
MN50 – Computaciones de altas prestaciones...
28
MN50 – Computaciones de altas prestaciones Matlab Práctica 2: Introducción a las matrices dispersas David Perrin ETSII / UTBM
-
Upload
vuongkhanh -
Category
Documents
-
view
213 -
download
0
Transcript of MN50 – Computaciones de altas prestaciones...

MN50 – Computaciones de altas prestaciones
Matlab Práctica 2: Introducción a las matrices dispersas
David Perrin
ETSII / UTBM

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 2 -
Sumario _
• Descomposición LU y CHOL (formato denso) 3
• Descomposicón LU y CHOL (formato disperso) 5
• Aproximación del los ordenes de flops en formato disperso 7
• Formato denso contra formato disperso 8
• Mandos dispersos aleatorios de MATLAB 9
• Generación de matriz aleatoria (matriz dispersa) 9
• Generación de matriz aleatoria (matriz simétrica dispersa) 10
• Ejemplo de matriz dispersa (SPARSKIT Collección ) 10
• Bases de la conversión de formatos dispersos 11
• Conversión de formato disperso (COO hacia CSR) 12
• Conversión de formato disperso (COO hacia CSR) 13
• Conversión de formato disperso (CSC hacia COO) 14
• Producto matriz dispersa por vector ( formato CSR) 15
• Producto matriz dispersa por vector (formato CSC) 15
• Coste del operación producto según el formato empleado 16
• Introducción a las funciones estacionarias de MATLAB 18
• Evaluación de los métodos estacionarias 19
• Métodos estacionarias sin precondicionadores, formato denso 20
• Métodos estacionarias sin precondicionadores, formato disperso 22
• Métodos estacionarias con precondicionadores, formato disperso 24
• Resolución S.E.L. mediante el método clásico de Matlab 27
• Convergencia de los métodos estacionarios de MATLAB 28

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 3 -
Ejercicio 1 - Introducción a las matrices dispersas
Nota: En los siguientes ejercicios vamos a ver la eficiencia de trabajar con el formato de almacenamiento disperso del entorno MATLAB, así como los comandos y métodos que se utilizan cuando se trabaja en matrices dispersas.
a) Compara el coste computacional y en flops de las funciones lu y chol del
MATLAB para matrices de tamaño 150 hasta 400 con incremento de 50. Realiza una tabla que contemple los resultados como se muestra en el ejemplo de abajo.
Nota: En este ejercicio utilizaremos las matrices que se obtienen de la función penta.m. • Descomposición LU y CHOL (formato denso) Función comp_1a.m : function comp_1a; % comparación costes flops format short e; h = waitbar(0,'Espera...'); N=50; T=[]; Flu=0; Tlu=0; Fch=0; Tch=0; for i=150:50:400 for j=1:N A=penta(i); flops(0); tic; lu(A); if j==1 Flu=flops; end Tlu=Tlu+toc/N; flops(0); tic; chol(A); if j==1 Fch=flops; end Tch=Tch+toc/N; end T=[T;i Flu Tlu Fch Tch]; waitbar(i*j/(6*N),h) end close(h); save data.txt T -ASCII -DOUBLE -tabs;
UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 4 -
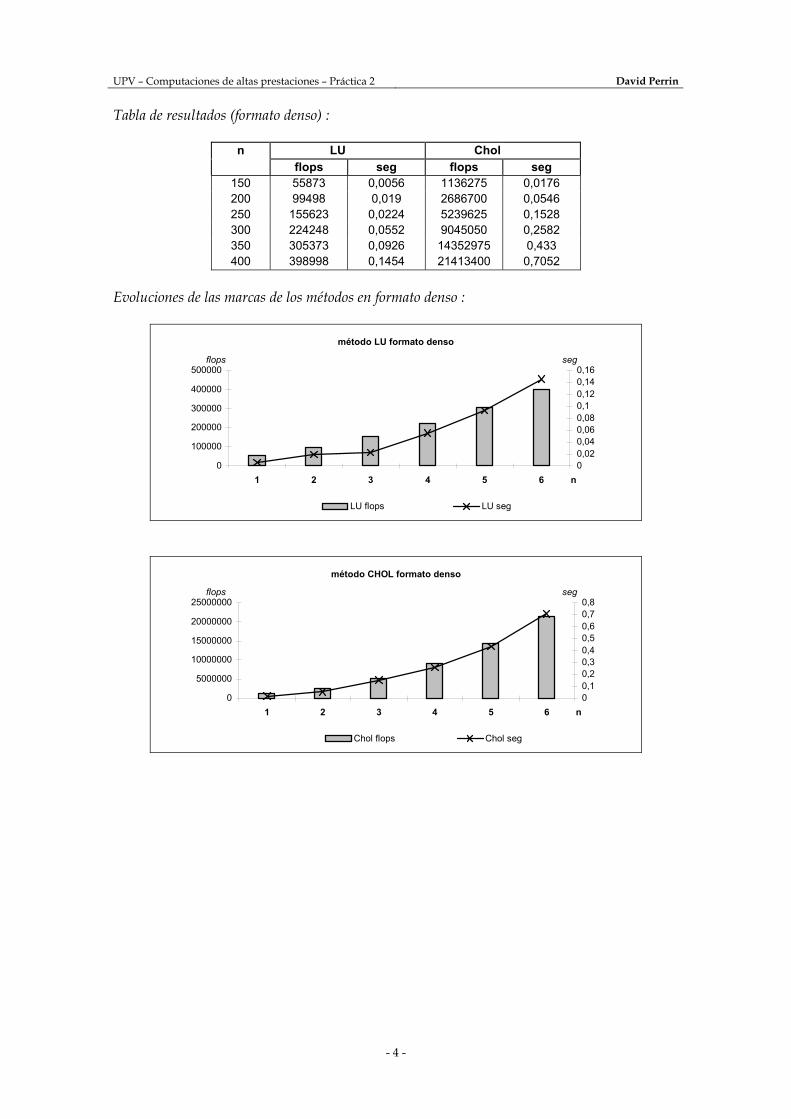
Tabla de resultados (formato denso) :
n LU Chol flops seg flops seg
150 55873 0,0056 1136275 0,0176 200 99498 0,019 2686700 0,0546 250 155623 0,0224 5239625 0,1528 300 224248 0,0552 9045050 0,2582 350 305373 0,0926 14352975 0,433 400 398998 0,1454 21413400 0,7052
Evoluciones de las marcas de los métodos en formato denso :
método LU formato denso
0
100000
200000
300000
400000
500000
1 2 3 4 5 6 n
seg
00,020,040,060,080,10,120,140,16
flops
LU flops LU seg
método CHOL formato denso
0
5000000
10000000
15000000
20000000
25000000
1 2 3 4 5 6 n
seg
00,10,20,30,40,50,60,70,8
flops
Chol flops Chol seg

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 5 -
b) Repite el apartado anterior modificando el formato de almacenamiento utilizado, es decir, una vez generada la matriz almacénala en formato disperso, es decir A=penta(n), AS=sparse(A).
• Descomposicón LU y CHOL (formato disperso) Función comp_1b.m : function comp_1b; % comparación costes flops format short e; h = waitbar(0,'Espera...'); N=50; T=[]; Flu=0; Tlu=0; Fch=0; Tch=0; for i=150:50:400 for j=1:N A=sparse(penta(i)); flops(0); tic; lu(A); if j==1 Flu=flops; end Tlu=Tlu+toc/N; flops(0); tic; chol(A); if j==1 Fch=flops; end Tch=Tch+toc/N; end T=[T;i Flu Tlu Fch Tch]; waitbar(i*j/(6*N),h) end close(h); save data.txt T -ASCII -DOUBLE -tabs;

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 6 -
Tabla de resultados (formato disperso) :
n LU Chol flops seg flops seg
150 3418 0,0024 1337 0 200 4568 0,0072 1787 0,002 250 5718 0,0114 2237 0,003 300 6868 0,0146 2687 0,0054 350 8018 0,018 3137 0,0054 400 9168 0,0256 3587 0,0054
Evoluciones de las marcas de los métodos en formato denso :
método LU formato disperso
0
2000
4000
6000
8000
10000
1 2 3 4 5 6 n
seg
0
0,005
0,01
0,015
0,02
0,025
0,03flops
LU flops LU seg
método CHOL formato disperso
0500
1000150020002500300035004000
1 2 3 4 5 6 n
seg
0
0,001
0,002
0,003
0,004
0,005
0,006flops
Chol flops Chol seg
UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 7 -
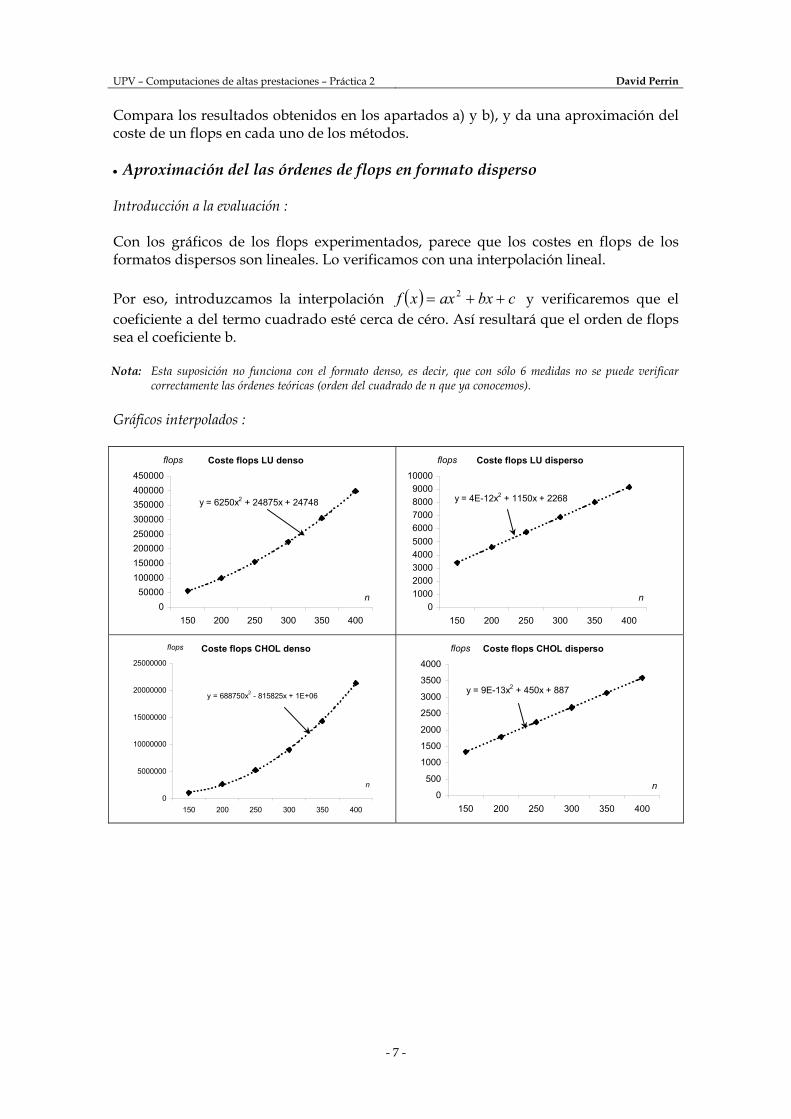
Compara los resultados obtenidos en los apartados a) y b), y da una aproximación del coste de un flops en cada uno de los métodos. • Aproximación del las órdenes de flops en formato disperso Introducción a la evaluación : Con los gráficos de los flops experimentados, parece que los costes en flops de los formatos dispersos son lineales. Lo verificamos con una interpolación lineal. Por eso, introduzcamos la interpolación ( ) cbxaxxf ++= 2 y verificaremos que el coeficiente a del termo cuadrado esté cerca de céro. Así resultará que el orden de flops sea el coeficiente b. Nota: Esta suposición no funciona con el formato denso, es decir, que con sólo 6 medidas no se puede verificar
correctamente las órdenes teóricas (orden del cuadrado de n que ya conocemos). Gráficos interpolados :
Coste flops LU denso
y = 6250x2 + 24875x + 24748
050000
100000150000200000250000300000350000400000450000
150 200 250 300 350 400
n
flops
Coste flops LU disperso
y = 4E-12x2 + 1150x + 2268
0100020003000400050006000700080009000
10000
150 200 250 300 350 400
n
flops
Coste flops CHOL denso
y = 688750x2 - 815825x + 1E+06
0
5000000
10000000
15000000
20000000
25000000
150 200 250 300 350 400
n
flops
Coste flops CHOL disperso
y = 9E-13x2 + 450x + 887
0
500
1000
1500
2000
2500
3000
3500
4000
150 200 250 300 350 400
n
flops

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 8 -
Observaciones : Habíamos visto en la precedante práctica el coste en flops de las decomposiciones con formato denso, es decir del orden de 2nflops = . La interpolación nos permite aproximar el orden con formato de almanecamiento disperso. Así encontramos mediante las previas interpolaciones los costes siguientes:
Descomposición Orden del flops
LU nk1
Cholesky nk2
Nota: 21 ,kk son constantes seguramente dependientes de nnz (el número de elementos no nulos).
Las soluciones exactas de los flops teoricos no se encuentran fácilmente en la literatura1. Sólo unas fuentes2 nos indican que estos costes son funciones complicadas y dependen de los números de elementos no nulos. Nota: Los ensayos de esta parte han sido efectuados con un ordenador Pentium II 64Mo con windows 98.
• Formato denso contra formato disperso Evaluación de la potencia : Para evaluar la potencia de las descomposiciones, se juntan en un sólo factor las medidas de tiempo y de flops de las partes a) y b), así tenemos solo factor. Tabla de resultados :
n LU Chol denso sparse denso sparse
150 9977321 1424167 64561080 #¡DIV/0! 200 5236737 634444 49206960 893500 250 6947455 501579 34290740 745667 300 4062464 470411 35031177 497593 350 3297765 445444 33147748 580926 400 2744140 358125 30365003 664259
Observaciones : Es raro observar el hecho siguiente: aunque las descomposiciones con formato disperso sean más rápidas con relación a las del formato denso, el número de flops por unidad de tiempo es mucho más elevado con el formato denso.
1 David Herández López.- Acerca de la compensación de grandes redes geodesicos aplicando la teoria de los grafos,
matrices dispersas y programación orientada a objetos.- thesis doctoral. UPV/DICGF: 1999. [UPV: BTES/3089]
2 Applied Numerical Computing.- http://www.seas.ucla.edu/ee103v/lu4.pdf.- UCLA : 2001-2002

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 9 -
Ejercicio 2 - Generación de matrices dispersas
• Mandos dispersos aleatorios de MATLAB El comando sprandn genera una matriz dispersa aleatoria y el comando sprandsym genera una matriz dispersa aleatoria simétrica, pueden utilizarse de las siguientes formas: R = SPRANDN(S) Genera una matriz dispersa aleatoria con la
misma estructura que la matriz S
R = SPRANDN(m, n, densidad) Genera una matriz dispersa de dimensión mxn con un grado de dispersión aproximado densidad*m*n
R = SPRANDN(m, n, densidad, rc) Genera una matriz dispersa de dimensión mxn con un grado de dispersión aproximado densidad*m*n y un número de condición recíproco de rc
a) Genera una matriz dispersa aleatoria de dimensión 800x800 con un 0.05% de
elementos no nulos. Represéntala y calcula el número de elementos no nulos. • Generación de matriz aleatoria (matriz dispersa) Aplicación en MATLAB: R=sprand(800,800,0.0005); Spy(R,’s’); nnz(R)=320
0 100 200 300 400 500 600 700 800
0
100
200
300
400
500
600
700
800
nz = 320 Matriz dispersa aleatoria con
800x800x0.0005=320 elementos

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 10 -
b) Genera una matriz simétrica dispersa aleatoria de dimensión 1200x1200 con un 0.01% de elementos no nulos y un número de condición 1.0e12. Represéntala y calcula el número de elementos no nulos.
• Generación de matriz aleatoria (matriz simétrica dispersa) Aplicación en MATLAB: R=sprandsym(1200,0.0001,1e-12); Spy(R,’s’); nnz(R)=1200
0 200 400 600 800 1000 1200
0
200
400
600
800
1000
1200
nz = 1200 Matriz dispersa aleatoria con
1200x1200x0.0001=1200 elementos R=sprandsym(1200,0.001,1e-12); spy(R,’s’); nnz(R)=1370
0 200 400 600 800 1000 1200
0
200
400
600
800
1000
1200
nz = 1368 Matriz dispersa aleatoria con
1200x1200x0.001=1440 elementos Nota: El número de condición recíproco coresponde a (número de condición)-1 c) Visualiza y analiza un par de matrices en formato Matrix-Market de la siguiente
dirección: http://math.nist.gov/MatrixMarket/ • Ejemplo de matriz dispersa (SPARSKIT Collección )
Estructura Vista “City“

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 11 -
Ejercicio 3 - Conversión de formatos
• Bases de la conversión de formatos dispersos
Dada la matriz A siguiente:
=
500043201
A
Mediante los métodos vistos en los apuntes, pueden escribirse los formatos dispersos siguientes: Estructura Coordenado (COO):
[ ]52431=oS
[ ]31221=oI
[ ]33211=oJ Estructura Compress Sparse Column (CSC):
[ ]52431=cS
[ ]31221=cI
[ ]6431=cJ Estructura Compress Sparse Row (CSR):
[ ]54321=rS
[ ]6531=rI
[ ]31131=rJ Nota: Nos serviremos de estos vectores para verificar el funcionamiento de nuestros programas

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 12 -
a) Implementa el convertidor de matrices de formato coordenado (COO) a formato disperso comprimido por filas CSR, coo_csr. Pruébalo para una matriz aleatoria de dimensión 5x5 con un coeficiente de dispersión 0.3. Nota el comando find extrae el formato coordenado de una matriz almacenada en el formato utilizado por MATLAB.
• Conversión de formato disperso (COO hacia CSR) Función coo_csr.m: function [Ir,Jr,Sr]=coo_csr(Ms) if issparse(Ms)~=1 error('Matriz no dispersa'); end [Io,Jo,So]=find(Ms); [nfil,ncol]=size(Ms); nnoz=length(So); Ir_=1; cont=1; for i=1:nfil+1 Ir(i)=Ir_; for j=1:nnoz if Io(j)==i Sr(cont)=So(j); Jr(cont)=Jo(j); cont=cont+1; Ir_=Ir_+1; end end end Aplicación en MATLAB: » A=[1 0 2;3 4 0;0 0 5]; » AS=sparse(A); » [Ir,Jr,Sr]=coo_csr(AS) Ir = 1 3 5 6 Jr = 1 3 1 2 3 Sr = 1 2 3 4 5 Observaciones: Se encuentran bien los vectores Ir, Jr y Sr previamente vistos en la parte teórica.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 13 -
Implementa el convertidor de matrices de formato coordenado (COO) a formato disperso comprimido por columnas CSC, coo_csc. Pruébalo para la misma matriz anterior. • Conversión de formato disperso (COO hacia CSR) Función coo_csc.m: function [Ic,Jc,Sc]=coo_csc(Ms) if issparse(Ms)~=1 error('Matriz no dispersa'); end [Io,Jo,So]=find(Ms); [nfil,ncol]=size(Ms); nnoz=length(So); Jc_=Jo(1); for i=1:nfil+1 Jc(i)=Jc_; for j=1:nnoz if Jo(j)==i Jc_=Jc_+1; end end end Ic=Io'; Sc=So'; Aplicación en MATLAB: » A=[1 0 2;3 4 0;0 0 5]; » AS=sparse(A); » [Ic,Jc,Sc]=coo_csc(AS) Ic = 1 2 2 1 3 Jc = 1 3 4 6 Sc = 1 3 4 2 5 Observaciones: Se encuentran bien los vectores Ic, Jc y Sc previamente vistos en la parte teórica.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 14 -
b) Implementa el convertidor de matrices de formato disperso comprimido por columnas CSC a formato coordenado (COO).
• Conversión de formato disperso (CSC hacia COO) Función csc_csc.m: function [Io,Jo,So]=csc_coo(Ic,Jc,Sc) ncol=length(Jc)-1; for i=1:ncol Jo(Jc(i):Jc(i+1)-1)=i; end Io=Ic; So=Sc; Aplicación en MATLAB: » A=[1 0 2;3 4 0;0 0 5]; » AS=sparse(A); » [Ic,Jc,Sc]=coo_csc(AS); » [Io,Jo,So]=csc_coo(Ic,Jc,Sc) Io = 1 2 2 1 3 Jo = 1 1 2 3 3 So = 1 3 4 2 5 Observaciones: Se encuentran bien los vectores Io, Jo y So previamente vistos en la parte teórica.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 15 -
Ejercicio 4 - Producto matriz dispersa por vector
a) Implementa en lenguaje MATLAB una función que realice el producto matriz dispersa (formato CSR) por vector, la función se llamará function [y]= mv_csr(I,J,S,x) y se almacenará en el fichero mv_csr.m. Construye una tabla que muestre el coste computacional y en flops para matrices de tamaño 500 a 1000 con incrementos de 100.
• Producto matriz dispersa por vector ( formato CSR) Función mv_csr.m: function b=mv_csr(x,I,J,S) %calculó de b con Ms*x=b nfil=length(I)-1; if nfil~=length(x) error('Dimensión inadecuadas'); end b=zeros(nfil,1); for i=1:nfil for j=I(i):I(i+1)-1 b(i)=b(i)+S(j)*x(J(j)); end end • Producto matriz dispersa por vector (formato CSC) Función mv_csc.m: function b=mv_csc(x,I,J,S) %calculó de b con Ms*x=b ncol=length(J)-1; nfil=max(I); if ncol~=length(x) error('Dimensión inadecuadas'); end b=zeros(nfil,1); for j = 1:ncol for k=J(j): J(j+1)-1 i=I(k); b(i)=b(i)+x(j)*S(k); end end

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 16 -
b) A partir de la tabla anterior, averiguar cuál es el coste de un flop, y compara con el coste de un flop si se utilizan las sentencias:
A=penta(1000); A=sparse(A); y=A*b;
Nota: Si los tiempos son muy pequeños, para medirlos realiza la operación muchas veces y saca la media. • Coste del operación producto según el formato empleado Función comp_4b.m: function comp_4b; % comparación costes flops format short e; h = waitbar(0,'Espera...'); N=3; T=[]; Fcsr=0; Tcsr=0; Fcsc=0; Tcsc=0; Fcoo=0; Tcoo=0; Fmat=0; Tmat=0; k=0; for i=500:100:1000 for j=1:N A=penta(i); As=sparse(A); [Ir,Jr,Sr]=coo_csr(As); [Ic,Jc,Sc]=coo_csc(As); x=ones(i); flops(0); tic; mv_csr(x,Ir,Jr,Sr); if j==1 Fcsr=flops; end Tcsr=Tcsr+toc/N; flops(0); tic; mv_csc(x,Ic,Jc,Sc); if j==1 Fcsc=flops; end Tcsc=Tcsc+toc/N; flops(0); tic; As*x; if j==1 Fcoo=flops; end Tcoo=Tcoo+toc/N; flops(0); tic; A*x; if j==1 Fmat=flops; end Tmat=Tmat+toc/N; k=k+1; end T=[T;i Fcsr Tcsr Tcsr/Fcsr Fcsc Tcsc Tcsc/Fcsc Fcoo Tcoo Tcoo/Fcoo Fmat Tmat Tmat/Fmat]; waitbar(k/(6*N)) end close(h); save data.txt T -ASCII -DOUBLE -tabs;
UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 17 -
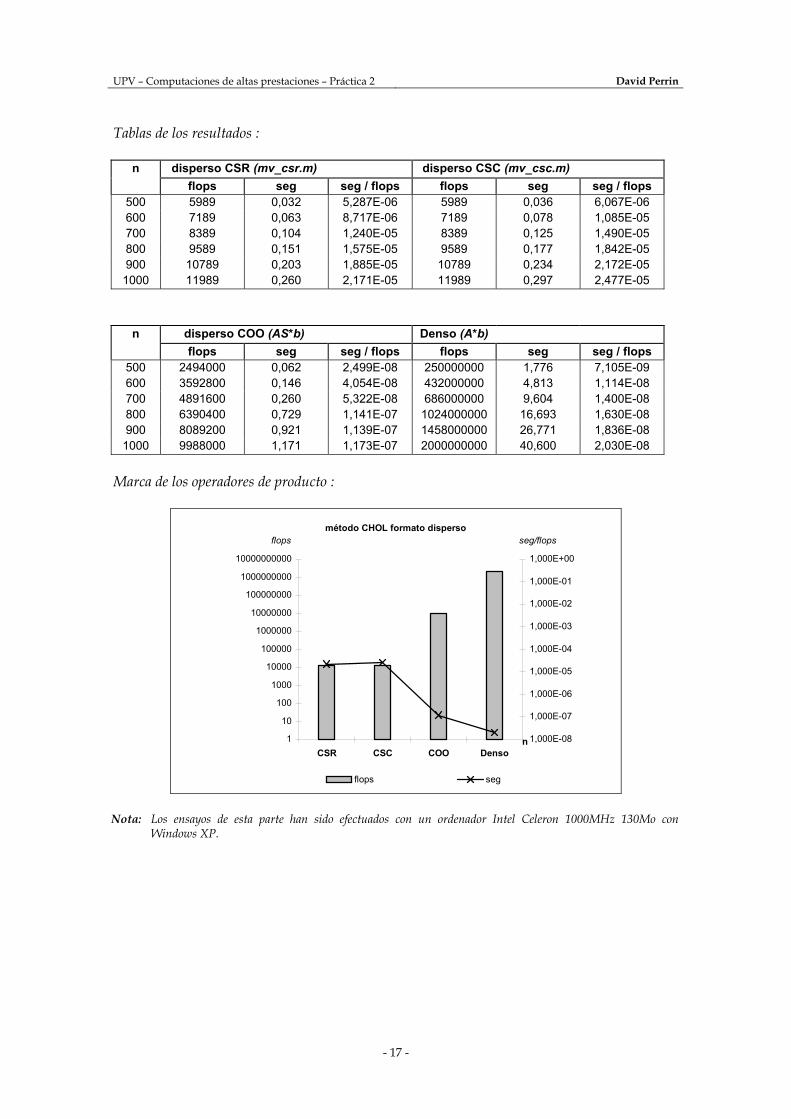
Tablas de los resultados :
n disperso CSR (mv_csr.m) disperso CSC (mv_csc.m) flops seg seg / flops flops seg seg / flops
500 5989 0,032 5,287E-06 5989 0,036 6,067E-06 600 7189 0,063 8,717E-06 7189 0,078 1,085E-05 700 8389 0,104 1,240E-05 8389 0,125 1,490E-05 800 9589 0,151 1,575E-05 9589 0,177 1,842E-05 900 10789 0,203 1,885E-05 10789 0,234 2,172E-05 1000 11989 0,260 2,171E-05 11989 0,297 2,477E-05
n disperso COO (AS*b) Denso (A*b) flops seg seg / flops flops seg seg / flops
500 2494000 0,062 2,499E-08 250000000 1,776 7,105E-09 600 3592800 0,146 4,054E-08 432000000 4,813 1,114E-08 700 4891600 0,260 5,322E-08 686000000 9,604 1,400E-08 800 6390400 0,729 1,141E-07 1024000000 16,693 1,630E-08 900 8089200 0,921 1,139E-07 1458000000 26,771 1,836E-08 1000 9988000 1,171 1,173E-07 2000000000 40,600 2,030E-08
Marca de los operadores de producto :
método CHOL formato disperso
1
10
100
1000
10000
100000
1000000
10000000
100000000
1000000000
10000000000
CSR CSC COO Denson
seg/flops
1,000E-08
1,000E-07
1,000E-06
1,000E-05
1,000E-04
1,000E-03
1,000E-02
1,000E-01
1,000E+00
flops
flops seg
Nota: Los ensayos de esta parte han sido efectuados con un ordenador Intel Celeron 1000MHz 130Mo con
Windows XP.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 18 -
Ejercicio 5 - Comparación de métodos estacionarios
• Introducción a las funciones estacionarias de MATLAB Se tratará en esta parte de la comparación y del comportamiento de los métodos siguientes:
• pcg, método del gradiente conjugado precondicionado.
• bicg, método del gradiente biconjugado.
• bicgstab, método del gradiente biconjugado estabilizado.
• cgs, método del gradiente conjugado cuadrático ‘squared’.
• gmres, método del mínimo residual generalizado.
• qmr, método residual cuasi-mínimo.
Nota: para los sistemas de ecuaciones obtenidos mediante la función A=penta(n) y b=crea_b(A);

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 19 -
a) Realiza una tabla que contemple los flops, el tiempo, el número de iteraciones y el error residual en la resolución de los sistemas teniendo en cuenta las siguientes condiciones:
• Evaluación de los métodos estacionarias Introducción : Para cada una de las partes, se construirá un programa cuyos entradas sean el tamaño de la matriz pentadiagonal que probar (o sea n) y la tolerancia de los precondicionadores (o sea prec). Así tendremos:
- comp_5a2(n) Métodos iterativos sin precondicionadores, almanecamiento en formato denso
- comp_5a2(n) Métodos iterativos sin precondicionadores, almanecamiento en formato disperso
- comp_5a3(n,prec) Métodos iterativos con precondicionadores, almanecamiento en formato disperso
Al final se construirá dos ficheros data.txt y err.txt conteniendo respectivamente a los costes de todos los métodos (tiempo, flops, precisión final y numeros de iteraciones) y a los errores dentro de cada iteración. Para el tratamiento, se utilizará una precisión de 2.2204e-016 (o sea el mando eps de MATLAB) y un número maximum de iteraciones de 100. Además, en la última parte con precondicionadores se elegirán para los métodos bicg, bicgstab, cgs, gmres, qmr los precondicionadores L y U tal que:
[L,U]=luinc(A,prec) Soló el método pcg utilizará los precondicionadores definidos positivos M1 y M2 tal que:
M2=cholinc(A,prec) y con M1=M2' Nota: prec será la variable de la tolerancia. En un primer lugar se elegirá 10-5 y después ‘0’, este último será el
precondicionador MILU.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 20 -
• Métodos estacionarias sin precondicionadores, formato denso Función comp_5a1.m : function comp_5a1(n) A=penta(n); b=crea_b(A); T=[]; E=[]; tol=eps; maxit=100; flops(0); tic; [x,flag,relres,iter,resvec]= pcg(A,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),1)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= bicg(A,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),2)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= bicgstab(A,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),3)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= cgs(A,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),4)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= gmres(A,b,n,tol,maxit); T=[T,[toc;flops;relres;iter(1);iter(2)]]; E(1:length(resvec),5)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= qmr(A,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),6)=resvec; save data.txt T -ASCII -DOUBLE -tabs; save err.txt E -ASCII -DOUBLE -tabs;

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 21 -
Análisis de los costes con tamaño 500 : comp_5a1(500) PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 0,89 1,156 1,219 0,641 1,234 1,203 flops 69046293 103180293 94246530 51391157 77430218 105316375 precisión (x1.e-15) 0,599 0,599 0,366 0,140 3,858 0,358 iteraciones 66 66 45 34 1 / 64 68
Sin preacionadores, n=500
020000000400000006000000080000000
100000000120000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
00,20,40,60,811,21,4
flops
flops seg
Análisis de los costes con tamaño 1000 : comp_5a1(1000) PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 3,438 4,39 4,781 2,922 4,656 4,547 flops 275092293 411360293 383524537 234897177 293629718 418630875 precisión (x1.e-15) 0,760 0,760 0,624 0,269 6,038 0,403 iteraciones 65 65 47 37 1 / 67 68
Sin preacionadores, n=1000
0
100000000
200000000
300000000
400000000
500000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
0123456
flops
flops seg

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 22 -
• Métodos estacionarias sin precondicionadores, formato disperso Función comp_5a2.m : function comp_5a2(n) A=penta(n); AS=sparse(A); b=crea_b(A); T=[]; E=[]; tol=eps; maxit=100; flops(0); tic; [x,flag,relres,iter,resvec]= pcg(A,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),1)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= bicg(AS,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),2)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= bicgstab(AS,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),3)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= cgs(AS,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),4)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= gmres(AS,b,n,tol,maxit); T=[T,[toc;flops;relres;iter(1);iter(2)]]; E(1:length(resvec),5)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= qmr(AS,b,tol,maxit); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),6)=resvec; save data.txt T -ASCII -DOUBLE -tabs; save err.txt E -ASCII -DOUBLE -tabs;

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 23 -
Análisis de los costes con tamaño 500 : comp_5a2(500) PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 0,875 0,063 0,062 0,047 0,375 0,11 flops 69046293 1702833 1607358 899933 8623550 2353879 precisión (x1.e-15) 0,599 0,597 0,286 0,156 3,856 0,362 iteraciones 66 66 44 34 1 / 68 65
Sin preacionadores, n=500
0
20000000
40000000
60000000
80000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
0
0,2
0,4
0,6
0,8
1flops
flops seg
Análisis de los costes con tamaño 1000 : comp_5a2(1000) PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 3,437 0,109 0,125 0,063 0,734 0,188 flops 275092293 3407833 3250338 2065773 17018050 4708379 precisión (x1.e-15) 0,760 0,759 0,267 0,268 5,916 0,664 iteraciones 65 65 43 37 1 / 68 68
Sin preacionadores, n=1000
050000000
100000000150000000200000000250000000300000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
0
1
2
3
4flops
flops seg

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 24 -
• Métodos estacionarias con precondicionadores, formato disperso Función comp_5a3.m: function comp_5a3(n,prec) A=penta(n); AS=sparse(A); b=crea_b(A); T=[]; E=[]; tol=eps; maxit=100; [L,U]=luinc(AS,prec); M2=cholinc(AS,prec); M1=M2'; flops(0); tic; [x,flag,relres,iter,resvec]= pcg(A,b,tol,maxit,M1,M2); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),1)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= bicg(AS,b,tol,maxit,L,U); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),2)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= bicgstab(AS,b,tol,maxit,L,U); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),3)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= cgs(AS,b,tol,maxit,L,U); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),4)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= gmres(AS,b,n,tol,maxit,L,U); T=[T,[toc;flops;relres;iter(1);iter(2)]]; E(1:length(resvec),5)=resvec; flops(0); tic; [x,flag,relres,iter,resvec]= qmr(AS,b,tol,maxit,L,U); T=[T,[toc;flops;relres;iter;0]]; E(1:length(resvec),6)=resvec; save data.txt T -ASCII -DOUBLE -tabs; save err.txt E -ASCII -DOUBLE -tabs;

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 25 -
Análisis de los costes con tamaño 500 : Nota: para los métodos bicg, bicgstab, cgs, gmres, qmr utiliza los precondicionadores:
[L,U]=luinc(A,1e-5). Soló el método pcg utiliza el precondicionador definido positivo: M2=cholinc(A,1.e-5); M1=M2'.
comp_5a3(500,1e-5) PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 0,016 0,015 0 0 0,047 0,016 flops 1517013 43953 31979 40465 222192 111198 precisión (x1.e-15) 0,026 0,024 0,024 0,029 0,259 0,031 iteraciones 1 1 1 1 1 / 5 2
Con preacionadores, n=500
0
500000
1000000
1500000
2000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
0
0,01
0,02
0,03
0,04
0,05flops
flops seg
Análisis de los costes con tamaño 1000 : Nota: para los métodos bicg, bicgstab, cgs, gmres, qmr utiliza los precondicionadores:
[L,U]=luinc(A,1e-5); Soló el método pcg utiliza el precondicionador definido positivo: M2=cholinc(A,1.e-5); M1=M2'.
comp_5a3(1000,1e-5) PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 0,078 0,016 0 0,015 0,735 0,031 flops 6034013 87953 63979 80965 284060 222922 precisión (x1.e-15) 0,018 0,017 0,017 0,020 0,684 0,088 iteraciones 1 1 1 1 1 / 1 2
Con preacionadores, n=1000
01000000200000030000004000000500000060000007000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
0
0,2
0,4
0,6
0,8flops
flops seg
Observaciones: La solución inicial es la de por defecto.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 26 -
Análisis de los costes con tamaño 500 : Nota: para los métodos bicg, bicgstab, cgs, gmres, qmr utiliza los precondicionadores:
[L,U]=luinc(A,’0’); Soló el método pcg utiliza el precondicionador definido positivo: M2=cholinc(A, ’0’); M1=M2'.
comp_5a3(500,'0') PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 0,031 0 0 0 0,047 0,016 flops 1517013 43953 31979 40465 142060 111422 precisión (x1.e-15) 0,022 0,027 0,027 0,084 0,425 0,040 iteraciones 1 1 1 1 1 / 2 2
Con preacionadores, n=500
0
500000
1000000
1500000
2000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
0
0,01
0,02
0,03
0,04
0,05flops
flops seg
Análisis de los costes con tamaño 1000 : Nota: para los métodos bicg, bicgstab, cgs, gmres, qmr utiliza los precondicionadores:
[L,U]=luinc(A,’0’); Soló el método pcg utiliza el precondicionador definido positivo: M2=cholinc(A, ’0’); M1=M2'.
comp_5a3(1000,'0') PCG BICG BICGSTAB CGS GMRES QMR tiempo (ms) 0,094 0,015 0 0,016 0,156 0,016 flops 6034013 87953 63979 80965 444192 222922 precisión (x1.e-15) 0,015 0,019 0,019 0,082 0,594 0,089 iteraciones 1 1 1 1 1 / 3 2
Con preacionadores, n=1000
01000000200000030000004000000500000060000007000000
PCG BICG BICGSTAB CGS GMRES QMR
seg
0
0,05
0,1
0,15
0,2flops
flops seg
Observaciones: La solución inicial es la de por defecto, La solución inicial tomada ha sido:
for i=1:500; x0(i)=i*((-1)^i); end
Nota: Los ensayos de esta parte han sido efectuados con un ordenador Intel Celeron 1000MHz 130Mo con
Windows XP.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 27 -
b) Compara los resultados obtenidos con los resultados obtenidos por las siguientes sentencias: A=penta(n);b=crea_b(A);flops(0);tic;x=A\b; Tiempo=toc,Flops=flops y A=sparse(penta(n));b=crea_b(A);flops(0);tic;x=A\b; Tiempo=toc, Flops=flops
• Resolución S.E.L. mediante el método clásico de Matlab Sentencia de MATLAB utilizada para el formato denso :
A=penta(n);b=crea_b(A);flops(0);tic;x=A\b; Tiempo=toc, Flops=flops
Sentencia de MATLAB utilizada para el formato disperso :
A=sparse(penta(n));b=crea_b(A);flops(0);tic;x=A\b; Tiempo=toc, Flops=flops
Resultados obtenidos :
formato denso disperso
n 500 1000 500 1000
Flops 4279176 337833518 1727 34589
Tiempo (ms) 0.3120 2.5470 0.0320 0.0150
Observaciones : Se nota la diferencia en tiempo de utilizar el formato disperso. Nota: Los ensayos de esta parte han sido efectuados con un ordenador Intel Celeron 1000MHz 130Mo con
Windows XP.

UPV – Computaciones de altas prestaciones – Práctica 2 David Perrin
- 28 -
• Convergencia de los métodos estacionarios de MATLAB Escala normal : Con el fichero err.txt, se puede ver la velocidad de convergencia de los métodos estacionarios. Sólo sacaremos el primer valor del orden de 400 y que impide ver las curvas, además con una escala normal sólo las diez primeras iteraciones son significativas. Los ensayos siguientes son con matriz pentadiagonal, n=1000, sin precondicionadores y formato denso (comp_5a1(1000))
Métodos estacionarios formato disperso, error |Ax-b| (n=1000)
0,00E+00
5,00E-01
1,00E+00
1,50E+00
2,00E+00
2,50E+00
3,00E+00
3,50E+00
1 2 3 4 5 6 7 8 9 10
iteración
error
PCG / BICGBICGSTABCGSGMRES / QMR
Escala logarítmica : Con escala logarítmica, se pude ver todas las iteraciones y el aspecto para alcanzar la precisión pedida.
Métodos estacionarios formato disperso, error |Ax-b| (n=1000)(escala logaritmica)
1,E-131,E-121,E-111,E-101,E-091,E-081,E-071,E-061,E-051,E-041,E-031,E-021,E-011,E+001,E+01
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94
iteración
error
PCG / BICGBICGSTABCGSGMRES / QMR
Observaciones : Se nota que el método del gradiente conjugado cuadrático es más rápido que los otros. Además todos tienen un aspecto lineal (mientras que con la escala normal será
( )iterbAx exp=− ), excepto el método del gradiente biconjugado estabilizado que tiene en todo los casos una perturbación cerca de la iteración 60. Nota: En estos gráficos se juntan PCG con BICG y GMRES con QMR porque tienen casi la misma velocidad, si
no, no se podria verlos.


















