ESTADÍSTICA TEÓRICA: DISTRIBUCIONES DE …estadistica.net/Algoritmos2/web-distribuciones.pdf ·...
122
Gestión Aeronáutica: Estadística Teórica Facultad Ciencias Económicas y Empresariales Departamento de Economía Aplicada Profesor: Santiago de la Fuente Fernández ESTADÍSTICA TEÓRICA: DISTRIBUCIONES DE PROBABILIDAD
Transcript of ESTADÍSTICA TEÓRICA: DISTRIBUCIONES DE …estadistica.net/Algoritmos2/web-distribuciones.pdf ·...

Gestión Aeronáutica: Estadística TeóricaFacultad Ciencias Económicas y EmpresarialesDepartamento de Economía AplicadaProfesor: Santiago de la Fuente Fernández
ESTADÍSTICA TEÓRICA: DISTRIBUCIONES DE PROBABILIDAD

Distribuciones de Probabilidad 2

Distribuciones de Probabilidad 3
DISTRIBUCIONES VARIABLE ALEATORIA DISCRETA
DISTRIBUCIÓN UNIFORME
La variable aleatoria discreta X se dice que tiene una distribución uniforme si puedetomar los n valores 1 2 nx , x , , x con probabilidad
= = ∀i1P(X x ) in
+ − −
μ = σ = σ =2 2
2X X X
n 1 n 1 n 12 12 12
DISTRIBUCIÓN de BERNOUILLI
Experimento aleatorio que sólo admite dos resultados excluyentes (éxito y fracaso).
La variable aleatoria discreta X asociada a este experimento toma el valor 1 cuandoocurre el suceso éxito con probabilidad =P(A) p y el valor 0 cuando ocurre el
suceso fracaso con probabilidad =P(A) q
X = iP(X x )0 q1 p
μ = σ = σ =2X X Xp p . q p . q
DISTRIBUCIÓN BINOMIAL
Cuando se realizan n pruebas de Bernouilli sucesivas e independientes.
La variable aleatoria discreta X se denomina variable binomial cuando:
X = "número de veces que ocurre el suceso éxito en n pruebas" ∼X B(n, p)
La función de probabilidad o cuantía: −⎛ ⎞= = ⎜ ⎟
⎝ ⎠k n kn
P(X k) . p . qk
−μ = σ = σ = =2
X X X sq pn. p n. p.q n. p.q An. p.q
(coeficiente asimetría)
La moda de una distribución binomial viene dada por el valor (número entero) queverifica d(np q M np p)− ≤ ≤ + .Generalmente será un valor (la parte entera de la media) y podrán ser dos valoresmodales cuando (np q)− y (np p)+ sea un número entero.
Si el experimento consiste en extracciones de una urna, éstas han de ser conreemplazamiento para mantener la probabilidad de éxito a lo largo de todas laspruebas.

Distribuciones de Probabilidad 4
Si ∼X B(n, p) cuando n es grande y ni p ni q son próximos a cero, se puede
considerar que ( )∼X N n. p , n. p.q
( )k n k n.p 5nP(X k) . p . q N n. p ; n. p.q
k− ≥⎛ ⎞
= = ⎯⎯⎯⎯→⎜ ⎟⎝ ⎠
y, por tanto, la variable −
= ∼X n.pz N(0,1)n.p.q
(Teorema de Moivre)
La distribución de Poisson es una buena aproximación de la distribuciónbinomial cuando el tamaño n es grande y la probabilidad p es pequeña.
En general, cuando ≥n 30 y p 0,1≤
k
k n k n . p 5nB(n, p) p q P( ) e
k!k− −λ<⎛ ⎞ λ
= ⎯⎯⎯⎯→ λ =⎜ ⎟⎝ ⎠
con n.pλ =
Las distribuciones binomiales son reproductivas de parámetro p, es decir, dadasdos variables aleatorias independientes ∼X B(n, p) e Y B(m, p)∼ se verifica queX Y B(n m, p)+ +∼ .
A partir de este resultado es inmediato que una variable aleatoria ∼X B(n, p)puede descomponerse en suma de n variables aleatorias independientes deBernouilli de parámetro p.
DISTRIBUCIÓN de POISSON
Una variable X se dice que sigue una distribución de probabilidad de Poisson sipuede tomar todos los valores enteros (0,1, 2, , n) con las siguientesprobabilidades:
k
P(X k) ek!
−λλ= = siendo 0λ > 2
X X Xμ = λ σ = λ σ = λ
X = "número de ocurrencias de un suceso durante un gran número de pruebas"
Existen un gran número de modelos experimentales que se ajustan a unadistribución de Poisson:
Número de piezas defectuosas en una muestra grande, donde la proporción dedefectuosas es pequeña.
Número de llamadas telefónicas recibidas en una centralita durante ciertotiempo.
Número de clientes que llegan a una ventanilla de pagos de un banco durantecierto tiempo.

Distribuciones de Probabilidad 5
La suma de n variables aleatorias de Poisson independientes es otra variablealeatoria de Poisson cuyo parámetro es la suma de los parámetros originales.
Sí i iX P( )λ∼ donde i 1, 2, ,n= variables aleatorias independientes de Poisson
n n
i ii 1 i 1
Y X P= =
⎛ ⎞= λ⎜ ⎟
⎝ ⎠∑ ∑∼
Si para cada valor t 0> , que representa el tiempo, el número de sucesos de unfenómeno aleatorio sigue una distribución de Poisson de parámetro tλ , lostiempos transcurridos entre dos sucesos sucesivos sigue una distribuciónexponencial.
Cuando 10λ ≥ la distribución de Poisson se aproxima a una distribución
normal ( )N ,λ λ
DISTRIBUCIÓN GEOMÉTRICA o de PASCAL
La distribución geométrica o de Pascal consiste en la realización sucesiva depruebas de Bernouilli, donde la variable aleatoria discreta:
X = "número de la prueba en que aparece por primera vez el suceso A", dondeX G(p)∼
Para hallar la función de probabilidad o cuantía P(X k)= hay que notar que la
probabilidad del suceso es:
k-1
A.A.A. .A . A
En consecuencia, k 1P(X k) q . p−= =
22
q1 qp p p
μ = σ = σ =
La distribución geométrica es un modelo adecuado para aquellos procesos en losque se repiten pruebas hasta la consecución del resultado deseado.
Si el experimento consiste en extracciones de una urna, éstas han de ser conremplazamiento.
DISTRIBUCIÓN BINOMIAL NEGATIVA
La distribución binomial negativa Bn(n, p) es un modelo adecuado para tratarprocesos en los que se repite n veces una prueba determinada o ensayo hastaconseguir un número determinado k de resultados favorables (por vez primera).

Distribuciones de Probabilidad 6
Si el número de resultados favorables buscados fuera 1 sería el caso de unadistribución geométrica, esto es, la distribución binomial negativa puedeconsiderarse una extensión o ampliación de la distribución geométrica.
X = "número de pruebas necesarias para lograr k‐éxitos " X Bn(n, p)∼
k n kn 1P(X n) p .q
k 1−−⎛ ⎞
= = ⎜ ⎟−⎝ ⎠ 2
2
k.qk.q k.qp p p
μ = σ = σ =
Si el experimento consiste en extracciones de una urna, éstas han de ser conremplazamiento.
Adviértase que si el número de resultados favorables fuera 1 (k 1)= la distribuciónbinomial negativa sería una distribución geométrica:
n 1 n 1n 1P(X n) p.q p.q
0− −−⎛ ⎞
= = =⎜ ⎟⎝ ⎠
DISTRIBUCIÓN POLINOMIAL o MULTINOMIAL
Es una generalización de la distribución binomial cuando en cada prueba seconsideran k sucesos excluyentes 1 2 k(A , A , , A ) con probabilidades respectivas
1 2 k(p , p , , p ) , siendo 1 2 kp p p 1+ + + =
Suponiendo que se realizan n pruebas independientes de este tipo y considerandolas variables iX = "número de veces que ocurre el suceso iA en las n pruebas"
1 2 kn n n1 1 2 2 k k 1 2 k
1 2 k
n!P(X n ; X n ; ; X n ) p p pn ! n ! n !
= = = =
DISTRIBUCIÓN HIPERGEOMÉTRICA
Es una variante de la distribución binomial (experiencias independientes oextracciones con reemplazamiento).
La distribución hipergeométrica corresponde a extracciones sin reemplazamiento.
En las demás cuestiones presenta el mismo marco de consideraciones, es decir, dossituaciones excluyentes (éxito y fracaso) que se realizan en n pruebas.
Sean N elementos, con la probabilidad de éxito p en la primera extracción. Los Nelementos se distribuyen en (N.p) éxitos y (N.q) fracasos.
La variable aleatoria X = "número de éxitos k en n extracciones" donde
AX H n, N, N⎡ ⎤⎣ ⎦∼

Distribuciones de Probabilidad 7
N.p N.qk n kP(X k)
Nn
⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟−⎝ ⎠ ⎝ ⎠= =
⎛ ⎞⎜ ⎟⎝ ⎠
2X X
N n N nn.p n.p.q. n.p.q.N 1 N 1− −
μ = σ = σ =− −
Cuando N es grande respecto a n, es decir, n 0,1N< , se puede decir que la variable
hipergeométrica sigue aproximadamente una distribución binomial. Esto es,
k n kn 0,1N
N.p N.qnk n kP(X k) p .q
N kn
−<
⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟ ⎛ ⎞−⎝ ⎠ ⎝ ⎠= = ⎯⎯⎯⎯→ ⎜ ⎟⎛ ⎞ ⎝ ⎠
⎜ ⎟⎝ ⎠
En general, de forma análoga a la distribución polinomial, en una población con Nelementos repartidos en k clases excluyentes 1 2 k(A , A , , A ) con elementosrespectivos de cada clase 1 2 k(N , N , , N ) , 1 2 kN N N N+ + + = , al tomarconsecutivamente n elementos sin reemplazamiento y denotando por:
iX = "número de elementos que hay de la clase iA en la muestra de tamaño n"
1 2 k
1 2 k1 1 2 2 k k
N N N. . .
n n nP(X n ; X n ; ; X n )
Nn
⎛ ⎞ ⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠= = = =
⎛ ⎞⎜ ⎟⎝ ⎠
siendo 1 2 k
1 2 k
N N N Nn n n n+ + + =⎧
⎨ + + + =⎩
Distribuciones de Probabilidad 8
DISTRIBUCIONES VARIABLE ALEATORIA CONTINUA
La ley de probabilidad de una variable aleatoria continua X está definida, bien si seconoce su función de densidad f(x) , bien si se conoce su función de distribuciónF(x) , verificando:
b
aF(x) P(X x) P(a X b) f(x) dx f(x) dx 1
∞
−∞= ≤ < < = =∫ ∫
La función de densidad f(x) y la función de distribución F(x) se encuentranrelacionadas por la expresión:
x d F(x)F(x) f(x) dx f(x)dx−∞
= =∫
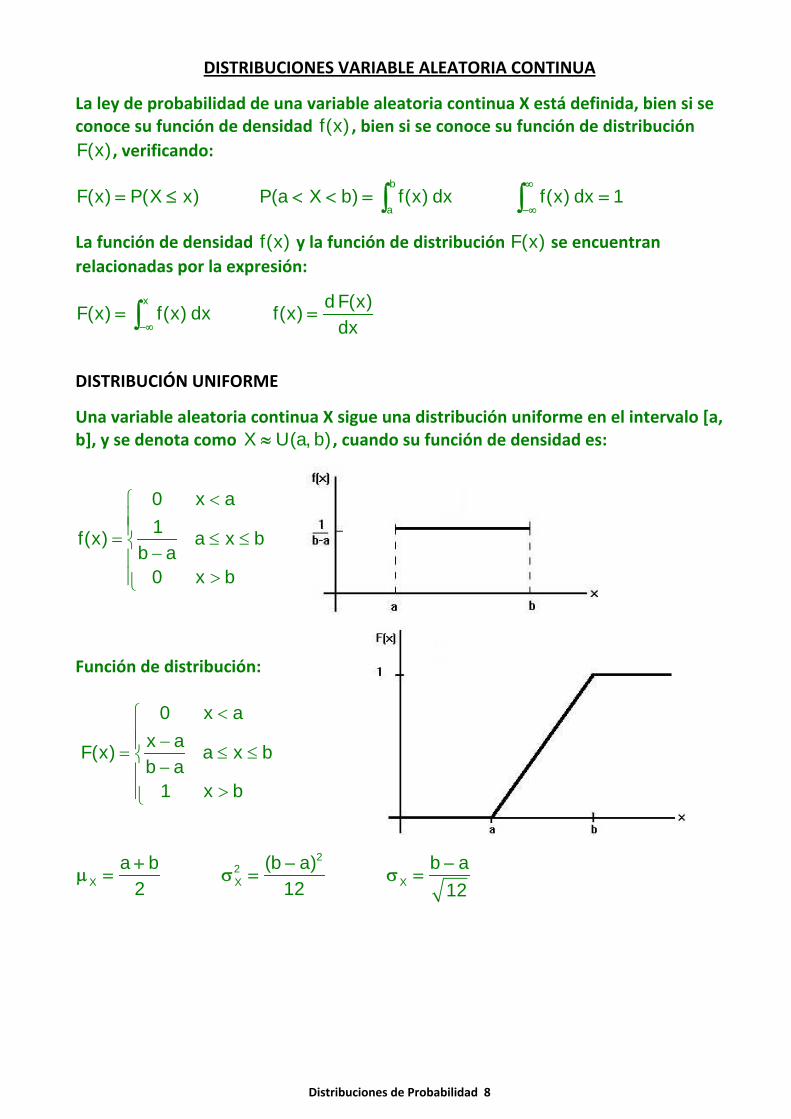
DISTRIBUCIÓN UNIFORME
Una variable aleatoria continua X sigue una distribución uniforme en el intervalo [a,b], y se denota como X U(a, b)≈ , cuando su función de densidad es:
0 x a1f(x) a x b
b a0 x b
<⎧⎪⎪= ≤ ≤⎨ −⎪
>⎪⎩
Función de distribución:
0 x ax aF(x) a x bb a
1 x b
<⎧⎪ −⎪= ≤ ≤⎨ −⎪
>⎪⎩
22
X X Xa b (b a) b a
2 12 12+ − −
μ = σ = σ =

Distribuciones de Probabilidad 9
DISTRIBUCIÓN NORMAL o de LAPLACE‐GAUSS
Una variable aleatoria continua X se dice que tiene una distribución normal o deLaplace‐Gauss de media μ y desviación típica σ si su función de densidad es:
2
2(x )
21f(x) . e 0. 2
−μ−
σ= − ∞ < μ < ∞ σ >σ π
Función de distribución:
2
2(x )x
21F(x) . e dx. 2
−μ−
σ
−∞
=σ π ∫
Si una variable 1X es 1 1N( , )μ σ y otra 2X es 2 2N( , )μ σ independientes entre sí,entonces la nueva variable 1 2X X X= ± sigue también una distribución normal
( )2 21 2 1 2N ,μ ± μ σ + σ . Propiedad que se puede generalizar a n variables aleatorias
independientes.
Si una variable X sigue una distribución normal N( , )μ σ , la nueva variableXz − μ
=σ
sigue también una distribución normal N(0,1) .
La variable z se le denomina variable tipificada de X y a la curva de su función dedensidad curva normal tipificada.
La función de densidad será,
2z21f(z) . e z
2
−= − ∞ < < ∞
π
Función de distribución:
2tz21F(z) . e dt
2
−
−∞
=π ∫
Si X es una variable binomial B(n, p) con n grande y ni p ni q son próximos acero, podemos considerar que X sigue aproximadamente una distribución
N n . p, n . p . q⎡ ⎤⎣ ⎦ y, en consecuencia, la variable
X n. pz N(0,1)
n. p . q−
= ∼ (Teorema de Moivre)
En general, la transformación es aceptable cuando p 0,5 y n . p 5≤ >
Para utilizar correctamente la transformación de una variable discreta X (con

Distribuciones de Probabilidad 10
distribución binomial) en una variable continua z (con distribución normal) esnecesario realizar una corrección de continuidad.
P(X a) P(X a 0,5)< = ≤ − P(X a) P(X a 0,5)≤ = ≤ +
P(X a) P(a 0,5 X a 0,5)= = − ≤ ≤ +
P(a X b) P(a 0,5 X b 0,5)< < = + ≤ ≤ − P(a X b) P(a 0,5 X b 0,5)≤ ≤ = − ≤ ≤ +
DISTRIBUCIÓN CHI‐CUADRADO ( 2χ ) de PEARSON
Sean n variables aleatorias ( )1 2 nX , X , , X independientes entre sí, con ley
N(0,1)
La variable 2 2 2 2n 1 2 nX X Xχ = + + + recibe el nombre de 2χ (chi‐cuadrado) de
Pearson con n grados de libertad.
La función de densidad es 2
x 2 (n 2) 1n 2
1 e . x 0 x2 . (n 2)f (x)
0 x 0
− −
χ
⎧ < < ∞⎪ Γ= ⎨⎪ ≤⎩
La función gamma se define p 1 x
0(p) x e dx
∞− −Γ = ∫
Algunas fórmulas de interés para el cálculo de (p)Γ :
1 (p) (p 1)! (p 1) (p 1) (p) . (p 1)2 senp
π⎛ ⎞Γ = π Γ = − = − Γ − Γ Γ − =⎜ ⎟ π⎝ ⎠
Distribuciones de Probabilidad 11
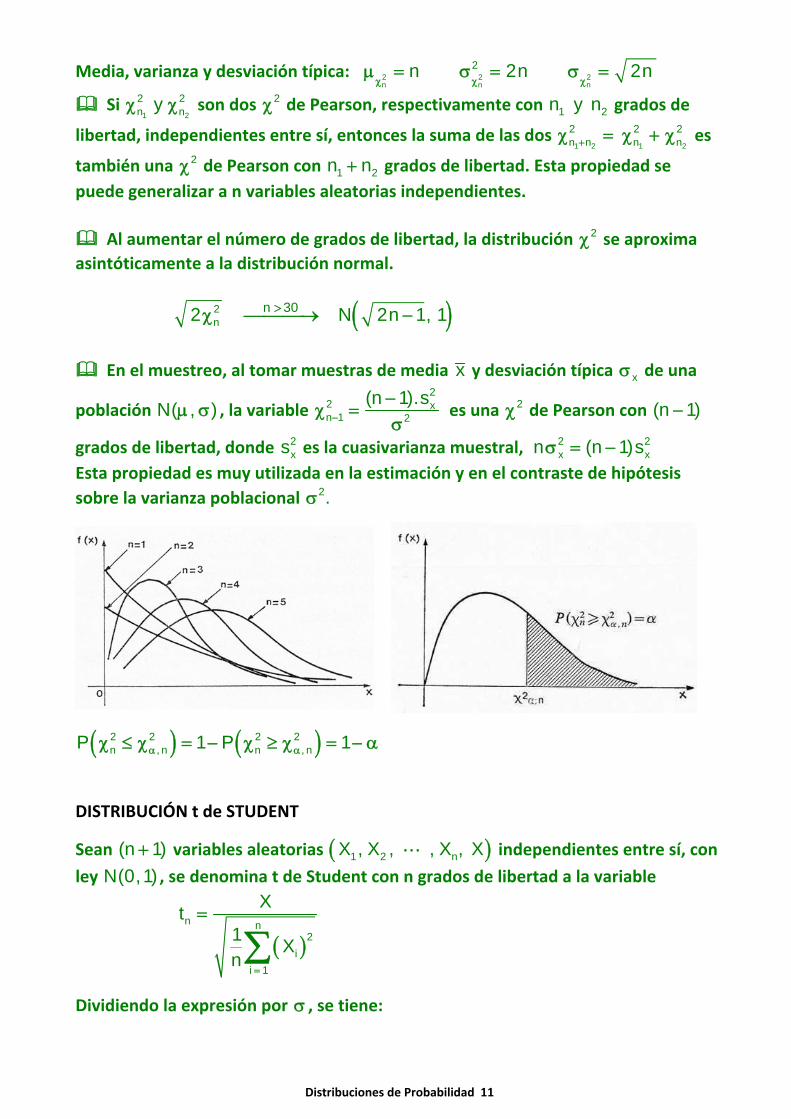
Media, varianza y desviación típica: 2 2 2n n n
2n 2n 2nχ χ χ
μ = σ = σ =
Si 1 2
2 2n nyχ χ son dos 2χ de Pearson, respectivamente con 1 2n y n grados de
libertad, independientes entre sí, entonces la suma de las dos 1 2 1 2
2 2 2n n n n+χ = χ + χ es
también una 2χ de Pearson con 1 2n n+ grados de libertad. Esta propiedad sepuede generalizar a n variables aleatorias independientes.
Al aumentar el número de grados de libertad, la distribución 2χ se aproximaasintóticamente a la distribución normal.
( )2n
n 302 N 2n 1, 1>χ ⎯⎯⎯→ −
En el muestreo, al tomar muestras de media x y desviación típica xσ de una
población N( , )μ σ , la variable 2
2 xn 1 2
(n 1).s−
−χ =
σ es una 2χ de Pearson con (n 1)−
grados de libertad, donde 2xs es la cuasivarianza muestral, 2 2
x xn (n 1)sσ = −Esta propiedad es muy utilizada en la estimación y en el contraste de hipótesissobre la varianza poblacional 2.σ
( ) ( )2 2 2 2n , n n , nP 1 P 1α αχ ≤ χ = − χ ≥ χ = − α
DISTRIBUCIÓN t de STUDENT
Sean (n 1)+ variables aleatorias ( )1 2 nX , X , , X , X independientes entre sí, con
ley N(0,1) , se denomina t de Student con n grados de libertad a la variable
( )n n
2i
i 1
Xt1 Xn
=
=
∑Dividiendo la expresión por σ , se tiene:
Distribuciones de Probabilidad 12
( )n n n 2
22 i nii 1 i 1
X X zt11 1 XX nn n
= =
σ= = =
⎛ ⎞ χ⎜ ⎟σ⎝ ⎠∑ ∑
La función de densidad: n
n 12 2
t1 xf (x) 1
1 n nn. ,2 2
+
⎛ ⎞= +⎜ ⎟⎛ ⎞ ⎝ ⎠β⎜ ⎟
⎝ ⎠
Algunas fórmulas de interés para el cálculo de (p, q)β , p 0 y q 0> > , son:
1p 1 q 1
0(p, q) x (1 x) dx− −β = −∫ con el cambio
tx1 t
=+
se tiene
p 1
p q0
t(p, q) dt(1 t)
−∞
+β =+∫
otra forma de representar la función, ( ) ( )2
2p 1 2q 1
0(p, q) 2 sent cos t dt
π− −
β = ∫(p) . (q)(p, q)(p q)
Γ Γβ =
Γ + (p, q) (q, p)β = β simetría
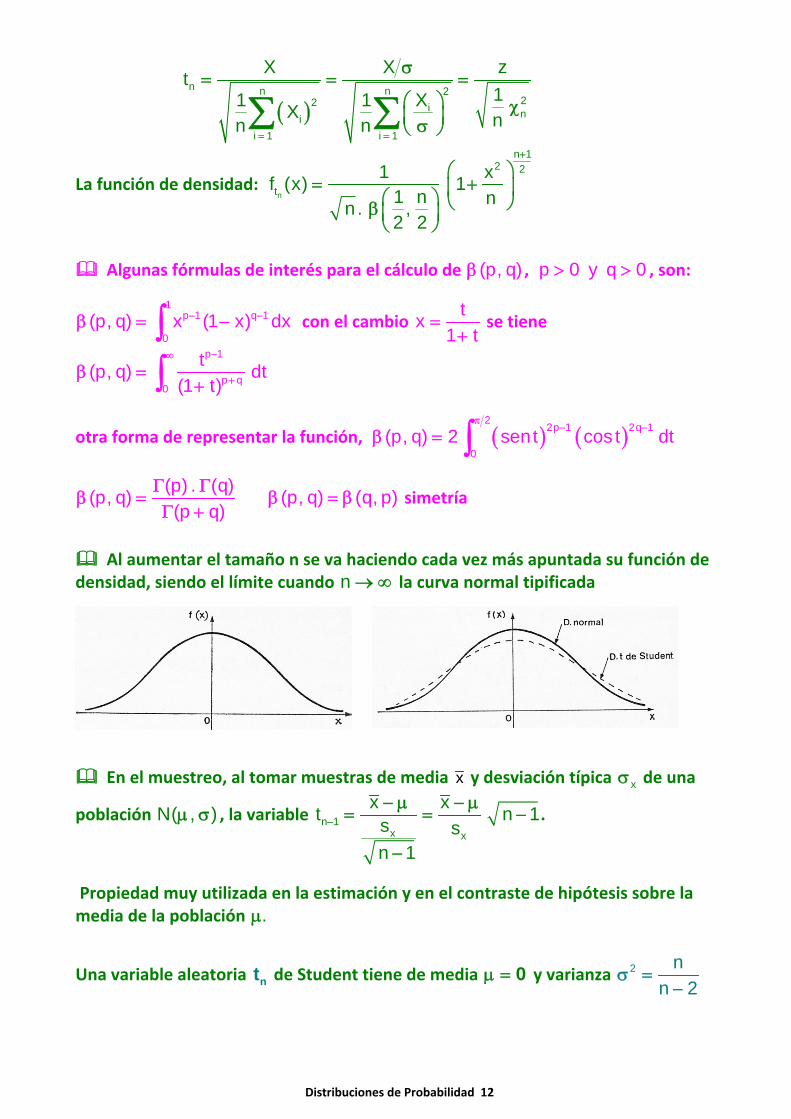
Al aumentar el tamaño n se va haciendo cada vez más apuntada su función dedensidad, siendo el límite cuando n → ∞ la curva normal tipificada
En el muestreo, al tomar muestras de media x y desviación típica xσ de una
población N( , )μ σ , la variable n 1x x
x xt n 1s sn 1
−
− μ − μ= = −
−
.
Propiedad muy utilizada en la estimación y en el contraste de hipótesis sobre lamedia de la población .μ
Una variable aleatoria nt de Student tiene de media μ = 0 y varianza 2 nn 2
σ =−

Distribuciones de Probabilidad 13
DISTRIBUCIÓN F de FISHER‐SNEDECOR
Sean 2 21 2yχ χ dos variables 2χ de Pearson, respectivamente con 1 2n y n grados
de libertad, independientes entre sí, se denomina F de Fisher‐Snedecor con
1 2n y n grados de libertad a la variable: 1 2
21 1
n , n 22 2
nFn
χ=χ
Tiene por función de densidad:
1
1
1 2
1 2
n 2
1 2 1(x 2) 1
2(n n )/2
1 2n ,n 1
2
n n n.2 n x x 0n nf (x) n. 1 x2 2 n
0 x 0
−
+
⎧ ⎛ ⎞+⎛ ⎞⎪Γ ⎜ ⎟⎜ ⎟⎝ ⎠⎪ ⎝ ⎠ >⎪= ⎛ ⎞ ⎛ ⎞⎨ ⎛ ⎞Γ Γ⎜ ⎟ ⎜ ⎟ +⎪ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠⎪
⎪ ≤⎩
1 2 1 2n ,n ; n ,nP(F F )α≥ = α
1 2 1 2 1 2 1 2n ,n ; n ,n n ,n ; n ,nP(F F ) 1 P(F F ) 1α α< = − ≥ = − α
Para valores 0,95 y 0,99α = α = se considera la relación 1 2
2 1
; n ,n1 ; n , n
1FFα
−α
=
En el muestreo es un estadístico utilizado para la razón de varianzas de dospoblaciones normales y en el contraste de hipótesis sobre la igualdad de varianzaspoblacionales.
DISTRIBUCIÓN de PARETO

Distribuciones de Probabilidad 14
Una variable aleatoria continua X se dice que sigue una distribución de Pareto deparámetros ( , )α θ si puede tomar valores iguales o superiores a θ y tiene comofunción de densidad:
1. x 0 0f(x) x0 x
α
α+
⎧α θ≥ θ > α >⎪= ⎨
⎪ < θ⎩
Función de distribución 1 xF(x) x
0 x
α⎧ θ⎛ ⎞− ≥ θ⎪ ⎜ ⎟= ⎨ ⎝ ⎠⎪ < θ⎩
Media, varianza y desviación típica para 2α >
2 22
x x x2 2. . .
1 ( 1) . ( 2) ( 1) . ( 2)α θ α θ α θ
μ = σ = σ =α − α − α − α − α −
Es muy utilizada en economía, ya que la distribución de las rentas personalessuperiores a una cierta renta θ sigue una distribución de Pareto de parámetros( , )α θ
El parámetro θ puede interpretarse como un ingreso mínimo de la población,tratándose de un indicador de posición. Si la población fuera el conjunto desalarios una nación que trabaja ocho horas al día, el parámetro θ sería el salariomínimo nacional.
El parámetro α se determina generalmente a partir de la media muestral.Normalmente, toma valores próximos a 2. A mayores valores de α se obtienendensidades de Pareto más concentradas en las proximidades del mínimo, esto es,menos dispersas.
El Coeficiente de Variación
2
2.
( 1) . ( 2)CV .
1
θα θα − α −
= =α θα −
( 1)α
α − ( 2).
α −
α θ1α −
1. ( 2)
=α α −
Reflejando que la dispersión depende sólo del parámetro α , se necesitaría un valorde 10α > para obtener un coeficiente de dispersión menor del 10%.
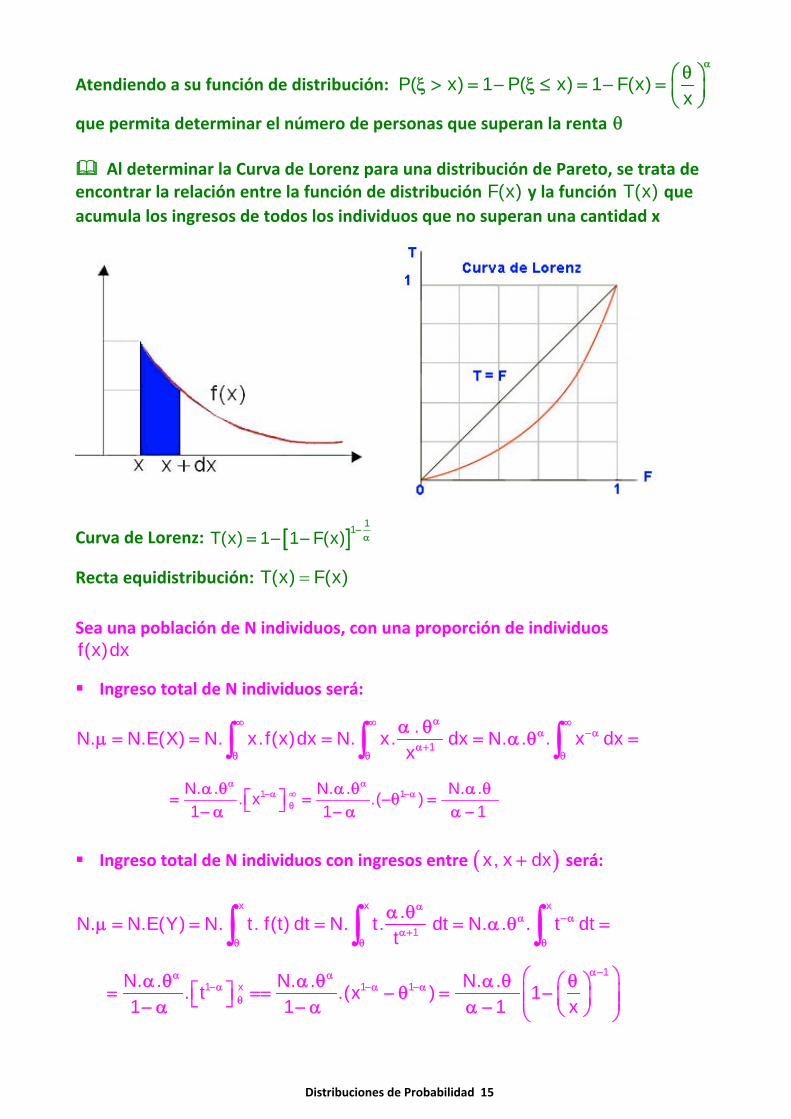
Distribuciones de Probabilidad 15
Atendiendo a su función de distribución: P( x) 1 P( x) 1 F(x)x
αθ⎛ ⎞ξ > = − ξ ≤ = − = ⎜ ⎟⎝ ⎠
que permita determinar el número de personas que superan la renta θ
Al determinar la Curva de Lorenz para una distribución de Pareto, se trata deencontrar la relación entre la función de distribución F(x) y la función T(x) queacumula los ingresos de todos los individuos que no superan una cantidad x
Curva de Lorenz: [ ]11T(x) 1 1 F(x) −α= − −
Recta equidistribución: T(x) F(x)=
Sea una población de N individuos, con una proporción de individuosf(x)dx
Ingreso total de N individuos será:
1.N. N.E(X) N. x.f(x)dx N. x. dx N. . . x dx
x
α∞ ∞ ∞α −α
α+θ θ θ
α θμ = = = = α θ =∫ ∫ ∫
1 1N. . N. . N. .. x .( )1 1 1
α α−α ∞ −α
θ
α θ α θ α θ⎡ ⎤= = −θ =⎣ ⎦− α − α α −
Ingreso total de N individuos con ingresos entre ( )x, x dx+ será:
x x x
1.N. N.E(Y) N. t. f(t) dt N. t. dt N. . . t dt
t
αα −α
α+θ θ θ
α θμ = = = = α θ =∫ ∫ ∫
1
1 x 1 1N. . N. . N. .. t .(x ) 11 1 1 x
α−α α−α −α −α
θ
⎛ ⎞α θ α θ α θ θ⎛ ⎞⎡ ⎤= == − θ = −⎜ ⎟⎜ ⎟⎣ ⎦ ⎜ ⎟− α − α α − ⎝ ⎠⎝ ⎠

Distribuciones de Probabilidad 16
En la curva de Lorenz, con la distribución de Pareto, la ordenada T(x) será:
1
1
N. . 11 xN.E(Y)T(x) 1N. .N.E(X) x
1
α−
α−
⎛ ⎞α θ θ⎛ ⎞−⎜ ⎟⎜ ⎟⎜ ⎟α − ⎛ ⎞⎝ ⎠ θ⎛ ⎞⎝ ⎠= = = −⎜ ⎟⎜ ⎟⎜ ⎟α θ ⎝ ⎠⎝ ⎠α −
La relación entre distribución F(x) y la función T(x) que acumula los ingresosde todos los individuos que no superan una cantidad x
[ ]1/F(x) 1 1 F(x) 1 F(x)x x x
α ααθ θ θ⎛ ⎞ ⎛ ⎞ ⎛ ⎞= − ⇒ = − ⇒ = −⎜ ⎟ ⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠ ⎝ ⎠
( ) [ ] [ ]1 1 111/ 1T(x) 1 1 1 F(x) 1 1 F(x) 1 1 F(x)
x
α− α−α−α −α α
⎛ ⎞θ⎛ ⎞ ⎡ ⎤= − = − − = − − = − −⎜ ⎟⎜ ⎟⎜ ⎟ ⎣ ⎦⎝ ⎠⎝ ⎠
La relación [ ]11T(x) 1 1 F(x) −α= − − sólo depende del parámetro α , verificando
F( ) 0 y F( ) 1 , T( ) 0 y T( ) 1θ = ∞ = θ = ∞ =
De otra parte, la función T(x) es creciente y cóncava:
[ ] [ ]1/1T '(x) 1 1 F(x 0 para F 0,1− α⎛ ⎞= − − > ∈⎜ ⎟α⎝ ⎠ creciente
[ ] [ ]( 1 )/1 1T ''(x) 1 . . 1 F(x 0 para F 0,1− − α α⎛ ⎞= − − > ∈⎜ ⎟α α⎝ ⎠ cóncava
El Índice de Gini es el doble del área comprendida entre la curva de Lorenz y larecta de equidistribución T F= , con lo que:
[ ] [ ]1 11 11 1
0 0I 2 F 1 1 F dF 2 F 1 1 F dF− −
α α⎡ ⎤⎛ ⎞ ⎛ ⎞= − − − = − + − =⎜ ⎟ ⎜ ⎟⎢ ⎥
⎝ ⎠ ⎝ ⎠⎣ ⎦∫ ∫G
1122
12
0
F (1 F) 1 1 12 F 2 1 212 2 2 2 12
−α
−α
⎡ ⎤⎛ ⎞⎡ ⎤ ⎢ ⎥⎜ ⎟ ⎡ ⎤− α⎛ ⎞⎢ ⎥= − − == − + = − + =⎢ ⎥⎜ ⎟⎜ ⎟ ⎢ ⎥⎢ ⎥ α −⎝ ⎠ ⎣ ⎦⎢ ⎥⎜ ⎟−⎢ ⎥⎣ ⎦ ⎢ ⎥α⎝ ⎠⎣ ⎦
( )
2 1 2 122 2 1 2 1
⎡ ⎤− α + + α= =⎢ ⎥α − α −⎣ ⎦
El Índice de Gini 1I
2 1=
α −G sólo depende del parámetro α , es independiente del
ingreso mínimo θ . Tiende a 1 cuando 1α

Distribuciones de Probabilidad 17
DISTRIBUCIÓN LOGNORMAL
Una variable X se dice que tiene una distribución lognormal si los logaritmosneperianos de sus valores están normalmente distribuidos, es decir, si la variable
elog Xη = es N( , )μ σ
La función de densidad:
2e
2
(log x )
21 e x 0f(x) 2 .x.0 x 0
− μ−
σ⎧⎪ >= ⎨ π σ⎪
≤⎩
La media y varianza son: ( )2
2 222 22x xe e e
σμ+ μ + σ μ + σμ = σ = −
La distribución lognormal tiene, entre otras, las siguientes aplicaciones:
Permite fijar tiempos de reparación de componentes, siendo el tiempo lavariable independiente de la distribución.
Describe la dispersión de las tasas de fallo de componentes, ocasionada porbancos de datos diferentes, entorno, origen diferente de los datos, distintascondiciones de operación, etc. En este caso la variable independiente de ladistribución es la tasa de fallos.
Representa la evolución con el tiempo de la tasa de fallos, l(t), en la primera fasede vida de un componente, la correspondiente a los fallos infantiles en la 'curvade la bañera', entendiendo como tasa de fallos la probabilidad de que uncomponente que ha funcionado hasta el instante t, falle entre t y t + dt. En estecaso la variable independiente de la distribución es el tiempo.
DISTRIBUCIÓN LOGÍSTICA
La curva logística es una curva adecuada para describir el crecimiento de laspoblaciones, estudio de la mortalidad, y en general, los procesos de crecimientoque experimentan estados de saturación.
Una variable aleatoria logística X de parámetros yα β , abreviadamente L( , )α β ,tiene como función de densidad y distribución, respectivamente:
2e 1f(x) F(x) x
1 e1 e
− αβ
− α− αββ
= = − ∞ < < ∞⎛ ⎞ +β +⎜ ⎟⎜ ⎟⎝ ⎠
x
xx
Con el cambio XY − α
=β
se obtiene la distribución logística estándar L(0,1) ,

Distribuciones de Probabilidad 18
que tiene: 2
2Y e d Y
( )M M3πβ
μ = = = α σ =
DISTRIBUCIÓN EXPONENCIAL (Lambda)
Se dice que una variable aleatoria absolutamente continua X sigue una distribuciónExponencial de parámetro λ , si la v.a. X describe el tiempo transcurrido entre dossucesos consecutivos de Poisson o el tiempo de espera hasta que ocurre un sucesode Poisson.
Una v.a. con distribución Exponencial se denota como X Exp( )λ∼ ,donde λ es el número de sucesos de Poisson por unidad de tiempo.
Función de densidad: e x 0
f(x)0 x 0
−λ⎧λ ≥= ⎨
<⎩
x
Función de distribución 1 e x 0
F(x) P(X x)0 x 0
−λ⎧ − ≥= ≤ = ⎨
<⎩
x
La esperanza matemática, varianza, desviación típica y tasa instantánea deocurrencia:
2X X X2
1 1 1E(X)μ = = σ = σ =λ λ λ
Tasa instantánea ocurrencia: f(x)(x)
1 F(x)λ =
−
Función característica: itX 1(t) E e t11 it⎡ ⎤ρ = = ∀ ∈⎣ ⎦
−λ
La distribución exponencial Exp( )λ es un caso particular de la distribución gamma,describe el tiempo hasta la primera ocurrencia de un evento, tiene una aplicaciónimportante en situaciones donde se aplica el proceso de Poisson.
Tiene un lugar importante tanto en teoría de colas como en problemas deconfiabilidad.
El tiempo entre las llegadas en las instalaciones de servicios y el tiempo de fallos enlos componentes eléctricos y electrónicos frecuentemente están relacionados conla distribución exponencial. Con aplicación importante en biometría (estudio de lasleyes probabilísticas que gobiernan la mortalidad humana) y cuestiones actuariales.
Una característica de la distribución exponencial es su FALTA DE MEMORIA: Laprobabilidad de que un individuo de edad t sobreviva x años más, hasta la edad

Distribuciones de Probabilidad 19
(t x)+ , es la misma que tiene un recién nacido de sobrevivir hasta la edad x.
Generalmente, el tiempo transcurrido desde cualquier instante 0t hasta que ocurreel evento, no depende de lo que haya ocurrido antes del instante 0t .
La perdida de memoria se refleja mediante la expresión:
[ ][ ] [ ]
−λ +−λ
−λ
≥ +⎡ ⎤≥ + ≥ = = = = ≥⎣ ⎦ ≥
(x h)h
x
P X x h eP X x h X x e P X hP X x e
DISTRIBUCIÓN GAMMA
Se dice que una variable aleatoria absolutamente continua X sigue una distribuciónGamma de parámetros α y λ , si la v.a. X describe el tiempo transcurrido hasta el
- ésimoα suceso de Poisson.
Una variable aleatoria Gamma de parámetros α y λ , se denota por ( , )γ α λ con0α > y 0λ > , donde el parámetro λ es el número medio de sucesos de Poisson
por unidad de tiempo.
Función de densidad: 1 xx e x 0
f(x) X ( , )( )0 x 0
αα− −λ⎧ λ
≥⎪= γ α λΓ α⎨⎪ <⎩
∼
La función ( )Γ α se denomina función gamma de Euler y se define como la integralimpropia para todo 0α > , dada por
1 x
0
( ) x e dx∞
α − −Γ α = ∫ siendo ( ) ( 1)! NΓ α = α − ∀α∈
La esperanza matemática, varianza y desviación típica de la variable aleatoriaX ( , )γ α λ∼ es:
2X X X2E(X)
αα αμ = = σ = σ =
λ λ λ
La variable aleatoria gamma ( , )γ α λ describe el tiempo hasta que ocurre el sucesoα en un proceso de Poisson de intensidad λEsto es, la suma de α variables aleatorias independientes de distribuciónexponencial con parámetro λ
La distribución exponencial es un caso particular de la distribución gamma conparámetro 1α = :

Distribuciones de Probabilidad 20
1 x x
X ( , )X Exp( )
1f(x) x e f(x) e( )
αα− −λ −λ
γ α λλ
α =λ= ⎯⎯⎯→ = λΓ α
∼∼
X Exp( ) (1, )λ = γ λ∼
Si 1 2 nX , X , , X son n variables aleatorias independientes distribuidas según
N(0,1) . La nueva variable aleatoria 2 2 21 2 nY X , X , , X= sigue una distribución
n 1,2 2
⎛ ⎞γ ⎜ ⎟⎝ ⎠
. En consecuencia, la distribución Chi‐cuadrado es una distribución
Gamma cuando n2
α = y 12
λ = , tal que 2 n 1X ,2 2
⎛ ⎞χ = γ ⎜ ⎟⎝ ⎠
∼
Cuando el parámetro α es entero, la distribución ( , )γ α λ se conoce comodistribución de Erlang.
La distribución gamma se suele utilizar en intervalos de tiempo entre dos fallos deun motor. Intervalos de tiempo entre dos llegadas de automóviles a una gasolinera.Tiempos de vida de sistemas electrónicos. Análisis de la distribución de la renta.
DISTRIBUCIÓN BETA
Se dice una variable aleatoria absolutamente continua X sigue una distribuciónBeta de parámetros α y β , con 0α > y 0β > , y se denota como X ( , )∼ β α β , si lafunción de densidad de la v.a. X viene definida por
1 1( )f(x) . x . (1 x)( ). ( )
α − β −Γ α + β= −Γ α Γ β
x (0,1)∈
Esperanza matemática de la v.a. X ( , )∼ β α β : [ ]E X α=α + β
Varianza v.a. X ( , )∼ β α β : 22
.Var(X)( ) . ( 1)
α βσ = =
α + β α + β +
Como casos particulares de la distribución Beta se tiene:
Sí 1α = y 1β = f(x) 1= sí [ ]0 x 1 X U 0,1< < ⇒ ∼ Sea X ( , ) 1 X ( , )β α β − β β α∼ ∼
La función ( , )β α β se denomina función Beta de Euler y se define como la integralimpropia para todo 0α > y 0β > , dada por
1
1 1
0
( , ) x . (1 x) dxα − β −β α β = −∫ siendo ( ). ( )( , )( )
Γ α Γ ββ α β =
Γ α + β

Distribuciones de Probabilidad 21
Algunas características de interés para el cálculo de ( , )β α β son: Simetría: ( , ) ( , )β α β = β β α
Siendo 2x sen t= se tiene: 2
2 1 2 1
0
( , ) 2 (sent) . (cos t) dtπ
α − β −β α β = ∫ Siendo
tx1 t
=+
se tiene: 1
0
t( , ) dt(1 t)
∞ α −
α + ββ α β =+∫
DISTRIBUCIÓN de CAUCHY
Se dice que una variable aleatoria absolutamente continua X sigue una distribuciónde Cauchy con parámetro de escala 0μ > y parámetro de localización θ∈ , y sedenota como X C( , )∼ μ θ , si su función de
densidad viene dada tal que 2 2f(x) x(x )μ
= ∀ ∈⎡ ⎤π μ + − θ⎣ ⎦
La esperanza y la varianza de la v.a. X con distribución de Cauchy no existen.
La función característica de la v.a. X C( , )∼ μ θ de parámetros μ y θ
viene dada por i(t) E e e e t−μθ⎡ ⎤ρ = = ∀ ∈⎣ ⎦i ttX t
Como casos particulares de la distribución de Cauchy, se tiene:
Sí 1μ = y 0θ = X C(0,1)⇒ ∼ con 21f(x) x
(1 x )= ∀ ∈π +
XX C( , ) C(1, 0)− θ∼ μ θ ⇔ ∼
μ

Distribuciones de Probabilidad 22
Sean A y B dos sucesos incompatibles con P(A B) 0.∪ >
Demostrar que P(B)
P(B/ A B)P(A) P(B)
∪ =+
Solución:
A y B incompatibles A B 0 P(A B) P(A) P(B)∩ = ∪ = +
[ ]P B (A B) P(B)P(B / A B)
P(A B) P(A) P(B)
∩ ∪∪ = =
∪ +
Sean A y B dos sucesos tales que P(A) 0,6.= Calcular P(A B)∩ en cada caso:a) A y B mutuamente excluyentesb) A está contenido en Bc) B está contenido en A y P(B) 0,3=d) P(A B) 0,1∩ =
Solución:
a) A y B mutuamente excluyentes A B P(A B) 0
P(A B) P(A) P(A B) P(A) 0 0,6
⇒ ∩ = φ ∩ =
∩ = − ∩ = − =
b) A B P(A B) P(A) P(A B) P(A) P(A B) P(A) P(A) 0⊂ ⇒ ∩ = ∩ = − ∩ = − =
c) B A P(A B) P(B)
P(A B) P(A) P(A B) P(A) P(B) 0,6 0,3 0,3
⊂ ⇒ ∩ =
∩ = − ∩ = − = − =
d) P(A B) P(A) P(A B) 0,6 0,1 0,5∩ = − ∩ = − =
Se sabe que P(B / A) 0,9 , P(A /B) 0,2 y P(A) 0,1= = =a) Calcular P(A B) y P(B)∩b) ¿Son independientes los sucesos A y B?c) Calcular P(A B)∪
Solución:
a) X XP(B A)
P(B / A) 0,9 P(B A) 0,9 P(A) 0,9 0,1 0,09P(A)∩
= = ∩ = = =
XP(A B) 0,09
P(A /B) 0,2 P(A B) 0,2 P(B) 0,09 P(B) 0,45P(B) 0,2∩
= = ∩ = = = =

Distribuciones de Probabilidad 23
P(B) 1 P(B) 1 0,45 0,55= − = − =
b) Los sucesos no son independientes, dado X Xque: P(A B) 0,09 P(A) P(B) 0,1 0,45∩ = ≠ =
o bien, no son independientes porque
P(A /B) 0,2 P(A) 0, 1= ≠ =
c) P(B) 1 P(B) 1 0,45 0,55 = − = − =
0,1 0,54 0,64 P(A B)
P(A) P(B) P(A B) 0,1 0,55 0,01 0,64
= + =⎧∪ = ⎨= + − ∩ = + − =⎩
Si la probabilidad de que ocurra un suceso A es 1/5a) ¿Cuál es el mínimo número de veces que hay que repetir el experimento paraque la probabilidad de que ocurra al menos una vez sea mayor que 1/2?.b) ¿Cuál es la probabilidad de que ocurra al menos dos veces A al realizar 5 veces elexperimento?
Solución:
a) X "número de éxitos en n pruebas", X B(n, 0,2) , p 0,2 , q 0,8= ∼ = =
1 1 1P(X 1) P(X 1) P(X 0)
2 2 2≥ > < ≤ ⇒ = ≤
0 n n 40,8 0,4096n 1P(X 0) . 0,2 . 0,8 0,8 n 4
0 2=⎛ ⎞
= = = ≤ ⎯⎯⎯⎯⎯⎯→ =⎜ ⎟⎝ ⎠
Para que el suceso A tenga al menos una probabilidad mayo que 1/2 hay querealizar el proceso un mínimo de 4 veces.
b) Se trata de una distribución binomial B(5; 0,2)
[ ] 0 5 1 45 5P(X 2) 1 P(X 0) P(X 1) 1 . 0,2 . 0,8 . 0,2 . 0,8
0 1
⎡ ⎤⎛ ⎞ ⎛ ⎞≥ = − = + = = − + =⎢ ⎥⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠⎣ ⎦
1 (0,3277 0,4096) 0,2627= − + =

Distribuciones de Probabilidad 24
Un estudiante busca información del sector aeronáutico en tres manuales, lasprobabilidades de que esa información se encuentre en el primero, segundo otercer manual, respectivamente, son iguales a 0,6 , 0,7 y 0,8.¿Cuál es la probabilidad de que la información figure sólo en dos manuales?.
Solución:
Sean A, B y C los tres sucesos en cuestión talesque P(A) 0,6= , P(B) 0,7= y P(C) 0,8= .
Cada uno de los sucesos A, B y C esindependiente con los otros dos, además lossucesos (A B C)∩ ∩ , (A B C)∩ ∩ y (A B C)∩ ∩son incompatibles.
[ ][ ] [ ] [ ]
P (A B C) (A B C) (A B C)
P (A B C) P (A B C) P (A B C)
P(A) P(B) P(C) P(A) P(B) P(C) P(A) P(B) P(C)
∩ ∩ ∪ ∩ ∩ ∪ ∩ ∩ =
= ∩ ∩ + ∩ ∩ + ∩ ∩ =
= + + = 0,6.0,7.0,2 0,6.0,3.0,8 0,4.0,7.0,8 0,452= + + =
Se lanzan tres monedas al aire. Sea la variable aleatoria X = "número de carasque se obtienen". Se pide:a) Distribución de probabilidad de Xb) Función de distribución de X y su representación gráfica.c) Media, varianza y desviación típica de Xd) Probabilidad de que salgan a lo sumo dos carase) Probabilidad de que salgan al menos dos caras
Solución:
a) Espacio muestral:
{ }(c,c,c), (c,c,e), (c,e,c), (e,c,c),(c,e,e), (e,c,e), (e,e,c), (e,e,e)Ω =
siendo X = "número de caras que se obtienen", se tiene:
X(c,c,c) 3= P(X 3) 1 8= =X(c,c,e) X(c,e,c) X(e,c,c) 2= = = P(X 2) 3 8= =X(c,e,e) X(e,c,e) X(e,e,c) 1= = = P(X 1) 3 8= =X(e,e,e) 0= 81)0X(P ==
La distribución de probabilidad es, en consecuencia,

Distribuciones de Probabilidad 25
iX x= iP(X x )= i ix . P(X x )= 2ix
2i ix . P(X x )=
0 1 8 0 0 0
1 3 8 83 1 3 8
2 3 8 6 8 4 12 8
3 1 8 3 8 9 9 8
1 12 8 24 8
b) La función de distribución i
ix x
F(x) P(X x) P(X x )≤
= ≤ = =∑x 0< F(x) P(X x) P( ) 0= ≤ = φ =0 x 1≤ < F(x) P(X x) P(X 0) 1 8= ≤ = = =1 x 2≤ < F(x) P(X x) P(X 0) P(X 1) 4 8= ≤ = = + = =2 x 3≤ < F(x) P(X x) P(X 0) P(X 1) P(X 2) 7 8= ≤ = = + = + = =x 3≥ F(x) P(X x) P(X 0) P(X 1) P(X 2) P(X 3) 1= ≤ = = + = + = + = =
Gráficamente:
0 x 0
1 8 0 x 1
4 8 1 x 2F(x)
7 8 2 x 3
1 x 3
<⎧⎪ ≤ <⎪⎪ ≤ <= ⎨⎪ ≤ <⎪
≥⎪⎩
c) Media 4
x i ii 1
12E(X) x . P(X x ) 1,5
8=
μ = = = = =∑Varianza
42 2 2 2 2 2 2x x x i i x
i 1
24E(X ) E(X ) ( ) x . P(X x ) ( ) (1,5) 0,75
8=
σ = − μ = − μ = = − μ = − =∑Desviación típica x 0,75 0,87σ = =
d) 1 3 3 7P(X 2) P(X 0) P(X 1) P(X 2)
8 8 8 8≤ = = + = + = = + + =
También 7
P(X 2) F(2)8
≤ = =
e) 3 1 4 1P(X 2) P(X 2) P(X 3)
8 8 8 2≥ = = + = = + = =
También 4 1
P(X 2) 1 P(X 2) 1 F(1) 18 2
≥ = − < = − = − =

Distribuciones de Probabilidad 26
La variable discreta X tiene como distribución de probabilidad
X 1 2 3 4
iP(X x )= 0,30 0,25 0,10 0,35
Se realiza un cambio de origen hacia la izquierda de dos unidades y un cambio deescala de 3 unidades. Se pide:a) Media y varianza de la Xb) Media, varianza y coeficiente de variación de la variable transformada por elcambio de origenc) Media, varianza y coeficiente de variación de la variable transformada por elcambio de escalad) Media, varianza y coeficiente de variación de la variable transformada por elcambio de origen y escala
Solución:
a)
iX x= i iP(X x ) p= = i ix . p 2ix
2i ix . p
1x 1= 0,30 0,30 1 0,30
2x 2= 0,25 0,50 4 1,00
3x 3= 0,10 0,30 9 0,90
4x 4= 0,35 1,40 16 5,60
1 2,5 7,8
Media: 4 4
1 X i i i ii 1 i 1
E(X) x . P(X x ) x . p 2,5= =
α = μ = = = = =∑ ∑4 4
2 2 22 i i i i
i 1 i 1
E(X ) x . P(X x ) x . p 7,8= =
α = = = = =∑ ∑
Varianza: 2 2 2x 2 1 7,8 2,5 1,55σ = α − α = − =
Desviación típica: X 1,55 1,245σ = =
Coeficiente de variación: XX
X
1,245CV 0,498
2,5σ
= = =μ
b) Sea Y la variable transformada, al realizar un cambio de origen hacia la izquierdade dos unidades hay que restar 2, quedando: Y X 0rigen X ( 2) X 2= − = − − = + .
Media: [ ]Y YE(Y) E X 2 E(X 2) E(X) 2 E(Y) 2,5 2 4,5μ = = + = + = + μ = = + =

Distribuciones de Probabilidad 27
Varianza: [ ]2 2 2 2Y X X YVar X 2 Var(X) Var(2) 0 1,55σ = + = + = σ + = σ σ =
Desviación típica: Y 1,55 1,245σ = =
Coeficiente de variación: Y XY x
Y X
1,245CV 0,28 CV
2 4,5σ σ
= = = = ≠μ μ +
En consecuencia, el cambio de origen afecta a la media y, en consecuencia, alcoeficiente de variación.
c) Al realizar un cambio de escala de 3 unidades, la variable transformada es X
Y3
=
Media: Y Y X
X 1 1 2,5E(Y) E . E(X) .
3 3 3 3⎡ ⎤μ = = = μ = μ =⎢ ⎥⎣ ⎦
Varianza: 2 2 2Y X Y
X 1 1 1 1,55Var .Var(X) . . 1,55
3 9 9 9 9⎡ ⎤σ = = = σ σ = =⎢ ⎥⎣ ⎦
Desviación típica: Y X
1,55 1 1. 1,55 .
9 3 3σ = = = σ
Coeficiente de variación: X
Y XY X
Y XX
1.
3CV CV 0,4981.
3
σσ σ= = = = =μ μμ
El cambio de escala afecta a la media y a la desviación típica de la misma forma, enconsecuencia deja invariante al coeficiente de variación.
Resultados que se observan en la tabla, donde X
Y3
=
jY y= j jP(Y y ) p= = j jy . p 2jy
2j jy . p
1y 1 3= 0,30 0,1 1 9 0,3 9
2y 2 3= 0,25 0,5 3 4 9 1 9
3y 1= 0,10 0,1 1 0,1
4y 4 3= 0,35 1,4 3 16 9 5,6 9
1 2,5 3 7,8 9
Media: 4 4
1 Y j j j j Xj 1 j 1
2,5 1E(Y) y .P(Y y ) y . p .
3 3= =
α = μ = = = = = = μ∑ ∑4 4
2 2 2 22 j j j j
j 1 j 1
7,8 1E(Y ) y .P(Y y ) y . p . E(Y )
9 9= =
α = = = = = =∑ ∑

Distribuciones de Probabilidad 28
Varianza: 2
2 2 2Y 2 1 X
7,8 2,5 1 1,55.
9 3 9 9⎛ ⎞σ = α − α = − = σ =⎜ ⎟⎝ ⎠
Desviación típica: Y X
1,55 1 1. 1,55 .
9 3 3σ = = = σ
Coeficiente de variación: X
Y XY X
Y XX
1.
3CV CV 0,4981.
3
σσ σ= = = = =μ μμ
d) Al realizar simultáneamente un cambio de origen de 2 unidades a la izquierda y
un cambio de escala de 3 unidades, la variable transformada es X 2
Y3+
=
Media: Y
X 2 1 1 2 1 2 4,5E(Y) E . E(X 2) . E(X) . 2,5 1,5
3 3 3 3 3 3 3+⎡ ⎤μ = = = + = + = + = =⎢ ⎥⎣ ⎦
Varianza: 2 2Y X
X 2 1 1 1Var(Y) Var .Var(X 2) .Var(X) .
3 9 9 9+⎡ ⎤σ = = = + = = σ⎢ ⎥⎣ ⎦
Desviación típica: Y X
1,55 1 1. 1,55 .
9 3 3σ = = = σ
Coeficiente de variación: X
Y XY x
Y XX
1. 1,2453CV 0,28 CV
1 2 2 4,5.3 3
σσ σ= = = = = ≠μ μ +μ +
El cambio de origen y de escala afecta a la media y desviación típica de distintaforma, en consecuencia también queda afectado el coeficiente de variación.

Distribuciones de Probabilidad 29
Una empresa de transportes está analizando el número de veces que falla lamáquina expendedora de billetes. Dicha variable tiene como función de cuantía:
ixi iP(X x ) 0,7 0,3 x 0, 1, 2,= = ⋅ =
a) ¿Cuál es la probabilidad de que un día la máquina no falle?b) ¿Cuál es la probabilidad de que un día falle menos de 4 veces?c) ¿Cuál es la probabilidad de que falle 5 veces?
Solución:
a) 0P(X 0) 0,7 0,3 0,7= = ⋅ =
b) P(X 4) P(X 0) P(X 1) P(X 2) P(X 3)< = = + = + = + = =
( )0 1 2 3
0 1 2 3
0,7 0,3 0,7 0,3 0,7 0,3 0,7 0,3
0,7 0,3 0,3 0,3 0,3 0,9919
= ⋅ + ⋅ + ⋅ + ⋅ =
= ⋅ + + + =
Considerando la suma de una progresión geométrica 1 nn
a a . rS
1 r−
=−
( )n 1
0 1 2 3 n
nn
1 0,3 . 0,3P(X n) 0,7 0,3 0,3 0,3 0,3 0,3 0,7 .
1 0,3
1 0,3 0,7 . 1 0,3
0,7
−−≤ = ⋅ + + + + + = =
−−
= = −
4P(X 4) 1 0,3 0,9919< = − =
c) 5P(X 5) 0,7 0,3 0,001701= = ⋅ =

Distribuciones de Probabilidad 30
En una región se cobra a los visitantes de los parques naturales, estimando quela variable aleatoria número de personas que visitan el parque en coche sigue lasiguiente distribución:
ix 1 2 3 4 5
iP(X x )= 0,15 0,2 0,35 0,2 0,1
a) Hallar el número medio de visitantes por vehículosb) Hallar cuánto debe pagar cada visitante para que la ganancia por coche sea 2
euros.c) Si cada persona paga p euros, ¿cuál es la ganancia esperada en un día en que
entran mil vehículos?
Solución:
a) X = "Número de personas que visitan el parque en coche"
5
i i
i 1
x x x x xE(X) x P(X x ) 1 0,15 2 0,2 3 0,35 4 0,2 5 0,1
2,9 visitante/vehículo=
= = = + + + + =
=
∑
b) Sea la variable aleatoria Y = "Ganancia por coche"
x2
E(Y) E(pX) pE(X) p 2,9 2 p 0,6892,9
= = = = = =
c) Sea la variable aleatoria U = "Ganancia de un día"
Número personasNúmero dePrecio por vehículo vehículosvisita
x x
nte
U p c X =
x xGanancia esperada día: E(U) E(pc X) pc E(X) p 1000 2,9 2 2900 p= = = = =
Sí p 0,689 = la ganancia esperada en un día será: x2900 0,689 1998,1 euros.=

Distribuciones de Probabilidad 31
Una empresa de mensajería sabe que en condiciones normales un paquete esentregado en plazo el 90% de las veces, aunque si hay sobrecarga de trabajo (queocurre un 5% de las veces) el porcentaje de retrasos se eleva al 30%.a) Cuál es la probabilidad de que un paquete llegue en plazo a su destino.b) Sabiendo que se ha recibido una queja por retraso en el envío, el mensajeroafectado aduce que ese día hubo sobrecarga de trabajo, aunque realmente norecuerda bien que sucedió. ¿Qué probabilidad hay de qué efectivamente esté en locierto?.
Solución:
Sean los sucesos:
E = "Entrega a tiempo del paquete"S = "Hay sobrecarga de trabajo"
a) X X X XP(E) P(S) P(E / S) P(S) P(E/ S) 0,05 0,7 0,95 0,9 0,89= + = + =
b) X0,05 0,3P(S E)P(S/ E) 0,136
P(E) 1 0,89∩
= = =−
Se desea conocer el número de automóviles que se deben poner a la ventadurante un periodo determinado para que se satisfaga una demanda media de 300unidades con una desviación típica de 100 unidades, con una probabilidad noinferior al 75%.
Solución:
Sea la variable aleatoria X = "número de automóviles a la venta", con 300μ = y100σ =
Por la desigualdad de Chebychev:
2 2
x x x2 2P X k 1 P k X k 1k kσ σ
⎡ ⎤− μ ≤ ≥ − ⎯⎯→ μ − ≤ ≤ μ + ≥ −⎡ ⎤⎣ ⎦⎣ ⎦
2
2
0,75
100P 300 k X 300 k 1
k− ≤ ≤ + ≥ −⎡ ⎤⎣ ⎦

Distribuciones de Probabilidad 32
2 2
2
100 1000,75 1 k 200 300 k 300 200 500 automóviles
k 0,25= − = = + = + =
En un cine de verano hay instaladas 800 sillas, sabiendo que el número deasistentes es una variable aleatoria de media 600 y desviación típica 100.¿Qué probabilidad existe de que el número de personas que vaya al cine un díacualquiera sea superior al número de sillas instaladas?
Solución:
Sea la variable aleatoria X = "número de sillas del cine", donde 600 , 100μ = σ =
Por la desigualdad de Chebychev:
[ ]2
x 2P X 800 P X kkσ
⎡ ⎤> < − μ > ≤⎣ ⎦
x k 800 k 800 600 200μ + = = − =
[ ]2
2
100 1P X 800 0,25
200 4> ≤ = =
La demanda media de un producto es de 100 unidades con una desviación típicade 40 unidades. Calcular la cantidad del producto que se debe tener a la venta parasatisfacer la demanda de forma que puedan ser atendidos al menos el 80% de losclientes.
Solución:
Sea la variable aleatoria X = "demanda de un producto", con 100μ = y 40σ =
Por la desigualdad de Chebychev:
2 2
x x x2 2P X k 1 P k X k 1k kσ σ
⎡ ⎤− μ ≤ ≥ − ⎯⎯→ μ − ≤ ≤ μ + ≥ −⎡ ⎤⎣ ⎦⎣ ⎦
2
2
0,80
40P 100 k X 100 k 1
k− ≤ ≤ + ≥ −⎡ ⎤⎣ ⎦
2 2
2
40 400,80 1 k 89,44
k 0,20= − = = . Se deben poner a la venta 90 unidades.

Distribuciones de Probabilidad 33
La función de densidad de una variable aleatoria es:2ax b 0 x 2
f(x)0 en el resto
⎧ + < <= ⎨⎩
sabiendo que 1
P x 1 0,16662⎡ ⎤< < =⎢ ⎥⎣ ⎦
. Determinar a
y b.
Solución:
Hay que calcular dos parámetros (a y b), por lo que se necesitan dos ecuaciones:
• Por ser función de densidad:
22 2 3
2
0 0 0
8ax1 f(x) dx (ax b) dx a bx 2b 8a 6b 3
3 3
⎡ ⎤= = + = + = + + =⎢ ⎥
⎣ ⎦∫ ∫•
11 1 32
1/2 1/2 1/2
1 xP x 1 f(x) dx (ax b) dx a bx 0,1666
2 3
⎡ ⎤⎡ ⎤≤ ≤ = = + = + =⎢ ⎥⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫ ,
con lo que:
13
1/2
x a a b 7a ba bx b 0,1666 7a 12b 43 3 24 2 24 2
⎡ ⎤ ⎡ ⎤ ⎡ ⎤+ = + − + = + = + ≈⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦⎣ ⎦
en consecuencia,2
a 0,22 8a 6b 3 16a 12b 6 97a 12b 4 7a 12b 4 16 11 11
6b 3 b 0,209 9 54
⎧ = =⎪+ = + =⎫ ⎫ ⎪→⎬ ⎬ ⎨+ = + =⎭ ⎭ ⎪ = − = = =⎪⎩

Distribuciones de Probabilidad 34
La variable X ="número de centímetros a que un dardo queda del centro de ladiana" al ser tirado por una persona tiene como función de densidad:
k 0 x 10
f(x)0 en otros casos
< <⎧= ⎨⎩
Se pide:
a) Hallar k para que f(x) sea función de densidad. Representarlab) Hallar la función de distribución. Representarlac) Media, varianza y desviación típicad) ≤P(X 1)e) Probabilidad de acertar en la diana
Solución:
a) Para que f(x) sea función de densidad debe verificar:0 10 10
0 10 01 f(x)dx f(x)dx f(x)dx f(x)dx f(x)dx
∞ ∞
−∞ −∞= = + + =∫ ∫ ∫ ∫ ∫
La primera y tercera integral son cero al ser f(x) 0= en esos intervalos.
[ ]10 10 10
00 0
11 kdx k dx 10 x 10k k
10= = = = =∫ ∫
En consecuencia, 1
0 x 10f(x) 10
0 en otros casos
⎧ < <⎪= ⎨⎪⎩
b) La función de distribución se define x
F(x) f(t)dt−∞
= ∫x 0<
x
F(x) f(t)dt 0−∞
= =∫0 x 10≤ ≤
x 0 x x
0 0
1 xF(x) f(t)dt f(t)dt f(t)dt dt
10 10−∞ −∞
= = + = =∫ ∫ ∫ ∫x 10>
x 0 10 x 10
0 10 0
1F(x) f(t)dt f(t)dt f(t)dt f(t)dt dt 1
10−∞ −∞
= = + + = =∫ ∫ ∫ ∫ ∫En consecuencia,

Distribuciones de Probabilidad 35
<⎧⎪⎪= ≤ ≤⎨⎪
>⎪⎩
0 x 0xF(x) 0 x 10
101 x 10
c) Media∞
−∞
⎡ ⎤α = μ = = = = = =⎢ ⎥
⎣ ⎦∫ ∫ ∫1010 10 2
1 X0 0 0
1 1 1 xE(X) xf(x)dx x . . dx x dx 5cm
10 10 10 2
Varianza: 2 2X 2 1σ = α −α
1010 10 32 2 2 2
20 0 0
1 1 1 xE(X ) x f(x)dx x . . dx x dx
10 10 10 3
1 1000 100 0
10 3 3
∞
−∞
⎡ ⎤α = = = = = =⎢ ⎥
⎣ ⎦⎡ ⎤= − =⎢ ⎥⎣ ⎦
∫ ∫ ∫
2 2 2 2X 2 1
100 255 cm
3 3σ = α −α = − =
Desviación típica: X
252,9 cm
3σ = =
d) 1P(X 1) F(1)
10≤ = =
O también, [ ]1 1
1
00 0
1 1 1 1P(X 1) dx dx x
10 10 10 10≤ = = = =∫ ∫
e) Probabilidad de acertar en la diana: P(X 0) 0= = por ser una variable continua
0 0 0
0 0 0
1 1P(0 X 0) f(x)dx dx dx 0
10 10≤ ≤ = = = =∫ ∫ ∫

Distribuciones de Probabilidad 36
Se ha verificado que la variable X ="peso en kilos de los niños al nacer" es unavariable aleatoria continua con función de densidad
kx 2 x 4
f(x)0 en otros casos
≤ ≤⎧= ⎨⎩
Se pide:
a) Hallar k para que f(x) sea función de densidad. Representarlab) Hallar la función de distribución. Representarlac) Media, varianza y desviación típicad) Probabilidad de que un niño elegido al azar pese más de 3 kilose) Probabilidad de que pese entre 2 y 3,5 kilosf) Qué debe pesar un niño para tener un peso igual o inferior al 90% de los niños
Solución:
a) Para que f(x) sea función de densidad debe verificar:
2
1 f(x)dx f(x)dx−∞
= = +∫4
2 4f(x)dx f(x)dx
∞ ∞
−∞+ =∫ ∫ ∫
4
2f(x)dx∫
44 4 4 2
2 2 2 2
x 16 4 11 f(x)dx kxdx k xdx k k 6k k
2 2 2 6
⎡ ⎤ ⎡ ⎤= = = = = − = =⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦∫ ∫ ∫
x2 x 4
f(x) 60 en otros casos
⎧ ≤ ≤⎪= ⎨⎪⎩
b) La función de distribución se define x
F(x) f(t)dt−∞
= ∫x < 2
x
F(x) f(t)dt 0−∞
= =∫2 x 4≤ ≤
xx x x 2 2 2
2 2 2
t 1 t 1 x 4 x 4F(x) f(t)dt f(t)dt dt
6 6 2 6 2 12−∞
⎡ ⎤ ⎡ ⎤− −= = = = = =⎢ ⎥ ⎢ ⎥
⎣ ⎦ ⎣ ⎦∫ ∫ ∫x 4>
4x 4 x 4 2
2 4 2 2
t 1 t 1 16 4F(x) f(t)dt f(t)dt f(t)dt dt 1
6 6 2 6 2−∞
⎡ ⎤ −⎡ ⎤= = + = = = =⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦∫ ∫ ∫ ∫

Distribuciones de Probabilidad 37
2
0 x 2
x 4F(x) 2 x 4
121 x 4
<⎧⎪ −⎪= ≤ <⎨⎪
≥⎪⎩
c) Media44 4 3
21 X
2 2 2
x 1 1 xE(X) xf(x)dx x . . dx x dx
6 6 6 3
1 64 8 56 3,1 kilos
6 3 3 18
∞
−∞
⎡ ⎤α = μ = = = = = =⎢ ⎥
⎣ ⎦⎡ ⎤= − = =⎢ ⎥⎣ ⎦
∫ ∫ ∫
Varianza: 2 2X 2 1σ = α −α
44 4 42 2 2 3 2
22 2 2
x 1 1 x 1 256 16E(X ) x f(x)dx x . . dx x dx 10 kilos
6 6 6 4 6 4 4
∞
−∞
⎡ ⎤ ⎡ ⎤α = = = = = = − =⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦∫ ∫ ∫2 2 2 2X 2 1 10 3,1 0,39 kilosσ = α −α = − =
Desviación típica: X 0,39 0,62 kilosσ = =
d) 23 4 5 7
P(X 3) 1 P(X 3) 1 F(3) 1 1 0,5812 12 12−
> = − ≤ = − = − = − = =
O también, 44 4 2
3 3 3
x 1 x 1 9 7P(X 3) f(x) dx dx 8 0,58
6 6 2 6 2 12
⎡ ⎤ ⎛ ⎞> = = = = − = =⎜ ⎟⎢ ⎥ ⎝ ⎠⎣ ⎦∫ ∫e)
23,5 4P(2 X 3,5) F(3,5) F(2) 0 0,6875
12−
≤ ≤ = − = − =
3,53,5 3,5 2
2 2 2
x 1 x 1 12,25 4 8,25P(2 X 3,5) f(x) dx dx 0,6875
6 6 2 6 2 2 12
⎡ ⎤ ⎛ ⎞≤ ≤ = = = = − = =⎜ ⎟⎢ ⎥ ⎝ ⎠⎣ ⎦∫ ∫f) Sea k el peso del niño, se tiene:
22 2k 4
F(k) P(X k) 0,9 0,9 k 4 10,8 k 14,812−
= ≤ = ⎯⎯→ = ⇒ − = ⇒ =
k 14,8 3,85= = , es decir, el niño debe pesar 3,85 kilos para tener para tener al
90% de los niños con un peso igual o inferior.

Distribuciones de Probabilidad 38
Sea X una variable aleatoria continua con función de densidad tal que
2
81 x 8
7 xf(x)
0 otro caso
⎧ ≤ ≤⎪= ⎨⎪⎩
a) Calcular el primer y tercer cuartil, el decil 7 y el percentil 85b) Calcular la mediana y moda
Solución:
a) Función de distribución:
[ ]xx x
21 1
8 8 1 8(x 1)F(x) P X x f(t)dt dt 1 x 8
7 t 7 t 7x−∞
⎡ ⎤ −= ≤ = = = − = ≤ ≤⎢ ⎥
⎣ ⎦∫ ∫sustituyendo, queda:
11 1 1 1 1 25
1
1 8(Q 1) 32F(Q ) 7Q 32(Q 1) Q 1,28 Q P 1,2
4 7Q 25−
= = = − = = = =
33 3 3 3 3 5 75
3
3 8(Q 1) 32F(Q ) 21Q 32(Q 1) Q 2,91 Q D P 2,91
4 7Q 11−
= = = − = = = = =
77 7 7 7
7
7 8(D 1) 80F(D ) 49D 80(D 1) D 2,58
10 7D 31−
= = = − = =
8585 85 85 85
85
85 8(P 1) 800F(P ) 595P 800(P 1) P 3,90
100 7P 205−
= = = − = =
b) e 2 5 50M Q D P= = =
ee e e e
e
1 8(M 1) 16F(M ) 7M 16(M 1) M 1,78
2 7M 9−
= = = − = =
La Moda dM se obtiene calculando el máximo de la función de densidad:
2 3
8 16f(x) f '(x) 0
7 x 7 x= = − < La función es decreciente
De forma que f(1) f(x) f(8)≥ ≥ , con lo que dM 1=

Distribuciones de Probabilidad 39
Dada la función 2xf(x) e−=a) Comprobar si puede ser función de densidad de una variable aleatoria X cuandosu campo de variación es el intervalo x 0≥b) En caso de que no lo pueda ser, qué modificaciones habría que introducir paraque lo fuera.
Solución:
a) Para que sea función de densidad, debe cumplir dos condiciones en el campo devariación de la variable aleatoria: f(x) no puede ser negativa La integral de f(x) en el campo de variación es 1
2x 2xf(x) e 0 L e L0 2x x− −= ≥ ≥ ⇒ − > − ∞ ⇒ < ∞ es positiva
2x 2x
0 0
1 1 1e dx e 0 1
2 2 2
∞∞− −⎡ ⎤ ⎡ ⎤= − = + = ≠⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦∫ .
No se cumple, luego la función dada no es de densidad en el intervalo.
b) Para que sea función de densidad, se define 2xf(x) k e−=
Una variable aleatoria continua X tiene por función de densidad
1 x 0 x 1
f(x) x 1 1 x 2
0 otros casos
− ≤ <⎧⎪= − ≤ ≤⎨⎪⎩
Se pide:
a) Representa la función de densidad
b) Hallar la función de distribución y su gráfica
c) 1
P(0 X 1) P( 2 X 2) P X2
⎛ ⎞≤ ≤ − ≤ ≤ ≤ < ∞⎜ ⎟⎝ ⎠
Solución:
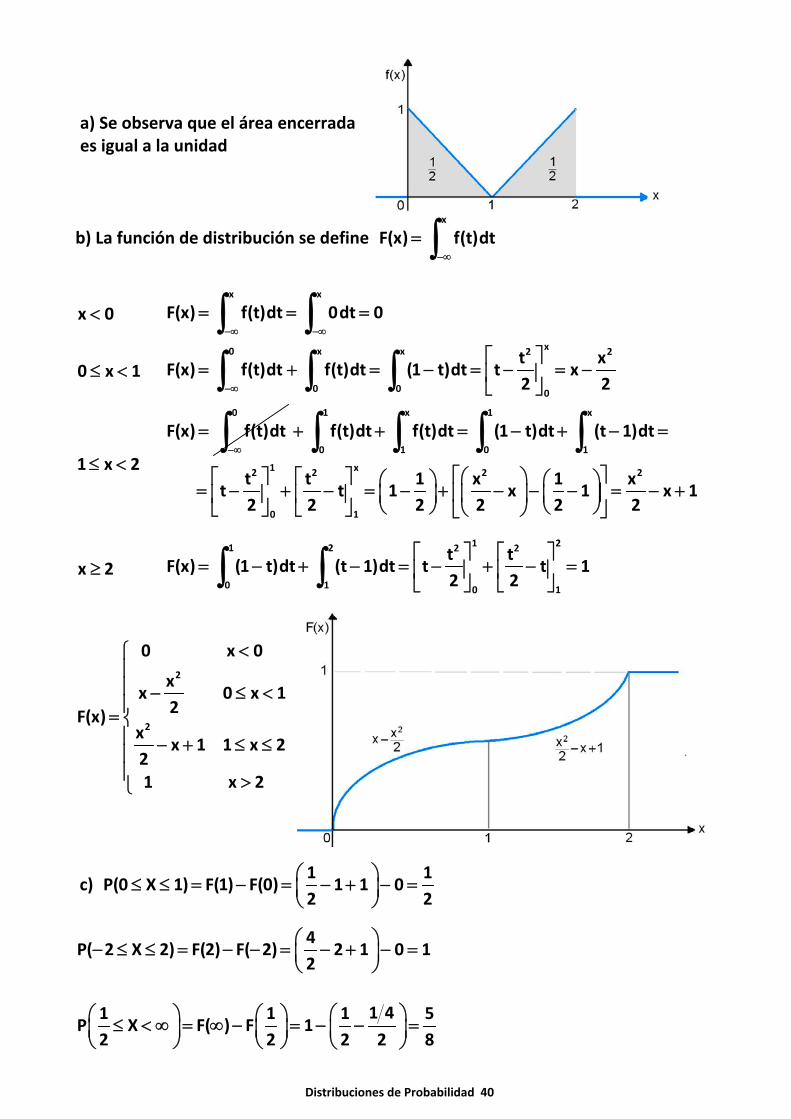
Distribuciones de Probabilidad 40
a) Se observa que el área encerradaes igual a la unidad
b) La función de distribución se define x
F(x) f(t)dt−∞
= ∫
x 0<x x
F(x) f(t)dt 0dt 0−∞ −∞
= = =∫ ∫0 x 1≤ <
x0 x x 2 2
0 0 0
t xF(x) f(t)dt f(t)dt (1 t)dt t x
2 2−∞
⎡ ⎤= + = − = − = −⎢ ⎥
⎣ ⎦∫ ∫ ∫
1 x 2≤ <
0
F(x) f(t)dt−∞
= ∫1 x 1 x
0 1 0 1
f(t)dt f(t)dt (1 t)dt (t 1)dt+ + = − + − =∫ ∫ ∫ ∫
1 x2 2 2 2
0 1
t t 1 x 1 xt t 1 x 1 x 1
2 2 2 2 2 2
⎡ ⎤⎡ ⎤ ⎡ ⎤ ⎛ ⎞⎛ ⎞ ⎛ ⎞= − + − = − + − − − = − +⎢ ⎥⎜ ⎟⎜ ⎟ ⎜ ⎟⎢ ⎥ ⎢ ⎥⎝ ⎠ ⎝ ⎠⎣ ⎦ ⎣ ⎦ ⎝ ⎠⎣ ⎦
x 2≥1 21 2 2 2
0 1 0 1
t tF(x) (1 t)dt (t 1)dt t t 1
2 2
⎡ ⎤ ⎡ ⎤= − + − = − + − =⎢ ⎥ ⎢ ⎥
⎣ ⎦ ⎣ ⎦∫ ∫
2
2
0 x 0
xx 0 x 1
2F(x)x
x 1 1 x 221 x 2
<⎧⎪⎪ − ≤ <⎪= ⎨⎪ − + ≤ ≤⎪⎪ >⎩
c) 1 1
P(0 X 1) F(1) F(0) 1 1 02 2
⎛ ⎞≤ ≤ = − = − + − =⎜ ⎟⎝ ⎠
4P( 2 X 2) F(2) F( 2) 2 1 0 1
2⎛ ⎞− ≤ ≤ = − − = − + − =⎜ ⎟⎝ ⎠
1 41 1 1 5P X F( ) F 1
2 2 2 2 8⎛ ⎞⎛ ⎞ ⎛ ⎞≤ < ∞ = ∞ − = − − =⎜ ⎟ ⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠
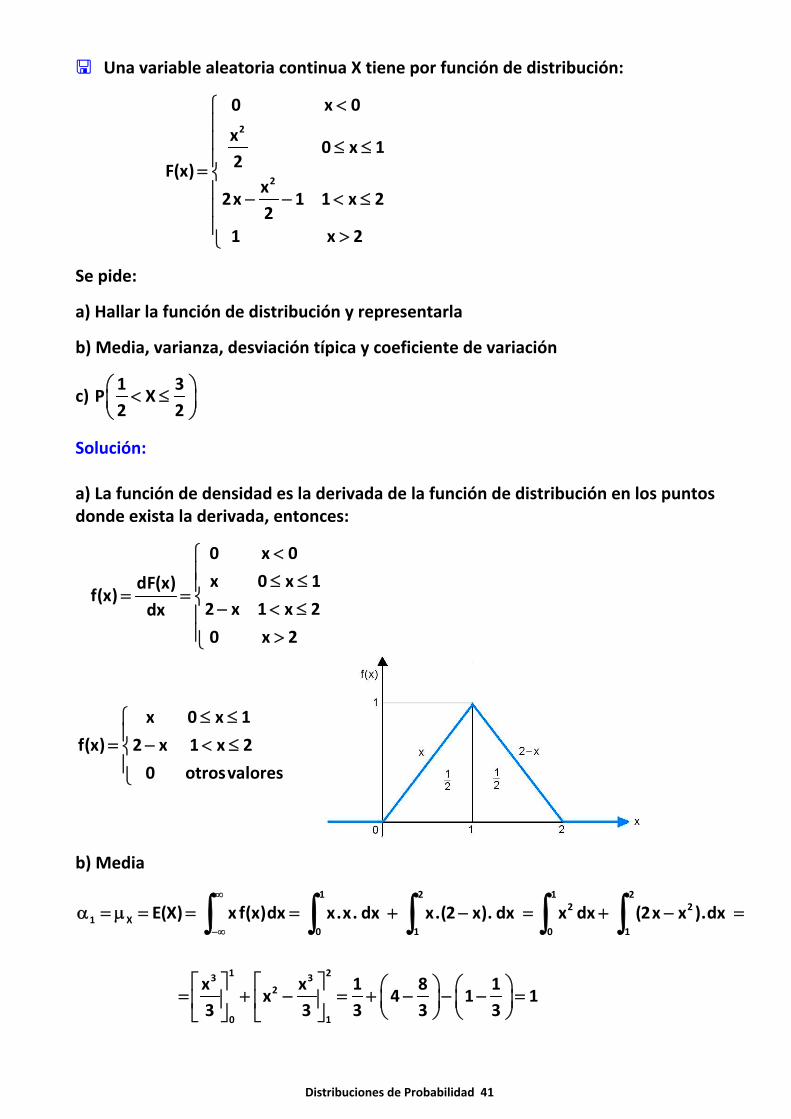
Distribuciones de Probabilidad 41
Una variable aleatoria continua X tiene por función de distribución:
2
2
0 x 0
x0 x 1
2F(x)x
2x 1 1 x 22
1 x 2
<⎧⎪⎪ ≤ ≤⎪= ⎨⎪ − − < ≤⎪⎪ >⎩
Se pide:
a) Hallar la función de distribución y representarla
b) Media, varianza, desviación típica y coeficiente de variación
c) 1 3
P X2 2
⎛ ⎞< ≤⎜ ⎟⎝ ⎠
Solución:
a) La función de densidad es la derivada de la función de distribución en los puntosdonde exista la derivada, entonces:
0 x 0
x 0 x 1dF(x)f(x)
2 x 1 x 2dx
0 x 2
<⎧⎪ ≤ ≤⎪= = ⎨ − < ≤⎪⎪ >⎩
x 0 x 1
f(x) 2 x 1 x 2
0 otrosvalores
≤ ≤⎧⎪= − < ≤⎨⎪⎩
b) Media
1 2 1 22 2
1 X0 1 0 1
E(X) x f(x)dx x.x. dx x.(2 x). dx x dx (2x x ).dx∞
−∞
α = μ = = = + − = + − =∫ ∫ ∫ ∫ ∫
1 23 3
2
0 1
x x 1 8 1x 4 1 1
3 3 3 3 3
⎡ ⎤ ⎡ ⎤ ⎛ ⎞ ⎛ ⎞= + − = + − − − =⎜ ⎟ ⎜ ⎟⎢ ⎥ ⎢ ⎥⎝ ⎠ ⎝ ⎠⎣ ⎦ ⎣ ⎦

Distribuciones de Probabilidad 42
Varianza: 2 2x 2 1σ = α −α
1 2 1 22 2 2 2 3 2 3
20 1 0 1
E(X ) x f(x)dx x .x. dx x .(2 x). dx x dx (2x x ).dx∞
−∞
α = = = + − = + − =∫ ∫ ∫ ∫ ∫
21 34 4
o 1
2xx x 1 16 16 2 1 14 74 3 4 4 3 4 3 4 12 6
⎡ ⎤⎡ ⎤ ⎛ ⎞ ⎛ ⎞= + − = + − − − = =⎢ ⎥ ⎜ ⎟ ⎜ ⎟⎢ ⎥⎝ ⎠ ⎝ ⎠⎣ ⎦ ⎣ ⎦
2 2 2x 2 1
7 11
6 6σ = α −α = − =
Desviación típica: x
10,41
6σ = =
Coeficiente variación: xx
x
0,41CV 0,41
1
σ= = =μ
c) 2 2(3 2) (1 2)1 3 3 1 3
P X F F 2. 12 2 2 2 2 2 2
⎛ ⎞ ⎛ ⎞⎛ ⎞ ⎛ ⎞ ⎛ ⎞< ≤ = − = − − − =⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠
9 1 3
3 1 0,758 8 4
= − − − = =
Una variable aleatoria continua X tiene por función de distribución:
0 x 1
F(x) x 1 1 x 2
1 x 2
<⎧⎪= − ≤ <⎨⎪ ≥⎩
a) Calcular la función de densidad o función de cuantía
b) Calcular la media, mediana y coeficiente de variación
Solución:
a) La función de densidad o función de cuantía es la derivada de la función dedistribución en los puntos donde exista la derivada, entonces:
0 x 11 1 x 2dF(x)
f(x) 1 1 x 2 f(x)0 en otro casodx
0 x 2
<⎧≤ <⎧⎪= = ≤ < ⎯⎯→ =⎨ ⎨
⎩⎪ ≥⎩
b) Media: 22 2
1 x1 1
x 1 3E(X) x f(x)dx xdx 2 1,5
2 2 2
∞
−∞
⎡ ⎤α = μ = = = = = − = =⎢ ⎥
⎣ ⎦∫ ∫

Distribuciones de Probabilidad 43
La Mediana de una distribución es el valor que deja el 50% de la distribución a laderecha y el otro 50% a la izquierda, por lo que:
[ ]e e
e
e e e
M MM
e e11 1
F(M ) 0,5 M 1 0,5 M 1,5
f(x) 0,5 dx 0,5 x 0,5 M 1 0,5 M 1,5
= ⇒ − = ⇒ =⎧⎪⎪⎨⎪ = ⇒ = ⇒ = ⇒ − = ⇒ =⎪⎩∫ ∫ Coeficiente de variación:
22 32 2 2
21 1
x 8 1 7E(X ) x f(x)dx x dx
3 3 3 3
∞
−∞
⎡ ⎤α = = = = = − =⎢ ⎥
⎣ ⎦∫ ∫2
2 2x 2 1 x
7 3 7 9 1 10,08
3 2 3 4 12 12⎛ ⎞σ = α − α = − = − = → σ = =⎜ ⎟⎝ ⎠
xx
x
0,08CV 0,05
1,5
σ= = =μ
Una variable aleatoria continua X tiene por función de densidad
kx(2 x) 0 x 2
f(x)0 otros casos
− < <⎧= ⎨⎩
Se pide:
a) P(a x b) si 0 a b 2< < < < <
b) P(a x b) si a 0 2 b< < < < <
Solución:
a) La función de densidad o función de cuantía debe verificar:22 2 2 3
2 2
0 0 0 0
x1 kx(2 x) dx k x(2 x) dx k (2x x ) dx k x
3
⎡ ⎤= − = − = − = −⎢ ⎥⎣ ⎦∫ ∫ ∫
3x(2 x) 0 x 28 3
k 4 1 k f(x) 43 4 0 otros casos
⎧ − < <⎪⎡ ⎤− = = ⇒ = ⎨⎢ ⎥⎣ ⎦ ⎪⎩
b 2 2 3 3b 32
a a
3(b a ) (b a )3 3 xSi 0 a b 2 P(a x b) x(2 x)dx x
4 4 3 4
⎡ ⎤ − − −< < < < < = − = − =⎢ ⎥⎣ ⎦∫

Distribuciones de Probabilidad 44
b) 0 2 b
a 0 2
3Si a 0 2 b P(a x b) 0dx + x(2 x) dx 0dx 1
4< < < < < = − + =∫ ∫ ∫
La función de distribución asociada a la producción de una máquina, en miles deunidades, es del tipo:
0 x 0
F(x) x(2 x) 0 x k
1 x k
<⎧⎪= − ≤ ≤⎨⎪ >⎩
a) Determinar k para que sea función de distribuciónb) Hallar la función de densidadc) Calcular la media, mediana, moda y varianza de la producciónd) Hallar P(X 0,5)< y P(X 0,25)>e) Función de densidad y de distribución de la variable aleatoria continuaY 6X 3= −
Solución:
a) Para que sea función de distribución se debe verificar:2
x k x k x k1 lim F(x) lim F(x) lim x(x 2) k(k 2) 1 k 2k 1 0 k 1
+ − −→ → →= = − = − = − + = ⇒ =
En consecuencia, la función de distribución es:
0 x 0
F(x) x(2 x) 0 x 1
1 x 1
<⎧⎪= − ≤ ≤⎨⎪ >⎩
b) La función de densidad o función de cuantía es la derivada de la función dedistribución en los puntos donde exista la derivada.
0 x 02 2x 0 x 1dF(x)
f(x) 2 2x 0 x 1 f(x)0 en otro casodx
0 x 1
<⎧− ≤ ≤⎧⎪= = − ≤ ≤ ⎯⎯→ =⎨ ⎨
⎩⎪ >⎩
c) Media: 1 1
21 X
0 0
E(X) xf(x)dx x (2 2x)dx (2x 2x )dx∞
−∞
α = μ = = = − = − =∫ ∫ ∫
132
0
2x 2 1x 1
3 3 3
⎡ ⎤= − = − =⎢ ⎥⎣ ⎦
Para calcular la Moda hay que ver el valor que hace mínima la función de densidado de cuantía, es decir:

Distribuciones de Probabilidad 45
2 2x 0 x 1 2 0 x 1
f(x) f '(x)0 en otro caso 0 en otro caso
− ≤ ≤ − ≤ ≤⎧ ⎧= =⎨ ⎨⎩ ⎩
La derivada de la función de cuantía es f '(x) 2 0= − < , por lo que se trata de unafunción decreciente y toma el valor máximo en el extremo superior del intervalo0, 1⎡ ⎤⎣ ⎦ , por tanto la moda dM 0=
La Mediana de una distribución es el valor que deja el 50% de la distribución a laderecha y el otro 50% a la izquierda, por lo que:
( ) 2 2e e e e e e eF(M ) 0,5 M 2 M 0,5 M 2M 0,5 0 2M 4M 1 0= ⇒ − = ⇒ − + = ⇒ − + =
2e e e
4 16 8 4 2 2 22M 4M 1 0 M 1
4 4 2
± − ±− + = = = = ±
De las dos soluciones se rechaza aquella que es mayor que 1, por lo que la Medianaes
e
2M 1
2= −
Varianza de la producción: 2 2X 2 1σ = α −α
11 3 42 2 2
20 0
2x x 2 1 1E(X ) x f(x)dx x (2 2x)dx
3 2 3 2 6
∞
−∞
⎡ ⎤α = = = − = − = − =⎢ ⎥
⎣ ⎦∫ ∫2
2 2X 2 1
1 1 16 3 18
⎛ ⎞σ = α − α = − =⎜ ⎟⎝ ⎠
d) Función de distribución 0 x 0
F(x) x(2 x) 0 x 1
1 x 1
<⎧⎪= − ≤ ≤⎨⎪ >⎩
P(X 0,5) P(X 0,5) F(0,5) 0,5(2 0,5) 0,75< = ≤ = = − =
P(X 0,25) 1 P(X 0,25) 1 F(0,25) 1 0,25(2 0,25) 0,5625> = − ≤ = − = − − =
Mediante la función de cuantía 2 2x 0 x 1
f(x)0 en otro caso
− ≤ ≤⎧= ⎨⎩
0,5 0 ,50 ,52
00 0
P(X 0,5) f(x)dx (2 2x)dx 2x x 1 0,25 0,75⎡ ⎤< = = − = − = − =⎣ ⎦∫ ∫1 1
12
0 ,250,25 0 ,25
P(X 0,25) f(x)dx (2 2x)dx 2x x 1 (0,5 0,0625) 0,5625⎡ ⎤> = = − = − = − − =⎣ ⎦∫ ∫

Distribuciones de Probabilidad 46
e) Función de densidad de Y 6X 3= −
Cambio de variable en la función de densidad: dx
g(y) f(x).dy
=
y 3 dx d y 3 1x
6 dy dy 6 6+ +⎛ ⎞= = =⎜ ⎟
⎝ ⎠
Dominio de definición de la variable x 0 y 3
Y 6X 3x 1 y 3
= → = −⎧= − ⎨ = → =⎩
resultando:
y 3 1 3 y2 2 . 3 y 3 3 y 3dx
g(y) f(x). g(y)6 6 18dy 0 en otro caso0 en otro caso
⎧⎡ + ⎤ −⎛ ⎞ ⎧− − ≤ ≤ − ≤ ≤⎪ ⎪⎜ ⎟⎢ ⎥= = → =⎝ ⎠⎨ ⎨⎣ ⎦⎪ ⎪⎩⎩
Función de distribución:
y 2
3
0 y 3 0 y 3
1 y 6y 27F(y) (3 t)dt 3 y 3 F(y) 3 y 3
18 361 y 31 y 3
−
< − < −⎧ ⎧⎪ ⎪− + +⎪ ⎪= − − ≤ < = − ≤ <⎨ ⎨⎪ ⎪
≥⎪ ⎪≥ ⎩⎩
∫
Sean las variables aleatorias independientes X e Y, donde X se distribuye comouna binomial B(15, 0,4) e Y como una binomial B(85,0,4) a) ¿Cómo se distribuye la variable aleatoria X Y+ ?b) ¿Se puede aproximar la variable aleatoria X Y+ a una distribución normal?,¿Con qué parámetros?c) ¿Cuando la suma de dos distribuciones binomiales independientes no se puedeaproximar a una distribución normal?. Poner un ejemplo.
Solución:
a) Las distribuciones binomiales independientes son reproductivas cuando tienenel mismo parámetro p. En consecuencia, X B(15, 0,4)∼ e Y B(85,0,4) ∼ se tiene queX Y B(100, 0,4)+ ∼
b) X Y B(100, 0,4)+ ∼ donde p 0,4 0,5= < y xnp 100 0,4 40 5= = > , por elteorema de Moivre o el Teorema Central del Limite (TCL) la distribución binomialde X Y+ se puede aproximar a una distribución normalN(40, 4,89) siendo np 40μ = = y 100 0,4 0,6 4,89σ = =x x
c) Cuando el tamaño fuera pequeño (n pequeña). Ejemplo: X Y B(8, 0,4)+ ∼

Distribuciones de Probabilidad 47
Dada una variable aleatoria X con distribución exponencial de parámetro λ ,calcular generatriz de los momentos (f.g.m.), función característica, esperanza yvarianza.
Solución:
Sea X Exp( )λ∼ , su función de densidad xe x 0
f(x)0 otro caso
−λ⎧λ >= ⎨⎩
t x t x t x x ( t) x
0 0
M(t) E e e . f(x) . dx e . e . dx e dx∞ ∞ ∞
−λ − λ −
−∞
⎡ ⎤= = = λ =λ =⎣ ⎦ ∫ ∫ ∫ ( t) x ( t )x
00
( t) e dx e tt t t
∞∞− λ − λ −λ λ λ⎡ ⎤= − − λ− = − = ∀ < λ⎣ ⎦λ − λ− λ−∫
i t x i t x i t x x ( i t) x
0 0
(t) E e e . f(x) . dx e . .e . dx e dx∞ ∞ ∞
−λ − λ −
−∞
⎡ ⎤ϕ = = = λ =λ =⎣ ⎦ ∫ ∫ ∫ ( t) x ( i t ) x
00
( it) e dx e tit it it
∞∞− λ − λ −λ λ λ⎡ ⎤= − − λ− = − = ∀ < λ⎣ ⎦λ − λ− λ−∫
La función generatriz M(t) coincide con la función característica (t)ϕ para t it= .
Con la función generadora de los momentos M(t) o función característica (t)ϕ sepueden calcular los momentos respecto al origen mediante la expresión:
n n
nn n n
t 0 t 0
1E(X ) M(t) (t)
t i t= =
ϑ ϑ= = ϕϑ ϑ
Momentos respecto al origen con la función generatriz:
(1)1 2
t 0 t 0 t 0
M(t) 1E(X) M (0)
t t t ( t)= = =
ϑ ϑ λ λ⎡ ⎤α = = = = = =⎢ ⎥ϑ ϑ λ − λ − λ⎣ ⎦
22 (2)
2 2 2t 0t 0t 0
4 2t 0
M(t)E(X ) M (0)
t t t t t ( t)
2 ( t) 2
(1 t)
===
=
ϑ ϑ ⎡ ϑ λ ⎤ ϑ λ⎛ ⎞⎛ ⎞α = = = = =⎜ ⎟ ⎜ ⎟⎢ ⎥ϑ ϑ ϑ λ − ϑ λ −⎝ ⎠ ⎝ ⎠⎣ ⎦
λ λ −= =
− λ2
22 1 2 2
2 1 1Var(X) ⎛ ⎞= α − α = − =⎜ ⎟λ λ λ⎝ ⎠
Momentos respecto al origen con la función característica:

Distribuciones de Probabilidad 48
(1)1
t 0 t 0
2 2
t 0 t 0
1 1 (t) 1E(X) (0)
i i t i t it
1 i 1
i ( it) ( it)
= =
= =
⎡ ⎤ϑϕ ϑ λ⎛ ⎞ ⎛ ⎞ ⎛ ⎞α = = ϕ = = =⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎢ ⎥ϑ ϑ λ −⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎣ ⎦
λ λ⎛ ⎞= = =⎜ ⎟ λ − λ − λ⎝ ⎠
22 (2)
2 2 2 2 2t 0 t 0
2
2 2 2 3 2
t 0 t 0
1 1 (t) 1E(X ) (0)
i i t i t t it
1 i 1 2i ( it) 2
i t ( it) i ( it)
= =
= =
⎡ ⎤⎛ ⎞ϑ ϕ ϑ ϑ λ⎛ ⎞ ⎛ ⎞ ⎛ ⎞α = = ϕ = = =⎢ ⎥⎜ ⎟⎜ ⎟ ⎜ ⎟ ⎜ ⎟ϑ ϑ ϑ λ −⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠⎣ ⎦
⎛ ⎞ϑ λ λ λ −⎛ ⎞ ⎛ ⎞= = =⎜ ⎟⎜ ⎟ ⎜ ⎟ϑ λ − λ − λ⎝ ⎠ ⎝ ⎠⎝ ⎠
Encontrar la función generadora de los momentos de una variable aleatoriadiscsreta que sigue una binomial B(n, p)
Solución:
La función de probabilidad n kknp(X k) p q donde p q 1
k−⎛ ⎞
= = + =⎜ ⎟⎝ ⎠
n nt x tk n k n kk t k t n
k 0 k 0
n nM(t) E(e ) e p q (e p) q (e p q)
k k− −
= =
⎛ ⎞ ⎛ ⎞= = = = +⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠∑ ∑
n 1(1) t n t t1 t 0 t 0
t 0
M(t)E(X) M (0) (e p q) n (e p q) e p np
t t−
= ==
ϑ ϑ ⎡ ⎤α = = = = + = + =⎣ ⎦ϑ ϑ
2n 12 (2) t n t t
2 2 t 0t 0t 0
n 2 n 1t t 2 t t 2
t 0
M(t) dE(X ) M (0) (e p q) (n (e p q) e p)
t t t t
n (n 1)(e p q) (e p) n (e p q) e p n (n 1)p np
−
===
− −
=
ϑ ϑ ϑ ϑ⎡ ⎤α = = = = + = + =⎢ ⎥ϑ ϑ ϑ ϑ⎣ ⎦
= − + + + = − +
2 2 2 22 1Var(X) n (n 1) p np (np) np np np (1 p) np q= α −α = − + − = − + = − =
La función generadora de momentos de una variable aleatoria X se define como:
tx
t x
t x
e p(x) X es discreta M(t) E(e )
e . f(x) . dx X es continua∞
−∞
⎧⎪= = ⎨⎪⎩
∑∫

Distribuciones de Probabilidad 49
Hallar la función característica y la función generadora de momentos de unavariable aleatoria continua X con distribución uniforme en a, b⎡ ⎤⎣ ⎦
Solución:
Función de densidad 1
a x bf(x) b a
0 otro caso
⎧ ≤ ≤⎪= −⎨⎪⎩
b bit x i t x i t x i t x
a a
1 1(t) E e e . f(x) . dx e . . dx e dx
b a b a
∞
−∞
⎡ ⎤ϕ = = = = =⎣ ⎦ − −∫ ∫ ∫
bit x i tb i ta
a
1 e e esi t 0
b a it it(b a)
⎡ ⎤ −= = ≠⎢ ⎥− −⎣ ⎦
b bt x t x t x t x
a a
1 1M(t) E e e . f(x) . dx e . . dx e dx
b a b a
∞
−∞
⎡ ⎤= = = = =⎣ ⎦ − −∫ ∫ ∫
bt x tb ta
a
1 e e esi t 0
b a t t(b a)
⎡ ⎤ −= = ≠⎢ ⎥− −⎣ ⎦
Sea X una variable aleatoria continua con función de densidad
xe x 0
f(x)0 otro caso
−⎧ >= ⎨⎩
a) Función generatriz de los momentos (f.g.m.)b) Esperanza y varianza a partir de la f.g.m.c) Función característica
Solución:
a) t x t x t x x(t 1)x
0 0
M(t) E e e . f(x) . dx e . e . dx e dx∞ ∞ ∞
−−
−∞
⎡ ⎤= = = = =⎣ ⎦ ∫ ∫ ∫ x(t 1)
0
1 1 e si t 1
t 1 1 t
∞−⎡ ⎤= = <⎣ ⎦− −
b) A partir de la función genertriz, derivando y haciendo t 0= , se pueden obtenerlos distintos momentos respecto al origen:
(1)1 2
t 0 t 0 t 0
M(t) 1 1E(X) M (0) 1
t t 1 t (1 t)= = =
ϑ ϑ ⎡ ⎤α = = = = = =⎢ ⎥ϑ ϑ − −⎣ ⎦

Distribuciones de Probabilidad 50
22 (2)
2 2 2 3t 0t 0t 0 t 0
M(t) d 1 1 2E(X ) M (0) 2
t t t 1 t t (1 t) (1 t) === =
ϑ ϑ ⎡ ϑ ⎤ ϑ ⎛ ⎞⎛ ⎞α = = = = = = =⎜ ⎟ ⎜ ⎟⎢ ⎥ϑ ϑ ϑ − ϑ − −⎝ ⎠ ⎝ ⎠⎣ ⎦
22 1Var(X) 2 1 1= α − α = − =
c) La función característica se puede calcular utilizando la relación entre funcióncaracterística y los momentos:
2 3 k h
1 2 3 k h
h 0
(it) (it) (it) (it)(t) 1 (it) si t 1
2! 3! k! h!
∞
=
ϕ = + α + α + α + + α + = α <∑
Sea X una variable aleatoria continua, cuya función de densidad es
2
X
3x 0 x 1f (x)
0 en otro caso
⎧ < <= ⎨⎩
Sea 2Y 1 X= − una transformación de la v.a. X
a) Calcular la función de densidad de la v.a. Yb) Calcular la función de distribución de la v.a. Y
Solución:
a) La transformación asociada a la v.a. Y es derivable y estrictamente monótonacuando X toma valores en el intervalo (0, 1). En consecuencia, se puede aplicar latransformación, quedando la función de densidad:
2 1 dx 1Y 1 X x 1 y g (y) 1 y
dy 2 1 y− −
= − = − = − =−
La función de densidad de la variable continua Y se obtiene:
( )X
21
Y
dx 1 3f (y) f g (y) . 3 1 y 1 y
dy 22 1 y− −⎡ ⎤= = − = −⎣ ⎦ −
Función de densidad de la v.a. Y: Y
31 y 0 y 1
f (y) 20 en otro caso
⎧ − < <⎪= ⎨⎪⎩
b) Función de distribución:

Distribuciones de Probabilidad 51
y
Y
0
Y
y 0 F (y) f(t)dt 0
0 y 1 F (y) f(y)dy
−∞
−∞
≤ = =
< < =
∫∫
yy y3 3
0 0 0
0
Y
3f(t)dt 1 t dt (1 t) 1 (1 y)
2
y 1 F (y) f(y)dy−∞
⎡ ⎤+ = − = − − = − −⎣ ⎦
≥ =
∫ ∫
∫1 y
0 1f(t)dt f(t)dt+ +∫ ∫
1 1
0 0
3f(t)dt 1 t dt 1
2= = − =∫ ∫
Función de distribución de la v.a. Y será: 3Y
0 y 0
F (y) 1 (1 y) 0 y 1
1 y 1
≤⎧⎪
= − − < <⎨⎪ ≥⎩
Sea X una variable aleatoria continua, cuya función de densidad es
X
11 x 1
f (x) 20 en otro caso
⎧ − < <⎪= ⎨⎪⎩
Sea 2Y X= una transformación de la v.a. X
a) Calcular la función de densidad de la v.a. Yb) Calcular la función de distribución de la v.a. Y
Solución:
La transformación 2Y X= es derivable, pero no es estrictamente monótona, puestoque en el intervalo ( 1, 0] − la transformación es decreciente y en el intervalo[0, 1) es creciente.
En este caso, hay que determinar la función de distribución de la variable aleatoriaY para el caso general de las transformaciones de una variable aleatoria, ya que nose puede aplicar el método descrito en el ejercicio anterior. Hay que comenzarencontrando la función de distribución.
b) Cálculo de la función de distribución
[ ]y
2Y
y
F (y) P Y y P X y P X y P y X y f(x)dx−
⎡ ⎤ ⎡ ⎤⎡ ⎤= ≤ = ≤ = ≤ = − ≤ ≤ = =⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ∫ [ ]
yy
yy
1 1 dx x y
2 2 −−
= = =∫
La función de distribución de la v.a. Y es: Y
0 y 0
F (y) y 0 £ y 1
1 y ³ 1
<⎧⎪
= <⎨⎪⎩

Distribuciones de Probabilidad 52
a) Función de densidad YY
10 y 1dF (y) 2 yf (y)
dy0 enotro caso
⎧ ≤ <⎪= = ⎨⎪⎩
Utilizando la aplicación del teorema central del límite a la distribución de lasuma de n variables aleatorias de Poisson de media 1λ = demostrar que
n kn
xk 0
n 1lim e
k! 2−
→ ∞=
=∑Solución:
Sean 1 2 nX ,X , ,X variables de Poisson de parámetro 1λ = . Sea n
n ii 1
X=
η =∑Por ser reproductiva respecto a λ la distribución de Poisson, nη es una variable de
Poisson de parámetro nλ = ; y se tiene nnE( ) n nηη = σ =
Con lo cual, n k
nn
k 0
nP( n) e
k!−
=
η ≤ = ∑Por el teorema central del límite (TCL), teorema de Lévy‐Lindeberg, cuando n→∞ ,
nη es normal N(n, n) , y así resulta:
nn
n n n 1P( n) P P(z 0)
2n n
η − −⎡ ⎤η ≤ = ≤ = ≤ =⎢ ⎥⎣ ⎦
Sean las variables X e Y independientes. La variable X se distribuye como unaPoisson con varianza igual a 5. La variable Z X Y = + se distribuye también comouna Poisson con esperanza igual a 15. ¿Cuánto vale la esperanza de la variable Y?Analice bajo qué condiciones se puede afirmar que la distribución de Poisson esaditiva o reproductiva y determine con qué parámetros.
Solución:
La suma de variables aleatorias de Poisson independientes es otra variablealeatoria de Poisson con parámetros la suma de los parámetros.
2XX P( 5) 5
Y P( 10) E(Y) 10Z P( 15) E(Z) 15
⎧ λ = σ = λ =λ = =⎨
λ = = λ =⎩
∼∼
∼

Distribuciones de Probabilidad 53
Las variables aleatorias en estudio son independientes. Analiza si lasafirmaciones son verdaderas o falsas:a) X sigue una distribución binomial B(1, 0,3) e Y una distribución binomialB(1, 0,2) entonces (X Y) + sigue una binomial B(2, 0,5) . ¿Bajo qué condiciones sedice que la distribución binomial es aditiva o reproductiva?b) X sigue una distribución de Poisson P( 2) λ = e Y una distribución de PoissonP( 3) λ = entonces (X Y) P( 5)+ λ =∼c) Si X N(0, 1) ∼ y XF es su función de distribución entonces X XF ( x) = 1 F (x)− −
Solución:
a) Las distribuciones binomiales son reproductivas de parámetro p, es decir, dadasdos variables aleatorias X B(n, p)∼ e Y B(m, p)∼ siendo independientes se verificaque (X Y) B(n m, p)+ +∼ . En consecuencia, una variable aleatoria X B(n, p)∼ sepuede descomponer en suma de n variables aleatorias independientes de Bernouillide parámetro p.Para poder aplicar la propiedad reproductiva, han de ser independientes y con lamisma probabilidad.
b) Es cierto, la distribución de Poisson es reproductiva.
c) Por la simetría de la distribución normal se verifica x∀ ∈
Un ascensor limita el peso de sus cuatro ocupantes a 300 kilogramos. Si el pesode una persona sigue una distribución normal ( )N 71,7 , calcular la probabilidad de
que el peso 4 personas supere los 300 kilogramos.
Solución:
Método I: Si el peso de una persona sigue una distribución normal ( )N 71,7 , la
muestra de 4 personas sigue una distribución normal ( )71N 71, N 71, 3,5
4
⎛ ⎞≡⎜ ⎟⎜ ⎟
⎝ ⎠
1 2 3 41 2 3 4
X X X X 300P (X X X X ) 300 P P x 75
4 4
+ + +⎡ ⎤+ + + > = > = > =⎡ ⎤ ⎡ ⎤⎣ ⎦⎣ ⎦ ⎢ ⎥⎣ ⎦
x 71 75 71
P x 75 P P z 1,143 0,12653,5 3,5− −⎡ ⎤= > = > = > =⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦⎢ ⎥⎣ ⎦
Interpolando: 0,1271 0,1251 x 0,1251 0,002 x 0,12511,14 1,15 1,143 1,15 0,01 0,007
− − −= =
− − − −
0,002 . 0,007x 0,1251 0,1265
0,01= + =

Distribuciones de Probabilidad 54
Método II: Sí 4
i i
i 1
. nn.
x N 71; 7 x N 4 . 71 ; 7 . 4 N 284 ; 14=
σμ⎡ ⎤⎢ ⎥
=⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦⎢ ⎥⎢ ⎥⎣ ⎦
∑∼ ∼
[ ]
4
i4i 1
i
i 1
x 284300 284
P x 300 P P z 1,143 0,126514 14
=
=
⎡ ⎤−⎢ ⎥⎡ ⎤ −⎢ ⎥⎢ ⎥≥ = ≥ = ≥ =⎢ ⎥⎢ ⎥ ⎢ ⎥⎣ ⎦
⎢ ⎥⎣ ⎦
∑∑
La probabilidad de que un banco reciba un cheque sin fondos es 0.01a) Si en una hora reciben 20 cheques, ¿cuál es la probabilidad de que tenga algúncheque sin fondos?b) El banco dispone de 12 sucursales en la ciudad, ¿cuál es la probabilidad de queal menos cuatro sucursales reciban algún cheque sin fondos?c) La media del valor de los cheques sin fondos es de 600 euros. Sabiendo que elbanco trabaja 6 horas diarias, ¿qué cantidad no se espera pagar?d) Si se computasen los 500 primeros cheques, ¿cuál es la probabilidad de recibirentre 3 y 6 (inclusive) cheques sin fondos?
Solución:
a) X = "Número de cheques sin fondos" con X B(20, 0,01)∼
[ ] [ ] [ ] 0 2020P X 1 1 P X 1 1 P X 0 1 .0,01 .0,99 1 0,980 0,182
0⎛ ⎞
≥ = − < = − = = − = − =⎜ ⎟⎝ ⎠
b) Y = "Número de sucursales que reciben al menos 1 cheque sin fondos" Y B(12, 0,182)∼
[ ] [ ] [ ] [ ] [ ] [ ]P Y 4 1 P Y 4 1 P X 0 P X 1 P X 2 P X 3⎡ ⎤≥ = − < = − = + = + = + = =⎣ ⎦
[ ]
0 12 1 11 2 10
3 9
12 12 121 .0,182 .0,818 .0,182 .0,818 .0,182 .0,818
0 1 2
12 .0,182 .0,818 1 0,0897 0,2396 0,2932 0,2174 0,16
3
⎡⎛ ⎞ ⎛ ⎞ ⎛ ⎞= − + + +⎢⎜ ⎟ ⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠ ⎝ ⎠⎣⎤⎛ ⎞
+ = − + + + =⎥⎜ ⎟⎝ ⎠ ⎦
c) 1hora 6 horasn 120 cheques
20 cheques n cheques= =
Los cheques sin fondos esperados: E(X) n . p 120 . 0,01 1,2 chequesμ = = = =En consecuencia, se espera no pagar 1,2 . 600 720 euros=

Distribuciones de Probabilidad 55
d) U = "Número de cheques sin fondos computados" donde U B(500, 0,01)∼ , queal ser n . p 500 . 0,01 5= = se aproxima a una distribución de Poisson de parámetro
[ ]P 5λ =
[ ] [ ] [ ] [ ] [ ]P 3 U 6 P U 3 P U 4 P U 5 P U 6≤ ≤ = = + = + = + = =
[ ]3 4 5 6
5 55 5 5 5.e 20,833 26,042 26,042 21,701 .e 0,6375
3! 4! 5! 6!− −⎡ ⎤
= + + + = + + + =⎢ ⎥⎣ ⎦
El departamento comercial de una industria alimenticia conoce que 2 de cada10 consumidores reconocen su producto en una prueba a ciegas.¿Cuántas pruebas ciegas de sabor deberían hacerse para que la proporción de quelos que conocen la marca oscile entre el 16% y el 24% con una probabilidad mínimade 0,8?
Solución:
Reconocen el producto el 20% p = 0,2 ˆP(0,16 p 0,24) 0,8≤ ≤ ≥
xpq 0,2 0,8 0,4ˆ ˆp N p, p N 0,2, N 0,2 ,n n n
⎛ ⎞ ⎛ ⎞ ⎛ ⎞≈ → ≈ =⎜ ⎟ ⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠
( )0,16 0,2 0,24 0,2P z P 0,1 n z 0,1 n 0,8
0,4 / n 0,4 / n
− −⎛ ⎞< < = − < < =⎜ ⎟⎝ ⎠
( ) ( ) ( )P 0,1 n z 0,1 n 1 2P z 0,1 n 0,8 P z 0,1 n 0,1− < < = − > = ≥ =
0,1 n 1,282 n 165= =
Para una probabilidad como mínimo de 0,8 harían falta 165 pruebas.

Distribuciones de Probabilidad 56
Las puntuaciones en la Escala de Inteligencia para Adultos de Wechsler (WAIS)siguen en una población una distribución normal de media 100 y desviación típica16. Al extraer una muestra aleatoria simple de 25 individuos, calcular:a) Probabilidad de que la media de esos 25 individuos sea inferior a 95b) Probabilidad de que la media esté comprendida entre 98 y 102.
Solución:
Según el teorema de Fisher 16
x N , x N 100, N(100, 3,2)n 25
σ⎛ ⎞ ⎛ ⎞≈ μ → ≈ ≡⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
a) x 100 95 100
P(x 95) P P(z 1,56) P(z 1,56) 0,05943,2 3,2− −⎛ ⎞≤ = ≤ = ≤ − = ≥ =⎜ ⎟
⎝ ⎠
b) 98 100 x 100 102 100
P(98 x 102) P P( 0,62 z 0,62)3,2 3,2 3,2− − −⎛ ⎞≤ ≤ = ≤ ≤ = − ≤ ≤ =⎜ ⎟
⎝ ⎠P(z 0,625) P(z 0,62) P(z 0,62) P(z 0,62) 1 P(z 0,62) P(z 0,62)
1 2P(z 0,62) 0,4648
= ≥ − − ≥ = ≤ − ≥ = − ≥ − ≥ == − ≥ =
Las puntuaciones obtenidas en la escala de Locus de Control de James por lossujetos depresivos, siguen una distribución normal de media 90 y desviación típica12. Si se extraen muestras aleatorias simples de 30 sujetos depresivos.¿Por debajo de que cantidad se encontrará el 90% de las veces el valor de lavarianza de la muestra?.
Solución:
En virtud del teorema de Fisher: En el muestreo, si se toman muestras aleatorias demedia x y desviación típica xσ de una población N( , )μ σ , la variable
22n 1 2
(n 1)s−
−χ =
σ, donde 2s es la cuasivarianza muestral, 2 2
xn (n 1)sσ = −
Las puntuaciones obtenidas siguen una distribución N(90,12)
2 2 2
2 2x xn 1 292 2
(n 1)s n 30144−
− σ σχ = = → χ =
σ σ
De las tablas de la Chi‐cuadrado:
2 229 29P( k) 0,9 P( k) 0,1 k 39,087χ ≤ = ⇒ χ ≥ = = con lo cual,
( )2
2 2xx x
x30 39,087 144P 39,087 0,9 P P 187,62 0,9
144 30
⎛ ⎞σ ⎛ ⎞≤ = → σ ≤ = σ ≤ =⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
El valor pedido será 187,62

Distribuciones de Probabilidad 57
Calcular la media y la varianza de una variable aleatoria 5t de Student
Solución:
Una variable aleatoria nt de Student tiene de media 0μ = y varianza 2 nn 2
σ =−
La media y la varianza de una 5t de Student, respectivamente, son 0μ = y 2 53
σ =
En una población de mujeres, las puntuaciones de un test de ansiedad‐riesgosiguen una distribución normal N(25,10) . Al clasificar la población en cuatro gruposde igual tamaño, ¿cuales serán las puntuaciones que delimiten estos grupos?.
Solución:
Siendo la variable aleatoria X = "Puntuaciones en un test de ansiedad‐riesgo"
Las puntuaciones que delimitan estos cuatro grupos serán el primer 1Q , segundo
2Q y tercer cuartil 3Q de la distribución.
1 11
X 25 Q 25 Q 25P(X Q ) 0,25 P P z 0,25
10 10 10− − −⎛ ⎞ ⎛ ⎞≤ = ≤ = ≤ =⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠
( )P z 0,67 0,25≤ − = ( )P z 0,67 0,25≥ =
11 x
Q 250,67 Q 25 0,67 10 18,3
10−
= − = − =
En la distribución normal la media y la mediana son iguales: e 2M Q 25μ = = =
3 33
3
X 25 Q 25 Q 25P(X Q ) 0,75 P P z 0,75
10 10 10Q 25
P z 0,2510
− − −⎛ ⎞ ⎛ ⎞≤ = ≤ = ≤ =⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
−⎛ ⎞≥ =⎜ ⎟⎝ ⎠
33 x
Q 250,67 Q 25 0,67 10 31,7
10−
= = + =
Por consiguiente, el primer grupo serían las mujeres con puntuaciones inferiores oiguales a 18,3. El segundo grupos son aquellas mujeres con puntuaciones entre 18,3y 25. El tercer grupo son las mujeres con puntuaciones entre 25 y 31,7. El cuartogrupo son mujeres que tengan puntuaciones superiores a 31,7.

Distribuciones de Probabilidad 58
El número de millones de metros cúbicos que tiene un embalse sigue unadistribución normal N(980,50). El consumo diario de las poblaciones que sirve esuna normal N(85, 30). Si se sabe que durante una tormenta la cantidad de aguaque se embolsa es una normal N(50, 25) .Un día han caído dos tormentas, calcular la probabilidad de que al final del día elagua embalsada sea menor o igual que 980 metros cúbicos.
Solución:
Agua del embalse: 1 1 1X N( , ) N(980,50)μ σ ≡∼
Consumo diario: 2 2 2X N( , ) N(85,30)μ σ ≡∼
3 3 3Agua una tormenta: X N( , ) N(50,25)∼ μ σ ≡
[ ][ ]
3 32
3 3
x
x
E(2X ) 2E X 2 50 100Agua dos tormentas:
Var(2X ) 4Var X 4 25
⎧ = = =⎪⎨ = =⎪⎩
2 22 2
3 i i i ii 1 i 1
X X2X N , N(2 0 , 2 25)= =
⎛ ⎞⎜ ⎟λ μ λ σ ≡⎜ ⎟⎝ ⎠∑ ∑∼
Agua embalse un día con dos tormentas:
3 32 2
1 2 3 i i i ii 1 i 1
Y X X 2X siendo Y N ,= =
⎛ ⎞= − + λ μ λ σ⎜ ⎟⎜ ⎟
⎝ ⎠∑ ∑∼
( )2 2 2xY N 980 85 100, 50 30 4 25 N(995, 76,81)− + + + ≡∼
Y 995 980 995P(Y 980) P P(z 0,19) P(z 0,19) 2P(z 0,19) 0,4247
76,81 76,81− −⎡ ⎤≤ = ≤ = ≤ − = ≥ = ≥ =⎢ ⎥⎣ ⎦

Distribuciones de Probabilidad 59
Una maca de frutas ha observado que el peso medio de los melones en gramossigue una distribución normal N(1700, 100) . Hallar:a) Probabilidad de que los melones pesen menos de 1500 gramos y más de 2000gramos.b) Sabiendo que son rechazados para la explotación aquellos melones que difierenmás de 300 gramos del promedio. Determinar la proporción de melonesrechazados.
Solución:
a) Sea la variable aleatoria X ="Peso de los melones en gramos", X N(1700, 100)∼
[ ]P (X 1500) (X 2000) P(X 1500) P(X 2000)< ∪ > = < + > =
X 1700 1500 1700 X 1700 2000 1700P P P(z 2) P(z 3)
100 100 100 100− − − −⎡ ⎤ ⎡ ⎤= < + > = < − + > =⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
P(z 2) P(z 3) 0,0228 0,00135 0,02415= > + > = + =
b) 1400 1700 X 1700 2000 1700
P(1400 X 2000) P P( 3 z 3)100 100 100− − −⎡ ⎤≤ ≤ = ≤ ≤ = − ≤ ≤ =⎢ ⎥⎣ ⎦
1 2P(z 3) 1 2 x 0,00135 0,9973 melones aceptados= − ≥ = − =
Melones rechazados: 2P(z 3) 2 x 0,00135 0 027,0≥ = =
El error cometido en expedir tiques por una maquina en el aeropuerto sigueuna normal N(0, )σ .a) ¿Cuál es la probabilidad de que el error cometido en valor absoluto de unamedida cualquiera sea al menos σ ?b) ¿Cuánto valdría la probabilidad si se toma como medida la media aritmética de10 medidas independientes?
Solución:
a) Sea la variable aleatoria X = "Expedir tiques por la maquina", X N(0, )σ∼
[ ] [ ] [ ]X 0 0P X P P z 1 P (z 1) (z 1) P(z 1) P(z 1)
⎡ − σ − ⎤≥ σ = ≥ = ≥ = ≤ − ∪ ≥ = ≤ − + ≥ =⎢ ⎥σ σ⎣ ⎦
xP(z 1) P(z 1) 2P(z 1) 2 0,1587 0,3174= ≥ + ≥ = ≥ = =
b) Sea la variable aleatoria 10
1 2 10 ii 1
1Y X X X y X
10 =
= + + + = ∑

Distribuciones de Probabilidad 60
10 10
i ii 1 i 1
1 1 1E(y) E X E X 10 0
10 10 10= =
⎡ ⎤ ⎡ ⎤= = = μ = μ =⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦∑ ∑
10 10 22 2y i i
i 1 i 1
1 1 1Var(y) Var X Var X 10
10 100 100 10= =
⎡ ⎤ ⎡ ⎤ σσ = = = = σ =⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦∑ ∑
y N 0,10
σ⎡ ⎤⎢ ⎥⎣ ⎦
∼
y 0 0P y P P z 10
/ 10 / 10
P (z 10) (z 10) P(z 10) P(z 10)
P(z 10) P(z 10) 2P(z 3,16) 0,0016
⎡ − σ − ⎤ ⎡ ⎤⎡ ≥ σ⎤ = ≥ = ≥ =⎣ ⎦⎣ ⎦ ⎢ ⎥σ σ⎣ ⎦
⎡ ⎤= ≤ − ∪ ≥ = ≤ − + ≥ =⎣ ⎦
= ≥ + ≥ = ≥ =
Las variables aleatorias en estudio son independientes.Sean: 1 2 3X N(10,2) , X N(15,2) y X N(20,2)∼ ∼ ∼ donde 1 2 3Y 5X 4X 3X= + − y
2 2 2
1 2 3X 10 X 15 X 20U
2 2 2− − −⎛ ⎞ ⎛ ⎞ ⎛ ⎞= + +⎜ ⎟ ⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠ ⎝ ⎠.
Calcular: a) [ ]P 20 Y 30≤ ≤ b) [ ]P U 11≤
Solución:
a) 3 3
2 21 2 3 i i i i
i 1 i 1
Y 5X 4X 3X siendo Y N ,= =
⎛ ⎞⎜ ⎟= + − λ μ λ σ⎜ ⎟⎝ ⎠∑ ∑∼
2 2 2 2 2 2x x x x x xY N 5 10 4 15 3 20 , 5 2 4 2 ( 3) 2 Y N 50 , 2 50⎡ ⎤ ⎡ ⎤+ − + + −⎣ ⎦ ⎣ ⎦∼ ∼
[ ] 20 50 Y 50 30 50P 20 Y 30 P P( 2,12 z 1,41)
2 50 2 50 2 50
− − −⎡ ⎤≤ ≤ = ≤ ≤ = − ≤ ≤ − =⎢ ⎥⎣ ⎦
P(1,41 z 2,12) P(z 1,41) P(z 2,12) 0,0793 0,0170 0,0623= ≤ ≤ = ≥ − ≥ = − =
b) 1 2 3X 10 X 15 X 20N(0,1) N(0,1) N(0,1)
2 2 2− − −∼ ∼ ∼
[ ] [ ] [ ]2 2 2
2 2 2 21 2 33
X 10 X 15 X 20U N(0, 1) N(0, 1) N(0, 1)
2 2 2− − −⎛ ⎞ ⎛ ⎞ ⎛ ⎞= + + = + + = χ⎜ ⎟ ⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠ ⎝ ⎠
[ ] 2 23 3P U 11 P 11 1 P 11 1 0,05 0,95⎡ ⎤ ⎡ ⎤≤ = χ ≤ = − χ ≥ = − =⎣ ⎦ ⎣ ⎦

Distribuciones de Probabilidad 61
Un dispositivo está formado por muchos elementos que trabajabanindependientemente, siendo la probabilidad de fallo durante la primera hora detrabajo muy pequeña e iguales en todos los elementos.Si la probabilidad de que en ese tiempo falle por lo menos un elemento es 0,98.a) Hallar la media y desviación típica del número de elementos que fallen en laprimera hora.b) Calcular la probabilidad de que fallen a lo sumo dos elementos en ese tiempo.
Solución:
a) Habiendo muchos elementos independientes, el tamaño (n) es muy grande, conuna probabilidad de fallo muy pequeña, condiciones para que el dispositivo sigauna distribución de Poisson.
Sea la variable aleatoria X = "Fallo en la primera hora de un elemento", X P( )λ∼
donde k
P(X k) ek!
−λλ= =
0
P(X 1) 0,98 P(X 1) P(X 0) e 0,02 e 0,020!
−λ −λλ≥ = < = = = = =
ln 0,02 3,91 3,91 3,91 1,98−λ = λ = ⇒ μ = λ = σ = λ = =
b) 0 2
3,9 3,9 3,93,9 3,9 3,9P(X 2) P(X 0) P(X 1) P(X 2) e e e
0! 1! 2!− − −≤ = = + = + = = + + =
2
3,9 3,9x3,9
1 3,9 e 12,505 e 0,25312
− −⎡ ⎤= + + = =⎢ ⎥⎣ ⎦
Encontrar la moda de una variable aleatoria X B(14 , 0,2)∼
Solución:
La moda de una distribución binomial viene dada por el valor (número entero) queverifica d(np q M np p)− ≤ ≤ + .Generalmente será un valor (la parte entera de la media) y podrán ser dos valoresmodales cuando (np q)− y (np p)+ sea un número entero.
En este caso, np q 14.0,2 0,8 2 np p 14.0,2 0,2 3− = − = + = + =
d dnp q M np p 2 M 3− ≤ ≤ + → ≤ ≤La distribución es bimodal y las modas son 2 y 3

Distribuciones de Probabilidad 62
Una compañía de seguros garantiza pólizas de seguros individuales contraretrasos aéreos de más de doce horas. Una encuesta ha permitido estimar a lolargo de un año que cada persona tiene una probabilidad de una de cada de mil deser víctima de un retraso aéreo que esté cubierto por este tipo de póliza y que lacompañía aseguradora podrá vender una media de cuatro mil pólizas al año.Se pide hallar las siguientes probabilidades:a) Que el número de retrasos cubiertos por la póliza no pase de cuatro por añob) Número de retrasos esperados por añoc) Que el número de retrasos sea superior a dos por añod) Que ocurran doce retrasos por año
Solución:
Sea X = "Número de retrasos por año", la variable sigue una distribución binomial
1n 4000 , p 0,001 , b(4000 , 0,001)
1000= = =
con lo que, k 4000 k4000P(X k) .0,001 .0,999 k 0,1, ,4000
k−⎛ ⎞
= = =⎜ ⎟⎝ ⎠
Es necesario buscar una distribución que sea una buena aproximación de ésta. Ladistribución de Poisson es una buena aproximación de la binomial b(4000 , 0,001) ,ya que p 0,001= es muy pequeña y n.p 4000.0,001 4 5= = < .
Por tanto, X b(4000 , 0,001) X P( n.p 4)∼ ≈ ∼ λ = = k
44P(X 4) .e
k!−= =
a) P(X 4) P(X 0) P(X 1) P(X 2) P(X 3) P(X 4)≤ = = + = + = + = + = =
[ ]0 1 2 3 4
4 44 4 4 4 4.e 1 4 8 10,667 10,667 .e 0,6289
0! 1! 2! 3! 4!− −⎡ ⎤
= + + + + = + + + + =⎢ ⎥⎣ ⎦
b) El número de retrasos esperado por año es la media x 4μ = λ =
c) [ ]P(X 2) 1 P(X 2) 1 P(X 0) P(X 1) P(X 2)> = − ≤ = − = + = + = =
[ ]0 1 2
4 44 4 41 .e 1 1 4 8 .e 1 0,381 0,7619
0! 1! 2!− −⎡ ⎤
= − + + = − + + = − =⎢ ⎥⎣ ⎦
d) 12
4 44P(X 12) .e 0,035.e 0,00064
12!− −= = = =

Distribuciones de Probabilidad 63
El 7% de los pantalones de una determinada marca salen con algún defecto. Seempaquetan en caja de 80 pantalones para diferentes tiendas. ¿Cuál es laprobabilidad de que en una caja haya entre 8 y 10 pantalones defectuosos?
Solución:
Sea X = "Número de pantalones defectuosos en una caja"
Se trata de una distribución binomial (los pantalones son o no son defectuosos), esdecir, una binomial con n 80= , p 0,07= : B(80 , 0,07) , donde:
n.p 80. 0,07 5,6 n.p.q 80.0,07. 0,93 2,28μ = = = σ = = =
Adviértase que se dan las condiciones para aproximar la distribución discretabinomial a una distribución continua normal:
p 0,07 0,5 y n.p 80. 0,07 5,6 5= ≤ = = >
con lo que, B(n, p) N n.p , n.p.q B(80 , 0,07) N 5,6 , 2,28⎡ ⎤μ = σ = → ⎡ ⎤⎣ ⎦⎣ ⎦∼ ∼
Para utilizar correctamente la transformación de una variable aleatoria discreta X(distribución binomial) en una variable aleatoria continua z (con distribuciónnormal) es necesario hacer una corrección de continuidad:
[ ] TipificandoN(5,6 ;2,28)Transformación
P 8 X 10 P 7,5 X 10,5•⎡ ⎤≤ ≤ = ≤ ≤ =⎣ ⎦
[ ]7,5 5,6 X 5,6 10,5 5,6P P 0,83 z 2,15
2,28 2,28 2,28
•⎡ ⎤− − −= ≤ ≤ = ≤ ≤ =⎢ ⎥
⎣ ⎦
[ ] [ ]P z 0,83 P z 2,15 0,2033 0,0158 0,1875= > − > = − =

Distribuciones de Probabilidad 64
Un servicio dedicado a la reparación de electrodomésticos recibe por términomedio 15 llamadas diarias. Determinar la probabilidad de que reciba un día más de20 llamadas.
Solución:
Sea X "= Número de llamadas recibidas al día"
La variable aleatoria: [ ] [ ]k
1515X P 15 P X k . e
k!−λ = ⇒ = =∼
[ ] 15 10P 15 N 15, 15λ = > ⎡ ⎤λ = ⎯⎯⎯⎯⎯→ ⎣ ⎦
[ ] [ ]X 15 (20 0,5) 15P X 20 P P z 1,16 0,1230
15 15
⎡ ⎤− − −> = > = > =⎢ ⎥
⎢ ⎥⎣ ⎦
En una fábrica se sabe que la probabilidad de que r artículos sean defectuosos
es [ ]4k4 . e
P X kk!
−
= = . Determinar la probabilidad de que en 100 días el número de
artículos defectuosos esté comprendido entre (400, 600)
Solución:
Es una distribución de Poisson: [ ]k
P X k . e 4 , 4 2k!
−λλ= = λ = σ = =
En 100 días: ( ) ( ) ( )1 2 100X , X , , X P n. , n. P 100.4 , 100.4 P 400 , 20λ λ = =⎡ ⎤⎣ ⎦∼
( )n . 400 10P n. N 400, 400 N 400, 20λ = > ⎡ ⎤λ ⎯⎯⎯⎯⎯⎯→ ≡⎡ ⎤⎣ ⎦ ⎣ ⎦
[ ] [ ]400 400 X 400 600 400P 400 X 600 P P 0 z 10
20 20 20− − −⎡ ⎤≤ ≤ = ≤ ≤ = ≤ ≤ =⎢ ⎥⎣ ⎦
[ ] [ ]P z 0 P z 10 0,5= ≥ − ≥ =

Distribuciones de Probabilidad 65
Se ha realizado una muestra aleatoria simple (m.a.s.) de tamaño 10 de unapoblación considerada normal, llegando a que la varianza muestral es 4.Calcular la probabilidad P x 1,51⎡ − μ ≤ ⎤⎣ ⎦
Solución:
[ ]9 9
x 1,51P x 1,51 P P t 2,265 P 2,265 t 2,265
2 / 3 2 / 3⎡ − μ ⎤
⎡ − μ ≤ ⎤ = ≤ = ⎡ ≤ ⎤ = − ≤ ≤ =⎣ ⎦ ⎢ ⎥ ⎣ ⎦⎣ ⎦
[ ] [ ] [ ] [ ][ ]
9 9 9 9
9
P t 2,265 P t 2,265 P t 2,265 P t 2,265
1 2P t 2,265 0,95
= ≥ − − ≥ = ≤ − ≥ =
= − ≥ =
Se realiza una encuesta para conocer la proporción de españoles a los que no legusta el fútbol, tomando una muestra aleatoria simple (m.a.s.) de tamaño 100.Por análisis anteriores se conoce que dicha proporción es del 45%. Calcular laprobabilidad de que la proporción muestral sea superior al 52%.
Solución:
Tamaño muestral n 100=
p 0,45 q 0,55= =
( )x0,45 0,55p̂ N 0,45, N 0,45, 0,05
100
⎛ ⎞=⎜ ⎟
⎝ ⎠∼
[ ] p̂ 0,45 0,52 0,45ˆP p 0,52 P P(z 1,4) 0,08080,05 0,05− −⎡ ⎤> = > = > =⎢ ⎥⎣ ⎦

Distribuciones de Probabilidad 66
El departamento comercial de una industria alimenticia sabe que 2 de cada 10consumidores reconocen su producto en una prueba a ciegas. ¿Cuántas pruebas aciegas de sabor deberían hacerse para que la proporción de que los que conocen lamarca oscile entre el 16% y el 24% con una probabilidad mínima de 0,8?
Solución:
Reconocen el producto el 20% p 0,2=
xpq 0,2 0,8 0,4ˆ ˆp N p, p N 0,2, N 0,2 ,n n n
⎛ ⎞ ⎛ ⎞ ⎛ ⎞≈ → ≈ =⎜ ⎟ ⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠
ˆ0,16 0,2 p 0,2 0,24 0,2ˆP(0,16 p 0,24) P0,4 / n 0,4 / n 0,4 / n
− − −⎛ ⎞≤ ≤ = ≤ ≤ =⎜ ⎟⎝ ⎠
P 0,1 n z 0,1 n P z 0,1 n P z 0,1 n⎡ ⎤ ⎡ ⎤ ⎡ ⎤= − ≤ ≤ = ≥ − − ≥ =⎣ ⎦ ⎣ ⎦ ⎣ ⎦
( ) ( )1 2P z 0,1 n 0,8 P z 0,1 n 0,1= − > = ≥ =
0,1 n 1,282 n 165= =
Para una probabilidad como mínimo de 0,8 harían falta 165 pruebas.
Para analizar el peso promedio de niños y niñas, siguiendo ambos pesos unadistribución normal, se utiliza una muestra aleatoria de 20 niños y 25 niñas. Elpromedio de los pesos de los niños es 45 kg. con una desviación típica de 6,4 kg.,mientras que el promedio del peso de las niñas es 38 kg. y una desviación típica de5,6 kg. ¿Cuál es la probabilidad de que en la muestra el peso promedio de los niñossea al menos 10 kg. mayor que el de las niñas?.
Solución:
Sean las variables aleatorias X = "Peso de los niños" e Y= "Peso de las niñas",( )x xX N ,≈ μ σ e ( )y yY N ,≈ μ σ , independientes entre sí.
En las muestras respectivas:
xx
6,4x N , N 45,
n 20
σ⎛ ⎞ ⎛ ⎞≈ μ ≡⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
e yy
5,6y N , N 38,
m 25
σ⎛ ⎞ ⎛ ⎞≈ μ ≡⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
.
22 22y yx x
x y x yx y N , N ,n mn m
⎛ ⎞ ⎛ ⎞σ σ⎛ ⎞σ σ⎛ ⎞⎜ ⎟ ⎜ ⎟ξ = − ≈ μ −μ + ≡ μ −μ +⎜ ⎟⎜ ⎟⎜ ⎟ ⎝ ⎠⎝ ⎠ ⎝ ⎠⎝ ⎠

Distribuciones de Probabilidad 67
La variable 2 26,4 5,6
x y N 45 38, N(7, 1,82)20 25
⎛ ⎞ξ = − ≈ − + =⎜ ⎟
⎝ ⎠
7 10 7P( 10) P P(z 1,648) 0,05
1,82 1,82ξ − −⎛ ⎞ξ ≥ = ≥ = ≥ =⎜ ⎟
⎝ ⎠
Un fabricante vende un artículo a un precio fijo de 100 euros. Si el peso x delartículo es inferior a 8 gramops no lo puede vender y representa una pérdida total.La distribución de los pesos es una normal N( , 1)μ y el coste de producción de cadaartículo es C 30 5= − μ . Determinar el peso medio μ que haga máximo el beneficioesperado.
Solución:
La probabilidad de que el peso de un artículo sea inferior a 8 gramos, efectuando latipificación con N( , 1)μ es:
2 2
2
(x ) z2 2N(0,1)1 1
f(x) e f(z) e2 2
− μ− −
σ= ⎯⎯⎯→ =σ π π
28 z2
1P( ) P(x 8) P(x 8 ) P(z 8 ) e dz
2
− μ−
−∞
μ = < = −μ < −μ = < −μ =π ∫
Beneficio esperado (B) para cada artículo: [ ]x xB 0 P( ) 100 1 P( ) (30 5 )= μ + − μ − − μ
Para hacer el beneficio máximo se iguala a cero la derivada primera:
2(8 ) 222
5 2dB 1 (8 )100 e 5 0 ln (8 ) 4,154
d 2 1002
− μ− ⎛ ⎞π− μ
= − + = − = − μ =⎜ ⎟⎜ ⎟μ π ⎝ ⎠
8 4,154 5,96 10,04− μ = ± → μ = μ =
Para comprobar la raíz correspondiente al máximo se hace la derivada segunda, y elpeso medio que hace máximo el beneficio esperado es 10,04μ =

Distribuciones de Probabilidad 68
Sean las variables aleatorias independientes: 1 2X N(8,2) , X N(15,5)∼ ∼
3y X N(12,3)∼ donde 1 2 3Y X X 2X= − + y 2 2 2
1 2 3X 8 X 15 X 12U
2 5 3− − −⎛ ⎞ ⎛ ⎞ ⎛ ⎞= + +⎜ ⎟ ⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠ ⎝ ⎠Calcular 'a' y las probabilidades:
a) [ ]P 25,4 Y 29,25≤ ≤ b) ⎡ ⎤≤ ≤ =⎣ ⎦P a Y 19 0,4695
c) [ ]2 1 3P X X X 6− − < d) [ ]P U 9,83≤
Solución:
a) 3 3
2 21 2 3 i i i i
i 1 i 1
Y X X 2X siendo Y N ,= =
⎛ ⎞⎜ ⎟= − + λ μ λ σ⎜ ⎟⎝ ⎠∑ ∑∼
2 2 2 2x xY N 8 15 2 12 , 2 5 2 3 Y N 17, 65⎡ ⎤ ⎡ ⎤− + + +⎣ ⎦ ⎣ ⎦∼ ∼
[ ] 25,4 17 Y 17 29,25 17P 25,4 Y 29,25 P P(1,04 z 1,52)
65 65 65
− − −⎡ ⎤≤ ≤ = ≤ ≤ = ≤ ≤ =⎢ ⎥⎣ ⎦
P(z 1,04) P(z 1,52) 0,1492 0,0643 0,0849= ≥ − ≥ = − =
b) [ ]P a 11 19 0,4695≤ ≤ =
[ ] a 17 Y 17 19 17 a 17P a Y 19 P P z 0,25
65 65 65 65
− − − −⎡ ⎤ ⎡ ⎤≤ ≤ = ≤ ≤ = ≤ ≤ =⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
[ ]a 17 a 17P z P z 0,25 0,4695 P z 0,4695 0,4013 0,8708
65 65
− −⎡ ⎤ ⎡ ⎤= ≥ − ≥ = ≥ = + =⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
x
a 17 a 17 a 17P z 0,8708 P z P z 0,1292
65 65 65
a 17 1,13 a 17 1,13 65 7,89 a 7,89
65
− − −⎡ ⎤ ⎡ ⎤ ⎡ ⎤≥ = ≤ = ≥ − =⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦ ⎣ ⎦
−− = = − = =
c) [ ]3 3
2 22 1 3 2 1 3 i i i i
i 1 i 1
P X X X 6 Sea W X X X donde W N ,= =
⎛ ⎞⎜ ⎟− − < = − − λ μ λ σ⎜ ⎟⎝ ⎠∑ ∑∼
2 2 2W N 15 8 12 , 5 2 3 W N 5, 38⎡ ⎤ ⎡ ⎤− − + + −⎣ ⎦ ⎣ ⎦∼ ∼
[ ] [ ]2 1 3
W 5 6 5P X X X 6 P W 6 P P(z 1,78) 1 P(z 1,78)
38 38
+ +⎡ ⎤− − < = < = < = < = − ≥ =⎢ ⎥⎣ ⎦
1 0,0375 0,9625= − =

Distribuciones de Probabilidad 69
d) 1 2 3X 8 X 15 X 12N(0,1) N(0,1) N(0,1)
2 5 3− − −∼ ∼ ∼
[ ] [ ] [ ]2 2 2
2 2 2 21 2 33
X 8 X 15 X 12U U N(0, 1) N(0, 1) N(0, 1)
2 5 3− − −⎛ ⎞ ⎛ ⎞ ⎛ ⎞= + + = + + = χ⎜ ⎟ ⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠ ⎝ ⎠
[ ] 2 23 3P U 9,83 P 9,83 1 P 9,83 1 0,02 0,98⎡ ⎤ ⎡ ⎤≤ = χ ≤ = − χ ≥ = − =⎣ ⎦ ⎣ ⎦
Se llama distribución uniforme en un intervalo aquélla caracterizada por tenerigual probabilidad todos los posibles valores de la variable en el intervalo dedefinición.Sea el intervalo a, b⎡ ⎤⎣ ⎦ , se pide:a) ¿Cuál es la función de densidad y la función de distribución de esta variable?b) ¿Cuál es la probabilidad de que al tomar un valor de la variable al azar, dichovalor esté comprendido entre m y n, siendo a m n b?≤ ≤ ≤
Solución:
a) Si en todos los puntos del intervalo a, b⎡ ⎤⎣ ⎦ la función de probabilidad ha de seridéntica, la función de densidad ha de ser constante, esto es:
b b
a a
1f(x) dx k dx 1 k(b a) 1 k
b a= = − = =
−∫ ∫
Así, pues, la función de densidad será:
0 x a
1f(x) a x b
b a0 x b
<⎧⎪⎪= ≤ ≤⎨ −⎪
>⎪⎩
La función de distribución
x x
a
0 x a 0 x a
dx x aF(x) f(x)dx a x b a x b
b a b a0 x b 0 x b
−∞
<⎧ <⎧⎪ ⎪ −⎪ ⎪= = ≤ ≤ = ≤ ≤⎨ ⎨− −⎪ ⎪
>⎪ ⎪> ⎩⎩
∫ ∫
b) n
m
1 n mP(m X n) dx
b a b a−
≤ ≤ = =− −∫
La probabilidad resulta proporcional a la longitud del subintervalo.

Distribuciones de Probabilidad 70
El consumo familiar de cierto artículo se distribuye uniformemente conesperanza 10 y varianza unidad. Determinar la probabilidad de que el consumo dedicho artículo se encuentre comprendido entre 8 y 12 unidades.
Solución:
Sea X = "Número de unidades consumidas del artículo", donde X U(10, 1)∼ en el
intervalo a, b⎡ ⎤⎣ ⎦
Se tiene: 2
2a b (b a)E(X) 10 1
2 12+ −
μ = = = σ = =
[ ]22
b 10 3 11,73a b 20b (20 b) 12 (2b 20) 12
(b a) 12 a 10 3 8,27
⎧ = + =+ =⎧ ⎪− − = − = ⇒⎨ ⎨− = = − =⎩ ⎪⎩
La distribución es uniforme entre 8,27 y 11,73, en consecuencia la probabilidad deque el consumo del artículo se encuentre comprendido entre 8 y 12 es la unidad.
La renta media mensual de los habitantes de un país se distribuyeuniformemente entre 1.700 y 3.500 euros. Calcular la probabilidad de que alseleccionar al azar a 100 personas la suma de sus rentas mensuales supere los260.000 euros.
Solución:
Media y varianza de una distribución uniforme en el intervalo [ ]1.700, 3.500 :
22 21.700 3.500 (3.500 1.700)
2.600 euros 270.000 euros2 12+ −
μ = = σ = =
Sea v.a. iX = "Renta mensual de un habitante", donde iX U(2600,270000)∼
La suma de las 100 variables 100
ii 1
Y X=
= ∑ se distribuye como una normal, siendo:
2 2xYY
x= 100 2.600 = 260.000 euros 100 270.000 27.000.000 eurosμ σ = =
Y 27.000.000 5196,15 eurosσ = = 100
ii 1
Y X N(260.000 , 5196,15)=
= ∑ ∼
Y 260.000 270.000 260.000P(Y 3000) P P(z 1,92) 0,0274
5.196,15 5.196,15− −⎛ ⎞> = > = > =⎜ ⎟
⎝ ⎠
Es decir, la probabilidad de que la suma de las rentas de 100 personasseleccionadas al azar supere los 260.000 euros es tan sólo del 2,74%.

Distribuciones de Probabilidad 71
Un corredor de bolsa adquiere 50 acciones diferentes, concertando con susclientes una ganancia de 1200 euros por acción. Por experiencias anteriores, sesabe que los beneficios de cada acción son independientes y se distribuyenuniformemente en el intervalo 1000, 2000⎡ ⎤⎣ ⎦ .¿Qué probabilidad tiene el corredor de no perder dinero?.
Solución:
Denotando por
X = "Ganancia por acción" y G ="Ganancia total del corredor de bolsa"
G 50.(X 1200) 50.X 60000= − = −
1 1 x 1000X U(1000, 2000) f(x) F(x)
2000 1000 1000 2000 1000−
= = =− −
∼
1000 x 2000≤ ≤
[ ] [ ]P G 0 P 50.X 60000 0 P 50.X 60000 P X 1200≥ = − ≥ = ≥ = ≥ =⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦
[ ]2000 2000
2000
12001200 1200
1 1 800f(x)dx dx x 0,8
1000 1000 1000= = = = =∫ ∫
o también,
[ ] [ ] 1200 1000 200P X 1200 1 P X 1200 1 F(1200) 1 1 0,8
2000 1000 1000−
≥ = − ≤ = − = − = − =−
La demanda de un producto oscila diariamente entre 20 y 40 unidades.Suponiendo la independencia de la demanda de cada día, determinar laprobabilidad de que el número de unidades demandadas supere 6370 unidadesen 182 días.
Solución:
Sea v.a. iX = "Demanda del producto cada día", donde iX U(20,40)∼ , con media
i
20 4030
2+
μ = = y varianza 2
2i
(40 20) 400 10012 12 3−
σ = = =
Considerando la independencia de la demanda cada día, por el Teorema Central del
Límite 182
i
i 1
X X=
=∑ se ajusta a una distribución normal de media
i182. 182.30 5460μ = μ = = y desviación típica 182
2i
i 1
100182. 77,89
3=
σ = σ = =∑ ,

Distribuciones de Probabilidad 72
182
i
i 1
X X N 5460, 77,89=
= ⎡ ⎤⎣ ⎦∑ ∼
[ ] [ ]X 5460 6370 5460P X 6370 P P z 11,68 0
77,89 77,89− −⎡ ⎤> = > = > =⎢ ⎥⎣ ⎦
La demanda diaria de un determinado artículo (x) es una variable aleatoria conla función de densidad adjunta. Los beneficios diarios dependen de la demandasegún la función 0B
0
10 x 4 5 si x 28
5 si 2 x 4 12 xf(x) 4 x 12 B
10 si 4 x 8640 otro caso 15 si 8 x 12
⎧ < ≤ − <⎪ ⎧⎪ ⎪ < ≤−⎪ ⎪= < ≤ =⎨ ⎨ < ≤⎪ ⎪⎪ ⎪ < ≤⎩⎪⎩
Calcular:
a) Probabilidad de que en un día cualquiera la demanda sea superior a 10b) Probabilidad de que la demanda sea inferior a 3c) La esperanza y la varianza de la demandad) Función de distribución de la demandae) Función de cuantía y función de distribución de la variable aleatoria beneficiosdiarios.f) Esperanza y varianza de la variable beneficios
Solución:
a) ( )1212 12 2
10 10 10
12 x 1 x 1P X 10 f(x) dx dx 12x 0,03125
64 64 2 32
⎡ ⎤−> = = = − = =⎢ ⎥
⎣ ⎦∫ ∫
b) ( ) [ ]3 3
3
00 0
1 1 3P X 3 f(x) dx dx x 0,375
8 8 8< = = = = =∫ ∫
c) 4 12
x0 4
E(X) x .f(x) dx x .f(x) dx x .f(x) dx∞
−∞
μ = = = + =∫ ∫ ∫
4 12 4 122
0 4 0 4
12342 2
04
1 12 x 1 1x. dx x. dx x dx (12x x ) dx8 64 8 64
1 1 x 1 1728 64 13x 6x 1 864 96 4,33
16 64 3 64 3 3 3
−= + = + − =
⎡ ⎤ ⎛ ⎞⎡ ⎤= + − = + − − + = =⎜ ⎟⎢ ⎥⎣ ⎦ ⎝ ⎠⎣ ⎦
∫ ∫ ∫ ∫

Distribuciones de Probabilidad 73
4 12 4 122 2 2 2 2 2
0 4 0 4
1 12 xE(X ) x . f(x) dx x . f(x) dx x . f(x) dx x . dx x . dx
8 64
∞
−∞
−= = + = + =∫ ∫ ∫ ∫ ∫
124 12 4
42 2 3 3 3
00 4 4
1 1 1 1 xx dx (12x x ) dx x 4 x
8 64 24 64 4
⎡ ⎤⎡ ⎤= + − = + − =⎢ ⎥⎣ ⎦
⎣ ⎦∫ ∫ ( )64 1 5120 80
6912 5184 256 64 26,6724 64 192 3
= + − − + = = =
22 2 2x x
80 13 71V(X) E(X ) ( ) 7,89
3 3 9⎛ ⎞σ = = − μ = − = =⎜ ⎟⎝ ⎠
d) La función de distribución de la demanda: x
F(x) f(t) dt−∞
= ∫x x
x 0 x
0
sí x 0 f(x) dx 0 dx 0
1 xsí 0 x 4 f(x) dx 0 dx dx
8 8F(x)
sí 4 x 12 f(x) dx
−∞ −∞
−∞ −∞
−
< = =
≤ < = + =
=
≤ <
∫ ∫∫ ∫ ∫
x 4 x 2
0 4
x 0 4 12 x
0 4 12
1 12 x 1 1 xdx dx 12x 40
8 64 2 64 2
1 12 xsí x 12 f(x) dx 0 dx dx dx 0 dx 1
8 64
∞
−∞ −∞
⎧⎪⎪⎪⎪⎪⎨
⎛ ⎞−⎪ = + = + − + −⎜ ⎟⎪ ⎝ ⎠⎪⎪ −
≥ = + + + =⎪⎩
∫ ∫ ∫∫ ∫ ∫ ∫ ∫
En definitiva, 2
0 si x 0
x si 0 x 4
8F(x)
1 1 x12x 40 si 4 x 12
2 64 2
1 si x 12
<⎧⎪⎪ ≤ <⎪
= ⎨ ⎛ ⎞⎪ + − + − ≤ <⎜ ⎟⎪ ⎝ ⎠⎪ ≥⎩
e) Función de cuantía y la función de distribución de la variable aleatoria beneficiosdiarios:
0
10 x 4 5 si x 28
5 si 2 x 4 12 xf(x) 4 x 12 B
10 si 4 x 8640 otro caso 15 si 8 x 12
⎧ < ≤ − <⎪ ⎧⎪ ⎪ < ≤−⎪ ⎪= < ≤ =⎨ ⎨ < ≤⎪ ⎪⎪ ⎪ < ≤⎩⎪⎩

Distribuciones de Probabilidad 74
0iB
0 0iP(B B )=
5−2 2
0 0
1 1f(x) dx dx 0,25
8 4= = =∫ ∫
54 4
2 2
1 1f(x) dx dx 0,25
8 4= = =∫ ∫
1088 8 2
4 4 4
12 x 1 xf(x) dx dx 12x 0,375
64 64 2
⎛ ⎞−= = − =⎜ ⎟
⎝ ⎠∫ ∫15
1212 12 2
8 8 8
12 x 1 xf(x) dx dx 12x 0,125
64 64 2
⎛ ⎞−= = − =⎜ ⎟
⎝ ⎠∫ ∫La función de distribución
0 0i
0 0 0 0 0i i
B B
F(B ) P(B B ) P(B B )≤
= ≤ = =∑0iB
0 0iP(B B )= 0 0 0
iF(B ) P(B B )= ≤ 0 0 0i iB . P(B B )= 0 2 0 0
i i(B ) . P(B B )=
5− 0,25 0,25 − 1,25 6,255 0,25 0,50 1,25 6,2510 0,375 0,875 3,75 37,515 0,125 1 1,875 28,125
5,625 78,125
f) 0
4
0 0 0 0i iB
i 1
E(B ) B . P(B B ) 5,625=
μ = = = =∑4
0 2 0 2 0 0i i
i 1
E (B ) (B ) . P(B B ) 78,125=
⎡ ⎤ = = =⎣ ⎦ ∑( )2
0 0
222 0 0
B BV(B ) E(B ) ( ) 78,125 5,625 46,48σ = = − μ = − =
Desviación típica de los beneficios 0B46,48 6,817σ = =

Distribuciones de Probabilidad 75
Una empresa produce un artículo que sigue una distribución uniforme entre25000 y 30000 unidades. Sabiendo que vende cada unidad a 10 euros y la funciónde costes viene dada por C 100.000 2X= + , ¿cuál será el beneficio esperado?
Solución: X U(25.000, 30.000)∼
Función de densidad 1 1
25.000 x 30.000f(x) 30.000 25.000 5.000
0 otros valores
⎧ = ≤ ≤⎪= −⎨⎪⎩
Los beneficios B Ventas Costes= −
x x x xE(B) E(V C) E 10 X (100.000 2 X) E(8 X 100.000) 8 E(X) 100.000= − = − + = − = − =⎡ ⎤⎣ ⎦x8 27.500 100.000 120.000= − = euros
siendo, 25.000 30.000
E(X) 27.5002+
μ = = =
Una variable aleatoria X se distribuye uniformemente en el intervalo (2, 4) .Se pide:
a) P(X 2,5)< b) P(X 3,2)>c) P(2,2 X 3,5)< < d) Esperanza y varianza
Solución:
Función densidad: Función distribución:
1 12 x 4
f(x) 4 2 20 otros valores
⎧ = ≤ ≤⎪= −⎨⎪⎩
0 x 2
x 2F(x) P(X x) 2 x 4
4 21 x 4
<⎧⎪ −⎪= ≤ = ≤ ≤⎨ −⎪
>⎪⎩
a) 2,5 2P(X 2,5) F(2,5) 0,25
2−
< = = =
o también, [ ]2,5 2,5
2,5
22 2
1 1 2,5 2P(X 2,5) f(x)dx dx x 0,25
2 2 2−
< = = = = =∫ ∫b) 3,2 2 4 3,2
P(X 3,2) 1 P(X 3,2) 1 F(3,2) 1 0,42 2− −
> = − ≤ = − = − = =
o también, [ ]4 4
4
3,23,2 3,2
1 1 4 3,2P(X 3,2) f(x)dx dx x 0,4
2 2 2−
> = = = = =∫ ∫c) 3,5 2 2,2 2 3,5 2,2
P(2,2 X 3,5) F(3,5) F(2,2) 0,652 2 2− − −
< < = − = − = =

Distribuciones de Probabilidad 76
o también, [ ]3,5 3,5
3,5
2,22,2 2,2
1 1 3,5 2,2P(2,2 X 3,5) f(x)dx dx x 0,65
2 2 2−
< < = = = = =∫ ∫d)
222 4 (4 2) 4 1
E(X) 32 12 12 3+ −
= = σ = = =
El tiempo de revisión del motor de un avión sigue aproximadamente unadistribución exponencial, con media 22 minutos.a) Hallar la probabilidad de que el tiempo de la revisión sea menor de 10 minutosb) El costo de la revisión es de 200 euros por cada media hora o fracción.¿Cuál es la probabilidad de que una revisión cueste 400 euros?c) Para efectuar una programación sobre las revisiones del motor, ¿cuánto tiempose debe asignar a cada revisión para que la probabilidad de que cualquier tiempode revisión mayor que el tiempo asignado sea solo de 0,1?
Solución:
a) Sea X = "Tiempo de revisión del motor de un avión en minutos"
x
1 1E(X) 22minutos
22μ = = = λ =
λ X Exp 1 22⎡ ⎤⎣ ⎦∼
Función de densidad: Función distribución:
x 221e x 0
f(x) 220 x 0
−⎧ ≥⎪= ⎨⎪ <⎩
x 221 e x 0F(x) P(X x)
0 x 0
−⎧ − ≥= ≤ = ⎨
<⎩
[ ] 10 22 5 11P X 10 F(10) 1 e 1 e 0,365− −< = = − = − =
o bien,
[ ]10 10
10x 22 x 22 10 22 5 11
00 0
1P X 10 f(x)dx e dx e e 1 1 e 0,365
22− − − −⎡ ⎤ ⎡ ⎤< = = = − = − + = − =⎣ ⎦⎢ ⎥⎣ ⎦∫ ∫
b) Como el costo de la revisión del motor es de 200 euros por cada media hora ofracción, para que la revisión cueste 400 euros la duración de la revisión debe deser inferior o igual a 60 minutos. Es decir, se tendrá que calcular [ ]P 30 X 60< ≤
[ ] 60 22 30 22P 30 X 60 F(60) F(30) 1 e 1 e− −⎡ ⎤ ⎡ ⎤< ≤ = − = − − − =⎣ ⎦ ⎣ ⎦ 30 22 60 22 15 11 30 11e e e e 0,19− − − −= − = − =o bien,
[ ]60 60
60x 22 x 22 60 22 30 22
3030 30
1P 30 X 60 f(x)dx e dx e e e
22− − − −⎡ ⎤ ⎡ ⎤⎡ ⎤< ≤ = = = − = − + =⎣ ⎦ ⎣ ⎦⎢ ⎥⎣ ⎦∫ ∫
15 11 30 11e e 0,19− −= − =

Distribuciones de Probabilidad 77
c) Sea t = "Tiempo que se debe asignar a la revisión", verificando [ ]P X t 0,1> =
[ ] x 22 x 22 t 22
tt t
1P X t f(x)dx e dx e 0 e 0,1
22
∞ ∞∞− − −⎡ ⎤ ⎡ ⎤> = = = − = + =⎣ ⎦⎢ ⎥⎣ ⎦∫ ∫
t 22e 0,1 t 22 Ln(0,1) t 22 2,30 t 50,6 51− = − = − = − ⇒ = ≈ minutos
La duración de vida de una pieza de un motor sigue una distribuciónexponencial, sabiendo que la probabilidad de que sobrepase las 100 horas de usoes de 0,9. Se pide:a) Probabilidad de que sobrepase las 200 horas de usob) ¿Cuántas horas se mantiene funcionando con probabilidad 0,95?
Solución:
a) Sea v.a. X = "Tiempo de vida de la pieza del motor" donde X Exp( )λ∼
Función de densidad y la función de distribución:
x xf(x) .e F(x) 1 e x 0−λ −λ= λ = − ∀ >
Siendo [ ] [ ] 100 100P X 100 1 P X 100 1 F(100) 1 1 e e 0,9− λ − λ⎡ ⎤> = − ≤ = − = − − = =⎣ ⎦
100e 0,9 100 Ln0,9 100 0,105 0,00105− λ = − λ = ⇒ − λ = − ⇒ λ =
Por tanto, 0,00105. x 0,00105. xX Exp(0,00105) f(x) 0,00105.e F(x) 1 e x 0− −= = − ∀ >∼
[ ] [ ] 0,00105.200P X 200 1 P X 200 1 F(200) 1 1 e 0,81−⎡ ⎤> = − ≤ = − = − − =⎣ ⎦
o bien, [ ] 0,00105. x 0,00105. x
200200 200
P X 200 f(x)dx 0,00105.e dx e 0,81∞ ∞
∞− −⎡ ⎤> = = = − =⎣ ⎦∫ ∫b) [ ] [ ] [ ] 0,00105.tP X t 0,95 P X t 1 P X t 1 F(t) e 0,95−> = > = − ≤ = − = =
0,00105.te 0,95 0,00105t Ln0,95 0,00105 t 0,05129 t 48,85− = − = ⇒ − = − ⇒ =

Distribuciones de Probabilidad 78
El tiempo de vida media de un marcapasos sigue una distribución exponencialcon media 16 años. Se pide:a) Probabilidad de que a una persona a la que se ha implantado un marcapasos sele deba de implantar otro antes de 20 añosb) Si el marcapasos lleva funcionando correctamente 5 años en un paciente, ¿cuáles la probabilidad de que haya de cambiarlo antes de 25 años?
Solución:
a) La variable aleatoria X = "Duración del marcapasos" ⎡ ⎤λ = =⎢ ⎥μ⎣ ⎦
∼ 1 1X Exp16
con función de densidad: −⎧ ≥⎪= ⎨
⎪ <⎩
x 161e x 0
f(x) 160 x 0
Función de distribución: x 161 e x 0
F(x) P(X x)0 x 0
−⎧ − ≥= ≤ = ⎨
<⎩
20 16P(X 20) F(20) 1 e 0,7135−≤ = = − =
o bien, 20 20
20x 16 x 16 20 16
00 0
1P(X 20) f(x)dx e dx e e 1 0,7135
16− − −⎡ ⎤≤ = = = − = − + =⎣ ⎦∫ ∫
b) [ ] 25/16 5/16
5/16
P 5 X 25 F(25) F(5) (1 e ) (1 e )P X 25 X 5
P(X 5) 1 F(5) 1 (1 e )
− −
−
≤ ≤ − − − −≤ ≥ = = = =⎡ ⎤⎣ ⎦ ≥ − − −
5/16 25/16
5/16
e e 0,5220,7135
e 0,7316
− −
−
−= = =
También, mediante la función de densidad:
25 2525x 16 x 16 25 16 5 16
55 5
1P(5 X 25) f(x)dx e dx e e e 0,522
16− − − −⎡ ⎤≤ ≤ = = = − = − + =⎣ ⎦∫ ∫
x 16 x 16 5 16
55 5
1P(X 5) f(x)dx e dx e 0 e 0,7135
16
∞ ∞∞− − −⎡ ⎤≥ = = = − = − + =⎣ ⎦∫ ∫
Adviértase que [ ]P X 25 X 5 P X 20 0,7135≤ ≥ = ≤ =⎡ ⎤⎣ ⎦ , circunstancia que era de
esperar en un modelo exponencial.
Es decir, la duración que se espera tenga el marcapasos, no influye en nada eltiempo que lleva funcionando. Esta particularidad lleva a decir que 'la distribuciónexponencial no tiene memoria'.

Distribuciones de Probabilidad 79
Sea X la variable aleatoria que describe el número de clientes que llega a unsupermercado durante un día (24 horas). Sabiendo que la probabilidad de quellegue un cliente en un día es equivalente a 100 veces la que no llegue ningúncliente en un día, se pide:a) Probabilidad de que lleguen al menos 3 clientes al díab) Si acaba de llegar un cliente, calcular la probabilidad que pase más de 25minutos hasta que llegue el siguiente cliente (o hasta que llegue el primer cliente)c) En dos semanas, ¿cuál es la probabilidad aproximada de que lleguen comomucho 1300 clientes al supermercado?
Solución:
a) Se trata de una distribución de Poisson: k
P(X k) ek!
−λλ= =
0
P(X 1) 100 .P(X 0) e 100 . e . e 100 . e 1001! 0!
−λ −λ −λ −λλ λ= = = = λ = λ =
3 100P(X 3) P z P(z 9,7) P(z 9,7) 1
10−⎡ ⎤≥ = ≥ = ≥ − = ≤ ≈⎢ ⎥⎣ ⎦
b) Es una función exponencial, es decir, el tiempo de espera hasta que ocurre unsuceso (que llegue el siguiente cliente), donde λ ≡ 'Número de sucesos de Poissonpor unidad de tiempo', siendo X Exp( )λ∼
Para calcular el parámetro λ se establece una proporción:
100 10 024 .60 25
λ= λ =
. 2524 .6 0
2501,736
144= =
x 1,736 .1P(X x) F(x) 1 e P(X 1) F(1) 1 e 0,8238−λ −≤ = = − ≤ = = − =
c) 1300 1400P(X 1300) P z P(z 2,67) P(z 2,67) 0,00379
1400
⎡ ⎤−≤ = ≤ = ≤ − = ≥ =⎢ ⎥
⎢ ⎥⎣ ⎦

Distribuciones de Probabilidad 80
El número promedio de recepción de solicitudes en una ventanilla de atenciónal cliente es de tres al día.a) ¿Cuál es la probabilidad de que el tiempo antes de recibir una solicitud excedacinco días?b) ¿Cuál es la probabilidad de que el tiempo antes de recibir una solicitud seamenor de diez días?c) ¿Cuál es la probabilidad de que el tiempo antes de recibir una solicitud seamenor de diez días, si ya han pasado cinco días sin recibir solicitudes?
Solución:
a) X = "Días antes de recibir una solicitud", es una distribución exponencial conparámetro 3λ =
3x 3xf(x) 3e F(x) P(X x) 1 e− −= = ≤ = −3.5 15P(X 5) 1 P(X 5) 1 F(5) 1 (1 e ) e− −> = − ≤ = − = − − =
b) 3 x 10 30P(X 10) F(10) 1 e 1 e− −< = = − = −
c) ( )30 15 15 30
1515 15
P(5 X 10) F(10) F(5) 1 e (1 e ) e eX 10P 1 eX 5 P(X 5) 1 F(5) e e
− − − −−
− −
< < − − − − −< = = = = = −> > −
Adviértase que P(X 10 / X 5) P(X 5)< > = ≤ lo que significa que la variable aleatoriaexponencial no tiene memoria.
Para aprobar la asignatura de estadística teórica se realiza un test con veinteítems. Sabiendo que una persona determinada tiene una probabilidad de 0,8 decontestar bien cada ítem. Se pide:a) Probabilidad de que la primera pregunta que contesta bien sea la tercera quehace.b) Para aprobar el test es necesario contestar diez ítems bien. ¿Cuál es laprobabilidad de que apruebe al contestar el doceavo ítem?.
Solución:
a) La variable X = "Número de ítems que tiene que hacer hasta que respondauno bien" sigue una distribución de Pascal o geométrica. X G(0,8) p 0,8 q 0,2= =∼
2 2P(X 3) q . p 0,2 . 0,8 0,032= = = =
b) La variable X = "Número de ítems que tiene que realizar hasta contestar 10 bien"sigue una distribución binomial negativa.
( )X Bn 12, 0,8 k 10 p 0,8 q 0,2= = =∼

Distribuciones de Probabilidad 81
10 2 10 2 10 2
10 2
12 1 11 11!P(X 12) 0,8 . 0,2 0,8 . 0,2 0,8 . 0,2
10 1 9 2!9!
11 .10 0,8 . 0,2 0,24
2
−⎛ ⎞ ⎛ ⎞= = = = =⎜ ⎟ ⎜ ⎟−⎝ ⎠ ⎝ ⎠
= =
En una caja hay 5 triángulos, 3 círculos y 2 rectángulos. Realizando extraccionescon reemplazamiento, se piden las siguientes probabilidades:a) Al realizar 8 extracciones, se obtengan en 4 ocasiones un círculo.b) Se necesiten 8 extracciones para obtener 4 círculos.c) Que aparezca el primer círculo en la 8 extracción.d) Al realizar 8 extracciones aparezcan 3 triángulos, 3 círculos y 2 rectángulos.e) Al realizar 6 extracciones sin reemplazamiento aparezcan en 2 ocasiones un
círculo.
Solución:
a) Hay dos situaciones (círculo, no‐círculo), se trata de una distribución binomial,B(8 , 0,3) n 8 p 3 10 0,3= = =
4 4 48 8! 8.7. 6P(X 4) 0,3 0,7 0,21
4 4! 4!
⎛ ⎞= = = =⎜ ⎟
⎝ ⎠
.54. 3. 2
4 40,21 70.0,21 0,136.1
= =
b) La variable aleatoria X = "Número de extracciones hasta que aparece la cuartaextracción de círculo" sigue una distribución binomial negativa.X Bn(8 , 0,3) n 8 k 4 p 0,3 q 0,7= = = =∼
4 4 4 4 48 1 7 7! 7.6.5P(X 8) 0,3 . 0,7 0,21 0,21 0,21 0,0681
4 1 3 4!3! 3.2
−⎛ ⎞ ⎛ ⎞= = = = = =⎜ ⎟ ⎜ ⎟−⎝ ⎠ ⎝ ⎠
c) La variable aleatoria X = "Aparece el primer círculo en la octava extracción"sigue una distribución geométrica o de Pascal X G(0,3)∼
8 1 7P(X 8) q . p 0,7 . 0,3 0,0247−= = = =
d) La variable aleatoria X = "Número de veces que se extrae triángulo, círculo orectángulo en ocho extracciones". Se trata de una distribución polinomial, esdecir, en cada prueba se consideran k sucesos independientes.
3 3 23 3 28! 5 3 2
P(T 3 ; C 3 ; R 2) 560 . 0,5 . 0,3 . 0,2 0,07563! 3!2! 10 10 10
⎛ ⎞ ⎛ ⎞ ⎛ ⎞= = = = = =⎜ ⎟ ⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠
e) Hay dos situaciones excluyentes (círculo, no‐círculo).X = "Número de veces que se extrae círculo en una muestra de tamaño ocho" sigueuna distribución hipergeométrica.N 10 n 6 k 2 p 0,3 q 0,7 Np 3 Nq 7= = = = = = =

Distribuciones de Probabilidad 82
N.p N.q 3 7
k n k 2 4 3 .35P(X k) P(X 2) 0,5
N 10 210n 6
⎛ ⎞ ⎛ ⎞ ⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟−⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠= = = = = =
⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
Por prescripción médica, un enfermo debe hacer una toma de tres píldoras deun determinado medicamento. De las doce píldoras que contiene el envase haycuatro en malas condiciones. Se pide:a) Probabilidad de que tome sólo una buenab) Probabilidad de que de las tres píldoras de la toma al menos una esté en malascondicionesc) ¿Cuál es el número de píldoras que se espera tome el enfermo en buenascondiciones en cada toma?d) Si existe otro envase que contenga cuarenta píldoras, de las que diez seencuentran en malas condiciones. ¿Qué envase sería más beneficioso para elenfermo?
Solución:
a) Hay dos situaciones excluyentes (buena, no‐buena). La variable X = "Número depíldoras buenas al tomar tres" sigue una distribución hipergeométricaX H(3, 12, 8)∼ , en donde
N 12= píldoras 8buenas p 8 12 2 3
4malas q 4 12 1 3
= =⎧⎨ = =⎩
2 qN. p 12. 8 N. q 12. 4 n 3
3 3= = = = =
N.p N.q 8 4 4!8 .
k n k 1 2 242!2!P(X k) P(X 1) 0,22
12!N 12 1103!9!n 3
⎛ ⎞ ⎛ ⎞ ⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟−⎝ ⎠ ⎝ ⎠ ⎝ ⎠ ⎝ ⎠= = = = = = =
⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
b) La probabilidad de que al menos una esté en malas condiciones equivale a laprobabilidad de que a lo sumo dos píldoras sean buenas. Por tanto:
2 24 56 82P(X 2) P(X 0) P(X 1) P(X 2) 0,75
110 110 110 110≤ = = + = + = = + + = =

Distribuciones de Probabilidad 83
8 4
0 3 1 . 4 4 .3!9! 4P(X 0)
12!12 12!3! 9!3
⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠= = = = =⎛ ⎞⎜ ⎟⎝ ⎠
. 3 . 212
20,02
110.11 .10= =
8 4 8! 8 .7. 4 . 4 .3! 9!2 1 562!6! 2P(X 2) 0,5112!12 12! 1103!9!3
⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠= = = = = =⎛ ⎞⎜ ⎟⎝ ⎠
c) El número de píldoras que se espera que tome es la media de la distribución:
X
2n. p 3 . 2
3μ = = = píldoras
d) Para tomar una decisión, hay que calcular el número de píldoras esperado enbuenas condiciones al tomar tres del segundo envase.
N 40= píldoras 30buenas p 30 40 3 4 0,75
10malas q 10 40 1 4 0,25
= = =⎧⎨ = = =⎩
Y n. p 3 . 0,75 2,25μ = = = píldoras
El segundo envase es más beneficioso para el enfermo.

Distribuciones de Probabilidad 84
Sea una variable aleatoria bidimensional con distribución de probabilidad
Y X −1 1
1 1 6 1 3
2 1 12 1 4
3 1 12 1 12
Se pide:
a) ¿Son X e Y independientes?b) Hallar las medias y desviaciones típicas de X e Yc) Hallar las probabilidades: ≤ >⎡ ⎤⎣ ⎦P X 2 ; Y 0 [ ]P X 2≥ [ ]P Y 0<d) Hallar el coeficiente de correlación
Solución:
a) Para analizar si X e Y son independientes hay que hallar las distribucionesmarginales de X e Y, y ver si verifica que ij i j i jp p . p (x , y )• •= ∀
Y X −1 1 ip •
1 1 6 1 3 1 2
2 1 12 1 4 1 3
3 1 12 1 12 1 6
jp• 1 3 2 3 1
11 1 1
1 1 1p p .p .
6 2 3• •= = =
21 2 1
1 1 1 1p p .p .
12 3 3 9• •= ≠ = =
31 3 1
1 1 1 1p p .p .
12 6 3 18• •= ≠ = =
12 1 2
1 1 2p p .p .
3 2 3• •= = =
22 2 2
1 1 2 2p p .p .
4 3 3 9• •= ≠ = =
32 3 2
1 1 2 1p p .p .
12 6 3 9• •= ≠ = =
Luego las variables X e Y no son independientes.
b) Para hallar las medias y desviaciones típicas de X e Y hay que considerar lasdistribuciones marginales:

Distribuciones de Probabilidad 85
Distribución marginal de la de la variable aleatoria X
iX x= ip • i ix . p •2ix
2i ix . p •
1 1 2 1 2 1 1 2
2 1 3 2 3 4 4 3
3 1 6 3 6 9 9 6
1 10 6 20 6
Media: 3
10 X i ii 1
10E(X) x . p
6•=
α = μ = = =∑3
2 220 i i
i 1
20E(X ) x . p
6•=
α = = =∑
Varianza: [ ]2
22 220 x
20 10 20 5Var(X) E(X ) E(X)
6 6 36 9⎛ ⎞μ = σ = = − = − = =⎜ ⎟⎝ ⎠
Desviación típica: x
50,745
9σ = =
Distribución marginal de la variable aleatoria Y
jY y= jp• j jy . p•2jy
2j jy . p•
1− 1 3 1 3− 1 1 3
1 2 3 2 3 1 2 3
1 1 3 1
Media: 2
01 Y j jj 1
1E(Y) y . p
3•=
α = μ = = =∑2
2 202 j j
j 1
E(Y ) y . p 1•=
α = = =∑
Varianza: [ ]2
22 202 y
1 8Var(Y) E(Y ) E(Y) 1
3 9⎛ ⎞μ = σ = = − = − =⎜ ⎟⎝ ⎠
Desviación típica: y
80,943
9σ = =
c) Probabilidades:

Distribuciones de Probabilidad 86
≤ >⎡ ⎤⎣ ⎦P X 2 ; Y 0 [ ]P X 2≥ [ ]P Y 0<
Y X 1− 1
YX 1− 1
YX 1− 1
1 1 6 1 3 1 1 6 1 3 1 1 6 1 3
2 1 12 1 4 2 1 12 1 4 2 1 12 1 4
3 1 12 1 12 3 1 12 1 12 3 1 12 1 12
1 1 7P X 2 ; Y 0 P X 1 ; Y 1 P X 2 ; Y 1
3 4 12≤ > = = = + = = = + =⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦ ⎣ ⎦
[ ]P X 2 P X 2 ; Y 1 P X 2 ; Y 1 P X 3 ; Y 1 P X 3 ; Y 1≥ = = = − + = = + = = − + = = =⎡ ⎤ ⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦
1 1 1 1 6 112 4 12 12 12 2
= + + + = =
[ ] 1 1 1 1P Y 0 P X 1 ; Y 1 P X 2 ; Y 1 P X 3 ; Y 1
6 12 12 3< = = = − + = = − + = = − = + + =⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦ ⎣ ⎦
d) Coeficiente de correlación
i j ijx .y . p
Y X 1− 1 1− 1
1 1 6 1 3 1 6− 1 3
2 1 12 1 4 2 12− 2 4
3 1 12 1 12 3 12− 3 127 12− 13 12 6 12
3 2
11 i j iji 1 j 1
6 1E(XY) x .y . p
12 2= =
α = = = =∑∑ Covarianza: XY 11 10 01
1 10 1 1Cov(X,Y) . . 0,555
2 6 3 18σ = = α − α α = − = − = −
Coeficiente de correlación: XYXY
x Y
0,5550,79
. 0,745 . 0,943σ −
ρ = = = −σ σ
Siendo XY 0,79ρ = − , valor cercano a 1− , existe una fuerte relación lineal entre lasvariables X e Y.
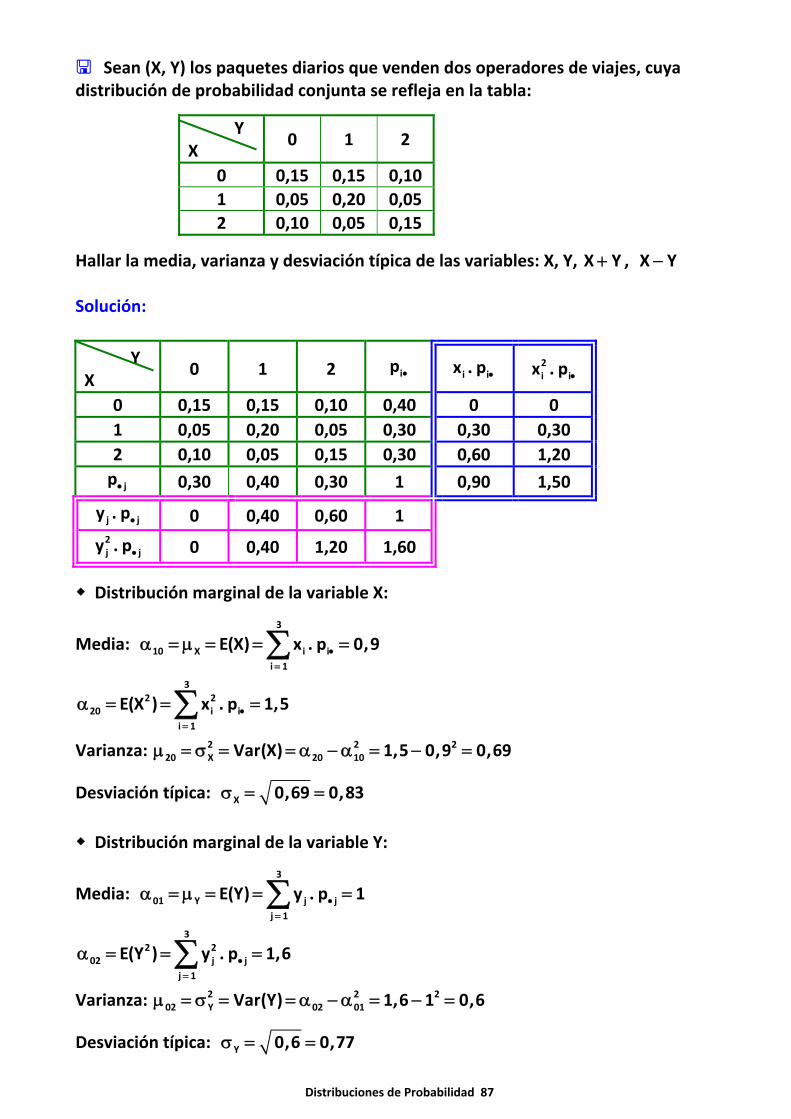
Distribuciones de Probabilidad 87
Sean (X, Y) los paquetes diarios que venden dos operadores de viajes, cuyadistribución de probabilidad conjunta se refleja en la tabla:
Y X
0 1 2
0 0,15 0,15 0,101 0,05 0,20 0,052 0,10 0,05 0,15
Hallar la media, varianza y desviación típica de las variables: X, Y, X Y+ , X Y−
Solución:
Y X
0 1 2 ip • i ix . p •2i ix . p •
0 0,15 0,15 0,10 0,40 0 01 0,05 0,20 0,05 0,30 0,30 0,302 0,10 0,05 0,15 0,30 0,60 1,20
jp• 0,30 0,40 0,30 1 0,90 1,50
j jy . p• 0 0,40 0,60 12j jy . p• 0 0,40 1,20 1,60
Distribución marginal de la variable X:
Media: 3
10 X i ii 1
E(X) x . p 0,9•=
α = μ = = =∑3
2 220 i i
i 1
E(X ) x . p 1,5•=
α = = =∑Varianza: 2 2 2
20 X 20 10Var(X) 1,5 0,9 0,69μ = σ = = α − α = − =
Desviación típica: X 0,69 0,83σ = =
Distribución marginal de la variable Y:
Media: 3
01 Y j jj 1
E(Y) y . p 1•=
α = μ = = =∑3
2 202 j j
j 1
E(Y ) y . p 1,6•=
α = = =∑Varianza: 2 2 2
02 Y 02 01Var(Y) 1,6 1 0,6μ = σ = = α −α = − =
Desviación típica: Y 0,6 0,77σ = =

Distribuciones de Probabilidad 88
Distribución de la variable (X Y)+ :
Media: X Y E(X Y) E(X) E(Y) 0,9 1 1,9+μ = + = + = + =
Se tiene: 3 3
X Y i j iji 1 j 1
E(X Y) (x y ).p+= =
μ = + = +∑∑
Y X
0 1 2
0 0,15 0,15 0,101 0,05 0,20 0,052 0,10 0,05 0,15
X Y x x x
x x x
x x x
0 0,15 1 0,15 2 0,10
1 0,05 2 0,20 3 0,05
2 0,10 3 0,05 4 0,15 1,9
+μ = + + +
+ + ++ + =
La varianza 2X Y Var(X Y) Var(X) Var(Y) 2Cov(X,Y)+σ = + = + + X e Y no
independientes
i j ijx .y . p
Y X
0 1 2 0 1 2
0 0,15 0,15 0,10 0 0 01 0,05 0,20 0,05 0 0,20 0,102 0,10 0,05 0,15 0 0,10 0,60
0 0,30 0,7 1
3 3
11 i j iji 1 j 1
E(XY) x .y . p 1= =
α = = =∑∑Covarianza: XY 11 10 01Cov(X,Y) . 1 0,9.1 0,1σ = = α − α α = − =
2X Y Var(X Y) Var(X) Var(Y) 2Cov(X,Y) 0,69 0,6 2.0,1 1,49+σ = + = + + = + + =
Se tiene: [ ]22 2X Y E (X Y) E(X Y)+ ⎡ ⎤σ = + − +⎣ ⎦
Y X
0 1 2
0 0,15 0,15 0,101 0,05 0,20 0,052 0,10 0,05 0,15
2 x x x
x x x
x x x
E (X Y) 0 0,15 1 0,15 4 0,10
1 0,05 4 0,20 9 0,05
4 0,10 9 0,05 16 0,15 5,1
⎡ ⎤+ = + +⎣ ⎦+ + ++ + + =
[ ]22 2 2X Y X YE (X Y) E(X Y) 5,1 1,9 1,49 1,49 1,22+ +⎡ ⎤σ = + − + = − = σ = =⎣ ⎦

Distribuciones de Probabilidad 89
Distribución de la variable (X Y)− :
Media: X Y E(X Y) E(X) E(Y) 0,9 1 0,1−μ = − = − = − = −
2X Y Var(X Y) Var(X) Var(Y) 2Cov(X,Y) 0,69 0,6 2.0,1 1,09−σ = − = + − = + − =
Sea (X, Y) una variable aleatoria bidimensional con función de densidad:
k 0 y x 1
f(x,y)0 restantes valores
< < <⎧= ⎨⎩
a) Hallar k para que sea función de densidadb) Hallar las funciones de densidad marginales. ¿Son X e Y independientes?c) Hallar las funciones de distribución marginalesd) Hallar las funciones de densidad condicionadas
Solución:
a) Para que f(x, y) sea función de densidad tiene que verificarse:
f(x, y) dx dy 1∞ ∞
−∞ −∞
=∫ ∫[ ]
11 x 1 x 1 1 2x
00 0 0 0 0 0 0
x kkdx dy k dy dx k y dx k xdx k 1 k 2
2 2
⎛ ⎞ ⎡ ⎤= = = = = = =⎜ ⎟ ⎢ ⎥
⎣ ⎦⎝ ⎠∫ ∫ ∫ ∫ ∫ ∫
2 0 y x 1f(x,y)
0 restantes valores
< < <⎧= ⎨⎩
b) Funciones de densidad marginales:
[ ]x
x
1 00
f (x) f(x,y)dy 2dy 2 y 2x 0 x 1∞
−∞
= = = = < <∫ ∫[ ]
11
2 yy
f (y) f(x, y)dx 2dx 2 x 2 2y 0 y 1∞
−∞
= = = = − < <∫ ∫X e Y son independientes cuando 1 2f(x, y) f (x). f (y)=
1 2f (x). f (y) 2x .(2 2y) 4x 4x y 2 f(x, y)= − = − ≠ = luego no son independientes

Distribuciones de Probabilidad 90
c) Funciones de distribución marginales:
x x xx2 2
1 1 1 00 0
F (x) f (t)dt f (t)dt 2tdt t x 0 x 1−∞
⎡ ⎤= = = = = < <⎣ ⎦∫ ∫ ∫y y y
y2 22 2 2 0
0 0
F (y) f (t)dt f (t)dt (2 2t)dt 2t t 2y y 0 y 1−∞
⎡ ⎤= = = − = − = − < <⎣ ⎦∫ ∫ ∫d) Funciones de densidad condicionadas:
2
f(x, y) 2f(x / y) 0 y 1 0 x 1
f (y) 2 2y= = < < < <
−
1
f(x, y) 2f(y / x) 0 x 1 0 y 1
f (x) 2x= = < < < <
Sea (X, Y) una variable aleatoria bidimensional con función de densidad:
1 y x ; 0 x 1
f(x,y)0 restantes valores
⎧ < < <= ⎨⎩
a) Comprobar que f(x, y) es función de densidadb) Hallar las medias de X e Y
c) Hallar las probabilidades: 1P X ; Y 0
2⎡ ⎤< <⎢ ⎥⎣ ⎦
y 1 1 1
P X ; Y2 2 2
⎡ ⎤> − < <⎢ ⎥⎣ ⎦
Solución:
a) f(x, y) es función de densidad si se verifica: f(x, y) dx dy 1∞ ∞
−∞ −∞
=∫ ∫[ ]
1 x 1 x 1 11x 2
x 00 x 0 x 0 0
f(x, y) dx dy dx dy dy dx y dx 2xdx x 1∞ ∞
−−∞ −∞ − −
⎛ ⎞⎡ ⎤= = = = = =⎜ ⎟ ⎣ ⎦
⎝ ⎠∫ ∫ ∫ ∫ ∫ ∫ ∫ ∫
En consecuencia, f(x, y) es función de densidad.
b) Para hallar las medias de X e Y hay que calcular primero las funciones dedensidad marginales:

Distribuciones de Probabilidad 91
[ ]x
x
1 0 xx
f (x) f(x,y)dy dy y 2x 0 x 1∞
−−∞ −
= = = = < <∫ ∫[ ]
[ ]
11
yy
2 11
yy
dx x 1 y 1 y 0
f (y) f(x,y)dx
dx x 1 y 0 y 1
∞ −−
−∞
⎧= = + − < <⎪
⎪= = ⎨⎪ = = − < <⎪⎩
∫∫
∫11 3
10 x 10 0
x 2E(X) x f (x)dx x.2xdx 2
3 3
∞
−∞
⎡ ⎤α = μ = = = = =⎢ ⎥
⎣ ⎦∫ ∫0 1
01 y 2 2 21 0
0 1 0 12 2
1 0 1 0
0 12 3 2 3
1 0
E(Y) y f (y)dy y f (y)dy y f (y)dy
y(1 y)dy y(1 y)dy (y y )dy (y y )dy
y y y y 1 1 1 1 0
2 3 2 3 2 3 2 3
∞
−∞ −
− −
−
α = μ = = = + =
= + + − = + + − =
⎡ ⎤ ⎡ ⎤= + + − = − + + − =⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
∫ ∫ ∫∫ ∫ ∫ ∫
c) Probabilidades:
[ ]1 2 0 1 2 0 1 2
0
x0 x 0 x 0
1 21 2 2
0 0
1P X ; Y 0 f(x, y)dxdy dy dx y dx
2
x 1 xdx
2 8
−− −
⎛ ⎞⎡ ⎤< < = = = =⎜ ⎟⎢ ⎥⎣ ⎦ ⎝ ⎠
⎡ ⎤= = =⎢ ⎥
⎣ ⎦
∫ ∫ ∫ ∫ ∫
∫[ ]
[ ]
1 1 2 1 1 2 1 21 2
1 21 2 1 2 1 2 1 2 0
11
1 21 2
1 1 1P X ; Y f(x, y)dxdy dy dx y dx
2 2 2
1 dx x
2
−− −
⎛ ⎞⎡ ⎤> − < < = = = =⎜ ⎟⎢ ⎥⎣ ⎦ ⎝ ⎠
= = =
∫ ∫ ∫ ∫ ∫∫

Distribuciones de Probabilidad 92
La función de densidad asociada a la emisión de billetes de una compañía áreaes:
x y 0 x 1 0 y 1
f(x,y)0 en el resto
+ < < < <⎧= ⎨⎩
a) Hallar la función de distribuciónb) Hallar las funciones de densidad marginales de X e Yc) ¿Son X e Y independientes?
Solución:
a) x y x y x y
0 0 0 0
F(x,y) f(u,v) dvdu (u v)dudv (u v)dv du−∞ −∞
⎛ ⎞= = + = + =⎜ ⎟
⎝ ⎠∫ ∫ ∫ ∫ ∫ ∫ [ ] [ ]
y xx x x2 2 2 2 2y x
0 00 0 00 0
v y y u yu v du uy du uy du y u
2 2 2 2 2
⎛ ⎞⎡ ⎤ ⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎜ ⎟= + = + = + = + =⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎜ ⎟⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦⎝ ⎠∫ ∫ ∫
2 2
2 2y x y x 1(y x y x) 0 x 1 0 y 1
2 2 2= + = + ≤ < ≤ <
En consecuencia,
2 2
21
22
0 x 0 ó y 0
1(y x y x) 0 x 1 0 y 1
21
F(x,y) F (x) (x x) 0 x 1 , y 121
F (y) (y y ) 0 y 1 , x 12
1 x 1 , y 1
< <⎧⎪⎪ + ≤ < ≤ <⎪⎪
= = + ≤ < ≥⎨⎪⎪ = + ≤ < ≥⎪⎪
≥ ≥⎩
b) Funciones de densidad marginales de X e Y
[ ]11 2
1
1 00 0
y 1f (x) f(x, y)dy (x y)dy x y x 0 x 1
2 2
∞
−∞
⎡ ⎤= = + = + = + < <⎢ ⎥
⎣ ⎦∫ ∫[ ]
11 21
2 00 0
x 1f (y) f(x,y)dx (x y)dx y x y 0 y 1
2 2
∞
−∞
⎡ ⎤= = + = + = + < <⎢ ⎥
⎣ ⎦∫ ∫Adviértase que:
2 21 21 2
F (x) 1 1 F (y) 1 1f (x) (x x) x f (y) (y y ) y
x x 2 2 y y 2 2ϑ ϑ ϑ ϑ⎡ ⎤ ⎡ ⎤= = + = + = = + = +⎢ ⎥ ⎢ ⎥ϑ ϑ ϑ ϑ⎣ ⎦ ⎣ ⎦
c) X e Y son independientes cuando se verifica 1 2f(x, y) f (x). f (y)=

Distribuciones de Probabilidad 93
1 2
1 1f (x). f (y) x . y x y f(x,y) No son independientes
2 2⎛ ⎞ ⎛ ⎞= + + ≠ + =⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
Sea (X,Y) una variable aleatoria bidimensional con función de probabilidad
i j i jij
c x y x 2, 1, 0 ,1,2 , y 2, 1, 0 ,1,2p
0 enotro caso
⎧ + = − − = − −⎪= ⎨⎪⎩
a) Calcular el valor de la constante cb) [ ]P X 0 , Y 2 P X 1 P X Y 1= = = ⎡ − ≤ ⎤⎡ ⎤⎣ ⎦ ⎣ ⎦
Solución:
a) Para determinar el valor de la constante c se elabora la tabla, siendo
ij i jp c x y= +
YX
− 2 − 1 0 1 2 ip •
− 2 4c 3c 2c c 0 10c− 1 3c 2c c 0 c 7c0 2c c 0 c 2c 6c1 c 0 c 2c 3c 7c2 0 c 2c 3c 4c 10c
jp• 10c 7c 6c 7c 10c 40c
i5 5i j
jij iji 1 j 1
x 2 , 1, 0 ,1,21x y1
y 2, 1, 0 ,1,2p 40c 1 c p 4040
0 enotro caso= =
⎧ = − −⎧+⎪ ⎨ = − −= = = = ⎨ ⎩
⎪⎩
∑∑
1 1P X 0 , Y 2 0 2
40 20= = = + =⎡ ⎤⎣ ⎦
[ ] 7P X 1 7c
40= = =
zonasombreada 28 7P X Y 1 28c
40 10⎡ − ≤ ⎤ = = =⎣ ⎦

Distribuciones de Probabilidad 94
P X Y 1 P X 2,Y 2 P X 2,Y 1
P X 1,Y 2 P X 1,Y 1 P X 1,Y 0
P X 0 ,Y 1 P X 0 ,Y 0 P X 0 ,Y 1
P X
⎡ − ≤ ⎤ = = − = − + = − = −⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦⎣ ⎦+ = − = − + = − = − + = − =⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦ ⎣ ⎦+ = = − + = = + = =⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦ ⎣ ⎦+ =
[ ]1,Y 0 P X 1,Y 1 P X 1,Y 2
P X 2,Y 1 P X 2,Y 2
28 7 28c
40 10
= + = = + = =⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦ ⎣ ⎦+ = = + = =⎡ ⎤⎣ ⎦
= = =
La función de distribución asociada a un fenómeno de la naturaleza es:
x y(1 e ).(1 e ) x 0 , y 0
F(x,y)0 en el resto
− −⎧ − − > >= ⎨⎩
a) Hallar la función de densidadb) Hallar las funciones de densidad marginales de X e Yc) Hallar las funciones de densidad condicionadasd) Calcular el coeficiente de correlación
Solución:
a) ( )x y2 (1 e ).(1 e )F(x, y) F(x, y)
f(x,y)x y y x y x
− −⎡ ⎤ϑ − −ϑ θ ϑ θ⎡ ⎤ ⎢ ⎥= = = =⎢ ⎥ϑ ϑ ϑ ϑ ϑ ϑ⎣ ⎦ ⎢ ⎥⎣ ⎦
x y
y y x x(1 e ) (1 e )(1 e ) (1 e ).e e .
y x y y
− −− − − −⎡ ⎤θ ϑ − θ ϑ −⎡ ⎤= − = − = =⎢ ⎥ ⎣ ⎦ϑ ϑ ϑ ϑ⎣ ⎦
x y (x y)x yx1
e e e x 0 , y 0e
− − − ++= = = > >
Función de densidad (x y)e x 0 y 0
f(x,y)0 en el resto
− +⎧ > >= ⎨⎩
b) Funciones de densidad marginales
(x y) x y x y x y1 0
0 0 0
x xx
f (x) f(x, y)dy e dy e .e dy e e dy e e
e ( 1) e
∞ ∞ ∞ ∞∞− + − − − − − −
−∞
− −
⎡ ⎤= = = = = − =⎣ ⎦
= − − =
∫ ∫ ∫ ∫
(x y) y x y x y x2 0
0 0 0
y yx
f (y) f(x, y)dx e dx e .e dx e e dx e e
e ( 1) e
∞ ∞ ∞ ∞∞− + − − − − − −
−∞
− −
⎡ ⎤= = = = = − =⎣ ⎦
= − − =
∫ ∫ ∫ ∫

Distribuciones de Probabilidad 95
Independencia de X e Y (x y) x y1 2 xf(x,y) e f (x). f (y) e e− + − −= = =
X e Y son independientes ⇒ La covarianza 11 xy 0μ = σ = ⇒ 0ρ =
c) Funciones de densidad condicionadas(x y)
x1y
2
f(x, y) ef(x / y) e f (x)
f (y) e
− +−
−= = = = al ser X e Y independientes
(x y)y
2x1
f(x, y) ef(y / x) e f (y)
f (x) e
− +−
−= = = = al ser X e Y independientes
d) El coeficiente de correlación 11xy
x yx
μρ = σ =
σ σ
x x x10 x 1 0
0 0
x x
0
E(X) x.f (x)dx x.e dx x.e e dx
x.e e 1
∞ ∞ ∞∞− − −
−∞
∞− −
⎡ ⎤α = μ = = = − + =⎣ ⎦
⎡ ⎤= − − =⎣ ⎦
∫ ∫ ∫
y y y01 y 2 0
0 0
y y
0
E(Y) y.f (y)dy y.e dy y.e e dy
y.e e 1
∞ ∞ ∞∞− − −
−∞
∞− −
⎡ ⎤α = μ = = = − + =⎣ ⎦
⎡ ⎤= − − =⎣ ⎦
∫ ∫ ∫
Nota: x xx x x
0 00 0
x.e dx x.e e dx x.e e∞ ∞
∞ ∞− −− − −⎡ ⎤ ⎡ ⎤= + = −⎣ ⎦ ⎣ ⎦∫ ∫
Cambio x x x
00
u x du dx
dv e dx v e dx e∞
∞− − −
= =⎧⎪⎨
⎡ ⎤= = = −⎪ ⎣ ⎦⎩ ∫
(x y)11
0 0 0 0
x y
0 0
x
E(X.Y) x . y . f(x,y) dx dy x . y . e dx dy
x . e dx y.e dy 1
∞ ∞ ∞ ∞− +
∞ ∞− −
α = = = =
⎛ ⎞ ⎛ ⎞= =⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
∫ ∫ ∫ ∫∫ ∫
x x x2 2 2 220 1 0
0 0
E(X ) x .f (x)dx x . e dx x . e 2 . x. e dx∞ ∞ ∞
∞− − −
−∞
⎡ ⎤α = = = − + =⎣ ⎦∫ ∫ ∫ x x x x x x2 2
0 0 0x . e 2 x . e e x . e 2 . x . e 2 . e 2
∞ ∞ ∞− − − − − −⎡ ⎤ ⎡ ⎤ ⎡ ⎤= − + − − = − − − =⎣ ⎦ ⎣ ⎦ ⎣ ⎦
Análogamente, 202 E(Y ) 2α = =
2 2 2 2x 20 10 x y 02 01 y2 1 1 1 1 2 1 1 1 1σ = α − α = − = σ = = σ = α −α = − = σ = =

Distribuciones de Probabilidad 96
covarianza: 11 xy 11 10 01 x. 1 1 1 0μ = σ = α − α α = − =
Coeficiente de correlación 11xy
x yx x
00
1 1μ
ρ = σ = = = ⇒σ σ
Las variables son
incorreladas
Sean 1 2X , X dos variables aleatorias con la misma distribución. Probar que lasvariables 1 2X Xη = + y 1 2X Xξ = − están incorreladas.
Solución:
Siendo μ la media de la distribución de 1 2X , X
1 2 1 2E( ) E(X X ) 2 E( ) E(X X ) 0η = + = μ ξ = − =
21 2 1 2 1 1 2xE( ) E (X X )(X X ) E(X X Xηξ = + − = −⎡ ⎤⎣ ⎦ 2 1xX X+ 2
2X ) 0− =
1111 2 2x x
xE( ) E( ) E( ) 0 2 0 0 0
η ξσ
μμ = ηξ − η ξ = − μ = → ρ = =
σ
Dada la variable aleatoria bidimensional 1 2( , )ξ ξ con función de densidad2 2
2x y
22(1 y )
2
1f(x,y) e
2 1 y
− −+=
π + en todo el plano. Probar que las variables 1ξ y 2ξ
están incorreladas, pero no son independientes.
Solución:
• La función de densidad marginal de 2ξ es:
2 2 22
2 2
22
2
x y xy22(1 y ) 2(1 y )2
2 2 2
xy2(1 y )2
2 20
1 1f (y) f(x,y)dx e dx e e dx
2 1 y 2 1 y
1 1 e e dx
1 y 1 y
∞ ∞ ∞− − −−+ +
−∞ −∞ −∞
∞ −− +
= = = =π + π +
= =π + π +
∫ ∫ ∫
∫2 2y2
2 1 ye
− π + 2y2
1e
2 2
−=
π
2
2x 2
2(1 y ) 1/2 t 1/2 t2
0 0 0
2 2 2
221/22 1/2
2
2(1 y )e dx 2(1 y ) t e dt t e dt
2
2(1 y ) 2(1 y ) 2 1 y(1 /2)
2 2 2
2(1 y )xCambio: t x 2(1 y ) t dx t dt
2(1 y ) 2
∞ ∞ ∞−+ − − − −
−
+= + = =
+ + π += Γ = π =
+= → = + → =
+
∫ ∫ ∫

Distribuciones de Probabilidad 97
• La función de densidad condicionada de 1ξ por 2ξ es:
2 2 22
2 2x y xy
22(1 y ) 2(1 y )22 2
2
xf(x,y) 1 1
g(x / y) e 2 e ef (y) 2 1 y 2 (1 y )
− − −+ += = π =
π + π +
De aquí se obtiene que 1 2E( / ) 0ξ ξ =2 2
2 2
2
2
x x22(1 y ) 2(1 y )
1 2 22 2
x22(1 y )
2
1 (1 y ) 2E( / ) x e dx x e dx
2(1 y )2 (1 y ) 2 (1 y )
2(1 y ) e 0
2 (1 y )
∞ ∞− −+ +
−∞ −∞
∞−
+
−∞
+ −ξ ξ = = − =
+π + π +
+= − =
π +
∫ ∫
Al ser la línea de regresión constante, las variables tienen covarianza 11 0μ = ycoeficientes de correlación nulos.
De otra parte, las variables 1ξ y 2ξ no son independientes puesto que ladistribución de 1ξ , condicionada por 2ξ , depende claramente de 2ξ
La venta en un mercado de abastos lleva asociada la función:
x y
k 1 0 x 1 1 y 1f(x,y) 2
0 en el resto
⎧ ⎡ ⎤+ < < − < <⎪ ⎢ ⎥= ⎣ ⎦⎨⎪⎩
a) Hallar k para que sea función de densidadb) Hallar la función de distribuciónc) Funciones de densidad marginales y condicionadasd) Se considera la transformación Z X Y= − y T X 2Y= + , hallar la función dedensidad de la variable (Z,T)
Solución:
a) f(x,y) 0 k 0≥ ⇔ ≥
f(x, y) es función de densidad sí se verifica f(x,y) dx dy 1∞ ∞
−∞ −∞
=∫ ∫[ ]−
− − −
⎛ ⎞⎛ ⎞ ⎡ ⎤⎡ ⎤ ⎡ ⎤ ⎜ ⎟+ = + = + =⎜ ⎟ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎜ ⎟ ⎜ ⎟⎣ ⎦ ⎣ ⎦ ⎣ ⎦⎝ ⎠ ⎝ ⎠∫ ∫ ∫ ∫ ∫11 1 1 1 1 2
1
10 1 0 1 0 1
x y x y yk 1 dxdy k 1 dy dx k x y dx
2 2 4
[ ]= = = = =∫1
1
00
12kdx 2k x 2k 1 k
2

Distribuciones de Probabilidad 98
La función de densidad x y 2
0 x 1 1 y 1f(x,y) 4
0 en el resto
+⎧ < < − < <⎪= ⎨⎪⎩
b) Función de distribución x y
F(x,y) P(X x , Y y) f(u,v) dv du−∞ −∞
= ≤ ≤ = ∫ ∫( )
x y x y x y
0 1 0 1 0 1
uv 2 uv 2 1F(x,y) dvdu dv du uv 2 dv du
4 4 4− − −
⎛ ⎞+ +⎡ ⎤ ⎡ ⎤= = = + =⎡ ⎤⎜ ⎟ ⎣ ⎦⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦⎝ ⎠∫ ∫ ∫ ∫ ∫ ∫ [ ]
yx x2 2y
10 01
1 v 1 uy uu 2 v du 2y 2 du
4 2 4 2 2−−
⎛ ⎞⎡ ⎤ ⎛ ⎞⎜ ⎟= + = − + + =⎜ ⎟⎢ ⎥⎜ ⎟⎣ ⎦ ⎝ ⎠⎝ ⎠
∫ ∫ ( ) ( )
x x2 2 2 2 2x x
0 00 0
1 y u 1 u x (y 1) x(y 1)2y u 2 u
4 2 2 2 2 16 2
⎡ ⎤⎛ ⎞ ⎛ ⎞ − += − + + = +⎢ ⎥⎜ ⎟ ⎜ ⎟
⎢ ⎥⎝ ⎠ ⎝ ⎠⎣ ⎦
En consecuencia, 2 2x (y 1) x(y 1)
F(x,y) 0 x 1 1 y 116 2− +
= + ≤ < − ≤ <
Las funciones de distribución marginales, resultan:
x y x 1 x 1
10 1 0 1
uv 2 uv 2F (x) P(X x) f(u,v)dvdu dvdu dv du
4 4−∞ −∞ − −
⎛ ⎞+ += ≤ = = = =⎜ ⎟⎜ ⎟
⎝ ⎠∫ ∫ ∫ ∫ ∫ ∫ [ ] [ ]
1x x21 x
1 00 o1
v 2u v du du u x 0 x 1
8 4 −−
⎛ ⎞⎡ ⎤⎜ ⎟= + = = = ≤ <⎢ ⎥⎜ ⎟⎣ ⎦⎝ ⎠∫ ∫x y 1 y 1 y
20 1 0 1
uv 2 uv 2F (y) P(Y y) f(u,v)dvdu dvdu dv du
4 4−∞ −∞ − −
⎛ ⎞+ += ≤ = = = =⎜ ⎟⎜ ⎟
⎝ ⎠∫ ∫ ∫ ∫ ∫ ∫[ ] ( )
( )[ ]
y1 12 2y
10 01
12 2 2 21
00
v 2 y 1 2u v du u y 1 du
8 4 8 4
y 1 u 2 y 1 y 1 y 8y 7y 1 u 1 y 1
8 2 4 16 2 16
−−
⎛ ⎞ ⎡ ⎤⎡ ⎤ ⎛ ⎞−⎜ ⎟= + = + + =⎢ ⎥⎜ ⎟⎢ ⎥⎜ ⎟⎣ ⎦ ⎝ ⎠⎣ ⎦⎝ ⎠
⎛ ⎞ ⎡ ⎤− − + + += + + = + = − ≤ <⎜ ⎟ ⎢ ⎥⎝ ⎠ ⎣ ⎦
∫ ∫
Se podría haber realizado a través de las funciones de densidad marginales:
[ ]11 2
1
1 11 1
x y 1 x y 1f (x) f(x, y)dy dy y 1
4 2 4 2 2
∞
−−∞ − −
⎡ ⎤⎡ ⎤= = + = + =⎢ ⎥⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫[ ]
x xx
1 1 00
F (x) P(X x) f (u)du du u x 0 x 1−∞
= ≤ = = = = ≤ <∫ ∫

Distribuciones de Probabilidad 99
[ ]11 2
1
2 00 0
x y 1 y x 1 y 4f (y) f(x,y)dx dx x
4 2 4 2 2 8
∞
−∞
⎡ ⎤ +⎡ ⎤= = + = + =⎢ ⎥⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫yy y 2 2
2 21 1
v 4 1 v y 8y 7F (y) P(Y y) f (v)dv dv 4v 1 y 1
8 8 2 16−∞ − −
⎡ ⎤+ + +⎡ ⎤= ≤ = = = + = − ≤ <⎢ ⎥⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫
Función de distribución conjunta
2 2
2
0 x 0 ó y 1
x (y 1) x(y 1)0 x 1 1 y 1
16 2x 0 x 1 , y 1 F(x,y)
y 8 y 71 y 1 , x 1
161 x 1 , y 1
< < −⎧⎪ − +⎪ + ≤ < − ≤ <⎪⎪ ≤ < ≥= ⎨⎪ + +⎪ − ≤ < ≥⎪⎪ ≥ ≥⎩
c) Las funciones de densidad marginales se pueden hallar a partir de la función dedistribución conjunta:
2
1 21 2
F (x) F (y) y 8y 7 y 4f (x) (x) 1 f (y)
x x y y 16 8
⎡ ⎤ϑ ϑ ϑ ϑ + + += = = = = =⎢ ⎥ϑ ϑ ϑ ϑ ⎣ ⎦
O bien, a partir de la función de densidad:
[ ]11 2
1
1 11 1
x y 1 x y 1f (x) f(x, y)dy dy y 1
4 2 4 2 2
∞
−−∞ − −
⎡ ⎤⎡ ⎤= = + = + =⎢ ⎥⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫[ ]
11 21
2 00 0
x y 1 y x 1 y 4f (y) f(x,y)dx dx x
4 2 4 2 2 8
∞
−∞
⎡ ⎤ +⎡ ⎤= = + = + =⎢ ⎥⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫ Funciones de densidad condicionadas:
21
f(x, y) (x y 2) 4 x y 2f(y / x) f (y)
f (x) 1 4+ +
= = = ≠
12
f(x, y) (x y 2) 4 2x y 4f(x / y) f (x)
f (y) (y 4) 8 y 4+ +
= = = ≠+ +
Las variables X e Y no son independientes al ser 1 2f(x, y) f (x). f (y)≠

Distribuciones de Probabilidad 100
d) En la transformación Z X Y
T X 2Y
= −⎧⎨ = +⎩
z z1 1x y(z, t)
J 3 0t t 1 2(x, y)x y
ϑ ϑ−ϑ ϑϑ
= == = = ≠ϑ ϑϑϑ ϑ
por lo que existe la función de densidad g(z, t)
Despejando (X,Y) en la función de (Z,T) secalcula el Jacobiano 1
x xz t(x, y)
Jy y(z, t)z t
ϑ ϑϑ ϑϑ
= =ϑ ϑϑϑ ϑ
2Z TXZ X Y 2Z 2X 2Y 3
T X 2Y T X 2Y Z TY
3
+⎧ =⎪= − = −⎧ ⎪⎨ ⎨= + = + − +⎩ ⎪ =
⎪⎩
1
2 3 1 3(x, y) 1J
1 3 1 3(z, t) 3ϑ
= = =−ϑ
La función de densidad 1 2 1xg(z, t) f h (z, t), h (z, t) J= ⎡ ⎤⎣ ⎦
1 2
0 x 1 0 2z t 32z t z th (z, t) h (z, t)
1 y 1 3 z t 33 3
< < < + <⎧+ − += = ⎨− < < − < − + <⎩
,
2z t z t1 (2z t)( z t)3 3g(z, t) .
4 3 108
+ − +⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥ + − +⎣ ⎦ ⎣ ⎦= =
0 x 1 0 2z t 3x y 2 (2z t)( z t)1 y 1 3 z t 3f(x,y) g(z, t)4 108
0 en el resto 0 en el resto
< < < + <⎧ ⎧+ + − +⎪ ⎪− < < − < − + <= =⎨ ⎨⎪ ⎪⎩ ⎩

Distribuciones de Probabilidad 101
Sea (X,Y) una variable aleatoria bidimensional absolutamente continua condensidad uniforme en el cuadrante unitario [ ] [ ]x0,1 0,1 .
Calcular la función de densidad conjunta U X Y= + y V X Y= −
Solución:
U VXU X Y 2
V X Y U VY
2
+⎧ =⎪= +⎧ ⎪⎨ ⎨= − −⎩ ⎪ =
⎪⎩
El Jacobiano 1
x x 1 1u v(x, y) 12 2Jy y 1 1(u,v) 2u v 2 2
ϑ ϑϑ ϑϑ
= = = = −ϑ ϑϑ
−ϑ ϑ
Función de densidad de la transformación:
U,V X,Y 1 2 1 X,Y 1 X,Y
X,Y
x x x
x x
u v u v u v u v 1f (u,v) f h (u,v), h (u,v) J f , J f ,
2 2 2 2 2
u v u v 1 1 1 f , 1
2 2 2 2 2
+ − + −⎡ ⎤ ⎡ ⎤= = = − =⎡ ⎤⎣ ⎦ ⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦+ −⎡ ⎤= = =⎢ ⎥⎣ ⎦
Dominio para las variables X e Y: [ ]
[ ]
u vX 0,1 0 u v 22
u v 0 u v 2Y 0,1
2
+⎧ = ∈⎪ ≤ + ≤⎧⎪⎨ ⎨− ≤ − ≤⎩⎪ = ∈⎪⎩
U,V
10 u 2 ; 1 v 1
f (u,v) 20 en otrocaso
⎧ ≤ ≤ − ≤ ≤⎪= ⎨⎪⎩
Sean X e Y variables aleatorias independientes e igualmente distribuidas condistribución exponencial de parámetro k.Demostrar que (X Y)+ y (X / Y) son independientes.
Solución:
La función de densidad conjunta 2 k(x y)k e x 0 y 0
f(x,y)0 en el resto
− +⎧ > >= ⎨⎩
2
2
2
t zz t x xz x y xt 1 (t 1)(x,y) zt 1 z tJ abs absx
t z y y 1 z(z,t) (t 1)yy
t 1 z t t 1 (t 1)
ϑ ϑ⎧= +⎧ =⎪ + +ϑ⎪ ⎪ + ϑ ϑ→ → = = = =⎨ ⎨= ϑ ϑ −ϑ +⎪ ⎪ =⎩ ⎪ + ϑ ϑ + +⎩

Distribuciones de Probabilidad 102
La función de densidad 2 kz
2
zk e z 0 t 0
(t 1)f(z,t)0 en el resto
−⎧ > >⎪ += ⎨⎪⎩
Funciones de densidad marginales:
2 kz 2 kz 2 kz 2 kz1 2 2
0 0 0
z dt 1f (z) k e dt k z e k z e k z e
(t 1) (t 1) t 1
∞∞ ∞− − − −−⎡ ⎤= = = =⎢ ⎥+ + +⎣ ⎦∫ ∫
22 kz kz
2 2 2 20 0
z k 1f (t) k e dz z e dz
(t 1) (t 1) (t 1)
∞ ∞− −= = =
+ + +∫ ∫p 1 w
0
kz w2 2 2
0
(p) w e dw (p) (p 1)!
1 1 1z e dz we dw (2)
k k kw 1
w kz z dz dwk k
∞− −
∞− −
Γ = Γ = −
= = Γ =
= → = =
∫∫ ∫
2 kz 2 kz1 2 2 2x x
1 zf (z) f (t) k z e k e f(z,t)
(t 1) (t 1)− −= = =
+ +
En consecuencia, las variables (X Y)+ y (X / Y) son independientes.
Sean (X,Y) dos variables aleatorias independientes, cada una con la función dedensidad:
x y
X Y
e x 0 e y 0f (x) f (y)
0 otro caso 0 otro caso
− −⎧ ⎧> >= =⎨ ⎨⎩ ⎩
Calcular la función de densidad de la variable aleatoria X Y+
Solución:
Por ser variables aleatorias independientes, la función de densidad conjunta de lavariable aleatoria bidimensional X Y+ es:
x y
X,Y
e x 0 , y 0f (x,y)
0 otro caso
− −⎧ > >= ⎨⎩
La transformación a aplicar es U X Y
V X
= +⎧⎨ =⎩
donde X 0 e Y 0 U 0 V 0 U V> > > > >

Distribuciones de Probabilidad 103
Despejando (X,Y) en la función de (U,V) se calcula el Jacobiano
1
x xU X Y X V u v 0 1(x, y)
J 1V X Y U V y y 1 1(u,v)
u v
ϑ ϑ= + = ϑ ϑ⎧ ⎧ ϑ
→ = = = = −⎨ ⎨= = − ϑ ϑ −ϑ⎩ ⎩ϑ ϑ
Función de densidad de la transformación 1 2h (u,v) v ; h (u,v) u v= = −⎡ ⎤⎣ ⎦ :
U,V X,Y 1 2 1 X,Y 1
X,Y X,Y
x x
x
f (u,v) f h (u,v), h (u,v) J f v , u v J
f v , u v 1 f v , u v
= = − =⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦= − − = −⎡ ⎤ ⎡ ⎤⎣ ⎦ ⎣ ⎦
v (u v) u
U,V X,Y
e e u 0 , v 0 , u vf (u,v) f (v , u v)
0 otro caso
− − − −⎧ = > > >= − = ⎨
⎩
Como se quiere obtener la función de densidad de la variable aleatoria U X Y= + , secalcula la función de densidad marginal de U:
[ ]uu u uu u u
U U,V U00 0
u.e u 0f (u) f dv e dv e v u.e f (u)
0 otro caso
−− − − ⎧ >
= = = = = ⎨⎩∫ ∫
Dada la variable aleatoria bidimensional (X,Y) absolutamente continua confunción de densidad conjunta
2 2cx y x y 1
f(x,y)0 en otro caso
⎧ ≤ ≤= ⎨⎩
Calcular:
a) El valor de la constante cb) [ ]P X Y≥c) Función de distribución conjunta
Solución:
a) Para el cálculo de la constante c se procede:
22
y 11 1 1 2 22
1 x 1 y x
cx y1 f(x,y) dy dx cx y dy dx dx
2
=∞ ∞
−∞ −∞ − − =
⎛ ⎞⎛ ⎞⎡ ⎤ ⎜ ⎟= = = =⎜ ⎟⎣ ⎦ ⎜ ⎟⎝ ⎠ ⎝ ⎠
∫ ∫ ∫ ∫ ∫

Distribuciones de Probabilidad 104
x 11 2 6 3 7
1 x 1
cx cx cx cx c c c c 4c 21dx c
2 2 6 14 6 14 6 14 21 4
=
− = −
⎡ ⎤ ⎡ ⎤ ⎡ ⎤= − = − = − − − + = =⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦ ⎣ ⎦∫
con lo cual, 2 221x y x y 1
f(x,y) 40 en otro caso
⎧ ≤ ≤⎪= ⎨⎪⎩
b) [ ]2
2
y x1 x 1 12 2 4 62
0 x 0 0y x
21 21x y 21x 21xP X Y x ydy dx dx dx
4 8 8 8
=
=
⎛ ⎞⎛ ⎞ ⎡ ⎤⎜ ⎟≥ = = = − =⎜ ⎟ ⎢ ⎥⎜ ⎟ ⎣ ⎦⎝ ⎠ ⎝ ⎠
∫ ∫ ∫ ∫
x 15 7
x 0
21x 21x 21 21 42 2140 56 40 56 280 140
=
=
⎡ ⎤= − = − = =⎢ ⎥⎣ ⎦
c) x y
F(x,y) f(u,v)dvdu−∞ −∞
= ∫ ∫ 1 x 1 , 0 y 1− ≤ < ≤ <
2 2
v yu x v y x x2 2 2 2 62
u 1 v u 1 1v u
21 21 u v 21 u y 21 uF(x,y) u v dv du du du
4 8 8 8
== =
=− = − −=
⎛ ⎞ ⎡ ⎤ ⎡ ⎤= = = − =⎜ ⎟ ⎢ ⎥ ⎢ ⎥⎜ ⎟ ⎣ ⎦ ⎣ ⎦⎝ ⎠∫ ∫ ∫ ∫
u x u x3 2 7 3 2 7 3 2 7 2
u 1 u 1
21 u y 21 u 7 u y 3 u 7 x y 3 x 7 y 324 56 8 8 8 8 8 8
= =
= − = −
⎡ ⎤ ⎡ ⎤ ⎡ ⎤ ⎡ ⎤= − = − = − − − + =⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦
3 2 7 27 3 7 3x y x y
8 8 8 8= − + −
1 x 1 , y 1− ≤ < ≥
2
u x v 12 3 2 7 2 3 7
u 1 v u y 1
21 7 3 7 3 7 3 1F(x,y) u v dv du x y x y x x
4 8 8 8 8 8 8 2
= =
= − = =
⎛ ⎞ ⎡ ⎤= = − + − = − +⎜ ⎟ ⎢ ⎥⎜ ⎟ ⎣ ⎦⎝ ⎠∫ ∫ x 1 , 0 y 1≥ ≤ <
2
u 1 v y2 3 2 7 2 2
u 1 v u x 1
21 7 3 7 3 7 3F(x,y) u v dv du x y x y y
4 8 8 8 8 4 4
= =
= − = =
⎛ ⎞ ⎡ ⎤= = − + − = −⎜ ⎟ ⎢ ⎥⎜ ⎟ ⎣ ⎦⎝ ⎠∫ ∫ x 1 , y 1≥ ≥
2
u 1 v 12 3 2 7 2
u 1 v u x 1 , y 1
21 7 3 7 3F(x,y) u v dv du x y x y 1
4 8 8 8 8
= =
= − = = =
⎛ ⎞ ⎡ ⎤= = − + − =⎜ ⎟ ⎢ ⎥⎜ ⎟ ⎣ ⎦⎝ ⎠∫ ∫

Distribuciones de Probabilidad 105
En consecuencia,
3 2 7 2
3 7
2
0 x 1
0 y 0
7 3 7 3x y x y 1 x 1 , 0 y 1
8 8 8 8F(x,y) 7 3 1
x x 1 x 1 , y 18 8 27 3y x 1 , 0 y 1
4 41 x 1 , y 1
< −⎧⎪ <⎪⎪
− + − − ≤ < ≤ <⎪⎪= ⎨
− + − ≤ < ≥⎪⎪⎪ − ≥ ≤ <⎪⎪ ≥ ≥⎩
El consumo diario de agua en metros cúbicos de un hogar es una variable
aleatoria con función de densidad de probabilidad 1
0 x 4 f(x) 4
0 otros valores
⎧ ≤ ≤⎪= ⎨⎪⎩
a) Calcular la distribución del consumo diario medio muestral y la probabilidad deque el mencionado consumo sea inferior a un metro cúbico, para una muestraaleatoria simple de dos días. ¿Coincide la esperanza de la media muestral con lapoblacional?
b) Probabilidad de que el consumo menor de la muestra sea inferior a 2 metroscúbicos y la probabilidad de que el máximo consumo de la muestra sea superior a 2metros cúbicos.
Solución:
a) El consumo diario medio muestral esperado de la población es de 2 metros
cúbicos: a b 0 4
E(X) 22 2+ +
= = =
Sean las variables aleatorias independientes 1 2X y X los consumos de agua delhogar en dos días elegidos al azar, con la función de densidad dada, donde 1 2(X , X )es una muestra aleatoria simple de tamaño dos. La función de densidad conjuntade la muestra será:
1 2 1 1 2 2 1 2
1 1 1f(x , x ) f (x ) . f (x ) . 0 x 4 , 0 x 4
4 4 16= = = ≤ ≤ ≤ ≤
El consumo diario medio muestral 1 2x xx
2+
= es otra variable aleatoria. Para
calcular su función de densidad se utiliza una variable auxiliar 1t x= , siendoentonces:

Distribuciones de Probabilidad 106
1
1
1 22
transformación inversat x x t
x x x 2x tx2
=⎧ =⎧⎪ ⎯⎯⎯⎯⎯⎯⎯⎯⎯→⎨ ⎨+ = −= ⎩⎪⎩
El jacobiano de la transformación es:
1 1
2 2
x xt x 1 0
2x x 1 2t x
ϑ ϑϑ ϑ
= = =ϑ ϑ −ϑ ϑ
J
La función de densidad: 1 2 x x1 1
g(t , x) f x (t, x) , x (t, x) 216 8
= = =⎡ ⎤⎣ ⎦ J
El recinto para las nuevas variables es:
1
21 2x (x x ) / 2
0 x 4 0 t 4
t t0 x 4 0 2x t 4 x 2
2 2= +
⎧ ≤ ≤ ⎯⎯⎯⎯⎯⎯→ ≤ ≤⎪⎨
≤ ≤ ⎯⎯⎯⎯⎯⎯→ ≤ − ≤ → ≤ ≤ +⎪⎩
1 t tg(t , x) 0 t 4 x 2
8 2 2= ≤ ≤ ≤ ≤ +
La variable para analizar es la media muestral x :
2x
2x2 0
0
1 1 x0 x 2 : g (x) g(t , x) dt dt t
8 8 4
∞
−∞
≤ ≤ = = = =∫ ∫
44
2 2x 42x 4
1 1 x2 x 4 : g (x) g(t , x) dt dt t 1
8 8 4
∞
−−∞ −
< ≤ = = = = −∫ ∫
La función de densidad del consumo diario medio muestral del hogar viene dadopor la función de densidad de probabilidad:

Distribuciones de Probabilidad 107
x0 x 2
4g(x)x
1 2 x 44
⎧ ≤ ≤⎪⎪= ⎨⎪ − < ≤⎪⎩
La probabilidad de que el consumo diario medio de la muestra sea inferior a un
metro cúbico es: 11 1 2
0 0 0
x x 1P(x 1) g(x)dx dx
4 8 8
⎡ ⎤< = = = =⎢ ⎥
⎣ ⎦∫ ∫Falta por verificar que la esperanza de la media muestral, esto es, el consumo diariomedio muestral esperado coincide con el poblcional de 2 metros cúbicos.
2 4 2 42 2
0 2 0 2
x x x xE(x) x g(x)dx x dx x 1 dx dx x dx
4 4 4 4
∞
−∞
⎛ ⎞⎛ ⎞= = + − = + − =⎜ ⎟⎜ ⎟⎝ ⎠ ⎝ ⎠∫ ∫ ∫ ∫ ∫
2 43 2 3
0 2
x x x 8 16 64 4 82
12 2 12 12 2 12 2 12
⎡ ⎤ ⎡ ⎤= + − = + − − + =⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
b) Para calcular la probabilidad del menor consumo de la muestra hay que calcularla función de densidad del menor valor de la muestra.
1
1 1
2 1n 1 4 44 1
1 1 1tt t t
1 1 1 1 4 tg(t ) n f(t ) f(x) dx 2 dx dx x 0 t 4
4 4 8 8 8
−−∞ ⎡ ⎤⎡ ⎤ −= = = = = ≤ ≤⎢ ⎥⎢ ⎥
⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫ ∫22 2
1 11 1 1
0 0
4 t 1 t 1 3P(t 2) dt 4t (8 2)
8 8 2 8 4
⎡ ⎤−< = = − = − =⎢ ⎥
⎣ ⎦∫Para calcular la probabilidad del máximo consumo de la muestra hay que calcular lafunción de densidad del máximo valor de la muestra.
n n n
n
n 1 2 1t t tt n
n n n00 0
1 1 1 1 tg(t ) n f(t ) f(x) dx 2 dx dx x 0 t 4
4 4 8 8 8
− −
−∞
⎡ ⎤ ⎡ ⎤= = = = = ≤ ≤⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦∫ ∫ ∫4
42nn n n 2
2
t 1 1 3P(t 2) dt t (16 4)
8 16 16 4> = = = − =∫

Distribuciones de Probabilidad 108
Un agricultor sabe que las peras siguen una distribución N( , 1)θ . En una muestrade peras, con peso medio de 300 gramos, se realizó un contraste con un nivel designificación del 5% y una potencia de 0,6443, en donde la hipótesis nula era de
0H : 0,4θ = kg. frente a la hipótesis alternativa de 1H : 0,3θ = kg.
Se desea saber:a) Tamaño de la muestra utilizada por el agricultor.b) Indicar qué hipótesis fue aceptada.
Solución:
a) En una distribución N( , 1)θ , en una muestra de tamaño n, la función deverosimilitud vendrá dada por la expresión:
2 2 21 2 n
n2
i
i 1
1 1 1(x ) (x ) (x )
2 2 21 2 n
1n (x )2
1 1 1L(x , x , ,x , ) e e e
2 2 2
1 e
2=
− − θ − − θ − − θ
− − θ
⎛ ⎞ ⎛ ⎞ ⎛ ⎞θ = =⎜ ⎟ ⎜ ⎟ ⎜ ⎟π π π⎝ ⎠ ⎝ ⎠ ⎝ ⎠
⎡ ⎤= ⎢ ⎥π⎣ ⎦
∑
Con las hipótesis del contraste, 0H : 0,4θ = y 1H : 0,3θ = . La región crítica óptima
se obtiene aplicando el teorema de Neyman‐Pearson:n
2i
n ni 12 2
i i
i 1 i 1
n2
i
i 1
1n (x 0, 4)2
1(x 0, 4) (x 0, 3)
21 2 n
1n (x 0, 3)1 2 n2
1e
L(x , x , ,x , 0,4) 2 eL(x , x , ,x , 0,3)
1e
2
=
= =
=
− −⎡ ⎤⎢ ⎥− − − −⎢ ⎥⎣ ⎦
− −
⎡ ⎤⎢ ⎥θ = π⎣ ⎦= = =
θ =⎡ ⎤⎢ ⎥π⎣ ⎦
∑∑ ∑
∑
n n n n n2 2i i i i i
i 1 i 1 i 1 i 1 i 1
1 1x 0, 16 n 0, 8 x x 0, 09 n 0,6 x 0, 7 n 0, 2 x2 2
1e e k= = = = =
⎡ ⎤⎛ ⎞ ⎛ ⎞ ⎡ ⎤⎢ ⎥⎜ ⎟ ⎜ ⎟ ⎢ ⎥− + − − − + − −⎢ ⎥⎜ ⎟ ⎜ ⎟ ⎢ ⎥⎢ ⎥⎝ ⎠ ⎝ ⎠⎣ ⎦ ⎣ ⎦= = ≤∑ ∑ ∑ ∑ ∑
Tomando logaritmos neperianos, resulta,
n
i
i 1
10, 7 n 0, 2 x
n2
1 i 1i 1
n
in i 1 1i 1
i 1
1e k 0,7 n 0,2 x lnk
2
x 0,7 n 2 lnk0,7 n 0,2 x 2 lnk x
n 0,2n
=
⎡ ⎤⎢ ⎥− −⎢ ⎥⎣ ⎦
=
=
=
⎡ ⎤≤ − − ≤ ⇒∑⎢ ⎥⎣ ⎦
∑ +⎛ ⎞⇒ − ≤ − → = ≤∑⎜ ⎟⎝ ⎠
∑
La forma de la mejor región crítica es: kx ≤

Distribuciones de Probabilidad 109
Ahora bien, la hipótesis nula 0H : 0,4θ = es cierta sí 1
x N 0,4 ,n
⎛ ⎞∈ ⎜ ⎟⎝ ⎠
.
• Con un nivel de significación del 5%, se tiene:
1 x 0,4 k 0,4 k 0,4P x k N 0,4 , P P z 0,05
n 1 / n 1 / n 1 / n
k 0,4 1,645 1,645 k 0,4
1 / n n
⎡ ⎤ ⎡ ⎤ ⎡ ⎤− − −⎛ ⎞≤ = ≤ = ≤ =⎢ ⎥⎜ ⎟ ⎢ ⎥ ⎢ ⎥⎝ ⎠ ⎣ ⎦ ⎣ ⎦⎣ ⎦− −
= − − =
• De otra parte, la potencia del contraste es 0,6443.
0 0 0 1Pot 1 P(Rechazar H H falsa) P(Rechazar H H cierta)= −β = ≡ .
Si se verifica la hipótesis alternativa 1H : 0,3θ = se tiene que 1
x N 0,3 ,n
⎛ ⎞∈ ⎜ ⎟⎝ ⎠
1 x 0,3 k 0,3 k 0,3P x k N 0,3, P P z 0,6443
n 1 / n 1 / n 1 / n
k 0,3 0,37 0,37 k 0,3
1 / n n
⎡ ⎤ ⎡ ⎤ ⎡ ⎤− − −⎛ ⎞≤ = ≤ = ≤ =⎢ ⎥⎜ ⎟ ⎢ ⎥ ⎢ ⎥⎝ ⎠ ⎣ ⎦ ⎣ ⎦⎣ ⎦−
= − =
Resolviendo el sistema:
1,645k 0,4
n 406 n2,015
0,1n
0,37 k 0,3184k 0,3
n
−⎧ − =⎪ =⎪
= →⎨⎪ =⎪ − =⎩
El tamaño de la muestra es de 406 peras.
b) La mejor región crítica será x k 0,3184≤ = , rechazándose la hipótesis nulacuando el peso medio de la muestra de peras sea inferior a 318,4 gramos.
Como en la muestra se obtuvo un peso medio de 300 gramos (300 318,4≤ ), serechaza la hipótesis nula de que el peso medio de las peras es de 0,4 kg.

Distribuciones de Probabilidad 110
En una distribución de Poisson se establece sobre el parámetro la hipótesisnula, 0H : 0,1λ = , y la alternativa, 1H : 0,4λ = . En muestras aleatorias simples de
tamaño 100, siendo el nivel de significación 0,1, se desea conocer:a) La mejor región crítica.b) La potencia del contraste.
Solución:
a) Una variable aleatoria X sigue una distribución de Poisson de parámetro λ
cuando: k
P(X k) ek!
−λλ= =
Aplicando el Lema de Neyman‐Pearson se determina la región crítica, el cociente delas funciones de verosimilitud:
1 2 100
1 2 100
x x x0,1 0,1 0,1
1 2 100 1 2 100x x x
0,4 0,4 0,41 2 100
1 2 100
0,1 0,1 0,1e e e
L(x , x , , x ; 0,1) x ! x ! x !
L(x , x , , x ; 0,4) 0,4 0,4 0,4e e e
x ! x ! x !
− − −
− − −
λ == =
λ =
100100 100 100
ii ii 1 i
i 1 i 1 i 1100
i
i 1
xx x x10
30 30 301
x40
xx x x
x
0,1 e 0,1 0,4e e 4 e k
0,4 0,10,4 e
== = =
=
− −−
−
⎛ ⎞ ⎛ ⎞= = = = ≤ →⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
∑ ∑ ∑ ∑
∑
100 100
i i
i 1 i 1
x x30 30
1 1
30100 1001
i ii 1 i 1
x x
x
4 e k ln 4 ln (e k )
ln (e k )x x k
ln 4
= =
− −− −
−
= =
→ ≤ → ≤ →
→ − ≤ ≥∑ ∑
∑ ∑
La mejor región crítica es 100
ii 1
x k=
≥∑
Bajo la hipótesis nula, 100
ii 1
x=∑ es una variable aleatoria, suma de cien variables
aleatorias independientes, que sigue una distribución de Poisson de parámetroxP( 100 0,1) P(10)λ = = . Por otra parte, como el tamaño muestral es lo
suficientemente grande se puede utilizar la aproximación normal (teorema central
del límite): 100
ii 1x N(10, 10)
=∑ ∼
El valor crítico k se determina mediante el nivel de significación 0,1α =

Distribuciones de Probabilidad 111
100
i100 i 1i
i 1
x 10k 10 k 10
P x k / N(10, 10) P P z 0,110 10 10
k 10 1,2817 k 14,05
10
=
=
⎡ ⎤−∑ ⎡ ⎤⎢ ⎥− −⎡ ⎤≥ = ≥ = ≥ =∑ ⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦ ⎢ ⎥⎣ ⎦⎢ ⎥⎣ ⎦
−→ = ⇒ =
Como los valores que toma una variable de Poisson son enteros, la mejor región
crítica es 100
ii 1
x 15=
≥∑ . Es decir, cuando la suma de los valores muestrales sea mayor
que 15, rechazaremos la hipótesis nula.
b) 0 0 0 1Pot P(Rechazar H H falsa) P(Rechazar H H cierta)= ≡
Bajo la hipótesis alternativa 1H : 0,4λ = el 100
ii 1
x=∑ sigue una distribución de Poisson
de parámetro x100 0,4 40λ = = : 100
ii 1
x P( 40)=
λ =∑ ∼
Teniendo en cuenta su aproximación a la distribución normal N(40, 40) , resulta:100
i100 i 1i
i 1ot
x 4015 40
P P x 15/N(40, 40) P P z 3,95 0,9999640 40
=
=
⎡ ⎤−∑⎢ ⎥−⎡ ⎤= ≥ = ≥ = ≥ − =⎡ ⎤∑ ⎢ ⎥ ⎣ ⎦⎢ ⎥⎣ ⎦ ⎢ ⎥⎣ ⎦
La potencia del contraste es prácticamente la unidad.
Un experto cree que el número medio de errores por página que comete es dos.Por otra parte, el editor defiende que el número medio es de cuatro. Para unamuestra aleatoria simple de 100 páginas, con un nivel de significación del 5%, sepide:a) Obtener la región crítica.b) Hallar la potencia del contraste.c) Si en la muestra aleatoria de 100 páginas se encontraron 250 errores, ¿quéhipótesis se acepta?Nota.‐ Se supone que el número de errores por página sigue una distribución dePoisson.
Solución:
a) La variable aleatoria X = 'número de errores por página' sigue una distribuciónde Poisson de parámetro λ (número medio de errores por página).
Sobre el parámetro λ se establecen las hipótesis nula y alternativa: 0
1
H : 2
H : 4
λ =⎧⎨ λ =⎩

Distribuciones de Probabilidad 112
La función de verosimilitud para una muestra aleatoria simple de tamaño n:n
i
1 2 n i 1
xx x x
n1 2 n n
1 2 ni
i 1x
L(x , x , , x , ) e e e ex ! x ! x ! !
=−λ −λ −λ − λ
=
⎛ ⎞⎛ ⎞ ⎛ ⎞λ λ λ λλ = =⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎜ ⎟
⎝ ⎠⎝ ⎠ ⎝ ⎠ ∏
∑
Para obtener la mejor región crítica se aplica el teorema de Neyman‐Pearson:
100
i
i 1
100 100
i i
i 1 i 1
100
i
i 1
x
200n
x xi1 2 n i 1 200 1
1 200x1 2 n
400n
ii 1
x
x
2e!L(x , x , , x , 2) 1 1 k
e kL(x , x , , x , 4) 2 2 e
4e!
=
= =
=
−
=
−
=
λ = ⎡ ⎤ ⎡ ⎤= = ≤ ⇒ ≤⎢ ⎥ ⎢ ⎥λ = ⎣ ⎦ ⎣ ⎦
∏
∏
∑
∑ ∑
∑
100
i
i 1
x 100 1001 1 1
i i200 200 200i 1 i 1
1 k 1 k kx ln ln (ln 2) x ln
2 e 2 e e=
= =
⎡ ⎤ ⎡ ⎤ ⎡ ⎤ ⎡ ⎤≤ ≤ ⇒ − ≤⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦
∑∑ ∑
2001001
ii 1
ln k / ex
ln 2=
⎡ ⎤⎣ ⎦≥ →∑ La mejor región crítica es de la forma 100
ii 1
x k=
≥∑El valor de k se obtiene considerando que el nivel de significación es del 5%, y
teniendo en cuenta que 100
ii 1
x=∑ , bajo la hipótesis nula, sigue una distribución de
Poisson de parámetro x100 2 200λ = = , es decir, 100
ii 1
x P( 200)=
∈ λ =∑ .
Por otra parte, 100
ii 1
x=∑ se puede aproximar mediante la distribución normal
N(200, 200) . En consecuencia:
100
100 ii 1
ii 1
x 200k 200 k 200
P x k P 0,05 1,645 k 223,3200 200 200
=
=
⎡ ⎤−∑⎡ ⎤ ⎢ ⎥− −≥ = ≥ = = → =⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦
∑
La mejor región crítica es 100
ii 1
x 223,3=
≥∑ . En otras palabras, si la suma de
observaciones muestrales es mayor que 223,3 se rechaza la hipótesis nula.

Distribuciones de Probabilidad 113
b) 0 0 0 1Pot 1 P(Rechazar H H falsa) P(Rechazar H H cierta)= −β = ≡
Considerando, de una parte, que bajo la hipótesis alternativa 1H : 4λ = , el 100
ii 1
x=∑
sigue una distribución de Poisson de parámetro x100 4 400λ = = , es decir,100
ii 1
x P( 400)=
∈ λ =∑ . Teniendo en cuenta su aproximación a la distribución normal
N(400, 400) , resulta:
100
100 ii 1
ii 1
x 400223 400
P x 223 P P z 8,85 1400 400
=
=
⎡ ⎤−∑⎡ ⎤ ⎢ ⎥−≥ = ≥ = ≥ − ≈⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎣ ⎦
⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦
∑
La potencia del contraste es prácticamente la unidad.
c) En la muestra aleatoria simple de 100 páginas se encontraron 250 errores, como
la región crítica es 100
ii 1
x 223,3=
≥∑ , con un nivel de significación del 5% se rechaza la
hipótesis nula del experto que aseguraba que el número medio de errores porpágina era de dos.
Las patatas cultivadas en la parcela A siguen una distribución 1N( , 144)α ;
mientras que las cultivadas en la parcela B siguen una distribución 2N( , 225)α .Un agricultor quiere contrastar que el peso medio de las patatas cultivadas enambas parcelas es el mismo, 0 1 2H : 0α − α = , frente a la hipótesis alternativa de
que el peso medio de las patatas cultivadas en la parcela A es de 80 gramos mayorque el de las cultivadas en la parcela B, 1 1 2H : 80α − α = .
Para ello, selecciona una muestra aleatoria de 100 patatas de la primera parcelacon un peso medio de 400 gramos; y otra de 81 patatas de la segunda parcela conun peso medio de 364 gramos.Se pide:a) Hallar la mejor región crítica.b) Calcular la potencia del contraste.c) ¿Se acepta la hipótesis de que las patatas cultivadas en ambas parcelas tienen elmismo peso medio?
Solución:
a) Sean la variable aleatoria X = ’peso medio de las patatas en la parcela A’, quesigue una distribución 1N( , 144)α . Análogamente, sea la variable aleatoria Y =
’peso medio de las patatas en la parcela B’, con una distribución 2N( , 225)α .

Distribuciones de Probabilidad 114
Sean, respectivamente, x e y , las dos medias muestrales de las dos muestrasaleatorias simples de patatas correspondientes a las dos parcelas.
1 1
144x N , N( ; 14,4)
100
⎡ ⎤α ≡ α⎢ ⎥⎣ ⎦∼ , 2 2
225y N , N( ; 25)
81
⎡ ⎤α ≡ α⎢ ⎥⎣ ⎦∼
La diferencia de las medias muestrales (x y)− se distribuye según una normal:
2 21 2 1 2(x y) N ; 14,4 25 (x y) N ; 28,85⎡ ⎤ ⎡ ⎤− α − α + → − α −α⎣ ⎦⎣ ⎦∼ ∼
Para hallar la mejor región crítica se aplica el teorema de Neyman‐Pearson:
2
2
( x )11 2f
1 2
(x
2
2
1
) e
1
28,85 2L(x, 0)
L(x, 80)
− μ−
σ=σ π πα − α =
=α − α =
[ ] 22
(x y) 0
2 x 28,85x e
1
28,85 2
− −−
π
[ ]
[ ] [ ]
2
2
222 2
(x y) 80
2 x 28,85
1 1( x y) (x y) 80 160 (x y) 6400
2 x 28,85 2 x 28,851
12
1
x
x
e
e e k
1160(x y) 6400 lnk
2 28,85
160(x y) 1664,64 lnk 6400 (x y) k
− −−
⎡ ⎤− − − − − − − −⎢ ⎥⎣ ⎦
=
= = ≤ →
→ − − − ≤ →⎡ ⎤⎣ ⎦
→ − ≥ − + → − ≥
Región crítica (x y) k− ≥
Para hallar el valor de k se considera que el nivel de significación es 0,05, bajo lahipótesis nula 0 1 2H : 0α − α = se tiene (x y) N(0; 28,85)− ∼
(x y) k kP (x y) k /N(0; 28,85) P P z 0,05
28,85 28,85 28,85
k 1,645 k 47,46
28,85
⎡ ⎤ ⎡ ⎤−− ≥ = ≥ = ≥ = →⎡ ⎤ ⎢ ⎥ ⎢ ⎥⎣ ⎦
⎣ ⎦ ⎣ ⎦
→ = =
Si la diferencia entre las medias de las dos muestras es superior a 47,46 gramos[ ](x y) 47,96 gramos− ≥ se rechaza la hipótesis nula de igualdad de medias
poblacionales.
b) Bajo la hipótesis alternativa 1 1 2H : 80α − α = se tiene (x y) N(80; 28,85)− ∼
0 0 0 1Pot P(Rechazar H H falsa) P(Rechazar H H cierta)= ≡

Distribuciones de Probabilidad 115
(x y) 80 47,46 80Pot P (x y) k /N(80; 28,85) P
28,85 28,85
P z 1,13 0,8708
⎡ ⎤− − −= − ≥ = ≥ =⎡ ⎤ ⎢ ⎥⎣ ⎦
⎣ ⎦= ≥ − =⎡ ⎤⎣ ⎦
c) La diferencia entre el peso medio de las muestras tomadas en ambas parcelases: 0(x y) 400 364 36 47,96 Se acepta H− = − = < → , concluyendo que ambasparcelas producen patatas con igual peso medio.
El precio de los productos vendidos por una empresa es una variable aleatoriacon función de densidad 1f(x) x θ−= θ , donde 0 x 1 , 0< < θ > , que depende delparámetro desconocido θ . Se quiere contrastar sobre el valor de dicho parámetrola hipótesis nula 0H : 1θ = frente a la alternativa 1H : 2θ = . Para ello, se toma una
muestra aleatoria simple de tamaño dos.Determinar el nivel de significación y la potencia del contraste, si se toma comoregión crítica 1 2x x 0,6≤
Solución:
0 0P(Rechazar H H cierta)α = .
En la región crítica 1 2x x 0,6≤ , bajo la hipótesis nula
1θ = , se tiene f(x) 1= , con lo cual:
2 2 11 1
2 21 1
x 0,6 x 1 x 1 x 0, 6 x
1 2 0 1 2 1 2x 0 x 0 x 0,6 x 0
P x x 0,6 H : 1 1 dx dx 1 dx dx= = = =
= = = =
⎡ ⎤α = ≤ θ = = + =⎣ ⎦ ∫ ∫ ∫ ∫
10,6 1 0,6 1
1 0, 6 x
2 1 2 1 1 1 10 00 0,6 0 0,6
0,6 1
1 10 0,6
x dx x dx dx (0,6 x ) dx
x ln x 0,6 0,6 (ln 1 ln 0,6) 0,6 0,6(0 0,51) 0,906
⎡ ⎤ ⎡ ⎤= + = + =⎣ ⎦ ⎣ ⎦
⎡ ⎤ ⎡ ⎤= + = + − = + + =⎣ ⎦ ⎣ ⎦
∫ ∫ ∫ ∫
La probabilidad de rechazar la hipótesis nula siendo cierta es alta, lo que indica queel contraste es malo.
0 0 0 1Pot 1 P(Rechazar H H falsa) P(Rechazar H H cierta)= −β = ≡
En la región crítica 1 2x x 0,6≤ , 1 2x x 0,6≤ , bajo la hipótesis alternativa 2θ = se
tiene f(x) 2x= , la potencia será:

Distribuciones de Probabilidad 116
2 2 11 1
2 21 1
1 2 0
x 0,6 x 1 x 1 x 0, 6 x
1 2 1 2 1 2 1 2x 0 x 0 x 0,6 x 0
Pot P x x 0,6 H : 2
2x 2x dx dx 2x 2x dx dx= = = =
= = = =
⎡ ⎤= ≤ θ = =⎣ ⎦
= + =∫ ∫ ∫ ∫1
0, 6 11 0, 6/x2 2
1 2 1 1 2 10 00 0, 6
0, 6 10,6 12
1 1 1 1 1 10 0,60 0,6
4x x 2 dx 4x x 2 dx
2 x dx 2 (0,36 / x )dx x 0,72 ln x
⎡ ⎤ ⎡ ⎤= + =⎣ ⎦ ⎣ ⎦
⎡ ⎤ ⎡ ⎤= + = + =⎣ ⎦ ⎣ ⎦
∫ ∫∫ ∫0,36 0,72 (ln1 ln0,6) 0,36 0,72 (0 0,51) 0,7272= + − = + + =
La potencia del contraste no resulta excesivamente alta, el contraste no es bueno.
Las ventas diarias de una multinacional (en millones de euros) es una variablealeatorias X en cuya función de densidad de probabilidad se establece la hipótesis
nula 0
xH : f(x) 0 x 2
2= < < frente a la hipótesis alternativa 1
1H : f(x) 0 x 2
2= < <
Para realizar el contraste se toma una muestra aleatoria simple de dos días, dondelos volúmenes de ventas fueron de 1.000.000 y 1.200.000 euros. Con un nivel designificación del 5%, se desea saber:
a) Con qué cantidad se rechaza la hipótesis nula.b) Potencia del contrastec) Qué hipótesis resulta aceptable.
Solución:
a) La región crítica se encuentra por el teoremade Neyman ‐ Pearson para una muestra aleatoriasimple de tamaño dos:
1 2
1 21 2
1 2
x x.L(x , x , f(x) x / 2) 2 2 x x k
1 1L(x , x , f(x) 1 / 2) .2 2
== = ≤
=
Se calcula k considerando el nivel de significación 0,05α =
{ }1
0 0 1 2
k/2 2 2 k/x
1 2 1 22 1 2 1
0 0 k/2 0
xP(Error Tipo I) P Rechazar H /H es cierta P x x k / f(x)
2
x x x x dx dx dx dx
4 4
⎧ ⎫α = = = ≤ = =⎨ ⎬⎩ ⎭
⎛ ⎞ ⎛ ⎞= + =⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠∫ ∫ ∫ ∫

Distribuciones de Probabilidad 117
12 k/xk/2 2 k/2 22 2 21 2 1 2 1
1 1 1 10 k/2 0 k/2 10 0
k/22 2 2 2 221
1 k/2
0
22
x x x x x kdx dx dx dx
4 2 4 2 2 8x
1 x k k k k 1lnx (ln2 lnk ln2) 2ln2 lnk
2 2 8 16 8 8 2
k1,886 lnk 0,05 k (1,886 lnk) 0,4 k 0,
8
⎡ ⎤ ⎡ ⎤= + = + =⎢ ⎥ ⎢ ⎥
⎣ ⎦ ⎣ ⎦
⎡ ⎤ ⎡ ⎤= + = + − + = + − =⎡ ⎤⎢ ⎥ ⎣ ⎦ ⎢ ⎥⎣ ⎦⎣ ⎦
= − = → − = →⎡ ⎤⎣ ⎦
∫ ∫ ∫ ∫
3733
La región crítica es de la forma 1 2x x 0,3733≤ , es decir, si el producto de las ventasde los dos días es inferior a 337.300 se rechaza la hipótesis nula.
b) { }1 1 1 2
1Pot Aceptar H /H es cierta P x x 0,3733 / f(x)
2⎧ ⎫= = ≤ = =⎨ ⎬⎩ ⎭
[ ] [ ]
[ ]
1
1
0,3733/2 2 2 0,3733/x
2 1 2 10 0 0,3733/2 0
0,3733/2 22 0,3733/x
2 1 2 10 00 0,3733/2
0,3733/2 20,3733/2 21
1 1 1 0,3733/200 0,3733/2 1
1 1dx dx dx dx
4 4
1 1x dx x dx
4 4
dx 0,3733 1 0,3733dx x lnx
2 4x 2 4
0,3
⎛ ⎞ ⎛ ⎞= + =⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎜ ⎟
⎝ ⎠ ⎝ ⎠
= + =
= + = + =⎡ ⎤⎣ ⎦
=
∫ ∫ ∫ ∫∫ ∫∫ ∫
733 0,3733 0,3733(ln2 ln0,3733 ln2) 1 2ln2 ln0,3733 0,31466
4 4 4+ − + = + − =⎡ ⎤⎣ ⎦
c) Los volúmenes de ventas de la muestra aleatoria simple de tamaño dos fueronde 1.000.000 y 1.200.000 euros, con lo que 1x 1= y 2x 1,2=
1 2x x 1,2 0,3733= > → Se acepta la hipótesis nula.

Distribuciones de Probabilidad 118
El gasto diario, en miles de euros, en electricidad de una empresa es unavariable aleatoria con distribución N( , 1).α Se desea contrastar con un nivel designificación del 5%, la hipótesis nula de que el gasto medio diario es de 30 eurosfrente a la hipótesis alternativa de que dicho gasto es menor que la citada cifra.Para ello se toma una muestra aleatoria simple de diez días en los que el gasto enelectricidad en euros fue:
29,5 29,3 30,5 31,5 29,1 29,9 30,1 31 31,5 30
Se pide:
a) ¿Cuál es la hipótesis aceptada?b) ¿Cuál habría sido la probabilidad de aceptar que el gasto diario medio es de 30euros, si el gasto medio diario fuese un 2% superior a la cifra supuesta en lahipótesis nula?
Solución:
a) La variable aleatoria X = 'Gasto diario en facturas de electricidad’ X N( , 1).∼ α
Hipótesis nula 0H : 30α = frente a la hipótesis alternativa 1H : 30α <
Para una muestra aleatoria simple de tamaño n, de una población N( , 1)α , lafunción de verosimilitud es:
2 2 21 2 n
n2
ii 1
1 1 1(x ) (x ) (x )
2 2 21 2 n
1n (x )2
1 1 1L(x ,x , ,x , ) e e e
2 2 2
1 e
2=
− − α − − α − − α
− − α
⎛ ⎞ ⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟ ⎜ ⎟α = =⎜ ⎟ ⎜ ⎟ ⎜ ⎟π π π⎝ ⎠ ⎝ ⎠ ⎝ ⎠
⎛ ⎞= ⎜ ⎟⎜ ⎟π⎝ ⎠
∑
Para obtener la región crítica se aplica el teorema de Neyman‐Pearson:n
2i
n ni 12 2
i ii 1 i 1
n2
ii 1
1n (x 3)2
1 1(x 3) (x )
2 21 2 n
1n1 2 n (x )2
1e
L(x ,x , ,x , 3) 2e
L(x ,x , ,x , 3)1
e2
=
= =
=
− −
− − + − α
− − α
⎛ ⎞⎜ ⎟⎜ ⎟α = π⎝ ⎠= = =
α <⎛ ⎞⎜ ⎟⎜ ⎟π⎝ ⎠
∑∑ ∑
∑
n n n n n22 2 2
i i i i ii 1 i 1 i 1 i 1 i 1
1 1(x 9n 6) x (x n ) 2 x n(9 ) (2 6) x
2 21e e k= = = = =
⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟− + − − − α + α − −α + α−⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠= = ≤∑ ∑ ∑ ∑ ∑

Distribuciones de Probabilidad 119
n2
ii 1
1n(9 ) (2 6) x
n2 21 i 1
i 1
1e k n(9 ) (2 6) x lnk
2=
⎛ ⎞⎜ ⎟− − α + α−⎜ ⎟⎝ ⎠
=
⎡ ⎤≤ ⇒ − − α + α − ≤∑⎢ ⎥
⎢ ⎥⎣ ⎦
∑
n n2 2
i 1 i 1i 1 i 1
1n(9 ) (2 6) x lnk (2 6) x 2 lnk n(9 )
2 = =
⎛ ⎞− − α + α − ≤ α − ≤ − − − α∑ ∑⎜ ⎟⎝ ⎠
2n 1
ii 1
2 lnk n(9 )x
(2 6)=
− − − α≤∑
α − dividiendo por n, resulta
n
ii 1
xx k
n=∑
= ≤
con lo que la forma de la región crítica es x k≤ .
Siendo 0,05α = , se tiene: 0P x k H : 30 0,05⎡ ⎤≤ α = =⎣ ⎦
Si la hipótesis nula es cierta, considerando que la muestra es de tamaño 10, la
media muestral se distribuye según una normal 1
x N 30 ,10
⎛ ⎞∼ ⎜ ⎟⎝ ⎠
, por tanto,
0
x 30 k 30 k 30P x k H : 30 P P z 0,05
1 10 1 10 1 10
⎡ ⎤ ⎡ ⎤− − −⎡ ⎤≤ α = = ≤ = ≤ =⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦ ⎣ ⎦
Observando las tablas de la N(0, 1) →k 30
1,645 k 29,481 10
−= − → =
La región crítica es: x 29,48≤
Por otra parte, la media muestral es:
10
ii 1
xx 30,24
10=∑
= =
Siendo x 30,24 29,48= > se acepta la hipótesis nula, con lo que el gasto mediodiario en electricidad de 30 euros con una fiabilidad del 95%.
b) Si el gasto medio diario fuera un 2% superior a 30 euros, sería de 30,6 euros, esdecir 30,6.α = En este caso, la media muestral se distribuye según una normal
1x N 30,6 ,
10
⎛ ⎞⎜ ⎟⎝ ⎠
∼ , por tanto, la probabilidad pedida sería:
0
x 30,6 29,48 30,6P Aceptar H 30,6 P P z 3,54 0,9998
1 10 1 10
⎡ ⎤− −⎡ ⎤α = = > = >− =⎡ ⎤⎢ ⎥ ⎣ ⎦⎣ ⎦⎣ ⎦

Distribuciones de Probabilidad 120
Las especificaciones de un tipo de báscula aseguran que los errores en laspesadas siguen una distribución normal con esperanza nula y varianza unidad. Sedesea contrastar la afirmación sobre la varianza frente a la hipótesis alternativa deque la varianza es 4. En este sentido, se realizan cinco pesadas en las que el errorcometido resultó ser
1 0,9 − 0,2 1,4 − 0,7
Para un nivel de significación del 5%, se pide:a) Obtener la mejor región crítica.b) Obtener la potencia del contraste.c) Indicar qué hipótesis resultada aceptada.
Solución:
a) Sea la variable aleatoria X = 'Error cometido en la báscula', X N(0 , ).σ∼
La hipótesis nula 20H : 1σ = frente a la hipótesis alternativa 2
1H : 4σ =
La función de verosimilitud para una muestra aleatoria simple de tamaño 5 es:
2 2 21 2 52 2 2
52i2
i 1
1 1 1x x x
2 2 2 21 2 5
15 x2
1 1 1L(x ,x , ,x , ) e e e
2 2 2
1 e
2=
− − −σ σ σ
−σ
⎛ ⎞ ⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟ ⎜ ⎟σ = =⎜ ⎟ ⎜ ⎟ ⎜ ⎟σ π σ π σ π⎜ ⎟ ⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠ ⎝ ⎠
⎛ ⎞= ⎜ ⎟⎜ ⎟σ π⎝ ⎠
∑
La región crítica óptima se obtiene aplicando el teorema de Neyman‐Pearson:5
2i
5 5i 12 2i i
i 1 i 15
2i
i 1
15 x2
1 1x x2 2 851 2 5
2 151 2 5 x2.4
1e
2L(x ,x , ,x , 1)2 e
L(x ,x , ,x , 4)1
e2 2
=
= =
=
−
− +
−
⎛ ⎞⎜ ⎟⎜ ⎟πσ = ⎝ ⎠= = =
σ =⎛ ⎞⎜ ⎟⎜ ⎟π⎝ ⎠
∑∑ ∑
∑
5 52 2i i
i 1 i 1
3 3x x 58 85 2
1 1 i 1i 1
3 2 e k e k 32 x ln (k 32)
8= =
− −
== ≤ → ≤ − ≤∑
∑ ∑
5 5 52 2 21 1i i i
i 1 i 1 i 1
ln (k 32) ln (k 32)x x x k
3 8 3 8= = =≤ ≥ ≥∑ ∑ ∑
− −
La forma de la mejor región crítica es 5 2
ii 1
x k=
≥∑

Distribuciones de Probabilidad 121
El valor de k se obtiene considerando que, 5 2 2
i 0i 1
P x k H : 1 0,05=
⎡ ⎤α = ≥ σ = =∑⎢ ⎥
⎢ ⎥⎣ ⎦
Si la hipótesis nula es cierta, la variable aleatoria se distribuye según una normal
N(0 , 1) , siendo 5 2
ii 1
x=∑ una variable aleatoria suma de cinco variables aleatorias
independientes con distribución N(0 , 1) . En consecuencia, 5 2
ii 1
x=∑ se distribuye
como una 25χ
Observando en las tablas: 5 2 2
i 5i 1
P x k P k 0,05 k 11,07=
⎡ ⎤⎡ ⎤≥ = χ ≥ = → =∑⎢ ⎥ ⎣ ⎦⎢ ⎥⎣ ⎦
La región crítica es: 5 2
ii 1
x 11,07=
≥∑
En otras palabras, se aceptará la hipótesis nula cuando la suma de los cuadrados delas observaciones muestrales sea menor que 11,07
b) 5 2 2
0 0 i 1i 1
Pot P Rechazar H / siendo H falsa P x 11, 07 H : 4=
⎡ ⎤= = ≥ σ =⎡ ⎤ ∑⎢ ⎥⎣ ⎦
⎢ ⎥⎣ ⎦
Sí la hipótesis alternativa es cierta, la variable aleatoria X se distribuye según unanormal N(0 , 2), con lo que dividiendo cada ix por la desviación típica 2σ = , se
tiene que 5 2
ii 1
(x 2)=∑ se distribuye según una 2
5χ , en consecuencia:
5 52 2 2 2i 1 i 5
i 1 i 1Pot P x 11, 07 H : 4 P (x 2) 2,7675 P 2,7675 0,75
= =
⎡ ⎤ ⎡ ⎤⎡ ⎤= ≥ σ = = ≥ = χ ≥ ≈∑ ∑⎢ ⎥ ⎢ ⎥ ⎣ ⎦⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦
c) El contraste se realiza hallando el 5 2
ii 1
x=∑ de la muestra aleatoria simple, siendo:
5 2 2 2 2 22i
i 1x 1 0,9 ( 0,2) 1,4 ( 0,7) 4,3 11,07
== + + − + + − = <∑
por lo que se acepta la hipótesis nula.

Distribuciones de Probabilidad 122
Gestión Aeronáutica: Estadística TeóricaFacultad Ciencias Económicas y EmpresarialesDepartamento de Economía AplicadaProfesor: Santiago de la Fuente Fernández