
Julia Díaz - Big data + modelos predictivos = optimización en la atención del paciente
Upload
data-mining-peruCategory
view
738download
0
Big Data Analytics: Automatización de
Modelos Predictivos
José Angel Alvarez

© 2007. MAySA
Big Data Analytics
• Responder preguntas "más grandes" (con mayor cantidad
y variedad de datos)…
• más detalladas…
• más rápidamente (en tiempo real, en muchos casos).
• Detección de fraude en transacciones en línea
• Marketing uno-a-uno en tiempo real
• Gestión de inventarios y distribuciones en grandes
cadenas
• Optimización de precios en tiendas departamentales
• Internet de las cosas
Se necesitan millones de modelos!

© 2007. MAySA
La única solución: automatización
Big Data Analytics Analytics
tradicional

© 2007. MAySA
Práctica actual (Analytics tradicional)

© 2007. MAySA
Objetivos
• Analizar las características de la automatización en herramientas de
modelamiento
• Proponer estrategias útiles en la práctica actual del analista para
acelerar los procesos de desarrollo de modelos

© 2007. MAySA
Tecnologías de Big Data Analytics involucradas
Automatización del modelamiento
Tecnologías de adquisición e integración de datos, de procesamiento en
línea e identificación de eventos, almacenamiento en diversos tipos de
arquitecturas (especialmente no relacionales), tecnologías de data
governance, tecnologías de estandarización de interfases (REST y
otras), tecnologías de exploración y visualización de datos, tecnologías
de orquestación de los diversos componentes en una plataforma
integrada de Analytics, tecnologías de procesamiento en memoria,
tecnologías de procesamiento distribuido y paralelo, etc.
© 2007. MAySA
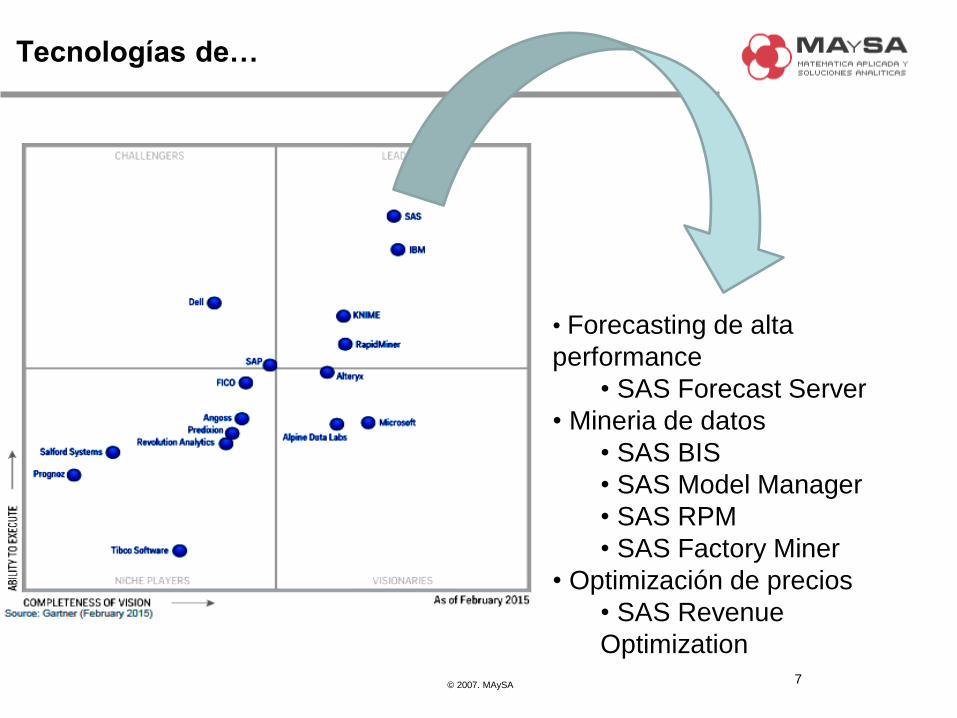
Tecnologías de…
7
• Forecasting de alta
performance
• SAS Forecast Server
• Mineria de datos
• SAS BIS
• SAS Model Manager
• SAS RPM
• SAS Factory Miner
• Optimización de precios
• SAS Revenue
Optimization

© 2007. MAySA
Forecasting de alta performance
– Pronósticos confiables de muchas series que deben actualizarse
frecuente y regularmente
– No hay suficientes recursos para pronósticos tradicionales

© 2007. MAySA
Forecasting “por excepción”
Series de tiempo
80% pueden pronosticarse automáticamente.
10% requieren un esfuerzo extra
10% no pueden pronosticarse precisamente.
El analista debe concentrarse en las series…
• problemáticas
• de alto valor

© 2007. MAySA
Herramientas de automatización
• Preparación automática de las series
• Repositorio de modelos
• Repositorio de eventos
• Selección automática de modelos apropiados
• Detección y modelamiento automático de outliers
• Forecasting jerárquico y reconciliación
• Resúmenes estadísticos del conjunto de modelos
• Exploración y modificación eficaz de series y modelos individuales
10

© 2007. MAySA
Repositorio de modelos de forecasting

© 2007. MAySA
Repositorio de eventos y variables
independientes

© 2007. MAySA
Jerarquías: agregación y reconciliación
16
8 4
20
10
32
0
+3 +1 0 0
+4
10
• Volatilidad
• Series cortas

© 2007. MAySA
Serie con y sin reconciliación

© 2007. MAySA
Tareas del analista
• Configuración inicial del proyecto
• Verificar los resultados generales del modelamiento
• Identificar las series de mayor interés o valor que no han alcanzado el
nivel de precisión apropiado
• Intervenir manualmente sobre estas series
15
© 2007. MAySA
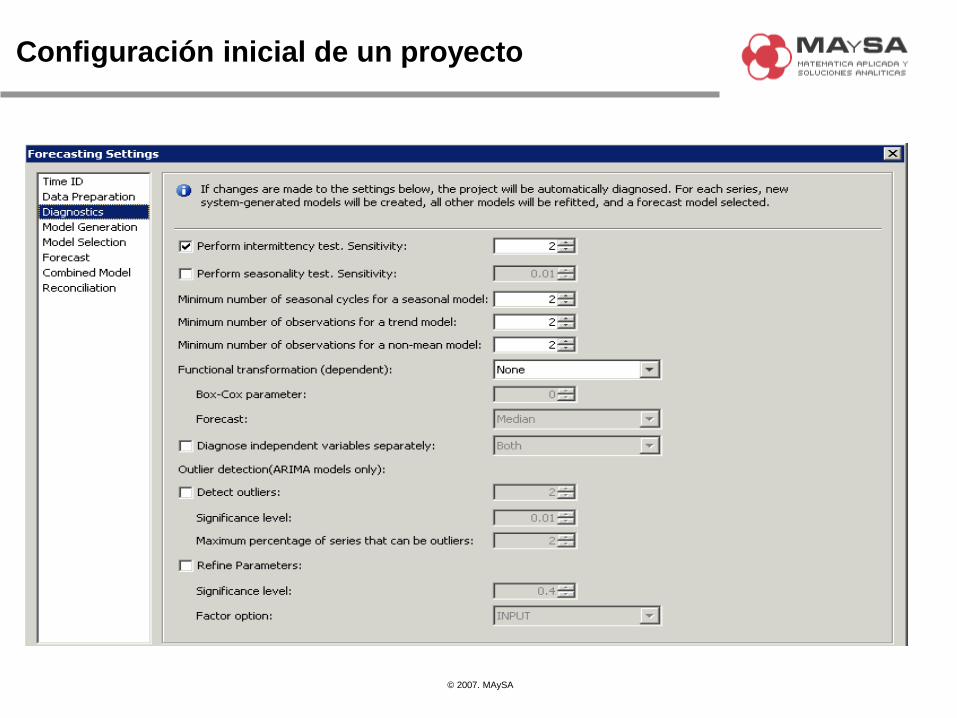
Configuración inicial de un proyecto
© 2007. MAySA
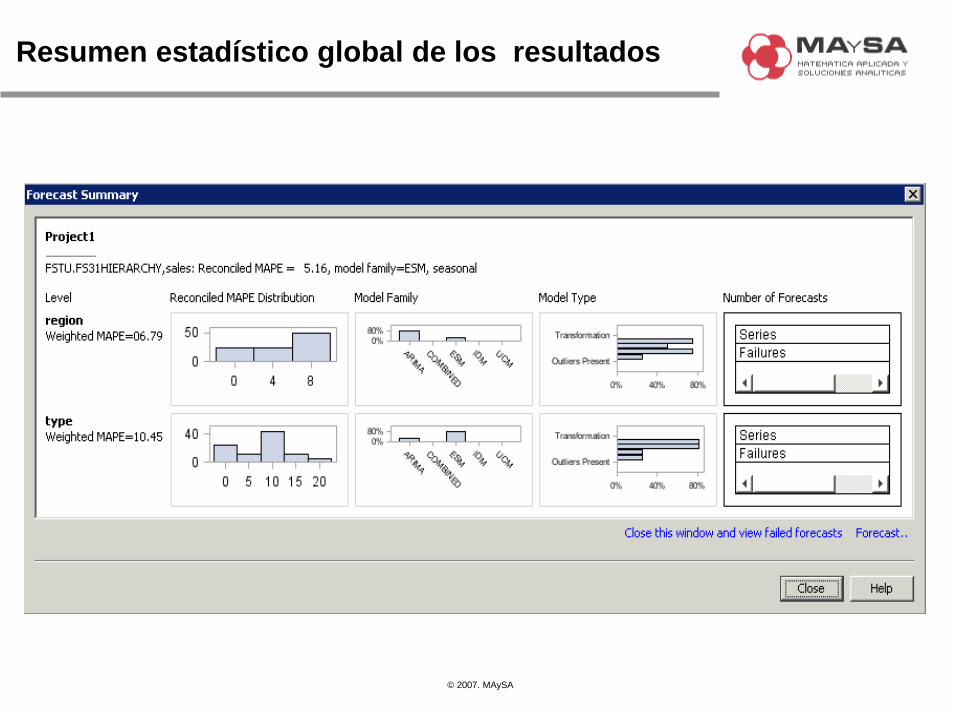
Resumen estadístico global de los resultados

© 2007. MAySA
Distribución de MAPEs de los modelos del
proyecto

© 2007. MAySA
Resumen de los tipos de modelos usados

© 2007. MAySA
Exploración de una serie individual

© 2007. MAySA
Automatización en forecasting
• Se basa en ajustar por fuerza bruta un conjunto de modelos a cada
serie (incluidas algunas transformaciones) y seleccionar el mejor
modelo en base a una métrica.
• Las tareas esenciales del analista son la configuración inicial del
proyecto (qué diagnósticos, qué transformaciones, qué modelos, qué
métrica, etc.) , la detección de aquellos modelos sobre los que vale la
pena que intervenga manualmente y su modificación
• La configuración inicial del proyecto es muy importante para acotar la
búsqueda de modelos por fuerza bruta.
21

© 2007. MAySA
Automatización de modelos de minería de datos
• SAS BIS
• SAS Model Manager
• SAS RPM
• SAS Factory Miner

© 2007. MAySA
Soluciones Empaquetadas para industrias
verticales
• DW , Data marts especializados y scripts de carga
• Plantillas de modelamiento
• Portal de administración
© 2007. MAySA
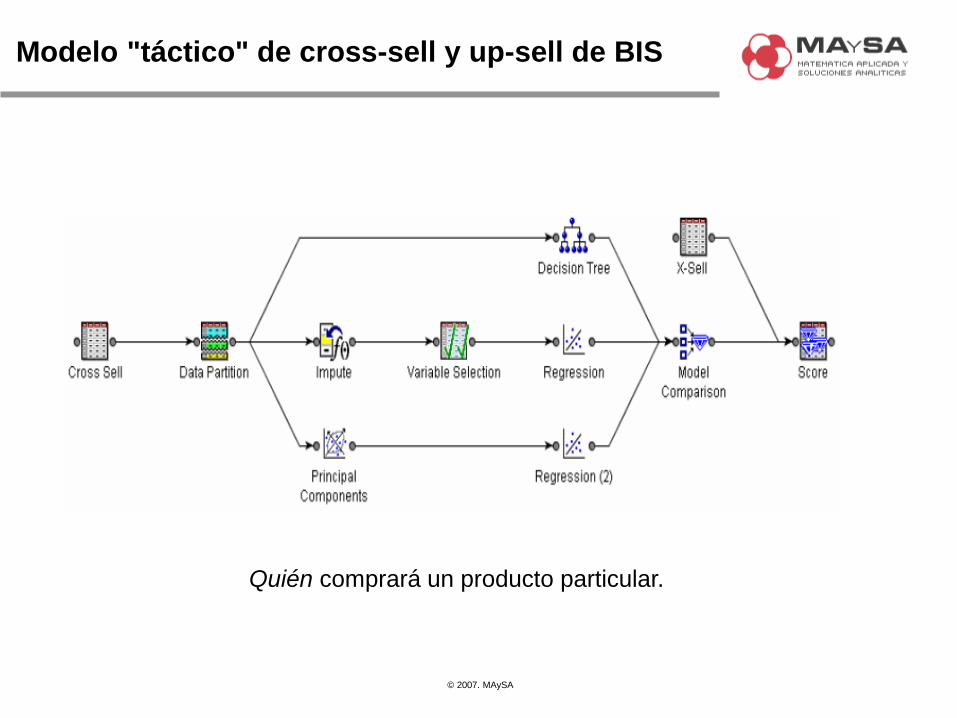
Modelo "táctico" de cross-sell y up-sell de BIS
Quién comprará un producto particular.

© 2007. MAySA
Soluciones Empaquetadas para industrias
verticales
• La arquitectura de datos, un data warehouse diseñado según las
mejores prácticas en un sector industrial y data marts para
aplicaciones específicas, permite a una empresa acelerar
considerablemente las etapas de diseño de estas estructuras y carga
de datos, al menos en la teoría.
• En la práctica, la aceleración en el desarrollo de un proyecto o
"sistema" de minería de datos es un poco más dificultosa de lo que
plantean estas soluciones en la teoría.
• Un déficit frecuente en las empresas usuarias de Analytics: el insumo
principal de proyectos son los datos, pero la adquisición de los
mismos, su análisis y mantenimiento (como datos), su
estandarización, su propia "semántica", etc. suele manejarse de un
modo inorgánico, desarticulado, etc., algo que tiene un impacto
importante sobre la eficiencia de uno de sus principales
consumidores: las tareas de Analytics.
25
© 2007. MAySA
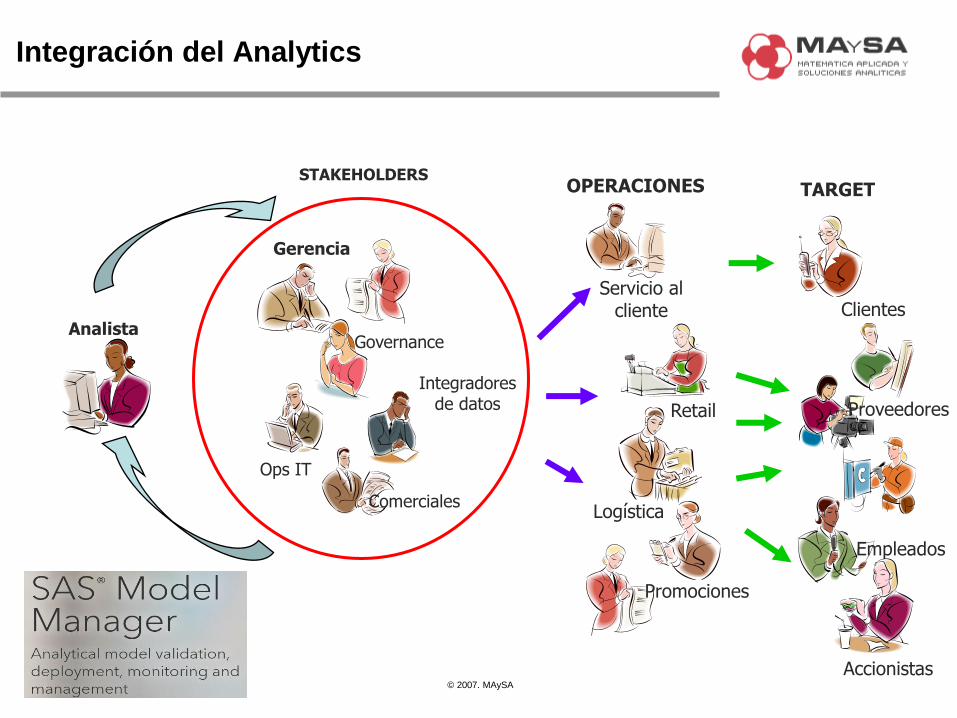
Integración del Analytics
Analista
Gerencia
Ops IT
Integradores de datos
Comerciales
Governance
STAKEHOLDERS
Servicio al cliente
Retail
Logística
Promociones
OPERACIONES TARGET
Clientes
Accionistas
Proveedores
Empleados

© 2007. MAySA
SAS Model Manager
• Herramienta de automatización de la gestión de modelos.
• Definir y gerenciar un workflow para automatizar parcialmente las
distintas etapas del ciclo de vida de un modelo y hacerlas más
eficaces
• Posee herramientas que permiten detectar cambios significativos en la
distribución de las variables que integran un modelo y generar alertas,
detectar cambios en la distribución de las predicciones de un modelo
(lo que habitualmente se llama estabilidad) y el deterioro en las
métricas de evaluación del mismo (lift, error cuadrático medio, K-S,
etc.).
• También puede realizar ajustes automáticos de los parámetros de un
modelo cuando este se ha desajustado, reemplazar un modelo por
otro competidor que en algún momento consigue mejor performance,
y la automatización de la puesta en producción de los modelos.
27

© 2007. MAySA
Interfase SAS Model Manager

© 2007. MAySA
Interfase SAS Model Manager
29

© 2007. MAySA
SAS Model Manager
30
Un modelo no es un objeto
aislado y separable de otros
diversos objetos.

© 2007. MAySA
SAS Rapid Predictive Modeler (RPM)
31
© 2007. MAySA
SAS Rapid Predictive Modeler (RPM)

© 2007. MAySA
SAS Rapid Predictive Modeler (RPM)
33

© 2007. MAySA
SAS Rapid Predictive Modeler (RPM
34

© 2007. MAySA
SAS Rapid Predictive Modeler (RPM)
35

© 2007. MAySA
SAS Rapid Predictive Modeler (RPM)
• La automatización consiste en aplicar técnicas básicas de
transformación, imputación y selección de variables, además de las
técnicas de modelamiento más comunes.
• En casi todos los casos se utilizan las configuraciones default de los
nodos.
• Al igual que en el Model Manager, la automatización se basa en
proyectos con una cantidad relativamente baja de modelos.
• La intervención del analista solamente ocurre en la configuración
inicial que es bastante básica y genérica, sin la posibilidad de hacer
algún ajuste en base a conocimiento de dominio.
• Lo sorprendente de estas plantillas genéricas es que usualmente esta
configuración muy elemental basta para generar modelos iniciales
bastante buenos que luego, si es necesario, pueden perfeccionarse.
36

© 2007. MAySA
SAS Factory Miner

© 2007. MAySA
SAS Factory Miner
• Modelamiento en paralelo de múltiples segmentos de una población
(subyace a esta característica la idea de la microsegmentación).
• Se ajustan automáticamente los modelos seleccionados (entre los que
pueden incluirse árboles de decisiones, regresión, redes neuronales,
modelos lineales generalizados, redes bayesianas, máquinas de
soporte vectorial y algún otro) y se selecciona en cada caso el modelo
campeón según alguna métrica elegida.
• Las herramientas de navegación facilitan la exploración de cualquier
modelo de cualquier segmento, se generan los gráficos usuales de
comparación y se calculan las métricas de evaluación habituales.
• La herramienta se basa en una arquitectura de alta performance que
le permite ajustar rápidamente modelos "pesados" como Random
Forest, máquinas de soporte vectorial y otros.
38

© 2007. MAySA
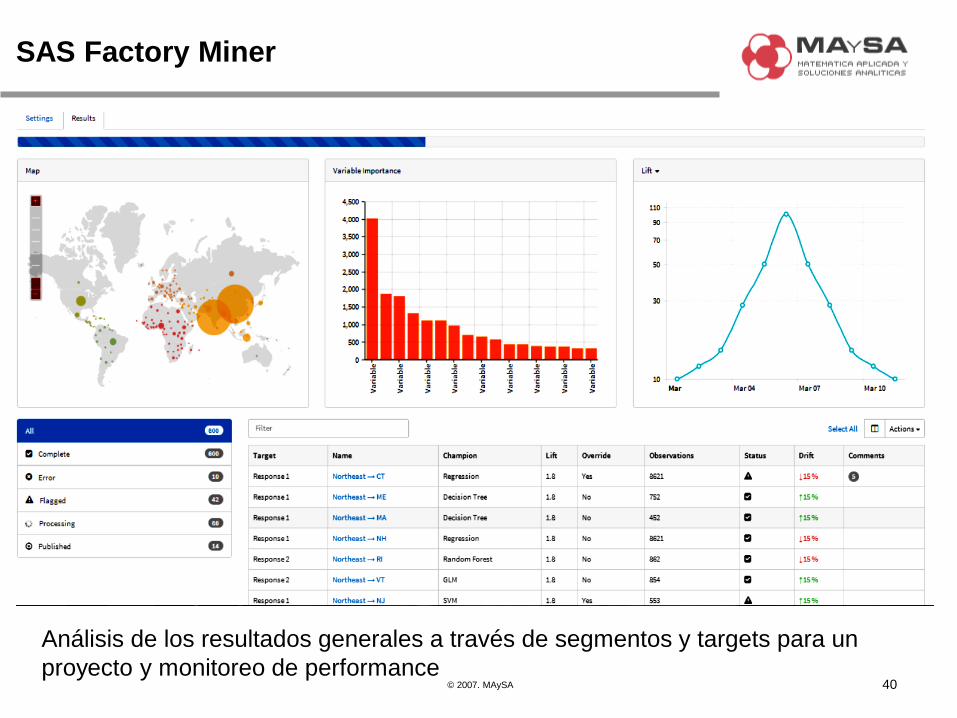
SAS Factory Miner
39
Visualización de los resultados de los modelos ajustados a un segmento de datos
© 2007. MAySA
SAS Factory Miner
40
Análisis de los resultados generales a través de segmentos y targets para un
proyecto y monitoreo de performance

© 2007. MAySA
Automatización en Minería de datos
• La estrategia de automatización es la prueba por fuerza bruta de
algunos pocos modelos, transformaciones, etc. Son los que tienen, en
la práctica, una frecuencia de utilización muy alta.
• En minería de datos no es "popular" la utilización de una estrategia de
predicción por excepción, pero esto no es incompatible en absoluto
con el diseño de las herramientas existentes
• Una cuestión que parece estar ausente en las aplicaciones
mencionadas, es la utilización del concepto de jerarquía de modelos.
• Recién en el SAS Factory Miner aparece la noción de modelamiento
simultáneo sobre distintos conjuntos de datos (segmentos) en un
mismo proyecto.
41

© 2007. MAySA
Automatización en Minería de datos
• El nivel de automatización y su alcance no permiten todavía a cubrir
las necesidades del Big Data Analytics, si bien el SAS Factory Miner
parece un buen primer paso
• La adquisición y preparación de datos tienen un bajo nivel de
automatización. La preparación de datos se basa en la prueba de
transformaciones básicas en versiones default.
• La administración de modelos tampoco tiene la escala necesaria. Se
necesita una gestión más "inteligente" y extensiva para reducir la
intervención manual
42

© 2007. MAySA
Automatización en Minería de datos
• El rol del analista es similar:
– Configuración inicial de un proyecto
– Exploración general de los resultados
– Intervención manual en modelos de alto valor que no hayan
alcanzado el estándar deseado
43
© 2007. MAySA
SAS® Revenue Optimization Suite
44

© 2007. MAySA
• Modelo de demanda
Estimacio-nes Elasticidad,
efectos cruzados, Promos
Pronóstico de base
Total Demanda
Optimización
User inputs
Reglas, objetivos, etc.
Total Demanda
Precio/ofer-ta óptima
Optimización de precios

© 2007. MAySA
SAS® Revenue Optimization Suite
• Estas soluciones implementan lo que SAS denomina "modelamiento
prescriptivo", el uso de modelos de demanda predefinidos, plantillas,
que permiten acelerar y automatizar su implementación y finalmente la
optimización.
• Las plantillas predefinidas son siete según el tipo de producto:
productos estacionales y otros con ciclos de vida cortos, productos
básicos no estacionales, etc.
• Cada plantilla posee un número de "especificaciones" que es
necesario calibrar según valores apropiados para el conjunto de
productos/puntos de venta del sector económico y la empresa a la que
se aplican.
46

© 2007. MAySA
Modelo de demanda típico
Los componentes se combinan para producir un pronóstico total para cada
item/punto de venta
Estacionalidad Tendencia Feriados
Promociones Ciclo de vida Efectos del precio
Predicción total

© 2007. MAySA
Modelo de demanda típico
Los componentes se combinan para producir un pronóstico total para cada
item/punto de venta
Estacionalidad Tendencia Feriados
Promociones Ciclo de vida Efectos del precio
Sales Fcst = Level Trend * Cyclical seasonality * Holiday effect *
Product life cycle effect *
Price effect *
Promo support 1 effect * ... * Promo support n effect *
Inventory effect
© 2007. MAySA
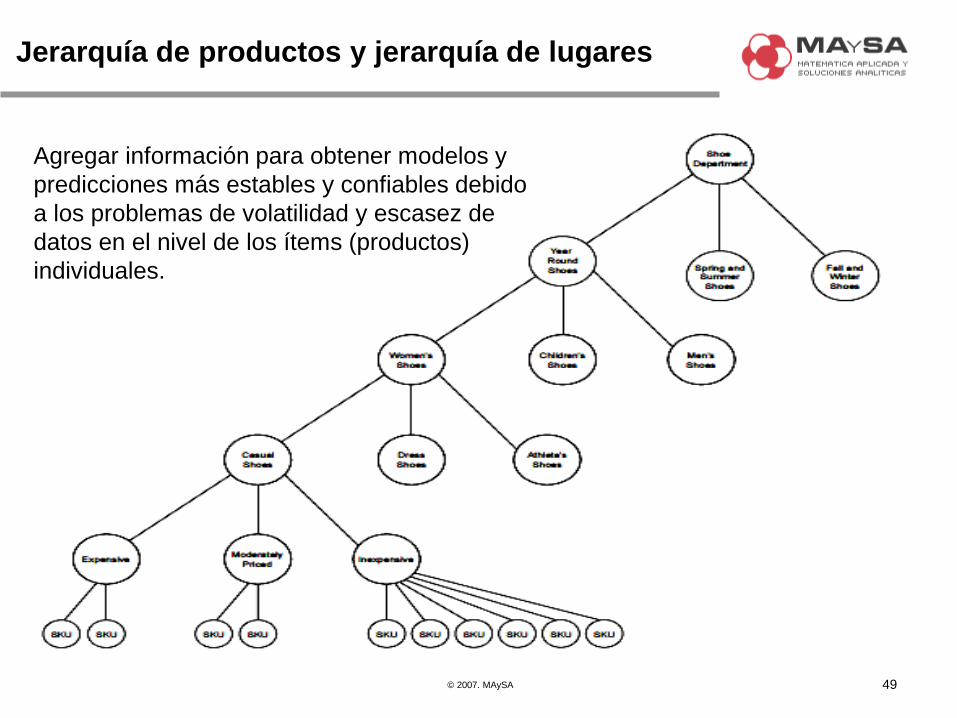
Jerarquía de productos y jerarquía de lugares
49
Agregar información para obtener modelos y
predicciones más estables y confiables debido
a los problemas de volatilidad y escasez de
datos en el nivel de los ítems (productos)
individuales.

© 2007. MAySA
Niveles TS, REG y FCST dentro de un grupo de
modelamiento
50

© 2007. MAySA
SAS® Revenue Optimization Suite
• La arquitectura de datos de la solución es bastante más estructurada y
definida que las soluciones anteriores, lo que se debe principalmente
a la naturaleza del problema. Esta característica facilita su
implementación en menor tiempo.
• La conformación de las jerarquías tiene un rol crucial, lo mismo que el
compartimiento vertical y horizontal de información para mejorar los
modelos.
• El modelo final para cada producto/punto de venta es el resultado de
la composición de varios modelos, incluso en distintos niveles.
• Las plantillas de modelamiento están compuestas de técnicas
estándar de forecasting de series de tiempo (utilizan las técnicas del
forecasting de alta performance) y de regresión con componentes
fijos.
• El rol del analista es fundamental en la configuración inicial de la
solución y el calibrado de los modelos predefinidos. Tanto en la
calibración como en el monitoreo posterior, el analista debe proceder
"por excepción".
51

© 2007. MAySA
Conclusiones sobre la automatización -
Similitudes
• Uso de procesos predefinidos (plantillas, proyectos, etc.) con un
conjunto pequeño de opciones de configuración que implementan
transformaciones y modelos estándar, repetitivos y muy frecuentes
• La intervención del analista se focaliza en la configuración inicial del
proceso automatizado, en la evaluación global de los resultados y en
la intervención específica sobre modelos en los que sea valioso
hacerlo (“modelamiento por excepción”).
• Compartir información a través de distintos niveles en una o diversas
jerarquías, para resolver problemas típicos de variabilidad, falta de
datos, etc.
• Combinar modelos: ya sea varios modelos que hacen predicciones
sobre el mismo suceso en una predicción de conjunto (lo que
habitualmente se denomina "ensemble learning") o modelos que
predicen distintos componentes de un suceso y luego se componen
en una predicción global, como era el caso del modelamiento de
demanda.
52

© 2007. MAySA
Conclusiones sobre la automatización -
Similitudes
• Organizar y estructurar opciones limitadas (aunque ampliables) en
base a las características generales o específicas de los fenómenos
que se deben modelar (repositorio de modelos, repositorio de eventos,
defaults de distintas técnicas, etc.)
• Organizar y estructurar los distintos componentes de un proyecto en
un conjunto fácil de identificar, almacenar, explorar y mantener.
53

© 2007. MAySA
Conclusiones sobre la automatización - Déficits
• Areas como la adquisición de datos y la administración de modelos no
han alcanzado aún una escala de automatización a la altura de las
necesidades del Big Data Analytics
• Un elemento importante en el Analytics de Big Data es la integración
de fuentes de datos de tipos diversos (campos estructurados, texto,
imágenes, etc.). Todas las automatizaciones consideradas se basan
en el uso de campos estructurados, lo que constituirá cada vez más
una limitación importante.
• Las transformaciones y modelos que se ajustan, seleccionan, etc.
automáticamente, si bien es cierto que son los más frecuentes, son
relativamente elementales. Sería deseable una mayor riqueza y
sofisticación.
54

© 2007. MAySA
Conclusiones sobre la automatización - Deficits
• La estrategia principal es la búsqueda de buenos modelos por fuerza
bruta
• No hay una selección “inteligente” más allá de la configuración inicial
del analista
• Los déficits en las tareas más abiertas de adquisición de datos, en la
transformación de los mismos y en una utilización más sofisticada de
modelos se debe a esta falta de “inteligencia”
• La estrategia de modelamiento por excepción consiste en concentrar
la tarea inteligente (la del analista) en los modelos de mayor valor.
55

© 2007. MAySA
¿Qué significa “inteligencia”?
• "Inteligencia" significa utilizar conocimiento de las técnicas de
modelamiento y de dominio sobre un fenómeno particular para poder
hacer inferencias y tomar decisiones. Algo para lo que, todavía, las
herramientas actuales necesitan del analista.
• El conocimiento debiera estar incorporado en la forma de "metadatos
analíticos".
• Estos permitirían junto con una capacidad elemental de inferencia
generar variables más relevantes en muchos modelamientos, hacer
una selección de variables en el proceso inicial de adquisición de
datos, determinar cómo y cuándo integrar información textual a
información estructurada, determinar que técnicas de modelamiento
podrían ser útiles, gestionar modelos y proyectos en función de su
importancia y relevancia para un problema dado, etc.
• Las herramientas que aportarían “inteligencia” se encuentran
disponibles desde hace mucho tiempo (Ingeniería del Conocimiento),
pero aún no han sido integradas a las herramientas de Analytics
56

© 2007. MAySA
Conclusiones sobre el trabajo del analista
• Es recomendable utilizar plantillas o procedimientos preconstruidos de
modelamiento. A estas plantillas se debe conectar la tabla con los
datos de entrada y luego analizar los resultados obtenidos.
• El tiempo mejor invertido del analista es aquel que dedica al análisis
de resultados de modelos generados rápidamente para obtener
conclusiones sobre el problema, los datos, las transformaciones y las
propias técnicas de modelamiento.
• Es decir, la mejor estrategia es una de refinamiento iterativo y
progresivo de un problema mediante modelos rápidos que puedan
mejorarse.
• Combinado con una estrategia de desarrollo mediante prototipos
rápidos que no esperan meses hasta haber reunido gran cantidad de
datos
• Aprovechar información redundante o complementaria en la forma de
jerarquías, segmentos y combinación de modelos.
• Trabajar con “paquetes” de modelamiento que reunen y conservan
toda la información y objetos relevantes. 57

© 2007. MAySA
Conclusiones sobre el entorno del analista
• La "inteligencia" que debe ser parte fundamental del desarrollo y
automatización del modelamiento no es y no debe ser exclusivamente
de la herramienta o del analista, sino de la empresa en su conjunto.
• Los analistas en una empresa debieran encontrarse en una situación
parecida a la de los sistemas automatizados: debieran poder limitarse
a hacer algunas pocas especificaciones iniciales para obtener
rápidamente un primer resultado a analizar.
• Deberían contar con herramientas como plantillas de modelamiento,
conjuntos de variables con una "semántica" estandarizada y
protocolos o herramientas que le faciliten mantener unidos los
distintos objetos involucrados en un proyecto de modelamiento,
mantener un modelo o pasarlo a producción.
58

© 2007. MAySA
Conclusiones sobre el entorno del analista
Grupo transversal de Analytics que se encargue de:
1. Definir plantillas de modelamiento con características similares a las
de las herramientas mencionadas pero ajustadas a los problemas
frecuentes de la empresa, mantenerlas y mejorarlas
progresivamente.
2. Ampliar el o los data warehouses con metadatos analíticos
estandarizados a nivel de la empresa que faciliten la conexión del
DW o los data marts con las plantillas de modelamiento y disminuyan
el trabajo de adquisición de datos por parte del analista.
3. Mantener repositorios "oficiales" de modelos, de eventos y de
transformaciones (en especial para la construcción de variables
"secundarias").
4. Implementar prácticas estandarizadas de la gestión de modelos que
aseguren que los distintos objetos vinculados a un modelo no se
dispersen o se pierdan.
59

© 2007. MAySA 60


















