
Resiliencia de la carga de trabajo con EMC VPLEX · Fallas del log de regiones defectuosas ... se...
19
Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas Resumen En este white paper, se brinda una breve introducción a EMC ® VPLEX™ y se describe la forma en que VPLEX proporciona mayor resiliencia de la carga de trabajo al data center. Las recomendaciones de mejores prácticas para implementaciones de alta disponibilidad se ofrecen junto con descripciones de la forma en que VPLEX maneja diferentes escenarios de fallas. Mayo de 2010
Transcript of Resiliencia de la carga de trabajo con EMC VPLEX · Fallas del log de regiones defectuosas ... se...

Resiliencia de la carga de trabajo con EMC VPLEX
Planificación de mejores prácticas
Resumen
En este white paper, se brinda una breve introducción a EMC® VPLEX™ y se describe la forma en que VPLEX proporciona mayor resiliencia de la carga de trabajo al data center. Las recomendaciones de mejores prácticas para implementaciones de alta disponibilidad se ofrecen junto con descripciones de la forma en que VPLEX maneja diferentes escenarios de fallas.
Mayo de 2010

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 2
Copyright © 2010 EMC Corporation. Todos los derechos reservados.
EMC considera que la información de esta publicación es precisa en el momento de su publicación. La información está sujeta a cambios sin previo aviso.
LA INFORMACIÓN DE ESTA PUBLICACIÓN SE PROPORCIONA “TAL CUAL”. EMC CORPORATION NO SE HACE RESPONSABLE NI OFRECE GARANTÍA DE NINGÚN TIPO CON RESPECTO A LA INFORMACIÓN DE ESTA PUBLICACIÓN Y, ESPECÍFICAMENTE, RENUNCIA A TODA GARANTÍA IMPLÍCITA DE COMERCIABILIDAD O CAPACIDAD PARA UN PROPÓSITO DETERMINADO.
El uso, la copia y la distribución de cualquier software de EMC descrito en esta publicación requieren una licencia de software correspondiente.
Para obtener una lista actualizada de nombres de productos de EMC, consulte las marcas comerciales de EMC Corporation en EMC.com (visite el sitio web de su país correspondiente).
Todas las demás marcas comerciales que aparecen en este documento son propiedad de sus respectivos dueños.
Número de referencia h7138.1

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 3
Tabla de contenido Resumen.........................................................................................................4 Introducción ...................................................................................................4
Público al que está dirigido .................................................................................................... 4 Descripción general de la tecnología VPLEX..............................................4
Arquitectura de agrupamiento en clusters de EMC VPLEX .................................................. 6 Virtualización de dispositivos VPLEX................................................................................. 6
Descripción general del hardware VPLEX...................................................7 Descripción general de la implementación .................................................8
Implementación de VPLEX Local .......................................................................................... 8 Cuándo implementar VPLEX Local.................................................................................... 9
Implementación de VPLEX Metro en un data center ............................................................ 9 Cuándo implementar VPLEX Metro en un data center.................................................... 10
Implementación de VPLEX Metro entre data centers ......................................................... 10 Cuándo implementar VPLEX Metro entre data centers................................................... 11
Resiliencia de la carga de trabajo ..............................................................11 Interrupciones de arreglos de almacenamiento................................................................... 12
Mejores prácticas ............................................................................................................. 12 Interrupciones de SAN......................................................................................................... 12
Mejor práctica................................................................................................................... 13 Fallas en los componentes VPLEX ..................................................................................... 14
Falla del puerto Fibre Channel ......................................................................................... 14 Falla de módulos de I/O ................................................................................................... 15 Falla de un director........................................................................................................... 15 Falla de la fuente de alimentación del motor ................................................................... 15 Falla en el ventilador del motor ........................................................................................ 16 Falla de subred IP en clusters.......................................................................................... 16 Falla de switches Fibre Channel en clusters.................................................................... 16 Falla de un motor VPLEX................................................................................................. 16 Falla en la fuente de alimentación en standby................................................................. 16 Falla de enlaces entre clusters......................................................................................... 16 Falla del volumen de metadatos ...................................................................................... 17 Fallas del log de regiones defectuosas............................................................................ 17 Falla del servidor de administración................................................................................. 17 Falla del sistema de alimentación ininterrumpida ............................................................ 17
Fallas en los clusters VPLEX............................................................................................... 18 Fallas de host....................................................................................................................... 18 Interrupciones del data center ............................................................................................. 18
Conclusión ...................................................................................................19 Referencias ..................................................................................................19

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 4
Resumen EMC® VPLEX™ es la solución de última generación para la transferencia de información y el acceso a ella dentro de data centers y entre ellos. Es la primera plataforma del mundo que proporciona federación local y distribuida.
La federación local ofrece la cooperación transparente de elementos físicos situados dentro de un site. La federación distribuida extiende el acceso entre dos ubicaciones distantes. VPLEX es una solución para la federación entre almacenamiento de EMC y de otros fabricantes.
La solución VPLEX complementa la infraestructura de almacenamiento virtual de EMC y suministra un nivel que soporta el almacenamiento virtual entre equipos host que ejecutan las aplicaciones de los data centers y los arreglos de almacenamiento que suministran el almacenamiento físico utilizado por dichas aplicaciones.
En este white paper, se analiza la forma en que puede usarse VPLEX para incorporar mayores niveles de resiliencia a las aplicaciones que se ejecutan dentro de los data centers y entre estos. Denominamos resiliencia de la carga de trabajo a esta funcionalidad.
Introducción Este white paper demuestra cómo puede usarse la tecnología VPLEX para incrementar la resiliencia de la carga de trabajo en el data center. Mediante la combinación de técnicas y prácticas de uso común en la actualidad con las mejores prácticas para la implementación de VPLEX, puede mejorarse la resiliencia de la carga de trabajo en el data center para resistir interrupciones de los arreglos e, incluso, eventos de alto impacto, como interrupciones de la alimentación o del mantenimiento de data centers. Estas funcionalidades se presentan con una breve descripción general de la tecnología VPLEX y los casos de uso correspondientes. A continuación, se describen el hardware de VPLEX y las implementaciones comunes de esta tecnología. El resto del white paper describe el comportamiento de VPLEX en diferentes condiciones de fallas que pueden ocurrir dentro del ambiente. Las recomendaciones de mejores prácticas se ofrecen para superar cada tipo de falla y para alcanzar los mayores niveles de resiliencia de la carga de trabajo en el data center con implementación de VPLEX.
Público al que está dirigido Este white paper está dirigido a arquitectos y administradores de almacenamiento que deseen conocer la forma en que VPLEX puede ayudar a incorporar resiliencia a la infraestructura de almacenamiento del data center. Se da por supuesto el conocimiento de los conceptos básicos de arreglos de almacenamiento, redes de almacenamiento (SAN) e infraestructura de servidores.
Descripción general de la tecnología VPLEX EMC VPLEX introduce una nueva arquitectura que incorpora la experiencia de EMC obtenida durante más de 20 años de diseño, implementación y perfeccionamiento de soluciones de clase empresarial de protección de datos distribuidos y de memoria caché inteligente.
Sobre las bases brindadas por motores de procesador escalables y de alta disponibilidad, EMC VPLEX está diseñado para escalar de manera ininterrumpida desde configuraciones pequeñas o medianas hasta configuraciones de gran tamaño. VPLEX reside entre los recursos de almacenamiento heterogéneo y los servidores, y se vale de una arquitectura de agrupamiento en clusters exclusiva que permite a los servidores de múltiples data centers tener acceso de lectura/escritura a dispositivos compartidos de almacenamiento en bloque.

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 5
Entre las características exclusivas de esta arquitectura, se incluyen las siguientes:
• Hardware de agrupamiento en clusters de escalamiento horizontal, que le permite comenzar con poco y crecer con niveles de servicio predecibles.
• Almacenamiento avanzado de datos en caché, que utiliza caché SDRAM a gran escala para aumentar el performance y reducir la latencia de I/O y los conflictos de los arreglos.
• Coherencia de caché distribuida para uso compartido, balanceo de cargas y failover de I/O automatizados en el cluster.
• Vista consistente de uno o más LUN entre clusters VPLEX separados por una corta distancia con un data center o por distancias síncronas. Esto permite nuevos modelos de alta disponibilidad y reubicación de la carga de trabajo.
Figura 1. Funcionalidad de federación de almacenamiento heterogéneo del sistema
EMC VPLEX EMC AccessAnywhere™, disponible con VPLEX, es una tecnología innovadora de EMC que permite reubicar y compartir una copia de datos, y acceder a ella a distancia. EMC GeoSynchrony™ es el sistema operativo de VPLEX.
VPLEX consta de dos productos: VPLEX Local y VPLEX Metro.
• VPLEX Local ofrece administración simplificada y capacidad de transferencia de datos no disruptiva entre arreglos heterogéneos.
• VPLEX Metro brinda acceso a los datos y capacidad de transferencia entre dos clusters VPLEX a distancias síncronas.
Figura 2. Oferta de EMC VPLEX con límites en la arquitectura
Con una exclusiva arquitectura de escalamiento vertical y horizontal, el almacenamiento avanzado de datos en caché y la coherencia de caché distribuida de VPLEX ofrecen resiliencia de la carga de trabajo y automatización del uso compartido, el balanceo y el failover de dominios de almacenamiento. Asimismo, permiten acceder a datos locales y remotos con niveles de servicio predecibles.
VPLEX Local soporta la federación local. VPLEX Metro ofrece funcionalidades de federación distribuida y amplía el acceso entre dos ubicaciones a distancias síncronas. VPLEX Metro aprovecha AccessAnywhere para permitir reubicar una sola copia de datos, compartirla y acceder a ella a distancia.
La combinación de un data center virtualizado y EMC VPLEX proporciona a los clientes métodos completamente nuevos para solucionar problemas de TI e introducir nuevos modelos de servicios informáticos. En concreto, los clientes pueden llevar a cabo las siguientes tareas:

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 6
• Transferir aplicaciones virtualizadas entre data centers. • Utilizar el balanceo de cargas de trabajo y la reubicación entre sites. • Agregar data centers y proporcionar servicios de TI de manera ilimitada las 24 horas.
Arquitectura de agrupamiento en clusters de EMC VPLEX VPLEX utiliza una arquitectura de agrupamiento en clusters exclusiva para ayudar a los clientes a eliminar los límites físicos del data center y permitir que los servidores de múltiples data centers tengan acceso de lectura/escritura a dispositivos compartidos de almacenamiento en bloque.
Una configuración de VPLEX Local se define mediante uno, dos o cuatro motores VPLEX, integrados en un solo cluster por medio de sus interconexiones totalmente redundantes de fabric entre motores. Esta interconexión de clusters permite la incorporación en línea de motores VPLEX, lo que proporciona escalabilidad excepcional para configuraciones de VPLEX Local y de VPLEX Metro. Toda la conectividad entre nodos de cluster VPLEX y entre configuraciones de VPLEX Metro es totalmente redundante, lo que asegura protección contra puntos únicos de falla.
Un cluster VPLEX se puede escalar verticalmente por medio de la incorporación de más motores y se puede escalar horizontalmente por medio de la conexión de clusters en VPLEX Metro (dos clusters VPLEX conectados a distancias metropolitanas). VPLEX Metro ayuda a transferir y compartir cargas de trabajo de manera transparente (incluidos hosts virtualizados), consolida data centers y optimiza la utilización de recursos entre data centers. Además, proporciona transferencia no disruptiva de datos, administración de almacenamientos heterogéneos y disponibilidad de aplicaciones mejorada. VPLEX Metro soporta hasta dos clusters, que pueden estar en el mismo data center en dos sites diferentes situados a distancias síncronas (aproximadamente, hasta 100 kilómetros o 60 millas).
Figura 3. Federación local y distribuida con EMC VPLEX Local y EMC VPLEX Metro
EMC VPLEX satisface las expectativas del Cliente en cuanto al almacenamiento de high-end en términos de disponibilidad. La disponibilidad de high-end excede la simple redundancia: consiste en operaciones y actualizaciones no disruptivas de conexión en línea permanente. EMC VPLEX ofrece lo siguiente:
• AccessAnywhere, con conectividad total de recursos en clusters y configuraciones de Metro-Plex. • Opciones de transferencia y migración de datos entre arreglos de almacenamiento heterogéneos. • La capacidad de garantizar los niveles de servicio y la funcionalidad a medida que crece la
consolidación. • Control simplificado de aprovisionamiento en ambientes complejos. • Balanceo de carga de datos dinámico entre arreglos de almacenamiento.
Virtualización de dispositivos VPLEX Las funcionalidades de virtualización de dispositivos en VPLEX permiten que los dispositivos de almacenamiento se consideren volúmenes de almacenamiento, donde pueden particionarse o encapsularse como extensiones y pueden usarse para conformar dispositivos combinados expuestos a hosts como volúmenes virtuales. VPLEX soporta varias transformaciones de dispositivos virtuales a físicos diferentes, que incluyen:
• Extensiones: una extensión es un dispositivo que conforma un rango contiguo de páginas de un volumen de almacenamiento. Una extensión puede encapsular totalmente un volumen de

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 7
almacenamiento o puede definir un fragmento particionado de un volumen de almacenamiento. Una página de VPLEX 4.0 consta de 4 KB de almacenamiento.
• RAID 0: un dispositivo RAID 0 es una agregación de dos o más dispositivos en la cual las páginas lógicas de almacenamiento se fraccionan en dichos dispositivos a fin de aumentar el performance de I/O mediante la distribución de datos entre varios ejes.
• RAID-C: un dispositivo RAID-C es una agregación de dos o más dispositivos concatenados de manera lógica para formar un dispositivo de almacenamiento de mayor capacidad.
• RAID 1: un dispositivo RAID 1 consume dos o más dispositivos locales de tamaño similar para generar un espejeado. Cada uno de estos dispositivos proporciona una copia completa de los datos, y las escrituras en el dispositivo RAID 1 se aplican a cada tramo de dicho espejeado.
• DR-1: un dispositivo DR-1 es un dispositivo RAID 1 distribuido; es similar a RAID 1, pero los tramos del dispositivo espejeado se suministran mediante clusters diferentes de un sistema VPLEX.
VPLEX 4.0 ofrece coherencia de caché distribuida, que complementa sus funcionalidades de virtualización de dispositivos. La memoria caché VPLEX se mantiene de manera global y consistente entre los diferentes directores del sistema. En conjunto, las memorias caché de los directores mantienen la falsa sensación de que cada volumen virtual es un solo disco, a pesar de que los datos de este volumen pueden expandirse a varios dispositivos distintos, pueden distribuirse entre data centers diferentes y pueden permitir el acceso a ellos desde dichos data centers.
Descripción general del hardware VPLEX Como se describió en la sección anterior, cada sistema VPLEX 4.0 consta de uno o dos clusters VPLEX que incluyen uno, dos o cuatro motores. Un motor VPLEX es un chasis que incluye dos directores, fuentes de alimentación redundantes, ventiladores, módulos de I/O y módulos de administración. Los directores son los componentes que impulsan el sistema y se encargan de procesar las solicitudes de I/O de los hosts, lo que permite prestar servicios de datos y mantenerlos en la memoria caché distribuida, brindar conversiones de I/O virtuales a físicas e interactuar con los arreglos de almacenamiento para prestar servicios de I/O.
La Figura 4 muestra un sistema VPLEX Metro que consta de dos clusters de cuatro motores.
Figura 4. VPLEX Metro con dos clusters de gran tamaño

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 8
La Figura 5 es una imagen de un motor VPLEX. Esta fotografía muestra doce módulos de I/O soportados por el motor; a cada director se le asignaron seis módulos. Cada director cuenta con dos módulos de I/O Fibre Channel de 8 Gb/s y cuatro puertos (dichos módulos se usan para la conectividad SAN de front-end [host]), y con dos módulos de I/O Fibre Channel de 8 Gb/s y cuatro puertos (dichos módulos se usan para la conectividad SAN de back-end [arreglos de almacenamiento]). Cada uno de estos módulos tiene ancho de banda PCI eficiente con conexión de 10 Gb/s para los equipos del director correspondiente. Un quinto módulo de I/O proporciona dos puertos de conectividad Fibre Channel de 8 Gb/s para la comunicación dentro de clusters y dos puertos de conectividad Fibre Channel de 8 Gb/s para la comunicación entre clusters. El sexto módulo de I/O incluye cuatro puertos Ethernet de 1 Gb/s y no se encuentra en uso actualmente.
Figura 5. Un motor VPLEX y sus componentes El motor alberga dos fuentes de alimentación redundantes que pueden suministrar alimentación total al chasis. Los módulos de administración redundantes brindan conectividad IP a los directores desde el servidor de administración que se ofrece con cada cluster. Dos subredes IP privadas suministran conectividad IP redundante entre los directores de un cluster y el servidor de administración del cluster. Cuatro ventiladores redundantes ofrecen enfriamiento al chasis del motor y soportan un modelo de configuración 3 + 1 que brinda enfriamiento suficiente frente a la falla de un ventilador único.
Cada motor cuenta con el soporte de una unidad de fuente de alimentación en standby redundante que suministra la alimentación para enfrentar condiciones de pérdida de alimentación temporales cuya duración sea de hasta cinco minutos.
Los clusters que incluyen dos o más motores cuentan con un par de switches Fibre Channel, los cuales brindan conectividad Fibre Channel redundante que soporta la comunicación dentro de clusters entre los directores. Cada switch Fibre Channel cuenta con backup por medio de un sistema de alimentación ininterrumpida (UPS) dedicado que ofrece soporte para enfrentar la pérdida de alimentación temporal.
Descripción general de la implementación VPLEX soporta varios modelos de implementación diferentes para satisfacer las diversas necesidades. Las siguientes secciones describen estos diferentes modelos y el momento en que deben usarse.
Implementación de VPLEX Local La Figura 6 muestra una implementación típica de un sistema VPLEX Local. Los sistemas VPLEX Local cuentan con soporte en configuraciones pequeñas, medianas o grandes que constan de uno, dos o cuatro motores, respectivamente, y ofrecen sistemas que brindan dos, cuatro u ocho directores.

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 9
Figura 6. Ejemplo de una implementación de VPLEX Local pequeña
Cuándo implementar VPLEX Local La implementación de VPLEX Local es apropiada cuando se requieren funcionalidades de almacenamiento virtual de reubicación de la carga de trabajo, resiliencia de la carga de trabajo y administración simplificada del almacenamiento dentro de un solo data center y cuando la capacidad de escalamiento de VPLEX Local es suficiente para satisfacer las necesidades de dicho data center. Si se necesita una mayor escala, considere la implementación de VPLEX Metro (se analiza a continuación) o la implementación de múltiples instancias de VPLEX Local.
Implementación de VPLEX Metro en un data center La Figura 7 muestra una implementación típica de un sistema VPLEX Metro en un solo data center. Los sistemas VPLEX Metro incluyen dos clusters, y cada uno de ellos cuenta con uno, dos o cuatro motores. No es necesario que los clusters en una implementación de VPLEX Metro cuenten con la misma cantidad de motores. Por ejemplo, un sistema VPLEX Metro 2 x 4 cuenta con el soporte de un cluster que incluye dos motores y de un segundo cluster que consta de cuatro motores.

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 10
Figura 7. Ejemplo de una implementación de VPLEX Metro en un data center
Cuándo implementar VPLEX Metro en un data center La implementación de VPLEX Metro en un data center es apropiada cuando se requieren funcionalidades de almacenamiento virtual de reubicación de la carga de trabajo, resiliencia de la carga de trabajo y administración simplificada del almacenamiento en un solo data center y se necesita mayor escalamiento que el que ofrece la solución VPLEX Local o cuando se requiere resiliencia adicional.
VPLEX Metro ofrece el siguiente beneficio de resiliencia adicional en comparación con VPLEX Local. Los dos clusters de un sistema VPLEX Metro pueden estar separados a una distancia máxima de 100 km. Esto ofrece una excelente flexibilidad para la implementación en un data center y permite la implementación de los dos clusters en extremos independientes de un cuarto de máquinas o en diferentes pisos para proporcionar aislamiento optimizado de fallas entre los clusters. Por ejemplo, esto permite la distribución de clusters en diferentes zonas de extinción de incendios, lo cual puede marcar la diferencia entre enfrentar una falla localizada, como un incendio contenido, y una interrupción total del sistema.
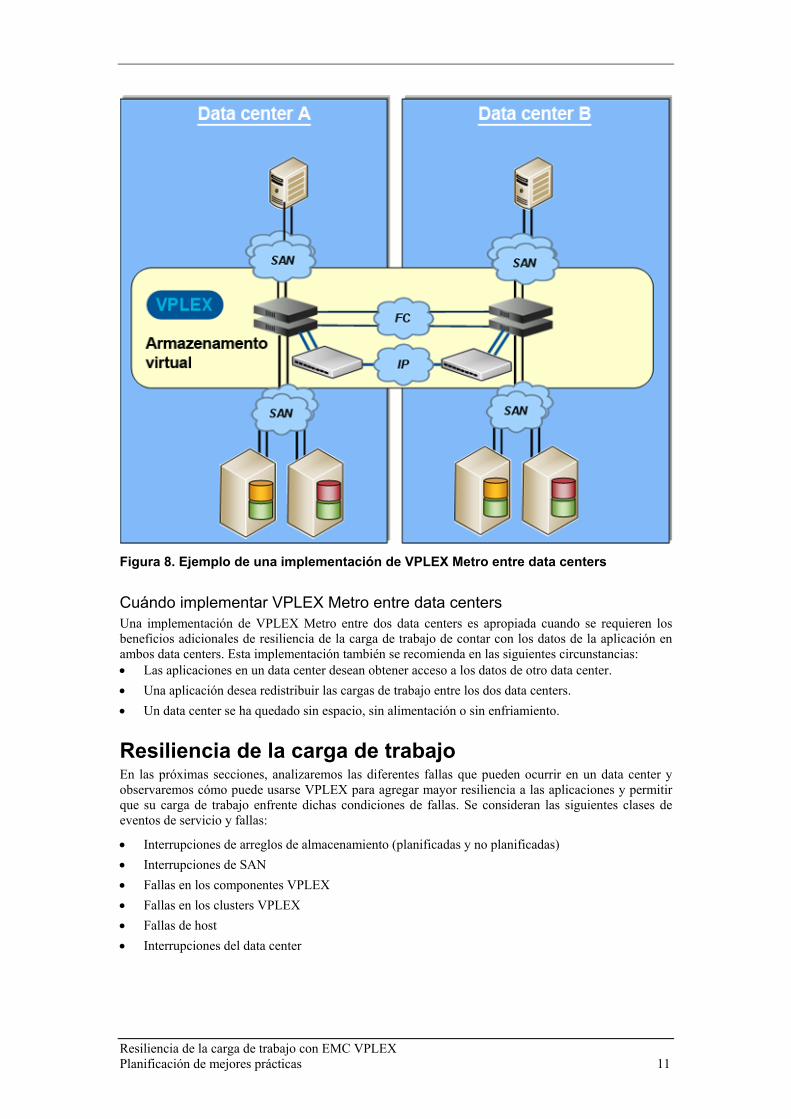
Implementación de VPLEX Metro entre data centers La Figura 8 muestra una implementación de un sistema VPLEX Metro entre dos data centers. Esta implementación es similar a la que se muestra en la sección “Implementación de VPLEX Metro en un data center”, excepto en que los clusters están ubicados en data centers independientes. Esto, normalmente, implica que hosts independientes se conectan a cada cluster. Las aplicaciones en cluster pueden tener, por ejemplo, un conjunto de servidores de aplicaciones implementado en el data center A y otro conjunto implementado en el data center B para incrementar la resiliencia y los beneficios de la reubicación de la carga de trabajo. Como se describe en la sección anterior, es importante comprender que una falla del site o del cluster total del cluster primario para un volumen distribuido requerirá la reanudación manual de la actividad de I/O en el site secundario.
Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 11
Figura 8. Ejemplo de una implementación de VPLEX Metro entre data centers
Cuándo implementar VPLEX Metro entre data centers Una implementación de VPLEX Metro entre dos data centers es apropiada cuando se requieren los beneficios adicionales de resiliencia de la carga de trabajo de contar con los datos de la aplicación en ambos data centers. Esta implementación también se recomienda en las siguientes circunstancias: • Las aplicaciones en un data center desean obtener acceso a los datos de otro data center. • Una aplicación desea redistribuir las cargas de trabajo entre los dos data centers. • Un data center se ha quedado sin espacio, sin alimentación o sin enfriamiento.
Resiliencia de la carga de trabajo En las próximas secciones, analizaremos las diferentes fallas que pueden ocurrir en un data center y observaremos cómo puede usarse VPLEX para agregar mayor resiliencia a las aplicaciones y permitir que su carga de trabajo enfrente dichas condiciones de fallas. Se consideran las siguientes clases de eventos de servicio y fallas:
• Interrupciones de arreglos de almacenamiento (planificadas y no planificadas) • Interrupciones de SAN • Fallas en los componentes VPLEX • Fallas en los clusters VPLEX • Fallas de host • Interrupciones del data center
Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 12
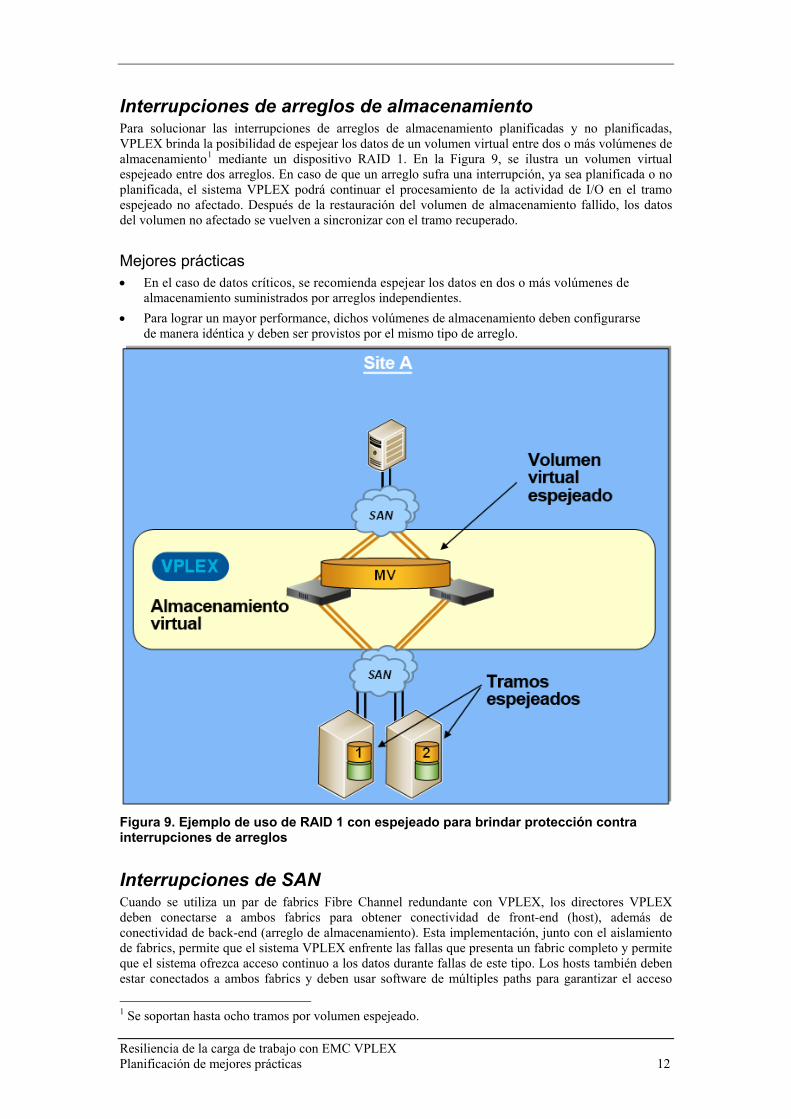
Interrupciones de arreglos de almacenamiento Para solucionar las interrupciones de arreglos de almacenamiento planificadas y no planificadas, VPLEX brinda la posibilidad de espejear los datos de un volumen virtual entre dos o más volúmenes de almacenamiento1 mediante un dispositivo RAID 1. En la Figura 9, se ilustra un volumen virtual espejeado entre dos arreglos. En caso de que un arreglo sufra una interrupción, ya sea planificada o no planificada, el sistema VPLEX podrá continuar el procesamiento de la actividad de I/O en el tramo espejeado no afectado. Después de la restauración del volumen de almacenamiento fallido, los datos del volumen no afectado se vuelven a sincronizar con el tramo recuperado.
Mejores prácticas • En el caso de datos críticos, se recomienda espejear los datos en dos o más volúmenes de
almacenamiento suministrados por arreglos independientes. • Para lograr un mayor performance, dichos volúmenes de almacenamiento deben configurarse
de manera idéntica y deben ser provistos por el mismo tipo de arreglo.
Figura 9. Ejemplo de uso de RAID 1 con espejeado para brindar protección contra interrupciones de arreglos
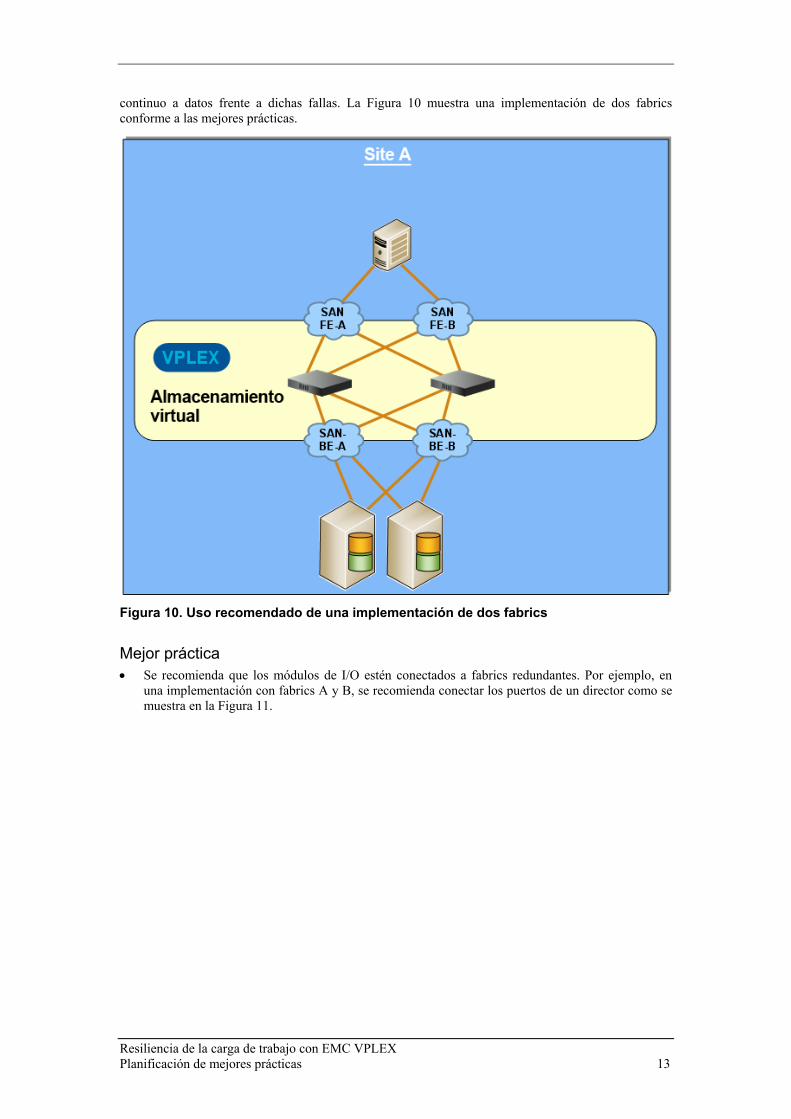
Interrupciones de SAN Cuando se utiliza un par de fabrics Fibre Channel redundante con VPLEX, los directores VPLEX deben conectarse a ambos fabrics para obtener conectividad de front-end (host), además de conectividad de back-end (arreglo de almacenamiento). Esta implementación, junto con el aislamiento de fabrics, permite que el sistema VPLEX enfrente las fallas que presenta un fabric completo y permite que el sistema ofrezca acceso continuo a los datos durante fallas de este tipo. Los hosts también deben estar conectados a ambos fabrics y deben usar software de múltiples paths para garantizar el acceso
1 Se soportan hasta ocho tramos por volumen espejeado.
Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 13
continuo a datos frente a dichas fallas. La Figura 10 muestra una implementación de dos fabrics conforme a las mejores prácticas.
Figura 10. Uso recomendado de una implementación de dos fabrics
Mejor práctica • Se recomienda que los módulos de I/O estén conectados a fabrics redundantes. Por ejemplo, en
una implementación con fabrics A y B, se recomienda conectar los puertos de un director como se muestra en la Figura 11.

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 14
Figura 11. Asignaciones de fabric recomendadas para los puertos FE y BE
Fallas en los componentes VPLEX Todos los componentes de procesamiento importantes de un sistema VPLEX usan redundancia mínima en grupos de dos para maximizar el acceso a los datos. Esta sección describe cómo se manejan las fallas de componentes de VPLEX y las mejores prácticas que deben usarse para permitir que las aplicaciones resistan dichas fallas.
Todas las fallas de componentes que ocurren en un sistema VPLEX se informan mediante eventos que se conectan con el Centro de servicios de EMC para garantizar una respuesta oportuna y la reparación de estas condiciones de falla.
Falla del puerto Fibre Channel Todas las comunicaciones de VPLEX ocurren en paths redundantes que permiten que la comunicación continúe en caso de fallas del puerto. Esta redundancia permite que el software de múltiples paths en los servidores de host lleve a cabo la retransmisión y el redireccionamiento de la actividad de I/O entre las fallas de paths que ocurren como resultado de fallas del puerto u otros eventos en la SAN que generan la pérdida de paths.
VPLEX utiliza su propia lógica de múltiples paths para conservar paths redundantes en el almacenamiento de back-end desde cada director. De esta manera, VPLEX puede enfrentar las fallas del puerto en puertos VPLEX de back-end, además de enfrentarlas en fabrics de back-end y en los puertos de arreglos que conectan el almacenamiento físico con VPLEX.
Los transceivers con conector SFP que se usan para la conectividad con VPLEX son Field Replaceable Units (FRU) que pueden recibir servicios.
Mejores prácticas • Asegurarse de que haya un path desde cada host hasta, por lo menos, un puerto de front-end en el
director A y, al menos, un puerto de front-end en el director B. Cuando el sistema VPLEX cuente con dos o más motores, asegúrese de que el host cuente como mínimo con un path “del lado A” en un motor y uno “del lado B” en un motor independiente. Para alcanzar la máxima disponibilidad, cada host puede contar con al menos un path hacia un puerto de front-end en cada director.
• Utilizar software de múltiples paths en los servidores de host para garantizar una respuesta oportuna y actividad de I/O continua frente a fallas del path.
• Garantizar que cada host tenga un path hacia cada volumen virtual por medio de cada fabric.

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 15
• Asegurarse de que el mapeo y el enmascaramiento de LUN para cada volumen de almacenamiento presentado desde un arreglo de almacenamiento hasta VPLEX incluyan los volúmenes de al menos dos puertos del arreglo en, por lo menos, dos fabrics diferentes y se conecten como mínimo con dos puertos distintos que cuenten con el servicio de dos módulos de I/O de back-end diferentes de cada director en un cluster VPLEX.
• Garantizar que la zonificación de fabrics brinde acceso redundante de hosts a los puertos VPLEX de front-end y proporcione a VPLEX acceso redundante a los puertos de arreglos.
Falla de módulos de I/O Los módulos de I/O de VPLEX cumplen funciones especializadas. Cada director VPLEX cuenta con dos módulos de I/O de front-end, dos módulos de I/O de back-end y un módulo de I/O COM que se utilizan para tener conectividad entre clusters y dentro de estos. Cada módulo de I/O es una FRU que puede recibir servicios. Las siguientes secciones describen el comportamiento del sistema y las mejores prácticas para maximizar la disponibilidad ante dichas fallas.
Módulo de I/O FE Si ocurre una falla en el módulo de I/O FE, se interrumpirá la actividad en todos los paths conectados a este módulo de I/O, y los paths sufrirán fallas. Deben seguirse las mejores prácticas que se muestran en la página 14 para garantizar que los hosts cuenten con un path redundante a sus datos.
Durante la extracción y el reemplazo de un módulo de I/O, se reiniciará el director afectado.
Módulo de I/O BE Si ocurre una falla en el módulo de I/O BE, se interrumpirá la actividad en todos los paths conectados a este módulo de I/O, y los paths sufrirán fallas. Deben seguirse las mejores prácticas que muestran en la página 14 para garantizar que cada director cuente con un path redundante a cada volumen de almacenamiento por medio de un módulo de I/O independiente.
Durante la extracción y el reemplazo de un módulo de I/O, se reiniciará el director afectado.
Módulo de I/O COM Si ocurre una falla en el módulo de I/O COM de un director, se reiniciará el director y se detendrán todos los servicios suministrados por dicho director. Las mejores prácticas que se muestran en la página 14 garantizan que cada host tenga acceso redundante a su almacenamiento virtual mediante varios directores, a fin de que el reinicio de un único director no ocasione que el host pierda el acceso a su almacenamiento.
Durante la extracción y el reemplazo de un módulo de I/O, se reiniciará el director afectado.
Falla de un director La falla de un director causa la pérdida de todos los servicios provenientes de dicho director. Cada motor VPLEX cuenta con un par de directores para redundancia. Los clusters VPLEX que incluyen dos o más motores se benefician de la redundancia adicional suministrada por los directores complementarios. Cada director dentro de un cluster puede presentar el mismo almacenamiento. Las mejores prácticas que se describen en la página 14 permiten que un host enfrente las fallas de un director al colocar paths redundantes en su almacenamiento virtual mediante los puertos proporcionados por diferentes directores. La combinación de software de múltiples paths en los hosts y paths redundantes por medio de diferentes directores del sistema VPLEX permite que el host enfrente la pérdida de un director.
En un sistema de varios motores, un host puede mantener el acceso a sus datos en el improbable caso de que varios directores fallen al presentar paths al almacenamiento virtual proporcionado por cada director del sistema.
Cada director es una FRU que puede recibir servicios.
Falla de la fuente de alimentación del motor Las fuentes de alimentación del motor VPLEX son completamente redundantes, y no se presentan pérdidas de servicio ni funciones en caso de una falla única en la fuente de alimentación.

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 16
Cada fuente de alimentación es una FRU que puede recibir servicio de mantenimiento, eliminarse y reemplazarse sin interrupciones en el sistema.
Falla en el ventilador del motor Las unidades de ventilación del motor VPLEX son completamente redundantes, y no existen privaciones de servicio ante la pérdida de una unidad de ventilación única. Cada motor incluye cuatro unidades de ventilación. En caso de que se produzca una falla única en el ventilador, las tres unidades de ventilación restantes continuarán proporcionando al sistema el suministro de enfriamiento necesario. En caso de que fallen dos ventiladores, el motor se apagará automáticamente para evitar daños causados por el sobrecalentamiento.
Cada unidad de ventilación es una FRU que puede recibir servicio de mantenimiento, eliminarse y reemplazarse sin interrupciones en el sistema.
Falla de subred IP en clusters Cada cluster VPLEX cuenta con un par de subredes IP locales privadas que conectan los directores al servidor de administración. Estas subredes se utilizan para el tráfico de administración y la protección contra el particionamiento dentro del cluster. La pérdida del enlace en una de estas subredes puede ocasionar la incapacidad de algunos miembros para comunicarse con otros miembros de dicha subred; esto permite que no se presenten pérdidas de servicio y que no se vea afectada la capacidad de administración debido a la presencia de una subred redundante.
Falla de switches Fibre Channel en clusters Cada cluster VPLEX con dos o más motores usa un par de switches Fibre Channel dedicados para lograr la comunicación dentro del cluster entre los directores del cluster. Se crean dos fabrics Fibre Channel redundantes con cada switch que presta servicios a un fabric diferente. La pérdida de un solo switch Fibre Channel no genera pérdidas de procesamiento ni de servicio.
Falla de un motor VPLEX En los clusters VPLEX que incluyen dos o más motores, el improbable evento de una falla del motor ocasionará la pérdida de servicio de los directores dentro de este motor, pero los volúmenes virtuales que reciban los servicios de los directores en otros motores no afectados permanecerán disponibles. Las “Mejores prácticas” que se muestran en la página 14 describen las mejores prácticas para la reubicación de paths redundantes en un volumen virtual en directores de diferentes motores en clusters VPLEX de varios motores.
Falla en la fuente de alimentación en standby Cada motor VPLEX cuenta con el soporte de un par de fuentes de alimentación en standby (SPS) que ofrece un tiempo de resistencia de cinco minutos, lo que permite al sistema enfrentar la pérdida de alimentación temporal. Una sola SPS ofrece suficiente alimentación para el motor conectado. VPLEX ofrece un par de SPS para lograr alta disponibilidad.
Cada SPS es una FRU que puede reemplazarse sin interrupción de los servicios suministrados por el sistema. El tiempo de recarga para una SPS es de hasta 5.5 horas, y las baterías del SPS pueden soportar dos interrupciones de cinco minutos secuenciales.
Falla de enlaces entre clusters Cada director de un sistema VPLEX cuenta con dos enlaces dedicados a la comunicación entre clusters. Cada uno de dichos enlaces debe configurarse (por ejemplo, por zonas) para suministrar paths a cada director en el cluster remoto. De esta manera, la conectividad total entre directores permanece disponible, incluso, en caso de una falla de un enlace único. En caso de que un director pierda ambos enlaces, se suspenderá toda la actividad de I/O entre los dos clusters para preservar la semántica de la fidelidad del orden de escritura y garantizar que el site remoto conserve una imagen que pueda recuperarse. Cuando esto ocurra, los espejeados remotos se dividirán y las reglas configuradas por el usuario, denominadas reglas sin conexión, se ejecutarán para determinar qué cluster VPLEX no debe

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 17
interrumpir la actividad de I/O para un espejeado remoto determinado. Estas reglas pueden configurarse por dispositivo, lo cual permite que algunos volúmenes permanezcan disponibles en un cluster y los otros volúmenes permanezcan disponibles en otro cluster.
Después de que se hayan reparado las fallas de los enlaces, será posible restaurar la actividad de I/O e iniciar las tareas de resincronización para restaurar los espejeados remotos. Dichas acciones se llevan a cabo automáticamente, o bien, pueden configurarse los volúmenes para exigir la reanudación manual de la actividad de I/O en caso de ser necesaria la coordinación con las acciones del servidor. La actividad de I/O en los dispositivos puede llevarse a cabo de manera inmediata, sin necesidad de esperar a que finalicen las tareas de resincronización.
Falla del volumen de metadatos VPLEX mantiene su estado de configuración, denominado metadatos, en los volúmenes de almacenamiento suministrados por los arreglos de almacenamiento de la SAN. Cada cluster VPLEX mantiene sus propios metadatos, que describen la información de configuración local para este cluster, además de cualquier información de configuración distribuida compartida entre clusters. Se recomienda configurar el volumen de metadatos para cada cluster con varios volúmenes de almacenamiento de back-end suministrados por diferentes arreglos de almacenamiento del mismo tipo. Las funcionalidades de protección de datos que ofrecen estos arreglos de almacenamiento, como RAID 1 y RAID 5, deben usarse para garantizar la integridad de los metadatos del sistema. Además, se recomienda realizar copias de backup de los metadatos cada vez que se modifique la configuración del sistema.
VPLEX utiliza estos metadatos persistentes durante el encendido completo del sistema y carga la información de configuración en cada director. Cuando se realizan cambios en la configuración del sistema, estos cambios se escriben en el volumen de metadatos. En caso de que se produzcan interrupciones en el volumen de metadatos, los directores VPLEX continuarán prestando sus servicios de virtualización utilizando la copia en la memoria de la información de configuración. Si el almacenamiento que soporta el dispositivo de metadatos no está disponible, debe configurarse un nuevo dispositivo de metadatos. Después de que se haya asignado y configurado un nuevo dispositivo, la copia en la memoria del dispositivo de metadatos mantenido por el cluster se registrará en el nuevo dispositivo de metadatos.
La capacidad para realizar cambios en la configuración se suspende cuando no está disponible el acceso al dispositivo de metadatos persistente.
Fallas del log de regiones defectuosas VPLEX Metro usa un log de regiones defectuosas para registrar información sobre las regiones de un espejeado distribuido fracturado que se actualizaron durante la desconexión de un tramo del espejeado. Esta información se conserva para cada tramo del espejeado desconectado. En caso de que este volumen no esté accesible, los directores registrarán el tramo completo como desactualizado y requerirán la resincronización completa de este tramo del volumen una vez que se vuelva a conectar al espejeado.
Falla del servidor de administración Cada cluster VPLEX cuenta con un servidor de administración dedicado que suministra acceso de administración a los directores y soporta la conectividad de administración para el acceso remoto al cluster par en un ambiente VPLEX Metro. Dado que el procesamiento de la actividad de I/O de los directores VPLEX no depende de los servidores de administración, la pérdida de un servidor de administración no interrumpirá los servicios de virtualización ni el procesamiento de la actividad de I/O que brinda VPLEX.
Falla del sistema de alimentación ininterrumpida En los clusters VPLEX con dos o más motores, un par de switches Fibre Channel soporta la comunicación dentro de clusters entre los directores de dichos motores. Cada switch cuenta con un UPS dedicado que suministra alimentación de backup en caso de pérdida de la alimentación temporal. Las unidades UPS permitirán que los switches Fibre Channel continúen funcionando durante un máximo de cinco minutos después de la pérdida de alimentación. El UPS inferior del rack también brinda alimentación de backup al servidor de administración.

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 18
Fallas en los clusters VPLEX VPLEX Metro soporta dos formas de dispositivos distribuidos: volúmenes virtuales con distribución Metro y volúmenes virtuales remotos. Los volúmenes virtuales con distribución Metro suministran copias sincronizadas (espejeados) de los datos del volumen en cada cluster. El volumen espejeado se muestra y funciona como un volumen único, y actúa de manera similar a la de un volumen virtual que utiliza un dispositivo RAID 1, pero con el valor agregado de que cada cluster mantiene una copia de los datos. Los volúmenes virtuales remotos ofrecen acceso a un volumen virtual cuyos datos residen en un cluster. Los volúmenes virtuales remotos, como los volúmenes virtuales con distribución Metro, pueden aprovechar la memoria caché coherente distribuida de VPLEX y sus algoritmos de búsqueda previa para proporcionar performance mejorado en comparación con la solución de ampliación de SAN.
Para cada volumen virtual con distribución Metro, una regla de desconexión identifica los clusters en un sistema VPLEX Metro que deben desconectar su tramo de espejeado (deben retirarlo del servicio) en caso de una pérdida de comunicación entre los dos clusters. Estas reglas definen de manera eficiente un site de compensación (o con privilegios ) en caso de que los clusters pierdan la comunicación entre sí. Existen dos condiciones que pueden ocasionar la pérdida de comunicación de los clusters: una es la falla de enlaces entre clusters, analizada en “Falla de enlaces entre clusters”, y la otra es la falla del cluster. Esta sección describe la última clase de falla. En caso de falla del cluster, cualquier volumen virtual con distribución Metro que cuente con una regla de desconexión que identifique el site no afectado como site con privilegios continuará recibiendo el servicio de mantenimiento de la actividad de I/O en el tramo no afectado del dispositivo. Los volúmenes cuyas reglas de desconexión especifiquen la desconexión de este site en caso de pérdida de comunicación sufrirán la suspensión de su actividad de I/O. Debido a la incapacidad para distinguir una falla del cluster de una falla del enlace, este comportamiento está diseñado para preservar la integridad de los datos en estos dispositivos distribuidos.
Existen dos casos de fallas para volúmenes virtuales remotos. Primero, si ocurre una falla en el cluster que alimenta los medios físicos del volumen virtual, el volumen virtual remoto se volverá completamente inaccesible. Para el segundo escenario, si ocurre una falla en el cluster remoto (cluster sin medios físicos para este volumen), el acceso al volumen virtual permanecerá disponible desde el cluster de host (el cluster con datos físicos), pero no desde el cluster remoto.
Fallas de host Si bien esta no es una funcionalidad suministrada por VPLEX, el agrupamiento en clusters basado en host es una importante técnica para maximizar la resiliencia de la carga de trabajo. Gracias al agrupamiento en clusters basado en host, una aplicación puede continuar brindando servicios en caso de fallas del host mediante un modelo de procesamiento activo/activo o activo/pasivo. Cuando esto se combina con las funcionalidades anteriormente mencionadas de VPLEX, el resultado es una infraestructura capaz de suministrar niveles muy elevados de disponibilidad.
Interrupciones del data center Un sistema VPLEX Metro distribuido entre dos data centers puede usarse para brindar protección contra pérdidas de datos en caso de una interrupción en el data center mediante el espejeado de datos entre los dos data centers. Esta implementación puede mejorar aún más el acceso a los datos en caso de una interrupción en el data center, según se describe en “Fallas en los clusters VPLEX” (es decir, si una interrupción del data center causa la pérdida de uno de los clusters VPLEX en un sistema VPLEX Metro). El acceso a datos permanecerá disponible para los volúmenes virtuales con distribución Metro cuyo cluster con privilegios sea el data center no afectado. Para los volúmenes cuyo cluster con privilegios es el data center con la interrupción, el acceso a los datos puede restaurarse en el otro cluster mediante la invocación de un comando manual para reanudar la actividad de I/O suspendida. La combinación con la lógica de failover para clusters de host permite lograr una infraestructura que puede restaurar las operaciones de servicio rápidamente, incluso, en caso de una interrupción del data center no planificada.
Ciertas interrupciones en el data center se originan en la pérdida de alimentación en el data center. VPLEX utiliza standby y UPS para superar las pérdidas temporales de alimentación que duran cinco minutos o menos. Esto debe combinarse con una infraestructura de soporte similar para hosts, equipos de red y arreglos de almacenamiento para una solución integral que tolere la pérdida de alimentación temporal. En caso de que se produzcan problemas de pérdida de alimentación cuya duración supere los cinco minutos, VPLEX suspenderá la prestación de servicios de virtualización. Las propiedades de

Resiliencia de la carga de trabajo con EMC VPLEX Planificación de mejores prácticas 19
almacenameinto en caché de escritura de VPLEX garantizan la escritura de los datos de las aplicaciones en los arreglos de almacenamiento de back-end antes de reconocer los datos en el host.
Conclusión VPLEX ofrece redundancia interna integral de hardware y software que garantiza la alta disponibilidad de los servicios VPLEX y mejora aún más la resiliencia de la carga de trabajo de la infraestructura adyacente. En combinación con las mejores prácticas del agrupamiento en clusters basado en host, múltiples paths, redundancia de fabrics, protección de medios de almacenamiento e infraestructura de alimentación en standby, la solución obtenida ofrece una base sólida para garantizar que el almacenamiento virtual brinde una solución sólida para la disponibilidad del almacenamiento.
Referencias Se proporciona más información sobre la infraestructura de almacenamiento virtual y las funcionalidades de VPLEX 4.0 en los siguientes white papers.
• Notas técnicas del servicio Implementación y planificación de mejores prácticas para EMC VPLEX • Uso de las plataformas de virtualización VMware con EMC VPLEX (planificación de mejores
prácticas) • Reubicación no disruptiva del almacenamiento: eventos planificados con EMC VPLEX
(planificación de mejores prácticas) • VMotion a distancia para Microsoft, Oracle y SAP activado por VCE Vblock1, EMC Symmetrix
VMAX, EMC CLARiiON y EMC VPLEX Metro (descripción general de la arquitectura) • Implementación de EMC VPLEX, Microsoft Hyper-V y SQL Server con soporte plus para failover
de clusters (tecnología aplicada)


















