
SISTEMA DE APRENDIZAJE Y RECONOCIMIENTO DE...
206
Centro Departamento SISTEMA DE APRENDIZAJE Y RECONOCIMIENTO DE OBJETOS 3D A PARTIR DE IMÁGENES PLANAS de Trazegnies Otero Carmen E.T.S.I. de Telecomunicación Tecnología Electrónica 84-689-5286-9 ISBN
Transcript of SISTEMA DE APRENDIZAJE Y RECONOCIMIENTO DE...

Centro
Departamento
SISTEMA DE APRENDIZAJE Y RECONOCIMIENTO DE OBJETOS 3D APARTIR DE IMÁGENES PLANAS
de Trazegnies Otero
Carmen
E.T.S.I. de Telecomunicación
Tecnología Electrónica
84-689-5286-9ISBN

de Trazegnies OteroApellidosCarmenNombre
Sistema de aprendizaje y reconocimiento de objetos 3D apartir de imágenes planas
27 de marzo de 2004
E.T.S.I. de TelecomunicaciónCentroTecnología ElectrónicaDepartamento
Dra. Dª Cristina Urdiales GarcíaDirección de la Tesis
Dr. D. Francisco Sandoval HernándezPresidente/a
Dr. D. Luis Álvarez LeónDr. D. Jorge Miranda Dias
Dr. D. Juan Antonio Rodríguez FernándezSecretario/a
Vocales
COMPOSICIÓN DEL TRIBUNAL / DIRECCIÓN DE LA TESIS
NOMBRE Y APELLIDOS DEL AUTOR
TÍTULO DE LA TESIS DOCTORAL
FECHA DE LECTURA
CENTRO Y DEPARTAMENTO EN QUE FUE REALIZADA LA LECTURA
CALIFICACIÓN OBTENIDA
SOBRESALIENTE CUM LAUDE
MENÚ
Dr. D. Luis Baumela Molina

UNIVERSIDAD DE MALAGAESCUELA TECNICA SUPERIOR DE INGENIERIA DE
TELECOMUNICACION
TESIS DOCTORAL
SISTEMA DE APRENDIZAJE YRECONOCIMIENTO DE OBJETOS 3D A
PARTIR DE IMAGENES PLANAS
AUTOR: Carmen de Trazegnies OteroLicenciada en Ciencias Fısicas
2004


Dna. CRISTINA URDIALES GARCIA, PROFESORA DEL DEPARTAMENTO DE TEC-NOLOGIA ELECTRONICA DE LA UNIVERSIDAD DE MALAGA
CERTIFICO:
Que Dna. Carmen de Trazegnies Otero, Licenciada en Ciencias Fısicas, ha realizado en elDepartamento de Tecnologıa Electronica de la Universidad de Malaga, bajo mi direccion el tra-bajo de investigacion correspondiente a su Tesis Doctoral titulada:
SISTEMA DE APRENDIZAJE Y RECONOCIMIENTO DE OBJETOS 3D A PARTIR DEIMAGENES PLANAS
Revisado el presente trabajo, estimo que puede ser presentado al Tribunal que ha de juzgarlo.
Y para que conste a efectos de lo establecido en el Real Decreto 778/1998 regulador de losestudios de Tercer Ciclo-Doctorado, AUTORIZO la presentacion de esta Tesis en la Universidadde Malaga.
Malaga, a 22 de Enero de 2004
Fdo. Cristina Urdiales GarcıaProfesora de Tecnologıa Electronica


i
Departamento de Tecnologıa ElectronicaE. T. S. I. Telecomunicacion
Universidad de Malaga
TESIS DOCTORAL
SISTEMA DE APRENDIZAJE YRECONOCIMIENTO DE OBJETOS 3D A PARTIR
DE IMAGENES PLANAS
AUTOR: Carmen de Trazegnies Otero
Licenciada en Ciencias Fısicas
DIRECTOR: Dna. Cristina Urdiales Garcıa
Dra. Ingeniera en Telecomunicacion


iii
Antes de estudiar Zen, las montanas son montanas y los rıos son rıos;mientras estas estudiando Zen, las montanas ya no son montanas y los rıos ya no son rıos;
pero una vez que alcanzas la iluminacion las montanas son nuevamente montanasy los rıos nuevamente rıos.
(Proverbio Zen)


Agradecimientos
Los tres ultimos anos han sido especialmente intensos y estimulantes dentro de mi vidaprofesional. En este tiempo he tenido la suerte de conocer y compartir mi tiempo con personasque me han orientado, alentado y apoyado en la realizacion de esta tesis, y a las que estoyprofundamente agradecida. Quisiera expresar un recuerdo especial de gratitud a:
Cristina Urdiales, mi directora de tesis, por su dedicacion y esfuerzo, por ensenarme tantascosas. Gracias por haber confiado en mi, por plantearme como reto unos objetivos que parecıaninalcanzables y por apoyarme con decision hasta alcanzarlos.
Francisco Sandoval, director del Departamento de Tecnologıa Electronica, por sus consejos,sus correcciones, por su ayuda y, sobre todo, por ofrecerme la oportunidad de realizar estainvestigacion dentro del programa de investigacion que dirige.
Antonio Bandera, por nuestras largas discusiones sobre las funciones de curvatura.
Mis companeros de departamento, por sus consejos y palabras de aliento.
Juan Miguel, por empujarme a iniciar este camino, aun cuando eso significara aguantar misnervios y someterse a escuchar pacientemente mis divagaciones. Gracias por su intuicion paralas matematicas y, especialmente, por abrirnos los ojos al mundo de las PCAs. Gracias, en fin,por animarme siempre y acompanarme en todo.
Mi hermana, por estar siempre ahı, dispuesta a escuchar e incluso compartir mis problemas,por tener tantas energıas y transmitirlas a los demas.
Mis padres, por su carino, su confianza, su apoyo, y por ensenarme a no ser conformista.
Sadegh Abbasi, Josef Kittler y Farzin Mokhtarian, de la Universidad de Surrey, Reino Unido,por compartir su base de datos de siluetas de peces y animales marinos para su uso publico.
Fa-Shyang Chang y Shu-Yuan Chen, de la Universidad Yuan-Ze, Republica China, por faci-litarme amablemente su base de datos de figuras geometricas y figuras geometricas deformadas,para su uso en las pruebas de reconocimiento de figuras planas.
La Comision Interministerial de Ciencia y Tecnologıa (CICYT) que, a traves de los proyectosTIC98-0562 y TIC2001-1758, han apoyado parcialmente la financiacion de esta tesis.
v


Resumen
Esta tesis presenta un nuevo sistema de reconocimiento de objetos 3D a partir de una secuen-cia de vistas planas del mismo. El sistema no solo es capaz de clasificar objetos pertenecientes auna base de datos sino tambien de incluir nuevos objetos mediante un algoritmo de entrenamien-to no supervisado cuando estos no presenten un grado aceptable de similitud con ninguno deobjetos ya conocidos.
El sistema propuesto puede trabajar en un entorno virtual o bien con objetos reales pre-viamente segmentados. Si bien los sistemas de segmentacion constituyen un amplio tema deinvestigacion que no sera abordado en la presente tesis, se debe considerar que con cualquiersistema de segmentacion aplicado a imagenes reales la imagen resultante es susceptible de sufrirdistorsiones, transformaciones, deformaciones y ruido. El sistema de reconocimiento debe serpor lo tanto resistente ante estos factores.
Un sistema de reconocimiento basado en vistas planas implica el procesado de un conjuntode datos relativamente extenso. Para que se pueda efectuar en un tiempo razonable es impre-scindible reducirla por algun metodo de codificacion. En primer lugar se extrae la silueta delobjeto contenido en cada imagen. Las siluetas se representan mediante su funcion de curvatu-ra calculada segun un nuevo metodo, propuesto en la presente tesis, que se adapta a la escalanatural de la curva, filtrando el eventual ruido y respetando la informacion relevante. Es muy im-portante que la representacion de las siluetas sea invariante a rotacion y a escala. La invarianza aescala se puede conseguir sin mas que interpolar la funcion de curvatura a una longitud fija. Paraconseguir invarianza a rotacion se trabaja con el modulo de los coeficientes de la transformadadiscreta de Fourier de la funcion de curvatura. La informacion contenida en las transformadasde Fourier se reduce aun mas mediante un analisis por componentes principales. Ası, cada vistaplana queda representada por un vector de caracterısticas de dimension reducida.
Un objeto se representa pues mediante una secuencia de vectores de caracterısticas. Lanaturaleza de cada vista de la secuencia depende basicamente de cual haya sido la vista anteriordel objeto, por lo tanto se puede analizar como un proceso estocastico de Markov. Ası, se puededefinir un modelo de Markov que describa a cada objeto y evaluar la probabilidad de que cadaobjeto de la base de datos de lugar a una determinada secuencia de vistas. Ası, es un problemafundamental la definicion de los estados de cada modelo de Markov. Se puede definir cadaestado como un tipo particular de vista. Sin embargo, dada la naturaleza del problema, cadanueva vista de un objeto puede pertenecer a varias clases distintas pertenecientes a su vez auno o varios objetos. Para poder manejar esta indeterminacion en la asignacion de estados esnecesario trabajar con modelos ocultos de Markov.
El metodo de reconocimiento propuesto no solo ofrece una medida de la similitud de losobjetos observados respecto de los almacenados en la base de datos, sino que ademas es posiblerealizar el entrenamiento de objetos nuevos de una forma no supervisada. El sistema ha sidoprobado tanto con objetos virtuales como reales, agrupando siempre los objetos que desde elpunto de vista humano, presentan una similitud apreciable en la forma.
vii


Abstract
This thesis presents a new view based 3D object recognition system. The proposed systemallows both recognition of known object and learning of new ones by means of a non supervisedtraining algorithm when the input object is unknown.
The proposed system can operate in virtual environments and also with real, previouslysegmented objects. Even though segmentation is not covered in this thesis, it is assumed thatsegmenting real images is a very hard problem and, hence, the resulting object may be affectednot only by transformations but also by noise, distortions and deformations. The recognitionsystem must be, consequently, resistant against all these factors.
A view based recognition system involves a huge data volume. In order to achieve a reasonableprocessing time, it is important to reduce such information by using an efficient coding method.First, the contour of each planar view of the object is extracted. Contours are represented bymeans of their curvature function, which is calculated by a new method proposed in this thesis.This new curvature function adapts itself to the natural scale of the curve and, hence, removesnoise in an optimal way and does not alter relevant information. Resistance against scale can beachieved by simply interpolating or decimating functions to a fixed length. However, to achieveresistance against rotations, we work with the module of the discrete Fourier Transform of thecurvature function. The information in this module is further reduced by means of PrincipalComponents Analysis so that each planar view is represented by a short feature vector.
An object can be represented by a sequence of so defined feature vectors. The nature ofeach view in the sequence basically depends on the previous view in each object and, hence,recognition can be evaluated as an stochastic Markov process. Thus, each object can be definedby a Markov model and recognition can be achieved by calculating the probability of each viewsequence of belonging to a learnt model. Thus, definition of the Markov states is critical forrecognition. It would have been possible to assign each state to a particular view but, sincedifferent objects may present similar views, we require Hidden Markov Models.
The proposed recognition system does not only return a measure of similarity among observedobjects and stored ones, but also allows non supervised learning of unknown objects. It has beensuccesfully tested both for real and virtual objects, which have usually been reasonably groupedfrom a human point of view regarding shape criteria.
ix


Indice general
1. Vision artificial y reconocimiento de objetos 11. Introduccion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12. Vision artificial y modelos de aprendizaje . . . . . . . . . . . . . . . . . . . . . . 33. Reconocimiento de objetos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64. Objetivos y organizacion del texto . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2. Descripcion de formas planas 111. Introduccion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112. Metodos de descripcion de la forma . . . . . . . . . . . . . . . . . . . . . . . . . . 133. Representacion de formas planas . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1. Representacion de objetos mediante curvatura . . . . . . . . . . . . . . . 153.2. Representacion de objetos mediante puntos caracterısticos . . . . . . . . . 223.3. Representacion de objetos mediante Componentes Principales de su cur-
vatura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264. Resultados y experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.1. Reconocimiento basado en curvatura . . . . . . . . . . . . . . . . . . . . . 354.1.1. Metodo de reconocimiento y metrica . . . . . . . . . . . . . . . . 354.1.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2. Reconocimiento basado en puntos caracterısticos . . . . . . . . . . . . . . 384.2.1. Metodo de reconocimiento . . . . . . . . . . . . . . . . . . . . . 384.2.2. Caracterizacion de puntos . . . . . . . . . . . . . . . . . . . . . . 404.2.3. Construccion del MOM . . . . . . . . . . . . . . . . . . . . . . . 414.2.4. Metrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424.2.5. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.3. Reconocimiento por Componentes Principales de la Curvatura . . . . . . 504.3.1. Metodo de reconocimiento . . . . . . . . . . . . . . . . . . . . . 504.3.2. Extraccion de una base . . . . . . . . . . . . . . . . . . . . . . . 514.3.3. Metrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 584.3.4. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3. Reconocimiento de objetos 3D. 671. Introduccion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 672. Descripcion de un conjunto de vistas . . . . . . . . . . . . . . . . . . . . . . . . . 723. Construccion de modelos de objetos 3D . . . . . . . . . . . . . . . . . . . . . . . 81
3.1. Definicion de los modelos ocultos de Markov . . . . . . . . . . . . . . . . 844. Aprendizaje y Reconocimiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 865. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
xi

xii Indice
5.1. Funcionamiento del sistema de reconocimiento frente a una base de objetospredefinida . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.2. Comportamiento del sistema frente a variaciones de escala de los objetospresentados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5.3. Comportamiento del sistema frente a un conjunto de objetos de formasimilar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
5.4. Comportamiento del sistema frente a deformaciones de los objetos originales1106. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4. Experimentos y resultados. 1191. Introduccion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1192. Metodo de Entrenamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1203. Reconocimiento de objetos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
3.1. Experimentos con objetos simples . . . . . . . . . . . . . . . . . . . . . . 1263.2. Experimentos con objetos complejos . . . . . . . . . . . . . . . . . . . . . 131
4. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
5. Conclusiones 1451. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1452. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
A. Modelos Ocultos de Markov. 1631. Modelos de Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1632. Modelos Ocultos de Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
2.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1652.2. Elementos de los Modelos ocultos de Markov . . . . . . . . . . . . . . . . 1682.3. Definicion de tres problemas basicos . . . . . . . . . . . . . . . . . . . . . 1692.4. Resolucion del problema de evaluacion . . . . . . . . . . . . . . . . . . . . 169
2.4.1. Algoritmo de avance . . . . . . . . . . . . . . . . . . . . . . . . . 1702.5. Resolucion del problema de busqueda de secuencia optima . . . . . . . . . 1722.6. Resolucion del problema de entrenamiento . . . . . . . . . . . . . . . . . . 1732.7. Modelos Ocultos de Markov de sistemas con variables de observacion con-
tinuas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176

Lista de Sımbolos y Acronimos
3DS Formato grafico, perteneciente al programa 3DStudio, para el almacena-miento de modelos de objetos tridimensionales virtuales.
Ap En un Modelo de Markov, matriz de probabilidades de transicion de unobjeto p.
Api,j En un Modelo de Markov, probabilidad de transicion del estado H i al
estadoHj .
AECF Funcion de curvatura adaptativa (Adaptively Estimated Curvature Func-tion).
Ang Angulo que forma la pendiente de un contorno dado en un punto respectode la horizontal.
αt(i) Variable de avance evaluada en la observacion t para un estado oculto H i.
Bp En un Modelo Oculto de Markov, matriz probabilidad de observacion deun objeto p.
Bi(V q) En un Modelo de Markov de observaciones continuas, probabilidad de queuna observacion valga V q, siendo el estado oculto H i.
bpi,q En un Modelo Oculto de Markov, probabilidad de obtener la observacion
V q, siendo el estado oculto H i.−→βi Proyeccion del vector
−→Xi, que representa a la figura i-esima, sobre la base
de componentes principales.
βt(i) Variable de retroceso evaluada en la observacion t para un estado ocultoH i.
C Matriz de autocorrelacion.
Cx Secuencia de esquinas de una forma plana x.
Cix Esquina i-esima de la secuencia de esquinas de una forma plana x.
||CFFFT|| Modulo de las componentes de la transformada de Fourier de la funcion decurvatura (Curvature Function Fast Fourier Transform).
CHM Metodo de los histogramas circulares (Circular Histograms Method).
∆ Operador incremento.
xiii

xiv Sımbolos y Acronimos
−→δi Delta de Dirac centrada en el punto i.
δt(i) En un Modelo Oculto de Markov, el mejor resultado de probabilidad deocurrencia de una secuencia de observaciones cuando la secuencia de estadosocultos asociada termina en el estado H i
E Eficiencia. Relacion entre el numero de esquinas detectadas por el detectorde esquinas optimo y el evaluado.
ε2 Error cuadratico medio.
F Fidelidad. Relacion entre el error cometido por un detector de esquinasoptimo y el evaluado.
FBR Funciones Base Radiales.
FC Funcion de curvatura.
FFT Transformada rapida de Fourier (Fast Fourier Transform).
FV Vector de caracterısticas (Feature Vector).−→φk k-esimo vector perteneciente a una base ortogonal del subespacio de dimen-
sion P que se utiliza para representar todas las figuras planas.
ϕj j-esima componente principal del vector de caracterısticas que representaa una figura plana.
γt(i) Probabilidad de que, dados un Modelo Oculto de Markov y una secuenciade observaciones, el proceso este en el estado oculto H i en el instante t.
H Conjunto de estados accesibles a un Modelo de Markov.
Hp Conjunto de estados accesibles al Modelo de Markov de un objeto p.
Hp,i Cada uno de los estados del Modelo de Markov de un objeto p.
IA Inteligencia Artificial.
IFFT Transformacion inversa de la transformada rapida de Fourier.
ISE Error cuadratico integral (Integral Square Error).
ISEaprox Error cuadratico integral entre el contorno original y una aproximacionpoligonal del mismo.
ISEopt Error cuadratico integral entre el contorno original y la aproximacion polig-onal optima del mismo.
k Maxima longitud libre de discontinuidades medida desde un punto sobre uncontorno dado. Es una cantidad variable utilizada en la estimacion adap-tativa de la funcion de curvatura.
λk Cada uno de los autovalores de una matriz de autocorrelacion.
λp Modelo Oculto de Markov de un objeto p.

Sımbolos y Acronimos xv
M Numero de elementos de un subconjunto de figuras planas a partir del cualse calcula una base del espacio de todas las figuras planas.
Maprox Numero de lados de una aproximacion poligonal de un contorno.
Mopt Numero de lados de la aproximacion poligonal optima de un contorno.
MAP Maximos A Posteriori. Metodo bayesiano para la estimacion de parametrosprobabilısticos de un sistema.
Merito Medida de la bondad de un detector de esquinas como metodo de aproxi-macion poligonal de un contorno.
MM Modelo de Markov.
MOM Modelo Oculto de Markov.
MSV Maquinas de Soporte Vectorial.
max Indice de similitud obtenido de la correlacion circular de dos funciones decurvatura.
N Numero de componentes de cada ||CFFFT|| de un contorno.
N0 Longitud en pixeles del contorno de una figura plana cualquiera.
P Dimension de los vectores de caracterısticas que representan figuras planas.
P (A) Probabilidad de ocurrencia del suceso A.
P (A|B) Probabilidad de ocurrencia del suceso A, habiendo ocurrido el suceso B.
PCA Analisis de Componentes Principales (Principal Components Analysis).
Πp En un Modelo de Markov, vector de probabilidades iniciales de observacionde un objeto p.
πi En un Modelo de Markov, probabilidad de encontrar el estado H i comoprimer estado de una secuencia.
Q En un proceso de Markov, secuencia de estados.
Q Conjunto de clases de puntos caracterısticos de una forma plana.
Qq q-esimo estado de la secuencia en un proceso de Markov.
qi Clase q-esima de puntos caracterısticos de una forma plana y, por extension,vector que representa a su prototipo.
RN Espacio vectorial N -dimensional.
RBV Reconocimiento Basado en Vistas.
ρ Radio de curvatura definido en un punto de una curva.
S Conjunto de todas las posibles ||CFFFT||s de figuras planas.

xvi Sımbolos y Acronimos
S En un proceso de Markov, una secuencia de estados generica.
Si En un proceso de Markov, estado i-esimo de una secuencia de estados S.
Sα Subconjunto abierto del conjunto de todas las posibles ||CFFFT||s de fig-uras planas.
SUSAN Metodo de reconocimiento de objetos bidimensionales basado en la detec-cion de caracterısticas de las esquinas de una imagen mediante mascaras(Smallest Univalue Segment Asimilating Nucleus).
T Numero total de observaciones pertenecientes a una secuencia.
TamF Longitud de una funcion de curvatura.
V q En un Modelo de Markov, q-esima vista de una secuencia de observaciones.−−→Xm Modulo de las componentes de la transformada de Fourier de la funcion de
curvatura del contorno de la figura m escrito en notacion vectorial.
x Conjunto de cartas inyectivas de S.
x Funcion de curvatura generica.
x Vector generico −→x .
xα Carta inyectiva del conjunto S cuya imagen es Sα.
x(i) valor i-esimo de una funcion de curvatura generica x.
ξt(i, j) Probabilidad de que, dados un Modelo Oculto de Markov y una secuenciade observaciones, se produzca una transicion del estado oculto H i en elinstante t y Hj en el instante t + 1.
−→Y Vector que representa una figura plana generica en el espacio vectorial RN .
y Funcion de curvatura generica.
y(i) valor i-esimo de una funcion de curvatura generica y.

Indice de figuras
1.1. Disenos de sistemas autonomos moviles con guiado por vision para: a) fabricas;b) museos; c) hogares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2. Interfaz hombre-maquina en la vision artificial . . . . . . . . . . . . . . . . . . . . 4
2.1. Representacion por curvatura: a) objeto generico; b) funcion resultante. . . . . . 192.2. Reconstruccion a partir de curvatura: a) objetos ruidosos ejemplo; b) AECF del
objeto; c) funcion de curvatura propuesta; d) reconstruccion a partir de AECF;y e) reconstruccion a partir de la funcion propuesta. . . . . . . . . . . . . . . . . 20
2.3. Comparativa entre detectores de esquinas: a) Contorno 1 y esquinas detectadascon los metodos CHM, AECF y propuesto ; b) contorno 2 y esquinas detectadascon el metodo CHM (k = 6); c)contorno 2 y esquinas detectadas con el metodoAECF; y d) contorno 2 y esquinas detectadas con el metodo propuesto . . . . . . 25
2.4. a) Variedad de dimension 1 extendida; y b) variedad de dimension 1 plegada . . 322.5. a) Conjunto de 6 figuras geometricas; y b) ejemplo de 15 deformaciones de una
de ellas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.6. a) Conjunto de 34 caracteres tomados de matrıculas de coches; y b) ejemplo de
30 versiones de un caracter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.7. a) Conjunto de 27 anagramas de senales de trafico: y b) ejemplos de deformaciones
aplicadas al conjunto anterior . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.8. Ejemplos de siluetas de prueba del conjunto de siluetas de peces (Mokhtarian y
Mackworth, 1986) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.9. Ejemplos de siluetas de prueba del conjunto de objetos tridimensionales . . . . . 362.10. a-b) Vistas rotadas del mismo objeto; c-d) funciones de curvatura; y e) correlacion
circular de c-d) y su maximo valor. . . . . . . . . . . . . . . . . . . . . . . . . . . 382.11. Objetos reconocidos mediante correlacion: a-d) clase 1; e-h) clase 2; i-l) clase 3;
y m-p) clase 4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392.12. Parametros de caracterizacion de una esquina . . . . . . . . . . . . . . . . . . . . 402.13. Patrones correctamente reconocidos: a) caracteres tipo letra; b) caracteres de
placas de matrıculas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442.14. Reconocimiento de objetos distorsionados: a) prototipo y esquinas; b) caracteres
de entrada y esquinas; c) evolucion de la probabilidad de ser el prototipo con cadaesquina evaluada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.15. Error de reconocimiento en objetos distorsionados: a) objeto de entrada y es-quinas; b) prototipos de la letra K y la letra N y sus esquinas; c) evolucion de laprobabilidad de ser cada uno de los prototipos con cada esquina evaluada. . . . . 45
2.16. Resultados de reconocimiento para conjunto de figuras geometricas: a) imagenesdeformada; b) lista de los elementos mas similares a cada uno de los propuestos. 46
xvii

xviii Indice de Figuras
2.17. a) Imagen original; b) caracteres extraıdos y sus esquinas; c) prototipos recono-cidos y sus esquinas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.18. Ejemplos de reconocimiento para los peces de a) a e), situados, de arriba a abajoen orden decreciente de probabilidad. . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.19. Comparativa entre el metodo propuesto (HMM) y el metodo CSS para el re-conocimiento de peces de a) a d), situados, de arriba a abajo en orden decrecientede probabilidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.20. Ejemplos de reconocimiento para los peces de a) a d), que presentan oclusionparcial del contorno. Los resultados estan situados de arriba a abajo en ordendecreciente de probabilidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.21. Ejemplos de reconocimiento para los peces de a) a d), presentando una defor-macion del contorno. Los resultados estan situados de arriba a abajo en ordendecreciente de probabilidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.22. Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calculadacon a) el conjunto de figuras geometricas (base 1); y el conjunto ampliado defiguras geometricas (base 2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.23. Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calculadacon a) el conjunto de 34 caracteres extraıdos de placas de matrıcula(base 3); y elconjunto ampliado de caracteres extraıdos de placas de matrıcula (base 4) . . . . 54
2.24. Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calculadacon a) el conjunto de anagramas de senales de trafico (base 5); y el conjuntoampliado de anagramas de senales de trafico (base 6) . . . . . . . . . . . . . . . . 54
2.25. Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calcu-lada con a) el conjunto de peces(base 7); y el conjunto de siluetas de objetostridimensionales(base 8) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
2.26. Error de representacion para: a) conjunto de siluetas de peces; y b) conjunto desiluetas de objetos tridimensionales . . . . . . . . . . . . . . . . . . . . . . . . . . 56
2.27. Error de representacion sobre la base 2, la base 5 y una combinacion de am-bas para: a) conjunto de siluetas de peces; y b) conjunto de siluetas de objetostridimensionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
2.28. Error de representacion sobre la base 3, la base 5 y una combinacion de am-bas para: a) conjunto de siluetas de peces; y b) conjunto de siluetas de objetostridimensionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
2.29. Distancias desde los vectores de caracterısticas del conjunto de caracteres ex-traıdos de matrıculas reales hasta cada uno de los cinco primeros modelos decaracteres: a) distancias euclıdeas; y b) distancias de Tanimoto . . . . . . . . . . 59
2.30. Vectores de caracterısticas: a) numeros 0; y b) numeros 4 . . . . . . . . . . . . . 602.31. Porcentaje de letras correctamente clasificadas en funcion del numero de compo-
nentes) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 632.32. Resultados de clasificacion para el numero 2: a) figuras correctamente clasificadas;
b) figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrecta-mente clasificadas dentro del grupo) . . . . . . . . . . . . . . . . . . . . . . . . . 64

Indice de Figuras xix
2.33. Resultados de clasificacion para la letra B: a) figuras correctamente clasificadas; b)figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrectamenteclasificadas dentro del grupo) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
2.34. Resultados de clasificacion para la letra R: a) figuras correctamente clasificadas; b)figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrectamenteclasificadas dentro del grupo) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
2.35. Resultados de clasificacion para la letra W : a) figuras correctamente clasificadas;b) figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrecta-mente clasificadas dentro del grupo) . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.1. Puntos de vista para un objeto 3D; b) vista plana y su vector de caracterısticas;y c) otra vista plana y su vector de caracterısticas . . . . . . . . . . . . . . . . . 73
3.2. Mapas de clases de un objeto 3D: a) Objeto; b) mapa de clases de vistas tomadascon un intervalo angular de 9o; y c) mapa de clases de vistas tomadas con unintervalo angular de 30o . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.3. a) Numero de clases de vistas frente al radio de agrupacion para un cubo; b)grupo de objetos de diversa complejidad; y c) Numero de clases de vistas frenteal radio de agrupacion para los objetos en (b) . . . . . . . . . . . . . . . . . . . . 80
3.4. Esquemas basicos de modelos de Markov sencillos: a) Modelo clasico de Markov;y b) Modelo oculto de Markov cuyas observaciones son elementos de un espaciovectorial bidimensional . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
3.5. a) Dado normal de juego; b) dado con la cara 4 repetida; y c) dado con las carasdesordenadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
3.6. a) Conjunto de 27 anagramas de senales de trafico: y b) ejemplos de deformacionesaplicadas al conjunto anterior . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
3.7. a) Cubo; y b) mapa de clases del cubo . . . . . . . . . . . . . . . . . . . . . . . . 923.8. Conjunto de objetos de prueba . . . . . . . . . . . . . . . . . . . . . . . . . . . . 923.9. Prueba de reconocimiento para el objeto en Fig. 3.8.c . . . . . . . . . . . . . . . 943.10. Prueba de reconocimiento para el objeto en Fig. 3.8.d cuando el sistema aun no
tiene modelo para el mismo: a) partiendo de una vista lateral; y b) partiendo deuna vista cenital . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
3.11. Prueba de reconocimiento para el objeto en Fig. 3.8.d una vez que el sistema tieneun modelo para el mismo: a) partiendo de una vista lateral; y b) partiendo deuna vista cenital . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
3.12. Prueba de reconocimiento para el objeto en Fig. 3.8.f: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 96
3.13. Prueba de reconocimiento para el objeto en Fig. 3.8.g: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 97
3.14. Prueba de reconocimiento para el objeto en Fig. 3.8.h: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 98
3.15. Prueba de reconocimiento para el objeto en Fig. 3.8.i: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 98
3.16. Prueba de reconocimiento erroneo para el objeto de la Fig. 3.8.j . . . . . . . . . . 993.17. Prueba de reconocimiento para el objeto en Fig. 3.8.k: a) cuando el sistema aun
no tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 1003.18. Prueba de reconocimiento para el objeto en Fig. 3.8.l: a) cuando el sistema aun
no tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 100

xx Indice de Figuras
3.19. Prueba de reconocimiento para el objeto en Fig. 3.8.m: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 101
3.20. Prueba de reconocimiento para el objeto en Fig. 3.8.n: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 101
3.21. Prueba de reconocimiento para el objeto en Fig. 3.8.p: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido . . 102
3.22. Segunda prueba de reconocimiento para el objeto en Fig. 3.8.j cuando el sistemaya dispone de muchos modelos: a) mientras el sistema aun no tiene modelo parael mismo; y b) una vez que su modelo ha sido adquirido . . . . . . . . . . . . . . 104
3.23. FCs de tres circunferencias de distintas longitudes: a) circunferencia de 594 pixelesde longitud; b) de 282 pixeles; y c) de 86 pixeles. . . . . . . . . . . . . . . . . . . 105
3.24. a) Mesa del conjunto inicial de objetos y su mapa de clases; b) la misma mesa al150 % de su escala natural y su mapa respecto de las clases de la mesa en (a); c)la misma mesa al 75 % de su escala natural y su mapa respecto de las clases de lamesa en (a); d) la misma mesa al 50% de su escala natural y su mapa respectode las clases de la mesa en (a); y e) Porcentajes de reconocimiento correcto de(b)-(c) como similares al objeto en (a) . . . . . . . . . . . . . . . . . . . . . . . . 107
3.25. Conjunto de objetos cilındricos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1083.26. Porcentajes de reconocimiento de los cilindros de la Fig. 3.25: a) cuando el sistema
carece de modelos para los cilindros (a), (c) y (d); b) cuando carece de modelospara los (a) y (c); y c) cuando carece de modelo para el (a) . . . . . . . . . . . . 108
3.27. Porcentajes de reconocimiento de los cilindros de la Fig. 3.25 a) cuando el sistemacarece de modelos para los cilindros (b), (c) y (d); b) cuando carece de modelospara los (b) y (c); y c) cuando carece de modelo para el (b) . . . . . . . . . . . . 109
3.28. a) Objeto del conjunto de entrenamiento y su mapa de clases de vistas; b-d)deformaciones del objeto en (a) y sus mapas de clases de vistas; y e) Porcentajesde reconocimiento correcto de (b)-(c) como similares al objeto en (a) . . . . . . . 111
3.29. Prueba de reconocimiento para el objeto en Fig. 3.28.b: a) reconocimiento erroneo;y b) reconocimiento correcto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
3.30. Prueba de reconocimiento para el objeto en Fig. 3.28.d: a) objeto desconocido; yb) reconocimiento correcto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
3.31. Comparacion de las FCs de dos contornos de un objeto parcialmente ocluido, a)oclusion de perfil concavo; y b) oclusion de perfil recto . . . . . . . . . . . . . . . 115
4.1. Base de datos de sillas para 3DStudio descargada de Internet . . . . . . . . . . . 1224.2. 72 vistas de una silla generadas por el modulo virtual de entrenamiento . . . . . 1234.3. Aprendizaje de un modelo virtual: a) objeto virtual; y b) mapa de vistas. . . . . 1244.4. Fallo en reconocimiento: entrenamiento. . . . . . . . . . . . . . . . . . . . . . . . 1254.5. Conjunto de objetos aprendidos en orden de entrenamiento. . . . . . . . . . . . . 1254.6. Segmentacion por substraccion de fondo: a) fondo sin objetos; b) imagen captura-
da; c) objetos detectados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1264.7. Prueba de reconocimiento para la taza 1 cuando el sistema aun no ha aprendido
su modelo: a) cuando el asa no es visible en la primera vista; y b) cuando el asaes visible ya en la primera vista . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
4.8. Prueba de reconocimiento para la taza 1, a) cuando el sistema aun no ha aprendidosu modelo pero contiene varios modelos compatibles con la primera vista; y b)cuando el sistema ya ha adquirido un modelo para la taza 1 . . . . . . . . . . . . 128

Indice de Figuras xxi
4.9. a-b) Distintas vistas de la taza 1; c-d) Siluetas segmentadas por sustraccion defondo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
4.10. Reconocimiento de una taza: a) objeto virtual; b) objeto real. . . . . . . . . . . . 1304.11. a-c) Distintas vistas de la taza 2; d-f) Siluetas segmentadas por sustraccion de
fondo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1314.12. Reconocimiento de una taza: a) objeto virtual; b) objeto real. . . . . . . . . . . . 1324.13. Objeto con una sola vista distorsionada: a) vista distorsionada; y b) mapa de
vistas alterado respecto del mapa del mismo objeto sin distorsionar, mostrado enFig. 4.3.b. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
4.14. a) Reconocimiento de una silla sin distorsionar; y b) reconocimiento de la mismasilla con oclusion parcial del respaldo en la primera vista. . . . . . . . . . . . . . 134
4.15. a) Reconocimiento de una silla sin distorsionar; y b) reconocimiento de la mismasilla con oclusion parcial de las patas en la primera vista. . . . . . . . . . . . . . 135
4.16. a) Reconocimiento de un objeto sin distorsion; y b) reconocimiento del mismoobjeto distorsionado. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
4.17. a) Contorno de una vista no distorsionada de una silla; b) contorno de una vistadistorsionada de la silla; y c) funcion de curvatura del contorno en (a) (lınea rojapunteada) y del contorno en (b) (lınea azul continua). . . . . . . . . . . . . . . . 137
4.18. Reconocimiento con todas las vistas deformadas: a) ejemplo con la silla de la Fig.4.1.a; y b) ejemplo con la silla de la Fig.4.1.d. . . . . . . . . . . . . . . . . . . . . 138
4.19. Porcentajes de reconocimiento con todas las vistas deformadas. . . . . . . . . . . 1394.20. a) Imagen capturada de una silla real; y b) vista segmentada por sustraccion de
fondo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1394.21. Reconocimiento de una silla sin brazos real: a) a partir de una secuencia ordenada
de vistas; b) a partir de una secuencia que incluye vistas desordenadas. . . . . . . 1404.22. a) Imagen capturada de una silla real; y b) vista segmentada por sustraccion de
fondo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1424.23. Reconocimiento de una silla con brazos real: a) a partir de una secuencia ordenada
de vistas; b) a partir de una secuencia que incluye vistas desordenadas. . . . . . . 142
5.1. a) Objeto 1, presentando cuatro esquinas de 90o; b) objeto 2, presentando cuatroesquinas de −90o; y c) funcion de curvatura del objeto 1 (lınea azul) y del objeto2 (lınea roja) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
A.1. a)Secuencia de operaciones para el calculo de la variable de avance, αt(i); b)secuencia de operaciones para el calculo de la variable de retroceso, βt(i); y c)secuencia de operaciones para el calculo de la probabilidad de transicion de H i aHj en el instante t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171


Indice de tablas
2.1. Comparativa de diversos detectores de esquinas . . . . . . . . . . . . . . . . . . . 262.2. Rango de extraccion del metodo propuesto y el desarrollado en (Chang y Chen,
2000) para la base de datos geometrica . . . . . . . . . . . . . . . . . . . . . . . . 47
3.1. Probabilidades de observacion de la secuencia V 4 con MM’s de distintos dados . 883.2. Probabilidades de observacion normalizadas de la secuencia V 4 con MM’s de
distintos dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 893.3. Resultados de reconocimiento para distintos radios de clasificacion de vistas . . . 103
xxiii


Capıtulo 1
Vision artificial y reconocimiento deobjetos
1. Introduccion.
El vertiginoso avance de la tecnologıa en el siglo XX ha estado definitivamente marcado
por la aparicion del primer ordenador, el Eniac, en 1945, ası como por la rapidısima expansion
de las computadoras y su imbricacion en la mayorıa de las disciplinas de la ciencia 1. El de-
sarrollo de las computadoras ha creado, como cabıa esperar, la expectativa de integrarlas en la
vida cotidiana de forma que ayuden al ser humano en sus tareas. Evidentemente, el problema
a resolver se convirtio en dotar de un cuerpo fısico a las computadoras para que estas pudiesen
interactuar con el entorno. El asentamiento de la robotica como disciplina y la comercializacion
de prototipos industriales de robots en 1946 de la mano de George Devol y Joe Engleberger re-
solvio, al menos en parte, esta dificultad. Los robots constituıan maquinas capaces de actuar de
una u otra forma en funcion de un programa. Posteriormente, a efectos de que estas maquinas
pudiesen introducirse eficazmente en un mundo hasta ese momento exclusivo para humanos,
se dedico un gran esfuerzo a simplificar la interfaz entre ambos. A ese respecto, era necesario
establecer un puente entre la forma de procesar de una computadora y la forma de pensar de
un ser humano. De esta tarea se encargo la inteligencia artificial (IA), que surge como disciplina
en 1956, durante la conferencia de Darthmouth. La IA permite que, en lugar de indicarle con
precision que debe hacer a una maquina mediante un programa informatico directamente liga-
do a sus componentes mecanicos, se le soliciten determinadas tareas en lenguaje mas o menos
natural y estas se resuelvan satisfactoriamente para conseguir el resultado deseado. Sin embar-
go, el planteamiento original de la IA ha estado dominado por la vision de la mente humana1Se estima que a principios del siglo XXI el porcentaje de penetracion de los ordenadores personales en Europa
esta en torno al 41.3%
1

2 Capıtulo 1. Vision artificial y reconocimiento de objetos
de acuerdo a los parametros de una computadora. Dicho planteamiento condujo a que, hasta
principios de los 80, la IA estuviese afectada por lo que se conoce como trampa internalista,
que generaba programas independientes del mundo fısico y disenados para operar a partir de
una representacion interna de la realidad, dejando de lado el hecho de encontrarse inmersos en
un entorno fısico (Varela et al., 1991). A efectos de interactuar con ese entorno, las maquinas
inteligentes u organismos artificiales, al contrario que los programas de ordenador que operan de
forma aislada al mundo exterior, deben estar dotados de la capacidad de percibir dicho entorno
e influir sobre el. Para ello, la maquina no solo debe soportar una estructura mecanica capaz de
desplazarla en funcion de la respuesta de la computadora que hace las veces de su cerebro sino
tambien de un conjunto de sensores a partir de los cuales observa el estado del mundo externo y
que forman parte de los datos de entrada para el problema que la computadora debe resolver. Es
inmediato constatar que este esquema funciona de forma realimentada: cuando la maquina in-
teractua con el entorno, hace que este varıe y, por tanto, cambia la entrada al problema, lo que a
su vez puede alterar la respuesta de esta. En general, los sistemas que obedecen a estas premisas
no solo varıan su comportamiento en funcion del mundo externo, sino que incluso pueden ser
capaces de aprender y evolucionar. Esto es lo que se ha venido denominando comportamiento
adaptativo y ha dominado el concepto de robotica durante las ultimas dos decadas. Es impor-
tante notar que los comportamientos emergentes en un sistema de este tipo son el resultado de
la mencionada adaptacion mas que de un programa determinado y, por tanto, a veces pueden
no ser siquiera susceptibles de interpretacion por un ser humano (Prem, 1995).
Actualmente, el mundo depende cada vez mas de las computadoras para todo tipo de
tareas. De forma similar, los sistemas autonomos inteligentes, capaces de desplazarse y tomar
decisiones por si mismos, se usan cada vez con mayor frecuencia. Sin embargo, es inmediato
constatar que su uso queda restringido en muchas ocasiones a entornos industriales o, al menos,
altamente controlados, mientras que aparecen mucho mas residualmente en entornos fuertemente
dinamicos como hogares, oficinas o establecimientos de todo tipo (Fig. 1.1). Una de las principales
razones de este hecho reside en que la enorme complejidad de estos entornos obliga a utilizar
sistemas sensoriales capaces de percibirla en su mayor parte. Al igual que en el caso del ser
humano, el sentido natural para esta tarea es la vision. Sin embargo, resulta extremadamente
complejo determinar en un entorno cualquiera que se esta percibiendo para poder tomar la
decision de como actuar en un momento determinado. Este problema constituye lo que se conoce
como vision artificial.

2. Vision artificial y modelos de aprendizaje 3
Figura 1.1: Disenos de sistemas autonomos moviles con guiado por vision para: a) fabricas; b)museos; c) hogares
2. Vision artificial y modelos de aprendizaje
La vision artificial puede definirse como el proceso de extraer informacion del entorno
a partir de una o mas imagenes de dicho entorno mediante una computadora. El proceso se
basa en imitar la vision humana de forma que la computadora sea capaz de percibir, carac-
terizar y reconocer objetos en dicho entorno, usando esta informacion para tomar una decision
o llevar cabo una accion determinada. Es interesante observar que, de acuerdo a esta defini-
cion, el reconocimiento de objetos es el objetivo final del proceso de vision, ya que aporta la
informacion necesaria acerca del entorno para que una maquina pueda resolver un determinado
problema. Segun Turing, una maquina podra ejecutar cualquier calculo en tanto que alguien
pueda explicarlo en su lengua natural y sin ambiguedad. Es, por tanto, necesario, definir de
forma clara y eficaz una interfaz hombre-maquina que permita traducir problemas del mundo
fısico a un lenguaje que una computadora pueda entender. Tal como se ha comentado antes,
esta traduccion ha sido tradicionalmente la competencia basica de la inteligencia artificial. Ası,
de forma natural, la vision artificial surge de combinar sensores de captacion de imagen y al-
goritmos de procesado de esta con tecnicas de inteligencia artificial a efectos de comprender y
procesar una escena concreta. En particular, la interfaz entre humanos y maquinas en el campo

4 Capıtulo 1. Vision artificial y reconocimiento de objetos
Figura 1.2: Interfaz hombre-maquina en la vision artificial
de la vision artificial se concreta en dos problemas: el renderizado, que permite traducir infor-
macion de la maquina al formato visual humano, y el problema inverso, la inferencia. La Fig.
1.2 muestra ambas interfaces. En un sistema perfecto, lo idoneo serıa cerrar el bucle y que a
partir de los resultados de la inferencia, se pudiese proceder al renderizado y obtener una imagen
completamente igual a la utilizada.
En un principio, las tecnicas de vision artificial se centraron en acercarse todo lo posible
al proceso visual humano. Debido a esto, la vision artificial ha estado mezclada con la neurologıa
visual en un intento de comprender los mecanismos del cortex que permiten ver a los animales.
Sin embargo, muy pronto se comprobo que dicho acercamiento no resultaba practico. El ser
humano es, hasta el momento, mucho mas flexible y adaptable que cualquier sistema basado
en computadoras. Sin embargo, los sistemas de vision artificial presentan la ventaja de ser mas
rapidos y precisos en tareas repetitivas, mediciones y procesado de volumenes elevados datos,
lo que ha facilitado su incorporacion en trabajos especıficos de este tipo como, por ejemplo,
inspeccion de calidad de montaje. El proceso de vision artificial comienza, pues, por la definicion
de la tarea a implementar. Dicha tarea debe descomponerse en partes que puedan afrontarse
desde un punto de vista hardware y software. Para cada uno de estos modulos, debe comenzarse
por cuantizar los parametros de entrada que un ser humano define desde un punto de vista
cualitativo, como grande, pequeno, oscuro o claro. Esta informacion debe procesarse para obtener
los datos necesarios para completar la tarea deseada. Para ello, hay que escoger los algoritmos
necesarios, que suelen incluir etapas de preproceso, segmentacion, deteccion y caracterizacion
de objetos y reconocimiento en su caso mas general. Por ultimo, una vez se ha extraıdo de esos
objetos la informacion relevante para la tarea deseada, esta puede llevarse a cabo. Es importante

2. Vision artificial y modelos de aprendizaje 5
notar que en ocasiones la informacion necesaria para completar una tarea puede no encontrarse
en una imagen o secuencia de estas independientemente de lo que pueda parecer, ya que el ser
humano usa informacion de contexto, patrones excesivamente sutiles y referencias visuales. En
estos casos, no podra usarse vision artificial para resolver el problema deseado. Por ejemplo,
con una unica imagen no se pueden medir distancias, a pesar de que el ser humano, gracias a
las referencias aprendidas y en funcion de la relacion de tamano de los objetos que reconoce en
una escena, puede determinar a partir de una sola imagen las distancias aproximadas a dichos
objetos. Es interesante notar que esta capacidad tambien hace al ser humano mas vulnerable a
enganos derivados de su experiencia previa, que se conocen como ilusiones opticas. No obstante,
si se desea conseguir un sistema de vision artificial robusto y flexible, es importante que, al igual
que el ser humano, este este dotado de la capacidad de aprender, adaptarse y evolucionar.
Construir sistemas que no requieran programacion explıcita no es un concepto nuevo.
La extension de las tecnicas clasicas de reconocimiento de patrones a problemas nuevos ha
abierto una nueva via, el aprendizaje supervisado o aprendizaje a partir de ejemplos, que, a
nivel de maquina, basicamente consiste en un problema de regresion para la interpolacion o
aproximacion de una funcion multivariable a partir de un conjunto discreto de datos. Desde
este punto de vista, la solucion tradicional al aprendizaje supervisado ha sido la regularizacion
o proceso que selecciona una entre las infinitas funciones que pueden ajustarse a un conjunto
discreto de puntos imponiendo que la funcion sea suave mediante minimizacion de una funcion
de coste (Wahba, 1990). De forma similar, el problema se ha enfrentado tambien mediante
metodos probabilısticos y Bayesianos (Poggio y Girosi, 1990), usando estimacion de maximos
a posteriori (MAP). Un segundo punto de partida para el aprendizaje lo constituye asumir
que, bajo condiciones generales, la solucion al problema de la aproximacion es una combinacion
lineal de funciones base centradas alrededor de cada dato. La forma de estas funciones base
depende depende del criterio de suavidad empleado (Girosi et al., 1995). Un caso especial de
esta tecnica lo constituyen las funciones base radiales (FBR) (Powell, 1987), que en su caso mas
general son gaussianas. Mas recientemente han cobrado protagonismo las maquinas de soporte
vectorial (MSV) (Vapnik, 1995), que parten del mismo concepto que la regularizacion pero se
basan en que para un conjunto finito de datos, la mejor aproximacion debe estar limitada a un
espacio de hipotesis reducido, lo que fuerza a que muchos de los coeficientes en las ecuaciones
de minimizacion sean nulos.
Desde un punto de vista practico, queda por ultimo destacar que la vision artificial se
ha utilizado tradicionalmente en mejora y restauracion de imagen, como filtrado adaptativo en
radiologıa (Hall, 1971) o inspeccion de placas de circuito impreso (Jarvis, 1980). Actualmente,

6 Capıtulo 1. Vision artificial y reconocimiento de objetos
se han incluido en el grupo sistemas mas complejos, como los de extraccion de informacion
geografica a partir de imagenes capturadas desde el aire o el espacio (Matsumoto et al., 1981) o
los de reconocimiento automatico de caracteres (Bellegarda et al., 1993) (Connell y Jain, 2001)).
La medicina es probablemente uno de los campos que ha aceptado de mejor grado la inclusion
de tecnicas de este tipo para la construccion de cariotipos (Charters y Graham, 1999), tecnicas
visuales no intrusivas para deteccion de cancer de mama (Bartrum y Crow, 1984) (Wolberg et
al., 1994) o analisis de electroencefalogramas (Bourne et al., 1981) (Zhou y Zhou, 1999). Aun
posteriores son las tecnicas avanzadas basadas en vision 3D como el modelado visual para la
inspeccion industrial (Rosen y Nitzan, 1977) (Kim et al., 1999), la tomografıa (Bhattacharya y
Majumder, 2000) o la reconstruccion de objetos y entornos (Johnson y Hebert, 1998) (Beauvais
y Lakshmanan, 2000). Cabe destacar el campo de la vision activa, donde el proceso visual se
lleva a cabo de forma realimentada a traves de una interaccion con el entorno. La vision activa
se ha empleado tradicionalmente en videovigilancia (Howarth y Buxton, 1996) (Kanade et al.,
1997), monitorizacion del trafico (Davis et al., 1997) o control de la actividad humana a partir
de imagenes aereas (Rao, 1996).
3. Reconocimiento de objetos
Tal como se ha comentado en el apartado anterior, el reconocimiento de objetos es un
paso clave en cualquier proceso generico de vision artificial. No es, por tanto, sorprendente
el hecho de que se haya concentrado un gran esfuerzo en este tema en las ultimas decadas,
centrado en particular en objetos tridimensionales que son, a fin de cuentas, los que suelen
encontrarse en un entorno real. El proceso se entiende en este contexto como el proceso de
aprendizaje de objetos nuevos y su posterior reconocimiento la siguiente vez que se le presentan
al sistema por comparacion con los objetos ya adquiridos. En general, el reconocimiento se suele
basar en la creacion de modelos de los objetos estudiados, que en lugar de preservar toda la
informacion pertinente a dichos objetos, tratan de minimizar dicha informacion almacenando la
menor cantidad de ella posible para optimizar el proceso de reconocimiento. La seleccion de los
parametros que definen un modelo es uno de los pasos mas crıticos del proceso de reconocimiento.
Los modelos pueden suministrarse a priori al sistema mediante aprendizaje supervisado, pero
tambien cabe la posibilidad de permitirle al sistema adquirir modelos nuevos a partir de pautas
establecidas mediante aprendizaje no supervisado. Una vez se dispone de un conjunto de modelos
aprendidos, cualquier objeto entrante puede reconocerse por comparacion con ellos. El proceso
de comparacion define al algoritmo de reconocimiento en sı.

4. Objetivos y organizacion del texto 7
El reconocimiento de objetos tridimensionales se ha afrontado desde diversas perspec-
tivas. Originalmente, este se basaba en metodos geometricos (Ullman, 1996), donde el objeto
se aproximaba mediante la combinacion de un conjunto determinado de representaciones como
cilindros generalizados, supercuadricas o parches bicubicos. El problema principal de estas tecni-
cas radicaba en que era necesario adquirir un modelo 3D completo de cada objeto para poder
reconocerlo positivamente. Ademas, los metodos geometricos resultaban lentos y excesivamente
sensibles a ruido, distorsiones y oclusiones. De forma alternativa, la mayorıa de los metodos
actuales se han decantado por el reconocimiento basado en vistas (RBV). En lugar de requerir
un modelo 3D completo de cada objeto para su analisis, el RBV se basa en adquirir un con-
junto discreto de imagenes del objeto desde distintos puntos de vista (Campbell y Flynn, 1999)
(Murase y Nayar, 1995). Es destacable el hecho de que en las ultimas decadas se ha encontrado
evidencia de que las neuronas en el cortex del cerebro trabajan de forma similar reconociendo
objetos a partir de vistas discretas (Logothetis y Pauls, 1995).
En los procesos de RBV, los objetos entrantes se comparan con los modelos conocidos
una vez se ha adquirido suficiente informacion sobre ellos. En el mejor de los casos, cuando el
espacio de entrada no presenta objetos con vistas iguales, una sola imagen puede ser suficiente
para su correcta identificacion (Campbell y Flynn, 1999). Sin embargo, en la mayorıa de los
casos es necesario adquirir varias y combinar la informacion que ofrece cada una de forma
estadıstica para que no queden dudas acerca de la naturaleza del objeto entrante. Este proceso
de comparacion es lo que define un sistema de reconocimiento. Es importante que el proceso
contemple la posibilidad de que los objetos esten sometidos a transformaciones geometricas,
ruido de captura, ası como distorsiones y deformaciones, ya que este sera el caso habitual.
4. Objetivos y organizacion del texto
El objetivo de esta tesis es el desarrollo de un sistema de reconocimiento de objetos 3D
basado en vistas de estos. Aparte de los motivos expuestos en la introduccion de este capıtulo,
como complejidad computacional y resistencia a errores, esta decision ha estado forzada por el
hecho de que el hardware con que se va a trabajar incluye unicamente una camara de vıdeo
convencional y un PC estandar. A efectos de controlar la posicion relativa de camara y ob-
jeto, las simulaciones se han llevado a cabo sobre el programa 3DStudio, mientras que en las
pruebas reales la camara se ha montado sobre una cabeza robotica, cuyo desplazamiento puede
cuantizarse facilmente.
Esta tesis se ha dividido en dos grandes bloques de acuerdo a las etapas del proceso

8 Capıtulo 1. Vision artificial y reconocimiento de objetos
de reconocimiento basado en vistas y cada uno de sus capıtulos se encarga de un bloque en
particular. Ası pues, presenta el siguiente contenido:
Capıtulo 2: Representacion de formas planas.
Este capıtulo contempla la extraccion de informacion a partir de cada una de las vistas del
objeto evaluado. En el se hace un breve recorrido por los distintos descriptores de objetos,
optando al final por la forma por las ventajas que se detallan en la seccion correspondi-
ente. De entre los criterios de representacion de forma existentes, se justifica la eleccion
de la curvatura para, a continuacion, proponer un metodo nuevo de extraccion de esta.
Dicho metodo ofrece una alta resistencia contra ruido, transformaciones, y distorsiones
moderadas. No obstante, la curvatura resulta poco practica para representar per se una
forma. Por tanto, se propone ası mismo una nueva tecnica para extraer la informacion
mas relevante de esta. A efectos de evaluar la bondad del sistema de representacion de
formas planas propuesto, se incluye un apartado de experimentos en que se proponen y
testean distintos metodos de reconocimiento de formas planas a partir de la informacion
que ofrece la funcion de curvatura desarrollada. La conclusion de estos experimentos es que
un numero reducido de componentes principales de dicha funcion de curvatura es suficiente
para representar de forma eficaz cualquier objeto plano y, por tanto, cualquier proyeccion
de un objeto 3D.
Capıtulo 3: Reconocimiento de objetos 3D.
Este capıtulo cubre el reconocimiento de objetos 3D a partir de secuencias de vistas.
Para ello, se efectua un breve recorrido por las tecnicas mas habituales de este tipo que,
basicamente, se diferencian en la tecnica de representacion de vistas escogida y en el metodo
de acumulacion de informacion a partir de un conjunto de estas. Usando el metodo de
representacion de figuras planas propuesto en el capıtulo 2, se propone un nuevo sistema
compacto de representacion de figuras 3D que permite reconocer estas mediante campos
ocultos de Markov. En el capıtulo se presenta tanto una nueva tecnica para aprender nuevos
objetos hasta entonces desconocidos como el proceso de reconocimiento basado en los
modelos 3D adquiridos. En este capıtulo se presentan diversas pruebas sobre un simulador
que permite observar los objetos desde cualquier punto de vista y segmentarlos de forma
simple. Ası, se testea el sistema basico en presencia de transformaciones geometricas y ruido
de cuantizacion pero sin ruido de captura y sin distorsiones, oclusiones o deformaciones
por segmentacion.
Capıtulo 4: Resultados

4. Objetivos y organizacion del texto 9
Este capıtulo presenta varios experimentos del sistema completo sobre imagenes reales a
efectos de probar su resistencia frente a los errores que no se comprobaron en el capıtulo
anterior. Asimismo, se testea, a traves de una fase de aprendizaje, la capacidad del sistema
para, habiendo aprendido modelos virtuales de objetos, reconocer su equivalente en el
mundo real. Por ultimo, se comprueba la capacidad del sistema para continuar aprendiendo
tras en entrenamiento inicial.
Capıtulo 5: Conclusiones
Este capıtulo presenta un resumen de las aportaciones mas significativas que se hacen a
lo largo del texto. Asimismo, se presentan las conclusiones que se han extraıdo de este
trabajo y finalmente se abren futuras lıneas de investigacion.


Capıtulo 2
Descripcion de formas planas
1. Introduccion.
El reconocimiento de objetos a partir de una secuencia de video esta ıntimamente ligado
al hecho de que dicha secuencia esta formada por imagenes 2D que corresponden a perspectivas
del objeto desde un determinados puntos de vista. Ası, una camara de video intrınsecamente
genera una representacion plana de un objeto tridimensional. En conjunto, la estructura 3D del
objeto vendra dada por la captura de un numero suficiente de vistas donde bien la camara o bien
el objeto se encuentren en movimiento (Buelthoff y Edelman, 1992). Es ası que la descripcion
de formas planas constituye una parte importante del reconocimiento de objetos 3D.
Existen varias tecnicas para el reconocimiento de objetos 3D a partir de secuencias de
imagenes planas. Partiendo de la aproximacion mas basica, algunos metodos optan por trabajar
con el bitmap completo correspondiente a una vista. Dado que un bitmap implica un elevado vo-
lumen de datos, generalmente se usan tecnicas como Analisis de Componentes Principales (PCA,
Principal Components Analysis), tambien conocidas como la transformada de Karhunen-Loeve
Transform (Sirovich y Everson, 1992), para reducir a un vector de caracterısticas las diferentes
vistas del objeto (Campbell y Flynn, 1999) (Mukherjee y Nayar, 1993). Desafortunadamente,
los bitmaps correspondientes a una vista suelen ser extremadamente sensibles a cambios de
iluminacion (Startchik et al., 1998), ası como a la naturaleza del fondo sobre el que se captura
el objeto a no ser que este se segmente y descarte.
Para evitar estos problemas, la mayorıa de los sistemas se basan en extraer algun tipo de
caracterıstica del objeto en si. En general, una de las principales caracterısticas que los diferencia
es la forma en que cada vista de un objeto se caracteriza de forma previa al reconocimiento.
Tradicionalmente, se define la forma como la propiedad de un objeto que depende de las posi-
11

12 Capıtulo 2. Descripcion de formas planas
ciones relativas de todos aquellos puntos que componen su contorno o superficie exterior. Esta
es una propiedad intrınseca de los objetos, de la que se pueden derivar muchas otras. El ser
humano suele asociar conceptos con formas, mas que con otras propiedades como el color o la
textura. Ademas, mientras que otras propiedades varıan considerablemente con las condiciones
de captura y la iluminacion e incluso no se mantienen constantes en objetos de una misma clase,
como por ejemplo el color de la portada de un libro o la textura de una silla, la forma resulta mas
resistente a estos factores. La caracterizacion de formas no es en absoluto un problema simple
por las siguientes razones:
La forma es difıcil de representar. Al contrario que otras propiedades que son facilmente
cuantificables, como intensidad o color, para definir correctamente una forma, habitual-
mente, es necesario extraer o calcular un gran numero de parametros, de entre los cuales
solo unos cuantos son adecuados para una aplicacion determinada.
No existe un fundamento biologico apropiado para inspirar una estrategia u otra, dado que
el ser humano trabaja simultaneamente con tal cantidad de parametros que es imposible
operar de forma similar.
La disciplina es relativamente nueva. Hasta la aparicion de la vision artificial, la descripcion
de formas complejas se ha llevado a cabo mediante descripciones verbales. La aparicion de
este nuevo campo acarreo la necesidad de presentar las formas en un formato apto para
su procesado y manipulacion automatico.
No obstante, existen diversos metodos en el campo del reconocimiento de objetos 3D
basados en la forma. Varios estudios se centran en caracterizar las mencionadas formas medi-
ante sus puntos relevantes, procediendo luego a compararlos con los puntos relevantes de un
conjunto limitado de vistas canonicas de cada objeto patron (Cross et al., 1999) (Lo y Kwok,
2001) (Roh y Kweon, 2000) (Rothwell et al., 1995). Las principales desventajas de los metodos de
este tipo son que la posicion y numero de puntos relevantes tiende a ser inestable frente a ruido
y condiciones de captura y no necesariamente se mantiene para distintos objetos de una misma
familia e incluso para versiones distorsionadas de un mismo objeto a poco que presenten mıni-
mas variaciones. Para evitar estos problemas, se han propuesto soluciones basadas en analisis
multiescala (Mikolajczyk y Schmid, 2001), pero tienden a resultar lentas y computacionalmente
costosas. Alternativamente, se puede trabajar con el contorno completo de un objeto, que tiende
a ser mas resistente a todos los factores mencionados y unicamente presenta variaciones impor-
tantes cuando aparecen errores significativos de segmentacion. La representacion de contornos

2. Metodos de descripcion de la forma 13
mediante funcion de curvatura (Urdiales et al., 2002) es particularmente aceptada en este campo
por sus caracterısticas de resistencia al ruido y transformaciones.
Este capıtulo se centra en la caracterizacion de objetos planos a partir de su forma, con
un especial enfasis en los sistemas que se han empleado en reconocimiento de objetos 3D: puntos
relevantes y curvatura. Dado que aun no se propone un sistema para el reconocimiento 3D,
se evaluaran las prestaciones de dichos sistemas en aplicaciones de reconocimiento de objetos
planos. La seccion 2 presenta una breve descripcion de los distintos sistemas de descripcion de
forma disponibles en la literatura. La seccion 3 se centra en la implementacion de tres metodos
de representacion de formas planas para su posterior comparacion. Los resultados de cada uno
de los tres metodos de representacion propuestos se presentan en la seccion 4. En la seccion 5
se discuten las conclusiones del presente capıtulo.
2. Metodos de descripcion de la forma
Tradicionalmente, los metodos de representacion de la forma se han dividido en dos
grandes bloques: escalares y del dominio espacial. Los metodos escalares dependen unicamente
de operaciones matematicas que se aplican de forma directa. Por tanto, presentan la ventaja de no
precisar ningun conocimiento sobre la forma a caracterizar. Los metodos del dominio espacial se
basan en describir las propiedades estructurales y relacionales de las formas en estudio mediante
la transformacion de informacion puramente numerica en datos explıcitos y con sentido.
Las tecnicas mas representativas entre los metodos escalares son las de escalar simple,
los descriptores de Fourier y los metodos estocasticos. Las tecnicas de escalar simple se basan en
parametros de la forma, como momentos de area, simetrıas, perımetro o elongaciones (Denisov,
1994) (Hsu y Hwang, 1997) (Inesta et al., 1996). Todos estos parametros son sencillos de obtener
y, en muchos casos, resistentes a transformaciones. No obstante, para describir una forma de
manera unica, habitualmente, es necesario un elevado numero de estos parametros, ya que ofrecen
en general informacion muy correlada, y es difıcil escoger un conjunto limitado de ellos que sirva
para una aplicacion minimamente general. Los descriptores de Fourier (Fonga, 1996) (Kauppinen
et al., 1995) son un numero limitado de coeficientes de la transformada de Fourier de la curvatura,
el radio o el contorno del objeto, capaces de caracterizar a este. Los descriptores son bastante
resistentes a transformaciones, pero el numero necesario de estos para caracterizar una forma
depende de su naturaleza y de la aplicacion a desarrollar. Ademas, en casi cualquier aplicacion
suele ser necesario un numero grande de descriptores. Los metodos estocasticos consisten en
ajustar modelos autoregresivos al contorno de los objetos, pero se ha probado que los descriptores

14 Capıtulo 2. Descripcion de formas planas
de Fourier ofrecen mejores resultados (Kauppinen et al., 1995).
Las tecnicas mas representativas del dominio espacial son las transformadas de eje medio
y simetrıas, la descomposicion de objetos en grupos simples, la aproximacion poligonal, la rep-
resentacion por puntos caracterısticos y la transformada de Hough. Las transformadas de eje
medio y simetrıas se basan en reducir la forma global del objeto a un esqueleto (Lerner et al.,
1995) (Zhou y Pavlidis, 1994) ya que resulta relativamente facil extraer los ejes de simetrıa de
contornos cerrados y la figura puede recuperarse si se almacena la distancia mınima al bor-
de desde cada punto del esqueleto. Su principal desventaja es que son muy sensibles al ruido
y resulta muy complejo medir la similitud entre dos esqueletos distintos. Ademas, los rasgos
asociados a concavidades del contorno no se representan de forma directa. Otras tecnicas se
basan en descomponer un objeto complejo en conjuntos de formas simples (Nair y Aggarwal,
1996). Desafortunadamente, estas tecnicas suelen ser computacionalmente costosas y la bondad
de la descomposicion resultante depende enormemente del tipo de objeto con que se trabaja. La
aproximacion poligonal de formas consiste en representar los contornos mediante un conjunto de
primitivas que se ajustan a estos entre ciertos puntos que se denominan puntos de ruptura (Lu,
1993). Sin embargo, no es obvio localizar de forma fiable dichos puntos ni encontrar primitivas
sencillas que permitan una baja carga computacional. Ademas, la descomposicion poligonal re-
sulta muy sensible a escala. Otras tecnicas se basan en reducir la forma a un conjunto de puntos
caracterısticos (Cheikh et al., 2000), bien minimizando algun tipo de error (Pavlidis y Horowitz,
1974) (Ray y Ray., 1993), bien localizando los puntos de maxima variacion de curvatura (Zhu y
Chirlian, 1995) (Chang y Chen, 2000) (de Trazegnies et al., 2002). La representacion por puntos
caracterısticos es similar a la descomposicion poligonal en tanto que tambien se basa en encontrar
puntos relevantes de un contorno. Sin embargo, como en este caso no es necesario aproximarlo,
estos sistemas no son tan sensibles a distorsiones de la forma, aunque si presentan sensibilidad
a ruido y a puntos que se presentan a distintas escalas naturales. La transformada de Hough
es una transformacion que permite detectar formas conocidas en una imagen (Costa y Sandler,
1993). Su principal ventaja es que es muy resistente al ruido, pero su complejidad se incrementa
en una dimension por cada variable adicional a la que ser insensible, como rotacion o escala.
Ademas, su eficiencia varıa considerablemente dependiendo de que forma se desee detectar.
Finalmente, merece la pena destacar que cuando se desea trabajar en entornos muy
sensibles a escala, puede hacerse uso de metodos de espacio-escala (Rosin, 1992), que trabajan
sobre un continuo de escalas simultaneamente. No obstante, es importante notar que estos
metodos pueden volverse excesivamente costosos si el numero de escalas a evaluar aumenta
demasiado.

3. Representacion de formas planas 15
3. Representacion de formas planas
Tal como se ha comentado en la introduccion, la mayorıa de los metodos de reconocimien-
to de objetos 3D a partir de formas planas se basan bien en extraccion de puntos caracterısticos
del contorno bien en el analisis de la curvatura de la forma. Por ello, el apartado siguiente se
centra en estos dos metodos. Adicionalmente, se va a proponer un metodo nuevo para repre-
sentar objetos planos a partir de los rasgos mas representativos de la curvatura de su contorno.
Todos los metodos propuestos en esta tesis se evaluaran en aplicaciones de reconocimiento de
objetos en el apartado de resultados para mostrar sus ventajas e inconvenientes.
3.1. Representacion de objetos mediante curvatura
Una de las formas mas tradicionales de caracterizar la forma es el estudio de su curvatura,
que es equivalente a cuanto se dobla el contorno en cada punto. Las principales ventajas de
trabajar con la curvatura de un objeto son que: i) se puede calcular con relativa facilidad y
rapidez; ii) no es necesario ningun conocimiento previo de la forma a describir; iii) la similitud
entre la curvatura de dos objetos se puede estimar de forma directa; y iv) es muy resistente a
transformaciones. La curvatura comienza a definirse como tal en el trabajo de Johannes Kepler
sobre el clasico Problema de Alhazin, pero no se formaliza de manera algebraica hasta los trabajos
de Fermat y Descartes y, en particular, Leibniz y Newton, que concretan el concepto de curvatura
partiendo de las siguientes premisas:
Un cırculo tiene curvatura constante e inversamente proporcional a su radio.
El mayor cırculo tangente a una curva por su parte concava en un punto cualquiera tiene
la misma curvatura que la curva en ese punto.
El centro de este cırculo es el centro de curvatura de la curva en dicho punto.
Mas adelante, define la curvatura en terminos infinitesimales, describiendo el centro de
curvatura como la interseccion de las normales a distancias infinitamente pequenas a ambos
lados del punto en cuestion (Whiteside, 1969). De ahı que Newton derive la siguiente formula
para la curvatura:
ρ =(1 + z2)3/2
z(2.1)
siendo z igual a yx , donde (x, y) son las coordenadas de los puntos que forman la curva. De acuerdo
a su teorıa, una curva generica presenta un numero indefinido de puntos de inflexion donde las

16 Capıtulo 2. Descripcion de formas planas
curvas se comportan como lıneas rectas y, por tanto, su radio de curvatura en dichos puntos es
infinito (Coolidge, 1952). Finalmente, Leonard Euler en 1774 (Kline, 1972) determina que para
cada vector tangente a una curva, puede asignarse un punto del cırculo unidad que corresponde a
la direccion del vector. A partir de esto, define la curvatura como ds′
ds , es decir, la variacion angular
de la tangente sobre la variacion del arco en longitud en terminos infinitesimales. Intuitivamente,
se aprecia que cambios grandes de angulo en pequenas distancias suponen curvaturas grandes y
viceversa. Euler propone la siguiente expresion analıtica para el radio de curvatura en un espacio
tridimensional:
ρ =1√
(x′′)2 + (y′′)2 + (z′′)2(2.2)
donde (x, y, z) son las coordenadas de los puntos de la curva. Actualmente, la definicion mas
utilizada es la que define la curvatura ρ de una curva cualquiera como la derivada de su pendiente
con respecto a la longitud del arco t:
ρ(t) =xy − yx
[x2 + y2]3/2(2.3)
siendo x, y, x y y la primera y segunda derivadas de las coordenadas de la curva x(t) e y(t)
respecto a t.
Para extender el concepto de curvatura al procesado de imagen es interesante conseguir
metodos que: i) sean poco costosos computacionalmente; ii) se puedan adaptar facilmente al
formato digital del problema; y iii) sean resistentes al ruido de cuantizacion y discretizacion.
Existen varios metodos para calcular la funcion de curvatura de un contorno digital. Freeman
y Davis (Freeman y Davis, 1977) calculan la curvatura de una forma como el producto de las
longitudes de secciones uniformes del codigo de cadena a ambos lados de cada pixel de la curva,
tras suavizar esta para eliminar parcialmente el ruido de cuantificacion. Liu y Srinath (Liu y
Srinath, 1990) utilizan el gradiente de bordes de cada pixel, calculado como la arcotangente
de su diferencia de Sobel en un vecindario 3x3, para generar la funcion, que luego normalizan
para evitar discontinuidades. Arrebola et al. (Arrebola et al., 1997) utilizan la correlacion de los
histogramas a derecha e izquierda en una vecindad k de cada punto, modificando despues la fun-
cion resultante para incluir informacion sobre concavidad y convexidad. Mas tarde, sustituyen
la correlacion por medias circulares de origen variable para incrementar la velocidad de proceso
del sistema, ası como para cuantificar mejor el angulo en las esquinas (Arrebola et al., 1999).
Agam y Dinstein (Agam y Dinstein, 1997) definen la curvatura como la diferencia de las pen-
dientes de los segmentos de curva a derecha e izquierda de cada punto, tomando las pendientes
precalculadas de una tabla. Bandera et al. (Bandera et al., 2000a) proponen un metodo similar
a este, pero variando de forma adaptativa la definicion de pendiente empleada para adaptarla

3. Representacion de formas planas 17
a la escala natural de los contornos. Usando este mismo concepto, Reche et al (Reche et al.,
2002) proponen un nuevo metodo para calcular la curvatura a partir del angulo que forman dos
vectores relacionados con los segmentos de maxima longitud libres de discontinuidades a ambos
lados de cada pixel evaluado. Basicamente, la mayorıa de los metodos comentados comparten la
idea de comparar, de una forma u otra, segmentos de k puntos a la derecha e izquierda del punto
en estudio para estimar la curvatura. Este proceso se conoce como evaluacion de pendiente-k,
donde la pendiente k de un pixel cualquiera se define como la pendiente de una lınea que conecta
dicho pixel con su k-esimo vecino a la derecha o izquierda. El problema de esta tecnica estriba
en que no es sencillo elegir un k adecuado. Si k es excesivamente pequeno, la curvatura es muy
ruidosa, pero si es grande, todos los puntos caracterısticos situados a distancia menor que k
pueden perderse y, por tanto, la informacion de curvatura se distorsiona. Solo en (Bandera et
al., 2000a) y (Reche et al., 2002) se introduce el concepto del calculo de k de acuerdo a la escala
natural de cada punto del contorno, si bien en ambos metodos la curvatura se obtiene finalmente
mediante una aproximacion que, salvo que se almacene el valor de k para todos los puntos del
contorno evaluado, hace imposible la recuperacion de la forma original a partir de la funcion
resultante.
En esta tesis se propone un nuevo metodo de calculo de curvatura adaptado a la escala
natural del contorno. En este metodo, la curvatura local de cada punto del contorno se va a car-
acterizar mediante el angulo subtendido por dos segmentos libres de discontinuidades a derecha
e izquierda del punto en cuestion pero, en lugar de calcular dicho angulo por aproximacion como
en metodos anteriores (Agam y Dinstein, 1997) (Bandera et al., 2000a) (Reche et al., 2002),
este se obtiene de forma analıtica como la integral de la funcion de curvatura adaptativa entre
los pasos por cero mas cercanos de dicha funcion a derecha e izquierda del punto analizado. La
ventaja mas representativa de este metodo reside en que, al no efectuarse aproximaciones, se
puede recuperar el contorno original filtrado a partir de la funcion de forma fiable. Ası, si es
necesario filtrado adicional, el metodo se puede aplicar iterativamente sin perdida de informacion
relevante. La funcion de curvatura propuesta consta de los siguientes pasos:
Codificacion del contorno mediante un codigo de cadena incremental. El codigo de cadena
incremental asociado a un pixel n es un vector (∆x(n),∆y(n)) que presenta la diferencia
en x e y entre los puntos n y n + 1 del contorno.
Para cada punto n, calculo de la maxima longitud de contorno k(n) libre de discon-
tinuidades en torno a n. El valor de k para cada pixel n, k(n), se obtiene comparando la
distancia Euclidea entre los pixeles n−k(n) y n+k(n) del contorno, ||n−k(n), n+k(n)||2,

18 Capıtulo 2. Descripcion de formas planas
con el numero de pıxeles de contorno entre ambos, lmax(k(n)). Ambas distancias tienden a
ser iguales en ausencia de puntos caracterısticos, incluso para contornos ruidosos. En caso
contrario, ||n− k(n), n + k(n)||2 es significativamente mas corta que lmax(k(n)). Ası, k(n)
es el valor mas alto que satisface la ecuacion:
||n− k(n), n + k(n)||2 ≥ lmax(k(n))− Uk (2.4)
donde Uk es una constante que depende unicamente del nivel de ruido tolerado en la
funcion. Cuando Uk es grande, los k(n) tienden a ser altos y algunos puntos relevantes
que se definen a pequena escala pueden llegar a desaparecer. Si Uk es bajo, sin embargo,
podrıa no eliminarse suficiente ruido y confundirse los picos generados por este con falsos
puntos relevantes. Afortunadamente, la eleccion de Uk no es un factor crıtico y, para la
resolucion de una camara de vıdeo estandar, un factor Uk = 0.4 suele funcionar en la
practica totalidad de los casos.
Calculo del codigo de cadena incremental adaptativo (∆x(n)k,∆y(n)k) asociado al pixel n
del contorno. Este nuevo codigo refleja la variacion en x e y entre los pıxeles del contorno
n− k(n) y n + k(n) y se calcula como:
∆x(n)k =n+k(n)∑
j=n−k(n)
∆x(j) (2.5)
∆y(n)k =n+k(n)∑
j=n−k(n)
∆y(j)
Calculo de la pendiente de la curva que forma el codigo de cadena incremental adaptativo
en cada punto del contorno n. Dicha pendiente puede aproximarse por el angulo formado
por el segmento (n− k(n), n + k(n)) y el eje vertical y. Dicho angulo se obtiene como:
Ang(n) = arctan(
∆x(n)k
∆y(n)k
)(2.6)
Calculo de la curvatura en cada punto n, que se define como la variacion de pendi-
ente con respecto a n, d(Ang(n))/dn. Este valor puede aproximarse por el incremento
∆(Ang(n))/∆n, o localmente por Ang(n + 1)−Ang(n).
La Fig. 2.1.b presenta la funcion de curvatura propuesta (FC) para explicar su senti-
do sobre una figura generica (Fig. 2.1.a). Las esquinas del objeto se han numerado de 1 a 7.
Puede observarse que las esquinas se marcan claramente como picos en la funcion, tanto mas
altos cuanto mas agudo es su angulo subtendido. Las esquinas convexas (1, 3, 4, y 6) aparecen

3. Representacion de formas planas 19
como picos positivos. Por otra parte, las rectas son tramos de curvatura 0, mientras que las
curvas presentan una curvatura aproximadamente constante. La funcion de curvatura presenta
desplazamientos en funcion del primer punto por el que comience su calculo. De forma analoga,
apareceran desplazamientos si se somete el objeto a rotacion. La escala produce un efecto de
diezmado o interpolacion sobre la curva, segun se disminuya o aumente el tamano del objeto,
si bien no varıa la forma de la funcion. El ruido se elimina de forma adaptativa, por lo que no
produce variacion alguna salvo en casos de relacion senal a ruido realmente pobres.
La bondad de la funcion de curvatura propuesta puede observarse en la Fig. 2.2, donde
se presentan dos contornos ruidosos distintos (Fig. 2.2.a) y los mismos contornos recuperados a
partir de la funcion de curvatura adaptativa (AECF,Adaptively Estimated Curvature Function)
(Bandera et al., 2000a) (Fig. 2.2.b) y de la funcion propuesta (Fig. 2.2.c). Tal como se observa en
la figura, el filtrado intrınseco al calculo habitual de curvatura provoca errores en la recuperacion
de los angulos en cada punto en los metodos habituales que degeneran en que los contornos no
pueden cerrarse en cuanto tengan un numero razonable de puntos caracterısticos. La funcion
propuesta, sin embargo, permite una recuperacion mucho mejor en tanto que pierde menos
informacion sobre el contorno. Tal como puede observarse, el contorno reconstruido resultante
esta visiblemente filtrado, pero no se han perdido puntos caracterısticos, lo que demuestra que
dicha funcion se comporta como un buen descriptor.
Las funciones de curvatura representan apropiadamente los contornos de objetos, son
resistentes frente a ruido, y deformaciones suaves. Siluetas parecidas representadas a distintas
escalas poseerıan funciones de curvatura de forma similar aunque de distintas longitudes. Por
lo tanto, la invarianza frente a cambios de escala se puede conseguir sin mas que interpolar las
funciones de curvatura a una longitud fija. Sin embargo, las funciones de curvatura no presentan
invarianza frente a rotacion, sino que sufren desplazamientos lineales en funcion de esta. Este
Figura 2.1: Representacion por curvatura: a) objeto generico; b) funcion resultante.

20 Capıtulo 2. Descripcion de formas planas
Figura 2.2: Reconstruccion a partir de curvatura: a) objetos ruidosos ejemplo; b) AECF del ob-jeto; c) funcion de curvatura propuesta; d) reconstruccion a partir de AECF; y e) reconstrucciona partir de la funcion propuesta.

3. Representacion de formas planas 21
problema se puede resolver si el punto de comienzo para el calculo de la funcion de curvatura
es siempre el mismo, independientemente de la posicion de la silueta sometida a analisis. Para
este fin es necesario definir un criterio, que dependera de caracterısticas globales de la silueta,
para elegir el punto de comienzo. En un sistema no supervisado la eleccion de tal criterio no es
trivial. Existen metodos de reconocimiento basados en contornos que necesitan definir un punto
de comienzo privilegiado. Los criterios utilizados para tal fin se pueden agrupar en dos grandes
grupos:
Metodos que dependen de caracterısticas globales de la figura. Por ejemplo, se pueden
definir unos ejes principales de la figura y escoger los puntos en los que cortan a la silueta
como puntos privilegiados (He y Kundu, 1991). Estos metodos tienen el problema de
que determinadas deformaciones de la figura original, aun sin ser muy intensas, pueden
desplazar los ejes principales de la figura.
Metodos que definen lo extremos de funciones locales como puntos privilegiados (Dreschler
y Nagel, 1982). Por ejemplo, se puede definir el punto de comienzo como el maximo o
el mınimo de la funcion de curvatura. Sin embargo, si seguimos este criterio el punto
de comienzo se puede ver desplazado si la silueta original se suaviza debido a ruido o
distorsion, de modo que puede aparecer un nuevo maximo o mınimo de la funcion de
curvatura situado en un punto distinto del original.
Si se requiere trabajar con funciones de curvatura cuyo punto de comienzo es eventual-
mente variable, es necesario que cualquier comparacion de similitud entre una pareja de funciones
de curvatura incluya la comparacion de la primera de ellas con todos los posibles desplazamien-
tos de la segunda. Esto es demasiado costoso desde el punto de vista computacional. Para evitar
este problema, cada silueta es representada por el modulo de la transformada discreta de Fouri-
er de su funcion de curvatura, calculada mediante el algoritmo de la transformada rapida de
Fourier (FFT). Un desplazamiento en la funcion de curvatura se traduce en un desfase en su
transformada de Fourier, por lo tanto la representacion mediante el modulo de la transforma-
da de Fourier de la funcion de curvatura (||CFFFT||) es independiente de la orientacion de la
figura original. Es importante notar que una vez extraıdo el modulo de la FFT de la funcion de
curvatura, se pierde la informacion de fase de la misma. La informacion extraıda de la figura no
es suficiente para realizar una transformacion inversa y reconstruir la figura original, es decir, el
metodo propuesto no puede funcionar como un metodo de compresion de imagenes. Sin embargo
sı podemos comprobar la validez de la representacion propuesta como metodo de caracterizacion
de formas para fines de reconocimiento.

22 Capıtulo 2. Descripcion de formas planas
Las funciones de curvatura que se van a utilizar en este trabajo cumplen la restriccion
de que su longitud es fija e igual a un cierto N0, lo que puede conseguirse mediante un sencillo
proceso de interpolacion o diezmado. Dado que las FCs son funciones reales, sus transformadas
de Fourier solo tienen N = N0/2 + 1 componentes independientes, por lo tanto consideraremos
las ||CFFFT||s como vectores de longitud N .
3.2. Representacion de objetos mediante puntos caracterısticos
La representacion por puntos caracterısticos de una forma se basa en localizar los puntos
del contorno que se consideran de interes. En general, dichos puntos son las esquinas de este,
aunque tambien pueden considerarse como tales los puntos de inflexion. Un caso especial es la
aproximacion poligonal, donde los puntos de interes se ajustan especıficamente para que el error
de aproximacion sera mınimo y, por tanto, no necesariamente tienen que presentar un sentido
estrictamente fısico de forma aislada. Existe un elevadısimo numero de tecnicas de deteccion de
esquinas en la literatura, que se dividen en dos grandes grupos: tecnicas basadas en procesar la
imagen completa y tecnicas basadas en presegmentar los objetos y codificar sus contornos en
funciones unidimensionales para, a continuacion, localizar los picos de dichas funciones mediante
algoritmos de umbralizacion mas o menos sofisticados.
Dentro de las tecnicas basadas en procesar la imagen completa, algunos sistemas se basan
en la relativamente sencilla deteccion de bordes mediante operadores para luego extraer la cur-
vatura de estos (Medioni y Yasumoto, 1987). Sin embargo, esta suficientemente documentado
que estos metodos fallan en las intersecciones. Moravec propone definir como puntos de interes
los picos de la funcion extraıda a partir del mınimo de la autocorrelacion local en cuatro di-
recciones de cada punto estudiado, pero la funcion que umbraliza suele resultar excesivamente
ruidosa (Moravec, 1979). Harris y Stephens mejoran dicha funcion estimando la autocorrelacion
a partir de las derivadas de primer orden de la imagen (Harris y Stephens, 1988). Si bien en este
caso las esquinas se detectan correctamente, su ubicacion no suele ser correcta. Kitchen y Rosen-
feld ajustan una superficie local cuadratica a la imagen para localizar las esquinas (Kitchen y
Rosenfeld, 1982). En (Dreschler y Nagel, 1982) y (Zuniga y Haralick, 1988) se usa el producto de
la magnitud del gradiente de la imagen por la curvatura del contorno de los bordes para detectar
las esquinas, pero los detectores propuestos son muy sensibles a ruido. Venkatesch (Venkatesh,
1990) y Rosenthaler (Rosenthaler et al., 1992) definen un conjunto de filtros para obtener la
energıa local de cada punto, quedandose con los maximos de dicha energıa. Liu y Tsai (Liu y
Tsai, 1990) utilizan momentos de gris para la tarea, pero tienen problemas con las intersecciones
y el ruido. El metodo SUSAN (Smith y Brady, 1997) se basa en detectar caracterısticas bidi-

3. Representacion de formas planas 23
mensionales de las esquinas en los pixeles de la imagen mediante una mascara y resuelve algunos
de estos problemas. Otros metodos combinan varios de los mencionados sistemas para mejorar
los resultados que obtienen individualmente (Singh y Shneier, 1990).
Los metodos basados en deteccion de puntos caracterısticos presentan la ventaja sobre
los anteriores de una menor carga computacional, en tanto que se aplican sobre un numero de
puntos muy reducido, ası como de una mayor independencia frente a condiciones de iluminacion
y captura. Sin embargo, dado que es necesaria una segmentacion previa, es importante asumir
que los contornos resultantes pueden ser ruidosos y presentar distorsiones mas o menos severas.
Dentro de la deteccion de puntos caracterısticos sobre el contorno del objeto presegmentado,
varios autores trabajan con aproximaciones poligonales (Ansari y Delp, 1991) (Perez y Vidal,
1994), que en su mayor parte se basan en el paradigma de division y mezclado o, lo que es
lo mismo, en dividir el contorno sucesivamente en un numero de puntos cada vez mas elevado
de forma aleatoria buscando que la aproximacion poligonal resultante tenga el error mas bajo
posible para proceder posteriormente a reducir dicho numero de forma controlada de acuerdo al
mismo criterio. Tambien suele usarse como criterio, a efectos de reducir la carga computacional
del proceso, el que el tramo de contorno entre dos de los puntos escogidos sea lo suficientemente
parecido a una recta, denominandose en este caso la aproximacion no optima. El principal
problema de estos metodos radica en que, dado que mas que buscar puntos representativos
se centran en minimizar el error de aproximacion de la curva, el numero y posicion de los
puntos resultantes suele resultar muy sensible a ruido, transformaciones y distorsiones. El resto
de las tecnicas de este grupo se basan en evaluar la curvatura del contorno para detectar los
puntos de maxima variacion, bien usando las coordenadas de este -metodos basados en caminos-
, bien estimando la orientacion de cada punto del contorno con respecto a una direccion de
referencia -metodos basados en orientacion-. Los metodos basados en caminos (Ansari y Delp,
1991) (Mokhtarian y Mackworth, 1986) suelen trabajar convolucionando las coordenadas del
contorno con un filtro gaussiano para extraer su curvatura. Resultan muy fiables siempre y
cuando el ancho de banda del filtro se escoja correctamente. Sin embargo, es muy complejo
escoger un valor unico valido para esquinas definidas a distintas escalas, lo que suele devenir en
una relacion senal a ruido muy pobre en la funcion de curvatura resultante y, por tanto, una
deteccion poco fiable en contornos de complejidad media y alta.
Los metodos basados en orientacion (Arrebola et al., 1997) (Freeman y Davis, 1977)
(Rosenfeld y Weszka, 1975) (Urdiales et al., 2003) utilizan, mayormente, las funciones de cur-
vatura descritas en el apartado anterior para detectar sus picos por umbralizacion. En estos
casos, la deteccion es tanto mejor cuanto mas resistente sea la funcion a ruido, distorsiones y

24 Capıtulo 2. Descripcion de formas planas
transformaciones. Un estudio efectuado en (Urdiales et al., 2003) muestra que la funcion que se
propone en esta tesis presenta unas caracterısticas especialmente deseables para su uso en apli-
caciones de deteccion de esquinas. Para probar esta afirmacion, se ha llevado a cabo un sencillo
experimento. En (Bandera et al., 2000b) se habıa evaluado comparativamente el comportamien-
to de varios detectores de esquinas, concluyendose que el metodo de los histogramas circulares
(CHM) (Arrebola et al., 1999) y el de umbralizacion de la funcion de curvatura adaptativa
(AECF) (Bandera et al., 2000a) eran los mas destacados en cuanto a estabilidad frente a ruido
y transformaciones. Es por ello que se van a comparar los resultados del detector propuesto
con dichos metodos para mostrar su bondad. La Fig. 2.3.a muestra un objeto ejemplo, en este
caso una letra A del alfabeto Times New Roman. Se ha escogido este objeto especificamente
porque dispone de esquinas definidas a distintas escalas, lo que supone un problema clasico para
detectores no adaptativos. Sobre dicha letra se encuentran marcadas con un cuadro las esquinas
que detectan el AECF, CHM y el metodo propuesto. En este caso, dado que el objeto tiene un
tamano elevado y no esta afectado por ruido, los resultados de los tres metodos son practicamente
similares y los puntos detectados coinciden correctamente con las esquinas del objeto. Las Figs.
2.3.b-d presentan una version rotada y escalada del mismo objeto, esta vez afectado por una
cantidad muy significativa de ruido. En estas condiciones mucho mas agresivas, los resultados de
los tres metodos comienzan a diferir. En particular, el CHM pierde algunas esquinas situadas a
la derecha del objeto y devuelve falsas detecciones en las zonas mas distorsionadas por el ruido.
El CHM detecta todas las esquinas, pero produce una falsa deteccion debido al ruido. El metodo
propuesto, sin embargo, ademas de devolver todas las esquinas, no produce falsas detecciones.
A efectos de evaluar de forma objetiva los resultados de este experimento, se usan dos criterios
distintos. El error cuadratico integral (ISE) es una de las medidas mas extendidas y se calcula
como:
ISE =N∑0
(di)2 (2.7)
donde N es la longitud del contorno en pixels y di es la distancia entre los puntos reales del
contorno y la aproximacion poligonal resultante a partir de los puntos detectados. Si bien esta
medida es representativa para detectar si se pierden esquinas o se ubican de forma incorrecta,
es inmediato apreciar que en contornos ruidosos el ISE disminuye incluso cuando todas las
esquinas se han detectado de forma correcta. Ademas, se pondera positivamente el que los
objetos tengan un numero de esquinas elevado, por lo que en objetos con curvas el ISE puede no
resultar representativo. Si bien en este ejemplo se ha usado un objeto sin curvas para evitar este

3. Representacion de formas planas 25
Figura 2.3: Comparativa entre detectores de esquinas: a) Contorno 1 y esquinas detectadas conlos metodos CHM, AECF y propuesto ; b) contorno 2 y esquinas detectadas con el metodo CHM(k = 6); c)contorno 2 y esquinas detectadas con el metodo AECF; y d) contorno 2 y esquinasdetectadas con el metodo propuesto
problema, se usa una segunda medida que se conoce como Merito, propuesta por Rosin (Rosin,
1996), que combina una medida de eficiencia E y una de fidelidad F :
Merito =√
EF =
√ISEopt ·Mopt
ISEaprox ·Maprox(2.8)
donde ISEopt e ISEaprox representan, respectivamente, el ISE de la aproximacion poligonal
optima y el de la construida con las esquinas obtenidas. Mopt y Mapprox equivalen al numero
de lados de los poligonos resultantes en ambos casos. En este experimento, se ha usado como
aproximacion poligonal optima el metodo de Perez y Vidal (Perez y Vidal, 1994). La tabla 2.1
presenta las medidas correpondientes a la figura para los ejemplos presentados. Puede observarse
que para la letra de la Fig. 2.3.a, el mayor ISE corresponde a la AECF. Las pequenas variaciones
que aparecen en el ISE se deben a que las esquinas inferiores de la letra estan redondeadas y,
por tanto, las esquinas se desplazan levemente de un metodo a otro. En este caso, la medida no
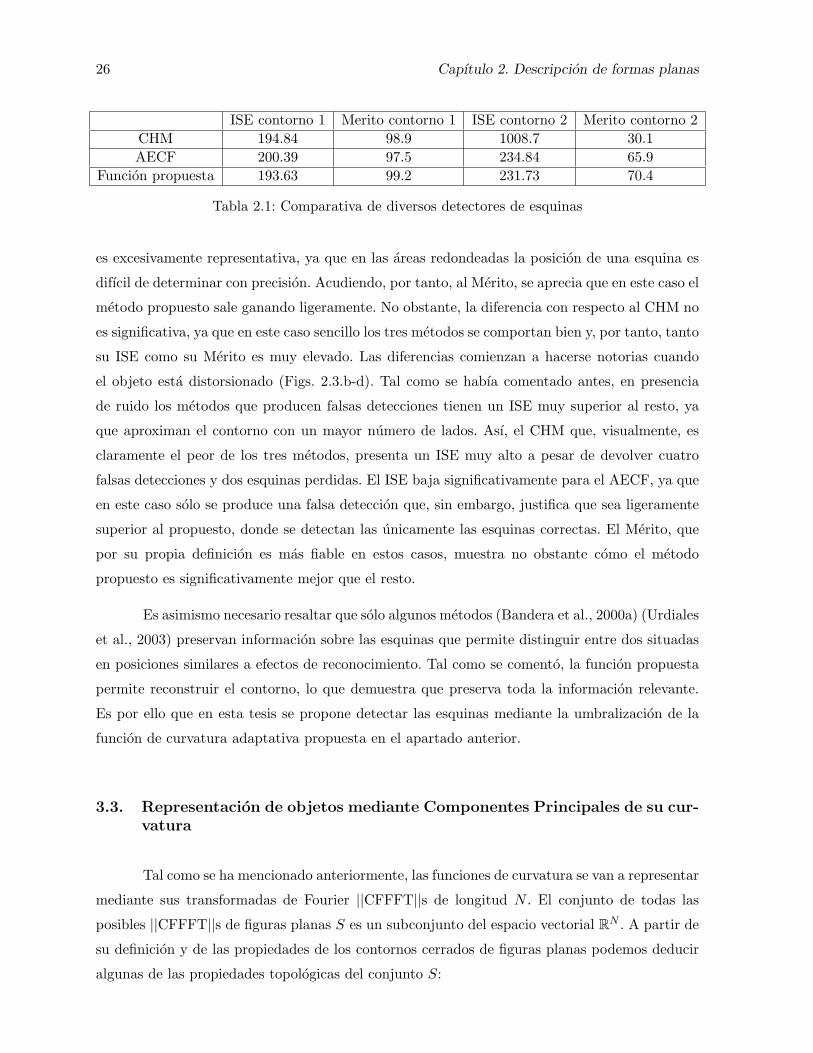
26 Capıtulo 2. Descripcion de formas planas
ISE contorno 1 Merito contorno 1 ISE contorno 2 Merito contorno 2CHM 194.84 98.9 1008.7 30.1AECF 200.39 97.5 234.84 65.9
Funcion propuesta 193.63 99.2 231.73 70.4
Tabla 2.1: Comparativa de diversos detectores de esquinas
es excesivamente representativa, ya que en las areas redondeadas la posicion de una esquina es
difıcil de determinar con precision. Acudiendo, por tanto, al Merito, se aprecia que en este caso el
metodo propuesto sale ganando ligeramente. No obstante, la diferencia con respecto al CHM no
es significativa, ya que en este caso sencillo los tres metodos se comportan bien y, por tanto, tanto
su ISE como su Merito es muy elevado. Las diferencias comienzan a hacerse notorias cuando
el objeto esta distorsionado (Figs. 2.3.b-d). Tal como se habıa comentado antes, en presencia
de ruido los metodos que producen falsas detecciones tienen un ISE muy superior al resto, ya
que aproximan el contorno con un mayor numero de lados. Ası, el CHM que, visualmente, es
claramente el peor de los tres metodos, presenta un ISE muy alto a pesar de devolver cuatro
falsas detecciones y dos esquinas perdidas. El ISE baja significativamente para el AECF, ya que
en este caso solo se produce una falsa deteccion que, sin embargo, justifica que sea ligeramente
superior al propuesto, donde se detectan las unicamente las esquinas correctas. El Merito, que
por su propia definicion es mas fiable en estos casos, muestra no obstante como el metodo
propuesto es significativamente mejor que el resto.
Es asimismo necesario resaltar que solo algunos metodos (Bandera et al., 2000a) (Urdiales
et al., 2003) preservan informacion sobre las esquinas que permite distinguir entre dos situadas
en posiciones similares a efectos de reconocimiento. Tal como se comento, la funcion propuesta
permite reconstruir el contorno, lo que demuestra que preserva toda la informacion relevante.
Es por ello que en esta tesis se propone detectar las esquinas mediante la umbralizacion de la
funcion de curvatura adaptativa propuesta en el apartado anterior.
3.3. Representacion de objetos mediante Componentes Principales de su cur-vatura
Tal como se ha mencionado anteriormente, las funciones de curvatura se van a representar
mediante sus transformadas de Fourier ||CFFFT||s de longitud N . El conjunto de todas las
posibles ||CFFFT||s de figuras planas S es un subconjunto del espacio vectorial RN . A partir de
su definicion y de las propiedades de los contornos cerrados de figuras planas podemos deducir
algunas de las propiedades topologicas del conjunto S:

3. Representacion de formas planas 27
El conjunto S es un conjunto continuo. Si se toma el contorno de una figura plana
cualquiera de longitud fija N0, se puede tomar un conjunto de contornos de figuras planas
obtenidas por deformaciones continuas de la primera figura. Este subconjunto del conjunto
de todas las figuras planas es un subconjunto continuo y abierto. La aplicacion que hace
corresponder a cada contorno cerrado el modulo de su transformada discreta de Fourier es
continua por definicion. El conjunto imagen de una aplicacion continua sobre un abierto
continuo es a su vez un conjunto abierto y continuo Por lo tanto S es continuo.
El conjunto S es conexo. Todo contorno de una figura plana se puede obtener mediante
la deformacion continua de cualquier otro contorno, por lo tanto el conjunto de todos los
posibles contornos cerrados es conexo. Como la aplicacion que hace corresponder a cada
contorno cerrado el modulo de su transformada discreta de Fourier es continua, el conjunto
S debe ser tambien conexo.
Existe una familia de cartas inyectivas de S. Si se supone un contorno inicial y un conjunto
de deformaciones del mismo que se puede obtener mediante la variacion de un conjunto
de parametros xα, entonces el conjunto imagen de la aplicacion definida por xα, al que se
denominara Sα es un subconjunto abierto de S. En ese caso xα es una carta de Sα. Si se
toma un conjunto de cartas x tal que la union de sus conjuntos imagen coincide con S,
entonces x es una familia de cartas de S
Dada una pareja de cartas xα y xβ del conjunto de todas las posibles ||CFFFT||s, si la
interseccion de sus imagenes Sα⋂
Sβ no es el conjunto vacıo, entonces existe una apli-
cacion diferenciable que relaciona xα y xβ para todo elemento que pertenezca a la inter-
seccion de las imagenes. Es decir si un cierto subconjunto abierto del conjunto S se puede
parametrizar mediante dos cartas distintas, entonces sus propiedades topologicas son las
mismas independientemente de que carta se escoja.
Un conjunto que cumple las propiedades anteriores es una variedad riemanniana (do
Carmo, 1990). En concreto, el conjunto de todas las posibles ||CFFFT||s de contornos de figuras
planas S es una variedad riemanniana incluida en el espacio vectorial euclıdeo RN de todas
las posibles funciones discretas de longitud N . Para que el subconjunto S de RN se pudiera
considerar un espacio vectorial serıa necesario definir una operacion suma y una operacion
producto interiores a S y que cumplieran una serie de propiedades. Se puede definir la suma
como la suma vectorial en RN . Sin embargo, dada una pareja de ||CFFFT||s de S, su suma
vectorial sera en general una funcion discreta de longitud N que no tiene por que corresponder
al modulo de la transformada de Fourier de un contorno cerrado. Por lo tanto la suma vectorial

28 Capıtulo 2. Descripcion de formas planas
no es una operacion cerrada en el conjunto S de todas las posibles ||CFFFT||s de figuras planas,
luego S no es un espacio vectorial.
Teniendo en cuenta que el objetivo es caracterizar los contornos planos mediante vectores
de caracterısticas y evaluar el parecido entre los mismos, se necesita definir una metrica de la
variedad riemanniana {S,x} de las ||CFFFT||s de figuras planas. En una variedad riemanniana
se puede definir una metrica natural en la cual la distancia entre cada dos puntos sea igual a
la longitud de una geodesica interior a la variedad (do Carmo, 1990). Para poder asignar una
distancia entre dos puntos cualesquiera es necesario calcular primero la geodesica optima que los
une. Este procedimiento es excesivamente costoso en tiempo de computacion. Para poder realizar
los calculos de distancias de una forma mas comoda convendrıa poder definir los elementos de S
como vectores de un espacio euclıdeo. Como todos los elementos de S pertenecen tambien a RN ,
se podrıa tomar como vectores de caracterısticas los vectores que representan a las ||CFFFT||sen este espacio. Sin embargo, aunque no se conozca la topologıa de S, es lıcito suponer que su
dimension intrınseca sea menor que N , por lo tanto serıa deseable encontrar una base de un
espacio vectorial de dimension menor que N que represente correctamente los elementos de S.
Para ello se van a hacer las siguientes suposiciones:
Las transformadas de Fourier presentan tıpicamente informacion redundante, luego se
puede suponer que la dimension intrınseca de S es mucho menor que N
Los elementos de la variedad {S,x} se pueden proyectar sobre un espacio vectorial de
dimension P , con P ≤ N , que sera un subespacio del espacio vectorial RN . Si S no
esta incluido en RP entonces se cometera un error de representacion al despreciar las
componentes de S exteriores al subespacio RP .
No se pueden generar todos los posibles contornos de figuras planas para encontrar el sube-
spacio RP optimo sobre el que proyectarlas, pero se puede suponer que dado un conjunto
limitado de M figuras planas, exigiendo que contenga figuras suficientemente variadas,
si encontramos una base de un subespacio RP tal que el error cometido en la proyec-
cion respecto de las ||CFFFT||s de las figuras originales sea suficientemente pequeno, esta
base sera valida para hacer una representacion de los elementos del conjunto S mediante
vectores de caracterısticas de longitud P .
El hecho de que se cometa un error apreciable en la representacion de figuras planas no
incluidas en el subconjunto utilizado para calcular la base indica que la dimension del
subespacio RP es demasiado pequena para proporcionar una representacion valida de S.
En efecto, si la base calculada para representar un subconjunto de figuras planas es una

3. Representacion de formas planas 29
base ortogonal, el error cometido en la representacion de cualquier figura no incluida en el
subconjunto inicial indicara que la figura propuesta contiene una componente adicional en
una direccion ortogonal a todas las de la base propuesta. Esto indicarıa que el subespacio
de todas las figuras planas tiene una dimension superior a la del subconjunto elegido.
Por lo tanto, el subconjunto elegido no serıa el mas adecuado para crear una base de
representacion generica.
Partiendo de estos supuestos, nuestro objetivo es encontrar un subespacio RP de RN de
la mınima dimension necesaria para representar a todos los contornos de figuras planas. Una base
del subespacio vectorial RP debe estar alineada con las direcciones principales de la variedad
{S,x} para que el error de representacion sea mınimo. El conjunto de figuras a partir del cual
calcularemos una base del subespacio RP es necesariamente limitado, pero lo consideraremos
suficientemente variado en el sentido anteriormente definido. Para este fin utilizaremos la tecnica
de Analisis de Componentes Principales (PCA, Principal Components Analysis). El metodo de
analisis por Componentes principales es una tecnica muy conocida para la reduccion dimensional
de conjuntos de datos extensos. Tiene muchas aplicaciones en compresion de informacion, analisis
de series temporales, procesado del lenguaje y reconocimiento de patrones (Startchik et al., 1998).
La mejor aproximacion de la proyeccion de un conjunto de ||CFFFT||s sobre un sube-
spacio vectorial de dimension P es la que se obtiene mediante las P Componentes Principales
asociadas a los P mayores autovalores de su matriz de autocorrelacion (Sirovich y Everson, 1992).
Los autovectores correspondientes a estos P autovalores forman una base ortogonal del subespa-
cio. Cada contorno correspondiente a una figura plana se puede representar en este subespacio
como un vector al que consideraremos su vector de caracterısticas (FV - Feature Vector).
Sea un conjunto de M FCs de longitud N0, obtenidas de un conjunto de M figuras planas.
Consideraremos sus ||CFFFT||s como vectores de longitud N = N0/2 + 1 . Este conjunto de
vectores,{−−→
Xm
}M
m=1, se puede representar como:
−→Xm =
N−1∑i=0
xim−→δi , (2.9)
siendo xim el i-esimo coeficiente de la m-esima ||CFFFT|| y−→δi una delta de Dirac centrada en
el punto i. Entonces el conjunto{−→
δi
}N
i=1es una base del espacio vectorial de dimension N que
contiene a todas las ||CFFFT||s de longitud N .

30 Capıtulo 2. Descripcion de formas planas
Para aproximar las ||CFFFT||s mediante solo P componentes, es necesario calcular una
base del subespacio de dimension P ,{−→
φk
}P
k=1tal que:
−→Xi=
P∑k=1
βik−→φ k, (2.10)
siendo βik los coeficientes aun desconocidos. La optimalidad de la base requerida se puede
cuantificar como el error cuadratico medio ε2 cometido en la representacion respecto de los
valores originales de los vectores{−−→
Xm
}M
m=1:
ε2 =1M
M∑i=1
∣∣∣∣∣∣−→Xi −P∑
j=1
βij−→φ j
∣∣∣∣∣∣2
(2.11)
Si la base es optima, su error asociado ε2 debe ser mınimo. En (Sirovich y Everson, 1992) se
demuestra que ε2 es mınimo si los P vectores{−→
φk
}P
k=1son los extraidos del conjunto de N
autovectores de la matriz de autocorrelacion de{−−→
Xm
}M
m=1, C:
C =1M
M∑i=1
−→Xi−→Xi
T (2.12)
donde T representa la operacion de transposicion vectorial. Los N autovectores{−→
φk
}N
k=1y
autovalores {λk}Nk=1 of C son las soluciones de:
C ·−→φ k = λk
−→φ k k = 1, ...n (2.13)
Si se ordenan los autovalores en orden decreciente, λ1 > λ2 > ... > λN y se representan los
autovectores correspondientes a estos autovectores como−→φ 1,
−→φ 2, ...
−→φ N , entonces el conjunto de
los P (P ≤ N) primeros autovectores es una base ortogonal del subespacio de dimension P en
el espacio vectorial original de dimension N . La proyeccion sobre este espacio de dimension P
de cada ||CFFFT|| del conjunto inicial,−→Xi, se puede representar como:
−→βi = [βi1, ...βij ...βiP ] (2.14)
donde βij es la j-esima Componente Principal de−→Xi y viene dada por:
βik = λ−1j (
−→φj
T−→X i) (2.15)
Por lo tanto la Componente Principal βij es un escalar que representa la norma del vector−→Xi
proyectado sobre el autovector−→φj .
Consecuentemente, la mejor aproximacion a los M vectores−→Xi del conjunto inicial se
obtiene mediante las P Componentes Principales asociadas a sus P mayores autovalores. Estas

3. Representacion de formas planas 31
P componentes forman una base ortogonal de un subespacio vectorial del espacio de todas
las posibles funciones reales y discretas de longitud N que contiene a las M ||CFFFT||s del
conjunto inicial salvo un error de representacion ε2. El nivel de error tolerable se puede ajustar
incluyendo mas o menos autovectores en la base, es decir, eligiendo una dimension adecuada
para el subespacio.
Si el conjunto inicial de M figuras es suficientemente variado, la base compuesta por los
vectores{−→
φk
}P
k=1se podra usar ademas para representar ||CFFFT||s de figuras inicialmente no
incluidas (−→βi). Dada una figura nueva, su vector asociado
−→X se obtiene proyectando su ||CFDFT||
sobre cada uno de los vectores de la base ortogonal propuesta. Ası, cada figura plana se puede
representar mediante un vector de caracterısticas−→Xi de dimension P . Este presenta al menos la
misma robustez frente a ruido y transformaciones que su correspondiente funcion de curvatura.
Para evaluar el error cometido al representar una figura no incluida en el conjunto inicial
utilizamos de nuevo la medida de ε2. En este caso, una figura generica viene representada por
un vector−→Y de dimension N que procede del calculo de su ||CFFFT|| y responde a la expresion
generica:
−→Y =
N−1∑i=0
yi−→δi , (2.16)
La optimalidad de su aproximacion mediante el vector de caracterısticas propuesto se puede
evaluar como:
ε2 =
∣∣∣∣∣∣−→Y −P∑
j=1
ϕj−→φ j
∣∣∣∣∣∣2
(2.17)
Siendo ϕj la proyeccion de−→Y sobre el autovector
−→φ j
Al contrario de lo que sucede con el error de representacion de las figuras del conjunto
inicial, el error cometido en la representacion de una figura generica no esta necesariamente
acotado a un valor maximo segun el numero de Componentes Principales escogido para la
representacion. En este caso el error depende ademas de la correlacion entre la ||CFFFT|| de
la nueva figura y las ||CFFFT||s de las figuras que componen el conjunto inicial. De aquı la
necesidad de incluir tantos elementos distintos como sea posible en el conjunto inicial.
La base ası obtenida es la base de un espacio vectorial sobre el que se proyecta la variedad
riemanniana S que contiene a todas las ||CFFFT||s de siluetas de figuras planas. En principio,
S es una variedad continua y conexa. Esto quiere decir que a figuras parecidas deben corre-
sponder puntos cercanos sobre la variedad. Sin embargo, si proyectamos una variedad sobre un

32 Capıtulo 2. Descripcion de formas planas
espacio vectorial cabe la posibilidad de que puntos lejanos sobre la variedad sean cercanos en el
espacio vectorial. Este hecho podrıa dificultar notablemente la tarea de clasificacion a partir de
vectores de caracterısticas, porque a figuras eventualmente muy distintas podrıan corresponder
puntos muy cercanos en el espacio, de modo que la separacion en clases del mismo las harıa
indistinguibles. Esto ocurre basicamente en dos casos:
1. Si la dimension intrınseca de la variedad S es igual a la dimension del espacio sobre el
que se proyecta pero la curvatura de S es muy pronunciada. En la Fig. 2.4 se muestra
un ejemplo de este caso. Por claridad en la representacion se ha escogido una variedad de
dimension intrınseca igual a 1 y se proyecta sobre una recta (Fig. 2.4.a). Los puntos A, B
y C estan colocados a intervalos regulares sobre S. Se puede observar como el pliegue en la
variedad hace que los puntos A y C parezcan mas cercanos entre sı que A y B cuando son
proyectados sobre la recta r que simula el espacio vectorial de representacion de dimension
1. Una posible solucion serıa aumentar la dimension del espacio de representacion de modo
que se pueda reflejar la diferencia entre A y C (Fig. 2.4.b)
Figura 2.4: a) Variedad de dimension 1 extendida; y b) variedad de dimension 1 plegada
2. Si la dimension del espacio de representacion es menor que la dimension intrınseca de
la variedad S, la proyeccion sobre el espacio vectorial se puede hacer a costa de perder
informacion. Si, por ejemplo, la variedad S es una superficie alabeada, y por tanto presenta
dimension intrınseca igual a 2, una proyeccion de S sobre una recta podrıa no ser valida
para la clasificacion de puntos pertenecientes a S. Este problema se puede solucionar
facilmente sin mas que aumentar la dimension del espacio vectorial a 2. Hay que destacar
tambien que no siempre es imprescindible que el espacio vectorial de representacion sea de

4. Resultados y experimentos 33
dimension igual o superior a la variedad S. Por ejemplo, una variedad que tuviera forma
de banda alargada tendrıa una dimension intrınseca igual a 2 pero su proyeccion sobre un
espacio de dimension 1 serıa suficiente, en general, con fines de clasificacion.
4. Resultados y experimentos
Hasta el momento, se han propuesto tres metodos distintos para representar un objeto
plano a partir de su forma: funcion de curvatura adaptativa, esquinas extraıdas a partir de esta
y proyeccion sobre las Componentes Principales de la transformada rapida de Fourier de dicha
funcion. Todos los metodos de representacion tienen sus pros y sus contras y, para evaluarlos,
es necesario establecer una metodologıa especıfica. Ya que el objetivo de esta tesis es el re-
conocimiento de objetos, se va a proceder a desarrollar los tres metodos para reconocimiento de
objetos planos a fin de evaluar cual es el mas apropiado como metodo de representacion. Para
ello, se va a hacer uso de algunas bases de datos propias y otras publicas a efectos de que puedan
compararse los resultados propuestos con otros metodos en igualdad de condiciones. Las bases
de datos empleadas son las siguientes:
1. Un conjunto reducido de 6 figuran geometricas simples cedido por los autores de (Chang
y Chen, 2000) a efectos comparativos (Fig. 2.5.a).
2. Un conjunto que incluye las 6 figuras del conjunto anterior junto con 14 deformaciones
de cada una hasta un total de 90 figuras. Las deformaciones se han creado utilizando un
software de tratamiento de imagenes e incluyen deformaciones por cambio de escala, pers-
pectiva, proyeccion esferica, cizalladura, ligeras oclusiones y algunas otras deformaciones
no lineales (Fig. 2.5.b).
3. Un juego de 24 caracteres alfabeticos mas 10 caracteres numericos, extraıdos de moldes de
matrıculas de coche espanolas. (Fig. 2.6.a).
4. El juego de caracteres anterior en el que se han incluido 30 ejemplos de cada caracter
hasta un total de 1020 figuras. Estos caracteres han sido obtenidos de imagenes reales
tomadas de matrıculas de coches, de modo que presentan ruido, sombras, deformacion por
perspectiva y errores de segmentacion en mayor o menor medida (Fig. 2.6.b).
5. Un conjunto de anagramas extraıdos de 27 senales de trafico. Este conjunto presenta formas
muy variadas, pero no incluye deformaciones ni ruido (Fig. 2.7.a).

34 Capıtulo 2. Descripcion de formas planas
Figura 2.5: a) Conjunto de 6 figuras geometricas; y b) ejemplo de 15 deformaciones de una deellas
Figura 2.6: a) Conjunto de 34 caracteres tomados de matrıculas de coches; y b) ejemplo de 30versiones de un caracter

4. Resultados y experimentos 35
Figura 2.7: a) Conjunto de 27 anagramas de senales de trafico: y b) ejemplos de deformacionesaplicadas al conjunto anterior
6. El conjunto de anagramas anterior incluyendo entre 3 y 5 versiones deformadas de ca-
da uno. Entre las deformaciones se pueden encontrar efectos de perspectiva, rotaciones,
cambios de escala o ruido (Fig. 2.7.b).
7. Un base de datos publica que presenta 1100 contornos distintos de peces y otro ani-
males marinos 1. Estos contornos no presentan distorsiones, pero varios contornos dis-
tintos pueden pertenecer al mismo tipo de pez. Esta base de datos fue la presentada en
(Mokhtarian y Mackworth, 1986) para ilustrar el metodo de indexado basado en CSS.
Algunos ejemplos de estas siluetas se muestran en la Fig. 2.8.
8. Un conjunto de figuras compuesto por figuras planas tomadas de imagenes sinteticas y
reales de objetos tridimensionales desde distintos puntos de vista. En este caso se han
incluido siluetas de objetos comunes. Algunas de estas siluetas se muestran en la Fig. 2.9.
4.1. Reconocimiento basado en curvatura
4.1.1. Metodo de reconocimiento y metrica
La forma mas intuitiva de reconocer objetos utilizando la funcion de curvatura (FC)
es emplearla en sı como descriptor. En este caso, para comparar dos objetos unicamente es
necesario comparar sus FCs (Bandera et al., 2000a). Sin embargo, a efectos de hacer el proceso
de reconocimiento invariante a transformaciones en la medida de lo posible, es necesario recordar1http://www.ee.surrey.ac.uk/Research/VSSP/imagedb/demo.html

36 Capıtulo 2. Descripcion de formas planas
Figura 2.8: Ejemplos de siluetas de prueba del conjunto de siluetas de peces (Mokhtarian yMackworth, 1986)
Figura 2.9: Ejemplos de siluetas de prueba del conjunto de objetos tridimensionales

4. Resultados y experimentos 37
que el tamano de la FC depende del numero de puntos del contorno y que las rotaciones provocan
desplazamientos en la funcion. Ası pues, resulta necesario diezmar o interpolar las funciones a
un tamano fijo, mientras que el efecto de las rotaciones obliga a usar una medida de similitud
que tenga en cuenta los desplazamientos, quedando excluidas distancias clasicas entre funciones
como los mınimos cuadrados. Una medida circular que tiene en cuenta este comportamiento
cıclico es, por ejemplo, la correlacion circular, en concreto, el maximo de esta:
max = maximo0≤i≤TamF−1(TamF−1∑
j=0
x(j) · y((j + i)modTamF )) (2.18)
donde max es el ındice de similitud, TamF es el tamano de las funciones de curvatura norma-
lizadas, y x(i) e y(i) son las funciones de curvatura a comparar.
La Fig. 2.10.c muestra la correlacion entre las FCs de las Figs. 2.10.a y 2.10.b. En este
caso en particular se puede apreciar como el maximo esta cercano a la unidad, ya que los
objetos comparados son muy similares. Para acelerar el proceso de correlacion, esta se efectua
en el dominio de Fourier, donde se transforma en un producto. A este efecto, cabe usar la
transformada rapida de Fourier (FFT), para lo que el tamano de normalizacion de las funciones
de curvatura se debe fijar en un multiplo de 2 (generalmente, 256 o 512). Ası, el valor del ındice
de similitud sera:
max = maximo0≤i≤TamF−1(IFFT [FFT [x(i)] · FFT [y(i)]]) (2.19)
donde max es el ındice de similitud, TamF es el tamano de las FFTs de las funciones de
curvatura, y x(i) e y(i) las funciones de curvatura.
4.1.2. Resultados
La Fig. 2.11 muestra diversas figuras reconocidas mediante el proceso descrito. Como
puede observarse, el mencionado proceso es resistente a ruido y transformaciones geometricas
como rotaciones, traslaciones y escala. Sin embargo, en tanto que se evalua la FC completa
como un todo, este proceso presenta inestabilidades con respecto a distorsiones y a elementos
que varıen la forma global del objeto, como por ejemplo, oclusiones parciales. Para evitar este
problema es necesario emplear criterios de reconocimiento mas complejos como se observa en
los subapartados siguientes.
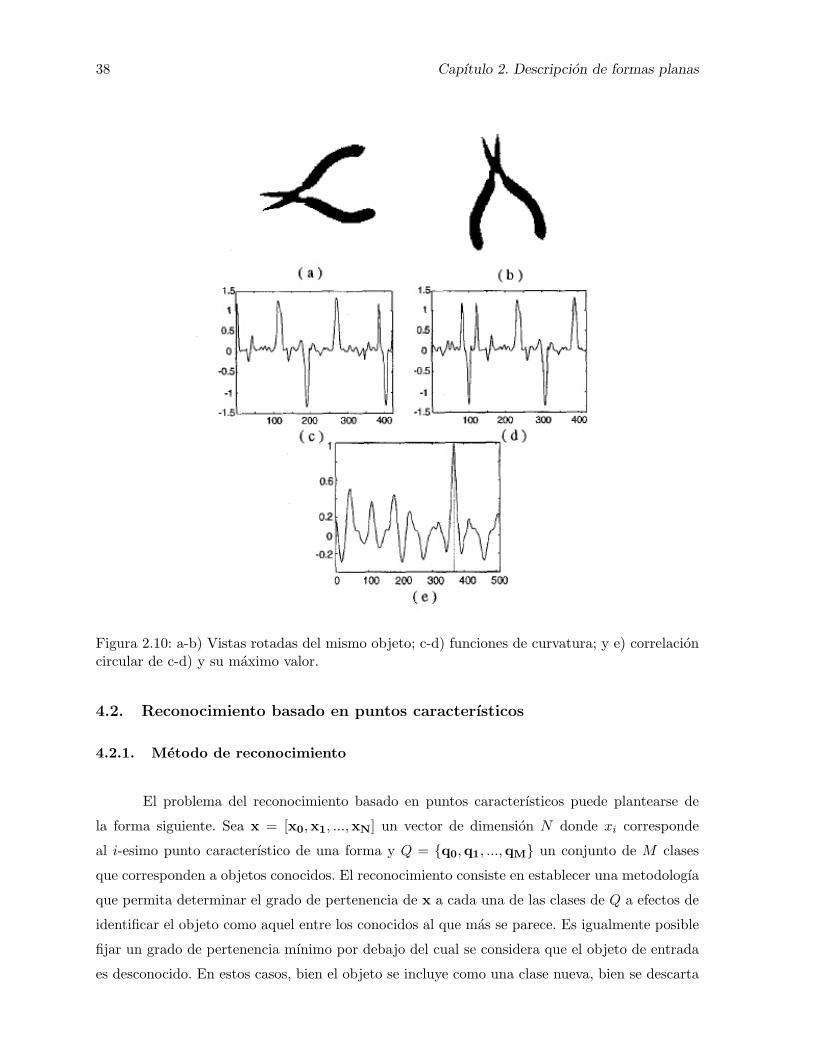
38 Capıtulo 2. Descripcion de formas planas
Figura 2.10: a-b) Vistas rotadas del mismo objeto; c-d) funciones de curvatura; y e) correlacioncircular de c-d) y su maximo valor.
4.2. Reconocimiento basado en puntos caracterısticos
4.2.1. Metodo de reconocimiento
El problema del reconocimiento basado en puntos caracterısticos puede plantearse de
la forma siguiente. Sea x = [x0,x1, ...,xN] un vector de dimension N donde xi corresponde
al i-esimo punto caracterıstico de una forma y Q = {q0,q1, ...,qM} un conjunto de M clases
que corresponden a objetos conocidos. El reconocimiento consiste en establecer una metodologıa
que permita determinar el grado de pertenencia de x a cada una de las clases de Q a efectos de
identificar el objeto como aquel entre los conocidos al que mas se parece. Es igualmente posible
fijar un grado de pertenencia mınimo por debajo del cual se considera que el objeto de entrada
es desconocido. En estos casos, bien el objeto se incluye como una clase nueva, bien se descarta

4. Resultados y experimentos 39
Figura 2.11: Objetos reconocidos mediante correlacion: a-d) clase 1; e-h) clase 2; i-l) clase 3; ym-p) clase 4.
como desconocido, catalogandose los algoritmos como sistemas con aprendizaje o con rechazo
respectivamente.
El metodo mas facil para resolver si el objeto x pertenece a una clase cualquiera qi
es definir una metrica y calcular la distancia entre x y el prototipo de qi . Sin embargo, la
mencionada metrica no puede establecerse de forma sencilla en cuanto x y qi tengan un tamano
distinto. Naturalmente, los vectores relacionados con objetos diferentes tendran como dimension
el numero de puntos caracterısticos que presenten los objetos correspondientes que, no solo no
tiene que coincidir para distintos objetos sino que incluso puede variar en versiones transformadas
y distorsionadas de un mismo objeto. Para resolver este problema, algunos metodos se basan
en morphing o correspondencia de grafos (Amit et al., 1997) (Singh, 1996). Si los resultados
no son satisfactorios, puede recurrirse a hacer los procesos iterativos, pero esta medida tambien
los hace computacionalmente costosos y, caso de presentar un objeto distorsiones severas, se ha
expuesto que estos procesos suelen no converger. Alternativamente, puede recurrirse a metodos
estadısticos para comparar dos vectores, donde la probabilidad de x de pertenecer a la clase qi
se define mediante la regla de Bayes como:
P (qi|x) =p(x|qi)P(qi)
P(x)=
p(x|qi)P(qi)∑j p(x|qj)P(qj)
(2.20)
donde P (qi) es la probabilidad previa de pertenecer a qi y p(x|qi) es la probabilidad condicionada
a la clase. Para acumular probabilidad cada vez que se evalua un punto caracterıstico cuando se

40 Capıtulo 2. Descripcion de formas planas
Figura 2.12: Parametros de caracterizacion de una esquina
evaluan vectores de distinta dimension, hay que trabajar con la probabilidad de que el objeto
pertenezca a la clase qi cuando presenta el punto xj (P (qi|xj)). Los modelos Bayesianos simples
no permiten aprovechar la secuencialidad en la aparicion de los puntos caracterısticos de una
forma y, por ello, en estos casos se recurre a procesos de Markov (Taylor y Karlin, 1994). El
principal problema de los procesos simples de Markov es que no permiten que un elemento
determinado pueda aparecer en dos objetos distintos. Dado que este sera el caso habitual en las
formas planas, en estas situaciones se opta por Modelos Ocultos de Markov (MOM), donde se
incluye una capa oculta que contiene los distintos estados del sistema (Rabiner, 1989).
4.2.2. Caracterizacion de puntos
Para determinar si dos puntos caracterısticos son iguales, es necesario caracterizarlos
de algun modo. En principio, en una secuencia de N esquinas Cx = (C1x, C2x, ..., CNx), cada
una puede caracterizarse usando distintos rasgos. El mas simple es, naturalmente, su posicion
(x, y) en la imagen, pero esta posicion es extremadamente variable frente a transformaciones
y distorsiones. Usando la informacion que incluye la funcion de curvatura (FC) propuesta, se
puede caracterizar una esquina i con los parametros que aparecen en la Fig. 2.12, que son: i)
el angulo que subtiende la esquina (Cφix), que se calcula como la integral de la FC entre dos
cruces por cero consecutivos antes y despues de Cix; y ii) la longitud de contorno (Crix) entre Cix
y C(i+1)x. Estos parametros son invariantes a rotacion y traslacion y, si las FC se normalizan
previamente, tambien a escala. Tal como se comento en el apartado correspondiente, la FC
propuesta es igualmente resistente al ruido, por lo que los parametros escogidos son bastante
estables. Es importante notar que estos parametros no van referidos a ningun punto especıfico
del objeto, usualmente el centroide (Chang y Chen, 2000) (Zhu y Chirlian, 1995), por lo que
las deformaciones, si bien pueden hacer aparecer o desaparecer algunas esquinas, no variaran
significativamente el resto.

4. Resultados y experimentos 41
4.2.3. Construccion del MOM
Tal como se ha comentado en el subapartado anterior, los puntos caracterısticos de una
forma estan sujetos a las distorsiones que esta pueda presentar. Para conseguir resistencia frente
a estas, ası como para comparar objetos con un numero de puntos caracterısticos potencialmente
distinto, se va a utilizar un Modelo Oculto de Markov (MOM) (Rabiner, 1989) cuyos estados
ocultos estan asociados a Cφix y Crix. La estructura de un MOM para un prototipo cualquiera
p se extrae de su secuencia de esquinas Cp evaluadas en el sentido de las agujas del reloj. Cada
MOM presenta los siguientes elementos:
Un conjunto M de estados ocultos H = {H1,H2, ...,H i,HM}. Estos estados no correspon-
den a ningun prototipo en particular sino que caracterizan esquinas aisladas que pueden
presentarse en diversos objetos. Para obtener los estados ocultos, todas las esquinas de
todos los objetos a analizar se almacenan en coordenadas polares, siendo el modulo y fase
de una esquina Cip en el prototipo p iguales a Crip y Cφip, respectivamente. Sobre este
conjunto se aplica un algoritmo de agrupacion K-medias (Hartigan, 1979) para dividir las
esquinas en M clases en funcion de Crip y Cφip. Se ha observado que el modulo de las
esquinas es mas estable frente a deformaciones y ruido que la fase y, por tanto, utilizamos
como distancia en el K-medias un factor que pondera el modulo frente a la mencionada
fase:
D2(Cip, Cjq) = d2(Cip, Cjq) +cos2θsin2θ
(Crip − Crjq)2 (2.21)
donde Cip es la esquina i-esima del prototipo p y Cjq es la esquina j-esima del prototipo q,
D(Cip, Cjq) es la distancia propuesta y d(Cip, Cjq) es la distancia Euclidea entre Cip y Cjq.
Los pesos relativos de modulo y fase pueden controlarse fijando heurısticamente el valor
de θ. Los M prototipos {H1,H2, ...,HM} de las clases resultantes son los estados ocultos
del sistema.
Una distribucion inicial de probabilidad Πp = (π1, π2, ..., πi, ..., πM ). Para cada prototipo de
objeto conocido debe calcularse un vector Πp. Cada coeficiente πi del vector de distribucion
de probabilidad inicial representa la probabilidad de aparicion del estado oculto H i en la
esquina inicial C1p del prototipo p.
Una matriz de transicion Ap para cada prototipo conocido. Cada coeficiente Apij de la
matriz Ap representa la probabilidad de transicion del estado oculto H i al Hj siguiendo
la secuencia de esquinas del prototipo p. Estas probabilidades se obtienen mediante el
algoritmo de Baum-Welch (Rabiner, 1989).

42 Capıtulo 2. Descripcion de formas planas
Una matriz de probabilidad de distribucion de la observacion Bp de dimension MxN ,
donde N es el numero de esquinas del prototipo p. Cada coeficiente Bpij es igual a la
probabilidad de la esquina Cip del prototipo p de encontrarse en el estado oculto Hj . Para
calcular un coeficiente Bpij cualquiera, se usa una distribucion gaussiana sobre la distancia
D entre la esquina observada Cip y el estado oculto Hj :
Bpij =
1√2πσ
e[− 1√
2πσk2
ij ] (2.22)
siendo kij un ındice entre 0 y N−1 que depende de la distancia D entre Cip y Hj , y siendo
σ la desviacion estandar de la distribucion gaussiana. σ se calcula de forma que solo las
esquinas mas cercanas a la estudiada tengan una aportacion significativa. Ası, el proceso
es mas resistente a perdidas y apariciones de esquinas o a errores de caracterizacion de
estas.
4.2.4. Metrica
Una vez que se dispone de una observacion consistente en una secuencia de N esquinas
Cx = (C1x, C2x, ..., Cnx) para un objeto x, se calcula su matriz Bx al igual que previamente se
calcularon las de los prototipos. Cada coeficiente Bxij da la probabilidad de la esquina Cix de la
secuencia observada Cx de encontrarse en el estado oculto Hj . Dado que no pueden observarse
directamente los estados ocultos, se asume que la secuencia Cx se puede generar a partir de
cualquier secuencia de estados ocultos S = (S1, S2, ..., SN ). Cada estado Si de S pertenece a los
estados ocultos H y, por tanto, aparecen MN secuencias viables. La probabilidad P (Cx, S|p) de
la secuencia Cx de pertenecer a un prototipo p se calcula como:
P (Cx, S|p) = P (Cx|S)P (S|p) (2.23)
= πS1BxC1xS1
AxS1S2
BxC2xS2
AxS2S3
...BxCN−1xSN−1
AxSN−1SN
BxCNxSN
Ası, la probabilidad P (Cx|p) de la secuencia Cx de ser p, independientemente del estado oculto
generado, es igual a la suma de P (Cx, S|p) para todas las secuencias viables:
P (Cx|p) =∑all S
P (Cx|S)P (S|p) (2.24)
Este calculo se lleva a cabo de forma iterativa, pero se mantiene una carga computacional
reducida utilizando el metodo Forward-Backward, como se sugiere en (Rabiner, 1989).

4. Resultados y experimentos 43
Puede observarse que cada vez que se pierde, gana o distorsiona severamente una esquina,
la probabilidad del objeto de ser reconocido disminuye pero, en tanto que estos errores no
aproximen al objeto a un segundo patron conocido, siempre sera mas probable identificarlo
correctamente o rechazarlo que generar un falso reconocimiento. Es interesante senalar que
este metodo devuelve todos los objetos conocidos que se parecen al observado en orden de
probabilidad descendiente de identificacion correcta. Por ello, ademas de para reconocer formas,
el proceso propuesto puede emplearse para extraccion cualitativa de elementos de bases de datos
(de Trazegnies et al., 2002).
4.2.5. Resultados
El metodo de reconocimiento basado en esquinas propuesto en este subapartado se ha
probado con las bases de datos publicas que se usan en este capıtulo. La Fig. 2.13 muestra
algunos ejemplos correspondientes a la base de letras. En la Fig. 2.13.a se muestran algunas
letras correctamente reconocidas, apareciendo a la izquierda los prototipos de las clases que,
como puede observarse, no estan sujetos a ruido ni a distorsiones y, por tanto, son relativamente
sencillos de reconocer. Si se anaden distintas deformaciones a estas letras despues de haber con-
struido los MOM, puede evaluarse la resistencia del metodo propuesto a dichas deformaciones
y, por tanto, la bondad de la funcion de curvatura propuesta para la caracterizacion de formas.
Puede observarse que las deformaciones incluyen perspectivas, abombamientos y cambios sig-
nificativos que, no obstante, permiten que las letras en la columna derecha de la Fig. 2.13.a se
reconozcan correctamente. Es de senalar que en caso de distorsiones extremas, el sistema puede
equivocarse, como se demostrara cuando se usen figuras mas complejas. La Fig. 2.13.b presenta
un segundo ejemplo donde se usa la base de datos anterior pero se le introducen caracteres de
matrıculas de automoviles sin y con errores. En este caso los errores aparecen como resultado de
fallos de segmentacion o desperfectos en las placas, ya que las matrıculas se han capturado de
imagenes reales. De nuevo, la mayorıa de los caracteres se reconocieron correctamente a pesar
de las distorsiones y errores.
En la Fig. 2.14 se muestra un ejemplo de como la probabilidad de ser un objeto determi-
nado va creciendo o decreciendo en funcion de las esquinas detectadas. La Fig. 2.14.a muestra el
prototipo de una letra E sin distorsiones del conjunto usado para crear los MOM. La Fig. 2.14.b
muestra distintas letras E extraıdas de placas de matrıculas reales y que presentan distintos
niveles de distorsion. La Fig. 2.14.c muestra como evoluciona la probabilidad de ser el patron E
para los objetos en la Fig. 2.14.b con cada esquina detectada. Puede observarse que la mayorıa de
ellos se identifican inmediatamente con la E apenas se estudia la segunda o tercera esquina. No

44 Capıtulo 2. Descripcion de formas planas
Figura 2.13: Patrones correctamente reconocidos: a) caracteres tipo letra; b) caracteres de placasde matrıculas.
ocurre ası en la segunda letra de la Fig. 2.14.b, donde las distorsiones varıan todas las relaciones
entre esquinas. Sin embargo, eventualmente el proceso se recupera de estos errores y reconoce
correctamente el objeto mas en funcion de la secuencialidad que de las esquinas detectadas. La
Fig. 2.15 muestra un ejemplo de reconocimiento incorrecto. El objeto de entrada (Fig. 2.15.a)
presenta una esquina adicional a la izquierda que lo asemeja mas, dada su distorsion, al pro-
totipo de la N que de la K. Ası, incluso despues de evaluar cuatro esquinas, el sistema sigue
convencido de estar estudiando una N distorsionada. Es importante notar, no obstante, que si
bien en terminos de curvatura los objetos son distintos, en terminos de esquinas caracterizadas
por el angulo que subtienden y la longitud de contorno entre ellas, ambos caracteres se parecen
mucho. Este hecho viene a resaltar la importancia de no prescindir del resto de la funcion de
curvatura en el reconocimiento independientemente de la precision con que se puedan localizar
sus esquinas.
Para comprobar la bondad de metodo propuesto y, por tanto, de la funcion de curvatura
para la caracterizacion de los puntos caracterısticos es interesante establecer una comparativa
con otros metodos (de Trazegnies et al., 2002). No existen demasiados trabajos sobre MOM
aplicado a secuencias de puntos caracterısticos, probablemente por la inestabilidad que muchos
metodos de deteccion presentan frente a ruido, transformaciones y distorsiones. No obstante,
en (Chang y Chen, 2000) los autores presentan un metodo de este tipo basado en deteccion
recursiva de esquinas y caracterizacion de estas mediante cuatro parametros, dos de ellos referidos

4. Resultados y experimentos 45
Figura 2.14: Reconocimiento de objetos distorsionados: a) prototipo y esquinas; b) caracteresde entrada y esquinas; c) evolucion de la probabilidad de ser el prototipo con cada esquinaevaluada.
Figura 2.15: Error de reconocimiento en objetos distorsionados: a) objeto de entrada y esquinas;b) prototipos de la letra K y la letra N y sus esquinas; c) evolucion de la probabilidad de sercada uno de los prototipos con cada esquina evaluada.

46 Capıtulo 2. Descripcion de formas planas
al centroide del objeto. Amablemente, los autores han cedido su base de datos para poder
establecer comparativas. Al igual que en sus trabajos, en esta comparativa se va a emplear una
medida de eficiencia denominada rango de extraccion, que se define como la media del ındice
de extraccion. Este ındice corresponde a su vez con el orden en que el prototipo correcto se
escoge al compararse con el patron de entrada, ya que, como se comento con anterioridad, los
MOM permiten ordenar los distintos patrones de la base de datos en probabilidad decreciente
de corresponder al objeto de entrada. Ası, cuanto mas cercano a 1 se encuentre este rango, mejor
es el proceso de reconocimiento. La Fig. 2.16 muestra un conjunto de patrones deformados de la
base de datos empleada en (Chang y Chen, 2000) y una lista de los seis prototipos mas parecidos
a cada uno. Es notorio el hecho de que el procedimiento propuesto soporta oclusiones moderadas.
Para testear mas aun la resistencia del sistema a distintos factores, se ha recurrido tambien a
escribir manualmente caracteres similares a los prototipos de la base de datos, segmentarlos y
alimentarlos al sistema. Los resultados se muestran en la Fig. 2.17. La Fig. 2.17.a muestra una
imagen original con caracteres de este tipo, mientras que la Fig. 2.17.b muestra los caracteres
ya segmentados. La Fig. 2.17.c muestra los prototipos que devuelve el sistema que, como puede
observarse, son correctos en tanto que la escritura siga las pautas generales de los prototipos
aprendidos.
Figura 2.16: Resultados de reconocimiento para conjunto de figuras geometricas: a) imagenesdeformada; b) lista de los elementos mas similares a cada uno de los propuestos.
En la tabla 2.2 se muestra el rango de extraccion para la base de datos geometrica
utilizada tanto para el metodo propuesto como para el que se presentaba en (Chang y Chen,

4. Resultados y experimentos 47
Figura 2.17: a) Imagen original; b) caracteres extraıdos y sus esquinas; c) prototipos reconocidosy sus esquinas.
2000). En ambos casos, el rango medio de ambos metodos es similar y el metodo propuesto,
descartando el hecho de ser mas rapido por la filosofıa de trabajo empleada, solo ofrece una
ligera ventaja en cuanto a resultados cuando se usa su base de datos, que resulta relativamente
sencilla. Sin embargo, el sistema propuesto ofrece una ventaja importante: los parametros con
que se caracteriza una esquina no estan referidos al centroide y, por tanto, son insensibles a
variaciones de este producidas, por ejemplo, por manchas, distorsiones puntuales o no lineales,
errores de segmentacion y oclusiones como las que se observan, por ejemplo, en la Fig. 2.13.b.
Forma Arbol Cruz Elipse Rectangulo Estrella Triangulo Media(Chang y Chen, 2000) 1.29 1.14 1.0 1.57 1.00 1.93 1.32
Metodo propuesto 1.00 1.29 1.07 1.50 1.00 1.86 1.29
Tabla 2.2: Rango de extraccion del metodo propuesto y el desarrollado en (Chang y Chen, 2000)para la base de datos geometrica
Finalmente, se van a efectuar tambien pruebas con una base de datos mucho mas compleja
y disponible publicamente que contiene en su mayorıa figuras de peces (de Trazegnies et al.,
2002). En la mayorıa de los casos y salvo distorsiones serias, tambien para esta base de datos
el sistema reconoce correctamente los objetos de entrada. Sin embargo, dado que se trabaja
con formas mucho mas complejas, resulta interesante incluir aquı en orden descendente el resto
de formas que, de acuerdo a la filosofıa de diseno, tienen parecido con el objeto de entrada.
Ello va a permitir apreciar cualitativamente que rasgos esta usando el sistema para reconocer
dicho objeto. En este caso se van a presentar los cuatro objetos mas parecidos al de entrada
independientemente de cual sea dicho parecido. Esto implica la posibilidad de que en algunos
casos se presenten objetos muy diferentes al de entrada simplemente porque ya no queda ninguno
similar. En todas las imagenes, la primera fila representa el mejor candidato que, salvo que se
mencione lo contrario, coincide con el objeto de entrada, y filas sucesivas presentan candidatos
cada vez menos probables. Ası, la Fig. 2.18 muestra un conjunto de peces que se reconocen

48 Capıtulo 2. Descripcion de formas planas
Figura 2.18: Ejemplos de reconocimiento para los peces de a) a e), situados, de arriba a abajoen orden decreciente de probabilidad.
correctamente y la segunda, tercera y cuarta opcion para cada uno de ellos. Puede observarse,
por ejemplo, que el lenguado de la Fig. 2.18.a tiene como segunda opcion a un pez mas estrecho,
por lo que al observador casual puede parecerle que la tercera opcion serıa mas indicada. Sin
embargo, es necesario recordar que no se esta usando informacion global de curvatura, sino
puntual sobre las esquinas. Ası, el sistema se basa mas en el parecido entre la cola de ambos
peces que en la forma de su contorno. En formas con mas esquinas (Fig. 2.18.b y c), este detalle
no influye tanto porque la mayor parte del contorno esta recogido en dichas esquinas. Incluso
en formas complicadas (Fig. 2.18.c) puede observarse que la segunda opcion guarda un parecido
significativo con el objeto de entrada incluso aunque no se trate del mismo pez.
Es importante indicar que el sistema propuesto, al basarse unicamente en dos parametros
de cada esquina, presenta, como se comento en experimentos anteriores, la desventaja de barajar
relativamente poca informacion a la hora de tomar decisiones. Esto puede observarse en la Fig.
2.19, donde se compara el metodo propuesto con uno basado en informacion global del contorno,
el CSS (Mokhtarian y Mackworth, 1986). Fig. 2.19.a muestra un ejemplo en que no hay ningun
objeto en la base de datos parecido al de entrada salvo el mismo, por lo que la segunda opcion
no es significativa. En estos casos, el metodo propuesto trabaja mejor que el CSS desde el punto
de vista del observador humano, ya que el segundo es incapaz de encontrar una forma global

4. Resultados y experimentos 49
Figura 2.19: Comparativa entre el metodo propuesto (HMM) y el metodo CSS para el re-conocimiento de peces de a) a d), situados, de arriba a abajo en orden decreciente de prob-abilidad.
adecuada que ajustar mientras que el metodo propuesto se conforma con que exista un parecido
residual en alguna parte del contorno. Aunque esto podrıa tomarse como una ventaja, la Fig.
2.19.b muestra que no lo es. Si dos formas distintas muestran un tramo de contorno similar, el
metodo propuesto las relaciona y, ası, en casos en que no es sencillo escoger un segundo candidato,
el metodo propuesto puede basarse en criterios tan erraticos como parecidos en la cola (Fig.
2.19.b), el morro (Fig. 2.19.c) o la aleta dorsal (Fig. 2.19.c), mientras que el CSS siempre busca
el mejor candidato desde un punto de vista global. Una vez mas, esto apoya la necesidad de
no descartar informacion de curvatura trabajando unicamente con puntos caracterısticos. Esta
obvia desventaja del metodo propuesto basado en esquinas se compensa en parte por su alta
resistencia a oclusiones parciales, como se muestra en la Fig. 2.20. Las oclusiones en esta figura
provocan la perdida de entre el 20 y el 50% de las esquinas pero, como un parecido parcial del
contorno es suficiente para una identificacion positiva, el sistema siempre escoge el candidato
correcto salvo en la Fig. 2.20.d. En este caso, el error se debe a que el tiburon de la segunda
fila de esa Fig. 2.19.d presenta la misma distribucion de esquinas que el pez de entrada salvo en
la cola que, en este caso en particular, esta ocluıda. El segundo candidato es, sin embargo, la
eleccion correcta.
Finalmente, la Fig. 2.21 presenta algunos ejemplos mas cuando se distorsionan los pa-

50 Capıtulo 2. Descripcion de formas planas
Figura 2.20: Ejemplos de reconocimiento para los peces de a) a d), que presentan oclusionparcial del contorno. Los resultados estan situados de arriba a abajo en orden decreciente deprobabilidad.
trones de entrada. La segunda fila de la figura muestra los patrones de la primera tras las
deformaciones, mientras que la tercera muestra los prototipos que devuelve el sistema en cada
caso. Puede observarse que los resultados son razonables desde el punto de vista humano incluso
cuando el objeto escogido se parece mas en cuanto esquinas al distorsionado que al original.
4.3. Reconocimiento por Componentes Principales de la Curvatura
4.3.1. Metodo de reconocimiento
Tal como se comento en el apartado correspondiente, la representacion por Componentes
Principales de la Curvatura se basa en asignar un vector de caracterısticas a cada forma. Dicho
vector debe ser resistente a ruido, transformaciones geometricas y distorsiones en la medida de
lo posible. Ademas, para ser representativo, es necesario que formas distintas esten asociadas
a vectores distintos. En resumen, puede afirmarse que dos objetos son iguales si el parecido
entre sus vectores de caracterısticas esta por debajo de un cierto umbral, que viene fijado por
la resistencia a deformaciones y distorsiones que presenta el mencionado vector. En tanto que
para reconocer un objeto es necesario haberlo visto con anterioridad al menos en una ocasion,
el metodo mas simple de reconocimiento basado en vectores consiste en comparar el vector a
reconocer con todos los conocidos. Si la distancia de dicho vector a cualquiera de ellos esta por
debajo de un cierto umbral, se reconoce como tal. Si existen varios candidatos posibles, se

4. Resultados y experimentos 51
Figura 2.21: Ejemplos de reconocimiento para los peces de a) a d), presentando una defor-macion del contorno. Los resultados estan situados de arriba a abajo en orden decreciente deprobabilidad.
escoge como valido aquel cuya distancia al vector estudiado sea menor. Si, por el contrario, no
existe ningun vector conocido cuya distancia al estudiado este por debajo de un umbral, bien se
almacena el vector como un nuevo objeto conocido -sistemas con aprendizaje-, bien se descarta
como objeto desconocido -sistemas con rechazo-. Es, por tanto, necesario para este metodo de
reconocimiento establecer unicamente tres elementos: la base a utilizar, la distancia empleada y
el umbral de reconocimiento.
4.3.2. Extraccion de una base
A efectos de extraer un vector de caracterısticas a partir de un contorno, tal como
se comento en el apartado correspondiente, es necesario calcular una base lo suficientemente
representativa como para que el error de representacion para elementos no conocidos cuando se
calculo dicha base sea lo suficientemente pequeno para su correcta identificacion. Intuitivamente,
las bases seran tanto mas representativas cuantos mas elementos se evaluen en su calculo y mas
distintos sean estos. No obstante, es importante evaluar de una manera formal que objetos deben
incluirse en el calculo de una base y cuanta informacion se pierde al utilizarla a efectos de obtener
el mejor vector de caracterısticas posible.

52 Capıtulo 2. Descripcion de formas planas
Utilizando cada una de las bases de datos mencionadas en este apartado de resultados, se
han calculado distintas bases optimas de dimensiones entre 1 y el numero de elementos de cada
conjunto, M , mediante el metodo de analisis por componentes principales descrito en la seccion
3.3. Las Figs. 2.22 - 2.24 presentan el error cometido al representar las figuras pertenecientes al
un mismo conjunto con un numero n creciente de componentes principales (lınea continua) y
el porcentaje de varianza explicado por las primeras n componentes (lınea discontinua), con n
variando entre 1 y M . En cada figura se han agrupado los resultados obtenidos con dos de los
conjuntos anteriores, a fin de facilitar la comparacion. El ejemplo presentado en la Fig. 2.22.a es
un caso especial. El conjunto inicial esta formado tan solo por las 6 figuras del conjunto 1. Estas
son relativamente variadas, por lo que comparten solo el 67% de su informacion, como indica el
valor del porcentaje de varianza explicado por la primera componente. Evidentemente, no son
necesarias mas de seis componentes para representar de forma fiel las seis imagenes pertenecientes
al conjunto inicial, pero es mas que probable que no contengan suficiente informacion para
representar una figura cualquiera no incluida en el conjunto inicial. La Fig. 2.22.b muestra los
resultados del conjunto de figuras geometricas mas sus deformaciones (base 2). De forma parecida
a lo que ocurrıa en el caso anterior, las figuras comparten un 68 % de la informacion. El parecido
con el primer conjunto era de esperar, teniendo en cuenta que este conjunto simplemente amplıa
el primero mediante la inclusion de deformaciones de cada figura del mismo. En este caso, tanto
la evolucion del porcentaje de varianza como la del error son bastante mas lentas que en la Fig.
2.22.a. Esto es debido a que la mayor variedad de las figuras de este conjunto solo puede ser
representada con un numero mayor de componentes, es decir, la mayor variedad introduce un
mayor numero de grados de libertad en la representacion. Tambien es interesante observar que
en este conjunto (Fig. 2.22.b), y en menor medida tambien en el conjunto siguiente (Fig. 2.23.a),
se aprecia un descenso brusco del error de representacion en torno a la decima componente
principal. Esto parece indicar que, en ambos casos, la dimension intrınseca de las variedades que
contienen a los elementos de cada uno de los dos conjuntos debe estar cercana a 10.
Las Figs. 2.23.a y b presentan perfiles muy similares entre sı. Al estar formado por un
conjunto de caracteres obtenidos de imagenes reales de matrıculas de coches, el conjunto 3 (Fig.
2.23.a) presenta ya una variedad apreciable. El conjunto 4 esta formado por imagenes del mismo
tipo, tomadas de un mayor numero de placas de matrıcula reales y, por tanto, incluyendo el
mismo tipo de ruido o distorsion que presentan las figuras del conjunto 3. Esto determina que
la informacion aportada por el conjunto 4 sea muy similar a la del conjunto 3. Ası, la evolucion
del error de representacion y porcentaje de varianza explicado con las componentes de ambos
conjuntos es muy similar (2.23.b). Es logico suponer que las variedades que contienen a estos dos
conjuntos deben ser muy parecidas, en la misma medida en la que se parece su representacion.
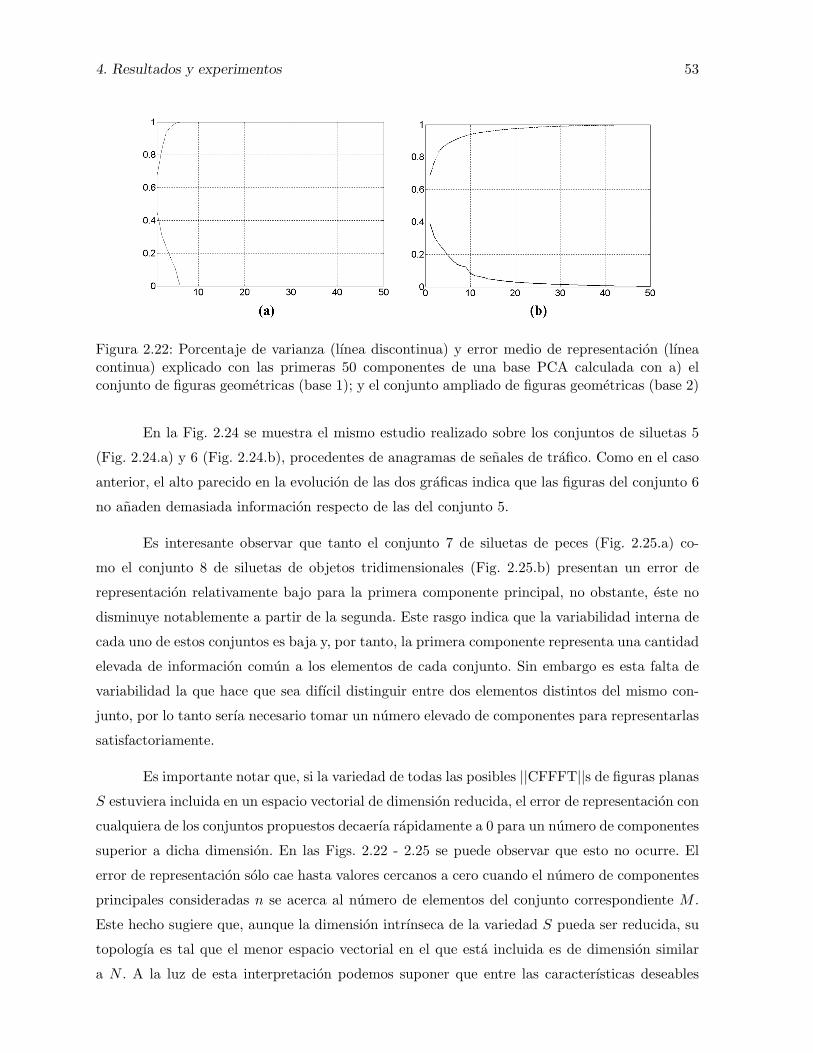
4. Resultados y experimentos 53
Figura 2.22: Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calculada con a) elconjunto de figuras geometricas (base 1); y el conjunto ampliado de figuras geometricas (base 2)
En la Fig. 2.24 se muestra el mismo estudio realizado sobre los conjuntos de siluetas 5
(Fig. 2.24.a) y 6 (Fig. 2.24.b), procedentes de anagramas de senales de trafico. Como en el caso
anterior, el alto parecido en la evolucion de las dos graficas indica que las figuras del conjunto 6
no anaden demasiada informacion respecto de las del conjunto 5.
Es interesante observar que tanto el conjunto 7 de siluetas de peces (Fig. 2.25.a) co-
mo el conjunto 8 de siluetas de objetos tridimensionales (Fig. 2.25.b) presentan un error de
representacion relativamente bajo para la primera componente principal, no obstante, este no
disminuye notablemente a partir de la segunda. Este rasgo indica que la variabilidad interna de
cada uno de estos conjuntos es baja y, por tanto, la primera componente representa una cantidad
elevada de informacion comun a los elementos de cada conjunto. Sin embargo es esta falta de
variabilidad la que hace que sea difıcil distinguir entre dos elementos distintos del mismo con-
junto, por lo tanto serıa necesario tomar un numero elevado de componentes para representarlas
satisfactoriamente.
Es importante notar que, si la variedad de todas las posibles ||CFFFT||s de figuras planas
S estuviera incluida en un espacio vectorial de dimension reducida, el error de representacion con
cualquiera de los conjuntos propuestos decaerıa rapidamente a 0 para un numero de componentes
superior a dicha dimension. En las Figs. 2.22 - 2.25 se puede observar que esto no ocurre. El
error de representacion solo cae hasta valores cercanos a cero cuando el numero de componentes
principales consideradas n se acerca al numero de elementos del conjunto correspondiente M .
Este hecho sugiere que, aunque la dimension intrınseca de la variedad S pueda ser reducida, su
topologıa es tal que el menor espacio vectorial en el que esta incluida es de dimension similar
a N . A la luz de esta interpretacion podemos suponer que entre las caracterısticas deseables
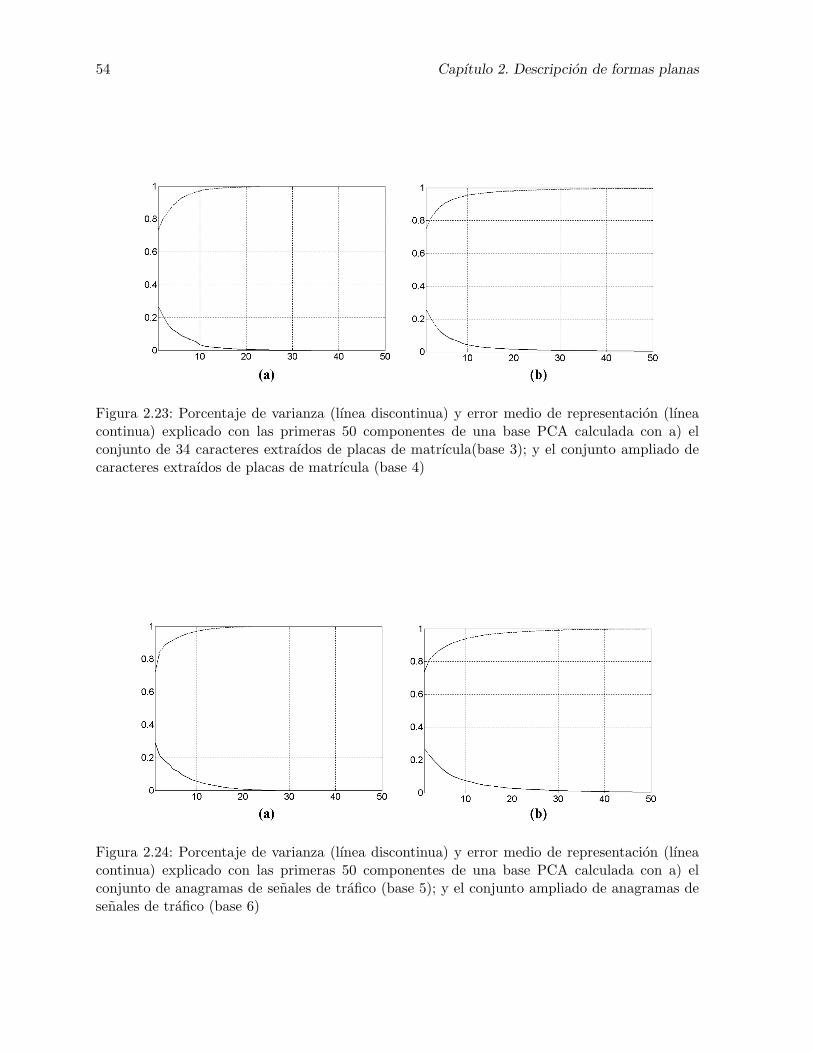
54 Capıtulo 2. Descripcion de formas planas
Figura 2.23: Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calculada con a) elconjunto de 34 caracteres extraıdos de placas de matrıcula(base 3); y el conjunto ampliado decaracteres extraıdos de placas de matrıcula (base 4)
Figura 2.24: Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calculada con a) elconjunto de anagramas de senales de trafico (base 5); y el conjunto ampliado de anagramas desenales de trafico (base 6)
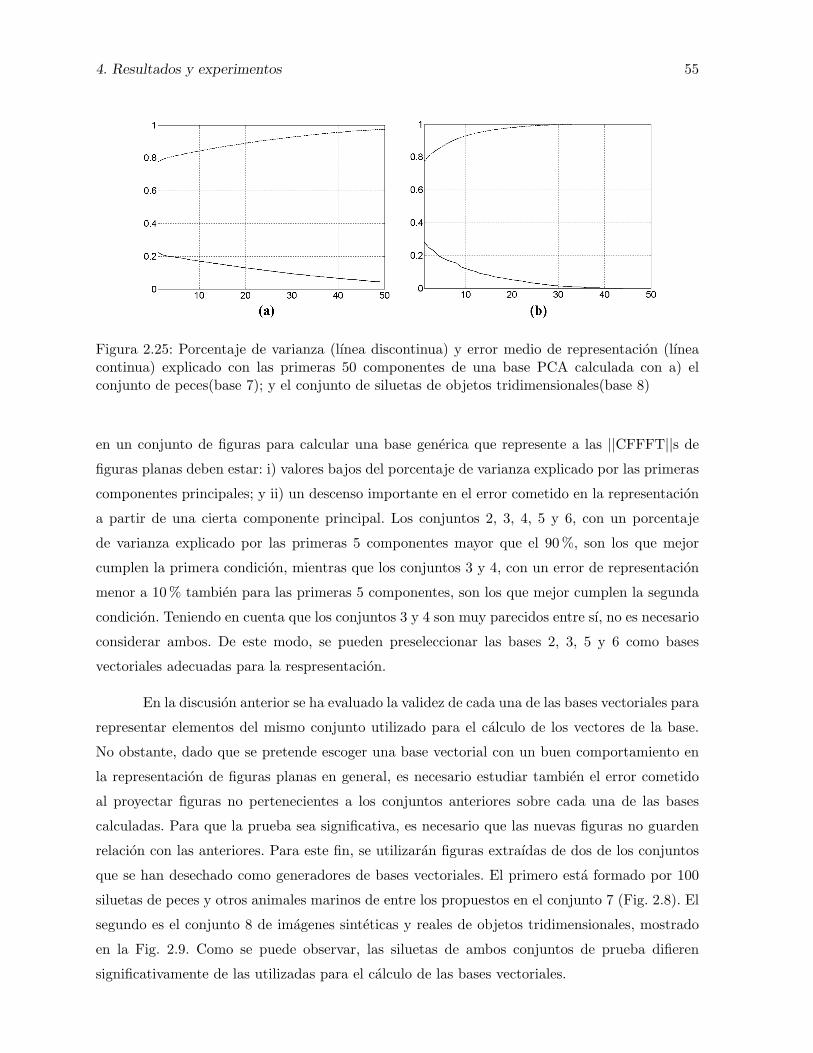
4. Resultados y experimentos 55
Figura 2.25: Porcentaje de varianza (lınea discontinua) y error medio de representacion (lıneacontinua) explicado con las primeras 50 componentes de una base PCA calculada con a) elconjunto de peces(base 7); y el conjunto de siluetas de objetos tridimensionales(base 8)
en un conjunto de figuras para calcular una base generica que represente a las ||CFFFT||s de
figuras planas deben estar: i) valores bajos del porcentaje de varianza explicado por las primeras
componentes principales; y ii) un descenso importante en el error cometido en la representacion
a partir de una cierta componente principal. Los conjuntos 2, 3, 4, 5 y 6, con un porcentaje
de varianza explicado por las primeras 5 componentes mayor que el 90 %, son los que mejor
cumplen la primera condicion, mientras que los conjuntos 3 y 4, con un error de representacion
menor a 10 % tambien para las primeras 5 componentes, son los que mejor cumplen la segunda
condicion. Teniendo en cuenta que los conjuntos 3 y 4 son muy parecidos entre sı, no es necesario
considerar ambos. De este modo, se pueden preseleccionar las bases 2, 3, 5 y 6 como bases
vectoriales adecuadas para la respresentacion.
En la discusion anterior se ha evaluado la validez de cada una de las bases vectoriales para
representar elementos del mismo conjunto utilizado para el calculo de los vectores de la base.
No obstante, dado que se pretende escoger una base vectorial con un buen comportamiento en
la representacion de figuras planas en general, es necesario estudiar tambien el error cometido
al proyectar figuras no pertenecientes a los conjuntos anteriores sobre cada una de las bases
calculadas. Para que la prueba sea significativa, es necesario que las nuevas figuras no guarden
relacion con las anteriores. Para este fin, se utilizaran figuras extraıdas de dos de los conjuntos
que se han desechado como generadores de bases vectoriales. El primero esta formado por 100
siluetas de peces y otros animales marinos de entre los propuestos en el conjunto 7 (Fig. 2.8). El
segundo es el conjunto 8 de imagenes sinteticas y reales de objetos tridimensionales, mostrado
en la Fig. 2.9. Como se puede observar, las siluetas de ambos conjuntos de prueba difieren
significativamente de las utilizadas para el calculo de las bases vectoriales.

56 Capıtulo 2. Descripcion de formas planas
En la Fig. 2.26 se muestran los errores de representacion para el conjunto de siluetas de
animales marinos y para el conjunto de siluetas de objetos tridimensionales. Por simplicidad en la
interpretacion, se han incluido solo las cuatro bases de componentes principales preseleccionadas
segun los criterios anteriores. La omision de las cuatro bases restantes no es relevante para este
analisis, puesto que, como se ha discutido anteriormente, no anaden informacion relevante para
la representacion. Los resultados de esta prueba se muestran en la Fig. 2.26. Se puede apreciar
que, para ambos conjuntos de prueba, el mayor error es el correspondiente a la base 3. Esto
es debido al hecho de que la distorsion mas frecuente en este conjunto de letras extraıdas de
matrıculas es el ruido de segmentacion, por lo que este serıa el rasgo mejor representado en
las imagenes de prueba. Las imagenes del conjunto de animales marinos no presentan ruido de
segmentacion y tienen perfiles muy diferentes a los de las letras, por lo tanto tienen rasgos que no
estan contenidos en el conjunto usado para la extraccion de la base y el error de representacion es
relativamente grande (Fig. 2.26.a). El conjunto de imagenes extraıdas de objetos 3D sı contiene
en cierta medida ruido de segmentacion, por lo que el error de representacion es menor que
en el caso anterior, pero, de todos modos, las siluetas son muy distintas de las de las letras
y el error de representacion es aun considerable (Fig2.26.b). Las tres bases de componentes
principales restantes presentan un error de representacion muy similar entre si. Es importante
observar que la similitud en el error de representacion aparece a pesar de que las bases de
componentes principales han sido calculadas con conjuntos de imagenes dispares. Entre el error
de representacion sobre las bases 5 y 6 practicamente no hay diferencias. Esto confirma la
hipotesis de que la ampliacion del conjunto 5, mediante la inclusion de figuras deformadas
del conjunto 6, no aporta informacion esencial para la representacion. Por lo tanto se puede
prescindir de la base calculada con el conjunto 6.
Figura 2.26: Error de representacion para: a) conjunto de siluetas de peces; y b) conjunto desiluetas de objetos tridimensionales
La diferencia entre los errores correspondientes a las bases calculadas con los conjuntos
2 y 5 es tambien muy pequena. En este caso los conjuntos iniciales no solo son distintos sino que
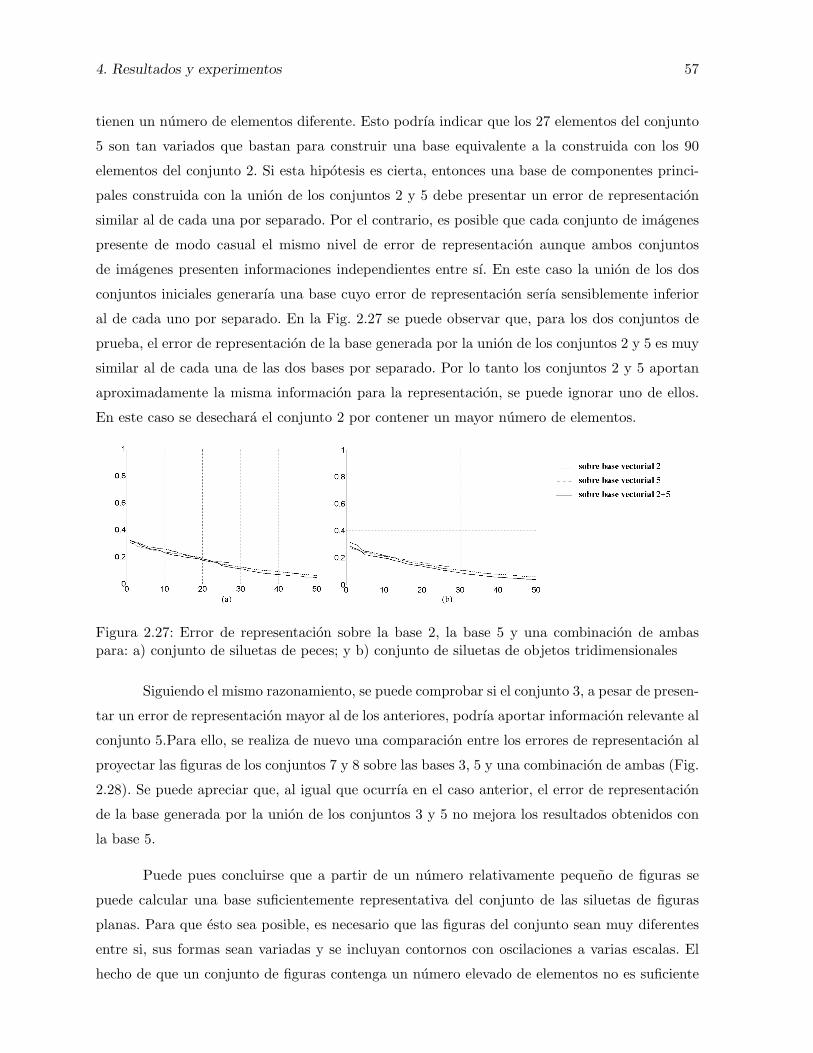
4. Resultados y experimentos 57
tienen un numero de elementos diferente. Esto podrıa indicar que los 27 elementos del conjunto
5 son tan variados que bastan para construir una base equivalente a la construida con los 90
elementos del conjunto 2. Si esta hipotesis es cierta, entonces una base de componentes princi-
pales construida con la union de los conjuntos 2 y 5 debe presentar un error de representacion
similar al de cada una por separado. Por el contrario, es posible que cada conjunto de imagenes
presente de modo casual el mismo nivel de error de representacion aunque ambos conjuntos
de imagenes presenten informaciones independientes entre sı. En este caso la union de los dos
conjuntos iniciales generarıa una base cuyo error de representacion serıa sensiblemente inferior
al de cada uno por separado. En la Fig. 2.27 se puede observar que, para los dos conjuntos de
prueba, el error de representacion de la base generada por la union de los conjuntos 2 y 5 es muy
similar al de cada una de las dos bases por separado. Por lo tanto los conjuntos 2 y 5 aportan
aproximadamente la misma informacion para la representacion, se puede ignorar uno de ellos.
En este caso se desechara el conjunto 2 por contener un mayor numero de elementos.
Figura 2.27: Error de representacion sobre la base 2, la base 5 y una combinacion de ambaspara: a) conjunto de siluetas de peces; y b) conjunto de siluetas de objetos tridimensionales
Siguiendo el mismo razonamiento, se puede comprobar si el conjunto 3, a pesar de presen-
tar un error de representacion mayor al de los anteriores, podrıa aportar informacion relevante al
conjunto 5.Para ello, se realiza de nuevo una comparacion entre los errores de representacion al
proyectar las figuras de los conjuntos 7 y 8 sobre las bases 3, 5 y una combinacion de ambas (Fig.
2.28). Se puede apreciar que, al igual que ocurrıa en el caso anterior, el error de representacion
de la base generada por la union de los conjuntos 3 y 5 no mejora los resultados obtenidos con
la base 5.
Puede pues concluirse que a partir de un numero relativamente pequeno de figuras se
puede calcular una base suficientemente representativa del conjunto de las siluetas de figuras
planas. Para que esto sea posible, es necesario que las figuras del conjunto sean muy diferentes
entre si, sus formas sean variadas y se incluyan contornos con oscilaciones a varias escalas. El
hecho de que un conjunto de figuras contenga un numero elevado de elementos no es suficiente

58 Capıtulo 2. Descripcion de formas planas
Figura 2.28: Error de representacion sobre la base 3, la base 5 y una combinacion de ambaspara: a) conjunto de siluetas de peces; y b) conjunto de siluetas de objetos tridimensionales
para que su correspondiente base sea representativa. Como demuestran las pruebas con los
conjuntos 3 y 4, si todas las figuras pertenecientes al conjunto inicial presentan rasgos comunes
y las distorsiones introducidas son siempre del mismo tipo, independientemente de que el numero
de elementos sea muy elevado (1020 elementos en el conjunto 4) el error de representacion de
figuras no pertenecientes al conjunto inicial puede ser relativamente grande. De acuerdo con los
criterios anteriores podemos seleccionar la base de componentes principales generada a partir
del conjunto 5 de 27 siluetas de senales de trafico, como una base valida para la representacion.
4.3.3. Metrica
Es de resaltar que en el metodo de reconocimiento de formas planas propuesto para
evaluar la bondad de representacion por vector de caracterısticas existıan dos alternativas: de-
terminar que cualquier objeto entrante es siempre conocido y optar por asignarlo al prototipo
disponible mas parecido o fijar un umbral de aprendizaje o rechazo que permita bien aprender
formas nuevas, bien rechazar las desconocidas. Este segundo procedimiento dota de mayor flexi-
bilidad y resistencia a error al sistema, ya que permite aumentar la base de datos de objetos
conocidos y no obliga a reconocer objetos que, en principio, pueden ser muy diferentes de los
conocidos. Sin embargo, en estos casos resulta necesario fijar un umbral que aporte tolerancia
frente a posibles errores, distorsiones, transformaciones y ruido pero tambien permita distinguir
correctamente objetos que se consideran distintos. A efectos de establecer este umbral, resulta
interesante observar la evolucion de las distancias entre objetos distorsionados y sus prototipos
en funcion de un conjunto de metricas.
Es importante notar que a partir de los experimentos realizados hasta el momento solo
puede deducirse que cuanto mas parecidas sean dos figuras menor sera la distancia entre sus
vectores de caracterısticas. Sin embargo, no se puede deducir que esta distancia vaya a estar
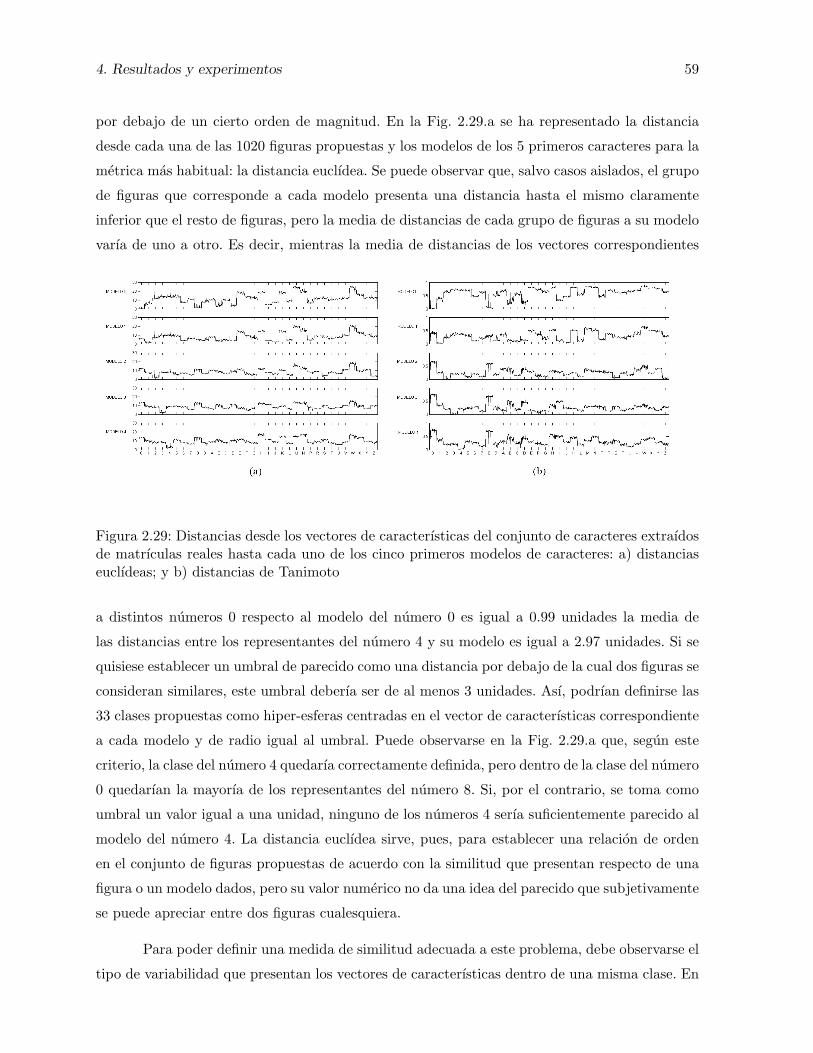
4. Resultados y experimentos 59
por debajo de un cierto orden de magnitud. En la Fig. 2.29.a se ha representado la distancia
desde cada una de las 1020 figuras propuestas y los modelos de los 5 primeros caracteres para la
metrica mas habitual: la distancia euclıdea. Se puede observar que, salvo casos aislados, el grupo
de figuras que corresponde a cada modelo presenta una distancia hasta el mismo claramente
inferior que el resto de figuras, pero la media de distancias de cada grupo de figuras a su modelo
varıa de uno a otro. Es decir, mientras la media de distancias de los vectores correspondientes
Figura 2.29: Distancias desde los vectores de caracterısticas del conjunto de caracteres extraıdosde matrıculas reales hasta cada uno de los cinco primeros modelos de caracteres: a) distanciaseuclıdeas; y b) distancias de Tanimoto
a distintos numeros 0 respecto al modelo del numero 0 es igual a 0.99 unidades la media de
las distancias entre los representantes del numero 4 y su modelo es igual a 2.97 unidades. Si se
quisiese establecer un umbral de parecido como una distancia por debajo de la cual dos figuras se
consideran similares, este umbral deberıa ser de al menos 3 unidades. Ası, podrıan definirse las
33 clases propuestas como hiper-esferas centradas en el vector de caracterısticas correspondiente
a cada modelo y de radio igual al umbral. Puede observarse en la Fig. 2.29.a que, segun este
criterio, la clase del numero 4 quedarıa correctamente definida, pero dentro de la clase del numero
0 quedarıan la mayorıa de los representantes del numero 8. Si, por el contrario, se toma como
umbral un valor igual a una unidad, ninguno de los numeros 4 serıa suficientemente parecido al
modelo del numero 4. La distancia euclıdea sirve, pues, para establecer una relacion de orden
en el conjunto de figuras propuestas de acuerdo con la similitud que presentan respecto de una
figura o un modelo dados, pero su valor numerico no da una idea del parecido que subjetivamente
se puede apreciar entre dos figuras cualesquiera.
Para poder definir una medida de similitud adecuada a este problema, debe observarse el
tipo de variabilidad que presentan los vectores de caracterısticas dentro de una misma clase. En

60 Capıtulo 2. Descripcion de formas planas
la Fig. 2.30 se muestran las primeras 13 componentes de los vectores de caracterısticas de todos
los numeros 0 (Fig. 2.30.a) y de todos los numeros 4 (Fig. 2.30.b). Los vectores de caracterısticas
de los numeros 4 son de mayor longitud que los de los numeros 0, por lo tanto es de esperar
que la distancia entre representantes de los numeros 0 sea mas pequena que la distancia entre
representantes de los numeros 4. Sin embargo, en ambos casos los elementos de una misma
clase estan fuertemente correlacionados entre sı. Es decir, para que una medida de similitud
cuantifique el parecido entre dos figuras es conveniente que incluya una medida de la correlacion
cruzada ası como una medida de la distancia euclıdea entre los vectores de caracterısticas que
las representan. Esta definicion intuitiva de distancia coincide con la definicion de la medida
Tanimoto de similitud entre vectores (Deichsel y Trampisch, 1985). Sean dos vectores x e y la
medida Tanimoto entre ellos se define como:
ST (x,y) =xTy
||x||2 + ||y||2 − xTy(2.25)
Figura 2.30: Vectores de caracterısticas: a) numeros 0; y b) numeros 4
De acuerdo con esta definicion, la medida Tanimoto es una medida adimensional que
evalua la correlacion cruzada entre los vectores x e y ponderandola de acuerdo con las longitudes
de ambos vectores. Esta definicion parece no considerar la distancia euclıdea entre los vectores
propuestos, sin embargo, operando aritmeticamente sobre ella es facil deducir que la expresion
2.25 es equivalente a:
ST (x,y) =1
1 + (x−y)T(x−y)xTy
(2.26)
Por tanto, la medida Tanimoto es inversamente proporcional al cuadrado de la distancia
euclıdea dividida por la correlacion entre x e y. Esta medida de similitud toma su valor maximo

4. Resultados y experimentos 61
e igual a 1 cuando ambos vectores son identicos. Independientemente de la distancia euclıdea,
si dos vectores son ortogonales la medida Tanimoto toma su valor mınimo e igual a 0. En el
caso de que dos vectores x este a la misma distancia euclıdea de dos vectores y y z, la medida
Tanimoto se alejara mas de uno para la pareja de vectores cuyo angulo relativo se acerque mas
a la ortogonalidad. Partiendo de la medida Tanimoto, puede definirse una distancia a la que se
llamara distancia Tanimoto como:
DT (x,y) = 1− ST(x,y) (2.27)
De este modo la distancia Tanimoto sera menor cuanto mas parecidos sean los vectores
llegando a 0 cuando ambos vectores sean iguales, lo que resulta mas adecuado como medida
de clasificacion. En la Fig. 2.29.b se puede ver la misma representacion que en la Fig. 2.29.a
cambiando la distancia euclıdea por la distancia Tanimoto. Se puede observar que, en este
caso, la distancia entre los vectores de caracterısticas de las figuras pertenecientes a una clase
y el modelo de la misma clase siempre toma un valor en torno a 0.05. La distancia al modelo
de una determinada clase de vectores de caracterısticas no pertenecientes a la misma es en
general mayor que 0.1. Es decir, podrıan definirse las clases correspondientes a los 33 caracteres
propuestos como los subconjuntos cuyos elementos esten dentro de un radio medido mediante
la distancia Tanimoto alrededor del vector que representa a cada modelo. El radio debe tomar
un valor entre 0.05 y 0.1.
Se concluye, por tanto, que la distancia Tanimoto entre dos vectores de caracterısticas
es una medida cuantificable del parecido subjetivo entre las dos figuras a las que dichos vectores
representan. Ası, en adelante se usara esta definicion de distancia para evaluar el parecido entre
figuras planas.
4.3.4. Resultados
Tal como ya se ha comentado anteriormente, una base puede no representar correc-
tamente determinadas formas planas, en particular, las que no se han utilizado a la hora de
calcularla. Asimismo, la calidad de la representacion depende de la dimension de la base em-
pleada, si bien se ha comprobado en el subapartado anterior que, en general, no se consiguen
mejoras apreciables a partir de una dimension determinada. En este subapartado se va a evaluar
mediante el metodo de reconocimiento propuesto la eficiencia de los Componentes Principales
de la curvatura como herramienta de representacion.

62 Capıtulo 2. Descripcion de formas planas
Es necesario, como se ha indicado, analizar la dimension de la base propuesta en relacion
con su capacidad para clasificar un conjunto de figuras. Para hacer esta prueba se ha escogido
el conjunto de figuras 4, compuesto por 1020 caracteres extraıdos de placas de matrıcula reales.
De acuerdo con la codificacion de las matrıculas, que elimina las letras O y Q por su parecido
con el numero 0, hay 10 numeros y 24 caracteres distintos entre sı. Nuestro conjunto incluye
30 ejemplos de cada uno. Se ha escogido este conjunto de prueba porque contiene una particion
natural en un maximo de 34 clases. Puede suponerse que las figuras que correspondan al mismo
caracter deben estar proximas entre si en el interior de la variedad S. Del mismo modo, los
grupos de figuras que correspondan a distintos caracteres estaran relativamente alejados. Es
importante notar que, en algunos casos, la diferencia entre dos caracteres depende solo de su
orientacion en el espacio. El ejemplo mas claro es el del 6 y el 9, cuyas siluetas son exactamente
iguales si se prescinde de la orientacion. La representacion propuesta en el presente trabajo e
invariante a rotacion, por lo tanto no debe apreciar diferencias entre ambos caracteres. Lo mismo
se puede decir de la comparacion entre la M y la W o entre la N y la Z, si bien en estos casos,
como se puede apreciar en la Fig. 2.6.a, cada silueta presenta algunas diferencias respecto de su
pareja. Por tanto, consideraremos en lo sucesivo que el conjunto propuesto contiene 33 clases
distintas, donde se incluyen el 6 y el 9 en una misma clase pero se distingue entre las letras M ,
N , W y Z.
Para evaluar la bondad de la clasificacion respecto de la dimension del espacio vectorial
de representacion, es decir, respecto del numero de componentes principales seleccionados para
la representacion, se han construido 33 modelos de caracteres. Cada uno de los modelos es
un vector de caracterısticas de dimension P calculado como el vector media aritmetica de los
vectores de caracterısticas de las primeras 10 siluetas correspondientes a cada uno de los 33
caracteres distintos. Ası, cada modelo engloba las caracterısticas comunes de los primeros diez
ejemplos de cada caracter. A continuacion, se ha hecho variar la dimension P desde 1 hasta
25. Para cada valor de P se ha ensayado una clasificacion de las 1020 figuras pertenecientes al
conjunto de prueba respecto de su distancia a los modelos calculados. Se considera que cada
figura pertenece a la clase de la cual esta mas cerca. Los resultados de este ensayo se muestran
en la Fig. 2.31, expresados en tanto por ciento de figuras correctamente clasificadas. Se puede
observar que la clasificacion mejora notablemente al crecer el numero de componentes utilizadas
entre una y cinco. A partir de cinco componentes, la mejora en la clasificacion es mas suave hasta
llegar a un valor estable cuando las componentes utilizadas son entre diez y quince. Es importante
notar que parece haber un maximo en la bondad de la clasificacion que se situa alrededor del
94 % de aciertos. Es decir, solo hay un numero limitado de componentes principales que aportan
informacion relevante para la clasificacion. Por encima de este numero la clasificacion no mejora.
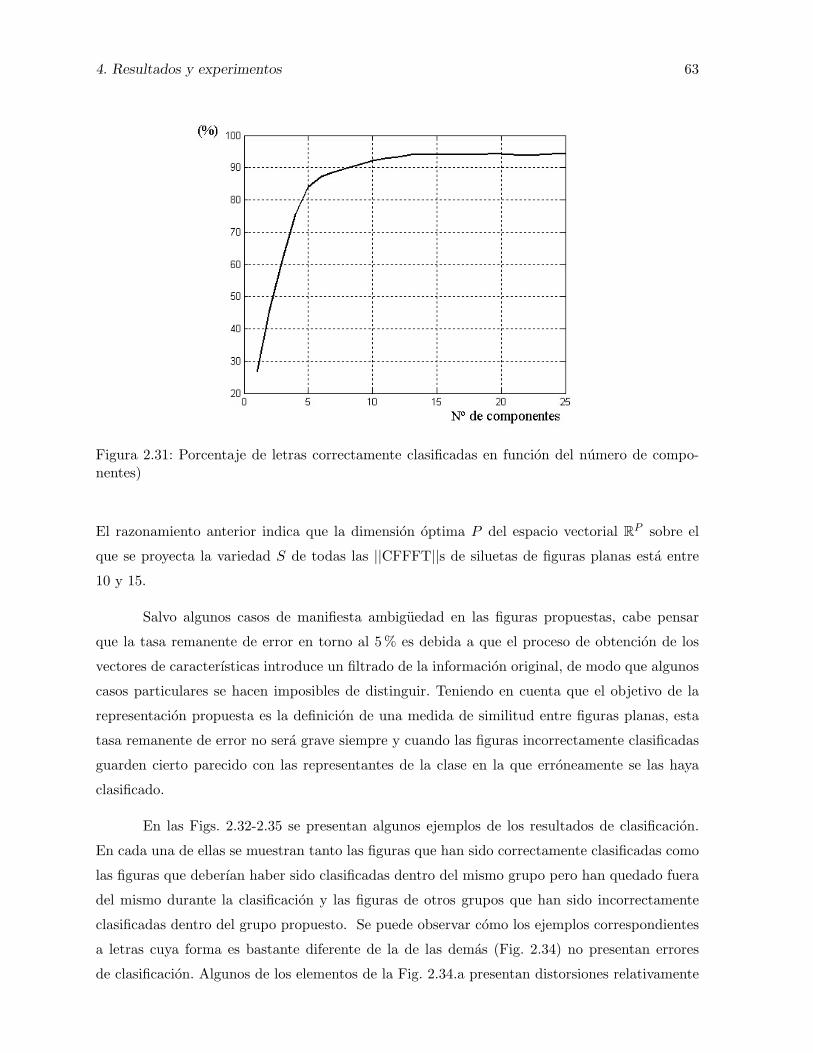
4. Resultados y experimentos 63
Figura 2.31: Porcentaje de letras correctamente clasificadas en funcion del numero de compo-nentes)
El razonamiento anterior indica que la dimension optima P del espacio vectorial RP sobre el
que se proyecta la variedad S de todas las ||CFFFT||s de siluetas de figuras planas esta entre
10 y 15.
Salvo algunos casos de manifiesta ambiguedad en las figuras propuestas, cabe pensar
que la tasa remanente de error en torno al 5 % es debida a que el proceso de obtencion de los
vectores de caracterısticas introduce un filtrado de la informacion original, de modo que algunos
casos particulares se hacen imposibles de distinguir. Teniendo en cuenta que el objetivo de la
representacion propuesta es la definicion de una medida de similitud entre figuras planas, esta
tasa remanente de error no sera grave siempre y cuando las figuras incorrectamente clasificadas
guarden cierto parecido con las representantes de la clase en la que erroneamente se las haya
clasificado.
En las Figs. 2.32-2.35 se presentan algunos ejemplos de los resultados de clasificacion.
En cada una de ellas se muestran tanto las figuras que han sido correctamente clasificadas como
las figuras que deberıan haber sido clasificadas dentro del mismo grupo pero han quedado fuera
del mismo durante la clasificacion y las figuras de otros grupos que han sido incorrectamente
clasificadas dentro del grupo propuesto. Se puede observar como los ejemplos correspondientes
a letras cuya forma es bastante diferente de la de las demas (Fig. 2.34) no presentan errores
de clasificacion. Algunos de los elementos de la Fig. 2.34.a presentan distorsiones relativamente

64 Capıtulo 2. Descripcion de formas planas
Figura 2.32: Resultados de clasificacion para el numero 2: a) figuras correctamente clasificadas;b) figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrectamente clasificadasdentro del grupo)
Figura 2.33: Resultados de clasificacion para la letra B: a) figuras correctamente clasificadas;b) figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrectamente clasificadasdentro del grupo)

5. Conclusiones 65
Figura 2.34: Resultados de clasificacion para la letra R: a) figuras correctamente clasificadas;b) figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrectamente clasificadasdentro del grupo)
importantes debidas al ruido introducido por la segmentacion. Sin embargo, como la forma de
la figura distorsionada se parece mas a la R que a ninguna otra letra, el vector de caracterısticas
que la representa estara mas cerca del modelo de la R que de ningun otro. En cambio en la
Fig. 2.32 se puede observar que un grado comparable de distorsion aplicado sobre un caracter
que presenta una cierta similitud morfologica con otro u otros puede llevar a una clasificacion
incorrecta. En la Fig. 2.32.c se puede observar que los tres elementos incorrectamente incluidos
en este grupo pertenecen a letras muy parecidas al numero 2 que ademas estan deformadas de
modo que el parecido se acrecienta. Las dos letras Z tienen sus esquinas suavizadas y la letra S
tiene una protuberancia que le hace parecer un 2 invertido. Cuando la similitud entre parejas
de caracteres es mas fuerte, el error de clasificacion se puede producir aunque no exista una
deformacion importante. Ası, es frecuente el caso de Ms clasificadas como W s y viceversa (Fig.
2.35). Un caso especial que merece atencion es el de la letra B(Fig. 2.33). Morfologicamente
esta situada entre el numero 8 y la letra D. Al hacer el test de clasificacion se repiten los errores
entre la B y el 8 y entre la B y la D, siendo infrecuente el caso de confusion entre 8 y D.
Atendiendo a estos resultados, puede afirmarse que en el espacio de caracterısticas propuesto
la distancia entre puntos es un buen indicador de las diferencias morfologicas entre las figuras
representadas por dichos puntos.
5. Conclusiones
En este capıtulo se ha presentado un metodo para la caracterizacion de un objeto. Dicho
metodo se basa en la creacion de una funcion de curvatura del contorno del objeto que describe el

66 Capıtulo 2. Descripcion de formas planas
Figura 2.35: Resultados de clasificacion para la letra W : a) figuras correctamente clasificadas;b) figuras incorrectamente clasificadas fuera del grupo; y c) figuras incorrectamente clasificadasdentro del grupo)
comportamiento de este. La principal novedad de la funcion propuesta estriba en que se calcula
de forma adaptativa de acuerdo a las caracterısticas o naturaleza del tramo en estudio, lo que
permite eliminar gran parte del ruido de cuantificacion sin perdida de puntos significativos.
Para probar la bondad de la caracterizacion propuesta, se han implementado varias apli-
caciones tıpicas basadas en ella: deteccion de esquinas, aproximacion poligonal y reconstruccion
del contorno. En los tres casos, los resultados obtenidos han sido mas que aceptables, sobre
todo, si se tiene en cuenta que los procesos descritos son bastante sencillos y de baja carga
computacional.

Capıtulo 3
Reconocimiento de objetos 3D.
1. Introduccion.
El proceso de reconocimiento de objetos puede enfocarse desde dos puntos de vista com-
plementarios: i) el problema de la identificacion de objetos en un entorno conocido a priori, en
el que existe un conjunto predefinido de objetos de interes; y ii) el problema del reconocimiento
cuando cada objeto observado puede pertenecer a una clase ya definida o bien ser un repre-
sentante de una clase nueva de objetos. La principal diferencia entre ambos enfoques es que
mientras en el primero todo el proceso de aprendizaje se ha completado antes de que el sistema
sea operativo, el segundo debe ser capaz de aprender nuevos modelos cada vez que un objeto
sea designado como desconocido (Ullman, 1996).
En el primer caso se puede establecer una relacion de clasificacion entre todos los objetos
que van a ser sometidos posteriormente al proceso de reconocimiento. Serıa posible utilizar un
metodo de clasificacion supervisada independiente del algoritmo de reconocimiento en el que las
clases pueden ser designadas segun criterios mas o menos heterogeneos. Esta filosofıa es muy
util cuando el sistema de reconocimiento se encuentra circunscrito a un ambiente conocido en
el cual todos los objetos que se le presentan pertenecen necesariamente a una de las categorıas
previamente definidas (Adan et al., 2001) (Kovacic et al., 1998). Si se requiere, por ejemplo,
desarrollar un metodo de reconocimiento para identificar sımbolos alfanumericos, la clasificacion
general se realizara atendiendo a su forma, pero algunos elementos deberan distinguirse entre
sı por otros criterios. Ası, algunos caracteres se distinguiran por su orientacion espacial, como la
M de la W o la N de la Z, e incluso estaran sometidos a criterios de contexto, como el necesario
para distinguir la letra O del numero 0. Sistemas de reconocimiento de este tipo pueden incluso
aportar modelos extraordinariamente precisos de los objetos a estudiar, pudiendo utilizarse con
67

68 Capıtulo 3. Reconocimiento de objetos 3D.
una alta fiabilidad en aplicaciones industriales muy concretas, como el suministro automatico de
piezas o el rechazo de piezas defectuosas durante procesos de fabricacion (Roh y Kweon, 2000).
La segunda aproximacion es mas adecuada en aplicaciones de reconocimiento en entornos
no estructurados en los que se deba establecer una clasificacion dinamica, es decir, los objetos
observados puedan ser clasificados como pertenecientes a una de las clases ya conocidas por el
sistema o bien puedan ser considerados como elementos nuevos ajenos a todas las clases conocidas
hasta el momento. En general, este tipo de sistemas no realizan funciones de identificacion sino
de categorizacion (Ullman, 1996). Por lo tanto, el objetivo no es reconocer el objeto observado
como identico a uno almacenado sino clasificarlo como similar a un modelo de una cierta clase de
objetos (Edelman, 1997). Como consecuencia, la relacion entre el objeto observado y el modelo
de una cierta clase de objetos se establece no como una identificacion precisa sino como un grado
de parecido entre objeto y modelo (Ando et al., 1999) (Hornegger y Niemann, 2000) (Nayar et
al., 1996) (Poggio y Edelman, 1990) (Seibert y Waxman., 1992) (Selinger y Nelson, 1999). Ası,
para evaluar la bondad de un sistema de reconocimiento de este tipo se debera contabilizar no
solo el porcentaje de elementos correcta e incorrectamente clasificados (tasa de reconocimiento y
error respectivamente), sino tambien el porcentaje de objetos que, siendo nuevos, son clasificados
dentro de una de las clases de objetos (tasa de falso reconocimiento), ası como el porcentaje de
objetos que, siendo conocidos, son designados como nuevos (tasa de rechazo). De acuerdo con la
importancia que se asigne a cada uno de los tipos de fallo se pueden definir multiples criterios
de bondad de los clasificadores (Courtney y Thacker, 2001)
Por otro lado, el hecho de que puedan aparecer objetos nuevos que requieran el aprendiza-
je de nuevos modelos para ser incluidos en el conjunto de modelos disponibles al sistema de re-
conocimiento obliga a que los algoritmos de entrenamiento y de reconocimiento esten fuertemente
interrelacionados. Si el sistema de reconocimiento debe ademas funcionar de modo autonomo,
el proceso de entrenamiento debe ser del tipo no supervisado (Ullman, 1996).
Para resolver este problema se han propuesto diversos metodos de tipo probabilıstico,
como el metodo bayesiano de modelado y reconocimiento propuesto por Hornegger (Hornegger
y Niemann, 2000) o metodos basados en redes neuronales (Ando et al., 1999). Este tipo de
metodos, evaluan la probabilidad de que distintas observaciones de un objeto sean la concrecion
real de un modelo ideal de un cierto tipo de objeto. Para su entrenamiento es necesario prever
los tipos de distorsion especiales en el entorno de observacion y disponer de varias versiones
distintas del mismo objeto para que la variabilidad de cada clase de objetos este correctamente
representada en su modelo. Si el sistema de reconocimiento encuentra un nuevo objeto solo
dispondra de un ejemplar del nuevo tipo de objetos y en consecuencia su modelo sera poco

1. Introduccion. 69
tolerante incluso a pequenas perturbaciones en la observacion.
Como alternativa a los metodos probabilısticos se han presentado numerosos metodos
de reconocimiento, que definen medidas de similitud entre la observacion de un objeto y cada
uno de los modelos almacenados. Ası, en principio, cada modelo es una representacion ideal
del objeto tıpico de una clase. En este caso, la tolerancia frente a posibles distorsiones de la
observacion se consigue mediante una definicion flexible de la similitud entre la observacion y el
modelo. Esta vision presenta la ventaja de que no es necesario disponer a priori de un juego de
versiones distorsionadas de cada objeto para que el sistema de reconocimiento sea flexible. Adi-
cionalmente, durante la definicion de cada modelo no se requiere una elevada precision respecto
de la forma exacta del objeto a modelar, ya que el posterior reconocimiento no se basa en una
total identificacion entre la observacion y el modelo sino solo en una medida de parecido entre
ellos.
Sullivan y Ponce proponen la construccion de modelos volumetricos a partir de vistas
planas de cada objeto (Sullivan y Ponce, 1998). A partir de cada vista plana, conocida su
orientacion respecto del objeto se traza una proyeccion conica en el espacio. Los puntos de
interseccion de las distintas proyecciones son puntos del espacio tridimensional que se definen
como vertices del modelo. Los vertices se unen entre sı con superficies planas para formar
un volumen solido. Cuando un objeto es observado, se hace casar su silueta con las posibles
siluetas de todos los objetos almacenados para minimizar una funcion de error. Este sistema, si
bien ofrece una aproximacion muy intuitiva al problema del reconocimiento, requiere una gran
exactitud en la determinacion de la posicion relativa del observador y el objeto durante la fase
de entrenamiento (Bottino y Laurentini, 2003). Ademas, supone un elevado coste computacional
y no asegura un resultado optimo para figuras afectadas de ruido u oclusion.
Murase y Nayar (Murase y Nayar, 1995) introducen un metodo de reconocimiento en
el que los modelos se construyen por reduccion de la informacion contenida en un conjunto de
vistas planas de un objeto mediante la transformada de Karuhen-Loewe (Sirovich y Everson,
1992). Ası, cada vista del objeto a modelar queda representada por un punto en el espacio
de los autovectores de las vistas del objeto y un objeto completo queda representado por una
trayectoria en este espacio. El reconocimiento de un objeto observado se realiza a partir de
una de sus vistas planas: si la proyeccion de la vista estudiada sobre el espacio de autovectores
esta suficientemente cerca de una de las trayectorias correspondientes a los objetos modelados
por el sistema, este considera que el objeto observado guarda un alto grado de similitud con el
objeto. Es importante notar que Murase y Nayar no trabajan con todas las vistas de cada objeto
sino solo con las correspondientes a un unico giro alrededor de este, colocando al observador a una

70 Capıtulo 3. Reconocimiento de objetos 3D.
distancia fija del objeto y siempre a la misma altura sobre el plano de apoyo del mismo. Es decir,
el metodo supone que existe un conjunto de vistas desde las cuales cada objeto es claramente
distinguible de los demas. Si una vista pudiera corresponder a varios objetos distintos, no habrıa
solucion para el problema de reconocimiento (Campbell y Flynn, 1999). Ademas, el sistema
trabaja con la imagen de color completa de cada vista, lo que hace que la clasificacion se haga
atendiendo no solo a la forma, sino tambien al color de los objetos (Nayar et al., 1996). Es
tambien importante notar que, en este caso, cambios de iluminacion o sombras anadidas a la
escena perturbarıan apreciablemente los resultados de su algoritmo (Startchik et al., 1998).
Ohba e Ikeuchi presentan un sistema en el que tambien se utiliza una descomposicion
por analisis de componentes principales, pero se aplica a segmentos de las imagenes en lugar
de a las imagenes completas (Ohba y Ikeuchi, 1997). Para reducir la cantidad de informacion
almacenada se utiliza un triple criterio de seleccion de segmentos atendiendo a su detectabilidad,
representatividad y unicidad. El reconocimiento de objetos se realiza mediante la busqueda en
una cualquiera de sus vistas de retazos que se puedan relacionar con los almacenados. Este
sistema se ha desarrollado con el objetivo de ser muy resistente a oclusiones. Sin embargo, no
presenta un buen comportamiento frente a cambios del entorno, como cambios de iluminacion
(Mamic y Bennamoun, 2002)
Selinger y Nelson (Selinger y Nelson, 1999) proponen un metodo cubista de reconocimien-
to. En este sistema se localizan rasgos diferenciadores contenidos en fragmentos de cada imagen.
Las imagenes son preprocesadas para extraer sus contornos, de modo que la informacion buscada
en la imagen sera puramente morfologica. El objeto es ası representado como una agrupacion
de rasgos locales combinados de forma flexible, que se pueden reconocer de forma independiente
y que se pueden asociar a uno o a varios de los objetos previamente modelados. Este tipo de
aproximaciones locales son muy robustas frente a oclusiones, puesto que no dependen de rasgos
globales del objeto y no requieren una segmentacion que extraiga cada objeto de la escena como
un objeto individual. Sin embargo, debido a que analizan rasgos muy parciales, pueden llevar a
confusion cuando la combinacion de los mismos sea compatible con varios objetos o bien cuando
los objetos no tengan rasgos individuales que se puedan circunscribir al entorno de unos pocos
pixeles sino que esten mas relacionados con la forma global del objeto (Carmichael y Hebert,
2002).
En la presente tesis, se propone un sistema de reconocimiento de objetos 3D basado
en la secuencialidad de un conjunto de vistas planas del objeto observado. La aplicacion de
este metodo guarda semejanzas con el metodo de reconocimiento de formas planas basado en
puntos caracterısticos expuesto en el capıtulo 2 (de Trazegnies et al., 2001) (de Trazegnies et al.,

1. Introduccion. 71
2003c). Para el reconocimiento de formas planas se utilizaba un modelo de tipo probabilıstico que
relacionaba secuencias de esquinas con el contorno de objetos bidimensionales. Un mismo tipo
de esquinas podıa pertenecer a varios contornos, no obstante, la secuencialidad de un conjunto
de esquinas permitıa la identificacion de cada uno de ellos. En el reconocimiento de objetos 3D
basado en vistas, cada observacion de un objeto consiste en una vista plana del mismo. Aun en
conjuntos de objetos de forma muy diversa, cada objeto presentara alguna vista comun con uno
o varios de los otros objetos del conjunto, es decir, en general, el analisis de una sola vista no es
suficiente para reconocer unıvocamente un objeto. En la presente tesis se propone la extension
del uso de modelos probabilısticos al reconocimiento de objetos tridimensionales mediante el
analisis de secuencias de vistas planas (de Trazegnies et al., 2003b) (de Trazegnies et al., 2003a).
El sistema de reconocimiento propuesto se divide en las siguientes fases: descripcion,
modelado y clasificacion, que se presentan en las secciones 2, 3 y 5 de este capıtulo, respectiva-
mente.
La fase de descripcion consiste en codificar cada objeto tridimensional, que puede ser
observado desde un numero ilimitado de puntos de vistas, donde cada vista consiste en una
imagen mapa de bits que contiene un volumen elevado de informacion. Para poder abordar
el problema del reconocimiento de objetos tridimensionales a partir de sus vistas planas es
imprescindible reducir esta cantidad ilimitada de informacion a un volumen manejable sin perder
la informacion relevante para la descripcion del objeto. El metodo de descripcion desarrollado
en esta tesis consiste en codificar cada vista como un vector de caracterısticas de dimension
reducida obtenido al extraer del contorno de la vista su funcion de curvatura adaptativa (de
Trazegnies et al., 2003a), calcular el modulo de su transformada de Fourier y proyectarlo sobre
una base vectorial ortogonal del espacio. Como se discutio en el capıtulo 2, esta representacion es
muy robusta frente a desplazamientos, giros, cambios de escala, deformaciones continuas o ruido.
Ası, cada objeto se describe mediante un mapa bidimensional en el que cada punto corresponde
a una vista. Los puntos de este mapa de vistas se pueden clasificar atendiendo a un criterio
de distribucion espacial de los vectores de caracterısticas indexados en cada punto, este criterio
tiene una correspondencia directa con el parecido entre vistas, de modo que el mapa de vistas
queda dividido en areas cada una de las cuales corresponde a un tipo de vistas del objeto original.
El mapa de vistas se puede representar a distintos grados de discretizacion, dependiendo de la
distancia angular prefijada entre vistas consecutivas, de modo que con un conjunto reducido de
vistas se obtiene un mapa representativo del objeto. Este metodo de caracterizacion se expone
en detalle en la seccion 2.
En la fase de modelado, dado que la sola descripcion de un objeto no es suficiente

72 Capıtulo 3. Reconocimiento de objetos 3D.
para asegurar su reconocimiento, es necesario construir, a partir de su descripcion, un modelo.
Generalmente, el modelo no incluye la descripcion completa sino que extrae de ella unicamente
los rasgos que son determinantes para el reconocimiento. El modelado debe realizarse de tal
manera que se pueda definir de forma sencilla un criterio de parecido entre objetos. En el
sistema de reconocimiento propuesto, el modelo de cada objeto se concreta en un Modelo Oculto
de Markov (MOM) construido a partir de secuencias de vistas consecutivas del mismo. Un MOM
es un proceso estocastico doble, en el cual existe un proceso de Markov simple, cuya evolucion
queda oculta al observador, y una funcion o conjunto de funciones estocasticas que relacionan los
estados ocultos del proceso de Markov con magnitudes observables (Rabiner, 1989). El modelado
de los objetos mediante MOMs tiene la ventaja de que cada modelo lleva implıcita una definicion
del parecido entre objeto observado y modelo, de tal modo que se puede calcular la probabilidad
de que una secuencia particular de vistas sea compatible con un modelo propuesto. El proceso
de modelado se describe en la seccion 3
En la fase de clasificacion, una vez que se dispone de una tecnica para obtener los modelos,
es necesario definir un proceso que comprenda las acciones a seguir con el fin de clasificar cada
objeto observable como perteneciente a una de las clases conocidas. Adicionalmente, en el caso
de que el objeto observado fuera clasificado como nuevo o desconocido, el sistema debe iniciar el
proceso de aprendizaje del nuevo modelo, que comprende las fases de descripcion y modelado.
De acuerdo con lo expuesto anteriormente, el proceso de clasificacion propuesto en esta tesis
utiliza como datos de entrada una secuencia de vistas planas del objeto. Para juzgar el parecido
de la secuencia de vistas con cada modelo se computa la probabilidad de que en una hipotetica
observacion de cada modelo se hayan podido observar vistas parecidas y en el mismo orden
que las observadas. En el caso de que la secuencia de vistas observada sea incompatible con
todos los modelos, el objeto observado se designa como nuevo. Ası, los procesos de aprendizaje y
clasificacion se alternan dependiendo de si el objeto presentado es o no reconocido. De acuerdo
con esta caracterıstica del sistema propuesto, en la seccion 5 se presentan no solo una coleccion
de ensayos de reconocimiento sino tambien multiples ejemplos de la interaccion entre los procesos
de aprendizaje y clasificacion.
2. Descripcion de un conjunto de vistas
Tal como se ha comentado anteriormente, el proceso de descripcion de un objeto consiste
en su codificacion a partir de un conjunto de imagenes del mismo, tomadas desde distintos puntos
de vista. De cada imagen se extrae la informacion mas significativa que describe la forma del

2. Descripcion de un conjunto de vistas 73
objeto desde cada punto de vista y, posteriormente, la informacion de todas las vistas se combina
para construir un descriptor del objeto completo. La Fig. 3.1.a muestra un objeto tridimensional
observado desde puntos de vista equiespaciados alrededor del mismo, que se representan en
coordenadas esfericas sobre un sistema de referencia centrado en el objeto observado. Cuando se
observa el objeto desde un punto arbitrario del espacio, puede extraerse de la imagen el contorno
de dicha vista que puede ser caracterizado mediante un vector de caracterısticas (Fig. 3.1.b y c)
por el procedimiento presentado en el capıtulo 2. Como los vectores de caracterısticas propuestos
son muy resistentes frente a cambios de escala (de Trazegnies et al., 2003b) (Urdiales et al.,
2002), se puede suponer que a todos los puntos de vista con las mismas coordenadas angulares
les corresponde el mismo vector de caracterısticas independientemente del valor que tome su
coordenada radial. Esto sera cierto siempre que el objeto sea observable en su totalidad dentro
del campo de la imagen y que su tamano no se vea tan reducido que llegue a ser del orden de unos
pocos pixeles. Ası, un objeto tridimensional puede ser descrito por un mapa bidimensional en el
que a cada pareja de coordenadas radiales le corresponde el vector de caracterısticas del objeto
observado desde el punto de vista definido por esas coordenadas y a una distancia arbitraria del
mismo.
Figura 3.1: Puntos de vista para un objeto 3D; b) vista plana y su vector de caracterısticas; yc) otra vista plana y su vector de caracterısticas
Aunque un objeto tridimensional puede presentar vistas muy diferentes entre sı depen-
diendo de la posicion del observador, estas vistas tienden a variar suavemente cuando el ob-
servador se mueve lentamente alrededor del objeto en cuestion. De este modo, los vectores de
caracterısticas de vistas que correspondan a capturas consecutivas, o incluso a puntos de ob-
servacion cercanos, deben ser muy parecidas entre sı, ya que los vectores propuestos presentan

74 Capıtulo 3. Reconocimiento de objetos 3D.
cierta resistencia frente a cambios de perspectiva (Urdiales et al., 2002). Ası, cabe la posibili-
dad de establecer una particion sobre el mapa de vistas de modo que se agrupen en zonas los
vectores de caracterısticas que muestren un elevado parecido entre sı. Por lo tanto, aunque en
teorıa se puede definir un vector de caracterısticas para cada punto del mapa de vistas, no es
necesario almacenar los vectores de todas las posibles vistas del objeto. En lugar de esto, es
posible almacenar solo un conjunto reducido de vistas significativas del objeto. Ası, en el mapa
de vectores de caracterısticas cada zona que corresponda a vistas parecidas entre sı se describe
con un unico vector de caracterısticas, que es representativo para toda esta zona.
En la practica es imposible trabajar con un conjunto de infinitos vectores de caracterısti-
cas, por lo que es indispensable discretizar este conjunto tomando, por ejemplo, muestras desde
puntos de vista angularmente equiespaciados. Con este fin, es necesario definir el nivel de dis-
cretizacion mas adecuado, es decir, la distancia angular entre dos vistas consecutivas, que mejor
describe el objeto. En principio, se podrıa pensar que cuanto mayor sea el numero de vistas
analizadas, mejor o mas exacta sera la descripcion. Sin embargo, se debe recordar que se pre-
tende agrupar los vectores de caracterısticas segun un criterio de parecido. Por lo tanto, tiene
sentido elevar el numero de vistas solo si las nuevas generan nuevas zonas de clasificacion. En
la Fig. 3.2.b y c se muestran dos ejemplos de mapas de representacion de un unico objeto, la
mesa de la Fig. 3.2.a, a dos resoluciones distintas. La clasificacion se ha realizado siguiendo el
mismo algoritmo que posteriormente se utilizara en las pruebas experimentales y cuya eleccion
se justifica mas abajo. A cada clase de vistas se ha asignado arbitrariamente un color a efectos de
visualizacion. Como se puede observar, al disminuir la resolucion del mapa (Fig. 3.2.c) se pierde
inevitablemente gran cantidad de informacion que aparecıa en el mapa de resolucion mayor (Fig.
3.2.b). El principal efecto de esta perdida de informacion es la simplificacion de la forma de las
clases sobre el mapa. No obstante, es logico suponer que los vectores de caracterısticas cercanos
a las fronteras entre zonas se parecen a ambas zonas y no son crıticos para el reconocimiento,
mientras que los vectores de caracterısticas del centro de las clases son muy representativos de
cada clase.
Este planteamiento coincide con la percepcion humana de los objetos tridimensionales.
Si tomamos como ejemplo un objeto geometrico sencillo como un cilindro, podemos observar que
para un ser humano este objeto esta caracterizado por presentar un perfil circular desde la vista
cenital y un perfil rectangular desde las vistas laterales. Para cualquier otra vista el observador
espera un perfil mas o menos elipsoidal de excentricidad variable. Sin embargo, la descripcion
exacta de dichos perfiles intermedios es irrelevante. Para la percepcion humana el hecho de
encontrar un objeto de perfil rectangular que al inclinarlo se suaviza hasta llegar a ser circular

2. Descripcion de un conjunto de vistas 75
Figura 3.2: Mapas de clases de un objeto 3D: a) Objeto; b) mapa de clases de vistas tomadascon un intervalo angular de 9o; y c) mapa de clases de vistas tomadas con un intervalo angularde 30o
es suficiente para identificarlo como un cilindro, independientemente de la posicion exacta del
lımite entre lo que se considera un rectangulo, un rectangulo suavizado por la perspectiva y un
cırculo.
Esto implica a su vez que es posible describir completamente el mapa de clases de un
objeto relativamente complejo tomando solo un conjunto reducido de vistas del mismo de tal
modo que las clases de vistas definidas por este conjunto sirvan para clasificar todas las vistas
posibles del objeto. En la presente tesis se ha escogido una representacion a partir de vistas
tomadas con 30o de separacion tanto en la direccion azimutal como en la polar.
En la discusion anterior se ha presentado un ejemplo del resultado del sistema de clasi-
ficacion utilizado en esta tesis. Para que el sistema de reconocimiento funcione de modo no
supervisado, es necesario que el sistema de clasificacion de las vistas de cada objeto sea un pro-
ceso automatico. A continuacion se presenta en detalle el algoritmo de clasificacion escogido y
se justifica su eleccion.

76 Capıtulo 3. Reconocimiento de objetos 3D.
Para poder definir el mapa de clasificacion de un objeto se necesita:
Una medida de parecido entre vectores de caracterısticas.
Un algoritmo de clasificacion para los vectores de caracterısticas.
Una definicion del vector de caracterısticas que representa a cada clase.
Una funcion de pertenencia de todos los posibles vectores de caracterısticas sobre el con-
junto de clases.
Como medida de parecido se puede utilizar la distancia Tanimoto definida en la seccion
4.3.3 del capıtulo 2. Como se discutio en dicha seccion, la distancia Tanimoto proporciona
una medida cuantitativa del parecido entre dos siluetas calculado a partir de los vectores de
caracterısticas que las representan. Ademas, como tambien se discutio en la seccion 4.3.3, el
valor de la distancia Tanimoto es aproximadamente proporcional al parecido que una persona
subjetivamente podrıa encontrar entre un grupo de siluetas. Ası, en general se puede afirmar
que si un grupo de siluetas desde el punto de vista humano presentan una cierta similitud,
las distancias Tanimoto entre sus vectores de caracterısticas seran de un orden de magnitud
parecido.
Una vez establecida una medida de la distancia, se necesita realizar una clasificacion de las
siluetas obtenidas de un determinado objeto cuando es observado desde distintos puntos de vista.
Esta clasificacion debe ser de tipo no supervisado, ya que se requiere que los modelos de distintos
objetos se almacenen de modo automatico. Los algoritmos no supervisados de clasificacion o
agrupacion son tecnicas que dividen el espacio en zonas, a cada una de las cuales corresponde
un centroide, que es un elemento caracterıstico de la clase a la que representa. En este caso, la
clasificacion debe atender a criterios basados en la distancia entre vectores de caracterısticas.
Por lo tanto, sera necesario utilizar un algoritmo de agrupacion por busqueda de los vecinos mas
proximos.
La mayorıa de los algoritmos de agrupacion se pueden agrupar en uno de los sigu-
ientes tipos: algoritmos jerarquicos, de particion o de solapamiento (Hartigan, 1979). Los al-
goritmos jerarquicos establecen una relacion de equivalencia mediante una estructura multinivel
o jerarquica que constituye mas bien un arbol de clases o dendograma que se puede construir en
sentido ascendente o descendente (Jain y Dubes, 1988) (Kaufman y Rousseeuw, 1990), siendo la
aproximacion mas frecuente la ascendente. En este caso se considera que cada elemento del con-
junto a clasificar constituye una clase en el nivel 0. En los sucesivos pasos se establecen relaciones

2. Descripcion de un conjunto de vistas 77
entre las clases, normalmente siguiendo algun criterio de proximidad o parecido. En cada nivel
de la estructura se pueden encontrar clases constituidas por la fusion de varias de las clases del
nivel inferior. El proceso continua hasta que se cumple algun criterio de convergencia. Las clases
de los niveles intermedios no se vuelven a revisar una vez completado el proceso, con lo cual
es difıcil anadir elementos nuevos a un conjunto ya clasificado. Los algoritmos jerarquicos son
faciles de aplicar para la clasificacion basada en distancias pero normalmente presentan cierta
indeterminacion derivada del criterio de convergencia utilizado.
Los algoritmos de particion normalmente comienzan haciendo la suposicion de que existe
un determinado numero k de clases y asignando a cada una de ellas un centroide (Hartigan,
1979). Partiendo de estas hipotesis se utiliza un metodo iterativo de reajuste de la posicion
de los centroides. Para ello es necesario definir una funcion de pertenencia de cada elemento a
uno de los centroides, normalmente por reglas de minimizacion de la distancia. Los ejemplos
mas tıpicos de algoritmos de agrupacion por particion son el k-medias y el k-medoides. La
diferencia entre ambos radica en la definicion del centroide a partir de los elementos de cada
clase: mientras el algoritmo k-medias define el centroide como la media aritmetica de los vectores
que representen a cada uno de los elementos pertenecientes a la clase, el k-medoides escoge como
centroide el elemento mas apropiado entre los pertenecientes a la clase. Teniendo en cuenta cada
nuevo subconjunto de elementos pertenecientes a cada clase se puede redefinir el centroide de
cada clase y volver a evaluar su contenido. El proceso se realiza de forma iterativa hasta que
se cumpla un criterio de convergencia, normalmente la no existencia de cambios respecto de la
ultima iteracion. A diferencia de los algoritmos jerarquicos, se pueden modificar las posiciones
de los centroides en el caso de que el conjunto inicial se enriquezca con elementos nuevos. No
obstante, la particion final suele depender fuertemente de la eleccion inicial de centroides, de
modo que del mismo conjunto inicial se pueden obtener distintas particiones que se adapten
mejor o peor a los elementos clasificados dependiendo de las condiciones iniciales del algoritmo.
Tanto los algoritmos jerarquicos como los de particion asignan a cada elemento la perte-
nencia a una unica clase. Sin embargo, a veces es deseable contar con cierto solapamiento entre
clases. Algunos algoritmos (Kaufman y Rousseeuw, 1990) asignan a cada elemento un coeficiente
difuso de pertenencia a cada una de las clases definidas. El valor de este coeficiente debe estar en
un rango de 0 a 1 y se puede entender como la probabilidad de que el elemento pertenezca a cada
una de las clases. La suma de los coeficientes de un mismo elemento respecto de todas las clases
debe ser igual a 1. Normalmente la distribucion optima de clases se obtiene mediante algorit-
mos de optimizacion relativamente complicados, como el Expectation Maximization (Friedman,
1998). Estos algoritmos de optimizacion son tıpicamente iterativos y cuando el numero de ele-

78 Capıtulo 3. Reconocimiento de objetos 3D.
mentos a clasificar es elevado la clasificacion es lenta.
Para seleccionar el tipo de agrupacion mas adecuado es necesario hacer un analisis de
los datos que se pretende clasificar. Dado un vector de caracterısticas arbitrario y un conjunto
de clases, teniendo en cuenta las consideraciones hechas en el capıtulo 2 sobre la relacion entre
parecido de las imagenes originales y distancia entre sus vectores de caracterısticas en el espacio
de representacion, es logico suponer que la pertenencia del vector propuesto a una de las clases
debe establecerse mediante un criterio de distancias. El criterio de distancia mınima, que en
principio puede parecer el mas adecuado, implica que siempre se va a establecer una relacion
de pertenencia, aun cuando la distancia mınima sea relativamente grande. Por otro lado, los
vectores de caracterısticas proceden de vistas obtenidas a intervalos regulares alrededor de un
mismo objeto. Es logico esperar que este conjunto de vectores se distribuya de forma mas o menos
regular ocupando una zona del espacio de caracterısticas (Campbell y Flynn, 1999) (Murase y
Nayar, 1995). Esto hace deseable que, al dividir esta zona del espacio de caracterısticas en clases,
estas presenten cierto grado de solapamiento. De lo contrario, un vector que estuviera situado a
una distancia similar de los centroides de dos clases, y por lo tanto solo fuera ligeramente mas
parecido a una que a otra, podrıa pertenecer solo a una clase, perdiendose ası la informacion
del parecido con la segunda clase, que podrıa ser valiosa para el reconocimiento. La forma mas
sencilla de representar el solapamiento entre clases es asignar una funcion de pertenencia que
tome un valor distinto de cero siempre que el vector propuesto este dentro de un radio definido
respecto del centroide de cada clase. Esta funcion de pertenencia se podrıa entender en un
sentido estadıstico como la probabilidad de que el vector propuesto pertenezca a cada una de
las clases de vectores de caracterısticas de un objeto dado. Para que no se pierda este significado
estadıstico, la suma de las probabilidades de pertenecer a cada una de las clases debe ser igual
a uno.
Hay que senalar tambien que el numero de clases resultante para cada objeto no tiene
por que coincidir. Es evidente que para describir, por ejemplo, una esfera, cuyas vistas son todas
identicas, solo se necesita una clase, mientras que la descripcion de un objeto de geometrıa
compleja puede incluir varios conjuntos de imagenes muy diferentes entre sı. Para obtener un
numero de clases variable se puede aplicar un algoritmo de clasificacion que crezca de forma
jerarquica.
El metodo de agrupacion que se ha utilizado en la presente tesis es una modificacion del
algoritmo de agrupacion por analisis modal (Urdiales et al., 2002) y cuyo desarrollo consta de
los siguientes pasos:

2. Descripcion de un conjunto de vistas 79
1. En el estado inicial, cada elemento del conjunto a clasificar se considera el centroide de
una clase que contiene un solo elemento.
2. A continuacion se compara cada centroide con todos los demas. Todos los elementos que
esten situados a una distancia del primero menor que el radio prefijado se consideraran
pertenecientes al mismo.
3. Cada clase se modificara de modo que el nuevo centroide estara situado en la media
aritmetica de todos los elementos que pertenezcan al mismo.
4. En el caso de que los centroides de varias clases coincidan en su posicion, se fusionan en
uno solo.
5. Se comparan los nuevos centroides con los elementos originales. Si hay alguna clase vacıa,
se elimina y si hay algun elemento que no pertenezca a ninguna clase, se anade como
centroide de una clase nueva.
6. Los pasos 2 al 5 se repiten hasta que el conjunto de centroides no sufra ningun cambio de
posicion.
Es de destacar que, tal como se ha definido el algoritmo de agrupacion por analisis modal,
no queda asegurada la convergencia para cualquier conjunto de datos de entrada. De hecho, se
puede demostrar que bajo ciertas condiciones el algoritmo no darıa una solucion estable sino
que oscilarıa entre dos o mas estados inestables. Sin embargo, dado el reducido numero de datos
de entrada y la distribucion aproximadamente regular que adoptan, es muy poco probable que
esto ocurra. De hecho, en los experimentos realizados no se ha llegado a dar nunca tal caso.
Un punto delicado en la implementacion del algoritmo de clasificacion propuesto es la
eleccion de un radio de agrupacion apropiado. Como se comento en la seccion 4.3.3 del capıtulo 2,
las figuras que muestran cierta similitud desde el punto de vista humano guardan entre ellas una
distancia que puede llegar a ser del orden de 0.1 unidades, pero pequenas variaciones alrededor
de este valor podrıan provocar grandes diferencias de interpretacion. Evidentemente, un valor
relativamente grande del radio no es deseable porque resta capacidad de diferenciacion entre
formas distintas. Sin embargo, la eleccion de un radio muy pequeno no es tampoco conveniente
porque esta opcion obligarıa a explorar el objeto a intervalos angulares mas pequenos debido
a que las imagenes del objeto captadas desde puntos intermedios a dos de los contemplados
en el mapa de clases podrıan quedar fuera de la clasificacion. Ademas, el numero de clases de
cada mapa serıa, en general, mayor y esto aumentarıa la carga computacional del sistema de
reconocimiento.

80 Capıtulo 3. Reconocimiento de objetos 3D.
Para escoger un radio de agrupacion apropiado se ha escogido un criterio que intenta
encontrar el mayor valor del radio para el cual se pueden distinguir figuras que una persona
considerarıa diferentes. Es necesario resaltar que, en realidad, no existe un valor ideal de radio
de clasificacion, puesto que depende del grado de parecido entre vistas que se considere ra-
zonable. En todo caso, se puede encontrar un lımite maximo para el radio, por encima del
cual todas las vistas se consideran iguales, y un lımite mınimo, que considera distintas incluso
vistas consecutivas. Para poder escoger un radio adecuado se ha tomado, en primer lugar, un
objeto muy simple: un cubo. El cubo puede ofrecer al observador vistas cuadradas, rectangulares
o romboidales. Es evidente en este caso que el radio de clasificacion debe ser tal que divida el
mapa de vistas en dos o a lo sumo en tres clases. Como se observa en la grafica de la Fig. 3.3.a, el
numero de clases resultante del analisis de las vistas de un cubo se mantiene estable e igual a dos
para valores del radio entre 0.05 y 0.185. Para radios menores el numero de clases se incrementa
rapidamente y para radios mayores las distintas vistas de un cubo serıan indistinguibles entre
sı. En principio, cualquier valor en este rango representarıa un parecido razonable, con mayor
o menor grado de coincidencia, entre las vistas. Para fijar un valor dentro de este rango es
necesario recordar que, para un observador humano, cualquier objeto, por complicado que sea,
siempre tiene un numero limitado de clases de vistas porque siempre se encuentra parecido entre
distintas vistas del mismo objeto. Resulta, ademas, muy conveniente limitar el numero de clases
de vistas para cada objeto por debajo de un cierto nivel para que la carga computacional del
metodo de reconocimiento no sea excesiva.
Figura 3.3: a) Numero de clases de vistas frente al radio de agrupacion para un cubo; b) grupode objetos de diversa complejidad; y c) Numero de clases de vistas frente al radio de agrupacionpara los objetos en (b)

3. Construccion de modelos de objetos 3D 81
Siguiendo este criterio se ha escogido un grupo de objetos de complejidad creciente (Fig.
3.3.b) y se ha estudiado cuantas clases de vistas contienen en funcion del radio de clasificacion
(Fig. 3.3.c). Como se puede observar en la Fig. 3.3.c, para un radio de 0.15 el numero de clases
para los objetos propuestos se mantiene entre 3 y 5, lo que puede resultar una clasificacion
poco precisa, especialmente teniendo en cuenta que el conjunto de la Fig. 3.3.b incluye objetos
relativamente complicados. Para un radio de 0.05 el numero de clases se encuentra entre 6 y 12,
es decir, hay un numero elevado de clases, que necesariamente representan diferencias menores
entre las vistas. El intervalo de radios establecido con el ejemplo de la Fig. 3.3.c es muy parecido
al que se obtenıa analizando un cubo. Por lo tanto, se puede aceptar que cualquier radio de
clasificacion entre estos dos serıa valido. En la presente tesis se ha escogido un radio de 0.075,
para el que las vistas de cada objeto de la Fig. 3.3.b y la mayorıa de los estudiados en esta tesis
se clasifican en menos de 10 clases. Esta eleccion, en la practica, cumple el doble objetivo de
limitar el coste computacional a la vez que representa un grado razonable de parecido entre las
vistas de una misma clase.
3. Construccion de modelos de objetos 3D
En general, la disponibilidad de un buen metodo de descripcion de cada objeto tridimen-
sional no resuelve por sı misma el problema del reconocimiento. Un sistema de reconocimiento
debe extraer de la descripcion de cada objeto aquellos rasgos que sean determinantes para el
reconocimiento y establecer un criterio de similitud entre objetos. Esta fase del algoritmo de
reconocimiento se conoce como modelado.
Existen diversas aproximaciones para la extraccion de rasgos caracterısticos del objeto.
Ası, en los sistemas de reconocimiento clasicos (Bardinet et al., 1995) (Leonardis et al., 1997)
los modelos constan de una representacion parametrica mas o menos aproximada al volumen
del objeto observado. Podrıan entrar tambien en este grupo sistemas como el presentado por
Roh y Kweon (Roh y Kweon, 2000), que aproxima cada objeto por un conjunto de vertices
cuya posicion en el espacio es conocida. Si se pueden detectar los vertices de una observacion, se
puede determinar la naturaleza del objeto por un criterio de cercanıa. Estos metodos presentan
el inconveniente de que, es necesario disponer de un sistema de reconstruccion tridimensional
a partir de vistas planas de un objeto. Normalmente, esto se resuelve por metodos de vision
estereoscopica. Sin embargo, el calculo de la posicion por triangulacion pierde precision a medida
que el objeto observado se aleja del observador. Por otro lado, ligeros cambios de iluminacion o
contraste en las imagenes pueden alterar la posicion y hasta la cantidad de rasgos caracterısticos

82 Capıtulo 3. Reconocimiento de objetos 3D.
de cada imagen observada, dificultando aun mas su comparacion con los modelos predefinidos
(Murase y Nayar, 1994).
En el extremo opuesto al anterior estarıan los metodos de modelado que extraen como
rasgos significativos algunas caracterısticas locales de los objetos. Un buen ejemplo de este tipo
de metodos es la aproximacion cubista de Selinger y Nelson (Selinger y Nelson, 1999).
En la presente tesis se propone el uso de Modelos Ocultos de Markov (MOM) para la
construccion de modelos de objetos tridimensionales. Los modelos de Markov (MM) son habit-
ualmente utilizados para modelar sistemas en los que se puede establecer una clara secuencialidad
de sucesos y se puede afirmar que la probabilidad de ocurrencia de un suceso depende unica-
mente del estado del sistema en el paso anterior y no de la historia del sistema. Una de las
aplicaciones tıpicas de los MM es el reconocimiento de estructuras que adoptan la forma de
una serie temporal, como el reconocimiento de palabras tanto en registros acusticos como en
textos mecanografiados o manuscritos (Kuo y Agazzi, 1994) (Natarajan et al., 2001). Tambien
se han aplicado con exito al reconocimiento de imagenes siempre en casos en los que se puede
extraer una clara secuencialidad del planteamiento del problema. En particular, los MOM han
sido aplicados al reconocimiento de figuras planas basado en la secuencialidad de su contorno.
He y Kundu (He y Kundu, 1991) presentan un sistema de clasificacion de formas planas basado
en modelos ocultos de Markov de densidad continua. En ese caso, la clasificacion se efectua
analizando las relaciones entre segmentos consecutivos del contorno de las figuras observadas.
En (Hornegger et al., 1991) el reconocimiento de figuras planas se basa en modelos ocultos de
Markov cuyos estados ocultos son rasgos de la aproximacion poligonal del contorno comple-
to. No dan resultados para contornos complejos o para figuras distorsionadas, ası que es difıcil
saber como se comportarıa en estos casos, especialmente teniendo en cuenta que las aproxima-
ciones poligonales suelen ser muy sensibles a transformaciones o ruido (Ansari y Delp, 1991).
En el capıtulo 2 se ha presentado un sistema de reconocimiento de figuras planas por medio de
modelos ocultos de Markov, aplicados a una secuencia de esquinas del contorno observado (de
Trazegnies et al., 2003c). En este caso cada contorno queda caracterizado por un conjunto de
esquinas definidas como los extremos de la funcion de curvatura del contorno y caracterizadas
por parametros geometricos locales. El contorno observado queda clasificado como perteneciente
a una clase si la secuencia de esquinas observada sobre su contorno presenta una probabilidad
alta de haber sido generada por el modelo de Markov de dicha clase.
La construccion de un MM para modelar un objeto 3D exige la definicion de los sucesos
o estados observables y el establecimiento de una secuencialidad de observacion. Ası, cada el
modelo de cada objeto constara de un conjunto limitado de estados del sistema y un conjunto

3. Construccion de modelos de objetos 3D 83
de variables que informaran sobre la probabilidad de encontrar cada estado como secuencial-
mente posterior a cualquier otro estado del sistema. Ası cada modelo llevara implıcita no solo
la informacion que describe al objeto que modela sino tambien la evaluacion de la probabilidad
de que una determinada observacion se corresponda con cada uno de los modelos previamente
almacenados. Una eleccion natural para el conjunto de estados de cada modelo serıa el conjunto
de clases de vistas descrito en la seccion 2. Sin embargo, dado que las clases de vistas pueden
solaparse entre sı, esta eleccion lleva asociada la posibilidad de que una cierta observacion pue-
da corresponder a varios estados del mismo modelo. Como ya se discutio en la seccion 2, una
clasificacion unıvoca de cada vista no serıa totalmente satisfactoria para clasificar un conjunto
de vistas cuya variacion es necesariamente continua. Si cada vista pudiera ser clasificada como
perteneciente a una unica clase, se podrıa resolver el problema con modelos clasicos de Markov.
Como cada vista del objeto puede pertenecer a multiples clases de vistas del mismo, es mas
adecuado el uso de modelos ocultos de Markov.
Un MOM es un MM cuyos estados no son directamente observables. En la Fig. 3.4.a se
muestra el diagrama de un ejemplo de MM con cuatro estados. Los estados son directamente
observables, es decir, en cada instante se puede determinar exactamente el estado actual. Como
se puede apreciar, desde cada estado Hi solo algunos de los otros estados son accesibles en el
orden que marcan las flechas. Cada transicion del estado Hi al estado Hj tiene una probabilidad
de ocurrencia Ai,j , siendo Ai,j = 0 para todas aquellas transiciones para las cuales no se ha
incluido una flecha en el diagrama de la Fig. 3.4.a. Ası, dada una secuencia de estados, se puede
comprobar facilmente si es compatible con el MM propuesto y, de ser ası, evaluar, con la ayuda de
las probabilidades de transicion Ai,j , la probabilidad de que dicha secuencia haya sido generada
como una concatenacion de transiciones entre estados del MM.
Figura 3.4: Esquemas basicos de modelos de Markov sencillos: a) Modelo clasico de Markov; yb) Modelo oculto de Markov cuyas observaciones son elementos de un espacio vectorial bidimen-sional

84 Capıtulo 3. Reconocimiento de objetos 3D.
En un MOM (Fig. 3.4.b), cada estado Hi del sistema esta oculto al observador. Este
solo puede observar el estado de cada instante a traves de medidas indirectas. Ası, un proceso
no estarıa formado por una secuencia de estados Hi sino por una secuencia de observaciones Vi.
Las observaciones ni siquiera tiene por que ser de la misma naturaleza que los estados ocultos.
En este ejemplo se muestra un modelo en el que los estados ocultos pertenecen a un conjunto
discreto de cuatro elementos y las observaciones a un espacio vectorial bidimensional, que es un
conjunto continuo. Cada una de las observaciones se puede relacionar con uno o varios estados.
En el ejemplo de la Fig. 3.4.b se muestra una posible secuencia de tres observaciones (V1, V2, V3).
En este caso, la observacion V1 puede representar al estado H1 o al estado H2, la observacion V2
indica unıvocamente la ocurrencia del estado H2, y la observacion V3 de nuevo puede representar
dos estados: H3 y H4. En estas condiciones es imposible saber con toda seguridad cual ha sido
la secuencia de estados ocultos que subyace bajo la secuencia de observaciones. No obstante,
es posible evaluar la probabilidad de que la secuencia de observaciones haya sido generada por
el modelo propuesto. Para ello de debe elaborar una lista de todas las posibles secuencias de
estados compatibles con la secuencia de observaciones y evaluar la suma de las probabilidades de
que cada una de dichas secuencias de estados hayan sido generadas por el modelo. En la presente
tesis se propone la construccion de MOMs que representan objetos 3D. Cada observacion de un
objeto esta compuesta por una secuencia de vistas del mismo. En la siguiente seccion se presenta
una definicion formal de los parametros que definen el MOM de un objeto.
3.1. Definicion de los modelos ocultos de Markov
Cada modelo λp de un objeto p viene definido por un conjunto de parametros: λp =
(Hp,Πp, Ap, Bp). La eleccion de los parametros apropiados para la definicion de cada MOM es
crucial para el comportamiento del sistema de reconocimiento. En el sistema de reconocimiento
propuesto en esta tesis los parametros λp se han escogido como se detalla a continuacion:
Un conjunto de estados ocultos Hp = {Hp,1,Hp,2, ...,Hp,i, ...,Hp,M} para cada modelo p.
Como se introdujo en la seccion 2, cada objeto almacenado en la base consta de un conjun-
to de observaciones a angulos regulares alrededor del objeto. Los vectores de caracterısti-
cas que representan estas observaciones se clasifican mediante el algoritmo de agrupacion
propuesto. Cada una de las clases procedentes del proceso de agrupacion son los estados
ocultos del modelo y su numero y composicion dependen del radio de agrupacion escogido.
Es necesario observar que, con la presente definicion, los estados ocultos se definen para
cada modelo de forma independiente. Los conjuntos de estados ocultos pueden variar de

3. Construccion de modelos de objetos 3D 85
un modelo a otro no solo en composicion sino tambien en numero, lo cual facilita, como
se comento en la seccion 2, que cada modelo este adaptado a la complejidad del objeto al
que corresponde.
Un vector de probabilidades iniciales de observacion Πp = (π1, π2, ..., πi, ..., πM ). Cada
elemento πi del vector Πp representa la probabilidad de que, observando el objeto p, se
encuentre una vista perteneciente a la clase i en la primera posicion de la secuencia. Las
componentes de Πp toman valores proporcionales a la frecuencia de aparicion de cada clase
de vistas en el objeto modelado, ajustados de modo que la suma de todas las componentes
este normalizada a la unidad:
M∑i=1
πi = 1 (3.1)
siendo M el numero de clases para cada modelo p.
Una matriz de transicion Ap. Cada elemento ai,j de Ap representa la probabilidad de que,
observando el objeto p, se encuentre una vista correspondiente a la clase j despues de
una vista perteneciente a la clase i. Los coeficientes de la matriz de transicion se ajustan
mediante la aplicacion del algoritmo de Baum-Welch (Rabiner, 1989).
Una matriz de probabilidad de observacion Bp(V q). Los coeficientes bpi,q de la matriz
Bp(V q) relacionan la secuencia de vistas observadas con los estados ocultos del mode-
lo p. Representan la probabilidad de que la q-esima vista observada pertenezca a cada una
de las clases que se identifican con cada estado oculto del sistema. Si la distancia entre la
q-esima vista (V q) y el centroide de la clase i del modelo p (Hp,i) es mayor que el radio
de agrupacion predefinido, entonces bpi,q es igual a 0. Todos los elementos no nulos de cada
columna adoptan el mismo valor de modo que se satisface la igualdad:
M∑i=1
bpi,q = 1 (3.2)
El juego de parametros (Hp,Πp, Ap, Bp) debe ser ajustado de acuerdo con cada modelo
p en la base de datos durante el proceso de entrenamiento. Gracias a la informacion que tenemos
del problema se pueden definir los parametros Hp, Πp, y Bp como se indica arriba. Sin embargo
es conveniente ajustar los coeficientes de Ap de modo que se maximice la probabilidad de que
dada cualquiera de las posibles secuencias de un objeto p esta secuencia haya sido generada por
el modelo λp. Este calculo, como ya se ha comentado, se realiza mediante el algoritmo de Baum-
Welch (Rabiner, 1989). El algoritmo de Baum-Welch, derivado del algoritmo de maximizacion

86 Capıtulo 3. Reconocimiento de objetos 3D.
de esperanza (Expectation Maximization Algorithm), es un metodo de optimizacion local. Por lo
tanto, la eleccion de los parametros iniciales del sistema determinan: i) el numero de iteraciones
necesarias para que el sistema converja a una solucion estable; y ii) la tendencia a converger a un
maximo optimo o de segundo orden. Con este fin se ha inicializado la matriz de transicion Ap con
los valores resultantes de la contabilizacion de transiciones entre cada pareja de estados ocultos
sobre el mapa de clases del objeto en cuestion. Estos valores deben estar cerca de los resultantes
del algoritmo de optimizacion y, de hecho, reducen el numero de iteraciones del algoritmo en la
mayorıa de los casos a menos de 5.
4. Aprendizaje y Reconocimiento
En el analisis mediante MOMs, la definicion de la probabilidad de que una determinada
secuencia de observaciones pertenezca a un objeto, representado por un modelo λp, no es un
problema trivial. En realidad el valor P (V Q|λp), proporcionado por el algoritmo de Baum-Welch
(Rabiner, 1989) indica la probabilidad de que, teniendo el modelo λp, se haya podido generar
una secuencia de observaciones como V Q de entre todas las posibles secuencias de observaciones
del objeto representado por el modelo.
Para ilustrar este punto se puede analizar un ejemplo sencillo de un dado de juego como
el de la Fig. 3.5.a, que puede girar sobre sı mismo, ofreciendo al observador una secuencia de
caras distintas y contiguas. En este caso, se supone que la observacion de cada cara da como
resultado el numero inscrito en la misma sin ninguna ambiguedad, por lo tanto se puede modelar
este proceso con un MM clasico que describa el dado.
El MM del dado se define mediante un vector de probabilidad inicial y una matriz de
transferencia entre estados, ya que, al ser un MM, no es necesario definir una probabilidad
de observacion. En este caso la probabilidad de encontrar una cara cualquiera como primer
elemento de la secuencia debe ser igual a 1/6. Por lo tanto el vector de probabilidad inicial del
dado tomara la forma:
πdado = (16,16,16,16,16,16) (3.3)
Una vez que se ha fijado la observacion de la primera cara, por ejemplo un 5, la probabil-
idad de que la siguiente observacion muestre cada una de las otras caras toma valores diferentes,
puesto que no todas las caras son accesibles desde la que contiene un 5. Es imposible que la

4. Aprendizaje y Reconocimiento 87
Figura 3.5: a) Dado normal de juego; b) dado con la cara 4 repetida; y c) dado con las carasdesordenadas
siguiente cara sea un 5, porque se supone que siempre se debe avanzar a una cara contigua, o
un 2, porque el 2 esta en la cara opuesta al 5 y no es accesible en un solo paso. Ası, se puede
construir una matriz de transicion del dado como:
Adado =
0 14
14
14
14 0
14 0 1
414 0 1
414
14 0 0 1
414
14
14 0 0 1
414
14 0 1
414 0 1
40 1
414
14
14 0
(3.4)
Si se propone una secuencia cualquiera de caras, por ejemplo V Q = (2, 4, 5, 3), se puede
calcular la probabilidad de que, observando una secuencia procedente del dado modelado, la
secuencia coincida con la propuesta:
P (V Q|λdado) = π2 ·A2,4 ·A4,5 ·A5,3 = 2.5 · 10−3 (3.5)
Evidentemente la probabilidad resultante no solo es baja sino que depende del numero
de vistas adquiridas, lo cual dificulta el uso de la probabilidad P (V Q|λdado), ası definida, para
calcular la probabilidad de que el objeto observado sea un dado. Si se quiere definir un umbral
fijo por debajo del cual se considere despreciable la probabilidad de que una secuencia se haya
obtenido de un determinado modelo, este umbral debera depender de una forma complicada

88 Capıtulo 3. Reconocimiento de objetos 3D.
del numero de vistas de la secuencia, del numero de estados de cada modelo, etc. Sin embargo,
sı se puede usar como una medida comparativa. Por ejemplo, se considera que hay tres dados
distintos, el primero es un dado normal de juego (Fig. 3.5.a), el segundo es un dado con la cara
4 repetida y sin cara 3 (Fig. 3.5.b), y el tercero es un dado que no respeta la regla general de que
la suma de sus caras opuestas sea igual a 7 (Fig. 3.5.c). Los modelos de Markov correspondientes
a los dos nuevos dados seran:
πdadob = (16,16, 0,
13,16,16) πdadoc = (1
6 , 16 , 1
6 , 16 , 1
6 , 16) (3.6)
(3.7)
Adadob =
0 14 0 1
214 0
14 0 0 1
2 0 14
0 0 0 0 0 014
14 0 0 1
414
14 0 0 1
2 0 14
0 14 0 1
214 0
Adadoc =
0 0 14
14
14
14
0 0 14
14
14
14
14
14 0 1
414 0
14
14
14 0 0 1
414
14
14 0 0 1
414
14 0 1
414 0
(3.8)
Si se supone que las vistas se adquieren de una en una, y para cada paso se evaluan las
tres probabilidades, se puede observar su evolucion respecto del numero de vistas, representada
en la tabla 3.1:
P (V 1|λx) P (V 2|λx) P (V 3|λx) P (V 4|λx)dado a 1
6124
148
196
dado b 16
112
124 0
dado c 16
124 0 0
Tabla 3.1: Probabilidades de observacion de la secuencia V 4 con MM’s de distintos dados
Debe notarse que los valores de probabilidad ası obtenidos no son en modo alguno la
probabilidad de que el objeto observado sea cada uno de los tres dados modelados, sino de que
con cada uno de los modelos, se pueda obtener la secuencia observada. Ası, si se comparan
valores parciales, se pueden interpretar resultados incorrectos. Por ejemplo, despues de tres ob-
servaciones, el modelo del segundo dado ofrece la probabilidad mas alta de encontrar la secuencia
propuesta. Esto ocurre porque, al no contener la secuencia ninguna observacion de la cara 3, se
puede considerar ligeramente mas probable que la observacion se haya hecho sobre un dado que
no contenga dicha cara. Una vez que aparece la cara 3 en la cuarta vista, la observacion se hace
incompatible con el modelo del segundo dado. El tercer dado contiene las mismas caras que el
primero pero en distintas posiciones. Por lo tanto solo se podra distinguir uno de los dos dados

4. Aprendizaje y Reconocimiento 89
como mas probable si de la secuencialidad de la observacion se puede derivar una probabilidad
de ocurrencia muy baja, o la incompatibilidad con uno de ellos. En el ejemplo propuesto, es
imposible que se observen en el tercer dado las caras 4 y 5 de forma consecutiva, por esto, tras
la cuarta observacion, el unico modelo que aun es posible es el del primer dado.
Ası, se pueden utilizar las probabilidades de observacion de la secuencia dada con cada
uno de los modelos de Markov como una prueba negativa, tomando un numero creciente de
observaciones hasta que se hayan anulado las probabilidades respecto de todos los modelos
existentes menos uno, o hasta que se considere que la comparacion entre los valores de probabi-
lidades es significativamente favorable a uno de ellos. Como los valores de probabilidad se van a
usar solo a titulo comparativo, se puede facilitar la comparacion mediante una normalizacion de
estos valores. En el ejemplo propuesto la probabilidad normalizada toma los valores propuestos
en la tabla 3.2
P ′(V 1|λx) P ′(V 2|λx) P ′(V 3|λx) P ′(V 4|λx)dado a 0.33 0.25 0.33 1dado b 0.33 0.5 0.67 0dado c 0.33 0.25 0 0
Tabla 3.2: Probabilidades de observacion normalizadas de la secuencia V 4 con MM’s de distintosdados
Debe notarse que estos valores sı se pueden interpretar como las probabilidades de que la
secuencia observada corresponda respectivamente a uno de los tres modelos de dados definidos.
Es decir, se puede entender que, conocidos los modelos de dados a, b y c, si se observa la
secuencia propuesta, esta solo puede corresponder al dado a. Debe observarse ası mismo que, si
esta secuencia en particular constara de menos de cuatro vistas, la informacion disponible no
serıa suficiente para distinguir con toda certeza a que dado corresponde.
Es importante observar que un sistema de reconocimiento como el arriba descrito dara re-
sultados muy diferentes dependiendo de la variabilidad del conjunto de modelos elegido. Si los
modelos son muy diferentes entre sı, hasta el punto de que la primera vista sea incompatible
con todos los modelos menos uno, el sistema dara como resultado una probabilidad normalizada
de 1 para pertenencia de la observacion a dicho modelo y no necesitara analizar las siguientes
observaciones de la secuencia.
Es importante remarcar que en el ejemplo anterior se ha presupuesto que las caras de

90 Capıtulo 3. Reconocimiento de objetos 3D.
los dados son perfectamente distinguibles y quedan identificadas unıvocamente por el numero
grabado sobre ellas. Es gracias a ello que este ejemplo se puede resolver mediante MMs. En esta
tesis se propone la resolucion del problema del reconocimiento de objetos 3D mediante MOMs
en lugar de MMs. No obstante, la probabilidad de observacion P (V q|λp), calculada mediante el
algoritmo de Baum-Welch, representa, al igual que en el ejemplo anterior, la probabilidad de
que, dado un objeto p, se encuentre una secuencia de observaciones V q. Este hecho justifica la
necesidad de normalizacion de las probabilidades calculadas respecto el total de los objetos de
cuyos modelos dispone el sistema en un momento dado. La normalizacion ası definida propor-
ciona una medida de la probabilidad de que la secuencia de vistas V q pertenezca al objeto p,
que es la medida de probabilidad utilizada en los resultados que se presentan a continuacion.
5. Resultados
Inicialmente el sistema carece totalmente de informacion sobre los objetos que le seran
presentados. La unica informacion de la que dispone el sistema al comienzo del proceso de
pruebas es una base vectorial del subespacio de dimension reducida que representa a las trans-
formadas discretas de Fourier de todos los posibles contornos de figuras planas y un valor fijado
a priori como radio de agrupacion.
La base vectorial, que se ha calculado como se introdujo en el capıtulo2, seccion 3.3, ha
sido extraıda del conjunto de 27 senales de trafico descrito en la seccion 4 del capıtulo 2 y que
se muestran de nuevo en la Fig. 3.6. La dimension de esta base vectorial es igual a 10 ya que,
como se discutio en la seccion 4.3 del capıtulo 2, esta dimension es suficiente para representar
cualquier contorno de un objeto plano con fines de clasificacion.
Durante el funcionamiento normal del sistema, el proceso de reconocimiento se inicia con
la observacion de la primera vista de un objeto. El sistema calcula la probabilidad de que dicha
vista pertenezca a cada uno de los modelos de los que disponga. Si existe un resultado unico
para el reconocimiento, el proceso se detiene y proporciona este resultado. De lo contrario, el
sistema adquiere una segunda vista y evalua la probabilidad de que la secuencia de dos vistas
pertenezca a cada modelo. El este paso del proceso se repite hasta que el reconocimiento sea
unico o hasta que ninguno de los modelos existentes sea compatible con la secuencia observada,
y por lo tanto se designe el objeto observado como nuevo. En este ultimo caso, se debe iniciar
el algoritmo de aprendizaje.
Al inicio del funcionamiento, dado que el sistema aun no dispone de ningun modelo, por

5. Resultados 91
Figura 3.6: a) Conjunto de 27 anagramas de senales de trafico: y b) ejemplos de deformacionesaplicadas al conjunto anterior
defecto se debe iniciar el aprendizaje del primer objeto presentado al sistema. En cualquiera de
los dos casos, el algoritmo de aprendizaje consta de los siguientes pasos:
1. Se capturan 72 vistas del objeto espaciadas regularmente alrededor del mismo cada 30o en
las direcciones azimutal y polar.
2. Se realiza un proceso de agrupacion no supervisado de las vistas almacenadas en clases.
El numero de clases, como se comento en la seccion 2 del presente capıtulo, depende del
radio de agrupacion escogido.
3. Se traza un mapa de las vistas del objeto de acuerdo con la distancia de cada una de ellas
a cada una de las clases de clasificacion. Para el caso del cubo de la Fig. 3.7.a, se muestra
este mapa en la Fig. 3.7.b, en la que se ha sobreimpreso, para mayor claridad, sobre cada
posicion del mapa una imagen de la vista a la que corresponde.
4. Se construye un modelo oculto de Markov correspondiente al mapa del objeto propuesto,
siguiendo el algoritmo Baum-Welch, como se describe en la seccion 3.1.
5.1. Funcionamiento del sistema de reconocimiento frente a una base de ob-jetos predefinida
Para comprobar el comportamiento del algoritmo propuesto, se ha generado un conjunto
de 15 objetos virtuales (Fig. 3.8). En este conjunto se han incluido intencionadamente objetos

92 Capıtulo 3. Reconocimiento de objetos 3D.
Figura 3.7: a) Cubo; y b) mapa de clases del cubo
Figura 3.8: Conjunto de objetos de prueba
que, aun siendo distintos, presentan vistas similares, de modo que podrıan llegar a dar lugar a
confusion en su reconocimiento.
En primer lugar, como aun no hay objetos ya entrenados en el sistema con los que poder
comparar, se ha forzado el entrenamiento de dos objetos geometricos sencillos: una esfera y un
cubo (Fig. 3.8.a y b). Para cada objeto el proceso de entrenamiento consiste en los siguientes
pasos:
Tras el proceso de entrenamiento, un objeto p queda representado por un modelo oculto
de Markov λp. Es importante resaltar que la informacion contenida en cada modelo λp no
incluye datos sobre cada una de las vistas exploradas para crearlo. El juego de parametros

5. Resultados 93
(Hp,Πp, Ap, Bp) que definen al modelo λp contiene unicamente informacion sobre un conjunto
reducido de vistas tıpicas del objeto en cuestion y un conjunto de parametros que expresan
la probabilidad de encontrar una determinada secuencia de vistas tıpicas al explorar el objeto
original. Esto significa que cuando se presente un nuevo objeto al sistema, la probabilidad de que
la secuencia observada pertenezca a un cierto objeto ya almacenado sera no nula siempre que
cada una de las vistas observadas sea similar a uno de los estados ocultos del modelo de dicho
objeto y que el orden en que dichas vistas han sido observadas no sea incompatible con la matriz
de transicion Ap del modelo. Es necesario recordar asimismo que para poder establecer una
comparacion entre la probabilidad de que la secuencia observada pertenezca a uno u otro objeto,
la suma de todas las probabilidades de observacion respecto de todos los modelos almacenados
en el sistema se normaliza a la unidad como se describe en la seccion mas arriba.
Tras la esfera y el cubo, se presenta un tercer objeto al sistema. El objeto presentado es
un paralelepıpedo alargado (Fig. 3.8.c) que presenta vistas muy similares a las del cubo desde
determinadas perspectivas. Si alguna de estas vistas fuera presentada como primera vista de
la secuencia, el sistema interpretarıa que el objeto observado es un cubo, ya que de los dos
objetos conocidos, el unico compatible con la vista observada es el cubo. No obstante, durante
las pruebas la orientacion de la vista inicial es escogida al azar, y en este caso la primera vista
no es compatible con ninguno de los dos objetos a disposicion del sistema (Fig. 3.9.a). En
consecuencia, el sistema no reconoce el objeto propuesto y demanda el entrenamiento de un
nuevo modelo.
Una vez adquirido el tercer modelo se puede repetir el experimento de reconocimiento
con el mismo objeto. Como se puede observar en la Fig. 3.9.b, la primera vista es similar a
algun estado oculto del cubo y a alguno del paralelepıpedo. En este caso la probabilidad de
ser reconocido como cualquiera de los dos modelos anteriores coincide. Sin embargo, una vez
adquirida la segunda vista, queda claro que el unico reconocimiento posible se da para el tercer
modelo.
El cuarto objeto presentado al sistema es el cilindro mostrado en la Fig. 3.8.d. La vista
superior del cilindro es igual a cualquier vista de la esfera, mientras que las vistas laterales son
similares a algunas del paralelepıpedo (Fig. 3.8.c). En este caso es previsible que las diferencias
entre unos y otros queden marcadas por la secuencialidad del conjunto de observaciones. En
la Fig. 3.10 se presentan dos pruebas de reconocimiento del nuevo objeto. En Fig. 3.10.a la
primera vista es un rectangulo. El sistema conoce dos objetos con vistas rectangulares: el cubo
y el paralelepıpedo. Ası, el sistema considera necesario adquirir una vista mas para tomar una
decision. La segunda vista no guarda parecido con ninguno de los dos objetos propuestos. Esta

94 Capıtulo 3. Reconocimiento de objetos 3D.
Figura 3.9: Prueba de reconocimiento para el objeto en Fig. 3.8.c
Figura 3.10: Prueba de reconocimiento para el objeto en Fig. 3.8.d cuando el sistema aun notiene modelo para el mismo: a) partiendo de una vista lateral; y b) partiendo de una vista cenital

5. Resultados 95
vista, por su forma redondeada, podrıa considerarse similar a la esfera, pero el modelo de la
esfera queda descartado por no casar con la primera vista. El nuevo objeto es etiquetado como
desconocido y comienza la rutina de entrenamiento.
Si la primera vista hubiera sido cenital (Fig. 3.10.b), el sistema habrıa dado un falso
positivo para la esfera, puesto que es el unico objeto conocido con vistas circulares. Por claridad
se ha anadido aquı una segunda vista que el sistema no pedirıa en este caso. Como la segunda
vista es similar a la circular, en este caso el reconocimiento queda confirmado como una esfera.
La Fig. 3.11 muestra las mismas pruebas de reconocimiento de la Fig. 3.10 una vez
que el sistema conoce el modelo del cilindro propuesto. En el primer ejemplo (Fig. 3.11.a), se
puede observar que ahora la primera vista lleva al sistema a una disyuntiva entre los modelos del
paralelepıpedo, el cubo y el cilindro. En principio los dos primeros aparecen con una probabilidad
de reconocimiento mayor. Esto es debido a que la probabilidad de encontrar una vista rectangular
en un paralelepıpedo es sensiblemente mayor a la probabilidad de encontrarla en un cilindro. Sin
embargo no es suficiente para clasificar el objeto observado, puesto que aun hay tres modelos
que casan con el objeto observado. En la siguiente vista ya aparece el perfil redondeado del
cilindro, gracias a lo cual el unico objeto al que puede corresponder esta secuencia es el cilindro.
En la Fig. 3.11.b el sistema necesita un total de tres vistas porque al empezar por figuras mas o
menos redondeadas, el sistema mantiene como posible solucion la esfera durante mas pasos de
la secuencia hasta poder distinguir claramente este cilindro.
Siguiendo el mismo proceso se han presentado al sistema los objetos que componen el
conjunto de prueba en el mismo orden en el que aparecen representados en la Fig. 3.8. La vista
de comienzo de la secuencia se ha elegido al azar. Si el sistema no lo reconoce, elabora el modelo
correspondiente y lo anade al conjunto de objetos conocidos para futuras pruebas. Los resultados
de estas pruebas se muestran en las Figs. 3.12-3.21.
Al presentar el cilindro de la Fig. 3.8.e el sistema considera que es similar al de la Fig.
3.8.d. En efecto, las diferencias entre ambos solo son patentes si se analiza una vista frontal, por
lo tanto el sistema no considera necesario el entrenamiento de un nuevo modelo para el mismo.
La primera vez que se presenta al sistema el cono en la Fig. 3.8.f, su forma caracterıstica
es ya apreciable en la primera vista, por lo que el sistema considera inmediatamente que es
desconocido. Despues de completar el proceso de entrenamiento del nuevo modelo, se vuelve
a presentar el mismo cono al sistema con el fin de confirmar que el modelo se ha almacenado
correctamente (Fig. 3.12.b). Se puede observar como el hecho de que la primera vista sea muy
caracterıstica hace que una vez que se dispone del modelo adecuado, el reconocimiento quede
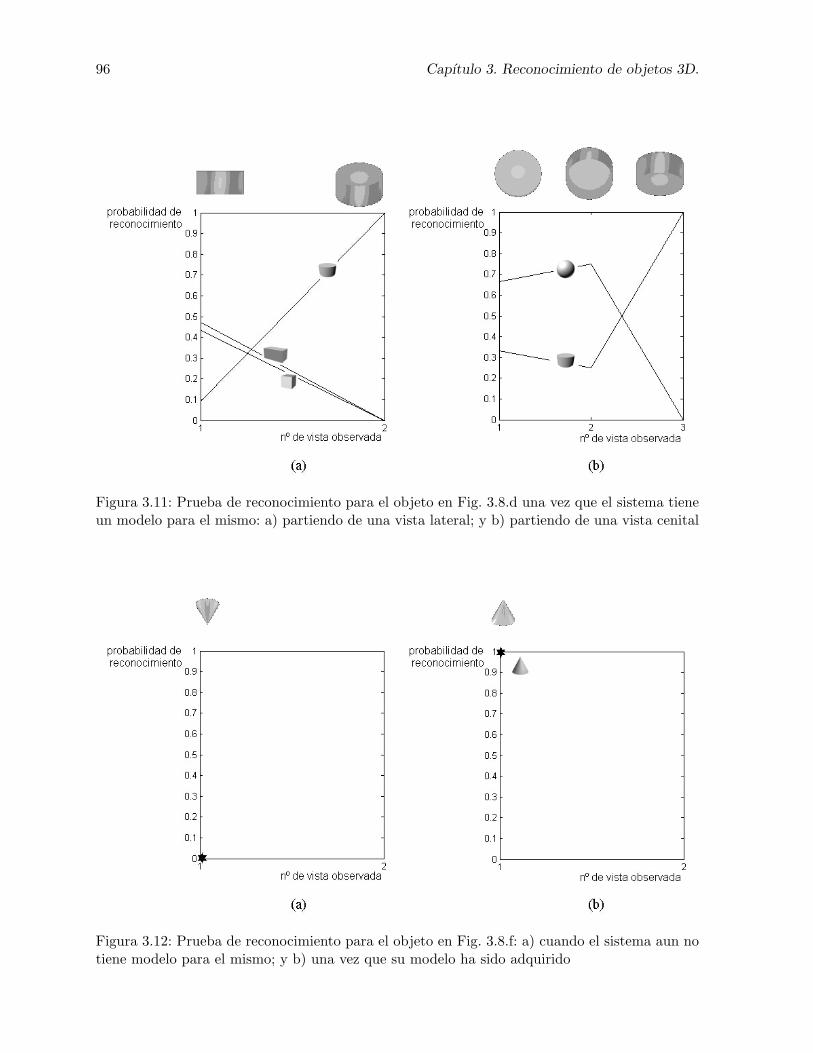
96 Capıtulo 3. Reconocimiento de objetos 3D.
Figura 3.11: Prueba de reconocimiento para el objeto en Fig. 3.8.d una vez que el sistema tieneun modelo para el mismo: a) partiendo de una vista lateral; y b) partiendo de una vista cenital
Figura 3.12: Prueba de reconocimiento para el objeto en Fig. 3.8.f: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido

5. Resultados 97
Figura 3.13: Prueba de reconocimiento para el objeto en Fig. 3.8.g: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido
determinado sin necesidad de adquirir nuevas vistas.
El cono de la Fig. 3.8.g es bastante mas obtuso que el anterior, en muchas de sus vis-
tas el vertice queda disimulado y su forma aproximadamente circular. En la Fig. 3.13.a se ha
presentado este objeto al sistema de forma que las dos primeras vistas pueden dar lugar a un
falso reconocimiento como una esfera o bien como un cilindro. Como el sistema no encuentra un
resultado unico, requiere una vista mas. En la tercera vista, el vertice es ya visible, la secuencia
resultante no puede pertenecer a ninguno de los objetos almacenados hasta el momento, por lo
tanto el sistema anade un modelo del nuevo objeto a los ya existentes. En la Fig. 3.13.b de nuevo
se muestra la confirmacion del reconocimiento correcto una vez adquirido el nuevo modelo.
Las Figs. 3.14 y 3.15 muestran dos ejemplos similares a los anteriores. En el primer
caso, la botella de la Fig. 3.8.h, todas las vistas del objeto presentado son muy distintas a los
objetos existentes. Tanto para la clasificacion del objeto como desconocido (Fig. 3.14.a) como
para la verificacion de reconocimiento posterior al entrenamiento (Fig. 3.14.b) una unica vista
es suficiente. En el caso de la botella en Fig. 3.8.i la vista cenital presenta un perfil circular, pero
una segunda vista es suficiente para que el sistema asigne una clasificacion correcta.
La Fig. 3.16 muestra un ejemplo de reconocimiento erroneo. En este caso el objeto prop-

98 Capıtulo 3. Reconocimiento de objetos 3D.
Figura 3.14: Prueba de reconocimiento para el objeto en Fig. 3.8.h: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido
Figura 3.15: Prueba de reconocimiento para el objeto en Fig. 3.8.i: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido

5. Resultados 99
Figura 3.16: Prueba de reconocimiento erroneo para el objeto de la Fig. 3.8.j
uesto, la copa en Fig. 3.8.j, muestra una secuencia de vistas que induce al sistema a relacionarla
con un modelo que no le corresponde y que, en realidad, solo presenta un vago parecido con la
misma. Evidentemente el problema se resolverıa si alguna de las vistas disponibles fuera frontal,
de modo que el perfil caracterıstico de la copa fuera visible. Sin embargo en esta prueba se ha
querido respetar el caracter no supervisado del sistema de reconocimiento para no influir en el
resultado de los experimentos con informacion a priori sobre la naturaleza de los objetos estudi-
ados. En cualquier caso, es importante puntualizar que el sistema de reconocimiento propuesto
debe ser capaz de entrenar nuevos modelos a medida que los necesite, siempre que encuentre
objetos desconocidos en su entorno. Ası, si en el futuro se vuelve a presentar la misma copa
desde otra perspectiva y el sistema no encuentra ningun modelo parecido a ella, se iniciara una
secuencia de entrenamiento y se anadira el nuevo modelo al conjunto. Despues de esto, una
repeticion del mismo experimento de la Fig. 3.16 no devolverıa un resultado erroneo.
El proceso de observacion y eventual entrenamiento de nuevos modelos continua presen-
tando uno a uno los objetos de la Fig. 3.8 en el orden en el que aparecen en dicha figura. Algunas
de estas pruebas se muestran en las Figs. 3.17-3.21. En los casos en los que ha sido necesaria la
adquisicion de un nuevo modelo por considerar que el objeto presentado es desconocido, se ha
presentado una segunda vez el mismo objeto para realizar una confirmacion del reconocimiento
correcto. En estos casos se han representado ambas pruebas en la misma figura.

100 Capıtulo 3. Reconocimiento de objetos 3D.
Figura 3.17: Prueba de reconocimiento para el objeto en Fig. 3.8.k: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido
Figura 3.18: Prueba de reconocimiento para el objeto en Fig. 3.8.l: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido

5. Resultados 101
Figura 3.19: Prueba de reconocimiento para el objeto en Fig. 3.8.m: a) cuando el sistema aunno tiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido
Figura 3.20: Prueba de reconocimiento para el objeto en Fig. 3.8.n: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido

102 Capıtulo 3. Reconocimiento de objetos 3D.
Figura 3.21: Prueba de reconocimiento para el objeto en Fig. 3.8.p: a) cuando el sistema aun notiene modelo para el mismo; y b) una vez que su modelo ha sido adquirido
Cada vez que se presente nuevamente un objeto al sistema, sera reconocido como corre-
spondiente a su propio modelo, como similar a alguno de los modelos existentes, o bien sera eti-
quetado como objeto desconocido y el sistema adquirira un nuevo modelo para el mismo. Al
cabo de algunos ensayos todos los objetos del conjunto de prueba deben tener un modelo propio
o bien un modelo al que son tan similares que no se justifica el entrenamiento de un modelo
propio. En el caso en particular de los objetos de la Fig. 3.8 finalmente se ha entrenado un
modelo para cada uno de los objetos. Es importante notar que el grado de parecido tolerable
entre objeto y modelo esta fuertemente influenciado por la eleccion del radio de clasificacion de
vistas, que se introdujo en la seccion 2. Si se hubiera escogido un radio mayor, para algunos
de los objetos del conjunto de entrenamiento no se habrıa requerido un modelo especıfico, en
lugar de esto, habrıan sido reconocidos como similares a alguno de los modelos a los que mas se
parecen. Para ilustrar este fenomeno, se ha incluido en la tabla 3.3 un resumen de los resultados
de la repeticion del conjunto de pruebas anteriores para varios valores del radio. En esta tabla,
en la primera columna aparecen los objetos del conjunto de pruebas, identificados por el mismo
codigo que se les asigno en la Fig. 3.8. En cada una de las columnas de la derecha aparecen
los objetos que han sido clasificados como similares a cada modelo. Los recuadros que aparecen
vacıos indican que para el radio de la columna correspondiente, el sistema no ha considerado
necesario adquirir ese modelo. Como se puede observar, a medida que aumenta el radio de clasi-

5. Resultados 103
Modelo \ Radio 0.075 0.1 0.15 0.2(a) esfera esfera esfera esfera esfera(b) cubo cubo cubo cubo cubo
paralelepıpedo paralelepıpedo(c) paralelepıpedo paralelepıpedo paralelepıpedo
(d) cilindro 1 cilindro 1 cilindro 1 cilindro 1 cilindro 1(e) cilindro 2 cilindro 2 cilindro 2 cilindro 2 cilindro 2
(f) cono 1 cono 1 cono 1 cono 1 cono 1bombilla
(g) cono 2 cono 2 cono 2 cono 2(h) botella 1 botella 1 botella 1 botella 1 botella 1
botella 2 botella 2tetera
(i) botella 2 botella 2 botella 2(j) copa 1 copa 1 copa 1 copa 1 copa 1
cono 2(k) copa 2 copa 2 copa 2 copa 2 copa 2
copa 3 copa 3botella 2 botella 2tetera tetera
(l) copa 3 copa 3 copa 3(m) bombilla bombilla bombilla bombilla
(n) mesa mesa mesa mesa mesa(p) tetera tetera tetera
Tabla 3.3: Resultados de reconocimiento para distintos radios de clasificacion de vistas
ficacion, el sistema necesita cada vez menos modelos para representar el conjunto de objetos.
No obstante, en todos los casos, los objetos para los cuales el sistema carece de un modelo, son
reconocidos como objetos con los cuales comparten un fuerte parecido. La eleccion de un radio
en particular depende del grado de similitud requerido en las pruebas. En la presente tesis se ha
fijado, como se comento en la seccion 2, el valor de 0.075.
Los objetos de la Fig. 3.8 han sido escogidos para presentar cierta similitud en algunas
vistas pero, en general, se pueden considerar distintos entre sı. Es interesante observar que el
hecho de que el sistema conozca mas objetos le dota de una mayor capacidad de resolucion para
distinguir entre objetos similares. Para ilustrar esta idea se ha repetido la prueba de la Fig.
3.16, donde habıa un error de reconocimiento, una vez que el sistema conoce modelos para la
mayorıa de los objetos propuestos. El resultado se muestra en la Fig. 3.22. En la prueba de la Fig.
3.16 el sistema solo conocıa los modelos de 6 objetos y eligio entre ellos el unico que resultaba
compatible con la secuencia de vistas. En esta ocasion (Fig. 3.22.a), el sistema ya conoce 13
modelos distintos. El hecho de que varios de los modelos conocidos sean compatibles con las dos

104 Capıtulo 3. Reconocimiento de objetos 3D.
primeras vistas de la secuencia de observaciones hace que el sistema pida una tercera vista con
la cual puede decidir que efectivamente el objeto era desconocido y requiere un modelo propio.
Figura 3.22: Segunda prueba de reconocimiento para el objeto en Fig. 3.8.j cuando el sistemaya dispone de muchos modelos: a) mientras el sistema aun no tiene modelo para el mismo; y b)una vez que su modelo ha sido adquirido
Cabe imaginar que, como las secuencias de vistas pueden comenzar desde cualquier
orientacion arbitraria alrededor del objeto, podrıan darse casos de secuencias de vistas ambıguas
que indujeran al sistema a un error de reconocimiento. Para comprobar la fiabilidad del sistema
en el reconocimiento de los objetos originales sin distorsion de ningun tipo se ha realizado una
prueba estadıstica con los objetos de la Fig. 3.8. Para realizar esta prueba se han presentado
al sistema cincuenta secuencias de vistas de cada objeto. La orientacion de la vista inicial ha
sido escogida al azar de modo que se puede suponer que la prueba incluye secuencias de vistas
uniformemente distribuidas alrededor de cada objeto. El resultado del reconocimiento es correcto
en el 100 % de los casos, es decir, aun en los casos en los que algunas de las vistas observadas
sean comunes a varios objetos, el sistema es capaz de relacionar todas las secuencias con los
objetos correctos.
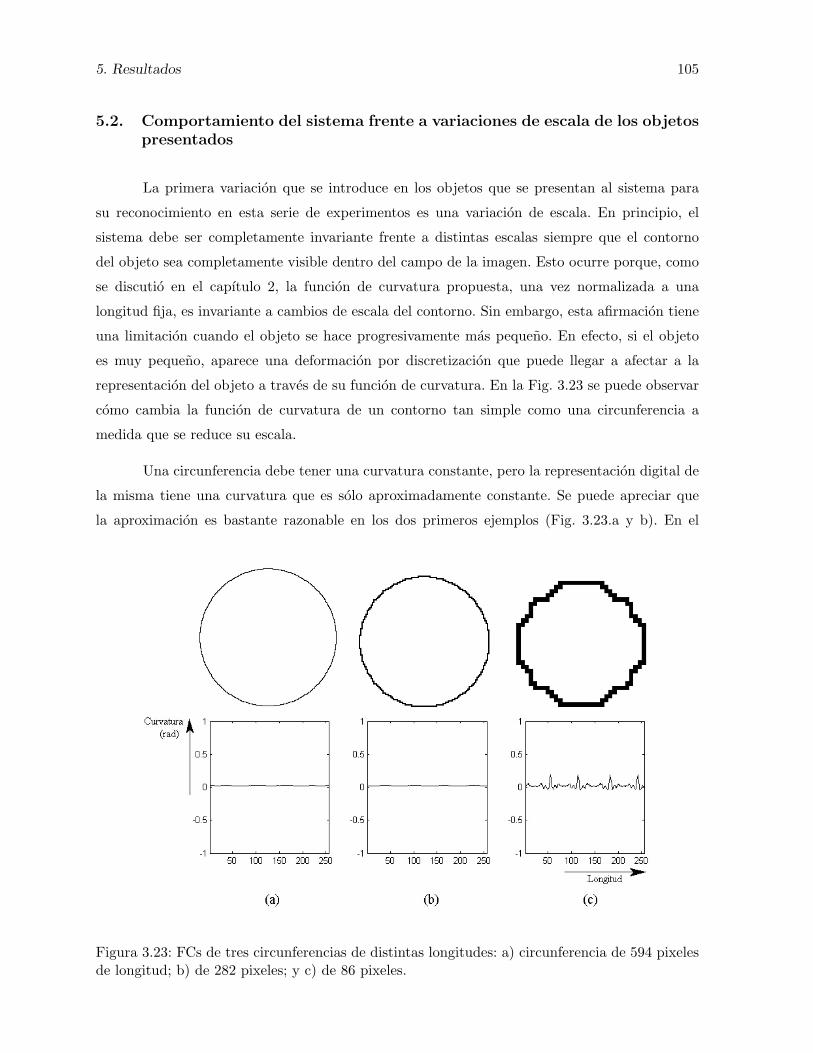
5. Resultados 105
5.2. Comportamiento del sistema frente a variaciones de escala de los objetospresentados
La primera variacion que se introduce en los objetos que se presentan al sistema para
su reconocimiento en esta serie de experimentos es una variacion de escala. En principio, el
sistema debe ser completamente invariante frente a distintas escalas siempre que el contorno
del objeto sea completamente visible dentro del campo de la imagen. Esto ocurre porque, como
se discutio en el capıtulo 2, la funcion de curvatura propuesta, una vez normalizada a una
longitud fija, es invariante a cambios de escala del contorno. Sin embargo, esta afirmacion tiene
una limitacion cuando el objeto se hace progresivamente mas pequeno. En efecto, si el objeto
es muy pequeno, aparece una deformacion por discretizacion que puede llegar a afectar a la
representacion del objeto a traves de su funcion de curvatura. En la Fig. 3.23 se puede observar
como cambia la funcion de curvatura de un contorno tan simple como una circunferencia a
medida que se reduce su escala.
Una circunferencia debe tener una curvatura constante, pero la representacion digital de
la misma tiene una curvatura que es solo aproximadamente constante. Se puede apreciar que
la aproximacion es bastante razonable en los dos primeros ejemplos (Fig. 3.23.a y b). En el
Figura 3.23: FCs de tres circunferencias de distintas longitudes: a) circunferencia de 594 pixelesde longitud; b) de 282 pixeles; y c) de 86 pixeles.

106 Capıtulo 3. Reconocimiento de objetos 3D.
tercer ejemplo (Fig. 3.23.c) se puede ver sin embargo, que la longitud de la circunferencia es tan
pequena que su discretizacion produce el efecto de convertir lıneas curvas en rectas separadas
entre sı por vertices. Como se puede observar en la Fig. 3.23.c, los tramos de curva sustituidos
por vertices ocupan aproximadamente un 10% de la longitud total de la curva, lo que constituye
una fraccion apreciable de la misma. A esta escala, el ruido de discretizacion no es filtrado por la
funcion de curvatura adaptativa porque el algoritmo de calculo considera que forma parte de los
rasgos significativos de la figura. Ası, la representacion mediante la funcion de curvatura empieza
a presentar cuatro picos bien diferenciados, mostrando ya una clara evolucion hacia la funcion
de curvatura que corresponderıa a un cuadrado. En conclusion, las funciones de curvatura de
figuras pequenas no tienen por que parecerse a las de sus homologas mayores. El lımite inferior
del tamano requerido para que la funcion de curvatura sea representativa vendra determinado
por la relacion de escala entre los rasgos significativos de la imagen y el ruido de discretizacion,
de tal modo que la escala natural del objeto y la del ruido de discretizacion sean distinguibles.
Cuando se extiende este razonamiento al reconocimiento de objetos tridimensionales a
distintas escalas, aparece la misma limitacion. Es decir, el reconocimiento de objetos tridimen-
sionales sera invariante a la escala en la que se presenten siempre que el objeto no se presente a
una escala extremadamente reducida. En la Fig. 3.24 se muestra la mesa de la Fig. 3.8 y tres rep-
resentaciones de la misma al 150 %, 75% y 50 % de su escala original, respectivamente. Debajo
de cada una de las tres mesas se muestra el mapa de clasificacion de sus vistas. En esta ocasion
la clasificacion se hace siempre respecto de los estados ocultos del modelo de la mesa original de
modo que, en este caso, un mismo color en dos mapas distintos sı se corresponde con un mismo
estado oculto. Se han dejado en negro las posiciones correspondientes a vistas cuyo vector de
caracterısticas no se ha podido relacionar con ninguno de los estados ocultos del modelo. Como
se puede observar, tanto para la representacion de mayor tamano como para la intermedia los
mapas de clasificacion son casi identicos al original, mientras que se notan diferencias apreciables
en algunas vistas de la representacion mas pequena. Se puede ver en la grafica de la Fig. 3.24.e
que la tasa de reconocimiento de la mesa mas pequena desciende hasta el 68% mientras que
para las demas se mantiene al 100 %. Es decir, salvo en los casos de reduccion drastica de escala
del objeto observado, el sistema de reconocimiento considera identicos los objetos que presentan
la misma forma aunque distinta escala.

5. Resultados 107
Figura 3.24: a) Mesa del conjunto inicial de objetos y su mapa de clases; b) la misma mesa al150 % de su escala natural y su mapa respecto de las clases de la mesa en (a); c) la misma mesaal 75% de su escala natural y su mapa respecto de las clases de la mesa en (a); d) la misma mesaal 50 % de su escala natural y su mapa respecto de las clases de la mesa en (a); y e) Porcentajesde reconocimiento correcto de (b)-(c) como similares al objeto en (a)
5.3. Comportamiento del sistema frente a un conjunto de objetos de formasimilar
La siguiente prueba esta destinada a comprobar el funcionamiento del sistema cuando se
le presentan varios objetos del mismo tipo. A tal fin se ha seleccionado un conjunto de objetos
de forma cilındrica que a partir de ahora estaran referidos como cilindros (a), (b), (c) y (d)
segun el etiquetado de la Fig. 3.25. Al comienzo de la prueba el sistema contiene los modelos
de todos los objetos estudiados hasta este momento, excepto el correspondiente al cilindro (d),
es decir, no contiene modelos de ningun objeto de forma cilındrica. Los cilindros de la Fig.
3.25 se presentan al sistema sucesivamente. Cada vez que se completa la adquisicion de un
nuevo modelo, se comprueba la tasa de reconocimiento de cada objeto respecto de cada modelo.
Debido a que, en algunos casos, los nuevos objetos son etiquetados como desconocidos, si se
permitiera operar al sistema libremente, este realizarıa el entrenamiento de todos ellos mucho
antes de haber completado la comprobacion. Para evitar este inconveniente se ha bloqueado la
rutina de entrenamiento y solo se permite acceder a ella una vez completada la comprobacion de
los porcentajes de reconocimiento. Ası, el orden de entrenamiento se escogera de tal manera que
los nuevos objetos adquiridos seran aquellos para los que la suma de las tasas de reconocimiento
respecto de todos los modelos de los que el sistema disponga sea menor. Los resultados de este
experimento se muestran en la Fig. 3.26.
Como primer objeto se escoge el cilindro de la Fig. 3.25.b, cuya forma esta en un punto

108 Capıtulo 3. Reconocimiento de objetos 3D.
Figura 3.25: Conjunto de objetos cilındricos
Figura 3.26: Porcentajes de reconocimiento de los cilindros de la Fig. 3.25: a) cuando el sistemacarece de modelos para los cilindros (a), (c) y (d); b) cuando carece de modelos para los (a) y(c); y c) cuando carece de modelo para el (a)
intermedio entre todos los demas cilindros y por tanto guarda cierto parecido con todos. Al
ser desconocido, el sistema adquiere un modelo para el mismo. De hecho, los porcentajes de
reconocimiento cuando el sistema solo dispone de este modelo son bastante satisfactorios. Como
se aprecia en la Fig. 3.26.b, dos de los cilindros estan relacionados incluso en un 100 % de
los ensayos con un modelo conocido. Los demas presentan tasas de reconocimiento que van
decreciendo a medida que la forma de los cilindros propuestos se va separando de la del cilindro
(b), utilizado para generar el modelo. Como el menor porcentaje de reconocimiento corresponde
al cilindro (d), se permite que se genere un modelo para el mismo.
Como se puede apreciar en la Fig. 3.26.b, las tasas de reconocimiento de los cilindros (a)
y (b) son identicas a las de la prueba anterior. Sin embargo, el cilindro (c) pasa de una tasa total
de reconocimiento del 86 % a 74 %, y ademas segun el punto de comienzo de la secuencia de
observaciones, el sistema le puede encontrar parecido con cualquiera de los dos modelos de los
cilindros (b) y (d) cuya forma es respectivamente un poco mas achatada o mas alargada que la
del cilindro (c). Es decir, ahora el sistema no solo es capaz de distinguir entre las observaciones
del cilindro (c) que se parecen mas al (b) o al (d) sino que tambien en ocasiones nota que se trata
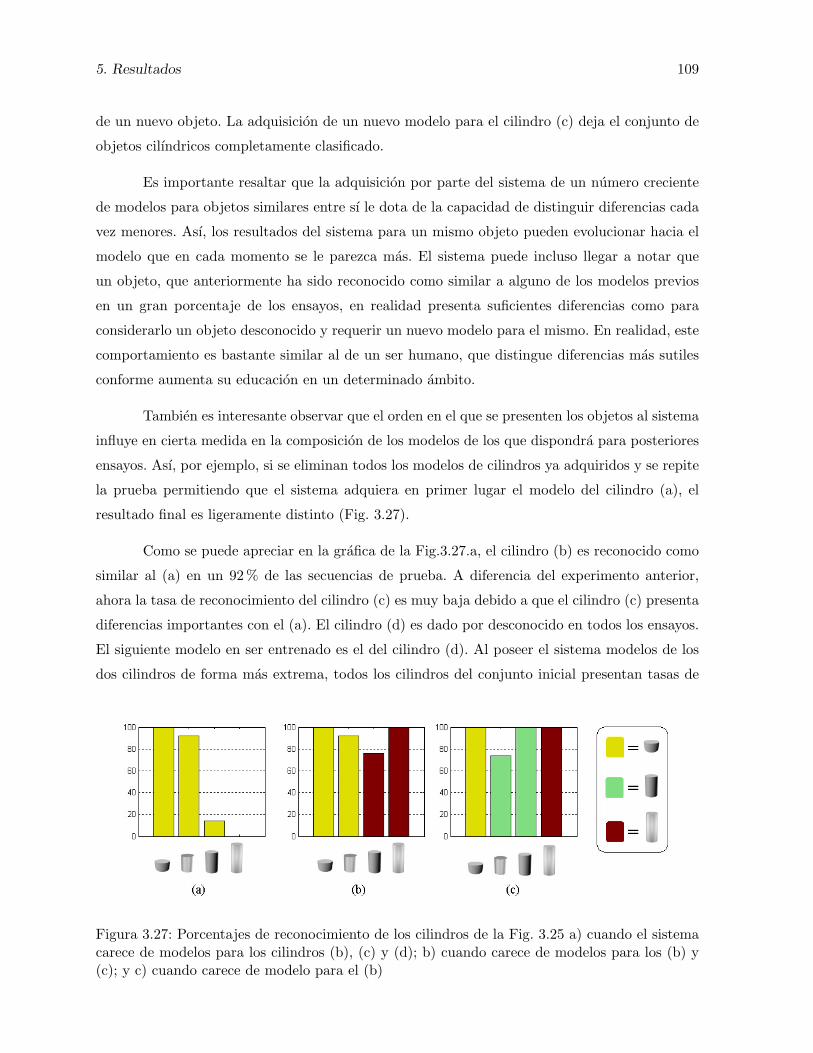
5. Resultados 109
de un nuevo objeto. La adquisicion de un nuevo modelo para el cilindro (c) deja el conjunto de
objetos cilındricos completamente clasificado.
Es importante resaltar que la adquisicion por parte del sistema de un numero creciente
de modelos para objetos similares entre sı le dota de la capacidad de distinguir diferencias cada
vez menores. Ası, los resultados del sistema para un mismo objeto pueden evolucionar hacia el
modelo que en cada momento se le parezca mas. El sistema puede incluso llegar a notar que
un objeto, que anteriormente ha sido reconocido como similar a alguno de los modelos previos
en un gran porcentaje de los ensayos, en realidad presenta suficientes diferencias como para
considerarlo un objeto desconocido y requerir un nuevo modelo para el mismo. En realidad, este
comportamiento es bastante similar al de un ser humano, que distingue diferencias mas sutiles
conforme aumenta su educacion en un determinado ambito.
Tambien es interesante observar que el orden en el que se presenten los objetos al sistema
influye en cierta medida en la composicion de los modelos de los que dispondra para posteriores
ensayos. Ası, por ejemplo, si se eliminan todos los modelos de cilindros ya adquiridos y se repite
la prueba permitiendo que el sistema adquiera en primer lugar el modelo del cilindro (a), el
resultado final es ligeramente distinto (Fig. 3.27).
Como se puede apreciar en la grafica de la Fig.3.27.a, el cilindro (b) es reconocido como
similar al (a) en un 92 % de las secuencias de prueba. A diferencia del experimento anterior,
ahora la tasa de reconocimiento del cilindro (c) es muy baja debido a que el cilindro (c) presenta
diferencias importantes con el (a). El cilindro (d) es dado por desconocido en todos los ensayos.
El siguiente modelo en ser entrenado es el del cilindro (d). Al poseer el sistema modelos de los
dos cilindros de forma mas extrema, todos los cilindros del conjunto inicial presentan tasas de
Figura 3.27: Porcentajes de reconocimiento de los cilindros de la Fig. 3.25 a) cuando el sistemacarece de modelos para los cilindros (b), (c) y (d); b) cuando carece de modelos para los (b) y(c); y c) cuando carece de modelo para el (b)

110 Capıtulo 3. Reconocimiento de objetos 3D.
reconocimiento relativamente altas y el conjunto inicial queda clasificado en dos clases claramente
diferenciadas por su forma. Sin embargo, la tasa de reconocimiento del cilindro (c) justifica que
se considere necesario adquirir un nuevo modelo para el mismo. Tras este paso, la clasificacion
del cilindro (b), para el cual el sistema no tiene modelo, pasa del modelo (a) al (c) con el que
guarda un mayor parecido. Es importante notar que, a pesar de que en este caso el numero
de modelos de que el sistema dispone tambien es igual a tres, la clasificacion del conjunto no
presenta la misma distribucion que en el caso anterior y, ademas, aun no es completa, es decir,
el orden en el que el sistema adquiere los modelos de los objetos de su entorno influye sobre
la distribucion de la clasificacion de los mismos y sobre el numero total de modelos que seran
necesarios para clasificar un determinado conjunto.
Estas caracterısticas del sistema de reconocimiento propuesto lo acercan en cierto modo
a la percepcion humana de la clasificacion. En efecto, el ser humano alcanza una gran resolucion
de clasificacion en conjuntos con los que esta muy familiarizado y sin embargo tiende a simplificar
cuando el conjunto de clasificacion le es parcialmente desconocido.
5.4. Comportamiento del sistema frente a deformaciones de los objetos orig-inales
Uno de los retos mas importantes en la tarea de reconocimiento de objetos es la capacidad
para reconocer o clasificar versiones deformadas de los objetos originales. Esto es especialmente
importante si se pretende que el sistema sea capaz de operar con objetos reales. Por ejem-
plo, los objetos observados en un entorno real pueden sufrir en mayor o menor grado fallos
de segmentacion como ruido u oclusiones. Ademas, algunos de los objetos observados pueden
pertenecer a la misma clase que uno de los modelos adquiridos aun cuando presenten pequenas
diferencias morfologicas.
Para que el sistema de reconocimiento sea flexible frente a distorsiones, deformaciones
o ruido de segmentacion es necesario que el metodo de representacion de figuras planas sea
invariante frente a distorsiones de la imagen plana o bien que el metodo de comparacion con
los modelos de objetos contemple cierta tolerancia. El sistema de reconocimiento propuesto en
la presente tesis desarrolla ambas estrategias. En primer lugar, el metodo de representacion de
vistas planas mediante vectores de caracterısticas filtra gran parte del eventual ruido en los
contornos de las figuras observadas. Como se demostro en el capıtulo 2, la funcion de curvatura
adaptativa representa cada contorno segun su propia escala natural, filtrando el ruido super-
puesto a la imagen. Posteriormente, la extraccion del vector de caracterısticas mediante Analisis
de Componentes Principales retiene unicamente la informacion relevante de la imagen. De este

5. Resultados 111
modo, los vectores de caracterısticas de una imagen y su version deformada seran muy parecidos
entre sı. Es decir, la representacion es robusta frente a deformaciones o distorsiones, pero no
es completamente invariante. Al no poder asegurar la identidad completa de los vectores de
caracterısticas de las versiones distorsionadas respecto del vector de caracterısticas de la ima-
gen original sin deformar, es necesario que la estrategia de reconocimiento tambien se plantee
considerando la posibilidad de pequenas diferencias entre los vectores de caracterısticas. Los
modelos ocultos de Markov son especialmente adecuados para este fin. Durante el proceso de
reconocimiento, como se detallo en la seccion 4, cada vista es relacionada de modo probabilıstico
con los estados ocultos del modelo correspondiente. Esta relacion se establece de acuerdo con
una medida del parecido entre el vector de caracterısticas de la vista observada y los asignados a
los estados ocultos. Ası, el hecho de que una vista se vea afectada de algun tipo de deformacion,
y por tanto su vector de caracterısticas cambie ligeramente respecto del original, solo afecta
ligeramente al valor de la probabilidad que lo relaciona con los estados ocultos del modelo. De
este modo las probabilidades de que la secuencia observada pertenezca a cada uno de los modelos
del sistema variara ligeramente en valor, pero no afectara significativamente al resultado final.
En la Fig. 3.28 se muestran los resultados una prueba de reconocimiento realizada sobre
distintas versiones deformadas de uno de los objetos del conjunto inicial. El objeto seleccionado
se muestra en la Fig. 3.28.a y las versiones deformadas en las Fig.3.28.b-d. Debajo de la repre-
sentacion de cada uno de los objetos se presenta el mapa de clasificacion de cada objeto respecto
de los estados ocultos del modelo del objeto en Fig. 3.28.a. Del mismo modo que se hizo en la
seccion 5.2, cuando una vista se pueda clasificar como dos o mas estados ocultos se representa
Figura 3.28: a) Objeto del conjunto de entrenamiento y su mapa de clases de vistas; b-d) defor-maciones del objeto en (a) y sus mapas de clases de vistas; y e) Porcentajes de reconocimientocorrecto de (b)-(c) como similares al objeto en (a)

112 Capıtulo 3. Reconocimiento de objetos 3D.
en el mapa con el color del estado oculto del cuyo centroide esta mas cerca. Algunas vistas de
los objetos deformados no se pueden clasificar satisfactoriamente como ninguno de los estados
ocultos. Esto ocurre porque en estas vistas la deformacion es tan fuerte que la distancia desde
los vectores de caracterısticas hasta cualquiera de los estados ocultos del modelo excede el radio
prefijado, es decir, la deformacion es tan fuerte que algunas vistas ya no se pueden considerar
parecidas a las del modelo original. Estas vistas de nuevo se han representado en negro. Se puede
observar que el objeto de la Fig. 3.28.c tiene exactamente el mismo mapa de clasificacion que
la figura original. Esto quiere decir que la deformacion aplicada, una deformacion continua que
pliega la copa original, practicamente no tiene influencia en la representacion del objeto y por
lo tanto es esperable que su tasa de reconocimiento sea muy alta. Los objetos de la Fig. 3.28.b
y d representan respectivamente el objeto deformado por un rizado de la superficie del objeto
original y el objeto original al que se cortado un pedazo simulando una oclusion parcial. En
ambos casos aparecen no solo vistas desconocidas sino tambien variaciones en la clasificacion de
las vistas respecto del mapa original. Esto ocurre porque, tras la deformacion, algunas de las
vistas se parecen mas al objeto original visto desde una perspectiva distinta que al estado oculto
que corresponderıa a la perspectiva que realmente les corresponde.
Para evaluar la fiabilidad en el reconocimiento se han realizado 50 pruebas de reconoci-
miento con cada una de las versiones deformadas del objeto. Del mismo modo que en pruebas
anteriores, la orientacion inicial del observador respecto del objeto es escogida aleatoriamente, de
modo que se puede considerar que los resultados obtenidos son estadısticamente significativos.
Estos resultados se muestran en la Fig. 3.28.e. Como se puede observar, el objeto de la Fig.
3.28.c es reconocido correctamente en el 100 % de los casos. Esto ocurre porque la deformacion
no es suficiente para alterar significativamente la posicion de los vectores de caracterısticas
correspondientes a sus vistas y por tanto, la informacion que recibe el sistema de este objeto
es virtualmente identica a la informacion que caracteriza el objeto original. En el caso de los
objetos de la Fig. 3.28.c y d, el porcentaje de reconocimiento correcto es sensiblemente inferior,
alcanzando unos valores del 68 % y 88 % respectivamente. Es importante notar que, aunque en
estos casos algunas vistas no se pueden clasificar como pertenecientes a ninguno de los estados
ocultos del modelo de la copa, es posible que estas vistas adquieran cierto parecido con otros
objetos del conjunto de prueba. Es decir, muchos de los fallos de reconocimiento no etiquetan el
objeto deformado como desconocido sino que lo relacionan con un objeto distinto del conjunto
inicial. Es logico que ası ocurra si se tiene en cuenta que los objetos del conjunto de pruebas se
han escogido intencionadamente parecidos.
En la Fig. 3.29 se muestra una prueba de reconocimiento erroneo y uno correcto para el
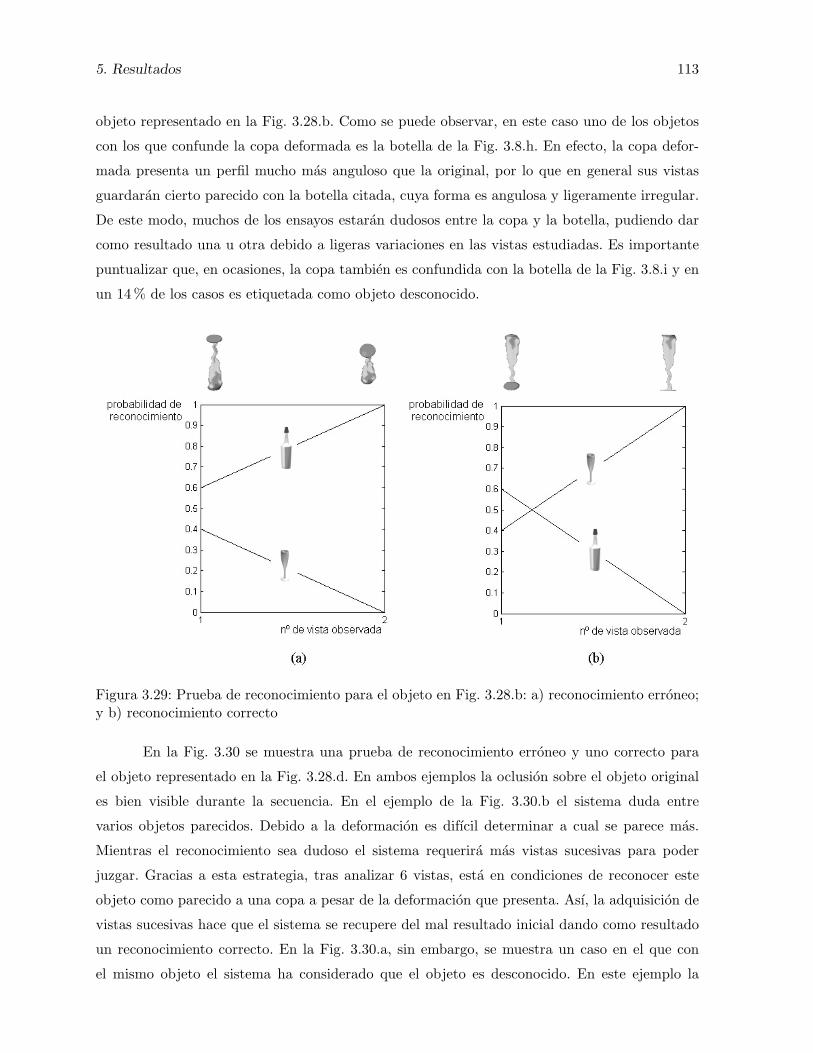
5. Resultados 113
objeto representado en la Fig. 3.28.b. Como se puede observar, en este caso uno de los objetos
con los que confunde la copa deformada es la botella de la Fig. 3.8.h. En efecto, la copa defor-
mada presenta un perfil mucho mas anguloso que la original, por lo que en general sus vistas
guardaran cierto parecido con la botella citada, cuya forma es angulosa y ligeramente irregular.
De este modo, muchos de los ensayos estaran dudosos entre la copa y la botella, pudiendo dar
como resultado una u otra debido a ligeras variaciones en las vistas estudiadas. Es importante
puntualizar que, en ocasiones, la copa tambien es confundida con la botella de la Fig. 3.8.i y en
un 14 % de los casos es etiquetada como objeto desconocido.
Figura 3.29: Prueba de reconocimiento para el objeto en Fig. 3.28.b: a) reconocimiento erroneo;y b) reconocimiento correcto
En la Fig. 3.30 se muestra una prueba de reconocimiento erroneo y uno correcto para
el objeto representado en la Fig. 3.28.d. En ambos ejemplos la oclusion sobre el objeto original
es bien visible durante la secuencia. En el ejemplo de la Fig. 3.30.b el sistema duda entre
varios objetos parecidos. Debido a la deformacion es difıcil determinar a cual se parece mas.
Mientras el reconocimiento sea dudoso el sistema requerira mas vistas sucesivas para poder
juzgar. Gracias a esta estrategia, tras analizar 6 vistas, esta en condiciones de reconocer este
objeto como parecido a una copa a pesar de la deformacion que presenta. Ası, la adquisicion de
vistas sucesivas hace que el sistema se recupere del mal resultado inicial dando como resultado
un reconocimiento correcto. En la Fig. 3.30.a, sin embargo, se muestra un caso en el que con
el mismo objeto el sistema ha considerado que el objeto es desconocido. En este ejemplo la

114 Capıtulo 3. Reconocimiento de objetos 3D.
vista inicial es un cırculo, que se puede identificar con cualquiera de los modelos de objetos
con simetrıa cilındrica almacenados, aunque, por simplicidad, se han omitido en el diagrama
los objetos cuya probabilidad de reconocimiento no alcanza el 10 %. En la siguiente vista la
deformacion se hace visible, pero la forma del objeto es suficientemente caracterıstica para
relacionarlo con el objeto original sin deformar ası como con la botella de la Fig. 3.8.i con la cual
guarda cierto parecido. Como aun no hay un resultado unico, el sistema requiere una vista mas
de la secuencia. Sin embargo la ultima vista difiere considerablemente de los estados ocultos de
los modelos almacenados tanto de la copa como de la botella, por lo tanto el objeto deformado
queda etiquetado como desconocido.
Figura 3.30: Prueba de reconocimiento para el objeto en Fig. 3.28.d: a) objeto desconocido; yb) reconocimiento correcto
Es importante notar que la mayor diferencia entre la secuencia de vistas de la Fig. 3.30.a
y la de la Fig. 3.30.b es que mientras en la primera el cambio es de un contorno que deberıa
ser convexo a uno concavo, en la segunda la deformacion provoca el suavizado de una esquina.
Se puede comprobar que aunque el tramo de contorno deformado del contorno de las figuras
planas observadas en cada vista es de longitud similar en ambos casos, el cambio en la funcion
de curvatura es bastante mas importante en una que en la otra. En la Fig. 3.31.a se compara
el contorno de la tercera vista de la Fig.3.30.a con el que tendrıa una copa sin deformar y
se muestra la diferencia entre sus respectivas funciones de curvatura. El tramo de funcion de
curvatura que corresponde a la deformacion consiste en un pico de curvatura negativa, que

5. Resultados 115
representa el tramo convexo, flanqueado de dos picos positivos de curvatura, que representan
las esquinas de union entre en tramo deformado y el resto del contorno. En la Fig. 3.31.b se
puede observar que la deformacion, consistente en el suavizado de la esquina superior izquierda
del contorno, produce un cambio en la magnitud de uno de los maximos parciales de curvatura
del contorno y un ligero desplazamiento en su posicion. El procesado posterior de la informacion
contenida en la funcion de curvatura hasta llegar a la representacion del contorno mediante
un vector de caracterısticas necesariamente mantiene la diferencia morfologica del primer caso,
mientras que tendera a minimizar las diferencias del segundo. Es decir, la representacion del
contorno de las figuras es resistente a oclusiones parciales siempre que estas no signifiquen un
cambio morfologico importante sobre las figuras originales.
Figura 3.31: Comparacion de las FCs de dos contornos de un objeto parcialmente ocluido, a)oclusion de perfil concavo; y b) oclusion de perfil recto

116 Capıtulo 3. Reconocimiento de objetos 3D.
6. Conclusiones
En este capıtulo se ha presentado la extension del sistema de representacion de formas
planas, introducido en el capıtulo anterior, a la representacion y reconocimiento de objetos
tridimensionales a partir de un conjunto, no necesariamente completo, de sus vistas. Utilizando
el vector de caracterısticas de cada una de las vistas y agrupando en regiones todos los que
presentan cierto parecido, mediante tecnicas estadısticas, se analiza la secuencialidad de las
regiones obtenidas. El capıtulo se centra en dos actividades interrelacionadas: aprendizaje y
reconocimiento.
Cuando un objeto es desconocido, la fase de aprendizaje consiste en adquirir un conjunto
de vistas de este tan extenso como permitan las circunstancias. Cada vista se representa mediante
un vector de caracterısticas. Estos vectores se agrupan en clases en funcion de su parecido. La
distribucion espacial de clases resultante representa al objeto completo observado desde una
distancia determinada. Dado que se demostro que los vectores de caracterısticas son resistentes
a cambios de escala, siempre que se asegure una vista completa del objeto, la distancia entre el
observador y el objeto es irrelevante. A partir de la distribucion espacial de vistas se construye un
modelo oculto de Markov. El modelo de cada objeto constituye una herramienta para evaluar
la probabilidad de que, habiendo observado una secuencia de vistas, esta sea compatible con
cada objeto en particular. Ası, un objeto 3D queda aprendido una vez se dispone de un modelo
oculto de Markov para el.
El reconocimiento de un objeto conocido comienza con la primera vista entrante. Si
dicha vista solo es compatible con un objeto, el objeto queda reconocido. Si la primera vista
es compatible con varios modelos aprendidos, se procede a acumular evidencia a lo largo de
vistas consecutivas hasta que la probabilidad de ser un objeto determinado es significativamente
superior a la de ser cualquier otro. Esta comparacion se efectua mediante la evaluacion de
probabilidad con los modelos ocultos de Markov previamente aprendidos. Si no existe ningun
modelo compatible que de una probabilidad satisfactoriamente alta, se considera que el objeto
es desconocido y se procede a su aprendizaje por parte del sistema.
Para probar la eficacia del sistema, se han realizado pruebas de aprendizaje y recono-
cimiento con un conjunto de objetos sinteticos. Se ha demostrado que, en condiciones optimas
de segmentacion, los objetos del conjunto propuesto son correctamente diferenciados de acuerdo
con su forma. Para evitar que cada prueba de reconocimiento se realice con una unica vista,
caracterıstica de cada objeto, los objetos del conjunto propuesto han sido escogidos de modo
que, a pesar de corresponder a formas variadas, presenten numerosas vistas comunes.

6. Conclusiones 117
Durante el reconocimiento de una secuencia, los objetos que permanecen durante mas vis-
tas consecutivas como posibles soluciones son los mas similares al propuesto. Se ha comprobado
que la invarianza a escala de los vectores de caracterısticas se traduce en una invarianza a escala
del metodo de reconocimiento, siempre que el objeto sea completamente visible en el campo de
la imagen y que no sea tan pequeno que la distorsion por discretizacion sea mas importante que
la forma del objeto. Con respecto a la invarianza a rotacion, si bien se ha comprobado que la
posicion de cada silueta dentro de las vistas no afecta en general a su representacion plana, es
necesario indicar que cada objeto debe reposar siempre en la misma direccion respecto de su base
de apoyo, ya que el eje con respecto al cual se secuencian las vistas determina la estructura del
modelo oculto de Markov con que dicho objeto se aprende. En cuanto a invarianza a ruidos de
captura y discretizacion ası como a problemas puntuales de segmentacion que puedan afectar a
vistas aisladas, el sistema de reconocimiento 3D presenta caracterısticas de estabilidad similares
a las de la representacion 2D.
Se ha comprobado que cuantos mas objetos de forma similar se presenten, mejor resolu-
cion tendra el sistema de reconocimiento para distinguir entre objetos parecidos. Esto concuerda
con el tipo de aprendizaje que cabe esperar en un ser humano: cuanto mayor sea su conocimiento,
mayor es su capacidad de distinguir pequenos detalles. Sin embargo, se ha comprobado que el
sistema es capaz de clasificar correctamente versiones distorsionadas o deformadas de un mismo
objeto, siempre y cuando la forma global de este no se vea afectada.


Capıtulo 4
Experimentos y resultados.
1. Introduccion.
En capıtulos anteriores se ha presentado un sistema de reconocimiento 3D a partir de
vistas de un objeto y se ha comprobado su eficacia para reconocer objetos virtuales de diversa
complejidad. No obstante, para demostrar que un sistema de reconocimiento de objetos funciona,
es necesario probarlo en condiciones reales o, lo que es lo mismo, a partir de imagenes captadas
en un entorno real. Dado que el sistema propuesto es capaz tanto de reconocer objetos como
de aprenderlos, resultara, por tanto, necesario no solo evaluar si es capaz de reconocer objetos
potencialmente afectados por ruido de captura, cambios en las condiciones de iluminacion y
errores en la extraccion del objeto sino tambien si es capaz de crearse un modelo a partir de un
conjunto limitado de vistas afectadas por los mismos mencionados factores.
Existen varios metodos de reconocimiento de objetos 3D que permiten extraer modelos
de imagenes reales (Basri et al., 1998) (Poggio y Edelman, 1990) (Suzuki et al., 1999). Eviden-
temente, su gran ventaja es su capacidad de aprendizaje no supervisado. La mayorıa de estos
metodos, sin embargo, suelen basarse en trabajar con la imagen completa a color a efectos de
obviar los problemas de segmentacion. Este sistema de aprendizaje, a veces denominado apren-
dizaje por fuerza bruta (Nelson y Selinger, 2000), suele estar limitado a objetos mas o menos
complejos pero sobre un fondo homogeneo, ya que, en caso contrario, cambios sobre este in-
fluirıan en el reconocimiento. De forma alternativa, se han propuesto metodos para extraer y
aprender la silueta de un objeto a partir de multiples vistas de este (Lorensen y Cline, 1987)
(Martin y Aggarwal, 1983) (Szeliski, 1993), pero no resultan robustos cuando los objetos pre-
sentan concavidades. Similares a estos son los metodos de tallado espacial (Kutulakos y Seitz,
1998) que desafortunadamente resultan excesivamente sensibles a errores de segmentacion y,
119

120 Capıtulo 4. Experimentos y resultados.
una vez mas, requieren el uso de fondos homogeneos. Para evitar esta problematica se han desa-
rrollado metodos basados en sombras (Shafer y Kanade, 1983) (Hambrick et al., 1987), donde
la segmentacion es mucho mas simple, pero presentan la desventaja de estar limitados a unas
condiciones de captura muy especıficas. El problema del conjunto de metodos citado es que
busca trabajar con la forma de manera global. Si, en lugar de eso, se adquiere informacion de
manera incremental como en el metodo propuesto en esta tesis, se gana tolerancia contra errores
de captura y adquisicion. Murase y Nayar (Murase y Nayar, 1995) usan una tecnica de tipo
incremental en la lınea de la que se propone pero solo ofrecen resultados para objetos virtuales.
Es, finalmente, importante resaltar que la bondad de los modelos adquiridos a partir de imagenes
reales, ası como el reconocimiento de objetos ya almacenados, depende particularmente para el
caso de imagenes reales de la resistencia de los vectores de caracterısticas que definen cada vista
frente a distorsiones y errores.
En este capıtulo, por tanto, se van a mostrar los resultados de emplear el metodo de
reconocimiento de objetos 3D propuesto en entornos reales. Para ello, se va a presentar en la
seccion 2 un metodo de entrenamiento. Es de resaltar que el hecho de que el sistema pueda
aprender de forma no supervisada a partir de imagenes capturadas del mundo real no excluye
en absoluto la existencia de este tipo de entrenamiento, que resulta mas que justificado bajo las
condiciones que se comentaran en esa misma seccion. En la seccion 3 se presentan resultados del
sistema de reconocimiento, tanto para objetos simples como para objetos de cierta complejidad,
bajo diversas condiciones de observacion. Con objeto de comprobar el funcionamiento del sistema
en un entorno real, se han incluido pruebas con objetos reales que presentan un gran parecido
con algunos de los objetos virtuales utilizados para el entrenamiento. En la seccion 4 se discuten
las conclusiones de los resultados expuestos en este capıtulo.
2. Metodo de Entrenamiento
Uno de los principales problemas de los metodos de reconocimiento basados en vistas
radica en que requieren tantas de estas vistas como sean necesarias hasta que la identidad
del objeto quede claramente definida. Si bien en algunos casos un par de vistas pueden ser
suficientes, en otros, y en particular para objetos que compartan vistas similares, puede ser
necesario un numero elevado de estas. El problema es especialmente complejo para objetos que
presentan fuertes simetrıas, ya que a lo largo de una secuencia cabe la posibilidad de obtener
una y otra vez la misma informacion. Naturalmente, la solucion a este problema estriba en coger
un numero lo suficientemente elevado de vistas equiespaciadas alrededor del objeto en cuestion.

2. Metodo de Entrenamiento 121
Sin embargo, en el mundo real no todos los puntos de vista se encuentran accesibles, ya que
los objetos forzosamente presentan una base de apoyo y, en el caso mas general, no pueden
manipularse, en especial si son grandes o pesados. Evidentemente, este hecho supone que los
modelos capturados siempre se construyen a partir de un numero limitado de vistas que, ademas,
pueden estar sujetas a error. Ello significa que en ocasiones no se podra distinguir entre objetos
que presenten vistas comunes y que un objeto conocido no se reconocera salvo que presente una
vista incluida en su modelo.
Para evitar, al menos parcialmente, este tipo de problemas es posible recurrir a un
entrenamiento del sistema en un entorno virtual. Este entrenamiento consiste en mostrarle a
dicho sistema un conjunto de objetos virtuales, que es probable que se encuentre en el entorno en
que trabaja. La gran ventaja de trabajar con objetos virtuales es que se tiene la seguridad de que
no estan afectados por distorsiones, ası como la posibilidad de observar el objeto desde cualquier
punto de vista. Naturalmente, la desventaja radica en que rara vez los objetos encontrados
en el mundo real van a ser identicos a los del modelo aprendido. Incluso en el mejor de los
casos, cuando el modelo virtual sea una copia exacta del real, las vistas reales estaran afectadas,
tal como se ha comentado previamente, por ruido de captura y errores de segmentacion. Ası,
en ocasiones, puede resultar complejo identificar un objeto real con su homonimo virtual. No
obstante, la experiencia ha demostrado que la naturaleza secuencial del proceso permite resolver
este problema de forma satisfactoria en la mayorıa de los casos, tal como se vera en la seccion
siguiente, aportando ademas datos interesantes sobre que implican los conceptos que el sistema
almacena sobre un tipo de objetos determinado. Es interesante notar que el ser humano funciona
de forma similar cuando, a partir de una serie de fotos o videos, es capaz de reconocer objetos
que jamas habıa visto anteriormente.
Una vez se ha optado por efectuar una fase de entrenamiento supervisado a partir de
objetos virtuales, es importante establecer la mecanica de este proceso de aprendizaje. En prin-
cipio, a nivel algorıtmico, no existe diferencia alguna entre el aprendizaje de objetos reales y
el de objetos virtuales a excepcion de que las vistas virtuales deben ser renderizadas y que,
en estos casos, puede trabajarse por comodidad con fondos homogeneos facilmente separables.
Por tanto, el unico requisito necesario para implementar este modulo de aprendizaje previo es
disponer de un sistema de renderizado que ofrezca un interfaz compatible con el algoritmo de
reconocimiento propuesto. Existen diversas opciones para manipular objetos virtuales: desde
librerias graficas hasta programas completos de alto nivel. Las librerıas graficas, como OpenGL
o Direct3D resultan, en general, demasiado basicas para manejar de forma eficiente objetos
complejos en el sistema de entrenamiento. Por otra parte, las aplicaciones de alto nivel como

122 Capıtulo 4. Experimentos y resultados.
Figura 4.1: Base de datos de sillas para 3DStudio descargada de Internet
MilkShape o 3DStudio presentan la desventaja de ofrecer muy poca capacidad de interaccion
con programas externos. Esto deja como alternativa el uso de motores graficos, que supone un
compromiso entre ambos extremos.
Los motores graficos ofrecen un conjunto de funciones de alto nivel al tiempo que per-
miten establecer interfaces con cualquier programa externo. Una ventaja adicional es que gran
variedad de ellos son de libre distribucion. Para escoger uno en particular para la aplicacion pro-
puesta, es recomendable que sea capaz de operar con formatos de graficos 3D estandarizados, de
forma que no sea necesario modelar los objetos que se desea ensenar al sistema si no que, por el
contrario, puedan usarse bases de datos ya disponibles. A este respecto, se ha comprobado que el
formato grafico 3D mas extendido en Internet y del que se encuentran disponibles publicamente
mas modelos es el 3DS, perteneciente al programa 3DStudio. La Fig. 4.1 muestra, por ejem-
plo, una de estas bases de datos consistente en un conjunto de sillas. Una vez evaluados todos
los puntos comentados, en esta tesis se ha optado por usar Genesis3D (Eclipse-Entertainment,
http://www.genesis3d.com) que, ademas de ser un motor de libre distribucion, soporta no solo
el formato 3DS sino tambien la mayorıa de los formatos comerciales. Utilizando Genesis3D, se
ha desarrollado una aplicacion capaz de abrir cualquier fichero 3DS y conectarse al sistema de
reconocimiento propuesto (de Trazegnies et al., 2003a). Cada vez que dicho sistema solicita un
punto de vista, esta aplicacion renderiza el objeto de que dispone en ese momento sobre un
fondo homogeneo y envıa la imagen resultante al sistema de reconocimiento. A partir de tantas
vistas de cada objeto como sean necesarias, el sistema aprende el prototipo del objeto virtual.
En particular, en la fase de aprendizaje desarrollada el sistema construye los prototipos
a partir de 72 vistas de estos, equiespaciadas sobre la superficie de una esfera de radio constante

2. Metodo de Entrenamiento 123
Figura 4.2: 72 vistas de una silla generadas por el modulo virtual de entrenamiento
alrededor del objeto estudiado (Fig. 4.2). En realidad, no son necesarias tantas vistas para
reconocer un objeto. Sin embargo, si bien en el mundo virtual los objetos flotan en el aire, en el
mundo real estan limitados a una posicion determinada en funcion de su punto de apoyo. Ası,
para adquirir una cierta inmunidad contra este, se contemplan todas las posibles posiciones que
un objeto podrıa tener, si bien muchas de ellas son fısicamente imposibles. Es interesante notar
que, incluso en el mejor de los casos posible, la captura de 72 vistas equiespaciadas llevarıa
muchısimo mas tiempo en el mundo real que en el sistema de aprendizaje propuesto, ya que
serıa necesario desplazar la camara una y otra vez. Ası, es inmediato observar que en la fase
de aprendizaje es posible adquirir un volumen elevado de informacion en un tiempo reducido.
Esto presenta interesantes ventajas, ya que, al trabajar con formatos de datos estandarizados,
el sistema puede adquirir un volumen muy elevado de conocimientos a partir de bases de datos
disponibles publicamente. Estos conocimientos podran ser utilizados para el reconocimiento de
objetos reales.
El proceso de entrenamiento a partir de un objeto 3D virtual comienza, pues, por la so-
licitud de una vista del mismo sobre fondo homogeneo, que se segmenta para extraer el contorno
del objeto y, de este, el vector de caracterısticas de la vista. Una vez se han extraıdo los vectores
de caracterısticas de las vistas necesarias del modelo virtual, tal como se indico en el capıtu-
lo anterior, dichos vectores se agrupan en clases (Fig. 4.3), extrayendose de esta agrupacion los

124 Capıtulo 4. Experimentos y resultados.
Figura 4.3: Aprendizaje de un modelo virtual: a) objeto virtual; y b) mapa de vistas.
modelos ocultos de Markov necesarios para su posterior reconocimiento. Este proceso se describe
en detalle en el capıtulo 3.
Es importante senalar que, si se intentan entrenar objetos similares, el sistema los re-
conocera y no creara ningun prototipo para ellos. Ası, antes de aprender un objeto determinado,
el sistema intenta reconocerlo a partir de la informacion de que dispone en ese momento. Solo si
ese objeto no se identifica, el sistema pasa a almacenarlo. Por ejemplo, en la base de datos que
se ha seleccionado en la Fig. 4.1, todos los objetos son lo suficientemente distintos como para
haberse aprendido por separado en el orden en que se presentan. La Fig. 4.4 muestra como, por
ejemplo, el sistema fracasa al intentar reconocer la silla de la Fig. 4.1.i a pesar de que ya ha
aprendido las de las Figs. 4.1.a-h. Si bien al principio supone que puede tratarse de los prototipos
en las Figs. 4.1.c o g, por la forma de los brazos o las patas, una segunda vista frontal descarta
ambas posibilidades y dispara el modulo de entrenamiento virtual, haciendo que se memorice
un nuevo modelo para ella.
3. Reconocimiento de objetos
A efectos de evaluar el sistema para imagenes reales, se han llevado a cabo una serie
de experimentos. En estos experimentos, previamente se entreno el sistema tanto con la base
de datos de la Fig. 4.1 como con una base de datos mucho mas simple (Fig. 4.5). Una base de
objetos compleja presenta la ventaja de que los objetos se diferencian mas entre sı, mientras
que en una base de datos simple, son mas faciles de almacenar y, en general, suelen ser menos
sensibles a los errores de captura y segmentacion porque su naturaleza no se define por detalles
pequenos. Ası, con las dos bases de datos entrenadas se contemplan los casos extremos.
Una vez el sistema disponıa de ambas bases de datos, se procedio a capturar secuencias

3. Reconocimiento de objetos 125
Figura 4.4: Fallo en reconocimiento: entrenamiento.
de objetos reales utilizando una camara fotografica digital Sony DSC-S70. Usando esta camara,
se han capturado manualmente diversas secuencias de objetos, estando todos los puntos de vista
situados en un anillo a una altura aproximadamente fija alrededor del objeto, que siempre se
soporta sobre la misma base. Resulta notable el hecho de que, al capturarse las imagenes de
forma manual, los puntos de vista no tienen por que coincidir con ninguno de los entrenados.
No obstante, dado que, tal como se comento en el capıtulo 2, los vectores de caracterısticas
presentan una cierta resistencia contra pequenos cambios de perspectiva, esto no constituye un
problema en la mayorıa de los casos.
Dado que esta tesis no se centra en segmentacion y, ademas, la segmentacion es un
problema difıcil de resolver en condiciones generales, para extraer los objetos de las imagenes
capturadas se ha optado por un metodo simple de extraccion de fondo (McKenna et al., 2000).
Figura 4.5: Conjunto de objetos aprendidos en orden de entrenamiento.

126 Capıtulo 4. Experimentos y resultados.
Figura 4.6: Segmentacion por substraccion de fondo: a) fondo sin objetos; b) imagen capturada;c) objetos detectados.
Este tipo de metodos se basan en disponer de una imagen del fondo sobre el que se situan los
objetos en ausencia de estos (Fig. 4.6.a). Cuando se captura una imagen con un objeto (Fig.
4.6.b), ambas se sustraen pixel a pixel y, despues de un procesado que habitualmente se basa en
eliminar ruido, etiquetar y eliminar clases pequenas, basicamente queda todo lo que en la imagen
no era fondo (Fig. 4.6.c). En los experimentos que se presentan en esta seccion no se ha incluido
en ningun caso mas de un objeto en la escena. Es importante indicar que los algoritmos de
segmentacion por sustraccion de fondo tambien estan sujetos a errores, principalmente debidos
a sombras y cambios de iluminacion o a que los objetos presenten colores parecidos al fondo.
Estos errores, que pueden afectar de distinta manera incluso a vistas consecutivas, provocaran
deformaciones en los contornos de objetos percibidos.
3.1. Experimentos con objetos simples
Un primer conjunto de experimentos se llevo a cabo escogiendo objetos reales que se
asemejaran a los que incluıa la base de datos mas simple de que se disponıa (Fig. 4.5). Dado
que, como ya se ha comentado, el principal problema de estas bases radica en que los objetos
se diferencian menos entre sı y presentan fuertes simetrıas, puede observarse que se incluyeron
a proposito en el entrenamiento tanto un conjunto de formas simples -esfera, paralelepıpedos y
cilindros- como dos modelos de tazas, de los cuales uno se asemeja bastante a un cilindro desde
varios puntos de vista.

3. Reconocimiento de objetos 127
Siguiendo el mismo metodo que en el capıtulo anterior, se han presentado al sistema los
objetos propuestos en las Fig. 4.5.a-f, pero se ha dejado fuera del conjunto inicial el objeto de
la Fig. 4.5.g. El sistema de reconocimiento crea modelos para cada uno de los objetos siempre
que no puede identificarlos con uno de los ya aprendidos. Como sucedıa en el capıtulo 3, es
posible que el sistema no considere necesario entrenar algunos de los objetos presentados si
casualmente la primera o primeras vistas del mismo se parecen a uno de los ya adquiridos. En
el caso del conjunto propuesto, debido al elevado numero de vistas comunes entre objetos, es
muy probable que esto ocurra. En particular, si cuando se presenta la taza 1, de la Fig.4.5.d,
la primera vista es cilındrica, la taza 1 sera reconocida como el cilindro de la Fig. 4.5.c. El
siguiente objeto en ser presentado es la taza de la Fig. 4.5.e, que es claramente distinta de
todos los objetos anteriores y, por lo tanto, se adquirira su modelo. Este efecto es muy sencillo
de corregir, forzando simplemente al sistema a tomar un numero mınimo de vistas antes de
proceder al reconocimiento. Sin embargo, durante las pruebas no se ha fijado este mınimo, con
el fin de analizar los resultados del algoritmo de reconocimiento tal como ha sido descrito en el
capıtulo anterior, sin la intervencion de rectificaciones de ningun tipo.
Figura 4.7: Prueba de reconocimiento para la taza 1 cuando el sistema aun no ha aprendido sumodelo: a) cuando el asa no es visible en la primera vista; y b) cuando el asa es visible ya en laprimera vista
Es interesante notar que todas las vistas de la taza 1 son parecidas a alguna del cilindro 1
o de la taza 2, pero el cilindro 1 y la taza 2 no tienen vistas comunes. Ası, al presentar al sistema
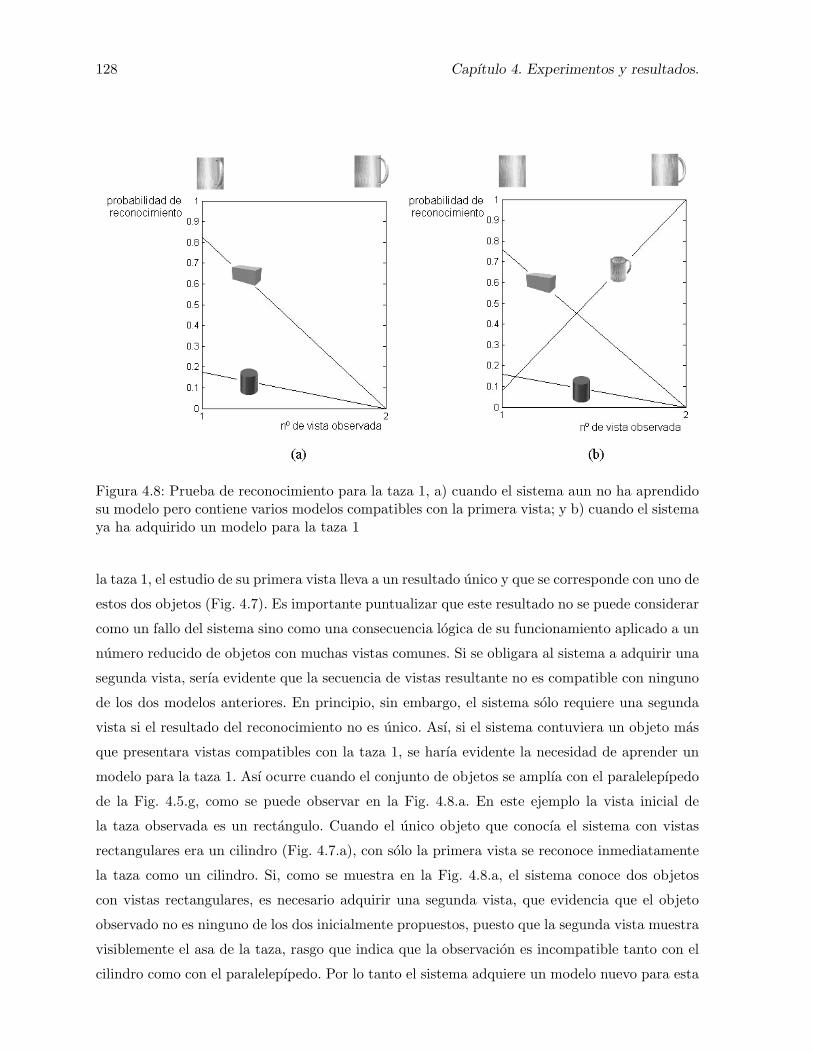
128 Capıtulo 4. Experimentos y resultados.
Figura 4.8: Prueba de reconocimiento para la taza 1, a) cuando el sistema aun no ha aprendidosu modelo pero contiene varios modelos compatibles con la primera vista; y b) cuando el sistemaya ha adquirido un modelo para la taza 1
la taza 1, el estudio de su primera vista lleva a un resultado unico y que se corresponde con uno de
estos dos objetos (Fig. 4.7). Es importante puntualizar que este resultado no se puede considerar
como un fallo del sistema sino como una consecuencia logica de su funcionamiento aplicado a un
numero reducido de objetos con muchas vistas comunes. Si se obligara al sistema a adquirir una
segunda vista, serıa evidente que la secuencia de vistas resultante no es compatible con ninguno
de los dos modelos anteriores. En principio, sin embargo, el sistema solo requiere una segunda
vista si el resultado del reconocimiento no es unico. Ası, si el sistema contuviera un objeto mas
que presentara vistas compatibles con la taza 1, se harıa evidente la necesidad de aprender un
modelo para la taza 1. Ası ocurre cuando el conjunto de objetos se amplıa con el paralelepıpedo
de la Fig. 4.5.g, como se puede observar en la Fig. 4.8.a. En este ejemplo la vista inicial de
la taza observada es un rectangulo. Cuando el unico objeto que conocıa el sistema con vistas
rectangulares era un cilindro (Fig. 4.7.a), con solo la primera vista se reconoce inmediatamente
la taza como un cilindro. Si, como se muestra en la Fig. 4.8.a, el sistema conoce dos objetos
con vistas rectangulares, es necesario adquirir una segunda vista, que evidencia que el objeto
observado no es ninguno de los dos inicialmente propuestos, puesto que la segunda vista muestra
visiblemente el asa de la taza, rasgo que indica que la observacion es incompatible tanto con el
cilindro como con el paralelepıpedo. Por lo tanto el sistema adquiere un modelo nuevo para esta

3. Reconocimiento de objetos 129
Figura 4.9: a-b) Distintas vistas de la taza 1; c-d) Siluetas segmentadas por sustraccion de fondo.
taza.
Como se observa en la Fig. 4.8.b, una vez que el sistema contiene un modelo de la
taza, este aparece como candidato posible en la primera vista. Es interesante notar que, tras la
observacion de una sola vista rectangular, el candidato mas probable es el paralelepıpedo con una
probabilidad relativamente elevada. Esto ocurre porque, teniendo en cuenta que el paralelepıpedo
contiene un elevado numero de vistas rectangulares, es mucho mas probable encontrar una vista
rectangular durante la observacion del mismo que cuando el objeto observado es un cilindro y,
por supuesto, mucho mas probable que con la taza. Sin embargo, el proceso de reconocimiento
no se detiene hasta que solo hay un candidato con probabilidad de reconocimiento significativa.
Por lo tanto, es necesario adquirir una segunda vista. En este ejemplo, la secuencia de dos vistas
sı determina unıvocamente el reconocimiento como la taza 1.
El experimento resulta mas interesante cuando se trabaja con objetos reales. La Fig.
4.9 muestra una serie de vistas capturadas de una taza real que, aunque no coincide exacta-
mente con el modelo entrenado, que resulta mas esbelto, se parece a este considerablemente. La
primera vista disponible de la taza muestra claramente su asa y, por tanto, resultarıa sencillo
identificarla inmediatamente. Sin embargo, como la silueta esta afectada de ruido, tambien se
podrıa interpretar como un cilindro deformado, por lo que el resultado del reconocimiento para
la primera vista no es unico. Puede observarse en la Fig. 4.10.b que inicialmente el sistema
estima que el objeto evaluado puede ser tanto una taza como cualquiera de los dos cilindros. Es
de senalar como curiosidad que la taza esbelta entrenada no se confundıa en ningun caso con el
cilindro mas bajo. En este caso se incluye esa posibilidad porque el asa redondea la silueta de

130 Capıtulo 4. Experimentos y resultados.
Figura 4.10: Reconocimiento de una taza: a) objeto virtual; b) objeto real.
la taza y la aproxima algo mas a una elipse, si bien el parecido no es muy alto y, por tanto, la
probabilidad de ser dicho cilindro es algo inferior a 0.2. Al captar una segunda vista, sin embar-
go, el sistema opta claramente por la taza entrenada, dejando atras los dos cilindros. Este hecho
no deja de resultar llamativo en tanto que la segunda vista sı que coincide plenamente con un
cilindro. Sin embargo, es necesario recordar que el sistema acumula informacion y, de acuerdo a
su esquema, si a la forma inicial, donde se intuye el asa, le sigue un cilindro, la probabilidad de
estar observando una taza es muy alta.
A continuacion, se procedio a capturar vistas de una segunda taza de forma distinta a
la anterior (Fig. 4.11). Si bien esta taza no es ni mucho menos identica a la de la Fig. 4.5.e,
se parece mas a ella que a la de la Fig. 4.5.d. No obstante, antes de experimentar con ella,
es importante determinar hasta que punto el sistema distingue entre las dos tazas aprendidas.
Para ello, se alimenta el sistema con una primera vista de la taza virtual de la Fig. 4.5.e. En la
Fig. 4.12.a puede apreciarse como, para esta primera vista, el sistema duda entre las dos tazas.
Una sola vista mas permite al sistema reconocer eficazmente la taza de la Fig. 4.5.e. Ahora se
alimenta al sistema con una vista de la taza real (Fig. 4.12.b), en la que cabe destacar que la
base es significativamente distinta de la de las tazas aprendidas. De nuevo el sistema reconoce ya
en la primera vista (Fig. 4.12.b) que se trata de una de las dos tazas, aunque no distingue cual
de ellas. En la segunda vista se empieza a ver el asa, pero su forma aun no es muy definida, por

3. Reconocimiento de objetos 131
lo que podrıa ser cualquiera de las dos tazas entrenadas. Dado que sigue habiendo dos opciones
plausibles, se captura una tercera vista, que muestra claramente el asa resaltada sobre el perfil
de la figura. Dado que la forma del asa es mas parecida a la de la taza de la Fig. 4.5.e que
a la de la taza de la Fig. 4.5.d, esta vista es determinante para que el sistema reconozca la
taza propuesta como la taza de la Fig. 4.5.e. Cabrıa, por tanto, vistos los resultados de ambos
experimentos, considerar que el sistema entiende como tazas objetos con cierta simetrıa y asas.
3.2. Experimentos con objetos complejos
Una vez comprobada la eficiencia del metodo de reconocimiento propuesto para reconocer
objetos sencillos y potencialmente parecidos, una segunda tanda de experimentos consistio en
tratar de reconocer objetos mas complejos, en particular, la base de datos de sillas de la Fig.
4.1. Tal como se ha comentado, el principal problema de los objetos complejos es que se definen
mediante detalles mas o menos significativos. La presencia de distorsiones, ruido de captura o
errores de segmentacion puede no afectar de forma muy significativa un cubo o un cilindro, pero
es mas que probable que cambie la naturaleza de, por ejemplo, una llave. Adicionalmente, los
objetos simples, como las tazas del subapartado anterior, suelen parecerse mucho entre sı, pero
los contornos de objetos complejos pueden presentar diferencias significativas. Ası, podrıa darse
el caso de que una silla parecida a cualquiera en la base de datos aprendida no se reconociese de
forma efectiva por, por ejemplo, diferencias en la inclinacion de las patas. Los experimentos de
este apartado han ido, por tanto, encaminados primero a probar la resistencia frente a errores
y distorsiones del reconocimiento de objetos complejos y, a continuacion, a probar la validez de
Figura 4.11: a-c) Distintas vistas de la taza 2; d-f) Siluetas segmentadas por sustraccion defondo.

132 Capıtulo 4. Experimentos y resultados.
Figura 4.12: Reconocimiento de una taza: a) objeto virtual; b) objeto real.
los objetos aprendidos para reconocer otros similares en el mundo real.
Dado que es complejo controlar los errores de segmentacion y distorsiones en el mundo
real, un primer conjunto de pruebas ha consistido en producir distorsiones controladas sobre
los modelos aprendidos y alimentarlos al sistema de reconocimiento. Ası se puede evaluar la
resistencia de este frente a los mencionados factores en condiciones conocidas. Una primera
prueba consistio en deformar unicamente una vista del objeto manualmente, para comprobar
la capacidad de recuperacion del sistema frente a errores puntuales. Dado que generalmente es
suficiente con unas pocas vistas para reconocer un objeto, en este caso se opto por distorsionar la
primera vista disponible. Para ello, se borro un pedazo irregular de la esquina superior izquierda
del respaldo de la primera silla. En la Fig. 4.13 se muestra la silla distorsionada (Fig. 4.13.a)
junto a su mapa de clases (Fig. 4.13.b). La clasificacion se ha realizado con el mismo codigo de
color que la de la Fig. 4.3 de modo que ambos mapas de clases se puedan comparar de forma
sencilla. Como se puede observar, el mapa de clases se ve afectado por la distorsion de esta vista,
de modo que la posicion del mapa correspondiente a la misma toma ahora otro color, es decir,
la vista distorsionada aun guarda parecido con algunas de las vistas de la silla sin distorsionar,
aunque no necesariamente con la vista que deberıa ocupar su posicion.
Un ejemplo de prueba de reconocimiento de la silla deformada de la Fig. 4.13 se muestra
en la Fig. 4.14.b. En la Fig. 4.14.a se ha incluido, a efectos de comparacion, una prueba de
reconocimiento para la silla sin deformar a partir de la misma secuencia de vistas. El sistema

3. Reconocimiento de objetos 133
reacciona de forma similar en ambos casos tanto en la naturaleza de los prototipos propuestos
inicialmente como en la evolucion de la probabilidad de que correspondan a cada uno de los mis-
mos. Tras analizar la primera vista de la silla sin distorsionar, la probabilidad de que pertenezca
a la silla correcta es ya la mas alta, mientras que para la silla distorsionada esta probabilidad
es relativamente baja. Sin embargo, dada la resistencia de los vectores de caracterısticas de las
vistas frente a distorsiones de este tipo, mantiene una cierta confianza en estar en presencia de
la silla de la Fig. 4.1.a. Para que el sistema pueda tomar una decision es necesario ponderar
la secuencialidad de las vistas. Con solo una segunda vista, esta vez sin distorsion, el sistema
reafirma en estar frente al prototipo de la Fig. 4.1.a, descartando completamente los demas. Es
importante senalar que este resultado satisfactorio solo es posible gracias a la tolerancia de los
MOMs ante la alteracion del orden de vistas de la secuencia de observaciones.
Esta prueba, si bien necesaria ya que no todas las vistas de un objeto tienen que estar
sujetas a los mismos errores, es relativamente simple, porque la perdida de parte del respaldo
de la silla de la Fig. 4.1.b no significa un cambio radical en su forma. De hecho, como se puede
observar en la Fig. 4.14, los candidatos propuestos para las sillas distorsionada o sin distorsionar
son inicialmente los mismos. La unica diferencia aparece en el valor de las probabilidades iniciales.
En vista de esto, en una segunda prueba se procedio a eliminar parcialmente las patas traseras
para observar como se comporta el sistema en este caso (Fig. 4.15). En la primera vista de la
secuencia sin distorsionar (Fig. 4.15.a) se puede observar un perfil de la silla de la Fig. 4.1.a. Tal
como cabrıa esperar, esta silla vista de perfil es similar a la mayorıa de las sillas del conjunto
inicial, ya que comparte rasgos muy significativos comunes a cualquier silla, tales como el perfil
del respaldo y el asiento formando un angulo entre sı cercano al recto. A medida que avanza
la secuencia de vistas, se impone como unico prototipo posible el de la Fig. 4.1.a, que es el
Figura 4.13: Objeto con una sola vista distorsionada: a) vista distorsionada; y b) mapa de vistasalterado respecto del mapa del mismo objeto sin distorsionar, mostrado en Fig. 4.3.b.

134 Capıtulo 4. Experimentos y resultados.
correcto. En la Fig. 4.15.b se presenta la prueba en la que se han eliminado parcialmente las
patas traseras en la primera vista. Es interesante observar que para la silla distorsionada aparecen
muchos menos prototipos compatibles con la primera vista. Esto ocurre porque el tener patas es
un rasgo fundamental de cualquier silla. Varios de los prototipos propuestos para las primeras
vistas de la prueba en Fig. 4.15.a lo son por el parecido que presentan sus patas con las de
la silla observada. Ası, eliminando las patas de la primera vista, el parecido con los prototipos
estara basado en otros rasgos, como la forma del respaldo o el perfil del asiento (Fig. 4.15.b).
El numero de candidatos en este caso sera necesariamente mas limitado: entre ellos esta la silla
de la Fig. 4.1.a, pero no necesariamente con la probabilidad de reconocimiento mas alta. No
obstante, una segunda vista, ya no distorsionada, permite reconocer la silla correctamente.
Dado que lo mas frecuente es que si una vista esta sujeta a una distorsion determinada,
tambien lo esten el resto, se ha efectuado un nuevo experimento bajo estas condiciones. Para
ello, se ha sometido el objeto completo a una distorsion suave y se ha alimentado al sistema
(Fig. 4.16). En este caso no se contemplan errores de segmentacion, pero la curvatura de la silla
varıa con respecto de la del prototipo. Puede observarse en la Fig. 4.17.a-b que la distorsion que
altera el contorno produce que algunos vertices esten ligeramente desplazados de su posicion
original, suavizados o resaltados segun los casos. El efecto sobre las correspondientes funciones
de curvatura es un ligero desplazamiento de algunos de los extremos locales, una diferencia en la
altura de los mismos o, incluso, la aparicion de nuevos extremos locales secundarios (Fig. 4.17.c).
Figura 4.14: a) Reconocimiento de una silla sin distorsionar; y b) reconocimiento de la mismasilla con oclusion parcial del respaldo en la primera vista.

3. Reconocimiento de objetos 135
Figura 4.15: a) Reconocimiento de una silla sin distorsionar; y b) reconocimiento de la mismasilla con oclusion parcial de las patas en la primera vista.
Como puede apreciarse en el resultado del reconocimiento, este cambio de curvatura hace que,
una vez mas, una primera vista conflictiva haga que los candidatos mas probables no coincidan
con el modelo correcto (Fig. 4.16.b). A lo largo de la secuencia de vistas puede observarse como
se mantiene una cierta probabilidad de reconocimiento de la silla correcta, si bien es menor que
la probabilidad de reconocimiento de otros modelos. En este caso es necesario llegar hasta la
cuarta vista para poder establecer un resultado unico de reconocimiento (Fig. 4.16.b), mientras
que con las vistas sin distorsionar es suficiente con analizar tres vistas para llegar a un resultado
correcto (Fig. 4.16.a).
Por ultimo, antes de pasar a las pruebas reales, se evaluo un caso mas en el que todas
las vistas del objeto se distorsionaron de forma independiente. Cada una de las vistas ha sufrido
una deformacion no afın que produce una ondulacion regular de su contorno. Ası se pretendıa
evaluar la combinacion de variaciones frente al prototipo y errores de segmentacion, que va a ser
el caso habitual con imagenes reales. La Fig. 4.18 muestra los resultados de dos pruebas de este
tipo. A pesar de que ninguna de las vistas de las que dispone en este caso el sistema son iguales a
las de los prototipos, sus vectores de caracterısticas sı son en cierto grado similares a los estados
ocultos de varios de los modelos. Se puede observar que, debido a la distorsion, los resultados
del reconocimiento con las primeras vistas son mas dudosos que con los ejemplos anteriores. Sin
embargo, gracias a la secuencialidad del proceso, el sistema es capaz de recuperar el resultado
correcto en la mayorıa de los casos sin mas que aumentar el numero de vistas de la secuencia.
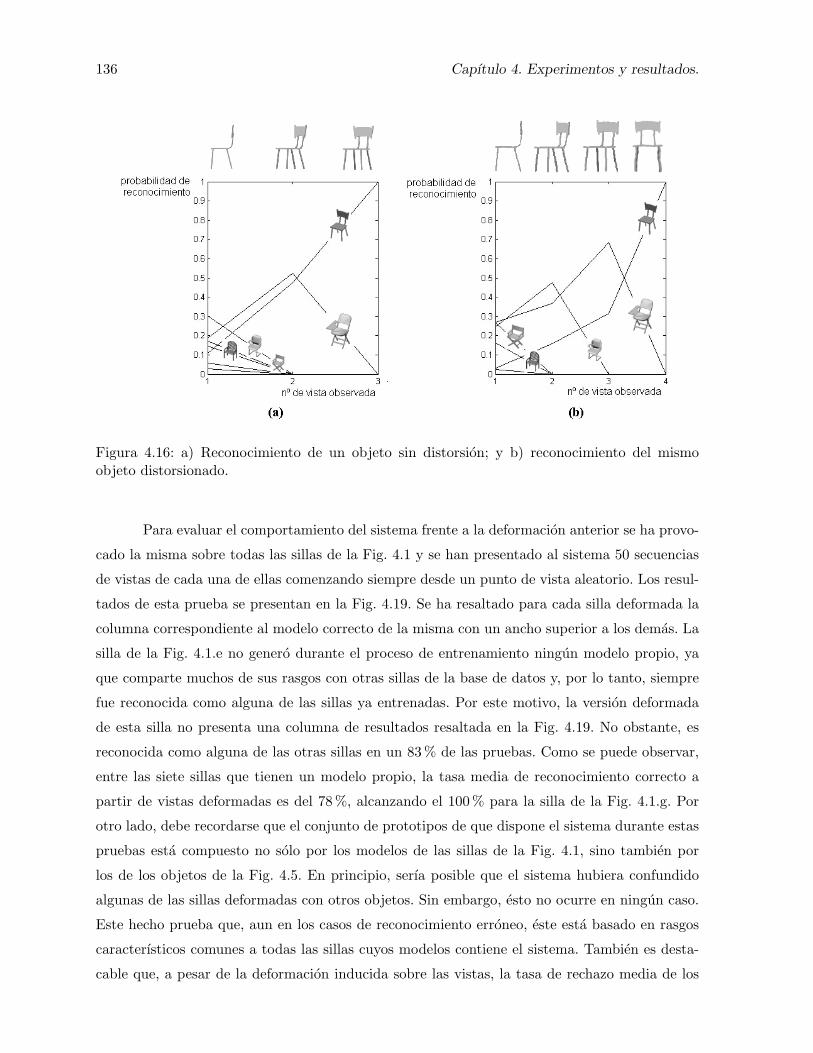
136 Capıtulo 4. Experimentos y resultados.
Figura 4.16: a) Reconocimiento de un objeto sin distorsion; y b) reconocimiento del mismoobjeto distorsionado.
Para evaluar el comportamiento del sistema frente a la deformacion anterior se ha provo-
cado la misma sobre todas las sillas de la Fig. 4.1 y se han presentado al sistema 50 secuencias
de vistas de cada una de ellas comenzando siempre desde un punto de vista aleatorio. Los resul-
tados de esta prueba se presentan en la Fig. 4.19. Se ha resaltado para cada silla deformada la
columna correspondiente al modelo correcto de la misma con un ancho superior a los demas. La
silla de la Fig. 4.1.e no genero durante el proceso de entrenamiento ningun modelo propio, ya
que comparte muchos de sus rasgos con otras sillas de la base de datos y, por lo tanto, siempre
fue reconocida como alguna de las sillas ya entrenadas. Por este motivo, la version deformada
de esta silla no presenta una columna de resultados resaltada en la Fig. 4.19. No obstante, es
reconocida como alguna de las otras sillas en un 83% de las pruebas. Como se puede observar,
entre las siete sillas que tienen un modelo propio, la tasa media de reconocimiento correcto a
partir de vistas deformadas es del 78 %, alcanzando el 100 % para la silla de la Fig. 4.1.g. Por
otro lado, debe recordarse que el conjunto de prototipos de que dispone el sistema durante estas
pruebas esta compuesto no solo por los modelos de las sillas de la Fig. 4.1, sino tambien por
los de los objetos de la Fig. 4.5. En principio, serıa posible que el sistema hubiera confundido
algunas de las sillas deformadas con otros objetos. Sin embargo, esto no ocurre en ningun caso.
Este hecho prueba que, aun en los casos de reconocimiento erroneo, este esta basado en rasgos
caracterısticos comunes a todas las sillas cuyos modelos contiene el sistema. Tambien es desta-
cable que, a pesar de la deformacion inducida sobre las vistas, la tasa de rechazo media de los

3. Reconocimiento de objetos 137
Figura 4.17: a) Contorno de una vista no distorsionada de una silla; b) contorno de una vistadistorsionada de la silla; y c) funcion de curvatura del contorno en (a) (lınea roja punteada) ydel contorno en (b) (lınea azul continua).
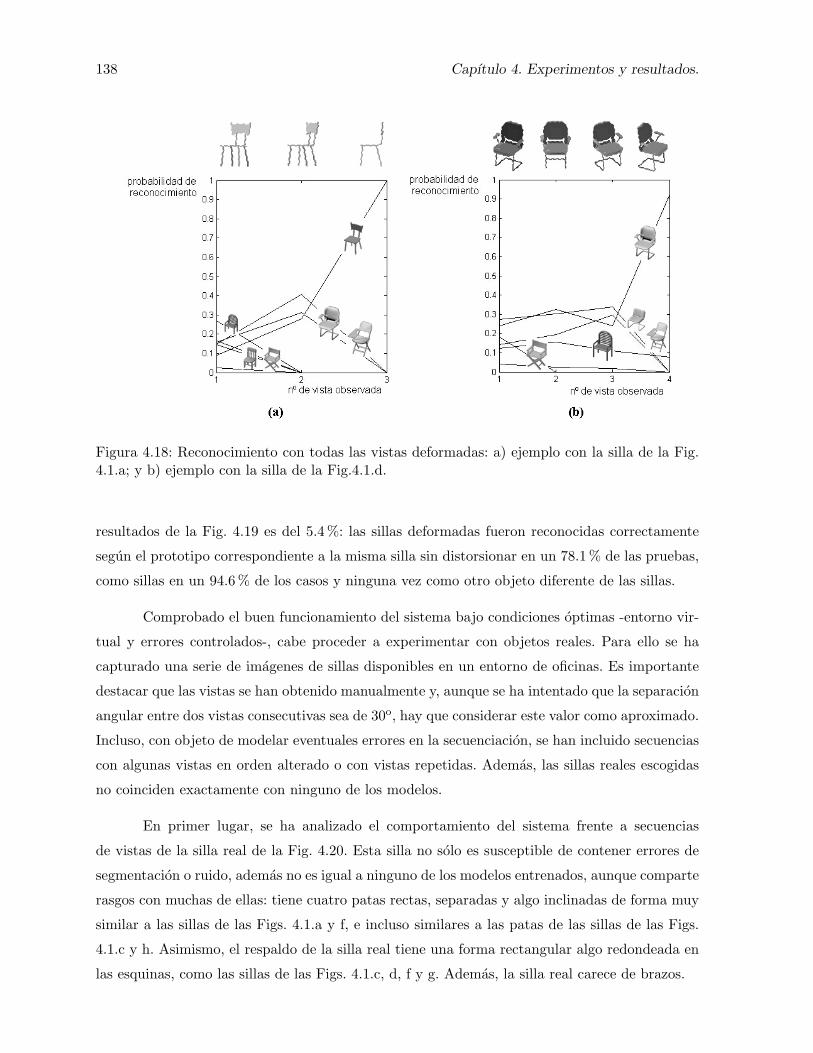
138 Capıtulo 4. Experimentos y resultados.
Figura 4.18: Reconocimiento con todas las vistas deformadas: a) ejemplo con la silla de la Fig.4.1.a; y b) ejemplo con la silla de la Fig.4.1.d.
resultados de la Fig. 4.19 es del 5.4 %: las sillas deformadas fueron reconocidas correctamente
segun el prototipo correspondiente a la misma silla sin distorsionar en un 78.1 % de las pruebas,
como sillas en un 94.6 % de los casos y ninguna vez como otro objeto diferente de las sillas.
Comprobado el buen funcionamiento del sistema bajo condiciones optimas -entorno vir-
tual y errores controlados-, cabe proceder a experimentar con objetos reales. Para ello se ha
capturado una serie de imagenes de sillas disponibles en un entorno de oficinas. Es importante
destacar que las vistas se han obtenido manualmente y, aunque se ha intentado que la separacion
angular entre dos vistas consecutivas sea de 30o, hay que considerar este valor como aproximado.
Incluso, con objeto de modelar eventuales errores en la secuenciacion, se han incluido secuencias
con algunas vistas en orden alterado o con vistas repetidas. Ademas, las sillas reales escogidas
no coinciden exactamente con ninguno de los modelos.
En primer lugar, se ha analizado el comportamiento del sistema frente a secuencias
de vistas de la silla real de la Fig. 4.20. Esta silla no solo es susceptible de contener errores de
segmentacion o ruido, ademas no es igual a ninguno de los modelos entrenados, aunque comparte
rasgos con muchas de ellas: tiene cuatro patas rectas, separadas y algo inclinadas de forma muy
similar a las sillas de las Figs. 4.1.a y f, e incluso similares a las patas de las sillas de las Figs.
4.1.c y h. Asimismo, el respaldo de la silla real tiene una forma rectangular algo redondeada en
las esquinas, como las sillas de las Figs. 4.1.c, d, f y g. Ademas, la silla real carece de brazos.

3. Reconocimiento de objetos 139
Figura 4.19: Porcentajes de reconocimiento con todas las vistas deformadas.
Figura 4.20: a) Imagen capturada de una silla real; y b) vista segmentada por sustraccion defondo.
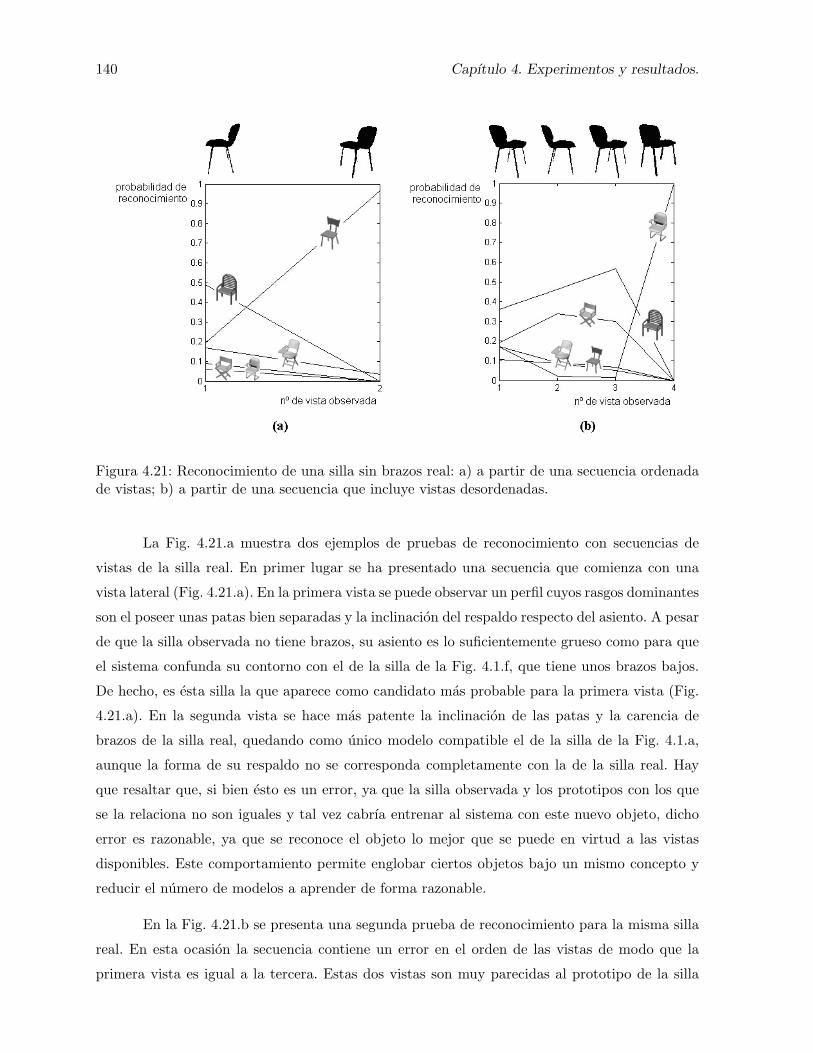
140 Capıtulo 4. Experimentos y resultados.
Figura 4.21: Reconocimiento de una silla sin brazos real: a) a partir de una secuencia ordenadade vistas; b) a partir de una secuencia que incluye vistas desordenadas.
La Fig. 4.21.a muestra dos ejemplos de pruebas de reconocimiento con secuencias de
vistas de la silla real. En primer lugar se ha presentado una secuencia que comienza con una
vista lateral (Fig. 4.21.a). En la primera vista se puede observar un perfil cuyos rasgos dominantes
son el poseer unas patas bien separadas y la inclinacion del respaldo respecto del asiento. A pesar
de que la silla observada no tiene brazos, su asiento es lo suficientemente grueso como para que
el sistema confunda su contorno con el de la silla de la Fig. 4.1.f, que tiene unos brazos bajos.
De hecho, es esta silla la que aparece como candidato mas probable para la primera vista (Fig.
4.21.a). En la segunda vista se hace mas patente la inclinacion de las patas y la carencia de
brazos de la silla real, quedando como unico modelo compatible el de la silla de la Fig. 4.1.a,
aunque la forma de su respaldo no se corresponda completamente con la de la silla real. Hay
que resaltar que, si bien esto es un error, ya que la silla observada y los prototipos con los que
se la relaciona no son iguales y tal vez cabrıa entrenar al sistema con este nuevo objeto, dicho
error es razonable, ya que se reconoce el objeto lo mejor que se puede en virtud a las vistas
disponibles. Este comportamiento permite englobar ciertos objetos bajo un mismo concepto y
reducir el numero de modelos a aprender de forma razonable.
En la Fig. 4.21.b se presenta una segunda prueba de reconocimiento para la misma silla
real. En esta ocasion la secuencia contiene un error en el orden de las vistas de modo que la
primera vista es igual a la tercera. Estas dos vistas son muy parecidas al prototipo de la silla

3. Reconocimiento de objetos 141
de la Fig. 4.1.f. Se puede observar que en estos dos pasos la probabilidad de la secuencia de
vistas de pertenecer al prototipo de la silla citada crece notablemente. La segunda vista, que es
muy similar a la primera de la secuencia de prueba en Fig. 4.21.a, es compatible con todos los
prototipos propuestos y, por tanto, no ayuda a distinguir entre ellos. La cuarta vista muestra
claramente la forma del respaldo, casi identica al de la silla en Fig. 4.1.d. Esta silla aparece
ahora como unico candidato posible, si bien es cierto que sus patas son distintas a las de la silla
observada, el parecido general de la forma del respaldo y del asiento justifican este resultado.
En una nueva prueba algo mas compleja, se presenta al sistema la silla real de la Fig.
4.22. Esta silla guarda cierto parecido con la de la Fig. 4.1.d, pero es necesario observar que no
son exactamente iguales: la forma de los brazos es distinta y tanto el respaldo como el asiento
de la silla real son mas gruesos que los del modelo virtual. En primer lugar, se alimenta al
sistema con una secuencia de vistas a partir de un perfil de la silla real (Fig. 4.23.a). Tal como se
puede observar, a partir de la primera vista se manejan como posibles candidatas dos sillas de
respaldo cuadrado y con brazos: las de las Figs. 4.1.d y h. Aunque las patas de la segunda son
significativamente distintas de las de la silla real, hay que recordar que el sistema solo ve siluetas
y que, desde este punto de vista elevado, lo que mas llama la atencion de la silla es su respaldo
y asiento cuadrado. Tambien aparecen como posibles candidatas, aunque con una probabilidad
muy baja, las sillas de la Fig. 4.1.a y g. La segunda y la tercera vistas hacen que la probabilidad
de ser la silla de la Fig. 4.1.d crezca sensiblemente, si bien se mantiene aun por debajo de la silla
de la Fig. 4.1h. Las probabilidades de reconocimiento de las otras sillas decrecen hasta casi ser
eliminadas. Es necesaria una cuarta vista para que el resultado sea unico. Esto ocurre porque la
vista posterior de la silla propuesta es muy reconocible, ya que muestra claramente la forma del
respaldo y la estructura de las patas mientras los brazos sobresalen visiblemente a los lados.
En la Fig. 4.23.b se presenta una prueba en la que se ha alimentado de nuevo el sistema
con la silla real de la Fig. 4.22, pero esta vez incluyendo un error de secuenciacion que consiste en
la repeticion de la primera vista. En las primeras dos vistas los brazos no son un rasgo dominante,
ya que quedan parcialmente disimulados por el asiento. Consecuentemente, el sistema encuentra
algunos candidatos con probabilidad alta de reconocimiento pero sin brazos. Se puede observar
que, al principio de la secuencia, el candidato mas probable es una silla que, a primera vista, no
se parece excesivamente a la observada. Este efecto se puede explicar notando que casualmente
la pata de la silla observada presenta un perfil similar al del respaldo y el asiento de la silla de la
Fig. 4.1.b, de modo que el sistema puede estar percibiendo el contorno de la silla observada como
una combinacion de dos respaldos y dos asientos de la citada silla. Se podrıa considerar que esta
asociacion es un error del sistema. Sin embargo, gracias a que el reconocimiento esta basado

142 Capıtulo 4. Experimentos y resultados.
Figura 4.22: a) Imagen capturada de una silla real; y b) vista segmentada por sustraccion defondo.
Figura 4.23: Reconocimiento de una silla con brazos real: a) a partir de una secuencia ordenadade vistas; b) a partir de una secuencia que incluye vistas desordenadas.

4. Conclusiones 143
en la secuencialidad del conjunto de vistas y dado que es poco probable que estas relaciones
casuales se den en varias vistas consecutivas, el sistema se podra recuperar de las mismas en
vistas sucesivas. De hecho, se puede observar que la tercera vista determina un reconocimiento
unico. Al igual que en el ejemplo de la Fig. 4.23.a, el resultado es la silla de la Fig. 4.1.d, que
es la que mas se parece a la silla real. Debe notarse tambien que el prototipo de la silla de la
Fig. 4.1.h aparece tambien entre los candidatos posibles en las dos primeras vistas. Esta silla
es muy similar tanto a la silla real como a la que aparece como resultado del reconocimiento,
siendo sus principales diferencias con aquellas su carencia de brazos y su mayor anchura. De
hecho, despues de analizar las dos primeras vistas la probabilidad de que la silla observada sea
la de la Fig. 4.1.h es incluso mayor que la de que sea la de la Fig. 4.1.d. Para explicar por que el
reconocimiento final se decanta por el modelo con brazos debe observarse que la tercera vista
muestra claramente las proporciones de la silla observada, que es bastante mas estrecha que la
de la Fig. 4.1.h. Ademas, a los lados de la silla se pueden observar los dos pequenos salientes
que indican la presencia de brazos.
Es de resaltar que en ningun momento el sistema ha barajado en estos experimentos que
los objetos entrantes no fuesen sillas. Si a ello se suma el hecho de que basicamente ha decidido
entre unos modelos y otros por la forma del respaldo y el asiento, los brazos y las patas, podrıa
considerarse que el concepto de silla se ha adquirido correctamente.
4. Conclusiones
En este capıtulo se han presentado varias pruebas y experimentos para comprobar el
funcionamiento del sistema de reconocimiento propuesto con objetos de diversa complejidad y
afectados por distintos errores. Se han mezclado intencionadamente objetos reales y virtuales
para probar la posibilidad de reconocerlos de forma cruzada. Esto ha permitido realizar parte
del entrenamiento del sistema con la ayuda de bases de datos virtuales. El entrenamiento con
objetos virtuales resulta muy util porque permite suministrar al sistema objetos libres de error y
desde cualquier punto de vista. Ademas, este tipo de entrenamiento es mucho mas rapido que el
efectuado con objetos reales, puesto que no implica el desplazamiento de camaras alrededor del
objeto. El hecho de que se puedan identificar correctamente objetos reales a partir de los modelos
de sus homologos virtuales es equivalente al hecho de que un ser humano pueda identificar un
objeto que no hubiera visto antes a partir, por ejemplo, de la fotografıa de otro similar.
Los experimentos realizados han resultado satisfactorios en todos los casos, ya que los
objetos iguales se han identificado correctamente, los desconocidos se han incorporado al sis-

144 Capıtulo 4. Experimentos y resultados.
tema como cabıa esperar y los errores han estado justificados siempre debido a un parecido en
ciertos rasgos comunes de distintos objetos. Deformaciones puntuales en las vistas capturadas
o distorsiones globales de la forma del objeto 3D se han recuperado satisfactoriamente, en la
mayorıa de los casos, gracias a la naturaleza secuencial del proceso.
Por ultimo, cabe resaltar que en los experimentos llevados a cabo, tanto los sucesivos
pasos del algoritmo de reconocimiento como los resultados finales, han sido siempre justificables
desde el punto de vista de un observador humano. Esto corrobora que el sistema de reconocimien-
to utiliza criterios de forma similares a los que utilizarıa un ser humano y que selecciona los
objetos paso a paso siguiendo una secuencia logica que resulta natural desde el punto de vista
humano.

Capıtulo 5
Conclusiones
1. Conclusiones
En esta tesis se ha presentado un nuevo sistema de reconocimiento de objetos 3D a partir
de secuencias de vistas planas de longitud variable de estos. Esta aproximacion ha sido motivada
por la tendencia al uso de camaras de vıdeo en la mayorıa de los sistemas de vision artificial por
factores de coste, disponibilidad, generalidad, etc. La vision convencional usando una o incluso
dos camaras (vision estereo) esta fuertemente condicionada por el hecho de que la mayor parte
del objeto permanece invisible en funcion de la posicion de dichas camaras, lo que puede dificul-
tar su reconocimiento en presencia de objetos con vistas comunes. Este problema se soluciona
intuitivamente desplazando las camaras alrededor del objeto para capturar las zonas ocultas.
Esta aproximacion permitirıa, en caso de necesidad, extraer informacion volumetrica usando una
unica camara (Sullivan y Ponce, 1998), lo que permite descartar la computacionalmente costosa
vision estereo.
El reconocimiento basado en vistas no es una idea nueva, sino que hay diversos trabajos
que se centran en esta aproximacion (Campbell y Flynn, 1999) (Murase y Nayar, 1995) (Kovacic
et al., 1998). La novedad de la presente tesis consiste en que en lugar de trabajar con imagenes
completas para cada una de las vistas capturadas, ya que esta suficientemente documentada la
bondad de la forma como descriptor de un objeto, se trabaja con dicha forma, reduciendose
ası significativamente el volumen de datos para representar cada vista y, en consecuencia, el
objeto completo. Esto es particularmente deseable en tanto que el sistema debe almacenar los
conocimientos que va adquiriendo de cada objeto y un formato compacto de datos facilita tanto
el almacenamiento de estas como el acceso posterior.
A efectos de codificar la forma de un objeto, es necesario desarrollar un sistema que
145

146 Capıtulo 5. Conclusiones
aporte invarianza con respecto a transformaciones, ruido y posibles distorsiones derivadas de la
separacion objeto-fondo. Una manera habitual de describir la forma es a traves de la curvatura
del contorno de la misma. Sin embargo, obtener la curvatura de un contorno discretizado y posi-
blemente afectado por ruido no resulta trivial. Si bien se han desarrollado numerosos algoritmos
para este fin, estos adolecen de la capacidad de adaptarse a la escala natural del contorno, ya
que implıcita o explıcitamente llevan a cabo un filtrado de este con un factor constante. Ası,
para obtener una mejor representacion, se ha desarrollado una nueva funcion de curvatura capaz
de adaptarse a la escala local del contorno en cada punto, de modo que respeta rasgos signi-
ficativos a cualquier escala pero filtra eficazmente el ruido. Esta funcion se ha comparado con
exito con las funciones de curvatura no adaptativas (Urdiales et al., 2003), si bien su bondad
queda lo suficientemente probada por el hecho de que conserva toda la informacion necesaria
para recuperar los contornos originales libres de ruido (de Trazegnies et al., 2003c).
La comparacion entre distintos contornos a traves de sus funciones de curvatura presenta
la dificultad adicional de que las funciones de curvatura pueden estar desplazadas entre sı.
Este desplazamiento depende del punto del contorno desde el cual se inicia el calculo. Dada
la imposibilidad de escoger un punto de comienzo de cada contorno que sea invariante frente
a giros, transformaciones, ruido, distorsiones u oclusiones parciales, es necesario definir una
descripcion del contorno independiente de la orientacion del mismo. Con este fin, aprovechando
la invarianza de la transformada de Fourier frente a traslaciones de la funcion original, la presente
tesis ha optado por una descripcion a partir del modulo de la transformada de Fourier de cada
funcion de curvatura. Si bien al realizar esta operacion se pierde inevitablemente la informacion
correspondiente a la fase de la transformada de Fourier, se ha comprobado que esta perdida no
reduce de forma significativa la capacidad de clasificacion de formas planas. Adicionalmente,
se ha comprobado que esta representacion es fuertemente redundante, por lo que en la tesis se
ha aplicado Analisis en Componentes Principales para extraer un vector de caracterısticas de
dimension reducida para representar cada vista (de Trazegnies et al., 2003b) (de Trazegnies et
al., 2003a).
Algunos sistemas de reconocimiento de objetos 3D basados en vistas utilizan, al igual
que en la presente tesis, la forma para identificar un objeto (Kovacic et al., 1998) (Mokhtar-
ian, 1997). Sin embargo, no aprovechan la disposicion global de las vistas del objeto para su
reconocimiento, perdiendo ası la posibilidad de distinguir entre objetos con vistas similares pero
dispuestas de forma diferente. Esto resulta especialmente grave en tanto que, si solo se trabaja
con contornos, muchos objetos comparten vistas parecidas. Ası, en esta tesis se ha propuesto un
nuevo algoritmo de reconocimiento basado en aprovechar la secuencialidad de las vistas de un

2. Trabajo futuro 147
objeto mediante acumulacion estadıstica de informacion. Para ello se ha hecho uso de Modelos
Ocultos de Markov. Este sistema se ha probado con exito tanto con objetos virtuales como reales
de distinta naturaleza (de Trazegnies et al., 2003b) (de Trazegnies et al., 2003a).
Es importante senalar que cada uno de los nuevos procedimientos propuestos en esta tesis
funcionan de manera no supervisada, lo que posibilita que los procesos de aprendizaje de nuevos
conceptos y reconocimiento de los mismos no se realicen de forma aislada sino que puedan inter-
actuar, de modo que el sistema pueda adquirir nuevos modelos toda vez que encuentre objetos
que no conoce. Una caracterıstica especialmente interesante derivada del buen comportamiento
frente a ruido, transformaciones o distorsiones del sistema es que es posible reconocer objetos
reales a partir de modelos virtuales. Ası, se abre la posibilidad de entrenarlo con bases de datos
predefinidas ya disponibles para el entorno en el que el sistema deba trabajar, sin perjuicio de
que, durante su funcionamiento, pueda adquirir nuevos modelos del mundo real.
2. Trabajo futuro
El sistema de reconocimiento presentado no responde a un esquema de ejecucion total-
mente cerrado, sino que es un desarrollo flexible que aborda el problema del reconocimiento de
objetos 3D de manera modular. Ası, es posible introducir diversas mejoras al algoritmo basico
sin alterar la estructura general del sistema y, por lo tanto, sin perder sus caracterısticas de
flexibilidad y adaptabilidad al entorno en el que deba operar. Para su exposicion en esta sec-
cion, entre las posibles mejoras que cabrıa proponer, se han seleccionado algunas por su especial
interes para subsanar las limitaciones del sistema y por constituir una continuacion natural de
la lınea de investigacion propuesta en esta tesis.
En primer lugar, es importante notar que una posible mejora en el metodo de repre-
sentacion de las vistas de un objeto redundarıa en una mayor fiabilidad en el reconocimiento.
Cualquier mejora en el metodo de representacion debe ir encaminada a presentar un mejor
comportamiento frente a ruido o distorsion o deformacion de los contornos, o bien a subsanar
defectos del metodo propuesto, sin por ello perder la invarianza frente a traslacion, rotacion o
cambio de escala. El comportamiento frente a distorsion o ruido de la representacion mediante
los vectores de caracterısticas descritos en el capıtulo 2 es suficientemente satisfactorio, por lo
que una mejora en este sentido no serıa muy significativa. Sin embargo, esta resistencia frente
a transformaciones, en casos muy especiales, podrıa dar lugar a la sobrevaloracion del parecido
entre dos imagenes que, en realidad, son distintas. En efecto, el vector de caracterısticas prop-
uesto como descriptor, es invariante frente a rotaciones debido a que retiene la informacion solo

148 Capıtulo 5. Conclusiones
Figura 5.1: a) Objeto 1, presentando cuatro esquinas de 90o; b) objeto 2, presentando cuatroesquinas de −90o; y c) funcion de curvatura del objeto 1 (lınea azul) y del objeto 2 (lınea roja)
del modulo de la transformada de Fourier de la funcion de curvatura. Para ello es necesario des-
preciar la informacion contenida en la fase de la funcion de curvatura. Si bien esta informacion,
en general, no es crıtica para diferenciar entre contornos distintos, es previsible que prescindir de
ella en algunos casos particulares pueda dar lugar a confusion. En la Fig. 5.1 se muestra un buen
ejemplo de este caso. Como se puede comprobar, los contornos de los objetos que se presentan
en las Figs. 5.1.a y b son muy distintos entre sı. Sus funciones de curvatura (Fig. 5.1.c) presen-
tan una evolucion parecida, pero son distinguibles porque su signo es opuesto. Sin embargo, las
transformadas de Fourier de estas dos funciones solo mostraran diferencias significativas en su
fase, lo que hace indistinguible una figura de otra. Dado que la rotacion de una vista produce
una traslacion circular de su funcion de curvatura, tambien se podrıa corregir este defecto si se
dispusiera de un descriptor cıclico del contorno. De esta manera se evitarıa tener que pasar por
una transformacion de Fourier del mismo y en su lugar se realizarıa directamente el Analisis por
Componentes Principales sobre el descriptor cıclico.
Como se ha comentado en los capıtulos 3 y 4, el resultado de reconocimiento de un ob-
jeto determinado depende en ocasiones de la idoneidad de la secuencia observada del mismo.

2. Trabajo futuro 149
Ası, es posible que dos objetos distintos de la base de datos, aun teniendo algunas vistas que
los diferencian claramente, tengan un alto numero de vistas comunes. Si la secuencia de obser-
vacion de cada uno de ellos solo incluye vistas comunes, seran indistinguibles para el sistema
de reconocimiento. Este problema se eliminarıa si el sistema pudiera prever cuales de las vistas
pueden diferenciar mejor a los candidatos propuestos, de modo que las secuencias de vistas con
las que se alimenta el sistema fueran siempre las optimas para distinguir entre objetos similares.
Es importante senalar que el modelo de cada objeto, tal como se describe en el capıtulo 3, no
contiene ninguna informacion sobre la distribucion de las vistas alrededor del objeto, sino solo
la informacion probabilıstica que relaciona cada vista con la siguente. Sin embargo, se podrıa
guardar tambien, junto con los datos de cada modelo, el mapa de clases de vistas del objeto.
De este modo, se podrıa plantear un algoritmo de planificacion de la mirada tal que, dados dos
o mas modelos compatibles con la primera o primeras vistas de un objeto observado, se trazara
el recorrido optimo alrededor del mismo para obtener una secuencia de vistas que permitiera el
reconocimiento correcto. El desarrollo de un sistema de planificacion de la mirada no supondrıa
un coste computacional elevado y evitarıa gastar tiempo analizando secuencias de vistas exce-
sivamente largas, situacion que se da frecuentemente cuando el resultado de reconocimiento es
ambiguo.
Las bases de datos escogidas en el desarrollo de esta tesis contienen un numero reduci-
do de objetos. Esto es ası porque, aunque teoricamente el numero de objetos podrıa crecer
indefinidamente, en la practica aparecen ciertas limitaciones. Ası, cuanto mayor sea la base de
datos mayor sera la probabilidad de que contenga a la vez dos modelos de objetos muy similares,
que solo son distinguibles desde puntos de vista privilegiados. Si se obtiene una secuencia de
vistas de uno de ellos, de modo que los rasgos diferenciadores queden ocultos, el sistema puede
llegar a realizar una vuelta completa alrededor del objeto sin que ninguna de las probabilidades
de reconocimiento de los dos modelos similares destaque respecto de la otra. Como no existe
un resultado unico, serıa necesario adquirir un nuevo modelo para este objeto. Sin embargo,
el sistema ya disponıa de un modelo adecuado al objeto presentado. A partir de ese momento,
cada vez que el sistema observe el mismo objeto, sera incapaz de decidir entre los dos modelos
repetidos y se vera en la obligacion de adquirir un nuevo, empeorando cada vez mas la situacion.
Esto plantea la necesidad de eliminar del sistema los modelos duplicados y la conveniencia de
eliminar modelos que, aun no siendo duplicados exactos, guarden un gran parecido con alguno de
los ya existentes. Para ello, es necesario desarrollar un criterio de parecido entre modelos. Esta
extension evitarıa el riesgo de este comportamiento no deseado y facilitarıa el uso del sistema
de reconocimiento en conjuntos extensos de modelos.


Bibliografıa
A. Adan, C. Cerrada, y V. Feliu. Global shape invariants: a solution for 3D free-form object
discrimination/identification problem. Pattern Recognition, 34(7), pp. 1331–1348, 2001.
G. Agam y I. Dinstein. Geometric separation of partially overlapping nonrigid objects applied
to automatic chromosome classification. IEEE Trans. on Pattern Analysis and Machine In-
telligence, 19(11), pp. 1212–1222, 1997.
Y. Amit, D. Geman, y K. Wilder. Joint induction of shape features and tree classifiers. IEEE
Trans. on Pattern Analysis and Machine Intelligence, 19(11), pp. 1300–1306, 1997.
H. Ando, S. Suzuki, y T. Fujita. Unsupervised visual learning of three dimensional objects using
a modular network architecture. Neural Networks, 12(7), pp. 1037–1051, 1999.
N. Ansari y E. Delp. On detecting dominant points. Pattern Recognition, 24(5), pp. 441–451,
1991.
F. Arrebola, A. Bandera, P. Camacho, y F. Sandoval. Corner detection by local histograms of
contour chain. Electronics Letters, 33(21), pp. 1769–1771, 1997.
F. Arrebola, P. Camacho, A. Bandera, y F. Sandoval. Corner detection and curve representation
by circular histograms of contour chain code. Electronics Letters, 35(13), pp. 1065–1067, 1999.
A. Bandera, C. Urdiales, F. Arrebola, y F. Sandoval. Corner detection by means of adaptively
estimated curvature function. Electronics Letters, 36(2), pp. 124–126, 2000a.
A. Bandera, C. Urdiales, J. Rodriguez, y F. Sandoval. Corner detection techniques for planar
images. En S. G. Pandalai, (Ed.), Recent Research Developments in Pattern Recognition, pp.
137–150. Transworld Research Network, Kerala, India, 2000b.
E. Bardinet, L. Cohen, y N. Ayache. Superquadrics and free-form deformations: a global model
to fit and track 3D medical data. International Conference on Computer Vision, Virtual
Reality and Robotics in Medicine (CVRMed’95), Nice, France, 1995.
151

152 Referencias
R. J. Bartrum y H. C. Crow. Transillumination light scanning to diagnose breast cancer: a
feasibility study. American Journal of Radiology, 142, pp. 409–414, 1984.
R. Basri, D. Roth, y D. Jacobs. Clustering appearances of 2D objects. En IEEE Conference
on Computer Vision and Pattern Recognition, pp. 414–420, Santa Barbara - CA, USA, June
1998.
M. Beauvais y S. Lakshmanan. CLARK: a heterogeneous sensor fusion method for finding lanes
and obstacles. Image and Vision Computing, 18(5), pp. 397–413, 2000.
E. J. Bellegarda, J. R. Bellegarda, D. Nahamoo, y K. S. Nathan. A probabilistic framework for
on-line handwritting recognition. En Proc. of the 3rd International Workshop on Frontiers in
Handwritting Recognition, pp. 225–234, Buffalo, USA, 1993.
M. Bhattacharya y D. D. Majumder. Registration of CT and MR images of Alzheimer’s patient:
a shape theoretic approach. Pattern Recognition Letters, 21(6-7), pp. 531–548, 2000.
A. Bottino y A. Laurentini. Introducing a new problem: Shape-from-silhouette when the relative
positions of the viewpoints is unknown. IEEE Trans. on Pattern Analysis and Machine
Intelligence, 25(11), pp. 1484–1493, 2003.
J. R. Bourne, V. Jagannathan, B. Hamel, B. H. Jansen, J. W. Ward, J. R. Hughes, y C. W. Erwin.
Evaluation of a syntactic pattern recognition approach to quantitative electroencephalographic
analysis. Electroencephalography and Clinical Neurophysiology, 52, pp. 57–64, 1981.
H. H. Buelthoff y S. Edelman. Psychophysical support for a 2D view interpolation theory of
object recognition. Proc. of the National Academy of Science, 89, pp. 60–64, 1992.
R. Campbell y P. Flynn. Eigenshapes for 3D object recognition in range data. En Proc. of
the International Conference on Computer Vision and Pattern Recognition (CVPR’99), pp.
505–510, Fort Collins - Colorado, USA, 1999.
O. Carmichael y M. Hebert. Object recognition by a cascade of edge probes. British Machine
Vision Conference (BMVC 2002), Cardiff, UK, 2002.
F. S. Chang y S. Y. Chen. Deformed shape retrieval based on Markov Model. Electronics Letters,
36(2), pp. 126–127, 2000.
G. C. Charters y J. Graham. Trainable grey-level models for disentangling overlapping chromo-
somes. Pattern Recognition, 32(8), pp. 1335–1349, 1999.

Referencias 153
F. A. Cheikh, A. Quddus, y M. Gabbouj. Shape recognition based on wavelet transform mod-
ulus maxima. En Proc. of VII International Conference on Electronics Circuits and Systems
(ICECS 2000), pp. 461–464, Beirut, Lıbano, 2000.
S. D. Connell y A. K. Jain. Template-based online character recognition. Pattern Recognition,
34(1), pp. 1–14, 2001.
J. Coolidge. The unsatisfactory story of curvature. The American Mathematical Monthly, 59
(6), 1952.
L. Costa y M. Sandler. Effective detection of bar segments with Hough transform. Computer
Vision, Graphics, and Image Processing: Graphical Models and Image Processing, 55(3), pp.
180–191, 1993.
P. Courtney y N. A. Thacker. Performance characterisation in computer vision: The role of
statistics in testing and design. En J. Blanc-Talon y D. Popescu, (Eds.), Imaging and Vision
Systems: Theory, Assessment and Applications. NOVA Science Books, New York, USA, 2001.
M. K. Cowles y B. P. Carlin. Markov Chain Monte Carlo convergence diagnostics: A comparative
review. Journal of the American Statistical Association, 91, pp. 883–904, 1996.
G. Cross, A. W. Fitzgibbon, y A. Zisserman. Parallax geometry of smooth surfaces in multiple
views. En Proc. 7th International Conference on Computer Vision, pp. 323–329, Korfu, Grecia,
1999.
L. Davis, R. Chellapa, Y. Yacoob, y Q. Zheng. Visual surveillance and monitoring of human
and vehicle activity. En Proc. of the Defense Advanced Research Projects Agency Image
Understanding Workshop, pp. 19–27, New Orleans - LA, USA, 1997.
C. de Trazegnies, J. Bandera, C. Urdiales, y F. Sandoval. A real 3D object recognition algorithm
based on virtual training. En IASTED Conference on Signal Processing, Pattern Recognition
and Applications, (SPPRA 2003), pp. 342–347, Rodas, Grecia, July 2003a.
C. de Trazegnies, F. J. Miguel, C. Urdiales, A. Bandera, y F. Sandoval. Planar shape recognition
based on Hidden Markov Models. Electronics Letters, 37(24), pp. 1448–1449, 2001.
C. de Trazegnies, C. Urdiales, A. Bandera, y F. Sandoval. Planar shapes indexing and retrieval
based on Hidden Markov Models. Pattern Recognition Letters, 23(10), pp. 1143–1151, 2002.
C. de Trazegnies, C. Urdiales, A. Bandera, y F. Sandoval. 3D object recognition based on
curvature information of planar views. Pattern Recognition, 36(11), pp. 2571–2584, 2003b.

154 Referencias
C. de Trazegnies, C. Urdiales, A. Bandera, y F. Sandoval. A Hidden Markov Model object recog-
nition technique for incomplete and disorted corner sequences. Image and Vision Computing,
21(10), pp. 879–889, 2003c.
G. Deichsel y H. J. Trampisch. Clusteranalyse und Diskriminanzanalyse. Gustav Fischer Verlag,
Stuttgart, 1985.
D. A. Denisov. Model-based chromosome recognition via hypotheses construction/verification.
Pattern Recognition Letters, 15(3), pp. 299–307, 1994.
M. P. do Carmo. Geometrıa diferencial de curvas y superficies. Alianza Universidad, Madrid,
1a edicion, 1990.
L. Dreschler y H. Nagel. On the selection of critical points and local curvature extrema of region
boundaries for interframe matching. En International Conference on Pattern Recognition, pp.
542–544, Munich, Alemania, 1982.
Eclipse-Entertainment. Genesis3D. 1998, http://www.genesis3d.com.
S. Edelman. Computational theories of object recognition. Trends in Cognitive Sciences, 1(8),
pp. 296–304, 1997.
H. Fonga. Pattern recognition in gray-level images by Fourier analysis. Pattern Recognition
Letters, 17(14), pp. 1477–1489, 1996.
H. Freeman y L. S. Davis. A corner-finding algorithm for chain-coded curves. IEEE Trans. on
Computers, 26, pp. 287–303, 1977.
N. Friedman. The Bayesian structural EM algorithm. En Proc. of the 14th Annual Conf. on
Uncertainty in Artificial Intelligence (UAI-98), pp. 129–138. Morgan Kaufmann Publishers,
San Francisco - CA, USA, 1998.
F. Girosi, M. Jones, y T. Poggio. Regularization theory and neural networks architectures.
Neural Computation, 7, pp. 219–269, 1995.
E. L. Hall. A survey of preprocessing and feature extraction techniques for radiographic images.
IEEE Trans. on Computers, 20(9), pp. 1032–1044, 1971.
L. N. Hambrick, M. H. Loew, y R. L. Carroll. The entry-exit. IEEE Trans. on Pattern Analysis
and Machine Intelligence, 9(5), pp. 597–607, 1987.

Referencias 155
C. Harris y M. Stephens. A combined corner and edge detector. En M. M. Matthews, (Ed.),
Proceedings of the 4th ALVEY vision conference, pp. 147–151, University of Manchester, UK,
September 1988.
J. Hartigan. A k-means clustering algorithm. Applied Statistics, 28, pp. 100–108, 1979.
Y. He y A. Kundu. 2D shape classification using Hidden Markov Models. Trans. on Pattern
Analysis and Machine Intelligence., 13(11), pp. 1172–1184, 1991.
J. Hornegger y H. Niemann. Probabilistic modeling and recognition of 3D objects. International
Journal of Computer Vision, 39(3), pp. 229–251, 2000.
J. Hornegger, H. Niemann, D. Paulus, y G. Schlottke. Object recognition using Hidden Markov
Models,. En E. Gelsema y L. Kanal, (Eds.), Pattern Recognition in Practice IV, pp. 37–44,
Amsterdam, 1991. Elsevier.
R. Howarth y H. Buxton. Visual surveillance monitoring and watching. En Proc. of the 4th
European Conf. on Computer Vision (ECCV’96), pp. 321–334, Oxford, UK, 1996.
J. Hsu y S. Hwang. A machine learning approach for acquiring descriptive classification rules of
shape contours. Pattern Recognition, 30(2), pp. 245–252, 1997.
J. M. Inesta, M. Buendia, y M. A. Sarti. Local symmetries of digital contours from their chain
codes. Pattern Recognition, 29(10), pp. 1737–1749, 1996.
A. Jain y R. Dubes. Algorithms for clustering data. Prentice-Hall, Englewood Cliffs - NJ, USA,
1988.
J. F. Jarvis. A method for automating the visual inspection of printed wiring boards. IEEE
Trans. on Pattern Analysis and Machine Intelligence, 2, pp. 77–82, 1980.
A. E. Johnson y M. Hebert. Surface matching for object recognition in complex three-
dimensional scenes. Image and Vision Computing, 16(9-10), pp. 635–651, 1998.
T. Kanade, Collins, R. T., A. Lipton, P. Anandan, P. Burt, y L. Wixson. Cooperative multi-
sensor video surveillance. En Proc. of the Defense Advanced Research Projects Agency Image
Understanding Workshop, pp. 3–10, New Orleans - LA, USA, 1997.
L. Kaufman y P. Rousseeuw. Finding groups in data: An introduction to cluster analysis. John
Wiley and Sons, New York, NY, 1990.

156 Referencias
H. Kauppinen, T. Seppanen, y M. Pietikainen. An experimental comparison of autoregressive
and fourier-based descriptors in 2D shape classification. IEEE Trans. on Pattern Analysis
and Machine Intelligence, 17(2), pp. 201–207, 1995.
T. Kim, T. Cho, Y. S. Moon, y S. H. Park. Visual inspection system for the classification of
solder joints. Pattern Recognition, 32(4), pp. 565–575, 1999.
L. Kitchen y A. Rosenfeld. Gray level corner detection. Pattern Recognition Letters, 1(2), pp.
95–102, 1982.
M. Kline. Mathematical Thought From Ancient To Modern Times. Oxford University Press,
New York, 1972.
S. Kovacic, A. Leonardis, y F. Pernus. Planning sequences of views for 3D object recognition
and pose determination. Pattern Recognition, 31(10), pp. 1407–1417, 1998.
S. S. Kuo y O. E. Agazzi. Keyword spotting in poorly printed documents using pseudo 2D
Hidden Markov Models. Trans. on Pattern Analysis and Machine Intelligence, 16(8), pp.
842–848, 1994.
K. N. Kutulakos y S. M. Seitz. A theory of shape by Space Carving. Technical Report TR692,
Computer Science Dept., University of Rochester, USA, 1998.
A. Leonardis, A. Jaklic, y F. Solina. Superquadrics for segmenting and modeling range data.
IEEE Trans. on Pattern Analysis and Machine Intelligence, 19(11), pp. 1289–1295, 1997.
B. Lerner, H. Guterman, I. Dinstein, y Y. Romem. Medial axis transform-base features and
neural network for human chromosome classification. Pattern Recognition, 28(11), pp. 1673–
1683, 1995.
H. Liu y D. Srinath. Partial shape classification using contour matching in distance transfor-
mation. IEEE Trans. on Pattern Analysis and Machine Intelligence, 12(11), pp. 1072–1079,
1990.
S. T. Liu y W. H. Tsai. Moment-preserving corner detection. Pattern Recognition, 23(5), pp.
441–460, 1990.
K. C. Lo y S. K. W. Kwok. Recognition of 3D planar objects in canonical frames. Pattern
Recognition Letters, 22(6-7), pp. 715–723, 2001.
N. Logothetis y J. Pauls. Psychophysical and physiological evidence for viewer-centered object
representations in the primate. Cerebral Cortex, 3, pp. 270–288, 1995.

Referencias 157
W. Lorensen y H. Cline. A high resolution 3D surface construction algorithm. Computer
Graphics, 21, pp. 163–169, 1987.
C. Lu. Shape matching using polygon approximation and dynamic alignment. Pattern Recog-
nition Letters, 14(12), pp. 945–949, 1993.
G. Mamic y M. Bennamoun. Representation and recognition of 3D free-form objects. Digital
Signal Processing, 12, pp. 47–76, 2002.
W. N. Martin y J. K. Aggarwal. Volumetric descriptions of objects from multiple views. Trans.
on Pattern Analysis and Machine Intelligence, 5, pp. 150–159, 1983.
K. Matsumoto, M. Naka, y H. Yamamoto. A new clustering method for landsat images using
local maximums of a multidimensional histogram. En Proc. of the Symposium on Machine
Processing Remotely Sensed Data, pp. 321–326, Purdue - IN, USA, 1981.
S. McKenna, S. Jabri, Z. Duric, A. Rosenfeld, y H. Wechsler. Tracking groups of people. Com-
puter Vision and Image Understanding, 80(1), pp. 42–56, 2000.
G. G. Medioni y Y. Yasumoto. Corner detection and curve representation using cubic B-splines.
Computer Vision, Graphics, and Image Processing, 39(3), pp. 267–278, 1987.
K. Mikolajczyk y C. Schmid. Indexing based on scale invariant interest points. En International
Conference of Computer Vision, pp. 525–531, Vancouver, Canada, July 2001.
F. Mokhtarian. Silhouette-based occluded object recognition through Curvature Scale Space.
Machine Vision and Applications, 10(3), pp. 87–97, 1997.
F. Mokhtarian y A. K. Mackworth. Scale-based description and recognition of planar curves
and two-dimensional shapes. IEEE Trans. Pattern Analysis and Machine Intelligence, 8(1),
pp. 34–43, 1986.
H. Moravec. Visual mapping by robot rover. En International Joint Conferences on Artifitial
Intelligence, pp. 598–600, Tokyo, Japon, 1979.
S. Mukherjee y S. K. Nayar. Object recognition and pose estimation in eigenspace using a RBF
network. Technical Report 40-93, Department of Computer Science, University of Columbia,
USA, 1993.
H. Murase y S. K. Nayar. Illumination planning for object recognition in structured environ-
ments. En Proc. of the IEEE, Computer Society Conference on Computer Vision and Pattern
Recognition, pp. 31 –38, Seattle, Washington, USA, June 1994.

158 Referencias
H. Murase y S. K. Nayar. Visual learning and recognition of 3D objects from appearance.
International Journal of Computer Vision, 14, pp. 5–24, 1995.
D. Nair y J. K. Aggarwal. A focused target segmentation paradigm. En Proc. of the 4th European
Conference in Computer Vision, (ECCV’96), pp. 579–588, Oxford, UK, 1996.
P. Natarajan, Z. Lu, R. Schwartz, I. Bazzi, y J. Makhoul. Multilingual machine printed OCR.
International Journal of Pattern Recognition and Artificial Intelligence, 15(1), pp. 43–63, 2001.
S. K. Nayar, S. A. Nene, y H. Murase. Real-time 100 object recognition system. En Proc. of
the IEEE,International Conference on Robotics and Automation, volume 3, pp. 2321 –2325,
Minneapolis, Minnesota, USA, April 1996.
R. Nelson y A. Selinger. Learning 3D recognition models for general object from unlabeled
imagery: An experiment in intelligent Brute Force. En International Conference on Pattern
Recognition(ICPR00), pp. 1–8, Barcelona, Espana, September 2000.
K. Ohba y K. Ikeuchi. Detectability, uniqueness, and reliability of eigen windows for stable
verification of partially occluded objects. IEEE Trans. on Pattern Analysis and Machine
Intelligence, 19(7), pp. 1043–1047, 1997.
T. Pavlidis y S. Horowitz. Segmentation of plane curves. IEEE Trans. on Computers, 23, pp.
860–870, 1974.
J. Perez y E. Vidal. Optimum polygonal approximation of digitized curves. Pattern Recognition
Letters, 15(8), pp. 743–750, 1994.
T. Poggio y S. Edelman. A network that learns to recognize three-dimensional objects. Nature,
343, pp. 263–266, 1990.
T. Poggio y F. Girosi. Networks for approximation and learning. Proceedings of the IEEE, p.
78, September 1990.
M. J. D. Powell. Radial basis functions for multivariable interpolation: A review. En J. C. Mason
y M. G. Cox, (Eds.), Algorithms for Approximation of Functions and Data, pp. 143–167, New
York, 1987. Oxford University Press.
E. Prem. Symbol grounding and transcendental logic. En L. Niklasson y M. Boden, (Eds.),
Current Trends in Connectionism, pp. 271–282. Lawrence Erlbaum, Hillsdale, NJ, USA, 1995.
L. R. Rabiner. A tutorial on Hidden Markov Models and selected applications in speech recog-
nition. Proceedings of the IEEE, 77(2), pp. 257–286, 1989.

Referencias 159
K. Rao. Shape description of curved 3D objects for aerial surveillance. En M. Kaufmann, (Ed.),
Proc. of the ARPA Image Understanding Workshop, pp. 1065–1076, Palm Springs - CA, USA,
1996.
B. Ray y K. Ray. Determination of optimal polygon from digital curve using L1 norm. Pattern
Recognition, 26(4), pp. 505–509, 1993.
P. Reche, C. Urdiales, A. Bandera, C. de Trazegnies, y F. Sandoval. Corner detection by means
of contour local vectors. Electronics Letters, 38(14), pp. 699–701, 2002.
K. S. Roh y I. S. Kweon. 3D object recognition using a new invariant relationship by single
view. Pattern Recognition, 33(5), pp. 741–754, 2000.
C. A. Rosen y D. Nitzan. Use of sensors in programmable automation. Computer, 10(12), pp.
12–23, 1977.
A. Rosenfeld y J. Weszka. An improved method of angle detection on digital curves. IEEE
Trans. on Computers, 24, pp. 940–941, 1975.
L. Rosenthaler, F. Heitger, O. Kubler, y R. von der Heydt. Detection of general edges and
keypoints. En Proc. 2nd European Conference on Computer Vision, (ECCV’92), pp. 78–86.
Springer-Verlag, 1992.
P. L. Rosin. Representing curves at their natural scales. Pattern Recognition, 25(11), pp.
1315–1325, 1992.
P. L. Rosin. Augmenting corner descriptors. Graphical Models and Image Processing, 58(3), pp.
286–294, 1996.
C. A. Rothwell, A. Zisserman, D. A. Forsyth, y J. L. Mundy. Planar object recognition using
projective shape representation. International Journal of Computer Vision, 16(1), pp. 57–99,
1995.
M. Seibert y A. M. Waxman. Adaptive 3D object recognition from multiple views. IEEE Trans.
on Pattern Analysis and Machine Intelligence, 14(2), pp. 107–124, 1992.
A. Selinger y R. Nelson. A perceptual grouping hierarchy for appearance-based 3D object
recognition. Computer Vision and Image Understanding, 76(1), pp. 83–92, 1999.
S. A. Shafer y T. Kanade. Using shadows in finding surface orientations. Computer Vision,
Graphics and Image Processing, 22, pp. 145–176, 1983.

160 Referencias
A. Singh y M. O. Shneier. Grey level corner detection: A generalization and a robust real time
implementation. Computer Vision, Graphics, and Image Processing, 51(1), pp. 54–69, 1990.
S. Singh. Shape detection using gradient features for handwritten character recognition. En
Proc. of the 13th International Conference on Pattern Recognition (ICPR’96), volume 3, pp.
145–149, Vienna, Austria, 1996.
L. Sirovich y R. Everson. Analysis and management of large scientific databases. Int. Journal
of Supercomputing Applications, 6(1), pp. 50–68, 1992.
S. Smith y J. Brady. SUSAN: A new approach to low-level image-processing. International
Journal of Computer Vision, 23(1), pp. 45–78, 1997.
S. Startchik, R. Milanse, y T. Pun. Projective and illumination invariant representation of
disjoint shapes. En Proc. of the Fifth European Conference on Computer Vision (ECCV ’98),
p. 264, Freiburg, Alemania, 1998.
S. Sullivan y J. Ponce. Automatic model construction and pose estimation from photographs
using triangular splines. IEEE Trans. on Pattern Analysis and Machine Intelligence, 20(10),
pp. 1091–1097, 1998.
S. Suzuki, H. Ando, y T. Fujita. Unsupervised visual learning of three-dimensional objects using
a modular network architecture. Neural Networks, 12(7-8), pp. 1037–1051, 1999.
R. Szeliski. Rapid octree construction from image sequences. Computer Vision, Graphics and
Image Processing, 58(1), pp. 23–32, 1993.
H. Taylor y S. Karlin. An introduction to stochastic modelling. Academic Press, New York,
1994.
S. Ullman. High-level Vision: Object Recognition and Visual Cognition. MIT Press, Cambridge
- MA, USA, 1996.
C. Urdiales, A. Bandera, y F. Sandoval. Non parametric planar shape representation based on
adaptive curvature functions. Pattern Recognition, 35(1), pp. 43–53, 2002.
C. Urdiales, C. de Trazegnies, A. Bandera, y F. Sandoval. Corner detection based on adaptively
filtered curvature function. Electronic Letters, 39(5), pp. 426–428, 2003.
V. Vapnik. The Nature of Statistical Learning Theory. Springer, New York, 1995.
F. J. Varela, E. Rosch, y E. Thompson. The Embodied Mind: Cognitive Science and Human
Experience. MIT Press/Bradford Books, Cambridge - MA, USA, 1991.

Referencias 161
S. Venkatesh. A Study of Energy Based Models for the Detection and Classification of Image
Features. PhD thesis, The University of Western Australia, Department of Computer Science,
1990.
G. Wahba. Spline Models for Observation Data. Regional Conference series in applied mathe-
matics. Society for Industrial and Applied Mathematics, Philadelphia, PA, 1990.
D. Whiteside. The Mathematical Papers of Isaac Newton, volume II. Cambridge University
Press, Cambridge, 1969.
W. Wolberg, W. Street, y O. Mangasarian. Machine learning techniques to diagnose breast
cancer from image-processed nuclear features of fine needle aspirates. Cancer Letters, 77, pp.
163–171, 1994.
J. Zhou y T. Pavlidis. Discrimination of characters by a multi-stage recognition process. Pattern
Recognition, 27(11), pp. 1539–1549, 1994.
W. D. Zhou y J. Zhou. The development of EEG real-time monitoring system. Shandong Journal
of Biomedical Engineering, 18(3), pp. 22–26, 1999.
P. Zhu y P. M. Chirlian. On critical point detection of digital shapes. IEEE Trans. Pattern
Analysis and Machine Intelliggence, 17(8), pp. 737–748, 1995.
O. A. Zuniga y R. M. Haralick. Gradient threshold selection using the Facet Model. Pattern
Recognition, 21(5), pp. 493–503, 1988.


Apendice A
Modelos Ocultos de Markov.
Un Modelo Oculto de Markov (MOM) es un proceso doblemente estocastico, que consta
de un proceso de Markov no observable (oculto) Q = {Q1, Q2, ..., QN}, constituido por una
secuencia no observable de estados y un proceso observado V q = {V q,1, V q,2, ..., V q,T }. El estado
del sistema en cada instante t, Qt, puede ser uno cualquiera a escoger entre los estados de un
conjunto predefinido H = {H1,H2, ...,HM}, que se conoce como conjunto de los estados ocultos
del proceso. Cada una de las observaciones V q de la secuencia presenta un valor dependiente es-
tocasticamente de los estados ocultos. A continuacion se presenta, en la seccion 1, una definicion
formal de los Modelos de Markov. En la seccion 2 se extiende la definicion a los Modelos Ocultos
de Markov. En esta seccion se incluye una breve explicacion de la construccion de un Modelo
Oculto de Markov, introduciendo los algoritmos usualmente empleados para la resolucion de
problemas tıpicos. En particular, en la seccion 2.6, se presenta el algoritmo de entrenamiento de
Modelos Ocultos de Markov utilizado en la presente tesis.
1. Modelos de Markov
Un Modelo de Markov (MM) es un modelo matematico capaz de predecir probabilıstica-
mente el comportamiento de un proceso de Markov. No todos los procesos estocasticos, que se
puedan representar como una cadena de estados, se pueden modelar mediante MMs. Un proceso
estocastico se puede llamar de Markov solo si se cumple que, para todo instante de tiempo t, el
estado del proceso en el instante t, Qt, depende unicamente del estado del sistema en el instante
t− 1, Qt−1, y no de la historia del proceso, es decir:
P (Qt = Hj |Qt−1 = H i, Qt−2 = Hk, ...) = P (Qt = Hj |Qt−1 = H i) (A.1)
163

164 Capıtulo A. Modelos Ocultos de Markov.
Ası, se puede definir, para cada proceso de Markov, una matriz de transicion A = Ai,j , a
cada una de cuyas componentes Ai,j se llama probabilidad de transicion del estado H i al estado
Hj , y expresa la probabilidad de que, en un proceso de Markov dado, se presente el estado Hj
en el instante t, habiendose observado el estado H i en el instante anterior t− 1:
Ai,j = P (Qt = Hj |Qt−1 = H i) (A.2)
Como los parametros Ai,j se definen como valores de probabilidad, su valor debe estar
comprendido entre 0 y 1. Ademas se debe cumplir que:
n∑j=1
P (Qt = Hj |Qt−1 = H i) = 1, para todo i (A.3)
ya que en el instante t el proceso debe presentar necesariamente uno de los estados incluidos en
el conjunto H. Esta propiedad tambien se puede expresar mediante los parametros Ai,j de la
siguiente forma:
n∑j=1
Ai,j = 1, para todo i (A.4)
El siguiente ejemplo muestra como se aplica el modelado de Markov a la prediccion del
comportamiento de un sistema simple, cuyos estados representan el estado del clima con una
frecuencia diaria:
H = {lluvia, nubes, sol} (A.5)
Cada dıa se observa si el clima corresponde a una de estas tres categorıas y se anota
su evolucion. Para poder aplicar MMs es necesario suponer que el clima observado unicamente
depende del clima que hiciera el dıa anterior. El proceso queda descrito por una matriz de
transicion A. La matriz de transicion puede haberse definido basada en informacion a priori
sobre las relaciones entre los estados, o bien haberse deducido de la informacion experimental
disponible por la evolucion previa del proceso. Se supone que los coeficientes de la matriz A
toman los siguientes valores:
A =
0.2 0.3 0.50.6 0.3 0.10.1 0.3 0.7
(A.6)
Segun esta matriz, por ejemplo, si un dıa estuvo nublado, lo mas probable, con una
probabilidad de 0.6, es que al dıa siguiente llueva, aunque tambien puede permanecer nublado

2. Modelos Ocultos de Markov 165
o despejarse con una probabilidad de 0.3 y 0.1 respectivamente. Asimismo, disponiendo de un
modelo como el descrito, se puede evaluar la probabilidad de que ocurra una secuencia cualquiera
de estados Q = (lluvia, sol, nubes, nubes) mediante la concatenacion de las probabilidades de
transicion:
P (Q) = Alluvia,sol ·Asol,nubes ·Anubes,nubes = 0.5 · 0.3 · 0.3 = 0.045 (A.7)
En un modelo de Markov ideal, se supone que siempre hay un instante anterior respecto
del cual se puede medir una probabilidad de transicion. Sin embargo, algunos procesos de tipo
secuencial, aun cumpliendo las condiciones para ser procesos de Markov en todas sus transiciones,
tienen un momento de comienzo, antes del cual el estado del sistema no esta definido. Para poder
extender el tratamiento mediante modelos de Markov a este tipo de procesos, es necesario definir
un vector de probabilidad inicial Π. Cada uno de los elementos Πi del vector de probabilidad
inicial representa la probabilidad de que en el instante inicial el sistema presente el estado H i.
En el ejemplo anterior se ha tomado una secuencia de observaciones que comienza en
un instante t = 0 con la observacion del estado lluvia. Se han evaluado las probabilidades de
transicion a partir de este instante, pero no para la transicion de t = −1 a t = 0, puesto que el
proceso no esta definido en t = −1. Para evaluar completamente la probabilidad de ocurrencia
de la secuencia anterior, es necesario anadir la estimacion de la probabilidad de encontrar el
estado lluvia como primer estado. Dado un vector probabilidad inicial Π = (0.2, 0.2, 0.6) se
puede anadir la correccion al calculo de P (Q):
P (Q) = Πlluvia ·Alluvia,sol ·Asol,nubes ·Anubes,nubes = 0.2 · 0.5 · 0.3 · 0.3 = 0.009 (A.8)
Los MMs son utiles para modelar procesos directamente observables, que son, en general,
procesos relativamente sencillos. Para abordar problemas mas complejos, en los que existe cierta
inexactitud en la determinacion de los estados del proceso en cada instante, es necesario extender
este desarrollo a los Modelos Ocultos de Markov.
2. Modelos Ocultos de Markov
2.1. Introduccion
Un Modelo Oculto de Markov es un Modelo de Markov junto con un proceso estocastico
que relaciona los estados ocultos del proceso con una secuencia de observaciones. En el caso

166 Capıtulo A. Modelos Ocultos de Markov.
mas sencillo, cada una de las observaciones V t, toma valores de un conjunto discreto S =
{S1, S2, ..., SN} de posibles observaciones.
Un proceso oculto de Markov evoluciona en el tiempo pasando aleatoriamente de un
estado a otro, sin que esta evolucion sea observable, y ofreciendo a un observador externo en
cada paso, al azar, algun elemento del conjunto S.
Del mismo modo que ocurrıa en los procesos simples de Markov, cuando en el instante
t− 1, el proceso se encuentra en el estado Qt−1 = H i, tiene la probabilidad Ai,j de encontrarse
en el instante t en el estado Qt = Hj . Sin embargo, se debe recordar que la observacion de los
estados Qt−1 y Qt no es posible sino a traves del conjunto de posibles observaciones S. Ası, si
las observaciones en los instantes t − 1 y t han sido respectivamente V t−1 = Su y V t = Sv,
sera necesario contabilizar tambien la probabilidad de que, dado el estado oculto H i se haya
obtenido la observacion Su y de que, dado el estado oculto Hj , se haya obtenido Sv. Estas
probabilidades, que se llaman probabilidades de observacion se definen formalmente como:
Bi(Su) = P (Su|H i) (A.9)
Para ilustrar esta idea, se puede retomar el ejemplo de la seccion anterior para el mo-
delado del clima. Los estados del sistema siguen siendo la descripcion diaria del clima, pero
ahora no son directamente observables, por ejemplo, porque el observador este encerrado en una
habitacion desde la que no puede ver el exterior. Los datos climatologicos deben ser observados
a traves de medios indirectos, como puede ser a traves de las medidas de un higrometro y un
termometro. Ası, el observador define el siguiente conjunto de observaciones segun la humedad
relativa, HR, sea mayor o menor del 80% y la temperatura, T , mayor o menor de 15o:
S =
S1| HR < 80 % , T > 15o;S2| HR < 80 % , T < 15o;S3| HR > 80 % , T > 15o;S4| HR > 80 % , T < 15o
(A.10)
El numero de estados ocultos no tiene, necesariamente, que coincidir con el numero de
posibles observaciones, y de hecho en este ejemplo no lo es. De este modo, para interpretar el
clima que hace en el exterior, el observador se ve obligado a definir un conjunto de probabili-
dades de observacion, B. Como tanto los estados como las observaciones pertenecen a conjuntos
discretos, las probabilidades de observacion se pueden definir en forma matricial:
B =
0.1 0.1 0.3 0.50.1 0.2 0.6 0.10.6 0.2 0.1 0.1
(A.11)

2. Modelos Ocultos de Markov 167
Al igual que en la seccion anterior, el observador parte de una secuencia de observa-
ciones, V = (V 1 = S4, V 2 = S2, V 3 = S1), y pretende determinar la probabilidad de que su
modelo climatico la haya generado. La diferencia fundamental con el caso anterior es que aho-
ra la secuencia de observaciones pertenece al conjunto S y no al H. En un MOM para cada
secuencia de observaciones hay multiples posibles secuencias de estados ocultos que podrıan
haberlas generado. Ası, el observador del ejemplo podrıa plantearse cual es la probabilidad
de que se haya observado la secuencia V y que ademas la secuencia de estados ocultos sea
Q1 = (lluvia, sol, nubes). Esta probabilidad se calcularıa de la siguiente manera:
P (V|Q1) = P (lluvia|t = 0) · P (S4|lluvia) · P (sol|lluvia) · P (S2|sol) · P (nubes|sol) · P (S1|nubes)
P (V|Q1) = Πlluvia · blluvia(S4) ·Alluvia,sol · bsol(S2) ·Asol,nubes · bnubes(S1) (A.12)
Este calculo es solo valido para la secuencia de estados ocultos propuesta. Hay que
considerar que en este caso, al haber tres posibles estados ocultos y tratarse de una secuencia
de tres observaciones, hay 33 posibles secuencias de estados ocultos que, con mayor o menor
probabilidad, podrıan haber generado la secuencia de observaciones propuesta. En general, para
una secuencia de T observaciones en un proceso de M estados, hay MT secuencias posibles de
estados ocultos. Ası, la probabilidad total de haber obtenido la secuencia de observaciones V con
el modelo climatico propuesto vendra dada por la suma de las probabilidades de haber obtenido
dicha secuencia de observaciones con cada una de las posibles secuencias de estados ocultos:
P (V) =∑todo i
P (V|Qi) (A.13)
Para tener una vision general del problema hay que tener en cuenta tambien que el modelo
propuesto no es el unico posible modelo climatico que se adapta a la observacion efectuada. Para
respetar una notacion rigurosa del problema, es necesario incluir explıcitamente en el calculo la
referencia al modelo con el cual se han hecho los calculos. Si se denomina λ al modelo arriba
definido, la ecuacion A.13 queda:
P (V|λ) =∑todo i
P (V,Qi|λ)
=∑todo i
P (V|Qi, λ) · P (Qi|λ)
=∑todo i
ΠQ1i· bQ1
i(S4) ·AQ1
i ,Q2i· bQ2
i(S2) ·AQ2
i ,Q3i· bQ3
i(S1) (A.14)

168 Capıtulo A. Modelos Ocultos de Markov.
2.2. Elementos de los Modelos ocultos de Markov
Formalmente, un MOM discreto λ se define como una quintupla que describe un proceso
oculto de Markov:
λ = (S,H,Π,A,B) (A.15)
A continuacion se define cada uno de los elementos del MOM:
S representa un conjunto discreto de N elementos que describen las N posibles observa-
ciones que se pueden dar en el proceso.
H es un conjunto discreto de M estados ocultos del sistema. La correcta eleccion de los
estados ocultos y del conjunto de observaciones con el fin de describir fielmente el proceso
es crucial para facilitar la construccion del MOM.
Un vector de probabilidades iniciales de observacion Π = (Π1,Π2, ...,ΠM ). Cada elemento
Πi del vector Π representa la probabilidad de que el estado H i sea el primero de la secuencia
Q de estados ocultos del conjunto H. Las componentes de Πp toman valores de probabilidad
de modo que, como con toda seguridad el primer estado de la secuencia pertenece al
conjunto H, la suma de todas las componentes de Π esta normalizada a la unidad:
M∑i=1
πi = 1 (A.16)
siendo M el numero de clases para cada modelo p.
Una matriz de transicion Ap. Cada elemento Ai,j de Ap representa la probabilidad de que
mediante el modelo λ, el proceso llegue al estado Hj en el instante t, dado el estado H i
en el instante t − 1. Como el estado al que llega el sistema en el instante t debe estar
comprendido entre los estados del conjunto H, la suma de las probabilidades de transicion
desde un estado H i a todos los estados del conjunto H debe estar normalizada a la unidad:
n∑j=1
Ai,j = 1, para todo i (A.17)
Una matriz de probabilidad de observacion B. Los coeficientes bi,u de la matriz B son
iguales a las probabilidades de observacion Bi(Su) y relacionan el conjunto de observaciones
S con el conjunto de estados ocultos H. Cada bi,u equivale a la probabilidad de que, dado
el modelo λ, se observe Su cuando el estado oculto es el H i. Como, dado un estado oculto
H i, la observacion del mismo debe dar como resultado uno de los elementos de S, la suma

2. Modelos Ocultos de Markov 169
de las probabilidades de observar todos los elementos de S debe estar normalizada a la
unidad:
N∑u=1
bi,u = 1, para todo i (A.18)
Un Modelo Oculto de Markov ası definido puede entenderse como el modelo matematico
de un proceso real. En este caso, el analisis mediante MOMs se puede aplicar a resolver en
general problemas de modelado, como pueden ser la generacion de secuencias de observaciones
equivalentes a las que habrıa generado un proceso real , o la explicacion por que un proceso real
da una determinada secuencia de observaciones.
2.3. Definicion de tres problemas basicos
Siempre que se aplican MOMs a problemas de modelado resulta necesario resolver proble-
mas matematicos relativamente complejos. Afortunadamente, los la mayorıa de estos problemas
pueden reducirse a los tres siguientes:
1. Dada una secuencia de observaciones V = {V q,1, V q,2, ..., V q,T } y un modelo λ, calcular
eficientemente la probabilidad de que ocurra la secuencia de observacion con este modelo,
P (V|λ).
2. Dada una secuencia de observaciones V = {V q,1, V q,2, ..., V q,T } y el modelo λ, elegir la
secuencia Q de estados ocultos que resulta optima para explicar la secuencia de observa-
ciones.
3. Dado un proceso, un conjunto S de posibles observaciones y un conjunto H de estados
ocultos, encontrar los valores de los parametros Π, A y B del modelo λ que maximizan
la probabilidad de ocurrencia de las secuencias de observaciones V que pueda generar el
sistema.
2.4. Resolucion del problema de evaluacion
El problema 1 o problema de evaluacion tal como se ha formulado arriba consiste en
calcular eficientemente la probabilidad de que ocurra una determinada secuencia de observacion
con un modelo, P (V|λ). No obstante tambien se puede entender como la evaluacion de en
que medida un modelo λ se ajusta a una secuencia de observaciones dada V. Este punto de
vista es especialmente util cuando se intenta elegir de entre varios modelos posibles cual es el

170 Capıtulo A. Modelos Ocultos de Markov.
que mejor se ajusta a la secuencia de observaciones. El calculo, evidentemente, se puede realizar
mediante la ecuacion A.14. Sin embargo, este calculo implicarıa un tiempo de computo excesivo
para sistemas de tamano mediano. Si se cuenta con M estados ocultos y T observaciones, como
hay MT posibles secuencias ocultas de estados, hay que realizar una suma de MT sumandos.
Ademas, cada sumando es un producto de 2 ·T terminos, por lo tanto, en total, hay que realizar
2 ·T ·MT operaciones. Afortunadamente, se puede reducir este numero de operaciones mediante
el algoritmo de avance (Forward Propagation Algorithm) (Rabiner, 1989).
2.4.1. Algoritmo de avance
Considerese la variable de avance αt(i) definida como la probabilidad ocurra una secuen-
cia parcial de longitud t < T , (V 1, V 2, ...V t) y que se de el estado H i en el instante t.
αt(i) = P (V 1, V 2, ...V t, Qt = H i|λ) (A.19)
αt(i) se puede definir por induccion de la siguiente manera:
1. Inicializacion:
α1(i) = Πi ·Bi(V 1) 1 ≤ i ≤ M (A.20)
2. Induccion:
αt+1(i) =
[M∑i=1
αt(i) ·Ai,j
]·Bj(V t+1) 1 ≤ i ≤ M
1 ≤ t ≤ T − 1 (A.21)
3. Terminacion
P (V|λ) =M∑i=1
αt(i) (A.22)
En el paso 1 se define α1(i) como la probabilidad de ocurra el estado H i en t = 1 y
se observe V 1, es decir P (V 1, Q1 = H i|λ). En el paso 2 se presenta ilustrado en la Fig. A.1.a.
En dicha figura se muestra como el estado Hj en el instante t + 1 puede ser alcanzado desde
cualquiera de los estados de H en el instante t. La probabilidad de llegar a Hj desde H i, habiendo

2. Modelos Ocultos de Markov 171
observado la secuencia V 1, V 2, ...V t es igual a la probabilidad de llegar a H i habiendo observado
V 1, V 2, ..., V t − 1 multiplicada por la probabilidad de transicion de H i a Hj , es decir:
P (V 1, V 2, ..., V t, Qt+1 = Hj |Qt = H i, λ) = P (V 1, V 2, ..., V t, Qt = H i|λ) ·Ai,j (A.23)
La probabilidad de, ademas, observar V t+1 en el instante t + 1 es:
P (V 1, V 2, ...V t+1, Qt+1 = Hj |Qt = H i, λ) = (A.24)
= P (V 1, V 2, ..., V t, Qt = H i|λ) ·Ai,j ·Bj(V t+1)
Las ecuaciones A.23 y A.24 representan la probabilidad de ocurrencia de Hj y observacion
de V 1, V 2, ..., V t+1, limitando la ocurrencia del estado anterior a H i. Si se quiere calcular la
Figura A.1: a)Secuencia de operaciones para el calculo de la variable de avance, αt(i); b) secuenciade operaciones para el calculo de la variable de retroceso, βt(i); y c) secuencia de operacionespara el calculo de la probabilidad de transicion de H i a Hj en el instante t

172 Capıtulo A. Modelos Ocultos de Markov.
probabilidad anterior pudiendose haber presentado cualquier estado oculto en el instante t, es
necesario sumar los terminos obtenidos en la ecuacion A.24 para todo i:
P (V 1, V 2, ..., V t+1, Qt+1 = Hj |λ) = (A.25)
=
[M∑i=1
P (V 1, V 2, ...V t, Qt = H i|λ) ·Ai,j
]·Bj(V t+1)
Esta ecuacion es equivalente a A.21. Es evidente que, con esta definicion de αt(i), la
igualdad en 2 es equivalente a esta otra:
P (V|λ) =M∑i=1
P (V 1, V 2, ...V t, QT = H i|λ) (A.26)
es decir, representa fielmente la probabilidad de haber observado la secuencia (V 1, V 2, ...V t, QT )
dado el modelo λ. se puede comprobar que de este modo se reduce el numero de operaciones
necesarias para calcular P (V|λ) a M2 · T .
2.5. Resolucion del problema de busqueda de secuencia optima
El segundo problema se plantea como la busqueda de la secuencia de estados ocultos
que mejor se adapta a la secuencia de observaciones, dado un modelo λ. Al contrario que en
el problema 1, este no tiene necesariamente una solucion unica. Una de las dificultades para
resolverlo es la definicion de un criterio de adaptabilidad entre secuencia de observaciones y
secuencia de estados ocultos. Una de las posibles soluciones, conocida como algoritmo de Viterbi
(Rabiner, 1989) esta basada en la definicion de secuencia de estados optima Qk, para unas
observaciones dadas V, a aquella que maximiza la probabilidad P (V,Qk|λ). De manera similar
a como se4 hizo en el algoritmo de avance, se define la cantidad δt(i), que contabiliza el mejor
resultado de probabilidad para una secuencia de observaciones (V 1, V 2, ...V t) y cuyo proceso
oculto termina en H i:
δt(i) = maxQ1,Q2,...,Qt−1
P (Q1, Q2, ..., Qt−1, Qt = H i, V 1, V 2, ...V t|λ) (A.27)
Por induccion se puede definir:
δt+1(j) =[max
iδt(i) ·Ai,j
]·Bj(V t+1) (A.28)

2. Modelos Ocultos de Markov 173
Para encontrar la secuencia optima de estados ocultos basta, entonces, con seguir la
secuencia de argumentos que maximizan A.28 desde el instante t = 1 hasta t = T (Rabiner,
1989).
2.6. Resolucion del problema de entrenamiento
El problema 3, o problema de entrenamiento, es el mas difıcil de resolver de los tres
propuestos, consiste en determinar los parametros Π A y B que mejor describen un proceso
dado. En primer lugar hay que notar que el problema, en realidad, empieza por la definicion del
conjunto de observaciones de interes y el conjunto de estados ocultos que resulta mas adecuado
para el modelado. Esto es especialmente importante si se tiene en cuenta que, en ocasiones,
incluso la naturaleza de los estados ocultos es desconocida al observador. Para entender esto,
imagınese que el observador del ejemplo de la seccion 2.1 anterior nunca hubiera salido de su
habitacion cerrada. En este caso, ignorarıa que los estados climaticos se corresponden en realidad
a una situacion exterior de sol, nubes o lluvia. No obstante, podrıa desarrollar un MOM que
describiera la secuencia de observaciones de la que ha sido testigo, aunque, evidentemente, una
eleccion correcta le resultarıa mucho mas difıcil que si tuviera un conocimiento a priori del
problema.
En realidad, no existe un modo analıtico de resolver el problema completo de entre-
namiento del modelo. De hecho, dada una secuencia de observaciones, no hay un metodo optimo
para obtener los parametros del modelo. A lo mas que se puede aspirar es a encontrar un
maximo local que proporcione unos parametros razonables para el modelo. Para ello se puede
utilizar el algoritmo de avance-retroceso (forward-backward algorithm), basado en el algoritmo
Baum-Welch, adaptado por Rabiner (Rabiner, 1989), que se presenta a continuacion.
Para desarrollar el algoritmo, es necesario definir una variable de retroceso βt(i), que
representa la probabilidad de que, dado el modelo λ y el estado en el instante t, H i, se produzca
la secuencia de observaciones V t+1, V t+2, ...V T entre los instantes t + 1 y T :
βt(i) = P (V t+1, V t+2, ...V T |Qt = H i, λ) (A.29)
De nuevo se puede definir la variable de retroceso por induccion, a partir del instante T :
1. Inicializacion:
βT (i) = 1 1 ≤ i ≤ M (A.30)

174 Capıtulo A. Modelos Ocultos de Markov.
2. Induccion:
βt(i) =M∑
j=1
Ai,j ·Bj(V t+1) · βt + 1(j) 1 ≤ i ≤ M
1 ≤ t ≤ T − 1 (A.31)
El paso 1 define el valor de βT (i) arbitrariamente como la unidad. El paso 2, que se
muestra de forma grafica en la Fig. A.1.b, define inductivamente βt(i) de modo que iguala la
probabilidad propuesta en la ecuacion A.29.
Con ayuda de las variables de avance y retroceso, αt(i) y βt(i), se puede definir una
nueva variable, ξt(i, j), como la probabilidad de que, dados el modelo λ y la observacion V =
(V 1, V 2, ...V T ), el proceso pase por el estado H i y el estado Hj en los instantes t y t + 1
respectivamente:
ξt(i, j) = P (Qt = H i, Qt+1 = Hj |V, λ) (A.32)
Se puede observar que, combinando el significado de las variables de avance y retroceso
(Fig. A.1.c), se puede igualar la definicion de la variable ξt(i, j) a la siguiente:
ξt(i, j) =αt(i) ·Ai,j ·Bj(V t+1) · βt
P (V|λ)(A.33)
Asimismo, se puede definir la variable γt(i) como la probabilidad de que el proceso pase
por el estado H i en el instante t, dados la secuencia de observaciones y el modelo. Esta nueva
variable es simplemente la suma de las variables ξt(i, j) para cualquier estado oculto en t + 1,
es decir:
γt(i) =M∑
j=1
ξt(i, j) (A.34)
Si se suma la variable γt(i) para todo instante t, dara una medida del numero de transi-
ciones esperables desde el estado H i, dado el modelo λ. De modo similar, si se suma la variable
ξt(i, j), el resultado sera el numero de transiciones esperables del estado H i al Hj , dado el
modelo λ:
T∑t=1
γt(i) = numero de transiciones esperables desde el estado H i (A.35)
T∑t=1
ξt(i, j) = numero de transiciones esperables del estado H i al Hj (A.36)

2. Modelos Ocultos de Markov 175
Usando estas dos cantidades, y el concepto de probabilidad como recuento de eventos,
se pueden recalcular los parametros del modelo:
Πi = frecuencia esperada de ocurrencia del estado H i en (t = 1) = γ1(i) (A.37)
Ai,j =numero de transiciones esperables del estado H i al Hj
frecuencia esperada de ocurrencia del estado H i=
=∑T
t=1 ξt(i, j)∑Tt=1 γt(i)
(A.38)
Bj(Su) =frecuencia esperada de ocurrencia del estado Hj y observando Su
frecuencia esperada de ocurrencia del estado Hj=
=
∑Tt=1,V t=Su γt(i)∑T
t=1 γt(i)(A.39)
Se puede ver que, dado un modelo λ optimo para la secuencia de observaciones, la eval-
uacion de las cantidades Πi , Ai,j y Bj(Su) deben dar como resultado los parametros originales
del modelo: Π, A y B. De lo contrario, las ecuaciones A.38, A.39 y A.39 se pueden utilizar para
hacer una estimacion iterativa de los mismos, hasta que la variacion de los parametros entre dos
pasos consecutivos de la iteracion sea suficientemente pequena.
Es importante notar que, dado que el procedimiento de estimacion de los parametros
del modelo no asegura la obtencion de una maximo global, es conveniente seguir un proceso de
inicializacion que situe el valor inicial de los mismos dentro de un rango razonable. Este proceso
puede hacerse facilmente si se dispone de alguna informacion sobre el comportamiento esperable
del sistema. Si no es ası, habrıa que complementar este metodo iterativo con algun mecanismo
estadıstico que estimara la bondad del maximo esperado, como el metodo de Montecarlo (Cowles
y Carlin, 1996).
Tambien se puede simplificar en gran medida el calculo si se pueden asignar las proba-
bilidades de observacion Bj(Su) a priori, de modo que no sea necesario evaluar su reestimacion
durante el entrenamiento del modelo. Esto es posible en muchos casos, siempre que se conozcan
o se puedan asignar los estados ocultos a mano y se conoce la relacion causa-efecto que gobierna
el proceso de generacion de observaciones.

176 Capıtulo A. Modelos Ocultos de Markov.
2.7. Modelos Ocultos de Markov de sistemas con variables de observacioncontinuas
Hasta ahora se ha considerado que todas las posibles observaciones pertenecen a un con-
junto discreto. Esto no siempre es conveniente para ajustar el modelo a la observacion, puesto
que la discretizacion de las variables de salida puede provocar una perdida de informacion, aun
a pesar de que los estados ocultos puedan pertenecer a un conjunto discreto. Para evitar esta
perdida se puede introducir la variabilidad continua de las observaciones en el tratamiento ante-
rior sin mas que sustituir la matriz de probabilidades de observacion B por una funcion densidad
de probabilidad de observacion Bj(s) para cada estado Hj , donde s es una variable observa-
da, perteneciente a un conjunto continuo de posibles observaciones S. Esta extension resulta
especialmente util a la hora de modelar sistemas reales, en los que las variables son continuas.
Ası, por ejemplo, en el modelo climatico propuesto, introducir en el modelo la observacion de
humedad relativa y temperatura como variables continuas serıa mucho mas fiel a la realidad. De
este modo se pueden representar las probabilidades de que el dıa sea lluvioso, nublado o soleado
como tres funciones densidad de probabilidad dependientes de la temperatura y la humedad.
Esta mejor adaptabilidad a la realidad redunda en una representacion mas precisa del proceso
modelado.


















