Personenidenti¯kation mittels Principal Component Analysis ...
101
JOHANNES KEPLER UNIVERSIT ¨ AT LINZ Netzwerk f¨ ur Forschung, Lehre und Praxis Personenidentifikation mittels Principal Component Analysis von Irisbildern Diplomarbeit zur Erlangung des akademischen Grades Diplomingenieur in der Studienrichtung Informatik Angefertigt am Institut f¨ ur Computational Perception Betreuung: a. Univ.-Prof. Dr. Josef Scharinger Eingereicht von: Matthias Schmidl Linz, 03/2005 Johannes Kepler Universit¨ at A-4040 Linz · Altenbergerstraße 69 · Internet: http://www.uni-linz.ac.at · DVR 0093696
Transcript of Personenidenti¯kation mittels Principal Component Analysis ...

JO H AN N E S KE P LE RUN IV E R S I T AT L I NZ
Ne t z w e r k f u r F o r s c h u n g L e h r e u n d P r a x i s
Personenidentifikation mittelsPrincipal Component Analysis
von Irisbildern
Diplomarbeit
zur Erlangung des akademischen Grades
Diplomingenieur
in der Studienrichtung
Informatik
Angefertigt am Institut fur Computational Perception
Betreuung
a Univ-Prof Dr Josef Scharinger
Eingereicht von
Matthias Schmidl
Linz 032005
Johannes Kepler UniversitatA-4040 Linz middot Altenbergerstraszlige 69 middot Internet httpwwwuni-linzacat middot DVR 0093696
Danksagung
Mein Dank ergeht an
a Univ Prof Dr Josef Scharinger dafur dass ich dieses Thema mit seinerUnterstutzung bearbeiten durfte
Meine Eltern
Meine Korrekturleserin OSTR Mag Evelyn Girtler
Alle Freiwilligen die sich als Testpersonen zur Verfugung gestellt haben
Elisabeth Baldauf Lukas Baldauf Martin Gotthartsleitner Christian HacklPatrick Haruksteiner Ingo Horejs Eva Horitzauer Thomas KockerbauerClemens Kogler Gabriel Kronberger Dipl Ing (FH) Stefan Leitner SigridLimberger Gerald Lindinger David Mitterhuber Lukas Oberdammer Do-minik Punz Mag Claudia Schmidl Dipl Ing Gunther Schmidl Prim DrJorg Schmidl Petra Thon Christian Watzl Norbert Watzl Johannes Zarl
Teile dieser Arbeit verwenden die CASIA Iris Bilder Datenbank die vomInstitute of Automation Chinese Academy of Sciences zusammengestelltwurde
3
Zusammenfassung
Biometrische Identifikation durch Vermessen der Iris ist ein erfolgreicher An-satz zur biometrischen Identifikation der derzeit faktisch nur uber Extrak-tion von Merkmalen basierend auf Gabor-Wavelets realisiert wird (und indieser Form durch existierende Patente abgedeckt ist) Marktbeherrschendsind Systeme die nach John Daugmans Methode des Iris Codes funktionie-ren1
Obwohl diese sehr gute Erkennungsraten bei gleichzeitig hoher Geschwindig-keit aufweisen ware ein System das mit einem nicht patentierten Verfahrenarbeitet als frei zugangliche Alternative interessant und wunschenswert Indieser Arbeit soll also untersucht werden wie gut die Principal ComponentAnalysis (PCA) als Alternative zur Merkmalsextraktion basierend auf Ga-bor Wavelets fur solche Aufgaben genutzt werden kann
Im Verlauf des Textes wird die Entwicklung eines biometrischen Systemsgegliedert in seine wichtigsten Einzelkomponenten - wie Techniken zur Bild-aufnahme Bildverbesserungsmaszlignahmen Segmentierung und Lokalisierungund schlieszliglich die Principal Component Analysis - beschrieben und eineabschlieszligende Bewertung gegeben
1rdquoHow Iris Recognition Worksrdquo by J Daugman
5
Abstract
Biometric identification based on iris measurements is a successful approachfor biometric identification which is at the time practically only accom-pished by means of feature extraction via Gabor-Wavelets (and in this formcovered by existing patents) Dominating the market are systems using JohnDaugmanrsquos Iris Code2
Even though these systems combine high recognition rates with high recogni-tion speed a system not using patented technologies whould be interestingand desireable as a freely available alternative This work examines inhowfarthe Principal Component Analysis (PCA) is suitable as an alternative to fea-ture extraction via Gabor Wavelets
Throughout this work the design of a biometric system divided into itsmost important components - like image acqusition image emhancementsegmentation localisation and finally the Principal Component Analysis -is decribed and the performance evaluated
2rdquoHow Iris Recognition Worksrdquo by J Daugman
7
Inhaltsverzeichnis
1 Einleitung 1511 Biometrische Systeme 1512 Die menschliche Iris 1613 Iriserkennungssysteme 1814 Aufgabenstellung 19
2 Bildaufnahme 2121 Uberblick 2122 Implementierung 2123 Qualitatskriterien 22
3 Vorverarbeitung 2531 Uberblick 2532 Reflexionen entfernen 2533 Medianfilter 2734 Histogramm strecken 2735 Kantenerkennung 2836 Augenlider entfernen 2937 Histogram Equalization 29
4 Normalisierung 3341 Uberblick 3342 Lokalisierung von Iris und Pupille 3343 Circular Hough Transformation 3444 Segmentierung 37
5 Principal Component Analysis 4151 Uberblick 4152 Herleitung 4353 Implementierung 4654 Beispiel 47
9
10 INHALTSVERZEICHNIS
6 Klassifizierung 5161 Uberblick 5162 Methoden zur Abstandsberechnung 51
7 Systembeschreibung 5571 Uberblick 5572 Implementierung 5573 Datenspeicherung 55
8 Experimentelle Ergebnisse 5981 Uberblick 5982 Maszligzahlen zur Bewertung 5983 Testdaten 6384 Parametertests 64
841 Abmessungen des Irisstreifen 66842 Abmessungen der Uberdeckungen fur Augenlider 67843 Anzahl der Shifts 68844 Anzahl der Augen furs Enrollment 70845 Anzahl der verwendeten Eigenvektoren 71
85 Zusammenfassung 72
9 Abschluss 7791 Zusammenfassung 7792 Erkenntnisse aus der Arbeit 7893 Zukunftige Arbeit 80
A Tabellen und Diagramme 83
Lebenslauf 97
Eidesstattliche Erklarung 99
Kolophon 101
Abbildungsverzeichnis
11 Das menschliche Auge 17
21 Lims System zur Bildaufnahme [Lim01] 22
31 Ablauf der Vorverarbeitung Lokalisierung und Segmentierung 2632 Histogramm vor und nach Streckung 3133 Ergebnis der Kantendetektion 3134 Irisstreifen mit ausgeschnittenem Bereich 3135 Ergebniss der Histogramm Equalization 31
41 Parameterraum bei der Circular Hough Transformation [You04] 3542 Circular Hough Transformation unter Verwendung der Gra-
dienten Information 3643 Rubber-Sheet Transformation 38
51 Beispiel fur Eigeniriden 43
61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz 52
71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten 56
72 Das Datenmodell zur Speicherung der Benutzerdaten 57
81 False Acceptance Rate und False Rejection Rate 6182 Equal Error Rate 6383 Einige Beispielbilder aus der CASIA Datenbank 6584 Intraclass-Verteilung ohne Shifts 6985 Intraclass-Verteilung mit 2 Shifts 6986 Prozent der Gesamtvarianz die durch die einzelnen Eigen-
vektoren erklart wird 7187 Verlauf von FAR und FRR bei verschiedenen Schwellwerten 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
11
12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
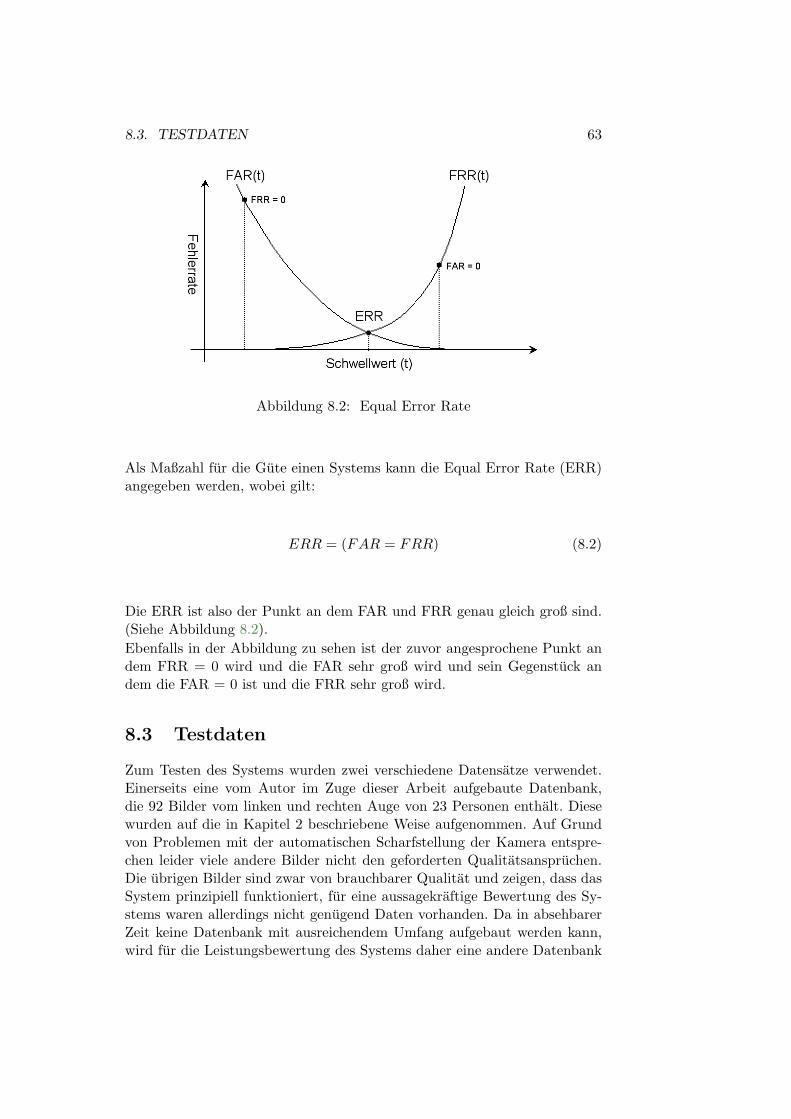
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Danksagung
Mein Dank ergeht an
a Univ Prof Dr Josef Scharinger dafur dass ich dieses Thema mit seinerUnterstutzung bearbeiten durfte
Meine Eltern
Meine Korrekturleserin OSTR Mag Evelyn Girtler
Alle Freiwilligen die sich als Testpersonen zur Verfugung gestellt haben
Elisabeth Baldauf Lukas Baldauf Martin Gotthartsleitner Christian HacklPatrick Haruksteiner Ingo Horejs Eva Horitzauer Thomas KockerbauerClemens Kogler Gabriel Kronberger Dipl Ing (FH) Stefan Leitner SigridLimberger Gerald Lindinger David Mitterhuber Lukas Oberdammer Do-minik Punz Mag Claudia Schmidl Dipl Ing Gunther Schmidl Prim DrJorg Schmidl Petra Thon Christian Watzl Norbert Watzl Johannes Zarl
Teile dieser Arbeit verwenden die CASIA Iris Bilder Datenbank die vomInstitute of Automation Chinese Academy of Sciences zusammengestelltwurde
3
Zusammenfassung
Biometrische Identifikation durch Vermessen der Iris ist ein erfolgreicher An-satz zur biometrischen Identifikation der derzeit faktisch nur uber Extrak-tion von Merkmalen basierend auf Gabor-Wavelets realisiert wird (und indieser Form durch existierende Patente abgedeckt ist) Marktbeherrschendsind Systeme die nach John Daugmans Methode des Iris Codes funktionie-ren1
Obwohl diese sehr gute Erkennungsraten bei gleichzeitig hoher Geschwindig-keit aufweisen ware ein System das mit einem nicht patentierten Verfahrenarbeitet als frei zugangliche Alternative interessant und wunschenswert Indieser Arbeit soll also untersucht werden wie gut die Principal ComponentAnalysis (PCA) als Alternative zur Merkmalsextraktion basierend auf Ga-bor Wavelets fur solche Aufgaben genutzt werden kann
Im Verlauf des Textes wird die Entwicklung eines biometrischen Systemsgegliedert in seine wichtigsten Einzelkomponenten - wie Techniken zur Bild-aufnahme Bildverbesserungsmaszlignahmen Segmentierung und Lokalisierungund schlieszliglich die Principal Component Analysis - beschrieben und eineabschlieszligende Bewertung gegeben
1rdquoHow Iris Recognition Worksrdquo by J Daugman
5
Abstract
Biometric identification based on iris measurements is a successful approachfor biometric identification which is at the time practically only accom-pished by means of feature extraction via Gabor-Wavelets (and in this formcovered by existing patents) Dominating the market are systems using JohnDaugmanrsquos Iris Code2
Even though these systems combine high recognition rates with high recogni-tion speed a system not using patented technologies whould be interestingand desireable as a freely available alternative This work examines inhowfarthe Principal Component Analysis (PCA) is suitable as an alternative to fea-ture extraction via Gabor Wavelets
Throughout this work the design of a biometric system divided into itsmost important components - like image acqusition image emhancementsegmentation localisation and finally the Principal Component Analysis -is decribed and the performance evaluated
2rdquoHow Iris Recognition Worksrdquo by J Daugman
7
Inhaltsverzeichnis
1 Einleitung 1511 Biometrische Systeme 1512 Die menschliche Iris 1613 Iriserkennungssysteme 1814 Aufgabenstellung 19
2 Bildaufnahme 2121 Uberblick 2122 Implementierung 2123 Qualitatskriterien 22
3 Vorverarbeitung 2531 Uberblick 2532 Reflexionen entfernen 2533 Medianfilter 2734 Histogramm strecken 2735 Kantenerkennung 2836 Augenlider entfernen 2937 Histogram Equalization 29
4 Normalisierung 3341 Uberblick 3342 Lokalisierung von Iris und Pupille 3343 Circular Hough Transformation 3444 Segmentierung 37
5 Principal Component Analysis 4151 Uberblick 4152 Herleitung 4353 Implementierung 4654 Beispiel 47
9
10 INHALTSVERZEICHNIS
6 Klassifizierung 5161 Uberblick 5162 Methoden zur Abstandsberechnung 51
7 Systembeschreibung 5571 Uberblick 5572 Implementierung 5573 Datenspeicherung 55
8 Experimentelle Ergebnisse 5981 Uberblick 5982 Maszligzahlen zur Bewertung 5983 Testdaten 6384 Parametertests 64
841 Abmessungen des Irisstreifen 66842 Abmessungen der Uberdeckungen fur Augenlider 67843 Anzahl der Shifts 68844 Anzahl der Augen furs Enrollment 70845 Anzahl der verwendeten Eigenvektoren 71
85 Zusammenfassung 72
9 Abschluss 7791 Zusammenfassung 7792 Erkenntnisse aus der Arbeit 7893 Zukunftige Arbeit 80
A Tabellen und Diagramme 83
Lebenslauf 97
Eidesstattliche Erklarung 99
Kolophon 101
Abbildungsverzeichnis
11 Das menschliche Auge 17
21 Lims System zur Bildaufnahme [Lim01] 22
31 Ablauf der Vorverarbeitung Lokalisierung und Segmentierung 2632 Histogramm vor und nach Streckung 3133 Ergebnis der Kantendetektion 3134 Irisstreifen mit ausgeschnittenem Bereich 3135 Ergebniss der Histogramm Equalization 31
41 Parameterraum bei der Circular Hough Transformation [You04] 3542 Circular Hough Transformation unter Verwendung der Gra-
dienten Information 3643 Rubber-Sheet Transformation 38
51 Beispiel fur Eigeniriden 43
61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz 52
71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten 56
72 Das Datenmodell zur Speicherung der Benutzerdaten 57
81 False Acceptance Rate und False Rejection Rate 6182 Equal Error Rate 6383 Einige Beispielbilder aus der CASIA Datenbank 6584 Intraclass-Verteilung ohne Shifts 6985 Intraclass-Verteilung mit 2 Shifts 6986 Prozent der Gesamtvarianz die durch die einzelnen Eigen-
vektoren erklart wird 7187 Verlauf von FAR und FRR bei verschiedenen Schwellwerten 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
11
12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Zusammenfassung
Biometrische Identifikation durch Vermessen der Iris ist ein erfolgreicher An-satz zur biometrischen Identifikation der derzeit faktisch nur uber Extrak-tion von Merkmalen basierend auf Gabor-Wavelets realisiert wird (und indieser Form durch existierende Patente abgedeckt ist) Marktbeherrschendsind Systeme die nach John Daugmans Methode des Iris Codes funktionie-ren1
Obwohl diese sehr gute Erkennungsraten bei gleichzeitig hoher Geschwindig-keit aufweisen ware ein System das mit einem nicht patentierten Verfahrenarbeitet als frei zugangliche Alternative interessant und wunschenswert Indieser Arbeit soll also untersucht werden wie gut die Principal ComponentAnalysis (PCA) als Alternative zur Merkmalsextraktion basierend auf Ga-bor Wavelets fur solche Aufgaben genutzt werden kann
Im Verlauf des Textes wird die Entwicklung eines biometrischen Systemsgegliedert in seine wichtigsten Einzelkomponenten - wie Techniken zur Bild-aufnahme Bildverbesserungsmaszlignahmen Segmentierung und Lokalisierungund schlieszliglich die Principal Component Analysis - beschrieben und eineabschlieszligende Bewertung gegeben
1rdquoHow Iris Recognition Worksrdquo by J Daugman
5
Abstract
Biometric identification based on iris measurements is a successful approachfor biometric identification which is at the time practically only accom-pished by means of feature extraction via Gabor-Wavelets (and in this formcovered by existing patents) Dominating the market are systems using JohnDaugmanrsquos Iris Code2
Even though these systems combine high recognition rates with high recogni-tion speed a system not using patented technologies whould be interestingand desireable as a freely available alternative This work examines inhowfarthe Principal Component Analysis (PCA) is suitable as an alternative to fea-ture extraction via Gabor Wavelets
Throughout this work the design of a biometric system divided into itsmost important components - like image acqusition image emhancementsegmentation localisation and finally the Principal Component Analysis -is decribed and the performance evaluated
2rdquoHow Iris Recognition Worksrdquo by J Daugman
7
Inhaltsverzeichnis
1 Einleitung 1511 Biometrische Systeme 1512 Die menschliche Iris 1613 Iriserkennungssysteme 1814 Aufgabenstellung 19
2 Bildaufnahme 2121 Uberblick 2122 Implementierung 2123 Qualitatskriterien 22
3 Vorverarbeitung 2531 Uberblick 2532 Reflexionen entfernen 2533 Medianfilter 2734 Histogramm strecken 2735 Kantenerkennung 2836 Augenlider entfernen 2937 Histogram Equalization 29
4 Normalisierung 3341 Uberblick 3342 Lokalisierung von Iris und Pupille 3343 Circular Hough Transformation 3444 Segmentierung 37
5 Principal Component Analysis 4151 Uberblick 4152 Herleitung 4353 Implementierung 4654 Beispiel 47
9
10 INHALTSVERZEICHNIS
6 Klassifizierung 5161 Uberblick 5162 Methoden zur Abstandsberechnung 51
7 Systembeschreibung 5571 Uberblick 5572 Implementierung 5573 Datenspeicherung 55
8 Experimentelle Ergebnisse 5981 Uberblick 5982 Maszligzahlen zur Bewertung 5983 Testdaten 6384 Parametertests 64
841 Abmessungen des Irisstreifen 66842 Abmessungen der Uberdeckungen fur Augenlider 67843 Anzahl der Shifts 68844 Anzahl der Augen furs Enrollment 70845 Anzahl der verwendeten Eigenvektoren 71
85 Zusammenfassung 72
9 Abschluss 7791 Zusammenfassung 7792 Erkenntnisse aus der Arbeit 7893 Zukunftige Arbeit 80
A Tabellen und Diagramme 83
Lebenslauf 97
Eidesstattliche Erklarung 99
Kolophon 101
Abbildungsverzeichnis
11 Das menschliche Auge 17
21 Lims System zur Bildaufnahme [Lim01] 22
31 Ablauf der Vorverarbeitung Lokalisierung und Segmentierung 2632 Histogramm vor und nach Streckung 3133 Ergebnis der Kantendetektion 3134 Irisstreifen mit ausgeschnittenem Bereich 3135 Ergebniss der Histogramm Equalization 31
41 Parameterraum bei der Circular Hough Transformation [You04] 3542 Circular Hough Transformation unter Verwendung der Gra-
dienten Information 3643 Rubber-Sheet Transformation 38
51 Beispiel fur Eigeniriden 43
61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz 52
71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten 56
72 Das Datenmodell zur Speicherung der Benutzerdaten 57
81 False Acceptance Rate und False Rejection Rate 6182 Equal Error Rate 6383 Einige Beispielbilder aus der CASIA Datenbank 6584 Intraclass-Verteilung ohne Shifts 6985 Intraclass-Verteilung mit 2 Shifts 6986 Prozent der Gesamtvarianz die durch die einzelnen Eigen-
vektoren erklart wird 7187 Verlauf von FAR und FRR bei verschiedenen Schwellwerten 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
11
12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Abstract
Biometric identification based on iris measurements is a successful approachfor biometric identification which is at the time practically only accom-pished by means of feature extraction via Gabor-Wavelets (and in this formcovered by existing patents) Dominating the market are systems using JohnDaugmanrsquos Iris Code2
Even though these systems combine high recognition rates with high recogni-tion speed a system not using patented technologies whould be interestingand desireable as a freely available alternative This work examines inhowfarthe Principal Component Analysis (PCA) is suitable as an alternative to fea-ture extraction via Gabor Wavelets
Throughout this work the design of a biometric system divided into itsmost important components - like image acqusition image emhancementsegmentation localisation and finally the Principal Component Analysis -is decribed and the performance evaluated
2rdquoHow Iris Recognition Worksrdquo by J Daugman
7
Inhaltsverzeichnis
1 Einleitung 1511 Biometrische Systeme 1512 Die menschliche Iris 1613 Iriserkennungssysteme 1814 Aufgabenstellung 19
2 Bildaufnahme 2121 Uberblick 2122 Implementierung 2123 Qualitatskriterien 22
3 Vorverarbeitung 2531 Uberblick 2532 Reflexionen entfernen 2533 Medianfilter 2734 Histogramm strecken 2735 Kantenerkennung 2836 Augenlider entfernen 2937 Histogram Equalization 29
4 Normalisierung 3341 Uberblick 3342 Lokalisierung von Iris und Pupille 3343 Circular Hough Transformation 3444 Segmentierung 37
5 Principal Component Analysis 4151 Uberblick 4152 Herleitung 4353 Implementierung 4654 Beispiel 47
9
10 INHALTSVERZEICHNIS
6 Klassifizierung 5161 Uberblick 5162 Methoden zur Abstandsberechnung 51
7 Systembeschreibung 5571 Uberblick 5572 Implementierung 5573 Datenspeicherung 55
8 Experimentelle Ergebnisse 5981 Uberblick 5982 Maszligzahlen zur Bewertung 5983 Testdaten 6384 Parametertests 64
841 Abmessungen des Irisstreifen 66842 Abmessungen der Uberdeckungen fur Augenlider 67843 Anzahl der Shifts 68844 Anzahl der Augen furs Enrollment 70845 Anzahl der verwendeten Eigenvektoren 71
85 Zusammenfassung 72
9 Abschluss 7791 Zusammenfassung 7792 Erkenntnisse aus der Arbeit 7893 Zukunftige Arbeit 80
A Tabellen und Diagramme 83
Lebenslauf 97
Eidesstattliche Erklarung 99
Kolophon 101
Abbildungsverzeichnis
11 Das menschliche Auge 17
21 Lims System zur Bildaufnahme [Lim01] 22
31 Ablauf der Vorverarbeitung Lokalisierung und Segmentierung 2632 Histogramm vor und nach Streckung 3133 Ergebnis der Kantendetektion 3134 Irisstreifen mit ausgeschnittenem Bereich 3135 Ergebniss der Histogramm Equalization 31
41 Parameterraum bei der Circular Hough Transformation [You04] 3542 Circular Hough Transformation unter Verwendung der Gra-
dienten Information 3643 Rubber-Sheet Transformation 38
51 Beispiel fur Eigeniriden 43
61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz 52
71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten 56
72 Das Datenmodell zur Speicherung der Benutzerdaten 57
81 False Acceptance Rate und False Rejection Rate 6182 Equal Error Rate 6383 Einige Beispielbilder aus der CASIA Datenbank 6584 Intraclass-Verteilung ohne Shifts 6985 Intraclass-Verteilung mit 2 Shifts 6986 Prozent der Gesamtvarianz die durch die einzelnen Eigen-
vektoren erklart wird 7187 Verlauf von FAR und FRR bei verschiedenen Schwellwerten 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
11
12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Inhaltsverzeichnis
1 Einleitung 1511 Biometrische Systeme 1512 Die menschliche Iris 1613 Iriserkennungssysteme 1814 Aufgabenstellung 19
2 Bildaufnahme 2121 Uberblick 2122 Implementierung 2123 Qualitatskriterien 22
3 Vorverarbeitung 2531 Uberblick 2532 Reflexionen entfernen 2533 Medianfilter 2734 Histogramm strecken 2735 Kantenerkennung 2836 Augenlider entfernen 2937 Histogram Equalization 29
4 Normalisierung 3341 Uberblick 3342 Lokalisierung von Iris und Pupille 3343 Circular Hough Transformation 3444 Segmentierung 37
5 Principal Component Analysis 4151 Uberblick 4152 Herleitung 4353 Implementierung 4654 Beispiel 47
9
10 INHALTSVERZEICHNIS
6 Klassifizierung 5161 Uberblick 5162 Methoden zur Abstandsberechnung 51
7 Systembeschreibung 5571 Uberblick 5572 Implementierung 5573 Datenspeicherung 55
8 Experimentelle Ergebnisse 5981 Uberblick 5982 Maszligzahlen zur Bewertung 5983 Testdaten 6384 Parametertests 64
841 Abmessungen des Irisstreifen 66842 Abmessungen der Uberdeckungen fur Augenlider 67843 Anzahl der Shifts 68844 Anzahl der Augen furs Enrollment 70845 Anzahl der verwendeten Eigenvektoren 71
85 Zusammenfassung 72
9 Abschluss 7791 Zusammenfassung 7792 Erkenntnisse aus der Arbeit 7893 Zukunftige Arbeit 80
A Tabellen und Diagramme 83
Lebenslauf 97
Eidesstattliche Erklarung 99
Kolophon 101
Abbildungsverzeichnis
11 Das menschliche Auge 17
21 Lims System zur Bildaufnahme [Lim01] 22
31 Ablauf der Vorverarbeitung Lokalisierung und Segmentierung 2632 Histogramm vor und nach Streckung 3133 Ergebnis der Kantendetektion 3134 Irisstreifen mit ausgeschnittenem Bereich 3135 Ergebniss der Histogramm Equalization 31
41 Parameterraum bei der Circular Hough Transformation [You04] 3542 Circular Hough Transformation unter Verwendung der Gra-
dienten Information 3643 Rubber-Sheet Transformation 38
51 Beispiel fur Eigeniriden 43
61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz 52
71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten 56
72 Das Datenmodell zur Speicherung der Benutzerdaten 57
81 False Acceptance Rate und False Rejection Rate 6182 Equal Error Rate 6383 Einige Beispielbilder aus der CASIA Datenbank 6584 Intraclass-Verteilung ohne Shifts 6985 Intraclass-Verteilung mit 2 Shifts 6986 Prozent der Gesamtvarianz die durch die einzelnen Eigen-
vektoren erklart wird 7187 Verlauf von FAR und FRR bei verschiedenen Schwellwerten 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
11
12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

10 INHALTSVERZEICHNIS
6 Klassifizierung 5161 Uberblick 5162 Methoden zur Abstandsberechnung 51
7 Systembeschreibung 5571 Uberblick 5572 Implementierung 5573 Datenspeicherung 55
8 Experimentelle Ergebnisse 5981 Uberblick 5982 Maszligzahlen zur Bewertung 5983 Testdaten 6384 Parametertests 64
841 Abmessungen des Irisstreifen 66842 Abmessungen der Uberdeckungen fur Augenlider 67843 Anzahl der Shifts 68844 Anzahl der Augen furs Enrollment 70845 Anzahl der verwendeten Eigenvektoren 71
85 Zusammenfassung 72
9 Abschluss 7791 Zusammenfassung 7792 Erkenntnisse aus der Arbeit 7893 Zukunftige Arbeit 80
A Tabellen und Diagramme 83
Lebenslauf 97
Eidesstattliche Erklarung 99
Kolophon 101
Abbildungsverzeichnis
11 Das menschliche Auge 17
21 Lims System zur Bildaufnahme [Lim01] 22
31 Ablauf der Vorverarbeitung Lokalisierung und Segmentierung 2632 Histogramm vor und nach Streckung 3133 Ergebnis der Kantendetektion 3134 Irisstreifen mit ausgeschnittenem Bereich 3135 Ergebniss der Histogramm Equalization 31
41 Parameterraum bei der Circular Hough Transformation [You04] 3542 Circular Hough Transformation unter Verwendung der Gra-
dienten Information 3643 Rubber-Sheet Transformation 38
51 Beispiel fur Eigeniriden 43
61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz 52
71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten 56
72 Das Datenmodell zur Speicherung der Benutzerdaten 57
81 False Acceptance Rate und False Rejection Rate 6182 Equal Error Rate 6383 Einige Beispielbilder aus der CASIA Datenbank 6584 Intraclass-Verteilung ohne Shifts 6985 Intraclass-Verteilung mit 2 Shifts 6986 Prozent der Gesamtvarianz die durch die einzelnen Eigen-
vektoren erklart wird 7187 Verlauf von FAR und FRR bei verschiedenen Schwellwerten 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
11
12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Abbildungsverzeichnis
11 Das menschliche Auge 17
21 Lims System zur Bildaufnahme [Lim01] 22
31 Ablauf der Vorverarbeitung Lokalisierung und Segmentierung 2632 Histogramm vor und nach Streckung 3133 Ergebnis der Kantendetektion 3134 Irisstreifen mit ausgeschnittenem Bereich 3135 Ergebniss der Histogramm Equalization 31
41 Parameterraum bei der Circular Hough Transformation [You04] 3542 Circular Hough Transformation unter Verwendung der Gra-
dienten Information 3643 Rubber-Sheet Transformation 38
51 Beispiel fur Eigeniriden 43
61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz 52
71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten 56
72 Das Datenmodell zur Speicherung der Benutzerdaten 57
81 False Acceptance Rate und False Rejection Rate 6182 Equal Error Rate 6383 Einige Beispielbilder aus der CASIA Datenbank 6584 Intraclass-Verteilung ohne Shifts 6985 Intraclass-Verteilung mit 2 Shifts 6986 Prozent der Gesamtvarianz die durch die einzelnen Eigen-
vektoren erklart wird 7187 Verlauf von FAR und FRR bei verschiedenen Schwellwerten 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
11
12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

12 ABBILDUNGSVERZEICHNIS
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shifts beioptimalen Parametersetzungen 90
A8 Intraclass-Standardabweichung bei verschiedener Anzahl vonShifts bei optimalen Parametersetzungen 90
A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen 92
Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Tabellenverzeichnis
81 False Acceptance Rate und False Rejection Rate bei unter-schiedlichen Schwellwerten (EER ist in Fettdruck gekenn-zeichnet) 74
A1 Decidability bei einer groben Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 84
A2 Decidability bei einer feinen Suche nach den besten Abmes-sungen des Irisstreifens mit xul = 625 yul = 59 xol =20 yol = 95 ns = 2 pEV = 1 neyes = 1 85
A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 86
A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mitxxs = 340 yys = 170 xol = 20 yol = 95 ns = 2 pEV =1 neyes = 1 87
A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 88
A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mitxxs = 340 yys = 170 xul = 7 yul = 76 ns = 2 pEV =1 neyes = 1 89
A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszlig-zahlen bei optimalen Parametersetzungen 91
A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen 92
A9 Prozent der erklarten Varianz vs FRR und FAR bei optima-len Parametersetzungen 93
13
Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Kapitel 1
Einleitung
11 Biometrische Systeme
Traditionelle Systeme zur Identifikation von Personen beruhen entweder aufBesitz (Schlussel Ausweise etc) oder auf Wissen (Passworter PINs etc)Diese Methoden haben aber einige Probleme Schlussel konnen verloren ge-hen Ausweise gefalscht werden Passworter und Zahlencodes konnen hinge-gen vergessen oder ausspioniert werdenIm Gegensatz dazu ermoglicht es ein biometrisches System eine Person an-hand eines biologischen Merkmals zu erkennen Das Vergessen oder Ver-lieren scheidet unter normalen Umstanden als Fehlerquelle praktisch ausAuch wenn die Tauschung eines Systems durch Falschungen naturlich nichtausgeschlossen werden kann konnen die meisten biometrischen Systeme miteinfachen Mitteln gegen Missbrauch gesichert werden Biometrische Systemebieten also eine einerseits komfortable und andererseits sichere Alternativezur herkommlichen IdentifikationUbliche Erkennungsmerkmale sind zB Fingerabdrucke das Gesicht das Ve-nengeflecht der Retina Unterschriften die DNA Handgeometrie die Stim-me oder die Iris Es finden sich aber auch eher ungewohnliche Merkmale wiedie Gangart der Geruch einer Person oder die Struktur ihrer Ohren
Unabhangig davon welches Merkmal gewahlt wird ist bei allen biometri-schen Systemen der generelle Ablauf sehr ahnlich Als erster Schritt muss dasMerkmal in geeigneter Form aufgenommen werden In vielen Fallen wird einBild des Merkmals aufgenommen bei der Stimmerkennung wurde ein kurzergesprochener Text aufgenommen Anschlieszligend wird aus der Aufnahme einbiometrisches Template berechnet welches das Merkmal in einer stark dis-kriminierenden normalisierten und kompakten Art darstellt und es erlaubtdas Merkmal objektiv mit anderen zu vergleichen Ublicherweise arbeitenbiometrische Systeme in zwei unterschiedlichen Modi Einerseits existiertein Enrollment Modus in dem Personen neu in das System aufgenommen
15
16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

16 KAPITEL 1 EINLEITUNG
werden und andererseits ein Identifikationsmodus in dem das aktuelle Tem-plate mit den bekannten im System vorhanden verglichen wird und so eineIdentifikation stattfindet Der offensichtlich wichtigste Entscheid beim De-sign eines biometrischen System ist die Wahl eines geeigneten MerkmalsDie wichtigsten Kriterien sind im nachsten Absatz zusammengefasst
Ein gutes biometrisches Merkmal zeichnet sich durch verschiedene Eigen-schaften aus Es soll fur unterschiedliche Personen sehr stark verschiedenund einzigartig sein sodass die Chance dass zwei Personen die gleiche Aus-pragung des Merkmals aufweisen sehr klein ist Es soll stabil bleiben sichalso im Verlauf der Zeit nicht wesentlich verandern Weiters soll es nichtmoglich sein das System mit einer Falschung zu tauschen Auszligerdem solldas Merkmal schnell und einfach aufgenommen werden konnen damit dieErkennung nicht unangenehm fur den Benutzer ist
12 Die menschliche Iris
Der Augapfel wird von auszligen nach innen von der Lederhaut der Aderhautund der Netzhaut umgeben Die Lederhaut geht an der Vorderseite des Au-ges in die durchsichtige Hornhaut uber In der Mitte des Auges unter derHornhaut befindet sich die Iris (Regenbogenhaut) Sie liegt ringformig aufder Linse des Auges auf und umschlieszligt so die Pupille In der Iris eingelager-te Pigmente geben dem Auge seine charakteristische Farbung Durch feineMuskel kann die Groszlige der Iris und somit der Lichteinfall ins Auge geregeltwerden was die Hauptaufgabe der Iris darstellt [Lex93]Die Pupille kann dabei zwischen 10 und 80 der Groszlige der Iris einnehmen[Dau02] Abbildung 11 auf der nachsten Seite zeigt eine Frontansicht desmenschlichen Auges und dessen fur die Iriserkennung wichtigste Teile
Bei naherer Betrachtung unterteilt sich die Iris in mehrere Schichten Dieunterste ist die Ephithel-Schicht und enthalt dicht gepackte PigmentzellenDaruber liegt die stromale Schicht die Blutgefaszlige Pigmentzellen und dieMuskel der Iris enthalt Bei jedem Menschen entwickeln sich diese Blutgefaszligeund Muskeln anders was der Iris ihr einzigartiges Muster gibt Die Dichteder Pigmentierung in dieser Schicht bestimmt die Farbe der Iris So erschei-nen zum Beispiel Augen bei denen hier fast keine Pigmente eingelagert sindblauDie oberste nach auszligen sichtbare Schicht unterteilt sich in zwei Zonen diesich teilweise in der Farbe unterscheiden Die auszligere cilliare Zone und dieinnere pupillare Zone die von dem Collarette getrennt werden Es ist alsZick-Zack-Muster in der Iris sichtbarDie Kombination aus den Blutgefaszligen und Muskeln in der stromalen Schichtund der einzigartige Aufbau des Collarette bieten eine fast unendliche Viel-
12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

12 DIE MENSCHLICHE IRIS 17
Abbildung 11 Das menschliche Auge
falt an unterschiedlichen Mustern die zur Unterscheidung von Personen her-angezogen werden konnen [Wol76]
Die Iris hat einige Eigenschaften die sie unter den Gesichtspunkten fur gutebiometrische Merkmale am Ende des vorigen Kapitels besonders geeignetfur die Biometrie machenDie charakteristischen Muster sind bei der Geburt schon vorhanden diePigmentierung ist im Verlauf des ersten Lebensjahres abgeschlossen Die Irisbleibt ab diesem Zeitpunkt das ganze Leben lang insofern stabil als dass siebis zum Erwachsenenalter nur mehr mit dem Auge mitwachst Verletzungenam Auge sind eher selten und es gibt auch keine Abnutzungserscheinungenoder Verschmutzungen wie zum Beispiel bei Fingerabdrucken [Dau02]Ein zweiter sehr wichtiger Punkt ist dass die Muster der Iris nicht genetischbeeinflusst sind Es handelt sich also um ein sogenanntes phanotypischesMerkmal bei dem es keine genetische Durchdringung gibt [Wil97] Andersals bei genotypischen Merkmalen das sind Merkmale die in Verbindungmit der genetischen Beschaffenheit stehen sind auch bei Zwillingen die Iris-muster ganzlich verschieden Da ca 1100 aller Geburten Zwillingsgebur-ten sind ergibt sich bei einem rein genotypischen Merkmal automatisch einFalse Acceptance Rate (FAR)1 von 1 Das ist bei der Verwendung vonIrismustern nicht der Fall Es ergibt sich also eine enorme Vielfalt von starkverschiedenen Mustern Angeblich liegt die Wahrscheinlichkeit fur das Auf-treten von zwei gleichen Iriden bei rund 1 zu 1078 [Way02]
Was die Iris weiters geeignet fur die Verwendung als biometrisches Merk-
1FAR = Anteil der Vergleiche bei der eine Person vom System falschlich akzeptiertwird Sie steht in umgekehrt proportionalem Verhaltnis zur False Rejection Rate (FRR)die ausdruckt wie viele Prozent der Personen falschlich vom System abgewiesen werden
18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

18 KAPITEL 1 EINLEITUNG
mal macht sind die relativ einfachen rdquoLife Checksrdquo Sie uberprufen ob essich bei dem prasentierten Objekt wirklich um die Iris bzw das Auge eineslebendigen Menschen handelt Es kann zum Beispiel das Auge kurz mit ei-nem Lichtstrahl beleuchtet und dabei beobachtet werden ob sich die Pupilleverengt oder mit einem kurzen Luftstoss das Auge zum Zwinkern angeregtwerdenDer letzte wichtige Punkt ist die einfache Merkmalsaufnahme Mit sehr gu-ten Kameras kann die Iris obwohl durchschnittlich nur 12mm groszlig trotz-dem von einer Entfernung von bis zu 1m aufgenommen werden [Dau02]Eher ublich sind allerdings Abstande von ca 30cm was im Allgemeinen vonden Benutzern noch nicht als unangenehm nahe empfunden wird
13 Iriserkennungssysteme
Im Vergleich zu anderen biometrischen Systemen wie Gesichterkennung Fin-gerabdruck Sprache DNA Analyse wird die Iriserkennung als eine der zu-verlassigsten Methoden betrachtetBiometrische Systeme zur Erkennung der Iris unterscheiden sich im Aufbauin den groben Einzelschritten nicht von anderen biometrischen SystemenEs muss ein Bild der Iris aufgenommen werden Dieses wird dann meistin verschiedenen Vorverarbeitungsschritten fur die Lokalisierung und Seg-mentierung vorbereitet Nachdem die Iris im Bild isoliert wurde muss einbiometrisches Template berechnet werden das dann in einer Datenbankabgespeichert zum Vergleich mit anderen Iriden herangezogen wird
Generell unterscheiden sich die bekannten Systeme nur in der Art der Be-rechnung des Templates Das erste gut funktionierende System wurde 1994von John Daugman zum Patent angemeldet und ist heute das bekannte-ste und verbreitetste System zur Iriserkennung (siehe [Dau93] [Dau94] und[Dau02]) Daugman berechnet als biometrisches Template den sogenann-ten Iriscode der sich uber die Verwendung von Gabor-Wavelets berechnenlasst Der Iriscode erlaubt sehr schnelle und auszligerst zuverlassige ErkennungDaugmans Patent gehort zur Zeit der Firma Iridian TechnologiesTrotz des groszligen Erfolgs von Daugmans System existieren noch verschiedeneandere Systeme die auch zum Teil unter Patentschutz stehen Die wichtig-sten sind wohl Wildes et al [Wil97] Boles und Boashash [WB98] Lim etal [Lim01] und Noh et al [Noh02]
Wildes bedient sich einer isotropischen Bandpass Dekomposition die ausder Anwendung von rdquoLaplacian of Gaussianrdquo Filtern abgeleitet wird Bo-les und Boashash entwickelten eine Methode rdquodie die 1D normalisierte IrisSignaturen auf einigen verschiedenen Auflosungen zerlegt und mittels Zero-Crossing der dyadischen Wavelet Transformationen dieser Signaturen ein
14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

14 AUFGABENSTELLUNG 19
Template berechnet [Noh02]rdquo Lims System arbeitet ebenfalls mit einemaus der Wavelettransformation berechneten Template Noh verwendet dieMultiresolution Independent Component Analysis M-ICA Diese hatte denVorteil dass keine fixen Basisvektoren wie bei den verschiedenen WaveletTransformationen verwendet werden leider zeigen die experimentellen Er-gebnisse der Forscher aber dass zum Beispiel bei der Verwendung von HaarWavelets eine besser Klassentrennung als bei der M-ICA erreicht werdenkann
14 Aufgabenstellung
Die Principal Component Analysis (PCA) wird zur Zeit erfolgreich im Be-reich der Gesichtserkennung eingesetzt Es handelt sich dabei im Gegensatzzu den auf Wavelets basierenden Methoden um ein statistisches variabe-lorientiertes Verfahren Mit Hilfe einer Linearkombination der Hauptkom-ponenten der Ausgangsdaten (Irisbilder) wird ein biometrisches Templateerstellt Dabei findet eine Dekorrelation der Ausgangsdaten sowie eine Da-tenreduktion statt Naheres zur PCA ist Kapitel 5 zu entnehmen
In dieser Arbeit soll untersucht werden inwieweit sich die PCA fur Zweckeder Iriserkennung einsetzen lasst Kapitel 2 beschaftigt sich mit der hierverwendeten Technik zur Bildaufnahme Kapitel 3 beschreibt die Vorverar-beitungsschritte die fur die Lokalisierung der Iris und Pupille notig sindund die bildverbessernden Maszlignahmen die das Bild fur die Merkmalsex-traktion vorbereiten Kapitel 4 erklart die Normalisierung und die damitverbundenen Methoden zur Lokalisierung und Segmentierung der Iris InKapitel 5 wird die Technik zur Merkmalsextraktion die Principal Compo-nent Analysis genau beschrieben Kapitel 6 befasst sich mit Methoden zurKlassifizierung der einzelnen Iriden Kapitel 7 gibt eine Systembeschreibungder fur diese Arbeit verwendeten Software und Hardware Kapitel 8 be-schreibt die experimentellen Ergebnisse der Arbeit und Kapitel 9 fasst nocheinmal die wesentlichen Erkenntnisse dieser Arbeit zusammen und lieferteinen Ausblick auf mogliche Verbesserungen der hier beschriebenen Verfah-ren
Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

Kapitel 2
Bildaufnahme
21 Uberblick
Fur die Iriserkennung sind sehr gute Aufnahmen des Auges eine zwingendeVoraussetzung um gute Erkennungsergebnisse zu erreichen Daher wurdebei der Literaturrecherche im Vorfeld dieser Arbeit ein besonderer Fokusauf die verschiedenen Bildaufnahmetechniken gelegt Sowohl Daugman alsauch Zhu et al [Zhu99] und Tisse [Tis02] verwenden ein System das Bilderim Nahe-Infrarot Bereich (750-960nm Wellenlange) aufnimmt Dies hat denVorteil dass die Muster sehr dunkler Augen auch ohne starke Beleuchtunggut sichtbar sind
Wildes [Wil97] arbeitet mit Kombination von 8 Halogen-Lichtquellen einemDiffusionsfilter der fur gleichmaszligige Beleuchtung des Auges sorgt und ei-nem zirkularen Polarisationsfilter vor der Kamera der die Lichtreflexionenauf der Augenoberflache filtert
22 Implementierung
Beide oben genannten Methoden ergeben nach Angaben der Autoren sehrgute Ergebnisse sind aber leider zu teuer fur einen Nachbau Deshalb fieldie Wahl auf ein technisch einfacheres SystemLim et al [Lim01] stellten eine Methode zur Bildaufnahme vor die trotzkleiner Abstriche in der Bildqualitat durchaus gute Bilder liefert und ein-fach im Aufbau ist Im Abstand von 64cm werden 2 Halogen-Strahler ge-genuberliegend montiert In der Mitte werden Kamera und Auge in jeweils10cm Abstand zum imaginaren Schnittpunkt rechtwinklig in Position ge-bracht Abbildung 21 auf der nachsten Seite zeigt schematisch den Aufbau
Der Aufbau wurde mit zwei Anderungen ubernommen Zum einen dient
21
22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

22 KAPITEL 2 BILDAUFNAHME
Abbildung 21 Lims System zur Bildaufnahme [Lim01]
zur Bildaufnahme eine gewohnliche Digitalkamera1 mit einer Auflosung von2048 times 1536 Pixel Die Iris wird so mit einem Durchmesser von ca 250 Pixelaufgenommen Das entspricht etwas 500 dpi und ist fur die Iriserkennungdurchaus ausreichendDie zweite Anderung betrifft die Helligkeit der Halogen-Strahler Hier wer-den statt 50W nur 20W starke Strahler eingesetzt da diese immer noch hellgenug sind und den Benutzer weniger stark blenden
Der Aufbau funktioniert prinzipiell gut da auch dunkle Augen gut ausge-leuchtet werden wobei allerdings auch auf einen Nachteil dieser Methodehingewiesen sein soll Daugman und Wildes konnen durch geschickte Konfi-gurationen das Auge frontal beleuchten und so Reflexionen in der Zone derIris vermeiden ohne den Benutzer extrem zu blenden Hier wird versuchtdies zu vermeiden indem die Lampen seitlich angeordnet sind Dadurch er-gibt sich allerdings zwangsweise eine Reflexion in den auszligeren Randzonender Iris was einen kleinen Teil der Iris unbenutzbar fur die Iriserkennungmacht (siehe Abbildung 11 auf Seite 17)
23 Qualitatskriterien
Um ein so aufgenommenes Bild fur die Iriserkennung geeignet zu machenmuss auf einige Qualitatskriterien geachtet werden Um die Erkennungsge-schwindigkeit hoch zu halten ist es gunstig dem System einen Bildaus-schnitt zu prasentieren der nur mehr das Auge enthalt Es muss vor allemdarauf geachtet werden dass im Bild keine Unscharfe vorhanden ist Eswurde beobachtet dass unscharfe Bilder beim Erkennungsprozess quasi als
1Minolta Dimage S304
23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-

23 QUALITATSKRITERIEN 23
universale Maske agieren und so zu vielen verschiedenen Irismustern passen
Auszligerdem muss hier auf eine Einschrankung im Umgang mit dem Systemhingewiesen werden Bei Systemen die Daugmans Methode ahneln ist einpixelweiser Ausschluss der Regionen die von Uberdeckungen durch Augen-lider betroffen sind moglich Das ist bei Verwendung der Principal Com-ponent Analysis (PCA) praktisch nicht moglich Bei jeder Erkennung warebeachtlicher Rechenaufwand notig um die PCA neu fur die eingeschrankteRegion zu berechnen Um dies zu erklaren ist ein Vorgriff notig der sehrunscharf den Ablauf der PCA umreiszligt
Alle vorhandenen Irismuster spannen einen n-dimensionalen Raum auf wo-bei n der Anzahl der Bildpunkte entspricht Die PCA berechnet aus denvorhandenen Irismustern eine rdquooptimalerdquo Basis fur diesen Raum Die Irismu-ster konnen dann als Linearkombinationen dieser Basisvektoren dargestelltwerden Im 3-dimensionalen Raum ist dieser Vorgang einfach zu veranschau-lichen
Fur die Vektoren
618
133
258
ist
100
010
001
eine
Basis
Durch deren Linearkombination lasst sich jeder dieser Vektoren darstellenZum Beispiel
6 middot
100
+ 1 middot
010
+ 8 middot
001
=
618
Ebenso funktioniert die Linearkombination im n-dimensionalen Raum
Wurde man versuchen die Uberdeckungen durch Augenlider vom Vergleichauszunehmen musste fur jeden Vergleich ein neuer (n minus x)-dimensionalerRaum aufgestellt werden wobei x der Anzahl der uberdeckten Bildpunkteentspricht Es musste also bei jedem Vergleich die PCA vollig neu berechnetwerden was sehr rechenintensiv ist
Deshalb ist es nur moglich einen fixen Bereich in allen Bildern vom Ver-gleich auszunehmen was zwar dazu fuhrt dass oft ein grosserer Teil als beidem aktuellen Bild notig ware ausgenommen wird andererseits konnen beiVerwendung der PCA nur so gute Vergleiche ohne Einfluss der Augenliderdurchgefuhrt werden
24 KAPITEL 2 BILDAUFNAHME
Wurde man die Verdeckungen einfach in den Vergleich miteinbeziehen wurdendie Bilder mit groszliger Sicherheit nicht anhand der Irismuster einander zuge-wiesen sondern anhand der Groszlige und Position der Verdeckungen da diesemehr Unterscheidungspotential haben als die doch sehr feinen Muster derIris
Das Problem der zu grossen Uberdeckungen kann gelindert werden indemman fordert dass beim Enrollment kaum Verdeckungen auftreten sprich dieAugen weit geoffnet werden Es wurde zwar festgestellt dass manche Test-personen ihre Augen nicht so weit offnen konnen dass keine Verdeckungenmehr auftreten aber kleine uberdeckte Bereiche stellen kein Hinderniss furdie Erkennung dar
Diese Qualitatskriterien zu uberwachen obliegt dem Benutzer des Systemsda im Unterschied zu anderen Systemen kein Schnittstelle zwischen Kameraund Computer (Framegrabber) die eine Echtzeitkontrolle der aufgezeichne-ten Bilder erlauben wurde eingesetzt werden konnte
Kapitel 3
Vorverarbeitung
31 Uberblick
Wird nun dem System ein Graustufenbild zugefuhrt das den obigen Qua-litatsanspruchen genugt werden einige Schritte durchgefuhrt die das Bildfur die anschlieszligende Lokalisierung der Pupille und der Iris und die Segmen-tierung vorbereitenDas Ergebnis der Segmentierung soll dann ein Bild sein das nur mehr furdie Merkmalsextraktion wichtige Daten enthalt also nur mehr die Iris DieSchritte der Vorverarbeitung helfen dabei die Qualitat der Lokalisierungder Pupille und Iris und somit auch der Segmentierung zu verbessern Diefolgenden Abschnitte beschreiben genauer inwiefern die einzelnen Schrit-te unterstutzend wirken Abbildung 31 auf der nachsten Seite zeigt denAblauf der Vorverarbeitung Lokalisierung und Segmentierung ausgehendvom Originalbild bis zum fertig segmentierten Endergebnis dem sogenann-ten Irisstreifen um das Zusammenwirken der Vorverarbeitungsschritte zuverdeutlichen
32 Reflexionen entfernen
Wie schon erwahnt ist in den bei der Bildaufnahme gewonnenen Augenimmer eine kleine Reflexion des Halogen-Strahlers zu sehen (siehe Abil-dung 11 auf Seite 17) Fur sie gilt dasselbe wie fur die Verdeckungen durchdie Lider Es hatte keinen Sinn diese aus dem zu vergleichenden Bild aus-zunehmen da der Aufwand sie zu entfernen zu groszlig ist Da sie aber imUnterschied zu den Lidern nur einen sehr kleinen Teil des Bildes ausmachen(ca 1-2 Prozent) konnen die Relflexionen als Fehlerquelle toleriert werdenDamit diese sehr helle Stelle spater nicht die Verbesserung des Kontrastsbehindert wird im ersten Schritt der Vorverarbeitung ein Schwellwert fest-gesetzt Alle Pixel deren Helligkeit grosser als dieser ist werden auf einenWert neutraler Helligkeit gesetzt
25
26 KAPITEL 3 VORVERARBEITUNG
Abbildung 31 Ablauf der Vorverarbeitung Lokalisierung und Segmentie-rung
33 MEDIANFILTER 27
Das so gewonnene Bild - ohne storenden Einfluss von Reflexionen - wird danneinerseits als Ausgangspunkt fur die weiteren Vorverarbeitungsschritte diedie Lokalisierung verbessern eingesetzt andererseits als Quelldatum fur dieanschliessende Segmentierung
33 Medianfilter
Optimal fur die Lokalisierung und Segmentierung ist ein Bild das grosseeinheitliche Flachen aufweist die sich stark voneinander unterschieden Sokonnen die Zone der Pupille der Iris und der Rest des Auges sicher unter-schieden werden
Der Medianfilter kann genau dies im Bild erreichen Er arbeitet mit einer Fil-termaske anpassbarer Grosse die sozusagen uber das Bild geschoben wirdAlle Pixel die sich unter der Filtermaske befinden werden nach Helligkeits-wert geordnet und der mittlerste Wert (Median) als neuer Helligkeitswertfur das zentrale Pixel unter der Filtermaske ausgewahltDie Auswahl des Medians gegenuber zum Beispiel der des arithmetischenMittels hat den Vorteil dass diese Methode sehr ausreisserstabil ist Wennsich unter der Filtermaske viele Pixel gleicher Helligkeit befinden und einzel-ne sehr verschiedene so haben diese keinen Einfluss auf den resultierendenHelligkeitswertSo wird eine verlassliche Glattung des Bildes erreicht da benachbarte Pixelmeist die gleichen oder zumindest ahnliche Helligkeitswerte erhalten
Obwohl der Medianfilter in der Berechnung aufwandiger ist als vergleichbareFilter zur Glattung wie etwa der Mittelwertfilter oder der Blurfilter sinddie Ergebnisse der Glattung doch beachtlich besser was den Mehraufwandrechtfertigt
34 Histogramm strecken
Um nach der Glattung des Bildes den Kontrast zwischen den Regionen zuverbessern wird das Histogramm1 gestreckt Ein Bild mit durchschnitt-lichem Kontrast nutzt typischerweise nicht die gesamte Breite des Histo-gramms aus Um den Kontrast zu verbessern wird das Histogramm auf diegesamte mogliche Breite gestreckt Es werden also alle Werte unter bzwuber einem bestimmten Wert auf den kleinsten bzw groszligten Helligkeitswertgesetzt und die Werte zwischen den Grenzen auf die volle Breite des Hi-stogramms gestreckt Die Grenzen werden bei einem Prozentwert festgelegt
1Diagramm uber die Helligkeitsverteilung im Bild
28 KAPITEL 3 VORVERARBEITUNG
zum Beispiel die funf dunkelsten Prozent um einerseits stabil gegenuberAusreissern zu sein und andererseits die Grenzen nicht bei einem fixen Hel-ligkeitswert zu setzten was den Erfolg der Kontrastverbesserung schmalernkonnteAbbildung 32 auf Seite 31 zeigt ein Histogramm vor und nach der Streckung
35 Kantenerkennung
An jeder Kante im Bild gibt es einen starken Anstieg oder Abfall der Hel-ligkeit im Bild Es gibt zwei Arten wie solche Helligkeitssprunge erkanntwerden konnen Entweder mittels der Gradienten 2 oder der LaplacersquoschenMethode Die Gradientenmethode sucht nach Extrema in der ersten Ab-leitung die Laplacersquosche Methode nach Nullstellen in der zweiten Ablei-tung Die Methoden sind mathematisch gleichwertig Interessant sind dieFiltermasken die verwendet werden um die erste bzw zweite Ableitung zuapproximieren Grundsatzlich sind mehrere verschiedene Masken zur Gradi-entenberechnung einsetzbar LaPlace Kirsch Prewitt
Hier wird auf den Sobel Operator zuruckgegriffen der aus den folgendenzwei 3x3 Masken besteht
-1 0 1-2 0 2-1 0 1
Gx
-1 0 1-2 0 2-1 0 1
Gy
Eine schatzt den Gradienten in X-Richtung (gx) die andere in Y-Richtung(gy) Berechnet man den Betrag des Gradientenvektors (gx gy) so erhaltman die Lange des Vektors der gleichzeitig auch der Starke des Helligkeits-sprunges im Bild entsprichtAbbildung 33 auf Seite 31 zeigt ein Beispiel fur eine Kantenerkennung
Sowohl die Gradientenvektoren als auch die Lange des Vektors bieten wich-tige Information und werden fur die spatere Lokalisierung gespeichert
Die Lange der Vektoren wird verwendet um bestehendes Rauschen im Bildzu unterdrucken Es werden dabei zwei Techniken eingesetzt
Erstens werden nur Vektoren mit einer Lange uber einem Schwellwert ge-speichert Zweitens werden mittels Non-Maximum-Unterdruckung Vektoren
2Der Gradient ist eine Funktion der die Anderungsrate und die Richtung des grosstenHelligkeitsanstiegs oder -abfalls im Bild angibt Der Gradientenvektor gibt zu einem Ur-sprungspunkt die Richtung und Grosse des starksten Helligkeitsanstiegs oder -abfalls an
36 AUGENLIDER ENTFERNEN 29
geloscht die einen benachbarten Vektor haben der langer ist als sie selbstMan erreicht so eine Reduktion der Vektoren da nur die langsten und so-mit aussagekraftigsten Vektoren in einer Nachbarschaft erhalten bleiben Sowird die Lokalisierung nicht nur praziser sondern auch schneller da nichtmehr so viele Vektoren beachtet werden mussen
Die Gradientenvektoren werden ebenfalls dazu verwendet den Rechenauf-wand der Lokalisierung zu senken wie im folgenden Kapitel uber die CircularHough Transformation genau erklart wird
36 Augenlider entfernen
Um die fur die Iriserkennung storenden Einflusse der Augenlider auszuschal-ten wird in dieser Phase der Vorverarbeitung ein fixer Bereich des Bildesentfernt Praktisch wird dabei nicht wie bei anderen Systemen ein Teil desBildes einheitlich eingefarbt sondern die Datenstruktur die den Irisstreifenenthalt um den Bereich der Uberdeckung verkleinert Das hat den Vorteildass der aufwandig zu berechnenden PCA weniger Daten zugefuhrt werdenwas wiederum die Berechnung beschleunigt Um moglichst wenig relevan-te Information zu verlieren werden halbe Ellipsen verwendet um die Formder Augenlider moglichst genau nachzuempfinden Die Form und Grosse desausgeschnittenen Teiles des Bildes sind in Abbildung 34 auf Seite 31 schwarzgekennzeichnet
37 Histogram Equalization
Obwohl im Effekt ahnlich der Histogrammstreckung unterscheidet sich dieHistogram Equalization doch im Prinzip davon Die Histogram Equalizationwird weniger dazu eingesetzt nur den Kontrast zu verbessern sondern vielmehr dazu das Histogramm zu normalisieren Es wird dabei versucht eineGleichverteilung im Histogramm zu erreichen sodass alle Helligkeitswertegleich oft im Bild auftreten Das ist besonders nutzlich wenn wie hier zweioder mehrere Bilder verglichen werden sollen die unter leicht variirendenUmstanden aufgenommen wurden
Scott Umbaugh [Umb99] beschreibt den Ablauf der Histogram Equalizationan einem Beispiel wie folgt
30 KAPITEL 3 VORVERARBEITUNG
Grauwert Anzahl der Pixel0 101 82 93 24 145 16 57 2
1 Erstelle die laufende Summe des Histogramms (Erster Wert = 10Zweiter Wert = 10+8 = 18 usw Hier ergibt sich 10 18 27 29 4344 49 51)
2 Normalisiere die Werte mittels Division durch die Gesamtsumme (1051
1851 27
51 2951 43
51 4451 49
51 5151)
3 Multipliziere diese Werte mit dem hellstmoglichen Grauwert in diesemFall 7 und runde anschlieszligend auf die nachste Ganzzahl (12446677)
4 Ersetzte die originale Grauwertspalte im Histogramm durch die geradeerrechneten Werte (Alle Pixel die im originalen Bild den Grauwert 0hatten haben jetzt Wert 1 1 wird zu 2 2 zu 4 usw)
Das so veranderte Histogramm ist zwar im Normalfall nicht flach aber zu-mindest naher an einer Gleichverteilung als das Original Um das Histo-gramm noch weiter zu glatten konnen auch zufallig ausgewahlte Pixel ausuberbesetzten Histogrammwerten in benachbarte unterbesetzte Regionenverschoben werden Ublicherweise ist dies aber nicht notig Abbildung 35 aufder nachsten Seite zeigt das Ergebnis einer Histogramm Equalization an ei-nem realen Bild
37 HISTOGRAM EQUALIZATION 31
Abbildung 32 Histogramm vor und nach Streckung
Abbildung 33 Ergebnis der Kantendetektion
Abbildung 34 Irisstreifen mit ausgeschnittenem Bereich
Abbildung 35 Ergebniss der Histogramm Equalization
Kapitel 4
Normalisierung
41 Uberblick
Fur den Vergleich zwischen den verschieden Iriden ist es wichtig eine nor-mierte Darstellung zu finden in der diese moglichst ohne storende Einflusseder Bildaufnahme verglichen werden konnen Dazu wird die Bildvorverar-beitung durchgefuhrt
Ausserdem sollen nur die Teile des Bildes verwendet werden die wirklichInformation beinhalten So bieten zum Beispiel die Pupille und die Leder-haut keinerlei biometrische Information und sollten somit beim Verleich auchnicht berucksichtigt werden Dazu ist es notig die Iris in geeigneter Form ausdem Bild zu extrahieren Beim Prozess der Segmentierung kann die Iris auchin ein einheitliches Format gebracht werden was den spateren Vergleich er-leichtert
42 Lokalisierung von Iris und Pupille
Um eine erfolgreiche Segmentierung der Iris vom Rest des Auges durchfuhrenzu konnen ist eine prazise Lokalisierung von Iris und Pupille VoraussetzungBeide konnen als Kreise angenahert werden es kann allerdings nicht ange-nommen werden dass diese konzentrisch sind Oft liegt die Pupille etwasnach unten und zur Nase hin verschoben was es notwendig macht das Zen-trum der Kreise fur Iris und Pupille einzeln zu bestimmen [Dau02] Wieaus Abbildung 31 auf Seite 26 zu ersehen ist sind einige Vorverarbeitungs-schritte auf die im vorhergehenden Kapitel genau eingegangen wird notigum die Qualitat der Lokalisierung zu verbessern
Die Lokalisierung an sich wird mittels der Circular Hough Transformationerreicht
33
34 KAPITEL 4 NORMALISIERUNG
43 Circular Hough Transformation
Die Hough-Transformation ist ein Standardalgorithmus der in vielen An-wendungen zur Objekterkennung eingesetzt wird Sie gehort zur Klasse derrdquoVotingrdquo-Techniken und wird dazu verwendet die Parameter von Objektenin einem Bild zu bestimmen Im Fall der Circular Hough Transformation(CHT) [You04] sind das der Radius und die Position eines Kreises
Die Idee hinter der CHT ist es einen Parameterraum aufzustellen in demdie Erkennung einfacher ist als im originalen Bild Die Koordinaten im Pa-rameterraum entsprechen dann den Parametern fur das gesuchte Objekt imBildSo wurde bei der klassischen CHT ein dreidimensionaler Parameterraumaufgestellt werden in dem die Achsen dem Radius und dem Mittelpunktdes Kreises in X- und Y-Koordinaten zugeordnet werden Die Erkennungdes Kreises reduziert sich dann auf ein Clustering Problem (Durch diverseOptimierungen lasst sich der Aufwand noch weiter senken wie spater be-schrieben wird)
Allgemein lasst sich der Algorithmus in drei Schritten beschreiben
1 Jeder Pixel im originalen Bild wird in eine Kurve oder eine Oberflacheabhangig von der Anzahl der Parameter transformiert Diese Kurvebzw Oberflache im Parameterraum hat dieselben Parameter wie dasgesuchte Objekt im Bild mit dem Unterschied dass im Parameter-raum alle Parameter variabel sind (Abbildung 41 auf der nachstenSeite gibt eine Vorstellung wie so eine Oberflache im Parameterraumfur einen Pixel bei der Kreiserkennung aussieht Sowohl der Radius alsauch der Mittelpunkt eines Kreises auf dem der aktuelle Pixel liegenkonnte sind variabel Es ergibt sich eine kegelartige Oberflache)
2 Der Parameterraum der auch Akkumulator genannt wird wird inZellen eingeteilt und jede Zelle mit dem Wert Null belegt Immer wennein Punkt auf der eben berechneten Kurve bzw Oberflache in eine derZellen fallt wird eine Stimme fur diese Zelle abgegeben also der Wertder Zelle um 1 erhoht (Daher der Begriff Voting-Technik)
3 Die Zelle die zum Schluss die meisten Stimmen erhalten hat wird aus-gewahlt und ihre Koordinaten werden als Parameter fur das gesuchteObjekt verwendet
Die Hough-Transformation gilt als sehr stabil gegenuber Uberdeckungen undRauschen was sie fur den Einsatz bei der Lokalisierung von Iris und Pupillesehr geeignet macht Durch die Augenlider konnen grosse Verdeckungen auf-treten und die Muster der Iris fuhren trotz aller Vorverarbeitungsschritte
43 CIRCULAR HOUGH TRANSFORMATION 35
Abbildung 41 Parameterraum bei der Circular Hough Transformation[You04]
zu Rauschen im Bild Beides verringert zwar die Qualitat der Hough Trans-formation macht die Lokalisierung aber nur in Extremfallen unmoglich
Ein grosses Problem der Hough-Transformation ist aber dass es sich umeinen exhaustiven Ansatz handelt der sehr viel Rechenzeit in Anspruchnimmt Es werden hier deshalb verschiedene Techniken eingesetzt um denAufwand zu senken
Der erste Ansatz um den Aufwand deutlich zu senken ist die Information ausden Gradientenvektoren die bei der Kantenerkennung berechnet wurden zunutzen Anhand Abbildung 42 auf der nachsten Seite soll erklart werdenwie diese genutzt werden kannAbgebildet ist ein schematisches Abbild des Auges durch den inneren grauausgefullten Kreis der die Pupille symbolisiert und den umgebenden Kreisder die Auszligengrenze der Iris darstellt Die vier kleineren Kreise im linkenBild zeigen alle Stimmen die fur die vier Punkte in deren Zentren fur einenfixen Radius abgegeben werden mussen (Das Bild kann als eine Ebene inAbbildung 41 betrachtet werden)Alle Punkte auf den kleinen Kreise mussen also als mogliches Zentrum deseigentlich gesuchten Kreises betrachtet werden Der Schnittpunkt der klei-nen Kreise der gleich dem Punkt mit den meisten Stimmen ist ist der wahreMittelpunkt des Kreises auf dem die 4 eingezeichneten Punkte liegen
Das rechte Bild zeigt die CHT unter Verwendung der Gradienteninformati-on Da die Pupille immer dunkler als die Iris und die Iris immer dunkler als
36 KAPITEL 4 NORMALISIERUNG
Abbildung 42 Circular Hough Transformation unter Verwendung der Gra-dienteninformation
die umgebende Lederhaut ist und beide nahezu rund sind kann man idea-lisiert annehmen dass der Gradientenvektor an den umgebenden Kreisenimmer zur Mitte der Pupille bzw Iris zeigtDurch diverse Storungen im Bild kommt es zu leichten Abweichungen wennman allerdings mehrere Punkte in Richtung des Gradientenvektors mit ca 3
Abweichung in beide Richtungen wahlt erlangt man schneller ein robusteresErgebnis der CHT als mittels des konventionellen Schemas da nicht mehralle Punkte auf den kleinen Kreisen in das Voting mit einbezogen werdenmussen sondern nur mehr der Teil der in Richtung des Gradientenabstiegsliegt
Eine weitere Optimierung betrifft den dritten Schritt der Hough Transfor-mation das Wahlen der Zelle mit den meisten Stimmen Verwendet manwie oben beschrieben einen dreidimensionalen Raum als Parameterraum soist das Finden der zwei Kreise fur Iris und Pupille nicht einfach Es musstenmittels dreidimensionalem Clustering1 die Zentroide2 der zwei dichtestenCluster gefunden werden was eine nicht triviale Aufgabe ist die viele Feh-ler ergeben kannDeshalb wird auf eine einfachere und bei weitem robustere Variante derHough-Transformation zuruckgegriffen Wie in [You04] vorgeschlagen wirdanstatt eines dreidimensionalen Raumes nur ein zweidimensionaler Parame-terraum verwendet Dabei wird die Dimension des Radius eliminiert undalle Stimmen fur alle Radien in einer einzigen Ebene vermerktEs wurde beobachtet dass es nicht einmal notig ist die Stimmen fur alle
1Eine Cluster ist eine Punktewolke im Raum die als eine Einheit betrachtet werdenkann Clustering ist der Vorgang des Zusammenfassens von Clustern
2Das Zentrum eines Clusters
44 SEGMENTIERUNG 37
moglichen Radien zu beachten es ist ausreichend nur jeden dritten Radiusan der Wahl teilnehmen zu lassen Das bedeutet einen weiteren Geschwin-digkeitzuwachsSo konnen jetzt sehr einfach im zweidimensionalen Raum mittels VirtualCircle Validation sowohl die zwei Zentrumspixel als auch die Radien fur diezwei gesuchten Kreise bestimmt werden
Es werden die 10 der moglichen Mittelpunkte mit den meisten Stimmenausgewahlt und der Virtual Circle Validation [Lim01] zugefuhrt Dabei wer-den vom Mittelpunkt ausgehend immer grosser werdende imaginare Kreiseuber das Kantenbild ( 33 auf Seite 31) gelegt und man pruft wieviele Pi-xel im Kantenbild mit den Pixeln auf dem Kreisumfang ubereinstimmenDie zwei Mittelpunkte die bei stark verschiedenen Radien prozentual ambesten mit den Kreisen im Kantenbild ubereinstimmen ergeben dann dieParameter fur die gesuchten Kreise
Sind nun die Mittelpunkte und Radien der Iris und der Pupille bekannt sokann mit der Segmentierung begonnen werden
44 Segmentierung
Um eine normierte Darstellung der Iris zu erhalten die fur die anschliessendeMerkmalsextraktion verwendet werden kann ist es wichtig eine Invarianz ge-genuber Grosse und Orientierung des Auges im Bild zu erreichen Durch denvariierenden Abstand des Auges von der Kamera oder unterschiedliche Ver-grosserungsfaktoren der Linse kann das Auge im Bild unterschiedlich grossabgebildet sein Unterschiedliche Beleuchtungsverhaltnisse fuhren dazu dassdie Pupille im Vergleich zur Iris unterschiedlich groszlig ist Eine Neigung desKopfes zur Seite lasst das Auge rotiert erscheinen All diesen Storeinflussenwird mittels der Segmentierung entgegengewirkt
Wie aus Abbildung 31 auf Seite 26 entnommen werden kann wird dafurauf das originale Bild des Auges ohne die Reflexionen der Beleuchtungzuruckgegriffen Alle anderen Vorverarbeitungsschritte bereiten das Bild nurauf die Lokalisierung von Iris und Pupille vor
Zur Segmentierung wird angelehnt an Daugman [Dau02] oder Lim [Lim01]eine homogene Rubber-Sheet Transformation durchgefuhrt Ziel ist es dasAusgangsbild in ein polares Koordinatensystem konstanter Dimensionen φtimesr zu transformieren (siehe Abbildung 43 auf der nachsten Seite)Dazu wird das Bild radial abgetastet und in das neue KoordinatensystemubertragenZuerst muss der aktuelle Abstand (rrsquo) zwischen dem Rand der Iris und der
38 KAPITEL 4 NORMALISIERUNG
Abbildung 43 Rubber-Sheet Transformation
Pupille beim aktuellen Winkel berechnet werden So kann nun ein Ska-lierungsfaktor s = rprime
r berechnet werden der die aktuelle Schrittweite beider Abtastung des Originalbildes angibt Ausgehend vom Rand der Pupille(
x1
y1
)kann mittels der Geradengleichung
(x1
y1
)+ s middot
(rn
rn
)eine kon-
stante Zahl von Pixel berechnet und so die Breite der Iris normiert werden(Wobei n von 1 r der fixen Breite der Iris lauft)
Dieser Vorgang wird mit einer Schrittweite von 1 fur alle Winkel wiederholt
Als Ergebnis der Transformation entsteht ein rechteckiger Irisstreifen derimmer konstante Dimensionen von φ times r Pixel hat So konnen gleich 3Storeinflusse behoben werden Wie schon erwahnt wurde liegt einerseitsdie Iris nicht konzentrisch um die Pupille andererseits ist die Pupille beiunterschiedlicher Beleuchtungsintensitat unterschiedlich groszlig Das fuhrt da-zu dass der Abstand (rrsquo) zwischen Auszligenrand der Pupille und Iris variiertBei der Transformation wird dieser Abstand vereinheitlicht Auch die unter-schiedliche Groszlige des gesamten Auges durch unterschiedliche Distanzen beider Aufnahme wird so ausgeglichen
Die eventuelle Rotation des Auges durch eine Neigung des Kopfes zur Seiteund somit eine Verschiebung des Irisstreifens nach links oder rechts wirderst beim Vergleich zwischen den Iriden ausgeglichen indem die zu verglei-chende Iris mehrmals leicht verschoben verglichen wird Dieser Vorgang wirdspater im Text auch als Shifting bezeichnet
Bevor nun die Normalisierung abgeschlossen ist wird noch eine HistogramEqualization und das Entfernen der Augenlider wie in Kapitel 3 beschieben
44 SEGMENTIERUNG 39
durchgefuhrt um den Einfluss unterschiedlicher Beleuchtung und der fur dieIriserkennung storenden Augenlider moglichst auszugleichen
Kapitel 5
Principal ComponentAnalysis
51 Uberblick
Die Principal Component Analysis (PCA) ist eine Faktoranalyse und somiteine Methode der multivarianten Verfahren in der Statistik zur Analyse vonDatensatzen Sie kann aber auch dazu eingesetzt werden ein biometrischesTemplate zu berechnen wie das folgende Kapitel erlautert Die PCA wurde1933 von Harold Hotelling [Hot33] basierend auf Arbeiten von Karl Pearsoneingefuhrt wird aber erst seit den siebziger Jahren haufiger benutzt da siebei groszligeren Datenmengen sehr aufwandig in der Berechnung ist
Ziel ist es die Originalvariablen eines Datensatzes durch eine kleinere An-zahl rdquodahinter liegenderrdquo Variablen zu ersetzen Es soll also die Informationdie in einer Menge von unabhangigen Variablen enthalten ist komprimiertwerden
Dazu wird eine lineare Transformation der ursprunglichen teilweise korre-lierten Variablen in eine neue Menge unkorrelierter Variablen die PrincipalComponents oder Hauptkomponenten durchgefuhrt Wenn ein Datensatzstark korrelierte Variablen enthalt sagen diese im Wesentlichen dasselbeaus und bieten keine neue InformationDie Varianz ist ein Maszlig mit dem man eine Korrelation zwischen Variablenfestgestellen kann Ist die Varianz klein so sind die Werte der Variableneinander ahnlich Stellt man so eine Korrelation zwischen zwei Variablenfest kann man da dabei nur wenig Information verloren geht nur eine derstark korrelierten Variablen erhalten und die andere aus dem DatensatzstreichenEs kann fur jede Variable gepruft werden wie viel der erklarten Varianzverloren geht wenn diese Variable aus dem Datensatz gestrichen wird Um
41
42 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
eine moglichst gute Datenreduktion zu erreichen versucht man mit einermoglichst kleinen Zahl von neuen Variablen die maximale Varianz aufzu-klarenBei der Durchfuhrung der PCA geht man nach genau diesem Muster vorMan versucht zuerst eine Dekorrelation der Daten zu erreichen die neuenVariablen die danach eine kleine Varianz haben werden gestrichen
Hilfreich zum Verstandnis der Berechnung dieser neuen Variablen ist eineVeranschaulichung im dreidimensionalen Raum Ausgegangen wird von ei-ner Menge von Punkten im Raum Wie schon in Abschnitt 23 auf Seite 23an einem Beispiel gezeigt wurde ist es durch Linearkombination von 3 zuein-ander orthogonal stehenden Basisvektoren (Principal Components) moglichalle Punkte im Raum zu erreichen Diese 3 Vektoren sind dadurch dass sieorthogonal zueinander stehen ganzlich unkorreliert und sie klaren 100 derVarianz auf
Bei der Durchfuhrung der PCA werden die Basisvektoren allerdings nichtwie in diesem Beispiel willkurlich festgelegt Ausgehend von einer n-dimen-sionalen Punktewolke wird ein neues Koordinatensystem in die Punktwolkegelegt wobei die Achsen sukzessive nach folgenden Regeln gewahlt werden
Die erste Achse wird so in die Punktewolke gelegt dass die Varianz derDaten in diese Richtung maximal wird Die folgenden Achsen werden sogewahlt dass sie erstens senkrecht auf die bisher gewahlten Achsen stehenund zweitens die verbleibende Varianz maximal erklaren
So ergeben sich im n-dimensionalen Raum n neue Achsen die alle orthogonalzueinander stehen Die Gesamtvarianz der Daten ergibt sich aus der Summeder einzelnen Varianzen die jede Achse erklart Wird nun durch die erstenp Achsen ein Groszligteil (95-99) der Varianz abgedeckt sind die Faktorendie durch die neuen Achsen reprasentiert werden ausreichend fur die Dar-stellung der Originaldaten Die ubrigen Achsen konnen eliminiert werdenda sie fast keine zusatzliche Information bieten Dabei ist zu erwahnen dassdiese Faktoren in Bezug auf die in der Gesichtserkennung ubliche Bezeich-nung rdquoEigenfacerdquo hier wohl am besten rdquoEigenirisrdquo genannt inhaltlich nichtunmittelbar interpretierbar sind wie das die ursprunglichen Achsen waren(Abbildung 51 auf der nachsten Seite gibt eine Vorstellung wie diese neuenAchsen aussehen)
Ordnet man die Achsen nach erklarter Varianz absteigend lasst sich mittelsder PCA eine gewissermassen optimale Datenreduktion finden Die Datenkonnen mit einer minimalen Anzahl von Koeffizienten optimal in Bezugauf den mittleren quadratischen Fehler dargestellt werden da immer dieunwichtigsten Achsen eliminiert werden Es lasst sich also die beste Appro-
52 HERLEITUNG 43
(a) Eigeniris hoher Ordnung
(b) Eigeniris niedriger Ordnung
Abbildung 51 Beispiel fur Eigeniriden
ximation bei der gleichzeitig besten Dekorrelation finden
Wenn auf diese Weise eine neue Basis gefunden wurde konnen die Datenwie zuvor am Beispiel im dreidimensionalen Raum erklart in dieser neuenBasis dargestellt werden Im Fall der Iriserkennung wird so das biometrischeTemplate zum Vergleich von Iriden berechnet Die Koeffizienten die sich beider Darstellung in der neuen Basis ergeben bilden das biometrische Tem-plate
Hier zeigt sich ein weiterer Vorteil bei der Verwendung der PCA zur Be-rechnung des biometrischen Templates Es speichert keine sensitiven Per-sonendaten Alleine mit den Daten des Templates kann das originale Augenicht rekonstruiert werden Dazu mussen zusatzlich die Eigenvektoren be-kannt sein Der Verlust oder Diebstahl des Templates stellt an sich keineGefahrdung sensitiver Personendaten dar
52 Herleitung
Dieser Abschnitt soll einen Einblick in die Funktionsweise der PCA ge-ben und dabei helfen den im folgenden Kapitel erklarten Ablauf der PCAbesser zu verstehen Die Herleitung wurde mit kleinen Anderungen undErganzungen des Autors aus [Cas98] entnommen
Gesucht wird eine Basis u fur einen Zufallsvektor xεltn in diesem Fall einIrisstreifen dargestellt als eindimensionaler Vektor sodass daraus mittelsLinearkombination der m orthogonalen Basisvektoren eine Annaherung desVektors wie folgt berechnet werden kann
x = y1u1 + y2u2 + + ymum (51)
44 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
wobei m lt n und yj der Koeffizient des Basisvektors uj ist und sich ausdem inneren Produkt von x und uj berechnet
yj = xT uj (52)
Durch Aufstellen einer k times n Beobachtungsmatrix X (eine Sammlung allerdem System bekannten Irisstreifen) deren Reihen einzelne BeobachtungenxT
k sind konnen Gleichungen 51 auf der vorherigen Seite und 52 so ausge-druckt werden
X = Y UTm (53)
Ym = XUm (54)
wobei Um eine n times m Matrix ist deren Spalten eine unkorrelierte Basis furX darstellt und Ym eine k timesm Matrix deren Spalten die Koeffizienten furjeden Spaltenvektor in Um sind
Durch die Orthogonalitat von Um und die zusatzliche Bedingung dass dieSpalten von Um den Betrag 1 haben also Uj = 1 folgt dass
UTmUm = Im (55)
wobei Im die m times m Einheitsmatrix ist
Das Problem beim Berechnen einer PCA ist also die Matrix Um so aufzu-stellen dass der Fehler ε der bei der Approximation von x mit x gemachtwird minimal ist
ε = x minus x =nsum
j=m+1
yjuj (56)
wobei ε die Darstellung aller unbenutzten Vektoren und somit der Fehler beider Approximation ist Der mittlere quadratische Fehler ξ ist ein geeignetesMaszlig um den Fehler der bei der Approximation gemacht wird zu schatzen
ξ = E[|ε|2] = E[|x minus x|2] (57)
wobei der Erwartungswert E einer beliebigen Funktion f(x) so definiertist
E[f(x)] =
infinintminusinfin
f(x)p(x)dx (58)
wobei p(x) die Wahrscheinlichkeitsdichtefunktion der Zufallsvariable x ist
52 HERLEITUNG 45
Weil der Erwartungswert linear ist und die Spalten von Um orthogonal zueinander stehen folgt dass
ξ = E[εT ε]
= E
( nsumi=m+1
yiui
)T nsum
j=m+1
yjuj
=nsum
j=m+1
E[y2j ] (59)
woraus wiederum folgt
E[y2j ] = E[(uT
j x)(xT uj)] = uTj E[xxT ]uj = uT
j Λuj (510)
wobei Λ die Korrelationsmatrix von x ist
Durch Einsetzen von Gleichung 510 in Gleichnung 59 erhalt man das zuminimierende Maszlig ξ
ξ =nsum
j=m+1
uTj Λuj (511)
Diese Minimierung kann man mit Hilfe einer multivarianten Differenzialglei-chung unter Verwendung von Lagrange-Multiplikatoren λj berechnen indemman die erste Ableitung des Erwartungswertes fur den mittleren quatdrati-schen Fehler bezuglich der Basisvektoren uj auf 0 setzt
part
partujξ = 2(Λuj minus λjuj) = 0 mit j = m + 1 n (512)
Es ist bekannt dass die Losungen fur diese Gleichung den Eigenvektorender Korrelationsmatrix Λ entsprechen
Es ist auszligerdem interessant dass die Korrelationsmatrix Λ und die Kova-rianzmatrix C bei einem zentrierten Datensatz das heiszligt dass der Mittel-wert jeder Zeile von den einzelnen Spaltenwerten von X abgezogen wurdeaquivalent sind Um die Eigenwerte und Eigenvektoren zu berechnen mussnur noch eine Eigenwertzerlegung der Kovarianzmatrix C berechnet werden
Die Eigenvektoren mit den groszligten Eigenwerten entsprechen dann den Ba-sisvektoren in deren Richtung im Zufallsvektor X die Varianz maximal istFolglich entsprechen die Spalten der Matrix U den Eigenvektoren und derFehler der bei der Approximation gemacht wird lasst sich durch die Summeder Eigenwerte aj des unbenutzten Teils der Basis dargestellen
ξ =nsum
j=m+1
aj (513)
46 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
Die Minimierung vereinfacht sich also auf das Sortieren der Basisvektorenuj nach Grosse der zugehorigen Eigenwerte Die Spalten mit den kleinstenEigenwerten treten im unbenutzten Teil der Basis U auf Die Spalten vonUm die fur die Rekonstruktion verwendet werden korrespondieren mit denm groszligten Eigenwerten
53 Implementierung
Bei der Implementierung der PCA wird das Wissen aus der Herleitung be-nutzt um die Berechnung moglichst einfach zu machen Durch das Zentrierender Daten kann zur Berechnung der Eigenwerte anstatt der Korrelations-matrix die Kovarianzmatrix verwendet werden Durch eine weitere Verein-fachung die im folgenden Text beschrieben ist kann der Aufwand bei derBerechnung nochmals gesenkt werden
1 Alle n dem System bekannten Irisstreifen x vom Format atimes b werdenin Vektoren vom Format abtimes 1 umgeformt und in einer neuen abtimes nMatrix X zusammengefasst
2 Um einen zentrierten Datensatz zu erhalten was die folgenden Berech-nungen vereinfacht wird ein Durchschnittsvektor Ψ berechnet SeineElemente entsprechen den Mittelwerten der einzelnen Spalten der Ma-trix X
3 Ψ wird jetzt von jeder einzelnen Spalte in X abgezogen und man erhalteinen zentrierten Datensatz A im Format ab times n
4 Wie aus der Herleitung der PCA bekannt ist kann zur Berechnung derEigenwerte und Eigenvektoren die Kovarianzmatrix verwendet werdenWeil A zentriert ist berechnet sich die abtimesab Kovarianzmatrix C sehreinfach aus C = AAT
5 In diesem Schritt wird die Eigenwertzerlegung von C berechnet umdie Eigenwerte und Eigenvektoren ui zu erhalten Da diese Berechnungin der Praxis sehr aufwandig ist es muss als Teilschritt eine ab timesab Matrix diagonalisiert werden (im hier betrachteten System eineca 21100times 21100 Matrix) wird auf eine weniger aufwandige Technikzuruckgegriffen
(a) Dazu wird die Matrix AT A (n times n) verwendet
(b) Man berechnet nun die Eigenvektoren vi von AT A
AT Avi = microivi
54 BEISPIEL 47
(c) AAT und AT A stehen dabei in folgendem folgendem Verhaltnis
AT Avi = microivi
AAT Avi = microiAvi
CAvi = microiAvi
Cui = microiui wobei ui = Avi
AAT und AT A haben also die gleichen Eigenwerte und die Ei-genvektoren stehen im Verhaltnis ui = Avi
(d) Dazu ist noch Folgendes anzumerken
bull AT A hat bis zu ab (hier ca 21100) Eigenwerte und Eigen-vektoren
bull AAT hat bis zu n (richtet sich nach der Anzahl der bekanntenPersonen) Eigenwerte und Eigenvektoren
bull Die n Eigenwerte von AT A und deren Eigenvektoren korre-spondieren mit den n grossten Eigenwerten und Eigenvekto-ren von AAT
(e) Man berechnet jetzt also die m besten Eigenvektoren ui von AAT ui = Avi die die gewunschten 95-99 der Varianz erklaren undnormiert diese auf Lange 1 (|ui| = 1)
6 Zur spateren Rekonstruktion der Daten speichert man nun den Durch-schnittsvektor Ψ und die ersten m Eigenvektoren welche die geforderteVarianz erklaren
Will man nun zur Klassifizierung eines bestimmten Irisstreifens x das Tem-plate berechnen so muss nur die aus der Herleitung bekannte Gleichungx = y middot UT gelost werden Das entspricht einer Darstellung des Irisstrei-fens in der neu berechneten Basis Der Koeffizientenvektor y mit nur mElementen wird als Template gespeichert und fur den Vergleich der Iridenverwendet Das Template ist sehr kompakt im Vergleich zum Ausgangsbildermoglicht aber gleichzeitig die beste Rekonstruktion in Bezug auf den mitt-leren quadratischen Fehler Mit Hilfe des Templates ist es jetzt auch moglichdie Iriden einfach mit einander zu vergleichen Der Abstand zwischen zweiTemplates gibt ein Maszlig fur die Ahnlichkeit verschiedener Iriden Der Ab-schnitt Klassifizierung beschaftigt sich mit der Berechnung dieses Abstands
54 Beispiel
Das folgende Beispiel soll nochmals die Berechung des biometrischem Tem-plates mittels der PCA zum Vergleich von Iriden erlautern Aus Grundender Ubersichtlichkeit wurden fur das Beispiel allerdings sehr viel kompak-tere Datensatze verwendet Man konnte sich fur das Beispiel vorstellen dass
48 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
die Iriden nur anhand von 7 Merkmalen voneinander unterschieden werdennicht wie in der Realitat an den ca 21100 Pixeln des Abbildes der Iris unddass dem System nur 5 Iriden bekannt sind
1 In der Matrix X sind also diese 5 Iriden mit ihren 7 Merkmalen zu-sammengefasst die als Ausgangspunkt fur die Berechnung der PCAdient
X =
2 5 3 4 12 7 3 5 35 3 4 8 53 9 3 2 38 5 6 9 73 4 3 2 35 3 5 2 5
2 Der Durchschnittsvektor Ψ lautet
Ψ =
3454734
3 Durch spaltenweise Subtraktion des Durchschnittsvektors Ψ von Xerhalt man den zentrierten Datensatz A
A =
minus1 2 0 1 minus2minus2 3 minus1 1 minus10 minus2 minus1 3 0minus1 5 minus1 minus2 minus11 minus2 minus1 2 00 1 0 minus1 01 minus1 1 minus2 1
54 BEISPIEL 49
4 Die Multiplikation AT A ergibt die rdquokleinerdquo Kovarianzmatrix C
C = AAT =
8 minus16 3 minus1 6
minus16 48 minus5 minus14 minus133 minus5 5 minus6 3minus1 minus14 minus6 24 minus36 minus13 3 minus3 7
5 Durch die Eigenwertzerlegung ergibt sich folgende Eigenwert- und Ei-genvektormatrix
micro =
616314 0 0 0 0
0 265245 0 0 00 0 248281 0 00 0 0 136126 00 0 0 0 0
V =
minus0287117 minus0269915 0312182 minus0739765 04472140880605 00785941 012731 minus00463752 0447214
minus00743944 minus0334657 minus0822786 00741182 0447214minus0289844 084206 minus00690256 00464827 0447214minus0229249 minus0316083 045232 0665539 0447214
6 Durch Multiplikation A middot V und Normierung der einzelnen Vektorenauf Lange 1 erhalt man die eigentlich gesuchten Eigenvektoren U Wieman aber anhand der Eigenwerte sieht sind die ersten 4 Vektorenausreichend um die Varianz zu 100 erklaren Zur Berechung desbiometrischen Templates tx werden also nur die ersten 4 Vektoren U prime
verwendet
U prime =
minus0282398 0369176 065446 minus0546469minus0411416 0440452 minus00374477 05547390325626 0524961 minus0229163 013549minus0709945 minus00719381 minus0528583 minus02783290325278 0309051 minus0471092 minus0538401minus0149091 minus014824 minus0124603 minus007958830113581 minus0521023 00301725 minus00400245
50 KAPITEL 5 PRINCIPAL COMPONENT ANALYSIS
7 Fur den ersten Vektor x1 in X ergibt sich als Template zum Beispiel
t1 = x1 middot U prime = (0833527 345082minus548922minus488709)
Aus den 4 Werte des Templates t1 kann x1 durch Multiplikation von t1mit uprimeT rekonstruiert werden Ausserdem dient es wie schon erwahntzum Vergleich der verschieden Iriden
Kapitel 6
Klassifizierung
61 Uberblick
Der Begriff der Klassifizierung beschreibt allgemein den Vorgang des Ein-teilens einer Menge in einzelne voneinander verschiedene Klassen anhandbestimmter diskriminierender Merkmale In diesem Fall ist das Ziel der Klas-sifizierung eine Zuteilung einer Iris zu genau einem Benutzer Als Merkmalzur Unterscheidung der verschiedenen Iriden wird dabei das zuvor berech-nete biometrische Template herangezogen
Fur jeden Benutzer der vom System erkannt werden soll muss naturlich einbekanntes Template vorliegen das dem System beim Enrollment-Prozessder Neuaufnahme eines Benutzers prasentiert wurde Ein solches Templateist nichts anderes als ein hochdimensionaler Vektor Um zwei Iriden zu ver-gleichen muss nur der Abstand ihrer Templatevektoren berechnet werdenUm eine Klassifizierung einer unbekannten Iris durchzufuhren wird ange-nommen dass die Templates mit dem absolut kleinsten Abstand am ehestender gleichen Iris entsprechen und so eine Zuordnung vorgenommen
62 Methoden zur Abstandsberechnung
Zur Berechnung des Abstandes zwischen den Templates sind verschiedeneAnsatze denkbar Vorerst soll die Mahalanobis-Distanz besprochen werdenda diese vom theoretischen Standpunkt betrachtet sehr gute Ergebnissebei der Unterscheidung ermoglicht Bei einer praktischen Betrachtung stelltsich allerdings heraus dass sie zu rechenaufwandig ist um zur Klassifizie-rung eingesetzt zu werden Deshalb wird im System der euklidische Abstand( 61 auf der nachsten Seite) der sehr einfach und schnell zu berechnen istverwendet
51
52 KAPITEL 6 KLASSIFIZIERUNG
Abbildung 61 Vergleich von euklidischer Distanz und Mahalanobis-Distanz
dE(x1 xn y1 yn) =1n
radicradicradicradic nsumi=0
(xi minus yi)2 (61)
Trotzdem sollen Berechnung und Einsatz der Mahalanobis-Distanz erklartwerden da diese einen sehr interessanten theoretischen Vorteil gegenuberdem euklidischen Abstand hat Da es sich bei der Menge der verschiedenenTemplates nicht um eine willkurliche Verteilung handelt lasst sich mit Hilfeder Statistik die Berechnung des Abstandes verfeinern
Die Mahalanobis-Distanz [Rob04] ist sehr gut dazu geeignet den Abstandeiner Menge von bekannten Werten von einem unbekannten Wert zu be-rechnen Sie berucksichtigt bei der Berechnung des Abstandes anders alsder euklidische Abstand die statistische Verteilung der Werte und beziehtMittelwert Varianz und Kovarianz in die Berechnung mit ein Das Ergebnisist ein dimensionsloses Maszlig das frei von Korrelation zwischen den Templa-tes istUm diese Eigenschaft zu erklaren hilft Abbildung 61
Aus der Formel zur Berechnung der euklidischen Distanz folgt dass al-le Punkte die den gleichen Abstand von einem Punkt haben auf einemSphariod im zweidimensionalen Fall einem Kreis liegen Wie man im lin-ken Teil der Abbildung 61 sieht ware mit Hilfe der euklidischen Distanznicht entscheidbar welcher der zwei Punkte vom Zentrum der Punktewol-ke aus gemessen besser zu der Klasse die von dieser Punktewolke gebildetwird passt
62 METHODEN ZUR ABSTANDSBERECHNUNG 53
Es ware also von Vorteil die Achsen mit hoher Varianz weniger stark zugewichten als die Achsen auf denen die Varianz eher klein ist Wenn mandie Achsen mit deren jeweiliger Varianz gewichtet ergibt sich anstatt einesSpharoids ein Ellipsoid auf dem alle Punkte gleich weit vom Zentrum ent-fernt sind Dies ist im rechten Teil der Abbildung 61 auf der vorherigen Seiteveranschaulicht Durch die Neugewichtung der Achsen gelten alle Punkt aufder Ellipse als gleich weit vom Zentrum entfernt Punkt x2 ist also eindeutignaher als Punkt x1
Die Formel fur die Mahalabobis-Distanz 62 beinhaltet genau die soebenangesprochene Neugewichtung der Achsen durch die Multiplikation mit derinvertierten Kovarianzmatrix
dt(x) =radic
(x minus mt)T Sminus1t (x minus mt) (62)
dt ist die Mahalanobis-DistanzSt ist die Kovarianzmatrix der Gruppe von bekannten Templatesmt ist ein Vektor der Mittelwerte der Koeffizienten der bekannten Templa-tesx ist der Vektor der Koeffizienten des unbekannten Templates
Bei der Berechnung des Abstandes zwischen den Templates wird die Maha-lanobis Distanz sehr ahnlich zum gerade angefuhrten Beispiel genutzt ImBeispiel soll festgestellt werden ob Punkte zu einer Klasse gehoren es wirdalso nur die Verteilung der einen Klasse berucksichtigtFur die Berechnung des Abstandes der einzelnen Templates will man dieBeziehungen der einzelnen Klassen zueinander berucksichtigen und benutztdaher die Daten aller Klassen Durch die Neugewichtung der Achsen erreichtman eine deutlichere Trennung der Klassen und kann somit ein unbekanntesTemplate besser einer Klasse zuordnen
Bei Testlaufen mit kleinen Datensatzen stellte sich heraus dass die Ma-halanobis-Distanz bessere Erkennungsleistungen zulasst als der euklidscheAbstand ein groszliges Problem ergibt sich allerdings daraus dass bei jederBerechnung der Mahalanobis-Distanz alle vorhandenen Templates in die Be-rechnung miteinbezogen werden mussen Bei grosseren Datensatzen wird dieBerechnung daher sehr rechenintensiv und eine Klassifizierung ist nicht inangemessener Zeit moglich
Kapitel 7
Systembeschreibung
71 Uberblick
Das Iriserkennungssystem wurde in Java Version 150-b64 implementiertund verwendet die Java Advanced Imaging Library in der Version 112Zur Benutzerverwaltung wird eine MySQL Datenbank Version 4020d ver-wendet Auszligerdem wurden Teile des Public Domain Projektes JAMA zurBerechnung der Eigenwertzerlegung verwendet
Alle Berechnungen wurden auf einem Intel Centrino 1500MHz 512MB RAMund einem AMD Athlon XP3000+ 2167MHz 1024MB RAM durchgefuhrt
Zur statistischen Auswertung wurde Microsoft Excel 2000 verwendet
72 Implementierung
Das System teilt sich in mehrere logisch getrennte Klassen (siehe Abbil-dung 71 auf der nachsten Seite) Die Klasse UserHandling enthalt Me-thoden zum Enrollment und zum Matching von Personen und benutzt alleweiteren Klassen Die Klasse Imaging enthalt alle Methoden welche dieBildvorverarbeitungsschritte aus Kapitel 2 umfassen Detection dient derLokalisierung und Segmentierung MatrixMath enthalt alle Methoden zurDurchfuhrung der PCA und zur Abstandsberechnung und benutzt dabei dieMethoden der Klasse EigenvalueDecomposition DBconn dient der Speiche-rung der Daten in Datenbank und auf Festplatte
73 Datenspeicherung
Die Daten die fur das Enrollment und das Erkennen von Personen wichtigsind werden je nach Zugriffshaufigkeit und Speicherplatzbedarf entwederauf Festplatte oder in der MySQL-Datenbank gespeichert
55
56 KAPITEL 7 SYSTEMBESCHREIBUNG
Abbildung 71 Ein Uberblick uber die einzelnen Klassen des Iriserkennungs-systems und deren Abhangigkeiten
73 DATENSPEICHERUNG 57
Abbildung 72 Das Datenmodell zur Speicherung der Benutzerdaten
Abbildung 72 zeigt die Daten die in der Datenbank gespeichert werden Furjeden Benutzer wird eine ID vergeben der Name und um Verwechslungenvorzubeugen der Geburtstag gespeichert Eine zweite Tabelle verwaltet dieIrisstreifen mit denen die Benutzer enrollt wurden Auch sie erhalten eineID Uber einen Fremdschlussel werden die Irisstreifen mit den Benutzern as-soziiert In der Spalte fur die Beschreibung kann zum Beispiel festgehaltenwerden ob es sich um das linke oder das rechte Auge handelt falls beideAugen uberpruft werden sollen Die rdquoinsertedrdquo Spalte halt fest wann dasbetreffende Auge registriert wurde Auf Wunsch konnen so die Bilder peri-odisch aktualisiert werden auch wenn das vom biologischen Standpunkt hernicht notig ware Uber die ID des Irisstreifens ist das zugehorige Templatewieder auffindbar
Das Template und der fertig vorverarbeitete Irisstreifen fur eine eventuelleNeuberechnung der PCA werden binar auf Festplatte gespeichert da derZugriff auf die Festplatte bedeutend schneller ist als der auf die Datenbank
Schliesslich mussen noch alle Daten gespeichert werden die fur das Matchinggebraucht werden Das sind die Eigenvektoren und der Durchschnittsvektorder bisher bekannten Benutzer Diese werden ebenfalls auf der Festplattegespeichert
Kapitel 8
Experimentelle Ergebnisse
81 Uberblick
In diesem Kapitel wird die Gesamtleistung des hier prasentierten Systemsuntersucht Um spater bestatigen zu konnen dass die Iris einzigartig undein geeignetes Maszlig zur Unterscheidung von Personen ist wird das Kon-zept der False Acceptance Rate (FAR) und der False Rejection Rate (FRR)erklart Mit Hilfe einer vom Institute of Automation der Chinese Acade-my of Sciences [oSIoA05] gesammelten Irisdatenbank werden in verschie-den Testlaufen die optimalen Parametersetzungen gesucht um die besteErkennungsleistung des Systems zu finden Dazu gehoren die Anzahl derVerschiebungen in jede Richtung um eine eventuelle Drehung des Augesauszugleichen die Groszlige der Regionen die ausgeschnitten werden um denStoreinfluss der Augenlider zu beseitigen die Anzahl der Templates diezum Enrollment benutzt werden und die Groszlige des Irisstreifens also derAuflosung bei der Erstellung des Irisstreifens
82 Maszligzahlen zur Bewertung
Bei jeder Messung biometrischer Daten herrschen leicht unterschiedlicheBedingungen Beleuchtungseinflusse Kameraoptik und der Benutzer selbstbeeinflussen die Erfassung des biometrischen Merkmals Das fuhrt dazudass auch Aufnahmen desselben Merkmales nie genau gleich erscheinen Esbesteht also auch beim Vergleich zweier Aufnahmen der gleichen Iris einAbstand zwischen den berechneten Templates Dieser wird der Intraclass-Abstand genannt Im Unterschied dazu gibt es den Interclass-Abstand derbeim Vergleich von zwei verschiedenen Iriden autritt
Aufgabe jedes Iriserkennungssystems ist es eine klare Trennung zwischen die-sen zwei Verteilungen herzustellen Wenn eine Trennung besteht kann einSchwellwert (Grenzabstand) gewahlt werden der eine genaue Entscheidung
59
60 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
zulasst ob ein Template der einen oder der anderen Verteilung angehortwenn zwei Templates verglichen werden Wenn der Abstand zwischen zweiTemplates kleiner ist als der Schwellwert stammen die beiden Templatesvon der gleichen Quelle Liegt der Abstand uber dem Grenzwert so stam-men die Templates von verschiedenen Augen
Um messen zu konnen wie gut die Trennung zwischen der Interclass-Ver-teilung und der Intraclass-Verteilung und damit die Leistung des Iriserken-nungssystems ist muss eine geeignete Metrik gefunden werden Denkbarware es einfach den Abstand zwischen maximaler Interclass-Distanz undmaximaler Intraclass-Distanz zu messen dieses Maszlig ware allerdings zu emp-findlich gegenuber AusreiszligernBesser eignet sich dazu die Decidability [Dau02] die wie folgt definiert ist
d =|micro1 minus micro2|radic
(σ21+σ2
2)2
(81)
wobei micro1 und micro2 die Mittelwerte und σ1 und σ2 die Standardabweichungender Interclass- und Intraclass-Verteilung sind Wie man der Formel entneh-men kann druckt die Decidability den Abstand zwischen den Mittelwertender beiden Verteilungen gewichtet mit der gemittelten Varianz aus Sie istsomit ein ausreiszligerstabiles Mass und eignet sich gut um die Trennscharfeder beiden Verteilungen zu bewertenMit Hilfe der Decidablility lasst sich besser als zum Beispiel durch Zahlenvon falschen Erkennungen die Leistung eines biometrischen Systems bezif-fern Sie ist deshalb auch eine wichtige Hilfe beim Einstellen von Parametern
Unter optimalen Bedingungen sollte also die Streuung des Intraclass-Ab-standes sowie des Interclass-Abstandes bei Vergleich sehr vieler Irispaareso klein sein dass keine Uberschneidungen der Wertebereiche auftritt ImRealfall ist das allerdings selten so Abbildung 81 auf der nachsten Seitezeigt eine typische Verteilung von gemessenen Abstanden
Sobald eine Uberschneidung der Wertebereiche zwischen Intraclass-Verteil-ung und Interclass-Verteilung auftritt ist nicht mehr exakt entscheidbar zuwelcher Klasse ein Template zugeordnet werden soll Es treten also zwangs-laufig Fehler auf Wie in Abbildung 81 auf der nachsten Seite gekennzeichnetist sind 2 Arten von Fehlern zu unterscheidenDie False Acceptance Rate (FAR) und die False Rejection Rate (FRR)
Liegt bei der Erkennung einer Iris der kleinste gefundene Abstand und so-mit das am ehesten passende Template uber dem Grenzwert so wird es
82 MASSZAHLEN ZUR BEWERTUNG 61
Abbildung 81 False Acceptance Rate und False Rejection Rate
62 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
auch abgelehnt wenn die Klassifizierung eigentlich richtig gewesen wareMan spricht hier von einer False Rejection (FR) Templates die eigentlichnicht mit dem zu klassifizierenden Template ubereinstimmen aber trotzdemden kleinsten Abstand haben und unter dem Schwellwert liegen werdenfalschlich akzeptiert Man spricht von einer False Acceptance (FA)
Die Wahl eines geeigneten Schwellwertes hangt immer von den Anforderun-gen ab die an das biometrische System gestellt werden Wurde man einenabsurd hohen Schwellwert wahlen (FRR geht gegen 0) ab dem ein Templateabgelehnt wird wird ein Template zwar immer der Klasse mit dem klein-sten Abstand zugeordnet und es entstehen so viele richtige Erkennungenallerdings gibt es auch keinerlei Sicherheit dass die Erkennung auch wirk-lich richtig war und der kleinste gefundene Abstand nicht zu einem falschenTemplate auftrittZieht man aber eine Grenze im Bereich zwischen den zwei Verteilungen sokann es sein dass richtige Klassifizierungen uber der Grenze liegen und des-halb abgelehnt werden Die Wahl eines niedrigen Schwellwertes verringertalso die Anzahl der Erkennungen steigert hingegen aber die Sicherheit desSystems FAR und FRR verhalten sich invers zu einander
FAR und FRR und damit Sicherheit oder Toleranz eines Systems konnendurch Wahl des richtigen Schwellwertes adjustiert werden Soll das Systemalso nur das am ehesten passende Template finden (FRR gleich 0) so istdie Erkennungsrate sehr hoch soll allerdings mit einer gewissen Sicherheitfestgestellt werden ob diese Ubereinstimmung auch korrekt ist wird die Er-kennungsrate sinken aber die Sicherheit der Erkennung steigen
Ein gutes Leistungsmass fur ein biometrischen System ist das erreichbareMinimum bei FAR und FRR auch wenn das nicht gleichbedeutend mit derhochsten erreichbaren Erkennungsrate ist
FAR und FRR sind denkbar einfach zu berechnen
FAR =Anzahl der falschlich akzeptierten TemplatesGesamtanzahl der akzeptierten Templates
FRR =Anzahl der falschlich abgelehnten TemplatesGesamtanzahl der abgelehnten Templates
83 TESTDATEN 63
Abbildung 82 Equal Error Rate
Als Maszligzahl fur die Gute einen Systems kann die Equal Error Rate (ERR)angegeben werden wobei gilt
ERR = (FAR = FRR) (82)
Die ERR ist also der Punkt an dem FAR und FRR genau gleich groszlig sind(Siehe Abbildung 82)Ebenfalls in der Abbildung zu sehen ist der zuvor angesprochene Punkt andem FRR = 0 wird und die FAR sehr groszlig wird und sein Gegenstuck andem die FAR = 0 ist und die FRR sehr groszlig wird
83 Testdaten
Zum Testen des Systems wurden zwei verschiedene Datensatze verwendetEinerseits eine vom Autor im Zuge dieser Arbeit aufgebaute Datenbankdie 92 Bilder vom linken und rechten Auge von 23 Personen enthalt Diesewurden auf die in Kapitel 2 beschriebene Weise aufgenommen Auf Grundvon Problemen mit der automatischen Scharfstellung der Kamera entspre-chen leider viele andere Bilder nicht den geforderten QualitatsanspruchenDie ubrigen Bilder sind zwar von brauchbarer Qualitat und zeigen dass dasSystem prinzipiell funktioniert fur eine aussagekraftige Bewertung des Sy-stems waren allerdings nicht genugend Daten vorhanden Da in absehbarerZeit keine Datenbank mit ausreichendem Umfang aufgebaut werden kannwird fur die Leistungsbewertung des Systems daher eine andere Datenbank
64 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
verwendet
Dafur wird die CASIA Iris Image Database des Institute of Automation derChinese Academy of Science [oSIoA05] verwendet Diese enthalt Daten vonjeweils einem Auge von 108 Personen Pro Auge wurden jeweils 7 Grau-stufenbilder aufgenommen die in zwei Gruppen von 3 und 4 Bildern diebei 2 Sitzungen im Abstand von einem Monat aufgenommen wurden Ins-gesamt enthalt die CASIA Datenbank also 756 Bilder Die Bilder wurdenspeziell fur die Forschung an Iriserkennungssystemen mit einer eigens vomNational Laboratory of Pattern Recognition entwickelten digitalen Optikaufgenommen Die Bilder stammen zum Grossteil von Personen asiatischerAbstammung mit sehr dunkel pigmentierten Iriden und schwarzen Wim-pern Da die Bilder bei Nahe-Infrarot Beleuchtung aufgenommen wurdenist die Iris dennoch sehr gut sichtbar und die Kontraste zwischen Iris undPupille sehr gut und zwischen Iris und Sclera grossteils gut
Da die CASIA Datenbank eine ausgesprochene Testdatenbank ist sind vielBilder inkludiert die ein Iriserkennungssystem auf die Probe stellen sol-len Man sollte deshalb auch nicht erwarten dass es moglich ist alle Bilderperfekt zu erkennen Abbildung 83 auf der nachsten Seite zeigt einige be-sonders extreme Beispiele die diesen Punkt unterstreichen sollen Man mussmit sehr unterschiedlichen Pupillengrossen teilweise sehr starken und vonBild zu Bild sehr unterschiedlichen Uberdeckungen durch Wimpern und Au-genlider und rotierten Bildern rechnen
Auf Grund dieser anspruchsvollen Bildauswahl in der CASIA Datenbankkonnten nur 550 Bilder von 95 Personen verwendet werden da festgestelltwurde dass schon sehr kleine Segmentierungsfehler eine Erkennung starkbehindern Es sei darauf hingewiesen dass mehr als die verwendeten 550Bilder richtig segmentiert wurden insgesamt ca 600 fur Tests mit der Da-tenbank war es allerdings notwendig dass mindestens 5 der 7 Bilder zu einerPerson richtig segmentiert wurden Deshalb wurden teilweise richtig segmen-tierte Bilder nicht fur die Tests verwendet Trotzdem sollte diese Menge anBildern fur eine Leistungsbewertung ausreichend sein
84 Parametertests
Da eine Auflistung und Besprechung der Fulle der Parametersetzungen diebis zur korrekten Segmentierung eines Bildes notig sind im Rahmen ei-ner Arbeit die sich mit einer Bewertung der Principal Component Analysisbeschaftigt zu umfangreich und fur des Thema nicht interessant ware sol-len hier nur Parametersetzungen besprochen werden die die PCA und dieKlassifizierung direkt betreffen Parameter die also anschliessend an eine
84 PARAMETERTESTS 65
(a) Durchschnittliches Bild (b) Extrem uberdeckt
(c) Sehr gute Qualitat (d) Stark rotiert
(e) Sehr grosse Pupille (f) Massiger Kontrast
Abbildung 83 Einige Beispielbilder aus der CASIA Datenbank
66 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
korrekte Segmentierung ausschlaggebend fur die Qualitat der Erkennungsind
Wichtige Schlusselparameter sind
bull Abmessungen des Irisstreifens (xis yis)
bull Abmessungen der Uberdeckungen fur unteres und oberes Augenlid imVerhaltnis zum Irisstreifen (xul yul) und (xol yol)
bull Anzahl der Shifts um Rotationen auszugleichen (ns)
bull Anzahl der Augen furs Enrollment (neyes)
bull Anzahl der verwendeten Eigenvektoren (pEV )
Zur Parameteroptimierung der ersten 3 Parameter wurden 95 Personen ausder CASIA Datenbank mit je einem Bild aus der ersten Sitzung im Systemgespeichert und anschlieszligend 95 Bilder der gleichen Personen aus der zwei-ten Sitzung damit verglichen Dabei wurden verschiedene Maszlige wie die An-zahl der Fehlerkennungen der Mittelwert und die Standardabweichung derIntraclass- und Interclass-Verteilung und die Decidability erhoben und so dieoptimalen Parametereinstellungen ermittelt Ausgehend von Schatzwertenfur die noch nicht optimierten Parameter wurden die Parameter schrittwei-se optimiert Die genauen Tests zu den einzelnen Parametern sind in denfolgenden Kapiteln zusammengefasst Dazugehorige Tabellen und Diagram-me sind in Anhang A zusammengefasst
841 Abmessungen des Irisstreifen
Faktoren welche die Qualitat der Erkennung signifikant beeinflussen sinddie radiale und angulare Auflosung des Irisstreifens der fur die Erkennungverwendet wird weil dadurch die Menge an Daten die zur Erkennnung zurVerfugung steht gesteuert wirdDeshalb wurde hier nicht wie bei anderen Parametern von Schatzwertenausgehend optimiert sondern eine genaue Untersuchung uber einen sehrgroszligen Parameterbereich durchgefuhrt Als Qualitatsmaszlig wurde die zuvorbesprochene Decidability verwendet Die Ergebnisse der vielversprechendenRegionen sind in Anhang A in Tabellen A1 auf Seite 84 und A2 auf Seite 85und Abbildungen A1 auf Seite 84 und A2 auf Seite 85 zusammengefasst
Tabelle A1 auf Seite 84 zeigt eine grobe Suche nach den optimalen Abmes-sungen des Irisstreifens Bei einer angularen Auflosen von 300 Pixel und einerradialen Auflosung von 200 Pixel findet man das Optimum fur die Decida-bility bei diesen Parametersetzungen Tabelle A2 auf Seite 85 untersuchtgenauer den Bereich rund um das Optimum das zuvor bei der Grobsuche
84 PARAMETERTESTS 67
gefunden wurde
Das Optimum fur die radiale bzw angulare Auflosung das bei der Feinsu-che gefunden wird liegt bei xis = 340 und yis = 170 Dieses Ergebnis istinteressant da bei anderen Systemen zum Beispiel nach Boles [WB98] Lim[Lim01] oder Daugman [Dau02] immer mit kleineren Auflosungen fur denIrisstreifen gearbeitet wurde So spricht Boles von einer radialen Auflosungvon 45 Pixel Lim 60 Pixel und Daugman von ca 100 - 140 Pixel AuflosungEs bleibt die Frage offen ob bei anderen Systemen nicht in diese Richtungoptimiert wurde oder ob andere Systeme mit kleineren Auflosungen arbei-ten konnen
842 Abmessungen der Uberdeckungen fur Augenlider
Da bei allen Bildern der Augen in der CASIA Datenbank verschieden groszligeUberdeckungen durch Augenlider auftreten ist es nicht trivial eine passen-de Groszlige fur die Bereiche die aus dem Bild ausgeschnitten werden zu fin-den Wurde man die Bereiche an die groszligte auftretende Uberdeckung durchdas obere und untere Augenlid angepasst wahlen wurde man in allen Bil-dern viel Information durch die zu groszlig ausgeschnittenen Bereiche verlierenWahlt man die Bereiche sehr klein wurde der Storeinfluss der Augenliderim Bild ansteigen Es muss also ein Kompromiss bei der Wahl der Groszligeder ausgeschnittenen Bereiche gefunden werden Deshalb wurde auch dieoptimale Groszlige der beide Bereiche experimentell ermittelt Ausgehend vonSchatzwerten wurden die Bereiche fur das obere und das untere Augenlidseperat ermittelt In einer groben und einer feinen Suche wurde fur beideAugenlider die optimale Grosse der Uberdeckung bestimmt Qualitatsmaszligist auch hier wieder die Decidability
Fur das untere Augenlid wurde ein Bereich von 70 - 150 Pixel angulareund 10 - 50 Pixel radiale Auslosung untersucht was etwa 41 - 88 derGesamthohe und 3 - 15 der Gesamtbreite des Irisstreifens entsprichtDas entspricht nach Beobachtung der ungefahren Groszlige der Uberdeckungendurch Augenlider in den Bildern der CASIA Datenbank Wie vermutet er-gab sich als optimale Groszlige nicht ein Bereich der alle Augenlider ganzlichausschneidet sondern eine Uberdeckung von 7 times 76 Das entspricht 25times 130 Pixel Auflosung und somit nur einem durchschnittlich groszligen ausge-schnittenen Bereich der in vielen Bildern nicht das gesamte Augenlid ent-fernt Die genauen Ergebnisse sind wiederum Anhang A Tabellen A3 aufSeite 86 und A4 auf Seite 87 sowie Abbildungen A3 auf Seite 86 und A4 aufSeite 87 zu entnehmen
Fur das obere Lid wurde der Bereich zwischen 100 und 165 Pixel also 59- 97 angularer und 50 - 80 Pixel also 15 - 24 radialer Auflosung un-
68 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
tersucht Optimal ist eine Auflosung von 19 times 91 also 65 times 155 PixelDieser Bereich uberdeckt praktisch alle Augenlider mit Ausnahme der Wim-pern komplett Die Ubersicht ist in Tabellen A5 auf Seite 88 und A6 aufSeite 89 sowie Abbildungen A5 auf Seite 88 und A6 auf Seite 89 zu finden
843 Anzahl der Shifts
Durch Verschieben (Shiften) des Irisstreifens um einige Pixel nach links oderrechts wird versucht leichten Rotationen des Kopfes bei der Aufnahme desAuges entgegenzuwirken Beim Uberblenden zweier Irisstreifen kann manfast immer feststellen dass durch eine leichte Verschiebung die Uberein-stimmung verbessert werden kann Je besser dadurch die Ubereinstimmungwird desto kleiner wird der mittlere Intraclass-Abstand der Bilder und dieStreuung der Werte in der Intraclass-Verteilung
Anhand von Abbildungen 84 auf der nachsten Seite und 85 auf der nachstenSeite kann man diesen Effekt beobachten In Abbildung 84 auf der nachstenSeite wurden keine Shifts vorgenommen Dem entsprechend ist die darge-stellte Intraclass-Verteilung relativ breit gestreut da viele Irisstreifen nichtkorrekt ubereinander liegen In Abbildung 85 auf der nachsten Seite hin-gegen wurden zwei Shifts nach links und rechts vorgenommen Man kanndeutlich erkennen dass die Verteilung jetzt eine kleinere Streuung aufweistda die Irisstreifen jetzt besser zu einander passen
Die erreichbare Qualitatssteigerung durch Verschieben des Irisstreifens lasstsich somit am besten an der Veranderung des Mittelwerts und der Standard-abweichung der Intraclass-Verteilung beobachten Gesucht wird das Mini-mum fur diese beiden Werte
Abbildungen A7 auf Seite 90 und A8 auf Seite 90 und Tabelle A7 aufSeite 91 zeigen die Entwicklung von Mittelwert und Standardverteilung beiansteigender Anzahl von Shifts Das Minimum und somit die besten Ergeb-nisse werden bei zwei Shifts erreicht
84 PARAMETERTESTS 69
Abbildung 84 Intraclass-Verteilung ohne Shifts
Abbildung 85 Intraclass-Verteilung mit 2 Shifts
70 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
844 Anzahl der Augen furs Enrollment
Abgesehen von reinem Parametertuning gibt es noch eine weitere sehr ein-fache Moglichkeit die Qualitat und Sicherheit der Erkennung zu steigernWerden beim Enrollmentprozess fur eine Person mehrere Bilder pro Auge- bevorzugt unter leicht unterschiedlichen Bedingungen - gespeichert so istes wahrscheinlicher dass beim spateren Vergleich das Auge wiedererkanntwird Bei der Gesichtserkennung mittels PCA ist es ublich zwischen 3 und16 Bilder des gleichen Gesichtes bei zum Beispiel unterschiedlicher Beleuch-tung verschiedener Kopfhaltung oder variablem Abstand von der Kamerains System aufzunehmen
Die Iris bietet vergleichsweise weniger Variationsmoglichkeiten und es wirdauch viel Aufwand bei der Normierung der Bilder betrieben trotzdem konnenBeleuchtung Pupillengrosse Augenlider und Rotation des Kopfes immernoch als Storfaktoren wirken Deshalb ist auch hier die Verwendung vonmehreren Augen zum Vergleich interessant
Es soll also untersucht werden wieviele Aufnahmen notig sind um alle Au-gen im Testdatensatz richtig zuzuordnen Dafur wird der Schwellwert nachdem sich FAR und FRR richten so hoch eingestellt dass die FRR = 0 ist(siehe Abbildung 82 auf Seite 63) Wie bereits erwahnt wurde wurden inden Testdatensatz nur Personen aufgenommen bei denen es moglich warmindestens 5 der 7 Aufnahmen richtig zu segmentieren So konnen 1 bis 4Bilder beim Enrollment abgepeichert werden und jeweils 1 Bild kann damitverglichen werden
Ziel ist es eine moglichst klare Unterscheidung zwischen Intra- und Inter-class Verteilung zu erreichen Abbildung A9 auf Seite 92 zeigt die beidenVerteilungen in einem Diagramm zusammengefasst Dafur wurden die bei-den Haufigkeitsachsen auf einheitliche Groszlige skaliert Man kann beobach-ten dass bei steigender Anzahl von Augen die beim Enrollment gespeichertwerden die Uberlappung zwischen den beiden Klassen immer kleiner wirdDabei ist zu beachten dass nur die Groszlige des Bereich der UberschneidungAussagekraft hat Die Haufigkeit hat auf Grund der Anpassung der Skalenkeine Bedeutung Aus Tabelle A8 ist anhand der Decidability ersichtlichdass die besten Ergebnisse bei 4 (oder mehr) Augen zu erwarten sind Daaber bereits bei 3 Augen eine FAR von 0 und eine FRR von 0 erreichbarist und jedes Auge mehr einen groszligeren Rechenaufwand bedeutet werden 3Augen furs Enrollment als idealer Wert angenommen
84 PARAMETERTESTS 71
845 Anzahl der verwendeten Eigenvektoren
Dieser Parameter nimmt einen besonderen Platz in der Liste der hier be-sprochen Parameter ein Er dient als einziger nicht dazu die Qualitat derErkennung zu steigern sondern um die Berechnung zu beschleunigen unddie Templates effzienter zu speichern Es soll festgestellt werden wievieleEigenvektoren fur die Berechnung der PCA ausser Acht gelassen werdenkonnen bevor ein Absinken der Qualitat der Erkennung bemerkbar wirdFur Details sei auf das Kapitel zur Principal Component Analysis 51 aufSeite 41 verwiesen hier nur die wichtigsten Fakten
Da die Eigenvektoren verschieden wichtig fur die Rekonstruktion der Origi-nalbilder sind ist es moglich die unwichtigsten nicht in die Berechnung derbiometrischen Templates mit einzubeziehen Ihre Wichtigkeit wird anhandder Varianz gemessen die sie erklaren Gesucht ist die Anzahl der Eigen-vektoren die gestrichen werden konnen wenn ein bestimmter Prozentsatzder Varianz erklart werden soll Abbildung 86 zeigt in einem sogenann-ten Scree-Plot wieviel Prozent der Gesamtvarianz die Eigenvektoren nachGroszlige geordnet erklaren Man kann erkennen dass die Eigenvektoren sehrschnell an Bedeutung fur die Rekonstruktion verlieren
Abbildung 86 Prozent der Gesamtvarianz die durch die einzelnen Eigen-vektoren erklart wird
Wenn also nicht alle Eigenvektoren gespeichert werden mussen lasst sicheinen Datenreduktion und ein Geschwindigkeitszuwachs bei der Berechnung
72 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
des Templates erreichen Auszligerdem kann auch das Template kompakter ge-speichert werden da es die Koeffizienten enthalt mit denen aus den Eigen-vektoren das Originalbild berechnet werden kann
Man muss sich allerdings daruber im Klaren sein dass man Informationverliert und so die Qualitat der Erkennung sinkt Tabelle A9 auf Seite 93zeigt die Entwicklung von FAR und FRR und die Zahl der verwendeten Ei-genvektoren in Abhangigkeit von den Prozent der erklarten Varianz (PoV)Will man keine Qualitatseinbuszligen hinnehmen konnen also nur 3 der Ei-genvektoren vernachlassigt werden Bei den 285 dem Testsystem bekanntenAugen sind das nur 7 Eigenvektoren
Aus anderen Quellen die sich allerdings mit Gesichtserkennung beschaftigenist bekannt dass teils nur die Eigenvektoren die 90 der Varianz erklarenverwendet werden Es kann nur angenommen werden dass entweder eineumfangreichere Datenbank notig ist um diesen Vorteil bei der Berechnungder PCA sinnvoll nutzen zu konnen oder was wahrscheinlicher ist die Va-riation von Gesicht zu Gesicht kleiner ist als die zwischen verschiedenenAugen und deshalb mehr Eigenvektoren zur korrekten Rekonstruktion notigsind
Hier ist der Vorteil relativ klein Ein Eigenvektor benotigt 145 KilobytePlatz bei 7 nicht verwendeten Eigenvektoren kann also ca 1 MegabyteSpeicherplatz gespart werden Das Template wird um 56 Byte kleiner esschrumpft also in der Gesamtgroszlige von 2280 Byte auf 2216 Byte Insgesamtsind das ca 16 Kilobye Platzersparnis Ein Geschwindigkeitsgewinn ist kaummessbar Erst wenn mehr als 10 der Eigenvektoren vernachlassigt werdenist ein wirklicher Vorteil erkennbar
85 Zusammenfassung
Zusammengefasst ergibt sich dass eine Auflosung von 340 times 170 Pixel opti-mal fur die Groszlige der Irisstreifen ist Die halbe Ellipse die als Uberdeckungfur das untere Lid dient sollte 25 times 130 Pixel oder 7 times 76 der Gesamtab-messungen des Irisstreifens messen Fur das obere Lid sind die Masse 65 times155 oder 19 times 91 am besten geeignet Zum Ausgleichen von Rotationendes Kopfes bei der Bildaufnahmen wird der Irisstreifen beim Matching 2 Pi-xel nach links und rechts verschoben Beim Enrollment muss das System mitmindestens 3 Augen pro Person trainiert werden um alle Personen richtigzuzuweisen Hier werden 3 Augen verwendet um die Erkennungsgeschwin-digkeit hoch zu halten Die Anzahl der fur die PCA verwendeten Eigenvek-toren richtet sich nach dem Prozentsatz der durch sie erklarten Varianz Beieiner erklarten Varianz von 997 das bedeutet dass 3 der Eigenvektoren
85 ZUSAMMENFASSUNG 73
nicht verwendeten werden (vergleiche Tabelle A9 auf Seite 93) ist noch einefehlerfreie Erkennung moglich
So wie das System aktuell konfiguriert ist wird von einer Identifikations-aufgabe ausgegangen es sucht beim Matching nach der wahrscheinlichstenUbereinstimmung ohne Rucksicht auf die Sicherheit mit der diese kor-rekt ist Der Grenzwert ab dem ein Template abgelehnt wird egal ob dieUbereinstimmung richtig war oder nicht liegt so hoch dass die FRR = 0ist Das kann bei bestimmten Anforderungen ausreichend sein ublicher istes allerdings dass das Matching auch mit einer gewissen Sicherheit durch-gefuhrt werden soll
Um fur alle Anforderungen geeignet zu sein und eine finale Leistungsbe-wertung abgeben zu konnen wird daher der Punkt gesucht an dem FalseRejection Rate (FRR) und False Acceptance Rate (FAR) gleich groszlig sindder Punkt der Equal Error Rate (EER) Dabei geht man nicht mehr voneiner Identifikation aus sondern von einer Verifikation Es wird also nichtmehr das am besten passende Template gesucht sondern nur mehr vergli-chen ob ein Template einen Abstand hat der hoher oder niedriger als derSchwellwert ist Templates unter dem Schwellwert werden akzeptiert Tem-plates uber dem Schwellwert abgelehnt
Tabelle 81 auf der nachsten Seite zeigt die False Acceptance und RejectionRates fur verschiedene Wertsetzungen des Schwellwertes der uber Akzep-tanz oder Ablehnung des Templates entscheidet Dabei wurden im Unter-schied zur vorangegangenen Parameteroptimierung 255 Bilder der Augender 95 bekannten Personen mit den im System gespeicherten Bildern ver-glichen Abbildung 87 auf der nachsten Seite stellt den Verlauf von FARund FRR grafisch dar und kennzeichnet den Punkt der EER Diese liegt bei04 und lasst durchaus gute Erkennnungsleistungen zu
Ein direkter Leistungsvergleich mit Daugmans System ist schwer da nichtbekannt ist welcher Datensatz zum Test des Systems verwendet wurdeGlucklicherweise fand sich bei der Literaturrecherche zu diesem Thema eineArbeit [Mas03] von Libor Masek einem Studenten der University of We-stern Australia School of Computer Science and Software Engineering Erhat es sich zur Aufgabe gemacht Daugmans Methode zur Berechnung desTemplates dem Iriscode nachzuimplementieren und einer transparenterenLeistungbewertung zu unterziehen Masek verwendet zum Test seines Sy-stems ebenfalls die CASIA Datenbank Ihm war es moglich eine FRR von0005 bei einer FAR von 0238 zu erreichen Auch Masekrsquos System konntedabei mehr als 100 Augen in der Datenbank nicht korrekt segmentieren wes-halb sicherlich auch nicht der exakt gleiche Testdatensatz verwendet wurdeTrotzdem sollen die folgenden Werte als ungefahres Vergleichsmaszlig zwischen
74 KAPITEL 8 EXPERIMENTELLE ERGEBNISSE
Threshold FAR FRR
1000 000 5490
1050 000 4353
1100 000 3765
1150 000 2863
1200 001 2353
1250 002 1804
1300 004 1255
1350 007 1098
1400 013 667
1450 021 314
1500 038 078
1515 043 039
1550 057 039
1600 085 039
1650 127 000
1700 181 000
1750 252 000
1800 334 000
1850 441 000
1900 553 000
Tabelle 81 False Acceptance Rate und False Rejection Rate bei unterschied-lichen Schwellwerten (EER ist in Fettdruck gekennzeichnet)
Abbildung 87 Verlauf von FAR und FRR bei verschiedenen Schwellwerten
85 ZUSAMMENFASSUNG 75
der etablierten Methode des Iriscodes und der hier vorgestellten Anwendungder PCA fur Iriserkennung dienen
Da Masek leider keine EER angibt wurde versucht die FAR und FRR inungefahr gleiches Verhaltnis zu bringen So ergibt sich fur das hier vorge-stellte System bei einer FRR von 0 eine FAR von 096 Will man eineFAR von 023 erreichen so liegt die FRR bei 196
Es kann also festgestellt werden dass die PCA zwar nicht ebenso gut funk-tioniert wie der derzeit beste Ansatz zur Identifikation via Irismuster JohnDaugmans Iriscode aber im Vergleich zu anderen Iriserkennungssystemenund besonders im Vergleich zu anderen biometrischen Merkmalen eine guteAlternative darstellt Dabei ist naturlich zu beachten dass der hier vor-gestellte Ansatz noch jung ist John Daugmans System wurde uber Jahreweiterentwickelt und optimiert
Kapitel 9
Abschluss
91 Zusammenfassung
In der vorliegenden Arbeit wurde ein System zur Erkennung von Irismusternzum Zweck der biometrischen Identifikation vorgestellt Ziel war es zu zei-gen dass die Principal Component Analysis (PCA) dafur geeignet ist einbiometrisches Template zu erstellen anhand dessen verschiedene Iriden miteinander verglichen und so von einander unterschieden werden konnen
Es wurde eine Technik zur Bildaufnahme vorgestellt die es erlaubt Bilderdes Auges unter vorteilhaften Bedingungen zu gewinnen Dafur wurde dasAuge von beiden Seiten mit einer Halogenlampe angestrahlt und mit einerDigitalkamera aus ca 30cm Abstand photographiert
Anschliessend an die Bildaufnahme wurden verschiedene Vorverarbeitungs-schritte durchgefuhrt um das Bild auf die automatisierte Weiterverarbei-tung vorzubereiten
Der nachste Schritt war die Anwendung eines Algorithmus zur automatisier-ten Lokalisierung von Iris und Pupille im Bild Es wurde ein Filter zur Kan-tendetektion und die Circular Hough Transformation eingesetzt um Kreisean die Grenzen zwischen Pupille und Iris beziehungsweise Iris und Leder-haut anzupassen
Zur Extraktion der fur die Iriserkennung wichtigen Daten und der weiterenNormalisierung des Bildes wurde mittels einer Rubbersheet Transformati-on der kreisformige Bereich der Iris in einen Streifen einheitlicher Breiteund Hohe transformiert
Um den fur die Erkennnung hinderlichen Einfluss der Augenlider zu lindernwurden zwei Bereiche die oberes und unteres Augenlid umfassen aus dem
77
78 KAPITEL 9 ABSCHLUSS
Bild entfernt
Schlieszliglich wurde die PCA dazu verwendet fur jedes Auge ein biometrischesTemplate zu berechnen Die euklidische Distanz zwischen den Templatesdient dabei als Unterscheidungsmaszlig
In einer statistischen Auswertung unter der Verwendung der CASIA Iristest-datenbank wurde festgestellt dass die PCA geeignet ist als Grundlage furein biometisches Iriserkennungssystem zu dienen Das System erreicht eineEqual Error Rate von 04
92 Erkenntnisse aus der Arbeit
Im Zuge der Arbeit hat sich herausgestellt dass die wichtigsten Punkte beimErkennungsprozess die Bildaufnahme und die Segmentierung sind Qualita-tive Mangel die bei der Bildaufnahme entstehen konnen spater kaum nochausgeglichen werden Besonders negativ wirken sich dabei Unscharfen ausda die feinen Muster der Iris schon bei geringer Defokussierung nicht mehrklar erkenntlich sind Auch anderen uberraschenden Einflussen wie zumBeispiel dem Schattenwurf der Augenlider oder Reflexionen durch das helleGehause der zur Bildaufnahme verwendeten Kamera muss unbedingt entge-gengewirkt werden
Die Segmentierung stellt ebenfalls eine grosse Herausforderung fur ein au-tomatisiertes System dar Bei einem Datensatz wie er vom Autor erstelltwurde der sehr gunstige Verhaltnisse fur die Erkennung bietet ist eine ho-he Erfolgsrate bei der Segmentierung moglich Bei der CASIA Datenbankallerdings die speziell dazu entwickelt wurde Iriserkennungssyteme auf dieProbe zu stellen ist das allerdings bedeutend schwieriger So konnten trotzgroszligem Aufwand und viel Detailarbeit nur ca 80 der Bilder korrekt seg-mentiert werden Das liegt groszligteils an Uberdeckungen durch Augenliderund Wimpern aber auch an teils schlechten Kontrastverhaltnissen wieder-um Storeinflusse denen schon bei der Bildaufnahme begegnet werden mussArbeitet man dann auf einem Datensatz mit optimal aufbereiteten Bildernist einen hohe Erkennungsrate moglich
Weiters interessant sind zwei eher kleine Details Erstens stellte sich aufGrund einer sehr breiten Suche nach den optimalen Abmessungen fur denIrisstreifen heraus dass die besten Ergebnisse nicht mit den realen Langen-zu Breitenverhaltnissen etwa 81 bis 101 erreichbar sind Am besten eig-net sich hier interessanterweise ein Verhaltnis von 21 Die Vermutung desAutors ist dass bei diesem Seitenverhaltnis die Muster der Iris deutlicherhervortreten als bei den originalen Seitenverhaltnissen
92 ERKENNTNISSE AUS DER ARBEIT 79
Der zweite Punkt betrifft ein Detail der PCA In verschiedenen Litera-turquellen ist zu lesen dass bei der Anwendung der PCA im Bereich derGesichtserkennung nur die Eigenvektoren die 90 der Gesamtvarianz auf-klaren zur Rekonstruktion der Originalbilder verwendet werden Hier wurdeallerdings festgestellt dass fur einen Rekonstruktion ohne Qualitatsverlust997 der Gesamtvarianz durch die verwendeten Eigenvektoren erklart seinmuss
Ausserdem sind noch zwei Einschrankungen bei der Verwendung der PCAaufgefallen Wie schon an anderer Stelle ausfuhrlich erlautert wurde ist esnicht sinnvoll die storenden Augenlider und Wimpern exakt zu entfernen dader entfernte Bereich im Unterschied zu zB Daugman immer gleich groszligsein muss Daugman hat den Vorteil dass immer nur zwei Templates vergli-chen werden Die Uberdeckungen konnen exakt berechnet und nicht in denVergleich beider Bilder einbezogen werden Will man die PCA nicht fur jedenVergleich neu berechen muss man immer mit den gleichen Uberdeckungenvergleichen Inwieweit sich dieser Nachteil auf die Erkennungsleistung aus-wirkt ist leider nicht bekannt
Der zweite Kritikpunkt im Umgang mit der PCA betrifft den hohen Auf-wand bei deren Berechnung Da hier die theoretische Moglichkeit unter-sucht wurde die PCA fur die Iriserkennung einzusetzen wurde das Sy-stem auf optimale Erkennungsleistungen getrimmt Eine hohe Erkennungs-geschwindigkeit war dabei nicht das Ziel Trotzdem soll erwahnt sein dassdie PCA im Punkt Geschwindigkeit entscheidende Nachteile gegenuber an-deren Ansatzen hat Daugman gibt an dass die Berechnung des Iriscodesauf einer 300 MHz Sun Workstation ca 100 ms dauert [Dau02] Einen Be-nutzer neu in die Datenbank aufzunehmen dauert ca 500 ms
Wird unter Verwendung der PCA ein Benutzer neu in das System aufge-nommen sollte1 die PCA neu berechnet werden Das bedeutet dass fur denneuen Benutzer nicht unabhangig von allen anderen Benutzern ein Templa-te berechnet und abgespeichert werden kann sondern dass die Templatesaller Benutzer neu berechnet werden mussen Je nach Anzahl der Benutzerund Templategroszlige bedeutet das dass mehrerer Rechenschritte mit Matri-zen mit sehr groszligen Dimensionen durchgefuhrt werden mussen (Bei 500Benutzern und der hier benutzten Templategrosse zum Beispiel eine Ma-trixmulitplikation von zwei Matrizen mit 500 times 21100 Eintragen)Auch wenn nur ein Template fur einen unbekannten Benutzer berechnet
1Sind dem System bereits sehr viele Benutzer bekannt kann das Template auch ausden bisher berechneten Eigenvektoren erstellt werden Die PCA muss also nicht unbedingtfur jeden neuen Benutzer neu berechnet werden da sich die Eigenvektoren durch einenneuen Benutzer bei vielen bestehenden Benutzern nicht wesentlich andern
80 KAPITEL 9 ABSCHLUSS
werden soll beinhaltet das Berechnungen mit einer Matrix derselben Di-mension Selbst auf einem Rechner mit 2 GHz Takt dauert das ca 1 s DerAufwand zur Templateberechnung ist also nicht vergleichbar
Fur Echtzeitsysteme ist die PCA derzeit also nicht geeignet
93 Zukunftige Arbeit
Obwohl das System gut funktioniert gibt es noch einige Punkte die ange-merkt werden sollten oder Ansatze zu weiteren Verbesserungen des Systemsbieten
Wie im letzten Abschnitt erklart wurde ist die PCA sehr rechenintensivIm Zuge dieser Arbeit wurde das Hauptaugenmerk auf die Qualtitat der Er-kennung gelegt In einer zukunftigen Weiterentwicklung konnten einerseitsOptimierungsmoglichkeiten im Code gesucht werden welche die Berechnungbeschleunigen Interessanter ware es allerdings Parameter zu suchen diegute nicht perfekte Erkennungsleistungen zulassen dabei aber einen Ge-schwindigkeitsvorteil versprechen Das groszligte Potenzial bieten dabei die Lo-kalisierung und die PCA selbst
Weiters verbesserungswurdig ist die Bildaufnahme Hier wurde mit einfa-chen Mitteln gearbeitet Im direkten Vergleich zwischen den fur die Arbeitaufgenommenen Bilderen und den Bildern in der CASIA Datenbank falltzum Beispiel auf dass die Beleuchtung im Nahe-Infrarot Bereich bessere Er-gebnisse zulasst als die Beleuchtung mit Halogenstrahlern auch wenn dieQualitat immer noch ausreichend ist Auszligerdem wurde der Einsatz einerCRT-Kamera in Verbindung mit einem Framegrabber anstatt einer Digi-talkamera die Bedienung erleichtern
Letztlich beinhaltet das System keine Sicherheitsmechanismen die ein um-gehen der Iriskontrolle verhindern sollen Beim aktuellen Aufbau ist die Ge-fahr der Umgehung aber relativ klein da bei der Bildaufnahme ein Betreiberanwesend sein mussSollte das System allerdings vollautomatisch zum Bespiel fur Zugangskon-trollen eingesetzt werden so musste es gegen verschiedene Gefahren abge-sichert werden Die Iris ist glucklicherweise was ihre Falschung anbelangtvon sich aus ein eher sicheres Merkmal Bisher sind nicht besonders vieleAngriffe bekannt mit denen ein Iriserkennungsystem erfolgreich getauschtwerden kann All diesen Angriffen kann mittels realtiv einfachen Life-Checksentgegengewirkt werden sofern eine Videosequenz des prasentierten Augesuntersucht werden kann
93 ZUKUNFTIGE ARBEIT 81
Denkbare Angriffe sind der Versuch das System mit einem Photo oder ei-ner Videosequenz eines anderen Auges zu tauschen Eine andere Moglichkeitsind undurchsichtige Kontaktlinsen die mit dem Muster einer fremden Irisbedruckt sind
Gegenmaszlignahmen sind zum Beispiel ein zeitlich zufallsgesteuerter Luftstoszligder das Auge zum Zwinkern anregt oder gezielte Beleuchtung unter Be-obachtung der Pupille die sich dabei verengen sollte Weiters kann auchein Punkt projeziert werden dessen Bewegung der Benutzer mit dem Augefolgen mussWildes [Wil97] berichtet dass sich die Pupille standig mit einer Frequenzvon ca 05Hz etwas weitet und wieder verengt was ein Photo ebenfalls alsFalschung entlarven wurde
Es gibt also sollte die Notwendigkeit entstehen viele Moglichkeiten das Sy-stem gegen Eindringlinge abzusichern Auszligerdem muss auch bedacht wer-den dass es im Unterschied etwa zu Fingerabdrucken Unterschriften oderDNA alleine schon schwer ist ohne das Wissen des Betroffenen ein Abbilddes Auges von ausreichender Qualitat zu gewinnen
Anhang A
Tabellen und Diagramme
83
84 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A1 Decidability bei einer groben Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
80 100 120 140 160 180 200 220 240
100 20900 20327 19940 21540 21181 20954 20230 19849 19921
200 23530 22129 22688 23687 23214 22040 22197 22595 22870
300 23426 24512 23781 23379 23703 24323 24560 23993 23767
400 24066 23824 23285 24237 23900 24009 23701 23045 23664
500 23509 22940 23836 23493 23415 22848 23000 23441 23926
600 22665 23777 23376 22797 22793 23292 23716 23307 23378
Tabelle A1 Decidability bei einer groben Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
85
Abbildung A2 Decidability bei einer feinen Suche nach den besten Ab-messungen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol =95 ns = 2 pEV = 1 neyes = 1
60 70 80 90 100 110 120 130 140
220 23598 23685 23386 22798 22868 22868 23668 23970 23970
240 24236 23591 23295 23321 23185 24118 24299 23975 23399
260 24075 23399 22862 23108 24132 24252 24099 23890 23515
280 23918 23635 23268 23873 24467 24293 23836 23598 23673
300 23891 23499 23426 24276 24512 24032 23781 23592 23379
320 23529 23321 24105 24533 24301 23793 23701 23482 23274
340 23694 23215 24281 24588 24139 23996 23472 23333 23427
360 23462 23711 24116 24200 24080 23856 23650 23444 24010
380 23241 23824 24099 23635 23757 23623 23201 23797 23966
150 160 170 180 190 200 210 220 230
220 23589 22694 22750 22745 23150 23035 22573 22986 23583
240 23397 23360 23270 23010 22866 23010 23943 24064 24197
260 22908 23300 23002 23197 23701 24123 24229 24406 24208
280 23217 23124 23508 24124 24112 24393 24579 24273 23992
300 23378 23703 24121 24323 24589 24560 24436 23993 23825
320 23631 24126 24315 24583 24584 24251 23960 23907 23724
340 24208 24407 24634 24447 24265 24015 23956 23909 23751
360 23980 24285 24244 24079 24083 24083 23796 23702 23539
380 24239 24177 24076 24132 24092 23787 23675 23498 23338
Tabelle A2 Decidability bei einer feinen Suche nach den besten Abmessun-gen des Irisstreifens mit xul = 625 yul = 59 xol = 20 yol = 95 ns =2 pEV = 1 neyes = 1
86 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A3 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
41 47 53 59 65 71 76 82 88
3 23003 23122 23245 23563 23751 23900 23920 24096 24082
6 23687 23904 24084 24621 24713 24862 24979 25058 25264
9 23920 24026 23726 24707 25259 25556 25454 25298 25081
12 23753 23586 24012 24413 24494 24280 24134 23516 23366
15 23745 24070 24683 24335 23771 23066 22453 22349 21811
Tabelle A3 Decidability bei einer groben Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
87
Abbildung A4 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
65 68 71 74 76 79
6 24713 24845 24862 24973 24979 24945
7 24772 25207 25392 25483 25647 25558
9 25259 25413 25556 25583 25454 25437
10 24891 24912 25000 24892 24708 24417
Tabelle A4 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das untere Augenlid mit xxs = 340 yys =170 xol = 20 yol = 95 ns = 2 pEV = 1 neyes = 1
88 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
59 65 71 76 82 88 94
15 21595 22887 23590 24372 24919 25169 24930
18 22163 23551 24301 25150 25537 25321 25540
21 22794 23918 24811 25045 25270 25754 25556
24 22975 24733 24990 25149 25412 25527 25170
Tabelle A5 Decidability bei einer groben Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
89
Abbildung A6 Decidability bei einer feinen Suche nach den optimalen Ab-messungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
76 79 82 85 88 91 94 97
17 24642 24889 25493 25471 25687 25335 25465 25285
18 25287 25628 25373 25690 25774 25732 25467 25700
19 25292 25266 25151 25524 26169 26174 25498 25800
21 25303 25155 25350 25513 25441 25759 25647 25567
22 25124 25092 25486 24840 25645 25573 25451 25008
Tabelle A6 Decidability bei einer feinen Suche nach den optimalen Abmes-sungen der Uberdeckungen fur das obere Augenlid mit xxs = 340 yys =170 xul = 7 yul = 76 ns = 2 pEV = 1 neyes = 1
90 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A7 Intraclass-Mittelwert bei verschiedener Anzahl von Shiftsbei optimalen Parametersetzungen
Abbildung A8 Intraclass-Standardabweichung bei verschiedener Anzahlvon Shifts bei optimalen Parametersetzungen
91
Interc-Mean Intrac-Mean Interc-Stdabw Intrac-Stdabw Decidability
0 3302 1913 635 562 24184
1 3316 1856 638 552 24457
2 3332 1778 637 538 26174
3 3336 1788 637 565 25860
4 3336 1799 638 595 24895
5 3336 1798 638 605 24709
6 3334 1801 639 625 24243
7 3334 1803 639 626 24173
8 3335 1806 640 629 24096
9 3337 1822 641 642 23598
10 3336 1820 641 639 23667
Tabelle A7 Auswirkung von Shifts auf verschiedene Optimierungsmaszligzah-len bei optimalen Parametersetzungen
92 ANHANG A TABELLEN UND DIAGRAMME
Abbildung A9 Inter- und Intraclass-Verteilungen bei steigender Anzahl vonAugen furs Enrollment und optimalen Parametersetzungen
Interc-Mean Intrac-Mean Interc-St Intrac-St Decidability FRR FAR1 3380 1538 638 352 33884 000 11582 2954 1158 641 266 36561 000 9473 2826 1017 652 248 36621 000 0004 2749 919 657 218 37306 000 000
Tabelle A8 Anzahl der Augen fur das Enrollment vs verschiedene Opti-mierungsmaszligzahlen bei optimalen Parametersetzungen
93
PoV Anzahl d EV Prozent d EV FRR FAR
9500 202 7088 000 316
9550 208 7298 000 211
9600 215 7544 000 211
9650 222 7789 000 211
9700 229 8035 000 211
9750 236 8281 000 211
9800 244 8561 000 105
9850 253 8877 000 105
9900 262 9193 000 105
9950 273 9579 000 105
9960 275 9649 000 105
9970 277 9719 000 000
9980 280 9825 000 000
9990 282 9895 000 000
10000 285 10000 000 000
Tabelle A9 Prozent der erklarten Varianz vs FRR und FAR bei optimalenParametersetzungen
Literaturverzeichnis
[Cas98] M Casey Auditory Group Theory with Applications to Sta-tistical Basis Methods for Structured Audio Masterrsquos thesisUniversity of East Anglia 1990 Norwich UK 1998 pages 43
[Dau93] J Daugman High confidence visual recognition of persons by atest of statistical independence IEEE Transactions on PatternAnalysis and Machine Intelligence 15 No 11 1993 pages 18
[Dau94] J Daugman Biometric personal identification system based oniris analysis United States Patent Patent No 5291560 1994pages 18
[Dau02] J Daugman How iris recognition works Proceedings of 2002International Conference on Image Processing 1 2002 pages16 17 18 33 37 60 67 79
[Hot33] Harold Hotelling Analysis of complex statistical variables in-to principal components Journal of Educational Psychology24417ndash441 1933 pages 41
[Lex93] Meyers Lexikonredaktion Meyers neues Lexikon Meyers Lex-konverlag 1993 pages 16
[Lim01] S Lim Efficient iris recognition through improvement of featurevector and classifier ETRI Journal 23 No 2 2001 pages 1118 21 22 37 67
[Mas03] L Masek Recognition of human iris patterns for biometric identi-fication Masterrsquos thesis University of Western Australia Schoolof Computer Science and Software Engineering 2003 pages 73
[Noh02] S Noh Multiresolution independent component analysis for irisidentification The 2002 International Technical Conference onCircuit Systems Computers and Communications Phuket Thai-land 2002 pages 18 19
95
96 LITERATURVERZEICHNIS
[oSIoA05] Chinese Academy of Science Institute of Automationhttpwwwsinobiometricscom CASIA Iris Image Data-base 2005 pages 59 64
[Rob04] UTCS Robotics Mahalanobis Distance No Author given 2004pages 52
[Tis02] C Tisse Person identification technique using human iris reco-gnition International Conference on Vision Interface Canada2002 2002 pages 21
[Umb99] S Umbaugh Computer Imaging Digital Image Analysis andProcessing CRC Press 1999 pages 29
[Way02] J Wayman Biometrics and how they work San Jose StateUniversitiy 2002 pages 17
[WB98] B Boashash WW Boles A human identification technique usingimages of the iris and wavelet transform IEEE Trans SignalProcessing 461185ndash1188 No 4 1998 pages 18 67
[Wil97] R Wildes Iris recognition an emerging biometric technologyProceedings of the IEEE 85 No 9 1997 pages 17 18 21 81
[Wol76] E Wolff Anatomy of the Eye and Orbit HK Lewis amp Co LTD7th edition 1976 pages 17
[You04] David Young Computer Vision Lecture 6 The Hough Trans-form Lecture Notes 2004 pages 11 34 35 36
[Zhu99] Y Zhu Biometric personal identification system based on irispatterns Chinese Patent Application No 99110256 1999 pages21
Lebenslauf
Personliche Daten
Name Matthias SchmidlGeburtstag 15 Oktober 1980Geburtsort Kirchdorf an der Krems OsterreichStaatsburgerschaft Osterreich
Bildung
2000ndashjetzt Student der Informatik Johannes-Kepler Universitat Linz1999ndash2000 Zivildienst Rotes Kreuz KirchdorfKrems1991ndash1999 Gymnasium Bundesrealgymnasium KirchdorfKrems1987ndash1991 Volksschule Volksschule II KirchdorfKrems1986ndash1987 Vorschule Volksschule II KirchdorfKrems
Arbeitserfahrung
2000ndash2003 Ars Electronica Center Linz
97
Eidesstattliche Erklarung
Ich erklare an Eides statt dass ich die vorliegende Diplom- bzw Magisterar-beit selbststandig und ohne fremde Hilfe verfasst andere als die angegebe-nen Quellen und Hilfsmittel nicht benutzt bzw die wortlich oder sinngemaszligentnommenen Stellen als solche kenntlich gemacht habe
Linz den 8 Marz 2005
Matthias Schmidl
99
Kolophon
Dieses Dokument wurde mit Aleksander Simoncics WinEdt 531 unter Ver-wendung von LATEX2ε und pdfeTEX von Christian Schenkrsquos MikTEX 222
auf einem Intel Centrino 1500 MHz unter Windows 2000 erstellt
Einige Abbildungen wurden mit Alexander Larsons DIA3 erstellt
Die folgenden LATEX Pakete wurden zum Erstellen dieses Dokuments unddes finalen PDFs verwendet
amsmath American Mathematical Society inputenc Alan Jeffrey Frank Mittelbachbabel Johannes Braams multicol Frank Mittelbach
backref David Carlisle Sebastian Rahtz pdfpages Andreas Matthiascolor David Carlisle psfig Trevor Darrell
graphicx David Carlisle subfigure Steven Cochranhypcap Heiko Oberdiek relsize Donald Arseneau Matt Swift
hyperref Heiko Oberdiek Sebastian Rahtz varioref Frank Mittelbach
1httpwwwwinedtcom2httpwwwmiktexorg3httpwwwgnomeorgprojectsdia
101
- 1 Einleitung
-
- 11 Biometrische Systeme
- 12 Die menschliche Iris
- 13 Iriserkennungssysteme
- 14 Aufgabenstellung
-
- 2 Bildaufnahme
-
- 21 Uumlberblick
- 22 Implementierung
- 23 Qualitaumltskriterien
-
- 3 Vorverarbeitung
-
- 31 Uumlberblick
- 32 Reflexionen entfernen
- 33 Medianfilter
- 34 Histogramm strecken
- 35 Kantenerkennung
- 36 Augenlider entfernen
- 37 Histogram Equalization
-
- 4 Normalisierung
-
- 41 Uumlberblick
- 42 Lokalisierung von Iris und Pupille
- 43 Circular Hough Transformation
- 44 Segmentierung
-
- 5 Principal Component Analysis
-
- 51 Uumlberblick
- 52 Herleitung
- 53 Implementierung
- 54 Beispiel
-
- 6 Klassifizierung
-
- 61 Uumlberblick
- 62 Methoden zur Abstandsberechnung
-
- 7 Systembeschreibung
-
- 71 Uumlberblick
- 72 Implementierung
- 73 Datenspeicherung
-
- 8 Experimentelle Ergebnisse
-
- 81 Uumlberblick
- 82 Maszligzahlen zur Bewertung
- 83 Testdaten
- 84 Parametertests
-
- 841 Abmessungen des Irisstreifen
- 842 Abmessungen der Uumlberdeckungen fuumlr Augenlider
- 843 Anzahl der Shifts
- 844 Anzahl der Augen fuumlrs Enrollment
- 845 Anzahl der verwendeten Eigenvektoren
-
- 85 Zusammenfassung
-
- 9 Abschluss
-
- 91 Zusammenfassung
- 92 Erkenntnisse aus der Arbeit
- 93 Zukuumlnftige Arbeit
-
- A Tabellen und Diagramme
- Lebenslauf
- Eidesstattliche Erklaumlrung
- Kolophon
-