Presentazione bd2
46
Gino Farisano Prof.ssa G. Tortora Prof. G. Polese Big Data Università degli Studi di Salerno Sistemi Informatici e Tecnologie del Software Basi di Dati II Anno 2014/2015
-
Upload
gino-farisano -
Category
Technology
-
view
495 -
download
0
Transcript of Presentazione bd2
Gino FarisanoProf.ssa G. Tortora Prof. G. Polese
Big Data
Università degli Studi di Salerno Sistemi Informatici e Tecnologie del Software
Basi di Dati IIAnno 2014/2015
Outline
Outline
Outline
Outline

Big Data? Perchè?
Bene, perché sono…

…BIG
“maggiore è la lotta, più glorioso sarà il trionfo”

How much data?• Ogni giorno vengono generati exabytes di dati sul www
• “il 90% dei dati nel mondo è stato generato negli ultimi due anni”. [Science Daily]
• “nel 2012 ogni giorno sono stati generati 2.5 exabyte” [IBM]
• L'idea di base dietro la frase “Big Data” è che, tutto quello che facciamo, lascia delle tracce digitali
• Big Data si riferisce quindi alla nostra capacità di utilizzare questi crescenti volumi di dati.

Activity data
• Attività semplici come l'ascolto di musica o la lettura di un libro generano dati.
• Lettori musicali digitali e eBook raccolgono dati sulle nostre attività.
• Lo smartphone raccoglie i dati su come lo si ut i l izza e i l browser web raccogl ie le informazioni su ciò che si sta cercando.
• La vostra carta di credito raccoglie i dati su ciò che si acquista.
• É difficile immaginare qualsiasi attività che non genera dati.

Le 3V dei Big Data
VOLUMETerabyteRecords
Transazioni Tabelle, Files
Kilobyte KB
Megabyte MB
Gigabyte GB
Terabyte TB
Petabyte PB
Exabyte EB
Zettabyte ZB
Yottabyte
(dieci alla ventitreesima)
YB
Le 3V dei Big Data
VELOCITÀ Batch
Near Real Time Real TimeStreams
Velocità di obsolescenza
dell’informazione
e
i dati invecchiano in fretta
Le 3V dei Big Data
VARIETÀ Strutturati
Non strutturati Semi strutturati

Data Conversation
Tina Mu
Tom Sit
Chloe
Name, Birthday, Family
Monetizable IntentJo Jobs
Not Relevant - Noise
Not Relevant - Noise

The Internet of things• L'Internet delle cose, o Internet of Everything collega
diversi dispositivi tra di loro
• I dati del traffico catturati da sensori sulla strada, ad esempio, inviano i dati al vostro orologio di allarme che vi sveglierà prima del previsto perché la strada potrebbe essere bloccata. Dovrete svegliarvi prima delle 9:00 per poter essere puntuali alla presentazione che si terrà alle 10:00!
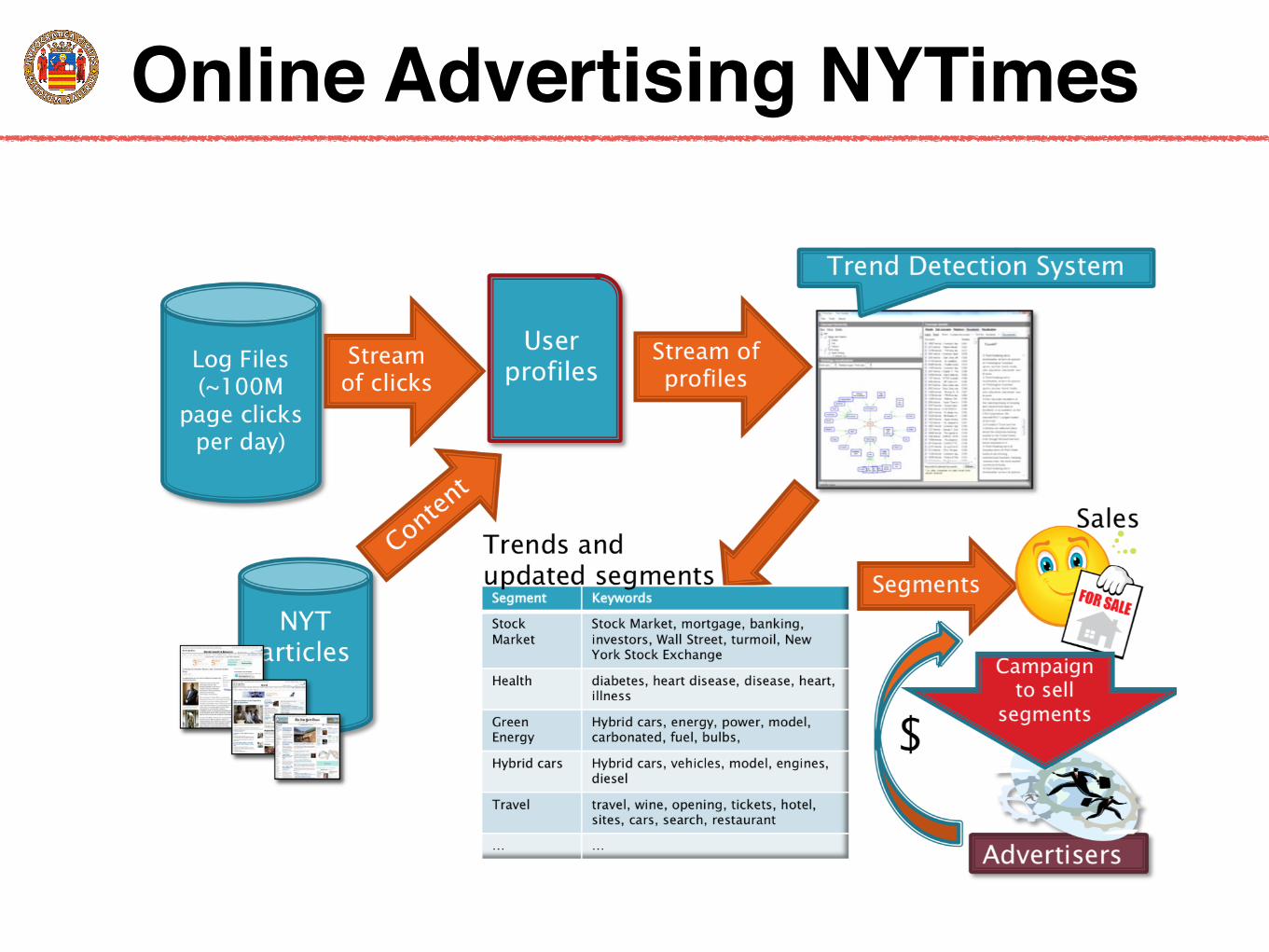
Online Advertising NYTimes

Ulteriori applicazioni
Sicurezza
Finanza Sanità Vendita su più canali
Telecomunicazioni
Settore manifatturiero
Controllo del traffico
Trading Analytics Frodi
Analisi dei log
Controllo qualità
Retail: Churn, NBO

Ci sono alcune cose che sono così grandi che hanno implicazioni per tutti…
I Big Data sono una di quelle cose e, stanno trasformando completamente il modo di fare
business…

Perché non abbiamo usato i Big Data prima?
• Key points: 1. Disponibilità di dati 2. Dispositivi di memorizzazione più
capienti e meno costosi 3. Nuove tecniche di memorizzazione
dei dati 4. Nuove tecniche di calcolo parallelo
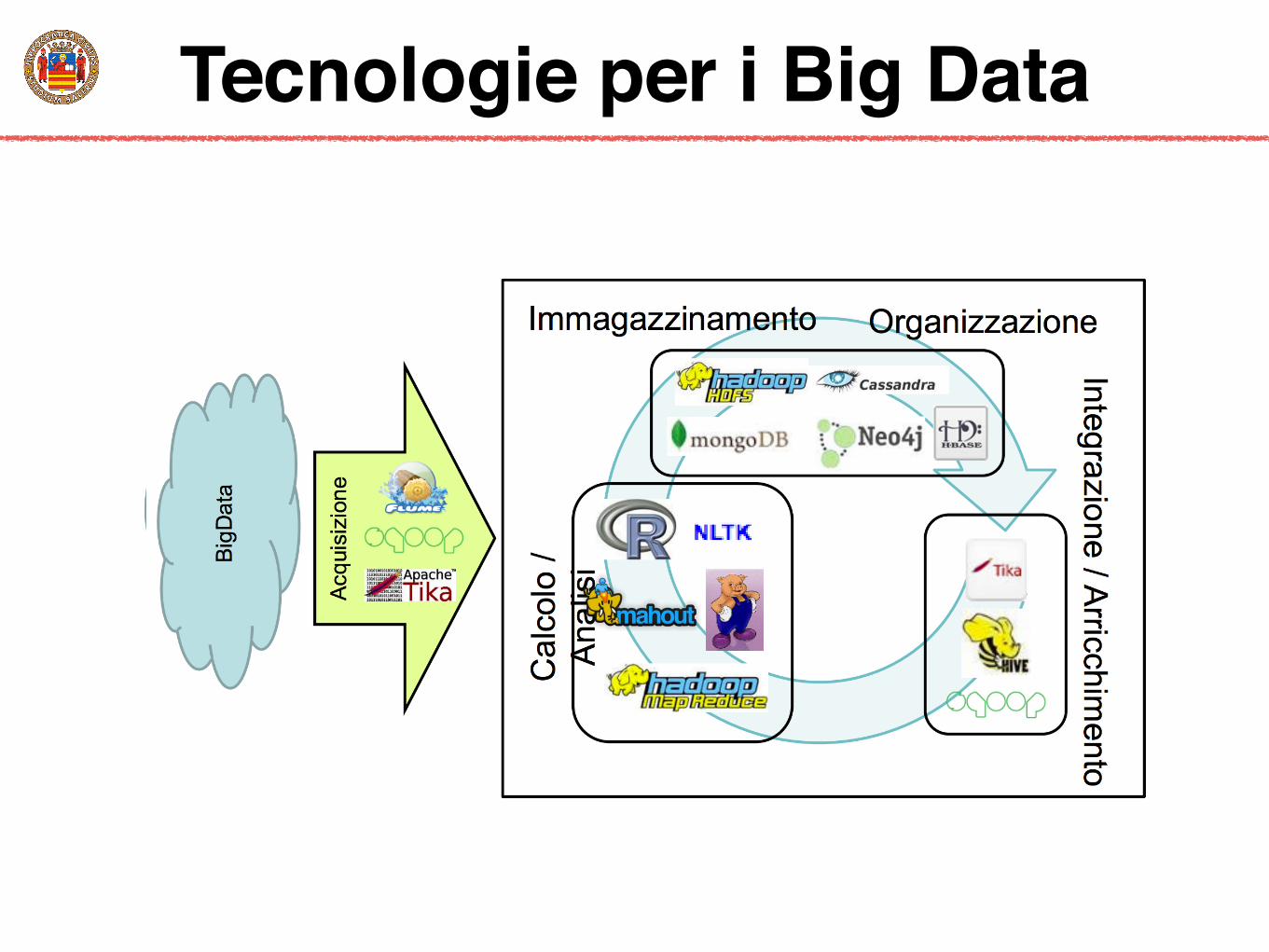
Tecnologie per i Big Data
Hadoop (1)
• Rilasciato dalla Apache Software Fondation • Scritto in Java • Elaborazione di grosse quantità di dati in applicazioni
distribuite • elevato numero di commodity hardware • orientato all’elaborazione batch • modello di computazione map/reduce

Yahoo! usa Hadoop
Facebook usa Hadoop

Twitter usa Hadoop

Storia• La storia di Hadoop inizia con Nutch
• Costruire un open source web search engine e web crawler che catturasse miliardi di URL al mese
• Problemi di scalabilità
• All’inizio degli anni 2000 Google aveva pubblicato GFS e MapReduce • La soluzione al problema posto da Nutch
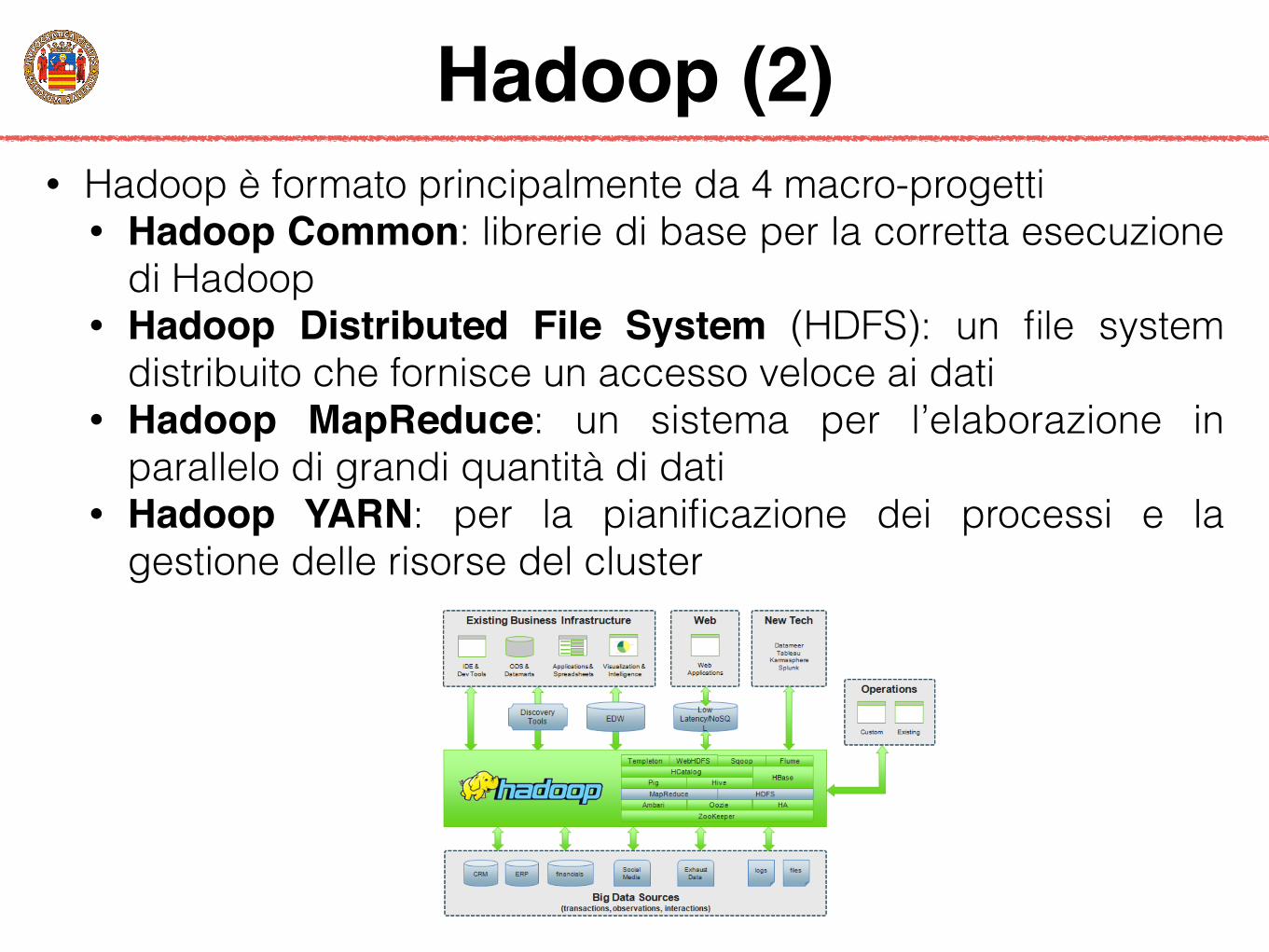
Hadoop (2)• Hadoop è formato principalmente da 4 macro-progetti
• Hadoop Common: librerie di base per la corretta esecuzione di Hadoop
• Hadoop Distributed File System (HDFS): un file system distribuito che fornisce un accesso veloce ai dati
• Hadoop MapReduce: un sistema per l’elaborazione in parallelo di grandi quantità di dati
• Hadoop YARN: per la pianificazione dei processi e la gestione delle risorse del cluster

HDFS (1)• Ispirato al Google File System (GFS) • Block-structured file system
• I singoli file sono suddivisi in blocchi di dimensioni fissate • Un file è costituito da vari blocchi non necessariamente
memorizzati sulla stessa macchina
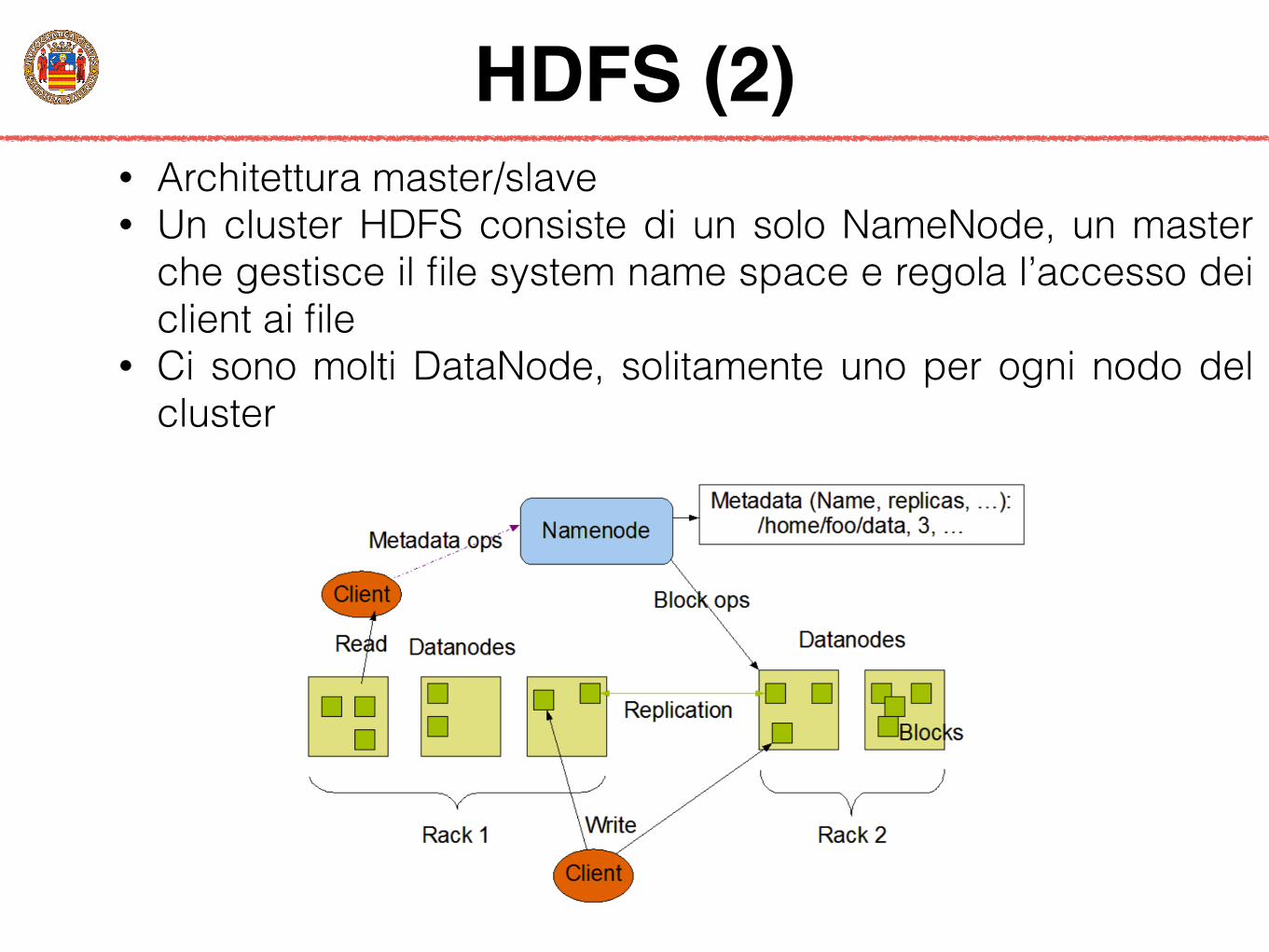
HDFS (2)• Architettura master/slave • Un cluster HDFS consiste di un solo NameNode, un master
che gestisce il file system name space e regola l’accesso dei client ai file
• Ci sono molti DataNode, solitamente uno per ogni nodo del cluster
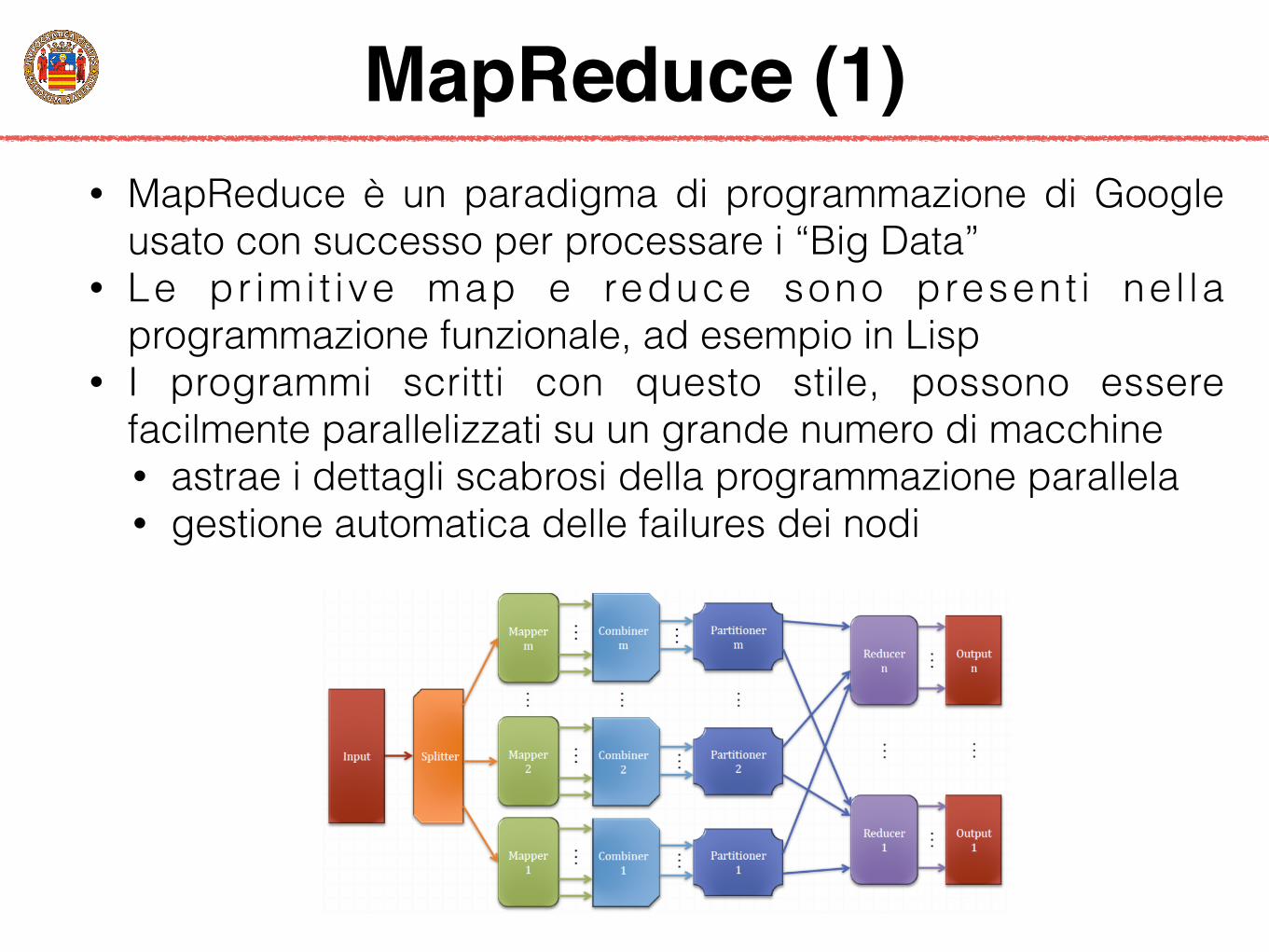
MapReduce (1)• MapReduce è un paradigma di programmazione di Google
usato con successo per processare i “Big Data” • Le pr imi t ive map e reduce sono present i ne l la
programmazione funzionale, ad esempio in Lisp • I programmi scritti con questo stile, possono essere
facilmente parallelizzati su un grande numero di macchine • astrae i dettagli scabrosi della programmazione parallela • gestione automatica delle failures dei nodi
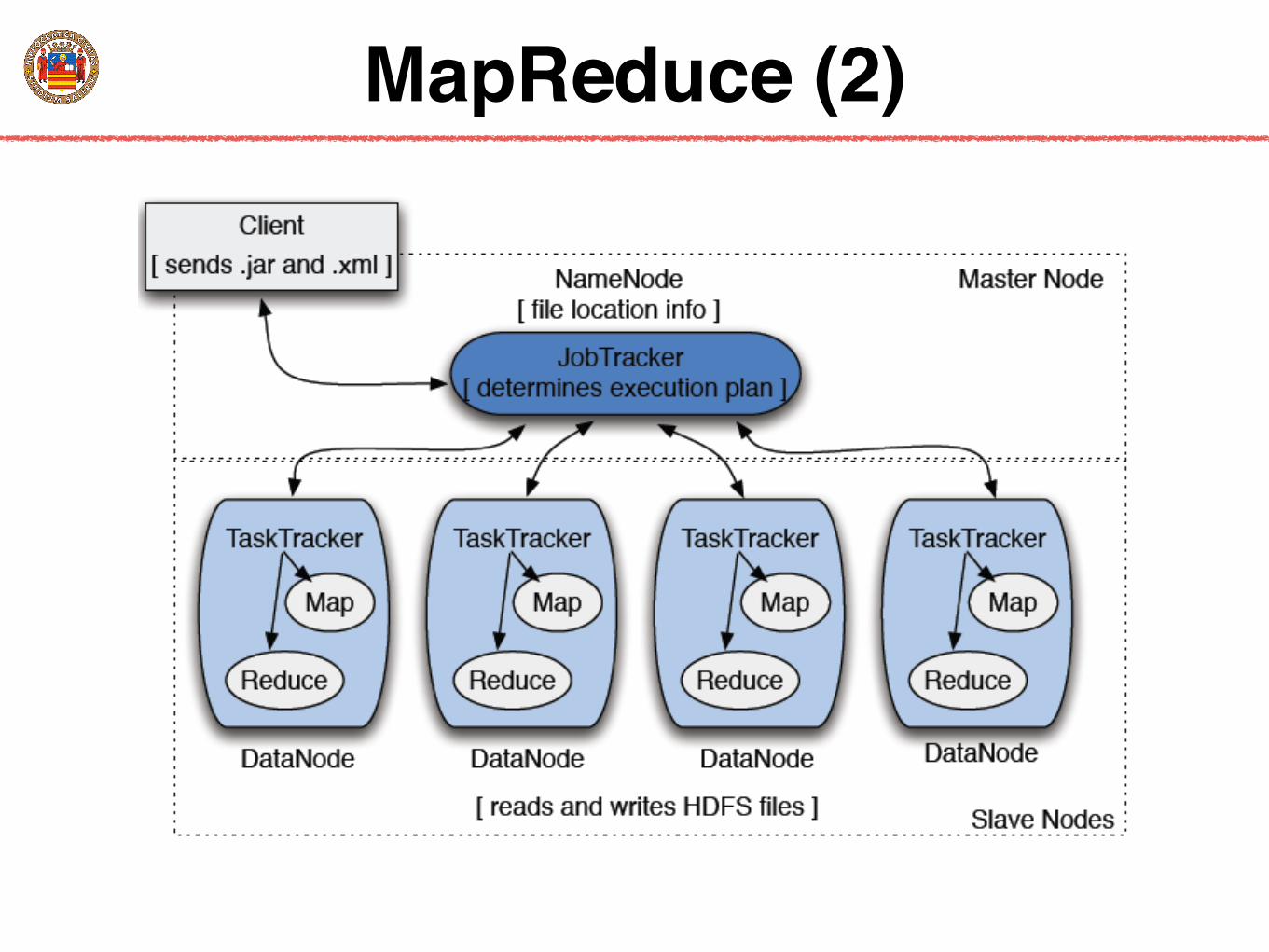
MapReduce (2)

Acquisizione dei Big Data
• API: Twitter API, Facebook API ed API dei motori di ricerca
• Web scraping: cURL, Apache Tika • ETL: Sqoop • Stream: Apache Flume

Twitter API
• Il lancio delle API twitter nel 2009 ha ispirato numerose iniziative di ricerca
• Oauth autentication • Sentiment analysis [Datumbox], mezzo di
comunicazione in caso di emergenze [Building a Data Warehouse for Twitter Stream Exploration]

Strumenti di web scraping - cURL
•Simulano la navigazione umana nel World Wide Web
•Confrontare prezzi online, monitorare dati meteorologici, ricerca scientifica
•Possibilità di specificare più URL: specificare più URLs: http://site.{one,two,three}.com
•Sequenze: ftp://ftp.numericals.com/file[1-100].txt
•Utilizzo di cookie, proxy

Apache Tika
•Strumento di knowledge management •Estrattore di metadati da documenti testuali •Se i metadati sono assenti o non rispettano metriche di qualità come quelle del Dublin Core Metadata vengono utilizzate tecniche di text mining per estrarre i metadati direttamente dal contenuto del documento
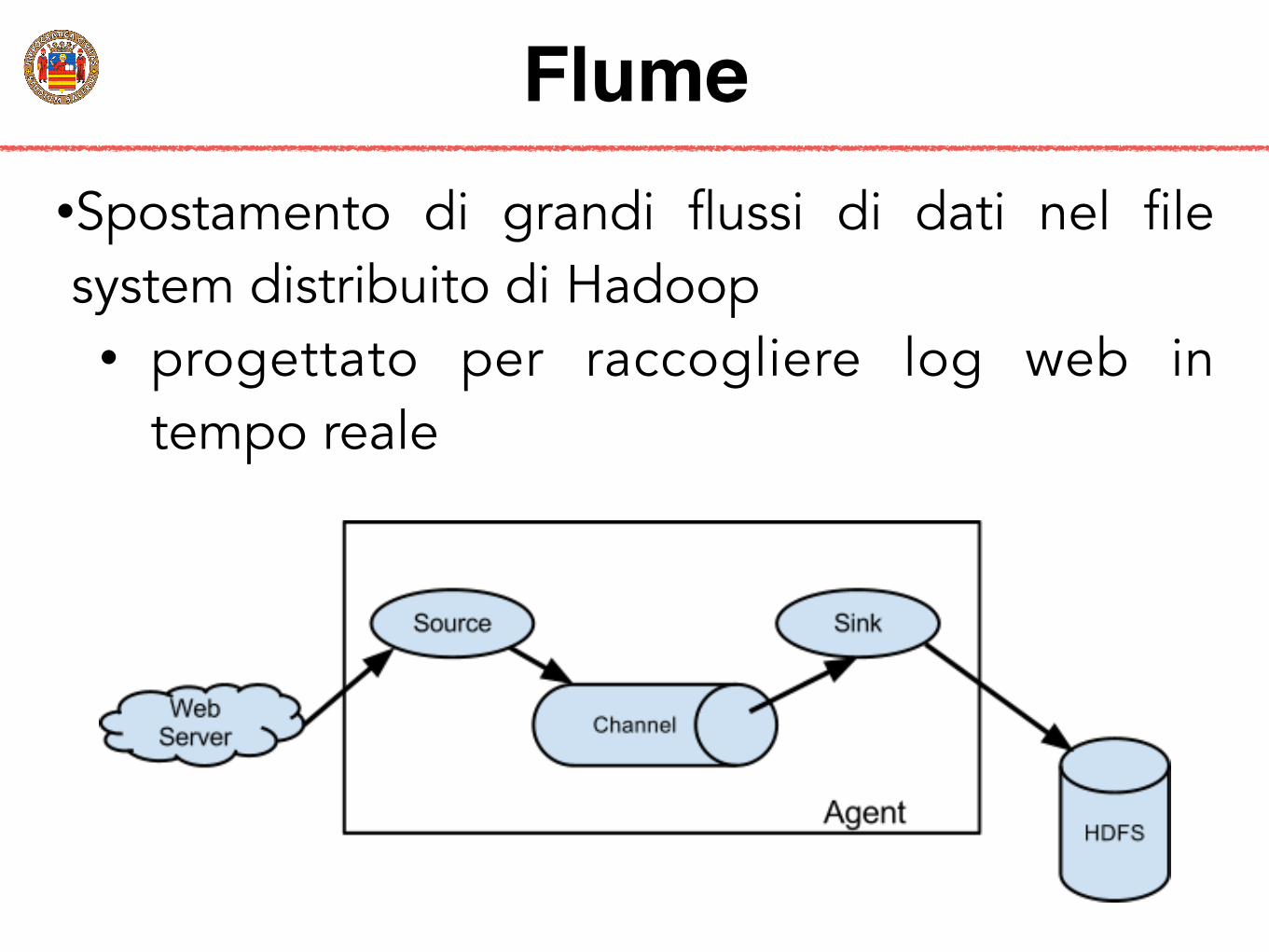
Flume•Spostamento di grandi flussi di dati nel file system distribuito di Hadoop
• progettato per raccogliere log web in tempo reale
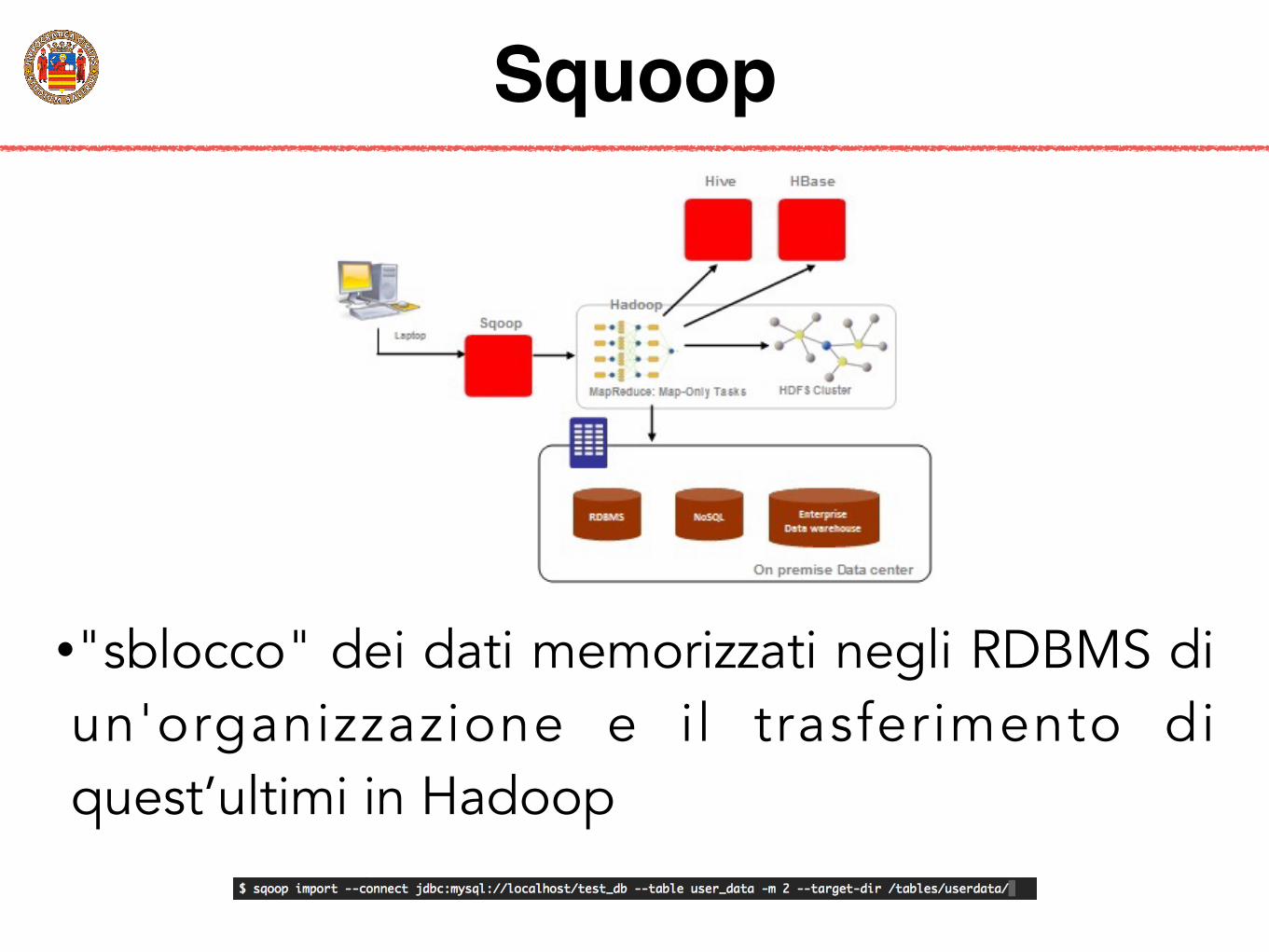
Squoop
•"sblocco" dei dati memorizzati negli RDBMS di un'organizzazione e il trasferimento di quest’ultimi in Hadoop

• Tecnologia per interrogare i Big Data come se fossero tabelle SQL
• HiveQL • Produce in modo trasparente software MapReduce • Inizialmente sviluppato da Facebook • Data presentation layer
• Come Hive, ma utilizza come linguaggio di alto livello Pig Latin
• Data preparation layer
Hive and Pig


Why SQL?•Schema predefinito per lo storage di dati strutturati •Struttura BCNF già familiare •Strong consistency •Transazioni •Maturi e accuratamente testati •Basati sulle proprietà ACID •Data Retrieval: Standard Query Language (SQL) - versatile e potente
•Scalabilità verticale: se volessimo rendere un DB SQL scalabile, l’unica alternativa sarebbe quella di potenziare l’hardware sul quale il DBMS è installato
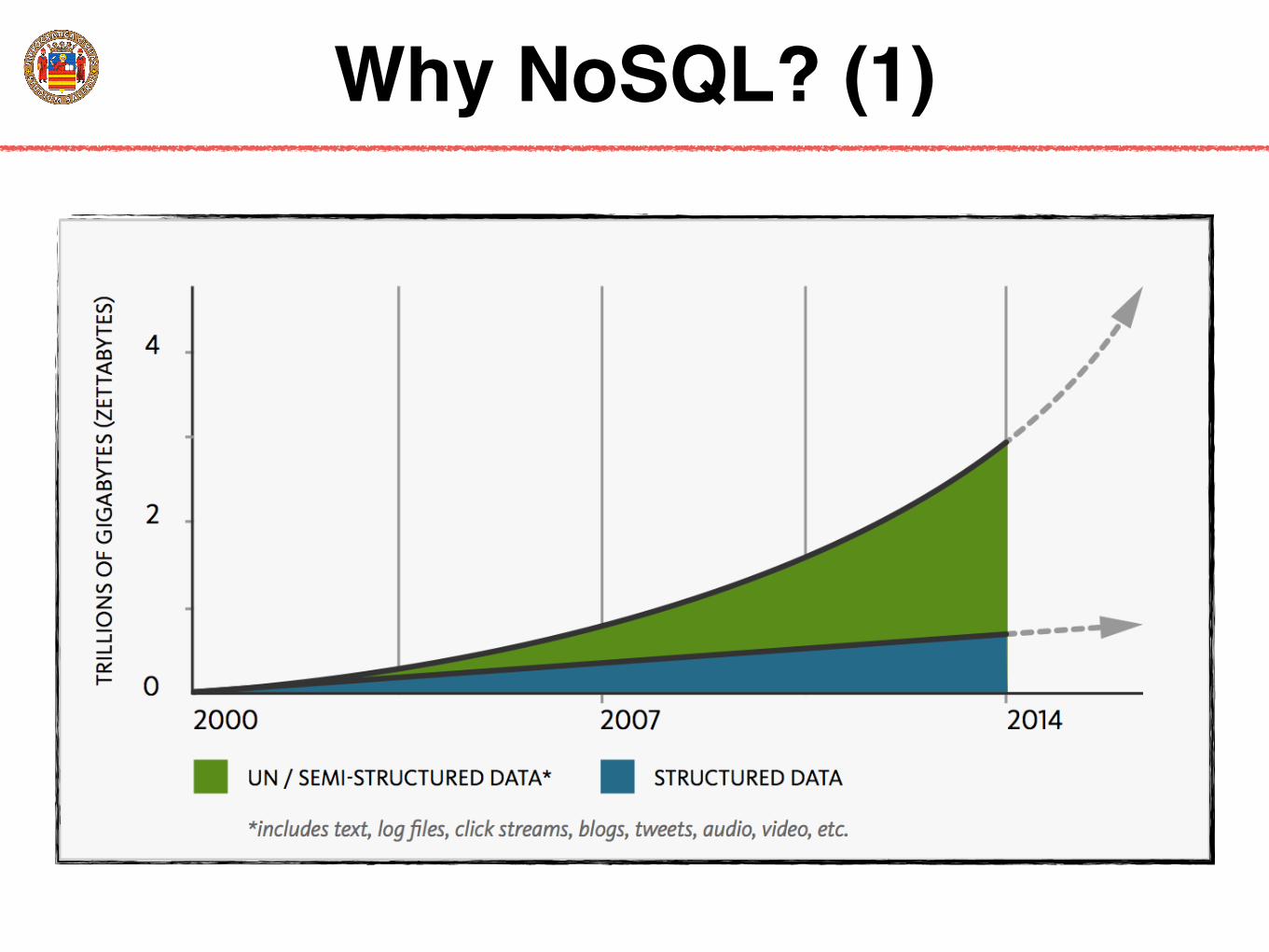
Why NoSQL? (1)

Why NoSQL? (2)
• Non relazionali: l’approccio rigido dei db relazionali non permette di memorizzare dati fortemente dinamici. I db NoSQL sono “schemaless” e consentono di memorizzare “on the fly” attributi, anche senza averli definiti a priori
• Distribuiti: la flessibilità nella clusterizzazione e nella replicazione dei dati permette di distribuire su più nodi lo storage, in modo da realizzare potenti sistemi “fault tollerance”
• Scalabili orizzontalmente: in contrapposizione alla scalabilità verticale, abbiamo architetture enormemente scalabili, che consentono di memorizzare e gestire una grande quantità di informazioni
• Open-source: filosofia alla base del movimento NoSQL
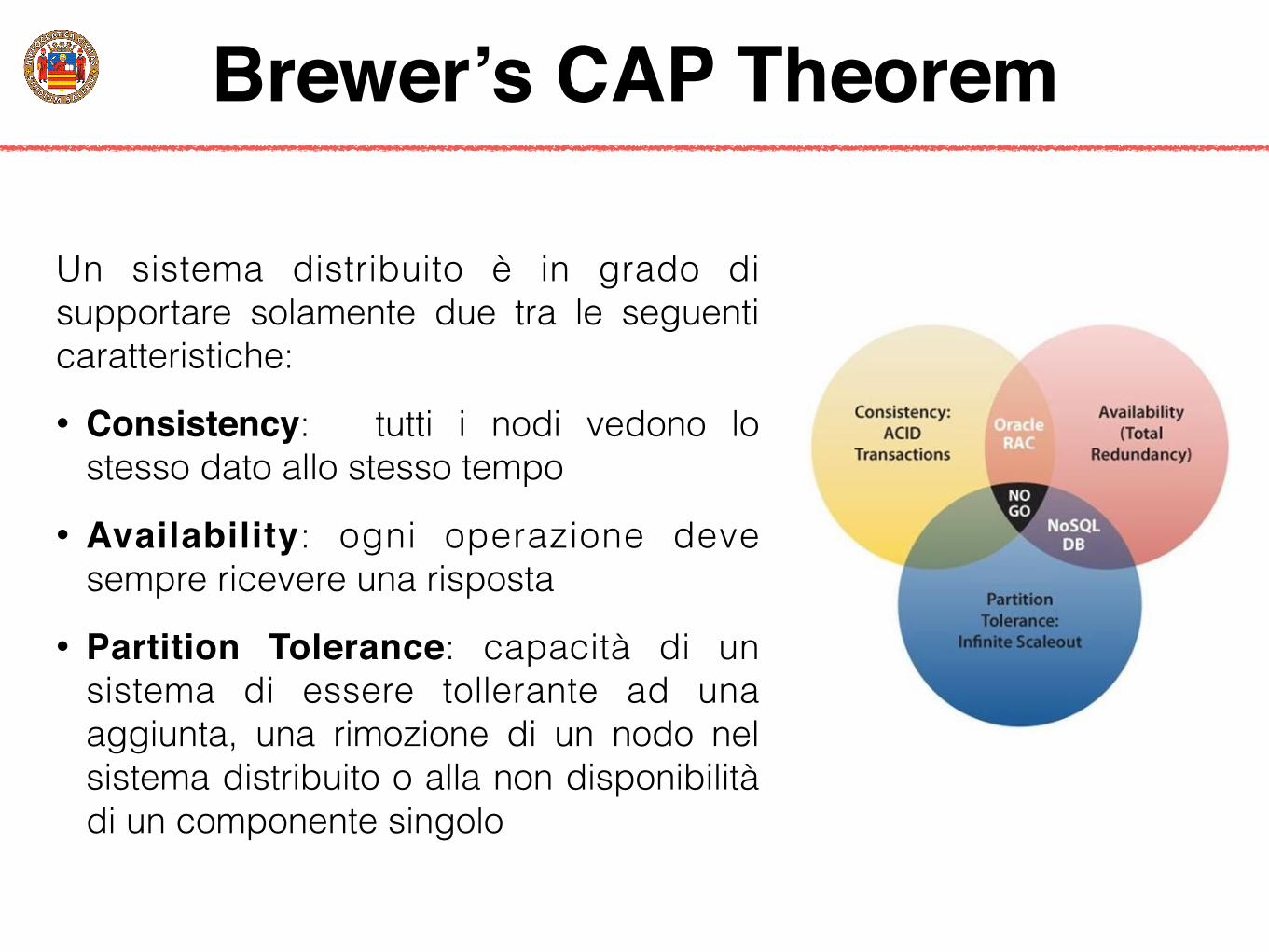
Brewer’s CAP Theorem
Un sistema distribuito è in grado di supportare solamente due tra le seguenti caratteristiche:
• Consistency: tutti i nodi vedono lo stesso dato allo stesso tempo
• Availability: ogni operazione deve sempre ricevere una risposta
• Partition Tolerance: capacità di un sistema di essere tollerante ad una aggiunta, una rimozione di un nodo nel sistema distribuito o alla non disponibilità di un componente singolo

Logica Base
• I database di tipo NoSQL, per poter essere scalabili come richiesto, devono sacrificare delle proprietà e dunque non possono in alcun modo aderire strettamente al modello ACID
• Logica operazionale BASE: • Basically Available: garantire sempre la disponibilità dei dati. • Soft-state: il sistema può cambiare lo stato anche se non si verificano scritture o letture
• Eventual consistency: la consistenza può essere raggiunta nel tempo.


NoSQL categoriesKEY-VALUE DATA STORE
• Utilizza un associative array (chiave-valore) come modello fondamentale per lo storage
• Storage, update e ricerca basato sulle chiavi
• Tipi di dati primitivi familiari ai programmatori
• Semplice
• Veloce recupero dei dati
• Grandi moli di dati
DOCUMENT DATA STORE
• Supporto a diversi tipi di documento
• Un documento è identificato da una chiave primaria
• Schema-less
• Scalabilità orizzontale
COLUMN-ORIENTED DATA STORE
• I dati sono nelle colonne anziché nelle righe
• Un gruppo di colonne è chiamato famiglia ed vi è un’analogia con le tabelle di un database relazionale
• Le colonne possono essere facilmente distribuite
• Scalabile
• Performante
• Fault-tollerance
GRAPH-BASED DATA STORE
• Utilizza nodi (entità), proprietà (attributi) e archi (relazioni)
• Modello logico semplice e intuitivo
• Ogni elemento contiene un puntatore all’elemento adiacente
• Attraversamento del grafo per trovare i dati
• Efficiente per la rappresentazione di reti sociali o dati sparsi
• Relazioni tra i dati centrali
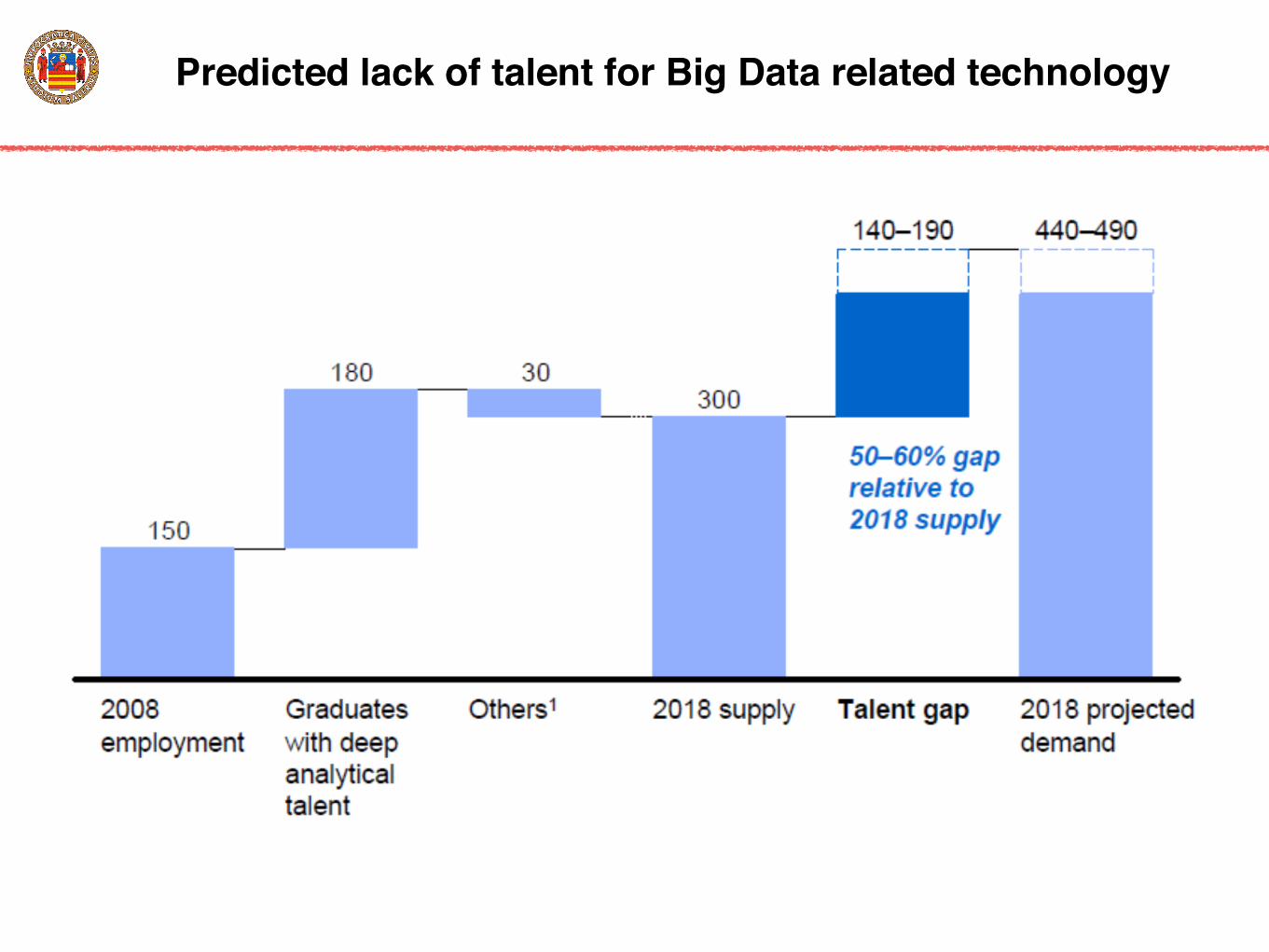
Predicted lack of talent for Big Data related technology