
disenio experimentos
119
DISEÑO DE EXPERIMENTOS. 1. Introducción.(2 hrs). 2. Diseño completamente al azar. (6) 3. Diseño en blo qu es comp letos al azar. (4 ) 4. Diseño en cuadro latino.(4) 5. Arr eglo de tra ta mientos en dos factores.(10) 6. Arr egl os de tra ta mientos mult if acto rial. (4 ) 7. Arreglos factoriales dos a la k.(6) 8. Confusión en l os arre gl os fa ct or iales dos a l a k .( 6) 9. Bloques incompletos.(4) 10. Factoriale s fr accionados.( 4) 11. Ar re gl os Orto go nales de Tag uchi .( 6) 12. Me todología de superficie d e respue st a.(8). INTRODUCCION 1. Relación entr e in vestigación y estadística. 2. Obj eti vo ge neral de la expe rimentaci ón. 3. Objetiv o d e un diseño e xperimental. 4. Ingre di entes de un di se ño exp eriment al. 5. Va ri ab le s y s us relaciones en un diseño experimental. 6. Modelos estadísticos para establecer las relaciones entre variables en un diseño experimental. Relación entre investigación y estadística: La investigación es una actividad inherente a todo ser humano. En mayor o menor grado desde pequeños se nota la inquietud por investigar ci er to s as pe ct os de interé s. Por ej empl o, una de las formas de aprendizaje más rudimentarias es la prueba y error, en donde la prueba realmente consiste en un ex pe rimento pa ra in ve st ig ar un cierto resultado. Las herramientas de investigación en algunos casos se van
Transcript of disenio experimentos

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 1/119
DISEÑO DE EXPERIMENTOS.
1. Introducción.(2 hrs).
2. Diseño completamente al azar. (6)
3. Diseño en bloques completos al azar.(4)4. Diseño en cuadro latino.(4)
5. Arreglo de tratamientos en dos factores.(10)
6. Arreglos de tratamientos multifactorial.(4)
7. Arreglos factoriales dos a la k.(6)
8. Confusión en los arreglos factoriales dos a la k.(6)
9. Bloques incompletos.(4)
10. Factoriales fraccionados.(4)11. Arreglos Ortogonales de Taguchi.(6)
12. Metodología de superficie de respuesta.(8).
INTRODUCCION
1. Relación entre investigación y estadística.
2. Objetivo general de la experimentación.
3. Objetivo de un diseño experimental.
4. Ingredientes de un diseño experimental.
5. Variables y sus relaciones en un diseño experimental.
6. Modelos estadísticos para establecer las relaciones entre
variables en un diseño experimental.
Relación entre investigación y estadística:
La investigación es una actividad inherente a todo ser humano. En
mayor o menor grado desde pequeños se nota la inquietud por investigar
ciertos aspectos de interés. Por ejemplo, una de las formas de
aprendizaje más rudimentarias es la prueba y error, en donde la prueba
realmente consiste en un experimento para investigar un cierto
resultado. Las herramientas de investigación en algunos casos se van

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 2/119
mejorando e incrementando, en otros no evolucionan y permanecen con
las mismas técnicas rudimentarias de investigación.
A nivel de actividad profesional, en todos los campos, debe ser una
actividad de primordial importancia. Por ejemplo, para los médicos, cada
paciente es un sujeto de investigación, cuyo objetivo es llegar a resolver
un problema. Por otro lado, a nivel del campo de la medicina se lleva a
cabo una labor muy intensa de investigación para el desarrollo de
nuevos fármacos, nuevas técnicas quirúrgicas, nuevos equipos en el
diagnostico y tratamiento de enfermedades, etc. El desarrollo en todos
los campos de actividad profesional se atribuyen en gran medida a la
aplicación de los resultados obtenidos a través de la investigación.
La gran mayoría de las investigaciones se llevan a cabo a través de la
aplicación del método científico que incluye los siguientes pasos:
1. Establecer el problema.
2. Formular la hipótesis.
3. Diseñar el experimento o muestreo.
4. Tomar las observaciones.
5. Interpretar los datos.
6. Concluir.
Este proceso lleva implícitos algunos pasos que son de naturaleza
estadística.
Empezando por la formulación de la hipótesis, punto de primordial
importancia para el desarrollo de la investigación. Una hipótesis
estadística debe incluir el juego de hipótesis que incluye:
La hipótesis nula (Ho).
La hipótesis alternativa (Ha).
La hipótesis alternativa es la correspondiente a la hipótesis de trabajo
del investigador, aplicada a una variable de interés, y por ello es la que
direcciona el proceso de investigación en lo referente a las evidencias
que el investigador debe colectar y mostrar debidamente procesadas
para apoyar su hipótesis.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 3/119
La hipótesis alternativa es un enunciado en forma de una desigualdad
que indica el conjunto de valores que el parámetro, correspondiente a la
variable de interés, debe tomar para ser consistente con la hipótesis de
trabajo. En base a la desigualdad, las hipótesis alternativas se
clasifican como:
1. Ensayos bilaterales o de dos colas, cuando el signo de la
desigualdad es diferente de (≠) lo cual implica que la hipótesis
alternativa va a ser apoyada en cualquiera de los dos extremos de
los valores del parámetro. Este tipo de alternativa se establece
siempre que no se tiene una clara idea de la dirección de cambio
en el valor del parámetro.
2. Ensayos unilaterales o de una cola, que corresponden a una
hipótesis de trabajo unidireccional, de tal manera que pueden ser
de cola izquierda (<) o de cola derecha (>). La hipótesis de cola
izquierda implica que el extremo izquierdo de los valores del
parámetro apoyan a la hipótesis de trabajo; esto es, entre mas
pequeño el valor del parámetro mas consistentes son los
resultados con la hipótesis de trabajo. De manera equivalente, en
un ensayo de cola derecha, implicaría que entre mas alto el valor
del parámetro mas se favorece a la hipótesis de trabajo.
Hay que hacer notar que la hipótesis alternativa siempre es establecida
como una desigualdad, en la que como tal, nunca debe aparecer el
signo de la igualdad, y debe ser establecida en términos de la hipótesis
de trabajo.
La hipótesis nula es lo contrario a la hipótesis alternativa, por lo
que siempre incluye el signo de la igualdad. De esta manera
corresponde a la negación de lo que el investigador desea probar en su
investigación, por lo que esta se considera como verdadera, hasta que
se muestran suficientes evidencias que apoyan a la hipótesis de trabajo.
La hipótesis nula es una hipótesis de consecuencias estadísticas
definidas, es decir, es posible llegar a determinar que se espera del valor
del parámetro si la hipótesis nula es verdadera.
El mecanismo de una prueba de hipótesis puede ser descritocomo una comparación entre las evidencias colectadas y lo que se

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 4/119
espera bajo la hipótesis nula. Este mecanismo siempre conduce a una
toma de decisión basada en probabilidades de riesgos de equivocarse.
Para establecer los diferentes escenarios a que puede conducir una
toma de decisión considere el siguiente cuadro, en donde las entradas
son el estado de naturaleza, es decir lo que realmente es en relación a la
hipótesis nula, y por otro lado, la toma de decisión a que conduce la
evidencia colectada:
DECISION Ho Verdadera Ho Falsa=Ha VerdaderaRechazar Ho Error tipo I Poder de la pruebaNo Rechazar Ho. Confiabilidad Error tipo II
Las posibles decisiones a que puede conducir el mecanismo de una
prueba de hipótesis son:
1. Rechazar Ho, cuando se tienen suficientes evidencias que apoyan
a la hipótesis alternativa. Este tipo de decisión se considera el
mas fuerte, ya que lleva a la implícito el hecho de que el
investigador ha logrado confirmar su sospecha original mediante
su trabajo de investigación. El error tipo I esta relacionado con
esta decisión al definirlo como: Rechazar Ho cuando Ho es
verdadera. A la probabilidad de este error se le denota por la letra
α (alfa) y para propósitos de toma de decisión, el alfa de la prueba
se establece a niveles muy bajos, tales como 0.10, 0.05 o 0.01. A
este nivel de error tipo I fijado en la prueba se le llama nivel de
significancia de la prueba.
2. No Rechazar Ho, cuando el investigador no ha logrado reunir los
suficientes elementos que confirmen su hipótesis de trabajo. Es
una decisión en la que la sospecha queda como tal, y si es
razonable, queda abierta la posibilidad de seguirla investigando,
con técnicas mejoradas o de manera mas minuciosa que lleve a la
colección de evidencias requeridas. El error tipo II esta
relacionado con esta decisión al definirlo como: No Rechazar Ho
cuando Ho es falsa. La probabilidad asociada a este error se le
denota por β (beta).

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 5/119
El mecanismo para llevar a cabo una prueba de hipótesis consiste de los
siguientes pasos:
1. Establecer el juego de hipótesis.
2. Establecer la estadística de prueba.
3. Determinar la distribución de la estadística de prueba bajo la
hipótesis nula.
4. Determinar el nivel de significancia y zona de rechazo.
5. Calculo de la estadística de prueba en base a la evidencia
colectada.
6. Toma de decisión-
7. Conclusión-
Diseñar el experimento o muestreo:
En estadística se tienen dos metodologías para la colección de
evidencias para probar una hipótesis, que son:
1. Diseño experimental.
2. Diseño de muestreo.
La colección de datos bajo un diseño experimental implica un proceso de
control por parte del investigador con la finalidad de asociar datos a
condiciones experimentales. El objetivo es determinar la relación causa
– efecto.
La colección de datos por muestreo es un examen de un sistema en
operación en el que el investigador no tiene oportunidad de asignar
diferentes condiciones a los objetos de estudio. El objetivo básico es la
caracterización del sistema en base a las variables evaluadas.
Entonces, el diseño experimental es una herramienta de metodología
estadística para colectar los datos bajo condiciones controladas y a la
vez construir, en base a la metodología de colección, los modelos
necesarios para analizar e interpretar los resultados.
La interpretación de resultados se lleva a cabo una vez que los
datos colectados son procesados y sometidos al mecanismo de una
prueba de hipótesis. La interpretación comprende básicamente la toma

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 6/119
de decisión y la conclusión, incluidas en el mecanismo de la prueba de
hipótesis.
De esta manera, en gran medida, el método científico esta
apoyado fuertemente por la metodología estadística, desde el
planteamiento de las hipótesis, colección de los datos, procesamiento,
interpretación y conclusión.
Objetivo general de la experimentación:
En términos muy sencillos un experimento es una prueba o ensayo que
conduce a un resultado cuantificable.
En términos prácticos es una manipulación deliberada de un proceso
con el propósito de medir el impacto del cambio en una o mas variables
de entrada sobre una o mas variables de salida.
Formalmente, el experimento es definido como una operación llevada a
cabo bajo condiciones controladas para descubrir un efecto
desconocido, probar una hipótesis o ilustrar una ley conocida.
En general, los experimentos son llevados a cabo para explorar, estimar
o confirmar.
Objetivo de un diseño experimental:
El diseño de experimentos o diseño estadístico de experimentos es una
disciplina basada en principios estadísticos, y construida a través de
años de experiencia en la ciencia y la ingeniería. Implica el proceso de
diseño y planeacion del experimento, de tal forma que datos apropiados
puedan ser colectados y posteriormente ser analizados por métodos
estadísticos para llegar a conclusiones validas y objetivas.
Los principales beneficios de la experimentación diseñada es que la
información critica es obtenida mas rápido, económica y confiable de lo
que seria si se aplicara un enfoque no planeado.
El DOE o SDE permite al investigador entender un proceso y determinar
como las variables de entrada (factores) afectan a las variables de salida

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 7/119
(respuesta). Es un enfoque sistemático para la optimización de
procesos. En general el DOE puede ser usado para:
1. Estudiar el efecto de varios factores sobre el comportamiento del
producto o proceso.
2. Entender la relación entre las variables de entrada y las variables
de salida.
3. Identificar las condiciones optimas de un proceso que maximizan
o minimizan la respuesta.
4. Reducir la variabilidad en las características de un producto.
5. Mejorar la confiabilidad del producto.
6. Reducir costos de manufactura.
7. Acortar el tiempo de desarrollo de productos o procesos.
Variables y sus relaciones en un diseño experimental:
En todo experimento debemos definir la unidad experimental, como el
material mínimo requerido para aplicar los tratamientos (las causas) y
evaluar las respuestas (los efectos).
También debemos definir los tratamientos como cada una de las
diferentes condiciones experimentales que van a ser evaluadas en el
experimento.
Las variables en un diseño experimental se clasifican fundamentalmente
en dos grandes grupos de acuerdo su rol en la unidad experimental:
1. Variables de entrada.
2. Variables de salida.
Las variables de entrada son todas aquellas variables a las que esta
expuesta la unidad experimental. Comprende los siguientes grupos de
variables:
1. Factores experimentales.
2. Factores de bloqueo.
3. Factores de ruido.
4. Variables deliberadamente controladas.
5. Variables no controladas.
Factores experimentales:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 8/119
Los factores experimentales son aquellas variables del proceso que
deliberadamente son manipuladas en un experimento para investigar su
impacto sobre las variables de respuesta. Cada uno de los valores de
estas variables incluidos en un experimento se denomina los niveles del
factor. Si el experimento incluye solo un factor (experimento unifactorial),
entonces cada uno de los niveles se constituye en un tratamiento. Si el
experimento incluye varios factores (experimento multifactorial),
entonces la combinación de los niveles de todos y cada uno de los
factores incluidos será lo que se constituya como un tratamiento.
Los factores experimentales se clasifican de acuerdo a varios criterios:
De acuerdo a la naturaleza de los niveles los factores se clasifican en:
1. Cualitativos o categóricos.
2. Cuantitativos o continuos.
Los cualitativos o categóricos son aquellos factores donde la escala de
los niveles es puramente nominal. Para este tipo de factores el interés se
centra en la comparación de los promedios, para seleccionar el mas
adecuado. Al graficar estos promedios no existe un orden único de los
niveles y por lo tanto nunca deben usarse líneas continuas o de puntos
en su representación, siendo lo mas conveniente una grafica de barras.
Los factores cuantitativos son aquellos cuyos niveles se expresan en
una escala numérica, siendo el principal objetivo del análisis el describir
un modelo de respuesta de acuerdo a los niveles de este factor. Su
representación grafica mas adecuada es a través de puntos o líneas.
De acuerdo a la forma de selección de los niveles del factor, se clasifican
como:
1. Factores fijos.
2. Factores aleatorios.
Los factores fijos son aquellos en los que la selección de los niveles esta
basada en el interés del investigador, quien decide cuales son los que
deben incluirse en el experimento. Para este tipo de factores las
conclusiones están restringidas al rango de niveles seleccionados, para
factores continuos, o estrictamente para los niveles seleccionados en
caso de los factores cualitativos.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 9/119
Los factores aleatorios son aquellos en donde los niveles del factor se
seleccionan de una población de niveles de una manera aleatoria. Para
este tipo de factores el interés esta centrado en investigar la variabilidad
que genera el cambio en los niveles de este factor.
Para los experimentos multifactoriales, los factores se clasifican de
acuerdo a la relación que guardan los niveles de los factores en:
1. Factores cruzados, en los que los niveles de dos factores son
independientes, es decir, los niveles de un factor se pueden
combinar sin ninguna restricción con los niveles del segundo
factor, generando así una estructura factorial de tratamientos.
2. Factores anidados, en los que los niveles de un factor de jerarquía
inferior depende de los niveles de un factor de jerarquía superior,
generando así una estructura jerárquica.
Factores de bloqueo: Cuando fuentes de variación extrañas e
indeseables pueden ser identificadas, podemos diseñar el experimento
de tal forma que eliminemos su influencia. La idea es arreglar las
unidades experimentales en grupos o bloques de unidades uniformes en
los valores de la variable de bloqueo, asignando luego, al azar, los
tratamientos dentro de cada bloque. La variabilidad entre bloques es
considerada en el análisis, lo que conduce a una mejora en la precisión
del experimento. Cuatro criterios son frecuentemente usados para
bloquear unidades experimentales: Proximidad de unidades
experimentales; características físicas de las unidades experimentales
que tengan un impacto fuerte en las variables de respuesta; tiempo;
administración de tareas en el experimento.
Factores de Ruido: Son las variables que solo pueden controlarse
durante la fase experimental, ya que resulta difícil o costoso tratar de
controlarlas durante la etapa de producción normal.
Variables deliberadamente controladas: Conjunto de variables en un
experimento que se caracterizan por tomar un valor constante durante la etapaexperimental, debido al control que ejerce el investigador sobre estas.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 10/119
Variables no controladas: Conjunto muy grande de variables que se les
permite variar sin control durante un experimento. Algunas pueden ser
monitoreadas y llegar a convertirse en covariables. Otras puede ser que no
sean medibles o accidentalmente ignoradas y este grupo es el que origina el
error experimental. En cualquier caso, el impacto que tienen sobre las variables
de respuesta debe ser mínimo. Si sucede que una variable de este grupo
cambia a la par con los niveles de un factor experimental, esto ocasiona una
confusión, ya que el análisis no puede separar el efecto en el cambio
simultaneo de ambas variables. Si el investigador no esta consciente de este
cambio simultaneo de variables, entonces la variable no controlada va a
enmascarar el efecto del factor experimental.
Las covariables deben reunir dos características: Guardar una relación lineal
con las variables de respuesta y que no deben ser impactadas por los
tratamientos. Estas variables, que pueden ser del ambiente físico o de las
mismas unidades experimentales, son analizadas conjuntamente con la
respuesta para mejorar la precisión del experimento.
Las variables de salida es el conjunto de variables que se van a evaluar
en la unidad experimental, una vez que el tratamiento haya impactado, para
determinar los efectos de tratamiento. Las respuestas se seleccionan en base a
dos criterios: Las respuestas que son sensibles a los factores experimentales
que se están investigando y las respuestas que son de importancia económica.
Componentes de un diseño experimental:
Dos características de todo diseño experimental son:
1. Repetición.
2. Aleatorizacion.
La repetición se refiere a que cada condición experimental debe ser aplicada
de manera independiente, al menos a dos unidades experimentales. A través
de las repeticiones en un tratamiento se evalúa la consistencia del tratamiento
en lo que se refiere a su efecto. Si los resultados en una variable de interés
son muy similares entre si, entonces el efecto del tratamiento es muyconsistente. Una medida de esta consistencia es el grado de dispersión que

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 11/119
tienen las repeticiones de un tratamiento con respecto a su media de
tratamiento, medida de variabilidad dentro de tratamiento que es conocida
como el error experimental. Además, el número de repeticiones repercute en la
estimación de la varianza de la media de tratamiento.
La aleatorización se refiere al proceso de asignación de tratamientos a las
unidades experimentales. El objetivo de este mecanismo de asignación es
distribuir en forma aleatoria las diferencias entre unidades experimentales, de
tal manera que ninguno de los tratamientos se favorezca o se perjudique con
alguna asignación tendenciosa generada a base del juicio del investigador.
A través de un diseño experimental se pretende entonces probar una hipótesis
acerca del efecto de los tratamientos bajo condiciones controladas. Para tal fin
todo diseño experimental consta de dos componentes:
1. Arreglo geométrico de las unidades experimentales. Este componente se
enfoca a mejorar la precisión de las estimaciones reduciendo variabilidad
de unidades experimentales dentro de tratamientos. El mecanismo para
definir arreglos geométricos es el manejo de las variables de bloqueo y
el sistema de aleatorizacion. Los principales arreglos geométricos son:
El diseño completamente al azar, el diseño en bloques al azar y el
diseño en cuadro latino.
2. Arreglo de tratamientos. Este componente se enfoca a generar la
estructura de los tratamientos adecuada a la hipótesis que se desea
probar. Las estructuras básicas son: Estructuras unifactoriales y
estructuras multifactoriales. En las multifactoriales podemos distinguir las
estructuras factoriales, estructuras jerárquicas y en parcelas divididas.
Modelos para establecer las relaciones entre variables en un diseño
experimental:
En diseño de experimentos todo el análisis de resultados se lleva a cabo
mediante el ajuste de modelos. Estos modelos, en general se establecen como:
RESPUESTA = INDEPENDIENTES + ERROR
En Las variables independientes deben distinguirse aquellas que son fijas de
las que son aleatorias. Las fijas se agrupan dentro de la parte sistemática del
modelo y las aleatorias en lo que se considera la parte aleatoria del modelo,

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 12/119
dentro de la cual se puede ubicar el error, por lo que la estructura del modelo
quedaría como:
RESPUESTA = SISTEMÁTICA + ALEATORIA
En la parte sistemática se incluiría entonces los factores experimentales y los
factores de bloqueo, en tanto que en la parte aleatoria se incluirían los efectos
aleatorios y el error experimental.
EL DISEÑO COMPLETAMENTE AL AZAR
Es el arreglo geométrico más simple, en el que se supone que tanto las
unidades experimentales como el ambiente físico en el que se lleva a cabo el
experimento son totalmente homogéneos, uniformes, sin cambio, lo cual
representaría un ambiente controlado y un material experimental estable. Bajo
estas condiciones ideales solo quedaría por definir los factores experimentales
y sus niveles para determinar los tratamientos o condiciones experimentales
que van a ser investigadas. Por esta razón, el único efecto incluido en el
modelo bajo este diseño, es precisamente el efecto de los tratamientos, que
sería la única fuente de variación identificable en este experimento.
Como puede ser sospechado, difícilmente se van a cubrir los requisitos para
poder aplicar este diseño, por lo que en la práctica solo se recomienda para
condiciones muy controladas, como es el caso de experimentos de laboratorio.
Aleatorizacion: Ya que las unidades experimentales y las condiciones físicas
en las que se va a llevar a cabo el experimento son muy homogéneas,
entonces el mecanismo de asignación de tratamientos a las unidades
experimentales es completamente al azar, lo cual se puede lograr mediante la
aplicación de cualquier método de sorteo aleatorio. Puede ser mediante el uso
de números aleatorios, mediante selección aleatoria de números asociados a
unidades experimentales y aplicación secuencial de tratamientos. Si en
realidad las unidades experimentales son muy homogéneas, entonces
cualquier número de subgrupos generados al azar van a ser también muy
similares, lo cual asegura una comparación muy justa de los tratamientos. Este
diseño, es una generalización, para comparar más de dos tratamientos, de la

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 13/119
comparación de dos medias mediante la prueba de t para muestras
independientes.
Datos en el diseño completamente al azar: Los datos en un diseño
completamente al azar solo tienen un criterio de clasificación, correspondiente
a los tratamientos. Para identificar a cada una de las observaciones, se
requieren entonces de dos subíndices ligados a la letra que representa la
variable de respuesta; de acuerdo al modelo estadístico
Yij = μ + τi + εij
El subíndice i esta asociado al tratamiento y el subíndice j esta asociada a la
repetición dentro de cada tratamiento.
Yij corresponde al valor de la variable de respuesta en la repetición j del
tratamiento i.
μ es la media general del experimento.
τi es el efecto del tratamiento i.
εij es el error experimental en la repetición j del tratamiento i.
i=1,2,…,t; j=1,2,…,r
Lo cual indica que en el experimento hay t tratamientos, y en cada tratamiento r
es el numero de repeticiones, cuando el numero de repeticiones es el mismo
en cada tratamiento; entonces el experimento esta balanceado. Cuando el
numero de repeticiones varia de tratamiento a tratamiento, el diseño
experimental será desbalanceado y el subíndice j llegara a un numero diferente
para cada tratamiento, lo cual puede ser indicado con j=1,2,…,r i .
Hipótesis que se desea probar: La hipótesis que se desea probar es la
referente al efecto de los tratamientos. La hipótesis estadística es:
Ho: Todos los efectos de tratamientos son iguales a cero.
Ho: τ1=τ2=…=τt=0
Ha: Al menos uno de los efectos de tratamiento es diferente de cero.
Para expresarla en términos de los parámetros del modelo tendría que ser una
hipótesis múltiple, que por el momento no es de interés llegar a detallar.
Lo importante en este punto es recordar que la hipótesis nula es de
consecuencias estadísticas definidas. En este caso la consecuencia de la
hipótesis nula, es que el modelo estadístico se reduce a:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 14/119
Yij = μ + εij
Al que se le llama el modelo reducido. Para probar esta hipótesis el
razonamiento que se sigue es evaluar la magnitud de los errores en ambos
modelos y determinar que tanto impacto tienen los efectos de tratamiento. Si lareducción en los errores es importante, entonces el efecto de los tratamientos
se declara significativo. Por el contrario, si la magnitud de los errores
prácticamente es la misma en ambos modelos, esto significa que los efectos de
tratamiento no contribuyen a explicar la respuesta, y por lo tanto son
declarados no significativos.
Análisis de los datos: El análisis de los datos de un diseño experimental
siempre se lleva a cabo mediante la técnica del análisis de varianza. Para
aplicar esta técnica se requiere del ajuste de los dos modelos al mismo
conjunto de observaciones, el completo y el reducido bajo la hipótesis nula,
para después comparar la magnitud de los errores obtenida en ambos
modelos.
El ajuste de un modelo consiste en estimar sus parámetros, es decir todos
aquellos componentes del modelo que no incluyan la secuencia completa de
subíndices usada en la variable de respuesta. En otras palabras, el único
componente que no se estima en el ajuste del modelo es el que corresponde al
error experimental.
En el ajuste del modelo se deben tener en cuenta las siguientes características
tanto del conjunto de observaciones como del modelo que se desea ajustar:
1. Numero total de observaciones: Corresponde al numero total de
valores en el diseño experimental. Vamos a denotar este numero con
la letra n.
2. Numero de parámetros independientes en el modelo que se ajusta:
Parámetros independientes son aquellos que no están sujetos a las
restricciones impuestas por la definición de los parámetros. Por
ejemplo el modelo reducido solo tiene un parámetro, que es
independiente; en el modelo completo del diseño completamente al
azar se impone la restricción de Σi=1τi = 0, por lo que el numero de
parámetros independientes seria t-1. A estos faltaría sumar el
parámetro μ, por lo que entonces serian t parámetros independientes.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 15/119
3. Grados de libertad para el modelo ajustado: Se refiere al numero de
componentes independientes en el conjunto de datos después de
haber ajustado un modelo. Los grados de libertad se van reduciendo
a medida que se introducen mas componentes en un modelo. Estos
grados de libertad son los que permiten estimar la varianza del error,
por lo que se recomienda en general que no deben ser inferiores de
10 a 12 en el modelo completo. Se estiman como:
G.L. = n – parámetros independientes en el modelo.
Para el modelo completo de un diseño completamente al azar se tiene:
G.L. = n – t
Para el modelo reducido se tienen:
G.L.= n – 1
Al revisar la estructura del modelo reducido y el modelo completo se puede
deducir que los resultados de las diferencias entre el modelo reducido
menos el modelo completo se pueden atribuir al termino que corresponde al
efecto de los tratamientos. Entonces:
G.L.Trat = t – 1
Estos grados de libertad son de particular importancia, ya que indican el
numero de parámetros independientes en un modelo ajustado al conjunto
de datos, tomando como variables independientes los tratamientos. Si el
factor es cuantitativo, entonces los grados de libertad indican el grado
máximo de polinomio en el modelo de regresión; si se trata de un factor
cualitativo, entonces los grados de libertad en los tratamientos indica el
numero máximo de comparaciones independientes entre los niveles del
factor.
Con esta información podemos empezar a generar la tabla de análisis de
varianza, que resume el ajuste de modelos y sus comparaciones. Para el
diseño completamente al azar, las fuentes de variación básicas que se
incluyen son:
Tratamientos
Error
Total.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 16/119
El total corresponde al ajuste del modelo reducido. De esta manera cuando
requiramos los grados de libertad del total, serán los grados de libertad al
ajustar el modelo reducido, esto es n-1.
El error corresponde al ajuste del modelo completo. Cuando hablemos de
los grados de libertado en un diseño completamente al zar, entonces se
calcularan como n – t.
Hasta aquí el análisis de varianza solo requiere de la información de
cuantas observaciones comprende el conjunto de datos y cuantos
tratamientos van a ser incluidos. Para el resto del análisis se requiere ya del
procesamiento de los datos y ajuste de los modelos.
Ajuste de modelos por mínimos cuadrados ordinarios: Los modelos de
anova se ajustan por mínimos cuadrados ordinarios, llamados así porque el
ajuste se lleva a cabo bajo las suposiciones convencionales de análisis,
esto es, suponiendo normalidad, independencia y homogeneidad de
varianzas en el componente de error. Una supocisión adicional es la
aditividad de los componentes del modelo. Los pasos para llevar a cabo el
ajuste son los siguientes:
1. Definir el modelo que se va a ajustar.
2. Definir las restricciones que se imponen en los parámetros del modelo.
3. Obtener la expresión para el error experimental despejando este termino
del modelo que se vaya a ajustar.
4. Obtener la expresión para la suma de cuadrados de los errores.
5. Derivar la expresión de la suma de cuadrados de los errores con
respecto a cada uno de los parámetros del modelo.
6. Igualar a cero las derivadas, para generar las ecuaciones normales de
mínimos cuadrados.
7. De las ecuaciones normales de mínimos cuadrados se despejan los
estimadores de los parámetros.
Vamos a considerar el modelo reducido del diseño completamente al azar
para ejemplificar los pasos del ajuste de un modelo:1. Modelo que se va a ajustar: Yij = μ + εij

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 17/119
2. Restricciones en los parámetros: No hay restricciones.
3. Error experimental: εij = Yij - μ
4. S.C.E. = ΣiΣ jεij2 = ΣiΣ j(Yij – μ)2
5. Derivada de la S.C.E. con respecto al parámetro μ: 2 ΣiΣ j(Yij – μ)(-1).6. Ecuación normal de mínimos cuadrados: -2 ΣiΣ j(Yij – μ) = 0
7. Estimador del parámetro: Media general de las observaciones.
Este proceso de estimación es para obtener las expresiones algebraicas de los
estimadores de mínimos cuadrados ordinarios y solo es necesario desarrollarlo
cuando estas se desconozcan, ya que si se tienen a la mano, pues solo
restaría aplicarlas al conjunto particular de observaciones. Por otro lado si se
tiene un paquete estadístico disponible, lo único que haría falta es cargar adecuadamente los datos y darle correctamente las instrucciones para que
genere los estimadores y todo el análisis completo. Por estas razones vamos a
enfocar la atención al manejo del paquete para captura y análisis de resultados
mas que a la teoría para generar estimaciones.
Sumas de cuadrados en la tabla de análisis de varianza: Una vez que los
estimadores de los parámetros del modelo han sido obtenidos, pueden
obtenerse los valores ajustados para cada una de las observaciones, a los que
se les denominan los valores predichos. Por diferencia de los observados
menos los predichos se obtienen los residuales o errores estimados para cada
una de las observaciones. Al elevar al cuadrado cada uno de los residuales se
obtienen solo cantidades positivas, que al sumarlas generan las sumas de
cuadrados de los errores para el modelo ajustado.
En cuanto a las sumas de cuadrados de los errores de un modelo ajustado se
deben hacer las siguientes observaciones:
a). Mientras mas reducido sea el modelo ajustado, esto es, mientras menor
sea el numero de parámetros que contiene, la suma de cuadrados de los
errores tendera a ser mayor.
b). Cada suma de cuadrados de los errores tiene asociados un cierto
numero de grados de libertad, que como ya se discutió, se calculan por la
diferencia del numero de observaciones menos el numero de parámetros
independientes que se van a estimar

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 18/119
c). La suma de cuadrados de los errores refleja, en general, que tan
separados están los valores observados de los valores ajustados por el
modelo.
d). Al comparar las sumas de cuadrados de los errores de un modelo
reducido contra un modelo completo, la diferencia puede ser atribuida a los
componentes que aparecen en el modelo completo pero que no aparecen en el
modelo reducido. Así entonces en el diseño completamente al azar, la
diferencia entre el modelo reducido Yij=μ + εij y el modelo completo Yij=μ+τi + εij
se puede atribuir al efecto de los tratamientos, y esta suma de cuadrados tiene
asociados t-1 grados de libertad.
Hasta aquí podemos construir la tabla de análisis de varianza para un diseño
completamente al azar, con las siguientes columnas:
Fuente de variación Grados de libertad Suma de cuadradosTratamientos t-1 Diferencia.Error n-t S.C.E. modelo completoTotal n-1 S.C.E. modelo reducido
Estadística de prueba en el análisis de varianza: A partir de estas columnas
en el análisis de varianza, que fueron generadas en base a la información
colectada de los datos y del ajuste de los modelos, se calcula otra columna
encabezada por el titulo de cuadrados medios, que contiene el estimador de
varianza para cada fuente de variación. Como cualquier varianza, estas
cantidades se calculan como el cociente de la suma de cuadrados entre sus
grados de libertad.
Finalmente, la estadística de prueba que se utiliza en el análisis de varianza es
una F, el cociente de dos varianzas, a partir de la cual se va a poder tomar unadecisión acerca de la hipótesis planteada en términos de los efectos de
tratamientos. La F calculada es el cociente del cuadrado medio de tratamientos
entre el cuadrado medio del error.
En los paquetes estadísticos una columna adicional es agregada a la tabla de
análisis de varianza para mostrar el valor de probabilidad, es decir, la
probabilidad de obtener un valor de F mayor o igual a la F calculada. Con este
único valor es posible llegar a una decisión acerca de la hipótesis, al

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 19/119
compararlo con el nivel de significancia de la prueba. Las decisiones basadas
en este criterio son:
Rechazar Ho si el valor de probabilidad es menor o igual al nivel de
significancia de la prueba.
No rechazar Ho si el valor de probabilidad es mayor que el nivel de
significancia de la prueba.
Ejemplo numérico 1: Observaciones de la producción de una reacción química
tomada a diferentes temperaturas fue registrada como sigue:
150 77.4150 76.7150 78.2200 84.1200 84.5200 83.7250 88.9250 89.2250 89.7300 94.8300 94.7300 95.9
La primer columna representa los niveles de temperatura que se incluyeron enel experimento y la segunda columna los valores correspondientes a la
producción de la reacción química. Como puede ser observado, se realizaron
tres repeticiones por cada uno de los cuatro niveles de temperatura.
Para empezar un análisis exploratorio del comportamiento de los datos,
siempre es recomendable graficar las observaciones contra los niveles del
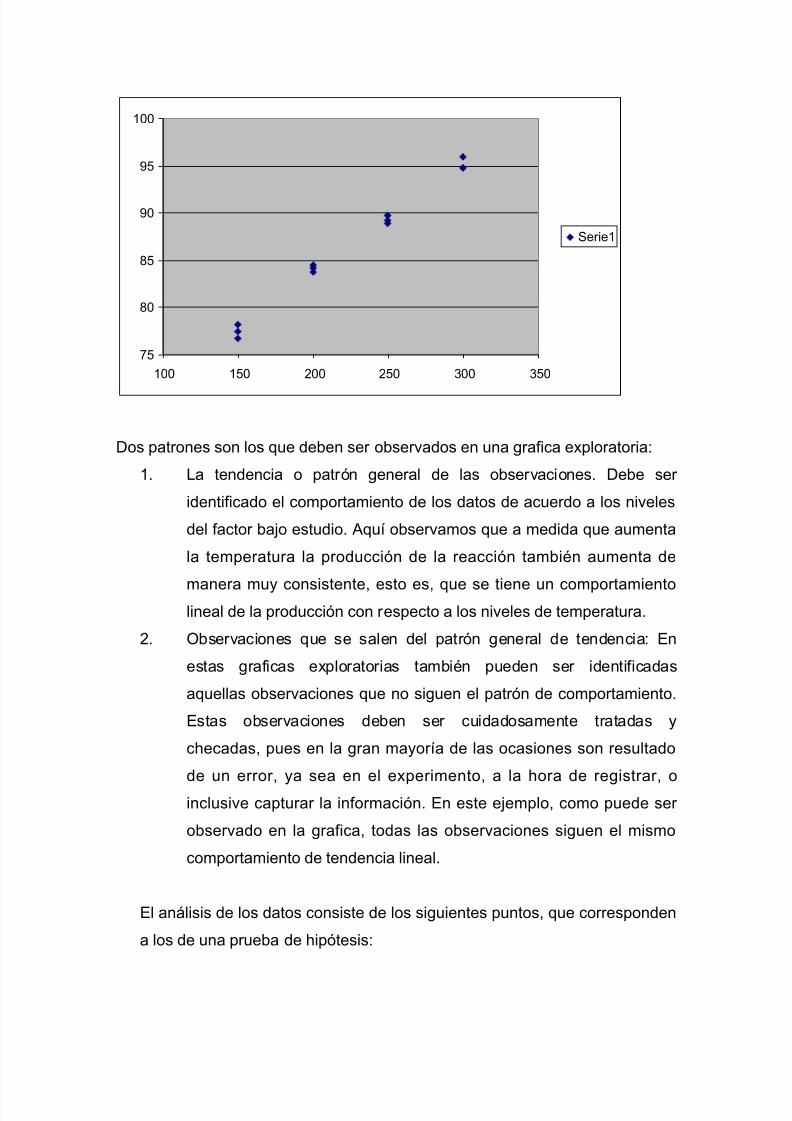
factor bajo estudio. En este caso la grafica resulta ser
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 20/119
75
80
85
90
95
100
100 150 200 250 300 350
Serie1
Dos patrones son los que deben ser observados en una grafica exploratoria:
1. La tendencia o patrón general de las observaciones. Debe ser
identificado el comportamiento de los datos de acuerdo a los niveles
del factor bajo estudio. Aquí observamos que a medida que aumenta
la temperatura la producción de la reacción también aumenta de
manera muy consistente, esto es, que se tiene un comportamientolineal de la producción con respecto a los niveles de temperatura.
2. Observaciones que se salen del patrón general de tendencia: En
estas graficas exploratorias también pueden ser identificadas
aquellas observaciones que no siguen el patrón de comportamiento.
Estas observaciones deben ser cuidadosamente tratadas y
checadas, pues en la gran mayoría de las ocasiones son resultado
de un error, ya sea en el experimento, a la hora de registrar, oinclusive capturar la información. En este ejemplo, como puede ser
observado en la grafica, todas las observaciones siguen el mismo
comportamiento de tendencia lineal.
El análisis de los datos consiste de los siguientes puntos, que corresponden
a los de una prueba de hipótesis:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 21/119
1. Establecer las hipótesis: Ho: Todos los efectos de tratamiento son
iguales a cero. Ha: al menos uno de los efectos de tratamiento es
diferente de cero.
2. Llevar a cabo la tabla de análisis de varianza.
Análisis de varianza de un factor ANÁLISIS DE VARIANZA
Origen de lasvariaciones
Suma decuadrados
Grados delibertad
Promedio de loscuadrados F Probabilidad
Valor crítico para F
Entre grupos 510.456667 3 170.152222 511.736007 1.7736E-09 4.06618056Dentro de losgrupos 2.66 8 0.3325
Total 513.116667 11
3. Cantidades básicas del anova:3.1 Coeficiente de determinación R-cuadrado:
3.2 Desviación estándar del error:
3.3 Probabilidad de un valor mayor de F:
El coeficiente de determinación R-cuadrado es el porcentaje de variación
explicado por el efecto de los tratamientos. Se calcula como una regla de
tres directa, en la que la suma de cuadrados del total es al 100 % como la
suma de cuadrados de tratamientos es al coeficiente de determinación.Para nuestro ejemplo:
513.116667 100%510.456667 Coeficiente de determinación
R-Cuadrado = 510.456667×100 = 99.4816
513.116667
Lo que significa que el 99.48 % de la variación en el conjunto de observaciones
esta siendo explicado por la variación en la temperatura y solo el 0.52 % sedebe a los factores de error.
La varianza del error lo constituye el cuadrado medio del error y la desviación
del error se calcula como la raíz cuadrada de la varianza, siendo en este caso
S = 0.5679
La probabilidad mayor de un valor de F es lo que se denomina el valor de P o
nivel de significancia observado, valor que nos permite tomar una decisión
sobre la hipótesis acerca del efecto de los tratamientos. En este caso el valor es

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 22/119
P = 1.7736E-09
Aun cuando parece mayor que uno, el componente E-09 indica que hay ocho
cero antes de la parte entera, lo que representa un valor muy inferior al 0.05
que consideramos como nivel de significancia de la prueba, por lo cual la
hipótesis nula es rechazada, y por lo tanto se concluye que los tratamientos si
tienen un efecto significativo sobre la respuesta.
Ya que se trata de un factor cuantitativo, la mejor manera de investigar el
efecto de los tratamientos es a través de una regresión polinomial, checando
hasta que nivel de tendencia llega a ser significativa.
Ejemplo numérico 2: Los datos siguientes se refieren a las perdidas de peso
de ciertas piezas mecánicas (en miligramos) debidas a la fricción cuando tres
diferentes lubricantes se utilizaron en condiciones controladas. El lubricante C
es el que se ha estado usando en el proceso, y ahora se desea evaluar dos
nuevas posibilidades, el lubricante A y el lubricante B.
Lubricante Desgaste A 12.2 A 11.8 A 13.1
A 11 A 3.9 A 4.1 A 10.3 A 8.4B 10.9B 5.7B 13.5B 9.4B 11.4B 15.7B 10.8
B 14C 12.7C 19.9C 13.6C 11.7C 18.3C 14.3C 22.8C 20.4
Análisis exploratorio:
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 23/119
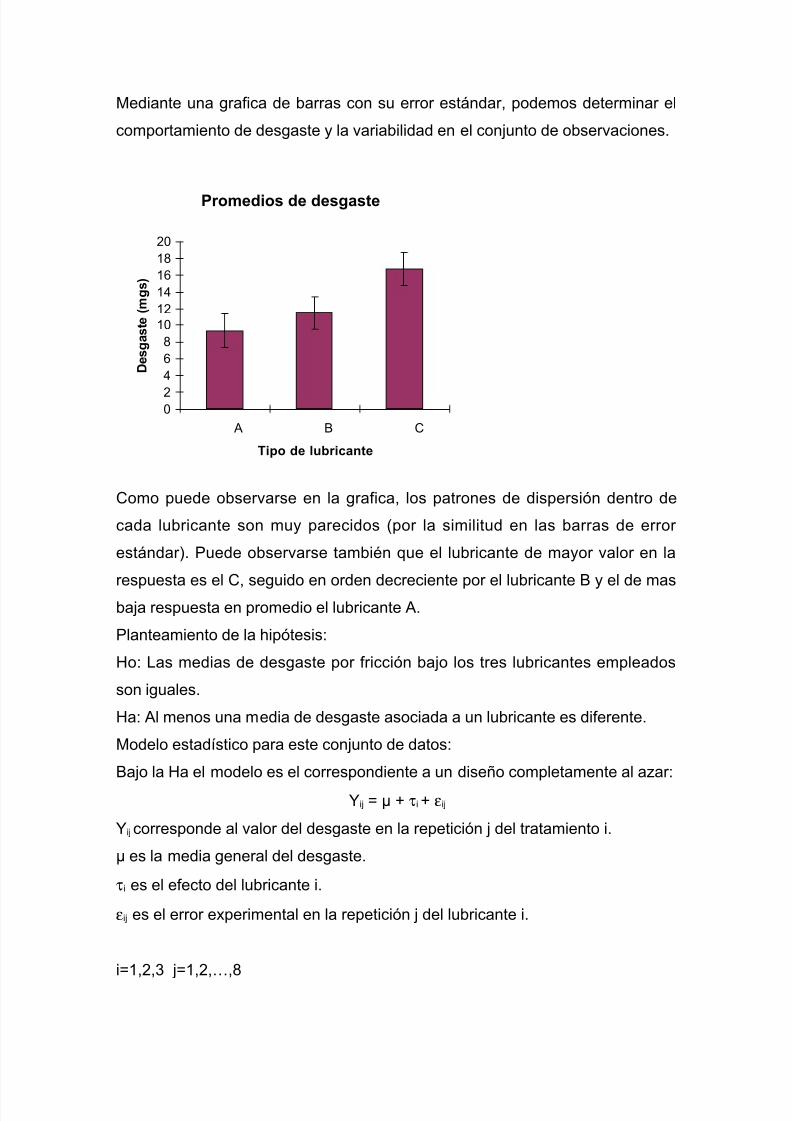
Mediante una grafica de barras con su error estándar, podemos determinar el
comportamiento de desgaste y la variabilidad en el conjunto de observaciones.
Promedios de desgaste
02
4
6
8
10
12
14
16
18
20
A B C
Tipo de lubricante
D e s g a s t e ( m g s )
Como puede observarse en la grafica, los patrones de dispersión dentro de
cada lubricante son muy parecidos (por la similitud en las barras de error
estándar). Puede observarse también que el lubricante de mayor valor en la
respuesta es el C, seguido en orden decreciente por el lubricante B y el de masbaja respuesta en promedio el lubricante A.
Planteamiento de la hipótesis:
Ho: Las medias de desgaste por fricción bajo los tres lubricantes empleados
son iguales.
Ha: Al menos una media de desgaste asociada a un lubricante es diferente.
Modelo estadístico para este conjunto de datos:
Bajo la Ha el modelo es el correspondiente a un diseño completamente al azar:
Yij = μ + τi + εij
Yij corresponde al valor del desgaste en la repetición j del tratamiento i.
μ es la media general del desgaste.
τi es el efecto del lubricante i.
εij es el error experimental en la repetición j del lubricante i.
i=1,2,3 j=1,2,…,8

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 24/119
Análisis de varianza para probar la hipótesis:
ANÁLISIS DE VARIANZAOrigen de lasvariaciones
Suma decuadrados
Grados delibertad
Promedio de loscuadrados F Probabilidad
Valor crítico para F
Entre grupos 230.585833 2 115.292917 8.74681521 0.00172472 3.46680011
Dentro de losgrupos 276.80375 21 13.181131
Total 507.389583 23
R-Cuadrado = 0.4544
Lo que significa que los lubricantes explican el 45 % de la variación en el
conjunto de datos. El 55 % se debe a factares no considerados en la
investigación.
Desviación estándar = 3.6306 que es el promedio del error en nuestro conjunto
de datos bajo el modelo completo.
Error estándar del la media = 1.2836
Lo que viene a confirmar el patrón de similitud en la variación de desgaste
dentro de cada lubricante, al obtener un error estándar muy similar a partir del
análisis de varianza, con los ya obtenidos para cada lubricante por separado.
Valor de P = 0.0017
Que por ser menor al nivel de significancia de la prueba (0.05) se toma la
decisión de rechazar Ho y concluir que las medias de desgaste en los tres
lubricantes no son iguales. Esto implica que el lubricante entonces si tiene un
impacto en el nivel de desgaste, por lo cual debemos investigar el patrón de
variación entre lubricantes y poder llegar a tomar una decisión acerca de cual
lubricante es el mas conveniente para conservar las piezas de la maquinaria.
MÉTODOS PARA IDENTIFICAR PATRONES DE VARIACIÓN PORTRATAMIENTOS
El método para factores cuantitativos es la regresión y para factores cualitativos
es la comparación de medias. Ambos procedimientos se pueden llevar a cabo
por sus métodos muy particulares o bien, bajo condiciones muy especificas,
ambos se pueden llevar a cabo por medio de los contrastes ortogonales.
Vamos a revisar primero los métodos específicos para cada tipo de factor yposteriormente se discutirá el enfoque general de contrastes ortogonales.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 25/119
REGRESIÓN:
La regresión es una metodología de análisis estadístico muy general,
que aplica cuando se quiere investigar la relación que guardan una variable
dependiente con una o mas variables independientes. La regresión es muy
extensa, y aquí solo nos limitaremos, en este punto, a la regresión lineal de tipo
polinomial en una variable independiente.
Los modelos de regresión polinomial se caracterizan por la potencia en
la variable independiente. Como se muestra en la siguiente tabla los modelos
de mas importancia son:
Grado Modelo Descripción
Lineal Yij=βo + β1Xij + εij LíneaCuadrático Yij = βo + β1 Xij + β2 X2
ij + εij Parábola
La estructura general del modelo polinomial consiste en que la variable
de respuesta se describe a través de un intercepto (βo) valor en la variable de
respuesta cuando la variable independiente es igual a cero y una serie de
términos aditivos que consisten en el producto de la pendiente (βi) multiplicada
por la variable independiente elevada a la potencia i. La pendiente o tasa de
cambio es el cambio en la variable de respuesta por unidad de cambio en la
variable independiente. De esta manera, estos polinomios pueden ser
generalizados a cualquier grado. Es conveniente, aclarar desde aquí, que el
ajuste de estos modelos va a estar limitado por el número de niveles en la
variable independiente en el conjunto de datos. El gado de polinomio máximo
va a estar dado por el numero de grados de libertad en los tratamientos, que
corresponde exactamente a los parámetros, quitando el intercepto, que se
incluyen en el modelo- Así un modelo lineal puede ajustarse a un conjunto de
datos con dos niveles en la variable independiente, un cuadrático requiere
mínimo tres niveles en la variable independiente para poder ser ajustado, etc.
Esto implica, que un modelo mas allá de ese grado no podrá ser ajustado, con
lo que no es posible llegar a determinar si en realidad dicho modelo ajusta bien
al conjunto de datos. Por esta razón se recomienda que cuando sospechemos
de un modelo polinomial de grado p, el numero de niveles en la variable
independiente sea al menos p+2, para que de esta manera tengamos

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 26/119
posibilidad de llevar a cabo un prueba de falta de ajuste. Esta prueba consiste
en comparar que tan bien se ajusta el modelo propuesto contra un modelo de
grado más alto. Cada grado que aumenta la ecuación polinomial de regresión,
se le asocia un grado de libertad, de los correspondientes a los tratamientos.
De esta manera, los grados de libertad que quedan después de ajustar una
ecuación polinomial de un cierto grado, se asocian a lo que se conoce como
falta de ajuste, con la que se prueba si alguna de las tendencias incluidas en
esta podría llegar a ser significativa, con lo cual se anularía el modelo
propuesto. Esta es la forma de checar si el modelo requiere de mas
parámetros de los que se están considerando.
Ejemplo numérico 3. Continuando con el ejemplo numérico 1, podemos
investigar el efecto de los tratamientos al ajustar una regresión lineal al
conjunto de datos:
CoeficientesError
Estandar Estadístico
t Probabilidad Inferior 95%
Superior 95%
Intercepto 60.2633333 0.74439685 80.9559223 2.0211E-15 58.6047138 61.9219529Temperatur 0.11653333 0.00321082 36.2940036 5.9937E-12 0.10937919 0.12368748
En este ajuste podemos observar que ambos parámetros son estadísticamentediferentes de cero, ya que al probar:
Ho: β1 = 0 vs. Ha β1 ≠ 0 P = 5.99 E-12, que para todo propósito practico es
igual a cero, y por lo tanto se rechaza Ho, y se concluye que la pendiente es
diferente de cero. Su valor estimado es de 0.1165 con un error estándar de
0.0032, lo que indica que la producción aumenta 0.1165 unidades por cada
grado de incremento en la temperatura. Por cada 100 grados de aumento, la
producción aumenta 11.65 unidades. Con este valor ya tenemos evaluado el
cambio que sufre la variable dependiente por un cambio en la independiente.
Ya no es necesario establecer comparaciones de medias para saber si son
estadísticamente diferentes, pues esto de antemano y se sabe.
Ho: β0 = 0 vs. Ha β0 ≠ 0 P = 2.02 E-15, que también es menor del nivel de
significancia de la prueba, y por lo tanto se rechaza Ho, concluyendo que el
intercepto es diferente de cero, con un valor estimado de 60.26 con un error
estándar de 0.74444, lo que debería interpretarse como el valor de la
producción cuando la temperatura fuera igual a cero. Aprovechando el ejemplo,
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 27/119
debemos comentar que esta interpretación seria correcta siempre y cuando la
tendencia en la producción se mantuviera constante como la que se encontró
de 150 a 350 grados, lo cual es poco creíble, y en todo caso, no se tiene la
evidencia suficiente de que así sea. Entonces, queda en entredicho la
interpretación que se pueda dar a este valor.
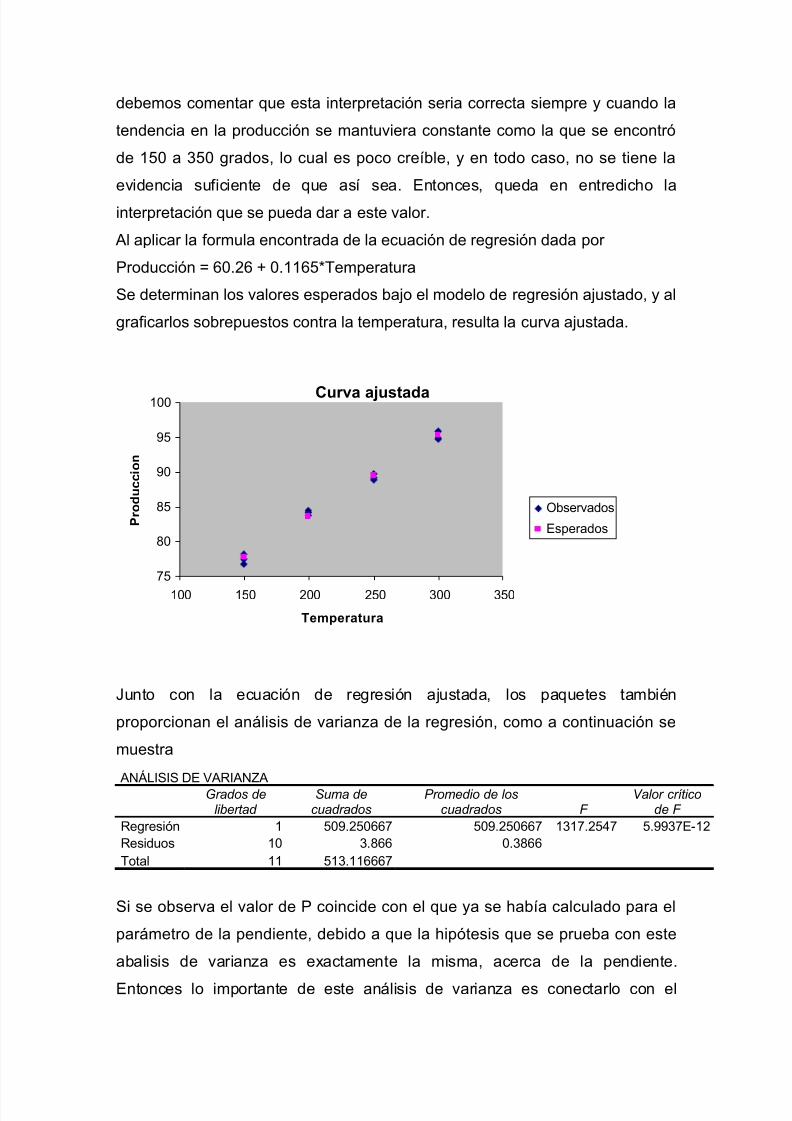
Al aplicar la formula encontrada de la ecuación de regresión dada por
Producción = 60.26 + 0.1165*Temperatura
Se determinan los valores esperados bajo el modelo de regresión ajustado, y al
graficarlos sobrepuestos contra la temperatura, resulta la curva ajustada.
Curva ajustada
75
80
85
90
95
100
100 150 200 250 300 350
Temperatura
P r o d u c c i o n
Observados
Esperados
Junto con la ecuación de regresión ajustada, los paquetes también
proporcionan el análisis de varianza de la regresión, como a continuación se
muestra
ANÁLISIS DE VARIANZA
Grados de
libertad Suma de
cuadradosPromedio de los
cuadrados F Valor crítico
de F
Regresión 1 509.250667 509.250667 1317.2547 5.9937E-12Residuos 10 3.866 0.3866Total 11 513.116667
Si se observa el valor de P coincide con el que ya se había calculado para el
parámetro de la pendiente, debido a que la hipótesis que se prueba con este
abalisis de varianza es exactamente la misma, acerca de la pendiente.
Entonces lo importante de este análisis de varianza es conectarlo con el

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 28/119
análisis de varianza para probar el efecto de los tratamientos. Para tal fin
debemos considerar los siguientes cálculos:
G.L.Trat – G.L.Reg.Lin = 3 – 1 = 2 que representan los grados de libertad
asociados a la tendencia cuadrática y cúbica que pueden ser ajustados a este
conjunto de datos por haber 4 niveles en la variable independiente.
S.C.Trat – S.C.Reg.Lin = 510.4566 – 509.2507 = 1.2059 que corresponde a la
suma de cuadrados debida a la tendencia cuadrática mas la suma de
cuadrados debida a la tendencia cúbica. Esta suma de cuadrados con los dos
grados de libertad asociados, se le conoce como falta de ajuste.
Esta información puede ser anexada en una tabla de anova con separacion de
tendencias por efecto de los tratamientos.
ANÁLISIS DE VARIANZAOrigen de lasvariaciones
Suma decuadrados
Grados delibertad
Promedio de loscuadrados F Probabilidad
Valor crítico para F
Entre grupos 510.456667 3 170.152222 511.736007 1.7736E-09 4.06618056SeparacionTendenciaLineal 509.2507 1 509.2507 1531.581053 0.000000 5.3176Falta de Ajuste 1.2059 2 0.6029 1.813230 0.224166 4.4589
Dentro de losgrupos 2.66 8 0.3325
Total 513.116667 11
Con la prueba acerca de la falta de ajuste se concluye que el modelo ajustado
a los datos no requiere de mas parámetros. Por lo que finalmente se puede
sugerir el modelo lineal encontrado es el que mejor ajusta a este conjunto de
observaciones.
Prueba de separación de medias:Es un método que se aplica después de que el análisis de varianza detecta
diferencias entre tratamientos, con la finalidad de llegar a determinar,
específicamente, cuales son las medias de tratamientos que son diferentes,
hasta llegar a formar grupos de tratamientos con medias iguales. Se han
propuesto una variedad de pruebas con este fin, algunas mas sensibles, otras
mas estrictas, generando conclusiones diferentes y que en algunas ocasiones
no se pueden explicar de manera sencilla, mucho menos interpretar.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 29/119
En este punto vamos a considerar solo uno de los métodos, que es el de uso
mas frecuente en la literatura científica, conocido como la prueba honesta de
Tukey. Este procedimiento fue diseñado para experimentos balanceados,
donde cada tratamiento tiene un numero de repeticiones igual a r.
El procedimiento para aplicar la prueba de Tukey consiste de los siguientes
pasos:
1. Calcular el error estándar de las medias. Recordar que se calcula
como la raíz cuadrada del cociente del cuadrado medio del error
entre el numero de repeticiones. Por ser balanceado el experimento,
este error estándar es el mismo para todas las medias de los
tratamientos.
2. Obtener el valor critico del rango estudentizado de acuerdo al nivel
de significancia (α), numero de tratamientos (t) y grados de libertad
en el error ( ν), representado por q(α, t, ν). Este valor es obtenido de
la tabla de rangos estudentizados que se localiza en los apéndices
de la mayoría de los libros de diseño de experimentos.
3. Obtener el valor HSD (diferencia significativa honesta) como el
producto del error estándar por el rango estdentizado.
4. Calcular la diferencia entre todas las posibles parejas de medias de
tratamientos.
5. Declarar diferencia significativa entre las medias de los tratamientos
cuando el valor absoluto de la diferencia sea estrictamente mayor
que el valor del HSD. De otro modo, las medias de los tratamientos
se declaran estadísticamente iguales.
Para facilitar el calculo e interpretación de las comparaciones, las medias se
ordenan de menor a mayor; se arma una tabla de doble entrada donde el
criterio de clasificación tanto por hileras como por columnas van a ser las
medias ordenadas de los tratamientos. En cada cuadro de la tabla se
calcula la diferencia entre la media de hilera y la de columna, y se establece
la decisión. Finalmente se hacen los grupos de medias iguales y sus
interconexiones, a través de superíndices alfabéticos o líneas verticales
uniendo las medias de los tratamientos que corresponden a cada grupo.
Cuando el experimento esta desbalanceado, entonces se calcula la mediaarmónica del número de repeticiones por tratamiento y esta se usa para

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 30/119
calcular el error estándar de las medias de los tratamientos. La media
armónica del numero de repeticiones se calcula por
r h = t/Σi(1/r i)
Ejemplo numérico 4. Llevar a cabo el procedimiento de la prueba honestade Tukey en los datos del ejemplo numerico2, referente a las marcas de
lubricantes.
A continuación se muestra una tabla con la media y varianza de cada uno
de los tratamientos.
Grupos Cuenta Suma Promedio Varianza
A 8 74.8 9.35 12.8542857B 8 91.4 11.425 9.53642857C 8 133.7 16.7125 17.1526786
Llevando a cabo el procedimiento de la prueba honesta de Tukey,
encontramos:
1. Error estándar de las medias de tratamiento = 1.2836
2. Rango estudentizado = q(.05,3,21) = 3.58
3. HSD(.05,3) = 4.5953
4. Parejas de medias:
A=74.8 B=91.4 C=133-7 A=74.8 A-A=0 B-A=16.6 * C-A=58.9 *B=91.4 B-B=0 C-B=42.3 *C=133.7 C-C=0
Conclusión: Estadísticamente las tres medias son diferentes entre si, por lo
que la selección optima del lubricante esta basada en aquella que genera el
menor desgaste de piezas de la maquinaria; de esta manera se
seleccionaría el lubricante A.
Contrastes ortogonales:
Un contraste en estadística es una combinación lineal de las medias de los
tratamientos definida por la suma de productos de las medias de
tratamiento por un coeficiente. Estos coeficientes deben cumplir con la
característica de que su suma es igual a cero, de tal manera que para
algunas medias sus coeficientes asociados son positivos y para otras son
negativos. Las reglas de asignación de los coeficientes va a depender de la
tendencia que se desee encontrar o de la comparación de medias que se

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 31/119
desee hacer. Cada contraste tendrá asociado un grado de libertad, debido
a que la comparación que se lleva a cabo es entre dos grupos de
tratamientos, lo que llevan el signo positivo contra los que llevan el signo
negativo. De esta manera el numero de posibles contrastes ortogonales en
un conjunto de datos corresponde exactamente a los grados de libertad
para los tratamientos.
Dos contrastes serán ortogonales si la suma de los productos de sus
correspondientes coeficientes es igual a cero. Esto implica que la
covarianza entre los dos contrastes es igual a cero, y por lo tanto los
contrastes van a ser independientes. En este sentido la ortogonalidad
implica independencia. Si todos los contrastes formulados son ortogonales
entre si, entonces esto llevara a que la suma de cuadrados acumulada en
todos los contrastes ortogonales corresponda exactamente a la suma de
cuadrados de los tratamientos. La suma de cuadrados asociada a un
contraste se calcula por el cuadrado de la combinación lineal de las medias
multiplicada por el numero de repeticiones y dividida por la suma de los
cuadrados de los coeficientes de la combinación lineal. Esta suma de
cuadraos siempre lleva asociada un solo grado de libertad.
Si se aplican contrastes no ortogonales, entonces existirá covarianza entre
ellos y esto implica que la información contenida en ellos esta relacionada
en un cierto grado, con lo cual se considera que la información contenida en
los datos esta siendo sobreutilizada. Esto se va a reflejar en el hecho de
que el acumulado de la suma de cuadrados de los contrastes no
ortogonales no cerrara a la suma de cuadrados de los tratamientos.
Contrastes ortogonales para el calculo de tendencias: Los contrastes
ortogonales pueden ser usados para estimar las sumas de cuadrados
asociadas a los diferentes componentes de un modelo polinomial, siempre y
cuando los datos experimentales tengan las siguientes dos características:
1. Experimento balanceado, lo que es un requisito general para aplicar
contrastes.
2. Los niveles del factor deben estar igualmente espaciados
Si alguna de estas características no se da en el conjunto de datos, serecomienda aplicar la técnica de la regresión para llevar a cabo la
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 32/119
separación de la suma de cuadrados de tratamientos en las diferentes
tendencias.
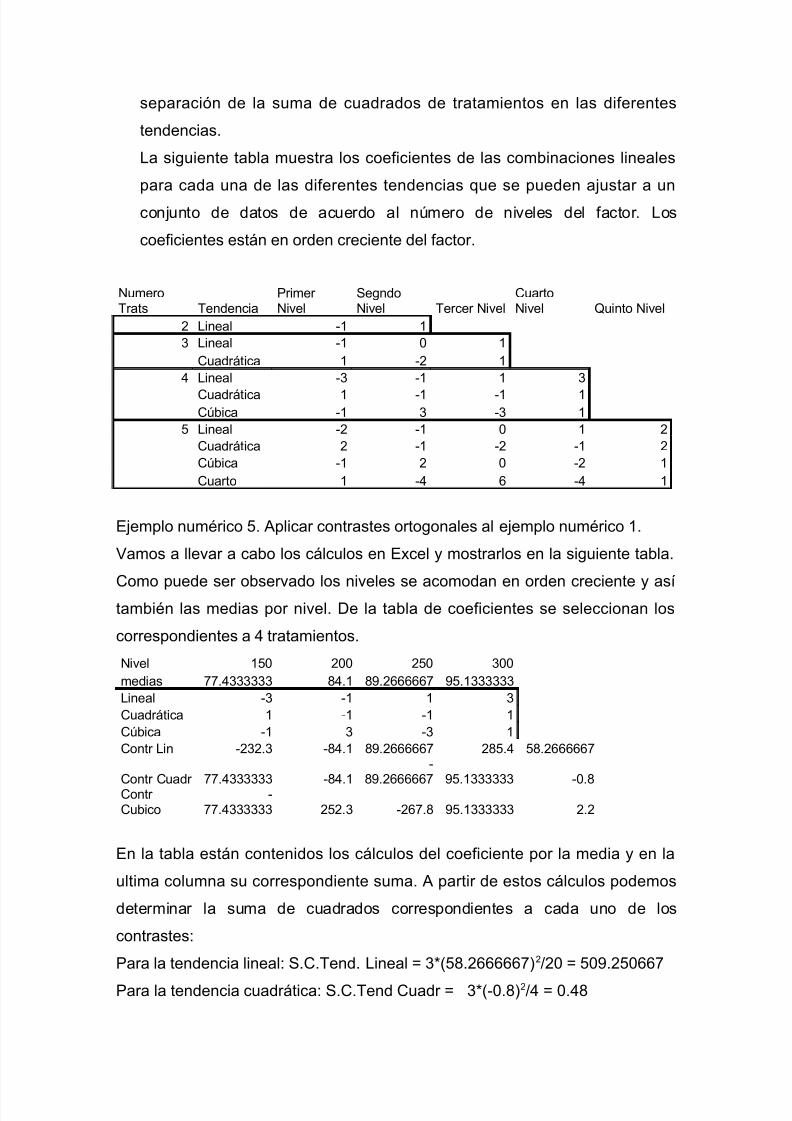
La siguiente tabla muestra los coeficientes de las combinaciones lineales
para cada una de las diferentes tendencias que se pueden ajustar a un
conjunto de datos de acuerdo al número de niveles del factor. Los
coeficientes están en orden creciente del factor.
NumeroTrats Tendencia
Primer Nivel
SegndoNivel Tercer Nivel
CuartoNivel Quinto Nivel
2 Lineal -1 13 Lineal -1 0 1
Cuadrática 1 -2 14 Lineal -3 -1 1 3
Cuadrática 1 -1 -1 1Cúbica -1 3 -3 1
5 Lineal -2 -1 0 1 2Cuadrática 2 -1 -2 -1 2Cúbica -1 2 0 -2 1Cuarto 1 -4 6 -4 1
Ejemplo numérico 5. Aplicar contrastes ortogonales al ejemplo numérico 1.
Vamos a llevar a cabo los cálculos en Excel y mostrarlos en la siguiente tabla.
Como puede ser observado los niveles se acomodan en orden creciente y asítambién las medias por nivel. De la tabla de coeficientes se seleccionan los
correspondientes a 4 tratamientos.
Nivel 150 200 250 300medias 77.4333333 84.1 89.2666667 95.1333333Lineal -3 -1 1 3Cuadrática 1 -1 -1 1Cúbica -1 3 -3 1Contr Lin -232.3 -84.1 89.2666667 285.4 58.2666667
Contr Cuadr 77.4333333 -84.1
-
89.2666667 95.1333333 -0.8Contr Cubico
-77.4333333 252.3 -267.8 95.1333333 2.2
En la tabla están contenidos los cálculos del coeficiente por la media y en la
ultima columna su correspondiente suma. A partir de estos cálculos podemos
determinar la suma de cuadrados correspondientes a cada uno de los
contrastes:
Para la tendencia lineal: S.C.Tend. Lineal = 3*(58.2666667)2/20 = 509.250667
Para la tendencia cuadrática: S.C.Tend Cuadr = 3*(-0.8)2/4 = 0.48

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 33/119
Para la tendencia Cúbica: S.C.Tend Cubica = 3*(2.2)2/20 = 0.726
Como puede ser comprobado, las sumas de cuadros para la tendencia lineal
coincide con la suma de cuadrados de la regresión lineal, y el acumulado de la
suma de cuadrados de la regresión cuadrática y cúbica coincide con la suma
de cuadrados de la falta de ajuste.
Se pudiera hacer el cuestionamiento acerca de la importancia de tener
diferentes métodos para realizar un mismo calculo. Aparte de la simplicidad de
los contrastes, otra gran ventaja es que puede ser utilizado para analizar los
arreglos factoriales de tratamientos que se verán posteriormente. Mediante la
técnica de contrastes ortogonales van a poder ser separadas las sumas de
cuadrados en componentes con un solo grado de libertad, sin importar la
naturaleza de los factores que se están investigando.
Contrastes ortogonales para comparación de medias: Para factores
cualitativos, la aplicación de los contrastes ortogonales es mas especifica para
cada problema. Se requiere de un conocimiento mas o menos profundo de lo
que son los tratamientos para poderlos agrupar. La idea de los contrastes para
factores cualitativos es ir formando dos grupos de comparación, cada uno de
los cuales va estar formado por uno o más tratamientos con alguna
característica común. Cada uno de los grupos se irán separando en otros dos
grupos de comparación, en base a otra característica de los tratamientos, y
este proceso continuara hasta que al final los contrastes comparen un
tratamiento contra otro.
Ejemplo de aplicación conceptual 1: Suponga que se esta llevando a cabo una
investigación para seleccionar un ingrediente proteico en la elaboración de un
alimento para mascotas. Se prueban tres fuentes de proteína: Carne de res,
carne de cerdo y soya. Lleve a cabo la comparación de los tratamientos por
contrastes ortogonales:
Los contrastes ortogonales que pueden planearse para estas tres fuentes son:
1. Proteína de origen animal (cerdo y res) contra proteína de origen
vegetal (soya).
2. Proteína de origen animal (res) contra proteína de origen animal
(cerdo).

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 34/119
Ejemplo de aplicación conceptual 2: Supóngase que se esta llevando a cabo
una investigación en la que se desea evaluar diferentes fuentes de carnes no
convencionales en la elaboración de un producto carnico de bajo costo. El
producto tradicional se elabora con carne de cerdo, y se desea investigar
fuentes no convencionales que incluyen: Caballo, burro, gallina y pavo. Planear
las comparaciones demedias por contrastes ortogonales.
Los contrastes ortogonales que pueden planearse para estos tratamientos son:
1. Testigo (cerdo) contra el promedio de los tratamientos (caballo,
burro, gallina y pavo).
2. Carnes de mamíferos (caballo y burro) contra carnes de aves (gallina
y pavo).
3. Caballo contra burro.
4. Gallina contra pavo.
Una vez que los contrastes ortogonales han sido planeados, debemos checar
el requisito de que el experimento este balanceado, y si es así debemos
obtener los coeficientes para cada uno de los contrastes. La mecánica para el
calculo de los coeficientes es la siguiente:
1. Los coeficientes de un grupo llevaran signo positivo y los del grupo
contrastante llevaran signo negativo. Esta es una selección
completamente arbitraria.
2. El valor del coeficiente de un grupo será igual al numero de
tratamientos que tiene el grupo contrastante.
Ejemplo numérico 6. Analice el ejemplo numérico 2 usando contrastes
ortogonales.
El ejemplo de los lubricantes y desgaste de las piezas consiste de tres
tratamientos, cada uno con 8 repeticiones. El A y B son lubricantes nuevos
y disponibles que se pueden usar en el proceso, y el lubricante C que es el
que convencionalmente se utiliza en el proceso. Entonces podemos generar
los siguientes contrastes con sus coeficientes y cálculos requeridos para
determinar las pruebas de significancia:
Lubricante A B CMedia 9.35 11.425 16.7125 SumaC vs (A B) 1 1 -2 -12.65
A vs. B 1 -1 0 -2.075
C vs (A B) 9.35 11.425 -33.425

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 35/119
A vs. B 9.35 -11.425 0
A partir de las cantidades en la tabla podemos calcular las sumas de
cuadrados correspondientes a cada contraste:
Contraste convencional vs. Nuevas alternativas:
S.C. = 8*(-12.65)2/6 = 213.3633
Contraste alternativa A vs. Alternativa B:
S.C. = 8*(-2.075)2/2 = 17.2225
Estas sumas de cuadrados pueden ser agregadas a la tabla de análisis de
varianza para completar las pruebas de significancia:
ANÁLISIS DE VARIANZAOrigen de lasvariaciones
Suma decuadrados
Grados delibertad
Promedio de loscuadrados F
Entre grupos 230.585833 2 115.292917 8.74681521C vs. A B 213.363333 1 213.363333 16.1872773 A vs. B 17.222500 1 17.222500 1.3066026Dentro de los grupos 276.80375 21 13.181131
Total 507.389583 23
El valor de P para el contraste C vs. A B resulto en 0.00061447 que es menor
del 0.05, por lo que se concluye que este contraste es significativo, es decir,
existe diferencia entre el lubricante convencional y las nuevas alternativas.
El valor de P para el contraste C vs. A B resulto en 0.26587522 que es mayor
del 0.05, por lo que se concluye que este contraste no es significativo, es decir,
no existe diferencia entre el lubricante las nuevas alternativas. Para la
selección del aceite entre las nuevas alternativas, se requiere de un criterio
adicional, pues en cuanto a la variable medida, el desgaste de las piezas, no
existe una diferencia. El criterio adicional puede ser el económico, ecológico, o
algún otro en el que uno de ellos tuviera ventaja.
DISEÑO EN BLOQUES COMPLETOS AL AZAR
Cuando las unidades experimentales no son homogéneas en alguna de las
variables identificadas como de impacto importante sobre la respuesta, o bien,
las condiciones físicas en que se lleva a cabo el experimento no son totalmente

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 36/119
uniformes, entonces se puede emplear un diseño en bloques para asegurar
comparaciones mas justas entre los tratamientos.
La idea de un bloque en diseño de experimentos se refiere a un conjunto de
unidades experimentales que tienen valores muy similares en cuanto a la
variable de bloqueo, o bien que están bajo condiciones experimentales muy
similares.
Una variable de bloqueo es una característica de las unidades experimentales
o del ambiente físico donde se lleva a cabo el experimento, que se ha
identificado como de impacto importante en la variable de respuesta. Esto es,
valores diferentes en la variable de bloqueo, tienen efecto sobre la variable de
respuesta. Por esto, si no se controlan a través del diseño de experimentos,
puede enmascarar el efecto de los tratamientos.
Una variable de bloqueo debe ser seleccionada de acuerdo al tipo de
experimento que se este llevando a cabo y a las variables de respuesta que se
estén evaluando. A menudo las unidades de equipo de prueba o maquinas son
diferentes en sus características de operación y constituyen un factor típico que
es necesario controlar. Lotes de materia prima, personas o tiempo son posibles
fuentes de variación que pueden ser controladas mediante un arreglo
geométrico en bloques al azar.
Por ejemplo, si se desea evaluar las características organolépticas en pasta de
manzana para pasteles, elaborados con diferentes edulcorantes; se debe
considerar como variables importantes que las impactan, a la variedad de la
manzana, el nivel de madurez del fruto, o inclusive la región de donde se
cosecho. Todas estas variables pudieran ser controladas como variables de
bloqueo, para obtener una estimación más pura del efecto de los tratamientos.
Una condición que debe conservarse para que este diseño sea valido, es que
no debe haber un efecto cruzado entre las variables de bloqueo y las variables
de respuesta. Esto implica que el efecto de un tratamiento se modifica por los
bloques de manera proporcional en todos los tratamientos. Esto permite
identificar diferencias de tratamientos, independientemente del bloque.
En un diseño en bloques completos al azar cada bloque generado debe
contener un numero de unidades experimentales igual al numero de
tratamientos, ya que cada bloque debe contener a todos los tratamientos. Losbloques en este diseño constituyen las repeticiones del experimento.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 37/119
Para poder llevar a cabo el arreglo geométrico en bloques al azar, es necesario
conocer el valor de la variable de bloqueo en cada una de las unidades
experimentales, para poder agruparlas en base a esta información y construir
los bloques, que deben quedar con valores muy similares en la variable(s) de
bloqueo. Es necesario también saber que la variable de bloqueo no tiene un
efecto cruzado con la variable de respuesta que se esta evaluando, esto es, el
valor de la variable de bloque no modifica el efecto de los tratamientos.
Ventajas del diseño en bloques con respecto al diseño completamente al
azar:
1. Con un agrupamiento efectivo, el diseño en bloques puede generar
resultados sustancialmente mas precisos de los que arrojaría un
diseño completamente al azar de tamaño comparable. En otras
palabras, el error experimental se puede controlar a niveles mas
bajos con el diseño en bloques.
2. La variabilidad de las unidades experimentales, o de las condiciones
físicas donde se lleva a cabo el experimento, puede ser
deliberadamente introducida para ampliar el rango de validez de los
resultados experimentales sin sacrificar precisión.
Desventajas del diseño en bloques comparado con el diseño
completamente al azar:
1. Los grados de libertad para el error experimental no son tan
grandes como en un diseño completamente al azar. Un grado de
libertad es perdido para cada bloque después del primero.
2. Mas suposiciones son requeridas para el modelo (varianza
constante de bloque a bloque y no efecto cruzado de bloque y
tratamiento) que para un diseño completamente al azar.
Aleatorizacion: Una vez que los bloques han sido formados, con unidades
experimentales lo mas parecido posible en cuanto a la variable de bloqueo,
cada bloque se considera como un grupo muy homogéneo de unidades
experimentales, pero con un alto grado de variación entre bloques. La forma de
asignar tratamientos a las unidades experimentales es al azar eindependientemente dentro de cada bloque.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 38/119
Modelo estadístico: El modelo completo de un diseño en bloques al azar
contiene los efectos de tratamiento (como en el completamente al azar) y el de
los bloques, dado por
Yij = μ + τi + β j + εij
I=1,2,…,t; j=1,2,…,b
Yij Es la variable de repuesta en el bloque j y el tratamiento i.
μ Es la media general del experimento.
τi Es el efecto del tratamiento i.
β j Es el efecto del bloque j.
εij es el error experimental en el bloque j y el tratamiento i.
Hipótesis del investigador: La hipótesis que se desea probar bajo este arreglo
experimental es:
Ho: No hay efecto de tratamientos (τi = 0 para toda i).
Ha: al menos un efecto de tratamiento es diferente de cero.
En relación al efecto de los bloques, debemos ser claros de que no se deseaba
investigar su efecto, solo se empleo como una forma de controlar la variabilidad
en las unidades experimentales, con la finalidad de hacer mas sensible el
experimento, es decir, poder detectar efecto de tratamientos cuando
verdaderamente existan. De esta manera, no se plantea una hipótesis asociada
el efecto de los bloques. Tampoco es posible probarla, ya que prácticamente
no se tienen repeticiones de bloques. Cabe hacer mención que si se tuvieran
repeticiones de bloques, entonces el experimento dejaría de ser bloques para
convertirse en un arreglo de tratamientos factorial, y en este caso la variable de
bloqueo ya pasaría a ser un factor.
ANOVA en el diseño en bloques al azar: El análisis de varianza en un diseño
en bloques al azar debe incluir las fuentes de variación de tratamientos y la
fuente de variación de bloques, además del error y total. Debe considerarse las
restricciones en los parámetros, dadas por:
1. Para los efectos de tratamientos: Στi = 0
2. Para los efectos de los bloques: Σβ j = 0
El arreglo en un diseño en bloques completos al azar y que no tenga datos
perdidos, siempre tendrá un numero de observaciones igual al producto del

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 39/119
numero de bloques por el numero de tratamientos (n = t × b). Entonces el
anova se construye como
Fuente de variación Grados de libertad Suma de cuadradosBloques b-1 Diferencia (1)Tratamientos t-1 Diferencia (2).Error (t-1)(b-1) S.C.E. modelo completoTotal n-1 S.C.E. modelo reducido
Los paquetes estadísticos en general reportan dos tipos de sumas de
cuadrados en un anova, denominadas las secuenciales y las ajustadas. Estos
nombres hacen referencia a la forma en que cada una es calculada. En el caso
de las secuenciales, son calculadas mediante la diferencia en sumas decuadrados de los errores de modelos conteniendo términos adicionales,
empezando con el modelo reducido y hasta llegar al modelo completo. Así para
un diseño en bloques al azar la secuencia de modelos serian:
1. Yij = μ + εij
2. Yij = μ + β j + εij
3. Yij = μ + τi + β j + εij
La suma de cuadrados secuencial para bloques seria la suma de cuadrados delerror en el modelo (1) menos la suma de cuadrados del error en el modelo (2).
La suma de cuadrados secuencial para tratamientos seria la suma de
cuadrados del error en el modelo (2) menos la suma de cuadrados del error en
el modelo (3). En estas sumas de cuadrados, la de tratamientos seria ajustada
por la presencia de los bloques, ya que se calculo como la diferencia con
respecto a un modelo conteniendo el efecto de los bloques.
Los modelos requeridos para el calculo de las sumas de cuadrados ajustadasserian:
1. Yij = μ + εij
2. Yij = μ + β j + εij
3. Yij = μ + τi + εij
4. Yij = μ + τi + β j + εij
La suma de cuadrados ajustada por efecto de los tratamientos se calcula por la
diferencia en la suma de cuadrados de los errores del modelo 3 menos la sumade cuadrados del error del modelo 4. La suma de cuadrados ajustada para los

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 40/119
efectos de tratamiento se calcularía por la diferencia en las sumas de
cuadrados de los errores del modelo (2) menos la del modelo (4).
Cuando el diseño esta balanceado estas sumas de cuadrados coinciden. Las
diferencias se presentan cuando el diseño esta desbalanceado, y en este caso
se deben considerar para la prueba de hipótesis las sumas de cuadrados
ajustadas.
Ejemplos Numéricos.
1. Una compañía constructora desea probar la eficiencia de 3 tipos de
aislantes diferentes. Ya que el área sobre la que la compañía
construye se caracteriza por diferencias importantes en el clima, la
compañía ha dividido, en base a esta característica, el área en 4
regiones geográficas. Dentro de cada región geográfica usa
aleatoriamente cada uno de los tres aislantes y registra la perdida de
energía como un índice. Valores mas pequeños del índice
corresponden a perdidas mas bajas de energía.
Aislante R.G. 1 R.G. 2 R.G. 3 R.G. 41 19.2 12.8 16.3 12.52 11.7 6.4 7.3 6.2
3 6.7 2.9 4.1 2.8
La hipótesis que se desea probar es:
Ho: No hay diferencias en el valor promedio del índice de perdida de
energía en los tres aislantes. ( Ho: τi = 0 para toda i).
Ha: Al menos el promedio del índice de perdida de energía para uno de los
aislantes es diferente (Ha: al menos una τi ≠ 0).
Una grafica para explorara las características de los datos es muyrecomendable. En este caso conviene graficar las observaciones de los tres
aislantes para cada región por separado, para determinar si el efecto de los
tratamientos es proporcional en todos los bloques.
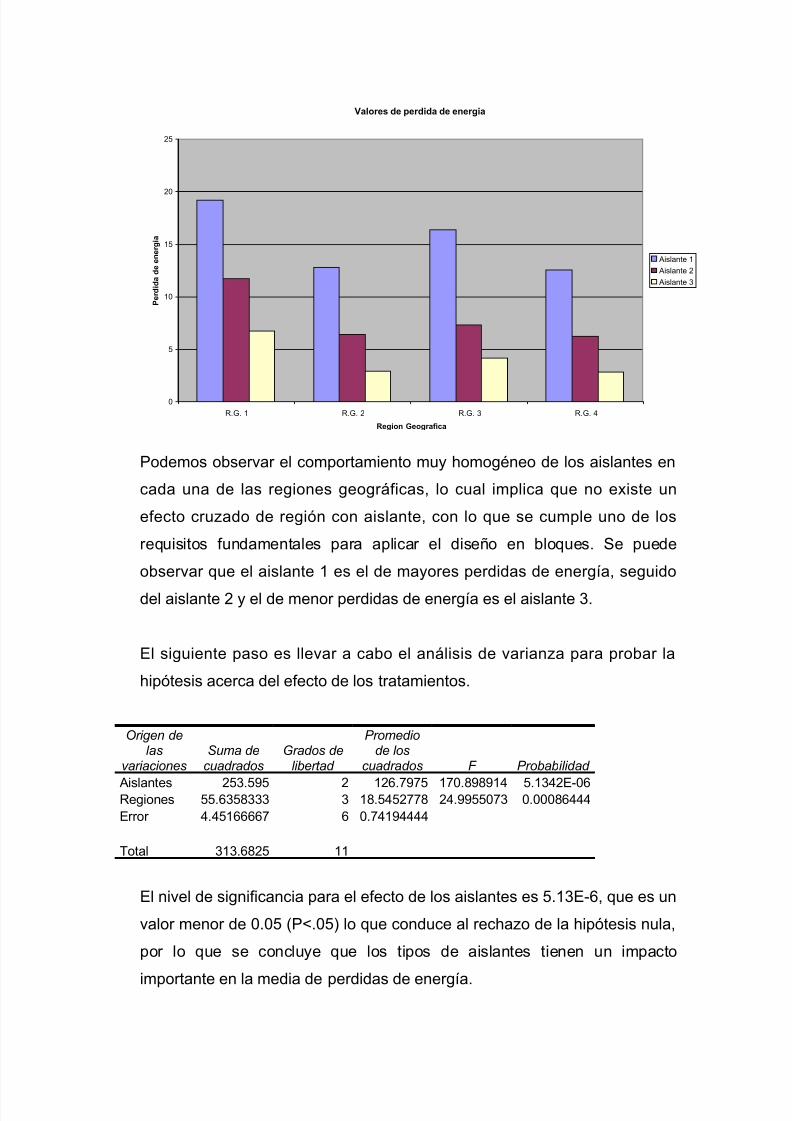
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 41/119
Valores de perdida de energia
0
5
10
15
20
25
R.G. 1 R.G. 2 R.G. 3 R.G. 4
Region Geografica
P e r d i d a d e e n e r g i a
Aislante 1
Aislante 2
Aislante 3
Podemos observar el comportamiento muy homogéneo de los aislantes en
cada una de las regiones geográficas, lo cual implica que no existe un
efecto cruzado de región con aislante, con lo que se cumple uno de los
requisitos fundamentales para aplicar el diseño en bloques. Se puede
observar que el aislante 1 es el de mayores perdidas de energía, seguido
del aislante 2 y el de menor perdidas de energía es el aislante 3.
El siguiente paso es llevar a cabo el análisis de varianza para probar la
hipótesis acerca del efecto de los tratamientos.
Origen delas
variacionesSuma de
cuadradosGrados de
libertad
Promediode los
cuadrados F Probabilidad
Aislantes 253.595 2 126.7975 170.898914 5.1342E-06Regiones 55.6358333 3 18.5452778 24.9955073 0.00086444Error 4.45166667 6 0.74194444
Total 313.6825 11
El nivel de significancia para el efecto de los aislantes es 5.13E-6, que es un
valor menor de 0.05 (P<.05) lo que conduce al rechazo de la hipótesis nula,
por lo que se concluye que los tipos de aislantes tienen un impacto
importante en la media de perdidas de energía.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 42/119
El siguiente paso es detectar cuales son las diferencias entre los aislantes.
Ya que nada es especificado acerca de la naturaleza de los aislantes, lo
único que procede es una comparación de todas contra todas las medias,
usando la prueba honesta de Tukey.
Construimos primero las medias de la variable perdida de energía por
aislante:
RESUMEN Repeticiones Suma Promedio Varianza
Aislante 1 4 60.8 15.2 10.0866667 Aislante 2 4 31.6 7.9 6.64666667 Aislante 3 4 16.5 4.125 3.29583333
Calculamos el error estándar de las medias: 0.4307Valor de la tabla de rangos estudentizados, con 3 medias, 6 grados de
libertad para el error y un nivel de significancia de 0.05: 4.34
Calculamos el valor de HSD: 1.8692
Enseguida, se construye la tabla de diferencias de medias:
7.9 (2) 15.2 (1)4.125 (3) (2)-(3) = 3.775 * (1)-(3) = 11.075 *7.9 (2) (1)-(2) = 7.3 *
* Diferencia significativa (P<.05)De estos resultados se concluye que las 3 medias son estadísticamente
diferentes, y por lo tanto, podemos hacer una selección del mejor aislante
desde el punto de vista de la variable de interés, perdida de energía. Ya que el
aislante tiene por objetivo la conservación de la energía, el mejor es aquel en el
que las perdidas son mínimas, por lo que tomamos la decisión de que el mejor
aislante es el tipo 3.
2. En una industria yesera se desea mejorar la resistencia del yeso a
las quebraduras. Para tal efecto se prueban dos aditivos orgánicos,
uno denominado n y otro denominado p, cada uno a dos niveles, y
además un tratamiento testigo, que consiste en el uso de un producto
convencional. La variable de interés es la resistencia a las
quebraduras, que se mide a través de la fuerza que debe aplicarse
para quebrar el yeso ya instalado. El experimento es llevado a cabo
en 5 diferentes zonas, caracterizadas por diferencias importantes en
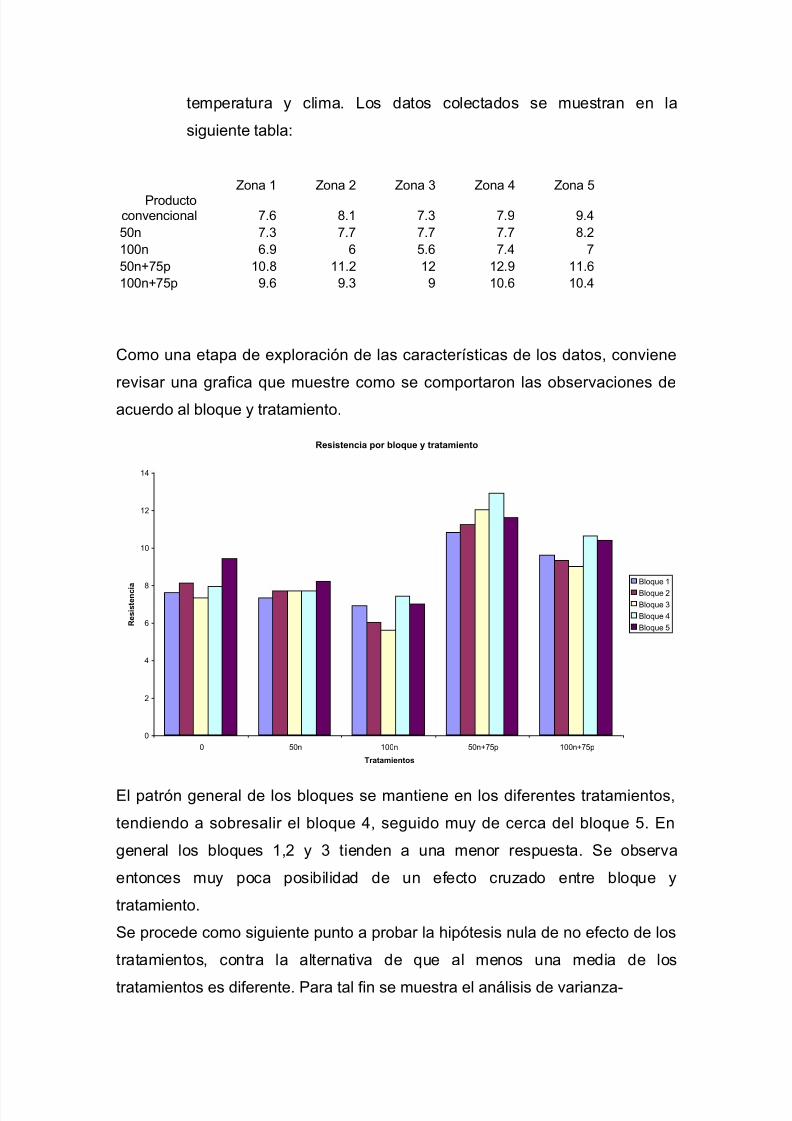
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 43/119
temperatura y clima. Los datos colectados se muestran en la
siguiente tabla:
Zona 1 Zona 2 Zona 3 Zona 4 Zona 5Producto
convencional 7.6 8.1 7.3 7.9 9.450n 7.3 7.7 7.7 7.7 8.2100n 6.9 6 5.6 7.4 750n+75p 10.8 11.2 12 12.9 11.6100n+75p 9.6 9.3 9 10.6 10.4
Como una etapa de exploración de las características de los datos, conviene
revisar una grafica que muestre como se comportaron las observaciones de
acuerdo al bloque y tratamiento.
Resistencia por bloque y tratamiento
0
2
4
6
8
10
12
14
0 50n 100n 50n+75p 100n+75p
Tratamientos
R e s i s t e n c i a Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 5
El patrón general de los bloques se mantiene en los diferentes tratamientos,
tendiendo a sobresalir el bloque 4, seguido muy de cerca del bloque 5. En
general los bloques 1,2 y 3 tienden a una menor respuesta. Se observa
entonces muy poca posibilidad de un efecto cruzado entre bloque y
tratamiento.
Se procede como siguiente punto a probar la hipótesis nula de no efecto de los
tratamientos, contra la alternativa de que al menos una media de los
tratamientos es diferente. Para tal fin se muestra el análisis de varianza-

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 44/119
Origen delas
variacionesSuma de
cuadradosGrados de
libertad
Promediode los
cuadrados F Probabilidad
Tratamientos 80.0384 4 20.0096 66.1255783 9.5744E-10
Bloques 4.9544 4 1.2386 4.09319233 0.01796691Error 4.8416 16 0.3026
Total 89.8344 24
Con un nivel de significancia de 9.57E-10 se rechaza la hipótesis nula y se
concluye que si existe diferencia en la resistencia promedio por efecto de los
tratamientos.
Como siguiente punto es de importancia llegar a determinar cuales son las
diferencias que pueden ser detectadas entre los tratamientos. Ya que se
conoce la naturaleza de los tratamientos, pueden llevarse a cabo los contrastes
ortogonales para separar las medias. Los cuatro contrastes que se
recomiendan son:
1. Testigo contra tratados.
2. 50 de n contra 100 de n.
3. 0 de p contra 75 de p.
4. Efecto cruzado de n y p.
A continuación se muestran las medias de los tratamientos y sus
correspondientes coeficientes para cada uno de los contrastes:
Tratamiento Repeticiones MediaTestigo vstratados 50n vs. 100n 0 p vs. 75 p
efectocruzado
0 5 8.06 4 0 0 0
50n 5 7.72 -1 -1 -1 1100n 5 6.58 -1 1 -1 -150n+75p 5 11.7 -1 -1 1 -1100n+75p 5 9.78 -1 1 1 1
El análisis de varianza aumentado con los contrastes se muestra a
continuación:
Origen delas
variaciones
Suma de
cuadrados
Grados de
libertad
Promediode los
cuadrados F Probabilidad
Tratamientos 80.0384 4 20.0096 66.1255783 9.5744E-10
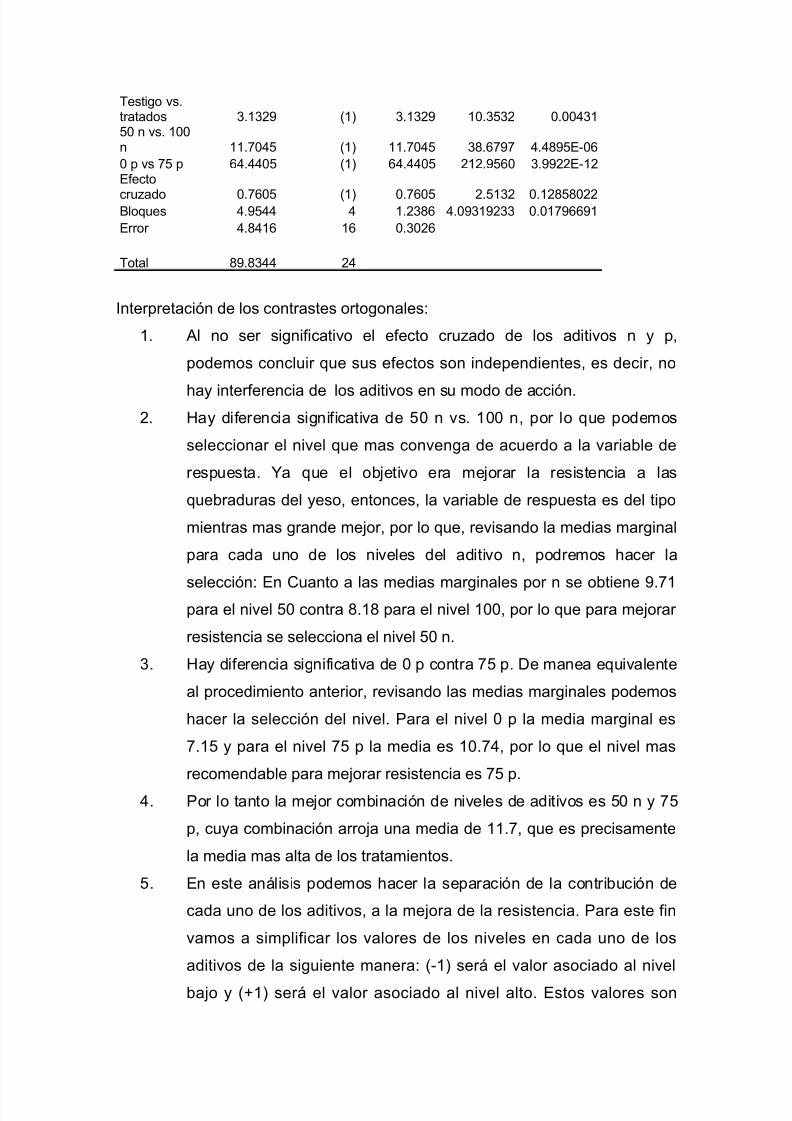
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 45/119
Testigo vs.tratados 3.1329 (1) 3.1329 10.3532 0.0043150 n vs. 100n 11.7045 (1) 11.7045 38.6797 4.4895E-060 p vs 75 p 64.4405 (1) 64.4405 212.9560 3.9922E-12Efecto
cruzado 0.7605 (1) 0.7605 2.5132 0.12858022Bloques 4.9544 4 1.2386 4.09319233 0.01796691Error 4.8416 16 0.3026
Total 89.8344 24
Interpretación de los contrastes ortogonales:
1. Al no ser significativo el efecto cruzado de los aditivos n y p,
podemos concluir que sus efectos son independientes, es decir, no
hay interferencia de los aditivos en su modo de acción.2. Hay diferencia significativa de 50 n vs. 100 n, por lo que podemos
seleccionar el nivel que mas convenga de acuerdo a la variable de
respuesta. Ya que el objetivo era mejorar la resistencia a las
quebraduras del yeso, entonces, la variable de respuesta es del tipo
mientras mas grande mejor, por lo que, revisando la medias marginal
para cada uno de los niveles del aditivo n, podremos hacer la
selección: En Cuanto a las medias marginales por n se obtiene 9.71para el nivel 50 contra 8.18 para el nivel 100, por lo que para mejorar
resistencia se selecciona el nivel 50 n.
3. Hay diferencia significativa de 0 p contra 75 p. De manea equivalente
al procedimiento anterior, revisando las medias marginales podemos
hacer la selección del nivel. Para el nivel 0 p la media marginal es
7.15 y para el nivel 75 p la media es 10.74, por lo que el nivel mas
recomendable para mejorar resistencia es 75 p.
4. Por lo tanto la mejor combinación de niveles de aditivos es 50 n y 75
p, cuya combinación arroja una media de 11.7, que es precisamente
la media mas alta de los tratamientos.
5. En este análisis podemos hacer la separación de la contribución de
cada uno de los aditivos, a la mejora de la resistencia. Para este fin
vamos a simplificar los valores de los niveles en cada uno de los
aditivos de la siguiente manera: (-1) será el valor asociado al nivel
bajo y (+1) será el valor asociado al nivel alto. Estos valores son

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 46/119
seleccionados para simplificar cálculos e interpretación de los valores
obtenidos. El cambio en promedios de la resistencia al cambiar del
nivel bajo al nivel alto, esta dado por la diferencia en el promedio al
nivel alto menos el promedio al nivel bajo. Para el aditivo n la
diferencia así definida es -1.53, de tal manera, que el cambio por
unidad convencional (al pasar de -1 a +1, 2 unidades de diferencia)
es -0.765. Por eso al seleccionar el nivel (-1) el incremento en la
respuesta promedio seria estimado en 0.765. De manera equivalente,
para el aditivo p, la diferencia en los promedios de los niveles esta
dada por 3.59 y el cambio por unidad de incremento en el aditivo p en
unidades convencionales es de 1.795. Por eso, al seleccionar el nivel
(+1) del aditivo p, el cambio en la respuesta promedio es de 1.795.
Con este sencillo análisis podemos evaluar el impacto independiente
que tienen cada uno de los aditivos para mejorar la resistencia.
Podemos concluir que el aditivo p es de mayor impacto en la mejora
de la resistencia, para los niveles investigados.
6. El contraste del testigo contra el promedio de los tratados resulto ser
significativo, con lo cual concluimos que el promedio de los tratados
(8.945) es significativamente diferente del promedio del testigo (8.06).
La diferencia 0.939 es la ganancia promedio por aplicación de
tratamientos.
3. El propósito de un experimento fue mejorar el valor nutricional de la
paja de trigo como alimento para ovejas. Los tratamientos de la paja
fueron: paja picada, paja molida, paja tratada con amonio y paja
tratada con urea. Un grupo de 24 ovejas fue usado en el
experimento. Se considero el peso inicial como variable de bloqueo
para llevar a cabo una separación en subgrupos de 4 animales mas
homogéneos. En cada uno de los 6 gripos se probaron las 4 dietasen
orden aleatorio. Para cada una de las 24 ovejas fue medido el
porcentaje de materia seca digerido. Los datos se muestran en la
siguiente tabla:
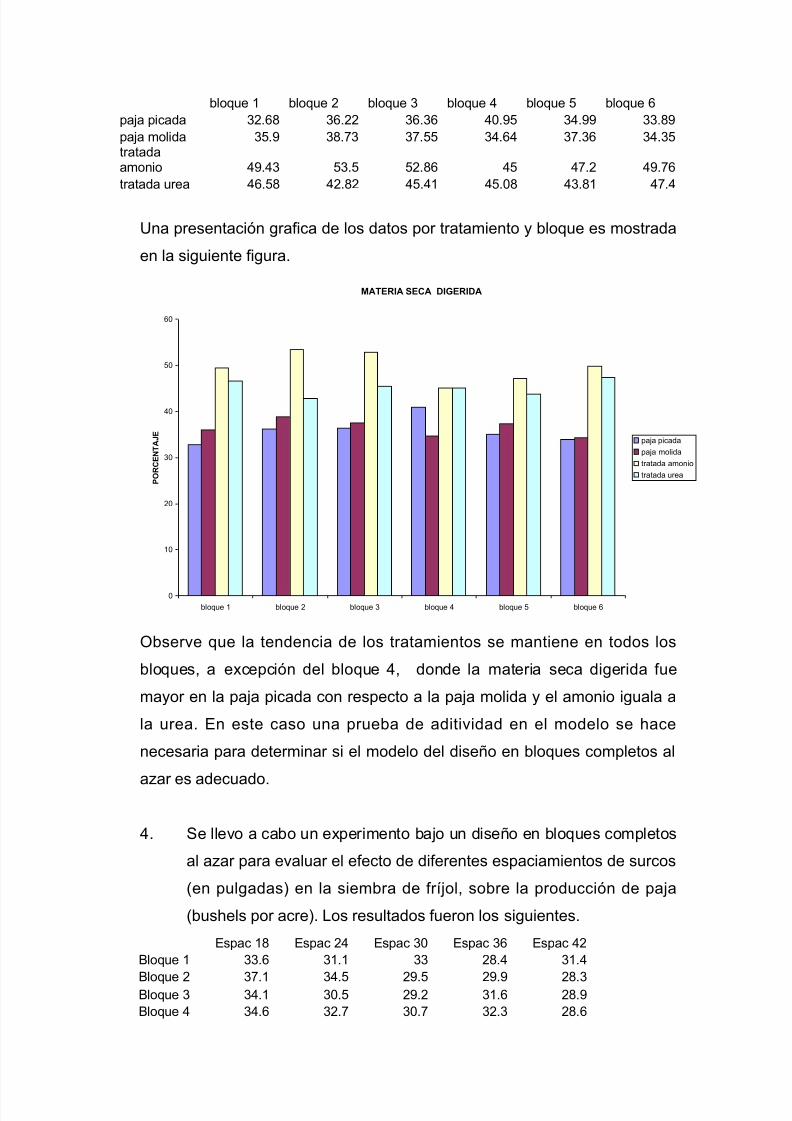
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 47/119
bloque 1 bloque 2 bloque 3 bloque 4 bloque 5 bloque 6paja picada 32.68 36.22 36.36 40.95 34.99 33.89paja molida 35.9 38.73 37.55 34.64 37.36 34.35tratadaamonio 49.43 53.5 52.86 45 47.2 49.76tratada urea 46.58 42.82 45.41 45.08 43.81 47.4
Una presentación grafica de los datos por tratamiento y bloque es mostrada
en la siguiente figura.
MATERIA SECA DIGERIDA
0
10
20
30
40
50
60
bloque 1 bloque 2 bloque 3 bloque 4 bloque 5 bloque 6
P O R C E N T A J E
paja picada
paja molida
tratada amonio
tratada urea
Observe que la tendencia de los tratamientos se mantiene en todos los
bloques, a excepción del bloque 4, donde la materia seca digerida fue
mayor en la paja picada con respecto a la paja molida y el amonio iguala a
la urea. En este caso una prueba de aditividad en el modelo se hace
necesaria para determinar si el modelo del diseño en bloques completos al
azar es adecuado.
4. Se llevo a cabo un experimento bajo un diseño en bloques completos
al azar para evaluar el efecto de diferentes espaciamientos de surcos
(en pulgadas) en la siembra de fríjol, sobre la producción de paja
(bushels por acre). Los resultados fueron los siguientes.
Espac 18 Espac 24 Espac 30 Espac 36 Espac 42Bloque 1 33.6 31.1 33 28.4 31.4
Bloque 2 37.1 34.5 29.5 29.9 28.3Bloque 3 34.1 30.5 29.2 31.6 28.9Bloque 4 34.6 32.7 30.7 32.3 28.6
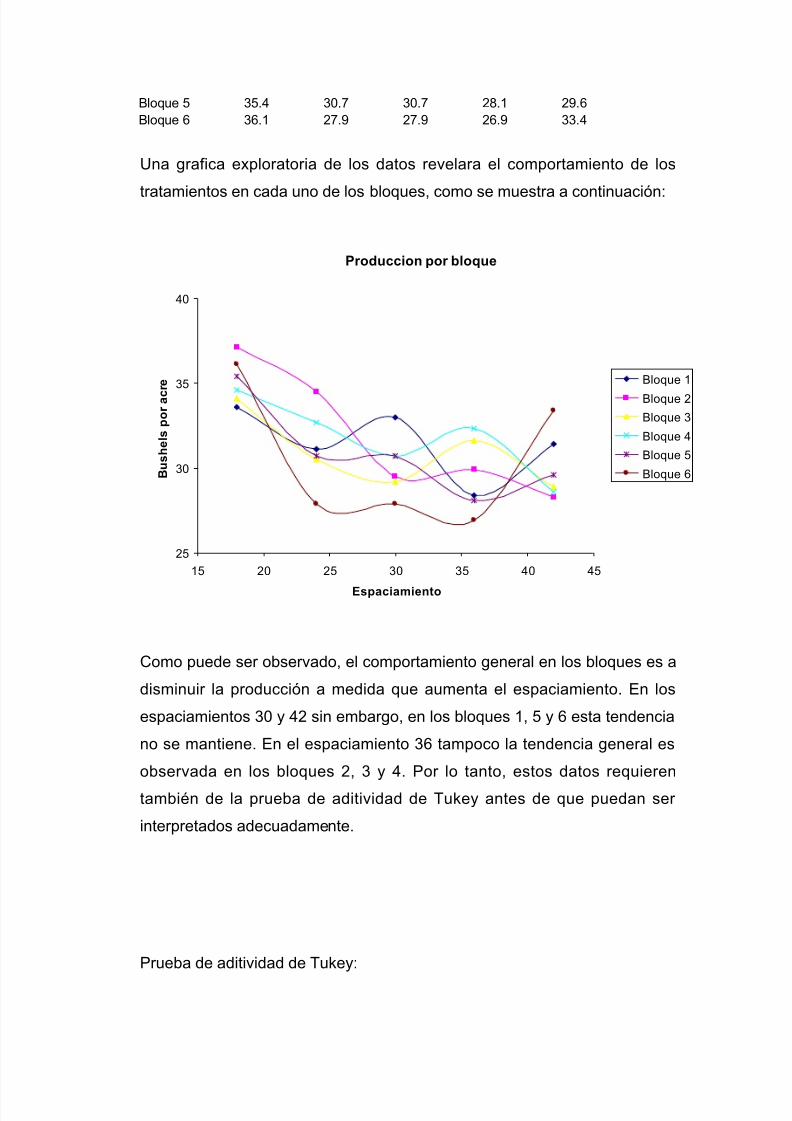
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 48/119
Bloque 5 35.4 30.7 30.7 28.1 29.6Bloque 6 36.1 27.9 27.9 26.9 33.4
Una grafica exploratoria de los datos revelara el comportamiento de los
tratamientos en cada uno de los bloques, como se muestra a continuación:
Produccion por bloque
25
30
35
40
15 20 25 30 35 40 45
Espaciamiento
B u s h e l s p o r a c r e
Bloque 1
Bloque 2
Bloque 3
Bloque 4
Bloque 5
Bloque 6
Como puede ser observado, el comportamiento general en los bloques es a
disminuir la producción a medida que aumenta el espaciamiento. En los
espaciamientos 30 y 42 sin embargo, en los bloques 1, 5 y 6 esta tendencia
no se mantiene. En el espaciamiento 36 tampoco la tendencia general es
observada en los bloques 2, 3 y 4. Por lo tanto, estos datos requieren
también de la prueba de aditividad de Tukey antes de que puedan ser
interpretados adecuadamente.
Prueba de aditividad de Tukey:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 49/119
Idealmente, los bloques representan influencias que uno esperaría que solo
incrementaran o disminuyeran el nivel general de respuesta, es decir,
constituirían un efecto puramente aditivo. Si los efectos de bloques y
tratamientos no fueran aditivos, un efecto cruzado entre bloques y
tratamientos ocurriría, lo cual es reflejado por un efecto diferencial de
tratamiento por bloque. Esto significa, que para algunos tratamientos un
bloque favoreciera la respuesta de interés, mientras que para otros bloques
la respuesta seria favorecida para otros tratamientos.
Estos efectos cruzados pueden ser clasificados como transformables y no
transformables. Los transformables son aquellos que pueden ser eliminados
mediante el análisis, usando alguna transformación de la variable de
respuesta, por ejemplo, el logaritmo, raíz cuadrada o reciproco de los datos
originales. La segunda categoría, los efectos cruzados no transformables,
son aquellos que no pueden ser eliminados por el análisis.
Un grado de libertad para la no aditividad transformable:
Una prueba formal para la no aditividad transformable basada en la
detección de una relación curvilínea entre los residuales después de ajustar
el modelo del diseño en bloques al azar y sus valores estimados, es debida
a J- W. Tukey. El procedimiento consiste en:
1. Analizar la variable original yij bajo el modelo del diseño en bloques al
azar.
2. Evaluar los valores estimados de la variable original bajo el modelo en
bloques al azar.
3. Evaluar los residuales en la variable original del modelo que
corresponde al diseño en bloques al azar:
4. Definir la variable qij como el cuadrado del valor estimado por el modelo
del diseño en bloques al azar.
5. Analizar la variable qij bajo el modelo de diseño en bloques al azar.
6. Obtener los valores estimados y los residuales de la variable qij.
7. Defina P como la suma de los productos cruzados de los residuales.
8. Defina Q como la suma de los cuadrados de los residuales de la variable
qij.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 50/119
9. Un grado de libertad asociado al error en el análisis de varianza de la
variable (y) es sustraído para la prueba de aditividad, y su suma de
cuadrados (suma de cuadrados de la regresión) asociada va a estar
dada por el producto del cuadrado de (P) por (Q), que debe ser restada
de la suma de cuadrados del error.
10. La hipótesis que se plantea es en términos del coeficiente de regresión γ
que cuantifica la relación de la variable original con el cuadrado de los
estimados bajo el modelo del diseño en bloques completos al azar, Ho:
γ=0 contra la Ha: γ ≠ 0. La hipótesis se prueba con la estadística F
definida por el cociente del cuadrado medio de la regresión entre el
cuadrado medio del residual.
11.Una decisión de no rechazar Ho conlleva a que el modelo del diseño en
bloques al azar cumple con la suposición de aditividad. Por otro lado el
rechazo de Ho puede indicar la necesidad de transformar los datos para
lograr que el modelo aditivo sea adecuado en los datos transformados.
5. Aplicación de la prueba de aditividad al ejemplo 3 de tratamientos de
paja.
a). Ajuste del modelo del diseño en bloques al azar a la variable original,
digestibilidad de materia seca.
bloque 1 bloque 2 bloque 3 bloque 4 bloque 5 bloque 6Media detrat
paja picada 32.68 36.22 36.36 40.95 34.99 33.89 35.8483333paja molida 35.9 38.73 37.55 34.64 37.36 34.35 36.4216667tratadaamonio 49.43 53.5 52.86 45 47.2 49.76 49.625tratada urea 46.58 42.82 45.41 45.08 43.81 47.4 45.1833333Media de blo 41.1475 42.8175 43.045 41.4175 40.84 41.35 41.7695833
A partir de estas medias por bloque, por tratamiento y la media general
podemos calcular los estimadores de los efectos de tratamiento:
Efectos de tratamiento:
Media detrat
Mediageneral Efecto de tratamiento
35.8483333 41.7695833 -5.9212536.4216667 41.7695833 -5.34791667
49.625 41.7695833 7.8554166745.1833333 41.7695833 3.4137541.7695833 41.7695833 0
Efectos de bloque:
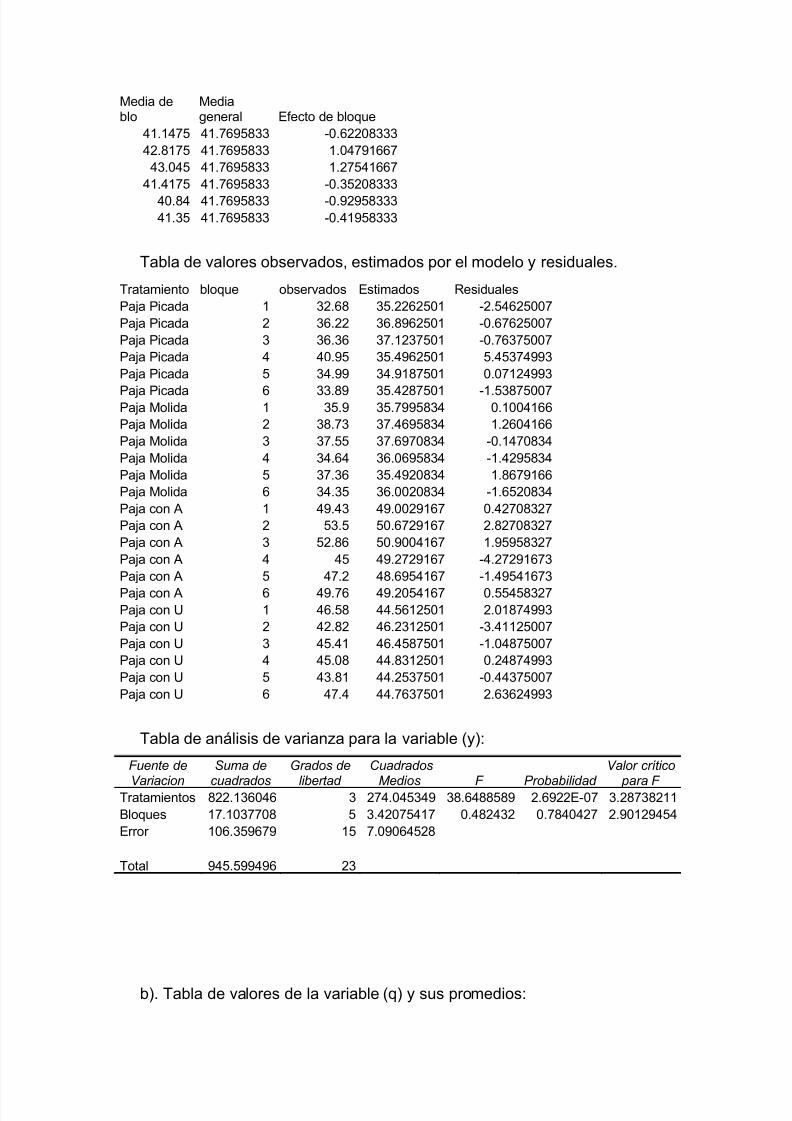
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 51/119
Media deblo
Mediageneral Efecto de bloque
41.1475 41.7695833 -0.6220833342.8175 41.7695833 1.0479166743.045 41.7695833 1.27541667
41.4175 41.7695833 -0.35208333
40.84 41.7695833 -0.9295833341.35 41.7695833 -0.41958333
Tabla de valores observados, estimados por el modelo y residuales.
Tratamiento bloque observados Estimados ResidualesPaja Picada 1 32.68 35.2262501 -2.54625007Paja Picada 2 36.22 36.8962501 -0.67625007Paja Picada 3 36.36 37.1237501 -0.76375007Paja Picada 4 40.95 35.4962501 5.45374993Paja Picada 5 34.99 34.9187501 0.07124993
Paja Picada 6 33.89 35.4287501 -1.53875007Paja Molida 1 35.9 35.7995834 0.1004166Paja Molida 2 38.73 37.4695834 1.2604166Paja Molida 3 37.55 37.6970834 -0.1470834Paja Molida 4 34.64 36.0695834 -1.4295834Paja Molida 5 37.36 35.4920834 1.8679166Paja Molida 6 34.35 36.0020834 -1.6520834Paja con A 1 49.43 49.0029167 0.42708327Paja con A 2 53.5 50.6729167 2.82708327Paja con A 3 52.86 50.9004167 1.95958327Paja con A 4 45 49.2729167 -4.27291673Paja con A 5 47.2 48.6954167 -1.49541673
Paja con A 6 49.76 49.2054167 0.55458327Paja con U 1 46.58 44.5612501 2.01874993Paja con U 2 42.82 46.2312501 -3.41125007Paja con U 3 45.41 46.4587501 -1.04875007Paja con U 4 45.08 44.8312501 0.24874993Paja con U 5 43.81 44.2537501 -0.44375007Paja con U 6 47.4 44.7637501 2.63624993
Tabla de análisis de varianza para la variable (y):
Fuente de
Variacion
Suma de
cuadrados
Grados de
libertad
Cuadrados
Medios F Probabilidad
Valor crítico
para F Tratamientos 822.136046 3 274.045349 38.6488589 2.6922E-07 3.28738211Bloques 17.1037708 5 3.42075417 0.482432 0.7840427 2.90129454Error 106.359679 15 7.09064528
Total 945.599496 23
b). Tabla de valores de la variable (q) y sus promedios:
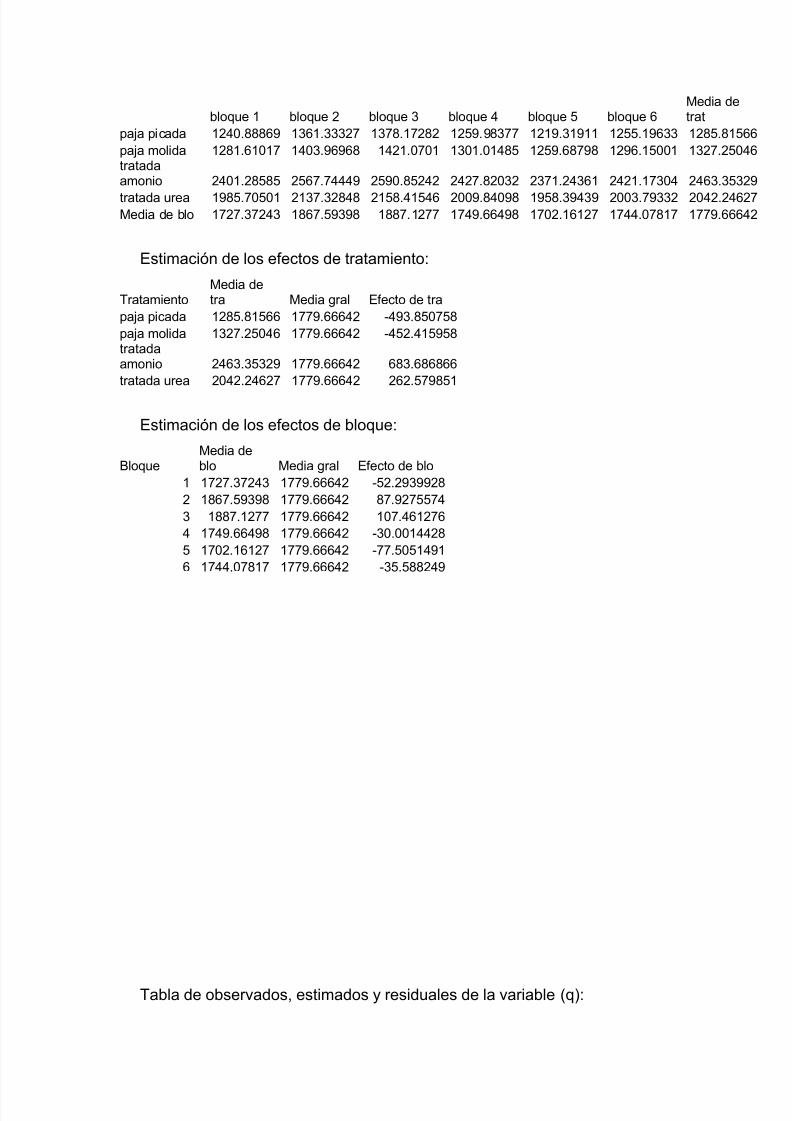
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 52/119
bloque 1 bloque 2 bloque 3 bloque 4 bloque 5 bloque 6Media detrat
paja picada 1240.88869 1361.33327 1378.17282 1259.98377 1219.31911 1255.19633 1285.81566paja molida 1281.61017 1403.96968 1421.0701 1301.01485 1259.68798 1296.15001 1327.25046tratadaamonio 2401.28585 2567.74449 2590.85242 2427.82032 2371.24361 2421.17304 2463.35329
tratada urea 1985.70501 2137.32848 2158.41546 2009.84098 1958.39439 2003.79332 2042.24627Media de blo 1727.37243 1867.59398 1887.1277 1749.66498 1702.16127 1744.07817 1779.66642
Estimación de los efectos de tratamiento:
TratamientoMedia detra Media gral Efecto de tra
paja picada 1285.81566 1779.66642 -493.850758paja molida 1327.25046 1779.66642 -452.415958tratadaamonio 2463.35329 1779.66642 683.686866tratada urea 2042.24627 1779.66642 262.579851
Estimación de los efectos de bloque:
BloqueMedia deblo Media gral Efecto de blo
1 1727.37243 1779.66642 -52.29399282 1867.59398 1779.66642 87.92755743 1887.1277 1779.66642 107.4612764 1749.66498 1779.66642 -30.00144285 1702.16127 1779.66642 -77.50514916 1744.07817 1779.66642 -35.588249
Tabla de observados, estimados y residuales de la variable (q):

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 53/119
Tratamiento bloque Observados Estimados ResidualesPaja Picada 1 1240.88869 1233.52167 7.36702187Paja Picada 2 1361.33327 1373.74322 -12.4099531Paja Picada 3 1378.17282 1393.27694 -15.1041219
Paja Picada 4 1259.98377 1255.81422 4.16954687Paja Picada 5 1219.31911 1208.31052 11.0085906Paja Picada 6 1255.19633 1250.22742 4.96891563Paja Molida 1 1281.61017 1274.95647 6.65369965Paja Molida 2 1403.96968 1415.17802 -11.208342Paja Molida 3 1421.0701 1434.71174 -13.6416441Paja Molida 4 1301.01485 1297.24902 3.76582465Paja Molida 5 1259.68798 1249.74532 9.9426684Paja Molida 6 1296.15001 1291.66222 4.4877934Paja con A 1 2401.28585 2411.0593 -9.77344757Paja con A 2 2567.74449 2551.28085 16.4636441Paja con A 3 2590.85242 2570.81456 20.0378587Paja con A 4 2427.82032 2433.35185 -5.53152257Paja con A 5 2371.24361 2385.84814 -14.6045288Paja con A 6 2421.17304 2427.76504 -6.59200382Paja con U 1 1985.70501 1989.95228 -4.24727396Paja con U 2 2137.32848 2130.17383 7.15465104Paja con U 3 2158.41546 2149.70755 8.70790729Paja con U 4 2009.84098 2012.24483 -2.40384896Paja con U 5 1958.39439 1964.74113 -6.34673021Paja con U 6 2003.79332 2006.65803 -2.86470521
La suma de productos cruzados de los residuales esta dada por
P = 87.3786269
Y la suma de cuadrados de los residuales en la variable (q) esta dada por
Q = 2343.60442
El estimador del efecto curvilíneo puede ahora ser calculado por
=γ 0.03728
y su suma de cuadrados asociada con un grado de libertad es:
S.C.R. = 3.2574
La suma de cuadrados del error con 14 grados de libertad en la variable (y)
es
106.359679-3.2574 = 103.102279
Y su correspondiente cuadrado medio 7.3644
Por esto la prueba de F para aditividad esta dada por
F = 0.4423

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 54/119
Que se distribuye como una F con 1 y 14 grados de libertad. Por lo tanto,
con este valor de la F no se rechaza Ho y se concluye que no existe
suficiente evidencia acerca de un efecto cruzado entre bloques y
tratamientos. Así, podemos tomar la decisión de que el modelo del diseño
en bloques al azar es adecuado para la variable (y) digestibilidad de materia
seca.
Siguiendo con el análisis de la variable (y), al detectar un efecto significativo
de tratamientos y conocer la naturaleza de los tratamientos, podemos
identificar las comparaciones de interés y llevarlas a cabo por el método de
contrastes ortogonales. Los contrastes de interés son:
Tratamientos físicos contra tratamientos químicos.
Paja picada contra paja molida.
Paja tratada con urea contra paja tratada con amonio.
La tabla siguiente muestra los coeficientes de los contrastes:
Tratamiento Repeticiones Media fis vs quimpicada vsmolida
amonio vsurea
paja picada 6 35.8483333 -1 -1 0paja molida 6 36.4216667 -1 1 0tratada
amonio 6 49.625 1 0 -1tratada urea 6 45.1833333 1 0 1
La tabla de anova con los contrastes integrados es mostrada a
continuación:
Fuente deVariacion
Suma decuadrados
Grados delibertad
CuadradosMedios F Probabilidad
Valor crítico para F
Tratamientos 822.136046 3 274.045349 38.6488589 2.6922E-07 3.28738211Fis vs quim 761.964704 (1) 761.964704 111.6922 2.4027E-08 4.54307712Picada vs
molida 0.98613333 (1) 0.98613333 0.139076 0.71441849 4.54307712Urea vsamonio 59.1852083 (1) 59.1852083 8.347 0.01123995 4.54307712Bloques 17.1037708 5 3.42075417 0.482432 0.7840427 2.90129454Error 106.359679 15 7.09064528
Total 945.599496 23
La diferencia detectada como significativa corresponde al contraste urea contra
amonio, lo cual significa que existe diferencia estadística entre el promedio de
digestibilidad de la paja tratada con urea (45.1833333) y la paja tratada con
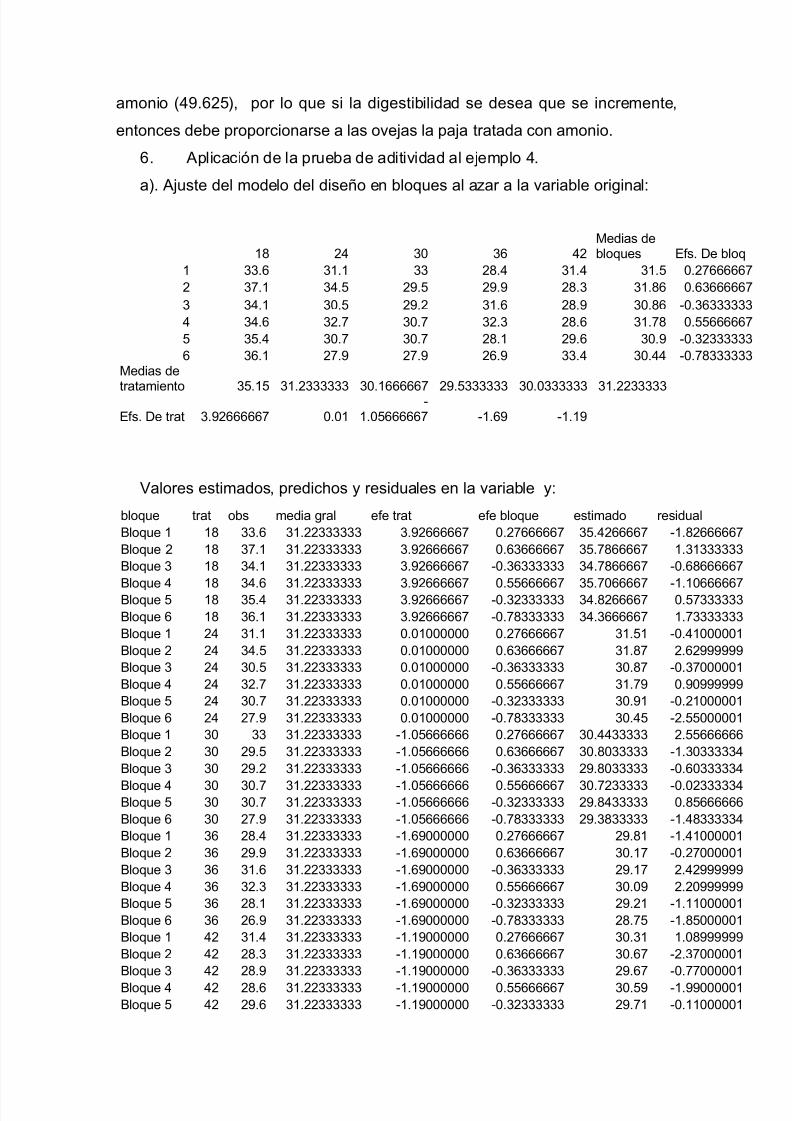
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 55/119
amonio (49.625), por lo que si la digestibilidad se desea que se incremente,
entonces debe proporcionarse a las ovejas la paja tratada con amonio.
6. Aplicación de la prueba de aditividad al ejemplo 4.
a). Ajuste del modelo del diseño en bloques al azar a la variable original:
18 24 30 36 42Medias debloques Efs. De bloq
1 33.6 31.1 33 28.4 31.4 31.5 0.276666672 37.1 34.5 29.5 29.9 28.3 31.86 0.636666673 34.1 30.5 29.2 31.6 28.9 30.86 -0.363333334 34.6 32.7 30.7 32.3 28.6 31.78 0.556666675 35.4 30.7 30.7 28.1 29.6 30.9 -0.323333336 36.1 27.9 27.9 26.9 33.4 30.44 -0.78333333
Medias de
tratamiento 35.15 31.2333333 30.1666667 29.5333333 30.0333333 31.2233333Efs. De trat 3.92666667 0.01
-1.05666667 -1.69 -1.19
Valores estimados, predichos y residuales en la variable y:
bloque trat obs media gral efe trat efe bloque estimado residualBloque 1 18 33.6 31.22333333 3.92666667 0.27666667 35.4266667 -1.82666667Bloque 2 18 37.1 31.22333333 3.92666667 0.63666667 35.7866667 1.31333333Bloque 3 18 34.1 31.22333333 3.92666667 -0.36333333 34.7866667 -0.68666667
Bloque 4 18 34.6 31.22333333 3.92666667 0.55666667 35.7066667 -1.10666667Bloque 5 18 35.4 31.22333333 3.92666667 -0.32333333 34.8266667 0.57333333Bloque 6 18 36.1 31.22333333 3.92666667 -0.78333333 34.3666667 1.73333333Bloque 1 24 31.1 31.22333333 0.01000000 0.27666667 31.51 -0.41000001Bloque 2 24 34.5 31.22333333 0.01000000 0.63666667 31.87 2.62999999Bloque 3 24 30.5 31.22333333 0.01000000 -0.36333333 30.87 -0.37000001Bloque 4 24 32.7 31.22333333 0.01000000 0.55666667 31.79 0.90999999Bloque 5 24 30.7 31.22333333 0.01000000 -0.32333333 30.91 -0.21000001Bloque 6 24 27.9 31.22333333 0.01000000 -0.78333333 30.45 -2.55000001Bloque 1 30 33 31.22333333 -1.05666666 0.27666667 30.4433333 2.55666666Bloque 2 30 29.5 31.22333333 -1.05666666 0.63666667 30.8033333 -1.30333334Bloque 3 30 29.2 31.22333333 -1.05666666 -0.36333333 29.8033333 -0.60333334
Bloque 4 30 30.7 31.22333333 -1.05666666 0.55666667 30.7233333 -0.02333334Bloque 5 30 30.7 31.22333333 -1.05666666 -0.32333333 29.8433333 0.85666666Bloque 6 30 27.9 31.22333333 -1.05666666 -0.78333333 29.3833333 -1.48333334Bloque 1 36 28.4 31.22333333 -1.69000000 0.27666667 29.81 -1.41000001Bloque 2 36 29.9 31.22333333 -1.69000000 0.63666667 30.17 -0.27000001Bloque 3 36 31.6 31.22333333 -1.69000000 -0.36333333 29.17 2.42999999Bloque 4 36 32.3 31.22333333 -1.69000000 0.55666667 30.09 2.20999999Bloque 5 36 28.1 31.22333333 -1.69000000 -0.32333333 29.21 -1.11000001Bloque 6 36 26.9 31.22333333 -1.69000000 -0.78333333 28.75 -1.85000001Bloque 1 42 31.4 31.22333333 -1.19000000 0.27666667 30.31 1.08999999Bloque 2 42 28.3 31.22333333 -1.19000000 0.63666667 30.67 -2.37000001Bloque 3 42 28.9 31.22333333 -1.19000000 -0.36333333 29.67 -0.77000001Bloque 4 42 28.6 31.22333333 -1.19000000 0.55666667 30.59 -1.99000001Bloque 5 42 29.6 31.22333333 -1.19000000 -0.32333333 29.71 -0.11000001
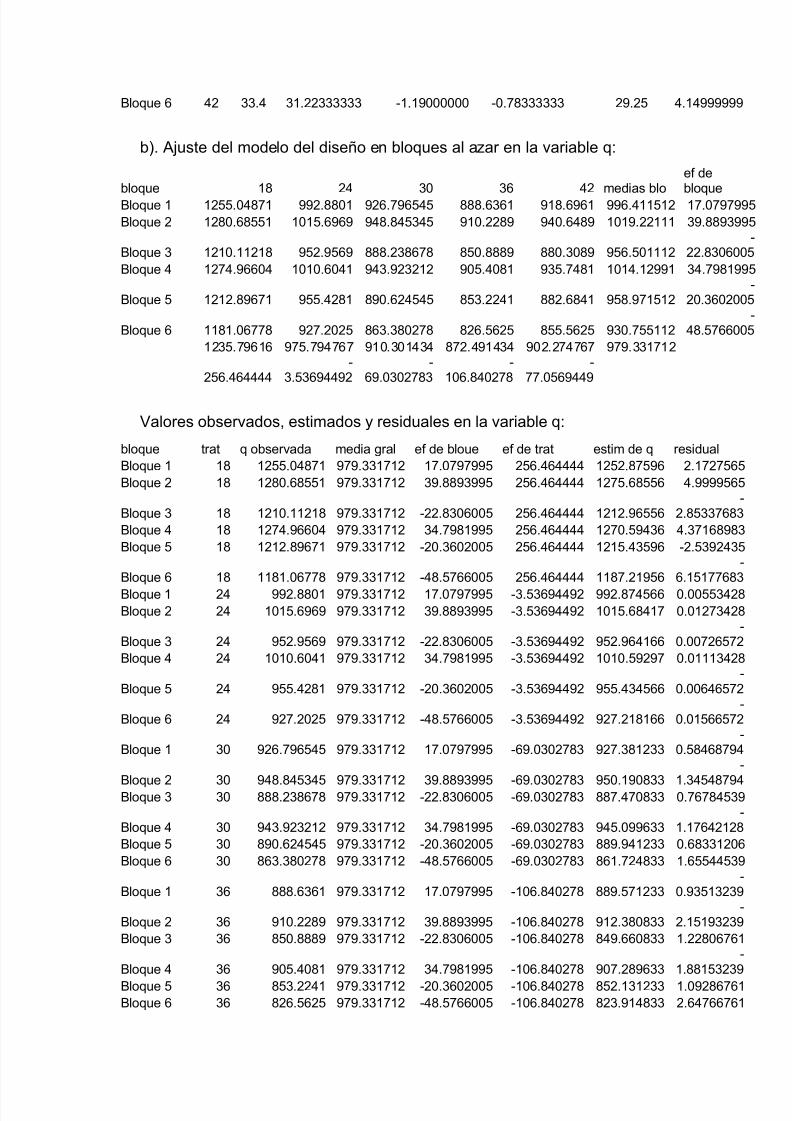
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 56/119
Bloque 6 42 33.4 31.22333333 -1.19000000 -0.78333333 29.25 4.14999999
b). Ajuste del modelo del diseño en bloques al azar en la variable q:
bloque 18 24 30 36 42 medias bloef debloque
Bloque 1 1255.04871 992.8801 926.796545 888.6361 918.6961 996.411512 17.0797995Bloque 2 1280.68551 1015.6969 948.845345 910.2289 940.6489 1019.22111 39.8893995
Bloque 3 1210.11218 952.9569 888.238678 850.8889 880.3089 956.501112-
22.8306005Bloque 4 1274.96604 1010.6041 943.923212 905.4081 935.7481 1014.12991 34.7981995
Bloque 5 1212.89671 955.4281 890.624545 853.2241 882.6841 958.971512-
20.3602005
Bloque 6 1181.06778 927.2025 863.380278 826.5625 855.5625 930.755112-
48.57660051235.79616 975.794767 910.301434 872.491434 902.274767 979.331712
256.464444-
3.53694492-
69.0302783-
106.840278-
77.0569449
Valores observados, estimados y residuales en la variable q:
bloque trat q observada media gral ef de bloue ef de trat estim de q residualBloque 1 18 1255.04871 979.331712 17.0797995 256.464444 1252.87596 2.1727565Bloque 2 18 1280.68551 979.331712 39.8893995 256.464444 1275.68556 4.9999565
Bloque 3 18 1210.11218 979.331712 -22.8306005 256.464444 1212.96556-
2.85337683Bloque 4 18 1274.96604 979.331712 34.7981995 256.464444 1270.59436 4.37168983Bloque 5 18 1212.89671 979.331712 -20.3602005 256.464444 1215.43596 -2.5392435
Bloque 6 18 1181.06778 979.331712 -48.5766005 256.464444 1187.21956-
6.15177683Bloque 1 24 992.8801 979.331712 17.0797995 -3.53694492 992.874566 0.00553428Bloque 2 24 1015.6969 979.331712 39.8893995 -3.53694492 1015.68417 0.01273428
Bloque 3 24 952.9569 979.331712 -22.8306005 -3.53694492 952.964166-
0.00726572Bloque 4 24 1010.6041 979.331712 34.7981995 -3.53694492 1010.59297 0.01113428
Bloque 5 24 955.4281 979.331712 -20.3602005 -3.53694492 955.434566-
0.00646572
Bloque 6 24 927.2025 979.331712 -48.5766005 -3.53694492 927.218166-
0.01566572
Bloque 1 30 926.796545 979.331712 17.0797995 -69.0302783 927.381233-
0.58468794
Bloque 2 30 948.845345 979.331712 39.8893995 -69.0302783 950.190833
-
1.34548794Bloque 3 30 888.238678 979.331712 -22.8306005 -69.0302783 887.470833 0.76784539
Bloque 4 30 943.923212 979.331712 34.7981995 -69.0302783 945.099633-
1.17642128Bloque 5 30 890.624545 979.331712 -20.3602005 -69.0302783 889.941233 0.68331206Bloque 6 30 863.380278 979.331712 -48.5766005 -69.0302783 861.724833 1.65544539
Bloque 1 36 888.6361 979.331712 17.0797995 -106.840278 889.571233-
0.93513239
Bloque 2 36 910.2289 979.331712 39.8893995 -106.840278 912.380833-
2.15193239Bloque 3 36 850.8889 979.331712 -22.8306005 -106.840278 849.660833 1.22806761
Bloque 4 36 905.4081 979.331712 34.7981995 -106.840278 907.289633-
1.88153239Bloque 5 36 853.2241 979.331712 -20.3602005 -106.840278 852.131233 1.09286761Bloque 6 36 826.5625 979.331712 -48.5766005 -106.840278 823.914833 2.64766761

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 57/119
Bloque 1 42 918.6961 979.331712 17.0797995 -77.0569449 919.354566-
0.65846572
Bloque 2 42 940.6489 979.331712 39.8893995 -77.0569449 942.164166-
1.51526572Bloque 3 42 880.3089 979.331712 -22.8306005 -77.0569449 879.444166 0.86473428
Bloque 4 42 935.7481 979.331712 34.7981995 -77.0569449 937.072966
-
1.32486572Bloque 5 42 882.6841 979.331712 -20.3602005 -77.0569449 881.914566 0.76953428Bloque 6 42 855.5625 979.331712 -48.5766005 -77.0569449 853.698166 1.86433428
c). Obtener los valores P y Q a partir de los residuales encontrados:
P = -7.25106222
Q = 136.658476
d). Obtener el estimador del efecto curvilíneo y su suma de cuadrados
asociada:
Beta = -0.053059
S.C.R. = 0.38474
e). Prueba de aditividad de Tukey:
F = 0.38474/81.933927 =0.0047 con 1 grado de libertad en el numerador y 19
grados de libertad en el denominador, por lo que se toma la decisión de no
rechazar la hipótesis nula, concluyéndose entonces que el modelo de bloques
al azar es apropiados a este conjunto de observaciones.
Continuando entonces con el análisis, establecemos las tendencias lineal y
cuadrática en el anova de la variable original:
Fuentevariacion S.C. G.L. C.M. F
Probabilidad
Valor crítico para F
Bloques 8.20966667 5 1.64193333 0.39892127 0.84373767 2.71088984Tratamientos 124.845333 4 31.2113333 7.58305123 0.00068956 2.8660814T. Lineal 85.4426667 1 85.4426667 20.7590016 0.00019193 4.3512435T.Cuadratica 36.8019048 1 36.8019048 8.94132674 0.00723358 4.3512435T. Cúbica 1.76816667 1 1.76816667 0.4295907 0.51965862 4.3512435T. Cuarto 0.83259524 1 0.83259524 0.20228589 0.65771869 4.3512435
Error 82.3186667 20 4.11593333
Total 215.373667 29
Las tendencias que resultan ser significativas son la lineal y la cuadrática, por
lo que se puede concluir que un modelo polinomial de segundo orden se ajusta
adecuadamente a este conjunto de observaciones.
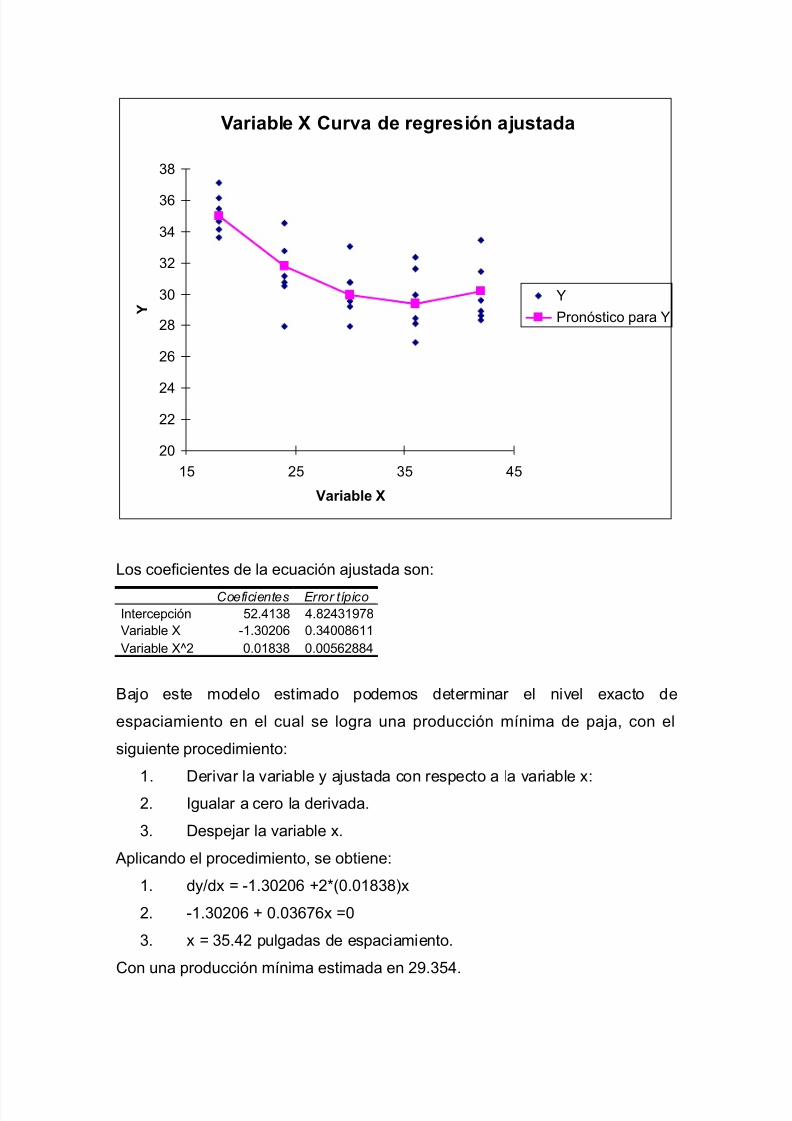
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 58/119
Variable X Curva de regresión ajustada
20
22
24
26
28
30
32
34
36
38
15 25 35 45
Variable X
YY
Pronóstico para Y
Los coeficientes de la ecuación ajustada son:
Coeficientes Error típico
Intercepción 52.4138 4.82431978Variable X -1.30206 0.34008611Variable X^2 0.01838 0.00562884
Bajo este modelo estimado podemos determinar el nivel exacto de
espaciamiento en el cual se logra una producción mínima de paja, con el
siguiente procedimiento:
1. Derivar la variable y ajustada con respecto a la variable x:2. Igualar a cero la derivada.
3. Despejar la variable x.
Aplicando el procedimiento, se obtiene:
1. dy/dx = -1.30206 +2*(0.01838)x
2. -1.30206 + 0.03676x =0
3. x = 35.42 pulgadas de espaciamiento.
Con una producción mínima estimada en 29.354.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 59/119
DISEÑO EN CUADRO LATINO
El diseño en cuadro latino es una generalización del diseño en bloques al azar,
consistente en que las variables de bloqueo usadas en el diseño son dos,
llamadas genéricamente la variable de hileras y la variable de columnas. El
nombre de este arreglo geométrico es debido a que el numero de niveles en las
variable de hileras es igual al numero de niveles en la variable de columnas y
es igual al numero de tratamientos, estos ultimos son denotados por letras
latinas dentro de las celdas del cuadrado que forman las hileras y las
columnas.
Una restricción en la aleatorizacion de este arreglo geométrico es que cada
letra correspondiente a uno de los tratamientos solo debe aparecer una vez en
cada hilera y en cada columna. El procedimiento de aleatorizacion en este
arreglo geométrico consiste de los siguientes pasos:
1. Empezar con la construcción de un cuadro latino estándar. Este
cuadro se caracteriza por el orden alfabético de las letras a partir de
la primera hilera y primera columna.
2. Aleatorizar las hileras para generar un segundo cuadro.
3. Aleatorizar las columnas del segundo cuadro para definir el cuadro
que va ser utilizado en el experimento.
Apliquemos el procedimiento de aleatorizacion a un cuadro latino de
dimension 4×4:
1. Cuadro latino estándar:
Columna 1 Columna 2 Columna 3 Columna 4Hilera 1 A B C DHilera 2 B C D AHilera 3 C D A BHilera 4 D A B C
2. Aleatorizar hileras: Para este fin se pueden obtener cuatro números
aleatorios que se asignan en secuencia de generacion a las hileras
ordenadas en el cuadro latino estándar. En seguida los números
aleatorios se ordenan en magnitud, indicando así el orden aleatorio en
que deben estar las hileras. Usando el generador de números aleatorios
disponible en Excel, los números aleatorios generados son:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 60/119
Numero Aleatorio
Orden Actual de
Hileras
Orden Aleatorio de
Hileras0.08060046 1 1
0.09297599 2 2
0.61098286 3 4
0.47095288 4 3
Así el nuevo cuadro, con hileras aleatorizadas debe ser
Columna 1 Columna 2 Columna 3 Columna 4Hilera 1 A B C DHilera 2 B C D AHilera 3 D A B CHilera 4 C D A B
3. Aleatorizar columnas: Este paso se lleva a cabo de manera equivalentea las hileras, solo que en este caso aplicado a columnas:
Numero Aleatorio
Orden Actual decolumna
Ordenaleatorio deColumna
0.4209566 1 20.41984865 2 10.90356138 3 40.88228072 4 3
Por lo que el nuevo cuadro será:Columna 1 Columna 2 Columna 3 Columna 4
Hilera 1 B A D CHilera 2 C B A DHilera 3 A D C BHilera 4 D C B A
Este seria el cuadro latino que debe usarse como arreglo geométrico del
diseño experimental. Las letras pueden también ser asignadas al azar a los
tratamientos.
MODELO ESTADÍSTICO DEL DISEÑO EN CUADRTO LATINO:
Aparte de los tratamientos, este arreglo geométrico debe incorporar en el
modelo las dos fuentes de bloqueo, las hileras y columnas. Para construir el
modelo debemos considerar 3 subindices (i, j, k) que correspondan a cada
una de las fuentes de variación, pero el subíndice de tratamiento queda

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 61/119
definido por los subíndices de hilera y columna, lo que es generado por el
hecho de que tratamiento este anidado a hilera y columna. Esta situación es
representada en el modelo como:
Yijk = μ + τ k(ij) +β i+ γ j+ εijk
i = 1,2,…,t ; j = 1,2,…,t; k = 1,2,…t
t = numero de tratamientos.
n = t2 , numero total de observaciones en el arreglo.
Donde
μ Es la media general de la población.
τ k(ij) Es el efecto del tratamiento k en la hilera i y columna j.
β i Es el efecto de la hilera i.
γ j Es el efecto de la columna j.
εijk Es el error experimental en la hilera i, columna j y tratamiento k.
La hipótesis que se desea probar es solo acerca del efecto de los tratamientos,
es decir:
Ho: Todos los efectos de tratamiento son iguales a cero.
Contra la Ha: al menos uno de los efectos de tratamiento es diferente de cero.
Las variables de bloqueo incluidas en este arreglo son estrictamente, como en
el arreglo en bloques, para el control de la variación en las unidades
experimentales o de las condiciones en que se lleva a cabo el experimento,
pero no son de interés como factores de investigación. El objetivo entonces de
las variables de bloqueo sigue siendo eliminar posibles fuentes de variación en
el experimento que pudieran impactar sobre la variable de respuesta y
enmascarar el efecto de los tratamientos.
ANÁLISIS DE VARIANZA EN EL DISEÑO EN CUADRO LATINO:
Como Lo establece el modelo del diseño en cuadro latino, se supone que los
efectos son aditivos e independientes, por lo que para el análisis establecemos
las siguientes restricciones acerca de los parámetros del modelo:
Σ τ k(ij) = 0
Σβ i = 0

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 62/119
Σ γ j = 0
Ya que el numero de niveles en cada fuente de variación es t, entonces el
numero de parámetros independientes que deben ser estimados por cada
fuente de variación es (t - 1), y así los grados de libertad son:Para el modelo reducido: t2 – 1 = (t + 1)(t - 1)
Para el modelo completo: t2 – 1 - 3(t - 1)= t2 - 3(t )+2 = (t – 1) (t – 2)
La estimación de los parámetros del modelo es la que se ha venido
identificando en los otros dos arreglos geométricos:
τ k(ij) = Media del tratamiento k – Media General
β i = Media de la hilera i – Media General.
γ j = Media de la columna j – Media General.
La suma de cuadrados asociada al efecto de los tratamientos esta dada por:
S.C.(tratamientos) = t × Σ τ2k(ij) con ( t – 1 ) grados de libertad.
S.C. (hileras) = t × Σβ2i con ( t – 1 ) grados de libertad.
S.C. (columnas) = t × Σ γ2 j con ( t – 1 )grados de libertad.
La suma de cuadrados del total y sus grados de libertad asociados se
obtienen del ajuste del modelo reducido, en tanto que la suma de cuadrados
del residual y sus grados de libertad se obtienen del ajuste del modelocompleto. El resto de la tabla de análisis de varianza reobtiene de la manera
convencional.
F.V. G.L. S.C. C.M. Fc Ft Pr > FcModelo 3( t - 1 ) S.C.To - S.C.EHileras t - 1 t (S.C.(ef. Hilera))Columnas t - 1 t (S.C.(ef. Columna))Tratamientos t - 1 t (S.C. (ef. Tratamiento)Error (t-1)(t-2) S.C.E. Mod. CompletoTotal t^2 - 1 S.C.E. Mod. Reducido
Ejemplo numérico 1. Se llevo a cabo un experimento en un diseño en
cuadro latino en el que se deseaba comparar el efecto de 5 fuentes de
fertilización nitrogenada y un testigo sobre la producción de azucar de
remolacha. Las fuentes a comparar fueron:
A: Sulfato de amonio.
B: Nitrato de amonio.
C: UreaD: Nitrato de calcio.
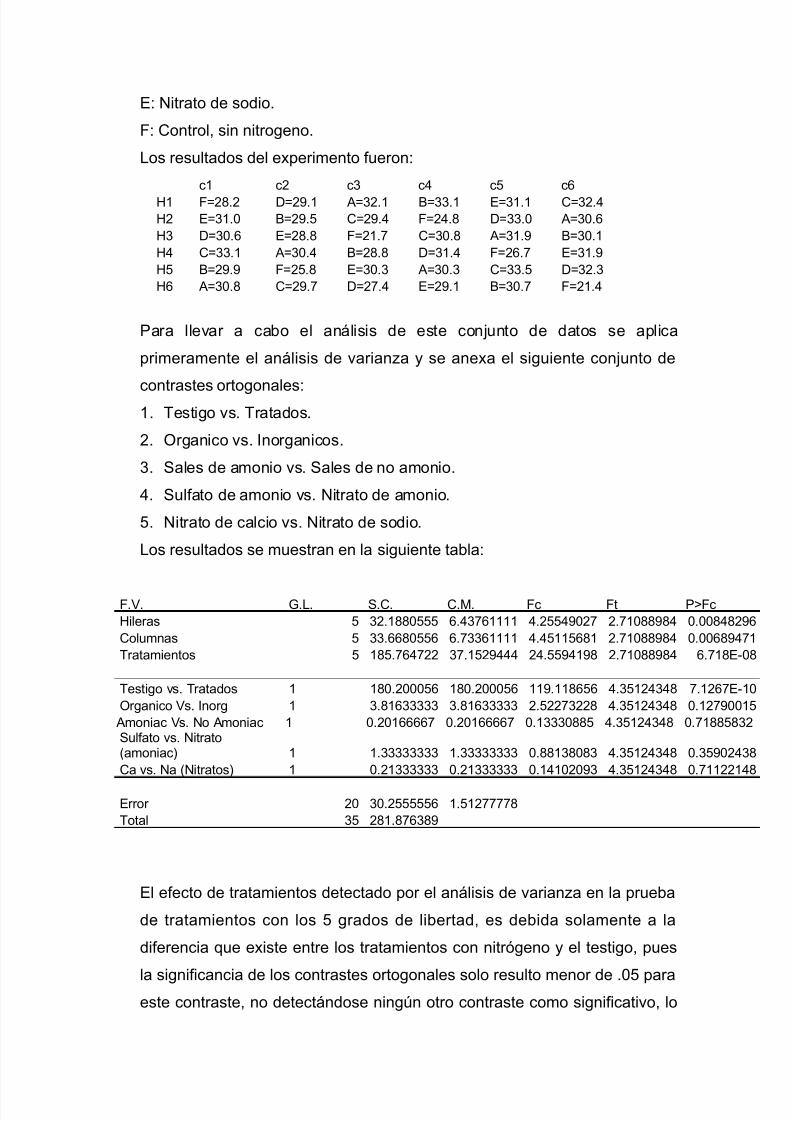
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 63/119
E: Nitrato de sodio.
F: Control, sin nitrogeno.
Los resultados del experimento fueron:
c1 c2 c3 c4 c5 c6H1 F=28.2 D=29.1 A=32.1 B=33.1 E=31.1 C=32.4H2 E=31.0 B=29.5 C=29.4 F=24.8 D=33.0 A=30.6H3 D=30.6 E=28.8 F=21.7 C=30.8 A=31.9 B=30.1H4 C=33.1 A=30.4 B=28.8 D=31.4 F=26.7 E=31.9H5 B=29.9 F=25.8 E=30.3 A=30.3 C=33.5 D=32.3H6 A=30.8 C=29.7 D=27.4 E=29.1 B=30.7 F=21.4
Para llevar a cabo el análisis de este conjunto de datos se aplica
primeramente el análisis de varianza y se anexa el siguiente conjunto de
contrastes ortogonales:1. Testigo vs. Tratados.
2. Organico vs. Inorganicos.
3. Sales de amonio vs. Sales de no amonio.
4. Sulfato de amonio vs. Nitrato de amonio.
5. Nitrato de calcio vs. Nitrato de sodio.
Los resultados se muestran en la siguiente tabla:
F.V. G.L. S.C. C.M. Fc Ft P>FcHileras 5 32.1880555 6.43761111 4.25549027 2.71088984 0.00848296Columnas 5 33.6680556 6.73361111 4.45115681 2.71088984 0.00689471Tratamientos 5 185.764722 37.1529444 24.5594198 2.71088984 6.718E-08
Testigo vs. Tratados 1 180.200056 180.200056 119.118656 4.35124348 7.1267E-10Organico Vs. Inorg 1 3.81633333 3.81633333 2.52273228 4.35124348 0.12790015 Amoniac Vs. No Amoniac 1 0.20166667 0.20166667 0.13330885 4.35124348 0.71885832Sulfato vs. Nitrato(amoniac) 1 1.33333333 1.33333333 0.88138083 4.35124348 0.35902438Ca vs. Na (Nitratos) 1 0.21333333 0.21333333 0.14102093 4.35124348 0.71122148
Error 20 30.2555556 1.51277778Total 35 281.876389
El efecto de tratamientos detectado por el análisis de varianza en la prueba
de tratamientos con los 5 grados de libertad, es debida solamente a la
diferencia que existe entre los tratamientos con nitrógeno y el testigo, pues
la significancia de los contrastes ortogonales solo resulto menor de .05 paraeste contraste, no detectándose ningún otro contraste como significativo, lo

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 64/119
que indica que en cuanto a la variable de respuesta evaluada, todos los
fertilizantes tienen el mismo efecto.
CUADROS LATINOS AUMENTADOS:
Una desventaja de este arreglo geométrico es que cuando el numero de
tratamientos es pequeño, esto trae como consecuencia un escaso numero
de grados de libertad para el error. Por ello se recomienda,
fundamentalmente en estos casos, aumentar el diseño en cuadro latino a
través de repeticiones completas de los cuadros, que puede estar asociada
a algún otro factor de bloqueo, diferente al empleado para definir las hileras
y columnas, por ejemplo, años en que se lleva a cabo el experimento, sitios
en que se lleva a cabo el experimento, etc. Debemos distinguir
fundamentalmente tres tipos de cuadros latinos repetidos:
1. Con hileras y columnas comunes en cada repetición del cuadro. Sucede
con hileras y columnas lo mismo que con los tratamientos, son los
mismos niveles en cada repetición, por lo que las repeticiones se
asocian mas comúnmente a tiempo. El modelo para este arreglo es el
del cuadro latino convencional con el efecto aditivo de repeticiones.
Yijkl = μ + ρi + τ l(ijk) +β j+ γ k+ εijkl
En este caso, entonces, solo se agrega la fuente de variación de repetición
en el anova con (r-1) grados de libertad, siendo r el numero de repeticiones
de cuadros latinos completos. Cada una de las fuentes de variación en el
modelo (hileras, columnas y tratamientos) contribuyen con (t-1) grados de
libertad. El numero total de observaciones es ahora r×t² , por lo que los
grados de libertad para el total son (r×t²-1) quedando para el error la
diferencia definida por (t-1)×[r×(t+1)-3].
Con tres repeticiones en un cuadro latino con tres tratamientos, los
grados de libertad en el error aumenta 9 veces en comparación con una
sola repetición.
Ejemplo numérico 2. Considere la situación experimental en una
industria en la que se están probando tres tipos de soldadura
(tratamientos) y se controlan como variables de bloqueo el fundente
(columnas) y el operador que lleva a cabo el proceso (hileras), en dosmaquinas soldadoras diferentes (repeticiones). La variable de respuesta
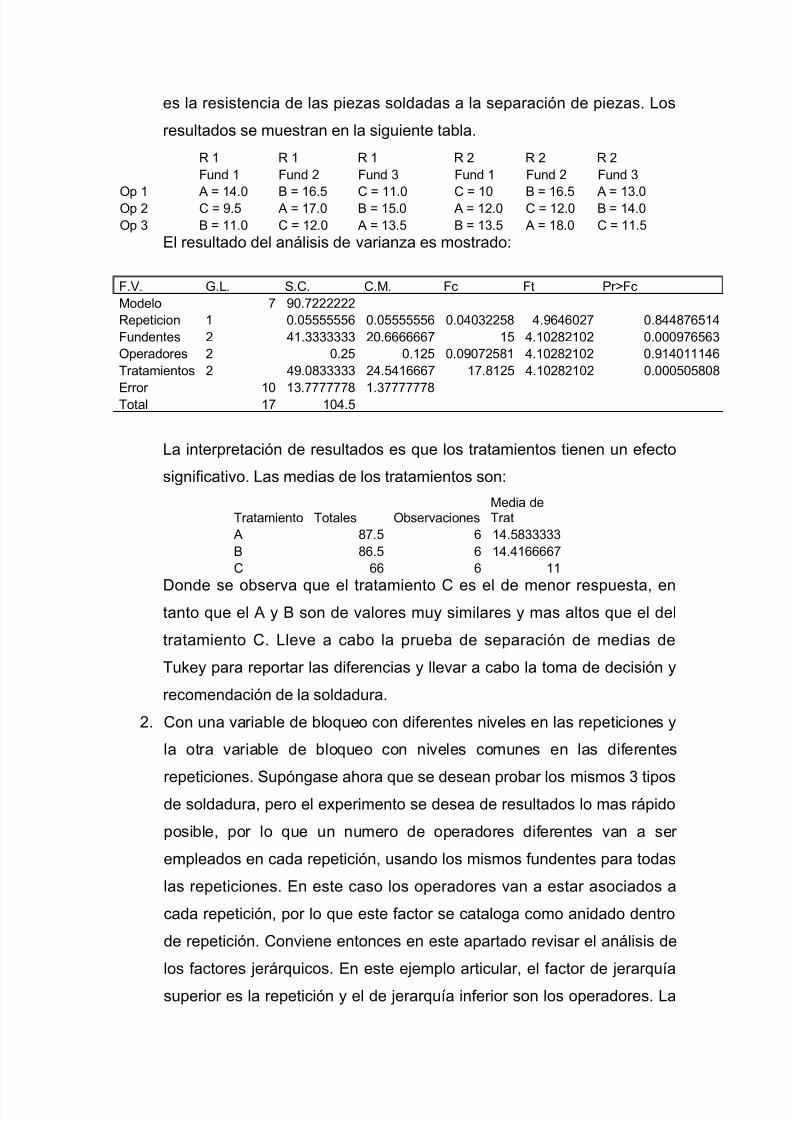
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 65/119
es la resistencia de las piezas soldadas a la separación de piezas. Los
resultados se muestran en la siguiente tabla.
R 1 R 1 R 1 R 2 R 2 R 2Fund 1 Fund 2 Fund 3 Fund 1 Fund 2 Fund 3
Op 1 A = 14.0 B = 16.5 C = 11.0 C = 10 B = 16.5 A = 13.0Op 2 C = 9.5 A = 17.0 B = 15.0 A = 12.0 C = 12.0 B = 14.0Op 3 B = 11.0 C = 12.0 A = 13.5 B = 13.5 A = 18.0 C = 11.5
El resultado del análisis de varianza es mostrado:
F.V. G.L. S.C. C.M. Fc Ft Pr>FcModelo 7 90.7222222Repeticion 1 0.05555556 0.05555556 0.04032258 4.9646027 0.844876514Fundentes 2 41.3333333 20.6666667 15 4.10282102 0.000976563Operadores 2 0.25 0.125 0.09072581 4.10282102 0.914011146Tratamientos 2 49.0833333 24.5416667 17.8125 4.10282102 0.000505808
Error 10 13.7777778 1.37777778Total 17 104.5
La interpretación de resultados es que los tratamientos tienen un efecto
significativo. Las medias de los tratamientos son:
Tratamiento Totales ObservacionesMedia deTrat
A 87.5 6 14.5833333B 86.5 6 14.4166667C 66 6 11
Donde se observa que el tratamiento C es el de menor respuesta, entanto que el A y B son de valores muy similares y mas altos que el del
tratamiento C. Lleve a cabo la prueba de separación de medias de
Tukey para reportar las diferencias y llevar a cabo la toma de decisión y
recomendación de la soldadura.
2. Con una variable de bloqueo con diferentes niveles en las repeticiones y
la otra variable de bloqueo con niveles comunes en las diferentes
repeticiones. Supóngase ahora que se desean probar los mismos 3 tiposde soldadura, pero el experimento se desea de resultados lo mas rápido
posible, por lo que un numero de operadores diferentes van a ser
empleados en cada repetición, usando los mismos fundentes para todas
las repeticiones. En este caso los operadores van a estar asociados a
cada repetición, por lo que este factor se cataloga como anidado dentro
de repetición. Conviene entonces en este apartado revisar el análisis de
los factores jerárquicos. En este ejemplo articular, el factor de jerarquía
superior es la repetición y el de jerarquía inferior son los operadores. La

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 66/119
estimación de los efectos del factor de jerarquía superior se llevan a
cabo de la manera acostumbrada, pero los efectos del factor de
jerarquía inferior se llevan a cabo dentro de cada nivel del factor de
jerarquía superior. En este ejemplo tenemos que llevar a cabo la
estimación de cada operador dentro de cada repetición del cuadro latino,
ya que en cada uno los operadores serán diferentes (media de operador
menos la media de repetición). Esto implica que en cada repetición se
deberán estimar (t-1) parámetros independientes, por lo que los grados
de libertad para esta fuente de variación serán r×(t-1). El modelo
estadístico es similar al del cuadro latino con repeticiones con factores
de bloqueo comunes, con la única diferencia de que ahora debe ser
especificado el anidamiento de una de las fuentes de bloqueo.
Yijkl = μ + ρi + τ l(ijk) +β j(i) + γ k+ εijkl
Los grados de libertad en el error para este modelo van a estar definidos
por (t-1)×(r×t – 2). El incremento en los grados de libertad en el error es
menor bajo este arreglo, por la mayor cantidad de parámetros
independientes que deben ser estimados.
Ejemplo numérico 3. A continuación se muestran los datos del segundo
experimento en la industria referente a la soldadura con diferentes
operadores en cada repetición. Una tabla de análisis de varianza es
mostrada enseguida de los datos. En dicha tabla se observa una
significancia para todos los efectos. Las medias de los tipos de soldadura
son requeridos para seleccionar el mejor nivel. Los valores resultaron ser:
Media A = 296 , Media B = 253.3, Media C = 210.6
Por lo que la mejor soldadura es la del tipo A.
Fundente 1 Fundente 2 Fundente 3Rep 1 Operador 1 B = 265 A = 311 C = 249
Operador 2 A =350 C = 284 B = 330Operador 3 C = 258 B = 305 A = 351
Rep 2 Operador 4 B = 220 A = 276 C = 189Operador 5 A = 319 C = 232 B = 264Operador 6 C = 175 B = 254 A = 307
Rep 3 Operador 7 B = 159 A = 205 C = 142
Operador 8 A = 262 C = 168 B = 246Operador 9 C = 198 B = 237 A = 283

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 67/119
F.V. G.L. S-C. C.M. Fc Ft P > Fc
Modelo 12 84904.2222
Repeticion 2 36140.5185 18070.2593 134.60819 3.73889183 7.2122E-10Oper(Rep 6 14565.7778 2427.62963 18.0837932 2.847726 7.4259E-06Fund 2 1344.51852 672.259259 5.00776446 3.73889183 0.02287974Tratamiento 2 32853.4074 16426.7037 122.365087 3.73889183 1.3582E-09
Error 14 1879.40741 134.243386Total 26 86783.6296
Conviene llevar a cabo la prueba de separación de medias de Tukey para
mostrar las diferencias significativas entre los tratamientos y poder
establecer la recomendación.
3. Con hileras y columnas con diferentes niveles en cada repetición del
cuadro.
Considere ahora la situación en que lo único que es común en las
repeticiones del cuadro latino son los tratamientos, usando diferentes
niveles del factor hilera y del factor columna en cada una de las
repeticiones. Esto implica que tanto hileras como columnas están anidadasdentro de cada repetición. El modelo estadístico para este arreglo
geométrico es
Yijkl = μ + ρi + τ l(ijk) +β j(i) + γ k(i)+ εijkl
En base a este modelo los grados de libertada para el error experimental
quedan definidos por la expresión (t-1)×(r×t-r-1) . Como puede sospecharse,
por el numero de parámetros a estimar, este es el cuadro latino repetido
que tiene un menor incremento en los grados de libertad en el error, ya quela estimación de efectos de hilera y columna se llevan a cabo dentro de
cada repetición.
Ejemplo numérico 4. Como un ejemplo considere la situación en la que se
están probando cuatro diferentes tratamientos (A, B, C, D) para mejorar el
valor nutricional de subproductos agrícolas para la alimentación del ganado.
Se dispone de dos zonas climáticas, cada una de las cuales produce cuatro
diferentes tipos de subproductos agrícolas que se pueden someter a losmismos tratamientos, y en cada zona climática son usados 4 diferentes

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 68/119
animales en los que se prueba el subproducto tratado. La variable a medir
es el porcentaje de disgestibilidad. Los resultados se muestran a
continuación:
S U B P R O D U C T O S
ANIMAL 1 2 3 41 C = 0.2 A = 0.24 D = 0.2 B = 0.272 B = 0.28 C = 0.19 A = 0.22 D = 0.283 D = 0.34 B = 0.23 C = 0.21 A = 0.284 A = 0.32 D = 0.22 B = 0.16 C = 0.27
5 6 7 85 B = 0.29 A = 0.25 C = 0.18 D = 0.286 D = 0.28 B = 0.18 A = 0.21 C = 0.257 C = 0.28 D = 0.23 B = 0.2 A = 0.28
8 A = 0.3 C = 0.19 D = 0.24 B = 0.25
Se requiere en primer lugar la estimación de los efectos de acuerdo al
modelo establecido:
Media general: 0.24375
Efecto de la repetición: Media de repetición – Media general.
Efecto de la repetición 1 = 0.000625
Efecto de la repetición 2 = - 0.000625
Efectos de hilera en la repetición 1: Media de la hilera – Media Repetición 1
Efecto de la hilera 1 (Repetición 1) = 0.016875
Efecto de la hilera 2 (Repetición 1) = -0.001875
Efecto de la hilera 3 (Repetición 1) = 0.020625
Efecto de la hilera 4 (Repetición 1) = -0.001875
Efectos de hilera en la repetición 2: Media de la hilera – Media Repetición 2
Efecto de la hilera 5 (Repetición 2) = 0.006875
Efecto de la hilera 6 (Repetición 2) = -0.013125
Efecto de la hilera 7 (Repetición 2) = 0.004375
Efecto de la hilera 8 (Repetición 2) = 0.001875
Recalcamos que una estimación de efectos anidados consiste en la estimación
separada de los efectos en cada nivel del factor de jerarquía superior.
Efectos de columna en repetición 1: Media de la columna – Media repetición 1
Efecto de la Columna 1 (Repetición 1) = 0.040625
Efecto de la Columna 2 (Repetición 1) = -0.024375

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 69/119
Efecto de la Columna 3 (Repetición 1) = -0.046875
Efecto de la Columna 4 (Repetición 1) = 0.030625
Efectos de columna en repetición 2: Media de la columna – Media repetición 2
Efecto de la Columna 5 (Repetición 2) = 0.044375
Efecto de la Columna 6 (Repetición 2) = -0.030625
Efecto de la Columna 7 (Repetición 2) = -0.035625
Efecto de la Columna 8 (Repetición 2) = 0.021875
Efecto de los Tratamientos: Media de tratamiento – Media general.
Efecto del tratamiento 1 = 0.01875
Efecto del tratamiento 2 = -0.01125
Efecto del tratamiento 3 = -0.0225
Efecto del tratamiento 4 = 0.015
En base a estos efectos estimados se pueden deducir los grados del libertad,
las sumas de cuadrados de los efectos, el modelo completo y el modelo
reducido, es decir, se puede derivar todo el análisis de varianza.
Vamos a repasar primero los grados de libertad asociados a los efectos
incluidos en el modelo. Como regla general, los grados de libertad del efecto
corresponde al numero de parámetros independientes estimados para dicho
efecto. Entonces:
Para repeticiones es un grado de libertad, ya que se estimaron dos efectos de
repetición, pero su suma es igual a cero, de tal forma que independientes solo
se estima uno.
Para hileras anidadas en repeticiones, se tienen 4 estimaciones en la repetición
uno y otras 4 en la repetición dos, pero, en cada caso su suma es cero, por lo
que solo quedan 3 estimaciones independientes en cada repetición, y así, los
grados de libertad para hileras en repetición son 6.
Para columnas anidadas en repetición, se tiene una situación equivalente a la
de hileras, 4 estimadores de columnas en cada repetición, pero solo tres
independientes en cada caso, por lo que los grados de libertad de columnas
anidadas en repetición son también 6.
Para tratamientos es una situación diferente, ya que los tratamientos son
comunes en ambas repeticiones, para calcular los estimadores de los efectos
se juntan ambas repeticiones y se obtienen solo 4 estimadores, de los cuales,
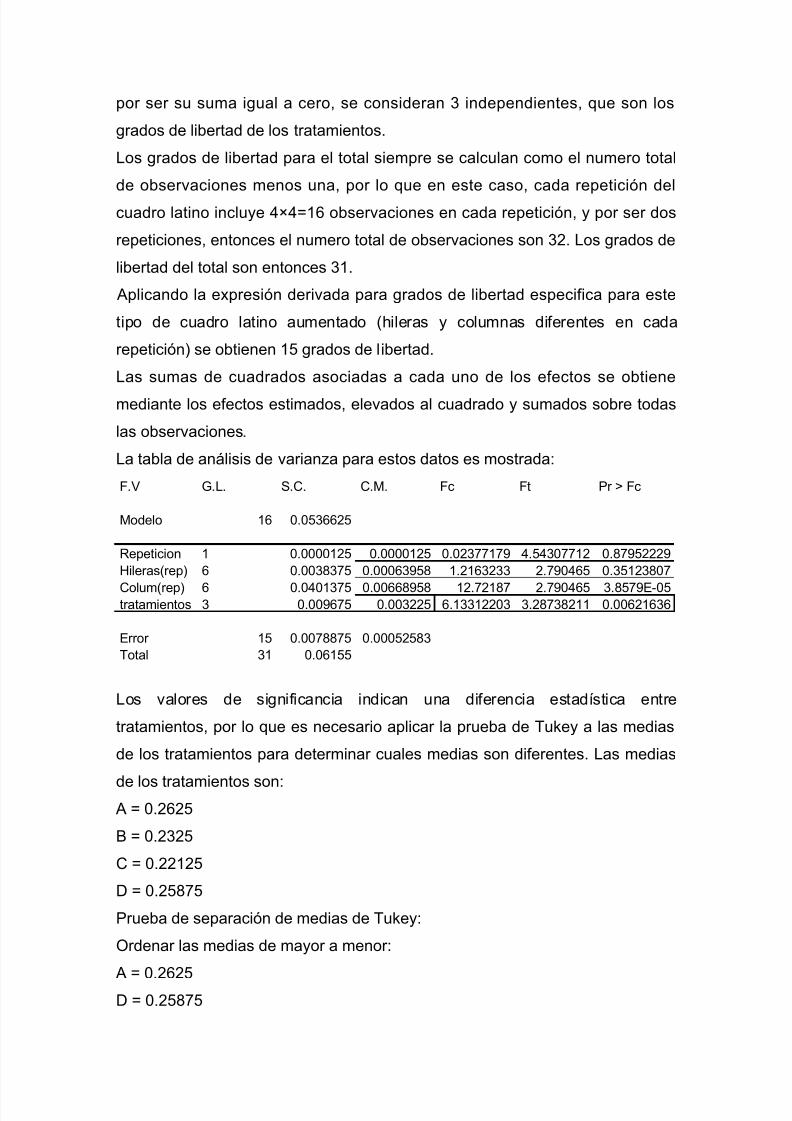
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 70/119
por ser su suma igual a cero, se consideran 3 independientes, que son los
grados de libertad de los tratamientos.
Los grados de libertad para el total siempre se calculan como el numero total
de observaciones menos una, por lo que en este caso, cada repetición del
cuadro latino incluye 4×4=16 observaciones en cada repetición, y por ser dos
repeticiones, entonces el numero total de observaciones son 32. Los grados de
libertad del total son entonces 31.
Aplicando la expresión derivada para grados de libertad especifica para este
tipo de cuadro latino aumentado (hileras y columnas diferentes en cada
repetición) se obtienen 15 grados de libertad.
Las sumas de cuadrados asociadas a cada uno de los efectos se obtiene
mediante los efectos estimados, elevados al cuadrado y sumados sobre todas
las observaciones.
La tabla de análisis de varianza para estos datos es mostrada:
F.V G.L. S.C. C.M. Fc Ft Pr > Fc
Modelo 16 0.0536625
Repeticion 1 0.0000125 0.0000125 0.02377179 4.54307712 0.87952229Hileras(rep) 6 0.0038375 0.00063958 1.2163233 2.790465 0.35123807
Colum(rep) 6 0.0401375 0.00668958 12.72187 2.790465 3.8579E-05tratamientos 3 0.009675 0.003225 6.13312203 3.28738211 0.00621636
Error 15 0.0078875 0.00052583Total 31 0.06155
Los valores de significancia indican una diferencia estadística entre
tratamientos, por lo que es necesario aplicar la prueba de Tukey a las medias
de los tratamientos para determinar cuales medias son diferentes. Las medias
de los tratamientos son: A = 0.2625
B = 0.2325
C = 0.22125
D = 0.25875
Prueba de separación de medias de Tukey:
Ordenar las medias de mayor a menor:
A = 0.2625D = 0.25875

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 71/119
B = 0.2325
C = 0.22125
Construir una tabla de diferencia de medias:
A D B C A A-D=0.00375 A-B=0.03000 A-C=0.04125D D-B=0.02625 D-C=.0375B B-C=0.01125C
Valor HSD: Diferncia honesta significativa de Tukey:
Error estándar de la media = 0.008107
Valor critico de la tabla de Tukey = 4.08
HSD = 0.008107×4.08 = 0.033Declaracion de diferencias significativas:
A-D < HSD , No significativa
A-B < HSD , No significativa
A-C > HSD , Significativa
D-B < HSD , No significativa.
D-C > HSD , Significativa.
B-C < HSD , No significativa.Separación de medias:
A = 0.2625a D = 0.25875a B = 0.2325ac C = 0.22125c
Los tratamientos A y D estadísticamente iguales son los que incrementaron
mas la respuesta. El tratamiento C es el de mas baja respuesta y
estadísticamente es igual al tratamiento B, que por estar en valor intermedio,
también es estadísticamente igual an los tratamientos A y D.
ARREGLOS DE TRATAMIENTOS:
Los arreglos de tratamientos se refieren al conjunto de tratamientos que deben
ser incluidos en un experimento para poder llevar a cabo las hipótesis que se
plantean en la investigación. De esta manera, si la hipótesis establece solo los
efectos de tratamientos referentes a un solo factor, entonces el arreglo de
tratamientos requerido es un arreglo unifactorial.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 72/119
Por otro lado, si las hipótesis que se desean probar se refieren a dos o
mas factores, entonces el arreglo a seleccionar es un arreglo multifactorial, que
puede ser un arreglo factorial o un arreglo en parcelas divididas.
El arreglo factorial es seleccionado cuando el tamaño de la unidad
experimental es el mismo para cualquiera de los factores que se desean
probar. Bajo este arreglo se aleatorizan independientemente los niveles de
cada uno de los factores a las unidades experimentales. De manera
equivalente, se pueden formular todas las posibles combinaciones de los
niveles de los factores y considerarlas como tratamientos, llevando a cabo una
aleatorizacion de acuerdo al arreglo geométrico de las unidades
experimentales.
El arreglo de parcelas divididas es seleccionado cuando el tamaño de la
unidad experimental requerido para probar los niveles de un factor es mas
grande (factor de parcela principal) comparado con el tamaño de la unidad
experimental para probar otro factor (factor de subparcela). En estos arreglos
de tratamientos las unidades experimentales para probar el factor de parcela
principal son aleatorizados de acuerdo a algún arreglo geométrico
seleccionado. Posteriormente la parcela principal ya tratada con el nivel del
factor de parcela principal es dividida (de ahí su nombre) en un numero de
subunidades igual al numero de niveles del factor de subparcela, el cual es
asignado de manera aleatoria.
Ejemplo típico de un arreglo factorial:
Se desea investigar el efecto de la fuente de proteína y la cantidad de proteína
en la dieta para mascotas de tipo roedor, sobre sus ganancias de peso, con la
finalidad de minimizar crecimiento. Las fuentes de proteína investigadas son de
tres tipos: Res, soya y puerco. Un factor fijo, cualitativo y con tres niveles. Los
niveles del factor cantidad de proteína en la dieta son dos, denominados el
nivel alto y el nivel bajo. Es un factor fijo, cuantitativo con dos niveles. La
denominación de los niveles de este factor (alto y bajo) no le quita la naturaleza
cuantitativa al factor. El arreglo factorial requerido para probar estos factores es
caracterizado como un 3×2, o sea, los tres niveles del factor tipo de proteína y
dos niveles del factor cantidad de proteína en la dieta, dando un arreglo con 6combinaciones , cada una de las cuales constituye un tratamiento. Ya que se

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 73/119
cuenta con un grupo homogéneo de 60 animales de este tipo, se separan en 6
grupos de 10 animales cada uno, en forma completamente aleatoria, asignando
a cada grupo un tratamiento. Este es un caso típico en que ambos factores
requieren del mismo tamaño de unidad experimental (el animal) para probar
ambos factores.
Los datos obtenidos de las ganancias de peso para cada animal se muestran
en la siguiente tabla:
ALTA
PROTEÍNABAJA
PROTEÍNARes Soya Puerco Res Soya Puerco
73 98 94 90 107 49
102 74 79 76 95 82118 56 96 90 97 73104 111 98 64 80 8681 95 102 86 98 81
107 88 102 51 74 97100 82 108 72 74 10687 77 91 90 67 70
117 86 120 95 89 61111 92 105 78 58 82
Las hipótesis que se desean probar son:
1. Ho: No hay efecto de la cantidad de proteína.
2. Ho: No hay efecto de la fuente de proteína.
3. Ho: No hay efecto de interacción de cantidad por tipo de proteína.
Efecto de interacción:
Siempre que se lleva a cabo un experimento multifactorial el objetivo
fundamental es investigar el efecto conjunto de los factores. Esto implicainvestigar como los niveles de un factor pueden modificar el efecto de otro
factor sobre una respuesta.
En nuestro ejemplo de las mascotas esto llevaría a determinar como el
efecto de la cantidad de proteína se ve modificado al cambiar las fuentes de
proteína. En otras palabras, indagar si el efecto de la cantidad de proteína
es el mismo para cada una de las fuentes investigadas.
Si el efecto de la cantidad de proteína resulta ser el mismo para cadafuente, es decir, el cambio en respuesta promedio por efecto de la cantidad

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 74/119
de proteína para cada fuente resulta muy homogéneo, esto refleja que la
fuente de proteína no modifica el efecto de la cantidad, por lo tanto, bajo
esta situación se considera que el efecto de los factores sobre la variable de
respuesta son independientes, esto es, cada uno de los factores tiene su
efecto sobre la respuesta indistintamente del nivel en el que se encuentra el
otro factor.
Sobre otro punto de vista, si el efecto de la cantidad de proteína se modifica
para cada una de las fuentes, entonces existe una dependencia entre los
dos factores. La magnitud de cambio en la variable de respuesta debido a la
cantidad de proteína va a depender de la fuente de proteína que se este
considerando, situación que caracteriza un efecto de interacción de
cantidad por fuente. Esto equivale a observar diferentes pendientes o tasas
de cambio de un factor para diferentes niveles de un segundo factor. El
efecto de un factor bajo una situación de interacción se potencializa o inhibe
de acuerdo al nivel del segundo factor. Los efectos de los factores no son
independientes, sino todo lo contrario, existe un efecto cruzado de los
factores.
Bajo una situación de interacción de factores no tiene sentido entonces
concluir acerca de cada uno de los factores por separado, por la
dependencia que existe del efecto de un factor y los niveles de un segundo
factor.
En los estudios multifactoriales vamos a distinguir dos tipos de efectos:
1. Los efectos principales, que evalúan el cambio en respuesta por los
niveles de un factor, ignorando los niveles del resto de los factores.
2. Los efectos de interacción, que evalúan el cambio en el efecto de un
factor a diferentes niveles de un segundo factor. Las interacciones se
clasifican de acuerdo al numero de factores que se consideran en la
interacción como:
a), Interacciones de primer orden, cuando solo se consideran dos
factores en la interacción. Por ejemplo, la interacción cantidad de
proteína por fuente de proteína es una interacción de primer orden y es

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 75/119
la única que puede ser investigada , ya que solo se incluyen en el
experimento estos dos factores.
b). Interacciones de segundo orden o de tres factores, que estudia el
efecto conjunto de tres factores, es decir, como se modifica el efecto de
un factor al variar los niveles de un segundo y un tercer factor en el
experimento.
Sucesivamente se pueden definir, de manera equivalente las
interacciones de mas alto orden. Al llevar a cabo el análisis de los datos
de un estudio multifactorial con repeticiones en cada combinación de
niveles de los factores, deben ser incluidas todas las posibles
interacciones, para poder determinar cuales son significativas.
EJEMPLO TÍPICO DE UN ARREGLO EN PARCELAS DIVIDIDAS:
Se realiza un experimento para determinar la dispersión del pigmento en
la pintura. Se estudian 4 mezclas de un pigmento particular. El
procedimiento consiste en preparar una mezcla y aplicarla sobre una
tabla mediante tres métodos de aplicación (con brocha, por aspersión y
con rodillo). La respuesta se mide mediante el porcentaje de reflexion del
pigmento. Se requieren de tres dias para llevar a cabo el experimento.
Los datos obtenidos se muestran a continuación:
M E Z C L ADia Método de Aplicación 1 2 3 4
1 1 64.5 66.3 74.1 66.52 68.3 69.5 73.8 703 70.3 73.1 78 72.3
2 1 65.2 65 73.8 64.8
2 69.2 70.3 74.5 68.33 71.2 72.8 79.1 71.53 1 66.2 66.5 72.3 67.7
2 69 69 75.4 68.63 70.8 74.2 80.1 72.4
De acuerdo a la descripción del experimento, se preparo cada una de las
mezclas (factor de parcela principal) y la mezcla es aplicada por tres
métodos (factor de subparcela). En cada día (bloque) se preparan y
aplican las cuatro mezclas. La parcela principal esta formada por la

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 76/119
mezcla y día y como un ejemplo se tienen los datos de la siguiente
parcela principal:
Dia Método de Aplicación MEZCLA 1
1 1 64.52 68.33 70.3
Y la subparcela seria método de aplicación, mezcla y día, cada una de
las piezas de información.
Dia Método de Aplicación MEZCLA 1
1 1 64.5
Las hipótesis que se desean probar son:
1. Ho: No hay efecto de mezcla.
2. Ho: No hay efecto de método de aplicación.
3. Ho: No hay efecto de interacción de mezcla por método de
aplicación.
Como puede ser visualizado a partir de estos ejemplos tipicos de cada arreglo
de tratamientos, la selección esta basada en un criterio netamente practicote
llevar a cabo la aplicación de los niveles de los factores a las unidades
experimentales; cada una de las diferentes situaciones debe reflejarse en el
modelo estadístico y consecuentemente en el análisis de resultados.
ARREGLO FACTORIAL DE TRATAMIENTOS:
El tema de arreglos factoriales de tratamiento debe ser revisado bajo la
siguiente secuencia de subtemas:
1. Arreglos factoriales en general.
2. Series 2 a la k.
3. Series 3 a la k.
4. Fracciones de las series 2 a la k aplicando la técnica de la confusión.5. Bloqueo en las series 2 a la k.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 77/119
Estos arreglos constituyen la base fundamental de los arreglos empleados en
las metodologías de optimización, tales como la metodología de Taguchi y la
metodología de superficie de respuesta.
ARREGLOS FACTORIALES EN GENERAL:
En este subtema vamos a considerar los arreglos factoriales en los que
cada factor tiene su numero muy particular de niveles. Suponga que se tienen 3
factores, que convencionalmente los denotamos con letras mayúsculas,
digamos el factor A, el factor B y el factor C. sea a el numero de niveles en el
factor A, b el numero de niveles en el factor B y c el numero de niveles en el
factor C. Cada uno de los niveles de los factores se pueden representar con la
letra minúscula del factor seguido de un subíndice que corre desde cero hasta
el numero de niveles en el factor menos uno. Así por ejemplo, el factor A con a
niveles, pueden ser representados por
a0,a1,…aa-1
esta notación para niveles puede ser usada también para el resto de los
factores.
Entonces tenemos un arreglo factorial denotado por
a×b×c
Esta notación convencional para caracterizar los arreglos factoriales nos
informa directamente el numero de factores que se están investigando en el
experimento y el numero de niveles en cada uno de los factores.
Adicionalmente, el resultado de la multiplicación corresponde al numero de
tratamientos que se generan en este arreglo. Cada tratamiento es una
condición experimental diferente que se caracteriza por un nivel particular en
cada uno de los factores. Así cada tratamiento debe corresponder a una de las
combinaciones de los niveles de los factores. Para generar una estructura
factorial se pueden emplear varios métodos, por ejemplo el método tabular, el
método de diagrama de arbol o el método computacional.
El método tabular trabaja de manera adecuada cuando son pocos los factores
que se van a considerar, a lo mas cuatro. Se construye una tabla de doble
entrada, con hileras correspondiendo a las combinaciones de dos factores (olos niveles de un factor) y las columnas correspondiendo a las combinaciones
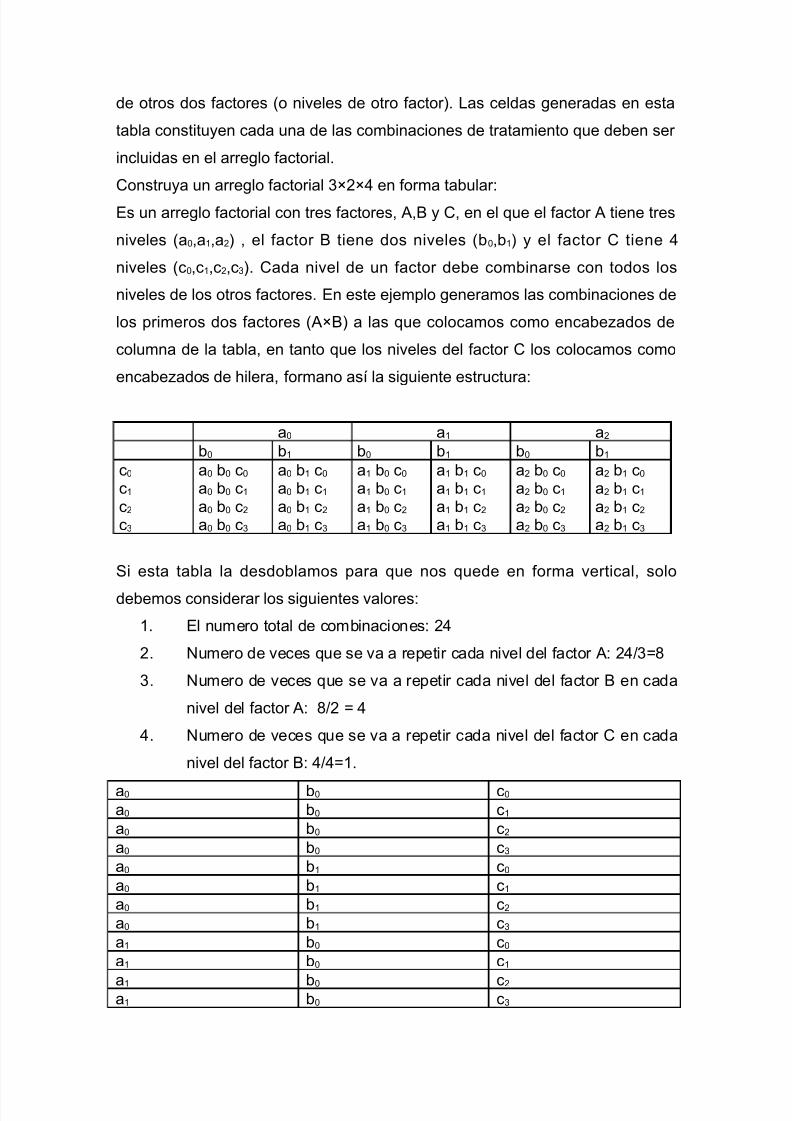
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 78/119
de otros dos factores (o niveles de otro factor). Las celdas generadas en esta
tabla constituyen cada una de las combinaciones de tratamiento que deben ser
incluidas en el arreglo factorial.
Construya un arreglo factorial 3×2×4 en forma tabular:
Es un arreglo factorial con tres factores, A,B y C, en el que el factor A tiene tres
niveles (a0,a1,a2) , el factor B tiene dos niveles (b0,b1) y el factor C tiene 4
niveles (c0,c1,c2,c3). Cada nivel de un factor debe combinarse con todos los
niveles de los otros factores. En este ejemplo generamos las combinaciones de
los primeros dos factores (A×B) a las que colocamos como encabezados de
columna de la tabla, en tanto que los niveles del factor C los colocamos como
encabezados de hilera, formano así la siguiente estructura:
a0 a1 a2
b0 b1 b0 b1 b0 b1
c0 a0 b0 c0 a0 b1 c0 a1 b0 c0 a1 b1 c0 a2 b0 c0 a2 b1 c0
c1 a0 b0 c1 a0 b1 c1 a1 b0 c1 a1 b1 c1 a2 b0 c1 a2 b1 c1
c2 a0 b0 c2 a0 b1 c2 a1 b0 c2 a1 b1 c2 a2 b0 c2 a2 b1 c2
c3 a0 b0 c3 a0 b1 c3 a1 b0 c3 a1 b1 c3 a2 b0 c3 a2 b1 c3
Si esta tabla la desdoblamos para que nos quede en forma vertical, solo
debemos considerar los siguientes valores:
1. El numero total de combinaciones: 24
2. Numero de veces que se va a repetir cada nivel del factor A: 24/3=8
3. Numero de veces que se va a repetir cada nivel del factor B en cada
nivel del factor A: 8/2 = 4
4. Numero de veces que se va a repetir cada nivel del factor C en cada
nivel del factor B: 4/4=1.
a0 b0 c0
a0 b0 c1
a0 b0 c2
a0 b0 c3
a0 b1 c0
a0 b1 c1
a0 b1 c2
a0 b1 c3
a1 b0 c0
a1 b0 c1
a1 b0 c2
a1 b0 c3

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 79/119
a1 b1 c0
a1 b1 c1
a1 b1 c2
a1 b1 c3
a2 b0 c0
a2 b0 c1
a2 b0 c2
a2 b0 c3
a2 b1 c0
a2 b1 c1
a2 b1 c2
a2 b1 c3
Modelo estadístico para una estructura factorial:
Para generar el modelo estadístico de una estructura factorial debemosconsiderar en primer lugar, el modelo estadístico básico que incluiría el arreglo
geométrico que se utilizo para acomodar los tratamientos a las unidades
experimentales y el efecto de los tratamientos, como si estos constituyeran una
estructura unifactorial.
Enseguida, vamos a desdoblar los efectos de tratamientos en los efectos
principales y efectos de interacción. Para ello debemos disponer de un
subíndice, adicional a los del arreglo geométrico, por cada factor incluido en el
arreglo factorial. Se deben considerar en el modelo estadístico todos los
efectos principales y todos los posibles efectos de interacción entre los
factores.
Ejemplo: Genere el modelo estadístico para el ejemplo de las mascotas.
1. Modelo estadístico Básico: Ya que se trata de un arreglo geométrico
completamente al azar con 6 tratamientos y 10 repeticiones por
tratamiento, el modelo estadístico básico es:
Yij = μ + τi + εij ; i=1,2,..,6 ; j=1,2,…,10
El estimador de la media general es la media de todas las observaciones, dada
por 87.86666667.
Los efectos de tratamiento vienen dados por:
12.13333333-1.96666666711.63333333
-8.666666667-3.966666667-9.166666667

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 80/119
El anova bajo este modelo esta dado por
Fuente devariación G.L. S.C. C.M Fc Ft Pr > Fc
Tratamientos 5 4612.9333 922.5866 4.2999 2.3860 0.0023Error 54 11586.0000 214.5555Total 59 16198.9333
La conclusión a partir de este análisis es que si existe una diferencia
significativa de los tratamientos; sin embargo, no sabemos si esta diferencia se
puede atribuir a efectos principales o a un efecto de interacción entre los dos
factores, por lo que se hace necesario separar la fuente de variación de los
tratamientos bajo un modelo que incluya los efectos principales y efecto de
interacción.
2. Desdoblamiento del efecto de tratamientos en efectos principales y
efectos de interacción: Los factores incluidos en el arreglo factorial
de tratamientos fueron la fuente de proteína, con tres niveles y la
cantidad de proteína con dos niveles, por lo que requerimos de 2
subindices, uno para cada factor, mas el subíndice para repeticiones.
Nuestro modelo incluyendo la estructura factorial queda como:
Yijk = μ + αi + β j + (αβ)ij + εijk ;
i=1,2,3; j=1,2; k=1,2, …,10
Donde
Yijk = Variable de respuesta en la repetición k del nivel i de la fuente de
proteína y el nivel j de la cantidad de proteína.
μ = Media general del experimento.
αi = Efecto del nivel i del factor fuente de proteína.
β j = Efecto del nivel j del factor cantidad de proteína.
(αβ)ij = Efecto de la interacción del nivel i de la fuente de proteína y el nivel jde la cantidad de proteína.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 81/119
εijk = Error experimental en la repetición k en el nivel i de la fuente de
proteína y el nivel j de la cantidad de proteína.
Para propósitos de estimación de los efectos las restricciones que deben
imponerse son:Restricción para la estimación de los efectos del factor fuente de proteína.
Σi αi = 0
Restricción para la estimación de los efectos del factor cantidad de proteína
Σ j β j = 0
Restricciones para la estimación de los efectos de interacción entre los factores
cantidad y fuente de proteínas.
Σi (αβ)ij = 0 Σ j (αβ) jj = 0 ΣΣij (αβ) jj = 0
Bajo este conjunto de restricciones las estimaciones de los efectos son:
Media general del experimento es la que corresponde a la media de todas las
observaciones. Para este conjunto de observaciones corresponde a la media
de las 60 observaciones que es igual a 87.86666667 y constituye el primer estimador independiente del modelo.
Efecto del nivel i de la fuente de proteína es igual a la media del nivel i de la
fuente de proteína menos la media general. Ya que los niveles del factor fuente
de proteína son res, cereal y puerco, entonces son tres estimadores los que
vamos a calcular, pero por la restricción impuesta su suma debe ser igual a
cero y por ello solo dos serán independientes
Fuente Promedio EfectoRes 89.6 1.733333333Soya 84.9 -2.966666667Puerco 89.1 1.233333333
Suma deestimadores 1.42109E-14

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 82/119
Efecto del nivel j de la cantidad de proteína es la media del nivel j de la
cantidad de proteína menos la media general. Para este factor solo se tienen
dos niveles, la cantidad alta y la cantidad baja de proteína, por lo que
calculamos dos estimadores, pero solo uno será independiente, ya que la suma
de ambos será cero:
Cantidad Media Efecto
Alta95.133333
3 7.266666667Baja 80.6 -7.266666667
Suma deefectos 1.42109E-14
Efecto de interacción del nivel i de la fuente con el nivel j de la cantidad es igual
a la media de las observaciones en el nivel i de la fuente y el nivel j de la
cantidad menos la media del nivel i de la fuente menos la media del nivel j de la
cantidad mas la media general. Para determinar el numero de estimadores
independientes de los efectos de interacción considere que en cada columna la
suma de los estimadores sobre las hileras debe ser cero y también la suma de
los estimadores sobre columnas en cada hilera debe ser cero, de tal manera
que los estimadores independientes en general van a ser:
ab – a – b + 1=a(b - 1) – (b - 1) = (a - 1)( b - 1)
donde a es el numero de niveles del factor A y b es el numero de niveles del
factor b. Como regla general entonces, el numero de efectos independientes
que se estiman en una interacción es igual al producto del numero de efectos
independientes que se estiman en cada uno de los factores en la interacción.
Para nuestro ejemplo construimos la tabla de las medias de fuente de proteína
por cantidad de proteína:
Res Soya Puerco Alto 100 85.9 99.5Bajo 79.2 83.9 78.7
Con estos promedios y los calculados anteriormente para cada nivel en cada
uno de los factores y la media general podemos estimar los efectos de
interacción:
Res Soya Puerco Alto 3.13333333 -6.26666667 3.13333333
Bajo -3.13333333 6.26666667 -3.13333333
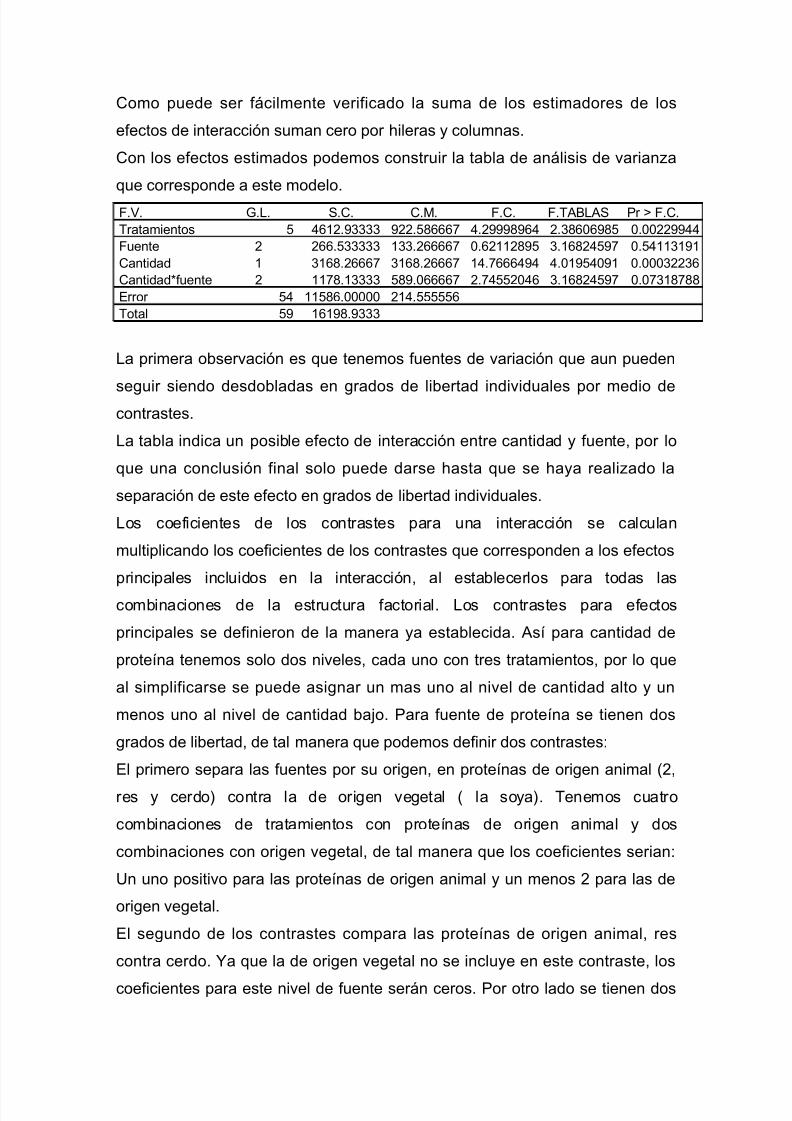
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 83/119
Como puede ser fácilmente verificado la suma de los estimadores de los
efectos de interacción suman cero por hileras y columnas.
Con los efectos estimados podemos construir la tabla de análisis de varianza
que corresponde a este modelo.
F.V. G.L. S.C. C.M. F.C. F.TABLAS Pr > F.C.Tratamientos 5 4612.93333 922.586667 4.29998964 2.38606985 0.00229944Fuente 2 266.533333 133.266667 0.62112895 3.16824597 0.54113191Cantidad 1 3168.26667 3168.26667 14.7666494 4.01954091 0.00032236Cantidad*fuente 2 1178.13333 589.066667 2.74552046 3.16824597 0.07318788Error 54 11586.00000 214.555556Total 59 16198.9333
La primera observación es que tenemos fuentes de variación que aun pueden
seguir siendo desdobladas en grados de libertad individuales por medio decontrastes.
La tabla indica un posible efecto de interacción entre cantidad y fuente, por lo
que una conclusión final solo puede darse hasta que se haya realizado la
separación de este efecto en grados de libertad individuales.
Los coeficientes de los contrastes para una interacción se calculan
multiplicando los coeficientes de los contrastes que corresponden a los efectos
principales incluidos en la interacción, al establecerlos para todas las
combinaciones de la estructura factorial. Los contrastes para efectos
principales se definieron de la manera ya establecida. Así para cantidad de
proteína tenemos solo dos niveles, cada uno con tres tratamientos, por lo que
al simplificarse se puede asignar un mas uno al nivel de cantidad alto y un
menos uno al nivel de cantidad bajo. Para fuente de proteína se tienen dos
grados de libertad, de tal manera que podemos definir dos contrastes:
El primero separa las fuentes por su origen, en proteínas de origen animal (2,
res y cerdo) contra la de origen vegetal ( la soya). Tenemos cuatro
combinaciones de tratamientos con proteínas de origen animal y dos
combinaciones con origen vegetal, de tal manera que los coeficientes serian:
Un uno positivo para las proteínas de origen animal y un menos 2 para las de
origen vegetal.
El segundo de los contrastes compara las proteínas de origen animal, res
contra cerdo. Ya que la de origen vegetal no se incluye en este contraste, los
coeficientes para este nivel de fuente serán ceros. Por otro lado se tienen dos
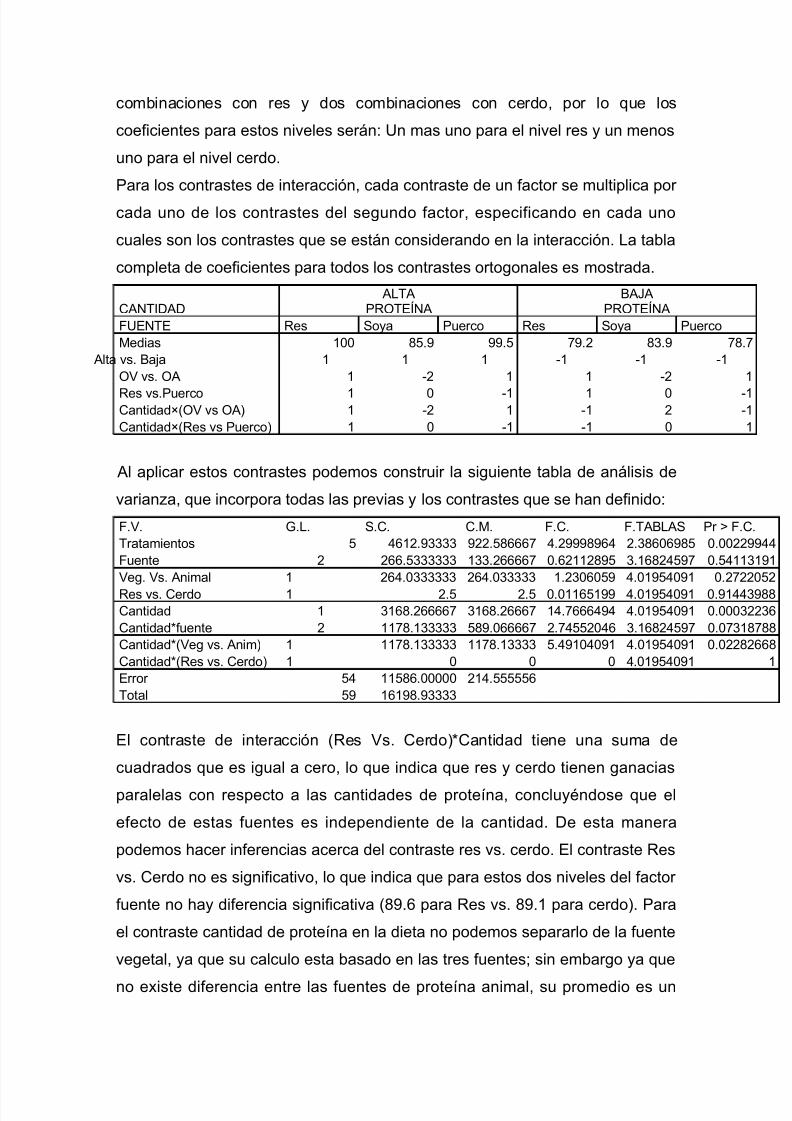
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 84/119
combinaciones con res y dos combinaciones con cerdo, por lo que los
coeficientes para estos niveles serán: Un mas uno para el nivel res y un menos
uno para el nivel cerdo.
Para los contrastes de interacción, cada contraste de un factor se multiplica por
cada uno de los contrastes del segundo factor, especificando en cada uno
cuales son los contrastes que se están considerando en la interacción. La tabla
completa de coeficientes para todos los contrastes ortogonales es mostrada.
CANTIDAD ALTA
PROTEÍNABAJA
PROTEÍNAFUENTE Res Soya Puerco Res Soya PuercoMedias 100 85.9 99.5 79.2 83.9 78.7 Alta vs. Baja 1 1 1 -1 -1 -1OV vs. OA 1 -2 1 1 -2 1
Res vs.Puerco 1 0 -1 1 0 -1Cantidad×(OV vs OA) 1 -2 1 -1 2 -1Cantidad×(Res vs Puerco) 1 0 -1 -1 0 1
Al aplicar estos contrastes podemos construir la siguiente tabla de análisis de
varianza, que incorpora todas las previas y los contrastes que se han definido:
F.V. G.L. S.C. C.M. F.C. F.TABLAS Pr > F.C.Tratamientos 5 4612.93333 922.586667 4.29998964 2.38606985 0.00229944Fuente 2 266.5333333 133.266667 0.62112895 3.16824597 0.54113191Veg. Vs. Animal 1 264.0333333 264.033333 1.2306059 4.01954091 0.2722052Res vs. Cerdo 1 2.5 2.5 0.01165199 4.01954091 0.91443988Cantidad 1 3168.266667 3168.26667 14.7666494 4.01954091 0.00032236Cantidad*fuente 2 1178.133333 589.066667 2.74552046 3.16824597 0.07318788Cantidad*(Veg vs. Anim) 1 1178.133333 1178.13333 5.49104091 4.01954091 0.02282668Cantidad*(Res vs. Cerdo) 1 0 0 0 4.01954091 1Error 54 11586.00000 214.555556Total 59 16198.93333
El contraste de interacción (Res Vs. Cerdo)*Cantidad tiene una suma de
cuadrados que es igual a cero, lo que indica que res y cerdo tienen ganacias
paralelas con respecto a las cantidades de proteína, concluyéndose que el
efecto de estas fuentes es independiente de la cantidad. De esta manera
podemos hacer inferencias acerca del contraste res vs. cerdo. El contraste Res
vs. Cerdo no es significativo, lo que indica que para estos dos niveles del factor
fuente no hay diferencia significativa (89.6 para Res vs. 89.1 para cerdo). Para
el contraste cantidad de proteína en la dieta no podemos separarlo de la fuente
vegetal, ya que su calculo esta basado en las tres fuentes; sin embargo ya que
no existe diferencia entre las fuentes de proteína animal, su promedio es un
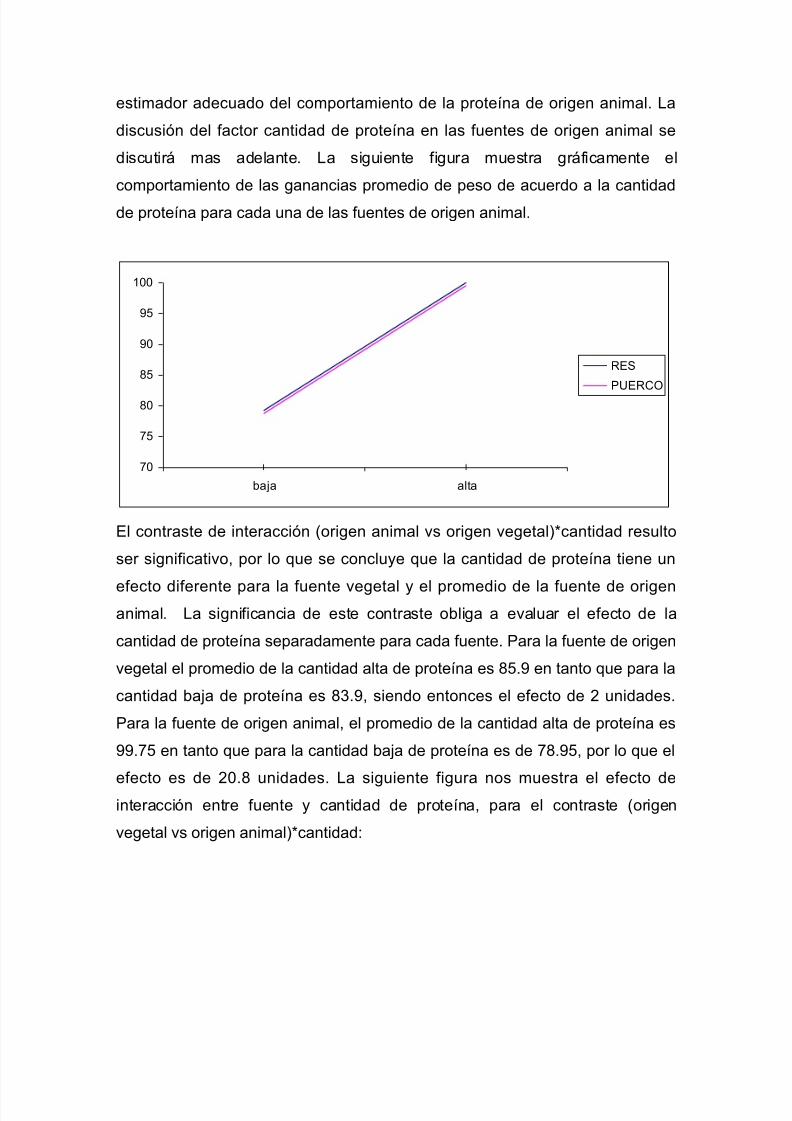
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 85/119
estimador adecuado del comportamiento de la proteína de origen animal. La
discusión del factor cantidad de proteína en las fuentes de origen animal se
discutirá mas adelante. La siguiente figura muestra gráficamente el
comportamiento de las ganancias promedio de peso de acuerdo a la cantidad
de proteína para cada una de las fuentes de origen animal.
70
75
80
85
90
95
100
baja alta
RES
PUERCO
El contraste de interacción (origen animal vs origen vegetal)*cantidad resulto
ser significativo, por lo que se concluye que la cantidad de proteína tiene un
efecto diferente para la fuente vegetal y el promedio de la fuente de origenanimal. La significancia de este contraste obliga a evaluar el efecto de la
cantidad de proteína separadamente para cada fuente. Para la fuente de origen
vegetal el promedio de la cantidad alta de proteína es 85.9 en tanto que para la
cantidad baja de proteína es 83.9, siendo entonces el efecto de 2 unidades.
Para la fuente de origen animal, el promedio de la cantidad alta de proteína es
99.75 en tanto que para la cantidad baja de proteína es de 78.95, por lo que el
efecto es de 20.8 unidades. La siguiente figura nos muestra el efecto deinteracción entre fuente y cantidad de proteína, para el contraste (origen
vegetal vs origen animal)*cantidad:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 86/119
70
75
80
85
90
95
100
105
baja alta
PROMEDIO O. ANIMAL
SOYA
ARREGLOS FACTORIALES 2K
Estos arreglos se caracterizan por tener incluidos K factores cada uno en dos
niveles. Estos arreglos son de gran interés en los diversos campos de la
ciencia y la ingeniería, donde la experimentación es la principal herramienta deinvestigación. Esto se debe a que constituye una gran diversidad de arreglos
de tratamientos que permiten investigar una gran cantidad de factores con
pocas corridas experimentales, principalmente en la fase de exploración de
impactos de las diferentes variables independientes sobre las variables de
respuesta. También son de interés porque constituyen la base para construir
diseños experimentales en la fase de optimización de procesos, como son los
diseños de metodología de superficie de respuesta y los arreglos ortogonalesde Taguchi.
Nomenclatura:
La nomenclatura particular para estos arreglos permite el manejo mas eficiente
de las combinaciones de tratamiento. Con la nomenclatura simplificada también
se logra un procedimiento para construir estos arreglos.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 87/119
A cada uno de los factores se les asocia una letra mayúscula latina,
empezando con la letra A y continuando así hasta los K factores que se
incluyen en el arreglo. Entonces tenemos los factores A, B, C,…,K.
Cada uno de los factores solo tiene dos niveles, a los que se les
denomina el nivel bajo y el nivel alto. Esta nomenclatura es arbitraria para
factores cualitativos no ordinales, pero para factores cuantitativos o cualitativos
ordinales estos se asocian de acuerdo a la magnitud del nivel en el factor. Los
niveles se representan con la letra minúscula correspondiente al factor,
denotando el nivel bajo con un subíndice cero y el nivel alto con un subíndice
uno. De esta manera los nieles del factor A son a0 y a1, a los cuales
genéricamente se les denomina el nivel bajo del factor A y el nivel alto del
factor A. De manera equivalente se sigue esta notación para los niveles de los
K factores.
Construcción de los arreglos factoriales 2K:
Los principios de construcción que se han revisado para los arreglos factoriales
en general se aplican también para estos arreglos. Lo especial en el proceso va
ser el orden estándar en que se acomodan las combinaciones de tratamiento.
Este orden estándar consiste en que los niveles de los factores se colocan en
columnas, empezando por el factor A, y así sucesivamente hasta el factor K.
Los niveles del primer factor irán variando de 20 = 1 en 1, es decir los niveles
del factor A van alternándose de uno en uno, empezando con el nivel bajo
seguido del nivel alto, y así sucesivamente hasta el numero de combinaciones
de tratamiento. En la segunda columna los niveles del factor irán variando de
21= 2 en 2, igualmente empezando con el nivel bajo y seguido por el nivel alto.
Este proceso continuaría hasta llegar al factor K., donde las primeras 2K-1
combinaciones de tratamiento llevarían el nivel bajo del factor K y la mitad
restante el nivel alto del factor K..
Como un ejemplo considere primero la construcción del arreglo 22 , con
los factores A y B.. En este arreglo factorial tenemos 4 combinaciones de
tratamiento (22 ) . Por esta razón empezamos con la primer columna hasta

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 88/119
completar cuatro combinaciones, alternando el nivel bajo y el nivel alto del
factor A:
a0
a1
a0
a1
En la segunda columna del arreglo factorial, los niveles del factor B van ir
variando de 2 en 2, de tal forma que se generan las 4 combinaciones, como se
muestra a continuación:
a0 b0
a1 b0
a0 b1
a1 b1
Si deseamos la construcción de una serie 2 el procedimiento es el
mismo, pero debemos completar hasta 8 combinaciones bajo el mismo
proceso, y al final agregar los niveles del factor C, que van a variar de 4 en 4,
como a continuación se muestra.
a0 b0 c0
a1 b0 c0
a0 b1 c0
a1 b1c0
a0 b0 c1
a1 b0 c1
a0 b1 c1
a1 b1c1
Este proceso se seguiría para cualquier valor de K. Sin embargo, a medida
que K aumenta, mas tardada es la descripción de las combinaciones. Para una
mayor simplificación, los subíndices de las combinaciones se prefirió pasarlo
como exponente, que al aplicarlo tiene simplemente el efecto de desaparecer
la letra de la combinación cuando el nivel es bajo y de dejarla cuando el nivel
es alto. En la primera combinación todas las letras desaparecerían, quedando
solamente un 1, que para distinguirlo como combinación este se coloca entre
paréntesis. Bajo estas reglas se tiene: Arreglo 22 :

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 89/119
(1)
a
b
ab
Con esta notación es mas directa la generación de la siguiente serie, pues solo
se duplica y a cada combinación duplicada se multiplica por el nuevo factor. Así
para un 23 se tiene:
(1)
a
b
ab
(1)*c = c
a*c = ac
b*c = bc
ab*c = abc
Ejemplo: Genere una serie 25:
(1) c d cd e ce de cdea ac ad acd ae ace ade acde
b bc bd bcd be bce bde bcdeab abc abd abcd abe abce abde abcde
Para la interpretación de estas combinaciones solo debemos recordar que de
los factores que entran en el factorial, las letras que aparecen en la
combinación son los que corresponden a un nivel alto del factor, mientras que
las que no aparecen, corresponden a los factores que se encuentran a un nivel
bajo. Debemos tener presente siempre que la combinación (1) es aquella en la
que todos los factores se encuentran a un nivel bajo.Contrastes en las series 2K :
Los contrastes, aparte de que son la herramienta para el análisis de los datos,
van a constituir un elemento crucial en las técnicas de factoriales fraccionados
y bloques incompletos en estos arreglos.
Lo primero que debemos puntualizar es que los contrastes deben estar
asociados a la estimación de efectos. En un arreglo 2K podemos estimar los
efectos principales de cada uno de los factores y en adición todas las posiblesinteracciones de 2, 3, …., K factores.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 90/119
Los efectos principales van a ser K.
Las interacciones de 2 factores van a ser KC2 .
Las interacciones de 3 factores van a ser KC3 .
Y así sucesivamente hasta llegar a una sola interacción de los K factores.
Así por ejemplo en la serie 25 los efectos que se van a poder estimar son:
5 efectos principales.
10 interacciones de 2 factores.
10 interacciones de 3 factores.
5 interacciones de 4 factores.
1 interacción de 5 factores.
Como podemos ver en este ejemplo, los efectos que podemos estimar, en
numero corresponden a los grados de libertad de los tratamientos.
Lo importante en estos arreglos es poder construir la tabla de contrastes, que
por el lado de las hileras va llevar como encabezado a los tratamientos y por el
lado de las columnas va a llevar los efectos que se van a estimar. El numero de
columnas va ser igual al numero de hileras menos una. Los coeficientes que se
van a emplear para construir los contrastes son siempre el -1 para el nivel bajo
del factor y el +1 para el nivel alto del factor.
Ejemplo: Construya la tabla de contrastes para la serie 23 :
A B AB C AC BC ABC(1) -1 -1 +1 -1 +1 +1 -1a +1 -1 -1 -1 -1 +1 +1b -1 +1 -1 -1 +1 -1 -1ab +1 +1 +1 -1 -1 -1 +1c -1 -1 +1 +1 -1 -1 +1ac +1 -1 -1 +1 +1 -1 -1bc -1 +1 -1 +1 -1 +1 -1
abc +1 +1 +1 +1 +1 +1 +1
Para cualquier serie 2K su tabla de contrastes tiene una propiedad muy
interesante que se deriva de sus coeficientes: Al elevar al cuadrado o cualquier
potencia par, cualquier columna genera un elemento neutro, es decir una
columna de puros unos. Esto implica que si multiplicamos las columnas
correspondientes a los estimadores del factor A y la correspondiente a la
interacción AB, entonces obtenemos A2B = B, ya que la potencia par a la que

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 91/119
esta elevada la columna A la transforma a un elemento neutro, que multiplicado
por la columna B, genera el mismo resultado.
Ejemplos numéricos de arreglos factoriales 2K:
1. Un ingeniero esta interesado en el efecto que tienen la rapidez de
corte (A), la configuración (B) y el ángulo de corte (C) sobre la
duracion de una herramienta. Se eligen dos niveles de cada factor y
se realiza un arreglo factorial 23 con 3 replicas. Los resultados se
muestran a continuación. Analice los resultados de este experimento
y seleccione la combinación para mejorar la durabilidad de la
herramienta.
Combinacion 1 2 3(1) 22 31 25a 32 43 29b 35 34 50
ab 55 47 46c 44 45 38ac 40 37 36bc 60 50 54abc 39 41 47
2. En la industria mueblera la calidad de acabado de las piezas diseñadas
es una característica importante. Tres factores van a ser probados , cada
uno en dos niveles, para evaluar su impacto en el acabado. El factor A es el
tipo de madera (a0 = roble, a1 = pino) ; el factor B es la tasa de alimentación
(b0 = 2 m/min, b1 = 4 m/min); el factor C es la profundidad de corte (c0 = 1
mm , c1 = 3 mm). Para cada combinación de tratamiento tres repeticiones
fueron llevadas a cabo usando un diseño completamente aleatorizado. La
siguiente tabla muestra el acabado para los 8 tratamientod- Entre mas
grande el valor mas aspero es el acabado.
Combinacion 1 2 3
(1) 6 8 9a 10 16 15

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 92/119
b 18 12 15ab 12 9 10c 20 26 29ac 34 28 32bc 36 44 46
abc 25 22 24
Analice los datos y seleccione la mejor combinación para mejorar el acabado.
Estimación de los efectos:
Mediante la información que se obtiene en el análisis por contrastes
ortogonales en estos arreglos factoriales, podemos calcular una ecuación de
regresión lineal múltiple en los diferentes efectos principales e interacciones en
unidades estandarizadas, es decir, considerando que los niveles de los factores
son menos uno y mas uno.
El cambio promedio en respuesta entre el nivel alto y el nivel bajo de un factor
es la diferencia en los promedios del nivel alto menos el del nivel bajo. Este
cambio promedio puede obtenerse a partir de la estimación del contraste (suma
de los productos de los coeficientes del contraste por sus correspondientes
medias) al considerar que cada nivel del factor tiene la mitad de las medias
incluidas en cada uno de los niveles. Entonces el cambio promedio en
respuesta entre los niveles de un factor se calcula como el cociente del
contraste entre la mitad del numero de combinaciones en el arreglo factorial
(2k-1).
El coeficiente de regresión se calcula como la pendiente de una recta, es decir
el cambio en la variable dependiente dividido por el cambio en la variable
independiente. El cambio en la variable dependiente el es cambio promedio en
la respuesta entre los dos niveles y el cambio en la independiente es del valor
-1 al valor +1, es decir dos unidades de cambio. De esta manera el coeficiente
de regresión se estima dividiendo el cambio promedio en la respuesta entre
dos.
Debemos puntualizar dos situaciones:
1. Estos cálculos son igualmente validos para los efectos de interacción.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 93/119
2. Estos cálculos pueden también ser llevados a cabo para factores
cualitativos, pero carecen completamente de sentido al interpretarlos
en unidades originales.
CONFUSIÓN EN LOS ARREGLOS FACTORIALES 2K
La confusión es una consecuencia que se presenta en la estimación de efectos
factoriales al no llevar a cabo la totalidad de las combinaciones en un arreglo
factorial y consiste en que un contraste estima la combinación de dos o mas
efectos factoriales.
Las combinaciones de tratamiento se dividen con dos objetivos básicos:
1. Generar bloques incompletos.
2. Generar factoriales fraccionados.
Los bloques incompletos se aplican cuando se tienen muchos factores que se
van a investigar y consecuentemente las combinaciones que se deben probar
son muchas y si las unidades experimentales no son homogéneas, entonces
probablemente no se puedan lograr bloques suficientemente grandes para
generar un diseño en bloques completos al azar, y de ahí que surja la
necesidad de los bloques incompletos. En este caso se pretende confundir el
efecto de bloques con un efecto que no sea de interés en el análisis de los
datos de un arreglo factorial, como pueden ser las interacciones de mas alto
orden.
Los factoriales fraccionados se procuran cuando no se tienen suficientes
recursos para llevar a cabo todas las combinaciones de un arreglo factorial
completo, o bien cuando los efectos que se desean estimar son aquellos de
mas bajo orden (efectos principales e interacciones de dos factores). Al
suponer que los efectos de mas alto orden no son de importancia en la variable
de respuesta, estos se pueden confundir con los de mas bajo orden, y sin
alterar demasiado la calidad de las estimaciones, estas se pueden hacer con
un numero menor de combinaciones de las que incluye el arreglo factorial
completo.
Bloques incompletos:
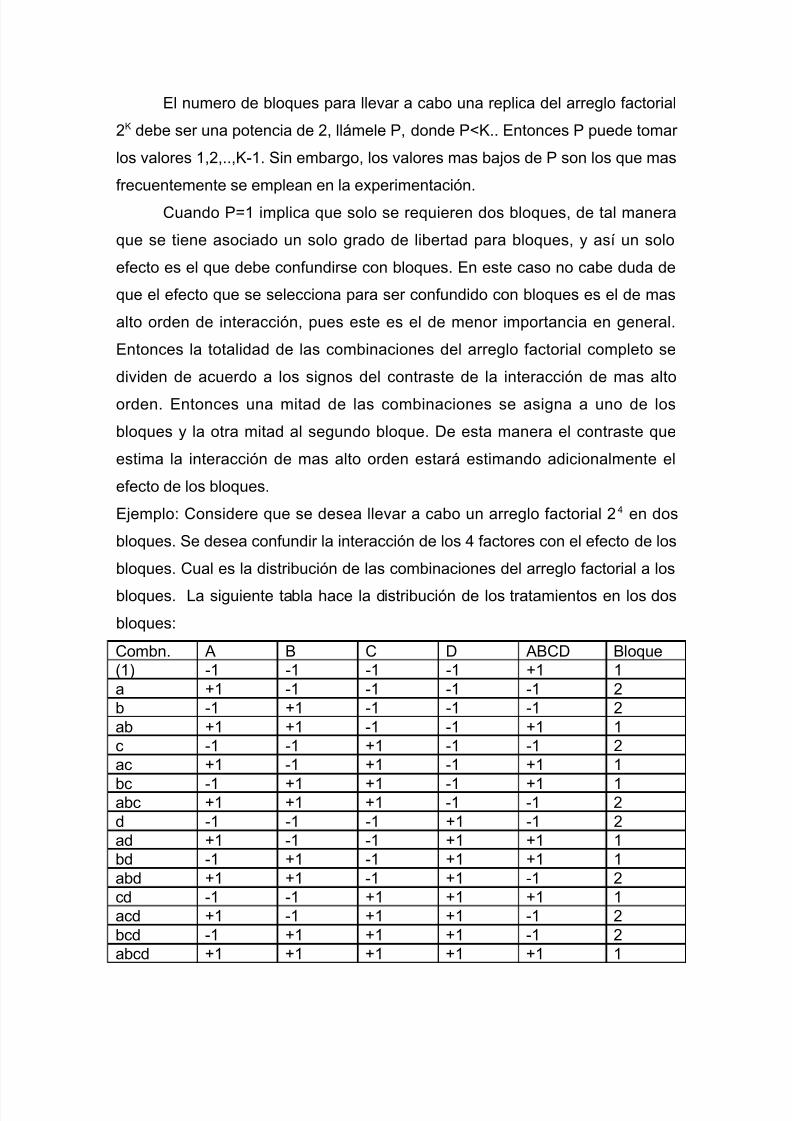
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 94/119
El numero de bloques para llevar a cabo una replica del arreglo factorial
2K debe ser una potencia de 2, llámele P, donde P<K.. Entonces P puede tomar
los valores 1,2,..,K-1. Sin embargo, los valores mas bajos de P son los que mas
frecuentemente se emplean en la experimentación.
Cuando P=1 implica que solo se requieren dos bloques, de tal manera
que se tiene asociado un solo grado de libertad para bloques, y así un solo
efecto es el que debe confundirse con bloques. En este caso no cabe duda de
que el efecto que se selecciona para ser confundido con bloques es el de mas
alto orden de interacción, pues este es el de menor importancia en general.
Entonces la totalidad de las combinaciones del arreglo factorial completo se
dividen de acuerdo a los signos del contraste de la interacción de mas alto
orden. Entonces una mitad de las combinaciones se asigna a uno de los
bloques y la otra mitad al segundo bloque. De esta manera el contraste que
estima la interacción de mas alto orden estará estimando adicionalmente el
efecto de los bloques.
Ejemplo: Considere que se desea llevar a cabo un arreglo factorial 24 en dos
bloques. Se desea confundir la interacción de los 4 factores con el efecto de los
bloques. Cual es la distribución de las combinaciones del arreglo factorial a los
bloques. La siguiente tabla hace la distribución de los tratamientos en los dos
bloques:
Combn. A B C D ABCD Bloque(1) -1 -1 -1 -1 +1 1a +1 -1 -1 -1 -1 2b -1 +1 -1 -1 -1 2ab +1 +1 -1 -1 +1 1c -1 -1 +1 -1 -1 2ac +1 -1 +1 -1 +1 1
bc -1 +1 +1 -1 +1 1abc +1 +1 +1 -1 -1 2d -1 -1 -1 +1 -1 2ad +1 -1 -1 +1 +1 1bd -1 +1 -1 +1 +1 1abd +1 +1 -1 +1 -1 2cd -1 -1 +1 +1 +1 1acd +1 -1 +1 +1 -1 2bcd -1 +1 +1 +1 -1 2abcd +1 +1 +1 +1 +1 1

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 95/119
El siguiente caso es cunado P=2, es decir cuando se tienen 22 bloques, lo que
representa cuatro bloques, teniendo así tres grados de libertad para bloques y
en cada bloque debe ir una cuarta parte del numero total de combinaciones en
el arreglo factorial. Los efectos que deben ser confundidos serán dos de ellos
independientes y el tercero lo constituirá la interacción de los dos
independientes. El objetivo en la selección de los independientes serán dos:
Primero que sean de alto orden y segundo, que la interacción de los dos
también sea de alto orden. Para obtener la interacción de dos efectos recuerde
que todas las letras de ambos efectos deben ser multiplicadas y aquellas que
queden con una potencia par se neutralizan y por lo tanto se anulan, quedando
solo aquellas con potencia impar.
Ejemplo: Considere que se desea correr un arreglo factorial 25 en 4 bloques.
Ya que son 4 bloques se deben confundir 3 efectos, dos de los cuales deben
ser independientes y el tercero resultara de la interacción de ambos. El efecto
de mas alto orden es la interacción de los 5 factores, es decir ABCDE. Si
seleccionamos una interacción de 4 factores, entonces la interacción va a
resultar en un efecto principal, lo que es totalmente reprobable. Debemos
entonces pensar en una interacción de tres factores, pero la interacción con la
de 5 va a resultar en una interacción de 2 factores, lo cual también, en la
mayoría de las ocasiones es reprobable. Esto nos lleva entonces a la
conclusión de que no es buena selección la interacción de 5 factores. La
siguiente opción es seleccionar la interacción de 4 factores, de tal forma que
uno de los 5 factores no esta incluido. Si combinamos dicho factor con dos de
los incluidos en la de cuatro factores, originara una interacción de 3 factores.
Esto es, suponiendo se selecciona la de 4 factores ABCD, el E no esta incluido.
El factor E lo combinamos con AB y resulta en ABE. La interacción de ambas
selecciones resulta en una interacción de tres factores. En las interacciones
seleccionadas, resultaría en CDE. Este es el orden mas alto de efectos que
pueden ser considerados para lograr separar las combinaciones del arreglo 25
en 4 bloques de 8 combinaciones cada uno. La separación esta basada ahora
en los signos de dos de las tres interacciones confundidas. A continuación se
muestra el arreglo factorial ordenado por bloques de acuerdo a las
interacciones previamente seleccionadas.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 96/119
Combinacion A B C D E ABE CDE Bloque1 -1 -1 -1 -1 -1 -1 -1 1
ab 1 1 -1 -1 -1 -1 -1 1cd -1 -1 1 1 -1 -1 -1 1abcd 1 1 1 1 -1 -1 -1 1ace 1 -1 1 -1 1 -1 -1 1bce -1 1 1 -1 1 -1 -1 1ade 1 -1 -1 1 1 -1 -1 1bde -1 1 -1 1 1 -1 -1 1a 1 -1 -1 -1 -1 1 -1 2b -1 1 -1 -1 -1 1 -1 2acd 1 -1 1 1 -1 1 -1 2bcd -1 1 1 1 -1 1 -1 2ce -1 -1 1 -1 1 1 -1 2
abce 1 1 1 -1 1 1 -1 2de -1 -1 -1 1 1 1 -1 2abde 1 1 -1 1 1 1 -1 2c -1 -1 1 -1 -1 -1 1 3abc 1 1 1 -1 -1 -1 1 3d -1 -1 -1 1 -1 -1 1 3abd 1 1 -1 1 -1 -1 1 3ae 1 -1 -1 -1 1 -1 1 3be -1 1 -1 -1 1 -1 1 3acde 1 -1 1 1 1 -1 1 3bcde -1 1 1 1 1 -1 1 3ac 1 -1 1 -1 -1 1 1 4bc -1 1 1 -1 -1 1 1 4ad 1 -1 -1 1 -1 1 1 4bd -1 1 -1 1 -1 1 1 4e -1 -1 -1 -1 1 1 1 4abe 1 1 -1 -1 1 1 1 4cde -1 -1 1 1 1 1 1 4abcde 1 1 1 1 1 1 1 4
Esta misma técnica se seguiría para un factorial con un mayor numero de
factores o con mas bloques incompletos.
Antes de finalizar esta sección solo resta recalcar que la confusión para
bloques incompletos se emplea para confundir algunos efectos con el efecto de
los bloques, pero el arreglo factorial se correría de manera completa.
Factoriales fraccionados:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 97/119
La confusión también se emplea cuando se desea seleccionar una parte del
arreglo factorial 2K completo, debido a que puede ser excesivo los recursos
requeridos en esto comparado con los efectos que se desean estimar. En
términos generales, los efectos que se desean estimar corresponden a los
efectos principales y las interacciones de dos factores, en tanto que el resto de
los efectos resultan de escasa o nula importancia. Bajo estas circunstancias se
prefiere seleccionar solo una fracción del arreglo factorial tal que permita la
estimación de estos efectos y un esquema de confusión de estos efectos
(estructura de alias) razonable tal que las estimaciones sean confiables.
Partimos, como en bloques incompletos, de un efecto que permite
fraccionar en dos mitades el arreglo factorial completo. A tal efecto le
denominamos el generador de la fracción y se denota con la letra I. Como en el
bloqueo, cuando se trata de una fracción mitad, el generador debe ser la
interacción de mas alto orden. Entonces en base a esta interacción las
combinaciones de tratamiento quedan divididas en dos mitades, una con el
signo positivo en la interacción y la otra con el signo negativo. Es realmente
indistinto cual se seleccione, reflejándose esto en el signo del generador.
Ejemplo: Suponga que se desea llevar a cabo una fracción mitad de un arreglo
factorial 25, seleccionando como el generador la interacción de mas alto orden.
Defina para tal mitad la estructura de alias.
En este arreglo factorial se consideran 5 factores, que denominaremos A, B, C,
D y E. El arreglo factorial completo incluye 32 combinaciones de tratamiento,
por lo que una mitad deberá contener 16 combinaciones. La interacción de mas
alto orden que se va a seleccionar como el generador es ABCDE=I.
Para construir la fracción mitad existen 3 métodos:
1. El arreglo factorial completo es generado, y para cada combinación
se obtienen los signos de la interacción mas alta. Se selecciona
como la fracción mitad aquellas combinaciones que tengan el signo
positivo.
2. Generar el arreglo con un factor menos que el deseado, con lo cual
se tiene la fracción mitad, agregando los niveles del ultimo factor como la interacción de los que ya están definidos.

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 98/119
3. Mediante la operación modulo 2 de la expresión definida por
L = X1a1 + X2a2 + X3a3 + X4a4 + X5a5
Donde las Xi toman el valor cero o uno dependiendo si el factor se encuentra
en el generador y ai toma el valor cero o uno dependiendo si el factor se
encuentra en la combinación de tratamiento.
La estructura de alias se define al multiplicar el generador en ambos lados de la
igualdad por el por el efecto cuyos alias se desean conocer.
Resolución del diseño:
Es el numero de factores en la interacción de mas bajo orden que forma parte
del generador.
ARREGLO EN PARCELAS DIVIDIDAS:
Es un arreglo multifactorial en el que cada uno de los factores a investigar
requieren de diferente tamaño de unidad experimental para ser aplicado. Así
entonces, en un proyecto de investigación podemos reconocer, desde el
momento de la planeacion el factor que debe aplicarse a parcela grande y cual
debe aplicarse a parcela pequeña. Esta decisión implica un aspecto netamente
practico. Por ejemplo, suponga que se desean probar en un experimento
agrícola diferentes camas de siembra y diferentes niveles de fertilización. Si la
aplicación del factor cama de siembra requiere de maquinaria, entonces, este
factor requeriría de una unidad experimental de mayor tamaño que aquella
para aplicar los diferentes niveles de fertilización. Entonces el experimento
debe ser planeado como un arreglo en parcelas divididas, con el factor de
parcela grande la cama de siembra y como factor de parcela pequeña la
fertilización. El experimento incluiría la aplicación de un nivel de cama de
siembra en una parcela grande, la cual seria dividida para la aplicación de los
diferentes niveles del factor fertilización.
En este arreglo debe también definirse en la planeacion del experimento cual
seria el arreglo geométrico de las parcelas grandes, ya que puede ser
completamente al azar, en bloques al azar (el mas común) o en cuadro latino.Se supone que la parcela grande es homogénea, y por lo tanto los niveles del

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 99/119
factor de parcela pequeña se pueden distribuir completamente al azar dentro
de cada parcela grande. Debemos entonces reconocer el arreglo geométrico
de las repeticiones de parcelas grandes, las mismas parcelas grandes y las
subparcelas dentro de cada parcela grande.
El modelo entonces debe incorporar el arreglo geométrico de las repeticiones
de parcela grande con su correspondiente error aleatorio, con el cual se
probara el efecto del factor de parcela grande; debe incorporar también el
diseño completamente al azar del as subparcelas, en el que se incluiría el
factor de subparcela, la interacción del factor de parcela grande son subparcela
y el error experimental con el que se probarían estos dos últimos efectos.
PARCELAS DIVIDIDAS EN UN DISEÑO COMPLETAMENTE AL AZAR:
Si las parcelas grandes son muy similares, entonces un arreglo geométrico
completamente al azar puede ser utilizado, por lo que el modelo quedaría
definido como:
Yijk = μ+αi+ρ j(i)+βk+(α )β ik+εijk
El subíndice i esta asociado a los niveles del factor de parcela grande, por lo
que i=1,2,…,a,
El subíndice j esta asociado a las repeticiones de parcela grande, por lo que
j=1,2,…,r.
El subíndice k esta asociado a los niveles del factor de subparcela, por lo que
k=1,2,…,b.
El modelo indica entonces que se tienen a niveles del factor de parcela
principal con r repeticiones en cada nivel. El error de parcela grande esta
representado por el componente ρ j(i) el efecto de la repetición anidada en el
nivel i del factor de parcela principal.
Los grados de libertad para este modelo quedan distribuidos de la siguiente
manera:
Fuente de variación G.L.Parcelas Grandes ar – 1

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 100/119
Factor A a – 1Error (a) a*(r - 1) Subparcelas: ar*( b - 1 ) Factor B b – 1Interacción A*B ( a - 1 ) *( b - 1 )Error (b) a*( b - 1)*( r - 1 ) Total (abr) - 1
Este modelo de parcelas divididas es muy frecuentemente empleado para
analizar datos que provienen de experimentos con mediciones repetidas al
considerar el factor tiempo como el factor de subparcela.
En algunas situaciones se sugiere emplear este arreglo experimental cuando la
precisión con que se desean llevar a cabo la comparación de las medias no es
la misma para amos factores; se seleccionaría como factor de subparcela aquel
en el que se quieren comparaciones mas precisas.
PARCELAS DIVIDIDAS EN UN DISEÑO EN BLOQUES COMPLETOS AL
AZAR:
Al aplicar este arreglo suponemos que las repeticiones e parcela principal
tienen un gradiente de variación que se desea controlar como variable de
bloqueo. Entonces si el factor de parcela principal tiene a niveles, cada bloque
debe contener a unidades experimentales, donde se distribuyen al azar los
niveles del factor de parcela principal. Supóngase que se tienen r bloques,
quedando el modelo descrito por
Yijk = μ+αi+ρ j+ (αρ) jj+βk+(α )β ik+εijk
Donde ahora ρ j constituye el efecto de los bloques y su interacción con el
factor A de parcela grande constituye el error de parcela grande. El
desdoblamiento de los grados de libertad se presenta en la siguiente tabla:
Fuente de variación G.L.Parcelas Grandes ar - 1 Factor A a - 1
Factor de bloqueo r - 1Error (a) ( a - 1 )*( r - 1 )

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 101/119
Subparcelas: ar*( b - 1 ) Factor B b - 1InteracciónB*bloqueo ( r - 1 )*( b - 1 )Interacción A*B ( a - 1 ) *( b - 1 )
Error (b) ( a - 1 )*( b - 1 )*( r - 1 ) Total (abr) - 1
PARCELAS DIVIDIDAS EN UN DISEÑO EN CUADRO LATINO:
Si las parcelas principales muestran variación en dos gradientes de bloqueo,
por hileras y columnas, entonces debe adoptarse un arreglo geométrico de las
parcelas principales en cuadro latino. Este arreglo debe ser representado en el
modelo como:
Yijk = μ+αi+ρ j+γk+ (αργ) jjk+βl+(α )β il+εijkl
El subíndice j esta asociado al efecto de las hileras y el subíndice k al efecto de
las columnas. La interacción de hileras columnas y tratamientos de parcela
principal es el componente de error para parcela grande.
El desdoblamiento de los grados de libertad queda como:
Fuente de variación G.L.Parcelas Grandes a^2 - 1 Factor A a - 1Factor de hileras a - 1Factor de columnas a - 1Error (a) ( a - 1 )*( a - 2 ) Subparcelas: a^2*( b - 1 ) Factor B b - 1Interacción A*B ( a - 1 ) *( b - 1 )
Error (b) a * ( a - 1 )*( b - 1 ) Total (a^2)*b - 1
De las principales desventajas que se tienen con el arreglo en parcelas
divididas es la estimación del error estándar de las diferencias de las medias,
para poder hacer las comparaciones de medias, que son diferentes para cada
factor y su interacción. Se recomienda que en caso de ser necesarias las
comparaciones estas se hagan en algún paquete que las arroje como parte de

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 102/119
la salida del análisis (como por ejemplo el SAS) o en su defecto, consultar los
errores estándar de las diferencias en una referencia de diseños
experimentales para poder aplicarlas manualmente. Desde luego este análisis
es mas complicado cuando la interacción resulta ser significativa.
Ejemplos:
2. Se llevo a cabo un experimento bajo un arreglo en parcelas divididas
para probar el efecto de 3 hibridos (utilizado como factor de parcela
principal) acomodados en un diseño en bloques completos al azar.
Dentro de cada parcela grande se acomodaron bajo un diseño
completamente al azar las 4 densidades (10,15,20 y 25 plantas por
hilera). Los datos se muestran a continuación:
BLOQUE HIBRIDO DENSIDAD RESPUESTA1 1 10 40.71 1 15 24.21 1 20 16.1
1 1 25 11.21 2 10 39.41 2 15 31.31 2 20 17.91 2 25 14.81 3 10 68.71 3 15 26.21 3 20 20.51 3 25 18.92 1 10 37.82 1 15 44.42 1 20 17.6
2 1 25 12.72 2 10 47.82 2 15 34.52 2 20 30.52 2 25 17.32 3 10 56.22 3 15 48.12 3 20 28.22 3 25 26.23 1 10 32.93 1 15 27.83 1 20 19.93 1 25 14.53 2 10 44.4
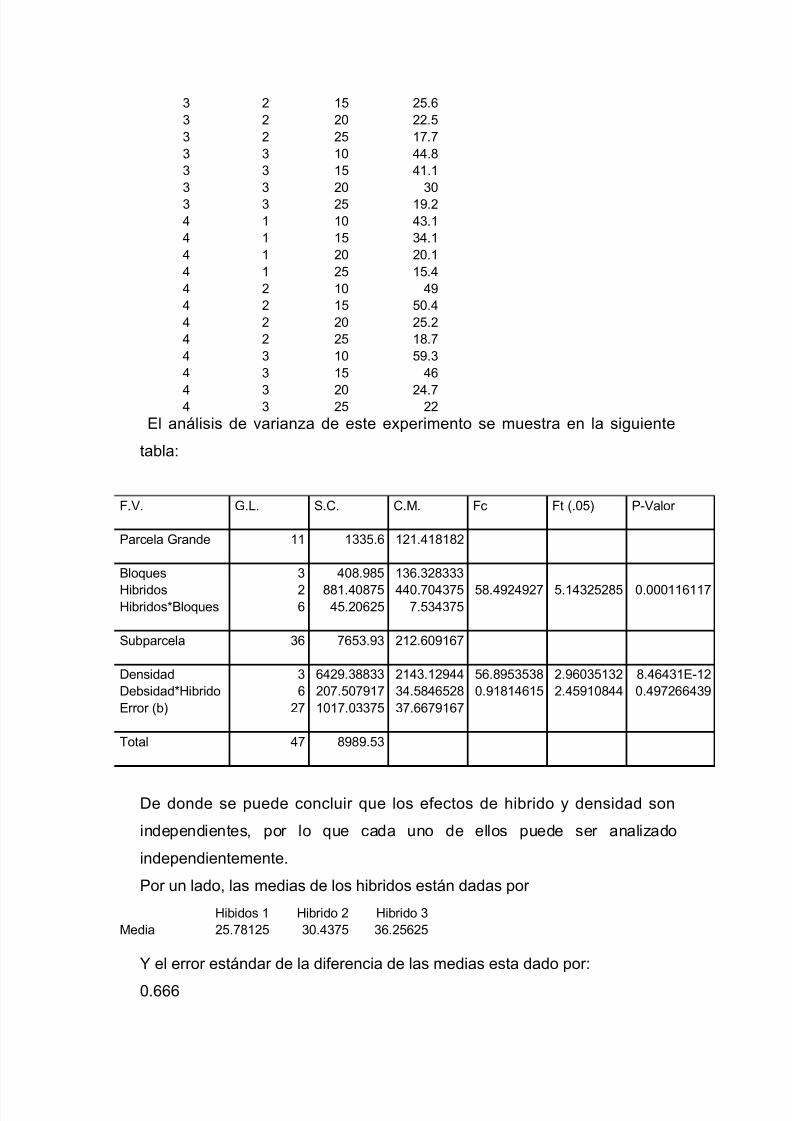
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 103/119
3 2 15 25.63 2 20 22.53 2 25 17.73 3 10 44.83 3 15 41.13 3 20 303 3 25 19.24 1 10 43.14 1 15 34.14 1 20 20.14 1 25 15.44 2 10 494 2 15 50.44 2 20 25.24 2 25 18.74 3 10 59.34 3 15 46
4 3 20 24.74 3 25 22
El análisis de varianza de este experimento se muestra en la siguiente
tabla:
F.V. G.L. S.C. C.M. Fc Ft (.05) P-Valor Parcela Grande 11 1335.6 121.418182
Bloques 3 408.985 136.328333
Hibridos 2 881.40875 440.704375 58.4924927 5.14325285 0.000116117Hibridos*Bloques 6 45.20625 7.534375
Subparcela 36 7653.93 212.609167
Densidad 3 6429.38833 2143.12944 56.8953538 2.96035132 8.46431E-12Debsidad*Hibrido 6 207.507917 34.5846528 0.91814615 2.45910844 0.497266439Error (b) 27 1017.03375 37.6679167
Total 47 8989.53
De donde se puede concluir que los efectos de hibrido y densidad son
independientes, por lo que cada uno de ellos puede ser analizado
independientemente.
Por un lado, las medias de los hibridos están dadas por
Hibidos 1 Hibrido 2 Hibrido 3Media 25.78125 30.4375 36.25625
Y el error estándar de la diferencia de las medias esta dado por:
0.666

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 104/119
Por lo que a un nivel de confianza del 95 % las tres medias resultan
estadísticamente diferentes, siendo entonces el mejor hibrido el numero 3.
Por otro lado el efecto de la densidad puede ser evaluado mediante una
regresión:
Respuesta = 66.61 – 2.045*Densidad
Con un coeficiente de determinación de 0.835 y un error estándar de 7.68.
De estos resultados se desprende entonces que el mejor hibrido es el 3 que
debe cultivarse bajo la densidad mas baja evaluada.
METODOLOGIA DE TAGUCHI:
La metodología de Taguchi es sinonimo de ingeniería de calidad y tiene por
objetivo diseñar calidad en todo producto y su correspondiente proceso.
Taguchi introduce una filosofía en la que la calidad es medida por la desviación
del valor de una característica con respecto a su valor óptimo. Factores no
controlables (ruido) ocasionan tales desviaciones. La eliminación de los
factores de ruido es impractico y muy a menudo imposible, de aquí que el
método de Taguchi procura minimizar los efectos de ruido. A través de esta
metodología se determina el nivel óptimo de los factores controlables
importantes basados en el concepto de robustez. El objetivo es crear un diseño
de producto / proceso que sea lo menos sensible posible a las fluctuaciones de
los factores de ruido (robusto) al establecer los factores controlables de
impacto en los niveles óptimos.
El diseño de parámetros usa la idea fundamental del procedimiento en dos
pasos para lograr la calidad:
1. Los niveles de los parámetros que minimizan la variabilidad de la
característica de calidad son seleccionados. En esta etapa se genera
un diseño que es robusto con respecto a las fuentes incontrolables
de variación.
2. Los parámetros que tienen un efecto en el valor promedio de la
característica de calidad, pero ningún impacto en la variabilidad, son
identificados. Estos parámetros conocidos como factores de ajuste,

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 105/119
son usados para mover la característica de calidad al valor otimo sin
incrementar varianza.
FUNCIÓN DE PERDIDA:
Para evaluar la calidad en términos monetarios, Taguchi crea la función de
perdida, la cual estima el costo que la sociedad tiene que pagar por una
desviación de la característica de calidad en un producto con respecto a su
valor blanco. En esta función se supone que la perdida es proporcional al
cuadrado de la desviación de la característica de calidad con respecto a su
valor blanco. Esta función se define de acuerdo al tipo de característica de
calidad:
Características de calidad del tipo Nominal es mejor:
L(y) = K ( y – m )2
L(y) es la función de perdida evaluada en el valor y de la característica de
calidad.
K es una constante de proporcionalidad.
m es el valor optimo de la característica de calidad.
El valor esperado de la función de perdida para este tipo de características de
calidad esta dado por:
K*(Varianza(y) + (media(y)-m) 2)
Características de calidad del tipo mas pequeñas es mejor:
L(y) = K ( y – 0)2
L(y) = K ( y )2
El valor esperado de la función de perdida es
K*(Media( y2))
Características de calidad del tipo mayor es mejor:
L(y) = K ( 1/y – 0)2
L(y) = K (1/ y )2
El valor esperado de la función de perdida es
K*(Media( 1/y)2)

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 106/119
Ejemplo numérico: Un producto tiene la especificación 1.5 ± 0.02 en una
característica de calidad. Al exceder justo estos limites el costo es de 50. 10
productos son seleccionados y se les mide su valor en dicha característica:
1.53 , 1.49, 1.50, 1.49 , 1.48 , 1.52 , 1.54 , 1.53, 1.51 , 1.52
Encuentre el promedio de perdida por unidad de producto.
El procedimiento para encontrar el valor de la constante K es sustituir los datos
conocidos en la función de perdida:
L(1.52) = L(1.48) = 50
y-m = 0.02
50 = K*(.02)²
K = 50/0.0004 = 125000
La función de perdida promedio esta dada por
E{L(y)} = 125000(0.000369 + 0.000121) = 61.25
Razón Señal a Ruido (RSR):
Taguchi define esta variable para el análisis de los datos obtenidos de sus
arreglos ortogonales. Incluye, como su nombre lo indica la razón de dos
componentes:
El termino señal representa el componente deseable, que preferiblemente
estará cercano al valor optimo de la característica de calidad.
El termino ruido representa el componente indeseable y es una medida de la
variabilidad de la característica de calidad, la cual preferiblemente debe estar
cercana a cero.
El valor optimo de la razón señal a ruido debe ser tan grande como sea posible,
sin importar el tipo de característica de calidad de que se trate.
RSR para variables de calidad del tipo nominal es mejor:
Para este tipo de características de calidad debemos distinguir dos casos:
1. Varianza no relacionada a la media: Bajo esta situación el principal
interés es reducir la varianza de la característica de calidad. La RSR
esta definida por
Z = –log(varianza).
2. Varianza relacionada a la media:
Z = 10 log(media/desv.est)²
RSR para variables de calidad del tipo mas pequeña es mejor:Z = -10 log (Media(y²))
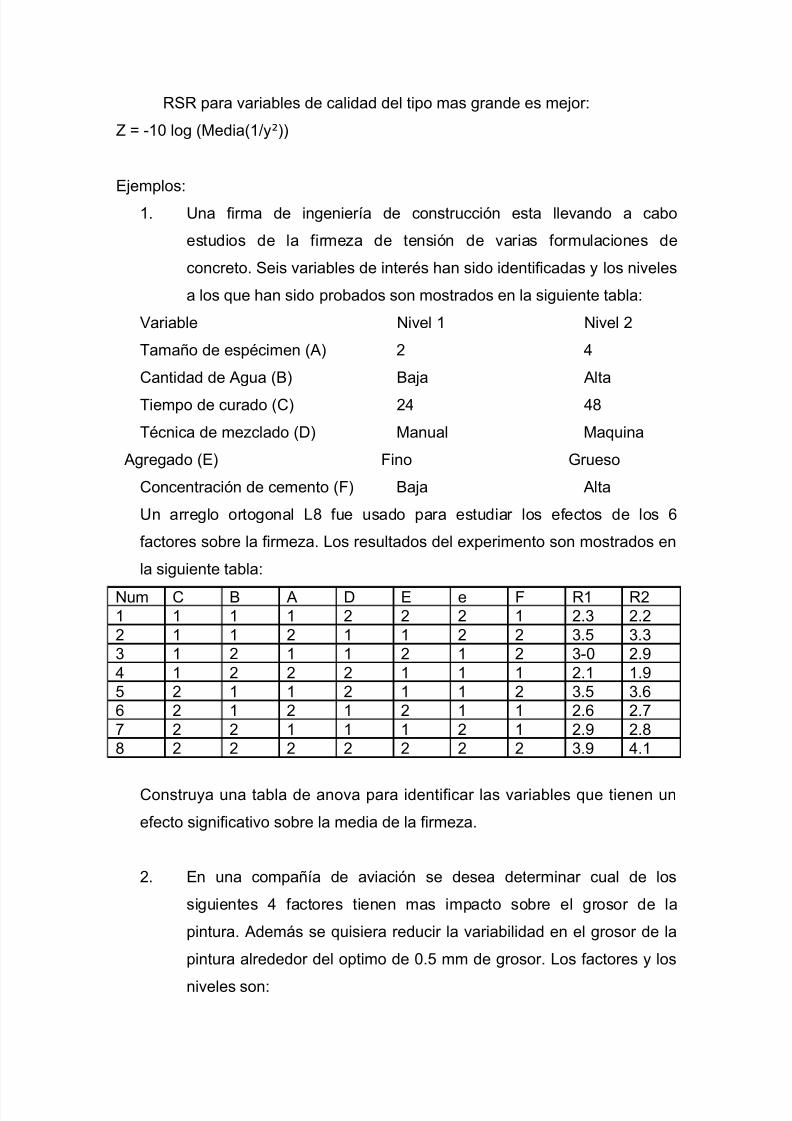
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 107/119
RSR para variables de calidad del tipo mas grande es mejor:
Z = -10 log (Media(1/y²))
Ejemplos:
1. Una firma de ingeniería de construcción esta llevando a cabo
estudios de la firmeza de tensión de varias formulaciones de
concreto. Seis variables de interés han sido identificadas y los niveles
a los que han sido probados son mostrados en la siguiente tabla:
Variable Nivel 1 Nivel 2
Tamaño de espécimen (A) 2 4
Cantidad de Agua (B) Baja Alta
Tiempo de curado (C) 24 48
Técnica de mezclado (D) Manual Maquina
Agregado (E) Fino Grueso
Concentración de cemento (F) Baja Alta
Un arreglo ortogonal L8 fue usado para estudiar los efectos de los 6
factores sobre la firmeza. Los resultados del experimento son mostrados en
la siguiente tabla:
Num C B A D E e F R1 R21 1 1 1 2 2 2 1 2.3 2.22 1 1 2 1 1 2 2 3.5 3.33 1 2 1 1 2 1 2 3-0 2.94 1 2 2 2 1 1 1 2.1 1.95 2 1 1 2 1 1 2 3.5 3.66 2 1 2 1 2 1 1 2.6 2.77 2 2 1 1 1 2 1 2.9 2.88 2 2 2 2 2 2 2 3.9 4.1
Construya una tabla de anova para identificar las variables que tienen un
efecto significativo sobre la media de la firmeza.
2. En una compañía de aviación se desea determinar cual de los
siguientes 4 factores tienen mas impacto sobre el grosor de la
pintura. Además se quisiera reducir la variabilidad en el grosor de la
pintura alrededor del optimo de 0.5 mm de grosor. Los factores y los
niveles son:

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 108/119
Variable Nivel 1 Nivel 2
Cantidad de tiner (A) 10 20
Presion de fluido (B) 15 30
Temperatura (C) 68 78
Marca de la pintura (D) X Y
Fue decidido conducir u arreglo ortogonal L8 con 4 replicas para cada
corrida experimental. La matriz de diseño no codificada y los resultados son
mostrados:
Ens A B C D R1 R2 R3 R41 10 15 68 X 0.638 0.489 0.541 0.477
2 10 15 78 Y 0.496 0.509 0.513 0.4953 10 30 68 Y 0.562 0.493 0.529 0.5314 10 30 78 X 0.564 0.632 0.507 0.7575 20 15 68 Y 0.659 0.623 0.636 0.5846 20 15 78 X 0.549 0.457 0.604 0.3867 20 30 68 X 0.842 0.910 0.657 0.9538 20 30 78 Y 0.910 0.898 0.913 0.878
3. Un ingeniero de proceso trata de mejorar la vida de una cierta
herramienta de corte. El ha corrido un experimento bajo un arreglo
ortogonal L8 usando tres factores: Velocidad de corte (A), dureza del metal
(B) y ángulo de corte (C). Los resultados obtenidos a partir del experimento
son mostrados:
Ensayo R1 R21 221 3112 325 4353 354 3484 552 472
5 440 4536 406 3777 605 5008 392 419
Lleve a cabo el anova para la RSR y obtenga la combinación de los niveles
de los factores que producen la mas larga vida de la herramienta.
3. En un componente de un motor automotriz se desea maximizar la
fuerza de empuje de una válvula. Los investigadores identificaron 4
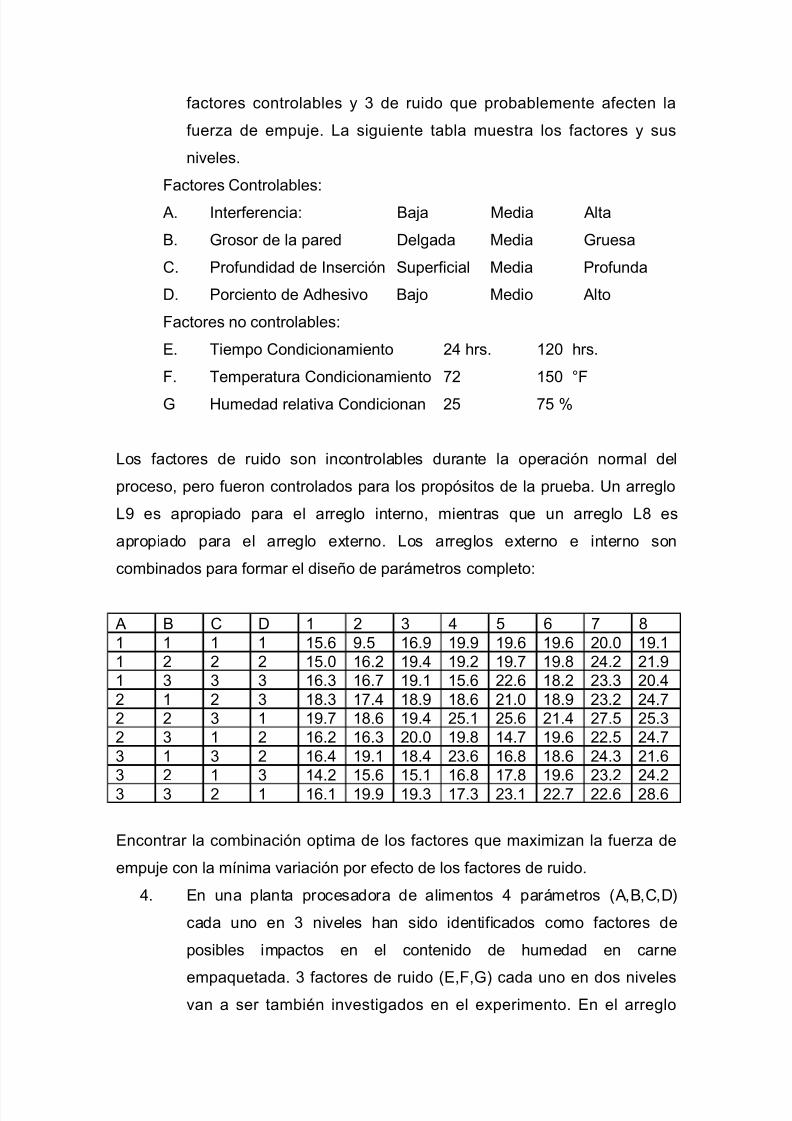
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 109/119
factores controlables y 3 de ruido que probablemente afecten la
fuerza de empuje. La siguiente tabla muestra los factores y sus
niveles.
Factores Controlables:
A. Interferencia: Baja Media Alta
B. Grosor de la pared Delgada Media Gruesa
C. Profundidad de Inserción Superficial Media Profunda
D. Porciento de Adhesivo Bajo Medio Alto
Factores no controlables:
E. Tiempo Condicionamiento 24 hrs. 120 hrs.
F. Temperatura Condicionamiento 72 150 °F
G Humedad relativa Condicionan 25 75 %
Los factores de ruido son incontrolables durante la operación normal del
proceso, pero fueron controlados para los propósitos de la prueba. Un arreglo
L9 es apropiado para el arreglo interno, mientras que un arreglo L8 es
apropiado para el arreglo externo. Los arreglos externo e interno son
combinados para formar el diseño de parámetros completo:
A B C D 1 2 3 4 5 6 7 81 1 1 1 15.6 9.5 16.9 19.9 19.6 19.6 20.0 19.11 2 2 2 15.0 16.2 19.4 19.2 19.7 19.8 24.2 21.91 3 3 3 16.3 16.7 19.1 15.6 22.6 18.2 23.3 20.42 1 2 3 18.3 17.4 18.9 18.6 21.0 18.9 23.2 24.72 2 3 1 19.7 18.6 19.4 25.1 25.6 21.4 27.5 25.32 3 1 2 16.2 16.3 20.0 19.8 14.7 19.6 22.5 24.73 1 3 2 16.4 19.1 18.4 23.6 16.8 18.6 24.3 21.6
3 2 1 3 14.2 15.6 15.1 16.8 17.8 19.6 23.2 24.23 3 2 1 16.1 19.9 19.3 17.3 23.1 22.7 22.6 28.6
Encontrar la combinación optima de los factores que maximizan la fuerza de
empuje con la mínima variación por efecto de los factores de ruido.
4. En una planta procesadora de alimentos 4 parámetros (A,B,C,D)
cada uno en 3 niveles han sido identificados como factores de
posibles impactos en el contenido de humedad en carne
empaquetada. 3 factores de ruido (E,F,G) cada uno en dos nivelesvan a ser también investigados en el experimento. En el arreglo
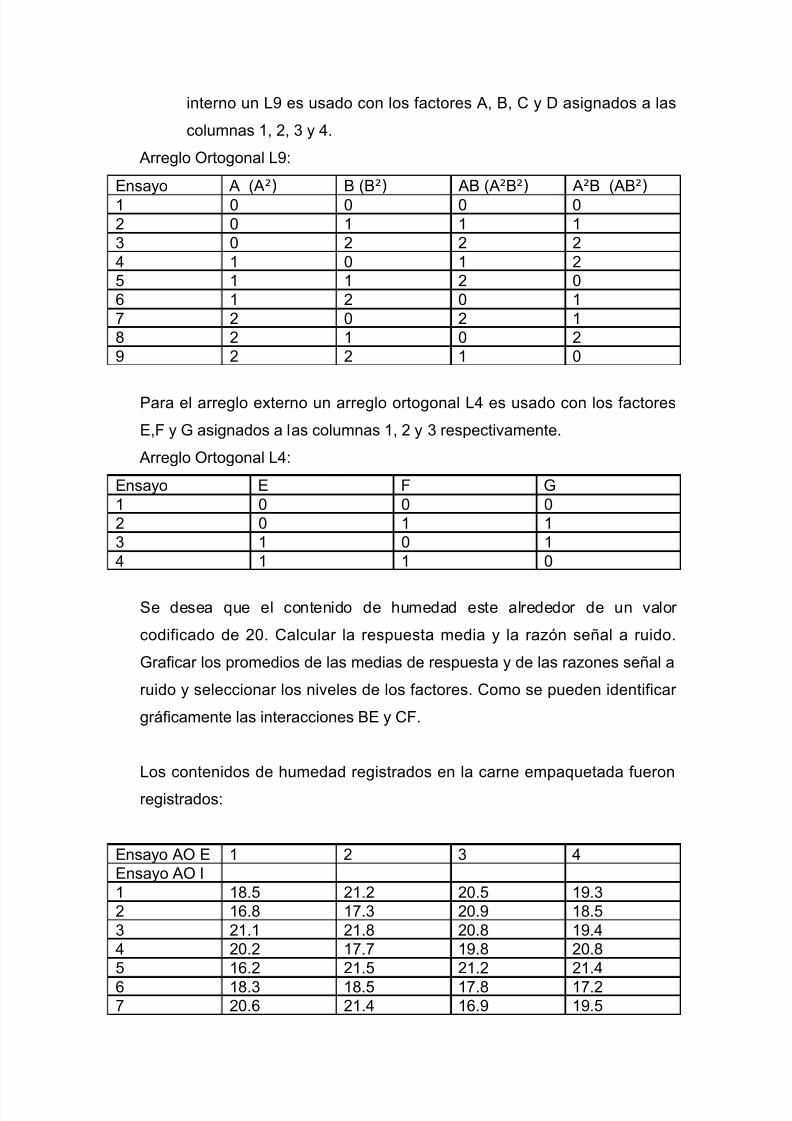
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 110/119
interno un L9 es usado con los factores A, B, C y D asignados a las
columnas 1, 2, 3 y 4.
Arreglo Ortogonal L9:
Ensayo A (A²) B (B²) AB (A²B²) A²B (AB²)1 0 0 0 02 0 1 1 13 0 2 2 24 1 0 1 25 1 1 2 06 1 2 0 17 2 0 2 18 2 1 0 29 2 2 1 0
Para el arreglo externo un arreglo ortogonal L4 es usado con los factores
E,F y G asignados a las columnas 1, 2 y 3 respectivamente.
Arreglo Ortogonal L4:
Ensayo E F G1 0 0 02 0 1 13 1 0 14 1 1 0
Se desea que el contenido de humedad este alrededor de un valor
codificado de 20. Calcular la respuesta media y la razón señal a ruido.
Graficar los promedios de las medias de respuesta y de las razones señal a
ruido y seleccionar los niveles de los factores. Como se pueden identificar
gráficamente las interacciones BE y CF.
Los contenidos de humedad registrados en la carne empaquetada fueron
registrados:
Ensayo AO E 1 2 3 4Ensayo AO I1 18.5 21.2 20.5 19.32 16.8 17.3 20.9 18.53 21.1 21.8 20.8 19.44 20.2 17.7 19.8 20.85 16.2 21.5 21.2 21.46 18.3 18.5 17.8 17.27 20.6 21.4 16.9 19.5

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 111/119
8 17.5 20.0 21.0 20.49 20.4 18.8 19.6 18.3
Suponga que se decide extender el arreglo externo a un L8 con lasasignaciones como sigue:
Efecto Columna
E 1
F 2
EF 3
G 4
EG 5Las otras dos columnas del arreglo L8 pueden ser asignadas al error
experimental.
Mostrar el diseño de parámetros completo. Calcular las respuestas
promedio y la razón señal a ruido apropiada. Graficar los promedios de las
razones señal a ruido y las respuestas promedio y discutir como van a ser
seleccionados los niveles óptimos de los factores.
Use las graficas de respuestas promedio para determinar la existencia delos efectos de interacción AE, BF, EF y EG.
La siguiente tabla muestra los contenidos de humedad registrados.
1 2 3 4 5 6 7 81 19.3 20.2 19.1 18.4 21.1 20.6 19.5 18.72 20.6 18.5 20.2 19.4 20.1 16.3 17.2 19.43 18.3 20.7 19.4 17.6 20.4 17.3 18.2 19.24 20.8 21.2 20.2 19.9 21.7 22.2 20.4 20.65 18.7 19.8 19.4 17.2 18.5 19.7 18.8 18.46 21.1 20.2 22.4 20.5 18.7 21.4 21.8 20.67 17.5 18.3 20.0 18.8 20.2 17.7 17.9 18.28 20.4 21.2 22.4 21.9 21.5 20.8 22.5 21.79 18.0 20.2 17.6 22.4 17.2 21.6 18.5 19.2

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 112/119
Metodología de superficie de respuesta:
La metodología de superficie de respuesta incluye una serie de herramientas
de optimización, que tienen por objetivo llegar a determinar bajo que
condiciones de las variables independientes investigadas se llega a maximizar
o minimizar la respuesta o variable dependiente de interés. Para lograr este
objetivo se emplea el ajuste de dos modelos de regresión:
En una primera etapa exploratoria se investiga secuencialmente una
región de las variables independientes mediante el ajuste de modelos de primer
orden, en donde se supone que los resultados del ajuste del modelo van
indicando la dirección en que deben moverse las variables independientes.
Para este fin se utilizan los diseños de primer orden, que consisten de dos
porciones:
Una porción factorial, que puede ser una factorial completo dos a la K o una
fracción del factorial, en caso de ser muchos los factores que se están
investigando.
Una porción central, que consiste en un punto en el que todos los factores se
prueban en el punto medio de los niveles empleados en el factorial, lo que
correspondería al cero en unidades codificadas. Este es el único punto es el
que lleva repeticiones y cuya finalidad es: Primero evaluar el error puro y en
segundo lugar probar curvatura en alguna de las variables cuyo efecto se esta
investigando.
Esta serie de diseños se van aplicando hasta que el análisis de datos detecta
una curvatura. En esta región se diseña un experimento para ajustar un modelo
de segundo orden, que permita ajustar un modelo de segundo orden con la
finalidad de identificar el punto optimo.
Los diseños de segundo orden, aparte de la porcion factorial y la porcion
central, llevan adicionalmente la porcion axial o porcion estrella, que son los
valores extremos en cada una de las variables independientes que se prueban
en el cero codificado del resto de las variables independientes. El valor
codificado de esta porcion en cada una de las variables independientes se
denomina alfa ( α ) y es igual a la raíz cuarta del numero de puntos en laporcion factorial, valor que le da la característica de rotabilidad al diseño, es

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 113/119
decir, la precisión de la estimación es la misma en cualquier punto de la región
investigada. Por eso, estos diseños se conocen como diseño central
compuesto rotable. La finalidad de esta porcion es aumentar el numero de
niveles en cada una de las variables independientes para poder ajustar el
modelo de segundo orden. Bajo este modelo, si no existe falta de ajuste,
entonces puede ser usado para encontrar el optimo en la variable de
respuesta.
Ejemplo 1: Los siguientes datos fueron recopilados por un ingeniero químico.
La respuesta Y corresponde al tiempo de filtración, X1 es la temperatura y X2
es la presión. Ajuste un modelo de segundo orden y analice la superficie
ajustada.
X1 X2 Y-1 1 54-1 -1 451 1 321 -1 47
-1.414 0 501.414 0 53
0 -1.414 470 1.414 510 0 410 0 390 0 440 0 420 0 40
Ejemplo 2: Los datos que se presentan en la siguiente tabla fueron
recopilados en un experimento para optimizar el crecimiento de cristales en
función de tres variables. Se desean valores altos de Y (rendimiento engramos). Ajuste un modelo de segundo orden. Determine bajo que condiciones
de las variables se logra un crecimiento optimo.
Codif X1 Codif X2 Codif X3 Resp Y-1 -1 -1 66-1 -1 1 70-1 1 -1 78-1 1 1 601 -1 -1 801 -1 1 70
1 1 -1 1001 1 1 75
-1.682 0 0 100
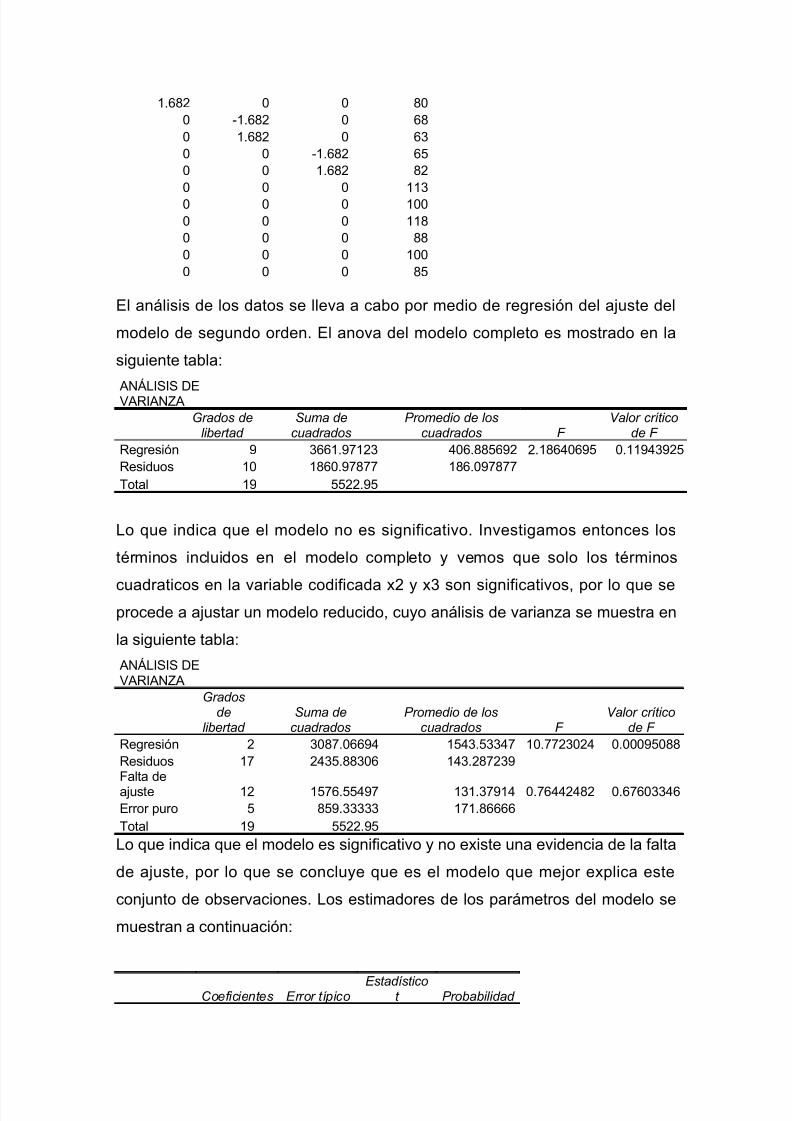
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 114/119
1.682 0 0 800 -1.682 0 680 1.682 0 630 0 -1.682 650 0 1.682 820 0 0 1130 0 0 1000 0 0 1180 0 0 880 0 0 1000 0 0 85
El análisis de los datos se lleva a cabo por medio de regresión del ajuste del
modelo de segundo orden. El anova del modelo completo es mostrado en la
siguiente tabla:
ANÁLISIS DEVARIANZA
Grados de
libertad Suma de
cuadradosPromedio de los
cuadrados F Valor crítico
de F
Regresión 9 3661.97123 406.885692 2.18640695 0.11943925Residuos 10 1860.97877 186.097877Total 19 5522.95
Lo que indica que el modelo no es significativo. Investigamos entonces los
términos incluidos en el modelo completo y vemos que solo los términos
cuadraticos en la variable codificada x2 y x3 son significativos, por lo que seprocede a ajustar un modelo reducido, cuyo análisis de varianza se muestra en
la siguiente tabla:
ANÁLISIS DEVARIANZA
Gradosde
libertad Suma de
cuadradosPromedio de los
cuadrados F Valor crítico
de F
Regresión 2 3087.06694 1543.53347 10.7723024 0.00095088Residuos 17 2435.88306 143.287239
Falta deajuste 12 1576.55497 131.37914 0.76442482 0.67603346Error puro 5 859.33333 171.86666Total 19 5522.95
Lo que indica que el modelo es significativo y no existe una evidencia de la falta
de ajuste, por lo que se concluye que es el modelo que mejor explica este
conjunto de observaciones. Los estimadores de los parámetros del modelo se
muestran a continuación:
Coeficientes Error típicoEstadístico
t Probabilidad
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 115/119
Intercepción 97.58157 4.1440598 23.5473372 2.0442E-14codif x2^2 -12.05327 3.13701026 -3.8422819 0.00130536codif x3^2 -9.225547 3.13701026 -2.9408725 0.00913491
Siendo ambos coeficientes negativos, se concluye que al separarse los niveles
del valor cero en las variables independientes de impacto la respuesta va a
tender a disminuir. Una grafica de los valores observados y los esperados por
el modelo ajustado nos da una vision de la aproximación del modelo.
esperados
50
55
60
65
70
75
80
85
90
95
100
50 60 70 80 90 100 110 120 130
Observados
e s p e r a d o s
El valor que genera la maxima respuesta es quel en el que las variables
independientes de impacto están en el valor cero.
Ejemplo 3.Un ingeniero químico esta interesado en determinar las condiciones
de operación que maximizan el rendimiento de una reacción. Dos variables
controlables Dos variables controlables influyen en este rendimiento: El tiempo
y la temperatura de reacción. Los datos obtenidos de un experimento se
analizan para ajustar un modelo de segundo orden y obtener las condiciones
en las cuales se optimiza la reacción:
VariableNat
VariableNat. Var. Codif Var Codif Resp
1 2 x1 x2 Y
80 170 -1 -1 76.580 180 -1 1 7790 170 1 -1 78
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 116/119
90 180 1 1 79.585 175 0 0 79.985 175 0 0 80.385 175 0 0 8085 175 0 0 79.785 175 0 0 79.8
92.07 175 1.414 0 78.477.93 175 -1.414 0 75.6
85 182.07 0 1.414 78.585 167.93 0 -1.414 77
En primer lugar se muestra la tabla de análisis de varianza donde se observa
que el modelo es significativo.
ANÁLISIS DE VARIANZA
Grados de
libertad Suma de
cuadradosPromedio de los
cuadrados F Valor crítico
de F
Regresión 5 28.2467034 5.64934069 79.668607 5.147E-06Residuos 7 0.49637349 0.0709105Total 12 28.7430769
De aquí se procede a revisar los estimadores de los parámetros para investigar
si todos tienen significancia.
Coeficientes Error típico Estadístico t Probabilidad
Intercepción 79.9399546 0.11908862 671.264433 4.3003E-18x1 0.99505025 0.09415493 10.5682224 1.4845E-05x2 0.5152028 0.09415493 5.47186207 0.00093401x1^2 -1.37644928 0.10098417 -13.6303472 2.693E-06x2^2 -1.001336 0.10098417 -9.91577205 2.262E-05x1*x2 0.25 0.13314513 1.8776504 0.10251919
Solo el termino de efecto cruzado de las dos variables se detecta como no
significativo, por lo que se procede a ajustar un modelo reducido, eliminando
dicho termino.
Ejemplo 4: Un ingeniero esta interesado en determinar las condiciones
optimas requeridas para una nueva sierra. Un diseño central compuesto fue
usado en un experimento para evaluar la vida de la sierra bajo diferentes
condiciones de operación fijadas por la velocidad de corte y la profundidad del
corte.
Velocidad Profundidad x1 x2 Vida Herr.
600 0.1 154600 0.05 132200 0.1 166
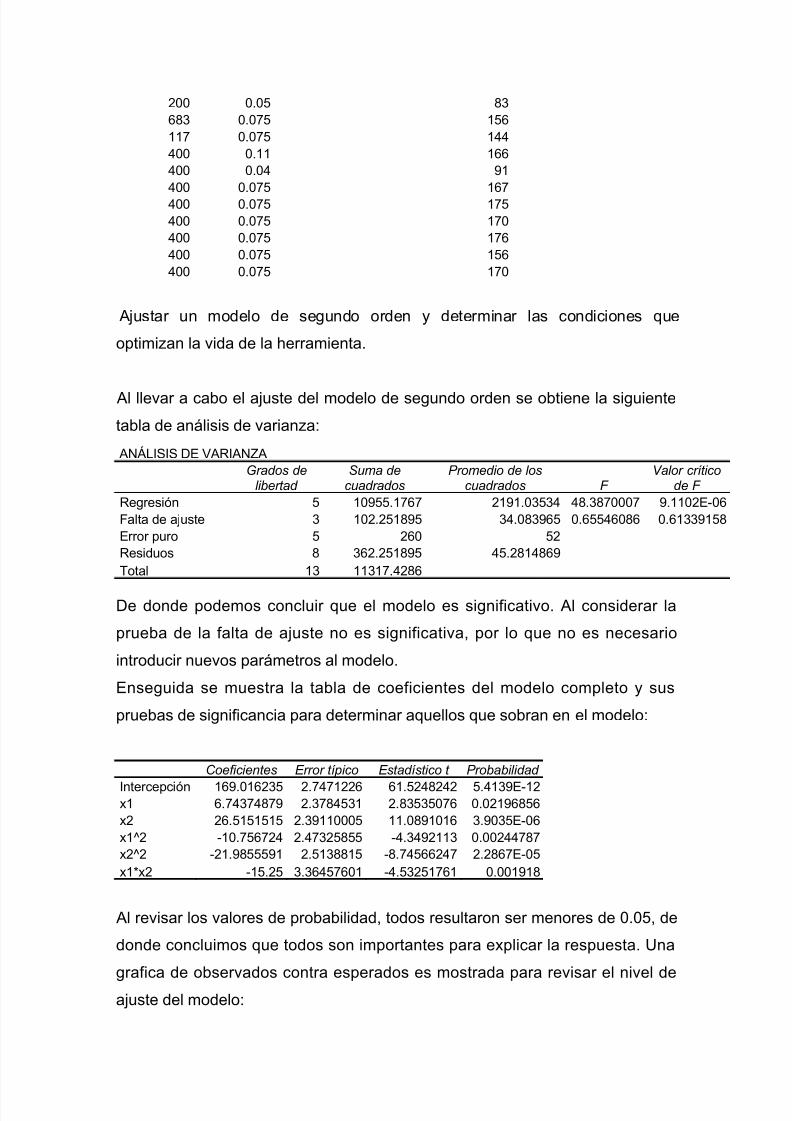
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 117/119
200 0.05 83683 0.075 156117 0.075 144400 0.11 166400 0.04 91400 0.075 167400 0.075 175400 0.075 170400 0.075 176400 0.075 156400 0.075 170
Ajustar un modelo de segundo orden y determinar las condiciones que
optimizan la vida de la herramienta.
Al llevar a cabo el ajuste del modelo de segundo orden se obtiene la siguiente
tabla de análisis de varianza:
ANÁLISIS DE VARIANZA
Grados de
libertad Suma de
cuadradosPromedio de los
cuadrados F Valor crítico
de F
Regresión 5 10955.1767 2191.03534 48.3870007 9.1102E-06Falta de ajuste 3 102.251895 34.083965 0.65546086 0.61339158Error puro 5 260 52Residuos 8 362.251895 45.2814869Total 13 11317.4286
De donde podemos concluir que el modelo es significativo. Al considerar la
prueba de la falta de ajuste no es significativa, por lo que no es necesario
introducir nuevos parámetros al modelo.
Enseguida se muestra la tabla de coeficientes del modelo completo y sus
pruebas de significancia para determinar aquellos que sobran en el modelo:
Coeficientes Error típico Estadístico t Probabilidad
Intercepción 169.016235 2.7471226 61.5248242 5.4139E-12x1 6.74374879 2.3784531 2.83535076 0.02196856x2 26.5151515 2.39110005 11.0891016 3.9035E-06x1^2 -10.756724 2.47325855 -4.3492113 0.00244787x2^2 -21.9855591 2.5138815 -8.74566247 2.2867E-05x1*x2 -15.25 3.36457601 -4.53251761 0.001918
Al revisar los valores de probabilidad, todos resultaron ser menores de 0.05, de
donde concluimos que todos son importantes para explicar la respuesta. Una
grafica de observados contra esperados es mostrada para revisar el nivel deajuste del modelo:
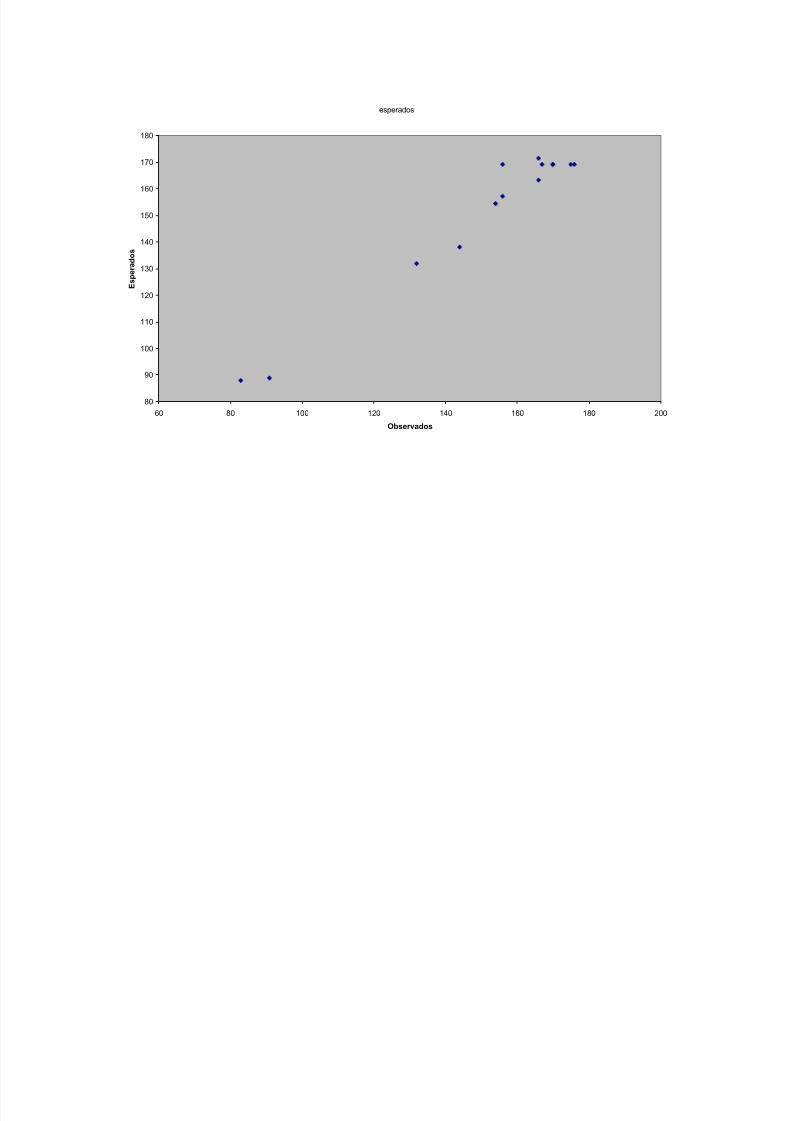
5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 118/119
esperados
80
90
100
110
120
130
140
150
160
170
180
60 80 100 120 140 160 180 200
Observados
E s p e r a d o s

5/13/2018 disenio experimentos - slidepdf.com
http://slidepdf.com/reader/full/disenio-experimentos 119/119


















