
Cloud Comp
92
Transcript of Cloud Comp

01_okladka.indd 2009-04-14, 16:201

02_rekl_CyberNET.indd 2009-04-14, 14:081

a modo de introducciónLinux, ¿menos de 1%?
3www.lpmagazine.org
Paulina PyrowiczRedactora Jefe de Linux+
Hoy por la mañana mi amiga me preguntó si Linux era fácil porque quería comprarse un portátil con Ubuntu preinstalado. El otro día otro amigo mío gracias a una Live CD de esta misma distribución sacó sus datos
del disco duro en el que falló Windows. En cada parte se puede oír o leer que Linux es más seguro, más barato, que las empresas y la administración pública se instalan este sistema operativo ma-sivamente para ahorrar dinero, que las empresas grandes cada vez venden más equipos con diferentes distribuciones preinstaladas, etc. Pero si todo esto es verdad, ¿cómo es posible que, como mues-tran las estadísticas en uno de los artículos publicados en la revista, Linux no haya superado todavía el 1% de sistemas utilizados en el mundo? ¿Son estas estadísticas fiables? ¿Creéis que son verdaderas? A lo mejor diréis que nosotros como una revista dedicada a este Sistema Operativo deberíamos saber estas cosas, poseer nuestras propias estadísticas. Pero la verdad es que es muy difícil obtener datos objetivos, las encuestas que solemos realizar entre nuestros lectores no pueden serlo por razones obvias. Por eso tenemos que basarnos en los datos recogidos por otras organizaciones, lo que significa que nos es imposible averiguar su objetividad. Lo que me interesa es, cómo a vosotros os parecen estas estadísticas, ¿creéis en ellas? ¿Realmente tan poca gente utiliza Linux en casa o en el trabajo? Nos gustaría recibir vuestras opiniones acerca de este tema, podéis escribirnos o publicar en nuestro foro. Los au-tores de las opiniones que publicaremos recibirán 3 números de la revista como regalo.
El tema central de este número es Cloud Computing, la tecno-logía que desde hace algún tiempo gana terreno con gran rapidez. ¿Qué es Cloud Computing? ¿Merece la pena aprovecharlo? ¿Es seguro? Las respuestas a estas y muchas otras preguntas las en-contraréis en una serie de artículos que publicamos en este número y que tratan sobre este tema. Esperamos os ayuden a profundizar las posibilidades que nos trae la nueva tecnología y ver los peligros que puede llevar consigo.
Además del tema central encontraréis otros artículos sobre los temas como seguridad (¿son realmente seguros nuestros datos?), virtualización (la segunda parte del extenso artículo sobre creación y uso de máquinas virtuales), programación (creación de frontends en Gambas y programación de Aplicaciones de Internet Enriqueci-das con Flex y AMFPHP) y mucho, mucho más.
¡Os deseamos buena lectura y nos vemos en julio!
Linux, ¿menos de 1%?
03_Wstepniak.indd 2009-04-14, 14:083

4 Linux+ 6/2009
índice
En este número
descripción de DVD
CentOSPedro Ramón Fariñas
novedades
NoticiasAlex Sandoval
UbuntuFrancisco Javier Carazo Gil
MandrivaJuan Gamez
FedoraDiego Rivero Montes
Cloud Computing
Cloud Computing: El sistema operativo EyeOSJosé B. Alós Alquézar
Bajo el término Cloud Computing, se engloba un conjunto de soluciones tecnológicas que permiten ofrecer servicios de computación a través de los protocolos TCP-IP, de forma que todo aquello que pueda ofrecer un sistema informático concreto, tanto a bajo nivel como a nivel de aplica-ción, es accesible a usuarios ajenos a éste.
Cloud Computing: ¿La gran oportunidad para Linux?Diego Gernan Gonzalez
Desde la liberación en 1992 de las primeras distribuciones se viene vaticinando el “gran despegue de Linux”. 17 años después ni el interés de grandes empresas como IBM, ni la aparición de una distro orientada específi camente al público masivo como UBUNTU, ni el atractivo inne-gable para el usuario sin conocimientos de proyectos como COMPIZ han permitido perforar el techo del 1% del mercado. En cuanto al tan deseado aluvión de nuevos usuarios que se esperaba a causa de la desilu-sión con Windows Vista se quedó en algunos miles, el resto de los no conformes se volvió a XP.
10
6Cloud Computing cobra su mayor sentido en una aproximación Open SourceJosé Manuel Rodríguez, director de Software de Sun Microsystems Ibérica
La consolidación de Internet como medio de acceso y compartición de la información y como plataforma de comunicaciones por parte de ciudada-nos, empresas y gobiernos (ya es utilizada por más de 1.000 millones de personas diariamente en todo el mundo, una cifra que se habrá doblado en 2011) ha forzado a los grandes proveedores de tecnologías de informa-ción a evolucionar sus estrategias hacia el aprovisionamiento de todo tipo de servicios informáticos a través de la red como si de un servicio básico y a medida se tratara.
Cloud Computing: ¿Stairway To Heaven?Lino García Morales
A mediados de los 90 Marc Andreessen (cofundador de la empresa Netscape Communications Corporation y coautor de Mosaic, uno de los primeros navegadores web con interfaz gráfi co) predijo que Micro-soft Windows estaba destinado a ser un “pobre conjunto de drivers ejecutándose en Netscape Navigator”. Netscape desapareció en Marzo del 2008, sin embargo, su predicción va camino de cumplirse en algún Navegador web.
12
13
14
Navegador web.
16
22
software
JuegosFrancisco Javier Carazo Gil
Interconexión de Sistemas AbiertosLino García Morales
El modelo de referencia de interconexión de sistemas abiertos (OSI, Open System Interconnection) fue desarrollado por la ISO (Organización Internacional de Normalización) en 1977 para describir las arquitectu-ras de redes y compatibilizar la comunicación entre los fabricantes de ordenadores.
38
36
32
30
04_05_Spis_tresci.indd 2009-04-14, 16:424

5www.lpmagazine.org
virtualización
Maquinas virtuales, parte IIDaniel García
En esta segunda entrega nos adentraremos en los detalles de implementa-ción sobre el entorno de prueba. Se detallará paso a paso una instalación de Debian, para los principiantes, clonación de máquinas virtuales y con-figuración de diversos servicios red, entre ellos: un firewall perimetral, un proxy cache transparente, un servidor DNS, etcétcera.
Cloud ComputingTema del número
programación
Gestión Potente de Procesos: Creación de FrontEnds en GambasJorge Emanuel Capurro
GNU/Linux posee infinitas alternativas a distintos programas de aplica-ción. Muchas de estas son de interfaz de modo texto, lo que lleva al usua-rio principiante/intermedio a una difícil interacción con el programa. Gambas pensó en este problema, por lo que como era de esperar, nos trae una solución: La creación de FrontEnds.
índice
seguridad
Su información, ¿a salvo?David Puente Castro (Blackngel)
¿De qué serviría un ordenador si no pudiésemos almacenar información en él? Absurda máquina si esto ocurriese. Pero aun no siendo así, de nada sirve si no podemos mantener esta información lejos de curiosos atacan-tes. El problema es claro. ¿Hasta qué punto la privacidad de nuestros datos está garantizada?
Aplicaciones de Internet Enriquecidas (RIA): Programando RIA con Flex y AMFPHPMatías Barletta
¿Qué programador no quisiera darle a sus usuarios la mejor experiencia de uso, una herramienta intuitiva, fácil de usar y que tenga los beneficios de las aplicaciones web? Además, que el desarrollo e implementación sea sencillo y... placentero.
opinión
Distribuidores polivalentesFernando de la Cuadra, director de Educación de Ontinet.com
Los administradores de sistemas de las empresas suelen tener que sufrir una gran dicotomía en su trabajo: ¿Windows o Linux? Es una batalla perdida. Por mucho que nos empeñemos, la inmensa mayoría de usuarios va a rechazar un cambio a Linux en los puestos de trabajo mientras sigan teniendo Windows en casa.
entrevista
Entrevista a Ignacio Molina Palacios, Proyect Manager de AXARnet Comunicaciones
42
58
66
80
86
88
04_05_Spis_tresci.indd 2009-04-14, 15:385

descripción de DVDDVDs
6 Linux+ 6/2009
Por fin ha salido esta tan esperada entrega de Centos, fue liberada el día uno de abril, un poco después de la Scientif (también basada en
Red Hat y liberada el día veintiocho de marzo). Es curiosa la larga espera que se ha tenido que sufrir hasta la aparición de esta versión pues la 5,3 de Red Hat fue liberada el 20 de enero, aunque queda patente que esta demora no es responsabilidad de la comunidad desarrollado-ra de Centos al darse el caso también en otras distribuciones derivadas de Red Hat.
Casi todas estas distribuciones como tam-bién se da el caso en Debian tienen un pequeño inconveniente que se convierte a la vez en ven-taja, tienen paquetes algo antiguos, lo que aun-que no te ofrece las últimas novedades hace que sea mucho más fiable al estar más probados sus paquetes. Si se quieren las últimas novedades habría que recurrir a Fedora.
Bueno, vamos a dejarnos de comentarios que pueden ser más o menos interesantes o cu-riosos y vamos a lo que realmente nos importa, la instalación y configuración básica de Centos. Lo primero es disponer de soporte de instalación, bien sea DVD o CD, en este caso nos decantare-mos por la instalación desde el DVD que acom-paña este número de la revista, si necesitamos los CD por que el equipo en el que lo vallamos a instalar no posea lector para DVD podremos ob-tenerlos en www.centos.org . Una vez arranca-mos desde la unidad lectora la primera pantalla que nos encontramos nos ofrece varias posibili-dades de arranque, en nuestro caso para instalar y teniendo en cuenta que nuestra máquina tiene suficiente procesador y RAM y vamos a instalar también el entorno gráfico nos decantamos por la instalación por defecto y pulsamos enter, en caso de instalar un servidor la mayoría de las veces no instalamos el entorno gráfico por lo que habría que modificar los parámetros de arranque para instalación de modo texto, prestando especial atención a que no necesitemos el entorno gráfico para el servidor como se da el caso en algunas bases de datosa aplicaciones de ERP y BW.
El siguiente paso que nos pide como en casi todas las versiones de Red Hat y distribuciones derivadas es la comprobación del disco, en este caso no es necesario y si la hemos descargado de Internet pasándole después la suma MD5 de comprobación se puede decir que tampoco, pero si tenemos dudas de la integridad del so-porte es muy recomendable. En nuestro caso al provenir de una fuente de confianza omitiremos este paso seleccionando Skip con el tabulador el enter. En estos momentos empieza a cargar
el Anaconda, instalador gráfico de Red Hat uti-lizado también por otras distribuciones como pue-dan ser sus derivadas u otras tan dispares como Linex o Valdemoro (Hasta donde sé a día de hoy discontinuada). Pulsamos siguiente y el primer paso consiste en la selección de idioma para ello tenemos la opción de recorrernos la lista buscán-dolo o empezar a escribirlo para que nos lo vaya buscando la instalación y ya nos movemos por muchas menos opciones, yo siempre me decanto por esta segunda opción (Hay que escribirlo en inglés). Seleccionamos el teclado adecuado, nor-malmente nos sirve el que viene por defecto y pro-cedemos al particionado del disco, tenemos varias opciones para ello desde todo por defecto para no complicarnos la vida hasta hacer las particiones de manera automática, en este caso como prima el valor didáctico al productivo nos decantamos por la opción de crear diseño personalizado.
Normalmente se ha hablado de la necesidad de tres particiones -una para el sistema, otra para datos y la última para swap (aunque actualmente podemos hablar de la necesidad de simplemente dos por la RAM que suelen tener los equipos que hacen innecesaria la partición para swap), aun-que en este caso vamos a crearla. En primer lugar vamos a crear la partición raíz y le vamos a dar por ejemplo cuatro gigas de espacio para ello nos vamos a nuevo, ponemos punto de montaje /, la dejamos como ext3 y la forzamos como pri-maria, en segundo lugar crearemos la swap (la que se dice que como norma general tendrá el doble de espacio que la memoria RAM hasta que
llegue ésta al medio giga, después tendrá la mis-ma dimensión) para ello nos vamos a nuevo, po-nemos swap y le damos el tamaño deseado y con lo que quede hacemos la tercera partición ext3 definiendo el punto de montaje como /home.
Cuando ya tenemos nuestras particiones de-finidas procedemos a lo que es ya la instalación en sí, es decir la copia de archivos al disco, lo pri-mero que nos pide es en qué partición deseamos instalar, en nuestro caso nos decidimos por la sda1 que es la que hemos preparado a tal efecto, y dejamos que nos instale el gestor de arranque grub en este caso, el que podemos modificar desde aquí mismo para adecuarlo a nuestras necesidades. El siguiente paso es el de la confi-guración de la red, en nuestro caso es a través de un servidor de DHCP ubicado en el ruter de co-nexión a Internet, en caso de que en vuestra red de área local tengáis configurada ip fija tendréis que rellenar los otros campos. Seleccionamos la zona horaria y ya nos pide la contraseña de root para después proceder a seleccionar los paquetes a instalar. En nuestro caso vamos a personalizar la instalación ahora, seleccionamos esa opción, pulsamos en siguiente y ya nos muestra los paquetes a instalar separados por categorías, en mi caso voy a instalar el entorno de escritorio gnome por defecto, las herramientas de autoría y publicación, los editores, gráficos, la Internet (tanto gráfica como texto), las herramientas de oficina, el sistema base, las herramientas de administración. Pulsamos siguiente, nos com-prueba las dependencias y después ya nos indica
Centos 5.3
Figura 1. Pantalla de arranque de Centos 5,3 desde la que podemos modificar los parámetros de arranque que deseemos para la instalación
06_07_Opis_DVD.indd 2009-04-14, 14:096

descripción de DVDsDVDs
7www.lpmagazine.org
que va a proceder a la instalación de los paquetes seleccionados.
Una vez completada la copia de archivos comenzamos con la configuración básica del sistema. El primer paso es el cortafuegos, si el equipo está conectado directamente a Internet es obligatorio tenerlo habilitado y si está dentro de una red de área local protegida por un cortafue-gos lo podemos deshabilitar y nos es más senci-lla la administración, cuestión de gustos. Luego nos pregunta por la configuración del Security-Enhanced Linux (SELinux), un parche para me-jorar la seguridad de linux que o es un entorno de muy alta seguridad o no es recomendable su empleo por que la complejidad de su configu-ración en un principio merma notablemente la productividad. Tras esto llega el momento de poner en hora el sistema. El siguiente paso es la creación de un usuario,muy importante si no quieres trabajar siempre como root. Y para fina-lizar la instalación comprobar la tarjeta de sonido y si hacen falta Cd's adicionales.
Ahora si se quiere se puede instalar com-piz para efectos 3D o las aplicaciones que ne-cesitemos pero al usarse principalmente en ser-vidores no le vamos a instalar escritorios que consuman recursos de la máquina de forma in-necesaria ni a mostrar la configuración de ser-vidores porque si no, nos alargaríamos más de lo conveniente.
Por Pedro Ramón Fariñas
BitDefender Antivirus Scanner for UnicesBitDefender Antivirus Scanner for Unices es una versátil solución antivirus bajo demanda diseñada para sistemas Linux y FreeBSD. Ofrece análisis antivirus y antispyware para UNIX y particiones basadas en Windows.
Características principales
• Análisis antivirus y antispyware bajo de-manda.
• Integración basada en Scripts y extensiones con diferentes aplicaciones y servicios:– Cliente de correo (Ej. Pine, Evolution)
y servicios de Servidor de Correo,– Servicios de programación (ej. Cron)
para asegurar la automatización del análisis y. actualización.
– Análisis clásico de línea de comando completo con una interfaz gráfica para una mayor integración con los entornos desktop.
– Inclusión automática del GUI del análi-sis al menú del sistema.
– Plugins Open source para tres de los más populares administradores de archi-vos: Konqueror (KDE), Nautilus (GNO-ME) y Thunar (Xfce).
– Configuración de acción basada en el tipo de resultado del análisis.
Requisitos del sistema
• Sistema operativo:Linux, FreeBSD• Linux Kernel: 2.4.x or 2.6.x (rec.)• FreeBSD: 5.4 (o superior con compat5x)• glibc: version 2.3.1 o superior, y libstdc++5
desde gcc 3.2.2 o superior• Procesador: x86 compatible 300 MHz; i686
a 500MHz rec.; amd64(x86_64)• Memoria mínima: 64MB (128MB rec.)• Espacio libre mínimo en disco duro: 100MB
Distribuciones soportadas
• RedHat Enterprise Linux 3 o superior• SuSE Linux Enterprise Server 9 o superior• Fedora Core 1 o superior• Debian GNU/Linux 3.1 o superior• Slackware 9.x o superior• Mandrake/Mandriva 9.1 o superior• FreeBSD 5.4 o superior
Política de licenciaLa solución BitDefender Antivirus Scannerfor Unices es totalmente gratuita únicamente en el caso de usuarios domésticos. Si desea utilizar BitDefender Antivirus for Unices con fines comerciales, la licencia deberá ser com-prada en la tienda online de BitDefender o a tra-vés de la red de distribuidores oficiales de Bit-Defender.
EyeOS, Cloud Computing Operating SystemEn el DVD encontraréis la distribución EyeOS, versión 32 bit. Sobre la distro y su uso podréis leer en el artículo de José B. Alos incluido en la revista.
Figura 3. Centos 5.3 con escritorio Gnome
Figura 2. Aquí tenemos nuestra tabla de particiones con las tres definidas
06_07_Opis_DVD.indd 2009-04-14, 14:097

08_09_rekl_ES045_B_LinuxPlus_0609.indd 2009-04-20, 15:542

08_09_rekl_ES045_B_LinuxPlus_0609.indd 2009-04-20, 15:543

10 Linux+ 6/2009
NEWS novedadessección llevada por Alex Sandoval [email protected]
Nftables, el nuevo firewall de Linux Al igual que ocurrió en el pasado con ipfwadm e ipchains, ahora le toca a iptables ir preparándose para quedar aparcado en el baúl de los recuerdos. El grupo encargado de Netfilter ha publicado una versión preliminar del que previsiblemente será su sucesor: nftables. La nueva herramienta es más adap-table, tiene una sintaxis más simple y permite ejecutar más de una acción por línea. Nfta-bles está formado por tres componentes: la implementación en el kernel, la biblioteca de comunicación (libnl) y el frontend. La reescritura ha sido necesaria ya que cada vez estaban siendo incluídas más extensiones en netfilter que resultaban difíciles de mane-jar para quienes administraban los sistemas. Se ha decidido, además, sacar del kernel la mayor parte del sistema de evaluación de reglas. El código se encuentra actualmente en estado alpha, lo que quiere decir que se puede empezar a experimentar con él.http://softlibre.barrapunto.com/softlibre/09/04/06/117240.shtml
Ututo XS 2009Finalmente se anunció el lanzamiendo de Ututo XS 2009, la más reciente actualiza-ción de la primera distribución GNU/Linux argentina. Esta nueva versión está disponible en formato LiveDVD e incluye importantes novedades, como por ejemplo: Soporte para conexión a redes de datos móviles (GPRS y 3G), mejor capacidad de placas de video con acceleración gráfica, se fusionan la versión instalable y el autoejecutable (Vivo!) en un solo DVD, Soporte para las MacBook Mac mini de Apple y las netbooks MSI Wind y ASUS EeePC, Kernel 2.6.28.1 con capaci-dades extendidas de detección de hardware, hibernación y suspensión del sistema.Para más adelante, el proyecto de Ututo promete versiones optimizadas para procesa-dores AMD de 32 y 64 bits, Intel de 64 bits e incluso el Intel Atom.https://www.ututo.org/www/modules/news/news.php?ID_news=339
Gmail te permite arrepentirteLos desarrolladores de Gmail siguen agregán-dole funciones a su popular servicio de correo electrónico. Antes fue un sistema para ad-juntar archivos y agregaron una herramienta para evitar que mandes correos estando ebrio. Ahora el correo electrónico de Google te per-mitirá cancelar el envío de un correo cuando te des cuenta que la dirección está mal escrita, el mensaje está incompleto o te arrepientes de haber enviado ese correo a tu jefe. Esta opción “Undo Send” se activa en Gmail Labs y entre-ga aproximadamente 5 segundos de reflexión después de presionar el botón “Enviar” para detener el viaje por internet. Después de ese lapso, ya no hay nada que hacer. Esta aplicación es ideal para aquellos usuarios de dedos rápidos que presionan impulsivamente “Send”, lo que les puede acarrear más de algún problema personal o laboral.http://gmailblog.blogspot.com/2009/03/new-in-labs-undo-send.html
Brasil ahorró US$ 167,8 millones usando software libreBrasil es uno de los países más comprome-
tidos con los programas de código abierto de latinoamerica y del mundo. Esa fidelidad al software libre le trajo un beneficio directo que según un cálculo de la organización Servicio Federal de Procesamiento de Datos (Serviço Federal de Processamento de Dados, Serpro) del Ministerio de Hacienda, muestra que en los últimos 12 meses, Brasil ha ahorrado 370 millones de reales, unos US$ 167,8 millones de dólares, con el uso de sistemas operativos, navegadores de Internet, correo electrónico y software libre para diversos fines. Según Marcus Vinicius Ferreira Mazón, presidente del Serpro, la cantidad podría ser aún mayor, ya que apenas 62 de las 90 reparticiones consultadas respondieron la encuesta. Las instituciones que contestaron cuentan en total con 2 millones de equipos. El Serpro utiliza Fedora en sus orde-nadores, además de soluciones de correos ele-ctrónicos Carteiro y Expresso. Actualmente, todas las dependencias del gobierno federal tienen al-guna experiencia con software libre, pero toda-vía existe potencial de desarrollo. La previsión indica que este ahorro continuará creciendo. “Conforme se verifican los resultados positivos de la tecnología libre, su uso aumenta fuerte-mente”, resumió Ferreira, quien señaló que los programas de código abierto son superiores no sólo por su precio, sino también por su adaptabi-lidad. El ahorro permitió la instalación de 5.000 telecentros para el programa de inclusión digital en comunidades carentes.
Después de la adopción del uso del software libre por parte del Gobierno brasileño, el 40%
de los organismos estatales ya implementó sus programas hasta el usuario final con sistemas de código abierto.
El 15 de abril, el Serpro hizo accesible pa-ra el público una plataforma para desarrollo de programas informáticos llamada Demoiselle en homenaje al piloto brasileño Santos Du-mont, quien en 1907 dejó libre el patente del avión que diseñó en Francia.
Esta buena noticia muestra a otros países, que existe vida más allá de MS Office y sis-temas operativos pagados en las instituciones gubernamentales.http://tecnologia.terra.com.br/interna/0,,OI3685118-EI4795,00-Governo+economiza+R+mi+com+sistemas+operacionais.html
El ahorro permitió la instalación de 5.000 telecentros para el programa de inclusión digital en comunida-des de escasos recursos
Sun termina negociaciones con IBM y acciones se desplomanLas acciones de Sun Microsystems Inc. ca-
yeron más del 22 por ciento tras rechazar una oferta de compra de IBM por 7.000 millo-nes de dólares, lo que dejó a la productora de servidores y programas vulnerable a demandas de sus accionistas.
Mientras aún creen que las negociaciones podrían reactivarse, una fuente cercana con información sobre el asunto dijo que los con-tactos cesaron el fin de semana luego de que Sun rechazara la oferta de IBM de 9,40 dólares por acción.
Las acciones de Sun cayeron un 22,5 por ciento a 6,58 dólares, aunque siguen cotizán-
dose por arriba del nivel de 4,97 dólares, que era el valor del papel antes de que las negocia-ciones con IBM fueran reportadas por primera vez en marzo de este año.
La primera reacción de Sun fue asegurar que no habrá cambio de nombres en la cúpula.
Nuestra política es no comentar rumores o especulaciones. Lo que podemos decir es que Sun sigue comprometida con su equipo de li-derazgo, estrategia de crecimiento y con crear valor para los accionistas, dijo la empresa en un comunicado enviado por correo electrónico.
El comunicado llegó en medio de espe-culaciones de que el fin de la negociación con
10_11_News.indd 2009-04-14, 14:1110

11www.lpmagazine.org
NEWS
sección llevada por Alex Sandoval [email protected]
novedadesNoticias
Publicada la versión 2.6.29 del kernel LinuxLinus Torvalds ha hecho oficial la disponi-bilidad del kernel Linux 2.6.29, tras meses después de la publicación del 2.6.28. Esta nueva versión, además del cambio temporal de mascota, cuenta entre sus nuevas carac-terísticas con el soporte de modesetting del subsistema gráfico, integración de la tecno-logía WiMAX, soporte de puntos de acceso Wi-Fi, el sistema de archivos SquashFS, una versión preliminar de Btrfs, una versión más escalable de RCU, cifrado de nombres de archivos con eCryptfs, modo no jour-naling de ext4, checksums para metadatos de OCFS2, nuevos drivers y muchas otras mejoras menores.http://softlibre.barrapunto.com/softlibre/09/03/24/1044208.shtml
G-Monster PCIe: PhotoFast anuncia un SSD de 1TB de capacidadUna noticia de hardware. Como ya hemos comentado en varias ocasiones anteriormen-te, el desarrollo de discos SSD sigue avan-zando a pasos agigantados. Ahora la compa-ñía japonesa Photofast ofrece las unidades de 256GB, 512GB y 1TB de capacidad. Igual de sorprendente es la velocidad de lectura y escritura de estas, ya que alcanzan tasas de transferencia de 750 y 700MB/s en cada caso.http://www.fayerwayer.com/2009/03/g-mons-ter-pcie-photofast-anuncia-un-ssd-de-1tb-de-capacidad/
EVO Smart: una nueva consola basada en LinuxEnvizions ha anunciado que ya se puede reservar su propia consola Linux, es la EVO Smart. Si la analizamos bien nos daremos cuenta que es un ordenador con forma de consola ya que tiene un procesador AMD Athlon 64 x2 5600 a 2.4 GHz, 2 GB de memoria RAM DDR2, su disco rígido es de 120 GB de almacenamiento y tiene una tarjeta gráfica ATi HD 3200.No menos destacable es que la EVO Smart usa una versión de Fedora de arranque rápido (conocida como Mirrors) y que Envizions tiene planeado vender juegos desde la web en tarjetas SD por un precio de 20 €.http://www.evosmartconsole.com/
Mandriva ayuda a portar K3B a Qt4Mandriva decidió ayudar a portar el popularísimo y premiado software de gra-bación de CDs y DVDs K3B a Qt4. Dos ingenieros del equipo de KDE de Mandriva comenzarán a trabajar con Sebastian Trueg, el desarrollador principal de K3B, para que su renovada versión pueda lanzarse más temprano y así incluirse en la versión final del próximo Mandriva 2009.1 "Spring". El resultado será que K3B podrá usar todo el poder de la plataforma de KDE4, como Solid, Phonon y todo el entorno Plasma.http://www.vivalinux.com.ar/eventos/mandriva-k3b-a-qt4
dente ejecutivo, Jerry Yang, rechazó una oferta de Microsoft por 47.500 millones de dólares el año pasado.
Yang eventualmente renunció en medio de fuertes críticas y fue reemplazado por Carol Bartz. Algunos analistas han dicho que de haber aceptado la oferta de Microsoft se habría creado 30.000 millones de dólares de valor para los accionistas de Yahoo. De verdad esperamos que a los accionistas no les toque un Yahoo, dijo Kei-th Wirtz, presidente de inversión de Fifth Third Asset Management, que tienen acciones tanto de Sun como de IBM.
Si bien IBM ha estado negociando el pre-cio de la adquisición a la baja, según una fuen-te, su última oferta aún representaba un premio de un 89 por ciento frente al precio de los títu-los de Sun cuando por primera vez se habló de las discusiones a mediados de marzo.
Dado el tamaño del premio y considerando que el directorio de Sun ha encabezado una baja de las acciones de la empresa en los últimos ocho años desde los 250 dólares a menos de 5 dólares, creemos que Sun va a enfrentar un malestar sig-nificativo de los accionistas, dijo el analista Toni Sacconaghi de Sanford C. Bernstein.
Sun es actualmente encabezada por Jona-than Schwartz, quien reemplazó a Scott Mc-Nealy en el 2006. McNealy, uno de los funda-dores del pionero de Silicon Valley, se mantie-ne como presidente del directorio.
http://www.emol.com/noticias/tecnologia/detalle/detallenoticias.asp?idnoticia=352520
Muchos analistas creen que tomar la oferta de IBM hubiese sido la mejor opción para Sun, que está per-diendo participación de mercado
IBM podía provocar la renuncia del presidente ejecutivo, Jonathan Schwartz.
Muchos analistas creen que tomar la oferta de IBM hubiese sido la mejor opción para Sun, que está perdiendo participación de mercado, y que el cese de las negociaciones dejó en evi-dencia que tenía una posición mucho más débil que el comprador.
Parece que están en un dilema. La historia operacional de Sun en los últimos cuatro a ocho trimestres no parece estar funcionando bien para ellos, ni tampoco sus esfuerzos por vender activos, dijo Tom Smith, analista de S&P Equity Research.
El analista bajó la recomendación para los papeles de Sun a vender de mantener y tam-bién redujo su precio objetivo de 12 meses a 6 dólares de 9,50 dólares.
Fuentes financieras aseguran que Sun se ha estado ofreciendo en el mercado por meses y que aparentemente no apareció ningún otro interesado más que IBM.
Las fallidas negociaciones con IBM im-plican que Sun debería tomar una oferta aún menor, o peor aún, ninguna oferta.
Otros creen que Sun podría venderse en partes a distintas empresas de software que no quieren, o no pueden pagar, la empresa en su to-talidad.
Otro Yahoo!Algunos pronostican que Sun puede exponerse a la ira de sus accionistas, como le ocurrió a Yahoo cuando su fundador y entonces presi-
10_11_News.indd 2009-04-14, 14:1111

novedadesUbuntu
12 Linux+ 6/2009
sección llevada por Francisco Javier Carazo Gil [email protected]
Fedora 11 vs Ubuntu 9.04Los seguidores de Ubuntu estamos acos-tumbrados a no poder disfrutar de lo último en las versiones más actuales de nuestra distribución preferida. Por sólo poneros un ejemplo, mirad esta comparativa entre Ubun-tu y Fedora:• Kernel: 2.6.29 (Fedora) vs. 2.6.28
(Ubuntu),• Firefox: 3.1 (Fedora) vs. 3.0 (Ubuntu),• Thunderbird: 3.0 (Fedora) vs. 2.0
(Ubuntu),• OpenOffi ce: 3.1 (Fedora) vs. 3.0 (Ubuntu).Como podéis apreciar Fedora 11 viene mucho mejor equipada en cuanto a últimas versiones de software muy importantes que Ubuntu 9.04, pero ¿por qué Canonical no incorpora las últimas versiones?La estabilidad es uno de los aspectos que más se le critica a la distribución de Canonical en comparación con otras como Debian o Slackware que aseguran fi abilidad en todas las circunstancias. La empresa creada por Shutt-leworth ha llegado a una solución de compro-miso entre tener versiones modernas del soft-ware y tener versiones estables. Las versiones que trae consigo Fedora son tan modernas que están llenas de bugs, como el tan comentado del sistema ext4, y que pueden tener conse-cuencias nefastas. En el caso de Ubuntu, el software que se incopora está más pulido y tenemos la seguridad de que su estabilidad es superior, aunque no esté tan contrastada como las versiones veteranas y no modifi cadas que incorporan otras distribuciones.
Quinto cumpleaños...Y ahora que lo pienso me parece que fue ayer cuando en la universidad oí hablar a un compañero de una distribución llamada Ubuntu. La primera impresión, con los tonos marrones, no me resultó buena en absoluto y tuvo que pasar 1 año para que me decidiera a sustituir mi antigua Mandrake por esta dis-tribución de la que cada vez leía más líneas en la red. Su nombre Ubuntu, la versión con la que empecé la 5.10 y aunque he probado otras muchas, ninguna me ha gustado tanto como Ubuntu (al menos hasta el momento). Esperemos que este cumpleaños, el quinto, sea sólo uno más y que se repitan durante años y podamos ver cada 6 meses novedades y una mejor posición para batallar contras los otros sistemas operativos de escritorio.
...cumpliendo los plazosSi algo caracteriza a Ubuntu es su exquisita puntualidad con respecto a otras distribucio-nes y proyectos de software libre a la hora de cumplir los plazos de salida. Hace ya un tiem-po, en la versión que debió ser la 6.04, hubo un retraso y al fi nal salió en Junio, por lo que su nombre cambió a 6.06. A excepción de este caso, las faltas de puntualidad han sido mí-nimas y la posibilidad de ver la planifi cación del proyecto a meses vista es todo una ventaja tanto para los usuarios domésticos como para los profesionales. Ni siquiera proyectos co-merciales cumplen los plazos en la medida en que lo hace Ubuntu.
Ubuntu 9.04 Jaunty JackalopeLa última versión de Ubuntu ya está dispo-
nible y con ella, todas las novedades que se esperan de la distribución más popular del mundo GNU/Linux en el mercado del escritorio. Antes de comenzar a comentar las novedades que incluye, como siempre, vamos a conocer el signifi cado de las dos palabras clave que lo iden-tifi can. Jaunty signifi ca alegre y el Jackalope, es un animal mitológico mezcla de liebre y antílope. Ya podemos empezar a comentarlas novedades de ésta, como siempre, espera-dísima versión.
Gnome 2.26La primera novedad es la inclusión de la nueva versión del entorno de escritorio Gnome. Sin lugar a dudas, es una de las partes más impor-tantes del sistema puesto que es la que la ma-yoría de lo usuarios utilizan para comunicarse con el mismo. Además de mejoras menores, incluye Brasero por defecto como grabador de CDs en sustitución de Gnome Baker (algo que ya hizo Ubuntu en la versión anterior) y aparte un mejorado sistema de manejo de mútiples monitores.
Servidor X.org 1.6Nueva versión del servidor X (el que soporta to-dos los gráfi cos en el sistema). Incluye un soporte mejorado para muchas tarjetas gráfi cas y aparte mejoras de rendimiento tanto en 2D como en 3D en muchas otras.
Arranque mejoradoMejoras en el sistema de arranque para rebajar el tiempo en que el sistema es utilizable por los usuarios. Éste ha sido uno de los aspectos que Ubuntu siempre ha procurado mejorar respec-to a otras distribuciones desde hace tiempo. Se han paralelizado procesos y se han hecho más efi cientes otros para mejorar el tiempo de carga del sistema sin perder estabilidad.
Kernel 2.6.28Gracias a él Ubuntu soporta ahora ext4 (puntodel que hablaremos a continuación) y ade-más trae otras novedades importantes, como son: GEM, un gestor de la memoria gráfi ca; soporte de Ultra Wide Band (UWB); USB inalámbrico; y UWB-IP, escalabilidad de la ges-tión de memoria, además de otras muchas mejoras técnicas que podéis consultar en la red. Además de por supuesto las mejoras en compatibilidad hardware que trae cada nuevo kernel.
Soporte para el sistema de fi cheros ext4El sistema de fi cheros más extendido del mundo GNU/Linux, el ext, tanto en su versión 2 como en la 3 tiene ya un sustituto llamado ext4. Mucho se ha hablado de si merece la pena incorporarlo por las mejoras en rendimiento que ofrece y por los problemas que han surgido en la fase beta del mismo. Por ahora, personalmente no lo reco-miendo y en lugar de usar ext4 utilizarías reiserfs si queréis probar algo distinto a ext3. El soporte está incluido, por lo que los más valientes tenéis libertad para probarlo.
Soporte para suspender e hibernar mejoradoDos de los aspectos más criticados en sistemas GNU/Linux, la no posibilidad en muchas ocasio-nes de suspender e hibernar, han sido objeto de un importante esfuerzo para mejorar la compati-bilidad con todo tipo de sistemas hardware, en es-pecial, con los portátiles y ultraportátiles que son los dispositivos que más manejan esta opción, debido al ahorro de energía que suponen.
Soporte mejorado para “hotkeys”Las hotkeys, las combinaciones de teclas que permiten modifi car aspectos como el brillo de la pantalla, subir el volumen o permutar la salida de gráfi cos, son de especial importancia cuando se trata, al igual que en el caso de las suspensión y la hibernación, de dispositivos como los portá-tiles y los ultraportátiles. Se ha mejorado la com-patibilidad aunque desde Canonical se pide quelos dispositivos en los que no funcione esta po-sibilidad sean notifi cados para así poder aumen-tar el número de dispositivos compatibles. La grancantidad y variedad presente en el mercado im-pide una compatiblidad total cuando los fabrican-tes de hardware no dan demasiadas facilidades.
KerneloopLa instalación por defecto de kerneloop posibi-lita que en caso de un fallo kernel, incluso de un kernel panic, error que deja al sistema totalmen-te bloqueado como a lo mejor habéis probado alguna vez vosotros mismos, la información del mismo se almacene y se transmita en el si-guiente arranque a un servidor donde se gestio-nará dicho error para ver las posibles fuentes del mismo y evitar que se produzca de nuevo. Éstas y algunas novedades más, como el nuevo siste-ma de notifi caciones del que se ha modifi cado la estética y se han añadido transparencias, hacen de esta versión, una lanza más en la larga guerra de los sistemas operativos de escritorio.
12_Ubuntu.indd 2009-04-14, 14:1112
sección llevada por Juan Gamez [email protected]
novedadesMandriva
13www.lpmagazine.org
Mandriva Enterprise Server 5 betaSe ha anunciado el inicio del periodo de pruebas de Mandriva Enterprise Server 5. Este producto es el sustituto del Corporate Server 4 y está basado en la versión 2009.0 de Mandriva. Entre las características más destacables tenemos:• Si se escoge un entorno grafico se
instalará un sistema GNOME con los mínimos requisitos.
• Nueva guía de configuración vía web para las funcionalidades propias de un servidor: correo electrónico, servidor de impresión, servidor de archivos, etc.
• Todos los servicios son gestionables desde Mandriva Directory Server.
• Vitalización con Xen y KVM.Mandriva está interesada en recabar toda la información, errores, etc. de las pruebas que realicen los usuarios. Podéis descargarla de: https://my.mandriva.com/mes5/beta/
Mandriva y el Google Summer of Code 2009Mandriva ha anunciado su disposición de apoyar a participantes en el Google Summer of Code. Para ello debemos proponer nuestros proyectos en el wiki de Mandriva (http://wiki.mandriva.com/en/Google_Summer_of_Code_2009_Ideas). Google Summer of Code 2009 consiste en el patrocinio por parte de Google a desarrolladores de software libre para llevar a cabo el proyecto propuesto. Un proyecto debe de ser guiado por un mentor, en este caso los mentores pertenecerían a Mandriva.
Mandriva Pulse 2 v.1.2Mandriva ha anunciado la publicación de Mandriva Pulse 2 en su version 1.2. Mandriva Pulse 2 es una herramienta Open Source para la gestión de ordena-dores portátiles y sobremesa, así como servidores. Mandriva Pulse 2 mantiene un inventario del software y hardware de cada ordenador en su base de datos, así como el despliegue y actualización de aplicaciones. Otras características incluyen el diagnóstico y los módulos de control remoto. Podéis bajaros una versión de evaluación (como imagen de WMware) de: https://my.mandriva.com/pulse-2/preview/
Mandriva impulsando el software libreMientras esperamos la publicación de la
nueva Madriva 2009 Spring con KDE 4.2, Gnome 2.26, firefox 3 y otras muchas nove-dades que ya comentaremos en su debido tiem-po, querría hablaros un poco de lo que está ha-ciendo Mandriva como divulgador y como opti-mizador del mundo GNU/Linux y del software libre en general. Es decir que es lo que Mandriva está aportando y ayudando fuera de su distribu-ción y dentro del software GNU/Linux.
Hace poco en el blog oficial de Mandriva (http://blog.mandriva.com/) leíamos que Man-driva había decidido ayudar a portar el famoso software de grabación de Cd y DVD k3b a qt4.2. es decir que ingenieros del equipo KDE de Mandriva trabajarían junto al líder de desarro-llo del proyecto de k3b, Sebastian Trueg, para que la nueva versión de este popular programa fuera publicada lo antes posible, incluso a tiem-po de ser incluida en Mandriva 2009.1 Spring. Con este trabajo se conseguirá que k3b utilice toda la potencia de la plataforma KDE4. Según nos cuenta en el blog He portado el soporte para arrastrar y soltar, arreglado la gestión de plu-gins, y algunas otras cosas que se rompieron con el cambio de KDE3 a KDE4. Esto generará una aplicación aún mejor y más depurada.
Así mismo en su versión 2009.1 Spring Man-driva ha decidido incluir el Qt Creator, un IDE multiplataforma orientado al desarrollo con C++ y Qt desarrollado por Qt software, nombre con el que renombró Nokia a Trolltech el 29 de sep-tiembre de 2008, meses después de su compra.
Con este IDE podremos crear proyectos en C++, además incorpora un diseñador de
formularios, autocompletado y reconocimien-to de propiedades y métodos, y como es usual en los productos de Trolltech, una abundante documentación integrada. Además incluye una herramienta de debugger y abundantes nuevas opciones.
Mandriva es una de las primeras distri-buciones de GNU/Linux que ofrece este IDE desde sus repositorios, estando, a partir de Mandriva 2009.1 Spring, a disposición de los usuarios dentro del repositorio Main.
Estos son solo dos de los ejemplos más re-cientes, a estos podemos incluir el impulso que dio Mandriva a Pulse Audio al ser la primeradistribución en incluirla, o bien, la fuerte apuesta que ha realizado Mandriva en el área de escrito-rios 3D, tanto con Compiz como con su escrito-rio propio Matisse.
Todo esto hace que Mandriva sea una de las distribuciones que más a la vanguardia se encuentra en el mundo GNU/Linux. Incorpora en cada lanzamiento las últimas versiones y no-vedades tanto del núcleo como de aplicaciones. Esto podría llevar asociado una inestabilidad de la distribución, pero gracias al duro trabajo de los ingenieros de Mandriva, siempre se encuen-tra un equilibrio entre lo nuevo y lo estable.
Por todo ello, Mandriva sigue siendo nues-tra distribución favorita, no solo por su calidad sino por el interés y compromiso tanto con el software libre como con su comunidad de usua-rios, esto último, muy valorable pues no de-bemos de olvidar el carácter de empresa priva-da que es Mandriva.
Mandriva Pulse 2 v.1.2
13_Mandriva.indd 2009-04-14, 14:1113

novedadesFedora
14 Linux+ 6/2009
sección llevada por Diego Rivero Montes [email protected]
¿Stallman contra Linux?Según se ha publicado en el diario Público en su página web, el padre del movimiento del Software libre no dejó títere con cabeza en su conferencia ofrecida el día 4 de marzo en el Medialab Prado de Madrid. Arremetió según el periódico contra Microsoft y Apple porque son ...representantes de una indus-tria que quiere imponer la dictadura de los programas privativos.... Los fabricantes de móviles no se quedaron sin su ración, mani-festando además Sería más cómodo para mí tener móvil, pero hay cosas más importantes que la comodidad, pero la mayor concentra-ción de su ira se la dedicó a Linus Torvalds y su creación, No es justo que el trabajo que hemos hecho desde hace 25 años se atribuya a uno [en referencia a Torvalds] que está en contra de los valores del software libre, dijo Stallman entre el silencio de los asistentes.http://www.publico.es/ciencias/206550/stallman/linux/software/libre
Fedora 8 EOLPara los usuarios que aún siguen aferrados a Fedora 8 ésta es sin duda una mala noticia, ya que lo que anunciamos es el fin del so-porte para la versión octava de Fedora. Pues sí, ya en enero se produjo el End of life, lo que significa que desde entonces los que aún disfruten de las bondades de esta release ya no tienen actualizaciones de ningún tipo para las aplicaciones implementadas en ella y que los bugs que se hayan encontrado para esta versión en especial se darán como cerrados sin solucionar. Bueno, todo no va a ser malo, para todos aquellos que aún sean usuarios e esta versión les animamos a actualizarse y migrar a una versión más reciente que de lo más seguro no les defraudará en absoluto.
Fedora ParaguayEl nacimiento de nuevas comunidades en Linux siempre es una buena noticia y en este caso aún más ya que se ha producido el lan-zamiento del sitio oficial de Fedora Paraguay, lo cual deja patente que la comunidad Fedora es una comunidad viva, unida y que crece día a día. En efecto en marzo inició su andadura en la web y desde aquí queremos dar la más cordial felicitación a los que han hecho posi-ble esta gran idea.http://proyectofedora.org/paraguay/
Fedora… Cada vez más usuariosNo es de extrañar al menos para la comuni-dad Fedora que el resto del mundo Linux se vea sorprendido gratamente por las cualida-des de las últimas versiones de esta distribu-ción. Las estadísticas, aunque siempre frías, no dejan lugar a dudas y nos muestran un incremento del 15% de usuarios en Fedora 10 respecto a la anterior versión.Entre los motivos que se apuntan como responsables de este aumento de usuarios podemos citar: el hecho de que la innovación sea un compromiso del equipo realizador, que la calidad sea una conditio sine qua non, y que es acreedora de una de las mayores y mejores comunidades de apoyo de Linux.
GNOME 2.26 para Fedora 11Aquí tenemos la última entrega del escri-
torio GNOME, uno de los más popu-lares entornos de escritorio. GNOME es sin duda uno de los que más han sido enfocados a la facilidad de uso, con unas características en lo que se refiere a estabilidad e interna-cionalización que pocos se acercan a lograr además de poseer una accesibilidad digna de encomio.
Además de tratarse por supuesto de Soft-ware Libre, lleva consigo las más usuales he-rramientas que todos necesitamos y deseamos encontrar en un equipo de nuestros tiempos ya sea si queremos enviar un e-mail, chatear, visitar webs, gestionar grupos de trabajo y ar-chivos, jugar, etc. Igualmente para aquellos que se dedican al desarrollo no se ha dejado de lado esta vertiente de la plataforma, con-virtiéndose e una de las más potentes en vías a la creación tanto para escritorio como si se trata de dispositivos móviles.
El proyecto GNOME se centra en los usu-arios y la usabilidad, y continúa en GNOME 2.26 con cientos de arreglos y mejoras pedidas por los usuarios. Este impresionante número de mejoras hacen imposible listar cada cambio que se ha realizado pero esperamos resaltar algunas de las características orientadas al usuario más excitantes de este lanzamiento de GNOME:
• Nueva grabación de discos completa,• Compartición de archivos simple,• Evolution evoluciona su migración desde
Windows,• Mejoras en el reproductor multimedia,• Control de volumen integrado con Pulse-
Audio,
• Soporte para múltiples monitores y proyec-tores,
• Comunicación casi telepática,• Barra de direcciones de Epiphany,• Integración de lector de huellas.
Y muchos otros cambios que harán el deleite de los usuarios.
Novedades para los desarrolladoresNo se trata sólo del escritorio, GNOME 2.26 es la última versión de la plataforma de de-sarrollo GNOME. Los desarrolladores saben bien lo que es esto, se trata de un conjunto de bibliotecas API y ABI disponibles bajo la licen-cia GNU LGPL que se pueden usar para de-sarrollar aplicaciones multiplataforma.
Según la web, a partir de GNOME 3.0 se empezarán a eliminar diversas partes de GNO-ME obsoletas, como libgnome, libgnomeui, libgnomeprint, libgnomeprintui, libgladey lib-gnomevfs. Para las aplicaciones que se inclu-yen en el Escritorio GNOME, se han llevado a cabo ciertas tareas de limpieza para asegu-rar que no se usa ningún código obsoleto. Esto asegurará una transición suave a GNO-ME 3.0.
Desde la página oficial del proyecto, se urge a los desarrolladores que sigan el ejemplo en sus propias aplicaciones.
GNOME 2.26
La velocidad en extremo¿Quién diría que podemos tener iniciado
el sistema en 5 segundos? Yo por supues-to que no... Acabo de leer que en la Linux Plumber Conference o sea la conferencia so-bre “fontanería” Linux, es decir lo que hace funcionar un Linux en las entrañas, que según se comenta ha sido lo más interesante de los últimos años en lo que a nuestro sistema se refiere. Pues bien los ingenieros de Intel que se dedican a Linux han hecho una demostra-ción pública de algo sorprendente, un siste-ma Linux que tarda en cargar únicamente cinco segundos. El sistema en cuestión se trata de un EEE PC de Asus y además con la parti-
cularidad de que estaba equipado con un dis-co duro flash, si se equipase con un disco duro tradicional la velocidad se vería reducida y tar-daría unos 10 segundos.
Aunque a simple vista pudiera parecer algo típico de Hackers y de dudosa utilidad para distribuciones de uso común, no es algo tan descabellado. Según se desprende de lo visto en la conferencia, en los sistemas de es-critorio el 95% se podría sustentar en un ker-nel con algunos módulos compilados estáti-camente y el 5% restante con un kernel alter-nativo que lleve initrd.
14_Fedora.indd 2009-04-14, 14:1114

Si no puedes leer el disco DVDy no notas ningún tipo de deterioro mecánico, por favor, pruébalo en al menos dos unidades de disco diferentes.
6/2009
En caso de problemas, escribir a: [email protected]
15_pod_dvd.indd 2009-04-14, 14:1211

Cloud ComputingCloud Computing: El sistema operativo EyeOS
16 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
l
Cloud Computing: El sistema operativo EyeOSBajo el término Cloud Computing, se engloba un conjunto de soluciones tecnológicas que permiten ofrecer servicios de computación a través de los protocolos TCP-IP, de forma que todo aquello que pueda ofrecer un sistema informático concreto, tanto a bajo nivel como a nivel de aplicación, es accesible a usuarios ajenos a éste.
José B. Alós Alquézar
En el paradigma Cloud Computing, de conformi-dad a lo establecido por IEEE Society, la infor-mación se almacena de forma permanente en ser-vidores conectados a la red, siendo enviada a las
cachés temporales de cada cliente, como equipos de sobreme-sa, portátiles, y por supuesto, los novedosos Netbooks a fi n de lograr un mejor aprovechamiento de los recursos ofertados por el hardware actual. Esto es especialmente importante de cara a no confundir con la computación Grid, en la que el propósito fi nal es la producción de un supercomputador virtual integrado por diferentes nodos remotos actuando conjuntamente para realizar actividades de proceso masivo de cálculos y datos.
Cualquier usuario al conectarse a Internet puede encon-trar numerosos ejemplos de todo ello, como los ofertados por Google Apps, Amazon EC2 y Microsoft Azure, que permiten acceder a aplicaciones comunes a partir de un navegador Web aprovechando la generalización de las tecnologías AJAX y Web 2.0.
Aun cuando existe una tendencia generalizada a con-fundir los términos Cloud Computing y Grid Computing, el motivo fundamental que explica su aparición es la necesidad de albergar aplicaciones como servicios externos (SaaS) a un
determinado dispositivo o computador, de forma que sean fácilmente accesibles a los usuarios de estos, sin necesidad de poseer una copia local de estas instaladas en sus equipos. Cloud Computing no es más que el resultado de la evolución lógica de la informática iniciada en la década de los 60 y 70 con los mainframes y continuada en los 80-90 con los equi-pos personales.
Otra alternativa, para evitar la posible dependencia de código no libre y que tanto preocupa a los responsables de la GNU Foundation son los sistemas FLOSS o SO libres para Clould Computing. En este sentido, el proyecto eyeOS nace como respuesta a estas necesidades, además de proporcio-nar una compatibilidad con soluciones propietarias actual-mente en uso así como a desarrollos cerrados de WebOS como Microsoft Azure.
• Instalación, confi guración y administración del SO eyeOS.
• Confi guración básica de eyeOS.
En este artículo aprenderás ...
16_17_18_19_20_21_EyeOS.indd 2009-04-14, 14:1216

Cloud ComputingCloud Computing: El sistema operativo EyeOS
17www.lpmagazine.org
El advenimiento de las tecnologías Web 2.0 ha conducido al desarrollo de sistemas opera-tivos basados en esta estructura, denominados como WebOS y que se prevé conduzca al nuevo paradigma Web 4.0 en el futuro.
EyeOS es un sistema operativo orientado a la computación distribuida y que require hospedaje HTTP para su instalación y posterior puesta en marcha elaborado por www.eyeos.org y liberado bajo la licencia GPL Affero (AGPL versión 3).
eyeOS=Internet + Ficheros +
Aplicaciones
El propósito fundamental de eyeOS consiste en la creación de un producto de fácil instalación, confi guración y gestión, que permita a un usua-rio de sistemas UNIX poseer su propio sistema de cloud computing bajo su entero control, permitiendo además la participación en una comunidad de usuarios y desarrolladores cada vez más amplia, con la fi nalidad de desarrollar sus propias aplicaciones para este sistema. En cualquier caso, los responsables del proyecto ofrecen como alternativa a la instalación del producto, la apertura de una cuenta de usuario en su sistema a fi n de poder evaluar las bon-dades del producto. Para mayor información, conectar con http://www.eyeos.info amén de numerosos documentos y podcast informati-vos acerca de este.
Caracterísitcas fundamentales de eyeOSEl sistema operativo eyeOS proporciona los servicios básicos descritos con antelación de los sistemas WebOS de cara a satisfacer la necesidad de que las aplicaciones sean ac-cesibles remotamente por los usuarios desde un navegador compatible con los estándares W3C:
• Gestión de fi cheros, permite la carga y des-carga (upload/download) de múltiples fi -cheros con capacidades de compresión ZIP/USTAR así como su visualización.
• Gestión de información personal y contac-tos, incluyendo calendario con múltiples vistas, gestor de contactos y posibilidad
de exportación e importación de estos en formato vCard.
• Aplicaciones ofi máticas; incorpora un pro-cesador de textos, hoja de cálculo y motor de presentaciones, todos ellos compatibles con MS Offi ce y las suites ofi máticas Ope-nOffi ce y StarOffi ce.
• Comunicaciones; posee un sistema de men-sajería interna para los usuarios de eyeOS, un bulletin board, cliente proxy FTP así como un lector de semillas RSS.
• Administración del sistema; permite la ins-talación de paquetes y cuenta además con un novedoso repositorio basado en ports, característica asimilada de los sistemas FreeBSD/NetBSD además de la gestión de usuarios y grupos.
• Nociones básicas de tecnologías Clo-ud Computing y Web 2.0.
• Conocimientos de sistemas Unix a ni-vel de desarrollador.
• Instalación de paquetes en sistemas GNU/Linux.
• Confi guración de servidores HTTP Apache 2.x.
Lo que deberías saber ...
Listado 1. Instalación de los módulos PHP
# yum install mod_suphp
=========================================================================
=======
Package Arch Version Repository
Size
=========================================================================
=======
Installing:
mod_suphp i386 0.6.3-1.fc9 fedora
89 k
Installing for dependencies:
php i386 5.2.6-2.fc9 updates-newkey
1.2 M
php-cli i386 5.2.6-2.fc9 updates-newkey
2.3 M
php-common i386 5.2.6-2.fc9 updates-newkey
228 k
Listado 2. Instalación del soporte multilenguaje PHP
# yum install php-mbstring
=========================================================================
=======
Package Arch Version Repository
Size
=========================================================================
=======
Installing:
php-mbstring i386 5.2.6-2.fc9 updates-newkey
1.1 M
Transaction Summary
=========================================================================
=======
Install 1 Package(s)
Update 0 Package(s)
Remove 0 Package(s)
Total download size: 1.1 M
• CVS : Control Version Source,• DAV : Web-based Distributed Autho-
ring and Versioning,• DSO : Dynamic Shared Object,• EC2 : Elastic Cloud Computing,• FLOSS : Free Libre Open Source
Software,• ODF : Open Document Format,• SaaS : Software As A Service,• SVN : Subversion Management System.
Acrónimos y abreviaturas
16_17_18_19_20_21_EyeOS.indd 2009-04-14, 14:1217
18 Linux+ 6/2009
Cloud ComputingCloud Computing: El sistema operativo EyeOS
Uno de los puntos más importantes que permite eyeOS es la posibilidad de gestionar múltiples instancias de una misma aplicación.
Por otra parte, eyeOS viene con un con-junto de aplicaciones instaladas aunque existe la posibilidad de migrar aplicaciones propias, simplificando ostensiblemente los costes de administración y mantenimiento, o desarrollar nuevas aplicaciones para el sistema.
Requisitos previosLos requisitos de instalación son los siguientes:
• Servidor HTTP con soporte PHP5 para ca-denas multibyte UTF-8, o superior, como Apache 2.0.39 o superior.
• Cliente HTTP compatible con las especifi-caciones W3C como Mozilla Firefox 2 o MSIE 6.
Generalmente, aunque la mayoría de las distri-buciones Linux incorporan el servidor Apache por defecto, los módulos DSO PHP no son instalados. Para obviar este inconveniente, es preciso descargar dicho servidor. En un sistema basado en la distribución de paquetes RPM, se podría realizar esta operación mediante yum.
que además deposita el fichero de configu-ración php.conf necesario para la carga de dicho módulo por el servidor Apache. Finalmente, es preciso instalar el modulo mbstring para habili-tar el soporte UTF-8 para aplicaciones PHP:
Una vez realizada la configuración del ser-vidor HTTP, el proceso de instalación es muy simple teniendo en cuenta el fichero de configu-ración httpd.conf del servidor Apache:
• En el directorio DocumentRoot, descom-primir el fichero eyeOS_1.8.0.4.zip:# cd /var/www/html
# unzip eyeOS_1.8.0.4.zip
• Posteriormente, seleccionar la URL http://localhost/eyehost y el proceso de insta-lación del producto se iniciará de forma automática.
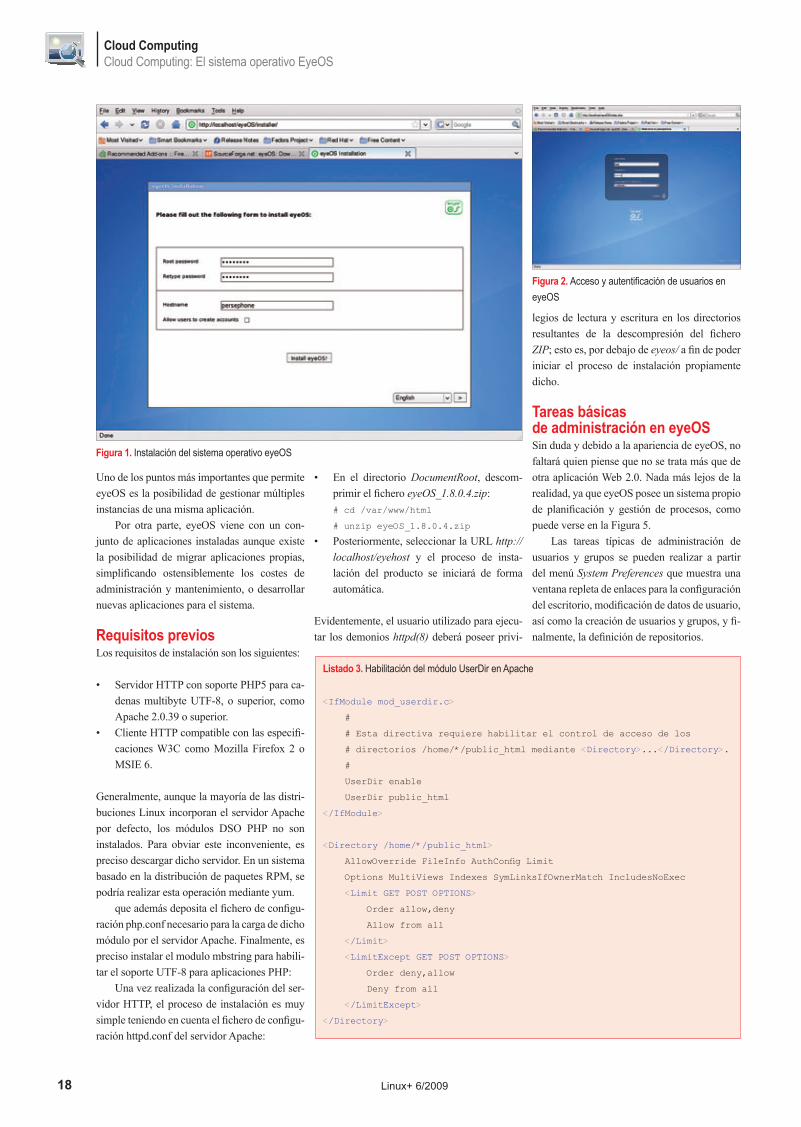
Evidentemente, el usuario utilizado para ejecu-tar los demonios httpd(8) deberá poseer privi-
legios de lectura y escritura en los directorios resultantes de la descompresión del fichero ZIP; esto es, por debajo de eyeos/ a fin de poder iniciar el proceso de instalación propiamente dicho.
Tareas básicas de administración en eyeOSSin duda y debido a la apariencia de eyeOS, no faltará quien piense que no se trata más que de otra aplicación Web 2.0. Nada más lejos de la realidad, ya que eyeOS posee un sistema propio de planificación y gestión de procesos, como puede verse en la Figura 5.
Las tareas típicas de administración de usuarios y grupos se pueden realizar a partir del menú System Preferences que muestra una ventana repleta de enlaces para la configuración del escritorio, modificación de datos de usuario, así como la creación de usuarios y grupos, y fi-nalmente, la definición de repositorios.
Listado 3. Habilitación del módulo UserDir en Apache
<IfModule mod_userdir.c>
#
# Esta directiva requiere habilitar el control de acceso de los
# directorios /home/*/public_html mediante <Directory>...</Directory>.
#
UserDir enable
UserDir public_html
</IfModule>
<Directory /home/*/public_html>
AllowOverride FileInfo AuthConfig Limit
Options MultiViews Indexes SymLinksIfOwnerMatch IncludesNoExec
<Limit GET POST OPTIONS>
Order allow,deny
Allow from all
</Limit>
<LimitExcept GET POST OPTIONS>
Order deny,allow
Deny from all
</LimitExcept>
</Directory>
Figura 1. Instalación del sistema operativo eyeOS
Figura 2. Acceso y autentificación de usuarios en eyeOS
16_17_18_19_20_21_EyeOS.indd 2009-04-14, 14:1218
19www.lpmagazine.org
Cloud ComputingCloud Computing: El sistema operativo EyeOS
Cada usuario eyeOS posee por defecto sus propias carpetas donde se almacenan tanto sus ficheros como los parámetros de configuración de estos:
./files/Documents:
./files/Images:
./files/Music:
./files/Videos:
./public:
./swap:
./tmp:
./trash:
Por otro lado, un usuario puede adscribirse a un grupo concreto, lo cual resulta de gran interés al generalizar el uso de eyeOS a entornos comple-jos e incluso de carácter empresarial.
Descripción de AplicacionesEyeOS introduce en su escritorio sustanciales mejoras, como una barra de aplicaciones minimi-zada indicando qué aplicación se está utilizando en cada momento, así como en la gestión de ventanas, que indica en todo momento la ventana activa; o como una nueva colección de iconos.
Además, existe la posibilidad de utilizar un escritorio menos pesado, ya existente en las versiones eyeOS 1.x y conocido como Light Desktop junto con la capacidad para utilizar ex-tensiones adicionales como Fusion y Oxigene, disponibles en la sección Theme, correspon-diente al menú System Preferences.
Dentro de este contexto, y teniendo en cuenta que eyeOS se encuentra todavía en fases tempranas de madurez (especialmente en lo concerniente a la documentación accesible), vamos a detallar alguna de las aplicaciones más importantes disponibles en la versión objeto del presente artículo.
Procesadores de textos: EyeOS Word ProcessorDotado de una apaciencia similar a los proce-sadores de textos existentes en la actualidad, tal y como aparece en la Figura 7, eyeOS Word Pro-cessor incorpora un diseño de página mejorado, con nuevas herramientas accesibles a través de una barra de herramientas y la posibilidad de trabajar con formatos MS Word, OpenDocument (ODF) además del formato nativo eyeOS.
Es importante recordar que la habilitación del soporte para los ficheros MS Office/Open Office requiere OpenOffice.org junto con la instalación macro de cara a poder utilizar esta funcionalidad con eyeOS Word Processor.
Gestión de Contactos: EyeAddressBookEyeOS incorpora por defecto un gestor de contactos con una colección de funcionalidades semejantes a las existentes en otras aplicaciones similares, permitiendo también la definición de grupos de contactos, la importación de imáge-nes, así como datos binarios.
Gestión multimedia audio: EyeMediaA fin de mejorar las prestaciones de eyeMP3, como aplicación disponible en anteriores ver-siones de eyeOS, Hunter Perrin ha desarrolla-do eyeMedia, que permite gestionar listas de música o playlists de cara a convertir eyeOS en una especie de reproductor de música online tal y como se muestra en la Figura 9.
Compartición de ficheros con otros usua-rios eyeOSEl cuadro de diálogo Share with… accesible tanto desde el menú contextual de eyeOS co-
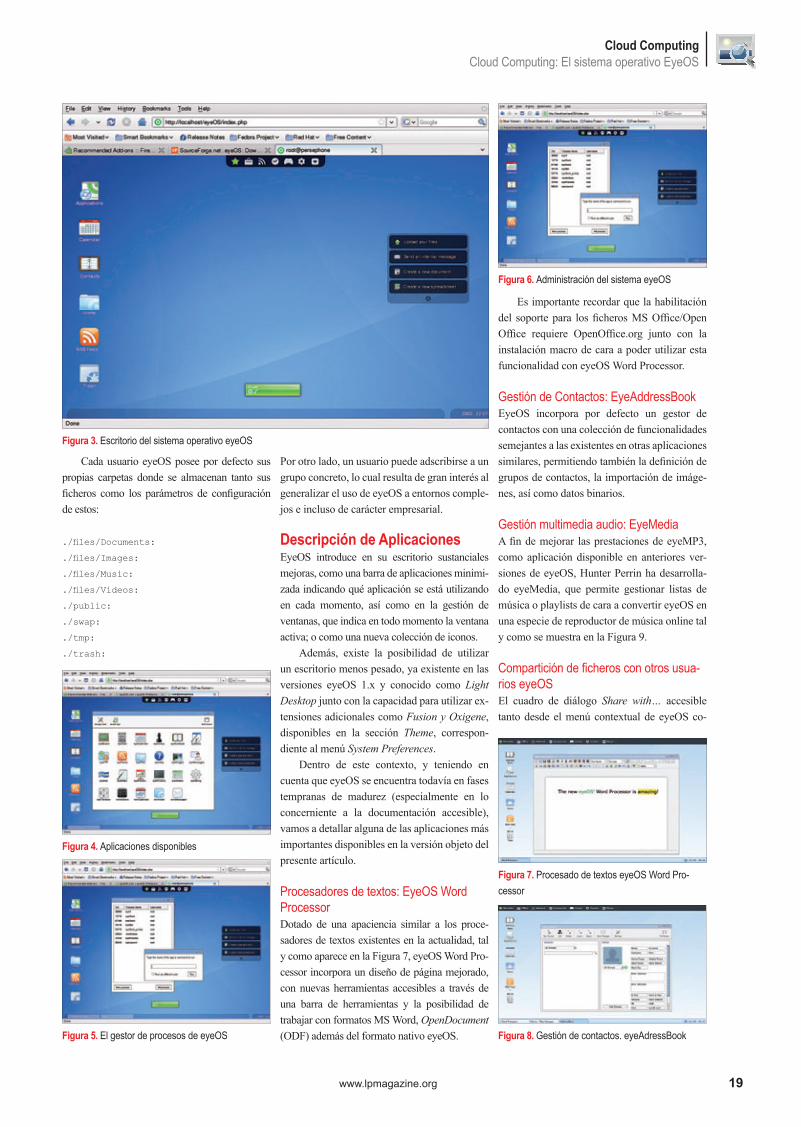
Figura 3. Escritorio del sistema operativo eyeOS
Figura 4. Aplicaciones disponibles
Figura 5. El gestor de procesos de eyeOS
Figura 6. Administración del sistema eyeOS
Figura 7. Procesado de textos eyeOS Word Pro-cessor
Figura 8. Gestión de contactos. eyeAdressBook
16_17_18_19_20_21_EyeOS.indd 2009-04-14, 14:1219

20 Linux+ 6/2009
Cloud ComputingCloud Computing: El sistema operativo EyeOS
mo desde el panel Actions presente en Files Manager permite la copia directa de ficheros a los grupos de usuarios creando enlances entre los ficheros privados de usuario y los grupos de usuarios compartidos, tal y como se indica en la Figura 10, a fin de hacer posible la distribución de ficheros, siempre y cuando se posean los permisos necesarios para ello.
También, y como colofón, es posible des-cargar e instalar o actualizar el sistema eyeOS a través del enlace Donwloads page presente en el escritorio; actividad a tener presente debido a que el desarrollo de eyeOS se encuentra en permanente evolución.
Instalación de nuevas aplicacionesUno de los puntos débiles de eyeOS en el momento actual es la ausencia de repositorios consolidados para la descarga de aplicaciones, así como su estado de madurez. No obstante, eyeOS permite la instalación de nuevas aplica-ciones mediante un sencillo procedimiento que se describe a continuación.
• Seleccionar el menú Applications AT,• Acceder al menú Install Apps,• Una vez aparece en pantalla la ventana con
el título Packages Manager, seleccionar Update.
De este modo, a la izquierda del escritorio eyeOS aparece el listado Categories que per-mite seleccionar la o las aplicaciones deseadas. Una vez realizada esta selección, únicamente es preciso seleccionar el botón Install y el proceso
de instalación se iniciará de forma automática, siempre y cuando se disponga de conexión a Internet.
Desarrollo de aplicaciones en eyeOSResulta interesante también aleccionar a la co-munidad de desarrolladores interesados en colaborar con el desarrollo de eyeOS como sistema webOS sobre los pasos a seguir de ca-ra al trabajo dentro de este ámbito. El código fuente de eyeOS es accesible a través del repo-sitorio SVN desde la siguiente URL: https://eyeos.svn.sourceforge.net/svnroot/eyeos/eyeOS/branches/production/.
que contiene la rama de desarrollo estable actual. A tal efecto, deberán instalarse en el equipo local los interfaces CLI de Subversion, disponibles en http://subversion.tigris.org.
Téngase en cuenta que la revisión de eyeOS dentro del repositorio Subversion está específicamente concebida para su utilización en un entorno de desarrollo de software y no está en absoluto pensada para los usuarios finales.
De este modo, la obtención del código de desarrollo puede resumirse en tres pasos deta-llados a continuación:
• Ejecutar el comando svn(1):$ svn checkout https://eyeos.svn
.sourceforge.net/svnroot/eyeos/
eyeOS/branches/production
• Opcionalmente, actualizar el código a la última versión mediante el comando:$ svn update
Una posibilidad interesante reside en utilizar el módulo userdir en el servidor Apache edi-tando el fichero httpd.conf tal y como se muestra en el Listado 1, de tal modo que descargue-mos la rama de desarrollo eyeOS dentro del directorio public_dir. Este módulo, permite la adición de un directorio definido previamente en el fichero de configuración httpd.conf ca-da vez que se inicie en el navegador WWW una solicitud que contenga la cadena ~user. Para ello deben satisfacerse las siguientes condiciones:
• El árbol de directorios que llevan hasta pu-blic_html deben ser accesibles al usuario que ejecuta el servidor HTTP.
• El directorio ~userid debe poseer permi-sos 711.
• El directorio ~userid/public_html debe po-seer permisos 755.
En caso de no procederse de la forma indicada, el servidor HTTP lanzará como resultado el error 403. Forbidden.
Tras lo cual, deberá procederse de nuevo a la parada y arranque del servidor HTTP mediante el comando: $ apachectl stop && apache ctl start a fin de efectuar la carga del nuevo módulo.
Figura 9. Aplicaciones multimedia. eyeMedia
Figura 10. Compartición de ficheros en eyeOS
Figura 11. Configuración de eyeSync
Figura 12. Configuración de eyeSync
16_17_18_19_20_21_EyeOS.indd 2009-04-14, 14:1220

21www.lpmagazine.org
Cloud ComputingCloud Computing: El sistema operativo EyeOS
Una vez obtenido el código fuente de eye-OS, es necesario dotarse de las herramientas de desarrollo cliente, presentes en eyeOS toolkit, que permitirán la realización de operaciones de depuración sin necesidad de volver a ejecutar la aplicación. Para ello, siempre y cuando el desarrollador utilice Firefox como navegador por defecto, es conveniente descargar el addon Firebug desde http://addons.mozilla.org.
Firebug es un complemento ideal no sólo para el desarrollo de aplicaciones eyeOS sino para cualquier tipo de aplicaciones web gracias a su integración con el navegador. En cualquier caso, y como conclusión, el siguiente paso será la lectura de la documentación asociada: eyeOS Application Manual y Developers Re-ference, disponibles en http://wiki.eyeos.org/Developers_Reference_Index.
Sincronización remota mediante eyeSyncEyeSync es una aplicación que permite sin-cronizar fi cheros entre plataformas locales de usuario como MS Windows XP, MacOS X Leopard y, por supuesto, GNU/Linux para ha-cerlos accesibles a eyeOS. Para la utilización, es preciso descargar el paquete de instalación. Desgraciadamente, sólo está disponible el pa-quete DEB, por lo cual, vamos a realizar la ins-talación a partir del código fuente, $ tar xvfz eyeSync_1.0_Alpha_Source.tar.gz && cd
eyeSync-1.0Alpha/
a partir de la URL http://www.eyeos.org/down-loads y seguir los siguientes pasos:
• Verifi car que el sistema anfi trión posee los siguientes paquetes instalados:– Qt 4.3 o superior,– Extensión Python pyQt4 disponible en
http://www.riverbankcomputing.co.uk/pyqt,
– Extensión PyNotify, disponible en http://pynotify.sourceforge.net para monitori-zación de sistemas de fi cheros.
En caso contrario, proceder a su instalación. En distribuciones GNU/Linux basadas en RPM, la forma más simple es mediante la utilidad YUM:
# yum install PyQt.i386 python-
inotify.i386
y para sistemas basados en Debian:
# apt-get install python-pyinotify
python-qt4
• Ejecutar el script Python eyeSync utilizan-do un usuario eyeOS con permisos de es-critura en este, que da como resultado una pantalla tal y como se muestra en la Figura 11 para su confi guración preliminar:
En el menú 'Preferences' deberá seleccionarse la URL de acceso al sistema eyeOS, tras lo cual, debe reiniciarse eyeSync.
• Finalmente, seleccionar los directorios del sistema operativo local que se deseen sin-cronizar con eyeOS tal y como se indica en la Figura 12.
El resultado de esta operación, puede apreciarse directamente en la Figura 13 al iniciar una se-sión en eyeOS, donde podemos ver los fi cheros correspondientes a este artículo directamente en nuestro entorno Cloud Computing.
Conviene no olvidar que eyeSync es una aplicación independiente que debe ser ejecu-tada por cada usuario defi nido en eyeOS con permisos de lectura/escritura, por lo que su ins-talación en el equipo local deberá ser accesible a todos los usuarios que deseen utilizarla.
Otra actividad importante es la realización de copias de seguridad, mediante eyeBackup, que estará disponible en un futuro próximo. De momento, la opción más razonable, es la reali-zación de copias de seguridad tradicionales o bien mediante software dedicado como Bacula, NAS Backup o BackupPC.
Conclusiones fi nalesTras esta breve introducción a eyeOS como uno de los exponentes más prometedores de la nueva generación de sistemas webOS para Cloud Computing, debe tenerse en cuenta la gran cantidad de posibilidades que encierra, especialmente con los esfuerzos de la comuni-dad de desarrolladores de nuevas aplicaciones. Para ello nada mejor que utilizar el repositorio SVN donde pueden encontrarse las últimas versiones disponibles de la documentación sobre este sistema.
Uno de los aspectos más destacables de eyeOS es la posibilidad de contar, además del nivel de soporte Open Source, con un soporte profesional, que ofrece a las empresas unos tiempos de respuesta a incidencias sustan-cialmente más reducidos (que llega incluso a niveles de asistencia in-house para el nivel de soporte Premium).
No contentos con ello, el proyecto eyeOS posee también tres niveles de formación, di-rigidos a usuarios fi nales, administradores del sistema y desarrolladores del mismo, respec-tivamente. Además, eyeOS ha sido seleccio-nado para la próxima Cloud Computing Expo 2009 a celebrar en Nueva York como alter-nativa libre.
Figura 13. Sincronización de directorios en eyeOS Figura 14. Jugando al ajedrez con eyeOS
• EyeOS Web SO Main Site: http://www.eyeos.org• Comunidad de desarrolladores
EyeOS: http://eyeos.org/en/developers • EyeOS Wiki Main Site: http://wiki.eyeos.org• Apache HTTP Server Main Site: http://www.apache.org • PHP Language Main Site: http://www.php.net • Subversion (SVN) Main Site: http://subversion.tigris.org
En la red
José B. Alós es administrador de sistemas especializado en SunOS 5.x/HP-UX/AIX desde 1999 de la mano de EDS, desarro-llando su trabajo en Telefónica de España, S. A. U.; y lleva trabajando con sistemas GNU/Linux desde los tiempos del núcleo 1.2.13. Ha sido profesor de la Universidad de Zaragoza. Está especializado en sis-temas de Alta Disponibilidad y posee un doctorado en Ingeniería Nuclear.
Sobre el autor
16_17_18_19_20_21_EyeOS.indd 2009-04-14, 14:1221

Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
22 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
lCloud Computing: ¿La gran oportunidad para Linux?Desde la liberación en 1992 de las primeras distribuciones se viene vaticinando el “gran despegue de Linux”. 17 años después ni el interés de grandes empresas como IBM, ni la aparición de una distro orientada específi camente al público masivo como UBUNTU, ni el atractivo innegable para el usuario sin conocimientos de proyectos como COMPIZ han permitido perforar el techo del 1% del mercado.
Diego Gernan Gonzalez
En cuanto al tan deseado aluvión de nuevos usua-rios que se esperaba a causa de la desilusión con Windows Vista se quedó en algunos miles, el resto de los no conformes se volvió a XP.
Digámoslo de esta manera, la batalla por el mercado de los sistemas operativos de escritorio está terminada y la ga-nó Microsoft. ¿Signifi ca eso que debemos resignarnos a ser una minoría? No, según algunos especialistas la industria informática tal cual la conocemos está por cambiar y con ese cambio la relación de los usuarios con sus computa-doras.
En los últimos tiempos en los portales y publicaciones dedicados a la informática se está hablando mucho de la com-putación en nube o Cloud Computing, algunos creen que será un punto de infl exión que marcará la nueva era en Internet. Para otros sin embargo es sólo la forma en que la industria de la tecnología de la información aplica una vieja técnica de los fabricantes de productos de consumo masivo, cambiar el envase para hacer creer que un producto es nuevo.
En este artículo vamos a explicar por qué creemos, o mejordicho, deseamos que la computación en nube sea una re-volución en el mercado de la informática y por qué en caso
de serlo es lo que Linux en particular y el código abierto en general estaban necesitando.
Características de la Cloud ComputingEstoy escribiendo el borrador de este artículo en mi Palm z22, para corregirlo lo pasaré por medio del programa JPI-LOT al disco rígido de mi computadora. Una vez terminado irá como archivo adjunto en un e-mail a la redacción de la revista, la cual lo guardará y reenviará a los betatester, que a su vez lo archivarán en sus respectivos dispositivos de almacenamiento. Imaginen en cambio que yo desde mi Palm lo mandará vía web a un servidor, ingresará a él desde mi computadora para hacer las correcciones y después co-municará a la revista que ya está listo para su revisión. Ellos a su vez habilitarán un acceso restringido a los betatester para hacer los comentarios que consideren convenientes, la can-tidad de hardware necesario y de copias se reduce notable-mente. Esa es la idea, el usuario con un equipo con las capa-cidades sufi cientes para conectarse a Internet puede acceder por medio de ésta al software y hardware que le haga falta sólo cuando le haga falta.
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-14, 14:1322

Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
23www.lpmagazine.org
Detrás de la computación en nube hay una tecnología y un concepto clave: virtualización y escalabilidad. La virtualización permite que varios usuarios utilicen en un mismo servidor diferentes sistemas operativos y aplicaciones. Cuando la capacidad de ese servidor se ve sobrepasada, el exceso de trabajo se transfi ere automáticamente a otro servidor conectado en línea, eso es escalabilidad.
Algunas de las consultas más comunes en los foros tienen que ver con el reemplazo de pro-gramas de Windows en Linux, existen casos de aplicaciones muy específi cas que todavía no tienen equivalencia. Con la tecnología de la com-putación en nube podríamos usar una de esas apli-caciones en Windows, hacer la carátula del infor-me en Mac y mandarla por e-mail con la versión Linux de Thunderbird, y todo sin resetear.
En un documento conocido como El ma-nifi esto de la nube abierta del cual hablaremos más tarde, se da una muy buena descripción sobre las posibilidades de esta tecnología.
La característica principal de la nube es la posibilidad de ofrecer servicios de computa-ción escalables a un costo efi ciente permitiendo al usuario utilizar todo su poder sin necesidad de tener que manejar las complejidades subya-centes a la tecnología.
Ya sea que la nube resida en la red privada de una organización o esté en Internet, sus ven-tajas son las siguientes:
Adaptación del tamaño según las necesidadesTanto las organizaciones como las personas debemos hacer frente a un entorno cambiante, cambios que requerirán diferentes soluciones computacionales. El organismo recaudador de impuestos de una zona de veraneo tiene que optar por ver colapsados sus equipos en los tres meses de mayor trabajo, o verlos su-butilizados los otros nueve. Un juego en red requiere diferentes capacidades gráfi cas que un procesador de textos, sin embargo, cuando escribimos, la tarjeta gráfi ca sigue estando ahí. El aporte de la cloud computing es, se paga por lo que se usa.
Reducción del centro de datosPara cualquier organización tener un centro de datos signifi ca una importante inversión en tecnología, programas, personal que lo opere e instalaciones adecuadas para su funciona-miento.
Mejoramiento de procesos de negociosAquí aunque opté por mantener una traducción literal del original inglés Improving Business
Processes y en la descripción del ítem los auto-res se refi eran claramente a actividades comer-ciales, bien podemos permitirnos una interpre-tación más amplia. En la redacción original se habla de organizaciones, sus asociados y sus proveedores compartiendo una infraestructu-ra tecnológica que les permita intercambiar información y reducir costos dedicándose a sus actividades específi cas. Sin embargo el modelo bien puede aplicarse a otros ámbitos. Alumnos preparando un trabajo práctico a través de un software de colaboración en red, el profesor califi cándolo y la nota ingresando automáticamente al expediente de cada uno. Todo hecho con una misma nube alojada en el datacenter de la Universidad.
Reducción de los costos de inicioToda actividad nueva requiere una inversión de puesta en marcha y difícilmente en la actuali-dad se pueda emprender alguna que no requiera la utilización de recursos computacionales. La nube pone a disposición de estos proyectos un datacenter ya funcionando permitiendo destinar más fondos a otras partes del proyecto.
Desde ya que no hay rosas sin espinas, analicemos brevemente algunos de los desafíos y barreras que según los signatarios del mani-fi esto deben tenerse en cuenta.
SeguridadSupongamos que Coca Cola y Pepsi utilizan el mismo proveedor de servicios de nube
y que por una vulnerabilidad en la base de datos de las claves de acceso, una de las em-presas logra tener acceso a los planes de de-sarrollo de nuevos productos de la otra. Las pérdidas de la empresa perjudicada serían varias veces mayores que el ahorro de costos en tecnología de la información. Pero no só-lo puede darse esta situación por neglicencia sino también por corrupción, los empleados de la empresa que administra la infraestruc-tura podrían utilizar su acceso privilegiado para ganarse un sueldo extra. Se trata enton-ces de establecer unos adecuados procedi-mientos en materia de autenticación, valida-ción, medios de acceso y utilización de los servicios, además de normas de control interno para el personal que garanticen la transparencia de las operaciones.
Interoperabilidad entre datos y aplicacionesPara que las ventajas de la computación en nu-be sean posibles es necesario que datos y apli-caciones alojados en diferentes lugares físicos puedan interactuar entre sí.
Portabilidad de datos y aplicacionesUno de los factores que tendrá en cuenta cualquier organización a la hora de optar por servicios de computación en nube es la depen-dencia de su proveedor, es decir la facilidad con que puede migrar a otro o volver a un
Figura 1. Participación de mercado de sistemas operativos en marzo 2009
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-14, 14:1323
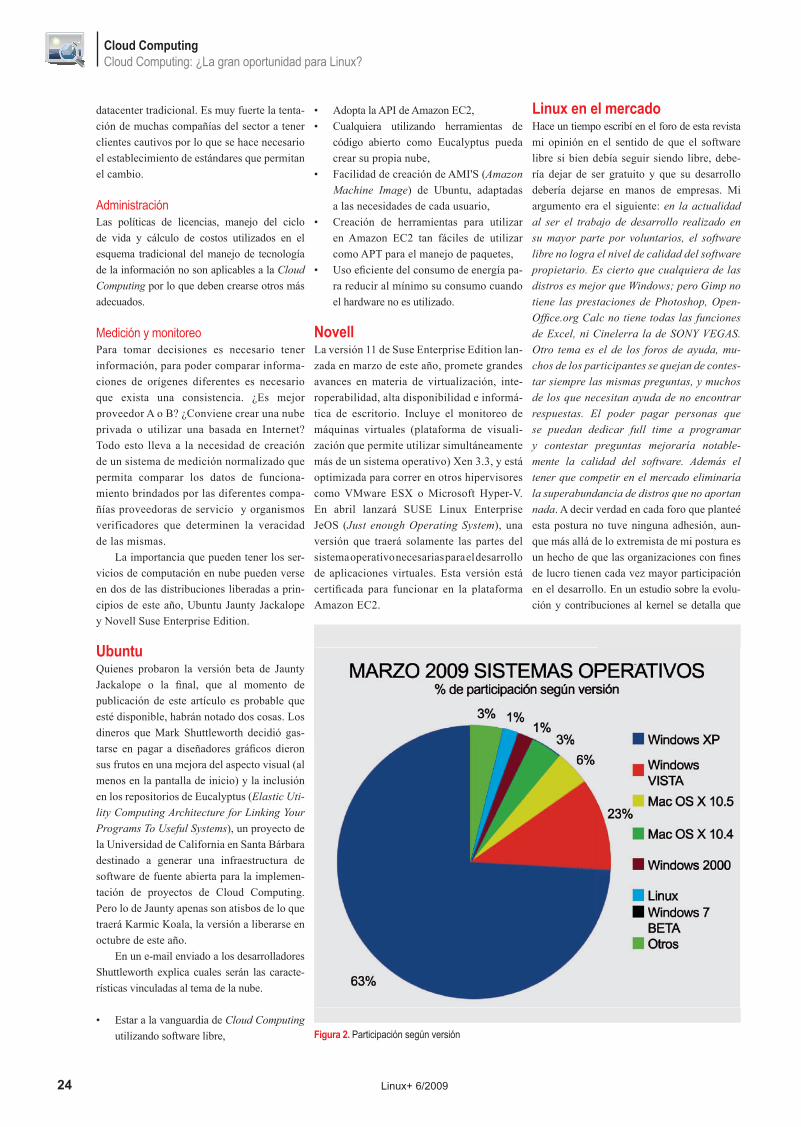
24 Linux+ 6/2009
Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
datacenter tradicional. Es muy fuerte la tenta-ción de muchas compañías del sector a tener clientes cautivos por lo que se hace necesario el establecimiento de estándares que permitan el cambio.
AdministraciónLas políticas de licencias, manejo del ciclo de vida y cálculo de costos utilizados en el esquema tradicional del manejo de tecnología de la información no son aplicables a la Cloud Computing por lo que deben crearse otros más adecuados.
Medición y monitoreoPara tomar decisiones es necesario tener información, para poder comparar informa-ciones de orígenes diferentes es necesario que exista una consistencia. ¿Es mejor proveedor A o B? ¿Conviene crear una nube privada o utilizar una basada en Internet? Todo esto lleva a la necesidad de creación de un sistema de medición normalizado que permita comparar los datos de funciona-miento brindados por las diferentes compa-ñías proveedoras de servicio y organismos verificadores que determinen la veracidad de las mismas.
La importancia que pueden tener los ser-vicios de computación en nube pueden verse en dos de las distribuciones liberadas a prin-cipios de este año, Ubuntu Jaunty Jackalope y Novell Suse Enterprise Edition.
UbuntuQuienes probaron la versión beta de Jaunty Jackalope o la fi nal, que al momento de publicación de este artículo es probable que esté disponible, habrán notado dos cosas. Los dineros que Mark Shuttleworth decidió gas-tarse en pagar a diseñadores gráfi cos dieron sus frutos en una mejora del aspecto visual (al menos en la pantalla de inicio) y la inclusión en los repositorios de Eucalyptus (Elastic Uti-lity Computing Architecture for Linking Your Programs To Useful Systems), un proyecto de la Universidad de California en Santa Bárbara destinado a generar una infraestructura de software de fuente abierta para la implemen-tación de proyectos de Cloud Computing. Pero lo de Jaunty apenas son atisbos de lo que traerá Karmic Koala, la versión a liberarse en octubre de este año.
En un e-mail enviado a los desarrolladores Shuttleworth explica cuales serán las caracte-rísticas vinculadas al tema de la nube.
• Estar a la vanguardia de Cloud Computing utilizando software libre,
• Adopta la API de Amazon EC2,• Cualquiera utilizando herramientas de
código abierto como Eucalyptus pueda crear su propia nube,
• Facilidad de creación de AMI'S (Amazon Machine Image) de Ubuntu, adaptadas a las necesidades de cada usuario,
• Creación de herramientas para utilizar en Amazon EC2 tan fáciles de utilizar como APT para el manejo de paquetes,
• Uso efi ciente del consumo de energía pa-ra reducir al mínimo su consumo cuando el hardware no es utilizado.
NovellLa versión 11 de Suse Enterprise Edition lan-zada en marzo de este año, promete grandes avances en materia de virtualización, inte-roperabilidad, alta disponibilidad e informá-tica de escritorio. Incluye el monitoreo de máquinas virtuales (plataforma de visuali-zación que permite utilizar simultáneamente más de un sistema operativo) Xen 3.3, y está optimizada para correr en otros hipervisores como VMware ESX o Microsoft Hyper-V. En abril lanzará SUSE Linux Enterprise JeOS (Just enough Operating System), una versión que traerá solamente las partes del sistema operativo necesarias para el desarrollo de aplicaciones virtuales. Esta versión está certifi cada para funcionar en la plataformaAmazon EC2.
Linux en el mercadoHace un tiempo escribí en el foro de esta revista mi opinión en el sentido de que el software libre si bien debía seguir siendo libre, debe-ría dejar de ser gratuito y que su desarrollo debería dejarse en manos de empresas. Mi argumento era el siguiente: en la actualidad al ser el trabajo de desarrollo realizado en su mayor parte por voluntarios, el software libre no logra el nivel de calidad del software propietario. Es cierto que cualquiera de las distros es mejor que Windows; pero Gimp no tiene las prestaciones de Photoshop, Open-Offi ce.org Calc no tiene todas las funciones de Excel, ni Cinelerra la de SONY VEGAS. Otro tema es el de los foros de ayuda, mu-chos de los participantes se quejan de contes-tar siempre las mismas preguntas, y muchos de los que necesitan ayuda de no encontrar respuestas. El poder pagar personas que se puedan dedicar full time a programar y contestar preguntas mejoraría notable-mente la calidad del software. Además el tener que competir en el mercado eliminaría la superabundancia de distros que no aportan nada. A decir verdad en cada foro que planteé esta postura no tuve ninguna adhesión, aun-que más allá de lo extremista de mi postura es un hecho de que las organizaciones con fi nes de lucro tienen cada vez mayor participación en el desarrollo. En un estudio sobre la evolu-ción y contribuciones al kernel se detalla que
Figura 2. Participación según versión
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-14, 14:1324

25www.lpmagazine.org
Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
en su mayor parte fueron hechas por programa-dores e ingenieros de software de grandes cor-poraciones norteamericanas, exactamente un 74,2%. Las principales contribuciones son de Red Hat, Novell, INTEL e IBM. Y si vamos más allá del núcleo, con excepción de Debian, las distros más usadas, Ubuntu, OpenSuse y Fedo-ra están apoyadas por empresas. Openoffi ce.org cuenta con el respaldo de Sun, el principal fi nanciador de la fundación Mozilla (Firefox y Thunderbird) es Google, Canonical paga de-sarrolladores y diseñadores gráfi cos para GNO-ME y KDE.
Como muchos de nosotros utilizamos ver-siones gratuitas tendemos a creer que desarro-llar Linux es gratis, sin embargo siempre según la Linux Foundation, el costo de desarrollar la versión 9 de Fedora puede calcularse en 10,8 billones de dólares (en EE.UU. un billón son mil millones) a lo que hay que sumarle 1,4 billones en desarrollo del kernel.
Para todos los que estudian la disciplina del marketing, los libros de Philip Kotler son el equivalente de la Biblia para los teólogos. Para entender el por qué sostenemos el fracaso de Linux permítanme un breve resumen de lo que dice este autor sobre la estructura de los mercados competitivos.
Este autor divide a los participantes en un mercado según sus fortalezas y debilidades en:
• Dominante: este participante en el merca-do puede controlar el comportamiento de los demás participantes.
• Fuerte: este participante en el mercado puede mantener su independencia y liber-tad de acción.
• Favorable: este participante tiene posibili-dades de mejorar su posición en el merca-do, obtiene resultados lo sufi cientemente buenos para justifi car su continuidad pero su existencia depende de lo que haga el competidor dominante y no está en sus manos mejorar su posición.
• Sostenible: este participante en el merca-do obtiene resultados lo sufi cientemente buenos para justifi car su continuidad pe-ro su existencia depende de lo que haga el competidor dominante y no está en sus manos mejorar su posición.
• Débil: este participante tiene un desem-peño insatisfactorio pero hay posibilida-des de mejorar.
• Inviable: este participante no tiene un desempeño satisfactorio ni tampoco po-sibilidad de mejorar.
Según su actitud pueden califi carse en:
• Competidor rezagado: no reacciona con rapidez ni fuerza a las acciones de los otros participantes.
• Competidor selectivo: solamente respon-de a determinado tipo de acciones de los otros participantes.
• Competidor tigre: reacciona rápidamente a todas las acciones de los otros partici-pantes.
• Competidor aleatorio: nadie sabe a qué, cómo y por qué va a reaccionar.
Según el tipo de posición competitiva que uno ocupe en el juego podrá adoptar distintas estrategias.
Estrategias de competencia
• Ampliación de mercado: si el número de usuarios aumenta, los ingresos lo harán en función de la participación en el mercado.
• Defensa de la participación del mercado: se trata de impedir que los competidores quiten clientes al competidor dominante.
• Aumento de la participación en el merca-do: se trata de quitarles sus clientes a los demás competidores.
• Nicho de mercado: se trata de encontrar un sector del mercado que no esté explo-tado por no haber sido descubierto o ser considerado no rentable por los demás participantes.
Utilicemos este modelo teórico en el análisis del mercado de los sistemas operativos de escrito-rio. Según las estadísticas de Net Applications a marzo de 2009 la situación es la siguiente:
• Windows en sus diferentes versiones tiene el 88,14% de la porción de mercado con-tra el 9,77 de Mac y el 0,90 de Linux,
• Comparado con abril de 2008 Windows perdió 2,94%, Mac creció 1,94% y Linux un 0,22%.
Si bajamos el análisis al detalle de utilización por versión, Linux desciende al sexto lugar detrás de:
• Windows XP 62,85%,• Windows Vista 22,91%,• Mac OS X 10.5 6%,• Mac OS X 10.4 2,66%,• Windows 2000 1,24%.
El comparativo con mayo del año pasado nos permite ver que Windows XP perdió un 9,27% mientras que el vapuleado Vista creció un 8,34%, como dato anecdótico la beta de Windows 7 alcanzó en 30 días un 0,26%, es decir más de la cuarta parte de la porción de mercado que Linux tiene después de 17 años. De acuerdo al esquema de Kotler no es difícil decidir que Microsoft es el competidor en posición dominante.
¿Un escenario pesimista? Bueno, tengo otro peor, el del sitio gs.statcounter.com corres-pondiente al período 1º de julio de 2008 - 31 de marzo de 2009:
• WinXP: 74,82%,• WinVista: 18,48%,• MacOSX: 1,96%,• Win2000: 1,13%,• Linux: 0,66%.
Conozco la frase de Mark Twain “existen tres grandes mentiras: las pequeñas, las medianasy las estadísticas”. También sé que “las estadís-ticas son como la minifalda, muestran algo muy interesante pero ocultan lo esencial”. Además presté la sufi ciente atención en las clases de la Facultad para saber que hay que tomar con pinzas el resultado de un muestreo hecho en base a las visitas a sitios web por más que entre esos sitios fi guren la Fundación Mozilla, el New York Times, la CNN y Fortune, pero son las estadís-ticas que tenemos para trabajar y basta con salir a la calle para confi rmarlo. ¿A cuántos familiares y amigos nuestros hemos convencido de que instalaran Linux por propia voluntad?
Hagamos el ejercicio de aplicar las catego-rías de Kotler a los sistemas operativos:
• Competidores tigres serían Microsoft con Windows y Canonical con Ubuntu,
• Competidor selectivo sería Apple y en el mercado empresarial Red Hat y Novell,
• Competidor rezagado sin dudas Debian al privilegiar la estabilidad por sobre la actualidad.
Se podría decir que Linux no fracasó sino que simplemente ocupa un nicho de mercado, tam-Figura 3. Participación a lo largo del año
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-14, 14:1325
26 Linux+ 6/2009
Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
bién teníamos pendiente el explicar el por qué para mí Linux estaba en una posición sostenible y no favorable. Para eso volvamos al libro de Kotler.
La historia de cualquier producto puede dividirse en cuatro etapas:
• Introducción: el producto va siendo len-tamente adoptado por los consumidores adictos a las novedades,
• Crecimiento: la cantidad de nuevos usua-rios del producto aumenta velozmente,
• Madurez: el producto fue aceptado por la mayoría de los consumidores poten-ciales,
• Decrecimiento: el ingreso de nuevos usua-rios disminuye y aumenta el cambio de usuarios actuales a otros productos.
El mercado de los sistemas operativos de es-critorio evidentemente llegó hasta donde podía llegar, ¿qué más pueden ofrecernos que ani-maciones más bonitas sin ninguna aplicación práctica? Como dijo Matt Assay de la consul-tora Alfresco: gran parte del fracaso de Vista es que Microsoft no pudo ofrecer una buena razón para dejar XP.
El futuro es abierto Si nos gusta el fútbol seguramente la emoción de jugar un partido contra Messi o Ronaldinho nos compensará por el hecho de que nos lle-nen de goles, ahora si lo que queremos es ga-narles lo mejor es proponerles una partida de ajedrez, lograr que jueguen a un juego en don-de sus habilidades no sean útiles y las nuestras si. En la industria informática el nuevo juego
tiene un nombre, recesión, nuevas reglas, gastar lo menos posible y un nuevo escenario, la nube.
Si todo el mundo habla sobre la compu-tación en nube, Richard Stallman fundador de la Free Software Foundation no iba a ser la excepción, su opinión sobre el tema fue: “la computación en nube es una trampa para obligar a más y más gente a comprar siste-mas propietarios cerrados que les costarán más y más caros con el tiempo. Es estúpido, peor que estúpido es una campaña de mar-keting publicitario, hay quienes dicen que es inevitable, y cuando alguien dice eso se pue-de estar seguro que detrás hay una campaña de marketing. Los usuarios de computadoras deben estar dispuestos a mantener su infor-
mación en sus propias manos, en lugar de entregarlos a un tercero. Una razón por la que no deben usarse aplicaciones web es que se pierde el control”. Dijo además: “Es tan malo como utilizar un programa propie-tario. Utilizar un programa propietario o una aplicación web lo pone en manos de quien desarrolló el software”.
Tal vez sea una postura un poco extre-mista pero sus preocupaciones son atendibles a tal punto que un grupo de organizaciones creó el antes mencionado Manifiesto de la Nube Abierta que postula los siguientes prin-cipios:
• Los proveedores de servicios de Cloud Computing deben trabajar juntos para responder a los desafíos que presenta su adopción: seguridad, integración, porta-bilidad, interoperabilidad, manejo y admi-nistración, medición y seguimiento. Es-tos deben abordarse a través de una co-laboración abierta y el uso adecuado de estándares.
• Los proveedores de servicios de Cloud Computing no deben utilizar su posición en el mercado para obligar a los consu-midores a permanecer en sus plataformaso limitarles sus opciones de elegir pro-veedores.
• Los proveedores de servicios de Cloud Computing deben utilizar y adoptar los estándares existentes siempre que sea apropiado. La industria de tecnología de la información ha invertido mucho en la creación de los estándares existentes y en la creación de organismos para dictar-los y aplicarlos por lo que no hay necesi-dad de reinventarlos o duplicarlos.
Figura 4. Página web de Net Applicactions
Figura 5. Página web de StatCounter
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-14, 14:1326

27www.lpmagazine.org
Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-14, 14:1327
28 Linux+ 6/2009
Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
• La creación de nuevos estándares o la modificación de los ya existentes, de ser necesario, debe hacerse de forma juicio-sa y pragmática. La función de los es-tándares es fomentar la innovación y no inhibirla.
• Los esfuerzos de la comunidad de la nube abierta deben estar dirigidos a satisfacer las necesidades de los clientes y no sola-mente la de los requerimientos técnicos de los proveedores de servicios de Cloud Computing. Debe probarse y verificarse que realmente se está respondiendo a sus requerimientos.
• Las organizaciones reguladoras de es-tándares, los grupos de promoción de la tecnología de Cloud Computing y la co-munidad deben trabajar de manera con-junta y coordinada para evitar que sus esfuerzos se superpongan y entren en con-flicto.
Es evidente que las corporaciones están dán-dose cuenta de que el modelo tradicional de negocios no funcionará en los años venideros por lo que se hace necesario crear uno acorde a las nuevas realidades. En 1913 el uso de automóviles en Estados Unidos no estaba demasiado difundido, por lo tanto no había sido necesaria una red vial en condiciones, la inexistencia de una red vial en condiciones trababa la venta de automóviles y ésto la de partes para autos fabricadas por terceros. Cuatro fabricantes de automóviles (General Motors, Packard y Wyllis Overland), un fa-bricante de neumáticos (Goodyear) y uno de faros (Prest -O-LITE) unieron esfuerzos para pavimentar diversos sectores de carretera a lo largo del país. La gente vio la practicidad del nuevo medio de transporte y exigió a sus gobernantes la construcción de más caminos modernos. La analogía se puede extender al mercado informático. Vista terminó por demostrar lo que Firefox, Opera y Google Chrome ya habían insinuado, Microsoft por sí solo no puede imponer nada que el consumi-dor no quiera aceptar, ya se trate de estándares
web, sistemas operativos o tecnologías. Linux por muy bonito visualmente que sea KDE 4 o inspirador el discurso del software libre no logra alcanzar los dos dígitos de participación en el mercado.
Durante mucho tiempo las relaciones económicas se entendieron como una gue-rra, para que el competidor A ganara tenía que perder (y de ser posible desaparecer) el competidor B, el bienestar económico de los trabajadores era incompatible con la rentabi-lidad de la empresa. Si es necesario aumen-tar los precios para obtener más ganancias se aumenta y que los clientes se arreglen como puedan. En palabras del escritor Gore Vidal, no es suficiente tener éxito, otros tie-nen que sucumbir. Ese tipo de pensamiento trasladado a la informática le dio muy buen resultado a Microsoft y en menor medida a Apple, en cambio para el software de código abierto fue un fracaso, Linux tiene apenas un 1% del mercado.
El modelo que necesitamos tiene nom-bre, Coopetencia. Quien lo bautizó fue Ray Norda, fundador de Novell, tal vez sea por eso que Novell fue la primera empresa en establecer acuerdos de colaboración con Microsoft. La coopetencia es una dinámica en la que uno al mismo tiempo compite y coo-pera con otros participantes en un mismo mercado.
De acuerdo a Nalebuff y Brandenburger, dos autores que desarrollaron la idea de Nor-da, el mercado puede imaginarse como un juego en el que intervienen cuatro tipos de participantes.
Clientes, Proveedores, Competidores y Com-plementadores. Los dos primeros definen a los dos últimos.
Desde el punto de vista de los compra-dores:
• Competidores: A y B son competidores cuando el consumidor valora más el pro-ducto de A cuando no existe el producto de B. Ejemplos Gnome y KDE,
• Complementadores: A y B son comple-mentadores cuando la gente valora más el producto A si tiene el producto B. Ejemplos Windows XP y Norton Anti-virus.
Desde el punto de vista del proveedor:
• Competidores: A y B son competidores cuando a un proveedor le es más conve-niente venderle solamente a uno de los dos que a los dos,
• Complementadores: A y B son comple-mentadores cuando a los proveedores les es conveniente venderles a los dos que a uno solo.
El gran cambio de la computación en nube con el modelo tradicional de la computación de escritorio es que convierte a Linux y Win-dows de competidores en complementadores. Para entender esto debemos dividir a la nube en tres capas:
• Infraestructura como un servicio: se re-fiere a la capacidad de ofrecer servicios
Figura 6. Página web de Open Cloud Manifesto
Figura 7. Página web de Linux Fundation
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-17, 11:4428

29www.lpmagazine.org
Cloud ComputingCloud Computing: ¿La gran oportunidad para Linux?
de almacenamiento, procesamiento y ve-locidad de transmisión del hardware,
• Plataforma como un servicio: se refi ere al sistema operativo virtualizado y servi-cios adicionales como motores de bases de datos,
• Software como un servicio: se trata de las aplicaciones que queremos usar den-tro del sistema operativo virtualizado.
El servicio básico de la nube es el de infra-estructura, es decir capacidad de almacena-miento y cálculo, independientemente del sistema operativo y aplicaciones. El pro-veedor más conocido Amazon EC2, permite seleccionar un sistema operativo o bien virtualizar uno seleccionado por el usuario. Se factura únicamente el tiempo de procesa-miento, el espacio de almacenamiento y el ancho de banda.
Existen también alternativas de código abierto como el ya mencionado proyecto Eucalyptus que tiene una interfaz compa-tible con el servicio comercial de Amazon. Otra es Enomalism que además de proveer funcionalidades similares a los otros dos incorpora Turbo Gear y Python.
Aquí vemos bien cómo funciona el con-cepto de complementarios. Las empresas de hardware que manufacturen los equipos ne-cesarios para la cloud computing necesitan software lo sufi cientemente potente como para sacarles el máximo provecho. Para los clientes de la cloud computing es necesario que existan aplicaciones que cubran sus necesidades y que no requieran un excesivo tiempo de aprendizaje cumpliendo además con los requisitos de interoperabilidad y por-tabilidad.
Los tres servicios de infraestructura mencionados están basados en Xen, un pro-yecto de código abierto de la Universidad de Cambridge que permite que varios sistemas operativos se ejecuten simultáneamente en un solo equipo. Puede encontrarse en los repositorios de las distribuciones más im-portantes.
Es indudable que las mejores aplicacio-nes están disponibles para Windows, ni si-quiera proyectos como Gimp u OpenOffi ce.
org pueden competir en prestaciones con Photoshop y Microsoft Offi ce por no hablar de necesidades como diseño CAD e inves-tigación cualitativa en la que las versiones Linux están varios años atrasadas. Gran parte de la culpa de ésto lo tiene la comunidad; como dijo Frank Feldman jefe de producto de Red Hat para el mercado asiático: puede ser difícil encontrar una cantidad de desarrolla-dores entusiasmados por crear una aplica-ción para calcular el pago de impuestos.
No se trata de renunciar al mercado de las aplicaciones ni convencer a la gente de las virtudes del software libre. Como defi-nen Nalebuff y Branderburger lo que debe-mos hacer es cooperar para crear un nuevo mercado y después competir por una mayor parte de él.
Palabras fi nalesEl borrador original de este artículo llevaba por título La nube y el elefante, lo de nube ya se imaginarán por qué es. El proboscideo era una metáfora basada en el famoso poema de John Saxe Cox en el que unos ciegos tocando cada uno una parte del animal sacan conclu-siones sobre cómo es el animal completo. Al fi nal tuve que renunciar a la idea porque hasta para lo que es habitual en mi el enfoque era demasiado raro.
Sin embargo la metáfora me sigue gustan-do, cada uno de nosotros, ciegos por la venda de nuestras expectativas, valores, creencias y actitudes ve una sola parte del estado actual de la informática. Stallman, con su postura de que todo lo que signifca software privativo es una amenaza, critica duramente a usuarios cuyo único interés es mandar facilmente mails, chatear con sus hijos que trabajan le-jos o compartir con sus antiguos compañeros de colegio la foto de su nieto recién nacido.
Microsoft en su preocupación por generar di-videndos a sus accionistas no duda en aplicar prácticas monopólicas y presiones judiciales contra pequeñas empresas que podrían apor-tar grandes innovaciones para todos. Dentro de la comunidad de usuarios de productos de código abierto estamos más entretenidos en pelearnos entre nosotros que en mejorar el producto fi nal para hacerlo accesible a todos los usuarios.
Si algo demostraron los últimos años (y ahora no estoy hablando solo de infor-mática) es que el esquema tradicional de pensamiento en el que el triunfo de uno depende del fracaso de los demás no dio re-sultado. Estamos viviendo una época difícil desde el punto de vista económico, millones de personas quedarán sin trabajo, empresas que eran sinónimo de sólidez están al borde de la quiebra. Más alla de un sistema opera-tivo, linux es una forma de trabajo. Una for-ma de trabajo en la que lo que cada uno sabe está a disposición de todos. Eso es lo que te-nemos para aportar a un mundo que necesita soluciones diferentes a problemas nuevos. Pero esas soluciones tienen que ser fáciles de aplicar y entendibles por todos. Esa es la lección que podemos aprender de Micro-soft.
Diego Germán Gonzalez maneja las áreas de Marketing y Sistemas de una pequeña empresa textil, además asesora a otras pymes sobre la utilización de soluciones de código abierto.
Sobre el autor
• http://www.netapplications.com/,• http://gs.statcounter.com/,• http://www.opencloudmanifesto.org/,• http://www.linuxfoundation.org/,• http://www.xen.org/,• http://eucalyptus.cs.ucsb.edu/,• http://www.enomaly.com/.
En la red
P U B L I C I D A D
22_23_24_25_26_27_28_29_Cloud_Linux.indd 2009-04-17, 11:4429

30
Cloud ComputingCloud Computing y Open Source
Linux+ 6/2009
te la primera plataforma Cloud Computing abierta del mercado. Bajo el nombre Sun Open Cloud la propuesta de Sun está basada en sus tecnologías de software open source -incluyendo el lenguaje de programación Java, la base de datos MySQL y el sistema operativo Open Solaris - y toda su innovación en almacenamiento Open Storage. Se trata de dar al mercado una alternativa clara y via-ble en sus aproximaciones al Cloud Computing que, además, supone un cambio paradigmático frente a los modelos cloud propietarios que li-mitan las opciones para el cliente e incrementan significativamente los costes ligados a licencias, especialmente de software.
En nuestra opinión, sólo triunfarán en Cloud Computing aquellas compañías que logren atraer a un mayor número de integradores y programa-dores para sus tecnologías. La comunidad Open Source es la mejor vía para el desarrollo del Clo-ud Computing del futuro.
Primeros serviciosEn la base de Sun Open Cloud estarán los dos primeros servicios – Sun Cloud Storage Service y Sun Cloud Compute Service – ya disponibles para desarrolladores y que lo estarán también
Conceptos como pago por uso de la tecnología -incluyendo hardware, software de base y aplicaciones- o SaaS (Software as a Service) son
cada vez más habituales para el usuario, de modo que entramos en una nueva etapa en la que los proveedores de tecnología pasamos, en gran me-dida, a seguir la estela de los suministradores de agua o electricidad. El modelo Cloud Computing permite, básicamente, eso, pero aplicado al apro-visionamiento de tecnologías de la información.
Cuando hace 25 años Sun escogió como lema The Network is the Computer, -la red es el ordenador-, se sentaron las bases de lo que hoy todos conocemos como Cloud Computing. La ex-presión tiene actualmente, así, más vigencia que nunca y, de hecho, es la materialización de lo que será una revolución en la informática corporativa en los próximos años.
Una apuesta férrea por el modelo Open SourceDesde el punto de vista de Sun, el modelo Cloud Computing tiene mayor sentido y fuerza si lo abordamos desde una aproximación Open Source. Por ello, la compañía ha presentado recientemen-
Cloud Computing cobra su mayor sentido en una aproximación Open Source
La consolidación de Internet como medio de acceso y compartición de la información y como plataforma de comunicaciones por parte de ciudadanos, empresas y gobiernos (ya es utilizada por más de 1.000 millones de personas diariamente en todo el mundo, una cifra que se habrá doblado en 2011) ha forzado a los grandes proveedores de tecnologías de información a evolucionar sus estrategias hacia el aprovisionamiento de todo tipo de servicios informáticos a través de la red como si de un servicio básico y a medida se tratara.
José Manuel Rodríguez, director de Software de Sun Microsystems Ibérica
30_31_Cloud_Sun.indd 2009-04-14, 15:3730

31
Cloud ComputingCloud Computing y Open Source
www.lpmagazine.org
para empresas y gobiernos el próximo verano. Los clientes podrán beneficiarse del modelo Open Source para sus aproximaciones al modelo Cloud Computing a través de Sun Open Cloud para acelerar el suministro de nuevas aplicaciones reduciendo los riesgos totales y obteniendo mayor escalabilidad y capacidad de almacenamiento. Nuestra propuesta Open Cloud pone a disposición de la comunidad todas las tecnologías y servicios necesarios para que cada cliente pueda construir sus propias nubes, públicas o privadas, aseguran-do la interoperabilidad entre ellas y el resto.
Además de la apuesta clara por el Open Source, otra de las claves para que una nube ten-ga éxito es que las tecnologías que se necesitan para crearla sean fáciles de usar en todos sus ám-bitos, es decir, desde el despliegue de aplicacio-nes, al suministro de recursos, pasando por todas las fases intermedias. En este sentido, Sun Cloud Compute Service está basado en las capacidades Virtual Data Center (VDC) adquiridas mediante la compra de la compañía Q-Layer por parte de Sun el pasado mes de enero de 2009, que ofrecen todo lo que un equipo de proyecto necesita para construir y poner en funcionamiento un centro de datos en la nube.
El VDC proporciona un interface unificado e integrado para ejecutar una aplicación que pueda correr sobre cualquier sistema operativo dentro de una nube, incluyendo OpenSolaris, Linux o Windows. Lleva consigo un método de arrastrar y soltar, además de interfaces de programación de aplicaciones -APIs- específicos y un interface de línea de comando para suministrar recursos de procesamiento, de almacenamiento y de co-nectividad a través de cualquier navegador. Por otra parte, el Sun Cloud Storage Service soporta
protocolos WebDAV para un acceso sencillo a los ficheros y APIs de almacenamiento de objetos compatibles con los APIs S3 de Amazon.
Como parte del compromiso de la compañía con la creación de comunidades, Sun también ha abierto sus APIs cloud para que puedan revisarse y comentarse por todos los desarrolladores de la comunidad Open Source, de forma que éstos puedan crear nubes públicas o privadas mejora-das y totalmente compatibles con Sun Open Clo-ud. Las especificaciones de los APIs de Sun Open Cloud han sido publicadas bajo licencia Creative Commons, que permite a cualquier persona el uso de las mismas de cualquier forma. Los desa-rrolladores podrán desplegar aplicaciones en Sun
Cloud de forma inmediata, aprovechando VMIs (Virtual Machine Images) pre-empaquetadas del software open source de Sun, eliminando la nece-sidad de descargar, instalar o configurar software de infraestructura.
Una oportunidad para todosUno de los beneficios más evidentes del Cloud Computing es la mejora de utilización de los re-cursos informáticos disponibles. El cambio eco-nómico inherente al pago por uso que el modelo Cloud Computing trae de la mano es una de las principales virtudes de este modelo. Sólo se paga por lo que se utiliza, y las tarifas son generalmente inferiores al coste de desarrollo y mantenimiento interno de los servicios equivalentes. Este mode-lo permitirá a las empresas, grandes y pequeñas, y a los gobiernos sustituir fuertes inversiones en infraestructura informática (CAPEX) por gastos de operación (OPEX), adaptando de forma flexi-ble la oferta a la demanda.
Los desarrolladores serán uno de los colecti-vos más importantes para la apuesta de Sun por el Cloud Computing. Ejemplo claro de ello son las ampliaciones que la compañía ha realizado en algunos de sus programas más conocidos. En una versión de la suite ofimática OpenOffice, espe-cialmente desarrollada para este fin, los usuarios podrán utilizar la nube pública de Sun para almacenar y recuperar documentos de la red, en lugar de emplear su ordenador; y con VirtualBox, nuestro producto de virtualización de escritorio, los usuarios podrán acceder a un servicio de carga cuando deseen ejecutar diferentes Sistemas Ope-rativos o aplicaciones en la nube de Sun.
Cloud Computing es el futuro, sin duda. Pero mejor, sobre el modelo Open Source.
30_31_Cloud_Sun.indd 2009-04-14, 15:3731

Cloud ComputingCloud Computing: ¿Stairway To Heaven?
32 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
l
Cloud Computing: ¿Stairway To Heaven?A mediados de los 90 Marc Andreessen (cofundador de la empresa Netscape Communications Corporation y coautor de Mosaic, uno de los primeros navegadores web con interfaz gráfi co) predijo que Microsoft Windows estaba destinado a ser un “pobre conjunto de drivers ejecutándose en Netscape Navigator”.
Lino García Morales
Netscape desapareció en Marzo del 2008, sin embargo, su predicción va camino de cum-plirse en algún Navegador web. En el artículo LINO Operating System [Linux+ 3/2009, pp:
42-45] se cuestiona el papel de los sistemas operativos en la actualidad en un mundo interconectado a alta velocidad lla-mado internet. Internet se puede considerar como un superor-denador cuya potencia está distribuida por todo el globo. El paradigma de la computación distribuida, divide y vencerás, convive a diferentes escalas (según la aplicación y unidades de proceso involucradas): uso de múltiples ordenadores en una empresa en lugar de uno solo centralizado (aplicado desde fi nales de los 70s), uso de múltiples ordenadores en red distribuidos en un área geográfi ca extensa o en el mundo entero (vía internet) o el uso de múltiples dispositivos inteli-gentes en red; todo ello para resolver un solo problema (con la ilusión de muchos a la vez).
Según TryCatch en su blog sobre programación: Web y tecnología: Sin miedo a las excepciones... (http://trycatch.lacoctelera.net/post/2008/12/15/cloud-computing-1-defi -nicion-es-y-caracteristicas), Cloud Computing no es una tecnología nueva ni una arquitectura o framework de desa-
rrollo Web más ágil y más productivo. Sino … un concepto, una comunión de ideas, como en su momento lo fue Web2.0, que engloba tanto nuevas tendencias como la evolución de servicios ya existentes. La IEEE la defi ne como… un paradigma en el cual la información está permanente-mente almacenada en servidores de Internet y es cacheadatemporalmente por los clientes que incluye desktops, móvi-les, monitores, sensores, portátiles, etc.
¿Qué es todo esto? Que tanto datos como procesos ya no están en nuestros equipos sino en la nube. Nuestro sistema es un simple accesorio con escaleras al cielo (navegador/cuenta/internet) para acceder y utilizar servicios (conjunto integrado de procesos) sin tener conocimientos expertos ni necesidad de controlar y confi gurar esas tecnologías o servicios. La Fi-gura 1 ilustra las clases de Cloud Computing que se describen a continuación.
SaaS (Software As A Service). Modelo de distribución de software donde una empresa sirve el mantenimiento, soporte y operación que usará el cliente durante el tiempo que haya contratado el servicio. Ejemplos: Salesforce (http://www.salesforce.com/es/), Basecamp (http://www.basecamphq.com/).
32_33_34_Cloud_heaven.indd 2009-04-14, 14:1832

Cloud ComputingCloud Computing: ¿Stairway To Heaven?
33www.lpmagazine.org
PaaS (Platform As A Service). Modelo en el que se ofrece todo lo necesario para soportar el ciclo de vida completo de construcción y pues-ta en marcha de aplicaciones y servicios web completamente disponibles en internet. Da soporte directamente al software que corre en la nube con la infraestructura contratada por el cliente. No hay descarga de software que instalar en los equipos de los desarrolladores. PaaS ofrece múltiples servicios, todos, como una solución integral en la web. Ejemplos: Google App Engine (http://code.google.com/intl/es-ES/appengine/).
IaaS (Infrastructure As A Service). Modelo de distribución de infraestructura de computa-ción como un servicio (se suele considerar co-mo la capa más inferior del modelo, incluyen-do la capa HaaS o, como muestra la Figura 1, la zona intermedia de toda la arquitectura), nor-malmente mediante una plataforma de virtuali-zación. En vez de adquirir servidores, espacio en un centro de datos o equipamiento de redes, los clientes compran todos estos recursos a un proveedor de servicios externo (hosting, capa-cidad de cómputo, mantenimiento y gestión de redes, etc.). Una diferencia fundamental con el hospedaje (hosting) virtual es que el aprovisio-namiento de estos servicios se hace de manera integral a través de la web. Ejemplos: Amazon Web Services (http://aws.amazon.com/) y Go-Grid (http://www.gogrid.com/).
DaaS (Data Storage As A Service). Alma-cén de datos como servicio. Proporciona la ges-tión y el mantenimiento completo de los datos del cliente. Trabaja al mismo nivel que IaaS.
CaaS (Communication As A Service). Provee el equipamiento de redes y la gestión de las comunicaciones como servicio (balance
de carga, por ejemplo). Trabaja al mismo nivel que IaaS.
Software Kernel. Gestión de los servidores físicos a través del sistema operativo, software de virtualización, middleware de gestión de clústeres y de la grid, etc.
HaaS (Hardware As A Service). Gestión del hardware (elementos físicos de la nube) como servicio. Normalmente centros de da-tos gigantescos con todo tipo de máquinas que proporcionan cómputo, almacenamiento, catálogos, etc.
Otras tecnologías consideradas Cloud Com-puting son:
• Web2.0 Herramientas y aplicaciones como redes sociales, blogs, wikis, foros, etc.
• Web Os (sistemas operativos en la Web). Web Semántica o Web 3.0, etc.
• Grid Computing. Evolución natural de la nube. Es una arquitectura de procesado en paralelo, que permite compartir/distribuir los recursos de proceso de muchas máqui-nas a través de la red de manera que fun-cionen como un super-computador gigan-te. Por raro que parezca, los procesadores están ociosos la mayor parte del tiempo y este tiempo se puede poner en función de la solución de problemas computaciona-les enormes. Un ejemplo de ello es el Pro-grama para la Búsqueda de Inteligencia Extraterrestre (SETI, Search for Extra-terrestrial Intelligence, http://setiathome.ssl.berkeley.edu/). La Grid Computing, también se conoce como Peer-to-peer Computing (red punto a punto o P2P), Uti-lity Computing, o simplemente Distributed Computing.
Las principales características de Cloud Computing provienen de las tecnologías que forman la nube y de las nuevas capa-cidades provenientes de la fusión de estos servicios:
• Escalabilidad. El sistema trabaja de for-ma eficiente aumentando o disminuyen-do el uso de recursos según demanda, de forma automática y transparente para el usuario.
• Virtualización. El usuario puede hacer uso de la plataforma o entorno que desee, ya sea contratándolos o creándolos él y pasándoselas al servicio. Existe una to-tal independencia entre datos y hard-ware; las aplicaciones corren en servido-res y el acceso se suele realizar desde un navegador.
• Calidad de Servicio. Se rige por un Acuerdo de Nivel de Servicio (SLA, Ser-vice Level Agreement), que define variaspolíticas como: rendimiento, tiemposde acceso, capacidad de tráfico, picos de conexión soportados, etc. Calidad de ser-vicio y escalabilidad están directamen-te relacionados; el sistema se encarga de gestionar los recursos según estos tér-minos.
• Accesibilidad. Debido a las propiedades anteriores la nube es accesible desde un amplio abanico de dispositivos.
Peldaños, plantas y desnivelesQue nuestros datos y relaciones no estén en nuestros equipos ni dependan del siste-ma operativo de nuestras máquinas no es nada nuevo. Todo lo contrario, es anterior incluso de la aparición del primer ordena-dor personal, cuando nos conectábamos a las máquinas grandes (Supercomputer, Ma-inframes, Minicomputer, utilizadas principal-mente por grandes organizaciones para ap-licaciones críticas como el proceso de una enorme cantidad de datos) a través de un ter-minal tonto (dummy). Desde un punto de vis-ta estrictamente técnico no es exactamente lo mismo. Nos comunicamos a internet a través de algún módem ADSL o interfaz inalám-brica como poco, en lugar de un solo su-perordenador gigante accedemos a muchos de menor potencia que interactúan entre sí para conseguir mayor funcionalidad y prestaciones, etc. Pero, desde un punto de vista funcional, sí. El navegador (browser) es una especie de versión superior del XTerm, y nuestro PC un terminal avanzado respecto al tonto en térmi-nos multimedia.Figura 1. Clases de Cloud Computing
32_33_34_Cloud_heaven.indd 2009-04-14, 14:1833

34 Linux+ 6/2009
Cloud ComputingCloud Computing: ¿Stairway To Heaven?
Cuando entramos en http://picasaweb.google.es/ a subir fotos para compartirlas con familiares y amigos desde cualquier lugar del mundo sólo necesitamos un navegador, acce-so a internet y una cuenta gmail. No sabemos dónde están, ni cómo son administradas, ni nos interesa; sólo que podemos verlas siem-pre que queramos, desde cualquier ordenador y lugar del planeta, cambiarlas o establecer permisos y restricciones de uso (a quién per-mitimos verlas, a quién descargarlas, etc.). Detrás de este servicio, puede haber mucho más de un ordenador (de diferente tecnología incluso) que valida la cuenta, sirve e inte-ractúa con los usuarios. Incluso si toda esta tecnología cambia, mientras que el servicio se mantenga igual, no notaremos ninguna di-ferencia.
¿Por qué todo esto? Pues porque no hay nada que instalar localmente, no nos ocupa espacio, no tenemos que preocuparnos de averías o fallos, la mayoría de los servicios son gratuitos o de menor coste que si intentá-ramos hacerlo por nuestra cuenta y son segu-
ros (Amazon ofrece un 99,95% de fi abilidad; tan solo 4,38 horas de caída al año). Eso sí, la información queda en manos de terceras personas; el propio Richard Stallman, consi-derado padre del software libre, ha dicho … el Cloud Computing es una trampa; pero bajo determinadas condiciones legales (esa letra pequeña que, aunque resulte un incordio, con-viene leer) y medidas de seguridad (respecto al acceso, uso, distribución, etc.) y no al libre albedrío.
Paradójicamente, con ordenadores cada vez más potentes, el uso de estos servicios sólo requiere ordenadores cada vez más ton-tos (cierta capacidad multimedia y conexión a red) pero esto tiene su lado positivo y es que aumenta el abanico de dispositivos desde dónde acceder/utilizar a/los servicios.
ConclusionesLa computación en nube es una realidad y permite tanto a, usuarios como a empresas, mayor fl exibilidad para ofrecer/consumir servicios. La interconexión de estas nubes permitirá crear/usar servicios cada vez más complejos de manera más simple y desde un mayor número de dispositivos, incrementar y compartir el patrimonio cultural, democra-tización de la información, y así, un largo etcétera. Ahí están los ejemplos de servicios de Google: Scholar (enorme conjunto de ar-tículos de interés educacional, científi co...), Maps (mapas callejeros, planifi cadores de rutas óptimas, páginas amarillas…), Bo-oks (biblioteca digital gigantezca…), Talk (comunicación, búsqueda de contactos…), Earth (visión tridimensional del planeta; navegación en cualquier parte del mundo, es
posible entrar incluso a los museos y acer-carse a las obras hasta el milímetro; señali-zación…), Youtube (probablemente la vi-deoteca más grande del mundo), Blogger (diarios digitales, bitácoras, narraciones compartidos, periodismo...).
Todo este entramado de servicios está in-fl uyendo notable y positivamente en nuestro modo de vida en la medida en que facilitan su uso a menor complejidad y coste. Gracias a estas nubes los científi cos pueden realizar cálculos en superordenadores de potencia ilimitada, un músico compartir sus creacio-nes, un cineasta sus películas, un escritor sus libros, narraciones o poesías, un grupo de amigos puede mantenerse en contacto, un conductor planifi car su viaje de vacaciones, un turista reservar su itinerario de vacacio-nes, un amante de la cocina compartir una buena receta, un inventor sus ideas, una empresa mantener sus documentos a salvo, etcétera, etcétera, etcétera.
La computación en nube es una vuelta al futuro. Llegará el día en que, aquellos que lo deseen, puedan olvidarse de los drivers, las tediosas instalaciones, la enorme espera del arranque del sistema operativo, la gestión de su equipo informático y puedan concentrarse en lo que realmente les importa; ese día, por fi n, la inmersión digital será una experiencia realmente placentera, habremos tocado el cielo.
Graduado de Ingeniería en Control Auto-mático, Máster en Sistemas y Redes de Comunicaciones y Doctor por la Universi-dad Politécnica de Madrid. Ha sido profe-sor en Instituto Superior de Arte, Univer-sidad Pontifi cia Comillas y la Universidad Meléndez Pelayo.
Actualmente Profesor de la Escuela Superior Politécnica de la Universidad Europea de Madrid y Director del Más-ter Ofi cial en Acústica Arquitectónica y Medioambiental. Lidera grupo de inves-tigación transdisciplinar en la intersección Arte, Ciencia, Tecnología y Sociedad. Ha recibido becas por la Agencia Española de Cooperación Internacional (AECI), la Fundación para el Desarrollo de la Función Social de las Comunicaciones (FUNDESCO), el Consejo Superior de In-vestigaciones Científi cas (CSIC) y la Uni-versidad Politécnica de Madrid.
Sobre el autor
Figura 2. Cloud Computing everything and kitchen sink
32_33_34_Cloud_heaven.indd 2009-04-14, 14:1834

35_rekl_arroba.indd 2009-04-14, 14:181

software
36
Juegos
Linux+ 6/2009
sección llevada por Francisco J. Carazo Gil
Este mes la sección comienza con un juego que mezcla dos géneros distintos consiguiendo un resultado divertido a la vez que original.
Se trata de Zero Ballistics, un juego comercial pero gratuito que bajo el lema Fácil de aprender pero difícil de dominar sus desarrolladores han conseguido una mezcla muy buena entre géneros un tanto dispares.
Los FPS, rápidos y de poco pensar como suelen decir al más puro estilo Quake junto con la estrategia y las posibilidades de todo juego de tanques. La mezcla consigue un equilibrio muy bueno, acaparando de cada uno características que se complementan. La rapidez de un FPS con la estrategia y el planeamiento de todo juego de tanques.
Los gráficos son otra parte muy conseguida del juego. Además de estar muy cuidados, tienen unas escenas de paisajes alpinos con mucho detalle. Además el juego incorpora un motor físico que mejora aún más la percepción de calidad. Los tanques disponen de tres armas principa-les y tres armas secundarias. Para poder llegar a ser un gran jugador,
Zero BallisticsHace ya mucho tiempo, allá por el número 45 de la revista si no
me engaña mi base de datos, comenté un juego dedicado a los solitarios llamados PySol y si lo leísteis probablemente sigáis usando para matar los ratos muertos. La inclusión del archiconocido solitario de Microsoft Windows, como juego por defecto en una versión del sistema operativo de Microsoft que ya ni recuerdo, implicó el resurgir de este tipo de juegos. En un mundo tan digitalizado como el actual y en una actividad en la que sólo hace falta una persona, como es la de jugar a un solitario, nada mejor que un programa de ordenador con cientos de variantes para tener posibilidades distintas para jugar año tras año.
Pero bueno, este no es nuestro tema ahora en el segundo juego que cierra la sección de este mes. El tema que nos ocupa es PyChess y como podréis deducir de su nombre es un juego de ajedrez, imple-mentado en Python. Sus creadores creo que no guardan relación alguna
con los creadores de Py-Sol, pero al igual que ocu-rre con los programas que comienzan o tienen una letra k significada que per-tenecen a Proyecto KDE, la Py se está convirtiendo en todo un distintivo de los programas realizados con Python.
En este caso el diseño es para Gnome y bajo su sencilla estética se escon-
de un potentísimo juego de ajedrez para jugar contra la máquina o con un amigo ya sea en persona o mediante la red (característica de la que pocos juegos de ajedrez libres puede presumir). Tenemos también opción de modificar la IA de la máquina, es decir, descargar otro motor de inteligencia artificial para jugar a ajedrez y cambiarlo, de manera que tendremos oponentes virtuales muy dispares. Por ejemplo, fruit y crafty son dos ejemplos de este tipo de motores de IA que además son software libre. Rybka, es otro famoso motor de IA, pero su código no es abierto. Esta caracterís-tica, junto con la de la red, hacen de él un juego único. Por cierto, en la Wikipedia en su versión inglesa encontraréis más motores de inteligen-cia artificial para juegos de ajedrez.
El juego es software libre y actualmente se encuentra en su versión 0.10 de nombre Staunton en fase Alfa 2. A pesar de ser una versión 0.10 ya han salido unas cuantas versiones anteriormente del juego, ya que la numeració comenzó con el 0.1. Existen paquetes descargables tanto en formato RPM como en formato DEB así como el código fuente comprimido y empaquetado en un tarball.
En definitiva, un juego simple que al igual que PySol nos permitirá desconectar fácilmente del trabajo y que nos permitirá además tener unas posibilidades que con la práctica totalidad de los otros juegos similares no podemos disfrutar como el cambio de motor de IA y la posibilidad de jugar a través de red. Como punto final, comentaros que se encuentra en pleno proceso de desarrollo (un desarrollo muy activo por cierto) por lo que cada poco tiempo podremos disfrutar de nuevas versiones y funcionalidades.
http://pychess.googlepages.com/
PyChess
jugabilidadgráficos
sonido
«««««««««««
NOTAjugabilidad
gráficossonido
«««««« N/A
NOTA
tendremos que llegar a dominar los tres parámetros de los que depende el éxito de nuestro disparo: la velocidad de nuestro oponente, la trayec-toria que cogerá el obús y la distancia real entre el objetivo y nosotros. Disponemos de multitud de posibilidades distintas de tanques, para las más diversas situaciones. Además de las distintas armas disponibles, también tenemos a nuestra disposición tanques y capacidad para sanar. Utilizamos tanto el ratón como las flechas del teclado para controlar nuestro tanque y tenemos posibilidad de jugar en red. Las dos modali-dades de juego son all vs. all o el juego por equipo.
Respecto a las necesidades hardware del equipo para ejecutarlo no necesitamos un gran equipo, porque aunque sean de calidad y estén muy cuidados, la cantidad de polígonos en movimiento no es dema-siado grande. Respecto a versiones disponibles para otros sistemas operativos, existe una versión para Windows, además de la existente para Linux. Es una pena que no sea software libre, pero como tiene suficiente calidad y es gratuito creo que a muchos no os importará.
En definitiva, un juego que combina dos géneros de manera original y con un resultado divertido y completo. La capacidad de jugar en equipo a través de la red, abre muchas posibilidades, ya que además del típico to-dos contra todos, el modo de juego en equipo favorece el crear estrategias en grupo y hacer un planteamiento previo muy interesante. Desde mi pun-to de vista personal, pasados los años y cuando los FPS se me empiezan a hacer algo repetidos ya, el aire fresco que da este título me ha resultado muy divertido y creo que a todos vosotros os pasará lo mismo.
http://www.zeroballistics.com/
Figura 1. Zero BallisticsFigura 2. PyChess
36_Juegos.indd 2009-04-14, 14:1836

Nombre(s) ................................................................................................... Apellido(s) ..................................................................................................
Dirección ..............................................................................................................................................................................................................................
C.P. .............................................................................................................. Población ....................................................................................................
Teléfono ..................................................................................................... Fax ...............................................................................................................
Suscripción a partir del No ...................................................................................................................................................................................................
e-mail (para poder recibir la factura) ..................................................................................................................................................................................
o Renovación automática de la suscripción
Por favor, rellena este cupón y mándalo por fax: +31 (0) 36 540 72 52 o por correo: EMD The Netherlands – Belgium,P.O. Box 30157, 1303 AC Almere, The Netherlands; e-mail: [email protected]
Pedido de suscripción
Título número de ejemplares
al año
número de suscripciones
a partirdel número Precio
Linux+DVD (1 DVD)Mensual con un DVD dedicado a Linux 12 69 €
En total
Realizo el pago con:
□ tarjeta de crédito (EuroCard/MasterCard/Visa/American Express) nO CVC Code Válida hasta
□ transferencia bancaria a ABN AMRO Bank, Randstad 2025, 1314 BB ALMERE, The Netherlands Número de la cuenta bancaria: 59.49.12.075 IBAN: NL14ABNA0594912075 código SWIFT del banco (BIC): ABNANL2A Fecha y firma obligatorias:
37_Formularz_prenumeraty.indd 2009-04-14, 14:1989

softwareInterconexión de Sistemas Abiertos
38 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
l
Tres décadas después, el modelo ha demostrado sobradamente su efi cacia y, probablemente, ha sido uno de los proyectos de las tecnologías de la información y comunicaciones mejor pensado.
El objetivo de este modelo fue la búsqueda de la integración/ desagregación natural de los componentes de un sistema según su funcionalidad para conseguir.
InteroperabilidadPosibilidad de trabajo interactivo entre terminales.
IndependenciaImplementación del modelo sobre cualquier arquitectura.
Extremos abiertosCapacidad de comunicación entre terminales que corren distinto software.
InterconectividadDefi ne las reglas que posibilitan la interconexión física y la transmisión de datos entre terminales diferentes (hardware/ software).
La formalización de un modelo de interconexión corres-ponde a un amplio catálogo de normalización. Tales normas se pueden dividir en dos categorías:
• Las normas de facto (de hecho),• Las normas de jure (por ley).
Las primeras se establecen sin ningún planteamiento formal; simplemente se imponen por su práctica. Las últimas son for-malizadas y adoptadas por un organismo internacional.
Capas, protocolos e interfacesLa organización de una red de elementos informáticos en ni-veles funcionalmente independientes, construidos sobre la base de sus predecesores y ordenados jerárquicamente, garantiza la reducción de la complejidad, el aumento de la modularidad de los diseños, interfaces entre módulos bien especifi cadas y docu-mentadas, posibilita la estandarización, etc.
El diseño de una red, por compleja que sea, se reduce a la desagregación en pequeños módulos, montados unos so-bre otros. La fi losofía de este modelo es dividir un problema grande en muchos problemas pequeños. Cada capa o nivel
Interconexión de Sistemas AbiertosEl modelo de referencia de interconexión de sistemas abiertos (OSI, Open System Interconnection) fue desarrollado por la ISO (Organización Internacional de Normalización) en 1977 para describir las arquitecturas de redes y compatibilizar la comunicación entre los fabricantes de ordenadores.
Lino García Morales
38_39_40_Interconnection.indd 2009-04-14, 14:1938

softwareInterconexión de Sistemas Abiertos
39www.lpmagazine.org
utiliza la funcionalidad proporcionada por las capas inferiores y crea, a su vez, un nuevo nivel de funcionalidad para las capas superiores (cada eslabón o nivel da solución a un nuevo problema teniendo en cuenta lo que ha solucionado el esla-bón anterior).
La funcionalidad de cada capa, el número de capas, la comunicación entre capas y el nombre de cada capa varía de una red a otra. Sin embar-go, en general para todas las redes el propósito de cada capa es ofrecer ciertos servicios a su nivel superior.
La conversación o diálogo entre las esta-ciones/ puntos terminales se realiza por capas (la capa N de un sistema interactúa con la capa N de los otros) y es controlada por un conjunto de reglas y convenciones de manera tal que no exista ambigüedad o incoherencia en el diálogo. Al conjunto de reglas y procedimientos que rige el diálogo entre dos niveles de igual orden en las estaciones que interactúan se le denomina proto-colo y el número de orden de tal protocolo está en correspondencia directa con el nivel para el cual se establece (procedimientos iguales pertenecien-tes a un mismo nivel de orden N en máquinas diferentes, dialogan o se comunican a través de un protocolo de nivel N).
Dentro de la estructura jerárquica de la red los protocolos definen las reglas para la comunica-ción armónica entre procesos situados en niveles jerárquicos equivalentes. La comunicación esta-blecida entre niveles equivalentes no es física sino virtual. Cada capa pasa la información de datos o control que desea enviar a su nivel equivalente sólo a través de su nivel inmediato inferior que la propaga por cada nivel hasta llegar al más bajo que es, en realidad, quien verdaderamente rea-liza el enlace o conexión física. Igualmente, los niveles inferiores pasan información de control o respuesta sólo a su nivel inmediato superior hasta que llegue al nivel al cual va dirigida. Las reglas de comunicación entre procesos situados entre niveles jerárquicos diferentes se denominan interfaces. Estos son los servicios que las capas inferiores ofertan a su capa inmediata superior.
En la comunicación parece como si una parte del nivel o capa se comunicara directamente con
su contraparte a través del protocolo correspon-diente; pero, en realidad, los datos pasan a la capa inferior a través de la interfaz. Cada capa obtiene los servicios de la capa inferior a través de la interfaz correspondiente. La comunicación entre los elementos de una capa o nivel en la estructura a través de una interfaz común se denomina co-municación jerárquica.
Existen muchas formas de estructurar las ca-pas y definir sus funciones. Uno de los aspectos más importantes para los diseñadores de redes es precisamente decidir la cantidad de niveles y sus funciones; así como las especificaciones acerca de las operaciones a realizar por cada interfaz en-tre un nivel y otro, de forma tal que minimice el volumen de información a transitar entre niveles a través de su correspondiente interfaz.
Al conjunto de niveles con sus respectivos protocolos se le denomina arquitectura de red. Las especificaciones de la arquitectura deben contener información suficiente para la imple-mentación de los protocolos de cada nivel. Los detalles de la implementación y las especifica-ciones de las interfaces no forman parte de la arquitectura (en todas las estaciones de la red las interfaces entre niveles no tienen porque ser iguales; la correspondencia es necesaria sólo respecto a los protocolos que rigen los diferentes niveles).
OSIEl modelo de interconexión de sistemas abier-tos (OSI, Open System Interconnection) es un modelo de referencia para las comunicaciones entre sistemas abiertos propuesto por la orga-nización internacional de normalización (ISO, International Standard Organization). Este mo-delo, ISO 7498, define un conjunto de normas y protocolos que permiten la interconexión de diversos sistemas TIC.
Niveles funcionalesEl modelo OSI define una jerarquía de siete capas de protocolos, cada uno de los cuales utiliza a los de nivel inferior para ofrecer un determinado servicio, al mismo tiempo que complementa los servicios proporcionados por los protocolos de nivel superior.
Los trabajos sobre la interconexión de sis-temas abiertos comenzaron cuando los usuarios comprendieron que no se podrían llevar a la práctica todas las posibilidades potenciales de las redes de datos y de los sistemas públicos de conmutación de paquetes; si cada dispositivo interconectado a la red exigiese el conjunto de protocolos que determinase su fabricante. Tra-dicionalmente los sistemas informáticos siempre fueron cerrados, es decir, los dispositivos se ajus-taban únicamente a las normas de interconexión establecidas por el fabricante o diseñador del sistema. Los protocolos que utilizaban los termi-nales estaban determinados por las características del ordenador o controlador de comunicaciones. Un terminante para emular el modelo especi-ficado de otro fabricante, e incluso del mismo fabricante pero de otra familia de productos, di-fícilmente podía conectarse al sistema, sin antes ser modificado convenienteme
Esta situación resultó aceptable mientras el número de dispositivos a integrar en un sistema era reducido y bajo el estricto control de un solo
Figura 1. Capas, protocolos e interfaces
N N
2
1
2
1
Protocolo
Interfaz
Nivel
Aplicación Aplicación
Presentación Presentación
Sesión Sesión
Transporte Transporte
Red Red Red Red
Enlace
Físico
Enlace
Físico
Enlace
Físico
Enlace
Físico
Medio Físico de InterconexiónProtocolo interno de la Subred de Transporte
Protocolo de Aplicación
Protocolo de Presentación
Protocolo de Sesión
Protocolo de Transporte
Figura 2. Modelo OSI de la ISO
38_39_40_Interconnection.indd 2009-04-14, 14:1939

40
softwareInterconexión de Sistemas Abiertos
Linux+ 6/2009
ordenador. Sin embargo el avance de las técni-cas informáticas, en las técnicas de interco-nexión a red y la proliferación de ordenadores y equipos relacionados con ordenadores, ha sido de tal magnitud que actualmente es inaceptable el concepto de red cerrada. Por el momento, tanto usuarios como fabricantes, coinciden en el bene-fi cio que reporta establecer una serie de normas o estándares para la interconexión de sistemas abiertos que permita la integración de funciones operacionales de los equipos a todos los niveles. El modelo de referencia de la ISO supone el primer intento serio hacia la consecuencia de ese objetivo.
FísicoProporciona el soporte de transmisión o medio material para que establecer y mantener el fl ujo de información entre varios terminales remotos y la señalización necesaria para la gestión de erro-res. Este nivel defi ne y caracteriza las propieda-des mecánicas, eléctricas y funcionales de los dispositivos involucrados en el enlace físico.
EnlaceGarantiza un servicio de transferencia de datos libre de error (en términos de mínima probabi-lidad). Esta capa es la responsable de establecer y liberar conexiones de enlace, dividir la informa-ción en tramas, delimitar y sincronizar, secuen-ciar, controlar el fl ujo de datos, detectar y recupe-rar errores, controlar el acceso al medio, etc.
RedProvee un servicio de conectividad universal independiente de la tecnología (oculta a las capas superiores las diferencias tecnológicas de las subredes) a la vez que ofrece una calidad de servicio. Sus funciones más importantes son el encaminamiento de la información (y almace-namiento y reenvío), la multiplexación, etc.
TransporteProporciona un servicio de transferencia de datos fi able y efectivo en coste a la vez que mantiene la calidad de servicio. Básicamente, realiza tres servicios:
• establecimiento de conexión,• difusión de la información a múltiples des-
tinatarios,• posibles transacciones.
Para ello debe establecer la correspondencia en-tre las direcciones de transporte y de red; multi-plexar y dividir; establecer y liberar conexiones de transporte; segmentar, agrupar y concatenar; etc. Esta capa independiza las aplicaciones de comu-nicaciones y media entre los requisitos de calidad
de servicio que imponen las aplicaciones y la calidad de servicio ofrecida por las redes.
SesiónOfrece mecanismos para que la aplicación pueda gestionar su diálogo, sincronizar y re-sincronizar el fl ujo de datos. Para ello establece y libera co-nexiones de sesión; establece correspondencia entre direcciones de sesión y transporte; seg-menta y concatena; gestiona testigos; sincroniza y re-sincroniza; etc. Es la auténtica interfaz del usuario hacia la red (con procedimientos de identifi cación de usuario mediante el uso de con-traseña).
PresentaciónIndependiza a la aplicación de los problemas relativos a la presentación de los datos (sintaxis de transferencia). Esta capa negocia y transforma sintaxis de transferencia, traduce alfabetos etc. Defi ne una sintaxis común para la representación de los símbolos (cada terminal o punto deberá establecer una correspondencia entre tal sintaxis y la correspondiente a su arquitectura interna).
AplicaciónProporciona los medios para que un proceso de aplicación acceda al entorno OSI. Es el único nivel que conoce la semántica asociada a la transferencia de información.
La segmentación funcional de las capas permite el intercambio de ellas sin perjudicar al sistema. Por ejemplo, el RS232 es un protocolo de nivel físico punto a punto, mientras que el RS485 es de tipo bus. La capa física defi ne la topología de la red: árbol, bus, anillo, etc. y la capa de enlace el protocolo de acceso.
Sin embargo es posible sustituir un enlace RS232 punto a punto por un enlace inalámbrico multipunto IEEE 802.11g sin que cambie la funcionalidad de los niveles por encima de la subred de transporte. Esta fl exibilidad garantiza la actualización/renovación del hardware de co-municación y el desarrollo de las aplicaciones independientemente de la tecnología.
ConclusionesEl modelo OSI ataca el problema de la compati-bilidad entre terminales (procesador, velocidad, almacenamiento, interfaz de comunicación, código de caracteres, sistema operativo, etc.) mediante la formalización de diferentes nive-les o capas de interacción. Esta desagregación provee dos benefi cios muy importantes: posibi-lita una mayor comprensión del problema a la vez que permite optimizar la solución de cada problema específi co. En esta arquitectura la información que genera/entrega un proceso a la capa de aplicación baja hacia la subred de trans-
porte y sube hacia la aplicación destino para su entrega al proceso correspondiente. Cada capa añade información redundante (adicional), para garantizar su servicio, en el proceso de descen-so, mientras que la elimina, en el proceso de ascenso. Cada capa realiza tareas únicas y espe-cífi cas; sólo tiene conocimiento de los niveles adyacentes, utiliza los servicios de la capa infe-rior y presta servicios a la capa superior.
Este modelo (con las defi niciones de servi-cios y protocolos asociados) es muy complejo y extenso y, por supuesto, no es perfecto. Muchas son las críticas que ha recibido durante todos estos años. Sin embargo aporta un método para enfocar la complejidad de un sistema (facilita la comprensión al dividir un problema com-plejo en partes más simples), normaliza los componentes de red y permite el desarrollo por parte de diferentes fabricantes (los cambios de una capa no afectan las demás capas y éstas pueden evolucionar más rápido), garantiza la comunicación entre procesos libre de error, evita los problemas de incompatibilidad (e in-directamente la obsolescencia), simplifi ca el aprendizaje, y así, un largo etcétera, que prorro-ga su caducidad.
Graduado de Ingeniería en Control Auto-mático, Máster en Sistemas y Redes de Comunicaciones y Doctor por la Universi-dad Politécnica de Madrid. Ha sido profe-sor en Instituto Superior de Arte, Univer-sidad Pontifi cia Comillas y la Universidad Meléndez Pelayo.
Actualmente Profesor de la Escuela Su-perior Politécnica de la Universidad Europea de Madrid y Director del Máster Ofi cial en Acústica Arquitectónica y Medioambiental. Lidera grupo de investigación transdiscipli-nar en la intersección Arte, Ciencia, Tecno-logía y Sociedad. Ha recibido becas por la Agencia Española de Cooperación Interna-cional (AECI), la Fundación para el Desa-rrollo de la Función Social de las Comunica-ciones (FUNDESCO), el Consejo Superior de Investigaciones Científi cas (CSIC) y la Universidad Politécnica de Madrid.
Además ha formado parte de las bandas Cartón Tabla y Música d’ Repuesto. Disco-grafía: Las palabras vuelven, Se fue, Bags, Flags, Faqs, Fotos d’ parque, These little things that keep inside, Mr. Fro (colaboración con Alejandro Frómeta), El eje del mal, Av abuc, Variaciones en la cuerda VOL. I.
Y ha publicado una novela: [email protected]
Sobre el autor
38_39_40_Interconnection.indd 2009-04-14, 14:1940

41_rekl_chicaslinux.indd 2009-04-14, 14:191

soluciones para empresasMáquinas virtuales
42 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
l
Explicados los conceptos, más o menos teóricos, vamos a instalar paso a paso una máquina vir-tual. Se intentará detallar lo máximo posible este proceso para que pueda ser seguido con la mayor
sencillez posible. El sistema que instalaremos será Debian. El motivo es su sencillez, el bajo número de recursos necesarios, el poco espacio que ocupa en disco y el hecho de resolver dudas en cuanto a la instalación, que mucha gente tiene.
Creando una nueva máquina virtualPara comenzar pulsaremos el botón Nuevo que se encuentra en la parte izquierda superior de la ventana. Nos aparecerá un asistente que nos dará la bienvenida. Pulsamos sobre Siguiente (o Next, dependiendo del idioma). Se nos pedirá que le demos un nombre a nuestra nueva máquina (Figura 1). El nombre puede ser cualquiera, pero sería conveniente elegir uno des-criptivo. En concordancia al sistema que vayamos a instalar. También es una buena práctica no usar espacios para el nombre para evitar posibles problemas posteriores con la codificación de carácteres que podrían tenerse en algunos sistemas. En su lugar podemos sustituir el espacio por la barra baja (_). Noso-tros llamaremos a nuestra máquina. Debian_base.
En el desplegable que aparece debajo hemos de indicarle el sistema operativo que vamos a instalar. Seleccionamos De-bian. Como curiosidad, se puede observar que, dependiendo del sistema operativo que elijamos, a la derecha aparece su logotipo asociado. Podemos ver en la imagen cómo como nos ha de quedar el cuadro de diálogo y la espiral de Debian.
Una vez hecho esto pulsamos el botón de Next. En esta pantalla podemos elegir la cantidad de memoria que queremos asignar a la máquina virtual (Figura 2). Este parámetro depende de varias cosas. La primera es la cantidad de memoria física de la que dispongamos. La segunda es el sistema operativo que vayamos a virtualizar. Por ejemplo, para un Windows XP, la cantidad de memoria no debería de ser menor de 512MB si queremos que su funcionamiento sea aceptable. En nuestro ca-so, al no instalar un entorno gráfico, y disponer solamente de la funcionalidad básica con 64 MB de RAM sería suficiente. Por lo tanto asignamos esa cantidad. Si nos fijamos bien VirtualBox tiene almacenada la cantidad de requisitos mínimos de memoria necesarios, según el fabricante, para el correcto funcionamiento del sistema operativo y nos sugerirá dicha cantidad de memoria. Presionamos Next para continuar. Aquí nos aparecen los, ya explicados, discos duros virtuales. Nos aparecerá una pantalla
Maquinas virtuales, parte IIEn esta segunda entrega nos adentraremos en los detalles de implementación sobre el entorno de prueba. Se detallará paso a paso una instalación de Debian, para los principiantes, clonación de máquinas virtuales y configuración de diversos servicios red, entre ellos: un firewall perimetral, un proxy cache transparente, un servidor DNS, etcétcera.
Daniel García
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2042

soluciones para empresasMáquinas virtuales
43www.lpmagazine.org
como la de la Figura 3. Puesto que no tenemos ningún disco duro creado con anterioridad, pul-samos el botón de Nuevo. VirtualBox nos mos-trará entonces otro asistente que nos permitirá crear un nuevo disco virtual. Al igual que antes nos dará la bienvenida. Pasamos a la siguiente pantalla pulsando Next. En el siguiente cuadro nos parecerá el tipo de disco deseado. Elegi-mos el tipo de Imagen de expansión dinámica y avanzamos de nuevo. Se nos pedirá un nom-bre para el nuevo disco y un tamaño máximo. Considero que es una buena costumbre el poner nombres descriptivos. Por eso llamaremos al disco: Debian_base_hd0. Este sufijo indica Hard Disk 0. Esta nomenclatura es idónea si posteriormente quisiéramos añadir nuevos discos. Si lo hiciéramos podríamos llamarlos: Debian_base_hd1, Debian_base_hd2, etcétera. En cuanto al tamaño que nos asigna VirtualBox por defecto es excesivo para el tipo de instala-ción que pretendemos hacer. Sería una buena idea asignar esa cantidad en un sistema Windo-ws, Ubuntu o cualquier otro en que vayamos a almacenar cierta cantidad de información. En nuestro caso nos bastará con 4GB. Por tanto escribiremos (o moveremos el indicador) hasta 4,00 GB. Hecho esto, en el siguiente paso se nos mostrará un resumen con las características elegidas. Presionamos el botón Finish y nuestro disco estará preparado.
Finalizado el asistente de creación de discos volvemos al punto donde nos quedamos. Como podemos observar en la Figura 4, el disco es seleccionado de forma automática como maes-tro. Esto, al igual que un PC físico, significa que será desde ese disco duro desde donde la má-quina virtual arrancará. Si después lo deseamos podemos añadir más discos esclavos. También vemos donde nos ha guardado los archivos que usa para emular el disco duro. Normalmente, a no ser que se le diga lo contrario, lo guardará en la carpeta personal del usuario. En un di-rectorio oculto llamado .VirtualBox/VDI. Con el siguiente paso, en el que se nos muestra un resumen de todo lo elegido, finalizamos la crea-ción de nuestra nueva máquina.
Instalación de DebianSi hemos seguido correctamente los pasos del punto anterior, ahora estamos en disposición de instalar nuestro sistema operativo. Esta instala-ción nos servirá como sistema base para el res-to de pruebas y ejemplos que se hagan. Mucha gente no instala Debian porque, dicen, es muy complicada su instalación. Nada más lejos de la realidad. Por eso se hará una instalación extre-madamente detallada para que nadie se pierda durante el proceso.
En primer lugar hemos de conseguir el CD de instalación de Debian. Podemos descargar la imagen desde la página oficial o seguir directa-mente este enlace: http://cdimage.debian.org/debian-cd/5.0.0/i386/iso-cd/debian-500-i386-netinst.iso. VirtualBox nos da la posibilidad de instalar el sistema sin necesidad de copiar la ima-gen en un cdrom, así que usaremos este método.
Abrimos el menú de configuración de la máquina que creamos en el apartado anterior. Seleccionamos el menú, que se encuentra a la izquierda, CD/DVD-ROM. Pulsamos cuadro de chequeo para activar del CDROM y marcamos la opción Archivo de imagen ISO. Pulsamos en el botón derecho para seleccionar la imagen que descargamos. Nos aparecerá una nueva venta-na. En ella tan solo tenemos que pulsar en Agre-gar y seleccionar el archivo que descargamos. Hecho esto pulsamos en seleccionar y se nos cerrará esa ventana. Volvemos a aceptar en el menú de propiedades. Ahora arrancaremos, por primera vez, nuestra máquina virtual. Pulsamos el botón Iniciar.
Cada vez que arranquemos una máquina virtual nos aparecerá una ventana que nos informa sobre la captura del teclado para la máquina virtual. Cuando iniciamos un sistema virtualizado es necesario disponer de todos los dispositivos físicos mínimos para funcionar, como es el teclado. El problema es que solo tenemos un teclado y no puede ser usado a la vez en el ordenador físico (u otras máquinas virtua-les) y en el virtual. Por lo tanto hay que elegir, o se utiliza en uno o en otro. Por eso, cuando po-nemos en funcionamiento el sistema virtual, éste se adueñará del teclado. Para expropiárselo y que el sistema operativo de la máquina física vuelva a recuperarlo han de pulsarse una combinación de teclas. Esto es así para cualquier entorno de virtualización. En VMWare, por ejemplo, es la combinación CTRL + ALT. En VirtualBox es la tecla control de la parte derecha del teclado. La izquierda no liberará el teclado. Volviendo al mensaje, si lo leemos, eso es lo que nos dice. Si no queremos que cada vez que iniciemos una máquina virtual nos aparezca, basta con marcar el botón de chequeo, que se encuentra en la parte inferior de la pantalla. Aceptamos y continuamos
con la instalación. La primera pantalla que se nos mostrará es la del gestor de arranque del CD (Fi-gura 5). Salvo que queramos añadir algún tipo de parámetro no escribiremos nada, solamente pul-saremos Intro. Se empezará a cargar el kernel, los módulos necesarios y una serie de servicios.
Acabado esto nos aparecerá como primer paso una pantalla en la que deberemos de se-leccionar el idioma. Elegiremos Spanish como idioma y pulsamos Intro. En la siguiente pantalla se nos preguntará en qué idioma deseamos confi-gurar el teclado. Por defecto, y si hemos elegido español, nos marcará por defecto castellano. Por tanto solo tenemos que pulsar Intro nuevamente. Entonces Debian empezará un proceso de reco-nocimiento de todo el hardware de su PC y carga de todos lo módulos necesarios para su correcto funcionamiento. Aunque estamos en un máquina virtual, el sistema de virtualización emula unos drivers y un sistema físico que requieren de su detección Exactamente igual que si estuviéra-mos en un PC real. Este proceso puede tomar al-gún tiempo, dependiendo del resto de programas que tenga abiertos ocupando el procesador, o la potencia de éste último.
Ahora tendremos que ponerle un nombre a nuestra máquina virtual (Figura 6). Este nom-bre lo usará el sistema, sobre todo, para servicios de red. Nosotros hemos usado como nombre el de revista, pero sin el signo +, por no ser un ca-rácter permitido como nombre. El lector puede usar el nombre que mejor le parezca. Una vez introducido pulsamos Intro para continuar. En la siguiente pantalla se nos pedirá un nombre de dominio. Este tiene sentido cuando pretendemos instalar un sistema que, junto con el nombre de la máquina, identificará al PC en la red. Puesto que no es nuestro caso, sencillamente lo dejamos en blanco y pulsamos Intro para continuar.
En el siguiente paso se nos pedirá que seleccionemos una réplica de red. Las réplicas (o mirrors) son sistemas servidores, todos idén-ticos entre si, que contienen todos los paquetes existentes, y disponibles, para un sistema Debian.
Figura 1. Selección del nombre de la máquina y sistema operativo
Figura 2. Selección del tamaño de la memoria
Figura 3. Nuevo disco duro virtual
Figura 4. Resultado añadir nuevo disco virtual
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2043

44 Linux+ 6/2009
soluciones para empresasMáquinas virtuales
mento de preparar los discos duros: particio-narlos, seleccionar de forma correcta los puntos de montaje, selección del sistema de archivos y formateado de las particiones. Existen varias formas de hacer esto: manualmente y automáti-camente. Con la primera se pueden ajustar todos los parámetros más detalladamente. Este sería el método ideal de instalación si fuéramos a usar el sistema para cualquier otra cosa que requiriera un mínimo de planificación. La segunda es realmen-te cómoda y para el fin de esta guía será más que suficiente, aunque se explicará qué son cada uno de los ajustes que decide por nosotros el asistente. Para comenzar el particionado debemos de elegir el disco duro. En nuestro caso, al tener solamente uno, no hay lugar a equivocación. Puesto que el disco duro lo está emulando VirtualBox, en el lugar que le correspondería al fabricante aparece VBOX HARDDISK (Figura 8). Por tanto pulsa-mos, sencillamente, Intro. La nueva pantalla es la que nos dará la posibilidad de elegir el tipo de particionado que queremos. Como dijimos antes seleccionaremos el particionamiento básico. Por tanto elegimos la opción Particionamiento guiado (Figura 9). Este tipo de particionado crea automáticamente todas las particiones necesarias, que serán dos. Una para los archivos del sistema y otra para el espacio de intercambio o swap. Para crearlas ocupa todo el espacio del disco duro virtual. El sistema de fichero usado por defecto es ext3. Un sistema probado a lo largo de los años. Demostrando, una y otra, vez su eficien-cia y tolerancia a fallos. Después de seleccionar esta opción se nos mostrará un nuevo menú. En éste elegiremos la opción en la que poner, entre paréntesis, para novatos. Como último paso se nos mostrará un cuadro de confirmación para autorizar la creación de las particiones en el dis-co. Elegimos Sí. Acto seguido nos aparecerá, de forma fugaz, un diálogo en que se indica que se está configurando la zona horaria y el reloj del sistema. Este proceso es automático porque estos datos son tomados de la BIOS del PC. Posterior-mente se nos pedirá la contraseña de superusuario (o administrador o root). Puede elegir la que le parezca conveniente. Nosotros elegiremos una muy usual en entornos de pruebas: holamundo. Este paso tendremos que repetirlo dos veces.
Una vez hecho tendremos que agregar un nuevo usuario al sistema. Primero se nos pedirá una descripción para el usuario. Se ha puesto una descripción acorde a este artículo (Figura 11): Creación de un entorno de pruebas con Virtual-Box.
A continuación de la descripción se nos pedirá el nombre del usuario con el que se ac-cederá al sistema (Figura 12). En este ejemplo: linuxplus. Al igual que para el superusuario ha de introducirse la contraseña para el nuevo usuario.
Listado 1. Eliminación de servicios del arranque del sistema
(paramos squid y lo eliminamos del inicio)
# /etc/init.d/squid stop
# update-rc.d -f squid remove
(paramos apache y lo eliminamos del inicio)
# /etc/init.d/apache2 stop
# update-rc.d -f apache2 remove
(paramos el servicidor DHCP y lo eliminamos del inicio)
# /etc/init.d/dhcp stop
# update-rc.d -f dhcp remove
(paramos snort y lo eliminamos del inicio)
# /etc/init.d/snort stop
# update-rc.d -f snort remove
(paramos mysql y lo eliminamos del inicio)
# /etc/init.d/mysql stop
# update-rc.d -f mysql remove
(paramos exim4 y lo eliminamos del inicio)
# /etc/init.d/exim4 stop
# update-rc.d -f exim4 remove
Listado 2. Clonado de todas las máquinas de la infraestructura
(Creamos el IDS)
# VboxManage clonevdi debian_base.vdi IDS.vdi
(Creamos el servidor web)
# VboxManage clonevdi debian_base.vdi servidor_web.vdi
(Creamos el servidor de base de datos)
(Creamos el servidor de control de versiones)
# VboxManage clonevdi debian_base.vdi servidor_svn.vdi
(Creamos la máquina que hará de firewall y router)
# VboxManage clonevdi debian_base.vdi router_firewall.vdi
(Creamos el proxy y servidor DHCP)
# VboxManage clonevdi debian_base.vdi servidor_proxy_dhcp.vdi
(Creamos el cliente uno)
# VboxManage clonevdi debian_base.vdi cliente1.vdi
(Creamos el cliente dos)
# VboxManage clonevdi debian_base.vdi cliente2.vdi
Listado 3. Configuración de la tarjeta red de Apache
auto eth0
iface eth0 inet static
address 10.10.1.10
netmask 255.255.255.0
gateway 10.10.1.1
Cada vez que queramos instalar cualquier soft-ware usando el gestor de paquetes de Debian será de ahí de donde lo descargará. Por tanto cuanto más rápida sea la conexión de ese ser-vidor antes bajaremos los paquetes. En internet existen listas con los mejores servidores. Si no sabe cual escoger, elíjalo de forma aleatoria, o el que se corresponda con su país. Atendiendo a es-te último criterio, habrá seleccionado el servidor de España. Una vez seleccionado nos aparecerá
una lista con los mirrors pertenecientes a ese país. Salvo que sepamos que el rendimiento de alguno de ellos es mejor que el del resto pode-mos elegirlo al azar.
A continuación tendremos que introducir la configuración del proxy (Figura 7). Salvo que salga a internet a través de uno, ha de dejar esta pantalla en blanco.
Las siguientes pantallas son las que más cuestan a los usuarios principiantes. Es el mo-
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2044
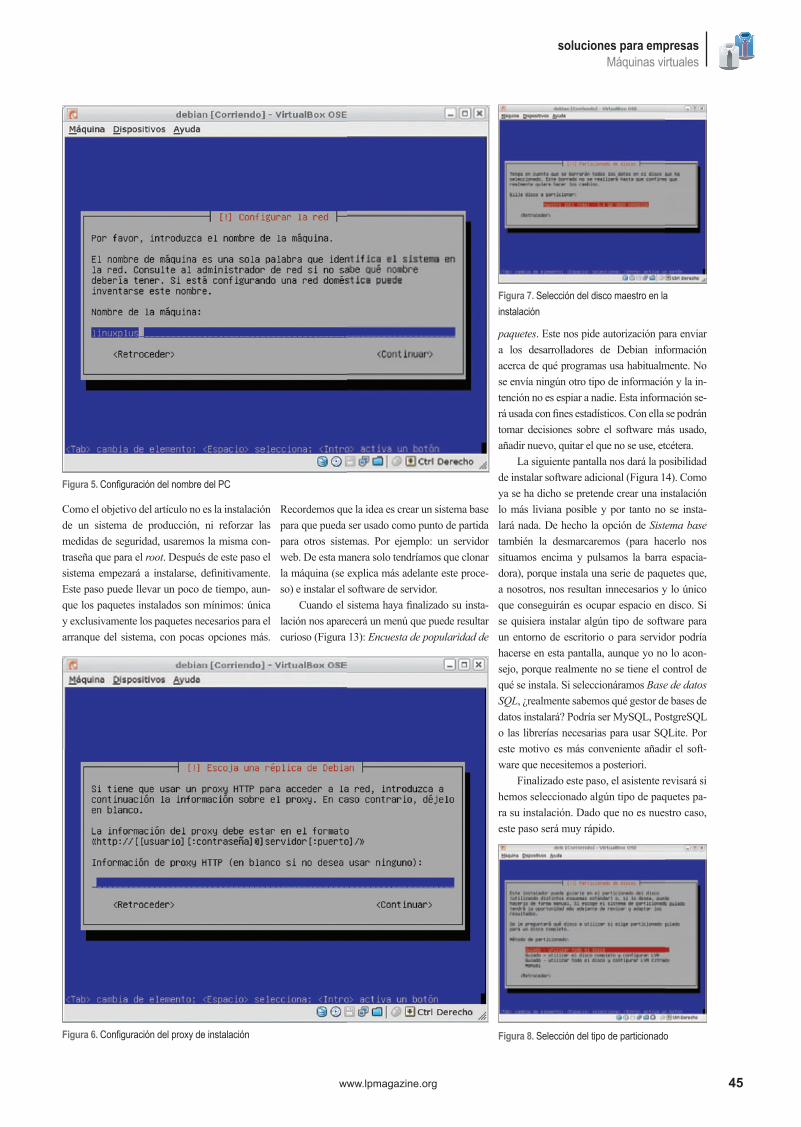
45www.lpmagazine.org
soluciones para empresasMáquinas virtuales
Como el objetivo del artículo no es la instalación de un sistema de producción, ni reforzar las medidas de seguridad, usaremos la misma con-traseña que para el root. Después de este paso el sistema empezará a instalarse, defi nitivamente. Este paso puede llevar un poco de tiempo, aun-que los paquetes instalados son mínimos: única y exclusivamente los paquetes necesarios para el arranque del sistema, con pocas opciones más.
Recordemos que la idea es crear un sistema base para que pueda ser usado como punto de partida para otros sistemas. Por ejemplo: un servidor web. De esta manera solo tendríamos que clonar la máquina (se explica más adelante este proce-so) e instalar el software de servidor.
Cuando el sistema haya fi nalizado su insta-lación nos aparecerá un menú que puede resultar curioso (Figura 13): Encuesta de popularidad de
paquetes. Este nos pide autorización para enviar a los desarrolladores de Debian información acerca de qué programas usa habitualmente. No se envía ningún otro tipo de información y la in-tención no es espiar a nadie. Esta información se-rá usada con fi nes estadísticos. Con ella se podrán tomar decisiones sobre el software más usado, añadir nuevo, quitar el que no se use, etcétera.
La siguiente pantalla nos dará la posibilidad de instalar software adicional (Figura 14). Como ya se ha dicho se pretende crear una instalación lo más liviana posible y por tanto no se insta-lará nada. De hecho la opción de Sistema base también la desmarcaremos (para hacerlo nos situamos encima y pulsamos la barra espacia-dora), porque instala una serie de paquetes que, a nosotros, nos resultan innecesarios y lo único que conseguirán es ocupar espacio en disco. Si se quisiera instalar algún tipo de software para un entorno de escritorio o para servidor podría hacerse en esta pantalla, aunque yo no lo acon-sejo, porque realmente no se tiene el control de qué se instala. Si seleccionáramos Base de datos SQL, ¿realmente sabemos qué gestor de bases de datos instalará? Podría ser MySQL, PostgreSQL o las librerías necesarias para usar SQLite. Por este motivo es más conveniente añadir el soft-ware que necesitemos a posteriori.
Finalizado este paso, el asistente revisará si hemos seleccionado algún tipo de paquetes pa-ra su instalación. Dado que no es nuestro caso, este paso será muy rápido.
Figura 5. Confi guración del nombre del PC
Figura 6. Confi guración del proxy de instalación
Figura 7. Selección del disco maestro en la instalación
Figura 8. Selección del tipo de particionado
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2045

46 Linux+ 6/2009
soluciones para empresasMáquinas virtuales
Después de la instalación del software se pe-dirá confi rmación para la instalación del gestor de arranque (Figura 15). Debian instala por defecto Grub. Actualmente, salvo contadas excepciones, debería de ser el gestor usado por la mayor parte de los usuarios ya que incorpora características que otros no hacen. Antiguamente era usado Lilo, pero se encuentra en desuso. El gestor de arran-que es imprescindible. De no contar con uno, el PC no sabría dónde encontrar el sistema operati-vo para arrancarlo. Esto es así porque, entre otras responsabilidades, el gestor de arranque indica al PC en qué partición se encuentra el sistema operativo que se quiere arrancar.
Finalmente se nos presentará un último men-saje confi rmándonos que la instalación se realizó con éxito y que solo nos queda quitar el CDROM y reiniciar (Figura 16). Puesto que nosotros no pusimos un CDROM, sino una imagen, hemos de ir al menú de confi guración de la máquina vir-tual (cuando esté apagada), a la sección del CD/DVD. Ahí podemos elegir deshabilitar el lector
Figura 9. Descripción de usuario nuevo
Figura 10. Nombre de nuevo usuario
Figura 11. Encuesta de popularidad de Debian
Listado 4. Código php para página de ejemplo
(creamos el archivo con nano)
nano -w /var/www/index.php
(escribimos el contenido)
<?
echo "<html>";
echo " <head>";
echo "<title>Pagina de prueba</title>";
echo " </head>";
echo " <body>";
for($i=0; $i<10;$i++){
echo "<p><b>Hola mundo</b>!</p>";
}
echo " </body>";
echo "</html>";
?>
Listado 5. Confi guración de la tarjeta red de MySQL
auto eth0
iface eth0 inet static
address 10.10a.1.11
netmask 255.255.255.0
gateway 10.10.1.1
Listado 6. Añadir un usuario a MySQL
(Nos conectamos al servidor MySQL)
# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 55
Server version: 5.0.32-Debian_7etch8-log Debian etch distribution
Type 'help;' or 'h' for help. Type 'c' to clear the buffer.
(Tecleamos el comando SQL)
mysql> CREATE USER 'USUARIO'@'10.10.1.10' IDENTIFIED BY 'PASSWORD'
(Damos los permisos adecuados al usuario)
mysql> GRANT ALL ON *.* TO 'USUARIO'@'10.10.1.10'
IDENTIFIED BY "PASSWORD";
(Aplicamos los cambios)
mysql>FLUSH privileges;
(Salimos del gestor)
mysql>quit
Listado 7. Confi guración de la tarjeta red de SubVersion
auto eth0
iface eth0 inet static
address 10.10.1.12
netmask 255.255.255.0
gateway 10.10.1.1
Listado 8. Creación del repositorio SubVersión
(Creamos el directorio del trabajo del servidor)
# mkdir /var/svn
(Creamos el nuevo repositorio, llamado linuxplux)
# svnadmin create /var/svn/linuxplus
(Arrancamos el servidor)
# svnserve -d -r /var/svn/
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2046

47www.lpmagazine.org
soluciones para empresasMáquinas virtuales
o elegir la primera opción y vincularlo a la unidad óptica del ordenador físico. Llegados a este pun-to, ya tenemos nuestro sistema GNU/Linux, con la distribución Debian, lista para ser usada.
Clonación de máquinas virtuales: Conceptos y usoEl concepto de clonación es bastante intuitivo. Estamos, incluso, acostumbrado a escucharlo
por televisión u otros medios de comunicación. Y eso es exactamente en lo que consiste: obtener un réplica exacta de algo que ya tenemos. Esto es sumamente útil cuando tratamos con máquinas virtuales. En el punto anterior instalamos un sistema virtualizado. Si no tuviéramos la posibili-dad de clonar máquinas, cada nuevo sistema que deseásemos deberíamos de crearlo desde cero, repitiendo este proceso una y otra vez, lo que es
sumamente incómodo. Por eso, normalmente, se crea un sistema base, como hicimos nosotros. A partir de éste sacaremos tantas réplicas como necesitemos. De ahí la importancia de la correcta instalación del sistema base.
En VirtualBox no existe ningún asistente que nos facilite este proceso, con lo que tendremos que hacerlo de forma manual en un terminal. Otros programas de virtualización, como VMWare, sí que lo llevan integrado. En este sentido Virtual-Box ha de mejorar considerablemente.
Para crear una copia de la máquina virtual abriremos un terminal. Nos situamos en nuestra carpeta personal y entramos en el directorio oculto .VirtualBox. En él están, por defecto, todos los archivos con nuestra confi guración personal y máquinas virtuales. Dentro de este, en el direc-torio VDI, están nuestros discos duros virtuales, que es lo que buscamos. Entonces tecleamos los siguientes comandos:
# cd /home/USUARIO/.VirtualBox/VDI/
# vboxmanage clonevdi Debian_base.vdi
Debian_maquina1.vdi
Donde USUARIO es el usuario con el que hemos accedido al sistema. El comando vboxmanage permite numerosas opciones y nos permite ges-tionar completamente todas nuestras máquinas. Le indicamos que queremos clonar (clonevdi), le decimos la máquina que queremos clonar (Debian_base.vdi) y cómo se llamará la nueva (Debian_maquina1.vdi).
Con este sencillo paso ya habremos creado nuestro clon. Para poder usarla habremos de ir a VirtualBox y seleccionar la opción de nueva máquina virtual. Se seguirán los pasos, como ya se explicaron, con la salvedad de que cuando lleguemos a la pantalla de confi guración de los discos virtuales elegiremos la opción existente y seleccionaremos el que acabamos de crear. Ahora sí, ya esta lista nuestra nueva máquina.
Confi guración de una red interna de máquinas virtuales. Conceptos y confi guraciónAnteriormente se hizo un breve comentario sobre este tipo de confi guración para las inter-
Figura 12. Selección de programas a instalar
Listado 9. Confi guración del acceso a SubVersión
[…]
anon-access = none
auth-access = write
password-db = passwd
[…]
Listado 10. Script de inicio para SubVersionauto eth0, eth1
iface eth0 inet static
address 10.10.3.2
netmask 255.255.255.0
gateway 10.10.3.1
iface eth1 inet static
address 10.10.2.1
netmask 255.255.255.0
Listado 11. Confi guración de la tarjeta red del proxy
test -x /usb/bin/svnsrve || exit 0
case "$1" in
start)
echo "Arrancando servidor de SubVersion"
svnserve -d -r /var/svn/
echo "Servidor SubVersion arrancado"
;;
stop)
echo "Apagando el servidor de SubVersion"
killall -9 svnserve
echo "Servidor de SubVersion apagado"
;;
*)
echo "Usar: $0 {start|stop}"
exit 1
esac
exit 0
Listado 12. Confi guración del servidor DHCPoption domain-name "linuxplus";
option domain-name-servers 10.10.2.2;
option routers 10.10.2.1;
default-lease-time 3600;
subnet 10.10.2.0 netmask 255.255.255.0 {
arrange 10.10.2.3 10.10.2.254;
}
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2047

48 Linux+ 6/2009
soluciones para empresasMáquinas virtuales
faces de red. A pesar de no ser muy popular, puede resultar extremadamente útil si se desea montar un entorno de laboratorio o de pruebas. El concepto es bastante simple. Se creará una red virtual, sin salida al exterior, en la que todas las máquinas cuya interfaz de red esté añadida a dicha red, tendrán visibilidad entre ellas. Co-mo puede comprobar, esto es lo que nosotros estamos buscando para montar nuestro propio entorno de pruebas.
La configuración de las interfaces es real-mente simple en VirtualBox (Figura 17). Se-leccionamos la máquina virtual que queramos añadir a la red privada. Abrimos su menú de configuración y nos dirigimos a la pestaña de red. Seleccionamos un adaptador de red que no tengamos en uso. En el segundo cuadro desple-gable, con nombre Attached to o Añadido a, seleccionamos Red Interna (recuadro rojo en la figura). Hemos de darle un nombre a nuestra red. En nuestro caso se ha llamado red_pruebas (recuadro azul en la figura). Ahora solo nos queda guardar los cambios.
Cualquier nueva máquina que queramos que pertenezca a esta red, tan solo habríamos de seguir los mismos pasos. Cabe señalar que cuando seleccionamos tipo de configuración para la red, no dispondremos de ningún servidor que nos asigne la IP de forma automática. Por lo que tendremos que ponerla de forma manual. Este proceso se verá con detalle en el ejemplo de arquitectura que se muestra más adelante. Como última puntualización, decir que pode-mos crear tantas redes virtuales como quera-mos. El único requisito es que, obviamente, tengan nombres diferentes.
Definición de una infraestructura de redEn estos momentos estamos en disposición de crear cualquier tipo de máquina virtual y obtener de ella tantos clones como gustemos. El obje-tivo de este artículo no es solamente la expli-cación del proceso de creación de una máquina virtual o la instalación de Debian. Se pretende llegar más allá. Por eso se simulará una red completa. Esta arquitectura será implementada con VirtualBox más adelante.
La definición que se ha seguido para el diseño de la infraestructura es el que se puede encontrar de forma más típica en cualquier in-tranet de una empresa media-grande. La Figura 18 expone esta arquitectura.
Para cada figura del diagrama se indica su funcionalidad y su IP dentro de la intranet. Para aquellos que no estén familiarizados con los esquemas de red, el elemento azul circular es un router y los otros dos elementos del mismo color son switches. Explicando brevemente el
Listado 13. Configuración del script de inicio del iptables del proxy
(Escribimos el contenido del fichero)
test -x /sbin/iptables|| exit 0
case "$1" in
start)
echo "Arrancando iptables"
/sbin/iptables -t nat -A PREROUTING -i
eth1 -p tcp -s 10.10.2.0/24 –dport 80 -j REDIRECT –-to-ports 3128
echo "Iptables arrancado"
;;
stop)
echo "Apagando iptables"
/sbin/iptables -F
/sbin/iptables -Z
/sbin/iptables -t nat -F
echo "Iptables apagado"
;;
*)
echo "Usar: $0 {start|stop}"
exit 1
esac
exit 0
Listado 14. Configuración de la tarjeta red del DNS
auto eth0
iface eth0 inet static
address 10.10.2.2
netmask 255.255.255.0
gateway 10.10.2.1
Listado 15. Configuración de las zonas de resolución del DNS
zone "servidor_web.com" {
type master;
file "/etc/bind/db.servidor_web";
};
zone "servidor_mysql.com" {
type master;
file "/etc/bind/db.servidor_mysql";
};
zone "servidor_subversion.com" {
type master;
file "/etc/bind/db.servidor_subversion";
};
Listado 16. Configuración de la zona servidor_web.com
; Archivo db.servidor_web
;
; BIND data file for local loopback interface
;
$TTL 604800
@ IN SOA servidor_web.com. root.servidor_web.com. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS servidor_web.com
@ IN A 10.10.1.10
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2048

49www.lpmagazine.org
soluciones para empresasMáquinas virtuales
ría todo el tráfico, con el fin de analizarlo. A la izquierda del switch no encontramos una línea que desemboca en un router. Todas las salidas y entradas desde, y hacia, internet están controla-das por un firewall (pared de ladrillo en dibujo). Estos dos elementos de la red serán simulados por una sola máquina, que tendrá funciones de routing y de cortafuegos, mediante Netfilter.
De la segunda línea o interfaz del router cuelga el proxy, intermediario entre los clientes y el resto de la intranet e internet. El cometido de éste es, sobre todo, acelerar las cargas de los contenidos que solicitan los clientes. Para ello almacena una caché interna, o espacio tempo-ral, del contenido de los lugares visitados ante-riormente por los usuarios. Cuando un usuario solicita una página web, por ejemplo, el proxy comprueba si esa página ya ha sido visitada por otro usuario. De ser así servirá la petición con la copia de la página que tiene guardada en su ca-ché interna. En caso contrario obtendrá la web y la almacenará para futuras peticiones de otros usuarios. Este proceso acelera considerable-mente la navegación por parte de los clientes, ya que para contenido que desean consultar no han de acceder directamente a internet, con el tiempo que ello conlleva. Ya que siempre será más lento el acceso a internet que a la red local, que interconecta al cliente con el proxy. Des-pués de la explicación del funcionamiento del proxy tiene sentido el que los clientes cuelguen de él, pasando a través suyo.
Un ejemplo práctico: Montaje y configuración de una red completaSegún el esquema planteado anteriormente, seexplicará cómo montar cada máquina paso a paso, instalando y configurando cada servicio de forma adecuada para crear un ejemplo práctico que pueda servir como sistema de aprendizaje. Aunque probablemente después deba ajustarlo a sus necesidades.
Debido a la cantidad de máquinas necesa-rias para montar la infraestructura completa, es aconsejable que se centre en la parte que pueda interesarle. Si necesita hacer pruebas para un perfil de desarrollador, tal vez necesite solamente el segmento en el que se encuentran los servidores. Si lo que quiere es hacer prue-bas con entornos de redes podría decantarse por implementar la parte en la que se encuen-tran los clientes, proxy, firewall y cortafuegos. Finalmente, si desea hacer pruebas de seguri-dad en un entorno lo más realista posible, lo ideal sería que implementase la infraestructura completada.
Aprovechando el ejemplo ya explicado en el que se detallaba una instalación de Debian
Listado 17. Configuración de la zona servidor_mysql.com
; Archivo db.servidor_mysql
;
; BIND data file for local loopback interface
;
$TTL 604800
@ IN SOA servidor_mysql.com. root.servidor_mysql.com. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS servidor_web.com
@ IN A 10.10.1.11
Listado 18. Configuración de la zona servidor_subversion.com
; Archivo db.servidor_subversion
; BIND data file for local loopback interface
;
$TTL 604800
@ IN SOA servidor_subversion.com. root.servidor.subversion.com. (
1 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS servidor_web.com
@ IN A 10.10.1.12
Listado 19. Configuración de las tarjetas de red del router/firewall
auto eth0, eth1, eth2
iface eth1 inet static
address 10.10.1.1
netmask 255.255.255.0
iface eth2 inet static
address 10.10.3.1
netmask 255.255.255.0
(Si se tiene IP estática para acceder a internet)
iface eth0 inet static
address IP_OPERADOR
netmask MASK_OPERADOR
gateway GW_OPERADOR
(Si ha configurado en modo NAT o se tiene IP dinámica)
iface eth0 inet dhcp
diagrama, de derecha a izquierda. En primer lugar nos encontramos los servidores corpora-tivos (suponemos siempre una intranet corpora-tiva): servidor web (Apache, IIS...), un sistema gestor de bases de datos (Oracle, SQLServer, DB2, MySQL, PostgreSQL...), un sistema de control de versiones (CVS,SubVersion...). Del switch también cuelga Snort. Snort es un IDS (Sistema de Detección de Intrusos). Este será
el encargado de detectar comportamientos so-spechosos en la red y guardar las alertas de to-das las incidencias que puedieran ocurrir. Esta información puede ser usada para mejorar el firewall, hacer seguimientos de ataques que se hayan recibido o, simplemente, para fines esta-dísticos. En la práctica toda la información que pasará por el switch sería replicada al puerto en que estuviera conectado. De esta manera recibi-
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2049

50 Linux+ 6/2009
soluciones para empresasMáquinas virtuales
para una máquina virtual, se va a tomar como punto de partida dicha instalación. Dependien-do del uso fi nal de la maqueta podríamos instalar el entorno de dos formas: Usar esta primera má-quina virtual e instalar todos los servicios que se van a usar en el entorno (apache, mysql, …) y a partir de esta máquina crear clones y, depen-diendo de la posición dentro la maqueta, activar unos servicios u otros. Esto, que a priori, puede resultar un método poco adecuado es suma-mente cómodo. Tan solo instalaremos todo el software necesario una vez, y a partir de ahí confi guraremos individualmente cada máqui-na. El otro método es instalar y confi gurar cada máquina de forma independiente. Si se desea un entorno realista, tal vez, debería decantarse por esta posibilidad que, aunque de instalación más lenta, será más óptima.
Por comodidad se usará el primer caso, haciéndose clones a partir de esta máquina. Co-mo primer paso instalaremos todo el software necesario para nuestra red. Para ello seleccio-naremos nuestra máquina virtual base. Confi -guraremos la tarjeta de red en modo nat y acto seguido la arrancamos. Es importante señalar que la conexión a internet es imprescindible.
Una vez arrancada nuestra máquina accede-remos con nuestro usuario (linuxplus) y contra-seña (holamundo). Lo primero que debemos de hacer es habilitar el uso de la red, por eso lo prime-ro es demandar un IP al servicio de nat de Virtual-Box. Para ello escribiremos en la consola:
# dhclient eth0
Donde eth0 es la interfaz de red. Si no tenemos confi gurada ninguna tarjeta más, esta será la que nos aparezca por defecto. Una vez hecho esto se nos asignará una IP con la que tendre-mos acceso a la red.
El siguiente paso es instalar todo el software anteriormente mencionado. Para eso hemos de usar el gestor de paquetes avanzado de Debian: aptitude. Aptitude tiene la misma funcionalidad que apt (y mucha más) pero tiene un mayor so-porte a la hora de resolver dependencias, lo que nos evitará más de un dolor de cabeza. El soft-ware que se instalará es: squid (proxy), apache (servidor web), mysql (gestor de bases de datos), subversion (sistema de control de versiones, para desarrolladores), php y módulos php para apache (lenguaje de scripting ampliamente usado para desarrollo web), dhcp (servidor de DHCP), snort (IDS, sistema de detección de intrusos). Para instalarlo ejecutaremos el siguiente comando. Si le aparecen ventanas para introducir información aceptaremos sin más. Modifi caremos las confi -guraciones más adelante:
# aptitude install squid apache2 php5
libapache2-mod-php5 mysql-
server-5.0
dhcp3-server subversion snort
bind9
Cuando se hayan instalado estos paquetes, por defecto, todos estos servicios nuevos serán puestos en funcionamiento y arrancarán de for-ma automática en cada inicio del sistema. Co-mo no en todas las máquinas necesitamos tener todos los servicios, ya que sería un consumo de recursos innecesario, los pararemos todos y se irán arrancando en aquellas que sea necesario. Para esto tecleamos el texto del Listado 1.
Parados los servicios innecesarios, y lista nuestra máquina maestra, clonaremos todas las máquinas necesarias. Antes de ejecutar los co-mandos, asegúrese de que tiene sufi ciente espa-cio en el disco duro, una única máquina ocupará sobre 1,5 GigaBytes. Si tiene en cuenta que se crearán ocho clones, el tamaño total alcanzará sobre 8 GigaBytes. Para hacer el clonado escri-biremos los comandos del Listado 2.
Ya tenemos preparadas todas nuestras má-quinas. Ahora tan solo queda interconectarlas. Comenzaremos por la parte de servicios. Este no pretende ser un artículo en el que se expli-quen todos los entresijos de los servicios que instalarán a continuación. Por ello se explicará, a modo de ejemplo, como confi gurar de manera básica todos ellos y tan solo aquello que sea necesario.
Confi guración de apacheClonada nuestra máquina, que hará las veces de servidor web, tendremos que confi gurarla. En primer lugar debemos de asignarle una direc-ción IP de forma estática, según el diagrama de red explicado anteriormente. Para ello editare-
mos el fi chero: /etc/network/interfaces. Y pon-dremos el texto del Listado 3.
El siguiente paso será añadir el servidor Apache al inicio del sistema. Teclearemos el siguiente comando para ello:
# update-rd.d apache2 defaults
Deberemos de cambiar los permisos del direc-torio en el que se servirán las páginas web.
Antes de probar nuestra conectividad hab-remos de asegurarnos que, en la interfaz de red, hemos seleccionado la opción Red Interna y pusimos el nombre de una red común, com-partida por el resto de servicios. Nosotros elegi-remos la red llamada red_servidores.
/var/www. Todo lo que se encuentre inclui-do en él será interpretado por Apache y servido a los clientes.
Como página de prueba, crearemos una sencilla página en php. Esta tan solo nos devol-verá un famoso hola mundo.
Creamos un archivo llamado index.php en /var/www (Listado 4).
Con este ejemplo tan simple y tonto ya tendremos nuestra pagina en "php" lista para servirse.
Confi guración de MySQLEn nuestro caso de pruebas, el servidor de Apache que montó en el punto anterior, hará uso de un gestor de bases de datos. El gestor usado, en nuestro caso, será MySQL. Habre-mos de seguir el mismo procedimiento que para Apache y asignarle una dirección IP de forma estática, según el diagrama de red su Ip será: 10.10.1.11. Pondremos la interfaz de red en modo Red Interna, con el nombre de la red será red_servidores, y editaremos el fi chero de confi guración: /etc/network/interfaces, que deberá de quedar como se presenta en el Lista-do 5.
El siguiente paso será añadir el servidor MySQL al inicio del sistema:
# update-rd.d mysql defaults
Para poder trabajar con MySQL debemos de agregar un usuario con permisos para manejar las bases de datos. Para conseguir esto tendre-mos que acceder, en modo consola, a la con-fi guración del gestor, pero primero tendremos que arrancarlo (puesto que estaba apagado). Arrancamos el gestor:
# /etc/init.d/mysql start
Hecho esto es el momento de añadir nuestro usuario. Para eso accederemos a la gestión de
Figura 13. Instalación del gestor de arranque: GRUB
Figura 14. Tarjetas de red en modo Red Interna
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2050
51www.lpmagazine.org
soluciones para empresasMáquinas virtuales
Listado 20a. Creación del firewall y script su script de inicio
(Escribimos el contenido del fichero)
test -x /sbin/iptables|| exit 0
# Definimos la configuración de las interfaces de red que disponemos. Serán usadas en el resto
# del script. Si varían nuestras interfaces de red tan solo tendremos que modificar estos valores.
IN_IFACE=eth0
SERVER_IFACE=eth1
CLIENTS_IFACE=eth2
function aplicar_reglas(){
#
# Activarmos, en el KERNEL, una serie de medidas de seguridad
#
# Rechazamos los mensajes ICMP echo-request enviados a direcciones broadcast o multicast
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_broadcasts
# Rechazamos los paquetes a los que se les ha modificado el recorrido de enrutado en la cabecera IP
echo 0 > /proc/sys/net/ipv4/conf/all/accept_source_route
# Nos protegemos frente al ataque SYN flood
echo 1 > /proc/sys/net/ipv4/tcp_syncookies
# Evitamos la redicceción de routas y puertas por defecto con mensajes ICMP. Tanto de envío como
# de recepción
echo 0 > /proc/sys/net/ipv4/conf/all/accept_redirects
echo 0 > /proc/sys/net/ipv4/conf/all/send_redirects
# Habilitamos la protección contra spoofing en las irecciones IP origen
echo 1 > /proc/sys/net/ipv4/conf/all/rp_filter
# Guardamos un registro con las IP de origen no válidas
echo 1 > /proc/sys/net/ipv4/conf/all/log_martians
#
# Establecemos las políticas por defecto para el filtrado. Se denegará todo el tráfico no autorizado
# expresamente.
#
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT ACCEPT
# Eliminamos todas la reglas anteriores que puedieran existir
iptables -F INPUT
iptables -F FORWARD
iptables -F OUTPUT
iptables -F -t nat
# Permitimos el acceso a la interfaz de red local
iptables -A OUTPUT -o lo -j ACCEPT
#
# Creamos una serie de reglas genéricas para poder ser usadas en todas las interfaces
#
# Filtrado del flood
iptables -N flood
iptables -F flood
iptables -A flood -m limit --limit 30/second --limit-burst 60 -j RETURN
iptables -A flood -m limit --limit 30/second --limit-burst 60 -j LOG --log-prefix "flood: "
iptables -A flood -j REJECT
# Filtrado ICMP
iptables -N ICMP_NON
iptables -F ICMP_NON
iptables -A ICMP_NON -p icmp --icmp-type redirect -j REJECT
iptables -A ICMP_NON -p icmp --icmp-type router-advertisement -j REJECT
iptables -A ICMP_NON -p icmp --icmp-type router-solicitation -j REJECT
iptables -A ICMP_NON -p icmp --icmp-type address-mask-request -j REJECT
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2051

52 Linux+ 6/2009
soluciones para empresasMáquinas virtuales
Listado 20b. Creación del firewall y script su script de inicio
iptables -A ICMP_NON -p icmp --icmp-type address-mask-reply -j REJECT
# Filtramos los paquetes inválidos y mal formados
iptables -N PKT_FAKE
iptables -F PKT_FAKE
iptables -A PKT_FAKE -m state --state INVALID -j REJECT
iptables -A PKT_FAKE -p tcp ! --syn -m state --state NEW -j REJECT
iptables -A PKT_FAKE -f -j REJECT
# Filtramos los paquetes TCP con combinaciones de flags no permitidas, usadas normalmente
# cuando se realizan escaneos
iptables -N FLAG_SCAN
iptables -F FLAG_SCAN
iptables -A FLAG_SCAN -p tcp --tcp-flags SYN,FIN SYN,FIN -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags SYN,RST SYN,RST -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags ALL FIN -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags SYN,FIN,PSH SYN,FIN,PSH -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags SYN,FIN,RST SYN,FIN,RST -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags SYN,FIN,RST,PSH SYN,FIN,RST,PSH -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags ALL ACK,RST,SYN,FIN -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags ALL NONE -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags ALL ALL -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags ALL FIN,URG,PSH -j REJECT
iptables -A FLAG_SCAN -p tcp --tcp-flags ALL SYN,RST,ACK,FIN,URG -j REJECT
#
# Filtros para la interfaz eth0, de entrada de internet a la red
#
# Filtrado de direcciones privadas
iptables -t nat -A PREROUTING -i $IN_IFACE -s 10.0.0.0/8 -j DROP
iptables -t nat -A PREROUTING -i $IN_IFACE -s 172.16.0.0/12 -j DROP
# Si se conecta la interfaz en modo gridge, descomente estas líneas
# iptables -t nat -A PREROUTING -i $IN_IFACE -s 192.168.0.0/24 -j DROP
# iptables -t nat -A PREROUTING -i $IN_IFACE -s 192.168.0.0/16 -j DROP
iptables -t nat -A PREROUTING -i $IN_IFACE -s 127.0.0.0/8 -j DROP
# Filtrado de direcciones en la que no se ha iniciado la conexión desde dentro de la subred
iptables -A INPUT -i $IN_IFACE -p tcp ! --syn -m state --state NEW -j DROP
# Pasamos los fitros definidos anteriormente
iptables -A INPUT -i $IN_IFACE -p tcp -j flood
iptables -A INPUT -i $IN_IFACE -p tcp -j ICMP_NON
iptables -A INPUT -i $IN_IFACE -p tcp -j PKT_FAKE
iptables -A INPUT -i $IN_IFACE -p tcp -j FLAG_SCAN
iptables -A INPUT -i $IN_IFACE -p tcp -j FLAG_SCAN
# Denegamos el udp y icmp
iptables -A INPUT -i $IN_IFACE -p udp -j DROP
iptables -A INPUT -i $IN_IFACE -p icmp -j DROP
#
# Filtros para la interfaz eth1, de acceso a los servidores
#
# Pasamos los fitros definidos anteriormente a todo el tráfico que se dirija a los servidores
iptables -A OUTPUT -i $SERVER_IFACE-p tcp -j flood
iptables -A OUTPUT -i $SERVER_IFACE -p tcp -j ICMP_NON
iptables -A OUTPUT -i $SERVER_IFACE -p tcp -j PKT_FAKE
iptables -A OUTPUT -i $SERVER_IFACE -p tcp -j FLAG_SCAN
iptables -A OUTPUT -i $SERVER_IFACE -p tcp -j FLAG_SCAN
# Denegamos el udp y icmp a todo el tráfico que se dirija a los servidores
iptables -A OUTPUT -i $SERVER_IFACE- -p icmp -j DROP
# Aceptamos solamente el tráfico que venga de nuestra red
iptables -A INPUT -i $CLIENTS_IFACE -s 10.10.1.0/24 -p tcp -j ACCEPT
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2052

53www.lpmagazine.org
soluciones para empresasMáquinas virtuales
Listado 20c. Creación del firewall y script su script de inicio
#
# Filtros para la interfaz eth2, de acceso a los clientes
#
# Pasamos los fitros definidos anteriormente a todo el tráfico que se dirija a los clientes o venga de
# ellos
iptables -A OUTPUT -i $CLIENTS_IFACE-p tcp -j flood
iptables -A OUTPUT -i $CLIENTS_IFACE -p tcp -j ICMP_NON
iptables -A OUTPUT -i $CLIENTS_IFACE -p tcp -j PKT_FAKE
iptables -A OUTPUT -i $CLIENTS_IFACE -p tcp -j FLAG_SCAN
iptables -A OUTPUT -i $CLIENTS_IFACE -p tcp -j FLAG_SCAN
iptables -A INPUT -i $CLIENTS_IFACE-p tcp -j flood
iptables -A INPUT -i $CLIENTS_IFACE -p tcp -j ICMP_NON
iptables -A INPUT -i $CLIENTS_IFACE -p tcp -j PKT_FAKE
iptables -A INPUT -i $CLIENTS_IFACE -p tcp -j FLAG_SCAN
iptables -A INPUT -i $CLIENTS_IFACE -p tcp -j FLAG_SCAN
# Aceptamos solamente el tráfico que venga de la ip del proxy
iptables -A INPUT -i $CLIENTS_IFACE -s 10.10.3.2/32 -p tcp -j ACCEPT
# Denegamos el udp y icmp a todo el tráfico que se dirija a los clientes o venga de ellos
iptables -A OUTPUT -i $CLIENTS_IFACE -p udp -j DROP
iptables -A OUTPUT -i $CLIENTS_IFACE -p icmp -j DROP
iptables -A INPUT -i $CLIENTS_IFACE -p udp -j DROP
iptables -A INPUT -i $CLIENTS_IFACE -p icmp -j DROP
}
case "$1" in
start)
echo "Arrancando iptables"
aplicar_reglas
echo "Iptables arrancado"
;;
stop)
echo "Apagando iptables"
/sbin/iptables -F
/sbin/iptables -X
/sbin/iptables -Z
/sbin/iptables -t nat -F
echo "Iptables apagado"
;;
*)
echo "Usar: $0 {start|stop}"
exit 1
esac
exit 0
mysql y crearemos el usuario en su propio len-guaje (SQL), según el Listado 6.
Solamente resta cambiar USUARIO y PAS-SWORD por los que elijamos. Entonces, para acceder a la base de datos, tan solo tendremos que conectarnos a la IP 10.10.1.10, con nuestro usuario y contraseña, al puerto 3306.
Configuración de SubVersionLa configuración para el servidor de control de versiones es prácticamente idéntica al de los otros dos servidores. Tan solo tendremos que poner la interfaz de red en modo Red Interna con el valor red_servidores, como hicimos an-
teriormente, y cambiar su IP, modificando el fi-chero: /etc/network/interfaces. Pondremos el texto del Listado 7.
Ahora tendremos que crear un repositorio para nuestros proyectos. En él iría su código fuente. Para hacerlo primero creamos el di-rectorio donde queremos alojar estos fuentes y después dicho repositorio. Acto seguido arrancaremos el servidor, indicándole donde se encuentra el directorio raíz a partir del cual tendrá que trabajar. Escribimos el contenido del Listado 8.
Si queremos añadir un mínimo de seguri-dad a nuestro servicio deberíamos de editar
un par de ficheros de configuración. En ellos modificaremos los derechos de acceso, exi-giendo la autenticación para acceder y de-shabilitando el acceso anónimo. Para cambiar-lo, editamos el archivo: /var/svn/linuxplus/conf/svnserve.conf. Habremos de asegurarnos que las siguientes líneas se encuentran des-cimentadas y con los siguientes valores. Es muy importante no dejar ningún espacio entre cada parámetro y el principio de la línea, se-gún se muestra en el Listado 9.
Ahora añadiremos un usuario, con su con-traseña, al que daremos acceso al repositorio que acabamos de crear. Para esto editamos
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2053

54 Linux+ 6/2009
soluciones para empresasMáquinas virtuales
Listado 21. Añadidos para las funciones de routing
function aplicar_routing(){
#
# Mandamos las peticiones de los clientes a los servidores internos
#
# Enviamos el tráfico al servidor web
iptables -A POSTROUTING -t nat -s 10.10.3.0/24 -o eth1 -d 10.10.1.10
–dport 80 -j SNAT --to-source x 10.10.1.1
# Enviamos el tráfico al servidor MySQL
iptables -A POSTROUTING -t nat -s 10.10.3.0/24 -o eth1 -d 10.10.1.11
–dport 3306 -j SNAT --to-source x 10.10.1.1
# Enviamos el tráfico al servidor SubVersion
iptables -A POSTROUTING -t nat -s 10.10.3.0/24 -o eth1 -d 10.10.1.12
–dport 3690 -j SNAT --to-source x 10.10.1.1
#
# Habilitamos el acceso a internet para el proxy
#
iptables -A POSTROUTING -t nat -s 10.10.3.0/24 -o eth1 -j MASQUERADE
}
[…]
start)
echo "Arrancando iptables"
aplicar_reglas
aplicar_routing
echo "Iptables arrancado"
;;
Listado 22. Script de autoarranque de la infraestructura
#!/bin/bash
VboxManage startvm servidor_web &
VboxManage startvm servidor_mysql &
VboxManage startvm servidor_svn &
VboxManage startvm router_firewall &
VboxManage startvm servidor_proxy &
VboxManage startvm cliente1 &
(o creamos) el fichero: /var/svn/linuxplus/conf/passwd. Añadimos la siguiente línea:
[…]
usuario_pruebas = holamundo
[…]
Donde usuario_pruebas es el nombre de usua-rio que hemos elegido, podría ser cualquiera. Y holamundo es la contraseña para dicho usua-rio. Este fichero tiene que tener tanta líneas, idénticas a esta, como usuarios queramos per-mitir el acceso al repositorio.
Para probar nuestro nuevo servidor, im-portaremos el repositorio y añadiremos un comentario. Suponiendo que los códigos fuente que queremos importar están en el directorio: /home/linuxplus/prueba, ejecutaremos:
svn import /home/linuxplus/prueba svn:
//servidor/linuxplus -m "Primer primer
import" -username usuario_pruebas
Si quisiéramos tener una copia local, con el usuario usuario_pruebas, del repositorio crea-do anteriormente, necesitamos hacer un chec-kout. Para ello nos situamos en el directorio donde tenemos los fuentes y ejecutamos:
svn checkout /home/linuxplus/prueba
svn://servidor/linuxplux -username
usuario_pruebas
Con Apache y MySQL hemos añadido el ser-vicio al arranque del sistema con los scripts preconfigurados que nos trae la distribución para esto. En el caso de SubVersion no se nos presen-ta esta posibilidad de forma automática. Por lo tanto nos haremos nosotros nuestro propio script de arranque. Para esto copiaremos el siguiente código en un archivo al que llamaremos subver-sion enas, del repositorio creado anteriormente, necesitamos hacer un checkout. Para ello nos situamos en el directorio donde tenemos los fuentes y ejecutamos: el directorio: /etc/init.d/. Esto es necesario hacerlo como root. Con el edi-tor nano, o el que prefiramos, escribimos:
(Creamos el fichero con nano)
# nano -w /etc/init.d/subversion
Escribimos el contenido en el fichero (Listado 10).En el script comprobamos, con test, si exis-
te el ejecutable para evitar errores posteriores. Después se implementan la opción de iniciar, start, y parar, stop, el servicio. También se con-templa la posibilidad de que no se pasen pará-metros al programa. Tan solo nos falta añadirlo al inicio. El sistema reconocerá el patrón usado
y llamará automáticamente al programa con el parámetro start. Para añadirlo hacemos, al igual que con Apache y MySQL:
# update-rd.d subversion defaults
Configuración del proxy y servidor DHCPSituado en este punto empezamos a definir la red desde el otro punto, la parte de los clientes. Las diferencias que encontraremos aquí serán, entre otra las direcciones IP usadas y la red a la que tendremos que añadir las máquinas.
En este punto tendremos una de las op-ciones más interesantes de esta arquitectura. Podremos configurar esta máquina virtual para
La primera interfaz de red (eth0) tiene la misma configuración que los otros servidores que hemos montado hasta ahora, es decir, Red
Interna. La única diferencia será la red a la que la añadiremos. Para este ejemplo el nombre elegido ha sido: red_proxy.
En la segunda interfaz diferenciamos, de-pendiendo del tipo de cliente que queramos co-nectar. Si queremos conectar clientes virtuales, añadiremos una nueva interfaz con la misma configuración de red que la anterior, pero que pertenezca a la red red_clientes. Si queremos clientes reales tendremos que habilitar una se-gunda interfaz y crear un bridge (como se expli-có en un apartado anterior) con una de las inter-faces reales del PC. La interfaz real tendría que ir conectada a un switch real, en que se conectarían todos los PC de los clientes que se deseasen.
Cuando se haya decidido cuál es la confi-guración deseada, la configuración es exacta-mente la misma para ambos casos, ya que para la máquina virtual esas configuraciones son
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2054

55www.lpmagazine.org
soluciones para empresasMáquinas virtuales
totalmente transparentes. Como se ha hecho anteriormente, configuraremos las interfaces de red. Se debe de tener cuidado a la hora de activarlas en el entorno de configuración de VirtualBox. La primera interfaz es la que debe de pertenecer a la red red_proxy y la segunda, dependiendo de su elección, es la que debería de estar bridgeada o pertenecer a la red red_clientes. De no ser así la configuración que aquí se expone no coincidirá con la que usted tiene y no funcionaría.
Editamos el fichero: /etc/network/interfaces, modificándolo hasta que sea como en el Lista-do 11.
Configuramos Squid editando el fichero: /etc/squid/squid.conf. La configuración aquí mostrada es muy básica. Tan solo se crearán una serie de filtros de acceso, se aumentará el tamaño de la caché y poco más. Puesto que el fichero de configuración es inmensamente largo se espe-cificará, por comodidad, el número de linea en que se encuentra el parámetro (aunque podría variar). Aquí están los parámetros con una pe-queña explicación. Para comentar una línea tan solo hay que poner el carácter almohadilla (#). Para descomentar se hará a la inversa, cuidando de no dejar ningún espacio entre el parámetro descomentado y el principio de la línea:
• Lineas 608-609: acl localnet src 172.16.0.0/12 y acl localnet src 192.168.0.0/16. Comentamos estas dos líneas y con esto estamos indicando que no permitimos el acceso a esas dos redes, ya que no perte-necen a nuestra red.
• Línea 607: acl localnet src 10.0.0.0/8, la cambiamos por acl localnet 10.10.2.0/24. Añadimos otra línea, igual que la recién añadida, con el texto acl localnet 10.10.1.0/24.
• Línea 1110: http_port 3128, la cambiamos por http_port 3128 transparent. Con esto añadiremos la funcionalidad de proxy transparente (explicada más adelante).
• Línea 1694: hierarchy_stoplist cgi-
bin ?, esto lo cambiamos por hierarchy_stoplist cgi-bin jsp do cfm asp aspx
php php4 php5 ?. Con esto evitamos que Squid guarde en su caché las páginas con contenido dinámico.
• Línea 1732: "cache_mem 8 MB". Desco-mentamos esta línea y cambiamos el valor 8 por 24. El valor ideal es un tercio de la memoria RAM.
• Línea 4627: "ipcache_size 1024", la desco-mentamos y cambiamos el valor 1024 por 2048. Este valor indica el tamaño que reser-va Squid para las direcciones IP almacena-das en su caché.
Una vez modificados estos parámetros básicos, tendremos nuestro Squid listo para funcionar. Tan solo nos queda añadirlo al arranque del sistema. Ejecutaremos: # update-rd.d squid defaults.
Ahora configuraremos un servidor DHCP. Para evitar que cada cliente tenga que asignarse manualmente una IP, montaremos este servicio. Según se definió en la infraestructura, se asig-narán IPs del rango: 10.10.2.3-10.10.2.254. Pa-ra establecer esta configuración modificaremos el fichero que define al servidor: /etc/dhcp3/dhcpd.conf. Escribiremos el texto presentado en el Listado 12.
Hecho esto, ya tenemos nuestro servidor preparado. Lo añadimos al arranque:
# update-rd.d dhcp3-server defaults.
Puesto que se pretende hacer un proxy traspa-rente, en el que no es necesario que el usuario añada ningún tipo de configuración en su nave-gador para que pueda salir a través de él, habre-mos de incluir unas cuantas reglas de iptables. Iptables nos permite filtrar el tráfico de la red e incluso hacer tareas de enrutamiento. Lo que le indicaremos será que todo el tráfico que entre por la interfaz eth1, en la que están conectados los clientes, sea redirigido de forma automática a Squid. Para el usuario será un proceso trans-parente. Para hacer esto habremos de añadir lo que llamamos reglas. Estas son las que le indi-can a iptables qué ha de hacer con el tráfico que recibe el sistema. Escribiremos en la consola:
(redireccionamos para
la transparencia del proxy)
# iptables -t nat -A PREROUTING -i
eth1 -p tcp -s 10.10.2.0/24 –dport 80
-j REDIRECT –-to-ports 3128
Como queremos que este comando se ejecute automáticamente al inicio de cara arranque del sistema, tendremos que fabricarnos, igual que hicimos con SubVersion, un script que se encargue de ello. Para hacerlo crearemos el fichero: /etc/init.d/iptables. Y escribiremos lo siguiente:
(Creamos el fichero con nano. CTRL+X
para salvar)
# nano -w /etc/init.d/iptables
Añadimos el código, que podemos encontrar en el Listado 13.
Para finalizar solo hay que añadir iptables al inicio del sistema:
# update-rd.d iptables defaults
Configuración de los clientesHayamos escogido el tipo de clientes que deseemos, virtuales o reales, la configuración para todos ellos tiene que tener, al menos, un punto en común. Este punto escriba en la confi-guración de la IP que el PC tendrá para acceder a la red. En ambos casos tendremos que usar un cliente DHCP. Esto es indistinto del tipo de sistema que se encuentre instalado en los sis-temas de usuario. Tanto Windows, Linux, Mac OS, FreeBSD, etcétera, disponen de un cliente DHCP. Windows o Mac traen de manera pre-determinada este tipo de configuración, al igual que algunas distribuciones de Linux, como Ubuntu. Por lo que no tendrá que tocar nada en los equipos de cliente de su red.
Si quiere configurar alguna de las máqui-nas que se clonaron anteriormente como cliente y activarle el DHCP, tan solo ha de configurar la tarjeta de red en modo Red Interna y establecer el nombre de la red en red_clientes. Después tendrá que modificar la máquina virtual y cam-biar el archivo de configuración: /etc/network/interfaces, y ha de poner lo siguiente:
auto eth0
iface eth0 inet dhcp
Con esa sencilla configuración, cada vez que arranque el sistema, el equipo pedirá IP al ser-vidor DHCP que instalamos anteriormente. Por su puesto éste ha de estar encendido.
Configuración del servidor DNSToda intranet que se precie, y más teniendo en cuenta que existen equipos con IPs fijas, debería disponer de un servidor DNS. Es sumamente incó-modo el recordar estas IP aunque tan solo sean 3. Por eso les asignaremos unos nombres que nos encargaremos de traducir estas IP con el servicio.
Como primer paso, configuraremos la in-terfaz de red, como hemos hecho hasta ahora. Pondremos la interfaz en modo Red Interna y introduciremos como nombre de red la red_clientes. Editamos el archivo de configuración para asignarle una IP: /etc/network/interfaces (Listado 14).
El servidor que usaremos es el archiconoci-do Bind9. Solámente se hará una configuración básica, que nos servirá para nuestra red de pruebas.
Los nombres que les asignaremos a los ser-vidores serán los siguientes: al servidor web servidor_web.com, al servidor mysql servidor_mysql.com y al servidor SubVersion servidor_subversion.com. Con estas premisas, y co-nocidas sus IP, configuraremos Bind9.
Editamos el fichero de configuración: /etc/bind/named.conf.local. En él añadiremos los
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2055

56 Linux+ 6/2009
soluciones para empresasMáquinas virtuales
tres servidores con sus resoluciones. Añadire-mos estas líneas al fichero (Listado 15).
Creamos los ficheros de configuración a partir de uno que ya existe, y que viene con la instalación del paquete: db.local. Creamos las tres copias:
# cp db.local db.servidor_web
# cp db.local db.servidor_mysql
# cp db.local db.servidor_subverion
Editamos, uno a uno, estos archivos de con-figuración. Quedándonos como sigue en los listados: Listado 16, Listado 17, Listado 18.
Con esos archivos le hemos indicado a Bind9 como ha de resolver los nombres de dominio. Ahora, cualquier usuario podrá introducir en su navegador la URL www.servidor_web.com y la ip que buscará para obtener la página será la del servidor de la red interna.
Ahora tendremos que añadir el servidor DNS al inicio del sistema:
# update-rd.d bind9 defaults
Configuración del firewall y routerTodo el entramado de máquinas virtuales e interconexiones entre ellas no serviría de nada si no tuviéramos un router que fuera capaz de hacer fluir el tráfico con el camino adecuado. Sin él, las peticiones de los clientes al servidor web no sabrían cómo llegar si no hubiera nadie que los dirigiera. Por esto nos hace falta un router. Si bien es cierto que podríamos haber conectado todo con una topología de BUS y ahorrarnos tanta complicación, esta estructura es muy poco escalable, eficiente, segura y, en general, una muy mala decisión.
El proceso de routing se hará con iptables que, como se dijo anteriormente, tiene soporte para ello.
En la misma máquina virtual se incluirá el firewall perimetral. Este será el encargado de decidir qué entra y sale a la intranet. En toda red corporativa es imprescindible. El filtrado también está soportado por iptables, y éste será en el que confiaremos la seguridad de la barrera de entrada de internet.
Esta es la máquina virtual en la que más se complicará la configuración de las interfaces de red. Si contamos en el diagrama que se presen-tó, necesitaremos tres. Una que conecte a la red de los servidores (eth1), otra a la de los clientes (eth2) y una tercera que será por la que se saldrá a internet (eth0). Esta última dependerá mucho de cómo desee hacer el acceso a la red externa. Si no desea este acceso puede incluso deshabili-tarla. Si quiere que haya salida al exterior, pero
no necesita permitir el acceso desde él, bastará con configurar la tarjeta en modo NAT. De querer que esta infraestructura pueda servir como ejemplo real, y ofrecer una serie de servicios al exterior, deberá de configurarla en modo bridge y disponer de una segunda interfaz física en el PC. Si desea hacer pruebas reales desde la red externa, como puede ser el caso de una PYME, probablemente tenga una IP estática, para acceder a internet, que le haya asignado su operador. En este caso deberá de ser configurada tal y como se ha venido haciendo hasta ahora. En el caso del la configuración NAT la IP será asignada automáticamente por DHCP. Vamos a configurar nuestras tarjetas de red. Como ya se ha dicho la única configuración que varía es la de la tarjeta eth0, que también se contemplará. Editamos, co-mo siempre, el fichero: /etc/network/interfaces. Y escribimos el contenido del Listado 19.
Donde IP_OPERADOR es la IP que nos ha asignado el perador, MASK_OPERADOR la máscara de red y GW_OPERADOR la puerta de enlace.
Hecho esto es el momento de implementar el filtrado y las funciones de routing.
En primer lugar añadiremos las funciones de firewall. Para esto crearemos un script de arranque automático del sistema, como ya se ha hecho en otros ejemplos. Cogeremos el código que se usó para las reglas de redireccionamien-to en el proxy transparente y le añadiremos las reglas adecuadas. Creamos por tanto el fichero iptables en el directorio /etc/init.d/ y añadimos las siguientes reglas (se comentará la funciona-lidad una a uno):
(Creamos el fichero con nano. CTRL+X
para salvar)
# nano -w /etc/init.d/iptables
Añadimos el código, que se encuentra en el Listado 20.
A pesar de que pueda parecer muy extenso, quedarían por implementar varias cosas, dado que el objetivo del artículo es la creación de firewalls, con este ejemplo será mas que sufi-ciente. Ahora tan solo nos quedan las funciones de routing. Para implementarlas solo tendremos que añadir una función a nuestro script anterior. No se escribirá todo el código, solamente la función y cómo quedaría en el nuevo caso de arranque del script (Listado 21).
Tan solo nos queda anadir el script al ini-cio, como hemos venido haciendo hasta ahora: # update-rd.d iptables defaults.
Configuración de SnortComo último punto para nuestra red de ejemplo hemos dejado a Snort. Este, como ya se comen-tó, es un complejo sistema de detección de in-trusos. Consta de infinidad de filtros y multitud de opciones. Para modificar los parámetros de configuración editaríamos el fichero:/etc/snort/snort.conf. En nuestro caso, al ser un entorno de maqueta, nos valdrá tal y como está.
Existen alguna opciones que merece la pe-na comentar, entre ellas las variables de entorno que se pueden asignar en Snort. Ejemplos de las mismas son: HOME_NET, DNS_SERVERS, SMTP_SERVERS... éstas le indicarán al IDS las redes que tiene que monotorizar.
En Snort existen unas cosas llamadas preprocesadores. Estos permiten extender su funcionalidad. De esta manera que el usuario pueda acceder a los paquetes capturados antes de que lo haga motor de Snort.
Existen, también, los llamados plugins de salida. Configurándolos de manera adecuada le ponemos cómo queremos que se nos muestre la información obtenida del análisis del tráfico. Los más comunes suelen ser la salida al fichero de log /var/log/snort/alert, donde podríamos consultar las alertas, y la posibilidad de guardar toda la información en una base de datos. Esta
Figura 15. Diagrama de la infraestructura de red a crear
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2056

57www.lpmagazine.org
soluciones para empresasMáquinas virtuales
última puede permitir analizar la información recogida por un software que se encargue de mostrarnos un resumen. Un ejemplo de esto es el ACID. Esta es una interfaz, en formato web, que muestra la información ordenada (entre otras posibilidades).
Ya que el fi n del artículo no es explicar la confi guración de Snort, y puesto que no es necesario para el correcto funcionamiento de nuestra infraestructura, lo dejaremos con la confi guración por defecto. Deberemos de poner su interfaz de red en modo Red Interna, aña-diéndolo a la red red_servidores. La interfaz se-rá confi gurada, por Snort, en modo promiscuo. Por tanto no es necesario asignarle ninguna IP. Tan solo nos queda añadir el servicio de snort al arranque del sistema: # update-rd.d snort defaults.
Miscelanea: Conversión de máquinas virtuales VMWare a máquinas de VirtualBoxMuchas veces, si ya se es usuario habitual de otro tipo de software de virtualización, nos resis-timos a migrar a cualquier otro. El problema es que, seguramente, tengamos todas nuestras má-quinas virtuales confi guradas y adaptadas para ese entorno. Por ello se va a explicar el proceso, mediante el cual, se puede convertir una imagen de VMWare en una de VirtualBox.
Antes de comenzar necesitamos instalar software adicional. Bien con el gestor de pa-quetes Synaptics, apt o emerge, debemos de instalar Qemu. Qemu tiene una serie de carac-terísticas que, para nuestro caso, nos resultarán muy útiles. Para instalarlo tecleamos:
• En Debian/Ubuntu: # apt-get install Qemu
• En Gentoo: # emerge qemu
Una vez instalado Qemu, haremos uso de él para convertir la máquina de VMWare a un formato binario. Este tipo de formatos, cuya ca-racterística principal es, precisamente la ausen-cia de formato, se les llama formato en crudo o raw. Realizaremos la conversión tecleando:
# qemu-img convert IMAGEN_VMWARE.vmdk
NUEVA_IMAGEN.bin
Donde IMAGEN_VMWARE.vmdk es la máquina que queremos convertir. Todas las imágenes de VMWare tienen la misma extensión, siendo fá-cilmente reconocibles. Y NUEVA_IMAGEN.bin es la imagen en crudo, anteriormente explicada. Ahora haremos uso de la herramienta de adminis-tración de VirtualBox para acabar la conversión.
Escribimos los siguientes comandos:
# VBoxManage covnvertdd NUEVA_
IMAGEN.bin IMAGEN_VIRTUALBOX.vdi
# VBoxManage modifyvdi
IMAGEN_VIRTUALBOX.vdi compact.
Usando como referencia el nombre del fi chero de salida obtenido con Qemu, han de pasarse los parámetros tal y como se muestran. IMA-GEN_VIRTUALBOX.vdi es la imagen fi nal que contendrá la conversión de la máquina virtual.
Conversión de máquinas virtuales VirtualBox a máquinas de VMWareAl igual que a veces es necesario migrar máqui-nas de VirtualBox a VMWare, otras podríamos encontrarnos en la situación de necesitar realizar el proceso inverso. Antes de hacer la conversión hay que llevar a cabo una serie de pasos para preparar los discos para el formato adecuado necesario para VMWare. Aunque el proceso de conversión se puede hacer de diferentes maneras, existen problemas asociados a la compatibilidas si no se hace con procedimiento adecuado, si-guiendo unos pasos rigurosos.
Como primer paso tendremos que hacer un proceso de conversión del disco duro virtual, obteniendo un sistema archivo de tip raw. En el siguiente paso se aplicará el formato adecuado para VMWare. Para esto haremos uso de la herra-mienta de administración de VirtualBox, Vbox-Manage, y qemu. Los comandos necesarios son:
(Conversión al formato raw)
# VboxManage internalcommands
converttoraw ORIGEN.vdi DESTINO.raw
(Conversión a formato VMWare)
# qemu-img convert -0 vmdk DESTINO.raw
MAQUINA_VMWARE.vmdk
Donde ORIGEN.raw es el disco duro virtual que queremos convertir. DESTINIO.raw es la imagen, tipo raw, que se crea como paso inter-medio y MAQUINA_VMWARE.vmdk es la que tendremos que abrir como nueva máquina virtual en VMWare.
Arrancando toda la infraestruc-tura con un solo comandoSi ha seguido el artículo paso ha paso, y ha creado todas las máquinas virtuales que se in-dican en el ejemplo, se habrá dado cuenta que cada vez que necesita arrancar todas ellas tiene que iniciarlas una a una desde el gestor gráfi co. Debido a esta incomodidad se propone a conti-nuación un pequeño script que hará esta tarea por usted. Con solo ejecutarlo, se encargará de
levantar todas las máquinas virtuales que desee. En el Listado 22 se presenta el código.
script presentado arriba, se encarga de arrancar todas las máquinas que se han creado durante el artículo. Tan solo habría que guardar-lo y darle permisos de ejecución. Esto se puede hacer así:
# nano -w arrancar_maquinas.sh
[…]
(damos permisos de ejecución)
# chmod 744 arrancar_maquinas.sh
En general, si queremos añadir una nueva má-quina que hayamos creado, tan solo hemos de añadirla al script según el formato: VbovMana-ge startvm MAQUINA &. Tendrá que cambiar la palabra MAQUINA por el nombre de la suya. El ampersand (&) es utilizado para que cada máquina no tenga que esperar a la anterior hasta que se acabe el proceso y puedan arrancar todas a la vez.
Daniel García es Diplomado en Ingeniería Técnica Informática por la Escuela Politéc-nica Superior de Informática de Albacete. Especializado en seguridad informática, trabaja actualmente como auditor de segu-ridad para Arcitel Ibérica S.A., en división de seguridad de Telefónica I+D. Puede loca-lizarse en la web en la que colabora, o en el correo electrónico:
Web: www.iniqua.comE-mail: [email protected]: [email protected]
Sobre el autor
• VirtualBox: http://www.virtualbox.org/ MySQL: http://doc.ubuntu-es.org/MySQL, http://www.desarrolloweb.com/
manuales/41/• Subversion: http://www.abbeyworkshop.com/howto/
misc/svn01/• Ejemplo fi rewall:
http://www.kalamazoolinux.org/presentations/20010417/jamesiptables.html
• Ejemplo avanzado de fi rewall: http://www.hacktimes.com/?q=node/49
• Snort: http://www.linuca.org/body.phtml?nIdNoticia=13
En la red
42_43_44_45_46_47_48_49_50_51_52_53_54_55_56_57_Maquinas_virtuales.indd 2009-04-14, 14:2057

seguridadSeguridad de datos
58 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
l
A lo largo de este artículo podrá ver cómo los datos que usted toma como defi nitivamente eliminados, no son tal. Cómo estos pueden ser recuperados y cómo esto afecta a su seguridad.
Pero para ello haremos un breve viaje a través de los medios de almacenamiento, el concepto de informática forense y los fallos más comunes de los sistemas operativos en materia de administración de fi cheros.
Daremos también un paseo por el software de borrado seguro y sus enemigas las herramientas de análisis forense. Cómo no, haremos nuestra propia implementación de borra-do seguro y para concluir realizaremos unas pruebas sencillas acerca de cómo recuperar un documento borrado en un medio de almacenamiento común haciendo uso de las aplicaciones anteriormente mencionadas.
Durante el transcurso del artículo se hablará tanto sobre Linux y entornos Unix, como de Windows, haciendo las prue-bas más importantes sobre el primero de ellos, como era de suponer. Pero entonces, ¿para qué tratar el segundo? Cuando descubra sus fallos, podrá tomárselo como un consejo para cambiar defi nitivamente de sistema operativo. Si estaba inde-ciso, dejará de estarlo.
Pero todo esto no son más que palabras. Pasemos a la acción...
Informática forensePodemos defi nir la informática forense como la ciencia de manipular, en cualquier sentido de la palabra, los datos que han sido procesados electrónicamente y que se encuentran almacenados en un medio computacional. Muchas veces, debido a las connotaciones, uno relaciona este término con el F.B.I. y esto no está totalmente equivocado, ya que ellos son uno de los primeros cuerpos en desarrollar software para la recolección de evidencia. Cabe decir que desarrollan mucho más software de tipo catalogado y para fi nes desconocidos.
Con la informática forense se logran 3 objetivos princi-pales:
• Compensación de daños.• Persecución y procesamiento judicial de los criminales.• Creación y aplicación de medidas preventivas.
Los analistas forenses utilizan muchas herramientas para hacer más fácil su labor a la hora de presentar puntos de evidencia.
Su información, ¿a salvo?¿De qué serviría un ordenador si no pudiésemos almacenar información en él? Absurda máquina si esto ocurriese. Pero aun no siendo así, de nada sirve si no podemos mantener esta información lejos de curiosos atacantes. El problema es claro. ¿Hasta qué punto la privacidad de nuestros datos está garantizada?
David Puente Castro (blackngel)
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2158

seguridadSeguridad de datos
59www.lpmagazine.org
Uno de los programas más conocidos para estas labores es EnCase hecho por Guindace Software Inc. Puede encontrar más información en la si-guiente dirección: http://www.guidancesoftware.com.
La desventaja más desagradable es que su precio no está al alcance de un usuario que solo desea hacer pruebas personales.
The Coroner Toolkit. Esta herramienta fue utilizada por Wietse Venema y Dan Farmer (dos conocidos expertos en seguridad informática) en una demostración de Unix Forensics, en la que dieron conocimiento de sus grandes posibilidades en la extracción de información tanto del sistema de ficheros como de la red.
Aquellos que se pasen por la página: http://www.porcupine.org/forensics, podrán encontrar, además del código fuente de esta herramienta y muchos de sus diferentes parches, un libro que han escrito los dos autores titulado Forensic Dis-covery y que puede ser leído online. La premisa del libro, como en el mismo se indica es que: La información forense puede ser encontrada en cualquier sitio que uno mire.
Entre las herramientas forenses podemos clasi-ficar las de monitorización, logueo, marcado de documentos e incluso herramientas de hardware para el análisis exhaustivo. Decir que los estudios que se hacen mediante dispositivos hardware son más conocidos como análisis de laboratorio.
Cabe decir que, los peores inconvenientes para un analista forense, pueden tratarse sobre todo de temas judiciales. No es tan sencillo co-mo parece presentar evidencias y cargos contra alguien en una corte. Aunque sea poco lo que le dificultemos nosotros (o un anti-forense) la tarea, mucho más difícil será para ellos demostrar que
la evidencia recolectada tiene un carácter real-mente fiable.
No dejaremos esta sección sin mencionar el famoso principio de Locard, por el cual se rige toda la técnica de la informática forense. Dice que: Todo contacto deja un rastro. Y esto es in-eludiblemente cierto.
Almacenamiento de datosAquí mencionamos los cuatro fenómenos uti-lizados para el almacenamiento de datos en un medio magnético:
• Una corriente eléctrica produce un campo magnético.
• Algunos materiales se magnetizan con faci-lidad cuando son expuestos a un campo ma-gnético débil. Cuando el campo se apaga, el material se desmagnetiza rápidamente. Se conocen como Materiales Magnéticos Suaves.
• En algunos materiales magnéticos suaves, la resistencia eléctrica cambia cuando el mate-rial es magnetizado. La resistencia regresa a su valor original cuando el campo magne-tizante es apagado. Esto se llama Magneto-Resistencia, o efecto MR. La Magneto-Re-sistencia Gigante, o efecto GMR, es mucho mayor que el efecto MR y se encuentra en sistemas específicos de materiales de pelícu-las delgadas.
• Otros materiales se magnetizan con dificul-tad (es decir, requieren de un campo mag-nético fuerte), pero una vez se magnetizan, mantienen su magnetización cuando el campo desaparece. Se conocen como per-manentes.
Para detalles de la construcción física y compo-sición interna de un disco duro puede echar un vistazo a la Figura número 1.
¿Cómo se escriben los datos?Los ordenadores almacenan datos en un disco magnético, al que conocemos como Disco Duro, en un sistema de numeración binario, es decir, una secuencia consecutiva de unos y ceros. Los bits se transforman en una onda de corriente eléctrica que es transmitida por medio de cables al rollo de la cabeza de escritura.
Un bit 1 se corresponde a un cambio en la polaridad de la corriente, mientras que un bit 0 corresponde a una ausencia de este cambio en la polaridad de la corriente de escritura. Los unos almacenados aparecen donde se produce una inversión en la dirección magnética en el disco, y los ceros residen entre los unos.
¿Cómo se leen los datos?Para realizar la lectura de los datos previamente almacenados se hace uso de una técnica llama-da efecto GMR que es utilizado por la cabeza de lectura. Al pasar una corriente por el elemento GMR, unos y ceros según convenga.
Existe un problema bastante desagradable, y es que, como todo componente eléctrico, las fuentes magnéticas generan ruido y esto puede ser mal interpretado por una cabeza de lectura, con sus consecuentes errores que a veces se vuelven irreversibles.
Zonas sensiblesEstudiaremos ahora las zonas débiles que imple-mentan los Sistemas Operativos en los conocidos sistemas de ficheros. Estas zonas son controladas por el Sistema Operativo pero también es sabido que pueden ser manejadas por software especial-mente diseñado para tal objetivo.
Pueden ser utilizadas para la recolección de rica y variada información, por este motivo, debemos ser conocedores de las mismas y ase-gurarnos de que no ofrezcan datos sensibles.
File slackPara entender este concepto, es requisito com-prender mínimamente la estructura de un siste-ma de archivos y cómo estos son almacenados en nuestro disco duro.
Todas las diferentes versiones de Windows dividen el disco duro en pequeños bloques denominados clusters, su tamaño es específico dependiendo del tamaño del disco y del sistema de archivos. Por ejemplo, para NTFS se decide del modo que puede ver en la Tabla número 1.
Para ser más estrictos, debemos decir que la unidad más pequeña de información que contiene un disco duro se conoce como Sector,
Figura 1. Composición interna de un Disco Duro
Platos
Cabezalectora
Motor
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2159
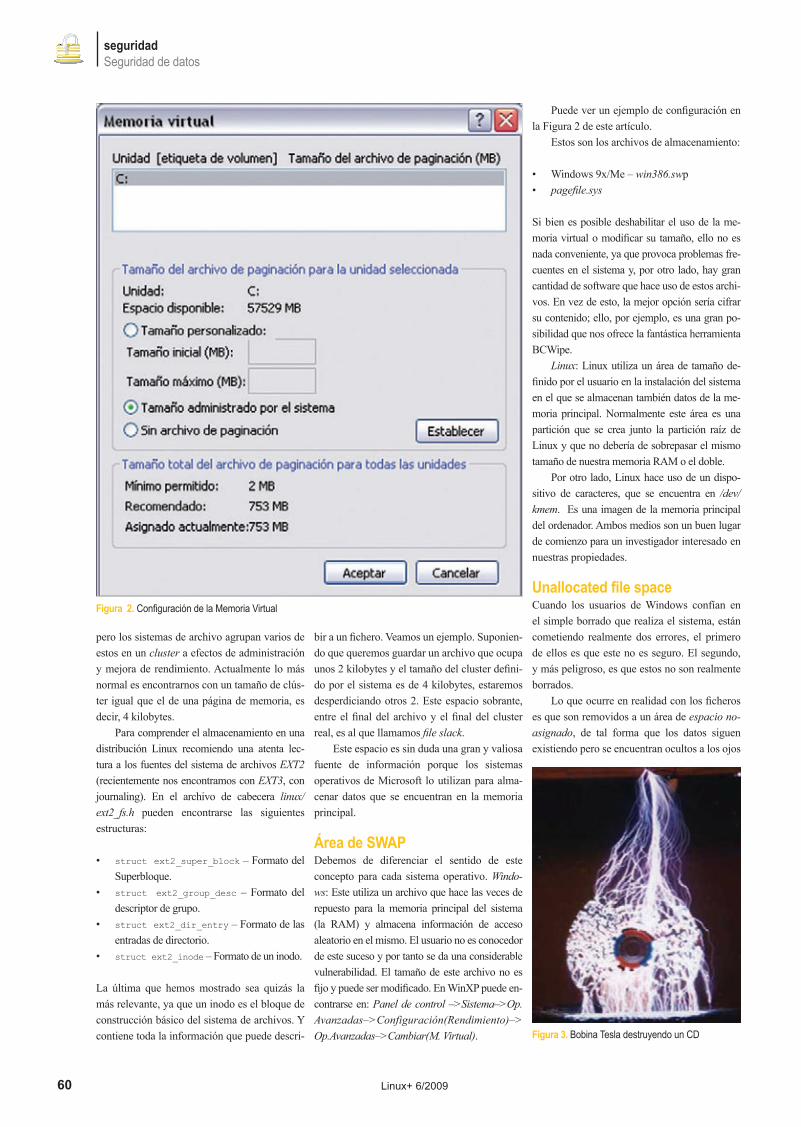
60
seguridadSeguridad de datos
Linux+ 6/2009
pero los sistemas de archivo agrupan varios de estos en un cluster a efectos de administración y mejora de rendimiento. Actualmente lo más normal es encontrarnos con un tamaño de clús-ter igual que el de una página de memoria, es decir, 4 kilobytes.
Para comprender el almacenamiento en una distribución Linux recomiendo una atenta lec-tura a los fuentes del sistema de archivos EXT2 (recientemente nos encontramos con EXT3, con journaling). En el archivo de cabecera linux/ext2_fs.h pueden encontrarse las siguientes estructuras:
• struct ext2_super_block – Formato del Superbloque.
• struct ext2_group_desc – Formato del descriptor de grupo.
• struct ext2_dir_entry – Formato de las entradas de directorio.
• struct ext2_inode – Formato de un inodo.
La última que hemos mostrado sea quizás la más relevante, ya que un inodo es el bloque de construcción básico del sistema de archivos. Y contiene toda la información que puede descri-
bir a un fichero. Veamos un ejemplo. Suponien-do que queremos guardar un archivo que ocupa unos 2 kilobytes y el tamaño del cluster defini-do por el sistema es de 4 kilobytes, estaremos desperdiciando otros 2. Este espacio sobrante, entre el final del archivo y el final del cluster real, es al que llamamos file slack.
Este espacio es sin duda una gran y valiosa fuente de información porque los sistemas operativos de Microsoft lo utilizan para alma-cenar datos que se encuentran en la memoria principal.
Área de SWAPDebemos de diferenciar el sentido de este concepto para cada sistema operativo. Windo-ws: Este utiliza un archivo que hace las veces de repuesto para la memoria principal del sistema (la RAM) y almacena información de acceso aleatorio en el mismo. El usuario no es conocedor de este suceso y por tanto se da una considerable vulnerabilidad. El tamaño de este archivo no es fijo y puede ser modificado. En WinXP puede en-contrarse en: Panel de control –>Sistema–>Op.Avanzadas–>Configuración(Rendimiento)–>Op.Avanzadas–>Cambiar(M. Virtual).
Puede ver un ejemplo de configuración en la Figura 2 de este artículo.
Estos son los archivos de almacenamiento:
• Windows 9x/Me – win386.swp• pagefile.sys
Si bien es posible deshabilitar el uso de la me-moria virtual o modificar su tamaño, ello no es nada conveniente, ya que provoca problemas fre-cuentes en el sistema y, por otro lado, hay gran cantidad de software que hace uso de estos archi-vos. En vez de esto, la mejor opción sería cifrar su contenido; ello, por ejemplo, es una gran po-sibilidad que nos ofrece la fantástica herramienta BCWipe.
Linux: Linux utiliza un área de tamaño de-finido por el usuario en la instalación del sistema en el que se almacenan también datos de la me-moria principal. Normalmente este área es una partición que se crea junto la partición raíz de Linux y que no debería de sobrepasar el mismo tamaño de nuestra memoria RAM o el doble.
Por otro lado, Linux hace uso de un dispo-sitivo de caracteres, que se encuentra en /dev/kmem. Es una imagen de la memoria principal del ordenador. Ambos medios son un buen lugar de comienzo para un investigador interesado en nuestras propiedades.
Unallocated file spaceCuando los usuarios de Windows confían en el simple borrado que realiza el sistema, están cometiendo realmente dos errores, el primero de ellos es que este no es seguro. El segundo, y más peligroso, es que estos no son realmente borrados.
Lo que ocurre en realidad con los ficheros es que son removidos a un área de espacio no-asignado, de tal forma que los datos siguen existiendo pero se encuentran ocultos a los ojos
Figura 3. Bobina Tesla destruyendo un CD
Figura 2. Configuración de la Memoria Virtual
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2160

61
seguridadSeguridad de datos
www.lpmagazine.org
de los usuarios (que no a software especialmen-te diseñado para leer este espacio).
En los sistemas Windows 9x/Me, cuando un archivo es borrado, la FAT (Tabla de Asignación de Ficheros) marca el espacio de este archivo co-mo libre para así poder ser sobrescrito con nue-vos datos, pero mientras esto no ocurre, la infor-mación se mantiene intacta con los consiguientes problemas de seguridad que ello conlleva.
Archivo de hibernaciónEl archivo de hibernación, como muchos saben, es un archivo de sistema que utilizan los siste-mas de Microsoft antes y después del estado de hibernación (o estado S4). Es una imagen del sistema que se escribe al disco antes de entrar en dicho estado y, cuando el usuario reinicia su sesión, este fi chero se carga y todo vuelve a la normalidad (al estado anterior).
Piensen fríamente ahora. ¿Qué mejor oca-sión para un atacante, que tener toda la confi gu-ración del sistema en un solo archivo?
La herramienta BCWipe tiene una opción que se encarga de este archivo y es conveniente hacerlo con regularidad, más fácil si lo activa-mos como tarea programada.
Borrado en LinuxAquí la otra cara de la moneda. Lo que Li-nux hace para borrar un archivo de nuestro sistema, es modifi car el contador de enlaces del inodo correspondiente al fi chero a borrar a 0, eliminando a su vez el nombre del mismo de las entradas de directorio. No vamos a mostrar aquí la estructura defi nida por EXT2 para un inodo, ya que esta es bastante amplia dado que contiene información administrativa como el UID del propietario, el tamaño del fi -chero, las fechas de acceso y modifi cación, el numero de bloques, sus direcciones y mucho más. Lo que sí mostramos es el elemento al que hacemos referencia como contador de en-laces: __u16 i_links_count; /* Links count */.
Una vez este llegue a ser cero, el espacio se queda en un estado disponible para otros archi-vos, pero ahora se plantean nuevos problemas:
• ¿Qué ocurre mientras este espacio no es utilizado?
• ¿Se podría acceder a este espacio?
Desgraciadamente el inodo sigue manteniendo información sobre el archivo al que hace refe-rencia; esto signifi ca que aunque se han modi-fi cado los meta-datos o en este caso el inodo a efectos de link con el valor de 0, y seguir el puntero de bloques hasta llegar exactamente al contenido del fi chero. Al igual que cualquier persona se preocupa de lo que sucede en su casa, su coche, y el resto de sus pertenencias, también debería preocuparse de lo que ocurre con su información y de lo que alguien podría llegar a hacer con ella. No sean conformistas.
Eliminación de disquetesNostalgia me produce el hablar de los tan cono-cidos “disquetes”, pero sin duda alguna muchos seguimos aún utilizándolos para pequeños tra-bajos y también para algunas preciadas mini-distribuciones de Linux
Por sí solos son medios bastante frágiles, pero siguen siendo fuentes signifi cativas de información y aquí expondremos diferentes modos para conseguir la destrucción completa de los mismos o, en su defecto, un borrado de datos seguro.
• Pasar un imán sobre la superfi cie electro-magnética del disquete hará que los datos se pierdan irremediablemente ya que estos son almacenados mediante pulsos electro-magnéticos y cualquier fuerza proveniente de una de estas fuentes provoca su cambio o pérdida.
• Incineración. No requiere de más explica-ción. El único inconveniente es la conta-minación ambiental. El que se tome esto a broma, le recomiendo se lea el How-To en español de Ecología y Linux.
• Vertido de alguna substancia corrosiva sobre la superfi cie magnética del disquete.
• Cortar en trozos el disquete asegurando que el disco interior queda convenientemente destruido. Se pueden recuperar datos de cada uno de los trozos.
• Sobrescritura del contenido del disquete. No es el método más bueno pero si el mas sencillo y práctico. Cuantas más veces se reescriba el mismo, más complicada será la recuperación de datos. Es más efi ciente uti-lizar un programa que realice las iteraciones de sobrescritura de forma automática.
Eliminación de CD'sDaremos ahora un rápido vistazo a las opciones de que disponemos para la eliminación de los da-tos en soporte CD. Claro es de suponer que cual-quiera de ellas provocara la inutilización total del mismo, pero ese es el principal objetivo.
• Retirar la lámina refl ectante con algún elemento cortante. Pueden seguir mante-niéndose datos en el policarbonato.
• Introducir el CD en un microondas. Esto trae consigo ciertos inconvenientes, puede causarse un cortocircuito debido al conte-nido de metales en el CD.
• Rayar la parte superior del CD que es la que contiene los datos.
• Cortar el CD en la mayor cantidad de trozos posibles asegurándose de que la lámina re-fl ectante queda destruida.
• Utilización de productos químicos sobre el soporte. Será sufi ciente con cualquier tipo de ácido corrosivo. Desde aquí no nos hace-mos responsables de las ideas que tengas en mente.
• Incineración del CD, la mas efectiva. Rei-teramos nuevamente la problemática am-biental.
• Si nuestro CD es regrabable, podemos hacer uso de la reescritura, pero aun después de varias pasadas, podría llega a sacarse in-formación. Aunque este es un proceso muy complejo y costoso.
• Y por último, para los más atrevidos y/o con medios disponibles a tal efecto, pueden probar a destruir un CD mediante descargas eléctricas producidas con el uso de bobinas Tesla (vean la Figura 3 para más detalles).
Aplicaciones de borrado seguroLas siguientes herramientas aquí presentadas, han sido analizadas y descritas bajo el punto de vista del autor de este artículo. Para un mejor conocimiento de cada una de estas utilidades, deben ser utilizadas con detenimiento.
MS-DoS & WindowsBCWipe: Estupendo producto de la casa Jetico. Su mayor defecto es que no es gratuito, fuera de esto, sus caraterísticas son ampliamente desta-cables. Una de sus facetas más interesantes es la de Cifrado de la Swap; con ello elevaremos de forma considerable nuestro grado de seguridad. Los algoritmos de cifrado disponibles son:
• Rijndael – 256-bit• Blowfi sh – 448-bit• GOST 28147-89 – 256-bit• Twofi sh – 256-bit
Figura 4. Logo Ofi cial de Helix3
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2161

62
seguridadSeguridad de datos
Linux+ 6/2009
Este software dispone de diversas opciones que pueden ser modificadas a gusto del usuario. Los métodos de borrado seguro son:
• Método Gutmann de 35 pasadas.• El recomendado en el manual NISPOM
del US DoD, 7 pasadas.• Una pasada aleatoria.
Esta fantástica herramienta trae consigo una utilidad llamada BCWipePD.exe, su objetivo es el de borrar todo el contenido de un disco
duro, desde los sistemas operativos hasta la tabla de particiones. Usa el método del US DoD de 7 pasadas. Evidentemente, eficaz si su sistema pasara por las manos de algún in-vestigador forense. Esto se lo pondría difí-cil.
Y continuamos. BCWipe Task Manager. Conesta aplicación podemos programar las tareas que queremos realizar cada cierto tiempo con BCWipe. Su uso es extremadamente sencillo, por ello no me detendré aquí y seguiremos con mas descripciones generales.
Norton Utilities: Este gran kit de herramien-tas trae consigo al omnipresente Wipe. Puede en-contrarlo en Inicio–>Programas–> N. Utilities–>Wipe Info. Una vez abierto, nos da la posibili-dad de borrar archivos, carpetas y el espacio li-bre del disco duro. Los métodos de borrado que nos ofrece son los siguientes:
• Fast Wipe – 1 pasada, sobrescribe con ceros pero el valor puede ser cambiado (0 a 255), 246 recomendado gubernamentalmente.
• Government Wipe – Sigue las indicaciones del manual NIPSON, 7 pasadas, sobrescri-tura de ceros y unos alternada, tiene varios parámetros modificables.
Antes de culminar con el proceso de borrado, esta aplicación mostrará un resumen con to-das las opciones que hemos elegido, así podrá asegurarse de que todo está en el orden co-rrecto.
PGP: Su gran amigo Pretty Good Privacy dispone de dos utilidades de cierta importancia:
• Wipe – Se encarga de la eliminación segu-ra de ficheros de nuestro sistema.
• FreeSpace Wipe – Se encarga de el borrado del espacio libre disponible en el medio de almacenamiento. Solo debemos de elegir la unidad deseada y el número de pasadas que nos parezcan.
La segunda herramienta tiene la bondad de indi-car el tiempo aproximado que tardará en realizar la operación.
UNIX & LINUXTHC-Secure Deletion: Esta herramienta, desa-rrollada por THC (The Hacker´s Choice) es un conjunto de utilidades que mantienen la seguri-dad de los datos que no podemos controlar en nuestro sistema o los cuales deseamos eliminar. Este paquete incluye:
• srm – Borrado seguro de ficheros.• sfill – Borrado seguro del espacio libre de
un disco.• sswap – Borrado seguro del area de swap.• smem – Borrado seguro de datos en la RAM.
El proceso utilizado por srm se basa 5 pasos básicos:
• Sobrescribe 38 veces.• Flush de la cache de disco entre cada pa-
sada.• Truncamiento del fichero.• Renombramiento del fichero.• Llamada a unlink( ).
Listado 1. Script bsecdat.pl
#!/usr/bin/perl
#####################################
# Nombre: Bsecdat V. 1.0 #
# By: blackngel #
#####################################
print "\n\n";
print " @@@@@@@@@@@@@@@@@@@@@@@@ \n";
print " @ Bsecdat by blackngel @ \n";
print " @@@@@@@@@@@@@@@@@@@@@@@@ \n";
print "\n\n";
print "Que archivo desea eliminar?: ";
$archi=<STDIN>;
chop $archi;
print "\nNumero de sobrescrituras?: ";
$num=<STDIN>;
chop $num;
open (ARCH,"+<$archi") or die "El documento no se ha abierto o no existe.";
# Extraemos la información del archivo para obtener su tamaño -> $tam
($dev, $ino, $info, $links, $IDuser, $IDgrp, $IDdev, $tam, $uacc, $umod,
$uino, $tambloqIO, $IO) = stat (ARCH);
sobreescribir(); # Sobrescribe el archivo 'num' veces
truncate(ARCH, 0); # Trunca el tamaño del archivo a 0
utime(0, 0, $archi); # Cambia la fecha de última modificación
close(ARCH);
# Nota: El archivo es renombrado y eliminado después de ser cerrado
renombrar(); # Renombra el archivo
unlink($archi); # Elimina el archivo
sub sobreescribir # Función o algoritmo de sobrescritura {
for($i=0; $i < $num; $i++){
seek(ARCH, 0, 0);
for($j=0; $j < $tam; $j++){
$car = rand(255);
printf ARCH "%c", $car;
}
}
}
sub renombrar # Función que genera un nombre aleatorio {
$n = rand(255);
$nom = sprintf("%f", $n);
rename($archi, $nom);
}
print "\n\n";
print " @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\n";
print " @@@@@ Bsecdat V. 1.0 by blackngel @@@@@\n";
print " @@@@@ black @ set-ezine.org @@@@@\n";
print " @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@\n";
print "\n";
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2162

63
seguridadSeguridad de datos
www.lpmagazine.org
The Defiler's Toolkit: Formada por dos herra-mientas complementarias, esta herramienta es conocida como una utilidad “anti-forensics”. Las dos utilidades que incluye son: “necrofile” y “klismafile”. En un sistema de archivos Unix/Linux cualquiera de las siguientes partes con-tendrá evidencia de la existencia de archivos:
• I-nodes (inodos)• Directory Entries (entradas de directorios)• Data Blocks (bloques de datos)
Entre necrofile y klismafile, se aseguran de eliminar cualquier rastro de información en las estructuras anteriormente mencionadas.
• Necrofile – Se encarga de la implemen-tación de borrado seguro en los i-nodos y de eliminar cualquier contenido de los bloques de datos.
• Klismafile – Su objetivo es sobrescribir las entradas de directorio que han sido elimina-das. La sobrescritura se realiza con ceros.
Puedes encontrar este set de herramientas en formato uuencode en el interior del fabuloso artículo creado por grugq, Defeating Forensics Analysis on Unix, publicado en el número 59 de la revista Phrack (Vea referencias para más detalles).
OTROSPM WIPE: Este herramienta es para el siste-ma OS/2, sólo tiene que elegir los archivos a eliminar y listo. Tiene una interfaz bastan-te amigable. OS/2 también hace uso de un archivo de swap para el almacenamiento de datos en memoria. Existen otras herramientas que solo borran directorios y otras de pago. Como siempre, Google puede echarle una mano con sus necesidades.
Herramientas forensesNos centraremos únicamente en las caracte-rísticas principales de cada utilidad. Para una información más detallada puede consultar las páginas man e info disponibles en cada una de ellas.
TCTVeamos el objetivo de cada una de las utilida-des que conforma este fantástico kit y también las del paquete TCT Utils que lo complementa:
• file – Busca archivos.• Icat – Contenido de un inodo.• Ils – Información de un inodo.• lastcomm – Últimos comandos ejecutados.• lazarus – Recupera datos de un dispositivo.
• unrm – Recupera datos de un dispositivo.• grave-robber – Información del sistema.• mactime – Fechas de acceso y modificación.• bcat – Contenido de un dispositivo de blo-
ques.• blockcalc – Crea un mapa de bloques.• fls – Lista entradas de directorio.• find_file – Dado un inodo e imagen deter-
mina el archivo.• find_inode – Dado un bloque e imagen
determina el inodo.• istat – Información de un inodo dado ino-
do e imagen.
Cuando hablo de imagen hago referencia a una imagen creada con la aplicación dd (disponible en cualquier Linux) de un dispositivo.
Manipulate_dataPaquete con tres herramientas simples pero bastante eficientes, su código fuente es fácil de comprender y se centra estrictamente en su ob-jetivo. Las tres utilidades son las siguientes:
• search_data – Busca una cadena en el dis-positivo de bloques y muestra el número correspondiente donde se encuentra.
• read_data – Lee tantos bytes como el usuario especifique a partir del número de bloque dado.
• write_data – Sirve para escribir en el dis-positivo.
Para encontrar esta herramienta, puede buscar en este estupendo repositorio: http://fux0r.phathookups.com/tools.
HEXDUMPEsta fantástica utilidad viene incluida práctica-mente en cualquier distribución Linux estándar. Realiza un volcado en hexadecimal. Para noso-tros es muy útil porque conseguimos pasar toda la información de un dispositivo a un fichero con el cual podremos trabajar después.
La ventaja está en que mediante sus ar-gumentos podremos especificar el formato de salida. El que más nos interesa en este caso es el de ASCII, así encontraremos de una forma más cómoda cualquier texto plano.
OtrosAlgunos otros nombres para los que deseen buscar más información:
• Partition recovery• Data Recovery Software• Magic Undelete• RIP• LDE (Linux Disk Editor).
DBAN: Es un disco de arranque que borra de un modo seguro cualquier disco duro que pueda detectar en un ordenador. Tal y como nos indica la propia página oficial, es la herramienta per-fecta para un borrado automático de emergen-cia (Vaya directamente a las referencias para más información).
Helix3: Se trata de una distribución Li-nux basada en la ya ampliamente conocida Ubuntu, desarrollada por la empresa e-fense, que está dedicada de una forma específica al campo del análisis forense y la respuesta ante incidentes. Se proporciona como Live-CD, de modo que pueda ser ejecutada sobre el or-denador que está siendo objetivo del análisis o estudio, y su estructura está especialmente diseñada con el fin principal de no alterar en modo alguno a éste, y no comprometer así cualquier evidencia que haya podido ser encon-trada.
Prueba de conceptoEstamos a punto de realizar una prueba sim-ple pero de la cual aprenderemos bastante. Trataremos de recuperar un archivo previa-mente borrado de un disquete. Lo haremos en este medio por la simple razón de que sería un poco angustioso que cada uno tuviera que an-dar jugando con su disco duro, de esta forma nos evitamos todos problemas y el autor no se hace responsable.
De todas formas, en cualquiera de los casos bastaría con cambiar las referencias a /dev/fd0 por /dev/hdx donde la x será variable para cada sistema.
Primero crearemos un archivo de texto dentro del disquete, esto seria algo así:
$ cd /media/floppy #Aquí debería de
estar montado el disquete
$ echo 'Tenemos 5 misiles' >
pruebas.txt
Como es de suponer, ahora solo queda borrarlo:
$ rm pruebas.txt
Utilizaremos el kit Manipulate Data para nues-tro objetivo. Tan solo harán falta las utilidades search_data y read_data. Con la primera buscaremos una cadena de la que nos acorde-mos, daré por supuesto que esta palabra es “mi-siles”. El comando se ejecutaría de esta forma:
$ search_data -i /dev/fd0 "misiles"
La opción -i hará que no se distingan mayúscu-las de minúsculas. La salida del programa será
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2163
64
seguridadSeguridad de datos
Linux+ 6/2009
un número de bloque que nos indicará dónde se encuentra la cadena deseada, algo así:
found at 17418: misiles
Ahora solo nos queda valernos de read_data para encontrar el resto del archivo. Como el texto completo que buscamos esta más atrás que misiles, tendremos que utilizar un núme-ro de bloque inferior y buscar más cantidad de bytes para alcanzar el final. Esto lo lograríamos con el comando:
$ read_data /dev/fd0 17408 30
La salida nos ofrecerá lo que buscamos y, ade-más, unos bytes de sobra que pueden o no tener información. Lo encontraremos en un archivo con el nombre 17408.30 en el directorio actual:
Tenemos 5 misiles_____________
#El subrayado representa datos
desconocidos
Método 2Mediante el uso de hexdump volcaremos el con-tenido del disquete a un archivo estático para después examinarlo con calma. El comando que podemos utilizar es:
$ hexdump -c /dev/fd0 > datos.txt
La opción -c provocará que la salida sea en for-mato hexadecimal y ASCII al mismo tiempo.
Como bien puede comprobar, redirecciona-mos la salida hacia un fichero que analizaremos seguidamente en busca de la cadena deseada.
$ grep -i 'misil' datos.txt
La salida sera algo parecido a esto:
00004400 54 65 6e 65 6d 6f 73 20 35
20 6d 69 73 69 6c 65 |Tenemos 5
misile|
Ahora solo tendríamos que buscar en el archi-vo, a partir de ese desplazamiento (00004400), el resto de la información.
Método 3En este último caso utilizaremos las herra-mientas que nos proporciona TCT, estas suelen acompañar con frecuencia a cualquier forense de entornos Unix.
Con la ayuda de lazarus conseguiremos recuperar los datos del disquete, expuesta por bloques. Presento aquí el comando y paso a ex-plicar cada uno de sus argumentos:
$ lazarus -hB -D blocks -H html -w
html /dev/fd0
• -h – Salida en formato HTML.• -B – No escribe bloques de binarios.• -D – Directorio donde se guardarán los
archivos con el contenido de los bloques.• -H – Igual que el anterior pero aquí se
guardan los archivos con extensión .html.• -w – Igual que el anterior (que alguien me
lo explique).
Ahora buscamos entre los archivos del directo-rio blocks, cual de ellos contiene el texto que a nosotros nos interesa. Puede utilizar un coman-do como el siguiente:
$ strings -af *.txt | grep -i 'misil'
18.t.txt: Tenemos 5 misiles
Según la documentacion de lazarus tambien podría usar algo parecido a esto:
$ egrep -l 'misil' blocks/*.txt >
allfiles
Y buscar entre los archivos listados en allfi-les. Para las imágenes bastaría con ejecutar lo siguiente: $ xv blocks/*.gif blocks/*.jpg.
Los ficheros del directorio anterior termina-rán con diferentes extensiones según lazarus interprete el contenido de los mismos. Puede observar un listado de las posibles extensiones en la Tabla número 2.
Con un poco de suerte, en nuestro caso, y sabiendo que el archivo se trataba de un txt, podríamos reducir las posibilidades y el tiempo de localización de esta forma: $ strings -af *.t.txt | grep -i misil.
Otro método que también es efectivo, es utilizar en conjunto las dos herramientas de recupera-ción: lazarus y unrm. Por ejemplo:
$ ./unrm /dev/fd0 > salida
$ ./lazarus -h salida
Los siguientes pasos son idénticos a los expli-cados anteriormente. En el primer comando, el fichero salida tiene que estar en un dispositivo diferente al examinado. También cabe decir que cada una de estas tareas lleva cierto tiempo según el sistema.
Script de borrado seguroPresento aquí una vaga implementación de un programa de borrado seguro. Como podrán comprobar, utiliza las funciones principales pero, sin duda alguna, está dispuesto a su-tiles mejoras, tanto de rendimiento como de seguridad.
¿Por qué utilizamos el lenguaje perl? Fácil respuesta. Por su gran potencial, rapidez teniendo en cuenta que es un lenguaje inter-pretado y lo compacto que resulta resolver cualquier problema. Debido a la portabilidad de este lenguaje, no debería de tener ningún problema a la hora de ejecutar este programa tanto en plataformas Linux como en Win-dows.
Excluyendo los logotipos que le dan algo de vida al script, este ha sido escrito de forma que sea altamente legible. Usted mismo puede realizar diversos cambios en el código y adap-tarlo a sus necesidades específicas.
Posibles mejoras:
• Entrada de datos como argumentos.• Operación sobre múltiples ficheros.• Flush de la cache de disco.
Tabla 1. Tamaños específicos de cluster
Tamaño del HD Tamaño del cluster512 MB o menos 512 bytes
513 MB - 1024 MB 1 KByte
1025 MB - 2048 MB 2 KByte
2049 MB o más 4 KBytes
Tabla 2. Extensiones de archivo de TCT
Extensión Formato Extensión Formato Extensión FormatoA Archivo M Mail U UUencoded
C Codigo C O Null W Contraseñas
E ELF P Programa X EXE
F Sniffer Q Mailq Z Comprimido
H HTML R Eliminado . Binario
I Imagen S Lisp ! Sonido
L Log T Texto
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2164

65
seguridadSeguridad de datos
www.lpmagazine.org
• Algoritmos más complejos (y más lentos).• Otros...
Algunos consejosAntes de terminar, me ofreceré a compartir algunos consejos que quizás sean de utilidad al lector más concienciado. Son gratuitos y, por lo tanto, libres de ser tenidos en cuenta:
• Ante todo, mantenga siempre cifrada la in-formación que permanezca estática en su ordenador (no nombraré las herramientas de cifrado como siempre, esto quedará a elección propia).
• Si una herramienta le permite elegir entre varios métodos de cifrado, a no ser que sea necesario, trate de elegir una de las opcio-nes que no estén por defecto, ya que este método sería el primero en ser atacado por alguien con malvadas intenciones.
• Utiliza siempre herramientas de borrado seguro, al fin de todo siempre merece la pena. Hoy por hoy podemos encontrar multitud de utilidades GUI amigables para el usuario, adaptadas a diferentes entornos y Sistemas Operativos.
• Mantenga una buena programación del horario de administración. Procure que
este horario sea aleatorio pero con sentido común, ya que de esta forma, por ejemplo, si realizáramos el borrado todos los martes de cada semana, un atacante se encargaría de sacarnos la información los lunes; de otra forma, manteniendo una buena alea-toriedad, tendrían que tener suerte para encontrar algo entre nuestra basura.
• Utilice un sistema de archivos que no este al alcance de una herramienta de análisis forense, como ocurre con Ext2, UFS, etc...
• No olvide nunca los métodos de destruc-ción de medios portátiles. Estos pueden dar sorpresas el día menos esperado. Hay que ser responsable y saber qué es lo que se guarda y dónde.
• A ser posible, utilice un sistema de archi-vos cifrado o, para más seguridad, uno
ConclusiónCon lo visto hasta ahora, es posible que se en-cuentre todavía más concienciado de que la in-formación es un bien que debe ser protegido.
Cierto, todo lo que hemos proporcionado puede ser interpretado tanto desde el lado del usuario doméstico que intenta protegerse como desde el lado de un atacante que busca nuevas formas de burlar la seguridad de los anteriores.
• The Coroner Toolkit en: http://www.porcupine.org/forensics
• Ecología y Linux HowTo en: http://docs.linux-es.org/HOWTO/translations/es/Ecologia-y-Linux-COMO
• BCWipe en: http://www.jetico.com
• Norton Utilities en: http://www.norton-online.com/es
• Pretty Good Privacy en: http://www.pgp.com
• The Hackers Choice en: http://freeworld.thc.org/welcome
En la red
P U B L I C I D A D
Pero la única verdad es que esta seguridad es una “lucha”, y sabiendo que la información es poder, nosotros solo ponemos las armas en ma-nos de aquellos que deseen empuñarlas.
Al final de este artículo, lo único que su au-tor desea, es que el lector se haya quedado con algo más que la idea de introducir un CD-ROM en su microondas.
58_59_60_61_62_63_64_65_Seguridad_de_datos.indd 2009-04-14, 14:2165

programaciónCurso de Programación en Gambas
66 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
l
Sin duda esta característica de Gambas, como mu-chas otras, son las que lo convierten en un lenguaje de programación único bajo GNU/Linux. Muchos de los programas utilizados por los usuarios son
en realidad, FrontEnds de aplicaciones en modo texto. Como ejemplo, podemos mencionar al legendario grabador de cd's K3B, que en realidad es la cara visible de aplicaciones en modo texto como cdrecord o mkisofs. Pero la principal pre-gunta radica en... ¿Qué es un FrontEnd? La respuesta es sim-ple. Un programa del tipo FrontEnd es aquel que se encarga de mostrar y/o generar la interfaz gráfi ca de un programa que no la tiene. Como contraejemplo, podemos citar el termino Bac-kEnd, el cual hace referencia a la inteligencia o lógica del pro-grama en sí, sin hacer hincapié en las características de interfaz de usuario gráfi cas que este requiere (si es necesario). En el mundo del diseño web, las defi niciones FrontEnd y BackEnd hacen referencia a la visualización del usuario navegante por un lado (front-end), y del administrador del sitio con sus res-pectivos sistemas por el otro (back-end). Igualmente, la idea es la misma. Pero.. ¿Por qué separar una aplicación en FrontEnd y BackEnd? La idea fundamental radica en que el FrontEnd se encargue de recolectar los datos del usuario para que luego,
mediante el BackEnd, estos se procesen y arrojen un resultado. Otra de las ventajas radica en que, si el programador no desea o no le es necesario que su programa tenga una interfaz gráfi ca para el usuario común, puede sólo desarrollar el BackEnd y hacerlo completamente funcional, y si en un futuro lo requie-re, podrá desarrollar el FrontEnd sin problema alguno. En la Figura 1, podemos observar a modo conceptual, como sería la interacción entre el FrontEnd y el BackEnd.
En esta entrega, veremos cómo desarrollar un frontend para una aplicación en particular. También, veremos cómo desarrollar nuestro BackEnd y enlazarlo con nuestro FrontEnd. Dejemos para más adelante estos temas tan interesantes y empecemos con otras características de Gambas que nos van a ser de suma utilidad y necesitaremos de ellas: Los Arrays y el Control de Excepciones.
ArraysUn Array ( también conocido como arreglo, vector o matrices) es un tipo de variable especial que puede agrupar muchos valores del mismo tipo de datos, en el cual estos valores son accedidos mediante un índice que representa su ubicación dentro del mis-mo. Los Arrays son muy utilizados en programación cuando se
Gestión Potente de Procesos: Creación de FrontEnds en GambasGNU/Linux posee infi nitas alternativas a distintos programas de aplicación. Muchas de estas son de interfaz de modo texto, lo que lleva al usuario principiante/intermedio a una difícil interacción con el programa. Gambas pensó en este problema, por lo que como era de esperar, nos trae una solución: La creación de FrontEnds.
Jorge Emanuel Capurro
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5266

programaciónCurso de Programación en Gambas
67www.lpmagazine.org
requiere almacenar muchos valores y no se desea manejar una variable por cada valor a manipular, lo cual facilita mucho la tarea del programador y hace a los programas más legibles y efi cientes. Por ejemplo, pensemos en un programa que re-quiera que se generen 1000 números aleatorios para luego ordenarlos de mayor a menor, y que cualquiera de estos números pueda ser accedido en forma individual cuando se requiera. Con los conceptos vistos hasta el momento, solamente podríamos declarar 1000 variables (¡Una ver-dadera Locura!) y generar un numero aleatorio en cada una de ellas. Con el concepto de Array, es posible generar un Array que contenga 1000 posiciones, en el cual se generen los números aleatorios automáticamente y luego accedamos a un valor en particular mediante su índice. En la Figura 2, veremos la estructura de un Array. Las letras corresponden a los elementos del Array, es decir, a los valores “útiles”, mientras que los números son el índice, el cual utilizaremos para hacer referencia a un valor en particular.
Existen diferentes tipos de Arrays: Los uni-dimensionales y los multidimensionales. La úni-ca diferencia entre ellos es la cantidad de índices que cada uno maneja. Por ejemplo, los Arrays de tipo unidimensional manejan un solo índice, mientras que los multidimensionales pueden ma-nejar 2 o más índices. Cuanto más índices tenga el Array, más complejo se hace manipularlo de manera óptima. Debido a que el uso del Array más común se da con los unidimensionales, sim-plemente nos remitiremos a ellos.
Para explicar la utilización de Arrays, nos valdremos de otra de las grandes características que posee Gambas: La posibilidad de utilizarlo como lenguaje de programación del tipo Script. Un lenguaje de programación del tipo Script, es aquel que no requiere ser compilado, es decir, solamente basta con tener un archivo de texto con código compatible para que este pueda ser ejecutado. Los lenguajes Script son también co-nocidos como “Lenguajes Interpretados”. Los ejemplos más populares de este tipo de lengua-jes son Bash y PHP, Python, LISP, entre otros. Esto en Gambas se hace posible gracias a un pequeño ejecutable que permite ejecutar código Gambas desde cualquier archivo de texto: el gbs2 (Gambas Scripter 2). Para poder crear un programa de Gambas Script, solamente nos ha-ce falta tener un editor de texto cualesquiera, ya que como se mencionó, no hace falta un compi-lador para poder crear el archivo ejecutable.
Utilización Básica de ArraysEmpecemos con la declaración de Arrays. La Sintaxis es la Siguiente:
DIM NombreDelArray [CantElementos]
AS Tipo
NombreDelArray: Es el identifi cador del Array. Tiene las mismas características que el nombre de una variable normal.
CantElementos: Es la cantidad de posicio-nes y valores que podrá almacenar el Array. Tiene
que tener en cuenta que la primera posición del Array es la numero cero. Por ejemplo, si se quiere declarar un Array que contenga 10 números, este se tendrá que declarar con 9 elementos (0-9).
Tipo: Cualquier tipo de dato manejado por Gambas. Por ejemplo, así se declararía un Array que pudiese albergar 1000 números enteros: DIM Numeros[999] AS Integer.
Para poder referenciar a un elemento en particular del Array, se debe hacer mediante el índice. Por ejemplo, la siguiente sentencia se encarga de recuperar en una variable del tipo In-teger llamada Valor, el contenido de la posición 285 del Array.
Dim Valor AS Intenger
Valor = Numeros[285]
Para poder verifi car estos conceptos, nada mejor que con un ejemplo. Este ejemplo lo haremos mediante Script, para que el lector pueda apreciar una característica más de las que brinda Gambas. Vale la pena aclarar que la utilización de Arrays no sólo se limita al lenguaje Script de Gambas, si-no que se puede aplicar sin ninguna modifi cación
La consola de GNU/Linux nos provee de dos comandos de suma utilidad a la hora de evaluar el estado de un proceso, ver la can-tidad de recursos que consume, consultar su PID, etc. Estos comandos son ps y top. El primero de ellos, nos provee información estática acerca de los procesos que se es-tán ejecutando en ese momento dado. Es información estática puesto que “saca una foto” de las propiedades de los procesos en el momento en que se ha invocado el comando. Por el contrario, top nos provee información dinámica. La información se va actualizando constantemente con el transcurso del tiempo. Vale aclarar que ambos comandos tienen muchas opciones disponibles, las cuales pueden consultarse en las páginas del manual.
Los Comandos PS y TOP
IDEas C es el primer FrontEnd desarrollado bajo Gambas para el excelente compilador gcc, el cual es de mi autoría. Posee resal-tado de sintaxis y compilación automática, entre otras características interesantes. Se centra principalmente en el lenguaje de Programación C. Para más información visite http://ideasc.sourceforge.net.
IDEas C
Listado 1. Ejemplo de Utilización de Arrays
#!/usr/bin/env gbs2
DIM Numero[1000] AS Integer
DIM SumaArray AS Integer
DIM i AS Integer
PRINT "Uso asmo de Arrays \n"
'Asignacion de un Valor en la Posicion 285 del Array
Numero[285] = 10
PRINT "Valor de Posicion 285 del Array: " & Numero[285]
'Genero Numeros Aleatorios Array
RANDOMIZE
FOR i = 0 TO 999
Numero[i] = Rnd(0, 10)
NEXT
'Array en Pantalla
FOR i = 0 TO 999
PRINT "\n Posicion [" & i & "] - Valor: " & Numero[i]
NEXT
'Suma de Todos los Elementos del Array
FOR i = 0 TO 999
SumaArray = SumaArray + Numero[i]
NEXT
'Suma de Array en _Pantalla
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5267

68
programaciónCurso de Programación en Gambas
Linux+ 6/2009
a los programas realizados con interfaz gráfi ca. Empecemos abriendo nuestro editor de texto fa-vorito, como puede ser el gedit, nano, emacs, o vi. Una vez allí, ingresamos lo que se muestra en el Listado 1. Este programa se encarga de declarar un Array o Vector de números enteros, y mostrar los contenidos vistos hasta el momento.
Luego de escribir el programa, abrimos un terminal, nos posicionamos sobre el directorio donde guardamos el archivo de texto y ejecutamos el siguiente comando que se encarga de pasarle como parámetro nuestro programa al Scripter de
Gambas (puede ser que se necesite permisos de administrador, para ello anteponer el comando sudo): gbs2 ./NombreDelArchivoNumero.
En la Figura 3, se muestra una parte de la posible salida del programa.
Algoritmos Específi cos aplica-dos a ArraysExisten diversos algoritmos que son amplia-mente utilizados en el mundo de la programa-ción, en este caso nos acotaremos a los específi -cos y más comúnmente vistos que se aplican a los Arrays. Estos algoritmos son los de ordenamien-to y búsqueda de elementos en un vector. En las secciones siguientes analizaremos los algoritmos que se mencionan a continuación:
En la actualidad existen libros enteros y per-sonas que han dedicado toda su vida al estu-dio de la Algoritmia. Es por ello, que no sólo existe un método para poder llevar a cabo la tarea de ordenar un algoritmo. Muchos mé-todos son igualmente (o más) efi cientes que el Método de Burbujeo Optimizado, obvia-mente todo esto dependiendo de la circuns-tancia y entorno donde se aplique. Algunos constan de varias ventajas, otros no. En de-fi nitiva, existen infi nidad de métodos con sus características que los destacan a cada uno en particular. Entre los más conocidos o clásicos métodos se encuentran el or-denamiento por inserción (Insertion sort), ordenamiento por selección (Selection sort), ordenamiento por árbol binario (Binary tree sort), ordenamiento rápido (Quicksort), etc.
Ordenando de mil y una formas
Podemos defi nir un algoritmo como “una sucesión fi nita de pasos bien específi cos, no ambiguos y que están relacionados entre sí de una manera sumamente lógica”. Dicho de otra forma, un algoritmo nos indica los pasos que tenemos que seguir para llegar a una determinada meta. Por ejemplo, si no-sotros queremos ir de compras al mercado, nuestros pasos serán más o menos así: Pri-mero nos despertamos luego de descansar un largo rato. Segundo, vamos al baño para luego tomar un desayuno. Tercero, termina-mos de desayunar y nos vestimos. Cuarto, cogemos dinero y nos dirigimos hacia la co-chera. Quinto, encendemos el motor del auto y nos dirigimos hacia el mercado.
Como vemos en este ejemplo absurdo, nuestro algoritmo nos indica los pasos a se-guir de manera lógica para poder realizar una determinada acción. Este concepto se aplica, en mayor o menor medida, igual en los algoritmos computacionales.
¿Qué es un Algoritmo?
Sí, lamentablemente no podremos hacernos ricos con nuestro desarrollo. Existen varios FrontEnds muy buenos desarrollados para ffmpeg que tienen cientos de características que nos serán de utilidad. Entre los más co-nocidos podemos mencionar a WinFF, Hy-per Video Converter, y Movic entre otros. Para más información, visite su sitio web ofi cial.
FrontEnds para ffplayer
Listado 2. Implementación del Algoritmo de Búsqueda Secuencial
#!/usr/bin/env gbs2
DIM Numeros[9] AS Integer
DIM ValorBuscado AS Integer
DIM Encontro AS Boolean
DIM Posicion AS Integer
'Inicializo Variable
Encontro = FALSE
'Inicializo Array como en la Figura 4
Numeros[0] = -6
Numeros[1] = 1
Numeros[2] = 16
Numeros[3] = 20
Numeros[4] = 21
Numeros[5] = 35
Numeros[6] = 37
Numeros[7] = 42
Numeros[8] = 80
PRINT "\n Ingrese el Valor a Buscar: "
INPUT ValorBuscado
PRINT "\n\n Buscando el Numero " & ValorBuscado & "... \n"
'Empieza el Algoritmo de Busqueda Secuencial
WHILE (Posicion < 8 AND Encontro = FALSE)
INC Posicion
IF Posicion < 8 THEN
IF Numeros[Posicion] = ValorBuscado THEN
'¡Eureka, hemos hallado el Numero!
Encontro = TRUE
ENDIF
ELSE
Encontro = FALSE
ENDIF
WEND
'Termina el Algoritmo de Busqueda Secuencial
'Verifi camos si el valor se encontro
IF Encontro = TRUE THEN
PRINT "El Valor se encuentra en la Posicion " & Posicion & " del Array"
ELSE
PRINT "El valor no se encuentra"
END IF
• Búsqueda: Algoritmo de Búsqueda Se-cuencial. Algoritmo de Búsqueda Binaria,
• Ordenamiento: método del Burbujeo Opti-mizado,
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5268

69
programaciónCurso de Programación en Gambas
www.lpmagazine.org
Por cuestiones de simplicidad, la comprobación práctica de ellos la realizaremos igual que en el modo anterior; es decir, mediante programa-ción de Script Gambas.
Búsqueda de Elementos en un Array: Método SecuencialEste método, también conocido como Búsqueda Lineal, consiste en recorrer el Array empezando desde la primera posición, comparando el valor a buscar con el elemento del Array actual, de forma secuencial; es decir, avanzando de a un elemento hasta que el Array se termine. Este método es muy efi ciente si el elemento a buscar se encuentra en las primeras posiciones del Array, pero pierde mucha efi ciencia y tarda mucho más que la búsqueda binaria, si el ele-mento se encuentra cerca de la última posición del Array. La búsqueda termina con éxito si el elemento a buscar es encontrado, de lo contrario se debe informar de que el elemento no existe.
Como ventaja, no es condición necesaria que el Array se encuentre ordenado para poder rea-lizar la búsqueda, y su implementación y com-presión es muy sencilla.
Supongamos que tenemos un Array de nú-meros enteros de 9 posiciones y deseamos buscar el elemento 46. Este escenario puede apreciarse en la Figura 4. Como vemos, la búsqueda secuen-cial debe realizar 8 comparaciones hasta llegar al elemento buscado, de un total de 9 comparacio-nes si se hubiese recorrido todo el Array. ¡Ojo! Si el numero 46 hubiese estado en la segunda posi-ción, la situación sería completamente diferente. Este es un claro ejemplo de la pobre performance que puede llegar a tener este algoritmo.
Este mismo escenario puede implementarse en Gambas, tal cual lo muestra el Listado 2. El funcionamiento de este código es muy sencillo. Primero, inicializamos un Array como lo ilustra la Figura 4. Luego, almacenamos en una varia-ble el valor que el usuario quiere buscar. Acto
Básicamente, podemos conocer a un pro-ceso como un sinónimo de programa. Esto no es del todo cierto. Considerando la de-fi nición de programa, podemos decir que este es una entidad pasiva, mientras que un proceso es una entidad activa.
Cuando un programa pasa de estar pasivo en el código fuente a estar ejecu-tándose en el CPU, ocupando recursos de este, se lo pasa a denominar proceso. En defi nitiva y muy burdamente, podemos con-siderar a un proceso como un programa en ejecución, cuya entidad pasa a ser activa en el momento de su carga en memoria.
Defi nición de Proceso
Listado 3. Implementación del Algoritmo de Ordenamiento Burbujeo Optimizado
#!/usr/bin/env gbs2
DIM Numeros[4] AS Integer
DIM N AS Integer
DIM ORD AS Boolean
DIM AUX AS Integer
DIM I AS Integer
'Inicializo Array como en la Figura 5
Numeros[1] = 1
Numeros[2] = 3
Numeros[3] = 2
PRINT "\n Orden Actual del Array \n"
FOR I=0 TO 3
PRINT " [" & Numeros[I] & "] "
NEXT
'N es igual al Tamaño del Array
N = 4
'Al comenzar, se asume que el Array esta desordenado
ORD = FALSE
WHILE (ORD = FALSE)
ORD=TRUE
N = N – 1
FOR I=0 TO N -1
IF (Numeros[I] > Numeros[I+1]) THEN
'Swapping AUX = Numeros[i]
Numeros[I] = Numeros[I+1]
Numeros[I+1] = AUX
ORD=FALSE
ENDIF
NEXT
WEND
PRINT "\n\n Orden del Array luego del Metodo de Burbejeo Optimizado \n"
FOR I=0 TO 3
PRINT " [" & Numeros[I] & "]"
NEXT
Figura 1. El FrontEnd y el BackEnd trabajando en conjunto
seguido, implementamos el método de Búsqueda Secuencial, que simplemente se recorre el Array mediante el bucle WHILE hasta que se encuentre el elemento o se haya llegado al fi nal. Dentro del
bucle, se van comparando los valores actuales con el valor a buscar. ¿Sencillo, no?
Antes de pasar al método de ordenamiento de Búsqueda Binaria, aprenderemos cómo orde-
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5269

70
programaciónCurso de Programación en Gambas
Linux+ 6/2009
Listado 4. Implementación Completa del Algoritmo de Búsqueda Binaria
' Gambas class file (Seccion de Declaracion)
PRIVATE Numeros[9] AS Integer
PUBLIC SUB verArray()
DIM I AS Integer
'Cada ves que se llama a esta funcion, se limpia el
ListView
lstArray.Clear
FOR I = 0 TO 8
'Agregamos el valor en el ListView en la Posicion
I. La funcion CStr convierte un Integer en un String
'que es el tipo de dato que pide el primer
parametro del metodo Add.
lstArray.Add(CStr(I), Numeros[I])
NEXT
END
PUBLIC SUB ordenarArray()
' Metodo del Burbujeo Optimizado
DIM N AS Integer
DIM ORD AS Boolean
DIM AUX AS Integer
DIM I AS Integer
'N es igual al Tamaño del Array
N = 9
'Al comenzar, se asume que el Array esta desordenado
WHILE (ORD = FALSE)
ORD = TRUE
N = N – 1
FOR I = 0 TO N – 1
IF (Numeros[I] > Numeros[I + 1]) THEN
'Swapping
AUX = Numeros[i]
Numeros[I] = Numeros[I + 1]
Numeros[I + 1] = AUX
ORD = FALSE
ENDIF
NEXT
WEND
END
PUBLIC FUNCTION busquedaBinaria
(ValorBuscado AS Integer) AS Boolean
'Mantiene el Elemento Central del Array
DIM IndiceCentral AS Integer
'Mantiene el "tope" de los SubArray
DIM IndiceMenor AS Byte
DIM IndiceMayor AS Byte
IndiceMenor = 0
IndiceMayor = 8
WHILE (IndiceMenor <= IndiceMayor)
'Determina el Inidice Central (Ver Paso A)
IndiceCentral = (IndiceMayor + IndiceMenor) / 2
'Si el Valor Central coincide con el Buscado,
retornamos TRUE
IF ValorBuscado = Numeros[IndiceCentral] THEN
Message.Info("Valor Encontrado en la Posicion
" & IndiceCentral & ". \n Salimos de la
funcion busquedaBinaria...")
RETURN TRUE
ENDIF
'Si el Valor Buscado es menor que el
elemento central, establece un nuevo valor de Alto
'que sera el nuevo SubArray
IF (ValorBuscado < Numeros[IndiceCentral]) THEN
IndiceMayor = IndiceCentral – 1
ELSE
IndiceMenor = IndiceCentral + 1
ENDIF
WEND
'Si nunca se encontro y salimos del While,
retornamos FALSE
RETURN FALSE
END
PUBLIC SUB Form_Open()
'Hasta que no se ordene el Array, no lo habilitamos
btnBinaria.Enabled = FALSE
'Inicializo Array
Numeros[0] = 42
Numeros[1] = 1
Numeros[2] = 21
Numeros[3] = 20
Numeros[4] = 16
Numeros[5] = 80
Numeros[7] = -6
Numeros[8] = 35
verArray()
END
PUBLIC SUB btnOrdenar_Click()
btnOrdenar.Enabled = FALSE
'Mostramos el Array en el ListView,
lo ordenamos y lo volvemos a mostrar
verArray()
ordenarArray()
verArray()
btnBinaria.Enabled = TRUE
END
PUBLIC SUB btnBinaria_Click()
'Buscamos explicitamente el Numero 42
IF busquedaBinaria(42) = TRUE THEN
Message.Info("La busqueda binaria
encontro el valor")
ELSE
Message.Error("La busqueda binaria NO
encontro el valor")
ENDIF
'Finalizamos el Programa
QUIT
END
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5270

71
programaciónCurso de Programación en Gambas
www.lpmagazine.org
nar un Arreglo mediante el Método del Burbujeo Optimizado, ya que esto es condición necesaria para poder implementar la Búsqueda Binaria.
Ordenamiento de un Array: Método del Burbujeo OptimizadoCuando se aprende un lenguaje de programa-ción y se está enseñando los Arrays, el algo-ritmo preferido para el ordenamiento de un vector es el de “Método de Burbujeo”. En este caso, haremos caso omiso a dicho algoritmo, ya que existe una variable que conserva mu-cha más performance a la hora de actuar y que puede llegar a consumir muchos menos recur-sos. Nuestro algoritmo será una extensión del clásico “Método del Burbujeo” al que llamare-mos “Método del Burbujeo Optimizado”. Este método, como cualquier otro, permite ordenar un Array de N elementos en orden creciente o decreciente.
Su implementación es sencilla, pero re-quiere de cierto detalle par su compresión. Pa-ra ello, examinaremos la Figura 5, en la cual se muestra una representación gráfica de cómo actúa dicho algoritmo. El algoritmo realiza los siguiente pasos:
• Se empieza a recorrer el Array desde el principio.
• Compara el elemento N del Array con el siguiente, es decir N + 1.
• Si el elemento N es mayor que el elemento N + 1, deberán de intercambiar la posi-ción, es decir N = N + 1 y N+1 = N.
• Se sigue recorriendo el Array hasta que este esté totalmente ordenado.
Observemos la Figura 5 y empecemos a anali-zarla. En un principio se muestra el Array desor-denado, con los elementos en el orden de 4 – 1 – 3 – 2 (Ver Figura 5 (A) ). Luego, se realiza la primera comparación, es decir, se compara el elemento 0 con el elemento 1 (Ver Punto 1). Ló-gicamente, en realidad se comparan los valores 4 con 1. Si el valor 4 es mayor que el valor 1, entonces se deben intercambiar, que es lo que su-cede a la izquierda de la Figura 5 (A) (Ver Punto 2). Seguidamente, se procede a comparar los valo-res de los siguientes elementos del Array. Esto ucede en la Figura 5 (B). Observamos cómo ahora el Algoritmo compara los valores si-guientes, empezando no desde el primer ele-mento, sino desde el último valor que comparó. El Array resultante se puede contemplar en la Figura 5 (B) del lado izquierdo.
Estos pasos se realizan hasta llegar al final del Array. Una vez finalizada la primera iteración, podemos observar cómo el Valor 4 del Array se encontraba, en un principio, en
Listado 5. Claro ejemplo de Error Lógico
IF Numero > 1 THEN
Message.Info("El Numero es Positivo")
ELSE
Message.Info("El Numero es Negativo")
ENDIF
Listado 6. Ejemplo de Error Sintáctico No se utiliza END WHILE, se utiliza WEND
WHILE (Paises > 1)
INC Contador
IF contador < 100 THEN
Paises = Paises + 10
EDN IF
END WHILE
Listado 7. Ejemplo de Error en Tiempo de Ejecución. El programa se interrumpe en el transcurso de su ejecución
DIM Arreglo[100] AS Integer
DIM I AS Integer
FOR I = 0 TO 100
Arreglo[I] = InputBox("Ingrese un Valor: ")
NEXT
Listado 8. Código que no valida la entrada de datos, propenso a generar una excepción
PUBLIC SUB btnDividir_Click()
IF txtNumero1.Text <> "" AND txtNumero2.Text <> "" THEN
'Codigo sin Manejo de Excepciones, propenso a errores
Resultado = CFloat(txtNumero1.Text) / Cfloat(txtNumero2.Text)
Message.Info("Resultado de la Division: " & Resultado)
ENDIF
END
Listado 9. Uso de CATCH para el Manejo de Excepciones
PUBLIC SUB btnDividir_Click()
DIM Resultado AS Float
IF txtNumero1.Text <> "" AND txtNumero2.Text <> "" THEN
Resultado = CFloat(txtNumero1.Text) / Cfloat(txtNumero2.Text)
Message.Info("Resultado de la Division: " & Resultado)
CATCH
'Si se produce un error, ejecutamos las sentencias que se encuentran
en CATCH
Message.Error("Error: No es posible dividir por cero")
'Tambien podemos utilizar la Clase Estatica ERROR para describir el
Error.
Message.Error("Codigo: " & Error.Code & "\n Descripcion: " &
Error.Text)
ENDIF
END
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5271

72
programaciónCurso de Programación en Gambas
Linux+ 6/2009
la posición 0 del Array, y terminó estando en el último lugar. Este desplazamiento de los valores sobre el Array es el que hace honor al nombre del Algoritmo. Los valores se despla-zan hasta llegar a la posición que les corres-ponde dentro del Array. Si el valor a compa-rar es cada vez más grande, en posiciones más altas del Array se ubicará. Similar es el des-plazamiento de una burbuja dentro de un vaso de gaseosa.
El Listado 3 muestra su implementación en Gambas. Primero, inicializamos un Array igual al que se muestra en la gráfi ca de la Figura 5. Luego, lo mostramos por pantalla. Una vez rea-lizado esto, inicializamos las variables N y ORD.
La variable N se encargará de llevar la cuenta de hasta qué posición del Array hay que comparar. Primero, se deberá comparar desde el 0 hasta N – 1, luego desde 0 hasta N – 2, y así sucesivamente. El recorrido de las posiciones del Array se va recortando ya que, como men-cioné anteriormente, el valor más alto se va desplazando hasta el fi nal del Array. Una vez que tengamos el valor más grande del Array en la última posición, ya no es necesario hacer comparaciones contra él, pues se sabe que es el elemento más grande.
La variable ORD (¿Ordenado?) es una variable del tipo Boolean que actúa como Flag, indicando si el Array sigue desordenado o no.
Esta variable es la que marca la gran diferencia con el Método del Burbujeo normal, permi-tiéndonos así optimizar de manera notable el algoritmo. Se asume que el algoritmoestá des-ordenado, por lo que se inicializa en FALSE.
Luego, nos introducimos en un bucle WHI-LE, pudiendo salir de él solamente cuando el Array esté ordenado (es decir, cuando ORD = TRUE). Aquí dentro, nos encargamos de reco-rrer el Array desde la posición 0 hasta la N – 1, esto lo hacemos mediante un bucle FOR... NEXT. Allí, comparamos el valor actual del Array (Numeros[i]) con su siguiente (Nume-ros[i+1]). Si la condición es verdadera, rea-lizamos lo que se conoce como swapping, que no es más que intercambiar los valores de una posición con la otra y viceversa. Pero ahora bien, aquí nos surge un problema. Para poder intercambiar los valores de una posición con otra, tengo que poder almacenar alguno de estos valores en una variable auxiliar (AUX, en este caso); de lo contrario, cuando asigne Numeros[i] a Numeros[i + 1] no podre asig-nar Numeros[i+1] a Numeros[i], puesto que estos valores serían iguales, porque se habrían superpuesto. Para ello, utilizamos la variable AUX que hace de contenedor temporal del va-lor para poder intercambiar los valores. Segui-damente, indicamos al fl ag ORD que el vector todavía no está ordenado, por lo cual provoca que no salga del bucle WHILE y genere así otro nuevo ciclo de ordenamiento. Esto se repite las veces que sea necesario hasta que el Array esté completamente ordenado.
Se recomienda al lector repasar este méto-do y comparar el Código Fuente 3 con la Figu-ra 5, tratando de comprender bien su accionar. Es de mucha utilidad utilizar un lápiz y un pa-pel para intentar recorrer el algoritmo de for-ma manual. Esto se utiliza mucho en progra-mación, y es lo que se conoce como la Prueba de Escritorio.
Búsqueda de Elementos en un Array: Método BinarioAhora bien, ya sabemos cómo ordenar un Array podremos aplicar el Algoritmo de Búsqueda utilizando el Método Binario. Su funcionamiento es básicamente el siguiente:
Listado 10. Uso de TRY/ERROR/FINALLY para el Manejo de Excepciones
PUBLIC SUB btnDividir_Click()
DIM Resultado AS Float
IF txtNumero1.Text <> "" AND txtNumero2.Text <> "" THEN
'Ajuntamos junto a TRY la sentencia propensa a errores
TRY Resultado = CFloat(txtNumero1.Text) / Cfl oat(txtNumero2.Text)
'Verifi camos mediante ERROR si TRY capturo un error
IF ERROR = TRUE THEN
Message.Info("Error: Error: No es posible dividir por cero")
ELSE
Message.Info("Resultado de la Division: " & Resultado)
ENDIF
'Se halla o no producido error, FINALLY siempre se ejecuta
FINALLY
Message.Info("Fin del Programa")
ENDIF
END
Listado 11. Procedimiento videoToGif, una de los más importantes de nuestro FrontEnd
PRIVATE SUB videoToGif()
DIM Extension AS String
DIM Proceso AS Process
Extension = Right$(txtArchivoSalida1.Text, 3)
Extension = Lower$(Extension)
IF Extension = "gif" THEN
IF txtArchivoEntrada1.Text <> ""
AND txtArchivoSalida1.Text <> "" THEN
Proceso = EXEC ["ffmpeg", "-i", txtArchivoEntrada1.Text,
"-pix_fmt", "rgb24", txtArchivoSalida1.Text]
Message.Info("Fin del Proceso " & Proceso.Id)
txtArchivoEntrada1.Clear
txtArchivoSalida1.Clear
ENDIF
ELSE
Message.Error("El Archivo de Salida NO tiene extension GIF")
txtArchivoSalida1.Clear
txtArchivoSalida1.SetFocus
ENDIF
END
Figura 2. Estructura de un Array Unidimensional
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5272
73
programaciónCurso de Programación en Gambas
www.lpmagazine.org
En primera instancia, se compara el dato buscado con el elemento en el centro del vec-tor:
• Si coinciden, hemos encontrado el dato buscado.
• Si el dato es mayor que el elemento central del vector, tenemos que buscar el dato en la segunda mitad del vector.
• Si el dato es menor que el elemento central del vector, tenemos que buscar el dato en la primera mitad del vector.
Como podemos deducir, mediante el paso B y C si el elemento a buscar no se encuentra, los elementos que hay que verificar para ver si son el dato a buscar se reducen a la mitad, ya que solo se verifica una mitad de Array. Es por esta razón que el Método Binario requiere que el Array esté ordenado.
Pasemos a observar la Figura 6 para enten-der este método mejor.
En esta gráfica, nos propondremos a buscar el elemento cuyo valor es 42 dentro del Array. Como vemos, de antemano el Array se encuen-tra ordenado, por ejemplo mediante el Método del Burbujeo Optimizado. Para comenzar a rea-lizar la Búsqueda Binaria, nos posicionamos en el elemento Central del Array, en este caso es el Índice 4, cuyo valor es 21. Luego, verificamos si el elemento central es igual al elemento bus-cado (Ver Paso A). Si es así, el Algoritmo termi-na con éxito, de lo contrario, preguntamos si el elemento actual es mayor al elemento buscado. Esta condición se verifica para poder lograr lo que se indica en el Paso B y/o C. Esto provoca el poder descartar una mitad del Array, bajo la lógica de que al estar el Array ordenado, no se encontrara el valor buscado en esa mitad. Paso siguiente, se vuelve a repetir el proceso hasta encontrar el valor buscado (si existe).
Pasemos a ver cómo implementar este Algoritmo en Gambas. Al ser condición estar ordenado el Array, primero tendremos que aplicarle el Método del Burbujeo Optimizado y luego implementar el cuerpo de la Búsqueda Binaria propiamente dicha.
En este ejemplo, mostraremos el uso de Arrays mediante un programa con interfaz gráfica. Creamos un nuevo proyecto llamado “Binaria”, en el cual colocaremos los siguien-tes controles:
• Button: Name: btnOrdenar• Button: Name: btnBinaria• ListView: Name: lstArray
El programa completo se muestra en el Listado 4. Dentro de este programa, podemos remarcar estos puntos importantes y de interés:
Listado 12. Procedimiento esperandoFinProceso(), que es llamado por videoToGif (Procesos Anidados)
PRIVATE SUB esperandoFinProceso(Proceso AS Process)
lblEsperando.Visible = TRUE
lblTitulo.Text = "Trabajando..."
DO WHILE Proceso.State = Process.Running
SELECT CASE lblEsperando.Text
CASE String$(100, "|")
lblEsperando.Text = String$(100, "/")
CASE String$(100, "/")
lblEsperando.Text = String$(100, "-")
CASE String$(100, "-")
lblEsperando.Text = String$(100, "\\")
CASE String$(100, "\\")
lblEsperando.Text = String$(100, "|")
CASE ELSE
lblEsperando.Text = String$(100, "|")
END SELECT
WAIT 0.1
LOOP
lblTitulo.Text = "FfrontMpeg"
lblEsperando.Visible = FALSE
END
Listado 13. Los dos primeros eventos hacen uso de Dialog
PUBLIC SUB txtArchivoEntrada1_DblClick()
Dialog.Title = "Abrir Archivo MPEG"
Dialog.OpenFile
txtArchivoEntrada1.Text = Dialog.Path
txtArchivoSalida1.SetFocus
END
PUBLIC SUB txtArchivoSalida1_DblClick()
Dialog.Title = "Guardar Archivo GIF"
Dialog.SaveFile
txtArchivoSalida1.Text = Dialog.Path
IF Exist(txtArchivoSalida1.Text) THEN
Message.Error("No se puede sobrescribir el Archivo")
txtArchivoSalida1.Clear
ENDIF
PUBLIC SUB btnGenerar_Click()
SELECT CASE TabStrip1.Index
CASE 0
videoToGif()
CASE 1
secuenciaVideo()
CASE 2
convertirWavMP3()
END SELECT
END Figura 3. Posible salida del programa de ejemplo de uso de Arrays
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5273

74
programaciónCurso de Programación en Gambas
Linux+ 6/2009
• Podemos observar que se repite muchas veces, pero en módulos distintos, la decla-ración de la variable I. Esto se puede hacer, gracias a que cuando se utiliza esta variable en, por ejemplo, una función, y se declara dentro de ella, una vez fi nalizada la función la variable muere y puede ser utilizado el mismo nombre (puesto que no es la misma variable). Todo esto tiene una explicación técnica mucho más compleja, que sobrepa-sa el alcance de este Curso.
• También podemos observar el comporta-miento del Control ListView. En su mé-todo Add, que nos sirve para agregar un ele-mento al ListView nos pide como primer argumento el Índice en el cual queremos agregar un Valor. Se puede deducir que el Control ListView es un Array Gráfi co, que posee propiedades y métodos en par-ticular. Como ejemplo, posee la opción de poder ordenar automáticamente el Lis-tView a medida que se agregan los valores en él (Ver Barra de Propiedades, la propie-dad Sort).
El Algoritmo de Búsqueda Binaria es sumamen-te simple. Se van realizando los Pasos descritos anteriormente, y se va ajustando el Array para poder descartar parte de este donde es seguro que no estará el valor a buscar. Este ajuste se logra limitando los extremos del Array (Ver variables InidiceMenor e InidiceMayor) dependiendo de si el valor a buscar es mayor o menor del ele-mento central. El Resultado de le ejecución del Programa se muestra en la Figura 7.
Se recomienda al lector repasar este algo-ritmo junto a la explicación gráfi ca. También se sugiere modifi car el código fuente para alterar su comportamiento y poder así entender mejor el porqué de el porqué de su funcionamiento.
Control de ExcepcionesEn este apartado, abordaremos el manejo y con-trol de Excepciones, pero para empezar defi ni-remos qué es una excepción. Una excepción es un evento que ocurre durante la ejecución del programa que interrumpe el fl ujo normal de las sentencias. Muchas clases de errores pueden
utilizar excepciones — desde serios problemas de hardware, como la avería de un disco duro, a los simples errores de programación, como tratar de acceder a un elemento de un Array fuera de sus límites. Comúnmente, los errores que pueden captar las excepciones no son todas las clases de errores (Por ejemplo, si el cabezal del disco duro se daña, un simple manejo de excepciones con Gambas no podrá hacer nada al respecto).
En materia de programación, los errores se dividen en tres clases fundamentales:
• Lógicos: Los errores lógicos son los que aparecen en la aplicación, una vez que está funcionando. Estos errores no per-miten que el programa no se ejecute, pero sí provocan que lo hagan de una manera en la cual arrojen resultados inesperados. Por ejemplo, consideremos el Listado 5. Aquí, se está evaluando el valor de la va-riable Numero para ver si esta corresponde
con un numero positivo o negativo. Este, es un claro ejemplo de error lógico de pro-gramación. Como podemos observar, el programador está evaluando si la variable es MAYOR que 1, es decir, EXCLUYE al numero 1 de los positivos (evaluara desde el numero 2 en adelante). Esto es un error muy grave de lógica de programación También, podemos observar que si el valor de la variable Numero es CERO, lo toma como negativo, y como todos sabemos esto no es cierto. Estos errores suelen provocarse por un mal diseño de la lógica e inteligencia del sistema y son uno de los errores más difíciles de depurar.
• Sintácticos: Los errores sintácticos son productos del mal tecleo por parte del pro-gramador. Estos errores impiden la com-pilación del programa y en consecuencia, su ejecución. Comúnmente, el compilador señalará el número de línea donde se en-cuentra el error. Por esta razón, son fáciles de detectar y corregir. Un ejemplo de ello se encuentra en el Listado 6, donde para terminar una estructura WHILE, se utiliza (mal) END WHILE, en vez de WEND. Otro error es el mal tecleo de la instrucción END IF.
• Ejecución: La última clase de errores es la de los errores en Tiempo de Ejecución. Es-tos errores producen un bloqueo o cuelgue del programa, terminando su ejecución de manera inmediata. A estos errores también
Figura 4. Búsqueda del numero 46 mediante el Algoritmo de Búsqueda Secuencial
Figura 5. Algoritmo de Ordenamiento: “Método del Burbujeo Optimizado”
-6 1 16 20 21 35 37 42 80Inicio
4 1 3 2 1 4 3 2
1 4 3 2 1 3 4 2
1 3 4 2 1 3 2 4
1 3 2 4 1 3 2 4
1 3 2 4 1 2 3 4
Primera Iteracion
Segunda Iteracion
A
B
C
D
E
n-1=3
n-1=2
Fin
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5274

75
programaciónCurso de Programación en Gambas
www.lpmagazine.org
se los conoce como Errores Fatales, ya que una vez que se producen, no se puede hacer nada para recuperar la instancia del progra-ma. Un ejemplo de ellos puede ser que se quiera acceder a un índice más alto del que posee un Array. Esto se ilustra en el Listado 7, donde queremos acceder al Índice 100 del Arreglo, siendo que este tiene desde 0 a 99 posiciones.
Como bien mencionamos antes, Gambas no puede manejar todos los tipos de errores, por una cuestión lógica. Para las que sí puede ma-nejarlos y controlarlos son para las excepciones del Tipo en Tiempo de Ejecución, que mediante una simple rutina, protegemos a un bloque de código en que sea factible que se produzca un error. Esta rutina que envolverá a nuestro blo-que de código está compuesta por la estructura
TRY.. CATCH.. FINNALY. Veamos el uso de cada una de estas sentencias:
• TRY: Se utiliza para proteger al código que sea susceptible de error.
• CATCH: Las instrucciones que la prosiguen solo se ejecutan si se ha producido un error. Si existe una instrucción FINALLY, ha de colocarse delante de CATCH.
• FINNALY: Las instrucciones que la prosi-guen han de ejecutarse siempre, se haya producido o no error.
Se puede verifi car si se ha producido un error consultando el valor de la sentencia ERROR. Pasemos a validar este tema con un ejemplo clásico: El error de la División por Cero. Para el común de la gente (y de las computadoras), la división por cero es un error. Siempre que haga-
mos un programa que tenga que dividir núme-ros, es imprescindible colocarle una rutina de control de errores. Consideremos el programa que se muestra en la Figura 8 cuya codifi cación se encuentra en se encuentra en el Listado 8.
Este código no verifi ca el famoso error de División por Cero. Por ejemplo, si como primer número ingresamos 10 y como segundo número ingresamos 0, el programa romperáy fi nalizará inmediatamente (error fatal). Para solucionar este inconveniente del código que puede llegar a generar una excepción, nos valemos de las sentencias TRY, CATCH, y FINALLY. El Listado 9, muestra la versión del programa que hace
Figura 6. Algoritmo de Ordenamiento: “Método Binario”
Figura 7. Ejecución del Proyecto “Binaria”
Figura 8. Programa de ejemplo para demostrar el Manejo de Excepciones
-6 1 16 20 21 35 37 42 80
-6 1 16 20 21 35 37 42 80
35 37 42 80
Busqueda Binaria (Total Comparaciones)
Inicio
Si
No
Si
No
21=42
21>42
21>42
21=42
Fin
Fin
Fin
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5275

76
programaciónCurso de Programación en Gambas
Linux+ 6/2009
uso correcto de Manejo de Excepciones. Otra versión del uso de Manejo de Excepciones, puede verse en el Listado 10.
Introducción a la creación de FrontEndsComo explicamos al comienzo de esta en-trega, los FrontEnd son la cara visible de nuestras aplicaciones. Con Gambas, podemos manipular los procesos correspondientes a los BackEnd para que puedan interactuar de una manera fácil y cómoda con el FrontEnd. En esta sección, abordaremos la creación de un sencillo FrontEnd del famoso programa ffm-peg. El logo que identifica el programa puede verse en la Figura 9.
Ffmpeg es una completa herramienta para la manipulación y procesamiento de audio y vídeo. El proyecto originariamente fue desa-rrollado para GNU/Linux, aunque actualmente puede utilizarse en la mayoría de los Sistemas Operativos, incluso Windows.
El Proyecto está compuesto por un amplio abanico de herramientas, donde entre las más importantes se encuentran las siguientes:
• ffmpeg: es una herramienta de línea de co-mandos para convertir un vídeo de un for-mato a otro. También puede capturar y co-dificar en tiempo real desde una tarjeta de televisión.
• ffserver: es un servidor de streaming mul-timedia de emisiones en directo que so-porta HTTP (la compatibilidad con RTSP está en desarrollo). Todavía no está en fase estable.
• ffplay: es un reproductor multimedia basa-do en SDL y las bibliotecas FFmpeg.
En nuestro FrontEnd nos valdremos de la utiliza-ción de ffmpeg. Como vemos en su descripción, claramente nos indica que es una utilidad de línea de comandos, por lo cual nosotros seremos los encargados de realizar la interfaz gráfica que interactúe con la aplicación. Por razones de espacio y tiempo, solamente desarrollaremos la GUI para un conjunto limitado de opciones dis-ponibles de ffmpeg, ya que este trae muchas y no podríamos abarcarlas todas en una sola entrega.
Instalando ffmpegPara poder crear un FrontEnd de ffmpeg es con-dición necesaria tenerlo instalado. Si no dispo-nemos de ffmpeg en nuestro ordenador, simple-
mente nos dirigimos a nuestra querida consola de GNU/Linux y tecleamos sudo apt-get ins-tall ffmpeg ¡Listo! Automáticamente se nosdescargará ffmpeg y se configurará para poder empezar a usarlo. La descarga e instalación ocu-pan aproximadamente 1300Kb.
Características de FFrontMpegAntes de implantar nuestro FrontEnd de ffm-peg, al que he bautizado FFrontMpeg, pre-sentaremos las características que este sopor-tará:
• Creación de Imagen GIF a partir de un vídeo: Útiles para hacer Avatares de Foros o querer tener un vídeo que ocupe poco espacio.
• Obtención de Secuencias de Imágenes a partir de un Vídeo: Útil para poder tener un preview del vídeo en cuestión, para po-der luego, por ejemplo, subirlo a internet.
• Conversión de WAV a MP3: Útil para tener un archivo de audio con menor tamaño, y poder almacenarlo por ejemplo, en un Reproductor de MP3 o en un Sitio Web.
Como vemos, nuestro programa tendrá caracte-rísticas con orientación a la web.
Conociendo ffmpegPara poder realizar las características antes mencionadas, nos hace falta conocer la sintaxis con la cual ffmpeg se maneja. A continuación, presentamos los comandos que utilizaremos al interactuar ffmpeg con FfrontMpeg.
Creación de Imagen GIF a partir de un vídeo
ffmpeg -i video.mpeg -pix_fmt rgb24
imagen.gif
Aquí le indicamos a ffmpeg que tome como en-trada el parámetro video.mpeg y cree una ima-gen GIF con ese archivo, llamada imagen.gif. Mediante la opcion -pix_fmt rgb24 le indica-mos que la imagen resultante tome un formato de píxeles RGB24.
Obtención de Secuencias de Imágenes a partir de un Vídeo
ffmpeg -i video.avi imagenes%d.jpg
En este lugar, le indicamos a ffmpeg que tome como entrada el parámetro video.avi y que genera una salida de imágenes del vídeo, cuya secuencia será imagenes%d.jpg. El valor de %d
Figura 10. Aspecto de nuestro FrontEnd “FFrontMpeg”
Figura 9. Logo de ffmpeg
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5276
77
programaciónCurso de Programación en Gambas
www.lpmagazine.org
será reemplazado por el número de secuencia de la imagen.
Conversión de WAV a MP3
fmpeg -i original.wav -ab 32 -ar 44100
salida.mp3
Aquí, como vemos, especificamos varios pa-rámetros. En primera instancia, el parámetro original.wav es la entrada para la posterior sa-lida del archivo salida.mp3. Dentro de este co-mando especificamos algunos argumentos. -ab 32 indica que el bitrate del archivo será de 32 kbps. Por último, el argumento -44100 indica que el archivo de salida tendrá una frecuencia de 44100Mhz. Estos parámetros pueden omitir-se para que tomen el valor por defecto.
Nota: La opción -i que se especifica en todos los comandos, indica cuál será el archivo de entrada (Input).
Para todos estos comandos existen varios parámetros. Por ejemplo, a la hora de crear se-cuencias de imágenes a partir de un vídeo, puede configurarse en tiempo entre cada imagen que va a ser captada. Por cuestiones de simplicidad y objetivos de este artículo, dichas opciones que-dan como tarea al lector investigarlas y de querer así, poder implementarlas en el FrontEnd.
Una vez conocidos los comandos con que nos vamos a manejar, ya estamos listos para crear la GUI del programa e interactuar con ffmpeg.
La Clase Process y el Comando EXECPara poder manipular procesos, Gambas nos provee una clase llamada Process. Gracias a ella, podemos sincronizar la ejecución de dos progra-mas (el FrontEnd y el BackEnd), comunicarse entre sí leyendo y escribiendo la entrada y salida estándar, conocer el estado de ejecución, y reci-bir mensajes de error. Esta clase nos provee de varias propiedades y métodos que nos serán de utilidad a la hora de manejar procesos.
La clase Process hace de contenedor del pro-ceso, mientras que el encargado real de ejecutar el proceso es la sentencia EXEC. Este comando
recibe como parámetro un proceso, y devuelve el descriptor de proceso. Este descriptor lo cap-taremos en un objeto de la Clase Process para poder ir determinando su comportamiento. A lo largo del desarrollo del programa iremos viendo algunas propiedades de la clase Process. La sin-taxis de EXEC se muestra a continuación:
[ObjetoProcess =] EXEC
[Comando] [ParametroN]
[WAIT] (FOR (READ |
WRITE | READ WRITE )
[TO String]
Para que los parámetros sean más legibles, EXEC requiere que estos se pasen como un Array de Strings. Por ejemplo, para ejecutar el coman-do ls -al, tendríamos que llamar a EXEC de la siguiente manera:
EXEC ["ls", "-al"]
El parámetro Comando es el único que se nece-sita como obligatorio. La palabra clave WAIT, se congelará hasta que este termine. Contemple-mos el siguiente ejemplo:
EXEC ["rm", "-rf", "$HOME"] WAIT
message.info("Ha finalizado el Borrado
del Directorio Home")
Aquí, un directorio como HOME contiene todos los archivos del usuario en cuestión. Si nosotros ejecutamos esta instrucción SIN el uso de WAIT, el comando EXEC empezará a borrar todos los archivos del directorio HOME pero inmediata-mente mostrará el mensaje de que ha finalizado el borrado, y esto no es cierto, ya que el comando que se encuentra dentro de EXEC seguirá traba-jando hasta que finalice su ejecución. Es por ello que en estos casos, es recomendable el uso de WAIT, siempre y cuando se le informe al usuario de que el comando está realizando su labor.
El uso de TO en una sentencia EXEC, lo que hará es redireccionar la salida que produzca el proceso que se está ejecutando. Por ejemplo, a la hora de convertir un archivo WAV en un
archivo MP3, ffmpeg nos muestra muchos datos acerca de cómo se está realizando la conversión. Al ejecutar EXEC sin la redirección con TO, estos datos nunca los veríamos, con lo que la salida de ffmpeg se perdería. En nuestro caso, la salida “de texto” de ffmpeg no nos sería de tanto interés, ya que en este ejemplo lo que en realidad buscamos es que nos genere el archivo MP3. A continua-ción, se muestra un ejemplo del uso de TO:
DIM Buffer AS String
EXEC ["who", "-r"] TO Buffer
message.info("Runlevel del Sistema: "
& Buffer)
Por último, el uso de READ o WRITE simplemen-te indican si el proceso será sólo para lectura, sólo para escritura o ambos casos. Su uso no es obligatorio.
El Comando SHELLPara la manipulación de Procesos, Gambas nos provee de otro comando de utilidad, con ligeras diferencias con EXEC: El Comando SHELL. Este comando lo que hace es lanzar un Shell o intér-pretes de comandos del sistema, comúnmente BASH, y se le pasa el comando en cuestión como una cadena de caracteres continua. Esto permi-te, por ejemplo, darle instrucciones del tipo cd o export que son parte de BASH y no comandos independientes. También se pueden usar pipes y comandos de redirección del tipo 2>, >, <, tee, etc. La sintaxis de SHEEL es la siguiente:
[ObjetoProcess =] SHELL
[Comando] [WAIT]
(FOR (READ | WRITE
| READ WRITE )
No abordaremos en particular el uso de SHELL, puesto que es muy similar a EXEC, siendo este último desde mi punto de vista más potente.
Diseñando la GUIBien, ya estamos con todos los conocimientos necesarios para la creación de nuestro primer FrontEnd. A lo largo del diseño, explicaré el concepto y cómo se manipulan los procesos en Gambas. Esto nos servirá para poder controlar el ffmpeg desde nuestro FrontEnd.
El diseño de la GUI de FFrontMpeg se muestra en la Figura 10. Es un diseño sencillo, pero que nos será de utilidad y bastará para realizar las tareas que nuestro programa tendrá a cargo. En la imagen se ven tres capturas de pantallas diferentes, pero muy similares. Esto es porque para la creación del FrontEnd, se uti-liza el control TabStrip, donde podemos tener una especie de múltiples formularios dentro del
Tabla 1. Propiedades y Métodos de la clase Dialog
Nombre Descripción TipoFilter Filtrado de Archivos (por ejemplo, solo GIF) Propiedad
Font Fuente utilizada en el Cuadro Propiedad
OpenFile Llama al Cuadro de Dialogo de Abrir Archivo Metodo
SaveFile Llama al Cuadro de Dialogo de Guardar Archivo Metodo
SelectColor Llama al Cuadro de Dialogo de Seleccionar Color Metodo
SelectDirectory Llama al Cuadro de Dialogo de Seleccionar Directorio Metodo
SelectFont Llama al Cuadro de Dialogo de Selecionar Fuente Metodo
Title Indica el Titulo contendra el Cuadro de Dialogo Propiedad
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5277

78
programaciónCurso de Programación en Gambas
Linux+ 6/2009
mismo, manejados mediante pestañas. Con el control TabStrip podemos generar aplicaciones al mejor estilo Mozilla Firefox. ¡No hay que confundirse, no son tres formularios diferentes, sino que son tres pestañas diferentes!
Para este diseño, nos harán falta los siguien-te controles:
• Control TabStrip, que se encuentra en la Categoría Container del Cuadro de Contro-les. La propiedad Count indica la cantidad de pestañas, por lo cual tendremos que asig-narle el valor 3.
• TextBox, que se llamarán txtArchivoEn-tradaX, donde X es el numero de Pestaña del TabStrip (por ejemplo, el primero se llamaria txtArchivoEntrada1).
• Controles TextBox, que se llamarán txtAr-chivoSalida1 (Pestaña 1, Conversión Video a Imagen GIF) y txtArchivoSalida3 (Pestaña 3, Conversión WAV a MP3).
• Control Buttom, llamado btnGenerar. Este botón será ÚNICO para todas las conver-siones y, dependiendo en qué pestaña esté el usuario, realizará la acción correspondiente.
• Varios Controles Labels. Uno de los label se llamará lblEsperando, con propidad VISI-BLE en FALSE, y se encontrará a la izquierda del Botón btnGenerar. Otro se llamará lblTitulo y tendrá el texto FFRontMpeg.
• Todos los TextBox tienen que tener su propiedad READONLY en TRUE (Para que el Usuario no ingrese por error rutas de archi-vo invalidas).
Podemos notar que en tiempo de diseño, al se-leccionar distintas pestañas del control TabStrip,
las propiedades se reinician. En realidad lo que sucede es que por cada pestaña, el control toma valores distintos, independientemente de cada pestaña en particular. Así, si queremos ponerle la propiedad Text con el valor Conversión WAV a MP3, primero tenemos que seleccionar la pes-taña a la que le queremos aplicar el texto, y lue-go ingresarlo.
Las imágenes que se muestran en el progra-ma son descargadas de Internet. Cada programa-dor es libre de elegir la imagen que desee, o de diseñar su propia GUI para el FrontEnd; pero si quieres que tenga las mismas imágenes que el ejemplo, envíame un email a [email protected].
Una vez terminada la Interfaz Gráfica del programa, podemos empezar a programar sus funciones. El funcionamiento genérico de cada una de ellas será el siguiente:
• El usuario hace doble clic sobre el primer TextBox (Archivo de Entrada). Automática-mente, se aparecerá un Cuadro de Dialogo pidiendo que seleccione un Archivo en par-ticular de audio o vídeo, según sea la oca-sión.
• Luego, el usuario hace doble clic sobre el segundo TextBox e ingresa el nombre de Archivo de Salida (con su correspondiente extensión, por ejemplo foto.gif).
• Como paso final, el usuario hace click sobre el botón ¡Generar! y espera a que concluya el proceso.
Desarrollando la Aplicación Final¡Dejémonos de hablar y comencemos a progra-mar! En este apartado, desarrollaremos TODA
la funcionalidad necesaria para poder convertir un vídeo en un archivo de animación GIF. Con los temas desarrolladores de este articulo, el lector estará lo suficientemente capacitado como para poder desarrollar las otras dos fun-ciones por cuenta propia (La de Conversión de WAV a MP3 y la de Generación de imágenes a partir de un vídeo) y de, si quiere, poder desa-rrollar FrontEnds de varias aplicaciones GNU/Linux. Se propone al lector como reto personal agregarle más funcionalidades al FrontEnd.
En primera instancia, nos ocuparemos de desarrollar el procedimiento más importante ahora: videoToGif. Esta función, como su nombre claramente indica, se encargará de to-mar el archivo que se encuentra en el TextBox txtArchivoEntrada1, convertirlo a imagen GIF, y generar su salida como lo indica el TextBox txtArchivoSalida1. Aquí desarrollaremos la troncal principal de nuestra primera caracte-rística del FrontEnd. Todo el desarrollo de esta función se muestra en el Listado 11.
Analicemos este Código. En primer lugar, se declara una variable del tipo String llama-da Extensión y un objeto del tipo Process llamado Proceso. A partir de allí, mediante la función $RIGHT obtenemos los últimos 3 ca-racteres que se almacenan en el TextBox txtAr-chivoSalida1, para almacenarlo en la variable Extensión. Luego, verificamos que estos tres carácteres correspondan con la extensión GIF. Esto lo hacemos para validar que el archivo que se haya seleccionado como Salida sea un archivo GIF; de lo contrario nuestro proceso generará un error al querer convertir el vídeo a dicha extensión de imagen. Una vez validada la entrada del Archivo de Salida y verificado que los TextBox no estén vacíos, es decir, que se hayan seleccionado los archivos, se procede a llamar al proceso mediante la la sentencia EXEC pasándole los parámetros correspondien-tes (Ver apartado Conociendo ffmpeg y La Clase Process y el Comando EXEC) . Observe como NO se hace uso de WAIT, pese a que este proceso puede tardar. Al contrario, se hace uso de un procedimiento personalizado que llama-mos esperandoFinProceso(), el cual recibe un objeto del tipo Process. El desarrollo de esta función lo veremos más adelante, por ahora basta decir que sirve para “entretener” al usua-rio mientras se realiza el proceso de conversión. Una vez terminada la tarea, se le informa al usuario que el proceso ha finalizado, indicando el número de identificación de este (PID) que se almacena en el campo ID del objeto Proceso (Ver cuadro Los Comandos PS y TOP ). Por último, se vacían los TextBox utilizados. Lis-to, ya tenemos nuestra primera funcionalidad realizada.Figura 11. Resultado de la llamada a Dialog
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5278

79
programaciónCurso de Programación en Gambas
www.lpmagazine.org
Como vemos, es muy sencilla la manipula-ción de procesos para la creación de FrontEnds, aunque todavía aprenderemos una característi-ca más de nuestra apreciada Clase Process.
Para que este procedimiento quede total-mente terminado, falta describir la codifi cación del proceso esperandoFinProceso(). Su im-plementación se muestra en el Listado 12.
Aquí, se recibe un objeto del tipo Process para trabajar con el. Luego, modifi camos el texto de nuestro lblTitulo para que indique que ahora se está trabajando en la tarea especifi cada por el usuario. También, hacemos visible al label lblEsperando, para que pueda mostrar lo que incluiremos en él a continuación. Se utiliza un bucle DO... WHILE que verifi ca que el estado del proceso (Proceso.State) esté en ejecución (Proceso.Running), es decir, que es-té trabajando. Mientras que esto sea verdadero, ejecutamos la “pseudoanimacion” que hemos creado dentro del bucle. La función $STRING se encarga de repetir la cadena de texto la cantidad de veces que se le pase como parámetro. Por ejemplo, la instrucción $STRING(5,“Linux+”) generará la cadena Linux+Linux+Linux+Linux+Linux+. Mediante la estructura SELECT CASE, verifi camos cuál es el texto que se encuentra actualmente cargado en el txtEsperando. Dependiendo del texto que haya, lo vamos mo-difi cando según el tiempo que especifi ca WAIT, generando así un efecto de animación.
Una vez que el proceso haya fi nalizado y, por ende, se salga del bucle, restauramos los valores de los Labels a su original, y regresa-mos al procedimiento videoToGif, realizando las tareas que anteriormente describimos.
Estos dos procedimientos deben estar en la sección de Declaraciones de nuestro formula-rio. Si el lector lo desea, puede almacenarlos en un módulo para su mayor compresión. De ser así, recuerde que debe llamarlos desde el FMain mediante NombreDeModulo. Procedimiento
Últimos Retoques..Finalmente, nos queda la tarea de poder introducir los archivos de entrada y salida correspondientes. Para ello, como bien aclaramos antes, haremos uso de los cuadros de dialogo de que nos provee Gambas, valiéndonos de la clase estática Dialog. Esta clase, contiene unas pocas propiedades y métodos que nos serán de muchísima ayuda pa-ra conseguir que el usuario seleccione un archivo de manera cómoda. Las propiedades y métodos de ella se listan en la Tabla 1.
Esta clase la utilizaremos en los eventos Do-ble Clic de los TextBox txtArchivoEntrada1 y txtArchivoSalida1, tal y como se muestra en el Listado 13. Este Código, genera lo que se muestra en la Figura 11.
Es muy sencillo su uso. En primer lugar, asignamos el título al Cuadro de Dialog. En el primer caso, es “Abrir Archivo GIF”. Luego, llamamos al cuadro de diálogo, que se muestra en la Figura 11. Cuando el usuario selecciona un archivo, la ruta del mismo (PATH) se almacena entxtArchivoEntrada1, que posteriormente será uti-lizado como parámetro del comando EXEC. Aquí, se podría haber utilizado la propiedad Filter, para que sólo muestre los archivos GIF. No se ha hecho para que el lector vea cómo pueden solucionarse problemas de distintas formas (por ejemplo, con el uso de funciones como $RIGHT).
En el Listado 13 se muestra por último el evento Clic del btnGenerar. Este botón, como dijimos anteriormente, realizará la tarea que le corresponda según en qué pestaña se encuentre. Para verifi car esto, consultamos el valor de INDEX (de índice) del TabStrip. Las pestañas se numeran desde Cero hasta N, siendo N la cantidad de pestañas que contenga, especifi ca-da en la propiedad Count del control. Observe que en este código también se mencionan los procedimientos secuenciaVideo() y con-
vertirWavMP3(). ¡Queda como tarea para el lector terminar la totalidad de las funciones del programa, agregarle más funciones (si lo de-sea), empaquetarlo, crear el instalador y luego enviármelo a mi dirección de correo!
Ejercicios PropuestosSe deja al lector una serie de ejercicios para que pueda practicar los temas vistos en esta entrega.
• Buscar e Implementar en Gambas algorit-mos de Ordenamiento que no se hayan visto aquí. Comprobar la efi ciencia de cada uno, ventajas y desventajas. Sacar conclusiones.
• Crear un programa que se encargue de in-troducir el Nombre y Teléfono de 1000 per-sonas, y luego ordenarlo mediante Nombre en forma decreciente. Investigar el uso de Arrays o Vectores apareados, para poder te-ner tipos de datos distintos en corresponden-cia válida.
• Pensar, diseñar y programar un FrontEnd para el uso de APT en Ubuntu.
• Investigar las propiedades y métodos de la clase Dialog. Implementarlas en un ejemplo real.
• Agregar al Editor de Texto realizado en la Entrega Nº2 del Curso, la posibilidad de Abrir/Guardar un archivo mediante Cuadros de Dialogo.
• Mediante la función $RIGHT, hemos vali-dado la entrada del txtArchivoSalida1. Puede comprobar el lector que, si en el txt-ArchivoEntrada1 introduce un archivo que NO es un vídeo, el programa fallará. Se le
propone al lector validar la entrada de este archivo, de la manera que le sea más con-veniente (mediante la propiedad Filter en el Dialog, o haciendo uso de RIGHT para verifi car la extencion del Archivo).
• Intente desarrollar un Algoritmo que se encargue de desordenar un Array especifi co. Se recomienda investigar el uso de Vec-tores Apareados para poder desordenar ordenando.
• Si conoce el Lenguaje de Programación C, realizar un programa en el que se encargue de, por ejemplo, recibir un número como pa-rámetro y que retorne su factorial. Mediante el uso de EXEC, realizar el FrontEnd del programa en Gambas en el cual llame a su programa de calculo de factorial y lo mues-tre en pantalla.
Se recomienda al lector realizar los ejercicios con el fi n de poder fi jar y realizar la prácticas de los temas estudiados.
Consideraciones FinalesEn esta entrega del curso hemos desarrollado una cantidad considerable de temas, como lo son los FrontEnds, Arrays, Algoritmos de Ordena-miento, Algoritmos de Busqueda, manipulación de procesos, Cuadros de Diálogos, Scripts, etc. Todos estos conceptos son muchos para captarlos de una sola vez. Es por ello que es recomendable repasarlos sin dejar ningún detalle de imprevisto.
Recuerda que siempre puedes consultar tus dudas a [email protected], trataré de responderte lo más claro y rápido posible. Esto es todo por hoy. Nos vemos en la próxima entrega del Curso. ¡Hasta la Vista!
Jorge Emanuel Capurro es estudiante de la Tec. Superior en Programación, carrera dic-tada en la Universidad Tecnológica Nacional - Facultad Regional Haedo, provincia de Bs As, Argentina. Principalmente, su área de in-vestigación se centra en los Sistemas Ope-rativos de tipo UNIX y de la programación bajo esta plataforma. Es el creador del pro-yecto IDEas (http://ideasc.sourceforge.net), que es el primer frontend desarrollado bajo Gambas del compilador gcc (http://gcc.gnu.org), que se utiliza con fi nes didácticos. Actualmente realiza funciones de programa-dor para la empresa IBM Argentina en el departamento de Applications Management Services, participando de diversos proyec-tos de desarrollo de software de carácter internacional.
Sobre el autor
66_67_68_69_70_71_72_73_74_75_76_77_78_79_Gambas.indd 2009-04-14, 14:5279

programaciónProgramando RIA con Flex y AMFPHP
80 Linux+ 6/2009
linux
@so
ftwar
e.co
m.p
l
Aunque muchos de nosotros quisiéramos esto, no todos tenemos la experiencia y el dominio de las herramientas que hacen eso posible. Sin embargo hoy por hoy las Aplicaciones de
Internet Enriquecidas (RIA por sus siglas en inglés) y sus herramientas de desarrollo se convirtieron en una muy buena opción para las empresas y desarrolladores que buscan brin-dar los benefi cios de las aplicaciones online sin perder mucho de los privilegios de las aplicaciones de escritorio. Hoy en día podemos desarrollar aplicaciones en línea que tienen muchos de los privilegios que antes estaban reservados a las aplicaciones de escritorio, como cortar, pegar, arrastrar, redi-mensionar, accesos multimedia, etc. En este artículo explora-remos el desarrollo de una aplicación de Internet enriquecida utilizando una plataforma conocida como Flex.
¿Qué son las RIA?Anteriormente a la aparición de las RIA, las aplicaciones Web cotidianas y que aún se ven por la web en demasía, son aplicaciones que necesitan recargarse constantemente, utili-zan sólo HTML/DHTML y un poco de Javascript, y ustedes pueden ver que son menos ágiles o más lentas para el uso. El
típico caso son los formularios donde uno escribe el conteni-do y fi nalmente hace clic en enviar, donde se vuelve a cargar otra página para así seguir el proceso sucesivamente.
Estas aplicaciones típicamente no tienen la capacidad de aprovechar el copy / paste de objetos de la página, tampoco pueden interactuar con la webcam ni el audio del equipo y ni hablar de arrastrar objetos para interactuar con la aplicación.
Para ver esto más claro podemos utilizar la opción HT-ML básico en Gmail, que hará que todas las funcionalidades RIA comunes a Gmail desaparezcan -chat, corrector orto-gráfi co, combinación de teclas, entre otros-. Podrán también apreciar que cada acción tendrá que ser procesada y la página recargada por cada operación.
En contraste con esto, las RIA (por lo general) son apli-caciones que se descargan casi completamente al iniciarse. Esto evita la necesidad de que se recargue cuando queremos ejecutar alguna acción.
Ahora bien, en este punto ya pueden imaginarse a una gran aplicación RIA como Gmail o Google Docs. En estas aplicaciones ustedes no tienen que esperar la recarga de todo el sitio para desarrollar una acción. Si seguimos con este ejemplo de Gmail, podemos ver que tiene la capacidad de
Aplicaciones de Internet Enriquecidas (RIA): Programando RIA con Flex y AMFPHP¿Qué programador no quisiera darle a sus usuarios la mejor experiencia de uso, una herramienta intuitiva, fácil de usar y que tenga los benefi cios de las aplicaciones web? Además, que el desarrollo e implementación sea sencillo y... placentero.
Matías Barletta
80_81_82_83_84_85_Flex ver2.indd 2009-04-14, 14:5380

programaciónProgramando RIA con Flex y AMFPHP
81www.lpmagazine.org
arrastrar y soltar los applets de contactos, calen-dario, documentos, etc. Se pueden mover estos applets dentro de Gmail sin necesidad de que se recargue todo el sitio, ubicarlos en otra parte, interactuar con ellos y/o deshabilitarlos.
También pueden ver que esta aplicación re-cientemente comenzó a interactuar con la cáma-ra web, permitiendo hacer vídeo chat desde el explorador, lo cual es una gran hazaña para una aplicación web (lamentablemente aún no está dis-ponible para nosotros, los usuarios de Linux).
En definitiva, tenemos una aplicación muy ágil con acceso a funciones multimedia, que no consume mucho ancho de banda (no recarga todo el sitio -y sus imágenes- varias veces), que es visualmente más atractiva y el usuario se siente más cerca de la funcionalidad de una aplicación de escritorio. Con este ejemplo de Gmail puede verse donde la misma aplicación está desarrollada de manera básica o avanzada (RIA) y podemos sentir la diferencia en presta-ciones, comodidad, agilidad y simpleza.
La tecnología que usa Google en la mayo-ría de sus aplicaciones se conoce como AJAX o Javascript Asíncrono y Xml. Google es quizás el que más ha impulsado esta tecnología, han rea-lizado muchas aplicaciones, extensiones y uti-lidades para facilitar la utilización de esta tec-nología AJAX.
Por último, vamos a ver un resumen de otras ventajas (Wikipedia):
• No necesitan instalación (solamente es ne-cesario mantener actualizado el navegador web).
• Las actualizaciones hacia nuevas versiones son automáticas.
• Se pueden utilizar desde cualquier ordena-dor con una conexión a Internet sin depen-der del sistema operativo que éste utilice.
• Generalmente, es menos probable la infec-ción por virus, que utilizando por ejemplo programas ejecutables.
• Más capacidad de respuesta, ya que el usuario interactúa directamente con el ser-vidor, sin necesidad de recargar la página.
• Ofrecen aplicaciones interactivas que no se pueden obtener utilizando sólo HTML, incluyendo arrastrar y pegar, cálculos en el lado del cliente sin la necesidad de enviar la información al servidor.
• Evita la problemática del uso de diferentes navegadores al abstraerse de ellos a través de un framework.
Como pueden ver, no son pequeñas las ventajas relacionadas con las RIA contra las aplicaciones de escritorio o aplicaciones web antiguas. El solo hecho de que no necesiten instalación y/o actuali-
zación elimina mucho gastos y dolores de cabeza a cualquier administrador de sistemas.
En resumen y para terminar la idea, las RIA son la evolución de las aplicaciones de Internet, que intentan asemejarse a las aplicaciones de escritorio al mismo tiempo que mantienen las cualidades de las aplicaciones Web, pueden tener básicamente la misma apariencia pero son más complejas y ofrecen mayor funcionalidad.
Tecnologías de RIAs: AJAX y FLEXAhora que ya sabemos bien qué es una RIA, vamos a hablar sobre la tecnología disponible para realizar estas aplicaciones.
Existen 2 grandes corrientes en el desarro-llo de RIA, una es mediante AJAX y la otra utilizando tecnología basada en Flash cono-cida como Adobe Flex. En el caso de AJAX verán que no es algo muy distinto a lo que hacían con HTML y Javascript, mientras que Adobe Flex puede ser para varias personas un cambio radical.
¿Cuál es mejor? Como siempre, depende de qué se quiera hacer y cuál sea el objetivo. Para una aplicación como Gmail es difícil imaginárse-lo en Flex, pero también Flash es increíblemente poderoso para las cuestiones multimedia y ani-maciones, incluso la versión 10 del reproductor ya soporta aceleración 3D lo que permitirá expandir las aplicaciones web a un mundo muy interesante. (Ver http://www.papervision3d.org/).
La tecnología AJAX es ya bastante conocida aunque no lo sepas, basta con utilizar cualquier aplicación de Google para saber cómo se siente. Está basada en la ejecución asíncrona de código Javascript. Por ejemplo, en Gmail cuando vamos a escribir un mensaje y comenzamos a escribir el nombre del destinatario, Gmail nos muestra un listado de nuestros contactos que coincida con lo que vamos tipeando. En este caso, cada vez que presionamos una tecla, el explorador ejecuta una función javascript que sin necesidad de recargar la página, ejecuta la instrucción al servidor y ahí mismo muestra el resultado. Esto hace que se vea muy ágil el uso de este sistema.
Por otra parte tenemos la tecnología de Ado-be Flex, la cual se basa en utilizar la tecnología de Flash para realizar nuestra aplicación. Las apli-caciones realizadas en Adobe Flex son una com-binación de programación utilizando ActionS-cript y XML. El código fuente de una aplicación Flex, como veremos más adelante, es práctica-mente archivos MXML (Macromedia XML) y Actionscript (parecido a Java) que al compi-larse el proyecto el resultado (generalmente) es un archivo swf (por sus siglas ShockWave Flash) que no hace falta más que un reproductor Flash para utilizarlo.
Esta tecnología impulsada por Adobe ha si-do muy bien aceptada para la realización de apli-caciones corporativas, basta con echar un vistazo a los proyectos que figuran en Adobe.com para tener una idea.
Adobe aprovecha su monopolio en cuanto a su reproductor Flash en un gran porcentaje de ordenadores del mundo. Esto hace posible que las aplicaciones basadas en Flex puedan ser eje-cutadas en cualquier navegador y/o equipo que lo soporte. Además, Adobe no debe esperar lar-gos ciclos de mejora a protocolos o estándares, la adopción de Flash es tan alta y los usuarios de Flash actualizan a las últimas versiones tan rápidamente (en menos de 2 meses de liberada la versión 10 de Flash, el 55% de los ordenado-res ya habían hecho el upgrade; pocos meses después, la adopción era casi de un 80%) que se puede dar el lujo de agregar y agregar funciona-lidades y mejoras continuamente y saber que la gente buscará tener la última versión.
En resumen tenemos 2 principales formas de realizar una RIA, utilizando AJAX o Flex. Lo recomendable sería que prueben ambas for-mas y se decidan por la que más se adecua a sus necesidades. En este caso vamos a trabajar con Adobe Flex y vamos a dar una ayuda en muchos conceptos claves.
Estructura de una RIAAl igual que las aplicaciones comunes de Inter-net, las RIA se basan en una estructura Cliente/
Listado 1. Creando la carpeta prueba1
CREATE TABLE 'prueba'.'contactos'
(
'nombre' varchar(10) NOT NULL,
'borrado' tinyint(1) NOT NULL
default '0',
'id' int(11) NOT NULL auto_
increment,
PRIMARY KEY ('id')
) ENGINE=MyISAM AUTO_INCREMENT=7
DEFAULT CHARSET=latin1
Figura 1. Pantalla de creación de nuevo proyecto en Adobe Flex Builder Linux
80_81_82_83_84_85_Flex ver2.indd 2009-04-14, 14:5381

82
Programando RIA con Flex y AMFPHP
Linux+ 6/2009
programación
Servidor, siendo el cliente el explorador (Firefox/ Opera/ Konqueror/ Explorer/ Safari, etc.) y el ser-vidor web (Apache/ Tomcat/ IIS, etc.). En nuestro caso de Flex, tenemos como cliente al conjunto Explorador + Flash. En el caso de AJAX el clien-te es solo el Explorador (que soporte Javascript).
El cliente está encargado de administrar toda la interacción con el usuario y procesar las respuestas del servidor. El Servidor está encar-gado de procesar todos los requerimientos que el cliente solicita, como acceso a la base de da-tos y a otros servicios, para finalmente enviarle el resultado para ser procesado.
En definitiva la estructura de una RIA es básicamente la misma que las aplicaciones Web, un cliente y un servidor a excepción que el Cliente está mucho más desarrollado y con muchas más prestaciones, de hecho pueden de-sarrollar una RIA utilizando su viejo servidor. En definitiva la parte del cliente es la más im-portante en una RIA dado que es aquí donde se dan las mayores prestaciones para el usuario.
Para el desarrollo de toda la interfaz del clien-te, se puede utilizar Adobe Flex o Ajax mientras que para el servidor se pueden utilizar diferentes sistemas, por ejemplo, un servidor Apache/ IIS/ ColdFusion, Flex data Services y otros. En el casode utilizar Flex la elección del servidor es a ve-ces compleja, existen muchas opciones y muchas diferencias que a veces son difíciles de comparar.
Desarrollando una aplicación en FlexPara darle forma y color a todo este conoci-
miento, vamos a desarrollar una pequeña apli-cación utilizando Adobe Flex y AMFPHP para poder probar nuestro conocimiento. El único requerimiento para desarrollar este ejemplo es un poco de experiencia con PHP y MySQL en gene-ral para poder concentrarnos en el aprendizaje de Flex y AMFPHP.
Utilizaremos Adobe Flex para desarrollar el cliente y un programa hecho en PHP en nuestro servidor. AMFPHP es el encargado de realizar la conexión entre PHP y Flex. AMFPHP se en-cargará de convertir los resultados del script de PHP en un formato AMF que Flex/Flash pueden comprender.
AMF por sus siglas en inglés Action Mes-sage Format es un protocolo abierto muy eficaz para la transferencia de objetos y datos en ge-neral, más eficaz que utilizar XML puesto que utiliza menos recursos de procesamiento y ancho de banda. Primero vamos a configurar nuestro entorno de desarrollo para luego hablar un poco más de las herramientas.
La aplicación será una pequeña lista de nom-bre de contactos que se encuentra en una base de datos, y mediante una interfaz de administración hecha en Flex, realizaremos un manejo muy básico como Agregar/ Borrar/ Listar los datos. Recuerden que nuestro objetivo es ver la inte-racción entre ambos sistemas y no aprender PHP. En el otro extremo tendremos una aplicación realizada en PHP que estará accesando la base de datos utilizando Adodb el cual hará más fácil el proceso. Si no conocen Adodb no se preocupen, es muy sencillo dado que haremos uso de cues-tiones básicas.
Software necesarioEl ejemplo lo vamos a desarrollar utilizando Adobe Flex Builder y Eclipse. Todo esto utili-zando como máquina de desarrollo un Ubuntu/ Kubuntu. Adobe Flex Builder para Linux tiene aún unas diferencias con su homónima versión de Windows, carece de Vista de Diseño, Vista de Estados y otros:
• Descargar Eclipse Europa 3.3. Deben ba-jar esta versión y no la 3.4 dado que Flex Builder no es compatible con la versión 3.4. (http://www.eclipse.org/downloads/packages/release/europa/winter)– Descomprimir eclipse.
• Descargar Adobe Flex Builder para Linux. (http://labs.adobe.com/downloads/flex-builder_linux.html).– Ejecutar en la consola del usuario lo-
gueado el instalador y seguir los pasos del instalador. Este instalador nos pedi-rá el directorio donde descomprimieron eclipse.
• Asegurarnos que tenemos instalado el Apa-che HTTPD en Ubuntu y MySQL. (apt-get install apache2 libapache2-mod-
php5 php5-mysql mysql-server-5.0).– Crear una base de datos llamada prueba.– Crear una tabla con el siguiente script.
• Descargar AMFPHP (http://sourceforge.net/projects/amfphp/) y descargar Adodb para php (http://adodb.sourceforge.net/).– Descomprimir ambos archivos en la
raíz de nuestro servidor web que en Ubuntu es /var/www.
– Luego vamos a renombrar la carpeta recién extraída de AMFPHP. 'mv amfphp-1.9.beta.20080120/amfphp
/var/www'.– Crear una carpeta llamada prueba1 en
el directorio /var/www.
Con estos pasos ya tenemos lo necesario para realizar aplicaciones utilizando Flex y AMFPHP. En dos primeros pasos descargamos e instalamos Flex.
Antes de comenzar a realizar el ejemplo va-mos a hablar un poco más acerca de Flex y AM-FPHP. La interacción de un cliente en Flex con un servidor se hace por medio de diferentes métodos:
• Primer método: Servicios Web:– Son servicios que se han creado especí-
ficamente para comunicación entre má-quinas y están definidos por un WSDL.
• Segundo método: Servicios HTTP:– Son los más comunes para los desarro-
lladores de sitios web, son llamadas HTTP como POST/GET. Este mecanismo es el menos recomendado pero también es muy sencillo de implementar, dado que podemos adaptar viejos servicios a Flex,exportando los datos a un XML.
• Tercer método: Objetos Remotos:– Son objetos de Java que se pueden
acceder desde el cliente.
En nuestro caso utilizaremos el tipo 3 que nos permitirá realizar clases de PHP en el servidor, y acceder a sus métodos desde el cliente. El méto-do 2 es utilizado para cuestiones muy sencillas y no os recomiendo para cosas complejas. El caso 1 es para cuando existen aplicaciones desarrolladas de antemano con esta habilidad para distribuir el servicio, pero no os recomiendo debido a que es más lento (para quien cobre la programación por horas esto puede ser bueno) que RemoteObject y verdaderamente más complejo el desarrollo.
Ejemplo desarrolladoComencemos con el desarrollo del ejemplo. Pri-mero vamos a crear los archivos como os expon-
Figura 3. Archivos generados al crear un proyecto en Flex
Figura 2. Configurando el servidor PHP
80_81_82_83_84_85_Flex ver2.indd 2009-04-14, 14:5382

83
Programando RIA con Flex y AMFPHP
www.lpmagazine.org
programación
Listado 2. Editando el archivo prueba.mxml
<?xml version="1.0" encoding="utf-8"?><mx:
Application xmlns:mx="http://www.adobe.com/2006/mxml"
layout="absolute" backgroundGradientAlphas="[1.0, 1.0]"
backgroundGradientColors="[#000000, #1D1D1D]"
creationComplete="init()" >
<mx:Script>
<![CDATA[
import mx.collections.ArrayCollection;
import mx.controls.Alert;
import mx.rpc.events.FaultEvent;
import mx.rpc.events.ResultEvent;
[Bindable]
private var nombres:Array;
private var obj:Object=new Object();
private function resultHandler
(event:ResultEvent):void
{
trace('Procesando resultado');
nombres = event.result as Array;
}
private function addresultHandler
(event:ResultEvent):void
{
Alert.show('Exitoso!');
amfPrueba.listar();
}
private function faultHandler
(event:FaultEvent):void
{
Alert.show(event.fault.faultDetail, "Error");
}
private function init():void{
trace('Iniciando aplicacion');
amfPrueba.listar();
}
private function agregar():void{
obj['nombre']=txtName.text;
amfPrueba.agregar(obj);
}
private function borrar():void{
obj['id']=contactos.selectedItem.id;
amfPrueba.borrar(obj);
}
]]>
</mx:Script>
<mx:RemoteObject id="amfPrueba" source="prueba"
destination="prueba"
fault="faultHandler(event)" >
<mx:method name="listar"
result="resultHandler(event)"/>
<mx:method name="agregar"
result="addresultHandler(event)"/>
<mx:method name="borrar"
result="addresultHandler(event)"/>
</mx:RemoteObject>
<mx:Panel x="199" y="162" width="526"
height="327" layout="absolute"
title="Prueba AMFPHP + FLEX" color="#000000"
fontSize="12">
<mx:AdvancedDataGrid id="contactos"
designViewDataType="flat" left="0" top="0"
width="100%" height="100%"
dataProvider="{nombres}" >
</mx:AdvancedDataGrid>
</mx:Panel>
<mx:ApplicationControlBar x="199" y="497" width="326">
<mx:Button label="Listar" click="init()"/>
<mx:Button label="Agregar" click="agregar()"/>
<mx:TextInput width="83" id="txtName"/>
<mx:Button label="Borrar" click="borrar()"/>
</mx:ApplicationControlBar>
&lt;/mx:Application>
Luego debemos crear en el directorio 'src'
el siguiente archivo llamado 'services-config.xml'
<?xml version="1.0" encoding="UTF-8"?>
<services-config>
<services>
<service id="amfphp-flashremoting-service"
class="flex.messaging.services.RemotingService"
messageTypes="flex.messaging.messages.
RemotingMessage">
<destination id="taskService">
<channels>
<channel ref="my-amf"/>
</channels>
<properties>
<source>*</source>
</properties>
</destination>
</service>
</services>
<channels>
<channel-definition id="my-amf"
class="mx.messaging.channels.AMFChannel">
<endpoint uri="\\localhost\amfphp\gateway.php"
class="flex.messaging.endpoints.AMFEndpoint"/>
</channel-definition>
</channels>
</services-config>
go y luego veremos qué hace cada uno. Inicie-mos Flex Builder y creemos un nuevo proyecto de Flex.
En la primera pantalla (Figura1) le ponemos el nombre prueba como nombre de proyecto, luego elegimos la primera opción en Application Type y, por último, seleccionan PHP en Server Technology. En la próxima pantalla (Figura 2) tendremos que configurar el directorio donde
están los documentos de Apache. Para quienes tienen Ubuntu, pueden seguir la imagen presen-tada en la Figura 2.
Los que utilicen otra distribución deberán ajustarlo de manera acorde. Finalizada la creación del proyecto Flex tendrán en la vista de archivos algo como la imagen presentada en l Figura 3. Luego editaremos el archivo llamado prueba.mxml que se encuentra en la carpeta src. (el
nombre del programa principal coincide con el nombre del proyecto). Dentro de este archivo vamos a colocar el contenido del Listado 2.
Estos pasos han sido para la creación del cliente en Flex. Antes de seguir con la parte del servidor debemos hacer un cambio en la configu-ración del proyecto (luego veremos de qué se trata). Vamos a hacer click derecho sobre el nombre del proyecto y luego elegimos la última opción lla-
80_81_82_83_84_85_Flex ver2.indd 2009-04-14, 14:5383

84
Programando RIA con Flex y AMFPHP
Linux+ 6/2009
programación
mada Properties. Ahí buscaremos la opción de-nominada Flex Compiler y haremos el cambio tal cual indica la imagen presentada en el Listado 4.
Luego debemos crear el siguiente archivo PHP que tiene que estar ubicado en la carpeta amfphp/services/ y se llamará prueba.php (Listado 3). Bien, ahora podemos elegir entre leer la explicación primera o apretar CTRL+F11 para lanzar el programa y verlo funcionando.
ExplicaciónEl primer paso será ver la parte del servidor dado que, como saben, PHP se puede ver de manera sencilla. AMFPHP tiene un directorio llamado services en el cual se aloja nuestro script. Cada archivo debe representar una Clase, y dentro de ese archivo debe estar definida la Clase utilizando el mismo nombre que se usó para crear el archivo. En nuestro caso el archivo se llama prueba.php por lo cual la clase se llamará prueba.
Dentro de esta clase estarán todos los mé-todos que deseemos publicar. En nuestro caso tenemos un constructor que es el encargado de realizar la conexión a la Base de Datos y luego los 3 métodos sencillos para nuestro ejemplo (Agregar/ Borrar/ Listar).
En primera instancia definimos en el cons-tructor las variables con respecto a la base de da-tos. Luego tenemos toda la lista de métodos que toman como variable un Arreglo que será enviada desde Flex. Dentro del arreglo tendremos más va-riables que podrán ser utilizadas para ejecutar las funciones. En el caso de Agregar vemos que la variable $Objeto['nombre'] tendrá el nombre del contacto y hacemos uso de esta variable para crear la Consulta que agregará el contacto.
Seguridad: Si tienen que realizar algún sistema utilizando AMFPHP recuerden que este ejemplo es básico y no implementa ningún meca-nismo de autenticación. AMFPHP trae algo que se conoce como Service Browser que permite re-visar los servicios expuestos sin necesidad de un cliente. Lo pueden probar en nuestro caso acce-sando a la URL http://localhost/amfphp/browse.
Continuemos ahora con la parte del Clien-
te. Esta parte está dividida en 2 secciones. Primero el archivo services-config.xml que contiene la configuración del servidor. Es un archivo bastante genérico donde los factores más importantes son:
• Destination: Este nombre se utilizará en el programa para identificar el servicio al cual me quiero conectar.
• Endpoint: Aquí está la dirección de amfphp.
Si se fijan bien, notarán que el Destination tiene una propiedad llamada channels que vincula el Destino con el canal. Si desean volver a usar este ejemplo, solamente deben adaptar Endpoint para que apunte a otro servidor. Por último llegamos al archivo principal prueba.mxml que contiene el código fuente Flex. Como pueden ver es un códi-go muy legible y utiliza prácticamente el formato XML para definir la parte visual y ciertas cosas programáticas. Sin embargo pueden ver que en la parte superior se encuentran la sección de scripts donde están las pequeñas funciones en lenguaje Actionscript. Como pueden ver es muy parecido a ver un archivo HTML+Javascript excepto que se ve más ordenado gracias al XML. En el XML podemos ver la definición de la tabla que conten-drá todos los datos y es la siguiente línea:
<mx:AdvancedDataGrid id="contactos"
designViewDataType="flat" left="0"
top="0" width="100%" height="100%"
Eso es lo mismo que se hacía en HTML con <table> excepto que mucho más complejo y di-námico. Si ejecutaron el ejemplo pueden ver que es una tabla muy simple, bonita y que tiene inclui-dos efectos y funciones modernas que no hicie-ron falta programar. Pueden llenar la lista y verán como aparece una barra lateral, también pueden ver que el mouse por encima de cada fila cambia el color de la fila, si seleccionamos un ítem éste queda iluminado, etc. Todo esto son funciones que trae lo que se conoce como Datagrid. Si segui-mos observando vamos a ver el código (Listado 4) que es el encargado de crear el objeto remoto, o sea el enlace entre el cliente y el servidor.
Un objeto remoto lo pueden ver como si ustedes hubiesen programado una Clase en el servidor que pueden acceder desde el Cliente. Para poder usar esa clase (que se encuentra en AMFPHP) ustedes deben declararla con esa ex-presión que vemos arriba donde figuran los méto-dos a los cuales quiero acceder con su respectivo manejador de resultados ResultHandler, así co-mo el nombre de la clase - source='prueba' - y el destino de ese objeto mediante Destination.
En resumen, como hemos declarado un objeto remoto amfprueba con sus 3 méto-
dos Listar/Borrar/Agregar, ahora podremos dentro del cliente realizando por ejemplo amfprueba.listar(), lo que hará que inme-diatamente se ejecute el método listar que está en la clase prueba.
En la parte del script vamos a ver las fun-ciones que se ejecutan al presionar los botones. Esto no requiere mucha explicación, se van a sentir muy cómodos dado que parece un sim-ple Javascript. Algo que podemos notar en es-te script es el uso de trace. Cada vez que elija-mos hacer un debug de una aplicación en Flex y tengamos Flash Debugger (ver Extras) va-mos a poder ver en la consola de Flex Builder los argumentos que pasemos a trace. Es muy parecido al uso de error_log en PHP.
Finalmente hablaremos de cómo llegan los datos al Datagrid y por qué no hemos definido columnas.
El método Listar en el servidor nos res-ponde con un Arreglo, el cual sin hacer nin-guna interacción y/o modificación lo tomamos y enviamos directamente al datagrid. Si, no estás soñando, no hay que iterar mil veces para poder mostrar esa información. La magia reside en que el datagrid es lo suficientemente inteligente para crear las columnas y filas necesarias para mos-trar la información que viene en ese arreglo.
El datagrid absorbe todos los datos que hay en el parámetro DataProvider que en nuestro caso corresponde a un arreglo llamado nombres y el cual se actualiza con el método listar.
ExtrasBueno, hemos llegado al final del ejemplo y aún nos queda mucho por aprender, pero os dejo a vo-sotros para que sigan investigando este sencillo ejemplo. Espero que os haya gustado y lean la sección Extras si desean comenzar la aventura de las RIA.
Debugueando FlexPueden hacer un debug a Flex utilizando Flash Debugger. Con solo instalar esta versión de Flashustedes podrán hacer uso de la opción Debug de Flex Builder y de esa manera tener un acerca-miento al funcionamiento interno de la aplicación.Figura 4. Configurando servicios en el Cliente
Figura 5. Aquí se puede ver el resultado del progra-ma en Flex
80_81_82_83_84_85_Flex ver2.indd 2009-04-14, 14:5384

85
Programando RIA con Flex y AMFPHP
www.lpmagazine.org
programación
das estas limitaciones se eliminan al realizar apli-caciones AIR puesto que tienen acceso a la PC al igual que cualquier otro software de escritorio.
Todo esto sin necesidad de realizar muchos cambios a la aplicación, lo que nos permite desarrollar una aplicación Web con funcionali-dades esenciales y luego una versión extendida que funciona en el escritorio y que permitiera muchas más cosas.
Frameworks: Marcos de DesarrolloLos frameworks son Marcos de desarrollo que implementan facilidades, mejores prácticas y ca-pas de abstracción. En otras palabras simplifi can el desarrollo de una aplicación, a la vez que otor-gan mejores prácticas y lineamientos para desa-rrollar una aplicación más segura, escalable y ele-gante (entre otras). Dentro del desarrollo en Flex existen varios frameworks entre los cuales se destacan:
• Craingorm,• Swiz,• PureMVC,• Mate.
Todos ellos merecen un artículo aparte, pero los incluimos aquí para que sepas por donde seguir con el desarrollo de una RIA. Personalmente te sugiero trabajar con Mate, es muy sencillo y claro, una vez que comprendes como fun-ciona te hará la vida muy sencilla, quizás hasta más sencillo que este ejemplo. Quizás el próximo artículo trabajemos directamente con alguno de estos frameworks.
Opciones a AMFPHPExisten varias opciones a AMFPHP que varían en detalles técnicos, uso y escalabilidad. La op-ción más completa es Adobe Live Cycle y es el sistema que vende Adobe para realizar todo tipo de RIAs y está netamente integrado con Flex, Flex Builder. Existen muchas opciones para varios len-guajes, pero las más conocidas son BlazeDS (Ja-va), Red5 (Java/Jython/JRuby) y Zend (PHP).
Listado 3. Creando el archivo prueba.php
<?php
require_once("../../adodb5/adodb.inc.php");
class prueba{
public function __construct() {
$host='localhost';
$user='root';
$pass='CLAVE_ROOT';
$db_name='prueba';
$this->qdb = & ADONewConnection('mysql');
$this->qdb->Connect($host, $user, $pass, $db_name);
$this->dbconn = $this->qdb;
$this->qdb->SetFetchMode(ADODB_FETCH_ASSOC);
error_log(" ::: DEBUG :: Coneccion usando ado------" . $host . "
// " .$user . " // " . $db_name,0);
}
public function __destruct() {
$this->qdb->close();
}
function agregar($Objeto){
$insert="insert into contactos (nombre) values
('".$Objeto['nombre']."')";
$result=$this->qdb->Execute($insert);
if($result)
return true;
else
return false;
}
public function listar() {
$query = "SELECT * FROM contactos WHERE borrado=0 ";
if($rid=$this->qdb->Execute($query)){
while(!$rid->EOF){
$ret[]=$rid->fi elds;
$rid->movenext();
}
return( $ret );
}else
return (false);
}
public function borrar($Objeto){
$query = "UPDATE contactos SET borrado=1 WHERE
id='".$Objeto['id']."'";
$this->qdb->Execute($query);
return true;
}
}?>
Listado 4. Creando el enlace entre el cliente y el servidor
<mx:RemoteObject id="amfPrueba" source="prueba" destination="prueba"
fault="faultHandler(event)" >
<mx:method name="listar" result="resultHandler(event)"/>
<mx:method name="agregar" result="addresultHandler(event)"/>
<mx:method name="borrar" result="addresultHandler(event)"/>
</mx:RemoteObject>
Matías Barletta dió sus primeros pasos como desarrollador de tecnología militar en Ar-gentina para luego convertirse en Linux Ad-min para empresas radicadas en Argentina, Estados Unidos, Costa Rica e Inglaterra. Actualmente lidera un grupo de desarro-lladores en implementaciones y desarrollos de software libre (SugarCRM, Asterisk) para varios países de América Latina. Su email: [email protected]
Sobre el autor
Flex al Escritorio: AIRAdobe parece haber pensado en todo, si bien Flex permite realizar RIA basadas en tecnolo-gías Web también ha desarrollado lo que se co-noce como AIR (previamente conocido como Apollo) que permite llevar estas aplicaciones
Web al escritorio, expandiendo el potencial de desarrollo.
Al desarrollar aplicaciones Flex nos encon-tramos con ciertas limitantes, por ejemplo acceso a dispositivos y periféricos directamente, acceso al disco (para tener información offl ine), etc. To-
80_81_82_83_84_85_Flex ver2.indd 2009-04-14, 14:5385

86
opiniónDistribuidores polivalentes
Linux+ 6/2009
Y si ya se sufren problemas en otros de-partamentos (los he conocido de cerca por el mero hecho de tener distintos proveedores de elementos de merchandising), en el de IT, que es crítico para el negocio, esos problemas se pueden multiplicar.
La solución pasa por los proveedores inte-grales de servicios que merezcan ese nombre. No es lo mismo tener tres departamentos que sepan de todo que un departamento que sepa de tres cosas. ¿Cómo vamos a esperar un buen cableado si el departamento que lo monta no es capaz de entender cómo necesitamos la sala de servidores? Luego es posible que la factura llegue bajo un solo CIF, pero no hemos ganado nada en integración.
El reto de encontrar un proveedor así no es sencillo, desde luego, pero nos encontramos
Los administradores de sistemas de las empresas suelen tener que sufrir una gran dicotomía en su trabajo: ¿Windows o Linux? Es
una batalla perdida. Por mucho que nos em-peñemos, la inmensa mayoría de usuarios va a rechazar un cambio a Linux en los puestos de trabajo mientras sigan teniendo Windows en casa.
Los administradores suelen confiar en Linux para determinadas misiones críticas en un entorno corporativo, como pueden ser los cortafuegos, los servidores web… Pero en la otra punta, tenemos sistemas Windows: admi-nistración, comercial…
Nos estamos acostumbrando a esta situa-ción, que no suele ser demasiado cómoda. A pe-sar de que lo ideal sería disponer de un siste-
Distribuidores polivalentes
Fernando de la Cuadra, director de Educación de Ontinet.com
ma unificado, no se llega a ese punto nunca. Y lo peor de todo es que en muchos casos, los administradores se ven obligados a disponer de proveedores distintos en función del área a la que se quiera atacar, Windows o Linux.
Un proveedor que se encargue de los siste-mas Windows no suele tener el chip adaptado a las soluciones Linux. No hay manera de explicar a esos distribuidores que sí, que el servidor de bases de datos funciona bajo SQL, pero que hemos sido nosotros los que hemos modificado el código para adaptarlo a los caprichos (perdón, quería decir necesidades) de la empresa.
El choque es muy fuerte, reconozcámoslo. Como si le dijéramos a un administrador de Li-nux que debe conectarse a un MS SQL Server sin tocar ni un solo punto del servidor más allá de las Opciones Avanzadas y Aceptar.
Entonces, como he comentado, la solu-ción suele ser tener dos proveedores (o más, normalmente) que puedan conocer nuestros problemas y los caprichos (otra vez… per-dón, necesidades) de la empresa, cada uno en un área distinta.
en un buen momento. La tan manida crisis está haciendo redoblar esfuerzos a muchos integra-dores, mejorando sus servicios, aumentando la cualificación de sus técnicos y elevando la calidad final del producto.
Ya no vale la estrategia del tente mientras cobro que luego el administrador se encarga de sudar por las noches. No, no hace falta. Bus-quemos a los que nos puedan ayudar a tener una red en condiciones, los sistemas siempre funcionando (Windows, Linux, Mac, Solaris, DOS, CP/M u OS/2, lo que sea) y los usuarios de la red sin problemas.
Que nos ofrezcan soluciones de verdad integrales, que aunque haya que recurrir a tres marcas distintas para un elemento, funcionen bien, integradas y sin que las horas extra que se hagan delante de una pantalla sean por cul-pa de una mala elección.
Puede parecer extraño, pero os aseguro que estos distribuidores existen, y no son tan raros. Busquémoslos y una vez comprobado que existen, sometámoslos a los caprichos de la empresa: entonces sí que serán necesi-dades.
86_Opinion.indd 2009-04-14, 14:5386
Páginas recomendadas
www.diariolinux.comwww.diariolinux.com www.elguille.infowww.elguille.info www.gatolinux.blogspot.comwww.gatolinux.blogspot.comwww.gatolinux.blogspot.comwww.gatolinux.blogspot.com
www.hispabyte.netwww.hispabyte.netwww.hispabyte.netwww.hispabyte.net www.linuxdata.com.arwww.linuxdata.com.arwww.linuxdata.com.arwww.linuxdata.com.ar
www.linuxhispano.netwww.linuxhispano.net www.pillateunlinux.wordpress.comwww.pillateunlinux.wordpress.comwww.pillateunlinux.wordpress.comwww.pillateunlinux.wordpress.comwww.pillateunlinux.wordpress.comwww.pillateunlinux.wordpress.com www.usla.org.arwww.usla.org.arwww.usla.org.arwww.usla.org.ar
www.opensourcespot.org
www.mundopc.netwww.mundopc.netwww.mundopc.netwww.mundopc.net www.picandocodigo.netwww.picandocodigo.netwww.picandocodigo.netwww.picandocodigo.net www.linuxuruguay.orgwww.linuxuruguay.orgwww.linuxuruguay.orgwww.linuxuruguay.org
87_webamigas.indd 2009-04-14, 14:5491

88
entrevistaEntrevista a Ignacio Molina Palacios, AXARnet Comunicaciones
Linux+ 6/2009
LiNUX+: ¿Cómo nació la empresa?Ignacio Molina Palacios: AXARnet nació
en 1996. En esa época había muy pocas empre-sas que ofrecieran este tipo de servicios ante un mercado emergente que requería soluciones y nuevas vías de expansión y a raíz de esto se comenzó con el proyecto.
L+: ¿Cómo se desarrolló?I.M.P.: Prácticamente no teníamos nada en
propiedad, nuestras instalaciones y máquinas eran alquiladas y dependíamos de terceros para la conectividad, hardware e incluso soporte téc-nico. Esta dependencia nos generaba inseguridad, además de que nos limitaba muchísimo el tiempo de respuesta ante nuestros clientes. Así comenzó poco a poco un proceso de independencia que su-puso grandes inversiones económicas y de esfuer-zo, compensados siempre por el apoyo y ánimo de nuestros clientes que siempre se mantuvieron a nuestro lado en esos duros momentos.
Hoy en día podemos enorgullecernos de todo lo conseguido, estamos en uno de los mejores Da-tacenters de Europa, tenemos conexiones BGP-4 multioperador, somos miembros del RIPE con nuestro propio sistema autónomo de direcciones ip, somos agentes registradores de ESNIC, somos partners de las grandes empresas de servidores como Dell y mantenemos acuerdos con HP, somos Platinum Partner de Parallels (empresa desarrolladora de software para soluciones de Hosting y Virtualización) y seguimos trabajando para mantener una infraestructura propia.
L+: ¿Nos podéis presentar algunos casos de éxito?
I.M.P.: Cada cliente que parte de una idea, la materializa y consigue mantenerse, es para nosotros un caso de éxito, tenemos casos de distribuidores nuestros que han empezado des-
sobre qué es lo que necesita; la calidad, ya que trabajamos con las mejores marcas; y el sopor-te, que siempre está a su disposición para cual-quier contratiempo que se les pueda presentar. Gracias a ésto nuestra oferta no está enfocada sólo a clientes nacionales sino que también nuestro mercado se abre hacia empresas euro-peas y americanas.
L+: ¿De qué servicios disponen vuestros clientes?
I.M.P.: En AXARnet disponemos de todos las soluciones de alojamiento para así poder cubrir cualquier necesidad, desde la más básica para el usuario doméstico hasta las soluciones más avanzadas para grandes empresas que re-quieran potencia, confiabilidad y seguridad.
Registro de dominios: Es la parte básica para cualquier particular o empresa que quiera tener presencia en internet. Registrar un domi-nio es obtener su marca registrada en internet. Nos sirve para que nos encuentren, para que nos recuerden y para que puedan contactar con nosotros. En AXARnet ofrecemos una amplia gama de extensiones de nombres de dominios, que cubren por supuesto las más importantes .com, .net, .org y .es. Además, al ser Agentes Registradores Autorizados por ESNIC (que es el departamento de la Entidad Pública Empresarial RED.ES, autoridad competente para la gestión del Registro de nombres de dominio de Internet bajo el código de país .es) tendrá la total garantía de que su dominio es registrado conforme esta-blece la normativa española y sin ningún tipo de intermediarios. Además al registrarlo a través de un Registrador Acreditado obtendrá precios muy competitivos, una rapidez y eficacia en la trami-tación y gestión de su dominio impecables. Aún sólo con el registro de dominio, AXARnet ofrece
de cero y poco a poco se han creado su propio mercado de clientes, tenemos empresas y par-ticulares fieles que llevan con nosotros desde nuestro comienzo, e incluso empresas que a través nuestra han contactado y han realizado colaboraciones conjuntas en sus actividades. Pero por supuesto el mérito es totalmente de ellos, nosotros simplemente les hemos dado las herramientas y en algunos casos ayudado y aconsejado para cumplir sus objetivos.
L+: En el mercado español hay unas em-presas muy grandes que ofrecen servicios de hosting (muchas veces internacionales) y mu-chas empresas pequeñas ¿cómo véis la situación de la competencia en vuestro campo, es posible competir con los gigantes internacionales? ¿Las empresas más pequeñas podrán sobrevivir?
I.M.P.: Competir directamente con estas grandes empresas es un reto difícil y costoso para las pequeñas y medianas empresas que tienen que recurrir a otras vías que les permitan entrar en este juego de la competitividad.
AXARnet siempre se ha caracterizado por una postura más cercana al cliente, basándose fundamentalmente en ofrecer un buen soporte y asesoramiento que refuerce su confianza. El obje-tivo que pretendemos es, en primer lugar estruc-turarnos, para potenciar la sensación de confianza frente al cliente que cada vez es más exigente. Es-to repercutirá en la imagen futura de la empresa de forma positiva permitiéndole crecer.
Pensamos que éstas son la pautas que tene-mos que seguir las empresas más pequeñas.
L+: En cuanto a Axarnet, ¿cuáles son las ventajas para los clientes de vuestra empresa en comparación con otras empresas?
I.M.P.: Fundamentalmente tres: la trans-parencia, porque siempre asesoramos al cliente
Entrevista a Ignacio Molina Palacios, Proyect Manager de AXARnet Comunicaciones
88_89_Wywiad.indd 2009-04-14, 14:5588

89
entrevistaEntrevista a Ignacio Molina Palacios, AXARnet Comunicaciones
www.lpmagazine.org
gratuitamente un completo panel de control para configurar de forma fácil, entre otros, los contac-tos del dominio, la gestión de DNS y para crear redirecciones web y de correo.
En este momento estamos en proceso de conseguir la acreditación de la ICANN como registrador de dominios, con todos los beneficios que esto conlleva para los clientes, como la posi-bilidad de acceder a cualquier tipo de dominio a precios muy competitivos, gestionar directamen-te con nosotros cualquier trámite con los domi-nios e incluso hacerse distribuidores para que así quienes quieran registrar dominios para terceras personas o empresas puedan hacerlo obteniendo interesantes descuentos por volumen.
Para aquellos usuarios que requieran de so-luciones económicas y sin demasiadas pretensio-nes en cuanto a requerimientos, características y configuraciones especiales podemos ofrecerles los Planes de Alojamiento Compartido, basados en servidores Windows y Linux, según necesi-ten. Todos nuestros Planes de alojamiento inclu-yen las últimas versiones del panel de control Plesk, desde donde podrá gestionar su dominio (correo, ftp, directorios, bases de datos, ...).
Como novedad, para clientes que deseen alojar varios dominios en su pack de hosting, hemos creado Planes Resellers, podrá alojar ilimitados dominios desde un solo plan. Desde el panel de control Parallels Plesk, podrá agregar, modificar y eliminar dominios de forma rápida y sencilla así como ofrecer a sus clientes un panel de control donde administrar su dominio, cuen-tas de correo, etc.
Con nuestros Planes Reseller no tendrá que preocuparse de la administración de su servidor, pues es un servicio totalmente administrado, nosotros nos encargamos de todo para que solo tenga que preocuparse de lo realmente importan-te, dar servicio a sus clientes.
Dentro de la gama de servicios avanzados podemos ofrecer los Servidores VPS que se com-portan exactamente como un servidor dedicado y dispone de sus propios recursos garantizados, de forma que si un vps excede el uso de ram o cpu asignado, no afecta al funcionamiento de los demás vps alojados en el nodo. Como Platinum Partners de Parallels, desarrolladores de Virtuo-zzo, en AXARnet podrá encontrar la gama más amplia de servidores privados virtuozzo, tanto en plataforma linux como windows. La tecnología Virtuozzo es increíble, Virtuozzo crea múltiples VPS separados en un mismo equipo físico para compartir hardware, licencias y esfuerzos de ad-ministración con la máxima eficiencia. Cada vps funciona de la misma manera que un servidor de-dicado normal desde el punto de vista de los usua-rios y de las aplicaciones y puede ser reiniciado independientemente al igual que dispone de ac-
ceso root, direcciones IP, memoria, procesos, ar-chivos, aplicaciones librerías de sistema y archi-vos de configuración. Una carga muy baja y un diseño eficiente hacen de Virtuozzo la mejor solución para servidores en producción con con-tenidos y aplicaciones reales. Cada vps esta com-pletamente aislado de los demás, disponiendo de un uso reservado de capacidad de almacenamien-to, teniendo además su propia configuración de sistema, aplicaciones, librerías , panel de control , etc y su funcionamiento no interfiere con los de-más servidores privados instalados en el mismo servidor o máquina física en cuestión.
Además podrá, siempre que lo desee, gene-rar una copia de seguridad de todo el sistema. Dicha copia se realiza en segundos e incluye no solamente sus datos de usuario sino también todos los programas y servicios. Podrá restaurar dicha copia cuando lo necesite sin necesidad de grandes conocimientos, solamente con un clic.
En su VPS también podrá disponer del me-jor panel de control del mercado, PLESK, para así poder realizar las tareas más comunes de la forma más fácil y amigable posible.
Nuestros Servidores VPS pueden encontrar-se tanto con el Sistema Operativo Linux como Windows y se ofrecen con diferentes configu-raciones de potencia y recursos según siempre las necesidades que tenga el cliente. Así pues encontramos VPS con paneles de control Plesk y cPanel o sin paneles de control (Root), y DDS que son Servidores Dedicados con la tecnología Virtuozzo inherente.
Como producto estrella, tanto por sus carac-terísticas como por su precio, tenemos los Servi-dores Dedicados, una opción cada día más soli-citada por su coste cada vez más reducido y por su potencia. Es la opción elegida por empresas o particulares que quieran ofrecer servicios de hosting a terceros, o para desempeñar tareas es-pecíficas, como servicios de VoIP, servidores de licencias, servidores de backups, ftp, streamming, o los que como bien destacáis en vuestro actual número para implementar la tecnología Cloud Computing.
Es una máquina totalmente a su disposición, que es entregada con el Sistema Operativo Win-dows o Linux y con los paneles de control Plesk si se van a utilizar para servicios de hosting. AXARnet garantiza la disponibilidad de red me-diante contrato SLA, que se refiere al tiempo en que el servidor tiene disponible la conectividad a Internet en el puerto de red asignado.
Para aquellos clientes que lo demanden dis-ponemos de un servicio de administración de ser-vidores para que usted solo tenga que preocu-parse de su negocio y no de los problemas que pueda encontrar en su servidor. Este servicio incluye entre otras, tareas de copia de seguridad
y restauración, configuración de cortafuegos, monitorización 24/7, actualizaciones de software del servidor, actuación y asesoramiento en caso de ataques, sustitución de hardware o incluso del servidor en caso de dañarse.
En AXARnet contamos con un equipo de profesionales capaces de resolver cualquier problema relacionado con su servidor de inme-diato.
Por supuesto todos nuestros servicios son escalables de forma que si el cliente necesita ampliarlos pueda hacerlo con el menor impacto posible para su funcionamiento.
L+: En todos los medios de la comunica-ción nos hablan de la crisis económica, ¿habéis notado sus efectos en vuestro negocio? En caso afirmativo, ¿cómo os defendéis de ellos?
I.M.P.: Es indudable que la crisis está afec-tando en mayor o menor medida a todos los sec-tores empresariales, ahora todas las inversiones que las empresas y particulares dedican a las nuevas tecnologías, y fundamentalmente a In-ternet están miradas con lupa y el cliente quiere cubrir sus necesidades con el coste justo. Noso-tros, conscientes de esta situación, ajustamos los precios y mejoramos el servicio. Creemos que es exactamente lo que el cliente necesita.
L+: Este número tiene como tema central la tecnología de Cloud Computing, muchas personas creen que es el futuro de la tecnolo-gía, sobre todo en la situación de crisis actual, ¿estáis de acuerdo con esta opinión?
I.M.P.: Totalmente. La situación actual del mercado requiere nuevas pautas de actuación por parte de las empresas y del usuario final. Estas he-rramientas permiten un gran ahorro en costes de inversión, por otro lado permite mantener en con-tacto a los comerciales y distribuidores de dife-rentes sedes con la estructura central mantenien-do siempre la información actualizada y accesib-le desde cualquier sitio y en cualquier momento, además de romper totalmente con las barreras físicas que impone la distancia. Podríamos decir que centralizamos para ampliar nuestro campo de actuación. Un producto ideal para este tipo de tecnologías son los Servidores Dedicados.
L+: ¿Qué planes de desarrollo tenéis para el futuro próximo?
I.M.P.: Seguiremos trabajando para ofrecer siempre el mejor servicio a nuestros clientes, para ello plantearemos nuevas estrategias de desarro-llo que nos permitan más autonomía, así como la posibilidad de seguir ofreciendo precios cada vez más competitivos sin que ello repercuta en la calidad de los productos.
L+: Muchas gracias por esta pequeña entrevista.
I.M.P.: Gracias a vosotros por hacernos partícipes.
Entrevista a Ignacio Molina Palacios, Proyect Manager de AXARnet Comunicaciones
88_89_Wywiad.indd 2009-04-14, 14:5589

El próximo número incluirá los siguientes artículos: • Ethical Hacking utilizando BackTrack• Historia de Hacking Práctico• Hacking para Linuxeros• Sistemas de encriptación alternativos• Seguridad en Linuxy mucho más...
La Redacción se reserva derecho a modifi car sus planes
El tema principal del siguiente número de Linux+ será:
Mensual Linux+ está publicado por Software-Wydawnictwo Sp. z o. o.
Producción: Marta Kurpiewska, [email protected] JefePaulina Pyrowicz, [email protected]:Francisco Javier Carazo Gil, José Carlos Cortizo Pérez,David Puente Castro, Jorge Emanuel Capurro
Correctores: Pablo Cardozo, Jose Luis Lz. de Ciordia SerranoAlberto Elías de Ayala
Preparación de DVDs: Ireneusz Pogroszewski, Andrzej Kuca
DTP:Marcin ZiółkowskiGraphics & Design Studio, www.gdstudio.pl
Diseño portada: Agnieszka Marchocka
Gráfico: Łukasz Pabian – "insane"Publicidad: [email protected]ón: [email protected]
Distribución: Coedis, S. L.Avd. Barcelona, 22508750 Molins de Rei (Barcelona), España
Dirección: Software–Wydawnictwo Sp. z o.o., ul. Bokserska 1, 02-682 Varsovia, Polonia
La Redacción se ha esforzado para que el material publicado en la revista y en los DVDs que la acompañan funcionen correctamente.Sin embargo, no se responsabiliza de los posibles problemas que puedan surgir.
Todas las marcas comerciales mencionadas en la revista son propiedad de las empresas correspondientes y han sido usadas únicamente con fi nes informativos.
La Redacción usa el sistema de composición automática
Los DVDs incluidos en la revista han sido comprobados con el programa AntiVirenKit, producto de la empresa G Data Software Sp. z o.o.
¡Advertencia! Queda prohibida la reproducción total o parcial de esta ublicación periódica, por cualquier medio o procedimiento, sin para ello contar con la autorización previa, expresa y por escrito del editor.
Linux ® es una marca comercial registrada de Linus Torvalds.
Seguridad y Ethical Hacking
90_zajawka_es.indd 2009-04-17, 11:5590

91_rekl_ademix.indd 2009-04-14, 14:551

92_rekl_consultor.indd 2009-04-14, 14:561


















