
SISTEMA PARA MEDIR TIEMPOS DE ESPERA EN COLAS...
61
PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE ESCUELA DE INGENIERIA SISTEMA PARA MEDIR TIEMPOS DE ESPERA EN COLAS DE SUPERMERCADO USANDO VISI ´ ON POR COMPUTADOR Y M ´ ETODOS ESTAD ´ ISTICOS. PEDRO CORTEZ CARGILL Tesis presentada a la Direcci´ on de Investigaci´ on y Postgrado como parte de los requisitos para optar al grado de Magister en Ciencias de la Ingenier´ ıa Profesor Supervisor: DOMINGO MERY Santiago de Chile, Enero 2011 c MMXI, PEDRO MANUEL CORTEZ CARGILL
Transcript of SISTEMA PARA MEDIR TIEMPOS DE ESPERA EN COLAS...

PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE
ESCUELA DE INGENIERIA
SISTEMA PARA MEDIR TIEMPOS DE
ESPERA EN COLAS DE SUPERMERCADO
USANDO VISION POR COMPUTADOR Y
METODOS ESTADISTICOS.
PEDRO CORTEZ CARGILL
Tesis presentada a la Direccion de Investigacion y Postgrado
como parte de los requisitos para optar al grado de
Magister en Ciencias de la Ingenierıa
Profesor Supervisor:
DOMINGO MERY
Santiago de Chile, Enero 2011
c� MMXI, PEDRO MANUEL CORTEZ CARGILL

PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE
ESCUELA DE INGENIERIA
SISTEMA PARA MEDIR TIEMPOS DE
ESPERA EN COLAS DE SUPERMERCADO
USANDO VISION POR COMPUTADOR Y
METODOS ESTADISTICOS.
PEDRO CORTEZ CARGILL
Miembros del Comite:
DOMINGO MERY
ALVARO SOTO
PABLO ZEGERS
DIEGO CELENTANO
Tesis presentada a la Direccion de Investigacion y Postgrado
como parte de los requisitos para optar al grado de
Magister en Ciencias de la Ingenierıa
Santiago de Chile, Enero 2011
c� MMXI, PEDRO MANUEL CORTEZ CARGILL

A mis padres, familia y amigos,
quienes me apoyaron durante este
trabajo y en todos mis estudios

AGRADECIMIENTOS
Me gustarıa agradecer a todas las personas que me ayudaron a realizar este trabajo. En
primer lugar, me gustarıa especialmente agradecer a Cristobal Undurraga por todo el apoyo,
ayuda y trabajos realizado en conjunto, tanto durante el desarrollo de esta tesis, como a lo
largo de mi carrera. Ademas me gustarıa dar las gracias a Hans-Albert Lobel y a Christian
Pieringer, por su ayuda en el desarrollo de la aplicacion y la grabacion de los complejos
videos de prueba. Tambien me gustarıa agradecer a mi profesor asesor, Domingo Mery por
su constante guıa, su interminable paciencia y sus buenos consejos que me han permitido
terminar con exito este trabajo.
Tambien me gustarıa agradecer a todas las personas que, directa o indirectamente se
involucraron en el desarrollo de los distintos aspectos de este trabajo. En primer lugar
me gustarıa dar las gracias al Latin American and Caribbean Collaborative ICT Research
por permitirme profundizar esta investigacion en Mexico. Tambien me gustarıa agrade-
cer a todos los estudiantes, pertenecientes al grupo de robotica, del Instituto Nacional de
Astrofısica, Optica y Electronica, que nos recibieron afectuosamente en Mexico. Ademas
me gustarıa agradecer al profesor Enrique Sucar por su breve pero productiva guıa en el
desarrollo de la aplicacion.
Finalmente, me gustarıa agradecer especialmente a mis padres, familia y amigos por
su valioso apoyo, confianza, ayuda y consejos, tanto durante toda mi carrera, como en el
exito de este trabajo.
iv

INDICE GENERAL
AGRADECIMIENTOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
INDICE DE FIGURAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vii
INDICE DE TABLAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ix
RESUMEN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . x
ABSTRACT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xi
1. INTRODUCCION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1. Motivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1. Tiempos de espera . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.2. Vision por Computador . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2. Marco Teorico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2.1. Descriptor de Covarianza . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.2. Naive Bayes Nearest Neighbor . . . . . . . . . . . . . . . . . . . . . 10
1.2.3. Online Multiple Instance Boosting (OMB) . . . . . . . . . . . . . . . 12
2. DISENO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.1. Hipotesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3. Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3. METODO PROPUESTO . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1. Representacion de la Imagen . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2. Modelo de Apariencia: Online Naive Bayes Nearest Neighbor (ONBNN) . 21
3.3. Modelo de Movimiento . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.4. Deteccion y reconocimiento de clientes . . . . . . . . . . . . . . . . . . . 26
4. EXPERIMENTOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
v

4.1. Modelo de apariencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2. Tiempos de espera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5. RESULTADOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.1. Modelo de apariencia propuesto: Online Naive Bayes Nearest Neighbor
(ONBNN) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.2. Tiempos de Espera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6. CONCLUSIONES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
6.1. Modelo de apariencia propuesto: Online Naive Bayes Nearest Neighbor
(ONBNN) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
vi

INDICE DE FIGURAS
1.1 Ejemplos de aplicaciones de vision por computador existentes. a) Deteccion y
reconocimiento de comportamientos extranos. b) Deteccion de expresiones y
reconocimiento de expresiones faciales para detectar somnolencia del conductor.
c) Control de calidad de alimentos a partir de caracterısticas visuales de una
imagen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 Ejemplo de como se construye el descriptor de covarianza de una region, a partir
de una imagen pasando por la creacion de la matriz de caracterısticas. . . . . 9
2.1 Configuracion de las dos camaras de video en una caja de supermercado. La
primera camara controla el ingreso de los clientes a la cola y la segunda controla
la salida del cliente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 Diagrama general del trabajo realizado. . . . . . . . . . . . . . . . . . . . . 17
3.1 Metodo para normalizar los parches. Notar que se crea una nueva imagen, de
esta forma se pueden utilizar ventanas de busquedas con transformaciones afines. 20
3.2 Distribucion de los cuatro cuadrantes a los cuales se le calcula el descriptor de
covarianza. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3 Diagrama del modelo de apariencia . . . . . . . . . . . . . . . . . . . . . . 22
3.4 Descripcion del modelo de movimiento. El rectangulo verde representa el ultimo
parche seguido Ot−1x,y,w,h, el rectangulo rojo representa el area de busqueda St
x,y,w,h
y los rectangulos azules representan las muestras T tx,y,w,h . . . . . . . . . . . 26
3.5 Diagrama del proceso de deteccion y reconocimiento de rostros entre camaras 28
4.1 Vista superior y lateral de la configuracion de las camaras. . . . . . . . . . . 32
5.1 Error (en pıxeles), cuadro a cuadro, de los centroides para cada secuencia
seleccionada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
vii

5.2 Video Faceocc1; cambios drasticos de apariencia y oclusion parcial. El rectangulo
verde representa el metodo propuesto ONBNN y el rojo representa el metodo
OMB. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Video Surfer; movimientos rapidos y cambios drasticos de apariencia. El
rectangulo verde representa el metodo propuesto ONBNN y el rojo representa el
metodo OMB. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.4 Video privado; oclusion total y rapidos movimientos. El rectangulo verde
representa el metodo propuesto ONBNN. . . . . . . . . . . . . . . . . . . . 38
5.5 Video Girl; cambios drasticos de apariencia y oclusion parcial. El rectangulo
verde representa el metodo propuesto ONBNN y el rojo representa el metodo
OMB. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.6 Video board; donde (a) representa el seguimiento con la ventana inicial corregida
y (b) no. El rectangulo verde representa el metodo propuesto ONBNN. . . . . 40
5.7 Video con una perspectiva superior o top view. El rectangulo verde representa el
metodo propuesto ONBNN. . . . . . . . . . . . . . . . . . . . . . . . . . . 40
viii

INDICE DE TABLAS
5.1 Error promedio de la ubicacion del centro (en pıxeles). Los algoritmos comparados
son: OAB con r = 1, ORF, PROST, NN, FragTrack, SemiBoost, OMB y ONBNN.
Los resultados destacados indican los mejores desempenos y los subrayados los
siguientes mejores. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.2 Error promedio de la ubicacion del centro (en pıxeles). Los algoritmos comparados
son; OMB (con sus cinco ejecuciones) y ONBNN. Los resultados destacados
indican los mejores desempenos y los subrayados los siguientes mejores. . . . 35
5.3 Error promedio de la ubicacion del centro (en pıxeles). Video con vista superior,
de larga duracion donde se siguieron 100 peatones. . . . . . . . . . . . . . . 35
5.4 Resultados del sistema para estimar tiempos de espera. . . . . . . . . . . . . 39
ix

RESUMEN
Las empresas con ventas al por menor, deben lidiar con diversas variables para man-
tener la satisfaccion del cliente en niveles aceptables, ya que estas estan directamente rela-
cionada con la fidelidad del cliente. Esto toma especial interes en los supermercados o
tiendas de auto servicio, ya que estas deben lidiar con los tiempos de espera, generados
en largas filas formadas por los clientes al momento de pagar por los productos; lo cual
afecta directamente la satisfaccion del cliente. Es por esto que, proponemos un sistema
para calcular tiempos de espera en colas de supermercados, a partir de tecnicas de vision
por computador, inteligencia de maquina y multiples vistas. Lo que en definitiva, nos
permitira proporcionar informacion necesaria para estimar la cantidad optima de cajeras
y cajas de atencion abiertas, para un momento especıfico. Para esto proponemos un sis-
tema de seguimiento aplicable a multiples vistas, sustentado por un nuevo y simple modelo
de apariencia propuesto en este trabajo, llamado Online Naive Bayes Nearest Neighbor; el
cual es robusto a oclusiones parciales prolongadas, a cambios drasticos de apariencia y solo
necesita un parametro de configuracion. El modelo propuesto esta basada en el descriptor
de covarianza (Tuzel, Porikli, & Meer, 2006) y en un clasificador Naive Bayes Nearest
Neighbor (Boiman, Shechtman, & Irani, 2008). Finalmente el sistema de seguimiento ob-
tuvo resultados prometedores, logrando seguir correctamente un 61.1% de los clientes que
ingresaron a la cola de espera y de estos el error promedio fue de solo un 2.9%. Ademas, el
sistema es capaz de detectar automaticamente 100% de los casos cuando el sistema falla, lo
que significa en terminos practicos, que podemos entregar mediciones con mayor precision
al momento de calcular los promedios. Con respecto al modelo de apariencia propuesto,
este obtuvo un rendimiento alentador, reduciendo el error promedio (en pıxeles) un 33.1%
comparado con otros metodos de seguimiento, basados en Online Boosting.
Palabras Claves: Vision por Computador, Seguimiento, Naive Bayes, Descriptor de
covarianza; Modelos dinamicos
x

ABSTRACT
Retail companies, must deal with different variables to keep customer satisfaction at
acceptable levels, since these are directly related to customer loyalty. This is specially im-
portant in supermarkets or self-service stores, because they must deal with waiting time
generated by long queues formed by customers paying for goods, which directly affects
customer satisfaction. That is why we propose a system using computer vision techniques,
machine intelligence and multiple views, used to calculate the queue waiting times in su-
permarkets. This calculation ultimately allow us to provide the information needed to es-
timate the optimal number of cashiers and open cash register for a specific time. For this,
we propose a tracking system applicable to multiple views, supported by a new and simple
appearance model proposed in this paper, called Online Nearest Neighbor Naive Bayes,
which is robust to prolonged partial occlusions, drastic appearance changes and just needs
one configuration parameter. The proposed model is based on the covariance descriptor
(Tuzel et al., 2006) and a Nearest Neighbor Naive Bayes classifier (Boiman et al., 2008).
Finally, the tracking system obtained a promising performance and was able to correctly
follow a 61.1% of the customers that joined the queue, where the mean error of these was
only a 2.9%. Furthermore, our system is able to automatically detect 100% of cases when
the system fails, which means in practical terms, that we can deliver more accurate mea-
surements at the moment of calculating the average waiting time. Moreover, the proposed
appearance model results were encouraging, reducing the average error (in pixels) a 33.1%
compared with state of the art tracking methods based on Online Boosting.
Keywords: Computer vision, Tracking, Naive Bayes, Covariance Descriptors; On-
line Model
xi

1. INTRODUCCION
En el contexto de las empresas con ventas al por menor o retail, la satisfaccion al
cliente es uno de los aspectos mas importantes en el proceso del negocio, ya que esta di-
rectamente relacionada con la fidelidad del cliente con la empresa. Las empresas de retail
gastan gran cantidad recursos en aumentar la calidad de servicio, especialmente al mo-
mento de la atencion. Esto toma especial interes, en los supermercados o tiendas de auto
servicio, ya que estas deben lidiar con los tiempos de espera, generados en largas filas for-
madas por los clientes al momento de pagar por los productos; lo cual afecta directamente
la satisfaccion del cliente. Es por esto que, proponemos un sistema para calcular tiempos de
espera en colas de supermercados, a partir de tecnicas de vision por computador, inteligen-
cia de maquina y multiples vistas. Lo que en definitiva, nos permitira estimar los tiempos de
espera promedio de los clientes y en consecuencia le proporcionara a los supermercados in-
formacion necesaria para estimar la cantidad optima de cajeras y cajas de atencion abiertas,
para un momento especıfico. Para esto proponemos un sistema de seguimiento aplicable a
multiples vista, sustentado por un nuevo y simple modelo de apariencia propuesto en esta
tesis, llamado Online Naive Bayes Nearest Neighbor.
1.1. Motivacion
A continuacion presentaremos los principales aspectos tecnicos que motivaron el de-
sarrollo de este trabajo. En esta seccion abordaremos los conceptos basicos de la teorıa de
colas relacionado con los tiempos de espera y los principales conceptos del area de vision
por computador.
1.1.1. Tiempos de espera
Hace ya un largo tiempo, la comunidad cientıfica reconoce la importancia y utilidad
de la teorıa de colas en situaciones de la vida cotidiana; tales como cajas de supermerca-
dos, bancos, semaforos, etc. El fenomeno de las colas surge cuando un recurso compartido
necesita ser accedido o dar servicio a un elevado numero de trabajos o clientes, lo cual
1

se traduce en un desequilibrio transitorio entre oferta y demanda; este problema se pre-
senta permanentemente en la vida diaria. Es por esto que los estudios han establecido una
significativa relacion entre teorıa y la vida cotidiana; los cuales han permitido encontrar
elementos que definen o influyen el comportamiento de una cola (Seow, 2000):
(i) Tasa de llegada de clientes o personal.
(ii) Tiempo operacional o tiempo necesario para atender al cliente.
(iii) Numero de servidores (cajeras) disponibles.
(iv) Comportamiento de los clientes en la cola.
Los clientes llegan por servicio a diferentes tiempos durante el dıa y se supone que la
llegada es al azar y extendida en el tiempo. Por lo tanto, el comportamiento del patron de
llegada del cliente y la reaccion de los elementos anteriormente descritos determinaran el
alcance de la cola en el sistema. A menudo se asume que en un cola, la tasa de llegada
de los clientes sigue una distribucion de Poisson; sin embargo, no todas los procesos de
llegadas se rigen por esta distribucion (Seow, 2000).
Entre todos los elementos relacionados con una cola, el tiempo de espera es el aspecto
mas relevante, ya que influencia profundamente el comportamiento del cliente. Algunos
podran optar por no hacer la cola a la vista de la longitud de esta; otros despues de hacer fila
por un tiempo considerable, optaran por salir de esta y los ultimos permaneceran en la cola
esperando, perdiendo su costo de oportunidad. Especıficamente en esta tesis, definimos el
tiempo de espera, como el tiempo que un cliente espera en una cola, hasta salir de la caja de
servicio; en el caso que se desee medir el tiempo que un cliente espera en una cola, antes de
ser atendido, simplemente se debe cambiar la configuracion de las camaras, para que solo
capten informacion hasta ese punto.
Los clientes llegan con la intencion de utilizar algun servicio provisto por la empresa.
Sin embargo, debido a largas colas y tiempos de espera extensos, no utilizan el servicio.
Esto provoca que los clientes abandonen el recinto, insatisfechos o disgustados. Es un
hecho conocido que la satisfaccion del consumidor es un indicador relevante en las orga-
nizaciones, ya que el principal factor que contribuye a este, es el tiempo de espera. El
2

numero de servidores (ej.: cajero/as) influencian directamente el largo de una cola. A
mayor numero de servidores, menor el tamano de la cola y por lo tanto, menor el tiempo de
espera. Colas cortas y tiempos de espera razonables traen satisfaccion al cliente; el desafıo
es encontrar la forma de predecir el numero optimo de servidores, a partir de la tasa de
llegada de los consumidores.
Ahora, cuando una organizacion tiene una buena gestion, sus objetivos suelen estar
centrados en encontrar una solucion entre dos extremos. Por un lado, contratar una nu-
merosa dotacion de personal de servicio (ej.: cajero/as) y ofrecer muchas instalaciones de
servicio (ej.: cajas de supermercado); lo cual puede resultar en una excelente atencion al
cliente, donde rara vez mas de uno o dos clientes esten en una cola. Los clientes estaran
satisfechos con la rapida respuesta y apreciaran la comodidad. Esto sin embargo, puede
ser muy costoso. Por otra parte, el otro extremo es tener al mınimo numero la dotacion de
personal y servidores (ej.: cajas de supermercado) abiertos. Esto mantiene el costo de los
servicios bajos, pero podran dar lugar a la insatisfaccion de los clientes debido a un mal
servicio.
La mayorıa de los gerentes reconocen el equilibrio que debe existir entre los costos de
proveer un buen servicio y el costo del tiempo de espera del cliente. Ellos quieren que las
colas sean lo suficientemente cortas, para que los clientes esten satisfechos, no abandonen
la cola sin haber sido atendido y esten dispuestos a regresar. Pero al mismo tiempo estan
dispuestos a permitir cierto tiempo de espera, si se compensa con un ahorro significativo
en los costos del servicio.
Ahora, en el contexto de equilibrar costos y latencia de servicio, el area de vision por
computador podrıa ser un gran complemento a la teorıa de colas; ya que esta puede proveer
informacion en tiempo real a los modelos matematicos, con respecto a variables relevantes
relacionadas con el cliente tales como; tiempos de espera, patrones de movimiento, etc. Es
por esto, que en el marco de esta tesis abordaremos en profundidad la teorıa relacionada con
el area de vision por computador e inteligencia artificial, y propondremos una aplicacion
respecto a la medicion de tiempos de espera de los clientes.
3

1.1.2. Vision por Computador
Una de las habilidades mas extraordinarias de la vision humana es el reconocimiento
de objetos y rostros. Sin importar el angulo, tamano, luminosidad u oclusion del objeto,
la vision humana logra en casi todos los casos, reconocer el objeto o persona. Esta habili-
dad es primordial en muchos aspectos de nuestras vidas, por ejemplo, sin la capacidad de
reconocer rostros o expresiones faciales no podrıamos tener una vida social satisfactoria.
Por otra parte, en el area de vision por computador, se pretende poder disenar maquinas
o sistemas que puedan lograr esta habilidad automaticamente y ası poder utilizarlos, por
ejemplo, en aplicaciones de vigilancia o control de calidad.
En el campo de vision por computador, los objetivos basicos para construir un apli-
cacion son; seguir, detectar y reconocer objetos presentes en diversas escenas de la vida
real; lo cual es un desafıo que todavıa no se logra solucionar en su totalidad. Gracias a los
avances e investigaciones de los ultimos anos se han podido obtener multiples aplicaciones
de deteccion, reconocimiento y seguimiento en muchas areas distintas. Estas incluyen
video juegos, asistencia para conductores, edicion de video, control de calidad, control de
transito, vigilancia, seguridad, tracking, etc. Por dar algunos ejemplos (Figura 1.1): en
asistencia para conductores existen aplicaciones donde se le advierte al conductor si se esta
quedando dormido, basandose en reconocimiento de expresiones (Ji, Zhu, & Lan, 2004);
en control de calidad existen aplicaciones las cuales pueden definir si un producto esta en
perfecto estado o no, a partir de las caracterısticas (tamano, forma, color, etc.) de la imagen
obtenida (Pedreschi, Mery, Mendoza, & Aguilera, 2004); por ultimo, en el area de seguri-
dad y vigilancia existen aplicaciones las cuales, a partir del video de seguridad, detectan
objetos o comportamientos extranos, tales como robos, violencia o bombas (Nguyen, Bui,
Venkatsh, & West, 2003).
Actualmente, para lograr estas tareas se utilizan distintas tecnicas, a traves de las cuales
se obtiene informacion relevante de las imagenes o videos, conocidos como descriptores
o caracterısticas (Mikolajczyk & Schmid, 2005). Un descriptor debe ser idealmente dis-
criminativo, robusto y facilmente computable. Existe una gran variedad de descriptores,
4

a) b) c)
FIGURA 1.1. Ejemplos de aplicaciones de vision por computador existentes. a)Deteccion y reconocimiento de comportamientos extranos. b) Deteccion de ex-presiones y reconocimiento de expresiones faciales para detectar somnolencia delconductor. c) Control de calidad de alimentos a partir de caracterısticas visuales deuna imagen.
algunos enfocados a ser calculados rapidamente, mientras que otros, en obtener la mayor
informacion posible. Por otra parte existen algoritmos que detectan regiones relevantes
e invariantes al tamano, luminosidad y perspectiva, de esta forma se calculan las carac-
terısticas solo a estas regiones relevantes y no a toda la imagen, esta tecnologıa se conoce
en ingles como viewpoint invariant segmentation (Kadir, Zisserman, & Brady, 2004; Sivic,
Schaffalitzky, & Zisserman, 2004). Es por esto que, la seleccion de caracterısticas es uno
de los pasos mas importantes en el problema de deteccion, reconocimiento y seguimiento
de objetos; ademas es el punto de partida para construir cualquier aplicacion de vision por
computador.
Ahora, en el area de vision por computador, el seguimiento (tracking) de peatones,
rostros u objetos en general, ha sido un tema extensamente estudiado por su gran utilidad
en una variedad de aplicaciones. Aunque se han obtenidos buenos resultados (Isard &
MacCormick, 2001; Birchfield, 1998), estos sistemas son altamente estructurados o se
sustentan en estrictas restricciones, las cuales generalmente se relacionan con el tipo de
objeto a seguir (entrenamiento off-line (Stalder, Grabner, & Leuven, 2009)) o el ambiente
en el que esta el objeto (sustraccion de fondo (Palaio & Batista, 2008)).
En terminos generales, un sistema de seguimiento tiene tres componentes: repre-
sentacion de la imagen, modelo de apariencia y modelo de movimiento. Actualmente existe
5

una variedad de metodos para crear el modelo de apariencia y muchos de estos utilizan in-
formacion estadıstica, la cuales puede ser definida manualmente o entrenada a partir del
primer cuadro (Adam, Rivlin, & Shimshoni, 2006). Estos metodos son simples pero ge-
neralmente tienen grandes dificultades cuando el objeto seguido cambia significativamente
de apariencia en el tiempo. Esto llevo al desarrollo de metodos especıficos capaces de
adaptar el modelo a medida que el objeto cambia de apariencia; estos modelos son cono-
cidos como Adaptive Appearance Model (Wu, Cheng, Wang, & Lu, 2009; Porikli, Tuzel,
& Meer, 2006). Existe un tercer metodo, donde el modelo de apariencia se rige a partir
de clasificadores debiles entrenados online, que detectan el objeto seguido y/o el fondo.
Este metodo conocido como Tracking by Detection (Babenko, Yang, & Belongie, 2009;
Grabner, Grabner, & Bischof, 2006), debe equilibrar entre la estabilidad del tracking y la
rapidez que aprenden los clasificadores.
El problema mas desafiante, al momento de actualizar el modelo de apariencia, es la
eleccion de nuevas muestras, tanto positivas como negativas. Babenko et al. (2009) pro-
ponen una metodologıa de muestreo optima, enfocado especıficamente en su modelo de
apariencia basado en clasificadores. Ademas, este modelo utiliza un metodo modificado
de Multiple Instance Learning o MIL (Viola, Platt, & Zhang, 2006) el cual permite se-
leccionar las mejores caracterısticas a seguir, incluidas en el objeto. Aunque este sistema
tiene excelentes resultados, tambien tiene sus limitaciones; al ser un sistema de Tracking
by Detection debe lidiar con el problema de equilibrar entre estabilidad y aprendizaje, lo
cual genera errores en los casos de oclusion parcial prolongada.
1.2. Marco Teorico
A continuacion, se presentara una descripcion completa de los principales algoritmos y
metodos empleados como sustento teorico a lo largo de esta tesis; esta descripcion incluye:
al descriptor de covarianza, al clasificador Naive Bayes Nearest Neighbor y al modelo de
apariencia Online Multiple Instance Boosting. Especıficamente, el descriptor de covarianza
y el clasificador Naive Bayes Nearest Neighbor seran utilizados como base para proponer
6

un nuevo modelo de apariencia dinamico y el modelo de apariencia Online Multiple In-
stance Boosting se empleara principalmente de comparacion.
1.2.1. Descriptor de Covarianza
Tuzel et al. (2006) propusieron una elegante solucion para integrar multiples carac-
terısticas, las cuales son simples y rapidas de calcular; como gradiente, color, posicion o
intensidad, inclusive se pueden utilizar caracterısticas de camaras infrarrojas o termicas.
En comparacion a otros descriptores como Haar (Viola & Jones, 2001) o gradientes de
histograma, este descriptor otorga mucho mas informacion y tiene la ventaja que no esta
sujeto al tamano de la ventana de busqueda. La region de covarianza se ha utilizado en
distintas aplicaciones y se han propuesto diversas mejoras y complementos, por ejemplo:
Tuzel, Porikli, and Meer (2008) y Yao and Odobez (2008) proponen utilizar el descriptor
de covarianza mas un clasificador LogitBoost, para la deteccion de peatones; Hu and Qin
(2008) proponen utilizar el filtro partıculas, para el seguimiento de objetos, utilizando como
peso de las partıculas, metricas de la matriz de covarianza; Porikli et al. (2006) proponen
un algoritmo para seguir objetos utilizando la region de covarianza y algebra de Lie para
crear un modelo de actualizacion.
De esta forma el, descriptor de covarianza, se define formalmente como:
F (x, y, i) = φi(I, x, y) (1.1)
donde I es una imagen (la cual puede estar en RGB, blanco y negro, infrarrojo, etc.), F es
una matriz de W ×H×d, donde W es el ancho de la imagen, H el alto de la imagen y d es
el numero de sub-caracterısticas utilizadas y φi es la funcion que relaciona la imagen con
la i-esima sub-caracterıstica, es decir la funcion que obtiene la i-esima sub-caracterıstica a
partir de la imagen I . Es importante destacar que las sub-caracterısticas se obtienen a nivel
del pıxel.
El objetivo es representar el objeto a partir de la matriz de covarianza de la matriz F ,
construida a partir de estas sub-caracterısticas. La covarianza es la medicion estadıstica
de la variacion o relacion entre dos variables aleatorias, esta puede ser negativa, cero o
7

positiva, dependiendo de la relacion entre ellas. En nuestro caso las variables aleatorias
representaran las sub-caracterısticas. En la matriz de covarianza las diagonales representan
la varianza de cada sub-caracterıstica, mientras que el resto representa la correlacion entre
las caracterısticas.
Utilizar la matriz de covarianza como descriptor tiene multiples ventajas, primero
unifica informacion tanto espacial como estadıstica del objeto; segundo provee una ele-
gante solucion para fusionar distintas caracterısticas y modalidades; tercero tiene una di-
mensionalidad muy baja; cuarto es capaz de comparar regiones, sin estar restringido a un
tamano de ventana constante o fija, ya que no importa el tamano de la region, el descrip-
tor es la matriz de covarianza, que es de tamano constante d × d, y quinto, la matriz de
covarianza puede ser facilmente calculable, para cualquier region o sub-region.
A pesar de todos los beneficios que trae la representacion del descriptor a partir de
la matriz de covarianza, el calculo para cualquier sub-ventana o region dado una imagen,
utilizando los metodos convencionales, la hace computacionalmente prohibitiva. Tuzel et
al. (2006) proponen un metodo computacionalmente superior, para calcular la matriz de
covarianza de cualquier sub-ventana o region (rectangular) de una imagen a partir de la
formulacion de la imagen integral; concepto inicialmente introducido por Viola and Jones
(2001), para el computo rapido de caracterısticas de Haar. A continuacion explicaremos
como se realiza este calculo:
Sea P una matriz de W ×H × d , el tensor de la imagen integral
P (x�, y�, i) =�
x<x�,y<y�
F (x, y, i) i = 1 . . . d (1.2)
Sea Q una matriz de W ×H × d× d, el tensor de segundo orden de la imagen integral
Q(x�, y�, i, j) =�
x<x�,y<y�
F (x, y, i)F (x, y, j) i, j = 1 . . . d (1.3)
Ademas definimos como
Px,y =�P (x, y, 1) . . . P (x, y, d)
�T(1.4)
8

FIGURA 1.2. Ejemplo de como se construye el descriptor de covarianza de unaregion, a partir de una imagen pasando por la creacion de la matriz de carac-terısticas.
Qx,y =
Q(x, y, 1, 1) . . . Q(x, y, 1, d)... . . . ...
Q(x, y, d, 1) . . . Q(x, y, d, d)
(1.5)
De esta forma la covarianza de cualquier region de la imagen se calcula de la siguiente
manera:
RQ = Qx�,y� +Qx��,y�� −Qx��,y� −Qx�,y�� (1.6)
RP = Px�,y� + Px��,y�� − Px��,y� − Px�,y�� (1.7)
CR(x�,y�;x��,y��) =1
n− 1[RQ −
1
nRPR
TP ] (1.8)
donde n = (x�� − x�)(y�� − y�). De esta forma, despues de construir el tensor de primer or-
den P y el tensor de segundo orden Q, la covarianza de cualquier region se puede computar
en O(d2). El proceso anteriormente descrito puede ser resumido por la Figura 1.2. Cabe
destacar que, el descriptor de covarianza no es un elemento del espacio Euclidiano, por lo
tanto no se pueden utilizar los clasicos algoritmos de inteligencia de maquinas, como por
9

ejemplo: vecinos cercanos, distancia de Mahanalobis, etc. Por otra parte, las matrices de
covarianza son simetricas positivas definidas, las cuales estan incluidas dentro de la algebra
de Lie o el espacio de Riemann (Tuzel et al., 2008). En la geometrıa de Riemann, el es-
pacio de Riemann es un espacio topologico con metricas Riemanianas, las cuales permiten
generalizar el espacio Euclidiano (Rossmann, 2002).
1.2.2. Naive Bayes Nearest Neighbor
El problema de clasificar imagenes ha acaparado considerablemente la atencion en la
comunidad de Vision por Computador. En los ultimos anos, el esfuerzo combinado de
la comunidad cientıfica dio lugar a nuevos y novedosos enfoques para la clasificacion de
imagenes. Estos metodos pueden dividir aproximadamente en dos grandes familias:
(i) Learning-based Classifiers: clasificadores que requieren una fase intensiva de
aprendizaje/entrenamiento de los parametros internos, como por ejemplo; SVM
(Cortes & Vapnik, 1995), Boosting (Viola & Jones, 2001), arboles de decision,
etc.
(ii) Non-parametric Classifiers: clasificadores que soportan su decision directamente
a traves de los datos y no requieren una fase de entrenamiento/aprendizaje de
parametros. Uno de los clasificadores no parametricos mas comun es el de Veci-
nos mas cercanos o Nearest Neighbor Classifier.
Los clasificadores no parametricos tienen relevantes ventajas, las cuales no son compartidas
por la mayorıa de los enfoques que utilizan Learning-based Classifiers. Primero, pueden
manejar naturalmente un gran numero clases. Segundo, evitan el sobre entrenamiento de
parametros, lo cual es uno de los problemas centrales en los Learning-based Classifiers.
Finalmente, no requieren entrenamiento.
A pesar de todas estas ventajas, en el area de clasificacion de imagenes, existe una gran
brecha de rendimiento entre los metodos que utilizan el enfoque Nearest Neighbor Classi-
fier y los metodos, en el estado del arte, que utilizan Learning-based Classifiers. Segun
10

Boiman et al. (2008), la degradacion de los metodos no parametricos en la clasificacion de
imagenes, sucede principalmente por dos practicas comunes:
(i) Cuantificacion de Descriptores: las imagenes son a frecuentemente represen-
tadas por un conjunto de descriptores locales; tales como SIFT (Lowe, 1999),
HOG (Dalal & Triggs, 2005), etc. Estos son a menudo cuantificados con el obje-
tivo de construir una relativamente pequena coleccion de descriptores relevantes
o bag of words, lo cual permite generar una representacion condensada de la
imagen. Esta reduccion, da a lugar a una significativa disminucion a la dimen-
sionalidad, pero tambien, a una importante disminucion al poder discriminativo
del descriptor.
(ii) Distancia Imagen-Imagen: en la clasificacion de imagenes, los metodos basados
en Vecinos mas Cercanos, proveen buenos resultados exclusivamente cuando la
imagen a clasificar es similar a una de las imagenes incluida en la base de datos
del clasificador. Lo cual no permite generalizar para clase con gran diversidad
de contenido incluido en la imagen.
En defensa de los Nearest Neighbor Classifier, Boiman et al. (2008) proponen un
clasificador, el cual obtiene rendimientos entre los principales lıderes en clasificacion de
imagenes, llamado Naive Bayes Nearest Neighbor (NBNN). El Algoritmo utiliza una dis-
tancia Nearest Neighbor en el espacio de los descriptores locales y no en el espacio de la
imagen. De esta forma el Naive Bayes Nearest Neighbor, calcula directamente una distan-
cia Imagen-Clase, sin cuantificar los descriptores. Ademas demuestran que bajo el supuesto
Naive Bayes, el algoritmo propuesto obtiene el clasificador optimo teorico, para la imagen.
El algoritmo de Naive Bayes Nearest Neighbor es sorprendentemente simple, ya que
gracias al enfoque de vecinos mas cercanos, el supuesto de Naive Bayes y la distribucion
de los descriptores; logra simplificar el clasificador optimo de imagenes definido por la dis-
tribucion probabilıstica p(d|C); donde d representa los descriptores de la imagen a clasi-
ficar y C la clase. Especıficamente, la distribucion de probabilidad de los descriptores es
modelada por la funcion kernel de Parzen, la cual es no parametrica y tiene una distribucion
11

donde casi todos los descriptores son mas bien aislados en el espacio, por tanto, muy lejos
de la mayorıa de los descriptores en la base de datos. Finalmente el algoritmo, a partir de
un imagen de entrada, calcula todos los descriptores locales d1...dn. Luego busca la clase
C que minimice�n
i=1 ||di − NNC(di)||2, donde NNC(di) representa el descriptor en la
clase C especıfica, mas cercano a di, segun vecinos mas cercanos. El metodo puede ser
resumido por el algoritmo 1.
Algoritmo 1: Naive Bayes Nearest Neighbor (NBNN)Data: imagen a consultar
Result: clase estimada C
Computar los descriptores d1, . . . , dn de la imagen de entrada;
∀di ∀C clasificar di en C a partir de vecinos mas cercanos: NNC(di);
C = argminc
�ni=1 �di −NNC(di)�2;
De esta forma, C representa la clase estimada, a partir de los d1, . . . , dn descriptores de la
imagen de entrada
1.2.3. Online Multiple Instance Boosting (OMB)
Babenko et al. (2009) proponen un nuevo algoritmo de Online Boosting para el proble-
ma de Multiple Instance Learning o MIL, el cual utiliza un enfoque estadıstico de Boosting,
que intenta optimizar una funcion de perdida (o ganancia) J especıfica. En este enfoque
los clasificadores debiles son seleccionados secuencialmente para optimizar el siguiente
criterio:
(hk,αk) = argmaxh∈H,α
J(Hk−1 + αh) (1.9)
Donde Hk−1 es un clasificador fuerte construido a partir de los (k−1) clasificadores debiles
y H es el conjunto de todos los posibles clasificadores debiles. En los algoritmos de Boost-
ing con aprendizaje previo, la funcion objetivo J es calculada a traves de todo el conjunto
de datos de entrenamiento. En este caso, para cada cuadro del video, se utiliza un set de
entrenamiento {(X1, y1), (X2, y2), . . . }, donde Xi = {xi1, xi2 . . . } es una conjunto (bag)
12

de muestras e yi es la clase o etiqueta. Ademas, el modelo de apariencia incluye un clasifi-
cador discriminativo, el cual es capaz de resolver p(y = 1|x), donde x es un parche de la
imagen e y es una variable binaria que indica la presencia del objeto de interes en el parche
x. Ahora, para actualizar o estimar p(y = 1|x), se debe maximizar la log verosimilitud de
estos datos. De esta forma, la probabilidad se modela como:
p(y = 1|x) = σ(H(x)) (1.10)
Donde σ = 11+e−x es la funcion sigmoidal y las probabilidades del conjunto de muestra
p(yi|Xi) son modeladas usando la funcion NOR (1.11).
p(yi|Xi) = 1−�
j
(1− p(yi|xij)) (1.11)
En todo momento el algoritmo mantiene un numero M de clasificadores debiles candidatos,
los cuales se actualizan todos en paralelo, para actualizar el clasificador. Cabe destacar
que, las muestras a pesar de ser traspasadas en conjuntos (bag), los clasificadores debiles
de un algoritmo MIL necesitan la clasificacion por instancia, es decir yij . Debido a que
esta informacion no esta disponible, todas las muestras xij son etiquetadas a partir de yi. A
continuacion, se seleccionan K (tal que K < M ) clasificadores debiles h desde el conjunto
disponible M , utilizando el siguiente criterio.
hk = argmaxh∈{h1,...,hM}
logL(Hk−1 + h) (1.12)
logL =�
i
(log(p(yi|Xi))) (1.13)
El metodo puede ser resumido por el algoritmo 2.
13

Algoritmo 2: Online Multiple Instance Boosting (OMB)Data: Conjunto {Xi, yi}Ni=1, donde Xi = {xi1, xi2, . . . }, yi ∈ {0, 1}
Result: Clasificador H(x) =�
k hk(x), donde p(y = 1|x) = σ(H(x))
Actualizar los M clasificadores debiles del conjunto, con {xij, yi};
Inicializar Hij = 0 para todos los i, j;
for k = 1 to K do
for m = 1 to M dopmij = σ(Hij + hm(xij));
pmi = 1−�
j(1− pmij );
Lm =�
i(yi log(pmi ) + (1− yi)log(1− pmi ));
end
m∗ = argmaxm Lm;
hk(x) ← hm∗(x);
Hij = Hij + hk(x);
end
A partir del marco teorico aquı presentado, podemos concluir que usando tecnicas de
el estado del arte en el area de vision por computador, es posible representar, reconocer
y seguir un objeto presente en una imagen. Esto nos permitira cumplir con los objetivos
planteados en esta tesis.
14

2. DISENO
2.1. Hipotesis
La hipotesis de este trabajo es que a partir de tecnicas de vision por computador, in-
teligencia artificial y multiples vistas; tales como el descriptor de covarianza y el modelo
de apariencia Naive Bayes Nearest Neighbor, es posible medir tiempos de esperas, en un
cola formada en una caja de servicio de un supermercado.
2.2. Objetivos
El objetivo general de este trabajo es medir tiempos de esperas de los clientes, a me-
dida que avanzan a traves de una cola de espera, formada en una caja de servicio de un
supermercado. Especıficamente nuestro objetivo es desarrollar un sistema de seguimiento
de rostros suficientemente preciso, tal que nos permita seguir al cliente, a lo largo de la cola
de espera; lo cual nos proporcionara el tiempo de espera del cliente. Debido a que las colas
son recurrentemente largas, nuestra solucion implica un sistema dos camaras sincronizadas,
una a la entrada de la cola y otra a la salida. De esta forma, nuestro sistema debera ser capaz
de asociar la informacion de ambas camaras para obtener mediciones precisas.
Para esto, construiremos un nuevo modelo de apariencia dinamico, robusto a oclu-
siones parciales prolongadas y a cambios de apariencia prolongados; basado en el descrip-
tor de covarianza (Tuzel et al., 2006) y en el clasificador Naive Bayes Nearest Neighbor
(Boiman et al., 2008). Ademas debera tener como principal caracterıstica, la capacidad de
aprender la apariencia del objeto seguido, a medida que pase el tiempo. Como lo expli-
camos anteriormente, nuestra solucion incluye dos camaras debido al gran tamano de las
colas; esto quiere decir que a medida que avanza el cliente en la cola, este hace un recorri-
do desde la primera camara hacia la segunda (Figura 2.1). De esta forma, en el momento
que el cliente abandona el campo visual de la primera camara, inmediatamente despues,
en la segunda camara el sistema debera detectar los rostros presentes en la escena y luego
reconocer al cliente.
15

FIGURA 2.1. Configuracion de las dos camaras de video en una caja de superme-rcado. La primera camara controla el ingreso de los clientes a la cola y la segundacontrola la salida del cliente.
Finalmente, como objetivo secundario, deseamos estudiar empıricamente las ventajas
y desventajas de una configuracion lateral de las camaras, en comparacion a una configu-
racion top view o vista superior.
2.3. Metodologıa
Con el fin de cumplir nuestros variados objetivos hemos disenado dos experimentos
independientes (2.2). El primero, esta divido en tres sub-experimentos, estara dirigido es-
pecıficamente a medir la precision y rendimiento del modelo propuesto. De esta forma, el
primer sub-experimento estara enfocado en comparar el modelo de apariencia propuesto
con un metodo en el estado del arte en el Online Boosting; el segundo sub-experimento
tendra nuevamente como objetivo comparar modelo de apariencia propuesto, pero con
un conjunto siete algoritmos de seguimiento en el estado del arte; y finalmente el tercer
sub-experimento tendra como objetivo probar el modelo propuesto en diferentes escenas
16

FIGURA 2.2. Diagrama general del trabajo realizado.
y situaciones extremas. Para esto utilizaremos catorce videos, los cuales, para facilitar la
explicacion, los separaremos en tres grupos.
El primer grupo incluye nueve videos publicos utilizados en los principales y mas mo-
dernos trabajos respecto al seguimiento de objetos, para las pruebas de comparacion. Cada
video tendra la informacion relacionada a la posicion real del objeto seguido para cada
cuadro (ground truth); ademas tendran diferentes resoluciones, frecuencias y podran ser
tanto blanco y negro, como a color. Para la comparacion se utilizaran siete algoritmos, en
el estado del arte (Grabner et al., 2006; Grabner, Leistner, & Bischof, 2008; Adam et al.,
2006; Babenko et al., 2009; Saffari, Leistner, Santner, Godec, & Bischof, 2010; Santner,
Leistner, Saffari, Pock, & Bischof, 2010; Gu, Zheng, & Tomasi, 2010), relacionados con
el area de seguimiento. El segundo grupo incluye cuatro videos realizados especıficamente
para esta tesis. Los videos fueron captados en una resolucion de 640×480, a 30 cuadros por
17
Pedro Cortez Cargill

segundo, en un supermercado local (Santiago, Chile) con camaras Point Grey y describen
escenas con fondos complejos, peatones y oclusiones extremas. Estos videos no incluyen
informacion respecto a la posicion real del objeto seguido para cada cuadro; ni comparacion
con otros algoritmos. El tercer y ultimo grupo es un video de larga duracion capturado
desde una perspectiva superior (top view)1, el cual describe el transito de peatones. Cada
peaton incluye informacion respecto a su posicion real para cada cuadro, pero al igual que
el segundo conjunto este no tendra comparacion con otros algoritmos.
El segundo experimento estara dirigido a medir la precision del sistema de seguimiento,
con el objetivo de estimar el tiempo de espera de los clientes y compararlos con los tiem-
pos reales medidos. Para esto utilizaremos dos videos, tomados especıficamente para esta
tesis, de larga duracion con una resolucion de 640 × 480, captados por dos camaras sin-
cronizadas (una escena, multiples vistas) a 30 cuadros por segundo, en un supermercado
local (Santiago, Chile) con camaras Point Grey.
1BIWI Walking Pedestrians Datasets - http://www.vision.ee.ethz.ch/datasets/index.en.html
18

3. METODO PROPUESTO
El sistema de seguimiento propuesto incluye los tres componentes descritos anteri-
ormente, representacion de la imagen, modelo de apariencia y modelo de movimiento.
Tanto la representacion de la imagen, como el modelo de movimiento fueron construidos
a partir de pequenas variaciones de metodos existentes. Sin embargo, el modelo de apari-
encia propuesto, nuestra principal contribucion, es un nuevo modelo llamado Online Naive
Bayes Nearest Neighbor, el cual es robusto a oclusiones parciales prolongadas y cambios
drasticos de apariencia. Adicionalmente incluiremos un cuarto componente, enfocado es-
pecıficamente al calcula de tiempos de espera; el cual nos permitira detectar y reconocer
clientes entre una camara y otra, de tal forma que podamos continuar el seguimiento. Este
componente utiliza el detector de rostros propuesto por Viola and Jones (2001) y el modelo
propuesto Online Naive Bayes Nearest Neighbor para reconocer al cliente.
3.1. Representacion de la Imagen
Para representar la imagen, utilizamos el descriptor de covarianza (Tuzel et al., 2006)
con un tensor de 12 caracterısticas, el cual esta definido por:
F (x, y, i) = [x y R G B |Ix| |Iy|�|Ix|2 + |Iy|2 |Ixx| . . .
|Iyy| tan−1( IxIy ) S]T (3.1)
donde x e y representan las coordenadas 2D de cada pıxel; R,G,B representa el valor
de rojo, verde y azul de cada pıxel; |Ix|, |Iy|, |Ixx|, |Iyy| representa la primera y segunda
derivada, en x e y, de la intensidad de la imagen ;�|Ix|2 + |Iy|2 representa la magnitud
de la segunda derivada; tan−1( IxIy ) reprensenta la orientacion de la primera derivada en x
e y (fase) y S representa un Saliency Map (Montabone & Soto, 2010). Cabe destacar que
Cortez, Undurraga, Mery, and Soto (2009) recomiendan utilizar 11 de las 12 caracterısticas
utilizadas; en nuestro caso ademas agregamos un Saliency Map debido a los excelentes
resultados empıricas obtenidos.
19

FIGURA 3.1. Metodo para normalizar los parches. Notar que se crea una nuevaimagen, de esta forma se pueden utilizar ventanas de busquedas con transforma-ciones afines.
Cabe destacar que en nuestro caso, no calculamos los tensores de toda la imagen, sino
que solo de los parches que nos interesan; en contraste al metodo original propuesto por
Tuzel et al. (2006). De esta forma podemos utilizar ventanas de busqueda rotados o con
transformaciones afines. El proceso incluye extraer el parche deseado (a fin de calcular
el descriptor) desde la imagen original, crear una nueva imagen y transformar la imagen
a un tamano fijo de 20 × 20 pıxeles, para objetos simetrico (rostros) y 20 × 40 pıxeles,
para casos asimetricos (peatones). Por otra parte, aunque el descriptor de covarianza tiene
un grado de invariabilidad a cambios de escala, este no es suficiente para casos extremos;
es por esto que al utilizar un tamano fijo para la nueva imagen, anadimos un nivel mas de
normalizacion a cambios de escala (Figure 3.1).
Por ultimo, como lo describimos anteriormente, el descriptor de covarianza no es un
elemento del espacio Euclidiano, ya que es una matriz semi definida positiva (SPD+).
Por lo tanto, los clasicos algoritmos de inteligencia de maquina, como por ejemplo PCA
(Pearson, 1901), LDA (Abdi, 2007), etc., en su forma original no pueden ser utilizados, ya
que utilizan una representacion vectorial y el espacio euclidiano para calcular la separacion
optima de los conjuntos. Las matrices SPD+ estan incluidas en el algebra de Lie o el
espacio de Riemann (Riemannian Manifolds) (Rossmann, 2002), ası que para poder com-
parar dos descriptores de covarianza, utilizamos una metrica para matrices semi definidas
positivas Log-Euclidiana (Ayache, Fillard, Pennec, & Nicholas, 2007), la cual se define
20

como:
ρ(X,Y) = �log(X)− log(Y)� (3.2)
Donde log(X) es el mapa logarıtmico de la matriz de covarianza, que esta definido por la de-
scomposicion de valores singulares de la matriz X. Sea la descomposicion de valores singu-
lares de X, SV D(X) = UΣUT , donde U es una matriz ortonormal y Σ = Diag(λ1, ....,λn)
es una matriz diagonal de valores propios. Por lo tanto, el mapa logarıtmico se define como:
log(X) = U[diag(log(λ1), ...., log(λn))]UT (3.3)
En este trabajo proponemos un nuevo modelo de apariencia conjunto que logra mezclar
tanto los modelos adaptivos como por deteccion, llamado Online Naive Bayes Nearest
Neighbor; el cual utiliza un clasificador Naive Bayes Nearest Neighbor (Boiman et al.,
2008) y el descriptor de covarianza (Tuzel et al., 2006).
3.2. Modelo de Apariencia: Online Naive Bayes Nearest Neighbor (ONBNN)
A partir de la idea de Boiman et al. (2008), disenamos un modelo de apariencia que
clasifica el parche de cada nueva muestra gracias un clasificador Naive Bayes Nearest
Neighbor. En el metodo propuesto, el clasificador Naive Bayes Nearest Neighbor es ac-
tualizado en cada iteracion con nuevas muestras positivas; donde cada muestra es repre-
sentada por el descriptor de covarianza del parche. De esta manera, construimos una “base
de datos” del objeto seguido, lo cual es necesario para el enfoque de vecinos mas cercanos
utilizado por el algoritmo Naive Bayes Nearest Neighbor.
Cada muestra esta representada por cuatro caracterısticas de covarianza, donde cada
descriptor representa uno de los cuatro cuadrantes de la imagen (Figura 3.2). De esta forma
el modelo de apariencia se define como M(q, i); donde q = 1, 2, 3, 4 representa uno de los
cuatro cuadrantes, i = 1, . . . ,mq es el numero de la muestra para el cuadrante q especıfico,
mq es el numero de muestras totales almacenadas en modelo para el cuadrante q y M(q, i)
es el descriptor de covarianza del cuadrante q para la muestra i. Notar que las muestras son
especıficas para cada cuadrante, pero estas deben ser menor o igual a N (Figura 3.3).
21

FIGURA 3.2. Distribucion de los cuatro cuadrantes a los cuales se le calcula eldescriptor de covarianza.
FIGURA 3.3. Diagrama del modelo de apariencia
A continuacion definimos P (q) como una muestra; donde nuevamente q = 1, 2, 3, 4
representa uno de los cuatro cuadrantes y P (q) es el descriptor de covarianza del cuadrante
q, calculado a partir de (1.8). Por lo tanto la distancia de una muestra P al modelo M se
define como:
d(M,P ) =4�
q=1
mini�mq
�ρ(M(q, i), P (q)) + λ�ZM(q, i)− ZP (q)�
�(3.4)
22

Donde utilizamos la metrica definida en (3.2), ya que M(q, i) y P (k) son matrices de
covarianza. Ademas agregamos informacion espacial perdida al utilizar los parches y no
la imagen completa, para calcular la matriz de covarianza, donde ZM(q, i) y ZP (q) son
la posicion (x, y) del centro del parche, con respecto a la imagen original, que representa
M(q, i) y P (q) respectivamente y λ es el factor de relevancia de la distancia euclidiana en
el modelo. De esta forma, agregamos la distancia euclidiana relativa a la imagen (distancia
en pıxeles), entre los centros de los cuadrantes de la muestra y del modelo.
Para actualizar el modelo definimos un protocolo, donde el cuadrante, del ultimo
parche estimado P ∗(q), con menor distancia promedio al modelo M(q, i) es agregado. La
distancia promedio, entre el cuadrante y las muestras del cuadrante para el modelo M(q, i),
se define como:
ω(M,P, q) =1
mq
mq�
i=1
ρ(M(q, i), P (q)) (3.5)
Donde q es el cuadrante al cual se le esta calculando la distancia promedio y mq es la
cantidad de muestras para el cuadrante q. Ademas definimos R(q, j), como una matriz
que almacena la distancia promedio al modelo obtenida, al momento de agregar una nueva
muestra al modelo (3.9).
Por ultimo, el modelo se actualiza de la siguiente manera:
q∗ = argminq
ω(M,P ∗, q) (3.6)
j =
mq∗ + 1 if mq∗ < N
argmaxi�mq∗
R(q∗, i) if mq∗ = N(3.7)
M(q∗, j) = P ∗(q∗) (3.8)
R(q∗, j) = ω(M,P ∗, q∗) (3.9)
Especıficamente, la ecuacion (3.6) busca el cuadrante de P ∗ con menor distancia promedio
al modelo; la ecuacion (3.7) describe como es seleccionado el indice donde se agregara
23

la muestra (del cuadrante q) en el modelo y la ecuacion (3.9) guarda la distancia prome-
dio de la muestra al modelo. Esta informacion es utilizada para definir el protocolo de
actualizacion (3.7).
Debido a que el modelo debe ser online, no es posible agregar infinitas muestras, por
lo tanto definimos N , como la memoria del modelo; en nuestras pruebas le asignamos un
valor de 30. Con el fin de otorgar cierta flexibilidad, al momento de actualizar un cuadrante
con N muestra en memoria, la muestra con mayor distancia promedio es eliminada y la
nueva muestra es agregada. La distancia que conforma el ranking de muestras es calculado
y almacenado cuando la nueva muestra es agregado al modelo. De esta forma evitamos
que el modelo se confunda en oclusiones parciales prolongadas, pero damos un “umbral de
aprendizaje” que otorga estabilidad.
Al momento de inicializar el modelo, los cuatro cuadrantes del parche inicial son
guardados, con distancia promedio al modelo igual a 0. Para mas detalle referirse al al-
goritmo 3, el cual recibe un conjunto de parametros que describen un conjunto de ventanas
de busqueda, donde (xk, yk) representa el centro, (wk, hk) representa el ancho y el largo y
θl representa la rotacion, de la ventana. Finalmente, el algoritmo devuelve la configuracion
de los parametros, que obtiene menor distancia al modelo.
24

Algoritmo 3: Online Naive Bayes Nearest NeighborData: {xk, yk, wk, hk, θk}Kk=1, M , R
Result: xk∗ , yk∗ , wk∗ , hk∗ , θk∗
for k = 1 to K do
I = getImage(xk, yk, wk, hk, θk); // Nueva imagen deformada
Pk = getCovarianceDescriptors(I);
dk = d(M,Pk); // ecuacion (3.4)
end
k∗ = argmink
dk;
P ∗ = Pk∗ ;
q∗ = argminq
ω(M,P ∗, q) ;
if mq∗ < N thenj = mq + 1
elsej = argmax
i�mq∗R(q∗, i) ;
end
M(q∗, j) = P ∗(q∗);
R(q∗, j) = ω(M,P ∗, q∗);
3.3. Modelo de Movimiento
Para poder destacar la real contribucion del modelo de apariencia propuesto, utilizamos
un modelo de movimiento muy simple, que realiza una busqueda exhaustiva local a multiples
escalas en un area menor incluida en la ultima posicion estimada.
Formalmente, sea Ot−1x,y,w,h sea el parche seguido en el instante t − 1 del video, con
centro x, y y dimensiones w, h. Se define el area de busqueda para el instante t como
Stx,y,w,h; donde:
Stx,y,w,h = Ot−1
x,y,wα , hα(3.10)
25

FIGURA 3.4. Descripcion del modelo de movimiento. El rectangulo verde rep-resenta el ultimo parche seguido O
t−1x,y,w,h, el rectangulo rojo representa el area de
busqueda Stx,y,w,h y los rectangulos azules representan las muestras T t
x,y,w,h
En el area Stx,y,w,h se busca exhaustivamente a partir del parche T t
x,y,w,h; donde los centros
T tx,y,w,h son las coordenadas de cada pıxel, dentro del area de busqueda St
x,y,w,h y βn es una
lista de escalares (Figura 3.4).
T tx,y,w,h = St
xp,yp,wβn,hβn(3.11)
Finalmente, al momento t, se selecciona el parche T txn,yn,wn,hn
con menor distancia al mo-
delo de apariencia. Notar que el modelo de movimiento es totalmente independiente al
modelo de apariencia.
3.4. Deteccion y reconocimiento de clientes
Para poder aplicar el metodo de seguimiento propuesto, en un ambiente de multiples
camaras, es necesario lograr reconocer y detectar el objeto (seguido), entre las camaras
presentes. Especıficamente para el problema de estimar tiempos de espera de clientes;
el sistema consta de dos modulos; un detector de rostros propuesto por Viola and Jones
(2001) y el clasificador Online Naive Bayes Nearest Neighbor para reconocer al cliente
(Figura 3.5).
El detector de rostros propuesto por Viola and Jones (2001) utiliza las caracterısticas
simples de Haar, la imagen integral y un detector en cascada (Boosting) para detectar
todos los rostros presentes en una imagen. En nuestro caso, utilizamos la implementacion
26

provista por OPENCV1 y dos conjuntos de pesos para las cascadas; uno para rostros de
perfil y otro para rostros frontales, con los siguientes parametros de configuracion:
(i) Factor de escala: 1.1.
(ii) Numero mınimo de vecinos: 3.
(iii) Poda de imagenes: a partir del detector de bordes de Canny.
(iv) Tamano mınimo de ventana: 25× 25 pıxeles.
A continuacion, a partir de los rostros detectados, se debe reconocer al cliente (seguido);
para esto utilizamos el mismo modelo de apariencia propuesto, con toda la informacion
acumulada durante el trascurso del seguimiento. Finalmente se selecciona el rostro detec-
tado con menor distancia al modelo. Cabe destacar que, luego de detectar y reconocer al
cliente en la nueva camara, el modelo de apariencia es reiniciado con nueva informacion
base del objeto (posicion inicial y se borra la memoria). El algoritmo 4 describe el proceso.
Algoritmo 4: Detector y Reconocedor de RostrosData: M , Frame
Result: xk∗ , yk∗ , wk∗ , hk∗
{xk, yk, wk, hk}Kk=1 = faceDetectionV iolaAndJones(Frame);
for k = 1 to K do
I = getImage(xk, yk, wk, hk, 0); // Nueva imagen deformada con θ = 0
Pk = getCovarianceDescriptors(I);
dk = d(M,Pk); // ecuacion (3.4)
end
k∗ = argmink dk;
1Open Source Computer Vision Library - http://opencv.willowgarage.com
27

FIGURA 3.5. Diagrama del proceso de deteccion y reconocimiento de rostros entre camaras
28

4. EXPERIMENTOS
Para alcanzar los objetivos propuestos en este trabajo, hemos disenado dos experimen-
tos independientes. El primero estara orientado en cuantificar el rendimiento del nuevo
modelo de apariencia. El segundo estara dirigido a medir la precision del calculo del tiempo
de espera de los clientes, a medida que avanzan en una cola.
4.1. Modelo de apariencia
Debido a la necesidad cuantificar la precision, el rendimiento y el real aporte del nuevo
modelo de apariencia, se han disenado un conjunto de experimentos. Especıficamente
el nuevo algoritmo sera probado en una serie de desafiantes videos, tanto publicos como
especıficos para esta tesis y en comparacion utilizaremos siete distintos algoritmos. A
continuacion se describiran la configuracion de los siete algoritmos, mas la configuracion
del modelo propuesto.
(i) Online-AdaBoost (OAB): propuesto por Grabner et al. (2006) e implementado
en (Babenko et al., 2009); donde el radio de busqueda se fijo en 35 pıxeles.
(ii) SemiBoost tracker: descrito por Grabner et al. (2008), utiliza informacion eti-
quetada solo del primer cuadro y luego, en los cuadros posteriores, actualiza
el modelo de apariencia vıa una metodologıa online semi-supervised learning.
Esto lo hace particularmente robusto a escenarios donde el objeto deja por com-
pleto la escena. Sin embargo, el modelo depende estrictamente del clasificador
entrenado a partir del primer cuadro.
(iii) FragTrack: descrito en (Adam et al., 2006), utiliza un modelo de apariencia
estatico basado en Integral Histograms, los cuales han demostrado ser muy efi-
cientes. El modelo de apariencia es Parte-based, lo cual lo hace robusto a oclu-
siones.
(iv) Online Multiple Instance Boosting (OMB): propuesto por Babenko et al. (2009),
es un algoritmo de seguimiento en el estado del arte del Online Boosting, utiliza
una tasa de aprendizaje para clasificadores debiles fijo en 0.85 y un ponderador
29

para el muestreo de ejemplares negativas fijo en 50. Ademas, debido a que el
algoritmo tiene una fuerte dependencia a la construccion al azar de las carac-
terısticas de Haar utilizaremos cinco intentos con la misma configuracion, para
cada video.
(v) Online Random Forests (ORF): propuesto por Saffari et al. (2010), es un al-
goritmo que combina las ideas de muestreo online, bosques (forest) extremada-
mente aleatorios y procedimientos para el crecimiento de arboles de decision
online; ademas incluye un esquema temporal de pesos para descartar algunos
arboles.
(vi) Parallel Robust Online Simple Tracking (PROST): propuesto por Santner et al.
(2010), es un algoritmo que combina en una cascada, un simple modelo basado
en plantillas, un novedoso sistema de optical flow basado en MeanShift y un
modelo de apariencia basado en un online Random Forest.
(vii) Efficient Visual Object Tracking with Online Nearest Neighbor Classifier (NN):
propuesto por Gu et al. (2010), es un algoritmo, con el enfoque de tracking by
detection, que combina un clasificador de vecinos mas cercanos, busqueda efi-
ciente de ventanas y un novedoso metodo de seleccion y poda de caracterısticas.
(viii) Online Naive Bayes Nearest Neighbor (ONBNN): para nuestro metodo prop-
uesto, el valor de los parametros para todos los experimentos son: λ = 0.05 ,
α = 2.5, βn = {0.8, 1, 1.1, 1.3} y N = 30.
Inicialmente, realizaremos un experimento con cinco videos publicos1, Surfer, Oc-
cluded Face, Occluded Face 2, Girl y David; frente a cinco intentos distintos del algoritmo
Online Multiple Instance Boosting. Luego realizaremos un segundo experimento con ocho
videos, los cuales incluiran cuatro de los videos anteriormente descritos (Occluded Face,
Occluded Face 2, Girl y David ) mas cuatro videos publicos2 adicionales, Lemming, Board,
Liquor y Box; donde comparamos a los siete algoritmos descritos anteriormente, mas el
1Tracking With Online MIL Research Page - http://www.vision.ucsd.edu/∼bbabenko/project miltrack.shtml2PROST Research page - http://gpu4vision.icg.tugraz.at/index.php?content=subsites/prost/prost.php
30

mejor intento para cada video especifico, del algoritmo Online Multiple Instance Boost-
ing (obtenida en el primer experimento). Cabe destacar que, la informacion de la posicion
real del centro del objeto seguido (ground truth), cada cinco cuadros, sera proveıda por
Babenko et al. (2009) y por (Santner et al., 2010). Adicionalmente realizaremos un tercer
experimento con un grupo de videos privados y publicos, sin utilizar algoritmos de com-
paracion. Este conjunto de videos incluye seguimiento de peatones, escenas con complejos
fondos o background y videos con vista superior o top view3.
Finalmente, para medir del desempeno, utilizamos un error (en pıxeles) promedio de la
ubicacion del centro; la cual calcula para cada cuadro, la norma euclidiana entre el centro
de la posicion estimada y la posicion real del centro del objeto seguido (4.1). Ademas, la
posicion, en el primer cuadro del video, del objeto a seguir sera ingresada manualmente,
por algun usuario.
e =1
n
n�
i=1
�Ox,y −Ogx,y� (4.1)
4.2. Tiempos de espera
Para corroborar nuestra hipotesis, en sıntesis debemos cuantificar la precision y el
rendimiento, de los tiempos de espera estimado, por el sistema de seguimiento propuesto.
Para esto, hemos definido un experimento a partir de una escena de larga duracion, captada
por dos camaras sincronizadas, donde se debe calcular el tiempo de espera de los clientes
que llegan a una caja de servicio especıfica.
Primero disenamos una distribucion especıfica para las camaras situadas en la caja de
servicio (Figura 4.1), de tal forma que cubra el mayor campo visual posible. Esta configu-
racion consta de dos camaras; la primera situada en la parte superior final de la caja y la
segunda situada aproximadamente a un 1.20 metros de altura, justo antes de comenzar la
caja registradora. Esta configuracion de dos camaras permite seguir a traves de la fila, al
cliente, de tal forma que si sale del campo visual de la primera camara, el cliente aparecera
3BIWI Walking Pedestrians Datasets - http://www.vision.ee.ethz.ch/datasets/index.en.html
31

(a) Vista Superior (b) Vista Lateral
FIGURA 4.1. Vista superior y lateral de la configuracion de las camaras.
en la segunda. Por otra parte, se privilegio esta distribucion, ya que disminuye la oclusion
al momento que la cola de espera crece.
Algoritmo 5: Criterio entrada y salida ClienteData: frames, rectEstimado
Result: estado del cliente en la camara
while frames.next ! = NULL do
if frames.next es de la camara 1 then
if rectEstimado.center.x < inLimit thenreturn cliente entro a la cola de espera;
else if rectEstimado.topLeft.x < outLimit thenreturn cliente salio de la camara;
end
else
if rectEstimado.topLeft.x < outLimit thenreturn cliente salio de la caja;
end
end
end
Segundo, para poder medir el tiempo de espera de un cliente, fijamos un umbral de
entrada y salida de la camara, en el espacio 2D de la imagen (Figura 2.1). Esto quiere decir
que en el caso que la posicion estimada del cliente, traspase un umbral (en X o Y ), se
considerara que el cliente entro o salio de la camara. Ademas, en el instante que el sistema
32

estime que un cliente salio de la primera camara, comenzara automaticamente a seguirlo
en la segunda camara, sin embargo si el sistema estima que salio de la segunda camara, se
estimara que el cliente salio de la fila.
Formalmente el umbral de entrada y salida se define en el Algoritmo 5. Donde rectEs-
timado.center.x representa la coordenada x del centro de la posicion estimada del rostro del
cliente, rectEstimado.topLeft.x representa la coordenada x de la esquina superior izquierda
de la posicion estimada del rostro del cliente, inLimit = 190 (pıxeles) y outLimit = 10
(pıxeles).
Tercero, debido a que el sistema de seguimiento utilizara como base el modelo de a-
pariencia propuesto, el sistema debera regirse a partir de las restricciones de este. Por lo
tanto, cada cliente que deba ser seguido por el sistema, se le debera marcar manualmente
su posicion inicial, en la primera camara; no ası en la segunda, ya que sera detectado
automaticamente por el sistema.
Finalmente, para comparar los resultados se hara una medicion manual de los mismos
clientes seguidos por el sistema, utilizando el mismo criterio descrito anteriormente (Al-
goritmo 5). Esto quiere decir que en el caso que un cliente pase el umbral de salida, se le
terminara el tiempo de espera, inclusive si llegara a devolverse a la caja.
33

5. RESULTADOS
Los resultados de los experimentos, anteriormente descritos, estaran divididos, al igual
que los experimentos, en dos grupos. Primero presentaremos los resultados respecto al
modelo de apariencia propuesto; a continuacion, los relacionados con el calculo del tiempos
de espera en una cola.
5.1. Modelo de apariencia propuesto: Online Naive Bayes Nearest Neighbor (ONBNN)
Los resultados obtenido en los experimentos fueron alentadores; nuestro algoritmo
Online Naive Bayes Nearest Neighbor siguio correctamente el objeto, en cinco de los ocho
videos utilizados; donde en tres de ellos obtuvo el menor error promedio en pıxeles (Tabla
5.1). En el video Occluded Face, el algoritmo FragTrack obtiene el mejor desempeno,
porque esta disenado especıficamente para manejar este tipo de oclusiones, ya que utiliza
un parte-base Model. Sin embargo, en videos similares, pero mas desafiantes, tal como el
video Occluded Face 2, el algoritmo FragTrack obtuvo pobres resultados, debido a que no
puede manejar adecuadamente el cambio de apariencia del objeto. Esto destaca las ven-
tajas de utilizar Adaptive Appearance Model. Es mas, los modelos de Online Boosting y
Semi Boosting tiene problemas con oclusiones parciales prolongadas. Por otra parte, en los
videos board, box, lemming y liquor, el algoritmo propuesto obtuvo mediocres resultados;
esto se debe principalmente a la existencia de oclusion completa; lo cual debido al pobre
modelo de movimiento y busqueda, provoca la perdida del objeto seguido. Ahora, en el
video board el error promedio obtenido, fue considerablemente mayor en comparacion a
los otros metodos; esto se debio a la ventana inicial seleccionada, la cual cubre en pro-
porcion casi la misma cantidad de fondo que de objeto. Esto es especialmente relevante
para el descriptor de covarianza, ya que el algoritmo utiliza todo la ventana para calcular
el descriptor, no ası otros descriptores (como SIFT) que solo utilizan areas relevantes o de
interes. Corrigiendo la ventana inicial (se roto 125o) se obtuvo un error promedio de 16.7
pıxeles (Figura 5.6), lo cual supera el algoritmo con mejor resultado (error promedio de
20.0 pıxeles).
34

TABLA 5.1. Error promedio de la ubicacion del centro (en pıxeles). Los algorit-mos comparados son: OAB con r = 1, ORF, PROST, NN, FragTrack, SemiBoost,OMB y ONBNN. Los resultados destacados indican los mejores desempenos y lossubrayados los siguientes mejores.
Secuencia # Frames OAB ORF OMB SemiBoost Frag PROST NN ONBNNGirl 502 43.3 - 31.6 52.0 25.5 19.0 18.0 13.9David 462 51.0 - 15.6 43.0 46 21.6 15.6 10.8Faceocc1 886 44.0 - 18.4 41.0 6.0 7.0 10.0 11.3Faceocc2 812 21.0 - 14.3 43.0 45 21.6 12.9 12.8Board 698 - 154.5 51.2 - 90.1 37.0 20.0 221.6Box 1161 - 145.4 104.6 - 57.4 12.1 16.9 121.0Lemming 1336 - 166.3 40.5 - 82.8 25.4 79.1 46.7Liquor 1741 - 67.3 165.1 - 30.7 21.6 15.0 85.4
TABLA 5.2. Error promedio de la ubicacion del centro (en pıxeles). Los algorit-mos comparados son; OMB (con sus cinco ejecuciones) y ONBNN. Los resultadosdestacados indican los mejores desempenos y los subrayados los siguientesmejores.
Secuencia # Frames OMB 1 OMB 2 OMB 3 OMB 4 OMB 5 ONBNNSurfer 375 4.9 7.7 13.4 5,5 14.6 4.5Faceocc1 886 18.4 32.4 19.6 31.6 34.4 11.3Faceocc2 812 30.7 22.8 16.7 14.3 16.5 12.8Girl 502 31.6 33.2 33.8 34.9 26.5 13.9David 462 19.6 19.8 23.8 15.6 30.1 10.8
TABLA 5.3. Error promedio de la ubicacion del centro (en pıxeles). Video convista superior, de larga duracion donde se siguieron 100 peatones.
ONBNN# Frames 1193# Peatones 100Error Prom. (pıxel) 5.70Error Max. (pıxel) 188.49
Ahora, comparado con un algoritmo en el estado del arte en el area de Online Boosting,
tal como el propuesto por Babenko et al. (2009), nuestro modelo obtuvo mejores resultados
(Tabla 5.2, Figura 5.1). En resumen, nuestro metodo logra disminuir un 33.1% el error
promedio (en pıxeles), en comparacion a la mejor combinacion de los cinco intentos (para
cada video) del algoritmo Online Multiple Instance Boosting (Babenko et al., 2009).
35
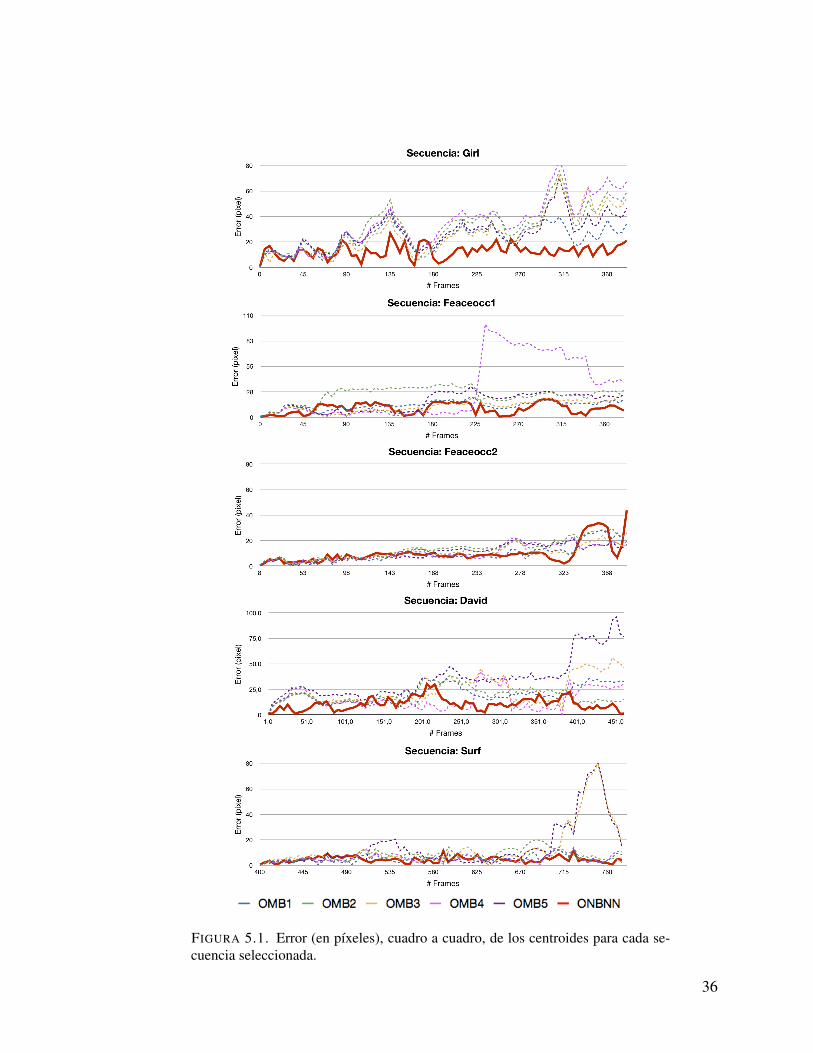
FIGURA 5.1. Error (en pıxeles), cuadro a cuadro, de los centroides para cada se-cuencia seleccionada.
36

FIGURA 5.2. Video Faceocc1; cambios drasticos de apariencia y oclusion parcial.El rectangulo verde representa el metodo propuesto ONBNN y el rojo representa elmetodo OMB.
Por otra parte, la memoria N del modelo fue seleccionada a partir de pruebas empıricas.
El modelo de apariencia con N > 30 tiende a resultados promedios similares al modelo
con N = 30; no ası cuando N < 30, el modelo tiene un comportamiento erratico por la
poca capacidad de aprender la apariencia del objeto. En nuestros experimentos, cuando
N < 30 el modelo utiliza principalmente la ultima caracterıstica seleccionada para hacer
la clasificacion.
Finalmente los resultados fueron satisfactorios. El modelo Online Naive Bayes Near-
est Neighbor propuesto, obtuvo un buen desempeno en videos con grandes cambios de
apariencia (Figuras 5.2 y 5.5), rapidos movimientos (Figura 5.3) y oclusiones parciales del
objeto. Ademas, obtuvimos excelentes resultados en los videos con vista superior (Figura
5.7), nuestro metodo obtiene un error promedio de 5.70 pıxeles (Tabla 5.3) y logra seguir
correctamente 99% de los peatones; lo cual se debe principalmente al descriptor de cova-
rianza y a la nula oclusion inherente a la posicion de la camara. No obstante, obtuvimos
pobres resultados en los casos donde existe completa oclusion y movimientos erraticos
(Figura 5.4); lo cual se debe principalmente al simple modelo de movimiento utilizado.
Para ver todos videos de prueba generados dirigirse a http://www.youtube.com/pcortez .
5.2. Tiempos de Espera
Luego de realizar los experimentos y comparar los tiempos estimados con los reales
(sujeto a la restriccion planteada en la metodologıa), los resultados (Figura 2.1 y Tabla 5.4)
37

FIGURA 5.3. Video Surfer; movimientos rapidos y cambios drasticos de aparien-cia. El rectangulo verde representa el metodo propuesto ONBNN y el rojo repre-senta el metodo OMB.
FIGURA 5.4. Video privado; oclusion total y rapidos movimientos. El rectanguloverde representa el metodo propuesto ONBNN.
FIGURA 5.5. Video Girl; cambios drasticos de apariencia y oclusion parcial. Elrectangulo verde representa el metodo propuesto ONBNN y el rojo representa elmetodo OMB.
son los siguientes: de los 36 clientes seguidos, un 61.11% fue correctamente seguido a
medida que avanzaba en la cola. A partir del 61.11% correctamente seguido, se obtuvo
un tiempo promedio estimado de espera de 75.82 segundos, lo cual en comparacion a los
tiempos reales es un error promedio de 2.25 segundos; lo que nos darıa un error de 2.93%.
Adicionalmente, la desviacion estandar del error es de 0.64 y el error maximo es de 11.96
segundos.
38

TABLA 5.4. Resultados del sistema para estimar tiempos de espera.
# Cliente Correcto Tiempo Estimado (seg) Tiempo real (seg) Error (seg)
1 T 51.48 52.0 0.52
2 T 31.84 32.0 0.16
3 T 21.92 22.0 0.08
4 T 18.72 20.0 1.28
5 T 19.21 20.0 0.79
6 T 10.60 11.0 0.40
7 F - - -
8 T 25.64 27.0 1.36
9 F - - -
10 T 44.72 45.0 0.28
11 T 27.00 28.0 1.00
12 F - - -
13 T 208.20 217.2 9.00
14 F - - -
15 F - - -
16 F - - -
17 F - - -
18 F - - -
19 F - - -
20 F - - -
21 T 101.92 104.0 2.08
22 T 44.72 46.0 1.28
23 T 51.24 52.0 0.76
24 T 32.64 33.0 0.36
25 T 82.88 84.0 1.12
26 T 37.68 36.0 1.68
27 T 41.48 43.0 1.52
28 F - - -
29 T 277.96 266.0 11.96
30 F - - -
31 F - - -
32 F - - -
33 T 223.32 230.0 6.68
34 T 49.32 50.0 0.68
35 T 229.32 232.0 2.68
36 T 36.12 40.0 3.88
Promedio T 75.82 76.83 2.25
# Clientes Clientes Correctos Clientes Incorrectos % Clientes Correctos
36 22 14 61.11%
39

(a)
(b)
FIGURA 5.6. Video board; donde (a) representa el seguimiento con la ventanainicial corregida y (b) no. El rectangulo verde representa el metodo propuestoONBNN.
FIGURA 5.7. Video con una perspectiva superior o top view. El rectangulo verderepresenta el metodo propuesto ONBNN.
Ahora, el error de los 14 clientes que no pudieron ser seguidos a traves de la cola,
se debe principalmente a dos problemas. Primero, el detector de rostros propuesto por
Viola and Jones (2001) no logra detectar el rostro del cliente (en el momento de pasar de la
primera a la segunda camara) en todos los casos; esto incluye que el rostro este ocluido, el
cliente este en una posicion extrana (perfil o de espalda) y que el detector simplemente no
detecte el rostro; y segundo, que el cliente salga inesperadamente antes de terminar, de la
cola. Sin embargo, cabe destacar, que en un 100% de estos clientes, el sistema estimo un
tiempo de espera igual al tiempo total del video, lo que permitio facilmente distinguirlos en
40

la muestra total de clientes. Es decir, nuestro sistema es capaz de detectar automaticamente
cuando el sistema de seguimiento falla, lo que significa en terminos practicos, que podemos
entregar mediciones 100% confiables. Esto ocurre en 6 de cada 10 personas, lo que para la
estimacion de tiempos de espera en colas de supermercado es mas que suficiente.
Finalmente, los resultados obtenidos fueron satisfactorios a pesar de que los videos
tenıan una serie de complejas situaciones (clientes con sombrero, personas de espalda,
etc). Los tiempos promedios de espera estimados tuvieron un error de solo 2.93%. Adi-
cionalmente, a pesar de que solo un 61.11% de los clientes fue seguido correctamente; el
porcentaje restante pudo ser automaticamente identificado, proporcionando mayor calidad
en las estimaciones.
41

6. CONCLUSIONES
En este trabajo hemos demostrado que es posible medir tiempos de espera, en un cola
formada en una caja de servicio de un supermercado, a partir de tecnicas de vision por
computador, inteligencia artificial y multiples vistas. Para esto, hemos construido un pre-
ciso sistema de seguimiento de rostros, el cual nos permitio estimar el tiempo de espera
del cliente. Este sistema se sustento, en el nuevo modelo de apariencia propuesto; Online
Naive Bayes Nearest, el cual fue el principal aporte de esta tesis. Por otra parte, en terminos
practicos pudimos estudiar extensamente las ventajas y desventajas de la configuracion lat-
eral de las camaras, en comparacion a una configuracion top view.
6.1. Modelo de apariencia propuesto: Online Naive Bayes Nearest Neighbor (ONBNN)
Los resultados obtenidos, por parte del algoritmo Online Naive Bayes Nearest Neigh-
bor, fueron muy alentadores, como podemos observar en la Tabla 5.1, nuestro metodo pro-
puesto logra seguir correctamente el objeto seis de los ocho videos utilizados (incluyendo
el video board con ventana inicial corregida). Ademas, nuestro metodo logra superar en
todos los casos, los metodos basados en online Boosting (Tabla 5.2). Especıficamente, el
algoritmo de SemiBoost descarta gran cantidad de informacion relevante al dejar todas las
imagenes extraıdas sin etiquetar, excepto por las del primer cuadro. Esto conduce a malos
resultados en los casos de cambios significativos de apariencia. Ası mismo el algoritmo
de Online Multiple Instance Boosting es particularmente bueno en lidiar con oclusiones
parciales rapidas, no ası con oclusiones parciales prolongadas.
El rendimiento superior se debe a la utilizacion de las caracterısticas de covarianza,
las cuales otorgan mayor informacion visual que otras caracterısticas (tales como Haar o
Histogramas) y a la manera optima de actualizar el modelo de apariencia usando un umbral
de aprendizaje. Por otra parte, nuestro sistema tiene bajos rendimientos en los casos donde
existe completa oclusion y movimientos erraticos; lo cual se debe principalmente al simple
modelo de movimiento utilizado.
42
Pedro Cortez Cargill

Cabe destacar que el metodo de apariencia propuesto es muy simple en comparacion
a los cuatro algoritmos anteriores, ya que necesita solo un parametros de configuracion,
ademas del hecho que el valor es generalmente muy estable a pesar de las diferentes escenas
(λ = 0.05).
Con respecto a los tiempos de procesamientos, nuestro metodo obtiene rendimientos
inferiores a los algoritmos utilizados para la comparacion; esto se debe principalmente
al enfoque exhaustivo utilizado en el modelo de movimiento. El modelo de movimiento
debe buscar exhaustivamente en un area menor pero proporcional al tamano de la ventana
estimada en el cuadro anterior; por lo tanto el tiempo de procesamiento esta intrınsecamente
relacionado con el tamano de la ventana estimada, lo cual lo hace poco eficiente. De
esta forma, en el caso de que la ventana sea pequena, como en los videos con perspectiva
superior o top view, los tiempos de procesamiento son aceptables.
6.2. Tiempos de Espera
El sistema para estimar tiempos de espera en una cola de supermercado, ademas de
ser un metodo novedoso, obtuvo resultados interesantes y alentadores, como podemos ob-
servar en la Tabla 5.4. Esto se debe principalmente a dos razones: la capacidad superior,
en comparacion a otros modelos, de adaptarse a los cambios de apariencia, del modelo
de apariencia propuesto Online Naive Bayes Nearest; y segundo, el aumento de precision
en el tiempo de espera estimado, proporcionado por la configuracion de multiples vis-
tas (dos camaras y sin calibracion) exitosamente implementada. Ası mismo, gracias a la
combinacion del detector de rostros propuesto por (Viola & Jones, 2001) y el modelo de
apariencia propuesto en este trabajo, pudimos reconocer efectivamente al cliente entre las
distintas camaras. Ademas, el sistema logro identificar precisamente a los clientes que no
pudieron ser correctamente seguidos, lo cual es especialmente relevante, al momento de
tomar decisiones, ya que otorga un nivel de seguridad y precision al usuario final.
43

6.3. Configuracion de las camaras de video
A partir de informacion empırica acumulada, nos pudimos dar cuenta que distribuir
las camaras desde una perspectiva lateral, en comparacion a una perspectiva superior o top
view, tiene como ventaja la posibilidad de capturar mayor informacion visual del cliente
a seguir. Esto se debe a la poca superficie que ocupa un cliente desde la vista superior;
no ası en desde una vista lateral. De esta forma, el cliente puede ser representado por una
imagen de alta calidad (en comparacion a una vista superior) de su rostro, lo cual tiene
una gran cantidad de informacion visual; en contraste desde la vista superior, el cliente es
representado por una imagen de baja calidad (ya que esta a una distancia mucho mayor del
cliente), de sus hombros y parte superior de la cabeza, lo cual entrega una cantidad limitada
de informacion visual, haciendo particularmente difıcil la tarea de reconocer (no ası la de
seguir). No obstante la perspectiva superior tiene menor informacion visual, esta incluye
una variedad de ventajas, tales como:
(i) Bajo el supuesto de seguir clientes (ergo personas), desde una vista superior es
muy poco probable que se produzcan oclusiones lo cual facilita enormemente el
seguimiento.
(ii) Evita problemas de tamano producidos por perspectivas forzadas (cambios drasticos
de tamano por acercarse a la camara).
(iii) La propiedad de discernimiento de los descriptores de covarianza aumentan,
dado que el fondo o background, en el caso de la vista superior, es muy estable
ya que es suelo (Figura 5.7, Tabla 5.3).
Ademas cabe destacar, que para la aplicacion especıfica de tiempos de espera, la dis-
tribucion de las camaras desde una perspectiva lateral, tiene que ser cuidadosamente elegida.
En nuestro caso, la mala posicion de la segunda camara produjo perdidas de informacion
relevante para discernir cuando el cliente abandonaba realmente la caja de servicio.
44

6.4. Trabajos Futuros
Finalmente, existen varias maneras de continuar y mejorar el trabajo realizado. Primero,
el modelo de movimiento utilizado es bastante simple y podrıa ser remplazado por algun
sistema mas sofisticado, tal como Filtro de Partıculas o algun algoritmo de busqueda efi-
ciente de sub-ventanas (Lampert, Blaschko, & Hofmann, 2009). Tambien serıa interesante
incluir, tal como lo hace Gu et al. (2010), una penalizacion para cambios drasticos de
tamanos, en la distancia al modelo (3.4); y para aumentar la precision del seguimiento en
situaciones complejas, un sistema para optimizar la seleccion inicial de las ventanas, ya
que el descriptor de covarianza es particularmente sensible a ventanas iniciales que incor-
poren alta proporcion de fondo. Ademas, serıa interesante combinar el metodo propuesto
en este trabajo con el algoritmo propuesto por Babenko et al. (2009), donde, en lugar de
etiquetar todas las muestras dentro de un area, como positiva con el algoritmo de Online
Multiple Instance Boosting, nuestro metodo podrıa proveer una probabilidad proporcional
a la distancia entre el modelo Online Naive Bayes Nearest Neighbor y la muestra.
Ahora, dado que utilizamos exitosamente dos videos para realizar el seguimiento; ex-
iste una real posibilidad de continuar esta investigacion desde la perspectiva de multiples
vistas (incluyendo al menos la vista superior y lateral) y calibracion de camaras. Lo
cual serıa de gran utilidad para minimizar el area de busqueda del detector de rostros y
del modelo de movimiento; ya que al tener la matriz de calibracion podemos conocer la
posicion estimada del objeto en las distintas camaras. Adicionalmente, se podrıa realizar
el seguimiento del rostro simultaneamente en las multiples vistas; pero utilizando la matriz
de calibracion y la muestra de la vista que tenga menor distancia al modelo de aparien-
cia, podrıamos optimizar el area de busqueda y aumentar la precision del seguimiento para
casos de oclusion extremos.
45

References
Abdi, H. (2007). Discriminant correspondence analysis. Encyclopedia of measure-
ment and statistics, 270–275.
Adam, A., Rivlin, E., & Shimshoni, I. (2006). Robust fragments-based tracking
using the integral histogram. In 2006 ieee computer society conference on computer
vision and pattern recognition (Vol. 1, pp. 798–805).
Ayache, A., Fillard, P., Pennec, X., & Nicholas, A. (2007). Geometric means in a
novel vector space structure on symmetric positive-definite matrices. Society, 29(1),
328–347.
Babenko, B., Yang, M., & Belongie, S. (2009). Visual tracking with online multi-
ple instance learning. In Ieee computer society conference on computer vision and
pattern recognition workshops, 2009. cvpr workshops 2009 (pp. 983–990).
Birchfield, S. (1998). Elliptical head tracking using intensity gradients and color his-
tograms. In Ieee computer society conference on computer vision and pattern recog-
nition (Vol. pages, pp. 232–237). Citeseer.
Boiman, O., Shechtman, E., & Irani, M. (2008, June). In defense of Nearest-
Neighbor based image classification. 2008 IEEE Conference on Computer Vision
and Pattern Recognition(i), 1–8.
Cortes, C., & Vapnik, V. (1995). SUPPORT-VECTOR NETWORKS 1 Introduction.
ReCALL(973).
Cortez, P., Undurraga, C., Mery, D., & Soto, A. (2009). Performance Evaluation of
the Covariance Descriptor for Target Detection. In 2009 international conference of
the chilean computer science society (pp. 133–141). IEEE.
46

Dalal, N., & Triggs, B. (2005). Histograms of Oriented Gradients for Human De-
tection. Pattern Recognition.
Grabner, H., Grabner, M., & Bischof, H. (2006). Real-time tracking via on-line
boosting. In Proc. bmvc (Vol. 1, pp. 47–56). Citeseer.
Grabner, H., Leistner, C., & Bischof, H. (2008). Semi-supervised on-line boosting
for robust tracking. In Proc. eccv (Vol. 2, pp. 234–247). Springer.
Gu, S., Zheng, Y., & Tomasi, C. (2010). Efficient Visual Object Tracking with On-
line Nearest Neighbor Classifier. x86.cs.duke.edu.
Hopfield, J. (1982). Neural networks and physical systems with emergent collec-
tive computational abilities. Proceedings of the National Academy of Sciences of the
United States of America, 79(8), 2554.
Hu, H., & Qin, J. (2008, June). Region covariance based probabilistic tracking.
2008 7th World Congress on Intelligent Control and Automation, 575–580.
Isard, M., & MacCormick, J. (2001). BraMBLe: A Bayesian multiple-blob tracker.
In Eighth ieee international conference on computer vision, 2001. iccv 2001. proceed-
ings (Vol. 2, pp. 34–41).
Ji, Q., Zhu, Z., & Lan, P. (2004). Real-time nonintrusive monitoring and prediction
of driver fatigue. Vehicular Technology, IEEE Transactions on, 53(4), 1052–1068.
Kadir, T., Zisserman, A., & Brady, M. (2004). An affine invariant salient region
detector. Computer Vision-ECCV 2004, 228–241.
Lampert, C., Blaschko, M., & Hofmann, T. (2009). Efficient subwindow search: A
branch and bound framework for object localization. Pattern Analysis and Machine
Intelligence, IEEE Transactions on, 31(12), 2129–2142.
47

Lowe, D. G. (1999). Object Recognition from Local Scale-Invariant Features. Com-
puter.
Mikolajczyk, K., & Schmid, C. (2005). A performance evaluation of local descrip-
tors. IEEE transactions on pattern analysis and machine intelligence, 1615–1630.
Montabone, S., & Soto, A. (2010, March). Human detection using a mobile plat-
form and novel features derived from a visual saliency mechanism. Image and Vision
Computing, 28(3), 391–402.
Nguyen, N., Bui, H., Venkatsh, S., & West, G. (2003). Recognizing and monitoring
high-level behaviors in complex spatial environments. 2003 IEEE Computer Society
Conference on Computer Vision and Pattern Recognition, 2003. Proceedings., II–
620–5.
Palaio, H., & Batista, J. (2008). A region covariance embedded in a particle filter
for multi-objects tracking. VS08.
Pearson, K. (1901). LIII. On lines and planes of closest fit to systems of points in
space. Philosophical Magazine Series 6, 2(11), 559–572.
Pedreschi, F., Mery, D., Mendoza, F., & Aguilera, J. (2004). Classification of Potato
Chips Using Pattern Recognition. JOURNAL OF FOOD SCIENCE-CHICAGO-,
69(6), 264–270.
Porikli, F., Tuzel, O., & Meer, P. (2006). Covariance Tracking using Model Update
Based on Lie Algebra. 2006 IEEE Computer Society Conference on Computer Vision
and Pattern Recognition - Volume 1 (CVPR’06), 728–735.
Rossmann, W. (2002). Lie Groups: An Introduction Through Linear Groups. Ox-
ford Press.
48

Saffari, A., Leistner, C., Santner, J., Godec, M., & Bischof, H. (2010). On-line
random forests. In Computer vision workshops (iccv workshops), 2009 ieee 12th
international conference on (pp. 1393–1400). IEEE.
Santner, J., Leistner, C., Saffari, A., Pock, T., & Bischof, H. (2010). PROST: Parallel
robust online simple tracking. In Computer vision and pattern recognition (cvpr),
2010 ieee conference on (pp. 723–730). IEEE.
Seow, H. (2000). Decisions on Additional Counters in the Banking Industry and
Applications of the Queuing Theory.
Sivic, J., Schaffalitzky, F., & Zisserman, A. (2004). Efficient object retrieval from
videos. In Proc. of the 12th european signal processing conference eusipco 04, vi-
enna, austria (pp. 1737–1740).
Stalder, S., Grabner, H., & Leuven, K. U. (2009). Beyond Semi-Supervised Tracking
: Tracking Should Be as Simple as Detection , but not Simpler than Recognition. In
Iccv.
Tuzel, O., Porikli, F., & Meer, P. (2006). Region Covariance : A Fast Descriptor for
Detection and Classificatio. Lecture Notes in Computer Science, 3952, 589.
Tuzel, O., Porikli, F., & Meer, P. (2008, October). Pedestrian detection via classifica-
tion on Riemannian manifolds. IEEE transactions on pattern analysis and machine
intelligence, 30(10), 1713–27.
Viola, P., & Jones, M. (2001). Rapid Object Detection using a Boosted Cascade of
Simple Features. In Proc. ieee cvpr 2001 (Vol. 00).
Viola, P., Platt, J., & Zhang, C. (2006). Multiple instance boosting for object detec-
tion. Advances in neural information processing systems, 18, 1417.
Wu, Y., Cheng, J., Wang, J., & Lu, H. (2009). Real-time Visual Tracking via Incre-
mental Covariance Tensor Learning. nlpr.labs.gov.cn(Iccv), 1631–1638.
49

Yao, J., & Odobez, J. (2008). Fast human detection from videos using covariance
features. Learning.
50


















