
Estadística Descriptiva Unidimensional - ujaen.esdmontoro/Metodos/Temas/Tema1.pdf · Capítulo 1...
23
Capítulo 1 Estadística Descriptiva Unidimensional El objetivo básico de la Estadística es extraer la información contenida en un conjunto de observaciones. Resumir los datos es un procedimiento útil para conseguirlo y puede hacerse mediante tablas, gráficos o valores numéricos. A lo largo de este tema veremos las principales técnicas numéricas y gráficas que nos permiten describir una característica de interés observada en una población, poniendo en relieve sus rasgos más importantes. 1.1. Conceptos básicos. Población y variable. El universo de objetos al cual se refiere el estudio que se pretende realizar recibe el nombre de población. Por ejemplo, todas las piezas terminadas en una cadena de montaje, los nacidos en un día determinado, los coches de una determinada marca, etc. Las poblaciones pueden ser finitas e infinitas (p.e. población de bacterias). En general, estudiar todos los individuos de una población (aún siendo finita) es difícil, fundamentalmente por cuestiones de tiempo y costo. Se suele entonces analizar únicamente una parte representativa de ella a la que llamamos muestra. A las características objeto de estudio en la población se les llama variables, ya que pueden variar de un individuo a otro. Por ejemplo, el grosor de una pieza, peso al nacer, consumo de gasolina, partido al que va a votar un individuo, etc. Según los valores que puedan tomar las variables, se clasifican en: 3
Transcript of Estadística Descriptiva Unidimensional - ujaen.esdmontoro/Metodos/Temas/Tema1.pdf · Capítulo 1...

Capítulo 1
Estadística Descriptiva
Unidimensional
El objetivo básico de la Estadística es extraer la información contenida en un conjunto de
observaciones. Resumir los datos es un procedimiento útil para conseguirlo y puede hacerse
mediante tablas, gráficos o valores numéricos. A lo largo de este tema veremos las principales
técnicas numéricas y gráficas que nos permiten describir una característica de interés observada
en una población, poniendo en relieve sus rasgos más importantes.
1.1. Conceptos básicos. Población y variable.
El universo de objetos al cual se refiere el estudio que se pretende realizar recibe el nombre
de población. Por ejemplo, todas las piezas terminadas en una cadena de montaje, los nacidos
en un día determinado, los coches de una determinada marca, etc. Las poblaciones pueden ser
finitas e infinitas (p.e. población de bacterias). En general, estudiar todos los individuos de una
población (aún siendo finita) es difícil, fundamentalmente por cuestiones de tiempo y costo. Se
suele entonces analizar únicamente una parte representativa de ella a la que llamamos muestra.
A las características objeto de estudio en la población se les llama variables, ya que pueden
variar de un individuo a otro. Por ejemplo, el grosor de una pieza, peso al nacer, consumo de
gasolina, partido al que va a votar un individuo, etc. Según los valores que puedan tomar las
variables, se clasifican en:
3

4 Capítulo 1. Estadística Descriptiva Unidimensional
Cualitativas (categóricas): No toman valores numéricos. Por ejemplo, causa de fallo de un
componente eléctrico, tipo de defecto presente en un material, partido al que se va a votar.
Supongamos que se distinguen tres causas de fallo para los componentes en estudio: A, B
y C. Estas son entonces las modalidades de la variable çausa de fallo". Las modalidades
han de ser exhaustivas e incompatibles. Eso significa en este caso que en A, B y C están
recogidas todas las posibles causas de fallo (exhaustivas), y cualquier componente ha de
presentar sólo una de esas causas de fallo (incompatibles).
Cuantitativas (numéricas): Toman valores numéricos. Por ejemplo, tiempo de fallo de un
componente, grosor de una pieza, altura, peso, etc. Estas a su vez se clasifican en:
• Discretas: Toman un número finito o infinito numerable de valores (toman valoresenteros). Por ejemplo, número de piezas defectuosas en un lote, número de hijos, etc.
• Continuas: Pueden tomar cualquier valor dentro de uno o varios intervalos de larecta real (pueden tomar valores con decimales). Por ejemplo, altura, temperatura,
tiempo de fallo, etc.
1.2. Organización de los datos. Tablas de frecuencias.
Un primer resumen de la información contenida en un conjunto de datos observado se
obtiene al organizarlos en lo que se llama una tabla de frecuencias. En ésta se recogen los
distintos valores (números o categorías) que toma la variable junto con sus correspondientes
frecuencias de aparición.
Supongamos que hemos medido una variable X (numérica) sobre un conjunto de N indivi-
duos. Llamamos xi al valor que presenta el individuo i en la variable X, con i = 1, ..., N. Si
observamos entre ellos k valores distintos, diremos que X toma valores x1, x2, ..., xk y deter-
minaremos la frecuencia asociada a cada uno de ellos.
Para un valor xi, i = 1, ..., k, definimos las siguientes frecuencias:
Frecuencia absoluta, ni : Número de individuos que presentan el valor xi.
kXi=1
ni = n1 + ...+ nk = N

1.2. Organización de los datos. Tablas de frecuencias. 5
Frecuencia relativa, fi : Proporción de individuos que presentan el valor xi.
fi =niN,
kXi=1
fi = 1
Frecuencia absoluta acumulada, Ni : Número de individuos que presentan un valor inferior
o igual a xi.
Ni =iX
j=1
nj = n1 + ...+ ni,
Nk = N
Frecuencia relativa acumulada, Fi : Proporción de individuos que presentan un valor
inferior o igual a xi.
Fi =iX
j=1
fj = f1 + ...+ fi =Ni
N,
Fk = 1
Observad que el cálculo de las frecuencias acumuladas sólo tiene sentido en variables numéri-
cas.
Sobre tres ejemplos vemos cómo construir la tabla de frecuencias.
Ejemplo 1.1: Supongamos que unas resistencias de cierto tipo son agrupadas en paquetes
de 50 unidades. Se seleccionaron 60 de esos paquetes y se contó el número de resistencias que
no cumplían con las especificaciones, resultando los siguientes datos:
Tabla 1.1. Número de resistencias defectuosas en cada caja de 50 unidades
2 1 2 4 0 1 3 2 0 5
3 3 1 3 2 4 7 0 2 3
0 4 2 1 3 1 1 3 4 1
2 3 2 2 8 4 5 1 3 1
5 0 2 3 2 1 0 6 4 2
1 6 0 3 3 3 6 1 2 3
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

6 Capítulo 1. Estadística Descriptiva Unidimensional
Lo primero que observamos es que la variable X = Número de resistencias defectuosas en un
paquete podría tomar valores 0,1,...,50, pero de entre ellos tan sólo 0,...,8 presentan frecuencia
no nula. Se trata de una variable cuantitativa discreta, y la tabla de frecuencias resulta:
Tabla 1.2. Tabla de frecuencias
xi ni fi Ni Fi
0 7 0.1167 7 0.1167
1 12 0.2 19 0.3167
2 13 0.2167 32 0.5334
3 14 0.2333 46 0.7667
4 6 0.1 52 0.8667
5 3 0.05 55 0.9167
6 3 0.05 58 0.9667
7 1 0.0167 59 0.9834
8 1 0.0167 60 1
N = 60 1
En la tabla se observa, por ejemplo, que tan sólo un 11.67% de los paquetes no presentan
resistencias defectuosas, y que un elevado porcentaje de paquetes, concretamente el 86.67%,
presentan como mucho cuatro resistencias defectuosas.
Ejemplo 1.2: Un artículo de la revista Transactions of the Institution of Chemical En-
gineers presenta datos de un experimento donde se investigó el efecto de varias variables de
un proceso sobre la oxidación en fase de vapor del naftaleno. A continuación se presenta una
muestra del porcentaje de conversión de moles de naftaleno a anhídrido maleico:
Tabla 1.3. Porcentaje de conversión de moles de naftaleno a anhídrido maleico
4.2 4.7 4.7 5.0 3.8 3.6 3.8 3.0 5.1 4.0
3.1 3.8 4.8 4.0 5.2 4.3 2.8 2.0 2.8 5.0
En este caso, la variable X = Porcentaje de conversión de moles de naftaleno a anhídrido
maleico es cuantitativa continua. Las variables continuas, al contener decimales, suelen presentar
muchos valores distintos (rara vez tendremos valores con frecuencia mayor que uno o dos) , por
lo que se suelen agrupar por intervalos. Lo mismo podría ocurrir en determinadas variables

1.2. Organización de los datos. Tablas de frecuencias. 7
discretas. ¿Cúantos intervalos hacemos y de qué amplitudes?. El número de intervalos o clases
depende del número de datos y de la dispersión de los mismos (si son parecidos o no entre sí),
pero en realidad no hay ninguna regla establecida. En la práctica se suele tomar un número de
intervalos aproximadamente igual a la raíz cuadrada del número de observaciones.
No de intervalos '√N
En cuanto a la amplitud, se suele tomar la misma en todos los intervalos. Una forma de
obtenerla es:
Amplitud=valor máximo de la variable-valor mínimo de la variable
número de intervalos
Entonces, el valor máximo sería el extremo superior del último intervalo, y el valor mínimo
el extremo inferior del primer intervalo. Como normalmente los extremos inferiores se abren y
los superiores se cierran, en lugar de tomar exactamente el mínimo de la variable, se toma un
valor próximo inferior, ya que en otro caso el valor mínimo no podría incluirse en el primer
intervalo.
Nota: Hacer intervalos con la misma amplitud puede no ser una elección sensata si el con-
junto de datos contiene puntos extremos (raros en relación al resto). En tal caso se podrían
tomar intervalos más estrechos en la zona de más concentración y más amplios en la de menos
concentración.
En este ejemplo tenemos 20 observaciones, por lo que podemos tomar 4 intervalos. Si quiero
que el primer intervalo empiece en 1.5 y que el último termine en 5.5, tendrán una amplitud de
1.
Tabla 1.4. Tabla de frecuencias
% Moles ni fi Ni Fi
(1.5-2.5] 1 0.05 1 0.05
(2.5-3.5] 4 0.2 5 0.25
(3.5-4.5] 8 0.4 13 0.65
(4.5-5.5] 7 0.35 20 1
Al punto central de un intervalo se le llama marca de clase. La del primer intervalo es
2=1,5 + 2,5
2.
Ejemplo 1.3: Se pregunta a un grupo de 20 alumnos de la asignatura de Métodos Estadís-
ticos, entre otras cosas, si hacen o no frecuentemente "botellón". Los resultados son:
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

8 Capítulo 1. Estadística Descriptiva Unidimensional
Tabla 1.4. Hábito "botellón"
sí sí no sí no no no sí no no
no sí sí sí sí sí no sí no sí
Tabla 1.5. Tabla de frecuencias
ni fi
sí 11 0.55
no 9 0.45
Un 55% hacen botellón frente a un 45% que no lo hacen.
1.3. Representaciones gráficas
Veremos las representaciones gráficas más comunes para cada tipo de variable.
Cualitativas
• Diagrama de barras o rectángulos
• Diagrama de Pareto
• Diagrama de sectores
Cuantitativas
• Histograma
• Polígono de frecuencias
• Diagrama de puntos
1.3.1. Diagrama de barras o rectángulos
Se construye dibujando sobre la categoría correspondiente un rectángulo con altura igual
a la frecuencia (absoluta o relativa). También es válido para variables cuantitativas discretas,
considerando en el eje de abcisas los valores de la variable en orden creciente en lugar de las
categorías.

1.3. Representaciones gráficas 9
Diagrama de barras
frec
uenc
ia
0
2
4
6
8
10
12
n s
1.3.2. Diagrama de Pareto
Se ordenan las categorías de mayor a menor frecuencia y se dibujan los rectángulos corre-
spondientes. Es muy utilizado en controles de la calidad, donde cada clase representa un tipo
de disconformidad o problema de producción.
1.3.3. Diagrama de sectores
Se dibujan en un círculo sectores con áreas proporcionales a las frecuencias de cada una de
las categorías.
Diagrama de sectoresHábito botellón
ns
45,00%
55,00%
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.
10 Capítulo 1. Estadística Descriptiva Unidimensional
1.3.4. Histograma
Es igual que el diagrama de rectángulos, considerando ahora en el eje de abcisas los intervalos
y en el ordenadas las frecuencias (absolutas o relativas). Si los intervalos tienen la misma
amplitud, las frecuencias son proporcionales a las alturas de los rectángulos del histograma, ya
que el área se obtiene multiplicando la base por la altura. Por lo tanto, cada altura da idea de la
densidad o concentración de datos en esa zona: donde hay más altura, aparecen frecuentemente
valores de la variable, donde hay menos, los datos son escasos. Sin embargo, esto no ocurre si
las amplitudes no son iguales, por lo que, en tal caso, se representa la frecuencia dividida por
la amplitud.
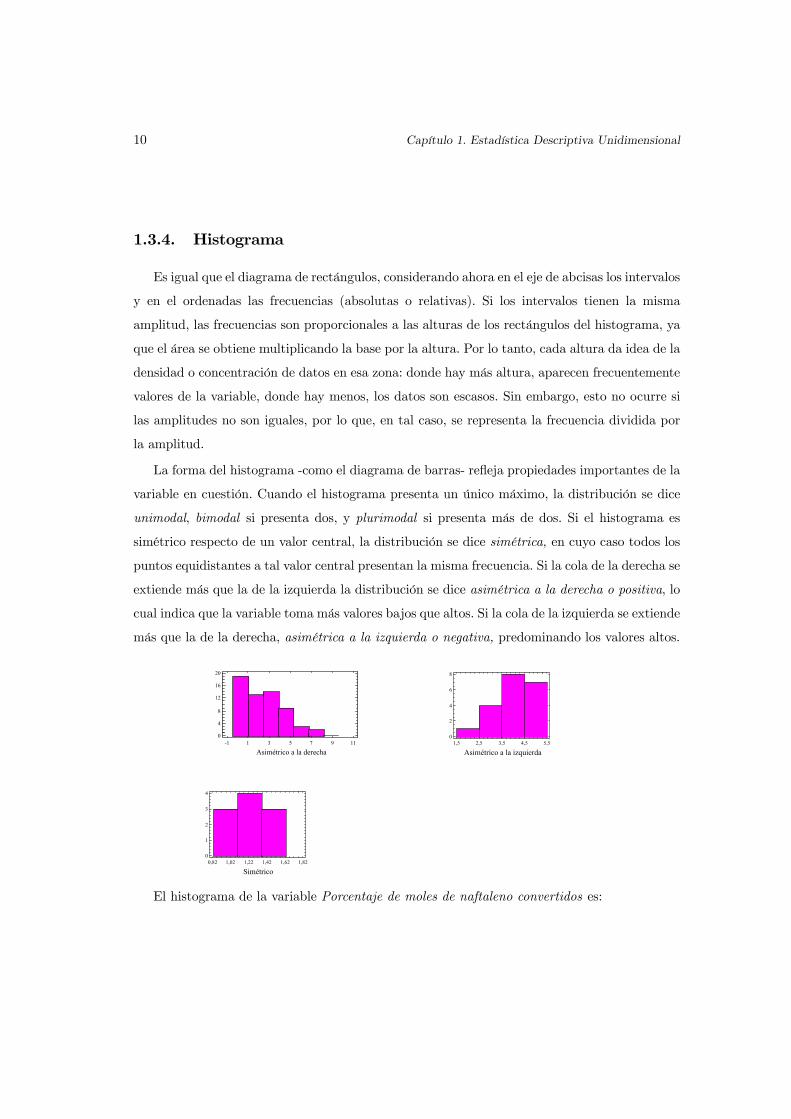
La forma del histograma -como el diagrama de barras- refleja propiedades importantes de la
variable en cuestión. Cuando el histograma presenta un único máximo, la distribución se dice
unimodal, bimodal si presenta dos, y plurimodal si presenta más de dos. Si el histograma es
simétrico respecto de un valor central, la distribución se dice simétrica, en cuyo caso todos los
puntos equidistantes a tal valor central presentan la misma frecuencia. Si la cola de la derecha se
extiende más que la de la izquierda la distribución se dice asimétrica a la derecha o positiva, lo
cual indica que la variable toma más valores bajos que altos. Si la cola de la izquierda se extiende
más que la de la derecha, asimétrica a la izquierda o negativa, predominando los valores altos.
Asimétrico a la derecha-1 1 3 5 7 9 11
0
4
8
12
16
20
Asimétrico a la izquierda1,5 2,5 3,5 4,5 5,5
0
2
4
6
8
Simétrico0,82 1,02 1,22 1,42 1,62 1,82
0
1
2
3
4
El histograma de la variable Porcentaje de moles de naftaleno convertidos es:
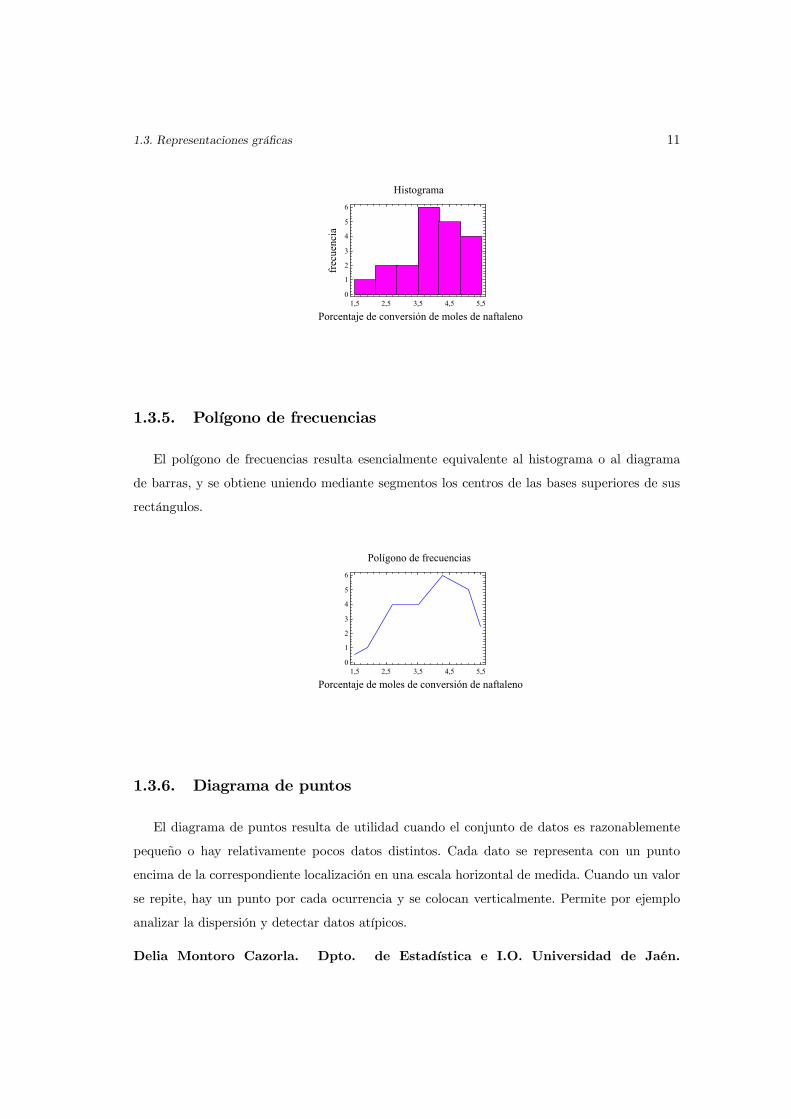
1.3. Representaciones gráficas 11
Histograma
Porcentaje de conversión de moles de naftalenofr
ecue
ncia
1,5 2,5 3,5 4,5 5,50
1
2
3
4
5
6
1.3.5. Polígono de frecuencias
El polígono de frecuencias resulta esencialmente equivalente al histograma o al diagrama
de barras, y se obtiene uniendo mediante segmentos los centros de las bases superiores de sus
rectángulos.
Polígono de frecuencias
Porcentaje de moles de conversión de naftaleno1,5 2,5 3,5 4,5 5,5
0
1
2
3
4
5
6
1.3.6. Diagrama de puntos
El diagrama de puntos resulta de utilidad cuando el conjunto de datos es razonablemente
pequeño o hay relativamente pocos datos distintos. Cada dato se representa con un punto
encima de la correspondiente localización en una escala horizontal de medida. Cuando un valor
se repite, hay un punto por cada ocurrencia y se colocan verticalmente. Permite por ejemplo
analizar la dispersión y detectar datos atípicos.
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

12 Capítulo 1. Estadística Descriptiva Unidimensional
Diagrama de puntos
Nº de resistencias defectuosas0 2 4 6 8
1.4. Descripción numérica de una variable
Las técnicas estudiadas anteriormente permiten una descripción visual de la distribución de
una variable. En muchos casos, el resumen puede hacerse eficazmente de una forma más sencilla
y precisa: utilizando valores numéricos que den idea de la ubicación o del centro de los datos
-medidas de posición- usando cantidades que informen de la concentración de las observaciones
alrededor de dicho centro -medidas de dispersión- y mediante números que reflejen la forma
(asimetría y apuntamiento) de la distribución -medidas de forma.
La conjunción de técnicas numéricas y gráficas permite una buena descripción de la variable.
1.4.1. Medidas de posición
Entre ellas estudiamos:
La media
La mediana
La moda
Cuantiles: deciles, cuartiles y percentiles
La media
Supongamos que hemos medido la variable X sobre N individuos y tenemos los valores
x1, x2, ...., xN . La media aritmética, o simplemente media, se calcula como:

1.4. Descripción numérica de una variable 13
- Si se dispone de los datos sin tabular :
−x =
PNi=1 xiN
=x1 + ...+ xN
N
- Si los datos están tabulados:
−x =
Pki=1 nixiN
=kXi=1
fixi
La media se mide en las mismas unidades que la variable, y tiene el inconveniente de verse
muy afectada por la presencia de datos que sean extremadamente grandes o pequeños (datos
atípicos).
Ejemplo 1.4: Cálculo de la media de los datos del ejemplo 1.1.
−x =
2 + 1 + 2 + 4 + ...+ 6 + 1 + 2 + 3
60= 2,53 resistencias defectuosas por caja.
A partir de la tabla de frecuencias,
xi ni nixi
0 7 0
1 12 12
2 13 26
3 14 42
4 6 24
5 3 15
6 3 18
7 1 7
8 1 8
N = 60 152
−x =
Pki=1 nixiN
=152
60= 2,53
Ejemplo 1.5: Cálculo de la media de los datos del ejemplo 1.2
Si trabajamos con los datos sin tabular,
−x =
4,2 + 4,7 + ...+ 2,8 + 5,0
20= 3,985
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

14 Capítulo 1. Estadística Descriptiva Unidimensional
Si trabajamos con los datos tabulados, hemos de calcular las marcas de clase.
% Moles ni xi nixi
(1.5-2.5] 1 2 2
(2.5-3.5] 4 3 12
(3.5-4.5] 8 4 32
(4.5-5.5] 7 5 35
20 81
−x =
81
20= 4,05
Nótese que 4.05 no es la media real, es un valor aproximado, ya que se está suponiendo que
los datos son:
2, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5.
En adelante, si es posible, siempre calcularemos las medidas a partir de los datos sin agrupar
en intervalos, para no perder precisión innecesariamente.
La mediana
Es el valor que divide al conjunto de observaciones ordenado de menor a mayor en dos partes
iguales, ocupa el lugar central. Deja por tanto al 50% de las observaciones por debajo y al 50%
por encima.
Mín 50% Mediana 50% Máx
Se calcula de las siguientes formas:
- Si los datos están sin tabular : una vez ordenados de menor a mayor se toma el valor
central si el número de observaciones N es impar; si es par se toma la media de los dos
valores centrales.
- Si los datos están tabulados : si existe un valor con frecuencia relativa acumulada igual a
0.5, se toma como mediana la media de tal valor y el siguiente. En otro caso, se toma
aquel valor que supere por primera vez en frecuencia relativa acumulada 0.5.

1.4. Descripción numérica de una variable 15
A diferencia de la media, la mediana no se ve afectada por la presencia de datos extremos.
Por lo tanto, en un conjunto de datos con valores extremos, la mediana será una medida de
centralización más representativa que la media.
Ejemplo 1.6: Cálculo de la mediana de los datos del ejemplo 1.2
Los datos ordenados de menor a mayor son:
2, 2,8, 2,8, 3, 3,1, 3,6, 3,8, 3,8, 3,8, 4, 4, 4,2, 4,3, 4,7, 4,7, 4,8, 5, 5, 5,1, 5,2
Mediana =4 + 4
2= 4
Interpretación: en el 50% de los experimentos se obtiene un porcentaje de conversión de
moles inferior o igual a 4.
Nótese que en el primer 4 se obtiene una frecuencia relativa acumulada de 0.5.
Ejemplo 1.7: Cálculo de la mediana de los datos del ejemplo 1.1
xi ni Fi
0 7 0.1167
1 12 0.3167
2 13 0.5334
3 14 0.7667
4 6 0.8667
5 3 0.9167
6 3 0.9667
7 1 0.9834
8 1 1
N = 60
El valor 2 es la mediana, ya que presenta una frecuencia relativa acumulada de 0.5334,
inmediatamente superior a 0.5
Interpretación: El 50% de los cajas presentan un número de resistencias defectuosas inferior
o igual a 2.
La moda
Es el valor más frecuente de la variable (mayor ni o fi). Es el valor que presenta mayor
altura en el diagrama de barras (caso discreto) o el intervalo con mayor altura en el histograma
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

16 Capítulo 1. Estadística Descriptiva Unidimensional
(caso continuo). La moda puede no ser única o no existir.
Ejemplo 1.8: Cálculo de la moda de los datos del ejemplo 1.1
El valor con máxima frecuencia (13) es el 3.
Moda = 3
Interpretación: lo más frecuente es encontrar cajas con 3 resistencias defectuosas.
Ejemmplo 1.9: Cálculo de la moda de los datos del ejemplo 1.2
En este caso señalamos el intervalo modal: (3.5-4.5]
Interpretación: el porcentaje de conversión de moles más frecuente está entre el 3.5 y el
4.5%.
Cuantiles: deciles, cuartiles y percentiles
Son medidas basadas en la ordenación de los datos. Dividen al conjunto de datos ordenado
en partes iguales. Según el número de partes, hablamos de:
Deciles: dividen al conjunto de datos en 10 partes iguales, cada una de las cuales engloba
un 10% de datos. Hay por tanto 9 deciles, D1, ...,D9.
Cuartiles: dividen al conjunto de datos en 4 partes iguales, cada una de las cuales engloba
un 25% de datos. Hay por tanto 3 cuartiles, Q1, Q2, Q3.
Percentiles: dividen al conjunto de datos en 100 partes iguales, cada una de las cuales
engloba un 1% de datos. Hay por tanto 99 percentiles, P1, ..., P99.
La mediana, al dejar por debajo a un 50% de los datos, coincide con el D5, Q2 y P50.
La forma de cálculo de los cuantiles es similar a la de la mediana.
Una franja de interés es [P25- P75] , que contiene al 50% de los datos centrales. Por debajo
del P25 quedan el 25% de los datos más pequeños, y por encima del P75 quedan el 25% de los
datos más grandes.
Ejemplo 1.10: Cálculo de los percentiles 25 y 75 de los datos del ejemplo 1.1
P25 = 1 (Fi = 0,3167 > 0,25)
P75 = 3 (Fi = 0,7667 > 0,75)

1.4. Descripción numérica de una variable 17
Otra forma de calcularlos: el P25 es aquel valor que deja por debajo al 25% de los datos,
que en este caso son 15 (25% de 60). Análogamente, el P75 es el valor que deja 45 datos (75%)
por debajo y 15 datos (25%) por arriba.
Interpretación: El 25% de los paquetes con menos resistencias defectuosas presentan como
mucho 1, y el 25% de los paquetes con más resistencias defectuosas presentan como mínimo 3.
Ejemplo 1.11: Cálculo de los percentiles 25 y 75 de los datos del ejemplo 1.2
P25 = 3,35,
P75 = 4,75
1.4.2. Medidas de dispersión
Las medidas de posición o centralización no siempre proporcionan información suficiente
para describir un conjunto de datos de manera adecuada. Por ejemplo, veamos los tres conjuntos
de datos siguientes:
Ejemplo 1.12:
Tabla 1.5: Conjunto de datos ejemplo 1.12
Conjunto 1: 10,20,30,40,50
Conjunto 2: 10,30,30,30,50
Conjunto 3: 30,30,30,30,30
Las medidas de centralización de cada uno de los conjuntos son:
Media Mediana Moda
Conjunto 1 30 30 No existe
Conjunto 2 30 30 30
Conjunto 3 30 30 30
A la vista de estas medidas podríamos llegar a la conclusión equivocada de que los tres
conjuntos de datos son muy similares. Sin embargo, hay una clara diferencia entre los tres
conjuntos: en el primero, hay gran dispersión en los datos (datos poco parecidos), en el tercero
la concentración de los datos es total, y en el segundo se da una situación intermedia. Es por
esto por lo que es necesario recurrir a otras medidas, las medidas de dispersión, que sean capaces
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

18 Capítulo 1. Estadística Descriptiva Unidimensional
de diferenciar estas situaciones. Claramente, el tercer conjunto de datos es el mejor; en él las
medidas de centralización serán plenamente representativas.
Entre las medidas de dispersión estudiamos:
Rango. Rango Intercuartílico
Varianza. Desviación típica
Coeficiente de variación
Rango. Rango Intercuartílico
Una medida de variabilidad basada en la ordenación de las observaciones es el rango, R,
definido como la difencia entre el valor máximo y el mínimo,
R =Max−Min
El rango de un conjunto de datos es muy fácil de calcular, pero ignora toda la información
contenida entre las observaciones más grande y más pequeña. Por ejemplo, las muestras 1,3,5,8,9
y 1,5,5,5,9 tienen el mismo rango igual a 8. Sin embargo, en la segunda muestra sólo existe
variabilidad en los valores extremos, mientras que en la primera los tres valores intermedios
cambian de manera considerable. Algunas veces, cuando el tamaño de la muestra es pequeño,
la pérdida de información no es muy seria. Por ejemplo, el rango se utiliza mucho en el control
de la calidad, donde se suelen utilizar muestras de tamaño 4 o 5. En general, lo que se desea
es tener una medida de variabilidad que dependa de todas las observaciones, más que de unas
cuantas.
Una medida menos sensible a los valores extremos es el rango intercuartílico, RI, definido
como la diferencia entre el tercer y primer cuartil,
RI = Q3 −Q1
Esta medida informa acerca de la representatividad de la mediana (Q2) : si el RI es pequeño,
el 50% de las observaciones centrales están muy concentradas entorno a la mediana.
Varianza. Desviación típica
La varianza y desviación típica miden la dispersión de los datos entorno a la media, y hacen
uso de todas las observaciones. Una forma intuitiva de medir la concentración de los datos

1.4. Descripción numérica de una variable 19
entorno a la media es calcular lo que distan los mismos de la media,
x1 − −x, ..., xN − −x
Si todas estas diferencias son pequeñas entonces las observaciones xi estarán próximas a−x
y diremos que hay poca variabilidad. Una forma sencilla de combinar todas las desviaciones
en una única medida es promediarlas, pero al sumarlas, desviaciones positivas y grandes en
magnitud pueden ser compensadas con desviaciones negativas grandes en magnitud.
NXi=1
(xi − −x)
N=
NXi=1
xi −N−x
N= 0
Una alternativa es promediar tales diferencias en valor absoluto o al cuadrado. Al promedio
de las desviaciones al cuadrado se le conoce como varianza, σ2,
σ2 =
NXi=1
(xi − −x)2
N=
NXi=1
x2i
N− −x
2
Si los datos están tabulados,
σ2 =kXi=1
fi(xi − −x)2 =
kXi=1
ni(xi − −x)2
N=
kXi=1
nix2i
N− −x
2
Se expresa en el cuadrado de las unidades de la variable.
Observad que σ2 ≥ 0 y que σ2 = 0 sí y sólo sí todas las observaciones son idénticas y por lotanto coinciden con la media (mejor de los casos).
A la raíz cuadrada de la varianza se le conoce como desviación típica,
σ =√σ2
En general podríamos pensar que a mayor valor en la varianza o desviación típica, mayor
dispersión y menor concentración de los datos entorno a la media. En relación a esta idea, se
presenta el problema de que ambas medidas dependen de las unidades de medida (o dimensión)
de los datos. Por ejemplo, una misma muestra de alturas en centímetros y en metros da lugar a
varianzas distintas, mayor en el primer caso. Por lo tanto la varianza y desviación típica no nos
permiten cuantificar la variabilidad ni comparar la dispersión de variables medidas en unidades
distintas.
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

20 Capítulo 1. Estadística Descriptiva Unidimensional
Nota: si en lugar de dividir en tales medidas por N dividimos por N − 1, se obtienen lacuasivarianza y cuasidesviación típica, que denotamos respectivamente por S2 y S,
S2 =
NXi=1
(xi − −x)2
N − 1 =
NXi=1
x2i −N−x2
N − 1 ,
S =√S2
Ejemplo 1.13: Cálculo de la varianza y desviación típica en datos de ejemplo 1.1
xi ni nixi nix2i
0 7 0 00
1 12 12 12
2 13 26 52
3 14 42 126
4 6 24 96
5 3 15 75
6 3 18 108
7 1 7 49
8 1 8 64
N = 60 152 582
−x =
Pki=1 nixiN
=152
60= 2,53,
σ2 =
NXi=1
x2i
N− −x
2
=582
60− 2,532 = 3,3
σ =√3,3
Coeficiente de variación
Como solución al problema de dependencia de las unidades de medida de las variables que
presentan la varianza y desviación típica, se crea una nueva medida adimensional (no depende
de las unidades de medida) conocida como coeficiente de variación, definido como el cociente
entre la desviación típica y la media (en valor absoluto),
CV =σ¯̄̄−x¯̄̄
Mide la concentración relativa de los datos entorno a la media. Cuanto más próximo a cero
esté (vale 0 cuando σ = 0), menor dispersión habrá, y por lo tanto más representativa será la
media.
Ejemplo 1.14: Con un micrómetro se realizan mediciones del diámetro de un balero, que
tienen una media de 4.03 mm y una desviación típica de 0.012 mm; con otro micrómetro se

1.4. Descripción numérica de una variable 21
toman mediciones de la longitud de un tornillo, que tienen una media de 1.76 pulgadas y una
desviación típica de 0.0075 pulgadas. Los coeficientes de variación son:
CVbalero =0,012
4,03= 0,003
CVtornillo =0,0075
1,76= 0,004
En consecuencia, las mediciones realizadas con el primer micrómetro presentan una vari-
abilidad relativamente menor que las efectuadas con el segundo.
1.4.3. Medidas de forma
Ya vimos cómo a partir de una representación gráfica se pueden estudiar algunos rasgos
importantes de la variable; comentamos cómo hacernos una idea de la simetría o asimetría
de una variable según la forma del histograma. La simetría o asimetría también puede estudi-
arse con una medida numérica, el coeficiente de asimetría. Exiten varios coeficientes, el que a
continuación vemos se debe a Fisher y presenta la siguiente expresión:
γ1 =
PNi=1(xi −
−x)3
Nσ3,
y
γ1 =
Pki=1 fi(xi −
−x)3
σ3=
Pki=1 ni(xi −
−x)3
Nσ3
si los datos están tabulados.
Si un coeficiente de asimetría vale 0, la distribución es simétrica, si es mayor que 0, asimétrica
a la derecha o positiva, y si es menor que cero, asimétrica a la izquierda o negativa.
También podemos hacernos una idea acerca de la simetría o asimetría de una variable
comparando su media y mediana. Claramente, en variables simétricas la media, la mediana y
la moda (si es única) coinciden. Si la distribución es marcadamente asimétrica a la derecha,
su media será bastante mayor que la mediana, ya que aunque sean pocos los valores altos que
tome (cola de la derecha) , tirarán de la media hacia arriba, mientras que a la mediana según
comentamos no le afectan los valores extremos. Si la distribución es marcadamente asimétrica
a la izquierda, la media será bastante menor que la mediana.
En relación a la forma aparece también el término curtosis, que hace referencia al apun-
tamiento de la distribución. Por ejemplo, si una variable presenta un histograma muy apuntado
(alta frecuencia ) y estrecho, sus datos estarán muy concentrados.
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

22 Capítulo 1. Estadística Descriptiva Unidimensional
1.4.4. Observaciones sobre las medidas numéricas descriptivas
1. Cambios de variable lineales: Supongamos que a, b, son dos números reales. Hacemos una
transformación en los datos de la forma yi = axi + b, i = 1, ..,N, es decir, Y = aX + b.
Entonces,
−y = a
−x + b,
σ2y = a2σ2x,
σy = |a|σx,
2. Variable tipificada: Tipificar una variable consiste en hacer una transformación lineal tal
que la nueva variable tenga media 0 y varianza 1. La transformación es
Z =X − −xσx
3. Variable clasificada en grupos o estratos: Supongamos que tenemos N observaciones clasi-
ficadas en L grupos. El grupo i presenta un tamaño ni, una media−xi, una varianza σ2i ,
y su peso en el total de la población es wi =niN. Entonces, la media total y la varianza
total (de las N observaciones) vienen dadas por:
−x =
LXi=1
wi−xi,
σ2x =LXi=1
wiσ2i +
LXi=1
wi(−xi − −x)2
1.5. Ejercicios
1. Los ingenieros industriales realizan periódicamente un análisis de la medición del trabajo
con el fin de determinar el tiempo requerido para generar una unidad de producción. En
una planta de procesamiento se registró durante 20 días el número de horas-obrero totales
requeridas para realizar cierta tarea. Los datos recogidos son:
128 119 95 97
113 109 124 132
146 128 103 135
124 131 133 131
100 112 111 150
1.5. Ejercicios 23
a) Obtén la tabla de frecuencias absolutas y relativas.
b) Construye el histograma.
c) Calcula la media, mediana y moda. Interpreta resultados.
d) ¿Cuánto tiempo requieren como máximo el 25% de los obreros más rápidos?. ¿Cuánto
tiempo requieren como mínimo el 25% de los que más tiempo emplean?.
e) En base al histograma estudia la simetría o asimetría de la distribución.
f ) Decide qué medida de posición puede ser representativa.
g) Calcula una medida de dispersión asociada a la medida de posición anterior.
2. Describe las características de los cuatro histogramas siguientes, y razona cuál es la medida
de centralización y dispersión más adecuada para la distribución correspondiente.
0 1 2 3 4 5 60
2
4
6
8
-1 1 3 5 7 9 110
10
20
30
40
-2,5 -1,5 -0,5 0,5 1,5 2,5 3,50
10
20
30
40
3. El técnico responsable del funcionamiento de una empaquetadora automática la ajustó,
en principio, para 450 g. Media hora después del principio de la producción se apartaron
10 paquetes para verificar su peso. Los resultados son:
Peso (g) 448 450 453 451 447 449 446 451 448 447
a) ¿Cuál es el peso medio de esa muestra?. Calcula la varianza y la desviación típica,
así como la mediana y los percentiles 25 y 75.
b) Se considera que la empaquetadora funciona correctamente si la media de una mues-
tra de 10 paquetes se sitúa en el intervalo [448,452]. ¿Cuál es la conclusión en el caso
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.

24 Capítulo 1. Estadística Descriptiva Unidimensional
de la muestra anterior?. ¿Te parece correcta la elección de tal método de decisión?.
¿Alguna idea para mejorar?.
4. El responsable en control industrial de una empresa somete a un test de fiabilidad 50
dispositivos electrónicos idénticos y anota su duración (tiempo hasta el fallo en horas).
La recogida de datos lleva a la distribución de frecuencias siguiente:
Duración (horas) No de dispositivos
0 < X ≤ 200 17
200 < X ≤ 400 9
400 < X ≤ 600 7
600 < X ≤ 800 7
800 < X ≤ 1000 6
1000 < X ≤ 1200 2
1200 < X ≤ 1400 1
1400 < X ≤ 1600 1
a) Obtén la tabla de frecuencias relativas y relativas acumuladas.
b) Representa el histograma. Señala el intervalo modal.
c) ¿Cuál es el tiempo medio de fallo de este tipo de dispositivos?.
d) ¿En qué intervalo se encontrará la mediana?.
e) ¿Qué porcentaje de dispositivos tienen una duración superior a 200h? ¿y a 600?.
¿Qué porcentaje de dispositivos tienen una duración comprendida en el intervalo
200 < X ≤ 400?.¿Qué porcentaje supera el tiempo medio de fallo?.
5. En una empresa se clasifican los accidentes laborales según causen o no la baja en el
trabajador. Los datos medidos mensualmente durante un año son:
No Accidentes
No causan baja 498
Causan baja 152
650
a) Calcula los porcentajes correspondientes a cada tipo de accidente.

1.5. Ejercicios 25
b) Obtén una representación gráfica.
6. En una empresa, los empleados se clasifican en dos categorías: técnicos y especialistas. El
número de empleados, el salario medio anual en miles de euros y la desviación típica se
muestran en la tabla siguiente:
Categoría No de empleados Salario medio Desv. típica
Especialista 20 24 3
Técnico 100 18 4
a) Calcula el salario medio y varianza del salario para el conjunto de trabajadores de
la empresa.
b) En la negociación del salario del año siguiente, se proponen dos alternativas. La
primera consiste en elevar los salarios un 5% a todo el personal. La segunda, en
elevar el salario 1.2 miles de euros al año a todo el personal. Calcula la media y
varianza para el conjunto de los trabajadores en ambas alternativas. ¿Qúe alternativa
es mejor?. Razona la respuesta.
7. En una liga de rugby femenino se contabilizaron y clasificaron las lesiones que tienen lugar
(A=rotura de menisco, B=rotura de ligamentos, C=rotura de tibia, D=rotura de rótula,
E=rotura de fémur). Los resultados son:
A B B A C A A D B A C
E B B A A C D C A C B
C C C A B B C A A B C
C A C B B D A B A C B
C C A B B A D E C A B
Realiza una tabla de frecuencias y dibuja el diagrama de Pareto. Interpreta resultados.
8. Se tienen dos proveedores en dos áreas geográficas diferentes. En la primera zona los
proveedores tienen una puntuación media de 6.23 con una desviación típica de 2.3. En
la segunda zona tienen una media de 5.2 con una desviación de 1.3. El proveedor de la
primera zona tiene una puntuación de 6.84 y el de la segunda tiene una puntuación de
6.31. ¿Cuál de los dos dos es mejor en relación a su zona?.
Delia Montoro Cazorla. Dpto. de Estadística e I.O. Universidad de Jaén.


















