
Comparación y análisis de desempeño de unidades de ... · Comparación y análisis de desempeño...
112
Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de computación paralela para procesos de simulación en ingeniería. Yerman Jahir Avila Garzón Universidad Nacional de Colombia Facultad de Ingeniería, Departamento de Ingeniería Eléctrica y Electrónica Bogotá DC, Colombia 2015
Transcript of Comparación y análisis de desempeño de unidades de ... · Comparación y análisis de desempeño...

Comparación y análisis de desempeño de unidades de procesamiento gráfico
como alternativa de computación paralela para procesos de simulación en
ingeniería.
Yerman Jahir Avila Garzón
Universidad Nacional de Colombia
Facultad de Ingeniería, Departamento de Ingeniería Eléctrica y Electrónica
Bogotá DC, Colombia
2015


Comparación y análisis de desempeño de unidades de procesamiento gráfico
como alternativa de computación paralela para procesos de simulación en
ingeniería.
Yerman Jahir Avila Garzón
Tesis presentada como requisito parcial para optar al título de:
Magister en Ingeniería – Automatización Industrial
Director:
Ph.D., M.Sc. Ing. Electricista Johan Sebastián Eslava Garzón
Línea de Investigación:
Arquitectura de Computadores y Computación Paralela, Electrónica Digital, Optimización
Grupo de Investigación:
GMUN: Grupo de Microelectrónica Universidad Nacional
Universidad Nacional de Colombia
Facultad de Ingeniería, Departamento de Ingeniería Eléctrica y Electrónica
Bogotá DC, Colombia
2015


El que ama la educación ama el saber; el que odia la educación es un tonto.
Proverbios 12, 1
A mi esposa Jazmín y mi pequeño hijo Diego
José quien está por nacer.
A mis padres Ismael y María Antonia, y a mi
hermano Arley.
A mis abuelas Erminda y Nohemy. A mis
abuelos Parmenio† y Celestino†.


Resumen y Abstract VII
Resumen
La computación de propósito general en las unidades de procesamiento gráfico GPU es una área de en
continuo crecimiento. Las arquitecturas actuales de las GPU permiten la optimización, a través de diferentes
lenguajes de programación (p. ej. CUDA C, CUDA Fortran, OpenCL, entre otros) aplicaciones existentes o
crear nuevas aplicaciones que permitan aprovechar el paralelismo natural de GPU. Se busca mejorar el
tiempo de ejecución algoritmos complejos, un mejor uso de los recursos computacionales y mayor acceso a
plataformas de computación de alto rendimiento.
A través del uso de GPUs como procesadores SIMD (Single Instruction Multiple Data) se buscan mejoras en
la metodología de diseño, modelo y proceso de simulación. Se busca comparar diferentes GPU que
permitan ejecución de tareas en paralelo e incluirlas como coprocesadores en una tarea de diseño digital.
Para tal fin se realizaron dos tareas principales: comparación de desempeño de tres GPUs mediante
benchmark y una implementación de software paralelo y ejecución del mismo en GPU dentro de un proceso
de diseño digital.
En la comparación de desempeño de las GPU, se utiliza un benchmark llamado SHOC el cual permite
realizar una serie de pruebas de manera iterativa sobre las tarjetas seleccionadas. Para la implementación
en el proceso de diseño digital se seleccionó una parte del proceso conocida como Verificación funcional de
hardware en el cual se implementaron diferentes combinaciones de ejecución de código tanto en CPU y
GPU.
La verificación funcional de hardware por simulación es un factor determinante en los tiempos de ejecución
en el proceso de diseño digital. La verificación funcional se realiza aplicando estímulos o vectores de prueba
al dispositivo bajo verificación (DUV) que generalmente es un sistema escrito en HDL y a un modelo de
referencia que hace la misma tarea, pero que se codifica en un lenguaje de alto nivel de programación. Se
crea un entorno de verificación funcional de hardware por simulación compuesto por:
Un generador de estímulos aleatorios (C++)
Un hardware a verificar que para este trabajo está escrito en Verilog. Este hardware es un sumador
de 8 bits.
Dos modelos de referencia o Golden Model escritos uno en C++ y otro en CUDA pero que cumplen
con la misma función dispositivo bajo verificación
Dos comparadores escritos uno en C++ y otro en CUDA con el fin de comparar los desempeños de
CPU y GPU al cumplir con la misma tarea.
Las unidades NVIDIA analizadas son: NVIDIA® GeForce GT 520M, NVIDIA® Quadro 600 y NVIDIA® Tesla
C2075 y lasCPUs analizadas Intel® Core i5, Intel® Xeon.Como principal resultado se tiene que la mejor
aplicación del proceso de verificación se da cuando el modelo de referencia está escrito en CUDA C y el
comparador en C ++. Los tiempos de ejecución del proceso de verificación para la configuración mencionada
son: 0,05 [s], 0,0308 [s] y 0,0270 [s] para GeForce, Quadro y Tesla, respectivamente, frente a 1,3 [s] y 1,17
[s] de Intel® Core i5 y del Intel® Xeon.Processor respectivamente.
Palabras clave: Computación GPU, Computación paralela, Diseño digital, CUDA, GPU, HDL, NVIDIA,
Simulación, Verificación, Verificación funcional.


Resumen y Abstract IX
Abstract
General Purpose Computing on graphics processing units is a wide area which is continually growing up. The
actual architectures of GPU let the optimization, through many different programing languages (e.g. CUDA C,
CUDA Fortran, OpenCL, among others), previous applications or made new ones that allow take an
advantage of the native parallelism of GPU. It seeks to improve execution time of complex algorithm, better
use of computational resources and bigger Access to platforms of high performance computing.
Through the use of GPUs as SIMD (Single Instruction Multiple data) processors it has sought improvements
in methodology of design, model and simulation process. This work looks for a comparison of different GPUs
that allow the parallel execution and include them as co-processors in a task of the process of digital
electronics design.. Two principal tasks were developed: a comparison of the performance for tree GPUs by
the use of a benchmark and a hybrid implementation of task in CPU-GPU
In the comparison of performance in the GPUs, a benchmark called SHOC is used. This benchmark allows
doing various iterative tests on chosen GPUs. A part of the digital design process was chosen for the
implementation, this part is known as Functional Verification of Hardware. In this part of the process different
combinations of execution on GPU or CPU were implemented.
Functional verification of Hardware by simulation is a determinant in the execution times in the process of
digital design. Functional verification is done applying stimuli or vector test to the device under verification
(DUV) that generally is a system in HDL and pass it to a golden model that do the same task but this model is
coded on a high level language of programming. The parts of an environment of functional verification of
hardware by simulation are:
A random stimuli generator (C++)A Verilog module as a hardware for verification. In this case an 8
bit adder.
Two golden models: first in C++ and the other in CUDA. Both of them have the same function.
Two comparators: first in C++ and the other in CUDA. Two comparators because the performance
of CPU vs. GPU need to be tested.
NVIDIA GPU for the test: GeForce GT 520M, Quadro 600 and Tesla C2075; CPU for compare Intel® Core i5
e Intel® Xeon Processor. Principal results are: better implementation of verification process when the
reference model is coded in CUDA C and the comparator is coded in C++. Results: 0.05 [s], 0,0308 [s] y
0.0270 [s] for GeForce, Quadro y Tesla respectively in front of 1.3 [s] of the Intel® Core i5 and 1.17[s] of the
Intel® Xeon Processor.
Keywords: CUDA, Digital Design, GPU, GPU Computing, HDL, NVIDIA, parallel computing, Functional
Verification.


Contenido XI
Contenido
Pág.
Resumen ............................................................................................................... VII
Abstract ................................................................................................................ IX
Lista de figuras ............................................................................................................. XIII
Lista de tablas .............................................................................................................. XV
Lista de Abreviaturas .................................................................................................... 17
Introducción ............................................................................................................... 19
1. Computación Paralela y Computación de Propósito General con GPU ............. 23 1.1 Computación de Propósito General con GPU ................................................ 27
2. Historia y arquitectura GPU ................................................................................... 31 2.1 Arquitecturas GPU ......................................................................................... 35 2.2 Arquitecturas NVIDIA ..................................................................................... 39 2.3 Computación paralela usando CUDA ............................................................ 47
3. Selección y Caracterización de GPUs .................................................................. 51 3.1 Selección de GPUs: ....................................................................................... 51 3.2 Caracterización de GPUs: ............................................................................. 55
3.2.1 Hardware Seleccionado ...................................................................... 55 3.2.2 Ambiente de desarrollo y pruebas básicas a las GPU seleccionadas. . 57 3.2.3 Especificaciones de las GPUs seleccionadas ..................................... 61
4. Desempeño con Benchmark SHOC ...................................................................... 69
5. Ejemplo de implementación de computación paralela en un proceso de diseño digital. ............................................................................................................... 83
5.1 Verificación funcional de hardware por simulación ......................................... 85 5.2 Verificación funcional de hardware usando CUDA C ..................................... 87 5.3 Ambiente de Verificación funcional de Hardware usando CUDA C. ............... 89 5.4 Módulo Golden Model y Comparador CUDA: add_comp_gm.cu ................... 93 5.5 Resultados experimentales en tiempos de ejecución ..................................... 97
Conclusiones ............................................................................................................. 105
Trabajo Futuro ............................................................................................................. 107
A. Código de comparador y Golden model en CUDA C ......................................... 109
Bibliografía ............................................................................................................. 111


Contenido XIII
Lista de figuras
Pág. Figura 1. Concepto de Paralelismo................................................................................. 23
Figura 2. Computación Heterogénea en GPU NVIDIA®. [38] ......................................... 28
Figura 3. Intel Core i5-2500K Sandy Bridge ................................................................... 31
Figura 4. Abstracción Arquitectura GPU vs. Arquitectura CPU ....................................... 35
Figura 5. Arquitectura General de una GPU [40] ............................................................ 36
Figura 6. Pipeline de gráficos NVIDIA GeForce 8800 ..................................................... 38
Figura 7. Fixed Shaders Vs. Unified Shader [43] ............................................................ 40
Figura 8. Arquitectura NVIDIA GeForce 8800 (G80). ...................................................... 40
Figura 9. Streaming Multiprocessor [43] ......................................................................... 41
Figura 10. Esquema general de la arquitectura de una GPU .......................................... 42
Figura 11. Arquitectura NVIDIA Fermi ............................................................................ 43
Figura 12. Arquitectura NVIDIA Kepler[44] ..................................................................... 44
Figura 13. Arquitectura NVIDIA Maxweel [45] ................................................................ 45
Figura 14. Programación Heterogénea [46] .................................................................... 48
Figura 15. Hello world en CUDA ..................................................................................... 49
Figura 16. Suma de Vectores en CUDA ......................................................................... 50
Figura 17 NVIDIA Tesla C2075 [50] ............................................................................... 55
Figura 18 NVIDIA Quadro 600 [51] ................................................................................. 56
Figura 19. NVIDIA GeForce GT 520M [52] ..................................................................... 57
Figura 20. Modelo de compilación Linux ........................................................................ 60
Figura 21. Prueba de ancho de banda GeForce GT 520M ............................................. 61
Figura 22. Prueba de ancho de banda Quadro 600 ........................................................ 62
Figura 23. Prueba de ancho de banda Tesla C2075 ...................................................... 62
Figura 24 Prueba de ancho de banda ............................................................................ 63
Figura 25. Velocidad de transferencia de datos a través del bus PCIe ........................... 77
Figura 26. Velocidad de lectura de memoria global y memoria local .............................. 78
Figura 27. Velocidad de escritura de memoria global y memoria local ........................... 78
Figura 28. Desempeño máximo GPU [GFLOPs] ............................................................ 79
Figura 29. Porcentaje de desempeño Pruebas Benchmark SHOC Nivel 1 - Precisión
Sencilla .......................................................................................................................... 81
Figura 30. Porcentaje de desempeño Pruebas Benchmark SHOC Nivel 1 - Precisión
Doble .............................................................................................................................. 82
Figura 31. Ambiente de verificación funcional ................................................................ 86
Figura 32. Ambiente de Verificación usando CUDA ....................................................... 87

Figura 33. Verificación de DUV (Verilog) usando GoldenModel y Comparador en C++ .. 90
Figura 34. Verificación de DUV (Verilog) usando GoldenModel en CUDA C y Comparador
en C++ ............................................................................................................................ 90
Figura 35, Verificación de DUV (Verilog) usando GM en C++ y Comparador en CUDA C
....................................................................................................................................... 91
Figura 36. Verificación de DUV (Verilog) usando GM en CUDA C y Comparador en
CUDA C .......................................................................................................................... 91
Figura 37. Kernel para sumar 2 vectores ........................................................................ 93
Figura 38. Llamado de kernel de suma de vectores en programa principal. .................... 94
Figura 39. Cálculo de índice tomando, indice de Thread e índice de bloque. .................. 94
Figura 40. Blocks y Threads............................................................................................ 95
Figura 41. Tiempo total de Verificación funcional de DUV ............................................... 98
Figura 42. Rendimiento promedio (Average Throughput) [GB/s] ..................................... 99
Figura 43. Tiempos de verificación. Diferentes configuraciones de ambiente. .............. 100
Figura 44. Tiempo de Ejecución de Tareas GPU .......................................................... 101

Contenido XV
Lista de tablas
Pág. Tabla 1. Clasificación de Flynn ....................................................................................... 24
Tabla 2. Primeros computadores con paralelismo .......................................................... 25
Tabla 3. Computación heterogénea. [38] ........................................................................ 29
Tabla 4. Historia de adaptadores de video ..................................................................... 32
Tabla 5. Criterios de selección GPU NVIDIA .................................................................. 53
Tabla 6. GPUs Nvidia - Funcionalidad Vs Arquitectura ................................................... 54
Tabla 7. Características principales NVIDIA C2075 ........................................................ 55
Tabla 8. Características principales NVIDIA Quadro 600 ............................................... 56
Tabla 9. Características principales NVIDIA GeForce GT 520M ..................................... 57
Tabla 10. Características NVIDIA CUDA Toolkit 6.5 ....................................................... 58
Tabla 11. Sistemas operativos soportados por CUDA Toolkit 6.5 ................................... 59
Tabla 12. Sistema Operativo y controladores de video para Toolkit 6.5 ......................... 59
Tabla 13. Pruebas bandwithTest .................................................................................... 63
Tabla 14. Ancho de banda D-T-D Experimental Vs. Informado por el Fabricante ........... 64
Tabla 15. Resultados deviceQuery ................................................................................. 66
Tabla 16. Pruebas presentes en SHOC Nivel 0 .............................................................. 70
Tabla 17. Pruebas presentes en SHOC Nivel 1 .............................................................. 71
Tabla 18. Pruebas presentes en SHOC Nivel 2 .............................................................. 72
Tabla 19. Pruebas seleccionadas y Resultados Benchmark SHOC Nivel 0 .................... 74
Tabla 20. Pruebas seleccionadas y Resultados Benchmark SHOC Nivel 1 .................... 76
Tabla 21. Porcentaje de desempeño obtenido comparado con el desempeño máximo
obtenido (GFLOPs) ........................................................................................................ 80
Tabla 22. Herramientas de software para ambiente de verificación usando CUDA C ..... 89
Tabla 23. Resultados Experimentales de Verificaciones Funcionales a adder_8bit.v ..... 97
Tabla 24. Resultados Experimentales de Verificaciones Funcionales a adder_8bit.v
(métricas exclusivas GPU) ............................................................................................. 98
Tabla 25. Mejor Desempeño obtenido ...........................................................................102
Tabla 26. Utilización de computo menor a 1% ...............................................................102


Introducción
Lista de Abreviaturas
Abreviaturas
Abreviatura Término
ALU Arithmetic Logic Unit
API Application Programming Interface
CPU Central Processing Unit
CUDA Compute Unified Device Architecture
DLP Data-Level Parallelism
DSP Digital Signal Processor
DUV Device Under Verification
ECC Error Correcting Code
FLOPS Floating Operation Per Second
FPGA Field Programable Gate Array
GM Golden Model
GPU Graphics Processing Unit
GPGPU Generla Pourpose computation on Graphics Processing Units
HDL Hardware Description Language
IBM International Business Machines
IEEE Institute of Electrical and Electronics Engineers
MISD Multiple Instruction, Single Data
MIMD Multiple Instruction, Multiple Data
OpenCL Open Computing Language
OpenMP Open Multi-Processing
RTL Registrer Transfer Level
SIMD Single Instruction, Multiple Data
SIMT Single Instruction, Single Data
S.O. Sistema Operativo
SOC System On Chip
SPMD Single Program, Multiple Data
TLP Task-Level Parallelism


Introducción
Introducción
La computación de propósito general usando unidades de procesamiento gráfico en
adelante GPU por sus siglas en inglés Graphics Processing Unit, es un área de amplio
crecimiento permitiendo su inclusión en procesos de computación de alto nivel y
desempeño [1]–[6] . Por ejemplo: GPUs para aceleración de procesos como acceso a
gran cantidad de datos simultáneamente [7], solución de ecuaciones pertenecientes al
modelado del cuerpo humano [8], [9], algoritmos de clasificación e identificación de
puntos [10]–[12], aplicaciones en estadística [13], solución de ecuaciones matriciales
pertenecientes a problemas de álgebra lineal [14]–[16], paralelización y optimización de
algoritmos existentes [17]–[23], técnicas de visualización [24], [25], tratamiento de
señales [11], [22], [26], entre otros.
El uso de GPUs para computación de propósito general non-graphics tasks se debe
principalmente a su micro-arquitectura la cual permite hacer uso de la Computación
Paralela [27]–[29]. En este tipo de computación los elementos de procesamiento
cooperan y se comunican para resolver rápidamente problemas grandes [1]–[3], [30],
[31]. Es decir que en la computación paralela se busca que una gran cantidad de cálculos
y operaciones se lleven a cabo simultáneamente.
Mediante la exploración e incursión en la computación de alto desempeño usando GPUs,
se busca aprovechar los beneficios de la computación paralela en actividades y procesos
en ingeniería por lo se plantea la posibilidad de incluir el uso continuo de dichas unidades
a fin de mejorar desempeños en ejecución de algoritmos, cálculos extensos,
procesamiento de datos, aceleración de aplicaciones existentes, entre otros.
Se busca a futuro, aprovechando las nuevas tecnologías y herramientas de
programación, usar de manera común la computación GPU en diferentes procesos
mejorando los tiempos de producción académica y comercial en la Universidad Nacional.

20 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
En este trabajo se realiza la comparación de tres GPUs con características de hardware
diferentes, función principal diferente y costo diferente. Como característica común de las
tres unidades de procesamiento gráfico se tiene la capacidad de ser programadas por el
usuario para ejecutar tareas de propósito general.
Para la comparación adecuada se ejecutaron los mismos algoritmos con las mismas
cargas de datos a procesar en las tarjetas disponibles y se indica, mediante el análisis de
los resultados obtenidos, qué ventajas o desventajas tiene el uso de tarjetas GPU como
coprocesadores dentro de un proceso típico de ingeniería que para este trabajo es un
proceso de diseño en electrónica digital conocido como verificación funcional de
hardware por simulación. Este proceso es común en ingeniería electrónica en áreas
relacionadas con el diseño previa a fabricación de SOCs y sistemas embebidos.
El documento presenta el siguiente orden: en el primer capítulo, 1. Computación
paralela y Computación de propósito general usando GPU, se plantea una
explicación de carácter introductorio a la computación paralela y GPGPU, su historia y
desarrollo. En el segundo capítulo, 2. Historia y Arquitectura GPU se describe la micro-
arquitectura perteneciente a las GPUs.
En el tercer capítulo, 3. Selección y Caracterización de GPUs, se muestran las
características usadas al seleccionar las unidades de procesamiento gráfico y el
funcionamiento de las GPUs seleccionadas mediante pruebas básicas y puesta a punto
del ambiente de desarrollo.
En los Capítulos 4 y 5 se presentan las pruebas y desarrollos planteados por este trabajo
así como los experimentos diseñados y las métricas de desempeño usadas. En el cuarto
capítulo, 4. Desempeño con Benchmark SHOC, se encuentran las especificaciones e
implementaciones de pruebas de alta carga computacional: Benchmark SHOC [32] el
cual hace es un compendio de pruebas seleccionadas específicamente para permitir un
acercamiento a las capacidades reales de las GPUs.

Introducción
En el quinto capítulo, 5. Verificación funcional de hardware usando CUDA C, se
presenta la implementación de un ambiente de verificación funcional de un elemento de
hardware en HDL; la verificación funcional es una tarea específica del diseño digital y que
implica un esfuerzo computacional significativo que puede, en algunos casos, ejecutarse
en un coprocesador como la GPU. En este capítulo se presentan también los resultados
obtenidos y su interpretación. Por último se presentan las conclusiones de la
investigación y se plantean los posibles trabajos futuros.


Capítulo 1
1. Computación Paralela y Computación de
Propósito General con GPU
La computación paralela es un tipo de cómputo en el cual diferentes elementos de
procesamiento, Hardware o Software, interactúan para resolver un problema. Dicho
problema se resuelve al dividirlo en múltiples problemas de menor tamaño o menor
complejidad y debe ser abordado simultáneamente [3], [30].
Un problema que es posible dividir en pequeños sub problemas a nivel de datos o a nivel
de instrucciones deberá ser ejecutado en varios procesadores o elementos de
procesamiento de manera simultánea como se representa en la Figura 1. Se tiene la
necesidad de hablar de Tipos de paralelismo y de Arquitecturas paralelas [1], [33] donde
los elementos de procesamiento cooperan y se comunican para resolver rápidamente
problemas grandes.
Figura 1. Concepto de Paralelismo
Dentro de la computación paralela se debe tener claro que existen diferentes tipos de
paralelismo y que según sea el caso existe una arquitectura de computadores adecuada
para su ejecución óptima y adecuada. En este sentido se tienen los siguientes tipos de
paralelismo:
24 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Paralelismo a nivel de Datos (Data-Level Parallelism) que está presente cuando
hay muchos elementos de datos que pueden ser operados a la vez.
Paralelismo a nivel de Tareas (Task-LP) que se da cuando existen tareas que
pueden funcionar de manera simultánea e independiente.
Paralelismo a nivel de Instrucciones (Instruction-Level Parallelism), es decir,
instrucciones diferentes aplicadas simultáneamente.
Paralelismo a nivel de Hilos (Thread-Level Parallelism) es posible tener
paralelismo, mediante hardware acoplado, tanto a nivel de tareas como de datos.
Paralelismo a nivel de solicitud (Request-Level Parallelism) está presente en la
ejecución de tareas totalmente desacopladas, es decir independientes. Estas
tareas las decide el programador o en algunos casos el sistema operativo.
Buscando el mejor aprovechamiento de hardware mediante la computación paralela, es
necesario que las aplicaciones (el software) ejecuten operaciones o se realicen cálculos
simultáneamente. La dificultad en la escritura y correcto funcionamiento de dichas
aplicaciones es mayor que en la programación secuencial debido a la complejidad de las
estructuras de programación empleadas y a la mayor probabilidad de presentar bugs en
la ejecución [1], [34] En 1966 M. Flynn propone lo que hoy en día se conoce como la
taxonomía o clasificación de los procesadores de Flynn (Taxonomy of Flynn) que
plantea:
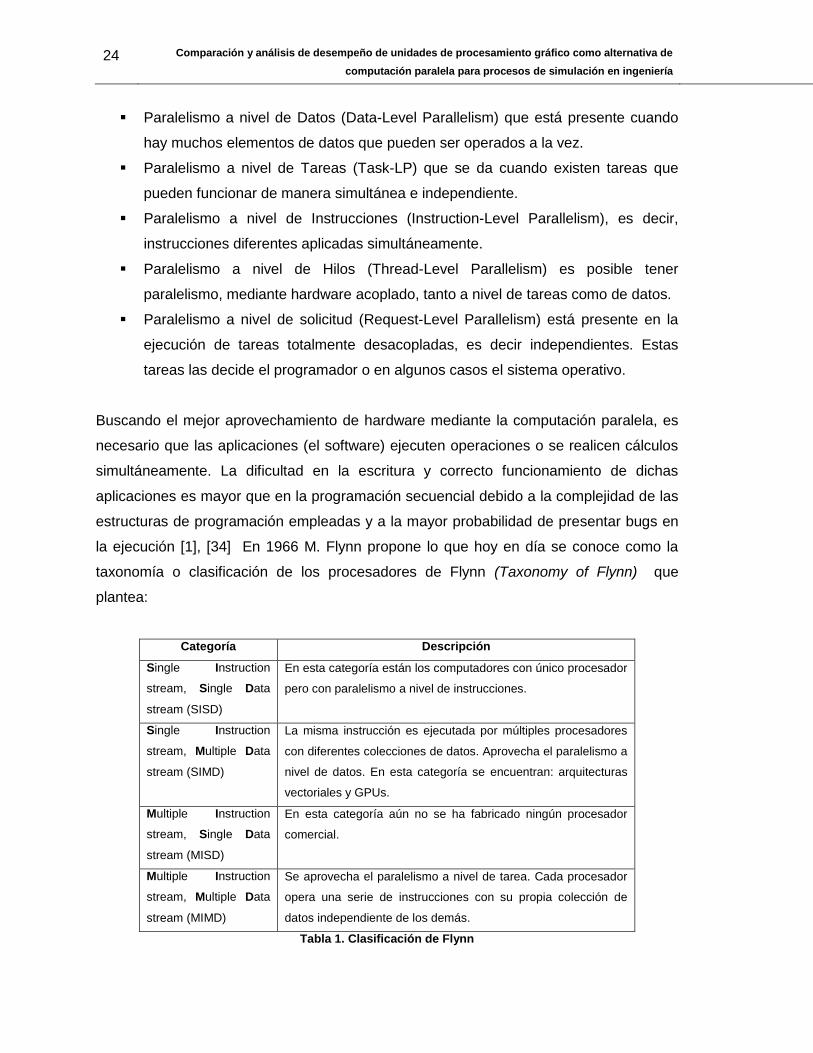
Categoría Descripción
Single Instruction
stream, Single Data
stream (SISD)
En esta categoría están los computadores con único procesador
pero con paralelismo a nivel de instrucciones.
Single Instruction
stream, Multiple Data
stream (SIMD)
La misma instrucción es ejecutada por múltiples procesadores
con diferentes colecciones de datos. Aprovecha el paralelismo a
nivel de datos. En esta categoría se encuentran: arquitecturas
vectoriales y GPUs.
Multiple Instruction
stream, Single Data
stream (MISD)
En esta categoría aún no se ha fabricado ningún procesador
comercial.
Multiple Instruction
stream, Multiple Data
stream (MIMD)
Se aprovecha el paralelismo a nivel de tarea. Cada procesador
opera una serie de instrucciones con su propia colección de
datos independiente de los demás.
Tabla 1. Clasificación de Flynn

Capítulo 1 25
Teniendo en cuenta la clasificación propuesta en la Tabla 1, la computación paralela
debe tener una arquitectura de computador específica que permita ejecutar bien sea
varias instrucciones simultáneamente sobre un mismo conjunto de datos MISD, una
instrucción sobre un gran conjunto de datos simultáneamente SIMD o una combinación
de las dos anteriores situaciones que sería MIMD.
Algunos de los primeros avances que dieron origen a la computación paralela están
clasificados en la Tabla 2. como una línea de tiempo desde (19541984). Es importante
tener en cuenta estos primeros desarrollos debido a que se evidencia el surgimiento de
los diferentes tipos de paralelismo que buscaban la eficiencia en las tareas de
computación. Surge la necesidad de tener varios núcleos de procesamiento conocidos
como multi-core. Adicionalmente las arquitecturas modernas de GPU son vistas como
many-core y se entra en la era de la computación de propósito general usando GPU
aprovechando el paralelismo típico de las arquitecturas de procesadores vectoriales. [1],
[35]
Año Avance Autor(es)
1954 IBM® 704: Hardware para operaciones aritméticas de punto flotante. IBM.® (Gene
Amadahl et.
al.)
1958
Se empieza a considerar la posibilidad de la programación paralela para disminuir tiempos
espera y para realizar cálculos numéricos.
S. Gill
IBM. John
Cocke. Daniel
Slotnick
1962
Computador D825 con 4 procesadores que accedian a 16 módulos de memoria a través de
un un conmutador de múltiples entradas y múltiples salidas (crossbar switch)
Burroughs
Corporation
1964 Se propone construir un computador con paralelismo masivo. El diseño propuesto por
Slotnick fue construido por la Fuerza Aerea de Estados Unidos se llamó ILLIAC IV. Fue el
primer computador con SIMD. Principio de los procesadores vectoriales. Cuando acabó de
construirse (1976) no fue comercialmente aceptado porque para esa época existían otros
Súper-computadores de mayor capacidad como el CrayI.
Slotnick
US Air Force
1967 Se habla de la posibilidad del procesamiento paralelo en American Federation of Information
Processing Societies Conference. Se propone la ley de Amadahl que define la máxima
velocidad de procesamiento debido al paralelismo (que tanto un algoritmo paralelo es más
rápido que su correspondiente secuencial)
Daniel
Slotnick. Gene
Amadahl
1969 Multics ystem, un sistema multiprocesador simétrico a con capacidad de realizar
procesamiento paralelo con 8 procesadores
Honeywell
1971 C.mmp (Computer multiminiprocessor). Parallelismo MIMD. William Wulf.
Carnegie
Mellon
University.
1984 Synapse N+1 primer arquitectura multiprocesador conectada mediante bus con snooping
cache (técnica usada en sistemas con memoria distribuida)
Elliot Nestle
Armond
Inselberg.
Tabla 2. Primeros computadores con paralelismo

26 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Como necesidad para poder hacer uso del hardware existente se usan diferentes
lenguajes, protocolos, estándares y librerías que permiten la creación de software con
algún tipo de paralelismo. El uso de alguno de estos lenguajes y de la estrategia de
programación depende del hardware a usar y del tipo de paralelismo que permita el
problema. Ejemplos de los principales lenguajes y estándares que permiten la
programación en paralelo son:
OpenCL u Open computing Language: permite la programación de procesadores
modernos (CPUs y GPUs) presentes en computadores personales, servidores,
dispositivos programables como DSPs y FPGAs
(https://www.khronos.org/opencl/)
CUDA o Compute Unified Device Architecture: permite la programaci\'on de
GPUs y procesadores vectoriales NVIDIA
(http://www.nvidia.com/object/cuda_home_new.html)
OpenMP u Open Multi Processing: es una interfaz de programación de
aplicaciones (API) que permite programar aplicaciones paralelas en C, C++ o
Fortran para diferentes arquitecturas y sistemas operativos.
(http://openmp.org/wp/)
A partir del año 1987 el planteamiento por parte de Estados Unidos de los grandes
desafíos de la computación (Grand Challenges Policy) se incentivó el desarrollo de la
computación de alto desempeño [36], por ende el uso de computación paralela. Muchos
de los problemas planteados en los grandes desafíos pueden ser abordados desde la
computación usando GPUs como procesadores de propósito general y este hecho ha
permitido que se desarrollen tanto el hardware como el software necesario en el campo
del Procesamiento de Propósito General usando GPU o como se conoce actualmente
Computación GPU.

Capítulo 1 27
1.1 Computación de Propósito General con GPU
La computación de propósito general es aquella donde los recursos computacionales
incluyen una o varias unidades de procesamiento gráfico independiente GPU que
permite, por su arquitectura vectorial, desarrollar procesos o tareas de manera
simultánea sobre grandes conjuntos de datos. Se puede hablar de las unidades gráficas
como procesadores del tipo SIMD.
Como paradigma GPU Computing se tiene por definición que el objetivo es desarrollar
tareas diferentes a las de audio y video tradicionales (non-graphics task/applications) sin
embargo es posible su aplicación en algoritmos gráficos. Por ejemplo en [37] se
encuentra la reconstrucción de una imagen usando un algoritmo basado en GPU
computing. Es por eso que no puede desligarse la GPU de su condición de potente motor
de gráficas que gracias a su modelo many-core permite acelerar procesos al realizarlos
de forma paralela.
Desde el año 2002 Mark Harris1 acuña el término GPGPU fundando
http://gpgpu.org/about2 , el término se refiere al trabajo realizado mediante la aceleración
de procesos al ejecutarlos en GPU, es decir, enviando tareas diferentes a las gráficas y
obteniendo resultados exitosos. En general gracias a ese cambio de paradigma y a los
desarrollos tempranos en el área es que las GPUs ingresaron a la computación de alto
nivel no sólo como co-procesadores sino como ejecutores de tareas principales y
definitivas para acelerar procesos.
Es posible el uso de GPUs en procesos de computación de alto nivel mediante la
aplicación de diferentes estrategias y herramientas de programación. La estrategia que
se usó para obtener los resultados presentados en los siguientes capítulos se conoce
como computación Heterogénea y es aquella en la cual se tiene la ejecución colaborativa
de tareas tanto en CPU como en GPU [32].
1 Chief Technologist for GPU Computing at NVIDIA
2 Página fundada por Harris en el 2002 hasta el 2010, actualmente mantenida por el mismo Harris.
Comunidad de desarrolladores e investigadores.

28 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
En la computación paralela se tiene como premisa la división de tareas para que cada
procesador, según su especialidad, realice el trabajo de manera rápida y eficiente. [27]
En este punto se plantea la división de los dos grandes procesadores de un equipo de
cómputo entre el procesador tradicional de propósito general conocido como CPU y la
unidad gráfica GPU. En adelante se hablará del equipo donde está la CPU y su conjunto
de periféricos y demás Hardware específico como el HOST y a la GPU se denominará
DEVICE.
La computación heterogénea (Figura 2) permite elegir partes del código de una
aplicación que está corriendo en el host y enviarlo hacia el Device. El código enviado a la
GPU tiene paralelismo a nivel de datos y el resto del código, al ser secuencial, se ejecuta
de mejor manera en el host.
Figura 2. Computación Heterogénea en GPU NVIDIA®. [38]
En la computación heterogénea se tiene un flujo específico de datos que permite tener
una sincronización adecuada de entradas, operaciones y salidas. Este flujo sigue como
se muestra en la Tabla 3. Computación heterogénea.
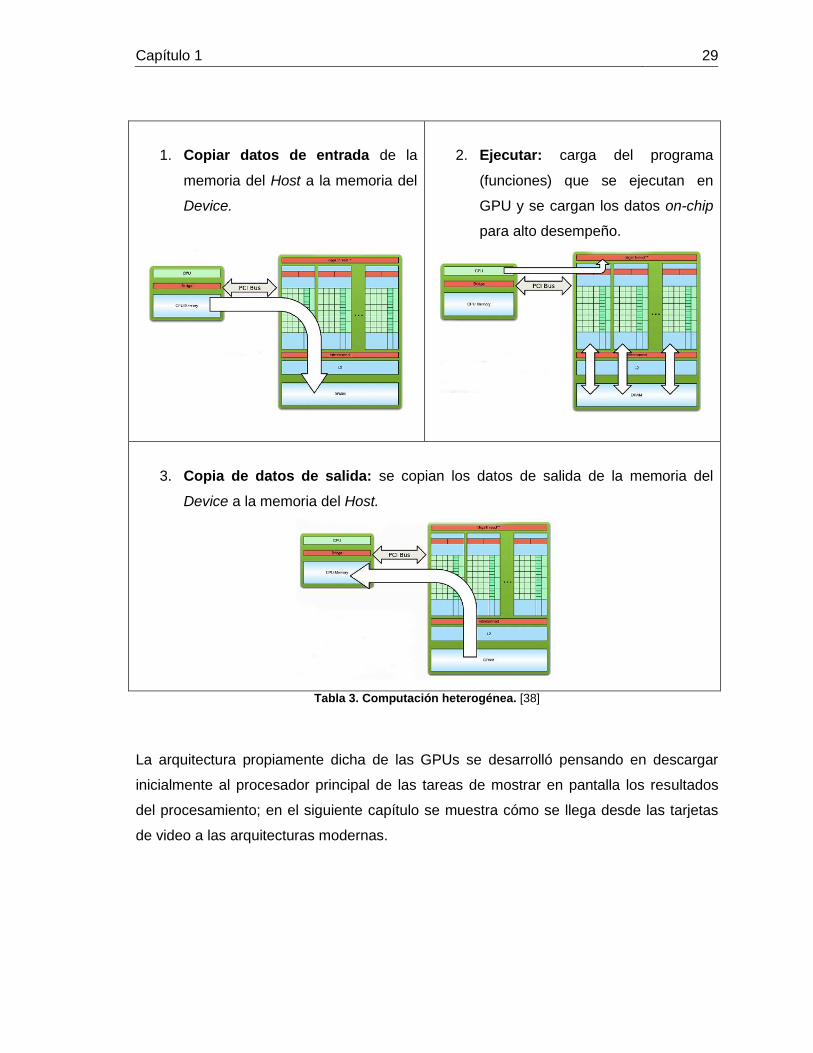
Capítulo 1 29
1. Copiar datos de entrada de la
memoria del Host a la memoria del
Device.
2. Ejecutar: carga del programa
(funciones) que se ejecutan en
GPU y se cargan los datos on-chip
para alto desempeño.
3. Copia de datos de salida: se copian los datos de salida de la memoria del
Device a la memoria del Host.
Tabla 3. Computación heterogénea. [38]
La arquitectura propiamente dicha de las GPUs se desarrolló pensando en descargar
inicialmente al procesador principal de las tareas de mostrar en pantalla los resultados
del procesamiento; en el siguiente capítulo se muestra cómo se llega desde las tarjetas
de video a las arquitecturas modernas.

30 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería

Capítulo 2 31
2. Historia y arquitectura GPU
Desde el surgimiento de la computación ha sido de gran interés el hecho de tener una
buena interfaz visual que permita al usuario el manejo de gráficos-texto y que permita
reducir la carga del procesador principal. Los primeros avances fueron conocidos como
tarjetas de video que han evolucionado hasta convertirse en dispositivos conocidos hoy
en día como unidades de procesamiento gráfico o GPU por sus siglas en inglés
(Graphics processing unit).
Aunque las GPUs tienen un amplio desarrollo no son comunes a todos los equipos y las
tarjetas de video no han desaparecido, incluso se han incluido secciones del procesador
principal dedicadas exclusivamente al control de la interfaz gráfica como es el caso de los
procesadres Intel ® Core™ con Intel HD Graphics que es una sección del circuito
integrado dedicada exclusivamente a procesamiento de imagen y video. (Ver Figura 3.
Intel Core i5-2500K Sandy Bridge)
Figura 3. Intel Core i5-2500K Sandy Bridge3
Las GPUs y tarjetas de video pueden encontrarse actualmente en muchos dispositivos
diferentes a los computadores, por ejemplo, consolas de video juegos o celulares; estos
últimos con GPUs incluidas en un mismo circuito junto con el procesador principal y
diversas funciones como adaptadores inalámbricos (SoC- System on Chip). Tal es el
caso del procesador para móviles con el SoC Snapdragon S4 que incluye un procesador
3 https://www.techpowerup.com/reviews/Intel/Core_i5_2500K_GPU/1.html

32 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
dual-core ARM Cortex A5 y una GPU Adreno 203 entre otras secciones necesarias para
su funcionamiento.
El desarrollo de todo el hardware actual de video se inicia con el surgimiento de las
primeras tarjetas de video en 1981 por parte de IBM. En este año se lanza el primer
computador personal de IBM capaz de mostrar texto en un monitor monocromático
(verde-negro); podía mostrar en la pantalla 25 líneas de 80 caracteres cada una, cada
carácter era de 14x9 puntos. Este computador personal contaba con la tarjeta MDA
(Monochrome Display Adapter) o adaptador monocromo lanzado como una memoria de
4KiB para monitores TTL . En general el adaptador leía de la memoria ROM una matriz
de puntos para mostrar en pantalla y dicha información se enviaba al monitor como
información serial. Esta tarjeta también contaba con un puerto de conexión directa para
impresoras.
En la década de los 80 IBM mejoró las capacidades de sus tarjetas incluyendo además
de la visualización de texto una interfaz gráfica con mayor cantidad de colores y
posibilidad de imágenes. También se amplió significativamente la memoria usada en la
transmisión de información de la CPU a la pantalla. En la Tabla 4. Historia de
adaptadores de videose observa el crecimiento de las tarjetas de video usadas por IBM
con las capacidades de mayor relevancia ordenadas cronológicamente.
Adaptador Año Texto Gráfico Colores Memoria
MDA: Monochrome Display Adapter 1981 80*25 - 1 4 KiB
CGA: Color Graphics Adapter 1981 80*25 640*200 4 16 KiB
HGC: Hercules Graphics Card 1982 80*25 720*348 1 64 KiB
EGA: Enhanced Graphics Adapter 1984 80*25 640*350 16 256 KiB
VGA: Video Graphics Array 1987 80*25 640*480 256 256 KiB
SVGA: Super VGA 1989 80*25 1024*768 256 1 MiB
XGA: Extended Graphics Array 1990 80*25 1024*768 65K 2 MiB
Tabla 4. Historia de adaptadores de video
En 1985 IBM® presentó los Commodore Amiga, este fue el primer equipo que usó un co-
procesador llamado Blitter que es circuito dedicado con capacidad de mover grandes
cantidades de datos de un área de memoria a otra funcionando en paralelo al

Capítulo 2 33
procesamiento en la CPU. IBM patentó el nombre blitter como “Personal computer
apparatus for block transfer of bit-mapped image data”. Este tipo de co-procesadores se
usaron para copiar y manipular gran cantidad de información gráfica. Puede considerarse
como uno de los antecesores de las actuales GPUs.
Las tarjetas de IBM dan inicio a la era de los gráficos en la computación y por ende son el
punto de partida para el surgimiento de las primeras GPUs. En los inicios de la década
de los 90 el manejo de gráficas 3D era pensado como ciencia ficción, sin embargo la
demanda de mejores capacidades gráficas, particularmente para videojuegos, hizo que a
finales de década fuera una realidad. En 1991 se presentan las primeras GPUs y desde
entonces han tenido un gran avance hasta la actualidad.
Posterior a los procesadores de gráficos y las tarjetas de video se introdujo el término
GPU propiamente dicho en el año 1999 NVIDIA (fabricante de unidades de
procesamiento gráfico) [39]


Capítulo 2 35
2.1 Arquitecturas GPU
La función principal de estas unidades de procesamiento es el manejo de imagen-video
permitiendo reducir carga al procesador y presentar un mejor resultado en pantalla. En la
actualidad a las funciones de gráficos 3D se agrega el procesamiento de propósito
general que es posible gracias al paralelismo inherente a la arquitectura usada para el
manejo de gran cantidad de información de imágenes.
Las GPUs se componen básicamente de varias y pequeñas unidades de control y
memorias cach; además una memoria DRAM para mover, manipular y presentar en
pantalla la información de video que para el caso de video juegos es de 60 veces por
segundo en cada escena 3D para obtener realismo. Las funciones bases de este manejo
de gráficas incluyen la descripción de la escena, iluminación, reflejos, posición y
orientación.
En la Figura 4. Abstracción Arquitectura GPU vs. Arquitectura CPU se puede observar
una comparación entre la arquitectura base de una CPU y una GPU que permite ver
cómo hay un mayor número de pequeñas ALU que permite realizar operaciones
paralelas sobre conjuntos de datos (pensado originalmente para manipulación de
imágenes-video). Si se piensa hipotéticamente en el mismo número de transistores en
ambos dispositivos, la GPU dedica mayor número de transistores para el procesamiento
de datos.
Figura 4. Abstracción Arquitectura GPU vs. Arquitectura CPU
Una descripción de la arquitectura general de una GPU, omitiendo la memoria RAM, se
encuentra en la Figura 5. Básicamente una unidad de procesamiento gráfico GPU es una
colección de elementos de procesamiento que es totalmente funcional. Cada elemento
de procesamiento se puede considerar como una unidad aritmético-lógica ALU. Estos

36 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
elementos de procesamiento se agrupan en unidades de procesamiento al agregarle
unidades de control y memorias caché a cada grupo.
Figura 5. Arquitectura General de una GPU [40]
Para el procesamiento de gráficos se usa DirectX u OpenGL. DirectX es una colección de
APIs para plataformas M.S. Windows que permite realizar tareas relacionadas con
multimedia, programación y ejecución de juegos, video y control de pantalla. OpenGL
(Open Graphis Library) es un lenguaje cruzado de programación para funciones gráficas,
es una API multiplataforma que permite el procesamiento de gráficos 2D y 3D en
cualquier equipo, generalmente se usa para interactuar con las GPUs.

Capítulo 2 37
Para dar una idea de lo poderoso que es el hardware de una GPU se muestra a
continuación la siguiente secuencia básica para el procesamiento de imagen 3D en un
videojuego [41]:
a) Se asume que todo está hecho de triángulos. Direct3D u OpenGL en conjunto con
la GPU permiten ubicar todos los triángulos de los que se compone una escena y
los vértices que los unen.
b) Ubicar todos los objetos en un sistema de coordenadas común en cada escena.
El hecho de tener un “sistema de coordenadas homogéneo” implica un gran
número de operaciones vectoriales de punto flotante para lo que se necesita un
hardware con capacidad para paralelismo en estas operaciones.
c) Se iluminan los triángulos y se les da el color. Cada triángulo se ilumina mediante
la suma de la iluminación de cada foco. Se usa la ecuación de iluminación de
Phong [42]. Esta operación implica realizar repetidamente el producto punto de
dos vectores, multiplicación de 4 componentes una operación de suma. El
hardware de la GPU está en capacidad de realizarlo.
d) Cada triángulo coloreado se proyecta en la línea de vista o primer plano de la
“cámara” o lo que ve el usuario. Luego de que las coordenadas son operadas de
manera vectorial, cada triángulo debe ser presentado como pixel.
e) El proceso de asignar pixeles a cada triángulo visible se llama rasterización. La
rasterización es un tipo de renderización que consiste en traducir la imagen
descrita en formato gráfico vectorial y que ya contiene información de iluminación
a un conjunto de pixeles para ser mostrados en una salida digital. Este proceso se
realiza de manera paralela al manejar conjuntos de pixeles a la vez.
f) A cada pixel coloreado e iluminado se agrega textura que está guardada en una
memoria de acceso rápido a la que se acede desde la GPU.
g) Algunos objetos ocultan otros objetos y la operación ideal es ubicar cada triángulo
desde el fondo hasta el frente de la escena, esta operación muchas veces no es
posible. Aunque las GPUs modernas tienen un buffer de profundidad que
almacena la distancia de cada pixel a la cámara o usuario, el pixel sólo se
muestra si está cerca del usuario.
Esta cantidad de operaciones se realiza rápida y precisamente. El desempeño depende
de la GPU, la memoria RAM, velocidades de reloj y buses de que disponga el equipo
38 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
pero en general se sigue el mismo proceso repetidas veces para que el ojo humano
pueda observar una escena y desplazarse en ella (caso de videojuegos).
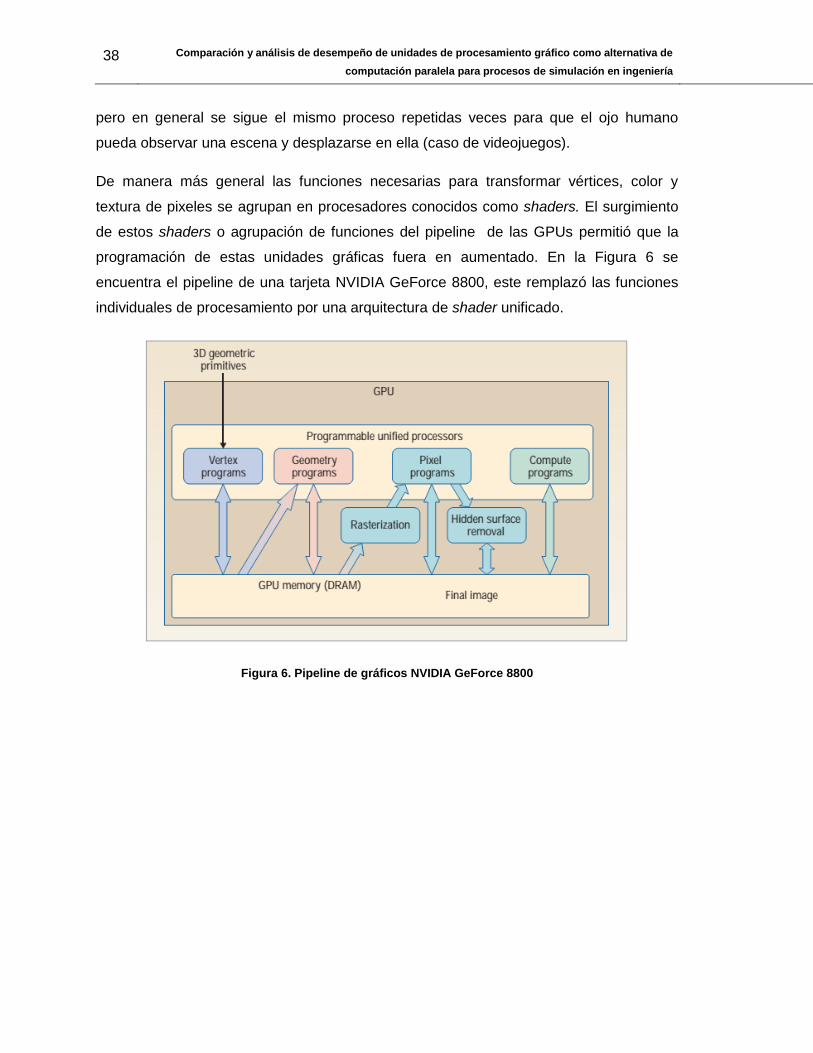
De manera más general las funciones necesarias para transformar vértices, color y
textura de pixeles se agrupan en procesadores conocidos como shaders. El surgimiento
de estos shaders o agrupación de funciones del pipeline de las GPUs permitió que la
programación de estas unidades gráficas fuera en aumentado. En la Figura 6 se
encuentra el pipeline de una tarjeta NVIDIA GeForce 8800, este remplazó las funciones
individuales de procesamiento por una arquitectura de shader unificado.
Figura 6. Pipeline de gráficos NVIDIA GeForce 8800

Capítulo 2 39
2.2 Arquitecturas NVIDIA
La arquitectura mencionada anteriormente, NVIDIA GeForce 8800 del año 2006 conocida
como G80 es la predecesora de las arquitecturas modernas. En esta primera tarjeta se
basan las actuales arquitecturas Kepler, Fermi y Maxwell. Se toma como ejemplo la
micro-arquitectura de la G80 por ser de mucho menor tamaño y complejidad que las
arquitecturas actuales y permite entender el funcionamiento de las tarjetas gráficas
NVIDIA.
Microarquitectura GeForce 8800 [43]
La GPU conocida como GeForce 8800, tanto GTX como GTS, es la predecesora de las
nuevas arquitecturas NVidia y su microarquitectura permite entender de mejor manera el
funcionamiento de las GPU como procesadores paralelos masivos.
Las tres características importantes y novedosas4 de esta tarjeta con respecto a sus
predecesoras está en la unificación de los procesadores de vértices, pixeles y colores
(shaders) en un modelo unificado “Unified Shader” que permite elimina la secuencialidad
en el procesamiento de gran cantidad de datos. El modelo de shader unificado permite
distribuir las cargas de procesamiento y utilizar al máximo las unidades de procesamiento
disponibles para ejecutar tareas diferentes sobre conjuntos de datos diferentes de
manera simultánea. En la Figura 7. Fixed Shaders Vs. Unified Shader5 se observa como
se busca una mejor distribución de la carga computacional evitando tener hardware
inactivo. Para la G80 el shader unificado tiene 128 procesadores individuales llamados
Streaming Processors SP funcionando a 1.35 GHz cada uno.
El objetivo de tener un procesador como único hardware es permitir realizar cualquier
operación para la que sea programado y evitar cuellos de botella al esperar los datos de
una etapa a otra del pipeline. Cada SP de esta arquitectura es un procesador de punto
flotante totalmente funcional que está encargado de realizar operaciones sobre conjuntos
de datos de imagen/video ya sean de geometría, vértices, pixeles o cálculos físicos.
4 Novedosas para la época. Tarjeta GeForce 8800 GTX y GeForce 8800 GTS Año 2006
5 Imagen modificada de GeForce 8800 [43]

40 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Cada uno de estos procesadores individuales está en capacidad de realizar un cálculo
completo e independiente sobre un conjunto de datos. La G80 agrupó en 8 SP en un
multiprocesador llamado Streaming Multiprocessor SM; cada SM tiene acceso a una
memoria caché de nivel L1 (o memoria compartida) que comparte con otro SM, es decir
que existen 8 bloques de memoria cache L1.
Cada memoria caché L1 se comunica de manera directa con un bloque de memoria
cache de nivel L2, es decir que también existen 8 bloques de memoria L2. Esta
memoria cache tiene conexión directa con un buffer de datos individual y en última
instancia con la memoria DRAM disponible para la GPU. (Ver Figura 8. Arquitectura
NVIDIA GeForce 8800 (G80).
Figura 8. Arquitectura NVIDIA GeForce 8800 (G80).
Figura 7. Fixed Shaders Vs. Unified Shader [43]

Capítulo 2 41
En resumen las características principales de la G80 son:
16 multi procesadores Streaming Multiprocessor SM.
128 unidades de punto flotante o Streaming Processor SP.
376 GFLOPs (Teórico, depende de todo el conjunto Host+Device)
768 MB de memoria DRAM
86.4 GB/s Velocidad de transferencia de datos en memoria y 4 GB/s
Velocidad de transferencia de datos a la CPU
8 bloques de caché L1.
8 Bloques de caché L2.
Cada Streaming Multiprocessor tiene la estructura de la Figura 9. Streaming
Multiprocessor [43]. La estructura de cada SM incluye 8 streaming processors que son
unidades con capacidad para realizar operaciones de multiplicación y adicción (MAD por
sus siglas en inglés Mul+ADd) y soporta el estándar IEEE 754 de precisión de punto
flotante. En la Figura 9 se observa que para cada 2 SM se tienen 4 unidades de
direccionamiento de registros de Textura (TA: texture addressing unit) y 8 unidades de
filtrado de Textura (TF: texture filtering unit) que tienen comunicación directa con la caché
de nivel L1 y esta última con la caché de nivel L2. Este diseño permite tener una
arquitectura balanceada y replicable, lo cual hace posible un crecimiento escalable para
las futuras GPUs.
Figura 9. Streaming Multiprocessor [43]

42 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
A partir de la G80 se tiene el concepto de GPU como arreglo de multiprocesadores
streaming o SM donde cada uno es capaz de soportar cientos de hilos de programas
concurrentes o simultáneos; cada SM es un conjunto de procesadores SP los cuales
ejecutan la misma instrucción en cada ciclo de reloj sobre un grupo de datos llamado
wrap. El reloj de cada SP es de velocidad superior al reloj general de funcionamiento de
la GPU, por ejemplo: en la G80 cada SP funciona a 1.35GHz mientras que la GPU tiene
un reloj general a 575MHz con lo que se logra que cada SP tenga un alto throughput de
datos conservando un consumo energético moderado en el circuito general.
De manera general, en la arquitectura de la GPU, se tiene como común denominador la
réplica masiva de unidades de procesamiento paralelo siguiendo el esquema de la Figura
10. Esquema general de la arquitectura de una GPU6 .
Figura 10. Esquema general de la arquitectura de una GPU
6 Imagen tomada de artículo web NVIDIA GPU Architecture & CUDA Programming Environment
https://code.msdn.microsoft.com/vstudio/NVIDIA-GPU-Architecture-45c11e6d

Capítulo 2 43
Se observa en la Figura 10 que la unidad de procesamiento gráfico (Device) es un
conjunto de N multiprocesadores. Cada multiprocesador es un conjunto de M
procesadores y cada procesador tiene de manera independiente sus propios registros.
Adicional a la individualidad de cada procesador, se tiene una memoria compartida y una
unidad de instrucciones para el conjunto de procesadores de cada multiprocesador. Por
último cada multiprocesador tiene una serie de memorias caché que permiten la conexión
y comunicación bidireccional con la memoria general del dispositivo (DRAM).
Microarquitecturas FERMI y KEPLER
La arquitectura FERMI se basa en la G80, posee el mismo esquema de replicar unidades
de multiprocesamiento que a su vez tienen unidades de procesamiento de punto flotante
en un alto número. En Figura 11 se observa la ubicación de las unidades de
procesamiento de punto flotante (color verde – cuadro pequeño) que son 32 por
Multiprocesador y los multiprocesadores que son 16 en total. El total de procesadores de
punto flotante, en adelante CUDA Cores, es de 512 CUDA Cores. Cada Core es una
Unidad Aritmético Lógica (ALU) independiente y funcional.
Figura 11. Arquitectura NVIDIA Fermi

44 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
En la arquitectura Kepler (Figura 12), se conserva el principio de replicación masiva de
procesadores y multiprocesadores, en este caso se tiene un total de 15 SM, cada SM
tiene un total de 192 SP para un total de 2880 unidades aritmético-lógicas de punto
flotante.
Figura 12. Arquitectura NVIDIA Kepler[44]
En cuanto a las nuevas arquitecturas, la idea se mantiene, aumentar la cantidad de
procesadores de punto flotante, disminuyendo consumos de potencia y permitiendo
desde esta generación ejecutar tareas de procesamiento paralelo diferentes en diferentes
zonas de la tarjeta, es decir paralelizando no solo a nivel de datos SIMD sino también de
instrucciones, lo que sería un procesador MIMD (ver Tabla 1. Clasificación de Flynn).
En la Figura 13 se muestra el diagrama de bloques general que pertenece a una tarjeta
GeForce-GTX-750-Ti, es de anotar que esta tarjeta tiene 128 unidades de punto flotante
por cada SM por ende el total de unidades de punto flotante es 1280, pero la tarjeta
TITAN X (GM200) tiene un total de 3072 CUDA Cores, la más grande de la actual
NVIDIA.

Capítulo 2 45
Figura 13. Arquitectura NVIDIA Maxweel [45]
A partir de las arquitecturas Fermi y Kepler, además del procesamiento paralelo masivo
en las GPU, se permite realizar agrupamiento de tarjetas mediante conexiones en el
mismo equipo (board-conections) o a manera de cluster de computación y mediante
redes de intranet e internet. Además la arquitectura Kepler permite un nuevo tipo de
paralelismo llamado paralelismo dinámico.


Capítulo 2 47
2.3 Computación paralela usando CUDA
CUDA: Compute Unified Device Architecture. Es un modelo de programación además de
una plataforma de software de desarrollo (CUDA Toolkit) que permite programar las
unidades NVidia con capacidades de procesamiento paralelo de propósito general.
Permite programar en un lenguaje de alto nivel de estilo C/C++ saltando las interfaces de
gráficas y APIs de desarrollo de imagen/video.
La arquitectura de las GPU NVIDIA puede ser programada para tareas de propósito
general mediante el uso de CUDA que es una plataforma para programación y ejecución
de computación paralela de propósito general. En esta plataforma se tiene la integración
de diferentes lenguajes de programación como C, C++, Fortran y librerías desarrolladas
para tareas específicas como la transformada de Fourier CUFFT. Todo el conjunto de
aplicaciones, librerías, compilador, y software de debugging integran los elementos
necesarios para realizar computación paralela y en adelante se denomina NVIDIA CUDA
Toolkit. [46]
CUDA C es uno de los lenguajes presentes en el Toolkit de CUDA. Es una extensión de
C que permite que el programador desarrolle funciones a ejecutar directamente en la
GPU; estas funciones se denominan kernels. Este lenguaje es preferido por
desarrolladores que prefieren lenguajes de alto nivel a diferencia de aquellos que
prefieren APIs de bajo nivel y usan OpenCL.
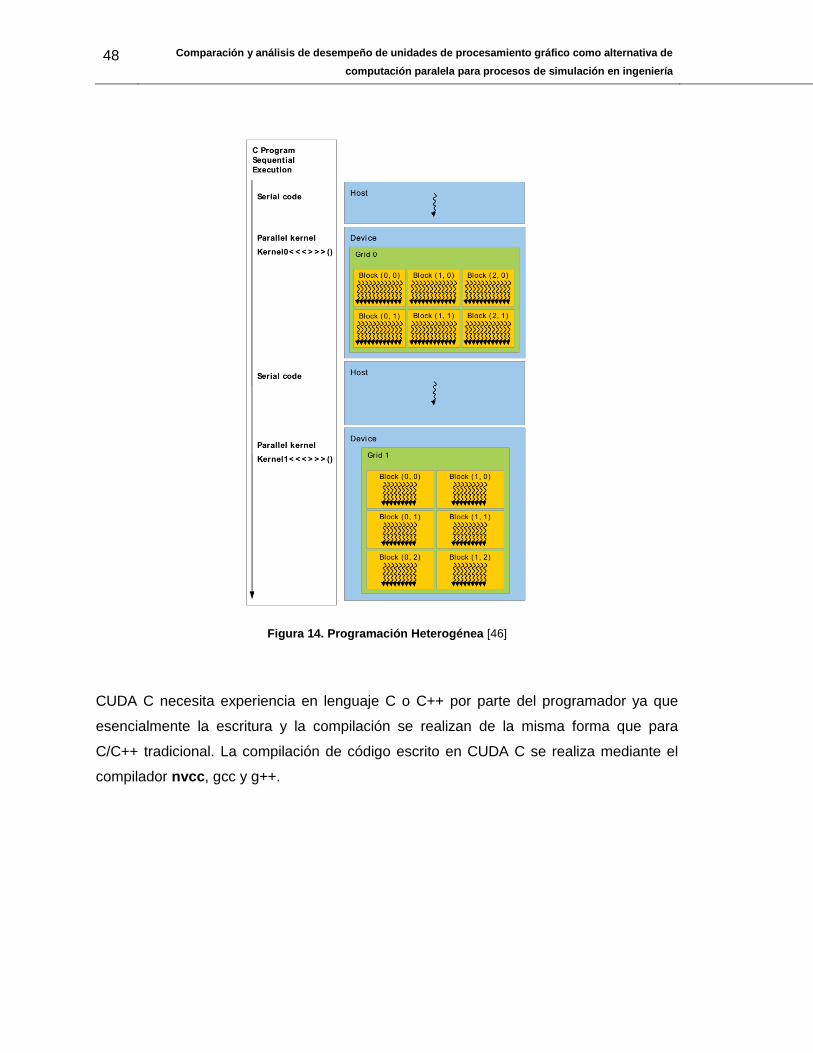
El modelo de programación SPMD (Single-program multiple-data) permite que los kernels
se ejecutan de manera simultánea permitiendo el paralelismo a nivel de CUDA Threads
o hilos de datos que se operan de manera simultánea. En general el código CUDA C es
ejecutado secuencialmente en la CPU o host y los kernels son ejecutados en la GPU
conocida como Device donde realmente existe el paralelismo a nivel de datos.
Los hilos se agrupan en bloques blocks y a su vez en cuadrículas denominadas grid. En
el modelo de computación heterogénea propuesto por NVIDIA se tiene que el código
principal escrito en C/C++ se ejecuta de manera serial en la CPU mientras que las
secciones funcionales con posibilidad de paralelizar se dirigen a la GPU como se
muestra en la Figura 14
48 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Figura 14. Programación Heterogénea [46]
CUDA C necesita experiencia en lenguaje C o C++ por parte del programador ya que
esencialmente la escritura y la compilación se realizan de la misma forma que para
C/C++ tradicional. La compilación de código escrito en CUDA C se realiza mediante el
compilador nvcc, gcc y g++.

Capítulo 2 49
Ejemplos de escritura en CUDA C se tiene en la Figura 15 y Figura 16. Cualquiera sea el
desarrollo se necesita realizar la compilación y ejecución del software en una consola con
los siguientes comandos:
$ nvcc –o NAME NAME.cu
$ ./NAME
Figura 15. Hello world en CUDA

50 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Figura 16. Suma de Vectores en CUDA
Para detalles de instalación y explicación completa del lenguaje de programación
remitirse a [46], [47]. Para descarga del software adecuado, se debe ingresar a la
siguiente dirección web https://developer.nvidia.com/cuda-toolkit.

Capítulo 3 51
3. Selección y Caracterización de GPUs
3.1 Selección de GPUs:
Para el proceso de selección de unidades de procesamiento que permiten la ejecución
de algoritmos escritos como software paralelo se deben identificar criterios específicos de
arquitectura, funcionamiento, desempeño, integración con el sistema operativo,
facilidades de programación, costos y facilidad de adquisición. De esta forma se plantea
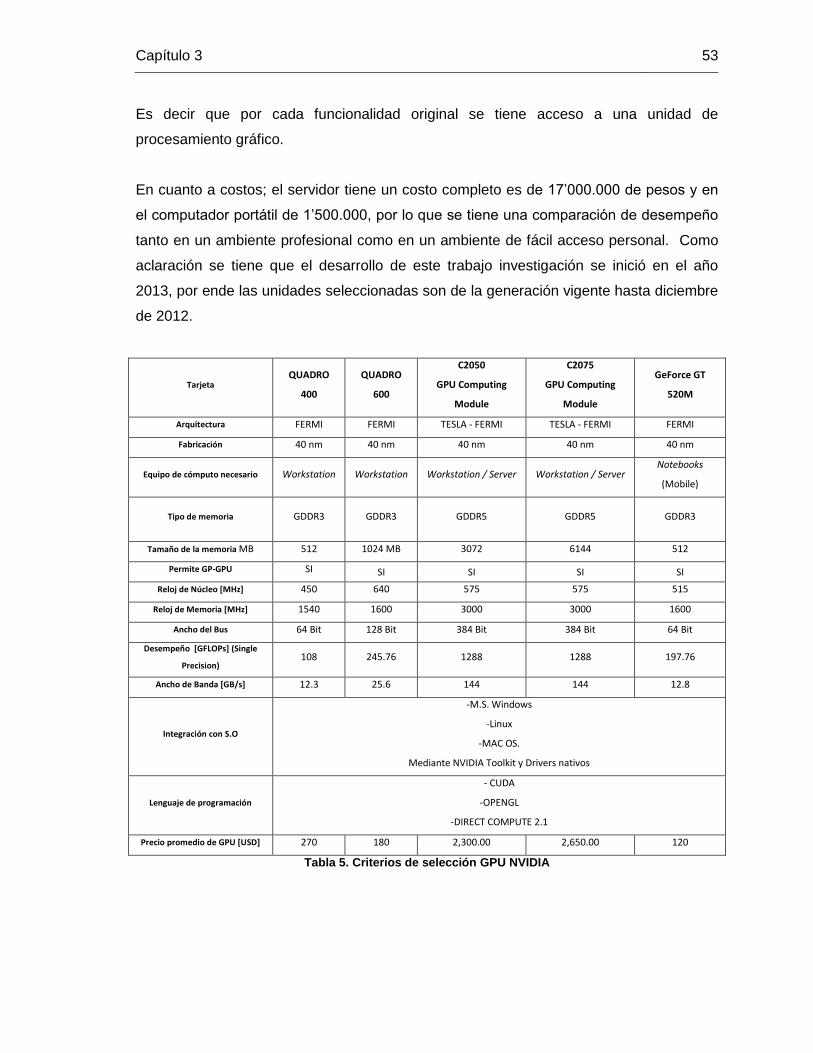
para el proceso de selección las características clasificadas en la Tabla 5.
En el proceso de selección uno de los principales factores fue el de poder realizar un
proceso de exploración de las características de cada hardware mediante la
documentación existente. En este caso se encontró un mayor soporte en la
documentación de NVIDIA con NVIDIA CUDA ZONE [48] que con la principal zona de
consulta de ATI AMD Developer Central [49] además de una mayor claridad y
organización de la información por parte de NVIDIA. Tanto información y desarrollos
oficiales como no oficiales se encuentran mediante documentos, libros y foros que
permiten un autoaprendizaje del lenguaje de programación y de la forma de usar las
GPUs como procesadores de propósito general.
Este primer filtro permite decantar la selección hacia una marca en particular, en este
caso NVIDIA, por ende todo el desarrollo se centra en la aplicación de las técnicas y
herramientas que el mismo fabricante indica. Como referente en la Tabla 5 se indican
algunas de las tarjetas analizadas en primera instancia, de este punto se parte para
escoger la mejor opción de integración de componentes y así obtener el mejor sistema
de cómputo con las GPU escogidas.
El sistema fue escogido teniendo en cuenta que era necesario tener al menos dos GPUs
para poder realizar un proceso de comparación. Para dicho fin se obtuvo un equipo de
cómputo DELL Precision T7600 tipo Servidor en configuración Workstation con dos
GPU NVIDIA de diferentes tecnologías y las cuales tienen la posibilidad de ser

52 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
procesadores de propósito general mediante los controladores de hardware adecuados,
el entorno de programación, compiladores y herramientas para la ejecución de
algoritmos, en este caso NVIDIA CUDA Toolkit.
Las tarjetas seleccionadas incluidas en el servidor son: NVidia Tesla C2075 y NVidia
Quadro 600. Estas GPUs tienen como condición especial el ser unidades de
procesamiento de desempeño profesional para tratamiento de video/audio y, en el caso
de la C2075, es caracterizada directamente por NVidia como un módulo de
procesamiento GPGPU.
Por último se tiene la GPU integrada en un computador personal portátil Lenovo Z470
del año 2011. Esta unidad de procesamiento es destinada a equipos portátiles ya que su
tamaño y consumo energético lo permiten. La GPU es una tarjeta NVIDIA GeForce GT
520M.
Los tamaños de las memorias y demás características relevantes están en la Tabla 5. La
decisión final al elegir estas referencias en primer lugar se da por la integración del
sistema DELL T7600 y sus costos diferenciales con otras marcas, ya que las
cotizaciones para compra no hicieron parte del proceso y el equipo se adquirió para la
Universidad Nacional así que no se incluyen más detalles en este documento.
En segundo lugar la elección se realiza para tres unidades GPUs de diferentes precios y
características diferentes pero con la misma arquitectura (FERMI). Se toma como criterio
para realizar comparación que la función principal, para la cual fue diseñada, sea
diferente.
En la Tabla 6 se indica cómo cada serie completa pertenece a una arquitectura
específica y tiene una función diferente; a saber: GeForce tarjetas pensadas para el
procesamiento de video y mayormente videojuegos con gran cantidad de detalle en
gráficas y movimiento 3D, Quadro tarjetas pensadas para el procesamiento de gráficas,
renders, imágenes o video de manera profesional. Generalmente de gran ayuda a
software de tipo CAD y Tesla que son la serie por excelencia pensada para realizar
cálculos de propósito general en computación de alto desempeño.
Capítulo 3 53
Es decir que por cada funcionalidad original se tiene acceso a una unidad de
procesamiento gráfico.
En cuanto a costos; el servidor tiene un costo completo es de 17’000.000 de pesos y en
el computador portátil de 1’500.000, por lo que se tiene una comparación de desempeño
tanto en un ambiente profesional como en un ambiente de fácil acceso personal. Como
aclaración se tiene que el desarrollo de este trabajo investigación se inició en el año
2013, por ende las unidades seleccionadas son de la generación vigente hasta diciembre
de 2012.
Tarjeta QUADRO
400
QUADRO
600
C2050
GPU Computing
Module
C2075
GPU Computing
Module
GeForce GT
520M
Arquitectura FERMI FERMI TESLA - FERMI TESLA - FERMI FERMI
Fabricación 40 nm 40 nm 40 nm 40 nm 40 nm
Equipo de cómputo necesario Workstation Workstation Workstation / Server Workstation / Server Notebooks
(Mobile)
Tipo de memoria GDDR3 GDDR3 GDDR5 GDDR5 GDDR3
Tamaño de la memoria MB 512 1024 MB 3072 6144 512
Permite GP-GPU SI SI SI SI SI Reloj de Núcleo [MHz] 450 640 575 575 515
Reloj de Memoria [MHz] 1540 1600 3000 3000 1600
Ancho del Bus 64 Bit 128 Bit 384 Bit 384 Bit 64 Bit
Desempeño [GFLOPs] (Single
Precision) 108 245.76 1288 1288 197.76
Ancho de Banda [GB/s] 12.3 25.6 144 144 12.8
Integración con S.O
-M.S. Windows
-Linux
-MAC OS.
Mediante NVIDIA Toolkit y Drivers nativos
Lenguaje de programación
- CUDA
-OPENGL
-DIRECT COMPUTE 2.1
Precio promedio de GPU [USD] 270 180 2,300.00 2,650.00 120
Tabla 5. Criterios de selección GPU NVIDIA

54 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Función principal
Entretenimiento Gráficas
profesionales
Computación de alto
desempeño
Arquitectura
Tesla GeForce 200 Series GeForce 8 Series GeForce 9 Series
Quadro FX Series Quadro Plex Series Quadro NVS Series
Tesla 10 Series
Fermi GeForce 500 Series GeForce 400 Series
Quadro Fermi Series Tesla 20 Series
Kepler GeForce 600 Series --- Tesla K20 Tesla K10
Tabla 6. GPUs Nvidia - Funcionalidad Vs Arquitectura

Capítulo 3 55
3.2 Caracterización de GPUs:
3.2.1 Hardware Seleccionado
NVIDIA Tesla C2075
Esta GPU tiene como condición especial que está diseñada y construida específicamente
como módulo para computación paralela individualmente o en arreglos de varias
unidades. Es una tarjeta de micro-arquitectura FERMI como la que se describe en el
capítulo 2. Permite mediante el toolkit de CUDA realizar cómputos paralelos.
Figura 17 NVIDIA Tesla C2075 [50]
Núcleos de procesamiento
paralelo NVIDIA CUDA Cores
448
Memoria de la GPU 6GB GDDR5 Memory
Ancho de banda total con ECC
off Memory bandwidth (ECC off)
144 GB/sec
Desempeño máximo en FLOPs
(precisión doble)
515 Gflops
Desempeño máximo en FLOPs
(precisión sencilla)
1030 Gflops
Interface de Memoria (BUS) 384 Bit
Consumo de potencia 225 W
Tabla 7. Características principales NVIDIA C2075

56 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Quadro 600
La GPU Quadro 600 es una unidad de procesamiento netamente gráfico con alto
desempeño en tratamiento de audio, video e imágenes acelerando procesos de software
existente CAD. Además de eso por su arquitectura y la cantidad de CUDA Cores
funciona correctamente en procesos de computación paralela.
Figura 18 NVIDIA Quadro 600 [51]
Núcleos de procesamiento paralelo
NVIDIA CUDA Cores
96
Memoria de la GPU 1GB GDDR3 Memory
Ancho de banda total con ECC off
Memory bandwidth (ECC off)
25.6 GB/sec
Desempeño máximo en FLOPs
(precisión doble)
- Gflops
Desempeño máximo en FLOPs
(precisión sencilla)
197.76 Gflops
Interface de Memoria (BUS) 128 Bit
Consumo de potencia 20 W
Tabla 8. Características principales NVIDIA Quadro 600

Capítulo 3 57
GeForce GT 520M
Figura 19. NVIDIA GeForce GT 520M [52]
Núcleos de procesamiento
paralelo NVIDIA CUDA Cores
96
Memoria de la GPU 512 MB GDDR3 Memory
Ancho de banda total con ECC
off Memory bandwidth (ECC off)
12.8 GB/sec
Desempeño máximo en FLOPs
(precisión doble)
Gflops
Desempeño máximo en FLOPs
(precisión sencilla)
197.76 Gflops
Interface de Memoria (BUS) 64 Bit
Consumo de potencia 15W
Tabla 9. Características principales NVIDIA GeForce GT 520M
3.2.2 Ambiente de desarrollo y pruebas básicas a las GPU
seleccionadas.
Para la programación y ejecución de tareas de propósito general en las GPUs
seleccionadas se usa el conjunto de herramientas dado por el fabricante que se
denomina NVIDIA CUDA Toolkit.
Este software tiene como función principal permitir interactuar los códigos escritos en
lenguajes específicos de programación en ambiente C y C++ denominado CUDA C con
las unidades de procesamiento gráfico mediante el compilador incluido para las

58 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
arquitecturas NVIDIA GPU CUDA CAPABLE usando el controlador de video instalado en
el sistema operativo seleccionado. Incluye también librerías matemáticas y herramientas
para debuggin y optimización de código [53].
En la Tabla 10 se tienen las características presentes en el toolkit seleccionado
independientemente del sistema operativo instalado.
Librerías aceleradas por GPU
Fast Fourier Transforms (cuFFT)
Basic Linear Algebra Subroutines (cuBLAS)
Sparse Matrix Routines (cuSPARSE)
Dense and Sparse Direct Solvers (cuSOLVER)
Random Number Generation (cuRAND)
Image & Video Processing Primitives (NPP)
Templated Parallel Algorithms & Data Structures (Thrust)
CUDA Math Library
Herramientas de Desarrollo
NVIDIA CUDA C/C++ Compiler (NVCC)
Nsight Integrated Development Environments
Visual Profiler
CUDA-GDB Command Line Debugger
CUDA-MEMCHECK Memory Analyzer
Material de referencia
CUDA C/C++ code samples
CUDA Documentation
Tabla 10. Características NVIDIA CUDA Toolkit 6.5
El NVIDIA CUDA Toolkit 6.5 está diseñado para trabajar con los drivers de video
instalados en el sistema operativo. Para esto tiene soporte para los siguientes sistemas
operativos [53]:

Capítulo 3 59
Sistema Operativo
Microsoft Windows Versión 64 bit 32 bit
Windows 8.1 x x
Windows 7 x x
Win Server 2012 R2 x
Win Server 2008 R2 x x
Window XP x
Distribuciones Linux x86 Distribución X86 64-bit X32 64-bit F0dora 20 x OpenSuse 13.1
x
RHEL 6 x CentOS 6 x RHEL 5 x CentOS 5 x SLES 11 (SP3)
x
SteamOS 1.0-beta
x
Ubuntu 14.04
x x
Ubuntu 12.04
x x
MAC OS OSX Release Package 10.8
PKG 10.9 10.6
Tabla 11. Sistemas operativos soportados por CUDA Toolkit 6.5
Al tener dos equipos de cómputo diferentes, con diferentes características de
configuración de hardware del sistema se decide usar una versión de sistema operativo
basada en Linux ya que permite una compilación y ejecución sin necesidad de instalar
software adicional al toolkit y al controlador de video. En la Tabla 11 se eligen los
sistemas operativos y los controladores de video así:
CUDA Toolkit 6.5
Equipo de Computo Sistema Operativo Versión de controlador
de Video NVIDIA
Lenovo Z470 Ubuntu 12.04 LTS 340.43
Dell T7600 Ubuntu 14.04 LTS 340.29
Tabla 12. Sistema Operativo y controladores de video para Toolkit 6.5
60 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
El controlador de video por defecto de la versión 6.5 no se usa ya que no permite en
muchos casos la visualización en la pantalla al entrar en conflicto con librerías y
controladores del sistema instalados previamente. Se modifica para que cada equipo
funcione adecuadamente.
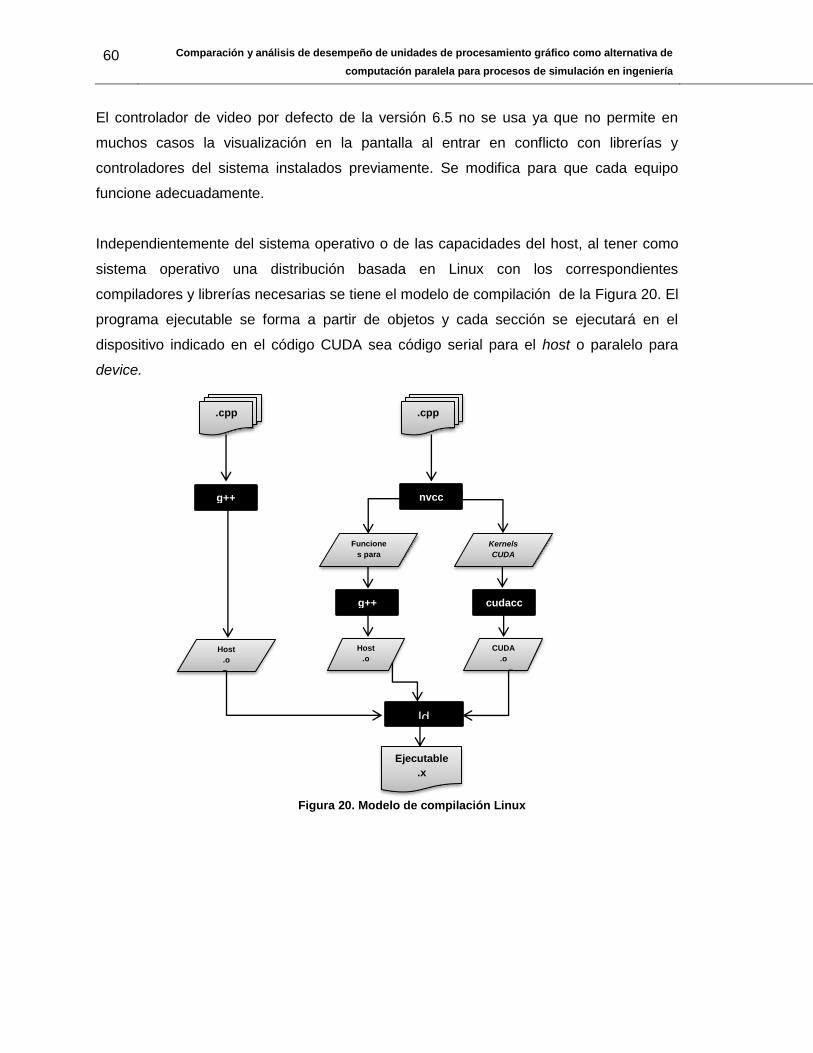
Independientemente del sistema operativo o de las capacidades del host, al tener como
sistema operativo una distribución basada en Linux con los correspondientes
compiladores y librerías necesarias se tiene el modelo de compilación de la Figura 20. El
programa ejecutable se forma a partir de objetos y cada sección se ejecutará en el
dispositivo indicado en el código CUDA sea código serial para el host o paralelo para
device.
.cpp
g++
Funcione
s para
HOST
.cpp
nvcc
Kernels
CUDA
g++ cudacc
Host
.o
Host
.o
CUDA
.o
ld
Ejecutable
.x
Figura 20. Modelo de compilación Linux

Capítulo 3 61
3.2.3 Especificaciones de las GPUs seleccionadas
Al instalar el software necesario también se instalan ejemplos compilables. Posterior a la
compilación se obtienen archivos ejecutables que permiten probar el funcionamiento de
las unidades. Como parte de estos ejemplos las dos primeras pruebas sugeridas por el
fabricante son una prueba de ancho de banda llamada bandwithTest y una prueba
denominada deviceQuery en la que se realiza lectura de las propiedades de cada GPU.
Ejecutar estas pruebas permite comprobar si existe una comunicación del compilador con
el controlador de video y después de generar un archivo ejecutable comprobar la
ejecución de tareas en la unidad de procesamiento gráfico.
Prueba de ancho de banda bandwidthTest
En la prueba bandwidthtest para NVIDIA® GeForce GT 520 M en la Figura 21, NVIDIA®
Quadro 600 Figura 22 y NVIDIA® Tesla C2075 Figura 23 se comprueba el ancho de
banda real al realizar copias de paquetes de datos entre GPU y Host. En Tabla 13 y en la
Figura 24 se muestran los resultados para la copia de un paquete de datos de tamaño
33554432 Bytes. El ancho de banda se refiere a la velocidad de acceso por parte de las
GPU o del equipo de cómputo a los datos almacenados bien sea en la memoria de la
GPU o en la memoria RAM del equipo.
Figura 21. Prueba de ancho de banda GeForce GT 520M
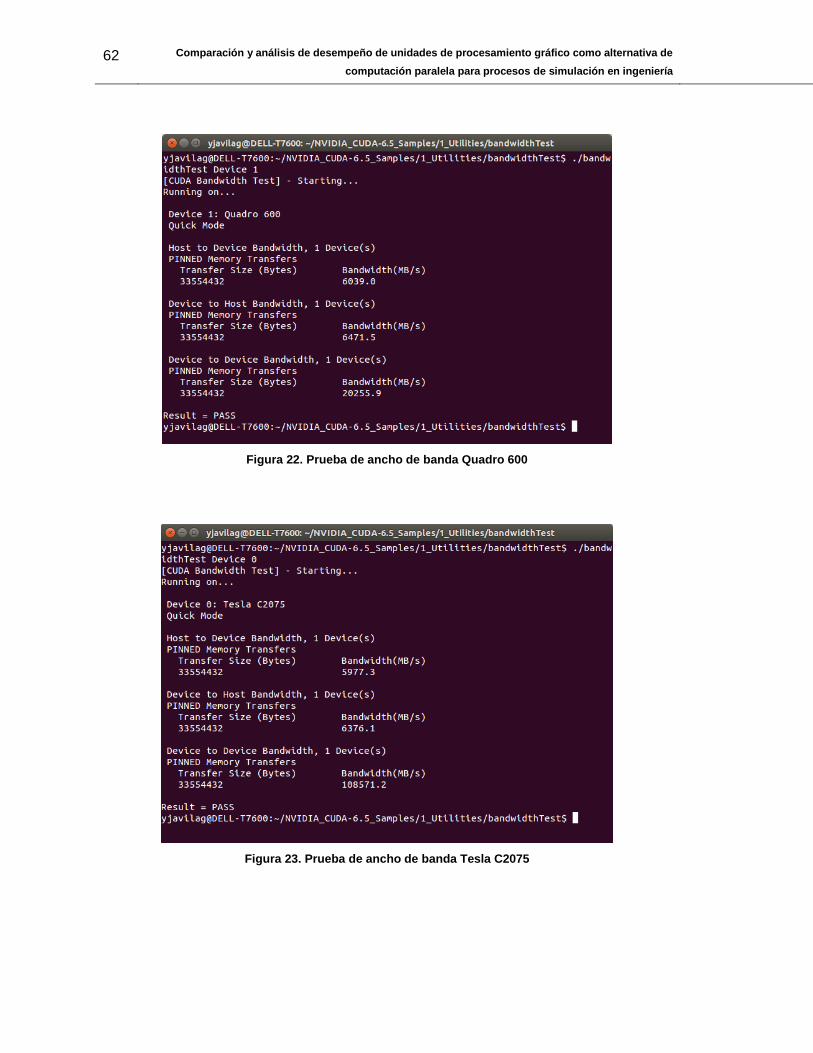
62 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Figura 22. Prueba de ancho de banda Quadro 600
Figura 23. Prueba de ancho de banda Tesla C2075

Capítulo 3 63
GPU Ancho de banda Host – to –
Device (H-T-D) [GB/s]
Ancho de banda
Device – to – Host
(D-T-H) [GB/s]
Ancho de banda Device – to –
Device (D-T-D) [GB/s]
GeForce GT
520M 6,20947266 6,2314453 11,161719
Quadro 600 5,89746094 6,3198242 19,781152
Tesla C2075 5,83720703 6,2266602 106,02656
Tabla 13. Pruebas bandwithTest
Figura 24 Prueba de ancho de banda
En la Figura 24 se observa que los anchos de banda de la comunicación desde la unidad
de procesamiento gráfico (Device) hacia el equipo de cómputo (Host) y desde el equipo
de cómputo (Host) hacia la unidad de procesamiento gráfico (Device) son similares para
las tres GPU. Esto debido a que los puertos de comunicación PCI-e de las tres memorias
desde y hacia el equipo de cómputo son de iguales características. Este bajo ancho de
banda muestra que la comunicación entre Device y Host es un limitante a la hora de
poder tener ejecuciones rápidas en sistemas heterogéneos.
Sin embargo en los resultados obtenidos para los accesos a datos en memoria de la
GPU desde ella misma se tiene que el ancho de banda de la GPU Tesla C2075 es
0
20
40
60
80
100
120
H-T-D D-T-H D-T-D
An
cho
de
Ban
da
[GB
/s]
Prueba de anchos de banda bandwidthTest
GeForce GT 520M Quadro 600 Tesla C2075
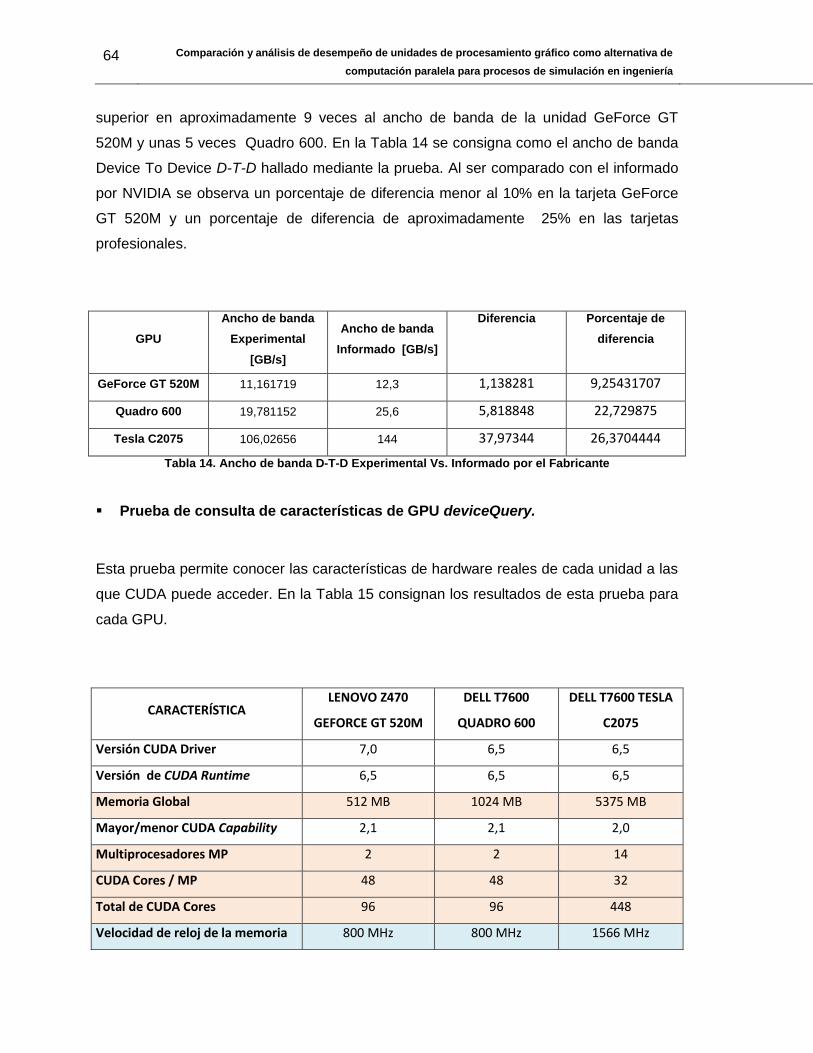
64 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
superior en aproximadamente 9 veces al ancho de banda de la unidad GeForce GT
520M y unas 5 veces Quadro 600. En la Tabla 14 se consigna como el ancho de banda
Device To Device D-T-D hallado mediante la prueba. Al ser comparado con el informado
por NVIDIA se observa un porcentaje de diferencia menor al 10% en la tarjeta GeForce
GT 520M y un porcentaje de diferencia de aproximadamente 25% en las tarjetas
profesionales.
GPU
Ancho de banda
Experimental
[GB/s]
Ancho de banda
Informado [GB/s]
Diferencia Porcentaje de
diferencia
GeForce GT 520M 11,161719 12,3 1,138281 9,25431707
Quadro 600 19,781152 25,6 5,818848 22,729875
Tesla C2075 106,02656 144 37,97344 26,3704444
Tabla 14. Ancho de banda D-T-D Experimental Vs. Informado por el Fabricante
Prueba de consulta de características de GPU deviceQuery.
Esta prueba permite conocer las características de hardware reales de cada unidad a las
que CUDA puede acceder. En la Tabla 15 consignan los resultados de esta prueba para
cada GPU.
CARACTERÍSTICA LENOVO Z470
GEFORCE GT 520M
DELL T7600
QUADRO 600
DELL T7600 TESLA
C2075
Versión CUDA Driver 7,0 6,5 6,5
Versión de CUDA Runtime 6,5 6,5 6,5
Memoria Global 512 MB 1024 MB 5375 MB
Mayor/menor CUDA Capability 2,1 2,1 2,0
Multiprocesadores MP 2 2 14
CUDA Cores / MP 48 48 32
Total de CUDA Cores 96 96 448
Velocidad de reloj de la memoria 800 MHz 800 MHz 1566 MHz
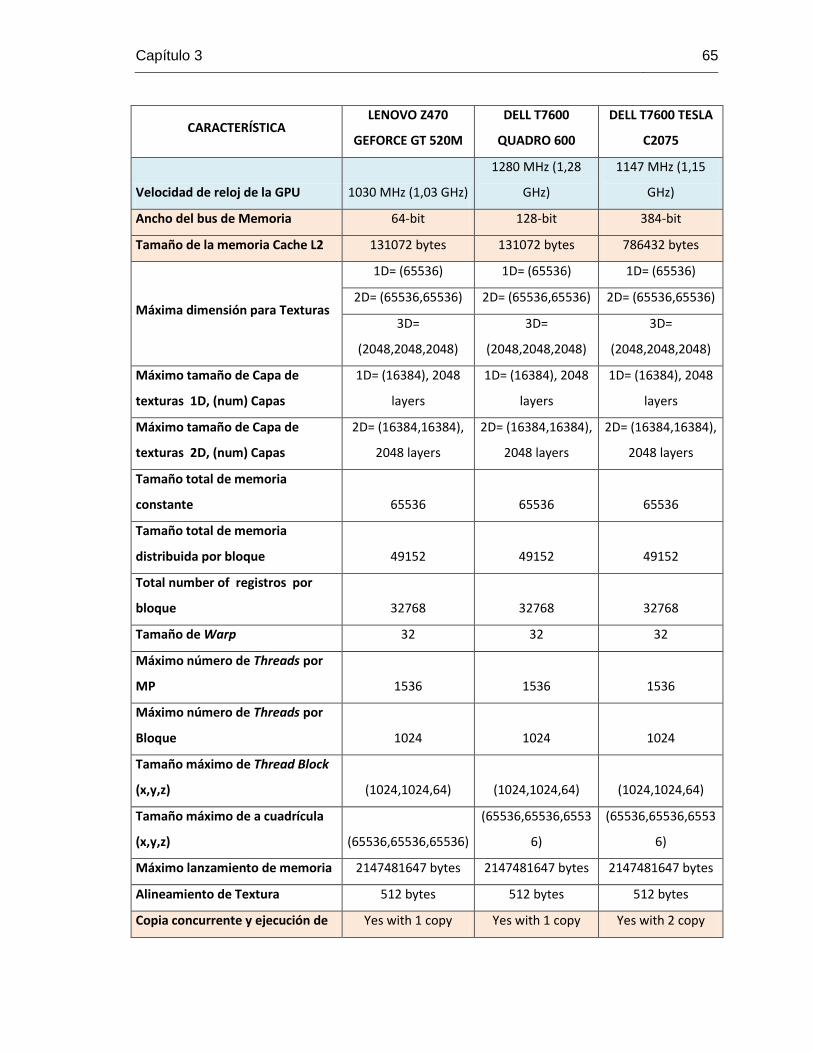
Capítulo 3 65
CARACTERÍSTICA LENOVO Z470
GEFORCE GT 520M
DELL T7600
QUADRO 600
DELL T7600 TESLA
C2075
Velocidad de reloj de la GPU 1030 MHz (1,03 GHz)
1280 MHz (1,28
GHz)
1147 MHz (1,15
GHz)
Ancho del bus de Memoria 64-bit 128-bit 384-bit
Tamaño de la memoria Cache L2 131072 bytes 131072 bytes 786432 bytes
Máxima dimensión para Texturas
1D= (65536) 1D= (65536) 1D= (65536)
2D= (65536,65536) 2D= (65536,65536) 2D= (65536,65536)
3D=
(2048,2048,2048)
3D=
(2048,2048,2048)
3D=
(2048,2048,2048)
Máximo tamaño de Capa de
texturas 1D, (num) Capas
1D= (16384), 2048
layers
1D= (16384), 2048
layers
1D= (16384), 2048
layers
Máximo tamaño de Capa de
texturas 2D, (num) Capas
2D= (16384,16384),
2048 layers
2D= (16384,16384),
2048 layers
2D= (16384,16384),
2048 layers
Tamaño total de memoria
constante 65536 65536 65536
Tamaño total de memoria
distribuida por bloque 49152 49152 49152
Total number of registros por
bloque 32768 32768 32768
Tamaño de Warp 32 32 32
Máximo número de Threads por
MP 1536 1536 1536
Máximo número de Threads por
Bloque 1024 1024 1024
Tamaño máximo de Thread Block
(x,y,z) (1024,1024,64) (1024,1024,64) (1024,1024,64)
Tamaño máximo de a cuadrícula
(x,y,z) (65536,65536,65536)
(65536,65536,6553
6)
(65536,65536,6553
6)
Máximo lanzamiento de memoria 2147481647 bytes 2147481647 bytes 2147481647 bytes
Alineamiento de Textura 512 bytes 512 bytes 512 bytes
Copia concurrente y ejecución de Yes with 1 copy Yes with 1 copy Yes with 2 copy
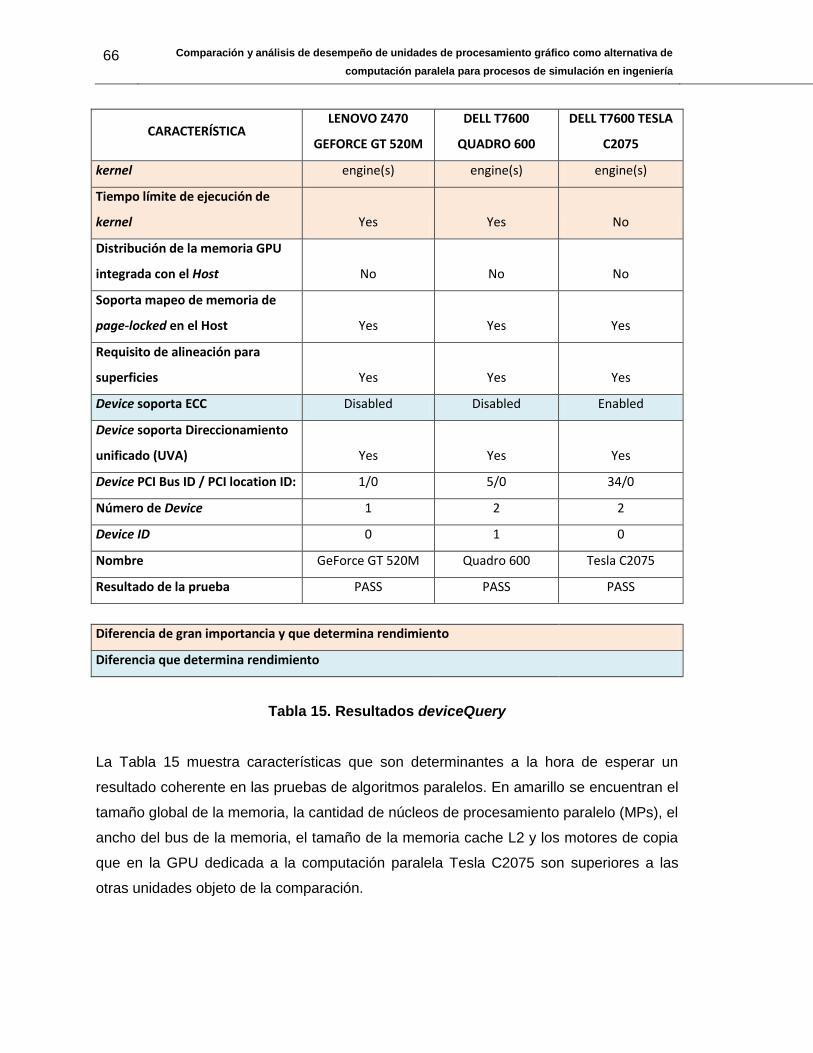
66 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
CARACTERÍSTICA LENOVO Z470
GEFORCE GT 520M
DELL T7600
QUADRO 600
DELL T7600 TESLA
C2075
kernel engine(s) engine(s) engine(s)
Tiempo límite de ejecución de
kernel Yes Yes No
Distribución de la memoria GPU
integrada con el Host No No No
Soporta mapeo de memoria de
page-locked en el Host Yes Yes Yes
Requisito de alineación para
superficies Yes Yes Yes
Device soporta ECC Disabled Disabled Enabled
Device soporta Direccionamiento
unificado (UVA) Yes Yes Yes
Device PCI Bus ID / PCI location ID: 1/0 5/0 34/0
Número de Device 1 2 2
Device ID 0 1 0
Nombre GeForce GT 520M Quadro 600 Tesla C2075
Resultado de la prueba PASS PASS PASS
Diferencia de gran importancia y que determina rendimiento
Diferencia que determina rendimiento
Tabla 15. Resultados deviceQuery
La Tabla 15 muestra características que son determinantes a la hora de esperar un
resultado coherente en las pruebas de algoritmos paralelos. En amarillo se encuentran el
tamaño global de la memoria, la cantidad de núcleos de procesamiento paralelo (MPs), el
ancho del bus de la memoria, el tamaño de la memoria cache L2 y los motores de copia
que en la GPU dedicada a la computación paralela Tesla C2075 son superiores a las
otras unidades objeto de la comparación.

Capítulo 3 67
Se seleccionan en color rojo claro los resultados de mayor relevancia a la hora de
comparar el hardware. El dispositivo con mejores capacidades es la GPU Tesla C2075
que tiene aproximadamente 4.6 veces mayor cantidad de procesadores CUDA que las
otras dos tarjetas objeto de la comparación y aproximadamente 5 veces mayor memoria
DRAM que la tarjeta Quadro 600 y 10 veces más que la GeForce GT 520M.
Estas características determinan el volumen de datos a operar y la velocidad de
operación sobre estos. Las características en azul determinan en gran medida la
cantidad de datos operados y resultados obtenidos en unidad de tiempo (Througput) y la
calidad de los datos ya que las unidades GeForce GT 520M y Quadro 600 no cuentan
con porción dedicada de la memoria de GPU para corrección de errores en los datos
operados ECC.
Por ende es de esperarse resultados superiores en la GPU creada para computación
paralela que en las dedicadas a juegos, video y audio.


Capítulo 4 69
4. Desempeño con Benchmark SHOC
Un Benchmark es una técnica que consta de una serie de pruebas diseñadas para
probar de manera consistente el rendimiento de un sistema o un componente del mismo.
Para probar realmente las capacidades de las GPUs instaladas se usa el Benchmark
denominado SHOC: Scalable HeterOgeneous Computing Benchmark Suit que es una
colección de programas que permiten ejecutarse en sistemas con posibilidad de
computación heterogénea, es decir, principalmente con GPUs y Multicores. Este
Benchmark fue seleccionado porque permite realizar pruebas en los estándares de
programación paralelos CUDA y OpenCL en diversas configuraciones de hardware
(incluidos clusters).
En cuanto a sistemas operativos Linux y Mac OS son soportados pero Windows está en
estado experimental. Además la versión 1.1.5 es de Noviembre año 2012 al igual que
las GPU seleccionadas [32]. En la Tabla 16 se muestran las pruebas presentes en
SHOC de nivel 0, es decir de acceso sencillo a las características de GPU. En la Tabla
17 las pruebas de nivel 1 o de aplicación y en la Tabla 18 las pruebas de nivel 2,
aplicaciones de alto desempeño.
Nivel 0:
comportamiento a
bajo nivel
BusSpeedDownload
Mide la velocidad (bandwidth) de
transferencia de datos a través del bus
PCIe al device
BusSpeedReadback
Mide la velocidad (bandwidth) de lectura
de datos desde el dispositivo después de
operados.
DeviceMemory
Mide la velocidad (bandwidth) de acceso
a la memoria en varios tipos de
memorias: Memoria global, Memoria local
y Memoria de imagen

70 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Nivel 0:
comportamiento a
bajo nivel
KernelCompile:
Mide el tiempo de ejecución de diferentes
kernels OpenCL con diferentes
complejidades.
MaxFlops
Mide el máximo número alcanzable de
operaciones de punto flotante usando una
combinación de kernels autogenerados y
programados manualmente.
QueueDelay Mide la sobrecarga del uso de la cola de
comandos OpenCL.
S3D
Un kernel computacionalmente intensive
del programa S3D de simulación de
combustion turbulenta.
Tabla 16. Pruebas presentes en SHOC Nivel 0

Capítulo 4 71
Nivel 1:
Desempeño en alto
nivel en
operaciones
BFS
Una búsqueda breadth-first que es una búsqueda
gráfica tipo árbol. Necesita ser ejecutado en un
dispositvo que soporte operaciones atomicas (CUDA
CAPABLE > 1.2)
FFT Transformada de Fourier 1D FFT
MD Cálculo del potencial de Lennard-Jones de dinámica
molecular
MD5Hash
Cálculo de muchos pequeños mensajes MD5-digests
(usados en criptografía), altamente dependientes de
operaciones bit a bit (bitwise).
Reduction Operaciones de reducción en un arreglo de datos de
punto flotante de precisión doble o sencilla.
SGEMM Multiplicación de matrices
Scan
Operación Scan, (conocida como suma acumulada)
en un arreglo de datos de punto flotante de precisión
doble o sencilla.
Sort Ordena un arreglo de parejas de datos key-value
usando el algoritmo Radix-sort
Spmv Multiplicación de matriz dispersa - vector
Stencil2D
Operación stencil de 9 puntos aplicada a un arreglo
de datos 2D. En la versión MPI los datos están
distribuidos a través de un proceso MPI organizad en
una topología cartesiana 2D. con intercambios
periódicos circulares.
Triad
Una versión del benchmark STREAM Triad,
implementado en OpenCL y CUDA. Esta versión
incluye el tiempo de transferencia en el bus PCIe.
Tabla 17. Pruebas presentes en SHOC Nivel 1

72 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Nivel 2: Comportamiento en
aplicaciones reales (real
kernels)
QTC Quality Threshold Clustering (Algoritmo de
agrupamiento)
S3D Un kernel computacionalmente intensive del
programa S3D de simulación de combustion
turbulenta.
Tabla 18. Pruebas presentes en SHOC Nivel 2
Se seleccionaron las pruebas que se muestran en la Tabla 19 y Tabla 20 ya que por sus
características permiten observar el desempeño de las tres tarjetas GPU y realizar una
comparación.

Capítulo 4 73
Operación Métrica
NVIDIA
GeForce
GT 520M
NVIDIA
Quadro
600
NVIDIA
Tesla
C2075
Unidad
Velocidad de Bus en descarga: bspeed_download
Velocidad de Bus en descarga: mide el
ancho de banda al transferir datos a
través del Bus PCIe a la GPU (Host-to-
Device)
6,545 6,1318 6,1477 GB/s
Velocidad de Bus en lectura de vuelta: bspeed_readback
Velocidad de Bus en lectura de vuelta:
mide el ancho de banda al leer datos de
vuelta a la CPU (Device-to-Host)
6,5466 6,6437 6,5943 GB/s
Ancho de banda en Memoría de
dispositivo: mide el ancho de banda del
acceso a los diferentes tipos de memorias de
la GPU (incluye memoria global, local y
memoria de imagen)
gmem_readbw Ancho de banda (velocidad) de lectura
de la memoria global 11,61 20,0177 89,6322 GB/s
gmem_readbw_strided
Ancho de banda (velocidad) de lectura
de la memoria global en intervalos
constantes “stride lenght”
1,4446 1,7703 10,2688 GB/s
gmem_writebw Ancho de banda (velocidad) de escritura
en la memoria global 11,3076 19,9737 104,005 GB/s
gmem_writebw_strided
Ancho de banda (velocidad) de escritura
en la memoria global en intervalos
constantes “stride lenght”
0,6957 1,0814 4,055 GB/s
lmem_readbw Ancho de banda (velocidad) de lectura
de la memoria local. 74,3328 92,6809 369,697 GB/s
lmem_writebw Ancho de banda (velocidad) de escritura
en la memoria local. 87,1603 108,625 444,865 GB/s
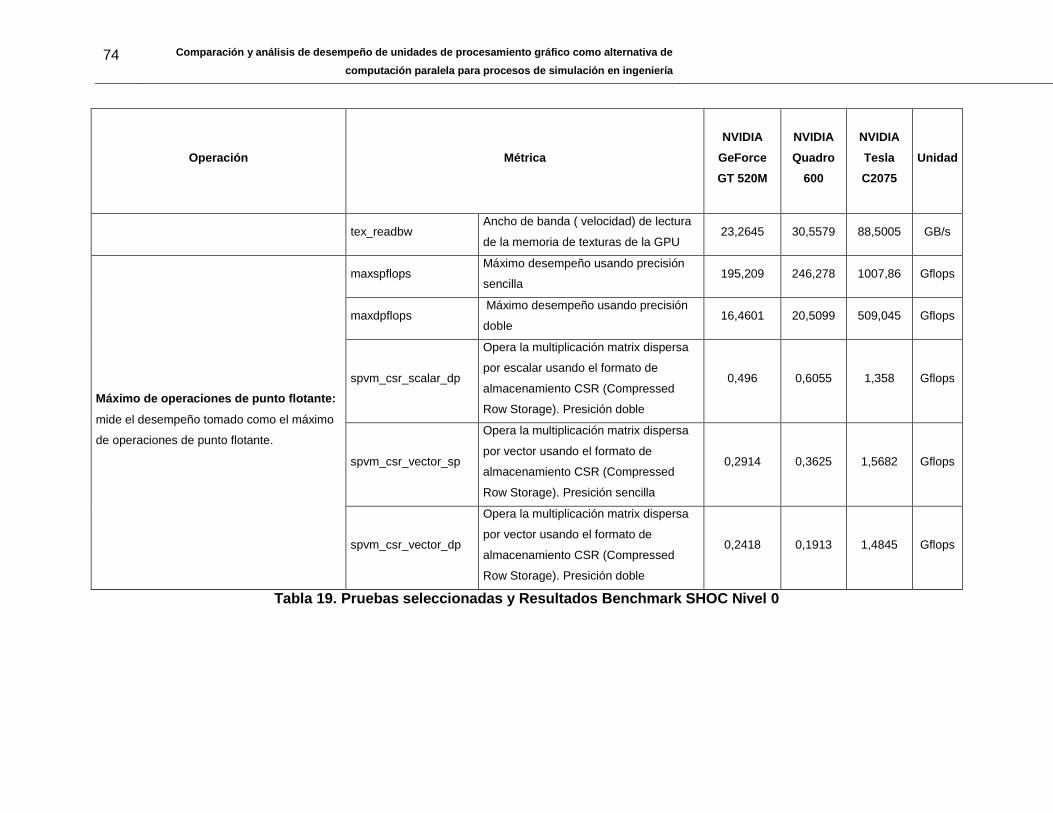
74 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Operación Métrica
NVIDIA
GeForce
GT 520M
NVIDIA
Quadro
600
NVIDIA
Tesla
C2075
Unidad
tex_readbw Ancho de banda ( velocidad) de lectura
de la memoria de texturas de la GPU 23,2645 30,5579 88,5005 GB/s
Máximo de operaciones de punto flotante:
mide el desempeño tomado como el máximo
de operaciones de punto flotante.
maxspflops Máximo desempeño usando precisión
sencilla 195,209 246,278 1007,86 Gflops
maxdpflops Máximo desempeño usando precisión
doble 16,4601 20,5099 509,045 Gflops
spvm_csr_scalar_dp
Opera la multiplicación matrix dispersa
por escalar usando el formato de
almacenamiento CSR (Compressed
Row Storage). Presición doble
0,496 0,6055 1,358 Gflops
spvm_csr_vector_sp
Opera la multiplicación matrix dispersa
por vector usando el formato de
almacenamiento CSR (Compressed
Row Storage). Presición sencilla
0,2914 0,3625 1,5682 Gflops
spvm_csr_vector_dp
Opera la multiplicación matrix dispersa
por vector usando el formato de
almacenamiento CSR (Compressed
Row Storage). Presición doble
0,2418 0,1913 1,4845 Gflops
Tabla 19. Pruebas seleccionadas y Resultados Benchmark SHOC Nivel 0
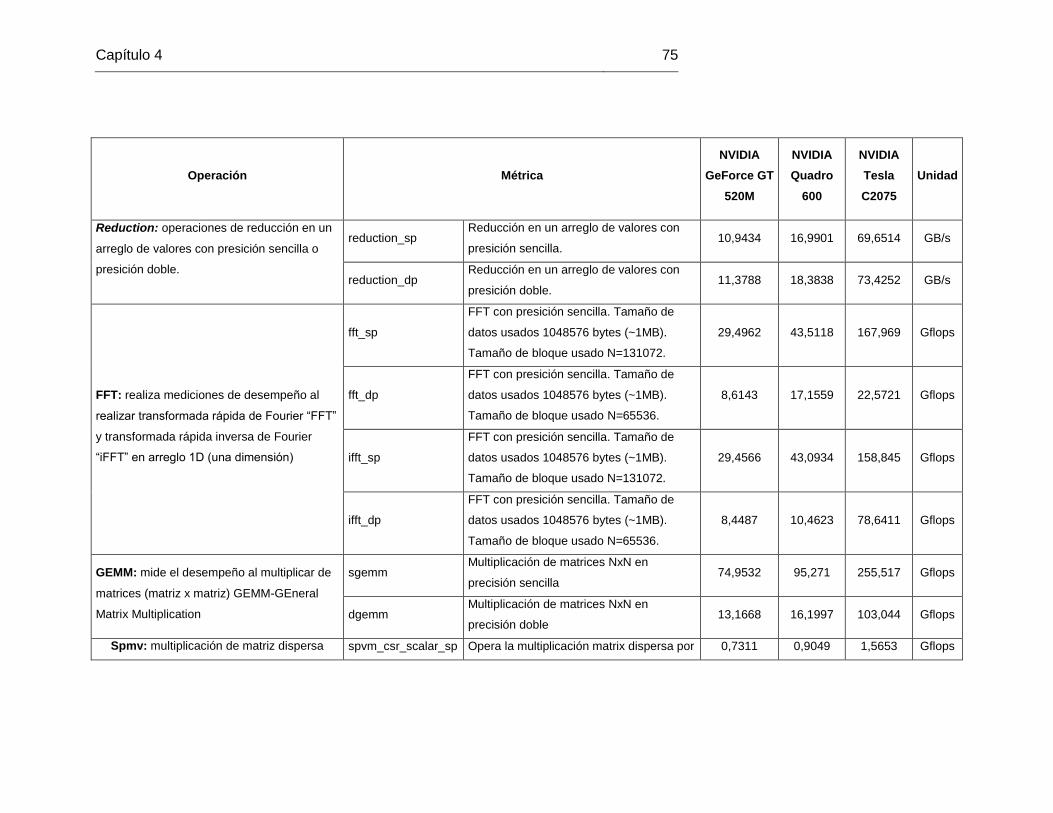
Capítulo 4 75
Operación Métrica
NVIDIA
GeForce GT
520M
NVIDIA
Quadro
600
NVIDIA
Tesla
C2075
Unidad
Reduction: operaciones de reducción en un
arreglo de valores con presición sencilla o
presición doble.
reduction_sp Reducción en un arreglo de valores con
presición sencilla. 10,9434 16,9901 69,6514 GB/s
reduction_dp Reducción en un arreglo de valores con
presición doble. 11,3788 18,3838 73,4252 GB/s
FFT: realiza mediciones de desempeño al
realizar transformada rápida de Fourier “FFT”
y transformada rápida inversa de Fourier
“iFFT” en arreglo 1D (una dimensión)
fft_sp
FFT con presición sencilla. Tamaño de
datos usados 1048576 bytes (~1MB).
Tamaño de bloque usado N=131072.
29,4962 43,5118 167,969 Gflops
fft_dp
FFT con presición sencilla. Tamaño de
datos usados 1048576 bytes (~1MB).
Tamaño de bloque usado N=65536.
8,6143 17,1559 22,5721 Gflops
ifft_sp
FFT con presición sencilla. Tamaño de
datos usados 1048576 bytes (~1MB).
Tamaño de bloque usado N=131072.
29,4566 43,0934 158,845 Gflops
ifft_dp
FFT con presición sencilla. Tamaño de
datos usados 1048576 bytes (~1MB).
Tamaño de bloque usado N=65536.
8,4487 10,4623 78,6411 Gflops
GEMM: mide el desempeño al multiplicar de
matrices (matriz x matriz) GEMM-GEneral
Matrix Multiplication
sgemm Multiplicación de matrices NxN en
precisión sencilla 74,9532 95,271 255,517 Gflops
dgemm Multiplicación de matrices NxN en
precisión doble 13,1668 16,1997 103,044 Gflops
Spmv: multiplicación de matriz dispersa spvm_csr_scalar_sp Opera la multiplicación matrix dispersa por 0,7311 0,9049 1,5653 Gflops

76 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Operación Métrica
NVIDIA
GeForce GT
520M
NVIDIA
Quadro
600
NVIDIA
Tesla
C2075
Unidad
escalar usando el formato de
almacenamiento CSR (Compressed Row
Storage). Presición sencilla
spvm_csr_scalar_dp
Opera la multiplicación matrix dispersa por
escalar usando el formato de
almacenamiento CSR (Compressed Row
Storage). Presición doble
0,496 0,6055 1,358 Gflops
spvm_csr_vector_sp
Opera la multiplicación matrix dispersa por
vector usando el formato de
almacenamiento CSR (Compressed Row
Storage). Presición sencilla
0,2914 0,3625 1,5682 Gflops
spvm_csr_vector_dp
Opera la multiplicación matrix dispersa por
vector usando el formato de
almacenamiento CSR (Compressed Row
Storage). Presición doble
0,2418 0,1913 1,4845 Gflops
Tabla 20. Pruebas seleccionadas y Resultados Benchmark SHOC Nivel 1

Capítulo 4 77
RESULTADOS BENCHMARK SHOC NIVEL 0
Las velocidades del bus de datos al transferir información desde y hacia la tarjeta se
muestran en la Figura 25, se observa que aunque en diferentes equipos y
configuraciones de hardware-software, las velocidades de transferencias son similares y
cercanos a 6.4 GB/s.
Figura 25. Velocidad de transferencia de datos a través del bus PCIe
Como se muestra en la Figura 26 las velocidades de lectura de memoria son mayores en
la lectura de memoria local que en la memoria global, siendo la mayor velocidad 369
GB/s entregada por la TESLA C2075.
5,8
5,9
6
6,1
6,2
6,3
6,4
6,5
6,6
6,7
bspeed_download bspeed_readback
Ve
loci
dad
de
tra
nsf
ere
nci
a [G
B/s
]
nVidia GeForce GT 520M nVidia Quadro 600
nVidia Tesla C2075
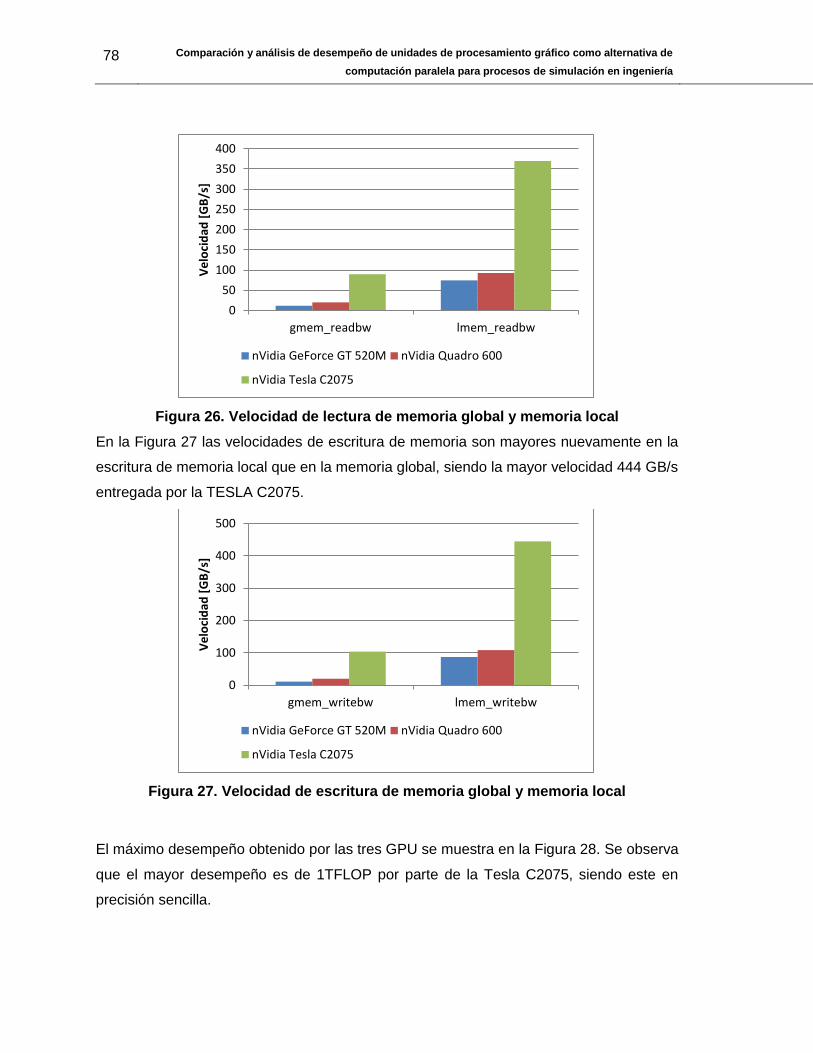
78 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Figura 26. Velocidad de lectura de memoria global y memoria local
En la Figura 27 las velocidades de escritura de memoria son mayores nuevamente en la
escritura de memoria local que en la memoria global, siendo la mayor velocidad 444 GB/s
entregada por la TESLA C2075.
Figura 27. Velocidad de escritura de memoria global y memoria local
El máximo desempeño obtenido por las tres GPU se muestra en la Figura 28. Se observa
que el mayor desempeño es de 1TFLOP por parte de la Tesla C2075, siendo este en
precisión sencilla.
0
50
100
150
200
250
300
350
400
gmem_readbw lmem_readbw
Ve
loci
dad
[G
B/s
]
nVidia GeForce GT 520M nVidia Quadro 600
nVidia Tesla C2075
0
100
200
300
400
500
gmem_writebw lmem_writebw
Ve
loci
dad
[G
B/s
]
nVidia GeForce GT 520M nVidia Quadro 600
nVidia Tesla C2075

Capítulo 4 79
Figura 28. Desempeño máximo GPU [GFLOPs]
RESULTADOS BENCHMARK SHOC NIVEL 1
En la Tabla 21, se plantea una comparación de los datos de rendimiento en GFLOPs de
cada función del Benchmark encontrando mediante una normalización que consiste en
tomar el dato obtenido en la prueba específica y compararlo con el máximo hallado
también experimentalmente.
Operación de
Benchmark SHOC
Nivel 1
Datos obtenidos
Porcentaje de desempeño obtenido
comparado con el desempeño
máximo
NVIDIA
GeForce GT
520M
NVIDIA
Quadro
600
NVIDIA
Tesla
C2075
NVIDIA
GeForce
GT 520M
NVIDIA
Quadro
600
NVIDIA
Tesla C2075
Resultado Resultado Resultado
maxspflops 195,209 246,278 1007,86 - - -
reduction_sp 10,9434 16,9901 69,6514 5,61% 6,90% 6,91%
fft_sp 29,4962 43,5118 167,969 15,11% 17,67% 16,67%
ifft_sp 29,4566 43,0934 158,845 15,09% 17,50% 15,76%
Sgemm 74,9532 95,271 255,517 38,40% 38,68% 25,35%
195,209 246,278
1007,86
16,4601 20,5099
509,045
0
200
400
600
800
1000
1200
nVidia GeForce GT520M
nVidia Quadro 600 nVidia Tesla C2075
De
sem
pe
ño
[G
FLO
Ps]
maxspflops maxdpflops
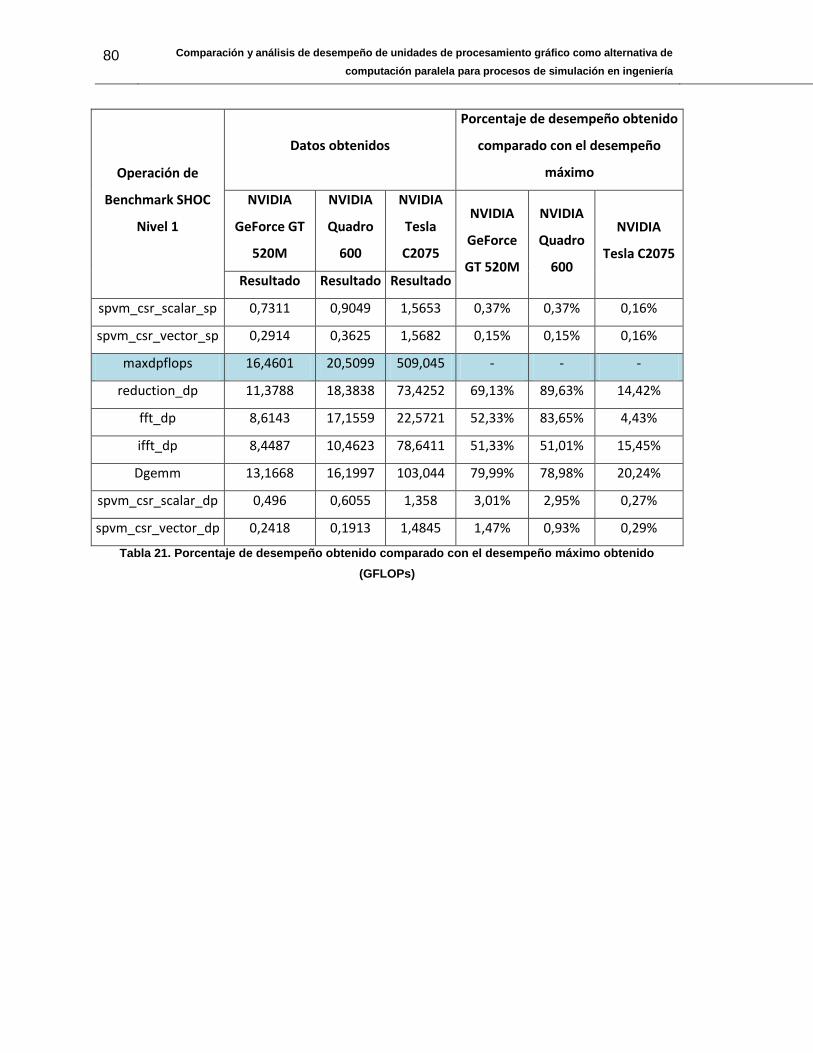
80 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Operación de
Benchmark SHOC
Nivel 1
Datos obtenidos
Porcentaje de desempeño obtenido
comparado con el desempeño
máximo
NVIDIA
GeForce GT
520M
NVIDIA
Quadro
600
NVIDIA
Tesla
C2075
NVIDIA
GeForce
GT 520M
NVIDIA
Quadro
600
NVIDIA
Tesla C2075
Resultado Resultado Resultado
spvm_csr_scalar_sp 0,7311 0,9049 1,5653 0,37% 0,37% 0,16%
spvm_csr_vector_sp 0,2914 0,3625 1,5682 0,15% 0,15% 0,16%
maxdpflops 16,4601 20,5099 509,045 - - -
reduction_dp 11,3788 18,3838 73,4252 69,13% 89,63% 14,42%
fft_dp 8,6143 17,1559 22,5721 52,33% 83,65% 4,43%
ifft_dp 8,4487 10,4623 78,6411 51,33% 51,01% 15,45%
Dgemm 13,1668 16,1997 103,044 79,99% 78,98% 20,24%
spvm_csr_scalar_dp 0,496 0,6055 1,358 3,01% 2,95% 0,27%
spvm_csr_vector_dp 0,2418 0,1913 1,4845 1,47% 0,93% 0,29%
Tabla 21. Porcentaje de desempeño obtenido comparado con el desempeño máximo obtenido
(GFLOPs)

Capítulo 4 81
Figura 29. Porcentaje de desempeño Pruebas Benchmark SHOC Nivel 1 - Precisión Sencilla
5,61%
15,11% 15,09%
38,40%
0,37% 0,15%
6,90%
17,67% 17,50%
38,68%
0,37% 0,15%
6,91%
16,67% 15,76%
25,35%
0,16% 0,16% 0,00%
5,00%
10,00%
15,00%
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
reduction_sp fft_sp ifft_sp sgemm spvm_csr_scalar_sp spvm_csr_vector_sp
Títu
lo d
el e
je
Pruebas Benchmark SHOC Nivel 1
Porcentaje de desempeño obtenido Vs. desempeño máximo (SP)
nVidia GeForce GT 520M nVidia Quadro 600 nVidia Tesla C2075
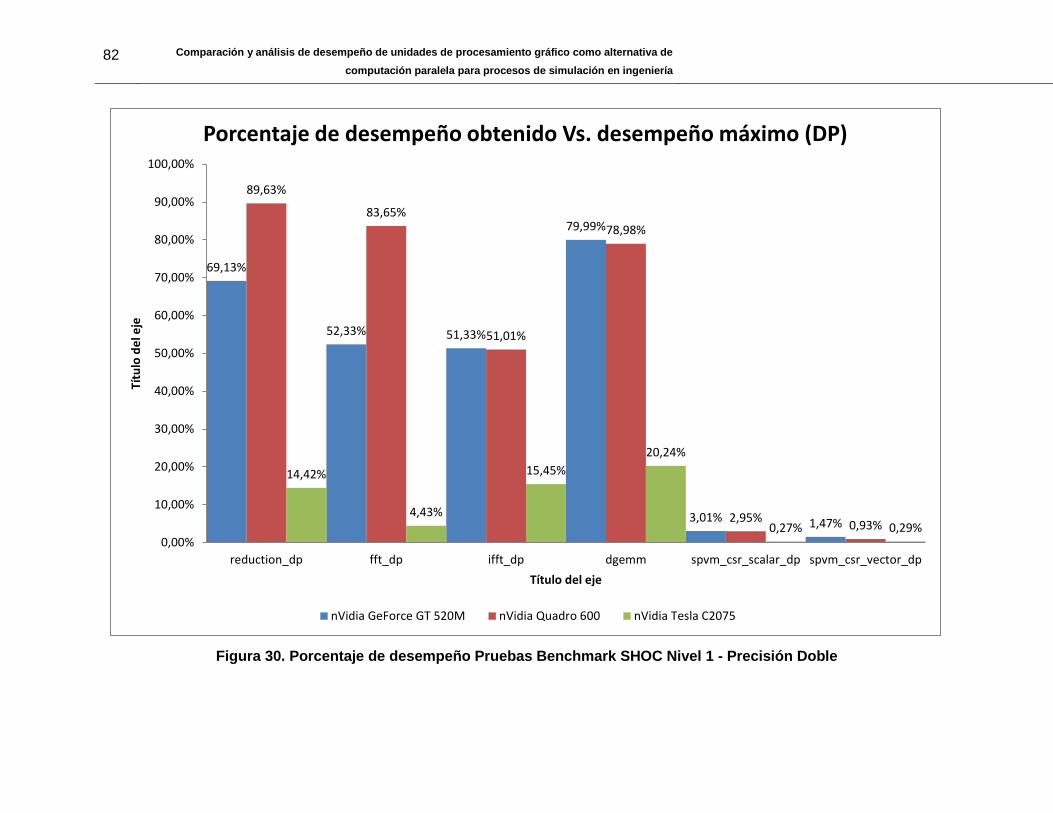
82 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Figura 30. Porcentaje de desempeño Pruebas Benchmark SHOC Nivel 1 - Precisión Doble
69,13%
52,33% 51,33%
79,99%
3,01% 1,47%
89,63%
83,65%
51,01%
78,98%
2,95% 0,93%
14,42%
4,43%
15,45%
20,24%
0,27% 0,29% 0,00%
10,00%
20,00%
30,00%
40,00%
50,00%
60,00%
70,00%
80,00%
90,00%
100,00%
reduction_dp fft_dp ifft_dp dgemm spvm_csr_scalar_dp spvm_csr_vector_dp
Títu
lo d
el e
je
Título del eje
Porcentaje de desempeño obtenido Vs. desempeño máximo (DP)
nVidia GeForce GT 520M nVidia Quadro 600 nVidia Tesla C2075

Capítulo 5 83
5. Ejemplo de implementación de
computación paralela en un proceso de
diseño digital.
Los resultados obtenidos en las pruebas realizadas a las unidades de procesamiento
gráfico mediante el benchmark SHOC son suficientes para determinar que:
Las tres unidades funcionan adecuadamente para procesamiento paralelo gracias
a la facilidad que presenta el uso del conjunto de herramientas de programación y
compilación CUDA toolkit.
Aunque se obtienen grandes desempeños con la GPU Tesla C2075 es posible
usar cualquier tarjeta y obtener resultados de calidad sea CUDA Capable.
El acceso a la computación de alto desempeño, con buenos resultados, es
posible en un nivel de costo moderado al usar unidades de procesamiento gráfico
de entretenimiento como es el caso de la GeForce.
El cuello de botella en el procesamiento con GPUs está presente en los tres
dispositivos analizados en las comunicaciones host-to-device y device-to-host
debido a las comunicaciones por PCIe. Es necesario disminuir las copias de datos
y aprovechar las comunicaciones device-to-device para obtener resultados con
mayor rapidez.
Teniendo en cuenta estos resultados resta probar como caso de estudio y ejemplo la
inclusión de la computación paralela en un proceso real de simulación en ingeniería. El
caso de estudio seleccionado y el cual se plantea a manera de ejemplo en este capítulo
es la Verificación funcional de hardware por simulación. Esta tarea es de suma
importancia a la hora de probar un diseño de hardware de manera previa a su fabricación
ya sea como sistema embebido o como hardware dedicado o SoC.
Se elige este proceso debido está presente en procesos industriales de diseño de
circuitos digitales e idealmente se lleva a cabo de manera automática. Aunque en este
trabajo no se realiza una comparación directa con herramientas comerciales o
profesionales de verificación funcional de hardware, se diseña un ambiente de

84 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
verificación haciendo uso de herramientas de software libres en conjunto con las
herramientas CUDA. Se diseñan varios escenarios con combinaciones de software serial
y paralelo obteniendo mejores resultados cuando existe parte del proceso paralelizado
mediante los kernels que se ejecutan en una GPU.

Capítulo 5 85
5.1 Verificación funcional de hardware por simulación
El proceso de Verificación Funcional de Hardware por simulación es una de las etapas
del diseño digital con la que se determina si el funcionamiento de un sistema digital está
libre de errores, es decir, que es correcto y cumple con la función para la cual fue
diseñado. Sin embargo no determina si el sistema tiene, por ejemplo, bajo consumo
eléctrico o si su batería tiene la duración adecuada. Se recalca entonces el hecho de
tener una simulación funcional.
Comprobar que un sistema es correcto antes de la producción de los primeros prototipos
permite reducir costos de producción evitando tener prototipos no funcionales o
parcialmente funcionales, es decir, con errores y que posiblemente fallen en un futuro.
En el proceso de verificación funcional de hardware por simulación se busca comprobar
la veracidad mediante la aplicación de estímulos y el monitoreo de la respuesta por parte
del hardware a verificar generalmente en nivel RTL7 de abstracción y escrito en lenguaje
de descripción de hardware o HDL. Los estímulos mencionados se aplican de manera
simultánea a un modelo funcional del sistema escrito en un lenguaje de alto nivel de
abstracción como C++, SystemC, Matlab, etre otros. [54], [55].
En la Figura 31 se plantea un entorno o ambiente de verificación que incluye:
1. Dispositivo bajo verificación (DUV – Device Under Test): es una descripción del
sistema que está hecha en un lenguaje de descripción de Hardware, debe ser
simulable y sintetizable.
2. Golden Model: modelo de referencia que está escrito en un lenguaje de
programación de mayor abstracción y del cual se sabe que es completo y correcto
7 Register Transfer Level

86 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
3. Generador de Estímulos: Serie de datos de entrada que se aplica a los puertos de
entrada tanto al Golden Model (GM) como al Dispositivo bajo verificación (DUV)..
4. Driver: Traduce los estímulos de datos a tipo de entrada requerida por el DUV.
5. Monitor: Traduce la salida del DUV a datos de tipo manejable por el Comparador.
6. Comparador: Comprueba la igualdad de las salidas del DUV con la referencia, es
decir, con las salidas del GM. Si las dos salidas son iguales se habla de un DUV
correcto a nivel funcional.
Figura 31. Ambiente de verificación funcional

Capítulo 5 87
5.2 Verificación funcional de hardware usando CUDA C
En este desarrollo se plantea un ambiente de verificación funcional que permita usar la
computación de propósito general GPGPU para verificar un módulo escrito en Verilog. En
la Figura 31 se muestra un ambiente de verificación genérico y en la Figura 32 el
ambiente desarrollado usando CUDA C.
Figura 32. Ambiente de Verificación usando CUDA
1. Generador de estímulos: Escrito en c++ stimuligen.cpp; permite generar dos
vectores de datos aleatorios de tamaño N, a [N] y b [N]. Almacena los datos
obtenidos en el archivo de texto stimuli.txt, a fin de poder leerlos de manera
adecuada desde el módulo de hardware bajo verificación. Se realiza de este
modo ya que CUDA no tiene descripción de hardware que permita usar puertos
de conexión directamente. Se generan datos aleatorios de tipo entero desde 0 a
255 ya que es el valor máximo que puede sumar el módulo en verilog por tener
restricción de 8 bits en sus vectores de entrada.
2. DUV: este módulo es un sumador con carry de dos vectores de 8 bits y salida de
8 bits (fulladder). El módulo adder_8bit.v está escrito en Verilog a nivel de
compuertas lógicas.

88 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
3. Driver: se encuentran en adder_8bit_tb su función es traducir los datos de
entrada presentes en stimuli.txt y guardarlos en registros para asignarlos a los
puertos de entrada del módulo sumador.
4. Monitor: al igual que el driver se encuentra en adder_8bit_tb su función es
traducir la salida almacenada en registros a datos y guardarlos en un archivo de
texto llamado output_adderVerilog.txt
5. Golden Model y Comparador: por facilidades de programación e integración con
el ambiente desarrollado, se plantean estos dos módulos en un único archivo
escrito en lenguaje CUDA C add_comp_gm.cu y teniendo las siguientes seis
funciones principales:
a. Leer y almacenar los datos de entrada generados.
b. Leer la salida del módulo de hardware HDL.
c. Realizar las funciones de Golden Model escrito en lenguaje C++
tradicional.
d. Realizar las funciones de Golden Model escrito en lenguaje CUDA.
e. Comparar la salida del módulo de hardware con la salida del GM en c++
f. Comparar la salida del módulo de hardware con la salida del GM en CUDA
6. Valida mediante comparación de salidas si el módulo HDL funciona
correctamente. Envía mensaje de veracidad del HDL.
Todos los códigos usados se incluyen en la copia digital de este documento.

Capítulo 5 89
5.3 Ambiente de Verificación funcional de Hardware
usando CUDA C.
El proceso de verificación funcional se realiza aprovechando el entorno de terminal o
consola de Linux. En este desarrollo se usó Ubuntu 14.04 LTS para el caso del servidor
Dell T7600 y Ubuntu 12.04 LTS para el computador personal Lenovo Z470. En este
entorno se puede realizar un proceso de diseño digital de co-desarrollo de
software/hardware siempre y cuando se tengan las herramientas necesarias.
El ambiente de verificación planteado en este trabajo necesita de varias de esas
herramientas específicas y que permitirán compilar y ejecutar los diferentes módulos del
sistema. Las herramientas y su función se organizan en la Tabla 22. Herramientas de
software para ambiente de verificación usando CUDA C
Herramienta Versiones
Sistema Operativo DELL T7600: Linux Ubuntu 14.04 LTS
Lenovo Z470: Linux Ubuntu 12.04 LTS
Compilador CUDA C y
adicionales NVIDIA Cuda Toolkit
6.5
- nvcc
- NVIDIA Visual Profiler
- Nsight Eclipse Edition
Compilador C gcc
Compilador verilog Iverilog
Visualizador de archivos .vcd
(señales digitales) gtkwave
Entorno de ejecución principal Terminal Ubuntu
Editor de texto gedit
Tabla 22. Herramientas de software para ambiente de verificación usando CUDA C
El ambiente de verificación planteado permite realizar las siguientes verificaciones
funcionales al módulo de hardware adder_8bit.
1. Comparación de salidas del DUV y del modelo de referencia GM; en este caso
tanto el Golden Model como el Comparador están escritos como funciones de
C++ tradicional. La configuración se muestra en la Figura 33

90 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Figura 33. Verificación de DUV (Verilog) usando GoldenModel y Comparador en C++
2. Comparación de salidas del DUV y del modelo de referencia GM; en este caso el
Golden Model está escrito en CUDA C y el Comparador está escrito como función
de C++ tradicional. La configuración se muestra en la Figura 34
Figura 34. Verificación de DUV (Verilog) usando GoldenModel en CUDA C y Comparador en C++
3. Comparación de salidas del DUV y del modelo de referencia GM escrito en C++ ;
en este caso el Comparador está escrito en CUDA C. La configuración se
muestra en la Figura 35.
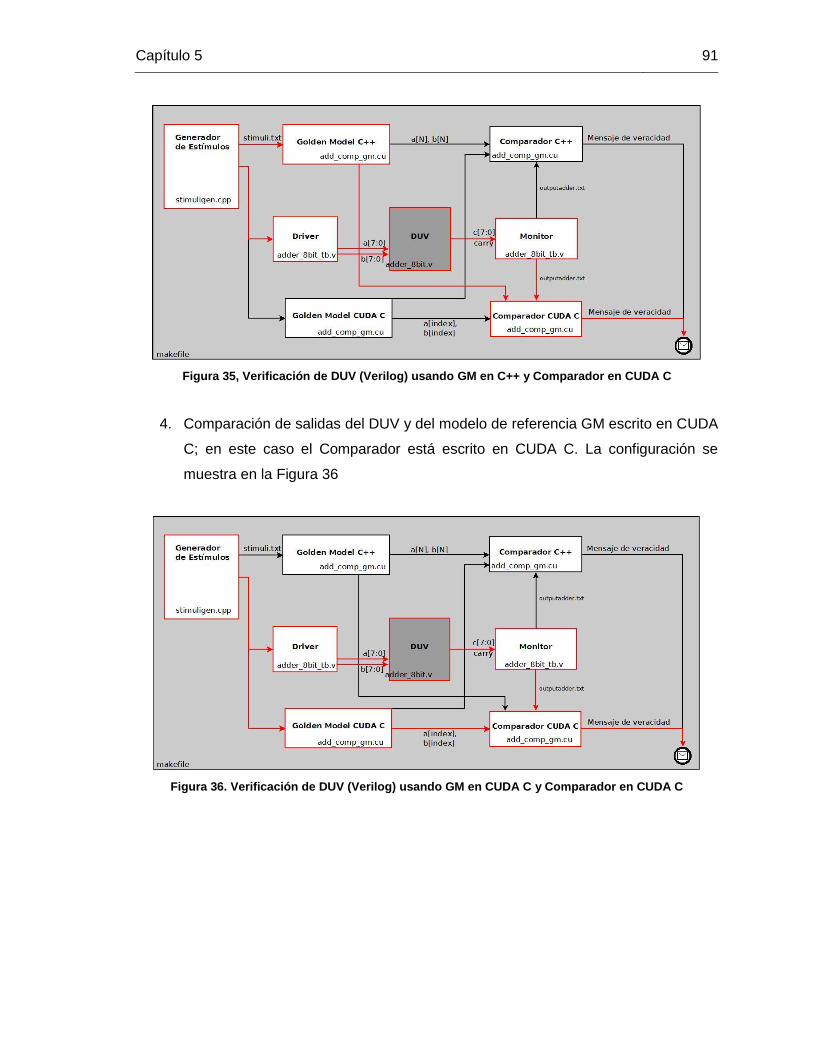
Capítulo 5 91
Figura 35, Verificación de DUV (Verilog) usando GM en C++ y Comparador en CUDA C
4. Comparación de salidas del DUV y del modelo de referencia GM escrito en CUDA
C; en este caso el Comparador está escrito en CUDA C. La configuración se
muestra en la Figura 36
Figura 36. Verificación de DUV (Verilog) usando GM en CUDA C y Comparador en CUDA C


Capítulo 5 93
5.4 Módulo Golden Model y Comparador CUDA:
add_comp_gm.cu
En esta sección se muestra cómo el módulo CUDA de la suma (función del sumador de 8
bits) y comparación (verificación automática) realiza los proceso de suma y comparación
de manera paralela permitiendo su inclusión en el proceso de verificación planteado.
Código completo en
1. Sumar dos vectores de manera simultánea: La suma de dos vectores
, con ( ) ( ) está dada por la siguiente
ecuación:
( )
Esta es una operación que conlleva realizar n sumas de elementos de vectores.
Computacionalmente se tienen 2*n operaciones de acceso a datos (a y b) y n
operaciones de escritura de datos (c). Operaciones que tradicionalmente se
realiza mediante un ciclo while o un ciclo for. El objetivo es aprovechar el
procesamiento paralelo de la GPU para realizar la operación de suma de manera
simultánea sobre cada una de las parejas y guardar su resultado en .
En la Figura 37. Kernel para sumar 2 vectores, se observa como la función
planteada para la suma de los vectores se simplifica a una línea de código donde
todos los valores de a y todos los de b se suman simultáneamente, y los
resultados se almacenan en c. La etiqueta __global__ indica que este código se
ejecutará en GPU.
Figura 37. Kernel para sumar 2 vectores

94 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
En la Figura 38. Llamado de kernel de suma de vectores en programa principal.
Se observa cómo se ejecuta, desde el programa principal, la función o kernel de
suma de vectores paralela.
Figura 38. Llamado de kernel de suma de vectores en programa principal.
En las Figura 37 y Figura 38 se muestran los trozos de código que permiten
ejecutar una operación como la suma de vectores en paralelo, sin embargo hay
secciones que deben ser explicadas como sigue:
A. En la Figura 37 se tienen los siguientes parámetros que permiten realizar la
suma de manera simultánea:
a. __global__ indica que la función se ejecuta en la GPU
b. Index es la posición del dato a operar el multiprocesador.
c. Index se calcula como threadIdx.x+blockIdx.x*blockDim.x; siendo el
primero threadIdx.x el índice o posición en la dimensión x del dato
dentro de un bloque. blockIdx.x el índice o posición en la dimensión x
del bloque y la variable blockDim.x es una variable build-in que permite
conocer el tamaño del bloque. Se puede ver en el siguiente ejemplo
visual (Figura 39) donde index=threadIdx.x+blockIdx.x*blockDim.x.
Se tiene que: index=5+2*8=5+16=21, si se cuenta desde la posición 0
hasta la posición azul se obtiene la casilla señalada.
Figura 39. Cálculo de índice tomando, indice de Thread e índice de bloque.
B. En la Figura 38 se llama al kernel add_gpu y se incluye los siguientes
parámetros entre triple bracket <<<N/THREADS_PER_BLOCK,
THREADS_PER_BLOCK>>>:

Capítulo 5 95
En este llamado se le indica a la GPU que se va realizar la operación
add_gpu() un número determinado de veces N/THREADS_PER_BLOCK
usando un número determinado de hilos de programa por bloque
THREADS_PER_BLOCK. En este caso se define N desde ele encabezado
del programa como N=(2048*2048) que es 4194304 y se define el número de
Threads por bloque a utilizar como 512. Con estos parámetros, la operación
add_gpu se realizaría 8192 veces usando 512 Threads por bloque.
En la Figura 40 cada SM se puede dividir en bloques y cada bloque se puede
dividir en Threads o hilos de programa (datos) que se ejecutarán
paralelamente dentro de cada bloque.
Figura 40. Blocks y Threads
C. En la Figura 38 en el kernel add_gpu se incluye los siguientes parámetros
entre paréntesis:
add_gpu<<<N/THREADS_PER_BLOCK, THREADS_PER_BLOCK>>>(dev_a, dev_b, dev_cgpu, N)
a. dev_a y dev_b son las copias de los vectores a y b que deben estar en la
memoria del dispositivo para poder ser operadas por la GPU
b. dev_c es el resultado de la suma en la GPU de todos los datos
simultáneamente. Copia guardada en el dispositivo, debe ser copiada al host
para poder ser usados los resultados.
c. N cantidad de datos máxima a operar para evitar sobrepasar los límites del
máximo lanzamiento de memoria en la GPU.

96 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
2. Comparación simultánea: para la comparación simultánea de vectores usando
GPU se usó la misma técnica descrita anteriormente pero usando la operación de
resta, esta operación permite obtener un valor 0 para cada comparación correcta
y un valor diferente de 0 para los errores. El código es similar al planteado en la
suma, sin embargo los parámetros de entrada a la función ya no son los vectores
a y b sino las salidas del GM y del RTL, osea dos vectores c que se desean
comparar.

Capítulo 5 97
5.5 Resultados experimentales en tiempos de ejecución
Para el proceso de verificación funcional, el generador de estímulos entrega un total de
4194304 datos tipo entero con valores aleatorios entre 0 y 255 ya que el módulo a
verificar está diseñado para realizar operaciones de enteros de 8 bits
(b’11111111’ =. d’255’).
El algoritmo reserva un total de memoria 100,67 MB en memoria RAM y de 100,67 MB
en memoria DRAM para almacenar los datos que usan en la CPU y en la GPU
respectivamente. El tiempo total de verificación es el tiempo de ejecución general del
ambiente de verificación incluyendo las posibles combinaciones entre modelos de
referencia y comparadores.
En la Tabla 23 y Tabla 24 se presentan los resultados experimentales de las pruebas de
desempeño al realizar un proceso real de verificación funcional de hardware por
simulación.
Resultados de Verificación Funcional Usando CUDA
Métrica Cantidad Unidad
Cantidad de memoria reservada para copia (RAM y DRAM) 100,663 [MB]
Tamaño de los vectores analizados 4194304 # datos
Métricas CPU y GPU Unidad Lenovo Z470 Dell T7600
GeForce GT 520 M Quadro 600 Tesla C2075
Tiempo total de proceso de verificación. [s] 112,807 94,823 85,726
Tiempo de verificación en CPU: GM y COMP en C++ [s] 1,3 1,270364 1,170364
Tiempo de verificación en GPU: GM en CUDA y
COMP en C++ [s] 0,05 0,030858 0,027014
Tiempo de verificación en CPU: GM en c++ y COMP
en CUDA [s] 0,05 0,034006 0,033651
Tiempo de verificación en GPU: GM en CUDA y
COMP en CUDA [s] 0,05 0,03486 0,031132
Tabla 23. Resultados Experimentales de Verificaciones Funcionales a adder_8bit.v
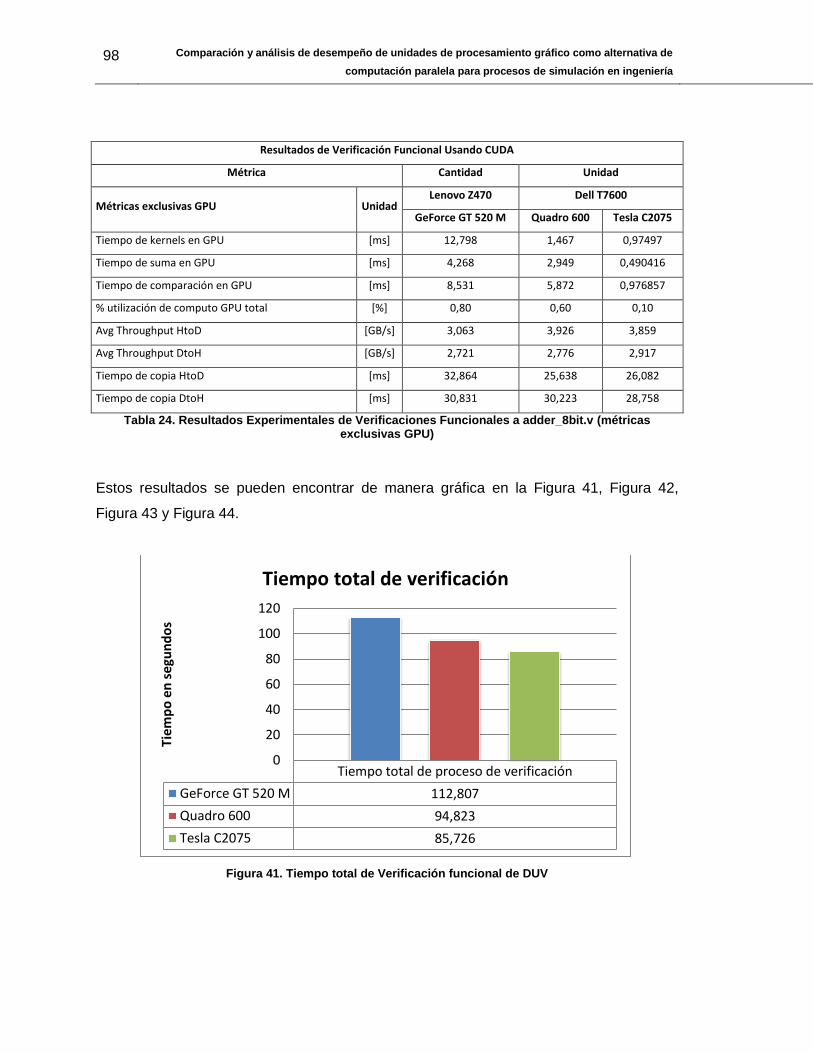
98 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Resultados de Verificación Funcional Usando CUDA
Métrica Cantidad Unidad
Métricas exclusivas GPU Unidad Lenovo Z470 Dell T7600
GeForce GT 520 M Quadro 600 Tesla C2075
Tiempo de kernels en GPU [ms] 12,798 1,467 0,97497
Tiempo de suma en GPU [ms] 4,268 2,949 0,490416
Tiempo de comparación en GPU [ms] 8,531 5,872 0,976857
% utilización de computo GPU total [%] 0,80 0,60 0,10
Avg Throughput HtoD [GB/s] 3,063 3,926 3,859
Avg Throughput DtoH [GB/s] 2,721 2,776 2,917
Tiempo de copia HtoD [ms] 32,864 25,638 26,082
Tiempo de copia DtoH [ms] 30,831 30,223 28,758
Tabla 24. Resultados Experimentales de Verificaciones Funcionales a adder_8bit.v (métricas exclusivas GPU)
Estos resultados se pueden encontrar de manera gráfica en la Figura 41, Figura 42,
Figura 43 y Figura 44.
Figura 41. Tiempo total de Verificación funcional de DUV
Tiempo total de proceso de verificación
GeForce GT 520 M 112,807
Quadro 600 94,823
Tesla C2075 85,726
0
20
40
60
80
100
120
Tiem
po
en
se
gun
do
s
Tiempo total de verificación
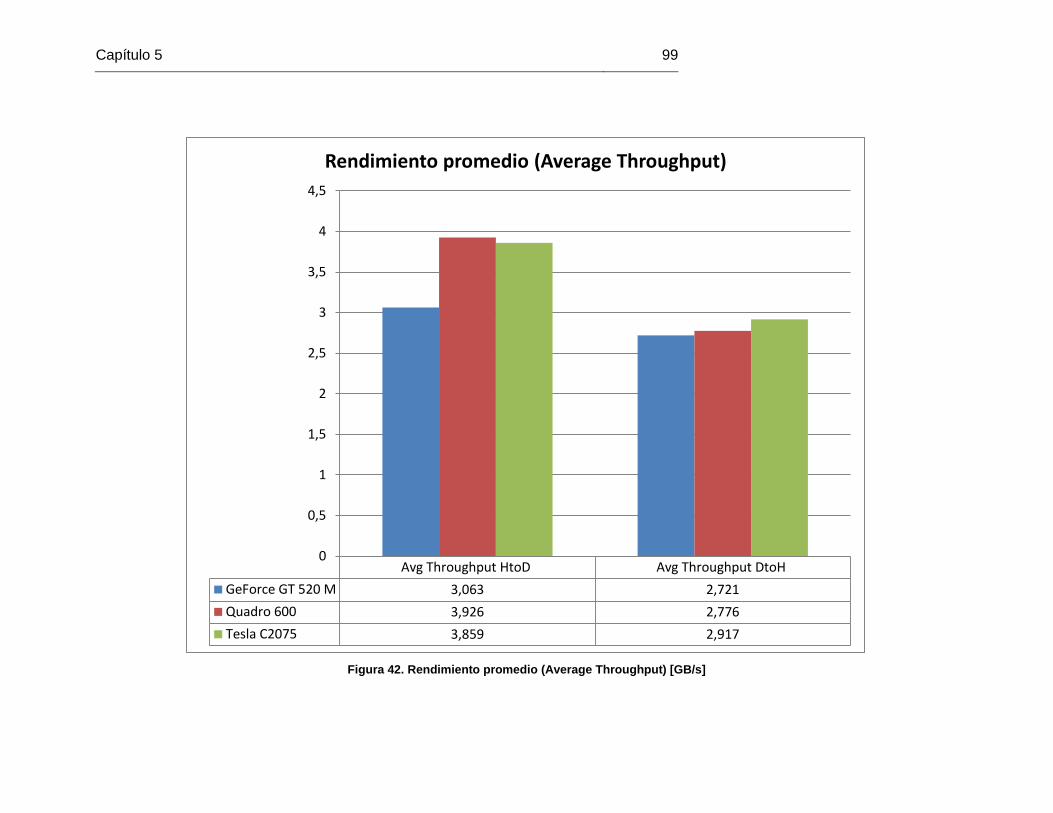
Capítulo 5 99
Figura 42. Rendimiento promedio (Average Throughput) [GB/s]
Avg Throughput HtoD Avg Throughput DtoH
GeForce GT 520 M 3,063 2,721
Quadro 600 3,926 2,776
Tesla C2075 3,859 2,917
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
Rendimiento promedio (Average Throughput)

100 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Figura 43. Tiempos de verificación. Diferentes configuraciones de ambiente.
Tiempo de verificaciónen CPU: GM y COMP
en C++
Tiempo de verificaciónen GPU: GM en CUDA
y COMP en C++
Tiempo de verificaciónen CPU: GM en c++ y
COMP en CUDA
Tiempo de verificaciónen GPU: GM en CUDA
y COMP en CUDA
GeForce GT 520 M 1,3 0,05 0,05 0,05
Quadro 600 1,270364 0,030858 0,034006 0,03486
Tesla C2075 1,170364 0,027014 0,033651 0,031132
0
0,2
0,4
0,6
0,8
1
1,2
1,4
Tie
mp
o e
n s
egu
nd
os
Tiempos de Verificación con cada una de las configuraciones del ambiente y en cada una de las tarjetas

Capítulo 5 101
Figura 44. Tiempo de Ejecución de Tareas GPU
Tiempo de kernelsen GPU
Tiempo de suma enGPU
Tiempo de copiaHtoD
Tiempo de copiaDtoH
GeForce GT 520 M 12,798 4,268 32,864 30,831
Quadro 600 1,467 2,949 25,638 30,223
Tesla C2075 0,97497 0,490416 26,082 28,758
0
5
10
15
20
25
30
35
Tie
mp
o e
n s
egu
nd
os
Tiempos de ejecución de tareas GPU
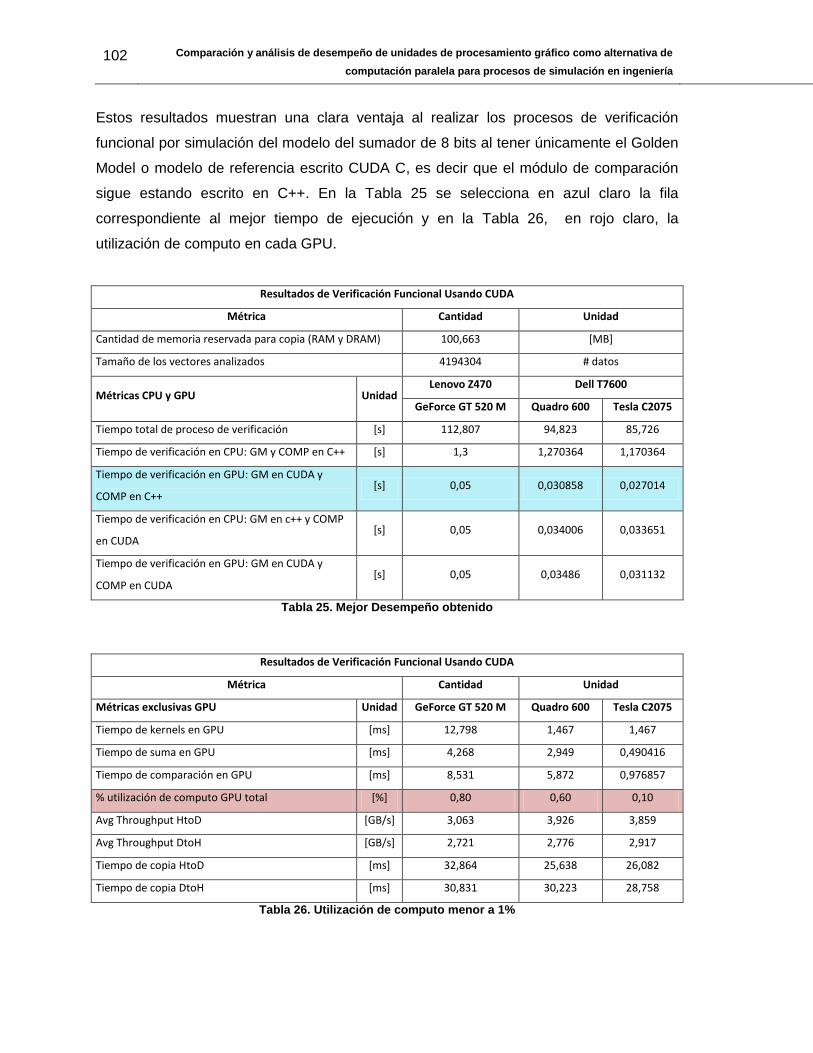
102 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería
Estos resultados muestran una clara ventaja al realizar los procesos de verificación
funcional por simulación del modelo del sumador de 8 bits al tener únicamente el Golden
Model o modelo de referencia escrito CUDA C, es decir que el módulo de comparación
sigue estando escrito en C++. En la Tabla 25 se selecciona en azul claro la fila
correspondiente al mejor tiempo de ejecución y en la Tabla 26, en rojo claro, la
utilización de computo en cada GPU.
Resultados de Verificación Funcional Usando CUDA
Métrica Cantidad Unidad
Cantidad de memoria reservada para copia (RAM y DRAM) 100,663 [MB]
Tamaño de los vectores analizados 4194304 # datos
Métricas CPU y GPU Unidad Lenovo Z470 Dell T7600
GeForce GT 520 M Quadro 600 Tesla C2075
Tiempo total de proceso de verificación [s] 112,807 94,823 85,726
Tiempo de verificación en CPU: GM y COMP en C++ [s] 1,3 1,270364 1,170364
Tiempo de verificación en GPU: GM en CUDA y
COMP en C++ [s] 0,05 0,030858 0,027014
Tiempo de verificación en CPU: GM en c++ y COMP
en CUDA [s] 0,05 0,034006 0,033651
Tiempo de verificación en GPU: GM en CUDA y
COMP en CUDA [s] 0,05 0,03486 0,031132
Tabla 25. Mejor Desempeño obtenido
Resultados de Verificación Funcional Usando CUDA
Métrica Cantidad Unidad
Métricas exclusivas GPU Unidad GeForce GT 520 M Quadro 600 Tesla C2075
Tiempo de kernels en GPU [ms] 12,798 1,467 1,467
Tiempo de suma en GPU [ms] 4,268 2,949 0,490416
Tiempo de comparación en GPU [ms] 8,531 5,872 0,976857
% utilización de computo GPU total [%] 0,80 0,60 0,10
Avg Throughput HtoD [GB/s] 3,063 3,926 3,859
Avg Throughput DtoH [GB/s] 2,721 2,776 2,917
Tiempo de copia HtoD [ms] 32,864 25,638 26,082
Tiempo de copia DtoH [ms] 30,831 30,223 28,758
Tabla 26. Utilización de computo menor a 1%

Capítulo 5 103
El tiempo de ejecución de las funciones de verificación del algoritmo es 26 veces menor
en NVIDIA® GeForce GT 520M con respecto a la ejecución en Intel® Core i5; 40 veces
menor en NVIDIA® Quadro 600 con respecto a la ejecución en Intel® Xeon Processor y
43 veces menor en NVIDIA® Tesla C2075.
Adicionalmente, la unidad gráfica con mejor desempeño a lo largo de todas las pruebas
ha sido la NVIDIA® TESLA C2075 ya que posee la mejor configuración para desarrollar
la computación heterogénea.
El Throughput y los tiempos de copia desde el Host hacia el Device y viceversa se puede
observar que para las tres unidades es similar ya que esta depende tanto del hardware
como del sistema operativo donde co-procesan estos dos elementos, sin embargo,
debido a la baja utilización de computo menor al 1% de la capacidad total de la GPU en
los tres caso por parte del algoritmo el pico teórico de cada tarjeta no se cumple.


Conclusiones y Trabajo Futuro 105
Conclusiones
Se logra realizar una adecuada comparación de desempeños de tres unidades de
procesamiento gráfico: NVIDIA® Tesla C2075, NVIDIA® Quadro 600 y NVIDIA®
GeForce 580M que fueron seleccionadas ya que su hardware permite la programación y
ejecución de software paralelo. Adicionalmente, como criterio de selección se consideró
el soporte, documentación y desarrollo donde NVIDIA® es pionero y actual líder de
mercado en computación paralela con GPU.
Las GPU seleccionadas permiten la ejecución de algoritmos programados como software
paralelo haciendo uso del lenguaje de programación CUDA C y la computación
heterogénea. La comparación fue posible gracias a los resultados obtenidos al ejecutar
las siguientes pruebas: ejecución del benchmark SHOC [32] y la implementación de un
ambiente de verificación de hardware por simulación que incluye tareas de computación
paralela en GPU.
Se obtiene menores tiempos de ejecución del proceso de verificación funcional de un
sumador de 8 bits escrito en Verilog al ejecutarse el proceso de verificación con el
modelo de referencia escrito en CUDA C. Los tiempos de simulación menores velocidad
de verificación usando el modelo de referencia en CUDA C y el comparador en C++
frente a la verificación exclusiva en los procesadores Intel® es 26 veces mayor en la
NVIDIA® GeForce 580M, 40 veces mayor en la NVIDIA® Quadro 600 y 43 veces mayor
en la NVIDIA® Tesla C2075.
El proceso de programación paralela requiere de un alto esfuerzo por parte del
programador quien debe conocer la arquitectura de la GPU que va a programar para
poder comprender la forma como los datos se operan, procesan y son presentados.
Adicional se requiere de un conocimiento con bases sólidas en programación de

106 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería Título de la tesis o trabajo de investigación
computadores. Como contraparte de las mejoras en tiempos de ejecución de algoritmos,
los tiempos de desarrollo pueden aumentarse proporcionalmente a la complejidad del
desarrollo.
Algunos procesos por sus características no son paralelizables por lo tanto dominan los
tiempos de ejecución del algoritmo general. En el ambiente de verificación diseñado se
tiene que el mayor tiempo de ejecución se da en la simulación del HDL en Verilog. El
software icarus Verilog está diseñado para aprovechar los procesadores multi-core pero
no tiene tareas que se ejecuten en GPU.
Se logra obtener una comparación de las GPU de tal forma que se observa una gran
ventaja de desempeño de la tarjeta NVIDIA Tesla C2075 frente a los demás
procesadores alcanzando 1TFLOPs como desempeño máximo en operaciones de punto
flotante con precisión sencilla y de 500 GFLOPs en precisión doble.
Sin embargo, se realizó una comparación de manera porcentual en los desempeños
obtenidos en varios algoritmos frente al desempeño máximo. En esta comparación
ninguna de las tarjetas llegó al 100% y la tarjeta con los mejores resultados fue Quadro
600 con 40% de desempeño en precisión sencilla y 89% en precisión doble; esta
situación indica que las capacidades de hardware no se están usando totalmente debido
a que las tareas programadas usan una pequeña sección de la GPU.

Conclusiones y Trabajo Futuro 107
Trabajo Futuro
El software paralelo requiere un gran esfuerzo de programación, es necesario plantear e
implementar metodologías de diseño de software adecuadas y que vinculen directamente
la arquitectura de hardware que se está usando (co-diseño Hardware/Software). Debe
buscar reducirse el tiempo y esfuerzo de programación a la hora de definir un modelo
computacional que use computación heterogénea.
Se deben generar módulos Golden Model escritos como software paralelo en CUDA C de
los módulos de hardware de mayor uso tanto académico como comercial a fin de que el
proceso de verificación funcional por simulación pueda parametrizarse y el esfuerzo de
desarrollo se centre en mejoras y optimizaciones del ambiente.
Se debe motivar a la comunidad académica vinculada a las áreas del desarrollo en
electrónica y diseño digital a que desarrollen un proceso de diseño digital completo, es
decir, incluyendo la verificación en su línea de trabajo; como trabajo futuro se deberá
realizar una implementar estrategia de acceso a los equipos de cómputo con las GPU de
tal forma que la comunidad tenga acceso a probar sus desarrollos y obtener mejoras en
sus tiempos de diseño y fabricación.
Un área de investigación y desarrollo de gran potencial y que vincula directamente la
investigación en microelectrónica y la computación paralela es el desarrollo de sistemas
embebidos con arquitectura GPU en dispositivos programables como FPGAs.
Explorar la integración de CUDA C como lenguaje de programación de alto nivel con
lenguajes de verificación propiamente dichos como SystemC, SystemVerilog, MyHDL
entre otros.


Conclusiones y Trabajo Futuro 109
A. Código de comparador y Golden model en CUDA C
// Yerman Avila
// Maestría en Ingeniería - Automatización
Industrial
// GoldenModel y Comparador para verificación
de Hardware usando
// C++ y CUDA C
#define N (2048*2048)
//#define N 512
#define THREADS_PER_BLOCK 512
#include <stdio.h>
#include <stdlib.h>
// Kernel para sumar dos vectores, se ejecuta
en GPU
__global__ void add_gpu( int *a, int *b, int
*c, int n){
int index = threadIdx.x + blockIdx.x *
blockDim.x;
if (index < n)
c[index] = a[index] + b[index];
}
// Kernel para comparar dos vectores, se
ejecuta en GPU
__global__ void compare_gpu( int *a, int *b,
int *c, int n){
int index = threadIdx.x + blockIdx.x *
blockDim.x;
if (index < n){
c[index] = a[index] - b[index];
}
}
// Función para sumar dos vectores en la CPU
void add_cpu (int *a, int *b, int *c, int n) {
for (int i=0; i < n; i++)
c[i] = a[i] + b[i];
}
// Función para comparar dos vectores en la CPU
int compare_ints( int *a, int *b, int n ){
int pass = 0;
for (int i = 0; i < N; i++){
if (a[i] != b[i]) {
printf("Valor diferente en %d, valor_1:
%d valor_2: %d\n",i, a[i], b[i]);
pass = 1;
}
}
if (pass == 0) printf ("Test CPU
Correcto!\n"); else printf ("El test de
comparación CPU ha fallado.\n");
return pass;
}
// Función para comparar dos vectores en la GPU
int validate( int *a, int n ){
int pass = 0;
for (int i = 0; i < N; i++){
if (a[i] != 0) {
printf("Valor diferente de 0 en i= %d,
valor_1= %d \n",i, a[i]);
pass = 1;
}
}
if (pass == 0) printf ("Test GPU
Correcto!\n"); else printf ("El test de
comparación GPU ha fallado.\n");
return pass;
}
/*
files:
* f1=stimuli.txt
* f2=output_adderVerilog.txt
*/
FILE *f1, *f2;
int main(int argc, char *argv[]){
cudaSetDevice(argc);
clock_t start = clock();
int size = N * sizeof( int );
//tamaño para reserva de memoria
//Variables a usar CPU:
int *a;
int *b;
int *c_verilog;
int *c_h;
int *c_gpu;
int *comp;
int *comp2;
//Variables a usar GPU:
int *dev_a;
int *dev_b;
int *dev_cgpu;
int *dev_ch;
int *dev_cver;
int *dev_compare;
int *dev_compare2;
//Reserva de memoria HOST
a = (int*)malloc( size );
b = (int*)malloc( size );
c_verilog = (int*)malloc( size );

110 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería Título de la tesis o trabajo de investigación
c_h=(int*)malloc( size );
c_gpu=(int*)malloc( size );
comp=(int*)malloc( size );
comp2=(int*)malloc( size );
//Reserva de memoria GPU
cudaMalloc( (void**)&dev_a, size );
cudaMalloc( (void**)&dev_b, size );
cudaMalloc( (void**)&dev_cgpu, size );
cudaMalloc( (void**)&dev_ch, size );
cudaMalloc( (void**)&dev_cver, size );
cudaMalloc( (void**)&dev_compare, size );
cudaMalloc( (void**)&dev_compare2, size );
clock_t start_ver_host = clock();
// lectura de vectores de entrada a[i] y b[i]
desde stimuli.txt
f1=fopen("stimuli.txt","r");
for(int i=0; i<N; i++){
fscanf(f1,"%d %d\n", &a[i], &b[i]);
}
fclose(f1);
//Lectura de vector de salida c_verilog[i]
desde output_adderVerilog.txt
f2=fopen("output_adderVerilog.txt","r");
for(int i=0; i<N; i++){
fscanf(f2,"%d\n", &c_verilog[i]);
}
fclose(f2);
//Golden Model Host: suma de dos vectores en
c++
add_cpu(a, b, c_h, N);
// Comparador en CPU: compara salida verilog
c_verilog con salida GM C
compare_ints(c_verilog, c_h, N);
printf("\n Tiempo total transcurrido
verificación del DUT con GM en C: %f \n",
((double)clock() - start_ver_host) /
CLOCKS_PER_SEC);
clock_t start_ver_GPU = clock();
// copia de a y b a GPU mem
cudaMemcpy( dev_a, a, size,
cudaMemcpyHostToDevice );
cudaMemcpy( dev_b, b, size,
cudaMemcpyHostToDevice );
// kernel de suma de vectores usando blocks and
threads
add_gpu<<< N/THREADS_PER_BLOCK,
THREADS_PER_BLOCK >>>( dev_a, dev_b, dev_cgpu,
N );
// copia de c desde GPU mem
cudaMemcpy( c_gpu, dev_cgpu, size,
cudaMemcpyDeviceToHost );
// Comparador en CPU: compara salida
verilog c_verilog con salida GM C
compare_ints(c_verilog, c_gpu, N);
printf("\n Tiempo total transcurrido
verificación del DUT con GM en CUDA: %f \n",
((double)clock() - start_ver_GPU) /
CLOCKS_PER_SEC);
clock_t start_ver_cuda= clock();
// Comparador en GPU: compara salida verilog
c_verilog con salida GM C
cudaMemcpy( dev_ch, c_h, size,
cudaMemcpyHostToDevice );
cudaMemcpy( dev_cver, c_verilog, size,
cudaMemcpyHostToDevice );
cudaMemcpy( c_gpu, dev_cgpu, size,
cudaMemcpyDeviceToHost );
compare_gpu<<< N/THREADS_PER_BLOCK,
THREADS_PER_BLOCK >>>( dev_cver, dev_ch,
dev_compare, N);
cudaMemcpy( comp, dev_compare, size,
cudaMemcpyDeviceToHost );
validate(comp,N);
printf("\n Tiempo total transcurrido
verificación del DUT con GM en C y comp CUDA:
%f \n", ((double)clock() - start_ver_cuda) /
CLOCKS_PER_SEC);
clock_t start_GMCuda2_ver = clock();
// Comparador en GPU: compara salida verilog
c_verilog con salida GMCUDA
cudaMemcpy( dev_ch, c_h, size,
cudaMemcpyHostToDevice );
cudaMemcpy( dev_cver, c_verilog, size,
cudaMemcpyHostToDevice );
cudaMemcpy( c_gpu, dev_cgpu, size,
cudaMemcpyDeviceToHost );
compare_gpu<<< N/THREADS_PER_BLOCK,
THREADS_PER_BLOCK >>>( dev_cver, dev_cgpu,
dev_compare2, N);
cudaMemcpy( comp2, dev_compare2, size,
cudaMemcpyDeviceToHost );
validate(comp2,N);
printf("\n Tiempo total transcurrido
verificación del DUT con GM en CUDA y comp
CUDA: %f \n", ((double)clock() -
start_GMCuda2_ver) / CLOCKS_PER_SEC);
// Cleanup CPU RAM
free(a);
free(b);
free(c_verilog);
free(c_h);
free(c_gpu);
free(comp);
free(comp2);
// Cleanup GPU DRAM
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_cgpu);
cudaFree(dev_ch);
cudaFree(dev_cver);
cudaFree(dev_compare);
cudaFree(dev_compare2);
printf("\n Tiempo total verificación
transcurrido: %f \n", ((double)clock() - start)
/ CLOCKS_PER_SEC);
printf("\n Cantidad de datos tipo entero en
cada vector %d \n", N);
return 0;
}

Bibliografía 111
Bibliografía
[1] J. L. Hennessy and D. A. Patterson, Computer Architecture: A quantitative approach, 5Th ed. Waltham, MA, 2012.
[2] D. A. Patterson and J. L. Hennessy, Computer Organization and Design: The hardware/software interface, 4Th ed. Waltham, MA: MK, 2012.
[3] J. Nakano, “Parallel computing techniques,” 2004. [4] Z. Chen, D. Kaeli, and N. Rubin, “Characterizing scalar opportunities in GPGPU
applications,” ISPASS 2013 - IEEE Int. Symp. Perform. Anal. Syst. Softw., pp. 225–234, 2013.
[5] D. A. Yuen, L. Wang, X. Chi, L. Johnsson, W. Ge, and Y. Shi, GPU Solutions to multi-scale problems in Science and Engineering. 2013.
[6] T. S. Crow, “Evolution of the Graphical Processing Unit,” no. December 2004. [7] S. Al-Kiswany, A. Gharaibeh, and M. Ripeanu, “GPUs as storage system accelerators,”
IEEE Trans. Parallel Distrib. Syst., vol. 24, no. 8, pp. 1556–1566, 2013. [8] R. M. Amorim and R. Weber dos Santos, “Solving the cardiac bidomain equations using
graphics processing units,” J. Comput. Sci., vol. 4, no. 5, pp. 370–376, 2013. [9] T. S. Crow, “Evolution of the graphical processing unit,” no. December 2004, 2004. [10] A. S. Arefin, C. Riveros, R. Berretta, and P. Moscato, “GPU-FS-kNN: a software tool for fast
and scalable kNN computation using GPUs.,” PLoS One, vol. 7, no. 8, p. e44000, Jan. 2012.
[11] D. Aracena-Pizarro and N. Daneri-Alvarado, “Detección de puntos claves mediante SIFT paralelizado en GPU,” Ingeniare. Rev. Chil. Ing., vol. 21, no. 3, pp. 438–447, 2013.
[12] D. Defour and M. Marin, “FuzzyGPU: A Fuzzy Arithmetic Library for GPU,” 2014 22nd Euromicro Int. Conf. Parallel, Distrib. Network-Based Process., pp. 624–631, Feb. 2014.
[13] V. Beddo, “Applications of Parallel Programming in Statistics,” University of California, Los Angeles, 2002.
[14] P. Benner, P. Ezzatti, H. Mena, E. Quintana-Ortí, and A. Remón, “Solving Matrix Equations on Multi-Core and Many-Core Architectures,” Algorithms, vol. 6, no. 4, pp. 857–870, 2013.
[15] Y. Zhang, Y. H. Shalabi, R. Jain, K. K. Nagar, and J. D. Bakos, “FPGA vs. GPU for sparse matrix vector multiply,” Proc. 2009 Int. Conf. Field-Programmable Technol. FPT’09, pp. 255–262, 2009.
[16] T. Cheng, “Accelerating universal Kriging interpolation algorithm using CUDA-enabled GPU,” Comput. Geosci., vol. 54, pp. 178–183, 2013.
[17] M. Biazewicz, K. Kurowski, B. Ludwiczak, K. Napieraia, T. E. Simos, G. Psihoyios, and C. Tsitouras, “Problems Related to Parallelization of CFD Algorithms on GPU, Multi-GPU and Hybrid Architectures,” pp. 1301–1304, 2010.
[18] Y. Zhao, Q. Qiu, J. Fang, and L. Li, “Fast parallel interpolation algorithm using cuda,” pp. 3662–3665, 2013.
[19] M. N. Velev, “Efficient Parallel GPU Algorithms for BDD Manipulation *,” pp. 750–755, 2014.
[20] T. T. Zygiridis, “High-Order Error-Optimized FDTD Algorithm With GPU Implementation,” IEEE Trans. Magn., vol. 49, no. 5, pp. 1809–1812, 2013.
[21] G. Beliakov, M. Johnstone, D. Creighton, and T. Wilkin, “An efficient implementation of Bailey and Borwein’s algorithm for parallel random number generation on graphics processing units,” Computing, vol. 95, no. 4, pp. 309–326, 2012.
[22] S. Ghetia, N. Gajjar, and R. Gajjar, “Implementation of 2-D Discrete Cosine Transform Algorithm on GPU,” vol. 2, no. 7, pp. 3024–3030, 2013.
[23] O. Maitre, N. Lachiche, P. Clauss, L. Baumes, A. Corma, and P. Collet, “Efficient parallel implementation of evolutionary algorithms on GPGPU cards,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 5704 LNCS, pp. 974–985, 2009.
[24] M. Bailey, “Using GPU shaders for visualization, Part 3,” IEEE Comput. Graph. Appl., vol. 33, no. 3, pp. 5–11, 2013.

112 Comparación y análisis de desempeño de unidades de procesamiento gráfico como alternativa de
computación paralela para procesos de simulación en ingeniería Título de la tesis o trabajo de investigación
[25] D. Weiskopf, GPU-Based Interactive Visualization Techniques. Berlin: Springer, 2007. [26] V. Galiano, O. López, M. P. Malumbres, and H. Migallón, “Parallel strategies for 2D
Discrete Wavelet Transform in shared memory systems and GPUs,” J. Supercomput., vol. 64, no. 1, pp. 4–16, 2012.
[27] M. Arora, “The Architecture and Evolution of CPU-GPU Systems for General Purpose Computing.”
[28] E. Kandrot and J. Sanders, CUDA by Example, vol. 21. 2011. [29] W. Nvidia, N. Generation, and C. Compute, “Whitepaper NVIDIA’s Next Generation CUDA
Compute Architecture,” ReVision, vol. 23, no. 6, pp. 1–22, 2009. [30] J. Nakano, “Handbook of Computational Statistics,” pp. 243–271, 2012. [31] Y. Deng, Applied Parallel Computing, vol. XXXIII, no. 2. Singapore: World Scientific
Publishing Co. Pte. Ltd., 2013. [32] DakarTeam, “SHOC : The Scalable HeterOgeneous Computing Benchmark Suite,”
Building, no. November, pp. 1–8, 2011. [33] D. Culler and J. P. Singh, “Parallel Computer Architecture,” 1997. [34] J. Nakano, “Parallel Computing Techniques,” pp. 243–271, 2012. [35] J. Nickolls and W. J. Dally, “The GPU Computing Era,” IEEE Micro, pp. 56–70, 2010. [36] OfficeOfScienceAndTechnologyPolicy, “A Research and Development Strategy for High
Performance Computing,” Sci. Technol., 1987. [37] C.-Y. Chou, Y. Dong, Y. Hung, Y.-J. Kao, W. Wang, C.-M. Kao, and C.-T. Chen,
“Accelerating image reconstruction in dual-head PET system by GPU and symmetry properties.,” PLoS One, vol. 7, no. 12, p. e50540, Jan. 2012.
[38] NVIDIA, “Cuda Education & Training,” 2015. [Online]. Available: https://developer.nvidia.com/cuda-education-training.
[39] C. Mcclanahan, “History and Evolution of GPU Architecture,” pp. 1–7, 2010. [40] J. J. Durillo, “Programming GPUs Lecture 1 GPU Programs and Introduction to OpenCL ( I
) Section 1 Executing Programs in GPU.” . [41] D. Luebke and G. Humphreys, “How GPUs Work,” 2007. [42] B. T. Phong, “Illumination for Computer-Generated Images,” Commun. ACM, vol. 18, no. 6,
pp. 311–317, 1975. [43] Nvidia, “GeForce 8800 GPU Architecture - Technical Brief,” Architecture, no. November,
2006. [44] NVIDIA, “Kepler GK110 Overview,” Overview, 2014. [45] F. F. Maxwell and G. P. U. Technology, “NVIDIA GeForce GTX 750 Ti,” pp. 1–11, 2014. [46] NVIDIA, “CUDA C Programming Guide,” no. February, p. 240, 2015. [47] C. Cuda, “Best Practices Guide,” Nvidia Corp., no. DG-05603–001_v6.0, 2014. [48] NVIDIA, “CUDA ZONE,” 2015. [Online]. Available: https://developer.nvidia.com/cuda-zone. [49] AMD, “Developer AMD,” 2015. . [50] Nvidia, “NVIDIA Tesla C2075 Companion Processor,” Prod. Br., 2011. [51] NVIDIA, “Quadro 600.” [Online]. Available: http://la.nvidia.com/object/product-quadro-600-
la.html. [52] NVIDIA, “GeForce GT 520M.” [Online]. Available: http://la.nvidia.com/object/product-
geforce-gt-520m-la.html. [53] Nvidia_CUDA_Toolkit, “Nvidia cuda toolkit v6.5,” no. November, 2013. [54] D. C. Black, J. Donovan, B. Bunton, and A. Keist, System C From de Grown Up. New York:
Springer, 2010. [55] Y. Avila, “Uso de herramientas libres para la Verificación funcional por simulación de
sistemas digitales,” Universidad Nacional de Colombia, 2012.


















