
Grupo de Visión Artificial - BIENVENIDO A LA PÁGINA DEL ... · Para lograr estos objetivos...
180
UNIVERSIDAD POLITÉCNICA DE MADRID DEPARTAMENTO DE ELECTRÓNICA, AUTOMÁTICA E INFORMÁTICA INDUSTRIAL Grupo de Visión Artificial Procesamiento y Visualización Tridimensional de Imágenes Biomédicas del Microscopio Confocal Autor: Marta García Nuevo Tutor: Carlos Platero Dueñas
Transcript of Grupo de Visión Artificial - BIENVENIDO A LA PÁGINA DEL ... · Para lograr estos objetivos...

UNIVERSIDAD POLITÉCNICA DE MADRID
DEPARTAMENTO DE
ELECTRÓNICA, AUTOMÁTICA E
INFORMÁTICA INDUSTRIAL
Grupo de Visión Artificial
Procesamiento y Visualización Tridimensional de Imágenes
Biomédicas del Microscopio Confocal Autor: Marta García Nuevo Tutor: Carlos Platero Dueñas


Nadie sabe de lo que es capaz hasta que lo intenta.
Sirio, Publio
La gota horada la roca, no por su fuerza sino por su constancia.
Ovidio
Tras estos años de estudio concluye una de las etapas de mi vida, a la que este proyecto es el encargado de poner fin.
Ha sido mucha la gente que me ha apoyado en estos años y a todos ellos les quiero dedicar este trabajo.
A mis padres y hermano que siempre están ahí para darme un empujoncito cuando más lo necesito. A mis compañeros de la escuela porque me daban ánimo cuando llegaban esos momentos en los que parecía que nada iba a salir bien. Mis compañeros del proyecto David, Ricardo, Jose, Fernando, Abdel, Jeroen, Woter que me han ayudado en todo lo que han podido y sobre todo a Thomas con quien tantas horas he pasado frente a la pantalla de Galileo. Gracias a todos mis amigos por esos momentos de distracción tan útiles para desconectar de vez en cuando. No quiero olvidarme de los profesores de los que tanto he aprendido y sobre todo a Carlos Platero por invitarme a culminar mi carrera de forma brillante con éste proyecto.
Muchas gracias a todos.
Marta


Resumen
En este proyecto vamos a trabajar con imágenes biomédicas, intentando apoyar a la medicina en el desarrollo de nuevas técnicas basadas en la Visión Artificial.
El proyecto trata de hacer la reconstrucción de imágenes tridimensionales, partiendo de series de imágenes bidimensionales obtenidas con el microscopio confocal. Estas imágenes son difíciles de tratar porque ocupan mucho espacio, alrededor de 20 MB. Trataremos de encontrar un modo sencillo y eficaz de visualizar esta imagen tridimensional, e incluso mejorarla utilizando distintas técnicas de procesamiento digital de imágenes.
Para lograr estos objetivos usaremos Matlab con algunas de sus Toolboxes, como Image Processing Toolbox y Morphology Toolbox, también usaremos The Visualisation Toolkit (VTK).
Como esta visualización y procesamiento requiere mucha capacidad computacional, nos sumergiremos en el mundo del clustering, para intentar distribuir el trabajo de los programas que implementemos en varias máquinas y así reducir tiempo requerido para obtener los resultados.
El proyecto se realiza dentro del Grupo de Visión Artificial de la Escuela Universitaria de Ingeniería Técnica Industrial (UPM). Se finalizó en el año 2003.


Abstract
The aim of this project is work with biomedical images in order to create new techniques based on Artificial Vision that are very important for the medicine.
The project tries to reconstruct a 3D representation from a series of 2D images, made with a confocal microscope. The typical size of the data comingfrom the confocal microscope is about 20 MB. We want to find an easy way to displaythe 3D image and to have the possibility to view the volume from different angles.We want to enhance the quality of the images by the means of debluring,enhancement of the signal-to-noise ratio and deconvolution. To reach these goals we use the Matlab software with some additional Toolboxes (e.g. Image ProcessingToolbox, Morphology Toolbox) and the Visualisation Toolkit (VTK).
This processing and visualisation needs a very big computational capacity, we will try to develop a computer cluster to calculate processor intensitive tasks.


Índice
1 INTRODUCCIÓN....................................................................... 1
1.1 Objetivos....................................................................................................... 2
1.2 Sumario del proyecto .................................................................................. 3
2 ESTADO DE LA TÉCNICA ....................................................... 5
2.1 Introducción................................................................................................. 5
2.2 Principios de la microscopía confocal [SART] [TWIL] [DADA] .......................... 6 2.2.1 Funcionamiento del microscopio confocal [SOTO] ...................................... 6 2.2.2 Limitaciones del microscopio óptico......................................................... 8 2.2.3 Ventajas del microscopio confocal [ABEC] [LOCI] [ERIC]................................. 8 2.2.4 Otros métodos para mejorar las imágenes [DADA] .................................... 10 2.2.5 Aplicaciones del microscopio confocal [JDOB] [JMCU] ................................ 10 2.2.6 Imágenes 3D con el microscopio confocal [ABEC].................................... 12 2.2.7 Limitaciones de la microscopia confocal ................................................ 13

2.3 Eliminación del ruido ................................................................................ 13 2.3.1 La imagen digital [AMAR] .......................................................................... 13 2.3.2 Deconvolución [CNBT]............................................................................... 14 2.3.3 Blind Deconvolución [JCHI] ...................................................................... 14 2.3.4 Debluring [TMAT]....................................................................................... 15 2.3.5 Denoise .................................................................................................... 16 2.3.6 Renderización .......................................................................................... 17 2.3.7 Métodos de renderización........................................................................ 17 2.3.8 Renderización en Matlab ......................................................................... 18 2.3.9 Razones para cambiar la renderización ................................................... 19
2.4 Aproximación poligonal [CHEN] [CHXU] ....................................................... 19 2.4.1 Métodos para realizar la aproximación poligonal ................................... 21 2.4.2 Esquema de continuidad y proceso de poligonalización. ........................ 22 2.4.3 Comentarios............................................................................................. 23
2.5 Procesamiento distribuido [ENZO] [OPIN]..................................................... 24 2.5.1 Ventajas del procesamiento distribuido................................................... 24 2.5.2 Desventajas del procesamiento distribuido ............................................. 25 2.5.3 Transparencia........................................................................................... 27 2.5.4 Tendencia a lo distribuido ....................................................................... 28 2.5.5 Migración de procesos............................................................................. 29 2.5.6 Comunicación entre procesos.................................................................. 30 2.5.7 Entrada – salida ....................................................................................... 30 2.5.8 Clusters [OPIN] [KHWA] [SGAL] ....................................................................... 31
2.5.8.1 Características de los cluster............................................................. 32 2.5.9 Clustering con OpenMosix...................................................................... 34
2.5.9.1 Características de OpenMosix .......................................................... 36 2.5.10 Clustering con MPI (ParaView) [ACAL] .................................................. 41
3 HERRAMIENTAS DE VISUALIZACIÓN ................................. 45
3.1 Matlab [MWOR] [DMUU] .................................................................................. 45
3.2 VTK [KITW] .................................................................................................. 47
3.3 SDC [SDCM]................................................................................................... 49
3.4 OPENMOXIS [NO3D] .................................................................................. 50
3.5 PARAVIEW [PARA]......................................................................................... 51
3.6 MPI [CARA] ................................................................................................... 52

4 PROCESAMIENTO ................................................................. 55
4.1 Ficheros gráficos [FPIC] ............................................................................... 55 4.1.1 Formato gráfico *.pic .............................................................................. 56 4.1.2 Regiones de interés (ROI) ....................................................................... 57
4.1.2.1 Selección de la ROI ............................................................................ 57 4.1.2.2 Filtrado de la ROI ............................................................................. 58
4.2 Descripción de los comando usados en los códigos................................. 58 4.2.1 Apertura del .pic con Matlab ................................................................... 58 4.2.2 Procesamiento de la imagen con Matlab ................................................. 59 4.2.3 Procesamiento de la imagen usando SDC ............................................... 61 4.2.4 Procesamiento de la imagen usando VTK............................................... 63 4.2.5 Procesamiento usando VTK y Matlab..................................................... 65 4.2.6 Observaciones.......................................................................................... 65
4.3 Renderización ............................................................................................ 65 4.3.1 Métodos de renderización........................................................................ 66 4.3.2 Renderización en Matlab ......................................................................... 66 4.3.3 Renderización con VTK .......................................................................... 67 4.3.4 Razones para cambiar la renderización ................................................... 67 4.3.5 Renderización de volúmenes ................................................................... 68 4.3.6 Renderización de superficies ................................................................... 68 4.3.7 PICvisu toolbox ....................................................................................... 69
4.3.7.1 openpic.m.......................................................................................... 69 4.3.7.2 vtk3D.m ............................................................................................ 73
4.3.8 PICsuper toolbox ..................................................................................... 80 4.3.8.1 Picsuper / picsuperbw....................................................................... 80
5 APROXIMACIÓN POLIGONAL .............................................. 91
5.1 Niveles de detalle [MKRU] [CHXU] .................................................................. 91
5.2 Simplificación poligonal ............................................................................ 94
5.3 Algoritmos .................................................................................................. 96

5.3.1 Análisis de Mallas Arbitrarias de Multiresolución.................................. 96 5.3.2 Mallas Progresivas................................................................................... 97 5.3.3 Aproximación de Rango Completo de Poliedros Triangulados .............. 98 5.3.4 Simplificación por Sobres ....................................................................... 99 5.3.5 Simplificación de Superficie Dentro de un Volumen de Tolerancia..... 101
5.4 Snakes [CHXU]............................................................................................. 103
5.5 Implementación ....................................................................................... 105 5.5.1 Selección de puntos del contorno .......................................................... 106 5.5.2 Unión de los puntos del contorno.......................................................... 107 5.5.3 Aproximación poligonal en 3D ............................................................. 110
5.6 Conclusiones............................................................................................. 117
6 PROCESAMIENTO DISTRIBUIDO[ENZO]............................... 119
6.1 Linux [PHPB] [GLUS] ....................................................................................... 120 6.1.1 ¿Qué es LINUX?.................................................................................... 120 6.1.2 Trabajando con Linux............................................................................ 121 6.1.3 El Shell: comandos básicos de Linux .................................................... 123 6.1.4 Ejecución de Programas ........................................................................ 128
6.2 OpenMoxis[MCAT] ..................................................................................... 133 6.2.1 Breves nociones de OpenMosix ............................................................ 133
6.2.1.1 Comandos más utilizados ............................................................... 134 6.2.2 Cómo construir el cluster....................................................................... 136
6.2.2.1 Ejecutamos un ejemplo................................................................... 137
6.3 MPI ........................................................................................................... 141
6.4 ParaView [EHEL] [LBER] .............................................................................. 142 6.4.1 Argumentos de la línea de comandos .................................................... 143 6.4.2 Ejecución de ParaView sobre MPI........................................................ 144
6.5 MPICH[DASH] ............................................................................................ 145 6.5.1 Instalación de MPICH ........................................................................... 145 6.5.2 Herramientas.......................................................................................... 146
6.5.2.1 mpirun............................................................................................. 146 6.5.2.2 MPIRegister tool............................................................................. 147 6.5.2.3 Configuration tool........................................................................... 147 6.5.2.4 Update tool...................................................................................... 149
6.5.3 Ejecutamos un ejemplo.......................................................................... 149

6.6 Conclusiones............................................................................................. 152
7 BIBLIOGRAFÍA..................................................................... 153
7.1 Microscopio confocal............................................................................... 153
7.2 Eliminación del Ruido............................................................................. 154
7.3 Aproximación Poligonal.......................................................................... 155
7.4 Procesamiento distribuido ...................................................................... 156 7.4.1 MPI ........................................................................................................ 156 7.4.2 Paraview ................................................................................................ 156 7.4.3 OpenMosix ............................................................................................ 157 7.4.4 Mpich..................................................................................................... 157
8 ÍNDICE DE FIGURAS............................................................ 159
8.1 Estado de la Técnica. ............................................................................... 159
8.2 Herramientas de Visualización .............................................................. 160
8.3 Procesamiento .......................................................................................... 161
8.4 Aproximación Poligonal.......................................................................... 162
8.5 Aproximación Poligonal.......................................................................... 163




Marta García Nuevo Introducción
1 Introducción El análisis digital de datos, más específicamente, imágenes digitales de percepción
remota orbital, posibilitó, en los últimos veinticinco años, un gran desarrollo de las técnicas orientadas al análisis de datos multidimensionales, adquiridos por diversos tipos de sensores. Estas técnicas han recibido el nombre de procesamiento digital de imágenes.
Por ‘Procesamiento Digital de Imágenes’ se entiende la manipulación de una imagen a través de un computador, de modo que la entrada y la salida del proceso sean imágenes. Para comparar, en la disciplina de reconocimiento de patrones, la entrada del proceso es una imagen y la salida consiste en una clasificación o una descripción de la misma. Por otro lado, la elaboración de gráficos por computador envuelve la creación de imágenes a partir de descripciones de las mismas.
El objetivo de utilizar el procesamiento digital de imágenes, es mejorar el aspecto visual de ciertos elementos estructurales para el analista y proveer otros subsidios para su interpretación, inclusive generando productos que puedan ser posteriormente sometidos a otros procesamientos.
GVA-ELAI-UPMPFC0077-2003 1

Introducción Marta García Nuevo
Éste área ha generado un gran interés en las dos últimas décadas. Tanto la evolución de la tecnología de computación, como el desarrollo de nuevos algoritmos para tratar señales bidimensionales está permitiendo una gama de aplicaciones cada vez mayor.
Estudiar, analizar y describir imágenes médicas a partir del procesamiento digital, constituye en la actualidad, una herramienta de trabajo, cuya precisión facilita al especialista la obtención de inferencias de valor diagnóstico y pronóstico de enfermedades, con el lógico beneficio para el paciente. Son muchas las técnicas de procesamiento digital empleadas en el campo de la medicina. Estas van desde el mejoramiento de contraste, la detección de contornos, hasta los más complejos sistemas de reconocimiento de patrones y reconstrucciones tridimensionales.
Con todo esto, vemos como la Informática ha impulsado con fuerza el desarrollo de la Medicina en éstas últimas décadas, para beneficio de todos.
1.1 Objetivos
El objetivo fundamental de este proyecto es, como su título indica: Procesamiento y visualización 3D de cuerpos biológicos mediante microscopio confocal.
Para lograr este objetivo general dividiremos el trabajo en los procesos algo más específicos, estos son:
Procesamiento de imágenes del microscopio confocal.
Visualización 2D.
Visualización 3D.
Renderización y eliminación del ruido.
Implementación de algoritmos para el estudio de imágenes biomédicas.
Aproximación Poligonal.
Procesamiento distribuido.
Todos estos pasos están íntimamente ligados, unos conducen a otros, para al final obtener con éxito nuestro objetivo, una correcta visualización de las imágenes del microscopio confocal, adecuadas para facilitar en trabajo que queramos realizar con ellas.
2 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Introducción
1.2 Sumario del proyecto
El proyecto se estructura en seis capítulos y dos anexos.
En los primeros capítulos se describe algunos de los avances obtenidos en los campos sobre los que va a tratar el proyecto y se explica en que van a consistir y el fin del trabajo que se desarrolla en sucesivos capítulos.
En el tercer capítulo el proyecto enumera las herramientas que vamos a utilizar para realizar el trabajo.
El cuarto capítulo habla sobre el microscopio confocal, las imágenes que se obtienen con él y el procesamiento que se realiza sobre ellas.
Con el microscopio confocal obtenemos imágenes en dos dimensiones. Estas imágenes son los cortes virtuales de una muestra, realizados cada 0.5 micras aproximadamente. Estas imágenes llegan a nosotros en un formato gráfico *.pic, que tenemos que leer y visualizar.
Para visualizar este formato, usaremos fundamentalmente la programación en Matlab y las VTK. Estos programas y bibliotecas nos servirán también para realizar la composición de estas imágenes bidimensionales, para su representación tridimensional.
Una vez capaces de leer y representar las imágenes, tendremos que mejorarlas y adaptarlas para facilitar la operación que en el futuro queramos realizar con éstas. Para ello empleamos distintas técnicas de filtrado, deconvoluciones y finalmente su renderización.
Todo esto lo haremos implementando los algoritmos adecuados en los lenguajes convenientes, en nuestro caso Matlab y TCL.
Para describir todo lo relativo a la aproximación poligonal que se realiza sobre nuestras imágenes tenemos el quinto capítulo.
Para simplificar las imágenes con las que estamos trabajando y no manejar un volumen de datos tan grande, trataremos de hacer una aproximación poligonal a nuestra imagen, utilizando los mismos programas que hasta ahora. Hacer la aproximación poligonal de una imagen consiste en trazar un contorno más o menos preciso según sea necesario y transformar una compleja imagen en un conjunto de líneas que se ajustan a su superficie ocupando mucho menos espacio.
En el sexto capítulo tratamos todo lo referente al procesamiento distribuido, analizamos la construcción de un cluster y su manejo.
GVA-ELAI-UPMPFC0077-2003 3

Introducción Marta García Nuevo
Al procesar imágenes completas nos encontramos con la necesidad de una capacidad computacional muy elevada, y un tiempo de procesamiento también demasiado largo. Para tratar de reducir este tiempo y poder usar computadores menos potentes realizaremos el procesamiento distribuido en varias máquinas. Este procesamiento distribuido lo haremos de dos formas diferentes, bajo Linux usando OpenMosix, y bajo Windows usando Mpich.
El apéndice A, nos muestra la bibliografía utilizada y el anexo B es el índice de las imágenes incluidas en el proyecto.
4 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
2 Estado de la técnica
2.1 Introducción
Generalmente, las imágenes biomédicas son interpretadas por expertos humanos, pero cuando las condiciones de las imágenes no son buenas, o se cuenta con un gran número de ellas, el trabajo de analizarlas se vuelve sumamente tedioso y monótono, siendo propenso a errores, o bien, que por cansancio, se evita un análisis minucioso. Es aquí donde el desarrollo de algoritmos de análisis de imágenes permitirá automatizar muchas de las tareas, y se convertirá en una gran herramienta del analista humano. Dejándole las imágenes preanalizadas o cuantificadas, para que sólo se concentre en el trabajo más creativo y en la interpretación o diagnóstico final.
Este capítulo pretende ser una breve presentación, de los proyectos y líneas de investigación, que se han elaborado o se están desarrollando en la actualidad en el campo del procesamiento y análisis digital de imágenes biomédicas.
Cómo este proyecto se centra en el proceso y análisis 2D y 3D de imágenes biomédicas, en este capítulo se hará hincapié en los proyectos que puedan ser de interés para la comprensión de este o puedan resultar complementarios.
GVA-ELAI-UPMPFC0077-2003 5

Estado de la Técnica Marta García Nuevo
También se darán nociones de los avances en la aproximación poligonal hechos hasta la fecha. Analizando los objetivos buscados y el modo de obtener los mejores resultados cuanto a velocidad de procesamiento y sencillez de manejo.
2.2 Principios de la microscopía confocal [SART] [TWIL] [DADA]
La Microscopía Confocal permite el estudio de muestras con marcaje fluorescente, haciendo secciones ópticas de las mismas. Se excita la muestra punto a punto por medio de un láser. La longitud de onda de emisión de esa muestra es mayor a la de excitación, y es esta última la que al pasar por un pequeño diafragma (pinhole) permite la detección de un solo plano focal.
Esta técnica microscópica se basa iluminar una muestra y eliminar la luz reflejada o fluorescente de los planos fuera de foco, de este modo se obtienen imágenes de mayor nitidez y contraste permitiendo además el estudio tridimensional de la muestra. Se puede utilizar con especimenes con autofluorescencia o susceptibles de ser teñidos por una sustancia fluorescentes. También se puede utilizar en muestras metálicas que reflejen la luz.
Tiene aplicaciones en: biología celular y molecular (estudios de estructuras celulares y citoesqueleto), estudios de microbiología, genética, biología vegetal, anatomía patológica, neurología, ciencias de los alimentos, ciencias de materiales (fracturas metálicas), geología (estudios de microfisuras y porosidad en rocas) , etc.
2.2.1 Funcionamiento del microscopio confoca
Este nuevo tipo de microscopio se basa en elimimicroscopía óptica normal, producen las regiones que foco. Para esto, se ha optado por pasar la luz que incideagujero o ranura y enfocarla en el plano de la imagennumérica . De esta manera, la luz que es reflejada poplano focal del objetivo, regresa al mismo y es reenfocpequeño agujero o ranura sin ninguna pérdida. En camblos puntos que se encuentran fuera del plano de la completamente. De esta manera, se obtiene una imagen dpunto en el plano focal, sin que haya una contribución sencuentran fuera de foco. Debido a que las aperturas retorno de la imagen tienen un foco común, se ha denocomo "microscopio confocal". Puede resumirse su funconfocal se basa en mejorar la relación entre la señal y el
En la figura se muestra un esquema de un tipo pen el cual, la fuente de luz que se utiliza es un rayo láse
6
Figura 2.1: Imagen del confocal
l [SOTO]
nar el velo que, en una imagen de se encuentran fuera del plano de sobre la muestra por un pequeño de un objetivo de gran apertura r el punto que se encuentra en el ada y transmitida a su vez por un io, la luz dispersada o emitida por imagen es atenuada o bloqueada e alto contraste y definición de un ignificativa de las regiones que se tanto de la iluminación como del minado este tipo de microscopios ción diciendo que la microscopía ruido de la imagen.
articular de microscopio confocal: r. El haz de luz se hace pasar por
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
una ranura (P1) e incidir en un espejo dicroico (que refleja totalmente la luz que incide con un ángulo de cerca de 45 grados), para posteriormente enfocarlo sobre la muestra usando el propio objetivo del microscopio. La luz emitida por la muestra es colectada por el mismo objetivo y, pasando a través del espejo dicroico es enfocada en una ranura detectora (P2). La luz que penetra a menor o mayor profundidad en la muestra (planos fuera de foco), incide por delante o por detrás de la ranura detectora (haces de luz representados en líneas punteadas en la figura. Debido a que la cantidad de luz que incide sobre la muestra es sumamente pequeña, es necesario usar fuentes de iluminación muy poderosas como es el rayo láser.
Figura 2.2: Esquema del microscopio confocal
El procedimiento descrito, nos da la imagen de un pequeño punto de la muestra,
para obtener una imagen completa es necesario usar complejos procedimientos que permitan mover el punto de iluminación en toda la muestra, e integrar esta imagen formada de puntos individuales en una imagen única. Para esto, se usan sistemas que permiten desplazar la muestra o mover el punto de iluminación, barriendo toda el área que se desea observar. Por esto último, se denomina a los microscopios como "microscopio confocal de barrido". Como resultará obvio, para construir una imagen es necesario recorrer toda la muestra de manera uniforme, además de que el rayo de iluminación y la vía de retorno, deberán estar perfectamente alineadas. Esto implica que la mayoría de los instrumentos que hasta ahora se han desarrollado, se basen en complejos sistemas electromecánicos que resultan en un alto costo, ya que tienen que generarse pequeños desplazamientos perfectamente uniformes, e integrarse la imagen en un computador.
GVA-ELAI-UPMPFC0077-2003 7

Estado de la Técnica Marta García Nuevo
Para eliminar el problema asociado con el diseño de sistemas que permitan barrer la imagen, se han ofrecido diversas alternativas, algunas de las cuales se encuentran ya en microscopios confocales comerciales. Uno de éstos es el microscopio confocal en que el barrido lo hace el haz de luz. Para ello se utilizan espejos dicroicos que vibran rápidamente recorriendo todo el espécimen. Otra solución al problema lo constituye el "microscopio confocal de barrido en cascada". En el cual, un pequeño anillo que se encuentra por detrás del objetivo tiene múltiples hoyos (de 20 a 60 micras de diámetro) en forma de espiral, al rotar este anillo, se genera una imagen completa de toda la preparación, tomando simultáneamente muestras de una gran cantidad de puntos no adyacentes. Este tipo de microscopio tiene la ventaja de que se obtienen imágenes en tiempo real, permitiendo la observación directa en el microscopio.
Figura 2.3: Microscopio confocal real
2.2.2 Limitaciones del microscopio óptico
Cuando usamos un microscopio óptico convencional para observar objetos como células completas, la imagen que visualizamos es poco definida y de todas las estructuras de la célula a la vez. Si enfocamos sobre una zona determinada también veremos las áreas situadas fuera de foco dando como resultado una imagen borrosa. Además no podemos hacernos una idea de la distribución tridimensional de las diferentes organelas.
Cuando queremos observar imágenes definidas, debemos recurrir a realizar cortes finos de la muestra, pero esto es imposible cuando lo que estamos estudiando son células vivas.
2.2.3 Ventajas del microscopio confocal [ABEC] [LOCI] [ERIC]
El microscopio confocal permite que solo observemos el plano que está situado en el punto de foco del sistema óptico eliminando, de forma óptica a través de un diafragma o "pinhole", la luz proveniente de los planos que están fuera de foco.
8 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
Cualquiera que sea el procedimiento que se utilice para barrer la muestra, las imágenes del microscopio confocal son notablemente superiores a las que se obtienen con el microscopio óptico convencional, ya que las imágenes generadas contienen detalles volumétricos y de textura imposibles de alcanzar con este último. Una ventaja adicional se obtiene en los casos en que se desea explorar especimenes con fluorescencia. En estos casos, el efecto deletéreo que sobre la imagen tienen las áreas fuera de foco es especialmente notable; además, la iluminación de la muestra hace que se pierda rápidamente la fluorescencia.
Por estas razones, el microscopio confocal es especialmente ventajoso para observar especimenes fluorescentes, ya que además de eliminar el efecto de las regiones fuera de foco, solamente se ilumina una pequeñísima región de la muestra en cada momento, eliminándose con ello el efecto de "blanqueado" que, sobre la fluorescencia, induce la iluminación continua.
La microscopía confocal permite también estudiar los especimenes usando luz transmitida o reflejada, ello implica que se puedan estudiar muestras que, por su grosor o por sus características, no son transparentes. Esto ha permitido que se desarrollen nuevas técnicas de preparación de los especimenes a observar, las cuales no implican el corte en rebanadas delgadas como se hacia anteriormente, ampliando así significativamente las posibilidades de estudiar las relaciones estructura-función, ya sea a nivel uni o multicelular.
La importancia de la microscopía confocal rnueva y poderosa herramienta para examinar las estru
Podemos resumir sus ventajas diciendo que:
1) Pueden observarse tejidos intactos así comhacer cortes histológicos.
2) Se obtiene un aumento notable en la resolfluorescencia.
3) Reduce el blanqueado de la fluorescencia.
4) Permite hacer reconstrucciones tridimensioen menor tiempo que por otros métodos.
GVA-ELAI-UPMPFC0077-2003
Figura 2.4: Ejemplo del uso de luces
adica entonces en que constituye una cturas celulares y sus funciones.
o secciones gruesas sin necesidad de
ución, especialmente en muestras con
nales más precisas de mejor calidad y
9

Estado de la Técnica Marta García Nuevo
Por todo lo anterior, es claro que en el corto plazo, el microscopio confocal pasará a formar parte del instrumental normal de trabajo, tanto en laboratorios de análisis clínico-patológico, como en los laboratorios de investigación básica, ya que se ha convertido en un auxiliar indispensable en los estudios de tipo funcional, en los cuales se pretende determinar los procesos que se llevan a cabo en tejidos vivos. Como resultado del desarrollo de la microscopía confocal, y de los métodos digitales de análisis de imágenes, es posible actualmente abordar cuestiones relativas a las relaciones estructura-función en los seres vivos, que anteriormente eran incontestables.
2.2.4 Otros métodos para mejorar las imágenes [DADA]
Se han desarrollado, además de la microscopía confocal, otros métodos que permiten mejorar significativamente la calidad de las imágenes que se obtienen con el microscopio óptico. Estos métodos se basan en el procesamiento digital de imágenes, por medio de procedimientos matemáticos que permiten calcular y eliminar el velo debido a las regiones que se encuentran fuera de foco. Otros métodos, para mejorar la calidad de imágenes en la microscopía, se basan en modificaciones en los ángulos de incidencia de la luz y, en el uso de varios haces de luz para iluminar las muestras.
Actualmente es posible separar las áreas enfocadas de las que están fuera de foco mediante complicados algoritmos matemáticos integrados en programas informáticos que son aplicados al conjunto de imágenes por un gran ordenador. A este tipos de programas se les denomina de "deconvolución", anglicismo que quiere decir algo así como desenrollamiento o desenmarallamiento. Aunque se pueden obtener resultados magníficos, los requerimientos hardware y software y el aprendizaje del manejo de los mismos hacen que solo se usen en aplicaciones muy determinadas y como complemento a otros sistemas.
2.2.5 Aplicaciones del microscopio confocal [JDOB] [JMCU]
Este avance en el campo de la microscopía nos posibilita el estudio tridimensional de las muestras, incluyendo su interior, e incluso, en el caso de determinados materiales, su reflexión.
Otra de las aplicaciones de la Microscopia Confocal es el estudio de la localización de distintos marcadores en una región concreta. Además gracias a las características espectrales del equipo se consiguen excitar muestras en el rango del ultravioleta, estudiar las características de los espectros de emisión, eliminar o minimizar los típicos problemas de solapamiento de espectros así como separar la emisión de los marcajes fluorescentes de la posible auto fluorescencia de la muestra. También se pueden aplicar nuevas técnicas como FRAP, FRET, FLIP, CAL.
A continuación mostramos algunas imágenes empleadas para biomedicina, tomadas con el microscopio confocal, empleando distintos tipos de marcajes.
10 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
Es capaz de mostrason visualizadas en condiperdiendo resolución. A pbacteriano o el número deDNA
Por lo tanto, utilparámetros deseados. Porcicatrices de quitina, medilos filamentos de actina ymediante medida de la parámetros a la vez, comoFITC, se pueden comprobaetc.
Dentro del campo herramienta eficaz al visuforma de interaccionar entinteresantes experimentos
GVA-ELAI-UPMPFC0077-2
Figura 2.5: Imagen de barrido de uncultivo de células epiteliales
r con todo detalle levaduras, algas y protozoos, las bacterias sólo ciones especiales de grandes aumentos ópticos y electrónicos, esar de ello, se puede estudiar la condensación del cromosoma los mismos, mediante el uso de fluorocromos que se unen al
izando los fluorocromos adecuados se pueden estudiar los ejemplo, con levaduras se puede estudiar la posición de las ante primulina o calcofluor; se puede comprobar la situación de de los microtúbulos; se pueden realizar cinéticas de activación movilización del Ca intracelular, se pueden estudiar varios es la viabilidad, mediante IP y la cantidad de proteína mediante r las variaciones morfológicas debidas a mutaciones específicas,
Figura 2.6: E. Coliteñidas con cloruro de propidio, para observar la condensación del cromosoma.
de la infección, la microscopía confocal ha demostrado ser una alizar los microorganismos dentro de las células huésped y la re los dos organismos. En la actualidad se están llevando a cabo, en esta área.
003 11
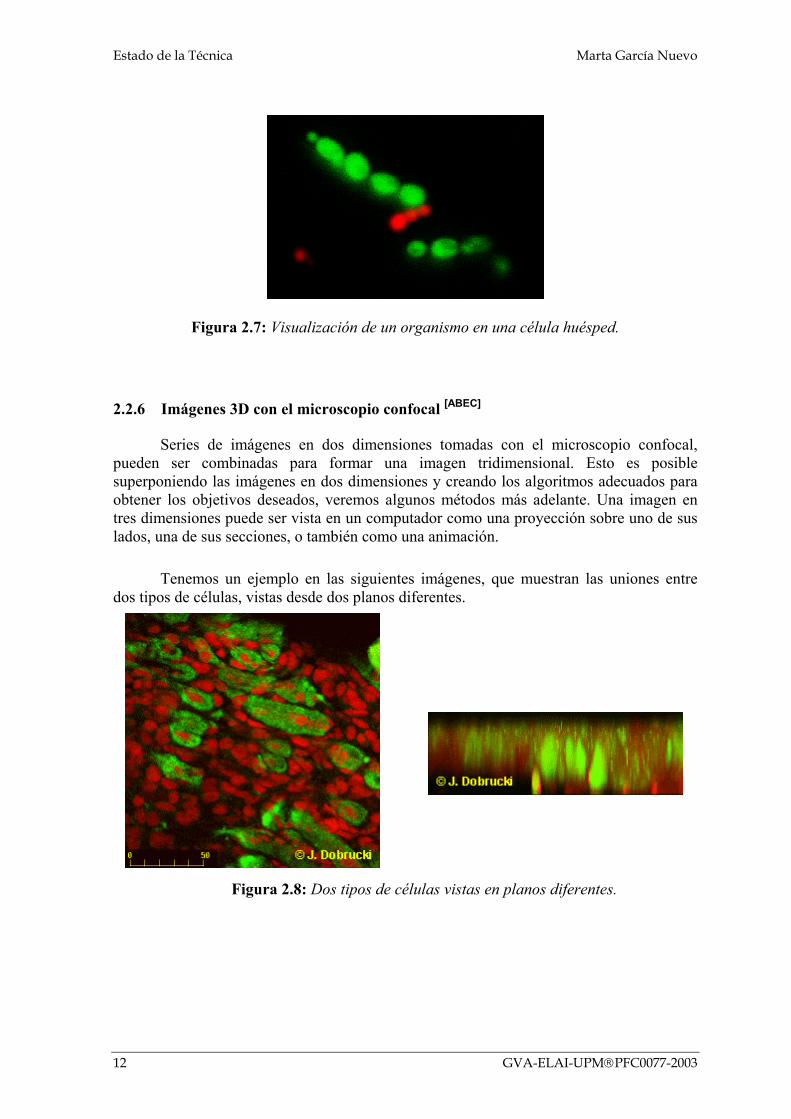
Estado de la Técnica Marta García Nuevo
Figura 2.7: Visualización de un organismo en una célula huésped.
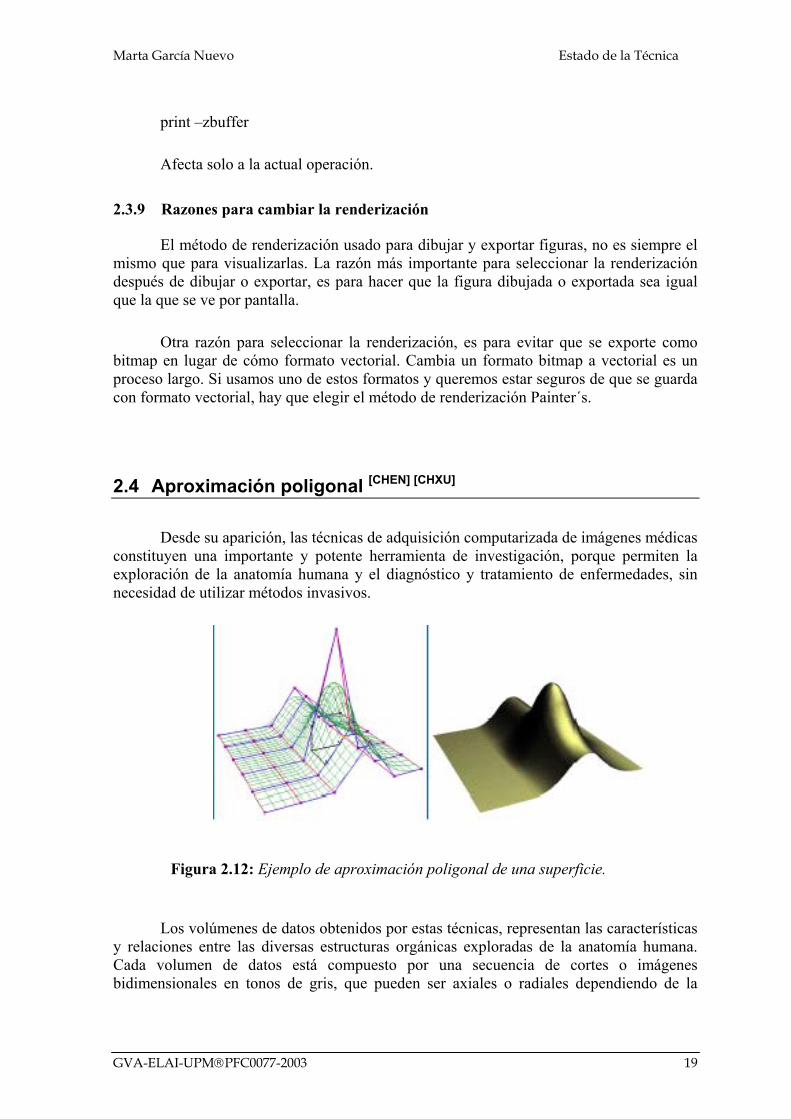
2.2.6 Imágenes 3D con el microscopio confocal [ABEC]
Series de imágenes en dos dimensiones tomadas con el microscopio confocal, pueden ser combinadas para formar una imagen tridimensional. Esto es posible superponiendo las imágenes en dos dimensiones y creando los algoritmos adecuados para obtener los objetivos deseados, veremos algunos métodos más adelante. Una imagen en tres dimensiones puede ser vista en un computador como una proyección sobre uno de sus lados, una de sus secciones, o también como una animación.
Tenemos un ejemplo en las siguientes imágenes, que muestran las uniones entre dos tipos de células, vistas desde dos planos diferentes.
Figura 2.8: Dos tipos de células vistas en planos diferentes.
12 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
2.2.7 Limitaciones de la microscopia confocal
Una de las limitaciones de la microscopía confocal es el tamaño de los objetos que es capaz de visualizar. Es capaz de enfocar y obtener con nitidez imágenes muy pequeñas. Las zonas que se encuentran cerca, las obtenemos borrosas y desenfocadas. Sobre estas zonas habrá que aplicar procesamiento digital de imágenes, que es el siguiente punto del que trata el proyecto.
2.3 Eliminación del ruido
Las imágenes digitales están expuestas a diferentes tipos de ruidos, ya que hay diferentes formas de que el ruido se introduzca en una imagen, dependiendo de cómo haya sido creada.
Con Matlab, y más específicamente con la toolbox de ‘Image Processing’, tenemos distintos métodos de eliminar o al menos reducir el ruido de las imágenes digitales. Para ello nos servimos de distintos métodos según el tipo de ruido. Tenemos varias formas de filtrado: Linear filtering, Median filtering, Adaptative filtering.
2.3.1 La imagen digital [AMAR]
La imagen digital se ha incorporado a la práctica totalidad de los equipos de microscopía electrónica y microscopía confocal y está sustituyendo rápidamente a las tradicionales cámaras fotográficas en los microscopios ópticos.
Las ventajas de la imagen digital frente a la analógica vienen dadas por las múltiples posibilidades de manipulación que nos ofrece. A una imagen digital se le puede cambiar el contraste, el brillo, el color; se puede combinar con otras imágenes; se puede duplicar, rotar , aumentar o disminuir; puede cuantificarse y puede transmitirse a miles de kms de distancia en pocos segundos.
Para obtener una imagen que pueda ser tratada por el ordenador es preciso someter la imagen a un proceso de discretización tanto en las coordenadas como en la intensidad, a este proceso se le denomina digitalización.
La digitalización consiste en la descomposición de la imagen en una matriz de m*n puntos, donde cada punto tiene un valor proporcional a su color. Cada elemento en que se divide la imagen recibe el nombre de "píxel" (picture element).
La resolución espacial de la imagen viene dada por el número de píxeles que tiene la imagen. Cuanto mayor sea este número mayor va a ser la resolución. La resolución cromática depende del número de bits que utilicemos para almacenar el valor de un píxel. Si utilizamos un bit podemos tener únicamente dos valores (0, 1) (blanco y negro), si utilizamos 4 bits el número posible de niveles de gris será de 16 y si utilizamos 8 bits el número de niveles de gris posibles es de 256.
GVA-ELAI-UPMPFC0077-2003 13

Estado de la Técnica Marta García Nuevo
En el caso de imágenes en color la intensidad puede considerarse como un vector tridimensional cuyas componentes son las intensidades en las tres bandas espectrales: rojo, verde y azul. Hablándose en este caso de una imagen multibanda, puesto que la información de la imagen color se desglosa en tres imágenes correspondientes a cada una de las bandas del espectro visible. Para cada una de las bandas se utilizan 8 bits de información, 24 bits en total , lo que nos dan más de 16 millones de posibles combinaciones de colores.
2.3.2 Deconvolución [CNBT]
La deconvolución (Deconvolution = desenmarañamiento), es un término podríamos traducir de modo más general como "enfoque de imágenes sucias".
Es una técnica que permite restaurar una imagen borrosa y obtener de ella información adecuada. Aunque los algoritmos y programas que permiten aplicarla son conocidos desde hace mucho tiempo, fue la corrección digital de la "miopía" del telescopio espacial Hubbel con esta técnica lo que permitió que un proyecto fracasado de millones de dolares pasase a tener la utilidad científica para la que se concibió: obtener imágenes de calidad. Gracias a este hecho la deconvolución empezó a valorarse como una herramienta de gran utilidad en la comunidad científica.
Existe una creencia errónea de que un sistema de deconvolución, es un sustituto de un microscopio confocal a menor coste y que las personas que usan deconvolución, es por no tener suficiente presupuesto para un sistema confocal convencional. Este argumento no tiene sentido porque el precio del software más el sistema informático supera el coste de un microscopio confocal estándar.
En realidad se trata de técnicas complementarias: pueden solaparse en un 70 % de las aplicaciones pero cada una de ellas tiene un 30 % de aplicaciones que la otra no puede realizar.
2.3.3 Blind Deconvolución [JCHI]
Blind Deconvolution es una técnica que permite recuperar de una serie de imágenes borrosas otro conjunto de imágenes deconvueltas o enfocadas. El fundamento de la deconvolución es una función matemática: la función de la extensión de punto (PSF: point spread function) del sistema óptico donde se tomaron las imágenes. Existen técnicas lineales y no lineales de deconvolución pero en todas se necesita la PSF.
Un sistema de deconvolución consiste en un software específico con un hardware muy potente que a través de complicadas interacciones matemáticas permite calcular cuales son los píxeles en foco y cuales no, removiendo de la imagen todo aquello que corresponda a zonas del objeto que estén fuera de foco. El sistema realiza por software una tarea equivalente al pinhole en un microscopio confocal motivo por el que a las técnicas de deconvolución se las conoce también como sistema confocal-digital.
14 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
2.3.4 Debluring [TMAT]
Nuevos algoritmos fundamentales para enfocar imágenes borrosas. Entre estos algoritmos figuran Lucy-Richardson, deblurring regularizado y Wiener, cada uno de los cuales soporta problemas multidimensionales.
Utilice las funciones de deconvolución del conjunto de herramientas para restaurar las imágenes degradadas por el movimiento u otros factores. Para enfocar esta imagen de escala de grises de un fotógrafo se ha usado el algoritmo de Wiener, este es un tipo de filtro lineal, que se aplica sobre imágenes adaptativas. Este actúa automáticamente sobre la varianza, dando mayor o menor smothing. Esto suele producir mejores resultados que un filtro lineal normal. Este filtro adaptativo es más selectivo conservando mejor los bordes y otras partes importantes de una imagen.
.
Aquí mostramos ode la imagen de la izquierimagen. Esta región brillaque el fondo de la imamorfológica de proyecció
GVA-ELAI-UPMPFC0077-
Figura 2.9: Ejemplo del tipo de filtrado, fotógrafo
tro ejemplo del uso de la deconvolución, algunas de las estrellas da están ocultas por una región brillante situada en el centro de la nte hace que la iluminación de la imagen no sea uniforme. Dado gen es oscuro y los objetos son más claros, la transformada n ascendente puede paliar la irregularidad de la iluminación.
.
Figura 2.10: Ejemplo del tipo de filtrado, estrellas2003 15

Estado de la Técnica Marta García Nuevo
Este filtro también requiere mayor capacidad computacional y más tiempo que un filtro lineal, ya que hace implementaciones previas antes de mostrar el resultado.
2.3.5 Denoise
Ésta es la manera clásica de reducir el ruido aditivo en una imagen. El denoising se realiza en el dominio espacial
donde:
F(u, v) : es el Fourier transforma de la imagen original (uncorrupted imagen) con m f como medio
N(u, v) : es el Fourier transforma del ruido aditivo con m n como medio
Una alternativa al filtro anterior, es un algoritmo usado aliasing al denoise una imagen. La puesta en práctica corresponde al diagrama siguiente:
El operador que alisa es el "filtro gaussian"que controla la fuerza del aliasing. El operador del umbral es un "suave thresholding" con un parámetro t del umbral ese los controles que los valores bajos se suprimen.
Vemos un ejemplo de eliminación del ruido de Image Processing Toolbox, para ello introducimos ruido y luego lo quitamos con técnicas de filtrado. En la demos podemos ver cómo actúan los distintos tipos de filtros
16 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
Figura 2.11: Demo de la reducción del ruido con Matlab.
2.3.6 Renderización
Es el proceso mediante el cual una estructura poligonal (tridimensional) digital obtiene una definición mucho mayor. Esto se hace con juegos de luces, texturas y acentuado y mejorado de los polígonos, simulando ambientes y estructuras físicas.
Cuando se está trabajando en un programa profesional de diseño 3d por computadora, no se puede visualizar en tiempo real el resultado del diseño de un objeto o escena compleja ya que esto requiere una potencia de cálculo extremadamente elevada, por lo que después de diseñar el trabajo con una forma de visualización más simple y técnica, se realiza el proceso de renderización, tras el cual se puede apreciar el verdadero aspecto (aspecto final) de una imagen estática o animación.
2.3.7 Métodos de renderización
Definimos rendering, en tratamiento de gráficos por computadoras, como: Imagen tridimensional que incorpora la simulación de efectos de iluminación, tales como la sombra reflectiva.
Un renderer es software y/o hardware que procesan datos de gráficos, con objeto de visualizar, imprimir o exportar las figuras.
GVA-ELAI-UPMPFC0077-2003 17

Estado de la Técnica Marta García Nuevo
Hay tres métodos de renderización:
OpenGL: librería de generación de gráficos tridimensionales, es compatible con casi todos los sistemas de computadoras. Este tipo de renderización es el más rápido.
Z-Buffer: Matlab dibuja rápidamente porque, los objetos son coloreados píxel a píxel, y solo se renderizan los píxeles visibles en la escena. Este método puede consumir mucha memoria del sistema.
Painter´s: Es el método original de renderización en Matlab, es el más rápido si la figura contiene solo objetos sencillos o pequeños.
Los métodos OpenGL y Z-buffer dibujan imágenes usando el mapa de bits (gráficos raster). El método Painter´s dibuja usando gráficos de vectores, en general da resultados con mayor resolución que los otros métodos. Pero OpenGL y Z-buffer pueden trabajar en situaciones en las que Painter´s no produce buenos resultados o es incapaz de hacer nada.
2.3.8 Renderización en Matlab
Por defecto Matlab selecciona automáticamente los mejores métodos de renderización basándose en las características de las figuras y en algunas ocasiones el método de impresión o el formato del archivo usado.
En general, MATLAB usa:
OpenGL para superficies complejas de los dibujos, usando interpolación o juegos de luces.
Z-buffer cuando la visualización de la imagen no es en el color real.
Painter's para figuras de líneas, áreas dibujos (gráficos de barras, histogramas, etc...), y superficies sencillas.
Usando los comandos de Matlab:
Podemos seleccionar el tipo de renderización usando las propiedades de Renderer o el print command. Esto se hace de la siguiente manera, para Z-buffer.
set(gcf, 'Renderer', 'zbuffer');
Salva el nuevo valor de Renderer con la figura.
18 GVA-ELAI-UPMPFC0077-2003
Marta García Nuevo Estado de la Técnica
print –zbuffer
Afecta solo a la actual operación.
2.3.9 Razones para cambiar la renderización
El método de renderización usado para dibujar y exportar figuras, no es siempre el mismo que para visualizarlas. La razón más importante para seleccionar la renderización después de dibujar o exportar, es para hacer que la figura dibujada o exportada sea igual que la que se ve por pantalla.
Otra razón para seleccionar la renderización, es para evitar que se exporte como bitmap en lugar de cómo formato vectorial. Cambia un formato bitmap a vectorial es un proceso largo. Si usamos uno de estos formatos y queremos estar seguros de que se guarda con formato vectorial, hay que elegir el método de renderización Painter´s.
2.4 Aproximación poligonal [CHEN] [CHXU]
Desde su aparición, las técnicas de adquisición computarizada de imágenes médicas constituyen una importante y potente herramienta de investigación, porque permiten la exploración de la anatomía humana y el diagnóstico y tratamiento de enfermedades, sin necesidad de utilizar métodos invasivos.
Figura 2.12: Ejemplo de aproximación poligonal de una superficie.
Los volúmenes de datos obtenidos por estas técnicas, representan las características y relaciones entre las diversas estructuras orgánicas exploradas de la anatomía humana. Cada volumen de datos está compuesto por una secuencia de cortes o imágenes bidimensionales en tonos de gris, que pueden ser axiales o radiales dependiendo de la
GVA-ELAI-UPMPFC0077-2003 19

Estado de la Técnica Marta García Nuevo
técnica de adquisición empleada. Los tonos de gris de las imágenes representan los diferentes niveles de densidad de los tejidos orgánicos examinados.
Con la finalidad de auxiliar al especialista en la observación e interpretación de las imágenes médicas, se dispone de un conjunto de técnicas de visualización volumétrica, que utilizan la información contenida en los cortes que conforman los volúmenes adquiridos de datos, para construir modelos geométricos bidimensionales del objeto original. La finalidad es visualizar de forma interactiva estos modelos, mientras se aplican transformaciones visuales tales como rotaciones, traslaciones y escalamientos, que permitan una observación precisa y detallada sin la necesidad de incurrir en los costos y riesgos que los métodos quirúrgicos convencionales suponen.
Un primer enfoque para modelar la superficie consiste en ajustar un modelo matemático descrito mediante su ecuación matemática implícita. Otro enfoque consiste en obtener el modelo geométrico directamente del volumen de datos. En ambos casos el modelo geométrico de la superficie se construye por aproximación con parches poligonales utilizando algoritmos reconstructores de superficies tridimensionales, a partir de la información suministrada por la ecuación implícita o directamente por los datos.
Figura 2.13: Modelado de una superficie.
El enfoque básico que utilizan los algoritmos reconstructores de superficies, es el de recubrir con celdas cúbicas el espacio que ocupa la superficie que se desea reconstruir, recorriendo progresiva y sistemáticamente cada una de ellas para determinar cuales son
20 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
intersectadas por la superficie. En el proceso de poligonización, para cada una de las celdas intersectadas se construye una aproximación poligonal, por lo general representada por triángulos, de la superficie contenida en ellas. El conjunto final de todos los parches poligonales hallados constituye el modelo geométrico tridimensional que aproxima a la superficie.
En este trabajo se implementa una herramienta para el modelado geométrico de superficies contenidas en volúmenes de datos obtenidos con técnicas de adquisición de data médica, tales como Resonancia Magnética Nuclear (RMN), Tomografía Axial Computarizada (TAC) y Ultrasonido (US).
2.4.1 Métodos para realizar la aproximación poligonal
La herramienta para construcción de mallados poligonales de volúmenes y superficies implícitas primero construye el modelo geométrico de una superficie descrita por su ecuación matemática implícita, y después permite obtener mallados poligonales de superficies extraídas de un volumen de datos a partir de un valor umbral de densidad.
Figura 2.14: Mallado de una superficie.
Las tareas principales del programa, son:
· Proceso de poligonización controlado por parámetros proporcionados por el usuario.
· Partición del espacio geométrico de la superficie en celdas cúbicas de resolución fija, obtenidas por continuidad o por búsqueda exhaustiva.
· Detección automática de superficies.
· Obtención de valores de densidad mediante interpolación trilineal.
GVA-ELAI-UPMPFC0077-2003 21

Estado de la Técnica Marta García Nuevo
· Obtención de intersecciones mediante bisección o interpolación lineal.
· Almacenamiento caché de los valores evaluados de funciones y densidad.
· Obtención de salida en formato de puntos-polígonos: una lista de vértices puntos sobre la superficie) y una lista de triángulos que relacionan los vértices entre sí y definen el mallado poligonal.
· Transformaciones sobre los vértices, triángulos y vectores normales.
· Almacenamiento de las listas de vértices y triángulos en archivos de formatos gráficos conocidos.
2.4.2 Esquema de continuidad y proceso de poligonalización.
La poligonización es un método mediante el cual se obtiene una aproximación poligonal a una superficie y consiste de dos etapas principales: proceso de partición espacial y proceso de cálculo de intersecciones y generación de polígonos.
Figura 2.15: Aproximación de un contorno.
En el proceso de partición espacial por continuidad, la superficie de interés se recubre por celdas cúbicas de resolución fija. Para ello se recorre un camino aleatorio sobre el dominio de la función (continua o discreta), hasta que se encuentra un punto sobre la superficie. En este punto se ubica la primera celda cúbica, y se sigue un procedimiento iterativo de búsqueda de nuevos cubos que corten a la superficie, ensayando con los cubos vecinos a las seis caras de cada cubo, hasta recubrir por completo toda la superficie. En las esquinas de cada celda se evalúa la función implícita; los valores negativos se consideran dentro de la superficie y los positivos fuera de la superficie. Cuando se utilizan volúmenes de datos, los valores de las esquinas de las celdas son comparados con el valor umbral de densidad: los valores mayores que el umbral se consideran dentro de la superficie y los menores se consideran fuera de la superficie. Se genera un nuevo cubo adyacente a cada cara que contenga esquinas de signos opuestos o de configuración adentro/afuera.
En la siguiente etapa, se modelan mediante parches triangulares las intersecciones entre la superficie y la cáscara de cubos encontrada, intersectando directamente los cubos, o descomponiendo cada cubo en seis tetraedros que luego son intersectados con la superficie para producir los parches triangulares. El segundo método elimina los casos ambiguos que se presentan en la intersección directa.
22 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
Cada arista de la celda que conecta un par de esquinas adentro/afuera o positiva/negativa, contiene una intersección con la superficie. Al unir entre sí todos los vértices sobre la superficie encontrados para una celda de poligonización, obtenemos los polígonos que aproximan la superficie. Los vectores normales a los vértices de los triángulos se calculan por aproximación al gradiente utilizando diferencias divididas centradas con respecto a dicho vértice.
El resultado final es un conjunto de parches triangulares que aproximan la superficie de interés. El conjunto de parches se describe en formato punto-polígono y está contenido en listas de vértices y triángulos. Estas listas se almacenan en archivos de formatos gráficos conocidos o son leídas directamente por la clase, sirviendo como entrada a un visualizador en OpenGL Para acelerar el proceso de partición espacial y poligonización, los valores de índice de cubos, esquinas y puntos sobre la superficie son guardados en un caché organizado por tablas de hashing con dispersión abierta; de esta forma se evita recalcular cubos que ya fueron construidos y procesados, y evaluar la función implícita o interpolar redundantemente en los valores de esquinas y vértices que ya fueron calculados.
2.4.3 Comentar
Para obteimplícita o de uproporcionados po
Estos parámde poligonizaciónconstrucción del resultado requeridcantidad de triángelimina las ambigü
GVA-ELAI-UPMP
Figura 2.16: Visualización de una figura obtenida por Aproximación Poligonal.
ios
ner el modelo geométrico de una superficie a partir de su ecuación n volumen de datos, deben manejarse un conjunto de parámetros r el usuario.
etros, entre los cuales se encuentran la granularidad de la partición, tipo y el valor umbral de densidad, determinan la exactitud y el tiempo de mallado, por lo cual debe experimentarse con ellos hasta lograr el o o aceptable. La descomposición en tetraedros produce una mayor ulos, y debido a esto toma más tiempo el cálculo del mallado, pero edades que se presentan en algunos casos de la poligonización de celdas
FC0077-2003 23

Estado de la Técnica Marta García Nuevo
cúbicas. Este factor también influye en el tiempo de rendering, puesto que al ser mayor el número de triángulos, toma más tiempo la carga y despliegue del mallado. Tenemos entonces un compromiso detalle-precisión-tiempo al momento de elegir el valor de los parámetros.
2.5 Procesamiento distribuido [ENZO] [OPIN]
Un sistema distribuido es un conjunto de computadoras conectadas en red que le dan la sensación al usuario de ser una sola computadora. Este tipo de sistema brinda una serie de ventajas, tales como: compartición de recursos, la concurrencia, alta escalabilidad, y tolerancia a fallos. A pesar que agregar complejidad al software y disminuir los niveles de seguridad, los sistemas de procesamiento distribuidos brindan una buena relación precio-desempeño y pueden aumentar su tamaño de manera gradual al aumentar la carga de trabajo.
Actualmente se está caminando desde los sistemas operativos en red a los sistemas distribuidos, aunque aún no se han cumplido los objetivos de un sistema distribuido completamente tenemos ya algunos avances. Por ejemplo ya hay grandes avances en sistemas de ficheros para conseguir que exista un solo directorio raíz al igual que la existencia de una ubicación automática por parte del sistema de los ficheros. Se puede implementar un balanceo de la capacidad y redundancia en los datos para minimizar el impacto de posibles caídas de nodos.
2.5.1 Ventajas del procesamiento distribuido
Esta aproximación tiene varias ventajas, por ejemplo en un sistema operativo distribuido se cumplen todas los criterios de transparencia, con todas las ventajas que esto supone, aparte también se tienen las siguientes ventajas:
1. Economía: la relación precio rendimiento es mayor que en los sistemas centralizados sobretodo cuando lo que se buscan son altas prestaciones, los precios de los sistemas centralizados se disparan.
2. Velocidad: llega un momento en el que no se puede encontrar un sistema centralizado suficientemente potente, con los sistemas distribuidos siempre se podrá encontrar un sistema más potente uniendo esos mismos nodos. Se han hecho comparativas y los sistemas distribuidos especializados en cómputo han ganado a los mayores mainframes.
3. Distribución de máquinas: podemos tener unas máquinas inherentemente distribuidas por el tipo de trabajo que realizan.
4. Alta disponibilidad: cuando una máquina falla no tiene que caer todo el sistema sino que este se recupera de las caídas y sigue funcionando con quizás algo menos de velocidad.
24 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
5. Escalabilidad: puedes empezar un cluster con unas pocas máquinas y según se descubre que la carga es elevada para el sistema, se añaden más máquinas, no hace falta tirar las máquinas antiguas ni inversiones iniciales elevadas para tener máquinas suficientemente potentes. Ya se vió un ejemplo en su momento.
Figura 2.17: Sistemas distribuidos. Escalabilidad de servicios.
6. Comunicación: los ordenadores necesariamente están comunicados, para el correcto y eficaz funcionamiento del cluster se crean unas nuevas funcionalidad es avanzadas de comunicación. Estas nuevas primitivas de comunicación pueden ser usadas por los programas y por los usuarios para mejorar sus comunicaciones con otras máquinas.
7. Sistema de ficheros con raíz única: este sistema de ficheros hace que la administración sea más sencilla (no hay que administrar varios discos independientemente) y deja a cargo del sistema varias de las tareas.
8. Capacidad de comunicación de procesos y de intercambio de datos universal: podemos enviar señales a cualquier procesos del cluster, así mismo podemos hacer trabajo conjunto con cualquier proceso e intercambiar con el datos, por lo tanto podríamos tener a todos los procesos trabajando en un mismo trabajo.
2.5.2 Desventajas del procesamiento distribuido
La principal desventaja de estos sistemas es la complejidad que implica su creación. Básicamente se tienen todos los problemas que se puedan tener en un nodo particular pero escalados. Vamos a ver los problemas que ocurren al intentar implantar las ventajas que hemos visto en el apartado anterior. Los puntos 1, 2 y 3 no tienen problemas de implantación porque son inherentes a los sistemas distribuidos.
• 4.- Alta disponibilidad: podemos conseguir alta disponibilidad pues al tener varios nodos independientes, hay muchas menos posibilidades de que caigan todos a la vez. Pero esto por sí sólo no nos da alta disponibilidad. Tenemos que implantar los mecanismos necesarios para que cuando una máquina caiga, se sigan dando todos los servicios.
GVA-ELAI-UPMPFC0077-2003 25

Estado de la Técnica Marta García Nuevo
Normalmente se apuesta por la replicación de información. Si tenemos 3 servidores de ficheros, sirviendo los mismos ficheros, si uno de ellos cae podemos seguir obteniendo el servicio de alguno de los otros servidores (en el peor de los casos el servicio quizás se ralentice).
Este caso además ilustra otro problema que es la necesidad de actualizar todas las réplicas de un servicio: si un nodo escribe en uno de los servidores éste debe mandar los nuevos datos a los otros servidores para mantenerlos todos coherentes. De otro modo al caer uno de estos servidores perderíamos toda la información que hubiéramos ido grabando en este servidor y no en el resto.
También se tiene que disponer de los mecanismos adecuados para que el nodo que ve el fallo del servidor busque los servidores alternativos en busca de la información que necesita. Además también se debe disponer de los mecanismos necesarios para que los nodos que han caído, cuando vuelvan a conectarse al cluster puedan continuar con su trabajo normalmente.
• 5.- Escalabilidad: el problema es que más nodos suele implicar más comunicación, por lo que tenemos que diseñar un sistema lo más escalable posible. Por ejemplo elegir una comunicación todos con todos aunque tenga ciertas ventajas no es una solución en absoluto escalable pues cada nuevo nodo tiene que comunicarse con todos los demás, lo que hace que incluir un nodo no sea lineal.
Una solución para este problema son los clusters jerárquicos propuestos por Stephen Tweedie: clusters divididos en niveles. Un cluster como lo conocemos es un cluster de primer nivel, los nodos forman una lista de miembros. Hay un nodo privilegiado llamado líder. Para hacer clústeres más grandes se juntan todos los líderes en un metacluster. Se crean entonces dos listas, una de ellas contiene todos los nodos llamada subcluster membership y la otra contiene únicamente los líderes llamada metacluster membership. Si se cambia de líder se cambia también en el metacluster. Así podemos agrupar líderes de metaclusters en un cluster de tercer nivel, etc.
Esta disposición evita transiciones de todo el cluster, pues si hace falta añadir un nodo y crear una transición en el cluster sólo involucramos a los nodos de esa rama. Cuando el cluster necesite recuperación habrá nodos que participen y otros que no.
• 6.- Comunicación: un cluster tiene más necesidades de comunicación que los sistemas normales por lo tanto tenemos que crear nuevos métodos de comunicación lo más eficientes posibles. Un ejemplo de esto es Heartbeat.
• 7.-Sistemas de ficheros con raíz única: tenemos que independizar los sistemas de ficheros distintos de cada uno de los nodos para crear un sistema de ficheros general. Tenemos una fácil analogía con LVM, la cual abstrae al usuario de las particiones del disco duro y le hace ver un único volumen lógico.
Entre los problemas que nos encontramos en los sistemas de sabor UNIX se encuentran por ejemplo cómo manejar los directorios /proc y /dev. Hacer un solo directorio con ellos significaría en /proc tener PIDs independientes para cada nodo,
26 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
algo que no es tan complicado de conseguir y que tiene beneficios como que cada nodo sabe a ciencia cierta y sin ningún retardo cual es el siguiente PID que tiene que asignar.
Pero además incluye otra información como /proc/cpuinfo, /proc/meminfo, etc. que es específica del nodo y que o se modifican esos ficheros para poner la información de todos los nodos en ellos (lo cual rompería la compatibilidad con algunas aplicaciones de usuario) o poner la información en directorios distintos que tuvieran como nombre el número del nodo (lo que traería la duda de qué información colocar en /proc). Aún peor es el caso de /dev pues aquí están los dispositivos de cada nodo. Cuando los dispositivos de un nodo son totalmente distintos a los de otro no hay ningún problema (incluso poder acceder al dispositivo de otro nodo por este fichero sería perfecto) pero si todos los nodos tuvieran por ejemplo un disco duro IDE conectado en el primer slot como maestro con 3 particiones, tendríamos repetidos en cada nodo hda1, hda2 y hda3; por lo tanto tendremos que tener un nuevo esquema para nombrar los dispositivos.
• 8.-Capacidad de comunicación de procesos y de intercambio de datos universal: para conseguir este objetivo necesitamos una forma de distinguir unívocamente cada proceso del cluster. La forma más sencilla es dando a cada proceso un PID único, que llamaremos CPID (cluster process ID). Este CPID podría estar formado por el número de nodo y el número de proceso dentro de ese nodo. Una vez podemos direccionar con que proceso queremos comunicarnos, para enviar señales necesitaremos un sencillo mecanismo de comunicación y seguramente el mismo sistema operativo en el otro extremo que entienda las señales. Para compartir datos, podemos enviarlos por la red o podemos crear memoria compartida a lo largo del cluster. Sobre como crear esta memoria compartida hablaremos en el capítulo de sistemas operativos.
2.5.3 Transparencia
Como se expone en el anterior apartado otras de las ventajas de los sistemas distribuidos es que cumple con todos los criterios de transparencia. Pero conseguir estos criterios implica ciertos mecanismos que debemos implementar:
1. Transparencia de acceso.
Implica tener que mantener el viejo sistema para el nuevo cluster, por ejemplo mantener un árbol de directorios usual para manejar todos los dispositivos de almacenamiento del cluster. No tenemos que romper las APIs para introducir las nuevas funcionalidades.
2. Transparencia de localización.
A nivel más bajo tenemos que implantar una forma de conocer donde se encuentran los recursos, tradicionalmente se han usado servidores centralizados que lo sabían todo, ahora ya se va consiguiendo que esta información se distribuya por la red.
3. Transparencia de concurrencia.
GVA-ELAI-UPMPFC0077-2003 27

Estado de la Técnica Marta García Nuevo
Esto que no es excesivamente complicado en un sistema local, se ha convertido en un quebradero de cabeza en un sistema distribuido. Se han desarrollado varios métodos para conseguirlo. El mayor problema es la desincronización de los relojes pues es muy complejo que todos los relojes hardware lleven exactamente la misma temporización por tanto algunos ordenadores ven los acontecimientos como futuros o pasados respecto a otros ordenadores. Este tema se tratará con más profundidad en el capítulo de sistemas operativos.
4. Transparencia de replicación.
Básicamente el problema es que el sistema sepa que esas réplicas están ahíy mantenerlas coherentes y sincronizadas. También tiene que activar los mecanismos necesarios cuando ocurra un error en un nodo.
5. Transparencia de fallos.
Aunque haya fallos el sistema seguirá funcionando. Las aplicaciones y los usuarios no sabrán nada de estos fallos o intentarán ser mínimamente afectados, como mucho, el sistema funcionará más lentamente. Este punto está muy relacionado con la transparencia de replicación.
6. Transparencia de migración.
Tenemos que solucionar problemas sobre las decisiones que tomamos para migrar un proceso, hay que tener en cuenta las políticas de migración, ubicación, etc. Además tenemos que ver otros aspectos prácticos como si al nodo que vamos encontraremos los recursos que necesitamos, etc. La aplicación no tiene que saber que fue migrada.
7. Transparencia para los usuarios.
Implica una buena capa de software que de una apariencia similar a capas inferiores distintas.
8. Transparencia para programas.
La más compleja. Implica que los programas no tienen porque usar llamadas al sistema nuevas para tener ventaja del cluster. Mosix hace esto muy inteligentemente tomando la natural división en procesos de los programas para migrarlos de forma transparentemente.
2.5.4 Tendencia a lo distribuido
Existen varios métodos para intentar distribuir a nivel de aplicación, son métodos que abstraen las capas inferiores y hacen la vida más fácil a los programadores de las aplicaciones, que no se tendrán que preocupar sobre las peculiaridades de las capas inferiores consiguiéndose una mayor efectividad en la programación. Las tecnologías que se verán, en este orden, son:
28 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
RPC: Remote Procedure Calls. RMI: Remote Method Invocation. CORBA: Estándar de comunicación de objetos. Bonobo: Abstracción sobre CORBA de GNOME. KDE: Desktop Enviroment. Veremos: KIO, XMLRPC, DCOP. SOAP: Simple Object Access Protocol. DCOM: Tecnología de Microsoft.
2.5.5 Migración de procesos
Migración de procesos es mover el proceso desde donde originariamente se está ejecutando a un nuevo entorno. Aunque no se suela emplear en este caso, se podría hablar de migración cuando un proceso se mueve de procesador. Aquí consideraremos migración cuando un proceso se mueve de un nodo a otro.
En un sistema de tipo cluster lo que se pretende, como se verá en el capítulo de clusters, es compartir aquellas tareas para las que el sistema está diseñado. Uno de los recursos que más se desearía compartir, aparte del almacenamiento de datos, que es algo ya muy estudiado y por lo menos existen varias implementaciones, es el procesador de cada nodo. Para compartir el procesador entre varios nodos, lo más lógico es permitir que las unidades atómicas de ejecución del sistema operativo sean capaces de ocupar en cualquier momento cualesquiera de los nodos que conforman el cluster. A ese paso de un nodo a otro de un proceso se le llama migración del proceso.
En un sistema multiprogramable y multiusuario de tiempo compartido, la elección de qué proceso se ejecuta en un intervalo de tiempo determinado, la hace un segmento de código que recibe el nombre de scheduler u planificador. Una vez que el scheduler se encarga de localizar un proceso con las características adecuadas para comenzar su ejecución, es otra sección de código llamada dispatcher la que se encarga de sustituir el contexto de ejecución en el que se encuentre el procesador, por el contexto del proceso que queremos correr. Las cosas se pueden complicar cuando tratamos de ver este esquema en un multicomputador. En un cluster, se pueden tener varios esquemas de actuación.
Para saber cuándo se debe realizar una migración nuestro nodo debe estar en contacto con los demás nodos y recolectar información sobre su estado y así, y teniendo en cuenta otros parámetros como la carga de la red, se debe hacer una decisión lo más inteligente posible y decidir si es momento de migrar y qué es lo que se migra.
Las causas que hacen que se quiera realizar la migración van a depender del objetivo del servicio de la migración. Así si el objetivo es maximizar el tiempo usado de procesador, lo que hará que un proceso migre es el requerimiento de procesador en su nodo local, así gracias a la información que ha recogido de los demás nodos decidirá si los merece la pena migrar o en cambio los demás nodos están sobrecargados también.
GVA-ELAI-UPMPFC0077-2003 29

Estado de la Técnica Marta García Nuevo
La migración podría estar controlada por un organismo central que tuviera toda la información de todos los nodos actualizada y se dedicase a decidir como colocar los procesos de los distintos nodos para mejorar el rendimiento, esta solución aparte de ser poco escalable pues se sobrecargan mucho la red de las comunicaciones y estamos sobrecargando uno de los equipos, su mayor error es que si este sistema falla se dejarán de migrar los procesos.
El otro mecanismo es una toma de decisiones distribuida, cada nodo tomará sus propias decisiones usando su política de migración asignada. Dentro de esta aproximación hay dos entidades que pueden decidir cuando emigrar: el proceso o el kernel. Si el proceso es quien va a decidirlo tenemos el problema de que el proceso tiene que ser consciente de la existencia de un sistema distribuido. En cambio si es el kernel quién decide tenemos la ventaja de que la función de migración y la existencia de un sistema distribuido puede ser transparente al proceso. Esta es la política que usa OpenMosix.
2.5.6 Comunicación entre procesos
En un cluster existe un nuevo problema, si movemos un proceso y lo movemos a otro nodo, ese proceso debe seguir pudiendo comunicarse con los demás procesos sin problemas, por lo que necesitamos enviar las señales que antes eran locales al nodo a través de la red.
Por tanto cada sistema tiene sus propias primitivas de comunicación para enviar toda la comunicación a través de la red. Hay mecanismos de comunicación más problemáticos que otros, por ejemplo las señales no son demasiado problemáticas pues se puede encapsular en un paquete qué se envíe a través de la red y el sistema destino coge el paquete, saca la información de que proceso emitió la señal, que señal fue y a qué proceso se emite y ya se tiene una forma global de enviar señales. El único problema es que implicaría que el sistema debe saber en todo momento el nodo dónde está el proceso con el que quiere comunicar o hacer una comunicación broadcast a todos los nodos para enviar una sola señal. Otros mecanismos de comunicación entre procesos son más complejos de implementar, por ejemplo la memoria compartida, se necesita tener memoria distribuida y poder compartir esa memoria distribuida. Los sockets como el caso de la familia Unix, también son candidatos difíciles a migrar por la relación que tienen los servidores con el nodo. Para migrar estas interacciones entre procesos de manera elegante y eficiente se necesita un sistema especialmente diseñado para ello, por ejemplo del tipo SSI de Compaq.
2.5.7 Entrada – salida
En un sistema tradicional, la entrada/salida es local al nodo en el que se produce, pero desde la aparición de las redes se han venido aprovechando éstas para acceder a determinados recursos de entrada/salida colocados en un ordenador distante. Por ejemplo es típico en las empresas comprar una única impresora cara para obtener la mejor calidad posible y dejar que esa impresora sea accedida desde cualquier ordenador de la intranet de la empresa, aunque esto significa el desplazamiento físico de los empleados, puede ser un ahorro considerable a instalar una impresora en cada uno de los ordenadores. Otro ejemplo muy común es NFS que permite centralizar los accesos al sistema de ficheros, podemos
30 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
disponer de ordenadores sin discos duros o permitimos que todo el trabajo se actualice en un solo lugar.
El problema es que para estos dos ejemplos se han desarrollado soluciones específicas que necesitan un demonio escuchando peticiones en un determinado puerto y en el caso de NFS algún cambio en los sistemas de ficheros. Pero desarrollar una solución general es mucho más complejo y quizás incluso no deseable. Para que cualquier nodo pueda acceder a cualquier recurso de entrada/salida, primero se necesita una sincronización que como ya vimos en una sección anterior de este capítulo puede llegar a ser complejo. Pero también se necesitan otras cosas como conocer los recursos de entrada/salida de los que se dispone, una forma de nombrarlos de forma única a través del cluster etc.
Para el caso concreto de migración de procesos el acceso a entrada y salida puede evitar que un proceso en concreto migre o más convenientemente los procesos deberían migrar al nodo donde estén realizando toda su entrada/salida para evitar que todos los datos a los que están accediendo tengan que viajar por la red. Así por ejemplo un proceso en OpenMosix que esté muy vinculado al hardware de entrada/salida no migrará nunca (X, lpd, etc.). Los sockets como caso especial de entrada y salida también plantean muchos problemas porque hay servicios que están escuchando un determinado puerto en un determinado ordenador para los que migrar sería catastrófico pues no se encontrarían los servicios disponibles para los ordenadores que accediera n a ese nodo en busca del servicio. Hay gente que apoya el SSI en la que todos los nodos ven el mismo sistema y que no importa donde estén los recursos o los programas porque se acceden a ellos siempre correctamente, esto significaría que los sockets podrían migrar porque realmente no importa donde esté el servicio para acceder a él.
2.5.8 Clusters [OPIN] [KHWA] [SGAL]
Aunque parezca sencillo de responder a la pregunta, ¿qué es un cluster? no lo es en absoluto. Podría incluirse alguna definición de algún libro pero el problema es que ni los expertos en clusters, ni la gente que los implementa se ponen de acuerdo en qué es aquello en lo que trabajan.
Muy vagamente un cluster podemos entenderlo como:
Un conjunto de máquinas unidas por una red de comunicación trabajando por un objetivo conjunto. Según el tipo puede ser dar alta disponibilidad, alto rendimiento etc...
Por poner unos ejemplos de la disparidad de opiniones que existen se adjuntan las definiciones que dan ciertas autoridades de esta materia:
``Un cluster consiste en un conjunto de máquinas y un servidor de cluster dedicado, para realizar los relativamente infrecuentes accesos a los recursos de otros procesos, se accede al servidor de cluster de cada grupo'' del libro Operating System Concepts de Silberschatz Galvin.
GVA-ELAI-UPMPFC0077-2003 31

Estado de la Técnica Marta García Nuevo
``Un cluster es la variación de bajo precio de un multiprocesador masivamente paralelo (miles de procesadores, memoria distribuida, red de baja latencia), con las siguientes diferencias: cada nodo es una máquina quizás sin algo del hardware (monitor, teclado, mouse, etc.), el nodo podría ser SMP o PC. Los nodos se conectan por una red de bajo precio como Ethernet o ATM aunque en clusters comerciales se pueden usar tecnologías de red propias. El interfaz de red no está muy acoplado al bus I/O. Todos los nodos tienen disco local.
Cada nodo tiene un sistema operativo UNIX con una capa de software para soportar todas las características del cluster'' del libro Scalable Parallel Computing de Kai Hwang y Khiwei Xu.
``Es una clase de arquitectura de computador paralelo que se basa en unir máquinas independientes cooperativas integradas por medio de redes de interconexión, para proveer un sistema coordinado, capaz de procesar una carga'' del autor Dr. Thomas Sterling.
Como se puede apreciar cada una de las definiciones difiere de las demás llegando incluso a contradecirse.
2.5.8.1 Características de los cluster
Si no hay acuerdo sobre lo que es un cluster poco podrá acertarse en sus características. En este apartado se explican los requisitos que deben cumplir un conjunto de computadoras para ser consideradas cluster, tal y como se conocen hasta el momento.
Para crear un cluster se necesitan al menos dos nodos. Una de las características principales de estas arquitecturas es que exista un medio de comunicación (red) donde los procesos puedan migrar para computarse en diferentes estaciones paralelamente. Un solo nodo no cumple este requerimiento por su condición de aislamiento para poder compartir información. Las arquitecturas con varios procesadores en placa tampoco son consideradas clusters, bien sean máquinas SMP o mainframes debido a que el bus de comunicación no suele ser de red, sino interno.
Por esta razón se deduce la primera característica de un cluster:
a.) Un cluster consta de 2 o más nodos.
Como hemos visto los nodos necesitan estar conectados para llevar a cabo su misión, de nada nos sirven 10 ordenadores que no se pueden traspasar información. Por tanto la segunda característica queda como:
b.) Los nodos de un cluster están conectados entre sí por un canal de comunicación funcional.
32 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
Por ahora hemos hablado de las características físicas de un cluster, que son las características sobre las que más consenso hay. Pero existen más problemas sobre las características del programa que se ejecuta sobre los mismos, pues es el software el que finalmente dotará al conjunto de máquinas de capacidad para migrar procesos, balancear la carga en cada nodo, etc.
c.) Los clústeres necesitan software especializado.
El problema también se plantea por los distintos tipos de clusters, cada uno de ellos requiere un modelado y diseño del software distinto. Se dan casos de programas que efectúan el trabajo de un cluster, pero que por el contrario son consideradas como aplicaciones individuales sin ningún tipo de conexión, que se comportan de manera organizada por eventos de cada nodo, como podría ser un sistema realizado a base de llamadas rexec solicitadas a cada nodo. Como es obvio la funcionalidad las características del cluster son completamente dependientes del software, por lo que no entraremos en las funcionalidades del software de momento, sino, en el modelo general de software que compone un cluster.
Para empezar, parte de este software se debe dedicar a la comunicación entre los nodos. Existen varios tipos de software que pueden conformar un cluster:
• Software a nivel de aplicación, software generado por bibliotecas especiales dedicadas a clusters.
o Este tipo de software se sitúa a nivel de aplicación, se utilizan generalmente bibliotecas de carácter general que permiten la abstracción de un nodo a un sistema conjunto, permitiendo crear aplicaciones en un entorno distribuido de manera lo más abstracta posible. Este tipo de software suele generar elementos de proceso del tipo rutinas, procesos o tareas, que se ejecutan en cada nodo del cluster y se comunican entre sí a través de la red.
• Software a nivel de sistema.
o Este tipo de software se sitúa a nivel de sistema, suele estar implementado como parte del sistema operativo de cada nodo, o ser la totalidad de este. Es más crítico y complejo, por otro lado suele resolver problemas de carácter más general que los anteriores y su eficiencia, por norma general, es mayor.
A pesar de la categorización de este software, existen casos en los cuales se hace uso de un conjunto de piezas de software de cada tipo para conformar un sistema cluster completo. Es decir, un cluster puede tener implementado a nivel de kernel parte del sistema y otra parte estar preparada a nivel de usuario.
GVA-ELAI-UPMPFC0077-2003 33

Estado de la Técnica Marta García Nuevo
Figura 2.18: Cluster a nivel de sistema y nivel de aplicación
2.5.9 Clustering con OpenMosix
La mayor parte del tiempo tu computadora permanece ociosa. Si lanzas un programa de monitorización del sistema como xload o top, verás probablemente que la lectura de la carga de tu procesador permanece generalmente por debajo del 10%.
Si tienes al alcance varias computadoras los resultados serán los mismos ya que no podrás interactuar con más de una de ellas al mismo tiempo. Desafortunadamente cuando realmente necesites potencia computacional (como por ejemplo para comprimir un fichero Ogg Vorbis, o para una gran compilación) no podrás disponer de la potencia conjunta que te proporcionarían todas ellas como un todo.
La idea que se esconde en el trasfondo del clustering es precisamente poder contar con todos los recursos que puedan brindarte el conjunto de computadoras de que puedas
34 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
disponer para poder aprovechar aquellos que permanecen sin usar, básicamente en otras computadoras.
La unidad básica de un cluster es una computadora simple, también denominada nodo. Los clusters pueden crecer en tamaño (o mejor dicho, pueden escalar) añadiendo más máquinas.
Un cluster como un todo puede ser más potente que la más veloz de las máquinas con las que cuenta, factor que estará ligado irremediablemente a la velocidad de conexión con la que hemos construido las comunicaciones entre nodos.
Además, el sistema operativo del cluster puede hacer un mejor uso del hardware disponible en respuesta al cambio de condiciones. Esto produce un reto a un cluster heterogéneo (compuesto por máquinas de diferente arquitectura) tal como se irá viendo en este proyecto.
OpenMosix es un parche (patch) para el kernel de Linux que proporciona compatibilidad completa con el estándar de Linux para plataformas IA32. Actualmente se está trabajando para portarlo a IA64.
Figura 2.19: Logo de OpenMosix
El algoritmo interno de balanceo de carga migra, transparentemente para el usuario, los procesos entre los nodos del cluster. La principal ventaja es una mejor compartición de recursos entre nodos, así como un mejor aprovechamiento de los mismos.
El cluster escoge por sí mismo la utilización óptima de los recursos que son necesarios en cada momento, y de forma automática.
Esta característica de migración transparente hace que el cluster funcione a todos los efectos como un gran sistema SMP (Symmetric Multi Processing) con varios procesadores disponibles. Su estabilidad ha sido ampliamente probada aunque todavía se está trabajando en diversas líneas para aumentar su eficiencia.
OpenMosix está respaldado y siendo desarrollado por personas muy competentes y respetadas en el mundo del open source, trabajando juntas en todo el mundo.
El punto fuerte de este proyecto es que intenta crear un estándar en el entorno del clustering para todo tipo de aplicaciones HPC.
GVA-ELAI-UPMPFC0077-2003 35

Estado de la Técnica Marta García Nuevo
Los clusters OpenMosix pueden adoptar varias formas. Para demostrarlo intentad imaginar que compartes el piso de estudiante con un chico adinerado que estudia ciencias de la computación. Imaginad también que tenéis las computadoras conectadas en red para formar un cluster OpenMosix.
Asume también que te encuentras convirtiendo ficheros de música desde tus CDs de audio a Ogg Vorbis para tu uso privado, cosa que resulta ser legal en tu país.
Tu compañero de habitación se encuentra trabajando en un proyecto de C++ que según dice podrá traer la paz mundial, pero en este justo momento está en el servicio cantando cosas ininteligibles, y evidentemente su computadora está a la espera de ser intervenida de nuevo.
Resulta que cuando inicias un programa de compresión, como puede ser bladeenc para convertir un preludio de Bach desde el fichero .wav al .ogg, las rutinas de OpenMosix en tu máquina comparan la carga de procesos en tu máquina y en la de tu compañero y deciden que es mejor migrar las tareas de compresión ya que el otro nodo es más potente debido a que el chico disponía de más medios económicos para poderse permitir una computadora más potente, a la vez que en ese momento permanece ociosa ya que no se encuentra frente a ella.
Así pues lo que normalmente en un Pentium 233 tardaría varios minutos te das cuenta que ha terminado en pocos segundos.
Lo que ha ocurrido es que gran parte de la tarea ha sido ejecutada en el AMD Athlon XP de tu compañero, de forma transparente a ti.
Minutos después te encuentras escribiendo y tu compañero de habitación vuelve del servicio. Éste reanuda sus pruebas de compilación utilizando pmake, una versión del make optimizada para arquitecturas paralelas. Te das cuenta que OpenMosix está migrando hacia tu máquina algunos subprocesos con el fin de equilibrar la carga.
Esta configuración se llama single-pool: todas las computadoras están dispuestas como un único cluster. La ventaja o desventaja de esta disposición es que tu computadora es parte del pool: tus procesos serán ejecutados, al menos en parte, en otras computadoras, pudiendo atentar contra tu privacidad de datos. Evidentemente las tareas de los demás también podrán ser ejecutadas en la tuya.
2.5.9.1 Características de OpenMosix
Pros de OpenMosix
• No se requieren paquetes extra • No son necesarias modificaciones en el código
Figura 2.20: Logo de Linux
36 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
Contras de OpenMosix
• Es dependiente del kernel • No migra todos los procesos siempre, tiene limitaciones de funcionamiento • Problemas con memoria compartida
Además los procesos con múltiples threads no ganan demasiada eficiencia
Tampoco se obtendrá mucha mejora cuando se ejecute un solo proceso, como por ejemplo el navegador.
Subsistemas de OpenMosix
Actualmente podemos dividir los parches de OpenMosix dentro del kernel en cuatro grandes subsistemas, veámoslos.
a.) Mosix File System (MFS)
El primer y mayor subsistema (en cuanto a líneas de código) es MFS que te permite un acceso a sistemas de ficheros (FS) remotos (i.e. de cualquier otro nodo) si está localmente montado.
El sistema de ficheros de tu nodo y de los demás podrán ser montados en el directorio /mfs y de esta forma se podrá, por ejemplo, acceder al directorio /home del nodo 3 dentro del directorio /mfs/3/home desde cualquier nodo del cluster. Figura 2.21: Logo de Linux
b.) Migración de procesos
Con OpenMosix se puede lanzar un proceso en una computadora y ver si se ejecuta en otra, en el seno del cluster.
Cada proceso tiene su único nodo raíz (UHN, unique home node) que se corresponde con el que lo ha generado.
El concepto de migración significa que un proceso se divide en dos partes: la parte del usuario y la del sistema.
La parte, o área, de usuario será movida al nodo remoto mientras el área de sistema espera en el raíz.
OpenMosix se encargará de establecer la comunicación entre estos 2 procesos.
GVA-ELAI-UPMPFC0077-2003 37

Estado de la Técnica Marta García Nuevo
c.) Direct File System Access (DFSA)
OpenMosix proporciona MFS con la opción DFSA que permite acceso a todos los sistemas de ficheros, tanto locales como remotos. Para más información dirígase a la sección de Sistema de ficheros de las FAQs (preguntas más frecuentes) del presente documento.
d.) Memory ushering
Este subsistema se encarga de migrar las tareas que superan la memoria disponible en el nodo en el que se ejecutan. Las tareas que superan dicho límite se migran forzosamente a un nodo destino de entre los nodos del cluster que tengan suficiente memoria como para ejecutar el proceso sin necesidad de hacer swap a disco, ahorrando así la gran pérdida de rendimiento que esto supone. El subsistema de memory ushering es un subsistema independiente del subsistema de equilibrado de carga, y por ello se le considera por separado.
El algoritmo de migración
De entre las propiedades compartidas entre Mosix y OpenMosix podemos destacar el mecanismo de migración, en el que puede migrar-se cualquiera proceso a cualquier nodo del cluster de forma completamente transparente al proceso migrado. La migración también puede ser automática: el algoritmo que lo implementa tiene una complejidad computacional del orden de O(n), siendo n el número de nodos del cluster.
Para implementarlo OpenMosix utiliza el modelo fork-and-forget, desarrollado en un principio dentro de Mosix para máquinas PDP11/45 empleadas en las fuerzas aéreas norteamericanas. La idea de este modelo es que la distribución de tareas en el cluster la determina OpenMosix de forma dinámica, conforme se van creando tareas. Cuando un nodo está demasiado cargado, y las tareas que se están ejecutando puedan migrar a cualquier otro nodo del cluster. Así desde que se ejecuta una tarea hasta que ésta muere, podrá migrar de un nodo a otro, sin que el proceso sufra mayores cambios.
Podríamos pensar que el comportamiento de un cluster OpenMosix es como una máquina NUMA, aunque estos clusters son mucho más baratos.
El nodo raíz
Cada proceso ejecutado en el cluster tiene un único nodo raíz, como se ha visto. El nodo raíz es el nodo en el cual se lanza originalmente el proceso y donde éste empieza a ejecutarse.
Desde el punto de vista del espacio de procesos de las máquinas del cluster, cada proceso (con su correspondiente PID) parece ejecutarse en su nodo raíz. El nodo de ejecución puede ser el nodo raíz u otro diferente, hecho que da lugar a que el proceso no
38 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
use un PID del nodo de ejecución, sino que el proceso migrado se ejecutará en éste como una hebra del kernel. La interacción con un proceso, por ejemplo enviarle señales desde cualquier otro proceso migrado, se puede realizar exclusivamente desde el nodo raíz.
El usuario que ejecuta un proceso en el cluster ha accedido al cluster desde el nodo raíz del proceso. El propietario del proceso en cuestión tendrá control en todo momento del mismo como si se ejecutara localmente.
Por otra parte la migración y el retorno al nodo raíz de un proceso se puede realizar tanto desde el nodo raíz como desde el nodo dónde se ejecuta el proceso. Esta tarea la puede llevar a término el administrador de cualquiera de los dos sistemas.
El mecanismo de migrado
La migración de procesos en OpenMosix es completamente transparente. Esto significa que al proceso migrado no se le avisa de que ya no se ejecuta en su nodo de origen. Es más, este proceso migrado seguirá ejecutándose como si siguiera en el nodo origen: si escribiera o leyera al disco, lo haría en el nodo origen, hecho que supone leer o grabar remotamente en este nodo.
¿Cuándo podrá migrar un proceso?
Desgraciadamente, no todos los procesos pueden migrar en cualquiera circunstancia. El mecanismo de migración de procesos puede operar sobre cualquier tarea de un nodo sobre el que se cumplen algunas condiciones predeterminadas. Éstas son:
• el proceso no puede ejecutarse en modo de emulación VM86
• el proceso no puede ejecutar instrucciones en ensamblador propias de la máquina donde se lanza y que no tiene la máquina destino (en un cluster heterogéneo)
• el proceso no puede mapear memoria de un dispositivo a la RAM, ni acceder directamente a los registros de un dispositivo
• el proceso no puede usar segmentos de memoria compartida
Cumpliendo todas estas condiciones el proceso puede migrar y ejecutarse migrado. No obstante, como podemos sospechar, OpenMosix no adivina nada. OpenMosix no sabe a priori si alguno de los procesos que pueden migrar tendrán algunos de estos problemas.
Por esto en un principio OpenMosix migra todos los procesos que puedan hacerlo si por el momento cumplen todas las condiciones, y en caso de que algún proceso deje de cumplirlas, lo devuelve de nuevo a su nodo raíz para que se ejecute en él mientras no pueda migrar de nuevo.
Todo esto significa que mientras el proceso esté en modo de emulación VM86, mapee memoria de un dispositivo RAM, acceda a un registro o tenga reservado/bloqueado
GVA-ELAI-UPMPFC0077-2003 39

Estado de la Técnica Marta García Nuevo
un puntero a un segmento de memoria compartida, el proceso se ejecutará en el nodo raíz, y cuando acabe la condición que lo bloquea volverá a migrar.
Con el uso de instrucciones asociadas a procesadores no compatibles entre ellos, OpenMosix tiene un comportamiento diferente: solo permitirá migrar a los procesadores que tengan la misma arquitectura.
La comunicación entre las dos áreas
Un aspecto importante en el que podemos tener interés es en cómo se realiza la comunicación entre el área de usuario y el área de kernel.
En algún momento, el proceso migrado puede necesitar hacer alguna llamada al sistema. Esta llamada se captura y se evalúa
• si puede ser ejecutada al nodo al que la tarea ha migrado, o
• si necesita ser lanzada en el nodo raíz del proceso migrado
Si la llamada puede ser lanzada al nodo dónde la tarea migrada se ejecuta, los accesos al kernel se hacen de forma local, es decir, que se atiende en el nodo dónde la tarea se ejecuta sin ninguna carga adicional a la red.
Por desgracia, las llamadas más comunes son las que se han de ejecutar forzosamente al nodo raíz, puesto que hablan con el hardware. Es el caso, por ejemplo, de una lectura o una escritura a disco. En este caso el subsistema de OpenMosix del nodo dónde se ejecuta la tarea contacta con el subsistema de OpenMosix del nodo raíz. Para enviarle la petición, así como todos los parámetros y los datos del nodo raíz que necesitará procesar.
El nodo raíz procesará la llamada y enviará de vuelta al nodo dónde se está ejecutando realmente el proceso migrado:
• el valor del éxito/fracaso de la llamada
• aquello que necesite saber para actualizar sus segmentos de datos, de pila y de heap
• el estado en el que estaría si se estuviera ejecutando el proceso al nodo raíz
Esta comunicación también puede ser generada por el nodo raíz. Es el caso, por ejemplo, del envío de una señal. El subsistema de OpenMosix del nodo raíz contacta con el subsistema de OpenMosix del nodo dónde el proceso migrado se ejecuta, y el avisa que ha ocurrido un evento asíncrono. El subsistema de OpenMosix del nodo dónde el proceso migrado se ejecuta parará el proceso migrado y el nodo raíz podrá empezar a atender el código del área del kernel que correspondería a la señal asíncrona.
40 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
Finalmente, una vez realizada toda el operativa necesaria de la área del kernel, el subsistema de OpenMosix del nodo raíz del proceso envía al nodo donde está ejecutándose realmente el proceso migrado el aviso detallado de la llamada, y todo aquello que el proceso necesita saber (anteriormente enumerado) cuando recibió la señal, y el proceso migrado finalmente recuperará el control.
Por todo esto el proceso migrado es como sí estuviera al nodo raíz y hubiera recibido la señal de éste. Tenemos un escenario muy simple donde el proceso se suspende esperando un recurso. Recordemos que la suspensión esperando un recurso se produce únicamente en área de kernel. Cuando se pide una página de disco o se espera un paquete de red se resuelto como en el primero caso comentado, es decir, como un llamada al kernel.
Este mecanismo de comunicación entre áreas es el que nos asegura que
• la migración sea completamente transparente tanto para el proceso que migra como para los procesos que cohabiten con el nodo raíz
• que el proceso no necesite ser reescrito para poder migrar, ni sea necesario conocer la topologia del cluster para escribir una aplicación paralela
No obstante, en el caso de llamadas al kernel que tengan que ser enviadas forzosamente al nodo raíz, tendremos una sobrecarga adicional a la red debida a la transmisión constante de las llamadas al kernel y la recepción de sus valores de vuelta.
Destacamos especialmente esta sobrecarga en el acceso a sockets y el acceso a disco duro, que son las dos operaciones más importantes que se habrán de ejecutar en el nodo raíz y suponen una sobrecarga al proceso de comunicación entre la área de usuario migrada y la área de kernel del proceso migrado.
2.5.10 Clustering con MPI (ParaView) [ACAL]
MPI es una estándar creado por un amplio comité de expertos y usuarios con el objetivo de definir una infraestructura común y una semántica específica de interfaz de comunicación. De esta forma los productores de software de procesamiento paralelo pueden implementar su propia versión de MPI siguiendo las especificaciones de este estándar, con lo cual múltiples implementaciones de MPI cambiarían solamente en factores tales como la eficiencia de su implementación y herramientas de desarrollos, pero no en sus principios básicos.
Existen actualmente diferentes implementaciones de MPI, algunas son comerciales y otras son gratis y portables a múltiples arquitecturas. En nuestras prácticas trabajaremos con LAM (Local Area Multicomputer) que es un ambiente de desarrollo y programación de MPI orientado a arquitecturas heterogéneas de ordenadores distribuidos en una red local. Con LAM tanto un "cluster" dedicado como un una simple red local de ordenadores puede actuar como un ordenador multiprocesador.
GVA-ELAI-UPMPFC0077-2003 41

Estado de la Técnica Marta García Nuevo
MPI [7] es una interfaz estándar de paso de mensajes cuyos objetivos básicos son: la funcionalidad, la eficiencia y la portabilidad. Aunque la semántica que especifica MPI para el paso de mensajes permite su utilización en aplicaciones y entornos multithread, en la actualidad no existe ninguna implementación de este estándar que verdaderamente pueda ser utilizada para desarrollar un programa MPI multithread.
El uso de threads en una aplicación que emplea paso de mensajes y la implementación de un sistema de paso de mensajes utilizando threads puede ser muy útil por varias razones:
o Los threads permiten una implementación natural de operaciones no bloqueantes, basta con crear un thread que procese la operación no bloqueante.
o El uso de threads puede incrementar la eficiencia de la implementación de operaciones colectivas.
o Los threads ofrecen un modelo natural para implementar ciertas operaciones que requieren memoria compartida. En general todo proceso que emplea paso de mensajes para comunicarse con otros, lleva a cabo dos tareas bien diferenciadas, una de cómputo y otra de intercambio de mensajes. Estas tareas pueden implementarse de forma eficiente utilizando threads dentro del mismo proceso.
o Los threads se están convirtiendo en el mecanismo de programación paralela de los multiprocesadores de memoria compartida, ya que permiten explotar el paralelismo de dichas arquitecturas de una forma eficiente.
A continuación se describen algunas de las principales características que ofrece MPI:
• Operaciones colectivas. Una operación colectiva es una operación ejecutada por todos los procesos que intervienen en un cálculo o comunicación. En MPI existen dos tipos de operaciones colectivas: operaciones de movimiento de datos y operaciones de cálculo colectivo. Las primeras se utilizan para intercambiar y reordenar datos entre un conjunto de procesos. Un ejemplo típico de operación colectiva es la difusión (broadcast) de un mensaje entre varios procesos. Las segundas permiten realizar cálculos colectivos como mínimo, máximo, suma, OR lógico, etc, así como operaciones definidas por el usuario.
• Topologías virtuales, ofrecen un mecanismo de alto nivel para manejar grupos de procesos sin tratar con ellos directamente. MPI soporta grafos y redes de procesos.
• Modos de comunicación. MPI soporta operaciones bloqueantes, no bloqueantes o asíncronas y síncronas. Una operación de envío bloqueante bloquea al proceso que la ejecuta sólo hasta que el buffer pueda ser reutilizado de nuevo. Una operación no
42 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Estado de la Técnica
bloqueante permite solapar el cálculo con las comunicaciones. En MPI es posible esperar por la finalización de varias operaciones no bloqueantes. Un envío síncrono bloquea la operación hasta que la correspondiente recepción tiene lugar. En este sentido, una operación bloqueante no tiene por que ser síncrona.
• Soporte para redes heterogéneas. Los programas MPI están pensados para poder ejecutarse sobre redes de máquinas heterogéneas con formatos y tamaños de los tipos de datos elementales totalmente diferentes.
• Tipos de datos. MPI ofrece un amplio conjunto de tipos de datos predefinidos (caracteres, enteros, números en coma flotante, etc.) y ofrece la posibilidad de definir tipos de datos derivados. Un tipo de datos derivado es un objeto que se construye a partir de tipos de datos ya existentes. En general, un tipo de datos derivado se especifica como una secuencia de tipos de datos ya existentes y desplazamientos (en bytes) de cada uno de estos tipos de datos. Estos desplazamientos son relativos al buffer que describe el tipo de datos derivado.
• _ Modos de programación. Con MPI se pueden desarrollar aplicaciones paralelas que sigan el modelo SPMD o MPMP. Además el interfaz MPI tiene una semántica multithread (MT-safe), que le hace adecuado para ser utilizado en programas MPI y entornos multithread.
Implementaciones existentes
A continuación se describen algunas de las implementaciones de MPI existentes en la actualidad:
LAM, es una implementación disponible en el centro de supercomputación de Ohio, que ejecuta sobre estaciones de trabajo heterogéneas Sun, DEC, SGI, IBM y HP.
CHIMP-MPI, es una implementación desarrollada en el Centro de Computación Paralela de Edimburgo basada en CHIMP [6]. Esta implementación ejecuta sobre estaciones de trabajo Sun, SGI, DEC, IBM y HP, y máquinas Meiko y Fujitsu AP-1000.
MPICH, es una implementación desarrollada de forma conjunta por el Laboratorio Argonne y la Universidad de Mississippi. Esta implementación ejecuta sobre diferentes plataformas, redes de estaciones de trabajo Sun, SGI, RS6000, HP, DEC, Alpha, y multicomputadores como el IBM SP2, Meiko CS-2 y Ncube.
UNIFY, disponible en la Universidad del Estado de Mississippi, es una implementación que permite el uso de llamadas MPI y PVM de forma simultanea dentro del mismo programa.
_ MPI-LITE, es una implementación multithread de MPI, que ofrece un núcleo para la creación, terminación y planificación de threads de usuario. Esta implementación es la
GVA-ELAI-UPMPFC0077-2003 43

Estado de la Técnica Marta García Nuevo
única conocida por los autores que ofrece un cierto soporte para la ejecución de programas multithread. Sin embargo, el modelo que ofrece MPI-LITE es muy rígido, puesto que los threads son de usuario, cada thread ejecuta una copia de un programa MPI, y además, el número de threads en el programa es fijo y se especifica como un argumento de entrada a un programa MPI.
44 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Herramientas de Visualización
3 Herramientas de Visualización Vamos ha hacer ahora una breve explicación delas herramientas usadas para la
visualización. Éstas son Matlab y VTK programando en Tcl. Para el procesamiento distribuido bajo Linux, utilizamos OpenMoxis y bajo Windows utilizamos ParaView.
3.1 Matlab [MWOR] [DMUU]
MATLAB (MATrix LABoratory) es un lenguaje de alto nivel que incorpora herramientas de cálculo numérico y visualización. Es un programa de Mathworks para realizar todo tipo de cálculos con vectores y matrices. Además presenta la posibilidad de realizar gráficos en dos y tres dimensiones.
GVA-ELAI-UPMPFC0077-2003 45
Figura 3.1: Logo Matlab

Herramientas de Visualización Marta García Nuevo
Se pueden programar funciones con un código propio muy parecido a otros lenguajes de programación. Normalmente se expresan como scripts o macros que realizan las funciones deseadas sin necesidad de teclear comando a comando. Los archivos tienen extensión *.m. Incluye una herramienta de debug útil para corregir errores de código de los scripts creados.
Matlab es un programa muy potente que realiza con gran precisión operaciones complejas. Se emplea en todo tipo de investigaciones donde se trabaja con funciones matemáticas o matrices de puntos. Su entorno gráfico es simple y su aprendizaje no requiere gran esfuerzo.
Las nuevas versiones de Matlab, han sido adaptadas a la metodología de diseño DSP, ya que permiten comenzar con la estructura del sistema en alto nivel e ir descendiendo a los detalles específicos del algoritmo o la implementación.
El desarrollo de sistemas basados en DSP se enmarca en un entorno de grandes cambios tecnológicos y no todas las herramientas de diseño han sido capaces de seguir y adaptarse a esta situación. Dentro del proceso de diseño, normalmente suelen convivir separadamente las fases de desarrollo de algoritmo y la de implementación del prototipo. Antes de implementar el algoritmo sobre el prototipo real, este ha de ser simulado en otro entorno con la finalidad de analizar su comportamiento.
b
Los errores que phardware suponen volver nuevo. Para evitar este conde diseño llamada Diseño algoritmo con el diseño dealto nivel y una rápida revalidación del algoritmo
46
Figura 3.2: Ejemplo de pantalla de Matla
uedan aparecer en las etapas de diseño del software o del a la etapa inicial de desarrollo del algoritmo y comenzar de tratiempo muchos ingenieros están aplicando una metodología
Acelerado de DSP. Este nuevo enfoque integra el desarrollo del l sistema, utilizando para ello una simulación del algoritmo en
alización del prototipo, con la finalidad de obtener una pronta y del diseño del mismo. Esta metodología proporciona una
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Herramientas de Visualización
estructura jerárquica en la que el ingeniero de DSP puede simular cada paso con tanto detalle como sea necesario para conseguir el comportamiento necesario.
Con Matlab se pueden desarrollar de una forma rápida nuevas ideas, incorporar funciones de toolboxes colecciones de funciones de MATLAB en torno a un área específica de trabajo, como el área del procesado de señales, de imágenes, de redes neuronales, etc.), ejecutar una secuencia de simulaciones usando diferentes parámetros, y analizar el comportamiento resultante del sistema.
3.2 VTK [KITW]
VTK (Visualization Toolkit) son un conjunto de librerías destinadas a la visualización y el procesado de imágenes. Incluyen código abierto y software orientado a objetos. Son muy amplias y complejas, pero aún así, están diseñadas para ser sencillas de usar con cualquier lenguaje de programación orientado a objetos, como son C++, Java, Tcl….
Son capaces de realizar generar modelos en tres dimensio
En apartados posteriores posible combinación con Matlab.
Debido a su gran potenciaPC para poder aprovechar en su t
GVA-ELAI-UPMPFC0077-2003
Figura 3.3: Logo VTK
operaciones sobre imágenes en dos dimensiones y de nes con pocas líneas de código.
se detallarán las fases de creación de objetos VTK, y su
, se hacen necesarios amplios recursos de memoria en el otalidad sus funcionalidades.
Figura 3.4: Figura procesada con VTK.47

Herramientas de Visualización Marta García Nuevo
Tenemos un ejemplo de uso de estas librerías, con los objetos que utiliza. El resultado que se obtiene es el siguiente:
En este ejemplo, objeto de la clase vtkSescalares
La asignación se recibe el nombre del arcrenderizados por medio transferencia que relacalmacenado.
48
Figura 3.5: Figura procesada con VTK.
se lee un archivo con datos 3D, el cual se utiliza para inicializar un tructuredPoints, el cual modela una grilla regular de valores
realiza por medio de un objeto vtkStructuredPointsReader, el cual hivo y fuerza la lectura con el método update. Los datos 3D son de transparencias, por lo que es necesario definir una función de ione el color y absorción de cada celda en función del valor
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Herramientas de Visualización
Un modelo para estas funciones es utilizar paletas definidas por medio de funciones lineales a trozos. La clase vtkPiecewiseFunction soporta este comportamiento, al poder ser definida por medio de segmentos.
La clase vtkColorTransferFunction soporta este mismo comportamiento para paletas. En el ejemplo se utiliza un objeto de cada clase, para el color y la opacidad. Después de ser definidos, son asignados como propiedades del volumen por medio de un objeto intermedio de la clase vtkVolumeProperty. Estas propiedades serán interpoladas trilinealmente durante el rendering.
La geometría del volumen de datos y el método de evaluación de la misma se ponen en conjunción con un objeto de la clase vtkVolumeMapper.La salida de este objeto, junto con las propiedades del volumen, son asignadas a un objeto vtkVolume, el cual es finalmente asignado al renderizador.
3.3 SDC [SDCM]
SDC Morphology Toolbox para MATLAB es un software para el análisis de imágenes y procesamiento de señales. Está compuesto por una familia de filtros discretos, no lineales. Éstos filtros, llamados operadores morfológicos, son muy útiles para restauración, segmentación y análisis cuantitativo de imágenes y señales.
Las SDC Morphology Toolseñales), y es tipo de datos orieprocesamiento en escala de grisealgoritmo automáticamente.
Las imágenes (o señales) bascula de bit-gris y 16-bascurespectivamente, por un lógico uin
Los operadores morfológoperadores elementales: dilatacióeficientes para la dilatación y erembargo, para obtener más eficalgoritmos rápidos especiales. Adistancia, reconstrucción, etiquetan
GVA-ELAI-UPMPFC0077-2003
Figura 3.6: Logo SDC.
box trabajan con escala de grises y imágenes binarias (o ntados. Así, la mayoría de los operadores realizan el s o imagen binaria y la selección de la apropiada del
pueden ser representadas por los formatos: binario, 8-la de bit-gris, donde cada píxel es representado, t8, un uint8 y uint16 tipo de datos.
icos pueden ser escritos jerárquicamente desde dos n y erosión. SDC tiene unas implementaciones muy osión de herramientas para dilatación y erosión. Sin iencia, varios operadores son tratados también por
lgunos de estos operadores son transformación de la do y apertura de áreas.
49

Herramientas de Visualización Marta García Nuevo
.
Dilataciones y erosillamadas elementos estructu
La SDC Morphology Solaris. SDC depende deToolbox
Imagen origina
3.4 OPENMOXIS [NO
OpenMosix es una Linux que permite una dislargo de las máquinas que del programa.
50
Figura 3.7: Imagen binarizada y dilatada
ones son parametrizadas por imágenes particulares (o señales), rantes.
y Toolbox es soportada en 3 plataformas: Win 95/98/NT, Linux la versión de Matlab 5, o superior. No depende de ninguna otra
Imagen procesada l Imagen procesada con VTK. Figura 3.8
3D]
especie de modificación o conjunto de parches del kernel de tribución automática y transparente de la carga de tareas a lo forma el cluster. Y todo ello sin tener que modificar el código
Figura 3.9: Logo OpenMosix.
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Herramientas de Visualización
Con OpenMosix se puede lanzar un proceso en una computadora y ver si se ejecuta en otra, en el seno del cluster. Cada proceso tiene su único nodo raíz (UHN, unique home node) que se corresponde con el que lo ha generado.
El concepto de migración significa que un proceso se divide en dos partes: la parte del usuario y la del sistema. La parte, o área, de usuario será movida al nodo remoto mientras el área de sistema espera en el raíz. OpenMosix se encargará de establecer la comunicación entre estos 2 procesos.
De entre las propiedades compartidas entre OpenMosix podemos destacar el mecanismo de migración, en el que puede migrarse cualquiera proceso a cualquier nodo del cluster de forma completamente transparente al proceso migrado.
La idea de este modelo es que la distribución de tareas en el cluster la determina OpenMosix de forma dinámica, conforme se van creando tareas. Cuando un nodo está demasiado cargado, y las tareas que se están ejecutando puedan migrar a cualquier otro nodo del cluster. Así desde que se ejecuta una tarea hasta que ésta muere, podrá migrar de un nodo a otro, sin que el proceso sufra mayores cambios.
Pros de OpenMosix
· No se requieren paquetes extra · No son necesarias modificaciones en el código
Contras de OpenMosix
· Es dependiente del kernel (núcleo del sistema operativo) · No migra todos los procesos siempre, tiene limitaciones de funcionamiento · Problemas con memoria compartida entre procesos”
También hay que señalar según se comenta que OpenMosix consigue muy bien balancear la carga de programas que lanzan múltiples procesos mientras que no es demasiado efectivo si se trata de distribuir un proceso “gordo”. Otro aspecto que me ha llamado la atención es que parece que la actual implementación no se lleva demasiado bien con el Hyper-Threading de Intel por lo que se recomienda desactivarlo.
3.5 PARAVIEW [PARA]
Figura 3.10: Logo ParaView
GVA-ELAI-UPMPFC0077-2003 51

Herramientas de Visualización Marta García Nuevo
ParaView es una aplicación diseñada por la necesidad de visualizar archivos con gran cantidad de datos. Los objetivos del proyecto de ParaView, incluyen lo siguiente:
• Desarrollar un código abierto para la visualización multiplataforma.
• Support distributed computation models to process large data sets.
• Crear una interface de usuario abierta, flexible e intuitiva.
• Desarrollar una arquitectura extensible basada en estándares abiertos.
Figura 3.11: Ejemplo imagen con tratada con SDC.
ParaView funciona satisfactoriamente tanto en sistemas distribuidos en paralelo y compartiendo memoria como en sistemas de un único procesador, se ha probado en Windows, Linux y los varios sitios de trabajo y cluster de Unix. En su base, ParaView utiliza VTK como procesador de datos y motor de la renderización y de la visualización, tiene un interfaz escrita usando una mezcla única de Tcl/Tk y de C++.
ParaView fue creado por Kitware junto con Jim Ahrens, el objetivo de este proyecto es desarrollar una herramienta paralela escalable que realice procesamiento distribuido de memoria. El proyecto incluye algoritmos el paralelo, infraestructura de entrada y salida, ayuda, y dispositivos de demostración. Una característica significativa es que todo el software desarrollado está hecho como código abierto. Por lo tanto ParaView está disponible gratuitamente.
3.6 MPI [CARA]
Figura 3.12: Logo MPI.
52 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Herramientas de Visualización
MPI es una estándar creado por un amplio comité de expertos y usuarios con el objetivo de definir una infraestructura común y una semántica específica de interfaz de comunicación. De esta forma los productores de software de procesamiento paralelo pueden implementar su propia versión de MPI siguiendo las especificaciones de este estándar, con lo cual múltiples implementaciones de MPI cambiarían solamente en factores tales como la eficiencia de su implementación y herramientas de desarrollos, pero no en sus principios básicos.
Figura 3.13: Logo MPI Reserch.
Existen actualmente diferentes implementaciones de MPI, algunas son comerciales y otras son gratis y portables a múltiples arquitecturas. En éste proyecto trabajaremos con MPICH que es un ambiente de desarrollo y programación de MPI orientado a arquitecturas heterogéneas de ordenadores distribuidos en una red local. Con MPICH tanto un "cluster" dedicado como un una simple red local de ordenadores puede actuar como un ordenador multiprocesador.
GVA-ELAI-UPMPFC0077-2003 53

Herramientas de Visualización Marta García Nuevo
54 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
4 Procesamiento La interpretación de las imágenes de microscopía electrónica requiere de una gran
calidad de éstas, libres de ruido y señal espuria proveniente del sistema óptico del microscopio. Por lo tanto, resulta conveniente en la mayoría de las veces procesarlas digitalmente y eliminar las señales no deseadas por medio del manejo de diferentes técnicas.
4.1 Ficheros gráficos [FPIC]
Cuando se desea almacenar un gráfico o imagen digitalizada en un computador, esto se hace mediante el uso de un fichero gráfico.
Estos ficheros normalmente se dividen en dos partes, una denominada comúnmente cabecera (header) donde se almacenan datos relativos al gráfico que se almacena tales como ancho, alto, relación entre píxel y unidad de medida, unidad de medida, tipo de imagen (color o blanco y negro), codificación del color (componentes RGB, HSI, YCR, etc. o tabla de transformación o "Lookup Table"), método de compresión si lo hay, etc. A continuación de la cabecera, vienen los datos del gráfico o de la imagen digitalizada. Éstos datos pueden encontrarse comprimidos o no.
GVA-ELAI-UPMPFC0077-2003 55

Procesamiento Marta García Nuevo
Así los ficheros que contienen gráficos tienen por lo general la estructura que se muestra en la siguiente ilustración:
Cabecera
Gráfico o imagen digitalizada
Algunos programas que acompañan a dispositivos que digitalizan imágenes (tarjetas de adquisición de imágenes), no dan como salida ficheros gráficos con un formato "estándar", sino que se limitan a dar la imagen digitalizada como una matriz de píxel con valores de niveles de gris o bien con alguna de las coordenadas de color (RGB, HSI, ...), a este tipo de fichero es a lo que vamos a denominar como ficheros raw o raster, es decir, ficheros donde la imagen se almacena digitalizada sin ningún tipo de cabecera, de forma que los datos relativos a tamaño de la imagen en píxeles, tipo de imagen, etc. se deben conocer con anterioridad.
4.1.1 Formato gráfico *.pic
Este formato de ficheros gráficos es en el que vienen los ficheros obtenidos del microscopio confocal. Este formato permite almacenar una imagen digitalizada por fichero, que puede se en tonos de gris o bien en color (RGB y HSI), y también una secuencia de imágenes en cada fichero. Se denomina slice a cada una de las imágenes que contiene el fichero, y siendo en este caso imágenes en tonos de gris.
Los ficheros en este formato constan de una cabecera y a continuación se encuentran cada uno de los slices que componen el fichero. La cabecera del fichero está compuesta por los datos que se dan en la siguiente tabla:
56 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
4.1.2 Regiones de
Una región dimagen, que quereoperación sobre ella.creando una máscara del mismo tamaño procesar. La máscaraqueremos procesar y c
4.1.2.1 Selección d
El comando rcomando elegiremos original.
GVA-ELAI-UPMPFC0
Figura 4.1: Cabecera de los archivos *.PIC
interés (ROI)
e interés es una porción de una mos filtrar o realizar alguna Definimos una región de interés binaria, que es una imagen binaria que la imagen que queremos
contiene unos en las zonas que eros en el resto.
e la ROI
oipoly, permite elegir una los bordes del polígono pu
077-2003
Figura 4.2: Selección de una ROI
región de interés poligonal. Con este lsando con el ratón sobre la imagen
57

Procesamiento Marta García Nuevo
BW = roipoly;
También podemos usar como máscara una imagen binaria, siendo ésta del mismo tamaño que la imagen original. Por ejemplo, si queremos filtrar una imagen de intensidad, podemos crearnos una máscara, filtrando sólo los píxeles que superen una determinada intensidad. Podemos crear esta máscara con el siguiente comando:
BW = (I > 0.5);
Otra forma de crea una máscara adecuada es utilizando el comando roicolor, que define la región de interés basándose en el rango de intensidad o color.
Figura 4.3: ROI de nuestra imagen
4.1.2.2 Filtrado de la ROI
Podemos usar el comando roifilt2 para procesar la región de interés. Al usar éste comando, tenemos que especificar una imagen de intensidad, una máscara binaria y el filtro que queremos aplicar. A estas operaciones la s llamamos filtros de máscara.
4.2 Descripción de los comando usados en los códigos
4.2.1 Apertura del .pic con Matlab
Para lograr abrir los ficheros .pic en Matlab o en cualquier otro programa, lo más importante, es saber leer e interpretar bien la cabecera del archivo.
Tendremos que ir leyendo uno a uno los datos, con su correspondiente tamaño y tipo, e iremos guardándolos como constantes.
58 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
Los datos leídos y guardados, son: el nombre del fichero, tamaño en píxeles de las dos coordenadas de las imágenes en 2D, el número de imágenes bidimensionales.
Teniendo estos datos ya somos capaces de interpretar la información sobre las imágenes correctamente. Haremos un bucle que busque la imagen que queremos visualizar y nos indique si hay algún error en la elección del número de la slice.
Figura 4.4: Imagen original del microscopio confocal
4.2.2 Procesamiento de la imagen con Matlab
Ya hemos logrado leer la cabecera de nuestro fichero .pic en Matlab, y gracias a esto abrir y visualizar en 2D la slice elegida. Ahora vamos a procesar la imagen, sometiéndola a diferentes técnicas de filtrado.
Los comandos que vamos a describir a continuación, son los que han sido usados en el programa picfilter2.m
Lo primero que hacemos es elegir nuestra región de interés. Para ello aplicamos el comando roicolor.
BW = ROICOLOR(A,LOW,HIGH)
BW es una imagen binaria con ceros fuera de la región de interés y unos dentro de ésta.
GVA-ELAI-UPMPFC0077-2003 59

Procesamiento Marta García Nuevo
Llega el momento de buscar el tipo de filtro que mejor se adapta a nuestros objetivos. Para esto vemos las opciones que nos ofrece FSPECIAL, que crea filtros especiales en 2D.
H = FSPECIAL(TYPE)
Los tipos a elegir, son: 'AVERAGE', 'DISK', ’GAUSSIAN', 'LAPLACIAN', 'LOG’, 'MOTION', 'PREWITT', 'SOBEL', ‘UNSHARP'.
En nuestro caso el que mejor funciona es el ’GAUSSIAN', que funciona como se muestra:
H = FSPECIAL('gaussian',HSIZE,SIGMA)
HSIZE: es un vector que especifica el número de filas y de columnas de H
SIGMA: es la desviación
Por defecto los valores que toma Matlab son: HSIZE es [3 3] y SIGMA 0.5.
Ahora aplicaremos el filtro a la región de interés.
B = IMFILTER(A,H)
Filtra el array multidimensional A, con el filtro multidimensional H.
Seguidamente realizaremos una erosión sobre la región de interés ya filtrada, definiremos primeramente una matriz identidad de 3*3 que usaremos como elemento estructurante y luego lo aplicamos a la imagen.
SE = eye (3)
BW2 = ERODE(B,SE)
Definimos ahora la deconvolución que vamos a realizar sobre la imagen. Usaremos el comando DECONBLIND, que realiza una restauración de la imagen usando el algoritmo de la blin deconvolución. Tenemos que elegir un elemento estructurante, es nuestro caso nos viene bien una matriz de unos de dimensión 4.
[J,PSF] = DECONVBLIND(I,INITPSF,NUMIT)
INITPSF: es el elemento estructurante
60 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
NUMIT: número de iteraciones
Ahora realizamos el producto de la imagen obtenida con la ROI, para así obtener la imagen final.
Picfilt = J .* BW2filt
El .* es un operador de arrays, realiza el producto de las imágenes bit a bit.
4.2.3 Procesamiento de la imagen usando SDC
El programa implementado usando SDC Morphology Toolbox para Matlab, da como resultado un mejor procesamiento y visualización de las imágenes.
Nuestra imagen original, abierta con el comando MMSHOW, es:
Describimo
Muchos defuncionamiento ge
IM2BW lo Se producen imáge
BW = IM
GVA-ELAI-UPMP
Figura 4.5: Imagen original abierta con ‘mmshow’.
s seguidamente los comandos usados nuestro programa picarea.m.
estos comandos están ya descritos en el apartado anterior, y el neral es el mismo
usamos para convertir la imagen a binario por técnicas de tresholding. nes binaras procedentes de imágenes indexed, intensity, o RGB.
2BW(I,LEVEL)
FC0077-2003 61

Procesamiento Marta García Nuevo
Con MMAREAOPEN quitamos los puntos pequeños dispersos pos la imagen. Quita las zonas con área menor que A de la imagen original.
Y = MMAREAOPEN( F, A, BC )
F – Escala de grises (uint8 or uint16) o imagen binaria (logical uint8).
A - Integrador no negativo.
BC – Elemento estructurante
Una vez limpia la imagen dejando sólo pocos píxeles ‘semilla’, procedemos a hacer una dilatación de la imagen buscando la región de interés.
Primeramente hacemos una dilatación condicionada, esto es, hacemos crecer la imagen ya filtrada que contiene sólo los píxeles semilla, tomando como guía de crecimiento la imagen original. Esto lo logramos utilizando el comando MMCDIL.
Y = MMCDIL( F, G, B, N )
F – Imagen binaria o en escala de grises
G – Imagen condicional binaria o en escala de grises
B – Elemento estructurante
N – Número de iteraciones
Después de la dilatación condicionada, hacemos una dilatación normal, para así terminar de definir nuestra región de procesamiento. En este caso usamos el comando MMDIL.
Y = MMDIL( F, B )
F - Imagen binaria o en escala de grises
B - Elemento estructurante
62 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
a
Figura 4.6: Dilatación condicionad
Finalmente realizando el producto eobtenemos nuestra imagen final.
4.2.4 Procesamiento de la imagen usan
Vamos a trabajar VTK. Con esta bprogramando en Tcl, crearemos un programa qabra y visualice la imagen en tres dimensiones.
GVA-ELAI-UPMPFC0077-2003
Figura 4.7: Dilatación normal
ntre la imagen de la ROI y la original,
Figura 4.8: Resultado usando SDC
do VTK
iblioteca open-source para visualización ue lea la cabecera de nuestro fichero .pic y
63

Procesamiento Marta García Nuevo
Para trabajar con esta librería iremos empleando clases, que se irán interrelacionando unas con otras, de forma que todas quedan enlazadas.
Las clases empleadas son:
vtkImageReader: La empleamos para leer la cabecera del fichero y guardar los datos de tamaños, colores... de forma que podamos recurrir luego a ellos de forma sencilla.
vtkPieceWiseFunction: Es la función de transferencia que relaciona el color y la absorción de cada celda.
vtkColorTransferFunction: Tiene el mismo comportamiento que el anterior pero para paletas de colores.
vtkVolumeProperty: Toma los objetos anteriormente definidos de color y opacidad como propiedades del volumen. Define como se van a visualizar los datos.
vtkVolumeRayCastCompositeFunction: Define como renderizar nuestra imagen.
vtkVolumeRayCastMapper: Aplica el compositeFunction a los datos que vamos a leer.
vtkVolume: Junta lo obtenido en el volumeMapper y volumeProperty, podríamos también usarlo para definir posiciones u orientaciones.
vtkRenderer: Para finalmente renderizar la escena.
Con todo esto obtenemos la visalización de la imagen en tres dimensiones.
Figura 4.9: Imagen 3D abierta con VTK
64 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
4.2.5 Procesamiento usando VTK y Matlab
Desde Matlab podemos ejecutar programas externos a éste, y hacerlo mediante hebras que no bloquean el funcionamiento del PC. Esto es lo que vamos a aplicar en éste caso.
Realizaremos un programa que introduciendo el archivo .pic que queremos abrir y el número de la primera y última slice, llame al programa de VTK openpic3D.tcl y se visualice la imagen.
Vamos a ejecutar el programa desde Matlab. Llamaremos a la función vtkopenpic.m, que nos pide los tres argumentos. Esta función guarda los datos de la primera y última slice que queremos abrir en dos archivos, y guarda también el nombre del fichero que queremos abrir en otro archivo.
Para llamar al programa en tcl, introducimos la siguiente línea de código:
!openpic3d.tcl &
Estos tres archivos son luego leídos por openpic3D.tcl y usados como parámetros.
El resultado de la visualización es el mismo que en el apartado anterior, pero pudiendo elegir las slices.
4.2.6 Observaciones
En este momento estamos centrando la investigación en aplicar los filtros más convenientes y en seleccionar de forma apropiada la ROI. Por ello los resultados de los programas anteriormente descritos no son aún los más apropiados y están pendientes de futuras mejoras.
4.3 Renderización
Es el proceso mediante el cual una estructura poligonal (tridimensional) digital obtiene una definición mucho mayor. Esto se hace con juegos de luces, texturas y acentuado y mejorado de los polígonos, simulando ambientes y estructuras físicas.
Cuando se está trabajando en un programa profesional de diseño tridimensional por computadora, no se puede visualizar en tiempo real el resultado del diseño de un objeto o escena compleja ya que esto requiere una potencia de cálculo extremadamente elevada, por lo que después de diseñar el trabajo con una forma de visualización más simple y técnica, se realiza el proceso de renderización, tras el cual se puede apreciar el verdadero aspecto (aspecto final) de una imagen estática o animación.
GVA-ELAI-UPMPFC0077-2003 65

Procesamiento Marta García Nuevo
4.3.1 Métodos de renderización
Definimos rendering, en tratamiento de gráficos por computadoras, como: Imagen tridimensional que incorpora la simulación de efectos de iluminación, tales como la sombra reflectiva.
Un renderer es software y/o hardware que procesan datos de gráficos, con objeto de visualizar, imprimir o exportar las figuras.
Hay tres métodos de renderización:
OpenGL: librería de generación de gráficos tridimensionales, es compatible con casi todos los sistemas de computadoras. Este tipo de renderización es el más rápido.
Z-Buffer: Matlab dibuja rápidamente porque, los objetos son coloreados píxel a píxel, y solo se renderizan los píxeles visibles en la escena. Este método puede consumir mucha memoria del sistema.
Painter´s: Es el método original de renderización en Matlab, es el más rápido si la figura contiene solo objetos sencillos o pequeños.
Los métodos OpenGL y Z-buffer dibujan imágenes usando el mapa de bits (gráficos raster). El método Painter´s dibuja usando gráficos de vectores, en general da resultados con mayor resolución que los otros métodos. Pero OpenGL y Z-buffer pueden trabajar en situaciones en las que Painter´s no produce buenos resultados o es incapaz de hacer nada.
4.3.2 Renderización en Matlab
Por defecto Matlab selecciona automáticamente los mejores métodos de renderización basándose en las características de las figuras y en algunas ocasiones el método de impresión o el formato del archivo usado.
En general, MATLAB usa:
- OpenGL para superficies complejas de los dibujos, usando interpolación o juegos de luces.
- Z-buffer cuando la visualización de la imagen no es en el color real.
- Painter's para figuras de líneas, áreas dibujos (gráficos de barras, histogramas, etc...), y superficies sencillas.
Usando los comandos de Matlab:
66 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
Podemos seleccionar el tipo de renderización usando las propiedades de Renderer o el print command. Esto se hace de la siguiente manera, para Z-buffer.
set(gcf, 'Renderer', 'zbuffer');
Salva el nuevo valor de Renderer con la figura.
print –zbuffer
Afecta solo a la actual operación.
4.3.3 Renderización con VTK
Para representar y procesar una pila de imágenes en tres dimensiones las librerías de VTK son mucho mejores que Matlab. Usamos las librerías de VTK en los programas escritos en TCL/TK. Este modo de trabajar con estas librerías es muy cómodo. No es necesario construir , unir y compilar para tener un ejecutable como en otros lenguajes, por ejemplo en C++.
Hemos escrito dos ficheros para representar las imágenes en tres dimensiones, según el modo de representación usaremos uno u otro:
openpic3d.tcl Para el método de renderización de volúmenes. Este archivo es aplicable para visualizar archivos ‘*.pic’ originales o filtrados, que estén definidos con 256 niveles de gris.
picsuper3d.tcl Esta segunda opción la usamos para renderización de superficies. Con este fichero podemos representar ficheros ‘*.pic’ en blanco y negro, por ejemplo, los que se obtienen con los programas de Matlab ‘picsuper.m’ y ‘picsuperbw.m’
4.3.4 Razones para cambiar la renderización
El método de renderización usado para dibujar y exportar figuras, no es siempre el mismo que para visualizarlas. La razón más importante para seleccionar la renderización después de dibujar o exportar, es para hacer que la figura dibujada o exportada sea igual que la que se ve por pantalla.
Otra razón para seleccionar la renderización, es para evitar que se exporte como bitmap en lugar de cómo formato vectorial. Cambia un formato bitmap a vectorial es un proceso largo. Si usamos uno de estos formatos y queremos estar seguros de que se guarda con formato vectorial, hay que elegir el método de renderización Painter´s.
GVA-ELAI-UPMPFC0077-2003 67

Procesamiento Marta García Nuevo
4.3.5 Renderización de volúmenes
Está técnica de renderización, consiste en dividir el objeto que nos interese representar en pequeños elementos de volumen llamados voxels, que miden cada uno una unidad de volumen. Cada voxel contiene valores sobre medidas u otras propiedades del volumen, su representación típica es como un cubo.
En este tipo de representación procesamos todos los voxels del objeto para lograr la visualización, lo que implica procesar mucha información, esto emplea muchos recursos del computador y hace que sea un proceso lento. Los resultados obtenidos son correctos y podremos realizar secciones para visualizar el interior del objeto. Todas las operaciones que realicemos necesitarán mucho tiempo de computación, ya que se efectúan sobre un número muy elevado de dados. Una de las ventajas de esta técnica es que podemos visualizar el objeto sin necesidad de tener información sobre el tamaño o la forma de nuestra región de interés.
4.3.6 Renderización de s
En la renderización dprocesados por distintos métextracciones de los bordes... que nos interesa, es decir, com
El tiempo computaciocaso anterior al ser el procesay aplicar de forma exacta visualización, al rotar el objesólo la información del conto
68
Figura 4.10: Volumen renderizado
uperficies
e superficies, los datos del volumen a representar deben ser odos según nos convenga, como isosurfacing, isocontouring, quedándonos solo con la información del exterior del objeto o si el objeto estuviese hueco por dentro.
nal para la visualización es elevado, incluso más que en el miento más complicado, serán necesarios potentes algoritmos y correcta los filtros. La ventaja es que a la hora de la to o realizarle otras operaciones es mucho más rápido al tener rno, por esto no necesita mucha memoria para visualizarlo.
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
Figura 4.11: Superficie renderizada
4.3.7 PICvisu toolbox
Con los programas de esta toolbox, pretendemos tratar los ficheros ‘*.pic’. Los leeremos y posteriormente haremos su visialización en dos o tres dimensiones según corresponda. En estos, al hacer la visualización en tres dimensiones, haremos una renderización de volumen utilizando las librerías de VTK.
4.3.7.1 openpic.m
El programa ‘openpic.m’ nos permite visualizar las lonchas que elijamos de un fichero ‘*.pic’.
Este programa lee el fichero entero y busca las lonchas que queremos representar. Esta representación puede ser en dos dimensiones, si solo elegimos una loncha, en este caso realizará la visualización con Matlab. Si queremos representar más de un loncha usaremos VTK, con estas librerías realizaremos la renderización de volumen y su visualización.
Podemos elegir realizar o no la visualización, independientemente de esto, el resultado será guardado en una variable de Matlab, sobre la que podemos operar comodamente.
Para ejecutar este programa en Matlab, en la línea de comandos pondremos:
>> figure = openpic('nuevo1.pic',20,40,1);
De esta manera, tomaremos el fichero indicado, abriremos desde la loncha 20, hasta la 40 y, por haber puesto el último parámetro distinto de cero, se realizará la visualización de estas 20 lonchas en 3D. En Matlab quedará guardada una variable llamada ‘figure’, con los datos de éstas lonchas visualizadas.
GVA-ELAI-UPMPFC0077-2003 69

Procesamiento Marta García Nuevo
Ahora veremos el código fuente de esta función de Matlab. Los comentarios adjuntos facilitarán la comprensión del código, aunque no son muy extensos y puede ser necesario recurrir a la función help de Matlab para comprender algunos comandos.
La primera parte de la función ‘vtkopenpic.m’ es para leer la información importante de la cabecera del fichero, y para decidir la forma de actuar, según los argumentos introducidos.
function Img3D = openpic(acFilename, nLimInf, nLimSup, Visu); fid = fopen(acFilename,'rt','l'); nPictureSize = fread(fid,[1,2],'int16'); nX = nPictureSize(1,1); nY = nPictureSize(1,2); nNumberOfImages = fread(fid,1,'int16'); xRampAndNotes = fread(fid,6,'int16'); acNametemp = fread(fid,[1,32],'uchar'); acName = char(acNametemp); xTemp = fread(fid,26,'int8'); nSliceNumber = nLimSup - nLimInf; nNum1 = nLimInf; nNum2 = nLimSup; warning('off', 'all');
La siguiente parte de la función es para realizar la visualización en dos o tres dimensiones, según proceda.
Si el número de la loncha inferior y de la superior es el mismo, estaremos en el primer caso, procesaremos una sola loncha y la visualizaremos en dos dimensiones.
Lo primero que hacemos es buscar la loncha indicada, si es la primera, leemos los sus datos y realizamos sobre ellos el procesamiento ya descrito en el apartado anterior. Si en ‘visu’ no hemos introducido “cero” realizamos la visualización del resultado con Matlab.
%For only one slice, it is visualice with Matlab if nSliceNumber == 0 nNum = nLimInf; if nNum == 1 pic = fread(fid, [nX, nY], 'uint8'); if Visu ~= 0; imshow(uint8(pic)); Img3D(:,:)=(uint8(pic)); else Img3D(:,:)=(uint8(pic)); display('You choose not to visualice'); end
70 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
Si la loncha elegida no es la primera tendremos que leer los datos anteriores hasta llegar a los que nos interesan. Sobre estos datos realizamos el mismo procesamiento anterior y la visualización si procede. Detectaremos aquí posibles errores en los datos introducidos, mostrando un mensaje de error si es necesario.
elseif (1 < nNum) & (nNum <= nNumberOfImages) for i = 1:nNum pic = fread(fid,[nX, nY],'uint8'); end if Visu ~= 0; imshow(uint8(pic)); Img3D(:,:,1)=(uint8(pic)); else Img3D(:,:,1)=(uint8(pic)); display('You choose not to visualice'); end else display ('Wrong image number, it must be betwen 0 and the last slice'); end fclose(fid);
Cuando lo que queremos es visualizar una imagen en tres dimensiones, es decir, varias lonchas, recurrimos a las librerías VTK con las que el proceso es más rápido y sencillo. El programa busca las lonchas elegidas, sobre éstas realiza el procesamiento y la visualización si procede. Guardaremos en archivos de texto la información de los argumentos introducidos, para que puedan ser leídos por el programa ‘openpic3D.tcl’, que es el fichero de VTK encargado de realizar la visualización.
%For more than one slice, it is visualice with VTK else if nLimInf < nLimSup if (nNum1 > 0) & (nNum2 <= nNumberOfImages) for i = 1:(nNum1-1) fread(fid,[nX, nY],'uint8'); end for i = 1: (nSliceNumber+1) pic=fread(fid,[nX, nY],'uint8'); Img3D(:,:,i)=(uint8(pic)); end if Visu == 0; display('you choose not to visualice'); fclose(fid); else fclose(fid); %Create new file for read the number of the first slice
GVA-ELAI-UPMPFC0077-2003 71

Procesamiento Marta García Nuevo
fid = fopen('VTKFirstSlice.txt','wt'); fwrite(fid, sprintf('%d',(nNum1 -1)),'char'); fclose(fid); %Create new file for read the number of the last slice fid = fopen('VTKLastSlice.txt','wt'); fwrite(fid, sprintf('%d',(nNum2 -1)),'char'); fclose(fid); %Create new file for read the name of the file *.PIC to open fid = fopen('VTKFilename.txt','wt'); fwrite(fid, sprintf('%c',acFilename),'char'); fclose(fid); %Calls the tcl program, to open the image .pic !openpic3d.tcl & end else display('Wrong image numbers, nLimInf must be bigger than 0, and
nLimSup must be smaller than the last slice'); end else display('Wrong image numbers, nLimInf must be smaller than nLimSup'); end end
Vemos ahora un ejemplo de una imagen obtenida con este programa.
72
Figura 4.12: Imagen 3D obtenida con ‘openpic.m’
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
4.3.7.2 vtk3D.m
El programa ‘vtk3D.m’ nos permite visualizar una variable de Matlab en 3D. Esta variable será una pila de imágenes en dos dimensiones, por ejemplo, las variables generadas en el programa anterior, ‘openpic.m’.
Para poder visualizar estas variables de Matlab, como lo hacíamos con los ficheros ‘*.pic’, tendremos que saber cual es el tamaño de cada loncha en dos dimensiones y el número de lonchas que tenemos. Esto es lo que hacemos en la primera parte del programa, que seguidamente detallamos:
function[] = vtk3D(Img3D); nSize=[1 1 1]; nSize=size(Img3D); nX=nSize(1,1); nY=nSize(1,2); warning('off', 'all'); %if we have more than one slice, Img3D is 3D if size(nSize)==[1 3] nNumberOfImages=nSize(1,3) %if we have only one slice, Img3D is 2D else display('we have not a 3D image'); end
Guardaremos estos datos en un fichero auxiliar que tendrá el mismo formato que los ‘*.pic’ habituales, así podremos usar para abrirlo los mismos ficheros que anteriormente.
%for save the size and datafield in the correct format acFilename=('/temp/newfile.pic'); fid1 = fopen(acFilename,'w','l'); fwrite(fid1,nX,'int16'); fwrite(fid1,nY,'int16'); fwrite(fid1,nNumberOfImages,'int16'); fread(fid1, 70, 'uint8'); fwrite(fid1, Img3D, 'uint8'); fclose(fid1);
Una vez que tenemos escrita la cabecera del fichero auxiliar, y los datos de las imágenes, guardemos los datos que VTK necesita para hacer la visualización en ficheros de texto. Hecho esto llamaremos a ‘openpic3D.tcl’ para realizar la visualización. Nos damos cuenta que estamos actuando de idéntica forma que en anteriores ocasiones.
GVA-ELAI-UPMPFC0077-2003 73

Procesamiento Marta García Nuevo
%Create new file for read the number of the first slice fid = fopen('VTKFirstSlice.txt','wt'); fwrite(fid, sprintf('%d',1),'char'); fclose(fid); %Create new file for read the number of the last slice fid = fopen('VTKLastSlice.txt','wt'); fwrite(fid, sprintf('%d',(nNumberOfImages -1)),'char'); fclose(fid); %Create new file for read the name of the file *.PIC to open fid = fopen('VTKFilename.txt','wt'); fwrite(fid, sprintf('%c',acFilename),'char'); fclose(fid); %Calls the tcl program, to open the image .pic !openpic3d.tcl &
1.7.3 savepic.m
Ahora que podemos crear variables de Matlab con un pila de imágenes en dos dimensiones, nos interesa poder guardarlo como archivos con formato ‘*.pic’. Así crearemos nuevos archivos de imagen con las lonchas que que nos den la información más adecuada a nuestras necesidades. Para ello usamos este programa.
Para ejecutarlo tendremos que indicar la variable de Matlab que queremos guardar y el nombre con el que queremos hacerlo, de ésta forma:
>> savepic(variable,’nueva.pic’);
El código del programa necesario para hacer esto es el siguiente:
function savePIC (Img3D, achFile) nSize=[1 1 1]; nSize=size(Img3D); nX=nSize(1,1); nY=nSize(1,2); %if we have more than one slice, Img3D is 3D if size(nSize)==[1 3] nNumberOfImages=nSize(1,3); %if we have only one slice, Img3D is 2D else nNumberOfImages=1; end
74 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
%for save the size and datafield in the correct format fid = fopen(achFile,'w','l'); fwrite(fid,nX,'int16'); fwrite(fid,nY,'int16'); fwrite(fid,nNumberOfImages,'int16'); fread(fid, 70, 'uint8'); fwrite(fid, Img3D, 'uint8'); fclose(fid);
Lo primero que hemos hecho es ver el tamaño de las imágenes y el número de éstas para crear la cabecera del fichero con el formato establecido para los ficheros ‘*.pic’, y tras la cabecera copiaremos la variable de Matlab, que contiene una matriz con la información de la imagen.
Mostramos un ejemplo en el que usamos los tres programas anteriores para entender así mejor su aplicación:
Tomamos de nuestro fichero de pruebas ‘nuevo1.pic’, las diez lonchas centrales que son las más nítidas, lo hacemos usando ‘openpic.m’, no lo visualizamos, tan solo obtenemos una variable que llamamos ‘imagen’.
b
Ahora con ‘savepic.m’ ‘imagen.pic’.
GVA-ELAI-UPMPFC0077-2003
Figura 4.13: Workspace de Matla
guardamos la variable como archivo ‘*.pic’, con el nombre
75

Procesamiento Marta García Nuevo
Figura 4.14: Current Directory de Matlab
Visualizamos este archivo entero y vemos que solo esta formado por las diez lonchas centrales del ‘nuevo1.pic’.
Para realizar este proceso los comandos exactos que hay que teclear en la ventana
de Matlab, son los siguientes:
76 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
Figura 4.16: Pantalla al ejecutar el programa ‘openpic.m’
Este proceso es meramente demostrativo, para ver como enlazar los distintos programas y su aplicación. Para realizar esta visualización, habría sido suficiente con poner algo distinto de cero en el último parámetro de la primera llamado a ‘openpic.m’, obteniendo el mismo resultado, pero sin tener guardado el archivo ‘imagen.pic’.
1.7.4 openpic3D.tcl
Los programas ‘opensup.m’ y ‘opensupbw.m’ los usamos para procesar y seleccionar los datos que luego necesita ‘openpic3D.tcl’ para realizar la visualización.
Este programa está escrito en tcl, que es un leguaje de programación de fácil aprendizaje y manejo. Utiliza las librerías de VTK, ya descritas anteriormente.
Daremos ahora una breve explicación del código fuente del programa ‘openpic3D.tcl’, las lineas precedidas de ‘#’ son comentarios y no forman parte del código fuente.
#Estas dos primeras lineas son estandar de los ficheros ‘*.tcl’. #Se encargan de llamar a las librerias de VTK y
GVA-ELAI-UPMPFC0077-2003 77

Procesamiento Marta García Nuevo
#al programa para ejecutar el código fuente escrito debajo. catch {load vtktcl} source vtkInt.tcl #Ahora leemos los ficheros de texto con la información obtenida de Matlab #y lo guardamos como variables de TCL set fd1 [open "VTKFirstSlice.txt" "r"] set fd2 [read $fd1] set fd3 [open "VTKLastSlice.txt" "r"] set fd4 [read $fd3] set file1 [open "VTKFilename.txt" "r"] set file2 [read $file1] set head1 [open $file2] set head2 [read $head1 6] binary scan $head2 s1s1s1 nx ny nz set nx [expr $nx -1] set ny [expr $ny -1] set nz [expr $nz -1] # Ahora tenemos el reader para los datos # seleccionamos el nombre del fichero, las dimensiones de la pila de imágenes # y el vtkImageReader reader reader SetFileName "$file2" reader SetFileDimensionality 3 reader SetDataExtent 0 $nx 0 $ny 0 $nz reader SetDataVOI 0 $nx 0 $ny $fd2 $fd4 reader SetDataOrigin 0 0 0 reader SetDataScalarTypeToUnsignedChar reader SetDataSpacing 1.0 1.0 1.0 reader SetHeaderSize 76 # Ahora tenemos un filtro para quitar las partes oscuras del fondo de las # imágenes vtkPiecewiseFunction opacityTransferFunction opacityTransferFunction AddPoint 60 1.0 opacityTransferFunction AddPoint 255 1.0 opacityTransferFunction ClampingOff #Con la transfer function cambiamos los colores de escala de grises a RGB vtkColorTransferFunction colorTransferFunction colorTransferFunction AddRGBPoint 0.0 0.0 0.0 0.0 colorTransferFunction AddRGBPoint 255.0 1.0 1.0 1.0
78 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
# Modificamos las propiedades definiendo el VolumeProperty vtkVolumeProperty volumeProperty volumeProperty SetColor colorTransferFunction volumeProperty SetScalarOpacity opacityTransferFunction volumeProperty SetInterpolationTypeToLinear # En este paso definimos el modo de lectura, usamos el volume rederer # Cambiamos las lonchas a un volumen en 3D vtkVolumeRayCastCompositeFunction compositeFunction vtkVolumeRayCastMapper volumeMapper volumeMapper SetVolumeRayCastFunction compositeFunction volumeMapper SetInput [ reader GetOutput] # La última parte crea la ventana y enlaces necesarios a las propiedades vtkVolume volume volume SetMapper volumeMapper volume SetProperty volumeProperty vtkRenderer ren1 ren1 AddVolume volume vtkRenderWindow renwin renwin AddRenderer ren1 vtkRenderWindowInteractor iren iren SetRenderWindow renwin ren1 SetBackground 0 0 0 renwin SetSize 500 500 iren Initialize iren AddObserver SetExitMethod { exit } wm withdraw . wait forever El resultado obtenido aparece en la pantalla tras el tiempo necesario para el
procesamiento. En la siguiente figura mostramos uno de los resultados que es posible obtener. La imagen de la ventana es un volumen que podemos mover y rotar pulsando con el botón izquierdo del ratón sobre la imagen. Podemos también hacer un zoom aumentando o reduciendo la figura pulsando con botón derecho del ratón. Pero estas operaciones de giro o zoom requieren gran capacidad computacional, si no tenemos un computador potente puede resultar algo lento.
GVA-ELAI-UPMPFC0077-2003 79

Procesamiento Marta García Nuevo
4.3.8 PICsu
HemosLo que hacen los bordes o utilizando VTK
4.3.8.1 Picsu
selecciona el áimágenes el procesamientonegro. La seleprogramas. Paalgo parecido
80
Ejemplo de “openpic3d.tcl”
’
per tool
creado ulos proga selecci
.
per / p
La funcirea de inblanco parecidocción adra ejecuta esto:
>> bord
Figura 4.17: Resultado de ‘openpic3D.tcl
box
na toolbox en Matlab para realizar la renderización de superficie. ramas que contiene, es procesar las imágenes atendiendo a extraer onar la región de interés, para después realizar su visualización
icsuperbw
ón ‘picsuper.m’ se encarga de procesar el archivo ‘*.pic’ entero, terés de cada loncha en 2D, y extrae los bordes, devuelve la pila de y negro. La función de Matlab ‘picsuperbw.m’ realiza un , extrae las regiones de interés y devuelve las imágenes en blanco y ecuada de la ROI, la vemos a continuación el los códigos de los ar estos programas, en la línea de comandos tendremos que teclear
es = picsuper('nuevo1.pic', 'savename.pic');
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
Haciendo esto, procesaremos el archivo ‘nuevo1.pic’, y guardaremos el resultado en ‘savename.pic’, se guardará una pila de imágenes en blanco y negro con la información de los bordes y formato ‘*.pic’. Si la imagen no la tenemos en el directorio actual de Matlab, tendremos que especificar la ruta de directorios donde encontrarlo. Pasa igual para especificar dónde queremos guardar el resultado, si no especificamos ruta de directorios se guardará el directorio actual de Matlab.
Ahora veremos el código fuente de esta función de Matlab. Los comentarios adjuntos facilitarán la comprensión del código, aunque no son muy extensos y puede ser necesario recurrir a la función help de Matlab para comprender algunos comandos.
La primera parte de la función ‘picsuper.m’ es para leer la información importante de la cabecera del fichero, y para copiar la cabecera el fichero destino, ya que el nuevo archivo tendrá el mismo tamaño y número de imágenes que el original.
function[bor] = picsuper(acFilename, acSavename); fid = fopen(acFilename,'rt','l'); %original file identifier nPictureSize = fread(fid,[1,2],'int16'); nX = nPictureSize(1,1); %width in pixels nY = nPictureSize(1,2); %height in pixels nNumberOfImages = fread(fid,1,'int16'); %number of slices fclose(fid); fid = fopen(acFilename,'rt'); %original file identifier cabezera = fread(fid, 76, 'uint8'); %read the whole header fid2 = fopen(acSavename,'wt'); %destination file identifierfwrite(fid2, cabezera, 'uchar'); %write header to destination . La siguiente parte del fichero es igual en este grupo de programas. En esta parte
elegimos la región de interés como ya explicamos en el apartado correspondiente, extraemos los bordes de la ROI y lo guardamos en el archivo especificado.
for i = 1:nNumberOfImages pic = fread(fid,[nX,nY],'uint8'); bw = im2bw(uint8(pic), 0.25); %convert to black & white im = mmareaopen(uint8(bw), 250); bw1 = im2bw(uint8(pic), 0.2); im1 = mmareaopen(uint8(bw1), 550); b1 = mmcdil(im, im1, mmsecross(10), 10); %dilation with conditions x = mmdil(b1, mmsedisk(2)); bor(:,:,i) = edge(x, 'canny'); %find the borders end fclose(fid); %close the original file fwrite(fid2, bor, 'uchar'); %write the processesed file fclose(fid2); %close the destination file
La diferencia con ‘picsuperbw.m’ , es que en este no extraemos los bordes, pero usamos las imágenes en blanco y negro de la ROI.
GVA-ELAI-UPMPFC0077-2003 81

Procesamiento Marta García Nuevo
Seguidamente mostramos un ejemplo de cómo se visualizan las imágenes procedentes de ‘picsuper.m’ y ‘picsuperbw.m’, seleccionando para la visualización una sola loncha del archivo obtenido.
82
Figura 4.18: Resultado de ‘picsuper.m’ Figura 4.18: Resultado de ‘picsuperbw.m’GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
1.7.2 Opensup / opensupbw
Los programas ‘opensup.m’ y ‘opensupbw.m’ realizan un procesamiento idéntico al que realizan ‘picsuper.m’ y ‘picsuperbw.m’. La gran ventaja de éstos respecto a los anteriores, es que ahora no es necesario procesar el archivo completo, sino que podemos elegir una o más lonchas sobre las que realizar el procesamiento. En este caso no se guardan directamente los resultados el un fichero, sino que se salva como una variable de Matlab, que contiene una matriz con los datos de las imágenes procesadas. Tendremos después la opción de guardar estos datos con el formato *.pic, utilizando el programa ‘savePIC.m’, del que describiremos su funcionamiento más adelante.
Para ejecutar estos programas, en la línea de comandos tendremos que teclear algo parecido a esto:
>> bordes = opensup('nuevo1.pic', limInf, limSup, visu);
Haciendo esta operación, tomamos el archivo ‘nuevo1.pic’, y seleccionamos en éste la información desde la loncha indicada por limInf, hasta la que indica limSup, si ambas coincidiesen se procesaría una única loncha y haciendo la visualización lo obtendríamos en 2D. Ésta imagen, o pila de imágenes será guardada como una variable de Matlab, una matriz con la información de las rodajas procesadas, al no tener cabecera no es de formato ‘*.pic’, habrá que añadirla si deseamos guardarlo así.
En la primera parte de este programa leemos de la cabecera del fichero indicado. Tomamos los datos necesarios para la representación, éstos datos son el número de imágenes y su tamaño. En esta parte definimos también el número de imágenes que vamos a visualizar, con los datos que tenemos de la primera y última lonchas de interés. Nos quedaremos apuntando al primer dato de la primera imagen.
function Sup = openSup(acFilename, nLimInf, nLimSup, Visu); fid = fopen(acFilename,'rt','l'); %opens file indicated by "acFilename" nPictureSize = fread(fid,[1,2],'int16'); %reads the first two double-bytes %with the size of each picture nX = nPictureSize(1,1); nY = nPictureSize(1,2); nNumberOfImages = fread(fid,1,'int16'); xRampAndNotes = fread(fid,6,'int16'); acNametemp = fread(fid,[1,32],'uchar'); acName = char(acNametemp); xTemp = fread(fid,26,'int8'); nSliceNumber = nLimSup - nLimInf; nNum1 = nLimInf; nNum2 = nLimSup;
En este caso, como en otros ya descritos, dividiremos el resto del programa en dos partes, la primera de ella será para cuando tengamos que visualizar una sola loncha en dos
GVA-ELAI-UPMPFC0077-2003 83

Procesamiento Marta García Nuevo
dimensiones, en la otra parte programaremos como hacer el procesamiento de varias lonchas y su visualización el tres dimensiones.
if nSliceNumber == 0 nNum = nLimInf; if nNum == 1 pic = fread(fid, [nX, nY], 'uint8'); bw = im2bw(uint8(pic), 0.25); im = mmareaopen(uint8(bw), 250); bw1 = im2bw(uint8(pic), 0.2); im1 = mmareaopen(uint8(bw1), 550); b1 = mmcdil(im, im1, mmsecross(5), 5); b2 = mmareaclose(b1, 50); x = mmdil(b2, mmsecross); pic(:,:,nNum) = edge(x, 'canny'); Sup(:,:)=(uint8(pic)); if Visu ~= 0; imshow(pic); else display('You choose not to visualice'); end elseif (1 < nNum) & (nNum <= nNumberOfImages) for i = 1:(nNum-1) aux = fread(fid,[nX, nY],'uint8'); end pic = fread(fid,[nX, nY],'uint8'); bw = im2bw(uint8(pic), 0.25); im = mmareaopen(uint8(bw), 250); bw1 = im2bw(uint8(pic), 0.2); im1 = mmareaopen(uint8(bw1), 550); b1 = mmcdil(im, im1, mmsecross(5), 5); b2 = mmareaclose(b1, 50); x = mmdil(b2, mmsecross); pic(:,:,1) = edge(x, 'canny'); Sup(:,:)=(uint8(pic)); if Visu ~= 0; imshow(pic); else display('You choose not to visualice'); end else display ('Wrong image number, it must be betwen 0 and the last slice'); end fclose(fid);
Realizamos ahora la visualización en tres dimensiones.
84 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
%For more than one slice, it is visualice with VTK else if nLimInf < nLimSup if (nNum1 > 0) & (nNum2 <= nNumberOfImages) for i = 1:(nNum1-1) fread(fid,[nX, nY],'uint8'); end for i = 1: (nSliceNumber+1) pic=fread(fid,[nX, nY],'uint8'); bw = im2bw(uint8(pic), 0.25); im = mmareaopen(uint8(bw), 250); bw1 = im2bw(uint8(pic), 0.2); im1 = mmareaopen(uint8(bw1), 550); b1 = mmcdil(im, im1, mmsecross(5), 5); b2 = mmareaclose(b1, 50); x = mmdil(b2, mmsecross); pic(:,:,i) = edge(x, 'canny'); Sup=(uint8(pic)); end if Visu == 0; display('you choose not to visualice'); fclose(fid); else fclose(fid);
Nos encontramos ahora con un problema, para realizar la visualización con VTK, utilizaremos el programa picsuper3D.tcl descrito en el siguiente punto. Este programa logra visualizar ficheros ‘*.pic’, es decir ficheros con cabecera y datos. El problema es que nosotros hasta ahora tenemos guardados nuestros resultados como una variable de Matlab, que contiene sólo datos, tendremos que guardarlos ahora en un fichero dónde escribiremos también la cabecera adecuada. Tras ésta operación guardaremos los datos que más tarde necesitará el programa de VTK, como ya hemos hecho en otras ocasiones.
nSize=[1 1 1]; nSize=size(Sup); nX=nSize(1,1); nY=nSize(1,2); nNumberOfImages=nSize(1,3); acFilename1=('newfile.pic'); fid3 = fopen(acFilename1,'w','l'); fwrite(fid3,nX,'int16'); fwrite(fid3,nY,'int16'); fwrite(fid3,nNumberOfImages,'int16'); fread(fid3, 70, 'uint8'); fwrite(fid3, Sup, 'uint8'); fclose(fid3);
GVA-ELAI-UPMPFC0077-2003 85

Procesamiento Marta García Nuevo
%Creamos un nuevo fichero para leer el numero %Create new file for read the number of the first slice
fid = fopen('VTKFirstSlice.txt','wt'); fwrite(fid, sprintf('%d',1),'char'); fclose(fid); %Create new file for read the number of the last slice fid = fopen('VTKLastSlice.txt','wt'); fwrite(fid, sprintf('%d',(nNumberOfImages -1)),'char'); fclose(fid); %Create new file for read the name of the file *.PIC to open fid = fopen('VTKFilename.txt','wt'); fwrite(fid, sprintf('%c',acFilename1),'char'); fclose(fid); %Calls the tcl program, to open the image .pic !picsuper3D.tcl & end else
display('Wrong image numbers, nLimInf must be bigger than 0, and nLimSup must be smaller than the last slice');
end else display('Wrong image numbers, nLimInf must be smaller than nLimSup'); end end
Vemos ahora un ejemplo de una imagen obtenida con este programa.
86
Figura 4.19: Resultado de ‘opensup.m’
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
El programa ‘opensupbw.m’, funciona con idéntica estructura que el descrito anteriormente ‘opensup.m’. La única diferencia es a la hora del procesamiento, en el caso anterior nos quedábamos sólo con los bordes y ahora con la superficie completa. Vemos un ejemplo.
Figura 4.20: Resultado de ‘opensupbw.m’
1.7.2 Picsuper3d.tcl
Este programa de VTK lo usamos para hacer renderización de superficies. Con este programa podemos visualizar ficheros ‘*.pic’ en blanco y negro
Los programas ‘opensup.m’ y ‘opensupbw.m’ los usamos para procesar y seleccionar los datos que luego necesita ‘openpic3D.tcl’ para realizar la visualización.
Toda la primera parte del programa es igual que la del programa ‘openpic3D.tcl’, que está explicada anteriormente. Solo expondremos ahora las partes diferentes del programa.
… … … reader SetHeaderSize 76 #Esta parte es un filtro para mejorar la imagen vtkImageGaussianSmooth smooth smooth SetInput [reader GetOutput] smooth SetDimensionality 3 smooth SetStandardDeviations 0.5 0.5 0.5 smooth SetRadiusFactors 1.0 1.0 1.0
GVA-ELAI-UPMPFC0077-2003 87

Procesamiento Marta García Nuevo
#Ahora estamos quitando las partes oscuras del fondo de la imagen vtkPiecewiseFunction opacityTransferFunction opacityTransferFunction AddPoint 0.5 1.0 opacityTransferFunction AddPoint 1 1.0 opacityTransferFunction ClampingOff #Con esta ‘ transfer function’ cambiamos los colores de B/N a RGB vtkColorTransferFunction colorTransferFunction colorTransferFunction AddRGBPoint 0.0 0.0 0.0 0.0 colorTransferFunction AddRGBPoint 1.0 1.0 1.0 1.0 #Ahora aplicamos las propiedades antes definidas al volumen vtkVolumeProperty volumeProperty volumeProperty SetColor colorTransferFunction volumeProperty SetScalarOpacity opacityTransferFunction volumeProperty SetInterpolationTypeToLinear volumeProperty ShadeOn #En este método definimos el método de rederización, # usamos la renderización de superficie #esto cambia las lonchas a un volumen en tres dimensiones vtkVolumeRayCastIsosurfaceFunction isosurfaceFunction isosurfaceFunction SetIsoValue 0.3 vtkVolumeRayCastMapper volumeMapper volumeMapper SetInput [ reader GetOutput] volumeMapper SetVolumeRayCastFunction isosurfaceFunction volumeMapper SetSampleDistance 0.5 #Cambiamos la iluminación del volumen vtkLight light light SetColor 0.9 0.9 0.9 light SetFocalPoint 250 250 50 light SetPosition 500 500 70 light SetLightTypeToHeadlight light SetIntensity 7 # La última parte crea la ventana y enlaces necesarios a las propiedades vtkVolume volume volume SetMapper volumeMapper volume SetProperty volumeProperty
88 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento
vtkRenderer ren1 ren1 AddVolume volume ren1 AddLight light
vtkRenderWindow renwin renwin AddRenderer ren1 vtkRenderWindowInteractor iren iren SetRenderWindow renwin ren1 SetBackground 0.2 0.2 0.2 renwin SetSize 500 500 iren Initialize iren AddObserver SetExitMethod { exit } wm withdraw . vwait forever
Al ejecutar este programa se abrirá una ventana con el resultado obtenido, mostramos un ejemplo de este resultado en la siguiente figura. La imagen de la ventana es un volumen, que podemos mover y rotar pulsando con el botón izquierdo del ratón sobre la imagen. Podemos también hacer un zoom aumentando o reduciendo la figura pulsando con botón derecho del ratón. Pero estas operaciones de giro o zoom requieren gran capacidad computacional, si no tenemos un computador potente puede resultar algo lento.
GVA-ELAI-UPM
PFC00
Figura 4.21: Resultado de ‘opensupbw.m’
77-2003 89

Procesamiento Marta García Nuevo
90 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
5 Aproximación Poligonal
5.1 Niveles de detalle [MKRU] [CHXU]
Los requerimientos de computación y almacenamiento para las imágenes con las que trabajamos exceden por mucho la capacidad del hardware. Estas imágenes tienen una estructura compleja y su despliegue requiere un número grande de polígonos no obstante cuando se considera solo la porción de la escena que es visible para el marco dado. Para solucionar estos problemas computacionales es posible el uso de versiones mas simples de la geometría. Estas simplificaciones son llamadas Niveles de Detalle (LODs).
La meta de la simplificación poligonal, cuando se usa para la generación de los niveles de detalle, es remover primitivas de una malla original para producir modelos mas simples los cuales retienen la característica visual importante del objeto original. Idealmente, el resultado deberían de ser una serie completa de simplificaciones, la cual puede ser usada en varias condiciones. La idea, para mantener una tasa de marco constante, es encontrar un buen balance entre lo rico de los modelos y el tiempo que toma para desplegarlos.
GVA-ELAI-UPMPFC0077-2003 91

Aproximación Poligonal Marta García Nuevo
Se necesita una serie de simplificaciones a ser seleccionadas al tiempo de despliegue. Si esta lista es continua, es decir dos LODs sucesivos difieren por solamente uno o dos polígonos, es llamada geomórfica . Los algoritmos producen estructuras de datos de las cuales cualquier simplificación puede ser recuperada. Tales estructuras de datos habilitan un despliegue suave de LODs y el cambio de uno al siguiente no es notable.
Figura 5.1: Una sucesión de LODs
La práctica mas común es producir un número limitado de LODs. Ya que las diferencias de LODs son entonces mas grandes, la conmutación de uno a otro es comúnmente notable por el observador (esto es conocido como el efecto popping). La principal dificultad en este caso es calcular cuales niveles de simplificacion pudieran ser necesitados en la escena.
La simplificación debe de conducirse de tal forma que la forma general y las características que hacen que el objeto sea identificable fácilmente sean preservadas. Entonces, los algoritmos tienen que mirar por algunas formas distintas del objeto:
• El área planar puede ser identificada inspeccionando las normales de los polígonos adyacentes. Estos polígonos pueden entonces ser combinados para formar unos mas grandes. Este es el tipo mas común de simplificacion ya que es relativamente fácil de calcular (no obstante la relación de adyacencia debe ser conocida).
• Los bordes pronunciados pueden aparecer y deben ser preservados. Ellos se pueden encontrar al comparar el ángulo entre las normales de las caras adyacentes. Ellos pueden entonces ser simplificados al combinar bordes conectados las cuales son casi colineales.
• Los bordes apuntados (tales como la punta de una pirámide) deben ser preservados ya que tienen mucha oportunidad de aparecer en la silueta del objeto. Ellos pueden ser detectados midiendo la curvatura local alrededor de un vértice. Ellos pueden ser simplificados empujando los vértices próximos hacia la punta del pico.
La mayoría de los algoritmos buscan bordes pronunciados, bordes colineales conectados y caras adyacentes coplanares.
Pero cuando se prueba, por ejemplo por caras coplanares, los algoritmos tienen un valor de umbral para el ángulo entre las normales, arriba del cual las caras no son consideradas planares. Mientras mas alto sea este valor, más caras serán consideradas
92 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
coplanares y será simplificado. Pero ajustar el umbral no es fácil. Reddy en usa las características de la percepción visual humana para estimar este umbral, pero es más a menudo dejado al usuario y es aún un asunto de prueba y error. Mientras que los algoritmos recientes son mas flexibles que los antiguos, la mayoría son apropiados para algunos tipos de objetos, como aquellos usados en aplicaciones médicas las cuales rara vez tienen bordes pronunciados.
Para controlar la simplificación, el error de aproximación debería de ser medido localmente (en cada primitiva). Pero para que el usuario sea capaz de especificar la simplificación, una cota global debería ser puesta para el error. Algunos algoritmos usan una cota para el error local o una distancia a la malla original. Otros usan una construcción geométrica para asegurar que la simplificación no exceda un cierto límite. Un uso para la medida del error es determinar si una simplificación puede ser usada ya que sus diferencias con el modelo original pueden no ser notables.
La mayoría de los algoritmos permite al usuario especificar el límite superior para la aproximación del error local. Esto no es muy intuitivo y requiere alguna práctica. Alternativamente, algunos algoritmos permiten al usuario especificar cuantos polígonos deberían de ser dejados en la simplificación.
Durante el curso de la simplificación, una opción que el algoritmo puede tener es simplificar la topología. Las simplificaciones pueden conducir a llenar un hoyo o partir un objeto dentro de varias partes no conectadas. Al permitir que la topología sea modificada deja más espacio para simplificación, el resultado es raramente útil ya que las diferencias con el objeto original son demasiado notables.
Figura 5.2: Usando LODs para objetos distantes.
Es algunas veces interesante permitir que la cantidad de simplificación varíe a través de la malla, para preservar algunas partes, no obstante simplificar otras más agresivamente. Esta clase de adaptividad involucra principalmente consideraciones visuales semánticas que pueden ser hechas a priori y son controladas por el usuario. Otros problemas ocurren cuando el tamaño del objeto es grande con respecto a la escena. En tales condiciones, alguna parte del objeto estará constantemente en el frente y la mayoría del detalle será siempre usado. El objeto debería de partirse en varias piezas, cada una de las cuales podría tener un número de LODs de los cuales escoger. Sin embargo, no hay manera universal de partir el objeto y la continuidad deberá ser mantenida entre dos piezas
GVA-ELAI-UPMPFC0077-2003 93

Aproximación Poligonal Marta García Nuevo
adyacentes así que no aparezcan errores cuando dos piezas son simplificadas independientemente. El algoritmo de simplificación deberá tomar cuidado de esto.
5.2 Simplificación poligonal
Unos pocos operadores simples puede ser usado para remover primitivas de un modelo:
• Normalización: remoción de caras degeneradas o bordes y cualquier primitiva definida múltiples veces.
• Simplificación de Vértices: combinación de todos los puntos incluidos dentro de un volumen (cualquiera una esfera o una celda de rejilla). Entonces, los puntos y las caras cercanas son combinadas.
• Simplificación de Borde: remoción de todos los bordes más pequeños que algún umbral.
• Simplificación Basada en Angulo: remoción de bordes los cuales forman un ángulo cerrado. Inversamente, los bordes que están alineados son combinados.
• Simplificación del Tamaño de la Cara: remoción de todas las caras las cuales tienen un área más pequeña que algún umbral. Los hoyos pudieran tener que ser llenados.
• Simplificación de la Normal de la Cara: combinación de todas las caras adyacentes con normales casi paralelas.
Estos operadores simples aparecen en paquetes comerciales, sin embargo, ellos deben ser usados dentro de alguna clase de mecanismos de control para guiar la simplificación.
Los algoritmos de simplificación poligonal caen en tres diferentes categorías:
Geometría de la Remoción:
Los algoritmos en esta categoría producen una versión simplificada de un modelo mediante la selección de un número de primitivas las cuales deben ser removidas. La selección es hecha usando alguna clase de heurística. Por ejemplo, el algoritmo identifica vértices los cuales están cerca de regiones planares. Este criterio es disminuido en cada interacción hasta que ningún vértice adicional pueda ser removido. Este tipo de simplificación es la más popular entre los algoritmos recientes. Hinker y Cansen usaron esta técnica con un criterio de planaridad. Muchos de los algoritmos presentados aquí son de esta categoría, pero ellos varían en sus opciones de heurística y su manera de medir la aproximación del error.
94 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
Figura 5.3: Geometría de la Remoción
Subdivisión Adaptiva
Esta categoría construye una simplificación inicial la cual es la versión más simple del modelo original. Esta entonces añade más detalles en el modelo al subdividir este así que se obtiene una cercanía al modelo original. Este entonces es subdividido y la posición de cada nuevo vértice es cambiada para tener más cercanía a la superficie original. Este tipo de simplificación no es tan popular como las previas ya que construir la simplificación inicial no es simple en el caso general.
Figura 5.4: Subdivisión Adaptativa
Muestreo
Finalmente, los algoritmos en esta categoría escogen un cierto número de primitivas que deberían de ser preservadas (como opuesto a la primera categoría, la cual escoge primitivas que deberán ser removidas). Una manera de seleccionar estas primitivas es haciendo una selección pseudoaleatoria, basada en alguna clase de heurística. Otro método más poderoso es muestrear el modelo y escoger un representativo único para cada grupo de la muestra. Por ejemplo, mientras que esté embebido el modelo en una rejilla uniforme de 3D, un vértice puede ser escogido en cada celda para reemplazar todos los otros vértices en su celda.
GVA-ELAI-UPMPFC0077-2003 95

Aproximación Poligonal Marta García Nuevo
Figura 5.5: Sampling
5.3 Algoritmos
Se presentan aquí seis algoritmos que fueron introducidos durante los dos últimos años. Se realzan sus principales características y sus opciones con respecto a las características presentadas en las secciones previas.
5.3.1 Análisis de Mallas Arbitrarias de Multiresolución
Esto no es realmente un algoritmo de simplificación, sino un preprocesador para otro algoritmo el cual produce una representación de multiresolución de una malla el cual es un geomorfo compacto conteniendo una malla base simple y una serie de coeficientes "wavelet" que son usados para introducir detalles dentro de la malla. De esta representación, una nueva malla puede usar una subdivisión recursiva (es decir, donde cada triángulo es subdividido usando un operador de partición 4 a 1) hasta que la cantidad deseada de detalle es alcanzada. Semejante malla es encodificada dentro de una representación de multiresolución. El algoritmo que se presenta aquí puede ser usado para convertir cualquier malla a una en la cual se tiene la propiedad de subdivisión recursiva.
Figura 5.6: Cuatro pasos en el algoritmo MRA
Este algoritmo es uno de subdivisión adaptiva el cual preserva la topología, pero identifica cualquier forma característica en la malla. El error de aproximación es medido usando la distancia a la malla original. Los mapas armónicos son usados en varios pasos para parametrizar una malla 3D dentro de una triangulación planar. El algoritmo tiene cuatro pasos principales:
96 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
1. Particionamiento: Un diagrama parecido al de Voronoi es construido sobre la malla original (Figura 5.6.1) usando un algoritmo de buscador de trayectoria multi-semilla en el gráfico dual de la malla (donde los nodos son las caras de la malla y los arcos representan adyacencias y son pesados usando la distancia entre los centros de caras adyacentes). Este diagrama es entonces triangulado usando un método parecido al de Delamay y los mapas armónico para hacer rectos los bordes (Figura 5.6.2).
2. Parametrización: el resultado es una malla base (Figura 5.6.3) que es parametrizada usando un mapa armónico. La parametrización es forzada a ser continua a través de las caras para que el número de coeficientes "wavelet" sea mínimo.
3. Remuestreo: la malla base es ahora remuestreada usando un operador de división 4 a 1 hasta que la malla esté en una cierta distancia a la malla original (Figura 5.6.4). Cada paso es parametrizado como en el paso 3.
4. Análisis de Multiresolución: la sucesión resultante de mallas es pasada al algoritmo de análisis de multiresolución para ser encodificada usando "wavelets".
Este algoritmo es atractivo en su formalismo matemático. Produce un amplio rango de simplificación y no obstante detalles que pueden ser añadidos en partes específicas de la malla. Pero esto es computacionalmente caro también. Además, extrayendo una malla válida desde una representación basada en "wavelet" es caro.
5.3.2 Mallas Progresivas
Este algoritmo de remoción geométrico también produce geomorfas y es derivado de un algoritmo mas antiguo. Este busca áreas planares y bordes característicos. La simplificación es hecha aplicando un operador colapso de borde, donde un colapso de borde produce un nuevo vértice removiendo las dos caras y un vértice. El resultado es una malla de base simplificada y series de particiones de vértice las cuales son un inverso de los colapsos de borde y son usadas para introducir detalles dentro de la base de la malla. Esto es llamada Malla Progresiva y un amplio número de simplificaciones pueden ser extraídas de este.
La característica mas importante de este algoritmo es que toma en cuenta información tal como color, textura, y discontinuidades normales sobre la superficie de cada malla. Las formas importantes del modelo las cuales son representadas por esta clase de información (y no por simple geometría) son también preservadas. Por ejemplo, la figura muestra como las ventanas de un avión son preservadas.
GVA-ELAI-UPMPFC0077-2003 97

Aproximación Poligonal Marta García Nuevo
Figura 5.7: Ejemplo de un Malla Progresiva
La minimización de una función de energía es usada para guiar la simplificación. Esta función tiene cuatro términos. El primero asegura que la malla simplificada permanece cercana a la original. La segunda favorece triángulos con mejores proporciones. El tercer término desalienta la simplificación de discontinuidades de color y textura. Finalmente, el último término desalienta la simplificación de las discontinuidades topológicas y normales.
Los pasos básicos del algoritmo son estos:
1. Ordenar los bordes usando el mínimo costo de simplificación. Este costo es medido usando una variación de la función de energía.
2. Aplicar el operador de colapso de bordes para el borde en la cabeza de la lista y registrar la correspondiente partición del vértice en la estructura de malla progresiva (incluyendo color, textura e información normal)
3. La posición del nuevo vértice es seleccionado entre los dos vértices iniciales y el centro del borde, dependiendo sobre el cual uno es el más cercano a la malla original.
4. Recalcular el costo para los bordes que han sido afectados por el operador y reordenar la lista.
5. Si la lista está vacía o el costo de la siguiente simplificación excede un cierto límite, el algoritmo termina y regresa la malla final progresiva. De otra manera, regresa al paso 2.
6. Este algoritmo es relativamente rápido y toma en cuenta el color y la textura, los resultados son usualmente muy buenos.
5.3.3 Aproximación de Rango Completo de Poliedros Triangulados
Este algoritmo de remoción geométrica preserva áreas planares pero no la topología. Este usa un operador de región de combinación, el cual es burdamente equivalente a un colapso de borde. Uno de los vértices iniciales es usado como un resultado del operador. El error de aproximación es medido usando la distancia a la malla original.
98 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
Semejante al algoritmo previo, este usa una función de energía la cual tiene dos términos. El primero, el error local de teselación asegura que la orientación de las normales es preservada y que las nuevas caras no se traslapan. El segundo término, el error local geométrico, preserva a la malla de moverse demasiado lejos de la original. Los pasos básicos del algoritmo son como sigue:
1. Ordenar todos los bordes respecto a su aumento de costo.
2. Aplicar el operador de combinación de la región al primer borde en la lista.
3. Modificar la posición del vértice resultante para obtener este más cercano a la malla original.
4. Recalcular el costo para los bordes modificados y ordenar la lista. El costo es acumulado en cada iteración así que la simplificación es más parejamente distribuida a través de la malla.
5. Si la lista está vacía o si el costo del siguiente borde es más alto que un umbral, el algoritmo termina. De lo contrario regresa al paso 2.
No obstante las suposiciones básicas son bastante diferentes, uno puede notar que este algoritmo es muy similar al previo. Este también es mucho más eficiente en preservar las características de los objetos que lo que fue su antecesor.
5.3.4 Simplificación por Sobres
Este algoritmo de remoción geométrica preserva áreas planares y bordes agudos, tan bien como la topología. La principal meta de este algoritmo es no usar la medida del error sino solamente la construcción geométrica para controlar la simplificación. La Simplificación por Sobres son dos superficies construidas una de cada lado de la supeficie original usando un distancia (offset) especificada por el usuario y asegurando que estas superficies no se autointersectan. El espacio entre las dos superficies es entonces usado para construir una nueva superficie, la única restricción entonces es que los nuevos polígonos no deberían de intersectar con cualquier superficie. Esta reconstrucción puede ser hecha en varias maneras, de las cuales aquí se presentará solamente una.
La cantidad de simplificación es controlada por la distancia (offset) usada para construir las superficies. El caso donde las superficies del sobre son más probables a intersectarse es a lo largo de los bordes agudos de la malla original, donde no habrá mucho espacio para construir una de las superficies. Las superficies que se auto entersectan deben entonces ser movidas mas cercanas a la malla original hasta que la condición es corregida. Entonces, cerca de los bordes agudos los espacios entre las dos superficies serán mas pequeños y más pocas simplificaciones serán permitidas. Inversamente, en las áreas planares, la distancia será máxima y así será la simplificación.
GVA-ELAI-UPMPFC0077-2003 99

Aproximación Poligonal Marta García Nuevo
Figura 5.8: Construyendo sobres internos y externos para un triángulo
El algoritmo inicia construyendo los sobres:
1. Distanciar (offset) la superficie externa a lo largo de las normales a los vértices por una fracción de la distancia (offset) final deseada.
2. Si, para cualquier vértice, la superficie se autointersecta, cancelar el movimiento para ese vértice.
3. Repetir los pasos 1 y 2 hasta que incremento ningún adicional pueda ser alcanzado sin intersección, o la distancia (offset) haya alcanzado el valor deseado.
4. Repetir los pasos del 1 al 3 para la superficie interna.
5. Repetir los pasos del 1 al 3 para los tubos de los bordes. Estos son construidos a lo largo de los bordes de objetos no cercanos para permitir la simplificación ahí también.
Esta manera interactiva de construir las superficies distancia (offset) produce resultados no óptimos, es decir los sobres son algunas veces más cercanos a la malla original que lo que ellos deberían de ser. Calcular la solución optima requiere evaluar los bordes Voronoi en el espacio 3D, el cual computacionalmente es muy caro.
El algoritmo entonces actúa generando la malla simplificada. Para cada vértice de la malla inicial:
1. Remueve el vértice y las caras adyacentes.
2. Si es posible, iterativamente llenar el hoyo por triangulación usando las caras más grandes posibles y asegurando que ellas no se intersectan con las superficies distancias (offset). Si no es posible, cancelar la remoción y tratar el siguiente vértice.
100 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
Este algoritmo es atractivo ya que no usa cualquier medida del error. Los sobres son el único control sobre la simplificación. Es computacionalmente caro no obstante, especialmente durante la fase de construcción del sobre.
5.3.5 Simplificación de Superficie Dentro de un Volumen de Tolerancia
Este algoritmo de remoción geométrica, remueve bordes como en A3, pero el control es hecho usando la Tolerancia de Volumen. Pero, en este algoritmo el volumen es construido alrededor de la superficie simplificada y la superficie simplificada es restringida para no permitir a la superficie original salirse del volumen de tolerancia. La cantidad de simplificación es controlada por el grosor de ese volumen.
El volumen de tolerancia es calculado como una esfera alrededor de cada vértice y representa la acumulación del error introducido por simplificación el cual conduce a la creación del vértice (por la aplicación del operador de colapso de borde). Este es entonces interpolado a través de los bordes y caras Figura 1 y 2 respectivamente). Una de las propiedades agradables del algoritmo es asegurar que el volumen del objeto no es cambiado por la simplificación (dentro de una tolerancia dada). Esto es muy útil para algunos dominios de aplicación tales como la visualización de datos médicos.
Figura 5.9: La construcción y el mantenimiento del volumen de tolerancia
Los pasos básicos del algoritmo son los siguientes. La simplificación inicial es simplemente una copia de la malla original. Los volúmenes de error se ponen en valor nulo. Para cada borde por orden de aumento de longitud:
1. Aplicar el operador de colapso de borde. La posición del nuevo vértice es calculado al resolver las ecuaciones que aseguran que permanece cercano a la malla inicial y que el volumen es preservado.
GVA-ELAI-UPMPFC0077-2003 101

Aproximación Poligonal Marta García Nuevo
2. Comprobar que las normales de las caras modificadas no han sido invertidas. Si ellas lo están, cancelar el colapso del borde e ir al siguiente borde.
3. Comprobar que las nuevas caras tengan buenas proporciones. Esto es evaluado usando una función de la superficie y la longitud de los bordes y comprobando que esta función no cambie demasiado después que el operador es aplicado. Si ha cambiado, cancele el colapso del borde e ir al siguiente borde.
4. Actualizar la lista de bordes para tomar en cuenta la modificación introducida por la simplificación.
5. Calcular la nueva tolerancia de volumen para que contenga el volumen previo.
6. Si el diámetro del volumen de tolerancia para el nuevo vértice es más grande que un umbral dado (es decir, que la malla original no es incluida dentro del volumen de tolerancia), entonces los bordes que comparten este vértice, son removidos de la lista y ninguna simplificación adicional tomará lugar en esa área.
A6 - Simplificación de Malla
Este algoritmo de remoción geométrica es original en que no mide el error de aproximación, excepto que usa un proceso de agrupamiento para asegurar que la simplificación es restringida en ciertas áreas. Este agrupamiento es hecho mediante la búsqueda de bordes característicos y áreas planares. Los bordes característicos son aquellos que están compartidos por caras las cuales forman una ángulo más grande que un umbral dado. Típicamente, hay muchos bordes característicos en áreas donde hay pocas caras coplanares.
Figura 5.10: Pasos en el Algoritmo de Simplificación de Malla Inspirado por A6.
El algoritmo hace las siguientes operaciones:
1. Buscar por bordes característicos y etiquetar los vértices usando un número de bordes característicos que lo comparten. Un vértice "0" no tiene bordes característicos dejando a este.
102 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
2. Construir agrupamientos de polígonos coplanares. Buscar bordes entre dos vértices "0" y usar ellos para construir pares de caras coplanares donde los bordes entre dos vértices "0" no son conectados (Figura 5.10.1).
3. Dentro de cada agrupación, aplicar un operador de colapso de borde hasta que ninguna simplificación adicional pueda ser hecha (Figura 5.10.2 a 5.10.4).
4. Buscar bordes de característica colineal dejando vértices "2", tales como los vértices sobre los bordes de un cubo (Figura 5.10.4). Esto no puede ser simplificado por un operador de colapso de borde ya que las dos caras adyacentes no son coplanares. Estos bordes son combinados y el vértice resultante es empujado hacia el otro vértice. El resultado es mover los vértices sobre un borde característico hacia sus extremidades (Figura 5.10.5).
5. Buscar vértices "0" en rodeados por solamente vértices no "0", como el del centro de un lado de un cubo (Figura 5.10.5). Tales vértices no pueden ser removidos por el método previo ya que no hay otros vértices "0" adyacentes para construir un agrupamiento. Así que semejantes vértices son removidos, y el hoyo es triangulado (Figura 5.10.6).
Este algoritmo es atractivo por su simplicidad, pero la simplificación no es siempre óptima. Mejores resultados pueden ser obtenidos gradualmente incrementando los umbrales de planaridad y colinealidad mientras el algoritmo procede.
5.4 Snakes [CHXU]
Los contornos activos o ‘snakes’ son unos generadores de curvas que se van ajustando a los contornos hasta obtener su límite o frontera. Este método es usado habitualmente en la visión a través de computadoras y en el análisis de imágenes para localizar objetos y describir su contorno.
Son múltiples los usos que se pueden dar a este procedimiento. Por ejemplo, una ‘snake’ puede ser usada para encontrar una zona en concreto en una cadena de montaje, o para encontrar el contorno de un órgano en una imagen médica, e incluso para automáticamente identificar caracteres sobre una carta postal.
Según lo potente que sea la programación de la snake, será capaz de resolver grandes problemas, con estos métodos se han solventado muchos problemas que habían surgido alrededor de la visión por ordenador.
Estos problemas eran que las serpientes no podían moverse hacia los objetos que estaban demasiado a lo lejos ni en concavidades divisorias o mellas (como la cima del carácter U), ha costado mucho trabajo resolver esto, porque cuando se proponía un método para solucionarlo, surgían problemas nuevos.
GVA-ELAI-UPMPFC0077-2003 103

Aproximación Poligonal Marta García Nuevo
.
Figura 5.11: Ejemplo de localización de concavidades divisorias
Esta ‘snake’ del ejemplo comienza con el cálculo de un campo de fuerzas, llamadas el GVF fuerza, sobre el dominio de imagen. Las fuerzas de GVF son usadas para conducir la serpiente, modelada como un objeto físico que tiene una resistencia tanto al estiramiento como al doblamiento, hacia las fronteras del objeto. Las fuerzas de GVF son calculadas aplicando ecuaciones de difusión generalizadas a ambos componentes del gradiente de un mapa de borde de imagen.
Figura 5.12: Contornos subjetivos
Las fuerzas GVF externas son que hacen esta serpiente intrínsecamente diferente de serpientes anteriores, porque como las fuerzas de GVF son sacadas de una operación de difusión, tiende a extenderse muy a lo lejos del objeto, esto amplía " la gama de captura " de modo que las serpientes puedan encontrar los objetos que están bastante a lo lejos de su posición inicial.
Esta misma difusión crea las fuerzas que pueden tirar contornos activos en regiones cóncavas. Una diferencia fundamental entre esta formulación y la formulación tradicional
104 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
es que las fuerzas de GVF no son puramente fuerzas irrotacionales (sin rizo). De hecho, normalmente se utilizan tanto campos irrotacionales como campos solenoidales.
Figura 5.13: Imágenes en escala de grises
Hemos probado la serpiente GVF sobre muchos tipos de objetos, de formas simples a las imágenes de resonancia magnéticas del corazón y el cerebro. También hemos ampliado GVF a tres dimensiones, donde superficies deformables, o globos, son definidas. El objetivo de seguir investigando es usar un globo de GVF tridimensional para encontrar la corteza entera humana cerebral de imágenes de resonancia volumétricas magnéticas.
Figura 5.14: Superficies deformables tridimensionales
5.5 Implementación
Las imágenes que utilizamos en este proyecto contienen gran cantidad de información, para ciertas aplicaciones de éstas imágenes no es necesaria tanta información y sólo sirve para hacer que los procesos sean más lentos y requieran demasiado procesamiento. Es estos casos lo mejor es realizar una aproximación poligonal de nuestras imágenes para quedarnos sólo con la información que necesitamos. Para realizar la aproximación poligonal de las imágenes vamos a utilizar programación en Matlab, como hemos hecho ya anteriormente.
GVA-ELAI-UPMPFC0077-2003 105

Aproximación Poligonal Marta García Nuevo
5.5.1 Selección de puntos del contorno
Para realizar la aproximación poligonal lo primero que tenemos que hacer quedarnos con los puntos más significativos del contorno. Para ello lo más sencillo es pasar nuestras imágenes que están en niveles de gris a blanco y negro, partiendo de estas imágenes tomaremos puntos del contorno para posteriormente unirlos de manera adecuada.
Es necesario que sean detectados los puntos que pertenecen a un mismo objeto, y los que pertenecen a objetos distintos para la conectividad entre los puntos. Para realizar esta selección de los puntos usaremos el comando de Matlab BWLABEL, cuya función es conectar los puntos de una imagen binaria. Por ejemplo, el comando:
L = BWLABEL(BW,N)
Devuelve una matriz L, del mismo tamaño que la imagen en blanco y negro BW, conteniendo etiquetas de los elementos conectados en BW. Este comando solo admite objetos en dos dimensiones.
El parámetro N, puede tener un valor de 4 ó 8, dependiendo de los objetos a conectar.
Otro comando que vamos a necesitar es BWLABEL, esta función realiza medidas sobre cada una de las regiones que se han etiquetado anteriormente.
STATS = IMFEATURE(L,MEASUREMENTS)
Marca cada región etiquetada con un color diferente, STATS es una estructura, los campos de esta estructura son las diferentes medidas de cada región, según especifiquemos con el comando MEASUREMENTS.
El conjunto de valore válidos que se puedes dar a este parámetro son los siguientes: 'Area', 'ConvexHull', 'EulerNumber', 'Centroid', 'ConvexImage', 'Extrema', 'BoundingBox', 'ConvexArea', 'EquivDiameter', 'MajorAxisLength', 'Image', 'Solidity', 'MinorAxisLength', 'FilledImage', 'Extent', 'Orientation', 'FilledArea' 'PixelList', 'Eccentricity'.
En nuestro programa, lo usamos de la siguiente manera:
function stat = AproxPoly (ImBW)
[ImLabel,num] = bwlabel(bwperim(ImBW),8)
stat=imfeature(ImLabel,'PixelList');
imshow(ImBW,gray(2));
106 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
De esta manera desplegamos la lista de píxeles que rodean el contorno de nuestras imágenes.
Figura 5.15: Lista de píxeles del contorno de la imagen
5.5.2 Unión de los puntos del contorno
Ahora que ya tenemos los puntos que del contorno de nuestras imágenes tenemos que unirlos coherentemente.
Dependiendo de la cantidad de puntos que tomemos y de la situación de esos puntos la exactitud de la aproximación será mayor o menor. Es importante que se hayan etiquetado correctamente las regiones para que los puntos se unan encerrando las superficies.
Tenemos aquí un ejemplo de una aproximación demasiado sencilla, tomamos muy pocos puntos del contorno, pero logramos que nos identifique las áreas cerradas y que las encierre, aunque sea cometiendo un gran error.
GVA-ELAI-UPMPFC0077-2003 107

Aproximación Poligonal Marta García Nuevo
Hay que tener cuidado con el modo en que se unen los puntos, determinando distintos criterios de cercanía o sentido de la búsqueda del punto siguiente.
Realizamos la aproximación para las rodajas de una en una, porque los comandos que estamos utilizando hasta ahora nos funcionan con tres dimensiones.
Para lograr esta sencilla aproximación el programa que usamos se basa en los comandos anteriormente mencionados, primero etiqueta las superficies que no están unidas y después toma puntos del contorno de estas superficies y traza un polígono que las envuelve.
function stat = AproxPoly (ImBW) [ImLabel,num] = bwlabel(ImBW); stat=imfeature(ImLabel,'ConvexHull'); stat %Visualizacion imshow(ImBW,gray(2)); hold on; for i=1:size(stat,1) plot([stat(i).ConvexHull(:,1);stat(i).ConvexHull(1,1)],... [stat(i).ConvexHull(:,2);stat(i).ConvexHull(1,2)]); end
108 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
Figura 5.16: Aproximación con poca exactitud de la rodaja 5
.
Figura 5.17: Aproximación con poca exactitud de la rodaja 35
GVA-ELAI-UPMPFC0077-2003 109

Aproximación Poligonal Marta García Nuevo
5.5.3 Aproximación poligonal en 3D
Hasta ahora hemos logrado realizar la aproximación en cada una de las lonchas, lo que vamos a intentar ahora es buscar la continuidad que nuestra pila de imágenes debe poseer. Para ello realizaremos la aproximación de cada loncha pero asociándola con la aproximación que se realizará en las lonchas anterior y posterior.
Para realizar esta aproximación tenemos el programa ‘puntos3D2.m’, que tomará una variable de Matlab que contenga una pila de imágenes en blanco y negro y realizará su aproximación poligonal.
El programa actúa de la siguiente manera, primero etiqueta las regiones de cada loncha, obteniendo los puntos del perímetro de cada región. Ahora estas regiones las seleccionaremos según tamaños y descartaremos las que sean muy pequeñas, grabamos estas regiones rodeadas de por los puntos de su contorno. El siguiente paso es unir estos puntos, para ello usamos el comando snakedisp que inicializa la ‘snake’ para la aproximación pero antes de poder usar este comando tenemos que ordenar lo puntos del contorno de las regiones.
El programa ‘OrdenarPerimetro.m’ se encarga de asignar un orden para los puntos que tenemos y así evitar errores en su unión. Desde ‘puntos3D2.m’ llamamos a ‘OrdenarPerimetro.m’ cada vez que tenemos etiquetada una loncha y así ordenamos todos los puntos de cada loncha de la variable con la que estemos trabajando.
Ahora que ya tenemos todos los puntos ordenados tenemos que ejecutar la ‘snake’, para ello hemos escrito el programa ‘snakedisp.m’ que se encargará de efectuar la representación gráfica de las aproximaciones poligonales de cada loncha.
Para ejecutar esta aproximación en dos dimensiones y media, lo primero que tenemos que hacer es crearnos una variable en blanco y negro, que contenga las lonchas sobre las que queremos ejecutar el programa. Una vez creada esta variable comprobamos que está en el ‘workspace’ de Matlab.
110
Figura 5.18: Workspace de Matlab
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
Visto que tenemos la variable creada, nos aseguramos que tenemos los tres programas necesarios, ‘Puntos3D2.m’, ‘OrdenarPerimetro.m’ y ‘snakedisp.m’ en ‘Current Directory’ de Matlab.
Figura 5.19: Current Directory de Matlab
Si todo es así no debe haber ningún problema para ejecutar el programa, en la ‘command window’ de Matlab teclearemos;
>> puntos3D2(a,'new');
Figura 5.20: Ejecución del programa ‘puntos 3D2’ en Matlab
GVA-ELAI-UPMPFC0077-2003 111

Aproximación Poligonal Marta García Nuevo
Se ejecutará el programa, que guardará en el directorio actual un fichero de texto con la información de los puntos que forman los objetos de cada rodaja. Se desplegará una ventana con la imagen de la primera loncha del fichero con su aproximación poligonal superpuesta y cuando pulsemos la barra espaciadora veremos la siguiente imagen y así sucesivamente hasta finalizar la visualización de la pila de imágenes que contiene nuestra variable.
Mostramos a continuación algunas de las imágenes que son desplegadas:
112 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
Figura 5.21: Sucesión de imágenes creadas por ‘Puntos3D2.m’
Vemos que los resultados de este programa son muy representativos, podemos observar que los contornos de las primeras son muy pequeños, y que van aumentando de tamaño según vamos llegando a las lonchas centrales del fichero, y a partir la loncha central vuelven a reducirse los contornos. Es fácil darnos cuenta con estos resultados de que sí hay continuidad en la materia.
Mostramos ahora algunas imágenes indicando la loncha a la que corresponden, mostrando sólo la aproximación poligonal y no la imagen inicial, podemos observar lo comentado anteriormente.
GVA-ELAI-UPMPFC0077-2003 113

Aproximación Poligonal Marta García Nuevo
Figura 5.22: Aproximación rodaja 2
Figura 5.23: Aproximación de la rodaja 11
114 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
Figura 5.24: Aproximación de la rodaja 35
Figura 5.25: Aproximación de la rodaja 44
GVA-ELAI-UPMPFC0077-2003 115

Aproximación Poligonal Marta García Nuevo
Figura 5.26: Aproximación de la rodaja 57
Figura 5.27: Aproximación de la rodaja 66
116 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Aproximación Poligonal
5.6 Conclusiones
Nuevos algoritmos de simplificación poligonal son ahora capaces de producir niveles satisfactorios de detalles con respecto a los requerimientos visuales y geométricos. Sin embargo, no importa el algoritmo que sea usado, mucha práctica es todavía requerida antes de ser capaz de predecir la cantidad de simplificación y especificar los valores correctos para los varios parámetros. Además, los algoritmos no usan la características de la percepción humana visual para poner estos parámetros. La generación de LOD permanece mucho como una actividad de modelación.
Por otro lado, la complejidad de los objetos involucrados en simulaciones de realidad virtual aumenta cada día. La información de textura y luz (tal como la producida por el cálculo de la radiosidad) es añadida para producir presentaciones mas realístas. Entonces los algoritmos deben evolucionar para tomar en cuenta esta información y adaptarlos durante el proceso de simplificación.
Finalmente, la creación y selección de LODs debería de ser integrada a técnicas de administración de escenas [5]. El cálculo de la relación de la partición y la visibilidad de escena puede ayudar a la simplificación en la selección de la cantidad de simplificación que es requerida para una escena particular.
GVA-ELAI-UPMPFC0077-2003 117

Aproximación Poligonal Marta García Nuevo
118 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
6 Procesamiento distribuido[ENZO] En este capítulo vamos a describir modos y ventajas de realizar un cluster,
enfocándolo sobre todo a lograr el procesamiento distribuido. De esta manera trataremos de ahorrar tiempo y capacidad computacional para ejecutar los programas que se han implementado en capítulos anteriores de el proyecto.
El concepto de cluster nació cuando los pioneros de la supercomputación intentaban difundir diferentes procesos entre varias computadoras, para luego poder recoger los resultados que dichos procesos debían producir. Con un hardware más barato y fácil de conseguir se pudo perfilar que podrían conseguirse resultados muy parecidos a los obtenidos con máquinas mucho más costosas.
GVA-ELAI-UPMPFC0077-2003
s
La unidad básica de un cluster es un PC convencional que se puede comprar en cualquier tienda. Esta unidad básica recibe el nombre de nodo. Necesitaremos muchos ordenadores individuales que trabajen en paralelo para reunir una capacidad de cálculo respetable, usaremos los ordenadores del laboratorio para construir el cluster, estos nodos estar interconectados usando la tecnología Ethernet.
Figura 6.1: Cluster como cúmulo de PC
119

Procesamiento distribuido Marta García Nuevo
Usando varios PCs, trataremos de darles tanta capacidad de procesamiento como si se tratase de un gran servidor . Tendremos la posibilidad de monitorear la carga de CPU, memoria RAM, uso de Discos, etc., de cada uno de los nodos que componen el cluster. De este modo podemos tener un control total del funcionamiento del conjunto, y evitar sobrecarga en los nodos, detectar mal funcionamiento, derivar procesos de manera optima, entre otros.
Habrá que comentar las herramientas de administración y gestión que vamos a utilizar. Pues con el paso del tiempo se han ido desarrollando y perfeccionando librerías y programas de código abierto que se han ido encargando de estos temas. En este apartado destacan librerías de paso de mensajes como MPI y PVM.
Figura 6.1: Cluster como cúmulo de PCs
Figura 6.2: Cluster como cúmulo de PCs
6.1 Linux [PHPB] [GLUS]
En la actualidad existen una gran cantidad de sistemas operativos dependiendo del tipo de ordenador en el que se va a ejecutar. Por ejemplo para los PC uno de los sistemas operativos más difundidos en Microsoft Windows, tanto en las versiones 95, 98, 2000 y NT 4.0. Otros posibles sistemas operativos para este tipo de ordenadores son Solaris, OS/2, BeOS, Microsoft DOS, o uno de los sistemas operativos más poderosos y en rápida expansión para PC, LINUX.
6.1.1 ¿Qué es LINUX?
Linux es un sistema operativo gratuito y de libre distribución inspirado en el sistema Unix, escrito por Linus Torvalds con la ayuda de miles de programadores en Internet. Unix es un sistema operativo desarrollado en 1970, una de cuyas mayores ventajas es que es fácilmente portable a diferentes tipos de ordenadores, por lo que existen versiones de Unix para casi todos los tipos de ordenadores, desde PC y Mac hasta estaciones de trabajo y superordenadores. Al contrario que otros sistemas operativos, como por ejemplo MacOS (Sistema operativo de los Apple Macintosh), Unix no está pensado para ser fácil de emplear, sino para ser sumamente flexible. Por lo tanto Linux no es en general tan sencillo de emplear como otros sistemas operativos, aunque, se están realizando grandes esfuerzos para facilitar su uso. Pese a todo la enorme flexibilidad de Linux y su gran estabilidad ( y el bajo coste) han hecho de este sistema operativo una opción muy a tener en cuenta por aquellos usuarios que se dediquen a trabajar a través de redes, naveguen por Internet, o se dediquen a la programación. Además el futuro de Linux es brillante y cada vez más y más gente y más y más
120 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
empresas (entre otras IBM, Intel, Corel) están apoyando este proyecto, con lo que el sistema será cada vez más sencillo de emplear y los programas serán cada vez mejores.
Figura 6.3: Logo de Linux
Las distribuciones más conocidas son RedHat, Debian, Slackware, SuSE y Corel Linux, todas ellas incluyen el software más reciente y empleado lo cual incluye compiladores de C/C++, editores de texto, juegos, programas para el acceso a Internet, así como el entorno gráfico de Linux X Window.
Una distribución es un agrupamiento del núcleo del sistema operativo Linux (la parte desarrollada por Linus Torvalds) y otra serie de aplicaciones de uso general o no tan general. En principio las empresas que desarrollan las distribuciones de Linux están en su derecho al cobrar una cierta cantidad por el software que ofrecen, aunque en la mayor parte de las ocasiones se pueden conseguir estas distribuciones desde Internet, de revistas o de amigos, siendo todas estas formas gratuitas y legales.
6.1.2 Trabajando con Linux
Al contrario que otros sistemas operativos, por defecto el trabajo con Linux no se realiza de una forma gráfica, sino introduciendo comandos de forma manual. Linux dispone de varios programas que se encargan de interpretar los comandos que introduce el usuario y realiza las acciones oportunas en respuesta. Estos programas denominados shell son el modo típico de comunicación en todos los sistemas Unix incluido Linux. Para muchas personas el hecho de tener que introducir los comandos de forma manual les puede parecer intimidante y dificultoso, aunque como se verá más adelante los comandos de Linux son relativamente simples y muy poderosos.
No obstante, casi todas las distribuciones más recientes incluyen el sistema X Window (no X Windows), el cual es el encargado de controlar y manejar la interfaz de usuario. Como se verá más adelante X Window es mucho más poderoso que otros
GVA-ELAI-UPMPFC0077-2003 121

Procesamiento distribuido Marta García Nuevo
entornos similares como Microsoft Windows, puesto que permite que el usuario tenga un control absoluto de la representación de los elementos gráficos.
Linux es un sistema operativo multitarea y multiusuario. Esto quiere decir que es capaz de ejecutar varios programas (o tareas) de forma simultánea y albergar a varios usuarios de forma simultánea.
Por lo tanto, todos los usuarios de Linux deben tener una cuenta de usuario en el sistema que establezca los privilegios del mismo. A su vez Linux organiza a los usuarios en grupos de forma que se puedan establecer privilegios a un determinado grupo de trabajo, para el acceso a determinados archivos o servicios del sistema.
Al contrario que lo que ocurre con Microsoft Windows la instalación de Linux no es un proceso sencillo, puesto que Linux permite el control y la personalización de una cantidad mayor de parámetros y opciones. Pese a todo se están realizando grandes progresos buscando que la instalación de Linux sea un proceso lo menos traumático posible, dependiendo la sencillez de la misma de la distribución que se emplee. Por el momento la distribución más sencilla de instalar es Red Hat y aquellas que derivan de esta (Linux Mandrake, …).
Existe un concepto fundamental a la hora de instalar y usar Linux que es el de Super Usuario o usuario root. Este usuario es el administrador del sistema y se crea durante la instalación. Como administrador que es puede acceder y modificar (así como destruir) toda la información del sistema, por lo que hay que evitar en la medida de lo posible trabajar como usuario root.
El sistema de archivo de Linux sigue todas las convenciones de Unix, lo cual significa que tiene una estructura determinada, compatible y homogénea con el resto de los sistemas Unix. Al contrario que en Windows o MS-DOS el sistema de archivos en cualquier sistema Unix no está ligado de una forma directa con la estructura del hardware, esto es, no depende de si un determinado ordenador tiene 1, 2 o 7 discos duros para crear las unidades c:\, d:\ o m:\.
Todos el sistema de archivos de Unix tiene un origen único la raíz o root representada por /. Bajo este directorio se encuentran todos los ficheros a los que puede acceder el sistema operativo. Estos ficheros se organizan en distintos directorios cuya misión y nombre son estándar para todos los sistema Unix.
X Window es el entorno gráfico habitual de los sistemas Unix. El sistema X Window se compone de dos parte principales el servidor X y el programa para la gestión de las ventanas. El servidor X es el programa que se encarga realmente de dibujar en la pantalla. Por el contrario el gestor de ventanas como su nombre indica es el encargado de crear las ventanas y gestionar su apariencia. Debido a este modelo, la apariencia de las aplicaciones varía según se use uno u otro gestor de ventanas, entre los que destacan por su sencillez de uso los entornos GNOME y KDE.
122 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
6.1.3 El Shell: comandos básicos de Linux
Hasta este momento se han visto los entornos gráficos existentes para Linux más importantes, no obstante cualquier usuario de Linux acabará antes o después relacionándose con el sistema empleando el modo texto. Este modo se basa en la ejecución de una serie de comandos, que son interpretados por un programa o shell. Linux dispone de varios de estos programas pero el más habitual es conocido como bash o Bourne Shell. Si Linux se ha arrancado en modo texto el sistema arranca de forma directa el shell y queda a la espera de introducción de nuevos comandos. Si se ha arrancado en modo gráfico se puede acceder al shell de dos formas:
• Se puede acceder al shell del sistema presionando alguna de las siguientes combinaciones de teclas:
<ctrl>+<alt>+<F1> <ctrl>+<alt>+<F2> <ctrl>+<alt>+<F3> <ctrl>+<alt>+<F4> <ctrl>+<alt>+<F5>
Esto hace que el sistema salga del modo gráfico y acceda a alguna de las seis consolas virtuales de Linux, a las cuales también se puede acceder cuando se arranca en modo de texto. Para volver al modo gráfico hay que presionar <ctrl>+<alt>+<F7> o <ctrl>+<alt>+<F8>.
• La segunda forma es más cómoda y menos radical permitiendo acceder al shell desde el mismo entorno gráfico. Para esto hay que abrir un programa llamado terminal o consola, por ejemplo:
kconsole (en el entorno KDE), xterm, gnome-terminal ( en GNOME), etc como se ha visto anteriormente.
Existen una serie de nociones básicas que hay que tener en cuenta a la hora de introducir los comandos. En primer lugar citaremos las siguientes:
• Los comandos hay que teclearlos exactamente.
• Las letras mayúsculas y minúsculas se consideran como diferentes.
• En su forma más habitual (los shells de Bourne o de Korn), el sistema operativo utiliza un signo de $ como prompt para indicar que está preparado para aceptar comandos, aunque este carácter puede ser fácilmente sustituido por otro u otros elegidos por el usuario. En el caso de que el usuario acceda como administrador este signo se sustituye por #.
GVA-ELAI-UPMPFC0077-2003 123

Procesamiento distribuido Marta García Nuevo
• Cuando sea necesario introducir el nombre de un fichero o directorio como argumento a un comando, Linux, permite escribir las primeras letras del mismo y realiza un auto rellenado al presionar la tecla del tabulador. Si no puede distinguir entre diversos casos rellenará hasta el punto en el que se diferencien.
Para efectuar el cambio o la introducción de un password o contraseña se utiliza el comando passwd.
A continuación se describen algunos comandos sencillos de que pueden ser útiles para familiarizarse con los comandos del sistema.
date Muestra por pantalla el día y la hora.
cal 1949 Muestra el calendario del año 1949.
cal 05 1949 Muestra el calendario de mayo de 1949.
who Indica qué usuarios tiene el ordenador en ese momento, en qué terminal están y desde qué hora.
whoami Indica cuál es la terminal y la sesión en la que se está trabajando.
man comando Todos los manuales de Linux están dentro del propio sistema operativo, y este comando permite acceder a la información correspondiente al comando comando.
clear Este comando limpia la consola
Como se ha visto anteriormente el directorio personal es un directorio con un determinado nombre asignado a un usuario. Los directorios personales habitualmente son subdirectorios de /home (en algunos casos se utiliza mnt, u otro subdirectorio de orden inferior). Generalmente el nombre coincide con el del nombre de usuario, aunque puede no ser así, y varios usuarios pueden estar trabajando en el mismo directorio. Cada usuario de Linux puede crear una estructura en árbol de subdirectorios y archivos tan compleja como desee bajo su directorio personal pero normalmente nunca fuera de él.
Una de las acciones más habituales a la hora de trabajar es mostrar el contenido de un directorio, como se ha visto existen herramientas gráficas con este fin, no obstante el shell incluye un programa con este mismo fin: ls que muestra los nombres de los ficheros y subdirectorios contenidos en el directorio en el que se está.
El comando mkdir (make directory) permite a cada usuario crear un nuevo subdirectorio:
124 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
mkdir subdir1 donde subdir es el nombre del directorio que se va a crear.
Este comando borra uno o más directorios del sistema (remove directory), siempre que estos subdirectorios estén vacíos.
Por ejemplo: rmdir subdir1,donde subdir es el nombre del directorio que se va a eliminar.
Este comando permite cambiar de directorio a partir del directorio actual de trabajo. Por ejemplo, cd /home/Pedro En este ejemplo pasamos del directorio actual de trabajo al nuevo directorio /home/Pedro, que será desde ahora nuestro nuevo directorio.
cd dire nos traslada al subdirectorio dire (que deberá existir como subdirectorio en el directorio actual).
cd .. Retrocedemos un nivel en la jerarquía de directorios. Por ejemplo, si estamos en /home/Pedro y usamos este comando, pasaremos al escalafón inmediatamente superior de la jerarquía de directorios, en este caso a /home.
Nota: al contrario que en MS-DOS en Linux no existe la forma cd.. sin espacio entre cd y los dos puntos.
cd Nos sitúa nuevamente en el directorio personal del usuario.
El comando pwd (print working directory) visualiza o imprime la ruta del directorio en el que nos encontramos en este momento. Este comando es uno de los pocos que no tiene opciones y se utiliza escribiendo simplemente pwd.
Linux a diferencia de Windows no utiliza letras ("a:", "c:", "d:", ...) para acceder a las distintas unidades de disco de un ordenador. En Linux para acceder al contenido de una unidad de disco o de un CD-ROM este tiene que haber sido previamente "montado". El montado se realiza mediante el comando mount, con lo que el contenido de la unidad se pone a disposición del usuario en el directorio de Linux que se elija. Por ejemplo para acceder al CD-ROM se teclearía el siguiente comando:
mount -t iso9660 /dev/cdrom /mnt/cdrom
El comando cp tiene la siguiente forma, cp file1 file2 y hace una copia de file1 y le llama file2. Si file2 no existía, lo crea con los mismos atributos de file1. Si file2 existía antes, su contenido queda destruido y es sustituido por el de file1. El fichero file2 estará en el mismo directorio que file1. Tanto file1 como file2 indican el nombre de un archivo, que puede incluir el la ruta al mismo si alguno de ellos no se encuentra en el directorio actual.
GVA-ELAI-UPMPFC0077-2003 125

Procesamiento distribuido Marta García Nuevo
cp file1 file2 namedir, que hace copias de file1 y file2 en el directorio namedir.
mv file1 file2
El comando mv realiza la misma función que el anterior (cp) pero además destruye el fichero original. En definitiva traslada el contenido de file1 a file2; a efectos del usuario lo que ha hecho es cambiar el nombre a file1, llamándole file2. De igual forma,mv file1 file2 namedir traslada uno o más ficheros (file1, file2,...) al directorio namedir conservándoles el nombre.
El comando, mv namedir1 namedir2 cambia el nombre del subdirectorio namedir1 por namedir2. Hay que recalcar que el comando mv sirve así mismo para cambiar el nombre de los ficheros.
En Linux un mismo fichero puede estar repetido con más de un nombre, ya que con el comando cp se pueden realizar cuantas copias se desee del fichero. Pero, a veces, es más práctico tener un mismo fichero con varios nombres distintos, y lo que es más importante, poder acceder a él desde más de un directorio. En Linux esto recibe el nombre de enlaces múltiples a un fichero. El ahorro de espacio de disco es importante al poder compartir un fichero más de un usuario.
Estos enlaces son muy prácticos a la hora de utilizar ficheros que pertenecen a directorios distintos. Gracias a los enlaces se puede acceder a muchos ficheros desde un mismo directorio, sin necesidad de copiar en ese directorio todos esos ficheros. La forma de este comando es, ln file1 file2. A partir de este momento el fichero file1 tiene dos nombres: file1 y file2. A diferencia de los comandos cp y mv, este comando toma más precauciones, ya que advierte previamente si el nombre file2 está ocupado, y en este caso no se ejecuta. ln panacea subdir/panacea
rm file1 file2
Este comando elimina uno o más ficheros de un directorio en el cual tengamos permiso de escritura. Con este comando resulta facilísimo borrar ficheros inútiles, y desgraciadamente, también los útiles.
Por eso es conveniente y casi imprescindible emplear lo opción -i, de la forma siguiente:
rm -i file1 file2
Con esta opción, Linux pedirá confirmación para borrar cada fichero de la lista, de si realmente se desea su destrucción o no. Se recomienda usar siempre este comando con esta opción para evitar el borrado de ficheros útiles. Por ejemplo, si se teclea, rm -i superfluo, aparecerá en pantalla el aviso siguiente:
126 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
remove superfluo?
y habrá que contestar y (yes) o n (not).
Este comando realiza una serie de comprobaciones en un fichero para tratar de clasificarlo. Su formato es:
file fich
Tras su ejecución este comando muestra el tipo del fichero e información al respecto del mismo.
Los permisos de cada fichero se pueden ver con el comando ls -l. Para cambiar los permisos de un fichero se emplea el comando chmod, que tiene el formato siguiente:
chmod [quien] oper permiso files
Este comando permite visualizar el contenido de uno o más ficheros de forma no formateada.
También permite copiar uno o más ficheros como apéndice de otro ya existente. Algunas formas de utilizar este comando son las siguientes, cat filename, saca por pantalla el contenido del fichero filename.
El comando less es muy similar al anterior pero permite el desplazamiento a lo largo del texto empleando las teclas de cursores pudiendo desplazarse hacia arriba o abajo de un fichero.
El comando grep localiza una palabra, clave o frase en un conjunto de directorios, indicando en cuáles de ellos la ha encontrado. Este comando rastrea fichero por fichero, por turno, imprimiendo aquellas líneas que contienen el conjunto de caracteres buscado. Si el conjunto de caracteres a buscar está compuesto por dos o más palabras separadas por un espacio, se colocará el conjunto de caracteres entre apóstrofes ('). Su formato es el siguiente:
grep 'conjuntocaracteres' file1 file2 file3, siendo 'conjuntocaracteres' la secuencia de caracteres a buscar, y file1, file2, y file31 los ficheros donde se debe buscar.
Tanto el comando tar como gzip son ampliamente empleados para la difusión de programas y ficheros en Linux. El primero de ellos agrupa varios ficheros en uno solo o “archivo”, mientras que el segundo los comprime. En conjunto estos dos programas actúan de forma muy similar a programas como Winzip. Para crear un nuevo archivo se emplea:
GVA-ELAI-UPMPFC0077-2003 127

Procesamiento distribuido Marta García Nuevo
tar –cvf nombre_archivo.tar fichero1 fichero2 …
donde fichero1, fichero2 etc. son los ficheros que se van a añadir al archivo tar.
Si se desea extraer los ficheros se emplea:
tar –xpvf nombre_archivo.tar fichero1 …
Al contrario que tar que agrupa varios ficheros en uno, gzip comprime un único fichero con lo que la información se mantiene pero se reduce el tamaño del mismo. El uso de gzip es muy sencillo
gzip fichero, con lo que se comprime fichero (que es borrado) y se crea un fichero con nombre fichero.gz.
Si lo que se desea es descomprimir un fichero se emplea entonces:
gzip –d fichero.gz, recuperando el fichero inicial.
Como se ha comentado al principio es típico emplear tar y gzip de forma consecutiva, para obtener ficheros con extensión tar.gz o tgz que contienen varios ficheros de forma comprimida (similar a un fichero zip). El comando tar incluye la opción z para estos ficheros de forma que para extraer los ficheros que contiene:
tar –zxf fichero.tar.gz
El comando lpr se emplea para imprimir una serie de ficheros. Si se emplea sin argumentos imprime el texto que se introduzca a continuación en la impresora por defecto. Por el contrario,
lpr nombre_fichero, imprime en la impresora por defecto el fichero indicado.
6.1.4 Ejecución de Programas
Para ejecutar un programa en el fondo, es decir, recuperando inmediatamente el control del terminal, basta añadir el carácter & al final del comando de ejecución:
program <datos.d >resultados.r &, inmediatamente aparecerá en el terminal, debajo de esta línea, un número que es el número de proceso de la ejecución de este programa. Para detener definitivamente dicha ejecución (no se puede detener temporalmente) se puede utilizar el comando kill:
kill númerodeproceso
128 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
La ejecución de un programa en el fondo no impide que aparezcan en la pantalla los mensajes de error que se produzcan (a no ser que se haya redirigido la salida de errores), y que el programa se pare cuando se salga del sistema. Para que el programa continúe ejecutándose aún cuando nosotros hayamos terminado la sesión, hay que utilizar el comando nohup:
nohup program
Si no se utilizan redirecciones todas las salidas del programa se dirigen a un fichero llamado nohup.out. Cuando se utiliza nohup el ordenador entiende que el usuario no tiene prisa y automáticamente disminuye la prioridad de la ejecución. Existe un comando, llamado nice, que permite realizar ejecuciones con baja prioridad, es decir se le indica al ordenador que puede ejecutar de forma más lenta esta aplicación si existen otras que sean más urgentes. Se utiliza en las formas,
nice program & nice nohup program &
Para darle al programa la prioridad mínima habría que utilizar el comando,
nice -19 program &, donde el -19 indica la mínima prioridad.
El comando time, precediendo a cualquier otro comando, suministra información acerca del tiempo total empleado en la ejecución, del tiempo de CPU utilizado por el programa del usuario, y del tiempo de CPU consumido en utilizar recursos del sistema. Por ejemplo para saber el tiempo utilizado en la compilación y montaje del programa prueba.c utilizaríamos el comando, time gcc prueba.c
Linux incluye una aplicación llamada top cuya finalidad es manipular la ejecución de programas de una forma interactiva. Esta aplicación muestra una lista de los procesos que se están ejecutando. Los principales comandos de top son: u que muestra los procesos que pertenecen a un determinado usuario, k equivalente al comando kill para matar un proceso y h que muestra la ayuda del programa.
El sistema operativo Linux, al igual que otros sistemas operativos, permite realizar programas de comandos, esto es, programas constituidos por distintos comandos que podrían teclearse interactivamente uno por uno en una terminal, pero que es muchas veces más cómodo agruparlos en un fichero, y ejecutarlos con una sola instrucción posteriormente.
Los comandos de Linux pueden ser externos - que implican la creación de un nuevo proceso, cuyo código está en /bin o /usr/bin- e internos - cuyo código está incluido en el del intérprete shell que los ejecuta.
Una cierta primera forma de agrupar comandos la ofrece Linux por medio del carácter. Por ejemplo, tecleando el comando,
GVA-ELAI-UPMPFC0077-2003 129

Procesamiento distribuido Marta García Nuevo
date; ls; who el ordenador ejecutará sucesivamente los comandos date, ls y who. También podría crearse con un editor de textos un fichero llamado comandos que contuviera las líneas siguientes:
date ls who
Para ejecutar este fichero de comandos puede teclearse,
sh comandos o bien convertir el fichero comandos en directamente ejecutable por medio del comando chmod en la forma,
chmod a+x comandos de modo que el programa de comandos comandos puede ejecutarse simplemente tecleando su nombre, comandos.
Los comandos sh comandos y comandos no son enteramente equivalentes. Así, el primero de ellos exige que el fichero comandos esté en el directorio de trabajo, mientras que el segundo sólo exige que el fichero comandos esté en uno de los directorios de búsqueda de comandos especificados en la variable PATH.
Cuando se ejecuta un fichero de comandos Linux abre lo que se llama un nuevo shell, es decir un nuevo entorno para la ejecución de los comandos. Para que las variables del caparazón original conserven su valor en el nuevo caparazón es necesario prepararlas con la sentencia export antes de abrir el nuevo shell. Por ejemplo, como consecuencia de lo que se acaba de decir, si en el interior de un fichero de comandos se cambia de directorio con el comando cd, al acabar la ejecución de dicho fichero volveremos automáticamente al directorio inicial.
Para introducir líneas de comentarios en un programa de comandos basta comenzar dichas líneas con el carácter #. Hay que tomar la precaución de que este carácter no sea el primer carácter del fichero de comandos, porque entonces el ordenador interpreta que el programa está escrito en Cshell (una variante especial de UNIX desarrollada en la Universidad de Berkeley) y el resultado es imprevisible. Puede ser buena práctica comenzar todos los ficheros de comandos con una línea en blanco.
El comando echo imprime un determinado texto en la terminal. Un ejemplo de utilización de dicho comando puede ser el siguiente:
echo Me gusta el sistema operativo UNIX
El comando echo es de gran utilidad en los ficheros de comandos. Cuando el texto que se desea escribir en la terminal contiene alguno de los caracteres especiales de UNIX ( * ? [ ] > >> < & ; \ ' ) hay que tomar precauciones especiales desconectando su significado. Una forma de hacerlo es precediendo dicho carácter con la barra invertida (\). Así, para escribir mediante el comando echo tres asteriscos, utilizaríamos
130 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
echo \*\*\*
si no utilizáramos la barra invertida, el asterisco se interpretaría como un carácter de sustitución y se imprimiría el nombre de todos los ficheros del directorio.
Otra forma de anular el significado de los caracteres especiales es encerrando el texto a escribir mediante comillas (") o entre apóstrofos normales ('). Los apóstrofos (') anulan el significado de todos los caracteres comprendidos entre ellos. Así pues, el triple asterisco lo podríamos escribir con el comando,
echo '***'
Las comillas (") son menos restrictivas, y anulan el significado de todos los caracteres excepto los tres siguientes: ( ` \). Esto es muy importante porque si VAR es el nombre de una variable, y VAR aparece en un comando echo entre apóstrofos se escribe VAR, mientras que si aparece entre comillas se escribe el valor de la variable, al cumplir el carácter su cometido.
El carácter (\) tiene otros significados, además del ya visto de anular el significado especial de otros caracteres. Así, sirve como indicador de que un comando continúa en la línea siguiente. Cuando se utiliza en la definición interactiva de un comando, en la línea siguiente aparece el prompt secundario (>), que indica que se debe seguir tecleando el comando. Cuando en un comando echo aparecen los caracteres (\c) y (\n) quiere decir, respectivamente, que no se cambie de línea y que se salte de línea, al escribir por la pantalla.
El carácter apóstrofo inverso o acento grave (`) tiene también un significado especial. Cuando en un comando echo aparece el nombre de otro comando encerrado entre apóstrofos inversos (por ejemplo, `date`, `who`, `ls`, ...), el nombre de dicho comando se sustituye por el resultado que genera al ejecutarse interactivamente. Un ejemplo podría ser el siguiente:
echo "Los usuarios del sistema son \n\n `who`"
A los ficheros de comandos pueden pasárseles como parámetros un conjunto de una o más variables. Dentro del fichero de comandos estas variables o parámetros se conocen con los nombres 0, 1, 2, ..., 9. La variable 0 representa el propio nombre del fichero de comandos, y 1, 2, ..., 9 son los nombres de los parámetros propiamente dichos. Vamos a comenzar viendo un ejemplo muy sencillo de programa de comandos al que se le pasa sólo una variable o parámetro. El comando de borrar de Linux rm no confirma la operación de borrado si no se le pone la opción (-i). Esto es peligroso porque uno fácilmente puede olvidarse de teclear dicha opción y borrar lo que no quería borrar. Vamos a crear un fichero de comandos llamado del que incluya dicha opción. Dicho fichero podría estar formado por,
echo "Quiere borrar el fichero 1?" rm -i 1
GVA-ELAI-UPMPFC0077-2003 131

Procesamiento distribuido Marta García Nuevo
Después de darle a este fichero el correspondiente permiso de ejecución con el comando chmod, podríamos borrar con confirmación el fichero file tecleando, del file
Los ficheros de comandos tienen muchas más posibilidades que las que se han apuntado en esta introducción: pueden leer variables, preguntar por la existencia de un fichero y por si es ejecutable o no, y admiten construcciones lógicas del tipo IF, DO, DO WHILE, etc. Para utilizar estas posibilidades acudir al manual correspondiente.
El comando make sirve para organizar la compilación y el enlazado de programas complicados que dependen de muchos módulos y librerías diferentes. Cuando se ejecuta este comando, se construye un nuevo ejecutable volviendo a compilar sólo aquellos ficheros fuente que son más recientes que el los ficheros compilados correspondientes, teniendo en cuenta para ello las fechas de última modificación de cada fichero.
Este comando se basa en un fichero ASCII (llamado por defecto makefile) que contiene una relación de dependencias entre los distintos módulos, así como las acciones que hay que realizar para poner a punto cada módulo, es decir para pasar de un fuente a un objeto, por ejemplo. Este comando tiene la siguiente forma general:
make [–f makefilename] [–arg_opt] [exe_name]
El fichero makefile (con éste o con otro nombre invocado por medio de la opción –f) contiene cuatro tipos de líneas diferentes:
• Líneas de comentario, que comienzan por el carácter (#). Si en una línea cualquiera aparece el carácter (#), se ignora todo lo que aparece a continuación de dicho carácter en dicha línea.
• Líneas de definición de macros. Tienen la forma general,
IDENTIFICADOR = cadena_de_caracteres
Si en alguna otra línea aparece (IDENTIFICADOR), dicha ocurrencia se sustituye por cadena_de_caracteres. No es necesario que el nombre del identificador esté escrito con mayúsculas, pero es una costumbre bastante extendida el hacerlo así. Mediante el uso de macros se pueden representar brevemente pathnames o listas de nombres de ficheros largos. Si el identificador tiene una sola letra, no hace falta poner los paréntesis. El comando make tiene una serie de macros definidas por defecto que se pueden listar con el comando make –p.
132 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
6.2 OpenMoxis[MCAT]
OpenMosix, un paquete software que posibilita que una red de computadoras basadas en GNU/Linux funcionen como un cluster.
Figura 6.4: Logo de OpenMosix
6.2.1 Breves nociones de OpenMosix
El mantenimiento de un sistema resulta incluso más delicado y costoso (en tiempo) que su correcta instalación. En este capítulo se tomará contacto con todas las herramientas con las que cuenta OpenMosix para poder gestionar tu sistema.
OpenMosix proporciona como principal ventaja la migración de procesos hacia aplicaciones HPC. El adminsitrador puede configurar el cluster utilizando las herramientas de área de usuario de OpenMosix (OpenMosix-user-space-tools8) o editando la interfície que encontraremos en /proc/hpc y que será descrita con más detalle seguidamente.
Los valores en los ficheros del directorio /proc/hpc/admin presentan la configuración actual del cluster. El administrador del mismo puede configurar estos valores para cambiar la configuración en tiempo de ejecución.
El demonio de auto-detección de nodos, omdiscd, proporciona un camino automático para la configuración de nuestro cluster OpenMosix. Con él podremos eliminar la necesidad de configuraciones manuales como son la edición del fichero /etc/mosix.map .
omdiscd genera un envío de paquetes multicast (a todas las direcciones, en nuestro caso, nodos) para notificar a los otros nodos que hemos añadido uno nuevo. Esto significa que al añadir un nodo sólo tendremos que iniciar omdiscd en él.
Debemos ocuparnos de algunos requisitos previos como pueden ser una buena configuración de la red de interconexión de los nodos, principalmente para el correcto enrutamiento de paquetes. Sin una ruta por defecto deberemos especificar a omdiscd la interfície con la opción -i.
GVA-ELAI-UPMPFC0077-2003 133

Procesamiento distribuido Marta García Nuevo
Las herramientas del área de usuario, permitirán un fácil manejo del cluster OpenMosix. Seguidamente se enumeran con todos sus parámetros.
La importancia de poder automatizar el reconocimiento de nuevos nodos conectados al sistema ha facilitado que se llegue a la simplicidad con la que contamos actualmente para iniciar dicha detección, con el comando omdiscd.
6.2.1.1 Comandos más utilizados
Estas herramientas permitirán un fácil manejo del cluster OpenMosix. Seguidamente se enumeran con todos sus parámetros.
migrate [PID] [OpenMosix ID] envía una petición de migrado del proceso identificado con el ID, al nodo que indiquemos..
mon es un monitor de los daemons basado en el terminal y da información relevante sobre el estado actual que puede ser visualizada en diagramas de barras.
mosctl es la principal utilidad para la configuración de OpenMosix.
Su sintaxis es:
mosctl [stay|nostay] [block|noblock] [quiet|noquiet] [nomfs|mfs] [expel|bring] [gettune|getyard|getdecay] mosct whois [OpenMosix_ID|IP-address|hostname] mosct [getload|getspeed|status|isup|getmem|getfree|getutil] [OpenMosix_ID] mosctl setyard [Processor-Type|OpenMosix_ID||this] mosctlsetspeed interger-value mosctlsetdecay interval [slow fast]
Describimos ahora la función de algunos comandos sencillos:
clear resetea las estadísticas cpujob informa a OpenMosix que el proceso está ligado al procesador iojob informa a OpenMosix que el proceso está ligado a la E/S slow informa a OpenMosix que actualice las estadísticas más lentamente fast informa a OpenMosix que actualice las estadísticas más rápidamente stay desactiva la migración automática nostay migración automática (defecto) lstay local processes should stay nolstay los procesos locales podrán migrar block bloquea la llegada de otros procesos noblock permite la llegada de procesos
134 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
quiet desactiva la posibilidad de dar información sobre la carga del nodo noquiet activa la posibilidad de dar información sobre la carga del nodo nomfs desactiva MFS mfs activa MFS expel envía fuera del nodo los procesos que han llegado previamente bring traerá todos los procesos migrados hacia su nodo raíz gettune muestra el parámetro de overhead getyard muestra la utilización actual de Yardstick getdecay muestra el estado del parámetro decay whois nos muestra el OpenMosix-ID, la dirección IP y los nombres de host del
cluster getload muestra la carga (OpenMosix-) getspeed muestra la velocidad (OpenMosix-) status muestra el estado y la configuración actual isup nos informa de si un nodo está funcionando o no (ping OpenMosix) getmem muestra la memoria lógica libre getfree muestra la memoria física libre getutil muestra la utilización del nodo setyard establece un nuevo valor para Yardstick setspeed establece un nuevo valor para la velocidad (OpenMosix-) setdecay establece un nuevo valor para el intervalo del decay
Con mosrun ejecutaremos un comando especialmente configurado en un nodo establecido.
Su sintaxis:
mosrun [-h|OpenMosix ID| list of OpenMosix IDs] command [arguments]
El comando mosrun puede ser ejecutado con diversas opciones. Para evitar complicaciones innecesarias viene con ciertas pre-configuraciones para ejecutar las tareas con configuraciones especiales de OpenMosix.
nomig ejecuta un programa cuyos procesos no han migrado runhome ejecuta un comando bloqueado en el nodo raíz runon ejecutará un comando el cuál será directamente migrado y bloqueado a
cierto nodo cpujob informa a OpenMosix que el proceso está ligado a la CPU iojob informa a OpenMosix que el proceso está ligado a la E/S nodecay ejecuta un comando e informa al cluster de no refrescar las estadísticas de carga slowdecay ejecuta un comando con intervalo de decay grande para acumular en las
estadísticas fastdecay ejecuta un comando con intervalo de decay pequeño para acumular en las
estadísticas
GVA-ELAI-UPMPFC0077-2003 135

Procesamiento distribuido Marta García Nuevo
6.2.2 Cómo construir el cluster
Lo primero que tendremos que hacer es comenzar la instalación de OpenMosix. Podemos bajarnos el software desde varias paginas web, nosotros lo hemos hecho desde:
http://kernel.org/pub/linux/kernel/v2.4
El nombre del archivo que debemos bajar desde esta página al directorio temporal es ‘linux-2.4.20.tar.gz’.
Necesitaremos también bajarnos las herramientas ‘OpenMosix-2.4.20-20.gz’, desde:
http://sourceforge.net/project/showfiles.php?group_id=46729
Desde el directorio temporal tecleamos:
tar zxvf linux-2.4.20.tar.gz
Y de este modo crearemos un nuevo directorio: linux-2.4.20/ , desde este nuevo directorio, teclearemos:
zcat .../ OpenMosix-2.4.20-20.gzpatch –p1
Ahora debemos cofigurar y compilar el kernel, para ello usaremos los comandos:
make xconfig para configurarlo y make dep para compilarlo make bzImage make modules make modules_install
Tenemos que instalar las herramientas, sólo necesitaremos rpm, para hacerlo pondremos:
rpm –ivf OpenMosix-tools-0.2.4-1.i386.rpm
Configuramos ahora los nodos, debemos indicarle a la computadora dónde va a poder encontrar los nodos que van a formar parte del cluster.
# MOSIX CONFIGURATION # =================== # # Each line should contain 3 fields, # mapping IP addresses to MOSIX node-numbers:
136 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
# 1) first MOSIX node-number in range. # 2) IP address of the above node (or node-name from /etc/hosts). # 3) number of nodes in this range. # # Example: 10 machines with IP 192.168.1.50 - 192.168.1.59 # 1 192.168.1.50 10 # # MOSIX-# IP number-of-nodes # ============================ 1 138.100.101.131 1 2 138.100.100.134 1 3 138.100.100.138 1 Be sure to check the /etc/hosts. It should look like this: 138.100.100.134 jdelacierva.elai.upm.es jdelacierva 127.0.0.1 localhost.localdomain localhost
6.2.2.1 Ejecutamos un ejemplo
Vamos a ejecutar ahora un caso real, nos creamos un programa al que vamos a llamar ‘test’ y lo guardamos en una carpeta temporal.
Tenemos tres nodos:
Nodo número 1 es un Intel Pentium 4, procesador de 2.4 GHz, 512 Mb RAM. Nodo número 2 es un Pentium 2, 350 Mhz, 512 Mb RAM. Nodo número 3 no lo usamos en el test for x in 1 2 3 4 do awk ’BEGIN {for(i=0;i<10000;i++)for(j=0;j<10000;j++);}’ & done
Hay que ejecutar esto a través de chmod 755 test.
* 138.100.101.131 • (1) ./test
Esto significa que para ejecutar el script hemos consumido 109 segundos, solo ha sido usado el nodo 1.
Durante el proceso podemos chequear todos los procesos que se estén ejecutando, usando ps:
GVA-ELAI-UPMPFC0077-2003 137

Procesamiento distribuido Marta García Nuevo
[marta@jdelacierva Documents]$ ps PID TTY TIME CMD 1760 pts/2 00:00:00 bash 1796 pts/2 00:00:09 awk 1797 pts/2 00:00:09 awk 1798 pts/2 00:00:09 awk 1799 pts/2 00:00:09 awk 1800 pts/2 00:00:00 ps • (2) runon 2 ./test
Ahora todos los procesos están siendo ejecutados en el nodo 2, consume 649 segundos, vemos que es mucho más lento que el nodo 1.
• (3) mosrun -l ./test
Los procesos comienzan a ejecutarse en el nodo 1, pero seguidamente comienza la migración, el tiempo empleado es de 98 segundos.
* 138.100.100.134 • (4) ./test
Ejecutamos el scrip localmente, nos lleva 640 segundos.
• (5) runon 1 ./test
Tarda 123 segundos en completar la ejecución en el nodo 1, vemos que es más lento debido al retardo en la transmisión a través de la red.
• (6) mosrun -l ./test
El proceso comienza el nodo 2, y tras unos instantes comienza la migración, tarda 109 segundos
.
Comparando resultados
• Comparando el test número 1 con el número 5
138 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
Vemos que el test 5 es 15 segundos más lento que el test 1, es un 13% más lento. Ambos cálculos han sido realizados desde el nodo número 1, deducimos que el retraso es debito al retardo de la red.
• Comparando el test número 2 con el número 4
Ahora ambos cálculos han sido hechos desde la computadora más lenta, el test número 4 no necesita trasmitir datos a través de la red, va algo más rápido que el test 2.
• Comparando el test número 3 con el número 6
El test número 3 es más rápido porque es iniciado en la computadora más rápida, pasa algo de tiempo hasta que el proceso comienza a migrar, y en este corto periodo de tiempo el nodo número 1 hace los cálculos más rápido que el nodo número 2.
• Comparando el test número 1 con el número 3
El test número 3 es un 10% más rápido, aquí vemos claras las ventajas de OpenMosix, los resultado serían aún más evidentes si las dos computadoras fueran Pentium 4, 2.4Ghz.
• Comparando el test número 4 con el número 5
Aquí vemos como OpenMosix reduce mucho tiempo computacional, el test 5 es un 81% más rápido porque la mayor parte del proceso se ha ejecutado en el nodo1.
• Comparando el test número 4 con el número 6
El balance de carga es la razón por la que el proceso 6 es más rápido que el proceso número 4.
Figura 6.5: Principio del test: sin migración
GVA-ELAI-UPMPFC0077-2003 139

Procesamiento distribuido Marta García Nuevo
Figura 6.6: Test al cabo de unos instantes: comienza la migración
Figura 6.7: Visualización del proceso con mosmon
Figura 6.8: Visualización de la velocidad con mosmon
140 GVA-ELAI-UPMPFC0077-2003
Marta García Nuevo Procesamiento distribuido
Figura 6.9: Visualización de la memoria con mosmon
Figura 6.10: Visualización del uso con mosmon
6.3 MPI
MPI (Message-Passing Interface) es una especificación estándar para las librería de paso de mensajes. PVM / MPI son herramientas que han estado ampliamente utilizadas y son muy conocidas por la gente que se dedica a la supercomputación. MPI es el estándar abierto de bibliotecas de paso de mensajes. MPICH es una de las implementaciones más usadas de MPI, tras MPICH se puede encontrar LAM, otra implementación basada en MPI también con bibliotecas de código abierto. PVM (Parallel Virtual Machine) es un primo de MPI que también es ampliamente usado para funcionar en clusters. PVM habita en el espacio de usuario y tiene la ventaja que no hacen falta modificaciones en el kernel de Linux, básicamente cada usuario con derechos suficientes puede ejecutar PVM.
GVA-ELAI-UPMPFC0077-2003 141

Procesamiento distribuido Marta García Nuevo
6.4 ParaView [EHEL] [LBER]
Mas que una librería, ParaView es una aplicación escrita en C++ y Tcl/Tk que utiliza algunos componentes de VTK. Desarrollada por encargo del Departamento de Energía USA como parte de su programa VIEW ("Visual Interactive Environment for Weapons Simulation") dentro del programa ASCI ("Accelerated Strategic Computing Initiative". El paquete ha sido diseñado originariamente como herramienta para el análisis de cantidades masivas de datos (del orden de Terabytes) aprovechando las posibilidades de computación en paralelo. A pesar de la aparatosidad de sus orígenes, dispone de una interfaz flexible e intuitiva así como una arquitectura extensible basada en estándares abiertos (una de las condiciones del Departamento de Energía es que fuese de código abierto -Open Source-).
Figura 6.11: Pantalla de inicio de ParaView
142 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
Figura 6.12: Ejemplo funcionamiento de ParaView
6.4.1 Argumentos de la línea de comandos
Hay varios comandos que pueden ser utilizados para controlar la ejecución de ParaView. A continuación los enumeramos dividiéndolos en tres categorías:
General:
--start-empty, -e : Inicia ParaView sin ningún módulo por defecto. Esta opción se usa cuando queremos personalizar ParaView y queremos inutilizar todas las fuentes que vienen por defecto filtros, lectores y botones de barra de tareas. --disable-registry, -dr : No use este registro para ejecutar ParaView, úselo sólo para hacer pruebas. Con esta opción, ParaView no hará caso de todos los ajustes de usuario almacenados y usará los valores por defecto. Ninguno de los ajustes serán salvados. --play-demo, -pd : Ejecuta la demo de ParaView. --help : Visualiza los comando válidos.
Paralelo --use-rendering-group, -p : Use un subconjunto de procesos para renderizar. Esto es útil sobre los sistemas/cluster que tienen un número limitado de nodos. Permite ejecutar ParaView sobre más de un nodo. --group-file, -gf : Cuando usamos las opciones de --use-rendering-group, el número de nodos dónde realizar la renderización, se leen del fichero (usage --group-file=fname).
GVA-ELAI-UPMPFC0077-2003 143

Procesamiento distribuido Marta García Nuevo
--use-tiled-display, -td : Duplica el dato final a todos los nodos y el nodo raíz muestra 1-n en una demostración total. Duplicate the final data to all nodes and tile node displays 1-N into one large display. --tile-dimensions-x, -tdx : -tdx=X where X is number of displays in each row of the display. --tile-dimensions-y, -tdy : -tdy=Y where Y is number of displays in each column of the display.
Mesa
--use-software-rendering, -r : Use software (Mesa) rendering on all nodes. This is useful when the user wants to have a window only on the first node's display. This is accomplished with using this option in combination with the PV_OFFSCREEN environment variable. --use-satellite-software, -s : Use software (Mesa) rendering only on satellite processes. This is useful when the user wants to have a window only on the first node's display. This is accomplished with using this option in combination with the PV_OFFSCREEN environment variable. Furthermore, since the first node uses hardware accelerated rendering, the performance is not compromised when rendering locally.
6.4.2 Ejecución de ParaView sobre MPI
Si compilamos ParaView sobre MPI, ParaView se podrá lanzar como cualquier otro uso de MPI. El método para comenzar el uso de MPI depende del sistema y de la implementación con la que se haya instalado.
Una vez que esté comenzado, el interfaz de uso aparecerá el la pantalla con el proceso (proceso con la identificación 0). El display de otros procesos (procesos basados en los satélites), aparecerán ventanas independientes. Éstos no tienen asociados interfaces de uso y no se pueden manipular por el usuario. Observamos que todos los procesos tienen un display para visualizarlo.
Esto no requiere la presencia de un monitor. Mientras ParaView pueda abrir ventanas de todos los procesos y leer su contenido, funcionará correctamente. Si varios procesos comparten el mismo display, ocurriría como si las ventanas abiertas por estos procesos se solapasen. Si sucede esto, el contenido de esas ventanas no se puede leer por ParaView y la imagen en la ventana principal (la que está con el interfaz de uso) será errónea. Igualmente pueden suceder si hay otras ventanas que ocultan la parte o toda la ventana de los procesos basados en los satélites. ParaView apoya fuera de la pantalla la representación en nodos basados en los satélites.
144 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
6.5 MPICH[DASH]
MPICH es una implementación frecuente del estándar MPI que corre sobre una gran variedad de aplicaciones.
Con la liberación del estándar MPI, MPICH fue diseñado para proporcionar una puesta en práctica del estándar MPI que podría sustituir los sistemas propietarios de paso de mensajes en los enormes ordenadores paralelos de aquellos días.
Como MPICH fue diseñado para permitir a puertos a otros sistemas, muchos vendedores de ordenadores paralelo y grupos de investigación han usado MPICH como la base para su implementación. Muchos usuarios se han familiarizado ahora sólo con la versión de MPICH que usa el dispositivo ch_p4 para el puesto de trabajo y el cluster Beowulf. Sin embargo, MPICH sigue apoyando otros sistemas y sigue sirviendo como una plataforma para la investigación en implementaciones MPI.
Vamos a utilizar MPICH bajo Windows, necesitaremos tener en los ordenadores que formarán el cluster WindowsNT/2000/XP Profesional o Server, y necesitaremos tambien hacer conexiones TCP/IP sobre todos los nodos.
6.5.1 Instalación de MPICH
Lo primero que haremos para lograr una correcta instalación del programa es obtener el archivo ‘mpich.nt.1.2.5.exe’. La forma de obtener este archivo es bajándolo de la página:
www.mcs.anl.gov/mpi/mpich/download.html;
Ejecutamos este archivo en todos los ordenadores con los que vamos a construir el cluster, seleccionamos la instalación por defecto.
También es posible realizar una instalación manual si nos encontrásemos con algún problema en la instalación por defecto.
Si instalamos MPICH en varios nodos tendremos que configurarlos, para ello usaremos la herramienta MPICH Configuration tool. Tendremos que introducir los nodos donde hemos instalado MPICH y pulsar al icono de aplicar para que se guarde la lista de nodos en el registro de Windows y así simplemente con escribir los nombres cuando sean necesarios se seleccionarán los nodos donde ejecutar el proceso. Para salir pulsaremos OK.
GVA-ELAI-UPMPFC0077-2003 145

Procesamiento distribuido Marta García Nuevo
Figura 6.13: MPICH Configuration tool
6.5.2 Herramientas
Describimos en este apartado las funciones de cada una de las herramientas de MPI.
6.5.2.1 mpirun
‘mpirun’ es el instrumento que se comunica con el lanzador de proceso de mpd para comenzar usos MPI. Viene de dos formas diferentes ‘mpirun’ y ‘guimpirun’. ‘mpirun’ es la versión en línea de comandos del instrumento y ‘guimpirun’ es la versión gráfica. La versión en línea de comando fue desarrollado primero y luego ‘guimpirun’ implementado sobre este, es la razón por la que el instrumento de línea de mando es más estable.
A continuación mostramos un ejemplo del formato de configuración: exe c:\somepath\myapp.exe OR \\host\share\somepath\myapp.exe [args arg1 arg2 arg3 ...] [env VAR1=VAL1|VAR2=VAL2|...|VARn=VALn]
146 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
[dir drive:\some\path] [map drive:\\host\share] hosts hostA #procs [path\myapp.exe] hostB #procs [\\host\share\somepath\myapp2.exe] hostC #procs
...
Las líneas encerradas entre corches son opcionales. Vemos dos modos de configuración. exe c:\temp\myapp.exe hosts fry 1 jazz 2 Este otro ejemplo, muestra un escenario más complicado. exe c:\temp\slave.exe env MINX=0|MAXX=2|MINY=0|MAXY=2 args -i c:\temp\cool.points hosts fry 1 c:\temp\master.exe fry 1 #light 1 jazz 2 Ambos procesos recibirán, como argumentos de la línea de comandos:
“-i c: n temp n cool.points”
6.5.2.2 MPIRegister tool
MPIRegister.exe es un instrumento para cifrar una cuenta y la contraseña en el registro para el usuario corriente. Se encuentra en el directorio ‘MPICH\mpd\bin’. La información que almacena es usada por ‘mpirun’ para lanzar procesos del usuario especificado. Si no se usa ‘mpiregister’ entonces ‘mpirun’ creará una nueva cuenta y contraseña cada vez que sea llamado.
6.5.2.3 Configuration tool
Este instrumento es un interfaz gráfico, que registra los ajustes que controlan algunas de las opciones de configuración MPICH.
Para ejecutar una aplicación en varios nodos sin especificarlos en un fichero de configuración, el lanzador de los procesos debe saber todos los nodos en los que el programa está instalado. MPIConfig.exe puede encontrar a los nodos donde el programa ha sido instalado y escribe esta lista de nodos en el registro. Con esta información ‘mpirun’ puede escoger los nodos de la lista en el registro para determinar donde lanzar los procesos.
GVA-ELAI-UPMPFC0077-2003 147

Procesamiento distribuido Marta García Nuevo
Figura 6.14: Ejemplo de MPICH Configuration tool
Creamos la lista de nodos:
La primera sección del diálogo tiene una lista que tiene que estar llena con los nombres de los nodos donde mpd ha sido instalado. Usamos los botones y/o escribimos los nombres del anfitrión directamente en la ventana para crear la lista.
Selección de las opciones de configuración:
El la siguiente sección del diálogo, podemos seleccionar distintas opciones de configuración, seleccionamos los que nos convengan.
Aplicamos los cambios:
Pulsamos el botón ‘Apply’ o ‘Apply single’ según nos interese, para que se hagan efectivos los cambios.
148 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
6.5.2.4 Update tool
Esta herramienta permite al administrador bajar las mps y las dlls de mpich en un cluster de máquinas.
Figura 6.15: MPICH Update tool
Lo primero que tenemos que hacer es seleccionar la lista de nodos, tras ello seleccionaremos lo que queremos bajar y finalmente aplicaremos los programas obtenidos.
6.5.3 Ejecutamos un ejemplo
En este sencillo ejemplo trataremos de ejecutar en programa en un computado trabajando desde otro diferente, y visualizando los resultados del programa en la máquina dónde estamos trabajando.
Para ello lo primero que hemos hecho es instalar MPICH en algunos de los ordenadores del laboratorio, construyendo así nuestro cluster, para ello nos ayudamos de la
GVA-ELAI-UPMPFC0077-2003 149
Procesamiento distribuido Marta García Nuevo
herramienta ‘Configuration tool’, donde la lista de nodos que hemos agregado es la siguiente:
Figura 6.16: Ventana de selección de nodos
Ya tenemos determinados los nodos de los que va a constar nuestro cluster. Visualizamos actualmente como están los trabajos pendientes y vemos que no los hay.
Figura 6.17: MPICH Job manager
150 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo Procesamiento distribuido
Con esta herramienta vemos el estado actual del cluster y podríamos cancelar procesos para enviar otro nuevo si fuese necesario.
Los que pretendemos en este ejemplo es ejecutar el programa ‘cpi.exe’, para ello necesitamos que el programa esté ubicado en el mismo directorio en todos los ordenadores que vayan a participar, así que lo guardaremos en el directorio C:\temp\cpi.exe de Copernico y de Fourier que son los nodos que vamos a usar.
Estamos trabajando en Copernico, para lograr ejecutar el programa en Fourier, usaremos la herramienta guiMPIRun, como se muestra en la siguiente figura, indicando dónde se encuentra el programa a ejecutar y los nodos que usaremos.
Figura 6.18: guiMPIRun
Para ejecutar el programa pulsamos ‘Run’ y en ese momento comienza la transferencia de información a Fourier, al intentar entrar en otro computador, por seguridad de la red del laboratorio, será necesario introducir una contraseña con ese permiso.
GVA-ELAI-UPMPFC0077-2003 151

Procesamiento distribuido Marta García Nuevo
Figura 6.19: Ventana de usuario y contraseña
Con todo esto logramos que se ejecute el programa remotamente, haciendo trabajar a Fourier y recibiendo los resultados en Copernico.
6.6 Conclusiones
Está claro que el hecho de que el clustering esté teniendo tal auge en estos momentos se debe a la confluencia de un cúmulo de factores como el abaratamiento del precio, desarrollo y aumento de prestaciones tanto del hardware de los nodos, como de la red de interconexión y herramientas de gestión, etc...
Lo visto en este capítulo son solo pequeñas nociones de la gran potencia computacional que podemos obtener con los grandes clusters que se están construyendo hoy en día. Pero creo queda suficientemente demostrada la importancia del clustering y el por qué de tan gran auge.
El pequeño ejemplo mostrado solo es un pequeño pasito para el trabajo que seguro culminarán con éxito compañeros de próximas promociones.
152 GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo ANEXO A
7 BIBLIOGRAFÍA
7.1 Microscopio confocal
[SART] IEEE Transactions On Biomedical Engineering, Vol. 47, No. 12, December 2000. Alessandro Sarti, Carlos Ortiz de Solórzano, Member, IEEE, Stephen Lockett, and Ravikanth Malladi*
[TWIL] Confocal Microscopy. T. Wilson. London, U.K. Academic, 1990. [DADA] D. Adalsteinsson and J. A. Sethian, “A fast level set method for propagating
interfaces,” J. Comp. Phys., vol. 118, no. 2, pp. 269–277, May 1995. [SOTO] La Microscopia Confocal. Enrique Soto Eguibar. Centro de Ciencias
Fisiológicas. Instituto de Ciencias Universidad Autónoma de Puebla. [UAMA] http://photonics.cnb.uam.es/Photonic_sp/Review/confocal.htm ORIOS DE
MICROFOTONICA Departamento de Inmunología y Oncología Centro Nacional de Biotecnología Universidad Autónoma de Madrid
[AALV] http://www.cnic.es/web_citometria/docs/doc/RESCFCA.DOC Introducción
a La Microscopía Confocal. Aplicaciones en Microbiología, Alberto
GVA-ELAI-UPMPFC0077-2003

ANEXO A Marta García Nuevo
Álvarez Barrientos, Unidad de Citometría, Centro Nacional de Investigaciones Cardiovasculares, ISCIII, Madrid
[ERIC] http://www.physics.emory.edu/~weeks/ Dr. Eric R. Weeks. . ©1996-2003
Physics Department, Emory University [LOCI] http://www.loci.wisc.edu/index.html laboratori of optical and computational
Istrumentation
[ABEC] http://www10.uniovi.es/serv_com/confoc/ext_co.htm Servicio de Proceso de Imágenes Bloque Polivalente A. Julián Clavería. S/N. Universidad de Oviedo
[ABEC] http://www.chemie.uni-marburg.de/~becker/image.html Quantitative Image Analysis by NIH Image. Andreas Becker.
[JDOB] http://wellpath.uniovi.es/es/contenidos/seminario/tecnicas_imagen/main.htm..
Jerzy Dobrucki [JMCU] http://www2.cbm.uam.es/confocal/imagenes.htm. Autores, J. M. Cuezva,
M. A. Alonso
7.2 Eliminación del Ruido
[MWOR] www.mathworks.com Perform image processing, analysis, and algorithm development © 2002 by The MathWorks.
[IPTU] Image Processing Toolbox User’s Guide
(R) COPYRIGHT 1993 - 1998 by The MathWorks, Inc. [UMAT] Using MATLAB. COPYRIGHT 1984 - 2002 by The MathWorks, Inc. [IIPM] Introduction to Image Processing in Matlab. By Kristian Sandberg,
Department of Applied Mathematics, University of Colorado at Boulder
[SDCM] SDC Morphology Toolbox V1.1 1,5 Jan02
[AMAR] La Imagen Digital. Ángel Martínez Nistal.
[CNBT] http://photonics.cnb.uam.es/ Centro Nacional de Biotecnología. Madrid.
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo ANEXO A
[TMAT] http://www.mathworks.es/products/image/ The MathWorks, Inc.
[JCHI] Blind Deconvolution Page. Julian Christou.
[KITW] http://www.kitware.com/ Kitware Inc
[FPIC] Formato Gráfico PIC. Por Fco. Mario Hernández Tejera y J. Javier Lorenzo Navarro.
7.3 Aproximación Poligonal
[CHEN] Generalized gradient vector flow external forces for active contours1 Chenyang Xu, Jerry L. Prince2,*
[JHOP] http://iacl.ece.jhu.edu/projects/gvf/ Johns Hopkins University & Image
Analysis and Communications Lab © Copyright 2002-2003
[CHXU] C. Xu, Deformable Models with Application to Human Cerebral Cortex Reconstruction from Magnetic Resonance Images, PhD Dissertation, Department of Electrical and Computer Engineering, Johns Hopkins University, Baltiomre, MD, 21218, USA.
[MKRU] http://www.acm.org/crossroads/espanol/xrds3-4/levdet.html Por Mike Krus, Patrick Bourdot,Françoise Guisnel, and Guillaume Thibault
[RVIL] Herramienta con Implementación Orientada a Objetos para Construcción de Mallados Poligonales de Volúmenes y Superficies Implícitas. Villegas R.(1), Montilla G.(2),Villegas H.(3), Bosnjak A., Torrealba V. y Paluzny M.(4)
[MKRU] http://www.acm.org/crossroads/espanol/xrds3-4/levdet.html Mike Krus is a PhD student of the Univerisity Paris XI, Orsay, France
[PKUM] http://www.ams.sunysb.edu/~piyush/ Piyush Kumar. Dept. of Mathematics,
I.I.T. Kharagpur. September 10, 1998 [CHXU] http://iacl.ece.jhu.edu/ Gradient Vector Flow Chenyang Xu and J.L. Prince
GVA-ELAI-UPMPFC0077-2003

ANEXO A Marta García Nuevo
7.4 Procesamiento distribuido
[ENZO] http://ib.cnea.gov.ar/~ipc/ Enzo A. Dari y Jorge O. Sofo. Febrero 2002.
[OPIN] Los Clusters. Por Oscar Pino Morillas, Roberto Francisco Arroyo Moreno y Francisco Javier Nievas Muñoz.
[LMUR] El Procesamiento Paralelo, Enfoque Cualitativo y Simulación. Por Leslie Murray. Escuela de Ingeniería Electrónica, Universidad Nacional de Rosario, Argentina. Mayo 26, 2000.
[KHWA] Scalable Parallel Computing de Kai Hwang y Khiwei Xu.
[SGAL] Operating System Concepts de Silberschatz Galvin.
[PHPB] http://www.linuxespanol.com/ Powered by phpBB 2.0.6 © 2001, 2002 phpBB Group
[GLUS] Guía de Linux Para el Usuario. Copyright Oc 1993, 1994, 1996. Larry Greenfield
7.4.1 MPI
[FGAR] F. García, A . Calderón, J. Carretero MiMPI: A Multithread Implementation of MPI. 6th European PVM/MPI. User’s Group Meeting, 207–214, Sep 1999.
[PMIG] F. García, J. Carretero, F. Pérez, and P. de Miguel. Evaluating the ParFiSys Cache Coherence Protocol on an IBM SP2. Technical Report FIM/104.1/datsi/98, Facultad de Informática, UPM, January 1998.
[CARA] http://www.cnb.uam.es/~carazo/practica_mpi.html#Introduccion
[MPIS] www.mpiforum.orf/docs/mpi-11.ps Message Passing Interface Forum. MPI: A Message-Passing Interface Standard. 1995.
7.4.2 Paraview [ACAL]
http://www.ibiblio.org/pub/Linux/docs/LuCaS/Presentaciones/1999hispalinux/conf-acaldero/3.pdf Alejandro Calderón, Félix García, Jesús Carretero. Octubre de 1999
[EHEL] Author: ehelp Corporation. Copyright (c) 1992-2002. http://www-vis.lbl.gov/software_support/paraview/docs/HTML/running_paraview_with_mpi.htm
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo ANEXO A
[PARA] http://www.paraview.org
[LBER] http://www-vis.lbl.gov/software_support/paraview/ The Visualization Group at Lawrence Berkeley National Laboratory. Jun-2003.
7.4.3 OpenMosix
[MCAT] http://www.redes-linux.com/manuales/cluster/howTo-openMosixES_0.4beta.pdf .Inspirado en el HOWTO de Kris Buytaert
[KERN] http://kernel.org/pub/. This site is operated by the Kernel.Org Organization.
[NO3D] Noticias3D.com, (c)2000-2003. http://www.noticias3d.com/articulos/200305/cluster/2.asp
7.4.4 Mpich
[DASH] Installation and User´s Guide to MPICH, by David Ashton, William Gropp, and Ewing Lusk
[MPIC] http://www-unix.mcs.anl.gov/mpi/mpich/
GVA-ELAI-UPMPFC0077-2003

ANEXO A Marta García Nuevo
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo ANEXO B
8 Índice de figuras
8.1 Estado de la Técnica.
Figura 2.1: Imagen del confocal
Figura 2.2: Esquema del microscopio confocal
Figura 2.3: Microscopio confocal real
Figura 2.4: Ejemplo del uso de luces
Figura 2.5: Imagen de barrido de un cultivo de células epiteliales
Figura 2.6: E. Coliteñidas con cloruro de propidio, para observar la condensación del cromosoma.
Figura 2.7: Visualización de un organismo en una célula huésped.
GVA-ELAI-UPMPFC0077-2003

ANEXO B Marta García Nuevo
Figura 2.8: Dos tipos de células vistas en planos diferentes.
Figura 2.9: Ejemplo del tipo de filtrado, fotógrafo.
Figura 2.9: Ejemplo del tipo de filtrado, estrellas.
Figura 2.10: Demo de la reducción del ruido con Matlab .
Figura 2.11: Ejemplo de aproximación poligonal de una superficie.
Figura 2.12: Modelado de una superficie.
Figura 2.13: Mallado de una superficie.
Figura 2.14: Aproximación de un contorno.
Figura 2.15: Visualización de una figura obtenida por Aproximación Poligonal.
Figura 2.16: Sistemas distribuidos. Escalabilidad de servicios.
Figura 2.17: Cluster a nivel de sistema y nivel de aplicación
Figura 2.17: Logo de openMosix
Figura 2.19: Logo de Linux
Figura 2.20: Logo de Linux
8.2 Herramientas de Visualización
Figura 3.1: Logo Matlab
Figura 3.2: Ejemplo de pantalla de Matlab
Figura 3.3: Logo VTK
Figura 3.4: Figura procesada con VTK.
Figura 3.5: Figura procesada con VTK.
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo ANEXO B
Figura 3.6: Logo SDC.
Figura 3.7: Imagen binarizada y dilatada.
Figura 3.8: Imagen procesada con VTK.
Figura 3.9: Logo OpenMosix.
Figura 3.10: Logo ParaView
Figura 3.11: Ejemplo imagen con tratada con SDC.
Figura 3.12: Logo MPI
Figura 3.13: Logo MPI Reserch.
8.3 Procesamiento
Figura 4.1: Cabecera de los archivos *.PIC
Figura 4.2: Selección de una ROI
Figura 4.3: ROI de nuestra imagen
Figura 4.4: Imagen original del microscopio confocal
Figura 4.5: Imagen original abierta con ‘mmshow’.
Figura 4.6: Dilatación condicionada
Figura 4.7: Dilatación normal
Figura 4.8: Resultado usando SDC
Figura 4.9: Imagen 3D abierta con VTK
Figura 4.10: Volumen renderizado
Figura 4.11: Superficie renderizada
Figura 4.12: Imagen 3D obtenida con ‘openpic.m’
GVA-ELAI-UPMPFC0077-2003

ANEXO B Marta García Nuevo
Figura 4.13: Workspace de Matlab
Figura 4.14: Current Directory de Matlab
Figura 4.15: 10 lonchas del archivo *.PIC
Figura 4.16: Pantalla al ejecutar el programa ‘openpic.m’
Figura 4.17: Resultado de ‘openpic3D.tcl’
Figura 4.18: Resultado de ‘picsuper.m’
Figura 4.19: Resultado de ‘opensup.m’
Figura 4.20: Resultado de ‘opensupbw.m’
Figura 4.21: Resultado de ‘opensupbw.m’
8.4 Aproximación Poligonal
Figura 5.1: Una sucesión de LODs
Figura 5.2: Usando LODs para objetos distantes.
Figura 5.3: Geometría de la Remoción
Figura 5.4: Subdivisión Adaptativa
Figura 5.5: Sampling
Figura 5.6: Cuatro pasos en el algoritmo MRA
Figura 5.7: Ejemplo de un Malla Progresiva
Figura 5.8: Construyendo sobres internos y externos para un triángulo
Figura 5.9: La construcción y el mantenimiento del volumen de tolerancia
Figura 5.10: Pasos en el Algoritmo de Simplificación de Malla Inspirado por A6.
Figura 5.11: Ejemplo de localización de concavidades divisorias
GVA-ELAI-UPMPFC0077-2003

Marta García Nuevo ANEXO B
Figura 5.12: Contornos subjetivos
Figura 5.13: Imágenes en escala de grises
Figura 5.14: Superficies deformables tridimensionales
Figura 5.15: Lista de píxeles del contorno de la imagen
Figura 5.16: Aproximación con poca exactitud de la rodaja 5
Figura 5.17: Aproximación con poca exactitud de la rodaja 35
Figura 5.18: Workspace de Matlab
Figura 5.19: Current Directory de Matlab
Figura 5.20: Ejecución del programa ‘puntos 3D2’ en Matlab
Figura 5.21: Sucesión de imágenes creadas por ‘Puntos3D2.m’
Figura 5.22: Aproximación rodaja 2
Figura 5.23: Aproximación de la rodaja 11
Figura 5.24: Aproximación de la rodaja 35
Figura 5.25: Aproximación de la rodaja 44
Figura 5.26: Aproximación de la rodaja 57
Figura 5.27: Aproximación de la rodaja 66
8.5 Aproximación Poligonal
Figura 6.1: Cluster como cúmulo de PCs
Figura 6.2: Cluster como cúmulo de PCs
Figura 6.3: Logo de Linux
Figura 6.4: Logo de OpenMosix
GVA-ELAI-UPMPFC0077-2003

ANEXO B Marta García Nuevo
Figura 6.5: Principio del test: sin migración
Figura 6.6: Test al cabo de unos instantes: comienza la migración
Figura 6.7: Visualización del proceso con mosmon
Figura 6.8: Visualización de la velocidad con mosmon
Figura 6.9: Visualización de la memoria con mosmon
Figura 6.10: Visualización del uso con mosmon
Figura 6.11: Pantalla de inicio de ParaView
Figura 6.12: Ejemplo funcionamiento de ParaView
Figura 6.13: MPICH Configuration tool
Figura 6.14: Ejemplo de MPICH Configuration tool
Figura 6.15: MPICH Update tool
Figura 6.16: Ventana de selección de nodos
Figura 6.17: MPICH Job manager
Figura 6.18: guiMPIRun
Figura 6.19: Ventana de usuario y contraseña
GVA-ELAI-UPMPFC0077-2003


















