
Tècniques i Eines Bioinformàtiques
34
Tècniques i Eines Bioinformàtiques • Bioinformatics, Sequence and Genome Analysis David W. Mount • Flexible Pattern Matching in Strings (2002) Gonzalo Navarro and Mathieu Raffinot • Algorithms on strings (2001) M. Crochemore, C. Hancart and T. Lecroq • http://www-igm.univ-mlv.fr/~lecroq/string/index.html
-
Upload
kristen-wong -
Category
Documents
-
view
18 -
download
0
description
Tècniques i Eines Bioinformàtiques. Bioinformatics, Sequence and Genome Analysis David W. Mount Flexible Pattern Matching in Strings (2002) Gonzalo Navarro and Mathieu Raffinot Algorithms on strings (2001) M. Crochemore, C. Hancart and T. Lecroq - PowerPoint PPT Presentation
Transcript of Tècniques i Eines Bioinformàtiques

Tècniques i Eines Bioinformàtiques
•Bioinformatics, Sequence and Genome Analysis
David W. Mount
•Flexible Pattern Matching in Strings (2002)
Gonzalo Navarro and Mathieu Raffinot
•Algorithms on strings (2001)
M. Crochemore, C. Hancart and T. Lecroq
•http://www-igm.univ-mlv.fr/~lecroq/string/index.html

Algorismes i estructures eficients de cerca
String matching: definition of the problem (text,pattern)
depends on what we have: text or patterns• Exact matching:
• 1 pattern ---> The algorithm depends on |p| and ||
• k patterns ---> The algorithm depends on k, |p| and ||
• The text ----> Data structure for the text (suffix tree, ...)
• The patterns ---> Data structures for the patterns
• Approximate matching: • Dynamic programming • Sequence alignment (pairwise and multiple)

Approximate string matching
For instance, given the sequence
CTACTACTACGTGACTAATACTGATCGTAGCTAC…
search for the pattern ACTGA allowing one error…
… but what is the meaning of “one error”?

Edit distance
We accept three types of errors:
The edit distance d between two strings is the minimum number of
substitutions,insertions and deletionsneeded to transform the first string into the second one
d(ACT,ACT)= d(ACT,AC)= d(ACT,C)=d(ACT,)= d(AC,ATC)= d(ACTTG,ATCTG)=
3. Deletion: ACCGTGAT ACCGGAT
2. Insertion: ACCGTGAT ACCGATGAT
1. Mismatch: ACCGTGAT ACCGAGAT
Indel

Edit distance
We accept three types of errors:
The edit distance d between two strings is the minimum number of
substitutions,insertions and deletionsneeded to transform the first string into the second one
3. Deletion: ACCGTGAT ACCGGAT
2. Insertion: ACCGTGAT ACCGATGAT
1. Mismatch: ACCGTGAT ACCGAGAT
d(ACT,ACT)= d(ACT,AC)= d(ACT,C)=d(ACT,)= d(AC,ATC)= d(ACTTG,ATCTG)=
Indel
0 1 23 1 2

Edit distance and alignment of strings
• ACT and ACT : ACT ACT
• ACTTG and ATCTG:
• ACT and AT: ACT A -T
ACTTG ATCTG
ACT - TGA - TCTG
Given d(ACT,ACT)=0 d(ACT,AC)=1 d(ACTTG,ATCTG)=2which is the best alignment in every case?
The Edit distance is related with the best alignment of strings
Then, the alignment suggest the substitutions, insertions and deletions to transform one string into the other

Edit distance and alignment of strings
But which is the distance between the strings
ACGCTATGCTATACG and ACGGTAGTGACGC?
… and the best alignment between them?
1966 was the first time this problem was discussed…
and the algorithm was proposed in 1968,1970,…
using the technique called “Dynamic programming”

Edit distance and alignment of strings
C T A C T A C T A C G T
ACTGA

Edit distance and alignment of strings
C T A C T A C T A C G T
ACTGA

Edit distance and alignment of strings
C T A C T A C T A C G T ACTGA
The cell contains the distance between AC and CTACT.

Edit distance and alignment of strings
C T A C T A C T A C G T A C T GA
?

Edit distance and alignment of strings
C T A C T A C T A C G T 0 A C T GA
?

Edit distance and alignment of strings
C T A C T A C T A C G T 0 1 A C T GA
-C
?

Edit distance and alignment of strings
C T A C T A C T A C G T 0 1 2 A C T GA
- -CT
?

Edit distance and alignment of strings
C T A C T A C T A C G T 0 1 2 3 4 5 6 7 8 …A C T GA
- - - - - -CTACTA

Edit distance and alignment of strings
C T A C T A C T A C G T 0 1 2 3 4 5 6 7 8 …A ?C ?T ?GA

Edit distance and alignment of strings
C T A C T A C T A C G T 0 1 2 3 4 5 6 7 8 …A 1C 2T 3G…A
ACT - - -

C T A C T A C T A C G T 0 1 2 3 4 5 6 7 8 …A 1C 2T 3GA
C T A C T A C T A C G T A C TGA
Edit distance and alignment of strings
BA(AC,CTA) -C
BA(A,CTA)CC
BA(A,CTAC)C -
BA(AC,CTAC)= best
d(AC,CTAC)=min
d(AC,CTA)+1
d(A,CTA)
d(A,CTAC)+1

Edit distance and alignment of strings
Connect to
http://alggen.lsi.upc.es/docencia/ember/leed/Tfc1.htm
and use the global method.

Edit distance and alignment of strings
How this algorithm can be applied
to the approximate search?
to the K-approximate string searching?

K-approximate string searching
C T A C T A C T A C G T A C T G G T G A A …
ACTGA
This cell …

K-approximate string searching
C T A C T A C T A C G T A C T G G T G A A …
ACTGA
This cell gives the distance between (ACTGA, CT…GTA)…
…but we only are interested in the last characters
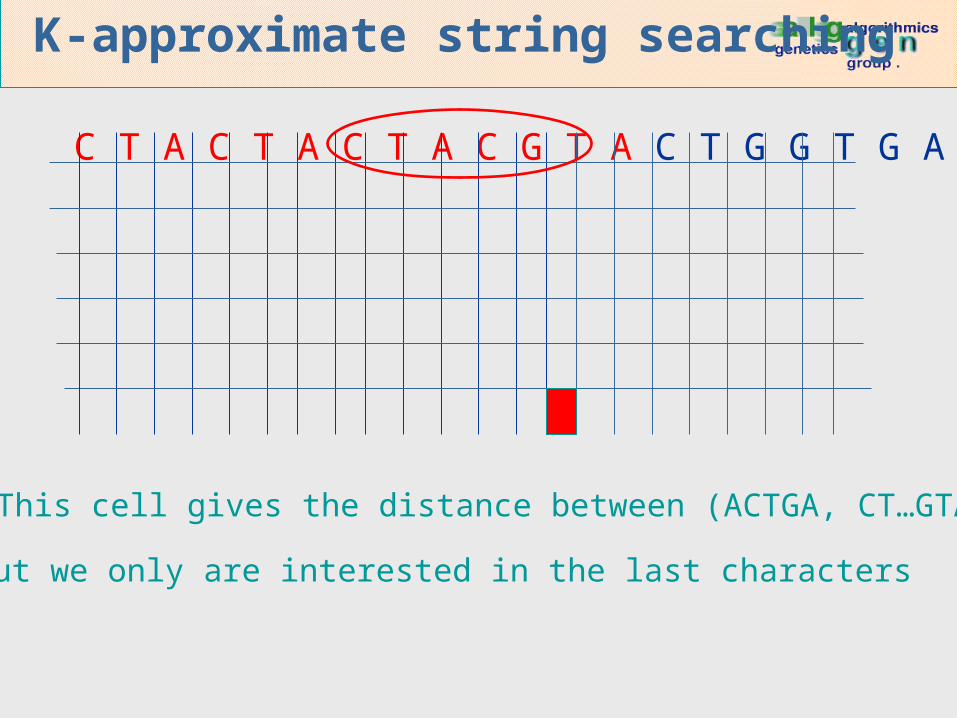
K-approximate string searching
C T A C T A C T A C G T A C T G G T G A A …
ACTGA
This cell gives the distance between (ACTGA, CT…GTA)…
…but we only are interested in the last characters

K-approximate string searching
* * * * * * C T A C G T A C T G G T G A A …
ACTGA
This cell gives the distance between (ACTGA, CT…GTA)…
…but we only are interested in the last characters…
…no matter where they appears in the text, then…

K-approximate string searching
* * * * * * C T A C G T A C T G G T G A A … 0ACTGA
This cell gives the distance between (ACTGA, CT…GTA)…
…but we only are interested in the last characters…
…no matter where they appears in the text, then…

K-approximate string searching
* * * * * * C T A C G T A C T G G T G A A … 0ACTGA
This cell gives the distance between (ACTGA, CT…GTA)…
…but we only are interested in the last characters…
…no matter where they appears in the text, then…

K-approximate string searching
C T A C T A C T A C G T A C T G G T G A A … 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0ACTGA
This cell gives the distance between (ACTGA, CT…GTA)…
…but we only are interested in the last characters…
…no matter where they appears in the text, then

K-approximate string searching
Connect to
http://alggen.lsi.upc.es/docencia/ember/leed/Tfc1.htm
and use the semi-global method.

Bioinformatics
Pairwise and multiple alignment

Pairwise alignment
Edit distance:
match=0 mismatch=1 indel=1
d(A,CTAC)+1d(AC,CTACT)=minimum d(A,CTA)….+1 d(AC,CTA)+1
Similarity:
match=1 mismatch=-1 indel=-2
s(A,CTAC)-2s(AC,CTACT)=maximum s(A,CTA) 1 s(AC,CTA)-2
-+

Pairwise alignment
Connect to
http://alggen.lsi.upc.es
Links to TEACHING EMBER LePA

A
C
A
-1__
Pairwise to multiple alignment
What happens with three strings?
Let n be their lenght, then the cost becomes
S3
S2
S1
O(n3) “O(23)” “O(32)”
And with k strings? O(nk 2k k2)

Multiple alignment
Programs of multialignment use different heuristics:
Clustal (Progressive alignment)
http://www.ebi.ac.uk/clustalw
TCoffee (Progressive alignment + data bases)
http://igs-server.cnrs-mrs.fr/Tcoffee_cgi/index.cgi
HMM (Hidden Markov Models)

Multiple alignment
Connect to
http://alggen.lsi.upc.es/
and follow the links TEACHING EMBER.


















