

Estadistica y Machine Learning para Todos
43
Estadística y Machine Learning para Todos...TODOS! Terminología, casos de uso, herramientas y caminos para poner un pié en la Ciencia de Datos en México. Copyright © @xuxoramos 2017
-
Upload
jesus-ramos -
Category
Data & Analytics
-
view
893 -
download
0
Transcript of Estadistica y Machine Learning para Todos

Estadística y Machine Learning para Todos...TODOS!
Terminología, casos de uso, herramientas y caminos para poner un pié en la Ciencia de Datos en México.
Copyright © @xuxoramos 2017

Objetivos
Que sepan cómo desmenuzar estadísticamente una aseveración.
Que sepan qué es el aprendizaje automático y sus partes.
Que sepan para qué sirve el aprendizaje automático.
Que sepan por qué es importante para México ponerse chingón en aprendizaje automático.
2Copyright © @xuxoramos 2017

Las noticias
Declaración típica de político:
3Copyright © @xuxoramos 2017
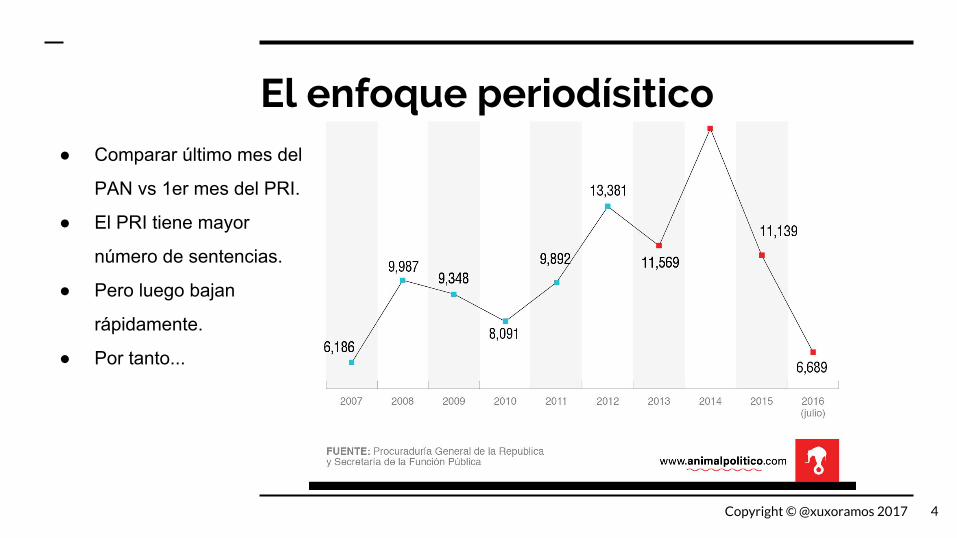
El enfoque periodísitico● Comparar último mes del
PAN vs 1er mes del PRI.
● El PRI tiene mayor
número de sentencias.
● Pero luego bajan
rápidamente.
● Por tanto...
4Copyright © @xuxoramos 2017
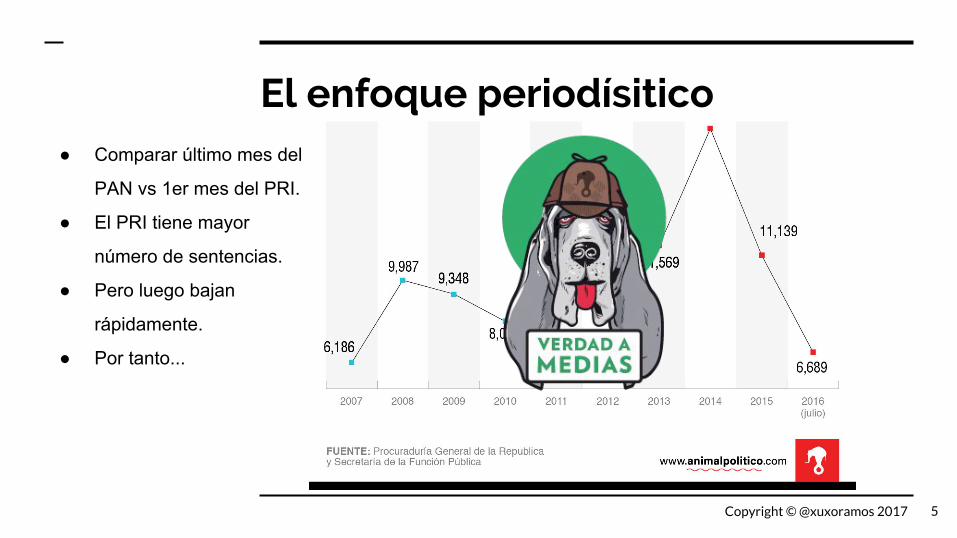
El enfoque periodísitico● Comparar último mes del
PAN vs 1er mes del PRI.
● El PRI tiene mayor
número de sentencias.
● Pero luego bajan
rápidamente.
● Por tanto...
5Copyright © @xuxoramos 2017
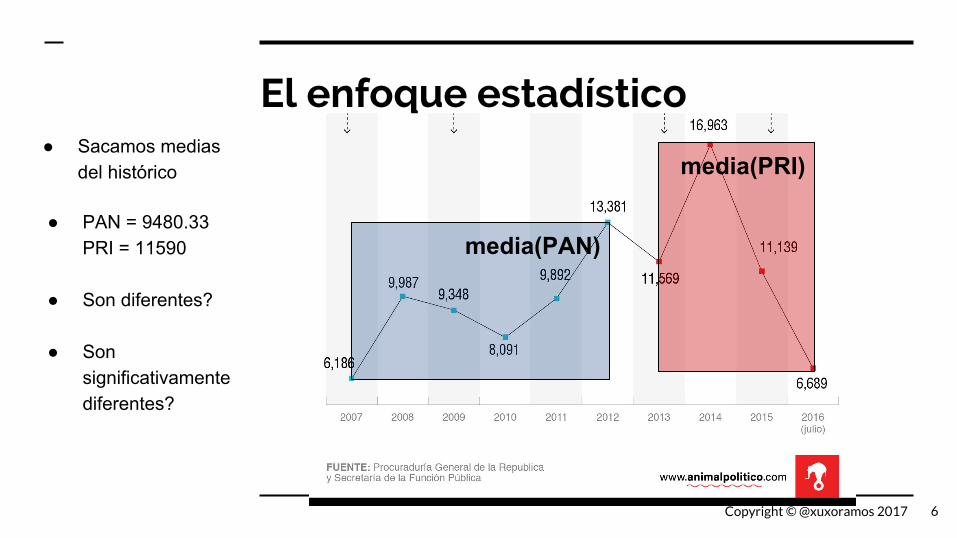
El enfoque estadístico
media(PAN)
media(PRI)● Sacamos medias
del histórico
6
● PAN = 9480.33PRI = 11590
● Son diferentes?
● Son significativamente diferentes?
Copyright © @xuxoramos 2017
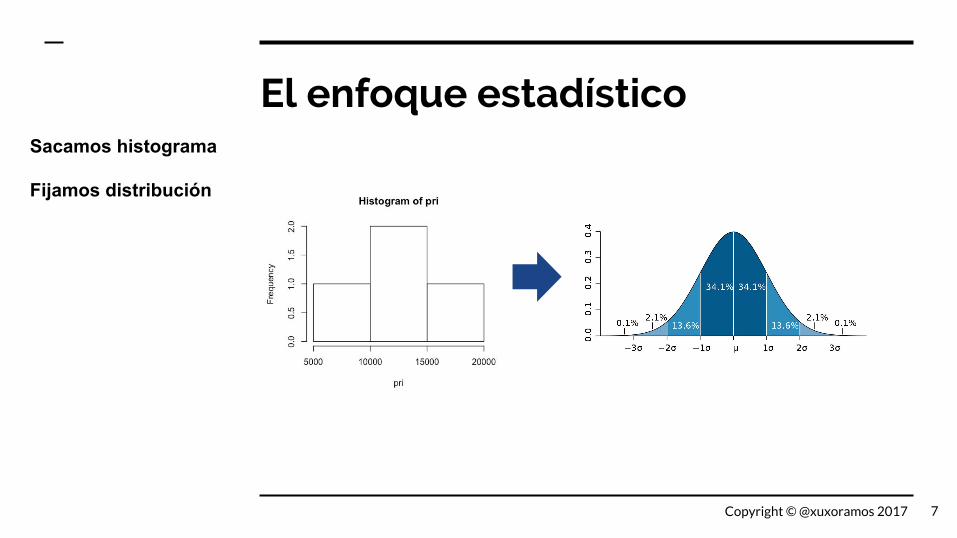
El enfoque estadísticoSacamos histograma
Fijamos distribución
7Copyright © @xuxoramos 2017
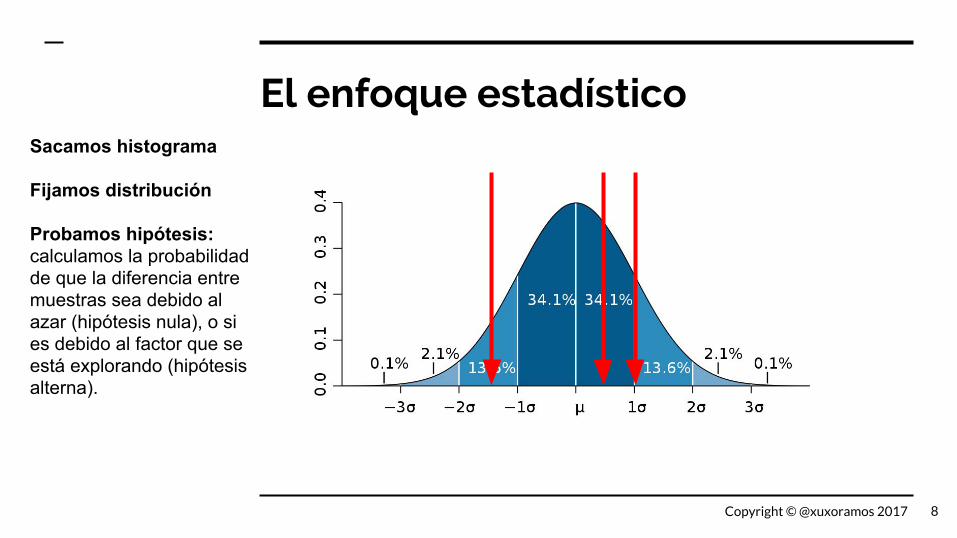
El enfoque estadísticoSacamos histograma
Fijamos distribución
Probamos hipótesis: calculamos la probabilidad de que la diferencia entre muestras sea debido al azar (hipótesis nula), o si es debido al factor que se está explorando (hipótesis alterna).
8Copyright © @xuxoramos 2017
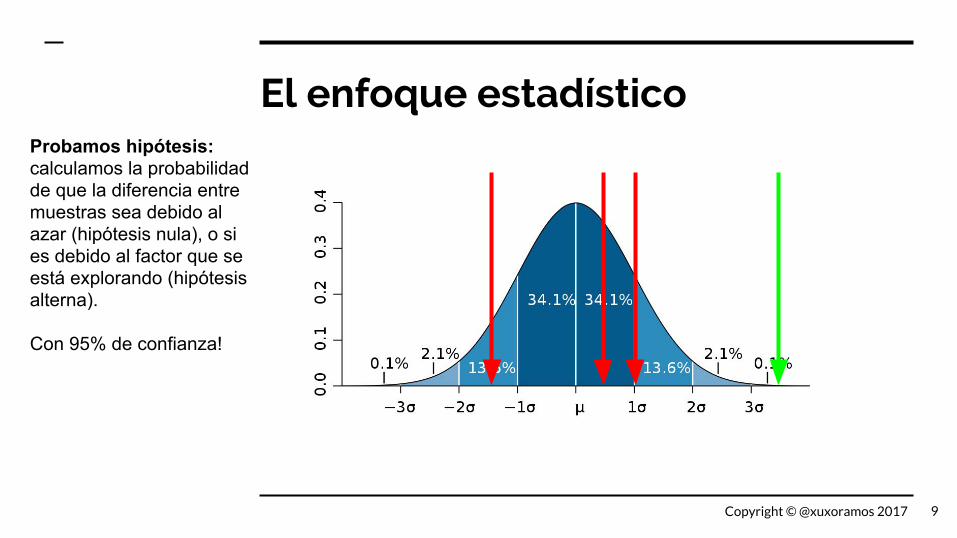
El enfoque estadísticoProbamos hipótesis: calculamos la probabilidad de que la diferencia entre muestras sea debido al azar (hipótesis nula), o si es debido al factor que se está explorando (hipótesis alterna).
Con 95% de confianza!
9Copyright © @xuxoramos 2017

El enfoque estadísticoProbamos hipótesis: calculamos la probabilidad de que la diferencia entre muestras sea debido al azar (hipótesis nula), o si es debido al factor que se está explorando (hipótesis alterna).
Con 95% de confianza!
10Copyright © @xuxoramos 2017
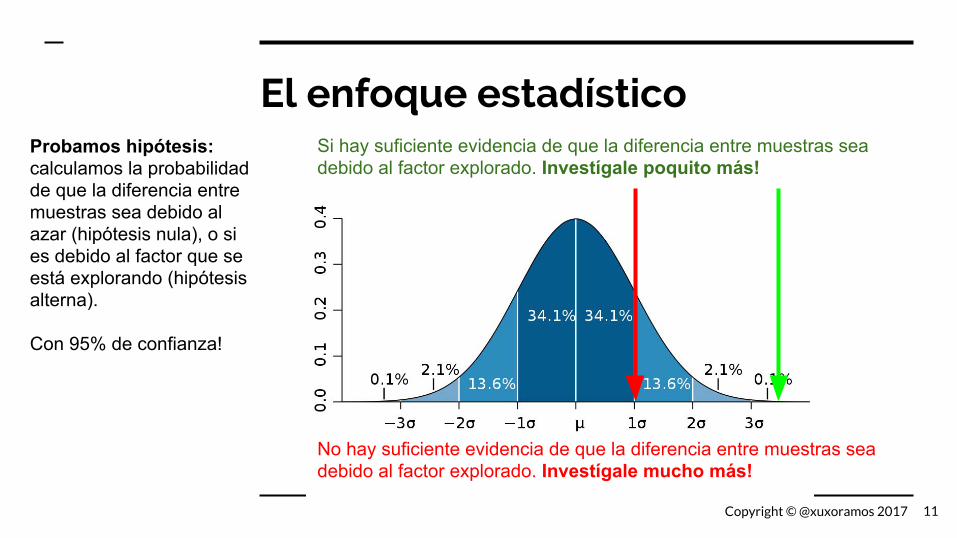
El enfoque estadísticoProbamos hipótesis: calculamos la probabilidad de que la diferencia entre muestras sea debido al azar (hipótesis nula), o si es debido al factor que se está explorando (hipótesis alterna).
Con 95% de confianza!
No hay suficiente evidencia de que la diferencia entre muestras sea debido al factor explorado. Investígale mucho más!
Si hay suficiente evidencia de que la diferencia entre muestras sea debido al factor explorado. Investígale poquito más!
11Copyright © @xuxoramos 2017
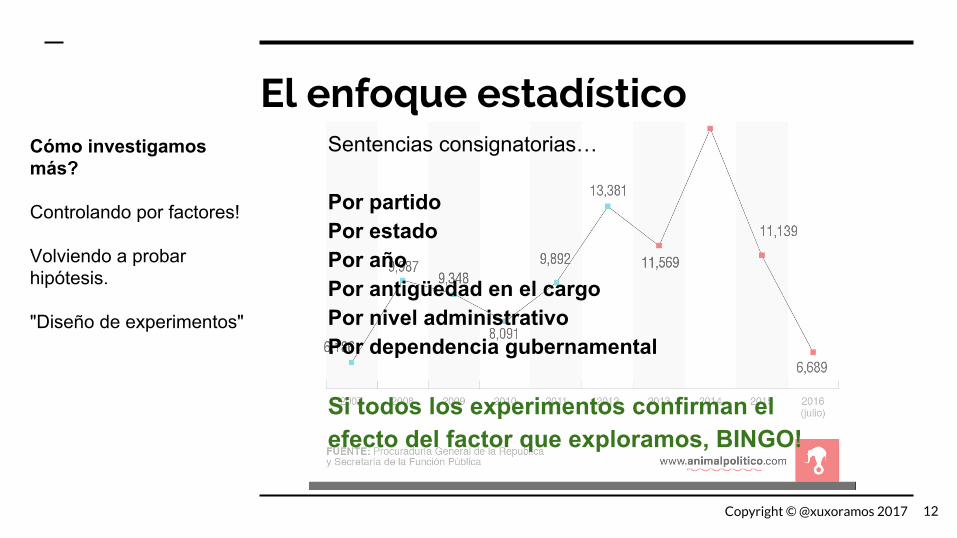
El enfoque estadísticoCómo investigamos más?
Controlando por factores!
Volviendo a probar hipótesis.
"Diseño de experimentos"
Sentencias consignatorias…
Por partidoPor estadoPor añoPor antigüedad en el cargoPor nivel administrativoPor dependencia gubernamental
Si todos los experimentos confirman el efecto del factor que exploramos, BINGO!
12Copyright © @xuxoramos 2017

Qué hueva! Como automatizo?
13Copyright © @xuxoramos 2017
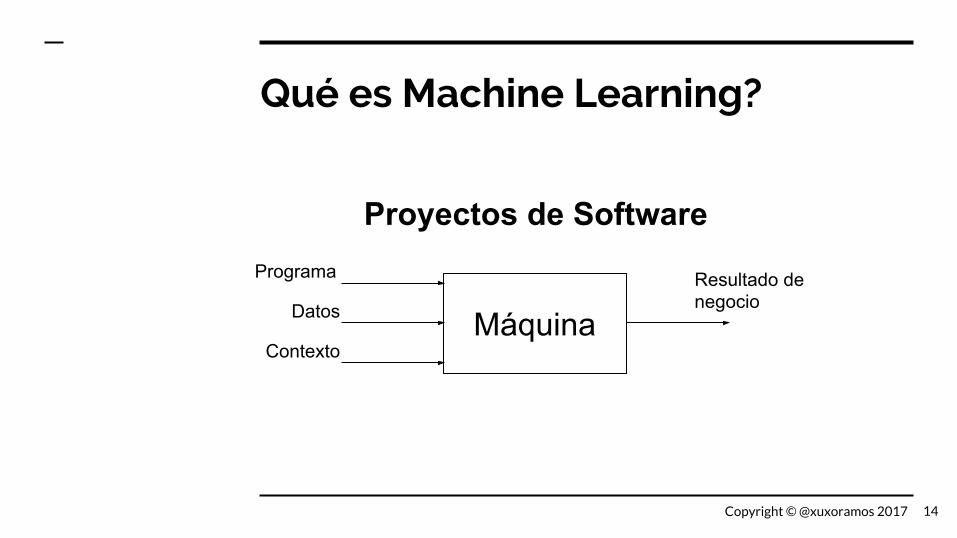
Qué es Machine Learning?
Máquina
Programa
Datos
Contexto
Resultado de negocio
Proyectos de Software
14Copyright © @xuxoramos 2017
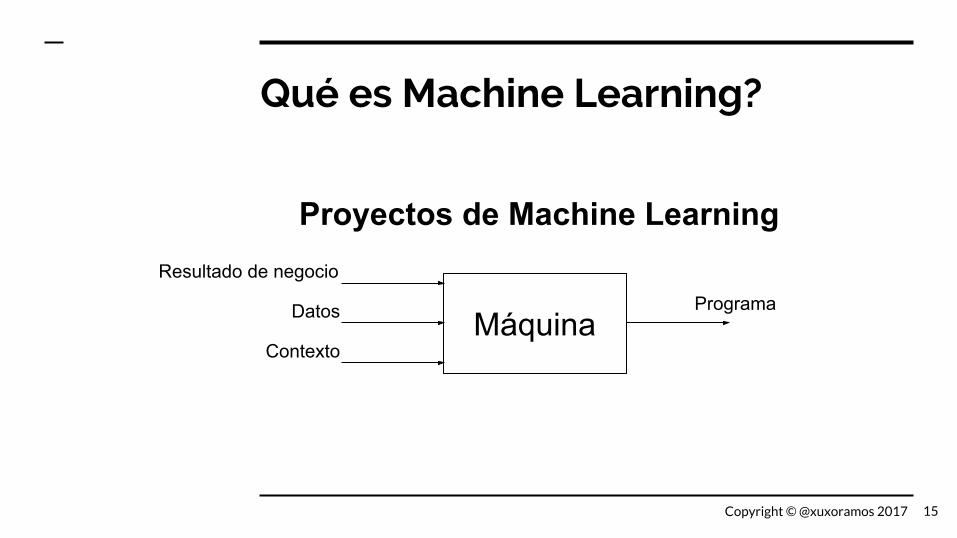
Qué es Machine Learning?
Máquina
Resultado de negocio
Datos
Contexto
Programa
Proyectos de Machine Learning
15Copyright © @xuxoramos 2017
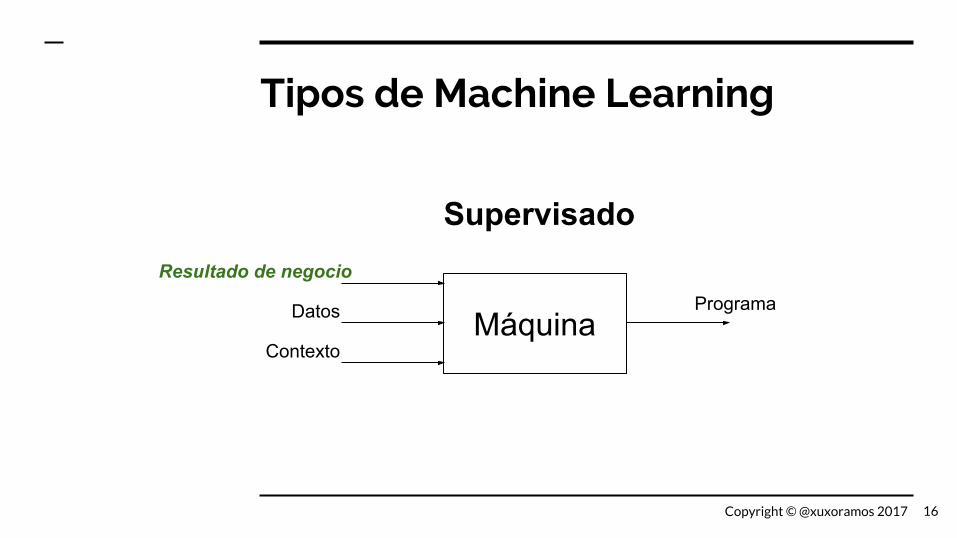
Tipos de Machine Learning
Máquina
Resultado de negocio
Datos
Contexto
Programa
Supervisado
16Copyright © @xuxoramos 2017

Tipos de Machine Learning
MáquinaDatos
Contexto
Programa
No-supervisado
17Copyright © @xuxoramos 2017
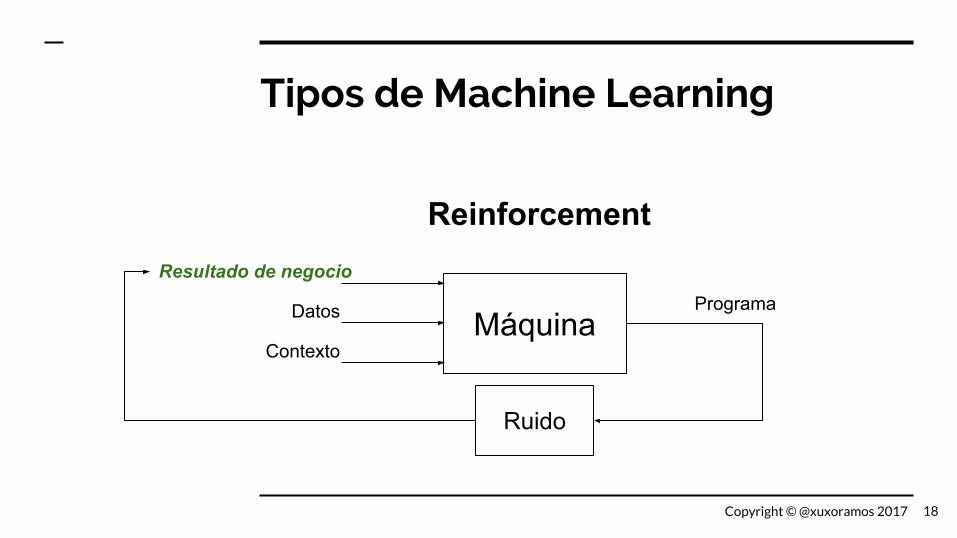
Tipos de Machine Learning
MáquinaDatos
Contexto
Programa
ReinforcementResultado de negocio
Ruido
18Copyright © @xuxoramos 2017

Objetivo
Identificar patrones equivocándose lo menor posible.
19Copyright © @xuxoramos 2017
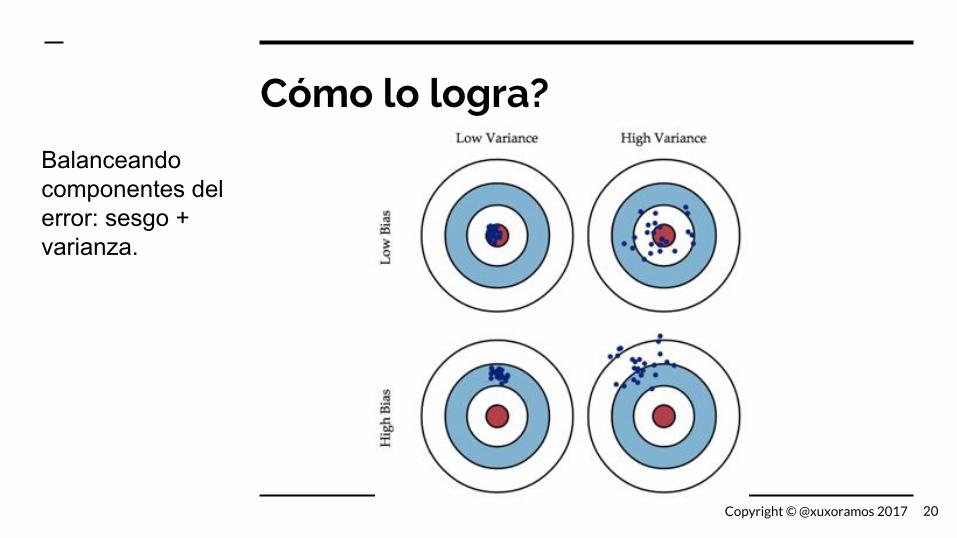
Cómo lo logra?
Balanceando componentes del error: sesgo + varianza.
20Copyright © @xuxoramos 2017

Ejemplo
21
Posible sesgo de la muestra
Sesgo de selección Varianza del fenómeno
Copyright © @xuxoramos 2017
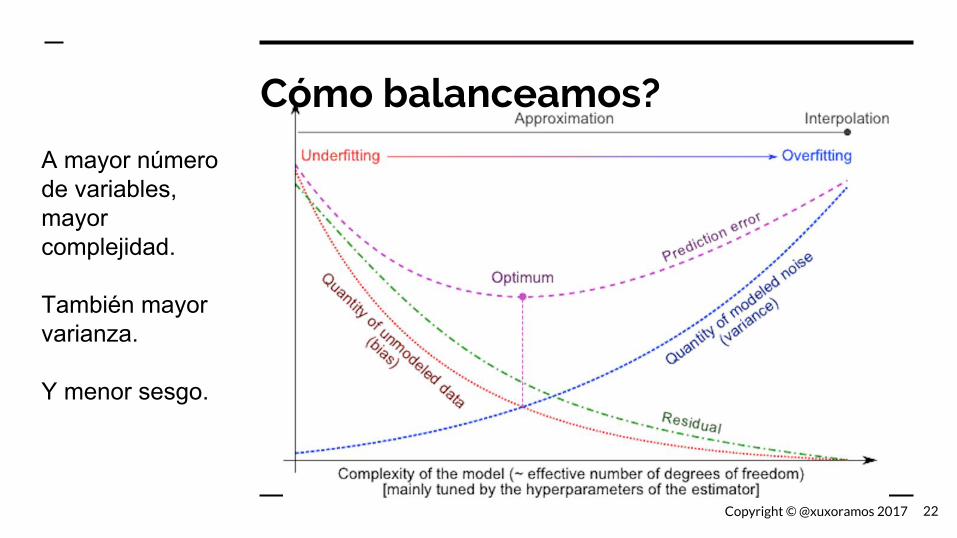
Cómo balanceamos?
A mayor número de variables, mayor complejidad.
También mayor varianza.
Y menor sesgo.
22Copyright © @xuxoramos 2017
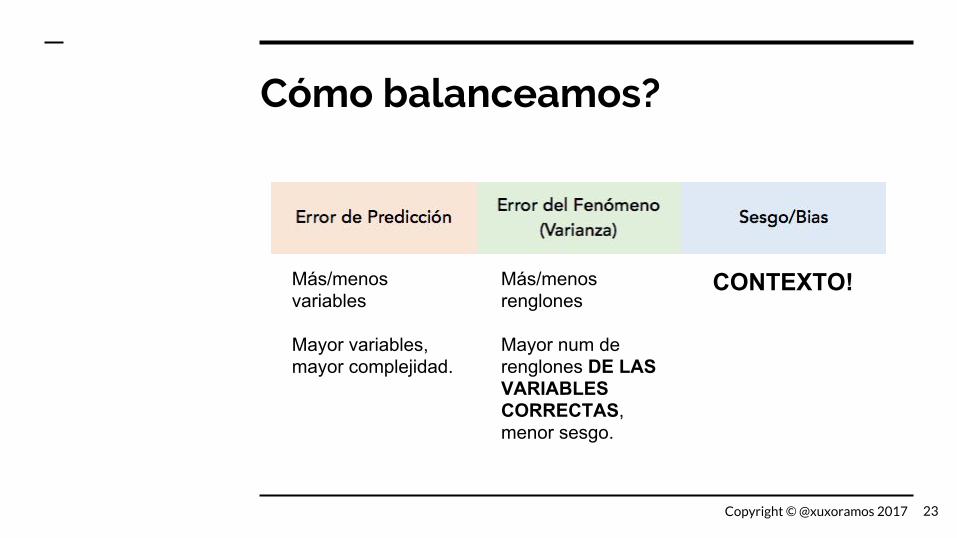
Cómo balanceamos?
Más/menos variables
Mayor variables, mayor complejidad.
Más/menos renglones
Mayor num de renglones DE LAS VARIABLES CORRECTAS, menor sesgo.
CONTEXTO!
23Copyright © @xuxoramos 2017

Usos de Machine Learning
Clasificación
Partir el espacio de datos en N categorías con funciones.
24Copyright © @xuxoramos 2017
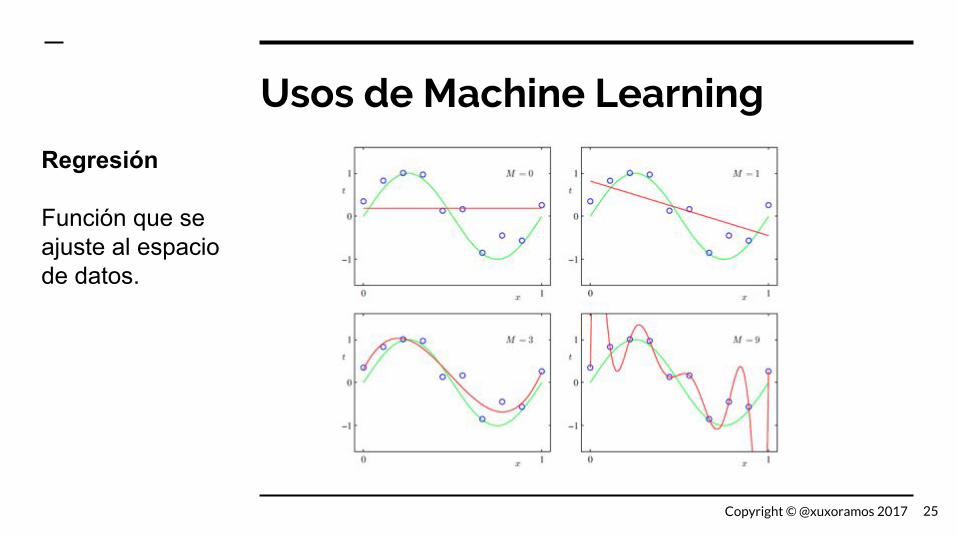
Usos de Machine Learning
Regresión
Función que se ajuste al espacio de datos.
25Copyright © @xuxoramos 2017
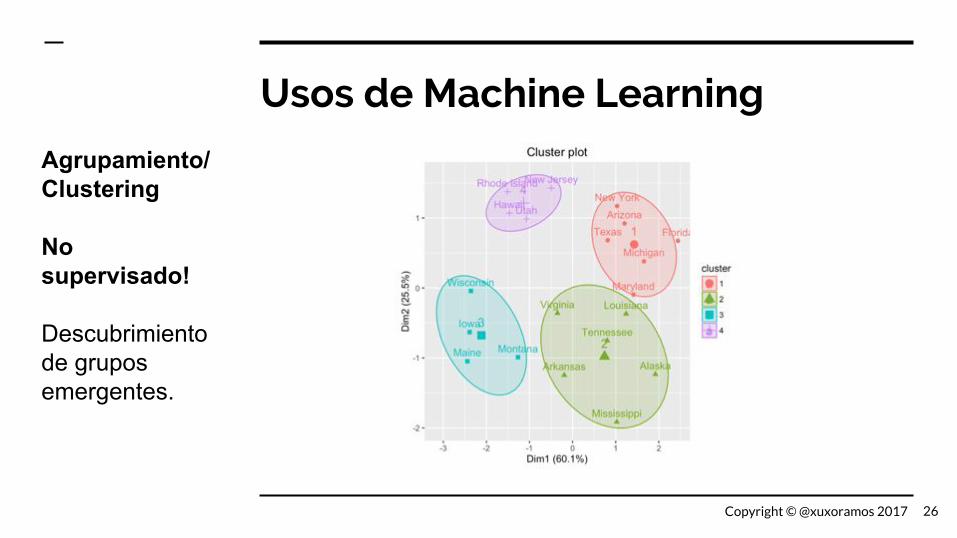
Usos de Machine Learning
Agrupamiento/Clustering
No supervisado!
Descubrimiento de grupos emergentes.
26Copyright © @xuxoramos 2017
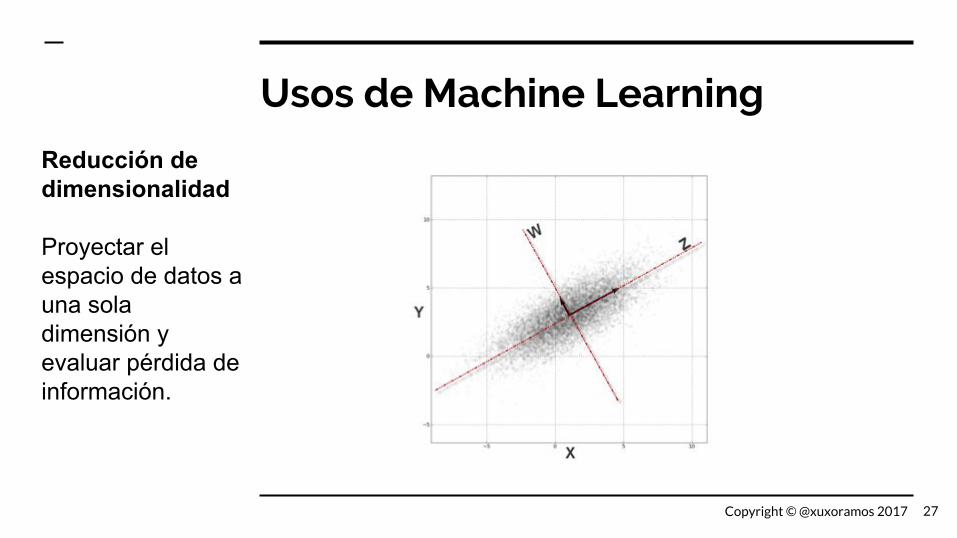
Usos de Machine Learning
Reducción de dimensionalidad
Proyectar el espacio de datos a una sola dimensión y evaluar pérdida de información.
27Copyright © @xuxoramos 2017

Y cómo lo aplico al ejemplo?
1. Definición del problema
2. Recolección y exploración de datos
3. Inferencia Estadística
4. Construcción del modelo
5. Selección del modelo.
28Copyright © @xuxoramos 2017

Y cómo lo aplico al ejemplo?
1. Definición del problema
2. Recolección y exploración de datos
3. Inferencia Estadística
4. Construcción del modelo
5. Selección del modelo.
Queremos ver si EPN miente?
Si sus fuentes mienten?
Si su comunicación es efectiva?
O si El Sabueso opera bien su metodología?
29Copyright © @xuxoramos 2017
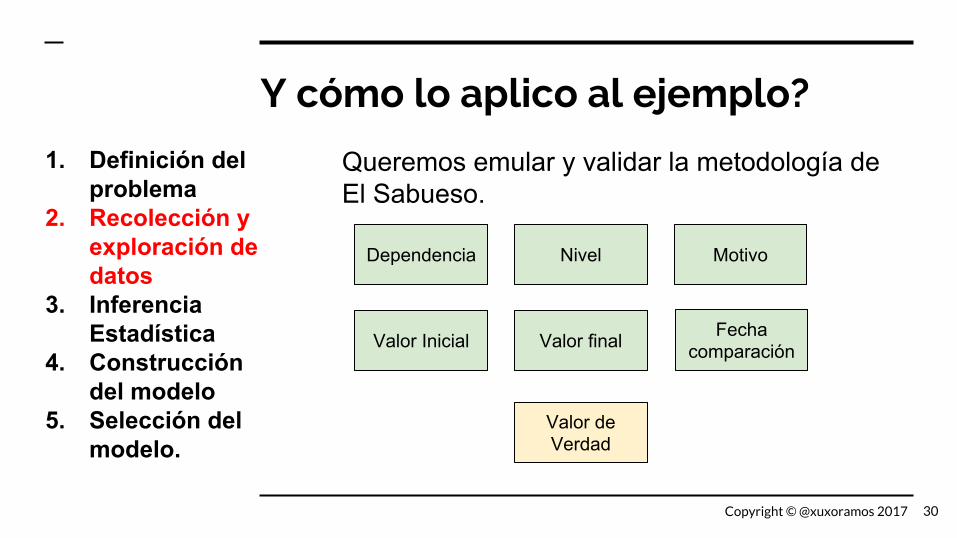
Y cómo lo aplico al ejemplo?
1. Definición del problema
2. Recolección y exploración de datos
3. Inferencia Estadística
4. Construcción del modelo
5. Selección del modelo.
Queremos emular y validar la metodología de El Sabueso.
Dependencia Nivel Motivo
Valor Inicial Valor final Fecha comparación
Valor de Verdad
30Copyright © @xuxoramos 2017
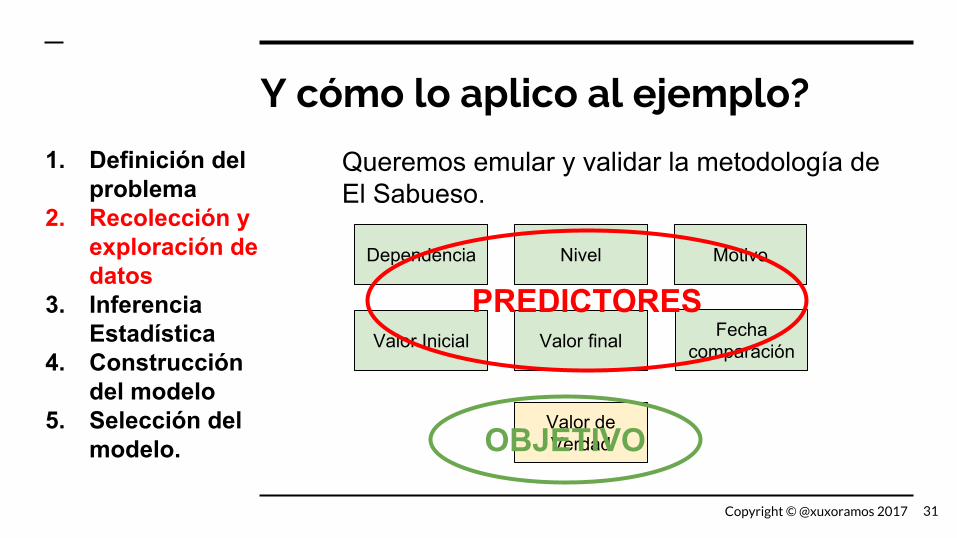
Y cómo lo aplico al ejemplo?
1. Definición del problema
2. Recolección y exploración de datos
3. Inferencia Estadística
4. Construcción del modelo
5. Selección del modelo.
Queremos emular y validar la metodología de El Sabueso.
Dependencia Nivel Motivo
Valor Inicial Valor final Fecha comparación
Valor de Verdad
PREDICTORES
OBJETIVO
31Copyright © @xuxoramos 2017
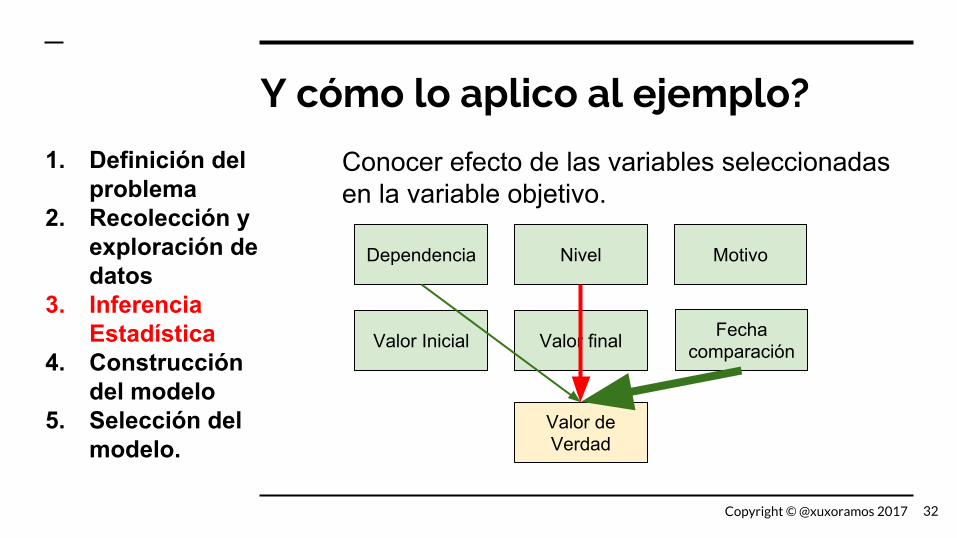
Y cómo lo aplico al ejemplo?
1. Definición del problema
2. Recolección y exploración de datos
3. Inferencia Estadística
4. Construcción del modelo
5. Selección del modelo.
Conocer efecto de las variables seleccionadas en la variable objetivo.
Dependencia Nivel Motivo
Valor Inicial Valor final Fecha comparación
Valor de Verdad
32Copyright © @xuxoramos 2017
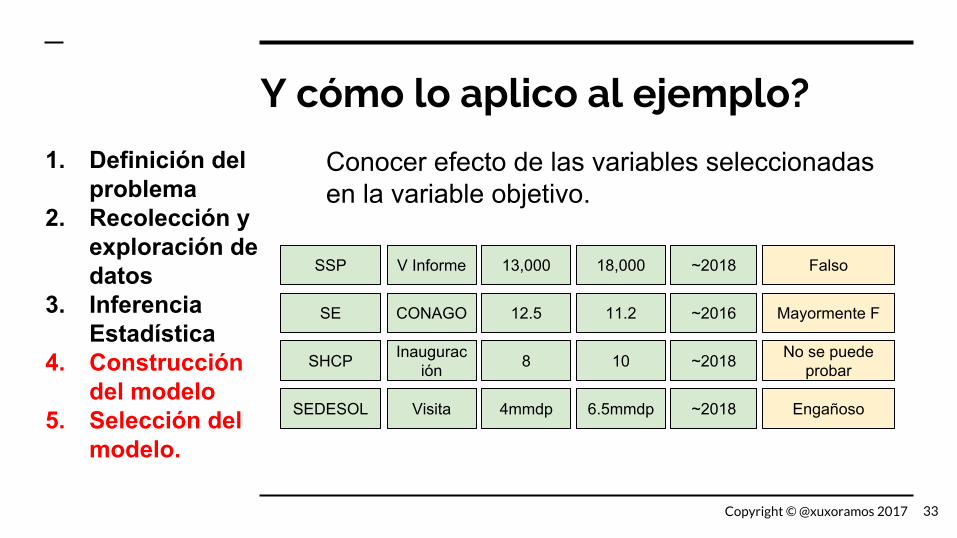
Y cómo lo aplico al ejemplo?
1. Definición del problema
2. Recolección y exploración de datos
3. Inferencia Estadística
4. Construcción del modelo
5. Selección del modelo.
Conocer efecto de las variables seleccionadas en la variable objetivo.
SSP V Informe 13,000 18,000 ~2018 Falso
SE CONAGO 12.5 11.2 ~2016 Mayormente F
SHCP Inauguración 8 10 ~2018 No se puede
probar
SEDESOL Visita 4mmdp 6.5mmdp ~2018 Engañoso
33Copyright © @xuxoramos 2017
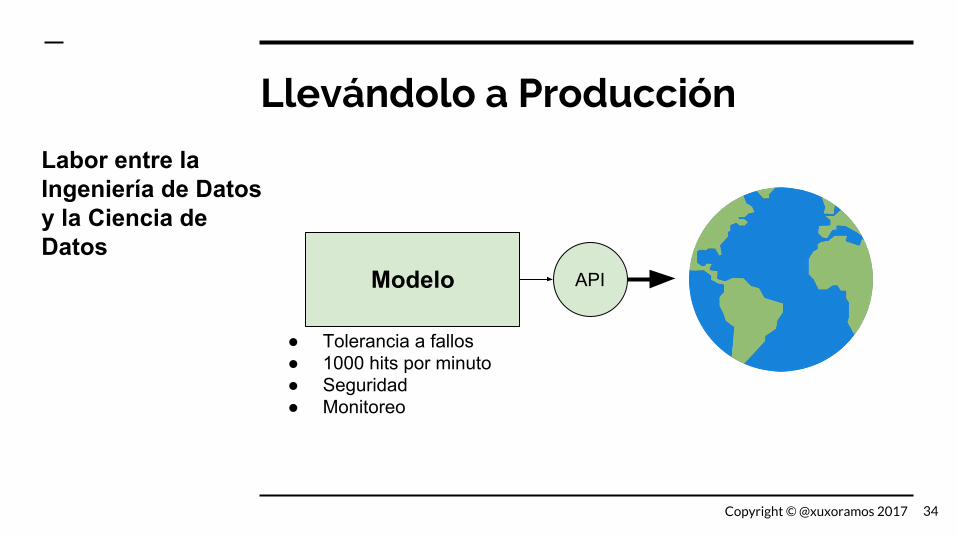
Llevándolo a Producción
Labor entre la Ingeniería de Datos y la Ciencia de Datos
Modelo
● Tolerancia a fallos● 1000 hits por minuto● Seguridad● Monitoreo
API
34Copyright © @xuxoramos 2017

Cómo anda MX en esto?
113K Ingenieros de Software al año.
350 Matemáticos, actuarios, físicos y estadísticos.
No se conoce la diferencia entre Data Scientist (DS) y Data Engineer (DE).
Tenemos miles de Data Engineers chingones.
No tenemos casi Científicos de Datos.
Tenemos muchos DE queriendo ser DS cuando no saben ni proba.
+
35Copyright © @xuxoramos 2017

Qué puede salir mal?
Telco importante dando créditos a sospechosos criminales.
Empresa importante de internet no le atina a predicción de AH1N1.
Gran empresa de software crea un bot sexualmente cargado y racista.
Empresa de internet clasifica foto de 2 afroamericanos como gorilas.
Crisis financiera de 2008.
Victoria de Trump.
36Copyright © @xuxoramos 2017

Debe México convertirse en un hub de Ciencia de Datos?La frontera norte se cierra a nuestros productos y servicios.
Poco petróleo, y a precio muy bajo.
Corrupción rampante.
Mercado interno débil.
Variables macroeconómicas malas.
La "mano de obra barata" no será relevante en la era de la automatización.
37Copyright © @xuxoramos 2017

Cómo pueden ayudar?
Entra a un programa académico completo.
Regresa a la escuela a aprender mates.
Usa la educación abierta en internet para hacer tu propia maestría.
Únete a grupos profesionales.
Únete a comunidades.
38Copyright © @xuxoramos 2017

Mates aplicadas @ ITAM, UNAM, IPN
Física @ UNAM
Economía @ ITAM, UNAM
MSc Ciencia de Datos @ ITAM
MSc Inteligencia Analítica @ UAnáhuac
Programas académicos en MX*
+
* Evaluación de 63 candidatos para posiciones de Ciencia de Datos en Bolsa Mexicana de Valores, GBM, TERAN/TBWA, Klustera, Globant, OPI y ConCrédito.
39Copyright © @xuxoramos 2017

Intro to Mathematical Thinking: Stanford + Coursera
Intro to Logic: Stanford + Coursera
Business Analytics: Wharton + Coursera
Data Science Specialization: JHU + Coursera
Machine Learning: Stanford + Coursera
Executive Data Science: JHU + Coursera
"Hága su propia maestría"*
* Ver ratings de cursos en https://www.class-central.com/ 40Copyright © @xuxoramos 2017

Sociedad de Científicos de Datos de MéxicoGrupo más académico.
SocialTICMenos Ciencia, más visualización, periodismo e infoactivismo.
Instituto Internacional de Ciencia de DatosMás governance y proyectos "empresariales".
Grupos Profesionales
41Copyright © @xuxoramos 2017

The Data Pub (FB: /thedatapub, TW: @thedatapub)
2500 miembros. Meetups cada último Jueves del mes.
Presentamos 2 proyectos donde el negocio o la vida humana sean primero, las mates segundo, y la tecnología tercero.
Cursos de Stats & Machine Learning para Developers.
Job posting - porque sigue habiendo confusión entre DS y DE.
Badges - porque los endorsements de LinkedIn son "la hoguera de las vanidades".
Comunidades
42Copyright © @xuxoramos 2017


















