
INSTITUTO TECNOLÓGICO DE MORELIAdsc.itmorelia.edu.mx/~jcolivares/courses/cr11a/refactoring.pdf ·...
133
MORELIA MICHOACÁN 30 DE AGOSTO DE 2010 INSTITUTO TECNOLÓGICO DE MORELIA DIVISIÓN DE ESTUDIOS PROFESIONALES DEPARTAMENTO DE SISTEMAS Y COMPUTACIÓN OPCION II. ELABORACION DE UN LIBRO DE TEXTO REESTRUCTURACIÓN DE CÓDIGO QUE PARA OBTENER EL TÍTULO DE: INGENIERA EN SISTEMAS COMPUTACIONALES PRESENTA: BETZABETH SEPULVEDA LECHUGA ASESOR: M.C. MIRIAM ZULMA SÁNCHEZ HERNÁNDEZ SUBSECRETARÍA DE EDUCACIÓN SUPERIOR DIRECCIÓN GENERAL DE EDUCACIÓN SUPERIOR TECNOLÓGICA INSTITUTO TECNOLÓGICO
Transcript of INSTITUTO TECNOLÓGICO DE MORELIAdsc.itmorelia.edu.mx/~jcolivares/courses/cr11a/refactoring.pdf ·...

MORELIA MICHOACÁN 30 DE AGOSTO DE 2010
INSTITUTO TECNOLÓGICO DE MORELIA
DIVISIÓN DE ESTUDIOS PROFESIONALES
DEPARTAMENTO DE SISTEMAS Y COMPUTACIÓN
OPCION II. ELABORACION DE UN LIBRO DE TEXTO
REESTRUCTURACIÓN
DE CÓDIGO
QUE PARA OBTENER EL TÍTULO DE:
INGENIERA EN SISTEMAS COMPUTACIONALES
ING. EN SISTEMAS COMPUTACIONALES
PRESENTA:
BETZABETH SEPULVEDA LECHUGA
DULCE MAYDÉ RODRÍGUEZ CONTRERAS
ASESOR:
M.C. MIRIAM ZULMA SÁNCHEZ HERNÁNDEZ
M.C. MIRIAM ZULMA SÁNCHEZ HERNÁNDEZ
SUBSECRETARÍA DE EDUCACIÓN SUPERIOR
DIRECCIÓN GENERAL DE EDUCACIÓN SUPERIOR
TECNOLÓGICA
INSTITUTO TECNOLÓGICO

"Una persona predestinada es la que construye un sólido edificio, con los
ladrillos que le van tirando los que quieren voltearlo"
David Brinkley
"Las personas no son recordadas por el número de veces que fracasan,
sino por el número de veces que tienen éxito."
Thomas A. Edison
"Un buen maestro sólo puede enseñarte los caminos al éxito. Eres tú
quien debe explorarlos."
Omar Henríquez
El que no posee el don de maravillarse ni de entusiasmarse, más le
valdría estar muerto, porque sus ojos están cerrados.
Albert Einstein

Agradecimientos
Son tantas las personas a quienes deseo de corazón agradecerles, de no permitir que olvidara lo
importante que es el no dejar inconclusa ninguna etapa de desarrollo personal ni académico en mi
vida, y por tanto apoyo que me brindaron en la realización de la presente tesis, un millón de
gracias.
A ti mamá, por tus palabras, por tu incansable ánimo, apoyo, presencia, amor, paciencia,
tolerancia, solidaridad, comunicación, porque siempre has creído en mí, porque pase lo que pase
siempre estarás conmigo, porque no hay nada en el mundo entero que pueda sentimentalmente
alejarte de mí, gracias porque en lo único que siempre has pensado desde que tengo memoria, es
en mi bienestar y nadie deseaba esta culminación por mí y para mí tanto como tú, gracias mamá.
A ti amor, porque trajiste a mi vida tantas cosas buenas, que sería imposible enlistar; porque
siempre me has permitido refugiarme en ti como el mejor de los amigos; porque siempre has
hecho el esfuerzo de apoyarme a pesar de las circunstancias, porque me aceptas como soy, por tu
entrega, tu amor, tu ternura, tu nobleza, por ser el padre de nuestros hijos y por todo lo que
representas para mí, gracia amor.
A mis tres pedacitos de cielo, porque ustedes son lo más importante en mi vida, porque me han
permitido formar parte de sus vidas, porque son razón suficiente para que no me caiga aún en los
momentos más difíciles de mi vida, porque creen en mi de tal forma que me dan fuerza y
seguridad para seguir adelante, por su amor, apoyo incondicional, su ternura, su obediencia, su
nobleza y buenos sentimientos; gracias por ser mis hijos.
A ti abue, por haber sido como mi madre, por todas tus palabras, tu amor, tu incomparable
compañía, por esas pláticas que teníamos todos los días, porque aunque ya no estás físicamente
conmigo te sigo pensando, ya que fuiste una de esas personas que llenaron de tal forma mi vida,
que sería verdaderamente imposible dejar de recordarte; donde quiera que estés, gracias abue.
A mi asesora y amiga Miriam Zulma Sánchez Hernández por haberme dado la oportunidad de
participar en este proyecto, gracias por haberme tendido la mano como asesora y como amiga,

por escucharme con paciencia y respeto y por apoyarme en todo lo que se pudo, por los consejos
y orientación mil gracias.
A mis revisores M.C. Cristóbal Villegas Santoyo, M.C. Cristhian Torres Millarez y Laura Nelly
Alvarado Zamora por haberse involucrado en mi trabajo con paciencia, confianza, profesionalismo
pero sobretodo con amistad y solidaridad, gracias por su apoyo constante que me permitieron
hacer un trabajo de calidad, gracias por sus consejos porque siempre fueron de superación, mil
gracias.
A ti Honey porque formas parte de mi familia y desde que inicie este proyecto te convertiste en mi
compañía inseparable y no me dejaste sentirme sola.
Finalmente a todas y cada una de las personas que han cruzado por mi vida dejando en mí sus
mejores sentimientos y deseos, mil gracias.

Contenido
Ingeniería de Software
Contenido
Introducción…………………………………………………………………………………………………………………….……………… i
CAPITULO I..………………………………………………………………………………………………………………………............... 9
PRINCIPIOS DE LA REESTRUCTURACION……………………………………………………………………………………….… 9
1.1 Conceptos básicos…………………………………………………………………………………………………………….…… 10
1.2 Pasos de la refactorización……………………………………………………………………………………..…………..... 13
1.3 Problemas de la reestructuración………………………………………………………………………………………….. 14
1.3.1 El factor humano…………………………………………………………………………………………………….. 14
1.3.2 Trabajo en equipo…………………………………………………………………………………………………… 15
1.3.3 Problemas al refactorizar bases de datos………………………………………………………………… 16
1.3.4 Problemas en el cambio de interfaces…………………………………………………………………….. 17
1.4 Refactorización y desempeño del software……………………………………………………………………………. 18
1.5 Herramientas para la refactorización…………………………………………………………………………………….. 19
1.5.1 Criterios técnicos para una herramienta de refactorización……………………………………. 19
1.5.2 Criterios prácticos para una herramienta de refactorización…………………………………… 21
1.5.3 Herramientas de ambientes integrados………………………………………………………………….. 22
1.6 Primer ejemplo de refactorización…………………………………………………………………………………………. 23
CAPITULO II..……………………………………………………………………………………………………………………................. 29
CATALOGO DE REFACTORIZACIONES………………………………………………………………………………………………. 29
2.1 Composición de Métodos………………………………………………………………………………………………………. 30
2.1.1 Extract Method………………………………………………………………………………………………………. 30
2.1.2 Inline Method…………………………………………………………………………………………………………. 30
2.1.3 Inline Temp…………………………………………………………………………………………………………….. 31
2.1.4 Replace Temp with Query………………………………………………………………………………………. 32
2.1.5 Introduce Explaining Variable………………………………………………………………………………… 33
2.1.6 Split Temporary Variable ……………………………………………………………………………………….. 34
2.1.7 Remove Assignments to Parameters…………………………………………………………………….. 34
2.1.8 Replace Method with Method Object……………………………………………………………………. 34
2.1.9 Substitute Algorithm………………………………………………………………………………………………. 35

Contenido
Ingeniería de Software
2.2 Moviendo Características entre Objetos 36
2.2.1 Move Method…………………………………………………………………………………………………………. 36
2.2.2 Move Field………………………………………………………………………………………………………………. 37
2.2.3 Extract Class……………………………………………………………………………………………………………. 37
2.2.4 Inline Class………………………………………………………………………………………………………………. 37
2.2.5 Hide Delegate…………………………………………………………………………………………………………. 38
2.2.6 Remove Middle………………………………………………………………………………………………………. 39
2.3 Organización de Datos…………………………………………………………………………………………………………… 39
2.3.1 Self Encapsulate Field……………………………………………………………………………………………… 39
2.3.2 Replace Data Value with Object……………………………………………………………………………… 40
2.3.3 Change Value to Reference …….……………………………………………………………………………… 41
2.3.4 Change Reference to Value……………………………………………………………………………………… 41
2.3.5 Replace Array with Object…………………………………………………………………………………….… 41
2.3.6 Replace Magic Number with Symbolic Constant……………………………………………………… 42
2.3.7 Encapsulate Field…………………………………………………………………………………………………..… 42
2.3.8 Encapsulate Collection……………………………………………………………………………………….…… 43
2.3.9 Replace Type Code with Class…………………………………………………………………………….…… 43
2.3.10 Replace Type Code with Subclass…………………………………………………………………………… 44
2.3.11 Replace Type Code with State/Strategy…………………………………………………………………… 44
2.3.12 Replace Subclass with Field…………………………………………………………………………………….. 45
2.4 Simplificación de Expresiones Condicionales…………………………………………………………………………. 45
2.4.1 Descompose Conditional………………………………………………………………………………………… 45
2.4.2 Consolidate Conditional Expression………………………………………………………………………… 46
2.4.3 Consolidate Duplicate Conditional Fragments………………………………………………………… 46
2.4.4 Remove Control Flags……………………………………………………………………………………………… 47
2.4.5 Replace Nested Conditional with Guard Clauses…………………………………………………….. 47
2.4.6 Replace Conditional with Polymorphism…………………………………………………………………. 48
2.5 Simplificación de Llamadas…………………………………………………………………………………………………….. 48
2.5.1 Rename Method……………………………………………………………………………………………………… 48
2.5.2 Add Parameter………………………………………………………………………………………………………… 49
2.5.3 Remove Parameter………………………………………………………………………………………………… 49
2.5.4 Separate Query From Modifier………………………………………………………………………………. 50

Contenido
Ingeniería de Software
2.5.5 Parameterize Method……………………………………………………………………………………………… 50
2.5.6 Replace Parameter with Explicit Method………………………………………………………………… 50
2.5.7 Replace Parameter with Method……………………………………………………………………………. 51
2.5.8 Introduce Parameter Object…………………………………………………………………………………… 52
2.5.9 Remove Setting Method………………………………………………………………………………………… 52
2.5.10 Hide Method…………………………………………………………………………………………………………… 52
2.5.11 Replace Error Code with Exception…………………………………………………………………………. 53
2.6 Generalización……………………………………………………………………………………………………………………….. 53
2.6.1 Pull Up Field……………………………………………………………………………………………………………. 53
2.6.2 Pull Up Method………………………………………………………………………………………………………. 54
2.6.3 Pull Up Constructor Body………………………………………………………………………………………… 54
2.6.4 Push Down Method………………………………………………………………………………………………… 55
2.6.5 Push Down Field……………………………………………………………………………………………………… 56
2.6.6 Extract Subclass………………………………………………………………………………………………………. 56
2.6.7 Extract Superclass…………………………………………………………………………………………………… 57
2.6.8 Extract Interface……………………………………………………………………………………………………… 57
2.6.9 Collapse Hierarchy…………………………………………………………………………………………………… 58
2.6.10 Replace Inheritance with Delegation……………………………………………………………………… 58
2.7 Refactorizaciones Mayores……………………………………………………………………………………………………. 59
2.7.1 Separar la Herencia 60
2.7.2 Conversión de Procedimientos de Diseño a Objetos……………………………………………… 60
2.7.3 Separación del Dominio de la Presentación…………………………………………………………….. 61
2.7.4 Extraer Jerarquía…………………………………………………………………………………………………….. 62
2.8 Ejercicios………………………………………………………………………………………………………………………………… 62
CAPITULO III…………………………………………………………………………………………………………………………………….. 67
“BAD SMELLS” EN EL CODIGO………………………………………………………………………………………………………….. 67
3.1 Código Duplicado……………………………………………………………………………………………………. 68
3.2 Métodos Grandes……………………………………………………………………………………………………. 69
3.3 Clases Grandes………………………………………………………………………………………………………… 70
3.4 Lista de parámetros excesiva………………………………………………………………………………….. 71
3.5 Características de la “Envidia”…………………………………………………………………………………. 71
3.6 Sentencias switch……………………………………………………………………………………………………. 71

Contenido
Ingeniería de Software
3.7 Jerarquía de herencias paralelas……………………………………………………………………………… 72
3.8 Campos temporales………………………………………………………………………………………………… 72
3.9 Encadenamiento de mensajes………………………………………………………………………………… 73
3.10 Clases alternativas con diferentes interfaces…………………………………………………………… 73
3.11 Librerías de clases incompletas……………………………………………………………………………….. 73
3.12 Ejercicios…………………………………………………………………………………………………………………. 77
CAPITULO IV……………………………………………………………………………………………………………………………………. 79
REESTRUCTURACION, REUSO Y REALIDAD.……………………………………………………………………………………… 79
4.1 Rechazo a la reestructuración………………………………………………………………………………………………… 80
4.1.1 Comprensión del “cómo” y “dónde” se refactoriza…………………………………………………. 80
4.1.2 Miedo a las herramientas de refactorización…………………………………………………………… 81
4.1.3 Refactorizar es una sobrecarga de trabajo………………………………………………………………. 82
4.2 Implicaciones concernientes al reuso del software………………………………………………………………… 82
4.3 La realidad de la reestructuración………………………………………………………………………………………….. 83
4.3.1 Refactorización en el ITM………………………………………………………………………………………… 84
Referencia Bibliográfica…………………………………………………………………………………………………………………… 85
ANEXO A. Ejemplo de Refactorización………..……………………………….…………………………………………………. 86
Clase Pelicula…………………………………………………………………………………………………………………………. 87
Clase Renta……………………………………………………………………………………………………………………………. 88
Clase Cliente………………………………………………………………………………………………………………………….. 88
Primer Análisis del Programa…………………………………………………………………………………………………. 90
Sugerencia……………………………………………………………………………………………………………………………… 91
Primeros pasos de refactorización…………………………………………………………………………………………. 91
Sugerencia.…………………………………………………………………………………………………………………………….. 92
Descomponiendo y redistribuyendo el método estadoDeCuenta…………………………………………… 92
Código original……………………………………………………………………………………………………………………….. 93
Código modificado…………………………………………………………………………………………………………………. 94
Sugerencia……………………………………………………………………………………………………………………………… 96
Este es el código original………………………………………………………………………………………………………… 96
Aquí está el código renombrado……………………………………………………………………………………………. 96
Moviendo el monto calculado………………………………………………………………………………………………… 97
Extrayendo los puntos de clientes frecuentes……………………………………………………………………….. 102

Contenido
Ingeniería de Software
Eliminando variables temporales…………………………………………………………………………………………… 105
La Herencia……………………………………………………………………………………………………………………………. 113
ANEXO B. Herramientas de Refactorización Automática………………………………………………………………… 123

Reestructuración de Código
Ingeniería de Software i
Introducción
La Reestructuración del Código es una técnica de Ingeniería de Software y principalmente
modifica el código fuente y/o los datos en un intento de adecuarlos a futuros cambios.
Actualmente el término Reestructuración de Código se vincula mejor como Refactorización (del
inglés Refactoring que propone la eXtreme Programming) lo cual implica, “realizar modificaciones
en el código, con el objetivo de mejorar su estructura interna sin alterar su comportamiento
externo” y es el que manejaremos dentro de este texto.
Refactorizar no es una técnica para encontrar y corregir errores en una aplicación, de hecho, no
modificar el comportamiento externo de la aplicación es uno de los pilares de cualquiera de las
prácticas que forman parte de la técnica, por lo que es indispensable hacer uso de pruebas
unitarias para asegurarse de no haber realizado alguna modificación.
El término se creó como analogía con la factorización de números y polinomios. Por ejemplo, x2 −
1 puede ser factorizado como (x + 1)(x − 1), revelando una estructura interna que no era visible
previamente (como las dos raíces en -1 y +1). De manera similar, en la refactorización del
software, el cambio en la estructura visible puede frecuentemente revelar la estructura interna
"oculta" del código original.
Cuando tenemos un código mal diseñado, podemos mediante la refactorización transformarlo en
un programa fácil de entender aplicando tan solo algunos pasos simples. Estos pasos no son más
que pequeños cambios estructurales que afectan de manera positiva al código como por ejemplo,
llevando un campo de una clase a otra o quizá extrayendo algo de código fuera de un método
determinado para convertirlo en un método propio o incluso aplicando un poco de jerarquía al
mismo, etc. Al llevar a cabo estos pequeños cambios podremos mejorar radicalmente el diseño de
nuestro código.
Podemos concluir que la refactorización es la parte del mantenimiento del código que no arregla
errores ni añade funcionalidad. El objetivo, por el contrario, es mejorar la facilidad de
comprensión del código o cambiar su estructura y diseño y eliminar código muerto, para facilitar el
mantenimiento en el futuro. Añadir nuevo comportamiento a un programa puede ser difícil con la
estructura dada del programa, así que un desarrollador puede refactorizarlo primero para facilitar
esta tarea y luego añadir el nuevo comportamiento.
Dentro de este material se plasman diferentes aspectos de calidad relacionados con la
refactorización de código, ofreciendo una visión amplia sobre diferentes factores que se deben
tener en consideración para la construcción de software de calidad, proporcionando de esta
manera, una panorámica actual, amplia y completa sobre refactorización, basándonos en
investigaciones científicas con un enfoque práctico.
El material queda conformado de la siguiente manera, Capítulo 1 “Principios de la
Reestructuración de Código” se definen los conceptos básicos de la Reestructuración de código,

Reestructuración de Código
Ingeniería de Software ii
así como los problemas que se presentan al llevarlo a cabo, los pasos que hay que seguir para
realizarlo en un desarrollo de software y algunas herramientas que son utilizadas para poder
hacerlo en el ambiente de programación.
En el siguiente capítulo (“Bad Smells”) se puede analizar código el cual tenga problemas en su
estructura y no precisamente de funcionalidad (que no funcione), dentro de este capítulo se
pretende dar el criterio preciso para determinar cuándo es el momento ideal para refactorizar,
exponiendo algunas indicaciones que señalan cuando hay problemas que pueden ser resueltos
mediante la refactorización. Básicamente se plasman los conocimientos de Kent Beck obtenidos
de su experiencia, con conceptos explicados por Fowler1.
En el capítulo 3 “Catálogo de Refactorizaciones”, Fowler propone una enorme variedad de
técnicas para hacer refactorizaciones, mismas que agrupa en diferentes categorías las cuales se
mencionarán en este capítulo, tales como: La Composición de Métodos, Moviendo Características
entre Objetos, Organización de Datos, Simplificación de Expresiones Condicionales, Simplificación
de Llamadas a Métodos, Generalización y Refactorizaciones Mayores.
En el capítulo 4 “Reestructuración Reuso y Realidad” se analizan algunos aspectos relativos a la
aplicación de la refactorización en el mundo real, y hacia dónde se dirige actualmente ésta técnica.
Asimismo, se describe el reuso como parte fundamental del ámbito de desarrollo de software y
algunas implicaciones similares a la refactorización.
Anexo A “Ejemplo de Refactorización”, en este apartado se muestra un ejemplo completo de
refactorización ilustrado por Martín Fowler, que muestra cada uno de los pasos seguidos para
realizar la refactorización de código.
Todos los ejemplos de este material están escritos con lenguaje de programación Java. La
refactorización por supuesto, puede hacerse con otros lenguajes y se espera que este material sea
de utilidad también para los que trabajan con otros lenguajes.
El presente trabajo incluye una investigación bibliográfica sobre el área de Reestructuración de
Código apegado al contenido oficial de la materia que se imparte en el área de Ingeniería en
Sistemas.
1 Martin Fowler es un autor y conferencista internacional en desarrollo de software, especializado en análisis y diseño
de lenguajes orientados a objetos, UML , patrones y desarrollo de metodologías de software ágil, incluyendo la programación extrema. Autor del libro “Refactoring: Improving the Design of Existing Code”, entre otros.

Principios de la Reestructuración
Capítulo 1 9
CAPITULO I.
PRINCIPIOS DE LA REESTRUCTURACIÓN
En este capítulo se definen los conceptos básicos de la Reestructuración de
código, así como los problemas que se presentan al realizarla, los pasos que
hay que seguir para llevarla a cabo en un desarrollo de software y algunas
herramientas que son utilizadas para desarrollarla en el ambiente de
programación.

Principios de la Reestructuración
Capítulo 1 10
1.1 Conceptos básicos.
La refactorización (reestructuración)2 es el proceso de cambiar un sistema de software, mejorando
(modificando) su estructura interna de tal forma que no se altere su comportamiento externo, y al mismo
tiempo es una forma disciplinada de limpiar el código, lo que minimiza las posibilidades de introducir
errores dentro del código.
Lo anterior significa, que la refactorización no cambia el comportamiento observable del software ya que
éste deberá llevar a cabo la misma función que hacía antes de ser modificado y cualquier usuario, ya sea
usuario final u otro programador, no deberían notar cambio alguno en cuanto a la salida del programa.
La refactorización tiene como propósito hacer al software más fácil de entender y modificar. Se pueden
hacer muchas modificaciones pequeñas dentro de un software que casi no afecten su comportamiento
externo, pero sólo aquellas modificaciones realizadas, que tengan como propósito hacer el software más
fácil de entender se consideran Refactorizaciones. Un buen contraste es la Optimización del
Rendimiento. Al igual que la refactorización, la Optimización del Rendimiento usualmente no cambia el
comportamiento de un componente, sino que sólo altera la estructura interna. Sin embargo, el propósito
es diferente, ya que normalmente hace que el código sea más difícil de entender.
La Refactorización se aplica a una forma de edición en colaboración de la escritura de un código en la
que uno o varios participantes reestructuran, resumen, aclaran o elaboran una colección de
comentarios, anotaciones y otros escritos, dando coherencia lógica al software. [quantum]
Motivos para refactorizar código.
Algunas de las razones que justifican el utilizar esta técnica son:
Calidad. Es la razón primordial. Refactorizar es un proceso continuo de reflexión sobre nuestro
código que permite que aprendamos de nuestros desarrollos en un entorno en el que no hay
mucho tiempo para mirar hacia atrás. Un código de calidad es un código sencillo y bien
estructurado, que cualquiera puede leer y entender sin necesidad de haber estado integrado en
el equipo de desarrollo durante varios meses. Se debe terminar el tiempo en que imperaban los
programas escritos en una sola línea, en la que se hacía de todo y en el que se valoraba la
concisión aún a costa de la legibilidad.
Eficiencia. Mantener un buen diseño y un código estructurado es sin duda la forma más eficiente
de programar. El esfuerzo que se invierta en evitar la duplicación de código y en simplificar el
diseño, se verá compensado cuando se tengan que realizar modificaciones, tanto para corregir
errores como para añadir nuevas funcionalidades.
2 El término de refactorización se utilizará como sinónimo de reestructuración en todo el documento

Principios de la Reestructuración
Capítulo 1 11
Diseño evolutivo en lugar de gran diseño inicial. En muchas ocasiones los requisitos al principio
del proyecto no se especifican adecuadamente y debemos abordar el diseño de una forma
gradual. Cuando tenemos requisitos claros y no cambiantes, un buen análisis de los mismos
puede originar un diseño e implementación brillantes; pero cuando los requisitos van cambiando
según avanza el proyecto y se añaden nuevas funcionalidades según se le van ocurriendo a los
participantes o clientes, el diseño inicial deja de tener razón de ser.
Refactorizar nos permitirá ir evolucionando el diseño según se incluyan nuevas funcionalidades,
lo que implica muchas veces cambios importantes en la arquitectura.
Evitar la reescritura de código. En la mayoría de los casos, refactorizar es mejor que reescribir.
No es fácil enfrentarse a un código que no conocemos y que no sigue los estándares que uno
utiliza, pero eso no es una razón para empezar de cero. Sobre todo en un entorno donde el
ahorro de costos y la existencia de sistemas lo hacen imposible.
Refactorizar no es la cura para todos los males del software, pero sí tiene ciertas cualidades y aspectos
favorables que ayudan a escribir software de calidad:
Es un instrumento valioso que ayuda a mantener control sobre el código principalmente en su
estructura.
Permite mejorar el diseño del software o crearlo cuando se necesita de manera previa,
principalmente en casos donde no se entiende o es muy confuso el programa, es decir, le da
calidad.
Facilita la comprensión del diseño del código haciéndolo más legible a otros programadores.
Ayuda a ordenar de manera clara y precisa el programa.
Elimina la duplicidad de código.
Simplifica pasos de ejecución dentro del programa.
Valida constantemente la estructura del código para evitar redundancia.
En la mayoría de las ocasiones, reduce el tamaño del código.
No altera la salida del programa en ningún caso de manera definitiva.
Debe ser transparente para usuarios finales.
Le da rapidez de respuesta al programa en su salida.
Facilita el proceso de modificaciones futuras cuando sea necesario.
Las pruebas que son necesarias cuando se refactoriza, aseguran que el código no ha dejado de
funcionar y aún más, de que sigue haciendo lo que desde un principio estaba haciendo. Los
cambios que se deben generar son tan pequeños que permite no perder el sentido de lo que el
código hace y deberá seguir haciendo.
Ayuda a encontrar errores en el programa.
Fomenta buenos o incluso excelentes hábitos de programación para los desarrolladores.
Permite hacer código con mucho más rapidez, robusto y eficaz, apoyados de un buen diseño.

Principios de la Reestructuración
Capítulo 1 12
Promueve la reutilización de funciones dentro de todo el programa en el momento que se
necesite.
Un buen diseño indiscutiblemente es esencial para el rápido desarrollo de software, sin éste, se puede
avanzar rápidamente por un tiempo determinado, pero luego se comenzará a bajar lentamente la
velocidad, ya que como no hay diseño previo pasaremos un buen tiempo tratando de encontrar y
arreglar errores en vez de añadir nuevas funciones.
Cuando se debe refactorizar.
Los casos más comunes en los que la refactorización es una excelente opción de apoyo son:
I. Para añadir una función
II. Cuando se necesita localizar un error
III. Como revisión de código (o mantenimiento)
Normalmente no se calendariza la refactorización pues se debe hacer todo el tiempo en pequeñas
ráfagas cuando se es desarrollador o cuando se desea hacer algo más dentro de un programa
determinado, ya que la refactorización ayuda a hacer modificaciones de manera segura.
Uno de los casos más comunes para llevar a cabo una refactorización, es en el momento preciso en que
se va a agregar una nueva función. La razón principal por la que se necesita refactorizar es porque
ayuda a entender qué parte del código se necesita modificar, más aún si se considera que este programa
pudo haber sido escrito por alguien más o por nosotros mismos en el pasado, sin tener que preocuparse
de la existencia de un buen diseño de código previo.
En ocasiones cuando se agrega una función nueva, no se comprende por qué no hace el programa lo que
se desea y es que es tan confuso el mismo, que no se pueden ver a simple vista los errores que tiene.
Con la refactorización se pueden localizar de manera rápida los posibles errores que se hayan
introducido.
Por otro lado, existen organizaciones que se dedican a la tarea exclusiva de realizar revisiones continuas
a códigos a través de equipos de desarrollo de software, corrigiendo aspectos como los comentarios
dentro de los programas pues esto ayuda a entender lo que el programa está haciendo, auxiliando al
mismo tiempo a los desarrolladores. Ellos también tienen presente que se debe escribir código claro ya
que el código que elabora cada programador puede ser claro para él, pero no para los demás incluso
para su propio equipo de trabajo. Si el código se escribe de manera correcta, debe explicarse a sí mismo
[Andrew Glover].
Para que la refactorización funcione como revisión de código, deben tenerse grupos de pruebas que
permitan examinar todo el tiempo al código. Es recomendable tener dentro del equipo de trabajo, a un
revisor y al autor original de los programas juntos, debido a que el revisor sugiere cambios y entonces se
decide si los cambios pueden ser fácilmente refactorizados o no. Esta idea de la revisión de código activa

Principios de la Reestructuración
Capítulo 1 13
es llevada a cabo en la programación extrema (eXtreme Programming)3 [JetBrains, Academy
Development] y es una práctica que se lleva a cabo en parejas.
Kent Beck sugiere cuatro aspectos que se deben observar para determinar si un programa será difícil de
modificar, que es justamente lo que se pretende evitar con la refactorización y la programación ágil o
extrema, así que la refactorización se deberá llevar a cabo cuando:
1. Los programas son difíciles de leer.
2. Los programas tienen duplicidad lógica.
3. Requieren de comportamiento adicional para cambiar el código en ejecución.
4. Cuando los programas presenten una lógica condicional compleja.
Por lo tanto, se pretende que los programas no cambien su comportamiento debido a los cambios y que
permitan que la lógica condicional se exprese de la forma más sencilla posible.
En el anexo A de este documento, se analiza un ejemplo de refactorización, aplicando algunas de las
refactorizaciones que se manejan dentro del catálogo propuesto por Fowler1.
1.2 Pasos de la refactorización.
Además de conocer los aspectos teóricos de la refactorización, también es importante profundizar sobre
los aspectos más prácticos de la aplicación de esta técnica en un proyecto de desarrollo real.
En el caso de comenzar un proyecto desde cero, la refactorización continua es una práctica que conlleva
un gran número de beneficios y evita de forma natural algunos peligros mencionados, por lo que hay que
implantarla como parte del proceso de desarrollo de software.
Sin embargo, no siempre se parte de cero y lo habitual es encontrarnos con código cuyo diseño y/o
estructura están lejos de ser los más apropiados. En este caso, se tiene una refactorización a posteriori y
deben tomarse medidas específicas para que afecte lo menos posible el ritmo normal de desarrollo.
La refactorización debe realizarse de una manera progresiva, dentro del proceso de desarrollo de
software, por lo que es necesario seguir los siguientes pasos:
1. Escribir pruebas unitarias y funcionales. Refactorizar sin pruebas unitarias y funcionales resulta
demasiado costoso y de mucho riesgo.
2. Refactorizar los principales fallos de diseño. La recomendación es comenzar realizando
refactorizaciones concretas que corrijan los principales fallos de diseño, como puede ser código
duplicado, clases largas, etc. que son refactorizaciones sencillas de realizar y de las que se
obtiene un gran beneficio.
3 La programación extrema o Extreme Programming (XP) es un enfoque de la ingeniería de software formulado por Kent Beck,
autor del primer libro sobre la materia Extreme Programming Explained: Embrace Change (1999).

Principios de la Reestructuración
Capítulo 1 14
3. Ejecutar pruebas funcionales después de cada cambio. A medida que avance y se realicen
cambios pequeños, se deben ejecutar un conjunto de pruebas completo.
4. Comenzar a refactorizar el código tras añadir cada nueva funcionalidad en grupo. Una vez
corregidos los errores principales del código existente, la manera más común de aplicar
refactorización suele ser al añadir una nueva funcionalidad. Suele ser muy productivo, realizar
discusiones en grupos sobre la conveniencia de implementar alguna refactorización necesaria,
antes de desarrollar la nueva funcionalidad.
5. Implantar refactorización contínua al desarrollo completo. Este es el último paso y es cuando
cada desarrollador incorpora la refactorización como una tarea más dentro de su proceso de
desarrollo de Software.
1.3 Problemas de la Reestructuración.
Si para afirmar que sabemos refactorizar basta con conocer los principales patrones y seguir una serie de
sencillos pasos, para refactorizar con éxito es necesario tener en cuenta muchos factores propios de los
proyectos de desarrollo reales.
En un proyecto real hay que ser consciente de que no refactorizar a tiempo un diseño degradado puede
tener consecuencias muy negativas, pero a la vez se debe tener en cuenta que el tiempo dedicado a
refactorizar no suele ser considerado como un avance del proyecto por los usuarios, clientes o gestores
del mismo.
Otro factor clave para una correcta aplicación de la refactorización, es la forma en cómo se ven
afectados los miembros del equipo, por ejemplo, el hecho de que un desarrollador realice
refactorizaciones sobre código en el que todos están trabajando, o quizá, el que una refactorización
provoque que el código esté mucho tiempo sin funcionar o también, el efecto negativo de no
refactorizar, debido a que esto les da a los desarrolladores la sensación de no estar haciendo un trabajo
de calidad.
Por lo anterior, antes de tratar estos temas y como base para entender sus verdaderas implicaciones,
hay que comenzar por tratar un factor raramente considerado en los libros o artículos sobre
refactorización: el factor humano, es decir, cómo afecta al desarrollador o al equipo de desarrollo el
refactorizar poco o demasiado, el hacerlo pronto o tarde, etc.
1.3.1. El factor humano
Una realidad a veces olvidada, es que cualquier desarrollador prefiere hacer código de calidad. También
es cierto que esta realidad a veces queda oculta, debido a condiciones de presión excesiva o
menosprecio del trabajo técnico.

Principios de la Reestructuración
Capítulo 1 15
En este sentido refactorizar es una forma de mejorar la calidad y por tanto es una forma de hacer que el
desarrollador esté más orgulloso de su trabajo. Puede decirse que la refactorización bien realizada,
rápida y segura, genera satisfacción.
Pero también existe la posibilidad de que en la búsqueda de conseguir un resultado de calidad puede
llegar a suponer un número excesivo de refactorizaciones dando vueltas sobre diseños similares una y
otra vez.
Una posible solución consiste en mantener la refactorización bajo control, definir claramente los
objetivos antes de comenzar a refactorizar y estimar su duración. Si se excede el tiempo planificado es
necesario un replanteamiento. Quizá haya ocurrido que la refactorización era más complicada de lo
esperado pero también es posible que se esté refactorizando más de lo necesario.
Además de la evidente pérdida de tiempo, refactorizar demasiado suele llevar a dos efectos negativos. El
primero, es que la modificación del código incrementa la complejidad de nuestro diseño, que es justo el
efecto contrario de lo que intentábamos lograr al refactorizar y el segundo, es habitual fomentar la
sensación de bienestar del desarrollador o bien de todo el equipo de que no se está avanzando, una
sensación que conduce a repercusiones anímicas negativas.
1.3.2. Trabajo en equipo
Un equipo de desarrollo debe ser sólido y estar en completa comunicación. Todos los miembros del
equipo deben conocer la arquitectura en cada momento, el estado actual, los problemas que tenemos y
el objetivo que se busca. Una reunión diaria es una práctica que facilita la comunicación entre todos los
miembros del equipo, y brinda el momento adecuado a todos los miembros del grupo para plantear sus
ideas, dudas e inquietudes respecto al proyecto.
Cuando un desarrollador refactoriza, afecta al resto del equipo. En este sentido, las refactorizaciones
internas de una clase son menos problemáticas, pero con las arquitecturales es necesario tener mucho
cuidado. Este tipo de refactorizaciones supone cambios en un gran número de archivos y por tanto es
probable que se afecte a archivos que están siendo modificados por otros desarrolladores. La
comunicación y coordinación entre los afectados es fundamental para que esto no se convierta en un
problema. Por tanto es necesario que en la reunión diaria del equipo (u otro mecanismo de
comunicación equivalente) se planteen las refactorizaciones de este tipo. De esta forma se sabrá en todo
momento quienes son los afectados y cuál es el objetivo de la refactorización, así, se promueve la
colaboración de todos en la refactorización arquitectural que se va a llevar a cabo. A veces, el comentar
con el resto del equipo una refactorización que parece muy necesaria, puede observarse que lo que
parecía una muy buena idea, no lo es tanto por otros factores que ven otros compañeros y de los que no
se era consciente. Esto evita también refactorizaciones en sentidos contrarios, propias de equipos en los
que falta comunicación.

Principios de la Reestructuración
Capítulo 1 16
Las refactorizaciones en sentidos contrarios, suelen estar motivadas por tener cada miembro del equipo
una idea diferente del diseño hacia el que debe dirigirse ese código. Este problema de comunicación
puede tener repercusiones bastante negativas en el diseño resultante. Una vez que ocurre, se debe
trabajar para que todo el equipo comparta una misma visión de la arquitectura y mismo diseño del
sistema. Para ello la mejor manera es detener el desarrollo y reunir a todo equipo para alcanzar un
acuerdo común. En estas reuniones es muy útil el uso de pizarras y diagramas UML si son conocidos por
el equipo. Incluso los miembros del equipo que no se habían visto involucrados en la situación,
aprenderán de la experiencia para evitar que vuelvan a darse en el futuro.
Una vez extraídas las conclusiones, es posible que sea necesario realizar una refactorización más, para
devolver el código y el diseño a parámetros acordes con nuestros requisitos de calidad.
1.3.3. Problemas al refactorizar bases de datos
Una de las áreas problemáticas para la refactorización es justamente las bases de datos. La mayoría de
las aplicaciones de negocios están muy acopladas al esquema de bases de datos que los soporta y es por
esto principalmente que las bases de datos son difíciles de cambiar. Otra razón por la que la
refactorización presenta problemas en esta área, es la migración de datos, incluso cuando el sistema está
diseñado en capas para minimizar las dependencias entre el esquema de bases de datos y el modelo de
objetos, el problema se presenta al querer cambiar su esquema ya que obliga a migrar los datos y esto
puede ser una tarea larga y tensa.
Con las bases de datos nonobject (no manejan objetos, sino solamente registros), una manera de hacer
frente a este problema es colocar una capa de software (middleware) entre el modelo de objetos y el
modelo de bases de datos nonobject, de tal forma que se puedan aislar los cambios de los dos modelos
diferentes. Para actualizar un modelo no es necesario actualizar otro, simplemente habrá que actualizar
la capa de software intermedia. Esta capa añade complejidad, pero le da una gran flexibilidad y control,
incluso en situaciones en las que múltiples bases de datos o un modelo complejo de bases de datos lo
requieren.
No se tiene que comenzar con una capa separada, es decir con un middleware complejo, sino que
también se puede crear una capa con fragmentos o partes del modelo de objetos e irlos personalizando
a medida que se vaya requiriendo, porque nuestra capa se vuelve inconsistente, de esta manera, se
obtiene la mejor forma de preparar el código para hacer cambios necesarios.
Las bases de datos orientadas a objetos pueden ser tanto de ayuda como perjudiciales en el proceso de
la refactorización. Algunas bases de datos orientadas a objetos proporcionan la migración automática de
la versión de un objeto a otro. Esto reduce el esfuerzo, pero sigue teniendo un costo de tiempo
importante al momento de hacer la migración. Cuando la migración no es automática, se tiene que hacer
la migración de manera manual y esto implica una diversidad de costos principalmente de esfuerzo. En
esta situación hay que ser más cautelosos acerca de los cambios en la estructura de datos de las clases,
sobre todo cuando se desea mover los campos pues se tiene más libertad en relación de su
comportamiento, pero esto no implica que se deba descuidar este aspecto. Se recomienda utilizar

Principios de la Reestructuración
Capítulo 1 17
métodos para dar la apariencia de que los datos se han movido, incluso cuando no sea así. Cuando se
esté completamente seguro de a donde los datos deben ser migrados, se pueden trasladar en un solo
movimiento. Solamente los accesos necesitan ser cambiados para reducir el riesgo de errores.
1.3.4. Problemas en el cambio de interfaces
Una de las cosas importantes acerca de los objetos, es que permiten cambiar la aplicación de un módulo
de software independientemente de la interfaz. Se pueden hacer cambios seguros a las partes internas
de un objeto de forma transparente, pero la interfaz es importante y al cambiarla, cualquier cosa puede
suceder.
Lamentablemente hay algo sobre la refactorización que es preocupante y es que muchas de las
refactorizaciones cambian la interfaz, algo tan simple como el método Rename afecta directamente a la
misma. No hay problema por cambiar de nombre a un método si se tiene acceso a todo el código que
hace referencia a éste. Si el método es público y se pueden identificar todas las llamadas a ese método
para ser modificadas, es posible renombrar el mismo sin error alguno. Pero existe un problema cuando la
interfaz está siendo utilizada por cierto código que no pudo ser ni identificado, ni modificado conocido
como Interfaz Publicada (más allá de una interfaz pública). Una vez que se publique una interfaz, no se
podrá simplemente cambiar ni editar las llamadas de forma segura, se necesitará un proceso algo más
complicado.
Sintetizando, si una refactorización cambia una interfaz pública a interfaz publicada, se deberá guardar
tanto la interfaz antigua como la nueva, al menos hasta que los usuarios hayan tenido la oportunidad de
asimilar el cambio. Afortunadamente esto no es demasiado difícil, pues generalmente se pueden adaptar
las cosas de modo que la interfaz anterior siga trabajando. Una buena práctica sería tratar de hacer esto
con la finalidad de que la interfaz pública llame a la nueva interfaz cambiando solamente el nombre del
método, manteniendo así la interfaz anterior al llamar a la nueva. No se debe copiar el cuerpo del
método que ocasionaría código duplicado.
Como se ha visto en puntos anteriores, la refactorización debe estar justificada, además de que NO se
debe refactorizar en los siguientes casos:
Cuando el código existente es un desastre. Será mejor escribirlo de nuevo.
Cuando el código no funciona.
Cuando la salida del programa es errónea.
Cuando se tiene poco tiempo o una fecha límite de entrega.

Principios de la Reestructuración
Capítulo 1 18
1.4 Refactorización y desempeño del software.
Una preocupación común con la refactorización, es el efecto que tiene sobre el rendimiento de un
programa. Para hacer al software más fácil de entender, usualmente se deben realizar cambios que en
ocasiones harán que el programa se ejecute más lentamente, este es un costo alto si se toma en cuenta
que en ocasiones el software es rechazado por ser demasiado lento. La dificultad y el secreto de un
software rápido en cualquier contexto, es escribir software primero afinado, es decir, que funcione
correctamente bien sin problemas de redundancia de código u otros de los que la refactorización mejora
y luego hacer ajustes a ese software para obtener la suficiente velocidad.
Existen tres enfoques generales para el desarrollo de software de escritura rápida que se deben
considerar:
1) Presupuestar el tiempo de rendimiento, usado frecuentemente en sistemas de tiempo real.
2) Atención constante para tener un alto rendimiento. Este enfoque es atractivo, pero no funciona
muy bien dado que los cambios que mejoran el rendimiento general del programa, hace que
éste sea más difícil de trabajar, retrasando así el desarrollo del mismo.
3) Desarrollar el programa sin prestar atención a los resultados hasta que comience una etapa de
optimización de rendimiento, que generalmente es completamente tardía en el desarrollo del
programa.
Durante la fase de optimización del rendimiento, se sigue un proceso específico para ajustar el
programa. Se empieza por la ejecución del programa de acuerdo al perfil del código y así se observa
donde se está consumiendo indebidamente el tiempo y el espacio, todo esto para poder determinar
donde se encuentra esa pequeña parte del programa, donde el rendimiento es débil. Ahora se deberá
enfocar la atención en esos puntos débiles y usar la misma optimización solo si se inclina por el enfoque
de la atención constante. Al igual que en la refactorización habrá que realizar los cambios en pequeños
pasos. Después de cada paso se debe compilar, probar y volver a ejecutar el código. Si aún así no se
mejora el rendimiento del programa, se tendrán que deshacer los cambios, continuando el proceso de
encontrar y eliminar los puntos débiles hasta obtener el rendimiento que satisfaga a los usuarios.
Tener un programa bien refactorizado, ayuda en la optimización de dos maneras diferentes. En primer
lugar, tiempo en el ajuste de rendimiento pudiendo añadir funciones con mayor rapidez. En segundo
lugar, se tiene cierta claridad para el análisis de rendimiento. Sus perfiles te lleva a pequeñas partes del
código, que son más fáciles de ajustar; dado que el código es más claro, se tiene una mejor comprensión
de las opciones que hay y de qué tipo de trabajo se tratará.

Principios de la Reestructuración
Capítulo 1 19
1.5 Herramientas para la refactorización.
Uno de los mayores obstáculos para la refactorización ha sido la lamentable falta de apoyo de
herramientas para llevarla a cabo. Lenguajes en los que la refactorización es parte de la cultura como
Smalltalk, por lo general tienen poderosos ambientes que soportan muchas de las funciones necesarias
para refactorizar código.
Es completamente diferente refactorizar de manera manual a hacerlo con el apoyo de herramientas
especializadas para este fin, incluso si la refactorización manual se hiciera con un conjunto de pruebas,
se toma mucho tiempo en hacerlas. Este simple hecho hace que muchos de los programadores en la
actualidad, se nieguen a realizar refactorizaciones simplemente por el costo de tiempo que este proceso
implica, aunque sepan la importancia de esta práctica.
Muchos paquetes de programación en la actualidad, ya incorporaron a sus códigos herramientas
automatizadas para refactorizar mientras se está programando, de tal forma que poco a poco se vuelve
la refactorización una actividad separada de la programación.
Las herramientas de refactorización puede mejorar la velocidad y la precisión con la que los
desarrolladores crear y mantienen el software, pero sólo si se utilizan. En la práctica, las herramientas no
se utilizan tanto como podrían serlo, la razón es porque a veces no se alinean con la técnica de
refactorización preferido por la mayoría de los programadores. [E. Murphy – Hill and A. P. Black]
1.5.1. Criterios técnicos para una herramienta de refactorización
El objetivo principal de una herramienta de refactorización, es permitir que el programador refactorice
código sin tener que volver a probar el programa. Las pruebas consumen tiempo, incluso cuando son
automatizadas y el hecho de eliminarlas podría acelerar el proceso de refactorización en un porcentaje
importante. Al respecto de esto, se analizan brevemente los requerimientos técnicos necesarios para
una herramienta de refactorización que pueda transformar un programa, mientras se conserve el
comportamiento del mismo.
1.5.1.1. Programa de bases de datos
Uno de los primeros requerimientos reconocidos, fue buscar entidades que usen varios métodos en los
programas completos, por ejemplo con un método particular, se buscarían a todas las llamadas que
potencialmente puedan hacer referencia al método en cuestión, o con una variable instanciada,
identificando a todos los métodos que puedan leerla o escribirla. En ambientes fuertemente integrados,
como en ambientes Smalltalk, esta información se mantiene constantemente en una forma de
búsqueda. Esto no es una base de datos como tradicionalmente se entiende, pero es un almacén de
búsqueda. El programador puede realizar una búsqueda para encontrar referencias cruzadas a cualquier

Principios de la Reestructuración
Capítulo 1 20
elemento del programa, principalmente porque la compilación del código es dinámica. Tan pronto como
se realiza un cambio a cualquier clase, el cambio es inmediatamente compilado en bytecodes4 y la "base
de datos" se actualiza. En ambientes estáticos como Java, los programadores escriben código en archivos
de texto. Las actualizaciones de la base de datos deben realizarse mediante la ejecución de un programa
para procesar estos archivos y extraer la información relevante.
1.5.1.2. Arboles de análisis
La mayoría de refactorizaciones tienen que manipular partes del sistema por debajo del nivel del
método. Estas suelen ser referencias a los elementos del programa que están siendo cambiados. Por
ejemplo, si una variable instanciada es renombrada (un simple cambio de definición), todas las
referencias dentro de los métodos de esa clase y sus subclases deberán ser actualizadas. Otras
refactorizaciones están completamente por debajo del nivel del método, como por ejemplo la extracción
de una parte de un método en sí mismo, independientemente del método. Cualquier actualización a un
método tiene que ser capaz de manipular la estructura del mismo. Para ello se emplean los árboles de
análisis. Un árbol de análisis, es una estructura de datos que representa la estructura interna del método
en sí. Como por ejemplo consideremos el siguiente método:
public void hola( ){ System.out.println("Hola Mundo"); } El árbol de análisis correspondiente a este se vería como la figura siguiente:
4 El bytecode es un código intermedio más abstracto que el código máquina. Habitualmente es tratado como un archivo binario
que contiene un programa ejecutable similar a un módulo objeto, que es un archivo producido por el compilador cuyo contenido es el código objeto o máquina.
Figura 1.1. Árbol de análisis de
hola mundo

Principios de la Reestructuración
Capítulo 1 21
1.5.1.3. Precisión
Las refactorizaciones implementadas por una herramienta deben conservar el comportamiento de los
programas. La preservación total de la conducta es imposible de lograr. Por ejemplo, ¿qué pasa si la
refactorización hace a un programa de unos pocos milisegundos más rápido o más lento? Esto
generalmente no afectaría a un programa; pero que pasaría si los requisitos del programa incluyeran
fuertes restricciones sobre tiempo real, esto podría provocar que un programa fuera incorrecto. Incluso
los programas más tradicionales pueden terminar anormalmente, por ejemplo, si su programa construye
una cadena y utiliza Java Reflection API5 para ejecutar el método al que la cadena hace referencia,
renombrar al método hará que el programa lance una excepción que originalmente no se pretendía, sin
embargo, las refactorizaciones pueden hacerse razonablemente precisas en la mayoría de los programas.
1.5.2. Criterios prácticos para una herramienta de refactorización
Las herramientas son creadas para dar soporte al ser humano en tareas específicas. Si una herramienta
no se ajusta a la forma en que una persona trabaja, entonces no la usará. Los criterios más importantes
son los que integran el proceso de refactorización con otras herramientas.
Las herramientas automáticas de refactorización, son la mejor manera de gestionar la complejidad que
surge de como un proyecto de software evoluciona. Sin herramientas automatizadas, el software se
vuelve pesado y frágil. Debido a que Java es mucho más sencillo que otros lenguajes, es mucho más fácil
de desarrollar herramientas para refactorizar en él.
1.5.2.1. Velocidad
El análisis y las transformaciones necesarios para llevar a cabo refactorizaciones, pueden consumir
mucho tiempo si son muy sofisticados. Los costos relativos del tiempo y precisión siempre deben ser
considerados. Si una refactorización toma demasiado tiempo, un programador nunca utilizará la
refactorización automática, sino que simplemente lo hará a mano y vivirá con las consecuencias. La
velocidad siempre debe ser considerada.
1.5.2.2. Deshacer
La refactorización automática permite un enfoque exploratorio para el diseño. Se puede enviar el código
a otro lado y ver cómo se ve el nuevo diseño. Las versiones anteriores del navegador de refactorización
no contienen la función de deshacer, pero actualmente ya se incorporó. Esto hizo de la refactorización
5 El API Reflection de Java es una herramienta muy poderosa que nos permite realizar en Java cosas que en otros lenguajes es
imposible.

Principios de la Reestructuración
Capítulo 1 22
un poco más atractiva, aunque preservar el comportamiento externo del programa fue difícil. Con
frecuencia, se debía conservar una versión antigua del programa por si se debía empezar de nuevo,
situación que se mejoró con la opción de deshacer o también llamada undo.
Ahora se puede explorar sin penalizaciones, sabiendo que es factible volver a cualquier versión anterior.
Se pueden crear clases, métodos de movimiento en ellas para ver cómo el código se verá, todo esto
siguiendo una dirección totalmente diferente de manera rápida y trasparente.
1.5.3. Herramientas de ambiente integrado
En la última década el desarrollo del ambiente integrado (IDE) ha sido el núcleo de la mayoría de los
proyectos de desarrollo. El IDE integró un editor, compilador, enlazador, depurador y cualquier otra
herramienta necesaria para el desarrollo de programas, incluida una herramienta de refactorización.
Algunas de las herramientas disponibles para los principales lenguajes de programación son:
- Java • Xrefactory, RefactorIT, jFactor, IntelliJ IDEA, Eclipse, Netbeans
- Smalltalk • Refactoring Browser [Roberts et al. 1997]
- C++ • CppRefactory, Xrefactory
- C# • C# Refactoring Tool, C# Refactory
- Delphi • Modelmaker Tool, Castalia
- Entre otros.
Las herramientas disponibles para los principales Ambientes de Desarrollo (IDE’s) son:
- NetBeans
RefactorIT
- Oracle Jdeveloper
RefactorIT
- Borland JBuilder
RefactorIT
- Eclipse
built-in

Principios de la Reestructuración
Capítulo 1 23
- Emacs
Xrefactory
- Visual Studio .NET
C# Refactory
1.6. Primer ejemplo de refactorización
Refactorizar es una práctica, por lo que la mejor forma de entender esta técnica es aplicarla. Por
consiguiente se muestra un programa que ejemplificará paso a paso, la mala estructuración o problemas
que se pueden presentar y las posibles refactorizaciones que solucionarían dichos problemas.
Problema:
Implementar una clase que sirva para calcular todos los números primos de 1 a N utilizando la criba de
Eratóstenes.
Primera solución:
Se necesita crear un método que reciba como parámetro un valor máximo y devuelva como resultado un
vector con los números primos.
El código quedaría de la siguiente manera:
public class Criba { public static int[] generarPrimos (int max){ int i,j; if (max >=2){ //Declaraciones int dim=max + 1; //Tamaño del arreglo boolean[] esPrimo = new boolean[dim]; //Inicializar el arreglo for(i=0; i<dim; i++) esPrimo[i]=true; //Eliminar el 0 y el 1 que no son primos esPrimo[0]= esPrimo[1]=false; //Criba; for(i=2; i<Math.sqrt(dim)+1; i++){ if (esPrimo[i]){ //Eliminar los multiplos de i for(j=2*i; j<dim; j+=i) esPrimo[j]=false; } } //¿Cuantos primos hay? int cuenta=0; for(i=0; i<dim; i++){

Principios de la Reestructuración
Capítulo 1 24
if (esPrimo[i]) cuenta++; } //Rellenar el vector de numeros primos int[] primos=new int[cuenta]; for(i=0, j=0; i<dim; i++){ if (esPrimo[i]) primos[j++]= i; } return primos; }else { //max <2 return new int[0]; //Vector vacío } } } Para comprobar que el código funciona bien, se realiza un programa que incluye distintos casos de
prueba. Para esto se utilizará la herramienta de JUnit que trae incluida el Netbeans.
import junit.framework.TestCase; public class CribaTest extends TestCase { public CribaTest(String testName) { super(testName); } @Override protected void setUp() throws Exception { super.setUp(); } @Override protected void tearDown() throws Exception { super.tearDown(); } /** * Test del método generarPrimos , de la clase Criba. */ public void testGenerarPrimos() { System.out.println("generarPrimos"); int[] nullArray = Criba.generarPrimos(0); assertEquals(nullArray.length,0); int[] minArray = Criba.generarPrimos(2); assertEquals(minArray.length,1); assertEquals(minArray[0],2); int[] tresArray = Criba.generarPrimos(3); assertEquals(tresArray.length,2); assertEquals(tresArray[0],2); assertEquals(tresArray[1],3);
Principios de la Reestructuración
Capítulo 1 25
int[] cienArray = Criba.generarPrimos(100); assertEquals(cienArray.length, 25); assertEquals(cienArray[24],97); } } Al ejecutar los casos de prueba, se consigue tener cierta garantía de que el programa funciona
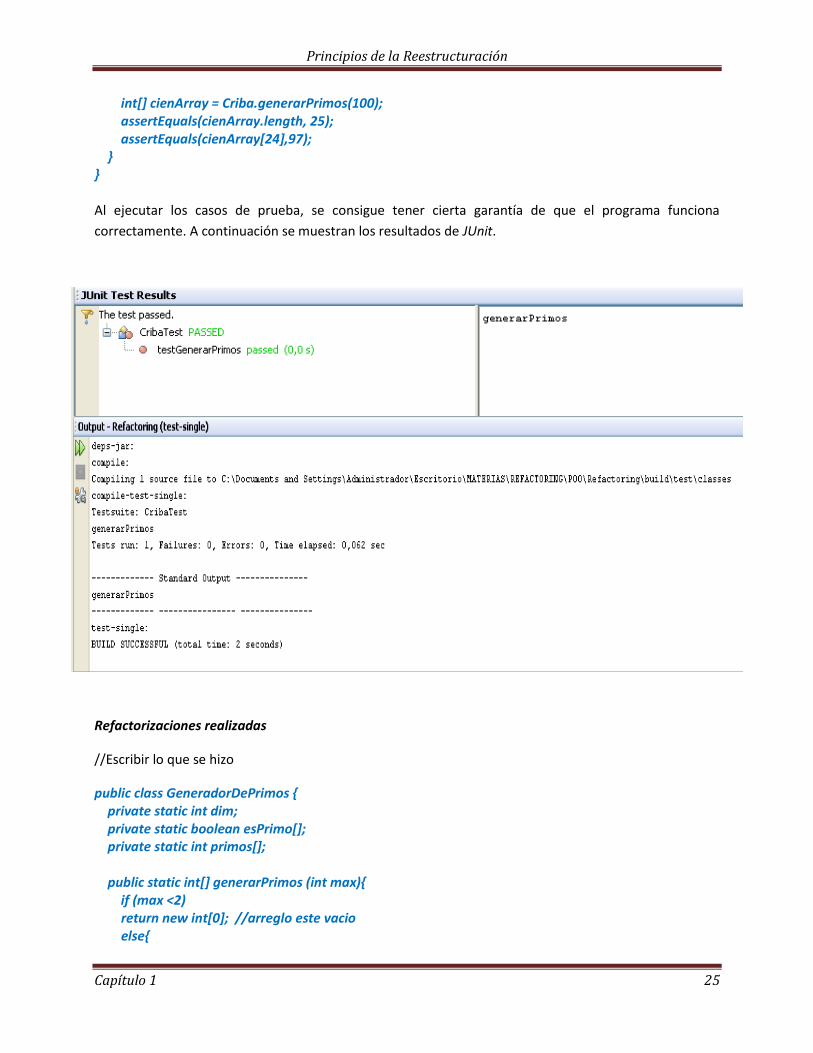
correctamente. A continuación se muestran los resultados de JUnit.
Refactorizaciones realizadas
//Escribir lo que se hizo
public class GeneradorDePrimos { private static int dim; private static boolean esPrimo[]; private static int primos[]; public static int[] generarPrimos (int max){ if (max <2) return new int[0]; //arreglo este vacio else{

Principios de la Reestructuración
Capítulo 1 26
inicializarCriba(max); cribar(); rellenarPrimos(); return primos; } } private static void rellenarPrimos(){ int i,j,cuenta; //Contar primos cuenta=0; for(i=0; i<dim; i++) if (esPrimo[i]) cuenta++; //Rellenar el vector de numeros primos primos=new int[cuenta]; for(i=0, j=0; i<dim; i++){ if (esPrimo[i]) primos[j++]= i; } } private static void cribar() { int i,j; for (i = 2; i < Math.sqrt(dim) + 1; i++) { if (esPrimo[i]) { //Eliminar los multiplos de i for (j = 2 * i; j < dim; j += i) esPrimo[j] = false; } } } private static void inicializarCriba(int max) { //Inicializar el arreglo int i; //Declaraciones dim=max + 1; //Tamaño del arreglo esPrimo = new boolean[dim]; for (i = 0; i < dim; i++) esPrimo[i] = true; //Eliminar el 0 y el 1 que no son primos esPrimo[0] = esPrimo[1] = false; }
}
Se pueden hacer simultáneamente en el mismo
for (1)
2 porque abajo se inicializa 0 y 1 con false (2)

Principios de la Reestructuración
Capítulo 1 27
Primeras mejoras
Parece evidente que nuestro método generarPrimos realiza tres funciones diferentes, por lo que de
generarPrimos extraemos tres métodos diferentes. Además, buscamos un nombre más adecuado para
la clase y eliminamos todos los comentarios innecesarios.
Segunda Refactorización
El código ha mejorado visiblemente, pero aún tiene código por mejorar, por ejemplo:
- Eliminar la variable dim por esPrimo.length
- Elegir identificadores más adecuados para los métodos
- Reorganizar el método inicializarCandidatos (el antiguo inicializarCriba)
El código quedaría como sigue:
public class GeneradorDePrimos { private static int dim; private static boolean esPrimo[]; private static int primos[]; public static int[] generarPrimos (int max){ if (max <2) return new int[0]; //arreglo este vacio else{ inicializarCandidatos(max); eliminarMultiplos(); obtenerCandidatosNoEliminados(); return primos; } } private static void obtenerCandidatosNoEliminados(){ // código del antiguo método rellenarPrimos } private static void eliminarMultiplos() { //código del antiguo método cribar } private static void inicializarCandidatos(int max) { //Inicializar el arreglo
Los mismos casos de prueba de antes nos permiten comprobar que, tras la refactorización, el
programa sigue funcionando correctamente.
Por el return se puede eliminar el else (3)

Principios de la Reestructuración
Capítulo 1 28
int i; //Declaraciones esPrimo=new boolean [max + 1]; //Tamaño del arreglo //Eliminar el 0 y el 1 que no son primos esPrimo[0] = esPrimo[1] = false; for (i = 0; i < esPrimo.length; i++) esPrimo[i] = true; }
}
El código resulta más fácil de leer tras esta refactorización. Sin embargo, aún podría mejorarse el código
ya que el método ObtenerCandidatosNoEliminados tiene dos partes bien definidas, por lo que se puede
extraer un método que se limite a contar el número de primos obtenidos.
Conclusión.
Con el ejemplo anterior se ha mostrado el concepto de refactorización de código, ya que se han
realizado cambios que mejoran la implementación sin modificar, su comportamiento externo (su
interfaz) y se ha verificado tras cada refactorización volviendo a ejecutar los casos de prueba. (1), (2) y
(3) que son refactorizaciones adicionales que podrían ser aplicadas.

Catálogo de Refactorizaciones
Capítulo 2 29
CAPITULO II.
CATÁLOGO DE REFACTORIZACIONES
Fowler propone una enorme variedad de técnicas para hacer
refactorizaciones, mismas que agrupa en diferentes categorías las
cuales se mencionarán en este capítulo, tales como: La Composición de
Métodos, Moviendo características entre objetos, Organización de
datos, Simplificación de expresiones condicionales, Simplificación de
llamadas a métodos y Generalización.

Catálogo de Refactorizaciones
Capítulo 2 30
2.1. Composición de Métodos
Las técnicas que Fowler presenta en esta categoría, tienen como propósito principal resolver problemas
relacionados con casos como: métodos muy grandes, métodos con demasiados argumentos, sustitución
de llamadas a los métodos por su código, entre otros.
La clave de refactorización para estos casos es la aplicación correcta de una refactorización que permita
que el método sea escrito de tal forma, que se pueda entender mucho mejor como éste trabaja y
solamente quedaría encontrar el algoritmo que pueda hacerlo más eficiente (si fuera necesario).
2.1.1. Extract Method
Extract Method se utiliza cuando un fragmento de código puede ser agrupado todo junto y se debe
asociar con un nombre que explique la finalidad del mismo [FOWLER]. El nuevo método que se ha
extraído contiene el código seleccionado y el código seleccionado del miembro existente, se reemplaza
por una llamada al nuevo método.
Código 2.1.1. Ejemplo de Extract Method.
Convertir un fragmento de código en su propio método, permite reorganizar el código de forma rápida y
precisa para que sea posible volver a utilizarlo y lograr una mejor legibilidad.
2.1.2. Inline Method
El cuerpo de un método debe ser tan claro como el nombre del mismo [FOWLER]. Para lograr esto, es
necesario poner el cuerpo del método dentro de sus propias llamadas y posteriormente pueda ser
eliminado como a continuación se muestra.

Catálogo de Refactorizaciones
Capítulo 2 31
Código 2.1.2. Ejemplo de Inline Method.
Un buen momento para usar Inline Method, es cuando se tiene un conjunto de métodos que parecen
mal estructurados. Se pueden alinear los métodos dentro de un método grande y después extraerlos
uno por uno, también es recomendable utilizar frecuentemente éste método, antes de usar el método
Replace Method with Method Object. Es más fácil mover un método que mover a un método y sus
métodos llamados.
2.1.3. Inline Temp
Al igual que en Inline Method, una característica primordial en Inline Temp, es que el cuerpo de un
método sea tan claro como su nombre y se pueda hacer uso de éste, cuando una variable temporal sea
asignada a una expresión simple una sola vez y ésta sea a su vez accesada de alguna forma por otras
refactorizaciones.
En el siguiente código podemos ver un ejemplo de esta refactorización, ya que se pueden reemplazar
todas las referencias de la variable temporal ‘precioBase’ con otra expresión.
Código 2.1.3. Ejemplo de Inline Temp.

Catálogo de Refactorizaciones
Capítulo 2 32
Lo que motiva a hacer esto, es que la mayoría del tiempo el método Inline Temp se usa como parte del
método Replace Temp with Query. Este método solamente se usa cuando encuentras una variable
temporal, que está asignada al valor de la llamada de un método.
Si la variable temporal es obtenida de alguna manera por alguna otra refactorización, como por ejemplo
por Extract Method, es justamente el momento adecuado para poner en práctica el método Inline
Temp.
2.1.4. Replace Temp with Query
Esta refactorización se emplea normalmente, cuando tiene una variable temporal para guardar el
resultado de una expresión [FOWLER]. La figura 2.1.4 muestra como se extrae la expresión de un
método, también como se reemplazan todas las referencias de la variable temporal con la una expresión
y por último como el nuevo método ahora puede ser utilizado en otros métodos.
El problema con las variables es que son temporales y locales; estas sólo pueden verse en el contexto del
método en el que son utilizadas, las variables temporales tienden a ser más favorables en métodos
largos. Mediante la sustitución de los temporales con un método de consulta, cualquier método dentro
de la clase puede llegar a accesar a la información. Eso ayuda mucho a tener código más limpio para la
clase.
El método Replace Temp with Query con frecuencia es un paso vital antes de utilizar el Extract Method.
Las variables locales provocan dificultades al momento de extraer algún fragmento de código, por lo que
se deben reemplazar tantas variables como se pueda mediante consultas.
Código 2.1.4. Ejemplo de Replace Temp with Query.
Los casos más sencillos de esta refactorización son aquellos en los que se asignan temporales sólo una
vez y aquellos en los que la expresión que genera la asignación, está libre de efectos secundarios.

Catálogo de Refactorizaciones
Capítulo 2 33
También existen casos que son más difíciles pero no imposibles, para ello quizá se necesite utilizar
primero el método Split Temporary Variable. Si la variable temporal es utilizada para obtener un
resultado, como por ejemplo la suma de un bucle, se tendrá que copiar por lógica dentro del método de
consulta.
Como ya dijimos las variables temporales con frecuencia, se utilizan para almacenar la información
resumida en los bucles. El bucle puede ser extraído en su totalidad dentro de un método, lo que elimina
varias líneas de código deficiente. Algunas veces un bucle puede ser utilizado para resumir varios valores.
2.1.5. Introduce Explaining Variable
Si se tuviera una expresión complicada, lo que se debe hacer es poner el resultado de la expresión o
parte de la expresión en una variable temporal, con un nombre que explique el propósito de la misma.
(Obsérvese el cuadro de código 2.1.5.)
Las expresiones pueden ser muy complejas y/o muy difíciles de leer, en tales situaciones las variables
temporales pueden ser útiles para simplificar la expresión o expresiones en algo más manejable.
Hacer uso del método Introduce Explaining Variable, es particularmente conveniente si se hace con una
condicional lógica, en donde es útil tomar cada cláusula de una condición y explicar que la condición es el
medio con el cual es bien nombrada la variable temporal. Otro caso es un algoritmo largo, en el cual en
cada paso dentro del cálculo, pueda ser definido con una variable temporal.
Código 2.1.5. Ejemplo de Introduce Explaining Variable.
Este método es una de las más comunes refactorizaciones, aunque hay programadores que prefieren
usar el Extract Method. Una variable temporal es normalmente usada solamente dentro del contexto de
un método y un método en cambio es utilizable en todo momento por todo el objeto e incluso por los

Catálogo de Refactorizaciones
Capítulo 2 34
demás objetos, sin embargo, cuando las variables locales dificultan la posibilidad de aplicar el Extract
Method, entonces es el momento de utilizar Introduce Explaining Variable.
2.1.6. Split Temporary Variable
Si se tiene una variable temporal asignada más de una ocasión que no sea una variable de un bucle, ni
tampoco una variable temporal colectora, habrá que hacer una variable temporal independiente para
cada tarea. Observe el código 2.1.6.
Código 2.1.6. Ejemplo de Split Temporary Variable.
2.1.7. Remove Assigments to Parameters
En el siguiente ejemplo, podemos observar que el código se asigna a un parámetro, la forma de poder
corregir este problema es usando una variable temporal en su lugar. Ver código 2.1.7.
Código 2.1.7. Ejemplo del método Remove Assigments to Parameters.
2.1.8. Replace Method with Method Object
En este caso se tiene un método largo que utiliza variables locales, de tal manera, que no se puede
utilizar el Extract Method. Como se aprecia en el código 2.1.8.

Catálogo de Refactorizaciones
Capítulo 2 35
Habrá que manipular el método dentro de su propio objeto y todas las variables locales convertirlas en
campos de ese objeto. Posteriormente, se puede descomponer el método dentro de otros métodos en el
mismo objeto.
Código 2.1.8. Ejemplo del método Replace Method with Method Object
2.1.9. Substitute Algorithm
Si se desea sustituir un algoritmo por otro que sea más claro, se deberá reemplazar el cuerpo del método
con el nuevo algoritmo, de tal forma que se pueda ver reflejado como se muestra en el siguiente
ejemplo.Ver código 2.1.9.

Catálogo de Refactorizaciones
Capítulo 2 36
Código 2.1.9. Ejemplo del método Substitute Algorithm.
2.2. Moviendo Características entre Objetos.
Se refiere escencialmente a que se tienen que replantear las responsabilidades de un objeto
determinado y sacar de éste todo lo que esté de sobra.
2.2.1. Move Method
Normalmente un método usa más características de otra clase, que de la clase en la cual se define el
mismo [FOWLER]. El siguiente ejemplo (código 2.2.1.) muestra una forma de crear un nuevo método con
un cuerpo similar dentro de la clase donde éste será más usado, ya sea haciéndolo una simple
delegación dentro del método original o eliminándolo totalmente.
Código 2.2.1. Ejemplo del Move Method

Catálogo de Refactorizaciones
Capítulo 2 37
2.2.2. Move Field
Por lo regular, un campo es o será usado más por otra clase, de lo que es utilizado por la clase en donde
está definido [FOWLER]. En la figura 2.2.2. se crea un nuevo campo dentro de la clase destino cambiando
de manera conjunta a todos sus usuarios.
Código 2.2.2. Ejemplo del método Move Field
2.2.3. Extract Class
La refactorización Extract Class, se emplea cuando una clase está haciendo el trabajo que deberían hacer
dos clases. Lo que se puede hacer en esta situación es crear una nueva clase y mover los campos y
métodos relevantes de la clase original a la clase nueva.
Código 2.2.3. Ejemplo del método Extract Class.
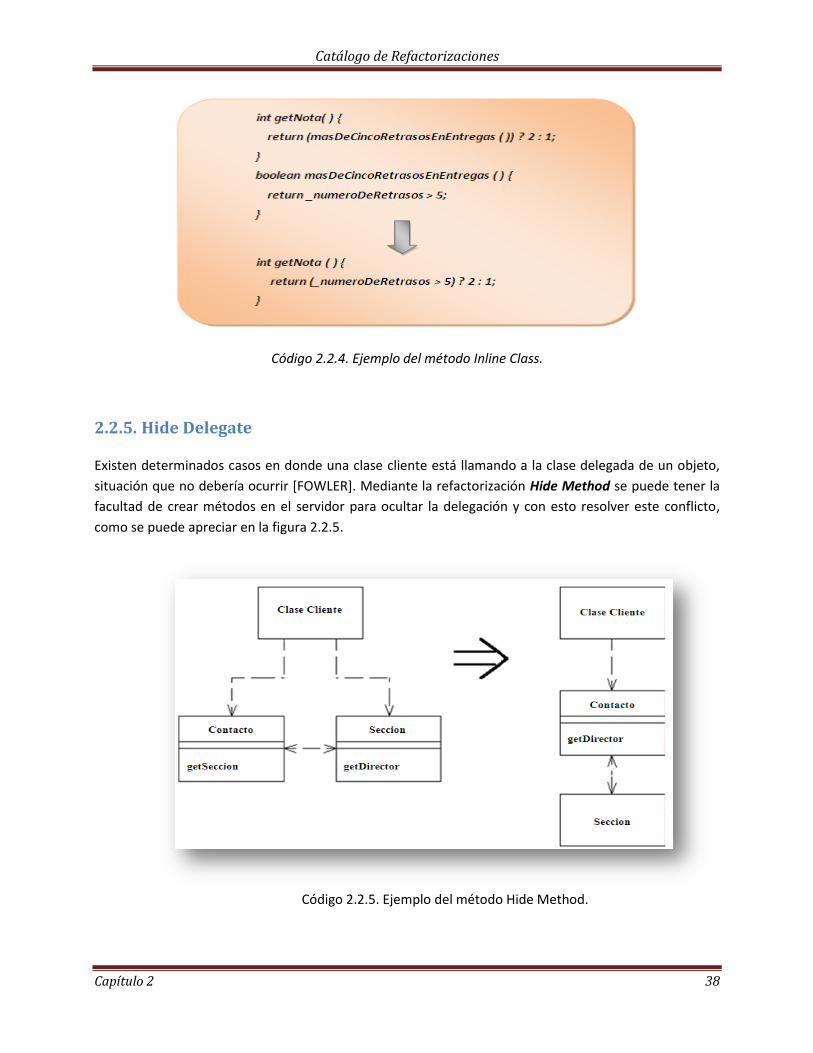
2.2.4. Inline Class
El cuerpo del método es tan claro como su nombre mismo [FOWLER]. Para lograr esto, se utiliza la
refactorización llamada Inline Class, la cual pone le cuerpo del método dentro del código que hace
referencia a sus propias llamadas y finalmente se elimina al método original. Vease la figura 2.2.4.
Catálogo de Refactorizaciones
Capítulo 2 38
Código 2.2.4. Ejemplo del método Inline Class.
2.2.5. Hide Delegate
Existen determinados casos en donde una clase cliente está llamando a la clase delegada de un objeto,
situación que no debería ocurrir [FOWLER]. Mediante la refactorización Hide Method se puede tener la
facultad de crear métodos en el servidor para ocultar la delegación y con esto resolver este conflicto,
como se puede apreciar en la figura 2.2.5.
Código 2.2.5. Ejemplo del método Hide Method.

Catálogo de Refactorizaciones
Capítulo 2 39
2.2.6. Remove Middle Man
Los expertos dentro de la rama de refactorización sugieren que “Una clase, hace la delegación mucho
más simple” [FOWLER]. Para lograr esto, hay que obtener al cliente para hacer la delegación
directamente y es justamente el método Remove Middle Man quien nos lo permite hacer. (Véase figura
2.2.6.)
Código 2.2.6. Ejemplo del método Remove Middle Man.
2.3. Organización de Datos.
La Organización de Datos propone una serie de lineamientos enfocados al correcto uso de la información
de un objeto, como puede ser el encapsulamiento de atributos, el reemplazo de referencias por valores,
el reemplazo de estructuras por objetos, el reemplazo de literales por cosntantes, etc.
2.3.1. Self Encapsulate Field
Podemos encontrar códigos en donde se accesa directamente un campo, pero el acoplamiento con éste
se torna poco manejable [FOWLER].
En casos como el anterior, mediante el método Self Encapsulate Field habrá que crear métodos de get y
set para manipular los campos y utilizar solo ésos métodos y así poder acceder a los campos, como
podemos observar en la figura 2.3.1.

Catálogo de Refactorizaciones
Capítulo 2 40
Código 2.3.1. Ejemplo del método Self Encapsulate Field.
2.3.2. Remplace Data Value with Object
Si un elemento necesita algún dato adicional o complementario, podrá resolverlo si al elemento de dato
lo vuelve un objeto [FOWLER], como se puede observar en la figura 2.3.2.
Código 2.3.2. Ejemplo del método Replace Data Value with Object.

Catálogo de Refactorizaciones
Capítulo 2 41
Código 2.3.3. Ejemplo del método Change Value to
Reference.
2.3.3. Change Value to Reference
2.3.4. Change Reference to Value
Hay momentos en que se tiene un objeto referenciado el cual es muy pequeño, inmutable y complicado
de manipular [FOWLER]. En este tipo de códigos es recomendable cambiar el valor del objeto mediante
el refactoring Change Reference to Value.
Código 2.3.4. Ejemplo del método Change Reference to Value.
2.3.5. Replace Array with Object
Si se tiene un arreglo dentro del cual existen ciertos elementos que representan diferentes cosas, se
debe reemplazar el arreglo por un objeto que tenga un campo por cada elemento, aprovechando los
beneficios que nos da el método Replace Array with Object, como se aprecia en la figura 2.3.5.
En ocasiones, se desea una clase
con muchos casos iguales al que se
desea reemplazar con un único
objeto, para hacer esto, hay que
convertir al objeto en un objeto de
referencia. (Ver figura 2.3.3.)

Catálogo de Refactorizaciones
Capítulo 2 42
Código 2.3.5. Ejemplo del método Replace Array with Object.
2.3.6. Replace Magic Number with Symbolic Constant
Cuando se tiene una literal numérica con un significado particular, es recomendable crear una constante,
nombrarla después de decidir cuál será su significado y por último reemplazar el número con ella
utilizando el refactoring Replace Magic Number with Symbolic Constant.
Código 2.3.6. Ejemplo del método Replace Magic Number with Symbolic Constant.
2.3.7. Encapsulate Field
Un campo público dentro de un sistema se puede mediante el método Encapsulate Field hacer a éste
privado y proveer accesos como se muestra en el código 2.3.7.

Catálogo de Refactorizaciones
Capítulo 2 43
2.3.8. Encapsulate Collection
Mediante Encapsulate Collection podemos hacer que un método devuelva una colección. Hacemos que
éste devuelva una vista de sólo lectura y proporcione métodos como agregar o quitar. Ver código 2.3.8.
Código 2.3.8. Ejemplo del método Encapsulate Collection.
2.3.9. Replace Type Code with Class
Código 2.3.9. Ejemplo del método Replace Type Code with Class.
Código 2.3.7. Ejemplo del
método Encapsulate Field.
Se dice que “Una clase tiene un
código de tipo numérico que no
afecta su comportamiento”
[FOWLER]. El método Replace
Type Code with Class nos
permite llegar a esta finalidad,
como podemos apreciarlo en el
código 2.3.9.
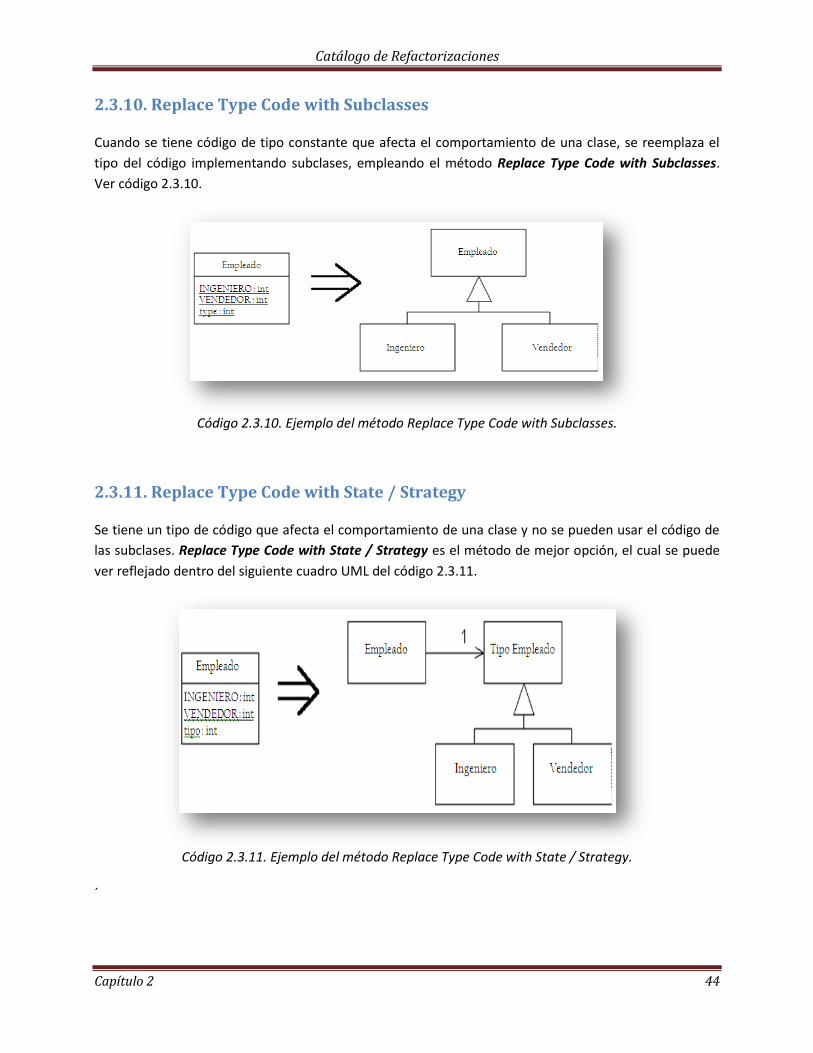
Catálogo de Refactorizaciones
Capítulo 2 44
2.3.10. Replace Type Code with Subclasses
Cuando se tiene código de tipo constante que afecta el comportamiento de una clase, se reemplaza el
tipo del código implementando subclases, empleando el método Replace Type Code with Subclasses.
Ver código 2.3.10.
Código 2.3.10. Ejemplo del método Replace Type Code with Subclasses.
2.3.11. Replace Type Code with State / Strategy
Se tiene un tipo de código que afecta el comportamiento de una clase y no se pueden usar el código de
las subclases. Replace Type Code with State / Strategy es el método de mejor opción, el cual se puede
ver reflejado dentro del siguiente cuadro UML del código 2.3.11.
Código 2.3.11. Ejemplo del método Replace Type Code with State / Strategy.
´

Catálogo de Refactorizaciones
Capítulo 2 45
2.3.12. Replace Subclass with Fields
Se tienen subclases que varían solamente dentro de los métodos y estas devuelven datos constantes. En
el siguiente diagrama, se muestra cómo se pueden cambiar los métodos a los campos de la superclase y
eliminar las subclases mediante el método Replace Subclass with Fields. Ver código 2.3.12.
Código 2.3.12. Ejemplo del método Replace Subclass with Fields.
2.4. Simplificación de Expresiones Condicionales.
La lógica condicional en cierta manera es difícil obtenerla, así que en este apartado se muestran algunos
métodos de refactorización que se pueden emplear para simplificarla.
2.4.1. Descompose Conditional
Cuando se tiene una declaración complicada de una condicional, como por ejemplo en un if-then-else,
habrá que extraer los métodos de la condicional para luego dividirlos lo más que se pueda, como se
muestra en el código 2.4.1. usando el método Descompose Conditional.

Catálogo de Refactorizaciones
Capítulo 2 46
Código 2.4.1. Ejemplo del método Decompose Conditional.
2.4.2. Consolidate Conditional Expression
Si se tiene una secuencia de pruebas condicionales con los mismos resultados, habrá que combinarlos
dentro de una expresión condicional simple y posteriormente extraerlos como se muestra en el código
2.4.2.
Código 2.4.2. Ejemplo del método Consolidate Conditional Expression.
2.4.3. Consolidate Duplicate Conditional Fragments
Si el mismo fragmento de código se encuentra en todas las ramas de una expresión condicional, hay que
moverlas fuera de la expresión [FOWLER]. Esto se puede lograr mediante la refactorización Consolidate
Duplicate Conditional Fragments. (Ver código 2.4.3.)

Catálogo de Refactorizaciones
Capítulo 2 47
Código 2.4.3. Ejemplo del método Consolidate Duplicate Conditional Fragments.
2.4.4. Remove Control Flag
El refactorig Remove Control Flag, se emplea en casos en donde exista una variable que actúe como
indicador de control para una serie de expresiones booleanas, ya que este refactoring sirve de
interruptor.
2.4.5. Replace Nested Conditional with Guard Clauses
Un método tiene un comportamiento condicional que no muestra claramente cuál es su ruta normal de
ejecución. Se puede usar el refactoring Replace Nested Conditional with Guard Clauses para todos los
casos especiales. Ver código 2.4.5.
Código 2.4.5. Ejemplo del método Replace Nested Conditional with Guard Clauses.

Catálogo de Refactorizaciones
Capítulo 2 48
2.4.6. Replace Conditional with Polimorphism
La aplicación de este patrón de refactorización, será posible en los casos donde una sentencia
condicional realice diferentes acciones dependiendo del tipo de objeto instanciado. Lo recomendado es
mover cada parte de la condicional hacia un método dentro de una subclase; de preferencia hacer al
método original abstracto. Ver código 2.4.6.
Código 2.4.6. Ejemplo del método Replace Conditional with Polymorphism.
2.5. Simplificación de Llamadas.
Todos los objetos están relacionados íntimamente con las interfaces. El trabajar con interfaces que son
fáciles de entender y usar, es una habilidad fundamental en el desarrollo de un buen software orientado
a objetos.
En esta sección se exploraran refactorings que hacen interfaces más simples. Con frecuencia lo más
simple y más importante que se puede hacer, es cambiar el nombre de un método, así como el de las
variables y clases cuando sea necesario.
2.5.1. Rename Method
Cuando el nombre del método no revela su propósito, es importante cambiar el nombre del mismo y
esto nos lo facilita el método Rename Method. Ver código 2.5.1.

Catálogo de Refactorizaciones
Capítulo 2 49
Código 2.5.1. Ejemplo del método Rename Method.
2.5.2. Add Parameter
Si un método necesita más información de su(s) propia(s) llamada(s), se puede agregar un parámetro
para el objeto el cual pueda pasar por esta información mediante la refactorización Add Parameter
[FOWLER]. Ver código 2.5.2.
Código 2.5.2. Ejemplo del método Add Parameter.
2.5.3. Remove Parameter
El método Remove Parameter es de gran soporte para los parámetros que no son frecuentemente
usados por el cuerpo de un método, simplemente haya que eliminarlos, como se muestra en la siguiente
imagen. Ver código 2.5.3.
Código 2.5.3. Ejemplo del método Remove Parameter.

Catálogo de Refactorizaciones
Capítulo 2 50
2.5.4. Separate Query From Modifier
Cuando se tiene un método que devuelve un valor y que éste cambia el estado de un objeto, lo mejor
será crear mediante el método Separate Query From Modifier dos métodos, uno para la búsqueda y
otro para la modificación. Ver código 2.5.4.
Código 2.5.4. Ejemplo del método Separate Query From Modifier.
2.5.5. Parameterize Method
Existen diversos métodos que realizan cosas similares pero con diferentes valores contenidos dentro del
cuerpo del método [FOWLER]. En estos casos, es recomendable crear un método que use un parámetro
para los diferentes valores. Ver código 2.5.5.
Código 2.5.5. Ejemplo del método Parameterize Method.
2.5.6. Replace Parameter with Explicit Method
En el caso de que se tenga un método que ejecute código diferente dependiendo de los valores del
parámetro enumerado, se aconseja crear un método independiente para cada valor del parámetro como
se muestra a continuación en el código 2.5.6.

Catálogo de Refactorizaciones
Capítulo 2 51
Código 2.5.6. Ejemplo del método Replace Parameter with Explicit Method.
2.5.7. Replace Parameter with Method
Si un objeto llama a un método que después pasa el resultado obtenido como parámetro para otro
método y finalmente el método receptor puede también invocar al primer método, entonces se tiene
que eliminar el parámetro y dejar que el receptor invoque directamente al otro método para así
ahorrarnos pasos. Ver código 2.5.7.
Código 2.5.7. Ejemplo del método Replace Parameter with Method.

Catálogo de Refactorizaciones
Capítulo 2 52
2.5.8. Introduce Parameter Object
Un grupo de parámetros que de manera natural vayan juntos, representan un problema y de preferencia
hay que reemplazarlos con un objeto mediante el método Introduce Parameter Object. Ver código 2.5.8.
Código 2.5.8. Ejemplo del método Introduce Parameter with Object.
2.5.9. Remove Setting Method
El tiempo de creación de un campo debería estar fijo y nunca alterado [FOWLER]. Con la refactorización
Remove Setting Method se puede eliminar cualquier método de configuración para ese campo y esto se
puede observar en el siguiente cuadro como se puede ver en la figura 2.5.9.
Código 2.5.9. Ejemplo del método Remove Setting Method.
2.5.10. Hide Method
Si un método no está siendo usado por ninguna otra clase, lo recomendable es hacerlo privado
utilizando la refactorización Hide Method. Ver código 2.5.10.
Código 2.5.10. Ejemplo del método Hide Method.

Catálogo de Refactorizaciones
Capítulo 2 53
2.5.11. Replace Error Code with Exception
Cuando un método devuelve un código especial para indicar un error, lo recomendable es hacer el uso
de una excepción en su lugar empleando el método Replace Error Code with Exception. Ver código
2.5.11.
Código 2.5.11. Ejemplo del método Replace Error Code with Exception.
2.6. Generalización.
Se trata de mover métodos entre superclases y subclases o también extraer interfaces a partir de clases
entre otros métodos más.
2.6.1. Pull Up Field
Dos subclases tienen el(los) mismo(s) campo(s). Lo correcto para simplificar código será mover el campo
a la superclase, como se especifica en el siguiente ejemplo el cual emplea la refactorización Pull Up Field.
Ver código 2.6.1.

Catálogo de Refactorizaciones
Capítulo 2 54
Código 2.6.1. Ejemplo del método Pull Up Field.
2.6.2. Pull Up Method
En los casos en los cuales se tengan métodos con resultados idénticos en subclases, se pueden mover los
mismos a una superclase de manera muy fácil implementando el método Pull Up Method. Ver código
2.6.2.
Código 2.6.2. Ejemplo del método Pull Up Method.
2.6.3. Pull Up Constructor Body
En los casos en que existan constructores en subclases con cuerpos en general idénticos, hay que crear
mediante la refactorización Pull Up Constructor Body una superclase constructora, a la cuál llamaremos
desde el método de una subclase, clarificando de ésta manera el código. Ver código 2.6.3.

Catálogo de Refactorizaciones
Capítulo 2 55
Código 2.6.3. Ejemplo del método Pull Up Constructor Body.
2.6.4. Push Down Method
El comportamiento de una superclase es relevante solamente para algunas subclases de esta, así que
hay que moverla hacia las subclases como se puede apreciar dentro del código 2.6.4, el cual hace
referencia al método Push Down Method.
Código 2.6.4. Ejemplo del método Push Down Method.
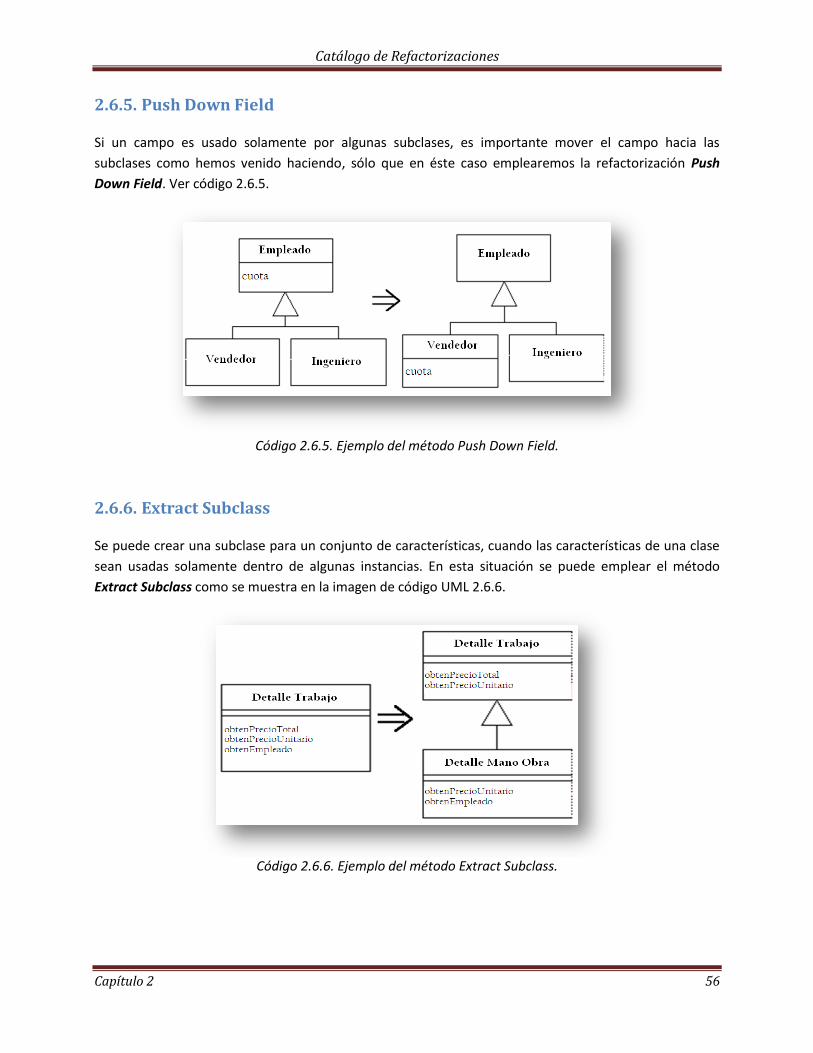
Catálogo de Refactorizaciones
Capítulo 2 56
2.6.5. Push Down Field
Si un campo es usado solamente por algunas subclases, es importante mover el campo hacia las
subclases como hemos venido haciendo, sólo que en éste caso emplearemos la refactorización Push
Down Field. Ver código 2.6.5.
Código 2.6.5. Ejemplo del método Push Down Field.
2.6.6. Extract Subclass
Se puede crear una subclase para un conjunto de características, cuando las características de una clase
sean usadas solamente dentro de algunas instancias. En esta situación se puede emplear el método
Extract Subclass como se muestra en la imagen de código UML 2.6.6.
Código 2.6.6. Ejemplo del método Extract Subclass.

Catálogo de Refactorizaciones
Capítulo 2 57
2.6.7. Extract Superclass
Analicemos el siguiente ejemplo de extracción de superclase en el código 2.6.7. Cuando se tienen dos
clases con características similares, se recomienda crear una superclase para mover ahí las
características comunes, de esa manera hacemos más práctico el código.
Código 2.6.7. Ejemplo del método Extract Superclass.
2.6.8. Extract Interface
Cuando varios clientes usan el mismo subconjunto de la interfaz de una clase o dos clases tienen parte
de sus interfaces en común, lo mejor será extraer el subconjunto en una sola interfaz, pudiendo utilizar
para este caso la refactorización Extract Interface. Ver código 2.6.8.
Código 2.6.8. Ejemplo del método Extract Interface.

Catálogo de Refactorizaciones
Capítulo 2 58
2.6.9. Collapse Hierarchy
Cuando una superclase y una subclase no son muy diferentes, entonces habrá que fusionarlas y así poder
simplificar el código existente. Dentro de la figura 2.6.9 se pude ver como se logra esto con facilidad
aplicando el método Collapse Hierarchy.
Código 2.6.9. Ejemplo del método Collapse Hierarchy.
2.6.10. Replace Inheritance with Delegation
En los casos en donde una subclase solo usa una parte de la interfaz de alguna superclase o ésta no
quiera heredar datos, hay que crear un campo para la superclase, ajustar los métodos para delegar en la
misma y finalmente eliminar a la subclase. Ver código 2.6.10.
Código 2.6.10. Ejemplo del método Replace Inheritance with Delegation.

Catálogo de Refactorizaciones
Capítulo 2 59
2.7. Refactorizaciones Mayores.
Los capítulos anteriores presentaron los movimientos individuales de la refactorización, pero en realidad
¿Qué es lo que falta para completar el sentido general de la refactorización? Se entiende por
refactorizaciones mayores, a la necesidad de aplicar a todo un sistema diferentes refactorizaciones que
complican el proceso, sobre todo cuando se intenta refactorizar un sistema el cual está en uso
constante. Uno de los principales exponentes de la refactorización a gran escala es William Kent, quien
ha aportado gran parte de estos conocimientos al mundo entero [FOWLER].
Desventajas de las refactorizaciones mayores:
Son muy complicados.
Se llevan meses y hasta años en completarse cuando se están empleando.
No siempre se llega al resultado deseado.
Es imprescindible hacerlo en equipo.
Es necesaria la coordinación total del equipo de desarrolladores para lograrlo.
Cuando se refactoriza, se hace por un propósito específico y no solamente por hacerlo. En esta sección
se podrá ver que las refactorizaciones individuales son mucho muy diferentes de las refactorizaciones
mayores, debido a que no se puede decir exactamente qué se debe hacer en cada una de las situaciones
de manera general, pues cada programa es diferente y como tal, arroja resultados diferentes los cuales
no se pueden estandarizar. En este material de apoyo, solo se dan sugerencias de cómo se pueden llevar
al cabo determinadas refactorizaciones, pero será muy diferente en la experiencia individual de cada
desarrollador.
Cuatro refactorizaciones mayores
Existen cuatro ejemplos de refactorizaciones mayores, que se explicarán mediante diagramas
esquemáticos que darán una idea general de cómo y para que funcionan. Estos son:
Separar la herencia (Tease Apart Inheritance).
Conversión del Procedimiento de Diseño a Objetos (Convert Procedural Design to Objects).
Separación del Dominio de la Presentación (Separate Domain from Presentation).
Extraer Herarquía (Extract Hierarchy).

Catálogo de Refactorizaciones
Capítulo 2 60
2.7.1. Separar la Herencia
Este puede verse reflejado en ciertos casos, como lo son cuando se tiene una jerarquía de herencia en
donde se están haciendo dos trabajos a la vez, situación que se puede resolver al crear dos jerarquías y
usar la delegación para invocar a una desde la otra como se puede apreciar en la figura del código 2.7.1.
Código 2.7.1. Ejemplo del método Separar la Herencia.
2.7.2. Conversión del Procedimiento de Diseño a Objetos
Cuando se tiene código escrito en un estilo de procedimiento, hay que colocar los registros de datos
dentro de los objetos, para después deshacer el comportamiento y entonces poder moverlo al objeto.
Ver el código 2.7.2.
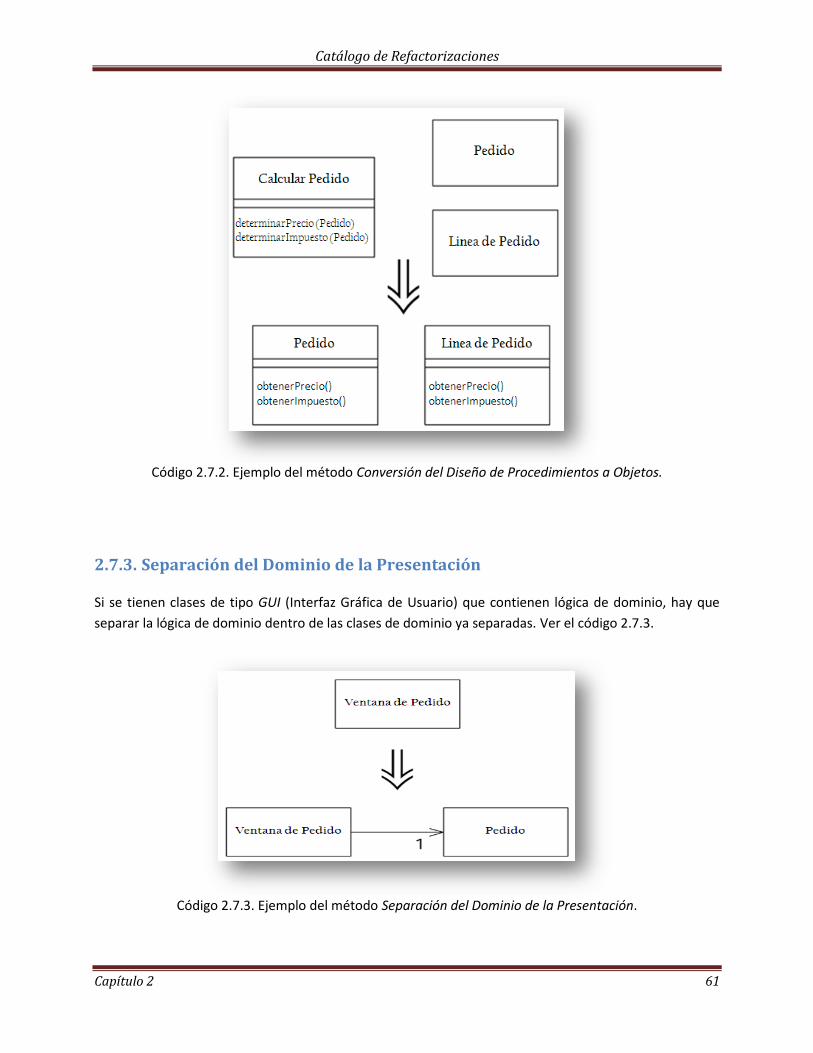
Catálogo de Refactorizaciones
Capítulo 2 61
Código 2.7.2. Ejemplo del método Conversión del Diseño de Procedimientos a Objetos.
2.7.3. Separación del Dominio de la Presentación
Si se tienen clases de tipo GUI (Interfaz Gráfica de Usuario) que contienen lógica de dominio, hay que
separar la lógica de dominio dentro de las clases de dominio ya separadas. Ver el código 2.7.3.
Código 2.7.3. Ejemplo del método Separación del Dominio de la Presentación.

Catálogo de Refactorizaciones
Capítulo 2 62
2.7.4. Extraer Jerarquía
En los casos en donde se tenga alguna clase la cual esté haciendo demasiado trabajo, en gran parte por
declaraciones condicionales mal manejadas, habrá que crear una jerarquía de clases en donde cada
jerarquía represente un caso especial. Ver el código 2.7.4.
Código 2.7.4. Ejemplo del método Extraer Jerarquía.
2.8. Ejercicios
En esta sección se tendrá una lista de ejercicios propuestos para que el alumno ejercite lo aprendido en
el capítulo, y pueda reforzar sus conocimientos sobre refactorizaciones a código.
Ejercicio 1. Aplique la refactorización de Encapsulate Field al siguiente código:
class ExamenDos{ public String romanos[ ]=new String [10]; public Numeros n; }

Catálogo de Refactorizaciones
Capítulo 2 63
Ejercicio 2. Aplique la refactorización de Consolidate Duplicate Conditional Fragments al siguiente código y
escriba el código resultante
public void buscar(String x[][], int num)throws IOException{ int n; String aux; System.out.println("Desea buscarlo por: \n1.Numero \n2.Nombre"); n=Integer.parseInt(lect.readLine()); if ((n==1)||(n==2)){ if (n==1){ System.out.println("\nIngresa el numero: "); aux=lect.readLine(); for (int i=0; i<num; i++){ int a= aux.compareTo(x[i][0]); if(a==0) System.out.println("Empleado: "+x[i][1]+" \tNumero:"+x[i][0]); } } else{ System.out.println("\nEsccribe el nombre del Empleado: "); aux=lect.readLine(); for (int i=0; i<num; i++){ int a= aux.compareTo(x[i][1]); if (a==0) System.out.println("Empleado: "+x[i][1]+" \tNumero:"+x[i][0]); } } }
Ejercicio 3. Aplicar la refactorización de Replace Nested Conditional with Clauses Guard y escriba el código
resultante.
double ObtenerPago() { double resultado; if (EstaMuerto) resultado= CantidadMuerte(); else { if (EstaSeparado) resultado= CantidadSeparado(); else { if (EstaRetirado) resultado=CantidadRetirado(); else resultado=PagoNormal(); } } return resultado; }
Ejercicio 4. En el siguiente código aplique Replace Type Code with Subclasses. Hágalo por pasos.
class Empleado... private int _tipo;

Catálogo de Refactorizaciones
Capítulo 2 64
static final int INGENIERO = 0; static final int VENDEDOR = 1; static final int ADMINISTRADOR = 2; Empleado (int tipo) { _tipo = tipo; }
Ejercicio 5. Aplique Consolidate Conditional Expresion al siguiente código
double incapacidadMonto() { if (_antiguedad < 2) return 0; if (_mesesIncapacidad > 12) return 0; if (_tiempoParcial) return 0; // calcular el monto de incapacidad ...
Ejercicio 6. Aplique en el siguiente código la refactorización de Parameterize Method
protected Dollars SalarioBase() { double result = Math.min(UsoFinal(),100) * 0.03; if (UsoFinal() > 100) { result += (Math.min (UsoFinal(),200) - 100) * 0.05; }; if (UsoFinal() > 200) { result += (UsoFinal() - 200) * 0.07; }; return new Dollars (result); }
Ejercicio 7. Aplicar la refactorización Replace Conditional with Polymorphism en el siguiente código.
public class Metro { private int estado; static final private int PARADO = 0; static final private int EN_MARCHA = 1; static final private int PARANDO = 2; static final private int ARRANCANDO = 3;
public void cambiaEstado() { if(estado==PARADO) { estado = ARRANCANDO; } else if(estado==EN_MARCHA) { estado = PARANDO; } else if(estado==PARANDO) { estado = PARADO; } else if(estado==ARRANCANDO) {

Catálogo de Refactorizaciones
Capítulo 2 65
estado = EN_MARCHA; } else { throw new RuntimeException("Estado desconocido"); } }
}
Ejercicio 8. Considerando el siguiente código aplique la refactorización Switch Statement
public void printIt(Operation op) { String out = "?"; switch (op.type) { case '+': out = "push"; break; case '-': out = "pop"; break; case '@': out = "top"; break; default: out = "unknown"; } System.out.println("operation=" + out); } public void doIt(Operation op, Stack s, Object item) { switch (op.type) { case '+': s.push(item); break; case '-': s.pop(); break; } }
Ejercicio 9. Considerando el siguiente fragmento de código, aplique la refactorización Conditional
Expression.
if (!((score > 700) || ((income >= 40000) && (income <= 100000) && authorized && (score > 500)) || (income > 100000))) reject(); else accept();
Ejercicio 10. Considerando el siguiente fragmento de código, aplique la refactorización Code Duplicated
public class Bird { // ... public void move(Point vector) { x += vector.x % maxX; y += vector.y % maxY;

Catálogo de Refactorizaciones
Capítulo 2 66
} } public class Button { // ... public void setPosition(Point p) { x = p.x; while (x >= maxX) x -= maxX; while (x < 0) x += maxX; y = p.y; while (y >= maxY) y -= maxY; while (y < 0) y += maxY; } }

“Bad Smells” en el Código
Capítulo 3 67
CAPITULO III.
“BAD SMELLS” EN EL CÓDIGO
Con frecuencia se puede analizar código el cual tenga problemas en su
estructura y no precisamente de funcionalidad, dentro de este capítulo se
pretende dar el criterio preciso para determinar cuándo es el momento ideal
para refactorizar, exponiendo algunas indicaciones que señalan cuando hay
problemas que pueden ser resueltos mediante la refactorización.
En el presente capítulo, se plasman los conocimientos de Kent Beck
principalmente obtenidos en la práctica, con conceptos explicados por
Fowler1.
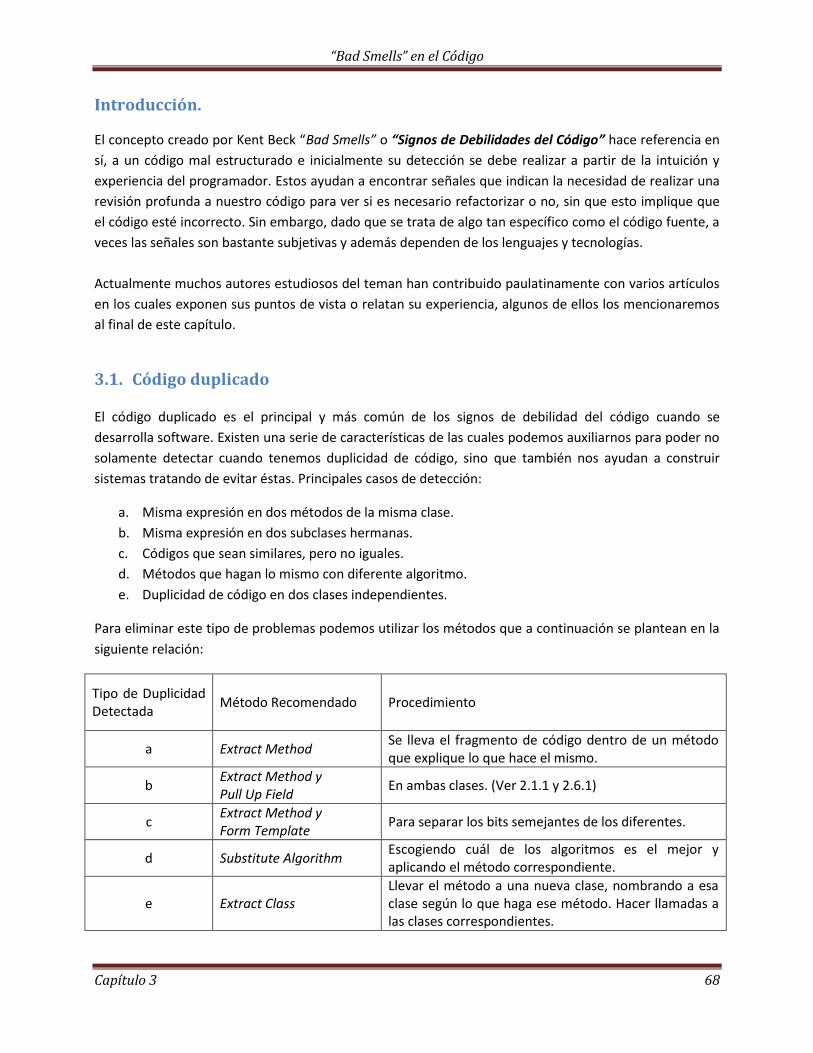
“Bad Smells” en el Código
Capítulo 3 68
Introducción.
El concepto creado por Kent Beck “Bad Smells” o “Signos de Debilidades del Código” hace referencia en
sí, a un código mal estructurado e inicialmente su detección se debe realizar a partir de la intuición y
experiencia del programador. Estos ayudan a encontrar señales que indican la necesidad de realizar una
revisión profunda a nuestro código para ver si es necesario refactorizar o no, sin que esto implique que
el código esté incorrecto. Sin embargo, dado que se trata de algo tan específico como el código fuente, a
veces las señales son bastante subjetivas y además dependen de los lenguajes y tecnologías.
Actualmente muchos autores estudiosos del teman han contribuido paulatinamente con varios artículos
en los cuales exponen sus puntos de vista o relatan su experiencia, algunos de ellos los mencionaremos
al final de este capítulo.
3.1. Código duplicado
El código duplicado es el principal y más común de los signos de debilidad del código cuando se
desarrolla software. Existen una serie de características de las cuales podemos auxiliarnos para poder no
solamente detectar cuando tenemos duplicidad de código, sino que también nos ayudan a construir
sistemas tratando de evitar éstas. Principales casos de detección:
a. Misma expresión en dos métodos de la misma clase.
b. Misma expresión en dos subclases hermanas.
c. Códigos que sean similares, pero no iguales.
d. Métodos que hagan lo mismo con diferente algoritmo.
e. Duplicidad de código en dos clases independientes.
Para eliminar este tipo de problemas podemos utilizar los métodos que a continuación se plantean en la
siguiente relación:
Tipo de Duplicidad Detectada
Método Recomendado Procedimiento
a Extract Method Se lleva el fragmento de código dentro de un método que explique lo que hace el mismo.
b Extract Method y Pull Up Field
En ambas clases. (Ver 2.1.1 y 2.6.1)
c Extract Method y Form Template
Para separar los bits semejantes de los diferentes.
d Substitute Algorithm Escogiendo cuál de los algoritmos es el mejor y aplicando el método correspondiente.
e Extract Class Llevar el método a una nueva clase, nombrando a esa clase según lo que haga ese método. Hacer llamadas a las clases correspondientes.

“Bad Smells” en el Código
Capítulo 3 69
Hasta ahora algunos expertos en la materia de refactorización viendo la necesidad de implementar
ciertas herramientas para auxiliar en la revisión del código, han desarrollado propuestas interesantes
como es el caso de PHPCPD, que es una herramienta que permite detectar código duplicado en scripts
PHP, una utilidad muy interesante sobre todo para aquellos proyectos grandes, en los que hay muchos
archivos y varios programadores involucrados con el código.
El PMD en Java, es otra de las herramientas que permite no solo detectar duplicidad de código, sino
también otro tipo de problemas relacionados con la calidad del mismo. El módulo Copy paste detector de
PMD de Java puede ser ejecutado desde la línea de comando o usando Java Web Start.
PANOPTICODE, es un proyecto dedicado a la toma de métricas de código tan ampliamente entendido,
que eleva la calidad del software en la industria. El proyecto Panopticode, proporciona un conjunto de
herramientas de código abierto para recoger, correlacionar y mostrar métricas de código. Este proyecto
emplea entre sus haberes la herramienta Simian para lo que respecta a la duplicidad de código.
3.2. Métodos grandes
Los mejores programas orientados a objetos y con mayor longevidad, son aquellos que tienen métodos
cortos. Desde los primeros días de la programación, las personas poco a poco se han dado cuenta de que
entre más largos son los procedimientos más difíciles son de entender. Los lenguajes estructurados
llevaban una sobrecarga en las llamadas a subrutinas, los lenguajes Orientados a Objetos aunque
prácticamente han resuelto ese problema porque han eliminado de la cabecera de los programas las
llamadas a los procesos, todavía existe el problema para el lector del código porque tiene que cambiar el
contexto para saber qué es lo que hace el subprocedimiento. Algo que siempre ayudará para evitar en lo
posible este paso, es que los métodos tengan un buen nombre para identificarlos y así no será necesario
revisar el código más adelante.
El programador debe ser mucho más agresivo sobre la descomposición de los métodos. Una forma de
hacer el proceso más claro, es escribir métodos que contengan comentarios de otros métodos y éste
deberá contener la intención de estos métodos pero no cómo interactúan de forma interna, solamente
es para darnos una idea clara de lo que hace un método determinado en cuanto a sus comentarios.
Podemos hacer esto en un grupo de líneas o en una sola línea de código. Lo hacemos incluso si la
llamada al método es más larga que el código al que sustituye, siempre que el nombre del método
explica el propósito del código. Aquí la clave no es la longitud del método, sino la distancia semántica
entre lo que el método hace y cómo lo hace.
Noventa y nueve por ciento de las veces, todo lo que tiene que hacer para acortar un método es emplear
el Extract Method, posteriormente se deben encontrar las partes del método que parecen estar bien
interrelacionadas y hacer un nuevo método.
Si se tiene un método con gran cantidad de parámetros y variables temporales, estos elementos también
se extraen. Si intenta utilizar el Extract Method, muchos de los parámetros y variables temporales

“Bad Smells” en el Código
Capítulo 3 70
terminarán pasando como parámetros hacia el método extraído, haciendo que el resultado sea un poco
más legible que el original. A menudo puede utilizar Replace Temp with Query para eliminar las
variables temporales. Las largas listas de parámetros se pueden afectar principalmente con el método
Introduce Parameter Object. Si se ha hecho todo lo anterior y aún se tienen muchas variables
temporales y parámetros, es momento de aplicar el método Replace Method with Method Object. (Ver
página 34)
¿Cómo identificar los bloques de código para extraer? Una buena técnica es buscar comentarios,
frecuentemente éstos dan la idea de la semántica del código. Un bloque de código con un comentario
que diga lo que está haciendo, puede ser sustituido por un método cuyo nombre haga referencia al
comentario, incluso una sola línea vale la pena extraer si necesita una explicación.
Las condicionales y bucles son también indicativos para hacer extracciones. Se debe usar el método
Descompose Conditional para resolver expresiones condicionales. Con respecto a los bucles, se deberá
extraer el bucle y el código.
3.3. Clases grandes
Cuando una clase está tratando de hacer demasiado, frecuentemente tiene demasiadas variables
instanciadas y cuando esto ocurre, probablemente haya duplicidad de código. La mayoría de las veces
este tipo de clases están íntimamente ligadas con la duplicidad de código.
Se puede usar el método Extract Class para empaquetar un cierto número de variables. Seleccione las
variables que van juntas dentro del componente que tenga sentido para cada una de ellas. En términos
más generales, los prefijos o sufijos comunes para algún subconjunto de variables dentro de la clase
sugieren la posibilidad de un componente.
A veces una clase no utiliza todas sus variables de instancia todo el tiempo, si es el caso, hay la
posibilidad de usar los métodos Extract Class o Extract Subclass muchas veces.
Cuando se trata de una clase larga por duplicidad de código, la solución más sencilla es eliminar la
redundancia en la clase misma. Si se tienen quinientos métodos en línea con las porciones de código en
común, puede ser capaz de convertirlos en cinco métodos de diez líneas, con otros diez métodos de dos
líneas extraídos de los métodos originales. En síntesis, para resolver el problema de una clase que
contenga múltiples variables y extenso código, será aplicar uno de los dos métodos siguientes: Extract
Class o Extract Subclass, también se puede emplear el método Extract Interface en caso de que se
quiera determinar cómo los usuarios utilizan la clase con el propósito de poder fraccionar lo más que se
pueda la misma.

“Bad Smells” en el Código
Capítulo 3 71
3.4. Lista de parámetros excesiva
Desde los primeros días de la programación, aprendimos a pasar dentro de los parámetros todo lo
necesario para una rutina, esto era comprensible porque los datos eran globales; con la Programación
Orientada a Objetos cambió esta situación, sin embargo, existen sistemas que tienen conflicto con su
tamaño, aunque las lista de parámetros tienden a ser mucho menor que en los programas tradicionales,
en muchas ocasiones siguen siendo un problema.
Las listas largas de parámetros son muy difíciles de entender ya que son inconsistentes y por lo mismo es
complicado usarlas, además se tiene que estar modificándolas constantemente cuando se desean más
datos. La mayoría de los cambios se eliminan mediante la transferencia de objetos porque se tiene
mucho más probabilidad de necesitar de solamente un par de peticiones para obtener nuevos datos.
Se puede emplear el método llamado Replace Parameters with Method (Ver página 51), cuando es
posible obtener datos dentro de un parámetro al hacer una petición de un objeto que ya conocemos.
Este objeto puede ser un campo o puede ser cualquier otro parámetro. Si se tienen varios elementos de
datos dentro de un objeto que no es lógico, podemos hacer el uso del método llamado Introduce
Parameters to Object (Ver página 52).
3.5. Característica de la “Envidia”
El punto principal de los objetos, es que son una técnica para agrupar datos con los procesos utilizados
en esos datos. Un “olor” clásico es un método que parece estar más interesado en una clase distinta a la
que el pertenece. El enfoque más común de la envidia son los datos, afortunadamente la solución es
obvia, el método claramente quiere estar en otro lugar, por lo que utilizar el Move Method es la solución
perfecta. Algunas veces sólo una parte del método sufre del problema de la envidia, en cuyo caso se
debe usar el Extract Method en la parte del código que este menos afectada por éste olor y
posteriormente utilizar el Move Method para ubicarla en una posición ideal.
Por supuesto que no todos los casos son fáciles de resolver porque habitualmente un método utiliza
características de varias clases. La heurística que se puede emplear es para determinar qué clase tiene la
mayor parte de los datos y donde ubicar el método con esos datos. Este paso suele ser frecuentemente
más fácil de llevar a cabo si utilizamos el Extract Method.
3.6. Sentencias switch
Uno de los “olores” o signos de debilidad del código más obvios de códigos orientados a objetos, es su
relativa carencia de declaraciones de sentencias switch y el problema con las declaraciones switch es
esencialmente la duplicidad. Con cierta frecuencia se encuentra la sentencia switch dispersa dentro de
un programa en diferentes lugares. Si se desea agregar una nueva cláusula para el switch, se deberán

“Bad Smells” en el Código
Capítulo 3 72
localizar todas estas declaraciones switch y cambiarlas. La Programación Orientada a Objetos con
Polimorfismo brinda una elegante manera de solucionar este problema.
La mayoría de las veces se puede observar que una sentencia switch debe llevarse a cabo con
polimorfismo, sin embargo el problema radica en la pregunta ¿dónde se debe aplicar el polimorfismo?;
frecuentemente, las declaraciones de los switch cambian según el tipo de código y es razonable que el
método o la clase que hospeda el valor sea el lugar preciso para éste, entonces se debe emplear el
Extract Method para tomar la declaración del switch y posteriormente hacer uso del Move Method para
obtenerlo en la clase donde el polimorfismo se necesita. Este es el momento en el que se debe decidir, si
es más conveniente usar el método Replace Type Code with Subclasses ó Replace Type Code with
State/Strategy; cuando finalmente se haya definido la estructura de la herencia, se aplica el método
Replace Conditional with Polymorphism.
El método Replace Parameter with Explicit Methods es una buena opción si sólo se tienen pocos casos
en que se afecta un solo método y no se espera un cambio.
3.7. Jerarquías de herencia paralelas
Las Jerarquías De Herencia Paralelas son en realidad un caso especial de la Shotgun Surgery6. Cada vez
que se crea una subclase de una clase X, hay que crear una subclase de otra clase y éste se puede
identificar por convención de nombres con prefijos. Se puede reconocer este olor porque los prefijos de
los nombres de la clase dentro de una jerarquía son los mismos que los prefijos de otra jerarquía.
La estrategia general a seguir para eliminar la duplicación, es asegurarse de que las instancias de una
jerarquía hagan referencia a las instancias de la otra. Si se utiliza el Move Method y el método Move
Fields, la jerarquía en la clase referenciada desaparece.
3.8. Campos temporales
En ocasiones, se puede observar un objeto en el que una variable se encuentra aislada, sin uso. Este
código es difícil de entender, porque se espera de un objeto que necesite de todas sus variables. Tratar
de entender ¿por qué una variable se encuentra ahí, cuando parece no ser utilizada?, es complicado.
Utilizar el método Extract Class para crear un lugar para las variables temporales, al mismo tiempo que
se debe de poner todo el código involucrado dentro de la clase que se creó. También se puede eliminar
el código condicional mediante el método Introduce Null Object, para crear un componente alternativo
para cuando las variables no sean válidas.
6 Shotgun Surgery o Cirugía de Escopeta es cuando cada vez que se hace un cambio se necesitan modificar muchas clases. No
existe la relación ideal: un cambio nuevo → modificar una única clase.

“Bad Smells” en el Código
Capítulo 3 73
Un caso común de campo temporal, se produce cuando un algoritmo complicado necesita de varias
variables; un factor probable es debido a que el compilador no quiso pasar por una enorme lista de
parámetros, los puso en los campos, pero los campos son válidos sólo mientras se ejecuta el algoritmo.
En este caso se puede utilizar el método Extract Class con estas variables y los métodos que las
requieran. El objeto nuevo es entonces un objeto método [Beck].
3.9. Encadenamiento de mensajes
Se pueden observar en largas líneas de métodos o en secuencias de código como en las cadenas de
mensajes, un cliente pide a un objeto por otro objeto, el cual después pregunta por otro diferente y así
sucesivamente. Navegando de esta manera significa que el cliente está acoplado a la estructura.
Cualquier cambio en las relaciones intermedias ocasionaría que el cliente tenga que cambiar. El
movimiento que se debe emplear aquí es utilizar el método Hide Delegate, pudiéndose usar este en
diferentes puntos dentro de la cadena.
Por principio de cuenta se debe manejar éste en cada objeto en la cadena, pero hacer esto implica
normalmente que cada objeto que se involucre se convierta en un intermediario, también conocido
como Middle Man. Frecuentemente una mejor alternativa, es ver que objeto resultante es el usado, se
debe analizar si es posible usar el Extract Method para tomar un pedazo de código con el cual se pueda
trabajar y posteriormente emplear el Move Method para empujarlo hacia abajo de la cadena. Si varios
clientes de uno de los objetos dentro de la cadena quieren navegar el resto del camino, habrá que
agregar un método que lo permita.
3.10. Clases alternativas con diferentes interfaces
Cuando en el código existan más de un método que haga lo mismo pero tenga asignaciones diferentes
con respecto al otro, se debe aplicar el Rename Method que cambia el nombre de los mismos sin alterar
nada más, sin embargo, esto con frecuencia no es suficiente, así que deberá seguirse empleando el
Move Method para manipular el comportamiento de las clases, hasta que los protocolos sean los
mismos y solo entonces se podrá utilizar el método Extract Method.
3.11. Librerías de clases incompletas
La reutilización de código a menudo es considerada como la finalidad de los objetos. Con los
constructores de clases rara vez se puede entender un diseño hasta que se haya construido la clase en su
mayoría, por lo que los constructores de bibliotecas tienen un trabajo muy complicado. El problema es
que la mayoría de las veces es imposible de modificar una biblioteca de clase para manipularla. Lo
anterior significa que está probado que tácticas como el Move Method son insuficientes.

“Bad Smells” en el Código
Capítulo 3 74
Se tiene un par de herramientas de propósito especial para este trabajo. Si se desea que cierta librería de
clase tenga tan solo un par de métodos, habrá que usar el método Introduce Foreign Method, pero si ahí
se encuentra la mayoría del funcionamiento se deberá utilizar el método Introduce Local Extension.
Artículos relacionados
Mika Mäntylä7 es un investigador de la universidad de Helsinki y es autor de una taxonomía muy
interesante donde agrupa los malos olores en cinco categorías en función del efecto que pueden
provocar dentro del software:
Los Infladores (The Bloaters). Estos agrupan “aromas” o señales que indican el crecimiento excesivo de
algún aspecto que hacen incontrolable el código, entre los cuales están:
Método Extenso (Long Method) que precisa de su reducción para ser más legible y mantenible.
Clase Larga (Large Class), con síntomas y consecuencias muy similares al caso anterior.
Obsesión Por Tipos Primitivos (Primitive Obsession), cuyo síntoma es la utilización de tipos
primitivos para almacenar datos de entidades pequeñas, por ejemplo usar un long para guardar
un número de teléfono.
Lista De Parámetros Larga (Long Parameter List), que incrementan la complejidad de un método
de forma considerable.
Grupos De Datos (Dataclumps), uso de un conjunto de variables o propiedades de tipos
primitivos en lugar de crear una clase apropiada para almacenar los datos, lo que a su vez
provoca el incremento de parámetros en métodos y clases.
Los que abusan de la Orientación A Objetos (The Object-Orientation Abusers), que aglutina problemas
de sintaxis los cuales indican que no se está aprovechando la potencia de este paradigma:
Sentencias Switch (Switch Statements), que podrían indicar una falta de utilización de
mecanismos de herencia.
Campo Temporal (Temporary Field), que se salta el principio de encapsulamiento y ocultación de
variables haciendo que éstas pertenezcan a la clase cuando su ámbito debería ser
exclusivamente el método que las usa.
Rechazo Del Legado (Refused Bequest), cuando una subclase “rechaza” métodos o propiedades
heredadas, atentando directamente contra uno de los principales pilares de la POO.
Clases Alternativas Con Distintas Interfaces (Alternative Classes With Different Interfaces) indica
la ausencia de interfaces comunes entre clases similares.
Los Impedidores de Cambios (The Change Preventers)
Cambio Divergente (Divergent Change), que hace que sean implementadas dentro de la misma
clase funcionalidades sin ninguna relación entre ellas, lo que sugiere extraerlas a una nueva
clase.
7 “¿A qué huele tú código?” autor: José M. Aguilar; Publicado en: http://www.variablenotfound.com/

“Bad Smells” en el Código
Capítulo 3 75
Cirujía De Escopeta (Shotgun Surgery), ocurre cuando un cambio en una clase implica modificar
varias clases relacionadas.
Jerarquías De Herencia Paralelas (Parallel Inheritance Hierarchies), paralelismo que aparece
cuando cada vez que se crea una instancia de una clase es necesario crear una instancia de otra
clase, uniendo ambas en una única clase final.
Los Prescindibles (The Dispensables), pistas aportadas por porciones de código innecesarias que podrían
y deberían ser eliminadas:
Clase Holgazana (Lazy Class), una clase sin apenas responsabilidades que hay que dotar de
sentido, o bien eliminar.
Clase De Datos (Data Class), cuando una clase sólo se utiliza para almacenar datos, pero no
dispone de métodos asociados a éstos.
Código Duplicado (Duplicate Code), presencia de código duplicado que dificulta enormemente el
mantenimiento.
Código Muerto (Dead Code), aparición de código que no se utiliza, probablemente procedente
de versiones anteriores, prototipos o pruebas.
Generalización Especulativa (Speculative Generality), ocurre cuando un código intenta
solucionar problemas más allá de sus necesidades actuales.
Los Emparejadores (The Couplers), son malos olores que alertan sobre problemas de acoplamiento de
componentes, a veces excesivo y otras veces demasiado escaso.
Característica de la envidia (Features Envy), aparece cuando existe un método de una clase que
utiliza de manera excesiva métodos de otra clase y podría sugerir la necesidad de moverlo a ésta.
Intimidad Inapropiada (Inappropriate Intimacy), ocurre cuando dos clases se conocen
demasiado y se usan con demasiada confianza, a veces de forma inapropiada (con la acepción
POO del término ;-))
Cadenas de Mensajes (Message Chains), mal olor desprendido por código que realiza una
cadena de llamadas a métodos de clases distintas utilizando como parámetros el retorno de las
llamadas anteriores, como A.getB().getC().getD().getTheNeededData(), que dejan entrever un
acoplamiento excesivo de la primera clase con la última.
Intermediario (Middle Man), que cuestiona la necesidad de tener clases cuyo único objetivo es
actuar de intermediario entre otras dos clases.
Es cierto que existen mil y una formas de escribir código y que además está sujeto a la lógica muy
personal de cada programador. Basado en este precepto, Jeff Bay8 en su artículo llamado Object
Calisthenics sugiere 9 reglas a seguir para construir software de calidad.
1. Usa solo un nivel de indentación por método (Use only one level of indentation per method).
2. No uses el “else” dentro de una condicional (Don’t use the else keyword).
8 Jeff Bay publicó “Object Calisthenic” en el cual propone el ejercicio de elaborar un programa de 1000 líneas siguiendo estas
reglas estrictamente (verán que son terriblemente restrictivas) con el objetivo de mejorar la orientación a objetos de nuestro código.

“Bad Smells” en el Código
Capítulo 3 76
3. Usa Wrappers para los tipos primitivos y las cadenas (Wrap all primitives and strings)
4. Solo usa un punto por línea (Use only one dot per line).
5. No abrevies (Don’t abbreviate).
6. Mantén las entidades pequeñas (Keep all entities small)
7. No utilices una clase que tenga más de 2 variables de instancia.(Don’t use any classes with more
than two instance variables)
8. Una clase que contenga una colección no debe contener otras variables de instancia (Use first-
class collections).
9. No use propiedades de los setters y getters (Don’t use any getters/setters/properties).
Obviamente estas reglas son bajo cierto criterio y lógica de un punto de vista determinado, de las cuales
debemos seguir las que mejor nos acomode ya que son solamente sugerencias.
Hay una gran diversidad de herramientas disponibles en ambientes Java para recopilar métricas de
código. Estas herramientas pueden ser de incalculable valor para tareas tales como:
- Establecimiento de prioridades y refactorización.
- Comprender las bases de código grande desconocido.
- Garantizar que los estándares de codificación se estén siguiendo.
- Evaluación de la calidad del software.
- Informes y toma de decisiones para la reescritura del código contra código nuevo.
- Demostrar que las obligaciones contractuales se han cumplido.
- Comparación de las herramientas de la competencia.
Aunque estas herramientas son de gran alcance, sufren de una serie de problemas, sin embargo se están
creando proyectos como el PANOPTICODE que fue concebido para abordar todos los problemas que
hasta el momento la mayoría de las herramientas conllevan.
Algunas de las herramientas que hasta ahora existen para ambientes Java son:
Emma
CheckStyle
JDepend
JavaNCSS
Simian
Subversion
Cobertura

“Bad Smells” en el Código
Capítulo 3 77
3.12. Ejercicios
En esta sección se tendrá una pequeña lista de ejercicios propuestos para que el alumno ejercite lo
aprendido en este capítulo y pueda reforzar sus conocimientos sobre las detecciones de anomalías en el
código.
Ejercicio 1. Subraye cuando puede ocurrir el defecto llamado “Envidia” (Feature Envy).
Los objetos empaquetan datos con los procesos que usan esos datos.
Método que parece más interesado en otras clases que en la que actualmente se encuentra.
Existen patrones de diseño que provocan este defecto para controlar el cambio divergente,
Estrategia, Visitor...
Posibles refactorizaciones: Extract Method y Move Method.
Ejercicio 2. Subraye cuales de las siguientes opciones hacen referencia a la anomalía “Código Duplicado”
(Duplicated Code).
Misma expresión en el mismo método.
Misma expresión de dos métodos de la misma clase.
Misma expresión en dos subclases.
Misma expresión en clases no relacionadas.
Posibles refactorizaciones: Extract Method, Extract Class, Pull Up Method, Form Template
Method.
Ejercicio 3. En el siguiente código subraye en que líneas se encuentra “Código Duplicado”.
public class Network{ public boolean requestWorkstationPrintsDocument(String workstation, String document, String printer, Writer report) {
boolean result = false; Node startNode, currentNode; Packet packet = new Packet(document, workstation, printer); startNode = (Node) workstations_.get(workstation); report.write("\tNode '"); report.write(startNode.name_); report.write("' passes packet on.\n"); report.flush(); currentNode = startNode.nextNode_; while ((! packet.destination_.equals(currentNode.name_))
& (! packet.origin_.equals(currentNode.name_))) { report.write("\tNode '"); report.write(currentNode.name_); report.write("' passes packet on.\n");

“Bad Smells” en el Código
Capítulo 3 78
report.flush(); currentNode = currentNode.nextNode_;
}; if (packet.destination_.equals(currentNode.name_)) {
result = printDocument(currentNode, packet, report); } else {
report.write(">>> Destinition not found, print job cancelled.\n\n"); report.flush(); result = false;
} return result;
} }
Ejercicio 4. Defina el significado del defecto llamado “Cirugía Escopeta” (Shotgun Surgery).
Cada vez que se hace una clase de cambio se necesita modificar muchas clases.
No existe la relación ideal: un nuevo cambio -> modificar una única clase.
Ejercicio 5. Subraye la definición de “Jerarquías Paralelas” (Parallel Inheritance Hierarchies).
Caso especial de shotgun surgery.
Si cada vez que se crea una subclase de una clase X, hay que crear una subclase de otra clase Y.
Se puede identificar por convención de nombres con prefijos.
No siempre es un problema; el patrón Fábrica Abstracta.

Reestructuración, Reuso y Realidad
Capítulo 4 79
CAPITULO IV.
REESTRUCTURACIÓN, REUSO Y
REALIDAD
En este capítulo se analizan algunos aspectos relativos a la aplicación de la
refactorización en el mundo real y hacia dónde se dirige actualmente ésta
técnica. Asimismo, se describe el reuso como parte intrínseca de la
refactorización de código y como resultado de un claro y sencillo desarrollo de
software.

Reestructuración, Reuso y Realidad
Capítulo 4 80
El problema de abordar una refactorización es que supone un esfuerzo que no se ve compensado por
ninguna nueva funcionalidad y por ese motivo muchas veces es complicado de justificar. Sin embargo, si
introducimos la refactorización como parte del desarrollo conseguiremos que nuestro código sea de
calidad y la experiencia dice que este tiempo que vamos empleando a lo largo del desarrollo, será
recuperado con creces según el avance proyecto.
Se puede afirmar que refactorizar nos facilita enormemente el mantenimiento de un código siempre
correctamente estructurado. El hecho de que el código esté bien estructurado, es una ventaja por su
mantenibilidad, extensibilidad y reuso. Sin embargo, esta técnica que parece tan ventajosa, requiere de
su aplicación continua, el empleo de pruebas que proporcionen seguridad a su aplicación, un buen
conocimiento de los patrones de diseño9 permite al desarrollador saber hacia dónde camina y abren la
posibilidad de la comunicación con todos los miembros del equipo.
4.1. Rechazo a la reestructuración
Los desarrolladores de software tienen que entender el problema que su sistema está intentando
resolver, encontrar la solución y lograr que el cliente esté totalmente satisfecho con los resultados
logrados. Este sería el escenario ideal, lo cual casi es un sueño.
Sin embargo, lo más frecuente que ocurre es que el desarrollador tiene una baja comprensión de que
está haciendo o que debería hacer, está bajo presión para producir código y por supuesto, si el sistema
que tiene en sus manos no es algo que él creó o quizá sea la primera vez que lo ve, obviamente la
refactorización no está ni remotamente por sus pensamientos. ¿Qué puede hacer ante esto?
La refactorización es una manera de reestructurar el software para hacer el diseño más explícito, para
desarrollar estructuras y extraer componentes reusables o para clarificar la arquitectura de software y
prepararla para realizar adiciones más fácilmente. Estas son ventajas muy deseables para cualquier
desarrollador pero, ¿porque ni aun así refactorizan sus programas?
Según Fowler, la mayoría de los desarrolladores de software no entienden como refactorizar, cuando se
debe realizar y en algunos casos, ni siquiera han escuchado el término para comprender realmente lo
que se debe hacer. Debido a esto, lo primero que hay que hacer es entender cómo y dónde se
Refactoriza.
4.1.1. Comprensión del “cómo” y “dónde” se refactoriza
Lo primero que hay que establecer es que se debe tener conocimiento de qué significa realmente
refactorizar, conocer las técnicas y herramientas existentes y cuando deben ser aplicadas. El catálogo
9 Patrones de diseño o más comúnmente conocidos como "Design Patterns", son soluciones simples y elegantes a problemas
específicos y comunes del diseño orientado a objetos. Son soluciones basadas en la experiencia y que se ha demostrado que funcionan. [FOWLER, Analysis Patterns]

Reestructuración, Reuso y Realidad
Capítulo 4 81
propuesto por Martín Fowler, son un buen inicio y también revisar la tesis de Opdyke y otros autores
relevantes al tema como lo son Joshua Kerievsky (Refactoring to Patterns) y Ralph E. Johnson
(Refactoring and Aggregation). A partir del 2007 se han realizado anualmente Reuniones de Trabajo
Sobre Herramientas de Refactorización, donde se exponen tanto herramientas como avances en el tema
de Refactorización. Esto debe ser información que todo desarrollador de software debe conocer.
Ahora, dado un programa o proyecto existente sobresalta la pregunta, ¿Debería aplicarse alguna
refactorización?, esto depende de los objetivos que se tengan. Una razón muy común para aplicar
refactorización es reestructurar el programa para hacer más fácil el añadir nuevas características.
Aunque generalmente el mantenimiento al software es una de las razones más poderosas para realizar la
refactorización, también existen muchísimas razones más para hacerlo.
Por otro lado, una herramienta automatizada puede ser usada para identificar debilidades estructurales
en un programa, tales como funciones que tienen un número excesivamente elevado de argumentos o
son demasiado grandes. Estas funciones son candidatas para refactorizar. También existen casos más
complejos que pueden ser detectados y corregidos con una herramienta automatizada, por tanto, las
herramientas pueden sugerir refactorizaciones que mejoren el diseño del programa y donde aplicarlas.
Sin embargo, el programador es el que finalmente decide cuales recomendaciones sugeridas aplicará al
programa, sabiendo que esos cambios deberían mejorar la estructura del mismo.
Antes de que los programadores puedan convencerse de que deben refactorizar el código, necesitan
entender cómo y dónde refactorizar como ya se había mencionado. Las herramientas automatizadas
pueden analizar la estructura de un programa y sugerir refactorizaciones que pueden mejorar la
estructura. Pero éstas pueden ayudar solo si son usadas. Lo que es claro, es que si los programadores
refactorizan su código, su comprensión con respecto del programa aumentará.
4.1.2. Miedo a las herramientas de refactorización
Un aspecto importante a considerar es el miedo que se tiene a todo conocimiento nuevo, sobre todo si
no ha habido buena experiencia en ello. En el WRT’0710 se tuvo un foro de discusión y entre muchas
otras cosas se habló de por qué los desarrolladores no terminaban de usar las herramientas de manera
extensiva. Se especuló sobre la calidad de las herramientas, la facilidad de uso, el hábito de los
desarrolladores, la velocidad de hacerlo con la herramienta vs. hacerlo a mano, los tipos de
refactorización que la herramienta puede hacer, la capacidad de respetar los comentarios y los espacios
en blanco y por supuesto, de lo confiable que son.
En el taller se fueron más hacia el hábito de los programadores, la facilidad de uso y lo “bonito” que
queda la herramienta en pantalla. Sin embargo al finalizar el foro, se concluyó que el problema
fundamental es otro.
10
Memorias de 1st
Workshop on Refactoring tools, Julio 31 del 2007 en Technical University de Berlin, https://netfiles.uiuc.edu/dig/RefactoringWorkshop/

Reestructuración, Reuso y Realidad
Capítulo 4 82
Una herramienta se utiliza cuando le facilita mucho más el trabajo a la persona que lo utiliza, es decir,
la herramienta es capaz de solucionar un problema que el usuario tiene de una manera más fácil, con
menos tiempo y con menor esfuerzo. Si la herramienta no es lo suficientemente buena, está incompleta,
sólo es aplicable a ciertos casos, es dificil de manejar, etc., esta no se llegará a usar por el usuario.
La mayoría de las herramientas de refactorización no están lo suficientemente avanzadas todavía y
tienen mucho camino por delante hasta llegar a ser herramientas imprescindibles para el programador.
Lo que más sobresalta en ellas es que no cubren todos los tipos de refactorizaciones (y esto lleva al
usuario a tener que hacer algunas manuales, por lo que si hace una, ¿por qué no hacer otras?) y sobre
todo, es que no son seguras al 100% en algunos tipos de refactorizaciones que son capaces de hacer.
4.1.3. Refactorizar es una sobrecarga de trabajo
Uno de los puntos que según Fowler, es afirmado por muchos programadores sobre el porqué del
rechazo a la refactorización, es que la consideran una actividad de sobrecarga, pues el pago de su trabajo
no lo incluye y por tanto, no se considera como parte de su trabajo habitual.
Esto se podría justificar como sigue:
a. Las tecnologías y las herramientas están disponibles para permitir que la refactorización sea
hecha rápidamente y relativamente “sin dolor”.
b. Las experiencias reportadas por algunos programadores sugieren que la sobrecarga de
refactorización es más que compensada por la reducción de esfuerzos e intervalos en otras fases
del desarrollo del programa.
Si la refactorización se realiza como parte del proceso de desarrollo de software, no se sentirá que es
una tarea extra, esta afirmación es fácil de hacer pero difícil de corroborar. Para los escépticos y
temerosos, Fowler aconseja que sólo lo hagan y luego decidan por sí mismos.
4.2. Implicaciones concernientes al reuso de software
Actualmente no solo se habla de refactorización en el ámbito de programadores, también el reuso de
código y la evolución del mismo, son puntos importantes para el desarrollo de software.
Realmente los problemas que se presentan en el reuso de software son similares a aquellos encontrados
en la refactorización. Por ejemplo:
- El equipo técnico puede no entender cómo se debe reutilizar o cuándo se debe reutilizar.
- El equipo técnico puede no motivarse a aplicar métodos de reuso a menos que puedan lograr
beneficios a corto plazo.

Reestructuración, Reuso y Realidad
Capítulo 4 83
- El adoptar un enfoque de reutilización, no deben ser perjudicial para un proyecto, ya que puede
parecer que existe mucha presión por aprovechar códigos o software ya existente. Las nuevas
implementaciones deben ser compatibles con el software realizado anteriormente para que este
enfoque de reuso tenga éxito.
Aplicar el reuso de software es similar a la aplicación de refactorización, ya que se requiere un proceso
detallado y bien planeado. Se requiere la planeación de una estrategia con los ejecutivos, equipo de
liderazgo, consultar con los jefes de proyectos de desarrollo, y dar a conocer los beneficios de estas
tecnologías a través de seminarios y publicaciones.
También es indispensable capacitar al personal en cuanto a los principios de ambos enfoques, los
beneficios que se lograrían y cómo estas técnicas ayudarían a introducir condiciones de mayor
seguridad.
Cabe hacer notar que lo anterior no se aplica solo a la refactorización de código y reutilización de
software, sino que son cuestiones genéricas de transferencia de tecnología, la cual es difícil, pero se ha
comprobado que se puede hacer.
4.3. La realidad de la reestructuración
En el mundo real de los desarrolladores de software, se pueden asumir las siguientes afirmaciones como
un sentir general respecto a la refactorización de código.
a. Los programadores pueden no haber entendido cómo refactorizar su código.
b. Si los beneficios son a largo plazo, ¿Por qué hacer el esfuerzo ahora? En el tiempo en que se
tengan los beneficios, quizás ya no se tenga relación alguna con el proyecto.
Refactorizar código es una tarea extra, es una actividad que sobrecarga de trabajo al desarrollador y a
éste solo se le paga por escribir nuevas funciones de código.
c. Refactorizar podría “tronar” el programa ya existente, o generarle problemas.
Según [Opdyke] en el ámbito profesional existen algunas preguntas que son motivo de preocupación
entre los desarrolladores de proyectos:
1. ¿Qué pasa si el código a refactorizar es de uso colectivo, es decir, es utilizado por varios
programadores?
En algunos casos, muchos de los mecanismos tradicionales de la gestión de cambios son
relevantes e indispensables. En otros casos, si el software fue bien diseñado y refactorizado, los
subsistemas serán lo suficientemente desacoplados, que la mayoría de las refactorizaciones
afectarán solo a pequeños subconjuntos del código base.

Reestructuración, Reuso y Realidad
Capítulo 4 84
2. ¿Qué pasaría si existen varias versiones de un código base?
En algunos casos, la refactorización puede ser pertinente para todas las versiones, en cuyo caso
todas las versiones deberían ser verificadas por seguridad, antes de que la refactorización sea
aplicada. En otros casos, la refactorización podría ser relevante para solo algunas versiones, lo
que simplificaría el proceso de verificación y refactorización del código.
La gestión de cambios a múltiples versiones a menudo requiere aplicar muchas de las técnicas
tradicionales de administración de versiones.
4.3.1. Refactorización en el ITM
Realizando una pequeña investigación en el Instituto Tecnológico de Morelia en el ámbito de desarrollo
de software, se encontraron algunos puntos que son interesantes dentro de este trabajo.
a. La mayor parte de los desarrolladores de software (profesores, alumnos e investigadores) no
conocen el catálogo de refactorizaciones propuestos por Fowler.
b. Todos han escuchado el término de reestructuración (o refactorización) de código dentro de su
ámbito de trabajo pero no lo aplican de forma consiente.
c. Ninguno de los encuestados utilizan las pruebas unitarias para comprobar su código o sus
refactorizaciones.
d. Existe interés por parte de los programadores o desarrolladores de software, pero no cuentan
con el tiempo para hacerlo, a pesar de saber que tendrían ventajas con ello.

Reestructuración de Código
Ingeniería de Software 85
Referencia Bibliográfica.
[FOWLER] Refactoring Improving the Design of Existing Code. 01/01/1999; ISBN: 978-0-201-48567-7;
Addison-Wesley Publishers B.V.
[JETBRAINS, ACADEMY DEVELOPMENT] www.jetbrains.com/devnet/academy/concepts/index.html; 13-
12-2009.
[KENT BECK] Embrace Change. Extreme programming; ISBN: 978-0-321-27865-4; 16-11-2004; Pearson
Education.
[QUANTUM] www.quantum3.co.za/CI%20Glossary.htm Glosario inteligente. 16-11-2009.
[FOWLER] Analysis Patterns Reusable Object Models., Addison-Wesley Professional; 1st
edition (October 9, 1996), ISBN: 978-0201895421.
[ANDREW GLOVER] In pursuit of code quality. Refactoring with code metrics.
http://www.ibm.com/developerworks/java/library/j-cq05306/; 30-05-2006; On-target refactoring with
code metrics and the Extract Method pattern
[JOSHUA KERIEVSKY] Refactoring to Patterns, ISBN: 978-0321213358; Pearson Education; 05-08-2004.
[RALPH E. JOHNSON] Refactoring and Aggregation Ralph E. Johnson y William F. Opldyke; ISBN: 978-3-
540-57342-5; 21-01-2006; http://www.springerlink.com/content/f6358qv33170768h.
[E. Murphy-Hill and A. P. Black] Refactoring tools: Fitness for purpose. IEEE Software, 25(5):38–44,
2008.

Reestructuración de Código
Anexo A 86
ANEXO A. Ejemplo de Refactorización
Cuando tenemos un código mal diseñado, podemos mediante la
refactorización transformarlo en un programa fácil de entender aplicando tan
solo ciertos pasos simples. Estos paso no son más que pequeños cambios
estructurales que afectan de manera positiva al código, como por ejemplo,
llevando un campo de una clase a otra o quizá extrayendo algo de código
fuera de un método determinado, para convertirlo en su propio método o
incluso, aplicando un poco de jerarquía al mismo, etc. Al llevar a cabo estos
pequeños cambios, podremos mejorar radicalmente el diseño de nuestro
código.

Reestructuración de Código
Anexo A 87
El programa debe servir para calcular e imprimir un estado de cuenta de gastos del cliente en una tienda
de videos. El programa menciona cuales películas rentó un cliente y por cuánto tiempo. Después, se
calculan los gastos que dependen de cuánto tiempo se alquila la película e identifica el tipo de película.
Existen tres tipos de películas: las generales, las infantiles y los estrenos. Además de calcular los cargos,
el estado de cuenta también puede mencionar los puntos generados por rentas frecuentes, que varían
dependiendo de si la película es de estreno o no.
En el siguiente diagrama de clases se muestran diversos elementos de un video club con diagramas UML.
Clase Pelicula
La clase Pelicula, es una simple clase de datos.
public class Pelicula { public static final int INFANTILES = 2; public static final int GENERALES = 0; public static final int ESTRENOS = 1; private String _titulo; private int _precioDelCodigo; public Pelicula(String titulo, int precioDelCodigo) { _titulo = titulo; _precioDelCodigo = precioDelCodigo; } public int getPrecioDelCodigo () { return _precioDelCodigo; } public void setPrecioDelCodigo (int arg) { _precioDelCodigo = arg; } public String getTitulo (){ return _titulo; } }
1
Película
precioDelCodigo:int
Cliente
estadoDeCuenta ( )
1 *
*
Renta
diasRentados:int

Reestructuración de Código
Anexo A 88
Clase Renta
La clase Renta, representa a un cliente rentando una película, como se muestra a continuación.
class Renta { private Pelicula _pelicula; private int _diasRentados; public Renta(Pelicula pelicula, int diasRantados) { _pelicula = pelicula; _diasRentados = diasRentados; } public int getDiasRentados() { return _diasRentados; } public Pelicula getPelicula() { return _pelicula; } }
Clase Cliente
La clase Cliente, representa al cliente de la tienda. Como las otras clases, ésta tiene datos y accesos.
class Cliente { private String _nombre; private Vector _rentas = new Vector(); public Cliente (String nombre){ _nombre = nombre; }; public void addRenta(Renta arg) { _rentas.addElement(arg); } public String getNombre (){ return _nombre; };
La clase Cliente también tiene un método que produce un Estado de Cuenta. La Figura A1.1 describe la
interacción para este método y se muestra a continuación.
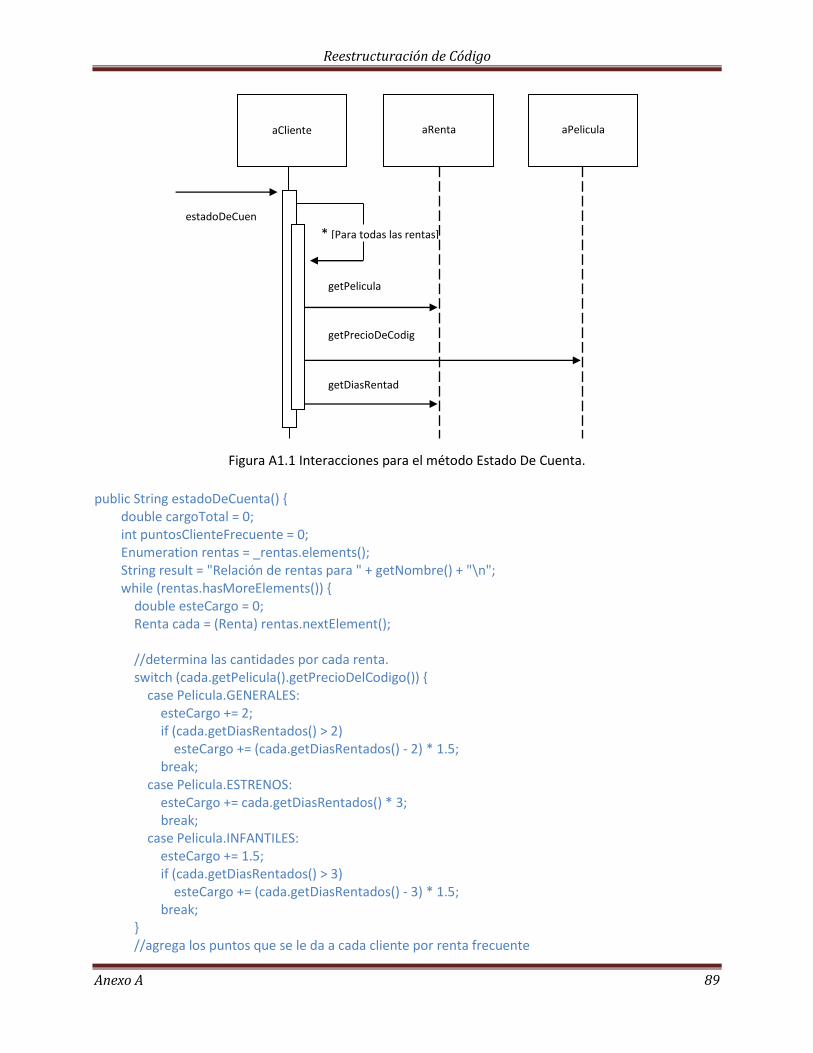
Reestructuración de Código
Anexo A 89
Figura A1.1 Interacciones para el método Estado De Cuenta.
public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { double esteCargo = 0; Renta cada = (Renta) rentas.nextElement(); //determina las cantidades por cada renta. switch (cada.getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: esteCargo += 2; if (cada.getDiasRentados() > 2) esteCargo += (cada.getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: esteCargo += cada.getDiasRentados() * 3; break; case Pelicula.INFANTILES: esteCargo += 1.5; if (cada.getDiasRentados() > 3) esteCargo += (cada.getDiasRentados() - 3) * 1.5; break; } //agrega los puntos que se le da a cada cliente por renta frecuente
aCliente
aRenta
aPelicula
estadoDeCuen
ta * [Para todas las rentas]
getPelicula
getPrecioDeCodig
o
getDiasRentad
os

Reestructuración de Código
Anexo A 90
puntosClienteFrecuente ++; //agrega los bonos por dos días de rentas de estreno if ((cada.getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENO) && cada.getDiasRentados() > 1) puntosClienteFrecuente ++; //muestra las cifras por este alquiler (incrementa los puntos) result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(esteCargo) + "\n"; cargoTotal += esteCargo; } //agrega líneas de pié de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + " Puntos de Cliente Frecuente"; return result; } }
Primer análisis del programa
El programa no está bien diseñado y definitivamente no es orientado a objetos. Para un simple programa
como este, el no ser orientado a objetos y no tener un buen diseño no parece tener importancia, pero
que pasaría si se tratara de un fragmento representativo de un sistema más complejo, entonces se
tendrían algunos problemas reales con este código. El método estadoDeCuenta dentro de la clase
Cliente, es demasiado largo y muchas de las cosas que hace, deberían realmente hacerse por otras
clases.
Sin embargo, el programa funciona ya que al compilador no le importa si el código está mal o bien
estructurado. Un sistema mal diseñado es difícil de cambiar, porque es complejo determinar donde son
necesarios los cambios y donde no lo son, entonces hay una gran posibilidad que el programador pueda
equivocarse o pueda introducir errores sin darse cuenta.
En este caso se propone un cambio que a los usuarios finales les gustaría experimentar. En primer lugar
los usuarios quieren un estado de cuenta que pueda ser accesado como un HTML, de manera que el
estado de cuenta pueda ser habilitado y actualizado desde la web. Debe considerarse el impacto de este
cambio. Si observamos, en el código se puede ver que es imposible reutilizar cualquiera de los
comportamientos del actual método estadoDeCuenta para un estado de cuenta en HTML; lo único que
hay que hacer, es escribir un método totalmente nuevo que duplique la mayor parte del
comportamiento del método estadoDeCuenta actual. Ahora, esto no es demasiado complicado, porque
se puede copiar simplemente el método estadoDeCuenta y hacer los cambios que se necesiten.

Reestructuración de Código
Anexo A 91
Pero ¿qué sucede cuando la política de costos cambia?, en realidad se tiene que garantizar y asegurar
que las correcciones sean consistentes tanto en el método estadoDeCuenta como en el método
htmlEstadoDeCuenta. Existe la posibilidad de copiar y pegar el código cuando se necesita cambiar el
código en cualquier momento. Si escribimos un programa que no se piensa cambiar o modificar, cortar y
pegar esta bien, pero si el programa es de vida larga y es probable que requiera algún cambio posterior,
cortar y pegar ocasionará muchos problemas.
Después de considerar el posible cambio anterior, nos enfrentamos a un segundo cambio. Los usuarios
quieren clasificar las películas, pero aún no han decidido sobre cómo hacerlo o que consideraciones
tomar para hacer estas clasificaciones. Tienen una serie de modificaciones en mente y estas alteraciones
afectan tanto a la manera en que los clientes pagan las películas como la manera en que se calculan los
puntos de rentas de los clientes frecuentes. Como desarrollador de software, se debe estar seguro de
que cualquier programa que se haga llegar a los usuarios, la única garantía que se tendrá, será que los
usuarios lo cambiarán de nuevo dentro de seis meses o quizá antes, según las necesidades que se
presenten.
El método estadoDeCuenta, es el preciso lugar en donde los cambios deberán ser realizados para hacer
frente a las modificaciones en clasificaciones y políticas de costos, sin embargo si copiamos el método
estadoDeCuenta a un htmlEstadoDeCuenta, tenemos que estar completamente seguros de que los
cambios sean consistentes. Además, como las normas se vuelven más complejas, será más difícil
averiguar el lugar exacto en donde se deberán hacer estas modificaciones y todavía más difícil llevarlas a
cabo, sin cometer algún error.
Es importante hacer el menor número posible de cambios al programa, después de todo, funciona bien.
El viejo adagio de ingeniería nos dice que "si no está roto, no lo arregles", o “si funciona, no lo toques”.
Quizá el programa no esté roto, pero está lastimado, así que es aquí justamente donde entra la
refactorización.
Sugerencia
Cuando se necesita agregar una función al código y éste no está estructurado en una forma conveniente
para añadir la misma, la primera refactorización al programa hará que sea más fácil de añadir la función
y después se podrá agregar ésta sin problema alguno. [Fowler]
Primeros pasos de refactorización
Cuando se desea hacer refactorización el primer paso siempre es el mismo, necesitaremos construir un
conjunto sólido de pruebas para la sección del código. Las pruebas son esenciales porque aunque
sigamos refactorizaciones estructuradas, éstas nos dan la oportunidad de evitar a toda costa la
introducción de errores.
Como resultado de la primera refactorización, el método estadoDeCuenta produce una cadena y para
comprobarlo, creamos pocos clientes, damos a cada cliente pocas rentas de diferentes tipos de películas
y generamos la cadena del estadoDeCuenta, posteriormente hacemos comparación de cadenas entre la

Reestructuración de Código
Anexo A 92
nueva cadena y alguna cadena de referencia que tenga que comprobarse manualmente y por último,
tomamos todas estas pruebas para poder correrlas con un comando de Java en línea de comandos. A las
pruebas les toman pocos segundos ejecutarse, así que como recomendación no se debe escatimar en
tiempo para hacer uso de ellas frecuentemente.
Una parte importante de las pruebas, es la manera en que informan los resultados. Si cualquiera de las
pruebas arroja un “OK”, quiere decir, que todas las cadenas son idénticas a la cadena de referencia o
pueden imprimir una lista de fallas, éstas serán las líneas que resultaron diferentes. Las pruebas son por
consiguiente de auto control. Es vital hacer el uso de pruebas auto controladas, porque si no se usan,
terminaremos pasando el tiempo comparando manualmente algunos números que vienen de la prueba
contra algunos números de una corrida de escritorio y eso es estresante, así que vale la pena usarlas
porque éstas nos dan la seguridad que necesitamos para cambiar más tarde el programa.
Sugerencia
Antes de empezar a refactorizar, debemos asegurarnos de tener un conjunto sólido de pruebas. Estas
pruebas deberán ser de auto control [Fowler].
Descomponiendo y redistribuyendo el método estadoDeCuenta
Cuando se observa un método largo como éste, se busca la forma de descomponer el método en
pequeñas partes. Estos pequeños fragmentos de código, tienden a hacer las cosas más manejables, las
cuales son más fáciles de manipular y moverse.
La primera fase de la refactorización que se ve aquí, muestra cómo dividir al método largo y trasladar
ciertos fragmentos de código hacia clases más convenientes. El objetivo entonces es hacerlo lo más fácil
posible para escribir un método htmlestadoDeCuenta con mucho menos duplicación de código.
Primero se debe encontrar un fragmento lógico de código y usar el Método Extraer (Extract Method).
Una parte de este código obviamente sería el switch del método estadoDeCuenta.
Cuando se extrae un método, como en cualquier refactorización, es importante estar consientes que
puede salir mal. Si la extracción sale mal se podría introducir un error en el programa, así que antes de
hacer la refactorización se debe averiguar cómo hacerla con seguridad.
Lo primero que se necesita hacer, es observar dentro del código algunas variables que se encuentren
dentro del método que estaremos analizando, como variables locales y parámetros. Este segmento de
código emplea dos variables: cada y esteCargo. La variable cada no es modificada por el código, pero
esteCargo sí lo es. Cualquier variable que no sea modificada se puede pasar como parámetro, en cambio,
con las variables que sí son modificadas no se pueden arrastrar igual, así que habrá que manejarlas de
otra manera y tendremos que ser más cuidadosos. Si sólo es una variable se puede devolver; la variable
temporal es inicializada a cero cada vez que recorre el bucle y no se altera hasta que llega al switch
pudiendo así asignar al resultado.

Reestructuración de Código
Anexo A 93
A continuación, se muestra el código antes y después de la refactorización. El código original se
encuentra en la primera parte, el código resultante se muestra por debajo del código original. El código
extraído del programa original y algunos cambios en el nuevo código que no son obvios están en
negrillas.
Código original
public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { double esteCargo = 0; Renta cada = (Renta) rentas.nextElement(); //determina las cantidades por cada renta. switch (cada.getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: esteCargo += 2; if (cada.getDiasRentados() > 2) esteCargo += (cada.getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: esteCargo += cada.getDiasRentados() * 3; break; case Pelicula.INFANTILES: esteCargo += 1.5; if (cada.getDiasRentados() > 3) esteCargo += (cada.getDiasRentados() - 3) * 1.5; break; } // se agregan los puntos cliente frecuente puntosClienteFrecuente ++; //se agrega un bono por 2 dias de renta de estrenos if ((cada.getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENOS) && cada.getDiasRentados() > 1) puntosClienteFrecuente ++; //muestra el costo para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(esteCargo) + "\n"; cargoTotal += esteCargo; } //se añade pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n";

Reestructuración de Código
Anexo A 94
result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; }
Código modificado
public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { double esteCargo = 0; Renta cada = (Renta) rentas.nextElement(); esteCargo = cargoPara(cada); //agrega los puntos a cliente frecuentes puntosClienteFrecuente ++; //se agrega un bono de 2 dias en la renta de estrenos if ((cada.getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENOS) && cada.getDiasRentados() > 1) puntosClienteFrecuente ++; //muestra el costo para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(esteCargo) + "\n"; cargoTotal += esteCargo; } //agrega pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; } } private int cargoPara(Renta cada) { int esteCargo = 0; switch (cada.getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: esteCargo += 2; if (cada.getDiasRentados() > 2) esteCargo += (cada.getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: esteCargo += cada.getDiasRentados() * 3;

Reestructuración de Código
Anexo A 95
break; case Pelicula.INFANTILES: esteCargo += 1.5; if (cada.getDiasRentados() > 3) esteCargo += (cada.getDiasRentados() - 3) * 1.5; break; } return esteCargo; }
Siempre que se va a hacer un cambio como este, se debe compilar y ejecutar una prueba (test). Un par
de pruebas realizadas nos dieron la respuesta equivocada. Este es un ejemplo para analizar y darnos
cuenta de posibles errores que pueden cometerse en cualquier momento. Erróneamente se declaró el
método cargoPara como int en lugar de double, así que se muestra a continuación el método cargoPara
ya corregido:
private double cargoPara(Renta cada) { double esteCargo = 0; switch (cada.getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: esteCargo += 2; if (cada.getDiasRentados() > 2) esteCargo += (cada.getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: esteCargo += cada.getDiasRentados() * 3; break; case Pelicula.INFANTILES: esteCargo += 1.5; if (cada.getDiasRentados() > 3) esteCargo += (cada.getDiasRentados() - 3) * 1.5; break; } return esteCargo; } Este es el tipo clásico de error absurdo que se hace frecuentemente y puede ser complicado rastrearlo.
En este caso, Java convierte double a int sin complicaciones mediante especificaciones de Java conocidas
como Java Spec. Afortunadamente fue fácil de encontrar el error en este ejemplo porque el cambio fue
muy pequeño, pero siempre es importante estar consciente que es necesario tener un buen conjunto de
pruebas para apoyarnos.
Debido a que cada cambio es tan pequeño, los errores son muy fáciles de encontrar. No se trata de
dedicar mucho tiempo a la depuración, sobre todo si se pone atención de no cometer errores como el
explicado.

Reestructuración de Código
Anexo A 96
Sugerencia
La Refactorización es hacer cambios a programas en pequeños pasos. Si se comete un error, es fácil
encontrarlo. [Fowler]
Con ciertas herramientas, puede ser realmente simple analizar el código para saber cómo podemos
manipular a las variables locales. Una herramienta de este tipo se encuentra en Smalltalk, éste es el
navegador de refactorización con el cual es muy fácil refactorizar. Solamente se marca el código, se
selecciona "Extract Method" del menú, se escribe el nombre del método y se lleva a cabo. Además, la
herramienta no comete errores absurdos como el anteriormente mencionado.
Ahora que hemos partido al método original en fragmentos más pequeños, se puede trabajar con ellos
por separado. No son convenientes algunos de los nombres de variables dentro del método cargoPara y
habrá que cambiarlos como se muestra a continuación.
Este es el código original
private double cargoPara(Renta cada) { double esteCargo = 0; switch (cada.getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: esteCargo += 2; if (cada.getDiasRentados() > 2) esteCargo += (cada.getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: esteCargo += cada.getDiasRentados() * 3; break; case Pelicula.INFANTILES: esteCargo += 1.5; if (cada.getDiasRentados() > 3) esteCargo += (cada.getDiasRentados() - 3) * 1.5; break; } return esteCargo; }
Aquí está el código renombrado
private double cargoPara(Renta aRenta) { double result = 0; switch (aRenta.getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: result += 2; if (aRenta.getDiasRentados() > 2) result += (aRenta.getDiasRentados() - 2) * 1.5; break;

Reestructuración de Código
Anexo A 97
case Pelicula.ESTRENOS: result += aRenta.getDiasRentados() * 3; break; case Pelicula.INFANTILES: result += 1.5; if (aRenta.getDiasRentados() > 3) result += (aRenta.getDiasRentados() - 3) * 1.5; break; } return result; }
Una vez que se ha hecho el cambio de nombre de estas variables, se compila y se prueba para
asegurarse de que no se haya roto el código.
¿Vale la pena hacer el esfuerzo de renombrar? Absolutamente. Un buen código debe comunicar lo que
está haciendo con claridad y los nombres de variables son la clave para aclarar al código, nunca se debe
tener miedo de cambiar los nombres de las variables, para mejorar la claridad del código. Existen
herramientas que nos permiten buscar y reemplazar éstas de una manera fácil y rápida. Hacer códigos y
pruebas robustas, ayuda a visualizar cualquier cosa extraña dentro de la estructura del código. La
comunicación clara es uno de los propósitos más importantes de un código, solo así se puede
comprender el programa.
Moviendo el monto calculado
Como vez en el método cargoPara, se puede observar que se utiliza información de la renta, pero no
utiliza la información del cliente. Esto inmediatamente nos da indicios de que el método está en el
objeto equivocado.
class Cliente... private double cargoPara(Renta aRenta) { double result = 0; switch (aRenta.getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: result += 2; if (aRenta.getDiasRentados() > 2) result += (aRenta.getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: result += aRenta.getDiasRentados() * 3; break; case Pelicula.INFANTILES: result += 1.5; if (aRenta.getDiasRentados() > 3) result += (aRenta.getDiasRentados() - 3) * 1.5; break;

Reestructuración de Código
Anexo A 98
} return result; }
En la mayoría de los casos un método debería estar en el objeto en donde sus datos son usados, por lo
que el método debería trasladarse a la clase Renta. Para hacer esto, usaremos el Move Method, además
se copiará el código a la clase Renta, para después adaptarlo y compilarlo como se muestra a
continuación:
class Renta... double getCosto() { double result = 0; switch (getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: result += 2; if (getDiasRentados() > 2) result += (getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: result += getDiasRentados() * 3; break; case Pelicula.INFANTILES: result += 1.5; if (getDiasRentados() > 3) result += (getDiasRentados() - 3) * 1.5; break; } return result; }
En este caso el concepto adaptación, significa eliminar el parámetro y también se renombró el método
cuando se hizo el movimiento, ahora podemos probarlo y ver si este método funciona. Para hacer esto,
se remplazará el cuerpo de Cliente.cargoPara para delegar al nuevo método.
class Cliente... private double cargoPara(Renta aRenta) { return aRenta.getCosto(); }
Nuevamente podremos compilarlo y probarlo para ver si no falla algo del código. El siguiente paso, es
encontrar todas las referencias con el método anterior y ajustar la referencia para usar el método nuevo
como sigue:
class Cliente... public String estadoDeCuenta() {

Reestructuración de Código
Anexo A 99
double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { double esteCargo = 0; Renta cada = (Renta) rentas.nextElement(); esteCargo = cargoPara(cada); //agrega puntos a clients frecuentes puntosClienteFrecuente ++; //se agrega un bono por 2 dias de renta de estrenos if ((cada.getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENOS) && cada.getDiasRentados() > 1) puntosClienteFrecuente ++;
//muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(esteCargo) + "\n"; cargoTotal += esteCargo; } //agrega pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; }
En este caso, este paso es fácil porque acabamos de crear el método y este se encuentra en un solo
lugar. Normalmente en otros sistemas se necesitaría hacer una búsqueda a través de las clases que
podrían estar usando a este método:
class Cliente public String estadoDeCuenta() { double cargoTotal = 0; int puntoClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { double esteCargo = 0; Renta cada = (Renta) rentas.nextElement(); esteCargo = cada.getCosto(); //agrega puntos por cliente frecuente puntosClienteFrecuente ++; //se agrega un bono por 2 dias de renta de estrenos if ((cada.getPelicula().getPrecioDeCodigo() == Pelicula.ESTRENOS) && cada.getDiasRentados() > 1) puntosClienteFrecuente ++;

Reestructuración de Código
Anexo A 100
//muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(esteCargo) + "\n"; cargoTotal += esteCargo; } //agrega pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; }
Cuando se ha hecho el cambio (Figura A1.2), el siguiente paso es eliminar el método anterior. El
compilador deberá decir si hay algo extraño dentro del código ya modificado, después se aplica un test
para ver si funciona correctamente.
Figura A1.2 Estado de las clases después de haber movido al método
para calcular el cargo total (getCosto).
En este momento dejaremos el método anterior para delegar al método nuevo. Esto es útil si se trata de
un método público y no se quiere cambiar la interfaz de otra clase.
Hay en realidad algo más que podría hacer con Renta.getCosto pero lo dejaremos por el momento y
volveremos a Cliente.estadoDeCuenta.
public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { double esteCargo = 0; Renta cada = (Renta) rentas.nextElement(); esteCargo = cada.getCosto(); //agrega puntos por cliente frecuente puntosClienteFrecuente ++; //se agrega un bono por 2 dias de renta de estrenos if ((cada.getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENOS) &&
* 1 Pelicula
precioDelCodigo : int
Renta
diasRentados : int
getCosto ( )
Cliente
estadoDeCuenta ( )

Reestructuración de Código
Anexo A 101
cada.getDiasRentados() > 1) puntosClienteFrecuente ++; //muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(esteCargo) + "\n"; cargoTotal += esteCargo; } //agrega pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; }
Observe que esteCargo es ahora redundante. Está definido por el resultado de cada.costo y no cambia
posteriormente. Por lo tanto, podemos eliminar esteCargo aplicando Replace Temp with Query:
public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); //agrega puntos por cliente frecuente puntosClienteFrecuente ++; //se agrega un bono por 2 dias de renta de estrenos if ((cada.getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENOS) && cada.getDiasRentados() > 1) puntosClienteFrecuente ++; //muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf (cada.getCosto()) + "\n"; cargoTotal += cada.getCosto(); } //agrega pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; } }

Reestructuración de Código
Anexo A 102
Una vez que se ha hecho el cambio, se compila y pone a prueba para asegurarse de que sigue
funcionando bien. Uno de los objetivos principales, es poder deshacerse lo más posible de las variables
temporales como éstas. Las variables temporales son a menudo un problema en el sentido de que
causan una gran cantidad de parámetros que están en todas partes, cuando no tienen por qué estar;
fácilmente puede perderse el enfoque de porque están ahí. Son particularmente insidiosas en los
métodos largos y por supuesto hay que pagar un precio en el rendimiento; aquí está cargado el cálculo
dos veces. Pero es fácil optimizar lo que se encuentra dentro de la clase Renta y se puede mejorar
eficazmente cuando el código está relacionado con la cuenta.
Extrayendo puntos de clientes frecuentes
El siguiente paso, es hacer algo similar para el cálculo de puntos de clientes frecuentes. Las políticas
varían según la película aunque hay menos diferencias que con el cargo. Parece razonable poner la
responsabilidad sobre la renta. En primer lugar tenemos que usar el Extract Method sobre la parte del
código donde se agregan los puntos frecuentes al cliente (en negritas):
public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); //agrega puntos por cliente frecuente puntosClienteFrecuente ++; //se agrega un bono de 2 dias en la renta de estrenos if ((cada.getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENOS) && cada.getDiasRentados() > 1) puntosClienteFrecuente ++; //muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(cada.getCosto()) + "\n"; cargoTotal += cada.getCosto(); } //agrega pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; } }

Reestructuración de Código
Anexo A 103
Una vez más nos fijamos en el uso de variables de ámbito local, de nuevo la variable cada es usada y
puede ser pasada como parámetro. La otra variable temporal utilizada es puntosClienteFrecuente. En
este caso puntosClienteFrecuente tiene un valor pre asignado. El cuerpo del método extraído no lee el
valor, sin embargo, no necesitamos pasarlo como parámetro de tipo long ya que utilizamos una
asignación adjunta.
Se hizo la extracción, se compiló y se realizaron pruebas, luego se movió, se compiló y probó de nuevo.
Con la refactorización los pequeños pasos son los mejores, de esa manera menos probabilidades existen
que algo pueda salir mal.
class Cliente... public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Relación de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); puntosClienteFrecuente += cada.getPuntosClienteFrecuente(); //muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(cada.getCosto()) + "\n"; cargoTotal += cada.getCosto(); } //agrega pie de página result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; } class Renta... int getPuntosClienteFrecuente() { if ((getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENOS) && getDiasRentados() > 1) return 2; else return 1; }
Vamos a resumir los cambios que acabamos de hacer con algunos antes y después de aplicar el Lenguaje
de Modelado Unificado (UML) explicado en los diagramas de las figuras A1.3 a la A1.6. Una vez más los
esquemas de arriba explican el código antes del cambio, los de abajo demuestran cómo queda el código
después del cambio. La figura A1.3 muestra el diagrama de clases antes de la extracción y del
movimiento del cálculo de los puntos de cliente frecuente.
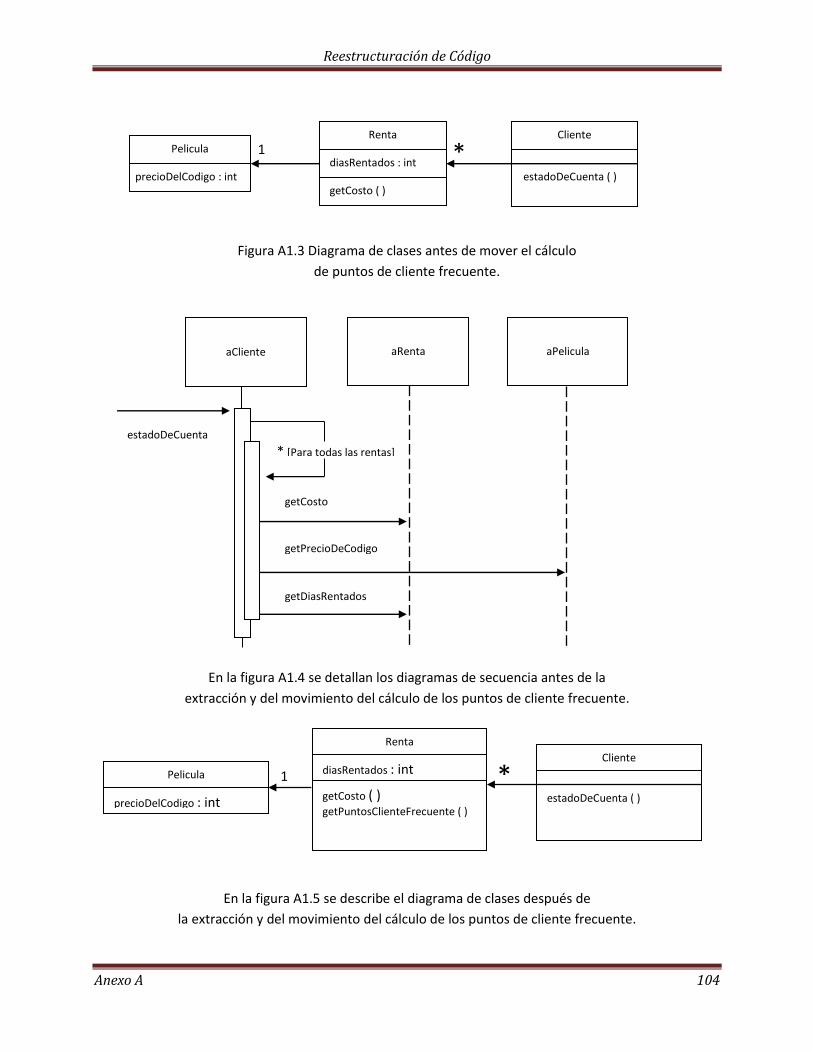
Reestructuración de Código
Anexo A 104
Figura A1.3 Diagrama de clases antes de mover el cálculo
de puntos de cliente frecuente.
En la figura A1.4 se detallan los diagramas de secuencia antes de la
extracción y del movimiento del cálculo de los puntos de cliente frecuente.
En la figura A1.5 se describe el diagrama de clases después de
la extracción y del movimiento del cálculo de los puntos de cliente frecuente.
* 1 Pelicula
precioDelCodigo : int
Renta
diasRentados : int
getCosto ( )
Cliente
estadoDeCuenta ( )
aCliente
aRenta
aPelicula
estadoDeCuenta
* [Para todas las rentas]
getCosto
getPrecioDeCodigo
getDiasRentados
* 1 Pelicula
precioDelCodigo : int
Renta
diasRentados : int
getCosto ( )
getPuntosClienteFrecuente ( )
Cliente
estadoDeCuenta ( )

Reestructuración de Código
Anexo A 105
La figura A1.6 muestra el diagrama de secuencia antes de la
extracción y el movimiento del cálculo de los puntos de cliente frecuente.
Eliminando variables temporales
Como se ha sugerido antes, las variables temporales pueden ser un problema, son útiles sólo dentro de
su propia rutina y por tanto las variable temporales fomentan largas rutinas complejas. En este caso
tenemos dos variables temporales las cuales están siendo utilizadas para obtener el total de las rentas
que acumula el cliente. Tanto las versiones en ASCII como las de HTML requieren de estos totales.
Podemos usar Replace Temp with Query para sustituir cargoTotal y puntosClienteFrecuente con
métodos de consulta. Las consultas son accesibles para cualquier método dentro de la clase y es por eso
que fomentan así un diseño más limpio, sin métodos largos ni complejos:
class Cliente... public String estadoDeCuenta() { double cargoTotal = 0; int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Registro de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); puntosClienteFrecuente += cada.getPuntosClienteFrecuente(); //muestra costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" +
getPuntosClienteFrecuente
aCliente
aRenta
aPelicula
estadoDeCuenta
* [Para todas las rentas]
getCosto
getPrecioDelCodigo
getPrecioDelCodigo

Reestructuración de Código
Anexo A 106
String.valueOf(cada.getCosto()) + "\n"; cargoTotal += cada.getCosto(); } //agrega resultado saldo result += "Su saldo es " + String.valueOf(cargoTotal) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; }
Se empezó sustituyendo a cargoTotal con costo, método en la clase Clientes:
class Cliente... public String estadoDeCuenta() { int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Registro de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); puntosClienteFrecuente += cada.getPuntosClienteFrecuente(); //muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(cada.getCosto()) + "\n"; } //agrega pie de página result += "Su saldo es " + String.valueOf(getCostoTotal()) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; } private double getCostoTotal() { double result = 0; Enumeration rentas = _rentas.elements(); while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); result += cada.getCosto(); } return result; } Esto no es un simple caso de Replace Temp with Query aplicada al cargoTotal dentro del bucle, sino que
se tiene que copiar el bucle dentro del método de consulta getCostoTotal.
Después de la compilación y las pruebas de esa refactorización, se hizo lo mismo para
puntosClienteFrecuente:

Reestructuración de Código
Anexo A 107
class Cliente... public String estadoDeCuenta() { int puntosClienteFrecuente = 0; Enumeration rentas = _rentas.elements(); String result = "Registro de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); puntosClienteFrecuente += cada.getPuntosClienteFrecuente(); //muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(cada.getCosto()) + "\n"; } //agrega pie de página result += "Su saldo es " + String.valueOf(getCostoTotal()) + "\n"; result += "Ha ganado " + String.valueOf(puntosClienteFrecuente) + "puntos de cliente frecuente"; return result; } public String estadoDeCuenta() { Enumeration rentas = _rentas.elements(); String result = "Registro de rentas para " + getNombre() + "\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); //muestra los costos para esta renta result += "\t" + cada.getPelicula().getTitulo()+ "\t" + String.valueOf(cada.getCosto()) + "\n"; } //agrega pie de página result += "Su saldo es" + String.valueOf(getCostoTotal()) + "\n"; result += "Ha ganado" + String.valueOf(getTotalPuntosClienteFrecuente()) + "puntos de cliente frecuente"; return result; } private int getTotalPuntosClienteFrecuente(){ int result = 0; Enumeration rentas = _rentas.elements(); while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); result += cada.getPuntosClienteFrecuente(); } return result; }
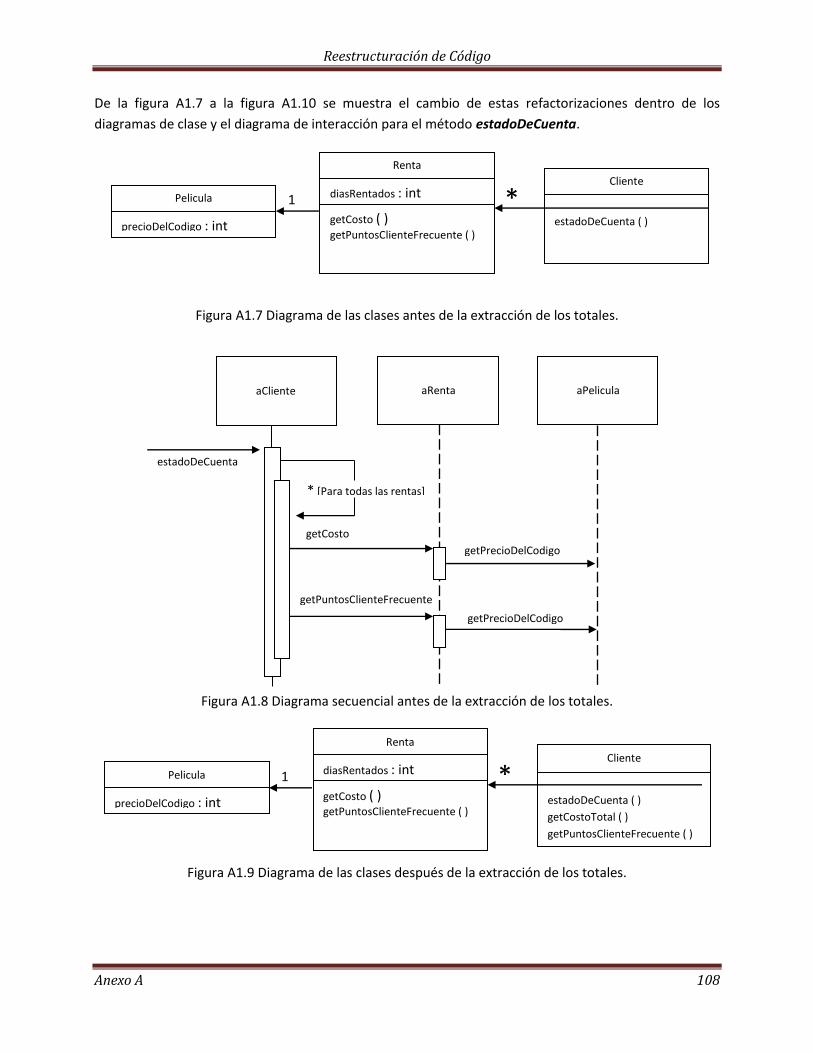
Reestructuración de Código
Anexo A 108
De la figura A1.7 a la figura A1.10 se muestra el cambio de estas refactorizaciones dentro de los
diagramas de clase y el diagrama de interacción para el método estadoDeCuenta.
Figura A1.7 Diagrama de las clases antes de la extracción de los totales.
Figura A1.8 Diagrama secuencial antes de la extracción de los totales.
Figura A1.9 Diagrama de las clases después de la extracción de los totales.
* 1 Pelicula
precioDelCodigo : int
Renta
diasRentados : int
getCosto ( )
getPuntosClienteFrecuente ( )
Cliente
estadoDeCuenta ( )
getPuntosClienteFrecuente
aCliente
aRenta
aPelicula
estadoDeCuenta
* [Para todas las rentas]
getCosto
getPrecioDelCodigo
getPrecioDelCodigo
* 1 Pelicula
precioDelCodigo : int
Renta
diasRentados : int
getCosto ( )
getPuntosClienteFrecuente ( )
Cliente
estadoDeCuenta ( )
getCostoTotal ( )
getPuntosClienteFrecuente ( )

Reestructuración de Código
Anexo A 109
Figura A1.10 Diagrama secuencial después de la extracción de los totales.
Vale la pena detenerse a pensar un poco sobre la última refactorización. La mayoría de las
refactorizaciones reducen la cantidad de código, pero en ésta se incrementa el código. Esto se debe a
que Java 1.1 requiere una gran cantidad de declaraciones para crear un resumen del bucle, incluso un
simple resumen del bucle con una línea de código por elemento, necesita seis líneas de soporte
alrededor de él. Esto es obvio para cualquier programador, pero son muchas líneas y todas semejantes.
Además esta refactorización miente en su ejecución. El código original ejecutado muestra un bucle
"while" solamente una vez, en cambio el código nuevo lo ejecuta en tres ocasiones. Un bucle while muy
largo puede afectar el rendimiento del programa, razón por la que muchos programadores no hacen esta
refactorización, pero observemos las palabras if y might. Hasta que no se completa el análisis del código,
es difícil decir o calcular, cuánto tiempo es necesitado para el bucle o si el bucle es llamado con la
frecuencia suficiente como para afectar el desempeño global del sistema. No hay que preocuparse
mientras se refactoriza, cuando se optimiza el código tendrá que preocuparse por él, pero estará en una
posición mucho mejor para hacer algo al respecto y se tendrán más opciones para optimizar de manera
eficaz.
Estas consultas están ahora disponibles para cualquier código escrito en la clase Cliente. Las consultas
son fácilmente agregadas a la interfaz de la clase y esto permite que otras partes del sistema que
necesitan esta información, puedan accesarla. Sin consultas como estas, otros métodos tienen que tratar
de conseguir la información sobre la clase Renta y construir bucles. En un sistema complejo, habrá
mucho más código para escribir y mantener.
getTotalPuntosClienteFrecuente
*[Para todas las rentas] getPuntosClienteFrecuente
aCliente
aRenta
aPelicula
estadoDeCuenta
*[Para todas las rentas] getCosto
getPrecioDelCodigo
getCostoTotal
getPrecioDelCodigo

Reestructuración de Código
Anexo A 110
Llegamos al punto en donde tenemos que dejar de refactorizar y empezar a codificar y añadir una
función. Recordemos que en el ámbito del desarrollador de software debemos adoptar una de dos
posturas (actitudes), una para codificar o la otra para refactorizar.
Podemos entonces, escribir el método htmlEstadoDeCuenta como sigue y se añadirán pruebas
adecuadas:
public String htmlEstadoDeCuenta() { Enumeration rentas = _rentas.elements(); String result = "<H1>Rentas para <EM>" + getNombre() + "</EM></ H1><P>\n"; while (rentas.hasMoreElements()) { Renta cada = (Renta) rentas.nextElement(); //muestra los costos para esta renta result += cada.getPelicula().getTitulo()+ ": " + String.valueOf(cada.getCosto()) + "<BR>\n"; } //agregas el pie de página result += "<P>Su saldo es <EM>" + String.valueOf(getTotalCosto()) + "</EM><P>\n"; result += "En esta renta usted ganó <EM>" + String.valueOf(getTotalPuntosClienteFrecuente()) + "</EM> puntos de cliente frecuente<P>"; return result; } Al extraer los cálculos, se puede crear el método htmlEstadoDeCuenta y reutilizar todo el código del
método estadoDeCuenta original. No en conveniente copiar y pegar, así que si las normas de cálculo
cambian, tendremos un solo lugar dentro del código a donde ir, ahora cualquier otro estado de cuenta,
será realmente rápido y fácil de generar. La refactorización no nos tomó mucho tiempo, de hecho,
pasamos la mayor parte del tiempo averiguando lo que el código hacía y además hubiéramos tenido que
hacerlo de todos modos.
Parte del código se copió de la versión ASCII principalmente debido a la composición del bucle y ahora la
refactorización podrá limpiarlo. Los métodos para la extracción de la cabecera, pie de página y detalle de
línea, son una ruta que podríamos tomar. Podemos ver cómo se hace esto en el ejemplo, para el método
Form Template Method, pero pasado un tiempo los usuarios reclaman de nuevo, ellos se están
preparando para cambiar la clasificación de las películas en la tienda y todavía no está claro qué cambios
quieren hacer con claridad; pero da la impresión como si nuevas clasificaciones se fueran a introducir y
las ya existentes pueden ser cambiadas. Las asignaciones de cargos y puntos de cliente frecuente para
estas clasificaciones se están decidiendo, así que por el momento hacer este tipo de cambios es difícil.
Tenemos que entrar dentro de los métodos de cargo y puntos de cliente frecuente y alterar el código
condicional para hacer los cambios a las clasificaciones de las películas.

Reestructuración de Código
Anexo A 111
Reemplazando la lógica condicional en pricecode con polimorfismo
La primera parte de este problema se encuentra ubicado en el switch del método estadoDeCuenta. Es
una mala idea hacer un switch basado en un atributo de otro objeto, si se necesita utilizar un switch
dentro del método estadoDeCuenta deberá tener sus propios datos y nada más.
class Renta... double getCosto() { double result = 0; switch (getPelicula().getPrecioDelCodigo()) { case Pelicula.GENERALES: result += 2; if (getDiasRentados() > 2) result += (getDiasRentados() - 2) * 1.5; break; case Pelicula.ESTRENOS: result += getDiasRentados() * 3; break; case Pelicula.INFANTILES: result += 1.5; if (getDiasRentados() > 3) result += (getDiasRentados() - 3) * 1.5; break; } return result; }
Esto implica que getCosto deberá avanzar en la película:
class Pelicula... double getCosto(int diasRentados) { double result = 0; switch (getPrecioDelCodigo()) { case Pelicula.GENERALES: result += 2; if (diasRentados > 2) result += (diasRentados - 2) * 1.5; break; case Pelicula.ESTRENOS: result += diasRentados * 3; break; case Pelicula.INFANTILES: result += 1.5; if (diasRentados > 3) result += (diasRentados - 3) * 1.5; break; }

Reestructuración de Código
Anexo A 112
return result; }
Para que esto trabaje, hemos tenido que mover el cuerpo de la renta, el cual por supuesto, es
información de la clase Renta. El método utiliza efectivamente dos partes de información, la longitud de
la renta y el tipo de película de que se trata. ¿Por qué se prefiere pasar la longitud de la renta de la
película, en lugar del tipo de película rentada? La razón es porque los cambios propuestos son todos
relacionados con la adición de nuevos tipos.
Figura A1.11 Aquí se muestra el diagrama de clases antes de ser
movidos los métodos a la clase Pelicula.
En la Figura A1.12 se detalla el diagrama de clases después de
haber movido los métodos a la clase Pelicula.
*
1
Pelicula
precioDelCodigo : int
Cliente
estadoDeCuenta ( ) htmlEstadoDeCuenta ( )
getCostoTotal ( )
getTotalPuntosClienteFrecuente ( )
Renta
diasRentados: int
getCosto ( )
getPuntosClienteFrecuente ( )
*
1
Cliente
estadoDeCuenta( ) htmlEstadoDeCuenta( )
getCostoTotal( )
getTotalPuntosClienteFrecuente( )
Renta
diasRentados: int
getCosto( )
getPuntosClienteFrecuente( )
Pelicula
precioDelCodigo: int
getCosto(dias: int )
getPuntosClienteFrecuente(dias: int)

Reestructuración de Código
Anexo A 113
La Información del tipo de película, generalmente tiende a ser más volátil. Si cambiamos el tipo de
película, entonces quisiéramos que hubiera la menor de las consecuencias posibles, por lo que se
prefiere calcular el costo junto con la película.
Se compila el método dentro de la clase Pelicula y luego se cambia el método getCosto en la clase Renta
para usar el método nuevo (Figuras A1.11 y A1.12):
class Renta... double getCosto() { return _pelicula.getCosto(_diasRentados); }
Una vez que se ha movido el método getCosto, haremos lo mismo con la cuenta o cálculo de puntos de
cliente frecuente. Este guarda ambas cosas que varían según el tipo, junto con la clase que tiene el tipo:
class Renta... int getPuntosClienteFrecuente() { if ((getPelicula().getPrecioDelCodigo() == Pelicula.ESTRENO) && getDiasRentados() > 1) return 2; else return 1; } Class Rental... int getPuntosClienteFrecuente() { return _pelicula.getPuntosClienteFrecuente(_diasRentados); } class Pelicula... int getPuntosClienteFrecuente(int diasRentados) { if ((getPrecioDelCodigo() == Pelicula.ESTRENO) && diasRentados > 1) return 2; else return 1; }
La Herencia
Tenemos varios tipos de películas que tienen diferentes formas de responder a la misma pregunta. Esto
suena como un trabajo para las subclases, tenemos tres subclases de películas cada una de los cuales
puede tener su propia manera de ser cargada (Figura A1.13).

Reestructuración de Código
Anexo A 114
Figura A1.13 Usando herencia sobre la clase Pelicula.
Esto permite reemplazar el switch del método estadoDeCuenta usando polimorfismo.
Lamentablemente, tiene una ligera falla, no funciona. Una película puede cambiar su clasificación
durante su tiempo vida, pero un objeto no puede cambiar su clase durante su longevidad. Hay una
solución para enfrentar este problema y es aplicar los patrones Estandar de diseño que fueron creados
por La Banda de los Cuatro (o Gang of Four11). Aplicando el patrón Estándar a las clases, se vería como
se muestra en la Figura A1.14.
A parte de añadir la indirección, podemos hacer la subclase tomando el cuerpo del precioDelCodigo y
cambiar el precio cuando lo necesitemos.
Si estás familiarizado con los patrones de La Banda de los Cuatro, puedes preguntarte, "¿Es este un
Estado o es un Estandar?". La clase Precio representa un algoritmo para calcular el precio (en cuyo caso,
preferimos llamarlo Pricer o PricingStrategy); o ésta representa un estado de la película, por ejemplo,
que Star Trek X fuera una película de estreno. En esta fase, el patrón elegido (y nombre) refleja la forma
en que se desea pensar en la estructura; en este momento vamos a pensar en un estado de película. Si
más tarde decidimos que convendría más pensar en una estrategia, solamente tendríamos que
refactorizar para hacer esto, aparte de cambiar los nombres.
11
Gang of Four es el nombre con el que se conoce comúnmente a los autores del libro Design Patterns (ISBN 0-201-63361-2),
referencia en el campo del diseño orientado a objetos. “La Banda de los Cuatro”', se compone de los siguientes autores: Erich
Gamma, Richard Helm, Ralph Johnson y John Vlissides
Pelicula
getCosto
Pelicula Generales
getCosto
Pelicula Infantiles
getCosto
Pelicula Estrenos
getCosto

Reestructuración de Código
Anexo A 115
Precio
getCosto
Precio Generales
getCosto
Precio Infantiles
getCosto
Precio Estrenos
getCosto
Pelicula
getCosto
return precio.getCosto
1
Figura A1.14 En esta figura se usa el patrón de diseño Estándar sobre la clase Pelicula.
Para introducir el patrón Estandar, utilizaremos tres refactorizaciones. En primer lugar, cambiaremos el comportamiento del tipo de código dentro del patrón de estado con Replace Type Code with State/Strategy, posteriormente podremos usar el método Pelicula para mover la declaración del switch dentro de la clase Precio, finalmente usaremos Replace Conditional with Polymorphism para eliminar el switch del método estadoDeCuenta.
Vamos a empezar con Replace Type Code with State/Strategy. En este primer paso usaremos Self
Encapsulate Field en el tipo de código para asegurarse que todos los usos del tipo de código van a pasar
por el método getting (obtener) y por el método setting (de ajuste). Debido a que la mayoría del código
viene de otras clases, casi todos los métodos ya usan el método getting. Sin embargo, los constructores
tienen acceso al código de la clase Precio:
class Pelicula... public Pelicula(String nombre, int precioDelCodigo) { _nombre = nombre; _precioDelCodigo = precioDelCodigo; } Podemos utilizar en su lugar, el método setting (de ajuste). class Pelicula public Pelicula(String nombre, int precioDelCodigo) { _nombre = nombre; setPrecioDelCodigo(precioDelCodigo); }
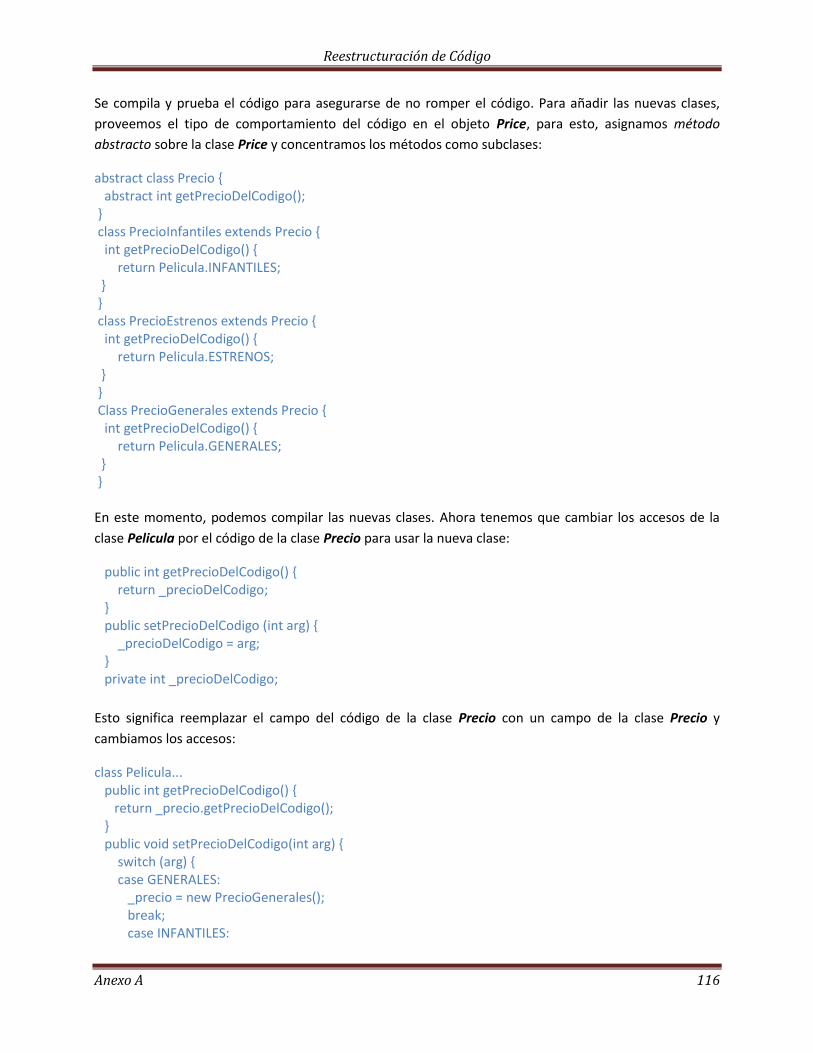
Reestructuración de Código
Anexo A 116
Se compila y prueba el código para asegurarse de no romper el código. Para añadir las nuevas clases,
proveemos el tipo de comportamiento del código en el objeto Price, para esto, asignamos método
abstracto sobre la clase Price y concentramos los métodos como subclases:
abstract class Precio { abstract int getPrecioDelCodigo(); } class PrecioInfantiles extends Precio { int getPrecioDelCodigo() { return Pelicula.INFANTILES; } } class PrecioEstrenos extends Precio { int getPrecioDelCodigo() { return Pelicula.ESTRENOS; } } Class PrecioGenerales extends Precio { int getPrecioDelCodigo() { return Pelicula.GENERALES; } } En este momento, podemos compilar las nuevas clases. Ahora tenemos que cambiar los accesos de la
clase Pelicula por el código de la clase Precio para usar la nueva clase:
public int getPrecioDelCodigo() { return _precioDelCodigo; } public setPrecioDelCodigo (int arg) { _precioDelCodigo = arg; } private int _precioDelCodigo;
Esto significa reemplazar el campo del código de la clase Precio con un campo de la clase Precio y
cambiamos los accesos:
class Pelicula... public int getPrecioDelCodigo() { return _precio.getPrecioDelCodigo(); } public void setPrecioDelCodigo(int arg) { switch (arg) { case GENERALES: _precio = new PrecioGenerales(); break; case INFANTILES:
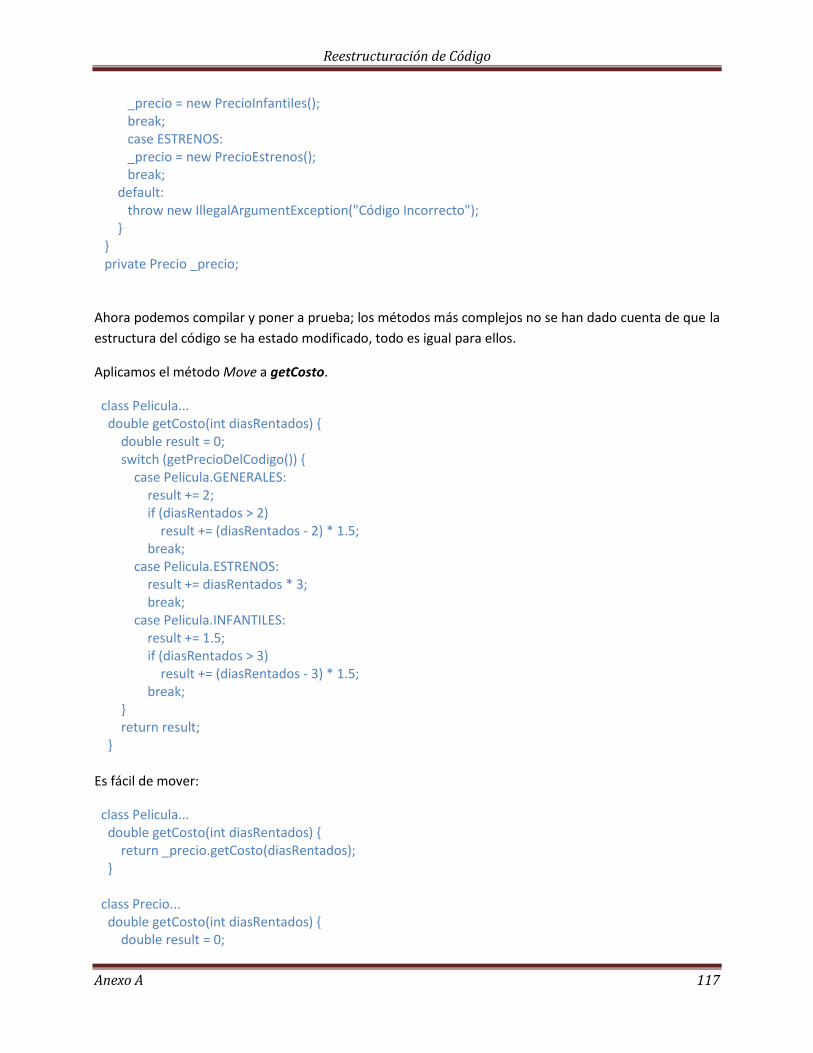
Reestructuración de Código
Anexo A 117
_precio = new PrecioInfantiles(); break; case ESTRENOS: _precio = new PrecioEstrenos(); break; default: throw new IllegalArgumentException("Código Incorrecto"); } } private Precio _precio; Ahora podemos compilar y poner a prueba; los métodos más complejos no se han dado cuenta de que la
estructura del código se ha estado modificado, todo es igual para ellos.
Aplicamos el método Move a getCosto.
class Pelicula... double getCosto(int diasRentados) { double result = 0; switch (getPrecioDelCodigo()) { case Pelicula.GENERALES: result += 2; if (diasRentados > 2) result += (diasRentados - 2) * 1.5; break; case Pelicula.ESTRENOS: result += diasRentados * 3; break; case Pelicula.INFANTILES: result += 1.5; if (diasRentados > 3) result += (diasRentados - 3) * 1.5; break; } return result; } Es fácil de mover:
class Pelicula... double getCosto(int diasRentados) { return _precio.getCosto(diasRentados); } class Precio... double getCosto(int diasRentados) { double result = 0;
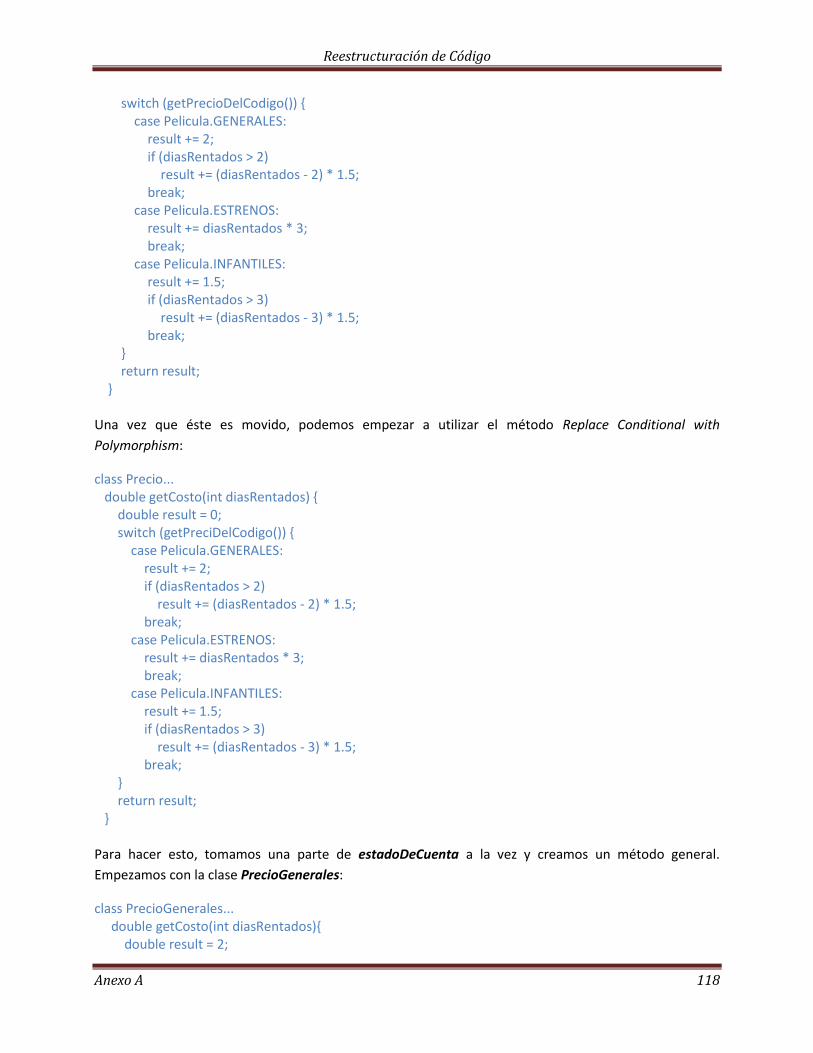
Reestructuración de Código
Anexo A 118
switch (getPrecioDelCodigo()) { case Pelicula.GENERALES: result += 2; if (diasRentados > 2) result += (diasRentados - 2) * 1.5; break; case Pelicula.ESTRENOS: result += diasRentados * 3; break; case Pelicula.INFANTILES: result += 1.5; if (diasRentados > 3) result += (diasRentados - 3) * 1.5; break; } return result; } Una vez que éste es movido, podemos empezar a utilizar el método Replace Conditional with
Polymorphism:
class Precio... double getCosto(int diasRentados) { double result = 0; switch (getPreciDelCodigo()) { case Pelicula.GENERALES: result += 2; if (diasRentados > 2) result += (diasRentados - 2) * 1.5; break; case Pelicula.ESTRENOS: result += diasRentados * 3; break; case Pelicula.INFANTILES: result += 1.5; if (diasRentados > 3) result += (diasRentados - 3) * 1.5; break; } return result; } Para hacer esto, tomamos una parte de estadoDeCuenta a la vez y creamos un método general.
Empezamos con la clase PrecioGenerales:
class PrecioGenerales... double getCosto(int diasRentados){ double result = 2;

Reestructuración de Código
Anexo A 119
if (diasRentados > 2) result += (diasRentados - 2) * 1.5; return result; } Esto anula el caso de declaración de padres. Compilamos y probamos para este caso, luego tomamos la
siguiente parte, compilamos y probamos nuevamente. Para asegurarnos de que estamos ejecutando el
código de la subclase, hay que lanzar un error deliberado y ejecutarlo para garantizar que las pruebas no
fallen.
class PrecioInfantiles double getCosto(int diasRentados){ double result = 1.5; if (diasRentados > 3) result += (diasRentados - 3) * 1.5; return result; } class PrecioEstrenos... double getCosto(int diasRentados){ return diasRentados * 3; } Una vez habiendo acabado con todas las partes, declaramos el método abstracto Precio.getCosto:
class Precio... abstract double getCosto(int diasRentados);
Ahora podemos hacer el mismo procedimiento con getPuntosClienteFrecuente:
class Renta... int getPuntosClienteFrecuente(int diasRentados) { if ((getPrecioDelCodigo() == Pelicula.ESTRENOS) && diasRentados > 1) return 2; else return 1; } Primero moveremos el método por encima de Precio:
Class Pelicula... int getPuntosClienteFrecuente(int diasRentados) { return _precio.getPuntosClienteFrecuente(diasRentados); } Class Precio... int getPuntosClientefrecuente(int diasRentados) { if ((getPrecioDelCodigo() == Pelicula.ESTRENOS) && diasRentados > 1) return 2;

Reestructuración de Código
Anexo A 120
else return 1; } En este caso, sin embargo, no hacemos a la superclase un método abstracto. En su lugar, creamos un
método general para nuevos lanzamientos y dejamos un método definido (por defecto) en la superclase:
Class ESTRENOS int getPuntosClienteFrecuente(int diasRentados) { return (diasRentados > 1) ? 2: 1; } Class Precio... int getPuntosClienteFrecuente(int diasRentados){ return 1; }
Figura A1.15 Interacciones utilizando el patrón Estado.
Llevó mucho esfuerzo introducir el patrón de diseño Estado a nuestro código, pero valió la pena,
además, no afectamos de ninguna manera al resto de la aplicación, ya que es una aplicación muy
pequeña y este es el principal motivo por el cual no tuvimos mayores problemas, en un sistema más
complejo con muchos más métodos dependientes, haría una gran diferencia. Podría darnos la impresión
de ser lento al escribir de esta manera todo lo anterior, pero en realidad, el proceso fluye con bastante
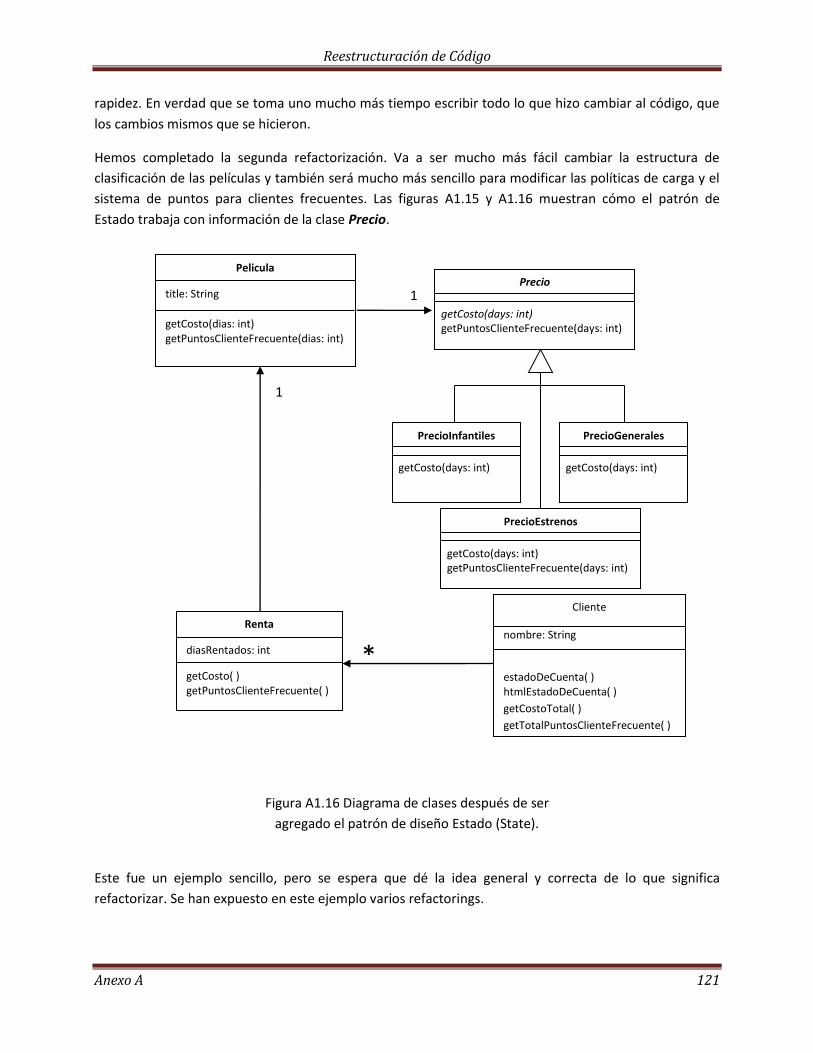
Reestructuración de Código
Anexo A 121
rapidez. En verdad que se toma uno mucho más tiempo escribir todo lo que hizo cambiar al código, que
los cambios mismos que se hicieron.
Hemos completado la segunda refactorización. Va a ser mucho más fácil cambiar la estructura de
clasificación de las películas y también será mucho más sencillo para modificar las políticas de carga y el
sistema de puntos para clientes frecuentes. Las figuras A1.15 y A1.16 muestran cómo el patrón de
Estado trabaja con información de la clase Precio.
Figura A1.16 Diagrama de clases después de ser
agregado el patrón de diseño Estado (State).
Este fue un ejemplo sencillo, pero se espera que dé la idea general y correcta de lo que significa
refactorizar. Se han expuesto en este ejemplo varios refactorings.
1
1
Renta
diasRentados: int
getCosto( ) getPuntosClienteFrecuente( )
Cliente
estadoDeCuenta( ) htmlEstadoDeCuenta( )
getCostoTotal( )
getTotalPuntosClienteFrecuente( )
nombre: String
Pelicula
title: String
getCosto(dias: int) getPuntosClienteFrecuente(dias: int)
Precio
getCosto(days: int) getPuntosClienteFrecuente(days: int)
PrecioGenerales
getCosto(days: int)
*
PrecioInfantiles
getCosto(days: int)
PrecioEstrenos
getCosto(days: int) getPuntosClienteFrecuente(days: int)

Reestructuración de Código
Anexo A 122
La lección más importante de este ejemplo, es el ritmo de refactorización: prueba, pequeño cambio,
prueba, pequeño cambio y así sucesivamente. Este es el ritmo que caracteriza a la refactorización para
que pueda mover el código de manera segura y rápidamente.

Reestructuración de Código
Anexo B 123
ANEXO B. Herramienta de Refactorización Automática
Todo el código tendrá que evolucionar y modificarse algún día, pues hasta el
software más sofisticado y actualizado, perderá en cualquier momento esas
características. Los nuevos estilos y prácticas de desarrollo propuestos en el
Manifiesto Ágil de Software y los procesos de implementación iterativa de
la Programación Extrema para mantener un software flexible y más útil con
el tiempo, son la tendencia actual. Los últimos artículos de Robert C. Martin,
destacan la importancia de la atención continua, mostrando que la
evolución del código, a través de un proceso de refactorización, es más
importante que el diseño inicial.
Todos estos expertos expresan que la refactorización debe considerarse
como una disciplina principal que debe aplicarse al código fuente en cada
iteración. La refactorización no es una moda, es un medio fundamental para
mantener el código flexible y limpio sin perder la atención de cuáles son las
necesidades reales de diseño.
Utilizar el método de refactorización hace muy manejable el cambio y
utilizando herramientas para refactorizar como RefactorIT hace que el
cambio sea más fácil.
Reestructuración de Código
Anexo B 124
Dentro de este apartado se expone solamente una herramienta que hay para realizar la refactorización
de manera automática llamada “RefactorIT”.
¿Qué es RefactorIT?
Para desarrollar software en Java existen una gran variedad de IDEs (Integrated Development
Environment — Ambiente de Desarrollo Integral).
Figura B1: Imagen del RefactorIT en acción con NetBeans.

Reestructuración de Código
Anexo B 125
Uno de los plugins más útiles en existencia es la herramienta para refactorizar de manera automática
RefactorIT de Aqris Software: un plugin que nos permite auditar el código que hemos implementado
mostrándonos cuáles son las debilidades de nuestro proyecto y cómo podemos corregirlas.
La funcionalidad que brinda RefactorIT es algo indispensable en los proyectos de software actuales,
donde pueden crearse cientos de componentes por decenas de desarrolladores y que deben ser
auditados para comprobar su correcta implementación. Aunque RefactorIT tiene muchas ventajas como
medición de métricas o refactorizaciones automáticas, el hecho de que es freeware y que lo podemos
descargar como un plugin de varias ambientes o incluso como un programa standalone, le dan un gran
valor al entrar a la fase de construcción en nuestros proyectos, especialmente porque no implica un
costo adicional al cliente y tiene una baja curva de aprendizaje.
RefactorIT es un módulo de NetBeans que realiza operaciones de refactorización comunes de forma
segura y automática. RefactorIT agrega nuevos elementos tales como Rename Method o Extract
Method. Ver B1.
Con esta herramienta es posible, de una forma segura realizar lo siguiente:
Seleccionar cualquier elemento y renombrarlo,
Extraer una parte de código dentro de un método separado,
Mover una clase determinada a un paquete diferente,
Encapsular un campo para ser accesado mediante los métodos get y set,
Aprovechar las ventajas del constructor dentro del método fabricado,
Explorar la jerarquía de clases,
Extraer una superclase o superinterface fuera de la clase existente,
Guardar y comparar snapshots de la API,
Permite saber donde es capturada alguna excepción,
Encontrar los campos y métodos no utilizados,
Conocer las métricas del código fuente,
Entre muchas otras cosas más.
Tecnología del RefactorIT
La funcionalidad básica no es el único factor de una herramienta de refactorización para ser considerada
como útil y eficaz. La herramienta también debe cumplir ciertos requisitos, entre los cuales destacan:
La precisión: las refactorizaciones automáticas deben conservar el comportamiento original del
código en la medida de lo posible y herramientas de análisis debe proporcionar información

Reestructuración de Código
Anexo B 126
precisa sobre el código. Este es claramente el requisito más básico para cualquier herramienta
de refactorización.
Velocidad: Se refiere a que el análisis y las transformaciones realizadas por una herramienta de
refactorización son muy sofisticadas, especialmente para proyectos grandes con cientos archivos
de código fuente. Si esos procesos no están bien optimizados, podrían tardar mucho tiempo.
Naturalmente si una herramienta de refactorización es muy lenta para realizar sus tareas, no
será utilizada.
Integración con la IDE: Una integración flexible a IDE (s) es una alta prioridad de RefactorIT.
Ventajas y Desventajas:
Como todo software, podemos encontrar en RefactorIT ventajas y desventajas las cuales se presentan a
continuación:
Ventajas
Nos permite auditar el código que hemos implementado mostrándonos cuales son las
debilidades de nuestro proyecto y cómo podemos corregirlas.
Medición de métricas.
Refactorings automáticos.
Es freeware o Standalone.
No hay limitaciones en la funcionalidad de todas las ediciones de RefactorIT en especial la
versión RefactorIT Release 2.5.
Es de bajo costo la Edición Personal porque ahora viene con el conjunto completo de
características incluyendo la integración Ant12.
RefactorIT Ralease 2.5 se integra desde la versión 4.0 de NetBeans + soporte CVS y totalmente
compatible con J2SE 5.0.
Proporciona un conjunto completo de funciones de consulta inteligente.
Analizador de dependencias gráficas y más de 100 métricas de calidad, de auditorias y medidas
correctivas que permiten analizar y controlar grandes cantidades de código.
Desventajas
En realidad hasta el momento no se han documentado en forma estricta las desventajas, sin
embargo, siempre habrá cierta diferencia en la parte teórica que en la práctica.
12
Ant es una herramienta Open-Source utilizada en la compilación y creación de programas Java; si esta familiarizado con Linux,
Ant es considerado un make para Java.
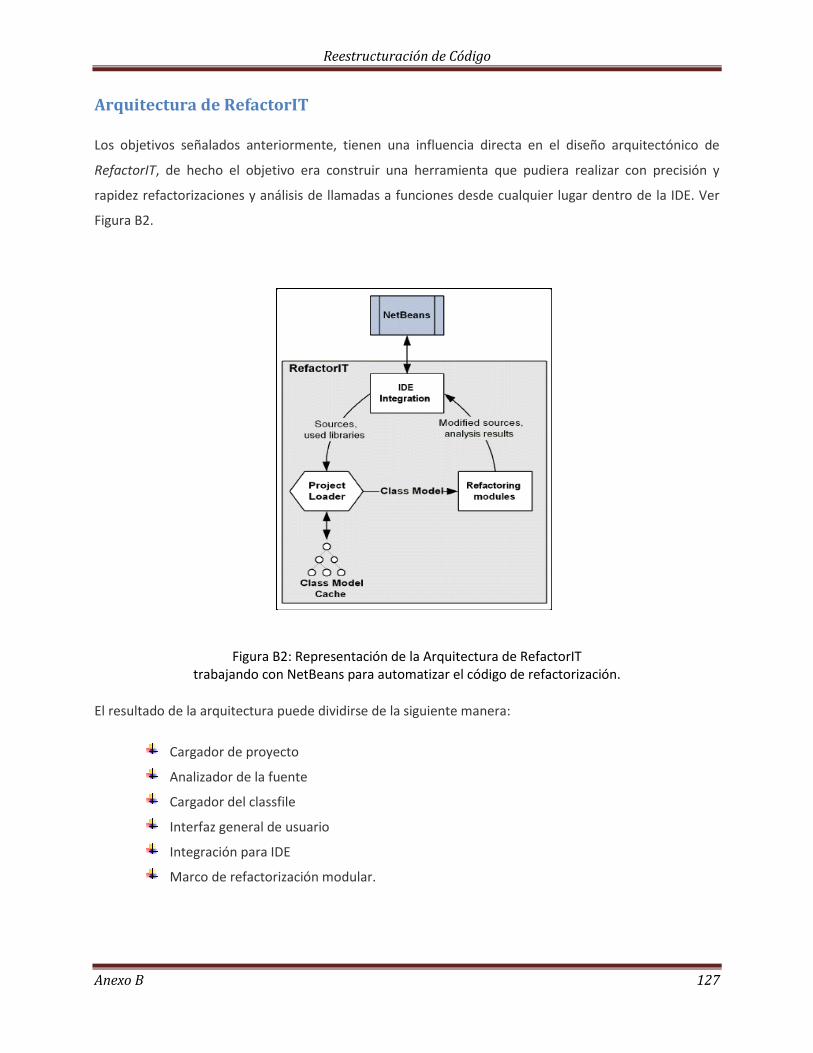
Reestructuración de Código
Anexo B 127
Arquitectura de RefactorIT
Los objetivos señalados anteriormente, tienen una influencia directa en el diseño arquitectónico de
RefactorIT, de hecho el objetivo era construir una herramienta que pudiera realizar con precisión y
rapidez refactorizaciones y análisis de llamadas a funciones desde cualquier lugar dentro de la IDE. Ver
Figura B2.
Figura B2: Representación de la Arquitectura de RefactorIT trabajando con NetBeans para automatizar el código de refactorización.
El resultado de la arquitectura puede dividirse de la siguiente manera:
Cargador de proyecto
Analizador de la fuente
Cargador del classfile
Interfaz general de usuario
Integración para IDE
Marco de refactorización modular.

Reestructuración de Código
Anexo B 128
El cargador del proyecto sube a memoria al código cuando el usuario desea hacer un análisis o una
refactorización. En el momento en el que se ejecuta, construye una clase modelo tomada de un conjunto
de archivos fuente y archivos de clase. Además, éste construye un árbol sintáctico abstracto llamado
AST, basado en el análisis del código fuente. El AST almacena información acerca de los archivos fuente y
vínculos de tipo definicion con sus propias referencias a través del código. Esta secuencia de hechos es la
considerada el corazón de RefactorIT.
RefactorIT procesa y manipula al AST refactorizándolo o analizando los componentes especificados por el
usuario, a partir de ahí RefactorIT despliega los resultados buscados o escribe el código fuente ya
refactorizado para sus archivos correspondientes.
Para optimizar el rendimiento, RefactorIT sube a la memoria caché el modelo de la clase y el árbol de
sintaxis del proyecto. En consecuencia para proyectos grandes, la primera corrida de una refactorización
o función de análisis se ejecutan relativamente lentos en tanto se construye el modelo de clase y los
árboles de sintaxis.
Posteriormente las corridas toman mucho menos tiempo porque el proyecto del modelo de la clase está
completamente construido y solo tiene que estar actualizado en lugares donde el usuario haya cambiado
el código.
RefactorIT tiene una arquitectura modular que se conecta entre sí, de hecho, todas las refactorizaciones
están implementadas en diferentes módulos. Esto permite a los desarrolladores agregar módulos
experimentales al RefactorIT sin tener que preocuparse de la compatibilidad, solo los módulos que estén
realmente probados son incluidos con el instalador.
RefactorIT en la práctica
Se tiene en la caché un mecanismo de cálculo. Al comenzar se construyen los resultados del cálculo que
se necesita guardar y después consultar en la memoria caché para ahorrar tiempo. Se ha creado ya la
estructura de datos MultiValueMap para almacenar la información. Esta estructura tiene que ser rápida,
se construye incrementalmente haciendo eficiente uso de la memoria.

Reestructuración de Código
Anexo B 129
Observe el siguiente ejemplo.
1. En la figura B3 se usará una característica que RefactorIT nos brinda “Búsqueda de Estructura”
para encontrar lugares donde es declarado un campo de tipo MultiValueMap.
Figura B3. Búsqueda de Estructura.
2. Seleccionamos todos los resultados e ignoramos u ocultamos objetos pequeños ya que esos no
deseamos desplegarlos. (Ver Figura B4)
Figura B4. Selección de Resultados.
3. Podemos observar en la figura B5 los resultados a partir de la elección de la figura B4, elegimos
cuando buscar donde se hace uso de los campos.
Com.xpdev.util.AdaptiveMultiValueMap

Reestructuración de Código
Anexo B 130
Figura B5. Selección de resultados.
4. Cuando observamos la lista en la figura B4 podemos elegir elementos para ocultar, haciendo que
la búsqueda resultante nos sirva totalmente.
Conclusión
RefactorIT ofrece una amplia gama de refactorizaciones y funciones de análisis que permiten a los
desarrolladores de la tecnología Java de forma rápida y exitosa, la reestructuración del código fuente del
programa, la mejora de su diseño, la evolución y el potencial de reutilización.
NetBeans fue elegida para ser la plataforma de integración principal de RefactorIT, porque es el hogar de
la innovación en todo el mundo en Java Tools. RefactorIT, a través de su estrecha integración con
NetBeans, hace que el proceso de refactorización sea más fácil, más rápido y más eficiente.


















