
Taller: Introducción a GPU's y Programación CUDA para...
161
Taller: Introducción a GPU's y Programación CUDA para HPC Amilcar Meneses Viveros Departamento de Computación CINVESTAV-IPN / LUFAC Computación Julio 2011 Friday, October 21, 2011
-
Upload
phamnguyet -
Category
Documents
-
view
220 -
download
3
Transcript of Taller: Introducción a GPU's y Programación CUDA para...

Taller: Introducción a GPU's y Programación CUDA para HPC
Amilcar Meneses Viveros Departamento de Computación CINVESTAV-IPN / LUFAC Computación
Julio 2011
Friday, October 21, 2011

CONTENIDO
I.- INTRODUCCION A GPU's Y CUDA
1.1 Preliminares de programación y computación paralela.
1.2 Arquitecturas basadas en GPU's.
1.3 El ambiente de desarrollo CUDA.
II. PRINCIPIOS Y CONCEPTOS DE PROGRAMACION CUDA
2.1 Tipos de funciones y manejo de memoria.
2.2 Bloques y grids.
III.- ESTRUCTURA DE LOS PROGRAMAS CUDA
3.1 Uso de codigo C y C++
3.2 Codigo CUDA (.cu)
3.3 El ambiente de desarrollo con Eclipse
IV.- EJEMPLOS Y EJERCICIOS
4.1 Ejemplos con programas de manejo de matrices y vectores: suma, resta, multiplicación, método gauss-jordan….
V.- COOPERACION ENTRE HILOS
5.1 Manejo de bloques
5.2 Sincronización y memoria compartida
Friday, October 21, 2011

Taller: Introducción a GPU's y Programación CUDA para HPC
PARTE I: Introducción a GPU's y CUDA
Friday, October 21, 2011
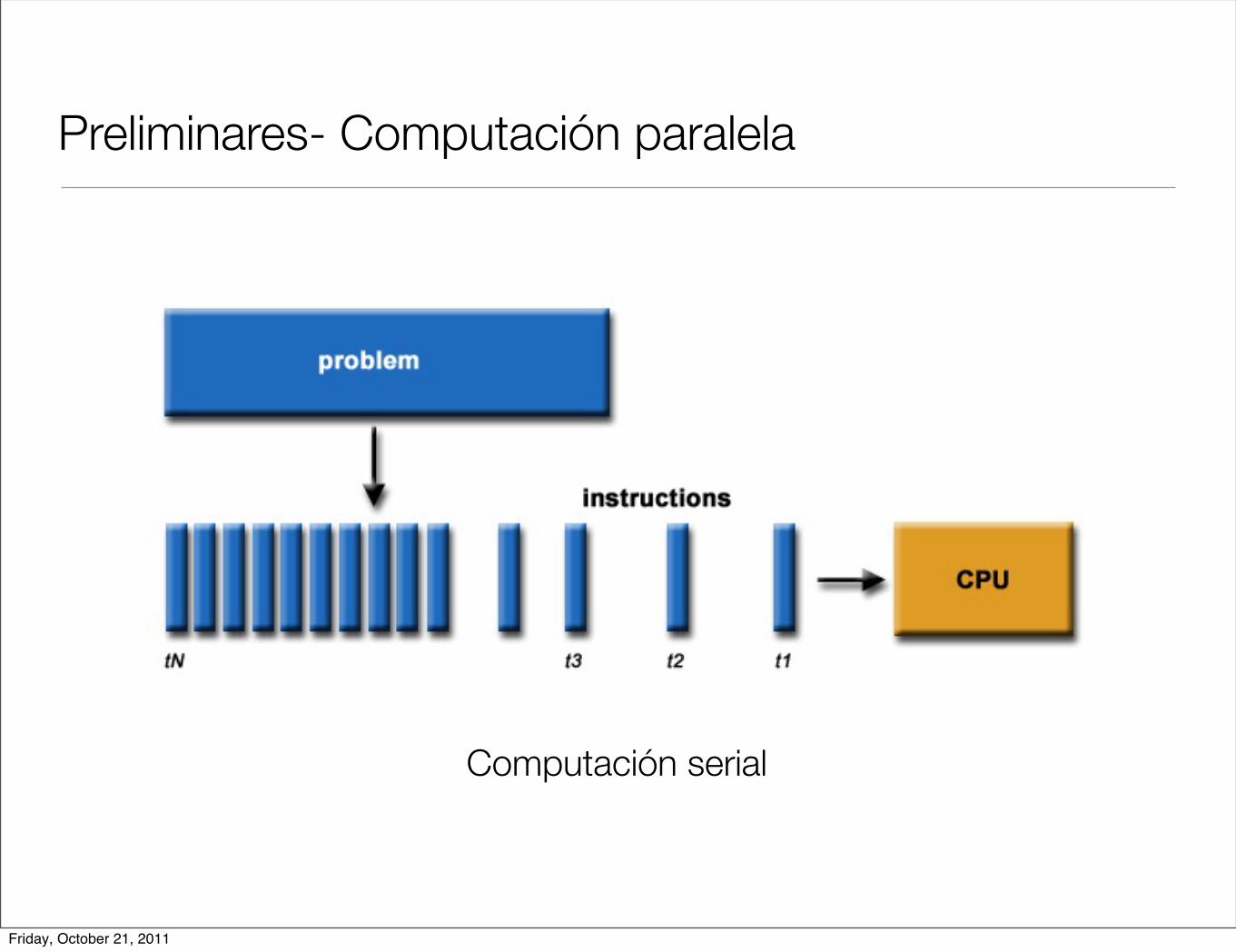
Preliminares- Computación paralela
Computación serial
Friday, October 21, 2011
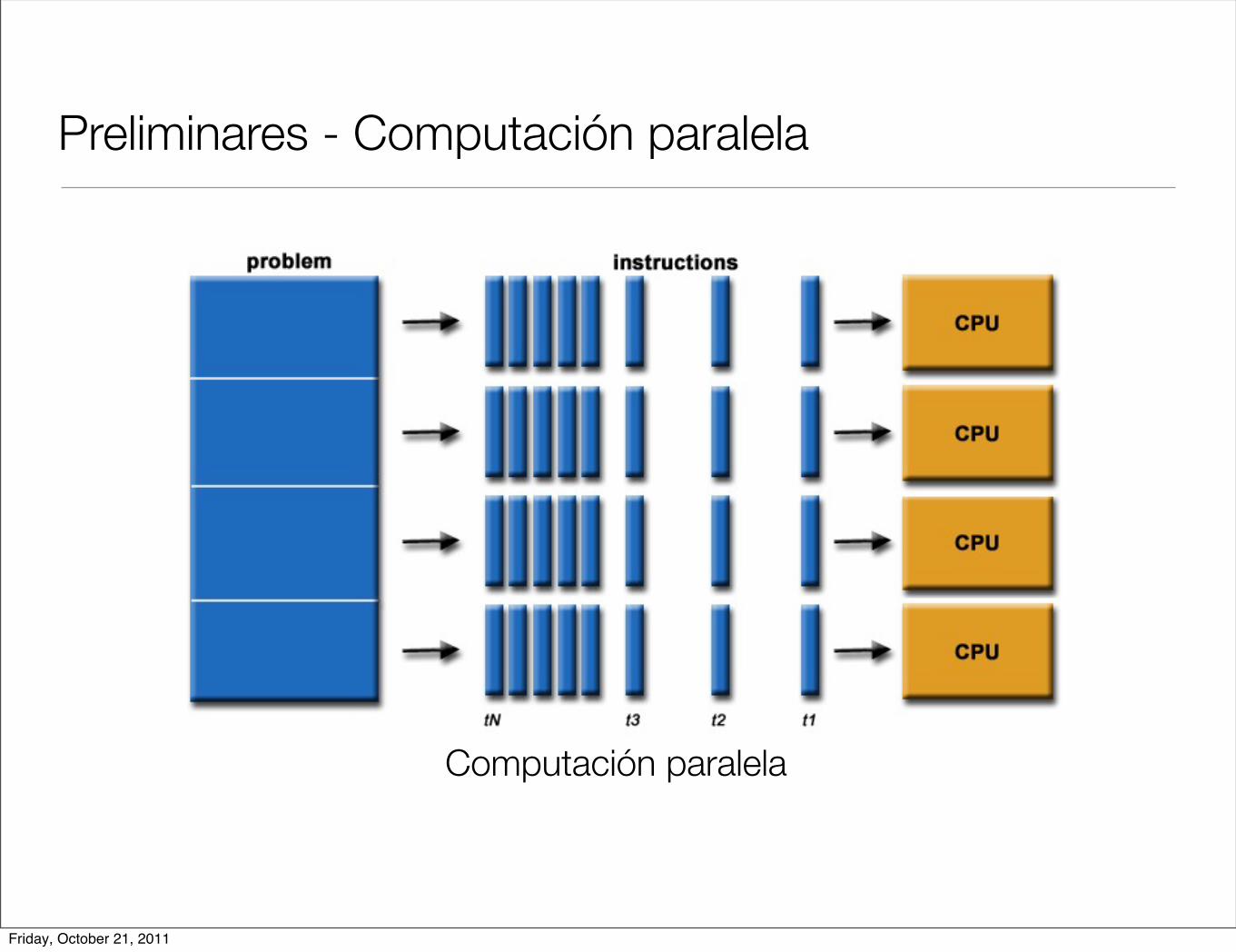
Preliminares - Computación paralela
Computación paralela
Friday, October 21, 2011

Preliminares - Computadora paralela
• Computadora con múltiples procesadores que soporta programación paralela. Hay dos categorias importantes de computadoras paralelas: multicomputadoras y multiprocesadores centralizados.
Friday, October 21, 2011
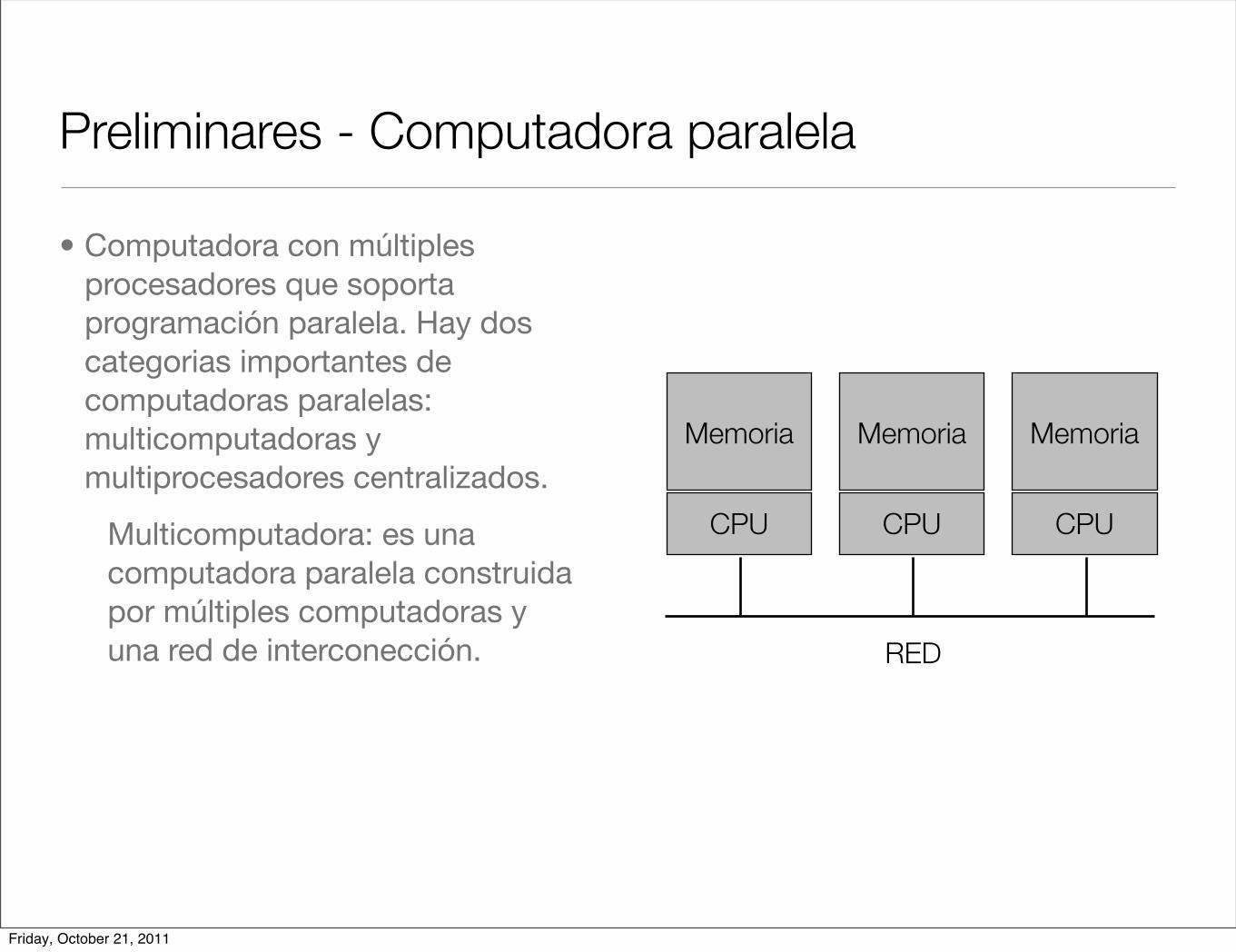
• Computadora con múltiples procesadores que soporta programación paralela. Hay dos categorias importantes de computadoras paralelas: multicomputadoras y multiprocesadores centralizados.
Multicomputadora: es una computadora paralela construida por múltiples computadoras y una red de interconección.
Preliminares - Computadora paralela
Memoria
CPU
Memoria
CPU
Memoria
CPU
RED
Friday, October 21, 2011
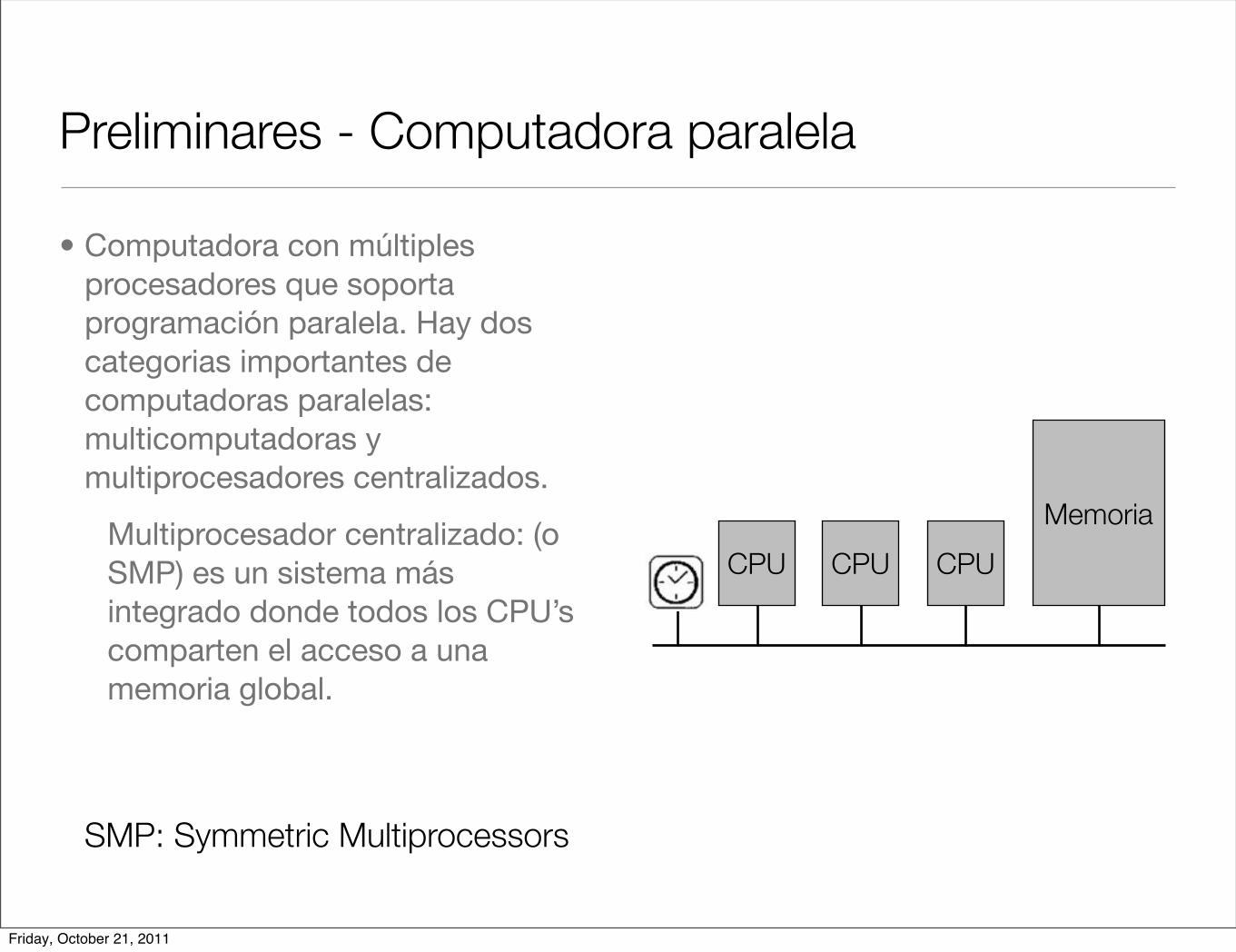
Preliminares - Computadora paralela
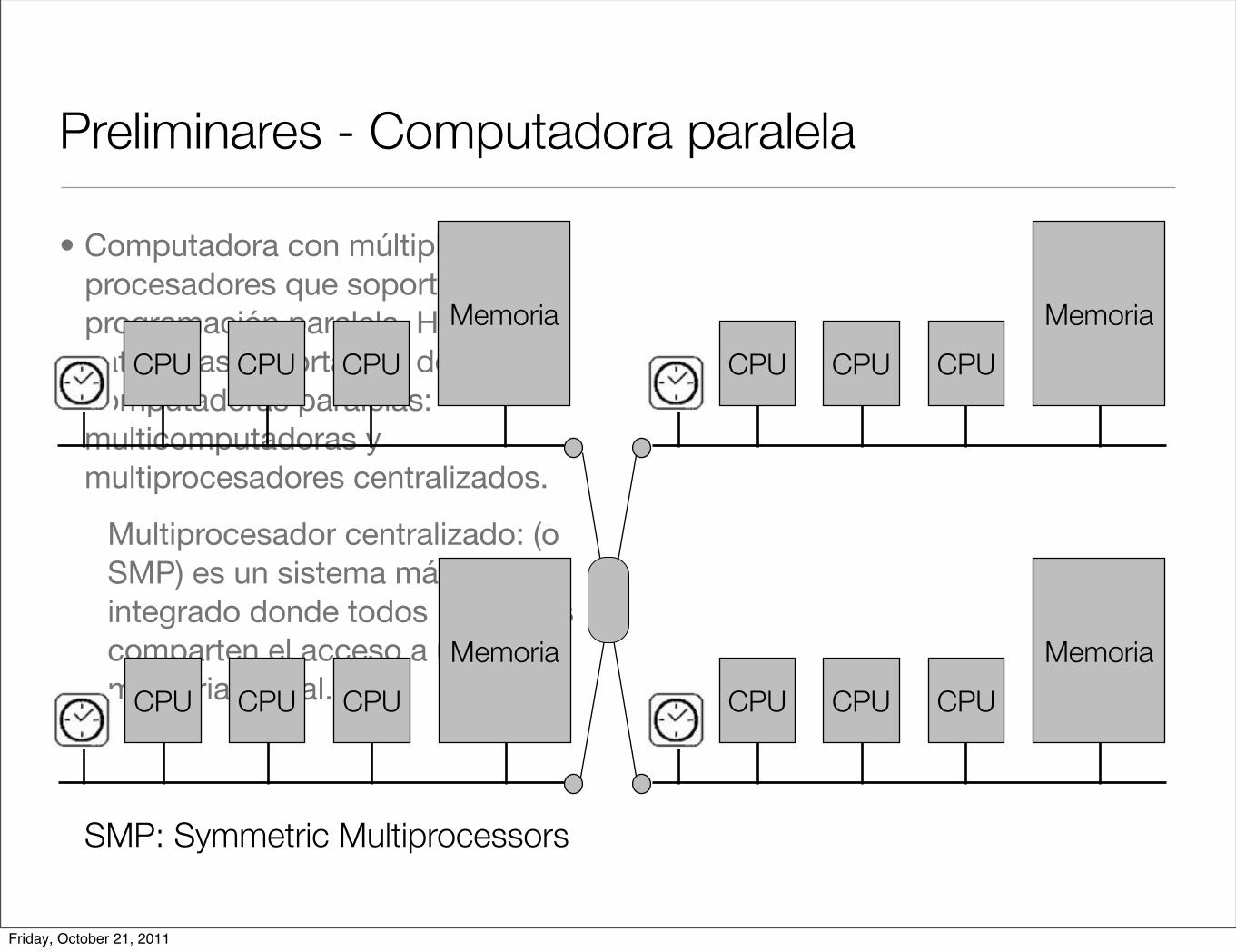
• Computadora con múltiples procesadores que soporta programación paralela. Hay dos categorias importantes de computadoras paralelas: multicomputadoras y multiprocesadores centralizados.
Multiprocesador centralizado: (o SMP) es un sistema más integrado donde todos los CPU’s comparten el acceso a una memoria global.
SMP: Symmetric Multiprocessors
CPU
Memoria
CPU CPU
Friday, October 21, 2011
• Computadora con múltiples procesadores que soporta programación paralela. Hay dos categorias importantes de computadoras paralelas: multicomputadoras y multiprocesadores centralizados.
Multiprocesador centralizado: (o SMP) es un sistema más integrado donde todos los CPU’s comparten el acceso a una memoria global.
Preliminares - Computadora paralela
SMP: Symmetric Multiprocessors
CPU
Memoria
CPU CPU
CPU
Memoria
CPU CPU CPU
Memoria
CPU CPU
CPU
Memoria
CPU CPU
Friday, October 21, 2011

Preliminares - Programación paralela
• Es la programación en un lenguaje que permita indicar explicitamente como distintas partes de una computación pueden ejecutarse concurrentemente por diferentes procesadores.
Friday, October 21, 2011
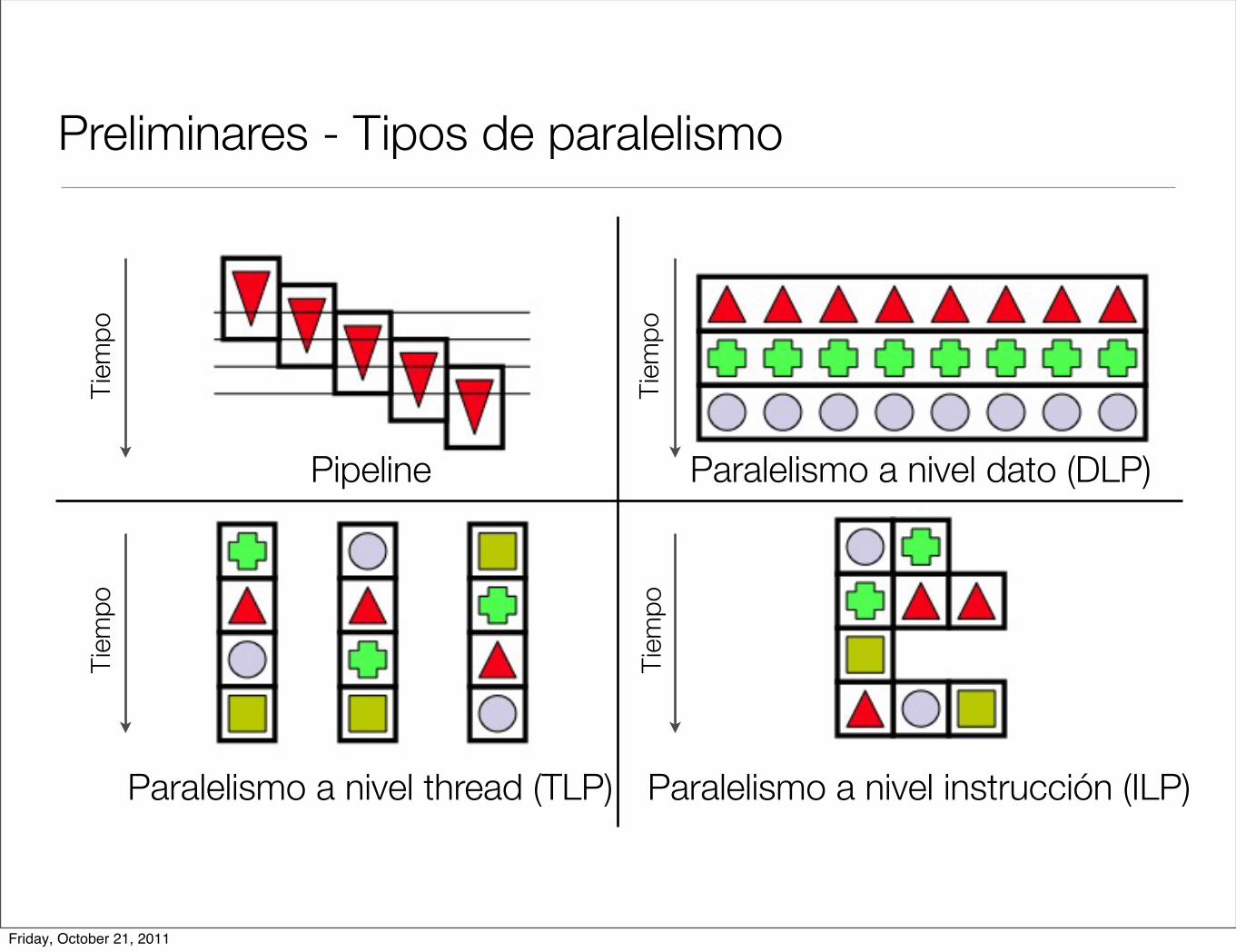
Preliminares - Tipos de paralelismoTi
empo
Tiem
po
Tiem
poTi
empo
Pipeline Paralelismo a nivel dato (DLP)
Paralelismo a nivel thread (TLP) Paralelismo a nivel instrucción (ILP)
Friday, October 21, 2011
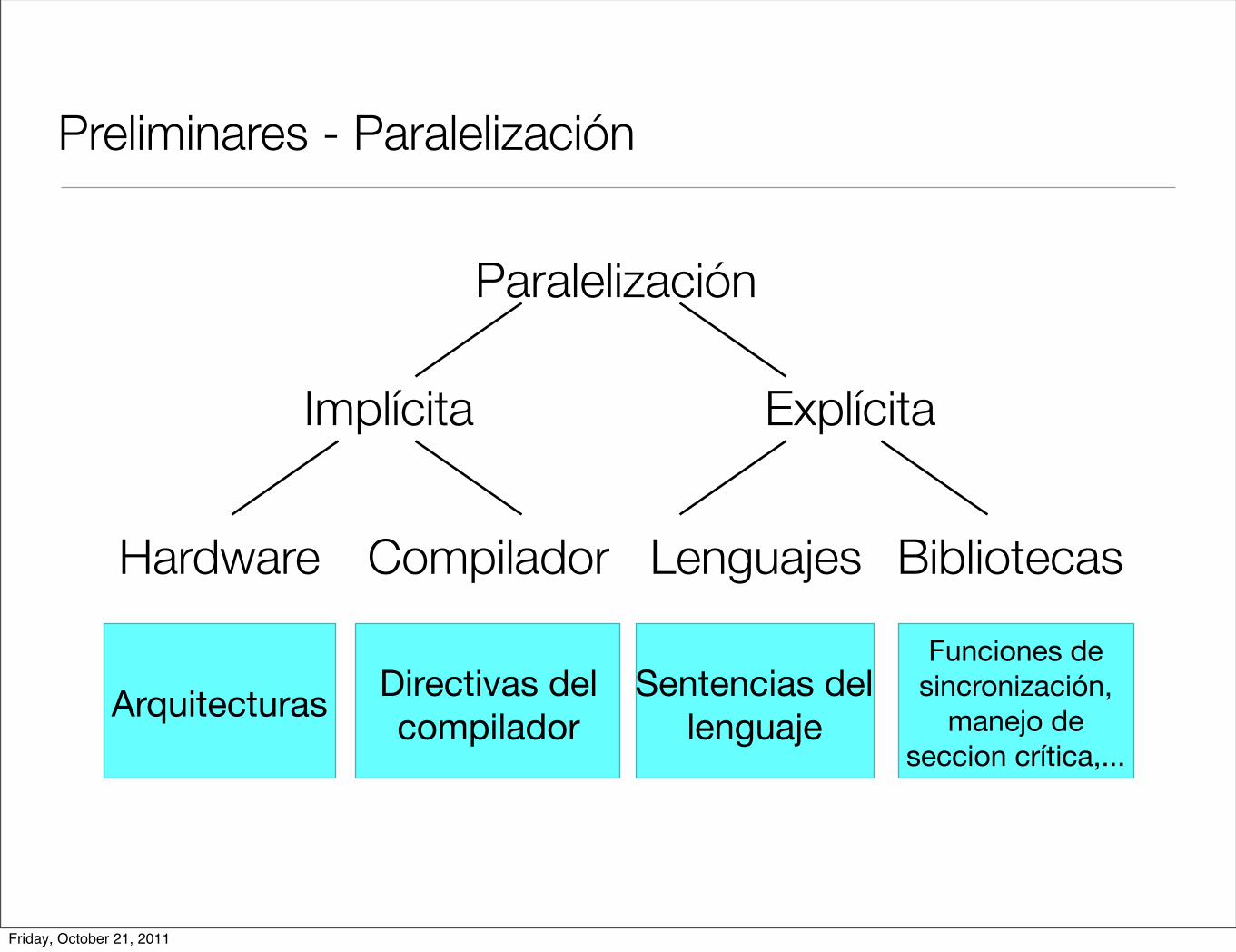
Preliminares - Paralelización
Paralelización
Implícita Explícita
Hardware Compilador Lenguajes Bibliotecas
Directivas del compilador
Arquitecturas
Funciones de sincronización,
manejo de seccion crítica,...
Sentencias del lenguaje
Friday, October 21, 2011
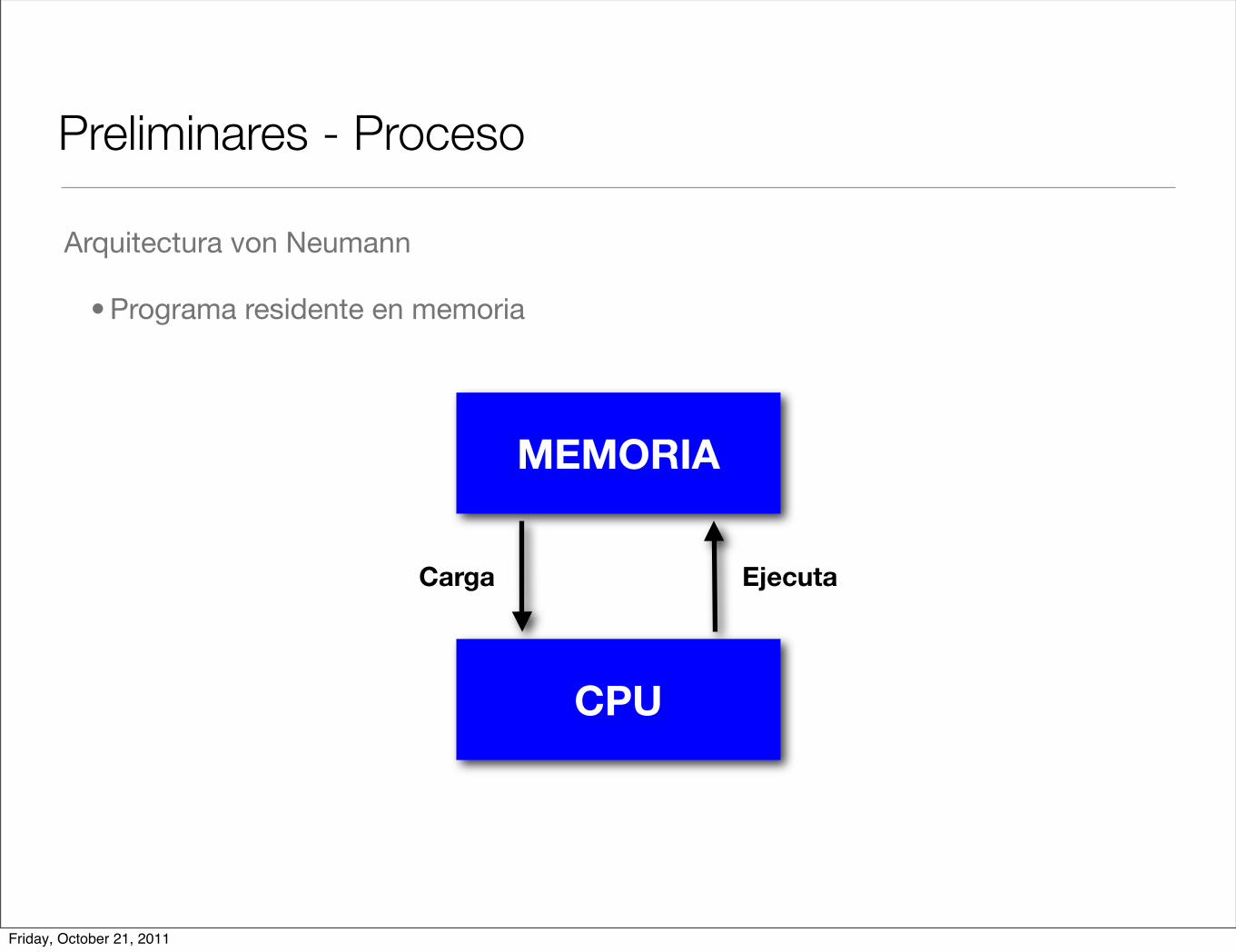
Preliminares - Proceso
Arquitectura von Neumann
• Programa residente en memoria
MEMORIA
CPU
Carga Ejecuta
Friday, October 21, 2011
14
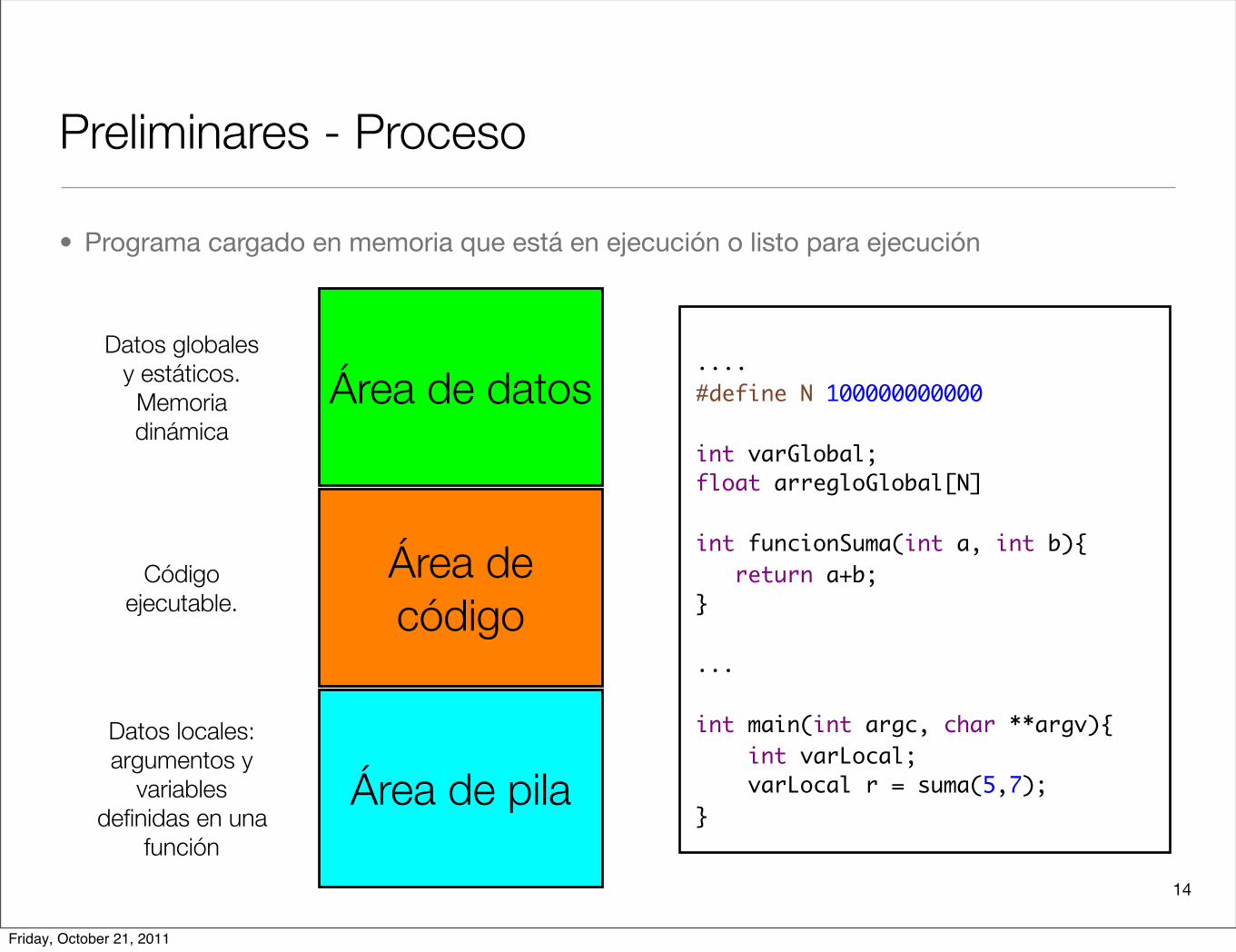
Preliminares - Proceso
• Programa cargado en memoria que está en ejecución o listo para ejecución
Área de datos
Área de código
Área de pila
Datos globales y estáticos. Memoria dinámica
Código ejecutable.
Datos locales: argumentos y
variables definidas en una
función
.... #define N 100000000000
int varGlobal; float arregloGlobal[N]
int funcionSuma(int a, int b){ return a+b; }
...
int main(int argc, char **argv){ int varLocal; varLocal r = suma(5,7); }
Friday, October 21, 2011
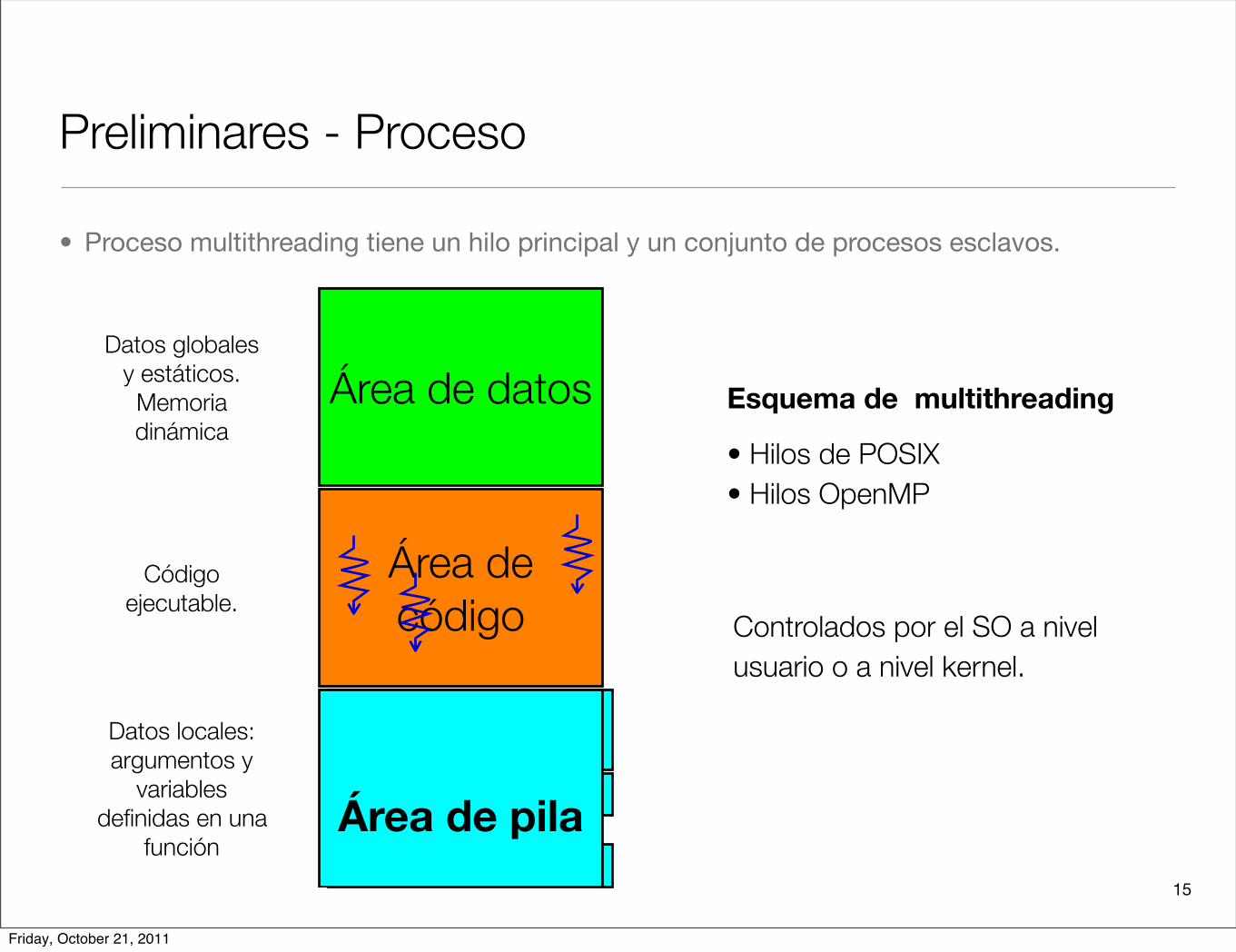
15
Preliminares - Proceso
• Proceso multithreading tiene un hilo principal y un conjunto de procesos esclavos.
Área de datos
Área de código
Datos globales y estáticos. Memoria dinámica
Código ejecutable.
Datos locales: argumentos y
variables definidas en una
función
Hilo principal (512MB)
Hilo esclavo 1 (4MB)
Hilo esclavo N (4MB)
Área de pila
Esquema de multithreading
• Hilos de POSIX• Hilos OpenMP
Controlados por el SO a nivel usuario o a nivel kernel.
Friday, October 21, 2011
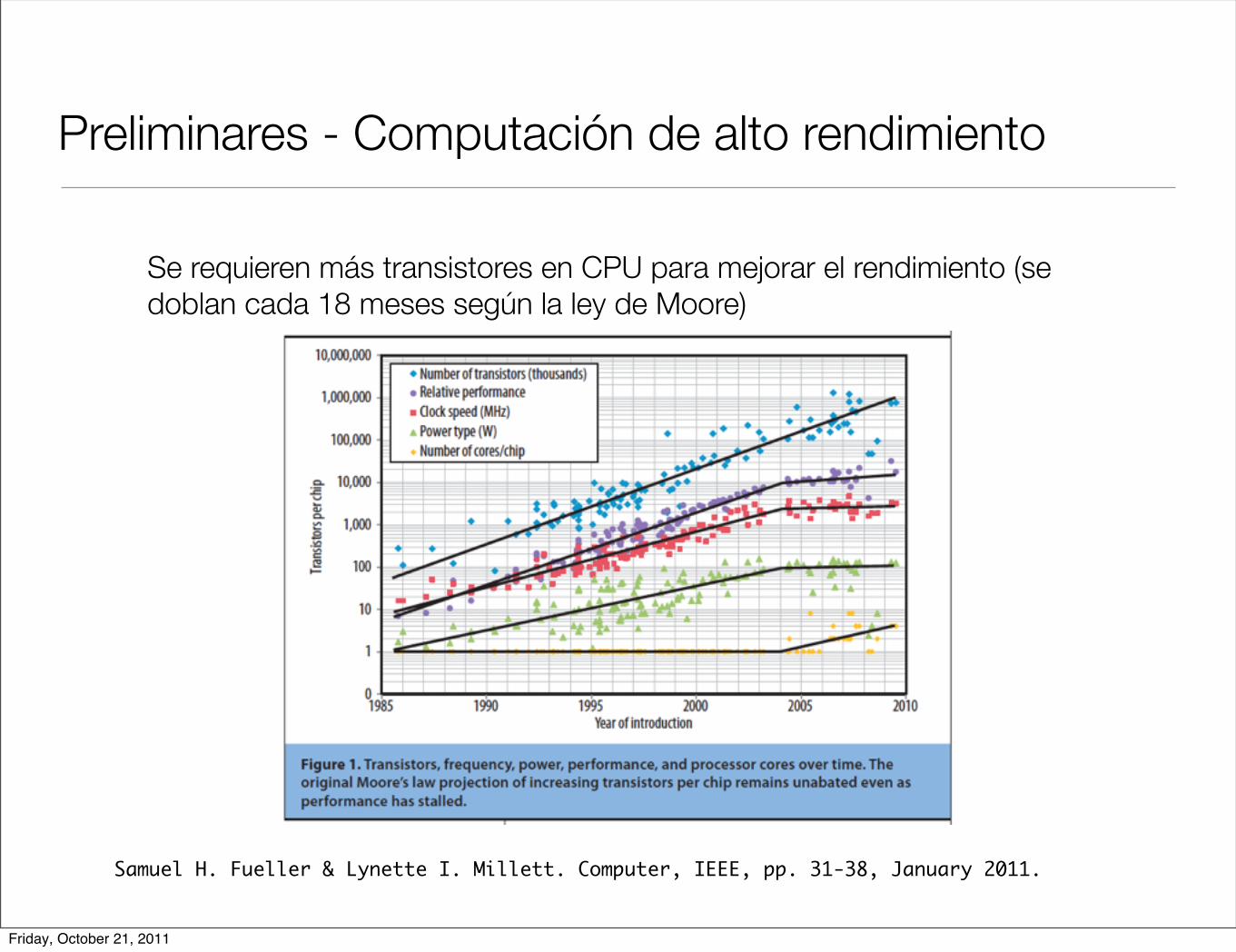
Preliminares - Computación de alto rendimiento
Se requieren más transistores en CPU para mejorar el rendimiento (se doblan cada 18 meses según la ley de Moore)
Samuel H. Fueller & Lynette I. Millett. Computer, IEEE, pp. 31-38, January 2011.
Friday, October 21, 2011

Preliminares - Computación de alto rendimiento
Se requieren más transistores en CPU para mejorar el rendimiento (se doblan cada 18 meses según la ley de Moore)
ILP - Paralelismo a nivel instrucción.Superscalar - Múltiples unidades funcionales.Superpipelining - Altas frecuencias.Hyperthreading - Múltiples flujos de ejecución para utilizar recursos ociosos.
Aumento en los ciclos de reloj 3.8 GHz: dispación de calor y consumo de energía
Friday, October 21, 2011

Preliminares - Computación de alto rendimiento
CPU: Tecnologías multicore. Para 2010 no habrá
más procesadores de 1 core
Friday, October 21, 2011

Preliminares - Computación de alto rendimiento
CPU: Tecnologías multicore. Se planea que para 2010 no habrá
más procesadores de 1 core
Friday, October 21, 2011
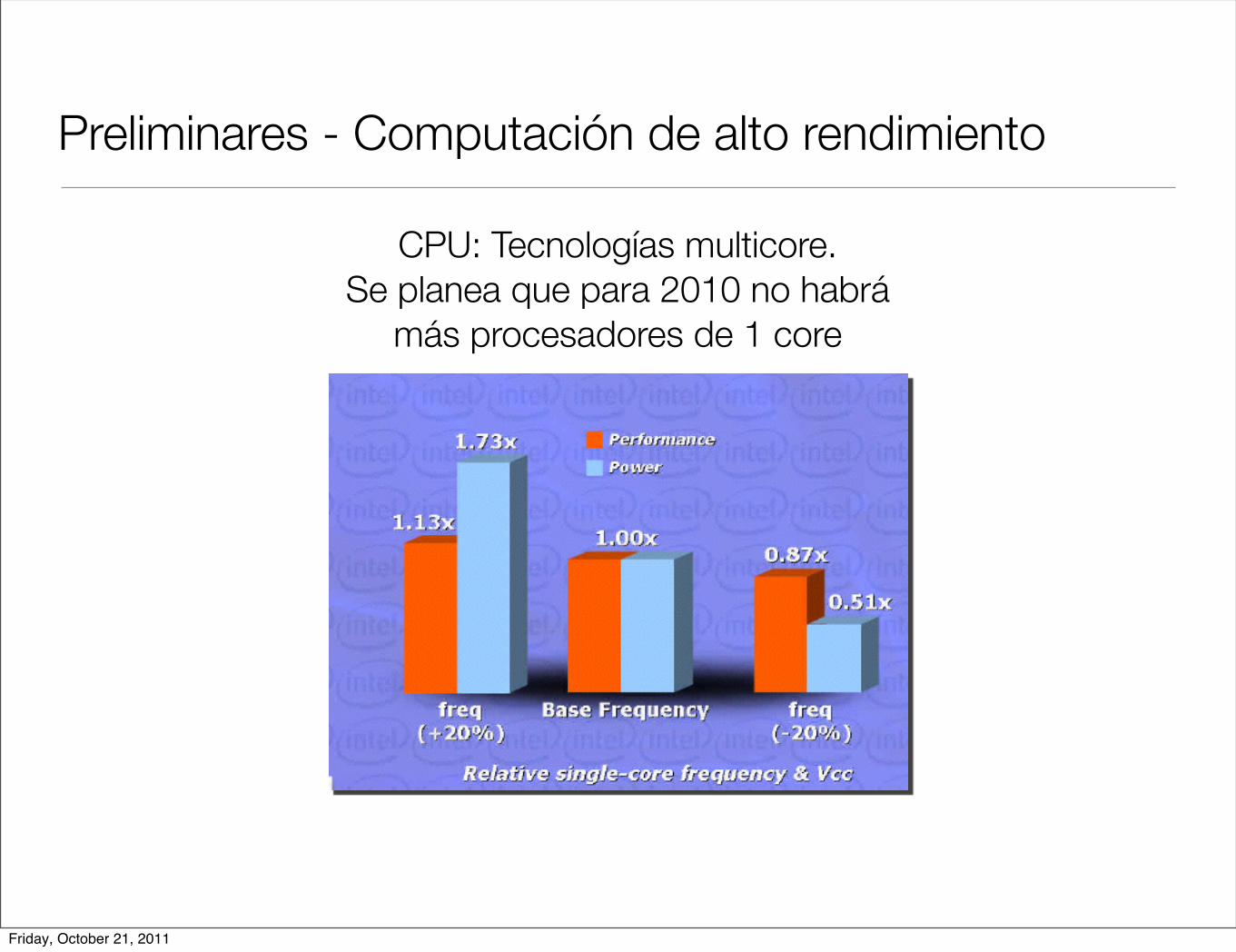
Preliminares - Computación de alto rendimiento
CPU: Tecnologías multicore. Se planea que para 2010 no habrá
más procesadores de 1 core
Friday, October 21, 2011
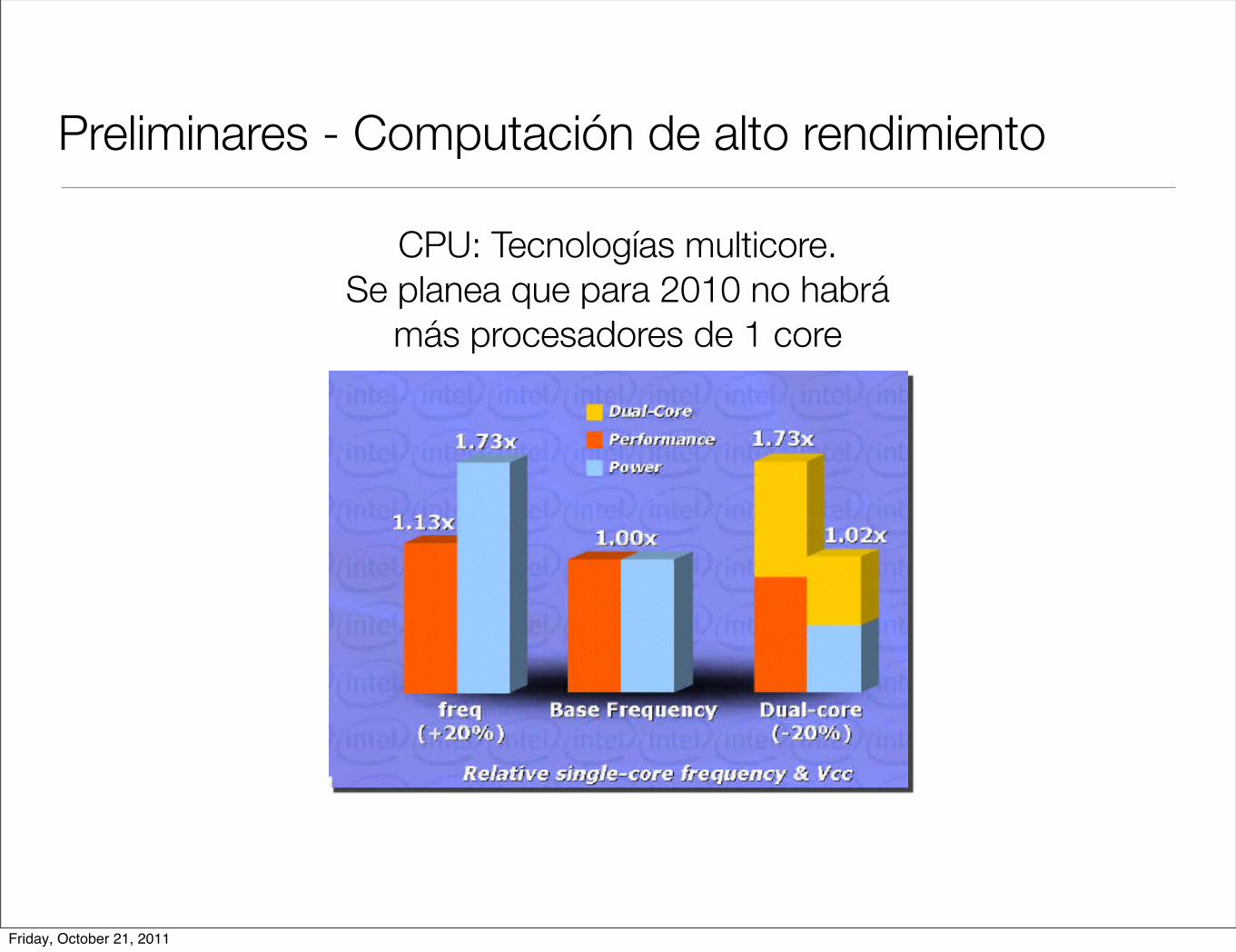
Preliminares - Computación de alto rendimiento
CPU: Tecnologías multicore. Se planea que para 2010 no habrá
más procesadores de 1 core
Friday, October 21, 2011
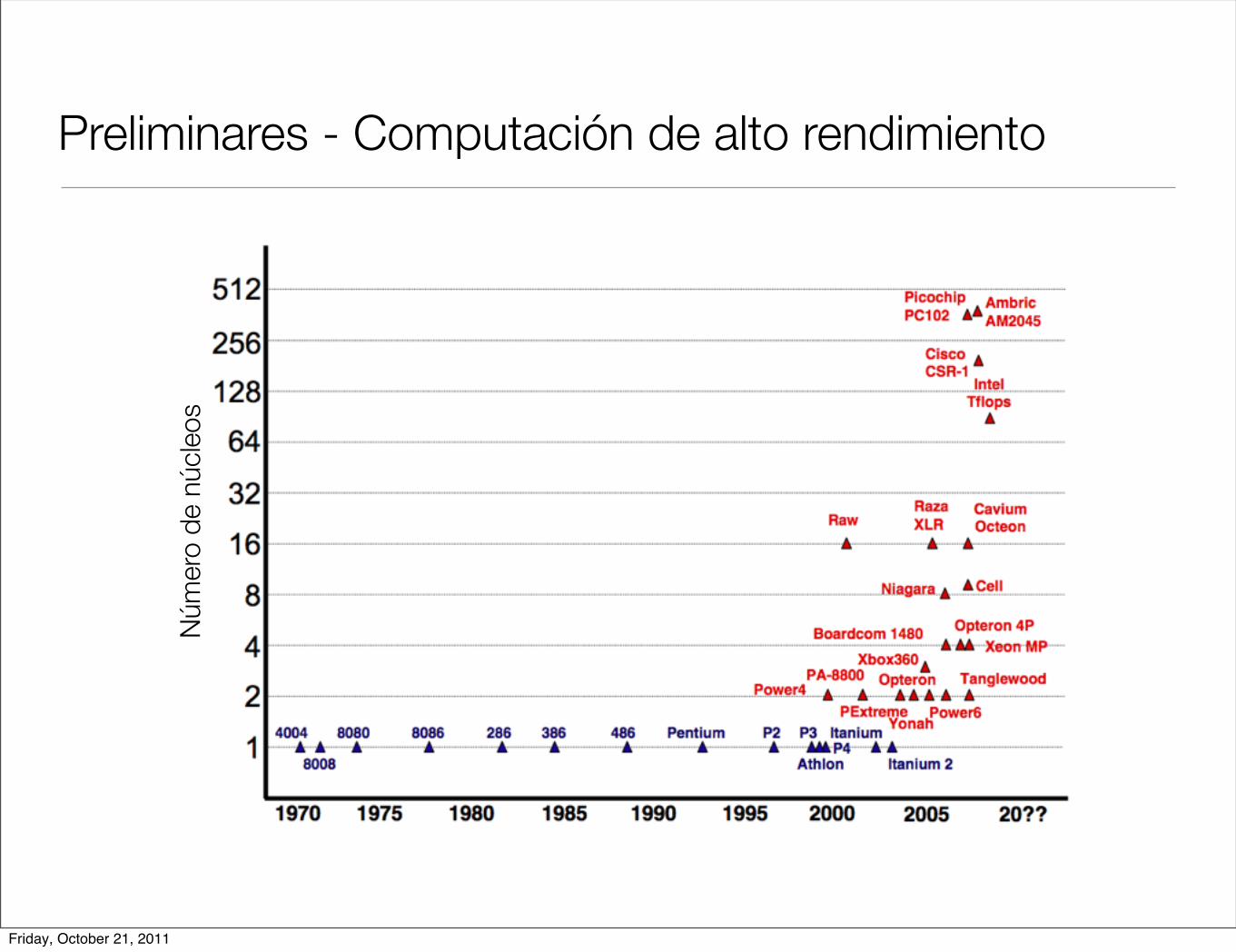
Preliminares - Computación de alto rendimientoN
úmer
o de
núc
leos
Friday, October 21, 2011

Preliminares - Computación de alto rendimiento
Teraflops
Friday, October 21, 2011

Preliminares - Computación de alto rendimiento
Teraflops
Friday, October 21, 2011

Preliminares - Computación de alto rendimiento
Teraflops
nvidia TESLA448 cores GPU’s
Friday, October 21, 2011
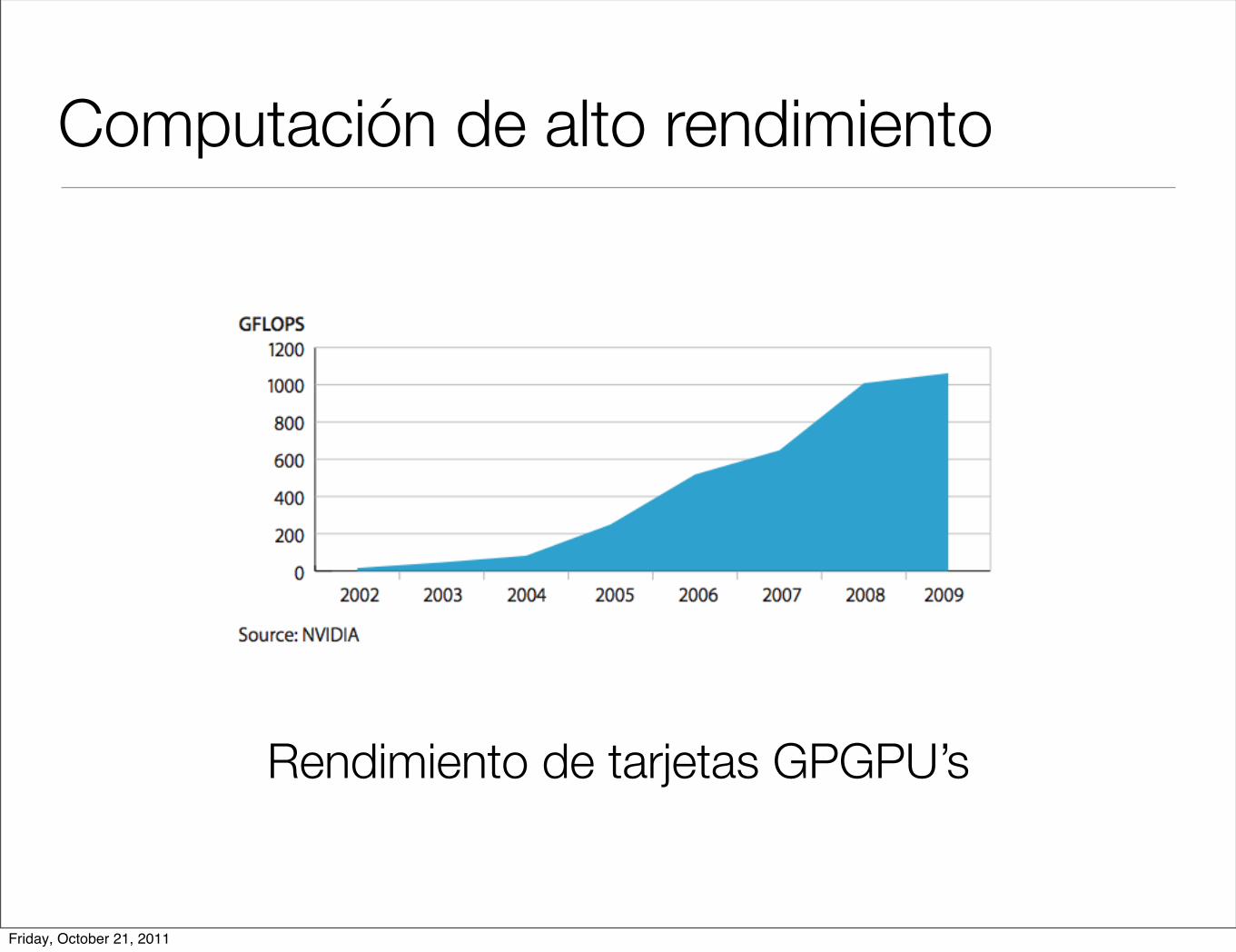
Computación de alto rendimiento
Rendimiento de tarjetas GPGPU’s
Friday, October 21, 2011
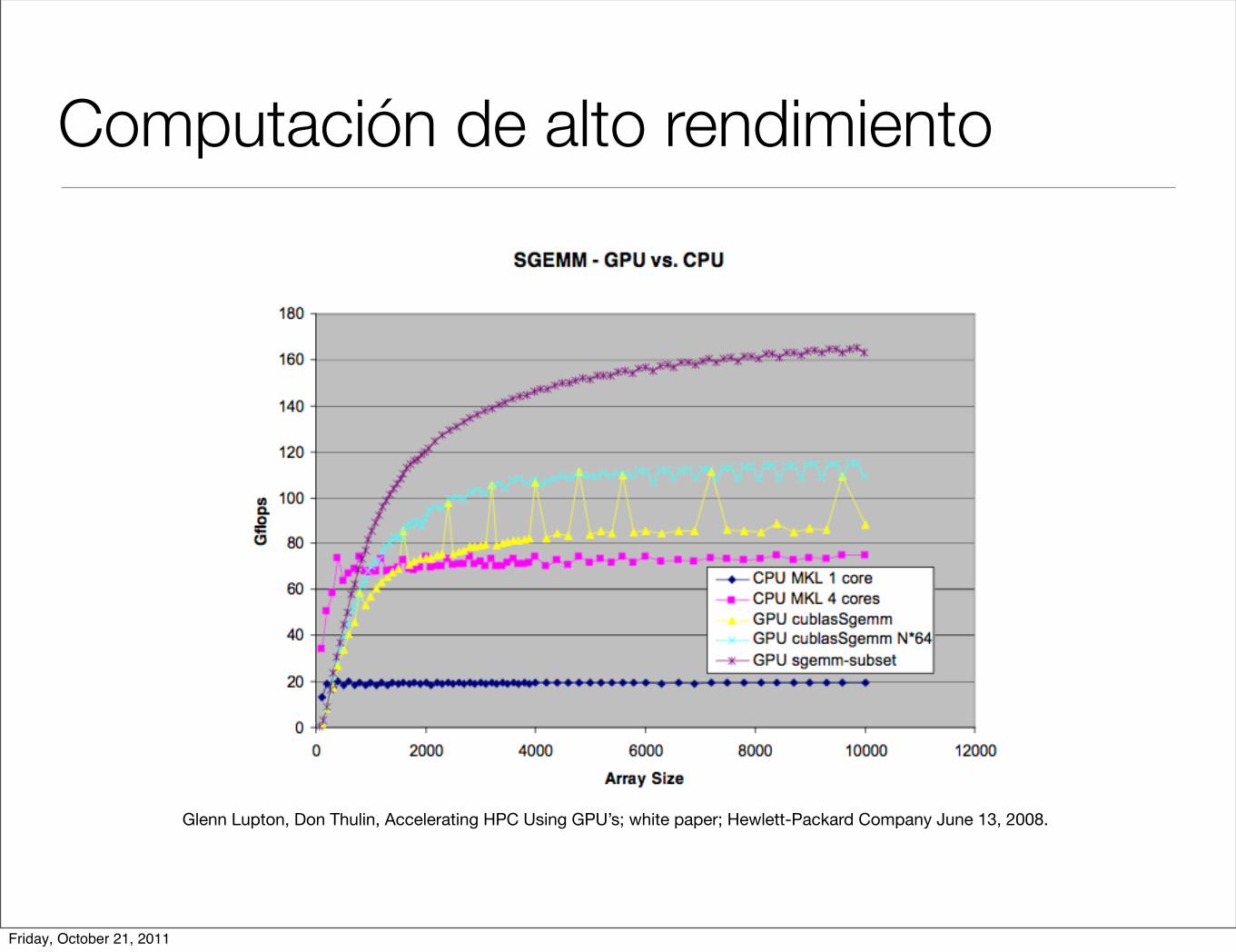
Computación de alto rendimiento
Glenn Lupton, Don Thulin, Accelerating HPC Using GPU’s; white paper; Hewlett-Packard Company June 13, 2008.
Friday, October 21, 2011
Tecnologías de GPGPU’s
• Unidades de procesamiento gráfico de propósito general.
• Procesadores vectoriales.
• Fabricantes: nVidia, ATI, Intel...
• La idea es aprovechar las unidades aritméticas y lógicas de los GPU’s para hacer computaciones de alto rendimiento.
Friday, October 21, 2011
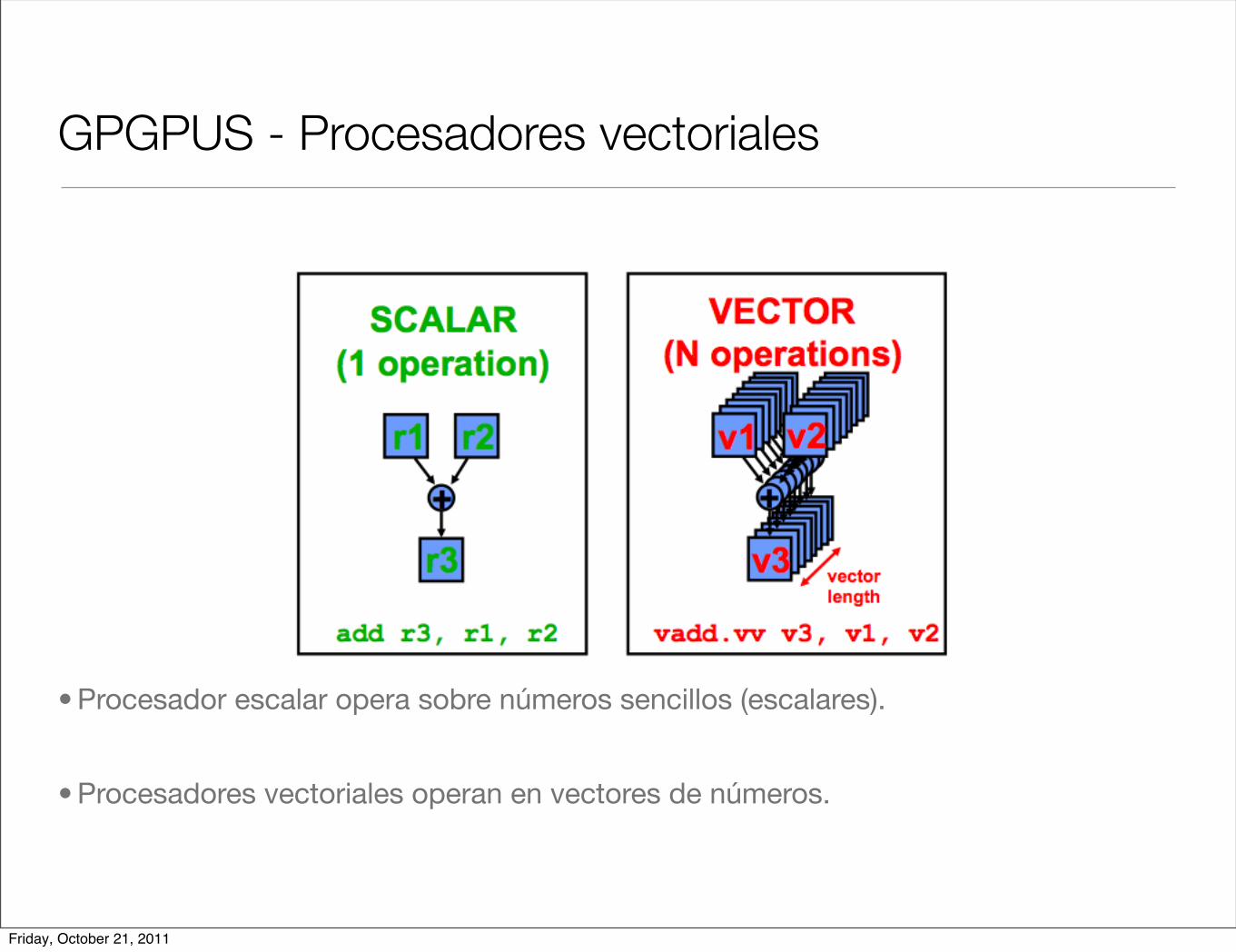
GPGPUS - Procesadores vectoriales
• Procesador escalar opera sobre números sencillos (escalares).
• Procesadores vectoriales operan en vectores de números.
Friday, October 21, 2011

GPGPUS - Procesadores vectoriales
Beneficios de los procesadores vectoriales
• Compacto: una simple instrucción define N operaciones.
• Ademas reduce la frecuencia de saltos.
• Paralelo: N operaciones son paralelas en datos.
• No hay dependencias.
• No se requiere de HW para detectar paralelismo.
• Puede ejecutar en paralelo asumiento N flujos de datos paralelos.
• Usa patrones de acceso a memoria continua.
Friday, October 21, 2011

CPU vs GPU
CPU
•Baja latencia de memoria. •Acceso aleatorio. •20GB/s ancho de banda. •0.1Tflop. •1Gflop/watt
•Modelo de programación altamente conocido.
GPU
•Gran ancho de banda. •Acceso secuencial. •100GB/s ancho de banda. •1Tflop. •10 Gflop/watt
•Modelo de programación muy poco conocido.
Friday, October 21, 2011

CPU vs GPU
Friday, October 21, 2011

33
Que es GPGPU ?
• Computación de propósito general usando GPU y API de gráficas en aplicación es distintas a gráficos en 3D.
• GPU acelera la trayectoria crítica de una aplicación.
• Algoritmos paralelos sobre datos aprovechan los atributos del GPU.
• Grandes arreglos de datos, rendimiendo de “streaming”.
• Paralelismo de grano fino SIMD.
• Computaciones de punto flotante de baja latencia.
• Aplicaciones – ver //GPGPU.org
• Efectos físicps de video juegos (FX), procesamiento de imágenes.
• Modelado físico, ingeniería computacional, algebra matricial, convolución, correlación, ordenamientos.
Friday, October 21, 2011
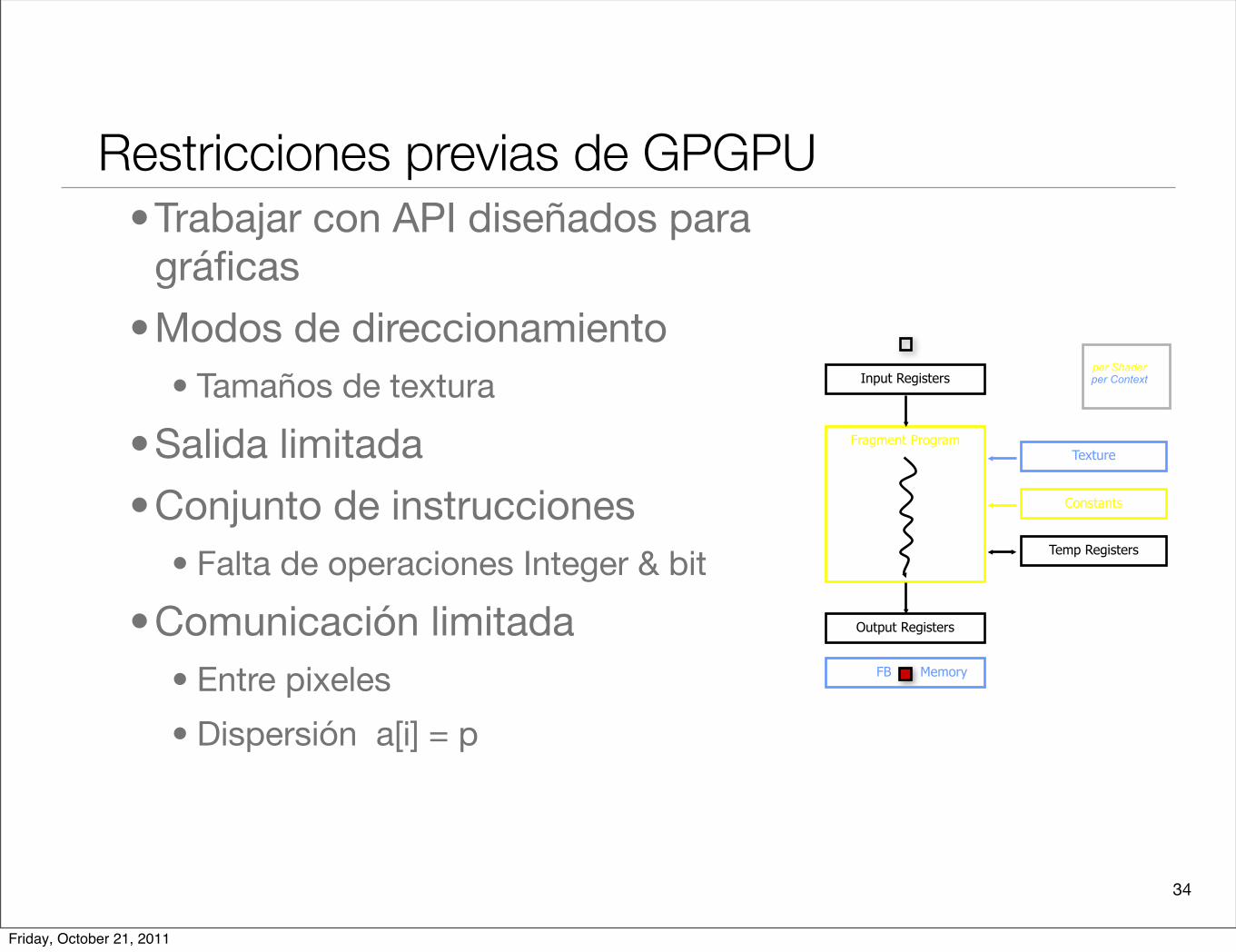
34
Restricciones previas de GPGPU•Trabajar con API diseñados para
gráficas
•Modos de direccionamiento• Tamaños de textura
•Salida limitada
•Conjunto de instrucciones• Falta de operaciones Integer & bit
•Comunicación limitada• Entre pixeles
• Dispersión a[i] = p
Input Registers
Fragment Program
Output Registers
Constants
Texture
Temp Registers
per threadper Shaderper Context
FB Memory
Friday, October 21, 2011

35
CUDA
• “Compute Unified Device Architecture”
• Modelo de programación de propósito general
• El usuario inicializa conjuntos de threads en el GPU
• GPU = super-threaded dedicado para procesamiento masivo de datos (co-processor)
• Conjunto de software dedicado
• Manejadores de dispositivos, lenguaje y herramientas.
• Manejador para carga de programas al GPU
• Manejador Independiente - Optimizado para computaciones
• Interfaz diseñada para computaciones - API no gráfica
• Comparte datos con objetos OpenGL en buffer
• Aceleración garantizada en los accesos a memoria
• Manejo explicito de la memoria del GPU
Friday, October 21, 2011
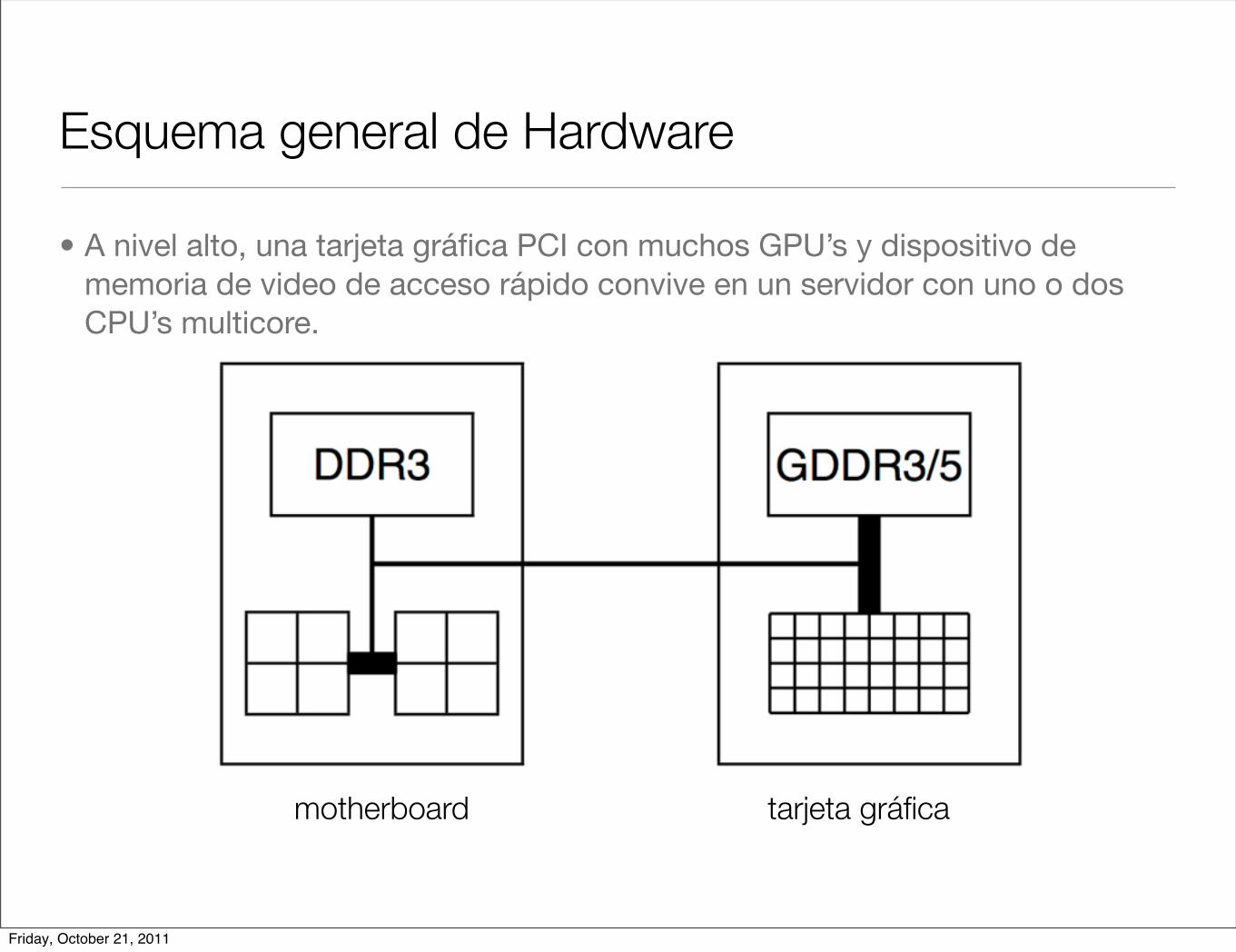
Esquema general de Hardware
• A nivel alto, una tarjeta gráfica PCI con muchos GPU’s y dispositivo de memoria de video de acceso rápido convive en un servidor con uno o dos CPU’s multicore.
motherboard tarjeta gráfica
Friday, October 21, 2011
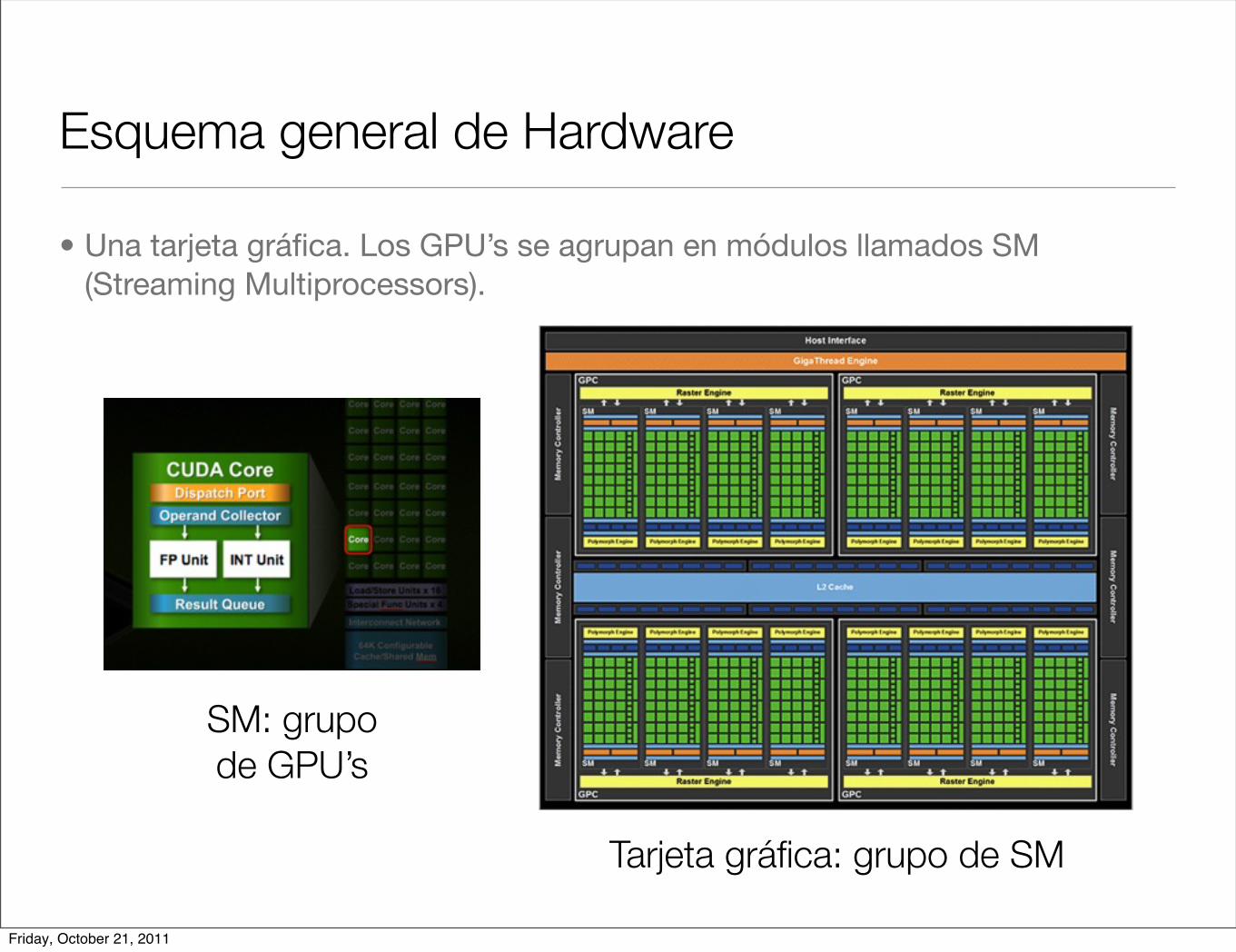
Esquema general de Hardware
• Una tarjeta gráfica. Los GPU’s se agrupan en módulos llamados SM (Streaming Multiprocessors).
Tarjeta gráfica: grupo de SM
SM: grupo de GPU’s
Friday, October 21, 2011
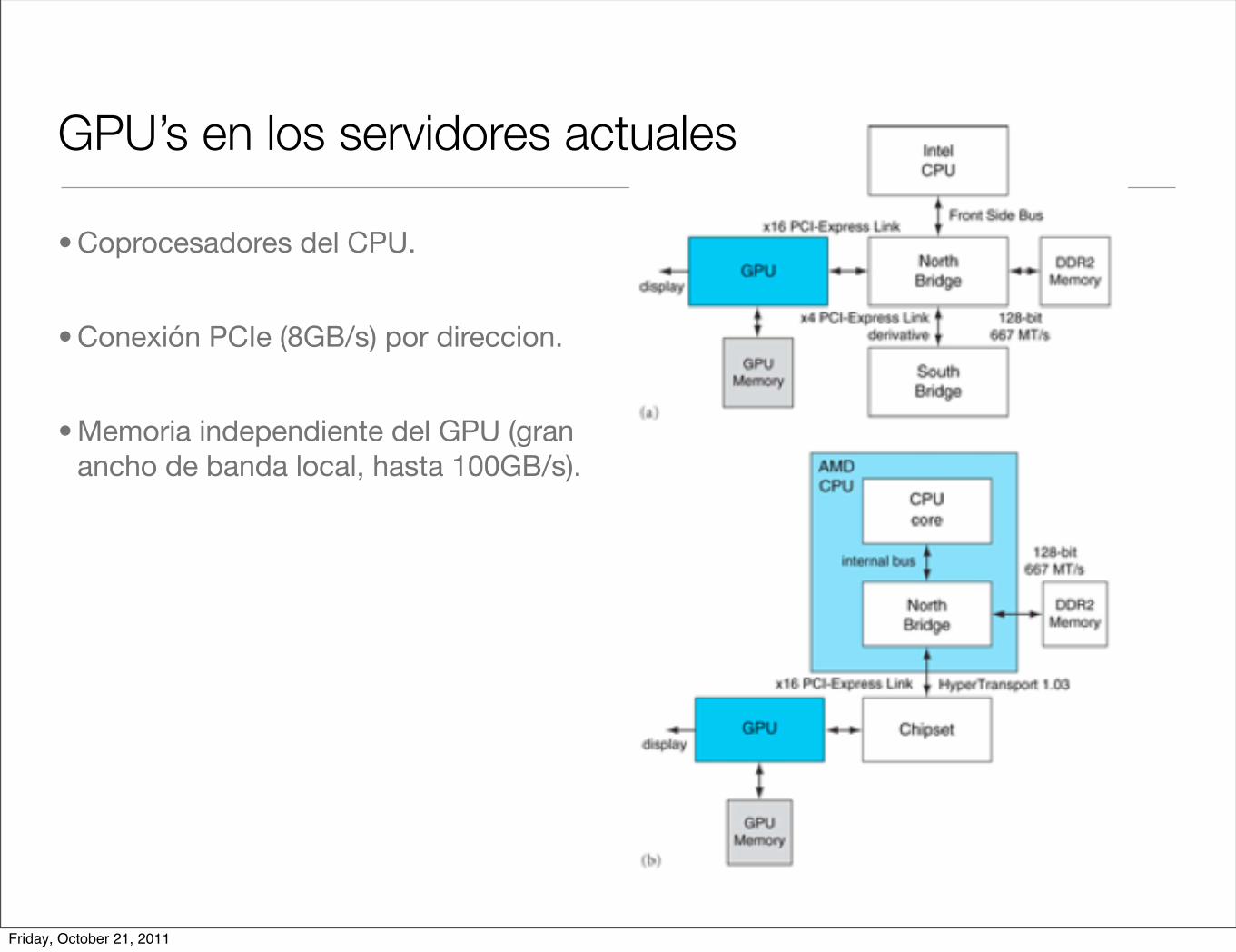
GPU’s en los servidores actuales
• Coprocesadores del CPU.
• Conexión PCIe (8GB/s) por direccion.
• Memoria independiente del GPU (gran ancho de banda local, hasta 100GB/s).
Friday, October 21, 2011

39
Un ejemplo del manejo de hardware para CUDA
CPU(host)GPU w/
local DRAM(device)
Friday, October 21, 2011
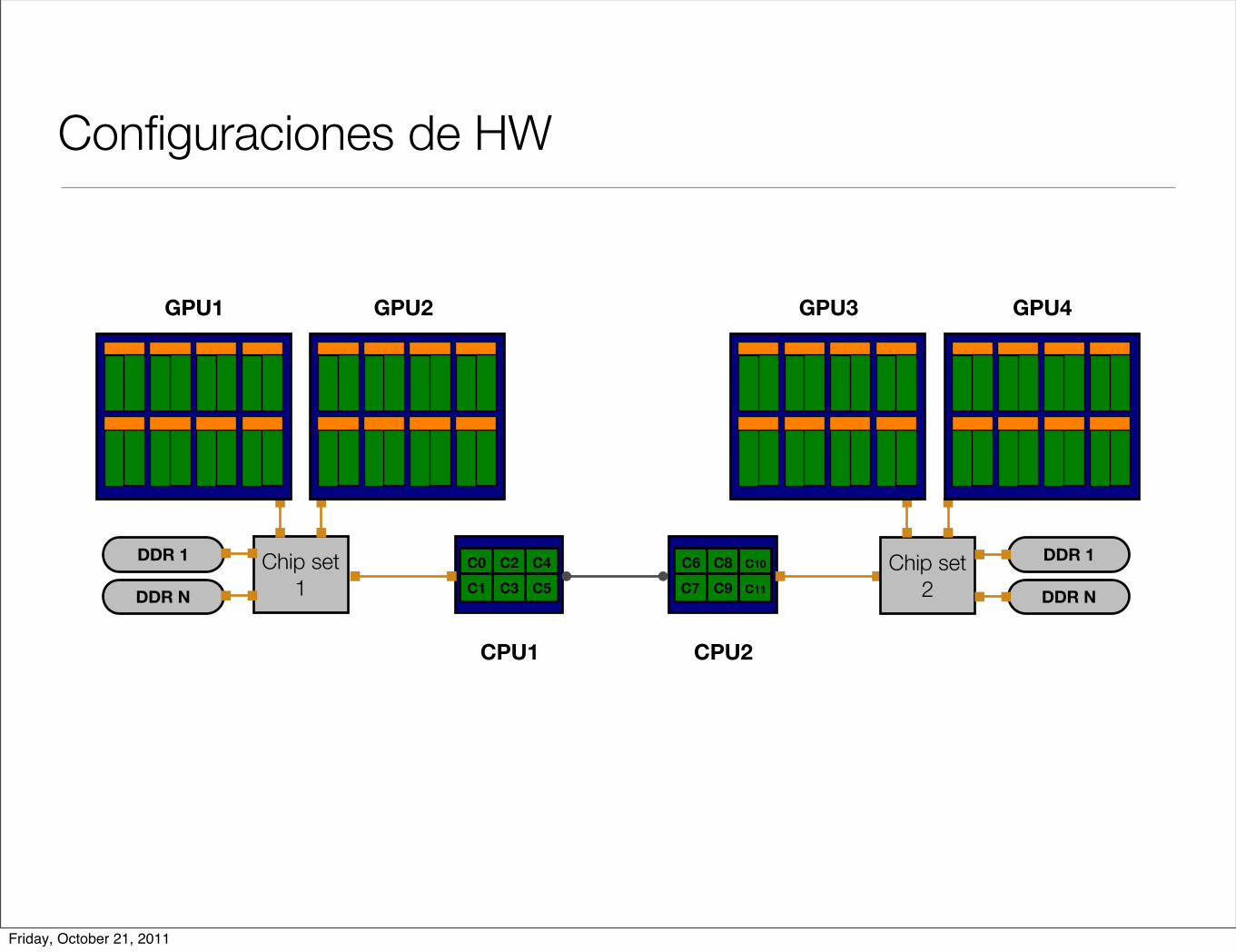
Configuraciones de HW
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
C11
CPU1 CPU2
Chip set 2
Chip set 1
DDR 1
DDR N
DDR 1
DDR N
GPU1 GPU2 GPU3 GPU4
Friday, October 21, 2011

41
Configuraciones de HW
a) b)
c) d)
Friday, October 21, 2011
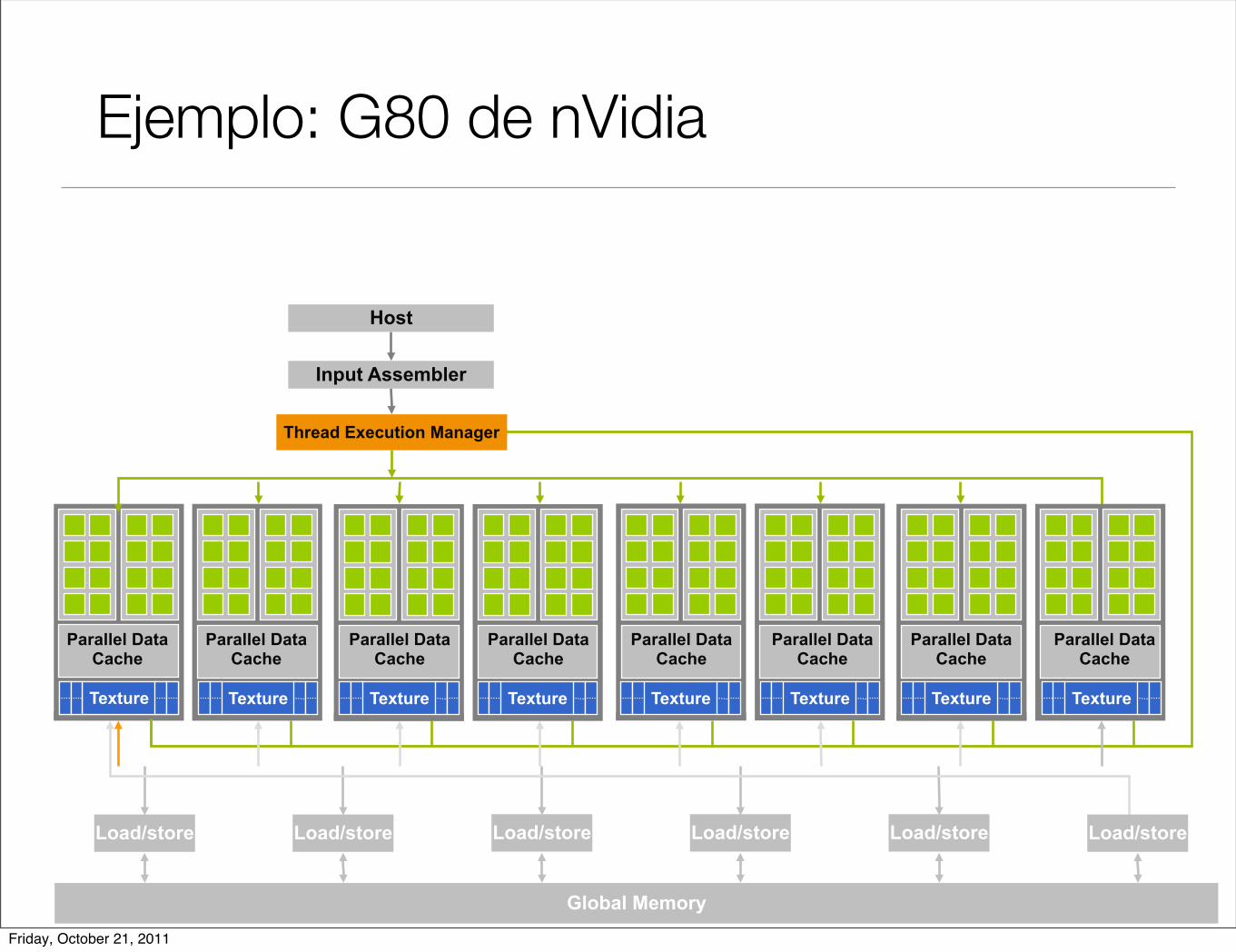
42
Ejemplo: G80 de nVidia
Load/store
Global Memory
Thread Execution Manager
Input Assembler
Host
Texture Texture Texture Texture Texture Texture Texture TextureTexture
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Load/store Load/store Load/store Load/store Load/store
Friday, October 21, 2011

43
Computación paralela en GPU
• 8-series GPUs proporcionar de 25 a 200+ GFLOPS en aplicaciones paralelas compiladas en C– Disponible en laptops, desktops, y clusters
• El paralelismo eh GPU se duplica cada año• Modelo de programación escala de forma
transparente
• Programación en C con herramientas CUDA• Modelo multihilos SPMD utiliza paralelismo en datos
y en hilos.
GeForce 8800
Tesla S870
Tesla D870
Friday, October 21, 2011

Plataformas de desarrollo
Frameworks, lenguajes y herramientas que nos permiten crear programas que corran en arquitecturas de GPGPU’s.
• OpenCL
• CUDA
• Brook+
• DirectCompute
• CAPS
Friday, October 21, 2011

Plataformas de desarrollo
Frameworks, lenguajes y herramientas que nos permiten crear programas que corran en arquitecturas de GPGPU’s.
• OpenCL
• CUDA
• Brook+
• DirectCompute
• CAPS
Friday, October 21, 2011
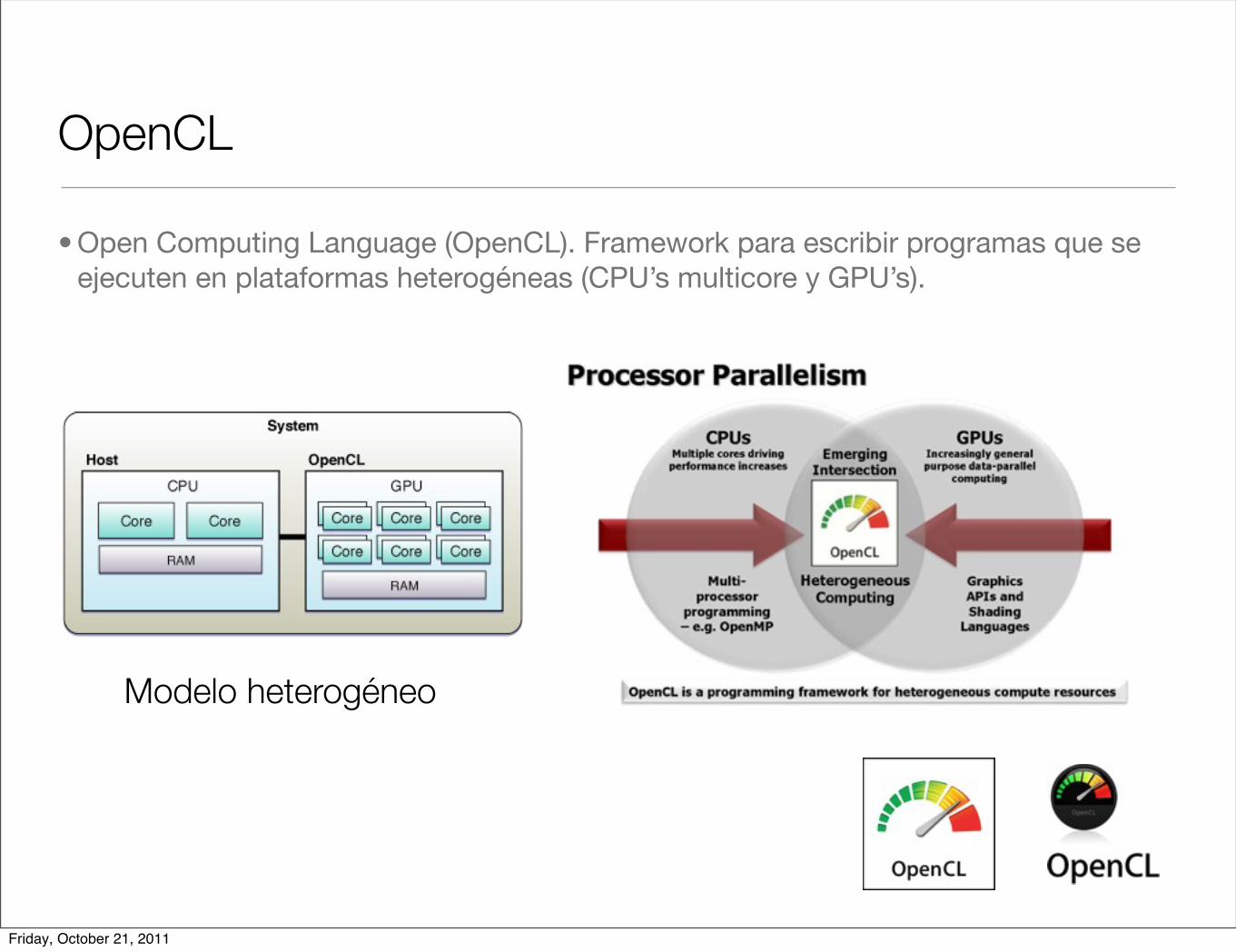
OpenCL
• Open Computing Language (OpenCL). Framework para escribir programas que se ejecuten en plataformas heterogéneas (CPU’s multicore y GPU’s).
Modelo heterogéneo
Friday, October 21, 2011

OpenCL
• Originalmente fue desarrollador por Apple (con colaboración de AMD, IBM, INTEL, nVidia). Apple manda la propuesta inicial al grupo Krhonos en 2008.
Friday, October 21, 2011
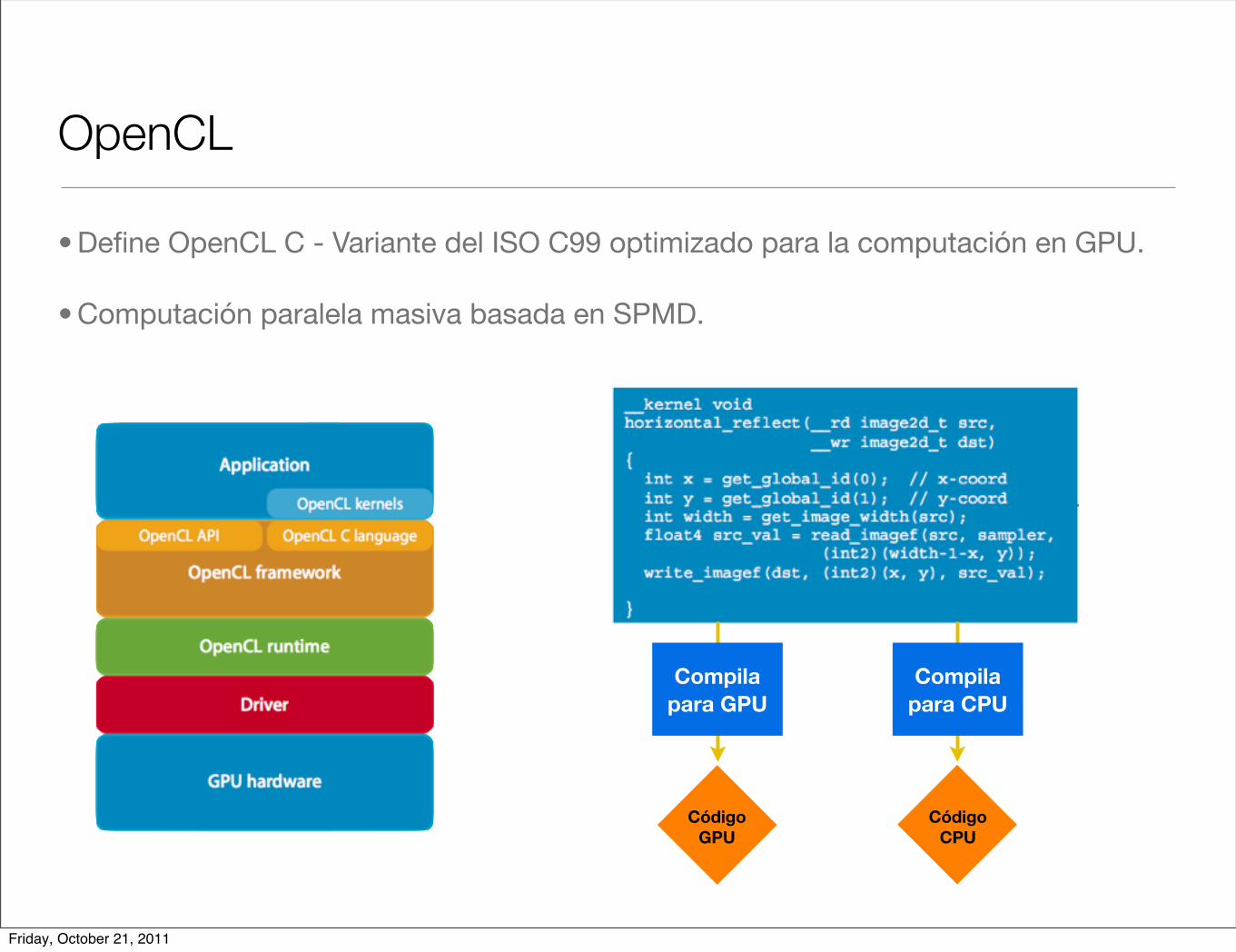
OpenCL
• Define OpenCL C - Variante del ISO C99 optimizado para la computación en GPU.
• Computación paralela masiva basada en SPMD.
CódigoCPU
CódigoGPU
Compila para GPU
Compila para CPU
Friday, October 21, 2011

OpenCL
• Define OpenCL C - Variante del ISO C99 optimizado para la computación en GPU.
• Computación paralela masiva basada en SPMD.
Friday, October 21, 2011
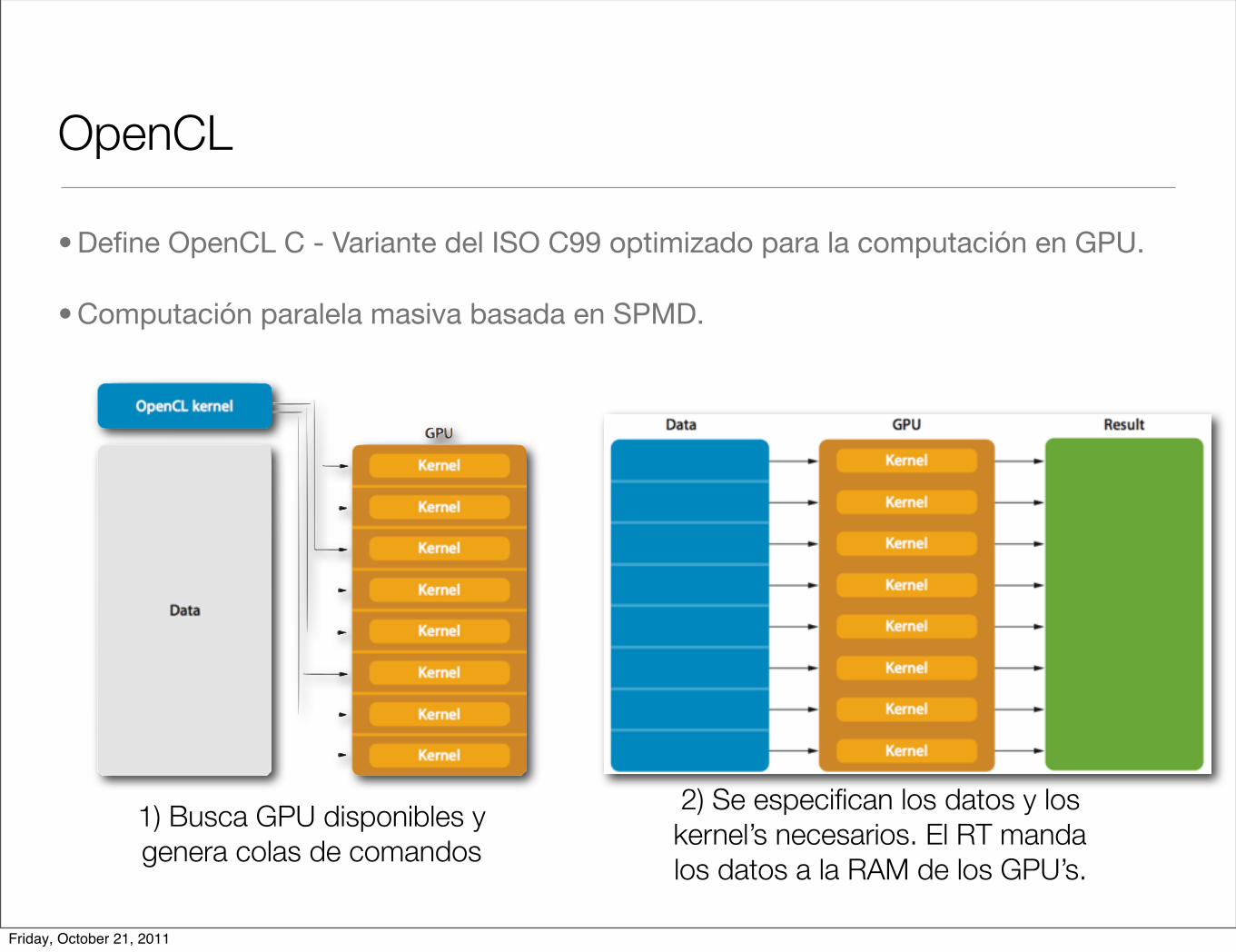
OpenCL
• Define OpenCL C - Variante del ISO C99 optimizado para la computación en GPU.
• Computación paralela masiva basada en SPMD.
1) Busca GPU disponibles y genera colas de comandos
2) Se especifican los datos y los kernel’s necesarios. El RT manda los datos a la RAM de los GPU’s.
Friday, October 21, 2011
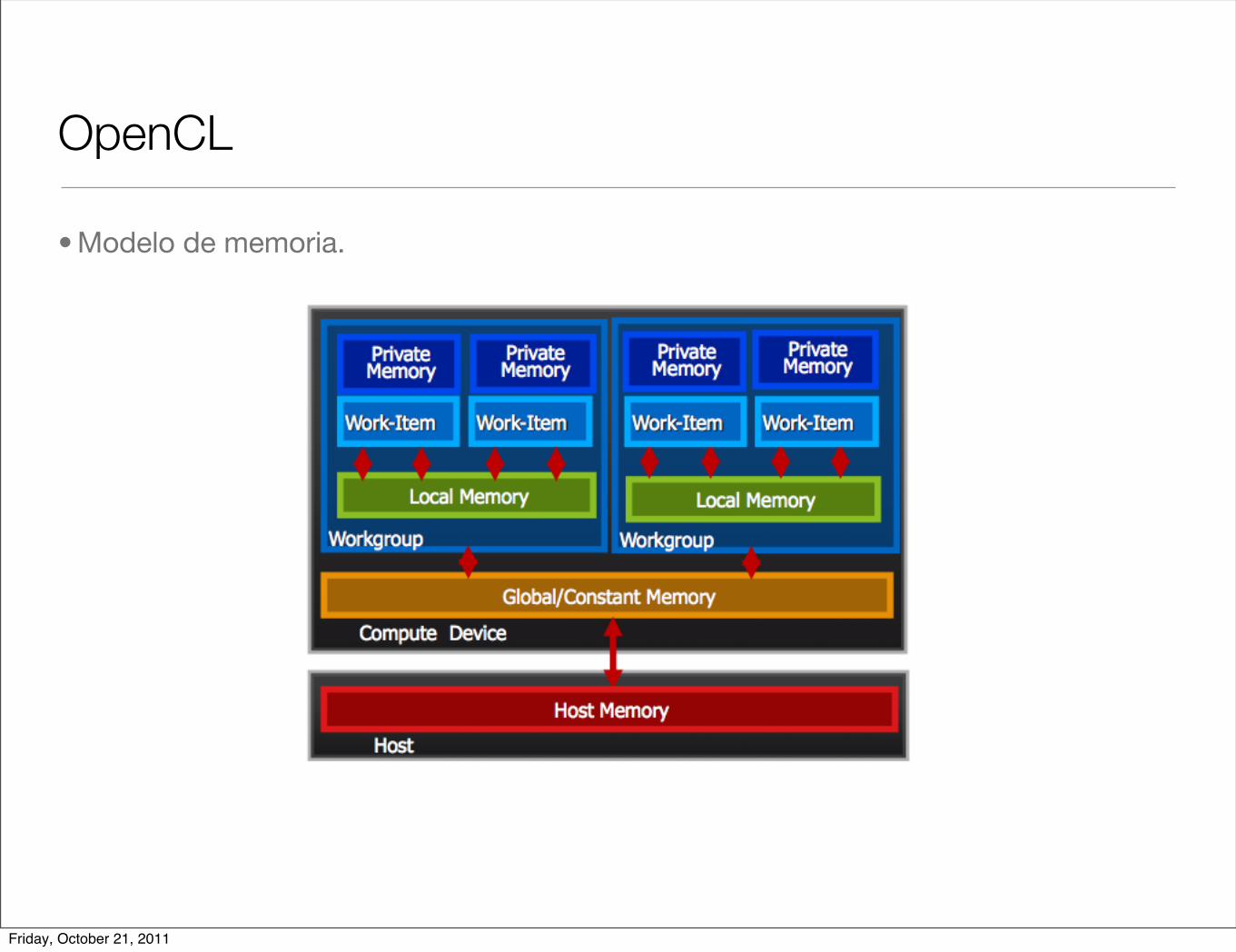
OpenCL
• Modelo de memoria.
Friday, October 21, 2011
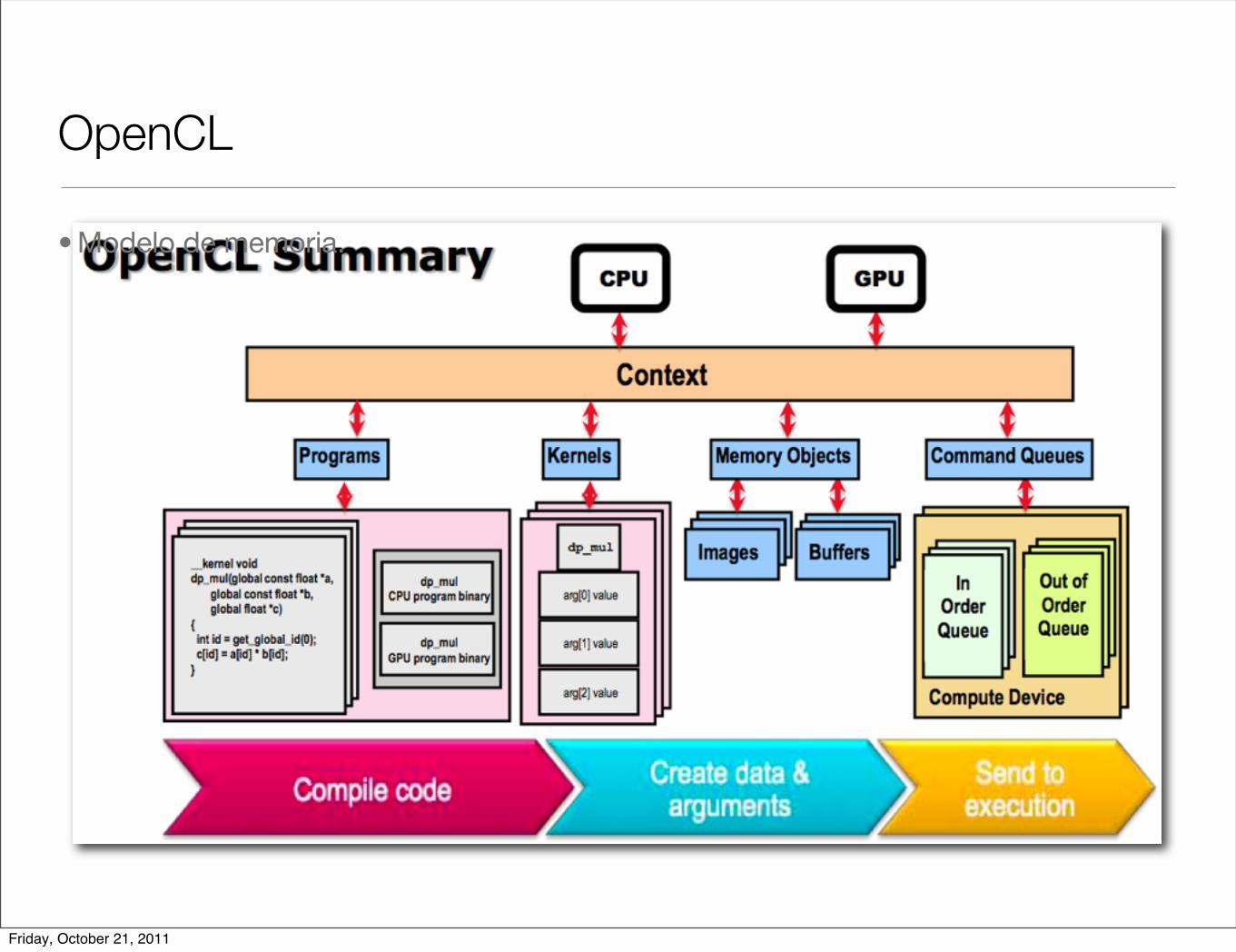
OpenCL
• Modelo de memoria.
Friday, October 21, 2011

Plataformas de desarrollo
Frameworks, lenguajes y herramientas que nos permiten crear programas que corran en arquitecturas de GPGPU’s.
• OpenCL
• CUDA
• Brook+
• DirectCompute
• CAPS
Friday, October 21, 2011

54
CUDA
•“Compute Unified Device Architecture”
•Modelo de programación de propósito general
•El usuario inicializa conjuntos de threads en el GPU
•GPU = super-threaded dedicado para procesamiento masivo de datos (co-processor)
•Conjunto de software dedicado
•Manejadores de dispositivos, lenguaje y herramientas.
•Manejador para carga de programas al GPU
•Manejador Independiente - Optimizado para computaciones
•Interfaz diseñada para computaciones - API no gráfica
•Comparte datos con objetos OpenGL en buffer
•Aceleración garantizada en los accesos a memoria
•Manejo explicito de la memoria del GPU
Friday, October 21, 2011
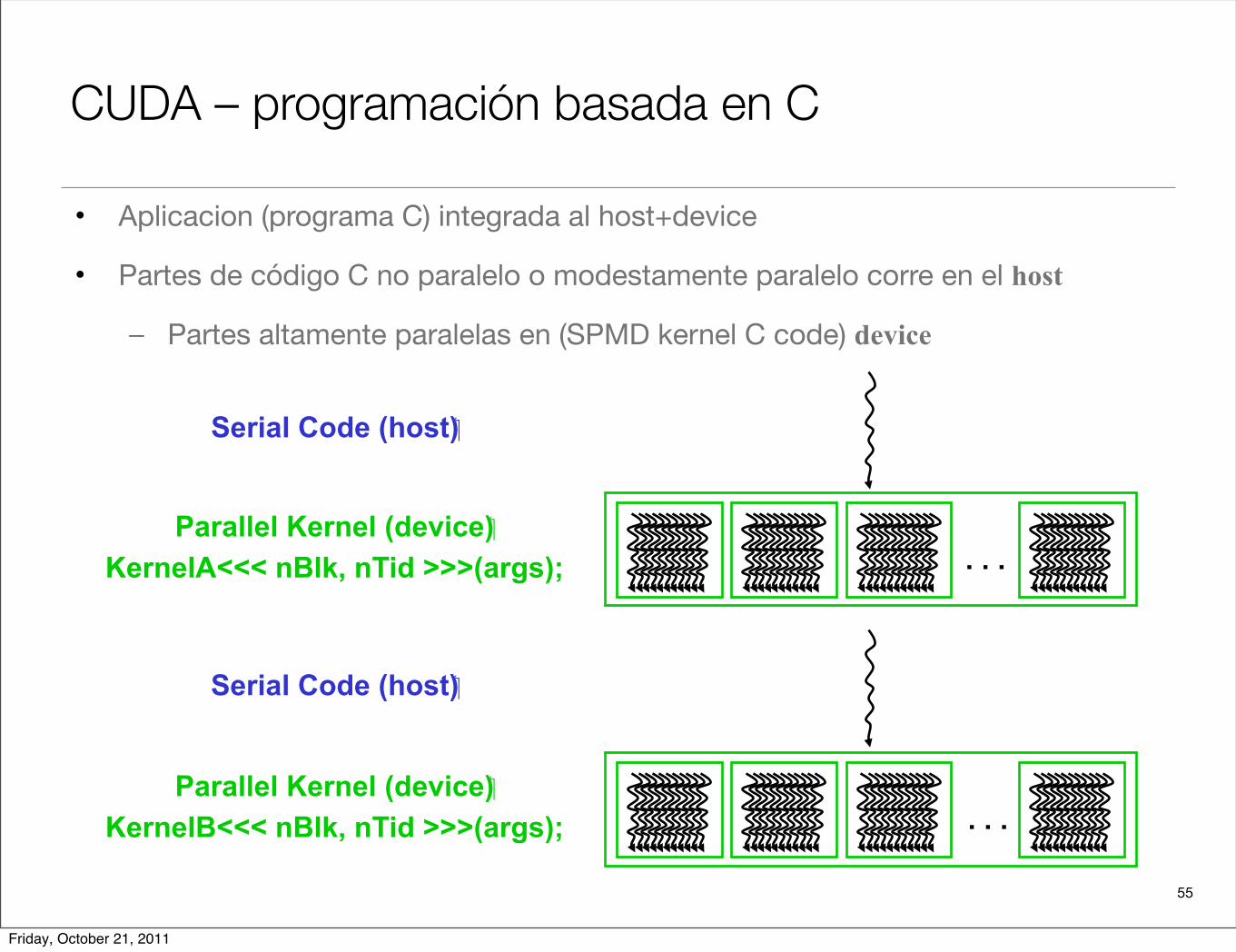
55
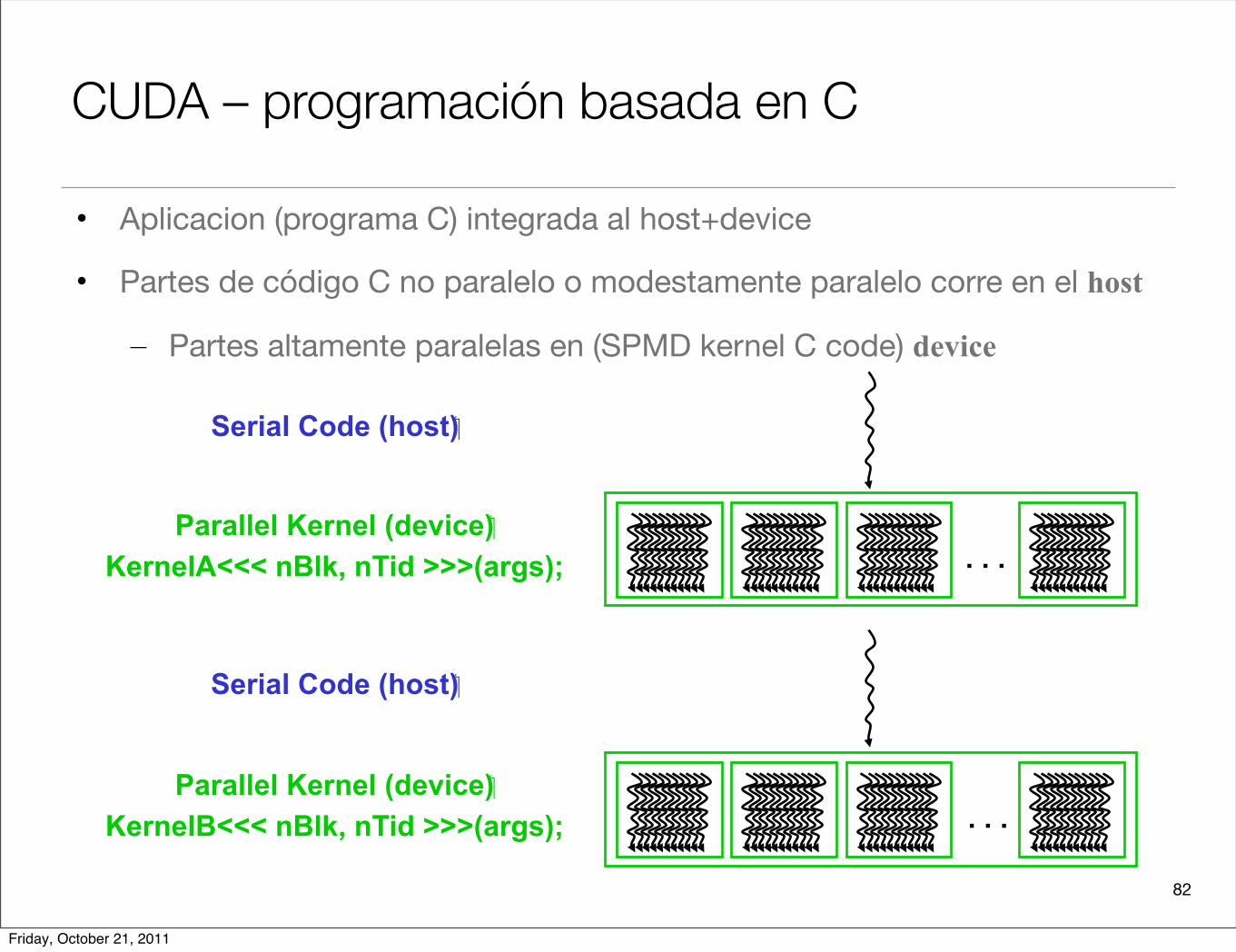
CUDA – programación basada en C
• Aplicacion (programa C) integrada al host+device
• Partes de código C no paralelo o modestamente paralelo corre en el host
– Partes altamente paralelas en (SPMD kernel C code) device
Serial Code (host)
. . .
. . .
Parallel Kernel (device)KernelA<<< nBlk, nTid >>>(args);
Serial Code (host)
Parallel Kernel (device)KernelB<<< nBlk, nTid >>>(args);
Friday, October 21, 2011

Plataformas de desarrollo
Frameworks, lenguajes y herramientas que nos permiten crear programas que corran en arquitecturas de GPGPU’s.
• OpenCL
• CUDA
• Brook+
• DirectCompute
• CAPS
Friday, October 21, 2011
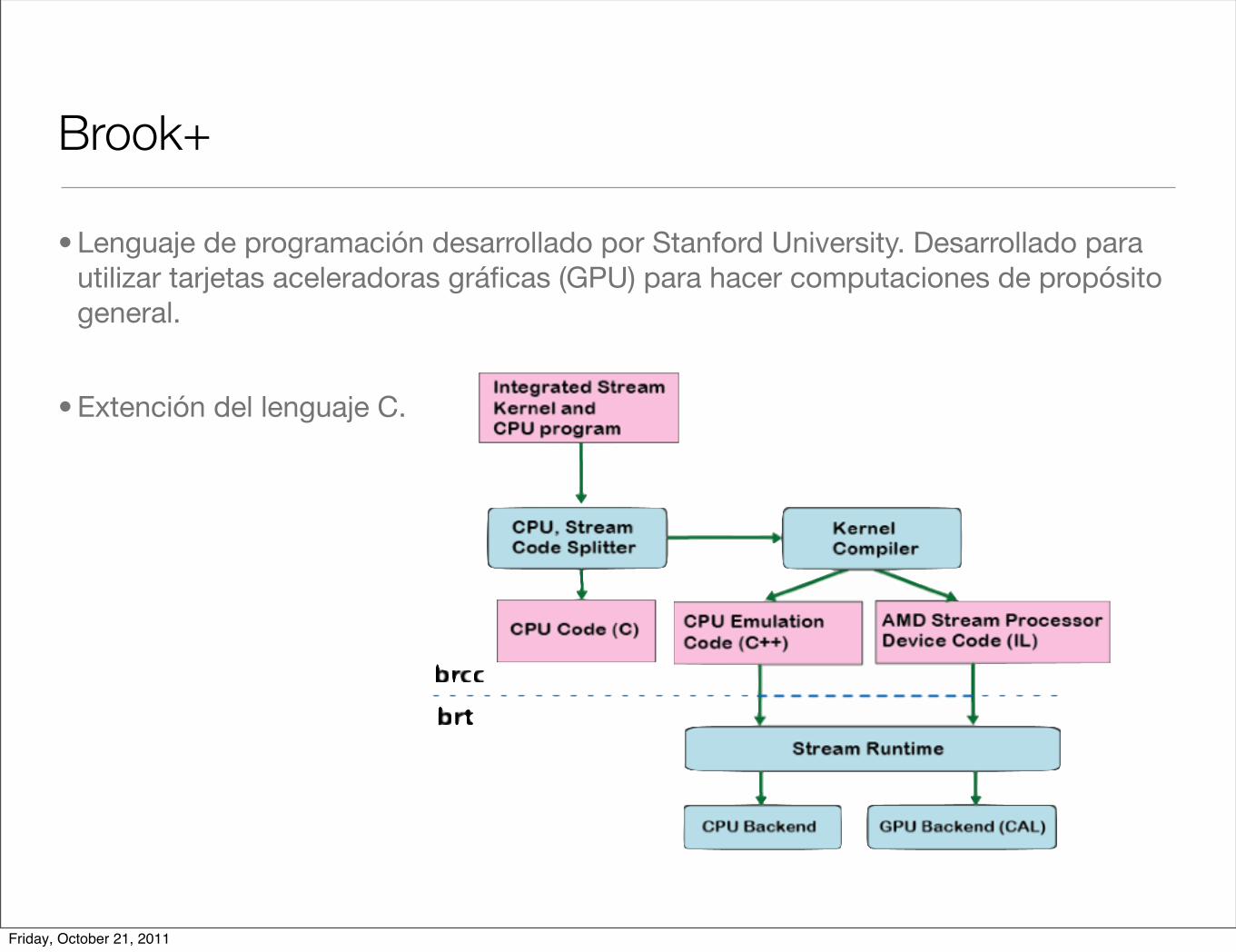
Brook+
• Lenguaje de programación desarrollado por Stanford University. Desarrollado para utilizar tarjetas aceleradoras gráficas (GPU) para hacer computaciones de propósito general.
• Extención del lenguaje C.
Friday, October 21, 2011

Plataformas de desarrollo
Frameworks, lenguajes y herramientas que nos permiten crear programas que corran en arquitecturas de GPGPU’s.
• OpenCL
• CUDA
• Brook+
• DirectCompute
• CAPS
Friday, October 21, 2011
DirectCompute
• API desarrollado por Microsoft para desarrollar aplicaciones de propósito específico en unidades de GPU.
• Corre en Windows Vista y Windows 7.
• Lenguaje HLSL, sintaxis similar a C.
Friday, October 21, 2011

Plataformas de desarrollo
Frameworks, lenguajes y herramientas que nos permiten crear programas que corran en arquitecturas de GPGPU’s.
• OpenCL
• CUDA
• Brook+
• DirectCompute
• CAPS
Friday, October 21, 2011
CAPS
• Software desarrollado por la compañia HPC Project.
• Genera código para GPU’s al estilo OpenMP a partir de código C o FORTRAN.
Friday, October 21, 2011

Contenido
• Introducción a HPC
• Tecnología de GPGPU
• Plataformas de desarrollo
• Estrategias de programación
• Comentarios finales y conclusiones
Friday, October 21, 2011

Estrategias de programación
• Buscar particionamiento sobre datos (SPMD).
• Dominio del problema.
• Estrategia de paralelismo incremental.
• Generar operaciones de grano fino. { { {
Tamaño del grano: número de computaciones que se ejecutan entre la comunicación y la sincronización.
Friday, October 21, 2011
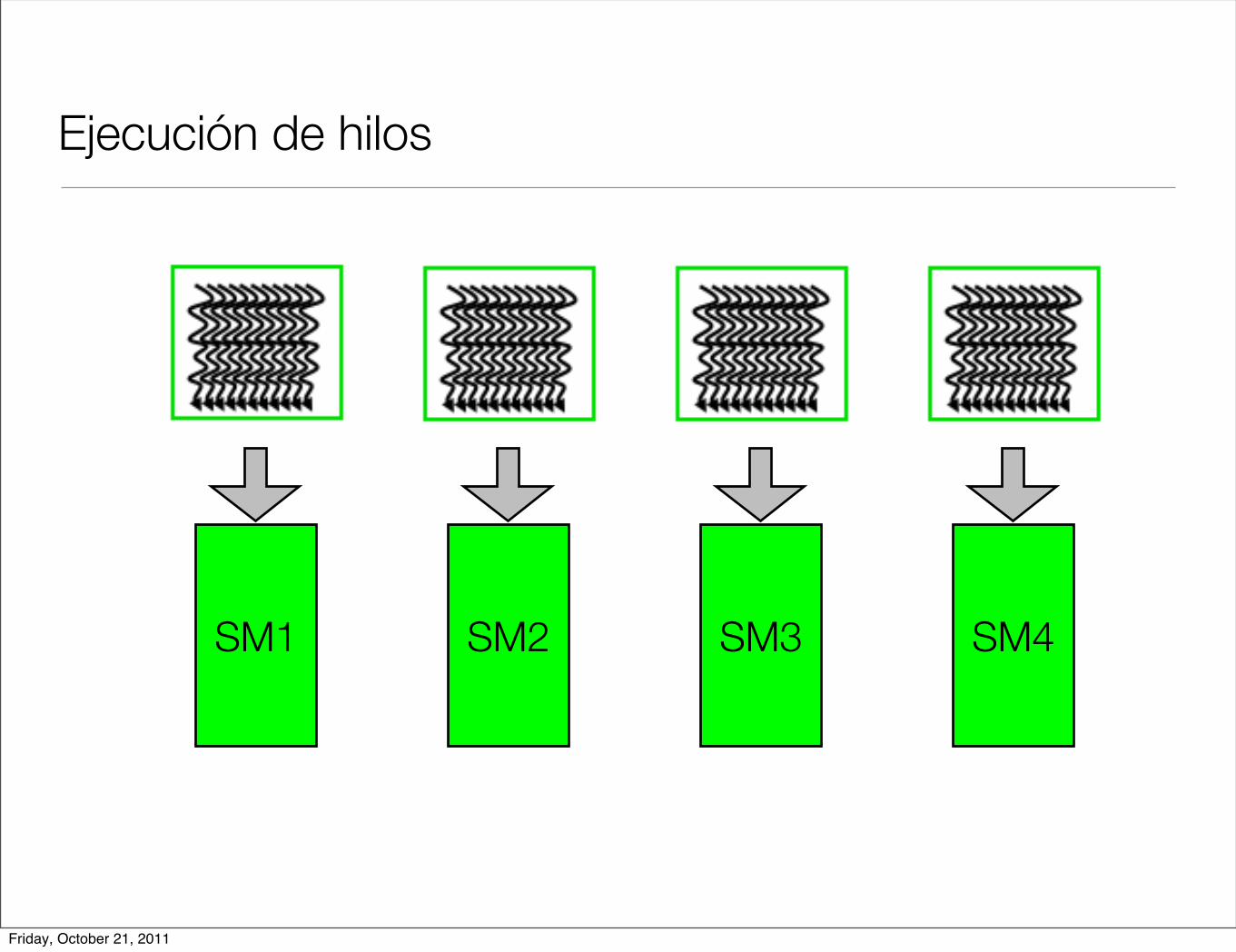
Ejecución de hilos
SM1 SM2 SM3 SM4
Friday, October 21, 2011
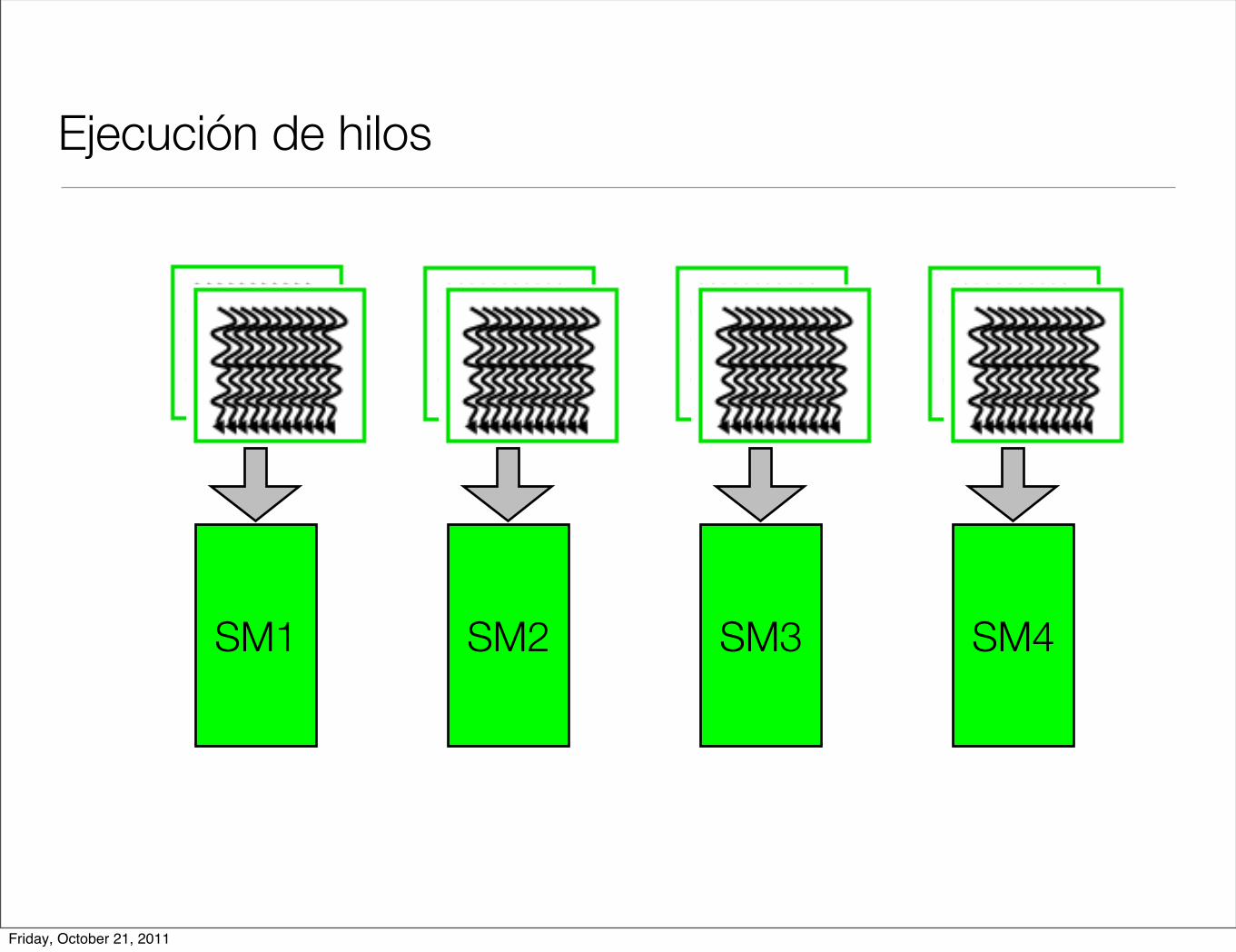
Ejecución de hilos
SM1 SM2 SM3 SM4
Friday, October 21, 2011

Manejo de cache
Kernel alineado
Kernel disperso
Friday, October 21, 2011
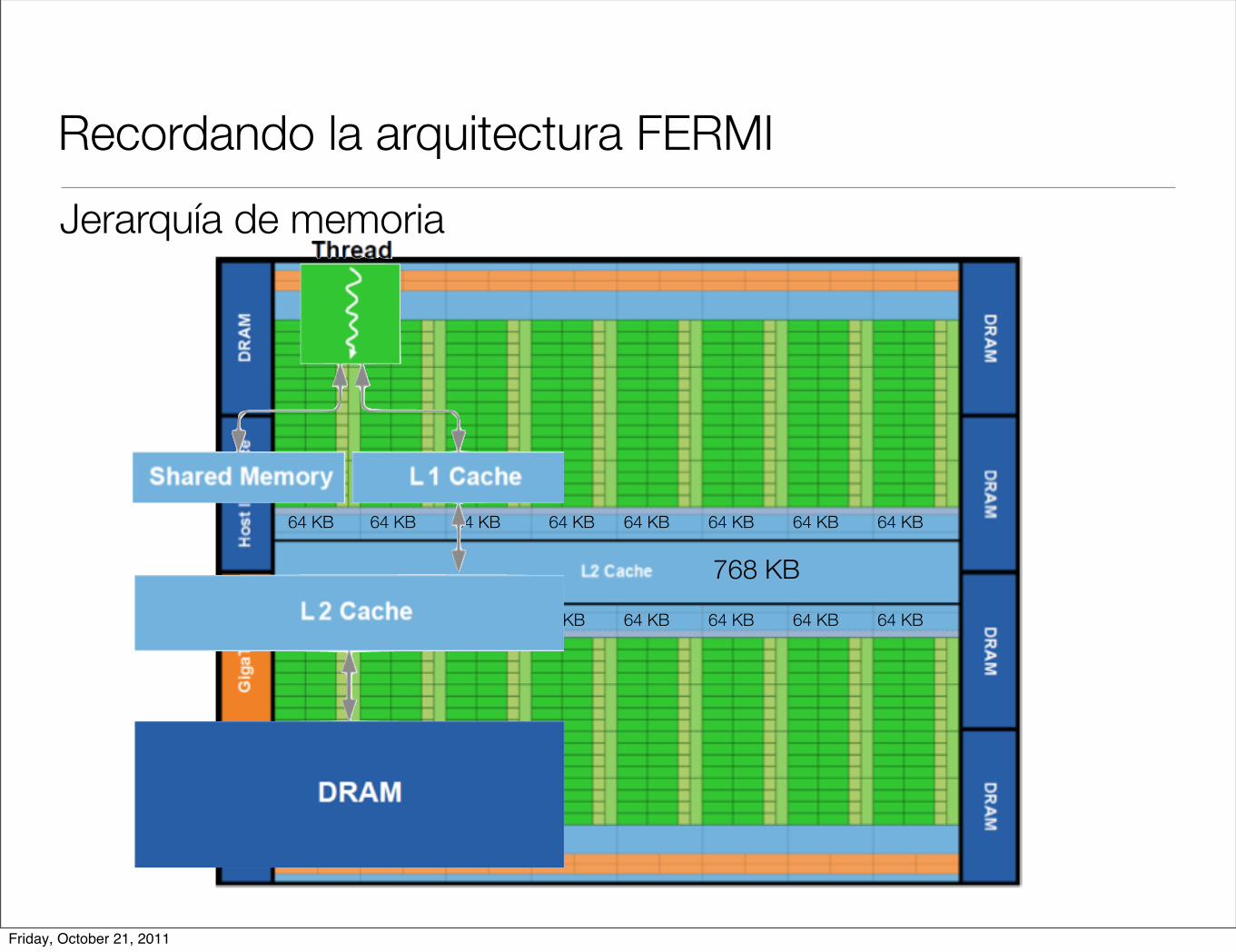
Recordando la arquitectura FERMI
Jerarquía de memoria
768 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
Friday, October 21, 2011

Registros
• Por omisión, variables locales de cada kernel se asignan a registros.
• FERMI:
Friday, October 21, 2011
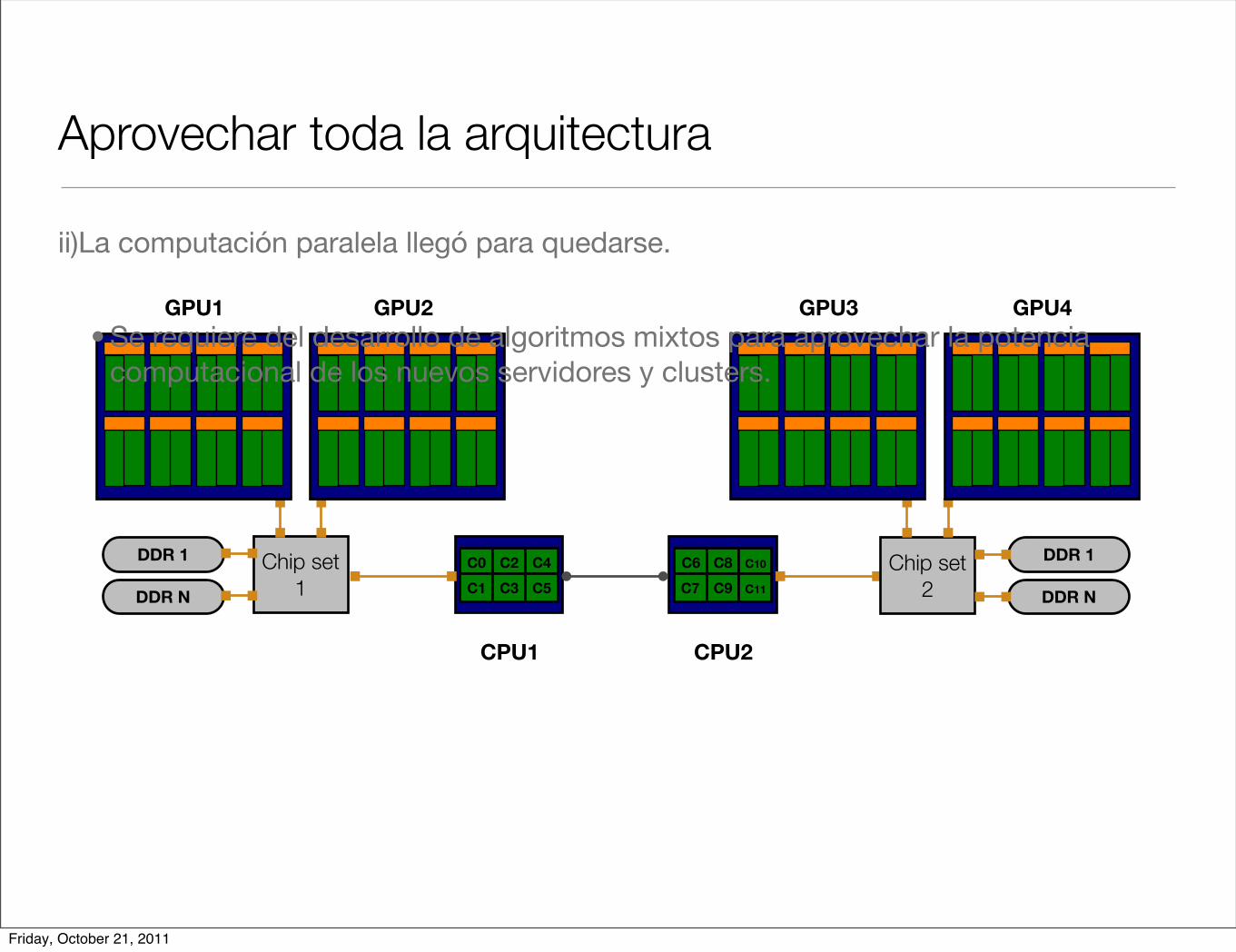
Aprovechar toda la arquitectura
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
C11
CPU1 CPU2
Chip set 2
Chip set 1
DDR 1
DDR N
DDR 1
DDR N
GPU1 GPU2 GPU3 GPU4
ii)La computación paralela llegó para quedarse.
• Se requiere del desarrollo de algoritmos mixtos para aprovechar la potencia computacional de los nuevos servidores y clusters.
Friday, October 21, 2011
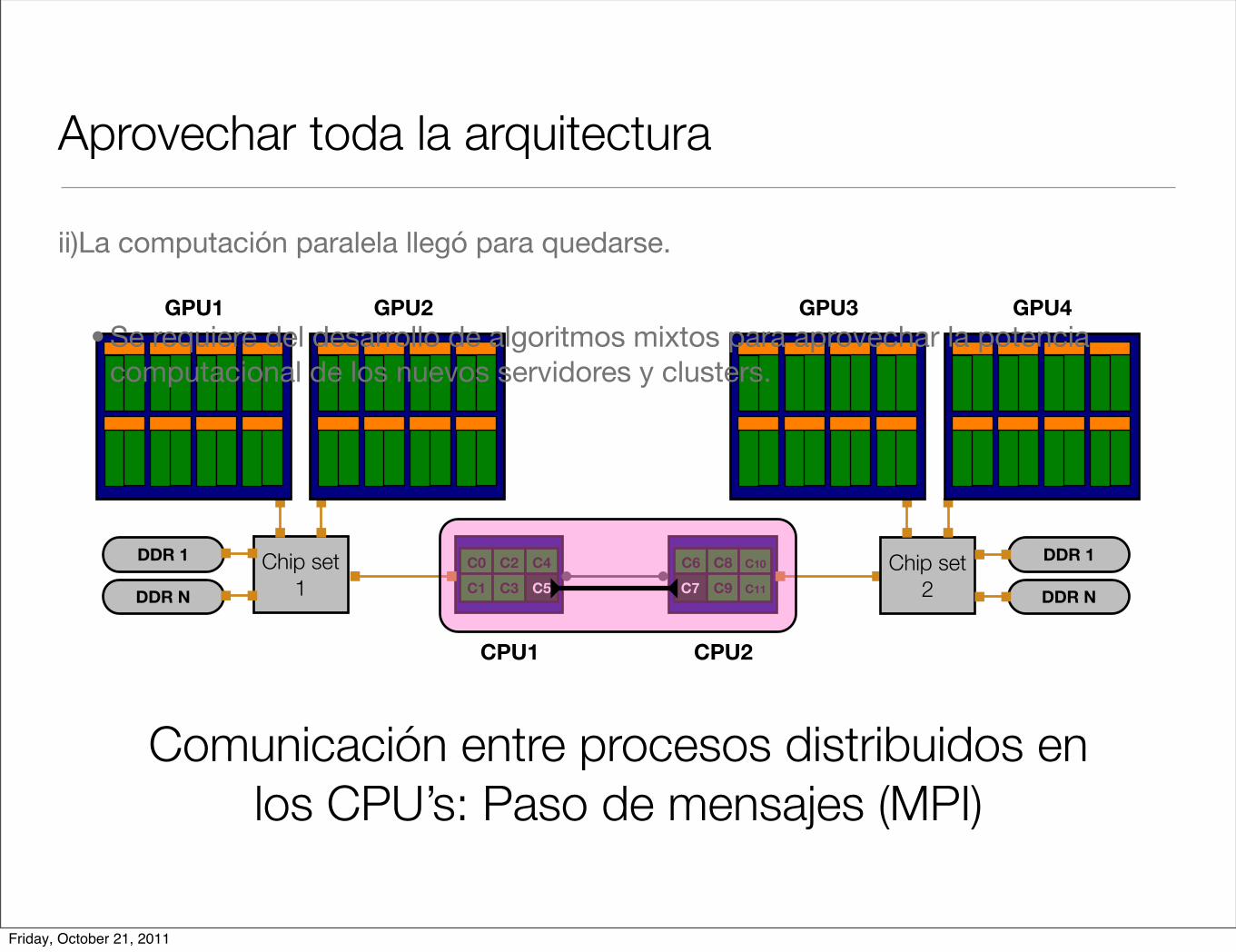
Aprovechar toda la arquitectura
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
C11
CPU1 CPU2
Chip set 2
Chip set 1
DDR 1
DDR N
DDR 1
DDR N
GPU1 GPU2 GPU3 GPU4
Comunicación entre procesos distribuidos en los CPU’s: Paso de mensajes (MPI)
ii)La computación paralela llegó para quedarse.
• Se requiere del desarrollo de algoritmos mixtos para aprovechar la potencia computacional de los nuevos servidores y clusters.
Friday, October 21, 2011
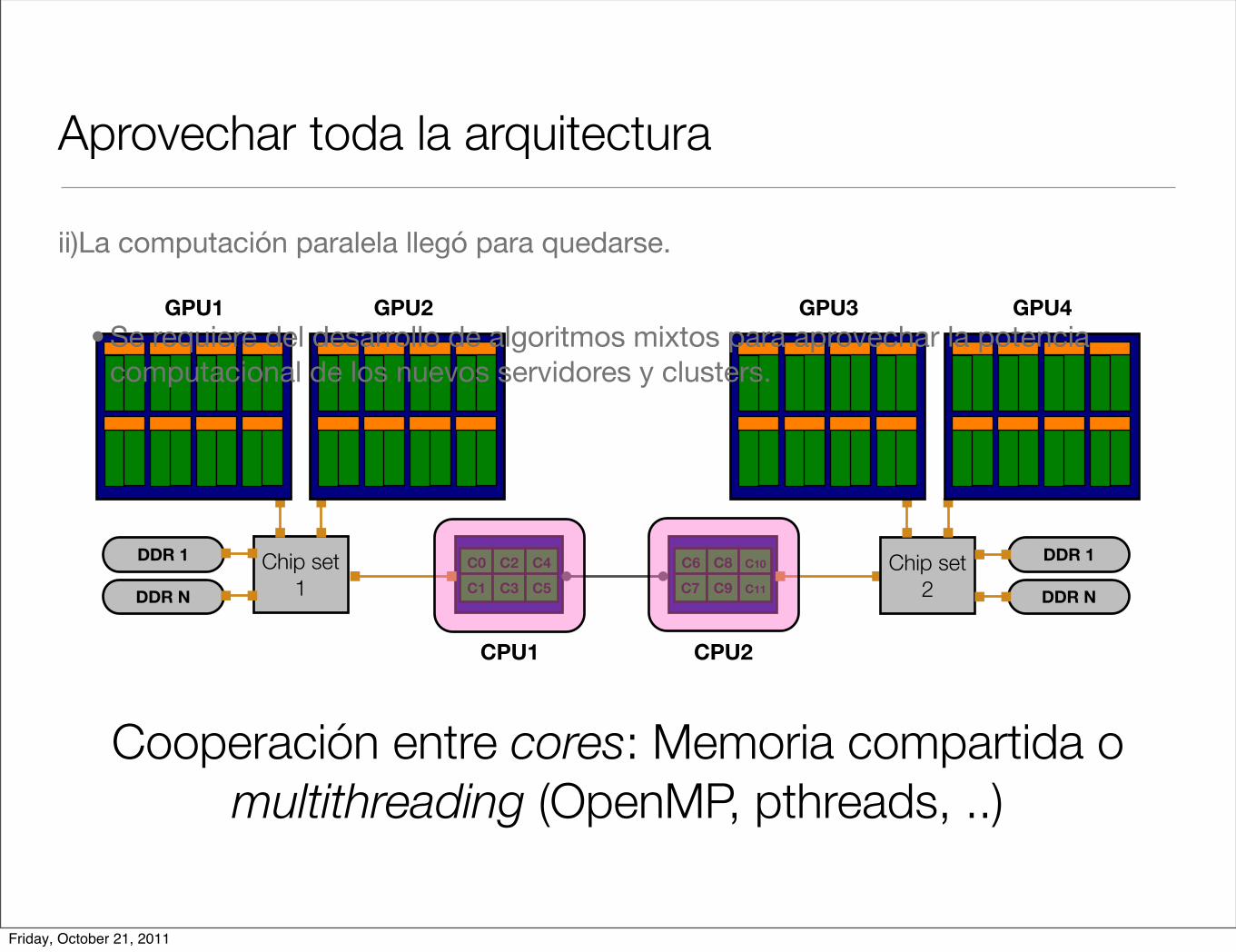
Aprovechar toda la arquitectura
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
C11
CPU1 CPU2
Chip set 2
Chip set 1
DDR 1
DDR N
DDR 1
DDR N
GPU1 GPU2 GPU3 GPU4
Cooperación entre cores: Memoria compartida o multithreading (OpenMP, pthreads, ..)
ii)La computación paralela llegó para quedarse.
• Se requiere del desarrollo de algoritmos mixtos para aprovechar la potencia computacional de los nuevos servidores y clusters.
Friday, October 21, 2011

Aprovechar toda la arquitectura
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
C11
CPU1 CPU2
Chip set 2
Chip set 1
DDR 1
DDR N
DDR 1
DDR N
GPU1 GPU2 GPU3 GPU4
Computación en la GPU: Memoria compartida de grano fino (OpenCL, CUDA, DirectCompute,CAPS,..)
ii)La computación paralela llegó para quedarse.
• Se requiere del desarrollo de algoritmos mixtos para aprovechar la potencia computacional de los nuevos servidores y clusters.
Friday, October 21, 2011
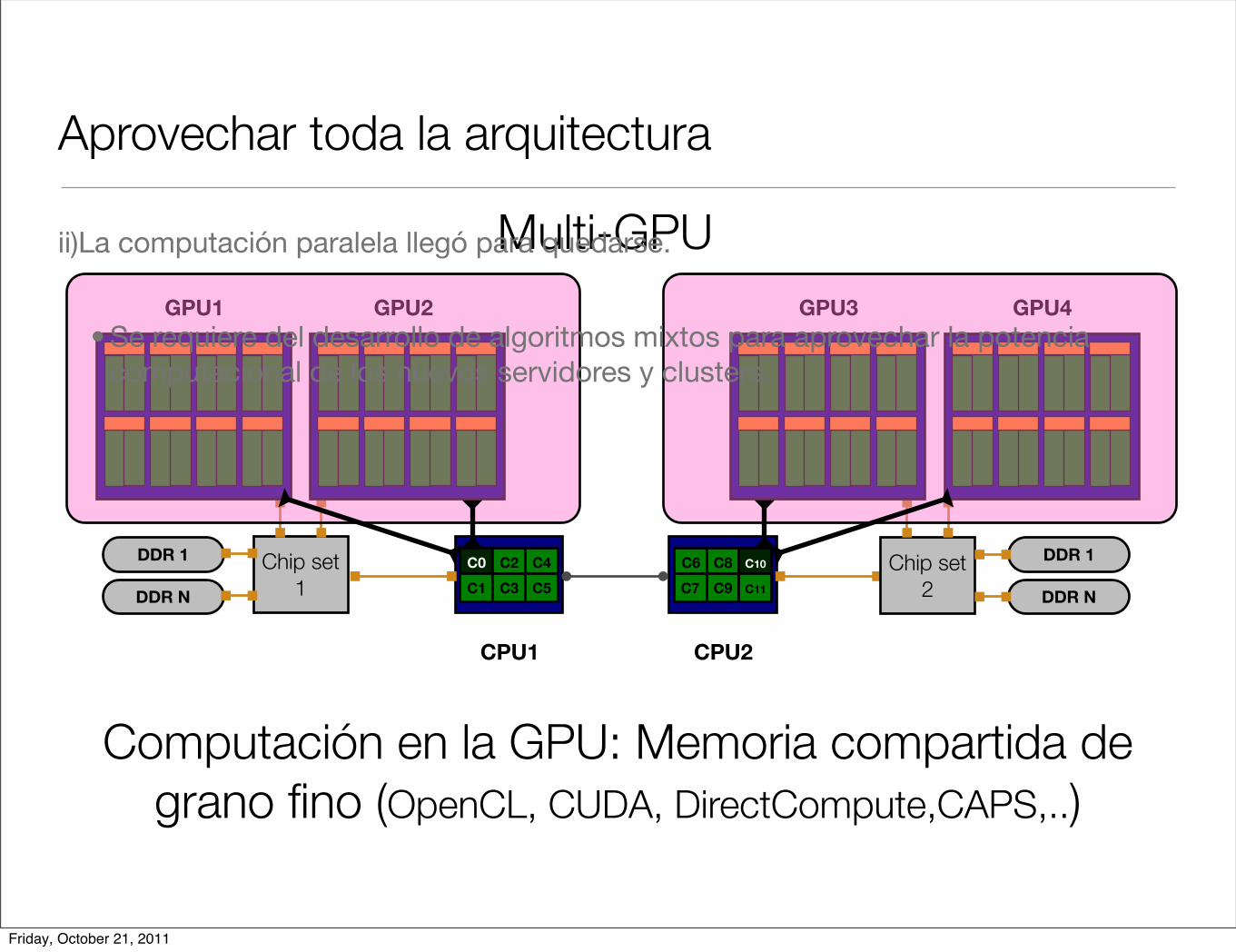
Aprovechar toda la arquitectura
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
C11
CPU1 CPU2
Chip set 2
Chip set 1
DDR 1
DDR N
DDR 1
DDR N
GPU1 GPU2 GPU3 GPU4
Computación en la GPU: Memoria compartida de grano fino (OpenCL, CUDA, DirectCompute,CAPS,..)
Multi-GPUii)La computación paralela llegó para quedarse.
• Se requiere del desarrollo de algoritmos mixtos para aprovechar la potencia computacional de los nuevos servidores y clusters.
Friday, October 21, 2011
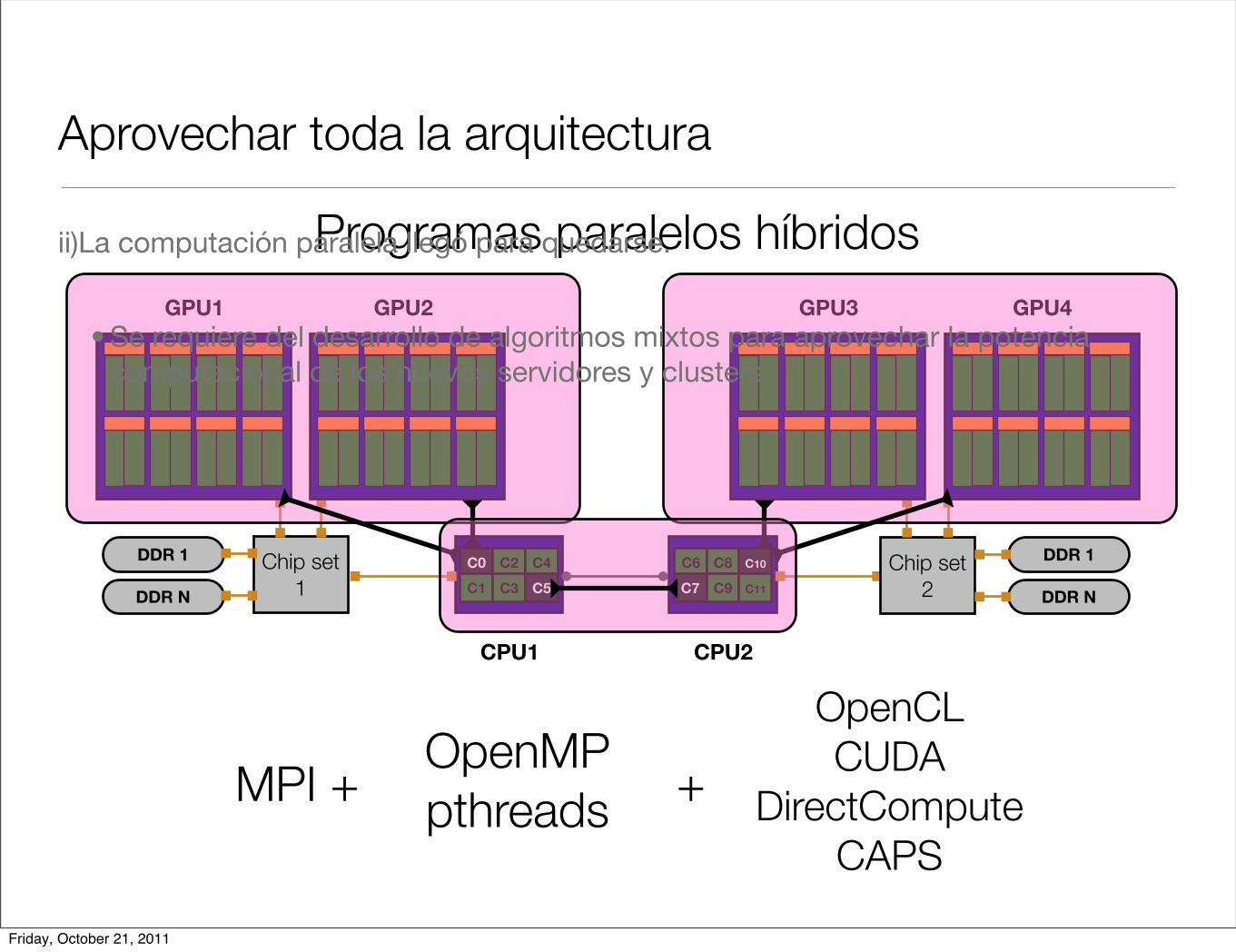
Aprovechar toda la arquitectura
C0
C1
C2
C3
C4
C5
C6
C7
C8
C9
C10
C11
CPU1 CPU2
Chip set 2
Chip set 1
DDR 1
DDR N
DDR 1
DDR N
GPU1 GPU2 GPU3 GPU4
MPI + OpenMPpthreads +
OpenCLCUDA
DirectComputeCAPS
Programas paralelos híbridosii)La computación paralela llegó para quedarse.
• Se requiere del desarrollo de algoritmos mixtos para aprovechar la potencia computacional de los nuevos servidores y clusters.
Friday, October 21, 2011

75
CUDA -- Entorno de desarrollo y lenguajeExtensiones a C• Declspecs
– global, device, shared, local, constant
• Palabras clave– threadIdx, blockIdx
• Escencial– __syncthreads
• Runtime API– Memory, symbol, execution
management
• Funcion de lanzamiento
__device__ float filter[N];
__global__ void convolve (float *image) {
__shared__ float region[M]; ...
region[threadIdx.x] = image[i];
__syncthreads() ... image[j] = result;}
// Allocate GPU memoryvoid *myimage = cudaMalloc(bytes)
// 100 blocks, 10 threads per blockconvolve<<<100, 10>>> (myimage);
Friday, October 21, 2011
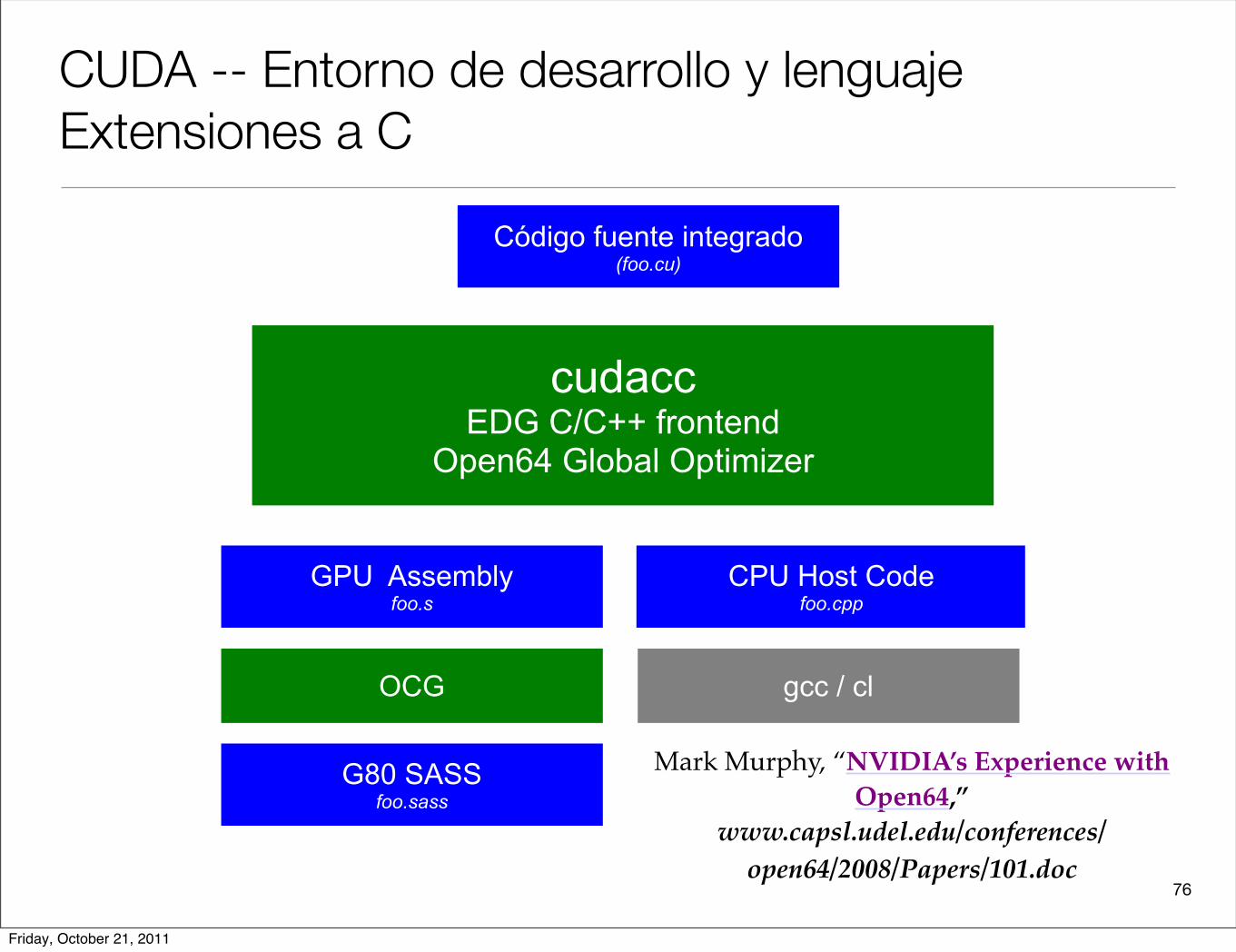
76
gcc / cl
G80 SASSfoo.sass
OCG
CUDA -- Entorno de desarrollo y lenguajeExtensiones a C
cudaccEDG C/C++ frontend
Open64 Global Optimizer
GPU Assemblyfoo.s
CPU Host Code foo.cpp
Código fuente integrado(foo.cu)
Mark Murphy, “NVIDIA’s Experience with Open64,”
www.capsl.udel.edu/conferences/open64/2008/Papers/101.doc
Friday, October 21, 2011
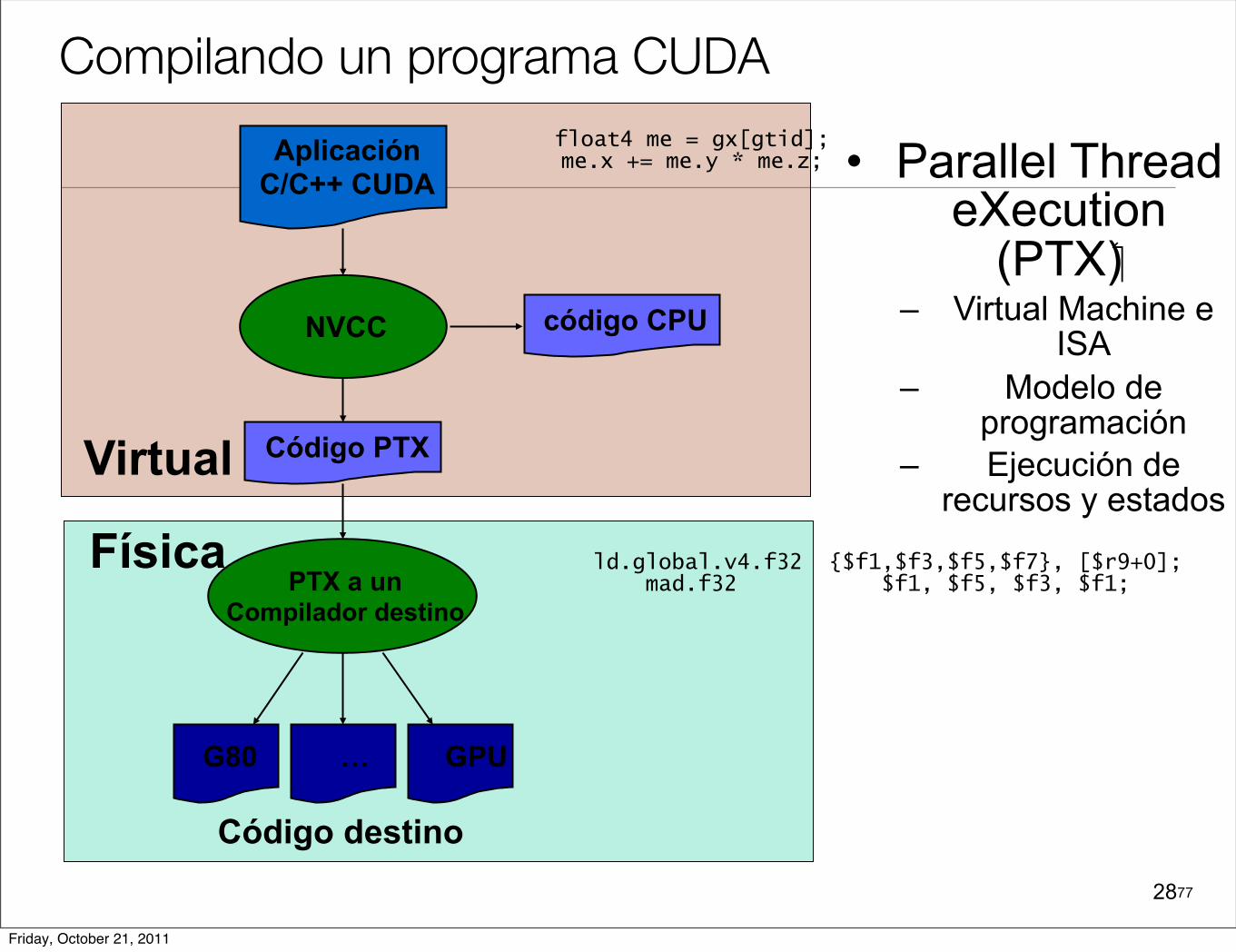
7728
Compilando un programa CUDA
NVCC
AplicaciónC/C++ CUDA
PTX a unCompilador destino
G80 … GPU
Código destino
Código PTXVirtual
Física
código CPU
• Parallel Thread eXecution
(PTX)– Virtual Machine e
ISA– Modelo de
programación– Ejecución de
recursos y estados
float4 me = gx[gtid];me.x += me.y * me.z;
ld.global.v4.f32 {$f1,$f3,$f5,$f7}, [$r9+0];mad.f32 $f1, $f5, $f3, $f1;
Friday, October 21, 2011

• Cualquier archivo fuente que contiene extensión CUDA (.cu) se debe compilar con nvcc.
• El nvcc es un manejador de compilación (compiler driver) que hace llamdos a las herramientas y compiladores necesarios como: cudacc, g++, cl, ...
•nvcc produce un archivo de salida que contiene:
• Código C (código CPU)
• PTX (Parallel Thread Excecution) o código objeto.
• Genera código ejecutable para las plataformas como WINDOWS, LINUX o Mac OS X.
Compilador CUDA nvcc
Friday, October 21, 2011
Ligado
• Cualquier archivo ejecutable con código CUDA requiere dos bibliotecas dinámicas:
• Biblioteca en tiempo de ejecución CUDA (cudart).
• Biblioteca de núcleo CUDA (cuda).
Friday, October 21, 2011

Taller: Introducción a GPU's y Programación CUDA para HPC
PARTE II: PRINCIPIOS Y CONCEPTOS DE PROGRAMACION CUDA
Friday, October 21, 2011

81
Dispositivos y threads CUDA
• Un dispositivo (device) de computadora
– Es un coprocesador al CPU o host
– Tiene su propia memoria DRAM (device memory) – Ejecuta muchos threads en paralelo
– Es un típico GPU pero además puede ser otro tipo de dispositivo de procesamiento paralelo
• Partes de código con paralelismo en datos se expresan como un dispositivos kernels en los cuales se ejecutan multiples hilos.
• Diferencias entre hilos GPU y CPU
– GPU hilos son extremadamente ligeros
• Muy poca sobrecarga de creación
– GPU requiere miles de threads para una eficiencia completa
• CPU multi-core necesita pocos para una eficienca completa
Friday, October 21, 2011
82
CUDA – programación basada en C
• Aplicacion (programa C) integrada al host+device
• Partes de código C no paralelo o modestamente paralelo corre en el host
– Partes altamente paralelas en (SPMD kernel C code) device
Serial Code (host)
. . .
. . .
Parallel Kernel (device)KernelA<<< nBlk, nTid >>>(args);
Serial Code (host)
Parallel Kernel (device)KernelB<<< nBlk, nTid >>>(args);
Friday, October 21, 2011
83
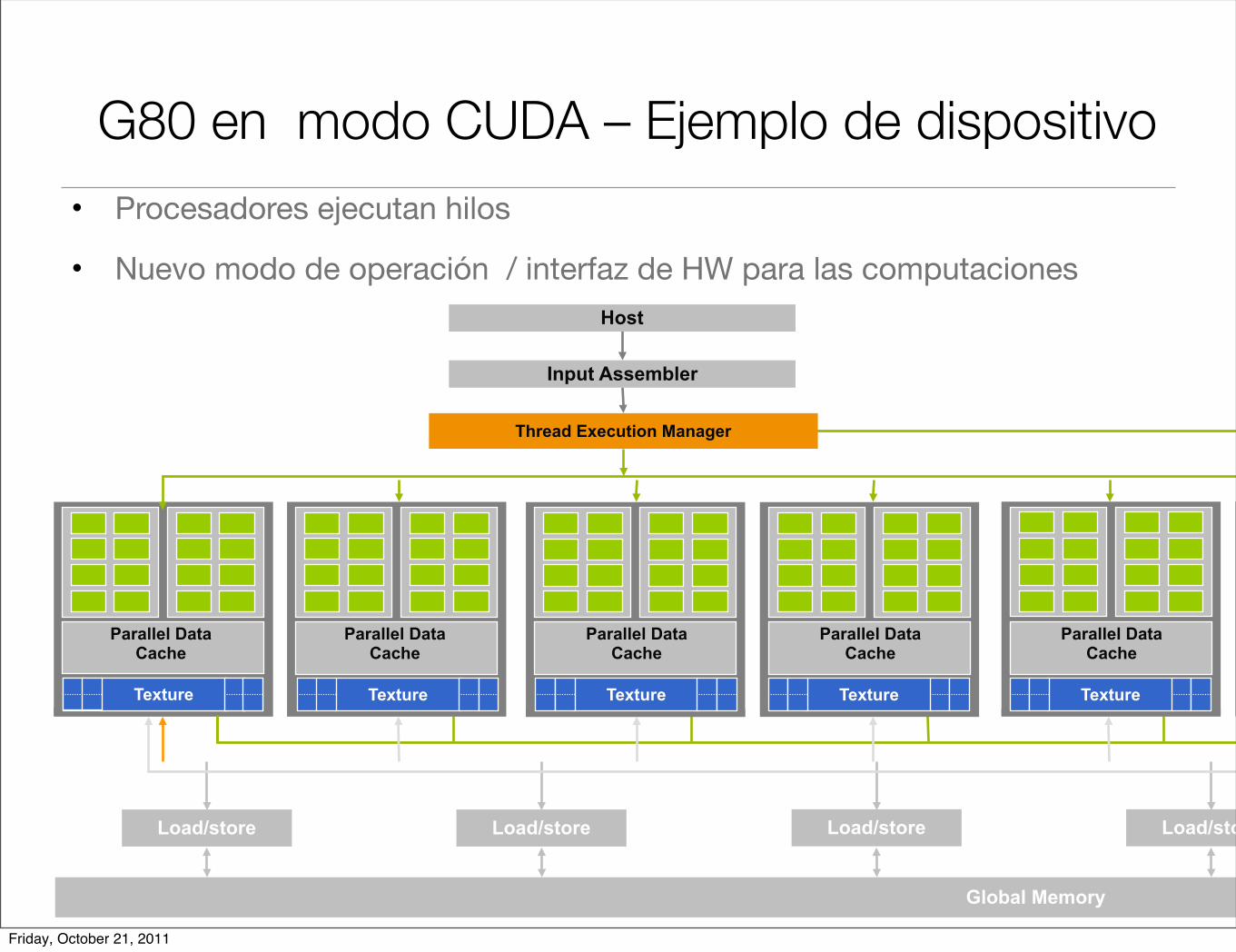
G80 en modo CUDA – Ejemplo de dispositivo
• Procesadores ejecutan hilos
• Nuevo modo de operación / interfaz de HW para las computaciones
Load/store
Global Memory
Thread Execution Manager
Input Assembler
Host
Texture Texture Texture Texture TextureTexture
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Load/store Load/store Load/store
Friday, October 21, 2011

84
Arreglos de Parallel Threads
• Un kernel de CUDA se ejecuta por un arreglo de threads– Todos los threads ejecutan el mismo código (SPMD)– Cada hilo tiene un ID que usa para el manejo de las
direcciones de memoria y para el control de decisión
76543210
…float x = input[threadIdx.x];float y = func(x);output[threadIdx.x] = y;…
threadIdx.x
Friday, October 21, 2011

85
…float x = input[threadIdx.x];float y = func(x);output[threadIdx.x] = y;…
threadIdx.x
Thread Block 0
……float x = input[threadIdx.x];float y = func(x);output[threadIdx.x] = y;…
Thread Block 1
…float x = input[threadIdx.x];float y = func(x);output[threadIdx.x] = y;…
Thread Block N-1
Thread Blocks: Cooperación Escalable
• Divide un arreglo monolítico de de hilos Divide en múltiples bloques
– Threads en un bloque cooperan via memoria compartida, operaciones atómicas y sincronización por barreras
– Threads en bloques distintos no pueden cooperar
76543210 76543210 76543210
Friday, October 21, 2011
86
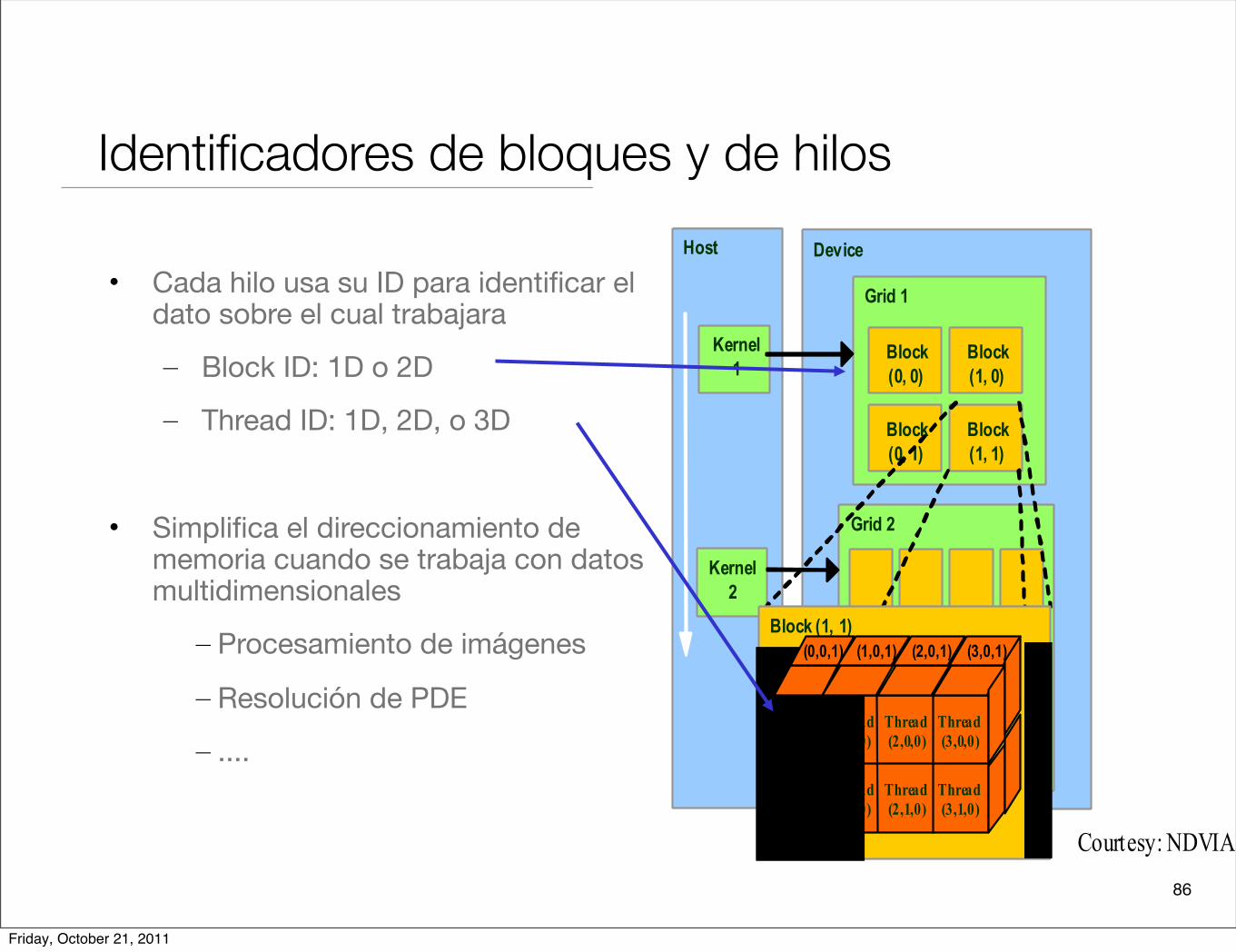
Identificadores de bloques y de hilos
• Cada hilo usa su ID para identificar el dato sobre el cual trabajara
– Block ID: 1D o 2D
– Thread ID: 1D, 2D, o 3D
• Simplifica el direccionamiento de memoria cuando se trabaja con datos multidimensionales
– Procesamiento de imágenes
– Resolución de PDE
– ....
Friday, October 21, 2011
87
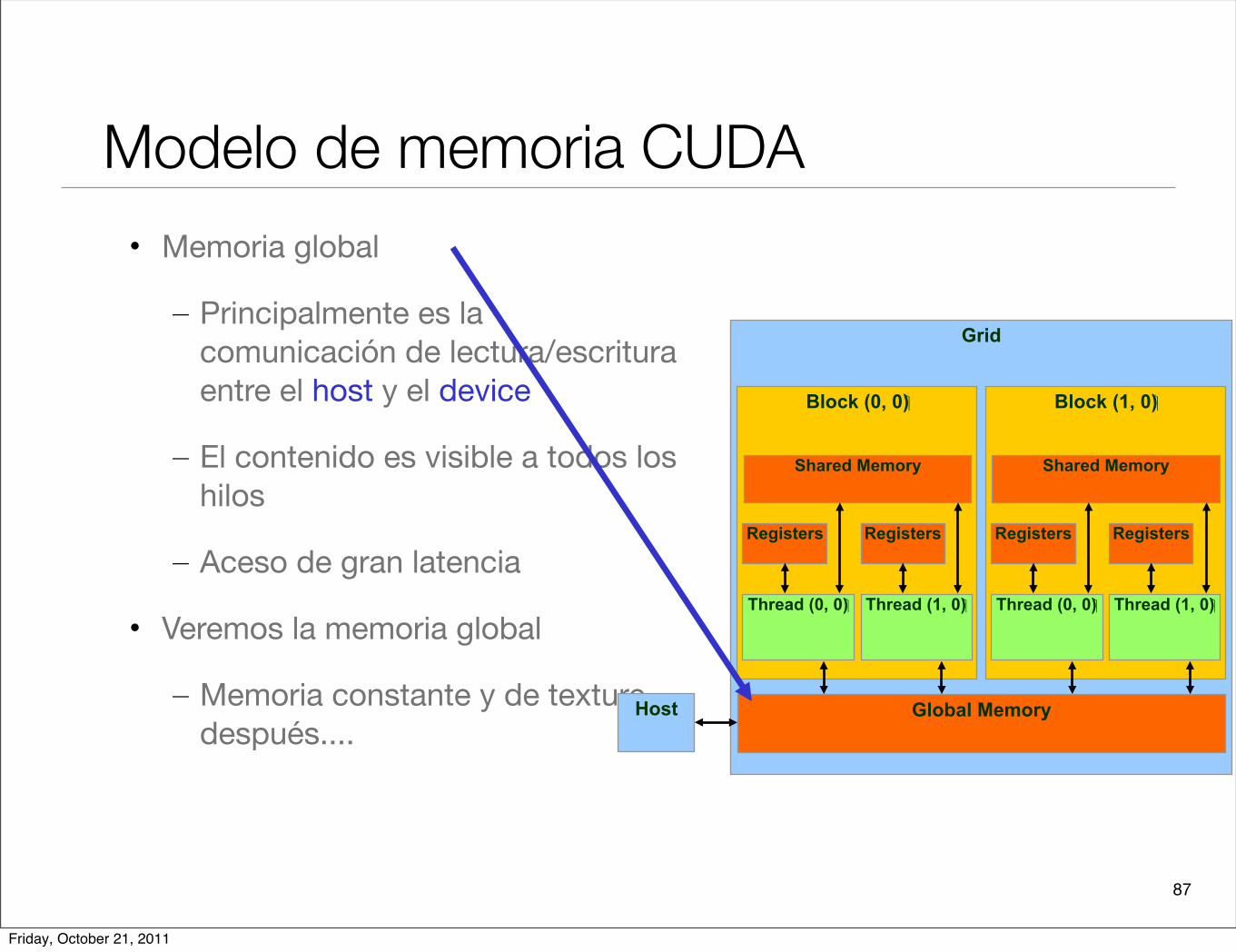
Modelo de memoria CUDA• Memoria global
– Principalmente es la comunicación de lectura/escritura entre el host y el device
– El contenido es visible a todos los hilos
– Aceso de gran latencia
• Veremos la memoria global
– Memoria constante y de texture después....
Grid
Global Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Friday, October 21, 2011
88
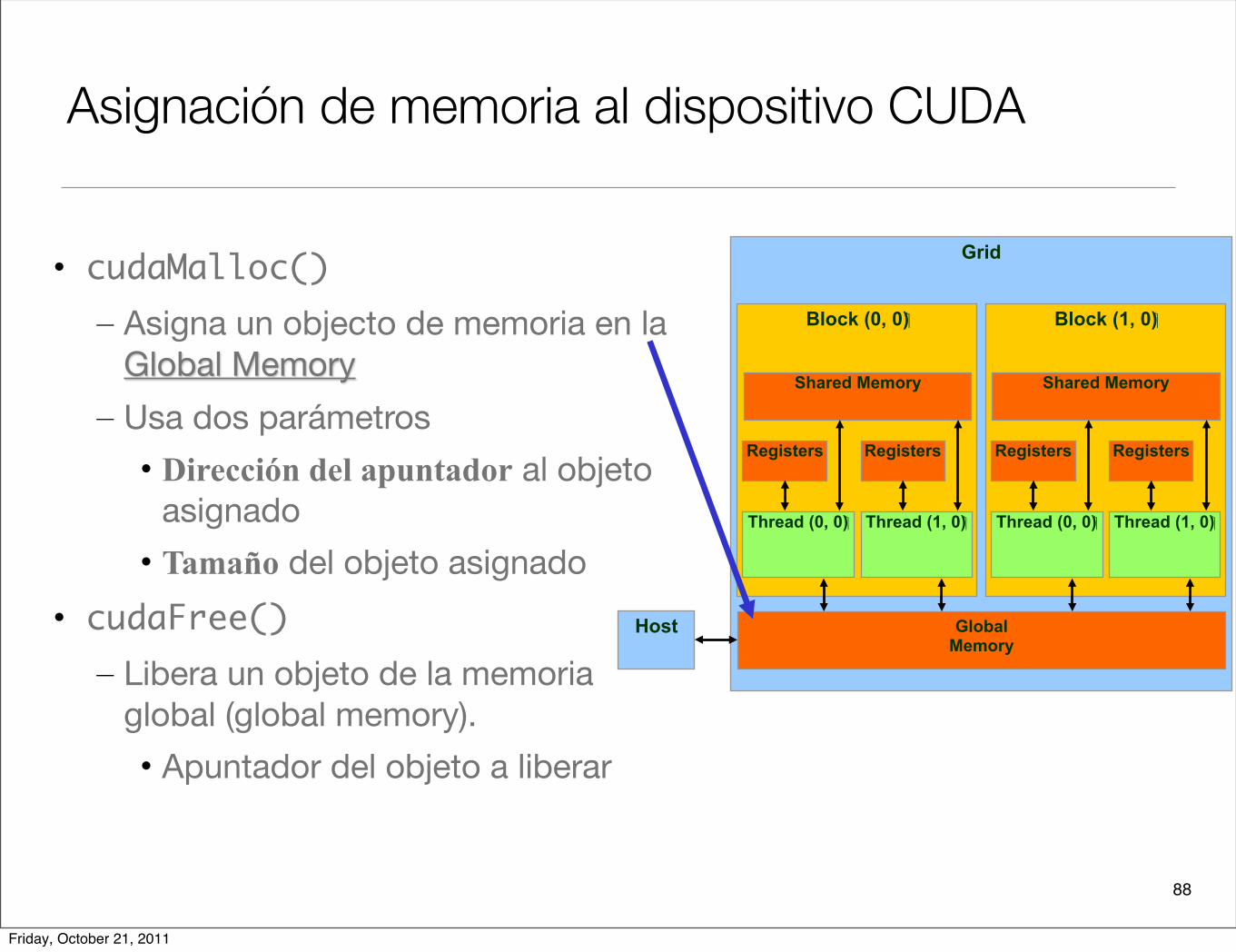
Asignación de memoria al dispositivo CUDA
• cudaMalloc()– Asigna un objecto de memoria en la
Global Memory
– Usa dos parámetros
• Dirección del apuntador al objeto asignado
• Tamaño del objeto asignado
• cudaFree()– Libera un objeto de la memoria
global (global memory).
• Apuntador del objeto a liberar
Grid
GlobalMemory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Friday, October 21, 2011

89
Asignación de memoria al dispositivo CUDA
• Ejemplo:
– Asignar memoria para un arreglo 64 * 64 de fp-sp
– Asociar la memoria asignada a Md
– (frecuentemente “d” se usa para indicar una estructura para datos en un dispositivo)
TILE_WIDTH = 64;Float* Md; // float *Md; int size = TILE_WIDTH * TILE_WIDTH * sizeof(float);
cudaMalloc((void**)&Md, size);cudaFree(Md);
Friday, October 21, 2011
90
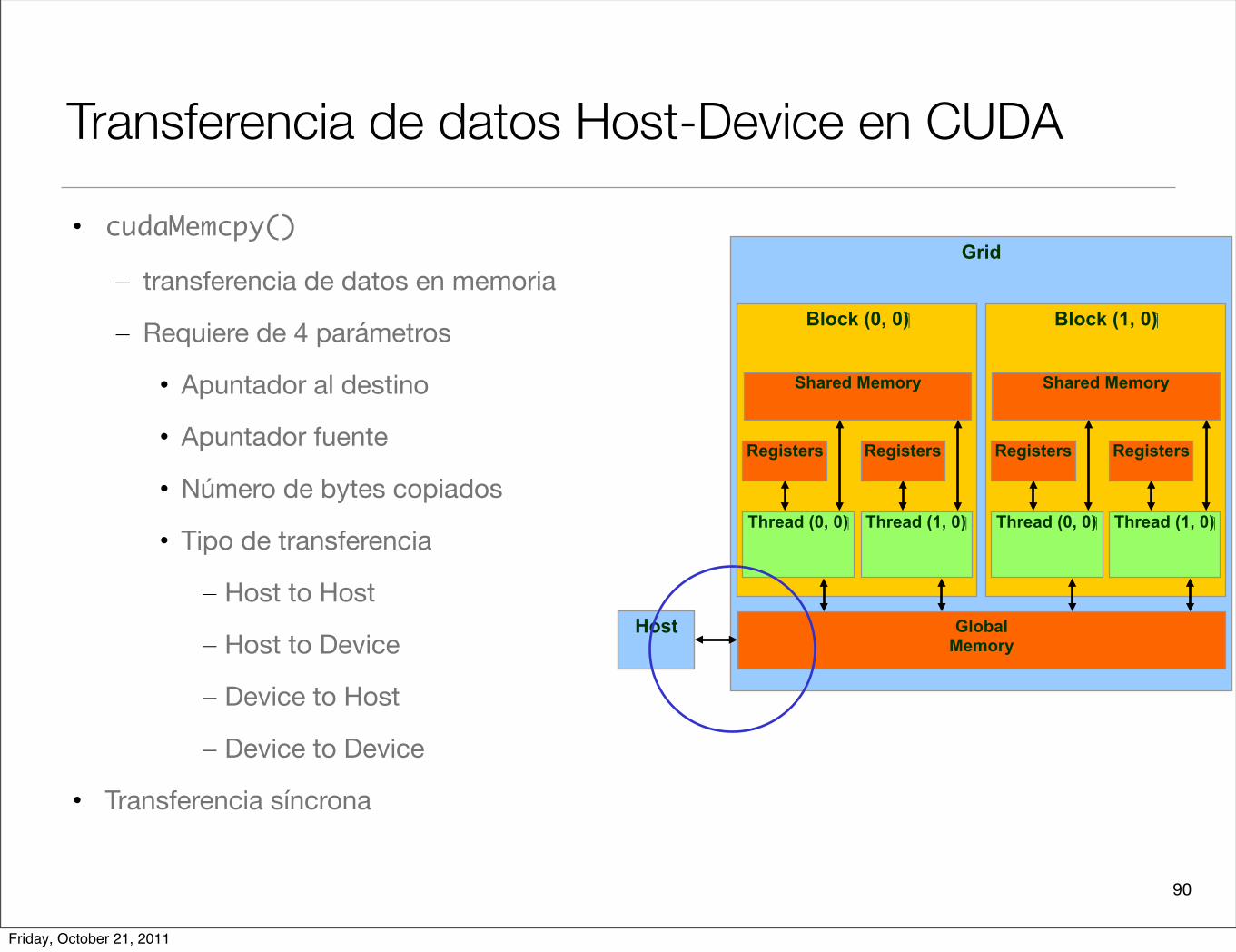
Transferencia de datos Host-Device en CUDA
• cudaMemcpy()
– transferencia de datos en memoria
– Requiere de 4 parámetros
• Apuntador al destino
• Apuntador fuente
• Número de bytes copiados
• Tipo de transferencia
– Host to Host
– Host to Device
– Device to Host
– Device to Device
• Transferencia síncrona
Grid
GlobalMemory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Friday, October 21, 2011

91
Transferencia de datos Host-Device en CUDA
• Ejemplo
– Transferir un arreglo de 64 * 64 de fp-sp
– M esta en la memoria del host y Md en la memoria del dispositivo
– cudaMemcpyHostToDevice y cudaMemcpyDeviceToHost son constantes simbólicas
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMemcpy(M, Md, size, cudaMemcpyDeviceToHost);
Friday, October 21, 2011
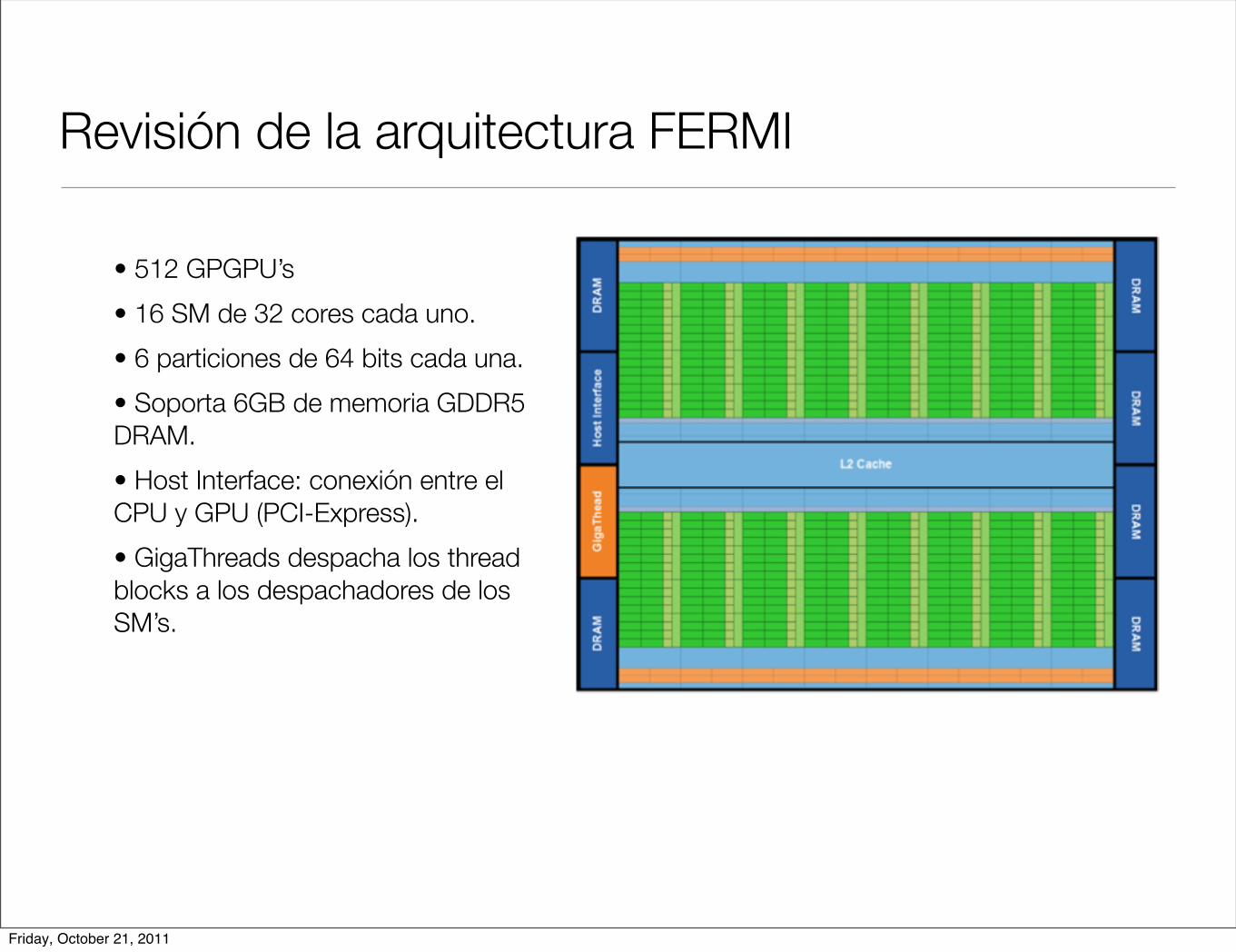
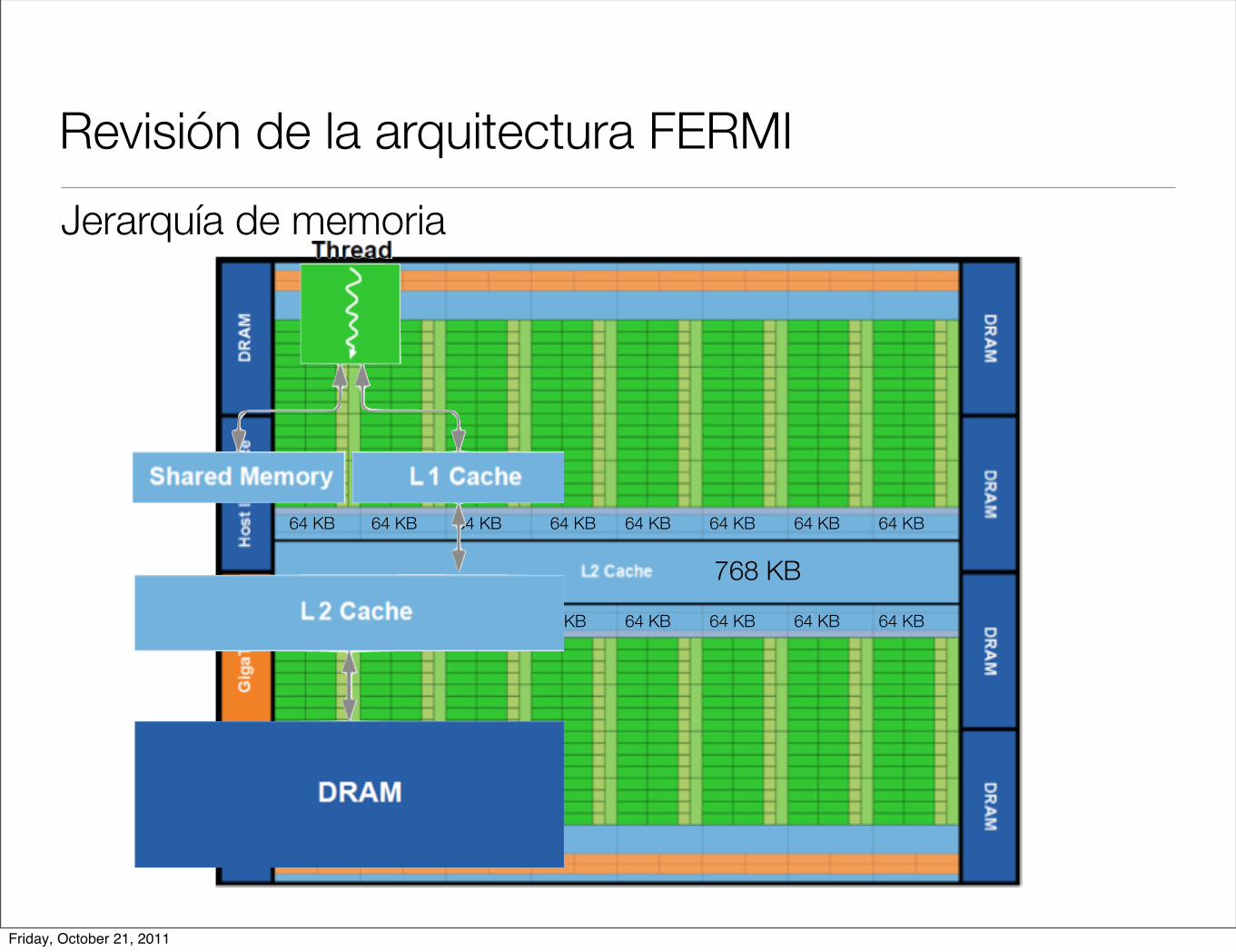
Revisión de la arquitectura FERMI
• 512 GPGPU’s
• 16 SM de 32 cores cada uno.
• 6 particiones de 64 bits cada una.
• Soporta 6GB de memoria GDDR5 DRAM.
• Host Interface: conexión entre el CPU y GPU (PCI-Express).
• GigaThreads despacha los thread blocks a los despachadores de los SM’s.
Friday, October 21, 2011
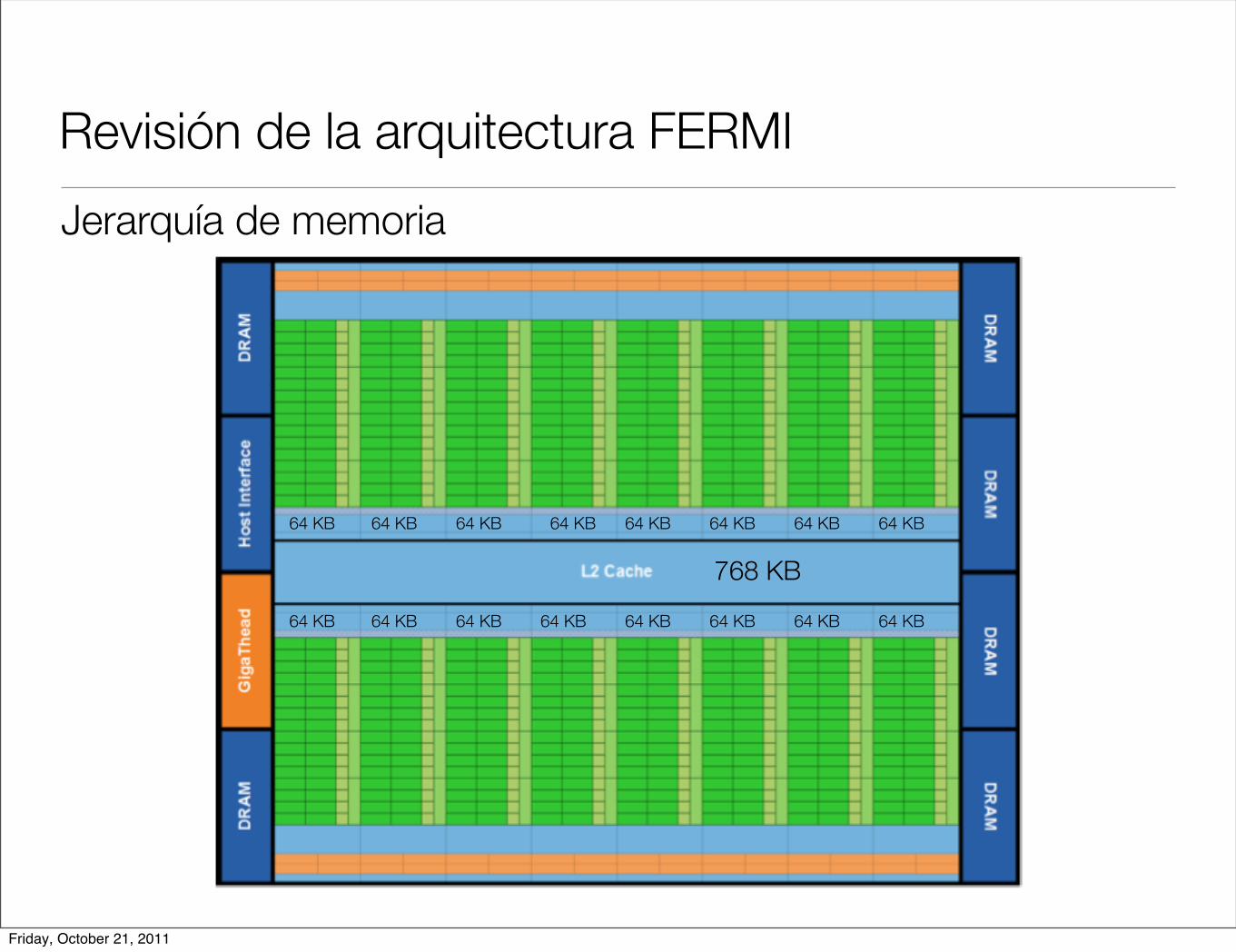
Revisión de la arquitectura FERMI
Jerarquía de memoria
768 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
Friday, October 21, 2011
Revisión de la arquitectura FERMI
Jerarquía de memoria
768 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
Friday, October 21, 2011
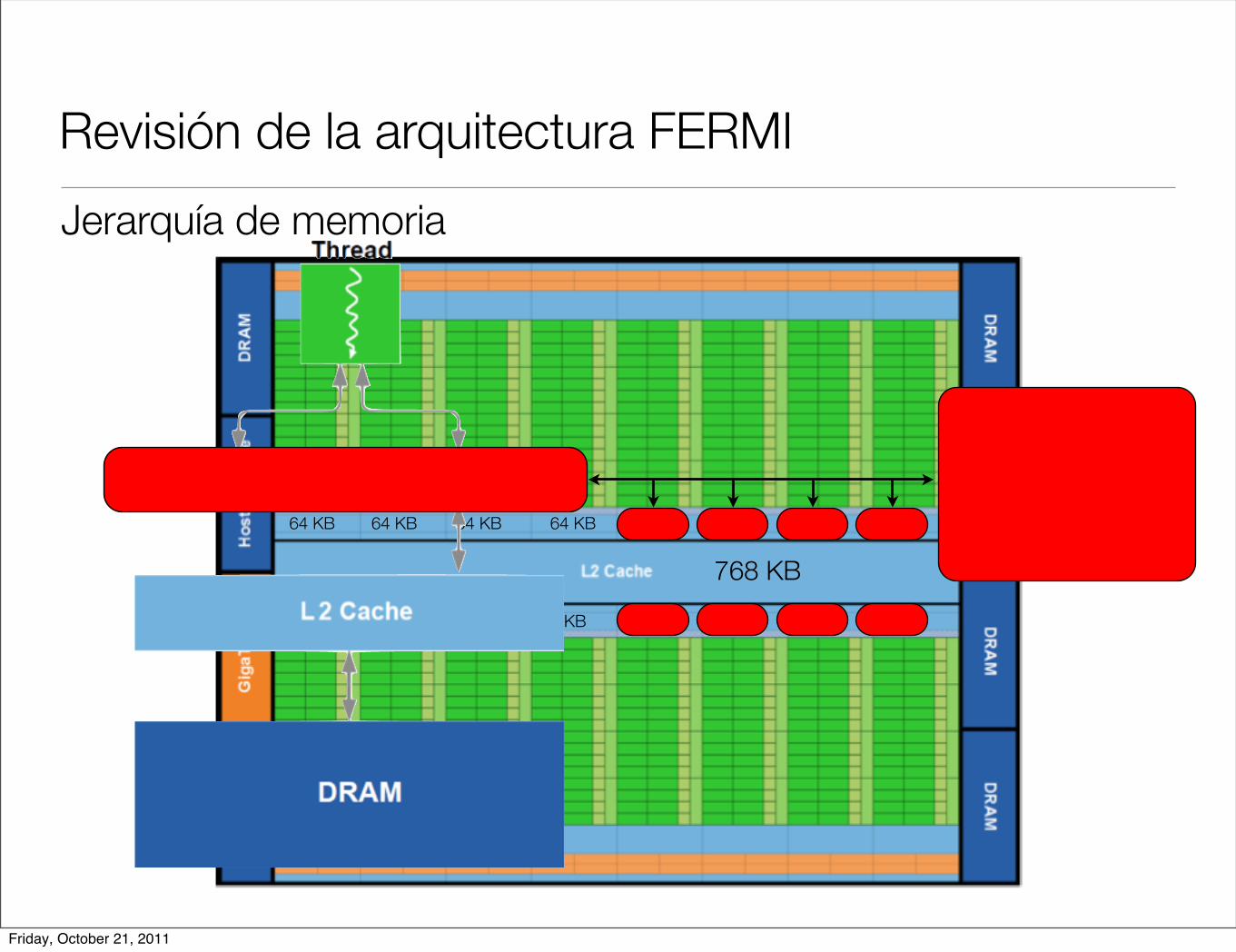
Revisión de la arquitectura FERMI
Jerarquía de memoria
768 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
Configuración 1. 48kb de mem. compartida.16kb de mem. L1 cache.
Configuración 2. 16kb de mem. compartida.48kb de mem. L1 cache.
Friday, October 21, 2011
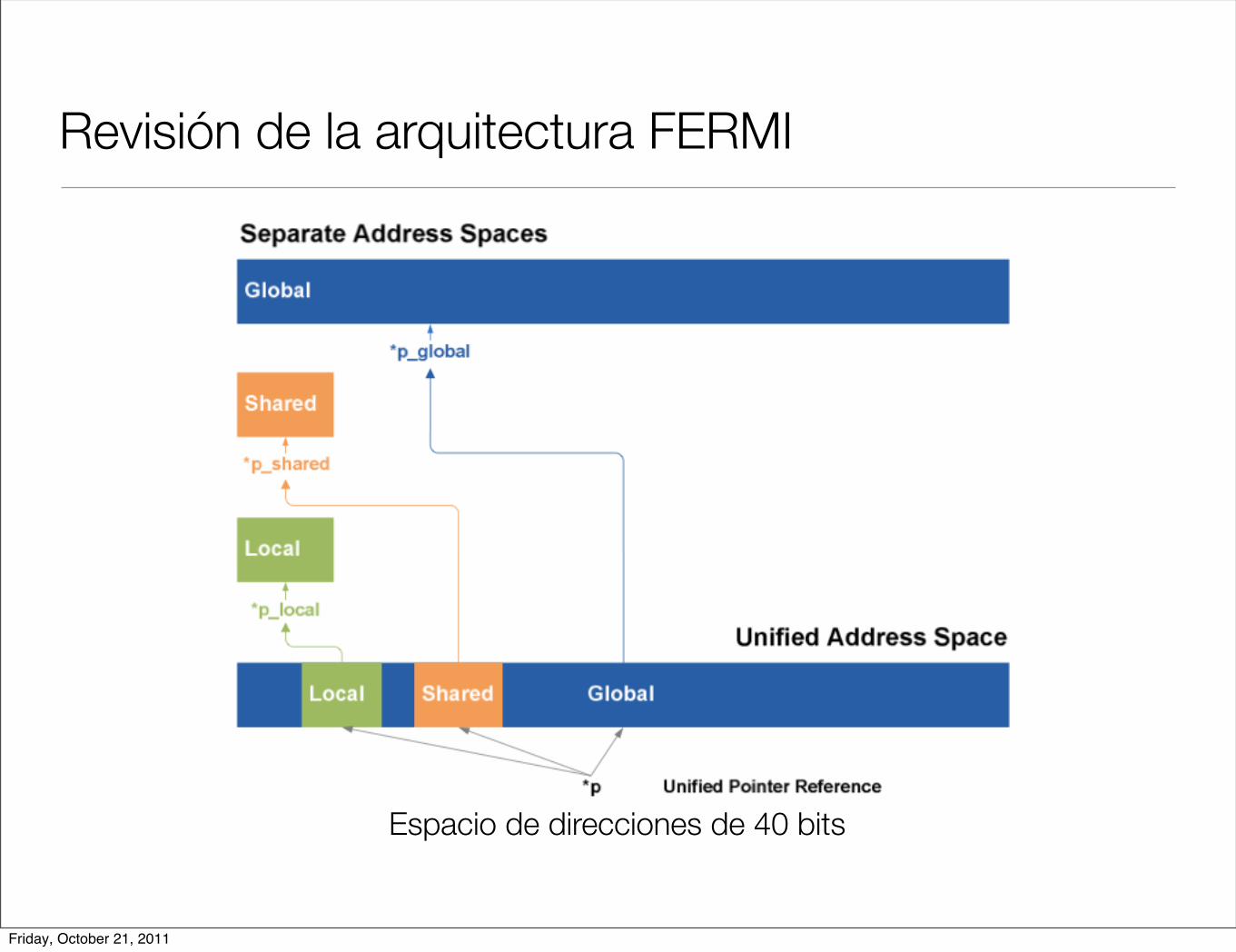
Revisión de la arquitectura FERMI
Espacio de direcciones de 40 bits
Friday, October 21, 2011
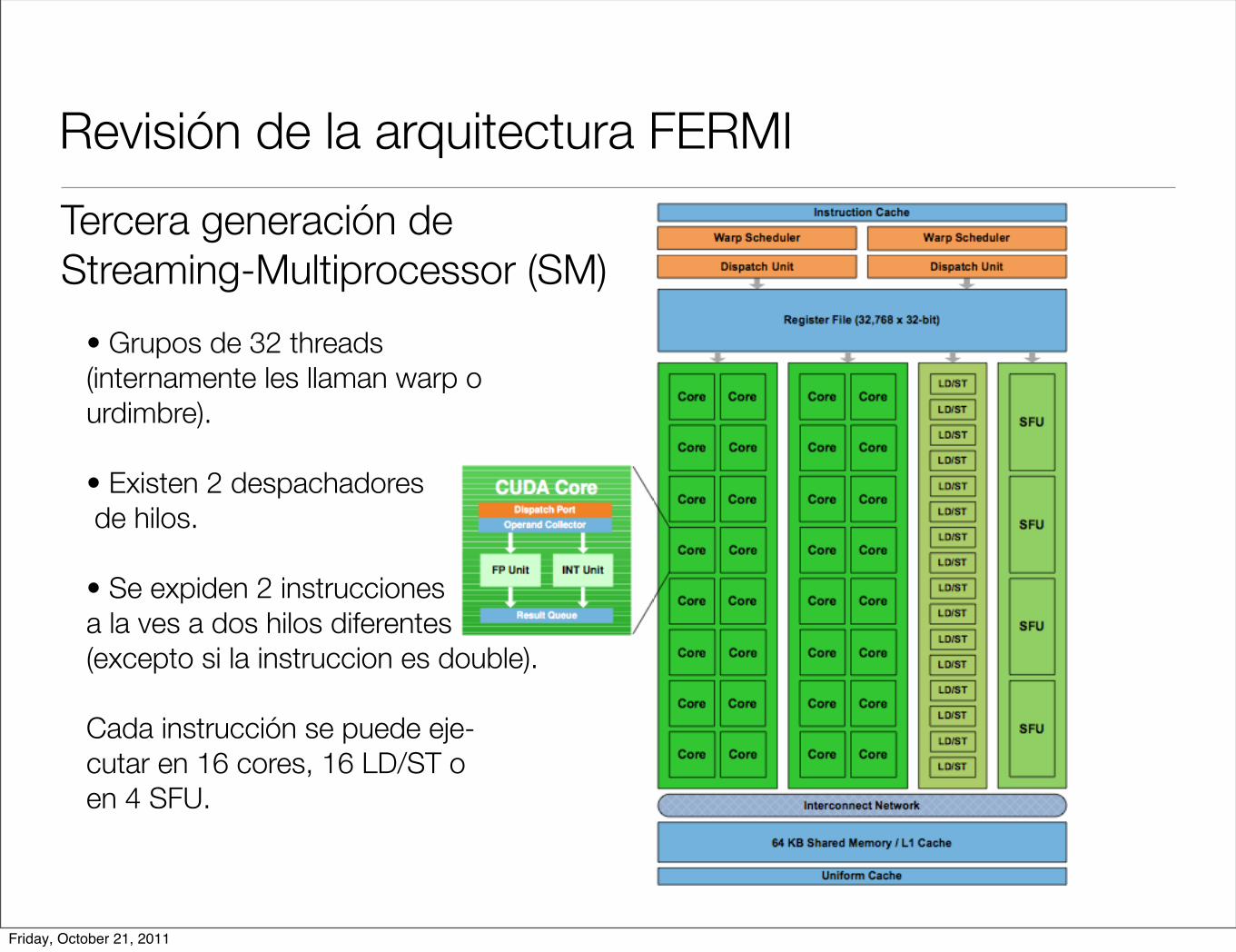
Revisión de la arquitectura FERMI
Tercera generación de Streaming-Multiprocessor (SM)
• Grupos de 32 threads (internamente les llaman warp o urdimbre).
• Existen 2 despachadores de hilos.
• Se expiden 2 instrucciones a la ves a dos hilos diferentes (excepto si la instruccion es double).
Cada instrucción se puede eje-cutar en 16 cores, 16 LD/ST o en 4 SFU.
Friday, October 21, 2011
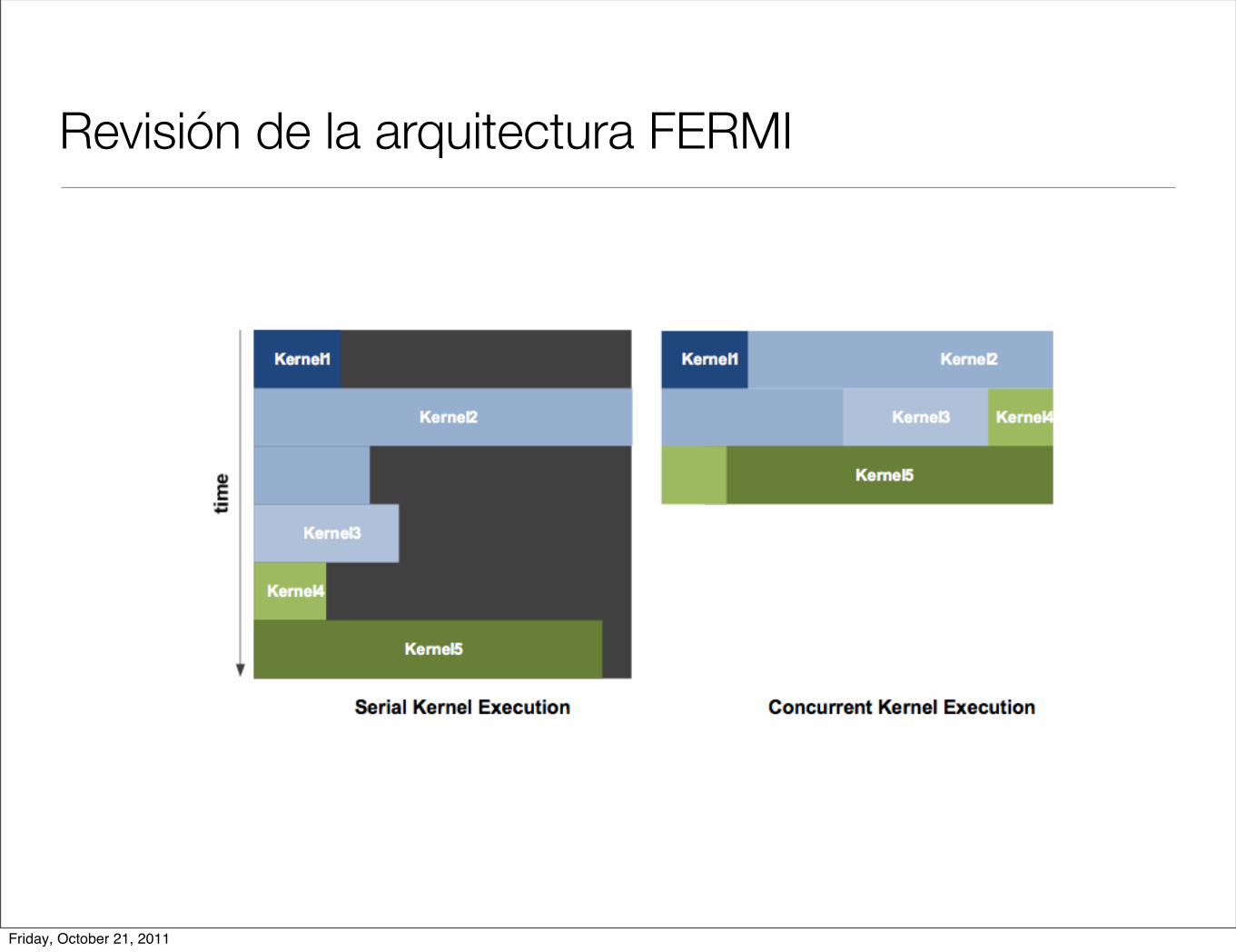
Revisión de la arquitectura FERMI
Friday, October 21, 2011
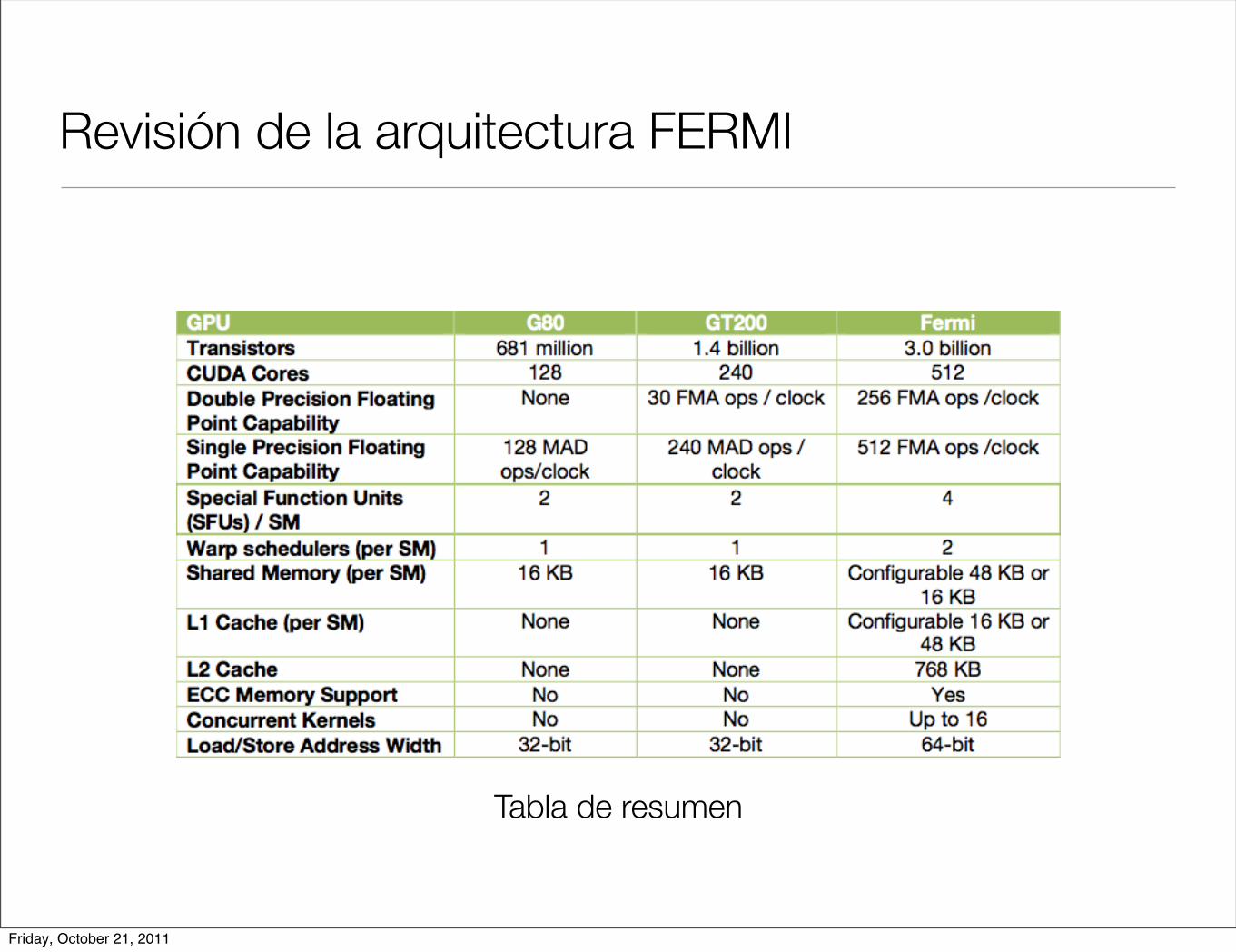
Revisión de la arquitectura FERMI
Tabla de resumen
Friday, October 21, 2011

Taller: Introducción a GPU's y Programación CUDA para HPC
PARTE III - ESTRUCTURA DE LOS PROGRAMAS CUDA
Friday, October 21, 2011
101
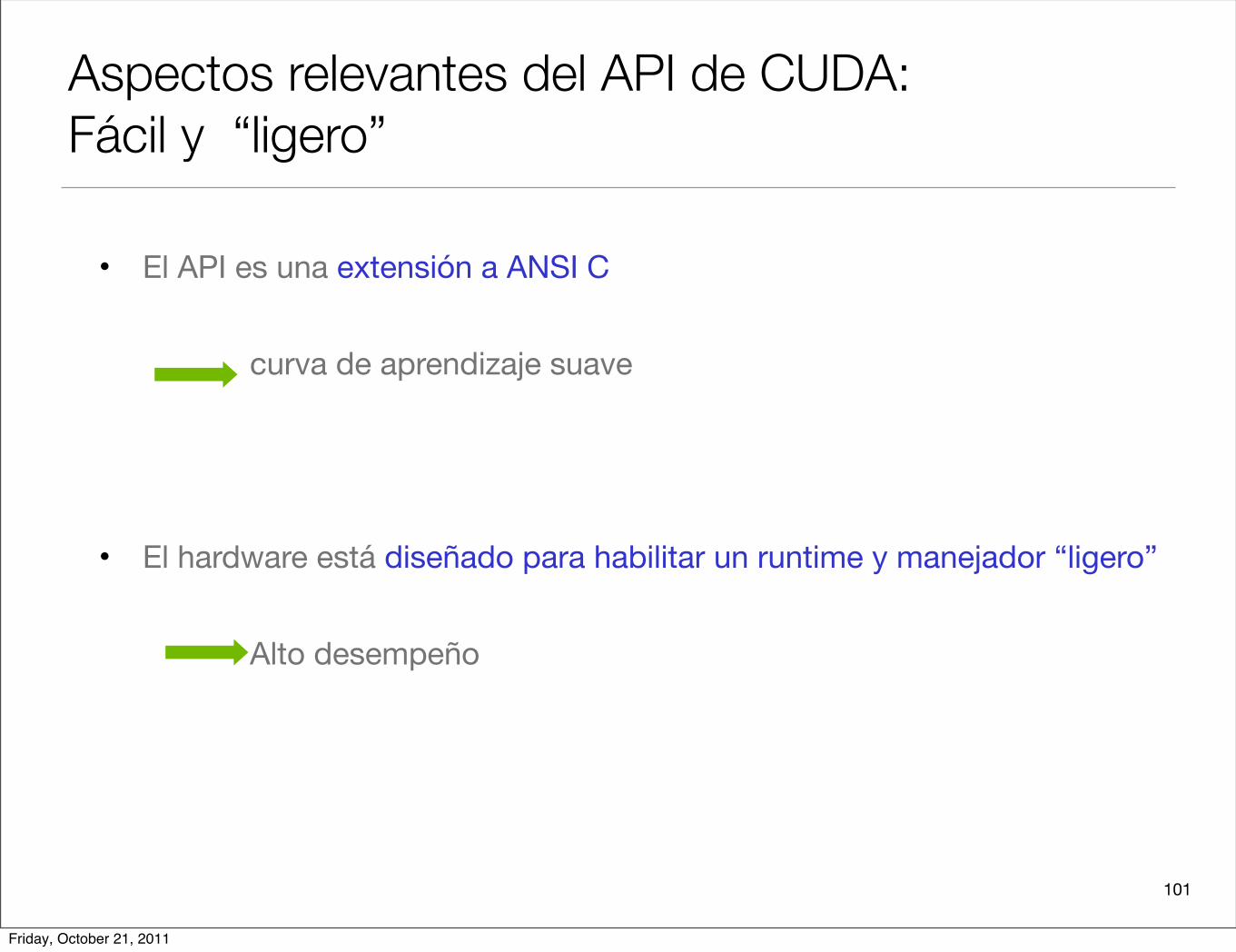
Aspectos relevantes del API de CUDA:Fácil y “ligero”
• El API es una extensión a ANSI C
curva de aprendizaje suave
• El hardware está diseñado para habilitar un runtime y manejador “ligero”
Alto desempeño
Friday, October 21, 2011
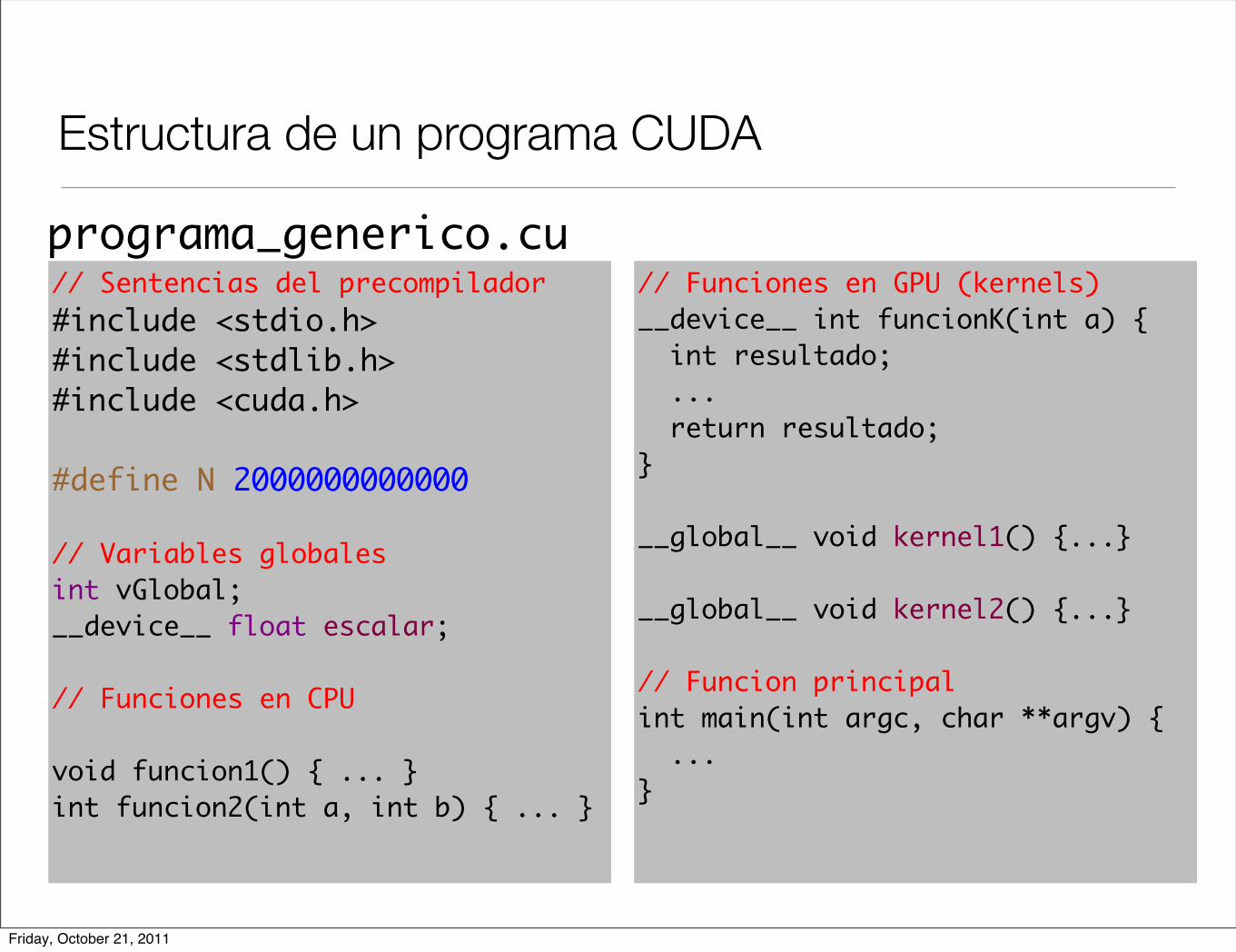
Estructura de un programa CUDA
// Sentencias del precompilador#include <stdio.h>#include <stdlib.h>#include <cuda.h>
#define N 2000000000000
// Variables globales int vGlobal; __device__ float escalar;
// Funciones en CPU
void funcion1() { ... } int funcion2(int a, int b) { ... }
// Funciones en GPU (kernels)__device__ int funcionK(int a) { int resultado; ... return resultado;}
__global__ void kernel1() {...}
__global__ void kernel2() {...}
// Funcion principal int main(int argc, char **argv) { ...}
programa_generico.cu
Friday, October 21, 2011
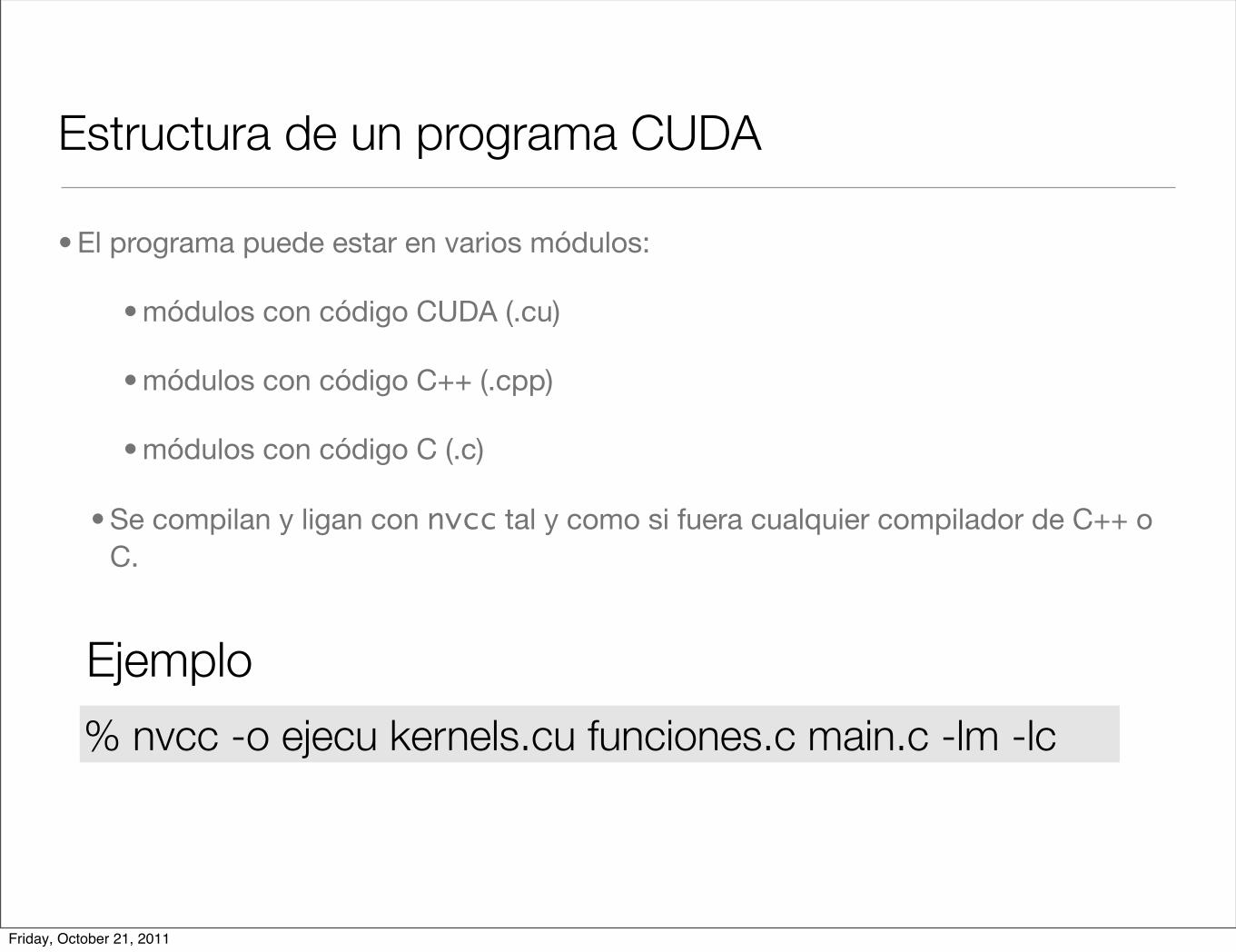
Estructura de un programa CUDA
• El programa puede estar en varios módulos:
• módulos con código CUDA (.cu)
• módulos con código C++ (.cpp)
• módulos con código C (.c)
• Se compilan y ligan con nvcc tal y como si fuera cualquier compilador de C++ o C.
% nvcc -o ejecu kernels.cu funciones.c main.c -lm -lc
Ejemplo
Friday, October 21, 2011

Declaración de funciones CUDA
hosthost__host__ float HostFunc()
hostdevice__global__ void KernelFunc()
devicedevice__device__ float DeviceFunc()
Sólo se invoca desde:
Se ejecuta en
__global__ define una funcion kernel
– Debe regresar void
Friday, October 21, 2011

Estructura de un programa CUDA
// Variables globales int vGlobal; __device__ float escalar;
// Funciones en CPU
void funcion1() { ...; vGlobal=valor; ...} int funcion2(int a, int b) { ... // llamado a kernel kernel1<<dimGrid,dimBlock>>() ... }
// Funciones en GPU (kernels)__device__ int funcionK(int a) { int resultado; ... return resultado;}
__global__ void kernel1() { int a = escalar; }
__global__ void kernel2() { ... r = funcionK(threadIdx.x); ...}
programa_generico.cu
Friday, October 21, 2011

Estructura de un programa CUDA
// Variables globales int vGlobal; __device__ float escalar;
// Funciones en CPU
void funcion1() { ...; vGlobal=valor; ...} int funcion2(int a, int b) { ... // llamado a kernel kernel1<<dimGrid,dimBlock>>() ... }
// Funciones en GPU (kernels)__device__ int funcionK(int a) { int resultado; ... return resultado;}
__global__ void kernel1() { int a = escalar; }
__global__ void kernel2() { ... r = funcionK(threadIdx.x); ...}
programa_generico.cu
Friday, October 21, 2011
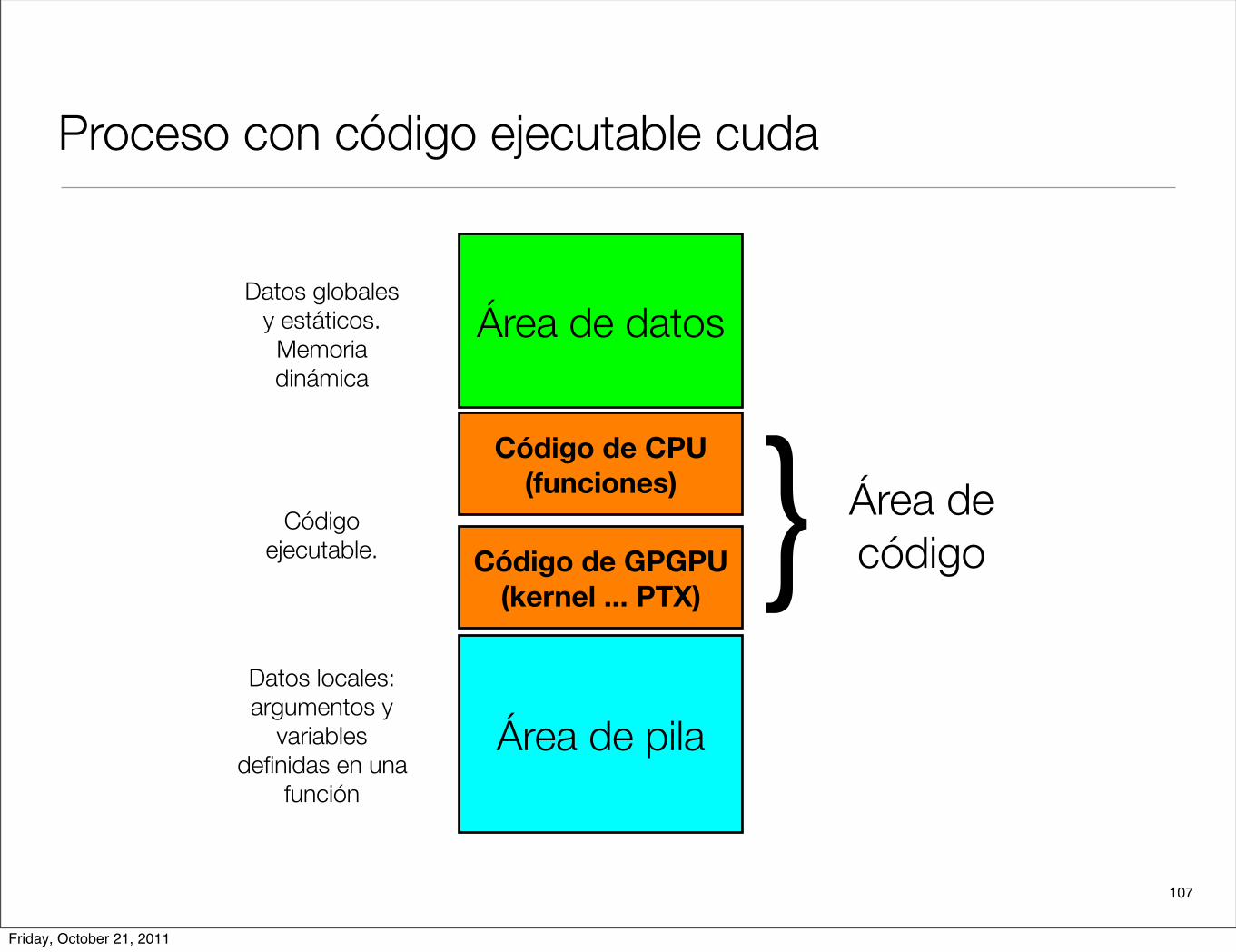
107
Proceso con código ejecutable cuda
Área de datos
Área de pila
Datos globales y estáticos. Memoria dinámica
Código ejecutable.
Datos locales: argumentos y
variables definidas en una
función
Código de CPU(funciones)
Código de GPGPU(kernel ... PTX)
Área de código}
Friday, October 21, 2011

Declaración de funciones CUDA
• __device__ functions - no se puede tener su dirección de memoria
• Para funciones ejecutadas en el device:
– No recursión
– No debe haber declaraciones de variables estáticas dentro de la función
– No pueden tener un número variable de argumentos
Friday, October 21, 2011

• Una función de kernel debe llamarse con una configuración de ejecución:
__global__ void KernelFunc(...);dim3 DimGrid(100, 50); // 5000 thread blocks dim3 DimBlock(4, 8, 8); // 256 threads per block size_t SharedMemBytes = 64; // 64 bytes of shared memoryKernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...);
• Cualquier llamado a una función de kernel function es asíncronca desde CUDA 1.0, se requiere de una síncronización explícita para el bloqueo.
Llamado a una función de Kernel - Creación de hilos
Friday, October 21, 2011

Programa CUDA
A nivel alto, tenemos un proceso principal el cual se ejecuta en el CPU y ejecuta los siguientes pasos:
1.Inicializa la tarjeta.
2.Asigna memoria en el “host” y en el “device”.
3.Copia datos del “host” al “device”.
4.Asinga multiples copias de “kernel’s” de ejecución al “device”.
5.Copia datos de la memoria del “device” a la memoria del “host”.
6.Repite pasos 3 a 5 como sea necesario.
7.Libera memoria (del “host” y “device”) y termina.
Friday, October 21, 2011

Ejecución de un proceso CUDA
A nivel bajo, en el GPU:
1.Cada copia de ejecución de un kernel se ejecuta en un SM.
2.Si el número de copias excede el número de SM, entonces mas de una copia se ejecutará en un SM si existen recursos disponibles (registros y memoria compartida).
3.Cada hilo en una copia del kernel accesa a su propia memoria compartida, pero y no puede accesar a la memoria compartida de la copia.
4.No hay garantia del orden de ejecución de las copias del kernel.
Friday, October 21, 2011
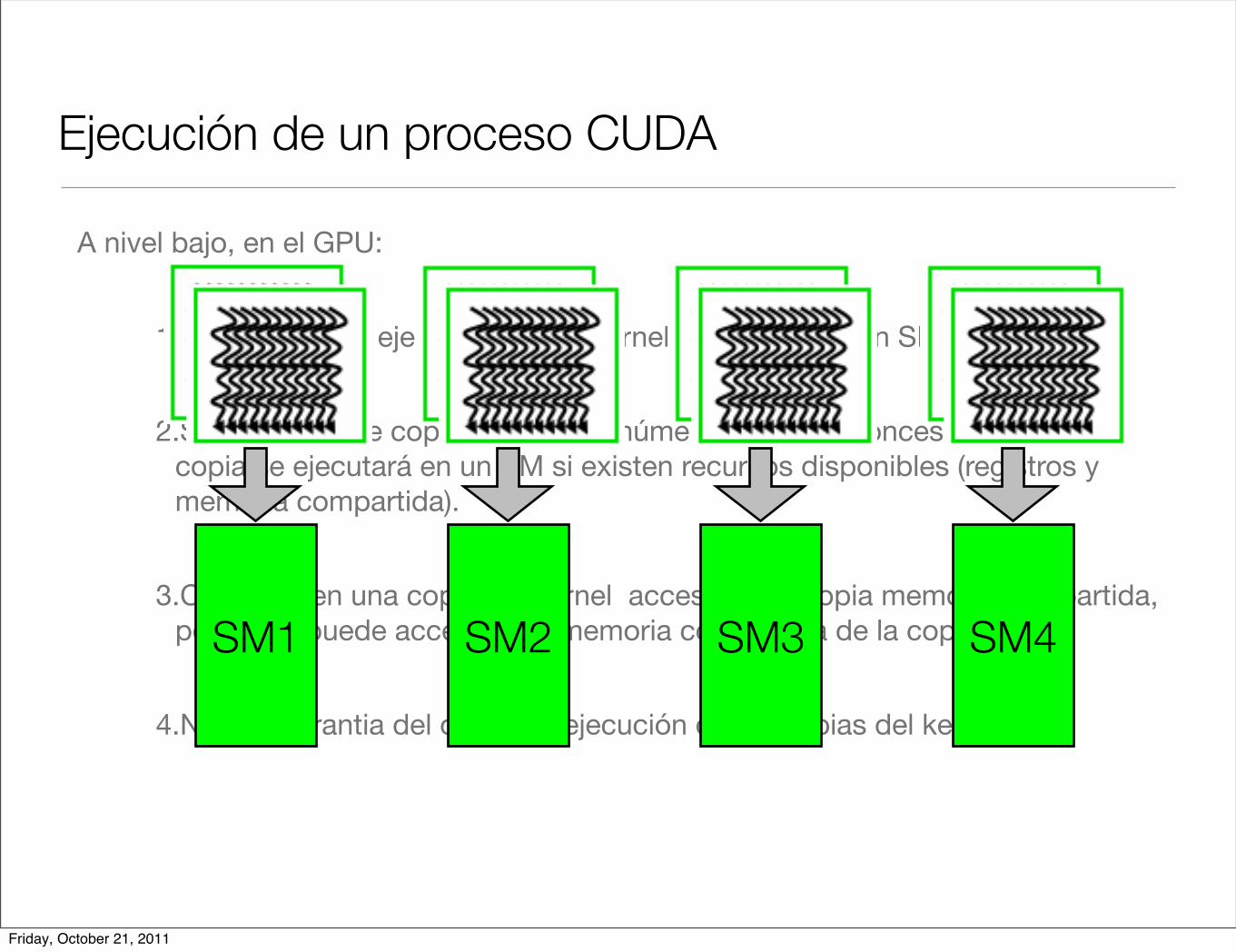
Ejecución de un proceso CUDA
A nivel bajo, en el GPU:
1.Cada copia de ejecución de un kernel se ejecuta en un SM.
2.Si el número de copias excede el número de SM, entonces mas de una copia se ejecutará en un SM si existen recursos disponibles (registros y memoria compartida).
3.Cada hilo en una copia del kernel accesa a su propia memoria compartida, pero y no puede accesar a la memoria compartida de la copia.
4.No hay garantia del orden de ejecución de las copias del kernel.
SM1 SM2 SM3 SM4
Friday, October 21, 2011

EJEMPLOS - Mi primer programa CUDA
• Recuerde que hay código para el “host” y código para el “device”.
int main(int argc, char **argv) { float *h_x, *d_x; // h=host, d=device int nblocks=2, nthreads=8, nsize=2*8;
h_x = (float *)malloc(nsize*sizeof(float)); cudaMalloc((void **)&d_x,nsize*sizeof(float)); my_first_kernel<<<nblocks,nthreads>>>(d_x); cudaMemcpy(h_x,d_x,nsize*sizeof(float), cudaMemcpyDeviceToHost);
for (int n=0; n<nsize; n++) printf(" n, x = %d %f \n",n,h_x[n]); cudaFree(d_x); free(h_x); }
primero.cu Código host
Friday, October 21, 2011

EJEMPLOS - Mi primer programa CUDA
• Recuerde que hay código para el “host” y código para el “device”.
//#include <cutil_inline.h>
__global__ void my_first_kernel(float *x) { int tid = threadIdx.x + blockDim.x*blockIdx.x;
x[tid] = threadIdx.x;}
primero.cu Código kernel
Friday, October 21, 2011

Taller: Introducción a GPU's y Programación CUDA para HPC
PARTE IV - EJEMPLOS Y EJERCICIOS
Friday, October 21, 2011

EJEMPLOS - Multiplicación de matrices
• Una simple ejemplo de multiplicación de matrices ilustra las características básicas de memoria y el manejo de hilos en programas CUDA.
• Usaremos sólo registros.
• Usaremos el identificador del usuario.
• Usaremos el API de transferencia de memoria entre “host” y el “device”.
• Por simplicidad, asumiremos que la matriz es cuadrada.
Friday, October 21, 2011
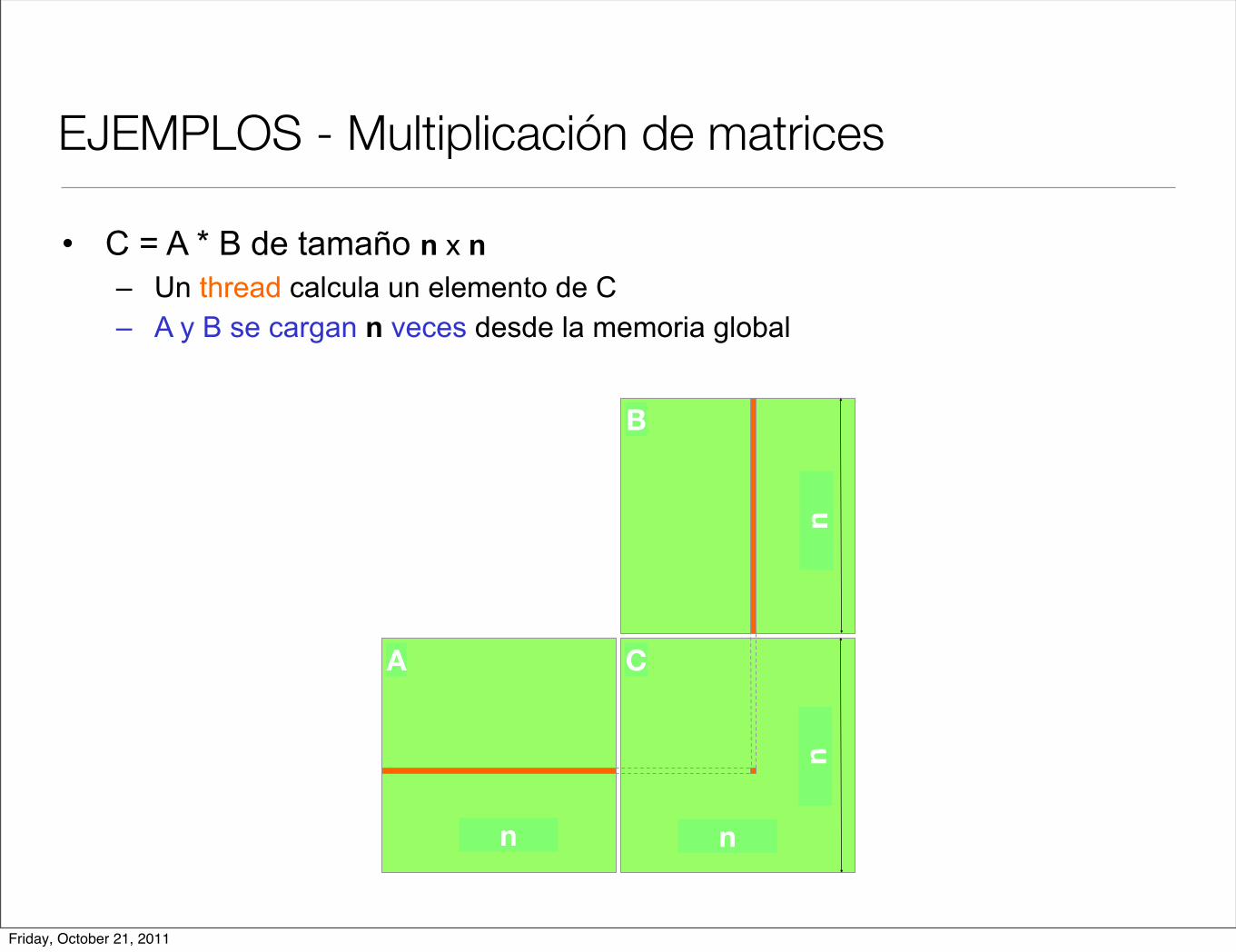
EJEMPLOS - Multiplicación de matrices
• C = A * B de tamaño n x n– Un thread calcula un elemento de C– A y B se cargan n veces desde la memoria global
M
N
P
WID
TH
WID
TH
WIDTH WIDTH
A C
B
n n
n
n
Friday, October 21, 2011

EJEMPLOS - Multiplicación de matrices
• Almacenamiento en la memoria de una matriz, en C.
M2,0
M1,1
M1,0M0,0
M0,1
M3,0
M2,1 M3,1
M2,0M1,0M0,0 M3,0 M1,1M0,1 M2,1 M3,1 M1,2M0,2 M2,2 M3,2
M1,2M0,2 M2,2 M3,2
M1,3M0,3 M2,3 M3,3
M1,3M0,3 M2,3 M3,3
M
Friday, October 21, 2011

EJEMPLOS - Multiplicación de matrices
PASO 1: La versión “simple” en C
119
M
N
P
WID
TH
WID
TH
WIDTH WIDTH
// Multiplicacion de matrices en el host (CPU) void MatrixMulOnHost(float *A, float *B, float *C, int n) { for (int i = 0; i < n; ++i) for (int j = 0; j < n; ++j) { float sum = 0; for (int k = 0; k < n; ++k) { float a = A[i * n + k]; float b = B[k * n + j]; sum += a * b; } C[i * Width + j] = sum; }}
i
k
kj
A C
B
n
n
n
n
Friday, October 21, 2011
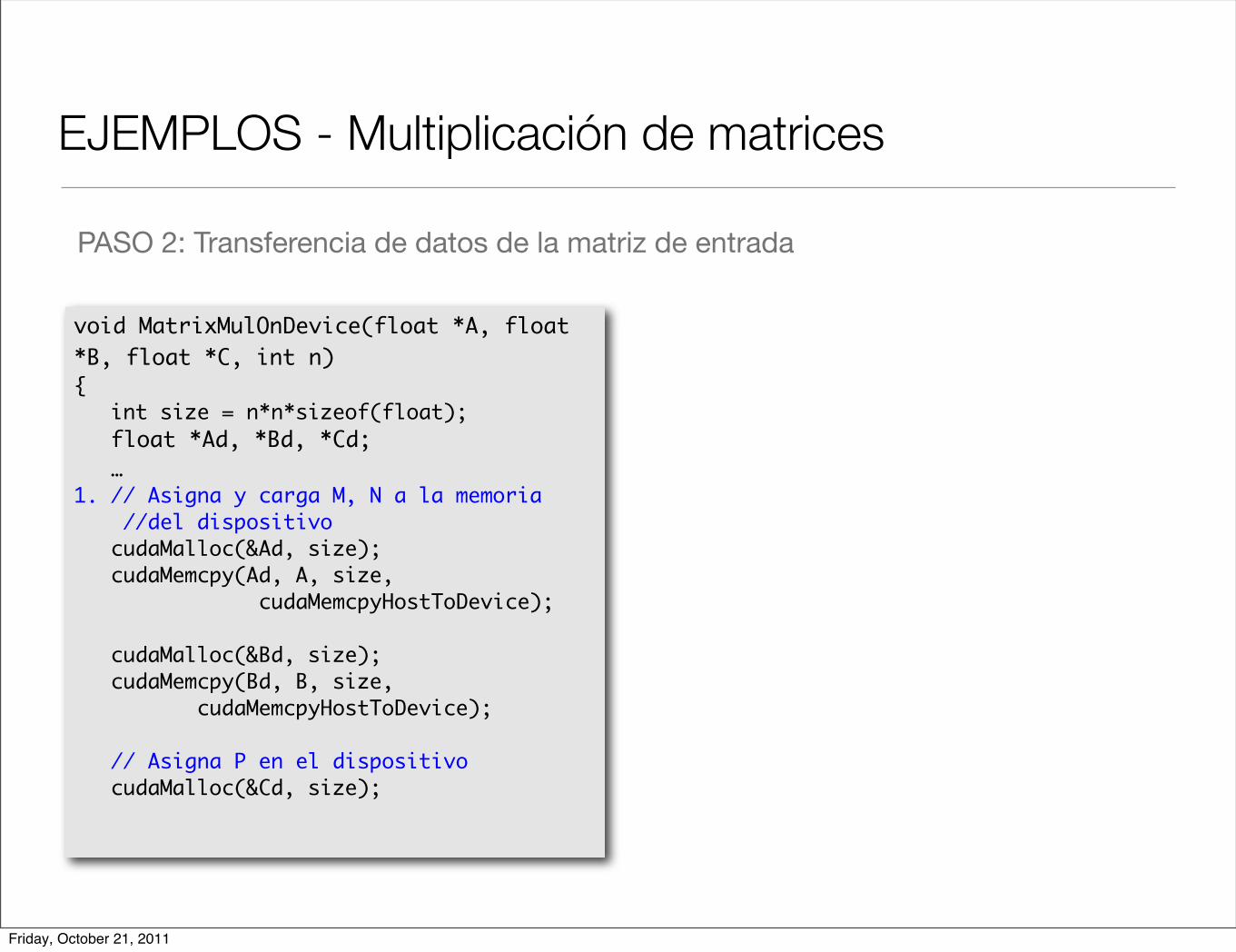
EJEMPLOS - Multiplicación de matrices
PASO 2: Transferencia de datos de la matriz de entrada
void MatrixMulOnDevice(float *A, float *B, float *C, int n){ int size = n*n*sizeof(float); float *Ad, *Bd, *Cd; …1. // Asigna y carga M, N a la memoria //del dispositivo cudaMalloc(&Ad, size); cudaMemcpy(Ad, A, size, cudaMemcpyHostToDevice);
cudaMalloc(&Bd, size); cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice);
// Asigna P en el dispositivo cudaMalloc(&Cd, size);
Friday, October 21, 2011
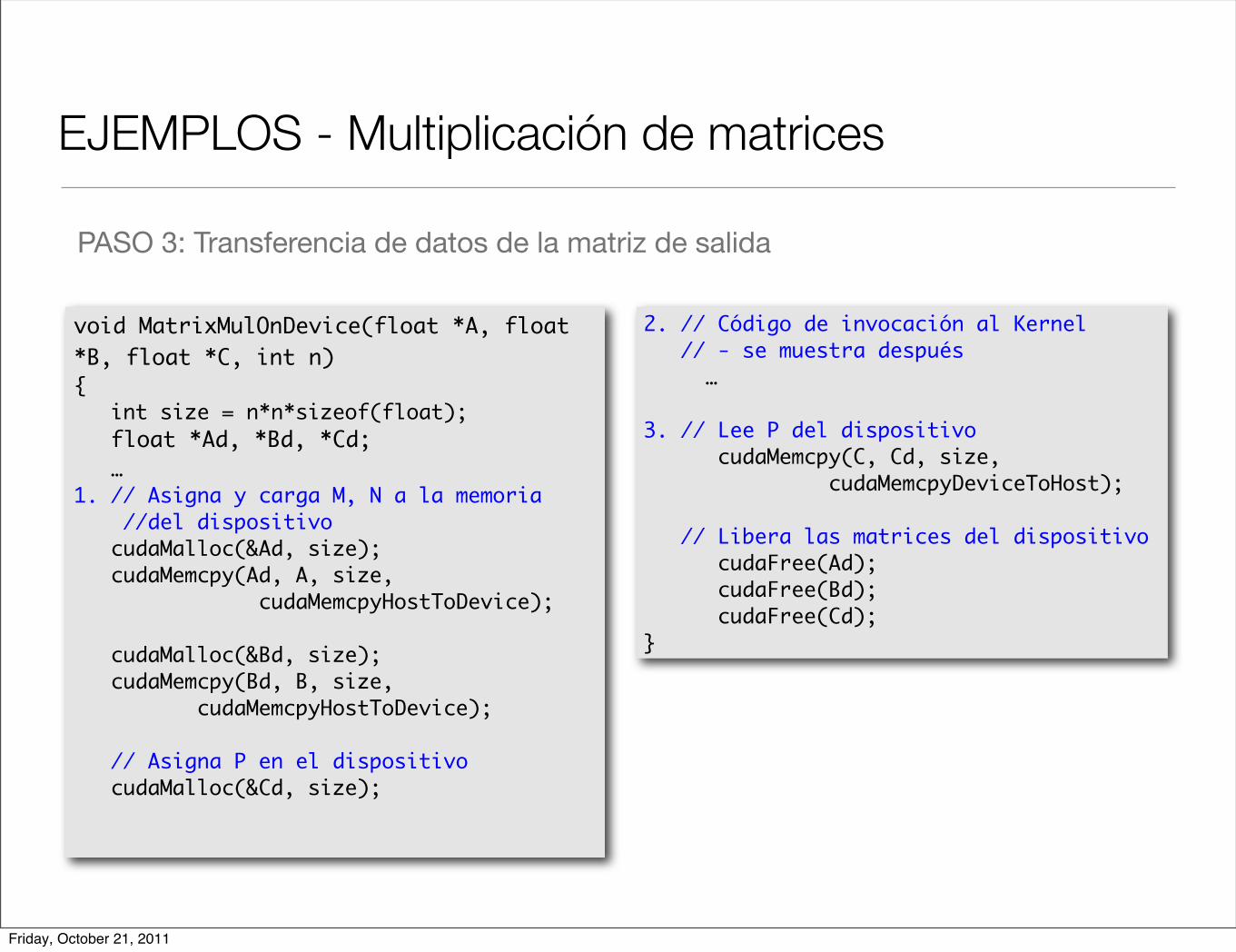
EJEMPLOS - Multiplicación de matrices
PASO 3: Transferencia de datos de la matriz de salida
2. // Código de invocación al Kernel // - se muestra después …
3. // Lee P del dispositivo cudaMemcpy(C, Cd, size, cudaMemcpyDeviceToHost);
// Libera las matrices del dispositivo cudaFree(Ad); cudaFree(Bd); cudaFree(Cd);}
void MatrixMulOnDevice(float *A, float *B, float *C, int n){ int size = n*n*sizeof(float); float *Ad, *Bd, *Cd; …1. // Asigna y carga M, N a la memoria //del dispositivo cudaMalloc(&Ad, size); cudaMemcpy(Ad, A, size, cudaMemcpyHostToDevice);
cudaMalloc(&Bd, size); cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice);
// Asigna P en el dispositivo cudaMalloc(&Cd, size);
Friday, October 21, 2011

EJEMPLOS - Multiplicación de matrices
PASO 4: Función del kernel
// kernel de la multiplicacion matricial - por hilo __global__ void MatrixMulKernel(float *A, float *B, float *C, int n){ float tmp=0.0; for (int k=0; k<n; k++) { float Aelement=A[threadIdx.y*n+k]; float Belement=B[k*n+threadIdx.x]; tmp += Aelement*Belement; }
C[threadIdx.y*n+threadIdx.x]=tmp; }
Nd
Md Pd
WID
TH
WID
TH
WIDTH WIDTH
ty
tx
ty
tx
k
A C
B
n
n
n
n
Friday, October 21, 2011
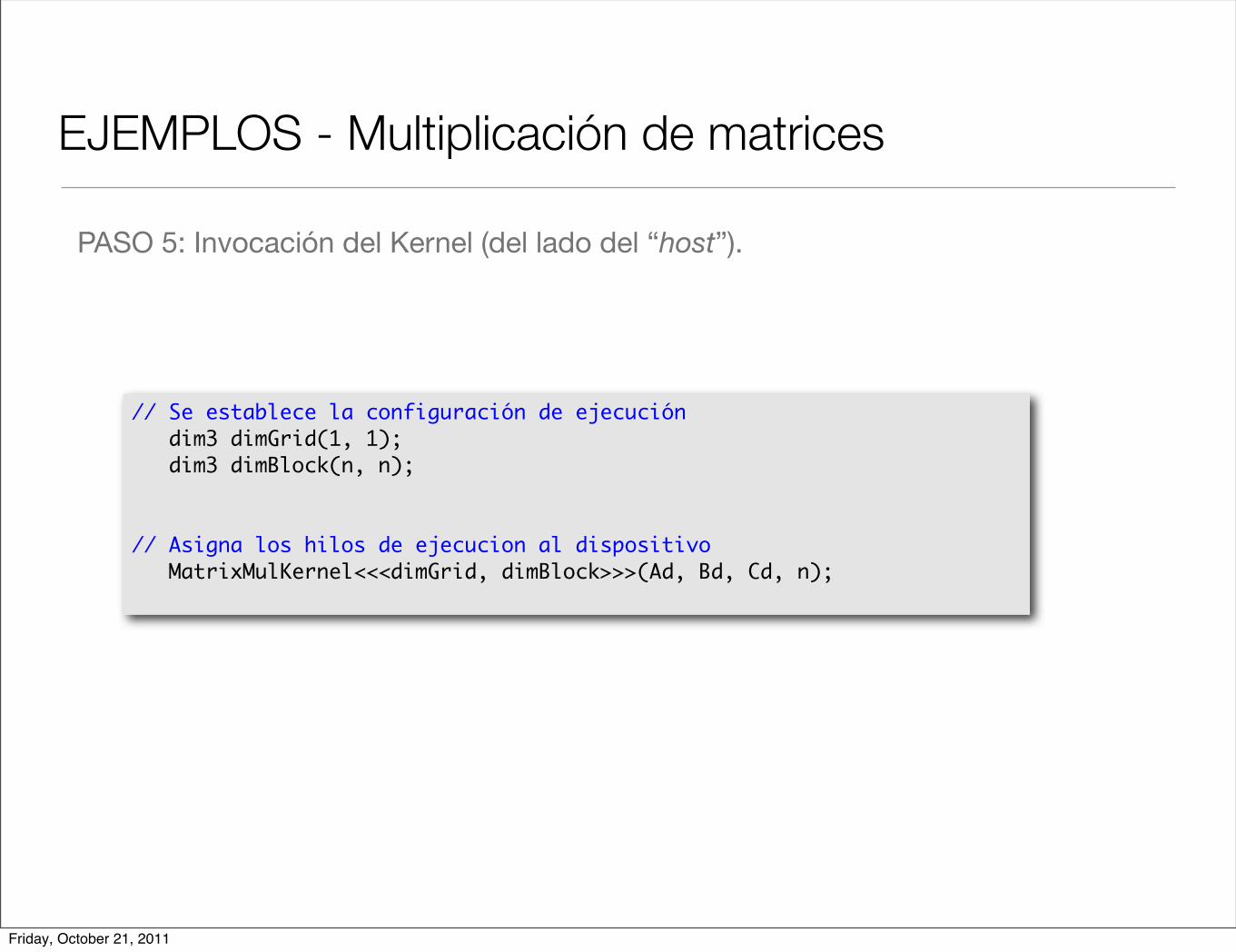
EJEMPLOS - Multiplicación de matrices
PASO 5: Invocación del Kernel (del lado del “host”).
// Se establece la configuración de ejecución dim3 dimGrid(1, 1); dim3 dimBlock(n, n);
// Asigna los hilos de ejecucion al dispositivo MatrixMulKernel<<<dimGrid, dimBlock>>>(Ad, Bd, Cd, n);
Friday, October 21, 2011
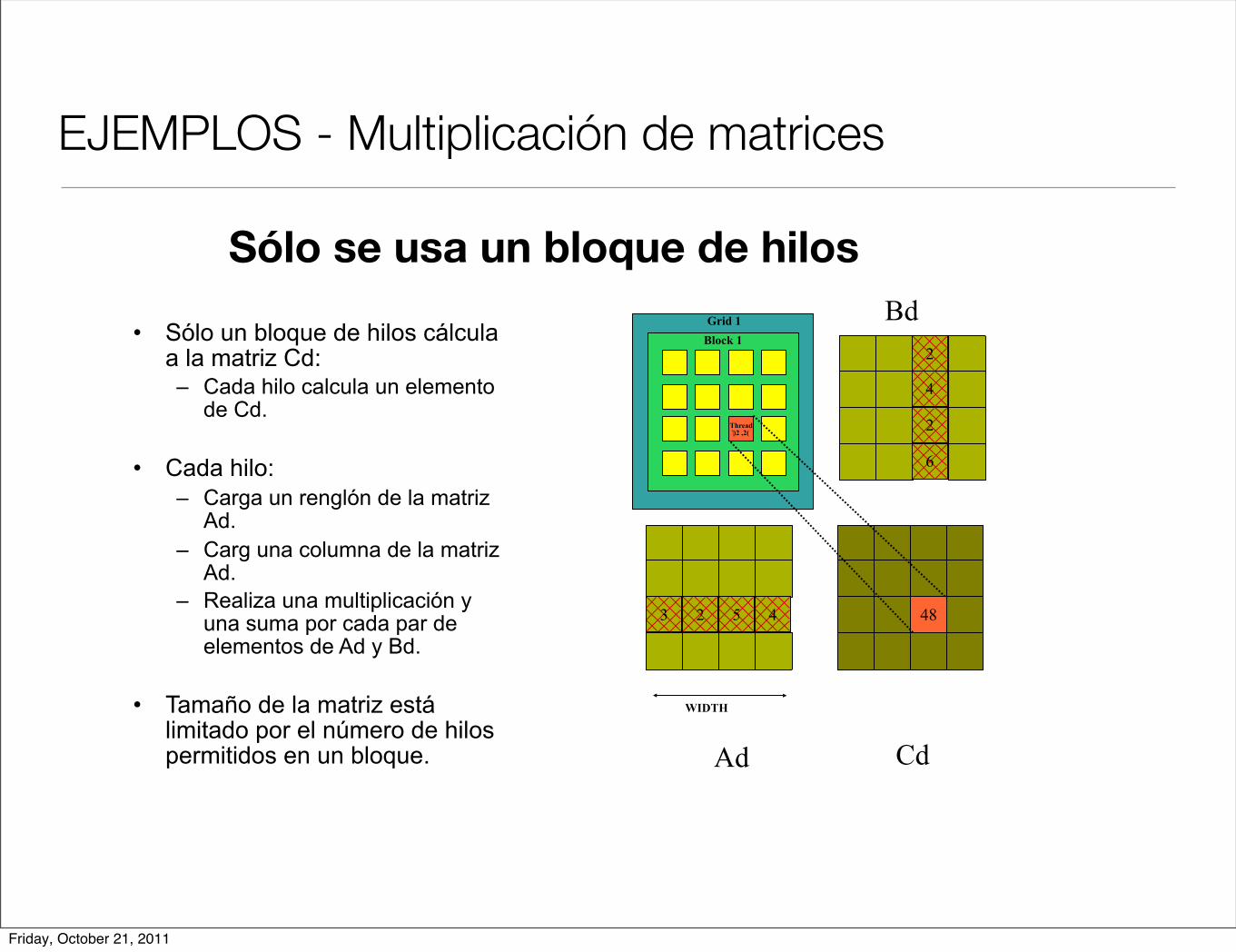
EJEMPLOS - Multiplicación de matrices
• Sólo un bloque de hilos cálcula a la matriz Cd:– Cada hilo calcula un elemento
de Cd.
• Cada hilo:– Carga un renglón de la matriz
Ad.– Carg una columna de la matriz
Ad.– Realiza una multiplicación y
una suma por cada par de elementos de Ad y Bd.
• Tamaño de la matriz está limitado por el número de hilos permitidos en un bloque.
Grid 1Block 1
48
Thread)2, 2(
WIDTH
Ad Cd
Bd
Sólo se usa un bloque de hilos
Friday, October 21, 2011
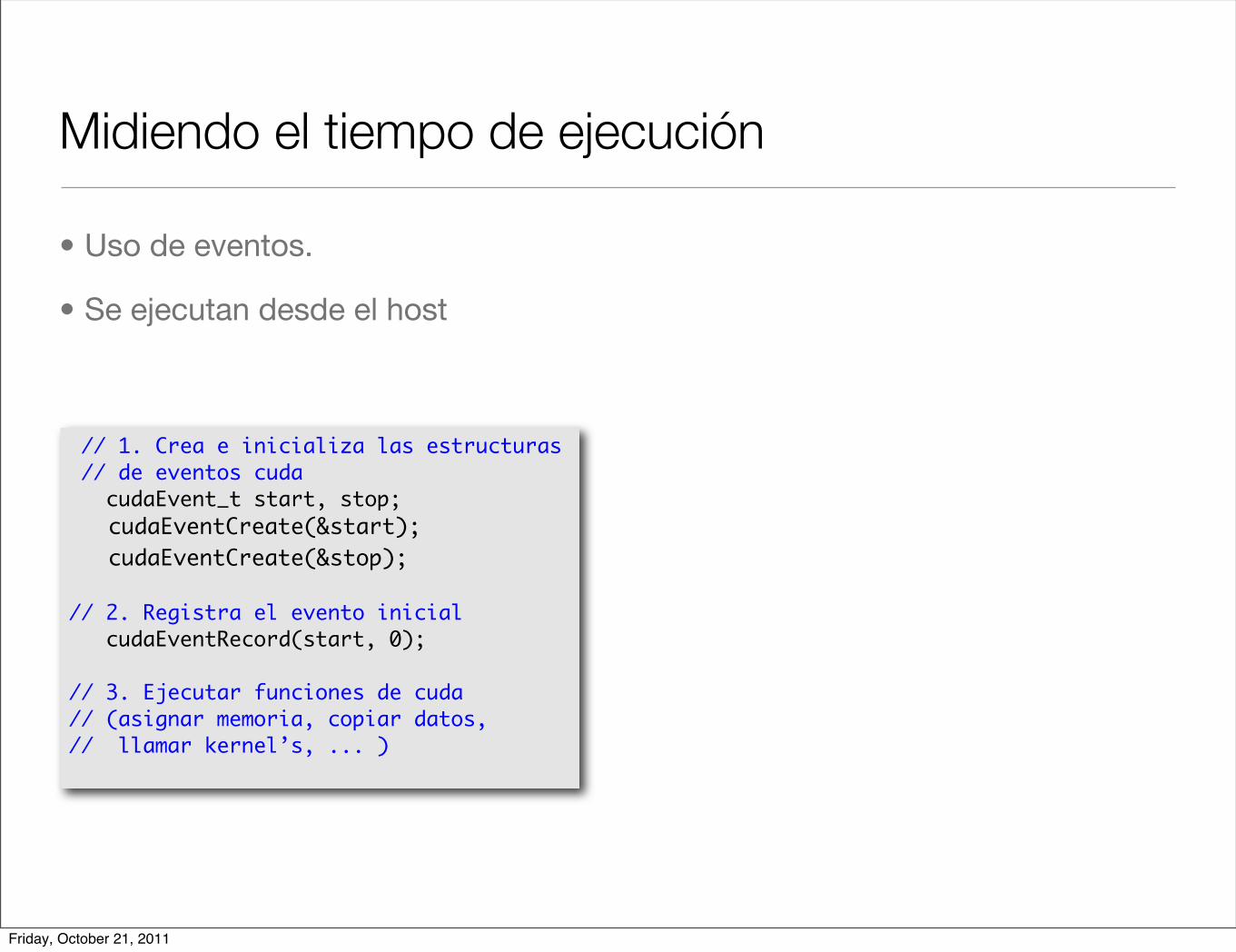
Midiendo el tiempo de ejecución
• Uso de eventos.
• Se ejecutan desde el host
// 1. Crea e inicializa las estructuras // de eventos cuda cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop);
// 2. Registra el evento inicial cudaEventRecord(start, 0);
// 3. Ejecutar funciones de cuda// (asignar memoria, copiar datos,// llamar kernel’s, ... )
Friday, October 21, 2011

Midiendo el tiempo de ejecución
• Uso de eventos.
• Se ejecutan desde el host// 4. Registra el evento final cudaEventRecord(stop, 0); cudaEventSynchronize(stop);
// 5. Calcular y desplegar el tiempo // de ejecucion float elapsedTime; cudaEventElapsedTime(&elapsedTime, start, stop); printf(“Tiempo %4.6f en milseg\n”, elapsedTime);
// 6. Dar de baja eventos cuda cudaEventDestroy(start); cudaEventDestroy(stop);
// 1. Crea e inicializa las estructuras // de eventos cuda cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop);
// 2. Registra el evento inicial cudaEventRecord(start, 0);
// 3. Ejecutar funciones de cuda// (asignar memoria, copiar datos,// llamar kernel’s, ... )
Friday, October 21, 2011

Ejercicios propuestos para el taller
• Suma de vectores (y matrices).
• Multiplicación de un escalar por una matriz.
• Método Gauss-Jordan para resolver un sistema de ecuaciones y para obtener la inversa de una matriz.
Friday, October 21, 2011

TALLER CUDA
PARTE V - COOPERACION ENTRE HILOS
Friday, October 21, 2011

Ejecución de hilos
#include <stdio.h>
#define N (33 * 1024)__global__ void add( int *a, int *b, int *c ) { int tid = threadIdx.x + blockIdx.x * blockDim.x; while (tid < N) { c[tid] = a[tid] + b[tid]; tid += blockDim.x * gridDim.x; }}
Friday, October 21, 2011
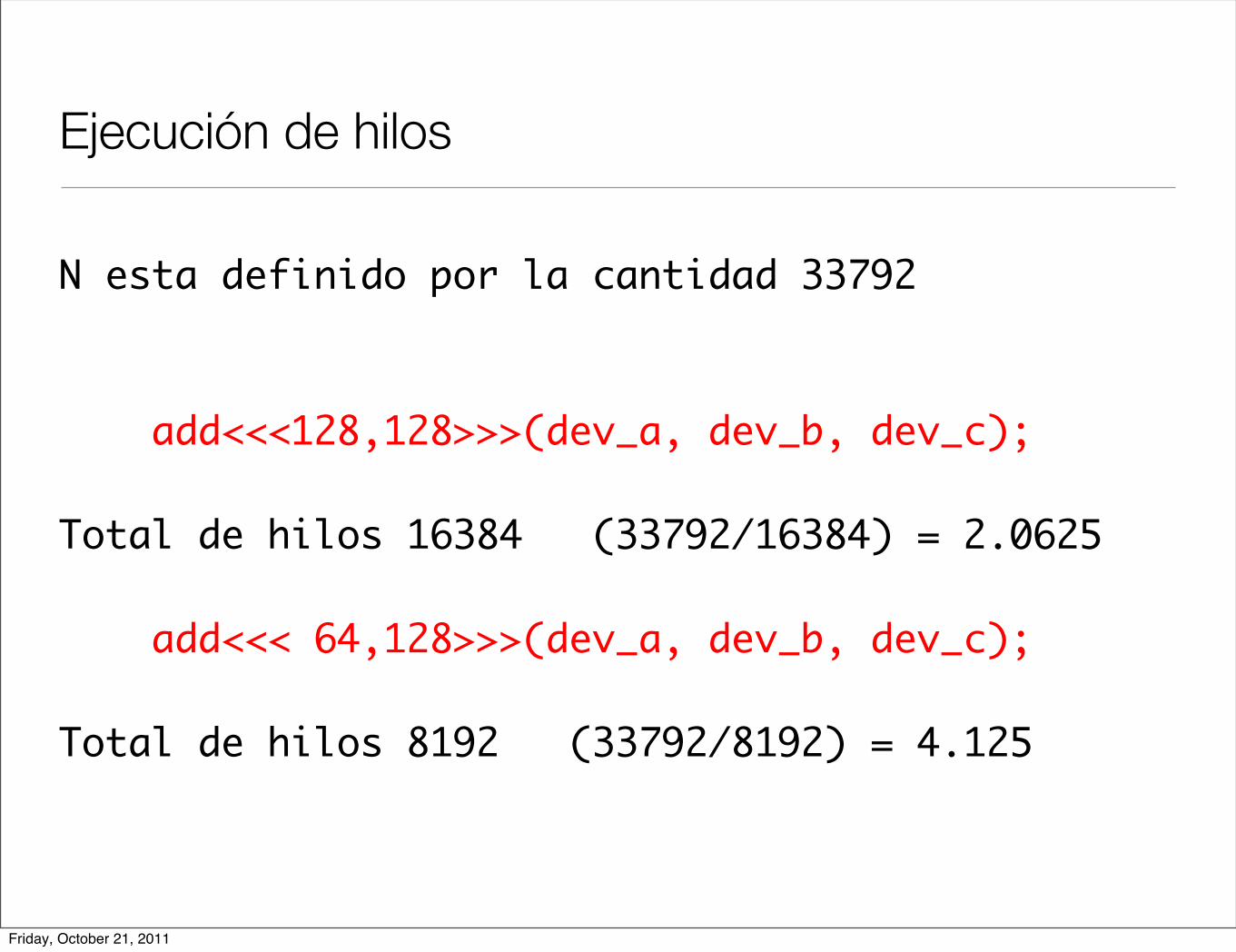
Ejecución de hilos
N esta definido por la cantidad 33792 add<<<128,128>>>(dev_a, dev_b, dev_c); Total de hilos 16384 (33792/16384) = 2.0625
add<<< 64,128>>>(dev_a, dev_b, dev_c);
Total de hilos 8192 (33792/8192) = 4.125
Friday, October 21, 2011
Ejecución de hilos
SM1 SM2 SM3 SM4
Friday, October 21, 2011
Ejecución de hilos
SM1 SM2 SM3 SM4
Friday, October 21, 2011
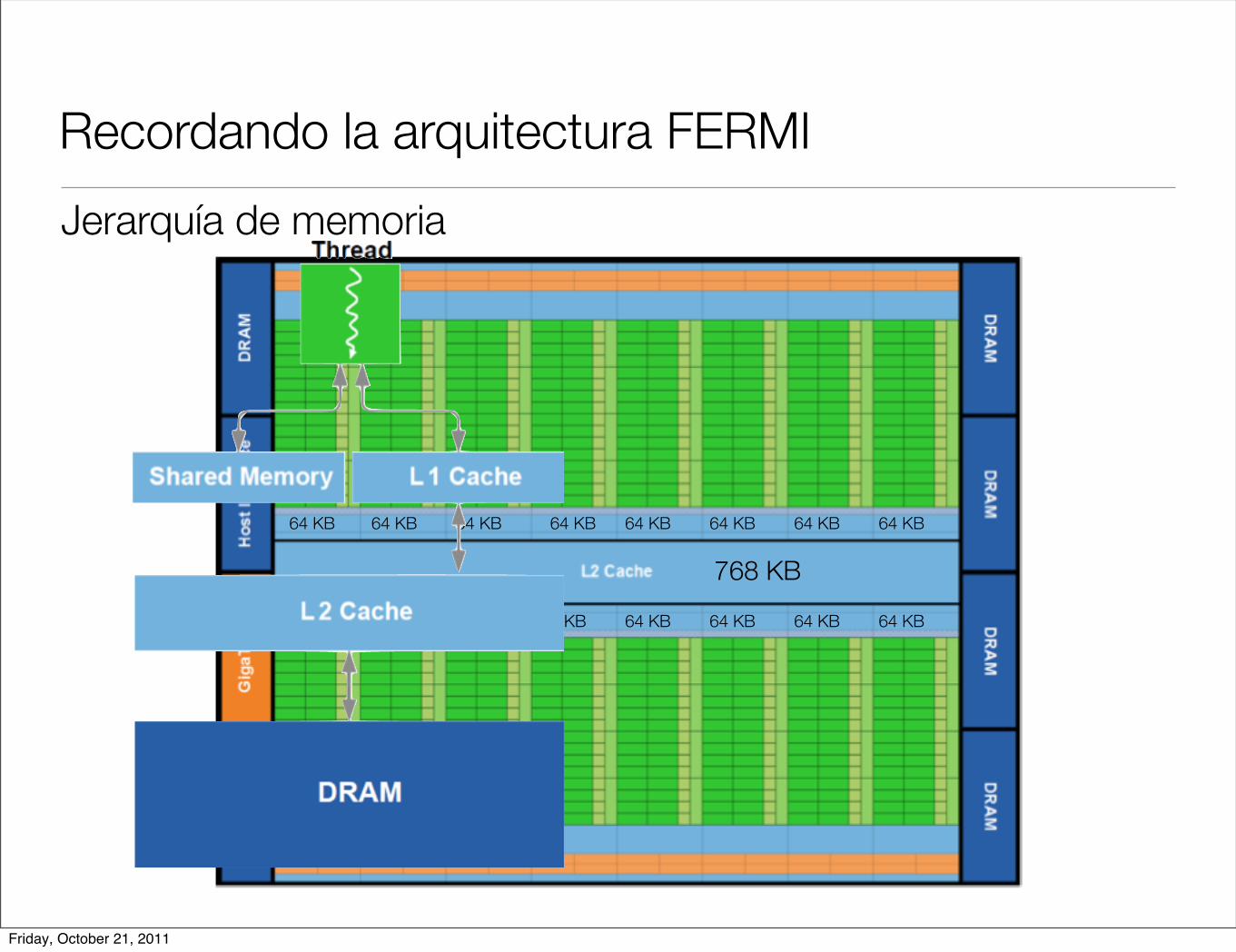
Recordando la arquitectura FERMI
Jerarquía de memoria
768 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
Friday, October 21, 2011

Manejo de cache
Kernel alineado
Kernel disperso
Friday, October 21, 2011

• Variables que son visibles desde distintos kernels.
• Variables en la memoria del device, no en el host.
• Cualquier kernel puede hacer operaciones de Lectura/Escritura.
• Se pueden declarar arreglos de tamaño fijo.
Variables globales
Friday, October 21, 2011

• Constantes que son visibles desde distintos kernels.
• Se inicializan desde el host con la función cudaMemcpyToSymbol
• Cualquier kernel puede hacer operaciones de Lectura.
• Se pueden declarar arreglos de tamaño fijo.
Variables constantes
__constant__ float a[1024];
Friday, October 21, 2011
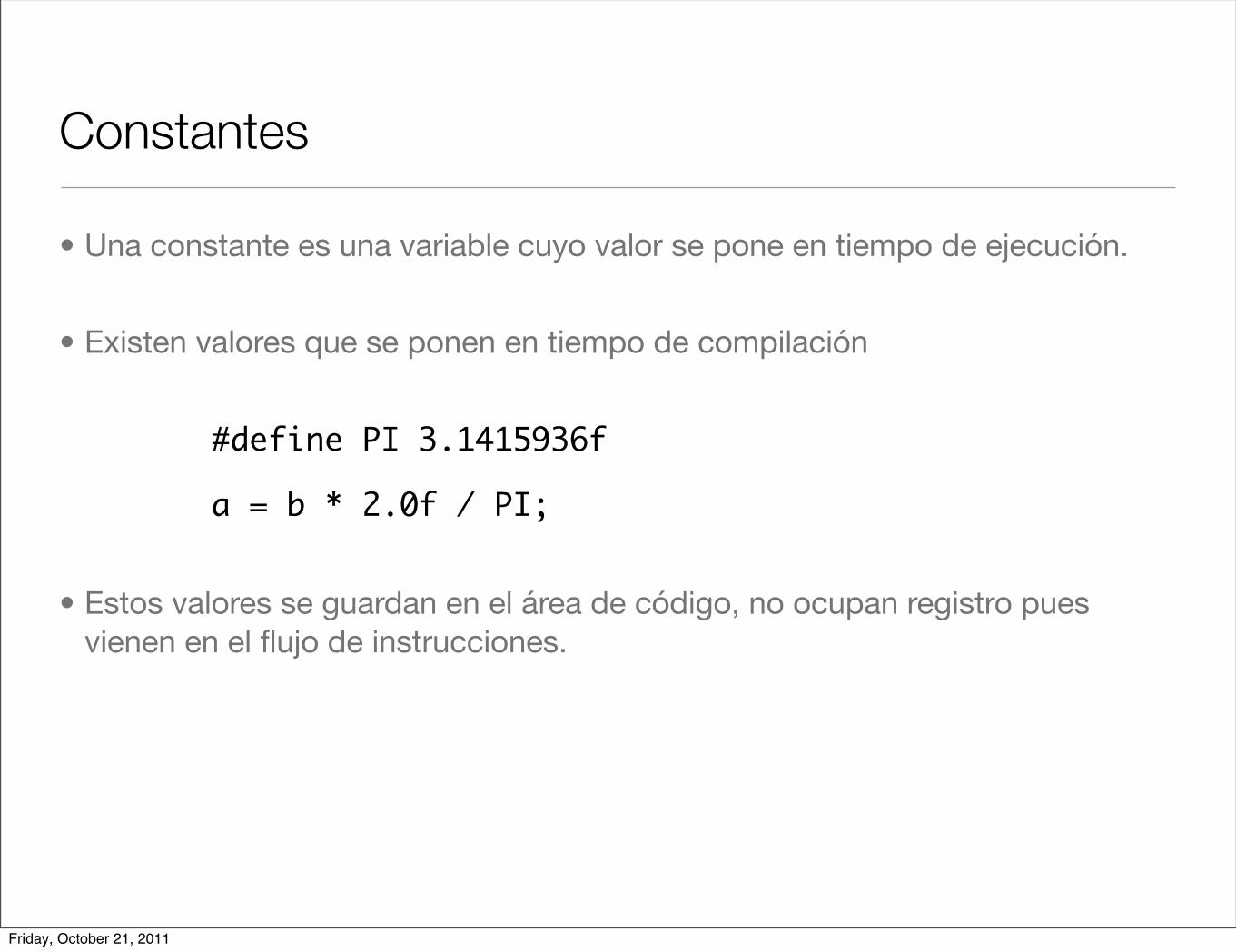
Constantes
• Una constante es una variable cuyo valor se pone en tiempo de ejecución.
• Existen valores que se ponen en tiempo de compilación
#define PI 3.1415936f
a = b * 2.0f / PI;
• Estos valores se guardan en el área de código, no ocupan registro pues vienen en el flujo de instrucciones.
Friday, October 21, 2011

• Por omisión, variables locales de cada kernel se asignan a registros.
• FERMI:
Registros
Friday, October 21, 2011

• Por omisión, variables locales de cada kernel se asignan a registros.
• TESLA:
Registros
Friday, October 21, 2011

Registros
Friday, October 21, 2011

Registros
El compilador transforma el vector a valores escalares
Friday, October 21, 2011

Memoria compartida
• Variables visibles por todos los hilos de un bloque.
• Se declaran dentro de un kernel.
• Puede ser una alternativa al uso de arreglos locales.
• Reduce el uso de registros cuando una variable tiene el mismo valor en todos los threads.
Friday, October 21, 2011
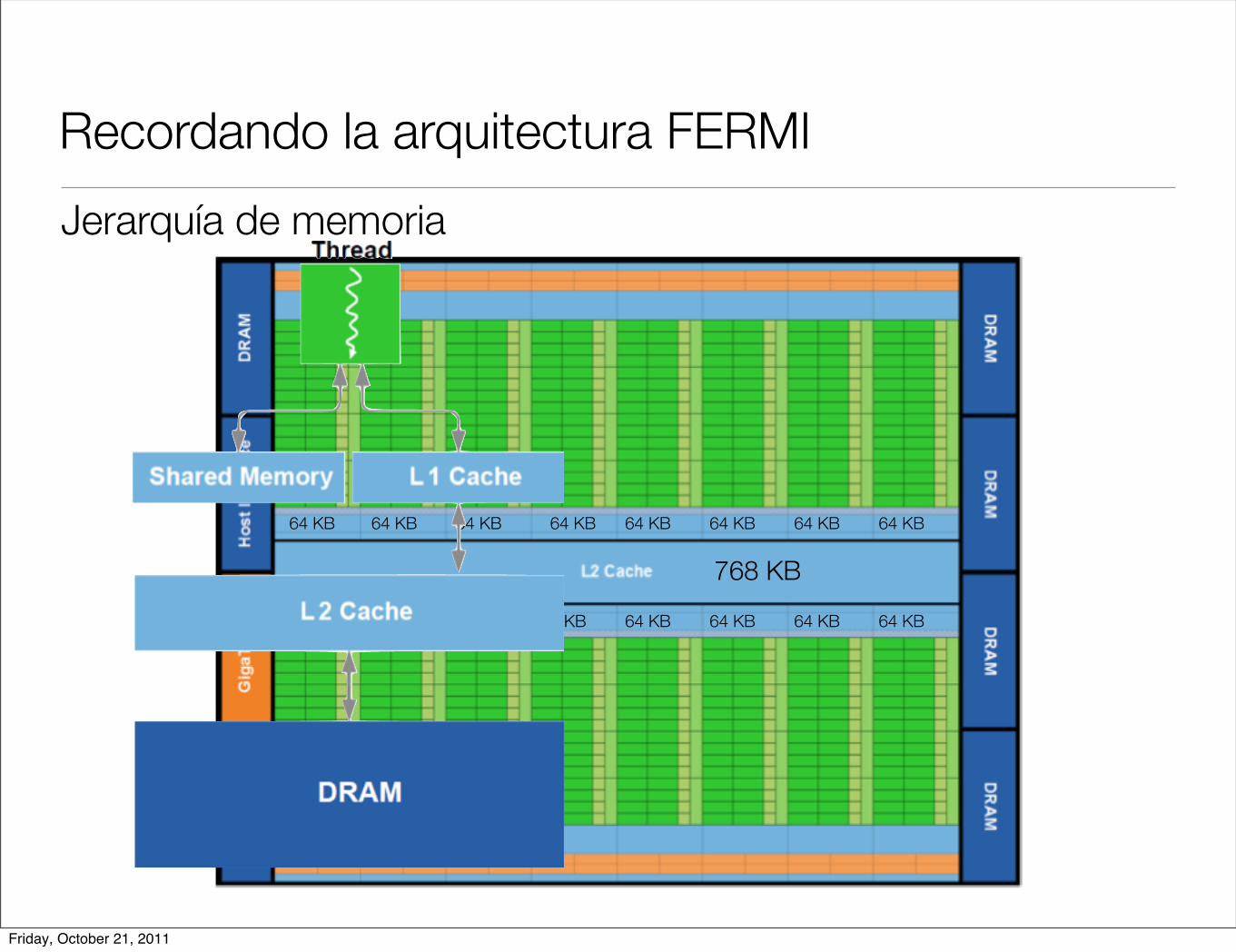
Recordando la arquitectura FERMI
Jerarquía de memoria
768 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB 64 KB
Friday, October 21, 2011

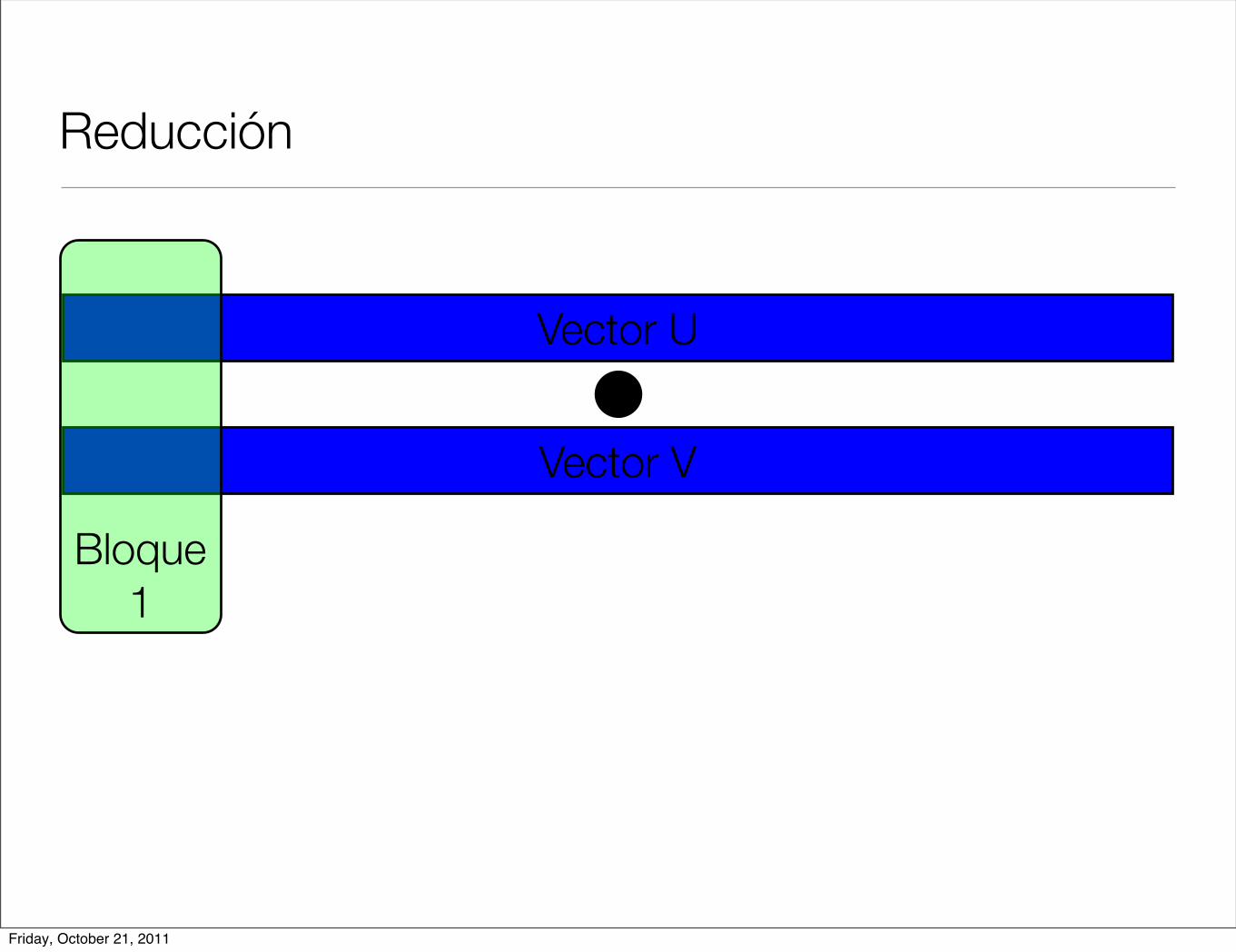
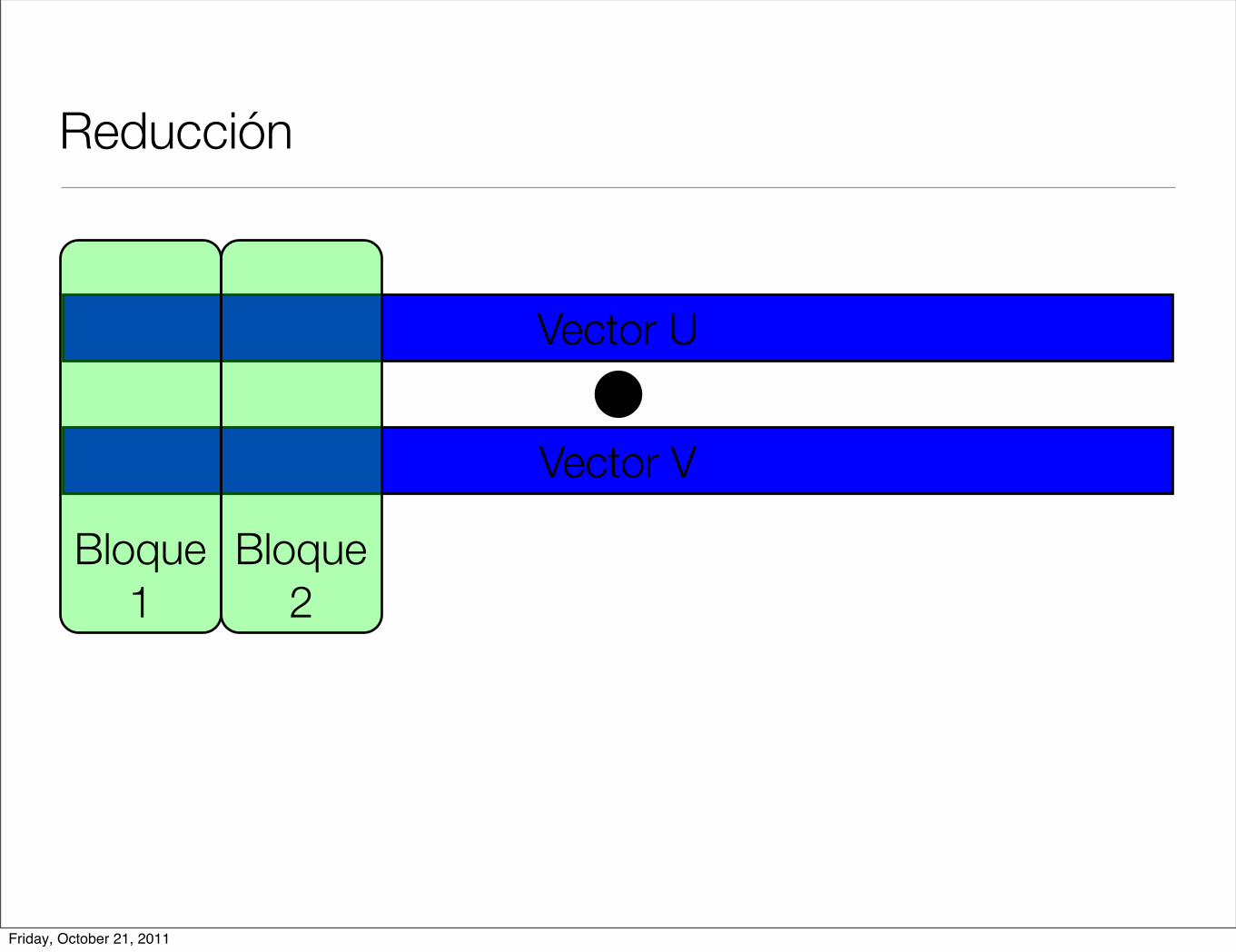
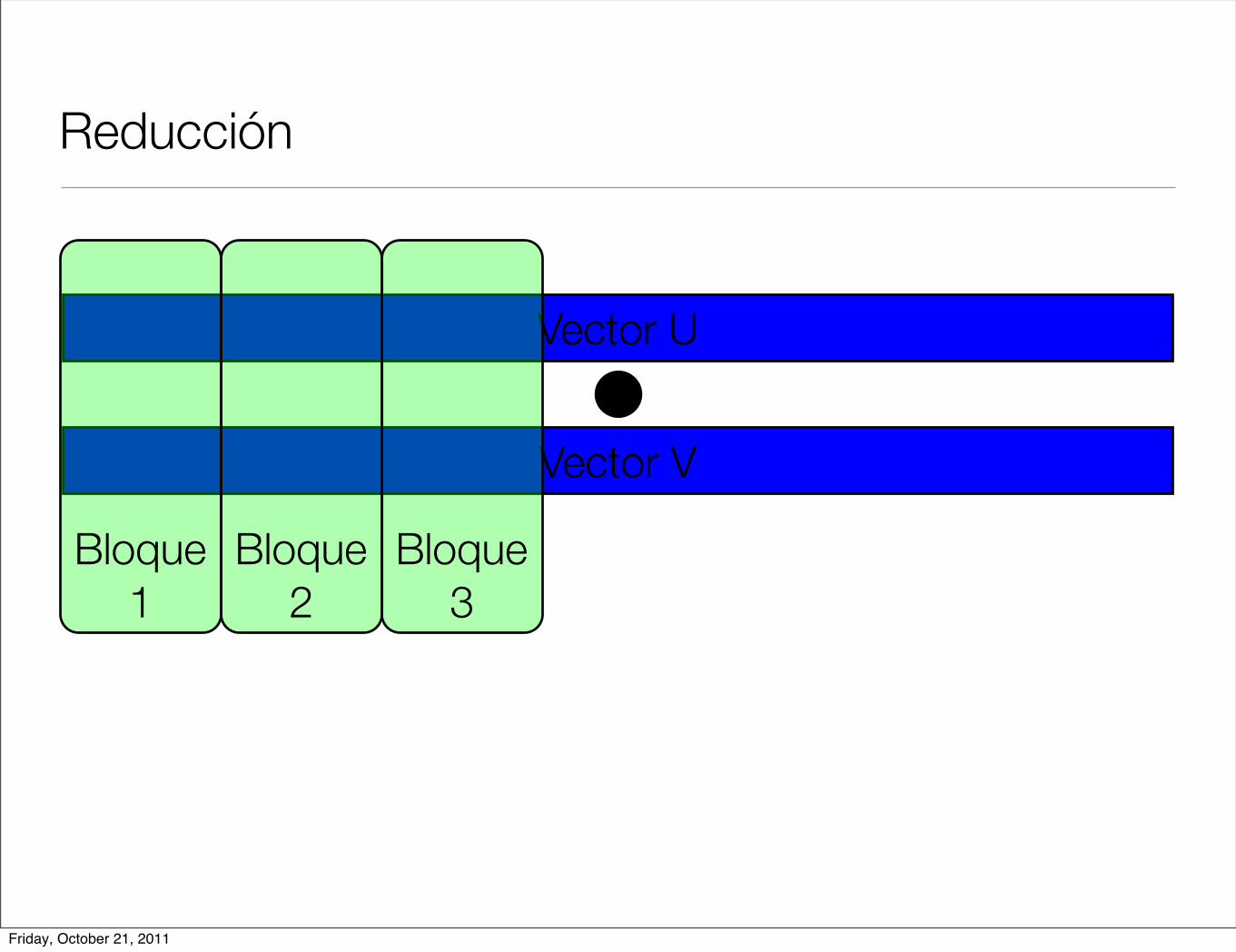
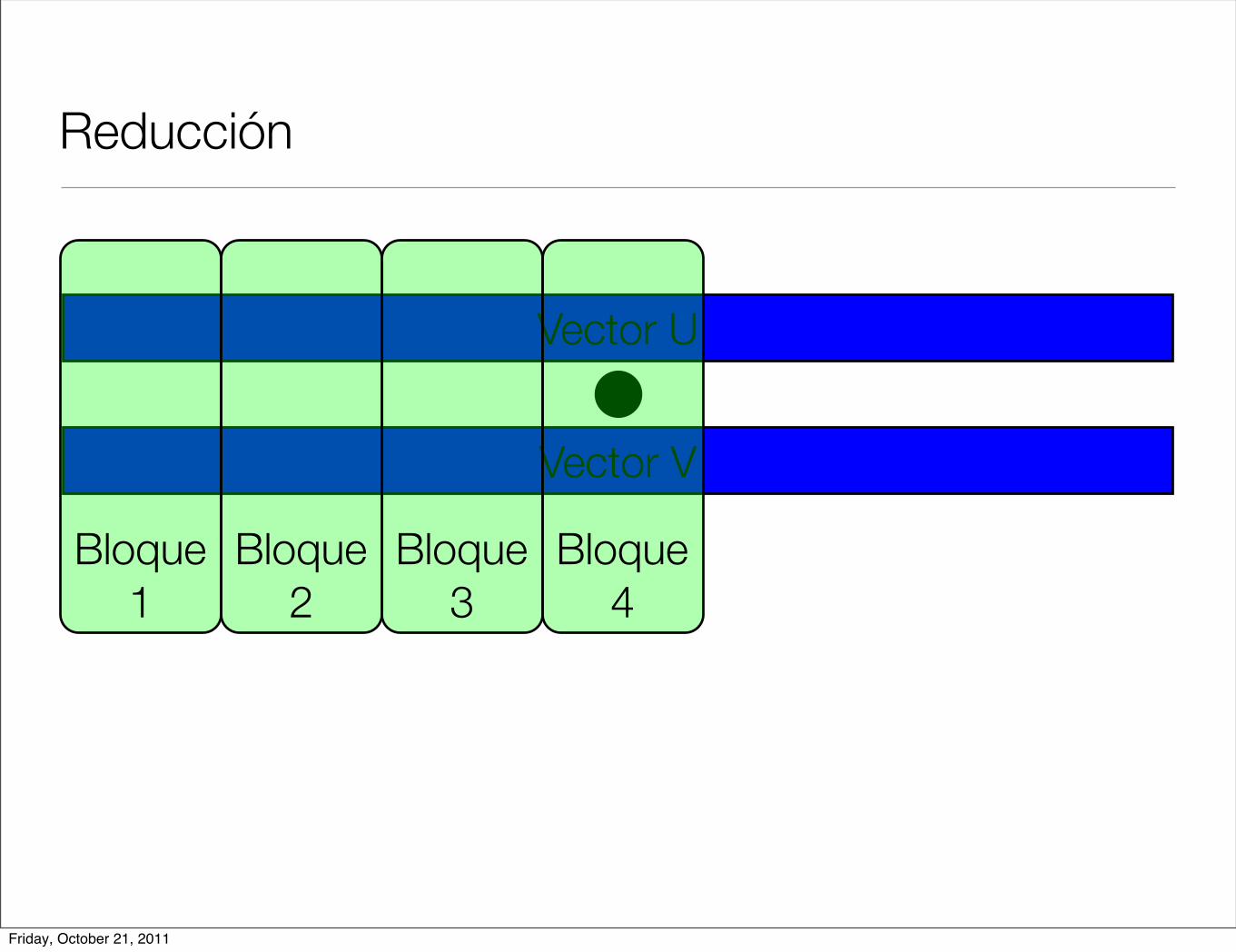
Reducción
< u, v >=N!1!
i=0
u[i] ! v[i]
• Operación producto interior
• Cada hilo hace una parte de la operación total y al final se suman los resultados parciales.
• En cuda podemos ver resultados parciales por hilo y por bloque.
Friday, October 21, 2011
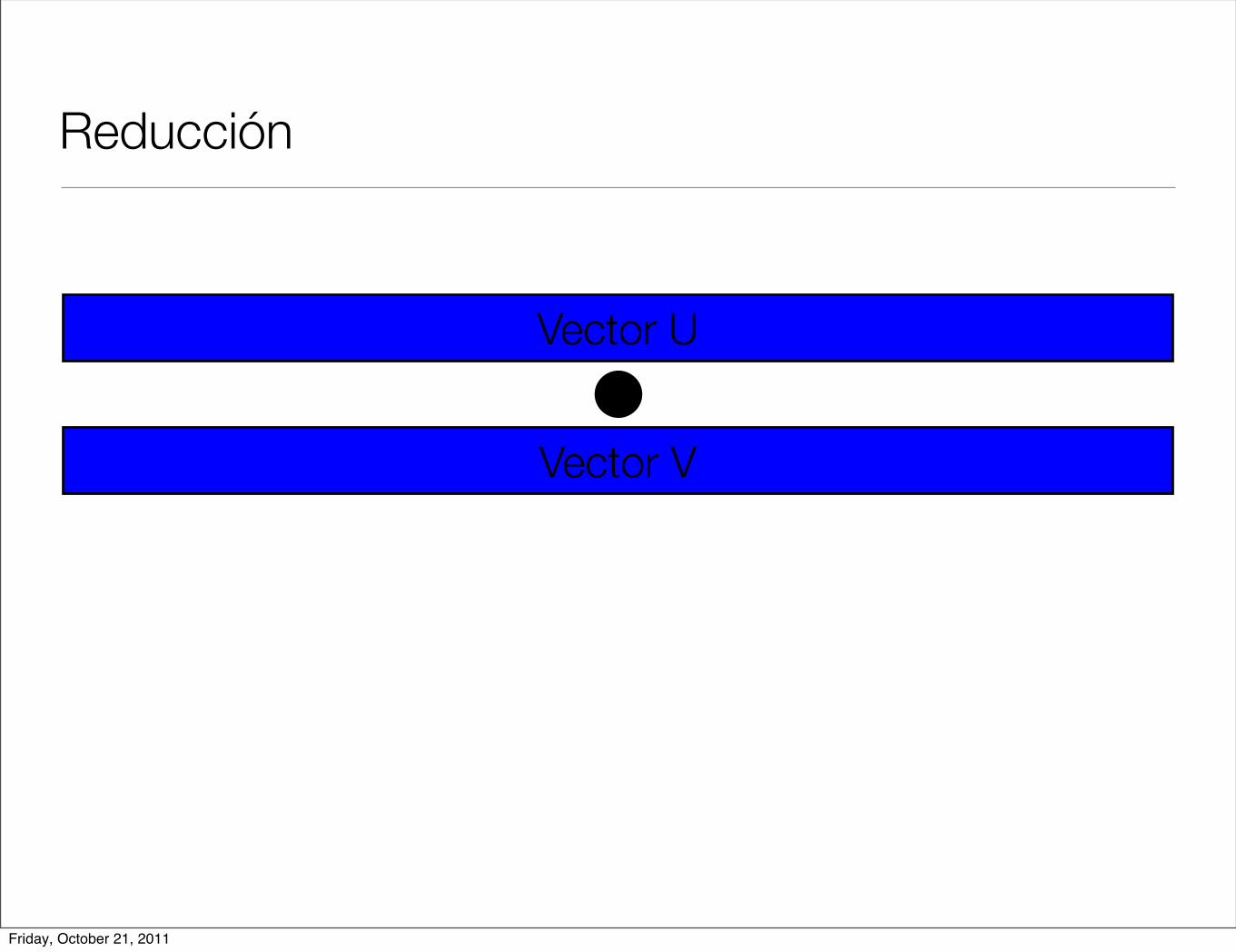
Reducción
Vector U
Vector V
Friday, October 21, 2011
Reducción
Vector U
Vector V
Bloque 1
Friday, October 21, 2011
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Friday, October 21, 2011
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Friday, October 21, 2011
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Friday, October 21, 2011
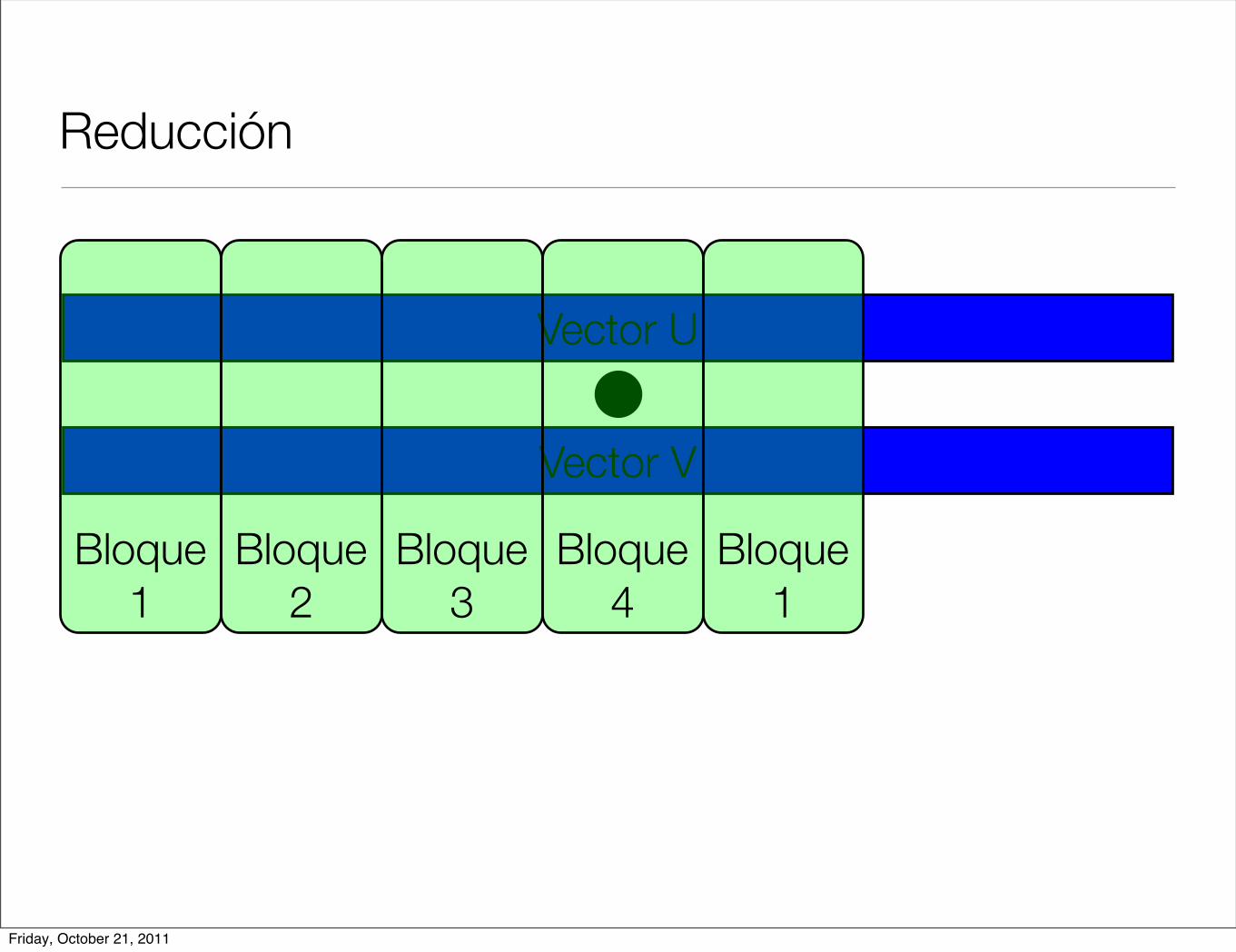
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 1
Friday, October 21, 2011
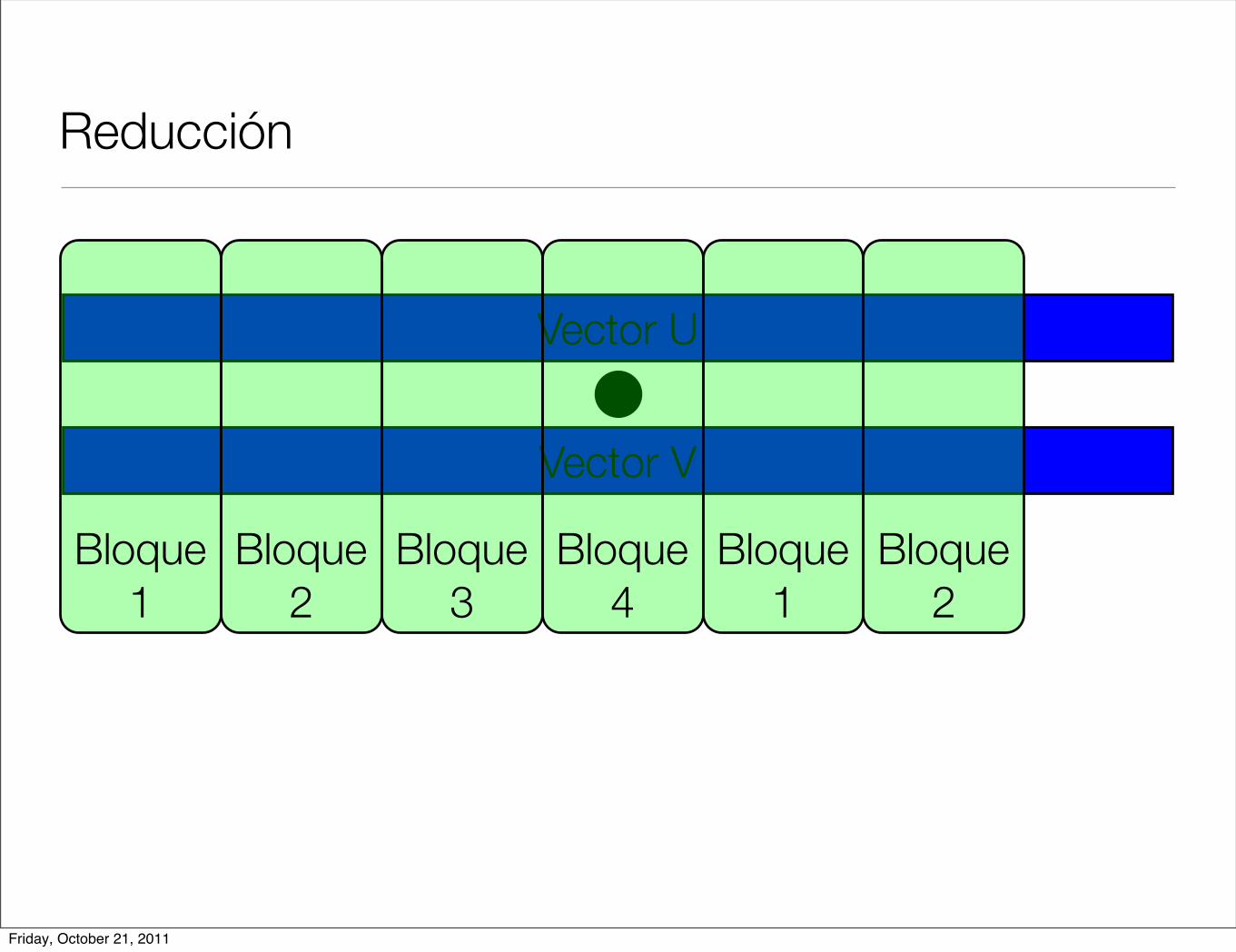
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 1
Bloque 2
Friday, October 21, 2011
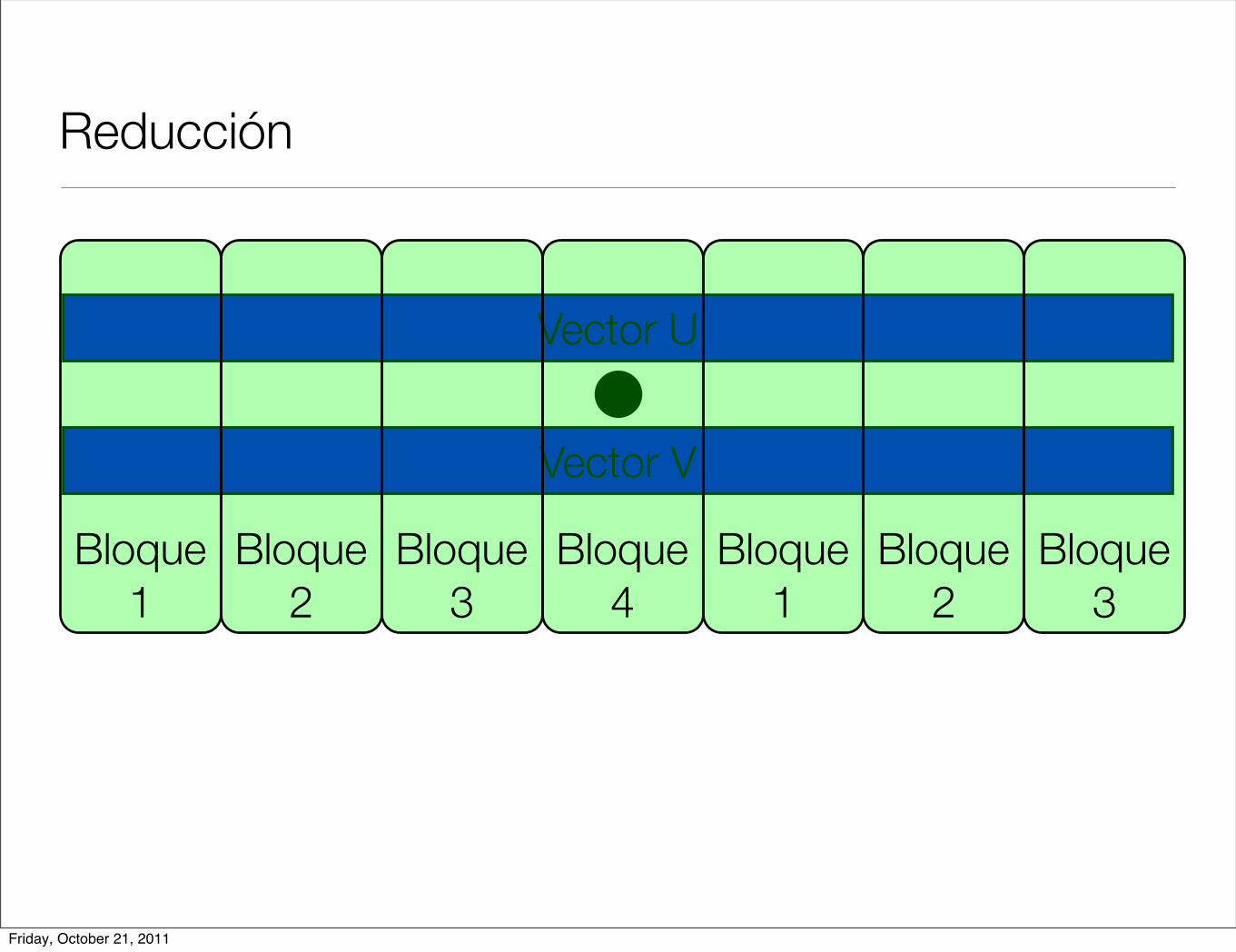
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 1
Bloque 2
Bloque 3
Friday, October 21, 2011
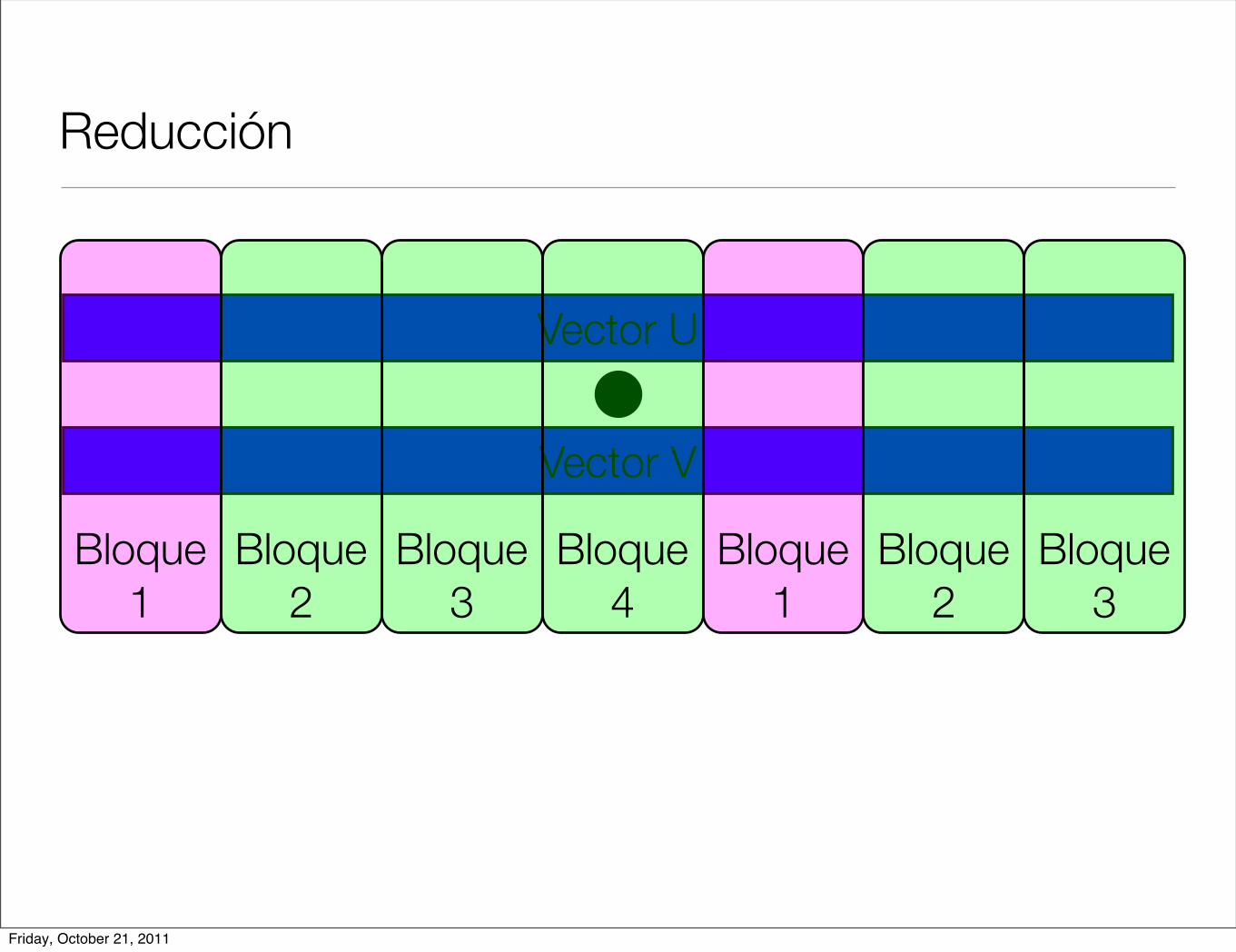
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 1
Bloque 2
Bloque 3
Friday, October 21, 2011
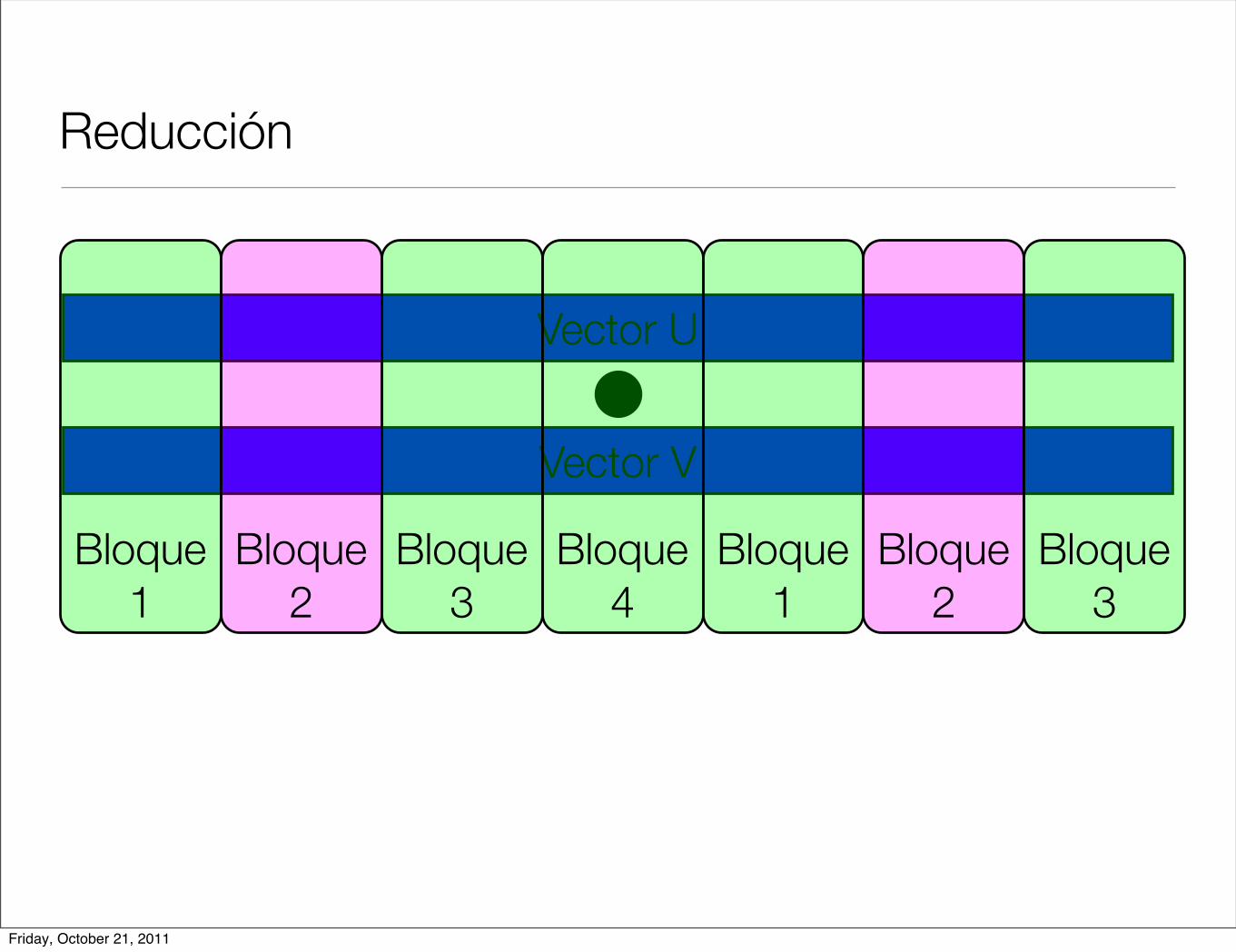
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 1
Bloque 2
Bloque 3
Friday, October 21, 2011
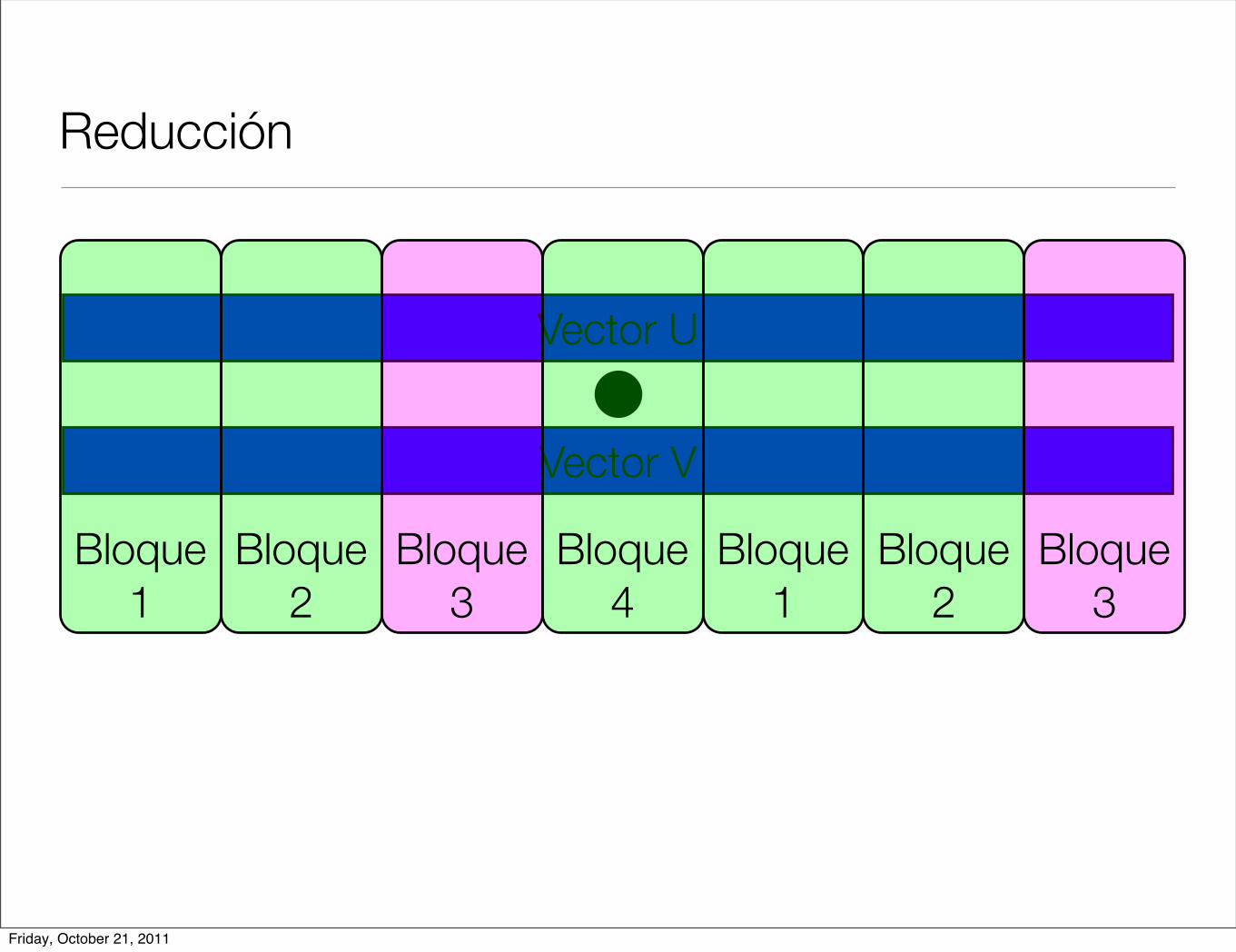
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 1
Bloque 2
Bloque 3
Friday, October 21, 2011
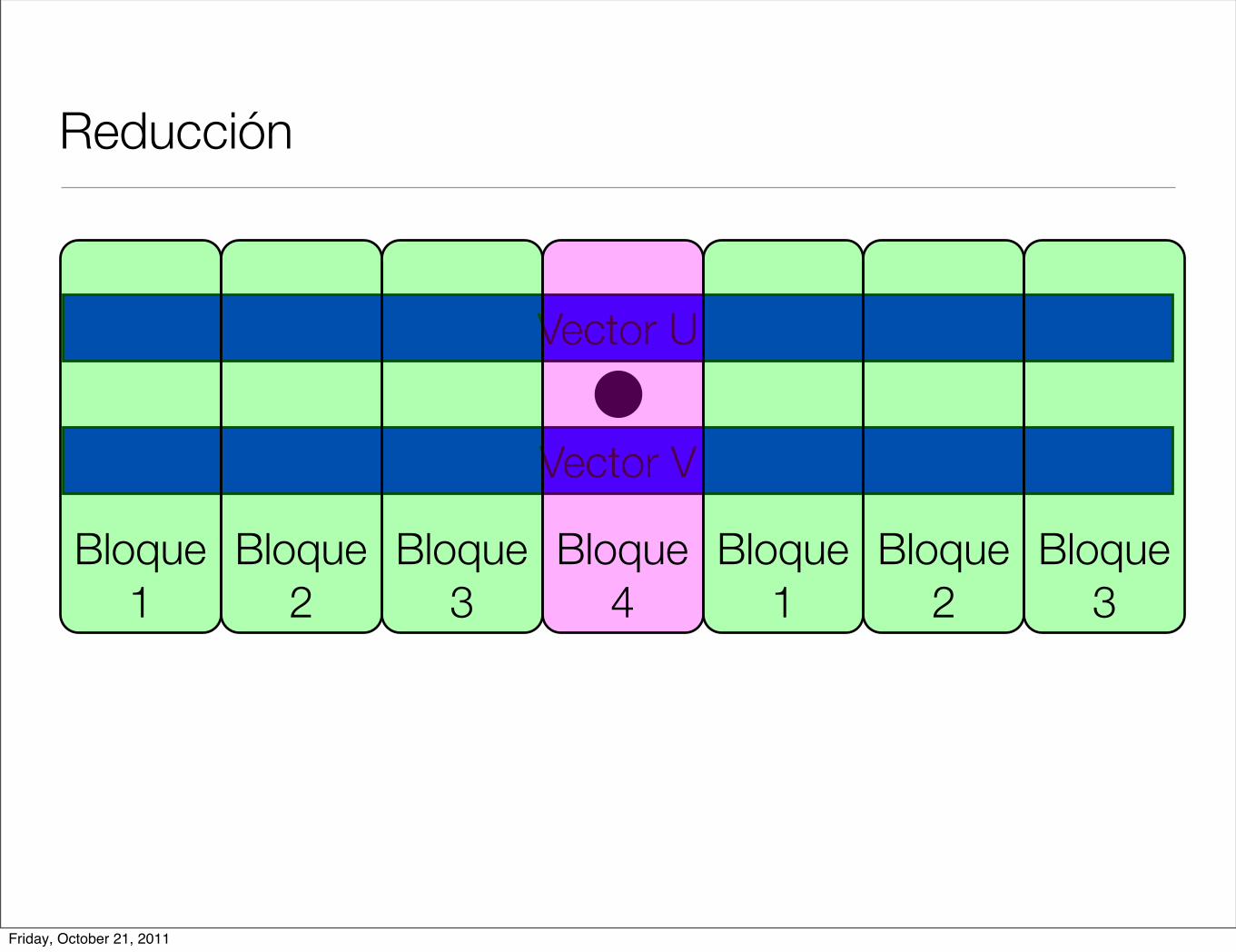
Reducción
Vector U
Vector V
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 1
Bloque 2
Bloque 3
Friday, October 21, 2011

Reducción
// Producto Punto
const int N = 33*1024; const int threadsPerBlock = 256; const int blocksPerGrid = 32;
__global__ void dot(float *a, float *b, float *c) { __shared__ float cache[threadsPerBlock]; int tid = threadIdx.x + blockIdx.x * blockDim.x; int cacheIndex = threadIdx.x;
float temp = 0; while (tid < N) { temp += a[tid] * b[tid]; tid += blockDim.x * gridDim.x; }
cache[cacheIndex] = temp;
__syncthreads(); int i = blockDim.x/2; while (i != 0) { if (cacheIndex < i) cache[cacheIndex] += cache [cacheIndex + i]; __syncthreads(); i /= 2; }
if (cacheIndex == 0) { c[blockIdx.x] = cache[0]; }}
Friday, October 21, 2011
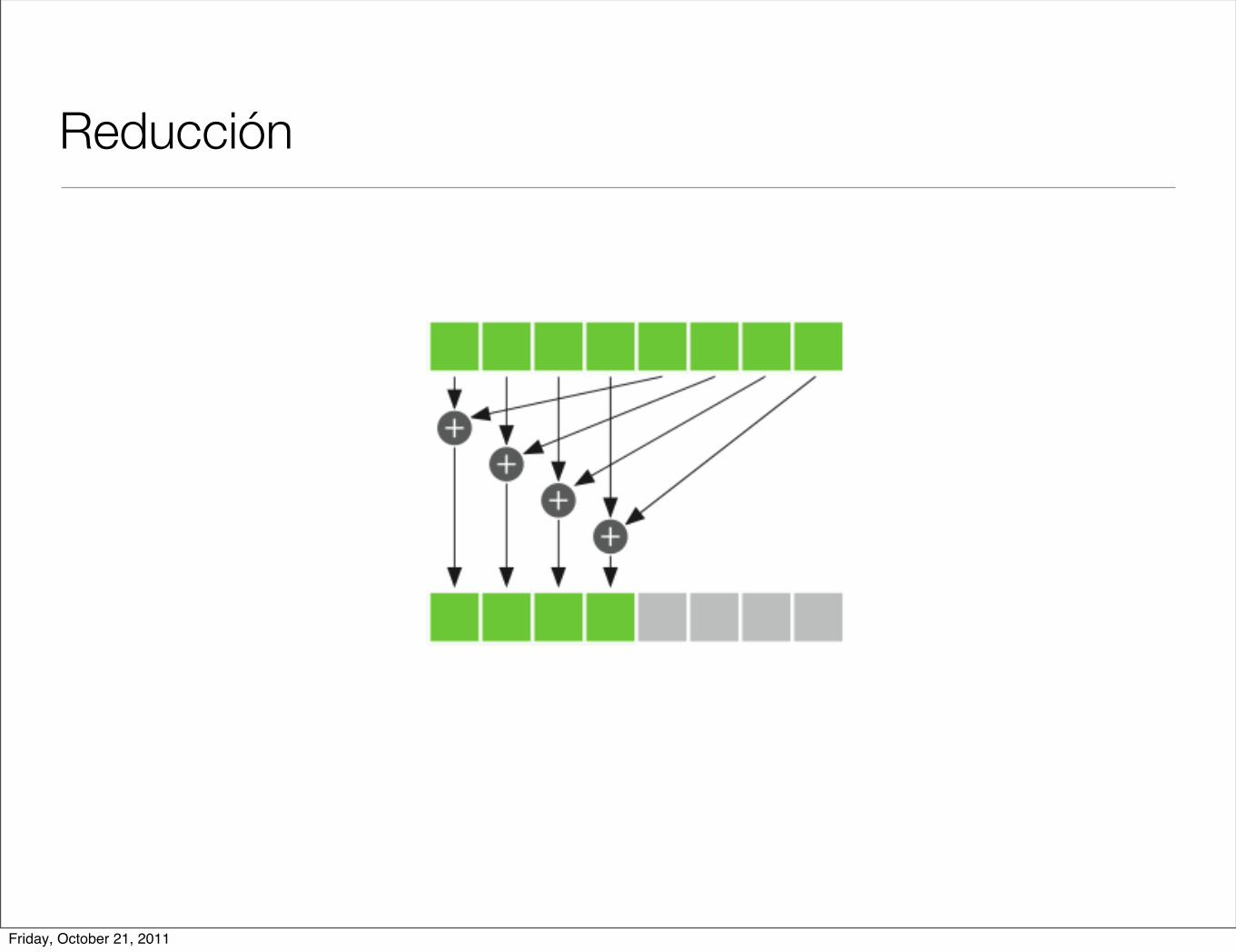
Reducción
Friday, October 21, 2011

159
Bibiografía
• J. Sanders & E. Kandrot; CUDA by Example: An Introduction to General-Purpose GPU Programming; Addison-Wesley Professional, 2010.
• NVIDIA Corporation ; NVIDIA CUDA C, Programming Guide, Version 3.2, Septiembre 2010.
• NVIDIA Corporation ; NVIDIA CUDA, CUDA C Best Practices Guide, Version 3.2, Agosto 2010.
• NVIDIA Corporation ; The CUDA Compiler Driver NVCC; Agosto 2010.
• NVIDIA Corporation; NVIDIA CUDA, Reference Manual, Version 3.2 Beta, Agosto 2010.
Friday, October 21, 2011

160
Bibiografía
• D. Kirk & Wen-Mei W. Hwu; Programming Massively Parallel Processors: A Hands-on Approach; Morgan Kaufmann, 2010.
• Mike Giles; Course on CUDA Programming on NVIDIA GPUs, July 2010.
• NVIDIA Corporation; CUDA Presentation 4.0; 2011.
• Michael J. Quinn; Parallel Programming in C with MPI and OpenMP; McGrawHill, International Edition, 2003.
• Jack Dongara, et. al.; Sourcebook of Parallel Computing, Morgan Kaufmann Ed.; 2003.
Friday, October 21, 2011

161
Bibiografía
• Jack Dongara, et. al.; Sourcebook of Parallel Computing, Morgan Kaufmann Ed.; 2003.
• T.G. Mattson, B.A. Sanders, B.L. Massingill; Patterns For Parallel Programming; Addison Wesley, 2007.
• G.E. Karniadakis, R.M. Kirby II; Parallel Scientific Computing in C++ and MPI; 2nd edition, Cambridge University Press, 2005.
Friday, October 21, 2011


















