
Selección de Hiperparámetros en Máquinas de Soporte … · SELECCION DE HIPERPAR´ AMETROS EN...
102
SELECCI ´ ON DE HIPERPAR ´ AMETROS EN M ´ AQUINAS DE SOPORTE VECTORIAL Por Ricardo Henao [email protected] Director: Jorge Eduardo Hurtado G´ omez ENVIADO EN PARCIAL CUMPLIMIENTO DE LOS REQUERIMIENTOS PARA EL GRADO DE MSC. EN CONTROL Y AUTOMATIZACI ´ ON INDUSTRIAL EN LA UNIVERSIDAD NACIONAL DE COLOMBIA MANIZALES, COLOMBIA MAYO 2004 c Derechos Reservados por Ricardo Henao, 2004
Transcript of Selección de Hiperparámetros en Máquinas de Soporte … · SELECCION DE HIPERPAR´ AMETROS EN...

SELECCION DE HIPERPARAMETROS EN MAQUINAS DE
SOPORTE VECTORIAL
Por
Ricardo Henao
Director:
Jorge Eduardo Hurtado Gomez
ENVIADO EN PARCIAL CUMPLIMIENTO DE LOS
REQUERIMIENTOS PARA EL GRADO DE
MSC. EN CONTROL Y AUTOMATIZACION INDUSTRIAL
EN LA
UNIVERSIDAD NACIONAL DE COLOMBIA
MANIZALES, COLOMBIA
MAYO 2004
c© Derechos Reservados por Ricardo Henao, 2004

UNIVERSIDAD NACIONAL DE COLOMBIA
FACULTAD DE
INGENIERIAS ELECTRICA, ELECTRONICA Y COMPUTACION
Los abajo firmantes certifican haber leido y recomendado a la facultad
de Facultad de Ingenierıa y Administracion la aceptacion de la tesis titulada
“Seleccion de Hiperparametros en Maquinas de Soporte Vectorial”
por Ricardo Henao en parcial cumplimiento de lor requerimientos para el
grado de Msc. en Control y Automatizacion Industrial.
Fecha: Mayo 2004
Director:Jorge Eduardo Hurtado Gomez
Jurados:German Castellanos D.
Julio Fernando Suarez
Oscar Ortega L.
II

UNIVERSIDAD NACIONAL DE COLOMBIA
Fecha: Mayo 2004
Autor: Ricardo Henao
Tıtulo: Seleccion de Hiperparametros en Maquinas de Soporte
Vectorial
Facultad: Ingenierıas Electrica, Electronica y ComputacionGrado: M.Sc. Termino: Julio Ano: 2004
Con esta se concede permiso a la Universidad Nacional de Colombia de circulary copiar este trabajo para propositos no comerciales y a discresion ante solicitud deindividuales o instituciones.
Firma del Autor
EL AUTOR SE RESERVA OTROS DERECHOS DE PUBLICACION Y NILA TESIS NI EXTRACTOS EXTENSOS DE ELLA PUEDEN SER PUBLICADOS OREPRODUCIDOS EN OTRA FORMA SIN LA AUTORIZACION POR ESCRITO DELAUTOR.
EL AUTOR CERTIFICA QUE HA OBTENIDO PERMISO PARA EL USO DECUALQUIER MATERIAL CON DERECHOS RESERVADOS QUE APARECIERE ENLA TESIS (EXCEPTO EXTRACTOS CORTOS QUE UNICAMENTE REQUIEREN UNRECONOCIMIENTO APROPIADO EN EL CASO ESCRITOS ACADEMICOS) Y QUETAL USO ES CLARAMENTE RECONOCIDO.
III

Indice General
Indice General IV
Indice de Tablas VII
Indice de Figuras VIII
Resumen IX
Abstract X
Agradecimientos XI
1. Introduccion 1
1.1. Trabajo Previo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2. Objetivos Principales del Trabajo . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3. Estructura del Documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2. Maquinas de Soporte Vectorial 5
2.1. Clasificacion con Vectores de Soporte . . . . . . . . . . . . . . . . . . . . . . 5
2.2. Caso Linealmente no Separable . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3. Maquinas de Soporte no Lineales . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4. Capacidad de Generalizacion . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4.1. Riesgo Actual, Riesgo Empırico y Dimension VC . . . . . . . . . . . 11
2.4.2. La Dimension VC de las SVM . . . . . . . . . . . . . . . . . . . . . 13
IV

2.4.3. Procedimiento Leave-One-Out . . . . . . . . . . . . . . . . . . . . . 13
2.4.4. Cotas para el Estimador de Leave-One-Out . . . . . . . . . . . . . . 14
2.5. Algoritmo de Entrenamiento . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.5.1. Metodo de Descomposicion . . . . . . . . . . . . . . . . . . . . . . . 18
2.5.2. Seleccion del Conjunto de Trabajo y Criterio de Parada . . . . . . . 19
2.5.3. Convergencia del Metodo de Descomposicion . . . . . . . . . . . . . 22
2.5.4. Solucion Analıtica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5.5. Calculo de b . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.5.6. Contraccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.5.7. Caching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.5.8. Complejidad Computacional . . . . . . . . . . . . . . . . . . . . . . 29
2.6. Maquinas de Soporte Multi Clase . . . . . . . . . . . . . . . . . . . . . . . . 30
3. Seleccion de Hiperparametros en Maquinas de Soporte Vectorial 32
3.1. Busqueda en Malla . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.2. Busqueda en Lınea . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.2.1. Cota de Radio/Margen para L2 . . . . . . . . . . . . . . . . . . . . . 35
3.2.2. Cota de Radio/Margen para L1 . . . . . . . . . . . . . . . . . . . . . 36
3.3. Limitaciones Actuales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4. Estrategias Evolutivas 39
4.1. Adaptacion Arbitraria de Distribuciones Normales . . . . . . . . . . . . . . 41
4.2. Adaptacion de la Matriz de Covarianza . . . . . . . . . . . . . . . . . . . . 43
4.3. Trayectoria Evolutiva: Cumulacion . . . . . . . . . . . . . . . . . . . . . . . 45
4.4. El Algoritmo (µW , λ)-CMA-ES . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.5. Valores para los Parametros Internos . . . . . . . . . . . . . . . . . . . . . . 49
4.6. Limitaciones y Aspectos Practicos . . . . . . . . . . . . . . . . . . . . . . . 50
5. Metodo Propuesto 51
5.1. CMA-ES-SVM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2. Caracterısticas del CMA-ES-SVM . . . . . . . . . . . . . . . . . . . . . . . 54
V

5.3. Implementacion y Aspectos Practicos . . . . . . . . . . . . . . . . . . . . . . 55
6. Resultados Numericos 56
6.1. Conjuntos Artificiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
6.1.1. Balanceado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.1.2. No Balanceado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.1.3. Damero . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.1.4. Dos Curvas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.1.5. Dos Anillos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.1.6. Anillos Cruzados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.2. Conjuntos Estandares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6.3. Conjunto Multi Clase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.4. Resultados con Kernel Polinomial . . . . . . . . . . . . . . . . . . . . . . . . 68
6.5. Conjuntos de Problemas Reales . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.5.1. Identificacion de Voces Patologicas . . . . . . . . . . . . . . . . . . . 69
6.5.2. Clasificacion de Arritmias en ECG . . . . . . . . . . . . . . . . . . . 70
7. Discusion Final, Sumario y Trabajo Posterior 73
A. Kernels 76
A.1. Kernels Definidos Positivos . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
A.2. Reproduccion de un Mapeo con Kernel . . . . . . . . . . . . . . . . . . . . . 77
A.3. Reproduccion de un Espacio de Hilbert mediante Kernels . . . . . . . . . . 79
A.4. El Kernel de Mercer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
A.5. Ejemplos y Propiedades de Kernels . . . . . . . . . . . . . . . . . . . . . . . 81
B. Algoritmo BFGS 83
Apendices 76
VI

Indice de Tablas
4.1. Parametros defecto para (µW , λ) . . . . . . . . . . . . . . . . . . . . . . . . 49
6.1. Estructura de los conjuntos artificiales . . . . . . . . . . . . . . . . . . . . . 57
6.2. Resultados para el conjunto balanceado . . . . . . . . . . . . . . . . . . . . 58
6.3. Resultados para el conjunto no balanceado . . . . . . . . . . . . . . . . . . 59
6.4. Resultados para el conjunto damero . . . . . . . . . . . . . . . . . . . . . . 61
6.5. Resultados para el conjunto dos curvas . . . . . . . . . . . . . . . . . . . . . 61
6.6. Resultados para el conjunto dos anillos . . . . . . . . . . . . . . . . . . . . . 63
6.7. Resultados para el conjunto anillos cruzados . . . . . . . . . . . . . . . . . . 63
6.8. Estructura de los conjuntos estandares . . . . . . . . . . . . . . . . . . . . . 65
6.9. Resultados para los conjuntos estandar . . . . . . . . . . . . . . . . . . . . . 66
6.10. Resultados para los conjuntos estandar. (Continuacion) . . . . . . . . . . . 67
6.11. Estructura de los conjuntos multi clase . . . . . . . . . . . . . . . . . . . . . 68
6.12. Resultados para conjuntos multi clase . . . . . . . . . . . . . . . . . . . . . 68
6.13. Resultados para kernel polinomial . . . . . . . . . . . . . . . . . . . . . . . 69
6.14. Estructura del conjunto para identificacion de voces patologicas . . . . . . . 70
6.15. Resultados para identificacion de voces patologicas . . . . . . . . . . . . . . 71
6.16. Estructura del conjunto para clasificacion de arritmias en ECG . . . . . . . 72
6.17. Resultados para clasificacion de arritmias en ECG . . . . . . . . . . . . . . 72
VII

Indice de Figuras
2.1. Hiperplanos que separan correctamente los datos . . . . . . . . . . . . . . . 7
2.2. Mapeo del espacio de entrada en otro de dimension alta . . . . . . . . . . . 10
2.3. Solucion analıtica de un problema de optimizacion de dos variables . . . . . 24
4.1. Lıneas de igual densidad de probabilidad en dos distribuciones normales . . 40
6.1. Izquierda: Conjunto balanceado. Derecha: Conjunto no balanceado . . . . . 57
6.2. Izquierda: Conjunto damero. Derecha: Conjunto dos curvas . . . . . . . . . 60
6.3. Izquierda: Conjunto dos anillos. Derecha: Conjunto anillos cruzados . . . . 62
A.1. Problema de clasificacion mapeado con kernel polinomial . . . . . . . . . . . 76
VIII

Resumen
Este trabajo de tesis presenta un nuevo metodo de seleccion automatica de hiperparametros
en maquinas de soporte vectorial utilizando estrategias evolutivas y cotas efectivas del error
de validacion o riesgo empırico. El desarrollo descrito en esta tesis involucra una tecnica
de estrategias evolutivas denominada adaptacion de matriz de covarianza, que a grandes
rasgos reduce el tiempo de convergencia en la medida que un menor numero de evaluaciones
de la funcion objetivo son necesarias y que desaleatoriza al maximo el procedimiento para
obtener soluciones mas estables. En particular, dos cotas del error de validacion fueron
empleadas, la validacion cruzada como generalizacion del esquema LOO y el span como
medida efectiva tanto teorica como practica ya que no necesita multiples evaluaciones de
la SVM, es continua, posee conexion directa con otras como Radio/Margen y requiere una
carga computacional considerablemente pequena. Ademas, permite la posibilidad de em-
plear diferentes funciones kernel debido a que no exige diferenciabilidad en dicha funcion,
esquemas multi clase y seleccion de multiples parametros sin tener que reformular substan-
cialmente todo el algoritmo. Por ultimo, los resultados numericos muestran un desempeno
bastante competitivo con las otras tecnicas revisadas en este trabajo.
IX

Abstract
This thesis work introduces a new method for automatic hiperparameter selection for
support vector machines using evolutive strategies and validation error or empirical risk
bounds. The actual approach involves an evolution strategy technique designated as covari-
ance matrix adaptation, which in general terms reduces the convergence rates and obtain
steady solutions due to its derandomized nature. In particular, two empirical risk bounds
where used, crossvalidation as generalized LOO scheme and span bound because do not
require multiple SVM evaluations, is continuous, and hold direct connection with some
others like Radius/Margin and its computational cost is low as well. Besides, this method
allows a wide variety of kernel functions since do not demand differentiability, multi-class
schemes and multiple parameter selection without substantial reformulation of the entire
algorithm. Finally, the numerical results reveal a competitive performance related to an-
other considered methods within this work.
X

Agradecimientos
El autor quiere agradecer al Profesor Jorge Eduardo Hurtado supervisor de esta tesis, por
sus multiples sugerencias y apoyo constante no solo durante el tiempo que duro este trabajo
sino desde que estoy trabajando con el. Tambien, al Profesor German Castellanos por todo
el apoyo prestado desde que estoy trabajando en investigacion.
Ademas, a los profesores S.S. Keerthi, C.J. Lin y N. Hansen por toda la ayuda prestada a
traves de correos electronicos.
Finalmente, Fabian Ojeda y Juan Carlos Riano por la ayuda prestada con la revision de
este trabajo y comentarios pertinentes, al grupo de Control y Procesamiento Digital de
Senales por proporcionar un espacio apropiado para el trabajo de investigacion, incluso
mas alla del alcance de este trabajo. Los demas supongo saben quienes son.
Esta investigacion fue realizada en el marco de la investigacion “Analisis y procesamiento
digital de imagenes medicas y senales bioelectricas” realizada por la Universidad Nacional
de Colombia sede Manizales mediante la orden contractual 472 de 2003 emitida por el
DIMA.
Manizales, Colombia Ricardo Henao
Julio 22, 2004
XI

Capıtulo 1
Introduccion
“I shall certainly admit a system as empirical or scientific only if it is capable of being tested by
experience. These considerations suggest that not the verifiability but the falsifiability of a system is
to be taken as a criterion of demarcation. It must be possible for an empirical scientific system to
be refuted by experience.”
K. Popper. The Logic of Scientific Discovery (1934, ch. 1, sect. 6)
En el area de reconocimiento de patrones y mas especıficamente en la parte de clasificacion, las
maquinas de soporte vectorial (SVM), se han convertido en los ultimos anos en una de las tecnicas
mas importantes sobre otras muy populares como: k−esimo vecino cercano (KNN), redes neu-
ronales artificiales (ANN) y arboles de clasificacion (CART); dado que su aparato matematico esta
fundamentado sobre bases muy solidas [ver Vapnik, 1995] que hacen que posea multiples ventajas
sobre las otras tecnicas mencionadas [ver Vapnik, 1998, Scholkopf and Smola, 2002]. Sinembargo,
Lin [2003] presenta en perspectiva la posibilidad de hacer que las maquinas de soporte vectorial
se conviertan en el principal metodo de clasificacion (segun “KDNuggets 2002 Poll 1”, las redes
neuronales y los arboles de clasificacion permanecen como principales herramientas) argumentando
que el problema de las SVM es el mal empleo que se les da probablemente por falta de conocimiento
1http:://www.kdnuggets.com, A Site for Data Mining, Knowledge Discovery, Genomic Mining, WebMining.
1

2
de la metodologıa. Lo que usualmente los usuarios desprevenidos estan haciendo es (ver blackboard
http://www.kernel-machines.org): convertir la informacion a clasificar al formato de algun progra-
ma SVM disponible sin tener en cuenta en la mayorıa de los casos las implicaciones del formato,
escalamiento, etc, para luego tratar aleatoriamente con valores de parametros y kernels indiscrimi-
nadamente sin hacer validacion y sin saber de antemano que los parametros por defecto en dichos
programas son sorprendentemente importantes y el hecho es que muchos de los usuarios obtienen
como resultado valores de error y generalizacion insatisfactorias.
Lo mınimo que se espera que haga el usuario segun Lin [2003] es escalar los datos para validacion
y entrenamiento, considerar el kernel RBF (Radial Basis Function) y encontrar valores adecuados
para C y σ2 (o γ). Ahora, esto de encontrar “valores adecuados” a veces no es tarea facil, sin
mencionar que lo que se pretende no es encontrar valores adecuados sino los mejores valores para
un caso dado. Hasta el momento, las tecnicas de seleccion de parametros o seleccion del modelo
como tambien es llamado son las siguientes: busqueda manual intuitiva, cotas para LOO (leave one
out) o para riesgo empırico, busqueda en dos sentidos y busqueda en malla.
1.1. Trabajo Previo
En el tema de seleccion de hiperparametros en SVM no se ha hecho mucho hasta el momento debido
a que es un tema relativamente nuevo, sinembargo el trabajo realizado es bastante significativo. En
el trabajo con reconocimiento de patrones y mas especıficamente en el area de clasificadores es
necesario encontrar medidas que sean proporcionales al error de clasificacion (funcion de riesgo y
dimension VC), es decir, que sean referentes al momento de seleccionar los parametros en la SVM
sin tener que realizar un proceso de validacion, que dependiendo del volumen de los datos puede
ser prohibitivo en terminos de tiempo y recursos computacionales. [Wahba et al., 2000] establece
mediante demostraciones matematicas y pruebas numericas la consistencia de la validacion cruzada
(en particular LOO) como medida del error en SVM con relacion a medidas de margen en el
hiperespacio de SVM. Joachims [2000] realiza pruebas con SVM utilizando como medidas del error:
error de entrenamiento, “hold-out testing”, Boostrap, Jack-knife y validacion cruzada en contraste a
una tecnica introducida por el llamada estimador ξα basada en la solucion de los α en el problema
dual de SVM y las perdidas del entrenamiento ξ, obteniendo mejores resultados que validacion
cruzada y Boostrap en varias bases de datos estandar. Vapnik and Chapelle [2000] introduce el
concepto de span de los vectores de soporte como forma de obtener parametros optimos en SVM

3
por este ser una medida bastante precisa de el error de validacion. Jaakkola and Haussler [1999]
realiza pruebas matematicas para llegar a una formulacion que genera una cota superior para
LOO analizando la solucion de la funcion de costo de SVM. Opper and Winther [2000] utilizan un
metodo inspirado en la teorıa de respuesta lineal y prueban que bajo el supuesto de que los vectores
de soporte no cambian cuando se remueve un ejemplo bajo el esquema de LOO se puede obtener
una matriz de productos punto entre los vectores de soporte que deriva en una cota superior para
la estimacion del error. Vapnik [1998] propone bajo el supuesto que la solucion de SVM no presenta
errores de entrenamiento, una cota para el error de validacion basada en LOO que es la relacion entre
el margen y el radio de los vectores de soporte de la maquina entrenada. Keerthi and Ong [2000]
hace un analisis del aporte del valor del corrimiento en la formulacion de SVM en la optimalidad del
entrenamiento. Sundararajan and Keerthi [2001] deriva resultados de la probabilidad surrogativa
de Geisser (GPP), error predictivo de Geisser (GPE) y error de validacion cruzada para escoger los
parametros del kernel en el caso RBF. Lee and Lin [2001] propone un metodo de seleccion automatica
basada en LOO y una reduccion simple del espacio de busqueda de los hiperparametros utilizando
una descomposicion matricial del problema dual de SVM (BSVM). Chapelle et al. [2002] propone
una metodologıa fundamentada en la diferenciabilidad del kernel, el criterio de Radio/Margen y
su dependencia con la solucion del problema de optimizacion de SVM para derivar un esquema
de gradiente descendiente para obtener hiperparametros optimos. Keerthi and Lin [2003] hacen un
analisis del comportamiento asintotico de los parametros de SVM con kernel gaussiano y derivan
un procedimiento heurıstico para encontrarlos y obtener un error de generalizacion bajo. Keerthi
[2002] presenta una implementacion del metodo de Chapelle et al. [2002] utilizando kernel RBF,
NPA (algoritmo de punto cercano) como algoritmo de optimizacion iterativo para SVM, SMO
(optimizacion secuencial mınima) para resolver el problema de Radio/Margen y quasi-Newton como
procedimiento de gradiente descendiente. Chung et al. [2003] utiliza la cota Radio/Margen con kernel
gaussiano para hacer una modificacion en el esquema de SVM y derivar a partir de L1-SVM y L2-
SVM un metodo de seleccion automatica de parametros. Duan et al. [2003] hace una evaluacion
empırica del desempeno de varias medidas para seleccion de hiperparametros, entre ellos: error de
validacion (como referente), validacion cruzada, cota χi − alpha, cota VC (Vapnik-Chervonekis),
Span aproximado y D2 ‖w‖2, utilizando bases de datos estandar en reconocimiento de patrones.

4
1.2. Objetivos Principales del Trabajo
Las publicaciones reportadas hasta la fecha presentan un marcado interes por encontrar cotas del
riesgo empırico de manera que no sea necesario llevar a cabo una validacion para evaluar la solucion
obtenida por una SVM para un problema dado. En la medida en que ha sido posible se han
desarrollado metodos de seleccion automatica de hiperparametros haciendo uso de dichas cotas y
metodos de optimizacion. Con esto, no es parte de esta tesis realizar un trabajo de investigacion
acerca de las cotas, ni de la forma o caracterısticas del espacio de los hiperparametros o relaciones
entre ellos. Teniendo en cuenta las consideraciones anteriores, los objetivos de este trabajo son:
Profundizar en las tecnicas actuales basandose en la teorıa de SVM con el fin de desarrollar
un algoritmo de seleccion automatica de hiperparametros en SVM con miras obtener un buen
desempeno de los clasificadores en cuanto a error de validacion y costo computacional.
Analizar las tecnicas actuales de seleccion de parametros para identificar sus ventajas y
desventajas, como base del trabajo a realizar. Investigar acerca de metodos de optimizacion,
busqueda y parametros efectivos en SVM para luego desarrollar un algoritmo de seleccion
de hiperparametros automatica que ofrezca ventajas sobre las otras desarrolladas hasta el
momento.
Para finalizar, se debe decir que en cuanto a los experimentos numericos realizados, las compara-
ciones con otras tecnicas han de realizarse de acuerdo a las posibilidades y el criterio del autor.
1.3. Estructura del Documento
Partiendo del hecho que se considera primordial que este documento sea lo mas compacto y completo
posible, en los capıtulos 2 y 4 se presentan respectivamente, los fundamentos teoricos y considera-
ciones practicas de las SVM y la clase de estrategias evolutivas empleadas en este trabajo. En el
capıtulo 3 se describen los metodos de seleccion automatica como componentes del marco com-
parativo usado para los experimentos en el capıtulo 6. En el capıtulo 5 se describe y se hacen
las consideraciones pertinentes con respecto al algoritmo propuesto. El documento termina con
un sumario de los resultados obtenidos e ideas para un trabajo posterior, ademas de un apendice
concerniente a kernels como complemento a los fundamentos teoricos de las SVM.

Capıtulo 2
Maquinas de Soporte Vectorial
Las Maquinas de Soporte Vectorial (SVM), han mostrado en los ultimos anos su capacidad en la
clasificacion y reconocimiento de patrones en general. El objetivo de este capıtulo es presentar los
fundamentos basicos, tanto teoricos como practicos de las SVM y soportar su potencial en tareas
de clasificacion. Intuitivamente, dado un grupo de datos distribuidos en dos clases, una SVM lineal
busca un hiperplano de tal manera que la mayor cantidad de puntos de la misma clase queden
al mismo lado, mientras se maximiza la distancia de dichas clases al hiperplano. De acuerdo a
Vapnik [1995], este hiperplano minimiza el riesgo de clasificaciones erroneas en el grupo tomado
para realizar el proceso de validacion.
2.1. Clasificacion con Vectores de Soporte
Para un grupo de entrenamiento de tamano N compuesto de pares atributo-etiqueta (xi, yi)1≤i≤N ,
siendo xi ∈ Rn y yi ∈ {−1, 1}, se desea obtener una ecuacion para un hiperplano que divida dicho
grupo de entrenamiento, de manera que aquellos puntos con igual etiqueta queden al mismo lado
del hiperplano. Esto significa encontrar un w y un b tal que
yi(w′xi + b) > 0, i = 1, ..., N (2.1)
5

6
Si existe un hiperplano que satisfaga (2.1), se dice que los datos son linealmente separables. En este
caso, w y b se pueden escalar ası,
mın1≤i≤N
yi(w′xi + b) ≥ 1
de tal manera, que el punto mas cercano al hiperplano tenga como distancia 1/‖w‖. Luego (2.1) se
puede escribir como
yi(w′xi + b) ≥ 1 (2.2)
ası, entre todos los posibles hiperplanos, aquel cuya distancia al punto mas cercano es maxima se
denomina el “optimo hiperplano de separacion” (OSH). Mientras la distancia al hiperplano optimo
sea 1/‖w‖, encontrar el OSH equivale a resolver el siguiente problema
mınw,b
12w′w
sujeto a yi(w′xi + b) ≥ 1, ∀i(2.3)
La cantidad 2/‖w‖ es llamada “margen” y el hiperplano que maximiza dicho margen, OSH. El
margen puede ser visto como una medida de la dificultad del problema, ası, entre mas pequeno sea
el margen mas difıcil es el problema; o de otro modo, se espera una mejor capacidad de generalizacion
si el margen es mas grande (ver figura 2.1).
Mientras w′w sea convexo, minimizar la ecuacion (2.3) sujeto a (2.2) es posible utilizando multipli-
cadores de Lagrange [Burges, 1998]. Sean α = {α1, ..., αN} los N multiplicadores de Lagrange no
negativos asociados a (2.2), para minimizar (2.3) se debe encontrar el punto de silla de la siguiente
funcion de Lagrange
L(w, b, α) =12w′w −
N∑i=1
αi[yi(w′xi + b)− 1] (2.4)
Para encontrar dicho punto, hay que minimizar la funcion (2.4) sobre w y b, y luego maximizarla
sobre los multiplicadores de Lagrange αi ≥ 0. El punto de silla debe satisfacer las condiciones de

7
Figura 2.1: Hiperplanos que separan correctamente los datos. El OSH de la derecha tieneun margen mayor por lo tanto se espera una mejor generalizacion
Karush-Kuhn-Tucker (KKT) [Burges, 1998],
∂L(w, b, α)b
=N∑
i=1
yiαi = 0
∂L(w, b, α)w
= w −N∑
i=1
αiyixi = 0
(2.5)
Substituyendo (2.5) en (2.4) el problema de optimizacion apunta ahora a resolver
maxN∑i
αi −12
N∑i,j
αiαjyiyjx′ixj
sujeto aN∑
i=1
yiαi = 0 y αi ≥ 0, ∀i
(2.6)
Esto puede ser logrado utilizando metodos de programacion cuadratica estandar [Burges, 1998].
Una vez el vector α0 = {α0i , ..., α
0N} solucion de (2.6) ha sido encontrado, a partir de (2.5), el OSH
(w, b) tiene la siguiente forma
w0 =N∑
i=1
α0i yixi (2.7)

8
mientras b0 puede ser obtenido a partir de las condiciones de KKT
α0i [yi(w′xi + b)− 1] = 0 (2.8)
Notese que de la ecuacion (2.8), los puntos para los cuales α0i > 0, satisfacen la desigualdad en
(2.2). Geometricamente, esto significa que aquellos puntos son los mas cercanos al OSH (ver figura
2.1). Estos puntos juegan un papel importante debido a que son los unicos valores necesarios en la
expresion para el OSH (ver ecuacion 2.7) y son llamados “vectores de soporte” (SV), por el hecho
que dan “soporte” a la expansion de w0.
Dado un vector de soporte xi, el parametro b puede ser obtenido de las condiciones KKT como
b0 = yi − w′0xi
El problema de clasificar un nuevo punto x, es resuelto examinando el signo de w′0x + b0. Ahora,
considerando la expansion (2.7) de w0, la funcion de decision f(x) para el hiperplano puede ser
escrita como
f(x) = sign
(N∑
i=1
α0i yix
′ix+ b
)
2.2. Caso Linealmente no Separable
Si los datos son linealmente no separables, buscar un OSH carece completamente de sentido. Con
la finalidad de posibilitar las violaciones, se pueden introducir variables “slack” (de relajacion)
(ξ1, ..., ξN ), para ξi ≥ 0 [Cortes and Vapnik], de manera que la expresion (2.2) se puede escribir
como
yi(w′xi + b) ≥ 1 + ξi, ∀i
El proposito de las variables ξi es permitir puntos erroneamente clasificados, los cuales correspondan
a ξi > 1, por lo tanto,∑
i ξ es una cota superior del numero de errores de entrenamiento. El OSH

9
generalizado puede ser obtenido como la solucion del siguiente problema
mınw,b
12w′w + C
N∑i=1
ξi
sujeto a yi(w′xi + b) ≥ 1 + ξi y ξ ≥ 0, ∀i
(2.9)
El primer termino es minimizado para controlar la capacidad de aprendizaje del mismo modo que
en el caso separable; el segundo termino permite mantener bajo control el numero de clasificaciones
erroneas. El parametro C es elegido por el usuario de manera que un valor grande es equivalente
a asignar una alta penalizacion a los errores. En analogıa con el caso separable, la utilizacion de
multiplicadores de Lagrange deriva en el siguiente problema de optimizacion,
maxN∑i
αi −12
N∑i,j=0
αiαjyiyjx′ixj
sujeto a∑
i
yiαi = 0 y 0 ≥ αi ≥ C, ∀i(2.10)
de la ecuacion (2.10) se puede notar que la unica diferencia hasta el momento con el caso separable
es que ahora α tiene una cota superior C.
2.3. Maquinas de Soporte no Lineales
El principio de SVM no lineal consiste en mapear el espacio de entrada a un espacio de representacion
de dimension alta a traves de una funcion no lineal elegida a priori [Boser et al., 1992], ver figura
2.2.
Sinembargo en este caso, surge un problema computacional, la dimension del espacio de repre-
sentacion puede ser muy alta y la dificultad radica en como construir un hiperplano de separacion
en este espacio. La respuesta al problema parte de que para construir dicho hiperplano, el mapeo
z = φ(x) no necesita ser explıcito, de manera que reemplazando x por φ(x) en (2.6) se tiene

10
Espacio de entrada
Espacio de representación
Hiperplano óptimo en el espacio de representación
Figura 2.2: La SVM mapea el espacio de entrada en otro de representacion de dimensionalta y luego construye un OSH sobre este ultimo
maxN∑i
αi −12
N∑i,j
αiαjyiyjφ(xi)′φ(xj)
sujeto aN∑
i=1
yiαi = 0 y αi ≥ 0, ∀i
de lo anterior, el algoritmo de entrenamiento solo depende de los datos a traves de los productos
punto en el espacio de representacion, esto es, funciones de la forma φ(xi)′φ(xj). Sea dada una fun-
cion kernel simetrica K tal que K(xi, xj) = φ(xi)′φ(xj), de modo que el algoritmo de entrenamiento
dependa solo de K y el mapeo φ no sea usado explıcitamente.
Dado φ : Rd → H, el kernel K es K(xi, xj) = φ(xi)′φ(xj), pero de manera inversa, dado un kernel
K se deben establecer las condiciones para que el mapeo exista. Tales condiciones son aseguradas
por las condiciones de Mercer (ver apendice A):
Teorema 1 Sea K(x, y) una funcion simetrica continua en L2(C), luego, existe un mapeo φ y una
expansion, tal que
K(x, y) =∞∑
i=1
φ(x)′iφ(y)i (2.11)

11
si y solo si, para algun g ∈ L2(C), tal que
∫C×C
K(x, y)g(x)g(y)dxdy ≥ 0 (2.12)
Notese que para casos especıficos, puede no ser facil mostrar cuando las condiciones de Mercer son
cumplidas, mientras que (2.12) debe mantenerse para algun g ∈ L2(C). Sin embargo, es facil probar
que la condicion se cumple para el kernel polinomial K(x, y) = (x′y)p [ver Burges, 1998].
Los primeros kernels investigados para reconocimiento de patrones fueron los siguientes
Polinomial: K(x, y) = (x′y + c)d para c > 0
Funcion de base radial (RBF): K(x, y) = exp(−γ‖x− y‖2) para γ > 0
Sigmoide: tanh(κx′y + ν)
El primero resulta en un clasificador con funcion de decision polinomial, el segundo un clasificador
con funcion de base radial y el ultimo un tipo particular de red sigmoidal de dos capas. Para el caso
de RBF, el numero de centros (numero de SV), los centros (SV), los pesos (αi) y el desplazamiento
(b) son generados automaticamente por la SVM en la etapa de entrenamiento y dan excelentes
resultados en comparacion a la red RBF clasica [Scholkopf et al., 1996]. De la misma forma, para el
caso del perceptron multicapa (MLP), la arquitectura (numero de nodos ocultos) es determinada
por el entrenamiento de la SVM.
2.4. Capacidad de Generalizacion
En esta seccion, se dan algunas bases teoricas que describen la capacidad de generalizacion de las
SVM.
2.4.1. Riesgo Actual, Riesgo Empırico y Dimension VC
Suponiendo que se tienen N observaciones (xi, yi)1≤i≤N para xi ∈ Rn y yi ∈ {−1, 1} donde yi es
la etiqueta para xi, se asume existe una probabilidad P (x, y) para la cual los datos estan descritos.
Sea dada una maquina cuya tarea es aprender a mapear xi → yi, dicha maquina es ciertamente

12
definida como un grupo de posibles mapeos x → f(x, α) donde las funciones f(x, α) son descritas
por los parametros ajustables α. Una eleccion particular de α, genera una “maquina entrenada” en
particular. Esto es, por ejemplo, una red neuronal con una arquitectura fija, donde α corresponde
a los pesos y los desplazamientos, es en efecto una maquina de aprendizaje.
La esperanza del error de validacion, para una maquina entrenada es por consiguiente [Vapnik,
1995]:
R(α) =∫
12|y − f(x, α)|dP (x, y)
La cantidad R(α) es llamada riesgo esperado o simplemente “riesgo”. Se llamara aquı riesgo actual
para enfatizar que es la cantidad en la que finalmente se esta interesado. El “riesgo empırico”,
Remp(x) esta definido como la medida de error en un grupo dado de validacion:
Remp(α) =1
2N
N∑i=1
|yi − f(x, α)|
La cantidad Q((xi, yi), α) = 12 |yi − f(x, α)| es llamada “perdida”. Para el caso descrito aquı, solo
toma valores entre 0 y 1. Si se escoge un η, de manera que 0 ≤ η ≤ 1, luego, con una probabilidad
de al menos 1− η, la siguiente cota se mantiene [Vapnik, 1995]
R(α) ≤ Remp(α) +
√(h(log(2N/h) + 1)− log(η/4)
N
)
donde h es un entero no negativo llamado dimension de Vapnik-Chervonenkis (VC) y es la medida
de la capacidad de la maquina de aprendizaje. El segundo termino de la desigualdad es llamado
“confidencia VC”, el cual es tan pequeno como la dimension VC, por lo tanto una forma de controlar
la capacidad de generalizacion de una maquina es manipular la dimension VC.
Sea definido un grupo de funciones {f(α)}, tal que para un grupo dado de N puntos, se puedan
etiquetar de todas las posibles 2N formas, y para cada etiqueta, un miembro del grupo {f(α)} pueda
encontrar la manera de asignar dichas etiquetas. Se dice que este grupo de puntos es fragmentado
por el grupo de funciones. La dimension VC para el grupo de funciones {f(α)} esta definido como
el numero maximo de puntos de entrenamiento que pueden ser fragmentados por {f(α)}.

13
2.4.2. La Dimension VC de las SVM
Primero, se presenta un teorema que establece una cota de la dimension VC para hiperplanos de
separacion
Teorema 2 Sea X ⊂ Rn un conjunto de vectores, ∀x ⊂ X, ‖x‖2 < R. Un subconjunto S de
hiperplanos, tales que ∀(w, b) ⊂ S,
infx⊂X|w′x+ b| = 1
|w| ≤ A
tiene una dimension VC acotada por
V Cdim < mın(R2A2, n) + 1
De manera que minimizando w′w, tambien la cota de la dimension VC para los hiperplanos de
separacion y, por lo tanto una mejor generalizacion esperada. Notese que en el caso de SVM no lineal,
este teorema debe ser aplicado sobre el espacio de representacion, ası, la capacidad de generalizacion
esta bajo control, incluso si el espacio es infinito dimensional.
2.4.3. Procedimiento Leave-One-Out
Una manera de predecir el desempeno de generalizacion de una SVM es estimar la dimension VC
calculando el termino R2w′w. Otra manera es utilizar un estimador Leave-one-Out (LOO) [Vapnik,
1998]. Dada una muestra de N +1 ejemplos de entrenamiento, el procedimiento para LOO consiste
en seguir los siguientes pasos (∀i):
Remover el ejemplo xi del grupo de entrenamiento
Entrenar la maquina con el nuevo grupo de entrenamiento a fin de obtener los αi
Probar si xi es correctamente clasificado
El numero de errores cometidos por la maquina en el procedimiento LOO esta denotado por LN+1.
Por definicion

14
LN+1 =N+1∑n=1
Q((xi, yi), α)
La cantidad LN+1N+1 , es la estimacion del error de generalizacion. Gracias a esto el siguiente teorema
es valido
Teorema 3 (Luntz y Brailovsky, 1969) El estimador LOO es no sesgado, esto es
E
(LN+1
N + 1
)= E(RN )
La esperanza del termino del lado izquierdo es tomada del grupo de entrenamiento de tamano
N + 1 y E(RN ) es la esperanza del riesgo actual para OSH construidos sobre la base de un grupo
de entrenamiento de tamano N . Entonces, para controlar la capacidad de generalizacion se debe
tratar de minimizar el numero de errores cometidos en el procedimiento LOO.
Nota 1 Para SVM, el procedimiento LOO se debe realizar solo en los vectores de soporte, los no
vectores de soporte seran reconocidos correctamente debido a que un no vector de soporte no afecta
la funcion de decision.
2.4.4. Cotas para el Estimador de Leave-One-Out
Se muestran aquı, diferentes cotas para el estimador LOO en SVM.
Numero de SV
Debido al hecho presentado en la nota 1, se puede restringir la sumatoria solo a los vectores de
soporte y luego acotar superiormente cada termino en la suma por 1, de lo cual se obtiene la
siguiente cota del numero de errores cometidos por el procedimiento LOO [Vapnik, 1995]
T =NSV
N
de donde NSV es el numero de vectores de soporte.

15
Jaakkola-Haussler
Para SVM sin valor de desplazamiento, analizando el proceso de optimizacion del algoritmo de SVM
cuando se calcula el error LOO, Jaakkola and Haussler [1999] provee la siguiente desigualdad
yp(f0(xp)− fp(xp)) ≤ α0pK(xp, xp) = Up
de la cual se extrae la siguiente cota
T =1N
N∑p=1
Ψ(α0pK(xp, xp)− 1)
En [Wahba et al., 2000] se propone una estimacion de los errores producidos bajo el esquema LOO,
para el cual en el caso de SVM con margen rıgido (C =∞) se vuelve
T =1N
∑α0
pK(xp, xp)
lo cual se puede ver como una cota superior de Jaakkola-Haussler siempre y cuando Ψ(x− 1) ≤ x
para x ≥ 0.
Opper-Winther
En el caso de SVM con margen rıgido sin desplazamiento, Opper and Winther [2000] utiliza un
metodo basado en la teorıa de respuesta lineal para probar que bajo el supuesto que un grupo de
vectores de soporte no cambia cuando se remueve un ejemplo p, se tiene
yp(f0(xp)− fp(xp)) =α0
p
(K−1SV )pp
donde KSV es la matriz de productos internos entre los vectores de soporte y que lleva a la siguiente
estimacion

16
T =1N
N∑p=1
Ψ(α0
p
(K−1SV )pp
− 1)
Radio-Margen
Sea que el margen optimo es igual a M y que las imagenes φ(xi) de los vectores de entrenamiento
xi, estan contenidas en una esfera de radio R. Entonces, el siguiente teorema se mantiene [Vapnik
and Chapelle, 2000]
Teorema 4 Dado un conjunto de entrenamiento Z = {(x1, y1), ..., (xN , yN )}, un espacio de repre-
sentacion en H y un hiperplano (w, b), el margen M(w, b, Z) y el radio R(Z) son definidos como
M(w, b, Z) = mın(xi,yi)∈Z
yi(w′φ(xi) + b)‖w‖
R((Z)) = mına,xi
‖φ(xi) + a‖
El algoritmo de margen maximo, LN : (X × Y)N → H × R toma como entrada el conjunto de
entrenamiento de longitud N y devuelve un hiperplano en el espacio de representacion, tal que
el margen es maximizado. Notese que asumiendo que dicho grupo de entrenamiento es separable,
entonces M(w, b, Z) > 0. Bajo este supuesto, para todas las medidas de probabilidad P (Z), la
probabilidad esperada de clasificacion erronea es
perr(w, b) = P (sign(w′φ(X) + b) 6= Y )
con la cota
E{perr(LN−1(Z))} ≤ 1NE
{R2(Z)
M2(L(Z), Z)
}(2.13)
donde la esperanza es tomada sobre un subconjunto aleatorio de Z de longitud N − 1 para el lado
izquierdo y N para el derecho en (2.13).
Este teorema se ajusta a la idea de construccion de un hiperplano que separe los datos con un margen
grande (entre mas grande sea dicho margen, mejor sera el desempeno del hiperplano construido).

17
De acuerdo al teorema 4, el desempeno promedio depende de E{
R2
M2
}y no simplemente de cuan
grande sea el margen M .
Para SVM sin desplazamiento y sin errores de entrenamiento, Vapnik [1998] propone la siguiente
cota superior para el numero de errores cometidos por LOO
T =1N
R2
M2(2.14)
donde R y M son respectivamente el radio y el margen definidos en el teorema 4.
Span de los Vectores de Soporte
Vapnik and Chapelle [2000] derivaron otra estimacion utilizando el concepto del span de los vectores
de soporte. Bajo el supuesto de que los SV permanecen intactos durante el procedimiento de LOO,
la siguiente igualdad es cierta
yp(f0(xp)− fp(xp)) = α0pS
2p
donde Sp es la distancia entre el punto φ(xi) y la coleccion Λp, y a su vez,
Λp =
∑i 6=p , α0
i >0
λiφ(xi) ,∑i 6=p
λ = 1
de lo que se obtiene, el numero exacto de errores cometidos por LOO bajo el supuesto previo. Ası,
la cota para LOO se define como sigue
T =1N
N∑p=1
Ψ(α0pS
2p − 1) (2.15)
Ademas, la estimacion del span puede ser relacionada con las otras mencionadas con formulaciones
simples [Chapelle et al., 2002].

18
2.5. Algoritmo de Entrenamiento
Considerando la formula general para la SVM, es decir, no lineal y no separable:
maxN∑i
αi −12
N∑i,j
αiαjyiyjK(xi, xj)
sujeto aN∑
i=1
yiαi = 0 y 0 ≤ αi ≤ C, ∀i
(2.16)
el metodo de descomposicion es tenido en cuenta considerando la densidad de la matriz kernel
K(xi, xj) de la ecuacion (2.11). Buena parte del trabajo al rededor de este metodo puede ser
encontrado en [Osuna et al., 1997, Joachims, 1999, Platt, 1999, Saunders et al., 1998].
2.5.1. Metodo de Descomposicion
Partiendo de la ecuacion (2.16) se puede realizar la siguiente representacion vectorial:
mınα
12α′Qα− e′α
sujeto a y′α = 0 y 0 ≤ αi ≤ C, ∀i(2.17)
donde Qij = yiyjK(xi, xj) y e = 1, ∀i.
Algoritmo 1
Dado un numero q < N , como tamano del conjunto de trabajo, se encuentra α1 solucion
inicial y se hace k = 1
Si αk es la solucion optima de la ecuacion (2.17) se termina, de otro modo se busca un con-
junto B ⊂ {1, ..., N} con tamano q. Se definen L ≡ {1, ..., N}\B, αkB y αk
L como subvectores
de αk correspondientes a B y a L respectivamente

19
Se resuelve el siguiente problema respecto de αB:
mınαB
12α′BQBBαB − (eB +QBLα
kL)′αB
sujeto a y′BαB = −y′LαkL y 0 ≤ (αB)i ≤ C, ∀i
(2.18)
donde
[QBB QBL
QLB QLL
]es una permutacion de la matriz Q
Se deja αk+1B como solucion optima de (2.18) y αk+1
L ≡ αkL. Se hace k = k + 1 y se vuelve al
paso 2
La idea basica del algoritmo de descomposicion es que en cada iteracion los ındices {1, ..., N} del
conjunto de entrenamiento, sean separados en dos mas pequenos B y L, donde B es el de trabajo. El
vector αL es fijado de manera que el objetivo sea 12α
′BQBBαB − (eB −QBLαL)′αB + 1
2α′LQLLαL−
e′LαL. Luego, se resuelve un subproblema respecto de αB , B es actualizado en cada iteracion (notese
que para simplificar la notacion se utiliza B en vez de Bk) y el decrecimiento estricto de la funcion
objetivo se sostiene (ver seccion 2.5.3 referente a la convergencia teorica del algoritmo).
2.5.2. Seleccion del Conjunto de Trabajo y Criterio de Parada
Una de las partes importantes en el algoritmo de descomposicion es la seleccion del grupo de trabajo
B. La condicion de Karush-Kuhn Tucker (KKT) en la ecuacion (2.17) muestra que existe un escalar
y dos vectores no negativos λ y µ, tales que
Qα+ e+ by = λ− µ
λiαi = 0, µi(C − α)i = 0
λi ≥ 0, µi ≥ 0, ∀i
(2.19)
Notese que si se escriben las condiciones de KKT para el primario y el dual, resultan ser las mismas y
el multiplicador de Lagrange de la restriccion lineal y′α = 0 coincide con el valor de desplazamiento
b en la funcion de decision. Luego, la ecuacion (2.19) puede reescribirse como

20
Qα+ e+ by ≥ 0, si α = 0
= 0, si 0 < α < C
≤ 0, si α = C
ahora, utilizando y = ±1, ∀i y asumiendo que C > 0, se tiene que
y = 1, αt < C ⇒ (Qα+ e)t + b ≥ 0⇒ b ≥ −(Qα+ e)t = −∇f(α)t
y = −1, αt > 0 ⇒ (Qα+ e)t − b ≤ 0⇒ b ≥ (Qα+ e)t = ∇f(α)t
y = −1, αt < C ⇒ (Qα+ e)t − b ≥ 0⇒ b ≤ (Qα+ e)t = ∇f(α)t
y = 1, αt > 0 ⇒ (Qα+ e)t + b ≤ 0⇒ b ≤ −(Qα+ e)t = −∇f(α)t
donde f(α) = 12α
′Qα+ e′α y ∇f(α) es el gradiente de f(α) en α y considerando
i ≡ argmax({−∇f(α)t|yt = 1, αt < C}, {∇f(α)t|yt = −1, αt > 0})
j ≡ argmin({∇f(α)t|yt = −1, αt < C}, {−∇f(α)t|yt = 1, αt > 0})(2.20)
de manera que B = {i, j} puede usarse como grupo de trabajo para el subproblema en la ecuacion
(2.18) del metodo de descomposicion, donde i y j son los dos elementos que mas violan las condi-
ciones de KKT. La idea de utilizar dos elementos como grupo de trabajo son tomadas del algoritmo
de optimizacion secuencial mınima (SMO) de Platt [1999]. La principal ventaja de esto, es que
la solucion analıtica de la ecuacion (2.17) puede ser obtenida sin la necesidad de un programa de
optimizacion comercial. Notese que la ecuacion (2.20) es un caso especial del metodo SVM light
en Joachims [1999]. Para ser mas preciso, en SVM light, si α es la solucion actual del problema, el
siguiente es resuelto
mınd∇f(α)′d
y′d = 0, −1 ≤ d ≤ 1,
dt ≥ 0, si αt = 0, dt ≤ 0, si αt = 0
(2.21)
|{dt dt 6= 0}| = q (2.22)
notese que |{dt dt 6= 0}| es el conjunto de componentes de d que no son cero. La restriccion en la
ecuacion (2.22) implica que la componente descendiente involucra solamente q variables. Luego, las

21
componentes de α con dt diferentes de cero son incluidas en el grupo de trabajo B utilizado para
construir el subproblema en la ecuacion (2.18). En efecto, d unicamente se usa para identificar B y
no para encontrar la direccion de busqueda.
Puede ser visto claramente que si q = 2 la solucion de la ecuacion (2.21) es
i = argmin{∇f(α)tdt|ytdt = 1; dt ≥ 0, si αt = 0; dt ≤ 0, si αt = C}
j = argmin(∇f(α)tdt|ytdt = −1; dt ≥ 0, si αt = 0; dt ≤ 0, si αt = C}
la cual es igual a la ecuacion (2.20) y corresponde a la segunda modificacion del algoritmo SMO en
Keerthi et al. [1999].
Ahora, se pueden definir
gi ≡
{−∇f(α)i si yi = 1, αi < C
∇f(α)i si yi = −1, αi > 0(2.23)
y
gj ≡
{−∇f(α)j si yj = −1, αj < C
∇f(α)j si yj = 1, αj > 0(2.24)
De la ecuacion (2.21) se tiene que
gi ≤ −gj (2.25)
lo cual implica que α es una solucion optima de la ecuacion (2.16), de manera que el criterio de
parada puede ser escrito e implementado de la siguiente forma como
gi ≤ −gj + ε (2.26)
donde ε es una constante positiva pequena.

22
2.5.3. Convergencia del Metodo de Descomposicion
La convergencia de los metodos de descomposicion fue inicialmente estudiada en Chang et al. [2000]
sinembargo, no coinciden con las implementaciones existentes. En esta seccion, solo se tienen en
cuenta resultados de convergencia para el metodo especıfico de descomposicion de la seccion 2.5.1.
A partir de Keerthi and Gilbert [2002] se tiene que
Teorema 5 Dado cualquier ε > 0 despues de un numero finito de iteraciones la expresion en (2.26)
sera satisfecha.
El teorema 5 establece la llamada propiedad de terminacion finita, de modo que se tiene la seguridad
de que luego de un numero finito de pasos el algoritmo terminara.
Teorema 6 Si {αk} es la secuencia generada por el algoritmo de descomposicion en la seccion
2.5.1, el lımite de cualquiera de sus subsecuencias convergentes es solucion optima de la ecuacion
(2.17).
El teorema 5 no implica el teorema 6 si se consideran gj y gj en la ecuacion (2.26) como funciones de
α que no son continuas. Por consiguiente no se puede tomar el lımite en ambos lados de la ecuacion
(2.26) y afirmar que cualquier punto convergente ya satisface las condiciones de KKT.
El teorema 6 fue inicialmente demostrado como una caso especial de los resultados generales en Lin
[2001c] donde algunos supuestos son necesarios. Partiendo de la demostracion en Lin [2001a], los
supuestos son eliminados, por tanto el teorema es completamente valido.
Considerando la convergencia local, debido a que el algoritmo utilizado es una caso especial de uno
discutido en Lin [2001b], se tiene el siguiente teorema
Teorema 7 Si Q es definida positiva y el dual del problema de optimizacion es degenerado (ver
supuesto 2 en Lin [2001b]), existe un c < 1, tal que luego de que k suficientemente grande,
f(αk+1)− f(α∗) ≤ c(f(αk)− f(α∗))
donde α∗ es la solucion optima de (2.17).

23
Con esto, el metodo de descomposicion aquı descrito es linealmente convergente. Los resultados
mostrados en esta seccion, son validos para kernels que pueden ser considerados como el producto
punto entre dos vectores de caracterısticas, esto es, Q es semidefinida positiva. Por ejemplo, para
algunos kernels como el sigmoidal (ver ecuacion A.5) Q puede no ser semidefinida positiva por
tanto la ecuacion (2.17) es un problema de optimizacion no convexo que puede contener varios
mınimos locales. Sinembargo, con unas pequenas modificaciones del algoritmo 1 se puede garantizar
la convergencia a un mınimo local (ver Lin and Lin [2003]).
2.5.4. Solucion Analıtica
Con la seleccion del grupo de trabajo en la seccion 2.5.2, la ecuacion (2.18) se convierte en un
problema de dos variables
mınαi,αj
12[αiαj ]
[Qii Qij
Qji Qjj
][αi
αj
]+ (Qi,LαL − 1)αi + (Qj,LαL − 1)αj
sujeto a yiαi + yjαj = 0 ≡ −y′LαkL
0 ≤ αi, αj ≤ C
(2.27)
En Platt [1999] se sustituye αi por yi(−y′LαL − yjαj) en la funcion objetivo de la ecuacion (2.18)
y se resuelve la minimizacion sin restricciones respecto a αi, obteniendose la siguiente solucion
αnewj ≡
αj + −Gi−Gj
Qii+Qjj+2Qijsi yi 6= yj
αj + Gi+Gj
Qii+Qjj−2Qijsi yi = yj
(2.28)
donde
Gi ≡ ∇fαi y Gj ≡ ∇f(α)j
Si este ultimo valor esta por fuera de de la posible region para αi, el valor en la ecuacion (2.28) es
truncado y asignado a αnewj . Por ejemplo, si yi = yj y C ≤ αi + αj ≤ 2C, αnew
j debe satisfacer
L ≡ αi + αj − C ≤ αnewj ≤ C ≡ H

24
de modo que el maximo valor para αnewi y αnew
j es C. Por consiguiente
αj +Gi +Gj
Qii +Qjj − 2Qij≤ L
entonces αnewj = L y
αnewi = αi + αj − αnew
j = C (2.29)
Esto puede ser ilustrado en la figura 2.3 en la cual se optimiza una funcion cuadratica sobre un
segmento de recta. El segmento de recta es la interseccion entre la restriccion lineal yiαi + yjαj y
las restricciones acotadas 0 ≤ αi y αj ≤ C.
Figura 2.3: Solucion analıtica de un problema de optimizacion de dos variables
No obstante, la igualdad en la ecuacion (2.29) podrıa no mantenerse si la operacion de punto flotante
causara que αi +αj−αnewj = αi +αj− (αi +αj−C) lo cual es diferente de C. Luego, en la mayorıa
de los casos, una pequena tolerancia εα es especificada de manera que todo αi ≥ C− εα es una cota
superior y αi ≤ εα = 0. Esto ultimo es necesario ya que algunos datos podrıan ser considerados
erroneamente como vectores de soporte. En adicion el calculo del valor de desplazamiento tambien
necesita correccion para aquellos valores libres de αi (0 ≤ αi ≤ C).
En Hsu and Lin [2002b] es senalado que si todos los αi obtienen sus valores mediante asignaciones
directas, no es necesario utilizar un valor de εα. Para ser mas precisos, en una operacion de punto
flotante si αi ← C es asignado, una futura comparacion entre αi y C retornara verdadero siempre
y cuando contengan la misma representacion interna.

25
Otro pequeno problema es que el denominador en la ecuacion (2.28) puede ser cero. Cuando esto
sucede,
Qij = ±(Qii +Qij)/2
por lo tanto
QiiQjj −Q2ij = QiiQjj − (Qii +Qjj)2/4 = −(Qii −Qij)2/a ≤ 0
Ahora, considerando que QBB es definida positiva, el denominador cero en la ecuacion (2.28) no es
posible. De ahı que este problema solo pueda suceder cuando Q sea singular de 2×2. A continuacion
se discuten dos situaciones en las cuales dicha matriz puede ser singular
La funcion φ no mapea los datos en vectores independientes en el espacio de alta dimensio-
nalidad haciendo que Q sea solo semidefinida positiva. Por ejemplo utilizando un kernel lineal
o polinomial de orden bajo.
Algunos kernels tienen una interesante propiedad por la cual φ(xi) ∀(i) son independientes
siempre y cuando xi 6= xj . Un ejemplo de esto es el kernel RBF (ver Micchelli [1986]), debido
a que en muchas situaciones practicas algunos xi son los mismos lo cual implica columnas (o
filas) de Q que son exactamente iguales y con esto la posibilidad de que QBB sea singular.
De cualquier manera, incluso si el denominador en la ecuacion (2.28) es cero no hay problemas
numericos desde que en la ecuacion (2.26) se puede ver que
gi + gj ≥ ε
y durante el proceso de iteracion
gi + gj = ±(−Gi −Gj), si yi 6= yj , (y)
gi + gj = ±(Gi −Gj), si yi = yj

26
Si la matriz del kernel no es semidefinida positiva Qii +Qjj±2Qij puede no ser positiva entonces la
ecuacion (2.28) puede no producir una actualizacion de modo que el valor objetivo sea disminuido.
Ademas el algoritmo puede permanecer en un solo punto quedandose en un ciclo infinito. En Lin
and Lin [2003] se estudia este problema en detalle y se propone la siguiente modificacion
αnewj ≡
αj + −Gi−Gj
max(Qii+Qjj+2Qij ,0) si yi 6= yj
αj + Gi+Gj
max(Qii+Qjj−2Qij ,0) si yi = yj
ası, se garantiza el decrecimiento estricto de la funcion objetivo.
2.5.5. Calculo de b
Despues de encontrar la solucion α al problema de optimizacion la variable b debe ser calculada para
ser utilizada en la funcion de decision. Las condiciones KKT de la ecuacion (2.17) fueron mostradas
en la ecuacion (2.20). Ahora, para el caso de y = 1 si existen αi que satisfagan 0 ≤ αi ≤ C entonces
se hace, r1 = ∇f(α)i. Para evitar errores numericos, se promedian como
r1 =
∑0≤αi≤C,yi=1∇f(α)i∑
0≤αi≤C,yi=1 1
Por otro lado, si no existe tal αi, r1 debe satisfacer
maxαi=C,yi=1
∇f(α)i ≤ r1 ≤ mınαi=0,yi=1
∇f(α)i
de donde r1 toma el punto medio del rango. Para yi = −1 un r2 se calcula de manera similar y
luego de que ambos r1 y r2 son obtenidos,
−b =r1 − r2
2
Notese que las condiciones de KKT pueden ser escritas como
maxαi>0,yi=±1
∇f(α)i ≤ mınαi<C,yi=±1
∇f(α)i

27
de modo que el siguiente criterio de parada puede ser utilizado practicamente: el algoritmo de
descomposicion para si en la iteracion α satisface
max(− mınαi<C,yi=1
∇f(α)i + maxαi>0,yi=1
∇f(α)i,
− mınαi<C,yi=−1
∇f(α)i + maxαi>0,yi=−1
∇f(α)i) < ε
donde ε > 0 es una constante elegida como tolerancia de parada.
2.5.6. Contraccion
Considerando que en muchos de los problemas practicos, el numero de vectores de soporte libres
(0 ≤ αi ≤ C) es pequeno, la tecnica de contraccion reduce el tamano del problema de trabajo
sin considerar algunas variables acotadas [Joachims, 1999]. En un punto cercano al final del pro-
ceso iterativo, el metodo de descomposicion identifica un posible conjunto A de modo que todos
los vectores de soporte libres queden contenidos en el. Para esto, el siguiente teorema muestra
que en las iteraciones finales de la descomposicion propuesta en la seccion 2.5.2 solo las variables
correspondientes a un conjunto pequeno tienen la posibilidad de moverse [Lin, 2002]
Teorema 8 Si lımk→∞ αk = α por el teorema 6, entonces, α es una solucion optima. Incluso,
cuando k es suficientemente grande, solo los elementos en
{t| − yt∇f(α)t = max( maxαi<C,yi=1
−∇f(α)i, maxαi>0,yi=−1
∇f(α)i)
= mın( mınαi<C,yi=−1
∇f(α)i, mınαi>0,yi=1
−∇f(α)i)
pueden todavıa seguir siendo modificados.
por lo tanto, se tiende a pensar que si la variable αi es igual a C para algunas iteraciones, al final
de la solucion, esta permanece como cota superior. De ahı que en vez de resolver todo el problema
de la ecuacion (2.17), se trabaja con uno de menor tamano
mınαA
12α′AQAAαA − (eA +QALα
kL)′αA
sujeto a y′AαA = −y′LαkL y 0 ≤ (αA)i ≤ C, ∀i
(2.30)

28
donde L = {1, ..., N}\A. Sinembargo, esta heurıstica puede fallar si la solucion de la ecuacion (2.30)
no es una parte correspondiente a la de la ecuacion (2.17). Cuando esto sucede, el problema completo
se vuelve a optimizar desde un punto donde αB es una solucion optima de la ecuacion (2.30) y αL
son variables acotadas identificadas antes del proceso de contraccion. Notese que mientras que se
esta resolviendo el problema de contraccion solo se conoce el gradiente QAAαA + QALαL + eA
de la ecuacion (2.30). Considerando esto ultimo, cuando se optimiza de nuevo el problema de la
ecuacion (2.17) se debe reconstruir completamente el gradiente de f(α)i lo cual es un tanto costoso
en terminos computacionales. Para evitar esto, en vez de iniciar el proceso de contraccion al final
del proceso iterativo, se inicia desde el principio como sigue:
Luego de cada mın(N, 1000) iteraciones se tratan de contraer algunas variables. Ası, durante
el proceso iterativo,
mın({∇f(αk)t|yt = −1, αt < C}, {−∇f(αk)t|yt = 1, αt > 0}) = −gii
<max({−∇f(αk)t|yt = 1, αt < C}, {∇f(αk)t|yt = −1, αt > 0}) = gjj
la ecuacion (2.25) no se satisface todavıa. Entonces, se supone que si gi ≤ −gii de la ecuacion
(2.23) y αt esta dentro del rango, es muy posible que αt no vuelva a cambiar, por lo tanto se
desactiva esa variable. Similarmente para −gj ≥ gjj de la ecuacion (2.24) con αt dentro del
rango. De esta manera, el conjunto A de variables activas es dinamicamente reducido cada
mın{L, 1000} iteraciones.
Es claro que la estrategia de contraccion arriba mencionada es muy agresiva considerando
que el metodo de descomposicion tiene una convergencia lenta y una gran cantidad de las
iteraciones es consumida alcanzando el dıgito final de precision requerido, no es deseado que
se pierdan iteraciones innecesariamente debido a una contraccion erronea. Con esto, cuando el
metodo de descomposicion alcanza primero la tolerancia gi ≤ −gj +10ε, el gradiente completo
es reconstruido. Luego, basados en la informacion correcta, se utilizan las ecuaciones (2.23)
y (2.24) para desactivar algunas variables y continuar con el metodo de descomposicion.
Como el tamano del conjunto A es dinamicamente reducido, para disminuir el costo computacional
del gradiente ∇f(α) durante las iteraciones se mantiene siempre
Gi = C∑αj=c
qij , ∀i

29
Ası, para el gradiente ∇f(α)i con i 3 A se tiene
∇f(α)i =∑i=1
Qijαj = Gi +∑
0<αj<C
Qijαj , ∀i
2.5.7. Caching
Otra tecnica para reducir el costo computacional es el caching. teniendo en cuenta que que Q es
completamente densa y puede no ser guardada en la memoria del computador, los elementos Qij
son calculados en cuanto sea necesario. Luego, utilizando la idea de almacenamiento de cache se
pueden guardar los elementos de Qij recientemente usados [Joachims, 1999] haciendo que el costo
computacional de posteriores iteraciones sea menor.
El teorema 8 soporta el uso de caching debido a que en las iteraciones finales, solo algunas columnas
de la matriz Q siguen siendo necesitadas de manera que si el cache contiene dichas columnas, se
pueden evitar la mayorıa de las evaluaciones del kernel para esta etapa.
Para la implementacion practica, se utiliza una estrategia simple consistente en dinamicamente
guardar solo las columnas recientes utilizadas de la matriz QAA de la ecuacion (2.30).
2.5.8. Complejidad Computacional
La discusion en la seccion 2.5.3 es acerca de la convergencia global asintotica del metodo de descom-
posicion. En adicion, la convergencia lineal (teorema 7) es una propiedad de la tasa de convergencia
local. En esta seccion, se discute la complejidad computacional del metodo.
La mayor cantidad de operaciones residen en el calculo de QBLαkL + eB y la actualizacion de
∇f(αk) a ∇f(αk+1). Notese que ∇f(α) es usada tanto en la seleccion del grupo de trabajo como
en la condicion de parada, de modo que puede considerarse todo junto como
QBLαkL + eB = ∇f(αk)−QBBα
kb (2.31)

30
y
∇f(αk+1) = ∇f(αk) +Q:,B(αk+1b − αk
B) (2.32)
donde Q:,B es la submatriz de Q con ındices en B. Esto es, en la k−esima iteracion con ∇f(αk)
conocido y la parte derecha de la ecuacion (2.31) como constructor del subproblema. Luego de
que el subproblema es resuelto, la ecuacion (2.32) es empleada para obtener el proximo ∇f(αk+1).
Como B contiene solo dos elementos y resolver el subproblema es facil, el costo sustancial reside
en el calculo de Q:,B(αk+1b − αk
B). La operacion en sı toma O(2N), sinembargo si Q:,B no esta
disponible en el cache y cada operacion del kernel cuesta O(n) en efecto, cada columna de Q:,B
necesita O(nN). De manera que la complejidad es iteraciones×O(N) o iteraciones×O(Nn) segun
sea el caso teniendo en cuenta que si se utiliza contraccion, N disminuye gradualmente. Desafor-
tunadamente, no se sabe mucho acerca de la complejidad del numero de iteraciones. Sinembargo,
algunos resultados interesantes fueron obtenidos por Hush and Scovel [2003] aunque solo para los
metodos de descomposicion descritos en Chang et al. [2000].
2.6. Maquinas de Soporte Multi Clase
En esta seccion se discute el metodo para SVM multi clase “uno contra uno” [Knerr et al., 1990],
en el cual k(k − 1)/2 clasificadores deben ser construidos para entrenar pares de diferentes clases.
La primera utilizacion de este metodo con SVM fue en Friedman [1996], KreSSel [1999]. Para el
entrenamiento de las clases i−esima y j−esima se resuelve el siguiente problema binario:
mınwij ,bij ,ξij
12(wij)′wij + C
∑t
(ξijt )
(wij)′φ(xt) + bij ≥ 1− ξijt , si xt ∈ I
(wij)′φ(xt) + bij ≥ −1 + ξijt , si xt ∈ J
ξijt ≥ 0
En la clasificacion se utiliza la estrategia de votacion de manera que la clase se asigna para cada
punto x como la resultante con mayor numero de votos o en el caso que dos clases tengan igual
numero de votos, simplemente la de menor ındice.

31
La otra tecnica mas usada para SVM multi-clase es “uno contra todos” en la cual se construyen
k modelos binarios entre la clase i−esima y el resto de las muestras de las otras clases juntas.
Sinembargo, no se considera debido a que en la literatura [Weston and Watkins, 1998, Platt et al.,
2000] presenta un menor desempeno que “uno contra uno”.
Ademas, si bien se entrenan mas clasificadores k(k− 1)/2, cada problema es mas pequeno (ademas
relativamente balanceado) haciendo que el tiempo de entrenamiento total no sea mayor al de “uno
contra todos”. Algunos detalles comparativos de estas y otras tecnicas puede ser encontrado en Hsu
and Lin [2002a].

Capıtulo 3
Seleccion de Hiperparametros en
Maquinas de Soporte Vectorial
En el problema de aprendizaje supervisado se toma un conjunto de pares entrada salida y se
trata de construir una funcion f que mapea los vectores de entrada xi ∈ Rn en etiquetas yi ∈{−1, 1}. El objetivo consiste entonces en encontrar una f ∈ F que minimize el riesgo empırico Remp
(ver seccion 2.4.1) en ejemplos posteriores. Los algoritmos de aprendizaje usualmente dependen de
parametros que controlan el tamano de la clase F o en la forma como la busqueda es realizada
en F . Actualmente existen varias tecnicas para encontrar dichos parametros. El riesgo empırico o
error de generalizacion puede ser estimado o bien utilizando algunos de los datos no empleados en el
entrenamiento (validacion de muestra independiente o validacion cruzada) o mediante alguna cota
dada por el analisis teorico (ver seccion 2.4.4).
Usualmente existen multiples parametros para ajustar al mismo tiempo, es mas, la estimacion del
error no es una funcion explıcita de tales valores de manera que la estrategia natural es una busqueda
exhaustiva en el espacio de los parametros lo cual corresponde a correr el algoritmo de entrenamiento
en cada valor posible previamente almacenado en un vector (sujeto a alguna discretizacion). Otra
manera, es encontrar una metodologıa que automaticamente los ajuste, en el caso de la SVM,
tomando ventaja tanto de sus propiedades de formulacion como de su algoritmo.
De manera especıfica, los parametros de los cuales depende la SVM son: el denotado como C que
32

33
controla el balance entre la maximizacion del margen y la penalizacion del error, ası como todos
los que aparecen en el mapeo no lineal al espacio de representacion o kernel. Como es ampliamente
conocido, uno de los factores mas importantes en el desempeno de las SVM es la seleccion de la
funcion kernel, sinembargo, en la practica muy pocos son utilizados debido a la dificultad inherente
en el ajuste de dichos parametros.
3.1. Busqueda en Malla
Esta tecnica ha sido utilizada durante los ultimos anos, aunque nunca fue presentada formalmente.
Debido a su simplicidad, es usada ampliamente por muchos investigadores del area de aprendizaje
de maquina. Esta procedimiento consiste en construir una malla acotada de vectores de parametros
conteniendo todas las posibles combinaciones en un espacio acotado de busqueda y para un paso
de discretizacion escogido. Debido a que es necesario utilizar alguna medida del desempeno de la
SVM, la validacion cruzada de n particiones es usada de modo que el vector de parametros elegido
es aquel para el cual el error de validacion sea menor para una tarea en especıfico. La busqueda en
malla para el kernel RBF esta dada por la siguiente definicion:
Definicion 9 Para un par de parametros de la SVM y el kernel: C y σ respectivamente, con
Cmin, σmin como cotas inferiores, Cmax, σmax como cotas superiores y C∆, σ∆ como los pasos de
discretizacion, la malla de entrenamiento puede ser construida como sigue:
(Ci, σj) = (Cmin + iCδ, σmin + jσδ) para 0 ≤ i ≤ n y 0 ≤ j ≤ m
donde n = Cmax−Cmin
C∆, m = σmax−σmin
σ∆y (Ci, σj) conforman una matriz de tamano n×m.
Dado que todas las combinaciones son necesarias para calcular una solucion, un total de (n+1)(m+
1) optimizaciones de la funcion de SVM son empleadas.
3.2. Busqueda en Lınea
Esta tecnica inicialmente presentada por Chapelle et al. [2002] emplea el hecho de que la cota
de Radio/Margen (ver seccion 2.4.4) es diferenciable, con el objeto de desarrollar un algoritmo

34
“optimo” para encontrar los parametros de la SVM partiendo de la idea que la busqueda exhaustiva
en el espacio de parametros puede ser prohibitiva. Esta metodologıa propone tomar ventaja de
propiedades especıficas de la formulacion de la SVM para minimizar una cota de la estimacion del
error de generalizacion empleando un algoritmo de gradiente descendiente sobre un conjunto de
parametros dados.
Reescribiendo la formula de Radio/Margen dada en la ecuacion (2.14) se tiene
LOO ≤ 4R2‖w‖2 (3.1)
donde w es la solucion de (2.3) y R es el radio de la esfera mas pequena conteniendo todos los φ(xi).
Ademas, Vapnik [1998] muestra que R2 es el valor objetivo del siguiente problema de optimizacion:
mınβ
1− β′Kβ
sujeto a 0 ≤ βi , i = 1, ..., l
eTβ = 1
(3.2)
sinembargo, debido a que es posible que los φ(xi) sean no linealmente separables no es practico usar
(2.3). Ademas, un φ altamente no lineal, puede producir facilmente sobre entrenamiento. Luego, es
mejor resolver una de las siguientes variaciones de (2.9),
mınw,b,ε
12w′w + C
N∑i=1
ξi L1− SVM (3.3)
o
mınw,b,ε
12w′w +
C
2
N∑i=1
ξ2i L2− SVM (3.4)
De modo que ahora se puede hacer referencia a dos clases de SVM, L1-SVM y L2-SVM respecti-
vamente dependiendo si los errores son penalizados lineal o cuadraticamente. A continuacion, se
describen los metodos de seleccion para Radio/Margen utilizando L1 y L2.

35
3.2.1. Cota de Radio/Margen para L2
Con relacion a la formulacion para L2-SVM en (3.4) y haciendo K(xi, xj) = zi.zj , el problema de
SVM puede ser convertido a margen rıgido como:
mınw
12‖w‖2
sujeto a yi(wi.zi + b) ≥ 0 ∀i(3.5)
donde zi denota la transformacion a un espacio de representacion modificado dado por:
zi.zj = K(xi, xj) = K(xi, xj) +1Cδij
con δij = 1, si i = j y 0 en otro caso. Ası, la expresion en (3.1) puede ser volverse a escribir como
se muestra en Vapnik and Chapelle [2000]
LOO ≤ f(C, σ) ,1NR2‖w‖2 (3.6)
siendo w como la solucion de (3.5). Debido a que (3.6) es diferenciable respecto de C y σ, es apro-
piado utilizar alguna de las tecnicas basadas en gradiente descendiente, por ejemplo el algoritmo
Quasi-Newton para minimizar f(C, σ). El calculo del gradiente de f(C, σ) requiere que ‖w‖2 y R2
sean conocidos, sinembargo, recientemente Chapelle et al. [2002] provee un resultado bastante util
que hace facil la obtencion de dichos gradientes una vez los duales de (3.4) y (3.2) son resueltos.
Con esto ultimo se mantiene que:
∂f
∂C=
1N
[∂‖w‖2
∂CR2 + ‖w‖2 ∂R
2
∂C]
∂f
∂σ2=
1N
[∂‖w‖2
∂σ2R2 + ‖w‖2 ∂R
2
∂σ2]
∂‖w‖2
∂C=∑
i
αi
C2
∂‖w‖2
∂σ2= −
∑i,j
αiαjyiyjK(xi, xj)‖xi − xj‖2
2σ4
∂R2
∂C= −
∑i
βi
C2(1− βi)
∂R2
∂σ2= −
∑i,j
βiβjK(xi, xj)‖xi − xj‖2
2σ4
luego, si ‖w‖2, R2, α y β estan disponibles, el gradiente de f(C, σ) es facil de obtener. Como es
sugerido en Chapelle et al. [2002], u1 = lnC y u2 = lnσ2 deben ser usados en vez de C and σ2.

36
Para este trabajo, BFGS como algoritmo quasi-Newton es empleado para minimizar f(C, σ) (ver
apendice B). Como se presenta en Keerthi [2002], una tecnica de gradiente descendiente requiere
muchas mas evaluaciones debido a la sensibilidad de tal procedimiento a errores de calculo numerico
en f(c, σ2) y sus gradientes. Para el algoritmo BFGS, se escogio ζ = 1 (ver ecuacion B) como
parametro inicial y C = 1, σ2 = n como condiciones iniciales donde n es la dimension de xi. El
criterio de parada fue tomado como |f(u + 1) − f(u)| ≤ 10−5f(u), segun sugerencia en Keerthi
[2002].
3.2.2. Cota de Radio/Margen para L1
En Chung et al. [2003] se propone la siguiente modificacion de (3.1) para L1-SVM:
(R2 +∆C
)(‖w‖2 + 2CN∑
i=1
ξi) (3.7)
siendo ∆ una constante positiva cercana a 1. Denotando (3.7) como f(C, σ2) y usandola como cota
de (3.3) las derivadas parciales se calculan como:
A = ‖w‖2 + 2CN∑
i=1
ξi B = R2 +∆C
∂f
∂C=∂A
∂CB +
∂B
∂CA
∂f
∂σ2=
∂A
∂σ2B +
∂B
∂σ2A
∂A
∂C= 2
∑i
ξi∂A
∂σ2= −
∑i,j
αiαjyiyjK(xi, xj)‖xi − xj‖2
2σ4
∂B
C= − ∆
C2
∂B
σ2= −
∑i,j
βiβjK(xi, xj)‖xi − xj‖2
2σ4
donde se toma el valor ∆ = 1 segun Chung et al. [2003]. Del mismo modo que para L2-SVM,
la transformacion de variable, algoritmo de optimizacion y condiciones iniciales fueron usadas.
Para el parametro de BFGS, ζ = 12 (ver ecuacion B) fue elegido debido a que es probable que se
obtengan valores mas alla de la region considerada ([-10,10]x[-10,10] para este trabajo) generando
una posible inestabilidad numerica. Ademas, para el criterio de parada se prefiere utilizar la siguiente
formulacion compuesta:

37
‖∇f(xk)‖‖∇f(x0)‖
≤ 10−3 or ‖∇f(xk)‖ ≤ 10−3
donde x0 es la solucion inicial. En Chung et al. [2003] se afirma que el criterio de parada propuesto
por Keerthi [2002] puede no ser adecuado para este caso, por eso se sigue mas bien el lineamiento
de Lin and More [1999].
3.3. Limitaciones Actuales
En esta seccion se presentan algunas discusiones acerca de la viabilidad y limitaciones de las tecnicas
arriba descritas.
Para el caso de busqueda en malla, los requerimientos en cuanto a evaluaciones de la funcion de SVM
pueden tornarse prohibitivos para grupos de datos de entrenamiento de mediano y gran tamano.
Si bien se sugiere que los valores maximos y mınimos para C y σ sean [-10,10]x[-10,10] como por
defecto, el tamano del paso es todavıa una incognita porque un valor grande no es suficiente para
obtener resultados satisfactorios y por el contrario uno pequeno, incrementa dramaticamente el
numero de evaluaciones sin de ninguna manera garantizar buenos resultados. En cuanto a ventajas,
dado que este procedimiento utiliza solamente validacion cruzada como medida de riesgo, el uso
indiscriminado de kernels y esquemas multi-clase es posible pero teniendo en cuenta que multiples
parametros tornan mas complejo el espacio de busqueda, por lo tanto, se espera un incremento
considerable en la carga computacional y por consiguiente es importante tener cuidado al escoger el
tamano del paso. Otro asunto importante es que el tamano de la particion en la validacion cruzada,
es directamente proporcional al numero de evaluaciones de la funcion de SVM ası que tambien debe
tenerse en cuenta.
En es esquema de busqueda en lınea utilizando Radio/Margen solo son necesarias una pocas evalu-
aciones de la funcion de SVM para satisfacer el criterio de parada, por esto, multiples parametros
pueden ser considerados para cualquier tarea. Desde que esta tecnica hace uso de propiedades de
diferenciabilidad, es imperativo obtener las funciones de los gradientes para cualquier dual y kernel
que se desee utilizar. Ademas, algunos problemas pueden devolver resultados inesperados ya que
la superficie del Radio/Margen posee diversos mınimos locales y se sabe bien que usualmente los
algoritmos basados en gradiente descendiente son sensibles a dicha condicion. Otro problema es

38
que aunque en la literatura disponible, los valores iniciales y el criterio de parada muestran buenos
resultados, aun permanecen como caso de estudio [Chung et al., 2003]. La principal ventaja de este
esquema es que resulta ser bastante conveniente para problemas a gran escala en el sentido que solo
basta con un numero pequeno de iteraciones para alcanzar el criterio de parada.
En resumen, la busqueda en malla es en terminos generales una solucion facil y flexible para la
seleccion del modelo para problemas relativamente pequenos y la busqueda en lınea una tecnica
especializada difıcil de implementar pero apropiada para tareas de cualquier tamano y tipo de
kernel desde que las condiciones de diferenciabilidad sean satisfechas.

Capıtulo 4
Estrategias Evolutivas
La estrategia evolutiva (ES) consiste en un algoritmo de busqueda estocastico que minimiza una
funcion objetivo no lineal, la cual es un mapeo de un espacio de busqueda S ⊆ R a R. Los pasos
dados para efectuar dicha busqueda son realizados por una variacion estocastica llamada mutacion
de los puntos o recombinaciones de ellos encontrados hasta un momento dado. La mutacion es
usualmente es efectuada anadiendo una realizacion a un vector aleatorio distribuido normal. Es
sencillo imaginar que los parametros de una distribucion normal son parte esencial en el desempeno
(en terminos del numero de evaluaciones de la funcion objetivo para alcanzar cierto valor) del
algoritmo de busqueda. Entre otros, los parametros que definen la distribucion de la mutacion
son llamados “parametros estrategicos” en contraste a los parametros concernientes a los puntos
en el espacio de busqueda denominados parametros objeto. En terminos generales, no existe un
conocimiento detallado acerca de una eleccion apropiada para los parametros estrategicos. Si bien,
el conjunto de valores para los parametros estrategicos que pueden ser observados durante el proceso
de busqueda es pequeno [Rechemberg, 1984] y un grupo de buenos valores iniciales para dichos
parametros difiere substancialmente de problema a problema, usualmente pueden cambiar durante
la busqueda incluso en varios ordenes de magnitud. Por esta razon, una auto adaptacion de la
distribucion de mutacion que dinamicamente varıe los parametros estrategicos durante el proceso
de busqueda es una caracterıstica imperativa en las ES.
A continuacion se revisan tres pasos consecutivos para adaptar una distribucion normal de mutacion
en ES.
39

40
Figura 4.1: Lıneas de igual densidad de probabilidad en dos distribuciones normales
1. La distribucion normal se escoge isotropica. Las superficies de igual densidad de probabilidad
son cırculos (figura 4.1, izquierda) o hiperesferas (si n ≥ 3) y la varianza de toda la distribucion
(como el paso global o longitud esperada del paso) es el unico parametro estrategico libre.
2. El concepto de paso global puede ser generalizado. Cada eje de coordenadas es asignado a
una varianza diferente (figura 4.1, centro) de modo que existan n parametros estrategicos
libres. La desventaja de este concepto es la dependencia del sistema de coordenadas y por
consiguiente la perdida de la invarianza respecto a la rotacion.
3. Una generalizacion posterior adapta el sistema de coordenadas ortogonal, de manera que
cada eje es asignado a una varianza diferente (figura 4.1, derecha). Ası, cualquier distribucion
normal con media cero puede ser producida con (n2 + n)/2 parametros estrategicos libres e
invarianza respecto a la rotacion en el espacio de busqueda.
La adaptacion de parametros estrategicos en ES tıpicamente hace parte de la idea de control muta-
tivo de parametros estrategicos (MSC). El concepto de control mutativo puede ser ejemplificado en
(1, λ)-ES para un unico paso global o mutativo puro con x(g) ∈ Rn y σ(g) ∈ R+ el vector de para-
metros objeto y el paso en la generacion g respectivamente. El paso de mutacion de la generacion
g a la g + 1 se mantiene para cada subdivision k = 1, ..., λ:
σ(g+1)k = σ(g) + exp(ξk)
x(g+1)k = x(g) + σ
(g+1)k zk
(4.1)
donde,

41
ξk ∈ R ,siendo k = 1, ..., λ realizaciones independientes de un numero aleatorio con media cero.
Tıpicamente, ξk es distribuido normal con desviacion estandar 1/√
2n [Back and Schwefel,
1993]. Usualmente se prefiere escoger P (ξk = 0,3) = P (ξk = −0,3) = 1/2 [Rechemberg, 1984]
zk ∼ N (0, I) ∈ Rn para k = 1, ..., λ realizaciones independientes de un vector aleatorio con dis-
tribucion normal con I matriz identica. Esto es, las componentes de zk estan identica e
independientemente (iid) distribuidas
Luego de que λ pasos de mutacion son realizados, la mejor subdivision (respecto del vector de
parametros objeto x(g)) es seleccionado para iniciar el siguiente paso generacional. La ecuacion
(4.1) hace posible la mutacion del parametro estrategico y la desviacion estandar de ξ representa
la fuerza de la mutacion en el nivel actual del parametro estrategico.
El concepto de adaptacion fue primeramente introducido por Rechemberg [1984] para pasos globales
e individuales. Schwefel [1992] expandio el proceso mutativo a la adaptacion arbitraria de distribu-
ciones normales de mutacion. Ostermeier et al. [1994] presento un primer nivel de desaleatorizacion
en el control de los parametros estrategicos para facilitar la adaptacion de pasos individuales en
poblaciones pequenas y constantes. Hansen and Ostermeier [2001] desarrolla un segundo nivel de
desaleatorizacion pero aplicado a la adaptacion de distribuciones normales arbitrarias o adaptacion
de matriz de covarianza (CMA).
4.1. Adaptacion Arbitraria de Distribuciones Normales
Fundamentalmente existen dos motivaciones para la adaptacion de distribuciones de mutacion nor-
males con media cero.
La codificacion apropiada para un problema dado es crucial para la busqueda eficiente uti-
lizando algoritmos evolutivos, por esta razon es deseable un mecanismo adaptivo de co-
dificacion. La restriccion de tal codificacion (decodificacion) a transformaciones lineales parece
razonable ya que O(n2) parametros requieren ser adaptados. Es facil demostrar que en el caso
de mutacion aditiva, las transformaciones lineales del espacio de busqueda son equivalentes
a transformaciones lineales de la distribucion de mutacion. Las transformaciones lineales de
la distribucion normal de mutacion siempre resultan nuevamente en distribuciones normales
con media cero mientras que cualquier distribucion normal con media cero puede ser obtenida

42
mediante una transformacion lineal apropiada. Esto ultimo sostiene la equivalencia entre una
codificacion (decodificacion) lineal generalizada y la adaptacion de todos los parametros de
la distribucion en la matriz de covarianza.
Se asume que la funcion objetivo sea no lineal y significativamente no separable, de otra ma-
nera el problema serıa comparativamente sencillo debido a que puede ser resuelto resolviendo
n problemas unidimensionales, mientras que la adaptacion de funciones objetivo no separables
no es posible si solamente pasos individuales son dinamicamente modificados. Esto requiere
una distribucion de mutacion mucho mas general que sugiere la adaptacion de funciones de
distribucion normales arbitrarias.
Escoger que la media sea cero es intuitivamente evidente y concuerda con Beyer and Deb [1994]
debido a que una media diferente de cero implica que la poblacion debe moverse a otro lugar en
el espacio de los parametros estrategicos, lo cual puede interpretarse como extrapolacion. En com-
paracion a un ES simple, la extrapolacion puede resultar ventajosa en muchas funciones de costo,
sinembargo en contraste a un ES con desaleatorizacion de toda la matriz de covarianza la venta-
ja no parece ser importante. En general, cualquier mecanismo de adaptacion que dinamicamente
modifique la forma de codificar o decodificar, debe cumplir las siguientes demandas fundamentales
[Hansen and Ostermeier, 2001]:
Adaptacion La adaptacion debe ser satisfactoria de manera que despues de una fase de adaptacion,
de modo que las tasas de progreso la funcion objetivo hiperesferica∑
i x2i deben ser compa-
rables a las realizadas para alguna funcion objetivo cuadratica convexa, esto es, una funcion
f : x 7−→ x′ Hx+b′x+c donde la matriz Hessiana H ∈ Rn×n es simetrica y definida positiva,
b ∈ Rn y c ∈ R [Beyer, 1995].
Desempeno El desempeno de la funcion hiperesferica debe ser comparable al correspondiente a
(1, 5)−ES con optimo paso, donde ln(f (g)best/f
(g+n)best )/λ ≈ 0,1410 es la perdida por un factor de
10 que sugiere ser aceptable.
Invarianza Las propiedades de invarianza del algoritmo (1, λ)−ES con distribucion de mutacion
isotropica con respecto a la transformacion del espacio de parametros objeto debe ser preser-
vada. En particular, la traslacion, rotacion y reflexion de los parametros objeto no debe
tener influencia en el comportamiento de la estrategia, aparte de ser estrictamente monotona
creciente.

43
Estacionariedad Con el fin de alcanzar un comportamiento razonable de la estrategia, algun tipo
de condicion de estacionariedad en los parametros estrategicos debe ser completamente so-
portada por una seleccion puramente aleatoria, lo cual es analogo a escoger un valor de media
igual a cero para la mutacion de los parametros objeto, de manera que la no estacionariedad
pueda ser cuantificada y evaluada.
Desde el punto de vista conceptual, el primer objetivo de la adaptacion de parametros estrategicos
es ser invariante a algunas transformaciones del espacio de parametros objeto. Sea dada la funcion
objetivo f : x 7−→ f(c · A · x), la adaptacion de un paso global puede producir la invarianza para
c 6= 0. La codificacion (decodificacion) generalizada puede adicionalmente resultar en invariante
respecto de la matriz A que es de rango completo. Esta ultima es un buen punto de inicio para
lograr las demandas de adaptacion, ademas, desde el punto de vista practico, dicha invarianza es
una caracterıstica util para evaluar un algoritmo de busqueda dado.
4.2. Adaptacion de la Matriz de Covarianza
La adaptacion de matriz de covarianza [Hansen and Ostermeier, 1996] es un esquema de auto
adaptacion desaleatorizada de segundo nivel. Para empezar, esta implementa directamente la idea de
MSC de aumentar la probabilidad de producir pasos de mutacion exitosos. La matriz de covarianza
de la distribucion de mutacion es cambiada con el fin de incrementar la probabilidad de producir
de nuevo un paso de mutacion seleccionado. Luego, la tasa de cambio es ajustada de acuerdo
al numero de parametros estrategicos a ser adaptados (esto es, ccov de la ecuacion (4.6)) y por
ultimo, sujeto a una seleccion aleatoria, la esperanza de la matriz de covarianza C es estacionaria.
Incluso, el mecanismo de adaptacion es inherentemente independiente del sistema de coordenadas
dado. En resumen, la CMA implementa el analisis de componentes principales (PCA) de los pasos
seleccionados previamente para determinar una nueva distribucion de mutacion.
Ası, considerese un metodo especial para producir realizaciones con distribucion normal de n di-
mensiones con media cero. Si los vectores z1, ..., zm ∈ R para m ≥ n que ademas llenan Rn y N (0, 1)
valores iid, se tiene
N (0, 1)z1 + ...+N (0, 1)zm (4.2)

44
es un vector aleatorio normal distribuido con media cero de manera que eligiendo zi = 1, ...,m
apropiadamente cualquier distribucion con media cero puede ser obtenida. La distribucion de la
ecuacion (4.2) es generada anadiendo distribuciones N (0, 1) ∼ N (0, ziz′i) de modo que si el vec-
tor zi es dado, la distribucion normal que produce dicho vector es la que tiene mayor densidad
de todas las distribuciones normales con media cero. Ası, la CMA construye la distribucion de
mutacion de los pasos seleccionados. De la ecuacion (4.2), en lugar de los vectores zi, los pasos
de mutacion seleccionados son utilizados con pesos exponencialmente descendientes con el objeto
de hacer tender la distribucion de mutacion a reproducir los pasos seleccionados en generaciones
pasadas realizando un alineamiento de las distribuciones antes y despues de la seleccion. Con esto
ultimo, si ambas distribuciones resultan parecidas bajo seleccion aleatoria se elimina la posibilidad
de cambios posteriores [Hansen, 2000].
A continuacion se presenta una descripcion precisa de CMA, como sigue
Aparte de la adaptacion de la forma de la distribucion, la varianza global de la distribucion de
mutacion es adaptada por separado. Se encuentra que dicha forma de adaptacion es util por
dos razones [Hansen and Ostermeier, 2001]. Primero, los cambios de la varianza global y de
la forma de la distribucion deben operar en diferentes escalas de tiempo, n para ser precisos
a diferencia de la forma de distribucion que opera a razon de n2 debido a que la varianza
debe estar en capacidad de cambiar tan rapido como se requiere en funciones objetivo simples
como la esfera∑
i x2i . Segundo, si la varianza global no es adaptada mas rapido que la forma
de la distribucion, un valor inicial pequeno para este parametro puede amenazar el proceso
de busqueda. Si esto no fuera, la estrategia verıa un entorno lineal haciendo que la adaptacion
erroneamente alargara la varianza en una direccion.
La CMA es formulada por un numero de fuentes µ ≥ 1 y multi recombinacion ponderada
resultando en una evidentemente mas sofisticada manera de calcular el paso seleccionado z(g)sel .
La tecnica de cumulacion es aplicada a los vectores que construyen la distribucion, de manera
que en vez de pasos simples z(g)sel , trayectorias evolutivas p(g) son empleadas ası, estas ultimas
representan una secuencia de pasos de mutacion seleccionados.
El esquema de adaptacion debe ser formalizado en el sentido de la matriz de covarianza debido
a que almacenar tanto como g vectores es prohibitivo. Esto es, en cada generacion g luego de la
seleccion de los mejores puntos de busqueda se lleva a cabo como:

45
1. La matriz de covarianza de la nueva distribucion C(g) es calculada con referencia a C(g−1) y
z(g)sel . En otras palabras, la matriz de covarianza de la distribucion actual es adaptada.
2. La varianza global es adaptada por medio del control de la longitud de la trayectoria cumu-
lativa reemplazando zk por una trayectoria evolutiva conjugada.
3. De la matriz de covarianza, el eje principal de la nueva distribucion y sus varianzas son
calculadas. Para producir realizaciones de la nueva distribucion, otras n son agregadas lo
cual corresponde a los ejes principales de la distribucion de mutacion con forma de elipsoide
(ver figura 4.1).
Con esto ultimo, los requerimientos de almacenamiento son O(n2). En general, para un n moderado
dicho costo es insignificante [Press and Flannery, 1992].
4.3. Trayectoria Evolutiva: Cumulacion
El concepto de MSC utiliza informacion de un solo paso generacional. En contraste, puede ser venta-
joso emplear toda la trayectoria seguida por la poblacion durante un numero dado de generaciones
ya que es preferible maximizar la tasa de progreso en vez de enfatizar la probabilidad de seleccion.
Consecuentemente, se expande la idea de control de parametros estrategicos en el sentido que la
adaptacion debe maximizar la probabilidad de subdivision satisfactoria [Hansen and Ostermeier,
1996].
Una trayectoria evolutiva contiene informacion adicional acerca de la seleccion en comparacion a
un simple paso, ası que las correlaciones entre pasos sucesivos tomados entre generaciones deben
ser tenidas en cuenta, ya que si la correlacion es paralela, significa que los pasos van en la misma
direccion, por lo tanto la trayectoria es relativamente larga, en cambio, si la correlacion es anti
paralela, los pasos se cancelan unos con otros, lo cual indica que la trayectoria es relativamente
corta. Consecuentemente, para maximizar el paso de mutacion eficientemente, es necesario realizar
pasos largos donde la trayectoria es larga y viceversa. La trayectoria evolutiva es calculada como
un proceso iterativo de sumas ponderadas de pasos seleccionados que obedece a
p(g+1) = (1− c)p(g) +√c(2− c)z(g+1)
sel(4.3)

46
donde 0 ≤ c ≤ 1 y p(0) = 0. Este procedimiento, introducido por [Ostermeier et al., 1994] se
denomina cumulacion. Ası mismo,√c(2− c) es el factor de normalizacion: asumiendo que z(g+1)
sel y
p(g) en la ecuacion (4.3) es iid, se mantiene que p(g+1) ∼ p(g) independientemente de c ∈ (0, 1] y sus
varianzas son identicas debido a que 1 = (1− c2) +√c(2− c). Si c = 1, no se lleva a cabo ninguna
cumulacion y p(g+1) = z(g+1)sel . La informacion acumulada en p(g) es estrictamente 1/c [Hansen and
Ostermeier, 1997], ası que luego de ∼ 1/c generaciones la informacion original en p(g) es reducida
por un factor de 1/e ≈ 0,37 sugiriendo que c−1 puede ser interpretado como el numero de pasos
sumados.
4.4. El Algoritmo (µW , λ)-CMA-ES
En esta seccion se describe formalmente la estrategia evolutiva basada en los metodos presentados
en las secciones 4.2 y 4.3. La recombinacion por pesos es una generalizacion de la recombinacion
multiple denotada como (µI , λ), donde todos los pesos son iguales [Beyer, 1995]. En este esquema, la
transicion de la generacion g a la g+1 de los parametros x(g)1 , ..., x
(g)λ ∈ Rn, p(g)
c ∈ Rn, C(g) ∈ Rn×n,
p(g)σ ∈ Rn y σ(g) ∈ R+ como se escribe de la ecuacion (4.4) a la (4.9) y que de hecho, definen
completamente el algoritmo. La inicializacion es haciendo p(0)c = p
(0)σ = 0 y C(0) = I, mientras
que el vector inicial de parametros objeto 〈x〉(0)W y el paso inicial σ(0) deben ser elegidos segun el
problema abordado.
El vector de parametros objeto x(g+1)k con individuos k = 1, ..., λ se calcula como
x(g+1)k = 〈x〉(g)
W + σ(g)B(g)D(g)z(g+1)k︸ ︷︷ ︸
∼N (0,C(g))
(4.4)
donde lo siguiente aplica:
x(g+1)k ∈ Rn , es el vector de parametros objeto del individuo k−esimo en la generacion g + 1
〈x〉(g)W := 1∑µ
i=1 wi
∑µi=1 wix
(g)i:λ , wi ∈ Rn , correspondiente a la media ponderada de los µ mejores
individuos en la generacion g, con i : λ el i−esimo mejor individuo
σ(g) ∈ R+ tamano del paso en la generacion g y σ(0) la componente inicial entendida como la
desviacion estandar del paso de mutacion

47
z(g+1)k ∈ Rn para k = 1, ..., λ y g = 1, 2, ... realizaciones independientes de un vector aleatorio (0, I)
con distribucion normal
C(g) matriz n × n simetrica definida positiva. C(g), es la matriz de covarianza del vector aleato-
rio con distribucion normal B(g)D(g)N (0, I). C(g) determina B(g) y D(g) haciendo C(g) =
B(g)D(g)(B(g)D(g))′ = B(g)(D(g))2B(g) y resolviendo la descomposicion de valor singular
(SVD)
D(g) matriz diagonal n × n (matriz de pasos) con d(g)ii de D(g) los valores propios de la matriz de
covarianza C(g)
B(g) matriz ortogonal n × n (matriz de rotacion) que determina el sistema de coordenadas. Las
columnas de B(g) se definen como los vectores propios de la matriz de covarianza C(g). La
i−esima componente diagonal al cuadrado (d(g)ii )2 de D(g) es el valor propio correspondiente
a la i−esima columna b(g)i de B(g), esto es, C(g)b
(g)i = (d(g)
ii )2b(g)i para i = 1, ..., n
Las superficies con igual densidad de probabilidad de D(g)z(g+1)k son hiperelipsoides paralelas. B(g)
reorienta dichas elipsoides para hacerlas independientes del sistema de coordenadas. La matriz
de covarianza C(g) determina D(g) y B(g) a partir de los signos de las columnas en B(g)y las
permutaciones de las columnas en ambas matrices.
Sea, C(g) adaptada segun la evolucion de la trayectoria de p(g+1)c , entonces para la construccion de
p(g+1)c se usa el ultimo termino de la ecuacion (4.4) quitando σ(g). Luego, la transicion de p(g)
c a
C(g) se calcula como sigue:
p(g+1)c = (1− cc)p(g)
c + cuc · cWB(g)D(g)〈z〉(g+1)k︸ ︷︷ ︸
cW
σ(g) (〈xW 〉g+1W −〈xW 〉gW )
(4.5)
Z(g+1) = B(g)D(g)
∑i∈I
(g+1)sel
z(g+1)i (z(g+1)
i )′
(B(g)D(g))′ (4.6)
C(g+1) = (1− ccov)C(g) + ccov(αcov · p(g+1)c (p(g+1)
c )′ + (1− αcov)Z(g+1)) (4.7)
donde,
p(g+1)c ∈ Rn , es la suma de las diferencias ponderadas de los puntos 〈x〉W . Ademas, p(g+1)
c (p(g+1)c )′
es matriz simetrica de rango uno

48
cc ∈ (0, 1) determina la acumulacion de tiempo para pc, la cual es en general 1/cc
cuc :=√cc(2− cc) normaliza la varianza de pc debido a que 1 = (1− cc)2 + (cuc )2 (ver seccion 4.3)
cW :=∑µ
i=1 wi√∑µi=1 w2
i
es seleccionado aleatoriamente de modo que cW 〈z〉(g+1)k y z(g+1)
k tengan la misma
varianza
〈z〉(g+1)k := 1∑µ
i=1 wi
∑µi=1 wiz
(g)i:λ con z
(g+1)k de la ecuacion (4.4) y i : λ y wi de la misma manera
que para 〈x〉(g)W
ccov ∈ (0, 1) razon de cambio de la matriz de covarianza C. Para la implementacion de la modifi-
cacion dada por Hansen et al. [2003] ccov = αcov2√
n+√
2+ (1− αcov) mın
(1, 2µ−1
(n+2)2+µ
)αcov ∈ (0, 1) parametro de control. Si αcov = 1 se tiene ccov como en el algoritmo original de CMA
y con αcov = 1/µ segun sugerencia en Hansen et al. [2003]
La adaptacion adicional del paso σ(g) es necesaria para el control de la longitud de la trayectoria en
el algoritmo CMA-ES, de modo que una trayectoria evolutiva “conjugada” debe ser calculada para
la cual el escalamiento con D(g) es omitido
p(g+1)σ = (1− cσ)p(g)
σ + cuσ · cWB(g)〈z〉(g+1)k (4.8)
σ(g+1) = σ(g) ·(
1dσ· ‖p
(g+1)σ ‖−Xn
Xn
)(4.9)
donde se tiene que,
p(g+1)σ ∈ Rn trayectoria evolutiva no escalada por D(g)
cWB(g)〈z〉(g+1)k es B(g)(D(g))−1(B(g))−1 cW
σ(g)
(〈xW 〉g+1
W − 〈xW 〉gW)
cσ ∈ (0, 1) determina la acumulacion de tiempo para pc, la cual es en general 1/cc
cuσ :=√cσ(2− cσ) que satisface 1 = (1− cσ)2 + (cuσ)2 (ver seccion 4.3)
dσ ≥ 1 parametro de condensacion que determina la posible tasa de cambio de σ(g) en la secuencia
generacional.
Xn = E(‖N (0, I)‖) =√
2 · Γ(
n+12
)/Γ(
n2
)esperanza del vector aleatorio N (0, I). Una buena
aproximacion es Xn ≈√n(1 + 1
4n + 121n2
)[Hansen and Ostermeier, 1997]

49
Sin tener en cuenta la omision de D(g), las ecuaciones (4.5) y (4.7) son identicas. Debido a que
B(g)〈z〉(g+1)k es distribuido normal, la longitud de los pasos en diferentes direcciones son comparables
y la esperanza de la longitud de pσ denotada como Xn es conocida [Hansen and Ostermeier, 2001].
La cumulacion en la ecuacion (4.5) a menudo acelera la adaptacion de la matriz de covarianza,
sinembargo, en realidad no es algo esencial de modo que cc puede tomarse como 1. Para el control
de la longitud de la trayectoria, la cumulacion es muy importante, luego c−1σ debe no ser conside-
rablemente mas pequeno que√n/2. A medida que se aumenta n la longitud de los pasos se vuelve
cada vez mas similar haciendo la seleccion irrelevante.
4.5. Valores para los Parametros Internos
Ademas del tamano de la poblacion λ y el numero de parientes µ, los parametros de estrategia
(w1, ..., wµ), cc, ccov, cσ y dσ deben ser elegidos. Para esto existen valores por defecto resumidos en
la tabla [Hansen and Ostermeier, 2001].
λ µ wi=1,...,µ cc ccov cσ dσ
4 + 3ln(n) λ/2 ln(
λ+12
)+ ln(i) 4
n+42
(2+√
(2))24
n+4 c−1σ + 1
Tabla 4.1: Parametros defecto para (µW , λ)
En terminos generales, la seleccion de los parametros λ, µ y (w1, ..., wµ) es comparativamente
no crıtica, de manera que pueden tomar valores en un rango muy amplio sin afectar el pro-
cedimiento de adaptacion. Se recomienda siempre elegir µ < λ/2 [Beyer, 1996, Herdy, 1993]
y los pesos de recombinacion acorde a w1 ≤ ... ≤ wµ ≤ 0 [Hansen and Ostermeier, 2001].
Aparte de eso, para implementar la modificacion de Hansen et al. [2003], debe hacerse ccov =
αcov2√
n+√
2+ (1 − αcov)mın
(1, 2µ−1
(n+2)2+µ
). Para el caso de (µI , λ)-CMA-ES es decir, cuando
w1 = ... = wµ se escoge µ = λ/4 por defecto. Para casos de exploracion extrema λ puede ser
tan grande como se desee, manteniendo una relacion acorde con µ, y en particular para problemas
donde no existe mucho ruido, λ = 9 es a menudo apropiado incluso para valores grandes de n
[Ostermeier and Hansen, 1999].

50
4.6. Limitaciones y Aspectos Practicos
Hasta el momento, las limitaciones de CMA resultan ser la insuficiencia de informacion para realizar
la seleccion (lo cual no sucede siempre y cuando la funcion de costo este bien formulada, ver Hansen
and Ostermeier [1997]) y problemas de precision numerica, que resultan en inestabilidad de la
busqueda y una condicion de la matriz de covarianza consistente en un incremento no acotado que
genera convergencia prematura.
El paso inicial σ(0) debe escogerse de manera que σ no tienda a incrementar significativamente
en las primeras 2/cσ generaciones, de otro modo el algoritmo puede ser ineficiente en el sentido
de requerir un numero considerable de evaluaciones adicionales. Para prevenir errores de calculo,
se debe asegurar una condicion maxima numerica para C(g) (por ejemplo 1014), de modo que
si la diferencia entre el mayor y el menor valor propio sobrepasan dicha condicion, la operacion
C(g) := C(g) +(max(d(g)ii )2/1014−mın(d(g)
ii )2))I limita la condicion de una manera razonable hasta
1014 + 1.
Debido a que el cambio de C(g) es comparativamente lento, es posible no actualizar B(g) y D(g) en
cada generacion, sino cada√n o mejor, luego de n/10 generaciones. Esto ultimo reduce la carga
computacional de la estrategia de O(n3) a O(n2,5) o O(n2) respectivamente.
Concerniente a la convergencia del metodo, no existe hasta ahora una prueba formal debido a
que usualmente parecen carecer de relevancia practica [Hansen, 2004], sinembargo Bienvenuea and
Francois [2003] presenta pruebas y dificultades de la convergencia global en estrategias evolutivas
con adaptacion del tamano del paso, Jagerskupper [2003] un analisis de estrategias evolutivas para
problemas de minimizacion en espacios euclıdeos y Rudolph [1999] contraejemplos en convergencia
global de estrategias evolutivas auto adaptivas.

Capıtulo 5
Metodo Propuesto
Luego de la etapa de revision bibliografica se llego a la conclusion que dos posibles soluciones al
problema de seleccion de hiperparametros en maquinas de soporte vectorial podrıan ser: seguir
utilizando las propiedades de diferenciabilidad de algunas cotas del error de generalizacion, lo cual
implicarıa, o bien buscar otra cota que no hubiera sido usada, o alternativamente emplear un
metodo diferente de busqueda en lınea, o descartar la diferenciabilidad y encontrar un metodo que
efectivamente minimize una funcion dada que tambien resulte ser cota del error de generalizacion.
El principal inconveniente de la primera idea es que las limitaciones derivadas de la diferenciabilidad
como un espacio de busqueda “restringido”, kernels y soporte multi clase permanecerıan, haciendo
que el mejoramiento de las tecnicas actuales residiera solamente en aumentos de la precision de
clasificacion y/o disminucion en el numero de vectores de soporte. En el segundo caso, existen
muchas posibilidades, ya que los llamados metodos de busqueda global que generalmente estan
inspirados en fenomenos naturales principalmente exigen solamente que la funcion tenga un mınimo
no necesariamente unico. Dentro de los metodos de busqueda global, tal vez los mas utilizados son
el recocido simulado, la quimotaxis y los algoritmos evolutivos, aunque esta ultima es tal vez la
mas investigada hasta el momento. La programacion genetica, tiene en terminos generales tres
subdivisiones: programacion evolutiva, algoritmos geneticos y estrategias evolutivas. Sin considerar
de antemano la programacion evolutiva, debido a que la historia de los algoritmos geneticos ha
sido principalmente construida a traves del pragmatismo puro, a diferencia de la historia de las
estrategias evolutivas que desde el principio se ha dedicado al entendimiento de los algoritmos
desde un punto de vista teorico [Beyer, 2001] y sin tener en cuenta otros factores como que los
51

52
algoritmos geneticos funcionan sobre un esquema de codificacion binaria, las estrategias evolutivas
fueron elegidas como punto de partida para encontrar un optimizador. El trabajo de investigacion
hasta ahora realizado ha demostrado que las estrategias evolutivas poseen un poder de optimizacion
muy grande, sinembargo, siempre hay un factor aleatorio en la solucion que puede ser balanceado
empleando un criterio de parada a menudo conocido y un numero considerablemente grande de
evaluaciones de la funcion de costo, de ahı el inconveniente de esta tecnica aplicada a la seleccion
de hiperparametros en SVM. Recientemente con el desarrollo de tecnicas de desaleatorizacion y
seleccion adaptiva del tamano del paso en estrategias evolutivas, se puede enfrentar razonablemente
el problema de este trabajo y mas teniendo en cuenta las propiedades del algoritmo CMA-ES
descrito en la seccion 4.4.
En este capıtulo se presenta una descripcion del algoritmo propuesto ademas de las caracterısticas
del mismo, detalles de su implementacion y aspectos practicos para tener en cuenta.
5.1. CMA-ES-SVM
El algoritmo propuesto consta basicamente de tres partes: la maquina de soporte vectorial (SVM)
descrita en el capıtulo 2, adaptacion de matriz de covarianza (CMA-ES) como esquema de auto
adaptacion del tamano del paso en la estrategia evolutiva que sirve como optimizador de los hiper-
parametros y finalmente la funcion que va a servir como cota del error de generalizacion y objetivo
de CMA-ES. Con relacion a la funcion objetivo, se seleccionaron dos funciones: validacion cruzada
de n particiones con la idea de mantener algo de la simplicidad del algoritmo de busqueda en malla
y el span de los vectores de soporte descrito en la seccion 2.4.4, basicamente para evitar multiples
evaluaciones de la funcion de SVM en cada iteracion del algoritmo de optimizacion.
Acerca de la funcion validacion cruzada solo hay que decir que para este trabajo, n es igual a 4.
Este valor se obtuvo en pruebas preliminares que no se presentan en este documento y el criterio
fue el mınimo valor de n para el cual se obtienen buenos resultados considerando conjuntos de
entrada de diferentes dimensiones. Intuitivamente se podrıa pensar que n deberıa ser una funcion
del tamano de la entrada pero si se aumenta proporcional con el tamano de la entrada tambien el
costo computacional y si se disminuye es obvio que la solucion tiende a no ser muy confiable debido
a que se presenta una variacion significante de los vectores de soporte (ver definicion de LOO que
es un caso particular de validacion cruzada en la seccion 2.4.3).

53
En el caso de la funcion span de los vectores de soporte, se escogio debido a que en Chapelle et al.
[2002] se muestra que existe una conexion directa entre esta y Jaakkola-Haussler, Opper-Winther
y Radio/Margen (ver seccion 2.4.4) es decir, son casos particulares. Aunque dos de las tecnicas de
seleccion automatica descritas en el capıtulo 3 utilizan Radio/Margen, en este trabajo no se emplea
por la razon enunciada anteriormente y ademas debido a que esta ultima es computacionalmente
mas exigente que la funcion span. De la ecuacion (2.15), S2p se calcula como:
S2p = 1/(K−1
sv )pp (5.1)
con Ksv =
(K 1
1′ 0
). Con el objeto de suavizar el comportamiento del span y hacer Λp continuo
a las variaciones de los vectores de soporte se introduce un termino de regularizacion (η = 0,1 para
este trabajo), ası:
Λp = mınλ,
∑λi=1
∥∥∥∥∥∥φ(xp)−n∑
i 6=p
λiφ(xi)
∥∥∥∥∥∥+ ηn∑
i 6=p
1α0
i
λ2i (5.2)
de (10), la ecuacion (5.3) se vuelve
S2p = 1/(K−1
sv +D)pp +Dpp
donde D es una matriz diagonal con elementos Dii = 1/α0i y Dn+1,n+1 = 0. Chapelle et al. [2002]
sugiere hacer Ψ(x) = (1+exp(−5x))−1 de la ecuacion (2.15) para suavizar la aproximacion del error
de validacion. Las constantes en Ψ(x) se obtienen de calcular la estimacion de densidad posterior
para una maquina de soporte vectorial [Platt, 2000].
Con la SVM y la funcion objetivo cubierta, el algoritmo CMA-ES utiliza como parametros defecto los
mostrados en la tabla 4.1, tamano del paso inicial 0,3 [Hansen, 2004] y entrada, los hiperparametros
que van a ser buscados por ejemplo, C, σ2 para el caso de kernel RBF con la transformacion de
variable u1 = ln(C) y u2 = ln(σ2) sugerida por Chapelle et al. [2002]. Los valores iniciales para los
hiperparametros son lnC = 0 y lnσ2 = 0 para el kernel RBF, tolerancia de parada 10−3, es decir,
|f(u+ 1)− f(u)| ≤ 10−3f(u) [Keerthi, 2003] y tolerancia de los parametros de entrada 10−5 de la
misma forma.

54
De lo anterior se conforman dos algoritmos diferentes: CMA-ES-CV y CMA-ES-SB para funcion
validacion cruzada y span de los vectores de soporte respectivamente. Sinembargo, debido a que
el span funciona sobre un esquema de clasificacion binaria, se propone una reformulacion para
problemas multi clase.
Proposicion 10 Siguiendo el esquema multi clase “uno contra uno” de la seccion 2.6 para un
conjunto de k clases se deben entrenar k(k− 1)/2 clasificadores, por lo tanto el la nueva funcion se
escribe,
Tspan mc =1k
k(k−1)/2∑i
Ti (5.3)
donde Ti es el span de cada problema binario. Ademas, como Ti ∈ R+ se mantiene que
LOO ≤ Ti ≤ Tspan mc
De modo que Tspan mc es tambien una cota del error de generalizacion.
Es facil ver que la funcion de la ecuacion (5.3) trata de minimizar independientemente los valores
de span para cada esquema binario.
5.2. Caracterısticas del CMA-ES-SVM
Considerando que CMA-ES-SVM no utiliza la diferenciabilidad de las funciones CV y SB, tampoco
lo requiere en la funcion kernel de manera que en lo que se refiere a la funcion kernel, la unica
limitacion es que la matriz K tenga inversa, que no supone un inconveniente si el kernel es de
Mercer (ver seccion 12). En cuanto a esquemas multi clase, el algoritmo CV no tiene problemas
y SB tampoco debido a la proposicion 10. Dadas las caracterısticas del algoritmo CMA-ES, se es-
pera que el numero de iteraciones requeridas para alcanzar el criterio de parada no sea superior a
las requeridas por la busqueda en malla. Sujeto a la cantidad de iteraciones necesarias, el algorit-
mo propuesto puede ser apropiado para resolver problemas con multiples parametros y/o de gran
tamano. Considerando que en CMA-ES se puede acotar el espacio de busqueda acotando el rango

55
de los parametros a buscar, se pueden resolver problemas con ciertos kernels o diferentes tipos de
formulacion de SVM que requieren dichos rangos y estan definidos.
5.3. Implementacion y Aspectos Practicos
La implementacion del algoritmo esta hecha de la siguiente manera: el algoritmo tanto de la SVM,
CMA-ES y span de los vectores de soporte estan escritos en Fortran90 y las llamadas a funciones y
la validacion cruzada, es decir la interfase, en Matlab, esto ultimo con propositos practicos referentes
a la realizacion de las pruebas. Debido a que el nucleo del algoritmo esta en Fortran, los tiempos de
ejecucion y requerimientos de memoria no son exigentes por lo menos para las pruebas realizadas
en este trabajo.
Con miras a mejorar el desempeno del algoritmo, los conjuntos de entrada deben estar en formato
ralo (“sparse”), esto considerando que en muchos casos de los conjuntos de entrada a una SVM
contienen muchos ceros que pueden ahorrar calculos internos, ademas el numero maximo de itera-
ciones del algoritmo fue seleccionado tal que en ningun momento supere el numero de iteraciones
que necesita la busqueda en malla para C = [−5, 5] y γ = [−5, 5] con ∆ = 0,5 es decir 484.

Capıtulo 6
Resultados Numericos
Los resultados numericos mostrados en esta seccion fueron obtenidos realizando tareas de clasi-
ficacion sobre tres tipos diferentes de datos: artificialmente construidos (toydata), estandares de
UCI (Repository Of Machine Learning Databases and Domain Theories) y StatLog (Department
of Statistics and Modelling Science) [ver Blake and Merz, 1998, King et al., 1995] y problemas
con bases de datos reales del medio, ademas de conjuntos multi clase y resultados para el kernel
polinomial. Los experimentos fueron llevados a cabo utilizando busqueda en malla, Radio/Margen
para L1 y L2 y el algoritmo propuesto CMA-ES-SVM (ver secciones 3.1, 3.2 y 5.1) para una SVM
entrenada con el algoritmo de descomposicion SMO [Platt, 1999] considerando las modificaciones
propuestas por Keerthi et al. [1999] y Joachims [1999] para mejorar el desempeno del clasificador
(ver seccion 2.5). Los kernel empleados fueron el RBF de la ecuacion (A.6) utilizando γ = 12σ2 para
la implementacion y el polinomial no homogeneo de la ecuacion (A.7).
6.1. Conjuntos Artificiales
Los conjuntos de datos utilizados para esta prueba fueron construidos artificialmente con base en
distribuciones normales para generar problemas de clasificacion binaria de dos dimensiones, con
fines practicos fueron denominados: balanceado, no balanceado, damero, dos curvas, dos anillos y
anillos cruzados. Para cada conjunto, tres subconjuntos de diferentes tamanos se conformaron como
56

57
se muestra en la tabla 6.1. El principal interes de esta prueba es la observacion de fenomenos como
sobre-entrenamiento y capacidad de generalizacion.
Subconjunto Grupo de Entrenamiento Grupo de Validacion TotalA 100 100 200B 1000 1000 2000C 400 1600 2000
Tabla 6.1: Estructura de los conjuntos artificiales
6.1.1. Balanceado
El conjunto llamado balanceado (ver figura 6.1:Izquierda), es el tıpico caso de clasificacion binario
compuesto de dos distribuciones normales diferentes en la media y la desviacion estandar. El nombre
se debe a que el 50% de las observaciones pertenecen a cada clase.
0 2 4 6 8 10 12 14 16 18 20−5
0
5
10
15
20
X1
X2
2 4 6 8 10 12 14 16 180
2
4
6
8
10
12
14
16
18
20
X1
X2
Figura 6.1: Izquierda: Conjunto balanceado. Derecha: Conjunto no balanceado
La tabla 6.2 muestra que la precision del clasificador “decrementa” con el numero de observaciones
utilizadas para el entrenamiento. En este caso, los resultados obtenidos en cuanto a precision y
numero de vectores de soporte es similar, sinembargo, para los subconjuntos A y B, R/M L1 mostro
un ligero mejor comportamiento mientras que para C, CMA-ES-SVM-SB presento un desempeno
superior. En cuanto a R/M L2, en todos los casos utiliza un numero menor de iteraciones aunque
la diferencia no es substancialmente grande sin considerar la busqueda en malla. Como se puede
observar, para la busqueda en malla en el subconjunto B solo 121 iteraciones fueron utilizadas en
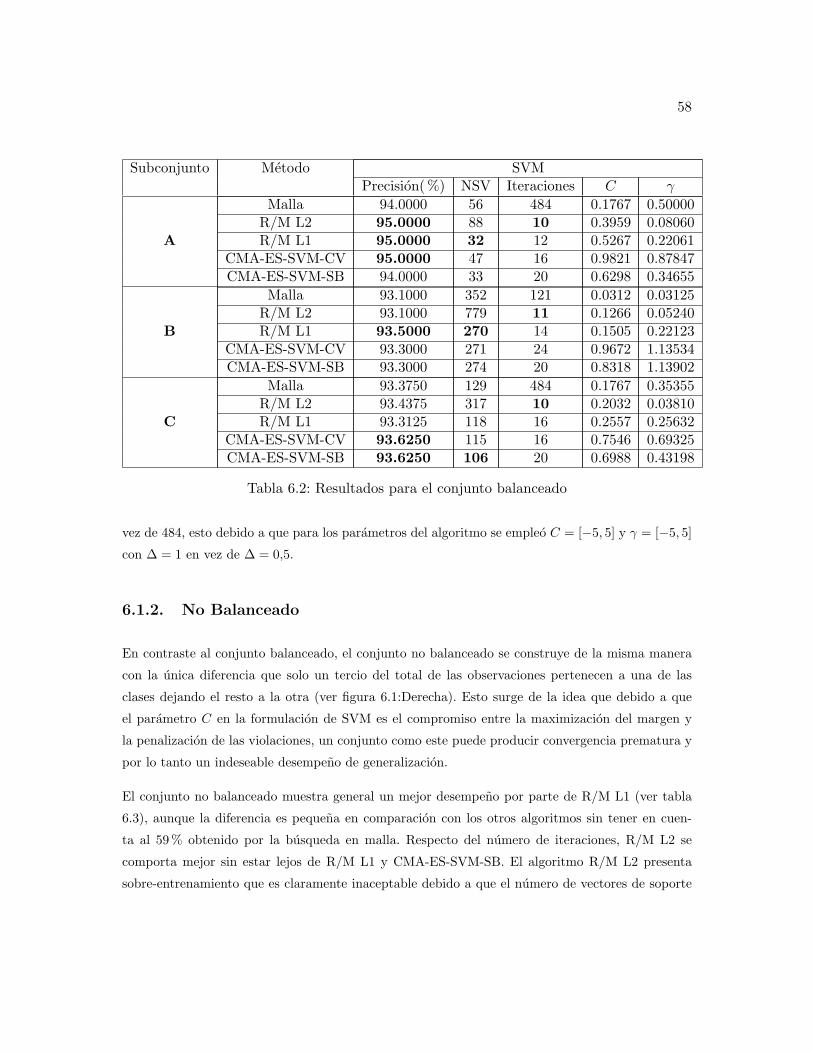
58
Subconjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 94.0000 56 484 0.1767 0.50000R/M L2 95.0000 88 10 0.3959 0.08060
A R/M L1 95.0000 32 12 0.5267 0.22061CMA-ES-SVM-CV 95.0000 47 16 0.9821 0.87847CMA-ES-SVM-SB 94.0000 33 20 0.6298 0.34655
Malla 93.1000 352 121 0.0312 0.03125R/M L2 93.1000 779 11 0.1266 0.05240
B R/M L1 93.5000 270 14 0.1505 0.22123CMA-ES-SVM-CV 93.3000 271 24 0.9672 1.13534CMA-ES-SVM-SB 93.3000 274 20 0.8318 1.13902
Malla 93.3750 129 484 0.1767 0.35355R/M L2 93.4375 317 10 0.2032 0.03810
C R/M L1 93.3125 118 16 0.2557 0.25632CMA-ES-SVM-CV 93.6250 115 16 0.7546 0.69325CMA-ES-SVM-SB 93.6250 106 20 0.6988 0.43198
Tabla 6.2: Resultados para el conjunto balanceado
vez de 484, esto debido a que para los parametros del algoritmo se empleo C = [−5, 5] y γ = [−5, 5]
con ∆ = 1 en vez de ∆ = 0,5.
6.1.2. No Balanceado
En contraste al conjunto balanceado, el conjunto no balanceado se construye de la misma manera
con la unica diferencia que solo un tercio del total de las observaciones pertenecen a una de las
clases dejando el resto a la otra (ver figura 6.1:Derecha). Esto surge de la idea que debido a que
el parametro C en la formulacion de SVM es el compromiso entre la maximizacion del margen y
la penalizacion de las violaciones, un conjunto como este puede producir convergencia prematura y
por lo tanto un indeseable desempeno de generalizacion.
El conjunto no balanceado muestra general un mejor desempeno por parte de R/M L1 (ver tabla
6.3), aunque la diferencia es pequena en comparacion con los otros algoritmos sin tener en cuen-
ta al 59 % obtenido por la busqueda en malla. Respecto del numero de iteraciones, R/M L2 se
comporta mejor sin estar lejos de R/M L1 y CMA-ES-SVM-SB. El algoritmo R/M L2 presenta
sobre-entrenamiento que es claramente inaceptable debido a que el numero de vectores de soporte

59
Subconjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 59.0000 67 484 22.627 0.70710R/M L2 69.0000 100 12 0.1051 0.04010
A R/M L1 69.0000 70 14 0.0031 0.00043CMA-ES-SVM-CV 62.0000 81 20 0.7659 1.74071CMA-ES-SVM-SB 66.0000 82 20 0.9797 0.57164
Malla 64.1000 644 121 1.0000 0.12500R/M L2 64.1000 1000 15 0.0344 0.04510
B R/M L1 64.1000 614 16 0.0420 0.00003CMA-ES-SVM-CV 66.0000 731 40 1.1510 1.33250CMA-ES-SVM-SB 66.1000 694 20 0.8310 0.64327
Malla 67.1250 310 484 0.0625 1.00000R/M L2 65.8125 400 14 0.0587 0.02700
C R/M L1 67.1250 280 16 0.0482 0.00002CMA-ES-SVM-CV 66.6250 286 64 0.7518 0.53596CMA-ES-SVM-SB 66.6250 278 20 1.4389 0.25882
Tabla 6.3: Resultados para el conjunto no balanceado
es igual al numero de observaciones utilizadas para el entrenamiento en los tres subconjuntos.
6.1.3. Damero
El problema damero (ver figura 6.2:Derecha) es bastante comun entre los investigadores de apren-
dizaje de maquina y es interesante debido a que aunque es separable en el espacio φ es realmente
difıcil de resolver [Kaufman, 1999], ademas es muy sensible al fenomeno de sobre-entrenamiento.
Los resultados obtenidos para el conjunto damero se muestran en la tabla 6.4 y aunque no son
buenos, representan para CMA-ES-SVM-SB una ventaja ya que para los subconjuntos A y C
obtiene una precision considerablemente superior. Si bien los resultados indican una tendencia al
sobre-entrenamiento en el caso de subconjunto B donde R/M L2 obtiene el mejor valor de precision
no debe ser tenido en cuenta considerando que el sobre-entrenamiento es crıtico. De los resultados
obtenidos se puede agregar que los procedimientos presentados no son suficiente para resolver un
problema como este partiendo de el hecho que una SVM lo puede resolver, dicho sea esto con un
ajuste manual y exhaustivo de los parametros [ver Keerthi et al., 2000].

60
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
X1
X2
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
X1
X2
Figura 6.2: Izquierda: Conjunto damero. Derecha: Conjunto dos curvas
6.1.4. Dos Curvas
El conjunto dos curvas (ver figura 6.2:Izquierda) pretende mostrar la adaptabilidad del hiperplano
construido con relacion a la maximizacion del margen y la penalizacion de violaciones debido a que
en particular, una penalizacion alta mejora la maximizacion del margen pero hace mas complejo
el hiperplano construido considerando que solo una pequena cantidad de puntos hacen imposible
obtener un hiperplano lineal.
Los resultados de la tabla 6.5 muestran para el subconjunto A que busqueda en malla se comporta
mejor a pesar del numero de iteraciones respecto de R/M L2 que solamente requiere 9. Para el
subconjunto B, R/M L2 obtiene la mejor precision en el menor numero de iteraciones pero CMA-
ES-SVM-CV y CMA-ES-SVM-SB necesitan una cantidad muy inferior de vectores de soporte con
un aumento razonable de iteraciones y una disminucion de 0,3 % en precision que dado el caso es
insignificante. En el caso del subconjunto C los resultados son claros para CMA-ES-SVM-CV.
6.1.5. Dos Anillos
El problema de dos anillos (ver figura 6.3:Izquierda) fue construido para mostrar cierto tipo de
hiperplanos circulares complejos que evidentemente conforman una solucion separable. A simple
vista podrıa parecer que es facil de solucionar para una SVM, sinembargo para la seleccion de
parametros puede ser complicado considerando que en muchos casos la solucion no resulta en una

61
Subconjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 49.0000 80 484 32.000 32.0000R/M L2 49.0000 100 9 0.1155 0.04040
A R/M L1 49.0000 90 16 4.8445 0.00003CMA-ES-SVM-CV 49.0000 91 24 0.7018 0.81822CMA-ES-SVM-SB 57.0000 91 20 1.3869 1.52333
Malla 49.0000 976 121 1.0000 1.00000R/M L2 51.0000 1000 13 0.0218 0.00720
B R/M L1 49.0000 950 14 28.942 0.00002CMA-ES-SVM-CV 49.5000 955 64 13.824 3.45486CMA-ES-SVM-SB 49.2000 984 20 1.3646 1.57509
Malla 51.7500 363 484 2.0000 22.6274R/M L2 49.0625 400 9 0.1424 0.04500
C R/M L1 49.8125 388 14 16.080 0.00002CMA-ES-SVM-CV 50.6875 372 64 1.9762 4.74398CMA-ES-SVM-SB 60.1250 391 20 1.0577 1.72699
Tabla 6.4: Resultados para el conjunto damero
Subconjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 99.0000 14 484 8.0000 0.06250R/M L2 99.0000 80 9 0.9041 0.82130
A R/M L1 99.0000 24 15 0.8297 1.65872CMA-ES-SVM-CV 99.0000 19 24 1.0836 1.16295CMA-ES-SVM-SB 99.0000 34 122 1.1894 0.28540
Malla 98.3000 193 121 1.0000 8.00000R/M L2 98.6000 635 7 0.3949 1.54160
B R/M L1 98.3000 186 12 0.4459 5.16419CMA-ES-SVM-CV 98.3000 54 24 1.2603 1.02717CMA-ES-SVM-SB 98.3000 65 20 0.5311 0.78951
Malla 97.6250 56 484 0.1767 1.00000R/M L2 97.1875 242 7 1.1144 1.92110
C R/M L1 97.4375 87 15 1.1897 4.81017CMA-ES-SVM-CV 98.8125 36 24 0.8901 1.03460CMA-ES-SVM-SB 98.7500 141 110 0.0395 0.80975
Tabla 6.5: Resultados para el conjunto dos curvas

62
forma regular que intuitivamente producirıa una mejor generalizacion.
−1.5 −1 −0.5 0 0.5 1 1.5−1.5
−1
−0.5
0
0.5
1
1.5
X1
X2
−1.5 −1 −0.5 0 0.5 1 1.5−1.5
−1
−0.5
0
0.5
1
1.5
X1
X2
Figura 6.3: Izquierda: Conjunto dos anillos. Derecha: Conjunto anillos cruzados
El problema dos anillos muestra en general (ver tabla 6.6) resultados similares con una precision
ligeramente superior para busqueda en malla en los casos A y B y para CMA-ES-SVM-CV en el
subconjunto C. En terminos de numero de vectores de soporte, CMA-ES-SVM-CV se comporta
mejor teniendo en cuenta que la diferencia con el mejor valor de precision para A y B es tan solo
1 % y 0,3 % respectivamente. En cuanto a iteraciones requeridas para alcanzar la solucion R/M L2
obtiene la menor cantidad, sinembargo R/M L1 y CMA-ES-SVM-SB estan en un rango comparable
con precision y NSV tendiente al mejor valor.
6.1.6. Anillos Cruzados
Anillos cruzados (ver figura 6.3:Derecha) es una modificacion de dos anillos con un nivel mas alto de
complejidad. Esta prueba se hace solo por razones comparativas en terminos de precision y numero
de vectores de soporte, este ultimo visto como una medida de generalizacion (ver seccion 2.4.4).
Los resultados en la tabla 6.7 son bastante similares a los de la tabla 6.6 con la particularidad
que CMA-ES-SVM-SB se comporta mejor en terminos de precision para los tres subconjuntos.
Aunque CMA-ES-SVM-SB en ninguno de los casos obtiene el menor numero de vectores de soporte
y la diferencia es relativamente grande sobre todo para el subconjunto A no sugiere una solucion
sobre-entrenada como si lo esta para R/M L2. Ademas, el numero de iteraciones utilizadas por
CMA-ES-SVM-SB es razonable en comparacion a los obtenidos por R/M L2 en A y C y R/M L1

63
Subconjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 74.0000 70 484 2.8284 0.17677R/M L2 74.0000 100 11 0.1711 6.58140
A R/M L1 73.0000 75 19 0.2619 6.36363CMA-ES-SVM-CV 73.0000 58 60 1.7536 2.68843CMA-ES-SVM-SB 74.0000 64 20 1.4504 0.91898
Malla 77.6000 535 121 2.0000 2.00000R/M L2 77.3000 1000 23 0.0669 6.17230
B R/M L1 77.5000 598 16 0.0998 13.0436CMA-ES-SVM-CV 77.2000 521 60 2.3166 1.25861CMA-ES-SVM-SB 77.0000 534 20 1.1002 1.23556
Malla 74.6875 254 484 8.0000 0.08838R/M L2 73.6875 400 11 0.0916 3.97070
C R/M L1 74.9375 264 19 0.1369 7.85481CMA-ES-SVM-CV 77.2500 247 56 0.6311 1.34829CMA-ES-SVM-SB 77.0625 249 20 2.3044 0.64741
Tabla 6.6: Resultados para el conjunto dos anillos
Subconjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 65.0000 62 484 22.627 22.6274R/M L2 50.0000 100 16 7.3345 0.00130
A R/M L1 71.0000 92 18 0.2139 6.50939CMA-ES-SVM-CV 76.0000 78 48 1.1665 1.59761CMA-ES-SVM-SB 77.0000 83 20 1.1963 1.10306
Malla 73.9000 785 121 0.0312 2.00000R/M L2 74.8000 1000 20 0.0714 5.26960
B R/M L1 74.5000 599 14 0.1025 17.0128CMA-ES-SVM-CV 76.4000 588 60 1.0145 1.30406CMA-ES-SVM-SB 76.7000 595 20 1.5732 0.82018
Malla 75.0625 209 484 1.0000 2.00000R/M L2 75.3750 400 8 0.1155 6.17310
C R/M L1 75.3125 237 23 0.1703 17.3078CMA-ES-SVM-CV 75.5625 249 60 1.1916 1.35039CMA-ES-SVM-SB 75.7500 252 20 1.2151 1.18019
Tabla 6.7: Resultados para el conjunto anillos cruzados

64
en B. Debido a que no se da una reduccion substancial en la precision y en el NSV se puede decir
que dos anillos y anillos cruzados tienen el mismo comportamiento, razon por la cual las variaciones
de complejidad anteriormente mencionadas no son relevantes para la SVM.
Los resultados obtenidos de las pruebas con conjuntos artificiales mostraron que los rangos de
precision para los metodos explorados no son tan grandes aunque CMA-ES-SVM-SB obtuvo la
mayor cantidad de maximos de precision con 9 en total seguido de CMA-ES-SVM-CV y R/M L2 con
6. En terminos de numero de vectores de soporte, los mejores fueron CMA-ES-SVM-CV y busqueda
en malla con 6 maximos y en peor R/M L2 que varias veces presento sobre-entrenamiento. En cuanto
al numero de iteraciones, es claro que el mejor es R/M L2 que en 16 ocasiones utilizo el mınimo
aunque en la mayorıa de los casos estaba bastante cerca de los requerimientos de R/M L1 y CMA-
ES-SVM-SB. En general, los hiperparametros encontrados por los diferentes metodos presentan en
rango una variacion considerable lo cual hace pensar que el espacio de tales hiperparametros es
bastante complejo.
6.2. Conjuntos Estandares
Los conjuntos de datos empleados en esta seccion son como se dijo anteriormente parte de la
coleccion UCI y StatLog y son: Australian Credit Approval (Australian), Banana, Wisconsin
Breast Cancer (Breast), Prima Indians Diabetes (Diabetes), German Credit Data (German),
Heart Disease (Heart), Johns Hopkins University Ionosphere (Ionosphere), Wisconsin Diagnostic
Breast Cancer (WDBC), Wine, Wisconsin Prognostic Breast Cancer (WPBC); todos ellos de
diferentes naturalezas y tamanos respecto a observaciones y caracterısticas. La estructura de los
conjuntos mencionados se muestra en la tabla 6.8. En la mayorıa de los casos la cantidad de datos
que deben ser utilizados para entrenamiento es sugerida por el autor, por esta razon es tenida en
cuenta donde es aplicable.
Los resultados para los conjuntos estandar mostrados en la tabla 6.9 establecen que para Aus-
tralian, R/M L1 se comporta mejor con un numero de iteraciones razonablemente bueno en com-
paracion a R/M L2. En el caso de Banana, R/M L2 obtiene el mejor resultado, sinembargo con un
numero de vectores de soporte muy inferior CMA-ES-SVM-CV y CMA-ES-SVM-SB obtienen una
precision similar. Para Breast, R/M L2 y CMA-ES-SVM-CV obtienen la misma precision pero el
segundo requiere casi cuatro veces menos vectores de soporte. Con el conjunto Diabetes, R/M L1

65
Conjunto Caracterısticas Grupo de Entrenamiento Grupo de Validacion TotalAustralian 14 390 300 690Banana 2 400 3900 4300Breast 9 383 300 683
Diabetes 8 468 300 768German 24 700 300 1000Heart 13 170 100 270
Ionosphere 34 200 151 351WDBC 30 300 269 569Wine 13 100 78 178
WPBC 33 100 94 194
Tabla 6.8: Estructura de los conjuntos estandares
obtiene el mejor resultado con un requerimiento de iteraciones superior al de R/M L2.
En la tabla 6.10, German presenta soluciones claramente sobre-entrenadas con numero de itera-
ciones similar excluyendo la busqueda en malla y un ligero mejor pero no substancial desempeno en
terminos de precision por parte de CMA-ES-SVM-SB. El conjunto Heart presenta dos soluciones
no sobre-entrenadas, sinembargo, en comparacion a la mejor considerando la precision, CMA-ES-
SVM-SB presenta la diferencia menos crıtica igual a 5 %. Los resultados para Ionosphere exhiben
un mejor valor de precision para CMA-ES-SVM-SB pero un menor numero de vectores de soporte
para CMA-ES-SVM-CV con un decremento pequeno en la precision (∼ 1,5 %) y numero de itera-
ciones para ambos en un rango razonable en comparacion al requerido por R/M L2. El conjunto
WDBC muestra resultados sobre-entrenados con un mejor desempeno por parte de R/M L2 en los
tres aspectos considerados. Para Wine y WPBC todas las soluciones estan sobre-entrenadas y el
rango de precision no es muy grande sinembargo, los mejores valores son obtenidos por CMA-ES-
SVM-SB.
En los casos en los que se obtienen soluciones sobre-entrenadas puede suceder que la cantidad de
informacion disponible no es suficiente para describir el problema, ahora un escalamiento del espacio
de entrada puede mejorar significativamente los resultados [Hsu et al., 2003] aunque no se hizo para
mantener intactos los conjuntos empleados.

66
Conjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 83.0000 366 484 8.0000 0.03125R/M L2 68.0000 390 17 0.0769 0.03960
Australian R/M L1 90.3333 227 24 2.9196 0.00135CMA-ES-SVM-CV 68.0000 390 24 1.0383 0.92379CMA-ES-SVM-SB 68.0000 390 20 0.9946 0.99855
Malla 52.0204 363 484 0.2500 22.6274R/M L2 88.5510 325 10 0.4043 2.56800
Banana R/M L1 44.0612 366 22 0.0009 2.54732CMA-ES-SVM-CV 88.0250 157 60 0.6588 0.82409CMA-ES-SVM-SB 87.2051 184 20 0.8646 0.45077
Malla 98.0000 144 484 1.0000 0.04419R/M L2 98.6667 211 10 0.3650 0.00820
Breast R/M L1 97.6667 194 22 2.6937 0.09096CMA-ES-SVM-CV 98.6667 53 68 2.4195 0.00178CMA-ES-SVM-SB 82.0000 280 8 1.2134 1.14696
Malla 73.0000 441 484 8.0000 0.03125R/M L2 76.6667 468 14 0.0876 0.00013
Diabetes R/M L1 99.6667 38 26 2.1907 0.00007CMA-ES-SVM-CV 99.0000 68 80 2.1544 0.89073CMA-ES-SVM-SB 90.3333 68 20 0.9978 0.99967
Malla 68.3333 699 484 8.0000 0.12500R/M L2 69.3333 700 13 0.0561 0.00360
German R/M L1 59.3333 700 31 1.8113 0.19466CMA-ES-SVM-CV 69.0000 700 24 1.5060 0.07581CMA-ES-SVM-SB 69.7333 700 24 0.0874 0.00874
Tabla 6.9: Resultados para los conjuntos estandar
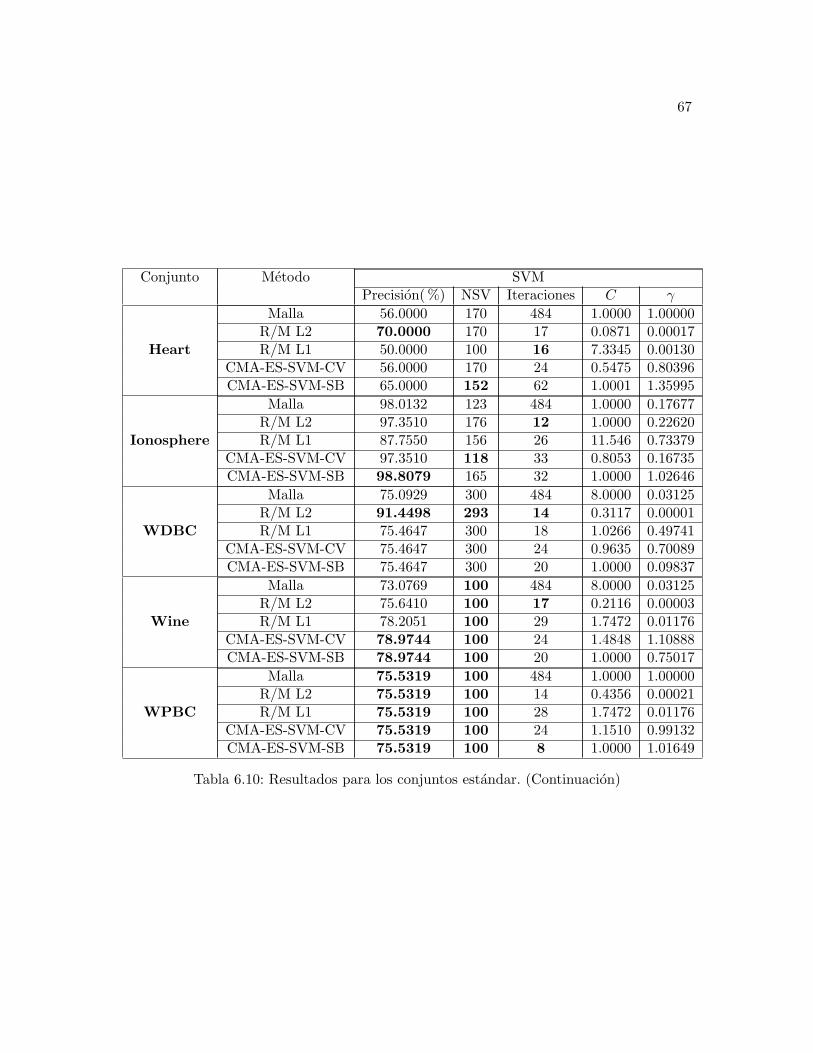
67
Conjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 56.0000 170 484 1.0000 1.00000R/M L2 70.0000 170 17 0.0871 0.00017
Heart R/M L1 50.0000 100 16 7.3345 0.00130CMA-ES-SVM-CV 56.0000 170 24 0.5475 0.80396CMA-ES-SVM-SB 65.0000 152 62 1.0001 1.35995
Malla 98.0132 123 484 1.0000 0.17677R/M L2 97.3510 176 12 1.0000 0.22620
Ionosphere R/M L1 87.7550 156 26 11.546 0.73379CMA-ES-SVM-CV 97.3510 118 33 0.8053 0.16735CMA-ES-SVM-SB 98.8079 165 32 1.0000 1.02646
Malla 75.0929 300 484 8.0000 0.03125R/M L2 91.4498 293 14 0.3117 0.00001
WDBC R/M L1 75.4647 300 18 1.0266 0.49741CMA-ES-SVM-CV 75.4647 300 24 0.9635 0.70089CMA-ES-SVM-SB 75.4647 300 20 1.0000 0.09837
Malla 73.0769 100 484 8.0000 0.03125R/M L2 75.6410 100 17 0.2116 0.00003
Wine R/M L1 78.2051 100 29 1.7472 0.01176CMA-ES-SVM-CV 78.9744 100 24 1.4848 1.10888CMA-ES-SVM-SB 78.9744 100 20 1.0000 0.75017
Malla 75.5319 100 484 1.0000 1.00000R/M L2 75.5319 100 14 0.4356 0.00021
WPBC R/M L1 75.5319 100 28 1.7472 0.01176CMA-ES-SVM-CV 75.5319 100 24 1.1510 0.99132CMA-ES-SVM-SB 75.5319 100 8 1.0000 1.01649
Tabla 6.10: Resultados para los conjuntos estandar. (Continuacion)
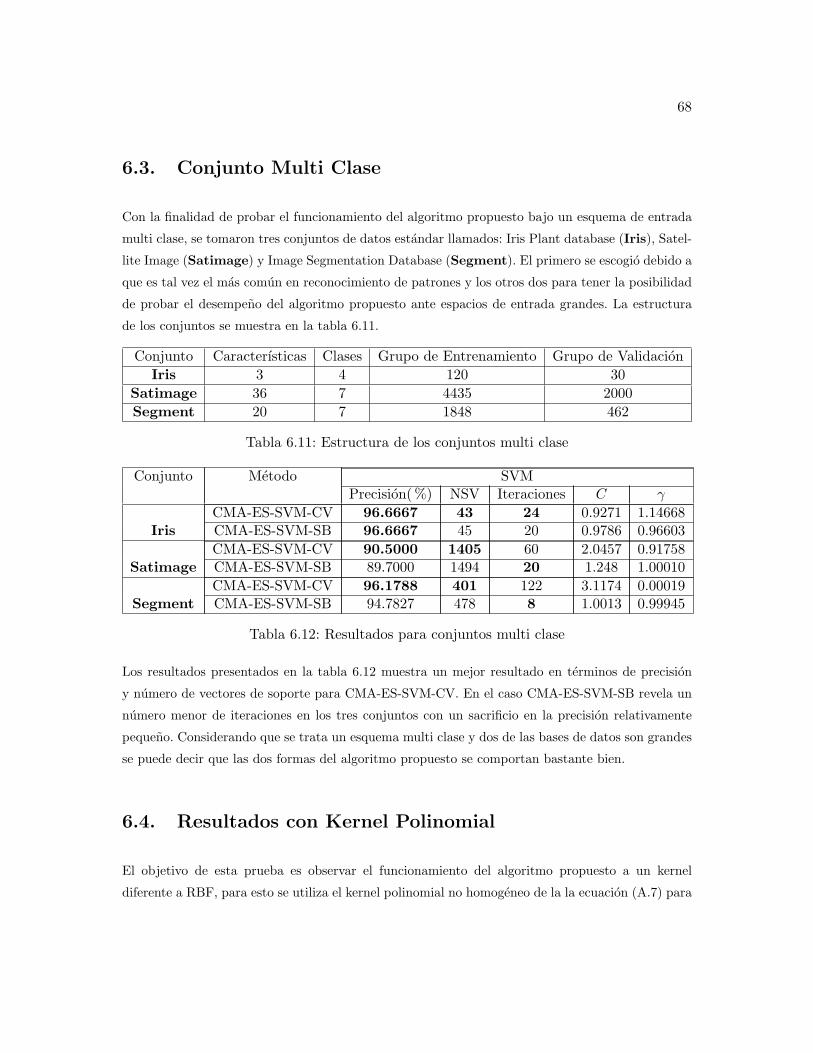
68
6.3. Conjunto Multi Clase
Con la finalidad de probar el funcionamiento del algoritmo propuesto bajo un esquema de entrada
multi clase, se tomaron tres conjuntos de datos estandar llamados: Iris Plant database (Iris), Satel-
lite Image (Satimage) y Image Segmentation Database (Segment). El primero se escogio debido a
que es tal vez el mas comun en reconocimiento de patrones y los otros dos para tener la posibilidad
de probar el desempeno del algoritmo propuesto ante espacios de entrada grandes. La estructura
de los conjuntos se muestra en la tabla 6.11.
Conjunto Caracterısticas Clases Grupo de Entrenamiento Grupo de ValidacionIris 3 4 120 30
Satimage 36 7 4435 2000Segment 20 7 1848 462
Tabla 6.11: Estructura de los conjuntos multi clase
Conjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
CMA-ES-SVM-CV 96.6667 43 24 0.9271 1.14668Iris CMA-ES-SVM-SB 96.6667 45 20 0.9786 0.96603
CMA-ES-SVM-CV 90.5000 1405 60 2.0457 0.91758Satimage CMA-ES-SVM-SB 89.7000 1494 20 1.248 1.00010
CMA-ES-SVM-CV 96.1788 401 122 3.1174 0.00019Segment CMA-ES-SVM-SB 94.7827 478 8 1.0013 0.99945
Tabla 6.12: Resultados para conjuntos multi clase
Los resultados presentados en la tabla 6.12 muestra un mejor resultado en terminos de precision
y numero de vectores de soporte para CMA-ES-SVM-CV. En el caso CMA-ES-SVM-SB revela un
numero menor de iteraciones en los tres conjuntos con un sacrificio en la precision relativamente
pequeno. Considerando que se trata un esquema multi clase y dos de las bases de datos son grandes
se puede decir que las dos formas del algoritmo propuesto se comportan bastante bien.
6.4. Resultados con Kernel Polinomial
El objetivo de esta prueba es observar el funcionamiento del algoritmo propuesto a un kernel
diferente a RBF, para esto se utiliza el kernel polinomial no homogeneo de la la ecuacion (A.7) para

69
dos conjuntos de datos anteriormente utilizados: uno binario, Breast y otro multi clase, Iris. El
grado del polinomio se escogio en el rango d = (1, 6) ∈ N, c = [0, 1] ∈ R y la transformacion para
u = lnC se mantiene. Como valores iniciales se seleccionaron d = 3, c = 0 y u = lnC = 0.
Conjunto Metodo SVMPrecision(%) NSV Iteraciones C d c
CMA-ES-SVM-CV 93.3333 13 28 1.2860 2 0.00000Iris CMA-ES-SVM-SB 93.3333 17 23 1.0758 3 0.13460
CMA-ES-SVM-CV 92.3333 31 28 1.0774 3 0.04723Breast CMA-ES-SVM-SB 94.6667 26 9 0.6611 2 0.00000
Tabla 6.13: Resultados para kernel polinomial
Los resultados obtenidos en la tabla 6.13 muestran que efectivamente al algoritmo propuesto fun-
ciona para este kernel en especıfico. De la formulacion del kernel polinomial se puede anotar que
en este caso se deben ajustar 3 parametros en vez de dos y que considerando esto la cantidad de
iteraciones sigue siendo considerablemente pequena. Aunque las pruebas presentadas en esta seccion
son para un solo kernel diferente, son concluyentes pues el numero de parametros se incremento,
el rango de d y c debe ser limitado para que el kernel cumpla con las condiciones de Mercer y en
general el kernel polinomial es problematico.
6.5. Conjuntos de Problemas Reales
En esta seccion, se presentan resultados producto de aplicaciones realizadas en el Grupo de Control
y Procesamiento Digital de Senales1 como parte de trabajos de grado. Detalles de las etapas de
preproceso, extraccion de atributos y comparativos con otras tecnicas pueden ser encontradas en
las referencias, en este trabajo solo se presentan resultados obtenidos para SVM.
6.5.1. Identificacion de Voces Patologicas
Las muestras de voz utilizadas, fueron obtenidas de una poblacion adulta de la ciudad de Manizales,
donde se evaluaron pacientes de ambos sexos con edades entre los 18 y 62 anos. El numero total de
registros analizados fue de 91, todos valorados por un fonoaudiologo. Cada muestra consiste en un
1Grupo de investigacion perteneciente a la Universidad Nacional de Colombia, Sede Manizales

70
registro de la fonacion sostenida de los cinco fonemas vocalicos (a, e, i, o, u). Las clases de voz a
identificar son: voz normal y voz patologica. Se conformaron seis conjuntos (ver tabla 6.14), los dos
primeros llamados A y B utilizan wavelets para extraccion de caracterısticas, los segundos C y D
caracterısticas acusticas y los ultimos dos C scaled y D scaled son versiones escaladas dividiendo
por el maximo en el rango de [−1, 1] debido a que todos los valores en estos conjuntos son mayores
que cero. Esto ultimo se hace para observar los efectos del escalamiento en los metodos tratados.
Los detalles de la extraccion de caracterısticas y resultados comparativos con otras tecnicas de
clasificacion pueden encontrarse en Ojeda [2003].
Conjunto Caracterısticas Grupo de Entrenamiento Grupo de ValidacionA 12 40 51B 60 40 51
C, C escalado 5 40 51D, D escalado 25 40 51
Tabla 6.14: Estructura del conjunto para identificacion de voces patologicas
Los resultados mostrados en la tabla 6.15 muestran en general mejor desempeno por parte de
CMA-ES-SVM-CV ya que en cinco de los seis conjuntos obtuvo la mayor precision con numero
de vectores de soporte e iteraciones cercanas a los valores maximos. En particular, el conjunto D
presenta soluciones muy pobres tanto en precision como en NSV (sobre-entrenamiento evidente).
Con relacion al escalamiento del espacio de entrada, es claro que aumenta el desempeno tanto en
precision como en numero de vectores de soporte y respecto del numero de iteraciones, la diferencia
es mınima.
Nota 2 Aunque el procedimiento de escalamiento es recomendado como preproceso de la maquina
de soporte vectorial, se debe considerar que no para todos los conjuntos dicho procedimiento fun-
ciona, es mas, se considera que solo debe ser aplicable cuando el vector de medias de conjunto de
entrada sea grande o los rangos de cada vector de caracterısticas esten en rangos bastante dispares.
6.5.2. Clasificacion de Arritmias en ECG
Se utilizo un metodo para clasificar senales de ECG con extraccion de caracterısticas basada en la
informacion contenida en los coeficientes de aproximacion de su descomposicion wavelet. El estudio
incluyo 11 formas de onda etiquetadas de la base de datos de arritmias MIT-BIH: Latido auricular
prematuro desviado (a), latido de escape ventricular (E), fusion de latido ventricular y normal

71
Conjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
Malla 94.1176 21 484 8.0000 0.06250R/M L2 92.1569 40 11 0.7107 0.30910
A R/M L1 80.3922 36 36 1.8009 1.68241CMA-ES-SVM-CV 94.1176 27 56 2.1107 0.21627CMA-ES-SVM-SB 92.3529 37 68 0.7632 1.02996
Malla 96.0784 35 484 1.0000 0.06250R/M L2 96.0784 33 12 309.30 0.06850
B R/M L1 96.0784 33 21 1.7700 0.06854CMA-ES-SVM-CV 96.0784 28 68 2.7656 0.05171CMA-ES-SVM-SB 94.7059 26 20 0.9023 0.99613
Malla 84.3137 33 484 1.0000 0.03125R/M L2 82.3529 40 11 1.4624 0.00990
C R/M L1 84.3137 34 22 2.4789 0.04060CMA-ES-SVM-CV 85.8235 40 24 1.1301 0.73876CMA-ES-SVM-SB 84.9020 40 20 0.8959 0.91364
Malla 50.9804 40 484 1.0000 1.00000R/M L2 66.6667 40 10 0.7190 0.00140
D R/M L1 50.9804 40 18 1.2500 0.49999CMA-ES-SVM-CV 50.9804 40 24 1.0931 0.73549CMA-ES-SVM-SB 50.9804 40 8 1.0000 1.21107
Malla 88.2353 19 484 2.8284 0.50000R/M L2 88.2353 30 13 3.6882 1.76240
C escalado R/M L1 88.2353 27 22 2.4000 2.58179CMA-ES-SVM-CV 88.2353 21 42 1.6667 0.74259CMA-ES-SVM-SB 88.2353 26 44 1.0000 1.04677
Malla 90.1961 24 484 4.0000 0.03125R/M L2 88.2353 40 11 0.6011 0.06510
D escalado R/M L1 74.5098 39 30 1.9495 0.65397CMA-ES-SVM-CV 92.1569 35 44 1.5011 0.28671CMA-ES-SVM-SB 74.5098 40 8 1.0000 1.01866
Tabla 6.15: Resultados para identificacion de voces patologicas

72
(F), fusion de latido acelerado y normal (f), bloqueo de rama izquierda (L), latido normal (N),
latido acelerado (P), onda P no conducida (p), bloqueo rama derecha (R), contraccion ventricular
prematura (V) y fibrilacion ventricular (VF) [ver Orozco, 2003]. Para esta prueba tres conjuntos
se seleccionaron para dos cantidades de varianza acumulada de un procedimiento de analisis de
componentes principales (PCA), es decir: A el conjunto completo, B para PCA varianza 95% y C
para PCA varianza 90%. La estructura de los datos se muestra en la tabla 6.16.
Conjunto Caracterısticas Grupo de Entrenamiento Grupo de ValidacionA 25 400 700B 11 400 700C 8 400 700
Tabla 6.16: Estructura del conjunto para clasificacion de arritmias en ECG
Conjunto Metodo SVMPrecision(%) NSV Iteraciones C γ
CMA-ES-SVM-CV 95.4286 232 60 15.875 0.30604A CMA-ES-SVM-SB 94.7143 229 26 1.0001 1.00010
CMA-ES-SVM-CV 94.7143 222 24 1.237 1.05880B CMA-ES-SVM-SB 94.2857 224 8 1.0001 1.00010
CMA-ES-SVM-CV 95.0000 207 28 1.8569 1.00010C CMA-ES-SVM-SB 94.2857 222 8 1.0001 1.00010
Tabla 6.17: Resultados para clasificacion de arritmias en ECG
Para el conjunto de arritmias, los resultados mostrados en la tabla 6.17 son en terminos generales
mas favorables para CMA-ES-SVM-CV, sinembargo, CMA-ES-SVM-SB no esta muy alejado de los
maximos de precision y NSV. Se debe anotar que los resultados son bastante buenos en adicion a
que el conjunto es multi clase y a que la respuesta de la SVM a PCA es consistente en terminos de
disminucion del numero de vectores de soporte.

Capıtulo 7
Discusion Final, Sumario y
Trabajo Posterior
En terminos generales, los resultados obtenidos en este trabajo muestran que el algoritmo propuesto
en sus dos variantes (CMA-ES-SVM-CV y CMA-ES-SVM-SB) es bastante competitivo en compara-
cion a las tecnicas basadas en la diferenciabilidad de las cotas del error (L1-SVM y L2-SVM), si se
observa que en varias ocasiones, las desarrolladas en este trabajo obtuvieron desempenos similares
y otras tantas veces superiores en las pruebas de conjuntos artificiales, estandares y de proble-
mas reales, sin tener en cuenta el beneficio adicional proporcionado por el soporte multi-clase, la
posibilidad de utilizar kernels no diferenciables y la seleccion de multiples parametros.
Si se observa cuidadosamente, el rango de precision para la diferentes pruebas efectuadas no fue muy
grande, sinembargo, muchas veces superior para el caso de CMA-ES-SVM-SB, ademas, en los casos
en los que las tecnicas utilizadas para realizar la comparacion obtuvieron mejores valores de precision
no lo eran tanto respecto del algoritmo desarrollado en este trabajo. Por otro lado, el numero de
vectores soporte obtenido en los diferentes experimentos es satisfactorio y considerablemente mejor
para CMA-ES-SVM-CV, si se parte de el hecho que NSV tambien es una medida de generalizacion
para SVM y sin mencionar que entre mas pequena sea esta cantidad menor es la carga computacional
requerida tanto para el entrenamiento como para la validacion.
En el tiempo en que se estaba planeando la realizacion de este trabajo, se tenıa pensado que
73

74
el algoritmo que se desarrollara, utilizarıa mayor cantidad de iteraciones dado que no se estaba
viendo como un problema de busqueda en lınea sino global, sinembargo dadas las caracterısticas
del optimizador que se iba a utilizar, es decir CMA-ES, se esperaba que por lo menos el numero
de iteraciones siempre fuera inferior al requerido por la busqueda en malla, por el contrarıo y dada
la dificultad de las funciones a minimizar (SB y CV), los experimentos mostraron que el algoritmo
propuesto estaba la mayorıa de veces relativamente cerca del mınimo. Ademas, si bien L2-SVM en
casi todas las pruebas requirio el mınimo de iteraciones, nunca lo obtuvo en NSV y en repetidas
veces mostro tendencia al sobre-entrenamiento.
Debido a que el soporte multi clase era una propiedad del algoritmo propuesto, se realizaron algu-
nas pruebas con la finalidad de observar su comportamiento y se aprovecho tambien para utilizar
espacios de entrada grandes en terminos de observaciones y caracterısticas. Aunque los resulta-
dos carecen de marco comparativo, en terminos de precision y NSV fueron bastante buenos y el
incremento en el numero de iteraciones requeridas por las dos variantes del algoritmo en ningun
caso fueron desproporcionadas a las que se observaron en las pruebas con conjuntos artificiales y
estandares.
Otra caracterıstica del algoritmo desarrollado en este trabajo es la posibilidad de utilizar diferentes
funciones kernel sin requerir propiedades de diferenciabilidad en ellas. En realidad, no se realizaron
pruebas para esto porque la utilizacion de kernels especializados (no son diferenciables generalmente)
esta reservada casi que exclusivamente para aplicaciones especıficas de las cuales el autor no posee
un conocimiento suficiente, sinembargo, con fines ilustrativos se presentaron algunos resultados
para el kernel polinomial no homogeneo, que ademas posee tres hiperparametros en vez de dos
y con la dificultad adicional de requerir hiperparametros acotados. Debido a que se carecıa de
marco comparativo, se utilizaron conjuntos de los experimentos anteriores con resultados del todo
satisfactorios.
Con referencia al los parametros requeridos por el algoritmo propuesto, se podrıa pensar que se esta
resolviendo un problema de seleccion de parametros que a su vez requiere parametros, lo cual es de
algun modo ironico, sinembargo, en cuanto al tamano inicial del paso, el parametro de la funcion
span y el criterio de parada, se siguieron estrictamente las sugerencias de los autores y aunque
son heurısticos funcionan bastante bien considerando los resultados obtenidos. En algunas pruebas
preliminares que no se incluyeron en este documento, se realizaron experimentos para probar la
viabilidad de los parametros mencionados anteriormente incluyendo el numero de particiones de
la validacion cruzada y el criterio de parada dependiente de los hiperparametros que de manera

75
definitiva llevaron a ponerlos como por defecto.
Los resultados obtenidos en este trabajo hacen que el algoritmo propuesto sea ideal para para aplica-
ciones especıficas donde se requiera un clasificador con arquitectura robusta sobre todo en terminos
de automatizacion, debido a que en muchas de ellas se necesita una maquina que se actualice o
se construya independientemente sin la necesidad de reformular completamente la estructura del
problema.
Si se trata de evaluar independientemente las dos variantes del algoritmo presentadas en este trabajo
se debe decir que: CMA-ES-SVM-SB es la eleccion apropiada teniendo en cuenta la precision y el
numero de iteraciones y CMA-ES-SVM-CV si en el problema que se esta tratando se considera mas
importante un numero de vectores de soporte menor ya sea por el costo computacional o por que
se tiene un numero limitado de observaciones. En contraste, si de antemano se tiene conocimiento
que el problema a resolver es muy complejo tal vez CMA-ES-SVM-SB ofrezca mas ventajas dados
los resultados obtenidos y la cantidad de iteraciones que naturalmente tenderıan a incrementar.
En resumen, se cree que los objetivos propuestos para este trabajo de tesis fueron cubiertos con creces
y que los resultados obtenidos contribuyen significativamente al campo del aprendizaje de maquina
en cuanto a que hacen que la SVM sea un clasificador autonomo en terminos de arquitectura, ademas
es un paso adelante para hacer que las SVM se conviertan en el principal metodo de clasificacion
que es lo que los investigadores en esta area tanto desean. Ademas, este trabajo puede suponer toda
una nueva gama de posibilidades, ya que la mezcla del aprendizaje de maquina con las estrategias
evolutivas podrıa dar respuesta a muchos problemas en los que una solucion como la que aquı se
plantea no ha sido contemplada todavıa.
Para finalizar, hay en este trabajo varias posibilidades para investigacion posterior. Tal vez la mas
evidente es la referente al criterio de parada que ni en este trabajo ni en la literatura disponible
encuentran una solucion definitiva. Evaluar el algoritmo propuesto con aplicaciones especıficas que
requieran funciones kernel especializadas y/o un numero considerablemente mayor de hiperpara-
metros, que dado el conocimiento del autor, se da principalmente en procesamiento de imagenes y
bioinformatica. Extender el algoritmo propuesto a esquemas de regresion y variantes de SVM como
aprendizaje activo, analisis de componente principales no lineal (KPCA), discriminantes de Fisher
con kernel (KFD) y seleccion de caracterısticas con SVM. Y alternativamente desarrollo de otra
cota o utilizacion de alguna diferente podrıa mejorar el desempeno del algoritmo propuesto.

Apendice A
Kernels
La funcion kernel es descrita como una medida de similitud que puede ser vista como el producto
punto en un espacio llamado de caracterısticas (ver figura A.1). El proposito de esto, es proporcionar
un entendimiento intuitivo de dichas funciones en vez de presentar la teorıa analıtica de cuales clases
de kernels admiten la representacion de un producto punto en un espacio de caracterısticas dado.
En esta seccion se hace de manera mas formal y precisa. Los kernels aquı presentados, son funciones
simetricas que corresponden a productos punto en un espacio de caracterısticas en H via un mapeo
φ.
Figura A.1: Ejemplo de un problema de clasificacion binaria mapeado en un espacio decaracterısticas utilizando un kernel polinomial
76

77
A.1. Kernels Definidos Positivos
Un kernel positivo definido es aquel para el cual, dado un conjunto X y una funcion K : X × Xproduce una matriz gramo positiva definida. El termino kernel proviene del primer uso de este tipo
de funciones en el campo de los operadores integrales estudiados por Hilbert y otros. Una funcion
k que produce un operador Tk utilizando (Tkf)(x) =∫X k(x, x
′)f(x′)dx′ es llamada kernel de Tk.
En la literatura, una gran cantidad de nombres han sido utilizados para designar kernels definidos
positivos tales como: kernels reproducidos, kernels de Mercer, kernels admisibles, kernel definido no
negativo, funcion de covarianza, etc. Sinembargo para evitar posibles confusiones, lo mas preferible
es utilizar el termino kernel semi definido positivo. Las definiciones de kernels y matrices definidos
positivos difieren en el hecho que para el primer caso es posible elegir libremente los puntos en los
que se evalua K de modo que para cualquier eleccion, una matriz positiva definida es obtenida.
La condicion de definido positivo implica ademas positividad en la diagonal y simetrıa incluso
para el caso de valores complejos. Las funciones kernel pueden ser vistas como productos punto
generalizados en el sentido que cualquier producto punto es un kernel, sinembargo la linealidad
de los argumentos vista como propiedad esencial de los productos punto, no lo es en los kernels
en general. De otro lado, la desigualdad de Cauchy-Schwarz valida en los productos puntos provee
tambien una natural generalizacion de los kernels.
A.2. Reproduccion de un Mapeo con Kernel
Asumiendo que K es un kernel definido positivo con valores reales y X es un conjunto no vacıo de
patrones que deben ser representados como su similitud respecto a todos los otros puntos de dicho
conjunto supone una representacion bastante amplia. A continuacion se presenta como construir un
espacio de caracterısticas asociado a φ. Para empezar, se debe construir un espacio de productos
punto que contenga todas la imagenes de la entrada bajo φ, para lo cual es necesario definir un
espacio vectorial tomando las combinaciones lineales de la forma
f(.) =m∑
i=1
αik(., xi) (A.1)
donde m ∈ N y x1, x2, ..., xm ∈ X . Ahora se define un producto punto entre f y otra funcion de

78
manera que
〈f, g〉 =m∑
i=1
m′∑j=1
αiβjk(xi, x′j) (A.2)
De modo que la ecuacion (A.2) contiene los coeficientes de expansion que no necesariamente tienen
que ser unicos. Como ultimo paso, debe ser probado que dicha funcion esta bien definida, para esto
〈f, g〉 =m′∑j=1
βjf(x′j) (A.3)
haciendo k(x′j , xi) = k(xi, x′j). La suma en la ecuacion (A.3), no depende entonces de una expansion
de f en particular. La ultima ecuacion y su version para g muestran que 〈., .〉 es bilineal y simetrico,
es mas, es definido positivo debido a que esto implica que k o cualquier funcion f escrita como A.1
mantiene
〈f, f〉 =m∑
i,j=1
αiαjk(xi, xj) ≥ 0
De modo que 〈., .〉 es definido positivo y ademas 〈k(., x), f〉 = f(x). Ası, un kernel definido positivo
puede verse como un producto punto en otro espacio con la siguiente propiedad
〈φ(x), φ(x′)〉 = k(x, x′) (A.4)
Por consiguiente, el espacio de productos punto H es en este sentido una posible realizacion del
espacio de caracterısticas asociado al kernel. La identidad en (A.4) forma la base para el llamado
truco kernel en el cual, “dado un algoritmo formulado en terminos de un kernel definido positivo k,
es posible construir una alternativa para reemplazar k por algun otro k tambien definido positivo”.

79
A.3. Reproduccion de un Espacio de Hilbert mediante Ker-
nels
En la seccion anterior, se trato con un tipo de funciones que reproducen espacios vectoriales y
que ademas estan dotadas de un producto punto. Estos espacios son designados como espacios
de productos punto o equivalentemente pre-espacios de Hilbert, la razon para eso ultimo, es que
pueden tornarse en espacios de Hilbert mediante la utilizacion de un simple truco matematico.
Esta conversion supone varias ventajas como que siempre es posible definir proyecciones. Ahora,
para convertir el pre espacio de Hilbert de funciones (A.1) dotadas del producto punto en (A.2)
en uno de Hilbert (en R), hay que completar la norma correspondiente a dicho producto punto
(‖f‖ :=√〈f, f〉) anadiendo limites de secuencias que son convergentes en esa norma.
Definicion 11 (Espacio de Hilbert reproducido por kernel (RKHS)) Sea un conjunto no
vacıo X y H un espacio de funciones f : X → R. Luego, H es llamado espacio reproducido de
Hilbert por kernel dotado de u producto punto 〈., .〉 y una norma ‖f‖ :=√〈f, f〉 si existe una
funcion k : X ×H → H con las siguientes propiedades
1. k tiene la propiedad de reproduccion
〈f, k(x, .)〉 = f(x)∀f ∈ H
en particular,
〈k(x, .), k(x′, .)〉 = k(x, x′) (A.5)
2. k abarca H, esto es H = span(k(x, .)|x ∈ X ) donde X denota la adherencia del conjunto X.
De (A.5), se puede probar que k es simetrico y ademas definido positivo. Notese tambien que RKHS
unicamente determina k, esto es, no existen dos kernels k y k′ que abarcan el mismo espacio H.
A.4. El Kernel de Mercer
En esta seccion se presenta otra construccion de un espacio de Hilbert que ha jugado un papel
crucial en el entendimiento de las SVM. Es por esto que generalmente en la literatura de SVM los

80
kernels son presentados utilizando el teorema de Mercer.
Teorema 12 (Mercer) Suponga k ∈ L∞(X∈) una funcion real simetrica tal que el operador in-
tegral
Tk : L2(X → L2(X ))
(TkF )(x) :=∫Xk(x, x′)f(x′)dµ(x′)
es positiva definida, esto es, ∀f ∈ L2(X ) se tiene
∫X 2k(x, x′)f(x)f(x′)dµ(x)dµ(x′) ≥ 0
Haciendo ψj ∈ L2(X ) las funciones propias ortonormales de Tk asociadas al valor propio λj > 0
ordenadas en sentido no decreciente, se tiene
1. (λj)j ∈ `1
2. k(x, x′) =∑NH
i=1 λjψj(x)ψj(x′) se mantiene para casi todos (x, x′). Tambien, NH ∈ N o
NH ∈ ∞, y en el ultimo caso, la serie converge absoluta y uniformemente para casi todos
(x, x′)
Del teorema anterior, se asume un espacio de medida finito (X , µ) donde µ es la probabilidad de
medida y X un subconjunto compacto de R. El termino“casi todos”se refiere excepto para conjuntos
de medida cero o en terminos de la medida de Lebesgue-Borel conjuntos enumerables de puntos
individuales son conjuntos de medida cero.
Ambos, el kernel de Mercer y el definido positivo, pueden ser representados como productos punto
en un espacio de Hilbert. El siguiente teorema muestra el caso cuando los dos tipos de kernels
coinciden.
Teorema 13 (Los kernels de Mercer son definidos positivos) Sea X = [a, b] un intervalo
compacto y k : [a, b]× [a, b]→ C continuo. Luego, k es definido positivo si y solo si
∫ b
a
∫ b
a
k(x, x′)f(x)f(x′)dxdx′ ≥ 0

81
para cada funcion continua f : X → C
Notese que las condiciones del teorema 13 son mas restrictivas que las del 12 y con esto los kernels
de Mercer tambien son kernels reproducidos.
A.5. Ejemplos y Propiedades de Kernels
En todos los ejemplos a continuacion se asume el espacio de entrada perteneciente a los reales
(X ∈ R).
Kernel polinomial homogeneo de grado d.
k(x, x′) = 〈x, x′〉d
Kernel Gaussiano de base radial, sugerido por Boser et al. [1992], con σ > 0 (o γ = 12σ2 ).
k(x, x′) = exp−‖x− x′‖2
2σ2(A.6)
Kernel sigmoidal, con κ > 0 y υ > 0. No es definido positivo para algunos valores de κ y υ
sinembargo ha sido utilizado en la practica.
k(x, x′) = tanh(κ〈x, x′〉+ υ)
Kernel polinomial no homogeneo, con d ∈ N y c ≥ 0
k(x, x′) = (〈x, x′〉+ c)d (A.7)
Bn-Spline kernel, con IX denotando la funcion caracterıstica del conjunto X y ⊗ el operador
de convolucion (f ⊗ g)(x) := f(x′)g(x′ − x)dx′. Este kernel calcula B-splines de orden 2p+ 1
con p ∈ N definidas por la convolucion de las 2p+ 1 particiones en el intervalo [−1/2, 1/2]
k(x, x′) = B2p+1(‖x− x′‖) con Bn := ⊗ni=1I[−1/2,1/2]

82
Kernel racional cuadratico, c ≥ 0
k(x, x′) = 1− ‖x− x′‖2
‖x− x′‖2 + c
Notese que todos los kernels mencionados anteriormente son unitariamente invariantes lo cual es
interesante (k(x, x′) = k(Ux,Ux′) si U> = U−1), es decir, son invariantes a rotaciones. Los kernels
de base radial (RBF), son los que pueden escribirse de la forma k(x, x′) = f(d(x, x′)) donde d es
una metrica en X y f una funcion en R+0 (por ejemplo los gaussianos y Bn-splines). Usualmente,
la metrica surge del producto punto d(x, x′) = ‖x − x′‖ =√〈x− x′〉, 〈x− x′〉. Los kernels RBF
ademas de ser unitariamente invariantes, son invariantes a la traslacion, en otras palabras, k(x, x′) =
k(x− x0, x′ − x0) para todo x0 ∈ X .
Una propiedad interesante de los kernels polinomiales es que son invariante a las transformaciones
ortogonales en R debido a que induce un mapeo al espacio de todos los monomios de grado d. Otra
estructura adicional de los kernels gaussianos RBF se debe a que k(x, x) = 1 para todo x ∈ X lo
cual implica que cada observacion tiene longitud unitaria. Es mas, como k(x, x′) > 0 para todo
x, x′ ∈ X todos los puntos son mapeados en el mismo cuadrante del espacio de caracterısticas,
equivalente a decir que el angulo entre dos puntos mapeados cualquiera es siempre menor que π/2.
Lo anterior parece indicar que para el caso gaussiano, los datos mapeados ocupan un area muy
pequena dentro del espacio de caracterısticas, sinembargo visto de otra manera, estos ocupan el
espacio que sea lo mas grande posible debido a que la matriz gramo de un kernel gaussiano es de
rango completo lo que significa que abarca un sub espacio m-dimensional de H. Es de suponer que
un kernel de este tipo definido en un dominio de infinita cardinalidad, sin restricciones previas del
numero de muestras de entrenamiento producira un espacio de caracterısticas infinito dimensional.

Apendice B
Algoritmo BFGS
Muchos de los problemas que se presentan en ingenierıa usualmente involucran un objetivo comun
relacionado con encontrar soluciones cuantitativas a partir de un conjunto de ecuaciones que ge-
neralmente no son lineales lo cual apunta a la aplicacion de la teorıa de optimizacion. Los problemas
de optimizacion pueden ser clasificados como restringidos o no restringidos como las SVM y las redes
neuronales del tipo perceptron respectivamente. Sinembargo, como un problema de optimizacion
restringido puede ser transformado en uno no restringido, muchos de los investigados involucrados
prefieren tratar con estos ultimos [Phua et al., 1997].
A grandes rasgos, un problema de optimizacion no restringido puede ser definido como sigue:
mınxf(x)
con x un vector n−dimensional real y f(x) una funcion no lineal en R.
Aunque existen muchos tecnicas para resolver problemas de optimizacion no restringidos, el metodo
quasi-Newton (QN) es tal vez el mas utilizado. Asumase que en la k−esima iteracion un punto de
aproximacion xk y una matriz Hk de dimension n × n estan disponibles, luego el metodo procede
generando una secuencia de puntos de aproximacion por medio de la ecuacion,
xk+1 = xk + ζkdk
83

84
donde αk > 0 es el paso calculado para satisfacer ciertas condiciones de la busqueda en linea y dk
es un vector real de dimension n que representa la direccion de la busqueda. Para los metodos QN,
dk esta definido por:
dk = −Hkgk
donde gk = ∇f(xk) es el gradiente del vector f(x) evaluado en el punto x = xk. Una caracterıstica
importante de los metodos QN es que la matriz Hk es usualmente seleccionada para satisfacer la
ecuacion QN,
Hk+1yk = λkδk
con δk = xk+1 − xk, yk = ∇f(xk+1)−∇f(xk) y λ > 0 un parametro libre.
Uno de los metodos QN mas conocidos es el BFGS propuesto independientemente por Broyden,
Fletcher, Goldfarb, Shanno [1970]. La actualizacion en BFGS esta definida por la siguiente ecuacion
Hk+1 = Hk +1
δ′kyk
((λk +
y′kHkyk
δ′kyk
)δkδ
′k − δky′kHk −Hkykδ
′k
)
con λ ≡ 1. El metodo BFGS fue inicialmente implementado por Shanno and Phua [1976] y esta
disponible en ACM Mathematical Software Library.

Referencias
T. Back and H.-P. Schwefel. An overview of evolutionary algorithms for parameter optimization.
Evolutionary Computation, 1(1):1–23, 1993.
H.-G. Beyer. Toward a theory of evolution strategies: On the benefit of sex - the (µ/mu1, λ)-theory.
Evolutionary Computation, 3(1):81–110, 1995.
H.-G. Beyer. On the asymptotic behavior of multirecombinant evolution strategies. In Springer,
editor, Proceedings of PPSN IV, Parallel Problem Solving from Nature, pages 122–133, Berlin,
1996.
H.-G. Beyer and K. Deb. On the desired behaviors of self-adaptive evolutionary algorithms. In
Springer, editor, Proceedings of PPSN VI, Parallel Problem Solving from Nature, pages 59–68,
Berlin, 1994.
Hans-Georg Beyer. The Theory of Evolution Strategies. Springer Verlag, Berlin, 2001. ISBN 3-540-
67297-4.
A. Bienvenuea and O. Francois. Global convergence for evolution strategies in spherical problems:
some simple proofs and dificulties. Theoretical Computer Science, 306(1):269–289, 2003.
C.L. Blake and C.J. Merz. UCI repository of machine learning databases, 1998.
B. Boser, I. Guyon, and V. Vapnik. A training algorithm for optimal margin classifer. In Pat
Langley, editor, In Proc. 5th ACM Workshop on Computational Learning Theory, pages 144–
152, Pittsburgh, PA, 1992.
C.J.C. Burges. A tutorial on support vector machines for pattern recognition. Knowledge Discovery
and Data Mining, 2(2):121–167, 1998.
85

86
C.-C. Chang, C.-W. Hsu, and C.-J. Lin. The analysis of decomposition methods for support vector
machines. IEEE Transactions on Neural Networks, 11(4):1003–1008, 2000.
Olivier Chapelle, Vladimir Vapnik, Olivier Bousquet, and Sayan Mukherjee. Choosing multiple
parameters for support vector machines. Machine Learning, 46(1-3):131–159, 2002.
K.-M. Chung, W.-C. Kao, C.-L. Sun, L.-L. Wang, , and C.-J. Lin. Radius margin bounds for support
vector machines with the rbf kernel. Neural Computation, 15(11):2643–2681, 2003.
C. Cortes and V. Vapnik. Support vector network. Machine Learning, 20(1).
K. Duan, S.S. Keerthi, and A.N. Poo. Evaluation of simple performance measures for tuning svm
hyperparameters. Neurocomputing, 51(1):41–59, 2003.
J. Friedman. Another approach to polychotomous classification. Technical report, Department of
Statistics, Stanford University, 1996.
N. Hansen. Invariance, self-adaptation and correlated mutations in evolution strategies. In Springer,
editor, Proceedings of PPSN VI, Parallel Problem Solving from Nature, pages 355–364, Berlin,
2000.
N. Hansen. Comunicacion personal, 2004.
N. Hansen, S.D Muller, and P. Koumoutsakos. Reducing the time complexity of the derandomized
evolution strategy with covariance matrix adaptation (cma-es). MIT Journals, 11(1):1–18, 2003.
N. Hansen and A. Ostermeier. Adapting arbitrary normal mutation distributions in evolution
strategies: The covariance matrix adaptation. In IEEE Press, editor, Proceedings of the 1996
IEEE International Conference on Evolutionary Computation, pages 312–317, Piscataway, New
Jersey, 1996.
N. Hansen and A. Ostermeier. Convergence properties of evolution strategies with the derandomized
covariance matrix adaptation: The (µ/µi, λ)cma-es. In Verlag Mainz, editor, Proceedings of
EUFIT’97, Fifth European Congress on Intelligent Techniques and Soft Computing, pages 650–
654, Aachen, 1997.
N. Hansen and A. Ostermeier. Completely derandomized self-adaptation in evolution strategies.
Evolutionary Computation, 9(2):159–195, 2001.

87
M. Herdy. The number of offspring as strategy parameter in hierarchically organized evolution
strategies. SIGBIO Newsletter, 13(2):2–7, 1993.
C.-W. Hsu and C.-J. Lin. A comparison of methods for multi-class support vector machines. IEEE
Transactions on Neural Networks, 13(2):415–425, 2002a.
C.-W. Hsu and C.-J. Lin. A simple decomposition method for support vector machines. Machine
Learning, 46(1):291–314, 2002b.
C.W. Hsu, C.C. Chang, and C.J. Lin. A practical guide to support vector classification. Tech-
nical report, Department of Computer Science and Information Engineering, National Taiwan
University, 2003.
D. Hush and C. Scovel. Polynomial-time decomposition algorithms for support vector machines.
Machine Learning, 51(1):51–71, 2003.
T. Jaakkola and D. Haussler. Probabilistic kernel regression models. In In Proceedings of the
1999 Conference on AI and Statistics, San Mateo, CA, 1999. Morgan Kaufmann Publishers, San
Francisco, CA.
Jens Jagerskupper. Analysis of a simple evolutionary algorithm for minimization in euclidean
spaces. In Springer Verlag, editor, ICALP2003 Thirtieth International Colloquium on Automata,
Languages and Programming, pages 1068–1079, Eindhoven, The Netherlands, 2003.
T. Joachims. Making Large-Scale Support Vector Machine Learning Practical, in Advances in Kernel
Methods - SupportVector Learning. MIT Press, Cambridge, MA, 1999. ISBN 0-262-19416-3.
Thorsten Joachims. Estimating the generalization performance of a SVM efficiently. In Pat Langley,
editor, Proceedings of ICML-00, 17th International Conference on Machine Learning, pages 431–
438, Stanford, US, 2000. Morgan Kaufmann Publishers, San Francisco, CA.
L. Kaufman. Solving the quadratic programming problem arising in support vector classification,
in Advances in Kernel Methods - Support Vector Learning. MIT Press, Cambridge, MA, 1999.
ISBN 0-262-19416-3.
S. Keerthi, S. Shevade, C. Bhattacharyya, and K. Murthy. Improvements to platt’s smo algorithm
for svm classifier design. Technical report, Control Division, Dept. of Mechanical Engineering,
National University of Singapore, 1999.

88
S. S. Keerthi and E. G. Gilbert. Convergence of a generalized SMO algorithm for SVM classifier
design. Machine Learning, 46(1-3):351–360, 2002.
S.S. Keerthi. Efficient tuning of svm hyperparameters using radius/margin bound and iterative
algorithms. IEEE Transactions on Neural Networks, 13(5):1225–1229, 2002.
S.S. Keerthi. Comunicacion personal, 2003.
S.S. Keerthi and C.-J. Lin. Asymptotic behaviors of support vector machines with gaussian kernel.
Neural Computation, 15(7):1667–1689, 2003.
S.S. Keerthi and C.J. Ong. On the role of the threshold parameter in svm training algorithms. Tech-
nical report, Dept. of Mechanical and Production Engineering, National University of Singapore,
2000.
S.S. Keerthi, S.K. Shevade, C. Bhattacharyya, and K.R.K. Murthy. A fast iterative nearest point
algorithm for support vector machine classifier design. IEEE Transactions on Neural Networks,
11(1):124–136, 2000.
R.D. King, C. Feng, and A. Sutherland. Statlog: Comparison of classification algorithms on large
real-world problems. Applied Artificial Intelligence, 306(1):289–333, 1995.
S. Knerr, L. Personnaz, and G. Dreyfus. Single-layer learning revisited: a stepwise procedure for
building and training a neural network, in Neurocomputing: Algorithms, Architectures and Ap-
plications. Springer, N.Y., 1990. ISBN 3-540-53278-1.
U. KreSSel. Pairwise Classification and Support Vector Machines, in Advances in Kernel Methods
and Support Vector Learning. MIT Press, Cambridge, MA, 1999. ISBN 0-262-19416-3.
Jen-Hao Lee and Chih-Jen Lin. Automatic model selection for support vector machines. Tech-
nical report, Department of Computer Science and Information Engineering, National Taiwan
University, 2001.
C.-J. Lin. Asymptotic convergence of an smo algorithm without any assumptions. IEEE Transac-
tions on Neural Networks, 13(1):248–250, 2001a.
C.-J. Lin. Linear convergence of a decomposition method for support vector machines. Tech-
nical report, Department of Computer Science and Information Engineering, National Taiwan
University, 2001b.

89
C.-J. Lin. On the convergence of the decomposition method for support vector machines. IEEE
Transactions on Neural Networks, 12(6):1288–1298, 2001c.
C.-J. Lin. A formal analysis of stopping criteria of decomposition methods for support vector
machines. IEEE Transactions on Neural Networks, 13(5):1045–1052, 2002.
C.-J. Lin and J. J. More. Newton’s method for large bound-constrained optimization problems.
SIAM Journal on Optimization, 9(4):1100–1127, 1999.
Chih-Jen Lin. Can support vector machine be a major classification method ?, 2003.
H.-T. Lin and C.-J. Lin. A study on sigmoid kernels for svm and the training of non-psd ker-
nels by smo-type methods. Technical report, Department of Computer Science and Information
Engineering, National Taiwan University, 2003.
C. A. Micchelli. Interpolation of scattered data: Distance matrices and conditionally positive definite
functions. Constructive Approximation, 2(1):11–22, 1986.
F. Ojeda. Extraccion de caracterısticas usando transformada wavelet en la identificacion de voces
patologicas. Trabajo de grado, Universidad Nacional de Colombia, Manizales, 2003.
M. Opper and O. Winther. Gaussian Processes and SVM: Mean Field and Leave-One-Out. In A.
Smola, P. Bartlett, B. Scholkopf and D.Schuurmans, Advances in Large Margin Classifiers. MIT
Press, Cambridge, MA, 2000. ISBN 0-387-94559-8.
M. Orozco. Clasificacion de arritmias cardıacas usando transformada wavelet y tecnicas de re-
conocimiento de patrones. Trabajo de grado, Universidad Nacional de Colombia, Manizales,
2003.
A. Ostermeier, A. Gawelczyk, and N. Hansen. Step-size adaptation based on non-local use of
selection information. In Springer, editor, Proceedings of PPSN IV, Parallel Problem Solving
from Nature, pages 189–198, Berlin, 1994.
A. Ostermeier and N. Hansen. An evolution strategy with coordinate system invariant adaptation
of arbitrary normal mutation distributions within the concept of mutative strategy parameter
control. In Morgan Kaufmann, editor, Proceedings of the Genetic and Evolutionary Computation
Conference, GECCO-99, pages 902–909, San Francisco, 1999.
E. Osuna, R. Freund, and F. Girosi. Training support vector machines: An application to face
detection. In IEEE, editor, In Proceedings of CVPRS97, pages 130–136, New York, NY, 1997.

90
K.H. Phua, Fan W., and D. Ming. Parallel algorithms for large scale nonlinear unconstrained opti-
mization. Technical report, Department of Information Systems & Computer Science, National
University of Singapore, 1997.
J. C. Platt, N. Cristianini, and J. Shawe-Taylor. Large margin dags for multiclass classification.
Advances in Neural Information Processing Systems, 12(1):547–553, 2000.
J.C. Platt. Probabilities in Support Vector Machines. In A. Smola, P. Bartlett, B. Scholkopf and
D.Schuurmans, Advances in Large Margin Classifiers. MIT Press, Cambridge, MA, 2000. ISBN
0-387-94559-8.
John C. Platt. Fast Training of Support Vector Machines using Sequential Minimal Optimization,
in Advances in Kernel Methods - Support Vector Learning. MIT Press, Cambridge, MA, 1999.
ISBN 0-262-19416-3.
Teukolsky S. Vetterling W. Press, W. and B. Flannery. Numerical Recipes in C: The Art of Scientific
Computing. Cambridge University Press, Cambridge, second edition edition, 1992. ISBN 0-521-
43108-5.
I. Rechemberg. The evolution Strategy: A Mathematical Model of Darwinian Evolution. Springer,
berlin, 1984.
Gunter Rudolph. Self-adaptation and global convergence: A counter-example. In Peter J. Angeline,
Zbyszek Michalewicz, Marc Schoenauer, Xin Yao, and Ali Zalzala, editors, Proceedings of the
Congress on Evolutionary Computation, pages 646–651, Mayflower Hotel, Washington D.C., USA,
1999. IEEE Press.
C. Saunders, M. O. Stitson, J. Weston, L. Bottou, B. Schlolkopf, and A. Smola. Support vector
machine reference manual. Technical report, Royal Holloway, University of London, Egham, UK,
1998.
B. Scholkopf, K. Sung, C. Burges, F. Girosi, P.Niyogi, T. Poggio, and V. Vapnik. Comparing support
vector machines with gaussian kernels to radial basis function classifiers. IEEE Transactions on
Signal Processing, A.I. Memo (1599), 45(11):2758–2765, 1996.
Bernhard Scholkopf and Alex Smola. Learning with Kernels Support Vector Machines, Regulariza-
tion, Optimization and Beyond. MIT Press, Cambridge, MA, 2002. ISBN 0-387-94559-8.

91
H.-P. Schwefel. Numerical Optimization of Computer Models. Wiley, Chichester, 1992. ISBN
0-471-09988-0.
D.F. Shanno and K.H. Phua. Algorithm 500: Minimization of unconstrained multivariate functions.
ACM Transactions on Mathematical Software, 2(1):87–94, 1976.
S. Sundararajan and S.S. Keerthi. Predictive approaches for choosing hyperparameters in gaussian
processes. Neural Computation, 13(5):1103–1118, 2001.
V. Vapnik. The Nature of Statistical Learning Theory. Springer, N.Y., 1995. ISBN 0-387-94559-8.
V. Vapnik. Statistical Learning Theory. Wiley, N.Y., 1998. ISBN 0-387-94559-8.
Vladimir Vapnik and Olivier Chapelle. Bounds on error expectation for support vector machines.
Neural Computation, 12(9):2013–2036, 2000.
G. Wahba, Y. Lin, and H. Zhang. Generalized Approximated Cross-Validation for Support Vec-
tor Machines: Another Way to Look at Margin Like Quantities. In A. Smola, P. Bartlett, B.
Scholkopf and D.Schuurmans, Advances in Large Margin Classifiers. MIT Press, Cambridge,
MA, 2000. ISBN 0-387-94559-8.
J. Weston and C. Watkins. Multi-class support vector machines. Technical report, Royal Holloway,
University of London, Egham, UK, 1998.


















