intervalos de confianza simultáneos
27
Universidad Anáhuac Mayab Análisis Multivariado Profesor. Leonardo Araujo Tarea 2. Inferencias para un vector de medias Baqueiro Hadad Paulina Gutiérrez Oropeza Cecilia Ibarra Ruiseñor María del Mar López Laviada Ana Paulina
-
Upload
ceci-renee-gtz-o -
Category
Documents
-
view
302 -
download
0
description
Análisis multivariado
Transcript of intervalos de confianza simultáneos

Universidad Anáhuac Mayab
Análisis Multivariado
Profesor. Leonardo Araujo
Tarea 2. Inferencias para un vector de medias
Baqueiro Hadad Paulina
Gutiérrez Oropeza Cecilia
Ibarra Ruiseñor María del Mar
López Laviada Ana Paulina
Mérida, Yucatán, México 24 de octubre del 2015

TAREA 2
EJERCICIO 5.1Evalúe T2 para probar H0: =[7,11]
Códigox<- matrix(c(2,8,6,8,12,9,9,10),4,2);xn=4p=2xbar<- colMeans(x); xbars<- cov(x); ssi<-solve(s); sialfa=0.05 mu <- matrix(c(7,11),1,2); mudifx<- xbar-mu; difxT2 <- n%*%difx%*%si%*%t(difx); T2
((n-1)*p)/(n-p)
F<-qf(1-alfa,p,n-p);FR<-((n-1)*p*F)/(n-p);R
Resultados#(a)T2=13.64#(b)Distribución 3 F2-2
#(c)13.64<57 ... No se debe rechazar H0 en favor de H1 al 5% de nivel de significancia

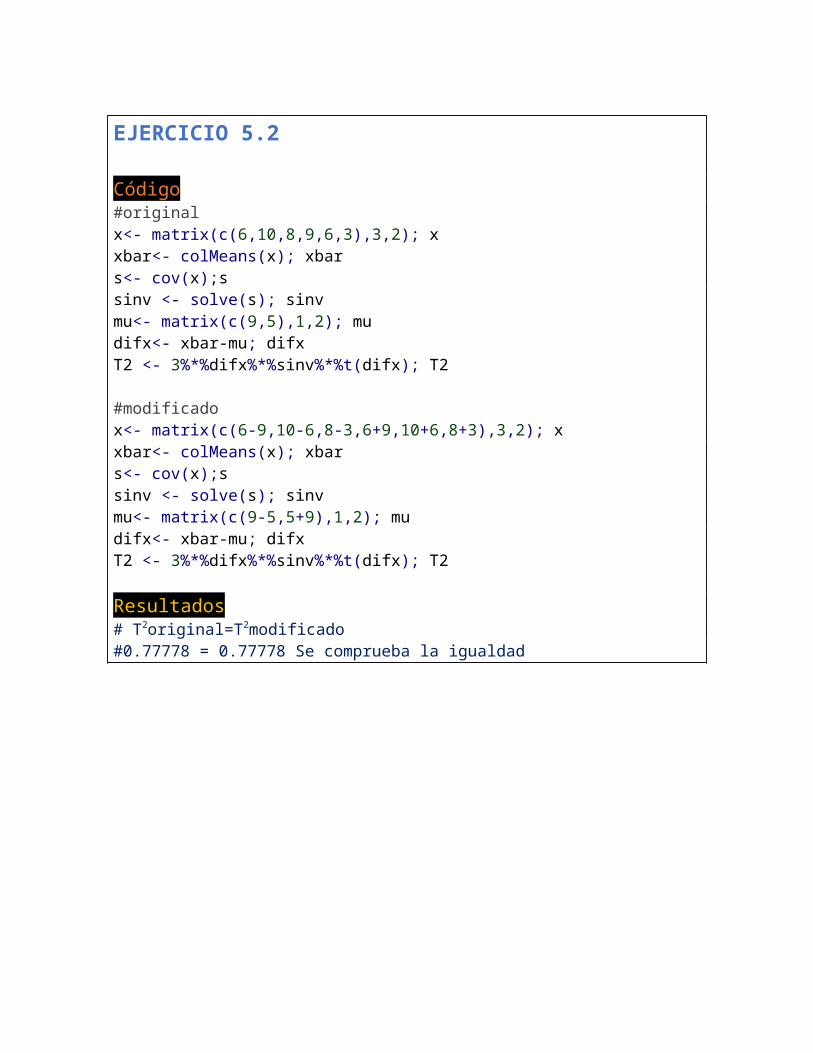
EJERCICIO 5.2
Código#originalx<- matrix(c(6,10,8,9,6,3),3,2); xxbar<- colMeans(x); xbars<- cov(x);ssinv <- solve(s); sinvmu<- matrix(c(9,5),1,2); mudifx<- xbar-mu; difxT2 <- 3%*%difx%*%sinv%*%t(difx); T2
#modificadox<- matrix(c(6-9,10-6,8-3,6+9,10+6,8+3),3,2); xxbar<- colMeans(x); xbars<- cov(x);ssinv <- solve(s); sinvmu<- matrix(c(9-5,5+9),1,2); mudifx<- xbar-mu; difxT2 <- 3%*%difx%*%sinv%*%t(difx); T2
Resultados# T2original=T2modificado#0.77778 = 0.77778 Se comprueba la igualdad
EJERCICIO 5.4B) Construye qqplot para las observaciones de sweat, de contenido de sodio y de potasio. Construye las 3 posibles graficas. ¿parece que la distribución normal multivariada se justifica?
Códigosweat <- read.csv("Sweat Data.csv", header=T); sweathist(sweat[,1], col='skyblue')qqnorm(sweat[,1], pch=2); qqline(sweat[,1],col='blue')hist(sweat[,2], col='lightpink')qqnorm(sweat[,2], pch=3); qqline(sweat[,2], col='pink')hist(sweat[,3], col='beige')qqnorm(sweat[,3], pch=9); qqline(sweat[,3], col='orange')mshapiro.test(t(sweat[,1]))mshapiro.test(t(sweat[,2]))mshapiro.test(t(sweat[,3]))Resultados##PARA 1 #Histograma, QQ plot
## SShapiro-Wilk normality test## data: Z## W = 0.97578, p-value = 0.8689##PARA 2 #Histograma, QQ plot

##Shapiro-Wilk normality test##data: Z##W = 0.98584, p-value = 0.9862
##PARA 3 #Histograma, QQ plot
## Shapiro-Wilk normality test## data: Z## W = 0.96385, p-value = 0.6233
##viendo las gráficas qqplot si parece formarse una línea recta con las variables, sin embargo al no ser muchos datos, con el histograma no se puede obtener una conclusión,
Por lo que utilizando shapiro.test pudimos llegar mejor a la conclusión de que si se tiene una distribución normal multivariada.

EJERCICIO 5.5Prueba de hipótesis y elipse de confianza
Códigorad <- read.csv("rad.csv", header=T)xb<- colMeans(rad)S<- cov(rad)xbar<- matrix(c(.564,.603),1,2); xbars<- matrix(c(.0144,.0117,.0117,.0146),2,2); ssi<-matrix(c(203.018,-163.391,-163.391,200.228),2,2); sin=42p=2alfa=0.05 mu <- matrix(c(.55,.60),1,2); mudifx<- xbar-mu; difxT2 <- n%*%difx%*%si%*%t(difx); T2F<-qf(1-alfa,2,40);FR<-((n-1)*2*F)/(n-p);Rlibrary("mixtools")plot(rad, pch=4, col="blue"); ellipse(mu=xb, sigma=S, alpha = alfa, npoints = 2000, col="pink"); points (.562,.589)
Resultados# si T2 > (n-1)pF/(n-p) ... se rechaza H0; 1.17<6.62 ... No se debe rechazar H0 en favor de H1 al 5% de nivel de significancia
#Los gráficos coinciden con la conclusión de la prueba de hipótesis, dado que el punto que representa a "0" se encuentra dentro de la región que marca la elipse de confianza, decimos que funciona como valor posible de ""
EJERCICIO 5.7T2 intervalos simultáneosCódigo

sweat <- read.csv("Sweat Data.csv", header=T); sweatn=20p=3a=0.05xbar<- colMeans(sweat); xbarS<- cov(sweat);SF<-qf((1-a), p, n-p); FIx1<- c(xbar[1]-sqrt(((p*(n-1))/(n*(n-p)))*F*S[1,1]), xbar[1]+sqrt(((p*(n-1))/(n*(n-p)))*F*S[1,1])); Ix1
Ix2<- c(xbar[2]-sqrt(((p*(n-1))/(n*(n-p)))*F*S[2,2]), xbar[2]+sqrt(((p*(n-1))/(n*(n-p)))*F*S[2,2])); Ix2
Ix3<- c(xbar[3]-sqrt(((p*(n-1))/(n*(n-p)))*F*S[3,3]), xbar[3]+sqrt(((p*(n-1))/(n*(n-p)))*F*S[3,3])); Ix3
Resultados# Para x1 hay un 95% de confianza de que el intervalo simultaneo (3.40,5.88) contenga a "0"
# Para x2 hay un 95% de confianza de que el intervalo simultaneo (35.05,55.74) contenga a "0"
# Para x3 hay un 95% de confianza de que el intervalo simultaneo (8.57,11.36) contenga a "0"
BonferroniCódigoT<-qt(1-(a/(2*p)),(n-1)); TI1<- c(xbar[1]-(T*sqrt(S[1,1]/n)), xbar[1]+(T*sqrt(S[1,1]/n))); I1I2<- c(xbar[2]-(T*sqrt(S[2,2]/n)), xbar[2]+(T*sqrt(S[2,2]/n))); I2I3<- c(xbar[3]-(T*sqrt(S[3,3]/n)), xbar[3]+(T*sqrt(S[3,3]/n))); I3
Resultados# Para x1 hay un 95% de confianza de que el intervalo de Bonferroni (3.64,5.64) contenga a "0"
# Para x2 hay un 95% de confianza de que el intervalo de Bonferroni (37.10,53.70) contenga a "0"
# Para x3 hay un 95% de confianza de que el intervalo de Bonferroni (8.85,11.08) contenga a "0"
Los intervalos simultáneos abarcan mayor rango que los Bonferroni, esto es ocasionado por la necesidad de acertar en las medias de las 3 variables a la vez.

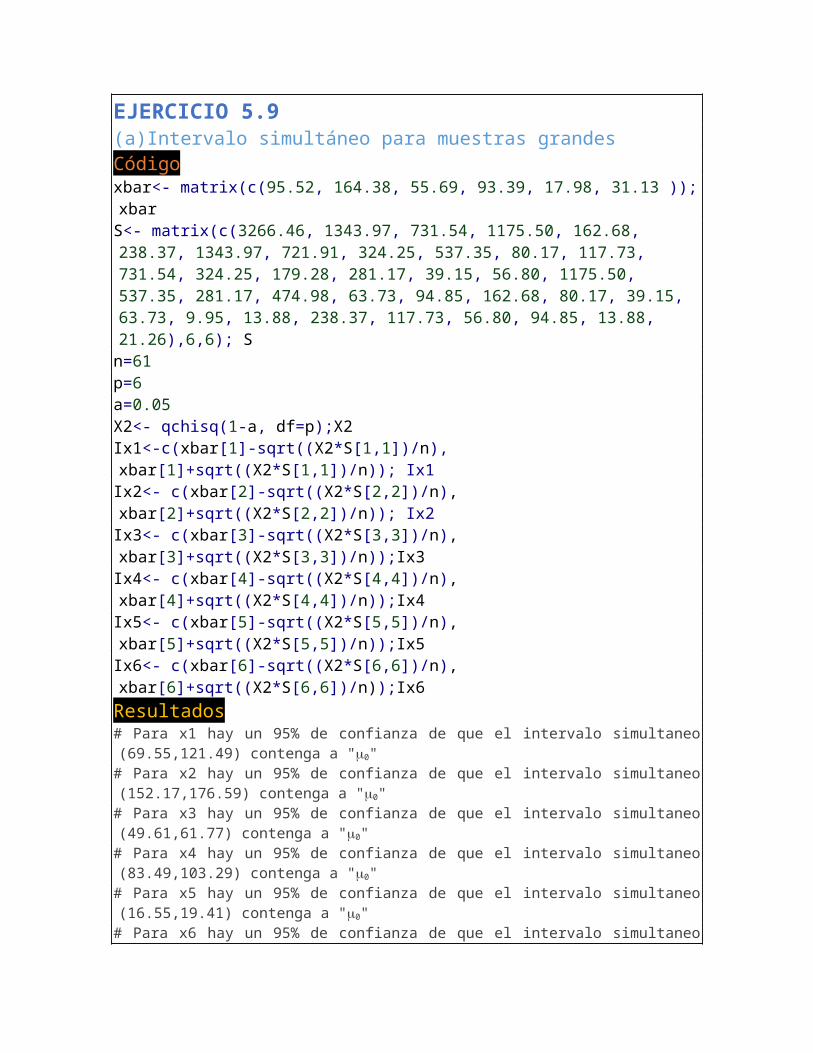
EJERCICIO 5.9(a)Intervalo simultáneo para muestras grandesCódigoxbar<- matrix(c(95.52, 164.38, 55.69, 93.39, 17.98, 31.13 )); xbarS<- matrix(c(3266.46, 1343.97, 731.54, 1175.50, 162.68, 238.37, 1343.97, 721.91, 324.25, 537.35, 80.17, 117.73, 731.54, 324.25, 179.28, 281.17, 39.15, 56.80, 1175.50, 537.35, 281.17, 474.98, 63.73, 94.85, 162.68, 80.17, 39.15, 63.73, 9.95, 13.88, 238.37, 117.73, 56.80, 94.85, 13.88, 21.26),6,6); S
n=61p=6a=0.05X2<- qchisq(1-a, df=p);X2Ix1<-c(xbar[1]-sqrt((X2*S[1,1])/n), xbar[1]+sqrt((X2*S[1,1])/n)); Ix1Ix2<- c(xbar[2]-sqrt((X2*S[2,2])/n), xbar[2]+sqrt((X2*S[2,2])/n)); Ix2Ix3<- c(xbar[3]-sqrt((X2*S[3,3])/n), xbar[3]+sqrt((X2*S[3,3])/n));Ix3Ix4<- c(xbar[4]-sqrt((X2*S[4,4])/n), xbar[4]+sqrt((X2*S[4,4])/n));Ix4Ix5<- c(xbar[5]-sqrt((X2*S[5,5])/n), xbar[5]+sqrt((X2*S[5,5])/n));Ix5Ix6<- c(xbar[6]-sqrt((X2*S[6,6])/n), xbar[6]+sqrt((X2*S[6,6])/n));Ix6Resultados# Para x1 hay un 95% de confianza de que el intervalo simultaneo (69.55,121.49) contenga a "0"
# Para x2 hay un 95% de confianza de que el intervalo simultaneo (152.17,176.59) contenga a "0"
# Para x3 hay un 95% de confianza de que el intervalo simultaneo (49.61,61.77) contenga a "0"
# Para x4 hay un 95% de confianza de que el intervalo simultaneo (83.49,103.29) contenga a "0"
# Para x5 hay un 95% de confianza de que el intervalo simultaneo (16.55,19.41) contenga a "0"
# Para x6 hay un 95% de confianza de que el intervalo simultaneo (29.03,33.22) contenga a "0"
(b) Elipse para peso medio y circunferenciaCódigos<-matrix(c(3266.46,1175.5,1175.5,474.98),2,2);slibrary(mixtools)ellipse(c(xbar[1],xbar[4]),s, 0.05, npoints = 2000, newplot = TRUE, draw = TRUE)
Resultados

(c) BonferroniCódigoz<-qnorm(1-(0.025/p));z2.638257B1<- c(xbar[1]-(z*sqrt(s[1]/n)), xbar[1]+(z*sqrt(s[1]/n))); B1B2<- c(xbar[2]-(z*sqrt(s[2]/n)), xbar[2]+(z*sqrt(s[2]/n))); B2B3<- c(xbar[3]-(z*sqrt(s[3]/n)), xbar[3]+(z*sqrt(s[3]/n))); B3B4<- c(xbar[4]-(z*sqrt(s[4]/n)), xbar[4]+(z*sqrt(s[4]/n))); B4B5<- c(xbar[5]-(z*sqrt(s[5]/n)), xbar[5]+(z*sqrt(s[5]/n))); B5B6<- c(xbar[6]-(z*sqrt(s[6]/n)), xbar[6]+(z*sqrt(s[6]/n))); B6Resultados# Para x1 hay un 95% de confianza de que el intervalo de Bonferroni (76.21406, 114.82594) contenga a "0"
# Para x2 hay un 95% de confianza de que el intervalo de Bonferroni (155.304 173.456) contenga a "0"
# Para x3 hay un 95% de confianza de que el intervalo de Bonferroni (51.16709, 60.21291) contenga a "0"
# Para x4 hay un 95% de confianza de que el intervalo de Bonferroni (86.0281, 100.7519) contenga a "0"
# Para x5 hay un 95% de confianza de que el intervalo de Bonferroni (16.91447, 19.04553) contenga a "0"
# Para x6 hay un 95% de confianza de que el intervalo de Bonferroni (29.57248, 32.68752) contenga a "0"
(d) Rectángulo de BonferroniCódigot<-qt((.05/(2*6)),n-1);t -2.728552B1<-(xbar[1])+(t*(sqrt(s[1]/n)));B1B2<-(xbar[1])-(t*(sqrt(s[1]/n)));B2B7<-(xbar[4])+(t*(sqrt(s[4]/n)));B7B8<-(xbar[4])-(t*(sqrt(s[4]/n)));B8ellipse(c(xbar[1],xbar[4]),s, 0.05, npoints = 2000, newplot = TRUE, draw = TRUE)
points(B1,B7, newplot=FALSE, draw=TRUE, col="red", pch='*')points(B1,B8, newplot=FALSE, draw=TRUE, col="red", pch='*')
points(B2,B7, newplot=FALSE, draw=TRUE, col="red", pch='*')points(B2,B8, newplot=FALSE, draw=TRUE, col="red", pch='*')Resultados
(e) Bonferroni head width- head lengthCódigon=61p=7xe<- xbar[6]-xbar[5]; xesnew<- S[6,6]-(2*S[5,6])+S[5,5]; snewT<-qt(1-(a/(2*p)),(n-1)); TIe<- c(xe-(T*sqrt(snew/n)), xe+(T*sqrt(snew/n))); IeResultados# Para head width- head length hay un 95% de confianza de que el intervalo de Bonferroni (12.49,13.81) contenga a "mu0"

EJERCICIO 5.11Para los análisis de minerales en 9 cabellos antiguos, los resultados de Cr(x1) y Sr(x2) se presentan en la tabla. Se sabe que la presencia de .100ppm o menos de cromo sugiere diabetes, mientras el estroncio revela consumo animal.
(a)elipse de confianza para 90% suponiendo muestra aleatoriaCódigox<-matrix(c(0.48, 40.53, 2.19, 0.55, 0.74, 0.66, 0.93, 0.37, 0.22, 12.57, 73.68, 11.13, 20.03, 20.29, 0.78, 4.64, 0.43, 1.08),9,2); x
xbar<-colMeans(x); xbars<- cov(x); ssi<- solve(s); sialfa=0.10n=9p=2library("mixtools")plot(x, ypch=4, xlim=c(-25,50), ylim=c(-50,80), col="purple") ellipse(mu=xbar, sigma=s, alpha = alfa, npoints = 2000, col="red")Resultados
(b)Intervalos de confianza simultáneos para 90% de confianza.. Evalúe el valor medio de 30, 10 en los niveles, comente su resultado
CódigoF<-qf((1-alfa), p, n-p); FIx1<- c(xbar[1]-sqrt(((p*(n-1))/(n*(n-p)))*F*s[1,1]), xbar[1]+sqrt(((p*(n-1))/(n*(n-p)))*F*s[1,1])); Ix1
Ix2<- c(xbar[2]-sqrt(((p*(n-1))/(n*(n-p)))*F*s[2,2]), xbar[2]+sqrt(((p*(n-1))/(n*(n-p)))*F*s[2,2])); Ix2
qqline(-4.83,col='blue');qqline(36.97,col='blue');
Resultado

#I1(-6.881, 17.252), I2(-4.827, 36.967) para una confianza del 90%, de manera simultánea, las medias se deberían encontrar dentro de estos intervalos.
#los valores medios 0.30,10 son un valor posible, ya que ambos se encuentran simultáneamente dentro de los intervalos correspondientes.
(c)Parecen ser bivariados normal?
Códigohist(x[,1], col='green')qqnorm(x[,1], pch=9); qqline(x[,1], col='darkgreen')mshapiro.test(t(x[,1]))hist(x[,2], col='yellow')qqnorm(x[,2], pch=9); qqline(x[,2], col='orange')mshapiro.test(t(x[,2]))
Resultado#PARA X1
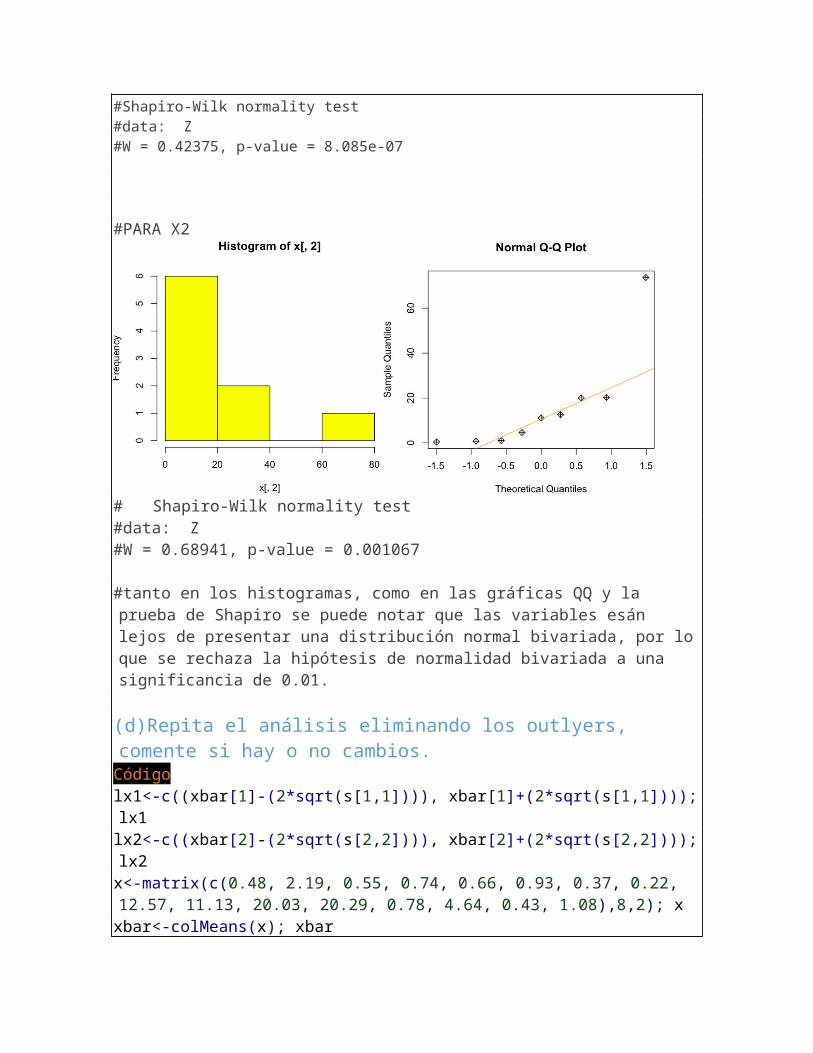
#Shapiro-Wilk normality test#data: Z#W = 0.42375, p-value = 8.085e-07
#PARA X2

# Shapiro-Wilk normality test#data: Z#W = 0.68941, p-value = 0.001067
#tanto en los histogramas, como en las gráficas QQ y la prueba de Shapiro se puede notar que las variables esán lejos de presentar una distribución normal bivariada, por lo que se rechaza la hipótesis de normalidad bivariada a una significancia de 0.01.
(d)Repita el análisis eliminando los outlyers, comente si hay o no cambios.Códigolx1<-c((xbar[1]-(2*sqrt(s[1,1]))), xbar[1]+(2*sqrt(s[1,1]))); lx1lx2<-c((xbar[2]-(2*sqrt(s[2,2]))), xbar[2]+(2*sqrt(s[2,2]))); lx2x<-matrix(c(0.48, 2.19, 0.55, 0.74, 0.66, 0.93, 0.37, 0.22, 12.57, 11.13, 20.03, 20.29, 0.78, 4.64, 0.43, 1.08),8,2); x
xbar<-colMeans(x); xbars<- cov(x); ssi<- solve(s); sialfa=0.10n=8p=2library("mixtools")plot(x, ypch=4, xlim=c(-1,3), ylim=c(-12,30), col="purple") ellipse(mu=xbar, sigma=s, alpha = alfa, npoints = 2000, col="red")F<-qf((1-alfa), p, n-p); FIx1<- c(xbar[1]-sqrt(((p*(n-1))/(n*(n-p)))*F*s[1,1]), xbar[1]+sqrt(((p*(n-1))/(n*(n-p)))*F*s[1,1])); Ix1
Ix2<- c(xbar[2]-sqrt(((p*(n-1))/(n*(n-p)))*F*s[2,2]), xbar[2]+sqrt(((p*(n-1))/(n*(n-p)))*F*s[2,2])); Ix2
qqline(0.47,col='blue');qqline(17.27,col='blue');hist(x[,1], col='green')qqnorm(x[,1], pch=9); qqline(x[,1], col='darkgreen')

shapiro.test(x[,1])hist(x[,2], col='yellow')qqnorm(x[,2], pch=9); qqline(x[,2], col='orange')shapiro.test(x[,2])Resultados
#I1(0.149, 1.386), I2(0.468, 17.269) para una confianza del 90%, de manera simultánea, las medias se deberían encontrar dentro de estos intervalos.
#los valores medios 0.30,10 son un valor posible, ya que ambos se encuentran simultáneamente dentro de los intervalos correspondientes.
#PARA X1
#Shapiro-Wilk normality test#data: Z#W = 0.76182, p-value = 0.01103
#PARA X2

#Shapiro-Wilk normality test#data: Z#W = 0.85803, p-value = 0.1148
#tanto en los histogramas, como en las gráficas QQ y la prueba de Shapiro se puede notar que la variable 1 está lejos de presentar una distribución normal bivariada, aunque la variable 2 si lo cumple pues todos sus puntos se comportan linealmente y el histograma va tomando la forma de la campana de gauss de manera ligera.#En general se concluye que los cambios que se obtuvieron al eliminar ese primer outlyer nos dejan con muestras distribuidas de manera más normal, y sus análisis suelen ser más acertados.
EJERCICIO 5.19#(a)CONSTRUYE LA ELIPSE DE 95% DE CONFIANZA PARA LAS MEDIAS(x1,x2) DE LA MATRIZCódigoa<-read.csv("lumber.csv",header=T);an<-30;p<-2F<-qf(.95,df1=p,df2=n-p);Fxbar<-colMeans(a);xbar s<-cov(a);sellipse(c(xbar[1],xbar[2]),s, 0.05, npoints = 2000, newplot = TRUE, draw = TRUE)RESULTADO
b) SIENDO Ho:u=(2000,10000) prueba que representa valores tipicos de acuerdo a la elise de a)Códigopoints (2000,10000, col='red') RESULTADO
Como vemos en la elipse, el punto u=(2000,10000) si se encuentra contenido, por lo que no podemos rechazar la Ho, aunque para que esta resion de confianza sea mejor representación de esa u, el punto debería estar más centrado.
c) ¿La distribución bivariada es viable en este modelo? Para probar una distribución normal con la Ho: la distribución es normal, con alpha= .05Códigoshapiro.test(a[,1]);shapiro.test(a[,2])qqnorm(a[,1]); qqline(a[,1])qqnorm(a[,2]);qqline(a[,2])mshapiro.test(t(a))
RESULTADOShapiro-Wilk normality testdata: a[, 1]W = 0.9749, p-value = 0.6798Shapiro-Wilk normality testdata: a[, 2]W = 0.97552, p-value = 0.6979Con esta prueba el p-valor es mayor a .05 por lo que si se cumple que es normal.Observando las graficas qqplot:

Con las graficas qq no tenemos informacion clara para asegurar que tenemos una distribucion normal o no.Para probar una distribucion bivareada con alpha de .05Shapiro-Wilk normality testdata: ZW = 0.93454, p-value = 0.0649Tenemos que no se rechaza la hipótesis de tener una distribución normal bivareada.

EJERCICIO 5.22Q-Q PLOTSCódigo#Graficos y pruebas de normalidadM <- read.csv("5.22.csv", header=T); Mhist(M[,1], col='skyblue')qqnorm(M[,1], pch=2) qqline(M[,1],col='blue')
hist(M[,2], col='pink')qqnorm(M[,2], pch=1) qqline(M[,2],col='pink')
hist(M[,3], col='green')qqnorm(M[,3], pch=3) qqline(M[,3],col='green')
shapiro.test(M[,1])shapiro.test(M[,2])shapiro.test(M[,3])
MSO <- read.csv("5.22 sin outliers.csv", header=T); MSOqqnorm(MSO[,1], pch=2) qqline(MSO[,1],col='blue')
qqnorm(MSO[,2], pch=1) qqline(MSO[,2],col='pink')
qqnorm(MSO[,3], pch=3) qqline(MSO[,3],col='green')
shapiro.test(MSO[,1])shapiro.test(MSO[,2])shapiro.test(MSO[,3])
Resultados
Variable 1: Fuel

Variable 2: Repair
Variable 3: Capital
VARIABLES SIN OUTLIERSVariable 1: Repair

Variable 2: repair
Variable 3:
Para las pruebas de normalidad:Tomando las alphas = 0.01, 0.05 y 0.1:
Variables con outliersshapiro.test(M[,1])Shapiro-Wilk normality testdata: M[, 1]W = 0.82747, p-value = 0.0006775R: No normal para todos los casos.
shapiro.test(M[,2])Shapiro-Wilk normality testdata: M[, 2]W = 0.92576, p-value = 0.06939R: Es normal solo cuando tomamos como alpha 0.05 y 0.01 por ejemplo,

al tomat alpha=0.1 resulta no ser normal.
shapiro.test(M[,3])Shapiro-Wilk normality testdata: M[, 3]W = 0.96902, p-value = 0.6204R: Es normal para todos los casos (alpha = 0.05,0.01,0.1)
Variables sin outliersshapiro.test(MSO[,1])Shapiro-Wilk normality testdata: MSO[, 1]W = 0.98351, p-value = 0.9564R: normal para todos los casos
shapiro.test(MSO[,2])Shapiro-Wilk normality testdata: MSO[, 2]W = 0.91177, p-value = 0.04452R: normal para los casos de alpha=0.05,0.01 pero no es normal cuando alpha=0.1.
shapiro.test(MSO[,3])Shapiro-Wilk normality testdata: MSO[, 3]W = 0.97264, p-value = 0.7519R:Normal para todos los casos.
EN RESUMEN: Al sacar los outlieres, la variable 1 (fuel) tuvo una distribucion normal, al principio (con los datos completos), esta variable era no normal para todos los casos, ya que tenia valores extremos. Al quitarlos se volvio normal para todos los casos que tomamos para la alpha. La variable 2(reoair) y la variable 3(capital) permanecieron constantes.
B)
BonferroniCódigon<-25p<-3a<-0.05xbar<- colMeans(M); xbar

S<- cov(M);SF<-qf((1-a), p, n-p); F
T<-qt(1-(a/(2*p)),(n-1)); TI1<- c(xbar[1]-(T*sqrt(S[1,1]/n)), xbar[1]+(T*sqrt(S[1,1]/n))); I1I2<- c(xbar[2]-(T*sqrt(S[2,2]/n)), xbar[2]+(T*sqrt(S[2,2]/n))); I2I3<- c(xbar[3]-(T*sqrt(S[3,3]/n)), xbar[3]+(T*sqrt(S[3,3]/n))); I3
Resultados# Para x1 (fuel) hay un 95% de confianza de que el intervalo de Bonferroni (9.789733,15.330267) contenga a "0"
# Para x2 (repair) hay un 95% de confianza de que el intervalo de Bonferroni (5.777122, 10.545278) contenga a "0"
# Para x3 (capital) hay un 95% de confianza de que el intervalo de Bonferroni (8.646243, 12.442557) contenga a "0"
Intervalos T^2Códigon<-25p<-3a<-0.05xbar<- colMeans(M); xbarS<- cov(M);SF<-qf((1-a), p, n-p); F
Ix1<- c(xbar[1]-sqrt(((p*(n-1))/(n*(n-p)))*F*S[1,1]), xbar[1]+sqrt(((p*(n-1))/(n*(n-p)))*F*S[1,1])); Ix1
Ix2<- c(xbar[2]-sqrt(((p*(n-1))/(n*(n-p)))*F*S[2,2]), xbar[2]+sqrt(((p*(n-1))/(n*(n-p)))*F*S[2,2])); Ix2
Ix3<- c(xbar[3]-sqrt(((p*(n-1))/(n*(n-p)))*F*S[3,3]), xbar[3]+sqrt(((p*(n-1))/(n*(n-p)))*F*S[3,3])); Ix3
Resultados# Para x1 (fuel) hay un 95% de confianza de que el intervalo de T^2 (9.159708,15.960292) contenga a "0"
# Para x2 (repair) hay un 95% de confianza de que el intervalo de T^2 (5.234926,11.087474) contenga a "0"
# Para x3 (capital) hay un 95% de confianza de que el intervalo de T^2 (8.214557 12.874243) contenga a "0"
Resumen: los dos tipos intervalos son muy parecidos, el cambio entre ellos son tan solo decimales.