
Palabras clave en el ADN y predicción computacional de elementos reguladores.
30
Otrosc´odigos Clusterizaci´on ADN Retos Grupo Palabras clave en el ADN y predicci´ on computacional de elementos reguladores Jos´ e L. Oliver Grupo de Gen´omica Evolutiva y Bioinform´ atica Dpto. de Gen´ etica Universidad de Granada http://www.ugr.es/˜oliver/ Jos´ e L. Oliver Palabras clave y predicci´on computacional de elementos reguladores
-
Upload
alberto-labarga -
Category
Technology
-
view
1.377 -
download
1
Transcript of Palabras clave en el ADN y predicción computacional de elementos reguladores.

Otros codigos Clusterizacion ADN Retos Grupo
Palabras clave en el ADN y prediccioncomputacional de elementos reguladores
Jose L. Oliver
Grupo de Genomica Evolutiva y BioinformaticaDpto. de Genetica
Universidad de Granadahttp://www.ugr.es/˜oliver/
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Evidencias Funcion y ADN no-codificador
Evidencias de otros codigos en el ADN
Tras la secuenciacion del genoma humano, sabemos que:
Solo hay 20.000-25.000 genes para proteınas
Equivalen al 2 % del genoma
Sin embargo, el 57-80 % del genoma se transcribe
Evidencias indirectas:
ADN no-codificador pero conservado evolutivamenteSeleccion purificadora en el 20-30 % del ADN no-codificador
Hay otras capas de informacion en el genoma
Codigo regulador: promotores, sitios de union a factores detranscripcion o TFBSs, enhancers, represores, microRNAs, RNAi,orıgenes de replicacion, secuencias centromericas, elementos separadores,etc... y los que no conocemos.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Evidencias Funcion y ADN no-codificador
Evidencias de otros codigos en el ADN
Tras la secuenciacion del genoma humano, sabemos que:
Solo hay 20.000-25.000 genes para proteınas
Equivalen al 2 % del genoma
Sin embargo, el 57-80 % del genoma se transcribe
Evidencias indirectas:
ADN no-codificador pero conservado evolutivamenteSeleccion purificadora en el 20-30 % del ADN no-codificador
Hay otras capas de informacion en el genoma
Codigo regulador: promotores, sitios de union a factores detranscripcion o TFBSs, enhancers, represores, microRNAs, RNAi,orıgenes de replicacion, secuencias centromericas, elementos separadores,etc... y los que no conocemos.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Evidencias Funcion y ADN no-codificador
Tres principios para predecir funcion
Sobre-abundancia de ciertas palabras (motifs).
Problema: se asume su independencia, ignorando las relacionesespaciales entre diferentes motivos. Es decir, solo se toman en cuentalas frecuencias de las palabras, pero no su organizacion espacial.
Conservacion evolutiva: las regiones conservadas en distintas especiesdeben tener un papel funcional.
Problema: casi la mitad de los elementos funcionalesno-codificadores en las regiones ENCODE no estan conservadosevolutivamente.
Grupos de genes co-regulados: los genes con el mismo perfil de expresion(activacion/silenciamiento) comparten elementos reguladores.
Problema: incertidumbre en cuanto al numero de grupos,naturaleza combinatoria de la regulacion.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Evidencias Funcion y ADN no-codificador
Tres principios para predecir funcion
Sobre-abundancia de ciertas palabras (motifs).
Problema: se asume su independencia, ignorando las relacionesespaciales entre diferentes motivos. Es decir, solo se toman en cuentalas frecuencias de las palabras, pero no su organizacion espacial.
Conservacion evolutiva: las regiones conservadas en distintas especiesdeben tener un papel funcional.
Problema: casi la mitad de los elementos funcionalesno-codificadores en las regiones ENCODE no estan conservadosevolutivamente.
Grupos de genes co-regulados: los genes con el mismo perfil de expresion(activacion/silenciamiento) comparten elementos reguladores.
Problema: incertidumbre en cuanto al numero de grupos,naturaleza combinatoria de la regulacion.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Evidencias Funcion y ADN no-codificador
Tres principios para predecir funcion
Sobre-abundancia de ciertas palabras (motifs).
Problema: se asume su independencia, ignorando las relacionesespaciales entre diferentes motivos. Es decir, solo se toman en cuentalas frecuencias de las palabras, pero no su organizacion espacial.
Conservacion evolutiva: las regiones conservadas en distintas especiesdeben tener un papel funcional.
Problema: casi la mitad de los elementos funcionalesno-codificadores en las regiones ENCODE no estan conservadosevolutivamente.
Grupos de genes co-regulados: los genes con el mismo perfil de expresion(activacion/silenciamiento) comparten elementos reguladores.
Problema: incertidumbre en cuanto al numero de grupos,naturaleza combinatoria de la regulacion.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Evidencias Funcion y ADN no-codificador
Un nuevo principio para predecir funcion
Basado en la extrapolacion a textos de una tecnica para medir desordenen sistemas cuanticos (Carpena et al., Physical Review E 79, 035102-4, 2009):
Las palabras relevantes/funcionales estan clusterizadas, mientras quelas palabras comunes se distribuyen al azar.
Se tienen en cuenta tanto la composicion (frecuencias) como laestructura (distribucion espacial) del texto genetico.
Genes, islas CpG, y sitios de union a factores de transcripcion estanclusterizados ⇒ este principio podrıa funcionar tambien en elgenoma.
El metodo para extraer palabras clave en el ADN se basa en lo quehemos aprendido analizando textos literarios normales y textos ”sincomas”(como el ADN!):tatcattcactttcagccaccaattcactttca...
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Evidencias Funcion y ADN no-codificador
Un nuevo principio para predecir funcion
Basado en la extrapolacion a textos de una tecnica para medir desordenen sistemas cuanticos (Carpena et al., Physical Review E 79, 035102-4, 2009):
Las palabras relevantes/funcionales estan clusterizadas, mientras quelas palabras comunes se distribuyen al azar.
Se tienen en cuenta tanto la composicion (frecuencias) como laestructura (distribucion espacial) del texto genetico.
Genes, islas CpG, y sitios de union a factores de transcripcion estanclusterizados ⇒ este principio podrıa funcionar tambien en elgenoma.
El metodo para extraer palabras clave en el ADN se basa en lo quehemos aprendido analizando textos literarios normales y textos ”sincomas”(como el ADN!):tatcattcactttcagccaccaattcactttca...
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
El espectro de una palabra en un texto
Para cada palabra, se determinan sus posiciones en el texto (suespectro).
Por ejemplo, en la siguiente frase el espectro de la palabra a serıa(1,6,10):
A great scientist must be a good teacher and a goodresearcher
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
El espectro de dos palabras equifrecuentes
Espectros de las palabras Quixote y but en las 50.000 primeras palabrasde la version inglesa del Quijote:
0 10000 20000 30000 40000 50000
(248 occurrences)
(288 occurrences)
'but'
'Quixote'
position (words)
Frequencia similar pero estructura muy diferenteLas palabras relevantes estan clusterizadas
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
Cuantificando la clusterizacion: σ y σnor
Ortuno, Carpena, Bernaola et al. (Europhysics Letters 57, 759-764, 2002):
σ ≡ s/〈d〉 (1)
siendo 〈d〉 la distancia media y s =√〈d2〉 − 〈d〉2 la desviacion standard
de P(d).
Sin embargo, σ depende de la frecuencia de la palabra. Dichadependencia se elimina mediante normalizacion (Physical Review E 79: 035102-4,2009):
σnor =σ√
1− p(2)
siendo p = n/N la probabilidad de la palabra en el texto.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
Cuantificando la clusterizacion: σ y σnor
Ortuno, Carpena, Bernaola et al. (Europhysics Letters 57, 759-764, 2002):
σ ≡ s/〈d〉 (1)
siendo 〈d〉 la distancia media y s =√〈d2〉 − 〈d〉2 la desviacion standard
de P(d).
Sin embargo, σ depende de la frecuencia de la palabra. Dichadependencia se elimina mediante normalizacion (Physical Review E 79: 035102-4,2009):
σnor =σ√
1− p(2)
siendo p = n/N la probabilidad de la palabra en el texto.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
Efecto de la normalizacion de σ
Simulacion de textos aleatorios:
0 100 200 300 400 500 600 700 800 900 10000.86
0.88
0.90
0.92
0.94
0.96
0.98
1.00a)
0 200 400 600 800 1000
0.84
0.88
0.92
0.96
1.00
<σ>
n (word count)
p = 0.01 p = 0.05 p = 0.1
<σ
nor>
n (word count)
Las lıneas horizontales son los valores esperados√
1− p.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
Significacion estadıstica: la medida C
Otra mejora importante que hemos incorporado ha sido asociar aσnor una significacion estadıstica.
Para ello, dada una palabra con frecuencia n, definimos la medida Ccomo un z-score:
C (σnor, n) ≡ σnor − 〈σnor〉(n)
sd(σnor)(n)(3)
C mide la desviacion de σnor con respecto al valor esperado en untexto aleatorio (〈σnor〉(n)) en unidades de la desviacion standardesperada (sd(σnor)(n)).
C = 0→ Distribucion aleatoria
C > 0→ Clusterizacion
C < 0→ Repulsion
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
Significacion estadıstica: la medida C
Otra mejora importante que hemos incorporado ha sido asociar aσnor una significacion estadıstica.
Para ello, dada una palabra con frecuencia n, definimos la medida Ccomo un z-score:
C (σnor, n) ≡ σnor − 〈σnor〉(n)
sd(σnor)(n)(3)
C mide la desviacion de σnor con respecto al valor esperado en untexto aleatorio (〈σnor〉(n)) en unidades de la desviacion standardesperada (sd(σnor)(n)).
C = 0→ Distribucion aleatoria
C > 0→ Clusterizacion
C < 0→ Repulsion
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores
Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
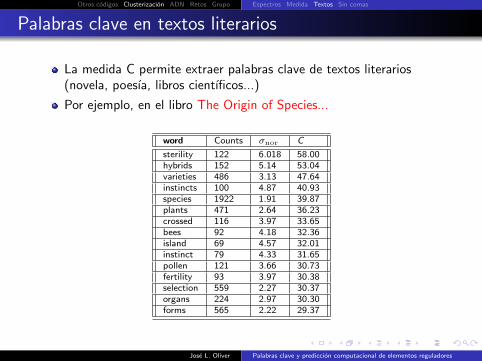
Palabras clave en textos literarios
La medida C permite extraer palabras clave de textos literarios(novela, poesıa, libros cientıficos...)
Por ejemplo, en el libro The Origin of Species...
word Counts σnor C
sterility 122 6.018 58.00hybrids 152 5.14 53.04varieties 486 3.13 47.64instincts 100 4.87 40.93species 1922 1.91 39.87plants 471 2.64 36.23crossed 116 3.97 33.65bees 92 4.18 32.36island 69 4.57 32.01instinct 79 4.33 31.65pollen 121 3.66 30.73fertility 93 3.97 30.38selection 559 2.27 30.37organs 224 2.97 30.30forms 565 2.22 29.37
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
Textos ’sin comas’
El metodo funciona tambien en textos ’sin comas’ (sin espacios nisenales de puntuacion).
Era de esperar porque, aunque se eliminen los espacios, las distanciasentre palabras relevantes y comunes siguen siendo diferentes.
Puesto que se desconoce la longitud de palabra, se toman todos losk-mers con longitud entre 2 y 35.
El resultado son linajes de palabras: cada palabra contiene palabrasmas cortas y esta contenida a su vez en otras palabras mas largas.
Por ejemplo, para la palabra ventero en El Quijote encontramosventer o entero (hijos) y lventero o venteroy (padres).
Para eliminar la redundancia, cada linaje se organiza en un graficoacıclico dirigido (DAG) y se eligen las palabras que sobrepasan ciertoumbral de C (percentiles 50, 75 o 95).
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
Textos ’sin comas’
El metodo funciona tambien en textos ’sin comas’ (sin espacios nisenales de puntuacion).
Era de esperar porque, aunque se eliminen los espacios, las distanciasentre palabras relevantes y comunes siguen siendo diferentes.
Puesto que se desconoce la longitud de palabra, se toman todos losk-mers con longitud entre 2 y 35.
El resultado son linajes de palabras: cada palabra contiene palabrasmas cortas y esta contenida a su vez en otras palabras mas largas.
Por ejemplo, para la palabra ventero en El Quijote encontramosventer o entero (hijos) y lventero o venteroy (padres).
Para eliminar la redundancia, cada linaje se organiza en un graficoacıclico dirigido (DAG) y se eligen las palabras que sobrepasan ciertoumbral de C (percentiles 50, 75 o 95).
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores
Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
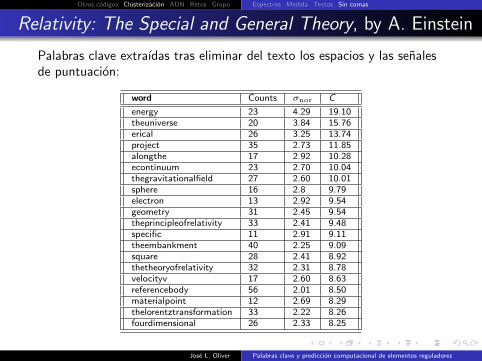
Relativity: The Special and General Theory, by A. Einstein
Palabras clave extraıdas tras eliminar del texto los espacios y las senalesde puntuacion:
word Counts σnor C
energy 23 4.29 19.10theuniverse 20 3.84 15.76erical 26 3.25 13.74project 35 2.73 11.85alongthe 17 2.92 10.28econtinuum 23 2.70 10.04thegravitationalfield 27 2.60 10.01sphere 16 2.8 9.79electron 13 2.92 9.54geometry 31 2.45 9.54theprincipleofrelativity 33 2.41 9.48specific 11 2.91 9.11theembankment 40 2.25 9.09square 28 2.41 8.92thetheoryofrelativity 32 2.31 8.78velocityv 17 2.60 8.63referencebody 56 2.01 8.50materialpoint 12 2.69 8.29thelorentztransformation 33 2.22 8.26fourdimensional 26 2.33 8.25
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Espectros Medida Textos Sin comas
http://bioinfo2.ugr.es/TextKeywords/
Libros analizados, con y sin espacios (tomados del proyecto Gutenberg):
EspanolDon Quijote, Miguel de CervantesLa Celestina, Fernando de Rojas
InglesRelativity: the especial and general theory, Albert EinsteinThe Origin of Species by means of Natural Selection, Charles DarwinDon Quixote, Miguel de CervantesThe Odyssey, HomeroThe Jungle Book, Rudyard KiplingMoby Dick, Herman MelvilleThe Three Musketeers, Alejandro Dumas
AlemanFaust: Der Tragodie erster Teil, Johann Wolfgang von GoetheFaust: Der Tragodie zweiter Teil, Johann Wolfgang von Goethe
ItalianoLa Divina Commedia di Dante, Dante Alighieri
LatınDe Bello Gallico, Julio Caesar
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
Clusterizacion en el ADN
La analogıa entre textos ’sin comas’ y ADN es solo aproximada:
Diferencia de tamano: 2-3 Mb en textos frente a los 150 Mb de uncromosoma medio.
El ADN es un texto de autor multiple: se reescribe continuamentepor puntos diferentes y con estilos (sesgos mutacionales) diferentes.⇒ Mezcla de distribuciones ⇒ Clusterizacion trivial
La clusterizacion trivial la eliminamos mediante unfolding: la σ senormaliza usando medias locales (a cierta escala s) en vez de lamedia global (Bohigas et al., Physical Review Letters 52, 1-4, 1984).
En el genoma humano, una escala entre 20 y 50 permite eliminar laclusterizacion trivial.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
Clusterizacion en el ADN
La analogıa entre textos ’sin comas’ y ADN es solo aproximada:
Diferencia de tamano: 2-3 Mb en textos frente a los 150 Mb de uncromosoma medio.
El ADN es un texto de autor multiple: se reescribe continuamentepor puntos diferentes y con estilos (sesgos mutacionales) diferentes.⇒ Mezcla de distribuciones ⇒ Clusterizacion trivial
La clusterizacion trivial la eliminamos mediante unfolding: la σ senormaliza usando medias locales (a cierta escala s) en vez de lamedia global (Bohigas et al., Physical Review Letters 52, 1-4, 1984).
En el genoma humano, una escala entre 20 y 50 permite eliminar laclusterizacion trivial.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
Un vocabulario para el genoma humano
DNAkeywords contiene datos de clusterizacion para los k-mers (k = 2− 12) de los 24 cromosomasdel genoma humano (hg18, NCBI Build 36.1):
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
Palabras clave en el genoma humano
Numero de palabras clave en la secuencia de referencia (hg18, NCBIBuild 36.1, k-mers para k = 2− 12)
Escala Umbral de C N (24 cromosomas) No-redundantes
20 50 599.964 207.650” 75 294.475 119.925” 95 52.312 28.145
50 50 592.729 199.860” 75 263.941 102.865” 95 26.532 15.690
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
Clusterizacion y funcion biologica
k = 2− 8, s = 50
0 1 2 3 4 52 0
3 0
4 0
5 0
6 0
7 0
8 0
% of
words
withi
n the
geno
me el
emen
t
������������������
������������������������ �����������
Muchos elementos genomicos son ricos en palabras clave
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores
Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
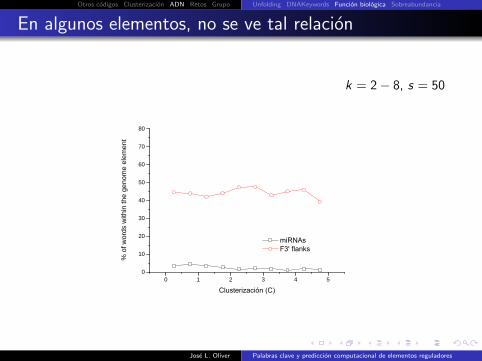
En algunos elementos, no se ve tal relacion
k = 2− 8, s = 50
0 1 2 3 4 50
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0%
of wo
rds wi
thin t
he ge
nome
elem
ent
����� ������������
����������������
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
Sobreabundancia estadıstica
Para cada elemento, se determina la frecuencia observada de cadapalabra, y se compara con la frecuencia en 100 segmentos (de la mismalongitud y elegidos al azar) del resto del genoma:
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo Unfolding DNAKeywords Funcion biologica Sobreabundancia
Proporcion de palabras sobreabundantes (z-score > 2.33)
Cromosomas 19-22, N = 2000, s = 50, percentil 95:
1 TFBSs conserved in the human/mouse/rat alignment→ (21.60 %)
2 CpG islands predicted by CpGcluster→ (65.35 %)
3 Promoter region of RefSeq Genes, (200 bp around the TSS)→ (43.80 %)
4 Promoter region from DBTSS (200 bp around the TSS)→ (39.70 %)
5 Curated regulatory regions, TFBSs, and regulatory polymorphisms→ (19.00 %)
6 TSSs predicted by the program Eponine→ (23.95 %)
7 ESPERR Regulatory Potential→ (21.25 %)
8 Vista HMR-Conserved Non-coding Human Enhancers from LBNL→ (0.85 %)
9 Conserved mammalian microRNA regulatory target sites for conserved microRNA families in the 3’ UTR regions of Refseq Genes,as predicted by TargetScanS→ (1.60 %)
10 microRNAs, C/D and H/ACA Box snoRNAs and scaRNAs from miRBase and snoRNABase→ (0.90 %)
11 poly(A) Sites, both reported and predicted→ (1.35 %)
12 Experimentally identified human genomic insulators→ (38.95 %)
13 Exons from RefSeq→ (39.50 %)
14 Introns from RefSeq→ (11.75 %)
15 Repeats by RepeatMasker→ (29.60 %)
16 PhastCons Conserved Elements→ (21.85 %)
El 80 % de las palabras clave detectadas se puede relacionar con alguno de loselementos genomicos conocidos
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo
Para el futuro
Busquedas no-exactas (fuzzy), obteniendo la distribucion compuestade distancias antes de calcular la clusterizacion.
Localizacion y organizacion de los clusters (homo- y heterotıpicos)de palabras en el cromosoma: combinatoria de la regulacion.
Desarrollo de predictores especıficos para distintos elementosfuncionales.
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores

Otros codigos Clusterizacion ADN Retos Grupo
Grupo
Fısica Aplicada II, Malaga:
Pedro BernaolaPedro CarpenaAna V. Coronado
Genetica, Granada:
Michael Hackenberg (posdoctoral)Guillermo Barturen (predoctoral)Teresa Galera (predoctoral)Angel Martın Alganza (administrador del sistema)
GRACIAS!
Jose L. Oliver Palabras clave y prediccion computacional de elementos reguladores


















