
sintaxis de los lenguajes de programación
63
Capítulo 2. Sintaxis de los Lenguajes de Programación Raúl José Palma Mendoza
Transcript of sintaxis de los lenguajes de programación

Capítulo 2. Sintaxis de los Lenguajes de Programación
Raúl José Palma Mendoza

Capítulo 2. Sintaxis de los Lenguajes de Programación
A diferencia de los lenguajes naturales como el Español o el Inglés, los lenguajes de programación deben ser precisos, su sintaxis y semántica deben ser definidos sin ambigüedad.
Para lograr esto los diseñadores de lenguajes usan notaciones formales sintácticas y semánticas.

Capítulo 2. Sintaxis de los Lenguajes de Programación
Por ejemplo, podríamos definir la sintaxis de los números naturales con la siguiente notación:
digit → '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
non_zero_digit → '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'
natural_number → non_zero_digit digit *
Los dígitos no son más que símbolos y les damos significado cuando decimos que representan los números naturales de cero a nueve, o si decimos que representan colores o la nota de una evaluación.

Capítulo 2. Sintaxis de los Lenguajes de Programación
En este capítulo nos concetraremos en la sintaxis de los lenguajes, especificamente en:
Cómo especificar las reglas estructurales de un lenguaje de programación.
Cómo el compilador identifica la estructura de un programa dado.
Para la primera tarea se usan expresiones regulares y gramáticas libres de contexto, para la segunda están los escáners y los parsers.

2.1 Especificando La Sintaxis: Expresiones Regulares y Gramáticas Libres de Contexto
Un conjunto de cadenas que pueden se definido usando las siguientes tres reglas es llamado un conjunto regular o un lenguaje regular:
Concatenación Alternación Repetición
Los conjuntos regulares son generados por expresiones regulares y son reconocidos por los escáners.

2.1 Especificando La Sintaxis: Expresiones Regulares y Gramáticas Libres de Contexto
Un conjunto de cadenas que pueden se definido usando las anteriores tres reglas más la recursión es llamado un Lenguaje Libre de Contexto (CFL).
Los Lenguajes Libres de Contexto son generados por Gramáticas Libres de Contexto y reconocidos por los parsers.

2.1.1 Tokens y Expresiones Regulares
Los tokens vienen en varios tipos como: palabras clave, identificadores, constantes de varios tipos, etc. Algunos tipos están formados por una sola cadena de caracteres (ej.: operador de incremento) y otros como el identificador que están formados por un grupo de cadenas de caracteres que tienen una forma común (ej.: miVariable).
El término token se usa para referirse tanto de forma genérica (ej.: identificador) como a un caso específico (ej.: operador de incremento).

2.1.1 Tokens y Expresiones Regulares
Ejemplo: El lenguaje C tiene más de 100 tipos de tokens, entre ellos: 37 palabras clave (double, if, return, etc.), identificadores (mi_variable, sizeof, printf, etc.), enteros (765, 0xfd23), números de coma-flotante (6.223e4), constantes de caracteres ('x', '\'', '\0170'), literales de cadena (”snerk”, “hola soy yo”), 54 puntuadores (+, ], ->, *=, :, ||, etc.).

2.1.1 Tokens y Expresiones Regulares
Para especificar los tokens usamos la notación de las expresiones regulares. Una expresión regular es cualquiera de las siguientes: Un caracter.
La cadena vacía, .∊ Dos expresiones regulares una después de la otra
(concatenación).
Dos expresiones regulares separadas por una barra vertical (alternación).
Una expresión regular seguida de una estrella de Kleene (repetición).

2.1.1 Tokens y Expresiones Regulares
Ejemplo: Sintaxis de las constantes numéricas aceptadas por una calculadora simple:
number → integer | real
integer → digit digit *
real → integer exponent | decimal ( exponent | )∊
decimal → digit * ( '.' digit | digit '.' ) digit *
exponent → ( 'e' | 'E' ) ( '+' | '-' | ) integer∊
digit → '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'

2.1.1 Tokens y Expresiones Regulares
Los símbolos a la izquierda de → representan los nombres de las expresiones regulares, el primero que es “number” lo escojimos como nombre de token, el resto sirve como ayuda para construir expresiones más grandes.
Los parentesis se usan para evitar ambigüedad con respecto al lugar donde termina un subexpresión e inicia otra.
Observe que la recursión no se utiliza, ni siquiera de forma indirecta.

2.1.1 Tokens y Expresiones Regulares
Asuntos de Formato Algunos lenguajes hacen diferencia entre
mayúsculas y minúsculas (ej.: Modula 2/3, C y sus descendientes) otros no (ej: Ada, Pascal, Common Lisp).
Algunos lenguajes sólo permiten letras y dígitos en sus identificadores (ej: Modula 3 y Standard Pascal), otros permiten guiones bajos (Pascal) y otros una variedad de símbolos (Common Lisp).

2.1.1 Tokens y Expresiones Regulares
Asuntos de Formato Los lenguajes modernos están incluyendo
soporte para conjuntos de caracteres multibyte, basados generalemente los estándares Unicode e ISO/IEC 10646.
Muchos permiten estos tipos de caracteres en cadenas y comentarios y cada vez también se están permitiendo también en los identificadores.

2.1.1 Tokens y Expresiones Regulares
Asuntos de Formato Muchos de los lenguajes modernos son también de
“formato libre” es decir que los programas son una secuencia simple de tokens, lo que importa es el orden de los mismos y no su posición en una página impresa. El “espacio en blanco” entre tokens es ignorado y sólo se usa para separar un token del siguiente.
Algunos lenguajes son excepción a esta regla, algunos usan los saltos de línea para separar expresiones (ej.: Visual Basic). Para otros la indentación es importante por ejemplo para determinar el cuerpo de un ciclo (ej: Haskell y Phyton).

2.1.2 Gramáticas Libres de Contexto
Las expresiones regulares son buenas para definir tokens, pero no pueden definir construcciones anidadas que son centrales en los lenguajes de programación, por ejemplo para definir la estructura de una expresión aritmética:
expr → 'id' | 'number' | '-' expr | '(' expr ')' | expr op expr
op → '+' | '-' | '*' | '/'
Nota: No se usan los paréntesis como metasímbolos.

2.1.2 Gramáticas Libres de Contexto
Cada una de las reglas de una gramática libre de contexto se conoce como producción.
Los símbolos de la izquierda de una producción se conoce como variables o símbolos no terminales.
Puede haber cualquier número de producciones para el mismo símbolo no terminal.
Los símbolos que conforman las cadenas derivadas de la gramática se conocen como símbolos terminales (entre comillas simples ' ').

2.1.2 Gramáticas Libres de Contexto
Los símbolos terminales no pueden aparecer en el lado izquierdo de una producción y son los tokens del lenguaje que defina la gramática libre de contexto.
Uno de los no terminales es llamado el símbolo de inicio y nombra a la construcción definida por toda la gramática.
La notación usada para expresar las gramáticas libres de contexto es conocida como BNF (Backus-Naur Form).

2.1.2 Gramáticas Libres de Contexto
Originalmente la forma BNF no incluía la estrella de Kleene ni los paréntesis para evitar ambigüedades, al incluirlos en la notación BNF, le llamaremos EBNF (Extended BNF).
Por ejemplo podríamos definir una lista de identificadores usando EBNF como:
id_list →' id' (',' 'id')*
que sería equivalente a (en BNF):
id_list → 'id'
id_list → id_list ',' 'id'

2.1.3 Derivaciones y Árboles de Parseo
Ejemplo: Derive la cadena “pendiente * x + interecepto”
expr expr op expr⇒
⇒ expr op id
⇒ expr + id
⇒ expr op expr + id
⇒ expr op id + id
⇒ expr * id + id
⇒ id * id + id
(pediente) * (x) + (intercepto)

2.1.3 Derivaciones y Árboles de Parseo
Una derivación es una serie de reemplazos que nos permiten concluir que una cadena de terminales surge de un símbolo de inicio siguiendo las producciones de una gramática libre de contexto.
Cada cadena de símbolos en el camino es llamada “forma sentencial”. La última forma sentencial que consiste sólo de terminales es llamada el producto de la derivación.
En la derivación anterior se reemplazó el no terminal más a la derecha, y por eso decimos que fue una derivación más a la derecha. También se pudo haber hecho una derivación más a la izquierda o seguido un efoque mezclado.
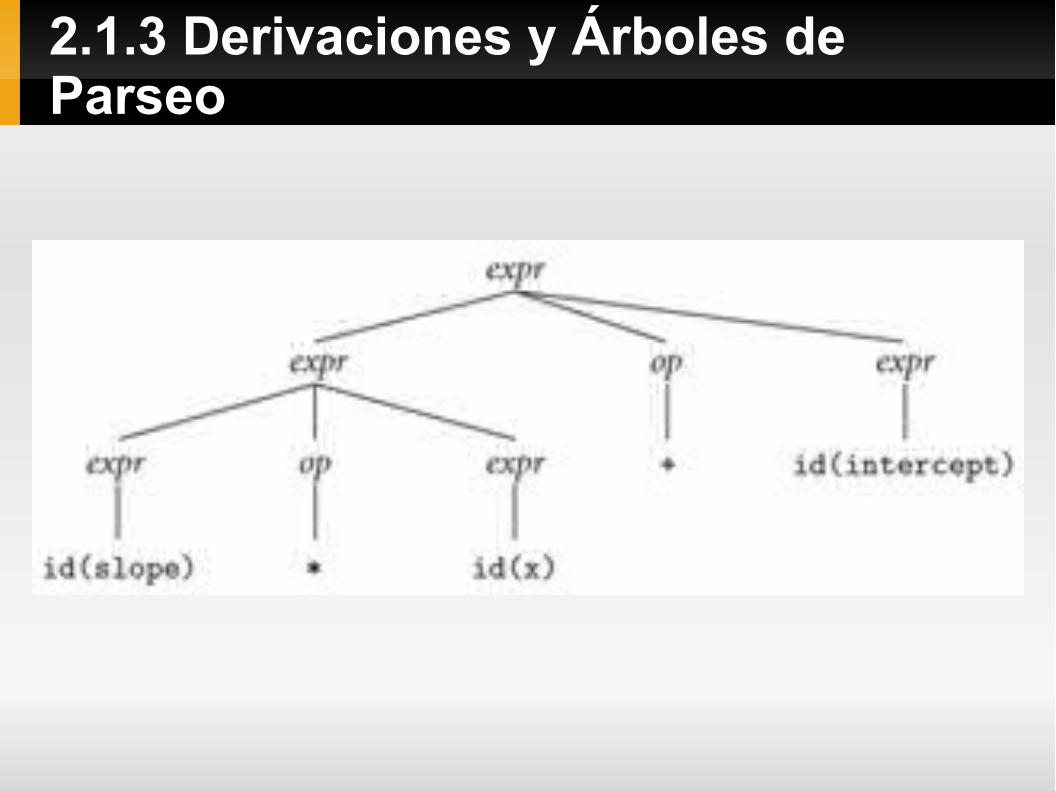
2.1.3 Derivaciones y Árboles de Parseo

2.1.3 Derivaciones y Árboles de Parseo
Usamos un árbol de parseo para representar gráficamente una derivación, la raíz del árbol es el símbolo de inicio, sus hojas son el producto y los nodos intermedios representan el uso de una producción.
Existen infinitas gramáticas libres de contexto para un determinado lenguaje. Aunque algunas son más útiles que otras, al diseñar un lenguaje de programación se busca una que refleje la estructura interna de los programas de forma que sea útil para el resto del compilador.

2.1.3 Derivaciones y Árboles de Parseo
Una grámatica que permite que se genere más de un árbol de parseo para una cadena de terminales se dice que es ambigüa y esto genera problemas a la hora de construir un parser (aunque muchos parser las permiten).
Ejercicio: Demostrar mediante un árbol de parseo que la gramática que hemos definido para las expresiones aritméticas es ambigüa.

2.1.3 Derivaciones y Árboles de Parseo
Ejemplo: Agregando producciones que capturen la asociatividad y la precedencia de los operadores podemos modificar la gramática anterior y convertirla en una gramática sin ambigüedades.
expr → term | expr add_op term
term → factor | term mult_op factor
factor → 'id' | 'number' | '-' factor | '(' expr ')'
add_op → '+' | '-'
mult_op → '*' | '/'
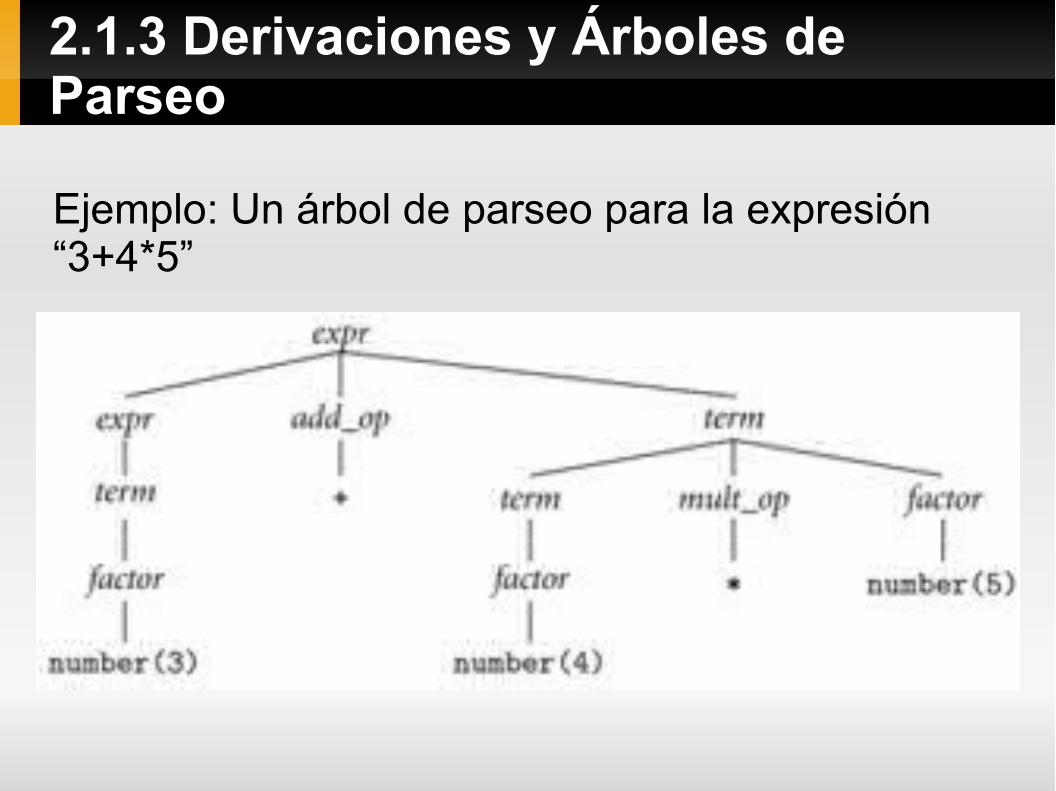
2.1.3 Derivaciones y Árboles de Parseo
Ejemplo: Un árbol de parseo para la expresión “3+4*5”

2.1.3 Derivaciones y Árboles de Parseo
Ejercicio: Cree un árbol de parseo para la expresión “10 - 4 - 3”.

2.2 Escaneo
Dadas las siguientes definiciones de tokens, para un lenguaje simple de una calculadora:
assign → ':='
plus → '+'
minus → '-'
times → '*'
div → '/'
lparen → '('
rparen → ')'

2.2 Escaneo
id → letter (letter | digit)* except for read and write
number → digit digit * | digit * ('.' digit | digit '.') digit *
comment → '/*' (non-* | '*' non-/)* '*/' | '//' (non-newline)*
Observemos que en la definición de id se han escrito dos tokens que son excepciones: “read” y “write”. Además por brevedad se usó los tokens “non-*”, “non-/” y “non-newline” para referirse a todos los carácteres que no son el asterisco, la pleca y una nueva linea respectivamente.
Vemos la última nueva línea que separa un comentario con '//' de otra cosa, no se incluye como parte del token.

2.2 Escaneo
¿Qué método usamos para reconocer los tokens de nuestro lenguaje?
A la primera respuesta a esta pregunta le llamamos opción “ad hoc”, por ser un software específico para los tokens de nuestro lenguaje.
A continuación mostraremos el pseudocódigo de un escáner de este tipo, que después de encontrar un token retorna al parser y cuando es invocado nuevamente busca un nuevo token usando los siguientes caracteres disponibles.

skip any initial white space (spaces, tabs, and newlines)
if cur_char {'(', ')', '+', '-', '*'}∈ return the corresponding single-character token
if cur_char = ':' read the next character if it is '=' then return assign else announce an error
if cur_char = '/' peek at the next character if it is '*' or '/' read additional chars until "*/" or newline is seen, respectively jump back to top of code else return div
(continua en la siguiente diapositiva ...)

if cur_char = . read the next character if it is a digit read any additional digits return number else announce an error
if cur_char is a digit read any additional digits and at most one decimal point return numberelse announce an error

2.2 Escaneo
Ejemplo: La capacidad de anidar comentarios puede ser buena para el programador (para comentar temporalmente grandes porciones de código), pero la mayoría de los escáners no reconocen estructuras anidadas. Por esto en C++ y en C99, no se permite anidar comentarios del mismo estilo, pero si se permite anidarlos con estilos diferentes (anidar “//” dentro de “/* … */” y viceversa).
Aunque se recomienda mejor usar la compilación condicional (#if).

2.2 Escaneo
La regla del token más largo, implica que es cada invocación del escáner se tratará de leer el token de mayor longitud posible, por ejemplo en un lenguaje como C se leerá un token com “3.1416” y nunca como “3”, luego “.” y después “1416”.

2.2 Escaneo
Generalmente los compiladores de producción usan escáners “ad hoc” pues el código es más compacto y eficiente.
Aunque durante el desarrollo es preferible construir un escáner de una forma más estructurada como una representación explícita de un autómata finito.
Los autómatas finitos puede ser creados automáticamente de un conjunto de expresiones regulares (facilitando los cambios).
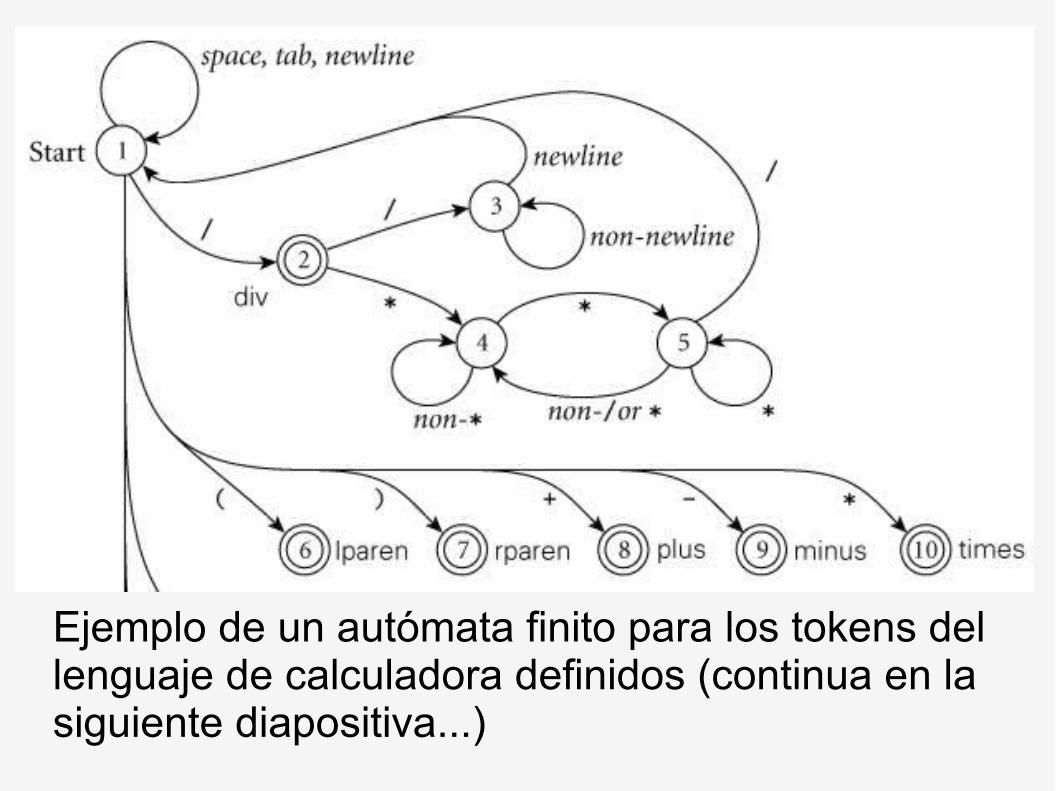
Ejemplo de un autómata finito para los tokens del lenguaje de calculadora definidos (continua en la siguiente diapositiva...)

Los estados finales donde se reconoce el token tiene un doble círculo.

2.2.1 Generando un Autómata Finito
Aunque podemos generar un autómata a mano, es más común hacerlo automáticamente a partir de un conjunto de expresiones regulares usando una herramienta de software. Ahora veremos el proceso manual.
El autómata de la figura anterior es determinista (AFD), no hay ambigüedad en lo que tiene que hacer, porque en un estado dado con un carácter de entrada dado nunca hay más de una posible transición (un arco o arista con la misma etiqueta).

2.2.1 Generando un Autómata Finito
El proceso de generación sigue tres pasos, el primero consiste en convertir las expresiones regulares en un autómata no determinista (AFND) que se diferencia de un AFD en que:
Puede haber más de una transición desde un estado a otro etiquetada con el mismo carácter.
Pueden existir transiciones “epsilon”, etiquetadas con “∊”.

2.2.1 Generando un Autómata Finito
Decimos que el AFND acepta un token si existe un camino desde el estado inicial hasta el final en el cual sus transiciones no epsilon, llevan como etiquetas los caracteres del token en orden.
Para evitar la necesidad de hacer una búsqueda entre todos los caminos por uno que funcione, el siguiente paso consiste en convertir el AFND en un AFD, y el tercer paso consiste en optimizar el AFD para que tenga el menor número de estados posible.

2.2.1 Generando un Autómata Finito
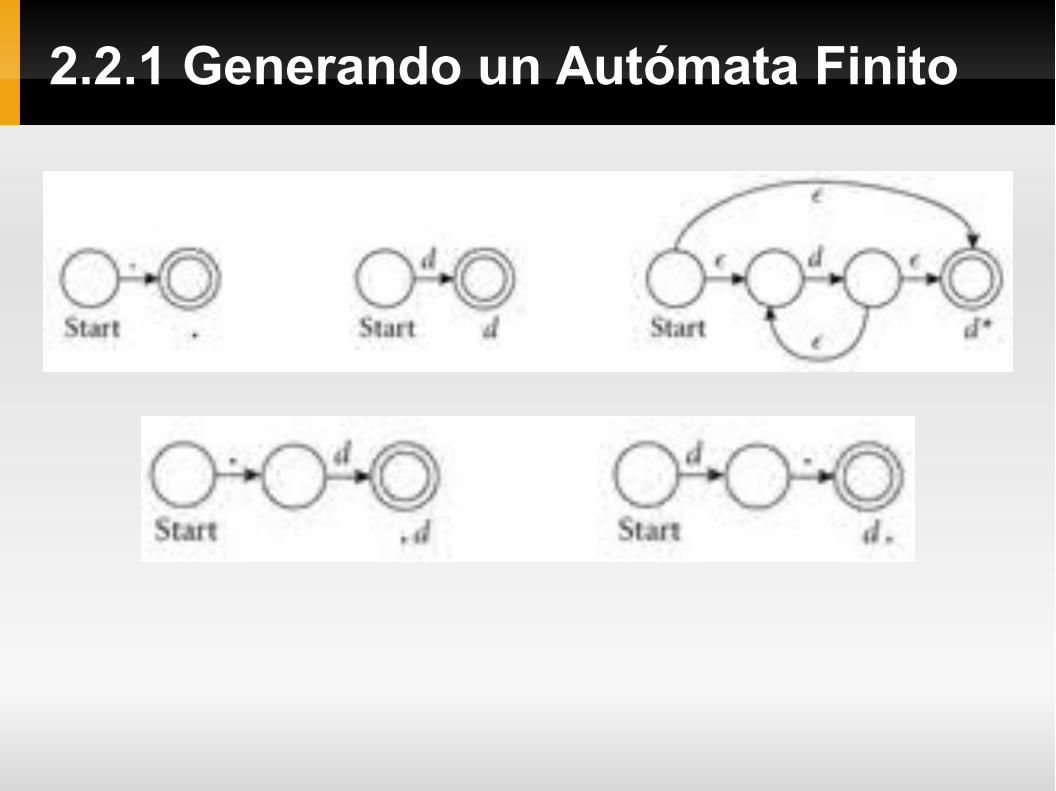
Una expresión regular que consiste en un simple carácter es equivalente al AFD de ilustrado en la parte (a) de la siguiente figura. De la misma forma una expresión regular compuesta por la cadena vacía se muestra como un AFND de dos estados unidos por una transición epsilon.
En las partes (b), (c) y (d) se muestran los AFND que se generan a partir de la concatenación, la alternación y la cerradura de Kleene, respectivamente.

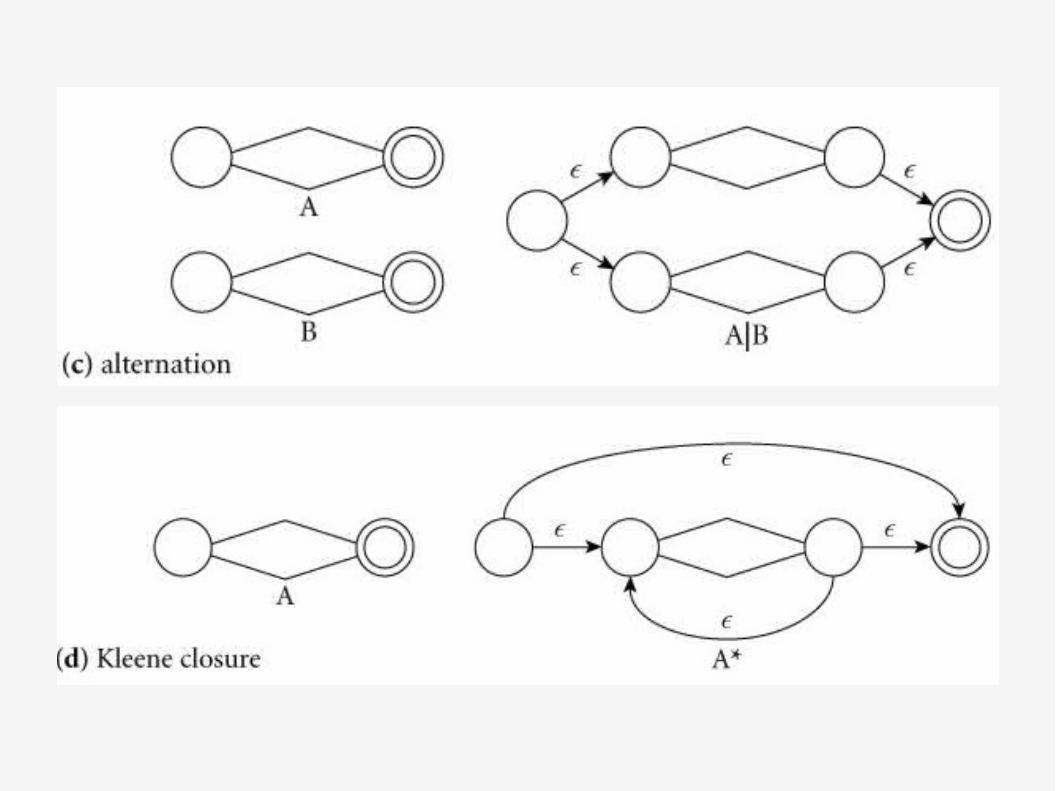

2.2.1 Generando un Autómata Finito
Ejemplo: Consideremos la creación de un AFD para el token “decimal”, que habiamos definido como:
decimal → digit * ('.' digit | digit '.') digit *
En las ilustraciones a continuación, usamos “d” para referirnos a la expresión regular “digit”, por brevedad.
2.2.1 Generando un Autómata Finito
2.2.1 Generando un Autómata Finito

2.2.1 Generando un Autómata Finito
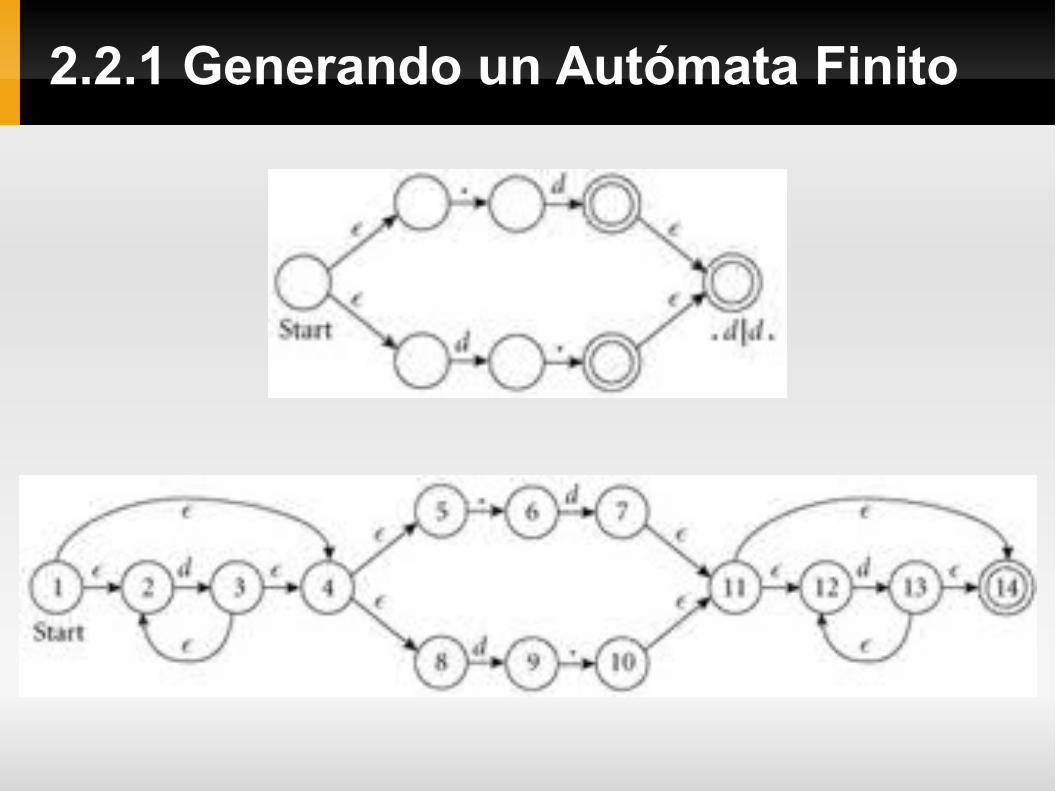
El segundo paso consiste en obtener un AFD. Para transformar el AFND en un AFD usaremos una contrucción llamada “conjunto de subconjuntos”, la idea clave es que un estado del AFD represente un grupo de estados a los que el AFND que pudo haber llegado a partir del mismo carácter en la entrada.
Al inicio antes de consumir cualquier entrada el AFND podría estar en el estado 1 o podría hacer transiciones epsilon a los estados 2, 4, 5 o 8. Por esta razón creamos un estado A en el AFD que represente este conjunto.

2.2.1 Generando un Autómata Finito
En una entrada de “d” nuestro AFND podría moverse del estado 2 al 3 o del 8 al 9 y del estado 3 podría hacer transiciones epsilon a los estados 2, 4, 5 u 8, por esta razón sea crea el estado B como lo muestra la ilustración a continuación.
Desde el estado A, con un “.”, nuestro AFND podría moverse del estado 5 al 6, no hay más transiciones posibles con este carácter desde ninguno de los estados de A ni tampoco transiciones epsilon desde el estado 6, por lo que creamos el estado C en el AFD sólo con el estado 6.

2.2.1 Generando un Autómata Finito
Regresando al estado B, con un “d” podríamos movernos del estado 2 al 3 o del estado 8 al 9. Pero al llegar al 3 podríamos hacer transiciones epsilon a los estados 2,4,5,u 8 y como todos estos estados están en B creamos un ciclo desde B hacia B en el AFD.
Siempre en B, con un “.” podríamos movernos del estado 5 al 6 o del 9 al 10 y luego desde 10 al 11,12 y 14 a través de transiciones epsilon. Por eso creamos el estado D según la ilustración.

2.2.1 Generando un Autómata Finito
El estado D se marca como final porque contiene el estado 14 que es final el AFND.
Continuando de este modo se crean también los estados finales E, F y G mostrados en la ilustración que contienen todos al estado 14 del AFND y por tanto son marcados como finales.
NOTA: La imagen original en el libro contiene un error, el estado G del AFD no debe contener al estado 11 del AFND. El error ya está corregido en la imagen a continuación.


2.2.1 Generando un Autómata Finito
En el ejemplo anterior el AFD termina siendo más pequeño que el AFND, esto es porque el lenguaje regular usado es muy simple. En teoría, el número de estados en el AFD podría se exponencial al número de estados en el AFND, pero este extremo no es común en la práctica.

2.2.1 Generando un Autómata Finito
El tercer paso en el proceso es la minización del AFD, proceso en el que por cuestiones de tiempo y espacio no profundizaremos.

2.2.1 Generando un Autómata Finito
En el ejemplo anterior construimos un autómata que es capaz de reconocer un sólo token: “decimal”. Para construir un escáner para un lenguaje con n diferentes tipos de tokens, iniciamos con un AFND como el que se ve en la ilustración a continuación.
Dados los AFND llamados Mi, 1 <= i <= n (uno para cada token), creamos un nuevo estado inicial con transiciones epsilon hacia los n estados iniciales de los AFND.

2.2.1 Generando un Autómata Finito
En contraste con la alternación no creamos un estado final, mantenemos los que ya están, cada uno etiquetado para el token del cuál es final.
Luego convertimos el AFND resultante en un AFD de la misma forma que ya lo hicimos, tomando en cuenta que si los estados finales de diferentes tokens se mezclan en el AFD, es por que tenemos definiciones de tokens ambiguas.

2.2.1 Generando un Autómata Finito

2.2.1 Generando un Autómata Finito
Finalmente, al hacer la minimización iniciamos con n + 1 clases de equivalencia, una clase para todos los estados no finales y n clases para los n diferentes estados finales que existen.

2.2.2 Código del Escáner
Podemos implementar un escáner a partir del AFD usando dos métodos principales:
El primero consiste en usar enunciados switchs anidados que imiten la estructura del AFD. Este es generalmente el método usado cuando se programa a mano.
A continuación mostramos la estructura de escáner programado de esta forma.

state := 1 -- start stateloop read cur_char case state of 1 : case cur_char of ' ', '\t', '\n' : ... 'a' ... 'z' : ... '0' ... '9' : ... '>' : ... ... 2 : case cur_char of ... ... n: case cur_char of ...

2.2.2 Código del Escáner
En el código anterior el enunciado switch exterior cubre los estados del autómata y los enunciados interiores cubren las transiciones entre los estados. La mayoría de éstos simplemente establecen un nuevo estado y algunos retornan del escáner con el token actual (si el último carácter leído no forma parte del token se coloca de nuevo en el flujo de entrada antes de retornar).

2.2.2 Código del Escáner
El segundo método para implementar un escáner consiste en crear una tabla y un driver para la tabla. Éste método es preferido por la herramientas que generan escáners automáticamente, pues es más fácil de generar para un programa que generar código. Ej.: Unix lex/flex.
Por cuestiones de tiempo y espacio no ahondaremos en detalles sobre este método.

2.2.2 Código del Escáner
Existen dos aspectos del código que usualmente se desvían de la formalidad de un autómata finito: el primero es el manejo de la palabras clave y el segundo es la necesidad de observar hacia adelante cuando un token puede ser extendido por dos o más caracteres, no sólo por uno (prefijo no trivial).
Con respecto al primer aspecto, es posible crear un autómata finito que diferencia entre palabras clave e identificadores, pero esto implicar agregar muchos estados.

2.2.2 Código del Escáner
La mayoría de los escáners tratan a las palabras clave como excepciones a la regla de los identificadores, antes de retornar un identificador al parser, el escáner revisa en una tabla si en realidad no se trata de una palabra clave.
Para explicar el segundo aspecto enunciamos un ejemplo a continuación.

2.2.2 Código del Escáner
Ejemplo: En el lenguaje C se da el problema del prefijo no trivial, con el manejo de los caracteres punto “.”, pues éstos forman en sí mismos un token o pueden formar parte de otro como un número real . Suponiendo que el escáner ha recientemente leído un “3” y luego encuentra un “.” necesita observar los caracteres siguientes para distinguir entre 3.14 (un sólo token), 3.foo (tres tokens: 3, . y foo, sintácticamente inválidos pero tokens) o por ejemplo 3...foo (cinco tokens sintácticamente inválidos, nuevamente).


















