
Estudio comparativo de modelos de machine learning para la ...
Upload
jorge-martinez-ortegaCategory
view
159download
0
Análisis de datos: una breve muestra de sus
aplicacionesJorge Martínez Ortega
Diciembre 10, 2015

¿Qué tienen en común?
• Un experimento de Altas Energías
• Una Startup dedicada a las microfinanzas
• El gobierno

Respuesta
• Que utilizan métodos estadísticos de clasificación para mejorar sus procesos. (Machine Learning)

Machine LearningMétodos de clasificación

Problema 1• 1.7M de colisiones por segundo
• 50 eventos relevantes por segundo guardados
• 5M de eventos después de hacer un preselección en parámetros físicos.
• 7K señal, 5M ruido.
• Encontrar una muestra suficientemente limpia para permitir hacer mediciones precisión. pureza ~ 5%, con 5K+ eventos de señal.
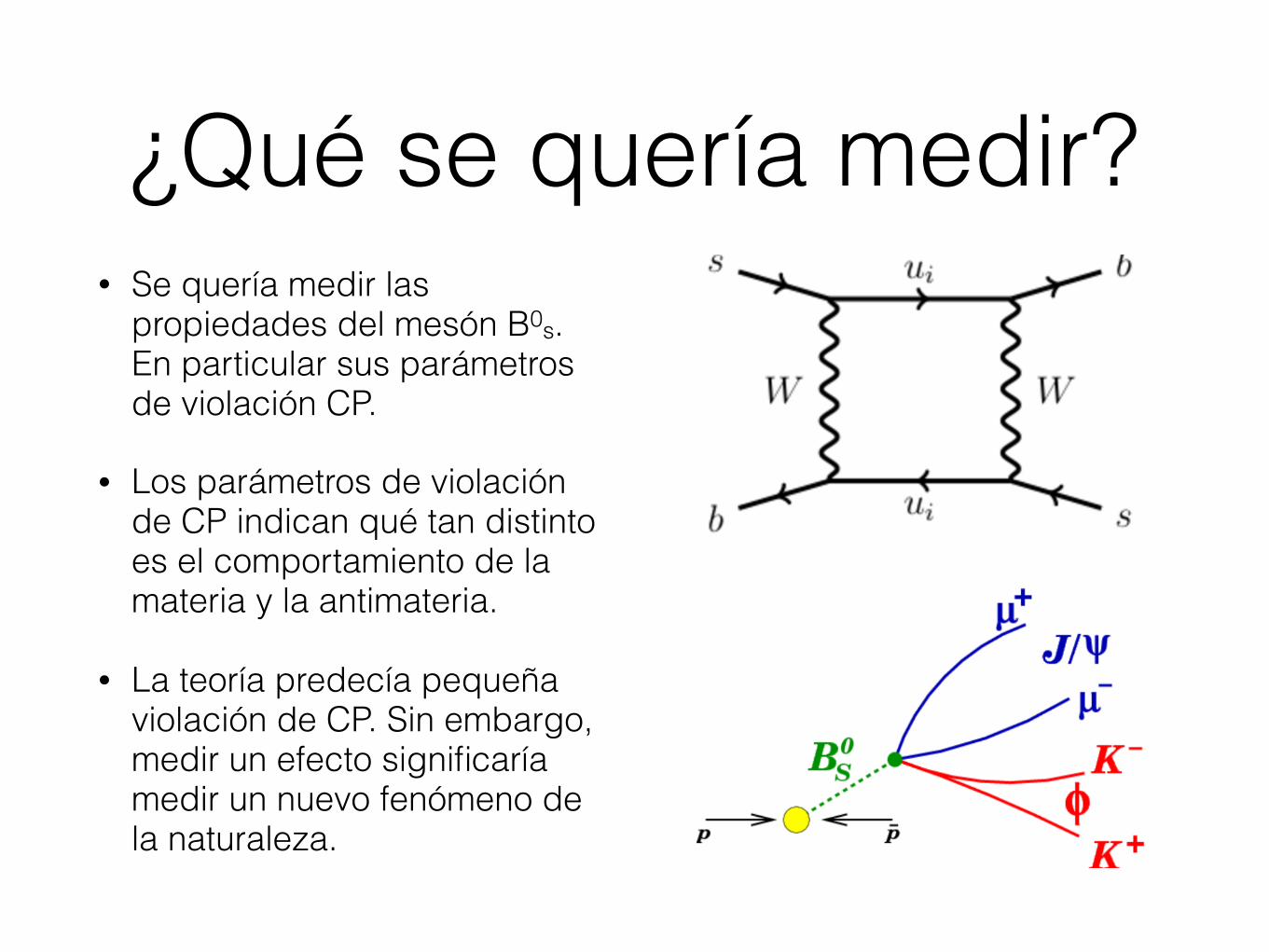
¿Qué se quería medir?• Se quería medir las
propiedades del mesón B0s. En particular sus parámetros de violación CP.
• Los parámetros de violación de CP indican qué tan distinto es el comportamiento de la materia y la antimateria.
• La teoría predecía pequeña violación de CP. Sin embargo, medir un efecto significaría medir un nuevo fenómeno de la naturaleza.
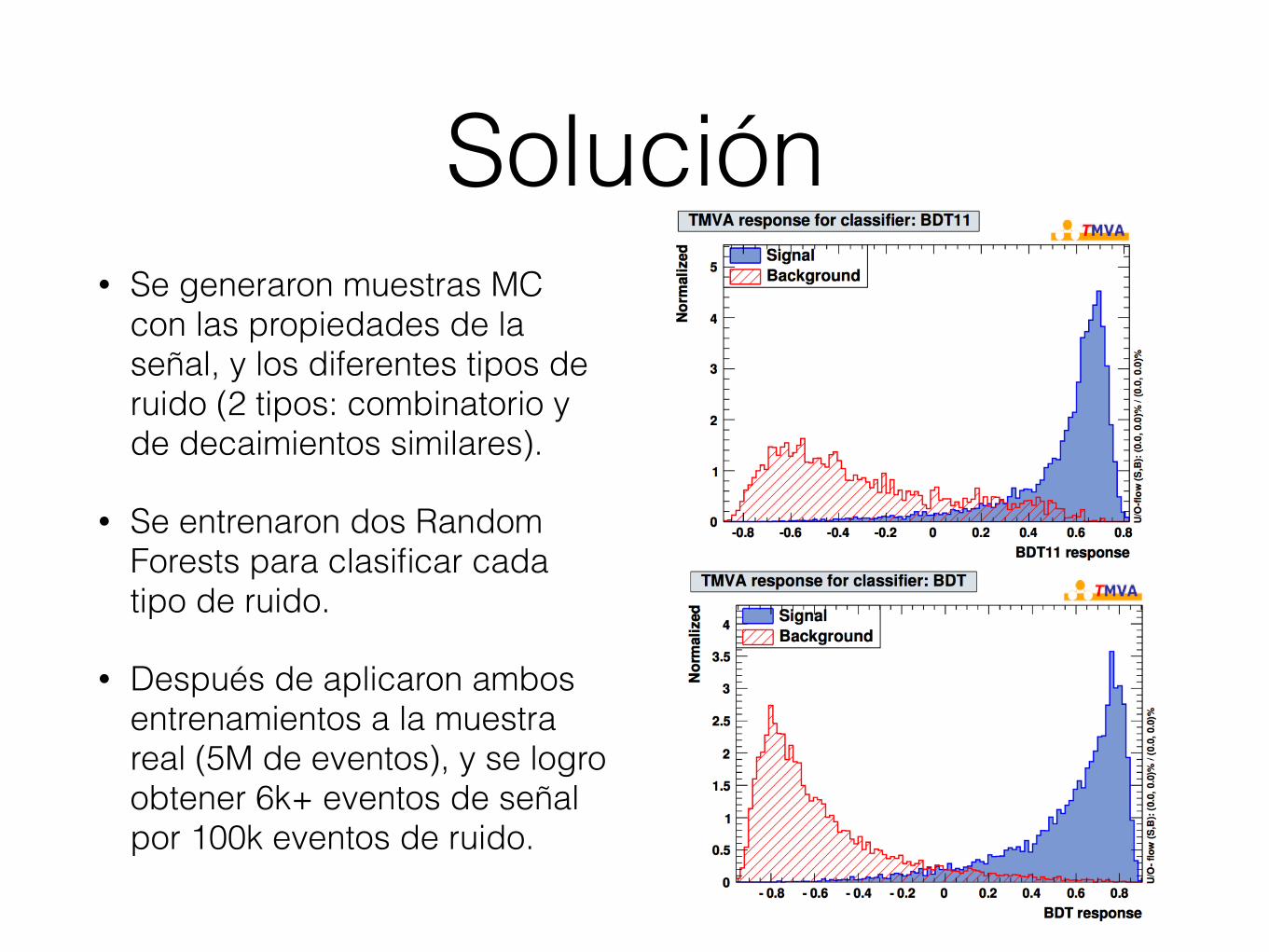
Solución• Se generaron muestras MC
con las propiedades de la señal, y los diferentes tipos de ruido (2 tipos: combinatorio y de decaimientos similares).
• Se entrenaron dos Random Forests para clasificar cada tipo de ruido.
• Después de aplicaron ambos entrenamientos a la muestra real (5M de eventos), y se logro obtener 6k+ eventos de señal por 100k eventos de ruido.
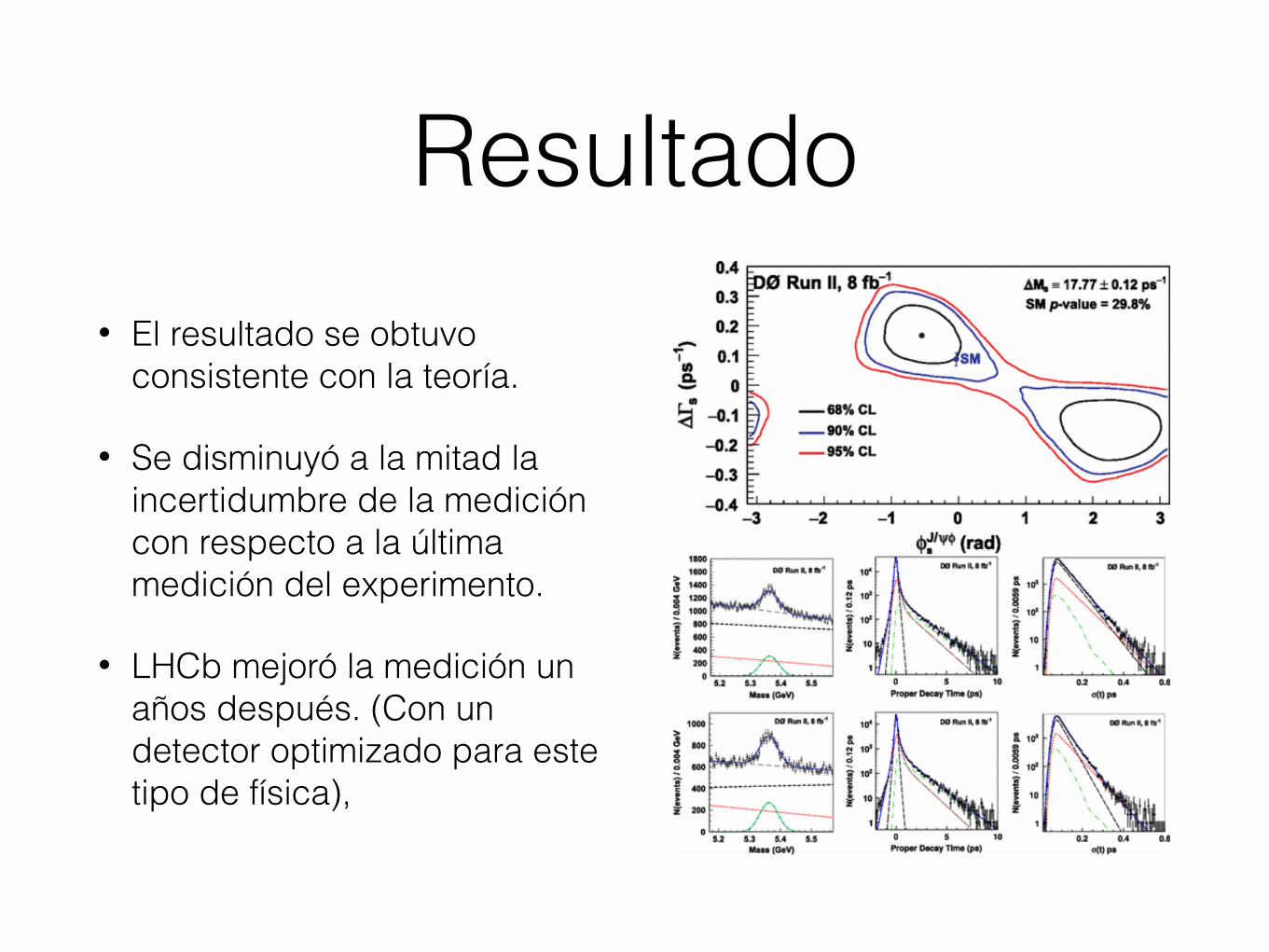
Resultado• El resultado se obtuvo
consistente con la teoría.
• Se disminuyó a la mitad la incertidumbre de la medición con respecto a la última medición del experimento.
• LHCb mejoró la medición un años después. (Con un detector optimizado para este tipo de física),
Problema 2
• Una startup con menos de 700 préstamos otorgados.
• 70% de impago.
• Se necesita reducir el impago a 20% para que la empresa pueda ser viable.

¿Qué se necesita medir?• Obtener alguna calificación que se pueda traducir
a riesgo crediticio, es decir, a probabilidad de incumplimiento.
• Para esto se usó información tradicional como Historial Crediticio y una Forma llenada en linea; así como información no tradicional como: Información de Redes Sociales, Huella en Linea, Grafo Social, Técnicas de Identificación de Dispositivos.
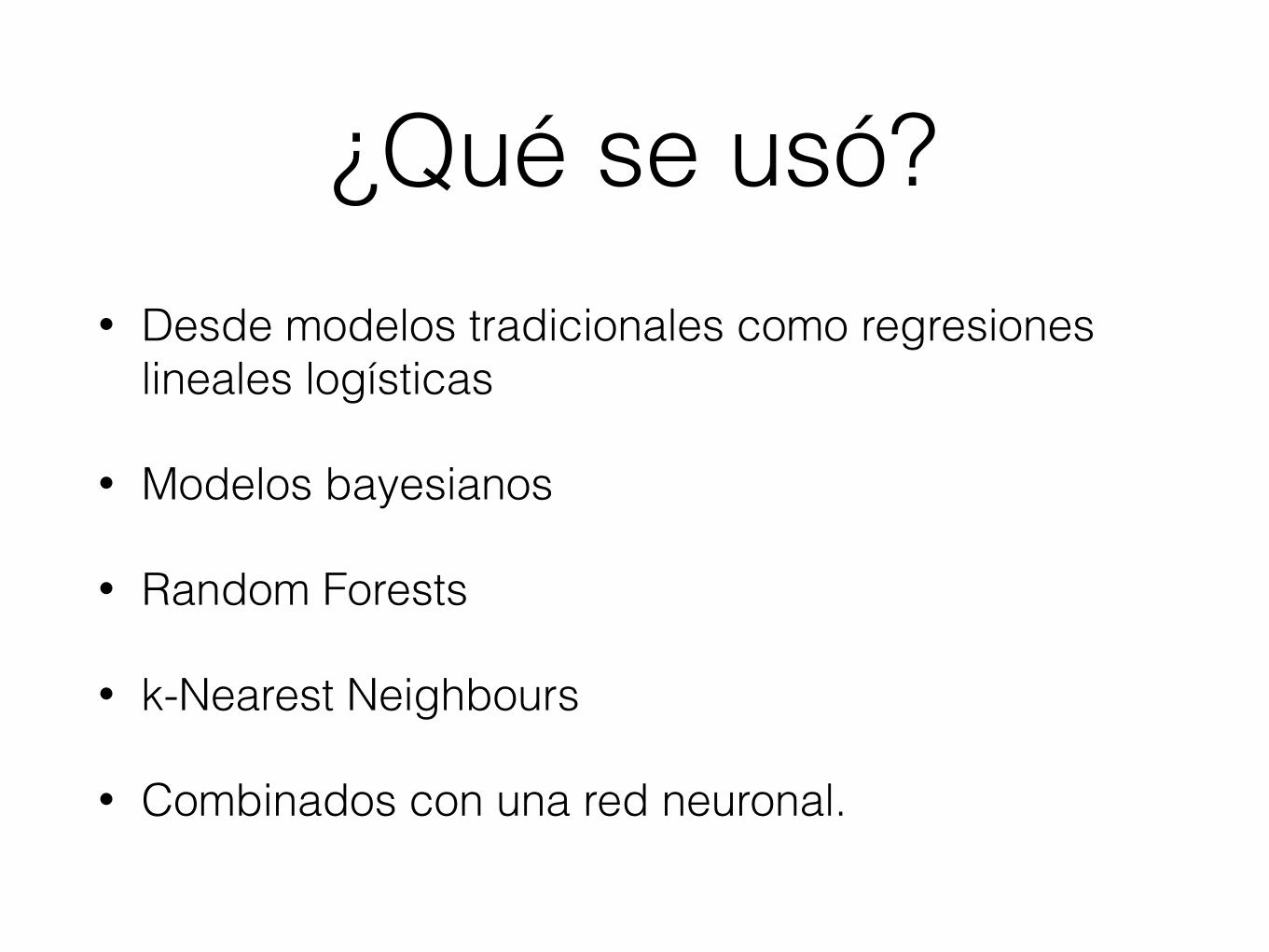
¿Qué se usó?• Desde modelos tradicionales como regresiones
lineales logísticas
• Modelos bayesianos
• Random Forests
• k-Nearest Neighbours
• Combinados con una red neuronal.

Resultados
• Se logró reducir el impago a niveles del 20% en el primer préstamo.
• La empresa acaba de cumplir su tercer año.
• Ha recibido más de 5M de dólares de inversión.
• Sigue creciendo en número de clientes y con finanzas saludables

Problema 3• El gobierno Federal está
obligado a responder las solicitudes de atención ciudadana.
• Al recibirlas, una persona debe leerlas y clasificarlas conforme a qué dependencia debe atender la solicitud.
• ¿Se puede automatizar esta tarea?

Status• Usando técnicas de NLP se
hace un análisis del texto recibido.
• Cada palabra representa una característica del documento.
• Usando un Random Forest se puede predecir a qué dependencia debe dirigirse la solicitud.
• La solución 0 ya está, pero el desarrollo sigue activo.

Lenguajes y Paquetes Usados:
• C++ (TMVA/ Cern ROOT)
• R (muchísimos paquetes)
• python (nltk, scikit-learn)

Conclusiones• Existen muchos problemas en las más diversas áreas
que se pueden atacar usando las mismas técnicas.
• El análisis de datos predictivo, en particular los métodos estadísticos de clasificación están en auge, y serán usados cada vez más en problemas cada vez más complicados.
• Recomendación: exploren y aprendan cada nueva técnica y paquete que se les presente. En cualquier momento puede llegar el problema que se puede solucionar con dicha técnica.

Gracias por su atención!


















