
Laboratorio de Estadística con Manejo de S-Plus Sesión 1 ... · Los nombres para los objetos en...
17
Laboratorio de Estadística con Manejo de S-Plus Sesión 1: " Introducción al Software y Análisis Exploratorio de Datos" Semana del 26 de Marzo del 2018 Patricio Videla J. Profesor Coordinador Laboratorio Estadística. Ángelo Gárate B. Ayudante Coordinador. INTRODUCCIÓN AL SOFTWARE Software El laboratorio de estadística utiliza el software S-PLUS, el cual es un poderoso paquete para análisis de datos, despliegue gráfico y estadísticas. Permite importar y exportar una gran variedad de formatos, incluyendo software tal como SAS, SPSS y Matlab; hojas de cálculo tal como Excel y Lotus; en general una variedad de formatos de texto. Una vez que los datos se encuentran disponibles, es posible analizarlos y explorarlos mediante las numerosas herramientas que posee el programa, las cuales se irán viendo en el transcurso de las sesiones de S-PLUS. Evaluación Se evaluará asistencia, controles y trabajos prácticos de acuerdo a la siguiente ponderación: Asistencia 30 % Controles 35 % Trabajos Prácticos 35 %
Transcript of Laboratorio de Estadística con Manejo de S-Plus Sesión 1 ... · Los nombres para los objetos en...

Laboratorio de Estadística
con Manejo de S-Plus
Sesión 1: " Introducción al Software y Análisis Exploratorio de Datos"
Semana del 26 de Marzo del 2018
Patricio Videla J. Profesor Coordinador Laboratorio Estadística.
Á n g e l o G á r a t e B . Ayudante Coordinador.
INTRODUCCIÓN AL SOFTWARE
Software
El laboratorio de estadística utiliza el software S-PLUS, el cual es un poderoso
paquete para análisis de datos, despliegue gráfico y estadísticas. Permite importar y
exportar una gran variedad de formatos, incluyendo software tal como SAS, SPSS y
Matlab; hojas de cálculo tal como Excel y Lotus; en general una variedad de
formatos de texto.
Una vez que los datos se encuentran disponibles, es posible analizarlos y
explorarlos mediante las numerosas herramientas que posee el programa, las cuales
se irán viendo en el transcurso de las sesiones de S-PLUS.
Evaluación
Se evaluará asistencia, controles y trabajos prácticos de acuerdo a la
siguiente ponderación:
Asistencia
30 %
Controles
35 %
Trabajos Prácticos
35 %

Esta nota entregará un factor Omega (ω) que va desde 0.95, para
aquellos alumnos con nota final 0, hasta un factor 1.1, para aquellos que tengan
nota final 100.
Tal como se muestra en la gráfica que se debe ingresar cortando y pegando,
línea a línea en S-Plus:
>plot(c(0,55,100),c(0.95,1,1.1),type="l",main="Factor Omega vs Nota
Laboratorio",xlab="Nota del Laboratorio",ylab="Factor Omega")
>abline(h=1,v=55,lty=3)
En línea punteada está para mostrar que el factor omega igual a 1
corresponde a una Nota de Laboratorio igual a 55.
Observación: El símbolo de mayor, (>), que aparece arriba y en todas las extracciones de código que se verán más adelante no se escriben en el código, éste indica las distintas operaciones, una vez ejecutado el programa.
Iniciando S-PLUS
S-PLUS consta de 2 formatos de visualización. El S-Plus gráfico con ventanas
de aplicaciones similares a las aplicaciones de Windows y el S-Plus sin interfaz
gráfica, que funciona sin las ventanas de aplicaciones, pero que tiene la ventaja de
ser mucho más estable que el anterior en redes. Durante el desarrollo de las
sesiones se utilizarán ambos.
Algo muy importante para ambos formatos, es abandonar el S-PLUS, con el
comando:
> q()
Este es el procedimiento recomendado, pues la función q() ejecuta una serie de
verificaciones durante el procedimiento de salida de S-PLUS.
Obteniendo ayuda
Es posible obtener ayuda seleccionando una opción bajo el menú Help en la
interfaz gráfica.
Alternativamente, para obtener ayuda de alguna función específica, el
comando es >help (opción), por ejemplo:
> help(solve)
O bien,
> ?solve

Usando la ventana de comandos
La ventana de comandos brinda un acceso interactivo al lenguaje S-PLUS.
Todo comando que es ingresado en S-PLUS es una expresión, éstas son evaluadas
una vez que es presionada la tecla ENTER. S i la tecla ENTER es presionada y la
expresión es sintácticamente incompleta, no será evaluada y no será generado un
mensaje de error, en lugar de esto S-PLUS espera que la expresión sea completada
utilizando + como indicador de expresión incompleta (por lo general faltan
paréntesis en dicha expresión).
Es posible escribir varias expresiones en una misma línea, para esto, deben
ser separadas por punto y coma (;). S-PLUS evalúa cada una de las expresiones en
secuencia cuando ENTER es presionado. No es requerido que un punto y coma
sea ingresado en cada final de línea, sólo entre múltiples expresiones dentro
de una línea. En S-PLUS las expresiones que inicien con el símbolo # son
consideradas comentarios y no son evaluados.
El resultado de cualquier expresión es un objeto, que puede ser salvado en el
directorio de trabajo mediante el operador de asignación <- (el operador de
asignación es formado por los símbolos "menor que" seguido por un "menos", no se
debe ingresar espacios entre estos dos símbolos), alternativamente, también es
posible utilizar como operador de asignación el símbolo =. Todos los datos usados
en S-PLUS son representados por algún tipo de objeto S-PLUS.
Muchas de las expresiones en S-PLUS llaman a funciones, para llamar una
función, ingrese el nombre de una función seguido por un conjunto de
paréntesis conteniendo los argumentos de la función (separados por comas).
Los comandos en S-PLUS son case sensitive, de este modo a y A son
variables diferentes. S-PLUS ignora los espacios en blanco adicionales, de este modo
es posible incluir u omitir espacios en blanco al ingresar expresiones, por otro lado
no se debe introducir espacios en blanco extra dentro del nombre de un objeto, o
entre dígitos o entre < y – en el operador de asignación.
La ventana de comandos usa el prompt >. En este documento, el texto
antecedido del símbolo > indica que debe ser ingresado en el prompt, pero el símbolo
> no debe ser ingresado. Si se desea realizar un quiebre de línea antes que S-PLUS
pueda interpretar el comando como completo, S-PLUS provee el prompt de
continuación + al inicio de la siguiente línea.
Observación: Se llama prompt al carácter o conjunto de caracteres que se muestran
en una línea de comandos para indicar que está a la espera de órdenes.

Elementos de S-PLUS
Los nombres para los objetos en S-PLUS deben iniciar con una letra y pueden
contener cualquier combinación de mayúsculas y minúsculas, números y puntos,
por ejemplo, los siguientes corresponden a nombres de objetos válidos.
Misdatos
datos.ozono
NumerosAleatorios
datos.1
ajuste.del.modelo
Intente no escoger nombres para objetos que coincidan con nombres de
funciones S-PLUS, si es creada una función o una variable con el mismo nombre
que una función disponible en S-PLUS, el acceso a la función S-PLUS es
temporalmente restringido hasta que el objeto creado sea eliminado (utilice la
función rm( ) para remover objetos), S-PLUS advierte cuando es enmascarada una
función con la creación de otra por parte del usuario, existen algunas funciones de
S-PLUS cuyo nombre consta de un carácter C, D, c, I, q, s y t, se debe prestar
atención a no crear objetos con estos nombres.
Un tipo de dato que es fundamental en S-PLUS corresponde a la clase vector,
éstos son objetos S conteniendo n elementos que pueden ser indexados
numéricamente, el comando básico para la creación de esta clase de datos es:
> x <- c(10.4, 5.6, 3.1, 6.4, 21.7)
* Note que la expresión anterior corresponde a una asignación que utiliza la
función de concatenación c(), esta función toma un número arbitrario de vectores y su valor es un vector concatenado. Vectores son caracterizados por
los atributos length y mode, para el ejemplo anterior tenemos:

> x
[1] 10.4 5.6 3.1 6.4 21.7
> length(x)
[1] 5
> mode(x)
[1] "numeric"
Note que la expresión:
> y <- c(x, 0.5, 11, 6.5, 13.1, -3.1, x)
Genera un vector de largo 15 llamado y.
Por otro lado, el siguiente comando:
> z <- c("ls", "ml", "em")
> mode(z)
[1] "character"
Permite crear vectores cuyo atributo de modo es de tipo carácter.
Vectores pueden ser utilizados en operaciones aritméticas, en cuyo caso éstas
son realizadas elemento a elemento, no es requerido que los vectores involucrados
en tales operaciones sean del mismo orden, si los vectores no son del mismo largo,
el valor de la expresión es del largo del vector mayor, aquellos vectores que sean más
"pequeños" son reciclados en dichos cálculos, para fijar ideas, note el siguiente
ejemplo:
> v <- 2*x + y + 1
Esto genera un vector de largo 15, en donde el vector 2*x ha sido reciclado 3
veces y el vector 1 por su parte, ha sido reciclado 15 veces. Es importante notar
que cuando el largo del operando mayor no es múltiplo del largo del vector menor se
generará un mensaje de error y la operación no es realizada, y en el caso de nuestro
ejemplo el vector v no será creado.

S-PLUS dispone de los operadores aritméticos +, -, *, /, así como ^ para
las potencias además de las funciones aritméticas log, exp, sin, cos, tan, sqrt
(consulte la ayuda de S-PLUS para una lista más detallada). Las funciones
min y max obtienen el elemento menor y mayor en un vector respectivamente, la
función range es un vector de largo 2, digamos c(min(x), max(x), length(x))
obtiene el largo del vector x, sum(x) obtiene la suma de los elementos de x y prod(x)
su producto.
Existen variadas funciones estadísticas, como mean(x), que calcula el
promedio muestral, esto es, sum(x)/length(x), y la función var(x), que calcula
sum((x – mean(x))^2)/(length(x) – 1)
O sea, la varianza muestral, o más generalmente si x es una matriz nxp, la
matriz de covarianzas pxp, entendiendo las n filas de la matriz x como una muestra
aleatoria de vectores p-dimensionales.
sort(x) retorna un vector del mismo largo que x cuyos elementos se
encuentran ordenados de manera creciente, rnorm(n) es una función que genera un
vector (o más generalmente un arreglo) con seudodígitos aleatorios generados desde
una variable aleatoria normal estándar de largo n.
Para generar secuencias es útil la siguiente expresión en S-PLUS,
> 1:10
[1] 1 2 3 4 5 6 7 8 9 10
*Note que 1:10 es equivalente al vector c(1, 2, ..., 10), y que 2*1:15, genera c(2,
4, 6, ..., 28, 30). Considere el siguiente ejemplo, e indique que es lo que se
obtendrá:
> n <- 10
> 1:n-1; 1:(n-1)
La construcción 30:1 puede ser utilizada para obtener secuencias en orden
decreciente. La función seq(), es una utilidad más general para construir secuencias,
esta función tiene cinco argumentos, sólo algunos de ellos pueden ser utilizados en
una llamada a esta función, los primeros dos argumentos especifican el inicio y el
final de la secuencia, los parámetros para seq() así como para muchas funciones en
S-PLUS, pueden ser dados indicando los nombres de los argumentos, en cuyo caso
el orden es irrelevante, en el siguiente ejemplo todas las expresiones son
equivalentes:
> 1:30; seq(1, 30); seq(from = 1, to = 30); seq(to = 30, from = 1)

Los siguientes dos parámetros de seq() son by=valor y length=valor, estos
especifican el tamaño del paso y el tamaño de la secuencia respectivamente., si
ninguno de estos es dado se asume como valor por defecto, by=1.
Por ejemplo:
> s3 <- seq(-5, 5, by = .2)
Genera el vector s3, c(-5.0, -4.8, ..., 4.8, 5.0). Similarmente:
> s4 <- seq(length = 51, from = 5, by = .2)
Genera en s4 el mismo vector que en s3. Una función relacionada es rep(), la
que es utilizada para replicar una estructura o vector, su forma más sencilla es:
> s5 <- rep(x, times = 5)
Esto es, 5 copias de x son obtenidas en s5.
Así como vectores numéricos y de caracteres, S-PLUS permite la manipulación
de cantidades lógicas, los elementos de un vector lógico sólo tiene dos valores
posibles representados por F (para falso) y T (para verdadero), vectores lógicos son
generados por condiciones, note esto en el siguiente ejemplo:
> x <- rnorm(5)
> x
[1] 0.10498028 0.23021549 2.39568112 0.08249998 -0.02488167
> z <- x > 0
> z
[1] T T T T F
Aquí z es un vector del mismo largo que x con valores F en aquellos elementos
en que la condición no es satisfecha, y T cuando sí lo es.

Los valores lógicos son <, <=, =>, >, == para la igualdad y != para
desigualdad. Además, si c1 y c2 representan expresiones lógicas, entonces c1
& c2 es su intersección, c1 | c2 es su unión y !c1 representa la negación de c1.
En algunos casos los componentes de un vector pueden no ser completamente
conocidos. Cuando un elemento o valor no esta disponible o es un valor perdido
en sentido estadístico, al valor dentro del vector le es atribuido el valor especial NA.
En general cualquier operación sobre un NA resulta en un NA. La motivación para
esta regla es simplemente que si la especificación para una regla es incompleta,
no es posible conocer su resultado y de este modo no es disponible.
Considere la siguiente operación sobre el vector x creado en el ejemplo
anterior,
> y <- log(x)
Warning messages:
NAs generated in: log(x)
> y
[1] -2.2539827 -1.4687395 0.8736676 -2.4949572 NA
La función is.na(x) retorna un vector lógico del mismo tamaño que x con un
valor T solamente si el correspondiente elemento en x es NA, en nuestro ejemplo,
obtenemos
> is.na(y)
[1] F F F F T
Subconjuntos de elementos de un vector pueden ser seleccionados mediante
utilizar vectores de índices, existen cuatro tipo de vectores que pueden ser utilizados
como índices, a saber.

Vectores lógicos:
En este caso el vector de índices debe ser del mismo largo que el vector desde
el cual los elementos están siendo seleccionados, los elementos en el vector de
índices cuyos valores sean T serán seleccionados, los valores F omitidos. Por
ejemplo:
> x <- y[!is.na(y)]
Crea un objeto x con aquellos valores de y que no son NA.
Vector de enteros positivos:
En este caso el vector de índices debe estar en el conjunto {1,2,...,length(x)}, el
vector de índices puede ser de cualquier tamaño y el resultado es del mismo tamaño
que el vector de índices, por ejemplo:
> ene <- rnorm(13,4,1)
> x <- (-ene)^2
> x[6] # extrae el sexto componente de x
> x[1:10]#selecciona los primeros 10 elementos de x (suponiendo que length(x)10).
Vector de enteros negativos:
Este vector de índices indica los elementos que serán extraídos, de este modo
> y <- x[-(1:5)]
Copia el vector x eliminando los primeros 5 elementos.
Vector de caracteres:
Esta posibilidad sólo aplica a aquellos vectores con atributo name para
identificar sus componentes. En este caso el subvector de nombres es usado del
mismo modo que el vector de enteros positivos indicado en el punto 2.

> lunch <- c("apple", "orange")
*Note que el resultado de la operación de extracción y/o selección de
elementos de un vector descrita aquí genera un vector con el mismo atributo
de modo, esto permite que los vectores sean clasificados como objetos
atómicos.
Otro objeto importante en S-PLUS son los arreglos bidimensionales o matrices,
en varios aspectos son similares a vectores. Para crear una matriz, utilice la función:
> a <- matrix(1:12, nrow = 3, ncol = 4)
> a
> b <- matrix(1:12, nrow = 4, ncol = 3)
> b
De este modo una matriz es una arreglo con dos subíndices, S-PLUS contiene
muchos operadores y funciones disponibles para matrices, por ejemplo t(X) es la
función transpuesta, las funciones nrow(A) y ncol(A) dan el número de filas y de
columnas de la matriz A.
El operador %*% es utilizado para multiplicación matricial, como sigue
> c <- a %*% b
En este caso los órdenes de las matrices involucradas deben concordar, si por
ejemplo, tenemos matrices del mismo orden podemos usar el operador de
multiplicación elemento a elemento (conocido como producto de Hadamard)
> a * a
Otras funciones importantes son solve(a, b) para resolver ecuaciones, svd()
para la descomposición valor singular, qr() para la descomposición QR y eigen() para
calcular valores y vectores propios.
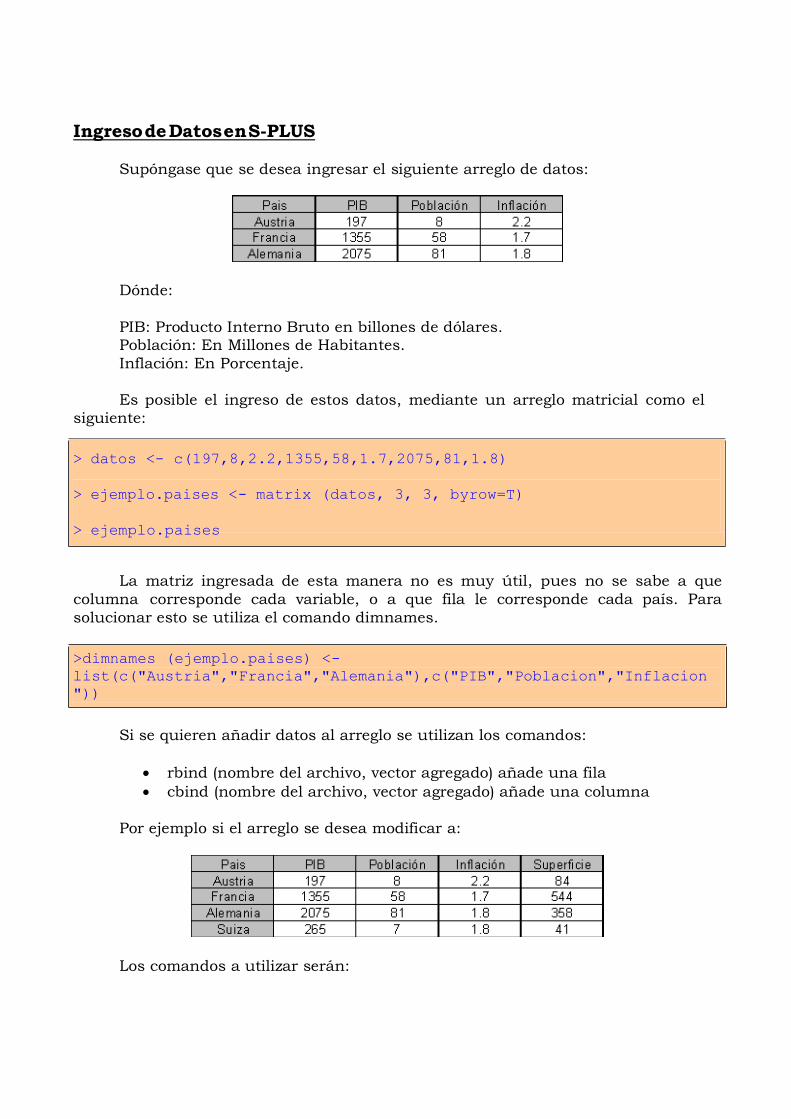
Ingreso de Datos en S-PLUS
Supóngase que se desea ingresar el siguiente arreglo de datos:
Dónde:
PIB: Producto Interno Bruto en billones de dólares.
Población: En Millones de Habitantes.
Inflación: En Porcentaje.
Es posible el ingreso de estos datos, mediante un arreglo matricial como el
siguiente:
> datos <- c(197,8,2.2,1355,58,1.7,2075,81,1.8)
> ejemplo.paises <- matrix (datos, 3, 3, byrow=T)
> ejemplo.paises
La matriz ingresada de esta manera no es muy útil, pues no se sabe a que
columna corresponde cada variable, o a que fila le corresponde cada país. Para
solucionar esto se utiliza el comando dimnames.
>dimnames (ejemplo.paises) <-
list(c("Austria","Francia","Alemania"),c("PIB","Poblacion","Inflacion
"))
Si se quieren añadir datos al arreglo se utilizan los comandos:
rbind (nombre del archivo, vector agregado) añade una fila
cbind (nombre del archivo, vector agregado) añade una columna
Por ejemplo si el arreglo se desea modificar a:
Los comandos a utilizar serán:

> ejemplo.paises <- rbind (ejemplo.paises,Suiza=c(265,7,1.8))
> ejemplo.paises <- cbind (ejemplo.paises,Superficie=c(84,544,358,41))
> ejemplo.paises
Para modificar algún valor especifico del arreglo, por ejemplo la población de
Austria de 8 millones a 10 millones se procede de la siguiente forma:
> ejemplo.paises["Austria","Poblacion"] <- 10
> ejemplo.paises
Si se desea un análisis de una serie de datos se puede utilizar el comando
"Summary", el cual nos entrega un resumen de las estadísticas más importantes.
Ingrese el siguiente comando:
> b<-rnorm(20,16,3)
> b
Esto nos genera una muestra de 20 observaciones de una variable con
distribución “Normal” de media 16 y una desviación estándar 3.
> summary(b)
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.28 14.87 18.63 17.55 19.67 23.84
Ocupe los siguientes comandos con esos mismos datos:
mean(b)
median(b)
min(b)
max(b)
var(b)
sqrt(var(b))

ANÁLISIS EXPLORATORIO DE DATOS
En esta sección exploraremos las diferentes variables contenidas en el
conjunto de datos la Cebada. Analizaremos las variables en una dimensión.
Posteriormente, se llevará a cabo el análisis de la dependencia entre las variables y
la exploración de estructuras de mayor dimensión.
Dividiremos el análisis de datos en dos categorías, exploración "descriptiva" y
"gráfica". El conjunto de datos de la Cebada (BARLEY).
Los datos de la Cebada representan mediciones de la producción, en buslels
por Acre, en diferentes sitios. El análisis comprende 6 sitios sembrados con 10
diferentes variedades de cebada en dos años sucesivos, 1931 y 1932. El conjunto
de datos por consiguiente contiene 120 mediciones de la producción de cebada.
Nuestro principal objetivo radica en determinar la razón de las distintas
producciones de cebada obtenidas por las diferentes constelaciones de variables,
como la cosecha de la quinta variedad del sitio 4 en 1931, y la cosecha de la séptima
variedad en el mismo sitio en 1932.
Para observar el conjunto de datos digitamos el comando:
> barley
Aquí podemos observar cómo se despliegan en pantalla las 120 mediciones de
las cuatro variables: Rendimiento, Variedad, Año y Sitio de la producción de cebada.
Debido a que se trata de un gran número de datos, podemos restringir la
visión de los mismos mediante el comando: > barley[c(2,17,64,70,82,98,118), c(1,2,3,4)]
Esto nos permite visualizar sólo las observaciones resultado de la intersección
de las filas 2, 17, 64, 70, 82, 98, 118 con las columnas 1, 2, 3, 4.
Si queremos obtener un resumen de las principales medidas descriptivas de
las variables contenidas en el set de datos, digitamos: > summary(barley)
Este comando entrega mediadas tales como el mínimo, máximo, media,
mediana y cuartiles de las variables, además del número de observaciones para
cada categoría de las variables cuantitativas.

Para tener un mejor acceso a las variables contenidas en el conjunto de datos,
debemos "vincular" las mismas. Esto se realiza digitando: > attach(barley)
Una manera fácil de "visualizar" la variabilidad existente en los datos, es
mediante la construcción de un diagrama de Tallo y Hoja. A modo de ejemplo, si se
digita: > stem(yield)
El resultado es un diagrama de este tipo para la variable Rendimiento.
Lo anterior se puede complementar con un Histograma:
> hist(yield)
Si se compara entonces lo obtenido con el histograma y con la forma del
diagrama hoja-tallo, tenemos una idea de cómo se encuentran distribuidos los
datos.
Los cuantiles permiten obtener fracciones acumuladas de las observaciones de
cada variable. Por ejemplo, si digitamos el comando:
> quantile(yield,seq(0.1,0.9,by=0.1))
Obtendremos diez "sectores" de 10% de las observaciones, de la variable
rendimiento. Es decir, en el 10% de los sitios el rendimiento fue de hasta 22.4967,
en el 50% fue de hasta 32.8667, etc.
Aun cuando en el resumen descriptivo obtenido anteriormente se muestran
los "cuartiles" uno y tres del rendimiento obtenido, con el comando:
> quantile(yield,c(0.25,0.75))
Los cuartiles dividen el conjunto en 4 "sectores" de 25% de las observaciones
cada uno. En la acción anterior se observa que en el 25% de los sitios el rendimiento
fue de hasta 26.875 y en el 75% fue de hasta 41.4.
Podemos obtener la raíz cuadrada de la varianza del rendimiento, mediante el
comando:
> sqrt(var(yield))
Como ya es sabido, la medida aquí obtenida se llama desviación estándar.

Como el interés radica en comparar el rendimiento en dos años sucesivos;
1931 y 1932, resulta interesante realizar un análisis para cada año por separado.
Utilizando el comando summary:
> summary(yield[year==1931])
Entrega un resumen de las principales medidas descriptivas obtenidas en al
año 1931.
Análogamente, para el año 1932, digitamos:
> summary(yield[year==1932])
Es evidente que el año 1931 produjo mejores rendimientos. Podemos reforzar
esta idea recurriendo a lo cuantiles.
A modo de ejemplo si digitamos:
> quantile(yield[year==1931],0.9)
Observamos que el 90% de los sitios, sembrados en el año 1931, tuvieron un
rendimiento de hasta 49.90334.
Análogamente, al digitar:
> quantile(yield[year==1932],0.9)
Obtenemos esta información para el año 1932. En este caso el rendimiento
fue de hasta 44.28.
La medida anterior se conoce como "percentil".
Los percentiles dividen el conjunto de las observaciones en 100 sectores de 1% de los datos cada uno.
En este ejemplo se calculó percentil 90.
Al digitar: > barley[yield>49.90334&year==1931,]
Se puede visualizar cuales fueron las observaciones que superaron el percentil
90 en el año 1931. Inmediatamente es posible identificar las variedades y los sitios
con las que se obtuvieron dichos rendimientos.

Para obtener esta información, en el año 1932, digitamos: > barley[yield>44.28&year==1932,]
Un resumen descriptivo de "todas" las variables, para cada año por separado,
se obtiene digitando:
> by(barley,year,summary)
CREACIÓN DE TABLAS DE FRECUENCIA
Ejemplos:
1) Los siguientes datos corresponden a las temperaturas medias diarias observadas
en una ciudad durante 100 días.
> temp <- c(20.27525,19.73013,16.21313,18.12827,21.53387,19.07346,
18.04411,20.15087,15.77415,18.19234,12.56067,18.71679,19.33679,
16.93241,21.95372,16.63082,20.01546,15.22050,22.17234,13.87402,
21.05035,19.31134,14.82105,16.64618,13.26309,18.53422,19.48640,
19.53956,19.86675,19.10431,17.89998,18.07431,16.82736,16.22484,
18.30725,21.77722,21.44611,15.01084,17.67678,19.19311,17.72124,
20.00985,18.25819,19.34646,21.75676,21.12706,13.83994,14.90698,
10.95077,19.88558,18.40093,21.68286,15.61882,20.43784,15.41067,
18.84347,13.99668,19.01989,21.09709,22.48008,24.90970,13.27500,
18.58879,20.89855,15.87310,17.22840,20.45063,21.93388,21.29527,
10.66450,15.22923,14.66002,18.85593,19.50307,16.06054,20.69968,
16.54046,18.85040,22.56469,14.36156,17.53381,21.60627,20.86276,
13.31121,17.11699,20.28564,16.18156,20.00518,23.06142,15.84457,
18.11561,14.28073,16.17877,14.07449,17.06696,16.08166,20.86127,
21.85060,18.43894,13.65300 )
Se desea agrupar estos datos mediante una tabla de frecuencia. Para esto se utilizarán los comandos Cut y Table.
> tabla.frec <- cut(temp,breaks=10)
> table(tabla.frec)
¿Qué conclusiones inmediatas puede obtener desde la tabla?

2) Utilizando la base de datos BARLEY, realice una tabla de frecuencia para la
variable YIELD, considerando 11 clases.
> barley
> attach(barley)
> ejemplo.dos<-cut(yield,breaks=11)
> table(ejemplo.dos)
¿Qué conclusiones inmediatas puede obtener desde la tabla? …
Patricio Videla J. Profesor Coordinador Laboratorio Estadística.
Ángelo Gárate B. Ayudante Coordinador.
Referencias
Krause, A. and Olson, M. (2000). The basic of S and S-Plus. Springer, New York.
Chambers, J. M. (1998). Programming with data. Springer, New York.
Venables, W. and Smith, D. (1992). Notes on S-Plus: A programming environment for data analysis
and graphics. Department of Statistics, The University of Adelaide.


















