
NOTAS Bioestadistica
67
GENERALIDADES Concepto de Bioestadística: La estadística es un conjunto de métodos y procedimientos utilizados para coleccionar datos con el fin de organizarlos, tabularlos e interpretarlos. Si estos datos u observaciones se relacionan con los seres vivos, se trata entonces de bioestadística. Se puede decir que la bioestadística es una ciencia puesto que la organización e interpretación de datos implica la utilización del método científico. Sin embargo también suele considerarse como un arte en cuanto que la recolección de datos requiere de habilidad y artificios, sobre todo para ajustarlos lo más posible a la realidad. Campo e importancia. La estadística juega un papel importante en casi todas las facetas y actividades del ser humano. Se ocupa inicialmente en asuntos de estado, negocios, economía, educación. Actualmente ha adquirido relevancia en el área de la salud, fundamentalmente en epidemiología. Los avances tecnológicos enfrentan al estudioso o investigador del área de la salud con información cuantitativa más que descriptiva. En este sentido la estadística viene a ser el lenguaje necesario para coordinar y manejar el material. Variables. Una característica relevante de los seres vivos es la de manifestar variabilidad, es decir, presentar diferencias entre individuos aunque pertenezcan al mismo grupo. Un símbolo que puede representar valores diferentes y previamente fijados se denomina variable independiente; si el símbolo representa valores correspondientes a los prefijados, se trata entonces de una variable dependiente. La variación puede ser continua o discreta. La continuidad implica que entre dos valores considerados siempre habrá la posibilidad de encontrar otros valores más. Cuando no ocurre esto se dice que los valores o los números son discretos. Elaboró: Guillermo Castañeda Tovar UACQB_UAG 1
description
ejemplos de bioestadistica
Transcript of NOTAS Bioestadistica

GENERALIDADES
Concepto de Bioestadística: La estadística es un conjunto de métodos y procedimientos utilizados para coleccionar datos con el fin de organizarlos, tabularlos e interpretarlos. Si estos datos u observaciones se relacionan con los seres vivos, se trata entonces de bioestadística.
Se puede decir que la bioestadística es una ciencia puesto que la organización e interpretación de datos implica la utilización del método científico. Sin embargo también suele considerarse como un arte en cuanto que la recolección de datos requiere de habilidad y artificios, sobre todo para ajustarlos lo más posible a la realidad.
Campo e importancia. La estadística juega un papel importante en casi todas las facetas y actividades del ser humano. Se ocupa inicialmente en asuntos de estado, negocios, economía, educación. Actualmente ha adquirido relevancia en el área de la salud, fundamentalmente en epidemiología.
Los avances tecnológicos enfrentan al estudioso o investigador del área de la salud con información cuantitativa más que descriptiva. En este sentido la estadística viene a ser el lenguaje necesario para coordinar y manejar el material.
Variables. Una característica relevante de los seres vivos es la de manifestar variabilidad, es decir, presentar diferencias entre individuos aunque pertenezcan al mismo grupo. Un símbolo que puede representar valores diferentes y previamente fijados se denomina variable independiente; si el símbolo representa valores correspondientes a los prefijados, se trata entonces de una variable dependiente. La variación puede ser continua o discreta. La continuidad implica que entre dos valores considerados siempre habrá la posibilidad de encontrar otros valores más. Cuando no ocurre esto se dice que los valores o los números son discretos.
Funciones. Si a cada valor posible de una variable X le corresponde un valor de otra variable Y, se dice entonces que Y es función de x, y se escribe Y= F(X). No necesariamente tienen que utilizarse los símbolos Y y X. Es mas, en ocasiones es mucho mejor utilizar otras letras que nos hablen más de lo que estamos representando con ellas.
Por ejemplo para representar tiempo una t, para representar volumen una v y así por el estilo. Si dijéramos por ejemplo que la producción de maíz en los últimos 3 años en el país PPP, fue de 20 000 toneladas en 1998, de 32 000 toneladas en 1999 y 37 000 toneladas en 2000, entonces estamos hablando de una función, donde para cada año hay una correspondiente cantidad de maíz, y podríamos utilizar la “M” para representar cantidad de maíz y la “a” para representar años. Así pues, M es función de a. M = F(a).
Gráficos. Un gráfico es la representación de las relaciones entre variables. En estadística se utilizan diferentes tipos de gráficos, según la naturaleza de los datos involucrados y el propósito del gráfico. Entre otros podemos citar los de barras, de líneas, circulares (pastel), de dispersión. Es importante entender que un gráfico debe servir para aclarar, no para confundir.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1

Redondeo. Sabemos que redondear significa aproximar una cantidad a otra. Para comprender el sentido de eso supongamos que el numero 230 lo queremos redondear en las centenas; para ello tenemos que pensar que dicho numero se encuentra entre 200 y 300, y mas cerca de 200, así que la aproximación del mismo es 200; si en cambio se tratara de redondear el 270, entonces tendríamos que decir que es 300, ya que el 270 también se encuentra entre 200 y 300, pero mas cerca de 300- Otro ejemplo: se tiene el numero 436 y se quiere redondear pero ahora en las decenas; este numero se encuentra entonces entre 430 y 440. Pero más cerca de 440. Por lo tanto al redondear escribiremos 440. Si por el contrario se tratara del número 432, entonces el redondeo sería 430. El problema pudiera ser para números que se encuentran a la misma distancia de los extremos, por ejemplo 250; para redondearlo en centenas, vemos que se encuentra a la misma distancia de 200 y de 300; en estos casos se adopta como criterio aproximar hacia el par, lo que implica en algunos casos incrementar una unidad en el numero precedente al 5, y dejarlo como está , en otros.
Notación exponencial. La notación exponencial consiste en escribir las cantidades, sobre todo cuando éstas tienen numerosas cifras, con unas cuantas y multiplicando por potencias de base 10. Por ejemplo: 2 000, 24 000, 800, 300 000, los podemos escribir como: 2xl03, 2.4x104, 8x102, 3x105 .También podemos pensar en números como: 0.000 16, 0.000 035, 0.004. Estos se escriben como: 1.6x10-4, 3.5x10-5, 4x10-3 respectivamente. Se suele utilizar normalmente una cifra entera.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

En esta tabla se presentan las velocidades orbítales de los planetas del sistema solar.Como se puede apreciar hay 2 variables, planeta y velocidad. La primera de ellas es discreta y la segunda continua
PRESENTACIÓN DE DATOS UTILIZANDO TABLAS
País Población(millones)
China IndiaU.R.S.SEE.UU.IndonesiaBrasilJapón
1038768278239173135121
Año Varones Hembras
1920193019401950196019701980
53.658.160.865.666.667.170.0
54.661.665.271.173.174.777.4
Año Elemental Media Superior
19601965197019751980
32.435.337.133.830.6
10.213.014.715.714.6
3.65.77.49.710.2
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3
Planeta Velocidad (m/s)
Mercurio VenusTierraMarteJúpiterSaturnoUranoNeptuno
29.729.818.515.08.16.04.23.4
En esta otra se presenta los siete países con mayor población en el año de 1986.La cantidad de habitantes en cada uno de esos se rodea a millones
Esta tabla da la expectativa de vida de un niño nacido en EE.UU. durante 1920-1980. Se establece diferencias entre varones y hembras
Aquí se ve la cantidad (en millones) de estudiantes en enseñanza elemental, media y superior, en EE.UU.

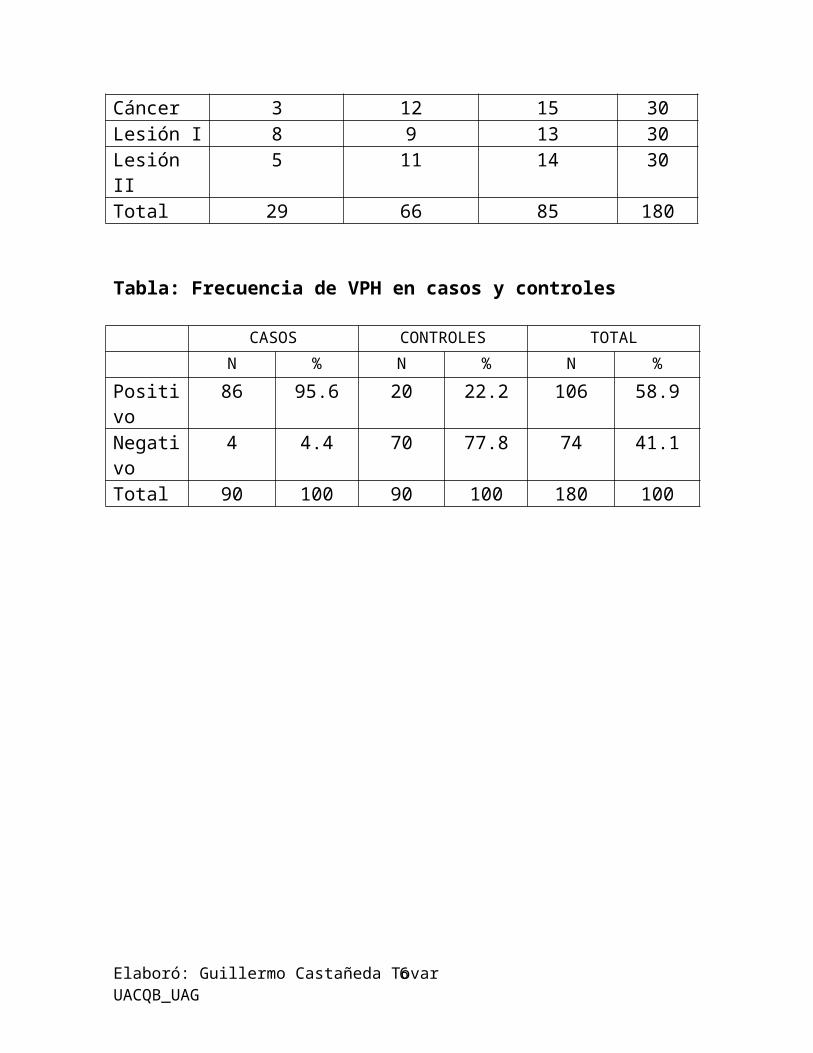
Tabla: Clasificación por tipo de lesión y polimorfismo X
Homocigoto Silvestre
Homocigoto Mutante
Heterocigoto
Normal 13 34 43 90Cáncer 3 12 15 30Lesión I 8 9 13 30Lesión II 5 11 14 30Total 29 66 85 180
Tabla: Frecuencia de VPH en casos y controles
CASOS CONTROLES TOTALN % N % N %
Positivo 86 95.6 20 22.2 106 58.9Negativo 4 4.4 70 77.8 74 41.1Total 90 100 90 100 180 100
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4
Plimorfismo X Total

ESCALAS DE MEDICIÓN
Una escala de medición determina grados o valores de una característica también determina los métodos estadísticos que se usan para analizar los datos. Por tanto, es importante definir las características por medir. Las tres escalas de medición que se presentan con mayor frecuencia en medicina son: nominales, ordinales y numéricas.
Escalas nominales
Se usan para el tipo más simple de medición cuando los valores de los datos se ajustan en categorías. Por ejemplo, para describir el resultado de los pacientes tratados con IL-2: si desarrollaron o no bacteriemia. En este ejemplo, el resultado puede tener uno de dos valores: sí o no.
Muchas clasificaciones en investigación médica se valoran con una escala nominal. Así como los resultados de un tratamiento médico o un procedimiento quirúrgico, la presencia de un riesgo posible o los factores de exposición se describen frecuentemente como presentes o ausentes. Los resultados también pueden describirse con más de dos categorías, como al clasificar el microorganismo aislado de cultivos de pacientes, Staphylococus aureus, Staphylococus epidermidis. .
Los datos evaluados en una escala nominal se llaman también observaciones cualitativas, debido a que describen la calidad de una persona o cosa estudiada, u observaciones categóricas porque los valores se agrupan en categorías. Por lo regular, los datos nominales o cualitativos se describen en términos de porcentajes o proporciones.
Escalas ordinales
Si hay un orden inherente entre las categorías, se dice que las observaciones se miden en una escala ordinal. Estas observaciones aun se clasifican, como en las escalas nominales, pero algunas tienen "más" o son "más grandes que" otras. Los clínicos a menudo usan escalas ordinales para ayudar a determinar la cantidad de riesgo que tiene un paciente o el tipo de tratamiento que es apropiado. Por ejemplo, los tumores, se clasifican en etapas según su grado de desarrollo. La clasificación internacional para valorar la etapa de un carcinoma de cuello uterino es una escala ordinal de O a IV, donde la etapa O representa carcinoma in situ y la etapa IV, carcinoma que se extiende más allá de la pelvis o que afecta a la mucosa de vejiga y recto.
Las clasificaciones basadas en el grado del trastorno también se aplican a otras enfermedades además del carcinoma. Por ejemplo, los sujetos con artritis se clasifican en cuatro clases de acuerdo con la gravedad del deterioro: clase I, actividad normal, a clase 4, incapacidad en silla de ruedas.
Una clase especial de escala ordinal es la llamada escala de posición, donde las observaciones se clasifican de mayor a menor (o viceversa). Por ejemplo, las causas de peso bajo al nacer en lactantes como desnutrición, abuso de drogas, cuidados prenatales inadecuados, etcétera; pueden colocarse dentro de un intervalo desde lo más frecuente hasta
Elaboró: Guillermo Castañeda Tovar UACQB_UAG5
lo menos usual; esto, para ayudar a los médicos a dirigir los esfuerzos de educación del paciente. También la duración de procedimientos quirúrgicos podría traducirse en una escala de posición u ordinal para obtener una medida de la dificultad del procedimiento (el más difícil, el segundo más difícil y así sucesivamente). En este ejemplo, la diferencia en tiempo para el primero y segundo procedimiento no es por fuerza la misma que para otros dos cualesquiera.
Al igual que en las escalas nominales, se emplean a menudo porcentajes y proporciones en escalas ordinales.
Escalas numéricas
Las observaciones donde las diferencias entre cifras se traducen a una escala numérica, se designan en ocasiones como observaciones cuantitativas, debido a que miden la cantidad de algo. Hay dos clases de escalas numéricas: continua, y discreta. Una escala continua tiene valores en continuo. La edad por ejemplo, es un dato continuo ya que puede tener cualquier valor decimal o entero entre cero y la edad del individuo más viejo, es decir, puede especificarse de manera tan precisa como sea necesario. En estudios de adultos, y en general es suficiente que la edad se anota con respecto al año más próximo; en niños pequeños, es mejor la edad respecto del mes más próximo. Otros ejemplos de datos continuos son peso, estatura, tiempo de supervivencia, grado de movimiento de una articulación y numerosos valores de laboratorio, como glucosa, sodio, potasio o ácido úrico séricos.
Cuando una observación numérica puede tomar sólo valores enteros, la escala de medición es discreta. Por ejemplo, el recuento de objetos (número de embarazos, de operaciones previas, de factores de riesgo) son medidas discretas. Si en un estudio se van a evaluar tres características de los pacientes: porcentaje de saturación del colesterol en bilis, edad y sexo; las dos primeras serian una escala numérica continua debido a que pueden tener cualquier valor individual en la escala de valores posibles. El sexo del paciente tiene una escala nominal sólo con dos valores. Si en otro estudio se observa a una determinada cantidad de pacientes durante un periodo determinado para observar si desarrollan cálculos biliares, el número de dichos cálculos es un ejemplo de una medición numérica discreta.
FILAS DE DATOS
Datos recogidos que no han sido organizados. Por ejemplo, alturas de los estudiantes de un grupo de cien estudiantes; puntajes de un Test aplicado a un grupo de 60 alumnos.
ORDENACIONES (RANGO). Una ordenación es un conjunto de datos numéricos en orden creciente o decreciente. La diferencia entre el mayor y menor se llama rango de ese conjunto de datos.
DISTRIBUCIONES DE FRECUENCIAS. Al resumir grandes colecciones de datos, es conveniente distribuirlos en clases o categorías, determinando la cantidad de individuos correspondientes a cada clase. A esta cantidad de
Elaboró: Guillermo Castañeda Tovar UACQB_UAG6

individuos por clase se le denomina frecuencia de clase. La tabulación de esas clases y sus correspondientes frecuencias constituyen una distribución de frecuencias.
FRECUENCIA ABSOLUTA y RELATIVA La frecuencia absoluta es, como ya lo hemos dicho la cantidad de individuos que hay en cada clase. La frecuencia relativa para cada clase es la relación entre la frecuencia absoluta y el número total de individuos. La suma de las frecuencias absolutas siempre será igual al número de individuos N, ∑fabs = N; mientras que la suma de las frecuencias relativas será igual a la unidad, ∑.frel = 1.
La siguiente tabla es un ejemplo de distribución de frecuencias de las alturas de 100 estudiantes varones de la universidad PQR
Altura (cm.)
Número de estudiantes
160-162163-165166-168169-171172-174
51842278
Los datos así organizados en clases como en la anterior distribución de frecuencias se llaman datos agrupados.
INTERVALOS DE CLASE y LÍMITES DE CLASE El símbolo que define una clase, como el 160-162 en la Tabla anterior, se llama un intervalo de clase. Los números extremos, 160 y 162, se llaman respectivamente. límite inferior de clase y límite superior de clase.
Un intervalo de clase que, al menos en teoría, carece de límite superior o inferior indicado, se llama intervalo de clase abierto, Por ejemplo, refiriéndonos a edades de personas, la clase «65 años o más» es un intervalo de clase abierto.
FRONTERAS DE CLASE Si se considera que entre el límite superior de una clase y el límite inferior de la siguiente clase existe la posibilidad de tener valores intermedios, entonces al punto medio entre ellos se le considera como el verdadero valor que separa una clase de la otra y se llama frontera de clase. Así pues 162.5 cm. es el punto medio entre 162 y 163. A veces se usan las fronteras de clase como símbolos para la clase. Así, las clases de la Tabla anterior se pueden indicar por 159.5-162.5, 162.5-165.5, etc.
TAMAÑO O ANCHURA DE UN INTERVALO DE CLASE El tamaño o anchura de un intervalo de clase es la diferencia entre las fronteras de clase superior e inferior. Si todos los intervalos de clase de una distribución de frecuencias tienen
Elaboró: Guillermo Castañeda Tovar UACQB_UAG7

la misma anchura, ésta será igual a la diferencia entre los límites inferiores o superiores de clases sucesivas.
MARCA O VALOR DE CLASE La marca de clase es el punto medio del intervalo de clase y se obtiene promediando los límites inferior y superior de clase. Así que las marcas de clase del intervalo 160- 162 es (160 + 162)/2 = 161. La marca de clase se denomina también punto medio de la clase.
REGLAS GENERALES PARA FORMAR DISTRIBUCIONES DE FRECUENCIAS 1. Determinar el mayor y el menor de todos los datos, hallando así el rango (diferencia entre ambos). 2. Dividir el rango en un número adecuado de intervalos de clase del mismo tamaño. Si ello no es factible, usar intervalos de clase de distintos tamaños o intervalos de clase abiertos. Se suelen tomar entre 5 y 20 intervalos de clase, según los datos. Los intervalos de clase se eligen también de modo tal que las marcas de clase ( o puntos medios) coincidan con datos realmente observados. Ello tiende a disminuir el llamado error de agrupamiento que se produce en análisis ulteriores. No obstante, las fronteras de clase no debieran coincidir con datos realmente observados. 3. Determinar el número de observaciones que caen dentro de cada intervalo de clase; esto es, hallar las frecuencias de clase. Esto se logra mejor con una hoja de recuentos.
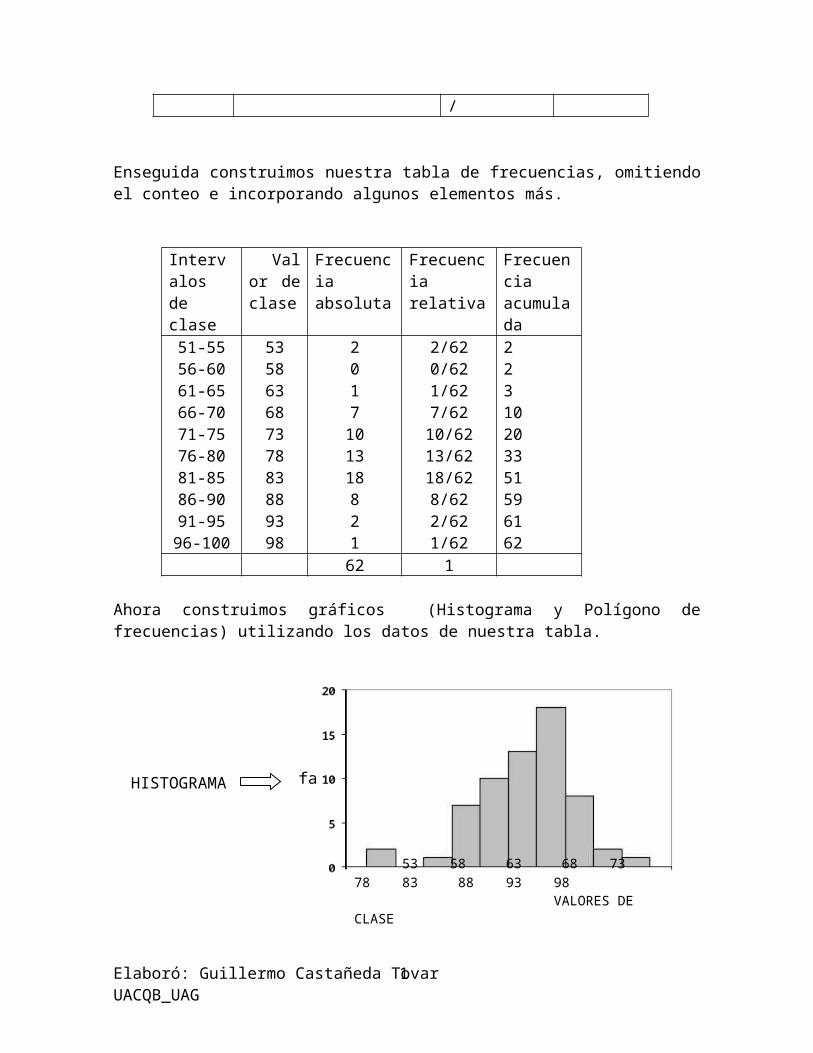
HISTOGRAMAS y POLIGONOS DE FRECUENCIAS Los histogramas y los polígonos de frecuencias son dos representaciones gráficas de las distribuciones de frecuencias. Un histograma o histograma de frecuencias, consiste en un conjunto de rectángulos con bases en el eje x. centros en las marcas de clase y longitudes iguales a los tamaños de los intervalos de clase y áreas proporcionales alas frecuencias de clase.
Si los intervalos de clase tienen todas las mismas anchuras, las alturas de los rectángulos son proporcionales a las frecuencias de clase, y entonces es costumbre tomar las alturas iguales a las frecuencias de clase. En caso contrario, deben ajustarse las alturas.
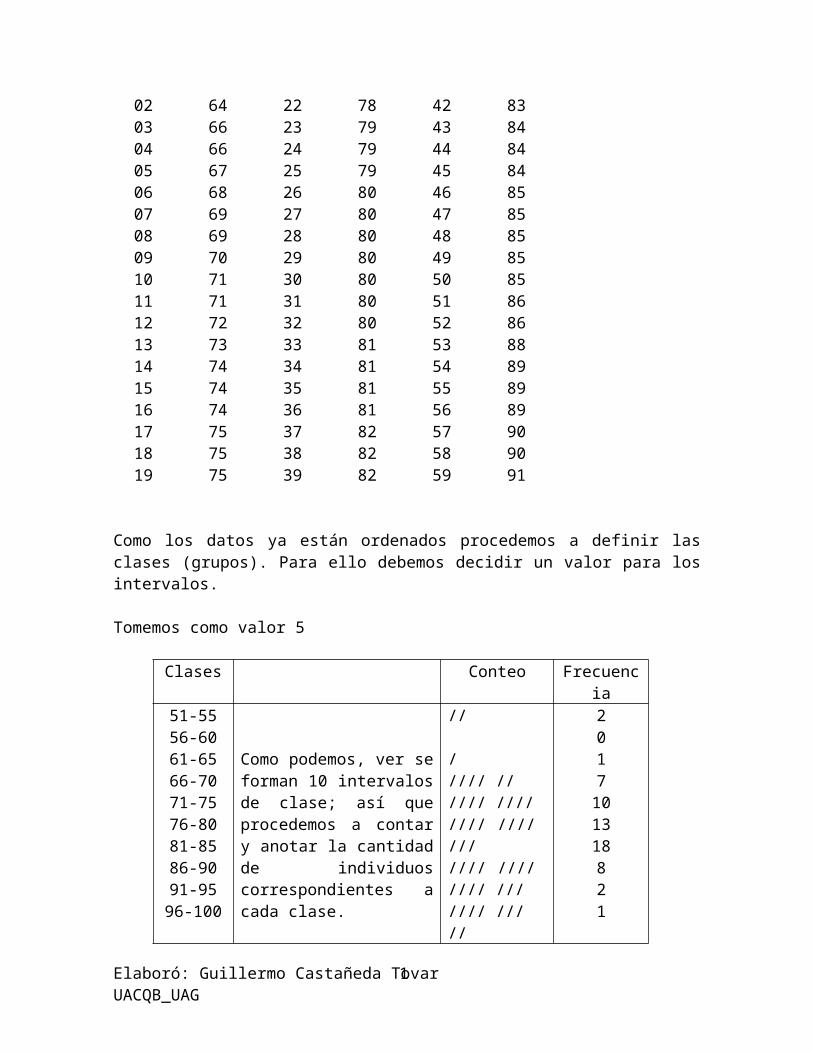
A continuación se presentan datos correspondientes a número de serie y valor de la altura en cm. de 62 plantas de trigo. Los valores están ordenados en forma creciente. Con esos datos construyamos una tabla de frecuencias.
Número Altura Número Altura Número Altura Número Altura000102030405060708
515564666667686969
202122232425262728
767778797979808080
404142434445464748
828383848484858585
6061
9299
Elaboró: Guillermo Castañeda Tovar UACQB_UAG8

0910111213141516171819
7071717273747474757575
2930313233343536373839
8080808081818181828282
4950515253545556575859
8585868688898989909091
Como los datos ya están ordenados procedemos a definir las clases (grupos). Para ello debemos decidir un valor para los intervalos.
Tomemos como valor 5
Clases Conteo Frecuencia51-5556-6061-6566-7071-7576-8081-8586-9091-9596-100
Como podemos, ver se forman 10 intervalos de clase; así que procedemos a contar y anotar la cantidad de individuos correspondientes a cada clase.
//
///// ////// //////// //// /////// //// //// /////// //////
2017101318821
Enseguida construimos nuestra tabla de frecuencias, omitiendo el conteo e incorporando algunos elementos más.
Intervalos de clase
Valor de clase
Frecuencia absoluta
Frecuencia relativa
Frecuencia acumulada
51-5556-6061-6566-7071-7576-8081-8586-9091-95
535863687378838893
201710131882
2/620/621/627/6210/6213/6218/628/622/62
223102033515961
Elaboró: Guillermo Castañeda Tovar UACQB_UAG9

96-100 98 1 1/62 6262 1
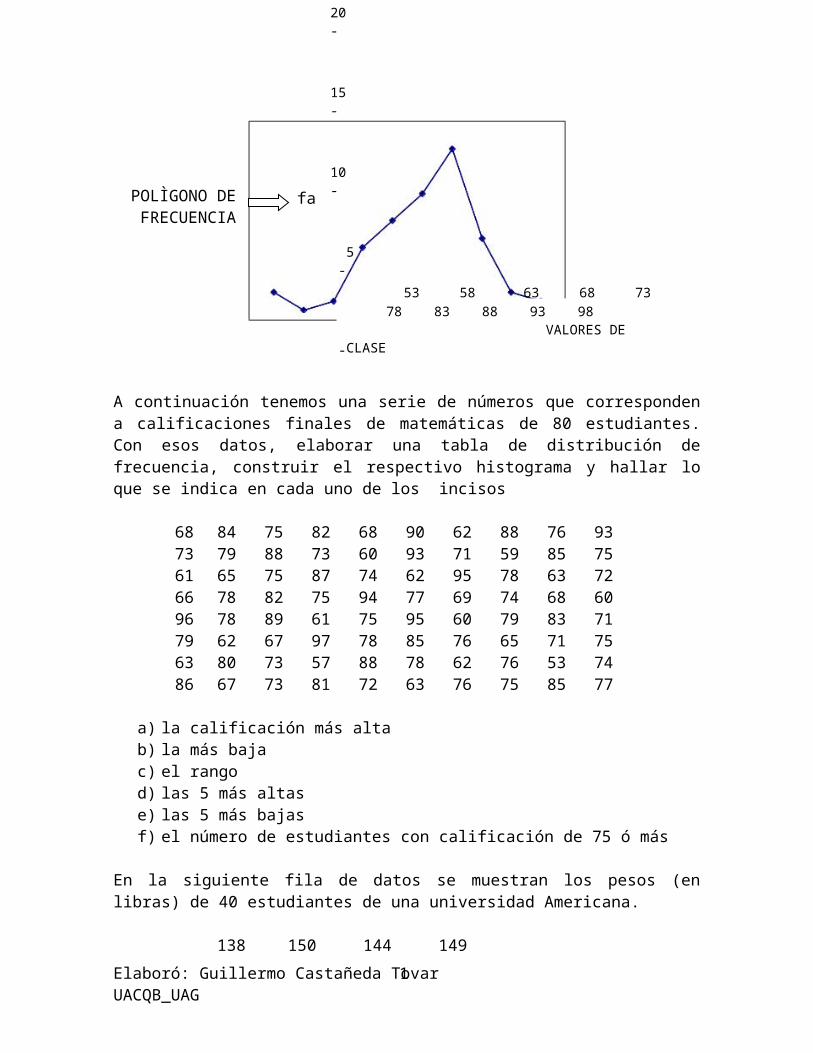
Ahora construimos gráficos (Histograma y Polígono de frecuencias) utilizando los datos de nuestra tabla.
A continuación tenemos una serie de números que corresponden a calificaciones finales de matemáticas de 80 estudiantes. Con esos datos, elaborar una tabla de distribución de frecuencia, construir el respectivo histograma y hallar lo que se indica en cada uno de los incisos
687361669679
847965787862
758875828967
827387756197
686074947578
909362779585
627195696076
885978747965
768563688371
937572607175
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1
53 58 63 68 73 78 83 88 93 98 VALORES DE CLASE
faHISTOGRAMA
fa
20 -
15 -
10 -
5 -
0 -
POLÌGONO DE FRECUENCIA
53 58 63 68 73 78 83 88 93 98 VALORES DE CLASE

6386
8067
7373
5781
8872
7863
6276
7675
5385
7477
a) la calificación más altab) la más bajac) el rangod) las 5 más altase) las 5 más bajasf) el número de estudiantes con calificación de 75 ó más
En la siguiente fila de datos se muestran los pesos (en libras) de 40 estudiantes de una universidad Americana.
138146168146161164158126173145
150140138142135132147176147142
144136163135150125148119153156
149152154140145157144165135128
Con estos datos construir dos tablas de frecuencias, una de 5 intervalos y otra de 12. En cada una de ellas se deberá considerar: clases, frecuencia, valor de clase y frecuencia acumulada, así como la construcción de los respectivos histogramas y polígonos de frecuencia.
GRÁFICOSUtilizando las tablas de datos que ya tenemos vamos a construir algunos gráficos manualmente y utilizando la computadora.
Con los datos de la primera tabla construir un gráfico circular; con los de la tercera un gráfico de columnas y con las demás cada cual elige el tipo de gráfico.
En el siguiente cuadro se pueden apreciar datos que corresponden a escalas nominales y ordinales.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1

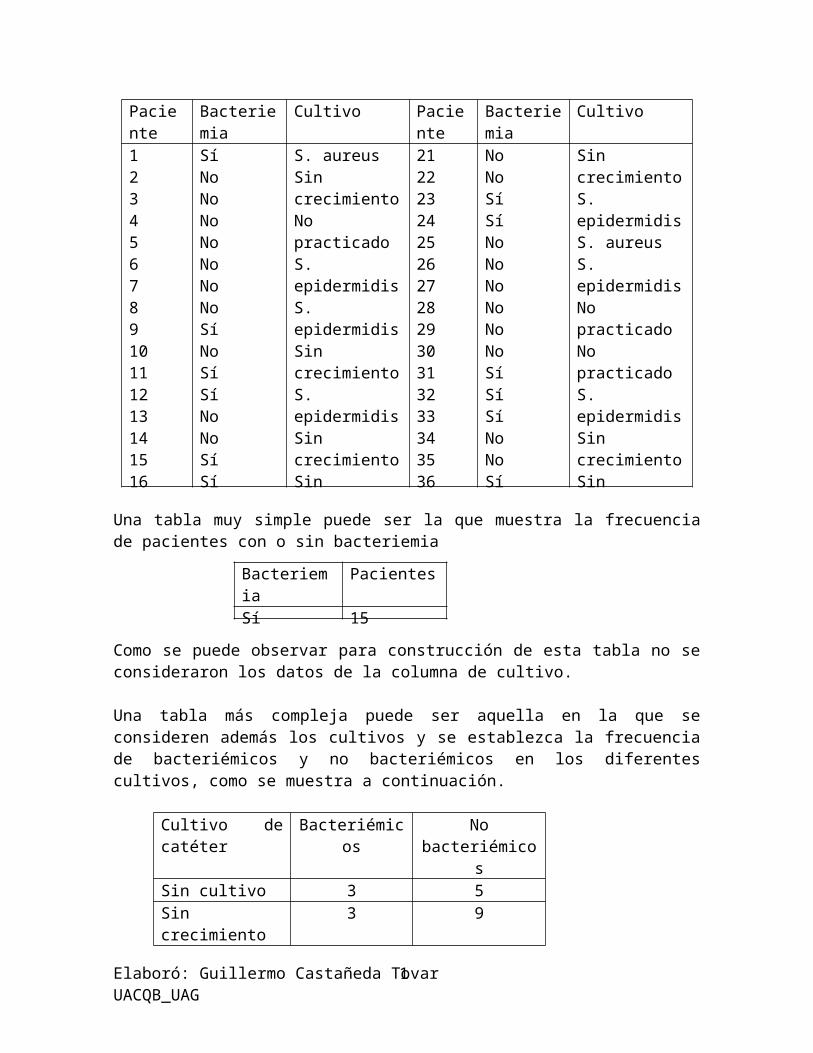
Cultivos de catéter de pacientes hipotéticos con o sin bacteriemia
Una tabla muy simple puede ser la que muestra la frecuencia de pacientes con o sin bacteriemia
Como se puede observar para construcción de esta tabla no se consideraron los datos de la columna de cultivo.
Una tabla más compleja puede ser aquella en la que se consideren además los cultivos y se establezca la frecuencia de bacteriémicos y no bacteriémicos en los diferentes cultivos, como se muestra a continuación.
Cultivo de catéter Bacteriémicos No bacteriémicosSin cultivo 3 5Sin crecimiento 3 9S. aureus 7 1S. epidermidis 2 10 Total 15 25
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1
Paciente Bacteriemia Cultivo Paciente Bacteriemia Cultivo1234567891011121314151617181920
SíNoNoNoNoNoNoNoSíNoSíSíNoNoSíSíSíNoNoNo
S. aureusSin crecimientoNo practicadoS. epidermidisS. epidermidisSin crecimientoS. epidermidisSin crecimientoSin crecimientoNo practicadoS. aureusS. aureusS. epidermidisSin crecimientoNo practicadoSin crecimientoS. aureusSin crecimientoS. epidermidisS. aureus
2122232425262728293031323334353637383940
NoNoSíSíNoNoNoNoNoNoSíSíSíNoNoSíSíNoSíNo
Sin crecimientoS. epidermidisS. aureusS. epidermidisNo practicadoNo practicadoS. epidermidisSin crecimientoSin crecimientoSin crecimientoNo practicadoNo practicadoS. aureusS. epidermidisS. epidermidisSin crecimientoS. aureusS. epidermidisS. epidermidisNo practicado
Bacteriemia PacientesSíNo
1525
MEDIDAS DE TENDENCIA CENTRAL
Una de las características más sobresalientes de la distribución de datos es su tendencia a acumularse hacia el centro de la misma. Esta característica se denomina Tendencia Central. En estadística las medidas de tendencia central son:
Media.Mediana.Moda.
Media: Es el promedio aritmético de las observaciones y se representa por X. Para calcularla se suman todas las observaciones y se divide entre el número de observaciones. La media aritmética de n valores, es igual a la suma de todos ellos dividida entre n. Esta puede representarse con la siguiente fórmula:
Ejemplo: Mediante los siguientes datos hallar la media aritmética.10, 8, 6, 5, 10, 9
Solución:
Además de la media aritmética que es a la que nos hemos referido, se puede considerar también la media geométrica y la media armónica.
Media geométrica: La media geométrica G, de un conjunto de números positivos es la raíz n-ésima del producto de esos números.
Por ejemplo, la media geométrica de 2, 4 y 8 es: Se prefiere este tipo de medida cuando se tienen valores en proporciones o porcentajes.
Ejemplo: En una cosecha de maíz se tomaron unas muestras de la relación del peso del grano con el peso del maíz en mazorca; las muestras fueron las siguientes:
De tal manera que:
o bien:
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1
Media armónica:La media armónica H, de un conjunto de números positivos es el recíproco de la media aritmética de los recíprocos de esos números.
Por ejemplo, la media armónica de los números 2, 4 y 8 es:
Esta medida se prefiere cuando los datos que se tienen son tasas, por ejemplo de nacimientos, de mortalidad, velocidades en km/h.
En relación a estos tres tipos de medias se puede decir que:X > G > H
MedianaEs el punto central de una serie de datos, es decir, la mitad de las observaciones es menor y la otra mitad es mayor. Para representarla suele utilizarse M o Md. Ejemplo:
Hallar la mediana en los siguientes datos. 25, 28, 30, 26, 32 Solución:
Se ordenan en forma creciente o decreciente y se toma el valor central. 25, 26, 28, 30, 32
mediana = 28
Pasos para su cálculo:
1.- Las observaciones se ordenan de menor a mayor o viceversa.2.- Contar para encontrar el valor medio. En número impar de observaciones, la mediana es el valor medio, para el número par se define como la media de los dos valores centrales. Una de sus ventajas es que es menos sensible a los calores extremos que la media.
Moda La moda es el valor que se presenta con mayor frecuencia. Por la regular se usa para un número grande de observaciones cuando el investigador desea hacer notar el "valor más popular". Por ejemplo,
Datos: 23, 25 20, 23, 21, 20, 23, 22Los números que se repiten son el 20 y el 23; el 20 dos veces y el 23 tres veces, así que la moda es 23.
Estas medidas también se pueden calcular con datos agrupados. Y reciben en ocasiones nombres particulares.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1
Media ponderadaLa media se conoce como media ponderada y se calcula mediante la siguiente fórmula:
Clase Modal:Para las tablas de frecuencia, la moda se estima por la clase modal, que es el intervalo que tiene el número más grande de observaciones, o dicho de otra manera, la frecuencia más alta.
Como ejemplo y para ahorrar tiempo, tomemos la tabla de distribución de frecuencia que tenemos en la página 8. No se requiere frecuencia relativa ni acumulada. Pero necesitamos de una columna donde tengamos el producto (valor de clase) (frecuencia absoluta).
Intervalos de clase
Valor de clase
Frecuencia absoluta
(V.C)(Fabs)
51-5556-6061-6566-7071-7576-8081-8586-9091-9596-100
53586368737883889398
2017101318821
1060634767301014149470418698
4871
Para calcular la media tenemos que sumar los productos de frecuencia por valor de clase y dividir el resultado entre 62.
Como se puede observar, el valor obtenido con los datos agrupados es muy similar al que se obtiene haciendo el cálculo con la fila de datos.
La moda con los datos agrupados es 83, que es el valor de clase del grupo en el que encontramos la mayor frecuencia. En este caso, en la fila de datos encontramos otros valores que se repiten más.
La moda en la fila de datos es 80, pues aparece 7 veces; y después está el 85, repetido 5 veces.
De tal manera que podemos concluir que la moda obtenida así no corresponde precisamente al valor más popular de una fila de datos.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1

La mediana con datos agrupados se calcula mediante la fórmula:
L1 = frontera de clase inferior del grupo donde se ubica la mediana.N = número de datos(∑f)1 = suma de las frecuencias inferiores a las de la medianafmed = frecuencia de la clase donde se ubica la mediana.I = tamaño del intervalo.
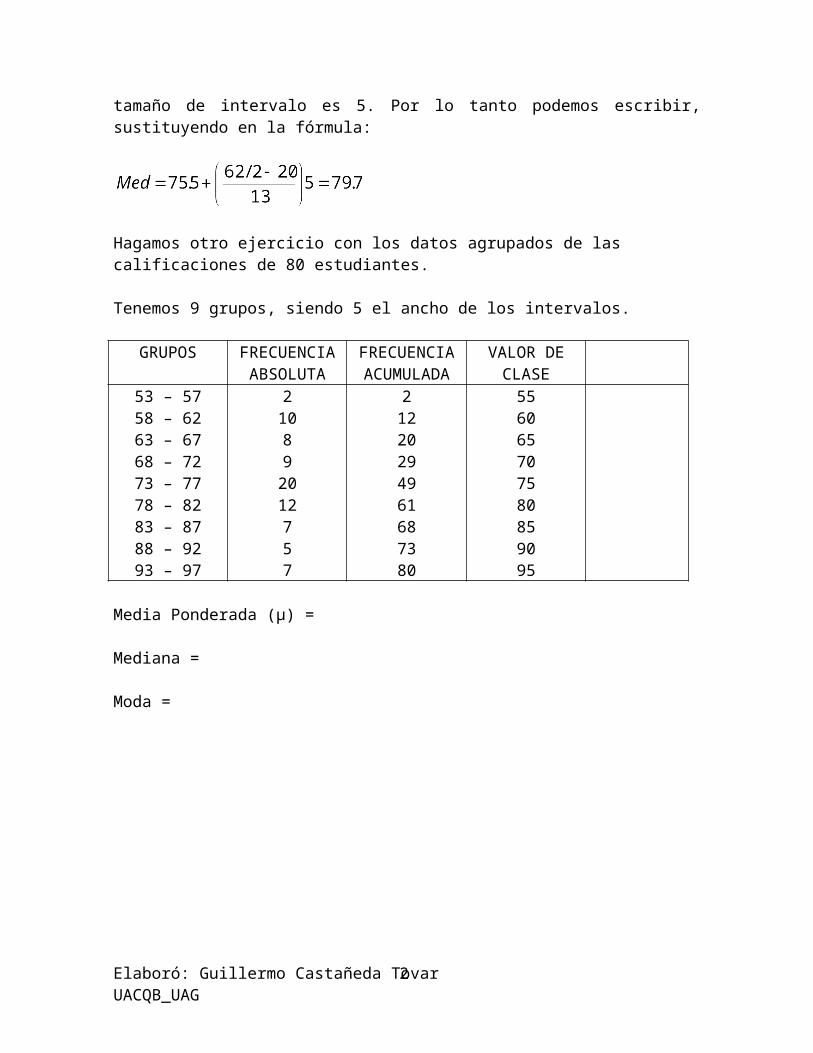
Observando con atención nuestra tabla de distribución nos damos cuenta que la frontera de clase inferior del grupo de la mediana es 75.5, la frecuencia acumulada del cuarto grupo es 20, la frecuencia del grupo de la mediana es 13 y el tamaño de intervalo es 5. Por lo tanto podemos escribir, sustituyendo en la fórmula:
Hagamos otro ejercicio con los datos agrupados de las calificaciones de 80 estudiantes.
Tenemos 9 grupos, siendo 5 el ancho de los intervalos.
GRUPOS FRECUENCIAABSOLUTA
FRECUENCIAACUMULADA
VALOR DECLASE
53 – 5758 – 6263 – 6768 – 7273 – 7778 – 8283 – 8788 – 9293 – 97
210892012757
21220294961687380
556065707580859095
Media Ponderada (µ) =
Mediana =
Moda =
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1
EJERCICIOUtilizando datos de la siguiente tabla, realicemos algunos cálculos
Pacientes Colesterol Total
Cambio en diámetro vascular
12345
6.85.36.14.35.0
0.13 0 -0.18 -0.15
0.11678910
7.15.53.84.66.0
0.43 0.41-0.12 0.06 0.06
1112131415
7.26.46.05.55.8
-0.19 0.39 0.30 0.18 0.11
161718
8.84.55.9
0.94-0.07-0.23
Tomemos los valores (ordenados) de colesterol total/HDL, de los 18 pacientes.
3.8, 4.3, 4.5, 4.6, 5.0, 5.3, 5.5, 5.5, 5.8, 5.9, 6.0, 6.0, 6.1, 6.4, 6.8, 7.1, 7.2, 8.8
Con ellos calculemos media, mediana y moda.
Para calcular la media, lo único que hacemos es sumar todos los valores y dividir entre 18, que es la cantidad de valores, dándonos como resultado: 5.81
La media es muy sensible a valores extremos. En nuestro ejemplo el valor 8.8 se dispara; si ese valor se quitara y nos quedáramos con 17 datos, entonces el resultado de promediar los 17 valores sería: 5.64, pudiéndose apreciar una diferencia relativamente notoria con 5.81
Para el cálculo de la mediana se deben ordenar los datos y tomar el punto medio de la cadena. Como son 18 datos, la mediana es el promedio de los valores noveno y décimo (5.8 y 5.9) o 5.85. La mediana indica que la mitad de los valores de colesterol total/HDL en este grupo de pacientes es menor de 5.85 y la mitad es mayor de 5.85.
La mediana es menos sensible a valores extremos que la media. Por ejemplo, si la observación más grande, 8.8, se excluyera de la muestra, la mediana sería el valor noveno, 5.8, que no es muy diferente de 5.85. Otra característica útil de la mediana es que puede
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1

usarse con observaciones ordinales, debido a que su cálculo no emplea los valores reales de las observaciones.
La moda es el dato que más se repite. Entre los datos de colesterol total/HDL de los 18 pacientes, ninguna observación sencilla se presenta con mayor frecuencia. Tanto 5.5 como 6.0 se repiten dos veces y las demás observaciones ocurren sólo una vez; de esta manera, desde el punto de vista técnico el valor de colesterol total/HDL de este grupo de pacientes tiene dos modas: 5.5 y 6.
Uso de las medidas de tendencia centralDado un conjunto de observaciones, un investigador puede preguntarse naturalmente ¿qué medida de tendencia central es mejor para usar con los datos? Para tomar una decisión al respecto son importantes dos factores: la escala de medición (ordinal o numérica) y el tipo de distribución de las observaciones, por ejemplo si una distribución es simétrica alrededor de la media o si se sesga a la izquierda o a la derecha de la media. Esta información ayuda a decidir cuál medida de tendencia central es mejor.
Si hay observaciones distantes sólo en una dirección (ya sean unos cuantos valores pequeños o unos cuantos grandes) se dice que es una distribución sesgada. Si los valores distantes son pequeños, la distribución se sesga a la izquierda o tiene sesgo negativo; si los valores distantes son grandes, la distribución se sesga a la derecha o presenta sesgo positivo. Una distribución simétrica tiene la misma forma a los dos lados de la media. Las siguientes reglas ayudan a un investigador a decidir la medida de tendencia central que conviene para un conjunto determinado de datos.
1 .La media se usa para datos numéricos y distribuciones simétricas (no sesgadas). 2. La mediana se emplea para datos ordinales o numéricos con distribución sesgada. 3. De manera básica, el modo se usa para distribuciones bimodales. 4. El uso primario de la media geométrica es para observaciones medidas en una escala logarítmica.
Los puntos siguientes ayudan al lector a conocer la forma de una distribución sin observarla en realidad. I. Si media y mediana son iguales, la distribución de observaciones es simétrica.2. Si la media es mayor que la mediana, la distribución está sesgada a la derecha. . 3. Si la media es menor que la mediana, la distribución está sesgada a la izquierda.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1

MEDIDAS DE DISPERSIÓN
Supóngase que todo lo que se sabe acerca de los 18 pacientes del caso anterior, es que la media de colesterol total/HDL es 5.81. Ésta es una información útil, pero para lograr una idea mejor de la distribución de valores de estos individuos se requiere conocer algo acerca de la dispersión o variación de las observaciones. En medicina se usan con frecuencia varias mediciones estadísticas para describir la dispersión de datos: rango, desviación estándar, coeficiente de variación. Estas se describen en las siguientes secciones.
Rango (amplitud). De ésta ya hemos hablado y sabemos que es la diferencia entre la observación más grande y la menor. Por ejemplo, el valor más pequeño de colesterol total/HDL entre los 18 pacientes sin crecimiento de la lesión es 3.8, y el más alto es 8.8; por tanto, el rango es 8.8 - 3.8 = 5. Muchos autores proporcionan los valores mínimo y máximo en lugar del rango, y en algunos casos estos valores constituyen información más útil. El rango real no puede determinarse a partir de datos presentados en una tabla de frecuencia, pero puede obtenerse un cálculo aproximado al utilizar el límite inferior del intervalo de clase menor y el límite superior del intervalo de clase más alto.
Desviación media. Es el promedio de los valores absolutos de las desviaciones, entendiéndose por desviaciones la diferencia entre cada uno de los datos y la media de la fila de datos.Dicho de otra manera, se trata de medir la forma en que las observaciones se dispersan alrededor de la media, parece buena idea calcular una desviación "promedio" o "media". Para ello se calcula la desviación de cada observación con respecto a la media, se suman estas desviaciones y se divide la suma entre n para formar una analogía con respecto a la propia media. En símbolos, la desviación media es:
n
xxDM
)(
El problema con este índice es que la suma de las desviaciones de las observaciones desde su media siempre es cero, y el valor del índice será cero en todos los casos. Es por eso que la suma se hace con los valores absolutos de las desviaciones. El valor absoluto de un número es su valor positivo y se simboliza con barras verticales a cada lado del número o la cifra. Por ejemplo, el valor absoluto de 5, es |5| y el valor absoluto de -5, es también |5|.
Aunque conceptualmente no hay error en esta fórmula, no tiene algunas propiedades estadísticas importantes, y por ello no se usa.
Desviación estándar. Es la medida de dispersión más frecuente para definir datos médicos y del área de la salud; aunque su significado y cálculo son algo complejos, en definitiva es valioso conocerla. Sin duda, la mayoría de los lectores usará una computadora (o calculadora) para determinar la desviación estándar, pero aquí se presentan los pasos que se requieren para su cálculo, debido a que ayudan a una mayor comprensión de esta medición estadística.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG1

Para calcular este índice, se toma como base el concepto anterior, elevando al cuadrado las desviaciones y reemplazando a n del denominador con n -1 (véase la explicación que sigue) y finalmente se extrae raíz cuadrada. La fórmula es entonces:
El nombre que recibe esta medición estadística antes de extraer raíz cuadrada es varianza, pero la desviación estándar es la medición estadística de interés primario.
La razón para el uso de n -1 en lugar de n en la fórmula para la desviación estándar es complicada. Simplemente, puede decirse que n-l en el denominador proporciona una estimación más precisa de la desviación estándar verdadera de la población, y tiene propiedades matemáticas deseables para las inferencias estadísticas. (Una explicación más exacta toma en cuenta las restricciones impuestas a los datos por la definición de desviación estándar; esto es, las cantidades al cuadrado y luego sumadas constituyen desviaciones de la media de los datos. Si hay n observaciones, también existen desviaciones de la media. No obstante, puesto que la suma de las desviaciones equivale a cero, una vez que se especifica n-l de las desviaciones, la última desviación ya está determinado como el valor que originará que la suma de las desviaciones sea cero. Por ende, el denominador usa el número de las cantidades independientes (en este caso n -1), lo que se conoce como grados de libertad.
La fórmula anterior para desviación estándar casi nunca se presenta, en libros introductorios, como la mejor para calcular este parámetro. La fórmula anterior se llama fórmula de definición.
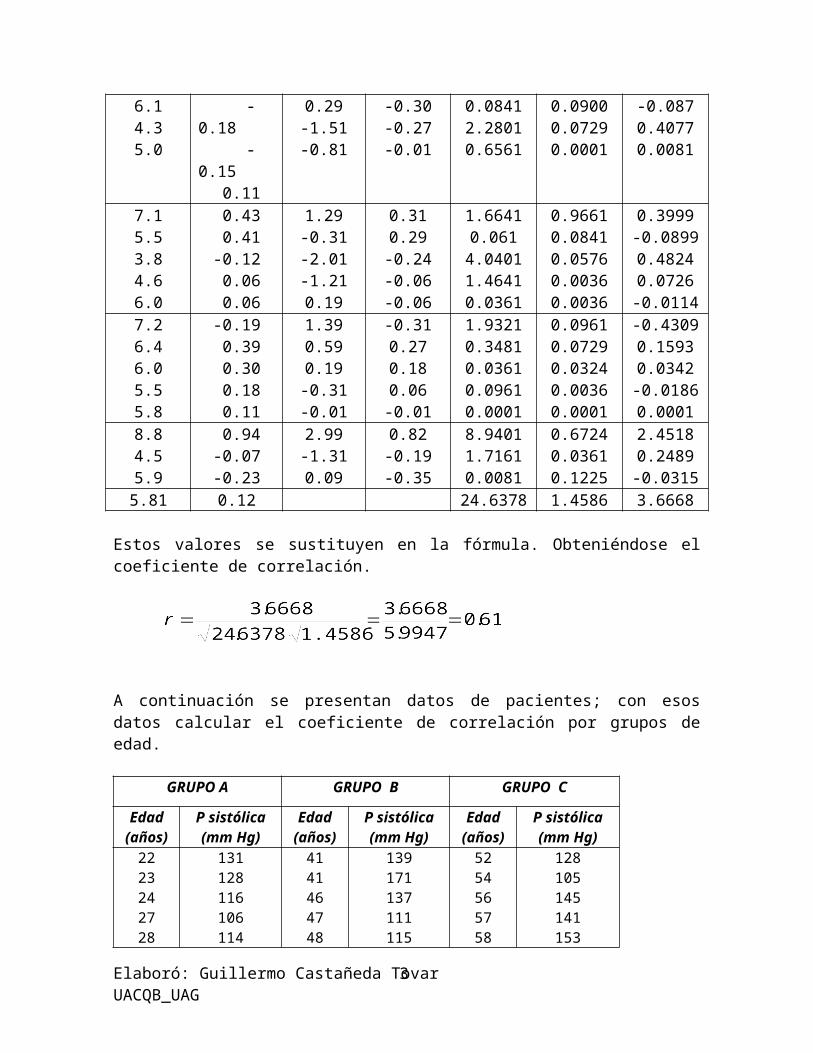
Ahora realizaremos un cálculo con las observaciones sobre el cambio de diámetro del vaso para 18 pacientes (tabla de la página 17). Los cálculos necesarios para computar la desviación estándar son los siguientes:
1. Si X es el cambio en el diámetro del vaso para cada paciente, entonces la media de estos cambios es: X= 2.18/18 = 0.12.
2. Este valor, 0.12, se sustrae de cada observación para formar las desviaciones X - X.
3. Se eleva al cuadrado cada desviación para formar (X -X )2 .(Obsérvese que los cálculos de la columna 4 se aproximaron a cuatro decimales para evitar error al redondear la cifra cuando se extraiga la raíz cuadrada en el paso 6.)
4. Súmense las desviaciones al cuadrado para formar: ∑(X- X )2 = 1.4586.
5. El resultado del paso 4 se divide entre n -1, se obtiene 0.0858. Este valor es la varianza.
6. Se obtiene la raíz cuadrada de la varianza (valor del paso 5); queda 0.29. Este valor es la desviación estándar.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

Pacientes x x-x’ (x-x’)2
12345
0.130
-0.18-0.150.11
0.01-0.12-0.30-0.27-0.01
0.00010.01440.09990.07920.0001
678910
0.430.41-0.120.060.06
0.310.29-0.24-0.06-0.06
0.09610.08410.05760.00360.0036
1112131415
-0.190.390.300.180.11
-0.310.270.180.06-0.01
0.09610.07290.03240.00360.0001
161718
0.94-0.07-0.23
0.82-0.19-0.35
0.67240.03610.1225
Sumas 2.18 1.4586
La desviación estándar del cambio en el diámetro del vaso es 0.29mm. Sin embargo, obsérvese la gran desviación al cuadrado, 0.6724, para el paciente 16. Esta observación sola contribuye casi con la mitad de la variación en los datos, debido a que la suma de las desviaciones al cuadrado es 1.4586. La desviación estándar de los 17 pacientes restantes (después de eliminar al paciente 16) es bastante menor, 0.22, lo cual demuestra el enorme efecto y que incluso una sola observación distante puede tener sobre el valor de la desviación estándar.
La desviación estándar, igual que la media, requiere datos numéricos y es muy importante en estadística. En primer lugar, es parte esencial de numerosas pruebas estadísticas. En segundo lugar, es muy útil para definir la dispersión de las observaciones alrededor de la media.
COEFICIENTE DE VARIACIÓN Es una medida útil de la dispersión relativa de los datos, y se usa a menudo en ciencias biológicas. Por ejemplo, supóngase que los autores del estudio sobre dieta y lipoproteínas desean comparar la variabilidad en la proporción de colesterol total/HDL con la del cambio del diámetro vascular de los 18 pacientes cuya lesión no creció. La media y la desviación estándar de colesterol total/HDL (en milimoles por litro) son 5.81 y 1.2, respectivamente;
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

para el cambio del diámetro vascular (en milímetros) son 0.12 y 0.29, de modo respectivo. Una comparación de 1.20 y 0.29 no tiene sentido debido a que colesterol y diámetro vascular se miden en escalas diferentes. El coeficiente de variación ajusta las escalas, de manera que puede efectuarse una comparación sensible.
El coeficiente de variación se define como la desviación estándar dividida entre la media por 100%. Origina una medida de la variación relativa con respecto a la media. Por tanto, la fórmula para coeficiente de variación (CV) es:
De esta fórmula, CV para colesterol total/HDL es (1.20/5.81) (100%) = 20.7% y CV para el cambio de diámetro vascular es (0.29/0.12) (100%) = 241.7%. Por tanto, puede concluirse que la variación relativa en el cambio de diámetro vascular es mucho mayor que la de proporción de colesterol.
MEDIDAS PARA DESCRIBIR RELACIONES ENTRE DOS CARACTERÍSTICAS
Las medidas descritas hasta ahora son apropiadas sólo para resumir observaciones sobre una característica. Sin embargo, gran parte de la investigación en medicina se interesa en la relación entre dos o más características. Las secciones siguientes se enfocan en el análisis de la relación entre dos variables medidas en la misma escala, sea numérica, ordinal o nominal.
COEFICIENTE DE CORRELACIÓN
El coeficiente de correlación es una medida de la relación entre dos características numéricas, simbolizada por X y Y. La fórmula del coeficiente de correlación, simbolizado por r, es:
22Y-Y
Y-Y
XX
XXr
Si tomamos los datos del cuadro de los 18 pacientes de estudio de dieta y lipoproteínas (hoja 17), podemos calcular el coeficiente de correlación entre los valores de colesterol total/HDL, y cambio del diámetro vascular. Para entender mejor cómo aplicar la fórmula, construiremos una tabla con los datos necesarios. Representaremos con X el colesterol total y con Y el cambio en el diámetro vascular. Los pasos a seguir son los siguientes: 1.- calcular la media, tal y como ya lo sabemos para cada característica, X, Y2.- calcular la diferencia entre cada valor X y su media 3.-calcular la diferencia entre cada valor Y y su media4.-realizar el producto de las diferencias 5.-calcular los cuadrados de cada una de las diferencias
X Y6.8 0.13 0.99 0.01 0.9801 0.0001 0.0099
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2
5.36.14.35.0
0 -0.18 -0.15
0.11
-0.510.29-1.51-0.81
-0.12-0.30-0.27-0.01
0.26010.08412.28010.6561
0.01440.09000.07290.0001
0.0612-0.0870.40770.0081
7.15.53.84.66.0
0.43 0.41-0.12 0.06 0.06
1.29-0.31-2.01-1.210.19
0.310.29-0.24-0.06-0.06
1.66410.0614.04011.46410.0361
0.96610.08410.05760.00360.0036
0.3999-0.08990.48240.0726-0.0114
7.26.46.05.55.8
-0.19 0.39 0.30 0.18 0.11
1.390.590.19-0.31-0.01
-0.310.270.180.06-0.01
1.93210.34810.03610.09610.0001
0.09610.07290.03240.00360.0001
-0.43090.15930.0342-0.01860.0001
8.84.55.9
0.94-0.07-0.23
2.99-1.310.09
0.82-0.19-0.35
8.94011.71610.0081
0.67240.03610.1225
2.45180.2489-0.0315
5.81 0.12 24.6378 1.4586 3.6668
Estos valores se sustituyen en la fórmula. Obteniéndose el coeficiente de correlación.
A continuación se presentan datos de pacientes; con esos datos calcular el coeficiente de correlación por grupos de edad.
GRUPO A GRUPO B GRUPO C
Edad(años)
P sistólica(mm Hg)
Edad(años)
P sistólica(mm Hg)
Edad(años)
P sistólica(mm Hg)
2223242728293032333540
13112811610611412311712299121147
4141464748494950515151
139171137111115133128183130133144
5254565758596367717781
128105145141153157155176172178217
Interpretación de coeficientes de correlación ¿Qué significa una correlación de 0.61 entre colesterol y cambio en el diámetro vascular? , ¿Cuál es la relación entre estas dos variables? Mencionaremos unas cuantas características
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

del coeficiente de correlación que ayudan a interpretar su valor numérico ya describir una relación.
El coeficiente de correlación oscila desde -1 a +1, en el que -1 describe una relación lineal (o línea recta) negativa perfecta, y +1 describe una relación lineal (o línea recta) positiva perfecta. Una correlación de 0 significa que no hay relación lineal entre las dos variables. Existe una correspondencia entre la cifra del coeficiente de correlación y lo disperso de las observaciones.
La interpretación del valor de r, depende en gran medida de las características medidas, por ejemplo si se trata de mediciones muy precisas, es posible esperar coeficientes de correlación muy elevados. En el área médica el comportamiento de las características biológicas de los individuos en muchas ocasiones no está definido de forma precisa el comportamiento de cada una en función de la otra, hay más variabilidad y en ocasiones los aparatos que se utilizan para su medición no son precisos, luego entonces, cabe esperar coeficientes de correlación más bajos.
1) Correlaciones de 0 a 0.25 (o de -25) indican correlación escasa o falta de correlación.2) de 0.25 a 0.5 (o de -0.25 a -0.50) indica cierto grado de correlación,3) de 0.50 a 0.75 (o de -0.50 a -0.75) la relación es de moderada a buena, y4) mayor de 0.75 (o de -0.75) es muy buena a excelente.
Cuando la correlación se aproxima a cero, la “forma” del patrón de observaciones es más o menos circular. Conforme el valor de la correlación se aproxima a + l o -1, la forma se vuelve más elíptica, hasta que en + l o -1 las observaciones quedan directamente sobre la línea recta. Con una correlación de 0.50, cabe esperar una dispersión de datos con forma más a menos oval.
En ocasiones, la correlación se eleva al cuadrado para formar un valor estadístico muy útil llamado coeficiente de determinación. El coeficiente de correlación posee varias características que merecen mencionarse. El valor del coeficiente de correlación es independiente de cualquier unidad usada para medir las variables. Por ejemplo, supóngase que dos estudiantes de medicina miden las estaturas y los pesos de un grupo de niños preescolares para determinar la correlación entre estatura y peso. La estatura se mide en centímetros y el peso en kilogramos, y se encuentra un coeficiente de correlación, de 0.70. ¿Cuál sería la correlación si se hubieran usado a. pulgadas y libras? Por supuesto, todavía la misma. 0.70, debido a que el denominador en la fórmula para el coeficiente de correlación se ajusta para la escala de las unidades.
El valor del coeficiente de correlación se altera de modo importante por la presencia de un valor alejado o distante, como sucede con la desviación estándar. En el ejemplo hipotético de 18 pacientes, el eliminar al individuo que presentaba valores elevados tiene un efecto sorprendente, reduciendo la correlación de 0.61, como se calculó en la sección previa, a 0.32.
VARIACION EN LOS DATOS
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

En numerosas instituciones hospitalarias, una enfermera reúne cierta información acerca de un paciente (por ejemplo estatura, peso, fecha de nacimiento, presión sanguínea, pulso) y la registra en el expediente médico antes de que el clínico examine al enfermo. Supóngase que la presión sanguínea del paciente quedo asentada en el expediente como 140/88; el medico que toma de nuevo la presión como parte del examen físico encuentra una lectura de 148/96. ¿Cuál de las presiones sanguíneas es correcta? ¿Cuáles podrían ser los factores de la diferencia de las observaciones? Aquí se emplean la presión sanguínea y otros ejemplos clínicos para analizar fuentes de variación en los datos y maneras de medir la confiabilidad de las observaciones.
Factores que pueden originar variación en las observaciones clínicas Las causas de variación – es decir, variabilidad en mediciones del mismo sujeto- de observaciones clínicas y de laboratorio, pueden clasificarse en tres categorías: 1) variación en las características que se están midiendo, 2) variación introducida por el examinador y 3) variación debida al instrumento o método empleado. Es especialmente importante controlar la variación que se origina por estos últimos dos factores, tanto como sea posible.
Puede haber una variabilidad sustancial en la medición de características biológicas. Por ejemplo, la presión arterial de un individuo no es igual de un momento a otro y por tanto, los valores de presión arterial variaran. La descripción de los síntomas que un paciente expresa a dos médicos distintos, puede variar debido a que es posible que el enfermo olvide algún dato. Los fármacos y las enfermedades también afectan la manera en que se comporta un paciente y cual es la información que recuerda para proporcionar a una enfermera o al medico.
Aun cuando no hay un cambio en el sujeto, observadores distintos pueden comunicar mediciones diferentes. Cuando el examen de una característica requiere agudeza visual, como la lectura de un esfigmomanómetro o la observación de los datos de un estudio radiológico, pueden originarse diferencias debido a las capacidades visuales variables de los observadores. Es posible que tales diferencias también desempeñen una función cuando se requiere escuchar (detectar ruidos cardiacos) o sentir (palpar órganos internos). Algunos individuos simplemente tienen mayor destreza que otros para obtener antecedentes o practicar ciertos exámenes.
Repetir aspectos dudosos del examen o pedir a un colega que efectué algún aspecto fundamental de aquel (de manera ciega, desde luego) reduce la posibilidad de error. Disponer de lineamientos operacionales bien definidos para el uso de escalas de clasificación, ayuda a los individuos a utilizarlas de modo consistente. Muchos errores pueden eliminarse asegurándose que los instrumentos estén calibrados de manera apropiada y se usen correctamente, con lo que se reduce la variación.
Maneras de determinar la confiabilidad de las medicionesUna manera frecuente de asegurar la confiabilidad de las mediciones, en especial con propósitos de investigación, consiste en repetir la medición y evaluar el grado de concordancia. Cuando una persona mide la misma característica dos veces y compara los resultados, se obtiene un índice de variabilidad intraobservador llamado confiabilidad intratasador o intraclasificador. Cuando dos o mas individuos determinan la misma
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

característica y sus mediciones se comparan, se obtiene un índice de variabilidad interobservadores llamado confiabilidad.
Como ejemplo, supóngase que un clínico desea determinar la confiabilidad de mediciones del diámetro traqueal en placas de tórax de cierto número de pacientes. Un enfoque consiste en medir la traquea en un grupo de placas y anotar las mediciones. Luego, algunos días o semanas después, deben medirse de nuevo las mismas placas sin consultar las cifras anteriores. El diámetro traqueal se mide en una escala numérica, y el parámetro estadístico usado para analizar la relación entre dos características numéricas es el coeficiente de correlación del cual ya hemos hablado anteriormente. Por tanto, la correlación entre dos conjuntos de mediciones del diámetro traqueal proporcionara una medida de cuan confiables son las mediciones del clínico.
Otro aspecto de la confiabilidad se refiere a los propios instrumentos y a su propiedad para proporcionar mediciones reproducibles. El coeficiente de variación expuesto con anterioridad, se usa típicamente para demostrar la confiabilidad de las mediciones o los análisis de laboratorio.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

PROBABILIDAD
ANTECEDENTES HISTÓRICOS DE LA PROBABILIDAD. La teoría de la Probabilidad nace en los juegos de azar, cuando los apostadores utilizaron las bases matemáticas para conocer las posibilidades que se tenían para ganar en un juego. En los inicios del siglo XVII, algunos matemáticos, como Gombauld, Pascal y Fermat, resolvieron algunos problemas sencillos y compartieron sus resultados. Las cartas que se escribieron estos tres personajes, constituyen las bases de la Teoría de la Probabilidad. Años más tarde, Bernoulli, Moivre, Bayes y Lagrange, desarrollaron fórmulas y técnicas para calcular probabilidades. A finales del siglo, otro matemático llamado Karl Gauss presentó también algunos trabajos relacionados con la probabilidad. Fue a principios del siglo XIX que Pierre Simon, marqués de Laplace, recopiló todas las ideas anteriores y compiló la primera Teoría General de Probabilidad.
Y aun cuando inicialmente la Teoría de Probabilidad fue aplicada en las mesas de juego, sin embargo, en la actualidad, se utiliza en estudios de problemas sociales, económicos, de salud y es la base para las aplicaciones estadísticas en esas disciplinas y para la toma de decisiones. “Es notable -comenta Laplace- que una ciencia que comenzó a partir de los juegos de azar pueda haberse convertido en el objeto más importante del conocimiento humano.”.
CONCEPTOS BÁSICOS DE PROBABILIDAD.Probabilidad: es la posibilidad de que algo suceda. (Incertidumbre).
La probabilidad se expresa o cuantifica mediante números fraccionarios, ejemplo: 1/3 , 1/6, ½, etc.; o tambien con números decimales, ejemplo: 0.150, 0.167, 0.500, 0.975. etc.; estos números están comprendidos entre el cero y el uno: 0 < P < 1 .
Cuando el valor de la probabilidad es cero, significa que algo nunca va a suceder (ocurrencia imposible); mientras que el valor de probabilidad igual a uno, indica que algo va a suceder con toda seguridad (ocurrencia segura).
El concepto de probabilidad es utilizado para aquellas situaciones en donde se tienen varias alternativas de la ocurrencia de un suceso o evento, todas posibles pero ninguna segura.Aquí están implicados 3 conceptos: la situación o experimento; lo que ocurre como consecuencia del experimento, llamado evento; todas las posibles ocurrencias, llamadas espacio de eventos o espacio muestral.
Experimento.- Es cualquier situación que puede ser repetida bajo condiciones esencialmente estables.
Evento.- Es uno o más de los posibles resultados de hacer algo.
Espacio muestral.- Es el conjunto de todos los eventos simples de un experimento.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

Al lanzar una moneda, si cae águila es un evento, si cae sol, es otro evento. Este proceso tendrá como posibles resultados dos eventos.
Al seleccionar a un alumno del grupo, los resultados posibles son tantos como el número de alumnos que tenga el grupo,
La suma que resulta de lanzar dos dados, tiene como eventos posibles los números 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 y 12. Pero no debemos confundirnos pensando que estos once números constituyen el espacio muestral. La cantidad de eventos simples de este experimento son 36 pues por ejemplo el caso de obtener 8 implica varias combinaciones 3,5 – 6,2 – 4,4 y otras más.
ENFOQUE CLÁSICO o “a priori” que proviene de los juegos de azar y se emplea cuando los espacios muestrales son finitos y tienen resultados igualmente probables. En estas condiciones la probabilidad de que ocurra un suceso determinado está dada por la relación entre el número de eventos favorables y la totalidad de casos posibles.
La probabilidad, como ya hemos dicho, varía entre 0 y 1 ó entre 0% y 100%. 0 < p < 1.
Ejemplo, si en una caja hay 10 canicas; 2 de ellas blancas y 8 negras, la probabilidad de tomar al azar una blanca sería:Total de eventos 10,Eventos favorables 2
Ejercicio 1. Lanzamiento de una monedaExisten 2 posibles resultados. 1.-La cara hacia arriba es águila
2.- La cara hacia arriba es sol
De tal manera que la probabilidad de que ocurra cualquiera de ellos es de
Ejercicio 2. De un paquete de barajas se saca una carta; este paquete consta de 52 cartas, 26 negras y 26 rojas: 13 espadas, 13 tréboles, 13 corazones y 13 diamantes, que a su vez constan de As, J, Q, K y del 2 al 10. Calcular:
La probabilidad de que la carta sea un as es de:
La probabilidad de que la carta sea negra es de.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

La probabilidad de que la carta sea trébol es de:
Ejercicio 3. Lanzamiento de dos dados (caras que caen hacia arriba)El espacio muestral de este experimento está constituido por 36 eventos simples, esto es, 36 pares de números, que se muestran en la siguiente tabla:
1,1 1,2 1,3 1,4 1,5 1,6
2,1 2,2 2,3 2,4 2,5 2,6
3,1 3,2 3,3 3,4 3,5 3,6
4,1 4,2 4,3 4,4 4,5 4,6
5,1 5,2 5,3 5,4 5,5 5,6
6,1 6,2 6,3 6,4 6,5 6,6
Consideremos algunos eventos para este experimento
A: caen dos números iguales
B: la suma es 7
C: cae más de 9
D: los dos son número par
Calcular ahora la probabilidad para cada uno de esos eventos:
P(A) =
P(B) =
P(C) =
P(D) =
Elaboró: Guillermo Castañeda Tovar UACQB_UAG2

ENFOQUE DE FRECUENCIA RELATIVA, o “a posteriori" que se basa en la frecuencia relativa de ocurrencia de un evento con respecto a un gran número de ensayos repetidos. La definición clásica se ve limitada a situaciones en las que hay un número finito de resultados igualmente probables. Sin embargo, hay problemas prácticos que no son de este tipo y la definición clásica no se puede aplicar.
Intentemos contestar las preguntas siguientes: ¿Cuál es la probabilidad de que yo viva 85 años? ¿Cuál es la probabilidad de un alumno de este grupo llegue a ser Presidente
de la República?
Lo más seguro es de que no podamos ser capaces de emitir una respuesta sin antes hacer algo de experimentación sobre cuales son esas probabilidades.A este planteamiento de probabilidad se le conoce como: Frecuencia Relativa de Presentación de un Evento. Un ejemplo es el estudio de cálculo del riesgo de pérdidas en las pólizas de seguros de vida y comerciales, que hicieron los británicos el siglo pasado al obtener datos sobre nacimientos y defunciones.
La frecuencia relativa de Presentación de un evento define la probabilidad como:
a) La frecuencia relativa observada de un evento durante un gran número de intentos ó
b) la fracción de veces que un evento se presenta a la larga, cuando las condiciones son estables.
Ejemplo: Una compañía de seguros posee datos actuariales registrados y sabe que de los hombres de 40 años de edad, 60 de cada 100,000 morirán al año. Entonces utilizando esta información, la compañía estima la probabilidad de muerte de personas de 40 años como:
P = 60 / 100,000 = 0.0006
Otro ejemplo: si se pregunta por la probabilidad de que un paciente sea curado mediante cierto tratamiento médico, o la probabilidad de que un determinado laboratorio clínico emita resultados falsos, entonces no hay forma de introducir resultados igualmente probables. Por ello se necesita un concepto más general de probabilidad.
Supongamos que se realiza un experimento n veces y que en esta serie de n ensayos el evento A ocurre exactamente r veces, entonces la frecuencia relativa del evento es r/n, o sea, fr (E) = f (E) = r/n.
A medida que aumentamos n, las frecuencias relativas correspondientes serán más estables; es decir; tienden a ser casi las mismas; en este caso decimos que el experimento muestra regularidad estadística o estabilidad de las frecuencias relativas. Esto se explica, por ejemplo, con el lanzamiento de una moneda gran número de veces.
Experimento:
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3

Arrojar al aire una moneda 100 veces 20 estudiantes
Estudiante 1 2 3 4 5 6 7 8 9 10CaraCruz
4456
4753
4951
5545
4555
4951
5149
4852
6238
4753
Sumas 100 100 100 100 100 100 100 100 100 10011 12 13 14 15 16 17 18 19 20 suma Desviación
4456
5545
4852
5050
4357
5446
5545
4555
4951
5842
9981002
+2-2
100 100 100 100 100 100 100 100 100 100 2000 0
TIPOS DE EVENTOS
Utilizaremos las dos tablas que aparecen a continuación para ilustrar algunas definiciones y reglas para determinar probabilidades en los diferentes tipos de eventos:
Tabla 1 Seropositividad en homosexuales
Tabla 2 sobre sexo y tipo sanguíneo.
Tipo sanguíneo Varones Mujeres TotalOAB
AB
0.210.2150.0550.02
0.210.2150.0550.02
0.420.430.110.4
0.50 0.50 1.00
En probabilidad, un experimento se define como cualquier proceso planeado de obtención de datos. En el caso de la tabla 1, el experimento es el proceso para determinar el estado seronegativo o seropositivo de un grupo de 50 varones homosexuales. Un experimento consiste en varias pruebas independientes bajo las mismas condiciones; en este ejemplo, una prueba consiste en determinar el estado del suero de un varón individual. Cada prueba
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3
Proporción T4/T8 baja
Proporción T4/T8 normal
Total
Seronegativos 4 27 31Seropositivos<= 29 meses
5 2 7
Seropositivos> 29 meses
11 1 12
Total 20 30 50

puede originar 1 de 3 resultados: p (seronegativo, seropositivo por 29 meses o menos, o seropositivo por más de 29 meses). La probabilidad de un resultado particular, léase resultado A, se simboliza P(A). Por ejemplo, si el resultado A es “seronegativo”, la probabilidad de que un homosexual en un estudio sea seronegativo es: P (seronegativo) = 31/50 = 0.62
En el caso de la tabla 2, las probabilidades de resultados diferentes ya se calcularon. Los resultados de cada prueba para determinar tipo sanguíneo son O, A, B y AB. De los datos del cuadro se puede decir que la probabilidad de que un individuo tenga tipo sanguíneo A es: P (tipo A) = 0.43. Los datos de tipo sanguíneo ilustran dos características importantes de la probabilidad:1.- la probabilidad de cada resultado (tipo sanguíneo) es mayor o igual a cero.2.- la suma de las probabilidades de los diversos resultados es 1.
Los eventos pueden definirse como resultados sencillos o como conjuntos de resultados. Por ejemplo, los resultados del estado del suero son seronegativo, seropositivo por 29 meses o menos, y seropósitivo por mas de 29 meses; pero se desea definir un evento como homosexual seronegativo y seropositivo. El evento “seropositivo” comprende dos resultados: <= 29 meses y >29 meses, en ocasiones se desea conocer la probabilidad de que un evento no ocurra: un evento opuesto al que interesa se designa como evento complementario de ser “seronegativo” es “no ser seronegativo”. La probabilidad del complemento es:
P(complemento de seronegativo) =P(no ser seronegativo) =P(seropositivo)
=
Observe que la probabilidad de un evento complementario también puede encontrarse restando de 1 la probabilidad del evento que interesa, y en algunas situaciones su cálculo puede ser más sencillo. Así, se obtiene: P (complemento de seronegativo) = 1-
P(seronegativo) = 1
Eventos mutuamente excluyentes y regla de adición.Dos eventos o más son mutuamente excluyentes si la ocurrencia de uno de ellos impide la de los demás. Para el caso de la tabla 1, los resultados son mutuamente excluyentes; es decir, un homosexual no puede ser a la vez seropositivo<=29 meses y seropositivo >29 meses. Además, todos los eventos complementarios se excluyen también de manera mutua, sin embargo, los eventos pueden ser mutuamente excluyentes sin ser complementarios si hay tres o más eventos posibles.
La probabilidad de que ocurran eventos mutuamente excluyentes es la probabilidad de que se presente uno u otro evento. Esta probabilidad se encuentra sumando las probabilidades de los dos eventos, lo cual se conoce como regla de adición para probabilidades.
P(A o B) = La probabilidad de que suceda el evento A o el B = P(A) + P(B)
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3
Por ejemplo, la probabilidad de tener tipo sanguíneo O o tipo sanguíneo A es: P(O o A) = P(O) + P(A) = 0.42 +0.43 =0.85
Otro ejemplo: Sea el grupo compuesto por Pablo, María, Juan, Pedro, Carmela, Roberto, Cecilia y Enrique. Se va a elegir un individuo.
1º.- ¿Cuál es la probabilidad de que Juan sea elegido? P(J) = 1/8 = 0.1252º.- ¿Cuál es la probabilidad de que el elegido sea Juan o Cecilia?
P(Juan o Cecilia) = 1/8 + 1/8 = 2/8 = ¼ = 0.25
La tabla siguiente contiene los datos sobre el tamaño de las familias de un pueblo del municipio de Chilpancingo. Se tiene interés en saber ¿Cuál es la probabilidad de que al escoger una familia de ese pueblo al azar, esta tenga cuatro o más hijos?
P(4, 5, 6 ó más) = P(4) + P(5) + P(6 ó más) = 0.15 + 0.10 + 0.05 = 0.30
¿Funciona la regla de adición para más de dos eventos? La respuesta es si, siempre que sean mutuamente excluyentes. Más adelante se estudiara este enfoque para eventos que no se excluyen de manera mutua.
¿Cuáles de los siguientes son parejas de eventos mutuamente excluyentes al sacar una carta de un mazo de 52 barajas?Un corazón y una reinaUna espada y una carta rojaUn número par y una espadaUn as y un número impar.
¿Cuáles de los siguientes son resultados mutuamente excluyentes al lanzar dos dados?Un total de cinco puntos y un cinco en un dado.Un total de siete puntos y un número par de puntos en ambos dados.Un total ocho puntos y un número impar de puntos en ambos dados.Un total de nueve puntos y un dos en uno de los dados.Un total de diez puntos y un cuatro en un dado.
Eventos independientes y regla de multiplicaciónDos eventos son independientes si el resultado de uno no tiene efecto en el del otro. Dicho de otra manera la ocurrencia de uno no impide que pueda ocurrir el otro. Usando el ejemplo del tipo sanguíneo, se definirá también un segundo evento, como el sexo del individuo, que consiste de los dos resultados “varón” y “mujer”. En este caso, sexo y tipo sanguíneo son dos eventos independientes; el sexo de un sujeto no afecta en modo alguno a su tipo sanguíneo y viceversa. La probabilidad de dos eventos independientes es la de que ambos
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3
Número de hijos 0 1 2 3 4 56
ó más
Proporción de familias que tienen esa cantidad de hijos
0.05 0.10 0.30 0.25 0.15 0.10 0.05

se presenten, y se encuentra multiplicando las probabilidades de los dos eventos, lo cual se conoce como regla de multiplicación para probabilidades. Por ejemplo, la probabilidad de ser varón y tener tipo sanguíneo O es: p (varón y tipo sanguíneo O) = P (varón) x P (tipo sanguíneo O) = 0.50 x 0.42 = 0.21
La probabilidad de ser varón, 0.50, y la probabilidad de tener tipo 0, 0.42, se designan como probabilidades marginales; es decir, se presentan en los “bordes” de una tabla de probabilidad. La probabilidad de ser varón y tener tipo sanguíneo 0, 0.21, se llama probabilidad de unión o unida; es la probabilidad de que el “varón” y “tipo sanguíneo O” ocurran de modo conjunto.
Eventos no independientes o condicionales y regla de multiplicación modificadaHallar la probabilidad de unión de dos eventos cuando no son independientes es un poco más complejo que la simple multiplicación de dos probabilidades marginales. Cuando dos eventos no son independientes, el que un evento suceda depende de si el otro ha ocurrido. Sea A el evento “razón T4/T8 baja”y B el evento “seropositivo”. Se desea conocer la probabilidad del evento A dado el evento B, que se escribe P(A/B), donde la línea vertical se lee “dado”. De los datos del cuadro, la probabilidad de una razón T4/T8 baja, dado que
el paciente es seropositivo, es: P(T4/T8 baja / seropositivo) = . Esta
probabilidad, que se designa como probabilidad condicional; es la de un evento, dado que se haya presentado otro evento. Puesto de otra manera, la probabilidad de una razón T4/T8 baja es condicional en el evento de seropositividad; ahora puede sustituir a P(T4/T8 baja) en la regla de multiplicación. Si se reúnen las expresiones, es posible encontrar la probabilidad de unión de tener una razón T4/T8 baja y ser seropositivo:P (T4/T8 baja y seropositivo)= P (T4/T8 baja | seropositivo) x P (seropositivo)=
La probabilidad de tener una razón baja y ser seropositivo puede determinarse también hallando la probabilidad condicional de ser seropositivo, dada una razón T4/T8 baja, y sustituyendo esa expresión en la regla de multiplicación para P (seropositivo). Por consiguiente, se obtiene: P (T4/T8 baja y seropositivo) = P (seropositivo y T4/T8 baja) = P (seropositivo | T4/T8
baja) x P(T4/T8 baja) =
Eventos no mutuamente excluyentes y regla de adición modificadaEn este caso dos eventos se pueden presentar al mismo tiempo, por lo que la probabilidad se reduce para evitar el conteo doble, ya que la posibilidad de que podamos obtener ambos eventos juntos existe.
P(A o B) = P(A) + P(B) – P(AB)
En donde: P(AB) es la probabilidad de que A y B sucedan juntos.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3

Ejemplo: ¿Cuál es la probabilidad de sacar un as o un corazón de un paquete de 52 cartas?P(as o corazón) = P(as) + P(corazón) – P(as y corazón)
P(as o corazón ) = 4/52 + 13/52 – 1/52 = 16/52 = 4/13
REPRESENTACIÓN DE LA PROBABILIDAD UTILIZANDO DIAGRAMAS DE JOHN VENN:
Dos eventos mutuamente excluyentes Dos eventos no mutuamente excluyentes
Otro ejemplo: Los empleados de una empresa han elegido a cinco de ellos para que los representen en una reunión administrativa sobre productividad. El perfil de ellos se muestra en la tabla anexa.
1. hombre edad 30 años2. hombre edad 32 años3. mujer edad 45 años4. mujer edad 20 años5. hombre edad 40 años
Este grupo de empleados decide elegir un vocero de manera aleatoria (sacando de un sombrero uno de los nombres de ellos), ¿cuál es la probabilidad de que el vocero sea una mujer o persona cuya edad esté por arriba de los 35 años?
P(mujer o mayor de 35 años) = P (mujer) + P(mayor de 35) – P(mujer y mayor de 35 años)
P(mujer o mayor de 35 años) = 2/5 + 2/5 – 1/5 = 3/5
Ejemplo: sexo y grupo sanguíneo no son eventos mutuamente excluyentes debido a que la ocurrencia de uno no impide la del otro. La regla de adición debe modificarse en esta situación; de otro modo, la probabilidad de que los dos eventos ocurran se agregara dos veces en el cálculo.
En la tabla 2, la probabilidad de ser varón es 0.50 y la probabilidad de tipo sanguíneo O es 0.42. Sin embargo, la probabilidad de ser varón o tener tipo sanguíneo O no es 0.50 + 0.42, debido a que en esta suma, los varones con tipo sanguíneo O se han contado dos veces. Por tanto, puede sustraerse la probabilidad de ser varón y tener tipo sanguíneo O, 0.21. El calculo es: P (varón o tipo O) = P (varón) + P (tipo O) – P (varón y tipo O)= 0.50 +0.42 - 0.21 = 0.71.
Por supuesto si no se sabe que P(varón y tipo O) = 0.21, debe usarse la regla de la multiplicación (en este caso, para eventos independientes) para determinar esta probabilidad.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3
A B AB

EJERCICIOS DIVERSOS
En un grupo de 30 estudiantes, de los cuales 20 son mujeres, encontramos que de éstas 12 son de tipo sanguíneo O, 6 del tipo A y 2 de tipo B; en los varones encontramos 6 de tipo O, 3 de tipo A y 1 de tipo B.Siendo los eventos:
M: mujeresH: hombresA: tipo sanguíneo AB: tipo sanguíneo BO: tipo sanguíneo O
calcular las siguientes probabilidades al seleccionar un estudiante de ese grupo:
a) P(H)b) P(M)c) P(A)d) P(B)e) P(O)
f) P(H | O)g) P(O | H) h) P(H o M)i) P(H y M)j) P(A o B)
Una urna contiene 6 bolas rojas, 4 blancas y 5 azules; calcular la probabilidad de que al extraer al azar una bola ésta:
a) sea rojab) sea blancac) sea azuld) no sea rojae) sea roja o blanca
Se lanzan dos dados sobre la mesa; calcular las probabilidades de que:
a) Las caras sumen 7b) Las caras sean igualesc) La suma de las caras sea número pard) Ambas caras sean número impare) La suma es 6 dado que ambas son número parf) Ambas son número par, dado que la suma es 6g) La suma es 6 y ambas son parh) La suma es 6 o ambas son par
Se lanzan tres monedas al aire; calcular la probabilidad de obtener:a) Dos águilas y un solb) Una águila y dos solesc) Las tres águilasd) Los tres soles o una águila y dos soles
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3

En la siguiente tabla aparece color y marca de 20 autos que participan en un concurso, de acuerdo con esos datos calcular las probabilidades que se solicitan:
a) Que el auto sea rojob) Que el auto sea un Platinac) Que el auto sea Tsuru o Corsad) Que el auto sea un Platina rojoe) Que el auto sea Platina sabiendo que es rojof) Que el auto sea Tsuru o azul
En un grupo de 20 pacientes se determinó que 4 eran de tipo sanguíneo A, 10 de tipo sanguíneo O, 5 de tipo B y sólo uno de tipo AB. Se tiene que seleccionar uno de esos pacientes; cual es la probabilidad de que el seleccionado sea:
a) de tipo A o Bb) de tipo O o AB
Se hace girar una perinola marcada del 1 al 5 en sus respectivas caras. Qué probabilidad hay de que al detenerse ocurran los siguientes eventos:
a) que pare en 3 ó 4b) que pare en número impar
En un hospital nacieron el día de ayer 20 bebes; los cuales se encuentran en cunas numeradas del 1 al 20. De éstos 6 tuvieron un peso menor de 3 kg, 4 pesaron exactamente 3 kg y 10 pesaron más de 3 kg. Calcular la probabilidad de que al seleccionar uno de los bebes, éste sea:
a) de 3 o más kilogramos.b) de 3 o menos kilogramos
Se está repartiendo un lote de autos a un grupo de personas que resultaron ganadoras de un concurso. 20 de los autos son de color rojo, 50 de color gris, 10 son de color amarillo y 20 de color azul. Si Juan resulto ganador, calcular la probabilidad de que le toque un auto:
a) gris o azulb) amarillo o rojo
Se extrae una carta de una baraja americana (52 cartas), calcular la probabilidad de que dicha carta:
a) sea un asb) sea de corazonesc) sea un as de corazonesd) sea un as, sabiendo que es de corazonese) sea de corazones, sabiendo que es asf) sea un as o bien sea de corazones
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3
Rojo AzulTsuru 5 3Platina 2 5Corsa 1 4

1.- En un estudio de vialidad de un grupo de 100 personas, de los cuales, 60 son hombres y 40 son mujeres, se obtuvieron los siguientes datos:
Mujeres Hombres TotalManejan hábilmente 18 20 30
Manejan con dificultad 10 30 50No saben manejar 12 10 20
40 60 100
Siendo los eventos:M: es mujerH: es hombreMH: maneja hábilmenteMD: maneja con dificultadNM: no sabe manejar
Calcular las probabilidades indicadas, al seleccionar un individuo de ese grupo:P(NM) =P(H) =P(MH|M) =P(MH y M) =P(MH o M) =P(MD o NM) =P(H y NM) =
Tres urnas contienen: la número uno, 9 bolas blancas y una negra; la número dos, 5 bolas blancas y 20 negras y la número 3, 8 bolas blancas 10 negras Se elige al azar una urna y se extrae, también al azar, una bola que resulta blanca. ¿Cuál es la probabilidad de que la urna elegida haya sido la primera?.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3

2.- En un estudio de personas adictas al tabaco donde se trabajo con un grupo de 100 personas, de las cuales 30 son mujeres, y 70 son hombres.Los resultados arrojaron que de las mujeres 10 fumaban y 20 no, y de los hombres 50 fumaban y 20 no lo hacían.
Mujeres Hombres TotalFuman 10 50 60
No fuman 20 20 4030 70 100
En un estudio realizado con el alumnado de una primaria de 100 alumnos, de los cuales 60 son mujeres y cuarenta hombres. Los resultados fueron: de las mujeres 24 usaban lentes y 36 no; de los hombres 16 usaban lentes y 24 no.
Mujeres Hombres TotalLentes 24 16 40
No lentes 36 24 6060 40 100
Elaboró: Guillermo Castañeda Tovar UACQB_UAG3

TEOREMA DE BAYES
La regla de multiplicación para probabilidades cuando los eventos no son independientes pueden usarse para derivar un tipo de una importante formula llamada TEOREMA DE BAYES. Debido a que P( B y D) es igual a P(B|D) x P(D) y a P(B) y P(D) no son iguales a cero.
Las dos formulas del teorema de Bayes son importantes debido a que con frecuencia dos clínicos conocen solo una de las probabilidades pertinentes y deben determinar la otra. (1)
TEOREMA DE BAYES: en el año 1763, dos años después de la muerte de Thomas Bayes (1702-1761), se publico una memoria en la que aparece, por primera vez , la determinación de la probabilidad de las causas a partir de los efectos que han podido ser observados. El cálculo de dichas probabilidades recibe el nombre de teorema de bayes.
El teorema de BAYES se apoya en el proceso inverso al que hemos visto en el teorema de la probabilidad total.
Teorema de la probabilidad total: a partir de las probabilidades del suceso A (probabilidad de que llueva o de que haga buen tiempo) deducimos la probabilidad del suceso B(que ocurra un accidente).Teorema de bayes: a partir de que ha ocurrido el suceso B (ha ocurrido un accidente) deducimos las probabilidades del suceso A (¿estaba lloviendo o hacia buen tiempo?).
La formula del Teorema de Bayes es:
EJEMPLO 1:
El parte metereologico ha anunciado tres probabilidades para el fin de semana:
a) Que llueva: probabilidad del 50%.b) Que neve: probabilidad del 30%.c) Que haya niebla: probabilidad del 20%
Según estos posibles estados metereológicos, la posibilidad de que ocurra un accidente es la siguiente:
a) Si llueve: probabilidad de accidente del 20%b) Si neva : probabilidad de accidente del 10%c) Si hay niebla: probabilidad de accidente del 5%
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4

Resulta que efectivamente ocurre un accidente y como no estábamos en la ciudad no sabemos que tiempo hizo (nevó, llovió o hubo niebla). El Teorema de Bayes nos permite calcular estas probabilidades:
Las probabilidades que manejamos antes de conocer que ha ocurrido un accidente se denominan “probabilidades a priori” (lluvia con el 50%, nieve con el 30% y niebla con el 20%).
Una vez que incorporamos la información de que ha ocurrido un accidente, las probabilidades del suceso A cambian: son probabilidades condicionadas P(A/B), que se denominan “probabilidades a posteriori”.
Vamos a aplicar la formula:
a) Probabilidad de que estuviera lloviendo:
La probabilidad de que efectivamente estuviera lloviendo el día del accidente (probabilidad a posteriori) es del 71.4%.
b) probabilidad de que estuviera nevando:
La probabilidad de que estuviera nevando es del 21.4%.
c) probabilidad de que hubiera niebla :
La probabilidad de que hubiera niebla es del 7.1%
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4

EJEMPLO 2: Tres industrias suministran microprocesadores a un fabricante de telemetria. Todos se elaboran supuestamente con las mismas especificaciones. No obstante, el fabricante ha probado durante varios años los microprocesadores, y los registros indican la siguiente información:
Se selecciona un microprocesador y al probarlo resulta defectuoso. Sea el evento B: que el articulo este defectuoso, y el evento Ai: que el articulo proviene de la i = enésima instalación (i = 1, 2,3), se puede evaluar entonces P(Ai/B).
Suponga que se desea determinar la probabilidad de que el artículo provenga de la instalación 3, dado que salió defectuoso.
R.- la probabilidad de que el artículo provenga de la instalación 3 dado que salió defectuoso es de un 12%.
Ejercicio 1: dos urnas contienen, la número uno, 9 bolas blancas y una negra; la número dos, 5 bolas blancas y 20 negras. Se elige al azar una urna y se extrae, también al azar, una bola que resulta blanca. ¿Cuál es la probabilidad de que la urna elegida haya sido la primera?.
Sean:
A = evento sale blancaH1 = evento se elige la primera urnaH2 = evento se elige la segunda urna
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4
Instalación proveedora
Fracción de defectuosos
Fracción suministrada por
1 0.02 0.152 0.01 0.803 0.03 0.05

Lo que debe calcularse es P (H2|A). Se supondrá que las dos urnas son exteriormente idénticas y consecuentemente que las probabilidades a priori p (Hi) son iguales, esto es:
P(H1) = P(H2) = ½
Además, de acuerdo con la composición de cada urna, se tiene:
P(A/H1) = , P(A/H2) =
En estas condiciones la fórmula de Bayes da:
= 81.8 %
Ejercicio 2: una prueba para detectar Diabetes tiene una eficiente del 95%, es decir, que solo 95 de cada 100 casos se detecta la diabetes con esta prueba a una persona que padece esta enfermedad. Supóngase que el 2% de las pruebas que resultan positivas son de gente sana, y que el 3% de la población del lugar padece esta enfermedad.
1. ¿Cuál es la probabilidad de que una persona seleccionada al azar pueda ser declarada diabética por la prueba?
2. si la prueba indica que la persona es Diabética, ¿Cuál es la probabilidad de que realmente lo sea?
Eventos: B1 = (Tiene Diabetes); B2 = (No tiene diabetes)Espacio muestral de B:S = (B1,B2)Evento E: (la prueba detecta diabetes)
Solución:
P(B1) = 0.03; P(B2) = 0.97P(E/B1) = 0.95; P(E/B2) = 0.02
1.- Probabilidad de que una persona sea declarada diabética por la prueba es:
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4

2.- probabilidad de que la prueba indique que la persona sea diabética y realmente lo sea:
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4

Ejercicio 3:En un hospital especializado ingresan 50% de enfermos con Leucemia, 30% con cáncer de colon y 20 % con anemia aplasica. La probabilidad de curación completa de Leucemia es de 0.7, de 0.8 para cáncer de colon y de 0.9 para anemia aplasica, un enfermo internado en el hospital fue dado de alta sano. ¿Hallar la probabilidad de que este enfermo tenía Leucemia?
P (L)= Enfermos que ingresan con Leucemia = 50%.P(C)= enfermos que ingresan con cáncer de colon 30%.P(A)= enfermos que ingresan con anemia aplasica = 20%.
B = enfermo que se curo.
P(B/L) = 0.7.
P(B/C) = 0.8.
P(B/A) = 0.9.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4
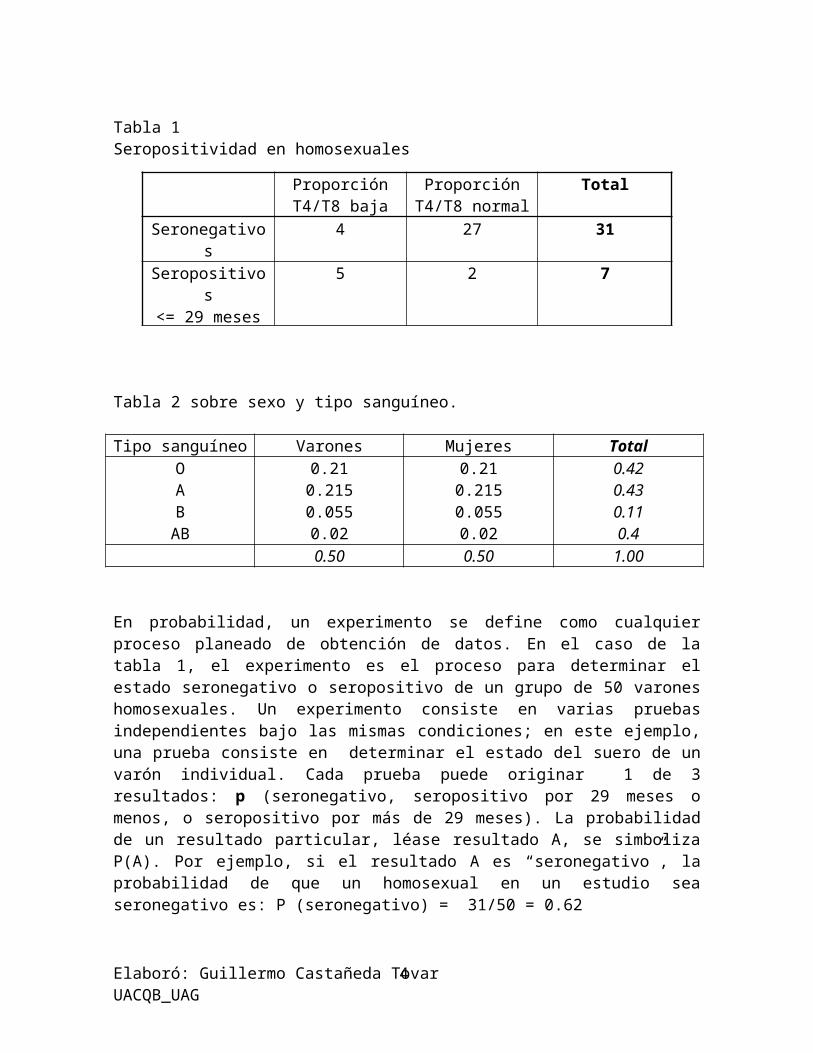
MUESTREOPoblación: Conjunto de individuos que poseen alguna característica en común que los define como grupo, se denomina población o universo. Cada población tiene su propia naturaleza y magnitud. En medicina el término población suele referirse a pacientes u otros organismos vivos, sin embargo también se utiliza para denotar conjuntos de objetos inanimados, tales como colecciones de informes, de radiografías, de cargos de un hospital, entre otros.
Muestra:En ocasiones las poblaciones son demasiado grandes y resulta poco práctico, inoperante e incluso, imposible trabajar con el universo total. En esos casos suele extraerse una cantidad limitada de individuos de la población total para trabajar con ella. A ese subconjunto se le denomina muestra. El muestreo permite realizar los estudios o investigaciones con mayor rapidez y menor costo.
En estadística las muestras se toman al azar; esto significa que todos los individuos de la población tienen la misma posibilidad de pertenecer al subconjunto muestra.
Tipos de muestreo: El muestreo puede ser: 1) Aleatorio simple; 2) Sistemático; 3) Estratificado; 4) De conglomerados.1) Aleatorio simple.En este tipo de muestreo cada sujeto de la población total tiene la misma probabilidad de ser seleccionado para el estudio. Para definir la muestra se utiliza normalmente una tabla de números aleatorios. (A continuación se presenta una tabla reducida).
927415926937867169857169512500
956521515107388342542747843384
168117014658832261032683085361
169280159944993050131188398488
326569821115639410926198774767
266541317592698969371071383837
062454806702837815926839854813
423050881309163631453853731620
670884772977622143767825978100
840940367506938278284716589512
845839729850231305916182147694
979662457758219737467113389180
851595449353169116139470433775
452454556695586865358095761861
262448806050756231528858107191
688990123754469281660128515960
461777722070258737342072759056
647487935916989450681203150336
221922740207525873734185773112
232624078048755998499711463857
398839854928866034254256781983
495004875559444933616625078184
881970246288785944243045380752
792001000144018016251938492215
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4

Existen diferentes formas para iniciar con la selección, una de ellas puede ser lanzar un dado 2 veces, la cara del primer lanzamiento corresponderá a un grupo grande de renglones, la del segundo lanzamiento indicará el renglón particular del grupo. A partir de allí se realiza un desplazamiento por las filas o por las columnas y se van seleccionando los números que corresponda a los datos reales, hasta completar el tamaño de la muestra.
2) Muestreo sistemático.Este consiste en seleccionar a los sujetos cada determinado número. (Cada tres, cada siete…). El número se determina dividiendo la población total entre el tamaño de la muestra. Por ejemplo si la población es de 2000 individuos y la muestra de 200, entonces la selección en la tabla de números aleatorios se hace cada 10 lugares.
3) Muestreo estratificado.Es aquel en el que previamente se divide la población en subgrupos, a los que se les llama estratos, y de cada estrato se elige una muestra parcial y posteriormente se suman las muestras de los diferentes estratos para tener así la muestra total.
4) Muestreo de conglomerados.Una muestra aleatoria de conglomerados se obtiene en un proceso de dos etapas.La población se divide en conglomerados y de estos se selecciona un subconjunto. Los conglomerados se basan en áreas geográficas o distritos, este enfoque es más utilizado en investigación epidemiológica que en investigación clínica.Ejemplos de conglomerados: Manzanas, colonias o barrios, instituciones de salud de una ciudad, determinadas localidades pertenecientes a los municipios, o los municipios de un estado, etc.
Elaboró: Guillermo Castañeda Tovar UACQB_UAG4


















