
Informática III - dsi.fceia.unr.edu.ar · Toyota tuvo que sacar del mercado millones del modelo...
96
Fiabilidad y tolerancia a fallos Informática III There are two ways of producing error-free software. But only the third will work ... (Unknown author)
-
Upload
nguyenthien -
Category
Documents
-
view
213 -
download
0
Transcript of Informática III - dsi.fceia.unr.edu.ar · Toyota tuvo que sacar del mercado millones del modelo...

Fiabilidad y tolerancia a fallos Informática III
There are two ways of producing
error-free software. But only the
third will work ... (Unknown
author)

Informática III Ing. Nora Blet Pág. 2
Bibliografía
Alan Burns, Andy J. Wellings "Sistemas de Tiempo Real y Lenguajes de Programación", Addison-Wesley (3º edición) cap. 5
Transparencias de Juan Antonio de la Puente http://polaris.dit.upm.es/~jpuente/

Informática III Ing. Nora Blet Pág. 3
Características de un STR
Grandes y complejos
Concurrencia/distribución
Interacción con interfaces hardware
Extremadamente fiable y seguro
Implementación eficiente
Funcionalidades de tiempo real
Manipulación de números reales

Informática III Ing. Nora Blet Pág. 4
Objetivos
Entender los factores que afectan la fiabilidad de un sistema
Introducir técnicas para tolerar fallos de software

Informática III Ing. Nora Blet Pág. 5
Indice
Fiabilidad, averías y fallos
Modos de fallo
Prevención y tolerancia de fallos
Redundancia estática y dinámica
Programación con N versiones
Bloques de recuperación
Redundancia dinámica y excepciones

Informática III Ing. Nora Blet Pág. 6
Algunas cifras El software del sistema de comunicaciones de Ericsson con 26 millones de líneas de código posee menos de 5’ de baja del sistema (medianamente fiable)
El software de control de robots industriales con 2.5 millones de línea de código sin detenerse por cerca de 7 años (aprox. 60000 horas), altamente fiable
Típicamente cada millón de líneas de código puede introducir 20000 bugs (1986), el 90% de ellas se descubren por test, de las 2000 restantes, en el 1º año de uso pueden detectarse 200, quedan sin detectar 1800. Las rutinas de mantenimiento pueden corregir 200 bug pero introducen 200 nuevos errores!!

Informática III Ing. Nora Blet Pág. 7
Algunas cifras
Típicamente el 50% del presupuesto de un desarrollo (tiempo/dinero) es para test y reparación de bugs
Del 60 al 90% de las fallas en un sistema informático son de software
Cuestan unos 60 billones anuales a la economía de EEUU

Informática III Ing. Nora Blet Pág. 8
Fallos de funcionamiento
Los fallos de funcionamiento de un sistema pueden tener su origen en
Una especificación inadecuada
Errores de diseño del software
Averías en el hardware
Interferencias transitorias o permanentes en las comunicaciones
Nos centraremos en el estudio de los errores de software

Informática III Ing. Nora Blet Pág. 9
Conceptos básicos
Randell et al. (1978) define fiabilidad (reliability) como:
“... Una medida del éxito con que el sistema se ajusta a alguna
especificación definitiva de su comportamiento.”

Informática III Ing. Nora Blet Pág. 10
Conceptos básicos
Una avería (failure) es una desviación (evento) del comportamiento de un sistema respecto de su especificación
Las averías se manifiestan en el comportamiento externo del sistema, pero son el resultado de errores (errors) internos
Las causas mecánicas o algorítmicas (declaradas o hipotéticas) de los errores se llaman fallos (faults)

Informática III Ing. Nora Blet Pág. 11
Relaciones de causa-efecto
Un error designa la parte de un estado del sistema que es «incorrecta», o sea está asociación a información
Una falla puede causar un error. Los errores pueden conducir a averías del sistema
Los errores son los efectos (manifestación o síntoma) de fallas. Las averías son los efectos (manifestación o síntomas) de los errores

Informática III Ing. Nora Blet Pág. 12
Ejemplo
Una falla en software se denomina “bug”, la cual podría ser un puntero NULL, sino se lo desreferencia nunca el error permanece enmascarado, si se lo hace produce una avería y el programa termina con una indicación de segmentation fault o violación de acceso. Lo mismo ocurre al desreferenciar un puntero no inicializado o que apuntaba al heap y fue ya liberado, al escribir fuera de los límites de un array o en el caso de acceder a punteros que son valores de retorno de una función pero declarados localmente (apuntan a una zona del stack y no del heap)

Informática III Ing. Nora Blet Pág. 13
Distinción entre falla y error
La diferencia puede apreciarse considerando la reparación de un sistema de base de datos.
Reparar una falla consiste en reemplazar el programa (o hardware) defectuoso por uno que funcione correctamente.
Reparar un error requiere que la información en la base de datos sea cambiada por los valores correctos de forma tal de poder continuar con la operación del sistema. En muchos sistemas esta operación es necesaria aunque no así la reparación de la falla(s) que causan estos errores, aunque deseable no es esencial

Informática III Ing. Nora Blet Pág. 14
Fallos encadenados

Informática III Ing. Nora Blet Pág. 15
Fallos encadenados
Avizinies et.al (2004)

Informática III Ing. Nora Blet Pág. 16
Taxonomía de fallos (Avizienis)

Informática III Ing. Nora Blet Pág. 17
Tipos de Fallo (s/persistencia) Fallos transitorios (Soft)
Ocurren una vez y desaparecen solos, no pueden rastrearse. Si se repite la operación, usualmente desaparecen
ejemplo: interferencias externas en comunicaciones
Fallos permanentes (sólidos, hard)
permanecen hasta que se reparan
ejemplo: roturas de hardware, errores de diseño de software (generalmente detectadas por debug)
Fallos intermitentes (plastic, seudotransitorias o sensibles a un patrón)
fallos transitorios que reaparecen a intervalos irregulares
ejemplo: malfuncionamiento temporario por calentamiento de un componente de hardware
Debe impedirse que los fallos de todos estos tipos causen averías

Informática III Ing. Nora Blet Pág. 18
Fallas transitorias/intermitentes
Son la clase de falla dominantes en los sistemas informáticos. Debido a su naturaleza transitoria y corta duración (ej.: menos de 100 ciclos de máquina) son difíciles de detectar.
Se les dice elusivas porque son difíciles de reproducir, generalmente sus condiciones de activación dependen de combinaciones complejas de estado interno del sistema y requerimientos externos que ocurren raramente. Casi todas las fallas residuales del desarrollo en software grandes y complejos son de este tipo

Informática III Ing. Nora Blet Pág. 19
Fallas transitorias/intermitentes
Típicamente están relacionadas con
Condiciones extrañas o transitorias en el hardware
Condiciones límites especiales (memoria agotada, overflow en un contador, etc.)
Deadlocks (olvidarse de requerir un semáforo)

Informática III Ing. Nora Blet Pág. 20
Fallas transitorias/intermitentes
Deadlocks y otras fallas relacionadas con concurrencia: debidos a velocidad de un operador, interoperabilidad con librerías de terceros, aplicaciones multithreads mal escritas, etc.Ej.:una falla que ocurría solamente cuando el sistema se cerraba, se encontró que se debía a 2 threads que se bloqueaban y esperaban cada uno al otro luego de interactuar con un componente de Microsoft
Problemas con redes de comunicación
Drivers/librerías de terceros
Impropia asignación de permisos a usuarios e información de configuración

Informática III Ing. Nora Blet Pág. 21
Fallas transitorias/intermitentes
Fugas de memoria, si no fue correctamente asignada/liberada el espacio utilizado puede incrementar (en especial con uso prolongado)
Excepciones no manejadas
Problemas temporales en la ejecución de acciones (manuales o automáticas). Ej.: Mozilla presentaba un comportamiento no anticipado cuando determinadas entradas se hacían rápidamente
Errores en discos físicos

Informática III Ing. Nora Blet Pág. 22
Precondiciones comunes
Carga de trabajo del procesador muy alta
Hardware con bajas velocidades de procesador y poca capacidad de memoria (operaciones que consumen muchos recursos)
Operaciones que están ejecutándose en forma continua por un periodo de tiempo largo
Fallas de sincronización
Determinados SO. Ej.:Microsoft Visual C++ sólo presentaba fallas en máquinas con Windows 2008 Server

Informática III Ing. Nora Blet Pág. 23
Precondiciones comunes
Fallas debidas a restarts o actualizaciones del software (interno o de terceros). Ej.:errores que ocurrieron en máquinas luego de actualizar Internet Explorer de la versión 7 a la 8
Lazos infinitos
Tests de pertubaciones (ej.: desconectar una conexión de red, un cable de alimentación, simulación de una falla física), las fallas son luego muy difíciles de repetir

Informática III Ing. Nora Blet Pág. 24
Fallas transitorias/intermitentes
Toyota tuvo que sacar del mercado millones del modelo Prius (híbrido) debido a una falla de software de este tipo
Las fallas en software se llaman «bugs». A las permanentes o sólidas se las llama Bohrbug (por el átomo de Bohr) y a las transitorias o intermitentes se las llama Heisenbug (por el principio de incertidumbre de Heisenberg, toda medición sobre un sistema lo perturba)

Informática III Ing. Nora Blet Pág. 25
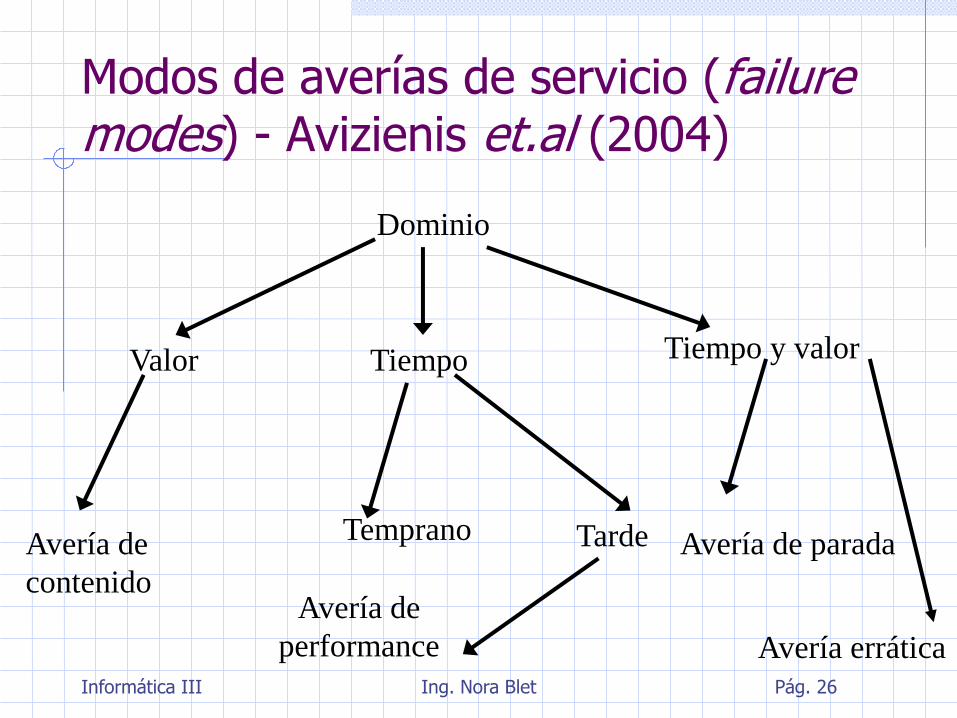
Modos de averías de servicio (failure modes) - Avizienis et.al (2004)
Un sistema puede y, generalmente lo hace, fallar de distintas formas
Estas distintas formas se las llama modos de averías y se las puede caracterizar desde distintos puntos de vista: el dominio de las averías, la detectabilidad, la consistencia y las consecuencias de las mismas sobre el entorno
Clasificar las averías y entender su naturaleza es fundamental para el diseño de un sistema capaz de tolerar y/o continuar con el servicio a pesar de malfuncionamientos
Informática III Ing. Nora Blet Pág. 26
Modos de averías de servicio (failure modes) - Avizienis et.al (2004)
Dominio
Valor Tiempo Tiempo y valor
Temprano Tarde Avería de
contenido
Avería de parada
Avería errática
Avería de
performance

Informática III Ing. Nora Blet Pág. 27
Mejoras en la Fiabilidad
Hay dos técnicas complementarias para aumentar la fiabilidad de un sistema:
Prevención de Fallos
Se trata de evitar que se introduzcan fallos en el sistema antes de que entre en funcionamiento
Tolerancia a Fallos
Se trata de conseguir que el sistema continúe funcionando aunque se produzcan fallos
En ambos casos el objetivo es desarrollar sistemas con tipos de averías bien definidos

Informática III Ing. Nora Blet Pág. 28
Técnicas para aumentar la fiabilidad

Informática III Ing. Nora Blet Pág. 29
Prevención de Fallos
Se realiza en dos etapas: Evitación (Intolerancia a fallos, Avizienis)
Se intenta acotar la introducción de componentes (hardware y software ) potencialmente defectuosos durante la construcción del sistema
A pesar de utilizar técnicas para evitar fallos, éstos se encontrarán inevitablemente en el sistema una vez construido. En concreto, pueden existir errores de diseño en los componentes (hardware y software).
Eliminación Consiste en encontrar y eliminar los fallos que se
producen en el sistema una vez construido

Informática III Ing. Nora Blet Pág. 30
Evitación de fallos-Hardware
Utilización de componentes mas confiables, dentro de las restricciones de costo y performance
Empleo de técnicas refinadas para la interconexión y ensamblado de componentes
Aislamiento de interferencias externas

Informática III Ing. Nora Blet Pág. 31
Evitación de fallos-Software
Especificaciones rigurosas/formales
Metodologías de diseño comprobadas
Uso de herramientas con abstracción, encapsulamiento y modularidad
Uso de herramientas de ingeniería de software para ayudar en la manipulación de los componentes software y en la gestión de la complejidad
Informática III Ing. Nora Blet Pág. 32
Técnicas de Eliminación de Fallos
Comprobaciones
Revisión de diseño
Verificación de programas
Inspección de código
Prueba (test) Nunca pueden ser exhaustivas Sólo se pueden utilizar para demostrar la
presencia de fallos, no su ausencia A menudo resulta imposible realizarlas bajo
condiciones reales simulación, no hay garantías de su exactitud
Los errores de especificación no se detectan hasta que el sistema no esté operativo

Informática III Ing. Nora Blet Pág. 33
Limitaciones de la prevención de fallos
Los componentes de hardware pueden fallar
La prevención resulta insuficiente si
la frecuencia o la duración de las reparaciones es inaceptable
no se puede detener el sistema para efectuar operaciones de mantenimiento y reparación. Ejemplo: naves espaciales no tripuladas
La alternativa es utilizar técnicas de tolerancia a fallos

Informática III Ing. Nora Blet Pág. 34
Niveles de tolerancia a fallos
Un sistema puede proveer tres niveles, según la calidad de servicio que puede proveerse luego de un fallo:
Tolerancia total de fallos (Fail operational)
El sistema sigue funcionando, al menos durante un tiempo, sin perder funcionalidad ni prestaciones
Los usuarios no notarán diferencias significativas en términos de expectativas
Los recursos adicionales para cubrir todos los posibles escenarios de falla son usualmente altamente prohibitivos para la mayoría de las aplicaciones
Ej.: funciones críticas de un Boeing 777

Informática III Ing. Nora Blet Pág. 35
Niveles de tolerancia a fallos
Degradación controlada (Graceful Degradation, Fail Soft)
El sistema sigue funcionando con una pérdida parcial de funcionalidad y/o prestaciones hasta la reparación del fallo
Es el comportamiento preferido frente a fallos: se prefiere a tener funcionalidad incorrecta o pérdida total de ella.
La idea es mantener, al menos, algunas de las funciones (normalmente las más críticas) con los actuales y limitados recursos disponibles. La elección de las funciones que siguen en pie depende del tipo de error detectado además de como fue diseñada la aplicación.
Relajar los requerimientos no funcionales tales como la performance, cuando ocurre una falla es otra opción. Ej. Un web server puede seguir operando aunque con menor rendimiento o mayores tiempos de respuesta
El resultado puede provocar molestias, incrementar la carga de trabajo de un operador o, la vigilancia requerida o, reducir la productividad

Informática III Ing. Nora Blet Pág. 36
Niveles de tolerancia a fallos
Parada segura (Fail Safe)
El sistema cuida de su integridad durante el fallo aceptando una parada temporal de su funcionamiento, hasta que se repare el fallo
No necesariamente significa detener completamente el sistema, esto es enteramente dependiente de la aplicación Ej.: semáforos y señalización ferroviaria, planta nuclear
Se privilegia la seguridad y limitar daños, la continuación de los servicios ya no es una prioridad, a menos que sean necesarios para garantizar la seguridad (incrementan la seguridad aunque no la fiabilidad)
El grado de tolerancia a fallos necesario depende de la aplicación

Informática III Ing. Nora Blet Pág. 37
Redundancia
La tolerancia de fallos se basa en la redundancia
Se utilizan componentes adicionales para detectar los fallos y recuperar el comportamiento correcto
Esto aumenta la complejidad del sistema y puede introducir fallos adicionales
Resulta aconsejable separar los componentes tolerantes a fallos del resto del sistema

Informática III Ing. Nora Blet Pág. 38
“The bug” (1981)

Informática III Ing. Nora Blet Pág. 39
Redundancia
Algunos consideran mejor evitar la redundancia y la diversidad en el software. Su visión es que el enfoque más adecuado es diseñar software tan sencillo como sea posible, con procedimientos muy rigurosos de verificación y validación.
Ambos enfoques se adoptan en sistemas comerciales críticos para la seguridad. Ej.: el hardware y software de control de vuelo del Airbus 340 es tan diverso como redundante mientras que el del Boeing 777 se centra en la simplicidad y no en la redundancia; ambas aeronaves son muy confiables

Informática III Ing. Nora Blet Pág. 40
Tolerancia a fallos de software
Técnicas para detectar y corregir errores de diseño
Redundancia estática (enmascaramiento) Programación con N versiones
Redundancia dinámica Dos etapas: detección y recuperación de
errores
Bloques de recuperación Proporcionan recuperación hacia atrás
Excepciones

Informática III Ing. Nora Blet Pág. 41
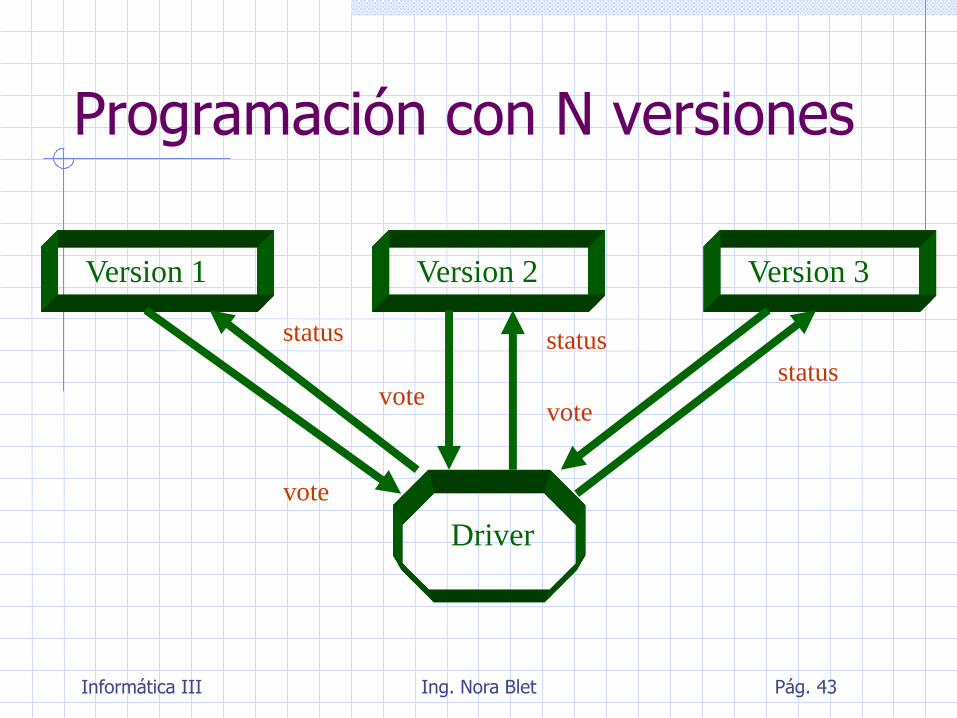
Programación con N versiones
Diversidad de diseño N (N>1) programas desarrollados
independientemente (funcionalmente equivalentes) a partir de la misma especificación
sin interacciones entre los equipos de desarrollo
Siempre que sea posible se usan distintos algoritmos, lenguajes de programación, compiladores, estructuras de datos, etc.
Es preferible que los desarrolladores tengan distinto entrenamiento y experiencia.

Informática III Ing. Nora Blet Pág. 42
Programación con N versiones
Ejecución concurrente proceso coordinador (driver)
intercambia datos con los procesos que ejecutan las versiones
todos los programas tienen las mismas entradas
las salidas se comparan (votación)
Es uno de los primeros métodos organizados para introducir redundancia en software y hoy día es una de las técnicas más desarrolladas. Se parte del supuesto que reduce la probabilidad de fallas comunes entre las versiones y por tanto incrementa la fiabilidad del sistema
Informática III Ing. Nora Blet Pág. 43
Programación con N versiones
Version 2 Version 1 Version 3
Driver
vote
status
vote vote
status
status

Informática III Ing. Nora Blet Pág. 44
Programación con N versiones La especificación inicial definiría:
La función a implementar
Formatos de datos para mecanismos especiales:
Vectores de comparación (“c-vectors”)
Indicadores de estado de la comparación (“cs-indicators”)
Puntos donde deben generarse los c-vectors: cross-check points (“cc-points”) para la votación
El algoritmo de votación. Rango de discrepancia en caso de resultados numéricos si corresponde
Las respuestas a los posibles resultados de la votación
Mecanismos de sincronización

Informática III Ing. Nora Blet Pág. 45
Programación con N versiones
C-vectors: estructuras de datos que representan un subconjunto del estado del programa de cada versión e interpretable por el driver, tienen sentido sólo cuando se alcanza un cc-point en dicho programa
En un cc-point los c-vectors contiene 2 tipos de información:
Las variables de comparación (c-variables)
Status flags indican si ocurrió (o no) algún evento significativo durante la generación de las c-variables. Ej.: EOF, condiciones de excepción detectada por el sistema, condiciones definidas en las especificaciones

Informática III Ing. Nora Blet Pág. 46
Programación con N versiones
Cs-indicators: usados para indicar acciones a realizar luego de la votación
Las posibles acciones dependen de:
Todas las versiones entregan los c-vectors dentro del tiempo especificado y,
Si los vectores acuerdan o desacuerdan
Las posibles acciones son:
Continuación
Terminación de una o más versiones
Continuación luego de cambios en los c-vectors de una o más versiones sobre la base de la decisión de la mayoría

Informática III Ing. Nora Blet Pág. 47
Programación con N versiones
Cuando la mayoría de las versiones producen resultados que concuerdan, éstos son tratados como resultados aceptables para determinada versión
Cualquier versión que genere resultados que difieran de los aceptables se designa como versión en desacuerdo

Informática III Ing. Nora Blet Pág. 48
Sincronización
Utilizada para sincronizar los pasos de cada versión
Cada versión usa sincronización para indicarle al driver que el c-vector está listo
El driver usa sincronización para indicarle a una versión que debe activarse, además la usa para prevenir que se realice la votación antes que todos los c-vectors estén listos.

Informática III Ing. Nora Blet Pág. 49
Sincronización

Informática III Ing. Nora Blet Pág. 50
Votación
Si la frecuencia de votación es demasiado baja se minimiza la sobrecarga de comunicaciones inherente y permite gran independencia en el diseño pero, pueden producirse mayores divergencias entre resultados numéricos debido al gran número de pasos ejecutados entre votaciones
Si la frecuencia es demasiado alta se requiere una semejanza en los detalles de la estructura de los programas y por tanto se reduce el grado de independencia entre las versiones. Además se incrementa la sobrecarga asociada con esta técnica

Informática III Ing. Nora Blet Pág. 51
Votación inexacta En caso de votación exacta (bitwise, ej.: enteros, booleanos, texto) los resultados deben ser exactamente los mismos para acordar
Cuando se trabaja con números pueden aparecer 2 tipos de desviaciones, que llevan a desacuerdos:
Una es “esperable” por representación inexacta del hardware o sensibilidad de los datos con respecto a un algoritmo
Otra, de tipo “inesperado” debido a un diseño inadecuado o implementación de un algoritmo o malfuncionamiento del hardware
En este caso la diferencia entre los votos debe ser menor a una tolerancia predeterminada propia de la aplicación, el cual debe ser elegido cuidadosamente. No hay enfoque analítico para ello

Informática III Ing. Nora Blet Pág. 52
Votación inexacta
Por tanto, se necesita en algunos casos, manejar votaciones con resultados no idénticos (votación inexacta)
No existe ningún enfoque para la votación inexacta que pueda aplicarse satisfactoriamente a todos los casos

Informática III Ing. Nora Blet Pág. 53
Estrategias de votación inexacta
Promedios con o sin ponderación de forma tal de reducir la influencia de los resultados más alejados del centro del rango de tolerancia especificado
Elección del valor que está más cerca del medio, los valores que más difieren del mismo son descartados aunque, pueden seguir operando con desacuerdo
Pluralidad de votos, se elige el conjunto de votos (al menos 2) con mayor número de acuerdos aún sino hay mayoría absoluta. Ej.: en 7 versiones elijo 3 con similares resultados y descarto las otras 4 tengan una gran discrepancia

Informática III Ing. Nora Blet Pág. 54
Estrategias de votación inexacta
Votación por mayoría (N+1/2 versiones dan resultados similares)
Las dos 1ºs estrategias siempre entregan un resultado sin importar cuánto se desvían entre ellos
Las dos últimas sólo entregan un resultado si se alcanza un acuerdo entre las variantes
Todavía existen más problemas con la votacion: múltiples resultados correctos. Ej.: ecuación cuadrática, aunque no hay fallo puedo tener 2 resultados en desacuerdo!!

Informática III Ing. Nora Blet Pág. 55
Problema de la comparación consistente
Cuando se usa aritmética de precisión finita (errores de redondeo y truncación, el resultado de una secuencia de cálculos depende del orden de los mismos y de la aritmética particular usada por el hardware en distintos algoritmos que no se comunican entre si
Existe una variante “inesperada” de problema de múltiples resultados correctos, aunque una aplicación puede parecer que tenga una única solución, la inconsistencia en las comparaciones conduce a este problema!
Esto se debe a que las diferentes versiones deben tomar distintos caminos basado en comparaciones requeridas por las especificaciones

Informática III Ing. Nora Blet Pág. 56
Problema de la comparación consistente

Informática III Ing. Nora Blet Pág. 57
Comparación consistente T3
> Tth yes
P3
> Pth
T1
> Tth
no
P1
> Pth
yes
V1
T2
> Tth
no
P2
no
> Pth
V2 V3
Cada versión produce un resultado distinto aunque correcto. No se arregla comparando con Tth, Pth

Informática III Ing. Nora Blet Pág. 58
Problema de la comparación consistente
Si las versiones calculan un valor que difieren menos de una dada tolerancia, ellas deben obtener una relación del mismo orden cuando comparan el valor calculado con una dada constante
Es importante entender que este problema no está relacionado con la votación inexacta!! Sino que deriva de la necesidad de las versiones de hacer comparaciones aisladas y que pueden dar valores de salida que son completamente diferente antes que valores que difieren meramente en una pequeña tolerancia

Informática III Ing. Nora Blet Pág. 59
Problema de la comparación consistente
Para resolver este problema se necesitaría un algoritmo que pueda ser aplicado por cada versión correcta para transformar el valor calculado a la misma representación que todas las otras versiones correctas. No es suficiente que todas las versiones tengan valores cercanos unos con otros puesto que, no importa qué tan cercanos estén, la relación con respecto a una constante puede aún ser diferente.
Actualmente este problema sigue sin solución práctica
Informática III Ing. Nora Blet Pág. 60
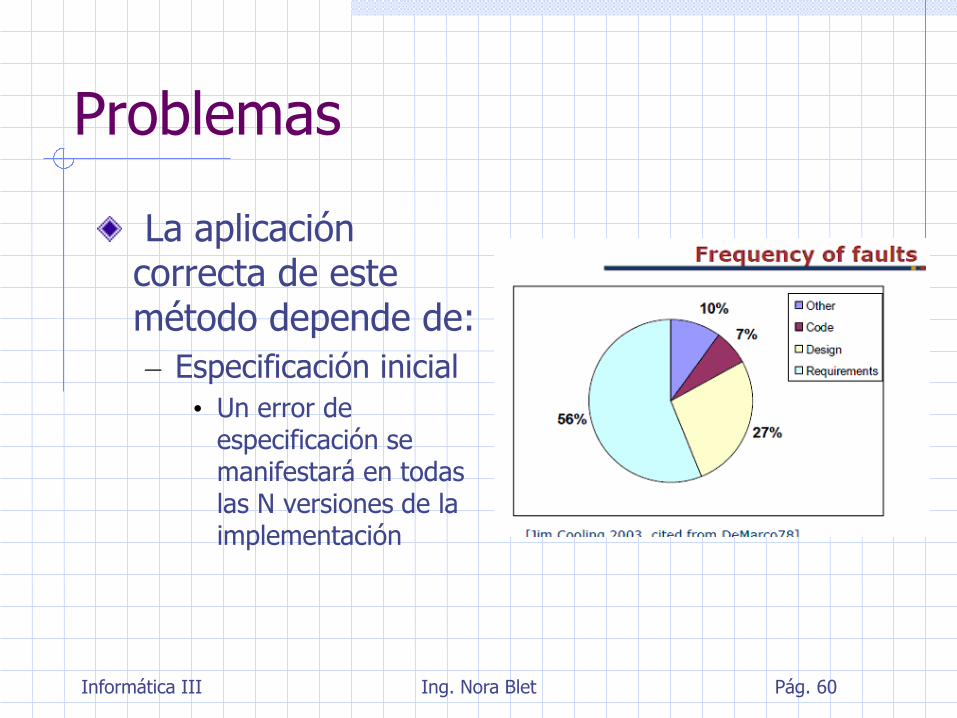
Problemas
La aplicación correcta de este método depende de:
– Especificación inicial
• Un error de especificación se manifestará en todas las N versiones de la implementación

Informática III Ing. Nora Blet Pág. 61
Problemas
Independencia en el diseño
No está claro que distintos programadores cometan errores independientes
Presupuesto suficiente
Los costes de desarrollo se multiplican
¿sería mejor emplearlos en mejorar una versión única?
El mantenimiento es también más costoso

Informática III Ing. Nora Blet Pág. 62
Resumen
Se ha utilizado en sistemas de aviónica críticos
Cuando el algoritmo de votación está implementado correctamente constituye un marco de trabajo simple y atractivo para obtener tolerancia a fallos

Informática III Ing. Nora Blet Pág. 63
Redundancia dinámica en software
Cuatro etapas: (dos pasivas y dos activas) Detección de errores
no se puede hacer nada hasta detectar un error
una falla no puede ser detectada directamente por el sistema mientras que su manifestación generará errores
Valoración y confinamiento de los daños diagnosis: averiguar hasta dónde ha llegado la información
errónea
Recuperación de errores llevar el sistema a un estado correcto, desde el que pueda
seguir funcionando (tal vez con funcionalidad parcial)
Reparación de fallos y continuación de servicio Aunque el sistema funcione, el fallo puede persistir y hay que
repararlo

Informática III Ing. Nora Blet Pág. 64
Redundancia dinámica en software
Puede haber considerable interacción entre las etapas, se dificulta su identificación. Ej.:
las medidas tomadas para hacer una valoración de los daños suelen usar técnicas de detección de errores
Según la técnica de recuperación de errores depende de la valoración de daños
La localización de fallas usualmente se basa en el uso de diagnostic checking que es una forma de detección de errores
El orden de las fases puede variar aunque el punto de partida suele ser la detección de errores
No siempre están operativas las 4 fases, depende de las decisiones tomadas durante el diseño del sistema, aunque no estén presentes no dejan de ser importantes! Durante el diseño hay que decidir dónde se requiere realmente aplicar tolerancia a fallas y evaluar hasta qué grado es necesario (redundancia)

Informática III Ing. Nora Blet Pág. 65
Técnicas de detección de errores
Por el entorno de ejecución
Por el hardware (Ej.: desbordamiento aritmético)
núcleo de ejecución o sistema operativo (Ej.: puntero nulo)
Por el software de aplicación
Comprobación de réplicas (programación con N-versiones) Una de las más potentes y completas pero de las más costosas en
términos de redundancia (estática) requerida
Comprobaciones temporales Temporizador guardián (watchdog timer) hardware o software
Útil para detectar procesos demasiado lentos, deadlocks, lazos infinitos
deadline checks
Inversión de funciones Aplicable a sistemas donde el cálculo inverso sea relativamente
sencillo y donde la relación entre I/O sea uno a uno
Principal problema: sobrecarga al calcular I a partir de O, puede tomar más tiempo que el cálculo directo!

Informática III Ing. Nora Blet Pág. 66
Técnicas de detección de errores
Códigos detectores de error Checksum, chequeos de paridad, Códigos de Hamming, CRC
Eficientes y económicos en términos de redundancia. A menudo son la única forma factible de chequear la aceptabilidad de grandes cantidades de datos (y complejos)
Comprobaciones de racionalidad: aplicable cuándo se conoce el conjunto completo de salidas válidas Aserciones (usadas principalmente en debug y no en ejecución)
Chequeos de rango (ángulo en º, límites de un array o string, temperaturas, valor de una probabilidad, lectura de un medidor de consumo eléctrico), de cambios de rango, chequeos de tipos de datos, consistencia con otros objetos en el sistema, verificación de tamaño (longitud nro de una cuenta bancaria) , verificación de representación (dirección de mail)
Validación estructural
cuenta de elementos de listas, punteros redundantes en estructuras de datos, información sobre el tipo de elementos, etc.

Informática III Ing. Nora Blet Pág. 67
Valoración y confinamiento de daños
Es importante confinar los daños causados por un fallo a una parte limitada del sistema (firewalling)
Las técnicas de valoración están estrechamente relacionadas con las técnicas de confinamiento usadas, se parte de una estima inicial del daño anticipado de antemano por el diseñador del sistema
Son difíciles de implementar, las mecanismos que son importantes para ello son aquéllos que tratan de estructurar el sistema de forma que se minimice el daño causado por los componentes defectuosos (compartimentos estancos, firewalls), poniendo restricciones al flujo de información del sistema
Técnicas
Descomposición modular
Acciones atómicas
Mecanismos de protección (listas de acceso)

Informática III Ing. Nora Blet Pág. 68
Recuperación de errores Es la etapa más importante
Se trata de situar el sistema en un estado correcto desde el que pueda seguir funcionando
Se han propuesto dos estrategias: Hacia delante (forward) : continuación desde el
estado erróneo con correcciones selectivas
Hacia atrás (backward): Se basa en restaurar el sistema a un estado seguro previo a la aparición del error y ejecutar una secuencia alternativa. El estado seguro se llama punto de recuperación (checkpoint)

Informática III Ing. Nora Blet Pág. 69
Recuperación hacia adelante
Se manipula el estado actual del sistema (erróneo, no presupone un estado correcto) e intenta obtener un nuevo estado (suficientemente) correcto
Requiere de un conocimiento completo de la naturaleza de la falla (por tanto del uso que se hace en ese estado) y (o por lo menos) de sus exactas consecuencias. No es apropiada para fallas residuales de diseño
Depende de una predicción correcta de los posibles fallos y de su situación (valoración de daños)

Informática III Ing. Nora Blet Pág. 70
Recuperación hacia adelante En un sistema embebido las correcciones selectivas pueden implicar proteger cualquier aspecto del entorno controlado que pudiera ser puesto en riesgo o dañado por el fallo
Por tanto, la forma de implementarla es específica para cada sistema, sin embargo cuando puede implementarse es simple y más eficiente en términos de la sobrecarga que impone (tiempo y espacio de memoria)
Ejemplos de técnicas (incluyen el uso (re)constructivo de redundancia de datos o algoritmos)
punteros redundantes en estructuras de datos
códigos autocorrectores (Ej.: código de Hamming) usados para corregir errores en una memoria, en protocolos de comunicaciones o aún errores en operaciones aritméticas
En código: Manejo de excepciones

Informática III Ing. Nora Blet Pág. 71
Recuperación hacia adelante
Otro ejemplo: repetir una acción que falló antes pensando que el fallo es transitorio, por ejemplo reenvío de un mensaje dañado en una red TCP y releer un bloque de un disco (usada por muchos controladores de disco), aquí no se usa redundancia, se realiza con los elementos existentes.
La literatura de esta técnica sigue siendo bastante limitada.
Ambas técnicas (rollback y rollforward) no son excluyentes, pueden combinarse

Informática III Ing. Nora Blet Pág. 72
Recuperación hacia atrás Consiste en retroceder a un estado anterior correcto y ejecutar un segmento de programa alternativo (con otro algoritmo, igual funcionalidad)
El punto al que se retrocede se llama punto de recuperación (checkpoint)
La acción de guardar el estado se llama chekpointing
No es necesario averiguar la causa ni la situación del fallo (técnica más general)
Sirve para fallos imprevistos (Ej.: errores de diseño)
¡Pero no puede deshacer los errores que aparecen en el sistema controlado!

Informática III Ing. Nora Blet Pág. 73
Recuperación hacia atrás La información a almacenar periódicamente (replicación de datos) es un snapshot del subconjunto del estado del sistema (ej: datos, programas, estado del hardware), necesario para continuar la operación exitosamente. La información se guarda en un medio de almacenamiento estable para protegerla de los efectos de las fallas
Para el checkpointing pueden implementarse mecanismos en hardware o software que automáticamente graben los datos modificados entre 2 checkpoints
Es por lejos la forma más popular de recuperación de errores

Informática III Ing. Nora Blet Pág. 74
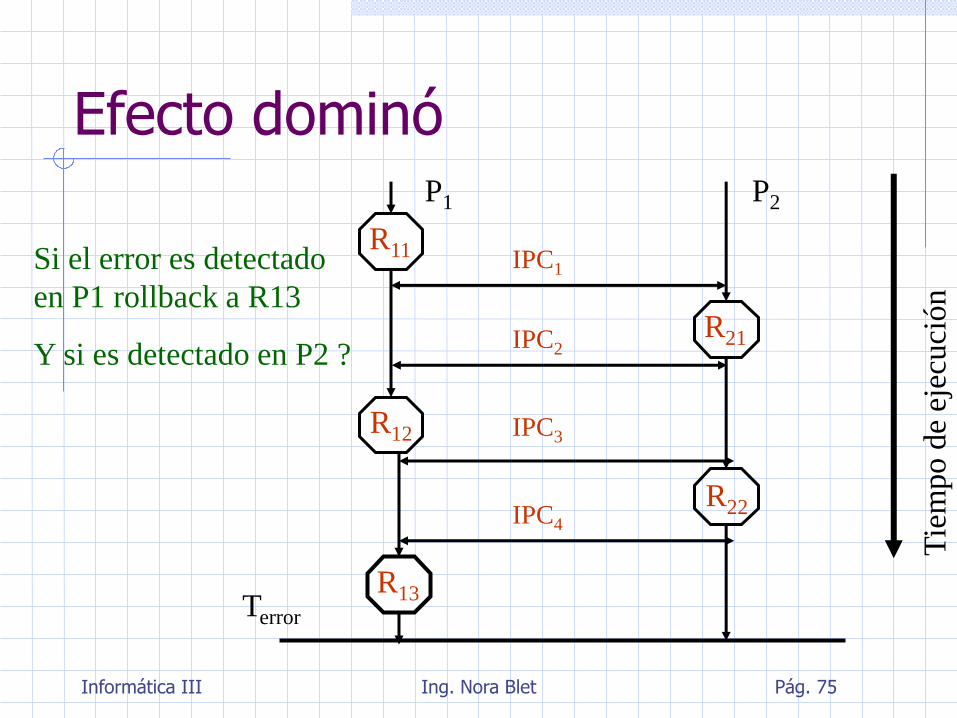
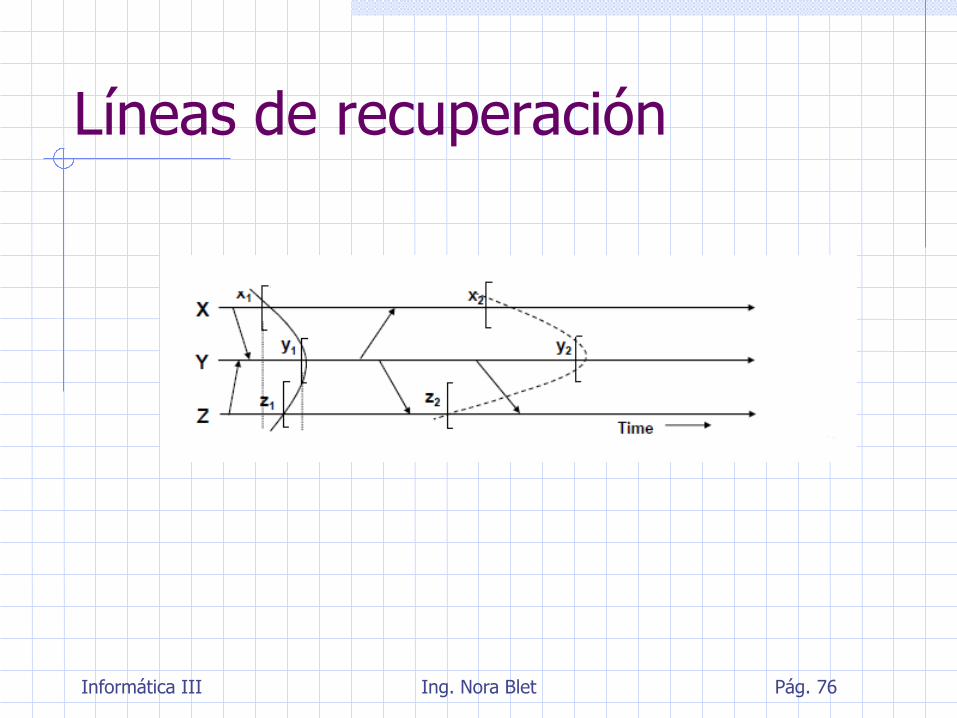
Efecto dominó
Cuando hay tareas concurrentes la recuperación hacia atrás se complica
Los puntos de recuperación deben ser diseñados consistentemente, de forma que un error detectado en uno de los procesos no produzca que todos los procesos con los que interactúa sean revertidos
En lugar de esto, los procesos pueden ser reiniciados desde un conjunto consistente de puntos de recuperación (líneas de recuperación) para todos ellos
Informática III Ing. Nora Blet Pág. 75
Efecto dominó
R22
R21
R13
R12
R11
IPC4
IPC3
IPC2
IPC1
Tie
mpo d
e ej
ecuci
ón
Terror
P1 P2
Si el error es detectado
en P1 rollback a R13
Y si es detectado en P2 ?
Informática III Ing. Nora Blet Pág. 76
Líneas de recuperación

Informática III Ing. Nora Blet Pág. 77
Recuperación hacia atrás
Casi todas las bases de datos (BD) incluyen rollback, cuando un usuarios realiza una operación en ellas, se inicia una transacción, los cambios hechos durante ella no son incorporados inmediatamente a la BD, sólo se la actualiza luego de que la transacción se termina y no se detectaron problemas. Si la transacción falla la BD no se actualiza
Otro modelo transaccional que lo usa: e-commerce

Informática III Ing. Nora Blet Pág. 78
Tratamiento de fallas La reparación automática es difícil y depende del sistema concreto, en general se hace manual o semiautomáticamente. Muchos sistemas no la hacen, suponen fallos transitorios o que las recuperación de errores fue lo suficientemente potente como para tratar fallos recurrentes
Hay dos etapas
Localización del fallo (diagnostic checking): análisis causal fallas/errores
Las técnicas de detección de errores pueden ayudar a realizar un seguimiento del fallo de un componente
Reparación del sistema: erradicación de fallas
Los componentes de hardware se pueden cambiar
Los componentes de software se reparan haciendo una nueva versión o reconfigurar el sistema (usando redundancia incorporada), de forma tal que, el componente sospechoso no se use o se use de forma diferente (falla permanezca dormida)
En algunos casos puede ser necesario reemplazar el componente defectuoso sin detener el sistema

Informática III Ing. Nora Blet Pág. 79
Continuación del servicio
Puede obtenerse terminando la ejecución del componente sospechoso o resumiendo la operación de dicho componente.
Otra alternativa es hacer un retry de la operación (redundancia temporal). Se utiliza con fallas transitorias y no haya restricciones temporales duras

Informática III Ing. Nora Blet Pág. 80
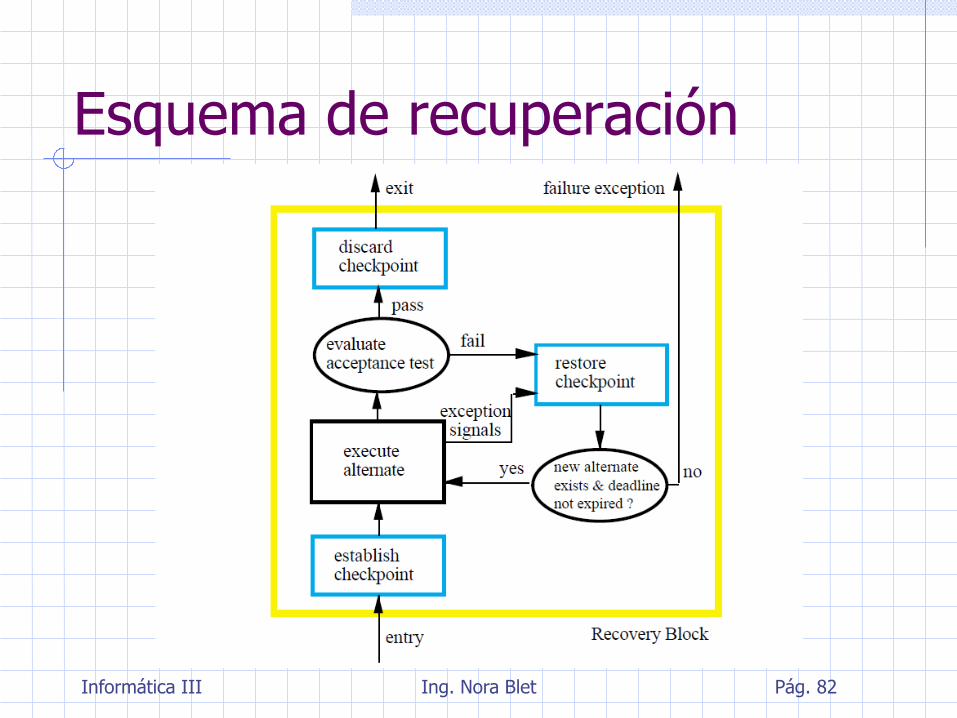
Bloques de recuperación (Horning/Randell (1974-75))
Es una técnica de recuperación hacia atrás integrada en el lenguaje de programación
Son bloques en el sentido normal de los lenguajes de programación pero,
su entrada es un punto de recuperación
a su salida se efectúa una prueba de aceptación
sirve para comprobar si el módulo primario del bloque termina en un estado aceptable

Informática III Ing. Nora Blet Pág. 81
Bloques de recuperación (Horning/Randell (1974-75))
si la prueba de aceptación falla, se restaura el estado inicial en el punto de
recuperación
se ejecuta un módulo alternativo del mismo bloque
si vuelve a fallar, se siguen intentando alternativas
cuando no quedan más, el bloque falla y hay que intentar al recuperación en un nivel más alto
Informática III Ing. Nora Blet Pág. 82
Esquema de recuperación

Informática III Ing. Nora Blet Pág. 83
Posible sintaxis
Puede haber bloques anidados
si falla el bloque interior, se restaura el punto de recuperación del bloque exterior
ensure <acceptance test>
by
<primary module>
else by
<alternative module>
else by
<alternative module>
...
else by
<alternative module>
else error

Informática III Ing. Nora Blet Pág. 84
Bloques anidados

Informática III Ing. Nora Blet Pág. 85
Problemas y consideraciones
A 1º vista puede parecer que el bloque de recuperación tiene una estructura muy simple pero hay que tener en cuenta algunas consideraciones:
Los tipos de fallas toleradas por los bloques de recuperación
Diseño de los módulos primario y alternativos
Diseño del test de aceptación
Diseño del mecanismo del caché de recuperación
Sobrecarga (espacio y tiempo) del sistema
Efecto dominó

Informática III Ing. Nora Blet Pág. 86
Rechazo del test de aceptación
Hay 4 posibles causas de rechazo de un bloque:
Un error dentro del bloque (primario o alternativo)
Falla por timeout (watchdog timer)
Detección de un error dentro de un bloque por los mecanismos implícitos (por ej.:división por 0)
Rechazo explícito o implícito dentro de un bloque interior (anidamiento) que agota la capacidad de recuperación a ese nivel

Informática III Ing. Nora Blet Pág. 87
Checkpointing
Se lo considera el «hard core» del esquema, es decir, se supone que es fiable y no fallará nunca. Normalmente se necesitan almacenar unas pocas variables globales puesto que casi todas las operaciones en los módulos son realizadas usando variables locales
Cuando se ejecuta un bloque alternativo debe presentársele el mismo entorno que cuando se ingresó al bloque primario: todas las operaciones del bloque primario deben deshacerse, todas las variables no locales alteradas por dicho bloque deben ser restauradas a sus valores previos
En cambio si se pasa el test de aceptación y se sale del bloque de recuperación se debe descartar toda la información del estado del sistema en el checkpoint

Informática III Ing. Nora Blet Pág. 88
Checkpointing
El uso de un caché de recuperación y mecanismos de recuperación hacia atrás introduce una sobrecarga en tiempo necesario para ejecutar el test de aceptación y en la implementación del caché de recuperación. Puede llegar a ser buena solución para un sistema de tiempo real si se tiene una correcta estimación del tiempo en que se dispondrá de una salida correcta antes de un deadline. Usar esta solución sólo para partes críticas del sistema
A veces conviene diseñar un test de aceptación más rápido aunque menos exacto. Ej: si el test debe verificar que las entradas de un array estén correctamente ordenadas (ascendente o descendente) una solución (costosa en tiempo) chequearía el orden de los ítems en el array y también la existencia de todos los ítems de entrada en la salida. Una alternativa más rápida aunque menos exacta: en vez de realizar el segundo chequeo verificar la suma de todos los ítems en la salida contra la misma suma con los ítems de entrada

Informática III Ing. Nora Blet Pág. 89
Checkpointing
También introduce sobrecarga de espacio de memoria para almacenar el código de los módulos alternativos y el test de aceptación

Informática III Ing. Nora Blet Pág. 90
Ejemplo: ecuación diferencial
El método explícito es más rápido, pero no es
adecuado para algunos tipos de ecuaciones
El método implícito sirve para todas las ecuaciones, pero es más lento
Este esquema sirve para todos los casos
Puede tolerar fallos de programación (test general)
ensure Rounding_err_has_acceptable_tolerance
by
Explicit Kutta Method
else by
Implicit Kutta Method
else error

Informática III Ing. Nora Blet Pág. 91
Prueba de aceptación Es el componente más crucial del esquema
Pueden usarse algunas de las técnicas de detección de error vistas
Hay que buscar un compromiso entre detección exhaustiva de fallos y eficiencia de ejecución (el bloque primario se ejecuta la mayor parte del tiempo)
Se trata de asegurar que el resultado es aceptable, no forzosamente correcto (no hace falta tener mismos resultados en todos los bloques, sólo el módulo primario debe ser correcto)
lo que permite que un componente pueda proporcionar un servicio degradado. Útil en sistemas de tiempo real, puede que no se disponga de tiempo suficiente para ejecutar una alternativa con la funcionalidad al 100%
Cuanto más bajo el nivel del módulo más degradado el servicio, más sencillo de diseñar, menos propenso a errores de diseño

Informática III Ing. Nora Blet Pág. 92
Prueba de aceptación La complejidad de su diseño (tal vez comparable a la del código verificado)puede hacerlo propenso a fallas de diseño de software, mantenerlo tan simple como sea posible
Si es defectuoso pueden quedar errores residuales sin detectar o resultados aceptables resultar rechazados
Decrementando la fiabilidad del sistema completo comparado con un módulo primario altamente fiable
Su construcción suele ser difícil. Ejemplo: caso de un generador de números seudo-aleatorio, determinar a partir de una única salida si es uniforme es imposible, el patrón de uniformidad sólo emerge cuando se dispone de muchas salidas

Informática III Ing. Nora Blet Pág. 93
Comparación

Informática III Ing. Nora Blet Pág. 94
Excepciones y redundancia dinámica
Son ocurrencias concretas de un error
Cuando un componente detecta un error debe señalarlo al invocador lanzando/generando (raise, signal, throw) una excepción
La respuesta del invocador se denomina gestión (manejo, captura) de la excepción

Informática III Ing. Nora Blet Pág. 95
Excepciones
La gestión de excepciones se puede considerar como un mecanismo de recuperación hacia delante
Sin embargo, también se pueden utilizar para proporcionar una recuperación de errores hacia atrás

Informática III Ing. Nora Blet Pág. 96
Modelo
Actividad Normal Manejador de Excepciones
Vuelta al Servicio
normal
Excepción Interna
Petición
De Servicio
Respuesta
Normal
Excepción
de Fallo
Excepción
de Interfaz
Petición
De Servicio
Respuesta
Normal Excepción
de Interfaz
Excepción
de Fallo


















