
LOS MODELOS DE PREDI CCIÓN DEL FRACASO …
31
1 LOS MODELOS DE PREDICCIÓN DEL FRACASO EMPRESARIAL. PROPUESTA DE UN RANKING José Manuel Pereira Profesor Adjunto Departamento de Contabilidade e Fiscalidade Escola Superior de Gestão Instituto Politécnico do Cávado e do Ave Mário Basto Profesor Adjunto Departamento das Ciências Escola Superior de Tecnologia Instituto Politécnico do Cávado e do Ave Fernando Díaz Gómez Profesor Titular Departamento de Informática Universidad de Valladolid Eduardo Barbas Albuquerque Assistente do 1.º Triénio Escola Superior de Estudos Industriais e de Gestão Instituto Politécnico do Porto Área temática : B) Valoración y Finanzas. Palabras clave : Ranking, Modelos, Fracaso Empresarial. 111b
Transcript of LOS MODELOS DE PREDI CCIÓN DEL FRACASO …

1
LOS MODELOS DE PREDICCIÓN DEL FRACASO EMPRESARIAL.
PROPUESTA DE UN RANKING
José Manuel Pereira Profesor Adjunto
Departamento de Contabilidade e Fiscalidade Escola Superior de Gestão
Instituto Politécnico do Cávado e do Ave
Mário Basto Profesor Adjunto
Departamento das Ciências Escola Superior de Tecnologia
Instituto Politécnico do Cávado e do Ave
Fernando Díaz Gómez Profesor Titular
Departamento de Informática Universidad de Valladolid
Eduardo Barbas Albuquerque Assistente do 1.º Triénio
Escola Superior de Estudos Industriais e de Gestão Instituto Politécnico do Porto
Área temática: B) Valoración y Finanzas.
Palabras clave: Ranking, Modelos, Fracaso Empresarial.
111b

2
LOS MODELOS DE PREDICCIÓN DEL FRACASO EMPRESARIAL.
PROPUESTA DE UN RANKING
Resumen
A lo largo de los últimos cuarenta años la literatura acerca del fracaso empresarial presenta una amplia gama de modelos de predicción de crisis empresarial, basados esencialmente en datos extraídos de los estados contables.
El objetivo del presente trabajo es elaborar una propuesta de un ranking de los modelos de predicción del fracaso empresarial utilizando una metodología distinta respecto a los autores que han abordado el tema.
Comparando nuestra propuesta de ranking con la propuesta por Aziz y Dar (2006) podemos verificar que hay una gran divergencia entre las posiciones ocupadas por los distintos modelos. Como ejemplo, en el referido trabajo el Análisis Discriminante ha obtenido la primera plaza, seguido del modelo logit mientras que el modelo probit y los Conjuntos Aproximados ocupan las últimas posiciones, muy diferentes de las que hemos presentado en nuestra propuesta.

3
1. INTRODUCCIÓN
La globalización impone que cada vez más las empresas tengan que desarrollar su actividad en un entorno económico en permanente mutación, caracterizado por una fuerte competencia, elevados niveles de exigencia, incertidumbre y situaciones coyunturales de crisis económicas.
La salud financiera de las empresas ha sido una de las grandes preocupaciones sociales, siendo muchos los agentes económicos, bien a nivel individual o colectivo, interesados en la continuidad empresarial.
A lo largo de los últimos cuarenta años la literatura acerca del fracaso empresarial presenta una amplia gama de modelos de predicción de crisis empresarial, basados esencialmente en datos extraídos de los estados contables. El objetivo de la mayoría de los estudios se ha circunscrito a la elaboración de modelos que permitiesen predecir la continuidad empresarial y, al mismo tiempo, destacar los elementos más significativos de los mismos.
Desde los trabajos pioneros de Beaver (1966) y Altman (1968) los investigadores buscan metodologías alternativas y nuevas herramientas con el objetivo de mejorar los resultados, soslayar limitaciones metodológicas y potenciar la utilidad de los modelos obtenidos.
El objetivo del presente trabajo es elaborar una propuesta de un ranking de los modelos utilizando una metodología distinta respecto a los autores que han abordado el tema.
2. BREVES CONSIDERACIONES SOBRE LOS MODELOS
Análisis Univariante Los modelos univariantes se “caracterizan por hacer recaer todo el peso de la
predicción en el resultado ofrecido por una sola variable económica” (Crespo, 2000: 25), es decir, son modelos que utilizan una sola variable independiente para predecir la quiebra. En general las investigaciones empíricas sobre la predicción del fracaso que utilizan esta metodología, tienen como principal objetivo comparar los ratios financieros de las empresas que fracasan con los ratios de las que no fracasan, para detectar diferencias sistemáticas que puedan ayudar a predecir dicha situación (Lev, 1978).
Análisis discriminante (ADL) El análisis discriminante ha surgido con el intento de distinguir
estadísticamente entre dos o más grupos de individuos u objetos, con respecto a varias variables simultáneamente. La aplicación de esta técnica al análisis financiero se ha dirigido inicialmente a la consideración del problema de la predicción de bancarrota o quiebra. El objetivo era obtener un indicador o puntuación «Z» (variable dependiente de una función) que resultaba de la

4
combinación lineal de determinadas variables independientes (ratios o indicadores financieros) Gabás (1990).
Modelos de Regresión Lineal (MRL) La regresión lineal nace de la tentativa de relacionar un conjunto de
observaciones de determinadas variables, designadas genéricamente por ix , con las lecturas de una determinada grandeza Y. En el caso de la regresión lineal, se
considera que la relación de respuesta con las variables ix es una función lineal en
los parámetros iβ siendo generalmente subyacente una relación del
tipo εβββ ++++= mm xxY ...110 (Reis, 1994).
El modelo logit El logit se obtiene a partir de la regresión logística. La regresión logística
puede ser utilizada cuando la variable dependiente es binaria o dicotómica (Hosmer y Lemeshow, 1989). Como señala Ferrando y Blanco (1998: 522) “en un modelo logit, la relación entre la probabilidad de quiebra en una empresa i (Pi) y el valor de los j ratios financieros de dicha empresa en un determinado año (Xji) es de una curva en S acotada entre cero y uno.”
El modelo probit Este tipo de análisis de regresión es apropiado para conjuntos de datos en los
que la variable dependiente es de tipo binario, dicotómico o dummy (Nelson, 1990). El modelo probit está asociado a la función acumulativa de probabilidad normal, suponiendo de antemano una distribución normal.
Análisis de Supervivencia (AS) El análisis de supervivencia o análisis estadístico de datos de supervivencia
engloba un conjunto de métodos y modelos estadísticos usados en el análisis de situaciones donde la variable de interés es el tiempo de supervivencia, que consiste en el tiempo que ocurre desde la entrada de un individuo en el estudio, también designado de tiempo o instante inicial, hasta la verificación de un determinado acontecimiento de interés. Lo que distingue el análisis de supervivencia de otras áreas de la estadística es la presencia de censura. Para algunos individuos en estudio, no es observada la realización del acontecimiento de interés durante el período en que los mismos están en observación. Apenas se dispone de información parcial sobre su “tiempo de vida”, sabiéndose simplemente que excede (censura a la derecha) o es inferior (censura a la izquierda) a determinado valor. En el análisis de supervivencia existen dos funciones de especial interés: la función de supervivencia y la función hazard.
Gráficos CUSUM De acuerdo con Montgomery (2000) los gráficos de Shewhart son una forma
tradicional de detectar una situación fuera de control y, consecuentemente un posible desvío de la variable objeto de estudio. Sin embargo estos gráficos no acumulan las informaciones de las muestras anteriores y presentan dificultades para detectar pequeños desvíos. Tales limitaciones han impulsado el desarrollo de modelos de gráficos de control que acumulan las informaciones de las sucesivas muestras recogidas. Uno de esos modelos de gráficos que acumulan informaciones incorporadas en la estadística analizada son los Gráficos de Control de Suma Acumulada (Cumulative Sum Control Charts – CUSUM). Estos gráficos son

5
capaces de detectar pequeños cambios en la distribución de la característica de la calidad y por otro lado facultar la estimación del nuevo nivel del proceso o de la nueva media (Alves, 2003).
Inducción de reglas e árboles de decisión (AD) El objetivo de la inducción de reglas es encontrar dependencias entre los
atributos o valores, a través del análisis de las probabilidades condicionales. En general los resultados son presentados en la forma de reglas X→Y, que significa que “si X está presente, entonces Y también tiene probabilidad de estar presente”. Las reglas tienen dos grados asociados: la confianza y el soporte. (Quinlan, 1998).
Los árboles de decisión son una forma de representación de un conjunto de reglas que siguen una jerarquía de clases o valores, expresando una lógica simple condicional. Para Zhu et al. (2007) los árboles de decisión son una forma simple pero eficaz de aprendizaje por inducción, infiriendo decisiones a partir de un conjunto de variables discretas o continuas. En términos gráficos se asemejan a un árbol, centrado en una estructura que interconexiona un conjunto de nodos a través de ramas resultantes de una partición recursiva (repetitiva) de los datos, desde el nodo raíz hasta los nodos terminales (hojas), que suministran la clasificación para la (acción) instancia..
Redes Neuronales (RNA) El sistema nervioso central de los seres humanos recibe, almacena, procesa
y trasmite información al exterior. La observación de su desempeño ha revelado una extraordinaria capacidad para ejecutar rápida y eficientemente tareas de gran complejidad tales como el procesamiento en paralelo de la información, la memoria asociativa y la capacidad para clasificar y generalizar conceptos. Aunque se desconoce bastante sobre la forma como el cerebro aprende a procesar la información, han surgido modelos que intentan mimetizar tales habilidades, denominados redes neuronales artificiales o modelos de computación conexionista. La elaboración de estos modelos supone, por un lado, la deducción de los rasgos o características esenciales de las neuronas y sus conexiones, y por otro, la implementación del modelo en un ordenador de forma que se pueda simular.
Conjuntos Aproximados (CA) La teoría de conjuntos aproximados (Rough Sets) propuesta original de
Zdzislaw Pawlak en los primeros años de la década de los 80 (Pawlak, 1982), surge de la necesidad de disponer de un marco formal para manejar conocimientos imprecisos, inciertos e incompletos expresados en forma de datos adquiridos experimentalmente. Según Díaz (2002) las fuentes de incertidumbre son múltiples y entre otras pueden citarse la imprecisión del conocimiento disponible, la incompletitud del mismo, la presencia de ruido en los datos o la vaguedad de los conceptos involucrados. El concepto de conjuntos aproximados se relaciona, de alguna forma, con otras teorías matemáticas desarrolladas para el tratamiento con incertidumbre e imprecisión.
Razonamiento Basado en Casos (CBR) El razonamiento basado en casos (Case-Based Reasoning o CBR) es el
proceso de resolver nuevos problemas basándose en las soluciones de problemas anteriores. Se puede decir que el CBR es un proceso de razonamiento a través de analogías. La filosofía básica de estos sistemas es que si un caso ha ofrecido buenos resultados con anterioridad, se podría utilizar para resolver problemas

6
similares en el futuro, mientras que si ha fallado en ocasiones anteriores, no se debería repetir el mismo error (De Andrés et al., 2005). Estos sistemas construyen bases de conocimiento (también conocidos como librería de casos, bases de conocimiento de casos o memoria) con el objetivo de proporcionar al usuario una serie de referencias sobre situaciones anteriores que tengan características similares a la actual y que, por lo tanto, puedan ayudar en la búsqueda de la solución.
Algoritmos genéticos (AG) Los algoritmos genéticos son una técnica utilizada en problemas de
optimización y se basan en los principios de las leyes de evolución natural, propuesta por Charles Darwin en 1859. De acuerdo con Goldberg (1989) los AG combinan las nociones de supervivencia del más apto con un intercambio estructurado y aleatorio de características entre individuos de una población de posibles soluciones, ajustando un algoritmo de búsqueda que puede aplicarse para resolver problemas de optimización en diversos campos. En un algoritmo genético, tras parametrizar el problema en una serie de variables, éstas se codifican en un cromosoma. Todos los operadores utilizados por un algoritmo genético se aplicarán sobre estos cromosomas, o sobre poblaciones de ellos. Las soluciones codificadas en un cromosoma compiten para ver cuál constituye la mejor solución.
Máquinas de Soporte Vectorial (SVM) La teoría de las máquinas de soporte vectorial (SVM del inglés Support Vector
Machine) es una técnica de clasificación que ha sido introducida en la última década por Vapnik y sus colaboradores (Schölkopf et al., 1999); (Burges, 1998). El objetivo de las SVM es elaborar una forma informáticamente eficiente de aprender “buenos” hiperplanos de separación en un espacio de características de una dimensión mayor, buscando la máxima separación entre clases (Lima, 2002). Según Díaz y Fernández (2005) las SVM operan a través de una transformación de los datos originales (representados en el espacio de entrada) en otra representación dentro del espacio de características con la intención de que, puntos no separables inicialmente en el espacio de entrada, sí lo sean en el espacio de características.
Procesamiento Humano de la Información (HIP) Para Laitinen (1991) el objetivo de este modelo es entender el juicio de los
decisores, representando la relación entre el juicio y las informaciones o indicaciones. Según Belkaoui (1989) el procesamiento humano de la información es un campo de investigación que estudia el comportamiento de los decisores. Una vez que la información contable es utilizada principalmente como auxilio en la toma de decisiones, el objetivo del procesamiento humano de la información en contabilidad es comprender, describir, evaluar y mejorar las decisiones realizadas y el proceso de decisión utilizado, con base en la información contable.
Modelo estadístico de fracaso en el juego (Gambler’s Ruin) La idea básica de esta teoría se relaciona con el juego con dinero, cuyo
jugador jugará con la probabilidad de ganar o perder. El juego continuará hasta que el jugador pierda todo su dinero. En el contexto del fracaso empresarial la empresa sustituye al jugador, la cual continuará operando hasta que su patrimonio neto sea cero, situación reveladora de fracaso (Aziz y Dar, 2006). La teoría asume que una empresa tiene una determinada cuantía de capital en dinero, que continuamente entra y sale de la empresa en función de sus operaciones. De acuerdo con Wilcox

7
(1973) en un periodo de tiempo una empresa se encuentra en una infinidad de posibles situaciones. Cada situación representa un nivel diferente de solidez financiera.
Cartoon Graphics (Dibujos Faciales) Según Smith y Taffler (1996) los métodos gráficos, especialmente aquellos
que posibilitan la representación de varias dimensiones simultáneamente pueden ser muy útiles en la presentación de la información contable. Para estos autores los métodos de presentación alternativos, principalmente aquellos que se refieren al uso del formato de la cara humana pueden ser suficientemente claros y fáciles de interpretar sin necesidad de una explicación detallada. En 1971 Chernoff, citado por Smith y Taffler (1996), inició la construcción de “caras” esquemáticas cuyas características pueden ser elaboradas para variar en tamaño y forma de acuerdo con el valor de la variable atribuida.
3. PROPUESTA DE RANKING DE LOS MODELOS
Existen algunos trabajos que hacen un análisis comparativo de los diversos métodos de predicción del fracaso empresarial, Keasey y Watson (1991), Dimitras et al. (1996), Morris (1998), Zhang et al. (1999) o Crouhy et al. (2000), pero son muy escasos los que intentan establecer un ranking de los distintos métodos.
Laitinen y Kankaanpää (1999) fueron de los primeros a intentarlo con 6 tipos de modelos, utilizando la misma muestra de empresas para todos. Uno de los últimos trabajos sobre esta temática se debe a Azis y Dar (2006) que presentan un ranking más elaborado en base a los resultados obtenidos por algunos de los trabajos desarrollados principalmente a lo largo de las últimas décadas del siglo pasado.
Estos autores calculan la media geométrica para cada uno de los modelos, siendo estos clasificados y ordenados en el ranking final en función de una ponderación de desviación estándar para la media global de todos los modelos.
El procedimiento adoptado por los referidos autores tiene el inconveniente de penalizar los modelos que presentan un buen porcentaje de acierto, ya que cuanto mayor es su distancia respecto a la media, más elevada será su desviación estándar. Con esta metodología los modelos que presentan medias geométricas elevadas ocupan una plaza en el ranking muy cerca de los modelos que tienen medias geométricas bajas.
En el presente trabajo proponemos una forma diferente de clasificación y ordenación. Así, la clasificación según el criterio relativo a los diferentes modelos es realizada en base a la ordenación del porcentaje de aciertos en la predicción para cada modelo. Sin embargo, como las diferencias observadas pueden ser solamente derivadas del resultado de fluctuaciones propias de las muestras, puede no tener, por dicho motivo significado estadístico, haciendo necesaria una comparación de los valores obtenidos a través de un test de hipótesis para determinar si las diferencias de suceso en las previsiones observadas son realmente significativas, permitiendo así una clasificación y ordenación de la eficacia de los diferentes modelos más realista.

8
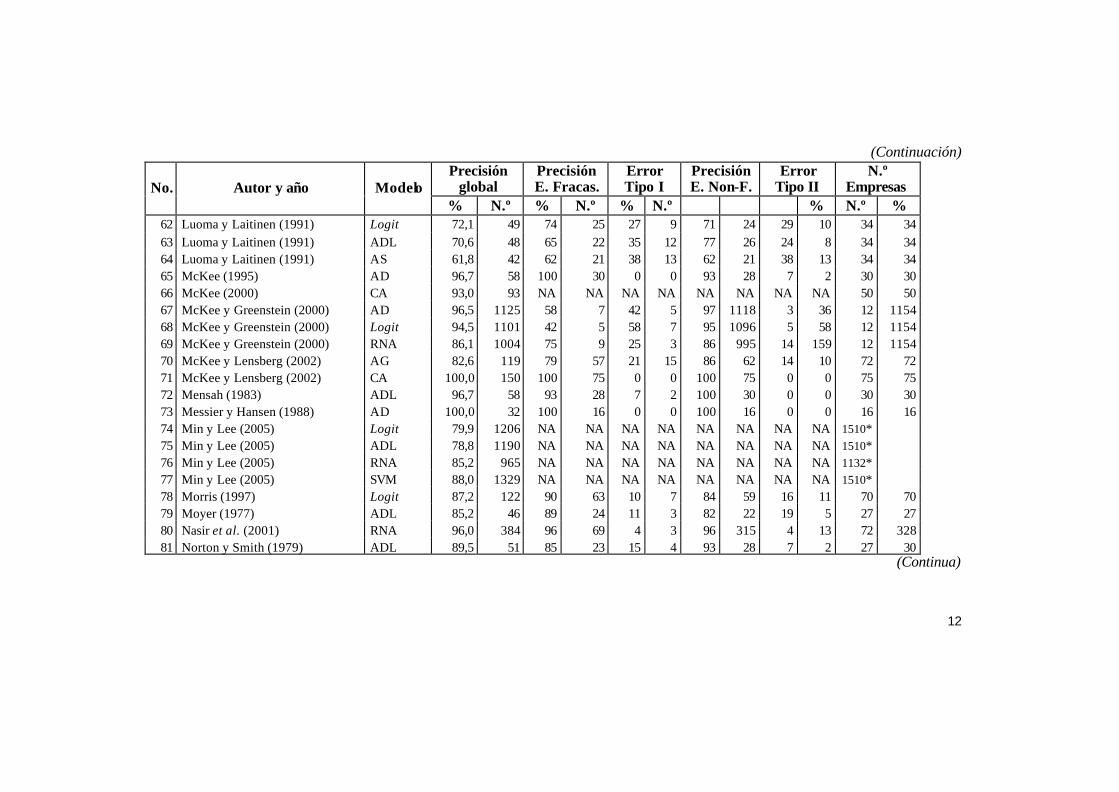
Para el desarrollo de nuestro estudio hemos analizado 70 trabajos publicados principalmente en revistas científicas internacionales que hacían referencia a 119 estudios empíricos sobre la predicción del fracaso empresarial. En la Tabla 1 se puede observar los porcentajes de acierto global de cada modelo, bien como el error Tipo I y Tipo II y la dimensión de la muestra para el año previo al fracaso.
A través del Gráfico 1 podemos verificar que casi un 30% de los estudios han preferido utilizar el modelo logit en la predicción del fracaso, seguido del ADL con 26%. Dentro del grupo de modelos que se basan en la inteligencia artificial las redes neuronales han sido el modelo más utilizado, habiendo sido adoptado en cerca de 13% de los estudios.
Gráfico 1. Modelos utilizados
Modelos utilizados
0 0,05 0,1 0,15 0,2 0,25 0,3
CBRUnivariate
SVMASCA
ProbitRNAADLMRLLogitHIP
F.JuegoAGAD
CUSUMD.Faciales

9
Tabla 1. Principales datos de cada uno de los estudios
Precisión global
Precisión E. Fracas.
Error Tipo I
Precisión E. Non-F.
Error Tipo II
N.º Empresas No. Autor y año Modelo
% N.º % N.º % N.º % N.º % 1 Altman (1968) ADL 95,5 63 94 31 6 2 97 32 3 1 33 33 2 Aly et al. (1992) ADL 73,1 38 73 19 27 7 73 19 27 7 26 26 3 Atiya (2001) RNA 89,4 439 87 163 13 25 91 276 9 27 188 303 4 Aziz et al. (1988) Logit 91,8 90 86 42 14 7 98 48 2 1 49 49 5 Aziz et al. (1988) ADL 88,8 87 NA NA NA NA NA NA NA NA 49 49 6 BarNiv (1990) Logit 90,9 120 91 60 9 6 91 60 9 6 66 66 7 Beaver (1966) Univariate 86,7 137 79 62 22 17 95 75 5 4 79 79 8 Beynon y Peel (2001) AD 93,3 56 90 27 10 3 97 29 3 1 30 30 9 Beynon y Peel (2001) Logit 80,0 48 83 25 17 5 77 23 23 7 30 30
10 Beynon y Peel (2001) ADL 78,3 47 83 25 17 5 73 22 27 8 30 30 11 Beynon y Peel (2001) CA 91,7 55 87 26 13 4 97 29 3 1 30 30 12 Booth (1983) ADL 85,3 29 82 14 18 3 88 15 12 2 17 17 13 Brockett et al. (1994) ADL 88,5 215 85 51 15 9 90 164 10 19 60 183 14 Brockett et al. (1994) RNA 89,3 217 73 44 27 16 95 173 5 10 60 183 15 Chalos (1985) ADL 88,9 64 89 32 11 4 89 32 11 4 36 36 16 Charalambous et al. (2000) Logit 82,3 158 NA NA NA NA NA NA NA NA 96 96 17 Charalambous et al. (2000) RNA 87,0 167 NA NA NA NA NA NA NA NA 96 96 18 Charitou et al. (2004) Logit 94,0 47 92 23 8 2 96 24 4 1 25 25 19 Charitou et al. (2004) RNA 96,0 48 100 25 0 0 92 23 8 2 25 25 20 Dhumale (1998) Logit 86,0 80 76 28 24 9 93 52 7 4 37 56
(Continua)

10
(Continuación) Precisión
global Precisión E. Fracas.
Error Tipo I
Precisión E. Non-F.
Error Tipo II
N.º Empresas No. Autor y año Modelo
% N.º % N.º % N.º % N.º % 21 Dimitras et al. (1999) Logit 90,0 72 93 37 8 3 88 35 13 5 40 40 22 Dimitras et al. (1999) ADL 90,0 72 88 35 13 5 93 37 8 3 40 40 23 Dimitras et al. (1999) CA 92,5 74 95 38 5 2 90 36 10 4 40 40 24 El Hennawy y Morris (1983) ADL 97,7 43 95 21 5 1 100 22 0 0 22 22 25 Foreman (2003) Logit 96,1 74 86 12 14 2 98 62 2 1 14 63 26 Frydman (1985) AD 94,5 189 84 49 16 9 99 140 1 2 58 142 27 Frydman (1985) ADL 86,0 172 71 41 29 17 92 131 8 11 58 142 28 Gentry et al. (1985) Logit 83,3 55 79 26 21 7 88 29 12 4 33 33 29 Gilbert et al. (1990) Logit 88,5 230 67 35 33 17 94 195 6 13 52 208 30 Gloubos y Grammatikos (1988) Logit 86,7 52 83 25 17 5 90 27 10 3 30 30 31 Gloubos y Grammatikos (1988) MRL 91,7 55 93 28 7 2 90 27 10 3 30 30 32 Gloubos y Grammatikos (1988) ADL 91,7 55 97 29 3 1 87 26 13 4 30 30 33 Gloubos y Grammatikos (1988) Probit 85,0 51 83 25 17 5 87 26 13 4 30 30 34 Gombola et al. (1987) ADL 89,0 82 NA NA NA NA NA NA NA NA 92* 35 Houghton (1984) HIP 79,0 19 76 9 24 3 82 10 18 2 12 12 36 Houghton y Sengupta (1984) HIP 84,0 30 78 9 22 3 87 21 13 3 12 24 37 Jo et al. (1997) CBR 81,5 442 NA NA NA NA NA NA NA NA 271 271 38 Jo et al. (1997) ADL 82,2 446 NA NA NA NA NA NA NA NA 271 271 39 Jo et al. (1997) RNA 83,8 454 NA NA NA NA NA NA NA NA 271 271 40 Kahya y Theodossiou (1999) CUSUM 82,5 156 82 59 18 13 83 97 17 20 72 117 41 Kahya y Theodossiou (1999) Logit 77,9 147 68 49 32 23 84 98 16 19 72 117
(Continua)

11
(Continuación) Precisión
global Precisión E. Fracas.
Error Tipo I
Precisión E. Non-F.
Error Tipo II
N.º Empresas No. Autor y año Modelo
% N.º % N.º % N.º % N.º % 42 Kahya y Theodossiou (1999) ADL 77,4 146 69 50 31 22 83 97 17 20 72 117 43 Keasey y McGuinness (1990) Logit 86,0 74 86 37 14 6 86 37 14 6 43 43 44 Keasey y Watson (1986) HIP 66,4 13 66 7 34 3 67 7 33 3 10 10 45 Keasey y Watson (1986) ADL 75,0 15 70 7 30 3 80 8 20 2 10 10 46 Keasey y Watson (1987) Logit 82,2 120 82 60 18 13 82 60 18 13 73 73 47 Kida (1980) ADL 90,0 36 85 17 15 3 95 19 5 1 20 20 48 Koh (1992) Logit 93,9 310 93 153 7 12 95 157 5 8 165 165 49 Koh y Tan (1999) RNA 100,0 300 100 150 0 0 100 150 0 0 150 150 50 Kolari e tal. (2002) Logit 96,3 1039 100 18 0 0 96 1021 4 40 18 1061 51 Laitinen (1991) ADL 95,5 21 91 10 9 1 100 11 0 0 11 11 52 Laitinen y Kankaanpaa (1999) AD 94,8 72 90 34 11 4 100 38 0 0 38 38 53 Laitinen y Kankaanpaa (1999) Logit 92,1 70 92 35 8 3 92 35 8 3 38 38 54 Laitinen y Kankaanpaa (1999) ADL 86,8 66 87 33 13 5 87 33 13 5 38 38 55 Laitinen y Kankaanpaa (1999) RNA 97,4 74 95 36 5 2 100 38 0 0 38 38 56 Laitinen y Kankaanpaa (1999) AS 88,2 67 87 33 13 5 90 34 11 4 38 38 57 Laitinen y Laitinen (1998) Logit 80,5 66 83 34 17 7 78 32 22 9 41 41 58 Lane e tal. (1986) ADL 87,2 285 62 57 38 35 97 228 3 7 92 235 59 Lane e tal. (1986) AS 88,4 289 87 80 13 12 89 209 11 26 92 235 60 Lensberg e tal. (2006) AG 82,0 738 NA NA NA NA NA NA NA NA 450 450 61 Lensberg e tal. (2006) Logit 77,0 693 NA NA NA NA NA NA NA NA 450 450
(Continua)
12
(Continuación) Precisión
global Precisión E. Fracas.
Error Tipo I
Precisión E. Non-F.
Error Tipo II
N.º Empresas No. Autor y año Modelo
% N.º % N.º % N.º % N.º % 62 Luoma y Laitinen (1991) Logit 72,1 49 74 25 27 9 71 24 29 10 34 34 63 Luoma y Laitinen (1991) ADL 70,6 48 65 22 35 12 77 26 24 8 34 34 64 Luoma y Laitinen (1991) AS 61,8 42 62 21 38 13 62 21 38 13 34 34 65 McKee (1995) AD 96,7 58 100 30 0 0 93 28 7 2 30 30 66 McKee (2000) CA 93,0 93 NA NA NA NA NA NA NA NA 50 50 67 McKee y Greenstein (2000) AD 96,5 1125 58 7 42 5 97 1118 3 36 12 1154 68 McKee y Greenstein (2000) Logit 94,5 1101 42 5 58 7 95 1096 5 58 12 1154 69 McKee y Greenstein (2000) RNA 86,1 1004 75 9 25 3 86 995 14 159 12 1154 70 McKee y Lensberg (2002) AG 82,6 119 79 57 21 15 86 62 14 10 72 72 71 McKee y Lensberg (2002) CA 100,0 150 100 75 0 0 100 75 0 0 75 75 72 Mensah (1983) ADL 96,7 58 93 28 7 2 100 30 0 0 30 30 73 Messier y Hansen (1988) AD 100,0 32 100 16 0 0 100 16 0 0 16 16 74 Min y Lee (2005) Logit 79,9 1206 NA NA NA NA NA NA NA NA 1510* 75 Min y Lee (2005) ADL 78,8 1190 NA NA NA NA NA NA NA NA 1510* 76 Min y Lee (2005) RNA 85,2 965 NA NA NA NA NA NA NA NA 1132* 77 Min y Lee (2005) SVM 88,0 1329 NA NA NA NA NA NA NA NA 1510* 78 Morris (1997) Logit 87,2 122 90 63 10 7 84 59 16 11 70 70 79 Moyer (1977) ADL 85,2 46 89 24 11 3 82 22 19 5 27 27 80 Nasir et al. (2001) RNA 96,0 384 96 69 4 3 96 315 4 13 72 328 81 Norton y Smith (1979) ADL 89,5 51 85 23 15 4 93 28 7 2 27 30
(Continua)

13
(Continuación) Precisión
global Precisión E. Fracas.
Error Tipo I
Precisión E. Non-F.
Error Tipo II
N.º Empresas No. Autor y año Modelo
% N.º % N.º % N.º % N.º % 82 Olmeda y Fernández (1997) AD 85,3 29 0 100 15 0 100 19 15 19 83 Olmeda y Fernández (1997) Logit 94,1 32 NA NA NA NA NA NA NA NA 15 19 84 Olmeda y Fernández (1997) ADL 88,2 30 NA NA NA NA NA NA NA NA 15 19 85 Olmeda y Fernández (1997) RNA 91,2 31 NA NA NA NA NA NA NA NA 15 19 86 Park y Han (2002) CBR 84,5 1812 NA NA NA NA NA NA NA NA 1072 1072 87 Peel y Peel (1987) Logit 88,4 99 86 48 14 8 91 51 9 5 56 56 88 Platt y Platt (1990) Logit 89,5 102 93 53 7 4 86 49 14 8 57 57 89 Platt et al. (1994) Logit 90,3 112 80 28 20 7 94 84 6 5 35 89 90 Poston et al. (1994) Probit 75,2 79 72 33 28 13 78 46 22 13 46 59 91 Shin y Lee (2002) AG 79,7 379 NA NA NA NA NA NA NA NA 476* 92 Skogsvik (1990) Probit 84,0 318 NA NA NA NA NA NA NA NA 51 328 93 Smith y Taffler (1996) D.Faciales 85,6 17 89 5 11 1 84 12 16 2 6 14 94 Stone y Rasp (1991) Logit 72,3 78 NA NA NA NA NA NA NA NA 108 108 95 Stone y Rasp (1991) MRL 70,4 76 NA NA NA NA NA NA NA NA 108 108 96 Sung et al. (1999) AD 83,3 65 72 21 28 8 90 44 10 5 29 49 97 Sung et al. (1999) ADL 82,1 64 69 20 31 9 90 44 10 5 29 49 98 Taffler (1983) ADL 97,8 90 96 44 4 2 100 46 0 0 46 46 99 Tam y Kiang (1992) AD 92,4 109 90 53 10 6 95 56 5 3 59 59
100 Tam y Kiang (1992) Logit 92,4 109 92 54 8 5 93 55 7 4 59 59 101 Tam y Kiang (1992) ADL 89,0 105 100 59 0 0 78 46 22 13 59 59
(Continua)

14
(Continuación) Precisión
global Precisión E. Fracas.
Error Tipo I
Precisión E. Non-F.
Error Tipo II
N.º Empresas No. Autor y año Modelo
% N.º % N.º % N.º % N.º % N.º BF NBF 102 Tam y Kiang (1992) RNA 96,6 114 100 59 0 0 93 55 7 4 59 59 103 Tennyson et al. (1990) Logit 76,1 35 74 17 26 6 78 18 22 5 23 23 104 Theodossiou (1991) Logit 95,9 348 93 50 7 4 96 298 4 11 54 309 105 Theodossiou (1991) MRL 95,3 346 89 48 11 6 96 298 4 11 54 309 106 Theodossiou (1991) Probit 94,5 343 93 50 7 4 95 293 5 16 54 309 107 Van Frederikslust (1978) ADL 92,5 37 95 19 5 1 90 18 10 2 20 20 108 Varetto (1998) AG 95,0 3649 98 1879 2 41 92 1770 8 150 1920 1920 109 Varetto (1998) ADL 96,7 3714 98 1888 2 32 95 1826 5 94 1920 1920 110 Westgaard y Wijst (2001) Logit 97,3 34346 77 737 23 217 98 33609 2 724 954 34333 111 Whittred y Zimmer (1984) ADL 82,4 61 97 36 3 1 68 25 32 12 37 37 112 Wilcox (1973) F. Juego 94,0 60 NA NA NA NA NA NA NA NA 32 32 113 Wilson et al. (1995) Logit 95,0 76 93 37 8 3 98 39 3 1 40 40 114 Wilson et al. (1995) RNA 98,8 79 98 39 3 1 100 40 0 0 40 40 115 Zhang et al. (1999) Logit 78,6 173 79 87 21 23 78 86 22 24 110 110 116 Zhang et al. (1999) RNA 86,8 191 86 95 14 15 87 96 13 14 110 110 117 Zmijewski (1984) Probit 97,7 821 63 25 38 15 100 796 1 4 40 800 118 Zurada et al. (1999) Logit 81,6 115 79 30 21 8 83 85 17 18 38 103 119 Zurada et al. (1999) RNA 79,4 112 58 22 42 16 87 90 13 13 38 103
*Los autores solo han presentado el número de empresas global, sin discriminar entre fracasadas y no fracasadas.
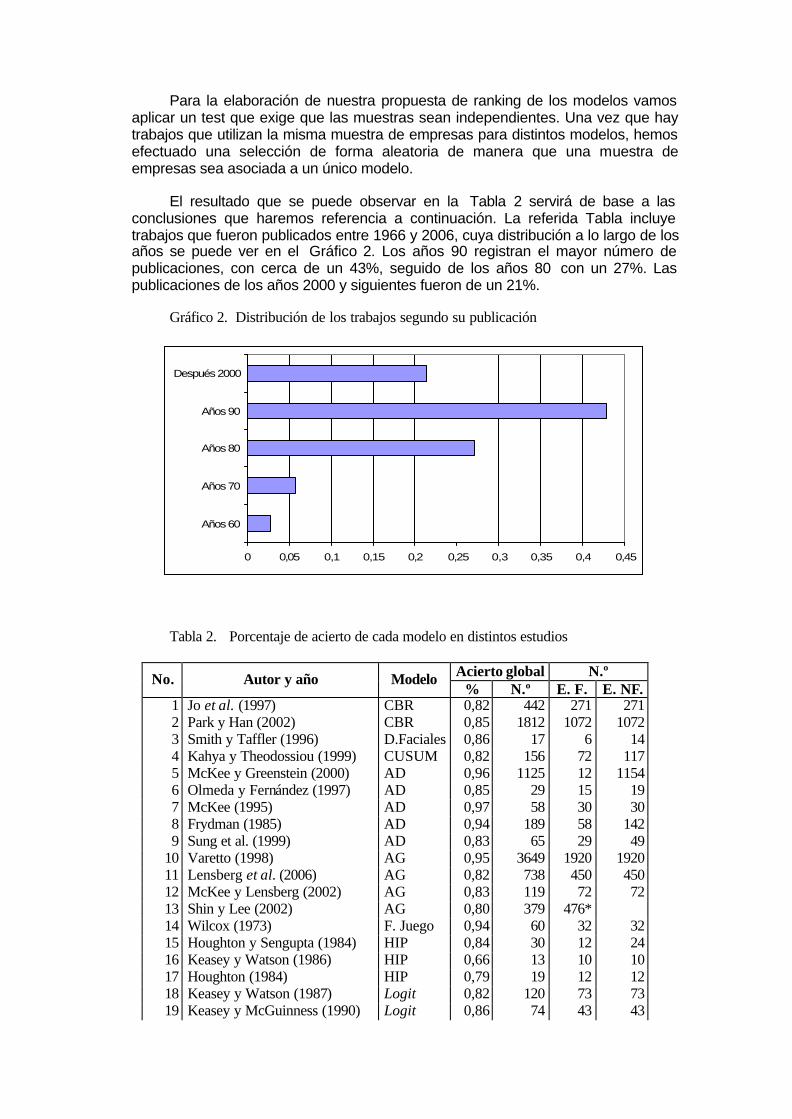
Para la elaboración de nuestra propuesta de ranking de los modelos vamos aplicar un test que exige que las muestras sean independientes. Una vez que hay trabajos que utilizan la misma muestra de empresas para distintos modelos, hemos efectuado una selección de forma aleatoria de manera que una muestra de empresas sea asociada a un único modelo.
El resultado que se puede observar en la Tabla 2 servirá de base a las conclusiones que haremos referencia a continuación. La referida Tabla incluye trabajos que fueron publicados entre 1966 y 2006, cuya distribución a lo largo de los años se puede ver en el Gráfico 2. Los años 90 registran el mayor número de publicaciones, con cerca de un 43%, seguido de los años 80 con un 27%. Las publicaciones de los años 2000 y siguientes fueron de un 21%.
Gráfico 2. Distribución de los trabajos segundo su publicación
0 0,05 0,1 0,15 0,2 0,25 0,3 0,35 0,4 0,45
Años 60
Años 70
Años 80
Años 90
Después 2000
Tabla 2. Porcentaje de acierto de cada modelo en distintos estudios
Acierto global N.º No. Autor y año Modelo % N.º E. F. E. NF.
1 Jo et al. (1997) CBR 0,82 442 271 271 2 Park y Han (2002) CBR 0,85 1812 1072 1072 3 Smith y Taffler (1996) D.Faciales 0,86 17 6 14 4 Kahya y Theodossiou (1999) CUSUM 0,82 156 72 117 5 McKee y Greenstein (2000) AD 0,96 1125 12 1154 6 Olmeda y Fernández (1997) AD 0,85 29 15 19 7 McKee (1995) AD 0,97 58 30 30 8 Frydman (1985) AD 0,94 189 58 142 9 Sung et al. (1999) AD 0,83 65 29 49
10 Varetto (1998) AG 0,95 3649 1920 1920 11 Lensberg et al. (2006) AG 0,82 738 450 450 12 McKee y Lensberg (2002) AG 0,83 119 72 72 13 Shin y Lee (2002) AG 0,80 379 476* 14 Wilcox (1973) F. Juego 0,94 60 32 32 15 Houghton y Sengupta (1984) HIP 0,84 30 12 24 16 Keasey y Watson (1986) HIP 0,66 13 10 10 17 Houghton (1984) HIP 0,79 19 12 12 18 Keasey y Watson (1987) Logit 0,82 120 73 73 19 Keasey y McGuinness (1990) Logit 0,86 74 43 43

20 Morris (1997) Logit 0,87 122 70 70 21 Peel y Peel (1987) Logit 0,88 99 56 56 22 Aziz et al. (1988) Logit 0,92 90 49 49 23 Foreman (2003) Logit 0,96 74 14 63 24 Gilbert et al. (1990) Logit 0,88 230 52 208 25 Koh (1992) Logit 0,94 310 165 165 26 Platt et al. (1994) Logit 0,90 112 35 89 27 Tennyson et al. (1990) Logit 0,76 35 23 23 28 Westgaard y Wijst (2001) Logit 0,97 34346 954 34333 29 Gentry et al. (1985) Logit 0,83 55 33 33 30 Dhumale (1998) Logit 0,86 80 37 56 31 Laitinen y Laitinen (1998) Logit 0,80 66 41 41 32 Platt y Platt (1990) Logit 0,89 102 57 57 33 Kolari et al. (2002) Logit 0,96 1039 18 1061 34 Stone y Rasp (1991) MRL 0,70 152 108 108 35 Theodossiou (1991) MRL 0,95 346 54 309 36 Gloubos y Grammatikos (1988) MRL 0,92 55 30 30 37 Norton y Smith (1979) ADL 0,89 51 27 30 38 Moyer (1977) ADL 0,85 46 27 27 39 Aly et al. (1992) ADL 0,73 38 26 26 40 Taffler (1983) ADL 0,98 90 46 46 41 Kida (1980) ADL 0,90 36 20 20 42 Chalos (1985) ADL 0,89 64 36 36 43 Whittred y Zimmer (1984) ADL 0,82 61 37 37 44 Mensah (1983) ADL 0,97 58 30 30 45 Altman (1968) ADL 0,95 63 33 33 46 Booth (1983) ADL 0,85 29 17 17
(Continua)
(Continuación) Aciero global N.º No. Autor y año Modelo % N.º E. F. E. NF.
47 El Hennawy y Morris (1983) ADL 0,98 43 22 22 48 Laitinen (1991) ADL 0,95 21 11 11 49 Gombola et al. (1987) ADL 0,89 82 92* 50 Van Frederikslust (1978) ADL 0,93 37 20 20 51 Atiya (2001) RNA 0,89 439 188 303 52 Brockett et al. (1994) RNA 0,89 217 60 183 53 Charalambous et al. (2000) RNA 0,87 167 96 96 54 Wilson et al. (1995) RNA 0,99 79 40 40 55 Zurada et al. (1999) RNA 0,79 112 38 103 56 Zhang et al. (1999) RNA 0,87 191 110 110 57 Charitou et al. (2004) RNA 0,96 48 25 25 58 Tam y Kiang (1992) RNA 0,97 114 59 59 59 Nasir et al. (2001) RNA 0,96 384 72 328 60 Zmijewski (1984) Probit 0,98 821 40 800 61 Poston et al. (1994) Probit 0,75 79 46 59 62 Skogsvik (1990) Probit 0,84 318 51 328 63 Dimitras et al. (1999) CA 0,93 74 40 40 64 Beynon y Peel (2001) CA 0,92 55 30 30 65 McKee (2000) CA 0,93 93 50 50 66 Lane et al. (1986) AS 0,88 289 92 235 67 Laitinen y Kankaanpaa (1999) AS 0,88 67 38 38

68 Luoma y Laitinen (1991) AS 0,62 42 34 34 69 Min y Lee (2005) SVM 0,88 1329 1510* 70 Beaver (1966) Univar. 0,87 137 79 79 *Los autores solo han presentado el número de empresas global, sin discriminar entre
fracasadas y no fracasadas. La dimensión de la muestra tiene una amplitud de 20 hasta 35287 empresas,
con muestras inferiores a 100 empresas usadas en cerca de 50% de los trabajos analizados. Sólo el 10% de los trabajos han utilizado muestras con más de 1000 empresas tal y como se muestra en el gráfico siguiente.
Gráfico 3. Dimensión de las muestras por trabajo
0 0,05 0,1 0,15 0,2 0,25 0,3 0,35 0,4 0,45 0,5
Menos 100
Entre 100 e 1000
Más de 1000
Sobre la metodología utilizada podemos observar que los modelos estadísticos han sido utilizados en un 66% de los estudios citados, seguido de los modelos basados en la inteligencia artificial con cerca del 29%, lo que es comprensible dado que son modelos cuya aplicación en la predicción del fracaso empresarial es relativamente reciente (Gráfico 4).
El Gráfico 5 resume la media ponderada de la precisión global de cada modelo un año anterior al fracaso. Podemos concluir que la mayoría de los modelos alcanza porcentajes de acierto superiores al 85%. Individualmente el modelo logit obtiene la mejor clasificación.
Debemos referir que hay dos modelos (Gambler’s Ruin – F. Juego y Cartoon Graphics- D. Faciales) que están representados por sólo un trabajo y con muestras pequeñas.

Gráfico 4. Distribución de los trabajos por tipo de modelo
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7
Outros modelos
Inteligencia Artificial
Estadísticos
Gráfico 5. Porcentaje global de acierto
% Global de Acierto
0,780,820,840,850,860,870,870,88
0,900,900,91
0,920,930,940,950,97
0,00 0,20 0,40 0,60 0,80 1,00
HIPCUSUM
CBRAS
D.FacialesMRL
UnivariateSVM
ADLRNAAG
ProbitCA
F. JuegoADL
Logit
Model
os
En la presencia de muestras independientes y dado también que el número de empresas testadas por cada uno de los modelos de predicción es relativamente elevado (excepto para dos modelos que no fueron considerados) permite que las diferencias observadas en el porcentaje de aciertos para diferentes métodos sea comparada a través de un test de hipótesis unilateral cuyo test estadístico sigue una distribución aproximadamente normal.
La hipótesis nula de igualdad en los porcentajes de aciertos será probada para todos los pares de modelos de predicción, siguiendo varios pasos, donde el valor de pX , T y p se obtienen a través de las siguientes fórmulas:

21
2211
nnXnXn
X p++
= [1]
)11
(*)1(*
)()(
21
2121
nnXX
ppXXT
pp +−
−−−=
[2]
)( tTPp ≥= [3]
Las hipótesis a probar serán:
H0: “Las diferencias en las proporciones de aciertos observadas no son estadísticamente significativas” ( 21 pp = );
H1: “Las diferencias en las proporciones de aciertos observadas son estadísticamente significativas” ( 21 pp > ).
1.º Paso
Empezaremos por testar los siguientes pares de modelos: Logit - AD; AD - CA; CA - Probit; Probit - AG; AG - RNA; RNA - ADL; ADL - SVM; SVM - Univariate; Univariate - MRL; MRL - AS; AS - CBR; CBR - CUSUM y CUSUM - HIP.
El valor p permite saber la probabilidad de error que podemos cometer para rechazar la hipótesis nula siendo esta verdadera, es decir, para valores muy bajos (p<0,01) rechazamos la hipótesis nula con mucha seguridad. Podremos decir que las diferencias en las proporciones de aciertos observadas son estadísticamente significativas.
De la Tabla 3 sólo podemos rechazar la hipótesis nula entre el par Logit-AD, es decir, podemos afirmar que con el modelo Logit se obtienen resultados superiores a los obtenidos con el modelo AD.
Tabla 3. Resultados del paso 1
Modelo Total
Empresas % Acierto pX T
(estadística) p
Logit 38140 0,9688916 AD 1538 0,9533034 0,9682874 3,4203587 0,0003127 CA 240 0,9250083 0,9494841 1,8615357 0,0313343 Probit 1324 0,9202135 0,9209493 0,2532983 0,4000189 AG 5360 0,9114787 0,9132089 1,0109778 0,1560135 RNA 1935 0,9049334 0,9097425 0,8612655 0,1945459 ADL 799 0,8997297 0,9034126 0,4189146 0,3376393

SVM 1510 0,8801320 0,8869135 1,4145170 0,0786051 Univariate 158 0,8670000 0,8788881 0,4813818 0,3151226 MRL 639 0,8655136 0,8658083 0,0490803 0,4804276 AS 471 0,8454522 0,8570011 0,9436333 0,1726785 CBR 2686 0,8391464 0,8400872 0,3444017 0,3652721 CUSUM 189 0,8246381 0,8381926 0,5234922 0,3003159 HIP 80 0,7811500 0,8117048 0,8339720 0,2021484
2.º Paso
A continuación testaremos los siguientes pares de modelos: Logit - CA; AD - Probit; CA - AG; Probit - RNA; AG - ADL; RNA - SVM; ADL - Univariate; SVM - MRL; Univariate - AS; MRL - CBR; AS - CUSUM y CBR - HIP.
Tabla 4. Resultados del paso 2
Modelo Total
Empresas % Acierto pX T
(estadística) p
Logit 38140 0,9688916 AD 1538 0,9533034 CA 240 0,9250083 0,9686172 3,8870594 0,0000507 Probit 1324 0,9202135 0,9379956 3,6599191 0,0001261 AG 5360 0,9114787 0,9120585 0,7240576 0,2345152 RNA 1935 0,9049334 0,9111411 1,5056574 0,0660776 ADL 799 0,8997297 0,9099545 1,0823320 0,1395525 SVM 1510 0,8801320 0,8940625 2,3469376 0,0094642 Univariate 158 0,8670000 0,8943260 1,2228002 0,1107026 MRL 639 0,8655136 0,8757853 0,9391494 0,1738270 AS 471 0,8454522 0,8508649 0,6579543 0,2552837 CBR 2686 0,8391464 0,8442137 1,6518902 0,0492785 CUSUM 189 0,8246381 0,8394918 0,6585229 0,2551011 HIP 80 0,7811500 0,8374690 1,3855441 0,0829431
Analizando la tabla anterior podemos señalar una separación entre el Logit y los CA, entre las AD y el Probit y también entre las RNA y SVM, es decir, los resultados están de acuerdo con el esperado.
3.º Paso
Los pares de modelos a testar serán: Logit - Probit; AD - AG; CA - RNA; Probit - ADL; AG - SVM; RNA - Univariate; ADL - MRL; SVM - AS; Univariate - CBR; MRL - CUSUM y AS - HIP. En base a los resultados de la Tabla 5 podemos rechazar la hipótesis nula en los siguientes pares de modelos: Logit - Probit, AD - AG y AG - SVM.

Tabla 5. Resultados del paso 3
Modelo Total
Empresas % Acierto pX
T (estadística)
p
Logit 38140 0,9688916 AD 1538 0,9533034 CA 240 0,9250083 Probit 1324 0,9202135 0,9672585 9,7846926 0,0000000 AG 5360 0,9114787 0,9208040 5,3542374 0,0000000 RNA 1935 0,9049334 0,9071486 1,0107351 0,1560716 ADL 799 0,8997297 0,9125043 1,6182417 0,0528053 SVM 1510 0,8801320 0,9045888 3,6623378 0,0001250 Univariate 158 0,8670000 0,9020698 1,5425087 0,0614750 MRL 639 0,8655136 0,8845252 2,0173231 0,0218309 AS 471 0,8454522 0,8718866 1,9661000 0,0246435 CBR 2686 0,8391464 0,8406938 0,9297432 0,1762520 CUSUM 189 0,8246381 0,8561833 1,4068295 0,0797390 HIP 80 0,7811500 0,8361162 1,4364956 0,0754307
4.º Paso
Los pares de modelos a testar en este paso serán: Logit - AG; AD - RNA; CA - ADL; Probit - SVM; AG - Univariate; RNA - MRL; ADL - AS Cgraphics; SVM - CBR; Univariate - CUSUM; MRL - HIP. Los resultados estadísticos se presentan en la Tabla 6, donde podemos rechazar la hipótesis nula para los siguientes pares de modelos: Logit - AG; AD - RNA; Probit - SVM, RNA - MRL, ADL - AS y SVM – CBR.
Tabla 6. Resultados del paso 4
Modelo Total
Empresas % Acierto pX T
(estadística) p
Logit 38140 0,9688916 AD 1538 0,9533034 CA 240 0,9250083 Probit 1324 0,9202135 AG 5360 0,9114787 0,9618173 20,5380270 0,0000000 RNA 1935 0,9049334 0,9263538 5,4209989 0,0000000 ADL 799 0,8997297 0,9055688 1,1743756 0,1201223 SVM 1510 0,8801320 0,8988575 3,5307288 0,0002072 Univariate 158 0,8670000 0,9102051 1,9274194 0,0269637 MRL 639 0,8655136 0,8951474 2,8200952 0,0024005 AS 471 0,8454522 0,8796000 2,8710809 0,0020454 CBR 2686 0,8391464 0,8538957 3,6076242 0,0001545 CUSUM 189 0,8246381 0,8439268 1,0828134 0,1394456 HIP 80 0,7811500 0,8561268 2,0268762 0,0213375
5.º Paso
Ahora testaremos los siguientes pares de modelos: Logit - RNA; AD -ADL; CA - SVM; Probit - Univariate; AG - MRL; RNA - AS; ADL - CBR; SVM - CUSUM; Univariate - HIP. Con los datos de la Tabla 7 podemos concluir que el Logit tiene un nivel de precisión superior al RNA, lo mismo sucede para los siguientes pares de modelos: AD - ADL, AG - MRL, RNA - AS y ADL - CBR.

Tabla 7. Resultados del paso 5
Modelo Total
Empresas % Acierto pX T
(estadística) p
Logit 38140 0,9688916 AD 1538 0,9533034 CA 240 0,9250083 Probit 1324 0,9202135 AG 5360 0,9114787 RNA 1935 0,9049334 0,9658035 15,1027220 0,0000000 ADL 799 0,8997297 0,9349870 4,9827803 0,0000003 SVM 1510 0,8801320 0,8862865 2,0342265 0,0209644 Univariate 158 0,8670000 0,9145403 2,2614567 0,0118655 MRL 639 0,8655136 0,9065826 3,7740131 0,0000803 AS 471 0,8454522 0,8932893 3,7495790 0,0000886 CBR 2686 0,8391464 0,8530362 4,2460865 0,0000109 CUSUM 189 0,8246381 0,8739588 2,1670361 0,0151160 HIP 80 0,7811500 0,8381429 1,6986363 0,0446939
6.º Paso
Por fin, sólo resta probar los siguientes pares de modelos: Logit - ADL; AD - SVM; CA - Univariate; Probit - MRL; AG - AS; RNA - CBR; ADL - CUSUM y SVM - HIP.
Tabla 8. Resultados del paso 6
Modelo Total
Empresas % Acierto pX T
(estadística) p
Logit 38140 0,9688916 AD 1538 0,9533034 CA 240 0,9250083 Probit 1324 0,9202135 AG 5360 0,9114787 RNA 1935 0,9049334 ADL 799 0,8997297 0,9674725 10,9067179 0,0000000 SVM 1510 0,8801320 0,9170538 7,3232721 0,0000000 Univariate 158 0,8670000 0,9019799 1,9042634 0,0284379 MRL 639 0,8655136 0,9024075 3,8265840 0,0000650 AS 471 0,8454522 0,9061454 4,7109915 0,0000012 CBR 2686 0,8391464 0,8666941 6,4909448 0,0000000 CUSUM 189 0,8246381 0,8853650 2,9140511 0,0017839 HIP 80 0,7811500 0,8751518 2,6101066 0,0045257
Con base en los resultados obtenidos en la Tabla 8 podemos rechazar la hipótesis nula para todos los pares de modelos, no obstante el par CA - Univariate presentar un p =0,028, que siendo superior a 0,01 es todavía pequeño.
Todos los restantes pares de modelos han sido testados. Como a partir de esta fase todos los valores de p son muy cerca de cero, no se justifica la presentación de todos los restantes tests.
Respecto a los modelos Univariante y HIP, cabe señalar que la dimensión de las respectivas muestras es suficiente para validar una aproximación a la distribución normal. Comparando con algunos de los modelos hay una gran diferencia en las respectivas dimensiones, lo que posibilita alguna fluctuación en el valor de p para situaciones en que cabría esperar un valor menor. Para los referidos casos el valor de p es bajo, pero superior a 0,01.
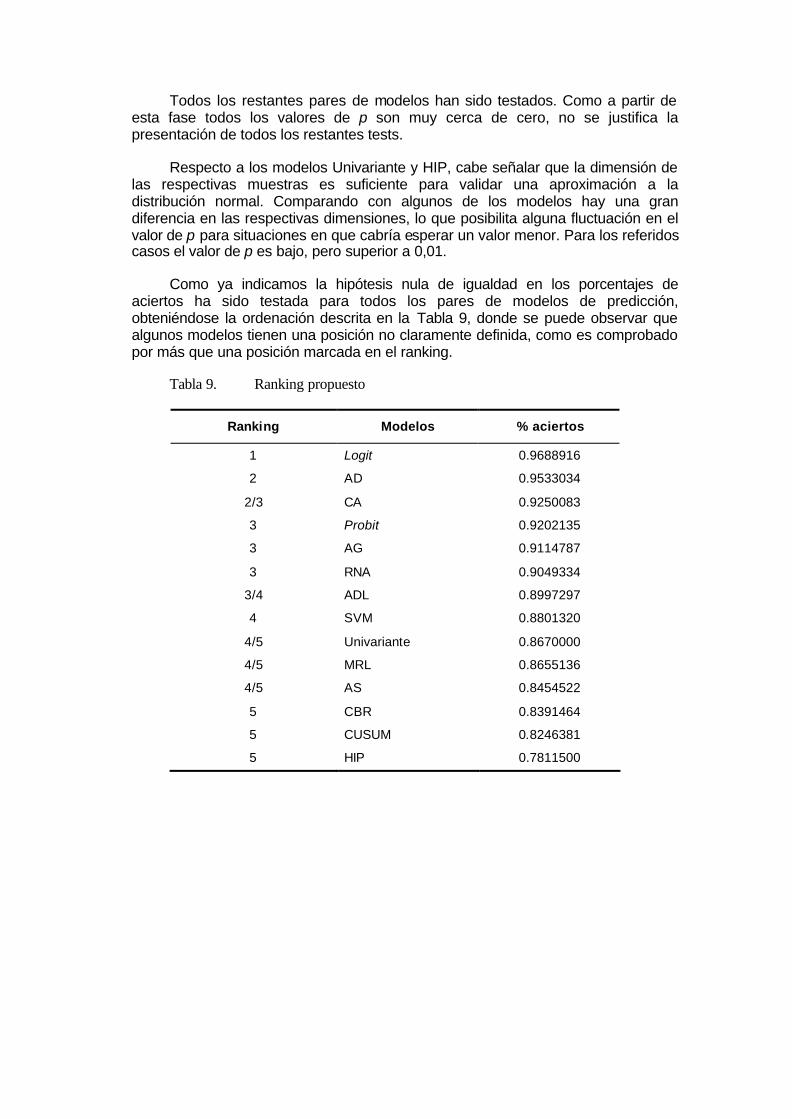
Como ya indicamos la hipótesis nula de igualdad en los porcentajes de aciertos ha sido testada para todos los pares de modelos de predicción, obteniéndose la ordenación descrita en la Tabla 9, donde se puede observar que algunos modelos tienen una posición no claramente definida, como es comprobado por más que una posición marcada en el ranking.
Tabla 9. Ranking propuesto
Ranking Modelos % aciertos
1 Logit 0.9688916
2 AD 0.9533034
2/3 CA 0.9250083
3 Probit 0.9202135
3 AG 0.9114787
3 RNA 0.9049334
3/4 ADL 0.8997297
4 SVM 0.8801320
4/5 Univariante 0.8670000
4/5 MRL 0.8655136
4/5 AS 0.8454522
5 CBR 0.8391464
5 CUSUM 0.8246381
5 HIP 0.7811500

CONCLUSIÓN
Comparando nuestra propuesta de ranking con la propuesta por Aziz y Dar (2006) podemos verificar que hay una gran divergencia entre las posiciones ocupadas por los distintos modelos. Como ejemplo, en el referido trabajo el ADL ha obtenido la primera plaza, seguido del modelo Logit mientras que el modelo Probit y los CA ocupan las últimas posiciones, muy diferentes de las que hemos presentado en nuestra propuesta, donde el modelo Logit ocupa la primera plaza seguido de los AD. Los CA e el modelo Probit ocupan las plazas siguientes.
La hipótesis nula de igualdad en los porcentajes de aciertos ha sido testada para todos los pares de modelos de predicción, obteniéndose la ordenación de los modelos, pero algunos modelos tienen una posición no claramente definida, como es comprobado por más que una posición marcada en el ranking. En la referida situación están los siguientes modelos: CA, ADL, Univariante, MRL e AS.
No obstante muchos de los estudios en que se basaron las propuestas sean los mismos, una parte significativa de las diferencias puede ser explicada por la distinta metodología utilizada.
Sobre la propuesta presentada pensamos que una forma de clarificar algunas posiciones sería la utilización de muestras más equilibradas respecto a su dimensión.

BIBLIOGRAFÍA
ALTMAN, E. I. (1968): “Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy”, The Journal of Finance, Vol. 23, N.º 4, September, pp. 589-609.
ALVES, C. C. (2003): Gráficos de Controle CUSUM: um enfoque dinâmico para a análise estatística de processos , Dissertação de Mestrado, Universidade Federal de Santa Catarina.
ALY, I. M.; BARLOW, H. A. y JONES, R. W. (1992): “The Usefulness of SFAS N.º 82 (Current Cost) Information in Discriminating Business Failure: An Empirical Study” Journal of Accounting, Auditing and Finance, Vol. 7, N.º 2, Spring, pp. 217-229.
ATIYA, A. F. (2001): “Bankruptcy Prediction for Credit Risk Using Neural Networks: A Survey and New Results”, IEEE Transactions On Neural Networks, Vol. 12, N.º 4, July, pp. 929-935.
AZIZ, A.; EMANUEL, D. C. y LAWSON, G. H. (1988): “Bankruptcy Prediction – An Investigation of Cash Flow Based Models”, Journal of Management Studies, 25, 5, pp. 419-437.
AZIZ, M. A. y DAR, H. A. (2006): “Predicting Corporate Bankruptcy: Where We Stand?”, Corporate Governance, Vol. 6, N.º 1, pp. 18-33.
BEAVER, W. H. (1966): “Financial Ratios As Predictors of Failure”, Journal of Accounting Research, Supplement, Vol. 4, N.º 3, pp. 71-111.
BELKAOUI, A. (1989): Human Information Processing in Accounting, Greenwood Press, Inc., Westport, CT.
BEYNON, M. J. y PEEL, M. J. (2001): “Variable Precision Rough Set Theory and Data Discretisation: An Application to Corporate Failure Prediction”, Omega, Vol. 29, N.º 6, December, pp. 561-576.
BOOTH, P. J. (1983): “Decomposition Measures and the Prediction of Financial Failure”, Journal of Business Finance & Accounting, Vol. 10, N.º 1, pp. 67-82.
BURGES, C. J. C. (1998): “A Tutorial on Support Vector Machines for Pattern Recognition”, Data Mining and Knowledge Discovery, Vol. 2, N.º 2, pp. 121-167.
CHALOS, P. (1985): “Financial Distress: A Comparative Study of Individual, Model, and Committee Assessments”, Journal of Accounting Research, Vol. 23, N.º 2, Autumn, pp. 527-543.
CHARALAMBOUS, C.; CHARITOU, A. y KAOUROU, F. (2000): “Comparative Analysis of Artificial Neural Network Models: Application in Bankruptcy Prediction”, Annals of Operations Research, 99, pp. 403–425.

CHARITOU, A; NEOPHYTOU, E. y CHARALAMBOUS, C. (2004): “Predicting Corporate Failure: Empirical Evidence for the UK”, European Accounting Review, Vol. 13, N.º 3, September, pp. 465-497.
CRESPO DOMÍNGUEZ, M. Á. (2000): Análisis de los Factores Explicativos del Fracaso Empresarial en Galicia: Un Análisis Empírico Mediante la Utilización de Modelos de Redes Neuronales, Edition del propio, Vigo.
CROUHY, M; GALAI, D. y MARK, R. (2000): A comparative analysis of current credit risk Models, Journal of Banking & Finance, 24, pp. 59-117.
DE ANDRÉS, J.; BONSÓN, E.; ESCOBAR, T. y SERRANO, C. (2005): Inteligencia Artificial y Contabilidad, Documentos AECA, Serie Nuevas Tecnologías y Contabilidad, N.º 5, Madrid.
DHUMALE, R. (1998): “Earning Retention as Specification Mechanism in Logistic Bankruptcy Models: A Test of the Free Cash Theory”, Journal of Business Finance and Accounting, Vol. 25, N.º 7/8, September/October, pp. 1005-1023.
DÍAZ GÓMEZ, F. (2002): Aprendizaje y Generación Automática de Conocimiento: Construcción de Redes Bayesianas mediante Rough Sets, Tesis Doctoral, Universidad de Vigo, Vigo.
DÍAZ GOMES, F. y FERNÁNDEZ-RIVEROLA, F. (2005): “Análisis de datos de microarrays”, en Avances en Bioinformática. De la teoría a la prática: métodos, técnicas y herramientas, Varios autores, Coordina: CORCHADO, J. M., Universidad de Salamanca, pp. 82-104
DIMITRAS, A. I.; SLOWINSKI, R.; SUSMAGA, R. y ZOPOUNIDIS, C. (1999): “Business Failure Prediction Using Rough Sets”, European Journal of Operational Research, Vol. 114, N.º 2, April, pp. 263-280.
DIMITRAS, A.I.; ZANAKIS, S.H. y ZOPOUNIDIS, C. (1996): “A survey of business failures with an emphasis on prediction methods and industrial applications”, European Journal of Operational Research , 90, pp. 487-513.
EL HENNAWY, R. H. A. y MORRIS, R. C. (1983): “The Significance of Base Year in Developing Failure Prediction Models, Journal of Business Finance & Accounting, Vol. 10, N.º 2, pp. 209-223.
FERRANDO BOLADO, M. y BLANCO RAMOS, F. (1998): “ La Previsión del Fracaso Empresarial en la Comunidad valenciana: Aplicación de los Modelos Discriminante y Logit”, Revista Española de Financiación y Contabilidad, Vol. XXVII, N.º 95, abril-junio, pp. 499-540.
FOREMAN, R. D. (2003): “A Logistic Analysis of Bankruptcy within the US Local Telecommunications Industry”, Journal of Economics and Business, Vol. 55, N.º 2, March, pp. 135-166.
FRYDMAN, H.; ALTMAN, E. I. y KAO, D.-L. (1985): “Introducing Recursive Partitioning for Financial Classification: The Case of Financial Distress”, The Journal of Finance, Vol. 40, N.º 1, March, pp. 269-291.
GABÁS TRIGO, F. (1990): Técnicas Actuales de Análisis Contable. Evaluación de la Solvencia Empresarial, Instituto de Contabilidad y Auditoria de Cuentas, Ministerio de Economía y Hacienda, Madrid.

GENTRY, J. A.; NEWBOLD, P. y WHITFORD, D. T. (1985): “Classifying Bankruptcy Firms with Funds Flow Components”, Journal of Accounting Research, Vol. 23, N.º 1, Spring, pp. 146-160.
GILBERT, L. R.; MENON, K. y SCHWARTZ, K. B. (1990): “Predicting Bankruptcy for Firms in Financial Distress”, Journal of Business Finance & Accounting, Vol. 17, N.º 1, Spring, pp. 161-171.
GLOUBOS, G. and GRAMMATIKOS, T. (1988): The success of bankruptcy prediction models in Greece, Studies in Banking & Finance, 7, pp. 37-46.
GOLDBERG, D. (1989): Genetic Algorithms in Search, Optimization and Machine Learning, Addison-Wesley Publishing Company, Inc.
GOMBOLA, M. J.; HASKINS, M. E.; KETZ, J. E. y WILLIAMS, D.D. (1987): “Cash Flow in Bankruptcy Prediction”, Financial Manangement, Winter, pp. 55-65.
HOSMER D. W. y LEMESHOW S. (1989): Applied Logistic Regression, John Wiley & Sons, Inc., USA.
HOUGHTON, K. A. (1984): “Accounting Data and the Prediction of Business Failure: The Setting of Priors and the Age of the Data”, Journal of Accounting Research, Vol. 22, N.º 1, Spring, pp. 361-368.
HOUGHTON, K. A. y WOODLIFF, D. R. (1987) : “Financial Ratios: The Prediction of Corporate “Success” and Failure”, Journal of Business Finance & Accounting, Vol. 14, N.º 4, Winter, pp. 537-554.
JO, H.; HAN, I. y LEE, H. (1987): “Bankruptcy Prediction Using Case-Based Reasoning, Neural Networks, and Discriminant Analysis”, Expert Systems With Applications, Vol. 13, N.º 2, August, pp. 97-108.
KAHYA, E. y THEODOSSIOU, P. (1999): Predicting Corporate Financial Distress: A Time-Series CUSUM Methodology, Review of Quantitative Finance and Accounting, Vol. 13, N.º 4, December, pp. 323-345.
KEASEY, K. e WATSON, R. (1991): “Financial Distress Prediction Models: A Review of Their Usefulness”, British Journal of Management, Vol. 2, N.º 2, July, pp. 89-102.
KEASEY, K. y McGUINNESS, P. (1990): “The Failure of UK Industrial Firms for the Period 1974-1976, Logistic Analysis and Entropy Measures”, Journal of Business Finance & Accounting, Vol. 17, N.º 1, Spring, pp. 119-135.
KEASEY, K. y WATSON, R. (1986): “The Prediction of Small Company Failure: Some Behavioural Evidence for the UK”, Accounting and Business Research, Vol. 17, N.º 65, Winter, pp. 49-57
KEASEY, K. y WATSON, R. (1987): “Non-Financial Symptoms and the Prediction of Small Company Failure: A Test of Argenti’s Hypotheses”, Journal of Business Finance & Accounting, Vol. 14, N.º 3, Autumn, pp. 335-354.
KIDA, T. (1980): “An Investigation into Auditors’ Continuity and Related Qualification Judgments”, Journal of Accounting Research, Vol. 18, N.º 2, Autumn, pp. 506-523.

KOH, H. C. (1992): “The Sensitivity of Optimal Cutoff Points to Misclassification Costs of Type I and Type II Errors in the Going-Concern Prediction Context”, Journal of Business Finance and Accounting, Vol. 19, N.º 2, January, pp. 187-197.
KOLARI, J.; GLENNON, D.; SHIN, H. y CAPUTO, D. (2002): “Predicting large US commercial bank failures”, Journal of Economics and Business, 54, pp. 361–387.
LAITINEN, E. K. (1991): “Financial Ratios and Different Failure Processes”, Journal of Business Finance & Accounting, Vol. 18 N.º 5, September, pp. 649-673.
LAITINEN, E. K. y LAITINEN, T. (1998): “Cash Management Behavior and Failure Prediction”, Journal of Business Finance and Accounting, Vol. 25, N. 7/8, September/October, pp. 893-919.
LAITINEN, T. y KANKAANPAA, M. (1999): “Comparative Analysis of Failure prediction Methods: The Finnish Case”, The European Accounting Review, Vol. 8, N.º1, May, pp. 67-92.
LANE, W.; LOONEY, S. y WANSLEY, J. (1986): “An application of the Cox proportional hazards model to bank failure”, Journal of Banking and Finance, 10, pp.511-531.
LENSBERG, T.; EILIFSEN, A. y McKEE, T. E. (2006): “Bankruptcy Theory Development and Classification Via Genetic Programming”, European Journal of Operational Research, Vol. 169, N.º 2, March, pp. 677-697.
LEV, B. (1978): Análisis de los Estados Financieros: Un Nuevo Enfoque, Ediciones ESIC, Madrid.
LIMA, A. R. G. (2002): Máquinas de Vetores Suporte na Classificação de Impressões Digitais, Dissertação de Mestrado, Universidade Federal do Ceará.
LUOMA, M., LAITINEN, E. K., (1991): “Survival Analysis as a Tool for Company Failure Prediction”, Omega, Vol. 19, Nº 6, March, pp. 673-678.
MCKEE, T. E. (1995): “Predicting Bankruptcy via Induction”, Journal of Information Technology, Vol. 10, N.º 1, March, pp. 26-36.
MCKEE, T. E. (2000): “Developing a Bankruptcy Prediction Model via Rough Sets Theory”, Internacional Journal of Intelligent Systems in Accounting, Finance & Management, Vol. 9, N.º 3, September, pp. 159-173.
MCKEE, T. E. y GREENSTEIN M. (2000): “Predicting Bankruptcy Using Recursive Partitioning and a Realistically Proportioned Data Set”, Journal of Forecasting, Vol. 19, N.º 3, April, pp. 219-230.
MCKEE, T.E. y LENSBERG, T. (2002): “Genetic programming and rough sets: A hybrid approach to bankruptcy classification” European Journal of Operational Research, Vol. 138, N.º 2, April, pp. 436-451.
MENSAH, Y. M. (1983): “The Differential Bankruptcy Predictive Ability of Specific Price Level Adjustments: Some Empirical Evidence”, The Accounting Review, Vol. 58, N.º 2, April, pp. 228-246.

MIN, J. H. y LEE, Y.-C. (2005): Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters, Expert Systems with Applications, Vol. 28, N.º 4, May, pp. 603-614.
MONTGOMERY, D. C. (2000): Introduction to Statistical Quality Control, 4th Edition, John Wiley, New York.
MORRIS, R. (1997): “Predicting Failure: a Failure in Prediction? – Just how are bankruptcy prediction models?”, Accountancy- International Edition, December, pp. 104-105.
MORRIS, R. (1998): “Bankruptcy prediction models: just how useful are they?”, Credit Management, May, pp. 43-45.
MOYER, R. C. (1977): “Forecasting Financial Failure: A Re-Examination”, Financial Management, Vol. 6, N.º1, Spring, pp. 11-17.
NASIR, M. L.; JOHN, R. I.; BENNETT, S. C. y RUSSELL, D. M. (2001): “Selecting the Neural Network Topology for Student Modelling of Prediction of Corporate Bankruptcy”, Campus-Wide Information Systems, Vol. 18, N.º 1, pp. 13-22.
NELSON, F. D. (1990): “Logit, Probit and Tobit”, en The New Palgrave: Econometrics, pp.136-144.
NORTON, C. L. y SMITH, R. E. (1979): “A Comparison of General Price Level and Historical Cost Financial Statements in the Prediction of Bankruptcy”, The Accounting Review, Vol. 54, N.º 1, January, pp. 72-86.
OLMEDA, I. y FERNÁNDEZ, E. (1997): “Hybrid Classifiers for Financial Multicriteria Decision Making: The Case of Bankruptcy Prediction”, Computational Economics, Vol. 10, N.º 4, November, pp. 317-335.
PARK, C.-S. y HAN, I. (2002): “A case-based reasoning with the feature weights derived by analytic hierarchy process for bankruptcy prediction”, Expert Systems with Applications, Vol. 23, N.º 3, October, pp. 255-264.
PAWLAK, Z. (1982): “Rough Sets”, International Journal of Computer and Information Sciences, 11, pp. 341-356.
PEEL, M. J. y PEEL, D. A. (1987): “Some Further Empirical Evidence on Predicting Private Company Failure”, Accounting and Business Research, Vol. 18, N.º 69, Winter, pp. 57-66.
PLATT, H. D. y PLATT, M. B. (1990): “Development of a Class of Stable Predictive Variables: The Case of Bankruptcy Prediction”, Journal of Business, Finance & Accounting, Vol. 17, N.º 1, Spring, pp. 31-51.
PLATT, H. D.; PLATT, M. B. y PEDERSEN, J. G. (1994): “Bankruptcy Discrimination with Real Variables” Journal of Business, Finance & Accounting, Vol. 21, N.º 4, June, pp. 491-509.
POSTON, K. M. y HARMON, W. K. (1994): “A Test of Financial Ratios as Predictors of Turnaround versus Failure among Financially Distressed Firms”, Journal of Applied Business Research, Vol. 10, N.º 1, Winter, pp. 41-56.
REIS, E. (1997): Estatística Multivariada Aplicada, Edições Sílabo, Lisboa.

SCHÖLKOPF, B.; BURGES, C. J. C. y SMOLA, A. J. (1999): Advances in Kernel Methods: Support Vector Learning. MIT Press, Cambridge.
SHIN, K.-S. y LEE, Y.-J. (2002): “A genetic algorithm application in bankruptcy prediction modelling”, Expert Systems with Applications, Vol. 23, N.º 3, October, pp. 321-328.
SKOGSVIK, K. (1990): “Current Cost Accounting Ratios as Predictors of Business Failure: The Swedish Case”, Journal of Business Finance and Accounting, Vol. 17, N.º 1, Spring, pp. 137-160.
SMITH, M. y TAFFLER, R. (1996): “Improving the communication of accounting information through cartoon graphics”, Accounting, Auditing and Accountability Journal, Vol. 9, N.º 2, pp. 68-85.
STONE, M. y RASP, J. (1991): “Tradeoffs in the Choice Between Logit and OLS for Accounting Choice Studies”, The Accounting Review, Vol. 66, N.º 1, January, pp. 170-187.
SUNG, T. K., CHANG, N. y LEE, G. (1999): “Dynamics of Modeling in Data Mining: Interpretive Approach to Bankruptcy”, Journal of Management Information Systems, Vol. 16, N.º 1, Summer, pp. 63- 85.
TAFFLER, R. J. (1983) – “The Assessment of Company Solvency and Performance Using a Statistical Model”, Accounting and Business Research, Vol. 13, N.º 52, Autumn, pp. 295-307.
TAM, K. y KIANG, M. (1992): “Managerial Applications of Neural Networks: The Case of Bank Failure Predictions, Management Science, Vol. 38, N.º 7, July, pp. 926-947.
TENNYSON, B. M.; INGRAM, R. W. y DUGAN, M. T. (1990): “Assessing the Information Content of Narrative Disclosures in Explaining Bankruptcy”, Journal of Business, Finance & Accounting, Vol. 17, N.º 3, Summer, pp. 391-410.
THEODOSSIOU, P. (1991): “Alternative Models for Assessing the Financial Condition of Business in Greece”, Journal of Business Finance and Accounting, Vol. 18, N.º 5, September, pp. 697-720.
VAN FREDERIKSLUST, R. A. I. (1978): Predictability of Corporate Failure, Martinus Nijhoff Social Sciences Division, Leiden, Boston, USA.
VARETTO, F. (1998): “Genetic Algorithms Applications in the Analysis of Insolvency Risk”, Journal of Banking and Finance, Vol. 22, N.º 10-11, October, pp. 1421-1439.
WESTGAARD, S. y WIJST, N. V. (2001): “Default Probabilities in a Corporate Bank Portfolio: A Logistic Model Approach”, European Journal of Operational Research, Vol. 135, N.º 2, December, pp. 338-349.
WHITTRED, G. y ZIMMER I. (1984): “Timeliness of Financial Reporting and Financial Distress”, The Accounting Review, Vol. 59, N.º 2, April, pp. 287-295.
WILCOX, J. W. (1973): “A Prediction of Business Failure Using Accounting Data”, Journal of Accounting Research, Supplement, Vol. 11, N.º 3, pp. 163- 179.

WILSON, N.; CHONG, K. S. y PEEL, M. (1995): “Neural Network Simulation and the Prediction of Corporate Outcomes: Some Empirical Findings”, International Journal of the Economics of Business, Vol. 2, N.º 1, February, pp. 31-50.
ZHANG, G.; HU, M. Y.; PATUWO, B. E. y INDRO, D. C. (1999): “Artificial Neural Network in Bankruptcy Prediction: General Framework and Cross-Validation Analysis”, European Journal of Operational Research, Vol. 116, N.º 1, July, pp. 16-32.
ZHU, Z.; HE, H.; STARZYK, J. A. y TSENG, C. (2007): “Self-organizing learning array and its application to economic and financial problems”, Information Sciences, Vol. 177, N.º 5, March, pp. 1180-1192.
ZMIJEWSKI, M. E. (1984): “Methodological Issues Related to the Estimation of Financial Distress Prediction Models”, Journal of Accounting Research, Vol. 22, Supplement, pp. 59-82.
ZURADA, J. M.; FOSTER, B. P.; WARD, T. J. y BARKER, R. M. (1998): “Neural Networks Versus Logit Regression Models for Predicting Financial Distress Response Variables”, The Journal of Applied Business Research, Vol. 15, N.º 1, Winter, pp. 21-29.


















