
TEMARIO REDES DE COMPUTADORAS Unidad 1 … · 2.1.1.1 Servicios Orientados a Conexion ... Existen...
55
TEMARIO REDES DE COMPUTADORAS Unidad 1 Capa de Red 1.1 Principios Basicos en Capa de Red 1.2 Direccionamiento Capa de Red 1.2.1 Determinacion Ruta Capa de Red 1.2.1.1 Algoritmos Encaminamiento 1.2.2 Subredes 1.3 Protocolos de Enrutamiento 1.3.1 El Enrutamiento en Entorno Mixtos de medios de LAN 1.3.2 Operaciones Basicas Router 1.3.3 Rutas Estaticas y Dinamicas 1.3.4 Ruta por Defecto 1.3.5 Protocolos Enrutados y de Enrutamiento 1.3.6 Informacion Utilizada por Routers para ejecutar sus funciones basicas 1.3.7 Configuracion de Rip 1.4 Arp , Rarp 1.5 Igrp , Egp Unidad 2 Capas superiores del modelo OSI 2.1 Capa Transporte Osi 2.1.1 Parametros para lograr la Calidad Servicio de Transporte 2.1.1.1 Servicios Orientados a Conexion 2.1.1.2 Servicios Orientados a no Conexion
Transcript of TEMARIO REDES DE COMPUTADORAS Unidad 1 … · 2.1.1.1 Servicios Orientados a Conexion ... Existen...

TEMARIO REDES DE COMPUTADORAS
Unidad 1 Capa de Red
1.1 Principios Basicos en Capa de Red
1.2 Direccionamiento Capa de Red
1.2.1 Determinacion Ruta Capa de Red
1.2.1.1 Algoritmos Encaminamiento
1.2.2 Subredes
1.3 Protocolos de Enrutamiento
1.3.1 El Enrutamiento en Entorno Mixtos de medios de LAN
1.3.2 Operaciones Basicas Router
1.3.3 Rutas Estaticas y Dinamicas
1.3.4 Ruta por Defecto
1.3.5 Protocolos Enrutados y de Enrutamiento
1.3.6 Informacion Utilizada por Routers para ejecutar sus funciones basicas
1.3.7 Configuracion de Rip
1.4 Arp , Rarp
1.5 Igrp , Egp
Unidad 2 Capas superiores del modelo OSI
2.1 Capa Transporte Osi
2.1.1 Parametros para lograr la Calidad Servicio de Transporte
2.1.1.1 Servicios Orientados a Conexion
2.1.1.2 Servicios Orientados a no Conexion

2.2 Capa De Sesion Osi
2.2.1 Intercambio de Datos
2.2.2 Administracion del Dialogo
2.2.3 Sincronizacion Capa Sesion
2.2.4 Notificacion de Excepciones
2.2.5 Llamada Procedimientos Remotos
2.3 Capa de presentación
2.3.1 Codigos de Representacion de Datos
2.3.2 Tecnicas Compresion Datos
2.3.3 Criptografia Capa Presentacion
2.4 Capa de aplicación
2.4.1 Configuracion Servicios
Unidad 3 Técnicas de conmutación
3.1 Conmutacion Circuitos
3.2 Conmutacion Mensajes
3.3 Conmutacion Paquetes
3.3.1 Topologia Redes de Paquetes
3.3.2 Datagramas y Circuitos Virtuales
3.3.2.1 Estructura Conmutadores
3.3.2.2 Conmutacion de Paquetes
3.3.3 Encaminamiento Redes de Paquetes

3.3.4 Gestion de Trafico
3.3.5 Control de Congestion
Unidad 4 TCP/IP
4.1 Modelo Cliente Servidor
4.2 Protocolo de Internet Ip movil
4.3 Protocolos de Transporte Udp Tcp
4.4 Protocolos Nivel Aplicacion
4.4.1 Smtp Protocolo
4.4.2 Ftp Protocolo
4.4.3 http Protocolo
4.4.4 Nfs Protocolo
4.4.5 Dns Protocolo

Unidad 1 Capa de Red
1.1 Principios Basicos en Capa de Red
Una de las tecnologías más prometedoras y discutidas en esta década es la de poder
comunicar computadoras mediante tecnología inalámbrica. La conexión de computadoras
mediante Ondas de Radio o Luz Infrarroja, actualmente está siendo ampliamente investigado.
Las Redes Inalámbricas facilitan la operación en lugares donde la computadora no puede
permanecer en un solo lugar, como en almacenes o en oficinas que se encuentren en varios
pisos.
Mientras que las redes inalámbricas actuales ofrecen velocidades de 2 Mbps, las redes
cableadas ofrecen velocidades de 10 Mbps y se espera que alcancen velocidades de hasta 100
Mbps. Los sistemas de Cable de Fibra Optica logran velocidades aún mayores, y pensando
futuristamente se espera que las redes inalámbricas alcancen velocidades de solo 10 Mbps.
Sin embargo se pueden mezclar las redes cableadas y las inalámbricas, y de esta manera
generar una “Red Híbrida” y poder resolver los últimos metros hacia la estación.
Existen dos amplias categorías de Redes Inalámbricas:
De Larga Distancia.- Estas son utilizadas para transmitir la información en espacios que pueden
variar desde una misma ciudad o hasta varios países circunvecinos (mejor conocido como
Redes de Area Metropolitana MAN); sus velocidades de transmisión son relativamente bajas,
de 4.8 a 19.2 Kbps.
De Corta Distancia.- Estas son utilizadas principalmente en redes corporativas cuyas oficinas se
encuentran en uno o varios edificios que no se encuentran muy retirados entre si, con
velocidades del orden de 280 Kbps hasta los 2 Mbps.
Existen dos tipos de redes de larga distancia: Redes de Conmutación de Paquetes (públicas y
privadas) y Redes Telefónicas Celulares. Estas últimas son un medio para transmitir
información de alto precio. Debido a que los módems celulares actualmente son más caros y
delicados que los convencionales, ya que requieren circuiteria especial, que permite mantener
la pérdida de señal cuando el circuito se alterna entre una célula y otra.
REDES DE AREA LOCAL (LAN).
Las redes inalámbricas se diferencian de las convencionales principalmente en la “Capa Física”
y la “Capa de Enlace de Datos”, según el modelo de referencia OSI. La capa física indica como
son enviados los bits de una estación a otra. La capa de Enlace de Datos (denominada MAC), se
encarga de describir como se empacan y verifican los bits de modo que no tengan errores.

PUNTOS DE ACCESO.
Las características a considerar son :
1.- La antena del repetidor debe de estar a la altura del techo, esto producirá una mejor
cobertura que si la antena estuviera a la altura de la mesa.
2.- La antena receptora debe de ser más compleja que la repetidora, así aunque la señal de la
transmisión sea baja, ésta podrá ser recibida correctamente.
Un punto de acceso compartido es un repetidor, al cual se le agrega la capacidad de
seleccionar diferentes puntos de acceso para la retransmisión. (esto no es posible en un
sistema de estación-a-estación, en el cual no se aprovecharía el espectro y la eficiencia de
poder, de un sistema basado en puntos de acceso).
TOPOLOGIA Y COMPONENTES DE UNA LAN HIBRIDA.
En el proceso de definición de una Red Inalámbrica Ethernet debe de olvidar la existencia del
cable, debido a que los componentes y diseños son completamente nuevos. Respecto al
CSMA/CD los procedimientos de la subcapa MAC usa valores ya definidos para garantizar la
compatibilidad con la capa MAC. La máxima compatibilidad con las redes Ethernet cableadas
es, que se mantiene la segmentación.
1.2 Direccionamiento Capa de Red
La dirección de red ayuda al router a identificar una ruta dentro de la nube de red, el router
utiliza esta dirección de red para identificar la red destino de un paquete dentro de la red. Lee
despacio estos conceptos, son muy sencillos y obvios pero si tienes la base clara te ayudará
mucho a comprender como funcionan las redes.
Además de la dirección de red, los protocolos de red utilizan algún tipo de dirección de host o
nodo. Para algunos protocolos de capa de red, el administrador de la red asigna direcciones de
red de acuerdo con un plan de direccionamiento de red por defecto. Para otros protocolos de
capa de red, asignar direcciones es una operación parcial o totalmente dinámica o automática.
Sin el direccionamiento de capa de red, no se puede producir el enrutamiento. Los routers
requieren direcciones de red para garantizar el envío correcto de los paquetes. Si no existiera
alguna estructura de direccionamiento jerárquico, los paquetes no podrían transportarse a
través de una red.
La dirección MAC (la que viene grabada de fábrica en las tarjetas de red) se puede comparar
con el nombre de las personas, y la dirección de red con su dirección postal. Si una persona se

muda a otra ciudad, su nombre propio seguiría siendo el mismo, pero la dirección postal
deberá indicar el nuevo lugar donde se puede ubicar. Los dispositivos de red (los routers así
como también los ordenadores individuales) tienen una dirección MAC y una dirección de
protocolo (capa de red). Cuando se traslada físicamente un ordenador a una red distinta, el
ordenador conserva la misma dirección MAC, pero se le debe asignar una nueva dirección de
red.
La función de capa de red es encontrar la mejor ruta a través de la red. Para lograr esto, utiliza
dos métodos de direccionamiento: direccionamiento plano y direccionamiento jerárquico. Un
esquema de direccionamiento plano asigna a un dispositivo la siguiente dirección disponible.
No se tiene en cuenta la estructura del esquema de direccionamiento. Un ejemplo de un
esquema de direccionamiento plano es el sistema de numeración del DNI.
1.2.1. Determinacion Ruta Capa de Red
La función que determina la ruta se produce a nivel de Capa 3 (capa de red). Permite al router
evaluar las rutas disponibles hacia un destino y establecer el mejor camino para los paquetes.
Los servicios de enrutamiento utilizan la información de la topología de red al evaluar las rutas
de red. La determinación de ruta es el proceso que utiliza el router para elegir el siguiente
salto de la ruta del paquete hacia su destino, este proceso también se denomina enrutar el
paquete.
Los routers, como dispositivos inteligentes que son, verán la velocidad y congestión de las
líneas y así elegirán la mejor ruta. Por ejemplo para ir de Logroño a Madrid pueden coger una
nacional con poco tráfico en lugar de la autopista con atasco de tráfico. Y viceversa puede
decidir ir por autopista aunque sea el camino mas largo (varios routers) que la carretera
directa mas lenta.
1.2.1.1 Algoritmos Encaminamiento
Podemos definir encaminamiento como un proceso mediante el cual tratamos de encontrar un
camino entre dos puntos de la red: el nodo origen y el nodo destino. El objetivo que se
persigue es encontrar las mejores rutas entre pares de nodos
Los algoritmos de encaminamiento pueden agruparse en:
Determinísticos o estáticos
No tienen en cuenta el estado de la subred al tomar las decisiones de encaminamiento. Las
tablas de encaminamiento de los nodos se configuran de forma manual y permanecen
inalterables hasta que no se vuelve a actuar sobre ellas. Por tanto, la adaptación en tiempo
real a los cambios de las condiciones de la red es nula.

ALGORITMOS DE ENCAMINAMIENTO.
Los algoritmos de encaminamiento se agrupan en dos tipos principales: no adaptativos y
adaptativos. Los algoritmos no adaptativos no basan sus decisiones de encaminamiento en
mediciones o estimaciones de trafico o topología Actuales.
ENCAMINAMIENTO POR EL CAMINO MÁS CORTO.
El camino mas corto es una forma de medir la longitud del camino. En el caso mas general, las
etiquetas de los arcos se podrían calcular como una función distinta, ancho de Banda,
promedio de trafico, costo de comunicación, longitud promedio de la cola de espera, retardo
medido, y algunos otros factores.
ENCAMINAMIENTO DE CAMINO MÚLTIPLE.
Existe un solo “mejor” camino entre cualquier par de nodos y que todo él trafico entre ellos
deberá utilizar. Con frecuencia, se puede obtener un mejor rendimiento al dividir él trafico
entre varios caminos, para reducir la carga en cada una de las líneas de comunicación. La
técnica se conoce como Encaminamiento de camino múltiple, o algunas veces
encaminamiento bifurcado. Se aplica tanto en subredes con data gramas, como en subredes
con circuitos virtuales .
ENCAMINAMIENTO CENTRALIZADO.
Si la topología es de característica estática y él trafico cambia muy rara vez. Sin embargo, si los
IMP y las líneas se desactivan y después se restablecen, o bien, si el tráfico varia violentamente
durante todo el día, se necesitará algún mecanismo para adaptar las tablas a las circunstancias
que imperan en este momento.
La vulnerabilidad del RCC Es un problema muy serio y para eso una solución es, tener una
segunda maquina disponible como respaldo. También se necesitará establecer un método de
arbitraje para tener la seguridad de que el RCC primario y el de respaldo no lleguen a entrar en
conflicto para saber quien es el jefe.
ENCAMINAMIENTO AISLADO
En los algoritmos de encaminamiento, únicamente basados en la información que los mismos
hayan reunido. No intercambia información de rutas con otros IMP. Sin embargo tratan de
adaptarse a los cambios de topología y trafico que se llegan a presentar. Baran (1964),
conocido como el algoritmo de la patata caliente.

En el momento en que llega un paquete, el IMP trata de deshacerse de él tan rápido como le
sea posible, al ponerlo en la cola de espera de salida más corta ósea llega un paquete, el IMP
cuenta él numero de paquetes que se encuentran en la cola de espera de cada una de las
líneas de salida. Entonces instala el nuevo paquete al final de la cola de salida más corta, sin
tomar en cuenta el lugar al que se dirige esta línea. Una posibilidad consisten utilizar la mejor
opción estática, a menos que la cola excediera un cierto valor de umbral. Otra posibilidad
consiste en utilizar la cola de espera más corta, a menos que, su peso estático seademasiado
pequeño.
Las simulaciones Que realizó Rudin, han demostrado que el valor de Ç puede escogerse para
dar un mejor rendimiento que el obtenido con un encaminamiento puramente centralizado o
aislado.
-Inundación.
La inundación es un caso extremo del encaminamiento aislado, en el cual cada paquete que
llega se transmite en todas las líneas de salida, exceptuando aquélla por la que llega. Con la
inundación se genera un número infinito, a menos que se tomen algunas medidas para
amortiguar el proceso. Una de tales medidas consiste en tener un contador de saltos
contenido en la cabecera de cada uno de los paquetes, el cual sé decremento con cada salto
que se lleva a cabo, y el paquete se desecha en el momento en que el contador alcance el
valor de cero.
El algoritmo de Camino Aleatorio; aquí el IMP se encarga simplemente de seleccionar una línea
aleatoriamente y reexpedir el paquete a través de ella. Si la subred tiene una cantidad
considerable de interconexiones, este algoritmo tiene una cantidad considerable de
interconexiones, este algoritmo tiene la propiedad de hacer un uso excelente de los
encaminamientos alternativos. También es muy robusto.
Encaminamiento distribuido.
Intercambia periódicamente información de encaminamiento explicito con cada uno de sus
vecinos. Esta entrada consta de dos partes: la línea preferida de salida que se utilice para dicho
destino, y alguna estimación del tiempo o distancia hacia él.
Encaminamiento Optimo.
Como una consecuencia directa del principio de optimización, se puede observa que, el
conjunto de rutas optimas, procedentes de todos los orígenes a un destino dato, forman un
árbol cuya raíz sale del destino. A este árbol se le llama árbol sumidero, este no contiene
ningún lazo, de tal forma que cada paquete será entregado a través de un número limitado
finito de saltos.

Encaminamiento basado en el flujo.
Para utilizar en forma adecuada, es necesario conocer anticipadamente cierto tipo de
información. Primero, se deberá conocer la topología de la red. Segundo la matriz de trafico
deberá darse a conocer. Tercero, también deberán conocerse la matriz de capacidades en las
líneas en Bits por segundo. Por ultimo se deberá seleccionar un algoritmo de
encaminamiento. El retardo incluye tanto tiempo de espera como el tiempo de servicio. Para
calcular el tiempo de retardo medio de la red completa, se toma la suma ponderada de cada
uno de los ocho enlaces, en donde la ponderación es la fracción del trafico total.
Encaminamiento jerárquico.
A medida que crece el tamaño de la red, tablas de encadenamiento de los IMP crecen también
en forma proporcional. No solamente se produce un aumento de memoria consumida en el
IMP al tener tablas más grandes, sino también es necesario tener un mayor tiempo de CPU
para explorarlas y más ancho de banda para transmitir los informes del estado que guardan.
Encaminamiento por difusión.
Para algunas aplicaciones, los hostales necesitan transmitir mensajes a todos los demás
hostales. En algunas redes los IMP pueden llegar a necesitar este tipo de servicio, por ejemplo,
distribuir la actualización de las tablas de encaminamiento. A la transmisión de un paquete, en
forma simultanea a todos los destinos, se les conoce como difusión, habiéndose ya propuesto
varios métodos para desarrollarla.
En un método de difusión en el que no es necesario que la subred tenga características
especiales, el extremo fuente solamente tiene que enviar un paquete distinto de información a
cada destino. Esto no solo trae como resultado un desperdicio considerable del ancho de
banda, sino también requiere que la fuente tenga una lista completa de todos los destinos.
Un algoritmo es el encaminamiento multidestino. Si este método se utiliza, cada paquete
contiene una lista de destinos o un mapa de bits, mediante el cual se indican los destinos
deseados.
ALGORITMOS DE CONTROL DE LA GESTION.
En esta sección se estudiaran cinco estrategias para el control de la congestión. Estas
estrategias toman en consideración la asignación de recursos en forma anticipada, que se
desechen los paquetes cuando no se puedan procesar, que se restrinja él numero de paquetes
en la subred, utilizar el control de flujo para evitar la congestión y obstruir la entrada de datos
cuando la subred esté sobrecargada.

Preasignación de tampones.
Si se utilizan circuitos virtuales dentro de la subred, es posible resolver por completo el
problema de la congestión de la manera siguiente. Cuando se establece un circuito virtual, el
paquete de solicitud de llamada sigue su camino a través de la subred, produciendo entradas
en las tablas según avanza. En el momento en que llega a su destino, la ruta que deberá seguir
todo él trafico subsiguiente ya se ha determinado, así como se han hecho entradas en las
tablas de encaminamiento de todos los IMP intermedios.
Descarte de paquetes.
En lugar de reservar todos los tampones anticipadamente, no se reserva absolutamente nada
por adelantado. Si llega un paquete y no existe un lugar disponible para colocarlo, el IMP
sencillamente lo descarta.
Descartar paquetes ha voluntad puede llegar demasiado lejos; Resultaría bastante tonto. Este
asentimiento le permitiría al IMP abandonar un paquete ya recibido y liberar así un tampón. Si
el IMP no cuenta con tampones disponibles, no podría recibir ningún paquete para ver si
contiene asentamientos, si la congestión tiene que ser evitada mediante el descarte del
paquete será necesario tener una regla para indicar cuando se deberá conservar o descartar
un paquete. Irland (1978.)
Control de flujo.
Algunas redes han intentado utilizar mecanismos de control de flujo para eliminar la
congestión. En la realidad, el control de flujo no puede llegar ha resolver fácilmente los
problemas de congestión, por él trafico de unas ráfagas.
Cuando varios usuarios soliciten el pico máximo al mismo tiempo cuando el control de flujo se
utiliza como un intento para acabar con la congestión se puede aplicar al trafico entre paredes:
1. Procesos de Usuarios.
2. Hostales.
3. IMP de origen y destino.
Además se puede restringir él numero de circuitos virtuales abiertos.
Paquetes reguladores.
Lo que en la realidad se necesita por consiguiente es : un mecanismo que se active cuando el
sistema sé llege a congestionar. Hay una variable U, asociada a cada una de las líneas, cuyo
valor entre cero y uno, refleja la utilización de esa línea. Si es el caso, el IMP transmite un

paquete regulador, de vuelta al Hostal de origen, tomando el destino del paquete mismo. El
paquete se etiqueta dé tal forma que no pueda generar mas paquetes reguladores después, y
se reexpida de manera normal cuando el hostal de origen recibe al paquete regulador se le
solicita que reduzca él trafico, enviado al destino especificado de acuerdo a un porcentaje X.
Bloqueos.
La congestión máxima es un bloqueo al que también se le conoce como estacionamiento. El
primer IMP no puede proseguir hasta que el segundo IMP lleve a cabo una acción, y el segundo
IMP tampoco puede continuar por que esta esperando que el primero haga algo. Los dos IMP
se han bloqueados por completo y permanecerán así en ese estado. Los dos se encuentran
bloqueados y ha esta función se le conoce como bloqueo de almacenamiento y reenvió
directo. Schweitzer(1980) en este esquema se construye un grafo dirigido, en el cual los
tampones son los nodos del grafico, los arcos conectan a pares de tampones localizados en el
mismo IMP o en IMP adyacentes el grafo se construye dé tal manera que si todos los paquetes
se mueven de un tampón a otro, alo largo de los arcos de grafo, entonces no podrían
presentarse bloqueos.
Podemos definir encaminamiento como un proceso mediante el cual tratamos de encontrar un
camino entre dos puntos de la red: el nodo origen y el nodo destino. El objetivo que se
persigue es encontrar las mejores rutas entre pares de nodos j-k.
a) Mejor Ruta. Por mejor ruta se entiende aquella que cumple alguna de estas condiciones:
* presenta el menor retardo medio de transito,
* consigue mantener acotado el retardo entre pares de nodos de la red (Tjk<To),
* consigue ofrecer altas cadencias efectivas independientemente del retardo medio de
transito
* ofrezca el menor coste.
b) Métrica de la Red. Citaremos dos de ellas:
* Numero de saltos (canales) necesarios para ir de un nodo a otro. No se comporta de forma
óptima, pero si ofrece buenos resultados, y es empleada con bastante frecuencia.. La distancia
(valor que se asocia a cada canal) es igual a 1 para todos los canales.
* Retardo de Transito entre nodos vecinos. En este caso la distancia se expresa en unidades
de tiempo (p.e ms), y no es constante a lo largo del tiempo sino que depende del trafico que
soporta el canal.
Algunos de los problemas con los que nos encontramos a la hora de encaminar son:
* La carga de los enlaces no va a ser constante (es decir, el mejor camino no siempre será el
mismo), al igual que la tasa de generación de mensajes. El encaminamiento busca el camino

óptimo, pero como el tráfico varía con el tiempo, el camino óptimo también dependerá del
instante en que se observa la red.
* Hay que tener en cuenta los cambios en la topología de la red (hay nodos que se caen, o se
añaden, o se quitan, etc).
* Existen recursos limitados, no pudiendose cursar todos los paquetes a infinita velocidad.
* Asincronía, en el sentido de que no hay un momento determinado para que ocurran las
cosas (un nodo transmite cuando le llega información, y esto sucede a su vez cuando el usuario
decide mandarla).
Por tanto, el encaminamiento debe proveer a la red de mecanismos para que ésta sepa
reaccionar ante situaciones como:
* Variabilidad del tráfico: se han de evitar las congestiones de la red.
* Variaciones topológicas, como las mencionadas arriba: caídas de enlaces, caídas de nodos,
altas y bajas.
* Cambios en la QoS (Quality of Service): a veces se pide un servicio donde no importa el
retardo y sí un alto throughput, y viceversa.
La nomeclatura que utilizaremos es la siguiente:
* Algoritmo de encaminamiento: método para calcular la mejor ruta para llegar de un sitio a
otro. La mejor ruta podrá calcularse en función de los ‘costes’, retardos, distancia…
* Protocolo de encaminamiento: es la manera que tienen los nodos de intercambiar la
información de encaminamiento (probablemente generada por el algoritmo). Los protocolos
serán los encargados de ocultar la red y comprobar que las condiciones de encaminamiento
impuestas se verifican siempre.
* Decisión de encaminamiento:
Nos centraremos en redes de conmutación de paquetes, tanto en modo datagrama como en
modo circuito virtual:
* Red en modo circuito virtual: Si la red funciona en modo circuito virtual generalmente se
establece una ruta que no cambia durante el tiempo de vida de ese circuito virtual, ya que esto
es lo más sencillo para preservar el orden de los paquetes. El encaminamiento se decide por
sesión y no se cambia a menos que sea imprescindible, es decir existen restricciones de cara a
no cambiar el encaminamiento en la sesión (ej. caída de un enlace). Cuando eso ocurre se
busca inmediatamente otra ruta, pero este cambio al tardar en propagarse por la red, al tardar
los nodos en enterarse, se puede manifestar en los sistemas finales de tres formas:
o no se manifiesta
o se pierde información
o se pierde la sesión.
* Red en modo datagrama: Como en este caso no debe garantizarse el ordenamiento final
de los paquetes, en una red funcionando en modo datagrama se puede cambiar el criterio de

encaminamiento por cada paquete que se ha de cursar (Esto da origen a menor numero de
problemas).
Los requisitos del algoritmo de encaminamiento son:
* Corrección: Se ha de entregar la información correctamente. Es algo obvio: queremos que
el paquete llegue precisamente al nodo al que lo mandamos.
* Simplicidad: debe aportar soluciones sencillas. Esto es útil para redes reales (grandes) y los
protocolos mas simples son los que en la actualidad tienden a imponerse (p.e. RIP: Routing
Interconexion Protocol).
* Robustez: El algoritmo ha de ser insensible a inestabilidades del sistema. Estas
inestabilidades son, por ejemplo, caidas de nodos, etc, que han de ser previstas de antemano.
* Estabilidad (convergencia): Es muy importante que se cumpla. El procedimiento debe
converger antes de que la red cambie de estado (caída de nodo, alta de usuario, etc.). Cuando
esto ocurre, se recalculan de nuevo las rutas, debiendo los nodos llevar a cabo acciones
coherentes que conduzcan a situaciones estables.
* Equidad (justicia): Debe tratar a todos los usuarios de la misma manera.
* Trazabilidad (gestionabilidad): Supone tener información (trazas) de lo que ha hecho la red
para que en el caso de que ocurran “cosas raras” sea posible corregirlas.
* Escalabilidad: Tengo que tener un comportamiento optimo sea cual sea el numero de
nodos ( incluso si este aumenta mucho).
5.2 Métodos de Encaminamiento: lo cual nos valdrá para hacer una posterior claseficación de
los métodos de encaminamiento atendiendo a la forma en la que los nodos recogen y
distribuyen la información que les llega de la red y a otros factores:
* FIB (Forward Information Base): Es la tabla de encaminamiento que se consulta para hacer
el reenvío de los paquetes generados por los usuarios (los PDU representan estos paquetes).
* RIB (Routing Information Base): Tabla que almacena las distancias a los nodos. Es la base
de información de encaminamiento que se consulta para decidir y formar la FIB. La
información de la RIB se consigue mediante interacción con el entorno local de cada nodo
(cada nodo observa sus enlaces) y mediante la recepción de R-PDUs d e información de control
procedentes de otros nodos vecinos que informan del conocimiento que estos nodos tienen
sobre el estado de la red. A su vez, con la información obtenida por la RIB, ésta manda PDUs
de control para informar del conocimiento del estado de la red que el nodo tiene a los demás
nodos.
* LOCAL: Información del entorno local del nodo. Contiene la información de lo que el nodo
ve (memoria disponible, enlaces locales, etc.), más la que hay que proporcionarle.
* R-PDU (Routing-PDU): Información de control entre nodos. Son paquete de control, los
cuales mandan otros nodos con información sobre la red (no son datos). Por ejemplo, se
manda información de que el nodo sigue activo, y también las distancias a otros nodos (vector
de distancias).

* PDU (Protocol Data Unit): Unidad fundamental de intercambio de información para un
nivel determinado (a veces se indica explícitamente el nivel poniendo N-PDU, o PDU de nivel
N), como nivel de enlace, red, etc. Son llamados también tramas.
5.2.2 Clasificación de los Métodos de Encaminamiento 1.- En función de donde se decide
encaminar:
* Fijado en el origen (Source Routing): son los sistemas finales los que fijan la ruta que ha de
seguir cada paquete. Para ello, cada paquete lleva un campo que especifica su ruta(campo RI:
Routing Information), y los nodos sólo se dedican a reenviar los paquetes por esas rutas ya
especificadas. Así pues, son los sistemas finales los que tienen las tablas de encaminamiento y
no se hace necesaria la consulta o existencia de tablas de encaminamiento en los nodos
intermedios. Este tipo de encaminamiento suele ser típico de las redes de IBM.
* Salto a salto (Hop by Hop): los nodos, sabiendo donde está el destino, conocen sólo el
siguiente salto a realizar.
2.- En función de la adaptabilidad:
* No adaptables (estáticos):
o Estáticos: Las tablas de encaminamiento de los nodos se configuran de forma manual
y permanecen inalterables hasta que no se vuelve a actuar sobre ellas. La adaptación a
cambios es nula. Tanto la recogida como la distribución de información se realiza por gestión
(se realiza de manera externa a la red), sin ocupar capacidad de red. El calculo de ruta se
realiza off-line (en una maquina especifica),y las rutas pueden ser las optimas al no estar
sometido al requisito de tiempo real. Este tipo de encaminamiento es el optimo para
topologias en los que solo hay una posibilidad de encaminamiento (topologia en estrella).
o Q-Estáticos: Este encaminamiento, es igual que el estático pero en vez de dar una sola
ruta fija, se dan además varias alternativas en caso de que la principal no funcione, de ahí que
tenga una adaptabilidad reducida.
Comparación entre ambos:
Fijado en Origen Salto a Salto
Conocimiento Los sistemas finales han de tener un conocimiento completo de la red
SIMPLICIDAD: Los nodos han de tener un conocimiento parcial de la red (saber qué
rutas son las mejores)
Complejidad Recae toda en los sistemas finales En los sistemas intermedios ya
que son los que tienen que encaminar
Problemas de Bucles No hay bucles: el sistema final fija la ruta (ROBUSTEZ). Sí
pueden ocurrir: no se tiene una visión completa de la red (INCONSISTENCIA)
* Adaptables (dinámicos):

o Centralizados: En este tipo de encaminamiento, todos los nodos son iguales salvo el
nodo central. Los nodos envían al central información de control a cerca de sus vecinos (R-
PDUs). El nodo central será el que se encargue de recoger esta información para hacer la FIB
de cada nodo, es decir, el nodo central decide la tabla de encaminamiento de cada nodo en
función de la información de control que éstos le mandan. El inconveniente de este metodo es
que consumimos recursos de la red, y además, se harian necesaria rutas alternativas para
comunicarse con el nodo central, ya que estos métodos es que dejarían de funcionar con la
caída de éste.
o Aislados: No se tiene en cuenta la información de los otros nodos a la hora de
encaminar. Se basa en que cada vez que un nodo recibe un paquete que tiene que reenviar
(porque no es para él) lo reenvía por todos los enlaces salvo por el que le llegó. Son muy útiles
para enviar información de emergencia. Destacan dos métodos de encaminamiento aislados:
+ Algoritmo de inundación: Ver anexo 1.
+ Algoritmo de aprendizaje hacia atrás(Backward Learning): Ver anexo 2.
+ Algoritmo de la patata caliente (“Hot Potatoe”).
o Distribuídos: Son los más utilizados. En este tipo de encaminamiento todos los nodos
son iguales, todos envían y reciben información de control y todos calculan, a partir de su RIB
(base de información de encaminamiento) sus tablas de encaminamiento. La adaptación a
cambios es optima siempre y cuando estos sean notificados. Hay dos familias de
procedimientos distribuídos:
+ Vector de distancias.
+ Estado de enlaces.
1.2.2 Subredes
Las redes se pueden dividir en subredes más pequeñas para el mayor aprovechamiento de las
mismas, además de contar con esta flexibilidad, la división en subredes permite que el
administrador de la red brinde contención de broadcast y seguridad de bajo nivel en la LAN. La
división en subredes, además, ofrece seguridad ya que el acceso a las otras subredes está
disponible solamente a través de los servicios de un Router. Las clases de direcciones IP
disponen de 256 a 16,8 millones de Hosts según su clase. El proceso de creación de subredes
comienza pidiendo “prestado” al rango de host la cantidad de bits necesaria para la cantidad
subredes requeridas. Se debe tener especial cuidado en esta acción de pedir ya que deben
quedar como mínimo dos bits del rango de host. La máxima cantidad de bits disponibles para
este propósito en una clase A es de 22, en una clase B es de 14 y en una clase C Es de 6.
El número de subredes que se pueden usar es igual a: 2 elevado a la potencia del número de
bits asignados a subred, menos 2. La razón de restar estos dos bits es por las direcciones que
identifican a la red original, la 000 y la dirección de broadcast de esta subred, la 111 según el
ejemplo anterior.

2N-2=Numero de subredes
Donde N es la cantidad de bits tomados al rango de host
Por lo tanto si se quieren crear 5 subredes VALIDAS (Preste atención al término validas), es
decir cumpliendo la formula 2N-2 tendrá que tomar del rango de host 3 bits:
23–2=6
Observe que no siempre el resultado es exacto, en este caso se pedían 5 subredes
pero se obtendrán 6
1.3 Protocolos de Enrutamiento
El Protocolo de información de enrutamiento permite que los routers determinen cuál es la
ruta que se debe usar para enviar los datos. Esto lo hace mediante un concepto denominado
vector-distancia. Se contabiliza un salto cada vez que los datos atraviesan un router es decir,
pasan por un nuevo número de red, esto se considera equivalente a un salto. Una ruta que
tiene un número de saltos igual a 4 indica que los datos que se transportan por la ruta deben
atravesar cuatro routers antes de llegar a su destino final en la red. Si hay múltiples rutas hacia
un destino, la ruta con el menor número de saltos es la ruta seleccionada por el router.
Como el número de saltos es la única métrica de enrutamiento utilizada por el RIP, no
necesariamente selecciona la ruta más rápida hacia su destino. La métrica es un sistema de
medidas que se utiliza para la toma de decisiones. luego veremos otros protocolos de
enrutamiento que utilizan otras métricas además del número de saltos, para encontrar la
mejor ruta a través de la cual se pueden transportar datos. Sin embargo, RIP continúa siendo
muy popular y se sigue implementando ampliamente. La principal razón de esto es que fue
uno de los primeros protocolos de enrutamiento que se desarrollaron.
Otro de los problemas que presenta el uso del RIP es que a veces un destino puede estar
ubicado demasiado lejos como para ser alcanzable. RIP permite un límite máximo de quince
para el número de saltos a través de los cuales se pueden enviar datos. La red destino se
considera inalcanzable si se encuentra a más de quince saltos de router. Así que resumiendo,
el RIP:
Es un protocolo de enrutamiento por vector de distancia
La única medida que utiliza (métrica) es el número de salto
El número máximo de saltos es de 15
Se actualiza cada 30 segundos
No garantiza que la ruta elegida sea la mas rápida
Genera mucho tráfico con las actualizaciones
1.3.1 El Enrutamiento en Entorno Mixtos de medios de LAN

Descripción de los componentes de enrutamiento: El enrutamiento determina cómo fluyen los
mensajes entre los servidores de la organización de Microsoft® Exchange y para los usuarios
externos a la organización. Para la entrega de mensajes internos y externos, Exchange utiliza el
enrutamiento con el fin de determinar primero la ruta más eficiente y, después, la ruta
disponible menos costosa. Los componentes del enrutamiento interno toman esta decisión
basándose en los grupos de enrutamiento y en los conectores que usted configura, y en los
espacios de direcciones y los costos asociados a cada ruta.
El enrutamiento es responsable de las siguientes funciones:
• Determinar el siguiente salto (el siguiente destino para un mensaje en ruta hasta su destino
final) según la ruta más eficiente.
• Intercambiar información de estado de los vínculos (el estado y la disponibilidad de los
servidores y las conexiones entre los servidores) dentro y entre los grupos de enrutamiento.
Tipos de componentes de enrutamiento Los componentes del enrutamiento componen la
topología, y las rutas empleadas para entregar correo interno y externo. El enrutamiento
utiliza los siguientes componentes que usted define dentro de la topología de enrutamiento:
• Grupos de enrutamiento Conjuntos lógicos de servidores que se utilizan para controlar el
flujo de correo y las referencias a carpetas públicas. Los grupos de enrutamiento comparten
una o varias conexiones físicas. Dentro de un grupo de enrutamiento, todos los servidores se
comunican y transfieren mensajes directamente entre sí.
• Conectores Rutas designadas entre los grupos de enrutamiento, hacia Internet o hacia otro
sistema de correo. Cada conector especifica una ruta unidireccional a otro destino.
• Información de estado de los vínculos Información acerca de grupos de enrutamiento,
conectores y sus configuraciones que el enrutamiento utiliza para determinar la ruta de
entrega más eficiente para un mensaje.
• Componentes del enrutamiento interno Los componentes del enrutamiento interno, en
particular el motor de enrutamiento, que proporcionan y actualizan la topología de
enrutamiento para los servidores de Exchange de su organización. Para obtener más
información acerca de los componentes del enrutamiento interno, consulte Descripción de los
componentes internos del transporte.
Descripción de los grupos de enrutamiento
En su estado predeterminado, Exchange Server 2003, como Exchange 2000 Server, funciona
como si todos los servidores de una organización formasen parte de un único grupo de

enrutamiento grande. Por lo tanto, cualquier servidor de Exchange puede enviar correo
directamente a cualquier otro servidor de Exchange de la organización. Sin embargo, en
aquellos entornos con necesidades administrativas especiales, una distribución geográfica y
conectividad de red variable, puede aumentar la eficacia del flujo de mensajes si se crean
grupos de enrutamiento y conectores de grupos de enrutamiento según la infraestructura de
red y los requisitos administrativos. Al crear grupos de enrutamiento y conectores de grupo de
enrutamiento, los servidores de un grupo de enrutamiento siguen enviándose mensajes
directamente entre sí, pero utilizan el conector de grupo de enrutamiento de esos servidores
con la mejor conectividad de red para comunicarse con servidores de otro grupo.
Para obtener más información acerca de la creación de grupos de enrutamiento y las
consideraciones necesarias, consulte Situaciones de implementación para la conectividad con
Internet.
• Los grupos administrativos definen los límites administrativos lógicos para los servidores de
Exchange.
• Los grupos de enrutamiento definen las rutas físicas por las que se transmiten los mensajes a
través de la red.
Sin embargo, la funcionalidad de los grupos de enrutamiento en un entorno de modo mixto,
donde algunos servidores ejecutan Exchange Server 2003 o Exchange 2000 Server mientras
otros ejecutan Exchange Server 5.5, es distinta de la del modo nativo. En modo mixto:
• No puede tener un grupo de enrutamiento que abarque varios grupos administrativos.
• No se pueden mover servidores entre grupos de enrutamiento que se encuentren en grupos
administrativos diferentes.
Descripción de los conectores
Los conectores proporcionan una ruta unidireccional para el flujo de mensajes hasta un
destino específico. Los conectores principales de Exchange Server 2003 son los siguientes:
• Conectores de grupo de enrutamiento Ofrecen una ruta unidireccional a través de la cual se
enrutan los mensajes desde los servidores de un grupo de enrutamiento hasta los servidores
de otro grupo de enrutamiento diferente. Los conectores de grupo de enrutamiento utilizan
una conexión del Protocolo simple de transferencia de correo (SMTP) para permitir la
comunicación con los servidores del grupo de enrutamiento conectado. Los conectores de
grupo de enrutamiento son el método preferido para conectar grupos de enrutamiento.

• Conectores para SMTP Se utilizan para definir rutas aisladas para el correo destinado a
Internet o a una dirección externa, o a un sistema de correo distinto de Exchange. No se
recomienda ni se prefiere el uso del conector para SMTP con el fin de conectar grupos de
enrutamiento. Los conectores para SMTP están diseñados para la entrega de correo externo.
• Conectores para X.400 Están diseñados principalmente para conectar servidores de
Exchange con otros sistemas X.400 o servidores de Exchange Server 5.5 que no pertenecen a la
organización de Exchange. Así, un servidor de Exchange Server 2003 puede enviar mensajes
con el protocolo X.400 a través de este conector.
Un algoritmo de estado de los vínculos ofrece las siguientes ventajas:
• Cada servidor de Exchange puede seleccionar la ruta óptima de los mensajes en el origen, en
lugar de enviar mensajes por una ruta en la que un vínculo (o una ruta) no está disponible.
• Los mensajes ya no van y vuelven entre los servidores porque cada servidor de Exchange
tiene información actualizada sobre si hay disponibles rutas alternativas o redundantes.
• Ya no se producen bucles de mensajes.
Costos y topología de enrutamiento
Si todas las conexiones entre los grupos de enrutamiento están disponibles, un servidor del
grupo de enrutamiento Seattle siempre enviará un mensaje al grupo de enrutamiento Bruselas
enviando el mensaje primero a través del grupo de enrutamiento Londres. Esta ruta tiene un
costo de 20 y es la ruta con el menor costo disponible. Pero si el servidor cabeza de puente de
Londres no está disponible, los mensajes cuyo origen sea Seattle y el destino sea Bruselas
viajarán a través del grupo de enrutamiento Tokio, que tiene un costo mayor de 35.
Hay que comprender un concepto importante y es que para que un conector se marque como
no disponible, todos los servidores cabeza de puente para ese conector deben estar inactivos.
Si ha configurado el conector del grupo de enrutamiento para utilizar la opción
predeterminada Cualquier servidor local puede enviar correo por este conector, se considerará
que el conector del grupo de enrutamiento siempre está en servicio. Para obtener más
información acerca de cómo configurar conectores de grupo de enrutamiento, consulte
“Conexión de grupos de enrutamiento” en Definición de grupos de enrutamiento.
El siguiente diagrama ilustra una empresa con la topología siguiente:
• Un conector para SMTP con un espacio de direcciones *.net y un costo de 20.

• Un conector para SMTP con un espacio de direcciones *, que engloba todas las direcciones
externas y tiene un costo de 10.
Cómo utiliza Exchange el espacio de direcciones para enrutar correo
En esta topología, cuando se envía correo a un usuario externo cuya dirección de correo
electrónico es [email protected], el enrutamiento busca primero un conector cuyo
espacio de direcciones coincida mejor con el destino de treyresearch.net. El conector para
SMTP que tiene el espacio de direcciones *.net es el que mejor coincide con el destino, por lo
que el enrutamiento utiliza este conector, independientemente de su costo.
El enrutamiento no conmuta por error desde un conector que tiene un espacio de direcciones
específico a un conector que tiene un espacio de direcciones menos específico. En el caso
anterior, si todos los usuarios pueden emplear ambos conectores y un usuario intenta enviar
correo a un usuario de treyresearch.net, el enrutamiento ve como su destino el conector que
tiene el espacio de direcciones .net. Si este conector no está en servicio o no está disponible, el
enrutamiento no intentará buscar un conector con un espacio de direcciones diferente y
menos restrictivo como *, ya que lo considerará otro destino distinto.
1.3.2 Operaciones Basicas Router
Un router (en español: enrutador o encaminador) es un dispositivo hardware o software de
interconexión de redes de computadoras que opera en la capa tres (nivel de red) del modelo
OSI. Este dispositivo interconecta segmentos de red o redes enteras. Hace pasar paquetes de
datos entre redes tomando como base la información de la capa de red.
El router toma decisiones lógicas con respecto a la mejor ruta para el envío de datos a través
de una red interconectada y luego dirige los paquetes hacia el segmento y el puerto de salida
adecuados. Sus decisiones se basan en diversos parámetros. Una de las más importantes es
decidir la dirección de la red hacia la que va destinado el paquete (En el caso del protocolo IP
esta sería la dirección IP). Otras decisiones son la carga de tráfico de red en las distintas
interfaces de red del router y establecer la velocidad de cada uno de ellos, dependiendo del
protocolo que se utilice.
1.3.3 Rutas Estaticas y Dinamicas
Rutas estáticas: Las rutas estáticas con aquellas que son puestas a mano o que vienen puestas
por defecto y que no tienen ninguna reacción ante nuevas rutas o caidas de tramos de la red.
Son las habituales en sistemas cliente; o en redes donde solo se sale a Internet.
Rutas dinámicas: Un router con encaminamiento dinámico; es capaz de entender la red y pasar
las rutas entre routers vecinos. Con esto quiero decir que es la propia red gracias a los routers

con routing dinámico los que al agregar nuevos nodos o perderse algún enlace es capaz de
poner/quitar la ruta del nodo en cuestión en la tabla de rutas del resto de la red o de buscar un
camino alternativo o más óptimo en caso que fuese posible.
1.3.4 Ruta por Defecto
La “ruta por defecto” se utiliza sólamente cuando no se puede aplicar ninguna de las otras
rutas existentes
Cuando el sistema local necesita realizar una conexión con una máquina remota se examina la
tabla de rutas para determinar si se conoce algún camino para llegar al destino. Si la máquina
remota pertenece a una subred que sabemos cómo alcanzar (rutas clonadas) entonces el
sistema comprueba si se puede conectar utilizando dicho camino.
Si todos los caminos conocidos fallan al sistema le queda una única opción: la “ruta por
defecto”. Esta ruta está constituída por un tipo especial de pasarela (normalmente el único
“router” presente en la red área local) y siempre posée el “flag” c en el campo de “flags”. En
una LAN, la pasarela es la máquina que posée conectividad con el resto de las redes (sea a
través de un enlace PPP, DSL, cable modem, T1 u otra interfaz de red.)
Si se configura la ruta por defecto en una máquina que está actuando como pasarela hacia el
mundo exterior la ruta por defecto será el “router” que se encuentre en posesión del
proveedor de servicios de internet (ISP).
1.3.5 Protocolos Enrutados y de Enrutamiento
DIFERENCIAS ENTRE PROTOCOLOS ENRUTADOS Y DE ENRUTAMIENTO.
PROTOCOLOS ENRUTADOS
Funciones:
1. Incluir cualquier conjunto de protocolos de red que ofrece información suficiente en
su dirección de capa para permitir que un Router lo envíe al dispositivo siguiente y
finalmente a su destino.
2. Definir el formato y uso de los campos dentro de un paquete.
El Protocolo Internet (IP) y el intercambio de paquetes de internetworking (IPX) de Novell son
ejemplos de protocolos enrutados. Otros ejemplos son DEC net, Apple Talk, Banyan VINES y
Xerox Network Systems (XNS).
PROTOCOLOS DE ENRUTAMIENTO

Los Routers utilizan los protocolos de enrutamiento para intercambiar las tablas de
enrutamiento y compartir la información de enrutamiento. En otras palabras, los protocolos
de enrutamiento permiten enrutar protocolos enrutados.
Funciones: - Ofrecer procesos para compartir la información de ruta. - Permitir que los Routers
se comuniquen con otros Routers para actualizar y mantener las tablas de enrutamiento.
Los protocolos no enrutables no admiten la Capa 3. El protocolo no enrutable más común es el
Net BEUI. Net Beui es un protocolo pequeño, veloz y eficiente que está limitado a la entrega de
tramas de un segmento.
Los routers guardan la información en una tabla de enrutamiento y la comparten.
Intercambian información acerca de la topología de la red mediante los protocolos de
enrutamiento.
La determinación de la ruta permite que un Router compare la dirección destino con las rutas
disponibles en la tabla de enrutamiento, y seleccione la mejor ruta. Si no hay información
acerca de una red destino en la tabla de enrutamiento, el router envía el paquete al Gateway
predeterminado (ruta por defecto). Los Routers conocen las rutas disponibles por medio del
enrutamiento estático o dinámico.
1.3.6 Información Utilizada por Routers para ejecutar sus funciones basicas
Los protocolos de enrutamiento son aquellos protocolos que utilizan los routers o
encaminadores para comunicarse entre sí y compartir información que les permita tomar la
decisión de cual es la ruta más adecuada en cada momento para enviar un paquete. Los
protocolos más usados son RIP (v1 y v2), OSPF (v1, v2 y v3), y BGP (v4), que se encargan de
gestionar las rutas de una forma dinámica. aunque no es estrictamente necesario que un
router haga uso de estos protocolos, pudiéndosele indicar de forma estática las rutas (caminos
a seguir) para las distintas subredes que estén conectadas al dispositivo.
1.3.7 Configuración de Rip
RIP son las siglas de Routing Information Protocol (Protocolo de información de
encaminamiento). Es un protocolo de pasarela interior o IGP (Internal Gateway Protocol)
utilizado por los routers (enrutadores), aunque también pueden actuar en equipos, para
intercambiar información acerca de redes IP.
Petición: Enviados por algún enrutador recientemente iniciado que solicita información de los
enrutadores vecinos.
Respuesta: mensajes con la actualización de las tablas de enrutamiento. Existen tres tipos:

Mensajes ordinarios: Se envían cada 30 segundos. Para indicar que el enlace y la ruta siguen
activos.
Mensajes enviados como respuesta a mensajes de petición.
Mensajes enviados cuando cambia algún coste. Sólo se envían las rutas que han cambiado .
Funcionamiento RIP
RIP utiliza UDP para enviar sus mensajes y el puerto bien conocido 520.
RIP calcula el camino más corto hacia la red de destino usando el algoritmo del vector de
distancias. La distancia o métrica está determinada por el número de saltos de router hasta
alcanzar la red de destino.
RIP tiene una distancia administrativa de 120 (la distancia administrativa indica el grado de
confiabilidad de un protocolo de enrutamiento, por ejemplo EIGRP tiene una distancia
administrativa de 90, lo cual indica que a menor valor mejor es el protocolo utilizado)
RIP no es capaz de detectar rutas circulares, por lo que necesita limitar el tamaño de la red a
15 saltos. Cuando la métrica de un destino alcanza el valor de 16, se considera como infinito y
el destino es eliminado de la tabla (inalcanzable).
La métrica de un destino se calcula como la métrica comunicada por un vecino más la distancia
en alcanzar a ese vecino. Teniendo en cuenta el límite de 15 saltos mencionado anteriormente.
Las métricas se actualizan sólo en el caso de que la métrica anunciada más el coste en alcanzar
sea estrictamente menor a la almacenada. Sólo se actualizará a una métrica mayor si proviene
del enrutador que anunció esa ruta.
1.4 Arp , Rarp
ARP son las siglas en inglés de Address Resolution Protocol (Protocolo de resolución de
direcciones).
Es un protocolo de nivel de red responsable de encontrar la dirección hardware (Ethernet
MAC) que corresponde a una determinada dirección IP. Para ello se envía un paquete (ARP
request) a la dirección de multidifusión de la red (broadcast (MAC = ff ff ff ff ff ff)) conteniendo
la dirección IP por la que se pregunta, y se espera a que esa máquina (u otra) responda (ARP
reply) con la dirección Ethernet que le corresponde. Cada máquina mantiene una caché con las
direcciones traducidas para reducir el retardo y la carga. ARP permite a la dirección de Internet

ser independiente de la dirección Ethernet, pero esto solo funciona si todas las máquinas lo
soportan. ARP está documentado en el RFC (Request For Comments) 826.
El protocolo RARP realiza la operación inversa. En Ethernet, la capa de enlace trabaja con
direcciones físicas. El protocolo ARP se encarga de traducir las direcciones IP a direcciones
MAC (direcciones físicas).Para realizar ésta conversión, el nivel de enlace utiliza las tablas ARP,
cada interfaz tiene tanto una dirección IP como una dirección física MAC.
Reverse Address Resolution Protocol
RARP son las siglas en inglés de Reverse Address Resolution Protocol (Protocolo de resolución
de direcciones inverso). Es un protocolo utilizado para resolver la dirección IP de una dirección
hardware dada (como una dirección Ethernet). La principal limitación era que cada MAC tenía
que ser configurada manualmente en un servidor central y se limitaba sólo a la dirección IP,
dejando otros datos como la máscara de subred, puerta de enlace y demás información que
tenían que ser configurados a mano. Otra desventaja de este protocolo es que utiliza como
dirección destino, evidentemente, una dirección MAC de difusión para llegar al servidor RARP.
Sin embargo, una petición de ese tipo no es reenviada por el router del segmento de subred
local fuera de la misma, por lo que este protocolo, para su correcto funcionamiento, requiere
de un servidor RARP en cada subred. Posteriormente el uso de BOOTP lo dejó obsoleto, ya que
éste funciona con paquetes UDP, los cuales se reenvían a través de los routers (eliminando la
necesidad de disponer de un servidor RARP en cada subred) y, además, BOOTP ya tiene un
conjunto de funciones mayor que permite obtener más información y no sólo la dirección IP.
RARP está descrito en el RFC 903.
1.5 Igrp , Egp
IGRP (Interior Gateway Routing Protocol, o Protocolo de enrutamiento de gateway interior) es
un protocolo patentado y desarrollado por CISCO que se emplea con el protocolo TCP/IP según
el modelo (OSI) Internet. La versión original del IP fue diseñada y desplegada con éxito en
1986. Se utiliza comúnmente como IGP pero también se ha utilizado extensivamente como
Exterior Gateway Protocol (EGP) para el enrutamiento inter-dominio.
IGRP es un protocolo de enrutamiento basado en la tecnología vector-distancia. Utiliza una
métrica compuesta para determinar la mejor ruta basándose en el ancho de banda, el retardo,
la confiabilidad y la carga del enlace. El concepto es que cada router no necesita saber todas
las relaciones de ruta/enlace para la red entera. Cada router publica destinos con una distancia
correspondiente. Cada router que recibe la información, ajusta la distancia y la propaga a los
routers vecinos. La información de la distancia en IGRP se manifiesta de acuerdo a la métrica.
Esto permite configurar adecuadamente el equipo para alcanzar las trayectorias más óptimas.
Funcionamiento:

IGRP manda actualizaciones cada 90 segundos, y utiliza un cierto número de factores distintos
para determinar la métrica. El ancho de banda es uno de estos factores, y puede ser ajustado
según se desee.
IGRP utiliza los siguientes parámetros:
Retraso de Envío: Representa el retraso medio en la red en unidades de 10 microsegundos.
Ancho de Banda: Representa la velocidad del enlace, dentro del rango de los 12000 mbps y 10
Gbps. En realidad el valor usado es la inversa del ancho de banda multiplicado por 107.
Fiabilidad: va de 0 a 255, donde 255 es 100% confiable.
Distancia administrativa (Load): toma valores de 0 a 255, para un enlace en particular, en este
caso el valor máximo (255) es el pero de los casos.
La fórmula usada para calcular el parámetro de métrica es:
(K1*Ancho de Banda) + (K2*Ancho de Banda)/(256-Distancia) + (K3*Retraso)*(K5/(Fiabilidad +
K4)).
EGP (Exterior Gateway Protocol) es un protocolo estándar. Su status es recomendado.
EGP es el protocolo utilizado para el intercambio de información de encaminamiento entre
pasarelas exteriores (que no pertenezcan al mismo Sistema Autónomo AS). Las pasarelas EGP
sólo pueden retransmitir información de accesibilidad para las redes de su AS. La pasarela
debe recoger esta información, habitualmente por medio de un IGP, usado para intercambiar
información entre pasarelas del mismo AS (ver Figura - La troncal ARPANET).
EGP se basa en el sondeo periódico empleando intercambios de mensajes Hello/I Hear You,
para monitorizar la accesibilidad de los vecinos y para sondear si hay solicitudes de
actualización. EGP restringe las pasarelas exteriores al permitirles anunciar sólo las redes de
destino accesibles en el AS de la pasarela. De esta forma, una pasarela exterior que usa EGP
pasa información a sus vecinos EGP pero no anuncia la información de accesibilidad de
estos(las pasarelas son vecinos si intercambian información de encaminamiento) fuera del AS.
Tiene tres características principales:
Unidad 2 Capas superiores del modelo OSI
2.1 Capa Transporte Osi

La capa transporte no es una capa más del modelo OSI. Es la base de toda la jerarquía de
protocolo. La tarea de esta capa es proporcionar un transporte de datos confiable y económico
de la máquina de origen a la máquina destino, independientemente de la red de redes física en
uno. Sin la capa transporte, el concepto total d los protocolos en capas tendría poco sentido.
2.1.1 Parámetros para lograr la Calidad Servicio de Transporte
Parámetros de calidad
La calidad del servicio que ofrece el nivel de transporte viene determinada por los siguientes
parámetros (nótese que algunos de ellos sólo tienen sentido en el caso de que el servicio sea
orientado a conexión):
Retardo de establecimiento de conexión Tiempo que transcurre entre una solicitud de
conexión de transporte y la confirmación que recibe el usuario del servicio. Incluye el retardo
de procesamiento en la entidad de transporte remota. Como en todos los parámetros que
miden un retardo, cuanto menor sea, mejor será la calidad del servicio ofrecido.
Para profundizar un poco en la diferencia entre el nivel de transporte y el de red, conviene
citar algunas de las técnicas que utilizan las entidades de transporte para mejorar la calidad
ofrecida por el servicio de red.
Una de ellas es la multiplexión en sus dos versiones: establecer varias conexiones de red para
una conexión de transporte que demanda gran ancho de banda, o bien establecer una sola
conexión de red correspondiente a varias conexiones de transporte, en el caso de que el coste
por conexión sea elevado.
2.1.1.1 Servicios Orientados a Conexion
Servicio Orientado a Conexión: Se modeló basándose en el sistema telefónico. Para poder
conseguir la conexión, se debe tomar el teléfono, marcar el número deseado y esperar hasta
que alguien conteste, de ser así, se puede decir que la conexión se realizó con éxito, de lo
contrario no hubo conexión. Los distintos niveles de red pueden ofrecer dos tipos de servicios
diferentes a las capas superiores : uno orientado a conexión y otro sin conexión. Este tipo de
conexion es mejor conocido como el sistema del telefono hot el cual tiene una capa
2.1.1.2 Servicios Orientados a no Conexion
Las características principales de un servicio de este tipo a nivel de red son las siguientes:
No hay establecimiento de ninguna conexión, sólo hay transferencia de datos.

Se usan primitivas del tipo Unit.Data.Request y Unit.Data.Indication , que contienen
como parámetros:
1. Direccion del destinatario.
2. Dirección de la fuente.
3. QoS (Parámetro que determina la calidad de servicio).
4. Datos del usuario.
Notas:
En CO las primitivas de Data.Request no necesitaban dirección (la red ya tiene
establecido un circuito virtual para la transmisión).
Cada paquete que se transmite se transporta de manera independiente con respecto a
los paquetes predecesores.
Las UNITDATA sólo pueden transmitir hasta un máximo de 64512 octetos y han de
preservar la integridad de la información.
El emisor sólo se encarga de vaciar el paquete en la red, deseando que todo resulte lo
mejor posible.
Servicio no Orientado a Conexión: Se modeló basándose en el sistema Postal, cada mensaje
(Carta) lleva consigo la dirección completa de destino y cada uno de ellos se encaminan, en
formato independiente, a través del sistema.
2.2 Capa De Sesión Osi
Esta capa ofrece varios servicios que son cruciales para la comunicación, como son:
Control de la sesión a establecer entre el emisor y el receptor (quién transmite, quién
escucha y seguimiento de ésta).
Control de la concurrencia (que dos comunicaciones a la misma operación crítica no se
efectúen al mismo tiempo).
Mantener puntos de verificación (checkpoints), que sirven para que, ante una
interrupción de transmisión por cualquier causa, la misma se pueda reanudar desde el
último punto de verificación en lugar de repetirla desde el principio.
Por lo tanto, el servicio provisto por esta capa es la capacidad de asegurar que, dada una
sesión establecida entre dos máquinas, la misma se pueda efectuar para las operaciones
definidas de principio a fin, reanudándolas en caso de interrupción.
2.2.1 Intercambio de Datos

La característica mas importante de la capa de sesión es el intercambio de datos. Una sesión,
al igual que una conexión de transporte, sigue un proceso de tres fases: la de establecimiento,
la de utilización y la de liberación. Las primitivas que se le proporcionan a la capa de
presentación, para el establecimiento, utilización y liberación de sesiones, son muy parecidas a
las proporcionadas a la capa de sesión para el establecimiento, uso y liberación de conexiones
de transporte. En muchos casos, todo lo que la entidad de sesión tiene que hacer, cuando
primitiva es invocada por el usuario de sesión, es invocar la primitiva de transporte
correspondiente para que se pueda así realizar el trabajo.
2.2.2 Administracion del Dialogo
En principio, todas las conexiones del modelo OSI son dúplex, es decir, las unidades de datos
del protocolo(PDU) se pueden mover en ambas direcciones simultáneamente sobre la misma
conexión. Aunque puede haber situaciones en las que el software de capas superiores esta
estructurado de tal forma que espera que los usuarios tomen turno convirtiendo la
comunicación en semidúplex. La administración del dialogo será uno e los servicio de la capa
de sesión y consistirá en mantener un seguimiento de a quien le corresponde el turno de
hablar y de hacerlo cumplir. En el momento en el que se inicia una sesión se seleccionara el
modo de funcionamiento y ya sea dúplex o semidúplex, la negociación inicial determina quien
tendrá primeramente el testigo de datos porque solo el usuario que posee el testigo podrás
transmitir mientras el otro se mantendrá en silencio. Cuando termine le pasara el testigo a su
interlocutor.
2.2.3 Sincronización Capa Sesión
Sincronización: Este servicio de la capa de sesión se encarga de llevar a las entidades de vuelta
a un estado conocido cuando se produce algún error o desacuerdo. Es necesario porque la
capa de transporte está diseñada para recuperar los errores de comunicación, pero pueden
suceder errores en niveles superiores, y hay que controlarlos.
La única responsabilidad del nivel de sesión es proporcionar la forma de poner, a través de la
red, una serie de señales numeradas de sincronización, pues el mantener a salvo el mensaje y
reenviarlo es misión de los niveles por encima del de sesión. Elementos a tener en cuenta en la
sincronización:
Puntos de sincronización mayores: Se deben confirmar explícitamente. Son utilizados
para que ciertas actividades se hagan completamente o no se hagan. Es necesario para
ponerlo tener el testigo de sincronización mayor o actividad.
Puntos de sincronización menores: Son puntos sin asentimiento, pues sincronizan
tareas menos críticas. Es necesario tener el testigo de sincronización menor.
Unidades de diálogo: Las delimitadas por los puntos de sincronización mayor.

2.2.4 Notificacion de Excepciones
Otra característica de la capa de sesión es la correspondiente a un mecanismo de propósito
general para notificar errores inesperados. Si un usuario tiene algún problema, por cualquier
razón, este problema se puede notificar a su corresponsal utilizando la primitiva S-U-
EXCEPTION-REPORT.request. Algunos datos del usuario se pueden transferir utilizando esta
primitiva. Los datos del usuario, generalmente, explicaran que es lo que sucedió. La
notificación de excepciones no solamente se aplica a los errores detectados del usuario.
El proveedor del servicio puede generar una primitiva S-P-EXCEPTION-REPORT.indication para
informarle al usuario sobre los problemas internos que existen dentro de la capa de sesión, o
sobre problemas que le reporten procedentes de las capas de transporte o inferiores. Estas
notificaciones contienen un campo que describe la naturaleza de la excepción. La decisión
sobre que acción tomar, si hay alguna, dependerá del usuario.
2.2.5 Llamada Procedimientos Remotos
El RPC (del inglés Remote Procedure Call, Llamada a Procedimiento Remoto) es un protocolo
que permite a un programa de ordenador ejecutar código en otra máquina remota sin tener
que preocuparse por las comunicaciones entre ambos. El protocolo es un gran avance sobre
los sockets usados hasta el momento. De esta manera el programador no tenía que estar
pendiente de las comunicaciones, estando éstas encapsuladas dentro de las RPC.
Las RPC son muy utilizadas dentro del paradigma cliente-servidor. Siendo el cliente el que
inicia el proceso solicitando al servidor que ejecute cierto procedimiento o función y enviando
éste de vuelta el resultado de dicha operación al cliente.
2.3 Capa de presentación
2.3.1 Códigos de Representación de Datos
El código Unicode (del inglés «universal» y «code» - universal y código o sea código universal o
unicódigo) es un estándar industrial cuyo objetivo es proporcionar el medio por el cual un
texto en cualquier forma e idioma pueda ser codificado para el uso informático. El
establecimiento de Unicode ha involucrado un ambicioso proyecto para reemplazar los
esquemas de codificación de caracteres existentes, muchos de los cuales están muy limitados
en tamaño y son incompatibles con entornos plurilingües. Unicode se ha vuelto el más extenso
y completo esquema de codificación de caracteres, siendo el más dominante en la
internacionalización y adaptación local del software informático. El estándar ha sido
implementado en un número considerable de tecnologías recientes, que incluyen XML, Java y
sistemas operativos modernos.

2.3.2 Tecnicas Compresion Datos
Las técnicas de compresión son objeto de otro de los trabajos de la asignatura, sin embargo
están muy relacionadas con los formatos de audio digital por lo que las trataré de forma muy
general y breve.
Las técnicas de compresión son la herramienta fundamental de la que se dispone para alcanzar
el compromiso adecuado entre capacidad de almacenamiento y de procesamiento requeridas.
Las técnicas de compresión más elaboradas proporcionan una reducción muy importante de la
capacidad de almacenamiento, pero requieren también de un importante procesado tanto
para compresión como para la descompresión (sobre todo en la compresión). Las técnicas más
simples ofrecen reducciones moderadas con poco procesamiento. Las características del
sistema digital implicado y la aplicación determinarán el compromiso entre estos factores y
permiten seleccionar las técnicas de compresión adecuadas. Las técnicas más avanzadas
analizan la respuesta del oído a la señal y simplifican aquellos elementos irrelevantes para la
sensación sonora, consiguiendo tasas de compresión mucho mayores.
2.3.3 Criptografía Capa Presentación
La capa de presentación (Nivel 6 del modelo OSI) provee la comunicación a nivel de lenguaje
entre el usuario y la máquina que esté empleando para acceder a la red
La capa de presentación realiza ciertas funciones que se necesitan bastante a menudo como
para buscar una solución general para ellas, más que dejar que cada uno de los usuarios
resuelva los problemas. En particular y, a diferencia de las capas inferiores, que únicamente
están interesadas en el movimiento fiable de bits de un lugar a otro.
Algunas de sus funciones son las siguientes:
Establece una sintaxis y semántica de la información transmitida. Se define la estructura de los
datos a transmitir (v.g. define los campos de un registro: nombre, dirección, teléfono, etc).
Define el código a usar para representar una cadena de caracteres (ASCII, EBCDIC, etc).
Criptografía: Ciencia que trata del enmascaramiento de la comunicación de modo que sólo
resulte inteligible para la persona que posee la clave, o método para averiguar el significado
oculto, mediante el criptoanálisis de un texto aparentemente incoherente.
CRIPTOGRAFÍA SIMÉTRICA (CLAVE SECRETA)
Es el sistema de cifrado más antiguo y consiste en que tanto el emisor como el receptor
encriptan y desencriptan la información con una misma clave k (clave secreta) que ambos

comparten. El funcionamiento es muy sencillo: el emisor cifra el mensaje con la clave k y se lo
envía al receptor. Este último, que conoce dicha clave, la utiliza para desencriptar la
información.
Es importante considerar que para que el sistema sea razonablemente robusto contra ataques
de tipo criptoanálisis, esta clave k ha de ser mayor de 40 bits, lo cual choca con las
restricciones de exportación de tecnología criptográfica del gobierno americano, que marca los
40 bits como límite de clave para programas que utilicen este tipo de tecnología.
Algoritmos típicos que utilizan cifrado simétrico son DES, IDEA, RC5, etc, El criptosistema de
clave secreta más utilizado es el Data Encryption Standard (DES) desarrollado por IBM y
adoptado por las oficinas gubernamentales estadounidenses para protección de datos desde
1977.
CRIPTOGRAFÍA ASIMÉTRICA (CLAVE PÚBLICA)
En 1976 Diffie y Hellman describieron el primer criptosistema de clave pública conocido como
el cambio de clave Diffie-Hellman. Estos criptosistemas están basados en propiedades
matemáticas de los números primos, que permite que cada interlocutor tenga una pareja de
claves propias. De esta pareja de claves, una se denomina privada o secreta y la otra, pública.
La clave privada no se transmite nunca y se mantiene secreta. La clave pública, por el
contrario, se puede y se debe poner a disposición de cualquiera, dado que es imposible
deducir la clave privada a partir de la pública.
La propiedad fundamental de esta pareja de claves es que lo que se cifra con una de estas
claves, se descifra con la otra. Esta potente característica asimétrica es la que permite a esta
tecnología servir de base el diseño de sistemas de comunicación segura.
Para que este sistema sea lo suficientemente robusto contra ataques de criptoanálisis, las
claves han de ser de una longitud mínima de 1024 bits, siendo recomendable, en los casos que
sea posible, utilizar claves de 2048 bits. De nuevo nos encontramos con el límite de 512 bits
impuestos por la legislación americana para la exportación de software criptográfico.
2.4.1 Configuracion Servicios
IPTABLES
En linux, el filtrado de paquetes se controla a nivel del kernel. Existen modulos para el kernel
que permiten definir un sistema de reglas para aceptar o rechazar los paquetes o las
comunicaciones que pasan por el sistema. Estos sistemas de reglas conforman lo que se
conoce como firewall o cortafuegos; en otros sistemas los firewall pueden estar
implementados en software y estar desvinculados del sistema operativo, pero en el caso de

linux, el firewall se puede montar a nivel de kernel y no es necesario instalar un software
adicional que para mas INRI a veces tiene agujeros.
-Ordenes básicas:
iptables –F : efectivamente, flush de reglas
iptables –L : si, listado de reglas que se estan aplicando
iptables –A : append, añadir regla
iptables –D : borrar una reglas, etc…
EJEMPLO DEL PUERTO 80 WWW
/sbin/iptables -A INPUT -i $EXTIF -p tcp —sport 80 -j ACCEPT
/sbin/iptables
-A OUTPUT -o $EXTIF -p tcp —dport 80 -j ACCEPT
Unidad 3 Técnicas de conmutación
3.1 Conmutacion Circuitos
La comunicación entre un origen y un destino habitualmente pasa por nodos intermedios que
se encargan de encauzar el tráfico. Por ejemplo, en las llamadas telefónicas los nodos
intermedios son las centralitas telefónicas y en las conexiones a Internet, los routers o
encaminadores. Dependiendo de la utilización de estos nodos intermedios, se distingue entre
conmutación de circuitos, de mensajes y de paquetes.
En la conmutación de circuitos se establece un camino físico entre el origen y el destino
durante el tiempo que dure la transmisión de datos. Este camino es exclusivo para los dos
extremos de la comunicación: no se comparte con otros usuarios (ancho de banda fijo). Si no
se transmiten datos o se transmiten pocos se estará infrautilizando el canal. Las
comunicaciones a través de líneas telefónicas analógicas (RTB) o digitales (RDSI) funcionan
mediante conmutación de circuitos.
Un mensaje que se transmite por conmutación de mensajes va pasando desde un nodo al
siguiente, liberando el tramo anterior en cada paso para que otros puedan utilizarlo y
esperando a que el siguiente tramo esté libre para transmitirlo. Esto implica que el camino
origen-destino es utilizado de forma simultánea por distintos mensajes. Sin embargo, éste
método no es muy útil en la práctica ya que los nodos intermedios necesitarían una elevada

memoria temporal para almacenar los mensajes completos. En la vida real podemos
compararlo con el correo postal.
Finalmente, la conmutación de paquetes es la que realmente se utiliza cuando hablamos de
redes. Los mensajes se fragmentan en paquetes y cada uno de ellos se envía de forma
independiente desde el origen al destino. De esta manera, los nodos (routers) no necesitan
una gran memoria temporal y el tráfico por la red es más fluido. Nos encontramos aquí con
una serie de problemas añadidos: la pérdida de un paquete provocará que se descarte el
mensaje completo; además, como los paquetes pueden seguir rutas distintas puede darse el
caso de que lleguen desordenados al destino. Esta es la forma de transmisión que se utiliza en
Internet: los fragmentos de un mensaje van pasando a través de distintas redes hasta llegar al
destino.
3.2 Conmutacion Mensajes
Conmutación de Mensajes. El mensaje es una unidad lógica de datos de usuario, de datos de
control o de ambos que el terminal emisor envía al receptor. El mensaje consta de los
siguientes elementos llamados campos: • Datos del usuario. Depositados por el interesado. •
Caracteres SYN. (Caracteres de Sincronía). • Campos de dirección. Indican el destinatario de la
información. • Caracteres de control de comunicación. • Caracteres de control de errores.
Además de los campos citados, el mensaje puede contener una cabecera que ayuda a la
identificación de sus parámetros (dirección de destino, enviante, canal a usar, etc.). La
conmutación de mensajes se basa en el envío de mensaje que el terminal emisor desea
transmitir al terminal receptor aun nodo o centro de conmutación en el que el mensaje es
almacenado y posteriormente enviado al terminal receptor o a otro nodo de conmutación
intermedio, si es necesario. Este tipo de conmutación siempre conlleva el almacenamiento y
posterior envío del mensaje lo que origina que sea imposible transmitir el mensaje al nodo
siguiente hasta la completa recepción del mismo en el nodo precedente.
3.3 Conmutacion Paquetes
La conmutación de paquetes surge intentando optimizar la utilización de la capacidad de las
líneas de transmisión existentes. Para ello seria necesario disponer de un método de
conmutación que proporcionara la capacidad de transmisión en tiempo real de la conmutación
de circuitos y la capacidad de direccionamineto de la conmutación de mensajes.
Esta se basa en la división de la información que entrega a la red el usuario emisor en paquetes
del mismo tamaño que generalmente oscila entre mil y dos mil bits.
Los paquetes poseen una estructura tipificada y, dependiendo del uso que la red haga de ellos,
contienen información de enlace o información de usuario.

El campo indicador (Flag) tiene una longitud de ocho Bits y su misión es la de indicar el
comienzo y el final del paquete.
El campo dirección (Adress) indica cual es el sentido en el que la información debe
progresar dentro de la red. Su longitud es de ocho Bits.
El campo de secuencia de verificación de trama (Frame Checking Secuence) es el
encargado de servir como referencia para comprobar la correcta transmisión del
paquete. Su longitud es de 16 Bits.
El campo de información posee una longitud indeterminada, aunque sujeta a unos
márgenes superiores, y es el contiene la información que el usuario emisor desea
intercambiar con el receptor. Además este campo incluye otros tipos de datos que son
necesarios para el proceso global de la comunicación como el numero del canal lógico
que se esta empleando, el numero de orden dentro del mensaje total, etc.
La técnica de conmutación de paquetes permite dos formas características de
funcionamiento: datagrama y circuito virtual.
En el modo de funcionamiento en datagrama, la red recibe los paquetes y, mediante el
análisis e interpretación del campo de dirección de los mismos, los encamina hacia su
destino, sin importar que lleguen al mismo ordenados o no y sin que en destino se
informe al origen de la recepción de los mismos. El funcionamiento en datagrama
requiere en destino de los medios adecuados para organizar la información según el
orden inicial que poseía.
En el modo de funcionamiento de circuito virtual, la red, mediante el análisis e
interpretación de los campos de control y de secuencia de verificación de trama,
averigua cual es la dirección de entrega y el numero que el paquete posee en el
conjunto global, para, de este modo, entregarlos en destino en el mismo orden en que
fueron entregados en origen.
La conmutación de paquetes es el método de conmutación que se emplea con mayor
profusión hoy día en las redes de datos publicas. Esta presenta ventajas que soportan su
creciente utilización en transmisión de datos. Entre ellas se citan especialmente la gran
flexibilidad y rentabilidad en las líneas que se logran gracias al encaminamiento alternativo que
proporcionas esta técnica.
3.3.1 Topologia Redes de Paquetes
Estas son las topologías usadas para la distribución de paquetes, al igual que sus descripciones,
ventajas y desventajas.
Topología de bus
La topología de bus es la manera más simple de organizar una red. En la topología de bus,
todos los equipos están conectados a la misma línea de transmisión mediante un cable,

generalmente coaxial. La palabra “bus” hace referencia a la línea física que une todos los
equipos de la red.
La ventaja de esta topología es su facilidad de implementación y funcionamiento. Sin embargo,
esta topología es altamente vulnerable, ya que si una de las conexiones es defectuosa, esto
afecta a toda la red.
Topología de estrella
En la topología de estrella, los equipos de la red están conectados a un hardware denominado
concentrador. Es una caja que contiene un cierto número de sockets a los cuales se pueden
conectar los cables de los equipos. Su función es garantizar la comunicación entre esos
sockets.
Topología en anillo
En una red con topología en anillo, los equipos se comunican por turnos y se crea un bucle de
equipos en el cual cada uno “tiene su turno para hablar” después del otro.
En realidad, las redes con topología en anillo no están conectadas en bucles. Están conectadas
a un distribuidor (denominado MAU, Unidad de acceso multiestación) que administra la
comunicación entre los equipos conectados a él, lo que le da tiempo a cada uno para “hablar”.
Protocolos orientados a conexión y no-conexión
Los protocolos pueden ser orientados a conexión y orientados a no-conexión. Los orientados a
conexión, las entidades correspondientes mantienen las información del estatus acerca del
dialogo que están manteniendo.
Esta información del estado de la conexión soporta control de error, secuencia y control de
flujo entre las correspondientes entidades. Es decir, La entidad receptora le avisa a la entidad
transmisora si la información útil llego correctamente, si no es así también le avisa que vuelva
a retransmitir.
El control de error se refiere a una combinación de detección de error (y corrección) y
reconocimiento (acknowledgment). El control de secuencia se refiere a la habilidad de cada
entidad para reconstruir una serie de mensajes recibidos en el orden apropiado. El control de
flujo se refiere a la habilidad para que ambas partes en un dialogo eviten el sobreflujo de
mensajes entre sí. Fragmentación y ensamblado
MTU, Maximum Transfer Unit (unidad de transferencia máxima). Es el tamaño máximo de
paquete que se puede dar en una capa de la arquitectura de protocolos (generalmente la capa
de enlace de datos)

Por tanto si algún paquete que viene de una red con un tamaño mayor que la MTU de la red
actual, el gateway entre la primera y la segunda red debe adaptar el tamaño de dicho paquete
a la MTU de la red actual mediante una fragmentación. La posibilidad de reensamblado es
opcional en el caso en que dicho paquete vuelva a una red con una MTU mayor que la actual,
pero no suele hacerse por necesitar esta opción de un procesamiento mayor.
Los protocolos orientados a conexión operan en tres fases.
La primera fase es la fase de configuración de la conexión, durante la cual las
entidades correspondientes establecen la conexión y negocian los parámetros que
definen la conexión.
La segunda fase es la fase de transferencia de datos, durante la cual las entidades
correspondientes intercambian mensajes (información útil) bajo el amparo de la
conexión.
Finalmente, la última fase, fase de liberación de la conexión, en la cual ambas
entidades se ponen de acuerdo para terminar la conexión. Un ejemplo de la vida diaria
de un protocolo orientado a conexión es una llamada telefónica. La parte originadora
(el que llama) deberá primero “marcar” el número del teléfono usuario (abonado)
destino. La infraestructura telefónica deberá asignar el circuito extremo-extremo,
entonces hace timbrar el teléfono del usuario destino. Al momento que éste levanta el
teléfono se establece la llamada o conexión y ambos empiezan a conversar. En algún
momento, alguno de los dos cuelga, y la conexión de termina y se libera el circuito.
Entonces se termina la llamada.
Los protocolos orientados a no-conexión difieren bastante a los orientados a conexión, ya que
estos (los de no-conexión) no proveen capacidad de control de error, secuencia y control de
flujo. Los protocolos orientados a no-conexión, están siempre en la fase de transferencia de
datos, y no les interesa las fases restantes de configuración y liberación de una conexión.
Los protocolos orientados a no-conexión se emplean en aplicaciones donde no se requiera
mucha precisión. Tal es el caso de la voz, música o el video. Pero en cambio en aplicaciones
donde se requiera mucha precisión [transacciones electrónicas bancarias, archivos de datos,
comercio electrónico, etc.] se utilizarían los protocolos orientados a conexión.
Protocolos ORIENTADOS A BITS y ORIENTADOS A BYTE (caracter)
En cualquier sesión de comunicación entre dispositivos, códigos de control son usados para
controlar otro dispositivo o proveer información acerca del estatus de la sesión. Los protocolos
orientados a byte o caracter utilizan bytes completos para representar códigos de control
establecidos tales como los definidos por el código ASCII (American Standard Code for
Information Interchange) o código EBCDIC (Extended Binary Coded Decimal Interchange Code).

En contraste, los protocolos orientados a bits confian en bits individuales para códigos de
control. Los protocolos orientados a Byte transmiten los datos como si fueran cadenas de
caracteres. El método de transmisión es asíncrono. Cada caracter es separado de un bit de
inicio y un bit de paro o termino, y no es necesario un mecanismo de reloj.
Ejemplos de caracteres usados: SYN (synchronize), SOH (start of header), STX (start of text),
ETX (end of text).
BIT oriented protocols
En una transmisión orientada a bit, los datos son transmitidos como constantes ráfagas de bits.
Antes de que la transmisión de datos empiece, caracteres especiales de sincronía son
transmitidos por el transmisor, así el receptor puede sincronizarse a sí mismo con la ráfaga de
bits. Este patrón de bits es comunmente representado en una cadena de 8 bits.
SDLC (Synchronous Data Link Control) de IBM es un protocolo orientado a bits. Su caracter de
sincronia (sync) es la cadena de bits 01111110, y esto es seguido por una dirección de 8 bits,
un campo de control y por por los datos (información útil). Una vez que el sistema receptor
recibe esas tramas iniciales, empieza a leer 8 bits a la vez (1 byte) desde la cadena de bits hasta
que aparezca un error o una bandera de término. Los protocolos SDLC y HDLC (High-level Data
Link Control) de IBM son orientados a bit. HDLC es usado comúnmente en las redes de
conmutación de paquetes X.25, SDLC es un subconjunto de HDLC.
Los protocolos orientados a bits son los usados comúnmente en la transmisión en las redes de
datos LAN y WAN.
3.3.2 Datagramas y Circuitos Virtuales
El concepto de circuito virtual se refiere a una asociación bidireccional, a través de la red, entre
dos ETD, circuito sobre el cual se realiza la transmisión de los paquetes.
Al inicio, se requiere una fase de establecimiento de la conexión, denominado: “llamada
virtual” Durante la llamada virtual los ETDs se preparan para el intercambio de paquetes y la
red reserva los recursos necesarios para el circuito virtual. Los paquetes de datos contienen
sólo el número del circuito virtual para identificar al destino.
Si la red usa encaminamiento adaptativo, el concepto de circuito virtual garantiza la
secuenciación de los paquetes, a través de un protocolo fin-a-fin (nodo origen/nodo destino).
El concepto de CV permite a un ETD establecer caminos de comunicación concurrentes con
varios otros ETDs, sobre un único canal físico de acceso a la red. El CV utiliza al enlace físico
sólo durante la transmisión del paquete.

Existen 2 tipos de CV
CVP: Circuito virtual permanente
CVT: Circuito virtual temporario
CVP: no requiere fase de establecimiento o llamada virtual por ser un circuito permanente
(punto a punto) entre ETDs.
CVT: Requiere de la llamada virtual.
El protocolo para uso de circuitos virtuales está establecido en la recomendación X.25 del
CCITT. (existe confirmación de mensajes recibidos, paquetes perdidos, etc.)
DATAGRAMAS
Es un paquete autosuficiente (análogo a un telegrama) el cual contiene información suficiente
para ser transportado a destino sin necesidad de, previamente, establecer un circuito.
No se provee confirmación de recepción por el destinatario, pero puede existir un aviso de no
entrega por parte de la red.
Algunas redes privadas trabajan en base a DATAGRAMAS, pero en redes públicas, donde
existen cargos por paquetes transmitidos, no existe buena acogida para este tipo de servicios.
Una alternativa al servicio de DATAGRAMA propuesto al CCITT, es la facilidad de selección
rápida o Fast Select, la cual es aplicable en la llamada virtual ð CVT Fast Select permite
transmitir datos en el campo de datos del paquete de control que establece el circuito virtual.
La respuesta confirma la recepción y termina el CV.
3.3.2.1 Estructura Conmutadores
3.3.2.2 Conmutacion de Paquetes
La conmutación es una técnica que nos sirve para hacer un uso eficiente de los enlaces físicos
en una red de computadoras. Si no existiese una técnica de conmutación en la comunicación
entre dos nodos, se tendría que enlazar en forma de malla. Una ventaja adicional de la
conmutación de paquetes, (además de la seguridad de transmisión de datos) es que como se
parte en paquetes el mensaje, éste se está ensamblando de una manera más rápida en el nodo
destino, ya que se están usando varios caminos para transmitir el mensaje, produciéndose un
fenómeno conocido como “transmisión en paralelo”. Además, si un mensaje tuviese un error
en un bit de información, y estuviésemos usando la conmutación de mensajes, tendríamos que
retransmitir todo el mensaje; mientras que con la conmutación de paquetes solo hay que

retransmitir el paquete con el bit afectado, lo cual es mucho menos problemático. Lo único
negativo, quizás, en el esquema de la conmutación de paquetes es que su encabezado es más
grande.
Ventajas generales: - Los paquetes forman una cola y se transmiten lo más rápido posible. -
Permiten la conversión en la velocidad de los datos. - La red puede seguir aceptando datos
aunque la transmisión se hará lenta. - Existe la posibilidad de manejar prioridades(si un grupo
de información es más importante que los otros, será transmitido antes que dichos otros).
Técnicas de Conmutación: Para la utilización de la Conmutación de Paquetes se han definido
dos tipos de técnicas: los Datagramas y los Circuitos Virtuales. Datagramas: Considerado el
método más sensible. - No tiene fase de establecimiento de llamada. - El paso de datos es más
seguro. - No todos los paquetes siguen una misma ruta. - Los paquetes pueden llegar al
destino en desorden debido a que su tratamiento es independiente. - Un paquete se puede
destruir en el camino, cuya recuperación es responsabilidad de la estación de destino.(esto da
a entender que el resto de paquetes están intactos) Circuitos Virtuales: - Son los más usados. -
Su funcionamiento es similar al de redes de conmutación de circuitos. - Previo a la transmisión
se establece la ruta previa a la transmisión de los paquetes por medio de paquetes de Petición
de Llamada (pide una conexión lógica al destino) y de Llamada Aceptada (en caso de que la
estación destino esté apta para la transmisión envía este tipo de paquete ); establecida la
transmisión, se da el intercambio de datos, y una vez terminado, se presenta el paquete de
Petición de Liberación(aviso de que la red está disponible, es decir que la transmisión ha
llegado a su fin). - Cada paquete tiene un identificador de circuito virtual en lugar de la
dirección del destino. - Los paquetes se recibirán en el mismo orden en que fueron enviados.
En síntesis, una red de conmutación de paquetes consiste en una “malla” de interconexiones
facilitadas por los servicios de telecomunicaciones, a través de la cual los paquetes viajan
desde la fuente hasta el destino.
3.3.3 Encaminamiento Redes de Paquetes
Cuando la red de conmutación de paquetes funciona en modo circuito virtual, generalmente la
función de encaminamiento establece una ruta que no cambia durante el tiempo de vida de
ese circuito virtual. En este caso el encaminamiento se decide por sesión.
Una red que funciona en modo datagrama no tiene el compromiso de garantizar la entrega
ordenada de los paquetes, por lo que los nodos pueden cambiar el criterio de encaminamiento
para cada paquete que ha de mandar. Cualquier cambio en la topología de la red tiene fácil
solución en cuanto a encaminamiento se refiere, una vez que el algoritmo correspondiente
haya descubierto el nuevo “camino óptimo.
3.3.4 Gestion de Trafico

En telefonía la gestión de tráfico o gestión de red es una actividad de administración de la red
telefónica cuyo objetivo es asegurar que el mayor número posible de llamadas telefónicas son
conectadas a su destino.
3.3.5 Control de Congestion
La congestión se refiere a la presencia en demasía de paquetes en una parte de una subred. En
casos de extrema congestión, los routers comienzan a “rechazar” paquetes, disminuyendo de
esta forma el rendimiento del sistema. Las razones de la congestión son muchas, entre ellas
están: • Por ejemplo, si por 4 líneas le llega información a un router y todas necesitan la misma
línea de salida → competencia. • Insuficiente cantidad de memoria en los routers. Pero añadir
más memoria ayuda hasta cierto punto solamente, ya que si tiene demasiada memoria, el
tiempo para llegar al primero de la cola puede ser demasiado. • Procesadores lentos en los
routers. El proceso de “analizar” los paquetes es caro, así que procesadores lentos pueden
provocar congestión. A. El control de flujo y el control de la congestión no son lo mismo:
Control de Flujo: se preocupa de que un emisor rápido no sature a un receptor lento.
Control de Congestión: su función es tratar de evitar que se sobrecargue la red.
El control de flujo es una más de las técnicas para combatir la congestión. Se consigue con ella
parar a aquellas fuentes que vierten a la red un tráfico excesivo. Las soluciones para el
problema de la congestión se pueden dividir en dos clases: Open Loop: Tratan de resolver el
problema con un buen diseño. Usan algoritmos para decidir cuando aceptar más paquetes,
cuando descartarlos, etc. Pero no utilizan el actual estado de la red. Closed Loop: La solución
en este caso se basa en la retroalimentación de la línea. Por lo general tienen tres partes: 1.
Monitorean el sistema para detectar cuándo y dónde ocurre la congestión. 2. Se pasa esta
información hacia donde se puedan tomar acciones. 3. Se ajustan los parámetros de operación
del sistema para corregir los problemas. Varias medidas del rendimiento pueden ser usadas
para medir la congestión.
Unidad 4 TCP/IP
4.1 Modelo Cliente Servidor
TCP es un protocolo orientado a conexión. No hay relaciones maestro/esclavo. Las
aplicaciones, sin embargo, utilizan un modelo cliente/servidor en las comunicaciones.
Un servidor es una aplicación que ofrece un servicio a usuarios de Internet; un cliente es el que
pide ese servicio. Una aplicación consta de una parte de servidor y una de cliente, que se
pueden ejecutar en el mismo o en diferentes sistemas.
Los usuarios invocan la parte cliente de la aplicación, que construye una solicitud para ese
servicio y se la envía al servidor de la aplicación que usa TCP/IP como transporte.

El servidor es un programa que recibe una solicitud, realiza el servicio requerido y devuelve los
resultados en forma de una respuesta. Generalmente un servidor puede tratar múltiples
peticiones(múltiples clientes) al mismo tiempo.
4.2 Protocolo de Internet Ip movil
IP Móvil Movilidad de terminales en Internet Originalmente, los métodos de enrutamiento
fueron definidos para redes estáticas, sin considerar que un terminal o nodo pudiese
desplazase de una red o subred a otra. El enrutamiento toma ventaja del “prefijo de red” que
contiene cada dirección IP para conocer la ubicación física de una computadora y por defecto,
dicha ubicación es fija.
La movilidad de terminales toma relevancia día a día debido al creciente uso de computadoras
portátiles y al deseo de sus usuarios de mantenerse continuamente conectados a Internet.
El Protocolo IP Móvil define procedimientos por los cuales los paquetes pueden ser enrutados
a un nodo móvil, independientemente de su ubicación actual y sin cambiar su dirección IP. Los
paquetes destinados a un nodo móvil primeramente son dirigidos a su red local. Allí, un agente
local los intercepta y mediante un túnel los reenvía a la dirección temporal recientemente
informada por el nodo móvil. En el punto final del túnel un agente foráneo recibe los paquetes
y los entrega al nodo móvil.
Este documento pretende describir el desarrollo actual del protocolo de Internet diseñado
para soportar movilidad de terminales, pudiendo ser usado como punto de partida válido por
todo aquél que desee iniciarse en el tema. Luego de consultar el nutrido acervo bibliográfico,
se expone en primer lugar, características y terminología, posteriormente su funcionamiento y
evolución. Por último se comentan problemas a cuestiones del protocolo, y posibles
soluciones.
Tomando fuente, encapsulador, desencapsulador y destino como nodos independientes. El
nodo que encapsula paquetes (encapsulador) es considerado el punto de entrada al túnel y el
nodo que los desencapsula el punto de salida del túnel. En general, pueden existir múltiples
pares fuente-destino usando el mismo túnel entre encapsulador-desencapsulador.
“El mecanismo de encapsulamiento por defecto que debe ser soportado por todos los agentes
de movilidad que usen IP Móvil, es IP-within-IP”.
Encapsulado IP-dentrode-IP - IP-within-IP- El encapsulado IP-dentro de-IP (IP-within-IP)
consiste en insertar una cabecera IP adicional antes de la cabecera propia del paquete inicial.
También es posible insertar otras cabeceras entre las dos cabeceras anteriores. (Figura 5).
El encabezado IP exterior contiene información sobre los extremos del túnel, es decir, la
dirección fuente y la dirección destino. El encabezado interior contiene información sobre la

dirección fuente y la dirección destino de los nodos emisor y receptor respectivamente del
paquete original y no puede ser modificado en ningún caso, salvo para decrementar el tiempo
de vida – TTL (Time To Live) - del paquete.
Los campos en el encabezado IP exterior son establecidos por el encapsulador como sigue:
Versión: 4 Longitud del encabezado de Internet: longitud del encabezado IP exterior medido
en palabras de 32-bits Tipo de servicio: es copiado del encabezado IP interior. Longitud total:
mide la longitud total del paquete IP encapsulado, incluyendo los dos encabezados, interior y
exterior, y la carga -payload-. Identificación, banderas y bit no-fragmentación: si el bit de “no
fragmento” se encuentra seteado en el encabezado interior, también debe estar seteado en el
encabezado exterior. Si el bit de “no fragmento” no está seteado en el encabezado interior,
éste podría ser seteado en el encabezado exterior. Tiempo de vida (TTL): este campo es
seteado con un valor apropiado en el encabezado exterior para entregar los paquetes
encapsulados al punto de salida del túnel. Protocolo: 4 Suma de comprobación del
encabezado: suma de comprobación en el encabezado IP exterior. Dirección fuente: la
dirección IP del encapsulador, es decir, el punto de entrada al túnel. Dirección destino: la
dirección IP del desencapsulador, el punto de salida del túnel. Opciones: algunas de las
opciones presentes en el encabezado IP interior no son copiadas en el encabezado IP exterior.
Durante el encapsulamiento del paquete, el TTL en el encabezado IP interior es decrementado
en uno si se encuentra dentro del túnel como parte del reenvío del paquete; en otro caso el
TTL no se modifica. Si el TTL resultante dentro del encabezado IP interior es igual a cero, el
paquete es descartado y un mensaje ICMP de tiempo excedido podría ser enviado al emisor.
El TTL del encabezado IP interior no cambia durante el desencapsulamiento. Si después de este
proceso el paquete interno tiene un TTL=0, el desencapsulador debe descartar al paquete. Si
después del desencapsulamiento, el desencapsulador reenvía el paquete a una de sus
interfaces, decrementa el TTL como en un reenvío normal.
El encapsulador generalmente usa las opciones IP permitidas para entregar la carga
encapsulada al final del túnel, puede usar también la fragmentación, a menos que esté
seteado el bit de no-fragmentación
Encapsulado mínimo El encapsulado mínimo es un método por el cual un paquete puede ser
encapsulado (conducido como carga) dentro de un paquete IP con menos gasto (overhead)
que la encapsulación IP-dentrode-IP, que agrega un segundo encabezado IP a cada paquete
encapsulado. Este método es levemente más complicado dado que la información de los
encabezados, interior y exterior, es combinada para reconstruir el encabezado IP original y en
consecuencia, reduce el gasto del encabezado.

Se define un encabezado de reenvío mínimo por paquetes no fragmentados antes de la
encapsulación. El uso de este método es opcional. El encapsulado mínimo no debe usarse
cuando un paquete original ya ha sido fragmentado, dado que no hay lugar en el encabezado
de reenvío mínimo para almacenar información de la fragmentación. Para encapsular un
paquete usando encapsulación mínima (Figura 6), se modifica el encabezado IP del paquete
original y se inserta el encabezado de reenvío mínimo después del encabezado IP, seguido por
la carga IP no modificada del paquete original (como por ejemplo encabezado y datos de
transporte). No se requiere agregar al paquete un encabezado IP adicional.
En el encapsulamiento, el encabezado IP del paquete original es modificado:
El campo protocolo en el encabezado IP es reemplazado por el número 55 El campo dirección
destino en el encabezado IP es reemplazado por la dirección IP del punto de salida del túnel. Si
el encapsulador no es la fuente original del paquete, el campo dirección fuente en el
encabezado IP es reemplazado por la dirección IP del encapsulador. El campo longitud total es
incrementado por el tamaño del encabezado de reenvío mínimo. El campo suma de
comprobación encabezado es recalculado en base a los cambios descriptos. A diferencia de la
encapsulación IP-dentrode-IP, el campo TTL en el encabezado IP no es modificado durante la
encapsulación, si el encapsulador está reenviando el paquete, éste podría decrementar el TTL
como resultado de un ruteo IP normal. Dado que el TTL original permanece en el encabezado
IP después de la encapsulación, los datos tomados por el paquete dentro del túnel son visibles,
por ejemplo realizando un “tracerouter”.
Protocolo: copiado del campo protocolo en el encabezado IP original Dirección fuente original
presente (S): si es igual a cero indica que el campo dirección fuente original no está presente.
Si es igual a uno indica que sí está presente. Reservado: seteado en cero, ignorado sobre
recepción. Suma de comprobación encabezado: suma de comprobación. Dirección destino
original: copiado del campo dirección destino del encabezado IP original. Dirección fuente
original: copiado del campo dirección fuente del encabezado IP original. Cuando un paquete es
desencapsulado, los campos en el encabezado de reenvío son restaurados a los del
encabezado IP y el encabezado de reenvío es removido del paquete. Además, al campo
longitud total en el encabezado IP se le resta el tamaño del encabezado de reenvío mínimo
removido y el campo suma de comprobación encabezado es recalculado en base a los cambios
producidos en el encabezado IP a raíz de la desencapsulación.
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 Protocolo S Reservado Suma
Comprobación Encabezado Dirección Destino Original Dirección Fuente Original (si está
presente)

Encapsulado GRE El encapsulado GRE (Generic Record Encapsulation) es el más flexible ya que
permite la encapsulación de cualquier tipo de paquete, incluidos los paquetes IP. El formato de
un paquete GRE consta de una cabecera externa, seguida de la cabecera GRE, y de los datos IP.
Contrariamente a los encapsulados IP-dentro de-IP y mínimo, el encapsulado GRE ha sido
específicamente diseñado para prevenir encapsulamientos recursivos. Concretamente, el
campo recur en la cabecera GRE es un contador que informa del número de encapsulados
adicionales que son permitidos.
4.3 Protocolos de Transporte Udp Tcp
El grupo de protocolos de Internet también maneja un protocolo de transporte sin conexiones,
el UDP (User Data Protocol, protocolo de datos de usuario). El UDP ofrece a las aplicaciones un
mecanismo para enviar datagramas IP en bruto encapsulados sin tener que establecer una
conexión. Muchas aplicaciones cliente-servidor que tienen una solicitud y una respuesta usan
el UDP en lugar de tomarse la molestia de establecer y luego liberar una conexión. El UDP se
describe en el RFC 768. Un segmento UDP consiste en una cabecera de 8 bytes seguida de los
datos. La cabecera se muestra a continuación. Los dos puertos sirven para lo mismo que en el
TCP: para identificar los puntos terminales de las máquinas origen y destino. El campo de
longitud UDP incluye la cabecera de 8 bytes y los datos. La suma de comprobación UDP incluye
la misma pseudocabecera de formato, la cabecera UDP, y los datos, rellenados con una
cantidad par de bytes de ser necesario. UDP no admite numeración de los datagramas, factor
que, sumado a que tampoco utiliza señales de confirmación de entrega, hace que la garantía
de que un paquete llegue a su destino sea mucho menor que si se usa TCP. Esto también
origina que los datagramas pueden llegar duplicados y/o desordenados a su destino. Por estos
motivos el control de envío de datagramas, si existe, debe ser implementado por las
aplicaciones que usan UDP como medio de transporte de datos, al igual que el reeensamble de
los mensajes entrantes. Es por ello un protocolo del tipo best-effort (máximo esfuerzo),
porque hace lo que puede para transmitir los datagramas hacia la aplicación, pero no puede
garantizar que la aplicación los reciba.
Tcp
Protocolo TCP/IP Una red es una configuración de computadora que intercambia información.
Pueden proceder de una variedad de fabricantes y es probable que tenga diferencias tanto en
hardware como en software, para posibilitar la comunicación entre estas es necesario un
conjunto de reglas formales para su interacción. A estas reglas se les denominan protocolos.
Un protocolo es un conjunto de reglas establecidas entre dos dispositivos para permitir la
comunicación entre ambos.
DEFINICION TCP / IP

Se han desarrollado diferentes familias de protocolos para comunicación por red de datos para
los sistemas UNIX. El más ampliamente utilizado es el Internet Protocol Suite, comúnmente
conocido como TCP / IP.
Es un protocolo DARPA que proporciona transmisión fiable de paquetes de datos sobre redes.
El nombre TCP / IP Proviene de dos protocolos importantes de la familia, el Transmission
Contorl Protocol (TCP) y el Internet Protocol (IP). Todos juntos llegan a ser más de 100
protocolos diferentes definidos en este conjunto.
El TCP / IP es la base del Internet que sirve para enlazar computadoras que utilizan diferentes
sistemas operativos, incluyendo PC, minicomputadoras y computadoras centrales sobre redes
de área local y área extensa. TCP / IP fue desarrollado y demostrado por primera vez en 1972
por el departamento de defensa de los Estados Unidos, ejecutándolo en el ARPANET una red
de área extensa del departamento de
4.4 Protocolos Nivel Aplicacion
El nivel de aplicación es el nivel que los programas más comunes utilizan para comunicarse a
través de una red con otros programas. Los procesos que acontecen en este nivel son
aplicaciones específicas que pasan los datos al nivel de aplicación en el formato que
internamente use el programa y es codificado de acuerdo con un protocolo estándar.Algunos
programas específicos se considera que se ejecutan en este nivel. Proporcionan servicios que
directamente trabajan con las aplicaciones de usuario. Estos programas y sus correspondientes
protocolos incluyen a HTTP (Hyper Text Transfer Protocol), FTP (Transferencia de archivos),
SMTP (correo electrónico), SSH (login remoto seguro), DNS (Resolución de nombres de
dominio) y a muchos otros.Una vez que los datos de la aplicación han sido codificados en un
protocolo estándar del nivel de aplicación son pasados hacia abajo al siguiente nivel de la pila
de protocolos TCP/IP.
En el nivel de transporte, las aplicaciones normalmente hacen uso de TCP y UDP, y son
habitualmente asociados a un número de puerto bien conocido (well-known port). Los puertos
fueron asignados originalmente por la IANA.
El protocolo de transferencia de hipertexto (HTTP, Hyper Text Transfer Protocol) es el
protocolo usado en cada transacción de la Web (WWW). HTTP fue desarrollado por el
consorcio W3C y la IETF, colaboración que culminó en 1999 con la publicación de una serie de
RFC, siendo el más importante de ellos el RFC 2616, que especifica la versión 1.1. HTTP define
la sintaxis y la semántica que utilizan los elementos software de la arquitectura web (clientes,
servidores, proxies) para comunicarse. Es un protocolo orientado a transacciones y sigue el
esquema petición-respuesta entre un cliente y un servidor. Al cliente que efectúa la petición
(un navegador o un spider) se lo conoce como “user agent” (agente del usuario). A la

información transmitida se la llama recurso y se la identifica mediante un URL. Los recursos
pueden ser archivos, el resultado de la ejecución de un programa, una consulta a una base de
datos, la traducción automática de un documento, etc.
HTTP es un protocolo sin estado, es decir, que no guarda ninguna información sobre
conexiones anteriores. El desarrollo de aplicaciones web necesita frecuentemente mantener
estado. Para esto se usan las cookies, que es información que un servidor puede almacenar en
el sistema cliente. Esto le permite a las aplicaciones web instituir la noción de “sesión”, y
también permite rastrear usuarios ya que las cookies pueden guardarse en el cliente por
tiempo indeterminado.
Transacciones HTTP
Una transacción HTTP está formada por un encabezado seguido, opcionalmente, por una línea
en blanco y algún dato. El encabezado especificará cosas como la acción requerida del
servidor, o el tipo de dato retornado, o el código de estado.
FTP (sigla en inglés de File Transfer Protocol - Protocolo de Transferencia de Archivos) en
informática, es un protocolo de red para la transferencia de archivos entre sistemas
conectados a una red TCP (Transmission Control Protocol), basado en la arquitectura cliente-
servidor. Desde un equipo cliente se puede conectar a un servidor para descargar archivos
desde él o para enviarle archivos, independientemente del sistema operativo utilizado en cada
equipo.
El Servicio FTP es ofrecido por la capa de Aplicación del modelo de capas de red TCP/IP al
usuario, utilizando normalmente el puerto de red 20 y el 21. Un problema básico de FTP es que
está pensado para ofrecer la máxima velocidad en la conexión, pero no la máxima seguridad,
ya que todo el intercambio de información, desde el login y password del usuario en el
servidor hasta la transferencia de cualquier archivo, se realiza en texto plano sin ningún tipo de
cifrado, con lo que un posible atacante puede capturar este tráfico, acceder al servidor, o
apropiarse de los archivos transferidos.
Para solucionar este problema son de gran utilidad aplicaciones como scp y sftp, incluidas en el
paquete SSH, que permiten transferir archivos pero cifrando todo el tráfico.
Simple Mail Transfer Protocol (SMTP) Protocolo Simple de Transferencia de Correo, es un
protocolo de la capa de aplicación. Protocolo de red basado en texto utilizado para el
intercambio de mensajes de correo electrónico entre computadoras u otros dispositivos
(PDA’s, teléfonos móviles, etc.). Está definido en el RFC 2821 y es un estándar oficial de
Internet.
Resumen simple del funcionamiento del protocolo SMTP [editar]

• Cuando un cliente establece una conexión con el servidor SMTP, espera a que éste envíe un
mensaje “220 Service ready” o “421 Service non available”
• Se envía un HELO desde el cliente. Con ello el servidor se identifica. Esto puede usarse para
comprobar si se conectó con el servidor SMTP correcto.
• El cliente comienza la transacción del correo con la orden MAIL FROM. Como argumento de
esta orden se puede pasar la dirección de correo al que el servidor notificará cualquier fallo en
el envío del correo (Por ejemplo, MAIL FROM:<fuente@host0>). Luego si el servidor
comprueba si el origen es valido, si es asi el servidor responde “250 OK”.
• Ya le hemos dicho al servidor que queremos mandar un correo, ahora hay que comunicarle a
quien. La orden para esto es RCPT TO:<destino@host>. Se pueden mandar tantas órdenes
RCPT como destinatarios del correo queramos. Por cada destinatario, el servidor contestará
“250 OK” o bien “550 No such user here”, si no encuentra al destinatario.
• Una vez enviados todos los RCPT, el cliente envía una orden DATA para indicar que a
continuación se envían los contenidos del mensaje. El servidor responde “354 Start mail input,
end with <CRLF>.<CRLF>” Esto indica al cliente como ha de notificar el fin del mensaje.
• Ahora el cliente envía el cuerpo del mensaje, línea a línea. Una vez finalizado, se termina con
un <CRLF>.<CRLF> (la última línea será un punto), a lo que el servidor contestará “250 OK”, o
un mensaje de error apropiado.
• Tras el envío, el cliente, si no tiene que enviar más correos, con la orden QUIT corta la
conexión. También puede usar la orden TURN, con lo que el cliente pasa a ser el servidor, y el
servidor se convierte en cliente. Finalmente, si tiene más mensajes que enviar, repite el
proceso hasta completarlos.
Características
POP3 está diseñado para recibir correo, no para enviarlo; le permite a los usuarios con
conexiones intermitentes ó muy lentas (tales como las conexiones por módem), descargar su
correo electrónico mientras tienen conexión y revisarlo posteriormente incluso estando
desconectados. Cabe mencionar que la mayoría de los clientes de correo incluyen la opción de
dejar los mensajes en el servidor, de manera tal que, un cliente que utilice POP3 se conecta,
obtiene todos los mensajes, los almacena en la computadora del usuario como mensajes
nuevos, los elimina del servidor y finalmente se desconecta. En contraste, el protocolo IMAP
permite los modos de operación conectado y desconectado.
Los clientes de correo electrónico que utilizan IMAP dejan por lo general los mensajes en el
servidor hasta que el usuario los elimina directamente. Esto y otros factores hacen que la

operación de IMAP permita a múltiples clientes acceder al mismo buzón de correo. La mayoría
de los clientes de correo electrónico soportan POP3 ó IMAP; sin embargo, solo unos cuantos
proveedores de internet ofrecen IMAP como valor agregado de sus servicios.
DNS
El sistema de nombre de dominio (en inglés Domain Name System, DNS) es un sistema de
nomenclatura jerárquica para computadoras, servicios o cualquier recurso conectado al
internet o a una red privada. Este sistema asocia información variada con nombres de
dominios asignado a cada uno de los participantes. Su función más importante, es traducir
(resolver) nombres inteligibles para los humanos en identificadores binarios asociados con los
equipos conectados a la red, esto con el propósito de poder localizar y direccionar estos
equipos mundialmente.
DNS en el mundo real
Los usuarios generalmente no se comunican directamente con el servidor DNS: la resolución
de nombres se hace de forma transparente por las aplicaciones del cliente (por ejemplo,
navegadores, clientes de correo y otras aplicaciones que usan Internet). Al realizar una
petición que requiere una búsqueda de DNS, la petición se envía al servidor DNS local del
sistema operativo. El sistema operativo, antes de establecer ninguna comunicación,
comprueba si la respuesta se encuentra en la memoria caché. En el caso de que no se
encuentre, la petición se enviará a uno o más servidores DNS.
La mayoría de usuarios domésticos utilizan como servidor DNS el proporcionado por el
proveedor de servicios de Internet. La dirección de estos servidores puede ser configurada de
forma manual o automática mediante DHCP. En otros casos, los administradores de red tienen
configurados sus propios servidores DNS.
En cualquier caso, los servidores DNS que reciben la petición, buscan en primer lugar si
disponen de la respuesta en la memoria caché. Si es así, sirven la respuesta; en caso contrario,
iniciarían la búsqueda de manera recursiva. Una vez encontrada la respuesta, el servidor DNS
guardará el resultado en su memoria caché para futuros usos y devuelve el resultado.
NFS
El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de
aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un
entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a
una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue
desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la
máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está

implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión) .[1] El protocolo
NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones
Linux.
Características
• El sistema NFS está dividido al menos en dos partes principales: un servidor y uno o más
clientes. Los clientes acceden de forma remota a los datos que se encuentran almacenados en
el servidor.
• Las estaciones de trabajo locales utilizan menos espacio de disco debido a que los datos se
encuentran centralizados en un único lugar pero pueden ser accedidos y modificados por
varios usuarios, de tal forma que no es necesario replicar la información.
• Los usuarios no necesitan disponer de un directorio “home” en cada una de las máquinas de
la organización. Los directorios “home” pueden crearse en el servidor de NFS para
posteriormente poder acceder a ellos desde cualquier máquina a través de la infraestructura
de red.
• También se pueden compartir a través de la red dispositivos de almacenamiento como
disqueteras, CD-ROM y unidades ZIP. Esto puede reducir la inversión en dichos dispositivos y
mejorar el aprovechamiento del hardware existente en la organización.
Todas las operaciones sobre ficheros son síncronas. Esto significa que la operación sólo retorna
cuando el servidor ha completado todo el trabajo asociado para esa operación. En caso de una
solicitud de escritura, el servidor escribirá físicamente los datos en el disco, y si es necesario,
actualizará la estructura de directorios, antes de devolver una respuesta al cliente. Esto
garantiza la integridad de los ficheros
4.4.1 Smtp Protocolo
Simple Mail Transfer Protocol (SMTP), o protocolo simple de transferencia de correo.
Protocolo de red basado en texto utilizado para el intercambio de mensajes de correo
electrónico entre computadoras o distintos dispositivos (PDA’s, teléfonos móviles, etc.). Está
definido en el RFC 2821 y es un estándar oficial de Internet.
Con el tiempo se ha convertido en uno de los protocolos más usados en internet. Para
adaptarse a las nuevas necesidades surgidas del crecimiento y popularidad de internet se han
hecho varias ampliaciones a este protocolo, como poder enviar texto con formato o archivos
adjuntos.
Funcionamiento [editar]SMTP se basa en el modelo cliente-servidor, donde un cliente envía
un mensaje a uno o varios receptores. La comunicación entre el cliente y el servidor consiste
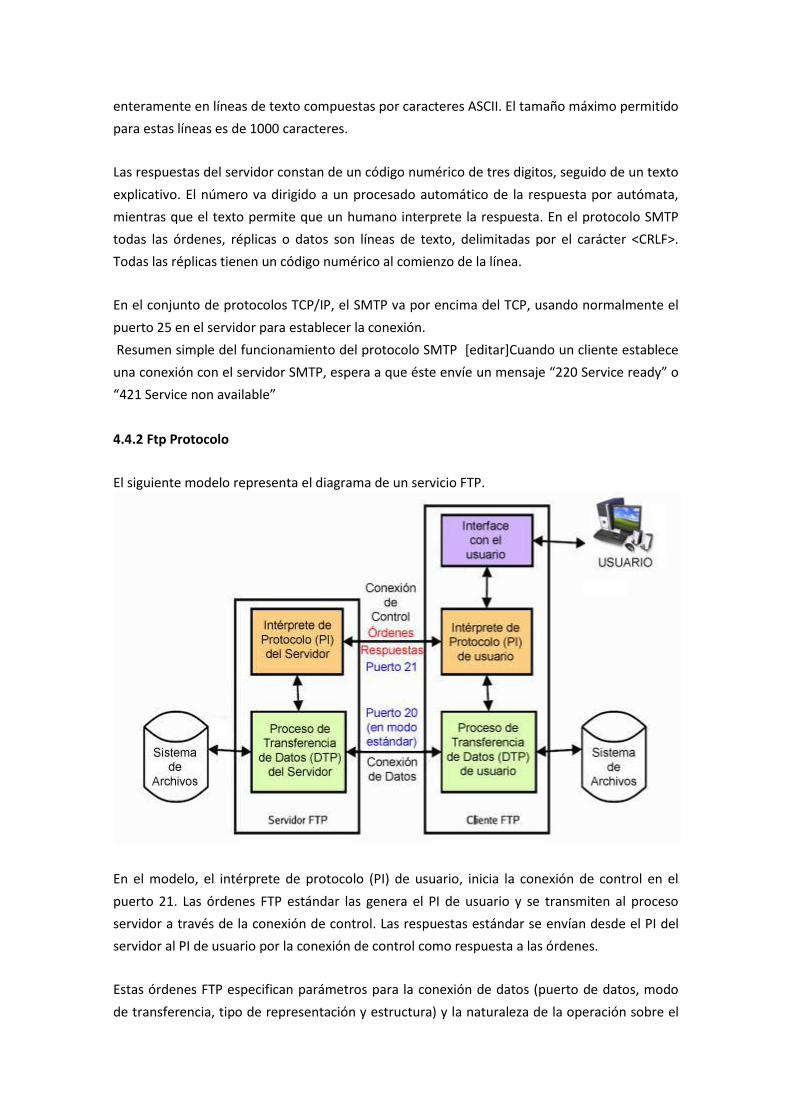
enteramente en líneas de texto compuestas por caracteres ASCII. El tamaño máximo permitido
para estas líneas es de 1000 caracteres.
Las respuestas del servidor constan de un código numérico de tres digitos, seguido de un texto
explicativo. El número va dirigido a un procesado automático de la respuesta por autómata,
mientras que el texto permite que un humano interprete la respuesta. En el protocolo SMTP
todas las órdenes, réplicas o datos son líneas de texto, delimitadas por el carácter <CRLF>.
Todas las réplicas tienen un código numérico al comienzo de la línea.
En el conjunto de protocolos TCP/IP, el SMTP va por encima del TCP, usando normalmente el
puerto 25 en el servidor para establecer la conexión.
Resumen simple del funcionamiento del protocolo SMTP [editar]Cuando un cliente establece
una conexión con el servidor SMTP, espera a que éste envíe un mensaje “220 Service ready” o
“421 Service non available”
4.4.2 Ftp Protocolo
El siguiente modelo representa el diagrama de un servicio FTP.
En el modelo, el intérprete de protocolo (PI) de usuario, inicia la conexión de control en el
puerto 21. Las órdenes FTP estándar las genera el PI de usuario y se transmiten al proceso
servidor a través de la conexión de control. Las respuestas estándar se envían desde el PI del
servidor al PI de usuario por la conexión de control como respuesta a las órdenes.
Estas órdenes FTP especifican parámetros para la conexión de datos (puerto de datos, modo
de transferencia, tipo de representación y estructura) y la naturaleza de la operación sobre el

sistema de archivos (almacenar, recuperar, añadir, borrar, etc.). El proceso de transferencia de
datos (DTP) de usuario u otro proceso en su lugar, debe esperar a que el servidor inicie la
conexión al puerto de datos especificado (puerto 20 en modo activo o estándar) y transferir los
datos en función de los parámetros que se hayan especificado.
Vemos también en el diagrama que la comunicación entre cliente y servidor es independiente
del sistema de archivos utilizado en cada ordenador, de manera que no importa que sus
sistemas operativos sean distintos, porque las entidades que se comunican entre sí son los PI y
los DTP, que usan el mismo protocolo estandarizado: el FTP.
También hay que destacar que la conexión de datos es bidireccional, es decir, se puede usar
simultáneamente para enviar y para recibir, y no tiene por qué existir todo el tiempo que dura
la conexión FTP.
Servidor FTP
Un servidor FTP es un programa especial que se ejecuta en un equipo servidor normalmente
conectado a Internet (aunque puede estar conectado a otros tipos de redes, LAN, MAN, etc.).
Su función es permitir el intercambio de datos entre diferentes servidores/ordenadores.
Por lo general, los programas servidores FTP no suelen encontrarse en los ordenadores
personales, por lo que un usuario normalmente utilizará el FTP para conectarse remotamente
a uno y así intercambiar información con él.
Las aplicaciones más comunes de los servidores FTP suelen ser el alojamiento web, en el que
sus clientes utilizan el servicio para subir sus páginas web y sus archivos correspondientes; o
como servidor de backup (copia de seguridad) de los archivos importantes que pueda tener
una empresa. Para ello, existen protocolos de comunicación FTP para que los datos se
transmitan cifrados, como el SFTP (Secure File Transfer Protocol).
Cliente FTP
Cuando un navegador no está equipado con la función FTP, o si se quiere cargar archivos en un
ordenador remoto, se necesitará utilizar un programa cliente FTP. Un cliente FTP es un
programa que se instala en el ordenador del usuario, y que emplea el protocolo FTP para
conectarse a un servidor FTP y transferir archivos, ya sea para descargarlos o para subirlos.
Para utilizar un cliente FTP, se necesita conocer el nombre del archivo, el ordenador en que
reside (servidor, en el caso de descarga de archivos), el ordenador al que se quiere transferir el
archivo (en caso de querer subirlo nosotros al servidor), y la carpeta en la que se encuentra.

Algunos clientes de FTP básicos en modo consola vienen integrados en los sistemas operativos,
incluyendo Windows, DOS, Linux y Unix. Sin embargo, hay disponibles clientes con opciones
añadidas e interfaz gráfica. Aunque muchos navegadores tienen ya integrado FTP, es más
confiable a la hora de conectarse con servidores FTP no anónimos utilizar un programa cliente.
4.4.3 http Protocolo
El Protocolo de Transferencia de Hiper Texto (Hypertext Transfer Protocol) es un sencillo
protocolo cliente-servidor que articula los intercambios de información entre los clientes Web
y los servidores HTTP. La especificación completa del protocolo HTTP 1/0 está recogida en el
RFC 1945. Fue propuesto por Tim Berners-Lee, atendiendo a las necesidades de un sistema
global de distribución de información como el World Wide Web.
Cachés de páginas y servidores proxy
Muchos clientes Web utilizan un sistema para reducir el número de accesos y transferencias
de información a través de Internet, y así agilizar la presentación de documentos previamente
visitados. Para ello, almacenan en el disco del cliente una copia de las últimas páginas a las que
se ha accedido. Este mecanismo, denominado “caché de páginas”, mantiene la fecha de
acceso a un documento y comprueba, a través de un comando HEAD, la fecha actual de
modificación del mismo. En caso de que se detecte un cambio o actualización, el cliente
accederá, ahora a través de un GET, a recoger la nueva versión del fichero. En caso contrario,
se procederá a utilizar la copia local.
Un sistema parecido, pero con más funciones es el denominado “servidor proxy”. Este tipo de
servidor, una mezcla entre servidor HTTP y cliente Web, realiza las funciones de cache de
páginas para un gran número de clientes. Todos los clientes conectados a un proxy dejan que
éste sea el encargado de recoger las URLs solicitadas. De esta forma, en caso de que varios
clientes accedan a la misma página, el servidor proxy la podrá proporcionar con un único
acceso a la información original.
La principal ventaja de ambos sistemas es la drástica reducción de conexiones a Internet
necesarias, en caso de que los clientes accedan a un conjunto similar de páginas, como suele
ocurrir con mucha frecuencia. Además, determinadas organizaciones limitan, por motivos de
seguridad, los accesos desde su organización al exterior y viceversa. Para ello, se dispone de
sistemas denominados “cortafuegos” (firewalls), que son los únicos habilitados para
conectarse con el exterior. En este caso, el uso de un servidor proxy se vuelve indispensable.
En determinadas situaciones, el almacenamiento de páginas en un caché o en un proxy puede
hacer que se mantengan copias no actualizadas de la información, como por ejemplo en el
caso de trabajar con documentos generados dinámicamente. Para estas situaciones, los
servidores HTTP pueden informar a los clientes de la expiración del documento, o de la

imposibilidad de ser almacenado en un caché, utilizando la variable Expires en la respuesta del
servidor.
Magic Cookies
Las ‘galletas mágicas’ son una de las incorporaciones más recientes al protocolo HTTP, y son
parte del nuevo estándar HTTP/1.1. Las cookies son pequeños ficheros de texto que se
intercambian los clientes y servidores HTPP, para solucionar una de las principales deficiencias
del protocolo: la falta de información de estado entre dos transacciones. Fueron introducidas
por Netscape, y ahora han sido estandarizadas en el RFC 2109.
Cada intercambio de información con un servidor es completamente independiente del resto,
por lo que las aplicaciones CGI que necesitan recordar operaciones previas de un usuario (por
ejemplo, los supermercados electrónicos) pueden optar por dos soluciones, que complican
bastante su diseño: almacenar temporalmente en el sistema del servidor un registro de las
operaciones realizadas, con una determinada política para eliminarlas cuando no son
necesarias, o bien incluir esta información en el código HTML devuelto al cliente, como
campos HIDDEN de un formulario.
Las cookies son una solución más flexible a este problema. La primera vez que un usuario
accede a un determinado documento de un servidor, éste proporciona una cookie que
contiene datos que relacionarán posteriores operaciones. El cliente almacena la cookie en su
sistema para usarla después. En los futuros accesos a este servidor, el browser podrá
proporcionar la cookie original, que servirá de nexo entre este acceso y los anteriores. Todo
este proceso se realiza automáticamente, sin intervención del usuario. El siguiente ejemplo
muestra una cookie generada por la revista Rolling Stone.
4.4.4 Nfs Protocolo
El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de
aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un
entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a
una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue
desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la
máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está
implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión) .[1] El protocolo
NFS está incluido por defecto en los Sistemas Operativos UNIX y las distribuciones GNU/Linux.
Características [editar]El sistema NFS está dividido al menos en dos partes principales: un
servidor y uno o más clientes. Los clientes acceden de forma remota a los datos que se
encuentran almacenados en el servidor.

Las estaciones de trabajo locales utilizan menos espacio de disco debido a que los datos se
encuentran centralizados en un único lugar pero pueden ser accedidos y modificados por
varios usuarios, de tal forma que no es necesario replicar la información.
Los usuarios no necesitan disponer de un directorio “home” en cada una de las máquinas de la
organización. Los directorios “home” pueden crearse en el servidor de NFS para
posteriormente poder acceder a ellos desde cualquier máquina a través de la infraestructura
de red.
También se pueden compartir a través de la red dispositivos de almacenamiento como
disqueteras, CD-ROM y unidades ZIP. Esto puede reducir la inversión en dichos dispositivos y
mejorar el aprovechamiento del hardware existente en la organización.
Todas las operaciones sobre ficheros son síncronas. Esto significa que la operación sólo retorna
cuando el servidor ha completado todo el trabajo asociado para esa operación. En caso de una
solicitud de escritura, el servidor escribirá físicamente los datos en el disco, y si es necesario,
actualizará la estructura de directorios, antes de devolver una respuesta al cliente. Esto
garantiza la integridad de los ficheros.
4.4.5 Dns Protocolo
El DNS ( Domain Name System ) o Sistema de Nombres de Dominio es una base de datos
jerárquica y distribuida que almacena informacion sobre los nombres de dominio de de redes
cómo Internet. También llamamos DNS al protocolo de comunicación entre un cliente (
resolver ) y el servidor DNS.
La función más común de DNS es la traducción de nombres por direcciones IP, esto nos facilita
recordar la dirección de una máquina haciendo una consulta DNS y nos proporciona un modo
de acceso más fiable ya que por multiples motivos la dirección IP puede variar manteniendo el
mismo nombre de dominio.
El DNS usa el concepto de espacio de nombres distribuido. Los nombres simbólicos se agrupan
en zonas de autoridad, o más comúnmente, zonas. En cada una de estas zonas, uno o más
hosts tienen la tarea de mantener una base de datos de nombres simbólicos y direcciones IP y
de suministrar la función de servidor para los clientes que deseen traducir nombres simbólicos
a direcciones IP. Estos servidores de nombres locales se interconectan lógicamente en una
árbol jerárquico de dominios.
Cada zona contiene una parte del árbol o subárbol y los nombres de esa zona se administran
con independencia de los de otras zonas. La autoridad sobre zonas se delega en los servidores
de nombres. Normalmente, los servidores de nombres que tienen autoridad en zona tendrán
nombres de dominio de la misma, aunque no es imprescindible. En los puntos en los que un
dominio contiene un subárbol que cae en una zona diferente, se dice que el servidor /

servidores de nombres con autoridad sobre el dominio superior delegan autoridad al servidor /
servidores de nombres con autoridad sobre los subdominios. Los servidores de nombres
también pueden delegar autoridad en sí mismos; en este caso, el espacio de nombres sigue
dividido en zonas, pero la autoridad para ambas las ejerce el mismo servidor . La división por
zonas se realiza utilizando registros de recursos guardados en el DNS.


















