
Objetivos - maysaconsultores.com.armaysaconsultores.com.ar/recursos/Analisis de...
52
1
Transcript of Objetivos - maysaconsultores.com.armaysaconsultores.com.ar/recursos/Analisis de...

1

2
2
Objetivos
• Plantear algunas limitaciones en la instrucción y la práctica de data mining
• Presentar algunas herramientas para aliviar (puntualmente) las limitaciones señaladas
• ROI vs. LTV es solo la “punta del iceberg”

3
3
Limitaciones
• Poca instrucción y aplicación de teoría estadística de las decisiones
• Poca instrucción y aplicación de los fundamentos de las disciplinas abarcadas por data mining
• Poca capacitación en tareas de modelización de complejidad mediana (ni hablar de alta)
• Algunas consecuencias:– Modelizaciones muy “ingenuas”– Aplicaciones inadecuadas o muy poco
eficaces
Data Mining, bastante básica en sus inicios, se dedicaba fundamentalmente a encontrar “patrones novedosos” (pepitas de conocimiento) y se orientaba conceptualmente a las consideraciones algorítmicas. Pero ha evolucionado en los últimos diez años hacia una disciplina que, especialmente en contextos de negocios, se encarga de la modelización predictiva, forecasting y optimización de todo tipo de fenómenos y problemas. Esto llevó a algunos a tratar de redefinir el campo, empezando por su denominación: sería “Analytics” en lugar de Data Mining. Más allá del nombre, el contexto actual plantea requerimientos importantes y mucho más exigentes a los profesionales que pretendan hacer “data mining”. Se requieren conocimientos y destrezas mucho más profundos en técnicas y fundamentos estadísticos, y una práctica mucho más diversa y compleja.

4
4
Algunas herramientas
• Mayor atención a la teoría y práctica de teoría estadística de las decisiones
• Criterios más complejos de evaluación de modelos, como LTV y otros
• Aplicación del análisis de supervivencia
Estas son solo algunas herramientas puntuales y acotadas que consideraremos en la presentación. Más en general, lo que es necesario, para resolver realmente las limitaciones antes planteadas, son, por lo menos, revisiones y ampliaciones de las curricula del lado educativo, y determinación de estándares y buenas prácticas para las aplicaciones.

5
5
Paradigma de data mining
La instrucción y el propio diseño de las herramientas de mining estimulan a pensar que existe una situación “paradigmática” típica del data mining predictivo que es la de encontrar un modelo “campeón”. Así lo plantean también unos cuantos libros de texto.

6
6
Scoring de modelos
• El propósito de una función de scoring es establecer un orden entre los modelos según su performance
• La performance se mide agregando el resultado de un conjunto de predicciones del modelo, una por cada caso del conjunto de testeo (scoring de nuevos casos)
• El orden define un modelo “ganador”• Es muy frecuente una aplicación inadecuada del scoring
de modelos por varias razones:– Rol de la selección de modelos– Funciones multiobjetivo– Necesidad de múltiples modelos– Selección de una función de scoring

7
7
Rol de la selección de modelos
• La selección de modelos indica cuál es el modelo “menos malo”, no necesariamente un buen modelo
• El modelo ganador puede ser bastante inadecuado en términos de lo que se desea modelizar
• Algunas técnicas como el análisis de regresión (en todas sus variantes) poseen numerosos diagnósticos y métodos que permiten evaluar la calidad de un modelo y ajustarlo, sin necesidad del enfoque de “competencia” de modelos
• El enfoque de selección de modelos solo es conveniente en situaciones restringidas
Lo que buscamos en general es un “buen” modelo, es decir, un modelo que sea capaz de representar las principales relaciones entre las variables de un problema, que nos permita comprender las características importantes del mismo y que tenga una buena performance predictiva. En general, esto no se logra organizando una “competencia” entre modelos.
El enfoque de selección de modelos se presta fácilmente a déficitsmetodológicos como la comparación de modelos de complejidad muy distinta y la utilización de métricas de performance no apropiadas, o no igualmente apropiadas para todos los modelos competidores.
Algunas de las situaciones restringidas en las que la selección de modelos puede ser apropiada son:•Cuando se emplean técnicas de modelización pobres en recursos diagnósticos. De todas maneras, esta es una situación que convendría evitar.•Cuando se desea decidir si un modelo existente puede ser reemplazado por otro en situaciones en las que el modelo existente acusa problemas de performance, o hay nueva información predictiva disponible. Los modelos que se comparan son muy similares en muchos aspectos. Esta es una situación apropiada para el enfoque de selección de modelos.

8
8
Funciones uniobjetivo
• La selección de modelos se basa en el orden establecido por una función uniobjetivo de scoring (función de valores escalares con un orden total)
• En general los nodos de evaluación de las herramientas de mining se basan en el máximo (o mínimo) de una sola métrica
• Criterios de selección más complejos deben aplicarse manualmente
• Siempre es conveniente examinar la consistencia o no de diversas métricas

9
9
Funciones multiobjetivo
• La selección de modelos es, en realidad, un problema de optimización: encontrar el máximo de una función de “bondad” de un modelo
• El espacio de búsqueda es el de todos los modelos posibles: cuánto más diversos o heterogéneos sean los modelos, más complejo es el problema de búsqueda y más improbable es que baste una función uniobjetivo
• La evaluación debe usar una función multiobjetivo (multicriterio): debe encontrar soluciones óptimas de compromiso entre criterios frecuentemente en conflicto
• Ejemplo: identificar los clientes más redituables pero menos riesgosos
La optimización es la disciplina que se encarga de encontrar una o más soluciones factibles que corresponden a valores extremos de una o más funciones objetivo. Se denominan “soluciones óptimas”. Debido a las propiedades extremas de las soluciones óptimas, los métodos de optimización son de mucha importancia en la práctica, en áreas como el diseño ingenieril, la experimentación científica y la toma de decisiones en problemas de negocios.
Cuando un problema de optimización involucra una sola función objetivo, la tarea de encontrar la solución óptima se llama “optimización uniobjetivo”. Cuando el problema involucra más de una función objetivo se denomina “optimización multiobjetivo”. Estos últimos problemas de búsqueda y optimización también se denominan “problemas multicriterio de decisión”.
La existencia de múltiples objetivos en conflicto (como minimizar simultáneamente el costo de fabricación y maximizar la confiabilidad de un producto, o maximizar la cartera de poseedores de tarjetas de crédito pero minimizar el promedio del índice de riesgo de la misma) es algo frecuente en muchos problemas prácticos. En estos casos, ninguna solución puede calificarse como solución óptima y por lo tanto, deben encontrarse soluciones óptimas de compromiso.
Formalmente, cuando la función de evaluación es una función de valores escalares, el problema es uniobjetivo, y cuando la función de evaluación es una función de valores vectoriales, el problema es multiobjetivo. Cada componente de un vector responde a algún criterio de valoración de la solución. La dificultad básica de los problemas multiobjetivo radica en que los diversos criterios pueden estar en conflicto entre sí, de modo que una solución óptima en una dimensión (objetivo) puede no serlo en otra u otras dimensiones. Esto hace que no se pueda considerar el caso multiobjetivo meramente como una extensión del caso uniobjetivo. Más bien, el problema uniobjetivo debe considerarse un caso degenerado de problema multiobjetivo.
Para poder decidir la optimalidad de una solución según un criterio nos basta que las soluciones estén totalmente ordenadas. El inconveniente en los problemas multiobjetivo reside en que no podemos, sin más, inducir un orden completo entre los vectores que representan la calidad de las soluciones a partir del orden de los componentes.
Para resolver un problema multiobjetivo existen básicamente dos enfoques. En un primer enfoque, podemos transformar de alguna forma la función de valores vectoriales en una función de valores escalares (es decir, componer los varios criterios en uno solo), o sea, transformar un problema multiobjetivo en un problema uniobjetivo; pero esta estrategia tiene sus dificultades. La principal es que la tarea de construir la función de evaluación combinada de modo de preservar los criterios fundamentales de valoración de una solución puede ser muy difícil o incluso imposible.
Parece mejor, entonces, un segundo enfoque que resuelva un problema multiobjetivo sin transformarlo en uniobjetivo. A partir del orden establecido por los diferentes criterios no podemos inducir un orden total en el conjunto de vectores (y por ende de soluciones), pero sí podemos definir un orden parcial. Este orden permite reconocer el conjunto de soluciones “no inferiores” o “no dominadas”. Una vez obtenido, debemos utilizar algún criterio, información extra, etcétera, relacionado con el problema que nos permita elegir una única solución. Los conjuntos de Pareto son una herramienta frecuentemente utilizada en economía para tratar de resolver problemas multicriterio.

10
10
Múltiples modelos• Problema: Predecir el monto de pago mensual de los
balances de tarjeta de crédito a partir de información de los clientes (transaccional, demográfica, etc.)
• Solución “ingenua”: Modelo de regresión, árbol de decisión, etc. que predice el monto concreto para cada cliente
• Solución apropiada:– La distribución de los pagos es bimodal: un porcentaje
hace el pago mínimo, otro hace el pago total– Modelo 1: Clasificador de pago mínimo– Modelo 2: Clasificador de pago total– Modelo 3: Predicción de monto de pago para los no
clasificados positivamente en los dos modelos anteriores– Mejora de un 25% en la precisión
Muchos problemas no se modelizan mediante un único modelo, sino mediante varios modelos que representan o predicen distintos aspectos o segmentos del problema. Si bien esto puede mejorar muchas veces el resultado final, hay que tener en cuenta varias cosas:•Se requiere un estudio preliminar de los datos y conocimiento de dominio para detectar los casos en los que es conveniente usar más de un modelo: multimodalidad, problemas heterogéneos, etc.•Se deben aplicar criterios de la teoría estadística de decisiones para determinar cómo combinar los modelos•A veces la combinación de modelos puede producir problemas de estabilidad.
Técnicas habituales (aunque no demasiado usadas) como ensemble learning y aprendizaje multiestratégico pueden considerarse casos particulares de una modelización múltiple, en las que se hace una búsqueda casi “ciega” de varios modelos que en realidad terminan modelizando los mismos aspectos (o similares) de un problema, aunque probablemente usando diferentes valores de parámetros (en particular, el ensemble learning).

11
11
Selección de una función de scoring• Como en la práctica suele ser difícil medir la “utilidad” de
un modelo en términos de la tarea concreta se recurre a funciones de scoring “genéricas” (p. ej. el error cuadrático) que tienen propiedades bien conocidas y son fáciles de calcular.
• Es muy común la utilización de funciones de scoringconvenientes (genéricas) pero totalmente inapropiadas para una aplicación dada
• Tipos de funciones:– Funciones genéricas– Funciones basadas en costo/ganancia
• Funciones basadas en el ROI• Funciones basadas en el NPV• Funciones basadas en el LTV
Diferentes funciones de scoring tienen distintas propiedades y son útiles en diferentes situaciones. Existen funciones de scoring para modelos (globales) y para patrones (locales). También existen diferentes funciones de scoring para modelos predictivos y descriptivos. Además, funciones de scoring para modelos de complejidad fija y funciones de scoring para modelos de distinta complejidad.
Cuanto más específica sea la función de scoring respecto del problema de aplicación, mayor será su potencia discriminadora sobre los modelos.

12
12
Funciones genéricas• Error de clasificación (Función de pérdida 0-1):
• Error cuadrático medio (ECM): 1/n ∑i (h(xi) – f(xi))2
• Medidas de separación:– Diferencia de medias de dos distribuciones– Estadístico K-S (Kolmogorov-Smirnov)– Area bajo la curva ROC (equivalente al test
Wilcoxon-Mann-Whitney)• Medidas que penalizan la complejidad del modelo:
AIC, SBC

13
13
Umbrales
66 9
4 21
Sen EspP
x1
x2
.84 .88
0 1
70 5
9 16.64 .93
57 18
1 24.96 .76
• Diferentes umbrales producen diferentes decisiones y diferentes matrices de confusión• Para determinar el umbral óptimo debe definirse un criterio de performance
Salvo en los clasificadores que asignan directamente una clasificación, los estadísticos basados en el error de clasificación (sensibilidad, valor predictivo positivo, riesgo, etc.) dependen de la selección de un valor de corte (umbral). Diferentes umbrales producen diferentes reglas de decisión y matrices de confusión.
Para determinar el umbral óptimo debe definirse un criterio de performance. Si el objetivo es aumentar la sensibilidad del clasificador, entonces el clasificador óptimo asignaría todos los casos a la clase 1. Si el objetivo fuera aumentar la especificidad, entonces el clasificador óptimo asignaría todos los casos a la clase 0. Para aplicaciones realistas, existe una solución de compromiso entre sensibilidad y especificidad. Umbrales más altos disminuyen la sensibilidad y aumentan la especificidad. Umbrales más bajos disminuyen la especificidad y aumentan la sensibilidad.

14
14
Diferencia de medias
Clase 0
Clase 1
Modelo 1 Modelo 2
⎯⎯⎯ Probabilidad Posterior ⎯⎯⎯
0 1 0 1
Los estadísticos que resumen la performance de un clasificador a través del rango de umbrales (como las medidas de separación) pueden ser útiles para evaluar la potencia discriminatoria global de los modelos. En el enfoque de las medidas de separación, se mide la divergencia entre las probabilidades posteriores predichas para cada clase. Cuanto más se superponen las distribuciones, más débil es el modelo.
Los estadísticos más simples se basan en la diferencia de medias de las dos distribuciones. Uno es el test t de Student, que tiene muchas propiedades óptimas cuando las dos distribuciones son simétricas, tienen varianzas iguales y colas no pesadas. Sin embargo, esto no suele ocurrir con las probabilidades posteriores predichas, que típicamente siguen distribuciones asimétricas con varianzas muy desiguales. Existen otros tests estadísticos para dos clases basados en distribuciones no normales.

15
15
Estadístico K-SPDF
0 1
0
1
Pro
babi
lidad
Pos
terio
r
EDF
0 10
1
D = .49
• Se basa en la distancia entre las dos distribuciones empíricas• D es la diferencia vertical máxima entre las distribuciones acumulativas
Modelo 2
El test para dos muestras de Kolmogorov-Smirnov se basa en la distancia entre las funciones de distribución empíricas. El estadístico D es la diferencia vertical máxima entre las distribuciones acumuladas. Si D es igual a cero, las distribuciones son idénticas en todos lados. Si D > 0, existen algunos valores de probabilidad posterior en los que las distribuciones difieren. El valor máximo del estadístico K-S, 1, ocurre cuando las distribuciones están perfectamente separadas. El uso del estadístico K-S para comparar modelos predictivos es popular en marketing en bases de datos.

16
16
Area bajo la curva ROC PDF EDF ROC
D = .24
D = .49 c = .82
c = .66Modelo 1
Modelo 2
Equivalente al test de Wilcoxon-Mann-Whitney
El test K-S es sensible a todo tipo de diferencias entre las distribuciones: localización, escala y forma. En el contexto de la modelización predictiva, puede argumentarse que las diferencias de localización son muy importantes. Debido a su generalidad, el test K-S no es particularmente potente para la detección de diferencias de localización. El test no paramétricopara dos muestras más potente es el de Wilcoxon-Mann-Whitney. Este test es equivalente al área debajo de la curva ROC. La versión de Wilcoxon se basa en los rangos de los datos. En el contexto de la modelización predictiva, las probabilidades posteriores predichas pueden ser ordenadas de menor a mayor. El estadístico se basa en la suma de los rangos en las clases. El área bajo la curva ROC, c, puede determinarse a partir de la suma de rangos en la clase 1.

17
17
Criterio de Schwarz-Bayes (SBC)constant)ln())(ln(2 ++−= npwlSBC
• SBC usa una penalización por complejidad dada por p ln(n), donde p es el número de parámetros en el modelo y n es el número de observaciones, y -2 ln(l(w)), una medida de verosimilitud que mide el ajuste del modelo a los datos
• SBC favorece entonces modelos que tienen buen ajuste a los datos pero que son parsimoniosos (menor número posible de parámetros)
• No existe una escala absoluta para SBC. Se prefieren los modelos con valores más bajos en este criterio
SBC es un ejemplo de medidas que además de utilizar algún criterio de performance predictivo utilizan una medida de la complejidad del modelo (penalizan la complejidad). Dos ventajas importantes de estas medidas son:•Establecen un terreno común para comparar modelos de distinta complejidad•Permiten usar todos los datos para entrenamiento y testeo, sin necesidad de hold-out o cross-validation.
La desventaja principal es que estas medidas no poseen una escala absoluta, lo que dificulta una interpretación fina de los resultados obtenidos.

18
18
• La regla de decisión óptima minimiza el costo esperado total (riesgo)
Funciones basadas en costo/ganancia
57 18
1 24
66 9
4 21
70 5
9 16
Costo Total
1*4 + 18 = 22
4*4 + 9 = 25
9*4 + 5 = 41
0 1
4 0
Predicho
Rea
l 0
1
0 1
Matriz de costos
Un enfoque formal para determinar el umbral óptimo utiliza la teoría estadística de las decisiones. Se asignan costos o ganancias a cada decisión. La regla de decisión óptima es aquella que minimiza el costo total esperado (riesgo) o maximiza la ganancia total esperada.

19
19
Regla bayesiana (dos clases)• Costo de clasificar un caso
con 1:(1 – p) costoFP
• Costo de clasificar un caso con 0:p costoFN
• Regla óptima: asignar un caso a 1 si(1 – p) costoFP < p costoFN
Asignar a clase 1 si
Si no asignar a clase 0
• La regla bayesiana solo depende de la tasa de los costos, no de sus valores concretos• Si los costos son iguales, la regla bayesiana corresponde a un umbral de 0.5
La regla bayesiana es la regla de decisión que minimiza el costo esperado. En la situación de dos clases, la regla bayesiana puede determinarse analíticamente como se expone arriba. p es la probabilidad posterior verdadera de que un caso pertenece a la clase 1. Como p debe estimarse a partir de los datos, la regla de Bayes usa p^. Una consecuencia es que la regla bayesiana puede no alcanzar el costo mínimo si la estimación de la probabilidad posterior es pobre.

20
20
Umbrales
• Cuando la tasa de costos es igual a 1, el costo esperado es proporcional a la tasa de error
• Un umbral de 0.5 tiende a minimizar la tasa de error (maximizar la precisión)
• Sin embargo, el uso de la tasa de error frecuentemente refleja que no se pensaron cuidadosamente los objetivos reales de la aplicación
• Cuando el suceso target es raro el costo de un falso negativo es usualmente mayor que el costo de un falso positivo (el costo de no ofrecer un producto o servicio a alguien que lo compraría es mayor que enviar la promoción a alguien que no lo comprará)
• Esto frecuentemente lleva a umbrales mucho menores que .5

21
21
Matriz de ganancias
57 18
1 24
66 9
4 21
70 5
9 16
Ganancia Total
24*4 - 18 = 78
21*4 - 9 = 75
16*4 - 5 = 59
0 -1
0 4
Predicho
Rea
l 0
1
0 1
Definir una matriz de ganancia (en lugar de una matriz de costos) no lleva a una regla de clasificación diferente. Sin embargo, permite utilizar un estadístico práctico para medir la performance de un clasificador. Un modelo produce probabilidades posteriores que junto con una matriz de ganancias o costos) clasifica a los individuos en probables positivos y probables negativos. Como en el conjunto de testeo se conoce la verdadera clasificación de esos individuos, es factible calcular la ganancia esperada individual y, por lo tanto, la ganancia total. Esta puede usarse como criterio de selección y evaluación de modelos.

22
22
ROI• El enfoque de retorno de la inversión se usa
frecuentemente porque es simple y fácil de comprender
• ROI= (Ganancias brutas – Inversión)/Inversión• Genera medidas simples de scoring basadas en la
aplicación del modelo y en relación con su objetivo inmediato
• Sin embargo, es una medida “miope”– Solo mide los resultados inmediatos– No busca optimizar las ganancias obtenibles
haciendo uso de datos y conocimiento disponibles al analista
Se invierte tanto en una promoción, por ejemplo, y se mide la respuesta. Se calcula la ganancia neta de las ventas a quienes respondieron a la promoción y se divide por la cantidad invertida. El resultado es el retorno de la inversión. Por ejemplo, se invierten $40.000 en mailing a 100.000 clientes en una promoción. Si se tiene una tasa de respuesta del 2% y se venden 2.000 ítems a $100 cada uno, con una ganancia neta de $50 por ítem, se tendrá una ganancia bruta de $100.000. Restando los $40.000 invertidos en el mailing de la ganancia bruta, el retorno es $60.000. El retorno sobre la inversión es de 1.5, algo respetable y comprensible.
El ROI es un modo de medir el resultado inmediato de un esfuerzo de marketing o algún otro tipo de actividad comercial que use un modelo como insumo.

23
23
NPV (Valor Neto Actual)• Valor neto actual (NPV): El valor en pesos actuales de las
ganancias futuras generadas por un producto o servicio• El cálculo de NPV es más complejo, requiere de la
estimación de diversos componentes según la aplicación:• Ejemplo en marketing:
– Probabilidad de respuesta: Estimación a partir de un modelo de respuesta
– Indice de riesgo: Indice determinado por un modelo o un análisis actuarial
– Ingresos: Valor presente de los ingresos producidos por un producto o servicio en un intervalo de tiempo (por ejemplo, 3 años)
– Costos: Costos diversos vinculados a la campaña de marketing
• Modelo: NPV = P(Activación) x Indice de riesgo x Ganancia del producto - Costos
Un enfoque de Valor Actual Neto (NPV) es un primer intento de resolver la miopía del ROI. Se intenta predecir la ganancia global de un producto durante una longitud de tiempo predeterminada. El valor se calcula sobre un cierto número de años descontado a pesos actuales. Aunque hay algunos métodos estándar para calcular el NPV, existen muchas variaciones a través de productos e industrias.
•La probabilidad de respuesta surge de algún modelo de respuesta•Indice de riesgo: Indice actuarial derivado de un análisis de segmentación de clientes. Representa un ajuste al NPV final basado en grupo de edad, género, estado civil, etc.•Ingresos: Estimación promedio de la ganancia que un producto o servicio produce en un intervalo de tiempo.•Costos: Los costos de las diversas tareas de una campaña de marketing: procesamiento, folletería, correo, etc.

24
24
Utilización modernade modelos
Repositoriode modelos
Interrase de miningInterfase de scoringSoftware estadístico
Códigoscoring
Registro del modelo
Testeo del modelo
Puesta en producción
Seguimiento delmodeloAmbiente de
desarrollo y administración
Retiro del modelo
Selección del modeloganador
Modelo en producción
InteractivoBatch
Tiempo real
Ambiente de producción
Concepción del ambiente de desarrollo, despliegue y administración de modelosde SAS.
En un contexto actual o futuro, donde una empresa considera sus modelospredictivos como un recurso estratégico y táctico importante, la existencia de múltiples modelosaplicables a los mismos clientes y situaciones influye de modo significativo en la forma de realizartareas analíticas.

25
25
Estandarización del ciclo de vida de un modelo (Concepción de SAS)
SEMMA RECARSARegisterEvaluateCompare (Test)ApproveReleaseScoreAssess
SampleExploreModifyModelAssess
Todavía en la concepción de SAS, al estándar de desarrollo de modelos (SEMMA) debe agregarse un estándar de administración de modelos (RECARSA).

26
26
Ciclo de vida del clienteProspecto Nuevo cliente Ex-cliente
Ingresos
Ganancia
Costos
Pérdida
Pérdida
Ganancia
Retención
Cross-sell
Up-sell
Recuperación
Ciente establecido
RiesgoRiesgo
Riesgo
Cobranza
Respuesta
Valor tiempode vida delprospecto
Cobranza
Activación
Valor tiempode vida del
cliente
En un contexto de Business Intelligence con enfoques de CRM integrales, de 360°, etc. tiene sentido considerar a los clientes en términos de su ciclo de vida como clientes, y anidar los distintos problemas de CRM y sus modelizaciones en este marco. El ciclo de vida del cliente se divide en tres partes principales: 1) prospecto, 2) cliente y 3) ex-cliente. Dentro de este ciclo de vida hay muchas oportunidades para desarrollar modelos predictivos. Un prospecto puede modelizarse por su propensión a responder y o activarse. También puede estimarse el nivel de riesgo usando modelización predictiva o segmentación. Combinando modelos de respuesta, activación y/o riesgo con algunas estimaciones del valor del cliente como attrition y/o ganancias subsiguientes, puede calcularse el valor de tiempo de vida de un prospecto. Después de que un prospecto se vuelve un cliente, existen numerosas oportunidades de modelización adicionales. Finalmente, después de que la relación con el cliente finaliza, hay modelos que pueden desarrollarse para mejorar las ganancias.
Formular un problema de modelización en este marco permite desarrollar modelos más apropiados y eficaces que pueden utilizar información más completa y precisa para su predicción y evaluación. Esto lleva directamente a la aplicación de un enfoque de LTV (tiempo de vida del cliente) en la modelización.

27
27
LTV• Valor de tiempo de vida (LTV): Valor esperado de un prospecto o
cliente durante un período de tiempo dado, descontado a pesos actuales. También se conoce como CLV (Customer Life Value)
• El cálculo de LTV es complejo, requiere de la estimación de diversos componentes según la aplicación:
• Ejemplo en marketing :– Duración esperada de la relación con el cliente– Período de tiempo: medida del incremento de LTV– Ingresos: Valor presente de los ingresos producidos por un
producto o servicio– Costos diversos – Tasa de retención– Factor de riesgo– Ganancias incrementales (Cross-sell/Upsell, referenciamiento,
etc.) – Modelo:
LTV = P(Activación) x Indice de riesgo x (Ganancia del producto + Cross-sell/Upsell) x Indice de retención - Costos
Un modelo de LTV intenta predecir el valor total de un cliente (persona o negocio) durante una longitud de tiempo predeterminado. De manera similar al NPV, se calcula sobre un cierto número de años y se descuenta a pesos actuales. Los métodos para calcular el valor de tiempo de vida también varían a través de productos e industrias. A medida que los mercados se achican y la competencia aumenta, las compañías buscan oportunidades para obtener ganancias de su base de clientes. Como resultado, muchas compañías expanden sus ofertas de productos y/o servicios en un esfuerzo por hacer cross-sell y up-sell a sus clientes existentes. Este enfoque crea la necesidad de ir más allá del valor neto actual de un producto, a un enfoque de valor de tiempo de vida del cliente (LTV). Esta valuación permite a las compañías asignar recursos en base al valor potencial del cliente. Las mediciones de LTV son útiles para adquirir clientes, manejar sus relaciones con los mismos e incluso cuantificar la salud financiera de largo plazo de una empresa en base a la calidad de su portfolio de clientes. Una vez que se asigna un LTV a cada cliente, la base de clientes puede segmentarse de diversas maneras. Con esta información, una compañía puede tomar acciones o evitarlas en base al beneficio a largo plazo para la compañía.•Duración esperada de la relación con el cliente: Este valor es uno de los más críticos para los resultados y difícil de determinar. Podría pensarse que una duración prolongada sería mejor para el negocio, pero hay dos desventajas. Primero, cuanto mayor es la duración, menor la precisión del modelo. Segundo, una gran duración demora la validación final.•Período de tiempo: medida del incremento de LTV. Generalmente es un año, pero puede reflejar diferentes periodos de renovación o ciclos de productos.

28
28
LTV en Marketing• La investigación de marketing tradicional es un enfoque
estático que puede complementarse con un enfoque más dinámico basado en el valor actual del cliente y su ciclo de vida
• Obstáculos de los enfoques de LTV:– Formalización teórica insuficiente– Requiere una competencia cuantitativa y conceptual más
compleja• Clases de enfoques:
– Modelos econométricos que buscan una comprensión en términos económicos de la conducta del consumidor
– Modelos de naturaleza probabilística: Pareto/NBD, BG/NBD
– Técnicas de Data Mining
La introducción del enfoque de LTV se basa en trabajos empíricos de investigadores de marketing. No existe aún un conjunto de fundamentos teóricos apropiados, si bien algunas de sus formulaciones (en general las menos prácticas) se basan en algunos instrumentos estadísticos y econométricos tradicionales. Para mayores consideraciones sobre estas cuestiones véase Castéran (2004).
Gupta et al. (2006) utilizan una clasificación más compleja de enfoques de LTV consistente en: Modelos RFM, Modelos probabilísticos, Modelos econométricos, Modelos de persistencia, Modelos computacionales, Modelos de difusión/crecimiento.

29
29
Modelo Pareto/NBD• Calcula P(activo) y predice el número de transacciones
(individuales y acumulativas)• Difícil de implementar• Supuestos del modelo:
– Las compras siguen una distribución de Poisson con tasa de compra λ
– El tiempo de vida sigue una distribución exponencial con tasa μ
– Heterogeneidad de los clientes:• Las tasas de compra y de deserciones tienen distribuciones
gamma• Tasas de compra y de deserciones son independientes
• Modelo:– Entrada: Vector de parámetros θ=(r, α , s, β ) y vector de
transacciones V=(X=x, t, T)– Salida: P(Activo|V, θ), E[V, TF, θ]
Modelo formulado por Schmittlein, Morrison y Colombo (1987). Es el modelo más conocido y referenciado. Conceptualmente simple aunque intrincado de implementar. Varios supuestos distribucionales.
Entrada: •Vector de parámetros θ=(r, α , s, β)
•(r, α): Parámetros de la distribución gamma de tasa de compras•(s, β): Parámetros de la distribución gamma de la tasa de deserción
•Vector de transacciones V=(X=x, t, T): información de las compras individuales, donde x es el número de transacciones en el período (0, T] y t es el tiempo de la última compra.
Salida:•P(Activo|V, θ): probabilidad de que un cliente todavía está activo dado un patrón individual de compra y parámetros del modelo•E[V, TF, θ]: Número esperado de compras dado un patrón individual de compra y parámetros del modelo

30
30
Resultado de un Modelo Pareto/NBD
•Batislam, Emine Persentili; Denizel, Meltem y Filiztekin, Alpay. “Empirical validation and comparison ofmodels for customer base analysis”. International Journal of Research in Marketing, 24, 3, 2007, pp. 201-209.•Castéran, Herbert. “Synthèse des approches probabilistes de la Life Time Value et premières propositionsd’extension”. Cahier de Recherche No. 3, ESCPAU, 2004, pp. 17-29.•Fader, Peter S., Bruce G. S. Hardie y Ka Lok Lee. “’Counting Your Customers’ the Easy Way: AnAlternative to the Pareto/NBD Model,” Marketing Science, 24 (2), 2005, pp. 275-284.•Fader, Peter S., Bruce G. S. Hardie y Ka Lok Lee. “RFM and CLV: Using Iso-Value Curves for CustomerBase Analysis,” Journal of Marketing Research, 42 (4), 2005, pp. 415-430.•Glady, Nicolas; Baesens, Bart y Croux, Christophe. “A modified Pareto/NBD approach for predictingcustomer lifetime value”. Department of Decision Sciences and Information Management (KBI), 2006.•Gupta, Sunil; Hanssens, Dominique; Hardie, Bruce; Kahn, Wiliam; Kumar, V.; Lin, Nathaniel; Ravishanker, Nalini y Sriram, S. “Modeling Customer Life Value”. Journal of Service Research, 9 (2), 2006, pp. 139-155.•Jain, D. and Singh, S.S. “Customer Lifetime Value Research in Marketing: A Review and FutureDirections,” Journal of Interactive Marketing, 16 (Spring), 2002, pp. 34–46.•Kamakura, Wagner; Mela, Carl F. et al. “Choice Models and Customer Relationship Management”.Marketing Letters, 16 (3/4), 2005, pp. 279–291.•Reinartz, W.J. y Kumar, V. “On the Profitability of Long Lifetime Customers: An Empirical Investigation andImplications for Marketing,” Journal of Marketing, 64, 2000, pp. 17–35. •Reinartz, W.J. y Kumar, V. “Customer Lifetime Duration: An Empirical Framework for Measurement andExplanation,” Journal of Marketing, 67 (January), 2003, pp. 77–99.•Schmittlein, David C., Donald G. Morrison y Richard Colombo. “Counting your customers: Who are theyand what will they do next?” Management Science, 33 (1), 1987, pp. 1-24.•Schmittlein, David C. y Robert A. Peterson, “Customer Base Analysis: An Industrial Purchase ProcessApplication,” Marketing Science, 13 (1), 1994, pp. 41-67.•Wangenheim, Florian v. “Customer Base Analysis For Managerial Decision Making: Are SophisticatedModels Better?”. Department of Services and Technology Marketing, Technische Universität München, 2007.

31
31
LTV en Data Mining• Se utilizan enfoques “pragmáticos”• Algunas definiciones simples:
• Definiciones más complejas incluyen factores de cross/upsell, riesgo, específicos a productos o servicios, etc.
∑ = +=
h
t tti
i dCF
LTV0
,
)1(
∑ == +=
Jh
jt ttji
i dCF
LTV ,
1,0,,
)1(
∑ =−
+−
=h
t ittititi
i ACd
rcpLTV
0,,,
)1()(
El LTV de un cliente i es el valor descontado de las ganancias futuras producidas por el cliente, donde CFi,t es el cash flow neto generado por la actividad del cliente en el tiempo t, h el horizonte de tiempo para estimar el LTV y d la tasa de descuento. En la segunda ecuación: CFi,j,t es el cash flow neto generado por la actividad del cliente relacionada con la clase de productos o servicios j en el tiempo t. En la tercera ecuación: pi,t es el precio pagado por un consumidor i en un tiempo t, ci,t es el costo directo del servicio al cliente i en el tiempo t, ri,t es la probabilidad de que i repita la compra o esté vivo en el tiempo t, ACi es el costo de adquisición del cliente i, h es el horizonte de tiempo para estimar el LTV y d es la tasa de descuento.
Una referencia básica para la definición y utilización de LTV en data mining es Parr Rud, Olivia. Data Mining Cookbook. Wiley, Nueva York, 2001, Cap. 12.

32
32
Problemas para Data Mining
• Las medidas de LTV son empíricas, con poco sustento teórico
• Representan transformaciones de un problema multiobjetivo en uno uniobjetivo
• Determinación del horizonte temporal• Determinación de tasa de retención
El horizonte temporal está en relación directa con la duración esperada de la relación con el cliente. Este valor es crítico y difícil de determinar. Podría pensarse que un horizonte temporal prolongado es beneficioso para una empresa y la modelización, pero existen algunos problemas metodológicos: cuanto mayor la duración, menor es la precisión de la predicción; duraciones prolongadas demoran o extienden demasiado la etapa de validación. Una duración apropiada depende del tipo de producto o servicio, del problema a modelizar, etc. En la práctica, por ejemplo, para productos financieros como tarjetas de crédito, servicios de telefonía movil, etc. el horizonte temporal nunca es mayor de dos años. Productos hipotecarios plantean un problema porque tienen horizontes bastante más extendidos.
La tasa de retención o una medida relacionada, la probabilidad de supervivencia, es la probabilidad de un suceso (el cliente mantiene la relación) en el tiempo. Este es un tipo de tarea para la que el data mining tradicional está mal preparado y motiva la utilización de herramientas complementarias como el llamado “análisis de supervivencia”.

33
Análisis de supervivencia

34
34
Enfoque tradicional de data mining en modelización predictiva
4 3 2 1 +1Jan Feb Mar Apr May Jun Jul Aug Sep
Data set de modelización
Data set de scoring 4 3 2 1 +1• El data set de modelización proviene del pasado• El scoring se hace en el presente para nuevos datos• Las predicciones se hacen para algún periodo fijo en el
futuro• Los modelos se construyen mediante árboles de
decisiones, redes neuronales, regresión logística, etc.

35
35
Limitación del data miningtradicional
• Predice la ocurrencia de sucesos específicos en un cierto intervalo (relativamente breve) de tiempo futuro, no cuándo ocurrirán:– Sí: Qué clientes probablemente desertarán el
mes que viene– No: Cuándo desertarán durante los próximos
dos años

36
36
Análisis de supervivencia
• Análisis del tiempo transcurrido hasta un suceso• Conceptos, herramientas y terminología provienen
de la medicina– Estimar cuánto sobrevivirán los pacientes en
base a cuáles se recuperan y cuáles no• Puede medir los efectos de variables (covariables
iniciales o covariables dependientes del tiempo) sobre el tiempo de supervivencia
• Herramienta natural para comprender la relacióncon los clientes
El data mining basado en análisis de supervivencia agrega el elemento de cuándo ocurren las cosas. La supervivencia es particularmente valiosa para ganar comprensiónde los clientes y cuantificar esa comprensión. Una estimación de cuánto durarán los clientes esútil para cálculos de valor, además de comparaciones directas entre diversos grupos La estimación de la duración de la relación con el cliente puede refinarse en base a lascaracterísticas del periodo inicial de análisis, además de con los sucesos que ocurren durante el ciclo de vida de un cliente.
El enfoque tradicional y el de supervivencia son complementarios. Ningúnenfoque es mejor que el otro. Para una campaña específica de marketing basada en el ROI, el enfoque tradicional usualmente funciona mejor que el enfoque de supervivencia, porque la campaña ocurre durante un periodo particular de tiempo. Para la comprensión de los clientes y cuantificar resultados en el tiempo, el análisis de supervivencia es preferible.
El análisis de supervivencia tiene su origen a finales del siglo XVII, fue utilizadopor diversas disciplinas a lo largo del siglo XX (medicina, industria, actuarios, finanzas, marketing, etc.) e introducido en data mining a comienzos del siglo XXI por Michael Berry y Gordon Linoff. La referencia básica es Berry; Michael J.A. y Linoff; Gordon S. Data Mining Techniques - For Marketing, Sales, and Customer Relationship Management. Wiley, Indianapolis, Indiana, 2004, 2a ed., Cap. 12.

37
37
Algunas aplicaciones del análisis de supervivencia
• ¿Cuánto durarán los clientes?• ¿Cuándo empezar a preocuparse si un cliente no
se reactiva?• ¿Cómo cuantificar el valor de un programa de
fidelización?• ¿Cuánto más valioso es un cliente con tarjeta
dorada que uno con tarjeta ordinaria?• ¿Cuál será la tasa futura de churn?• ¿Cuándo será la próxima transacción de un
cliente?• ¿Cuál es el efecto de diversos factores sobre la
duración de la relación con el cliente?

38
38
En general…
• Comprender cuándo ocurren sucesos particulares
• Comprender qué factores afectan el cuándo• Cuantificar qué ocurre a lo largo del tiempo

39
39
Algunas diferencias• Nos contentamos con un tiempo discreto (probabilidad versus
tasa) – El análisis de supervivencia tradicional usa tiempo continuo
• Hay cientos de miles o millones de ejemplos– El análisis de supervivencia tradicional solía hacerse con
docenas o cientos de participantes• Grandes cantidades de variables
– El análisis de supervivencia tradicional solo mira los factoresincorporados en el estudio
• Hay que tratar con efectos de “ventana” debido a las prácticascomerciales y realidades de las bases de datos– El análisis de supervivencia tradicional ignora el truncado
izquierdo
Estas son diferencias entre el tratamiento de la supervivencia en disciplinascomo medicina y control de calidad (los usos tradicionales del análisis de supervivencia) y en disciplinas como data mining y marketing.

40
40
Curvas de retención
• La supervivenciasiempre empieza en el 100% y disminuye con el tiempo
• Si nadie sobrevivió, la curva llega a 0; sino essiempre mayor que 0
• La supervivencia es útilpara comprar grupos
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 12 24 36 48 60 72 84 96 108
120
Permanencia (meses)
Porc
enta
je s
uper
vive
ncia
Grupo 1Grupo 2
La retención es una aproximación a la supervivencia, en especial cuando se considera un grupo de clientes que inician su relación con una empresa al mismo tiempo. La retención permite introducir conceptos clave del análisis de supervivencia como la vida media de un cliente y la permanencia (tenure) truncada promedio. El intervalo entre el inicio y el fin de la relación de un cliente es la permanencia de un cliente, una buena medida de retención. Si bien estas medidas parecen conceptualmente simples, muchasson difíciles de “operacionalizar” (distintas fechas posibles según tipo de producto o servicio).
Una vez que se calcularon las permanencias, pueden graficarse en una curva de retención, que muestra la proporción de clientes retenidos durante un período definido de tiempo. Una curva de retención es un histograma acumulativo. Cuando la curva representa clientes que inician la relación aproximadamente al mismo tiempo, esta es una aproximación cercana a la curva de supervivencia.
La figura compara la retención de dos grupos de clientes con una misma fecha de inicioen la relación. Las curvas muestran los porcentajes de clientes retenidos a lo largo de un intervalo de diezaños. Las diferencias entre la retención de los dos grupos pueden cuantificarse fácilmente. La forma másfácil es mediante la diferencia entre los valores de retención en diferentes períodos de tiempo.
Colocar a los clientes en diferentes grupos en base a las condiciones iniciales (tal comoproductos premium versus regulares) se llama estratificación. La estratificación solo funciona realmentecuando la variable de agrupación se define al comienzo del tiempo de vida del cliente.
Las curvas de supervivencia siempre inician en el 100% porque todos los clientes estánvivos en el tiempo de inicio. También decrecen monotónicamente; es decir, las curvas de supervivencianunca se curvan hacia arriba. Una vez que alguien dejó de ser cliente, no se le permite volver. Si todos losclientes hubiesen cesado, la supervivencia caería a 0 al final.
Estas curvas de supervivencia son suaves porque se basan en varios millones de clientes. Las curvas de supervivencia basadas en muestras más pequeñas son mucho más irregulares.
41
41
Tiempo de vida mediano
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 12 24 36 48 60 72 84 96 108
120
Permanencia (meses)
Porc
enta
je s
uper
vive
ncia
Grupo 1Grupo 2
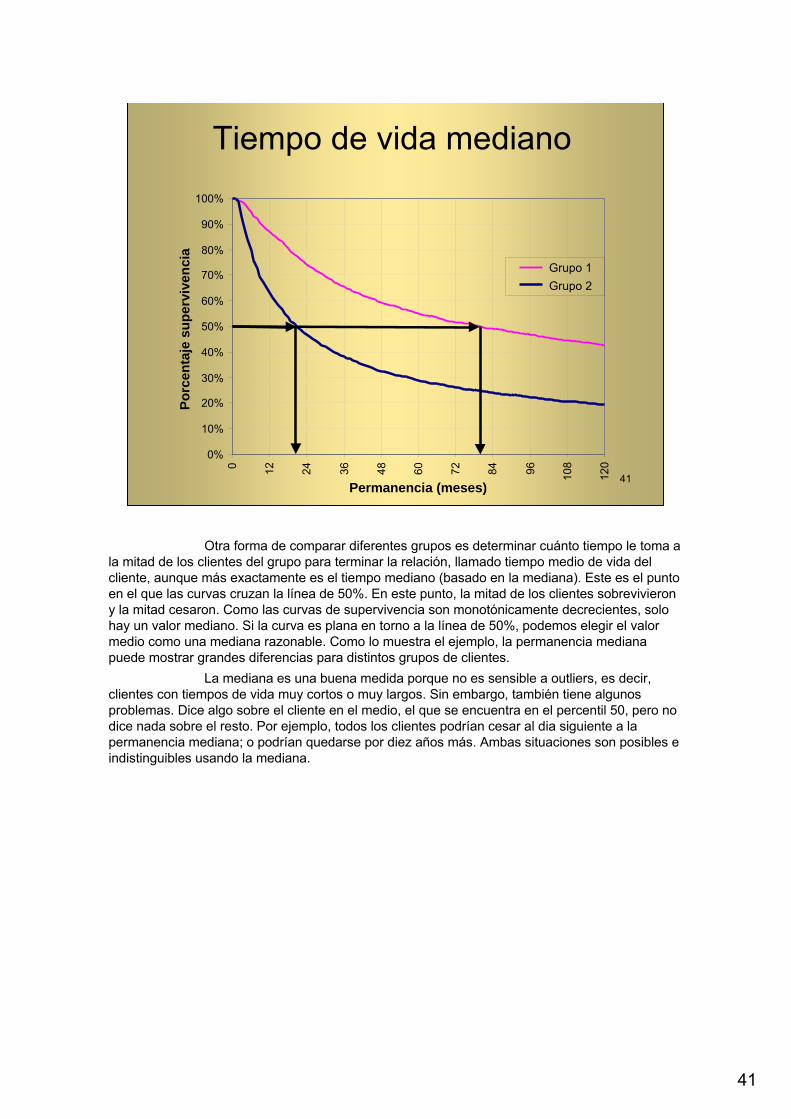
Otra forma de comparar diferentes grupos es determinar cuánto tiempo le toma a la mitad de los clientes del grupo para terminar la relación, llamado tiempo medio de vida del cliente, aunque más exactamente es el tiempo mediano (basado en la mediana). Este es el puntoen el que las curvas cruzan la línea de 50%. En este punto, la mitad de los clientes sobrevivierony la mitad cesaron. Como las curvas de supervivencia son monotónicamente decrecientes, solo hay un valor mediano. Si la curva es plana en torno a la línea de 50%, podemos elegir el valor medio como una mediana razonable. Como lo muestra el ejemplo, la permanencia medianapuede mostrar grandes diferencias para distintos grupos de clientes.
La mediana es una buena medida porque no es sensible a outliers, es decir, clientes con tiempos de vida muy cortos o muy largos. Sin embargo, también tiene algunosproblemas. Dice algo sobre el cliente en el medio, el que se encuentra en el percentil 50, pero no dice nada sobre el resto. Por ejemplo, todos los clientes podrían cesar al dia siguiente a la permanencia mediana; o podrían quedarse por diez años más. Ambas situaciones son posibles e indistinguibles usando la mediana.

42
42
Permanencia promedio
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 12 24 36 48 60 72 84 96 108
120
Permanencia
Porc
enta
je s
uper
vive
ncia
Grupo 1Grupo 2
Promedio permanencia 10 añosClientes Grupo 1 =73 meses (6.1 años)
Promedio permanencia 10 añosClientes Grupo 2 =
44 meses (3.7 años)
El tiempo de vida mediano no permite responder preguntas como: ¿Cuál es el valor promedio de los clientes durante un periodo de tiempo? Para poder responder esto necesitamos calcular el valor medio del cliente por unidad de tiempo y la retención promedio para todos los clientes. La mediana no puede producir esta información porque solo describe lo que le pasa al cliente “mediano”, el que se encuentra en el percentil 50.
Una medida más útil es la permanencia media (llamada también permanencia media truncada). Esta es la permanencia promedio de los clientes en un periodo de tiempo. En el gráfico, vemosque el cliente promedio del grupo 2 se espera que sobreviva aprox. 44 meses, mientras que el clientepromedio del grupo 1 se espera que permanezca por 73 meses. La diferencia de 29 meses, que se ve en el área superior, es menos notable que el valor de permanencia mediana.
La permanencia promedio puede usarse para los cálculos de valor del cliente, mientrasque la mediana no. Si los clientes producen $100 de ingreso neto por año, entonces la diferencia entre losdos grupos es de $290 en los diez años luego de la adquisición, o $29/año. Cuando se determina cuántodinero invertir en adquisición, esta información es muy útil.
El área debajo de la curva es simplemente la suma del valor de los puntos de supervivencia. Esto es evidente si se dibujan rectángulos en torno de cada punto de supervivencia. La longitud vertical es la supervivencia; el ancho horizontal es una unidad (en este caso, meses). El área del rectángulo es el valor de supervivencia en ese punto por 1. Una buena estimación del área bajo la curva esla suma de todos los rectángulos, que es la suma de todos los valores de supervivencia.

43
43
Riesgos
• El riesgo, h(t), en el tiempo t es la probabilidad de que un cliente que sobrevivió en el tiempo t no sobreviva en el tiempo t+1.
•h(t) =
• El valor del riesgo depende de la unidad de tiempo: días, semanas, meses, años.
• Difiere de la definición tradicional porque el tiempo esdiscreto, es la probabilidad de riesgo, no la tasa de riesgo
# clientes que cesan exactamente en t# clientes en riesgo de cesar en t
Por distintas razones es difícil modelizar las curvas de retención mediante un enfoque paramétrico (por ejemplo, aplicando una función exponencial como en la desintegraciónradioactiva). Esto dificulta la posibilidad de hacer proyecciones. Un análisis de riesgos tiene lasventajas de que permite aplicar un enfoque estadístico no paramétrico, hacer proyecciones y refinar las curvas de retención en curvas de supervivencia.
El riesgo (en realidad la probabilidad de riesgo) es la probabilidad en cualquierpunto en el tiempo de que un cliente deje de serlo en el tiempo t y antes del tiempo t + 1. El riesgo es una probabilidad, de modo que siempre tiene un valor entre 0 y 1. El valor específicodepende de las unidades de tiempo usadas.
Cuando usamos todos los datos (en lugar de nuestro ejemplo inicial en la quesolo considerábamos los clientes que tenían una fecha común de inicio), la probabilidad de riesgoes el número de clientes que dejaron de serlo con una permanencia particular dividido por el número de clientes con esa permanencia o mayor. Esto hace al cálculo particularmente fácil de comprender y visualizar.
Un supuesto sobre este cálculo es que la tasa de riesgo es estable en el tiempo. Una cuestión importante con los clientes es cómo cambian los riesgos. Diversos fenómenoscomo cambios en la política de una empresa pueden hacer que las tasas de riesgo seaninestables.

44
44
Ejemplo de función de riesgo
0.0%
0.5%
1.0%
1.5%
2.0%
2.5%
3.0%0-
1 añ
os
1-4
años
5-9
años
10-1
4 añ
os
15-1
9 añ
os
20-2
4 añ
os
25-2
9 añ
os
30-3
4 añ
os
35-3
9 añ
os
40-4
4 añ
os
45-4
9 añ
os
50-5
4 añ
os
55-5
9 añ
os
60-6
4 añ
os
65-6
9 añ
os
70-7
4 añ
os
Edad (Años)
Rie
sgo
Un buen ejemplo de curva de riesgo es la llamada función de riesgo con forma de bañera. Este ejemplo proviene de los datos de las tablas de mortalidad calculadas por la Oficina de Censos sobre toda la población estadounidense. Se llama riesgo de forma de bañeradebido a su forma, que comienza en valores más o menos altos, desciende y se aplana y luegoaumenta. Esto significa que los recién nacidos tienen un riesgo relativamente alto de morir antes de su primer año de vida, debido principalmente a complicaciones en el nacimiento. Una vez queel individuo superó este periodo, tiene un riesgo bajo de morir. De hecho, la mortalidad no aumenta hasta un valor similar al del primer año hasta que la persona tenga más de cincuentaaños. A partir de ese punto, el riesgo de morir aumenta a medida que envejece. Esta curva de riesgo es útil porque grafica lo que sabemos intuitivamente: las personas jóvenes tienen bajoriesgo de morir; la gente mayor tiene un riesgo alto.
Las funciones de bañera son comunes en las ciencias de la vida, pero tambiénen fenómenos de negocios como la telefonía celular y proveedores de servicios de Internet en el caso de contratos de servicios durante un periodo fijo de tiempo. Al comienzo del periodo de contrato los clientes pueden cesar debido a que el servicio es inapropiado o el cliente no paga. Durante el periodo estipulado del contrato, los clientes son disuadidos de abandonar debido a diversas razones (penalizaciones, costumbre, deseos de terminar el contrato, etc.). Cuando el contrato termina, algunos clientes se apresuran a terminar la relación y la tasa va en aumento. A partir de la terminación del contrato puede haber muchas razones para cesar: los precios ya no son tan competitivos, los mercados y tecnologias cambian, los clientes prefieren cambiar de proveedor que negociar tarifas más bajas con el proveedor existente, etc.
45
45
Función empírica de riesgo
0.00%
0.05%
0.10%
0.15%
0.20%
0.25%
0.30%
0 60 120 180 240 300 360 420 480 540 600 660 720
Permanencia (días)
Rie
sgo
diar
io d
e ch
urn
Las Las irregularidadesirregularidades se se debendeben a a variacivariacióónn
intrasemanalintrasemanal
BajasBajas porpor no no pagopago
La La declinacideclinacióónn gradual gradual de largo de largo plazoplazo eses unaunamedidamedida de de fidelidadfidelidad
RiesgoRiesgo alto en alto en tiempotiempo 00
Fin de la Fin de la promocipromocióónn
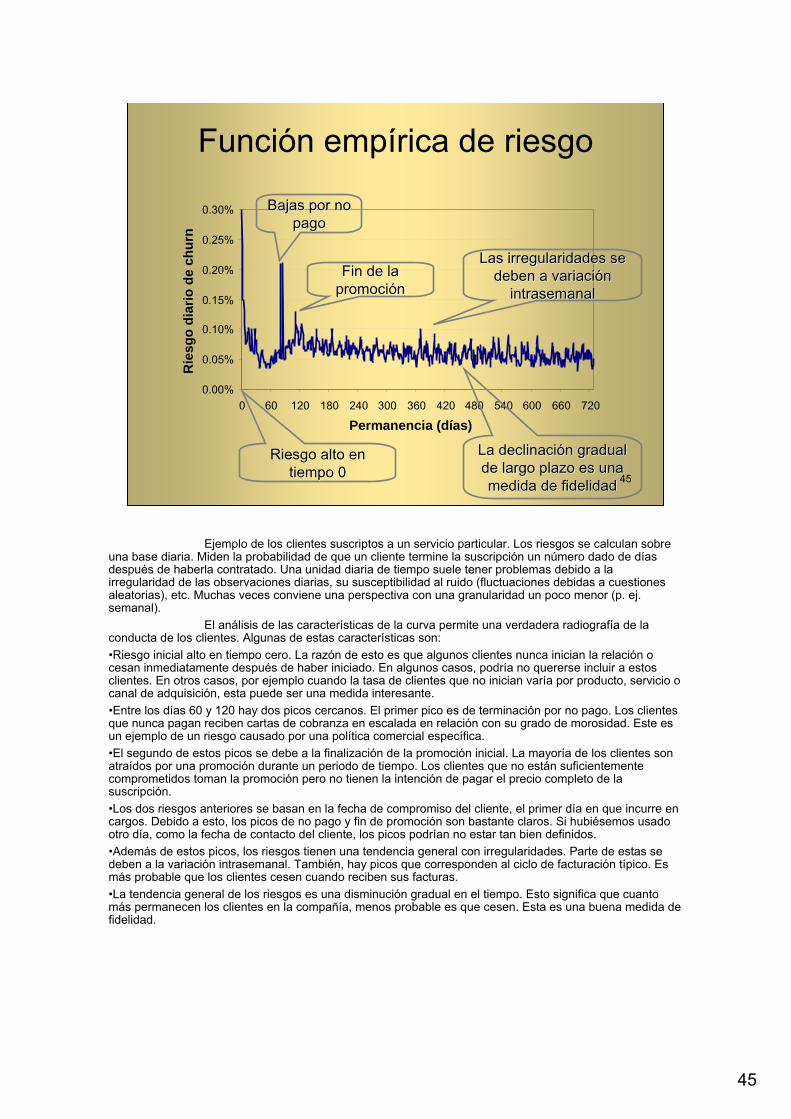
Ejemplo de los clientes suscriptos a un servicio particular. Los riesgos se calculan sobreuna base diaria. Miden la probabilidad de que un cliente termine la suscripción un número dado de díasdespués de haberla contratado. Una unidad diaria de tiempo suele tener problemas debido a la irregularidad de las observaciones diarias, su susceptibilidad al ruido (fluctuaciones debidas a cuestionesaleatorias), etc. Muchas veces conviene una perspectiva con una granularidad un poco menor (p. ej. semanal).
El análisis de las características de la curva permite una verdadera radiografía de la conducta de los clientes. Algunas de estas características son:•Riesgo inicial alto en tiempo cero. La razón de esto es que algunos clientes nunca inician la relación o cesan inmediatamente después de haber iniciado. En algunos casos, podría no quererse incluir a estosclientes. En otros casos, por ejemplo cuando la tasa de clientes que no inician varía por producto, servicio o canal de adquisición, esta puede ser una medida interesante.•Entre los días 60 y 120 hay dos picos cercanos. El primer pico es de terminación por no pago. Los clientesque nunca pagan reciben cartas de cobranza en escalada en relación con su grado de morosidad. Este esun ejemplo de un riesgo causado por una política comercial específica.•El segundo de estos picos se debe a la finalización de la promoción inicial. La mayoría de los clientes son atraídos por una promoción durante un periodo de tiempo. Los clientes que no están suficientementecomprometidos toman la promoción pero no tienen la intención de pagar el precio completo de la suscripción. •Los dos riesgos anteriores se basan en la fecha de compromiso del cliente, el primer día en que incurre en cargos. Debido a esto, los picos de no pago y fin de promoción son bastante claros. Si hubiésemos usadootro día, como la fecha de contacto del cliente, los picos podrían no estar tan bien definidos.•Además de estos picos, los riesgos tienen una tendencia general con irregularidades. Parte de estas se deben a la variación intrasemanal. También, hay picos que corresponden al ciclo de facturación típico. Es más probable que los clientes cesen cuando reciben sus facturas.•La tendencia general de los riesgos es una disminución gradual en el tiempo. Esto significa que cuantomás permanecen los clientes en la compañía, menos probable es que cesen. Esta es una buena medida de fidelidad.

46
46
Censura
Tiempo
Inicio clientes
Ex clientes (círculosblancos)
Clientes todavíaactivos (circ.
llenos).
Hoy(fecha censura)
Ana, Permanencia 12, Activa
Rober, Permanencia 6, cesó
Cora, Permanencia 6, cesó
Diana, Permanencia3, cesó
Ema, Permanencia 3,Activa
Fede, Permanencia 5, Cesó
Gus, Permanencia 6, cesó
Juan Permanencia 9, Activo
La censura significa eliminar (no incluir) a algunos clientes de algunos de los cálculos de riesgo. Es uno de los conceptos más importantes en el análisis de supervivencia. El ejemplo más básico de censura es que los clientes que cesaron no se incluyen en los cálculos después de que lo hicieron. Otroejemplo es el de los clientes cuya permanencia es t, pero están actualmente activos. Estos clientes no se incluyen en la población para el riesgo de permanencia t, porque los clientes podrían todavía cesar antes de t + 1. Estos clientes son eliminados para el cálculo de ese riesgo particular, aunque son incluidos en loscálculos de los riesgos para valores más pequeños de t. Además de los dos tipos de censura anteriores(riesgos para clientes después de que cesaron y riesgos para clientes que todavía están activos) existenmuchos otros tipos relevantes en los cálculos en distintas clases de fenómenos, tipos de productos o servicios, etc.
El gráfico muestra clientes que iniciaron y cesaron en diferentes momentos. Tres de losclientes cesaron en el pasado. Dos cesaron hoy, y tres están todavía activos. Conocemos la permanenciade los ex-clientes, porque tenemos una fecha de inicio y una fecha de finalización. Para los clientes activos, no conocemos si cesarán mañana o continuarán durante los próximos diez años. Es decir, solo tenemosuna cota inferior de su permanencia. Decimos que su permanencia está censurada.
Cuando examinamos los datos más recientes, la fecha de censura es hoy (o la fecha de actualización más reciente). Para algunos propósitos, como testeo, a veces es deseable fijar la fecha de censura en un punto en el pasado. Cuando hacemos esto, debemos estar seguros de excluir todainformación futura. Por ejemplo, si la fecha de censura fuera fijada en la barra de más a la izquierda, losdatos cambiarían. La permanencia de Ana sería menor. Rober, Cora, Ema, Fede y Juan no serían clientesporque no habrían comenzado. Gus todavia estaría activo, pero con una menor permanencia. El únicocliente que quedaría igual sería Diana.

47
47
Curva de retención no monotónica
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 10 20 30 40 50 60 70 80 90 100 110
Permanencia (Semanas)
Ret
enci
ón
Una curva de retención proporciona información sobre cuántos clientes fueronretenidos durante una cierta cantidad de tiempo. Una forma de calcularla es: para los clientes queiniciaron hace una unidad de tiempo, medir la retención de 1 unidad de tiempo, para los clientesque iniciaron hace dos unidades de tiempo, medir la retención de dos unidades de tiempo, etc.
Nótese que la curva es bastante dentada y no monotónica. A veces va haciaarriba y a veces hacia abajo. ¿Qué significa que la retención en las 21 semanas sea más alta quela retención a las 20 semanas? Esperaríamos que el número de personas con permanencia de 21 semanas que cesaron incluirían a los que cesaron a las veinte semanas más un númeroadicional.
Una razón podria ser el error de muestreo. Sin embargo, hay otras causas. Porejemplo, la mezcla de clientes que están siendo adquiridos podrían cambiar entre las dos semanas. Considérese un centro de telemarketing que utiliza para priorizar sus llamadas un puntaje de “buen cliente”. Tal vez los mejores de los buenos clientes fueron llamados hace 21 semanas. Estos son clientes que esperaríamos que tengan una mejor retención. Una semanadespués (hace 20 semanas) se llamaron a clientes no tan buenos y estos tienen una tasa mayor de cese.
Otro factor que podría variar en el tiempo es el número de clientes que estánsiendo adquiridos. Tal vez el número de inicios descendió a 0 en una de las semanas. En estecaso, la variación del muestreo puede jugar un papel importante en la variabilidad de la retención.
Este tipo de curvas ofrece algunas dificultades para algunos cálculos: el tiempode vida mediano podria no ser uno solo o la retención promedio con una permanencia dada podría ser mayor que la retención promedio con una permanencia menor.

48
48
Supervivencia vs. retención
• Retención solo usa clientes de un periodo de tiempo estrecho paracalcular cualquier punto
• Supervivencia usa tanta información como sea posible de todos losclientes para calcular cada punto
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 10 20 30 40 50 60 70 80 90 100 110
Permanencia (Semanas)
Ret
enci
ón/S
uper
vive
ncia
Los riesgos dan la probabilidad de que un cliente pueda cesar en un punto particular del tiempo. La supervivencia da la probabilidad de que un cliente sobreviva hasta ese momento. En cualquierpunto del tiempo, la probabilidad de que un cliente sobreviva hasta la siguiente unidad de tiempo es 1 –riesgo, lo que se llama supervivencia condicional en el tiempo t (condicional porque se supone que el cliente sobrevivió hasta el tiempo t). Para calcular la supervivencia total en un momento t dado, se multiplican todas las supervivencias condicionales hasta ese punto del tiempo. La curva de supervivenciaes siempre monotónica decreciente.
El gráfico muestra dos curvas, una para retención y otra para supervivencia, basadas en los mismos días. La curva de supervivencia parece una media móvil de la retención, pero no lo es. Un buenmodo de comparar las dos curvas es definir lo que significan. La curva de supervivencia provee un benchmark de la conducta de churn de los clientes. Cada punto en la curva de supervivencia incorporainformación de todo el data set. La curva de retención, por otro lado, provee la información más recientesobre cada punto. Por ejemplo, para la medición de retención de 50 semanas la información más recientees la de los clientes que iniciaron hace 50 semanas.
Desde esta perspectiva, se pueden interpretar las dos curvas de arriba. Durante lasprimeras semanas, la retención es más elevada que la supervivencia. Esto significa que los nuevos clientesde las últimas semanas tuvieron una mejor performance que los clientes como un todo durante las primerassemanas de permanencia. La adquisición de clientes está atrayendo clientes de mejor calidad. Gran partede la diferencia ocurre durante la primera semana. Tal vez la diferencia se deba una reducción grande del fenómeno llamado “remordimiento inicial del comprador”.
Durante otros períodos, la retención es inferior a la supervivencia. Esto implica que losclientes durante esas semanas fueron peores que los clientes en general. En el ejemplo, la curva de retención y la curva de supervivencia son bastante similares. Las diversas diferencias son pequeñas y podrían deberse solamente a variaciones aleatorias.
Debido a que el cálculo de supervivencia usa todos los datos, los valores son másestables que los cálculos de retención. Cada punto en una curva de retención se limita a los clientes queiniciaron en un punto particular del tiempo. También debido a que una curva de supervivencia esmonotónica decreciente, los cálculos de tiempo de vida mediano y permanencia promedio son másprecisos. Al incorporar más información, la supervivencia provee una imagen más precisa de la retenciónde los clientes. Como la supervivencia es acumulativa, produce un buen valor de resumen para comparardiferentes grupos de clientes y mejores estimaciones de retención para los cálculos de valor de tiempo de vida del cliente.
Por otro lado los riesgos hacen más evidentes las causas específicas. Es posibleidentificar sucesos durante el ciclo de vida del cliente que son causas de riesgos. Las curvas de supervivencia no destacan esos sucesos tan claramente como los riesgos. Pero no tiene sentido compararriesgos para diferentes grupos de clientes. El enfoque apropiado es transformar los riesgos en supervivencia y comparar los valores en las curvas de supervivencia.

49
49
Tiempo hasta la próxima compra, estratificado por número de compras
previas
Otro ejemplo de la aplicación de supervivencia es el tiempo hasta la próximacompra para sucesos de retail. En este caso, el inicio es cuando el cliente hace una compra. El fin es cuando (si ocurre) el cliente hace otra compra. Como supervivencia aquí mide la probabilidad de que un cliente no haga una compra, tiene más sentido considerar la inversa, la probabilidad de que un cliente hará una compra.
El gráfico muestra el tiempo hasta la próxima compra, estratificado por el númerode compras en el pasado. La línea gruesa gris es el promedio global para cualquier número de compras.

50
50
Otras aplicaciones
• Problemas de respuesta, activación, reactivación, cross-sell, up-sell, churn, attrition, etc.
• Forecasting al nivel del cliente en lugar del forecasting tradicional
• Truncado izquierdo• Riesgos competidores• Efectos de covariables (regresión de Cox)
•El forecasting tradicional hace predicciones a un nivel agregado, por ejemplo, cuántos clientes desertarán la próxima semana, pero no permite decir si un cliente dado desertará o no. El forecasting basado en el análisis de supervivencia se realiza en el nivel del cliente y hace posible incluso analizar los diversos factores relacionados con la deserción.•El truncado izquierdo ocurre cuando la información de los clientes dados de baja no se almacenócon anterioridad a un momento dado en la base de datos de análisis. Este problema produce dificultades en un análisis de supervivencia porque provoca la subestimación del cálculo de riesgos y la sobreestimación de la supervivencia. El truncado izquierdo es un fenómeno frecuente en empresas, debido a diversas circunstancias (una de ellas es la migración de la base de datos de clientes, momento oportuno para dejar caer la información histórica de clientes ya no vinculados). Existen varias formas de encarar el problema. Una de ellas, las ventanas temporales, tiene además otras aplicaciones interesantes como el manejo de modificaciones en la política de una empresa.•El análisis de riesgos competidores permite analizar el efecto de distintos tipos de riesgos sobre la supervivencia.•Efectos de covariables: se analiza el efecto de distintos factores sobre los riesgos. Estratificaciones y la muy conocida regresión de riesgos proporcionales de Cox (más brevemente regresión condicional de Cox o simplemente regresión de Cox) se concentran sobre el efecto de condiciones iniciales sobre los riesgos. Extensiones de este último método permiten analizar el efecto de covariables dependientes del tiempo (las condiciones pueden ocurrir en cualquier momento durante la permanencia del cliente, no necesariamente al inicio).

51
51
Síntesis
• Se presentaron conceptos y herramientas que debieran ser parte del “arsenal” habitual de quien pretenda hacer un data mining efectivo

52
52
José Angel Alvarezjalvarez@maysaconsultores.com.arwww.maysaconsultores.com.ar


















