
MÉTODOS MATEMÁTICOS EN TEORÍA - udec.clrparada/LibrosPublicados/libroMetodos... · autor: josé...
122
Transcript of MÉTODOS MATEMÁTICOS EN TEORÍA - udec.clrparada/LibrosPublicados/libroMetodos... · autor: josé...


Autor: José Rigoberto Parada Daza 1
MÉTODOS MATEMÁTICOS EN TEORÍA FINANCIERA
José Rigoberto Parada Daza
Universidad de Concepción, Chile Registro Propiedad Intelectual Nº120.798 I.S.B.N. 956-8029-19-2

Autor: José Rigoberto Parada Daza 2
ÍNDICE
CAPÍTULO I
OPTIMIZACIÓN CON RESTRICCIONES
1.1. DEFINICIÓN DE EXTREMOS DE UNA FUNCIÓN CON DOS VARIABLES X e Y SIN RESTRICCIONES. 6
1.1.1 Condiciones necesarias para la existencia de máximo o mínimo. 6
1.1.2 Condiciones suficientes para la existencia de máximo o mínimo 7
1.2. OPTIMIZACIÓN CON RESTRICCIONES, CASO DE DOS VARIABLES 13
1.3. OPTIMIZACIÓN CON RESTRICCIONES DE VARIAS VARIABLES 21
CAPITULO II
DISTRIBUCIÓN DE PROBABILIDADES BÁSICAS
2.1. DISTRIBUCIÓN BINOMIAL 22 2.2 DISTRIBUCIÓN NORMAL 33
CAPITULO III
CONCEPTOS MATEMÁTICOS SUBYACENTES EN MODELOS DE OPCIONES FINANCIERAS
3.1. CAPITALIZACIÓN EN TIEMPO CONTÍNUO 37 3.2. MOVIMIENTO BROWNIANO 41
3.2.1 Antecedentes Generales 41 3.2.2 Definición matemática del Movimiento Geométrico
Browniano 41 3.2.3 Aplicación movimiento Browniano al precio de
acciones 44 3.2.4 Procesos geométricos Browniano y Distribución
Normal. 49
3.3. VOLATILIDAD Y PROBABILIDAD DE RETORNOS CON MOVIMIENTOS BROWNIANOS 51
3.4. ¿QUÉ ES UN PROCESO ESTOCÁSTICO? 60

Autor: José Rigoberto Parada Daza 3
CAPITULO IV
CÁLCULO DIFERENCIAL ESTOCÁSTICO.
4.1. VARIACIÓN EN TIEMPO DISCRETO Y CONTÍNUO 63 4.2. CÁLCULO DE ITO 65 4.3. INTEGRAL DE RIEMANN 66 4.4. INTEGRAL DE RIEMANN Y FUNCION et 69 4.5. INTEGRAL DE RIEMANN-STIELTJES 71 4.6. INTEGRALES ESTOCÁSTICAS 75 4.7. LEMA DE ITO 77 4.8. DESARROLLO MODELO BLACK-SHOLES 81
CAPITULO V
ANALISIS MULTIVARIABLE
5.1 TÉCNICAS DE ANÁLISIS MULTIVARIABLE 84 5.2. ANÁLISIS DE COMPONENTES PRINCIPALES 84
5.2.1. Interpretación Intuitiva 85 5.2.2. Interpretación Matemática 86 5.2.3. Matriz de Varianzas-Covarianzas y Matriz de Correlación 95
5.2. ANÁLISIS FACTORIAL 97
5.2.1. Interpretación Intuitiva 97 5.2.2. Interpretación Matemática 98 5.2.3. Comparación del Método Componentes Principales con el
5.3. ANÁLISIS DISCRIMINANTE 106
5.3.1. Interpretación Intuitiva 107 5.3.2. Matemática del Análisis Discriminante para dos grupos. 108
APÉNDICE Nº 1 Conceptos de cálculo diferencial e integral usados en Teoría Financiera 115
APÉNDICE Nº 2 Conceptos de matemáticas financieras usados en Teoría Financiera. 118
APÉNDICE Nº 3 Modelos clásicos financieros 120
BIBLIOGRAFÍA 121

Autor: José Rigoberto Parada Daza 4
INTRODUCCIÓN
El desarrollo de las Finanzas, tanto en su vertiente teórica de Teoría Financiera como en su versión aplicada de Gestión Financiera, está basado, principalmente, en diferentes conceptos matemáticos y que normalmente en los textos de Teoría Financiera y Finanzas se dan por conocidos por el lector, supuesto que es razonablemente válido debido a que el estudio de estas materias financieras es normalmente posterior a las enseñanzas de matemáticas. Sin embargo, en la educación de las ciencias económicas y empresariales no siempre existe una relación instantánea entre la ciencia básica, matemáticas en este caso, con la ciencia aplicada, o sea Finanzas. Esto lleva a que en la enseñanza de esta última, a veces, se requiera un repaso o reestudio de las matemáticas.
En la perspectiva anterior, es que se ha elaborado este texto como ayuda y complemento directo hacia personas que estudien los conceptos de Teoría Financiera y Gestión Financiera. Por otro lado, en los cursos de postgrado puede ayudar a desarrollar más claramente los enfoques de Teoría Financiera, al margen de los modelos matemáticos subyacentes, pues estudiando previamente este texto, permitirá entender de mejor forma los modelos de Finanzas. Este libro, para una mejor comprensión, requiere de conocimientos previos de Cálculo Diferencial e Integral, Geometría Analítica y conceptos de Estadística-Matemática.
Este texto presenta un conjunto de conceptos matemáticos que soportan a diferentes modelos financieros, como es el caso de Cálculo Diferencial e Integral, Cálculo Diferencial Estocástico, Movimientos Brownianos y conceptos de Análisis Multivariables. Estas materias no siempre se imparten en un solo curso de matemáticas sino que son capítulos de diferentes asignaturas. El caso del Cálculo Diferencial Estocástico es bien particular, pues, normalmente no forma parte del currículum de estudios de pregrado en la enseñanza de economía y empresariales, por lo que se aborda aquí desde una perspectiva diferente a los cursos de postgrado. La forma de presentar los tópicos por separado se debe a que esta es la forma de como se usan en diferentes modelos de Finanzas, por lo que no implica alguna descoordinación como aparecería si lo observamos bajo una óptica puramente matemática. Esta característica del libro, lo hace diferente a aquellos textos que normalmente se usan bajo la denominación de Matemáticas Financieras, pues en estos últimos se incluyen métodos matemáticos aplicados a considerar principalmente el valor del dinero en el tiempo y que lo que de esta interpretación se deriva, que son métodos complementarios a los que se usan en este libro.
En el texto se desarrollan los siguientes tópicos: Optimización con restricciones para dos o más variables, algunas distribuciones de Probabilidades; Movimientos Brownianos; Proceso Estocástico; Cálculo Diferencial Estocástico; Análisis de Componentes Principales, Análisis Factorial y Análisis Discriminante.
En este texto se ha considerado como punto de partida sólo a los modelos clásicos de Finanzas, entendiendo por clásico lo que ha permanecido en el

Autor: José Rigoberto Parada Daza 5
tiempo, después de efectuadas las verificaciones empíricas. Lo anterior implica que hay varios otros modelos, que usando metodología matemática, no han servido de referencia para la elaboración de este libro. De igual forma, se han dejado afuera todos los conocimientos previos de Econometría, pues esta metodología, ampliamente usada en Finanzas, tiene cursos previos bastante desarrollados y tienen un uso, principalmente, de contratación de hipótesis. En Apéndice Nº 3 se indican los principales modelos financieros y sus metodologías matemáticas subyacentes.
El autor espera que este texto sea de ayuda a los profesores de Finanzas y, a la vez, que sea un documento amigable para los estudiantes, que les permita comprender a cabalidad los modelos de la Finanzas y que se pueda discernir con mayor claridad sobre la aplicación de estos modelos hacia realidades concretas, así como apreciar tanto las bondades como las limitaciones de dichos modelos y conceptos.
Como todo texto de Matemáticas su trascripción es laboriosa y quizás sea éste un trabajo tan relevante como su contenido y en esta tarea debo expresar mi reconocimiento a mi secretaria Sra. Ana Guerrero Arrué, quien pacientemente ha desarrollado esta tarea y ha debido corregir una y otra vez los borradores iniciales de la primera versión. También a mi hijo Miguel Parada Contzen quien me ha prestado su colaboración matemática e informática.

Autor: José Rigoberto Parada Daza 6
CAPITULO I
OPTIMIZACIÓN CON RESTRICCIONES
Tanto en Teoría Financiera como en Finanzas de Empresas, es común el planteamiento de alguna función que se debe optimizar, o sea el cálculo de un máximo o un mínimo, sujeto a restricciones. Es utópico, en Finanzas, suponer que se optimizan funciones sin ninguna restricción; es decir no se puede optimizar una función de rentabilidad sin considerar por ejemplo al menos la restricción de la capacidad de financiamiento. Por otro lado, es común optimizar funciones no necesariamente lineales, en el cual un caso típico es el problema de cálculo de las proporciones a invertir en una cartera o portafolio con una función de rentabilidad, generalmente lineal, y una función de riesgos, generalmente cuadrática. Por esta razón, en este capítulo se analiza el cálculo de máximo y mínimo de funciones no lineales y con restricciones, aunque como caso especial se verá primero una optimización sin restricciones.
1.1.- DEFINICIÓN DE EXTREMOS DE UNA FUNCIÓN CON DOS VARIABLES X e Y, SIN RESTRICCIONES.
Una función f(x,y) tiene un máximo (o un mínimo) f(a,b) en el punto P(a,b) si para todos los puntos P (x,y) diferentes de P, de un entorno suficientemente pequeño del punto P, se cumple:
f(a,b) > f(x,y) para máximo o f(a,b) < f(x,y) para mínimo
1.1.1.- Condiciones necesarias para la existencia de máximo o mínimo
Los puntos de máximo o mínimo se encuentran resolviendo el siguiente sistema de ecuaciones:
El sistema (1.1) es equivalente a:
)1.1(0),(
0),(
y
yxfy
x
yxf
dyy
yxfdx
x
yxfyxdf
),(),(0),(

Autor: José Rigoberto Parada Daza 7
1.1.2.- Condiciones suficientes para la existencia de máximo o mínimo.
Sea P(a,b) un punto estacionario de la función f(x,y), o sea df (a,b) = 0, aquí se puede dar si:
a) d2f(a,b) < 0, siendo dx2 + dy2 > 0 entonces f(a,b) es un máximo de la función f(x,y)
b) d2f(a,b)> 0, siendo dx2 + dy2 > 0, entonces f(a,b) es un mínimo de la función f(x,y)
c) d2f(a,b) cambia de signo, entonces f(a,b) no es un punto de máximo ni de mínimo de la función f(x,y)
Las condiciones anteriores son equivalentes a las siguientes:
Sea:
y sea: D = AC B2
Entonces se puede presentar lo siguiente:
1) D> 0 f(x,y) tiene un extremo en el punto P(a,b) y éste será: Máximo Sí A< 0 (o C < 0)
o
Mínimo Sí A > 0 (o C > 0)
2) D< 0 f(x,y) en punto P (a,b), lo que indica que no hay extremo 3) D = 0
f(x,y) en el punto P(a,b), entonces la existencia de extremo queda indeterminada y no se puede continuar la investigación.
Para el caso de varias variables, el procedimiento es análogo al de dos variables.
0),(),(
y
baf
x
baf
yx
bafB
x
bafA
),(),( 2
2
2
2
2 ),(
y
bafC

Autor: José Rigoberto Parada Daza 8
Ejemplo Nº 1.1: Sea la función z = ex-y (x2 2y2)
Calcule los valores extremos y sus puntos de máximo. Solución:
Resolviendo el sistema de ecuaciones, se tiene:
x1=0 e y1=0, o sea P(0,0) x2 = -4 e y2= -2 o sea P(-4,-2)
Entonces:
A = 2z/ x2 = ex-y x2 +4x+2 2y2
B = z/ x y =ex-y -x2 2x- 4y + 2y2
C = 2z/ y2 = ex-y x2-2y2 + 8y - 4
Expresando en una tabla los valores de A, B y C se tiene lo siguiente:
A B C P (0,0) 2 0 -4 P(-4,-2) -8e-2 8e-2 -12e-2
Cálculo de D para P (0,0) es el siguiente:
D = AC - B2 = -8 - 0 < 0, como D< 0, entonces no hay extremo
Cálculo de D para P (-4,-2)
D= AC - B2 = 96e-4 (8e-2)2 = 0,5861
Como D> 0 y A<0 P(a,b) = P(-4,-2) es máximo.
Función Máxima en P(a,b) = P(-4,-2) es
Z = e 4+2 16 - 8 = 8e-2
022 22 yxeyyxxeyxexx
z
042 22 yxyxyx yeeyexy
z

Autor: José Rigoberto Parada Daza 9
Ejemplo Nº 1.2
Un problema clásico en Gestión Financiera es la determinación de las cantidades a producir minimizando una función de costos. Sea la siguiente función:
Donde CT = Costo Total
R = Número de unidades elaboradas por secuencia de producción I = Unidades de existencia al principio de cada período Cs= Costos de instalación C1= Costo unitario variable de producción C2= Costo de mantenimiento unitario C3= Costo por falta de inventario q = Nº de unidades vendidas
Se trata de determinar cuál es el número de unidades elaboradas (R) y el nivel de unidades de existencias iniciales (I) de tal forma de optimizar los costos totales (CT). O sea se debe calcular, el siguiente sistema:
Del sistema de ecuaciones anteriores se obtiene:
3
32
2
2*C
CC
C
CqR s
32
3
2
2*CC
C
C
CqI s
Suponiendo que: q = 10.000 unidades C2 = $0,44 por unidad C3 = $1 por unidad Cs = $8.800
Entonces el valor óptimo de R e I son los siguientes:
R
IRCIC
RqC
R
qCCT s
232
21)(
22
1
00I
CTy
R
CT
0)()(
222
12
232
222 R
IR
R
IRCIC
RR
qC
R
CT s
01 3
2 IRR
CIC
RI
CT

Autor: José Rigoberto Parada Daza 10
Calculando el discriminante D en el punto P (a,b) = P (24.000; 16.667) se tiene:
A = 2 CT/ R2 > 0 B = ( 2CT/ R I) > 0 C = 2 CT/ I2 > 0
Entonces si D>0 y como A>0 o C>0, se tiene que en el punto P(a,b)=P(24.000;16.667) es un punto de Mínimo y el costo Mínimo es: (suponiendo que C1 = $ 50)
CT* = (8.800 X 10.000)/24.000+50 X 10.000+0,44(16.667)2/48.000+ + (24.000-16.000)2 /48.000=$507.333,34.
Ejemplo Nº 1.3
El modelo de Valoración de Activos de Capital o CAPM, determina como básico el cálculo de los coeficientes de volatilidad o Betas a partir del siguiente modelo:
Donde:
itR = Rentabilidad del activo financiero i en período t.
Rmt = Rentabilidad de un portafolio de mercado en período t. it = Errores estadísticos de estimación.
El modelo se basa en que para un conjunto de datos, rentabilidades en este caso, se tenga el mínimo error it, entre las rentabilidades Rit observadas y las Rit
calculadas según el modelo. O sea, se trata de minimizar los errores estadísticos para todos los títulos, y a partir de esa función minimizante obtener el parámetro Beta ( ) que es lo relevante, así como el parámetro .
La función a maximizar es la siguiente:
unidadesx
I 667.1644,1
1
44,0
000.10800.8*2*
n
ttmiti
n
tit RRF
1
2,,
1
2
itmtiitRR
unidadesxx
R 000.2444,144,0
800.8000.102*

Autor: José Rigoberto Parada Daza 11
Condiciones para cálculo de puntos extremos son las siguientes:
Resolviendo las ecuaciones y reordenándolas, se obtiene:
Del sistema de ecuaciones anterior, se obtiene:
iii RR
Donde: im = Covarianza entre los retornos de título i con los retornos del portafolio de
mercado m. 2m = Varianza del portafolio de mercado m.
Calculando los discriminantes A, B y C se tiene que:
A = 2F/ i 2> 0
B = 2F/ i > 0 C = 2F/ 2 < 0
n
tmtiiit
i
RRF
102
021
n
tmtiiitmt RRR
F
n
tmtii
n
tit RnR
11
n
t
mti
n
tmtimt
n
tit RRRR
1
2
11
221
)(
))((
m
im
tmmt
tmmtit
n
tit
iRR
RRRR

Autor: José Rigoberto Parada Daza 12
Entonces D>0 y como A>0 o (C>0) entonces el Punto P(a,b) =P( im/ 2m; iR - iRm)
es mínimo.
Ejemplo Nº 1.4
Suponga que una empresa produce dos productos los que se pueden vender en $10 y $15 la unidad. Las funciones de costos totales de ambos es la siguiente:
CT1 = 2q1 + 0,2 21q
CT2 = 3q2 + 0,15 22q
donde: CTi = Costo total variable de producción del producto i. qi = Cantidad del producto i producido.
Suponiendo que se desea maximizar el beneficio y que todo lo que se produce se vende, se desea saber cuál es el nivel de producción del producto 1 y 2. Función a Optimizar: 10q1 + 15q2 2q1 0,2 2
1q 3q2 0,15 22q
Aplicando las condiciones de optimización se tiene lo siguiente:
Los puntos de extremo son f(a,b) = f(20;40) que es la solución del sistema de ecuaciones. Para verificar si el punto es de máximo o mínimo se deben calcular los discriminantes A, B y C, que son los siguientes:
A = 2f/ q21 = -0,4
B = f/ q1 q2 = 0 C = 2f/ q2
2 = -0,3, calculando D se tiene: D = AC B2 = 0,12 y A< = 0 Punto Máximo,
Donde: Beneficio Máximo : $ 320 Costo máximo : $ 480
03,0315),(
22
21 qq
qqf
04,0210),(
11
21 qq
qqf

Autor: José Rigoberto Parada Daza 13
1.2.- OPTIMIZACIÓN CON RESTRICCIONES, CASO DE DOS VARIABLES
En Finanzas, normalmente, las funciones a maximizar están restringidas por condiciones impuestas, ya sea por el mercado o por factores internos propios de la empresa. Estas restricciones también pueden ser funciones en las que se incluyan las variables que se intentan optimizar. Por ejemplo, queremos seleccionar los mejores proyectos de inversión y que tengan la máxima rentabilidad, pero estos proyectos se pueden llevar delante de acuerdo a las disponibilidades de financiamiento, a factores legales e impositivos, a condiciones medio ambientales u otras, las que constituyen las restricciones al problema de maximización; por lo tanto los puntos de posibles óptimos, o puntos extremos, son extremos condicionados.
Para problemas con extremos condicionados se usa el Método de Lagrange que en una primera etapa se explicará para funciones de dos variables. Sea f(x,y) la función a optimizar sujeta a restricciones de una función g(x,y); con esto se plantea una función conocida con el nombre de función Lagrangeana L(x,y) la que se define de la siguiente forma:
L(x,y) = f(x,y) + g (x,y) con g(x,y) = 0
donde
= Coeficiente de Lagrange y que es una constante que constituye una incógnita del problema. A partir de la función L(x,y) se buscan nuevos puntos de extremo mediante el siguiente sistema de ecuaciones:
L/ x = f/ x + g / x = 0 L/ y = f/ y + g/ y = 0 L/ = g (x,y ) = 0
Las incógnitas en este sistema de ecuaciones son: , x e y
Para el cálculo de los puntos de extremos condicionados se debe analizar el signo que tendrá la segunda diferencial de la función Lagrangeana, o sea
para los valores x, y,
que se han obtenido como puntos extremos y que las diferenciales dx y dy cumplan la siguiente condición:
Sí d2F<0, entonces f(x,y) tiene un máximo condicionado.
Sí d2F>0, entonces f(x,y) tiene un mínimo condicionado.
22
222
2
22 2),( dy
y
Ldxdy
yx
Ldx
x
LyxFd
0dyy
gdx
x
gCon dx 2 + dy 2 0

Autor: José Rigoberto Parada Daza 14
o bien, se calcula el valor de D = AC-B2 para la función L(x,y) y si D>0 habrá un máximo condicionado de f(x,y) si A<0 (ó C<0)
o habrá un máximo condicionado de f(x,y) sí
A>0 (ó C>0)
El método se puede generalizar para varias variables y varias restricciones a la vez, con el mismo desarrollo que para dos variables, siempre considerando que el número de ecuaciones de restricciones debe ser menor que el número de variables que incluye el problema.
Ejemplo Nº 1.5
Un clásico problema en Finanzas es la selección de proporciones a invertir en una cartera minimizando el riesgo. Suponga que se invertirá las proporciones x e y en dos títulos bursátiles, cuya función de riesgos es:
2 = x2 x2 + y2
y2 + 2xy xy
sujeto a: x + y =1
La función de Lagrange es la siguiente:
L = x2x2 + y2 2
y + 2xy xy +
x+y-1
Entonces: L/ x = 2x x
2 + 2y xy + = 0 (1)
L/ y = 2y y2 + 2x xy + =0 (2)
L/ = x +y = 1 (3)
De (1) y (2) se tiene:
De donde se deduce que:
Reemplazando en (3) se tiene:
12
2
yxy
xyx
yx
yx
12
2
yyxyx
xyy
)4(2
2
xyx
xyyyx

Autor: José Rigoberto Parada Daza 15
Es decir
Reemplazando (5) en (4) se tiene:
Entonces los puntos de extremo son P(a,b)=
Supongamos los siguientes datos:
2x = 0,250
2y = 0,090
xy = 0,075
Entonces:
Reemplazando los valores de x e y, se tiene = - 0,1776 O sea P(a,b) = P (0,0789; 0,9211)
El cálculo de segundas derivadas es el siguiente :
2L / x2 = 2 2x
2L / x y = 2 xy 2L / y2 = 2 2
y
Entonces:
d2L(x,y) = 2dx2 + 2dy2
Sí x = 0,0789; y = 0,9211 y = -0,1776 Por tanto: d2 L(x,y) > 0 la solución es un punto de mínimo.
)5(2 22
2
yxyx
xyxy
yxyx
xyyx22
2
2
0789,009,015,025,0
075,009,0x
9211,009,015,025,0
075,025,0y
yxyx
xyx
yxyx
xyyP22
2
22
2
2;
2

Autor: José Rigoberto Parada Daza 16
Ejemplo Nº 1.6 Supongamos que tenemos dos bonos con los siguientes datos:
Bono 1 Bono 2 Precio inicial P1 = $10 P2 = $12 Tasa de Interés r1 = 10% r2 = 12%
Valor al final período P1e 1r 1t = 10e0,1 1t P2e 2r 2t = 12e0,12 2t
Período de vigencia t1 t2
Se desea maximizar el valor de la inversión y se debe determinar cuál debe ser el período de vigencia o de posesión de ambos bonos, o sea, t1 y t2 suponiendo que se desea que ambos no superen un año de inversión.
Entonces se tiene la siguiente función a maximizar:
Función a optimizar V = P1 e 1r 1t + P2 e2r 2t
V = 10 e 0,1 1t + 12 e0,12 2t
Sujeto a: t1 + t2 = 12 meses
Entonces L = 10 e 0,1 1t + 12 e 0,12 2t + t1 + t2 -12
Calculando las derivadas parciales se tiene:
De (1) y (2) se tiene:
O sea, e0,1 1t = 1,44 e0,12 2t
Calculando el logaritmo natural a ambos lados, se tiene:
0,1t 1 = ln(1,44) + 0,12 t2
)1(011,0
1
tedt
dL
)2(044,1 212,0
2
tet
L
)3(1221 ttdL
144,1 2
1
12,0
1,0
t
t
e
e

Autor: José Rigoberto Parada Daza 17
o, sea t1 = 10 ln(1,44) + 1,2t2
Reemplazando en (3) se tiene:
10 ln(1,44) + 1,2t2 + t2 = 12
Luego: t2 = 3,8; t1 = 8,2 y = -2,272
Calculando las segundas derivadas se tiene:
2L/ t12 = 0,1 e0,1 1t
2L/ t1 t2 = 0 2L/ t22 = 0,1728 e 0,12 2t
Entonces, la segunda derivada de la ecuación de Lagrange es:
d2L = 0,1e0,1 1t + 0,1728 e 0,12 2t > 0
Ejemplo Nº 1.7
Suponga que un inversionista debe distribuir sus recursos entre consumir hoy día (Co) y destinar parte de esos recursos a consumo futuro o ahorro (C1). La función de utilidad de esta distribución es U= Co
2 + C12 ; se trabaja con dos períodos de
referencia y su ingreso actual es de $15.000 y el ingreso esperado en el próximo período es $8.000; si el ahorro gana un interés de 7%. ¿Cuánto dinero debe destinar a consumo actual y a consumo futuro?
Función a optimizar: C 20 + C 2
1
Función condicionante: (15.000 - Co) + (8.000 - C1)/(1,07)
Entonces L = C2o + C2
1 +
(15.000 Co) + (8.000- C1)/1,07
)2(007,1/2 11
CC
L
)3(0)07,1/()8000()000.15( 1CCL
o
)1(02 oo
CC
L

Autor: José Rigoberto Parada Daza 18
De (1) y (2) se tiene:
Reemplazando en (3) se obtienen los valores de C0 y C1, luego se obtiene:
$15.000 1,07 C1 + $7.476,63 0,934579C1 = 0 Luego: C1 = $11.212,63 y Co = $11.997,53
Calculando las segundas derivadas, se tiene:
2L/ C 20 = 2
2L/ C 21 = 2
Por lo tanto, d2L > 0, entonces la función optimizada es un mínimo.
Ejemplo 1.8
Sea la siguiente función:
Donde V = Valor de una empresa (en $) U = Utilidad neta de la empresa (en $) b = Utilidades retenidas (en tanto por uno) (1 b) = Dividendos k = Tasa de Costo de Capital r = Tasa de rentabilidad de las reinversiones
De acuerdo al modelo presentado, determine si existe una política de dividendos que maximice el valor de la empresa.
Se trata de ver cuando se cumple dV/db = 0 que indicaría el probable punto de inflexión.
En este caso, la igualdad sólo se cumple cuando r=k, ya que se sabe que U>0 y (1+k)>0
11
1 07,107,1 CCC
C
C
Co
o
o
brk
kbUV
)1)(1(
0)(
))(1(2brk
krkU
db
dV

Autor: José Rigoberto Parada Daza 19
Si r k, entonces, dV/db nunca es igual a cero. Si r=k, entonces el valor óptimo de V será:
En el caso anterior, cualquiera sea el valor de b dará un máximo para V.
Si r < k ocurre lo siguiente: 0 b 1 1-b 0 y (k - br) 0
Como U> 0 y (1+k) >0, entonces V 0 para valores de b entre 0 b 1
Así si b=0 V = U (1+k)/k y si b= 1 V = 0 entonces existe un punto que maximiza y éste está en U(1+ k)/k . Esto implica que aquí convendría entregar todo como dividendos.
Sí r>k, entonces el valor de V tiende a infinito.
Ejemplo 1.9
Suponga que el valor de un bono se expresa por la siguiente fórmula:
Calcule si existe alguna variación en el valor del bono ante cambios en la Tasa de Interés k.
Por simplicidad, se toma el factor (1+k) como el factor que varía.
Entonces:
Si dB/d(1+k)=0 tendríamos un punto de extremo.
Esto se presenta en dos casos, los cuales son los siguientes:
Si k = 0 que será válido cuando n=0, ya que dB/d(1+k) = -C 1+2+.....n Sí 1+2+----n = n(n+1)/2 entonces sólo sería igual a cero cuando n=0.
Sí k , entonces dB/d(1+k) = 0, que sería el otro punto de extremo.
k
kUV
)1(
nk
C
k
C
k
CB
)1()1()1( 2
132 )1(.....
)1(
2
)1()1( nk
nC
k
C
k
C
kd
dB

Autor: José Rigoberto Parada Daza 20
Ejemplo 1.10
Sea la siguiente expresión:
Donde k = Costo de capital promedio de la empresa (en %) D = Deuda de la empresa (en $) C = Capital de la empresa (en $) k1 = Costo de la deuda (en %) k2 = Costo que exigen los propietarios (en %)
Determine si en estos modelos existe alguna relación deuda/capital que minimice el Costo de Capital promedio (k).
En este caso, previamente hay que hacer un arreglo algebraico de tal forma que aparezca la variable D/C, así se divide numerador y denominador por C y se obtiene la siguiente relación:
Calculando dk/d(D/C)= 0, ésta se cumple cuando k1 = k2.
Por otro lado se tiene:
Cuando k1>k2 es un punto de máximo, ya que d2k/d(D/C)2<0. Sí k1< k2 es un punto de mínimo, pues d2k/d(D/C)2 > 0
21 kCD
Ck
CD
Dk
1)/(1)/(
)/( 21 CD
kk
CD
CDk
0)1/(
)1/)((2
)/( 421
2
2
CD
CDkk
CDd
kd

Autor: José Rigoberto Parada Daza 21
1.3. OPTIMIZACIÓN CON RESTRICCIONES DE VARIAS VARIABLES
El procedimiento para optimizar una función f(xi), con i=1,.....n, sujeto a una función de restricciones g(xi) con i=1,... n, es similar, sólo que cambia el sistema de ecuaciones para encontrar los puntos de extremos y que se transforma en un sistema de n+1 ecuación con n + 1 variables.
En efecto, sea: L = f(xi) + g(xi),
Entonces los puntos de extremo se encuentran del siguiente sistema de ecuaciones: L/ x1 = f(xi)/ x1 + g(xi)/ x1 = 0 L/ x2 = f(xi)/ x2 + g(xi)/ x2 = 0 L/ x3 = f(xi)/ x3 + g(xi)/ x3 = 0
L/ xn = f(xi)/ xn + g(xi)/ xn = 0 L/ = g(x1,x2,... xn ) = 0
Para saber si es máximo o mínimo se requiere lo siguiente:
dxi, distintos de dxi = 0 i que satisfaga la siguiente ecuación:
g1dx1 + g2dx2 + .... + gndxn = 0
Si hay varias restricciones, entonces el sistema de ecuaciones aumenta y las restricciones se pueden expresar por otras funciones g i para las cuales se
expresan nuevos i, o sea la función de Lagrange es:
En los casos anteriores se ha trabajado principalmente con funciones no lineales; en el caso de optimizaciones donde las funciones a maximizar y las restricciones son lineales el método tradicional de cálculo de puntos de solución es el método Simplex, el que normalmente no es utilizado en Teoría Financiera, por lo que no se abordará en este capítulo.
ijconxgxfL ij
n
i
n
jji )()(
1
1
1
máximoes
mínimoesdxdxf
n
i
n
jjiij 0
0
1 1

Autor: José Rigoberto Parada Daza 22
CAPITULO II
DISTRIBUCIONES DE PROBABILIDADES BASICAS
En Finanzas es común el uso de alguna distribución de probabilidades para diferentes eventos y mediante ellas se determina la esperanza matemática del suceso, multiplicando el suceso por la probabilidad de ocurrencia. Así, se puede aplicar para el caso de la estimación de Valores Actuales esperados; precios de activos financieros esperados, tasas de rentabilidad esperadas, costos de la deuda esperados, etc. Las distribuciones de utilidades a utilizar dependen de si las variables son discretas o continuas.
Entre las distribuciones de probabilidades para casos discretos están:
Distribución Binomial Distribución Multinomial Distribución de Poisson
Entre las distribuciones de probabilidades de variables aleatorias contínuas están:
Distribución Normal Distribución Gamma Distribución Beta
En Teoría Financiera las distribuciones más utilizadas son la Distribución Normal, especialmente en la especificación de modelos de valoración de precios y la distribución Binomial para el caso de modelo de Valoración de Opciones. Por esta razón, se expondrán los aspectos centrales de ambas distribuciones.
2.1.- DISTRIBUCIÓN BINOMIAL
Sí p = Probabilidad de ocurrencia de un suceso en un solo ensayo, o probabilidad de éxito del suceso favorable.
q = (1-p) = Probabilidad de no ocurrencia del suceso en un solo ensayo o probabilidad de fracaso o de suceso desfavorable.
Entonces la probabilidad de que el suceso se presente exactamente x veces en n ensayos, o sea, x éxitos y (n-x) fracasos está dado por la siguiente expresión:
Con x = 0, 1, 2, 3,...... n y n! =n(n-1)(n-2)(n-3)..... 1 y 0! = 1 por definición
1.2)!(!
!)( xnxxnx
xnqp
xnx
nqpCxp

Autor: José Rigoberto Parada Daza 23
A esta distribución de probabilidad discreta se le denomina Distribución Binomial, ya que para las x = 0,1,2.... n, se corresponden sucesivos términos de la fórmula binomial del tipo:
(p+q)n = qn + nC1 qn-1p + nC2 q
n-2p2 + ...+ pn
Donde: nC1, nC2, nC3 son los coeficientes binomiales los que se pueden también obtener por el Triángulo de Pascal, el que para n=5 se presenta a continuación:
N
0 1
1 1 1
2 1 2 1
3 1 3 3 1
4 1 4 6 4 1
5 1 5 10 10 5 1
Las propiedades principales de esta distribución son las siguientes: Media = = np Varianza = 2 = npq Coeficiente de Sesgo= (npq)1/2
En la fórmula (2.1) se presentan las dos situaciones siguientes:
1) La Probabilidad de obtener cualquier combinación de x éxitos y (n-x) fracasos es pxqn-x
2) nx son todas las posibles combinaciones de los éxitos y fracasos.
Cuando n es muy grande, entonces el cálculo de las diferentes opciones es tedioso y normalmente se usa una aproximación a la Distribución Normal como se verá más adelante.
El modelo 2.1 es válido sólo cuando las probabilidades de los ensayos son constantes, de otra forma no se puede aplicar el Triángulo de Pascal. En efecto, la
igualdad (p 1 +q 1 )(p 2 +q 2 )=(p+q) 2 solo se cumple si: p1=p2 y q1=q2. Generalizando se tiene que:
sólo, si p1 = p2 = ..... = pn = p y q1 = q2 = q3 = .......... = qn = q
nj
n
i )qp()qp(

Autor: José Rigoberto Parada Daza 24
Ejemplo Nº 2.1
Supongamos que tenemos hoy día un bono con un precio de $1000; se estima que existen dos posibilidades frente a este precio; que suba en el período siguiente en 10% o que baje en 10%; la probabilidad de que suba, es decir el suceso favorable, es 2/3 y la probabilidad de que baje es 1/3, es decir, el suceso desfavorable. Supongamos un horizonte de tres períodos y deseamos determinar el probable precio del bono al cabo de esos tres años suponiendo que existen las condiciones de Distribución Binomial. En gráfico 2.1 se muestran las posibilidades que se presentan en este caso.
En esta situación se da un escenario de Distribución Binomial, pues se observan dos alternativas de cada suceso y además, se trabaja en tiempo discreto, es decir los períodos son: 1, 2 y 3.
GRAFICO 2.1 Gráfico de Posibilidad de Precios
Tiempo
Momento Inicial = 0 A $ 1.000 (Precio Inicial)
(*) + 10% - 10%
Fin año 1 $ 1.100 $ 900 B C
+ 10% - 10% + 10% - 10%
D E F Fin año 2 $ 1.210 $ 990 $ 810
+ 10% - 10% + 10% - 10% + 10% - 10%
G H I J Fin año 3 $1.331 $ 1.089 $ 891 $729
(*) Con el signo + se indica aumento de precio en 10% y con signo disminución en 10%.
En Gráfico 2.1 se ve que si se parte en el momento inicial con un precio de $1.000, entonces al término del año 1 existen dos posibilidades, que el precio de $1.000 aumente en 10%, o sea, $1.100 (Punto B) o disminuya en 10%, es decir el precio final es $900 (Punto C).

Autor: José Rigoberto Parada Daza 25
Entre el año 1 y 2 se dan las siguientes situaciones. Si el precio es de $1.100, entonces al término del año 2 éste puede aumentar en 10%, o sea, $1.210 (Punto D) o puede disminuir en 10%, o sea llega a $990 (Punto E). La otra posibilidad a inicios del año 2 es que el precio sea $900 y al término del año 2 éste puede aumentar en 10%, o sea suba a $990 o pueda disminuir en 10%, o sea alcance a $810 (Punto F).
Al término del tercer año se presentan seis posibilidades, las cuales dependen de los precios iniciales del tercer año y que son los que se tenían a fines del año 2. Así, si el precio a inicios del año 3 es de $1.210, entonces éste puede aumentar en 10%, o sea subir a $1.331 (Punto G) o bajar en 10%, o sea baja a $1.089 (Punto H); o bajar en 10%, o sea $891 (Punto I) o puede bajar 10%, o sea a $729 (Punto J).
En este ejemplo didáctico, se supone que las alzas y las bajas son iguales (10% en este caso); esto no tiene porqué ser necesariamente así, se puede suponer un escenario optimista y un escenario pesimista y los porcentajes de alzas no tienen porqué ser iguales a los porcentajes de las bajas, lo que depende exclusivamente de los pronósticos y variables consideradas en los análisis prospectivos. De igual forma tampoco se puede suponer tres, cuatro o cinco períodos; esto depende del horizonte de tiempo que los analistas consideren adecuado.
Cálculo de las probabilidades asociadas a los sucesos
Las posibilidades que se presentan en el ejemplo son las siguientes: Situación Favorable Desfavorable A 3 alzas 0 baja B 2 alzas 1 baja C 1 alza 2 bajas D 0 alzas 3 bajas
Situación Puntos de Gráfico Probabilidad a) 3 alzas A B D G 1x(2/3)3 = = 8/27 b) 2 alzas y 1 baja A B D H (2/3)(2/3)(1/3)
+A B E H +(2/3)(1/3)(2/3) +A C E H +(1/3)(2/3)(2/3)
TOTAL = 12/27
c) 1 alza y 2 Bajas A B E I (2/3)(1/3)(1/3) +A C E I +A C F I
+(1/3)(2/3)(1/3) +(1/3)(1/3)(2/3) Total =6/27
d) 3 bajas A C F J 1(1/3)3 =1/27 TOTAL = 1
Calculando las probabilidades para el tercer período usando el modelo 2.1 se tiene:

Autor: José Rigoberto Parada Daza 26
Reemplazando en fórmula se obtienen los siguientes resultados:
TOTAL = 1
Se observa que usando el modelo se llega al mismo resultado que el que se había obtenido directamente del gráfico. Entonces el valor esperado del precio del bono E(P) el que tendría una probabilidad de ocurrencia de p(Pi), al término del tercer período, según la Distribución Binomial de probabilidades sería:
E(P)= )(4
1i
ii PpP
E(P) = $1.331(8/27)+$1.089(12/27)+$891(6/27)+$729(1/27) E(P) = $1.103,37
Sin embargo, este ejemplo se puede resolver de una manera muy sencilla sin hacer uso del árbol binomial. Así, se determina el aumento (o disminución) esperado por período y posteriormente se determina el precio o variable final. Los datos serían los siguientes:
Aumento (o disminución) esperado 1er año = 10(2/3) + (-10)(1/3) = 3,333% Aumento (o disminución) esperado 2do. Año = 10(2/3) + (-10)(1/3) = 3,3333% Aumento (o disminución) esperado 3er. Año = 10(2/3) + (-10)(1/3) = 3,3333%
Precio Esperado =$1000(1,0333)3 = $1.103,37, que es el mismo obtenido en el ejercicio con el árbol binomial.
En este sencillo ejemplo se puede ver lo laborioso que resultaría calcular el mismo problema suponiendo que el ejercicio se proyectará para ocho, diez o más períodos, en esos casos se procede a tratar el problema como si fuera una Distribución Normal, debido al gran número de combinaciones que se deben
Situación Nº suceso favorable (x) Total (n) a) x=3 n=3 b) x=2 n=3 c) x=1 n=3 d) x=0 n=3
27/8)3/1()3/2!0!3/!33
3·) 0303qpa
2712)3/1()3/2(!1!2/!32
3) 22 qpb
271)3/1()3/2(!3!0/!30
3) 3030 qpd
276)3/1)(3/2(!2!1/!31
3) 22pqc

Autor: José Rigoberto Parada Daza 27
hacer. Si trabajamos con ocho períodos, entonces habrían nueve nodos finales que tendrían las siguientes situaciones:
Situación Nº sucesos favorable Total A X=8 n=8 B X=7 n=8 C X=6 n=8 D X=5 n=8 E X=4 n=8 F X=3 n=8 G X=2 n=8 H X=1 n=8 I X=0 n=8
Con los datos anteriores se aplica la fórmula Nº 2.1 y se obtiene la probabilidad de cada nodo.
Generalizando para n períodos, entonces el número de nodos final del árbol binomial es de (n+1) nodos. Para calcular un precio esperado al término de n períodos se pueden observar las siguientes reglas:
1.- Determinar el número de sucesos favorables para cada nodo, es decir x de la fórmula Nº2.1. Se desarrolla una columna que parte con x=n y desde ahí en adelante los sucesos favorables serán n-1; n-2,.... 0
2.- Para cada nodo se consideran los sucesos favorables y se determina el precio que será Po (1+a)n para el primer nodo; Po (1+a)n-1(1-b) en el segundo, donde a= incremento del precio, que es el suceso favorable y b=disminución del precio; ambos, o sea a y b, medidos en tanto por uno. 3.- Se multiplica la probabilidad de cada nodo por el valor del precio en cada nodo y posteriormente se suman todos los precios ponderados de los nodos por sus respectivas probabilidades. Esta suma total es el precio esperado.
No necesariamente puede ser el precio de un título, pueden ser utilidades, ingresos por ventas, dividendos, precios de diferentes bienes, etc. En la siguiente tabla se expresan los tres puntos anteriores.
Nodos Favorables Precios de cada Nodo Probabilidad del Nodo 1 X=n Po (1+a)n n!/(n!o!) pnq0
2 X=n-1 Po(1+a)n-1(1-b) n!/((n-1)!1!) pn-1q 3 X=n-2 Po(1+a)n-2(1-b)2 n!/((n-2)!2!)pn-2q2
4 X=n-3 Po(1+a)n-3(1-b)3 n!/((n-3)!3!)pn-3q3
.
.
. n X=1 Po(1+a)(1-b)n-1
n+1 X=0 Po(1-b)n n!/(o!(n)!)poqn

Autor: José Rigoberto Parada Daza 28
Ejemplo Nº 2.2
Se estima que el Índice de Precios al Consumidor (IPC) subirá en los próximos tres años; los escenarios son: que suba lo más alto en 4% anual o en un pronóstico optimista en 1% anual. La probabilidad que suba un 4% anual es de 2/5 y la probabilidad de que suba en un 1% al año es 3/5. ¿Cuál será la probable tasa inflacionaria al final del tercer año?
En este caso el suceso favorable es que suba menos, es decir 1% y el desfavorable es que suba más, o sea 4%. Es decir, se toma como suceso favorable el que provoque el menos malestar, aunque los dos sean desfavorables como es el caso de la inflación en este caso. Esta situación es equivalente al caso de incrementos en variables económicas como: costos de materiales, salarios u otros.
El Gráfico Nº2.2 explica la situación, suponiendo un IPC inicial de 100. En este Gráfico se determina que los IPC finales fluctuarán entre 103,03 y 112,49, es decir la tasa de inflación puede fluctuar entre 3,03% y 12,49% al cabo del año 3. En el gráfico se indica con signo + la situación favorable, es decir que el IPC aumente anualmente en sólo 1% y con signo la situación desfavorable que es un aumento de 4% anual.
Los nodos finales tienen las siguientes situaciones respecto a los sucesos favorables:
Situación Nº sucesos favorables(x) Total (n) a) 3 3 b) 2 3 c) 1 3 d) 0 3
Reemplazando en fórmula Nº 2.2 para calcular la probabilidad de cada uno de los nodos, se tiene:
Situación Probabilidad a) 3!/(3!0!)
(3/5)3(2/5)0 = 27/125 b) 3!/(2!1!) (3/5)2(2/5) = 54/125 c) 3!/(1!2!) (3/5) (2/5)2 = 36/125 d) 3!/(0!3!)
(3/5)0(2/5)3 = 8/125
Total 1

Autor: José Rigoberto Parada Daza 29
GRAFICO Nº 2.2 INCREMENTO DE IPC, AÑO 1 A 3
Inicio 100
1% 4%
(+) (-)
Fin año 1 101 104 1% 4% 1% 4%
(+) (-) (+) (-)
Fin año 2 102,01 105,04 108,16 1% 4% 1% 4% 1% 4%
(+) (-) (+) (-) (+) (-)
Fin año 3 103,3 106,09 109,24 112,49
Por lo tanto, el IPC esperado al final del año 3, es:
E(IPC) = 103,3(27/125) + 106,09(54/125) + 109,24(36/125) + 112,49(8/125) E(IPC) = 106,80
Entonces la inflación acumulada probable al cabo del año tres será de 6,8%, lo que en promedio anual esperado será 2,22%, que se calcula de la siguiente forma:
(1+iA)3 = (106,8/100) iA = 0,02217
Calculando directamente el aumento esperado por año éste sería igual a: 1(3/5)+4(2/5) = 2,2%
)()(4
1i
ii IPCpIPCIPCE

Autor: José Rigoberto Parada Daza 30
Ejemplo Nº 2.3
Durante los primeros tres años las utilidades por acción de una empresa tendrán un comportamiento probabilístico, presentándose dos escenarios. El primero, que es más optimista, indica que éstos pueden aumentar anualmente en 1% el primer año; 6% el segundo año y 2% el tercer año, con probabilidades de 2/3, 1/2 y 3/4 respectivamente. El otro escenario menos optimista es que las utilidades por acción en los próximos tres años presenten un incremento anual de 0,5% el primer año, 3% el segundo año y disminuyan en 5% el tercer año, con probabilidades de 1/3, 1/2 y 1/4 respectivamente. En estos escenarios, ¿Cuál será el valor de las utilidades por acción el tercer año si éste hoy alcanza a $1.000 ?.
En este caso el problema se puede resumir en la siguiente tabla:
Suceso Favorable Suceso Desfavorable Año % Aumento Probabilidad % Aumento Probabilidad 1 1% 2/3 0,5% 1/3 2 6% 1/2 3% 1/2 3 2% 3/4 -5% 1/4
En este caso la fórmula Nº 2.1 no se puede aplicar directamente porque las probabilidades para cada ensayo, número de años en este caso, no son constantes, por lo que se debe desarrollar el problema planteado a través del árbol binomial y que se presenta en Gráfico Nº 2.3.

Autor: José Rigoberto Parada Daza 31
GRÁFIC0 N° 2.3 UTILIDADES POR ACCIÓN
$1.000 A 1% +0,5%
p(x)=2/3 p(x)=1/3 B C
$ 1.010 $ 1.005
+ 6% + 3% + 6% +3%
p(x)=1/2 p(x)=1/2 p(x)=1/2 p(x)=1/2 D E F G
$ 1.070,6 $ 1.040,3 $ 1.065,3 $ 1.035,15
+2% -5% +2% -5% +2% -5% +2% -5% p(x)=3/4 p(x)=1/4 p(x)=3/4 p(x)=1/4 p(x)=3/4 p(x)=1/4 p(x)=3/4 p(x)=1/4
H I J K L M N O
$1.092,01 $1.017,07 $1.061,11 $988,29 $1.086,61 $1.012,04 $1.055,85 $983,39

Autor: José Rigoberto Parada Daza 32
En gráfico Nº 2.3 se presentan 8 nodos finales que tienen las siguientes rutas, probabilidades y valores esperados de utilidades:
Ruta Probabilidad (1)
Utilidad Acción (2)
Utilidad por Acc.Esperada=(1)x(2)
a) A B D H (2/3)(1/2)(3/4)=6/24 $1.092,01 $273,00 b) A B D I (2/3)(1/2)(1/4)=2/24 $1.017,07 $ 84,756 c) A B E J (2/3)(1/2)(3/4)=6/24 $1.061,11 $265,278 d) A B E K (2/3)(1/2)(1/4)=2/24 $ 988,29 $ 82,358 e) A C F L (1/3)(1/2)(3/4)=3/24 $1.086,61 $135,826 f) A C F M (1/3)(1/2)(1/4)=1/24 $1.012,04 $ 42,168 g) A C G N (1/3)(1/2)(3/4)=3/24 $1.055,85 $131,981 h) A C G O (1/3)(1/2)(1/4)=1/24
$ 983,39 $ 40,975 SUMA = 1 =$1.056,342
Entonces la utilidad esperada al término del año 3 sería de $1.056,34, con un rango de variación entre $983,39 y $1.092,01.
Al término del año 2, la utilidad por acción esperada sería: $1.070,6(2/3)(1/2)+1.040,3(2/3)(1/2)+$1.065,3(1/3)(1/2)+$1.035,15(1/3)(1/2)=$1.053,71
Al término del año 1, la utilidad por acción esperada sería: $1.010(2/3) + $1.005(1/3) = $1.008,33
Entonces se tiene: Año Utilidad Esperada Incremento (en %) 1 $1.008,33 0,833% 2 $1.053,71 4,5% 3 $1.056,34 0,25%
En este caso el problema habría sido muy sencillo calculando directamente los rendimientos esperados; éstos son:
Año Aumento Esperado (en %) 1 1%(2/3)+0,5%(1/3) =0,833% 2 6%(1/2)+3%(1/2) =4,50% 3 2%(3/4)+(-5%)(1/4)=0,25%
Autor: José Rigoberto Parada Daza 33
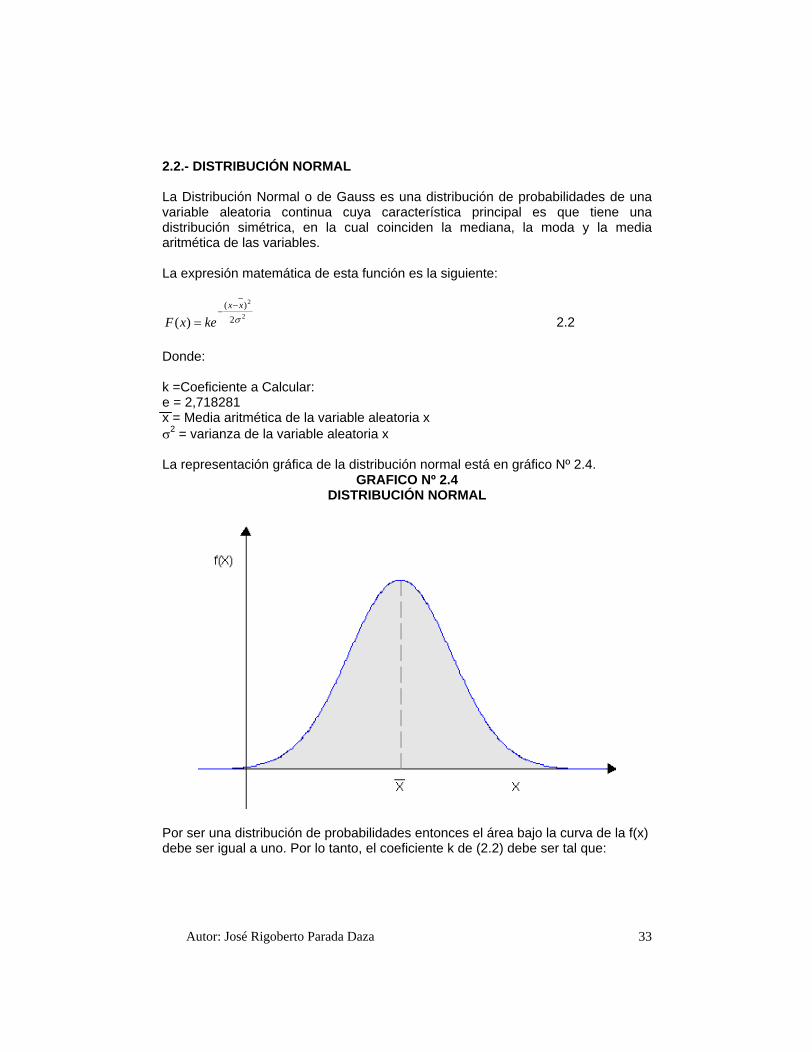
2.2.- DISTRIBUCIÓN NORMAL
La Distribución Normal o de Gauss es una distribución de probabilidades de una variable aleatoria continua cuya característica principal es que tiene una distribución simétrica, en la cual coinciden la mediana, la moda y la media aritmética de las variables.
La expresión matemática de esta función es la siguiente:
2
2
2
)(
)(xx
kexF 2.2
Donde:
k =Coeficiente a Calcular: e = 2,718281 x = Media aritmética de la variable aleatoria x
2 = varianza de la variable aleatoria x
La representación gráfica de la distribución normal está en gráfico Nº 2.4. GRAFICO Nº 2.4
DISTRIBUCIÓN NORMAL
Por ser una distribución de probabilidades entonces el área bajo la curva de la f(x) debe ser igual a uno. Por lo tanto, el coeficiente k de (2.2) debe ser tal que:

Autor: José Rigoberto Parada Daza 34
Calculando esta integral, el valor de k es: 1/ 2 , con esto se asegura que la función f(x) tiene un valor total igual a uno entre los puntos -
y +
que son asintóticos con el eje x.
Entonces, la f(x) tiene la siguiente expresión:
f(x) = (1/ 2 ) exp -(x - x) 2 / 2 2
2.3
La expresión (2.3) indica que para cualquier valor de x, su probabilidad de ocurrencia se puede calcular conociendo su media aritmética x y su varianza 2, lo que da una gran operatividad a esta función y lo que ha permitido generar tablas de cálculo, que se encuentran en casi todos los libros de estadística descriptiva. Esta función tiene un punto máximo, el que se calcula derivando (2.3) y se obtiene de:
En la derivada anterior se observa que cuando x= x se obtiene el punto máximo de la función.
Calculando los puntos de inflexión de la curva, mediante el cálculo de la segunda derivada y haciéndola igual a cero, se obtiene:
De la ecuación anterior se tiene que los puntos de inflexión son: x = x
Para calcular el área bajo la curva se debe calcular la integral entre los puntos que se desea obtener. A través de este método se puede buscar cualquier probabilidad de alguna otra distribución asumiendo que se comportan como una normal, pero se debe transformar la variable original en variable estandarizada t mediante el siguiente cálculo: t = ( x - x )/
Esta variable t tiene una media igual a cero y una desviación estándar igual a uno. Para aclarar, supongamos el siguientes ejemplo: se tiene una serie de precios de una acción de: $10, $11, $12 y $13. El precio promedio es: $11,5 y la desviación estándar se calcula de la siguiente forma:
[ (10 - 11,5)2 + (11 - 11,5)2 + (12 - 11,5)2 + (13 - 11,5)2 /3 ]1/2 = $1,29099 Calculando las variables estandarizadas se tiene:
1}2/)(exp:;1)( 22 dxxxkseaodxxf
0)()(1)(
2xfxx
dx
xdf
0)()(11)( 2
22
2
xfxx
x
xf

Autor: José Rigoberto Parada Daza 35
t1 = (10-11,5)/1,29099 = -1,161899 t2 = (11-11,5)/1,29099 = -0,38729 t3 = (12-11,5)/1,29099 = +0,38729 t4 = (13-11,5)/1,29099 = +1,161899
Calculando el promedio de la variable t, se tiene que este es igual a: 4
1
0)14/(i
it y su varianza es igual a:
1,161899 2 + 0,38729 2+ 0,38729 2 + 1,161899 2 /3 = 1
Según el Teorema Central del Límite si se tiene una muestra de una variable aleatoria suficientemente grande, entonces la distribución de la medias muestral es normal, independientemente de la distribución original. Mediante esta teoría se puede razonablemente suponer que cualquier distribución puede homologarse a la Normal y con este supuesto se puede usar la aproximación de la distribución Binomial a la Normal. Para explicar esto supongamos el siguiente ejemplo:
Se tiene una variable aleatoria discreta (por ejemplo precios de títulos) que tienen tres posibilidades de obtener éxitos, o sea tres posibles alzas en tres años; con p=2/3 y q=1/3, entonces la probabilidad de dos alzas en los tres años es la siguiente:
Si asumimos que la distribución de estos datos se asemeja a una Normal, no olvidar que éste es para variables continuas, entonces en este caso debemos calcular el promedio de los datos y su desviación, o sea:
E(x) = np = 3(2/3) = 2 2(x) = np(1-p)=npq = 3 (2/3)(1/3) = 2/3 = 0,66667
(x) = 0,81649658
La probabilidad de que las alzas sean iguales a 2 sería equivalente a que éste se mueva entre 1,5 y 2,5, o sea se deberían calcular las variables estandarizadas t1 y
t2.
t1 = (1,5-2) / 0,81649658 = - 0,612372 t2 = (2,5-2)/0,81649658 = 0,612372
Por lo tanto, se debe buscar el área en la Distribución Normal entre 0,612 y +0,612 entonces: P(-0,61237<x<0,61237) = 0,4516; valor que se aproxima bastante a la probabilidad obtenida directamente de la distribución binomonial. En este caso y en general para transformar la variable discreta en continua se considera que ésta oscila en 0,5 sobre los límites de la variable discreta; por ejemplo si se desea calcular en P= 5, entonces continuamente ésta se encuentra entre 4,5 y 5,5. Si se tienen dos datos discretos, por ejemplo de 3 a 6 sucesos
4444,027/12)3/1()3/2()!1!2/(!3)( 2232 qp

Autor: José Rigoberto Parada Daza 36
favorables, entonces continuamente éstos se pueden mantener entre 2,5 y 6,5 y se usan éstas últimas como variables a estandarizadas, o sea (2,5 x ) / y (6,5 x )/

Autor: José Rigoberto Parada Daza 37
CAPITULO III
CONCEPTOS MATEMÁTICOS SUBYACENTES EN MODELO DE OPCIONES FINANCIERAS.
3.1.- CAPITALIZACIÓN EN TIEMPO CONTÍNUO
El tratamiento tradicional de capitalización es de tipo discreto, es decir se capitaliza el interés ganado de un período a otro periodo, así, el valor final de un
Capital Inicial (Co), capitalizado f veces al año, al final de un período de n años y capitalizado a una tasa r anual es el siguiente:
A(n,r) = Factor de Acumulación de $1 en n años capitalizado a r de interés anual.
El interés continuo o capitalización continua equivale a que la frecuencia de capitalización es muy grande, en términos matemáticos significa f , por lo tanto a medida que la frecuencia de capitalización es grande, entonces el factor de acumulación cambia. En este caso es necesario analizar qué sucede con el factor A(n,r) cuando f , es decir cuando en el año hay muchas capitalizaciones, algo así como capitalizar en fracciones de segundos.
Tenemos que
Se debe calcular el siguiente límite: ),( rnAlímf
Matemáticamente para el cálculo de este límite hay que traspasar la función A(n,r) a función logarítmica y posteriormente usar la Regla de L Hopital. Así, se tiene:
Para calcular el límite sobre la función h(f) y g(f) se debe derivar numerador y denominador por f (Regla de L Hopital) y calcular límite cuando f . Entonces, se tiene:
Entonces, por definición,
LnA(n,r) = nr enr = A(n,r)
)1.3(),()1( rnACf
rCC o
fnof
)3.3()f(g
)f(h
fn/1
)f/r1(n)f/r1(nfn)r,n(nA
lll
)4.3(/1/1
)/1/()/(
)('
)('2
2
rnfr
rnlím
nf
frfrlím
fg
fhlím
fff
)2.3()1(),( fn
f
rrnA

Autor: José Rigoberto Parada Daza 38
Es decir, el factor de acumulación para $1 inicial, con capitalización contínua es el número neperiano enr. Lo anterior implica que la relación entre capitalización discreta y contínua es la siguiente:
nrce = (1+rd)n (3.5)
Donde:
rc = Tasa de capitalización contínua rd = Tasa de capitalización discreta.
Tomando logaritmo natural a ambos lados de la igualdad 3.5, se tiene:
Ln nrce = Ln (1+rd)n
rcn(lne) = nLn(1+rd) rcn = n Ln(1+rd) rc = ln (1+rd)
Por ejemplo, si un Banco paga 5% de interés capitalizado anualmente, entonces la tasa equivalente de capitalización contínua rc es la siguiente:
rc = ln (1,05) rc = 0,04879 = 4,879%
Para el cálculo de una serie de pagos constantes con capitalización contínua durante un período n, su valor actual es:
Donde:
VA = Valor Actual Ct = Pagos de anualidades constantes para cada período.
Para caso discreto, sabemos que el valor actual de C pagos anuales equivale a la sumatoria actualizada de los pagos (Ver Apéndice Nº 2). Para el caso de capitalización contínua, la sumatoria del caso discreto se transforma en una integral. Para resolver la integral de (3.6) se deben usar sustituciones con variables auxiliares. O sea:
e = e-rt
de donde se obtiene:
)6.3(dtCeVA t
n
o
rt

Autor: José Rigoberto Parada Daza 39
= -rt tomando la diferencial de la igualdad anterior, se tiene: du = -rdt despejando dt, se tiene: dt = -du /r
Reemplazando la última igualdad en (3.6) se tiene:
Resolviendo la integral, se tiene:
En capitalización discreta el factor de actualización de una renta de $1 por periodo es:
Se puede ver la similitud entre (3.7) y (3.8). Para explicar de mejor forma supongamos el siguiente ejemplo: Un banco paga por un depósito, un 10% de interés capitalizado anualmente durante 10 años. Si se deposita anualmente $100, entonces el valor actual, capitalizado de forma discreta es:
Capitalizando continuamente se tiene:
rc = Ln(1,1) = 0,095310
Entonces:
Se ve que el valor actual capitalizado continuamente es superior al pagado por capitalización discreta. La simplicidad de trabajar en modelos financieros con el número neperiano e ha llevado a que normativamente el supuesto de capitalización contínua inunde la literatura financiera; es matemáticamente más favorable y simplificador hacia el trabajo académico. Pero también la capitalización contínua, dada la transferencia
dueCr
VAn
T0
1
)7.3()1
(r
eCVA
rn
t
)8.3()1(
11
d
nd
r
r
46,614$)1,0
1,1/11(100
10
VA
692,644$09531,0
1100
1009531,0 xeVA

Autor: José Rigoberto Parada Daza 40
electrónica de dinero en pequeñas fracciones de tiempo, entre zonas geográficas distante a miles de kilómetros, ha permitido que este concepto teórico se haya incorporado al mundo real. Así un inversionista bursátil durante las veinticuatro horas del día encontrará una bolsa abierta en algún lugar del mundo cuando la suya esté cerrando, esto implica que si transfiere dineros, por transferencia electrónica, en realidad capitalice en pequeñas unidades de tiempo, lo que en el año equivale a capitalizar muchas veces, o sea casi infinitas veces.

Autor: José Rigoberto Parada Daza 41
3.2.- MOVIMIENTO BROWNIANO
3.2.1- Antecedentes Generales
El movimiento Browniano es un fenómeno descubierto por el botánico inglés Robert Brown y es muy útil para procesos estocásticos y Teoría de Probabilidades. El proceso se ha aplicado en algunas áreas, así para describir el movimiento mostrado por pequeñas partículas totalmente inmersas en un líquido o en gas. Se ha usado un test estadístico, análisis de precios de acciones y en Mecánica Cuántica.
Albert Einstein en 1905 mostró que el movimiento Browniano podría ser explicado asumiendo que las partículas inmersas estaban siendo continuamente sujetas a bombardeo por las moléculas del medio que las rodea, como lo afirma Ross (1996). El proceso geométrico Browniano ha sido originado en una descripción en Física de los movimientos de una partícula pesada suspendida en un medio de partículas livianas. Las partículas livianas se mueven en rededor rápidamente y por supuesto ocasionalmente tienen choques random o aleatorias con la partícula pesada. Cada colisión desplaza suavemente la partícula pesada; la dirección y magnitud de este desplazamiento es aleatorio e independiente de las otras colisiones, pero la naturaleza de esta aleatoriedad no cambia de una coalición a otra (en el lenguaje de la Teoría de Probabilidades, cada colisión es un evento aleatorio independiente e idénticamente distribuido).
El modelo de movimiento geométrico Browniano toma los cambios o desplazamiento de las partículas y usando matemáticas, deriva que los cambios de las partículas sobre largos períodos de tiempo deben ser normalmente distribuido, con media y desviación estándar dependiente solamente de la cantidad de tiempo que ha pasado. Es una observación interesante porque así se puede medir el promedio de los desplazamientos y la desviación estándar de estos desplazamientos sobre algún período corto de tiempo y esta medida será aplicada para largos períodos de tiempo. La aplicación de este principio hacia el movimiento del precio de las acciones aparece como algo novedoso y sugerente y a partir de homologación se desarrolla el movimiento geométrico Browniano hacia Finanzas y Economía.
3.2.2.- Definición Matemática del Movimiento Geométrico Browniano.
Un proceso estocástico Zz
Zz : t
0,
con tiempo contínuo se define como un movimiento Browniano con una tasa de expansión (drift)
y varianza 2, denotado por MB ( , 2) si:
i) Zo = 0 ii) Para algún 0 to t1 ............<tn ,
Ut,k Zt,k Zt,k-1 s (k=1,..... n)
Son independiente y normalmente distribuido con media tk y varianza

Autor: José Rigoberto Parada Daza 42
2 tk, donde tk = tk tk-1
El significado de la variable Z es que ésta puede ser un flujo o bien rentabilidades de títulos y que por convención se supone que se tienen datos desde el momento cero (to). Se asume que el primer flujo (rentabilidad o precio) es cero. El significado de ii) es que el cambio en el flujo (rentabilidad o precio) que se define como Utk
durante el período observado n son todos independientes entre sí y a la vez estos cambios están normalmente distribuidos. Expresados en una tabla, supongamos el siguiente ejemplo:
Observación
k Tiempo
t Flujo
Zt
Variación tpo. tk= tk - tk-1
Cambio en Flujo tk=Ztk-Zt,k-1
1 0 Zo = 0 - - 2 1 Z1=$10 1 $10=z12-z10
3 2 Z2=$16 1 $ 6=z23-z12
4 3 Z3=$21 1 $ 5=z34-z23
5 4 Z4=$22 1 $1=z45-z34
La definición de ii) significa que los cambios (última columna de la tabla) debe ser independiente y distribuidos normalmente.
Cuando MB(0,1) o sea media cero y varianza uno se denomina proceso Wiener. Esto significa que los cambios en la variable (precios o rentabilidades) deben tener media cero y varianza 1.
Para que tengan media cero y varianza uno, la variable Z debe ser estandarizada (Ver Cap.II,2.2), es decir, se debe hacer un desplazamiento de la variable. Así, pues, el proceso Wiener es un caso particular de Movimiento Browniano.
Las propiedades principales del Proceso Wiener son las siguientes:
1) Para intervalos de tiempo pequeño ( t) el incremento en la variable Z, Z(t) es: Z(t) = Z(t+ t) Z(t)
Z(t), en un pequeño intervalo de tiempo, es independiente de Z(t) y tiene una media y varianza proporcional a t. La función de distribución de probabilidad de la variable aleatoria es simétrica respecto al origen de t y tiene una distribución normal.
2) Z(t) está relacionado con un cambio en el tiempo t por la siguiente ecuación:
Z(t) = Y(t) Z
Y(t) es un proceso aleatorio Gauss o Normal con media cero y varianza uno, es decir, los datos de la variable están normalizados o estandarizados.

Autor: José Rigoberto Parada Daza 43
3) Ya se sabe, por definición, que los cambios en la variable Z(t) o Utk son independientes para cualquier par de diferentes intervalos cortos de tiempo t, que se define como que Z(t) sigue un proceso de Markov.
4) Se verifica que:
Zn = Zn-1 + Yn y Zo = zo , n = 1,2,... Z(t+ t) = Z(t) + Z(t)
Pero se define Z(t) = Y(t) t , luego reemplazando, se tiene:
Z(t+ t) = Z(t) + Y(t) t
Se supone que el proceso de desplazamiento se puede hacer con y varianza 2
por unidad de tiempo, entonces se tiene:
Z(t) = t + Y (t) t
La ecuación anterior indica que cualquier cambio en la variable de flujo (Rentabilidades o Precios) para un intervalo de tiempo pequeño t, tiene distribución normal con media t y varianza 2 t y es independiente de Z(t) y del cambio en cualquier otro intervalo de tiempo. Esta ecuación indica, además, que el cambio en la variable aleatoria está compuesto por un desplazamiento (igual que las partículas blandas) de
(drift) y una varianza 2 por unidad de tiempo ( t). Cuando la media es cero, entonces el proceso Wiener se reduce a:
De una manera más general, la ecuación de cambio en los precios constituye lo que se denomina Ecuación Diferencial Estocástica y ella es:
Donde Y(t) = V(t) / (t,z),
V es variable aleatoria con media cero y Varianza finita denotada por 2(t,z)
5) La función de Densidad de la variable Z(t) es:
ttYtZ )()(
)())(,())(,()( tYtZttZtftZ
tzt e
tZf 2/2
2
1)(

Autor: José Rigoberto Parada Daza 44
3.2.3.-Aplicación Movimiento Browniano al precio de Acciones.
Para la aplicación del movimiento Browniano se necesita conocer la media y la varianza de los datos. Estos cumplen un rol fundamental en todo el cálculo diferencial estocástico, y éstos son los conceptos válidos para el cálculo de
y . En la aplicación de estos conceptos en las ciencias naturales se requiere que ambos permanezcan constantes en el tiempo, sin embargo este supuesto es demasiado fuerte para el caso del precio de títulos financieros, de aquí que la media que se calcule debe tener una transformación para evitar la alta volatilidad de los precios y se considera más apropiado tomar el retorno del precio de las acciones como un mejor proxy, ya que sus oscilaciones son más pequeñas que la de los precios. Para esto supongamos que se tienen dos títulos A y B con los siguientes precios:
Título A
Título B
Tiempo
Precio
Variación
$ %
Tiempo
Precio
Variación
$ %
1 $100 1 $1000
3 $110 $10 10% 2 $1100
$100 10% 3 $121 $11 10% 3 $1210
$110 10% Varianza $ 8,576 Varianza $85,76
En el título A las variaciones en términos absolutos son 10 veces menores que las variaciones del título B y la varianza de ambas también están separadas por 10 veces. Por otro lado, si calculamos los cambios porcentuales con los precios de los dos títulos, éstos son de 10%. Al calcular la varianza de ambos retornos ésta se acerca a cero y es constante para todos los períodos. Por esta razón, se prefiere trabajar con el retorno de los títulos el que tiende a tener cuantitativamente menores variaciones que las variaciones cuantitativas de los precios.
En este caso el retorno de los títulos se ha considerado como la diferencia entre el precio de un período respecto al precio del período inmediatamente anterior, es decir:
Donde: rit = Retorno del título i en período t. y Pi,t = Precio del título i en período t.
1,
,
1,
1,,
ti
ti
ti
titiit P
P
P
PPr
11,
,
ti
tiit P
Pr
1,
1ti
itit P
Pr

Autor: José Rigoberto Parada Daza 45
En la bibliografía financiera también se usa el concepto de rentabilidad a través de logaritmo, como una forma aproximada de cálculo. A partir de rit, podemos plantear que:
Aplicando logaritmo natural se tiene:
Sí: Pi,t 1 + Pt = Pit
Entonces: lnPi,t = ln (Pi,t-1 + Pt)
Aplicando la Fórmula de la Serie de Taylor y tomando sólo los dos primeros términos, ya que el resto se puede despreciar pues tiende a cero, se tiene:
Reordenando queda:
Entonces la diferencia entre los logaritmos del Precio actual t más el precio del período t-1, es una manera aproximada de medir el retorno de los títulos. En el movimiento Browniano se asume que los retornos tienen Distribución Normal por eso es que a esta forma de cálculo, usando logaritmo, se les denomina función Log-normal, o sea los retornos se han calculado usando el logaritmo natural de los precios y los retornos siguen una distribución normal. La diferencia numérica entre el método tradicional de cálculo de retorno y el logaritmo no es tan elevada. En Tabla Nº3.1 se muestra un caso de diferentes precios y su cálculo de rentabilidad:
TABLA Nº3.1 RETORNO POR DIFERENCIAS DE PRECIOS Y POR LOGARITMO
Precio rit LnPt-lnPt-1 Diferencia $100 $110 10% 9,53% 0,47% $120 9,09% 8,70% 0,39% $130 8,33% 8% 0,33% $140 7,69% 7,41% 0,28% $150 7,14% 6,90% 0,24%
En tabla Nº 3.1 se ve que existe una diferencia pequeña la que se va haciendo más reducida a medida que las diferencias en valores absolutos son menores. Así de $100 a $110 la diferencia de cálculos por ambos métodos es de 0,47%
)ln()ln()ln( 1,,1,
tititi
it PPP
P
12
2
1,1,,
)(
!2
1
!1
1lnln
tti
ttiti
P
P
P
PPP
itti
titi rP
PPP
1,1,, lnln

Autor: José Rigoberto Parada Daza 46
mientras que para un cambio de precios de $140 a $150 la diferencia entre ambos sistemas de cálculo es de 0,24%. A medida que tenemos menor diferencia en los precios, entonces menor es la diferencia entre el cálculo de uno u otro método. Así, pues, el retorno nos da una medida de
y la varianza de esos retornos nos
da la volatilidad del retorno.
El Proceso Browniano supone que P/P está determinado por un retorno esperado de
y la segunda parte por la volatilidad del título, pero en un proceso estocástico, o para un tiempo instantáneo, o sea:
Por lo tanto un precio, según alguna distribución de probabilidades de ellos, debería ser:
(P+ P) = P+ tP + P Z(t) t
o sea; = P(1+ t + Z(t) t
De acuerdo con la ecuación anterior los retornos, o cambios en los precios, están representados por una tasa esperada y para un cambio de tiempo determinado t
más un factor estocástico dado por Z(t) t
Para aclarar numéricamente supongamos el siguiente ejemplo: Se tiene una acción cuya desviación estándar anual ( ) es 20% y tiene un rendimiento esperado, , de 10%. Si el precio en un momento inicial es $100, entonces anualmente se espera que éste varíe, o sea, el retorno del título, sería:
P/P = 0,1 t + 0,20 Z(t) t
o bien, P = P(0,1) ( t) + 0,20Z(t) t (P),
Si el precio al cabo de un año es $110. Entonces esta variación se debe a dos componentes:
a) Componente de retorno esperado:
P t = (100)*(0,1)*(1) = $10
b) Componente aleatorio: )(tZP t = 02,0/)1,01,0(20,0100 xx
En este caso z(t) corresponde al valor de una variable normalizada, por tener distribución normal, es decir:
ttZtPP )(/
ttZPPtP )()(

Autor: José Rigoberto Parada Daza 47
Es decir en este caso se dio el precio que se esperaba; si el precio hubiese subido a $130, entonces esta variación se explicaría por las siguientes datos:
Variación Total: $10 + $20
El ejercicio anterior implica que la variación se debió a $10, que se esperaba y a $20 por razones aleatorias.
En el caso del ejemplo anterior se ha considerado que la variación del tiempo es
un año, es decir t =1, sin embargo, para período de tiempo menores, por ejemplo un día, entonces tanto como deben expresarse de forma diaria, o sea:
d = anual/365 = 0,10/365 = 0,0002739 t = 1/365 = 0,0027397
Entonces, la variación de Precios (en $) para un día es:
P = 100 0,0002739 + 0,20z(t) 0027397,0 .
Esta última expresión señala que el aumento del precio de la acción es un valor aleatorio que tiene una distribución normal con media $0,02739 y una desviación
estándar de $1,0468 que se obtiene de $100x0,20x 0027397,0
En el caso del traspaso de varianza anuales a períodos menores, la relación que se establece es la siguiente:
2ANUAL = t 2
t o ANUAL= t t
Donde t = semestres, trimestres, meses, semanas o días. Así, se obtiene: 2ANUAL = 2 2
semestral o ANUAL= 2 semest.
2ANUAL = 4 2
trimestral o ANUAL= 4 trimest
2ANUAL = 12 2
meses o ANUAL= 12 meses
2ANUAL =52 2
semana o ANUAL= 52 semana
2ANUAL = 365 2
diario o ANUAL= 365 diario
En general:
20,010,010,0/
)(PP
tz
10$1*10,0*100) tPa
20$1*2,0
10,030,0*20,0*100)() ttzPb

Autor: José Rigoberto Parada Daza 48
2Tma = ( 2
Tme)Tme
donde: 2Tma = Varianza de Tiempo Mayor
2Tme = Varianza de Tiempo Menor
Tme = Tiempo menor respecto al total del tiempo mayor.
Ejemplo: Se sabe que 2 semestral = 0,15 si queremos calcular la varianza diaria,
entonces esta relación será:
2s = 180 2
d
2d = 2
s /180 =0,15/180=0,000833
En los cálculos presentados de rentabilidades diarias se ha considerado que el año tiene 365 días. Sin embargo, existe la opción de considerar 250 o 260 días, ya que esa, aproximadamente, son las veces que se transan acciones en el año considerando los días feriados. Sin embargo, esto puede llevar a confusiones pues se está despreciando el efecto Fin de semana , ya que si se toma un retorno simple, el retorno de los días lunes no es comparable con el del día viernes, pues la rentabilidad del día lunes corresponde a una rentabilidad de dos días, entonces si se trabaja con 250 días habría que corregir el promedio del día lunes de las series históricas.
La dificultad que se produce, al calcular promedios históricos con 365 días o 250 días, se debe a que si se calcula la rentabilidad del día lunes tomando el precio de cierre del lunes respecto al día viernes de la semana anterior, entonces la rentabilidad calculada y que aparece el día lunes corresponde en realidad al retorno de tres días. Si no se considera este detalle, entonces varía el promedio diario y la desviación estándar. El procedimiento más sencillo para mejorar esta información es considerar la rentabilidad del día lunes y tomar un período total de 365 días, ya que así se estaría estimando que la rentabilidad de acciones considera todos los días del año, independientemente de que sea hábil o no, ya que el dinero sigue invertido por sábados y domingos.
Al tomar 250 días y la rentabilidad del día lunes, se está considerando que el promedio de ese día está triplicado. Con los siguientes datos se explica esta situación:
Sea RL = Rentabilidad del día lunes (obtenida de la diferencia de precios entre los precios de cierre de lunes respecto al viernes de la semana precedente).
RM = Rentabilidad promedio de los días martes a viernes. Para fines de análisis supongamos que RL y RM son constantes, entonces se tiene:

Autor: José Rigoberto Parada Daza 49
Rentabilidad Promedio = MLML RR
RR792,0208,0
250
19852
En el cálculo anterior, en realidad se está considerando que durante 52 lunes se obtuvo una rentabilidad de RL, pero ésta es un resultado de tres días, por lo que, asumiendo un promedio simple, la rentabilidad de lunes es RL/3 = RL , es decir el promedio anual sería: 52(RL/3) + 198 RM /250. De no ser así, se considera como si en el numerador se tomó implícitamente sábados y domingos y en el denominador no se agregaron esos 104 días correspondientes a aproximadamente a sábados y domingo.
Otro aspecto que llama la atención es que al considerar un promedio simple de retornos se está obviando el proceso de reinversión del dinero. Puede ser válido considerar también un promedio correspondiente a una media geométrica del siguiente tipo:
Sea: rit= rentabilidad diaria de la acción i el día t. rid = Rentabilidad diaria promedio de la acción i
Entonces:
La expresión anterior es la rentabilidad diaria promedio de un título i pero que considera reinversión del dinero.
3.2.4.-PROCESOS GEOMÉTRICOS BROWNIANO Y DISTRIBUCIÓN NORMAL
En el proceso Browniano se asume que los retornos tienen una Distribución Normal, esto implica que cada retorno tiene asociado una distribución de probabilidades, por lo tanto se puede calcular la probabilidad de que se de un retorno, dado el valor de la tendencia
y el valor de su volatilidad dado por la varianza. Se asume, por definición estadística, que tanto varianza ( ) como media ( ) se mantienen constantes, situación que puede ser válida en cortos períodos de tiempo, pero no válido para largos períodos.
El movimiento Browniano ésta está dado por la función z(t) y que se define de la siguiente forma:
365365
1
)1()1(t
idit rr
11365
365
1titid rr

Autor: José Rigoberto Parada Daza 50
Con la función z(t) se puede calcular la probabilidad de superar la rentabilidad esperada de r, o la parte complementaria que equivale a obtener la probabilidad que la rentabilidad sea inferior a r. Siguiendo con el ejemplo anterior de
= 0,20 anual y =10% podemos calcular la probabilidad que la rentabilidad supere en 13% al nivel esperado de , es decir r = 0,10x1,13=11,3%.
Por lo tanto;
Entonces, la probabilidad de superar una rentabilidad de 11,3% sería el área marcada en la figura 3.1, o sea aproximadamente 47,21%, dato que se ha obtenido de una Tabla de Distribución Normal.
FIGURA 3.1
Con este procedimiento se puede calcular la probabilidad que el retorno caiga por debajo de un determinado valor negativo, por ejemplo - % o bien que suba sobre ese mismo valor pero positivo, o sea + %.
Supongamos que los retornos de un título tienen los siguientes datos: = 10% = 20%
Con estos datos podemos calcular qué probabilidad existe que el retorno caiga a 5% o suba a 15% (es decir +5%). Determinando las variables estandarizadas
para el primer y segundo caso se tiene:
t1 = (-0,05-0,10)/0,20=-0,75 y
rtz )(
065,020,0
10,0113,0)( tz

Autor: José Rigoberto Parada Daza 51
t2 = (0,15-0,10)/0,20 = 0,25
Según los datos obtenidos de una tabla de Distribución Normal, estas probabilidades serán:
P (r<-5%) = P(t < 0, 75) = 0,2266 y P(r>15%)= P (t > 0,25) = 0,4013 (Ver figura 3.2). O sea:
Figura 3.2
La probabilidad que esté entre 5% y 15% será la siguiente: P(-5%<r < 15%) = 0,2734+0,0987 = 0,3721, o sea un 37,21%.
3.3. VOLATILIDAD Y PROBABILIDAD DE RETORNOS CON MOVIMIENTOS BROWNIANOS
Tomando la Distribución Normal como base del proceso Browniano se puede analizar la incidencia de la volatilidad en los retornos y de la probabilidad de obtener dichos retornos. Para explicar ésto tomemos dos títulos con los siguientes datos:
Título A
Título B
A = 10%
B = 10%
A = 12%
B = 20%
Supongamos que queremos calcular la probabilidad de que ambos caigan a ( - )%, o suban (
+ )% entonces la probabilidad que el retorno se encuentre entre ambos tramos para diferentes se da en la siguiente tabla Nº 3.2.

Autor: José Rigoberto Parada Daza 52
TABLA Nº 3.2
TITULO A TITULO B
P( - <rA< + ) P( - < rB < + )
Probabilidad
Probabilidad
5% 0,3231 5% 0,1974
8% 0,4950 8% 0,3108
10% 0,5953 10% 0,3829
15% 0,7887 15% 0,5467
20% 0,9044 20% 0,6827
En Tabla Nº 3.2 se observa que el título menos volátil en este caso corresponde al título A, ya que tiene una menor desviación estándar. La probabilidad de obtener rentabilidades en un mismo rango es mayor para el que tiene la más baja volatilidad, que en el caso A es de 12% respecto al B que es de 20% y para ambos casos con un retorno esperado de 10%. Así, por ejemplo, se espera que el retorno baje en 5% o suba a +5%, o sea entre 5% y 15% tanto para A como para B, la probabilidad de obtener una rentabilidad entre ambos retornos es de 0,3256 para A y de 0,1974 para B. En el caso de que en ambos el retorno baje en
20% del actual o suba en 20% del actual, es decir una rentabilidad entre los rangos 10% y 30% ( -
r + , con =20% y con =10%), entonces la probabilidad de que el retorno se encuentre entre ambos retornos es de 0,905 para el título A y de 0,6826 para el título B.
Lo anterior indica que el título más volátil, es decir más riesgoso, tiene menos probabilidad de alcanzar rentabilidades entre rangos predeterminados. El caso extremo es de aquel título libre de riesgo, es decir =0, en que la probabilidad de

Autor: José Rigoberto Parada Daza 53
obtener rentabilidades entre cualquier rango es igual a 1. En efecto, se tiene lo siguiente:
Z(t) = (( + )- )/
P(- <r
< ) =1 por cálculo de la probabilidad según
una Distribución Normal.
Los cálculos de la Tabla Nº 3.2 se han obtenido de la siguiente forma:
TITULO A
= 10% = 12
p(- +
r
+ )
a) = 5%
5 10 5 5 10 /12 0,41666
5 10 5 15 10 /12 0, 41666
Es decir: P( -0,41666 < r < 0,41666) = 0,3231

Autor: José Rigoberto Parada Daza 54
b) = 8%
8 10 2% 2 10 /12 0,6666
10 8 18% (18 10) /12 0,6666
Es decir: P(-0,666< r < 0,666)=0,4950
b) =10%
10 10 0 0 10 /12 0,8333
10 10 20% 20 10 /12 0,8333a
Es decir: P(-0,8333<r < 0,8333)=0,5953

Autor: José Rigoberto Parada Daza 55
c) =15%
15 10 5% 5 10 /12 1, 25
15 10 25% 25 10 /12 1, 25a
O sea P(-1,25< r < 1,25)=0,7887
d) =20%
20 10 10% 10 10 /12 1,666
20 10 30% 30 10 /12 1,666a
P(-1,666< r < 1,666)=0,9044

Autor: José Rigoberto Parada Daza 56
TITULO B
B = 10% b = 20%
a) =5%
5 10 5% 5 10 / 20 0, 25
5 10 15% 15 10 / 20 0,25a
P(-0,25 < r < 0,25)=0,0987 x 2 = 0,1974 b) = 8%
8 10 2% 2 10 / 20 0, 4
8 10 18% 18 10 / 20 0,4a
P(-0,4<r < 0,4) = 0,3108

Autor: José Rigoberto Parada Daza 57
c) = 10%
10 10 0% 0 10 / 20 0,5
10 10 20% 20 10 / 20 0,5a
P(-0,5 < r < 0,5)=0,3829
d) =15%
15 10 5% 5 10 / 20 0,75
15 10 25% 25 10 / 20 0,75a
P(-0,75 < r < 0,75) = 0,5467

Autor: José Rigoberto Parada Daza 58
e) =20%
20 10 10% 10 10 / 20 1,00
20 10 30% 30 10 / 20 1,00a
P(-1 < r < 1) = 0,6827
Relación Probabilidad y Riesgo.

Autor: José Rigoberto Parada Daza 59

Autor: José Rigoberto Parada Daza 60
3.4. ¿QUÉ ES UN PROCESO ESTOCÁSTICO?
El concepto de proceso estocástico proviene de una definición estadística bien precisa y es lo que se desarrolla en este punto, siguiendo a Suriñach, López y Sausó (1995).
La idea central de un proceso estocástico radica en el uso de series temporales de datos o también denominado proceso generador de datos (PGD) que en nuestro caso está dado por series de precios de acciones y series de retornos de acciones. En términos teóricos y en trabajos econométricos considerando series de datos, se supone normalmente que tanto la media como la varianza de esos datos son constantes o estacionarios; esto implica que ni media ni varianza depende del tiempo. Este supuesto equivale en nuestro caso a considerar que la media de los retornos y la varianza de dichos retornos deberían ser constantes. Sin ser erudito en el tema económico basta con observar cualquier serie de precios y rentabilidades de títulos para ver que dicho supuesto es muy difícil de cumplir y en muchas ocasiones, ya sea la media o la varianza varían con el tiempo. De aquí se inicia la consideración de qué ocurriría con series de datos que no tengan esa característica dando origen a diferentes fenómenos y en los cuales se asume el proceso estocástico, como un caso particular.
Los problemas econométricos que origina el que las series de datos (precios y retornos) no tengan media y varianza constante son serios, ya que puede afectar el análisis de los test estadísticos tradicionales como son los test t, F, R y otros. Se han intentado subterfugios matemáticos para arreglar el problema o bien se hacen maquillajes de los datos.
Al desarrollar el tema de los PGD se analiza si la media y varianza siguen ciertas tendencias en función del tiempo lo que se presenta en Tabla Nº 3.3.
TABLA Nº3.3 TENDENCIA MEDIA VARIANZA
Ausencia /(1- ) 2 /(1- 2) Determinística /(1- )+ t/(1- ) 2 /(1- 2) Estocástica 0 t 2
Determinística y estocástica
t
t 2
Fuente: Elaboración a partir de Suriñach y otros, op.cit.
En tabla Nº 3.3 se observan cuatro situaciones que permiten analizar si los datos presentan tendencias en función del tiempo. En esta tabla se designa
como la media de los datos, 2
varianza de los errores de los datos, t el tiempo
considerado en los datos xt y
raíz en el polinomio autorregresivo. En la tabla se indica que tendencia en varianza significa que la varianza es una función del tiempo y si se asume que la media de los datos es cero (es decir datos normalizados) entonces existe un proceso estocástico.

Autor: José Rigoberto Parada Daza 61
En consecuencia, un proceso estocástico en una serie de datos, retorno o precios, implica que dichos datos temporales están estandarizados y que la varianza de ellos crece en función del tiempo, o sea es t veces la varianza. Los datos estandarizados indican que se ha generado una nueva serie de datos provenientes de la original donde cada dato nuevo es el original menos el promedio de la serie, o sea x t = xt - x, donde xt= retorno inicial; x t = retorno modificado y x es el promedio de los retornos de la serie temporal de datos.
El caso de una serie determinística indica que la media de los retornos de acciones están en función del tiempo t, pero no así de su varianza la cual, como se ve en la fórmula, no depende del tiempo. Cuando hay ausencia de tendencia esto indica que ni media ni varianza dependen del tiempo.
Así, pues, un proceso estocástico es una definición precisa y no es sinónimo de azar como a veces se tiende a asociar. Un ejemplo de estos procesos es lo que se denomina Recorrido Aleatorio que se explica a continuación con un ejemplo de retorno accionario:
Sea Rt = Retorno de Acciones en el período t, entonces el recorrido aleatorio es:
Rt - Rt-1 = (1- L)Rt = t con = 1
Donde t es un proceso ruido blanco y L es el operador de retardo definido como LRt= Rt-1 cuando =1 y = Coeficiente de raíz unitaria.
Definición de ruido blanco en las perturbaciones o errores t significa lo siguiente:
E( t ) = 0 E( 2
t ) = 2
E( t t ) = 0 t t
Que la varianza tenga tendencia, o sea no estacionariedad, se obtiene al sustituir recursivamente la expresión: Rt = R t-1 + t, es decir:
Sí =1 y 2 = varianza de t y la var (Ro) = 0, entonces la varianza de Rt será t 2. Así, pues, el Recorrido Aleatorio de los retornos tiene una tendencia en la varianza (depende del tiempo) y se debe a la existencia de la raíz unitaria en el polinomio autorregresivo, siendo este un caso de tendencia estocástica.
Puede ocurrir casos de tendencia estocástica, tal como se definió, con
= 0, es decir sin crecimiento, pero con tendencia en varianza, o sea:
E(R) = = 0 2 (R) = t 2
1
1
0t
t
i
io
tt RR

Autor: José Rigoberto Parada Daza 62
El caso anterior puede ser un proceso estocástico donde el retorno en t depende de los retornos en el período anterior más una perturbación o error cuya varianza de los errores es creciente con el tiempo. Esto indica que el retorno a largo plazo (con t grande) debería ser mayor que el retorno de corto plazo, es decir:
Rt = Rt-1 + t
A este último caso se le denomina un recorrido Aleatorio sin constante (drift).
Para el caso de las acciones y de su retorno, E. Fama (1965) realizó un estudio en Estados Unidos con las series de precios que le llevó a la conclusión de que estos seguían un recorrido aleatorio. Como datos básicos, Fama tomó las acciones del Indice de Acciones Dow-Jones entre los años 1957 y 1962. Para el cálculo de retornos usó lo siguiente:
LnPt = LnPt-1 + t
O reescrito tiene la siguiente implicación:
LnPt LnPt-1 = t
Como ya se indicó en páginas anteriores la diferencia de logaritmo natural es una manera aproximada de medir los retornos de las acciones, lo que indica la expresión última que esos rendimientos son todos resultado de un proceso estocástico, que implica que los precios del pasado no tienen ninguna significación en los precios futuros. En este caso, lo que Fama ha desarrollado es que las series de datos de precios de acciones tienen =1. El estudio comprueba la existencia de recorrido aleatorio, pero para fines de este trabajo no serán expuestas, pues se alejan del objetivo de este texto y sólo se menciona con fines referenciales.
Respecto a la Tabla Nº 3.3, el Proceso Browniano tiene las características de ser estocástico y determinista. Esto quiere decir que los retornos accionarios tienen tendencia en la media y tendencia en la varianza, es decir, los rendimientos accionarios varían en media según sea el tiempo considerado y varían en varianza según el tiempo. En el caso especial de Proceso Wiener, siguiendo los datos de Tabla Nº 3.3 se observa claramente la existencia de proceso estocástico con media cero y si se toma varianza igual a uno entonces el rendimiento depende del tiempo considerado. No debemos olvidar que media cero y varianza igual uno implican datos que se distribuyen alrededor de su promedio con distribución normal o Gaussiana.

Autor: José Rigoberto Parada Daza 63
CAPITULO IV
CÁLCULO DIFERENCIAL ESTOCÁSTICO.
El Cálculo Diferencial es un análisis respecto a como cambia una variable Y ante la variación en una o más variables X asumiendo que éstos son determinísticos y en tiempo continuo. Cuando se analizan las variaciones de un período a otro de ciertas variables y entre ellas existe alguna que genera dudas de su carácter determinístico existe alguna probabilidad de que ella no se dé en el cien por ciento de los casos, entonces hay una variable que represente esta probabilidad y en cuyo caso se habla de Cálculo Diferencial Estocástico. Normalmente en Cálculo Diferencial se trabaja con variaciones pequeñas y en tiempo continuo; pero también existen variaciones en tiempo discreto y que es lo que se analizará ahora.
4.1. VARIACIÓN EN TIEMPO DISCRETO Y CONTÍNUO.
Sea E = 0, 1, 2, 3,...... = Conjunto de número enteros positivos más cero
x(t) = Variable x en el tiempo t, con t T
Entonces un Sistema Dinámico Determinístico se puede describir por la siguiente ecuación en diferencia:
x(t+1) = f ( t, x(t)) , t T (4.1)
Con una condición inicial de x(0) = xo
El ejemplo citado indica que la variable x en t+1, que puede ser el precio de un activo en t+1, depende del tiempo t anterior y el precio en t. En economía hay varios modelos de este tipo, por ejemplo, tomemos el siguiente:
Ut = PtQt - CtQt
Donde: U t = Utilidad de la empresa en t.
P t = Precio de venta de los productos en t
Q t = Cantidad Producida y Vendida en t
C t = Costo Unitario de Producción en t
Supongamos que:
Pt = 0 +
1Q t-1
Esto quiere decir que el Precio en t depende de la cantidad producida en t-1, (período anterior), reemplazando y suponiendo que se conoce Qt, Ct, entonces se tiene:
11 )()( tttttot QQQCQU

Autor: José Rigoberto Parada Daza 64
El modelo anterior indica que la utilidad en t depende de la cantidad producida y vendida en el período anterior. Sin embargo, este tipo de modelo determinístico en economía es más bien ilusorio y no generalizable y lo común es que exista alguna parte de la variable dependiente que no es explicado totalmente por las variables independientes, siendo esa parte aleatoria. Así, para explicar Ut se puede agregar una variable aleatoria et a la cual se le asume una probabilidad de ocurrencia y su correspondiente distribución y puede ser con media cero y varianza finita, entonces el modelo sería:
El modelo anterior sería una ecuación en diferencia estocástica, así si tomamos (4.1) ahora con la variable estocástica, entonces se convierte en la siguiente ecuación en diferencia finita estocástica:
x(t+1) = f(t,x(t)) + v(t,x(t)) , con t T (4.2)
Entonces:
x(t+1) es una variable aleatoria f es una media condicional de la variable x(t+1) v es variable aleatoria con media cero y varianza finita denotada por 2 (t,x)
Este modelo tiene los siguientes supuestos:
La Distribución condicional de la variable estocástica v, dado x(t), es independiente de x(s) para s < t. La Distribución condicional de la variable estocástica v, dado x(t), es Normal de modo que la variable random (t), donde: (t)= v(t)/ (t,x) tiene Distribución Normal con media cero y varianza uno.
(t) es independiente de x.
La ecuación puede ser tomada como una secuencia de variables independientes distribuida normalmente con media cero y varianza uno, entonces (4.2) se puede convertir en:
X(t+1) = f(t,x(t)) + (t,x(t)) (t) (4.3)
La ecuación (4.3) constituye una ecuación en diferencia estocástica que es utilizada en modelaciones económicas.
Cuando las variaciones de tiempo son pequeñas y no discretas se trabaja en pequeñas variaciones infinitesimales, entonces el Sistema dinámico determinístico descrito en (4.1) se transforma en un Modelo Dinámico Determinístico descrito por la siguiente ecuación diferencial.
ttttttot eQQQCQU 11 )()(

Autor: José Rigoberto Parada Daza 65
Con condición inicial x(0) = xo. Expresando, al igual que el caso discreto con variable estocástica, (4.4) se transforma en:
dx= (f(t,x(t)) dt + (t,x(t))dz (4.5)
La ecuación (4.5) constituye una ecuación diferencial estocástica que es la base de modelos, como el de Opciones Financieras de Black-Sholes y es un tema desarrollado por Ito y se conoce, con el nombre de Ecuación Diferencial de Ito .
4.2. CÁLCULO DE ITO
Asumamos que los precios de las acciones siguen un proceso aleatorio, con media cero y varianza uno, es decir estandarizados, y con un Proceso Browniano que en este caso es además un proceso Wiener; sea St el precio de la acción en t y sus variaciones en t se pueden expresar como una ecuación diferencial estocástica del siguiente tipo:
dS(t) = (t,St) dt + (t,St) dZ(t) (4.6)
La ecuación (4.6) indica que el precio de un título varía en dSt en un pequeño período de tiempo y esta variación depende de una función (t,St) la cual puede ser conocida y también depende de una variación estocástica dada por (t,St) dZ(t). La variable Z(t) tiene Distribución Normal.
La ecuación (4.6) se puede transformar en la siguiente integral estocástica:
t
as
t
aat )s(dZ))s(x,s(ds)S,s(SS (4.7)
La ecuación (4.7) indica que la variación del precio desde el momento a a t se puede explicar por la suma de dos integrales, la primera conocida con el nombre de Integral de Rieman o Integral Ordinaria y que es la integral familiar de los cursos de Cálculo Diferencial Elemental. La segunda integral es más compleja y es la que definió Ito, por otro lado dZ(t) en realidad no existe. La idea central de la Integral de Ito es que y(s) = (s, Ss) es aproximada por una función simple yn(s), entonces la integral se define como:
Con ti 0, donde a= to < t1 < t2 < ... < tn = t. Cuando a=0 (o sea desde el momento inicial) entonces:
Para el caso (4.7) cuando a=0, entonces el problema se transforma en:
)4.4())(,( txtfdt
dx
)8.4()()( 1,11
ittii
n
tns
t
an zztydZsy
tot
t
ot zzzdz

Autor: José Rigoberto Parada Daza 66
4.3. INTEGRAL DE RIEMANN
Para recordar Cálculo Diferencial Básico se explicará aquí el concepto de Integral de Riemann que es la primera integral del lado derecho de (4.7).
Se tomará como intervalo cerrado de a,b
y sobre ese intervalo se presenta una función f(t). Sobre el intervalo cerrado y suponiendo que a=0, se puede hacer una partición del segmento del eje de las abscisas en porciones menores y esa partición será en n partes de tal forma:
Pn : 0 = to < t1 < ..... <tn-1 < tn = b
Para simplificar el análisis se supone que los límites del intervalo son a,b = 0,1 , o sea la partición Pn será:
0 = to < t1 < t2 < .... < tn = 1
Se define:
Tamaño del Intervalo = i = ti ti-1 , i =1, ...., n
Por otro lado se asume que ti-1 yi ti
Con estos datos se define la Suma de Riemann como lo siguiente:
La Suma de Riemann es la sumatoria de un área de pequeños espacios que tienen la medida de amplitud del intervalo particionado, o sea (ti-ti-1), y de altura la función f(yi). En otras palabras, la suma de Riemann es un área. Cuando el intervalo a,b = 0,1 y n es muy grande, entonces se da lo siguiente:
A esta expresión se le denomina Integral Ordinaria de Rieman en 0,1 .
En Gráfico 4.1 se presenta esta situación. En el eje de las abscisas se representa el tiempo t y sobre él se hacen cuatro particiones t1, t2, t3 y t4. Si suponemos que f(t) = t entonces en el eje de las ordenadas se presenta los f(t) y que se parte del punto (0,0). En cada intervalo particionado se toma el punto medio que en el gráfico están representado por y1, y2, y3, y4. Entonces, la suma de las áreas es:
)9.4()())(,(),( to sdZsxsdst
o sSsoStS
)10.4()())((1
11
iyfttyfSn
iiii
n
iin
1
1
)()(o
n
ii
nn
ndttfiyflímSlímS

Autor: José Rigoberto Parada Daza 67
S4 = t1 - 0 f(y1)+ t2 - t1 f(y2) + t3 - t2 f(y3) + t4 - t3 f(y4) Esta suma equivale, aproximadamente, al área bajo la función f(t) entre los puntos 0 y 1, que en términos de integrales equivale a:
GRAFICO 4.1 Representación de la función f(t) con particiones de t1,t2,t3 y t4.
f(t)
f(y4)
f(y3)
f(y2)
f(y1)
t1 t2 t3
t4 t y1 y2 y3 y4
Para llegar a que se tomen los puntos medios y1, y2, y3 e y4, hay que analizar dos gráficos uno de área superior (Gráfico 4.2) y otro de área inferior (Gráfico 4.2 ). Para esto se tomará intervalos de ti = i/4, i= 0,.....,4, en un intervalo cerrado de 0,1 y para una función f(t) = t.
En el Gráfico 4.2 , para la función f(t)= t la suma de los rectángulos con las líneas entrecortadas, es igual a lo siguiente: SI = 0,25 0,50-0,25 +0,50 0,75-0,50 + 0,75 1-0,75 = 0,375
En el Gráfico 4.2, la suma de los rectángulos con las líneas entrecortadas es: SD = 0,25 0,25-0 + 0,50 0,50-0,25 +0,75 0,75-0,50 + 1 1-0,75 = 0,625
El área bajo la función f(t) es la siguiente suma Sb:
Área de gráfico 4.2
: 0,375 + Área de cuatro Triángulos de 0,25*0,25 c/u : 0,125
Área total = Sb = : 0,500
1
o
b
atdttdt

Autor: José Rigoberto Parada Daza 68
GRAFICO 4.2. Participación de Función
f(t) 1
0,75 f(t)= t
0,50
0,25
0,25 0,50 0,75 1,0 t
GRAFICO 4.2 . Participación de Función
f(t) 1
0,75
f(t)= t
0,50
0,25
0,25 0,50 0,75 1 t

Autor: José Rigoberto Parada Daza 69
Se ve que la Suma de Riemann en este caso es 0,5 y se cumple lo siguiente: SI S SD
0,4 0,5 0,6
Ahora, calculando las y1, y2, y3 e y4 como los puntos medios de los intervalos, se tiene: y1 = (0+0,25)/2 = 0,125 f(y1) = 0,125 y2 = (0,25 + 0,50)/2 = 0,375 f(y2) = 0,375 y3 = (0,50+0,75)/2 = 0,625 f(y3) = 0,625 y4 = (1+0,75)/2 = 0,875 f(y4) =0,875 Entonces, la suma de Riemann es:
SR =0,5
Se puede ver que la SR es un promedio de área del Gráfico 4.2 y es coincidente con el cálculo del área bajo la curva Sb = 0,5, pero a la vez es equivalente a la
Integral Ordinaria de Riemann, en efecto:
Así, pues, la Integral Ordinaria de Riemann, es la clásica integral de Cálculo Diferencial y que nos indica un área bajo la función f(t) para un intervalo cerrado de a,b
4.4. INTEGRAL DE RIEMANN y FUNCION et
Una de las funciones favoritas del Cálculo Financiero y Económico es la función f(t)=et especialmente en el cálculo de acumulaciones de intereses con capitalización continua, tal como se desarrolló en el Capitulo III de este texto. Usando las definiciones de la Integral y Suma de Riemann se desarrolla el siguiente ejemplo. Tal como se demostró el valor actual de una renta unitaria con capitalización contínua se puede describir a través de la función e-kt. Para fines de simplificación supongamos que la tasa de interés k=1, entonces el problema se reduce a la siguiente función:
Valor Actual = f(t) = e-t
Supongamos que en el intervalo de tiempo 0,1
se desea calcular el valor actual de $1 que se capitaliza en el intervalo 0,1 en cinco oportunidades.
Esto implica 0 = to < t1 < t2 < t3 < t4 <t5 = 1
0751875,00575,0625,025,05,0375,0025,0125,0)(4
2i
iiR yfS
5,02
1
0
1
2
21
0
ttdttdt
b
a

Autor: José Rigoberto Parada Daza 70
Para el cálculo de yi sabemos que: ti-1 yi ti
Entonces ti = i/5 O sea,
to = 0 t1 = 1/5 = 0,20 t2 = 2/5 = 0,40 t3 = 3/5 = 0,60 t4 = 4/5 = 0,80 t5 = 5/5 = 1
En gráfico 4.3 se muestran los puntos to a t5. Siguiendo el procedimiento explicado calculamos los puntos yi como los puntos medios entre cada sub intervalo, es decir:
y1 = (to+t1)/2=0,1 y2 = (t1+t2)/2 = 0,3 y3 = (t2+t3)/2 = 0,5 y4 = (t4+t3)/2 = 0,7 y5 = (t5+t4)/2 = 0,9
Para cada yi se debe calcular f(yi) según el modelo de interés seguido, es decir:
f(y1) = e-t = e-0,1
f(y2) = e-0,3
f(y3) = e-0,5
f(y4) = e-0,7
f(y5) = e-0,9
El Gráfico 4.3, nos indica que la suma de Riemann, es aproximadamente igual al área bajo la curva e-t desde 0 a 1 y representa el valor actual de $1 recibido con capitalizaciones, es decir:
SR = (t1-to)f(y1)+(t2-t1)f(y2)+(t3-t2)f(y3)+(t4-t3)f(y4)+(t5-t4)f(y4) SR = 0,2e-0,1 + 0,2 e-0,3 + 0,2e-0,5 + 0,2 e-0,7 + 0,2 e-0,9 = 0,631068
El problema, es equivalente a usar la Integral Ordinaria, cuando las particiones son muy pequeñas, es decir:
En este caso la suma de Riemann, por ser una aproximación, subvaluó el valor actual en 0,17% que es extremadamente bajo. Sin embargo, lo que interesa aquí es señalar que el valor actual es una sumatoria de actualizaciones y cada vez que el número de estas capitalizaciones sean más grandes,
63212,01110
1
0eedteVA tt

Autor: José Rigoberto Parada Daza 71
entonces se habla de capitalización continua. Se puede demostrar que cuando n , la suma de Riemann se acerca a la Integral de Riemann.
GRÁFICO 4.3. REPRESENTACIÓN DE FUNCIÓN f(t)=e-t y suma de Riemann.
e -0,1
e -0,3
e -0,5
e -0,7
e -0,9 e t
y1=0,1 y2=0,3 y3=0,5 y4=0,7 y5=0,9
t t0 t1 t2
t3 t4
t5
0 0,2
0,4
0,6 0,8
1
4.5. INTEGRAL DE RIEMANN-STIELTJES
Esta integral es una generalización de la Integral de Riemann y es usada, especialmente, en cálculo de probabilidades para calcular el valor esperado de una variable random y para el caso que nos ocupa es útil cuando se toman las variables estocásticas.
Para la definición se usan los siguientes términos: Existen dos funciones f y g definidas en un intervalo a,b
Sobre el intervalo a, b = 0, 1 se hacen particiones, tal que
P = a = 0 = to < t1 < t2 <...............< tn=1
Sobre el conjunto de particiones, se hacen subparticiones intermedias en el intervalo 0,1 , o sea:

Autor: José Rigoberto Parada Daza 72
PM = y1, y2, .... yn
Tal que t i-1
yi ti i=1,......n
Existen variaciones de la función g, tal que:
gi = g(ti) g(ti-1) i =1, ..... n
Entonces, la suma de Riemann-Stieltjes se define como:
Cuando g(t)=t, entonces esta última suma coincide con la suma de Riemann.
La suma de Riemann-Stieltjes es un promedio ponderado de las variaciones de la función g por los valores de la función f en el punto de yi.
Cuando en la suma de Riemann-Stieltjes se tiene un n , entonces esta suma tiende a la siguiente integral:
Esta última integral existe cuando las funciones f y g son derivables en el intervalo 0,1 . Esto implica que las dos funciones deben ser contínuas en dicho intervalo.
Por otro lado, para la existencia de esta integral, la función f tiene p-variaciones límites y la función g tiene q variaciones con p>0 y q>0 tal que: p-1 + q-1 > 1.
La intregral de Riemann-Stieltjes se define como la integral de f respecto a g en el intervalo a;b . Cuando estas funciones no son contínuas, hay ciertos arreglos que se pueden efectuar para su cálculo. Con algunos ejemplos se aclara la definición operativa de esta integral.
Ejemplo 4.1
Sean las funciones f(t) = t y g(t) = 2t, entonces el cálculo de la suma de Riemann-Stieltjes, se efectúa de la siguiente forma:
a) Se determina el conjunto P = 0 = to < t1 < .... <tn = 1
En este caso, supongamos cinco particiones, o sea, ti = 1/5 = 0,2, entonces P = 0; 0,2; 0,4; 0,6; 0,8; 1
b) Sobre P se determinan un conjunto de Particiones Intermedias (PM), tal que ti-1 < y i< ti. Se tomaron los puntos medios entre t y t-1, o sea, yi = (ti + ti-1)/2
)11.4()()()(),( 111
ii
n
nii
n
iinn tgtgyfgyfPMPSS
1
0)()( tdgtf

Autor: José Rigoberto Parada Daza 73
Entonces:
PM = 0; 0,10; 0,30; 0,50; 0,70; 0,9
c) Sobre la función f, se determina los puntos de cada f(yi) , o sea: f(0); f(0,1);
f(0,30); f(0,50); f(0,70) y f(0,9).
d) Sobre la función g se determinan los g(ti ) y g( ti-1) para cada t, o sea, g(0); g(0,4); g(0,8); g(1,2),g(1,6) y g(2). Posteriormente se calculan las diferencias entre g(ti) g(ti-1)
e) Se multiplica cada f(yi) por g(ti) g(ti-1) y se suman.
En Tabla Nº 4.1 se presentan estos pasos.
TABLA Nº 4.1
SUMA DE RIEMANN-STIELTJES
(1)
ti
(2)
yi
(3)
f(yi)
(4)
g(ti)
(5)
g(ti-1)
(6)=(4)-(5)
gi
(3)*(6)
f(yi) gi
0 0 0 0 - 0 0 0,20 0,10 0,10 0,40 0 0,40 0,04 0,40 0,30 0,30 0,80 0,40 0,40 0,12 0,60 0,50 0,50 1,20 0,80 0,40 0,20 0,80 0,70 0,70 1,60 1,20 0,40 0,28 1 0,90 0,90 2 1,60 0,40 0,36 SUMA 1
Calculando la integral de Riemann-Stieltjes, se tiene: f(t) = t g(t) = 2t dg(t)/dt = 2 dg(t) = 2dt
Luego:
En este caso la suma de Riemann-Stieltjes coincide exactamente con el cálculo de la integral de Riemann.
1)2()()(1
0
1
0
10
2tdtttdgtf

Autor: José Rigoberto Parada Daza 74
Ejemplo 4.2 Calcular la siguiente integral de Riemann-Stieltjes:
Esta es una función discontínua y en gráfico Nº 4.2 se observa:
GRAFICO 4.2
Se calculan los puntos donde la función no es contínua, o sea:
t1 = 1 t2 = 2 t3 = 3
En esos puntos la función f(t) tiene los siguientes saltos:
En t1 pasa de 0 a 0,5 o sea un salto de 0,5 = S1
En t2 pasa de 0,5 a 0,8 o sea un salto de 0,3 = S2
En t3 pasa de 0,8 a 1 o sea un saldo de 0,2 = S3
Entonces la Suma de Riemann-Stieltjes, donde f(ti) valor de función en puntos de discontinuidad, es la siguiente:
f(t1) S1 + f(t2) S2 + f(t3) S3 = 1x 0,5 + 2x 0,3+3x 0,2 = 1,70
:,)(3
0cuandottdg
31
328,0
215,0
10
)(
tcuando
tcuando
tcuando
tcuando
tg

Autor: José Rigoberto Parada Daza 75
Lo interesante para cálculo estocástico es que la segunda parte de la integral de Ito en formula (4.7) se puede expresar análogamente como una integral del tipo Riemann-Stiltjes, ya que se observa que esta integral se define como la sumatoria de Riemann-Stieltjes coincidente, en la definición dada previamente y por esa razón en este texto se ha desarrollado esta integral con algún grado de detalle.
4.6 INTEGRALES ESTOCÁSTICAS
Las ecuaciones (4.6) y (4.7) son integrales que contienen elementos estocásticos y con las definiciones previas de Riemann-Stieltjes se pueden comprender de mejor forma los conceptos y procedimientos que involucra el cálculo de una integral estocástica.
Supongamos la siguiente ecuación en diferencia ordinaria:
dx = f(t,x)dt (4.12) con, x(0) = xo y t T = 0,T
La solución a la ecuación diferencial (4.12) es:
En términos de diferencias e integrales (4.13) se puede rescribir de la siguiente forma: Como se analizó en la integral de Riemann, el lado derecho de (4.14) indica que la integral se puede descomponer en una sumatoria de pequeñas particiones del intervalo s, t , siendo esos intervalos los siguientes:
S = to < t1 < t2 < ........ < tn = t
Donde los ti corresponden a las pequeñas particiones dentro del intervalo s,t , con estos antecedentes se puede reescribir (4.14) de la siguiente manera:
con, 0( ) 0 porque 0
La ecuación (4.15) es el caso tradicional de Riemann cuando las funciones son determinísticas. Análogamente y siguiendo el mismo procedimiento anterior podemos pasar a Cálculo Estocástico en cuyo caso (4.14) se convierte en lo siguiente:
)13.4())(,()(
Tscadaparasysfds
sdy
)14.4())(,()()(t
sdrryrfsyty
)15.4()(0)))((,()()(1
01
n
iiiii tttytfsyty

Autor: José Rigoberto Parada Daza 76
En (4.16) podemos separar las siguientes integrales:
En (4.16) podemos separar las siguientes integrales:
La suma de las dos integrales anteriores es una forma aproximada de obtener y(t)-y(s) y se observa que la primera integral es la tradicional Riemann y la segunda es del tipo Riemann-Stieltjes, sin embargo la solución de esta última no es un aspecto trivial para los casos estocásticos.
En caso determinístico la integral de Riemann-Stieltjes es claro el procedimiento anterior, pero el caso estocástico es más complejo. Para explicar esto con mayor detalle supongamos las siguientes funciones:
g(t,z) y z(t) y max tt+1 - ti 0
Entonces para un caso determinístico los límites inferior y superior son los siguientes: y
Si: g(t,z)= Z(t)
Si Z(t) sigue un proceso Wiener con varianza igual a uno, entonces los LI y LS se transforman en:
t t
srdzryrdrryrfsyty
0)16.4()())(,())(,()()(
t
s
1n
0i1iii )tt))(t(y,t(fdr))r(y,r(f
t
s
n
iiii tztztytrdzryr1
01 )(0)()())(,()())(,(
)()())(,(lím 1 iii
ii tztztztgLI
)()())(,(lím 111 iii
ii tztztztgLS
)()()( 1 iii
i tztztzlímLI

Autor: José Rigoberto Parada Daza 77
En los casos anteriores, si ellos son determinísticos no hay ambigüedad en los conceptos de convergencia. Así, si son funciones z(t) integrables, entonces los límites superior menos el inferior tienden a cero, o sea, LS-LI 0. Cuando la función z depende de una variable random con z(t,w), donde w es la variable random, entonces se debe especificar cual es el concepto de límite porque existen varios conceptos de convergencia. Así, por ejemplo, una interpretación al problema puede ser usando el concepto de límite en media cuadrado y puede usarse los siguientes conceptos:
4.7 LEMA DE ITO
Sea la función (t,x) válida en el intervalo 0,T xR R en el conjunto de números R y que es continua y doblemente derivable con las siguientes derivadas parciales:
Cuando un conjunto St
sigue un proceso estocástico dSt = (t,St)dt + (t,St)dZ,
entonces Yt= (t,x) sigue el siguiente proceso:
Para llegar a esta demostración se usa el Teorema de Taylor, (Ver Malliaris, pág.81-86). Lo anterior implica lo siguiente:
(dt)(dt)= 0 (dzt)(dzs) = 0 (t s)
(dt)(dzt)=0 (dzt)2 = dt
0))()(()(( 21 ii
ii tztztzLIE
0( 21 ii
i
tztzLSE
xxxtx
xt
x
xt
dt
xt2
2 ),(),(),(
ttxt t
xty
tx
xt2
2 ),(),(
:),('),(' dondedZStdtStdY tttt
2),(),(2
1),(),(),(),(' ttxxttxttt StStStStStSt
),(),(),(' ttxt StStSt
)()()(lím 11 iii
i tztztzLS
(4.17)
(4.18)
(4.19)

Autor: José Rigoberto Parada Daza 78
Ejemplo 4.3
Supongamos que (t,St) = lnSt y que esta función sigue un proceso del siguiente tipo: dSt = Stdt + Stdzt
Obtenga la función de la variable St para un t cualquiera en función de un So.
Desarrollo:
Para llegar a la expresión (4.17) y (4.18) se tiene que hacer el siguiente cambio de variables:
(t,St) = St y (t,St) = St
Por definición del problema, sabemos que: Yt = (t,St) = lnSt
Que es equivalente a St = tYe , es decir la variable St, la que puede representar a un precio de un título bursátil, sigue un proceso exponencial.
Calculando las derivadas parciales, se tiene: y
Reemplazando las derivadas parciales en (4.18) y (4.19) se tiene:
222
1
2
10),´( t
tt
tt S
SS
SSt
Con estos datos se puede obtener (4.17), de la siguiente forma:
tt
tx
tt SS
Stu
dt
St 1),(0
),(
2
2 1),(2
tt
xx SS
Stt
222 ),(1
),(' ttt
t SStyS
St
tttt
ttt dzS
Sdt
S
SStddY )
1()
2
1(),( 2

Autor: José Rigoberto Parada Daza 79
O sea:
Esta última expresión, por la definición previamente dada, expresada en términos de integral, es igual a:
Resolviendo las integrales se tiene:
y
Aplicando la definición de logaritmo natural, (o sea ln (a) = b eb = a), se tiene
Aplicando la definición de logaritmo natural, (o sea: Ln(a)=b eb=a), se tiene que:
o,
Esta última es la expresión pedida, que indica que la variable St, un precio de un título bursátil, se puede obtener en t a partir del precio en el momento cero o inicial, conociendo su media
, su desviación , el tiempo de cálculo t y la distribución de la variable Zt. Si suponemos que existe t, entonces se tiene:
y si t=1, entonces las diferencias de precios o retornos, siguen una Distribución Normal con: N( -(1/2) 2 ; 2)
tt dzdtdY ))2/1(( 2
t
t
t
ot dzdsYY0
2
0))2/1((
t
ttt seaozzzdz0
0 ,
tot ZtSS ))2/1(()/(ln 2
tot ZtSS ))2/1((exp/ 2
totZtSS ))2/1((exp 2
)())2/1((lnln 2ttttttt zztSSx
seaoSSSSYY
entoncesSYsabesecomoZtYY
ttot
ttt
),/ln(lnln
:,ln,))2/1((
00
210
))2/1((
)2/1()2/1())2/1((
2
20
2
0
2
t
ttSsdS tt

Autor: José Rigoberto Parada Daza 80
Ejemplo 4.4
Suponga que f(t) = t2, y que una variable B sigue un proceso Browniano. Calcule la diferencial de esta variable usando el Lema de Ito.
Otra forma de escribir el Lema de Ito es:
Porque f (t)=2t y f (t)=2
Pero se puede demostrar (ver Mikosch, 1998 pág. 98-99) que sí s=0, entonces:
y
o sea:
En general si f(t) = tn se tiene:
f (t)=ntn-1 y f (t)=n(n-1) tn-2
entonces:
t
sstx BfBfBdf )()()(
aestocásticIntegraltd tt
o xx )(2
1 2
t
o
t
o
t
o x tdxdxdxf2
2)("
2
1
tttdf tt
t
o x 2
1
2
1)(
2
1)( 22
)()()( st
t
s x ffdf
dxnn
dnt
s
nxx
nt
s x2
1
2
)1(
dxfdffdft
sxx
t
sxttt ''
2
1)('

Autor: José Rigoberto Parada Daza 81
4.8. DESARROLLO DE MODELO DE OPCIONES DE BLACK-SHOLES
En Finanzas uno de los modelos más utilizado es el de Black-Sholes (1973), mediante el cual se determina el valor que tendría una Opción Financiera. Se desarrolla en este punto, el enfoque matemático como un caso particular de Cálculo Diferencial Estocástico.
El planteamiento del modelo se inicia formando un portafolio que incluya simultáneamente Acciones Ordinarias o Comunes y Opciones de Compra sobre esas Acciones de tipo europea. El valor de este porfolio, es el siguiente:
V = QAPA +QoVo (4.20)
Donde:
V = Valor del Portafolio de arbitraje (En moneda) QA = Cantidad de Acciones Ordinarias en el Portafolio PA = Precio de Mercado de las Acciones Ordinarias Qo = Cantidad de Opciones de Compra en el portafolio Vo = Valor de la Opción de Compra.
A partir de (4.20) se plantea, la variación (en moneda) que se obtiene del portafolio de arbitraje; para ello se desarrolla la diferencial total de V, o sea
dV = ( V/ PA)dPA + ( V/ Vo)dVo
Como V/ PA = QA y V/ Vo = Qo, entonces se tiene que:
dV = QAdPA + QodVo (4.21)
El significado de (2) indica la variación (en $) si varía el precio de la Acción ordinaria (dPA) y el Valor de la Opción de Compra (dVo). Para que este cambio se formule como (2), se considera que éste debe darse en un intervalo de tiempo infinitesimal dt. Además, que la función V sea continua y derivable.
Si existe una tasa libre de riesgo r, entonces se le exige, que en ese intervalo de tiempo, el portafolio V, y su cambio dV, rindan al menos la utilidad que generaría una inversión que se coloque en algún activo financiero que rinde esa tasa libre de riesgo, o sea: rVdt. Para esta relación se exige que la capitalización sea efectuada de manera continua y en un período de tiempo dt. (Ver Cap. III, pág. 50). Entonces:
rVdt = QAdPA + QodVo (4.22)
Otra forma de expresar, es en términos de rentabilidad obtenida, o sea dV/V = rdt. En este caso, se espera que la variación de la cartera (en tanto por uno), sea al menos igual a la rentabilidad (en tanto por uno) que se obtendría invirtiendo en un activo financiero libre de riesgo.

Autor: José Rigoberto Parada Daza 82
Se supone que la cantidad de acciones QA = 1 y que la cantidad de Opciones Qo= -1/( Vo/ PA), luego el lado derecho de (4.22) sería:
dPA (1/( Vo/ PA)) dVo
El lado izquierdo de (4.22) sería (por reemplazo en r).
r PA Vo/( Vo/ PA)
Por lo tanto, la igualdad queda:
r PA-Vo/( Vo/ PA) = dPA (1/( Vo/ PA))dVo (4.23)
Haciendo arreglos algebraicos, se tiene lo siguiente:
Se supone que el precio de una Acción Ordinaria y el Valor de la Opción de Compra siguen un proceso estocástico, con Distribución Normal, es decir:
La relación anterior indica que la rentabilidad (o los precios) de una Acción Ordinaria tienen una rentabilidad (o precio), esperada instantánea de , una varianza instantánea de
y una variable estocástica dz que tiene media cero, desviación estándar igual a uno y normalmente distribuida. Esto es siguiendo, Cálculo Diferencial Estocástico, dado esto, entonces el cambio en el Valor de la Opción de Compra, se puede obtener usando el Lema de Ito, descrito en las páginas precedentes (Fórmula 4.18, pág.114) y se desarrolla de la siguiente forma:
Reemplazando (4.25) en (4.24) se tiene:
)24.4(
/
dtrVdtP
VrPdP
P
V
dtPV
VP
P
VrdP
P
VdV
oA
oAA
A
o
Ao
oA
A
oA
A
oo
dzPdtPdPodzdtP
dPAAA
A
A
)25.4(2
1 222
2
dtPP
Vdt
t
VdP
P
VdV A
A
ooA
A
oo

Autor: José Rigoberto Parada Daza 83
Haciendo arreglos algebraicos sobre (4.26), (restando a ambos lados ( Vo/ PA)dPA
y dividiendo por dt) se tiene:
La expresión anterior es una ecuación diferencial estocástica, la cual para su resolución se usan las definiciones del Valor de una Opción de Compra, en los dos casos, o sea:
Resolviendo la ecuación diferencial (4.27) con las definiciones de la Opción de Compra, donde E = Precio de ejecución de la Opción, se obtiene la solución:
Vo = PAN (d1) (E/ert) N (d2)
Donde:
N (d) = Valor de la Distribución Normal acumulativa evaluada hasta d (Ver Cap. II, Nº 2.2).
e = 2,7183 (Ver ejercicios 4.2 y 4.3 del Capítulo IV)
Para entender ert, ver Capítulo III, Nº 3.1
En el modelo son datos conocidos los siguientes: PA, E, r, y t.
)26.4(2
1 222
2
dtrVdtP
VrPdP
P
VdtP
P
Vdt
t
VdP
P
Vo
A
oAA
A
oA
A
ooA
A
o
)27.4(2
1 222
2
AA
o
A
oAo
o PP
V
P
VrPrV
t
V
EVsí
EVsíEVV
A
AA
o 0
t
trEPd A ))2/1(()/(ln 2
1
t
t))2/1(r()E/Pln(d
2A
2

Autor: José Rigoberto Parada Daza 84
CAPITULO V
ANALISIS MULTIVARIABLE
En diferentes casos de las Finanzas real y no teórica y de la Economía real y no teórica, en general, no siempre es fácil reducir el análisis a que el problema analizado dependa sólo de una variable o a lo más dos, a veces hay que trabajar con mas variables. En ocasiones por reducir un problema a una o dos variables explicativas, el análisis teórico de la vida real aparece como un simplismo exagerado y finalmente no se explica el problema con todos sus matices. Esto lleva a que se deben aplicar las técnicas apropiadas que expliquen los problemas reales, los que pueden incluir varias variables explicativas, siendo ésta la base intuitiva de lo que se denomina Análisis Estadístico Multivariable, el que se caracteriza por tratar de explicar un conjunto de datos (matrices de datos) con p variables observadas en n casos.
En Teoría Financiera ha sido común el uso de técnicas econométricas univariables y bivariables hacia diferentes problemas; específicamente el univariable aclara el análisis de una variable aleatoria y aspectos de inferencia estadística de la variable. En el caso del análisis bivariable se estudian las relaciones de dos variables entre sí, en cuyo caso se efectúan análisis de regresión y correlación simple con sus respectivos problemas de inferencia estadística; un ejemplo de este tipo de estudios es el Modelo de Valoración de Activos de Capital (CAPM) en el cual la rentabilidad de un título depende de la rentabilidad de un portafolio de mercado.
El Análisis Multivariable se ha empezado a usar en Teoría Financiera, a través de diferentes técnicas, por ejemplo el uso de Altman en 1968 del Análisis Discriminante, técnica de Análisis Multivariable, para intentar explicar la quiebra de empresas; el caso del Modelo de Teoría de Precios por Arbitraje (APT), de Roll y Ross (1979-1980) hace uso del Análisis Factorial, otra técnica del Análisis Multivariable, para explicar la rentabilidad de un título financiero, en contraposición a lo que es el CAPM. En 1966, King hizo uso de la técnica multivariable, Análisis de Componentes Principales, para ver los factores que explican el precio de las acciones en la Bolsa de Nueva York.
Por lo tanto, el Análisis Multivariable se ha usado en Finanzas y ello lleva a que en este capítulo se analicen las más relevantes, como una manera de mejorar el entendimiento de su aplicación.
5.1 TÉCNICAS DE ANÁLISIS MULTIVARIABLE.
Johnson y Wichern, (1992), exponen en su libro una clasificación de las técnicas de Análisis Multivariable. Así, se tienen:
I.- Inferencia respecto a modelos multivariables y modelos lineales.

Autor: José Rigoberto Parada Daza 85
En este tópico se analizan los modelos multivariables y los Modelos de Regresión Lineal Multivariable, concentrándose principalmente en aspectos de inferencias de los parámetros y en conceptos de regresión lineal.
II. Análisis de la estructura de la covarianza.
Aquí se agrupan las siguientes técnicas de análisis multivariable:
Componentes Principales Análisis Factorial Análisis de Cluster Escalas Multidimensionales no métricas.
Una descripción general de las técnicas de Análisis Multivariables es la siguiente:
Análisis de Componentes Principales. Se pretende reducir un problema que es explicado por k variables a un número menor de p componentes sin que cambie la varianza total de los datos observados de las k variables. Es un modelo estadístico y que permite comprender de mejor forma un análisis multivariable. Se trabaja con una matriz inicial de k variables por n observaciones de cada variable.
Análisis Factorial. Se pretende ver de qué forma una variable se puede descomponer en un número de factores que explican esa variable. Es también una técnica estadística que parte de la base que los factores no son observables, es decir, no tienen interpretación directa previa. Por ejemplo, se intenta ver cuántos factores explican la rentabilidad de un título sin especificar conceptualmente cuáles son esos factores.
Análisis Discriminante. El objetivo es analizar las variables que estadísticamente pueden separar o distinguir a dos o más grupos. Por ejemplo, ver qué variables estadísticas pueden discriminar o separar dos grupos de empresas: las familiares de las no familiares.
Análisis de Cluster. Divide las observaciones en grupos que sean homogéneos entre sí. Por ejemplo, se usa en Marketing para analizar el mapa de posicionamiento de productos.
5.2. ANÁLISIS DE COMPONENTES PRINCIPALES
5.2.1. Interpretación Intuitiva
Supongamos que se tiene un gran número de variables que intentan explicar una estructura de datos, por ejemplo para 220 sociedades anónimas se tiene cuarenta variables con sus datos para un período específico, entre las que encontramos: Rentabilidad del Capital, Rentabilidad Operacional, relación de endeudamiento, participación de mercado, etc. Cualquiera sea el modelo del tipo análisis de regresión, resulta un modelo de difícil interpretación y comprensión; entonces la técnica de Análisis de Componentes Principales responde a la siguiente pregunta: ¿Existirá una forma de cómo reducir esas cuarenta o más variables a una cantidad

Autor: José Rigoberto Parada Daza 86
de componentes menores que cuarenta y que sean una combinación de esas variables? En este caso el Análisis de Componentes Principales, da esa respuesta y así se puede conseguir una mejor comprensión del problema, interpretando más claramente sus resultados.
Mirado así el tema, el Análisis de Componentes Principales es un trabajo empírico y que no requiere de hipótesis previas de cuáles son las variables que explican una determinada componente; esto será trabajo directo del investigador quien deberá observar cuál es el peso que cada variable tiene en la Componente Principal. Este peso relativo es evaluado a través de coeficientes de sensibilidad que se calculan mediante un proceso algebraico y que se explicará a continuación en el fundamento matemática del tema.
De lo anterior, las Componentes Principales, consisten en lo siguiente:
a) Reducir el número de variables, que a priori explican un problema determinado, en un número menor de componentes.
b) Cada componente resulta de una combinación lineal de las variables. El peso de cada variable dentro de una componente es evaluado a través de coeficientes de sensibilidad o de la correlación entre esa variable y la componente.
c) El criterio para ver cuántas son las componentes que explican un problema está dado por la explicación, en %, que la varianza de cada componente explica a la varianza total de las observaciones.
d) El tema de las Componentes Principales es un método principalmente empírico y que requiere mucho conocimiento de parte del investigador respecto al problema que se está analizando, para que se interprete adecuadamente el significado de las componentes. En este sentido, cada componente no tiene siempre una interpretación clara y a veces cuesta encontrar algunas relaciones intrincadas que se pueden presentar entre las variables.
5.2.2.- Interpretación Matemática
Sea X Matriz de observaciones de p variables, x1, x2,...xp con n observaciones. x1 x2 x3 ............. xp
1 x11 x12 x13 ............. x1p
2 x21 x22 x23 ............. x2p
3 x31 x32 x33 ............. x3p
. . . . ............. .
. . . . ............. .
. . . . ............. .
. . . . ............ .
. . . . ............ . n xn1 xn2 xn3 ............ Xnp

Autor: José Rigoberto Parada Daza 87
Se pretende encontrar p variables nuevas y1, y2,.....yp denominadas Componentes Principales que constituyan combinaciones lineales de las xi variables, o sea:
b 1x1 =y1 = b11x1 + b21x2 + b31x3+...........+bp1xp
b 2x2 =y2 = b12 x1 + b22x2 + b32x3+...........+bp2xp
. . .
. . .
. . . b pxp=yp= b1px1 + b2px2 + b3px3+..............+bppxp
En términos matriciales se tiene:
Y = XB es decir:
Se trata de encontrar los coeficientes de sensibilidad bij denominados coeficientes Loadings o coeficientes factoriales.
Para resolver este problema se hacen los siguientes supuestos: a) Las Componentes Principales están de tal manera ordenada que sus respectivas varianzas están en orden decreciente, o sea:
Esto implica que la primera componente es una combinación lineal con la máxima varianza. Este proceso se obtiene maximizando la primera varianza, según método de Lagrange, suponiendo a la vez que b 1b1=1 .La segunda componente se obtiene maximizando la segunda combinación lineal (b 2x2) sujeto a que b 2b2 = 1 y cov(b 1x1, b2 x2) = 0; esta última restricción implica que la primera componente está incorrelacionada con la segunda componente.
b) Se asume, además, que la suma de las varianzas de las componentes no sea diferente a la suma de las varianzas de las x variables originales, o sea:
Además, se asume:
pppp
p
p
pp
bbb
bbbbbb
xxxxyyyy
21
22221
11211
321321
'
'
'
'
'
'
'
'
'),....,,(),......,,(
)(..........)()()( 23
22
21
2pyyyy
)(....)()()(.....)()()( 22
21
223
22
21
2pp xxxyyyy

Autor: José Rigoberto Parada Daza 88
Donde: x= Matriz de varianzas covarianzas de los datos originales.
c) Las componentes principales no deben tener correlación entre ellas, lo que se denomina ortogonal. Esto significa que las variables que agrupa una componente no quede explicado por la otra componente, evitando así la existencia de multicolinealidad.
A la matriz B se le denomina Matriz de vectores propios y es la que entrega los coeficientes de sensibilidad bij, es decir:
Los vectores i representan la varianza de la componente principal i y se obtiene
de la siguiente forma:
pi
i
i
piii
b
bb
xbbby
'
'
'
),......,,()(
2
1
2112
pppp
p
p
bbb
bbb
bbb
B
21
.
.
.2
.
.
.22
.
.
.21
11211
p
BxBy
000
...
...
...
000
000
000
)(3
2
1
1

Autor: José Rigoberto Parada Daza 89
Para este problema siempre existe una solución única ya que la matriz de varianza-covarianza, o sea = x, es una matriz cuadrada, simétrica, definida y no negativa. Los datos previamente deben centrarse respecto a su media. Para explicar el cálculo de los coeficientes de sensibilidad o Loadgins, supongamos que para una empresa se tienen los datos de las rentabilidades de propietario (x1) y rentabilidad operacional (x2) y en un período de seis años. Sólo se toman dos variables para simplificar el cálculo en beneficio de la comprensión.
Los datos son los siguientes:
Se sabe que la matriz de varianza-covarianza a partir de los datos centrados se puede obtener de la siguiente forma:
O bien, sin los datos centrados, se tiene:
Debemos buscar los coeficientes bij de las Componentes Principales, o sea:
Datos Centrados
Años X1 x 2
11 xx
22 xx
1 8% 10% -2 -3 2 9% 11% -1 -2 3 10% 12% 0 -1 4 11% 13% 1 0 5 12% 14% 2 1 6 10% 18% 0 5 Media 10% 13% 0 0
82
22
5
101
23
0
210
12
5
0
1
2
0
1
1
0
2
1
3
2
5
1x
131013
106
1810
1412
1311
1210
119
108
181413121110
1012111098
5
1x
8
2
2
2

Autor: José Rigoberto Parada Daza 90
y1 = b11x1 + b21x2
y2 = b12x1 + b22x2
Para ello se deben buscar los valores propios que según los conceptos de Geometría Analítica se obtienen del siguiente determinante:
O sea;
1 =8,60555 2 =1,39444
Total= 1 + 2 =10
1 y 2 se denominan valores propios y representan la varianza de la primera y segunda componente.
Calculando las varianzas de x1 y x2, se tiene: 2 (x1) = 2 y 2 (x2) = 8 Por lo tanto se cumple que: 2(x1) + 2(x2) = 2(y1)
+ 2 (y2) = 10
Esto implica que la primera componente explica el 86,055% (o sea 8,60535/10) de la varianza total y la segunda componente el 13,9444% restante (o sea 1,3944/10).
Para el cálculo de los coeficientes bij se procede de la siguiente forma:
Si 1 = 8,60555, entonces se deben buscar los Vectores Propios, los que se obtienen de la siguiente ecuación:
Es decir: (2-8,60555)y1+2y2 =0 y1 = 0,302775 y2
2y1+(8-8,60555)y2=0 y1 = 0,302775 y2
O sea: y1 = 0,303 y2
Según los conceptos de Geometría Analítica, debe existir un valor k de tal forma que y1 =1; lo que se plantea de la siguiente forma:
Y1=(0,303 k; k) donde y1 = 1, o sea:
0)8(2
2)2(
04)8)(2(012102
0
0
)8(
2
2
)2(
2
11
Y
Y
1303,0 22
1kky

Autor: José Rigoberto Parada Daza 91
Entonces: k = 0,95703
Entonces los coeficientes se obtienen de reemplazar los valores de k en y1 = (0,303k; k) o sea y1 = (0,29; 0,957) O sea y1 = 0,29x1 + 0,957x2
Si 2 = 1,39444, se tiene:
0,60556y1+2y2 =0 y2 = 0,30278 y1
2y1+6,60556 y2 =0 y2 = 0,30278 y1
Se debe cumplir que existe un k, tal que:
O sea:
Despejando k, se tiene: k = 0,95709
Por lo tanto, los coeficientes bij serían:
Y2 = (+0,95709; - 0,2897)
O sea: y2 = 0,957 x1 0,29 x2
En este caso, por ser un problema didáctico, la primera componente explica un elevado porcentaje de la varianza total, por lo que el problema en realidad está explicado por sólo una componente. Esa componente está, a la vez, explicado en mayor proporción por la variable 2, ya que es la que tiene el mayor coeficiente de sensibilidad (0,957) para la variable x2. La segunda componente explica sólo el 13,94% de la varianza total y en ella predomina en importancia la variable x1 que tiene un coeficiente de sensibilidad de 0,957. En este sencillo ejemplo una componente ha coincidido con una variable, es decir aquí no habría sido importante usar componentes principales. No debemos olvidar que esta técnica se usa cuando se tienen varias variables.
En el ejemplo se verifica que la matriz de varianzas-covarianzas de la componente Y es la siguiente:
0
0
)39444,18(2
2)39444,12(
2
1
y
y
130278,0; 22 yquetalkky
1)30278,0( 222 kky
xBBy 1

Autor: José Rigoberto Parada Daza 92
Tal como se explicó, los coeficientes de sensibilidad bij o factores Loadgins representan la importancia o peso que cada variable tiene en la composición lineal que da origen a la componente. Pero también dicha importancia se puede evaluar a través de los coeficientes de correlación entre la variable xi y la componente yj. Así se tiene que:
bij = cov (yj,xi)/2(yi)
O bien bij = cov (yj,xi)/ i
Se sabe que (yj,xi) = cov (yjxi)/( (yj) (xi))
Donde (yj,xi) =Coeficiente de correlación entre componente principal j y variable i.
Entonces, reemplazando se tiene: (yj,xi) = bij
2(yj)/( (yj) (xi))
Simplificando, se tiene lo siguiente:
(yj,xi) = bij ( (yj)/ (xi))
La matriz de correlación entre las Componentes Principales y las variables originales son muy importantes para interpretar el verdadero significado de la componente que se analiza y son la base tanto para entender el problema como para aproximarse a algún nombre que pueda tener esa componente principal.
El proceso manual de cálculo, tal como se aplicó en el ejercicio didáctico, puede resultar muy largo y tedioso; sin embargo hoy existen paquetes computacionales de análisis multivariable y que resuelven este problema en pequeñas fracciones de tiempo, por lo que ya no es una dificultad resolver este problema.
Un aspecto a tener en cuenta es que el número de componentes que se deben elegir no está dado a priori y éste es fijado por el investigador; puede ocurrir que el proceso de optimización de Lagrange permita obtener una primera componente cuya varianza explique un alto porcentaje de la varianza total, por ejemplo un 90%, en cuyo caso el problema estaría ampliamente explicado por una sola
29,0957,0
957,029,0
82
22
29,0957,0
957,029,01
y
2
1
0
0
39444,10
060555,8y

Autor: José Rigoberto Parada Daza 93
componente; pero también puede ocurrir lo contrario y así se debe ir probando el número de componentes que se desea. En general, los programas computacionales de análisis multivariable piden el número de componentes que el investigador desea.
En algunos enfoques en vez de la matriz de varianzas-covarianzas se usa la matriz de correlaciones y en tal caso se utiliza la misma metodología señalada pero la interpretación de los valores propios
no es igual, pues lo que indica son más bien coeficientes de regresión en vez de varianzas, como es el caso del ejemplo antes señalado. Resolviendo el problema con una matriz de correlación, se tiene lo siguiente:
Se sabe que ij = ij/( i j)
Entonces, la Matriz de Correlación R, es
a) Cálculo de Valores Propios ( )
Es decir (1- )2 = 0,52
(1- ) = 0,5 1 = 1,5 2 = 0,5
b) Cálculo de vectores propios:
Para = 1,5
82
22x
15,0
5,01R
0)1(5,0
5,0)1(
82;2 2112 yAquí
5,0)82/(212
tantoloPor
Coeficiente de Correlación

Autor: José Rigoberto Parada Daza 94
Es decir:
(1-1,5)e1 + 0,5e2 =0
0,5e1 + (1-1,5)e2=0
e2 =e1
Entonces existen pares (k,k) tal que: k = 0,707106
Como e1 = e2, entonces los coeficientes son 0,707106 Para 2 = 0,5
0,5e1 + 0,5e2 =0
0,5e1 + 0,5e2 =0
e1 = -e2
Entonces los coeficientes de sensibilidad son 0,707106 y
0,707106, es decir se tiene:
y1 = 0,707106x1 + 0,707106 x2
y2 = 0,707106 x1 0,707106x2
En este caso se tiene: 1+ 2 = 1,5 + 0,5 = 2
Por lo tanto, el Primer Componente Principal explica un 75%, (que se obtiene de 1,5/2), del total de los coeficientes de correlación y no de la varianza total como es el caso del cálculo de los coeficientes de sensibilidad a partir de la matriz de varianzas. Esto se puede ver en la matriz de partida y sumado sus diagonales; así S = 1+ 2; sabemos que 1=8,60555 y 2 = 1,39444, entonces se tiene: S = 8,60555 + 1,39444=10
0
0
)1(5,0
5,0)1(
2
1
e
e
1221 kky
0
0
)5,01(5,0
5,0)5,01(
2
1
e
e
707106,0
1222
k
kky

Autor: José Rigoberto Parada Daza 95
La diagonal es igual a la suma de las varianzas de todas las variables, por lo tanto cuando tomamos 1/S=86,05% y 2/S=13,94%, estamos diciendo que el primer factor explica el 86,05% de la suma de las varianzas de todas las variables del problema.
Para el caso de la Matriz de Correlación, se tiene:
S=2= 1+ 2 , sabemos que 1 =1,5 y 2 =0,5, entonces: 2= 1,5+0,5
En este caso cuando calculamos 1/S=1,5/2=0,75, o sea 75%, y 2/S=0,5/2, o sea 25%, estamos diciendo que la primera componente explica un 75% del total de coeficientes de correlación, que en este caso son dos variables. Por lo tanto, como la diagonal de la Matriz de Correlación siempre serán números unos, entonces, la suma será n para n variables y la explicación de cada factor será i /n, donde n
representa el número de variables. Resumiendo se puede afirmar, que la interpretación de la explicación de los componentes es diferente dependiendo de si se parte con una matriz de varianzas-covarianzas o de una matriz de correlación, y en ambas los resultados no son coincidentes.
5.2.3. Matriz de Varianzas-Covarianzas y Matriz de Correlación
En el ejemplo anterior se ha explicado que los valores propios i no tienen el
mismo significado dependiendo de si se parte de una u otra matriz. Sin embargo, existe un caso especial en que ambas interpretaciones coinciden en el sentido de que el vector propio explica un porcentaje de la varianza total de las variables y esto se presenta cuando los datos de las variables se estandarizan mediante la relación (xi- i)/ i donde
representa el promedio de la variable i y i la desviación estándar de dicha variable.
En el caso de estandarización de las variables, se demuestra que:
i2 = 1, =0; ij = ij
Es decir la matriz de Varianzas-Covarianzas, es igual a la matriz de correlación y en esta situación los valores propios representan el porcentaje de la suma de la diagonal de dicha matriz y que significan las varianzas de las variables, pero de nuevas variables que son las estandarizadas. Para el ejemplo, las variables estandarizadas son las siguientes:
Sdiagonalsuma
x
10
82
22
2
15,0
5,01
Sdiagonaldesuma
R

Autor: José Rigoberto Parada Daza 96
Observación (x1- x1)/ 1 (x2- x2)/ 2
Entonces se tiene:
15,0
5,01.. CovVariMatriz
2/12/1
11
00
8/506
8/12/25
02/14
8/103
8/22/12
8/32/21
12
Varianza
Media

Autor: José Rigoberto Parada Daza 97
5.3.-ANÁLISIS FACTORIAL
5.3.1. Interpretación Intuitiva
Supongamos que en una Bolsa de Valores se transan 300 acciones con una matriz de rentabilidades para un largo período de las trescientas acciones; entonces se trata de buscar factores que expliquen la mayor parte de la varianza común que existe entre todas las acciones. El número de factores debe ser necesariamente menor que el número de variables, en este caso esas variables son las rentabilidades de las acciones.
El Análisis Factorial supone que entre todas las variables, en este caso rentabilidad de acciones, existe una varianza que es común a todas ellas, es decir es la parte de la varianza total de la variable que es explicada por una varianza común; pero además existe una varianza única que es parte de la varianza de cada variable y que es propia y particular de cada variable. Es decir, que la rentabilidad de una acción en particular tiene una varianza que es común con la rentabilidad de todas las otras rentabilidades y tiene una varianza que es particular para cada rentabilidad de cada acción. A esta varianza común se le denomina Comunalidad.
El Análisis de Componentes Principales no hace esta distinción entre varianza común o Comunalidad y Varianza Propia; considera la varianza total como elemento central; esta diferencia lleva a que los métodos de cálculo de los coeficientes factoriales entre ambas técnicas sean diferentes. En Teoría Financiera, en el Modelo de Teoría de Precios por Arbirtraje de Roll-Ross (1979), se hace uso de la Técnica de Análisis Factorial y allí lo más relevante es el cálculo de los coeficientes factoriales.
El Análisis Factorial, desde un punto de vista operativo, se puede descomponer en las siguientes etapas:
a) Calcular la matriz de varianzas-covarianzas de los datos; que en nuestro caso son rentabilidades de acciones. También se usa la matriz de correlaciones entre las variables.
En este último caso para que se pueda aplicar Análisis Factorial se requiere, como requisito, que las variables estén altamente correlacionadas, por ello es que a veces se recomienda trabajar más con la matriz de correlaciones. Hay diferentes test estadísticos para verificar este requisito.
b) Se calcula lo que se denomina matriz reducida, ya sea de la matriz de correlaciones o de la Matriz de Varianzas-Covarianzas. Esta matriz reducida, se obtiene reemplazando en su diagonal, el factor de comunalidad el cual se calcula por diferentes y alternativos métodos convencionales.
La comunalidad se puede calcular, usando la siguiente regla:

Autor: José Rigoberto Parada Daza 98
h 2i * = 1- * Para el caso de la Matriz de Correlación
h 2i * = i
2 * Para el caso de la Matriz de Varianzas-Covarianzas
hi* = Comunalidad; 2i = Varianza de Variable i.
* = 1/rii
rii = Elemento de la diagonal de la Matriz Inversa de la Matriz de Varianzas-Covarianzas o de la Matriz de Correlación según sea el caso.
Existen otros métodos de cálculo tales como: estimar la comunalidad a partir del mayor coeficiente de correlación en la fila i-ésima de la Matriz de Correlaciones. Otro método es usar el coeficiente de correlación múltiple elevado al cuadrado entre una variable específica y las demás variables. Otro método sugerido en la literatura es usar el promedio de los coeficientes de correlación de una variable con todas las restantes.
c) A partir de la Matriz Reducida se obtienen los Valores Propios y los Factores Propios.
d) Se calculan los coeficientes factoriales, para lo cual también hay varios métodos, aunque el usual es el denominado Método del Factor Común.
5.3.2.- Interpretación Matemática
El Análisis Factorial, consiste en un vector x aleatorio y que es observable, con p factores, con media
y matriz de Varianzas-Covarianzas V. El modelo factorial se define como X que es linealmente dependiente de unos pocos factores aleatorios no observables F1,F2,......Fm, llamados Factores Comunes y con errores 1, 2,... p
denominados Factores Específicos; es decir:
x1 - 1 = b11F1 + b12F2 + ..... + b1mFm + 1
x2 - 2 = b21F1 +b22F2 + ... . + b2mFm + 2
. .
. .
. .
xp - p = bp1F1 + bp2F2 + .. .. + bpmFm + p
Lo anterior se puede escribir de la siguiente forma:
x - = BF +
(px1) (pxm)(mx1) (px1)
Los coeficientes bij se denominan coeficientes factorial (o loading) de la variable i con el Factor j, entonces la matriz B es Matriz de Coeficientes Factoriales.
El modelo supone que:
E(F) = 0 cov(F) = E(FF ) = I

Autor: José Rigoberto Parada Daza 99
Cov( ,F)=E( F )=0 (O sea F y son independientes)
A un modelo que cumpla con los supuestos anteriores se le denomina Modelo Factorial Ortogonal y que se resume en la siguiente relación:
x =
+ BF +
(px1) (px1) (pxm)(mx1) (px1) donde:
i = Media de la variable i i = Factor específico de la variable i.
Fj = Factor común j Bij = Coeficiente Factorial (o loading) de la variable i en el factor j.
El vector F es aleatorio y no observable; esto último implica que es un problema no definido y los factores F no tienen interpretación definida a priori, siendo más bien un problema estadístico. En este modelo se debe cumplir lo siguiente:
Matriz Varianzas-Covarianza= BB +
Var (xi) = b2i1 + b2
i2 + ....+ b2im + i
Cov (xi,xk) = bi1 bk1 + bi2bk2 + ... + bimbkm
Cov (x,F) = B o Cov(xi,Fj) = bij
Tal como se explicó, el Análisis Factorial implica:
Varianza de Variable xi = Comunalidad + Varianza Específica 2i = h2
i + i
donde:
Comunalidad = h2i = b2
i1 + b2i2 + b2
i3 + ..... + b2im
Varianza Específica = i con i = 1,2,.....,p
Entonces la varianza total de una variable i se descompone en dos porciones: una la varianza común de todas las variables denominada comunalidad y representada por la suma al cuadrado de los coeficientes factoriales y la otra parte de la varianza total de una variable xi es la varianza específica de esa variable, o sea i.
p
EE
....0
.
0
.0....00
0...0
0...0
)'()cov(0)(1
1
1

Autor: José Rigoberto Parada Daza 100
Para el cálculo de los coeficientes factoriales bij existen varios métodos; los más conocidos son el método del Factor Principal y el método de Máximo Verosimilitud. Se expondrá aquí el Método del Factor Principal o también denominado Método del Componente Principal.
El método de cálculo de los coeficientes factoriales se obtiene de las siguientes etapas:
a) Determinar Matriz de Varianzas-Covarianzas (S) o la Matriz de Correlaciones (R).
b) Los factores y sus coeficientes son definidos en función de los pares de datos de los valores propios, i, y de los vectores propios, e; o sea ( 1,e1),( 2,e2),.... ( p,ep) donde 1> 2> 3>.......> p. El número de Factores Comunes debe ser menor que p.
c) La Matriz de Coeficientes Factoriales, bij, está dada por la siguiente igualdad:
La varianza específica estimada se expresa por la diagonal de la matriz S-BB , o sea: donde : y
Comunalidad = h2i = b2
i1 + b2i2 + ..... + b2
im
y
Para el caso del cálculo de la Comunalidad se debe trabajar con una matriz reducida S r o R r para la de Varianzas-Covarianzas o Correlaciones respectivamente.
Estas matrices son las siguientes:
mm eeeB ....|,| 2211
p.....00
.
0....0
0....0
2
1
m
jijii bS
1
2
1
i
i
pp
j
SSSj
...2211
Proporción de la Varianza total explicada por un factor

Autor: José Rigoberto Parada Daza 101
Donde:
Donde rii es el elemento diagonal de la Matriz Inversa de R y ii es el elemento diagonal de la Matriz Inversa de Varianzas-Covarianzas.
d) A partir de la Matriz Reducida se calculan los valores propios y vectores propios.
Valores Propios: det (Rr
I ) = 0 I = Matriz Identidad; = Valor Propio det = Determinante
Vectores Propios e, se encuentran del siguiente sistema de ecuaciones:
e) Coeficientes Factoriales:
B = 1e1
2e2 ..... mem
Para explicar esta metodología tomemos el mismo caso del ejercicio de Componentes Principales, o sea:
Con estos datos se puede calcular los coeficientes factoriales: Etapas
ppp
p
p
r
ppp
p
p
r
h
h
h
So
hrr
rhr
rrh
R
221
22
212
1122
1
221
22221
1122
1
..
...
...
...
..
...
...
iiiiiiii hor
h1
111
11 22
0
.
.
0
0
.
.
.
....
....2
1
221
22212
1122
1
nnnn
n
n
e
e
e
hrr
rhr
rrh
15,0
5,01
82
22RoxS

Autor: José Rigoberto Parada Daza 102
a) Matriz Reducida:
Entonces
h21 = 1/0,6666=1,5= Comunalidad 1
h22 = 1/0,1666= 6 = Comunalidad 2
b) Valores Propios ( )
Resolviendo el sistema de ecuación tenemos: 1=6,76 2=0,74
c) Vectores Propios (e) (El método de cálculo es el mismo usado en Componentes Principales, y que es tomado de las definiciones de Geometría Analítica).
Si 1 = 6,76 (1,5-6,76)e1 + 2e2 = 0 2e1 + (6-6,76)e2 = 0
Del sistema anterior se tiene e 1 = 0,3802281e 2
Entonces existen pares de datos (0,38 k; k), con un k que cumple:
Se sabe que :
reducidaCovVardeMatriz
h
hSr
22
12
2
2
CovVarMatrizdeInversaS16666,01666,0
1666,066666,01
reducidaCovVardeMatrizSr 62
25,1
0)6(2
2)5,1(

Autor: José Rigoberto Parada Daza 103
Entonces, los vectores propios tienen los siguientes valores:
e1=0,3554 e2=0,9347
Por lo tanto, los coeficientes factoriales del primer factor serán:
Si 2 = 0,74
Entonces, los vectores propios (e) serían los que se obtienen del siguiente sistema de ecuaciones:
(1,5-0,74)e1 + 2e2 = 0 2e1 + (6-0,74)e2 = 0
Resolviendo se tiene: e2 = -0,38e1
Entonces los pares de datos, con k; serían (k;-0,38 k) tal que:
Entonces e1 = 0,93478 e2 = -0,3552 = -0,38(0,93478)
Los coeficientes factoriales del segundo factor serán:
Las comunalidades son: h1
2=(0,92405)2 + (0,804128)2 = 1,5 h2
2 = (2,43022)2 + (-0,30555)2 = 6 La varianza de cada variable es:
1= 12 h1
2= 2-1,5 = 0,5
934713,0
1)3802281,0( 221
k
kkF
40322,2)9347,0(76,6
92405,0)3554,0(76,6
12
11
b
b
93478,0
1)38,0( 22
k
kk
30555,0)3552,0(74,0)3552,0(
804128,0)93478,0(74,093478,0
222
221
xb
xb
Resolviendo para k, se tiene:

Autor: José Rigoberto Parada Daza 104
2= 22 h2
2= 8-6 = 2
Resultado Final
Coeficientes Factoriales
Varianza Específica Comunalidad
Varianza total
Variable
F1
F2
1=2i
h2i
hi2
2i
x1 0,92405 0,804128 0,5 1,5 2 x2 2,43022 -0,30555 2 6 8
F1 y F2 son los Factores 1 y 2 respectivamente.
De acuerdo, al Análisis Factorial, se debe cumplir la siguiente relación: Matriz Varia-Cov= x = BB +
En este caso se ve además que 1+ 2=7,5 que es igual a la suma de
hi2 (comunalidad) =1,5+6 = 7,5
El primer factor explica: 6,76/7,5=0,901, es decir un 90,1% de los aspectos comunes.
El segundo factor explica:0,74/7,5=0,099, es decir un 9,9% de los aspectos comunes o comunalidad.
Hay que notar que la explicación porcentual de los factores no se refiere a la varianza total, ya que el primer factor tiene una varianza común de 1,5 y no 2 como es el total; y el segundo factor, la comunalidad alcanza a 6 y no a 8 que es la varianza total.
Este problema también se puede resolver a partir de la matriz de correlación R, en vez de la matriz de varianza-covarianza; siguiendo la misma metodología explicada; sin embargo hay que tener cuidado con la interpretación de cuándo explican los factores, pues en este caso, la diagonal de la matriz de R son números uno y no varianzas, entonces un valor propio i explicará i/n, donde n es el número de variables. Sólo los i tendrán el mismo significado cuando las variables xi estén estandarizadas, tal como se analizó en las Componentes Principales, ya que en tal caso la diagonal de R es igual a la diagonal de S y serán números unos y a la vez se da 12= 12.
Resolviendo el mismo problema, pero ahora a partir de la Matriz de Correlaciones, se tiene:
20
05,0
62
25,1
82
22
20
05,0
30555,0804128,0
43022,292405,0
30555,043022,2
804128,092405,0
82
22
´BBx

Autor: José Rigoberto Parada Daza 105
h21= 1/1,333=0,75
h22= 1/1,333=0,75
Los valores propios calculados son:
1 =1,25 y 2 = 0,25.
Se tiene 1 + 2 =1,50 = Suma de diagonal de Matriz reducida. Entonces 1/ ( 1+ 2)= 83,33%, es decir el factor uno explica un 83,33% de la diagonal de la
matriz reducida, que en este caso son coeficientes de correlación y no varianzas como el caso en que se usó la Matriz de Varianza-Covarianza. Por eso es que el primer factor explica un valor diferente al del caso del primer factor usando la Matriz de Varianza-Covarianza.
Con estos datos, el resultado final del problema es el siguiente:
Coeficientes Factoriales Correlación
Específica Comunalidad Correlación
Total
Variable F1 F2 hi2
X1 0,79056 0,35355 0,25 0,75 1 X2 0,79056 -0,35355 0,25 0,75 1
La comunalidad se verifica, ya que:
h21 = (0,79056)2 + (0,35355)2 = 0,75
h22 = (0,79056)2 + (-0,35355)2 = 0,75
Además se verifica que:
R = BB +
O sea R = Rr+
333,16666,0
6666,0333,1
15,0
5,01 1RR
75,050,0
5,075,0rR

Autor: José Rigoberto Parada Daza 106
Es interesante resaltar que los Factores F1 y F2 no tienen interpretación explícita y además son no observables directamente, lo que implica que éste es un método más bien matemático. Para el caso de la rentabilidad de las acciones, la interpretación que se le puede dar es que la rentabilidad de un título bursátil cualquiera, la variable xi, depende de factores lineales y esos factores tienen diferentes ponderaciones en la rentabilidad, ponderaciones que se cuantifican por los coeficientes factoriales; pero estos factores, que matemáticamente explican la varianza, pueden ser diferentes aspectos. La comunalidad, para el caso de las rentabilidades de las acciones, serían elementos comunes a todas las acciones que se consideran en el estudio, es decir sería lo que se denomina Riesgo Sistemático, o sea el riesgo del sistema financiero en total y el resto de la varianza, es decir la varianza específica serían las características de cada acción en particular como pueden ser: niveles tecnológicos, capacidad gerencial y empresarial, mezcla de productos vendidos, etc. Así, se puede resumir, a través de matrices, la siguiente relación:
x = BB +
Riesgo Total = Riesgo Sistemático + Riesgo Propio.
5.3.3 COMPARACIÓN MÉTODO COMPONENTES PRINCIPALES Y ANÁLISIS FACTORIAL.
En una primera impresión, Análisis de Componentes Principales y Análisis Factorial parecieran conducir a las mismas conclusiones respecto a los coeficientes factoriales, sin embargo, su significado es diferente. El Análisis de Componentes Principales, es el resultado de una combinación lineal de las variables, es decir la Componente Principal es la variable dependiente de las variables observables xi; en este sentido las componentes pueden tener interpretación y como se señaló esa depende del conocimiento del investigador que está analizando el problema; es decir:
C Pi = b11x1 + .... + binxn
En el caso de Análisis Factorial, la variable dependiente es la observada, es decir xi; y las independientes son unos factores Fi que no son observables ni
25,00
025,0
75,050,0
50,075,0
15,0
5,01
25,00
025,0
35355,035355,0
79056,079056,0
35355,079056,0
35355,079056,0
15,0
5,01

Autor: José Rigoberto Parada Daza 107
interpretados directamente. Se ve, pues, que la variable dependiente en Componentes Principales es el resultado de variables observables de la realidad y representan algún suceso específico y explícito, en cambio en Análisis Factorial la variable dependiente es la observable y representa algún aspecto concreto del problema que se analiza, o sea:
xi = b11F1 + .... + binFn
Para el caso de rentabilidad de acciones, las Componentes Principales indican un conjunto de indicadores bursátiles y financieros que son agrupados linealmente; en cambio en Análisis Factorial existe un solo indicador conceptual que son rentabilidades de diferentes empresas; pero no muestran índices financieros. En conclusión son metodologías diferentes y no necesariamente sustitutos una de otra.
5.4.- ANÁLISIS DISCRIMINANTE
5.4.1.- Interpretación Intuitiva
Desde un punto de vista analítico en diferentes problemas económicos y financieros se tiende a separar grupos ya sea de personas, sectores económicos y empresas, de tal forma que las conclusiones que se obtengan de los estudios tengan un grado de homogeneidad en el grupo y a la vez se puedan comparar con otros grupos. El análisis de un grupo en particular requiere definir qué variables pueden diferenciar a un grupo de otro, es decir cuáles son aquellas variables que discriminan a un grupo de otro. Los investigadores a priori pueden especificar ciertas variables que teóricamente separen a los grupos, o bien a la inversa, que se presenten claramente los grupos, pero no se conozca con exactitud qué variables discriminan entre uno u otro grupo. Este es el problema que resuelve la metodología de Análisis Discriminante.
Un tema que se ha observado con esta técnica es el estudio de empresas quebradas y no quebradas, de Altman (1968). Así, se pueden separar dos grupos claramente diferenciables como son las empresas que han fracasado de aquellas exitosas; el tema aquí es buscar qué variables son las relevantes y que permiten separar a ambos grupos de empresas. Aquí se conocen a priori los grupos, con datos ex post, y desde un punto de vista de gestión interesa conocer las variables que permiten efectuar la separación o discriminación entre ambos grupos. Otro ejemplo, puede ser determinar qué variables identifican a los precios de las acciones de una empresa industrial de otra de servicios. La verificación de estas variables se efectúa a través de la elaboración de hipótesis nula e hipótesis alternativas, las que son contrastadas siguiendo el mismo enfoque metodológico estadístico de prueba de hipótesis para cualquier variable.

Autor: José Rigoberto Parada Daza 108
En términos matriciales el Análisis Discriminante se puede representar de la siguiente forma:
Grupo 1 Empresas exitosas
Grupo 2 Empresas no exitosas
Variables Empresa
x1 .x2 x3 ...xp
Variables Empresa
x1 .x2 x3 ...xp
1
1 2
2 . . . .
.
.
.
. n1
n2
Las xi pueden ser indicadores financieros del tipo Deuda/Capital, Rentabilidad Patrimonial, Activo Circulante/Pasivo Circulante, etc. y que a priori separarían estos dos grupos; si se acierta o no a estas variables es lo que se deduce del Análisis Discriminante.
5.4.2. Matemáticas del Análisis Discriminante para dos grupos.
Se aplicará aquí el método de determinar una función discriminante que es una combinación lineal de las variables. Usualmente se asume que la población está normalmente distribuida.
Una combinación lineal de las x toma el valor y11, y12,.... y1n1 para las observaciones del primer grupo y el valor y21, y22,...y2n2 para las observaciones del segundo grupo.
El objetivo es seleccionar una combinación lineal de las x para alcanzar el máximo de separación entre las medias grupales y 1 e y 2.
La recta que se busca es del tipo:
y = a1x1 + a2x2.... + apxp
de tal manera de maximizar el ratio.

Autor: José Rigoberto Parada Daza 109
Los coeficientes ai se calculan de la siguiente ecuación matricial:
x = Vector de las variables x1 y x2. S-1 =Matriz Inversa de la Matriz de Varianzas-Covarianzas Ponderada d = Vector de diferencia de medias ( 1x - 2x ) traspuesto ai = Coeficientes de la función discriminante.
Para estos cálculos se deben usar las siguientes matrices:
2
221 )(
tan
yS
yy
ydegrupalVarianza
ydegrupalesmediaslasde
cuadradoalciaDis
xSdy 1'
gruposegundodelnesObservacioxxx
grupoprimerdelnesObservacioxxx
n
nxp
n
nxp
x
x
222221
)(
111211
)(
,....,2
,....,1
2
1
1
11
1)1(
11Pr
n
jj
px
xn
GrupoimerMedia x
)')((1
11
11
11
1)(
1
1
1 xxxxn j
n
nj
pxp
S
2
12
2)1(
12
n
jj
px
xn
GrupoSegundoMedia x
2
)2.()1()1.()1(
21
21
nn
GrupoCovVarMatriznGrupoCovVarMatriznS
doer
Matriz Varianza-Covarianza 1er Grupo

Autor: José Rigoberto Parada Daza 110
Entonces la Matriz de Varianzas.Covarianzas Ponderada S es calculada de la siguiente forma:
Además se tiene lo siguiente:
Se calculan los y i de cada observación para determinar una regla de clasificación
a través de yc que es:
Si yi> yc entonces observación i corresponde al Grupo I. yi< yc entonces observación i corresponde al Grupo II.
Para analizar si los grupos son discriminados por las variables definidas se establecen las hipótesis siguientes:
Ho = No existe diferencia entre los grupos H A = Existe diferencia entre los grupos.
Para validar esta hipótesis se debe calcular la distancia D al cuadrado, o se:
Si H 0 es verdadera, entonces se calcula la función F.
)')((1
12
22
12
2
2
2
xxxxn
Sj
n
jj
)2(
)1()1(
)1()1(
1
)1()1(
1
21
2211
221
21
21
1
nn
SnSn
Snn
nS
nn
nS ponderada
21
211 )'( xSxxy
21
212 )'( xSxxy
2/)( IIIc yyy
)()'( 211
212 xxSxxD
Matriz Varianza Covarianza 2do Grupo:

Autor: José Rigoberto Parada Daza 111
F = (D2(N-p-1)n1n2)/p(N-2)N N = n1+ n2
p = Número de Variables
Si H 0 es verdadera entonces F se distribuye con una función F
con p y N-p-1
grados de libertad. Entonces si F>F
(el F de tabla) se acepta la hipótesis alternativa.
El siguiente ejemplo, con fines didácticos, permite aclarar esta metodología. Supongamos que se tienen dos grupos de empresas, clasificadas a priori como empresas sociedades anónimas con propiedad difusa (primer grupo) y sociedades de personas o familiares (segundo grupo). Se plantea que las variables (xi): rentabilidad operacional (x1) y la relación Deuda/Capital (x2) permiten diferenciar claramente estos dos grupos de empresas. Los datos para ambos grupos son los siguientes:
GRUPO 1 GRUPO 2 Sociedades Anónimas Sociedades de Personas Sociedad x1(en %) x2(en %) Sociedad x1(en%) x2(en %) 1 7 25 1 5 20 2 6 20 2 6 25 3 5 15 3 7 15 4 6 20 4 8 10
5 9 5
Se pretende buscar si realmente las variables x 1 y x 2 sirven para diferenciar a ambos grupos, es decir si discriminan o no. Ordenando los datos en forma matricial se tiene:
510
98
15
7
25
6
20
5
20
6
15
5
20
6
25
721 xx
15
7
20
621 xx

Autor: José Rigoberto Parada Daza 112
Los datos centrados para ambos grupos son los siguientes: Cálculo de Matriz de Varianzas-Covarianzas(Si)
Cálculo de Matriz Ponderada S.
Cálculo de coeficientes (a i ) de la función discriminante:
1050
10
5
2101
2
00
510
5
0
1
2º1º
22221111 jjiijjii xxxxxxxx
NGrupoNGrupo
6666,163333,3
3333,36666,0
00
5100
51
050
010
5
1
14
11S
5,6225,11
25,115,2
10
5
2
100
101
52
105010
2101
5
2
151
2S
857,425
57143,1
)245(
)15()14( 21 SSS
035368,0103156,0
103156,08842,01S

Autor: José Rigoberto Parada Daza 113
y = -0,36842x1 + 0,073644x2
En este caso el vector de diferencia de medias se ha obtenido de la siguiente forma:
Calculando:
Calculando los yi para cada empresa, y reemplazando los valores de xi en la función discriminante, se tiene:
Empresa yI Asignación Empresa yII Asignación 1 -0,74 I 1 -0,37 II 2 -0,74 I 2 -0,37 II 3 -0,74 I 3 -1,47 I 4 -0,74 I 4 -2,21 I
5 -2,95 I
Si yi>yc entonces la empresa i corresponde al primer grupo o si yi<yc entonces la empresa i corresponde al segundo grupo.
Con estos datos se puede crear lo que se denomina Matriz de Confusión, es decir cuántas empresas están bien clasificadas y cuántas no corresponden y en las intersecciones de esta matriz se buscan las correctas. La matriz es la siguiente:
Según Análisis Discriminante Grupo I Grupo II
Grupo I 4 3 Grupo Original Grupo II 0 2
Total 4 5
2
1
03536,0103156,0
103156,08842,051
x
xy
5
1
15
7
20
621 xx
738,020
6073644,036842,01y
474,115
7073644,036842,02y
11,12/)474,1738,0(2/)( 21 yyy c

Autor: José Rigoberto Parada Daza 114
Con un círculo se encierra el número de empresa donde coinciden las asignaciones de las empresas o los grupos según Análisis Discriminante y como estaban inicialmente asignadas. Así hay cuatro empresas del grupo que inicialmente estaban en ese grupo y según Análisis Discriminante este también es cuatro, es decir en el primer grupo no existe ninguna empresa mal clasificada. En el grupo II hay dos empresas que según Análisis Discriminante debería estar en grupo I. Por lo tanto, hay 6 empresas bien clasificadas y 3 mal clasificadas; las empresas mal clasificadas son los números 3,4 y 5 que habiendo sido primariamente pertenecientes al grupo II, según el Análisis Discriminante deberían estar agrupadas en el Grupo I.

Autor: José Rigoberto Parada Daza 115
APENDICE Nº 1
ALGUNOS CONCEPTOS DE CÁLCULO DIFERENCIAL E INTEGRAL USADOS EN TEORÍA FINANCIERA.
DERIVADAS
Sea y = f( ) = (x), o sea y = f( (x))
Se tiene:
Esta regla se puede aplicar a una cadena.
O sea:
)0(1ln1 xxdx
xdnx
dx
dx nn
)0,0(ln
1logln ax
axdx
xdaa
dx
da xx
)ln1( xxdx
dxe
dx
de xx
xx
)0(1ln
01
01
xxdx
xd
xpara
xpara
dx
xd
dx
du
du
dy
dx
dy.

Autor: José Rigoberto Parada Daza 116
Para la diferencial total (o sea dy) con y = F(x1, x2,.....xn)
INTEGRALES:
n
n
n dx
dx
dx
dx
dx
dx
dx
dy
dx
dy 1
3
2
2
1
1
...
nn
dxx
ydx
x
ydx
x
ydy .....2
21
1
cxxxxdxncn
xdxx
nn lnln)1(
1
1
ce
xdx
e
xcx
x
dxxx
1ln
cea
axdxxeac
a
adxa axax
xx
2
1)0(
ln
)1,0(ln
1AAA
AadxAcedxe baxbaxxx
11
3
2
2
1
1
!)1(
!)1.....(
)1(n
nn
nnnn
ax
axnaxn
axn
a
n
a
xn
a
xnn
a
nx
a
xe
dxexa
n
a
exdxex

Autor: José Rigoberto Parada Daza 117
)2(
1)1( 11ndx
x
e
n
a
xn
edx
x
en
ax
n
ax
n
ax
)2()()1(
1
)( 1m
eamex
dxemaxmax
ax

Autor: José Rigoberto Parada Daza 118
APENDICE Nº2
ALGUNOS CONCEPTOS DE MATEMÁTICAS FINANCIERAS USADOS EN TEORÍA FINANCIERA
1) Valor Actual Neto
Donde VAN = Valor Actual Neto; I = Inversión inicial; Fj = Flujo de Caja período j (j=1,...n); i = Tasa de Interés
Si VAN = 0, entonces i= TIR = Tasa Interna de Retorno
2) Interés Compuesto
Caso discreto
M = C(1+i)n ; M = Monto en n ; i = tasa de interés por período; n = período de capitalización
Cuotas de Pago Vencido (R) constantes por período. R = Va /A(n,i) Va = Valor Actual; A(n,i)= 1-(1+i)-n /i = Factor de Actualización de $1 periódico por
n períodos, capitalizado a la tasa i. n = período total; i = Tasa de interés;
3) Rentas Perpetuas (equivalente a n )
Va = R/i
4) Rentas Diferidas
Va= RF(n,i) Vm
F(n,i)= 1-(1+i)n /i m= Período de diferimiento, transcurrido desde el inicio de un contrato y durante los cuales no se percibe renta. n = Período, a partir de m, en el cual se empieza a recibir renta periódica.
5) Préstamos Bancarios y Bonos
P = RA(n,k)
nn
i
F
i
F
i
FIVAN
)1(......
)1()1( 221

Autor: José Rigoberto Parada Daza 119
P = Préstamo recibido; R = Cuota de Interés y amortización constante por período;
A(n,k) = Factor de Actualización de $1 periódico por n períodos; k = Tasa de interés.
Rk = Ck + Ik
Cj = R (1+k)n-j+1 o Ck = C1(1+k)j-1
Cj = Pago de amortización en período j
Ij = Interés (en $) del préstamo en período j.
6) Tasas Efectivas y Tasas Nominales
Sea j una tasa nominal de interés y con capitalización al término de t-ésimo de año, durante n períodos, entonces el valor futuro de $1 es: Sí existe una tasa efectiva por período de i, su valor futuro es:
(1+i)n
Entonces la relación entre tasa nominal j y tasa efectiva i se obtiene de la igualación de ambos factores, es decir:
)1(
)1(1)1,()1,(
1
kk
kkniFknikRFI
kn
j
tn
t
j)1(
1)1( t
t
ji

Autor: José Rigoberto Parada Daza 120
APENDICE Nº 3 ALGUNOS MODELOS CLÀSICOS FINANCIEROS.
Funciones aversión-riesgo 1971 Merton, R. C. Cálculo Diferencial Estocástico
Tasa de interés y Mercado eficientes
1977 Vasicek, O. Cálculo Diferencial Estocástico
Demanda defectivo 1980 Frenkel, J. Y Jovanovic B.
Cálculo Diferencial Estocástico
Inversión en Dinero 1956 Tobin, J. Cálculo Diferencial Inversión en Dinero 1969 Mao, J Programación
Dinámica Precio Acciones, Dividendos
1956 M. Gordon y E. Shapiro
Álgebra
MODELO
AÑO AUTOR TÉCNICA MATEMÁTICA SUBYACENTE
Valor Empresa 1958, 1963 Modigliani-Miller Álgebra, Regresión simple
Costo de Capital 1963 Ezra Solomon Álgebra Valor Empresa 1963 Fred Weston Regresión Múltiple Costo de Capital 1963 Alexander Barges Regresión Múltiple Portfolio 1952,1958 Harry Markowitz Cálculo Diferencial CAPM 1961,63,65
1966 W.Sharpe, Treynor, Mossin, Lintner
Regresión Corte Transversal
APT 1976,1980 R. Roll y S. Ross Análisis Factorial Opciones financieras 1973 F. Black y M. Scholes Cálculo Diferencial
Estocástico Opciones Financieras 1979 Cox, S. Rubinstein,M Estadística
Matemática (Distribución Binomial)
Mercados Eficientes 1970,1976 E. Fama Econometría Duración de Bonos 1938 F. Macaulay Álgebra Asignación de Recursos 1963 H. Weingartner Programación
Lineal Funciones de Utilidad 1964,1971 Pratt W., y
Arrow, K Estadística Matemática
Predicción Quiebra 1968 E. Altman Análisis Discriminante
Contrato Accionistas-Directivos
1984 Myers, J. y Majluf, N.
Teoría de Juegos

Autor: José Rigoberto Parada Daza 121
BIBLIOGRAFÍA
1. Copeland, T. y Weston, J.F. (1998), Financial Theory and Corporate Police , 3era Edition, Addison Wesley Publishing C. USA.
2. Demidovich, B. (1993), Problemas y Ejercicios de Análisis Matemático , Undécima Edición, Editorial Paraninfo, Madrid, España
3. Johnson, R.A. y Wichern,D (1992), Applied Multivariate Statistical Analysis , 3era Edition, Prentice Hall, Upper Saddle, N. Jersey.
4. Elton; E. y Grube, M. (1991) : Modern Portfolio Theory and Investment Analysis , New York.
5. Gil F, J.A. (1991), Elementos de Matemáticas para las Ciencias del Seguro , Fundación Mapfre Estudios, Instituto Ciencias del Seguro, Madrid, España.
6. Kariya, T. (1993), Geometría Analítica con Vectores y Matrices , 3era Reimpresión, Editorial Limusa, Mexico.
7. Malliaris, A.G. y Brock W.,(1982), Stochastic Methods in Economics and Finance , North-Holland, Amsterdam.
8. Mikosch, T. (1999), Elementary Stochastic Calculus , World Scientific, London.
9. Murdoch, D.C.,(1977), Geometría Analítica con Vectores y Matrices , 3era Reimpresión, Editorial Limusa, México.
10. Ross, S. (1996), Stochastic Processes , 2da Edition, John Willey and Sons, Inc. N. York.
11. Smoliansk, F. L. (1971), Tabla de Integrales Indefinidas , editorial Universitaria, Stgo. Chile.
12. Soldevilla, E. (1999), Los Fondos de Inversión: Gestión y Valoración , Editorial Pirámide, Madrid, España.
13. Suriñach, J.; Artís, M.; López, E. Y Sansó, A. (1995), Análisis Económico Regional: Nociones Básicas de la Teoría de la Cointegración , Antoni Bosch Editor, Barcelona, España.


















