
MODELIZACIÓN DE LA SATISFACCION DE LOS USUARIOS EN ... - CIT2018_v0.4.pdflas encuestas es el...
18
. MODELIZACIÓN DE LA SATISFACCION DE LOS USUARIOS EN SISTEMAS DE TRANSPORTE PUBLICO CON DATOS FALTANTES Eneko Echaniz Investigador, Universidad de Cantabria, España Luigi dell’Olio Profesor titular, Universidad de Cantabria, España Angel Ibeas Catedrático, Universidad de Cantabria, España RESUMEN El uso de encuestas de satisfacción se ha extendido por todo el mundo y para toda clase de modos de transporte como medio para establecer el nivel de satisfacción de los usuarios de los sistemas de transporte público. Un método muy habitual para analizar los resultados de las encuestas es el utilizar modelos de elección discreta, como pueden ser los modelos logit o probit ordenados. Sin embargo, para la estimación de estos modelos, se requieren una serie de datos concretos, que habitualmente requieren que cada persona encuestada valore (de forma cualitativa o cuantitativa) todos los atributos del servicio que se quieren incluir en el modelo. En este artículo se presenta una metodología basada en la obtención de evaluaciones de un set reducido de atributos para cada usuario. La información faltante para cada usuario se complementa con las valoraciones del resto de usuarios con similares características del viaje. Los resultados muestran que es posible estimar modelos de datos ordenados consistentes aun partiendo de información incompleta. 1. INTRODUCCIÓN Cuando se estudia la calidad percibida o la satisfacción de los usuarios es necesario recopilar dicha información a través de encuestas habitualmente de preferencias reveladas. Dependiendo de la metodología empleada para el análisis de la satisfacción se requerirá un tipo de satisfacción u otro. El proceso de recolección de datos es la parte más costosa, tanto económicamente como por tiempo, a la hora de estudiar la satisfacción de los usuarios, por lo tanto, una reducción en el tiempo necesario para recolectar supondría una mejora en la eficiencia y el coste de este tipo de estudios. Por lo tanto, en este artículo se plantea una comparativa entre los resultados que se pueden obtener al estudiar la satisfacción con una base de datos completa y una base de datos con información parcial, más concretamente, con la mitad de la información. Lo que se ha realizado es eliminar parte de la información obtenida en una encuesta de satisfacción y realizar el mismo proceso de análisis y modelización con la información completa e incompleta, para al final comparar dichos resultados, de forma que si los resultados son similares quiere decir que existe la posibilidad
Transcript of MODELIZACIÓN DE LA SATISFACCION DE LOS USUARIOS EN ... - CIT2018_v0.4.pdflas encuestas es el...

.
MODELIZACIÓN DE LA SATISFACCION DE LOS
USUARIOS EN SISTEMAS DE TRANSPORTE PUBLICO
CON DATOS FALTANTES
Eneko Echaniz
Investigador, Universidad de Cantabria, España
Luigi dell’Olio
Profesor titular, Universidad de Cantabria, España
Angel Ibeas
Catedrático, Universidad de Cantabria, España
RESUMEN
El uso de encuestas de satisfacción se ha extendido por todo el mundo y para toda clase de
modos de transporte como medio para establecer el nivel de satisfacción de los usuarios de
los sistemas de transporte público. Un método muy habitual para analizar los resultados de
las encuestas es el utilizar modelos de elección discreta, como pueden ser los modelos logit
o probit ordenados. Sin embargo, para la estimación de estos modelos, se requieren una serie
de datos concretos, que habitualmente requieren que cada persona encuestada valore (de
forma cualitativa o cuantitativa) todos los atributos del servicio que se quieren incluir en el
modelo. En este artículo se presenta una metodología basada en la obtención de evaluaciones
de un set reducido de atributos para cada usuario. La información faltante para cada usuario
se complementa con las valoraciones del resto de usuarios con similares características del
viaje. Los resultados muestran que es posible estimar modelos de datos ordenados
consistentes aun partiendo de información incompleta.
1. INTRODUCCIÓN
Cuando se estudia la calidad percibida o la satisfacción de los usuarios es necesario recopilar
dicha información a través de encuestas habitualmente de preferencias reveladas.
Dependiendo de la metodología empleada para el análisis de la satisfacción se requerirá un
tipo de satisfacción u otro. El proceso de recolección de datos es la parte más costosa, tanto
económicamente como por tiempo, a la hora de estudiar la satisfacción de los usuarios, por
lo tanto, una reducción en el tiempo necesario para recolectar supondría una mejora en la
eficiencia y el coste de este tipo de estudios. Por lo tanto, en este artículo se plantea una
comparativa entre los resultados que se pueden obtener al estudiar la satisfacción con una
base de datos completa y una base de datos con información parcial, más concretamente,
con la mitad de la información. Lo que se ha realizado es eliminar parte de la información
obtenida en una encuesta de satisfacción y realizar el mismo proceso de análisis y
modelización con la información completa e incompleta, para al final comparar dichos
resultados, de forma que si los resultados son similares quiere decir que existe la posibilidad

.
de obtener buenos resultados reduciendo la encuesta de obtención de datos. El análisis
realizado se ha basado en un estudio estadístico básico, comparando las satisfacciones
medias obtenidas, y una modelización de la calidad mediante el uso de modelos Ordered
Probit. El artículo se compone 7 apartados, en este primero se ha realizado una breve
introducción al problema planteado. En el segundo apartado establece una visión general del
estado del arte referente al estudio de la satisfacción en el transporte público de pasajeros
citando también los estudios más relevantes relacionados a la metodología empleada, la cual
se desarrolla en el apartado 3. Los resultados del análisis y la modelización se muestran en
el apartado 4. En el apartado 5 se desarrollan las conclusiones más importantes derivados
del estudio. El artículo finaliza con los agradecimientos y las referencias en los apartados 6
y 7 respectivamente.
2. ESTADO DEL ARTE
Las encuestas de satisfacción se han extendido por todo el mundo como fuente para medir
la calidad percibida por los usuarios de los sistemas de transporte públicos. Diversos estudios
muestran este hecho, desde los primeros pasos del análisis más genérico de la calidad
percibida (Parasuraman et al., 1985), hasta los estudios más actuales enfocados en el análisis
específico del transporte público de pasajeros (dell’Olio et al., 2010; Dell’Olio et al., 2011;
Fellesson and Friman, 2008; Rojo et al., 2013; Wongwiriya et al., 2017).
La mayoría de estos estudios se han centrado, por una parte, en definir aquellos atributos del
sistema que mejor definen el servicio de transporte público, este es el caso del proyecto
Quattro (EC, 1999) donde se definieron hasta 8 diferentes grupos de atributos o el estudio
realizado por Hensher (Hensher et al., 2003), donde se definió el SQI (Service Quality
Index). Por otro lado, la otra dirección que han seguido los estudios de calidad percibida o
satisfacción de usuarios es el de mejorar la metodología empleada para el análisis de los
datos obtenidos, hasta la fecha los métodos más empleados son: Modelos de Datos
Ordenados (Ordered Logit o Probit) (M. Bordagaray et al., 2014; dell’Olio et al., 2010;
Echaniz et al., 2017), ecuaciones estructurales ((Das et al., 2017; De Oña et al., 2013;
Farzana Rahman et al., 2016)) o arboles de decisión (de Oña et al., 2016; Hernandez et al.,
2016; Machado-León et al., 2017; Tsami and Nathanail, 2017). Sin embargo, y al menos
hasta donde llega el conocimiento de los autores, ningún estudio se ha centrado en optimizar
la fase de toma de datos sin perjudicar los resultados del análisis final.
El proceso de toma de datos es esencial para cualquier estudio de satisfacción, el proceso
para obtener la información es a base de encuestas de satisfacción, las cuales pueden
realizarse de forma presencial en los autobuses (M. Bordagaray et al., 2014; dell’Olio et al.,
2010; Echaniz et al., 2017) o mediante métodos más novedosos como puede ser el in incluir
códigos QR en las paradas para que los usuarios realicen las encuestas por su propia voluntad
(Guirao et al., 2015). En ambos casos, la duración de la encuesta es un factor determinante
para obtener una cantidad de datos adecuada. Una encuesta compuesta por muchos apartados
donde se quiera obtener mucha información generará una gran información muy útil para el
posterior análisis, sin embargo, la cantidad de usuarios que llegarán a completar la encuesta

.
se reduce significativamente, acabando con pocas respuestas completas. Por otra parte, una
encuesta demasiado corta puede proporcionar una cantidad de observaciones muy grande,
sin embargo al no disponer de demasiada información en cada encuesta puede que el número
de encuestas realizadas no sea suficiente para realizar un correcto análisis, cuestión que se
quiere comprobar en este estudio. El tiempo y coste relacionados con la toma de datos
depende directamente del número de encuestas que se desean realizar, la duración de la
encuesta y el método de obtención de datos (presencia, online, app…). En Rahman et al.,
2016 por ejemplo se realizaron encuestas a 2008 usuarios de transporte público durante los
meses de Junio y Julio de 2015, con una encuesta compuesta por dos apartados, una para la
obtención de datos socioeconómicos y otro para la obtención de la satisfacción de 21
atributos del sistema. En Rissel et al., 2016 se realizaron un total 512 encuestas de forma
online durante los meses de septiembre y octubre para obtener información sobre el modo
de transporte utilizado por los usuarios y el nivel de satisfacción que tenían con el mismo.
En Guirao et al., 2016 se realizaron 850 encuestas presenciales de los cuales 813 fueron
respuestas completas validas, la duración del periodo de encuestado fue de 2 semanas. En el
caso de Abenoza et al., 2017 a diferencia de los anteriores se disponía de una base de datos
muy extensa obtenida por el Barómetro de Transporte Publico Sueco para los años entre
2001 y 2014 con cerca de 450.000 encuestas telefónicas útiles. Los estudios mencionados se
tratan solo de un pequeño ejemplo de los últimos estudios de satisfacción llevados a cabo
donde se puede observar que, de forma general, un estudio de satisfacción de transporte
público requiere de la realización de una gran cantidad de encuestas, por lo tanto, una mejora
en la eficiencia de este proceso mejoraría considerablemente el coste total del proceso
completo, siempre y cuando la calidad de los datos no perjudique el análisis posterior.
Diversos estudios han demostrado (Maria Bordagaray et al., 2014; dell’Olio et al., 2010;
Dell’Olio et al., 2011; Echaniz et al., 2017; Rojo et al., 2013) que los modelos de datos
ordenados son muy adecuados para analizar la satisfacción de los usuarios en los sistemas
de transporte público. Estos modelos tienen la peculiaridad de que necesitan una serie de
datos muy concretos, los cuales se componen de una variable dependiente, la valoración
general del servicio, y unas variables independientes, los atributos del servicio. Cada usuario
encuestado debe evaluar la totalidad de las variables, lo que quiere decir que si se disponen
de 24 atributos para definir el sistema el encuestado debe responder al menos a 25 preguntas,
además de las posibles preguntas de caracterización. Estas han sido las razones principales
para escoger esta metodología para este estudio.
Para analizar una base de datos faltantes como si se dispusieran de la totalidad de los datos
es necesarios establecer metodologías para la cuplimentar esa información faltante. En este
aspecto, la Imputacion Multiple desarrollada por Donal Rubin (Rubin, 1977) ha demostrado
ser una metodologia muy utilizada para la obtención de datos faltantes en no-respuestas. La
Imputacion Multiple ha sido utilizada principalmente en el ámbito de la medicina (Sterne et
al., 2009; Van Buuren et al., 1999) y las ciencias sociales (Alegria et al., 2004; Allison, 2000;
Roth, 1994) para completar la información no disponible. En ambos casos, el uso habitual
de este método es para completar las observaciones en los que la información total no ha
podido ser obtenida por diversos motivos no controlables, como puede ser la falta de

.
información sobre un paciente o preguntas sin responder en encuestas domiciliarias. En este
artículo se realiza una omisión deliberada de la información, por lo que no presenta el caso
estándar de datos faltantes, sin embargo, tal y como se menciona en (Rubin, 2004) “An even
more extended definition of survey nonresponse includes any situation in which there are
missing values in the rectangular units-by-variables data matrix to be analyzed”, por lo que
el uso de la Imputacion Multiple es considerada adecuada para este caso, donde la
información faltante representa la mitad de la información real necesaria para el análisis.
3. METODOLOGÍA
3.1 Encuesta
La encuesta de satisfacción utilizada para este estudio se realizó en Mayo de 2015 donde se
consiguieron un total de 747 observaciones. Mediante esta encuesta se consiguieron dos
tipos de datos, por una parte, se realizó una caracterización de los usuarios de transporte
público encuestados mediante una serie de datos socioeconómicos (Tabla 1). Por otra parte,
se midió la satisfacción de los usuarios referente al servicio de transporte público en general
(OS) y a un conjunto de atributos que representan distintos aspectos del servicio (Tabla 1 ).
La satisfacción de los usuarios se midió mediante una escala Likert de 5 opciones.
Caracterización Atributos del Sistema TP
Sexo Tiempo de acceso a la parada (AT)
Edad Tiempo de espera de parada (WT)
Estado Laboral Tiempo de viaje (TV)
Posesión del carnet de conducir Tiempo a destino desde la parada (TD)
Posesión de vehículo propio Precios de los billetes (PR)
Motivo del viaje Facilidad de transbordos (TR)
Frecuencia de uso Servicios ofertados (Frecuencias) (SE)
Forma de pago habitual Fiabilidad del servicio (SR)
Salario mensual Líneas especiales (EL)
Servicio nocturno / durante el fin de semana (NS)
Cobertura de las líneas (LC)
Información en paradas (IP)
Información en soporte informático (IWM)
Información en el autobús (IB)
Ocupación (OC)
Calefacción/aire acondicionado (CA)
Espacio para personas de movilidad reducida (RM)
Confort y comodidad (CM)
Limpieza de los autobuses (CL)
Posibilidad de portar objetos/bultos (OB)
Forma de conducción (DS)
Amabilidad del conductor (DK)
Implantación de buses Híbridos (HY)
Contaminación acústica (NO)
Tabla 1 – Variables incluidas en la encuesta

.
3.2. Modelización mediante Ordered Probit
Para el siguiente apartado, se ha tomado como base el libro Modeling Ordered Choices: A
Primer (Greene y Hensher, 2010).
El modelo Probit Ordenado, en su forma contemporánea, basada en regresión, fue propuesto
por McKelvey y Zavoina, 1975, 1971 para el análisis de elecciones y respuestas ordenada,
categorizadas o no cuantitativas.
Los modelos de datos ordenados se basan en partir un espacio continuo de utilidad en franjas
discretas a través de un sistema de limitaciones.
𝑦𝑖∗ = 𝛽′𝑥𝑖 + 휀𝑖, 𝑖 = 1, … , 𝑛,
𝑦𝑖 = 1 𝑠𝑖 𝜇−1 < 𝑦𝑖∗ ≤ 𝜇𝑖1
= 2 𝑠𝑖 𝜇0 < 𝑦𝑖∗ ≤ 𝜇𝑖2
= 3 𝑠𝑖 𝜇1 < 𝑦𝑖∗ ≤ 𝜇𝑖3
= ⋯
= 𝐽 𝑠𝑖 𝜇𝐽−1 < 𝑦𝑖∗ ≤ 𝜇𝐽.
(1)
En una primera aproximación, se asume que tanto los coeficientes del modelo como los
parámetros de límite se consideran constantes para el conjunto de los individuos.
La idea clave del modelo reside en que las observaciones realizadas no son una simple
acumulación de resultados discretos que se puedan de cierta manera ordenar, sino que
consiste en una transformación de una única variable continua que debe de ser ordenada.
El modelo contiene las utilidades marginales desconocidas, β, además de J+2 parámetros de
limite, μj, todas ellas a estimar mediante n observaciones. Los datos consisten en los
parámetros xi de cada observación y de los resultados yi de cada uno de ellos. La variable
aleatoria εi completa el modelo. Se asume que la variable aleatoria εi se distribuye de
acuerdo a una función de distribución (CDF) conocida y definida a lo largo de todo el
dominio real. La asunción de la distribución de εi incluye la independencia o hexogeneidad
sobre xi. Centrando los modelos en el problema planteado en este estudio. Supongamos una
serie de respuestas disponibles para cada uno de los encuestados, donde las opciones sean
las siguientes:
0 Muy Mal
1 Mal
2 Normal
3 Bien
4 Muy Bien
El modelo de regresión muestra una subyacente y a la vez no observable de la preferencia
sobre la cuestión evaluada, 𝑦𝑖∗. Cada individuo encuestado, no proporciona el valor de 𝑦𝑖
∗,
sino que una versión limitada repartida en cinco posibles opciones, uno de los cuales es el
más cercano a su preferencia exacta. Las probabilidades asociadas a las respuestas

.
observadas son:
𝑃𝑟𝑜𝑏[𝑦𝑖 = 𝑗|𝑥𝑖] = 𝑃𝑟𝑜𝑏[휀𝑖 ≤ 𝜇𝑗 − 𝛽′𝑥𝑖] − 𝑃𝑟𝑜𝑏[𝜇𝑗−1 − 𝛽′𝑥𝑖], 𝐽 = 0,1, … , 𝐽 (2)
El modelo establecido describe la probabilidad de los valores de los resultados. No describe
una relación directa entre la valoración yi y los parámetros xi, no existe una relación de
regresión obvia entre ambos parámetros. Aunque no existe una relación mediante regresión
entre los parámetros xi e yi, puesto que yi es una mera etiqueta, puede ser interesante un
análisis mediante variables binarias.
𝑚𝑖𝑗 = 1 𝑠𝑖 𝑦𝑖 = 𝑗 𝑦 0 𝑒𝑛 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟𝑎𝑟𝑖𝑜 (3)
O
𝑀𝑖𝑗 = 1 𝑠𝑖 𝑦𝑖 ≤ 𝑗 𝑦0 𝑒𝑛 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟𝑎𝑟𝑖𝑜 (4)
O
𝑀𝑖𝑗′ = 1 𝑠𝑖 𝑦𝑖 ≥ 𝑗 𝑦 0 𝑒𝑛 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟𝑎𝑟𝑖𝑜 (5)
La segunda como la tercera ecuación, al igual que el caso mi0, pueden describirse mediante
un modelo de elección binaria aunque estos no son interesantes.
Para la estimación de los parámetros de los modelos son necesarios establecer una serie de
normalizaciones, los cuales se discuten a continuación.
En primer lugar, para mantener los signos positivos para todas las probabilidades, es
necesario 𝑞𝑢𝑒 𝜇𝑗 > 𝜇𝑗−1.
Segundo, si el soporte del modelo debe ser el dominio real completo, entonces 𝜇−1 = −∞ y
𝜇𝑗 = +∞. Dado que los datos no contienen información incondicional sobre la escala de la
variable dependiente (en caso de modificar la escala de 𝑦𝑖∗ con cualquier valor positivo,
modificando la escala de los valores desconocidos 𝜇𝑗y β con el mismo valor, se mantienen
las características de las observaciones) no es posible estimar el parámetro varianza libre
𝑉𝑎𝑟[휀𝑖] = 𝜎𝜀2. Es recomendable realizar una restricción que se basa en 𝜎𝜀 = 𝑐𝑡𝑒, 𝜎. Lo
habitual es asumir varianza igual a uno en el caso de un modelo Probit y varianza igual a
𝜋2/3en el caso del Logit. Por último, asumiendo que 𝑥𝑖contiene un término constante, es
necesario establecer 𝜇0 = 0. El cálculo de los parámetros de los modelos se realiza mediante
un problema de estimación de máxima verosimilitud (Greene, 2007, 2008; Pratt, 1981).
La función log verosimilitud es:
log 𝐿 = ∑ ∑ 𝑚𝑖𝑗log [𝐽
𝑗=0
𝑛
𝑖=0𝐹(𝜇𝑗 − 𝛽′𝑥𝑖) − 𝐹(𝜇𝑗−1 − 𝛽′𝑥𝑖)] (6)
Donde 𝑚𝑖𝑗 = 1 si 𝑦𝑖 = 𝑗 y 0 en los demás casos. La maximización se realiza sometida a
unas determinadas condiciones, 𝜇−1 = −∞, 𝜇0 = 0, y 𝜇𝐽 = +∞. Las restricciones restantes,

.
𝜇𝑗−1 < 𝜇𝑗, puede, en un principio, imponerse mediante una reparametrización mediante
parámetros estructurales.
𝜇𝑗 = 𝜇𝑗−1 + 𝑒𝛼𝑗
= ∑ 𝑒𝛼𝑚
𝑗
𝑚=1
(7)
Sin embargo, por lo general, no suele ser necesario.
La estimación de los parámetros de los modelos, en la práctica, se realiza mediante el uso de
software específico como es el caso del programa informático NLOGIT. Este mismo
programa ha sido el utilizado para calcular los modelos que se plantean en este proyecto.
3.3. Imputación Múltiple
El objetivo de la imputación múltiple es el de completar los datos faltantes de forma que la
base de datos se pueda estadísticamente analizar y modelizar de forma similar a la base de
datos completa. El fundamento teórico en el que se basa la imputación múltiple es la
imputación repetitiva (Rubin, 2004, 1996, 1977), por lo que para cada dato faltante se
imputan m valores en vez de solo uno. Partiendo del hecho de que los datos faltantes han
sido eliminados de forma aleatoria, podemos decir que los datos faltantes corresponden con
un tipo MAR (Missing and Random), por lo que el uso de este método es apropiado.
La metodología utilizada para la realización de la imputación múltiple se denomina
Especificación Totalmente Condicional (Fully Conditional Specification FCS), que utiliza
un método iterativo Monte Carlo con cadenas Markov.
La aproximación FCS se basa en imputar los datos variable-por-variable especificando un
modelo de imputación por cada uno de las variables con datos faltantes. El FCS intenta
definir 𝑃(𝑌, 𝑋, 𝑅|𝜃) especificando una densidad condicional 𝑃(𝑌𝑗|𝑋, 𝑌−𝑗, 𝑅, 𝜃𝑗) para cada 𝑌𝑗
, esta densidad se utiliza para imputar 𝑌𝑗𝑚𝑖𝑠 dados unos X, Y_-j y R. Una iteración consiste
en un ciclo completo a través de todas las 𝑌𝑗. (van Buuren, 2007). La imputación se realiza
mediante el uso del muestreo de Gibbs (Casella et al., 2016; Gilks et al., 1996) asumiendo
que la distribución de densidad condicional existe. Esta metodología se ha utilizado en un
gran número de estudios de simulación ((Brand, 1999; Brand et al., 2003; Horton et al.,
2016; Raghunathan et al., 2001; Van Buuren et al., 2006)) que han proporcionado la
suficiente evidencia de que los resultados obtenidos mediante el FCS son generalmente no
sesgados y con una cobertura adecuada.
Con el objetivo de optimizar el proceso de imputación se ha asumido que los datos de
satisfacción son considerados variables de tipo escala con valores comprendidos entre 0 y 4,
por lo que el modelo de imputación sigue una metodología de regresión lineal redondeando
al valor entero más cercano, puesto que se ha comprobado que la equivalencia de media
predictiva, una variante de la regresión lineal que iguala los valores imputados calculados
por el modelo de regresión con el valor observado más cercano, genera peores resultados.

.
Así se ha conseguido que los valores imputados coincidan con los valores reales de los
datos. De tal forma que, para el modelo de regresión, 𝑌𝑗 corresponde con las valoraciones de
los atributos faltantes y 𝑋 con todas las variables socioeconómicas de los encuestados y la
valoración general del servicio.
3.4. Comparativa
De acuerdo al objetivo final de este estudio, en el cual se pretende analizar si es posible
obtener unos resultados similares partiendo de una base de datos de información parcial, se
proponen 3 metodologías para realizar la modelización de la satisfacción de los usuarios
mediante modelos Ordered Probit.
El punto de partida es el modelo que llamaremos Base que se estima considerando la base
de datos completa obtenida de la encuesta. Para el resto de modelos se ha eliminado la mitad
de los datos de satisfacción obtenidos de forma aleatoria, esto es, solo se dispondrán de la
evaluación realizada a 12 de los 24 atributos del sistema, por lo que la información faltante
se ha completado mediante el uso de 3 métodos distintos.
El primer método se basa en utilizar la moda de las respuestas para completar la información
faltante de cada atributo, esto es, utilizar el valor más común entre los encuestados para cada
atributo, de forma que la el valor de la satisfacción de un usuario que no realiza la valoración
un atributo será igual al valor escogido por la mayoría que sí lo ha evaluado.
El segundo método consiste en estimar un modelo Ordered Probit para cada uno de los
atributos en función de las variables socioeconómicas preguntadas en la encuesta. De esta
forma, el valor faltante de la satisfacción de un usuario se inferirá de un modelo estimado
con las respuestas existentes para ese parámetro y en base a las características
socioeconómicas de las personas que lo han evaluado. La expresión matemática quedaría de
la siguiente forma: 𝑦𝑖∗representaría cada uno de los 24 atributos evaluados y 𝑥𝑖 las distintas
variables socioeconómicas; 𝛿𝑗𝑖 obtendría el valor 1 si una variable es evaluada por un
encuestado y 0 en caso contrario hasta un máximo de ∑ 𝛿𝑖𝑗24𝑗=1 = 12, puesto que se ha
asumido que en la versión restringida de la encuesta los encuestados solo realizarían la
evaluación de la mitad de los atributos. Este modelo será denominado el Modelo atributos a
lo largo del artículo.
𝑦𝑗𝑖∗ = 𝛿𝑗𝑖 𝛽′𝑥𝑖 + 휀𝑖 , 𝑖 = 1, … , 𝑛, 𝑦 𝑗 = 1, … ,24, .. (8)
Por último, el último método utilizado para completar los datos faltantes ha sido mediante
la utilización del sistema de imputación múltiple (apartado 3.3). Como indicadores para
inferir los datos faltantes se han utilizado tanto las variables socioeconómicas como las
evaluaciones realizadas a todos los atributos, al igual que la valoración general del servicio.
Se han realizado un total de 5 imputaciones con 100 interacciones cada una. Los resultados
de la Imputación Múltiple resultan en la generación de 5 bases de datos nuevas, 1 por cada
imputación. Con el objetivo de obtener un solo modelo, se ha estimado un modelo OP para

.
cada una de esas bases de datos y a continuación se ha calculado el promedio de cada
parámetro.
4. RESULTADOS
4.1. Análisis descriptivo
Los resultados han resultado ser principalmente mujeres (71%), de una edad media joven,
con dos tercios de los encuestados por debajo de los 44 años, trabajador (49%) o estudiante
(25%) y con carnet de conducir (59%) pero no siempre disponiendo de un vehículo propio
(40%). En cuanto al uso del servicio de transporte público, nos encontramos con un usuario
habitual (50% de los usuarios utilizan el servicio entre 5 y 15 veces por semana), donde el
principal motivo del viaje se encuentra relacionado con el hogar (32%). Se puede observar
que el uso de la tarjeta de transporte sin contacto se encuentra totalmente extendida (95%)
eliminando prácticamente totalmente el pago en efectivo (5%). En cuanto al nivel de renta
de los usuarios, los encuestados han resultado ser principalmente personas de un nivel de
renta medio – bajo un 31% con menos de 900€ al mes y un 23% entre 900 y 1500 € al mes,
algo más de un tercio (38%) de los encuestados ha preferido no contestar a esta pregunta, un
resultado habitual puesto que se trata de una pregunta muy sensible. Los datos estadísticos
completos de los usuarios se muestran en la Tabla 2 con mayor detalle.
Sexo Hombre 29%
Mujer 71%
Edad
<25 28%
25-34 16%
35-44 22%
45-54 16%
55-64 11%
>65 7%
Estado Laboral
Trabajador 49%
Desempleado 17%
Estudiante 25%
Jubilado 9%
Carnet de conducir
Si 59%
No 41%
Vehículo Propio Si 40%
No 60%
Frecuencia de uso
< 5 viajes/semana 29%
5 - 15 viajes/semana 50%
15 - 30 viajes/semana 18%
> 30 viajes/semana 3%
Motivo del viaje
Casa 32%
Trabajo 22%
Estudios 13%
Sanidad 4%
Compras 7%
Ocio 11%
Otros 11%
Forma de Paco Tarjeta sin contacto 95%
Efectivo 5%
Salario Mensual
< 900€ 31%
900 - 1500€ 23%
1500 - 2500€ 7%
> 2500€ 1%
NS/NC 38%
Tabla 2 – Analisis Descriptivo de los encuestados

.
En cuanto a la satisfacción de los usuarios con el servicio de transporte público, en la Tabla
3 se muestran los resultados obtenidos.
Para facilitar la comprensión se ha asociado cada una de las opciones de evaluación
cualitativas a un valor numérico comprendido entre 0 y 4, con 0 como “Muy Mal” y 4 como
Muy bien.
Los resultados muestran la comparativa entre las valoraciones medias de los atributos
considerando la encuesta real, con los datos completos, y las valoraciones medias calculadas
a partir de la base de datos generada al eliminar la mitad de las evaluaciones. AL final se
muestra la satisfacción general del servicio de los usuarios (OS).
DB Completo DB Parcial Diferencia
Media Moda Des.Est. Media Moda Des.Est. Media Moda Des.Est.
AT 2.91 3 0.80 2.86 3 0.85 -1.72% 0.00% 5.78%
WT 2.45 3 0.89 2.46 3 0.87 0.40% 0.00% -2.15%
TT 2.61 3 0.74 2.61 3 0.76 -0.03% 0.00% 3.19%
DT 2.87 3 0.70 2.87 3 0.71 0.20% 0.00% 0.86%
PR 2.07 2 0.98 2.04 2 1.00 -1.54% 0.00% 2.91%
TR 2.67 3 0.80 2.67 3 0.78 -0.01% 0.00% -1.72%
SE 2.49 3 0.82 2.53 3 0.80 1.42% 0.00% -1.60%
SR 2.76 3 0.73 2.75 3 0.72 -0.06% 0.00% -1.41%
EL 2.35 2 0.73 2.30 2 0.74 -2.30% 0.00% 1.41%
NS 2.15 2 0.83 2.11 2 0.84 -2.18% 0.00% 1.38%
LC 2.63 3 0.80 2.65 3 0.81 0.67% 0.00% 1.59%
IS 2.77 3 0.83 2.79 3 0.82 0.47% 0.00% -0.50%
IWM 2.88 3 0.81 2.90 3 0.79 0.88% 0.00% -2.19%
IB 2.59 3 0.74 2.60 3 0.72 0.70% 0.00% -2.88%
OC 2.39 2 0.81 2.43 3 0.83 1.74% 50.00% 2.20%
CA 2.44 3 0.78 2.51 3 0.78 2.74% 0.00% -0.02%
RM 2.57 3 0.86 2.59 3 0.83 0.83% 0.00% -3.29%
CM 2.73 3 0.59 2.74 3 0.59 0.28% 0.00% 0.50%
CL 2.86 3 0.66 2.84 3 0.67 -0.73% 0.00% 1.87%
OB 2.37 2 0.79 2.38 2 0.78 0.24% 0.00% -1.18%
DS 2.67 3 0.79 2.67 3 0.78 0.25% 0.00% -0.88%
DK 2.65 3 0.81 2.63 3 0.80 -0.86% 0.00% -0.46%
HY 3.05 3 0.75 3.05 3 0.75 -0.24% 0.00% 0.84%
NO 2.27 2 0.66 2.23 2 0.64 -1.79% 0.00% -1.87%
OS 2.81 3 0.63
Tabla 3 – Niveles de satisfacción de los usuarios
Los Resultados muestran que los usuarios se encuentran por lo general satisfechos con el
servicio en su conjunto y con todos los aspectos relativos a este.
El atributo que es considerado como peor es el precio de los billetes, este hecho puede
comprenderse puesto que los usuarios no tienden a evaluar bien este atributo por miedo a
una posible subida de precios del servicio, sin embargo, la valoración media se encuentra en
un nivel medio, por lo que no se considera como un factor no satisfactorio para los usuarios.

.
Por el contrario, el atributo mejor valorado es la implantación de autobuses híbridos, toda
acción asociada a una mejora ambiental del servicio es considerada buena en general por los
usuarios.
La comparativa realizada entre las dos bases de datos muestra que aun disponiendo de la
mitad de la información los resultados medios de las valoraciones no muestran una gran
variación, siendo las variaciones en las medias menores al 3% en todos los casos con una
gran parte menor al 1%.
Las mayores diferencias se encuentran en la variable ocupación, donde la moda cambia de
una valoración “normal” (2) a una valoración “Bien”, esto se debe a que debido a la
eliminación aleatoria de los datos, los datos de peor valoración han sido eliminados, sin
embargo esta diferencia solo se muestra en una variable de todo el set de atributos. Las
desviaciones estándar también muestran una diferencia pequeña, por lo general menor al 3%
a excepción del Tiempo de Acceso a la parada que muestra una variación cercana al 6%. Por
lo general se puede decir que los resultados obtenidos mediante las dos bases de datos es
muy similar.
4.2. Resultados de los modelos
Se han calculado un total de 4 modelos Ordered Probit. Como modelo base se ha utilizado
aquel que utiliza la base de datos completa. Dicho de otra forma, lo que se ha realizado es
una comparativa del modelo basado en los datos reales con los modelos estimados mediante
las bases de datos completadas con las metodologías anteriormente planteadas (Moda,
Modelos de atributos y Imputación Múltiple).
Los atributos incluidos en cada modelo se han ido eliminando siguiendo un proceso por
etapas hasta conseguir modelos donde todos los parámetros tengan un signo correcto (signo
positivo salvo la constante que debe de ser negativa (Echaniz et al., 2017) y una
significatividad estadística suficiente.
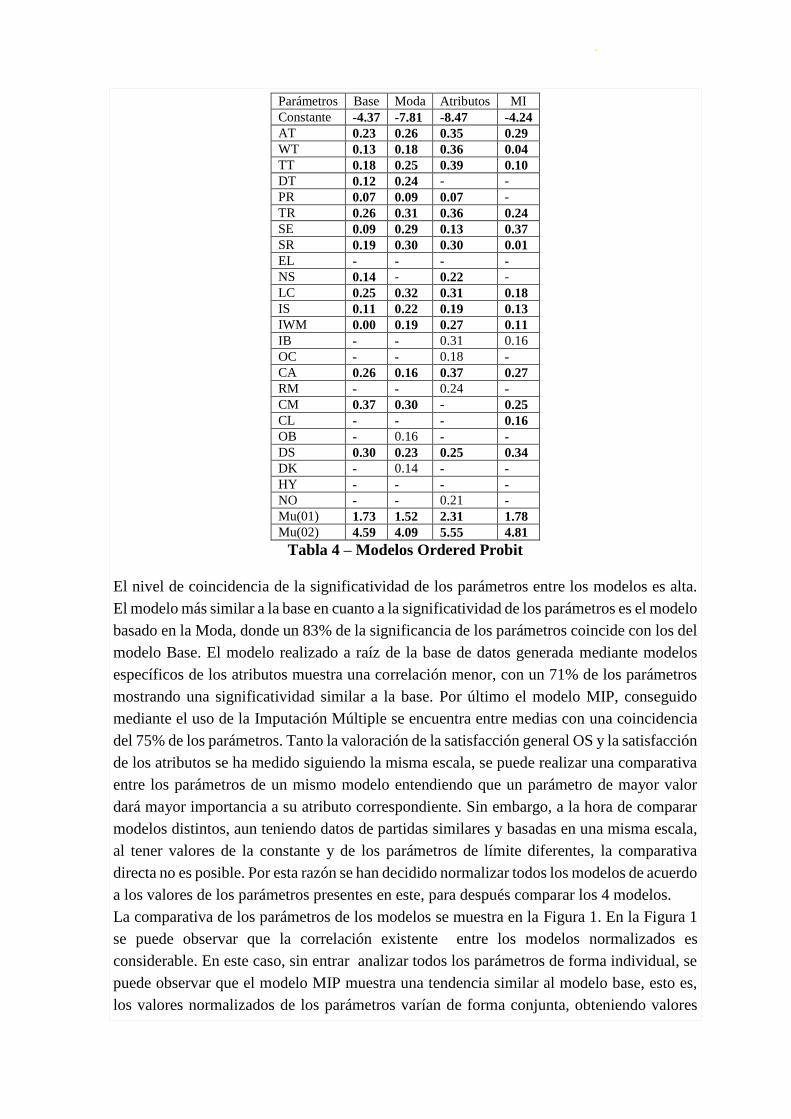
En la Tabla 4 se muestran los valores de los parámetros de cada uno de los modelos
estimados. Entra paréntesis se muestra el valor del test t que muestra el nivel de
significatividad estadística del parámetro dentro del modelo. Se han resaltado aquellos
valores cuan el parámetro es significante en un modelo y en el modelo base, de esta forma
se puede observar el nivel de coincidencia de los modelos basados en datos parciales con el
modelo base de datos completos.
Solo se muestran dos parámetros de limite debido a que en la encuesta realizada no se
observó ninguna respuesta correspondiente a la valoración “Muy Mal” (valor 0), por lo que
el valor 0 ahora representa la agrupación de las respuestas “Muy Mal” y “Mal”.
.
Parámetros Base Moda Atributos MI
Constante -4.37 -7.81 -8.47 -4.24
AT 0.23 0.26 0.35 0.29
WT 0.13 0.18 0.36 0.04
TT 0.18 0.25 0.39 0.10
DT 0.12 0.24 - -
PR 0.07 0.09 0.07 -
TR 0.26 0.31 0.36 0.24
SE 0.09 0.29 0.13 0.37
SR 0.19 0.30 0.30 0.01
EL - - - -
NS 0.14 - 0.22 -
LC 0.25 0.32 0.31 0.18
IS 0.11 0.22 0.19 0.13
IWM 0.00 0.19 0.27 0.11
IB - - 0.31 0.16
OC - - 0.18 -
CA 0.26 0.16 0.37 0.27
RM - - 0.24 -
CM 0.37 0.30 - 0.25
CL - - - 0.16
OB - 0.16 - -
DS 0.30 0.23 0.25 0.34
DK - 0.14 - -
HY - - - -
NO - - 0.21 -
Mu(01) 1.73 1.52 2.31 1.78
Mu(02) 4.59 4.09 5.55 4.81
Tabla 4 – Modelos Ordered Probit
El nivel de coincidencia de la significatividad de los parámetros entre los modelos es alta.
El modelo más similar a la base en cuanto a la significatividad de los parámetros es el modelo
basado en la Moda, donde un 83% de la significancia de los parámetros coincide con los del
modelo Base. El modelo realizado a raíz de la base de datos generada mediante modelos
específicos de los atributos muestra una correlación menor, con un 71% de los parámetros
mostrando una significatividad similar a la base. Por último el modelo MIP, conseguido
mediante el uso de la Imputación Múltiple se encuentra entre medias con una coincidencia
del 75% de los parámetros. Tanto la valoración de la satisfacción general OS y la satisfacción
de los atributos se ha medido siguiendo la misma escala, se puede realizar una comparativa
entre los parámetros de un mismo modelo entendiendo que un parámetro de mayor valor
dará mayor importancia a su atributo correspondiente. Sin embargo, a la hora de comparar
modelos distintos, aun teniendo datos de partidas similares y basadas en una misma escala,
al tener valores de la constante y de los parámetros de límite diferentes, la comparativa
directa no es posible. Por esta razón se han decidido normalizar todos los modelos de acuerdo
a los valores de los parámetros presentes en este, para después comparar los 4 modelos.
La comparativa de los parámetros de los modelos se muestra en la Figura 1. En la Figura 1
se puede observar que la correlación existente entre los modelos normalizados es
considerable. En este caso, sin entrar analizar todos los parámetros de forma individual, se
puede observar que el modelo MIP muestra una tendencia similar al modelo base, esto es,
los valores normalizados de los parámetros varían de forma conjunta, obteniendo valores

.
altos en el MIP cuando los valores son altos en el modelo base y viceversa. Este fenómeno
no se da en todas las variables, existen ciertos casos donde la correlación entre estos modelos
no es buena, como pueden ser en el caso del tiempo hasta el destino desde la parada o el
precio del billete, puesto que estas variables no son significativas en el modelo MIP pero si
en el modelo base. Se ha realizado un cálculo del coeficiente de correlación de cada uno de
los modelos con el modelo base y se ha observado una correlación muy alta, un valor de 0.95
para el modelo Moda, un 0.97 para el modelo Atributos y un 0.99 para el MIP.
Figura 1 – Comparativa de modelos normalizados

.
Por último se ha querido comparar la capacidad de predicción que se ha conseguido con los
distintos modelos para ello se ha utilizado el parámetro cuenta R2 (Echaniz et al., 2017;
Greene and Hensher, 2010), que de forma simplificada muestra el porcentaje de
observaciones reales es capaz de estimar correctamente cada modelo. Al igual que en los
casos anteriores, se ha establecido como base la capacidad de predicción del modelo base,
que ha mostrado un valore de cuenta R2 de 0.73, o lo que es lo mismo, es capaz de estimar
correctamente el 73% de los datos reales. En la siguiente tabla se muestran los resultados de
todos los modelos.
Modelo Cuenta R2 Log-Verosimilitud Nº Observaciones Grados de Libertad
Base 0.73 -497.72 747 17 Moda 0.63 -555.40 747 19 Atributos 0.7 -418.09 747 20
MIP 0.72 -494.721 747 151
Tabla 5 – Ajuste de los modelos
Ninguno de los modelos con datos faltantes es capaz de igualar la capacidad de predicción
que se consigue con el modelo base calculado con la totalidad de los datos (Tabla 5). Sin
embargo la diferencia con este es mínima, el modelo que más se le acerca es el Modelo MIP,
que muestra una capacidad solo un 1% menor. El peor resultado se ha conseguido con el
modelo basado en la Moda donde la pérdida de precisión es considerable (10%).
5. CONCLUSIONES
En este artículo se ha conseguido demostrar la posibilidad de analizar la satisfacción de los
usuarios partiendo de una base de datos reducida con la mitad de la información inicialmente
utilizada. El hecho de poder obtener datos muy similares partiendo de una cantidad de
información menor proporciona varias ventajas.
Por una parte, si por limitaciones relativas a la toma de datos parte de la información
requerida no ha sido posible obtener la totalidad de los datos necesarios para la estimación
de los modelos, se ha demostrado que los resultados obtenidos pueden seguir considerándose
adecuados.
Por otra parte, la posibilidad de reducir la encuesta en el apartado referente a la evaluación
de los atributos de servicio, proporciona un espacio para añadir nuevas opciones a las
encuestas o reducir el tiempo total requerido para responderlas. Se ha podido observar que
aun considerando la mitad de los datos disponibles, el análisis descriptivo de las
evaluaciones de los atributos sufre una variación muy pequeña, por lo que se puede decir
que no es necesario recopilar la totalidad de los datos si lo que se quiere es estudiar de forma
somera la satisfacción de los usuarios. Este método es comúnmente utilizado por las
1 Promedio de los valores obtenidos en los 5 modelos basados en la Imputación Múltiple

.
empresas operadoras de transporte público para obtener una imagen clara de la satisfacción
de los usuarios sobre su servicio, por lo tanto, lo aprendido en este estudio proporcionaría
una ventaja económica considerable para las empresas al necesitar menor tiempo y recursos
para realizar las encuestas. Dicho esto, es necesario recalcar que los resultados obtenidos en
este estudio pertenecen a una ciudad de tamaño medio con un único sistema de transporte
público de autobús, donde la media y variación de las valoración de los atributos y la
satisfacción del sistema de transporte en general son los que se han mostrado a lo largo del
artículo, por lo tanto, no sería recomendable la extrapolación directa de este estudio a
cualquier tipo ciudad o modo de transporte público sin un previo análisis. En cuanto a la
modelización de los resultados, se ha demostrado que la mejor metodología para obtener los
datos faltantes ha sido la Imputación Múltiple, la cual permite analizar los datos parciales
como si se dispusiese de los datos completos.
La comparativa entre los modelos ha demostrado que existe la posibilidad de obtener
resultados muy similares con ajustes a la realidad muy parecidos aun partiendo de una
información parcial. Al igual que el análisis estadístico, este hecho permite optimizar los
recursos de forma que el tiempo y el coste de las encuestas puede reducirse en gran medida
perdiendo mínimamente la información obtenida de la modelización de los datos.
6. AGRADECIMIENTOS
Este estudio ha sido posible gracias a la financiación del Ministerio de Economía, Industria
y Competitividad en el Proyecto TRA2015-69903-R y a la beca de formación FPU15/02990
del Ministerio de Educación, Cultura y Deporte.
7. REFERENCIAS
Abenoza, R.F., Cats, O., Susilo, Y.O., 2017. Travel satisfaction with public transport:
Determinants, user classes, regional disparities and their evolution. Transp. Res. Part
A Policy Pract. 95, 64–84. doi:10.1016/j.tra.2016.11.011
Alegria, M., Takeuchi, D., Canino, G., Duan, N., Shrout, P., Meng, X.-L., Vega, W., Zane,
N., Vila, D., Woo, M., Vera, M., Guarnaccia, P., Aguilar-Gaxiola, S., Sue, S.,
Escobar, J., Lin, K.-M., Gong, F., 2004. Considering Context, Place, and Culture: The
National Latino and Asian American Study. Int J Methods Psychiatr Res. Int J
Methods Psychiatr Res 13, 208–220.
Allison, P.D., 2000. Multiple imputation for missing data: A cautionary tale. Sociol.
Methods Res. 28, 301–309. doi:10.1177/0049124100028003003
Bordagaray, M., dell’Olio, L., Ibeas, A., Cecín, P., 2014. Modelling user perception of bus
transit quality considering user and service heterogeneity. Transp. A Transp. Sci. 10.
doi:10.1080/23249935.2013.823579
Bordagaray, M., Olio, L., Ibeas, A., Cecín, P., 2014. Transportmetrica A : Transport
Science Modelling user perception of bus transit quality considering user and service
heterogeneity. Transp. A Transp. Sci. 9935, 705–721.
doi:10.1080/23249935.2013.823579
Brand, J., 1999. Development , implementation and evaluation of multiple imputation

.
strategies for the statistical analysis of incomplete data sets.
Brand, J.P.L., Van Buuren, S., Groothuis-Oudshoorn, K., Gelsema, E.S., 2003. A toolkit in
SAS for the evaluation of multiple imputation methods. Stat. Neerl. 57, 36–45.
doi:10.1111/1467-9574.00219
Casella, G., George, E.I., Casella, G., George, E.I., 2016. Explaining the Gibbs Sampler
Stable URL : http://www.jstor.org/stable/2685208 Linked references are available on
JSTOR for this article : Explaining the Gibbs Sampler 3, 167–174.
Das, T., Apu, N., Hoque, M.S., Hadiuzzaman, M., Xu, W., 2017. Parameters Affecting the
Overall Performance of Bus Network System at Different Operating Conditions: A
Structural Equation Approach, in: Transportation Research Procedia. Elsevier B.V.,
pp. 5063–5075. doi:10.1016/j.trpro.2017.05.206
De Oña, J., De Oña, R., Eboli, L., Mazzulla, G., 2013. Perceived service quality in bus
transit service: A structural equation approach. Transp. Policy 29, 219–226.
doi:10.1016/j.tranpol.2013.07.001
de Oña, J., de Oña, R., López, G., 2016. Transit service quality analysis using cluster
analysis and decision trees: a step forward to personalized marketing in public
transportation. Transportation (Amst). 43, 725–747. doi:10.1007/s11116-015-9615-0
Dell’Olio, L., Ibeas, A., Cecin, P., 2011. The quality of service desired by public transport
users. Transp. Policy 18, 217–227. doi:10.1016/j.tranpol.2010.08.005
dell’Olio, L., Ibeas, A., Cecín, P., 2010. Modelling user perception of bus transit quality.
Transp. Policy 17, 388–397. doi:10.1016/j.tranpol.2010.04.006
EC, 1999. Quattro Final Report, Transport. ed. Paris.
Echaniz, E., Dell’Olio, L., Ibeas, Á., 2017. Modelling perceived quality for urban public
transport systems using weighted variables and random parameters. Transp. Policy.
doi:10.1016/j.tranpol.2017.05.006
Fellesson, M., Friman, M., 2008. Perceived satisfaction with public transport service in
Nine European cities. Transp. Res. Forum 47, 874770. doi:10.5399/osu/jtrf.47.3.2126
Gilks, W.R. (Wally R.., Richardson, S. (Sylvia), Spiegelhalter, D.J., 1996. Markov chain
Monte Carlo in practice. Chapman & Hall.
Greene, W., 2007. Limdep computer program: Version 9. Plainview, NY Econom. Softw.
Greene, W.H., 2008. Econometric Analysis, 6th edn. Prentice Hall.
Greene, W.H., Hensher, D. a., 2010. Modeling Ordered Choices: A Primer, Modeling
Ordered Choices: A Primer. doi:10.1017/CBO9780511845062
Guirao, B., Eugenia López, M., Comendador, J., 2015. New QR Survey Methodologies to
Analyze User Perception of Service Quality in Public Transport: The Experience of
Madrid. J. Public Transp. 18.
Guirao, B., García-Pastor, A., López-Lambas, M.E., 2016. The importance of service
quality attributes in public transportation: Narrowing the gap between scientific
research and practitioners’ needs. Transp. Policy 49, 68–77.
doi:10.1016/j.tranpol.2016.04.003
Hensher, D.A., Stopher, P., Bullock, P., 2003. Service quality - developing a service
quality index in the provision of commercial bus contracts. Transp. Res. Part A Policy
Pract. 37, 499–517. doi:10.1016/S0965-8564(02)00075-7
Hernandez, S., Monzon, A., de Oña, R., 2016. Urban transport interchanges: A
methodology for evaluating perceived quality. Transp. Res. Part A Policy Pract. 84,
31–43. doi:10.1016/j.tra.2015.08.008
Horton, N.J., Lipsitz, S.R., Horton, N.J., Lipsitz, S.R., 2016. Multiple Imputation in
Practice : Comparison of Software Packages for Regression Models with Missing
Variables Statistical Computing Software Reviews Multiple Imputation in Practice :
Comparison of Software Packages for Regression Models With Missing Vari 55,

.
244–254.
Machado-León, J.L., de Oña, R., Baouni, T., de Oña, J., 2017. Railway transit services in
Algiers: priority improvement actions based on users perceptions. Transp. Policy 53,
175–185. doi:10.1016/j.tranpol.2016.10.004
McKelvey, R.D., Zavoina, W., 1975. A statistical model for the analysis of ordinal level
dependent variables. J. Math. Sociol. 4, 103–120.
doi:10.1080/0022250X.1975.9989847
McKelvey, R.D., Zavoina, W., 1971. Ibm Fortran-Iv Program To Perform N-Chotomous
Multivariate Probit Analysis.
Parasuraman, A., Zeithaml, V.A., Berry, L.L., Parasuraman, 1985. A conceptual model of
service quality and its implications for future research. J. Mark. doi:10.2307/1251430
Pratt, J.W., 1981. Concavity of the Log Likelihood. J. Am. Stat. Assoc. 76, 103–106.
doi:10.1080/01621459.1981.10477613
Raghunathan, T.E., Lepkowski, J.M., Van Hoewyk, J., Solenberger, P., 2001. A
multivariate technique for multiply imputing missing values using a sequence of
regression models. Surv. Methodol. 27, 85–95.
Rahman, F., Das, T., Hadiuzzaman, M., Hossain, S., 2016. Perceived service quality of
paratransit in developing countries: A structural equation approach. Transp. Res. Part
A Policy Pract. 93, 23–38. doi:10.1016/j.tra.2016.08.008
Rahman, F., Das, T., Hadiuzzaman, M., Hossain, S., 2016. Perceived service quality of
paratransit in developing countries: A structural equation approach. Transp. Res. Part
A Policy Pract. 93. doi:10.1016/j.tra.2016.08.008
Rissel, C., Crane, M., Wen, L.M., Greaves, S., Standen, C., 2016. Satisfaction with
transport and enjoyment of the commute by commuting mode in inner Sydney. Heal.
Promot. J. Aust. 27, 80–83. doi:10.1071/HE15044
Rojo, M., dell’Olio, L., Gonzalo-Orden, H., Ibeas, Á., 2013. Interurban bus service quality
from the users’ viewpoint. Transp. Plan. Technol. 36, 599–616.
doi:10.1080/03081060.2013.845432
Roth, P.L., 1994. MISSING DATA: A CONCEPTUAL REVIEW FOR APPLIED
PSYCHOLOGISTS. Pers. Psychol. 47, 537–560. doi:10.1111/j.1744-
6570.1994.tb01736.x
Rubin, D.B., 2004. Multiple imputation for nonresponse in surveys. Wiley-Interscience.
Rubin, D.B., 1996. Multiple Imputation after 18+ Years. J. Am. Stat. Assoc. 91, 473–489.
doi:10.1080/01621459.1996.10476908
Rubin, D.B., 1977. Formalizing Subjective Notions About the Effect of Nonrespondents in
Sample Surveys Formalizing Sub jective Notions About the Effect of Nonrespondents
in Sample Surveys. Source J. Am. Stat. Assoc. 72144202, 538–543.
Sterne, J.A.C., White, I.R., Carlin, J.B., Spratt, M., Royston, P., Kenward, M.G., Wood,
A.M., Carpenter, J.R., 2009. Multiple imputation for missing data in epidemiological
and clinical research: potential and pitfalls. BMJ 338, b2393–b2393.
doi:10.1136/bmj.b2393
Tsami, M., Nathanail, E., 2017. Guidance Provision for Increasing Quality of Service of
Public Transport, in: Procedia Engineering. pp. 551–557.
doi:10.1016/j.proeng.2017.01.108
van Buuren, S., 2007. Multiple imputation of discrete and continuous data by fully
conditional specification. Stat. Methods Med. Res. 16, 219–242.
doi:10.1177/0962280206074463
Van Buuren, S., Boshuizen, H., Knook, D., 1999. Multiple imputation of missing blood
pressure covariates in survival analysis. Stat. Med. 18, 681–694.
doi:10.1002/(SICI)1097-0258(19990330)18:6<681::AID-SIM71>3.0.CO;2-R [pii]

.
Van Buuren, S., Brand, J.P.L., Groothuis-Oudshoorn, C.G.M., Rubin, D.B., 2006. Fully
conditional specification in multivariate imputation. J. Stat. Comput. Simul. 76, 1049–
1064. doi:10.1080/10629360600810434
Wongwiriya, P., Nakamura, F., Tanaka, S., Ariyoshi, R., 2017. User Satisfaction of
Songtaew in Thailand: Case Study of Khon Kaen City, in: Transportation Research
Procedia. doi:10.1016/j.trpro.2017.05.372


















