Curso de Administración de Oracle 10g (10.2) Español – Nivel Básico

Taller de administración:
Base de datos
Oracle 10g
Noviembre 2009

Taller de administración de Base de datos Oracle 10g 2009
Contenido 1. Arquitectura de una base de datos ........................................................................................................... 5
1.1 Definición de instancia ........................................................................................................................ 5
1.2 Definición de Base de Datos ............................................................................................................... 5
1.3 Estructuras de Memoria ..................................................................................................................... 6
1.3.1 System Global Area ...................................................................................................................... 6
1.3.2 Program Global Area .................................................................................................................... 6
1.3.3 Shared pool .................................................................................................................................. 6
1.3.4 Buffer Cache ................................................................................................................................. 6
1.3.5 Java Pool....................................................................................................................................... 7
1.3.6 Large Pool ..................................................................................................................................... 7
1.3.7 Redo log Buffer ............................................................................................................................ 7
1.3.8 Procesos de Background .............................................................................................................. 7
1.4 Estructuras Físicas ............................................................................................................................... 9
1.4.1. Data files ..................................................................................................................................... 9
1.4.2. Control files ................................................................................................................................. 9
1.4.3. Redo logs ..................................................................................................................................... 9
1.4.4 Archives ..................................................................................................................................... 10
1.4.5. Spfile .......................................................................................................................................... 10
1.4.6. Password file ............................................................................................................................ 10
1.5. Relación estructuras de memoria y físicas ....................................................................................... 11
1.6 Estructuras Lógicas ............................................................................................................................ 11
1.6.1. Tablespaces ............................................................................................................................... 11
1.6.2. Segmentos ................................................................................................................................. 12
1.6.3. Extents....................................................................................................................................... 12
2. Instalación y Configuración del Manejador de BD. ................................................................................. 13
2.1 Obtener Software ............................................................................................................................. 13
2.2 Verificar Documentación .................................................................................................................. 13
2.3 Prerrequisitos de hardware .............................................................................................................. 14
2.5 Creación de grupos y usuarios .......................................................................................................... 17

Taller de administración de Base de datos Oracle 10g 2009
2.7 Instalación y configuración ............................................................................................................... 18
2.8 Configuraciones de servicios de red ................................................................................................. 23
3. Análisis y Diseño de una BD .................................................................................................................... 25
3.1 Rol de la información para las empresas .......................................................................................... 25
3.2 Elementos a tomar en cuenta en un diseño de BD........................................................................... 25
3.3 Reglas de negocio ............................................................................................................................. 25
3.4 Normalización ................................................................................................................................... 25
3.5 Modelo entidad relación ................................................................................................................... 27
3.6 Métricas de una BD ........................................................................................................................... 28
3.7 Diccionario de Datos ......................................................................................................................... 28
3.8 Buen diseño vs Mal diseño ............................................................................................................... 29
3.9 Hacer tangible un diseño de BD, comparar buen diseño vs Mal diseño .......................................... 29
4. Diseño Físico de una BD .......................................................................................................................... 30
4.1 Data blocks ........................................................................................................................................ 30
4.2 OS blocks ........................................................................................................................................... 31
4.3 Datafiles ............................................................................................................................................ 31
4.4 Consideraciones de disco .................................................................................................................. 32
4.5 Distribución de la BD en disco .......................................................................................................... 32
4.6 Funcionalidad de ASM ...................................................................................................................... 32
5. Creación de una BD Oracle ..................................................................................................................... 33
5.1 Prerrequisitos para la instancia ........................................................................................................ 33
5.2 Prerrequisitos para la BD .................................................................................................................. 33
5.3 Configuración de storage .................................................................................................................. 33
5.4 Tablespaces Default .......................................................................................................................... 33
5.5 Configuración dedicada .................................................................................................................... 34
5.6 Configuración compartida ................................................................................................................ 34
5.7 Utilización de la herramienta DBCA .................................................................................................. 34
6. PL/SQL ..................................................................................................................................................... 46
6.1 Bloques anónimos ............................................................................................................................. 46
6.2 Procedimientos ................................................................................................................................. 47

Taller de administración de Base de datos Oracle 10g 2009
6.3 Funciones .......................................................................................................................................... 49
6.4 Paquetes ........................................................................................................................................... 50
6.5 Triggers .............................................................................................................................................. 52
7. Optimización de Queries ......................................................................................................................... 56
7.1 Explain plan ....................................................................................................................................... 56
7.2 Índices ............................................................................................................................................... 56

Taller de administración de Base de datos Oracle 10g 2009
1. Arquitectura de una base de datos
1.1 Definición de instancia
La instancia de la base de datos consta de datos (llamados estructuras de memoria) y de procesos en memoria (procesos background) necesarios para dar servicio a los usuarios de la base de datos. Puede haber más de una instancia si se distribuye la base de datos en más de una máquina. Cada instancia abre una y sólo una base de datos.
1.2 Definición de Base de Datos
Una Base de Datos es una colección compartida de datos lógicamente relacionados, junto con una descripción de estos datos, que están diseñados para satisfacer las necesidades de información de una organización. Una Base de Datos Oracle está almacenada físicamente en data files, y la correspondencia entre los data files y las tablas es posible gracias a las estructuras internas de la BD, que permiten que diferentes tipos de datos estén almacenados físicamente separados. Está división lógica se hace gracias a los tablespaces.

Taller de administración de Base de datos Oracle 10g 2009
1.3 Estructuras de Memoria
1.3.1 System Global Area
Es un grupo de estructuras de memoria que contienen datos e información de control para una instancia de una base de datos en Oracle. El SGA es compartido entre los usuarios. La SGA y los procesos de Oracle constituyen una instancia de Oracle. Oracle automáticamente asigna memoria a un SGA cuando se levanta/inicia la instancia. Con una infraestructura de SGA dinámico, el tamaño del buffer cache, el shared pool, large pool y área de memoria privada pueden ser alterados sin bajar/terminar la instancia.
1.3.2 Program Global Area
Es una región de memoria que contiene datos e información de control para un proceso servidor. Es un área de memoria no compartida creada por Oracle cuando el proceso es iniciado. La cantidad total de memoria PGA asignada para cada proceso se denomina aggregated PGA memory.
1.3.3 Shared pool
Es la porción del SGA que contiene las tres áreas mas grandes: library cache, dictionary cache y estructuras de control. Library Cache: incluye las áreas de SQL compartidas y privadas en caso de que sea un servidor de múltiples transacciones. Los procedimientos PL/SQL y paquetes, estructuras de control como los locks y manejadores del caché de librerías. Shared SQL Areas y Private SQL Areas: Oracle representa la ejecución de cada instrucción SQL con un área SQL privada y otra compartida. Reconoce cuando dos usuarios están ejecutando la misma instrucción SQL y reutiliza el área compartida para aquellos usuarios. Shared SQL Areas es un área compartida SQL que contiene un árbol proveniente del análisis (léxico, sintáctico y semántico) de la instrucción y su plan de ejecución.
1.3.4 Buffer Cache Es la porción del SGA que mantiene una copia de los bloques leídos de los data files. Todos los procesos de los usuarios conectados concurrentemente a la instancia compartida, acceden al buffer caché de la base de datos. Organización del Buffer Caché de la Base de Datos Write list: mantiene los buffers sucios, que contienen datos que han sido modificados, pero aún no han sido escritos a disco. LRU list: mantiene los buffers libres, pinned y sucios que no han sido movidos aún a write list.

Taller de administración de Base de datos Oracle 10g 2009
Free buffers: no contienen ningún dato útil y están disponibles para su uso Pinned buffers: son aquellos que están siendo accesados actualmente. Cuando un proceso de Oracle accede un buffer, el proceso mueve el buffer a los más utilizados (MRU) al final de LRU list. La primera vez que un proceso usuario requiere una pieza de datos, éste busca los datos en el buffer cache. Si el proceso los encuentra se tiene un cache hit. En caso contrario debe buscarlos en los data files y se tiene un cache miss.
1.3.5 Java Pool
Es un área de memoria de la SGA donde se almacenan objetos y códigos de aplicaciones java que son usados muy a menudo, para ser ejecutados de forma más dinámica y eficiente.
1.3.6 Large Pool
Provee grandes áreas de memoria para:
La información de la sesión para servidores compartidos
Procesos de I/O del servidor
Operaciones de backup y restore
1.3.7 Redo log Buffer
Es un buffer circular en el SGA que mantiene información acerca de los cambios hechos en la base de datos. Esta información es almacenada en los redo logs. Un redo log contiene la información necesaria para reconstruir o rehacer, los cambios hechos en la base de datos por las operaciones: INSERT, UPDATE, DELETE, CREATE, ALTER o DROP. Los redo logs son utilizados, en caso de ser necesarios para la recuperación de la base de datos. Los redo logs toman espacios continuos y secuenciales en el buffer.
1.3.8 Procesos de Background
Son provistos con el propósito de maximizar el desempeño y atender muchos usuarios. En muchos sistemas operativos, los procesos background son creados automáticamente cuando la instancia es iniciada. Entre ellos se tiene: Database Writer Process (DBWn) El (DBWn) escribe el contenido de los buffers en los data files. El proceso DBWn es responsable por la escritura de los buffers sucios del buffer cache al disco. Cuando un buffer en la base de datos es modificado, se marca como sucio. Un buffer free es un buffer que no ha sido usado recientemente de acuerdo con el algoritmo LRU. El DBWn escribe buffers sucios y fríos al disco para que los usuarios puedan encontrar buffers limpios que puedan usarse para la lectura de nuevos bloques en el caché. El proceso DBWn escribe buffers sucios al disco bajo las siguientes condiciones:

Taller de administración de Base de datos Oracle 10g 2009
Cuando un proceso no puede encontrar un buffer limpio reusable después de haber recorrido un número de determinado de buffers en el buffer caché, éste envía una señal al DBWn para la escritura. El DBWn escribe los buffers sucios al disco.
El DBWn periódicamente escribe los buffers cuando se lleva a cabo un checkpoint. Chekpoint es una posición en el hilo de redo (log) donde se iniciará luego la recuperación. La posición en el log esta determinada por el último buffer sucio en el buffer caché.
Log Writer Process (LGWR) El proceso LGWR es responsable del manejo del redo log buffer, las escrituras del redo log buffer al archivo de redo log en el disco. El LGWR escribe todos los registros de redo que han sido copiados en el buffer desde la última vez que éste se escribió. El redo log buffer es un buffer circular. Cuando LGWR escribe los registros del redo log buffer al redo log file, el proceso servidor puede copiar nuevos registros sobre aquellos que se pasaron a disco. LGWR normalmente escribe lo suficientemente rápido para asegurar que el espacio esté siempre disponible en el buffer para nuevos registros, aún cuando el acceso al redo log sea lento. LGWR escribe en porciones contiguas del buffer al disco. El LGRW escribe Un registro de commit cuando un usuario hace commit de una transacción Redo log buffers Cada tres segundos Cuando el redo log tenga un tercio lleno Cuando un proceso de DBWn escriba los buffers modificados a disco, si es necesario. Cuando un usuario lleva a cabo una instrucción de commit, el LGWR coloca el registro de commit en el log buffer y escribe la transacción a disco inmediatamente en el redo log. Los cambios correspondientes a los bloques de datos en el buffer caché, son dejados hasta que se tenga una escritura más eficiente que hacer. Esto se denomina el mecanismo de fast commit. La escritura de un registro de redo del commit de la transacción es un evento atómico. Checkpoint Process (CKPT) Cuando un checkpoint ocurre. Oracle debe actualizar todos los encabezados de los archivos de datos con los detalles del checkpoint. Esta es una tarea del CKPT. El CKPT no escribe los bloques a disco, realiza la llamada al DBWn para que éste lo haga. System Monitor Process (SMON) El proceso SMON lleva a cabo la recuperación, si es necesaria, de la instancia en el inicio de la misma. SMON también es responsable de limpiar los segmentos temporales que no estén en uso por algún tiempo y de determinar que algunos extents libres se encuentran continuos en el tablespace dictionary managed. Process Monitor (PMON) PMON lleva a cabo procesos de recuperación cuando un proceso de usuario falla. Es responsable de la limpieza del buffer caché y liberación de recursos que el proceso estaba usando. Por ejemplo este restaura el status de la tabla de transacciones activas, libera los locks y remueve el ID del proceso de la lista de procesos activos. Recover Process (RECO) RECO es un proceso background usado con la configuración de bases de datos distribuida que resuelve automáticamente las fallas de las transacciones distribuidas. Archiver Processes (ARCn)

Taller de administración de Base de datos Oracle 10g 2009
El ARCn copia los archivos de redo log online al dispositivo de almacenamiento terciario. ARCn sólo está recent cuando la base de datos está en el modo ARCHIVELOG y la opción automatic archiving está activa. Lock Manager Server Process (LMS) LMS provee manejo de recursos entre instancias. Queue Monitor Processes (QMNn) QMNn es un proceso opcional de background para el encolamiento avanzado de Oracle, que monitorea las colas de mensajes. El encolamiento avanzado se usa con comunicación asíncrona. Los procesos envían los mensajes y en lugar de esperar por la respuesta siguen con su trabajo.
1.4 Estructuras Físicas
1.4.1. Data files
Un data file es un archivo a nivel de sistema operativo en donde se guardarán físicamente los datos de una determinada base de datos. Cada tablespace se compone de uno o más data files en disco. Un data file puede pertenecer sólo a un tablespace. Los data files reciben un tamaño fijo en el momento de su creación, y cuando se necesita más espacio se deben añadir más data files al tablespace. Dividir los objetos de la BD entre múltiples tablespaces permite que los objetos sean almacenados físicamente en discos separados, dependiendo de donde estén los data files sobre los que se asientan.
1.4.2. Control files
Los Control Files mantienen la información física de todos los archivos que forman la BD, incluyendo sus rutas; así como el estado actual de la BD. Son utilizados para mantener la consistencia interna y guiar las operaciones de recuperación. Son imprescindibles para que la BD se pueda arrancar. Contienen:
Información de arranque y parada de la BD.
Nombres de los data files de la BD y redo log.
Información sobre los checkpoints.
Fecha de creación y nombre de la BD. Debe haber múltiples copias en distintos discos, mínimo dos, para protegerlos de los fallos de disco. La lista de los control files se encuentra en el parámetro CONTROL_FILES.
1.4.3. Redo logs
En ellos se graba toda operación que se efectué sobre la BD y sirven de salvaguarda de la misma. Tiene que haber por lo menos 2, uno de ellos debe estar activo (online), se escribe en ellos de forma cíclica, si la base de datos

Taller de administración de Base de datos Oracle 10g 2009
colapsara o se cayera por cualquier motivo la instancia se intentará recuperar con la información que hay en los redo logs.
1.4.4 Archives
Son archivos que contienen un historial de cambios en la base de datos (redo logs). Usando estos archivos y respaldo de la base de datos, podremos recuperar datos perdidos, es decir los archives logs permiten la restauración de data files. Para poder usar los archives, la base de datos debe de estar en modo Archive Log lo que podemos corroborar con el comando: ARCHIVE LOG LIST;
1.4.5. Spfile
A partir de la versión 9i de Oracle encontramos el archivo spfile.ora. Este es el primer archivo que va a "buscar" Oracle en su arranque de base de datos. Si no encuentra este archivo entonces irá a buscar el archivo init.ora Este archivo está codificado y las modificaciones en él se realizarán a través del comando ALTER SYSTEM añadiendo la cláusula SCOPE. Es cierto que este archivo podemos intentar abrirlo con el notepad solo que probablemente quede corrupto o inservible. La ubicación de este archivo es la misma que la del init.ora ($ORACLE_HOME/dbs)
1.4.6. Password file
El password file es un archivo que permite a los usuarios conectarse de manera remota a la base de datos para ejecutar tareas de administración. Si el administrador de la base de datos quiere iniciar la instancia, Oracle debe de tener una forma de autenticar a este usuario de manera segura con un password. Obviamente este password no puede estar guardado en la base de datos, porque Oracle no puede accesar a la base de datos antes de que sea inicializada. Por lo tanto, la autenticación del DBA debe realizarse desde fuera de la base de datos, para esto existe el password file. El parámetro remote_login_passwordfile específica si un password file se utiliza para autenticar a los DBA o no.

Taller de administración de Base de datos Oracle 10g 2009
1.5. Relación estructuras de memoria y físicas
1.6 Estructuras Lógicas
1.6.1. Tablespaces
Un tablespace es una división lógica de la base de datos. Cada base de datos tiene al menos uno (SYSTEM). Un tablespace puede pertenecer sólo a una base de datos. Los tablespaces se utilizan para mantener juntos los datos de usuarios o de aplicaciones para facilitar su mantenimiento o mejorar las prestaciones del sistema. De esta manera, cuando se crea una tabla se debe indicar el tablespace al que será asignada. Por defecto se depositan en el tablespace SYSTEM, que se crea por defecto. Este tablespace es el que contiene el diccionario de datos, por lo que conviene reservarlo para el uso del servidor, y asignar las tablas de usuario a otro tablespace. Lo razonable y aconsejable es que cada aplicación tenga su propio tablespace. Hay varias razones que justifican este modo de organización de las tablas en tablespaces:
Un tablespace puede quedarse offline debido a un fallo de disco, permitiendo que el SGBD continúe funcionando con el resto.
Los tablespaces pueden estar montados sobre dispositivos ópticos si son de sólo lectura.
Permiten distribuir a nivel lógico/físico los distintos objetos de las aplicaciones.

Taller de administración de Base de datos Oracle 10g 2009
Son una unidad lógica de almacenamiento, pueden usarse para aislar completamente los datos de diferentes aplicaciones.
Oracle permite realizar operaciones de backup/recovery a nivel de tablespace mientras la BD sigue funcionando.
Cuando se crean se les asigna un espacio en disco que Oracle reserva inmediatamente, se utilice o no. Si este espacio inicial se ha quedado corto Oracle puede gestionar el crecimiento dinámico de los data files sobre los que se asientan los tablespaces. Esto elimina la posibilidad de error en las aplicaciones por fallos de dimensionamiento inicial. Los parámetros de crecimiento del tamaño de los tablespaces se especifican en la creación de los mismos.
1.6.2. Segmentos
Los segmentos son los equivalentes físicos de los objetos que almacenan datos. El uso efectivo de los segmentos requiere que el DBA conozca los objetos que utiliza una aplicación, cómo los datos son introducidos en esos objetos y el modo en que serán recuperados. Como los segmentos son entidades físicas, deben estar asignados a tablespaces en la BD y estarán localizados en uno de los data files del tablespace. Un segmento está constituido por secciones llamadas extents.
1.6.3. Extents
Un extent es una unidad lógica de asignación de espacio de almacenamiento de base de datos formada por una serie de bloques contiguos de datos. Uno o más extents a su vez constituyen un segmento. Cuando el espacio existente en un segmento se usa totalmente, Oracle asigna un nuevo extent para el segmento. Diagrama general de la arquitectura de ORACLE.

Taller de administración de Base de datos Oracle 10g 2009
2. Instalación y Configuración del Manejador de BD.
2.1 Obtener Software Para poder obtener el software primero es necesario contar con un nombre de usuario y una contraseña validos, los cuales se pueden obtener ingresando al portal oficial de Oracle y registrándose de modo gratuito.
http://www.oracle.com
El software del manejador de base de datos Oracle se puede obtener gratuitamente para uso personal y no lucrativo en el sitio de Oracle en la siguiente dirección:
http://www.oracle.com/technology/software/products/database/index.html
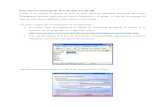
2.2 Verificar Documentación Una vez que se ha descargado el software del manejador, al descomprimirlo se obtendrá un directorio llamado 10201_database_linux32, dentro de él podemos encontrar tanto el software como la documentación. La documentación se encuentra ya sea en formato HTML o PDF en la siguiente ruta: 10201_database_linux32/database/doc/ Para este taller revisaremos la documentación en formato HTML, para abrirla, una vez ubicados en el directorio en el que se encuentra, si se está navegando por los directorios de manera grafica, hay que dar doble clic sobre el archivo index.htm para abrirla en el navegador, o si se está haciendo por medio de una terminal ejecutaremos el siguiente comando: firefox index.htm & En el navegador abrirá una página como la que se muestra a continuación:
En ella se pueden observar tres pestañas, “Getting Started”, “Documentation” y “READMEs”, la que es de interés por el momento es la segunda pestaña, daremos clic en ella y nos llevara a la página referente a documentación.

Taller de administración de Base de datos Oracle 10g 2009
Ahora se muestra una serie de documentos que nos serán útiles, así que es importante darse el tiempo para leerlos, por el momento solo se mencionara el que se llama “Quick Instalation Guide”, podemos abrirlos en el formato que mejor nos parezca, ya sea HTML o pdf. En este documento se encuentra información sobre el hardware, software, configuración necesaria, usuarios y estructuras de directorios, necesarios para la instalación del manejador de base de datos Oracle, aspectos sobre los que se habla más adelante en el presente documento.
2.3 Prerrequisitos de hardware Para poder instalar el software se deben de cumplir como mínimo con los siguientes requisitos:
Por lo menos 1GB de memoria RAM
La memoria SWAP depende del tamaño de la memoria RAM
RAM disponible Espacio en Swap Requerido
Entre 1GB y 2GB de RAM 1.5 veces el tamaño de la RAM
Entre 2GB y 8GB de RAM Igual al tamaño de la RAM
Mas de 8GB de RAM 0.75 veces el tamaño de la RAM
400 MB de espacio disponible en el directorio temporal (/tmp).
Entre 1.5 GB y 3.5 GB de espacio libre en disco duro para el software de Oracle, dependiendo de la instalación.
GB de espacio en disco para una base de datos pre configurada (opcional). Para asegurarse que se cumple con estos prerrequisitos se deben utilizar los siguientes comandos (también se puede ejecutar el script inf_servidor.sh): Para comprobar el tamaño de la memoria RAM:
# grep MemTotal /proc/meminfo
Para comprobar el tamaño de la memoria SWAP:

Taller de administración de Base de datos Oracle 10g 2009
# grep SwapTotal /proc/meminfo
Para comprobar el espacio el espacio de memoria SWAP y RAM disponible:
# free
Para comprobar el espacio disponible para /tmp:
# df -k /tmp
Para comprobar el espacio disponible en disco duro:
# df –k
Para conocer el modelo del procesador:
# grep "model name" /proc/cpuinfo
2.4 Prerrequisitos de software El sistema debe cumplir como mínimo con los siguientes requisitos de software: El sistema operativo debe de ser uno de los siguientes:
Red Hat Enterprise Linux 3.0 (Update 3 or later)
Red Hat Enterprise Linux 4.0
SUSE Linux Enterprise Server 9.0
Asianux 1.0
Asianux 2.0 NOTA: para este taller se utilizará el sistema operativo llamado Fedora en su versión 11 (Leonidas), un sistema derivado de Red Hat. El kernel del sistema operativo debe ser uno de los siguientes (o superior):
Red Hat Enterprise Linux 3.0 and Asianux 1.0 2.4.21-27.EL
Red Hat Enterprise Linux 4.0 and Asianux 2.0 2.6.9-5.0.5.EL
SUSE Linux Enterprise Server 9 2.6.5-7.97
Se deben de instalar los siguientes paquetes (o la versión más reciente de ellos):
Fedora 11 binutils glibc glibc-common libgcc libstdc++

Taller de administración de Base de datos Oracle 10g 2009
make elfutils-libelf elfutils-libelf-devel glibc-devel gcc gcc-c++ libstdc++-devel unixODBC unixODBC-devel libaio libaio-devel sysstat compat-libstdc++-33 libXp
Red Hat Enterprise Linux 3.0 and 4.0, and Asianux 1.0 and Asianux 2.0
make-3.79.1 gcc-3.2.3-34 glibc-2.3.2-95.20 compat-db-4.0.14-5 compat-gcc-7.3-2.96.128 compat-gcc-c++-7.3-2.96.128 compat-libstdc++-7.3-2.96.128 compat-libstdc++-devel-7.3-2.96.128 openmotif21-2.1.30-8 setarch-1.3-1
SUSE Linux Enterprise Server 9 gcc-3.3.3-43 gcc-c++-3.3.3-43 glibc-2.3.3-98 libaio-0.3.98-18 libaio-devel-0.3.98-18 make-3.80 openmotif-libs-2.2.2-519.1
Para asegurarse que el sistema cuenta con los prerrequisitos se debe ejecutar los siguientes comandos. Para conocer la versión del sistema operativo instalado:
# cat /etc/issue
Para conocer la versión del kernel instalado:
# uname –r
Para determinar si un paquete está instalado:

Taller de administración de Base de datos Oracle 10g 2009
# rpm -q nombre_del_paquete
2.5 Creación de grupos y usuarios Se requiere que los siguientes grupos y usuarios existan para la instalación del software:
El grupo para el inventario de Oracle (oinstall).
El grupo para administrador de base de datos de sistema operativo (dba).
El propietario del software de Oracle (oracle). Para cumplir con estos requisitos se debe de ejecutar los siguientes comandos Para crear los grupos oinstall y dba.
# groupadd oinstall # groupadd dba
Para crear el usuario oracle.
# useradd -g oinstall -G dba oracle
Establecer una contraseña para el usuario oracle.
# passwd oracle
OFA: Optimal Flexible Arquitecture OFA es una serie estándar de recomendaciones a la hora de nombrar archivos y directorios cuando se instala e implementa una base de datos. OFA esta diseñado para organizar grandes cantidades de software y datos en disco, simplificar tareas de administración, maximizar el desempeño y facilitar los cambios entre bases de datos. Algunos beneficios de OFA son que permite facilidad al realizar acciones tales como añadir hardware, crear bases de datos y añadir elementos a bases de datos existentes. Otro de los beneficios es que la carga de I/O es distribuida sobre todos los discos, para prevenir cuellos de botella. Básicamente consiste en dar nombres a los directorios y archivos que permitan diferenciar a los de una base de datos de otra, e incluso tener instalaciones de distintas versiones del manejador o incluso de la misma versión. Al punto de montaje de todos los dispositivos se les debe de poner una cadena constante mas un identificador numérico de dos dígitos por ejemplo /u01, /u02 etc. Para dar soporte a la posibilidad de instalar diferentes versiones se utiliza el “/ punto de montaje / directorio estándar / propietario / versión / nombre de instalación” por ejemplo: /u01/app/oracle/product/10.2.0/db_1.

Taller de administración de Base de datos Oracle 10g 2009
Para los archivos de una base de datos se puede utilizar el patrón “/ punto de montaje / oradata / nombre_base” por ejemplo: /u01/oradata/base1. Estas recomendaciones y mas se pueden leer en la documentación en el sitio oficial de Oracle.
2.6 Creación de directorios
Para poder instalar el software primero es necesario tener la siguiente estructura de directorios.
/u01/app/oracle/product/10.2.0/db_1
Para crear esta estructura de directorios se puede ejecutar el siguiente comando:
# mkdir -p /u01/app/oracle/product/10.2.0/db_1
Después dicha estructura debe de ser modificada para que el nuevo propietario sea el usuario Oracle perteneciente al grupo oinstall.
# chown –R oracle:oinstall /u01
Por último se deben de cambiar los permisos de estos directorios con el siguiente comando:
# chmod –R 775 /u01
2.7 Instalación y configuración Para poder iniciar la instalación del software primero se debe de configurar algunos parámetros del kernel, como se indica a continuación:
Abrir el archivo /etc/sysctl.conf y agregar las siguientes líneas.
# Configuracion para oracle kernel.shmall = 2097152 kernel.shmmax = 2147483648 kernel.shmmni = 4096 kernel.sem = 250 32000 100 128 fs.file-max = 65536 net.ipv4.ip_local_port_range = 1024 65000 rmem_default = 262144 rmem_max = 262144 wmem_default = 262144 wmem_max = 262144

Taller de administración de Base de datos Oracle 10g 2009
Abrir el archivo /etc/security/limits.conf y agregar las siguientes líneas.
# Configuracion para oracle oracle soft nproc 2047 oracle hard nproc 16384 oracle soft nofile 1024 oracle hard nofile 65536
Abrir el archivo /etc/pam.d/login y agregar las siguientes líneas.
# Configuracion para oracle session required /lib/security/pam_limits.so
Abrir el archivo /etc/profile y agregar las siguientes líneas.
# Configuracion para oracle if [ $USER = "oracle" ]; then if [ $SHELL = "/bin/ksh" ]; then ulimit -p 16384 ulimit -n 65536 else ulimit -u 16384 -n 65536 fi fi
Abrir el archivo /etc/redhat-release y reemplazar el contenido por la siguiente
línea.
redhat-4
Esto con la finalidad de que Oracle reconozca al sistema operativo como valido para la instalación. Como paso siguiente se deben de establecer algunas variables de ambiente para el usuario oracle. Conectarse como el usuario oracle con el comando:
# su – oracle
Abrir el archivo /home/oracle/.bash_profile y agregar las siguientes líneas:
# Configuracion para oracle ORACLE_BASE=/u01/app/oracle; export ORACLE_BASE ORACLE_HOME=$ORACLE_BASE/product/10.2.0/db_1; export ORACLE_HOME PATH=$ORACLE_HOME/bin:$PATH; export PATH LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib; export LD_LIBRARY_PATH

Taller de administración de Base de datos Oracle 10g 2009
CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib; export CLASSPATH
Por ultimo como el usuario oracle se debe de entrar al directorio en donde
esta el software (10201_database_linux32/database/) para correr el instalador
de Oracle con el siguiente comando.
$ ./runInstaller
Esto abrirá el Oracle Universal Instaler, que es una aplicación grafica para la instalación del manejador de Oracle. Utilizaremos la opción llamada Basic Installation, aquí se nos preguntara la ubicación de Oracle Home, y debería de aparecer tal como lo indicamos en la variable de ambiente ORACLE_HOME, también solicitara el tipo de instalación, para la cual se elegirá Enterprise Edition, para UNIX DBA Group utilizar el grupo llamado oinstall, no seleccionar la opción de crear una base de datos y dar clic en Next.
La siguiente pantalla nos pedirá la ubicación del directorio oraInventory, en el cual se colocaran los archivos instaladores, aquí utilizara la variable de ambiente ORACLE_BASE, como ya se ha definido el directorio debe aparecer como /u01/app/oracle/oraInventory, también se solicitara nuevamente el grupo del sistema operativo, para el cual si volverá a utilizar oinstall, nuevamente clic en Next.

Taller de administración de Base de datos Oracle 10g 2009
En la siguiente pantalla el instalador verificara que el sistema cumpla con los requerimientos mínimos, para la instalación, si se indica que hay problemas en este punto, se debe verificar y corregir para proseguir con la instalación, después dar clic en Next. NOTA: si se arroja un mensaje de un requisito por verificar y la nota acerca del es cobre Checking Network Configuration, dar clic en Next, y después en continuar.

Taller de administración de Base de datos Oracle 10g 2009
La siguiente pantalla nos mostrara el progreso de la instalación:
Una vez que ha terminado el proceso el instalador solicitara que se ejecuten un par de scripts de configuración como usuario root, ejecutarlos en una terminal y después presionar ok en la ventana que lo solicito.
La siguiente ventana nos mostrara un par de URL´s, que es importante conservar, puesto que sirven para utilizar la aplicación iSQL*Plus la cual permite ejecutar comandos SQL desde el navegador.

Taller de administración de Base de datos Oracle 10g 2009
2.8 Configuraciones de servicios de red El principal elemento de Oracle para dar servicios de red es el LISTENER, dicho elemento esta en todo momento escuchando las peticiones de conexión que se hacen a la base de datos. Oracle maneja la configuración de los servicios de red principalmente en dos archivos, los cuales se encuentran ubicados en $ORACLE_HOME/network/admin/ a continuación se habla sobre ellos.
listener.ora: en este archivo se encuentra la configuración para el LISTENER que utilizara el sistema, para recibir las peticiones de conexión. Dentro de el se indica que base de datos esta aceptando peticiones de conexión, el servidor, el ORACLE_HOME, la ubicación donde se colocara el log de conexiones, el protocolo que está utilizando y el puerto por el que se está escuchando y su estructura es como se muestra en el siguiente ejemplo:
LISTENER = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) ) LOG_DIRECTORY_LISTENER = /u01/app/oracle/product/10.2.0/db_1/network/log SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (GLOBAL_DBNAME = base1) (ORACLE_HOME = /u01/app/oracle/product/10.2.0/db_1) (SID_NAME = base1) ) )

Taller de administración de Base de datos Oracle 10g 2009
tnsnames.ora: en este archivo se encuentra una lista de servicios que nos ayudaran a conectarnos a otras base de datos, asignándoles a cada una un nombre de servicio, y el cual contiene el protocolo que se utilizara, la dirección del servidor, el puerto al que se espera conectarse y el nombre de la base de datos a la que esperamos conectarnos, la estructura de un servicio en el tnsnames.ora es como se muestra a continuación.
NOTA: tnsnames.ora puede contener tantos servicios como se necesiten.
BASE1 = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = XXX.XXX.XXX.XXX)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = base1) ) )
Ejemplo: Si se desea realizar una conexión de la base de datos en el servidor A a la base de datos en el servidor B, se requiere lo siguiente.
1. El servidor A debe de tener en su tnsnames.ora un servicio con la información del servidor B y la base de datos en el servidor B.
2. El servidor B debe de tener en su listener.ora la información para permitir la conexión a su base de datos. 3. En el servidor B se debe de iniciar el LISTENER con el comando:
4. Para probar la conexión desde el servidor A al servidor B se debe de ejecutar el siguiente comando en el servidor A:
$ tnsping servidorB
NOTA: se utiliza servidor B como nombre para el servicio utilizado en el tnsnames.ora del servidor A.
$ lsnrctl start

Taller de administración de Base de datos Oracle 10g 2009
3. Análisis y Diseño de una BD
3.1 Rol de la información para las empresas Ver presentación anexa.
3.2 Elementos a tomar en cuenta en un diseño de BD Ver presentación anexa.
3.3 Reglas de negocio Ver presentación anexa.
3.4 Normalización La normalización es la secuencia de las medidas por las que un modelo de base de datos relacional es creado y mejorado. La secuencia de etapas implicadas en el proceso de normalización se llama formas normales. La normalización o estandarización es la redacción y aprobación de normas que se establecen para garantizar el acoplamiento de elementos construidos independientemente, así como garantizar el repuesto en caso de ser necesario, garantizar la calidad de los elementos fabricados y la seguridad de funcionamiento. Tipo de anomalías:
Insertar anomalía.- causada cuando se inserta datos en el detalle y no tiene registro principal.
Eliminar anomalía.- causada cuando un registro se elimina de una tabla maestra, sin eliminar primero todos los registros hijos, en la tabla detalle.
Actualización de anomalía- es similar a la eliminación, en la que tanto el maestro y los registros de detalle debe ser actualizado a fin de evitar registros huérfanos en detalle. Asegurándose de que cualquier actualización de clave primaria que se han propagado a los hijos relacionados con las claves foráneas en tabla.
Definición de las formas normales de la Manera Más Fácil ¿Cómo puedo realizar una normalización de forma sencilla? ¿Por qué es fácil? En un mundo perfecto, la mayoría de los diseños modelo de base de datos relacional son muy similares. La normalización es, en su mayor parte, es fácil y sobre todo es sentido común, con algunos conocimientos empresariales. Hay, por supuesto, muchas circunstancias excepcionales y casos especiales en que la interpretación de la normalización no cubrir todas las necesidades al 100 por ciento. Primer Forma Normal
1) Elimina la repetición de grupos. 2) Define las claves principales.

Taller de administración de Base de datos Oracle 10g 2009
3) Todos los registros deben ser identificados únicamente con una clave principal. Una clave primaria es única y, por tanto, no se permiten valores duplicados.
4) Todos los campos distintos de la clave primaria deben depender de la clave principal, ya sea directamente o indirectamente.
5) Todos los campos deben contener un único valor. 6) Todos los valores de cada campo debe tener el mismo dato. 7) Crear una nueva tabla para mover la repetición de grupos de la tabla original.
Segunda Forma Normal La segunda forma normal se refiere a las relaciones y dependencias funcionales entre atributos no-claves. Una entidad que cumpla con la segunda forma normal debe tener las siguientes características:
1) La entidad debe estar en primera forma normal. 2) Que todos lo atributos no clave sean dependientes totalmente de la clave primaria.
De modo que si una entidad no se halla en segunda forma normal lo que deberemos hacer para convertirla será remover los atributos que son dependientes parcialmente (solo de parte) de la clave primaria. Si una entidad tiene clave primaria compuesta de varios atributos y/o relaciones, y si otro atributo depende únicamente de parte de tal identificador compuesto, entonces el atributo y la parte de la clave primaria de la cual depende, deberán formar la base de una nueva entidad. Indicando los dos puntos de una forma diferente, eliminar los campos que son independientes de la clave principal. Crear una nueva tabla para separar la parte parcialmente dependientes de la clave principal y sus dependientes campos. 2NF aparentemente realiza una función similar a la de 1NF, pero cuando crea una tabla y tenemos valores repetidos estos campos son trasladados a una nueva tabla. El nuevo cuadro es una de las principales clave que consta de un solo campo. Normalmente, 2NF crea relaciones de muchos a uno entre las relaciones dinámicas y los datos, la supresión de los datos de tablas transaccionales en las nuevas tablas. Tercera forma normal Para que una entidad esté en tercera forma normal deben cumplirse dos condiciones:
1) Que la entidad esté en segunda forma normal. 2) Que todos los atributos no claves son independientes de el resto de atributos no clave.
De modo que si deseo transformar una entidad que no esté en tercera forma normal, lo que deberá hacerse es remover los atributos no clave que dependen de otros atributos no clave. Si un atributo de una entidad es dependiente de otro atributo, el cual no es parte de la clave primaria, entonces estos atributos deberían formar parte de una nueva entidad, la cual tiene relación de uno a muchos con la entidad original. La clave primaria de la nueva entidad es aquel atributo sobre el cual el segundo atributo es dependiente. Cuarta forma normal Hace lo siguiente:
La tabla debe estar en 3NF o BCNF (Clave única) con 3NF.
Transforma las múltiples dependencias valoradas en dependencias funcionales. Esto implica que un valor de varios valores y no dependen de una clave principal.

Taller de administración de Base de datos Oracle 10g 2009
Eliminar varios conjuntos de múltiples valores o varios valores dependencias, a veces descrito como no trivial.
Quinta forma normal Cumple las siguientes condiciones:
1) La tabla debe estar en 4NF. 2) Las dependencias cíclicas deben ser eliminadas 3) En conclusion: 5NF es similar a 4NF en tanto que el intento de reducir al mínimo el número de campos de
claves compuestas.
3.5 Modelo entidad relación El modelo entidad-relación es el modelo conceptual más utilizado para el diseño conceptual de bases de datos. Fue introducido por Peter Chen en 1976. El modelo entidad-relación está formado por un conjunto de conceptos que permiten describir la realidad mediante un conjunto de representaciones gráficas y lingüísticas. Originalmente, el modelo entidad-relación sólo incluía los conceptos de entidad, relación y atributo. Más tarde, se añadieron otros conceptos, como los atributos compuestos y las jerarquías de generalización, en lo que se ha denominado modelo entidad-relación extendido. Entidad Cualquier tipo de objeto o concepto sobre el que se recoge información: cosa, persona, concepto abstracto o suceso. Por ejemplo: coches, casas, empleados, clientes, empresas, oficios, diseños de productos, conciertos, excursiones, etc. Las entidades se representan gráficamente mediante rectángulos y su nombre aparece en el interior. Un nombre de entidad sólo puede aparecer una vez en el esquema conceptual. Hay dos tipos de entidades: fuertes y débiles.
Una entidad débil es una entidad cuya existencia depende de la existencia de otra entidad. Una entidad fuerte es una entidad que no es débil.
Relación (interrelación) Es una correspondencia o asociación entre dos o más entidades. Cada relación tiene un nombre que describe su función. Las relaciones se representan gráficamente mediante rombos y su nombre aparece en el interior. Las entidades que están involucradas en una determinada relación se denominan entidades participantes. El número de participantes en una relación es lo que se denomina grado de la relación La cardinalidad con la que una entidad participa en una relación especifica el número mínimo y el número máximo de correspondencias en las que puede tomar parte cada ocurrencia de dicha entidad. La participación de una entidad en una relación es obligatoria (total) si la existencia de cada una de sus ocurrencias requiere la existencia de, al menos, una ocurrencia de la otra entidad participante. Si no, la participación es opcional (parcial). Las reglas que definen la cardinalidad de las relaciones son las reglas de negocio.

Taller de administración de Base de datos Oracle 10g 2009
Atributo Es una característica de interés o un hecho sobre una entidad o sobre una relación. Los atributos representan las propiedades básicas de las entidades y de las relaciones. Toda la información extensiva es portada por los atributos. Gráficamente, se representan mediante bolitas que cuelgan de las entidades o relaciones a las que pertenece Los atributos pueden ser simples o compuestos. Un atributo simple es un atributo que tiene un solo componente, que no se puede dividir en partes más pequeñas que tengan un significado propio. Un atributo compuesto es un atributo con varios componentes, cada uno con un significado por sí mismo. Un grupo de atributos se representa mediante un atributo compuesto cuando tienen afinidad en cuanto a su significado, o en cuanto a su uso. Un atributo compuesto se representa gráficamente mediante un óvalo.
3.6 Métricas de una BD
La métrica de las bases de datos nos permite determinar el tamaño de los registros de nuestras tablas y de esta
manera conocer el consumo de espacio en función del tiempo. A su vez, el tamaño del registro se obtiene del
tamaño y del tipo de dato de cada columna posea.
Cada tipo de dato en Oracle tiene un tamaño diferente en bytes, por lo cual es necesario decidir que tipo de dato
se debe usar para cada columna ya que en base a este punto se puede conocer el tamaño total del registro y así
calcular la suma total por cada una de las tablas.
Decidir el tipo de dato correcto y el tamaño adecuado es vital ya que haciéndolo acertadamente, se pueden
obtener beneficios destacados en cuanto al ahorro de espacio en disco. Si no se especifica el tamaño y tipo de dato
correcto, quizá el espacio en disco no se ve disminuido cuando se tienen tablas con pocos registros, en cambio
esto puede ser totalmente contrario cuando se tiene millones de registros en una tabla.
Para seleccionar el tamaño y tipo de dato correcto, se debe analizar cual será la información que contendrá la
columna. Por ejemplo, si se tiene una columna que almacenará valores numéricos, se debe considerar cuantos
dígitos serán los máximos a insertar o si se tiene una columna de tipo varchar2, tener en cuenta cual será la cadena
máxima a insertar y en base a eso determinar la longitud del campo a declarar.
Teniendo en cuenta la métrica, es posible calcular en bytes, el tamaño de los registros a futuro dependiendo de la
frecuencia en que se vayan insertando registros en las tablas. Es una práctica muy útil para saber cuanto espacio
será necesario y cuanto espacio podemos ahorrar, es por esto la importancia del diseño de la base de datos.
3.7 Diccionario de Datos El diccionario de datos contiene la definición de todos los objetos que existen en la base de datos, como por ejemplo nombre de las tablas, tipos de datos, nombre de vistas, nombre de usuarios, secuencias, índices, etc. El

Taller de administración de Base de datos Oracle 10g 2009
usuario SYS es el dueño del diccionario de datos y tiene todos los permisos sobre cualquier objeto de la base de datos. Adicionalmente, las bases de datos Oracle contienen tablas que guardan información acerca de la misma base de datos. Ejemplos de la información que contienen estas tablas incluyen el nombre de todas las tablas en la base, nombre y tipos de datos en las columnas de las tablas, número de registros que las tablas contienen e información de seguridad para saber que usuarios tienen permitido el acceso a las tablas. Esta información es conocida como metadatos y se tienen dos tipos de vistas para acceder a estos datos: Data Dictionary Views Estas vistas se distinguen de las dynamic performance views por contener cualquiera de los tres prefijos: dba_, all_ y user_. Las tablas que llevan el prefijo dba_ contienen todas las tablas de la base de datos pero solo usuarios con privilegios pueden haces uso de ellas. Aquellas tablas que tienen el prefijo all_ contienen todas las tablas que le pertenecen a un usuario en específico además de las tablas a las que tiene permiso acceder dicho usuario. Las tablas con el prefijo user_ contienen solo las tablas que le pertenecen a un determinado usuario . Algunos ejemplos de estas vistas son: dba_users, all_tables, user_objects, etc. Dynamic Performance Views Estas vistas se distinguen de las anteriores porque llevan el prefijo v$ y son útiles para ver las relaciones entre tablas y reglas definidas para almacenar información en las tablas. Estas vistas están disponibles aún cuando la base de datos no está abierta mientras que las data dictionary views necesitan que la base este abierta para poder ser utilizadas.
3.8 Buen diseño vs Mal diseño Ver presentación anexa.
3.9 Hacer tangible un diseño de BD, comparar buen diseño vs Mal diseño Ver presentación anexa.

Taller de administración de Base de datos Oracle 10g 2009
4. Diseño Físico de una BD
4.1 Data blocks
Un data block es el último eslabón dentro de la cadena de almacenamiento. El concepto de Data block es un concepto físico, ya que representa la mínima unidad de almacenamiento que es capaz de manejar Oracle. Igual que la mínima unidad de almacenamiento de un disco duro es la unidad de asignación, la mínima unidad de almacenamiento de Oracle es el data block. En un disco duro no es posible que un fichero pequeño ocupe menos de lo que indique la unidad de asignación, así si la unidad de asignación es de 4 Kb, un fichero que ocupe 1 Kb, en realidad ocupa 4 Kb.
Siguiendo con la cadena, cada segmento (o cada extensión) se almacena en uno o varios bloques de datos,
dependiendo del tamaño definido para el extensión, y del tamaño definido para el data block.
(*) Espacio ocupado en el data block por la primera NEXT EXTENSION. (#) Espacio ocupado en unidades de asignación del sistema operativo por los data blocks anteriores. El esquema muestra toda la cadena de almacenamiento de Oracle. Desde el nivel más físico al más lógico: · Unidades de asignación del sistema operativo (El más físico. No depende de Oracle) · Data blocks de Oracle · Extents · Segments · DataFiles · Tablespaces (El más lógico). El tamaño de las unidades de asignación del sistema operativo (os blocks) se define durante el particionado del disco duro (FDISK, FIPS…), y el espacio de los data blocks de Oracle se define durante la instalación y no puede ser cambiado. Como es lógico, el tamaño de un data block tiene que ser múltiplo del tamaño de una unidad de asignación, es

Taller de administración de Base de datos Oracle 10g 2009
decir, si cada unidad de asignación ocupa 4 K, los data blocks pueden ser de 4K, 8K, 12K… para que en el sistema operativo ocupen 1, 2, 3… unidades de asignación.
4.2 OS blocks Son la estructura mínima de almacenamiento físico de información definidos al momento de particionar el disco duro a nivel de sistema operativo. Un bloque de sistema operativo puede ser de 512 bytes a 2kb dependiendo del sistema operativo.
4.3 Datafiles Un datafile es la representación física de un tablespace. Son los "archivos de datos" donde se almacena la información físicamente. Un datafile puede tener cualquier nombre y extensión (siempre dentro de las limitaciones del sistema operativo), y puede estar localizado en cualquier directorio del disco duro, aunque su localización típica suele ser $ORACLE_HOME/Database. Un datafile tiene un tamaño predefinido en su creación (por ejemplo 100Mb) y este puede ser alterado en cualquier momento. Cuando creemos un datafile, este ocupará tanto espacio en disco como hayamos indicado en su creación, aunque internamente esté vacío. Oracle hace esto para reservar espacio continuo en disco y evitar así la fragmentación. Conforme se vayan creando objetos en ese tablespace, se irá ocupando el espacio que creó inicialmente. Un datafile está asociado a un solo tablespace y, a su vez, un tablespace está asociado a uno o varios datafiles. Es decir, la relación lógica entre tablespaces y datafiles es de 1-N, maestro-detalle.

Taller de administración de Base de datos Oracle 10g 2009
4.4 Consideraciones de disco Ver presentación anexa.
4.5 Distribución de la BD en disco Ver presentación anexa.
4.6 Funcionalidad de ASM Ver presentación anexa.

Taller de administración de Base de datos Oracle 10g 2009
5. Creación de una BD Oracle
5.1 Prerrequisitos para la instancia Cada instancia necesita un mínimo de 216 MB de memoria RAM para alojar las estructuras de memoria y los procesos de la misma, la distribución se muestra a continuación:
• SGA 160 MB • PGA 16 MB • Procesos de Oracle 40 MB
5.2 Prerrequisitos para la BD
Como prerrequisito para la creación de una base de datos es necesario cumplir con los siguientes prerrequisitos:
• Contar con 1GB libre de espacio en disco duro. • Una estructura de archivos para almacenar los datafiles por ejemplo: /u02/oradata/base1/
5.3 Configuración de storage
Oracle ofrece tres tipos de almacenamiento para la base de datos, las cuales se mencionan a continuación:
File System: es la configuración de almacenamiento mas común para Oracle. Este tipo de configuración pone a cargo del sistema operativo la gestión y el mantenimiento de los archivos definidos por el DBA. Cuando se elige esta configuración DBCA, sugiere una serie de nombres de archivos y directorios, basados en OFA, los cuales se pueden cambiar si así se desea.
ASM (Automated Storage Management): Es un mecanismo de almacenamiento nuevo, disponible en la versión Oracle 10g. Esta diseñado para aliviar la carga de disco y gestión de almacenamiento, para ello pone a cargo de Oracle el mantenimiento del almacenamiento de la base de datos, en vez de utilizar un grupo de datafiles individuales, ASM permite definir un grupo de discos para almacenamiento de archivos.
Al utilizar uno o varios grupos de discos como una unidad lógica, Oracle los toma como una unidad de almacenamiento individual.
Oracle maneja las definiciones de almacenamiento de la base de datos, dentro de una segunda base de datos utilizada solamente por ASM para llevar un registro de las localidades del grupo de discos.
Raw Devices: son discos que no son manejados por el sistema operativo, es decir a diferencia de cómo se maneja siempre, cuando el sistema operativo se encarga de escribir y leer el disco duro, cuando se selecciona Raw Devices, es Oracle el que se encarga directamente de estas tareas.
5.4 Tablespaces Default Cuando se crea una base de datos Oracle crea automáticamente los siguientes cuatro tablespace:
System: almacena los datos de las tablas de diccionario, y el código PL/SQL.
Sysaux: almacena segmentos utilizados por otras funciones de oracle como Automatic Workload Repository OLAP.
Temp: se utiliza para realizar grandes operaciones de ordenamiento.

Taller de administración de Base de datos Oracle 10g 2009
Users: se utiliza como tablespace default para almacenar la información de los usuarios de la base de datos.
Undotbs1: se utiliza para almacenar información de una transacción, para consistencia de lecutra y recuperación.
5.5 Configuración dedicada En esta configuración para cada cliente que se conecte, la base de datos asignara recursos específicamente para servir solo a ese cliente. Se debe de utilizar esta opción cuando se espere que el número total de conexiones de clientes sea pequeño, o que los clientes hagan conexiones persistentes y de larga duración a la base de datos.
5.6 Configuración compartida Bajo esta configuración un número significativo de clientes comparten un conjunto de recursos que les fue asignado. Se utiliza esta modalidad cuando un gran numero de usuarios necesitan conectarse a la base de datos simultáneamente y al mismo tiempo utilizar eficientemente los recursos del sistema.
5.7 Utilización de la herramienta DBCA EL manejador de bases de datos Oracle, incluye una útil herramienta que nos permite crear bases de datos de manera visual. A continuación se presenta un tutorial de cómo se crea una base de datos llamada “refac” paso a paso en DBCA.
Para iniciar la herramienta “dbca”, ejecutaremos el comando dbca en una terminal de UNIX, como se muestra en la pantalla. Nota: para que se pueda ejecutar correctamente esta herramienta, debemos tener en cuenta que las variables de ambiente que se explicaron durante la instalación de Oracle, estén correctamente definidas, y también debemos tener el espacio necesario, disponible en disco duro (aproximadamente 1 Gb).

Taller de administración de Base de datos Oracle 10g 2009
La primera pantalla que se nos muestra la herramienta es la pantalla de bienvenida y es la que se muestra arriba. Aquí tenemos que dar clic en el botón “Next”. En la segunda pantalla veremos varias opciones para manejar las bases de datos que tenemos (crear una base de datos, configurar una base de datos, borrar una base de datos, etc.), aquí elegiremos la opción de “Crear una base de datos” y le daremos clic al botón “Next”.

Taller de administración de Base de datos Oracle 10g 2009
Ahora la pantalla que vemos nos muestra los tipos de bases de datos que podemos crear, entre ellos podemos crear bases de datos personalizadas, bases de datos para data warehouse, bases de propósito general, bases de dataguard. En nuestro ejemplo usaremos una base de propósito general por lo que seleccionaremos esta opción y daremos clic en “Next”.
En esta pantalla el asistente nos pide el nombre de la base de datos y el identificador de la misma, aquí es recomendable poner el mismo nombre en ambos campos para evitar confusiones.

Taller de administración de Base de datos Oracle 10g 2009
La pantalla que nos muestra ahora el dbca nos indica si queremos usar el Enterprise Manager para administrar la base de datos, el Enterprise Manager es otra herramienta de Oracle que nos permitirá administrar nuestra base de datos de manera grafica en un navegador Web, esta herramienta puede llegar a ser muy útil, pero en este momento no la configuraremos por lo que deshabilitaremos esta opción y daremos clic en “Next”.
En el siguiente paso nos pedirá que especifiquemos los passwords para los usuarios SYS y SYSTEM, también podemos especificar un solo password para todos estos usuarios, en este caso usaremos esta opción y daremos clic en “Next”.

Taller de administración de Base de datos Oracle 10g 2009
Aquí se nos pregunta el mecanismo de almacenamiento que vamos a usar para nuestra base de datos, seleccionaremos “File System” y damos clic en “Next”
Especificaremos los directorios donde se guardaran los archivos de la base de datos aquí daremos clic en “Browser” y se nos mostrará una pantalla como la siguiente:

Taller de administración de Base de datos Oracle 10g 2009
Aquí buscaremos el directorio que previamente creamos en la ruta “/u02” en este directorio buscamos “refac” lo seleccionamos y damos clic en “OK”. En la siguiente pantalla se nos muestran las opciones para la recuperación de la base de datos, aquí no habilitaremos nada para nuestro ejemplo, después solo damos clic en “Next”.

Taller de administración de Base de datos Oracle 10g 2009
En esta pantalla el asistente nos pregunta si queremos crear los esquemas de ejemplo que trae por defecto el manejador, pero no habilitaremos nada en esta pantalla, por lo que damos clic en “Next” sin marcar nada.
En esta pantalla se presentan parámetros importantes de la base de datos, en la primera pestaña se muestran los de memoria para la base de datos, aquí seleccionaremos una configuración típica y le daremos el porcentaje mínimo que se nos permita (más adelante se explicará en el taller la manera de cómo calcular esta distribución de memoria de acuerdo a nuestras necesidades y recursos, pero en este caso solo usaremos la cantidad mínima de memoria disponible).

Taller de administración de Base de datos Oracle 10g 2009
En la pestaña de “Sizing” se nos pregunta el tamaño del Block Size, y el número de usuarios de Sistema operativo que se podrán conectar simultáneamente a la base de datos, nosotros dejaremos todo como viene por default.
En la pestaña de “carácter set” se configura el juego de caracteres que usará la base de datos, el lenguaje y los formatos de fecha, también aquí dejaremos todo por default.

Taller de administración de Base de datos Oracle 10g 2009
En esta última pestaña se debe de elegir el modo en que operará la base de datos, tenemos 2 opciones “Dedicated Server Mode” y “Shared Server Mode” estos modos serán también abordados en el taller, pero en el ejemplo usaremos el primer modo, y después daremos clic en “Next”.
Ahora veremos una pantalla como esta, aquí verificaremos donde se van a guardar todos los archivos de la base de datos, en el árbol de directorios de la izquierda nos podremos desplazar entre ellos.

Taller de administración de Base de datos Oracle 10g 2009
Primero verificaremos los control files todos deben de estar en la ruta que se muestra.
Después verificaremos que los data files estén en la ruta correcta (/u02/refac).

Taller de administración de Base de datos Oracle 10g 2009
Por último verificamos cada uno de los redo logs groups en la misma ruta y daremos clic en “Next”.
La penúltima pantalla que se nos muestra es esta, aquí solo activaremos la casilla de “Crear base de datos” y daremos clic en “Finish”.

Taller de administración de Base de datos Oracle 10g 2009
Ahora solo se nos muestra una pantalla de confirmación donde se presentan todos los parámetros con que será creada la base de datos, después de verificar estos parámetros daremos clic en “OK”.
Si todo fue correcto se comenzará a crear la base de datos con una pantalla como esta y habremos terminado.

Taller de administración de Base de datos Oracle 10g 2009
6. PL/SQL
6.1 Bloques anónimos Estructura de un bloque de PL/SQL La unidad mínima de agrupamiento de código en PL/SQL es el bloque. Un bloque de PL/SQL contiene la ejecución, la declaración de variables y la sección de manejo de excepciones (errores). PL/SQL permite tener bloques anónimos y bloques nombrados (procedimientos, funciones, triggers, etc). Un bloque de PL/SQL contiene las siguientes 4 secciones: ENCABEZADO (HEADER) IS SECCIÓN DE DECLARACIÓN BEGIN SECCIÓN DE EJECUCIÓN EXCEPTION EXCEPCIONES END;
Encabezado (opcional) Esta sección es utilizada para los bloques nombrados como los stored procedures, functions, etc. Esta parte identifica al bloque por medio de un nombre. Declaración (opcional) Como su nombre lo indica aquí se realizan las declaraciones de variables, tipos de datos, cursores, etc. Ejecución (obligatoria) Es el corazón de un programa de PL/SQL, aquí es donde se realizan todas las operaciones que va a realizar el programa. Excepciones (opcional) Maneja las excepciones generadas por el programa en tiempo de ejecución. Bloque Anónimo Vamos a comenzar por el tipo de bloque mas sencillo que existe, éste tipo de bloque no contiene sección de encabezado por lo tanto no tiene un nombre asignado, por eso se llama bloque anónimo. Este tipo de bloque no puede ser llamado por otro código debido a que no tiene un handler ó manejador por el cuál se identifique al programa, básicamente los bloques anónimos sirven de contenedores para ejecutar pequeños scripts o hacer llamadas a otros bloques PL/SQL como procedures o funciones.

Taller de administración de Base de datos Oracle 10g 2009
Sintaxis:
[ DECLARE
... declaración de variables, constantes, tipos, etc ... ] BEGIN
… todo lo que se desea ejecutar … [ EXCEPTION
... manejadores de excepciones ... ] END;
Hay que notar que las secciones en “[ ]” son opcionales y no es necesario ponerlas en un bloque anónimo a menos que se vayan a utilizar.
6.2 Procedimientos
Un procedimiento es un subprograma que ejecuta una acción especifica y que no devuelve ningún valor. Un procedimiento tiene un nombre, un conjunto de parámetros (opcional) y un bloque de código. La sintaxis de un procedimiento almacenado es la siguiente:
CREATE [OR REPLACE] PROCEDURE <procedure_name> [(<param1> [IN|OUT|IN OUT] <type>, <param2> [IN|OUT|IN OUT] <type>, ...)] IS -- Declaracion de variables locales BEGIN -- Sentencias [EXCEPTION] -- Sentencias control de excepcion
END [<procedure_name>];
El uso de OR REPLACE permite sobreescribir un procedimiento existente. Si se omite, y el procedimiento existe, se producirá, un error. La sintaxis es muy parecida a la de un bloque anónimo, salvo porque se reemplaza la seccion DECLARE por la secuencia PROCEDURE ... IS en la especificación del procedimiento. Debemos especificar el tipo de datos de cada parámetro. Al especificar el tipo de dato del parámetro no debemos especificar la longitud del tipo. Los parámetros pueden ser de entrada (IN), de salida (OUT) o de entrada salida (IN OUT). El valor por defecto es IN, y se toma ese valor en caso de que no especifiquemos nada.
CREATE OR REPLACE PROCEDURE Actualiza_Saldo(cuenta NUMBER,

Taller de administración de Base de datos Oracle 10g 2009
new_saldo NUMBER) IS -- Declaracion de variables locales BEGIN -- Sentencias UPDATE SALDOS_CUENTAS SET SALDO = new_saldo, FX_ACTUALIZACION = SYSDATE WHERE CO_CUENTA = cuenta;
END Actualiza_Saldo;
También podemos asignar un valor por defecto a los parámetros, utilizando la clausula DEFAULT o el operador de asiganción (:=) .
CREATE OR REPLACE PROCEDURE Actualiza_Saldo(cuenta NUMBER, new_saldo NUMBER DEFAULT 10 ) IS -- Declaracion de variables locales BEGIN -- Sentencias UPDATE SALDOS_CUENTAS SET SALDO = new_saldo, FX_ACTUALIZACION = SYSDATE WHERE CO_CUENTA = cuenta; END Actualiza_Saldo;
Una vez creado y compilado el procedimiento almacenado podemos ejecutarlo. Si el sistema nos indica que el procedimiento se ha creado con errores de compilación podemos ver estos errores de compilacion con la orden:
SHOW ERRORS en SQL *Plus. Existen dos formas de pasar argumentos a un procedimiento almacenado a la hora de ejecutarlo (en realidad es válido para cualquier subprograma). Estas son:
Notación posicional: Se pasan los valores de los parámetros en el mismo orden en que el procedure los define.
BEGIN Actualiza_Saldo(200501,2500); COMMIT; END;
Notación nominal: Se pasan los valores en cualquier orden nombrando explicitamente el parámetro.
BEGIN Actualiza_Saldo(cuenta => 200501,new_saldo => 2500); COMMIT; END;

Taller de administración de Base de datos Oracle 10g 2009
6.3 Funciones
Una función es un subprograma que procesa un valor. Las funciones y procedimientos estan estructuradas de forma similar, excepto que las funciones tienen una clausula de RETUNR para devolver un valor como resultado del procesamiento del valor de entrada. La sintaxis para construir funciones es la siguiente:
CREATE [OR REPLACE] FUNCTION <fn_name>[(<param1> IN <type>, <param2> IN <type>, ...)] RETURN <return_type> IS result <return_type>; BEGIN return(result); [EXCEPTION] -- Sentencias control de excepcion END [<fn_name>];
El uso de OR REPLACE permite sobreescribir una función existente. Si se omite, y la función existe, se producirá, un error. La sintaxis de los parámetros es la misma que en los procedimientos almacenado, exceptuando que solo pueden ser de entrada. Ejemplo:
CREATE OR REPLACE FUNCTION fn_Obtener_Precio(p_producto VARCHAR2) RETURN NUMBER IS result NUMBER; BEGIN SELECT PRECIO INTO result FROM PRECIOS_PRODUCTOS WHERE CO_PRODUCTO = p_producto; return(result); EXCEPTION WHEN NO_DATA_FOUND THEN return 0; END ;
Si el sistema nos indica que el la función se ha creado con errores de compilación podemos ver estos errores de compilación con la orden SHOW ERRORS en SQL *Plus. Una vez creada y compilada la función podemos ejecutarla de la siguiente forma:
DECLARE Valor NUMBER; BEGIN Valor := fn_Obtener_Precio('000100'); END;

Taller de administración de Base de datos Oracle 10g 2009
Las funciones pueden utilizarse en sentencias SQL de manipulación de datos (SELECT, UPDATE, INSERT y DELETE):
SELECT CO_PRODUCTO, DESCRIPCION, fn_Obtener_Precio(CO_PRODUCTO) FROM PRODUCTOS;
6.4 Paquetes
Un paquete es una estructura que agrupa objetos de PL/SQL compilados(procedures, funciones, variables, tipos ...) en la base de datos como una sola unidad. Esto nos permite agrupar la funcionalidad de los procesos en programas que guardan relación entre si. Lo primero que debemos tener en cuenta es que los paquetes están formados por dos partes: la especificación y el cuerpo. La especificación del paquete y su cuerpo se crean por separado. La especificación es la interfaz con las aplicaciones. En ella es posible declarar los tipos, variables, constantes, excepciones, cursores y subprogramas disponibles para su uso posterior desde fuera del paquete. En la especificación del paquete sólo se declaran los objetos (procedures, funciones, variables ...), no se implementa el código. Los objetos declarados en la especificación del paquete son accesibles desde fuera del paquete por otro script de PL/SQL o programa. Haciendo una analogía con el mundo de C, la especificación es como el archivo de cabecera de un programa en C. Para crear la especificación de un paquete la sintaxis general es la siguiente:
CREATE [OR REPLACE] PACKAGE <pkgName> IS -- Declaraciones de tipos y registros públicas {[TYPE <TypeName> IS <Datatype>;]} -- Declaraciones de variables y constantes publicas -- También podemos declarar cursores {[<ConstantName> CONSTANT <Datatype> := <valor>;]} {[<VariableName> <Datatype>;]} -- Declaraciones de procedimientos y funciones públicas {[FUNCTION <FunctionName>(<Parameter> <Datatype>,...) RETURN <Datatype>;]} {[PROCEDURE <ProcedureName>(<Parameter> <Datatype>, ...);]} END <pkgName>;
El cuerpo del paquete debe implementar lo que se declaró inicialmente en la especificación. Es el donde debemos escribir el código de los subprogramas. En el cuerpo de un package podemos declarar nuevos subprogramas y tipos, pero estos seran privados para el propio package. La sintaxis general para crear el cuerpo de un paquete es muy parecida a la de la especificación, tan solo se añade la palabra clave BODY, y se implementa el código de los subprogramas.

Taller de administración de Base de datos Oracle 10g 2009
CREATE [OR REPLACE] PACKAGE BODY <pkgName> IS -- Declaraciones de tipos y registros privados {[TYPE <TypeName> IS <Datatype>;]} -- Declaraciones de variables y constantes privadas -- También podemos declarar cursores {[<ConstantName> CONSTANT <Datatype> := <valor>;]} {[<VariableName> <Datatype>;]} -- Implementacion de procedimientos y funciones FUNCTION <FunctionName>(<Parameter> <Datatype>,...) RETURN <Datatype> IS -- Variables locales de la funcion BEGIN -- Implementeacion de la funcion return(<Result>); [EXCEPTION] -- Control de excepciones END; PROCEDURE <ProcedureName>(<Parameter> <Datatype>, ...) IS -- Variables locales de la funcion BEGIN -- Implementacion de procedimiento [EXCEPTION] -- Control de excepciones END; END <pkgName>;
Las ventajas de usar packages:
Permite agrupar juntos objetos relacionados, tipos y subprogramas como si fueran un solo modulo de PL/SQL.
Cuando un procedimiento es llamado en un paquete, se carga todo el paquete. Apesar que la primera vez puede ser muy costoso, la respuesta es más rápida en los llamados subsecuentes.
Los packages permiten crear tipos, variables y subprogramas que son privados o públicos. Es posible modificar el cuerpo de un paquete sin necesidad de alterar por ello la especificación del mismo. Los paquetes pueden llegar a ser programas muy complejos y suelen almacenar gran parte de la lógica de negocio.

Taller de administración de Base de datos Oracle 10g 2009
6.5 Triggers
Un trigger es un bloque PL/SQL asociado a una tabla, que se ejecuta como consecuencia de una determinada instrucción SQL (una operación DML: INSERT, UPDATE o DELETE) sobre dicha tabla. La sintaxis para crear un trigger es la siguiente:
CREATE [OR REPLACE] TRIGGER <nombre_trigger> {BEFORE|AFTER} {DELETE|INSERT|UPDATE [OF col1, col2, ..., colN] [OR {DELETE|INSERT|UPDATE [OF col1, col2, ..., colN]...]} ON <nombre_tabla> [FOR EACH ROW [WHEN (<condicion>)]] DECLARE -- variables locales BEGIN -- Sentencias [EXCEPTION] -- Sentencias control de excepcion END <nombre_trigger>;
El uso de OR REPLACE permite sobreescribir un trigger existente. Si se omite, y el trigger existe, se producirá, un error. Los triggers pueden definirse para las operaciones INSERT, UPDATE o DELETE, y pueden ejecutarse antes o después de la operación. El modificador BEFORE AFTER indica que el trigger se ejecutará antes o despues de ejecutarse la sentencia SQL definida por DELETE INSERT UPDATE. Si incluimos el modificador OF el trigger solo se ejecutará cuando la sentencia SQL afecte a los campos incluidos en la lista. El alcance de los disparadores puede ser la fila o de orden. El modificador FOR EACH ROW indica que el trigger se disparará cada vez que se realizan operaciones sobre una fila de la tabla. Si se acompaña del modificador WHEN, se establece una restricción; el trigger solo actuará, sobre las filas que satisfagan la restricción. La siguiente tabla resume los contenidos anteriores.
Valor Descripción
INSERT, DELETE, UPDATE Define qué tipo de orden DML provoca la activación del disparador.
BEFORE , AFTER Define si el disparador se activa antes o después de que se ejecute la orden.
FOR EACH ROW
Los disparadores con nivel de fila se activan una vez por cada fila afectada por la orden que provocó el disparo. Los disparadores con nivel de orden se activan sólo una vez, antes o después de la orden. Los disparadores con nivel de fila se identifican por la cláusula FOR EACH ROW en la definición del disparador.
La cláusula WHEN sólo es válida para los disparadores con nivel de fila.

Taller de administración de Base de datos Oracle 10g 2009
Dentro del ambito de un trigger disponemos de las variables OLD y NEW . Estas variables se utilizan del mismo modo que cualquier otra variable PL/SQL, con la salvedad de que no es necesario declararlas, son de tipo %ROWTYPE y contienen una copia del registro antes (OLD) y despues(NEW) de la acción SQL (INSERT, UPDATE, DELTE) que ha ejecutado el trigger. Utilizando esta variable podemos acceder a los datos que se están insertando, actualizando o borrando. El siguiente ejemplo muestra un trigger que inserta un registro en la tabla PRECIOS_PRODUCTOS cada vez que insertamos un nuevo registro en la tabla PRODUTOS:
CREATE OR REPLACE TRIGGER TR_PRODUCTOS_01 AFTER INSERT ON PRODUCTOS FOR EACH ROW DECLARE -- local variables BEGIN INSERT INTO PRECIOS_PRODUCTOS (CO_PRODUCTO,PRECIO,FX_ACTUALIZACION) VALUES (:NEW.CO_PRODUCTO,100,SYSDATE); END ;
El trigger se ejecutará cuando sobre la tabla PRODUCTOS se ejecute una sentencia INSERT.
INSERT INTO PRODUCTOS (CO_PRODUCTO, DESCRIPCION) VALUES ('000100','PRODUCTO 000100');
Orden de ejecución de los triggers Una misma tabla puede tener varios triggers. En tal caso es necesario conocer el orden en el que se van a ejecutar. Los disparadores se activan al ejecutarse la sentencia SQL.
Si existe, se ejecuta el disparador de tipo BEFORE (disparador previo) con nivel de orden.
Para cada fila a la que afecte la orden: o Se ejecuta si existe, el disparador de tipo BEFORE con nivel de fila. o Se ejecuta la propia orden. o Se ejecuta si existe, el disparador de tipo AFTER (disparador posterior) con nivel de fila.
Se ejecuta, si existe, el disparador de tipo AFTER con nivel de orden. Restricciones de los triggers El cuerpo de un trigger es un bloque PL/SQL. Cualquier orden que sea legal en un bloque PL/SQL, es legal en el cuerpo de un disparador, con las siguientes restricciones:
Un disparador no puede emitir ninguna orden de control de transacciones: COMMIT, ROLLBACK o SAVEPOINT. El disparador se activa como parte de la ejecución de la orden que provocó el disparo, y

Taller de administración de Base de datos Oracle 10g 2009
forma parte de la misma transacción que dicha orden. Cuando la orden que provoca el disparo es confirmada o cancelada, se confirma o cancela también el trabajo realizado por el disparador.
Por razones idénticas, ningún procedimiento o función llamado por el disparador puede emitir órdenes de control de transacciones.
El cuerpo del disparador no puede contener ninguna declaración de variables LONG o LONG RAW Utilización de :OLD y :NEW Dentro del ambito de un trigger disponemos de las variables OLD y NEW . Estas variables se utilizan del mismo modo que cualquier otra variable PL/SQL, con la salvedad de que no es necesario declararlas, son de tipo %ROWTYPE y contienen una copia del registro antes (OLD) y despues(NEW) de la acción SQL (INSERT, UPDATE, DELTE) que ha ejecutado el trigger. Utilizando esta variable podemos acceder a los datos que se están insertando, actualizando o borrando. La siguiente tabla muestra los valores de OLD y NEW.
ACCION SQL OLD NEW
INSERT No definido; todos los campos toman valor NULL.
Valores que serán insertados cuando se complete la orden.
UPDATE Valores originales de la fila, antes de la actualización.
Nuevos valores que serán escritos cuando se complete la orden.
DELETE Valores, antes del borrado de la fila. No definidos; todos los campos toman el valor NULL.
Los registros OLD y NEW son sólo válidos dentro de los disparadores con nivel de fila. Podemos usar OLD y NEW como cualquier otra variable PL/SQL. Utilización de predicados de los triggers: INSERTING, UPDATING y DELETING Dentro de un disparador en el que se disparan distintos tipos de órdenes DML (INSERT, UPDATE y DELETE), hay tres funciones booleanas que pueden emplearse para determinar de qué operación se trata. Estos predicados son INSERTING, UPDATING y DELETING. Su comportamiento es el siguiente:
Predicado Comportamiento
INSERTING TRUE si la orden de disparo es INSERT; FALSE en otro caso.
UPDATING TRUE si la orden de disparo es UPDATE; FALSE en otro caso.
DELETING TRUE si la orden de disparo es DELETE; FALSE en otro caso.

Taller de administración de Base de datos Oracle 10g 2009
Ejercicio Procedure
Crear un procedimiento que recupere los montos de venta del mes en curso por sucursal, el nombre del vendedor
con mayor venta en cada sucursal y el total de sus ventas. Los resultados debe enviarlos a un archivo de texto.
Crear un procedimiento que consulte el monto de venta mensual por producto en cada sucursal, y el porcentaje
que representa de la venta total mensual en forma descendente. Listando sucursal, el nombre del producto,
proveedor, monto de venta mensual, porcentaje del monto total.
Crear una función que reciba como parámetros una sucursal, un mes inicial y un mes final, que haga la comparativa
de ventas entre ambas y muestre, los montos de ventas y el porcentaje de incremento o decremento entre ambos
meses.
Crear una función que reciba como parámetro una zona, y despliegue los montos de venta en cada sucursal
asociada a esa zona en los últimos tres meses.
Crear un trigger que cuando se efectué una venta, se resten los productos vendidos al inventario de la sucursal.
Crear un trigger que cuando se le asigne a un empleado el puesto de gerente de surcursal, se le declare un sueldo
de 30 mil pesos mas comisiones con un porcentaje de 10 si la sucursal hace ventas mayores al millón de pesos.
Crear un package que consulte diariamente el inventario en todas las sucursales, y liste los productos que se
encuentran agotados, asociados al nombre del proveedor de cada producto. Dicha lista que se envíe a un archivo
de texto.

Taller de administración de Base de datos Oracle 10g 2009
7. Optimización de Queries
7.1 Explain plan Antes que el servidor de base de datos pueda ejecutar una sentencia, Oracle debe primero analizar la sentencia y desplegar el plan de ejecución. El plan de ejecución es una lista de tareas de ordenamientos que desgloza una operación de SQL potencialmente compleja en una serie de operaciones de acceso básico a datos. La sentencia EXPLAIN PLAN permite ingresar una sentencia SQL a Oracle y la base de datos tiene que preparar el plan de ejecución sin tener que ejecutarlo. El plan de ejecución esta hecho disponible en forma de registros insertados en una tabla especial llama plan table. Se pueden consultar los regustros en la tabla plan table utilizando la sentencia SELECT de forma que se pueden ver los pasos en el plan de ejecución para la sentencia que se analizó. Se pueden mantener varios planes de ejecución en la tabla plan table, cada uno de ellos con un identificador diferente, sin embargo es recomendable eliminarlos una vez que se terminen de utilizar. La sentencia EXPLAIN PLAN se ejecuta muy rápido, aun si la sentencia que esta siendo analizada es un query que pueda tardar horas. Esto es porque la sentencia es analizada de forma simple y su plan de ejecución almacenado en la tabla plan table. La sentencia actual nunca es ejecutada por el EXPLAIN PLAN. No se necesitan privilegios especiales de sistema para usar la sentencia EXPLAIN PLAN. Sin embargo, se necesitan privilegios de INSERT en la tabla PLAN TABLE, y se deben tener privilegios suficientes para ejecutar la setencia que se desea analizar. La diferencia es que cuando se ejecuta el EXPLAIN PLAN sobre vistas, se necesitan permisos en todas las tablas con las que construyeron la vista.
7.2 Índices
Un índice es una estructura de memoria secundaria que permite el acceso directo a las filas de una tabla (esté o no
agrupada). Aumenta la velocidad de respuesta de la consulta, mejorando su rendimiento y optimizando su
resultado. Su manejo se hace de forma inteligente. Es el propio Oracle quien decide qué índice se necesita.
Tipos de Índices.
Hay tres tipos de índices en Oracle.
Lectura/Escritura
B-tree (árboles binarios)
Function Based

Taller de administración de Base de datos Oracle 10g 2009
Reserve key
Sólo lectura (read only)
Bitmap
Bitmap join
Index-organized table (algunas veces usados en lectura/escritura)
Cluster y hash cluster
Domain (muy específicos en aplicaciones Oracle)
Índices creados automáticamente. Oracle de forma automática también crea índices. Al crearse la tabla se crea:
Un índice UNIQUE basado en B*-tree para mantener las columnas que se hayan definido como clave primaria de una tabla utilizando el constraint PRIMARY KEY de una tabla no organizada por índice.
Un índice UNIQUE basado en B*-tree para mantener la restricción de unicidad de cada grupo de columnas que se haya declarado como único utilizando el constraint UNIQUE.
Un índice basado en B*-tree para mantener las columnas que se hayan definido como clave primaria y todas las filas de una tabla organizada por índice.
Un índice basado en hashing para mantener las filas de un grupo de tablas (cluster) organizado por hash. Consideraciones: Un índice sólo es efectivo cuando es utilizado. El mantenimiento de un índice tiene efecto sobre el rendimiento de las operaciones de eliminación, inserción y actualización. ORACLE impone dos restricciones:
El número máximo de columnas: Btree --> 32 col. Bitmap --> 30 col.
El espacio requerido para almacenar una clave no puede exceder la mitad del espacio disponible para almacenar datos en un bloque ORACLE (restricciones en Oracle 8i)
Reglas en la construcción de Índices.
Indexe solamente las tablas cuando las consultas no accedan a una gran cantidad de filas de la tabla.
No indexe tablas que son actualizadas con mucha frecuencia.
Indexe aquellas tablas que no tengan muchos valores repetidos en las columnas escogidas. Las consultas muy complejas (en la cláusula WHERE) por lo general no ganan ventaja con el uso de los índices.

Taller de administración de Base de datos Oracle 10g 2009
Sintaxis. Básica CREATE INDEX nombre_indice ON [esquema.] nombre_tabla (columna1 [, columna2, ...])
UNIQUE garantizan que en una tabla (o “cluster”) no puedan existir dos filas con el mismo valor. Modificación. ALTER INDEX [schema.]index options

Taller de administración de Base de datos Oracle 10g 2009
Eliminación. DROP INDEX [schema.]index [FORCE] Estructura B* Tree. Se estructura como un árbol cuya raíz contiene múltiples entradas y valores de claves que apuntan al siguiente nivel del árbol. Nivel 0. tablas pequeñas de datos estáticos. Nivel 1. Indexa tablas dinámicas con el valor único de los identificadores de columna. Nivel 2. Indexa largas tablas o con poca cardinalidad.
Hay que respetar una serie de convenios. Los siguientes convenios son utilizados para el almacenamiento en un índice basado en B*- Tree: En caso de que un índice no sea UNIQUE, si múltiples filas poseen el mismo valor de la clave en la estructura del índice se repetirán los valores de dichas claves. Si una fila posee para todas las columnas de la clave el valor NULL, en el índice no existirá una entrada correspondiente a dicha fila. Si la tabla no está particionada, se utilizan ROWIDs restringidos para indicar la dirección de la fila. Esto se debe a que todas las filas de la tabla no se encuentran en un mismo segmento y con esta política el índice requiere menos

Taller de administración de Base de datos Oracle 10g 2009
espacio en disco. Estructura Bitmap. Son efectivos para columnas simples con poca cardinalidad, esto es muchos valores distintos. Son más rápidos que los B*-Tree en entornos de read-only y almacenan valores de 0 ó 1 en el ROWID. Ejemplo: create bitmap index person_region on person (region);