
Estudio comparativo de medidas de distancia para ...
56
UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA M´ aster Oficial en Sistemas Inteligentes y Aplicaciones Num´ ericas en Ingenier´ ıa Estudio comparativo de medidas de distancia para histogramas en problemas de reidentificaci´ on Pedro Antonio Mar´ ın Reyes Tutores: Jos´ e Javier Lorenzo Navarro Modesto Fernando Castrill´ on Santana Enero de 2015
Transcript of Estudio comparativo de medidas de distancia para ...

UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIAMaster Oficial en Sistemas Inteligentes y Aplicaciones Numericas en
Ingenierıa
Estudio comparativo de medidas de distancia parahistogramas en problemas de reidentificacion
Pedro Antonio Marın Reyes
Tutores: Jose Javier Lorenzo NavarroModesto Fernando Castrillon Santana
Enero de 2015


No dejes para manana lo que puedas hacer hoy
1

2

Agradecimientos
A mi familia que me ha tenido que aguantar con mis jaquecas y comentariosde conceptos que desconocıan, pero que poco a poco han llegado a compren-der ciertos puntos. Como tambien a mi pareja que me ha apoyado en todomomento con las decisiones que he tomado y el interes que ha mostradocuando le he ensenado un sinfın de graficas y tablas.
A mis amigos a los cuales les he expuesto el presente trabajo y hemos in-tercambiado experiencias de nuestros proyectos. Como tambien me gustarıaagradecer a cualquier posible lector que se muestre congratulado con el pre-sente trabajo que ha requerido su esfuerzo y dedicacion.
Y por ultimo y no menos importante a mis tutores, por la ayuda ofrecida y labuena planificacion de las reuniones, que han resultado bastante utiles parallevar a cabo el trabajo, ya que nos reuniamos en conjunto para contrastarinformacion, ver posibles erratas y compartir toda la informacion posibleentre nosotros. Cabe decir que son muy buenos gestores y se respira un buenambiente en el grupo de trabajo.
3

4

Indice general
1. Objetivos 13
2. Introduccion 152.1. Vision por computador . . . . . . . . . . . . . . . . . . . . . . 152.2. Reidentificacion . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3. Espacio de color . . . . . . . . . . . . . . . . . . . . . . . . . . 182.4. Histograma . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.5. Distancia entre histogramas . . . . . . . . . . . . . . . . . . . 22
3. Metodologıa 253.1. Bases de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.2. Diseno del experimento . . . . . . . . . . . . . . . . . . . . . . 273.3. Division mediante franjas . . . . . . . . . . . . . . . . . . . . . 293.4. Implementacion . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4. Resultados 334.1. Espacio de color . . . . . . . . . . . . . . . . . . . . . . . . . . 344.2. Numero de bins . . . . . . . . . . . . . . . . . . . . . . . . . . 354.3. Numero de franjas . . . . . . . . . . . . . . . . . . . . . . . . 374.4. Otras caracterısticas analizadas . . . . . . . . . . . . . . . . . 39
5. Conclusiones y lıneas futuras 43
Bibliografıa 46
Glosario 47
A. Anexo 49
5

6 INDICE GENERAL

Indice de figuras
2.1. Procesos en sistema de vision por computador. . . . . . . . . . 152.2. Imagenes de individuos captadas por dos camaras diferentes. . 162.3. Areas de conocimiento en reidentifiacion. Tomada de [Vezzani et al., 2013]. 172.4. Ejemplo de espacios de color. RGB y HSV. . . . . . . . . . . . 182.5. A Conjunto de valores; H(A) Histograma correspondiente a A. 212.6. Comparacion de histogramas. (A) Corresponde con la compa-
racion de dos histogramas y (B) Corresponde a la comparacionde dos histogramas similares a (A) pero con un bin mas quetiene valor nulo. . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1. Grupo de bases de datos. Tomada de [DENG et al., 2014]. . . 263.2. Curva CMC. Eje de abscisas representa posicion de reidenti-
ficacion y el eje de ordenadas representa la probabilidad deaparecer el probe en la posicion correspodiente. . . . . . . . . 28
3.3. Estructura del individuo. . . . . . . . . . . . . . . . . . . . . . 293.4. Etiquetado de imagen. (A) representa el identificador del pro-
be y (B) hace referencia numero de imagen tomada para elprobe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.1. Area CMC para distancias y espacio color. . . . . . . . . . . . 354.2. Area CMC para distancias y numero de bins. . . . . . . . . . 364.3. Area CMC para distancias y numero de franjas. . . . . . . . . 384.4. Rendimiento en horas para numero de bins y numero de franjas. 394.5. Area CMC para numero de franjas y numero de bins. . . . . . 404.6. Area CMC para espacio de color y numero de bins. . . . . . . 414.7. Area CMC para espacio de color y numero de franjas. . . . . . 42
7

8 INDICE DE FIGURAS

INDICE DE TABLAS
3.1. Comparativa de las bases de datos empleadas con numero deindividuos, resolucion (pıxeles) e imagen escalada. . . . . . . . 27
4.1. Area CMC de las distancias frente espacios de color . . . . . . 35
4.2. Area CMC de las distancias frente numero de bins . . . . . . . 36
4.3. Area CMC de las distancias frente numero de franjas . . . . . 38
4.4. Tiempo ejecucion. Numero de bins frente numero de franjas. . 40
4.5. Area CMC para numero de bins y numero de franjas. . . . . . 41
4.6. Area CMC para numero de bins de la imagen y espacio de color. 42
4.7. Area CMC para divisiones de la imagen y espacio de color. . . 42
5.1. Propuesta de configuracion inicial. . . . . . . . . . . . . . . . . 43
A.1. Porcentaje promedio del area bajo la curva CMC para 16 binse imagen completa. Espacios de color frente a distancias . . . 49
A.2. Porcentaje promedio del area bajo la curva CMC para 32 binse imagen completa. Espacios de color frente a distancias . . . 49
A.3. Porcentaje promedio del area bajo la curva CMC para 64 binse imagen completa. Espacios de color frente a distancias . . . 50
A.4. Porcentaje promedio del area bajo la curva CMC para 128bins e imagen completa. Espacios de color frente a distancias . 50
A.5. Porcentaje promedio del area bajo la curva CMC para 16 binse imagen dividida en 5 franjas. Espacios de color frente a dis-tancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
A.6. Porcentaje promedio del area bajo la curva CMC para 32 binse imagen dividida en 5 franjas. Espacios de color frente a dis-tancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
A.7. Porcentaje promedio del area bajo la curva CMC para 64 binse imagen dividida en 5 franjas. Espacios de color frente a dis-tancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
9

10 INDICE DE TABLAS
A.8. Porcentaje promedio del area bajo la curva CMC para 128bins e imagen dividida en 5 franjas. Espacios de color frente adistancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
A.9. Porcentaje promedio del area bajo la curva CMC para 16 binse imagen dividida en 10 franjas. Espacios de color frente adistancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
A.10.Porcentaje promedio del area bajo la curva CMC para 32 binse imagen dividida en 10 franjas. Espacios de color frente adistancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
A.11.Porcentaje promedio del area bajo la curva CMC para 64 binse imagen dividida en 10 franjas. Espacios de color frente adistancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
A.12.Porcentaje promedio del area bajo la curva CMC para 128bins e imagen dividida en 10 franjas. Espacios de color frentea distancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
A.13.Porcentaje promedio del area bajo la curva CMC para 16 binse imagen dividida en 25 franjas. Espacios de color frente adistancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
A.14.Porcentaje promedio del area bajo la curva CMC para 32 binse imagen dividida en 25 franjas. Espacios de color frente adistancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
A.15.Porcentaje promedio del area bajo la curva CMC para 64 binse imagen dividida en 25 franjas. Espacios de color frente adistancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
A.16.Porcentaje promedio del area bajo la curva CMC para 128bins e imagen dividida en 25 franjas. Espacios de color frentea distancias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54

Resumen
El presente trabajo se desarrolla en el campo de la vision por computador,mas concretamente en el area de reidentificacion, donde se pretende realizarun estudio del comportamiento al que las medidas de distancia entre his-togramas se encuentran afectadas ante diversos espacios de color, numerode franjas de la imagen y numero de bins del histograma. Se realizaran laspruebas en varias bases de datos de imagenes. Nos planteamos si existe unamedida de distancia entre histogramas que destaque sobre las demas, ası mis-mo tambien si hay un espacio de color, un determinado numero de franjas oun numero de bins que presente mejores caracterısticas de discriminacion.
Se plantea para cada base de datos realizar una normalizacion de la estructurapara poder validar si un individuo puede ser identificado en otra/s vistas quepueden corresponder con diferentes momentos o camaras. Se disenaran yrealizaran varios experimentos comparando los resultados obtenidos con lasdiferentes configuraciones de los parametros considerados.
Con las medidas de distancia entre histogramas se procedera a la realizacionde un ranking con lo que calcularemos el area bajo la CMC. Este area serael indicador que usaremos para validar si una medida de distancia es mejorque otra y comprobar si hay diferencias entre los distintos espacios de color,numero de franjas y numero de bins.
11

12 Resumen

Capıtulo 1
Objetivos
Como hipotesis inicial de trabajo nos hemos planteado si es posible encontraralguna medida de distancia para la comparacion de histogramas que muestreun mejor comportamiento en tareas de reidentificacion. Se espera obtenermejores resultados en las medidas de cross-bin que en las de bin to bin,ya que en las primeras se tiene encuenta el valor adyacente al que se estatratando y en la de bin to bin solo se tiene encuenta el valor que se trata.
Mientras se trabajaba en la hipotesis anterior han ido surgiendo nuevashipotesis para trabajar en ellas, por ejemplo, dividir la imagen en variasfranjas, con lo que se pretende deducir si la division de la imagen mejoralos resultados, con lo que se espera obtener mejores resultados conforme sedivide la imagen en franjas. Es necesario comprobar si existe algun punto desaturacion en este proceso, es decir, si con el aumento del numero de franjasllega un momento que no mejoren los resultados.
Ademas de evaluar si hay algun espacio de color que sea el mejor para eltratamiento de las imagenes. Se compararan varios espacios de color quetienen propiedades distintas gracias a las transformaciones que se emplean.
La ultima hipotesis que surge es si influye el agrupamiento del histogramaen un numero de bins determinado. Se espera que a menor numero de bins,por tanto en un mismo bin se agrupan diferentes colores, peores sean losresultados obtenidos.
13

14 Objetivos

Capıtulo 2
Introduccion
En este apartado lo que se pretende es dar a conocer ciertas nociones que sevan a ir argumentando a lo largo del trabajo. Donde se explicaran de formadetallada y concisa los conceptos que vamos a abarcar.
2.1. Vision por computador
De acuerdo a [Jimenez, 2000], vision por computador es un ”proceso de ex-traccion de informacion del mundo fısico a partir de imagenes, utilizando paraello un computador”, vease figura 2.1. Este area pretende construir sistemasque sean capaces de emular al sistema de vision humano.
Los principales problemas a los que estan afectados un proceso de vision porcomputador son la iluminacion de la escena, las caracterısticas del hardwarede obtencion y la forma de los objetos.
Figura 2.1: Procesos en sistema de vision por computador.
15

16 Introduccion
Este Trabajo de Fin de Master (TFM) se centra en concreto en la reidenti-fiacion.
2.2. Reidentificacion
Actualmente gracias al abaratamiento de los sensores y de procesadores paracamaras de vıdeo, en las ciudades o sitios publicos como en centros comer-ciales se estan extendiendo las redes de camaras de videovigilancia. Estascamaras pueden ser utiles a la hora de localizar personas desaparecidas, elseguimiento de ladrones, deteccion de accidentes, seguimiento de medios detransporte, etc. Los escenarios pueden ser muy variados, se podrıan dividir enzonas de interior y zonas de exterior como un hospital o autopista respectiva-mente. Estos sistemas de vigilancia acumulan gran cantidad de informacionla cual se podrıa extraer. La reidentificacion manual puede ser inviable enciertos escenarios, por eso surgen sistemas inteligentes para la reidentificacion[Wang, 2013].
Figura 2.2: Imagenes de individuos captadas por dos camaras diferentes.
De acuerdo a [Gong et al., 2014], el concepto de reidentificacion se definecomo la tarea fundamental para un sistema de camaras distribuidas o no,con las que se realiza una asociacion de las personas a traves de las imagenescaptadas por estas en cierta localizacion y tiempo. A continuacion se van adefinir dos conceptos que posteriormente se van a emplear, en el ambito de lareidentificacion. Se denomina probe al individuo identificado que se pretendereidentificar. Por otro lado, gallery alude al conjunto de individuos dondese va a realizar la busqueda. Como se puede apreciar en la ecuacion (2.1),se define formalmente la tarea de reidentificacion, donde T es el individuo

2.2. REIDENTIFICACION 17
reidentificado del gallery τ = {T1, ..., Tn} buscando probe Q. D() es unamedida de similitud.
T = argminTiD(Ti, Q), Ti ∈ τ (2.1)
La figura 2.2 muestra ejemplos de pares de imagenes del mismo individuocaptadas en dos camaras diferentes en distintos instantes de tiempo. Estoprovoca que las imagenes esten afectadas por ruido proveniente del entorno,ya sea brillo o sombras, por el angulo en el que se haya captado las imagenes,por el desplazamiento del individuo o por el tamano en el que se capturolas imagenes. El factor tiempo afecta a los resultados, se obtienen mejoresresultados cuando las imagenes son temporalmente proximas. Al no habermucha diferencia de tiempo, la probabilidad de que la persona haya cambiadode apariencia es menor.
Figura 2.3: Areas de conocimiento en reidentifiacion. Tomada de[Vezzani et al., 2013].
Existen diferentes parametros que se deben considerar en un problema dereidentificacion, ver figura 2.3. Esta ordenada por tipologıa, representadapor cada dimension de la figura, dentro de esta se encuentra cada elementoordenado de menor complejidad a mayor.
A la hora de abordar el problema de reidentificacion hay que tener en cuentaciertas caracterısticas del problema que se va a tratar. La primera constarıade la configuracion de la camara, el formato en el que se recoge la informaciony la situacion de las camaras. Pudiendo usarse una sola camara, multiplescamaras que estan solapadas, camaras calibradas y sin solapamiento o en elpeor de los casos camaras sin calibrar y sin solapamiento. Otra caracterısticaa tener en cuenta es si se posee un amplio conjunto de probe, pudiendo ser esteel caso mas simple a la hora de realizar reidentificacion porque por ejemplo

18 Introduccion
se podrıa tomar valores promedio de las capturas del probe. Si se dispone deuna sola imagen del probe y una imagen de cada persona en el gallery, seestarıa en un escenario single shot, mientras que si se dispone de conjuntosde imagenes obtenidas de un video tanto en el probe como en el gallery, elescenario serıa multiple shot. Otra caracterıstica fundamental es el escenariodonde se aplica la reidentificacion, no es lo mismo obtener las descripcionesde una imagen en un espacio cerrado donde las imagenes capturadas son acorta distancia que en la calle donde el tamano de la persona en la imagen esmenor y no nos permitirıa obtener de forma adecuada las descripciones delindividuo.
A la hora de describir los individuos hay que tener en cuenta los descripto-res que se calculan de los individuos. Ası, estos descriptores pueden basarseen color, forma, textura, posicion o descripciones biometricas. Este trabajose enmarca en la dimension del conjunto de caracterısticas, mas especıfica-mente en descriptores basados en color [Satta, 2013], donde existen multiplesespacios de color con sus cualidades respecto a la luminancia y crominancia.
2.3. Espacio de color
Segun el libro [Acharya and Ray, 2005], hay una serie de espacios de color,los cuales poseen su propio sistema de coordenadas de color, cada punto enel sistema de coordenadas representa un color diferente. Existe una ampliavariedad de modelos de color, poseen caracterısticas que los hacen utiles endeterminados tipos de problemas.
Figura 2.4: Ejemplo de espacios de color. RGB y HSV.
Los espacios de color que se suelen emplear en el ambito de vision por compu-tador son:

2.3. ESPACIO DE COLOR 19
RGB (Red Green Blue) : Es el tıpico espacio de color que se encuentraen cualquier dispositivo, lo conforman 3 canales (rojo, verde y azul)donde la luminancia y la crominancia no se encuentran por separado,lo ideal serıa poder desacoplar el factor de iluminacion del color paraanalizar las imagenes. Normalmente cada canal esta formado por 8 bits.No es un espacio perceptualmente uniforme. Colores distantes no sonpercibidos como tal, y a la inversa.
HSV (Hue Saturation Value) : Este espacio de color se compone portres canales que caracterizan a la tonalidad (H), saturacion (S) y valor(V). Es una transformacion no lineal del espacio de color RGB. veaseecuacion (2.2).
H =
no definido si MAX = MIN60o G−B
MAX−MIN+ 0o si MAX = R y G ≥ B
60o G−BMAX−MIN
+ 360o si MAX = R y G < B
60o G−RMAX−MIN
+ 120o si MAX = G
60o R−GMAX−MIN
+ 240o si MAX = B
S =
{0 si MAX = 01− MIN
MAXen otro caso
V = MAX
(2.2)
donde: MAX: Valor maximo de RGB y MIN : Valor mınimo de RGB.
CIELAB : Proviene de CIE (Commission Internationale de l’clairage),L (Lightness) y A y B para la dimension de color oponente. Se pretendeque CIELAB sea un espacio de color lineal. La transformacion de RGBa CIELAB aparece en la equacion (2.3).

20 Introduccion
X = 0,412453R + 0,357580G+ 0,180423BY = 0,212671R + 0,715160G+ 0,072169BZ = 0,019334R + 0,119193G+ 0,950227B L∗ = 116f(Y/Yn)− 16a∗ = 500(f(X/Xn)− f(Y/Yn))b∗ = 200(f(Y/Yn)− f(Z/Zn))
f(q) =
{q
13 si q > ( 6
29)3
13(296
)2q + 429
en otro caso
(2.3)
donde:
Xn, Yn y Zn son los valores del punto blanco de referencia definido porel estandar CIE de iluminacion.
YCbCr: Este espacio de color se compone por una componente de lu-minosidad (Y) y dos componentes de color (Cb y Cr), que representanla crominancia en azul y en rojo. La transformacion de RGB a YCbCraparece en la ecuacion (2.4).
YCb
Cr
=
16128128
+
65,481 128,553 24,966−37,797 −74,203 112
112 −93,786 −18,214
RGB
(2.4)
Comunmente es necesario la discretizacion de los valores de color de lasimagenes, esto genera una perdida de la informacion pero se gana veloci-dad a la hora de realizar computo. Una posible forma de recoger los valoresdiscretizados es a partir de un histograma de color.
A la hora de tratar las imagenes podrıa ser a nivel de pıxel donde se posee lo-calidad espacial de esta, o se podrıa obtener el histograma de la imagen, estemetodo tiene como objetivo obtener las cualidades cuantitativas de la ima-gen. A pesar de perder informacion de la imagen, se emplea con frecuencia es-te metodo como descriptores cuando se basa la reidentificacion en apariencia.[Seon et al., 2011, Cha and Srihari, 2002, Naik et al., 2009, Ling and Okada, 2006].

2.4. HISTOGRAMA 21
2.4. Histograma
Un histograma representa el numero de ocurrencias de los valores de unconjunto de datos, haciendo referencia a la ecuacion (2.5). En el tratamientode imagenes se emplean histogramas para obtener informacion cuantitativa,la distribucion del color en la imagen.
Hi(A) =n∑
j=1
cij donde cij =
{1 si aj = xi0 en otro caso
(2.5)
Algunas caracterısticas de los histogramas son las siguientes:
No contiene informacion espacial de la imagen
Dos imagenes diferentes pueden coincidir en histograma
La imagen no se puede obtener a partir de un histograma
La figura 2.5 representa un conjunto de datos y el histograma que se obtiene apartir del conjunto. Para el caso de vision por computador el conjunto repre-sentarıa la imagen con los valores de cada pıxel. En el histograma resultantese aprecia como se distribuyen los datos. A su vez, se puede simplificar demayor manera obteniendo divisiones resultantes que aglutinen varias divisio-nes iniciales, el bin serıa cada una de los intervalos en los que esta divididoel rango de valores de la medida que representa el histograma.
Figura 2.5: A Conjunto de valores; H(A) Histograma correspondiente a A.
A la hora de trabajar con histogramas, una buena practica es realizar unanormalizacion, se suele normalizar como funcion de probabilidad, ver ecua-cion (2.6). Esta tarea de preprocesado se lleva a cabo para llevar a un planocomun cualquier distribucion sin importar el numero de elementos que ten-gan.

22 Introduccion
H ′(A) =H(A)∑ni=1Ai
donden∑
i=1
H(A) = 1 (2.6)
Existe la necesidad de comparar histogramas para conocer como de similaresson, como se identifico en (2.1), por este motivo se hace uso de distintos tiposde medidas de distancias para histogramas.
2.5. Distancia entre histogramas
Citando [rae, 2014], ”una distancia la definen por un espacio o intervalo delugar o de tiempo que media entre dos cosas o sucesos”, pudiendo ser tambien”la diferencia, desemejanza notable entre unas cosas y otras”.
Una definicion mas formal es la siguiente, como una funcion de distanciad(x, y) definida en un espacio de dimension Rn, es una funcion d : Rn×Rn →R, debe cumplir las siguientes propiedades:
d(x, y) ≥ 0
d(x, x) = 0
d(x, y) = d(y, x)
Si ademas cumple:
d(x, y) = 0 iff x = y
d(x, y) ≤ d(x, k) + d(k, y)
Se dice que es una distancia metrica.
A la hora de calcular la distancia entre dos histogramas hay que tener en cuen-ta que distancia o conjunto de distancias son las que nos podrıan interesar,ya que cada distancia cumple con unas propiedades o serie de caracterısti-cas que las definen. Hay dos grupos de medidas, bin to bin y cross-bin. Elprimer grupo se centra en la comparacion del contenido del bin con el co-rrespondiente del segundo histograma, no aprovechan la informacion de losbins adyacentes. El segundo grupo hace enfasis en los valores adyacentes albin que corresponde a ser tratado.
Dependiendo de la medidas que se empleen se pueden obtener valores dis-tintos para histogramas que son aparentemente similares. Vease figura 2.6,

2.5. DISTANCIA ENTRE HISTOGRAMAS 23
Figura 2.6: Comparacion de histogramas. (A) Corresponde con la compara-cion de dos histogramas y (B) Corresponde a la comparacion de dos histo-gramas similares a (A) pero con un bin mas que tiene valor nulo.
dependiendo de la distancia que se emplee (A) tendra valor equivalente a (B)o no.
Algunas medidas comunmente usadas en distancias entre histogramas:
Bhattacharyya [Naik et al., 2009]: Es una medida del tipo bin to bin,la cual mide la similitud de dos distribuciones de probabilidad. Poseeuna complejidad computacional O(n).
Bhattacharyya(x, y) = 1−
√√√√ n∑i=1
√xiyi√∑n
i=1 xi∑n
i=1 yi(2.7)
Chi Cuadrado [Zhang and Canosa, 2014]: Es una medida del tipo binto bin, la cual tiene origen estadıstico. Posee una complejidad compu-tacional O(n).
X2(x, y) =1
2
n∑i=1
(xi − yi)2
(xi + yi)(2.8)
Correlacion [his, 2014]: Es una medida bin to bin, la cual refiere auna relacion estadıstica que implica dependencia[wik, 2014]. Posee unacomplejidad computacional O(n).
correlation(x, y) =
∑ni=1(xi − x)(yi − y)√∑n
i=1(xi − x)2∑n
i=1(yi − y)2(2.9)
Interseccion [Zhang and Canosa, 2014]: Es una medida del tipo bin tobin, la cual proviene de la interseccion de los dos histogramas. Esta me-dida tiene un alto rendimiento computacional. Posee una complejidadcomputacional O(n).
intersec(x, y) =n∑
i=1
min(xi, yi) (2.10)

24 Introduccion
KL [Liu and Shum, 2003]: Kullback-Leibler divergencia es una medidadel tipo bin to bin, la cual tiene origen en el area de la teorıa de la infor-macion, es una medida que no cumple con la propiedad de simetrıa. Enel segundo histograma no pueden haber bins con valor cero ya que es-to provoca una indeterminacion. Posee una complejidad computacionalO(n).
KL(x, y) =n∑
i=1
xi logxiyi
(2.11)
EMD [Zhang and Canosa, 2014]: Earth mover’s distance es una medidadel tipo cross-bin, la cual se define por el coste mınimo que deberıamospagar por transformar un histograma en el otro. Posee una complejidadcomputacional O(n3 log n).
EMDD(x, y) = minF={Fij}
∑i,j FijDij∑
i Fij
s.t :∑j
Fij ≤ xi∑i
Fij ≤ yj∑i,j
Fij = min(∑i
xi,∑j
yj)
Fij ≥ 0
(2.12)
Mahalanobis [Huang et al., 2010]: Es una medida del tipo cross-bin,la cual es la distancia entre un punto y una distribucion. Posee una
complejidad computacional O(
n(n−1)2
).
Mahalanobis(x, y) =
√(x− y)
1
S(x− y) (2.13)
donde:
S = Matriz de covarianza

Capıtulo 3
Metodologıa
En este apartado se va a exponer la metodologıa que se siguio para el desa-rrollo del estudio realizado en este TFM. Primero se realizara la definicionde los conjuntos en los que se van a realizar las pruebas, en segundo lugar seexpondra la planificacion del experimento. Y por ultimo se van a comentarlos indicadores que se van a utilizar para comparar los resultados obtenidospara las diferentes configuraciones estudiadas.
3.1. Bases de datos
Actualmente existe en la red un amplio abanico de bases de datos de image-nes, ya sean de personas a cuerpo entero, solo el rostro, ojos, huellas dactila-res, etc. Las bases de datos de imagenes surgen ante la necesidad de tener unaestructura de datos donde almacenar imagenes para que usuarios o investiga-dores las pueden utilizar para probar los algoritmos que han implementado.De esta forma se puede saber si el metodo que se ha desarrollado supera elestado del arte actual en cierta base de datos, evitando que los resultados nopuedan ser comparables si se utilizan conjuntos diferentes de imagenes.
Cada base de datos tiene sus propias caracterısticas, unas pueden estar afec-tadas por ruido, la camara con la que se adquirio las imagenes tienen suspropias caracterıstica, las imagenes pueden tener mucha variacion en ilumi-nacion o sombras. Por estos motivos es recomendable probar los algoritmosen varias bases de datos y obtener la tasa de acierto o la CMC (CumulativeMatch Curve) promedio.
A continuacion se listaran las bases de datos empleadas:
25

26 Metodologıa
Figura 3.1: Grupo de bases de datos. Tomada de [DENG et al., 2014].
CAVIAR4REID: Esta base de datos [cav, 2014] proviene del proyec-to CAVIAR que tiene por objetivo la investigacion de metodos paraextraccion de caracterısticas, segmentacion, integracion de funcionesvariando la localizacion y el momento de adquisicion, representaciony reconocimiento de objetos y situaciones, aprendizaje de evidenciasvisuales y control reactivo del proceso de reconocimiento.
La base de datos que se emplea tiene 1220 individuos de los cuales 72son probes, con resolucion comprendida entre 17x39 a 72x141 pıxeles,donde la camara apunta hacia el suelo, con puntos de vista variable delas personas con baja iluminacion.
i-LIDS: Forma parte de un conjunto de bases de datos utilizadas porel gobierno ingles para el analisis de sistemas de vıdeo. Ha sido desa-rrollado por el Centro de Ciencias Aplicadas y Tecnologıa (CAST) encolaboracion con el Centro para la Proteccion de la InfraestructuraNacional (IREC)[ili, 2014].
La base de datos que se emplea tiene 477 individuos de los cuales 119son probes, con resolucion comprendida entre 32x76 a 115x294 pıxeles,donde el punto de vista es la espalda y el perfil de las personas con altailuminacion.
VIPeR: Es una base de datos con multiples puntos de vista y variacionde luminosidad para que cumpla con los requisitos a los que se venafectado los sistemas de vigilancia modernos.[vip, 2007]
El conjunto de datos que se emplea tiene 1264 individuos de los cuales

3.2. DISENO DEL EXPERIMENTO 27
632 son probes, con resolucion de 48x128 pıxeles, donde el punto devista de las personas es variado con iluminacion cambiante.
QMUL GRID: Es una base de datos donde se han captado las imagenesen una estacion de metro con mucha afluencia de personas, se han hechouso de 8 camaras.[gri, 2014]
El conjunto de datos que se emplea tiene 1275 individuos de los cuales25 son probes con resolucion de 48x128 pıxeles, donde el punto de vistade las personas es frontal y de espalda con poca iluminacion.
Base de datosNumero deindividuos
Resolucion Imagen
CAVIAR4REID 1220 17x39 a 72x141
i-LIDS 477 32x76 a 115x294
VIPeR 1264 48x128
QMUL GRID 1275 48x128
Cuadro 3.1: Comparativa de las bases de datos empleadas con numero deindividuos, resolucion (pıxeles) e imagen escalada.
3.2. Diseno del experimento
Basandonos en la hipotesis de trabajo inicial del capıtulo 1, queremos conocersi existe alguna medida de distancia para histogramas que muestre mejorresultado sobre las demas, para estudiar el comportamiento de las medidasvamos a considerar diferentes parametros que pueden afectar a las mismas,como son: Espacio de color, la division en franjas de una imagen y el uso de

28 Metodologıa
un determinado numero de bin en el histograma, vease figura 3.3. Intentamosgeneralizar los resultados haciendo uso de varias bases de datos donde hemosempleado un tamano de imagen de 50x50.
A continuacion se plantea la configuracion de los parametros que se van aanalizar en el desarrollo de este experimento:
Medidas: Bhattacharyya, Chi Cuadrado, Correlacion, EMD, Intersec-cion, Mahalanobis y Kullback-Leibler
Espacios de color: RGB, HSV y CIELAB
Franjas en las que se divide la imagen: Imagen completa, 5 franjas, 10franjas y 25 franjas
Numero de bin para el histograma: 16, 32, 64 y 128
Bases de datos: CAVIAR4REID, i-LIDS, VIPeR, QMUL GRID
Figura 3.2: Curva CMC. Eje de abscisas representa posicion de reidentifica-cion y el eje de ordenadas representa la probabilidad de aparecer el probe enla posicion correspodiente.
Como indicador de rendimiento se va a hacer uso del area bajo la CMC,esta curva se emplea en reidentificacion de manera habitual a la hora decorroborar los resultados[Bolle et al., 2005]. Para calcular la CMC hay queordenar de mayor similitud a menor los individuos del gallery para cadaprobe, a partir de estas listas generadas hay que comprobar en que posicionaparece su respectivo probe, cada aparicion se acumula en su correspondienteposicion. Por ultimo se divide cada elemento entre el numero de probes y

3.3. DIVISION MEDIANTE FRANJAS 29
se genera la grafica a partir de estos valores como la acumulacion de loselementos anteriores.
Lo ideal serıa obtener en la primera posicion el 100 %, esto representarıaque para cada probe, el metodo lo encontro en la primera posicion o que elmas similar de todo el gallery era el individuo correspondiente al probe. Enla figura 3.2 se muestra un ejemplo de CMC. Para obtener un valor que sepueda comparar hacemos uso del area bajo la CMC.
Sintetizando, se van a emplear varias bases de datos donde se van a probarmultiples configuraciones para las medidas de distancia entre histogramasconsideradas en este trabajo y que se introdujeron en el capıtulo 2.
3.3. Division mediante franjas
Una aproximacion inicial a la hora de trabajar con histogramas de colores obtener el histograma a la imagen completa. El principal problema esque se pierde especificidad de la imagen, no se podrıan distinguir pequenasvariaciones sobre variaciones importantes de la imagen. Por este motivo sesuele dividir la imagen en franjas.
Figura 3.3: Estructura del individuo.
La division del individuo en franjas [Avraham et al., 2012] o en seccionespuede ser una metodologıa con la que obtener buenos resultados. Se mejoranlos resultados porque se obtiene una distribucion del color local, es afectadaen menor medida por ruidos. Por ejemplo se podrıa obtener la informacion

30 Metodologıa
de la cabeza, tronco y pies. Ademas se podrıa ponderar con valores bajoslas zonas con mayor variacion y altos las de menor. Por contra, hay queconfigurar detalladamente el numero de bins que tendran los histogramasporque no apareceran muchos colores en esa franja de la imagen.
3.4. Implementacion
Lo primero que se va a realizar es la normalizacion de la estructura dondeestan alojadas las imagenes para cada una de las bases de datos. Esto seva a realizar para estandarizar el proceso de carga y de verificacion de lasimagenes. Ya que va a ser una tarea que vamos a realizar multiples veces.La estructura a seguir va a ser una carpeta donde alojar todas las imagenessin diferenciar los probes de los gallerys. Como se aprecia en la figura 3.4,el nombre del archivo sigue la siguiente estructura, los 4 primeros dıgitosson para el identificador del probe y los 3 restantes para el identificador delnumero de imagen tomada del probe.
Figura 3.4: Etiquetado de imagen. (A) representa el identificador del probey (B) hace referencia numero de imagen tomada para el probe.
A la hora de cargar las imagenes vamos a obtener dos conjuntos de datos, elprimer conjunto hace referencia a todos los probes de la base de datos y elsegundo conjunto pertenece al gallery. Para obtener el conjunto de probes sevan leyendo las imagenes y el ındice de probe que no este en el conjunto seanade, sino se omite. Por otro lado, el conjunto de gallery lo conforman lasimagenes omitidas por el conjunto anterior.
La figura 3.3 alude a la estructura que siguen las imagenes a la hora deobtener sus caracterısticas. A las imagenes se les podra asignar un ancho y

3.4. IMPLEMENTACION 31
un alto y se obtendran los valores del espacio de color que se desee emplear.A continuacion se dividira la imagen en franjas horizontales, para los cualesse obtendran los histogramas correspondientes para cada canal y seccion conun determinado numero de bin. Para finalizar se normalizan los datos de loshistogramas usando una normalizacion por funcion de probabilidad (ecuacion2.6) y se concatenan los canales.
El siguiente paso a realizar es el matching el cual generara una lista ordenadapara cada probe a traves de la comparacion de histogramas haciendo uso delas medidas de distancias referenciadas en la seccion 3.2. El ranking estaraordenado de mayor similitud a menor. A continuacion se generara una listacon los valores correspondientes a cada posicion de la CMC y se obtendrael area bajo la curva, vease la seccion 3.2 donde se comenta como calcularla CMC. Con esta implementacion se va a extraer los datos necesarios paraanalizarlos y obtener los conclusiones.

32 Metodologıa

Capıtulo 4
Resultados
En este capıtulo se comentaran los resultados obtenidos para la fase de expe-rimentacion que se ha realizado. Dividiendose en 3 secciones, donde se anali-zaran el comportamiento de las medidas de distancia para distintos espaciode color, numero de bins y numero de franjas. No incluimos una seccion paraconfrontar las distancias con las distintas bases de datos porque no pretende-mos comprobar como se comportan ante cada una, sino lo que pretendemoses obtener una vision general que pueda servir como punto de partida a lahora de seleccionar los valores de los diferentes parametros en estudio.
Cabrıa resaltar que para el uso de las medidas de distancia para histogramasse han realizado pequenas modificaciones en las ecuaciones originales paraevitar posibles indeterminaciones a la hora de procesar cada bin, que produ-cirıa un error que se arrastrarıa a los bins restantes. Por otro lado, hay quecontemplar que entiende el algoritmo por mayor similitud, valores resultanteselevados o por el contrario proximos a cero.
Con el fin de eliminar posibles indeterminaciones a la hora de analizar losbins se han modificado las distancias Chi Cuadrado y KL. Para la primeradistancia, se puede observar en la ecuacion (2.8) que si el denominador tienevalor cero el resultado serıa infinito, esta situacion puede ocurrir cuandose esten procesando dos bins con valores nulos. Nuestra aproximacion paraeliminar esta indeterminacion ha sido desechar estos bins, no los incluimosen el calculo.
Si observamos la ecuacion (2.11) correspondiente a la distancia de Kullback-Liebler, no puede haber ningun bin con valor cero porque podrıa ocurrir dossituaciones: Que el denominador sea igual a cero y obtendrıamos como valorinfinito o que el numerador sea cero y como resultado obtendrıamos ln(0)
33

34 Resultados
que eso es igual a infinito. Como solucion hemos desechado del analisis lospares de bins que a la hora de compararlos alguno de ellos tenga valor nulo.
Se considerara como mayor similaridad o menor distancia entre histogramas,la distancia que obtenga menor valor numerico. Por lo tanto se han modi-ficado las ecuaciones (2.9, 2.10, 2.11) correspondientes a las distancias deCorrelacion, Interseccion y KL respectivamente. Esto surge por la necesidadde hacer uso del mismo operador de comparacion y no ir alternando unopor otro dependiendo de la distancia que se haga uso en la fase de imple-mentacion. Para solventar estos problemas se ha modificado las condicionesde las ecuaciones Correlacion e Interseccion como se observa en la ecuacion(4.1), ademas para solventar la distancia KL se ha anadido las siguientescondiciones, ecuacion (4.2).
Si distancia = {Correlacion o Interseccion}
distanciaf (x, y) = −distancia(x, y) (4.1)
Si distancia = KL{KLf (x, y) = KL(x, y) Si KL(x, y) ≥ 0KLf (x, y) = −KL(x, y) Si KL(x, y) < 0
(4.2)
A continuacion se van a comentar de forma detallada los resultados que sehan obtenido en la fase de experimentacion. Asimismo en el anexo A semuestran las tablas con los resultados obtenidos para cada configuracion denumero de bins y del numero de divisiones de la imagen, donde se enfrentanlas medidas de distancia y el espacio de color. Ademas destacar que existe uncampo donde se visualiza el promedio de cada medida de distancia frente alespacio de color como conclusion de las tablas. Tambien se analizaran otrosdatos que podrıan ser interesantes a la hora de concluir con los resultados.
4.1. Espacio de color
Para conocer como afecta al resultado el uso de diferentes espacios de color,se ha obtenido el area CMC generado por el promedio del numero de bins,numero de franjas y de las bases de datos. De esta forma conseguimos vi-sualizar los datos como aparecen en la figura 4.1, donde en el eje de abscisasagrupamos los resultado del area CMC para cada distancia con los espaciosde color.

4.2. NUMERO DE BINS 35
Figura 4.1: Area CMC para distancias y espacio color.
RGB HSV CIELAB
Bhattacharyya 81.99 % 86.22 % 84.13 %Chi cuadrado 82.16 % 86.29 % 84.06 %Correlacion 78.16 % 79.87 % 74.08 %EMD 79.79 % 83.92 % 80.90 %Interseccion 82.27 % 86.05 % 83.55 %Mahalanobis 62.17 % 62.40 % 60.28 %KL 70.61 % 74.02 % 73.81 %Distancia promedio 76.74 % 79.83 % 77.26 %
Cuadro 4.1: Area CMC de las distancias frente espacios de color
Las distancias que proporcionan mejores resultados son Bhattacharyya, ChiCuadrado e Interseccion, las tres medidas son medidas de bin to bin, ademasmuestran una aparente relacion, identica, entre los espacios de color. El espa-cio de color que obtuvo mejores resultados fue el HSV, esto puede ser debidoa la separacion en las componentes de la crominancia y la luminancia, vertabla 4.1.
4.2. Numero de bins
Para conocer como afecta al resultado el uso de diferentes configuracionespara el numero de bins se ha obtenido el area CMC generado por el promediodel espacio color, numero de franjas y de las bases de datos. De esta forma

36 Resultados
conseguimos visualizar los datos como aparecen en la figura 4.2, donde en eleje de abscisas agrupamos los resultado del area CMC para cada distanciacon las distintas configuraciones de bins.
Figura 4.2: Area CMC para distancias y numero de bins.
16 bins 32 bins 64 bins 128 bins
Bhattacharyya 85.49 % 85.64 % 85.58 % 85.60 %Chi cuadrado 85.49 % 85.59 % 85.48 % 85.49 %Correlacion 78.36 % 79.06 % 79.10 % 79.00 %EMD 84.24 % 83.63 % 82.86 % 82.18 %Interseccion 85.32 % 85.34 % 85.26 % 85.26 %Mahalanobis 62.93 % 64.37 % 66.12 % 67.73 %KL 78.70 % 76.30 % 73.25 % 69.93 %Distancia promedio 80.08 % 79.99 % 79.67 % 79.31 %
Cuadro 4.2: Area CMC de las distancias frente numero de bins
Las distancias que proporcionan mejores resultados son Bhattacharyya, ChiCuadrado e Interseccion, cabrıa resaltar que para la reduccion del histogramaempleando un tamano de bin mayor se obtienen resultados similares que conbins de menor tamano, por lo que serıa interesante cuando se usen estasdistancias, hacer uso de bins de mayor tamano porque los calculos serancomputados a mayor velocidad, al tener el histograma un numero menor debins.
Cabrıa comentar el comportamiento que se percibe en las medidas KL, Maha-

4.3. NUMERO DE FRANJAS 37
lanobis y EMD. En primer lugar la medida KL empeora los resultados cuantomayor es el numero de bins, esto se debe a la aproximacion que hemos usadopara solucionar las indeterminaciones que nos presenta KL. Al aumento delnumero de bins van a haber valores de color que no se emplean y van a formarhuecos en el histograma, estos huecos van a tener valor cero, lo que implicaque no se van a procesar a la hora de realizar el calculo de la distancia conel otro histograma de color, a pesar de que el otro histograma tenga valoresde color distintos de cero. Por lo que al disminuir el tamano de bin perdemosinformacion a procesar, una posible solucion es usar la medida divergenciade Jeffrey [Rubner et al., 2000].
Por otro lado, destacar el comportamiento de las distancias de Mahalanobisy de EMD. La primera mejora cuanto mayor sea el numero de bins, estose debe a que posee una matriz mayor para realizar la covarianza, por loque obtiene mayor numero de caracterısticas para discriminar las imagenes.Para la distancia EMD, cuanto mayor es el numero de bins peores resultadosse obtienen, esto se debe a que busca el mınimo numero de movimientospara conseguir que un histograma se parezca a otro, al existir muchos cerosesas partes del histograma van a generar ruido para la obtencion del mınimonumero de movimientos.
En la tabla 4.2 se refleja que el uso del menor numero de bins proporcionamejores resultados, pero no es una mejora significativa la que se obtiene,proponemos como configuracion inicial a un problema hacer uso de 16 o 32bins para el histograma, para no perder demasiada informacion.
4.3. Numero de franjas
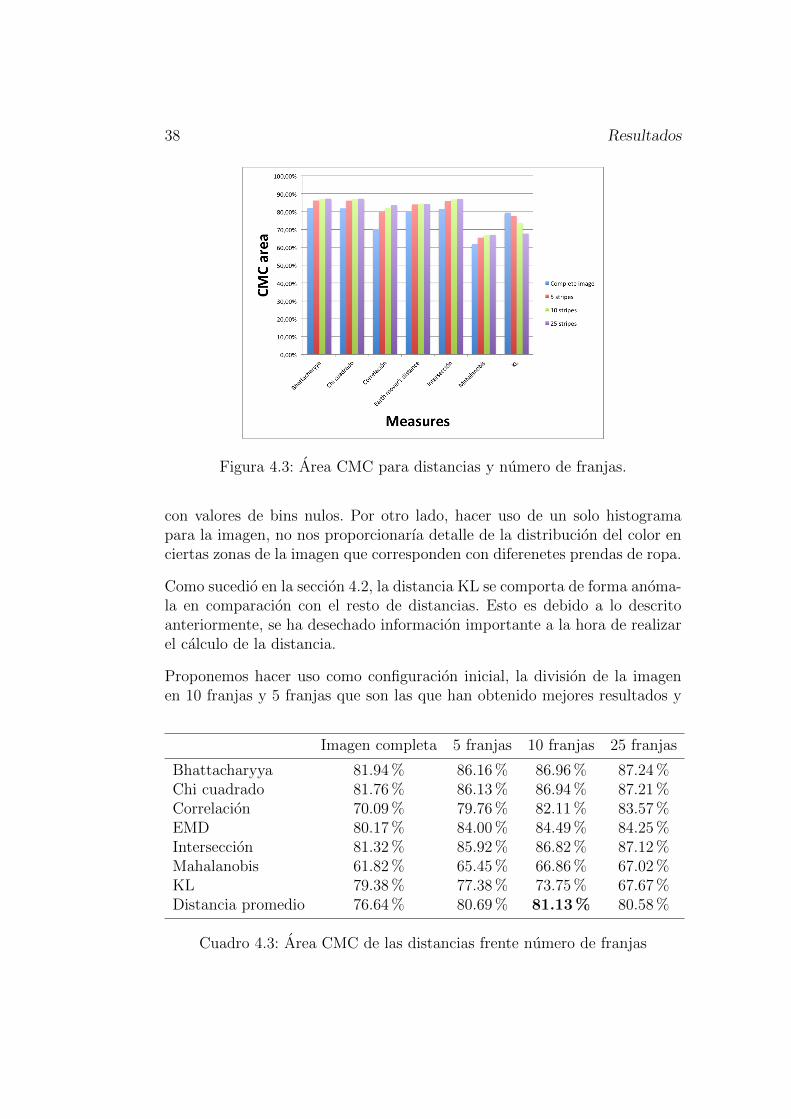
Para conocer como afecta al resultado el uso de diferentes configuracionesdel numero de franjas en la imagen se ha obtenido el area CMC generadopor el promedio del espacio color, numero de bins y de las bases de datos.De esta forma conseguimos visualizar los datos como aparecen en la figura4.3, donde en el eje de abscisas agrupamos los resultado del area CMC paracada distancia con diferente numero de franjas.
Las distancias que proporcionan mejores resultados son Bhattacharyya, ChiCuadrado e Interseccion. La division de la imagen en franjas mejora significa-tivamente los resultados, pero llega a un punto en el que el exceso de franjashace que empeore los resultados. Esto se debe a que se le esta anadiendo rui-do al histograma, al tener muchas franjas vamos a tener muchos histogramas
38 Resultados
Figura 4.3: Area CMC para distancias y numero de franjas.
con valores de bins nulos. Por otro lado, hacer uso de un solo histogramapara la imagen, no nos proporcionarıa detalle de la distribucion del color enciertas zonas de la imagen que corresponden con diferenetes prendas de ropa.
Como sucedio en la seccion 4.2, la distancia KL se comporta de forma anoma-la en comparacion con el resto de distancias. Esto es debido a lo descritoanteriormente, se ha desechado informacion importante a la hora de realizarel calculo de la distancia.
Proponemos hacer uso como configuracion inicial, la division de la imagenen 10 franjas y 5 franjas que son las que han obtenido mejores resultados y
Imagen completa 5 franjas 10 franjas 25 franjas
Bhattacharyya 81.94 % 86.16 % 86.96 % 87.24 %Chi cuadrado 81.76 % 86.13 % 86.94 % 87.21 %Correlacion 70.09 % 79.76 % 82.11 % 83.57 %EMD 80.17 % 84.00 % 84.49 % 84.25 %Interseccion 81.32 % 85.92 % 86.82 % 87.12 %Mahalanobis 61.82 % 65.45 % 66.86 % 67.02 %KL 79.38 % 77.38 % 73.75 % 67.67 %Distancia promedio 76.64 % 80.69 % 81.13 % 80.58 %
Cuadro 4.3: Area CMC de las distancias frente numero de franjas

4.4. OTRAS CARACTERISTICAS ANALIZADAS 39
entre ellas no difieren significativamente. Vease la tabla 4.3.
4.4. Otras caracterısticas analizadas
Hemos decidido que merece la pena comprobar el rendimiento en tiempo,ya que habrıa que tener un compromiso en relacion a tiempo y resultadosobtenidos a la hora de reidentificar. En la figura 4.4 se observa el tiempo enhoras en el que tardo en ejecutarse las pruebas, donde aludimos al numerode bins y al numero de franjas. Estos resultados aluden al tiempo total enejecutar 4 bases de datos con 3 espacios de color, 7 medidas de distanciay 16 configuraciones para el numero de bins y numero de franjas. El costecomputacional para ejecutar las pruebas de cada base de datos viene dadapor la ecuacion (4.3).
O
(48PG
[F
(5B +
B(B − 1)
2+B3 logB
)+ 3
(P 2G+ 1
)])(4.3)
Donde P representa el numero de individuos probes, G es el numero deindividuos engallery, F es el numero de franjas, B representa el numero debins.
Figura 4.4: Rendimiento en horas para numero de bins y numero de franjas.
Aumentar el numero de bins, como tambien el numero de franjas, aumen-ta el tiempo de ejecucion de las pruebas. Se puede observar que existe unarelacion en el aumento de las franjas, donde aumentan para cada bin aproxi-madamente de forma lineal, ver tabla 4.4. En cambio para el numero de binsno se aprecia una relacion clara.

40 Resultados
16 bins 32 bins 64 bins 128 bins
Imagen completa 0.45 0.55 0.80 1.575 franjas 1.43 1.88 3.08 6.3510 franjas 2.63 3.59 6.15 12.6625 franjas 5.69 8.80 14.74 31.31
Cuadro 4.4: Tiempo ejecucion. Numero de bins frente numero de franjas.
Estos aumentos de tiempo son debidos a que se tienen mas histogramas paracomputar y ademas para cada histograma se tiene un numero determinadode bins para analizar.
Se ha supuesto conveniente realizar un analisis de los resultados en cuanto alarea bajo la CMC a partir de la relacion que existe entre el numero de franjasy de bins. Como se observa en la figura 4.5, existe un aumento significativo aldividir la imagen en varias franjas, entre un 3.94 % y un 4.49 %, como se hacomentado en la seccion 4.3. Por otro lado, sin realizar division se mejoranlos resultados conforme se amplıan los numeros de bins, esto se debe a que alposeer un solo histograma con muchos bins obtenemos una mejor apreciacionde la distribucion del color en la imagen. Por contra, cuando se divide laimagen en franjas, se obtienen peores resultados cuanto mayor numero debins posee el histograma. Esto es debido a que el histograma tendra muchasposiciones con valores a cero que no representan valor a la imagen.
Figura 4.5: Area CMC para numero de franjas y numero de bins.
Otros resultados a comentar son el comportamiento que se aprecia del numerode bins y del numero de franjas sobre el espacio de color. Como se muestranen las graficas 4.6 y 4.7, se aprecia que muestran un comportamiento similar

4.4. OTRAS CARACTERISTICAS ANALIZADAS 41
16 bins 32 bins 64 bins 128 bins Promedio
Imagen completa 76.03 % 76.62 % 76.91 % 77.00 % 76.64 %5 franjas 80.98 % 81.03 % 80.58 % 80.15 % 80.69 %10 franjas 81.74 % 81.43 % 80.96 % 80.41 % 81.13 %25 franjas 81.56 % 80.87 % 80.21 % 79.69 % 80.58 %
Cuadro 4.5: Area CMC para numero de bins y numero de franjas.
cuando nos referimos al espacio de color. EL HSV es el espacio de color queobtiene mejores resultados, seguido de CIELAB y RGB. Ademas resaltar quecuando comprobamos las distancias con los espacios de color en la seccion4.1, se comportaban de forma similar a la actual. Por otro lado, volvemosa comprobar como el aumento de numero de bins los resultados empeoranlevemente y que conforme se divide la imagen con mas franjas, los resultadosmejoran hasta llegar a un punto de saturacion que empiezan a empeorar.
Figura 4.6: Area CMC para espacio de color y numero de bins.
En las tablas 4.6 y 4.7 se pueden ver los valores obtenidos a partir del pro-medio de las medidas de distancia y bases de datos, ademas de las mediasde numero de franjas y del numero de bins respectivamente de las tablascitadas.
Concluyendo con esta seccion y con este capıtulo, hemos contrastado queel espacio de color con el que se obtendran mejores resultados es el HSV,ademas de usar como configuracion inicial para la obtencion de los descrip-tores de la imagen, entre 5 y 10 divisiones en la imagen, como hacer uso deun numero reducido de bins, entre 16 y 32. Por ultimo, las distancias queproponemos usar como primeras configuraciones para cualquier problema de

42 Resultados
Figura 4.7: Area CMC para espacio de color y numero de franjas.
reidentificacion serıa Bhattacharyya, Chi Cuadrado e Interseccion, habiendoobtenido resultados muy similares.
16 bins 32 bins 64 bins 128 bins
RGB 78.26 % 77.90 % 77.70 % 77.40 %HSV 82.38 % 81.86 % 81.50 % 80.96 %CIELAB 79.60 % 80.21 % 79.80 % 79.58 %
Cuadro 4.6: Area CMC para numero de bins de la imagen y espacio de color.
Imagen completa 5 franjas 10 franjas 25 franjas
RGB 74.91 % 78.66 % 79.14 % 78.53 %HSV 78.61 % 82.82 % 83.06 % 82.20 %
CIELAB 76.40 % 80.57 % 81.20 % 81.02 %
Cuadro 4.7: Area CMC para divisiones de la imagen y espacio de color.

Capıtulo 5
Conclusiones y lıneas futuras
En este Trabajo de Fin de Master se ha enmarcado en el problema de reiden-tificacion, hemos optado por estudiar la reidentificacion basada en apariencia,haciendo uso de histogramas de color para la representacion de la imagen.Se han empleado una serie de medidas de distancia para la comparacion delos histogramas para varios espacios de color con diversas configuraciones denumero de bins y numero de franjas en la imagen, como se ha citado en laseccion 3.2.
Proponemos una configuracion inicial para resolver el problema de reiden-tificacion, esta configuracion no asegura ser la mejor configuracion para unproblema especıfico, proponemos una configuracion con alta probabilidad deobtener buenos resultados, acotando bastante el area de trabajo para la rea-lizacion de las pruebas. Tras la realizacion y el analisis del experimento sehan llegado a las siguientes conclusiones:
Configuracion preferente
Distancia Bhattacharyya, Chi Cuadrado e InterseccionEspacio de color HSVNumero de bins 16 y 32Numero de franjas 5 y 10
Cuadro 5.1: Propuesta de configuracion inicial.
Proponemos Bhattacharyya, Chi Cuadrado e Interseccion como primera apro-ximacion a la hora de resolver el problema, ya que estas medidas obtuvieronbuenos resultados y muy similares ante todas las configuraciones empleadasen el experimento. HSV es el espacio de color con el que obtuvimos mejores
43

44 Conclusiones y lıneas futuras
resultados con diferencia. Esto se debe a que posee mejores cualidades a lahora de tratar las imagenes, es debido a que este espacio proporciona unaseparacion entre las componentes de la crominancia y luminancia. Lo queresulta bastante util a la hora de tratar escenarios donde la iluminacion escambiante.
Para la configuracion del numero de bins del histograma hemos propuestousar como punto de partida entre 16 y 32 bins. Esto se debe a que un altonumero de bins genera ruido al histograma porque la imagen no contienetodo el rango de color. Ademas de anadirle un coste computacional a lahora de procesar los datos. Por ultimo, hemos optado por dividir la imagenentre 5 y 10 franjas que son las configuraciones con las que se han obtenidomejores resultados porque la imagen completa no aporta conocimiento sobrezonas especıficas. Por contra, hacer divisiones excesivas aportara ruido a loshistogramas.
Como propuestas de trabajo futuro estan hacer uso de mas espacios de colorpara la realizacion de las pruebas. Ademas serıa conveniente probar un mayornumero de bases de datos. El artıculo [DENG et al., 2014] expone una basede datos que es la aglomeracion de multiples conjuntos de imagenes, dondese engloban imagenes con multiples casuısticas. Ademas, serıa favorable parael estudio hacer uso de un mayor numero de medidas, como podrıa ser ladivergencia de Jeffrey para solucionar las indeterminaciones de la distanciaKL. Por ultimo lugar, se podrıa realizar un nuevo experimento partiendode nuestra propuesta de configuracion inicial y haciendo uso de distintostamanos de imagenes. Esto es ası debido al alto coste computacional derepetir todos los experimentos desde cero.

Bibliografıa
[ili, 2014] (10 Octubre, 2014). Imagery Library for Intelligent Detection Sys-tems.
[cav, 2014] (12 Noviembre, 2014). Context Aware Vision using Image-basedActive Recognition for Ridentification.
[wik, 2014] (14 October, 2014). Definicion de distancia de correlacion.
[vip, 2007] (2007). Viewpoint Invariant Pedestrian Recognition.
[his, 2014] (21 Abril, 2014). Histogram comparison.
[gri, 2014] (Julio, 2014). QMUL underGround Re-IDentification.
[rae, 2014] (Octubre, 2014). Definicion distancia RAE. http://lema.rae.
es/drae/srv/search?key=distancia.
[Acharya and Ray, 2005] Acharya, T. and Ray, A. K. (2005). Image preces-sing. Principles and Applications. WILEY.
[Avraham et al., 2012] Avraham, T., Gurvich, I., Lindenbaum, M., and Mar-kovitch, S. (2012). Learning implicit transfer for person re-identification.In 1st re-identification workshop. In conjunction with ECCV2012.
[Bolle et al., 2005] Bolle, R., Connell, J., Pankanti, S., Ratha, N., and Senior,A. (2005). The relation between the roc curve and the cmc. In AutomaticIdentification Advanced Technologies, 2005. Fourth IEEE Workshop on,pages 15–20.
[Cha and Srihari, 2002] Cha, S.-H. and Srihari, S. N. (2002). On measuringthe distance between histograms. Pattern Recognition, 35(6):1355 – 1370.
[DENG et al., 2014] DENG, Y., Luo, P., Loy, C. C., and Tang, X. (2014).Pedestrian attribute recognition at far distance. In Proceedings of theACM International Conference on Multimedia, MM ’14, pages 789–792,New York, NY, USA. ACM.
45

[Gong et al., 2014] Gong, S., Cristani, M., Yan, S., and Change, C. (2014).Person Re-Identification. Springer.
[Huang et al., 2010] Huang, J., Zhao, J., Gao, W., Long, C., Xiong, L., Yuan,Z., and Han, S. (2010). Local binary pattern based texture analysis forvisual fire recognition. In Image and Signal Processing (CISP), 2010 3rdInternational Congress on, volume 4, pages 1887–1891.
[Jimenez, 2000] Jimenez, J. G. (2000). Vision por Computador. Paraninfo.
[Ling and Okada, 2006] Ling, H. and Okada, K. (2006). Diffusion distancefor histogram comparison. In Computer Vision and Pattern Recognition,2006 IEEE Computer Society Conference on, volume 1, pages 246–253.
[Liu and Shum, 2003] Liu, C. and Shum, H.-Y. (2003). Kullback-leiblerboosting. In Computer Vision and Pattern Recognition, 2003. Proceedings.2003 IEEE Computer Society Conference on, volume 1, pages I–587–I–594vol.1.
[Naik et al., 2009] Naik, N., Patil, S., and Joshi, M. (2009). A scale adap-tive tracker using hybrid color histogram matching scheme. In EmergingTrends in Engineering and Technology (ICETET), 2009 2nd InternationalConference on, pages 279–284.
[Rubner et al., 2000] Rubner, Y., Tomasi, C., and Guibas, L. J. (2000). Theearth mover’s distance as a metric for image retrieval. Int. J. Comput.Vision, 40(2):99–121.
[Satta, 2013] Satta, R. (2013). Appearance descriptors for person re-identification: a comprehensive review. CoRR, abs/1307.5748.
[Seon et al., 2011] Seon, D., Cristani, M., Stoppa, M., Bazzani, L., and Mu-rino, V. (2011). Custom pictorial structures for re-identification. In Procee-dings of the British Machine Vision Conference, pages 68.1–68.11. BMVAPress. http://dx.doi.org/10.5244/C.25.68.
[Vezzani et al., 2013] Vezzani, R., Baltieri, D., and Cucchiara, R. (2013).People reidentification in surveillance and forensics: A survey. ACM Com-put. Surv., 46(2):29:1–29:37.
[Wang, 2013] Wang, X. (2013). Intelligent multi-camera video surveillance:A review. Pattern Recognition Letters, 34(1):3–19.
[Zhang and Canosa, 2014] Zhang, Q. and Canosa, R. L. (2014). A compari-son of histogram distance metrics for content-based image retrieval.

Glosario
bin to bin Tipo de distancia donde se comparan los elementos del mismoconjunto. La distancia total es la suma de la distancia de cada conjunto.13, 22–24, 35
crominancia Componente de una senal que contiene las informaciones delcolor. 18–20, 35, 44
cross-bin Tipo de distancia donde se comparan no solo los elementos delmismo conjunto sino tambien el resto. Se requiere una distancia bin tobin como base de distancia. 13, 22, 24
estandar CIE Sistema que se emplea como referencia para definir los colo-res que percibe el ojo humano y otros espacios de color. 20
gallery Termino usado en reidentificacion para el conjunto de imagenes deindividuos. 16–18, 28–30, 39
luminancia Densidad superficial de intensidad lumınica en una cierta di-reccion. 18, 19, 35, 44
matching Proceso en vision por computador que hace uso de descriptoreso caracterısticas para identificar a un individuo en un conjunto. 31
probe Termino usado en reidentificacion para la imagen base que se pre-tende reidentificar entre una serie de imagenes. 16–18, 26–28, 30, 31,39
47

48 Glosario

Apendice A
Anexo
RGB HSV CIELAB
Bhattacharyya 78.42 % 84.38 % 82.48 %Chi cuadrado 78.36 % 84.23 % 82.14 %Correlacion 71.40 % 70.66 % 65.78 %
EMD 77.88 % 82.91 % 80.77 %Interseccion 78.12 % 83.75 % 81.63 %Mahalanobis 61.25 % 59.47 % 53.58 %
KL 77.35 % 82.91 % 79.16 %Promedio 74.68 % 78.33 % 75.08 %
Cuadro A.1: Porcentaje promedio del area bajo la curva CMC para 16 binse imagen completa. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 78.54 % 84.40 % 83.05 %Chi cuadrado 78.38 % 84.24 % 82.80 %Correlacion 71.04 % 70.33 % 69.51 %
EMD 77.77 % 82.48 % 80.75 %Interseccion 78.25 % 83.69 % 82.07 %Mahalanobis 62.42 % 62.55 % 56.93 %
KL 77.33 % 82.58 % 80.00 %Promedio 74.82 % 78.61 % 76.45 %
Cuadro A.2: Porcentaje promedio del area bajo la curva CMC para 32 binse imagen completa. Espacios de color frente a distancias
49

50 Anexo
RGB HSV CIELAB
Bhattacharyya 78.55 % 84.39 % 83.04 %Chi cuadrado 78.42 % 84.21 % 82.85 %Correlacion 71.23 % 70.45 % 70.23 %
EMD 77.60 % 82.02 % 80.54 %Interseccion 78.22 % 83.75 % 82.20 %Mahalanobis 64.50 % 64.19 % 60.85 %
KL 76.64 % 82.04 % 79.17 %Promedio 75.02 % 78.72 % 76.98 %
Cuadro A.3: Porcentaje promedio del area bajo la curva CMC para 64 binse imagen completa. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 78.60 % 84.39 % 83.06 %Chi cuadrado 78.43 % 84.19 % 82.85 %Correlacion 71.14 % 69.70 % 69.56 %
EMD 77.40 % 81.59 % 80.30 %Interseccion 78.32 % 83.75 % 82.12 %Mahalanobis 66.31 % 66.79 % 63.06 %
KL 75.72 % 81.07 % 78.61 %Promedio 75.13 % 78.78 % 77.08 %
Cuadro A.4: Porcentaje promedio del area bajo la curva CMC para 128 binse imagen completa. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 83.06 % 88.45 % 86.77 %Chi cuadrado 83.18 % 88.48 % 86.70 %Correlacion 80.15 % 83.21 % 74.36 %
EMD 81.96 % 87.15 % 85.54 %Interseccion 83.07 % 88.25 % 86.47 %Mahalanobis 65.35 % 66.19 % 59.68 %
KL 77.95 % 83.46 % 81.19 %Promedio 79.24 % 83.60 % 80.10 %
Cuadro A.5: Porcentaje promedio del area bajo la curva CMC para 16 binse imagen dividida en 5 franjas. Espacios de color frente a distancias

Anexo 51
BD Media RGB HSV CIELAB
Bhattacharyya 83.09 % 88.38 % 87.17 %Chi cuadrado 83.11 % 88.37 % 87.15 %Correlacion 80.17 % 82.80 % 76.99 %
EMD 81.43 % 86.48 % 85.17 %Interseccion 83.02 % 88.17 % 86.69 %Mahalanobis 65.68 % 66.66 % 63.84 %
KL 75.99 % 81.09 % 80.22 %Promedio 78.93 % 83.14 % 81.03 %
Cuadro A.6: Porcentaje promedio del area bajo la curva CMC para 32 binse imagen dividida en 5 franjas. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 83.09 % 88.35 % 87.02 %Chi cuadrado 83.03 % 88.29 % 86.93 %Correlacion 80.27 % 82.94 % 76.67 %
EMD 80.72 % 85.73 % 84.62 %Interseccion 82.99 % 88.10 % 86.57 %Mahalanobis 65.61 % 66.65 % 65.56 %
KL 73.38 % 78.19 % 77.51 %Promedio 78.44 % 82.61 % 80.70 %
Cuadro A.7: Porcentaje promedio del area bajo la curva CMC para 64 binse imagen dividida en 5 franjas. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 83.17 % 88.36 % 87.07 %Chi cuadrado 83.07 % 88.27 % 86.99 %Correlacion 80.44 % 83.05 % 76.05 %
EMD 80.16 % 85.06 % 84.01 %Interseccion 83.03 % 88.09 % 86.60 %Mahalanobis 66.18 % 66.63 % 67.35 %
KL 70.25 % 74.21 % 75.15 %Promedio 78.04 % 81.95 % 80.46 %
Cuadro A.8: Porcentaje promedio del area bajo la curva CMC para 128 binse imagen dividida en 5 franjas. Espacios de color frente a distancias

52 Anexo
RGB HSV CIELAB
Bhattacharyya 84.05 % 89.11 % 87.51 %Chi cuadrado 84.19 % 89.23 % 87.50 %Correlacion 82.06 % 85.69 % 77.37 %
EMD 82.91 % 87.85 % 86.34 %Interseccion 84.19 % 89.11 % 87.44 %Mahalanobis 65.84 % 65.55 % 62.96 %
KL 75.81 % 81.14 % 80.72 %Promedio 79.86 % 83.95 % 81.41 %
Cuadro A.9: Porcentaje promedio del area bajo la curva CMC para 16 binse imagen dividida en 10 franjas. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 84.08 % 89.14 % 87.78 %Chi cuadrado 84.10 % 89.14 % 87.86 %Correlacion 82.14 % 85.55 % 79.16 %
EMD 82.06 % 86.99 % 85.83 %Interseccion 84.03 % 89.02 % 87.62 %Mahalanobis 65.63 % 66.36 % 66.13 %
KL 72.19 % 77.06 % 78.12 %Promedio 79.17 % 83.32 % 81.79 %
Cuadro A.10: Porcentaje promedio del area bajo la curva CMC para 32 binse imagen dividida en 10 franjas. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 84.07 % 89.10 % 87.62 %Chi cuadrado 84.01 % 89.03 % 87.58 %Correlacion 82.25 % 85.85 % 78.54 %
EMD 81.15 % 86.02 % 84.98 %Interseccion 83.95 % 88.94 % 87.36 %Mahalanobis 67.93 % 69.11 % 66.41 %
KL 69.14 % 72.62 % 74.46 %Promedio 78.93 % 82.95 % 80.99 %
Cuadro A.11: Porcentaje promedio del area bajo la curva CMC para 64 binse imagen dividida en 10 franjas. Espacios de color frente a distancias

Anexo 53
RGB HSV CIELAB
Bhattacharyya 84.20 % 89.10 % 87.71 %Chi cuadrado 84.05 % 89.00 % 87.64 %Correlacion 82.38 % 86.15 % 78.16 %
EMD 80.43 % 85.13 % 84.15 %Interseccion 83.97 % 88.89 % 87.37 %Mahalanobis 69.86 % 68.62 % 67.94 %
KL 65.34 % 67.19 % 71.24 %Promedio 78.60 % 82.01 % 80.60 %
Cuadro A.12: Porcentaje promedio del area bajo la curva CMC para 128 binse imagen dividida en 10 franjas. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 84.57 % 89.39 % 87.72 %Chi cuadrado 84.59 % 89.52 % 87.80 %Correlacion 82.99 % 87.34 % 79.31 %
EMD 83.02 % 87.96 % 86.58 %Interseccion 84.50 % 89.50 % 87.87 %Mahalanobis 63.41 % 66.54 % 65.39 %
KL 71.55 % 75.18 % 77.98 %Promedio 79.23 % 83.63 % 81.81 %
Cuadro A.13: Porcentaje promedio del area bajo la curva CMC para 16 binse imagen dividida en 25 franjas. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 84.64 % 89.43 % 87.93 %Chi cuadrado 84.52 % 89.40 % 87.98 %Correlacion 83.11 % 87.29 % 80.66 %
EMD 81.86 % 86.90 % 85.80 %Interseccion 84.39 % 89.34 % 87.84 %Mahalanobis 64.66 % 64.87 % 66.70 %
KL 67.55 % 69.45 % 74.02 %Promedio 78.68 % 82.38 % 81.56 %
Cuadro A.14: Porcentaje promedio del area bajo la curva CMC para 32 binse imagen dividida en 25 franjas. Espacios de color frente a distancias

54 Anexo
RGB HSV CIELAB
Bhattacharyya 84.65 % 89.38 % 87.70 %Chi cuadrado 84.47 % 89.28 % 87.66 %Correlacion 83.26 % 87.47 % 80.05 %
EMD 80.74 % 85.51 % 84.73 %Interseccion 84.39 % 89.20 % 87.46 %Mahalanobis 68.33 % 67.44 % 66.89 %
KL 62.89 % 63.70 % 69.25 %Promedio 78.39 % 81.71 % 80.54 %
Cuadro A.15: Porcentaje promedio del area bajo la curva CMC para 64 binse imagen dividida en 25 franjas. Espacios de color frente a distancias
RGB HSV CIELAB
Bhattacharyya 84.63 % 89.20 % 87.70 %Chi cuadrado 84.51 % 89.18 % 87.66 %Correlacion 83.43 % 87.84 % 80.09 %
EMD 79.88 % 84.35 % 83.64 %Interseccion 84.41 % 89.14 % 87.43 %Mahalanobis 70.13 % 71.76 % 68.16 %
KL 57.78 % 56.16 % 66.49 %Promedio 77.82 % 81.09 % 80.17 %
Cuadro A.16: Porcentaje promedio del area bajo la curva CMC para 128 binse imagen dividida en 25 franjas. Espacios de color frente a distancias


















![campaña y las medidas zoosanitarias que deberán …cva.org.mx/files/ACUERDO_IA_CERTIFICACION_JUL_2011[1].pdf · Cuadro Comparativo NOM-044-ZOO-1995 ACUERDO PARA INFLUENZA AVIAR](https://static.fdocuments.ec/doc/165x107/5bbaaceb09d3f28b418b57a9/campana-y-las-medidas-zoosanitarias-que-deberan-cvaorgmxfilesacuerdoiacertificacionjul20111pdf.jpg)