
Huffman New Ppt
22
Codificación Huffman TEORIA DE LA INFORMACION Y CODIFICACION. NOMBRES: MATRICULA: LESLY YAJAIRA ONTIVEROS DIAZ 1381932 VICTOR SAMUEL GONZALEZ TRISTAN 1139180 ERICK MARTINEZ MORALES 1254626
-
Upload
erick-martinez -
Category
Documents
-
view
34 -
download
0
Transcript of Huffman New Ppt

Codificación HuffmanTEORIA DE LA INFORMACION Y CODIFICACION.
NOMBRES: MATRICULA:
LESLY YAJAIRA ONTIVEROS DIAZ 1381932
VICTOR SAMUEL GONZALEZ TRISTAN 1139180
ERICK MARTINEZ MORALES 1254626

Introducción.
La codificación Huffman es un algoritmo usado para compresión de datos. El término se refiere al uso de una tabla de códigos de longitud variable para codificar un determinado símbolo (como puede ser un carácter en un archivo), donde la tabla ha sido rellenada de una manera específica basándose en la probabilidad estimada de aparición de cada posible valor de dicho símbolo.
Lo desarrollo David A. Huffman .
La codificación Huffman usa un método específico para elegir la representación de cada símbolo, que da lugar a un código prefijo que representa los caracteres más comunes usando las cadenas de bits más cortas, y viceversa.
Huffman fue capaz de diseñar el método de compresión más eficiente de este tipo: ninguna representación alternativa de un conjunto de símbolos de entrada produce una salida media más pequeña cuando las frecuencias de los símbolos coinciden con las usadas para crear el código.

Desarrollo. Es un código prefijo óptimo para un conjunto dado de probabilidades.
Puede alcanzar la entropía, aunque no lo hace siempre.
El código Huffman esta basado en dos propiedades de los códigos prefijos óptimos:
1. En un código prefijo óptimo, los símbolos más frecuentes –los que tienen mayor probabilidad- tienen palabras del código más cortas que las palabras menos frecuentes. 2. En un código prefijo óptimo, los dos símbolos que ocurren con menos frecuencia tendrán la misma longitud.

Alogaritmo del código Huffman.
Funciones:
Ordena los símbolos de más probable a menos probable.
Comienza a construir un árbol por las hojas combinando los dos símbolos menos probables.
Itera el procedimiento.
Genera el código de Huffman correspondiente a las siguientes posibilidades.
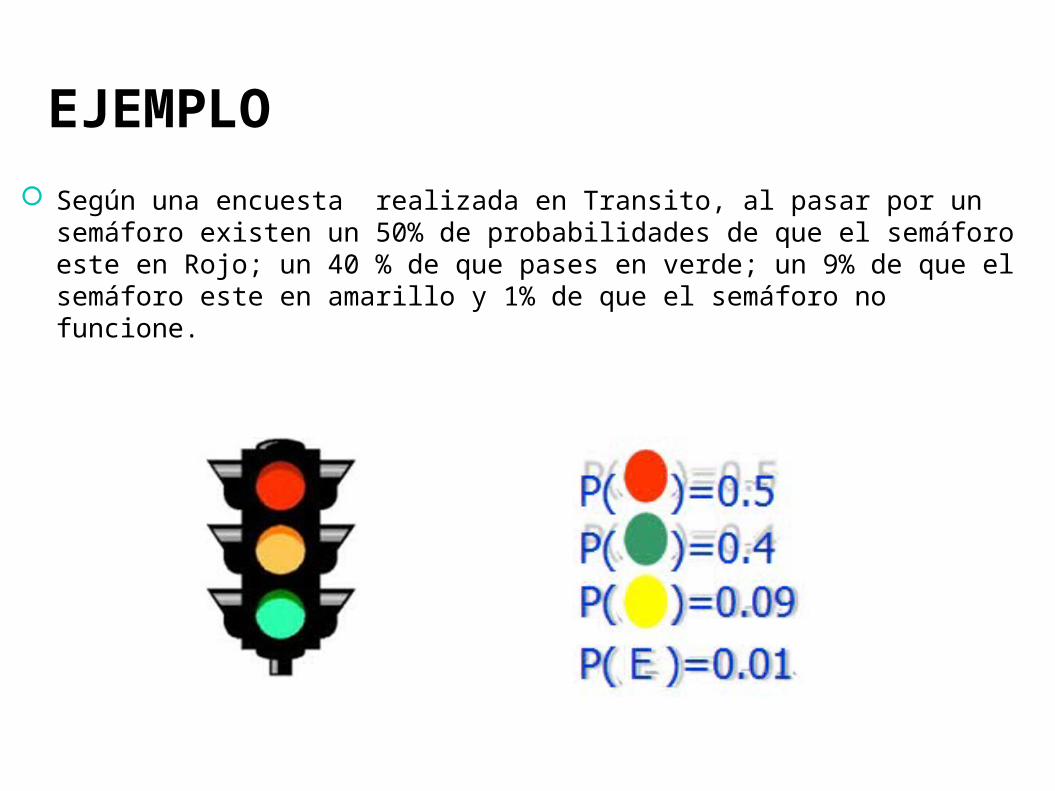
EJEMPLO
Según una encuesta realizada en Transito, al pasar por un semáforo existen un 50% de probabilidades de que el semáforo este en Rojo; un 40 % de que pases en verde; un 9% de que el semáforo este en amarillo y 1% de que el semáforo no funcione.
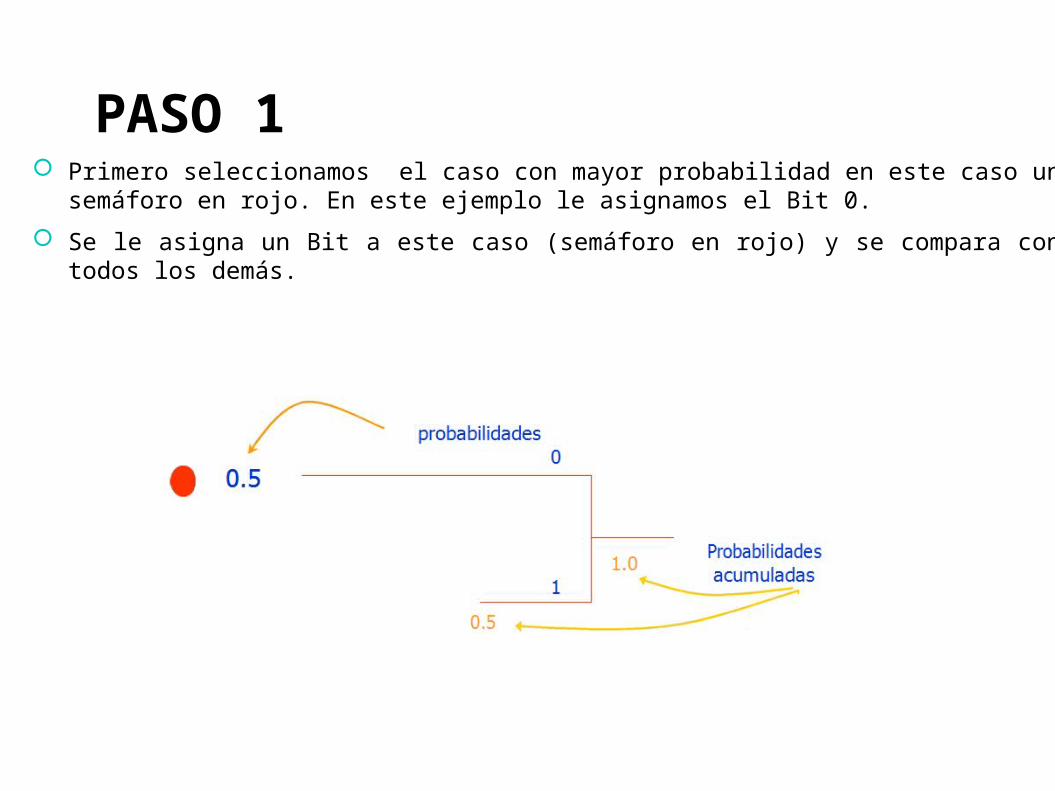
PASO 1 Primero seleccionamos el caso con mayor probabilidad en este caso un semáforo
en rojo. En este ejemplo le asignamos el Bit 0.
Se le asigna un Bit a este caso (semáforo en rojo) y se compara con todos los demás.
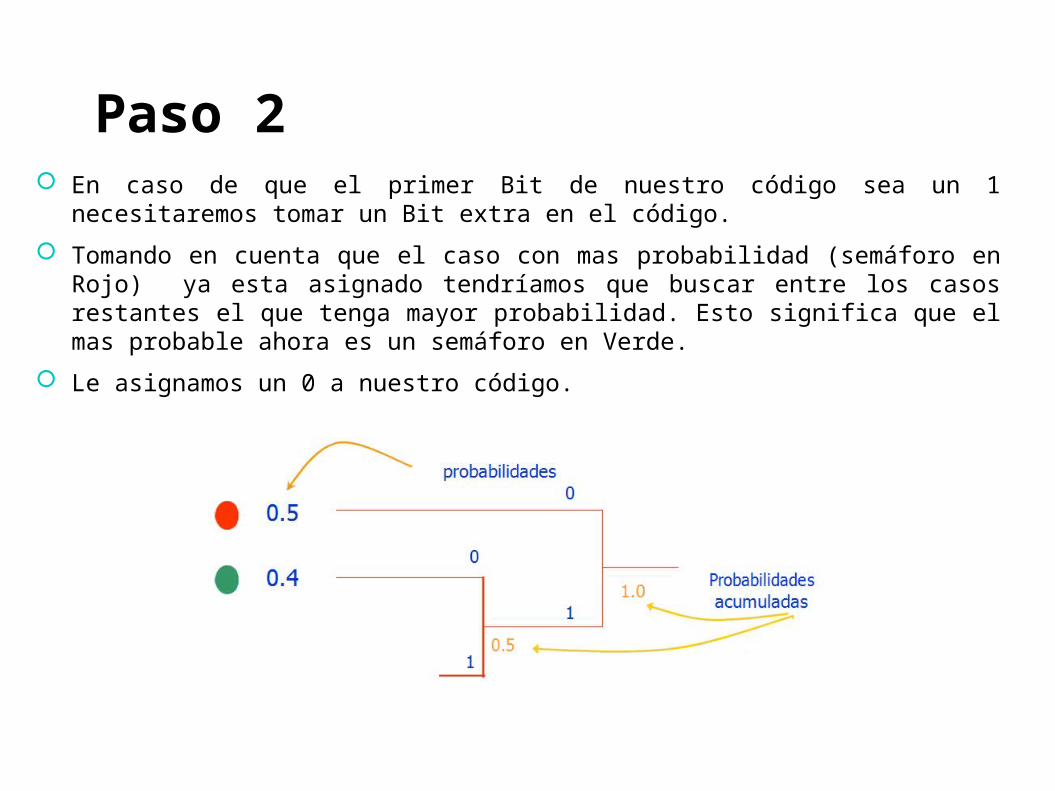
Paso 2 En caso de que el primer Bit de nuestro código sea un 1 necesitaremos
tomar un Bit extra en el código.
Tomando en cuenta que el caso con mas probabilidad (semáforo en Rojo) ya esta asignado tendríamos que buscar entre los casos restantes el que tenga mayor probabilidad. Esto significa que el mas probable ahora es un semáforo en Verde.
Le asignamos un 0 a nuestro código.
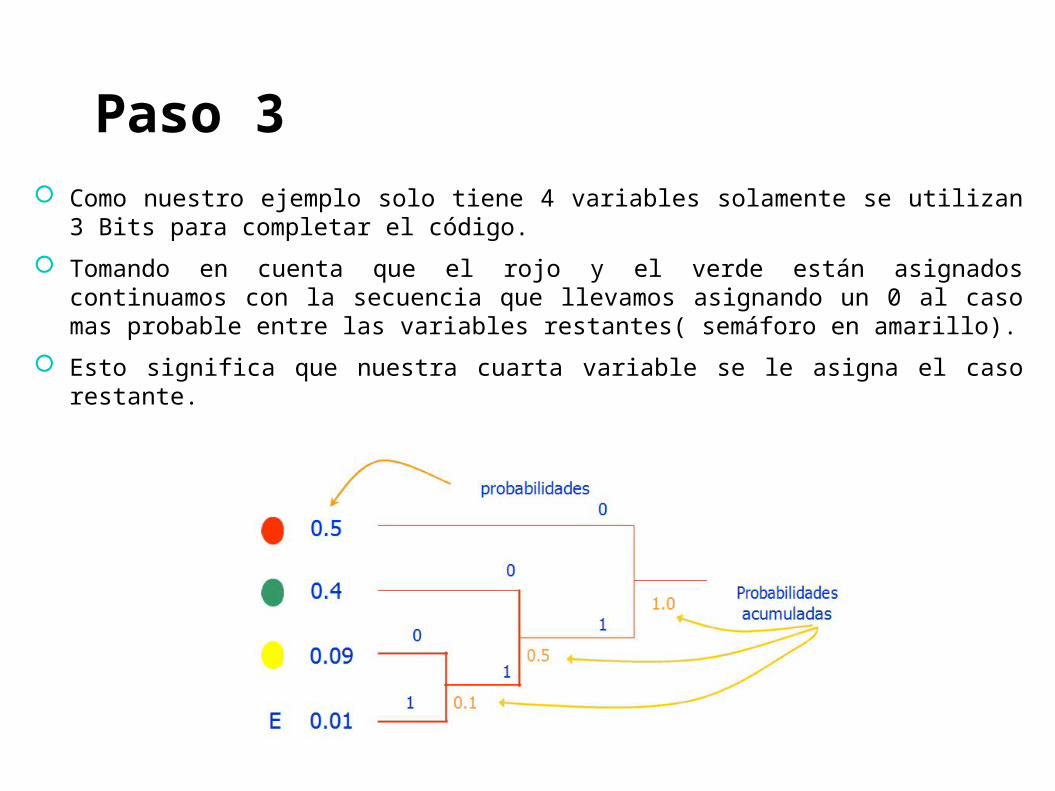
Paso 3
Como nuestro ejemplo solo tiene 4 variables solamente se utilizan 3 Bits para completar el código.
Tomando en cuenta que el rojo y el verde están asignados continuamos con la secuencia que llevamos asignando un 0 al caso mas probable entre las variables restantes( semáforo en amarillo).
Esto significa que nuestra cuarta variable se le asigna el caso restante.

Paso 4: Diccionario Huffman Tanto el trasmisor como el Receptor necesitan saber el significado
de estos símbolos.
Hoffman almacena en el “Diccionario” el significado de cada código con respecto a su variable.
Este Paso NO es necesario en un Hoffman Adaptable

Código de Huffman adaptativo
El código de Huffman necesita conocer la probabilidad de aparición de cada símbolo.
Para tener estas probabilidades podemos leer los datos para obtenerlas y luego codificar los símbolos usando el código de Huffman para dichas probabilidades,
o bien podemos ir construyéndolo (adaptativamente) mientras vamos leyendo los símbolos. Esta es la base del código Huffman adaptativo.
Para la construcción del árbol adaptativamente, veamos a continuación qué propiedades caracterizan a un árbol binario para que sea el correspondiente a un código de Huffman.

Consideremos un árbol binario correspondiente a un alfabeto de tamaño n en el que los símbolos del alfabeto son las hojas.Entonces, el número de nodos del árbol es 2n-1
A cada nodo del árbol binario le vamos a asignar dos campos: Número del nodo y peso del nodo.El número de nodo es un número único asignado a cada nodo del árbol entre 1 y 2n-1. Los números los notaremos y1,…,y2n-1.El peso de un nodo hoja es simplemente el número de veces que aparece el símbolo correspondiente y el de uno interno la suma de los pesos de sus dos hijos. Los pesos los notaremos x1,…,x2n-1.
Puede probarse que:Si al asignar números a los nodos comenzando por el uno y recorriendo el árbol por niveles (asignamos, de izquierda a derecha en cada nivel y de
las hojas (abajo) a la raíz (arriba) los pesos de los nodos quedan ordenados en un orden no decreciente
El árbol obtenido es un árbol binario correspondiente a un código de Huffman para dichos símbolos con las probabilidades de cada nodo hoja
igual a su peso dividido por la suma de los pesos.La propiedad anterior recibe el nombre de sibling property o node
number invariant.


Para la construcción del árbol adaptativamente, veamos acontinuación qué propiedades caracterizan a un árbol binariopara que sea el correspondiente a un código de Huffman.
Consideremos un árbol binario correspondiente a un alfabeto detamaño n en el que los símbolos del alfabeto son las hojas.Entonces, el número de nodos del árbol es 2n-1 (pruébalo porinducción).

A cada nodo del árbol binario le vamos a asignar doscampos: Número del nodo y peso del nodo.
El número de nodo es un número único asignado a cada nododel árbol entre 1 y 2n-1. Los números los notaremos y1,...,y2n-1.
El peso de un nodo hoja es simplemente el número de vecesque aparece el símbolo correspondiente y el de uno interno lasuma de los pesos de sus dos hijos. Los pesos los notaremosx1,...,x2n-1.

Puede probarse que:
Si al asignar números a los nodos comenzando por el uno yrecorriendo el árbol por niveles (asignamos, de izquierda aderecha en cada nivel y de las hojas (abajo) a la raíz(arriba) los pesos de los nodos quedan ordenados en unorden no decreciente
El árbol obtenido es un árbol binario correspondiente a uncódigo de Huffman para dichos símbolos con lasprobabilidades de cada nodo hoja igual a su peso divididopor la suma de los pesos.La propiedad anterior recibe el nombre de sibling property onode number invariant.
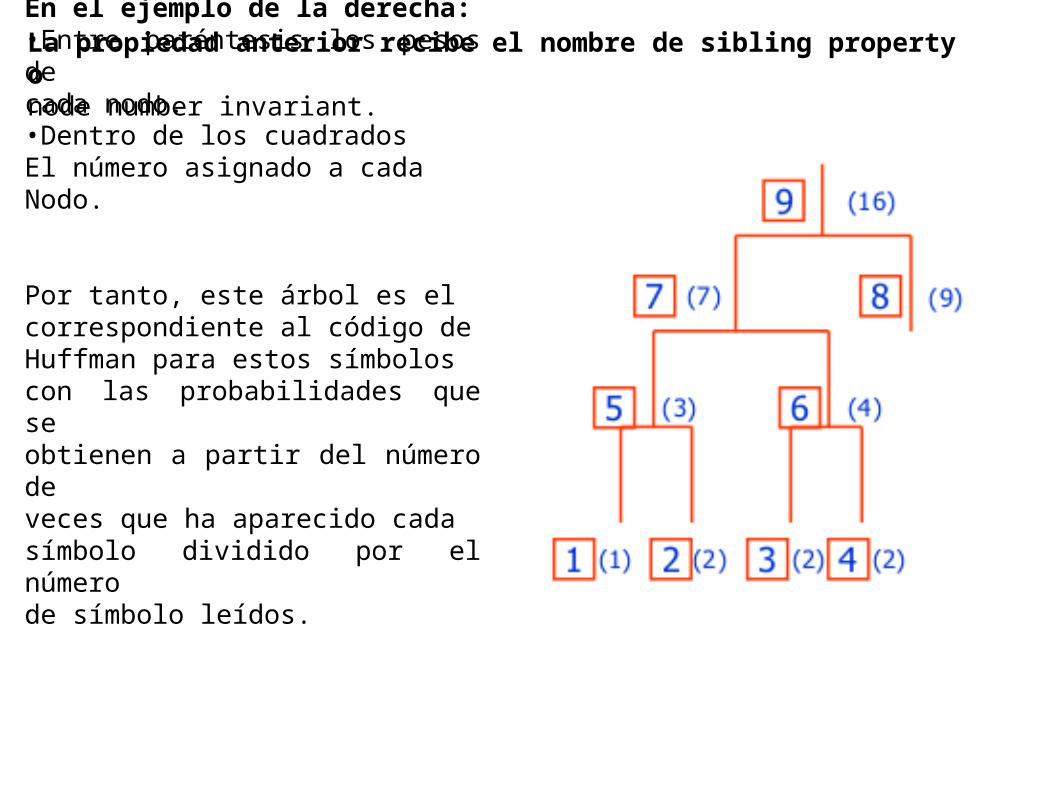
La propiedad anterior recibe el nombre de sibling property onode number invariant.En el ejemplo de la derecha:•Entre paréntesis los pesos decada nodo.•Dentro de los cuadradosEl número asignado a cadaNodo.
Por tanto, este árbol es elcorrespondiente al código deHuffman para estos símboloscon las probabilidades que seobtienen a partir del número deveces que ha aparecido cadasímbolo dividido por el númerode símbolo leídos.

En el código Huffman adaptativo ni el transmisor ni elreceptor conocen al principio las probabilidades de lossímbolos. Por eso:
1. Codificador y decodificar comienzan con un árbol con unnodo único que corresponde a todos los símbolos notransmitidos (NYT) y que tiene peso cero.2. Mientras progresa la transmisión se añadirán nodos alárbol correspondientes a símbolos que aparezcan porprimera vez, se modificarán los pesos (tanto si elsímbolo es nuevo como si es ya existente) y seactualizará el árbol para que siga cumpliendo the siblingproperty (siga siendo de Huffman).

El algoritmo de Huffman adaptativo consta de los siguientesElementos:
1. Inicialización (la decodificador).misma para el codificador y2 Algoritmo de codificación.3. Algoritmo de decodificación.4. Proceso de actualización del árbol para que mantengathe sibling property.
Antes de describir estas partes comentaremos brevementesobre la codificación de los símbolos:

Si el símbolo ya ha aparecido•Utilizamos la codificación que proporciona el árbol quevamos construyendo.
Codificación de un símbolo que aparece por primeraVez:
•Salvo que sea el primero de todos lo símbolos de lasecuencia, la codificación de un símbolo que aparece porprimera vez consta de la codificación que proporciona elárbol del nodo NYT seguido de un código fijo para el símboloque deben conocer codificador y decodificador
•En el caso en que sea el primer símbolo que aparece en lasecuencia no necesitamos transmitir el código de NYT.

Algoritmo de codificación para el código Huffman adaptativo
1. Si encontramos un símbolo nuevo (ver nota) entoncesgenerar el código del nodo NYT seguido del código fijo(ver nota) del símbolo. Añadir el nuevo símbolo alArbol.
2. Si el símbolo ya está presente, generar su códigousando el árbol.
3. Actualizar el árbol para que siga conservando thesibling property.
Nota: Recordemos que para el primer símbolo no hace falta transmitir elcódigo de NYT. El código fijo es conocido al principio por codificador ydecodificador.

Algoritmo de decodificación para el código Huffman adaptativo
1. Decodificar el símbolo usando el árbol actual.
2. Si encontramos el nodo NYT, usar el código fijo paradecodificar el símbolo que viene a continuación. Añadirel nuevo símbolo al árbol.
3. Actualizar el árbol para que siga conservando thesibling property.
Nota: recordar, de nuevo, que código de NYT

Actualización del árbol para el código Huffman adaptativo
1. Sea y la hoja (símbolo) con peso x.
2. Si y es la raíz, aumentar x en 1 y salir
3. Intercambiar y con el nodo con el número mayor quetenga el mismo peso que él (salvo que sea su padre)
4. Aumentar x en 1
5. Sea y el padre que tiene su peso x (el que sea, no eldefinido en 4) ir al paso 2 del algoritmo


















