
Integrales, reducción y...
46
Integrales, reducción y convolución Clase 3
Transcript of Integrales, reducción y...

Integrales, reducción y convolución
Clase 3

La integral se calcula sumando las areas de los trapecios
La función está definida por dos arrays, x e y de tamaño N,
Integración numérica por el método de trapecios
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�
]M = J(\M) � F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�]M = J(\M)
f(x)
x
y
2
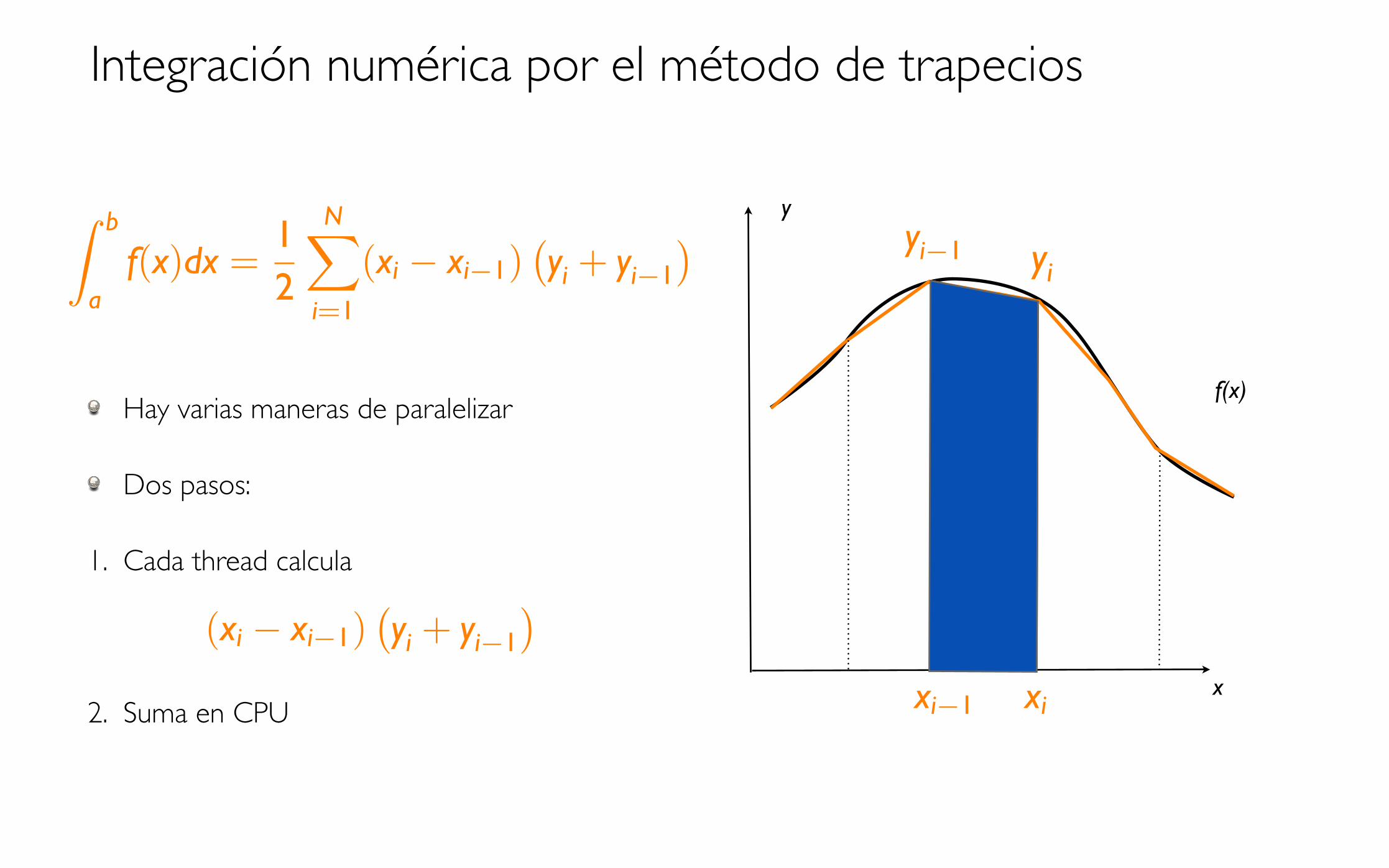
Hay varias maneras de paralelizar
Dos pasos:
1. Cada thread calcula
2. Suma en CPU
Integración numérica por el método de trapecios
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�]M = J(\M)
f(x)
x
y
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors xi = x[index]; // x_i xim = x[index-‐1]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index-‐1]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }
Método de trapeciosprom2.cu
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors xi = x[index]; // x_i xim = x[index-‐1]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index-‐1]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }
Método de trapecios
Este código tienevarios problemas....
prom2.cu
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors xi = x[index]; // x_i xim = x[index-‐1]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index-‐1]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }
Método de trapeciosprom2.cu

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors xi = x[index]; // x_i xim = x[index-‐1]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index-‐1]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }
Método de trapecios
Qué pasa si index=0
prom2.cu

¿Porqué no funciona?
y index0 1 2 4 5 6 8 9
El thread con index=0 es un caso particular
index-1-1 0 1 3 4 5 7 8
6

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors if(index>0){ xi = x[index]; // x_i xim = x[index-‐1]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index-‐1]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }else{ integral[0]=0.0; }
Método de trapeciosprom2.cu

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors if(index>0){ xi = x[index]; // x_i xim = x[index-‐1]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index-‐1]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }else{ integral[0]=0.0; }
Método de trapecios
index=0 es un caso particular
prom2.cu

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors xi = x[index]; // x_i xim = x[index>0?index-‐1:0]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index>0?index-‐1:0]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }
Método de trapeciosprom.cu

__global__ void trapz_simple(float* x, float *data, float *integral, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x ; float tmp; float h; float xi,xim,yi,yim;
// compute the average of this thread's neighbors xi = x[index]; // x_i xim = x[index>0?index-‐1:0]; // x_{i-‐1} yi = data[index]; // y_i yim = data[index>0?index-‐1:0]; // y_{i-‐1} h = xi-‐xim; // h = x_{i}-‐x_{i-‐1} tmp = (yi+yim)*0.5f; // tmp = (y_i+x_{i-‐1})/2 integral[index] = h* tmp; }
Método de trapecios
Otra forma de hacerlo
prom.cu

Pasando opciones al mainint main( int argc, const char** argv ) { .... if(argc==1){ // Help si no hay argumentos printf("Usage %s [array size] [number of threads per block]\n",argv[0]); exit(1); } if(argc==2){ // un solo argumento implica numthreads=32 printf("Assuming number of threads per block=32\n"); N = atoi(argv[1]); numthreads = 32; } if(argc==3){ N = atoi(argv[1]); numthreads = atoi(argv[2]); }

Pasando opciones al mainint main( int argc, const char** argv ) { .... if(argc==1){ // Help si no hay argumentos printf("Usage %s [array size] [number of threads per block]\n",argv[0]); exit(1); } if(argc==2){ // un solo argumento implica numthreads=32 printf("Assuming number of threads per block=32\n"); N = atoi(argv[1]); numthreads = 32; } if(argc==3){ N = atoi(argv[1]); numthreads = atoi(argv[2]); }
argc cuenta el número de argumentos

Pasando opciones al mainint main( int argc, const char** argv ) { .... if(argc==1){ // Help si no hay argumentos printf("Usage %s [array size] [number of threads per block]\n",argv[0]); exit(1); } if(argc==2){ // un solo argumento implica numthreads=32 printf("Assuming number of threads per block=32\n"); N = atoi(argv[1]); numthreads = 32; } if(argc==3){ N = atoi(argv[1]); numthreads = atoi(argv[2]); }
argv[0] es el nombre del exe
argc cuenta el número de argumentos

Pasando opciones al main[flavioc@gpgpu-fisica ~]$ cp -a /share/apps/codigos/Trapecios .
[flavioc@gpgpu-fisica ~]$ cd Trapecios
[flavioc@gpgpu-fisica ~]$ nvcc prom2.cu -o trap
[flavioc@gpgpu-fisica ~]$ ./trap
Usage ./trap [array size] [number of threads per block]
[flavioc@gpgpu-fisica ~]$ qsub submit_gpuh.sh 1024 32
Se pueden hacer varias corridas sin compilar

Su turno....
11

Hay varias maneras de paralelizar
Dos pasos:
1. Cada thread calcula
2. Suma en GPU
Reducción en GPU
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�]M = J(\M)
f(x)
x
y
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�

Reduction/Scan
Scan: una transformación de una secuencia de valores en otraEs una de las operaciones más importantes en gpgpuEs una operación ‘horizontal’ (ej: producto escalar) a diferencia de una operación ‘vertical’ o
componente a componente (ej: suma de vectores)prefix sum: cada elemento de la secuencia es suma de todos los anteriores
13
Sequence 4 0 5 5 0 5 5 1 3 1 0 3 1 1 3 5Scan 4 4 9 14 14 19 24 25 28 29 29 32 33 34 37 42

Reduction/Scan
Scan: una transformación de una secuencia de valores en otraEs una de las operaciones más importantes en gpgpuEs una operación ‘horizontal’ (ej: producto escalar) a diferencia de una operación ‘vertical’ o
componente a componente (ej: suma de vectores)prefix sum: cada elemento de la secuencia es suma de todos los anteriores
Sequence 4 0 5 5 0 5 5 1 3 1 0 3 1 1 3 5Scan 4 4 9 14 14 19 24 25 28 29 29 32 33 34 37 42
14

offset = 1 4 0 5 5 0 5 5 1 3 1 0 3 1 1 3 5offset = 2 4 4 5 10 5 5 10 6 4 4 1 3 4 2 4 8offset = 4 4 4 9 14 10 15 15 11 14 10 5 7 5 5 8 10offset = 8 4 4 9 14 14 19 24 25 24 25 20 18 19 15 13 17offset = 16 4 4 9 14 14 19 24 25 28 29 29 32 33 34 37 42
Prefix Sum
Algoritmo
15

Suma global: Entrelazada
Values (in shared memory)
Values
Values
Values
2 0 11 0 7 2 -3 -2 5 3 -2 0 -1 8 1 10
0 1 2 3 4 5 6 7
2 2 11 11 7 9 -3 -5 5 8 -2 -2 -1 7 1 11
0 1 2 3
2 2 11 13 7 9 -3 4 5 8 -2 6 -1 7 1 18
0 1
2 2 11 13 7 9 -3 17 5 8 -2 6 -1 7 1 24
0
2 2 11 13 7 9 -3 17 5 8 -2 6 -1 7 1 41 Values
Thread IDs
Step 1 Stride 1
Step 2 Stride 2
Step 3 Stride 4
Step 4 Stride 8
Thread IDs
Thread IDs
Thread IDs
Thanks to: Stanford, CS193G

Suma global: Contigua2 0 11 0 7 2 -3 -2 5 3 -2 0 -1 8 1 10 Values (in shared memory)
0 1 2 3 4 5 6 7
2 0 11 0 7 2 -3 -2 7 3 9 0 6 10 -2 8 Values
0 1 2 3
2 0 11 0 7 2 -3 -2 7 3 9 0 13 13 7 8 Values
0 1
2 0 11 0 7 2 -3 -2 7 3 9 0 13 13 20 21 Values
0
2 0 11 0 7 2 -3 -2 7 3 9 0 13 13 20 41 Values
Thread IDs
Step 1 Stride 8
Step 2 Stride 4
Step 3 Stride 2
Step 4 Stride 1
Thread IDs
Thread IDs
Thread IDs
Thanks to: Stanford, CS193G
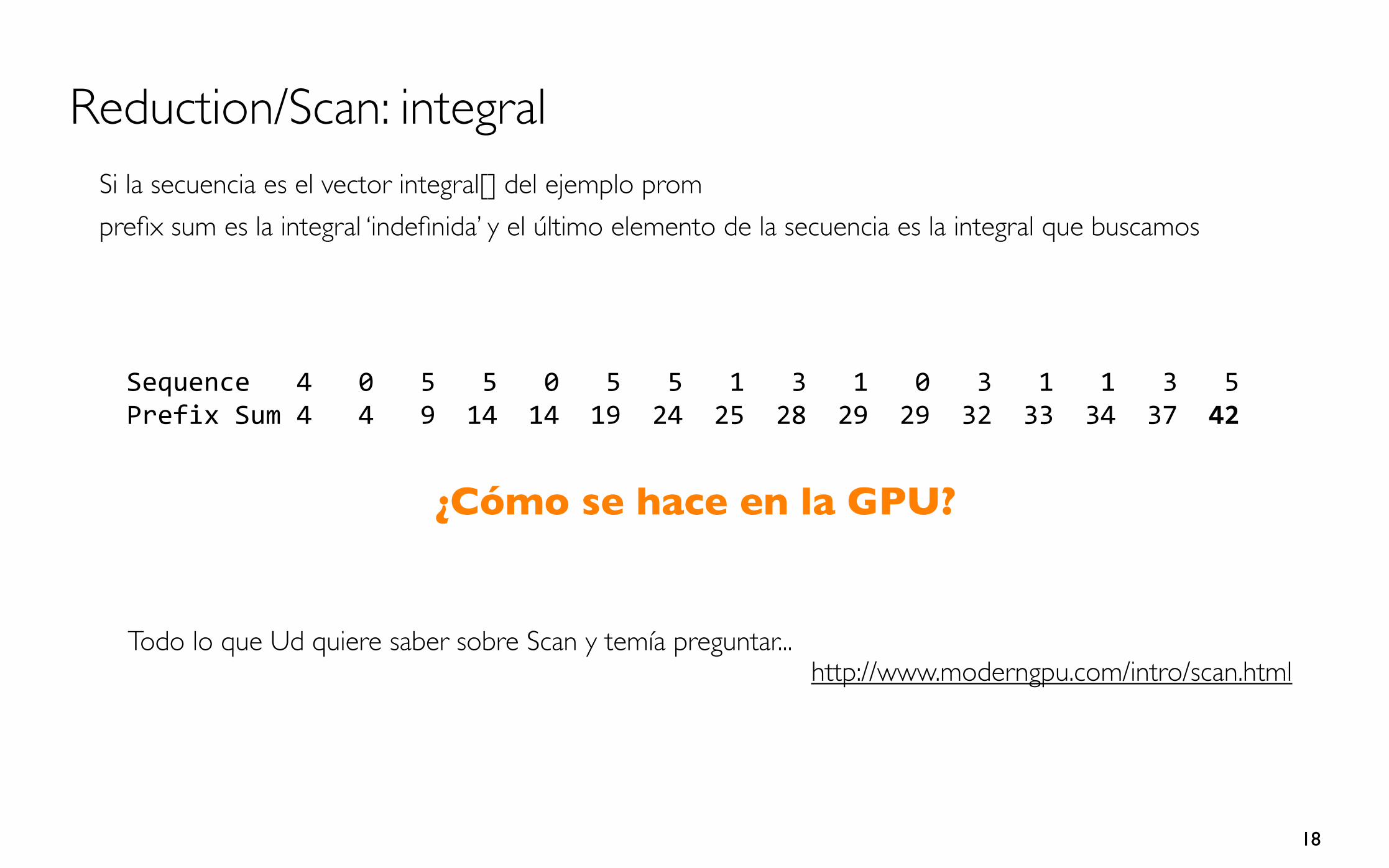
Reduction/Scan: integralSi la secuencia es el vector integral[] del ejemplo promprefix sum es la integral ‘indefinida’ y el último elemento de la secuencia es la integral que buscamos
Sequence 4 0 5 5 0 5 5 1 3 1 0 3 1 1 3 5Prefix Sum 4 4 9 14 14 19 24 25 28 29 29 32 33 34 37 42
¿Cómo se hace en la GPU?
Todo lo que Ud quiere saber sobre Scan y temía preguntar...http://www.moderngpu.com/intro/scan.html
18

1. Cada thread calcula
2. Se hace la suma global en cada bloque
3. Cada bloque devuelve un valor a CPU
4. Se hace una última reducción en CPU
Reducción en GPU
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�]M = J(\M)
f(x)
x
y
� F
EJ(\)H\ =
��
2�
M=�
(\M � \M��)�]M + ]M��
�

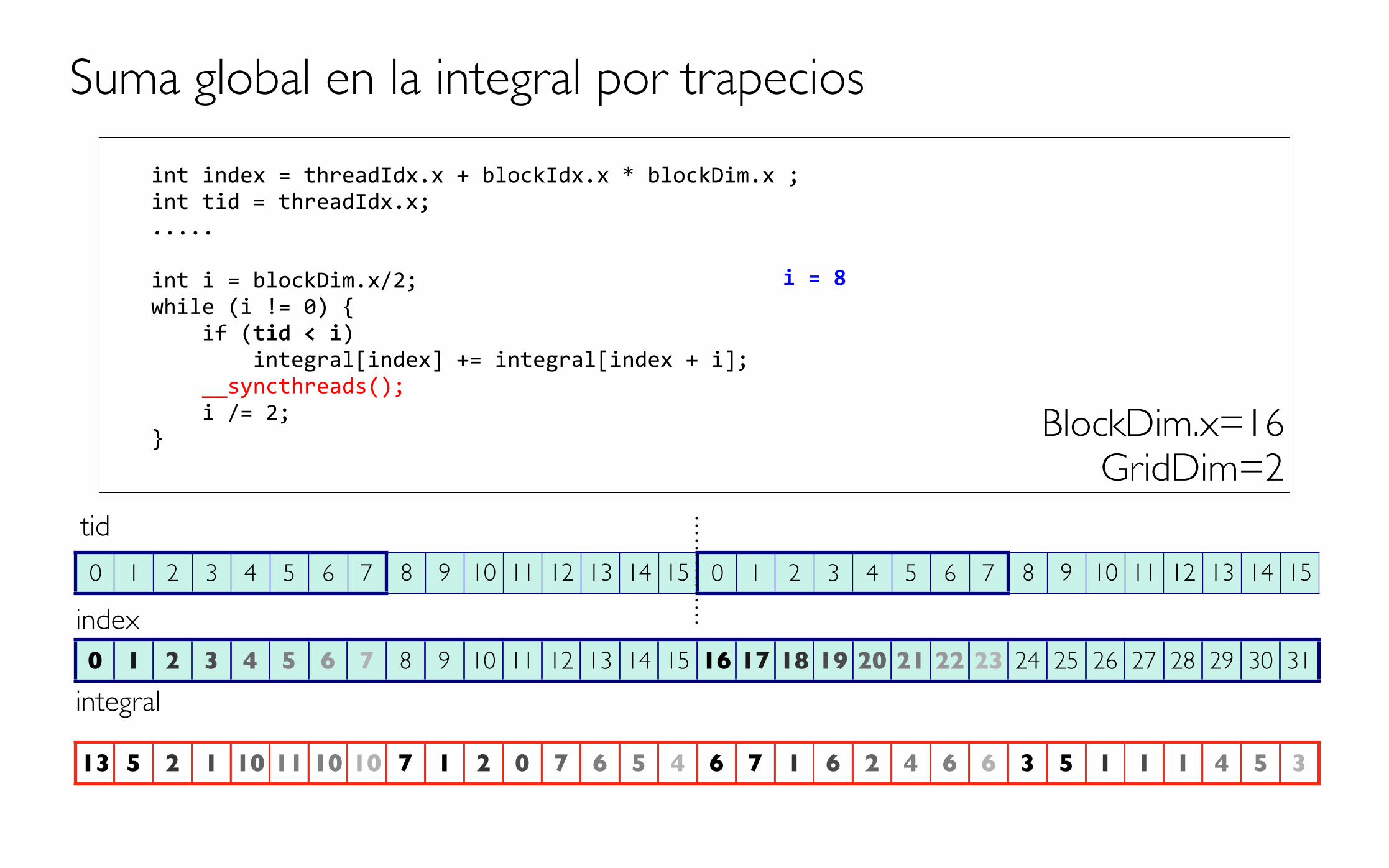
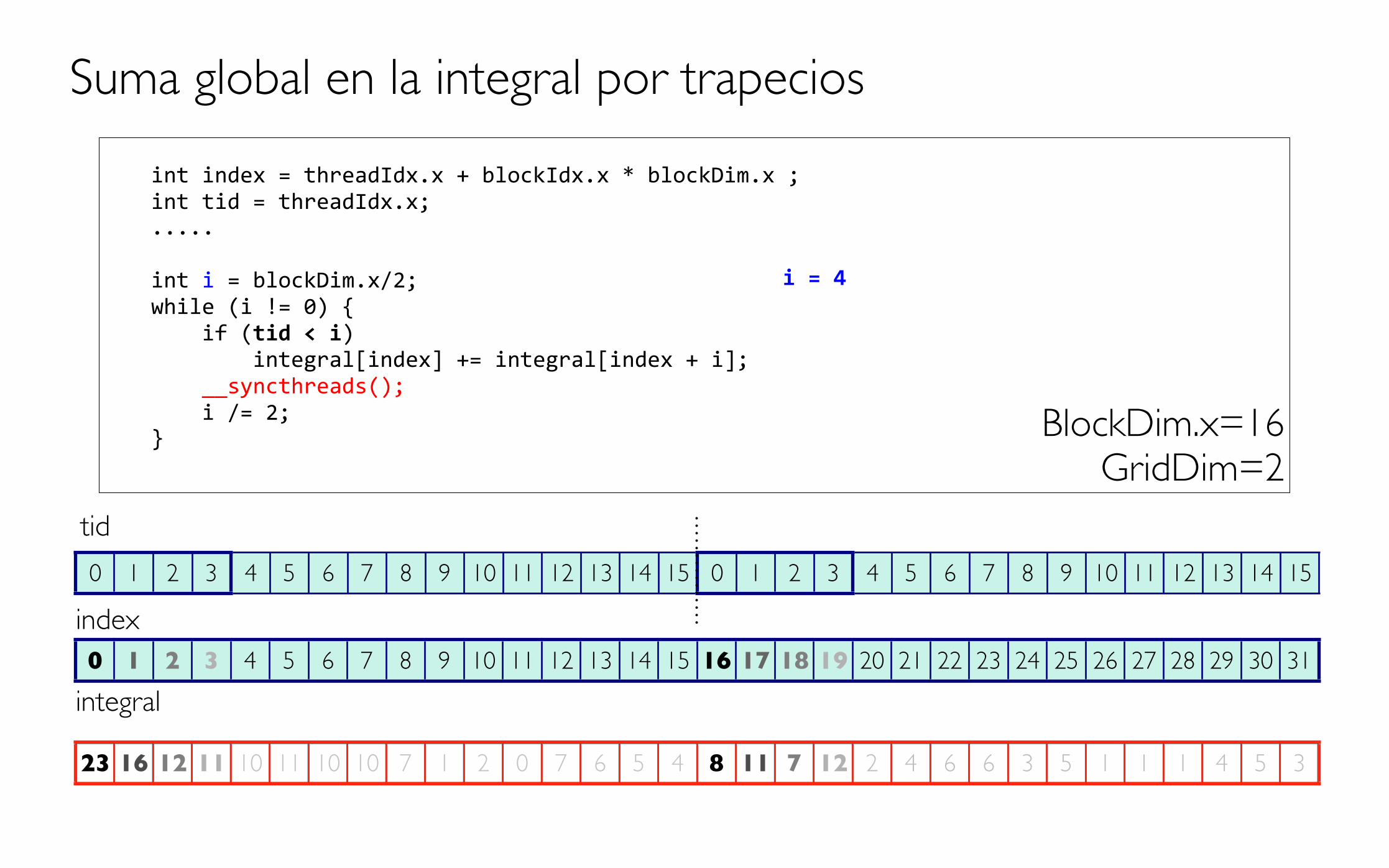
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
4 4 0 1 3 4 5 6 7 1 2 0 7 6 5 4 3 2 0 5 1 0 1 6 3 5 1 1 1 4 5 3

int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 8
4 4 0 1 3 4 5 6 7 1 2 0 7 6 5 4 3 2 0 5 1 0 1 6 3 5 1 1 1 4 5 3

int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
4 4 0 1 3 4 5 6 7 1 2 0 7 6 5 4 3 2 0 5 1 0 1 6 3 5 1 1 1 4 5 3
integral
i = 8
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 8
13 5 2 1 10 11 10 10 7 1 2 0 7 6 5 4 6 7 1 6 2 4 6 6 3 5 1 1 1 4 5 3

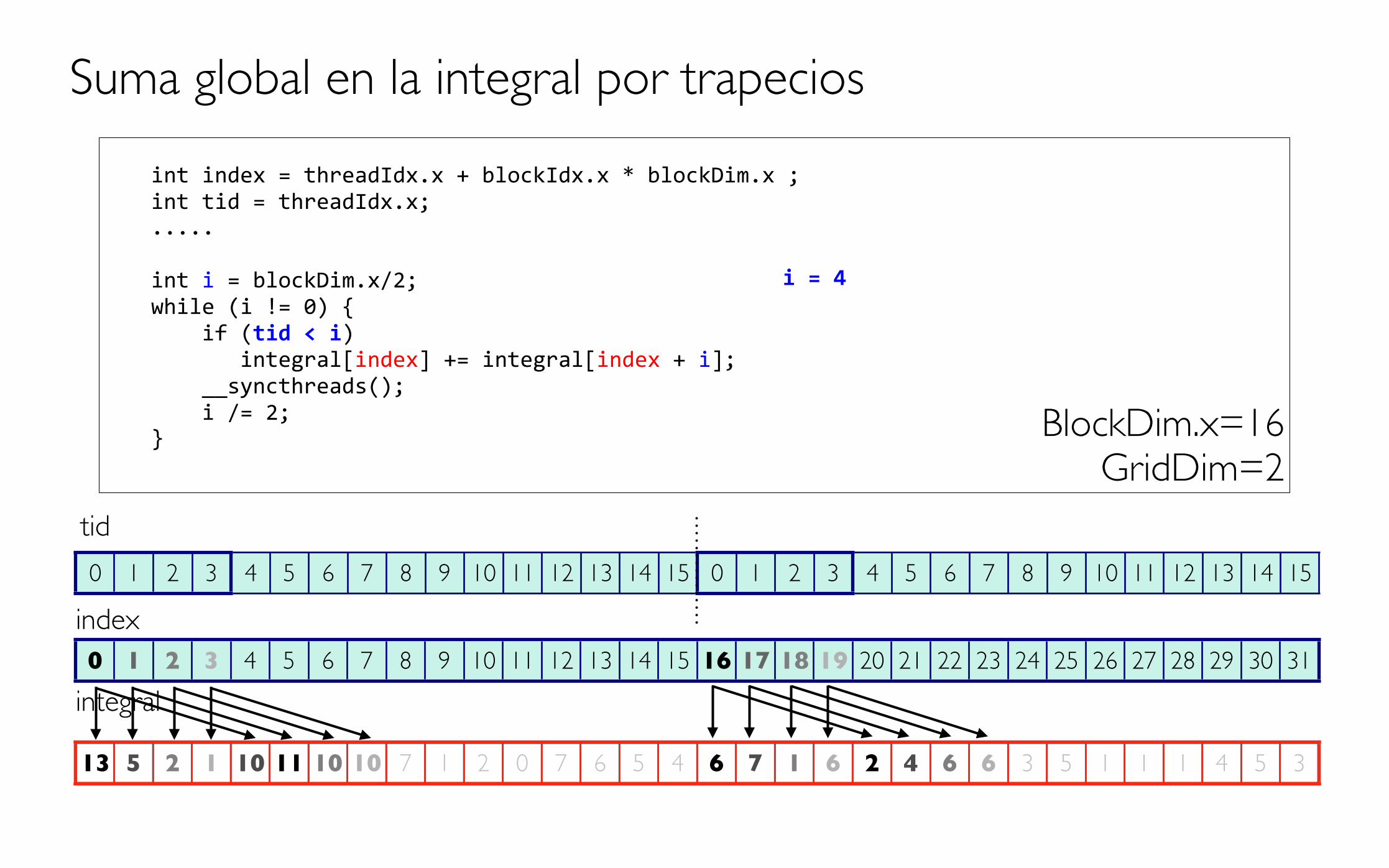
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 4
13 5 2 1 10 11 10 10 7 1 2 0 7 6 5 4 6 7 1 6 2 4 6 6 3 5 1 1 1 4 5 3
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 4
13 5 2 1 10 11 10 10 7 1 2 0 7 6 5 4 6 7 1 6 2 4 6 6 3 5 1 1 1 4 5 313 5 2 1 10 11 10 10 7 1 2 0 7 6 5 4 6 7 1 6 2 4 6 6 3 5 1 1 1 4 5 3
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 4
23 16 12 11 10 11 10 10 7 1 2 0 7 6 5 4 8 11 7 12 2 4 6 6 3 5 1 1 1 4 5 3

int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 2
23 16 12 11 10 11 10 10 7 1 2 0 7 6 5 4 8 11 7 12 2 4 6 6 3 5 1 1 1 4 5 323 16 12 11 10 11 10 10 7 1 2 0 7 6 5 4 8 11 7 12 2 4 6 6 3 5 1 1 1 4 5 3

int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 2
23 16 12 11 10 11 10 10 7 1 2 0 7 6 5 4 8 11 7 12 2 4 6 6 3 5 1 1 1 4 5 3

int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 2
35 27 12 11 10 11 10 10 7 1 2 0 7 6 5 4 15 23 7 12 2 4 6 6 3 5 1 1 1 4 5 3

0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 1
35 27 12 11 10 11 10 10 7 1 2 0 7 6 5 4 15 23 7 12 2 4 6 6 3 5 1 1 1 4 5 3

0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 1
35 27 12 11 10 11 10 10 7 1 2 0 7 6 5 4 15 23 7 12 2 4 6 6 3 5 1 1 1 4 5 3

0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int index = threadIdx.x + blockIdx.x * blockDim.x ; int tid = threadIdx.x; .....
int i = blockDim.x/2; while (i != 0) { if (tid < i) integral[index] += integral[index + i]; __syncthreads(); i /= 2; }
Suma global en la integral por trapecios
BlockDim.x=16GridDim=2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31index
tid
integral
i = 1
62 27 12 11 10 11 10 10 7 1 2 0 7 6 5 4 38 23 7 12 2 4 6 6 3 5 1 1 1 4 5 3

Suma final en CPU
62 27 12 11 10 11 10 10 7 1 2 0 7 6 5 4 38 23 7 12 2 4 6 6 3 5 1 1 1 4 5 3
Se devuelve integral a CPU
integral
HANDLE_ERROR( cudaMemcpy( integ, d_integ, N * sizeof(float),cudaMemcpyDeviceToHost ) );
float sum=0; for (int i=0; i<numblocks; i++) { int j = i*numthreads; sum = sum + integ[j]; } printf(“La integral es: %f\n”,sum);
La integral es: 100.0

Tesla C2075, GTX 470
Tesla C2070, GTX 570
GTX 480, GTX 8800 GT
gpgpu-fisica.cabib.local (10.73.25.207)
CCAD - Bariloche , Gerencia de Física
sysadmin: Gustavo Berman

¿ Dudas ?

problemas, dudas, consultas sobre el curso en general
Usar el subject!
todos los alumnos + profesores

problemas, dudas, consultas particulares
Usar el subject!
email dirigido a los docentes

David B. Kirk, Wen-mei W. Hwu. Programming Massively Parallel Processors: A Hands-on Approach, Morgan Kaufmann, 2010.
Jason Sanders, Edward Kandrot, CUDA by Example, Addison-Wesley, 2010.
Robert Farber, CUDA Application Design and Development, Morgan Kaufman, 2011.
Shane Cook, CUDA Programming, Morgan Kaufman, 2012.
NVIDIA Inc., CUDA C Programming Guide, version 5.5, 2013.
biblio
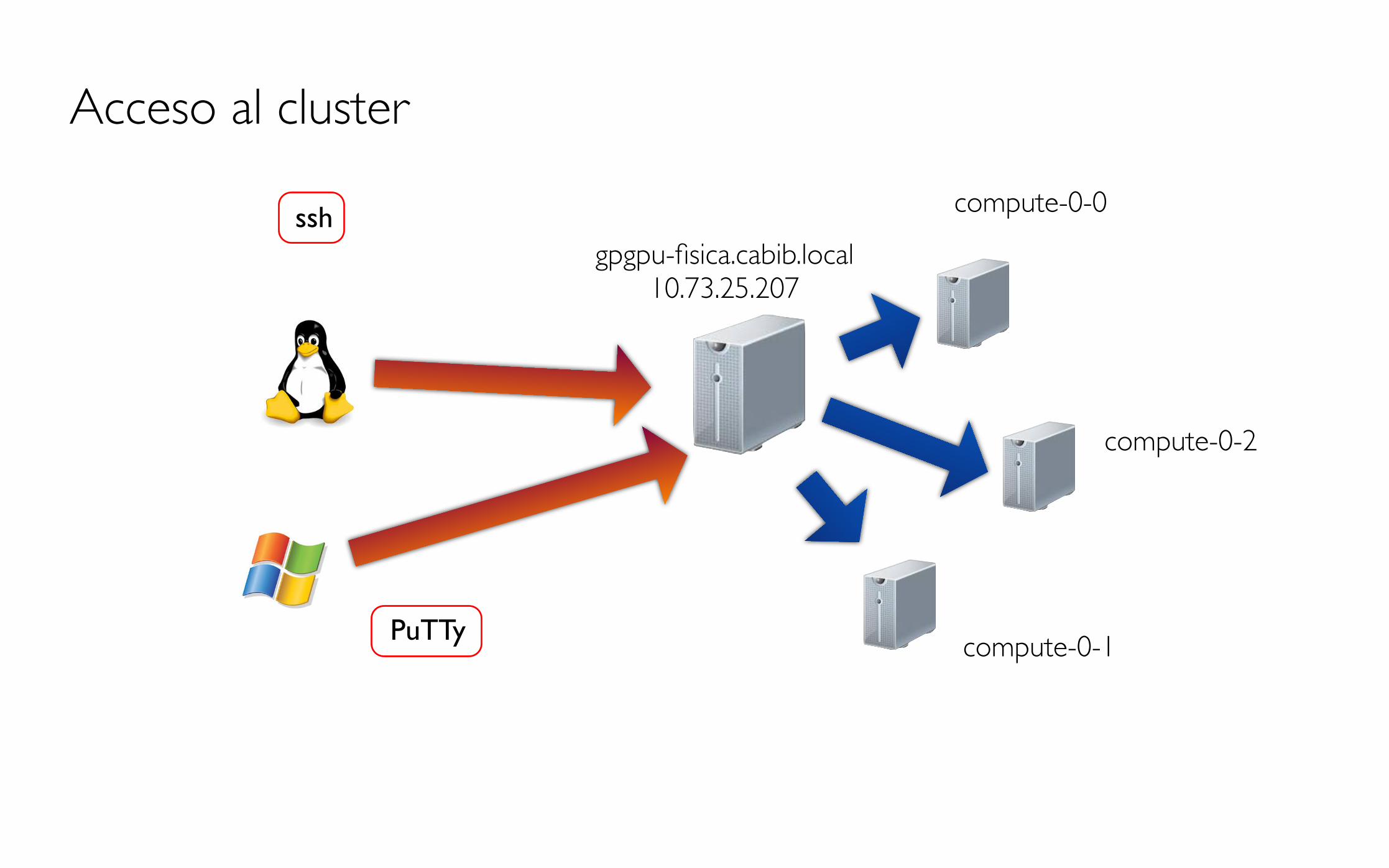
Acceso al cluster
gpgpu-fisica.cabib.local10.73.25.207
compute-0-0
compute-0-2
compute-0-1PuTTy
ssh

Acceso al cluster
40
gpgpu-fisica.cabib.local10.73.25.207
compute-0-0
compute-0-2
compute-0-1
login: fulanopasswd: fulano.2013


















