “On Scaling Newton’s Method for Polar Decomposition and the Matrix Sign Function”. SIAM J. Matrix Anal. Appl. 13(3), pp. 688–706, 1992.
[KeLa98] C. S. Kenney and A. J. Laub, “A Schur-Fréchet Algorithm for Computing the Logarithm and Exponential of a Matrix”. SIAM J. Matrix Anal. Appl., Vol. 19, Nº 3, pp. 640-663, 1998.
[KeLe82] H. B. Keller and M. Lentini, “Invariant Embedding, the Box Scheme and an Equivalence between them”. SIAM J. Numerical Analysis, 19, pp. 942-962, 1982.
[KeLe85] C. S. Kenney and R. B. Leipnik, “Numerical Integration of the Differential Matrix Riccati Equation”. IEEE Trans. on Automatic Control, AC-30, pp.962-970, 1985.
[Kniz91] L. A. Knizhnerman, “Calculation of Functions of Unsymmetric Matrices Using Arnoldi’s Method”. Comput Math. and Math. Phys. 31, pp. 1-9, 1991.
[KoBa95] C. K. Koc¸ and B. Bakkaloglu, “Halley’s Method for the Matrix Sector Function”. IEEE Trans. Automat. Control, 40, pp. 944–949, 1995.
[Lain76] Lainiotis, D.G., “Partitioned Riccati Solutions and Integration-free Doubling Algorithms” IEEE Trans. on Automatic Control, AC-21, pp. 677-689, 1976.
[LaMi85] P. Lancaster and M. Tismenetsky, “The theory of Matrices Second Edition with Applications”. Computer Science and Applied Mathematics, Academic Press Inc., 1985.
[Laub82] A. J. Laub, “Schur Techniques for Riccati Differential Equations”. Feedback Control of Linear and Nonlinear Systems, D. Hinrichsen and A. Lsidori (Eds.), Springer-Verlag, New York, pp. 165-174, 1982.

Bibliografía
332
[Leip85] B. Leipnik, “A Canonical Form and Solution for the Matrix Riccati Differential Equation”. Bull. Australian Math. Soc., 26, pp. 355-361, 1985.
[LiSw98] W. M. Lioen, J. J. B. de Swart, “Test Set for Initial Value Problems Solvers”. http://www.cwi.nl/cwi/projects/IVPtestset.
[Macd56] C. C. MacDuffee, “The Theory of Matrices”, Chelsea, New York, 1956. [MaHI92] M. Marqués, V. Hernández and J. Ibáñez, “Parallel Algorithms for Computing Functions of
Matrices on Shared Memory Multiprocessors”. Pacta´92, part 1, pp 157-166, 1992. [Mart99] G. Martín Herrán, “Symplectic Methods for the Solution to Riccati Matrix Equations
Related to Macroeconomic Models”. Computational Economics, 13, pp. 61-91, 1999. [Mast69] E. J. Mastascusa, “A Relation between Liou´s Method and Forth Order Runge-Kutta
Method for Evaluation of Transient Response”, Proc. IEEE, 57, 1969. [Meht89] M. L. Mehta, “Matrix Theory: Selected Topics and Useful Results”. Hindustan Publishing
Company, Delhi, second edition, 1989. [MiQD95] P. Misra, E. Quintana and P. M. Van Dooren, “Numerically Reliable Computation of
Characteristic Polynomials”. American Control Conference, Seattle, WA, 1995. [MoLK78] M. Morf, B. Levy and T. Kailath, “Square-root Algorithms for the Continuous Time Linear
Least-square Estimation Problem”. IEEE Trans. on Automatic Control, 23, pp. 907-911, 1978.
[MoVa03] C. B. Moler and Van Loan. “Nineteen Dubious Ways to Compute the Exponential of a Matrix, Twenty-Five Years Later*”. SIAM Review 45, pp. 3-49, 2003.
[MoVa78] C. B. Moler and Van Loan. “Nineteen Dubious Ways to Compute the Exponential of a Matrix”. SIAM Review 20, pp. 801-36, 1978.
[NgPa87] K.C. Ng and B. N. Parlett, “Programs to Swap Diagonal Blocks”. CPAM report, University of California, Berkeley, 1987.
[PaKL90] P. Pandey, C. Kenney and A. J. Laub, “A Parallel Algorithm for the Matrix Sign Function”, Int. J. High Speed Computing, 2(2), 181-191, 1990.
[Parl74] B. N. Parlett, “Computation of Matrix-value Functions”. SIAM J. Matrix Anal., Vol 14, pp. 1061-1063, 1974.
[Parl76] B. N. Parlett, “A Recurrence among the Elements of Functions of Triangular Matrices”, Linear Algebra Appl., Vol 14, pp. 117-121, 1976.
[PaSt73] M. S. Paterson and L. J. Stockmeyer, “On the Number of Nonscalar Multiplications Necessary to Evaluate Polynomials”. SIAM J. Comput., Vol 2, pp. 60–66, 1973.
[PeCK91] P. Petkov, N. Christov and D. Konstantinov, “Computational Methods for Linear Control Systems”. Prentice Hall International Series in Systems and Control Engineering, 1991.
[Poll89] A. A. Pollicini, “Using Toolpack Software Tools”. Kluwer Academic, 1989. [Prue86] S. Pruess, “Interpolation Schemes for Collocation Solution of TPBVPs”. SIAM J. Sci.
Statist. Comput. 7, pp. 322-333, 1986. [RaHi93] K. Radhakrishnan and A. C. Hindmarsh, “Description and Use of LSODE, the Livermore
Solver for Ordinary Differential Equations”. LLNL Report UCRL-ID-113855, December 1993.
[Rine78] R. F. Rinehart, “The Equivalence of Definitions of a Matrix Functions”. IEEE Trans. Auto. Cont., AC-24, pp. 320-321, 1978.
[Robe71] J. D. Roberts, “Linear Model Reduction and Solution of the Algebraic Riccati Equation by Use of the Sign Function”. CUED/B-Control/TR13, Departament of Engineering, University of Cambridge, 1971.
[Robe80] J. D. Roberts, “Linear Model Reduction and Solution of the Algebraic Riccati Equation by Use of the Sign Function”. International Journal Control, vol. 32. pp. 677-687, 1980.
[RuBi95] P. St. J. Russell, T. A. Birks, y F. D. Lloyd-Lucas, “Photonic Bloch Waves and Photonic Band Gaps”. Confined electrons and Photons: New Physics and Applications, E. Burstein and C. Weisbuch, eds. Plenum, New York, 1995.
[Rusn88] L. Rusnak, “Almost Analytic Representation for the Solution of the Differential Matrix Riccati Equation”. IEEE Trans. on Automatic Control, 33, pp. 191-193, 1988.
[Saad92] Y. Saad, “Analysis of some Krylov Subspace Approximations to the Matrix Exponential Operator”. SIAM J. Numerical Analysis, Vol. 29, pp. 209-228, 1992.
[SaCa94] J. M. Sanz-Serna, M. P. Calvo, “Numerical Hamiltonian Problems”. Mathematical Computation 7, Chapman&Hall, 1994.
[Sanz92] J. M. Sanz-Serna, “Symplectic Integrators for Hamiltonian Problems: An Overview”. Act. Numer. 1, pp. 243-286, 1992.

Bibliografía
333
[SBDG76] B. T. Smith, J. M. Boyle, J. J. Dongarra, B. S. Garbow, V. C. Klema, and C. B. Moler, “Matrix Eigensystem Routines- EISPACK Guide”. Vol 7 of Lecture Notes in Computer Science, Spronger-Verlag, Berlon, 1976.
[SBIK76] B. T. Smith, J. M. Boyle, Y. Ikebe, V. C. Klema, and C. B. Moler, “Matrix Eigensystem Routines: EISPACK Guide, 2nd Ed.”. Lecture Notes in Comp. Sd., 6, Springer Verlag, New York, 1976.
[ScLA97] S. Blackford, J. Choi, A. Cleary, E. D’Azevedo, I. Dhillon, J. Demmel, J. Dongarra, S. Hammarling, G. Henry, A. Petitet, K. Stanley, D. Walker, R.C. Whaley, “ScaLAPACK Users’ Guide”. SIAM Publications, Philadelphia, 1997.
[Scra71] R. E. Scraton, “Comment on Rational Approximants to the Matrix Exponential”. Electron. Lett., 7, 1971.
[SeBl80] S.M. Serbin and S.A. Blalock, “An Algorithm for Computing the Matrix Cosine”. SIAM J. Sci. Statist. Comput. Vol 1(2), pp. 198–204, 1980.
[Serb79] S.M. Serbin, “Rational Approximations of Trigonometric Matrices with Application to Second-order Systems of Differential equations”. Appl. Math. and Comput., Vol. 5, pp. 75-92, 1979.
[SGIA03] SGI Altix Applications Development an Optimization, Release August 1, 2003. [Shah71] M. M. Shah, “On the Evaluation of Exp(At)”. Cambridge Report CUED/B-Control TR.,
Cambridge, England, 1971. [ShGo75] L. F. Shampine and M. K. Gordon, “Computer Solution of Ordinary Differential
Equations: the Initial Value Problem”. W. H. Freeman and Co., San Francisco, January, 1975.
[ShTs84] L. S. Shieh, Y. T. Tsay, and C. T. Wang, “Matrix Sector Functions and their Applications to Systems Theory”. Proc. IEE-D, 131, pp. 171–181, 1984.
[ShWD76] L. F. Shampine, H. A Watts and S. M. Davenport, “Solving Non-stiff Ordinary Differential Equations-the State of the Art. SIAM Rev. 18, pp. 376-411, 1976.
[Sibu66] Y. Sibuya, “A Block-diagonalization Theorem for Systems of Ordinary Differential Equations and its Applications”. SIAM J. on Applied Mathematics, 14, pp. 468-475, 1966.
[SiSp76] B. Singer and S. Spilerman, “The Representation of Social Processes by Markov Models”. Amer. J. Sociology, 82, pp. 1–54, 1976.
[Smit03] M. I. Smith, “A Schur Algorithm for Computing Matrix pth Roots”. SIAM J. Matrix Anal. Appl., Vol. 24. No. 4, pp. 971-989, 2003.
[SpGu79] J. L Speyer and D. E. Gustafson, “Estimation of Phase Processes in Oscillatory Signals and Asymptotic Expansions”. IEEE Trans. on Automatic Control, AC-24, pp. 657-659, 1979.
[Stew73] G. W. Stewart, “Error and Perturbations Bounds for Subspaces Associated with certain Eigenvalues Problems”. SIAM Review, 15, pp. 727-764, 1973.
[StLe96] D. E. Stewart and T.S. Leyk, “Error Estimates for Krylov Subspace Approximations of Matrix Exponentials”. J. Comput. Appl. Math. 72, pp. 359-369, 1996.
[Tref00] L. N. Trefethen, “Spectral Methods in MATLAB”. Society for Industrial and Applied Mathematics (SIAM), 2000.
[Trot59] H. F. Trotter, “Product of Semigroups of Operators”. Prpc. Amer. Math. Soc., 10, 1959. [TsSY88] J. S. H. Tsai, L. S. Shieh, and R. E. Yates, “Fast and Stable Algorithms for Computing the
Principal nth Root of a Complex Matrix and the Matrix Sector Function”. Comput. Math. Applic., Vol. 15(11), pp. 903–913, 1988.
[VanL00] C.F.Van Loan, “Introduction to Scientific Computing. A Matrix-Vector Approach Using MATLAB”. Prentice-Hall, 2000.
[VanL78] C. F. Van Loan, “Computing Integrals Involving the Matrix Exponential”. IEEE Transactions on Automatic Control, Vol. AC-23, 1978.
[VanL79] C. F. Van Loan, “A Note on the Evaluation of Matrix Polynomials”. IEEE Transactions on Automatic Control, Vol. AC-24, 1979.
[Varah79] J. M. Varah, “On the Separation of Two Matrices”. SIAM J. Numerical Analysis, Vol. 16, pp. 216-222, 1979.
[Varg62] R. S. Varga, “Matrix Iterative Analysis”. Prentice Hall, Englewood Cliffs, New Jersey, 1962.
[Vaug69] d. r. Vaughan, “A negative Exponential Solution for the Matrix Riccati Equation”. IEEE Trans. on Automatic Control” AC-14, pp. 72-75, 1969.
[Wach88] E.L. Wachspress, “Iterative Solution of the Lyapunov Matrix Equation”. Appl. Math. Letters, 107:87–90, 1988.

Bibliografía
334
[Ward77] R. C. Ward, “Numerical Computation of the Matrix Exponential with Accuracy Estimate”. SIAM Journal Numerical Analysis, 14, 1977.
[Whit69] D. E. Whitney, “More Similarities between Runge-Kutta and Matrix Exponential Methods for Evaluating Transient Response”. Ibid., 57, 1969.
[Wilk92] J. H. Wilkinson, “The Algebraic Eigenvalues Problem”. Clarendon Press, Oxford. Reprinted, 1992.
[WiRe71] J. H. Wilkinson and C. Reinsch, “Handbook for Automatic Computation”. Vol. 2, Linear Algebra, Springer-Verlag, Heidelberg, 1971.
[Wonh68] W. M. Wonham, “On a Matrix Riccati Equation of Stochastic Control”. SIAM J. on Control, 6, pp. 681-697, 1968.
[Zaca05] M. Zacarés González, “Métodos Modales para el Análisis de la Propagación no Lineal en Fibras Ópticas”. Tesis Doctoral, Departamento de Óptica de la Universidad de Valencia, 2005.
[Zaca05] M. Zacarés González, “Métodos Modales para el Análisis de la Propagación no Lineal en Fibras Ópticas”. Tesis Doctoral, Departamento de Óptica de la Universidad de Valencia, 2005.


















