
Arquitecturas de software
34
Ingeniería de Software Arquitecturas de software 1 Instituto tecnológico de Nogales Materia: Ingeniera de software Nombre del profesor: Ing.- Erick Martínez Romero Tema: Arquitecturas de software Alumno(a): Torres Pulido Myrna Esperanza Fecha: 16 de mayo de 2013 Lugar: Salón S-1
-
Upload
myrna-esperanza-torres -
Category
Documents
-
view
437 -
download
0
description
Arquitecturas de software
Transcript of Arquitecturas de software

Ingeniería de Software Arquitecturas de software
1
Instituto tecnológico de Nogales
Materia:
Ingeniera de software
Nombre del profesor:
Ing.- Erick Martínez Romero
Tema:
Arquitecturas de software Alumno(a):
Torres Pulido Myrna Esperanza
Fecha:
16 de mayo de 2013
Lugar:
Salón S-1

Ingeniería de Software Arquitecturas de software
2
Contenido
3.1 DESCOMPOSICIÓN MODULAR ...................................................................................................... 3
3.2. PATRONES DE DISEÑO .................................................................................................................. 8
3.3 ARQUITECTURA DE DOMINIO ESPECÍFICO .............................................................................. 12
3.4 DISEÑO DE SOFTWARE DE ARQUITECTURA MULTIPROCESADOR ................................... 16
3.5 DISEÑO DE SOFTWARE DE ARQUITECTURA CLIENTE – SERVIDOR ................................. 18
3.6 DISEÑO DE SOFTWARE DE ARQUITECTURA DISTRIBUIDA ................................................. 20
3.7 DISEÑO DE SOFTWARE DE ARQUITECTURA DE TIEMPO REAL ......................................... 32
BIBLIOGRAFÍA ....................................................................................................................................... 34

Ingeniería de Software Arquitecturas de software
3
Es una disciplina en proceso de evolución.
No hay consenso con muchos decisiones de sus conceptos.
Existen diferentes interpretaciones de los términos.
¿Qué es definición de modelos?
1Es la acción de y efecto de modelar configurar a conformar algo no material.
El modelo de negocios se define como un proceso de representación de uno o
más conceptos de elementos de una empresa, tales como:
Sus propósito, su estructura, su funcionalidad, su dinámica su lógico de negocios y
sus componentes.
3.1 Descomposición modular
2Capacidad de descomposición modular. Si un método de diseño proporciona
un mecanismo sistemático para descomponer el problema en subproblemas,
reducirá la complejidad de todo el problema, consiguiendo de esta manera una
solución modular efectiva.
Capacidad de empleo de componentes modulares. Si un método de diseño
permite ensamblar los componentes de diseño (reusables) existentes en un
sistema nuevo, producirá una solución modular que no inventa nada ya inventado.
Capacidad de comprensión modular. Si un módulo se puede comprender como
una unidad autónoma (sin referencias a otros módulos) será más fácil de construir
y de cambiar.
Continuidad modular. Si pequeños cambios en los requisitos del sistema
provocan cambios en los módulos individuales, en vez de cambios generalizados
en el sistema, se minimizará el impacto de los efectos secundarios de los cambios.
1 Trabajo en clases
2 Unidad 6 Diseño y Arquitectura de Software

Ingeniería de Software Arquitecturas de software
4
Protección modular. Si dentro de un módulo se produce una condición aberrante
y sus efectos se limitan a ese módulo, se minimizará el impacto de los efectos
secundarios inducidos por los errores.
Finalmente, es importante destacar que un sistema se puede diseñar
modularmente, incluso aunque su implementación deba ser «monolítica». Existen
situaciones (por ejemplo, software en tiempo real, software empotrado) en donde
no es admisible que los subprogramas introduzcan sobrecargas de memoria y de
velocidad por mínimos que sean (por ejemplo, subrutinas, procedimientos). En
tales situaciones el software podrá y deberá diseñarse con modularidad como
filosofía predominante.
El código se puede desarrollar «en línea». Aunque el código fuente del programa
puede no tener un aspecto modular a primera vista, se ha mantenido la filosofía y
el programa proporcionará los beneficios de un sistema modular.
3El diseño modular propone dividir el sistema en partes diferenciadas y definir sus
interfaces.
Sus ventajas: Claridad, reducción de costos y re utilización.
Los pasos a seguir son:
1. Identificar los módulos
2. Describir cada módulo
3. Describir las relaciones entre módulos
Una descomposición modular debe poseer ciertas cualidades mínimas para que
se pueda considerar suficiente validad.
1. Independencia funcional
3 Ingeniería Del Software

Ingeniería de Software Arquitecturas de software
5
2. Acoplamiento
3. Cohesión
4. Comprensibilidad
5. Adaptabilidad
Independencia Funcional
Cada módulo debe realizar una función concreta o un conjunto de funciones
afines. Es recomendable reducir las relaciones entre módulos al mínimo.
Para medir la independencia funcional hay dos criterios: acoplamiento y cohesión
Acoplamiento
El acoplamiento es una medida de la interconexión entre módulos en la estructura
del programa. Se tiende a que el acoplamiento sea lo menor posible, esto es a
reducir las interconexiones entre los distintos módulos en que se estructure
nuestra aplicación. El grado de acoplamiento mide la interrelación entre dos
módulos, según el tipo de conexión y la complejidad de la interfaces:
Fuerte
Por contenido, cuando desde un módulo se puede cambiar datos locales de
otro.
Común, se emplea una zona común de datos a la que tienen acceso
varios módulos.
Moderado
De control, la zona común es un dispositivo externo al que están ligados
los módulos, esto implica que un cambio en el formato de datos los afecta
a todos.
Débil
De datos, viene dado por los datos que intercambian los módulos. Es
el mejor.
Sin acoplamiento directo, es el acoplamiento que no existe

Ingeniería de Software Arquitecturas de software
6
Cohesión
Un módulo coherente ejecuta una tarea sencilla en un procedimiento y
requiere poca interacción con procedimientos que se ejecutan en otras partes de
un programa. Podemos decir que un módulo coherente es aquel que
intenta realizar solamente una cosa.
Comprensibilidad
Para facilitar los cambios, el mantenimiento y la reutilización de módulos es
necesario que cada uno sea comprensible de forma aislada.
Para ello es bueno que posea independencia funcional, pero además es deseable:
Identificación, el nombre debe ser adecuado y descriptivo
Documentación, debe aclarar todos los detalles de diseño e implementación
que no queden de manifiesto en el propio código
Adaptabilidad
La adaptación de un sistema resulta más difícil cuando no hay independencia
funcional, es decir, con alto acoplamiento y baja cohesión, y cuando el diseño
es poco comprensible. Otros factores para facilitar la adaptabilidad:
Previsión, es necesario prever que aspectos del sistema pueden ser susceptibles
de cambios en el futuro, y poner estos elementos en módulos independientes, de
manera que su modificación afecte al menor número de módulos posibles
Accesibilidad, debe resultar sencillo el acceso a los documentos de especificación,
diseño, e implementación para obtener un conocimiento suficiente del sistema
antes de proceder a su adaptación
Consistencia, después de cualquier adaptación se debe mantener la consistencia
del sistema, incluidos los documentos afectados.

Ingeniería de Software Arquitecturas de software
7

Ingeniería de Software Arquitecturas de software
8
3.2. Patrones de diseño
4Los patrones de diseño son la base para la búsqueda de soluciones a
problemas comunes en el desarrollo de software y otros ámbitos referentes al
diseño de interacción o interfaces.
Un patrón de diseño resulta ser una solución a un problema de diseño. Para que
una solución sea considerada un patrón debe poseer ciertas características. Una
de ellas es que debe haber comprobado su efectividad resolviendo problemas
similares en ocasiones anteriores. Otra es que debe ser reutilizable, lo que
significa que es aplicable a diferentes problemas de diseño en distintas
circunstancias.
Los patrones de diseño pretenden:
Proporcionar catálogos de elementos reusables en el diseño de sistemas
software.
Evitar la reiteración en la búsqueda de soluciones a problemas ya
conocidos y solucionados anteriormente.
Formalizar un vocabulario común entre diseñadores.
Estandarizar el modo en que se realiza el diseño.
Facilitar el aprendizaje de las nuevas generaciones de diseñadores
condensando conocimiento ya existente.
Asimismo, no pretenden:
Imponer ciertas alternativas de diseño frente a otras.
Eliminar la creatividad inherente al proceso de diseño.
No es obligatorio utilizar los patrones, solo es aconsejable en el caso de tener el
mismo problema o similar que soluciona el patrón, siempre teniendo en cuenta
4 Trabajo en Clases

Ingeniería de Software Arquitecturas de software
9
que en un caso particular puede no ser aplicable. "Abusar o forzar el uso de los
patrones puede ser un error".
5Los patrones de diseño son la base para la búsqueda de soluciones a
problemas comunes en el desarrollo de software y otros ámbitos referentes al
diseño de interacción o interfaces.
Un patrón de diseño resulta ser una solución a un problema de diseño. Para que
una solución sea considerada un patrón debe poseer ciertas características. Una
de ellas es que debe haber comprobado su efectividad resolviendo problemas
similares en ocasiones anteriores. Otra es que debe ser reutilizable, lo que
significa que es aplicable a diferentes problemas de diseño en distintas
circunstancias.
Objetivo De Los Patrones De Diseño
Los patrones de diseño pretenden:
Proporcionar catálogos de elementos reusables en el diseño de sistemas
software.
Evitar la reiteración en la búsqueda de soluciones a problemas ya
conocidos y solucionados anteriormente.
Formalizar un vocabulario común entre diseñadores.
Estandarizar el modo en que se realiza el diseño.
Facilitar el aprendizaje de las nuevas generaciones de diseñadores
condensando conocimiento ya existente.
Asimismo, no pretenden:
Imponer ciertas alternativas de diseño frente a otras.
Eliminar la creatividad inherente al proceso de diseño.
No es obligatorio utilizar los patrones, solo es aconsejable en el caso de tener el
mismo problema o similar que soluciona el patrón, siempre teniendo en cuenta
5 Ingeniería en software

Ingeniería de Software Arquitecturas de software
10
que en un caso particular puede no ser aplicable. "Abusar o forzar el uso de los
patrones puede ser un error".
Plantillas O Estructuras De Patrones
Para describir un patrón se usan plantillas más o menos estandarizadas, de forma
que se expresen uniformemente y puedan constituir efectivamente un medio de
comunicación uniforme entre diseñadores. Varios autores eminentes en esta área
han propuesto plantillas ligeramente distintas, si bien la mayoría definen los
mismos conceptos básicos.
La plantilla más común es la utilizada precisamente por el GoF y consta de los
siguientes apartados:
Nombre del patrón: nombre estándar del patrón por el cual será
reconocido en la comunidad (normalmente se expresan en inglés).
Clasificación del patrón: creacional, estructural o de comportamiento.
Intención: ¿Qué problema pretende resolver el patrón?
También conocido como: Otros nombres de uso común para el patrón.
Motivación: Escenario de ejemplo para la aplicación del patrón.
Aplicabilidad: Usos comunes y criterios de aplicabilidad del patrón.
Estructura: Diagramas de clases oportunos para describir las clases que
intervienen en el patrón.
Participantes: Enumeración y descripción de las entidades abstractas (y
sus roles) que participan en el patrón.
Colaboraciones: Explicación de las interrelaciones que se dan entre los
participantes.
Consecuencias: Consecuencias positivas y negativas en el diseño
derivadas de la aplicación del patrón.
Implementación: Técnicas o comentarios oportunos de cara a la
implementación del patrón.
Código de ejemplo: Código fuente ejemplo de implementación del patrón.
Usos conocidos: Ejemplos de sistemas reales que usan el patrón.

Ingeniería de Software Arquitecturas de software
11
Patrones relacionados: Referencias cruzadas con otros patrones.
Aplicación En Ámbitos Concretos
Además de su aplicación directa en la construcción de software en general, y
derivado precisamente del gran éxito que han tenido, los patrones de diseño han
sido aplicados a múltiples ámbitos concretos produciéndose "lenguajes de
patrones" y extensos "catálogos" de la mano de diversos autores.
En particular son notorios los esfuerzos en los siguientes ámbitos:
Patrones de interfaces de usuario, esto es, aquellos que intentan definir las
mejores formas de construir interfaces hombre-máquina.
Patrones para la construcción de sistemas empresariales, en donde se
requieren especiales esfuerzos en infraestructuras de software y un nivel de
abstracción importante para maximizar factores como la escalabilidad o el
mantenimiento del sistema.
Patrones para la integración de sistemas, es decir, para la
intercomunicación y coordinación de sistemas heterogéneos.
Patrones de flujos de trabajo, esto es para la definición, construcción e
integración de sistemas abstractos de gestión de flujos de trabajo y
procesos con sistemas empresariales.

Ingeniería de Software Arquitecturas de software
12
3.3 Arquitectura de dominio específico
6El reto para el diseño es diseñar el software y hardware para proporcionar
características deseables a los sistemas distribuidos y, al mismo tiempo, minimizar
los problemas propios a estos sistemas. Es necesario comprender las ventajas y
desventajas de las diferentes arquitecturas de sistemas distribuidos. Aquí se tratan
dos tipos genéricos de arquitecturas de sistemas distribuidos: Arquitectura cliente-
servidor. En este caso el sistema puede ser visto como un conjunto de servicios
que se proporcionan a los clientes que hacen uso de dichos servicios. Los
servidores y los clientes se tratan de forma diferente en estos sistemas.
Arquitecturas de objetos distribuidos. Para esta arquitectura no hay distinción entre
servidores y clientes, y el sistema puede ser visto como un conjunto de objetos
que interaccionan cuya localización es irrelevante. No hay distinción entre un
proveedor de servicios y el usuario de estos servicios.
Ambas arquitecturas se usan ampliamente en la industria, pero la distribución de
las aplicaciones generalmente tiene lugar dentro de una única organización. La
distribución soportada es, por lo tanto, intraorganizacional. También se pueden
tomar dos tipos más de arquitecturas distribuidas que son más adecuadas para la
distribución interorganizacional: arquitectura de sistemas peer-to-peer (p2p) y
arquitecturas orientadas a servicios. Los sistemas peer-to-peer han sido usados
principalmente para sistemas personales, pero están comenzando a usarse para
aplicaciones de empresa.
Los componentes en un sistema distribuido pueden implementarse en diferentes
lenguajes de programación y pueden ejecutarse en tipos de procesadores
completamente diferentes. Los modelos de datos, la representación de la
información y los protocolos de comunicación pueden ser todos diferentes.
6 Ingeniería Software

Ingeniería de Software Arquitecturas de software
13
Un sistema distribuido, por lo tanto, requiere software que pueda gestionar estas
partes distintas, y asegurar que dichas partes se puedan comunicar e intercambiar
datos. El término middleware se usa para hacer referencia a ese software; se
ubica en medio de los diferentes componentes distribuidos del sistema.
Bernstein (Bernstein, 1996) resume los tipos de middleware disponibles para
soportar computación distribuida. El middleware es un software de propósito
general que normalmente se compra como un componente comercial más que
escribirse especialmente por los desarrolladores de la aplicación. Ejemplos de
middleware son software para gestionar comunicaciones con bases de datos,
administradores de transacciones, convertidores de datos y controladores de
comunicación.
Los sistemas distribuidos se desarrollan normalmente utilizando una aproximación
orientada a objetos. Estos sistemas están formados por partes independientes
pobremente integradas, cada una de las cuales puede interaccionar directamente
con los usuarios o con otras partes del sistema. Algunas partes del sistema
pueden tener que responder a eventos independientes. Los objetos software
reflejan estas características; por lo tanto, son abstracciones naturales para los
componentes de sistemas distribuidos.
Existen dos modelos de dominio específico:
1. Modelos genéricos que son abstracciones de varios sistemas reales.
2. Modelos de referencia que son modelos abstractos y describen a una clase
mayor de sistemas.
Modelo genérico: flujo de datos de un compilador
Modelo de Referencia: La arquitectura OSI.

Ingeniería de Software Arquitecturas de software
14
Aquí se tratan dos tipos genéricos de arquitecturas de sistemas distribuidos:
Arquitectura cliente-servidor. En este caso el sistema puede ser visto como un
conjunto de servicios que se proporcionan a los clientes que hacen uso de dichos
servicios. Los servidores y los clientes se tratan de forma diferente en estos
sistemas. Arquitecturas de objetos distribuidos.
Para esta arquitectura no hay distinción entre servidores y clientes, y el sistema
puede ser visto como un conjunto de objetos que interaccionan cuya localización
es irrelevante. No hay distinción entre un proveedor de servicios y el usuario de
estos servicios. Ambas arquitecturas se usan ampliamente en la industria, pero la
distribución de las aplicaciones generalmente tiene lugar dentro de una única
organización. La distribución soportada es, por lo tanto, intraorganizacional.
También se pueden tomar dos tipos más de arquitecturas distribuidas que son
más adecuadas para la distribución interorganizacional: arquitectura de sistemas
peer-to-peer (p2p) y arquitecturas orientadas a servicios.
Los sistemas peer-to-peer han sido usados principalmente para sistemas
personales, pero están comenzando a usarse para aplicaciones de empresa. Los
componentes en un sistema distribuido pueden implementarse en diferentes
lenguajes de programación y pueden ejecutarse en tipos de procesadores
completamente diferentes.
Los modelos de datos, la representación de la información y los protocolos de
comunicación pueden ser todos diferentes. Un sistema distribuido, por lo tanto,
requiere software que pueda gestionar estas partes distintas, y asegurar que
dichas partes se puedan comunicar e intercambiar datos. El término middleware
se usa para hacer referencia a ese software; se ubica en medio de los diferentes
componentes distribuidos del sistema. Bernstein (Bernstein, 1996) resume los
tipos de middleware disponibles para soportar computación distribuida. El
middleware es un software de propósito general que normalmente se compra

Ingeniería de Software Arquitecturas de software
15
como un componente comercial más que escribirse especialmente por los
desarrolladores de la aplicación. Ejemplos de middleware son software para
gestionar comunicaciones con bases de datos, administradores de transacciones,
convertidores de datos y controladores de comunicación. Los sistemas distribuidos
se desarrollan normalmente utilizando una aproximación orientada a objetos.
Estos sistemas están formados por partes independientes pobremente integradas,
cada una de las cuales puede interaccionar directamente con los usuarios o con
otras partes del sistema. Algunas partes del sistema pueden tener que responder
a eventos independientes. Los objetos software reflejan estas características; por
lo tanto, son abstracciones naturales para los componentes de sistemas
distribuidos.

Ingeniería de Software Arquitecturas de software
16
3.4 Diseño de software de arquitectura multiprocesador Un sistema multiproceso o multitarea es aquel que permite ejecutar varios
procesos de forma concurrente, la razón es porque actualmente la mayoría de las
CPU’s sólo pueden ejecutar un proceso cada vez. La única forma de que se
ejecuten de forma simultánea varios procesos es tener varias CPU’s (ya sea en
una máquina o en varias, en un sistema distribuido.
El multiproceso no es algo difícil de entender: más procesadores significa más
potencia computacional. Un conjunto de tareas puede ser completado más
rápidamente si hay varias unidades de proceso ejecutándolas en paralelo. Esa es
la teoría, pero otra historia es la práctica, como hacer funcionar el multiproceso, lo
que requiere unos profundos conocimientos tanto del hardware como del software.
Es necesario conocer ampliamente como están interconectados dichos
procesadores, y la forma en que el código que se ejecuta en los mismos ha sido
escrito para escribir aplicaciones y software que aproveche al máximo sus
prestaciones.
La ventaja de un sistema multiproceso reside en la operación llamada cambio de
contexto. Esta operación consiste en quitar a un proceso de la CPU, ejecutar otro
proceso y volver a colocar el primero sin que se entere de nada.
Ventajas
Es económica.
El uso de componentes comúnmente disponibles, en grandes cantidades,
permite ofrecer mayor rendimiento, a un precio menor que el de máquinas
con procesadores especialmente diseñados (como por ejemplo las
máquinas de procesadores vectoriales y de propósito específico).
Adicionalmente, las computadoras paralelas son inherentemente
escalables, permitiendo actualizarlas para adecuarlas a una necesidad
creciente.
Las arquitecturas “tradicionales” se actualizan haciendo los procesadores
existentes obsoletos por la introducción de nueva tecnología a un costo

Ingeniería de Software Arquitecturas de software
17
posiblemente elevado. Por otro lado, una arquitectura paralela se puede
actualizar en términos de rendimiento simplemente agregando más
procesadores.
Desventajas
En ocasiones se menciona también la limitante física; existen factores que
limitan la velocidad máxima de un procesador, independientemente del
factor económico.
Barreras físicas infranqueables, tales como la velocidad de la luz, efectos
cuánticos al reducir el tamaño de los elementos de los procesadores, y
problemas causados por fenómenos eléctricos a pequeñas escalas,
restringen la capacidad máxima de un sistema uniprocesador, dejando la
opción obvia de colocar muchos procesadores para realizar cálculos
cooperativamente.
Es necesario conocer ampliamente como están interconectados dichos
procesadores, y la forma en que el código que se ejecuta en los mismos ha sido
escrito para escribir aplicaciones y software que aproveche al máximo sus
prestaciones.

Ingeniería de Software Arquitecturas de software
18
3.5 Diseño de software de arquitectura Cliente – Servidor
7Este modelo es un prototipo de sistemas distribuidos que muestra como
los datos y el procesamiento se distribuye a lo largo de varios procesadores. Es
una forma de dividir las responsabilidades de un sistema de información
separando la interfaz del usuario de la gestión de la información. El
funcionamiento básico de este modelo consiste en que un programa cliente realiza
peticiones a un programa servidor, y espera hasta que el servidor de respuesta.
Características de un cliente En la arquitectura C/S el remitente de una solicitud es
conocido como cliente. Sus características son:
Es quien inicia solicitudes o
peticiones, tienen por tanto un
papel activo en la comunicación
(dispositivo maestro o amo).
Espera y recibe las respuestas del
servidor.
Por lo general, puede conectase a
varios servidores a la vez.
Normalmente interactúa
directamente con los usuarios
finales mediante una interfaz
gráfica de usuario.
Características de un servidor En los sistemas C/S el receptor de la solicitud
enviada por cliente se conoce como servidor. Sus características son:
Al iniciarse esperan a que lleguen las solicitudes de los clientes,
desempeñan entonces un papel pasivo en la comunicación (dispositivo
esclavo).
7 unidad VI Diseño y arquitectura de Software

Ingeniería de Software Arquitecturas de software
19
Tras la recepción de una solicitud, la procesan y luego envían la respuesta
al cliente.
Por lo general, aceptan conexiones desde un gran número de clientes (en
ciertos casos el número máximo de peticiones puede estar limitado).
No es frecuente que interactúen directamente con los usuarios finales.
Ventajas
Centralización del control: Los accesos, recursos y la integridad de los
datos son controlados por el servidor de forma que un programa cliente
defectuoso o no autorizado no pueda dañar el sistema.
Escalabilidad: Se puede aumentar la capacidad de clientes y servidores por
separado.
Fácil mantenimiento.
Desventajas
La congestión del tráfico (a mayor número de clientes, más problemas para
el servidor).
El software y el hardware de un servidor son generalmente muy
determinantes. Un hardware regular de un ordenador personal puede no
poder servir a cierta cantidad de clientes. Normalmente se necesita
software y hardware específico, sobre todo en el lado del servidor, para
satisfacer el trabajo. Por supuesto, esto aumentará el costo.

Ingeniería de Software Arquitecturas de software
20
3.6 Diseño de software de arquitectura distribuida 8Un sistema distribuido es un sistema en el que el procesamiento de
información se distribuye sobre varias computadoras en vez de estar confinado en
una sola máquina.
Ventajas:
Compartición de Recursos.
Apertura.
Concurrencia.
Escalabilidad.
Tolerancia a Defectos.
La arquitectura de software en ambientes distribuidos proporciona un concepto
holístico, que habrá que construirse. Describe la estructura y la organización de
los componentes del software, sus propiedades y la conexión entre ellos.
Inconvenientes:
Es más fácil diseñar y desarrollar el software para el trabajo en paralelo que para
una aplicación única lineal.
Hay que adquirir y aprender un software para las comunicaciones entre los
distintos ordenadores.
Se necesita un hardware de red de suficiente fiabilidad.
9Los sistemas distribuidos son comúnmente piezas complejas de software
cuyos componentes están dispersos en máquinas múltiples. Si se desea tener
control sobre esta complejidad, es crucial que estos sistemas estén
apropiadamente organizados.
La organización de los sistemas distribuidos depende mayormente de los
componentes de software que constituyen al sistema. Estas arquitecturas de
8 Trabajo en clases
9 Clase 03: Arquitecturas de Sistemas Distribuidos

Ingeniería de Software Arquitecturas de software
21
software establecen como son organizados varios componentes del software y
cómo interactúan entre ellos.
La implementación de un sistema distribuido requiere de la división e
identificación de los componentes de software y su instalación en máquinas
reales. La implementación e instalación final de la arquitectura de software se
conoce como arquitectura de software.
Como se explicó con anterioridad, un objetivo importante de los sistemas
distribuidos es separar las aplicaciones de las plataformas subyacentes mediante
una capa de middleware. La adopción de esta capa en una importante decisión
arquitectónica, y su principal objetivo es proveer una distribución transparente de
la aplicación. La transparencia de la distribución implica en muchos casos la
necesidad de hacer ciertos sacrificios o concesiones, por lo que es conveniente
que el middleware sea adaptable. Esta adaptabilidad también se puede lograr
permitiendo que el sistema monitoree su propio comportamiento y que tome las
medidas necesarias cuando se requiera. Estos sistemas distribuidos son
organizados frecuentemente en la forma de retroalimentación de control.
Estilos Arquitectónicos
Para iniciar la discusión sobre arquitecturas, se debe considerar en principio la
organización de sistemas distribuidos en componentes de software, también
conocida como arquitectura de software.
El estilo arquitectónico está formulado en términos de componentes, la
forma en que estos componentes están conectados unos con otros y los datos
intercambiados entre ellos. Un componente es una unidad modular con interfaces
bien definidas, y que puede ser reemplazado en el sistema.
Tal vez un término más complejo es el de conector, el cual generalmente es
descrito como un mecanismo que media la comunicación, coordinación o
cooperación entre componentes. Por ejemplo, un conector puede implementarse
mediante RPCs, transferencia de mensajes o flujos de datos.

Ingeniería de Software Arquitecturas de software
22
Existen varias configuraciones de componentes y conectores que definen el
estilo arquitectónico de un sistema distribuido. Los estilos más importantes son:
Arquitecturas en capas
Arquitecturas basadas en objetos
Arquitecturas centradas en datos
Arquitecturas basadas en eventos
La idea básica tras el estilo arquitectónico en capas es simple: los
componentes están organizados en forma de capas, en la que un componente en
una determinada capa puede llamar a componentes en la capa inmediata inferior.
Una observación clave es que el control generalmente fluye de capa en capa: las
peticiones van de arriba abajo y los resultados de abajo a arriba, tal como se
puede observar en la Figura 3.1(a).
Una organización, por mucho más suelta, se tiene en arquitecturas basadas
en objetos, tal como se muestra en la Figura 3.1(b). En esencia, cada objeto
corresponde a lo que hemos definido como componente, y estos componentes
están conectados mediante un mecanismo RPC. No es de sorprender que esta
arquitectura de software se adapte al modelo cliente-servidor que trataremos más
adelante.

Ingeniería de Software Arquitecturas de software
23
Figura 3.1. (a) Estilo arquitectónico en capas; (b) estilo arquitectónico basado en
objetos.
Las arquitecturas centradas en datos evolucionan en torno a la idea de que
los procesos se comunican a través de un repositorio o medio común, ya sea
pasivo o activo (ver Figura 3.2 (a)). Por ejemplo, una cantidad importante de
aplicaciones distribuidas en las que la comunicación se establece por medio de un
archivo compartido a través de un sistema de archivos distribuidos.
En las arquitecturas basadas en eventos, los procesos se comunican
esencialmente por medio de la propagación de eventos, los cuales de manera
opcional pueden llevar datos consigo, tal como se muestra en la Figura 3.2 (b).
Generalmente, en los sistemas distribuidos, la propagación de eventos se ha
asociado con lo que se conoce como sistemas publicar/subscribir
(publish/subscribe systems). La idea básica es que los procesos publican eventos
tras los cuales el middleware asegura que sólo esos procesos que se
subscribieron a esos eventos, los recibirán. La ventaja principal de esta
arquitectura es que los procesos están acoplados flojamente. En principio, no se
requiere una referencia explícita de proceso a proceso. A esto se le conoce como
desacoplamiento en el espacio o referencialmente desacoplados.
Figura 3.2. (a) Arquitectura centrada en datos; (b) arquitectura basada en eventos.
Arquitecturas de Sistemas

Ingeniería de Software Arquitecturas de software
24
Ya que se ha discutido brevemente sobre algunos estilos arquitectónicos
comunes, se verá cómo muchos sistemas distribuidos están organizados,
considerando la manera en que sus componentes de software fueron
establecidos. El determinar que componentes de software se usarán, cómo
interactuarán y cómo se distribuirán es lo que se conoce como una instancia de
arquitectura de software, también llamada arquitectura de sistema.
Arquitecturas Centralizadas
A pesar de las diferencias en cuanto a varios aspectos de los sistemas
distribuidos, solo hay un aspecto en los que muchos expertos coinciden: pensar en
términos de clientes que solicitan servicios a servidores ayuda a entender y
administrar la complejidad de los sistemas distribuidos.
En el modelo básico cliente-servidor, los procesos en un sistema distribuido
están divididos en dos grupos, que posiblemente se traslapan. Un servidor es un
proceso que implemente un servicio específico, por ejemplo, un servicio de
sistema de archivos distribuido o de base de datos. Un cliente es un proceso que
solicita un servicio a un servidor, enviándole una petición y subsecuentemente
esperando la respuesta del servidor. La interacción cliente-servidor, también
conocida como solicitud-respuesta, se muestra en la Figura 3.3.
Figura 3.3. Interacción general entre un cliente y un servidor.

Ingeniería de Software Arquitecturas de software
25
La comunicación entre un cliente y un servidor puede ser implementada por medio
de un simple protocolo no orientado a la conexión (sin conexión) cuando la red
subyacente es suficientemente confiable como es el caso de muchas redes de
área local (LANs). En estos casos, cuando un cliente solicita un servicio, empaca
simplemente el mensaje para el servidor, identificando el servicio que requiere y
anexando los datos de entrada necesarios. El mensaje es posteriormente enviado
al servidor. El servidor se encuentra continuamente en espera de recibir
solicitudes, tras lo cual las procesa, empaqueta los resultados en un mensaje de
respuesta, y finalmente envía este mensaje al cliente.
Implementación de aplicaciones en capas
El modelo cliente-servidor ha sido sujeto de muchos debates y controversias a lo
largo de los años. Una de las principales cuestiones es el cómo establecer una
clara distinción entre un cliente y un servidor. No es de sorprender que en muchas
ocasiones esta distinción no es tan clara. Por ejemplo, un servidor de una base de
datos distribuida a través de la web puede actuar continuamente como cliente
porque éste transfiere las solicitudes a varios servidores de archivos responsables
de implementar las tablas de las bases de datos. En este caso, el servidor de base
de datos por sí mismo no hace más que procesar las solicitudes de búsqueda o
filtrado. La Figura 3.4 muestra este caso.
Figura 3.4. Ejemplo de servidor actuando como cliente.

Ingeniería de Software Arquitecturas de software
26
Sin embargo, considerando que muchas aplicaciones cliente-servidor están
orientadas a facilitar al usuario el acceso a la base de datos, mucha gente ha
establecido una distinción entre los tres niveles siguientes, esencialmente usando
el estilo arquitectónico en capas que se vio previamente:
1. El nivel de interfaz de usuario.
2. El nivel de procesamiento.
3. El nivel de datos.
El nivel de interfaz de usuario contiene todo lo necesario para establecer una
interfaz directa con el usuario, tal como la administración del despliegue de la
información. El nivel de procesamiento típicamente contiene las aplicaciones. El
nivel de datos administra los datos sobre los cuales se está trabajando.
Los clientes normalmente implementan el nivel de interfaz de usuario. Este
nivel consiste de los programas que permiten al usuario final interactuar con las
aplicaciones. Hay una diferencia considerable en que tan sofisticada puede ser
una interfaz de usuario. La más simple no es más que una simple pantalla de
caracteres.
Como ejemplo considérese un motor de búsqueda en Internet. La interfaz
es muy simple: un usuario introduce una cadena de palabras claves y
subsecuentemente se le presenta una lista de títulos de páginas web. El extremo
opuesto de la operación está constituido por una gran base de datos de páginas
web, las cuales han sido extraídas e indexadas. El núcleo del motor de búsqueda
es un programa que transforma la cadena de palabras claves que proporcionó el
usuario en una o más peticiones de búsqueda a la base de datos.
Subsecuentemente clasifica los resultados en una lista y transforma esta lista en
una serie de páginas HTML. Dentro del modelo cliente-servidor, esta parte de
extracción de información es típicamente localizada en el nivel de procesamiento.
La Figura 3.5 muestra esta organización.

Ingeniería de Software Arquitecturas de software
27
Figura 3.5. Organización simplificada en tres niveles diferentes de un motor de
búsqueda.
Arquitecturas Descentralizadas
Las arquitecturas multinivel cliente-servidor, como la del ejemplo del motor de
búsqueda mostrado anteriormente, son una consecuencia directa del dividir las
aplicaciones en los tres niveles: interfaz de usuario, componentes de
procesamiento y datos. Los diferentes niveles corresponden directamente con la
organización lógica de las aplicaciones. En muchos ambientes, el procesamiento
distribuido es equivalente a organizar una aplicación cliente servidor como una
arquitectura multinivel. A este tipo de distribución se le conoce como distribución
vertical. La característica relevante de una distribución vertical es que esta puede
realizarse disponiendo componentes lógicamente diferentes en máquinas
diferentes máquinas. Una vez más, desde la perspectiva de administración
del sistema, el tener una distribución vertical puede ser una ayuda: las funciones
estás lógica y físicamente divididas y distribuidas en múltiples máquinas, mientras
cada máquina está configurada para trabajar óptimamente con un grupo
específico de funciones.
Sin embargo, la distribución vertical es tan solo una manera de organizar
aplicaciones cliente-servidor. En arquitecturas modernas, es común que la

Ingeniería de Software Arquitecturas de software
28
distribución de clientes y servidores sea el factor más importante, por lo que a este
forma de distribución se le conoce como distribución horizontal. En este tipo de
distribución, un cliente o un server puede estar físicamente dividido en partes
lógicamente equivalentes, pero cada parte opera con su proprio conjunto integral
de datos, balanceando (equilibrando) la carga del sistema. En esta sección se
analizará los sistemas peer-to-peer, una de las arquitecturas modernas que
soportan la distribución horizontal.
Un sistema distribuido peer-to-peer (de igual a igual), comúnmente abreviado P2P,
es una arquitectura compuesta por participantes que ponen a disposición directa
de los otros participantes del sistema parte de sus recursos (poder de
procesamiento, almacenamiento de disco, ancho de banda, etc.), sin la necesidad
de una instancia de coordinación central, tales como servidores o hosts
permanentes (ver Figura 3.6). Desde una alta perspectiva, los peers (iguales) de
un sistema P2P son todos iguales, lo que significa que las funciones que deben
ser desarrolladas en el sistema pueden ser realizadas por todo peer participante.
En consecuencia, mucha de la interacción entre los procesos participantes (peers)
es simétrica, por lo tanto, los peers pueden ser a la vez tanto proveedores
(servidores) como consumidores (clientes).
Figura 3.6. (a) Sistema peer-to-peer (P2P), (b) Sistema centralizado con cervidor

Ingeniería de Software Arquitecturas de software
29
Figura 3.8. Principio de operación de un sistema BitTorrent.
En un sistema BitTorrent para descargar un archivo, el usuario debe tener
acceso a un directorio global, el cual es un conjunto de páginas web. Este
directorio contiene referencial (enlaces o links) a lo que se conoce como archivos
.torrent. Un archivo .torrent contiene la información necesaria para descargar un
archivo específico. En particular, se establece una referencia a lo que se conoce
como tracker (rastreador), el cual es un servidor que mantiene un registro preciso
de todos los nodos activos que tienen partes del archivo deseado. Un nodo activo
es aquel que en el momento está descargando otro archivo. Obviamente, habrá
varios trackers diferentes, aunque generalmente solo habrá uno por archivo (o
colección de archivos).
Una vez que los nodos de los que se pueden descargar partes del archivo
han sido identificados, el nodo del usuario que desea descargar el archivo, se
vuelve activo. En este punto, este nodo será forzado a ayudar a otros, tal vez
proporcionando a otros las partes que aún no han obtenido del archivo que se está
descargando. Esta regla tiene origen en la siguiente regla: si el nodo P nota que el
nodo Q está descargando más de lo que está distribuyendo (subiendo) a otros, P
puede decidir reducir la velocidad a la que le envía información (parte de un
archivo, en este caso). Este esquema trabaja bien, siempre que P tenga algo que
descargar de Q. Por esta razón, los nodos obtienen referencias a muchos otros
nodos, lo cual los sitúa en una mejor posición para negociar datos.

Ingeniería de Software Arquitecturas de software
30
Arquitectura vs. Middleware
Cuando se consideran los aspectos arquitectónicos que se han considerado hasta
el momento, uno debe preguntarse dónde entra el middleware. Como se enseño
en clases pasadas, el middleware forma una capa entre las plataformas de
aplicación y distribución. Un propósito importante es proveer un cierto nivel de
transparencia en la distribución, ocultando en lo posible la distribución de datos, el
procesamiento y el control de la aplicación.
Lo que comúnmente pasa es que el middleware sigue un estilo
arquitectónico específico. Por ejemplo, muchos sistemas de middleware han
adoptado un estilo arquitectónico basado en objetos, tales como CORBA; otros,
como TIB/Rendeznous, siguen el estilo arquitectónico basado en eventos.
El moldear el middleware a un estilo arquitectónico específico tiene la ventaja de
diseñar aplicaciones más simples. Sin embargo, una desventaja es que el
middleware puede volverse dejar de ser óptimo para lo que el desarrollador tenía
en mente.
Aunque se supone que el middleware tiene como propósito transparentar la
distribución, generalmente se requiere que el middleware se adapte a las
aplicaciones. Una solución sería desarrollar varias versiones del middleware y otra
sería el crear middleware fácilmente configurable y adaptable, según lo requiera la
aplicación.
Autoadministración en Sistemas Distribuidos
Los sistemas distribuidos y el middleware asociado a ellos requieren proveer
soluciones generales orientadas a crear un escudo contra condiciones
indeseables inherentes a la red, de tal manera que puedan brindar soporte a
tantas aplicaciones como sea posible. Los sistemas distribuidos deben ser
adaptivos, más en cuanto a su comportamiento de su ejecución y no en cuanto a
los componentes de software que lo conforman.

Ingeniería de Software Arquitecturas de software
31
Cuando se requiere de adaptación automática, existe una fuerte interrelación entre
las arquitecturas del sistema y las arquitecturas del software. Por otro lado, se
requiere organizar los componentes de un sistema distribuido en tal forma que se
pueda implementar el monitoreo y ajuste del sistema; también decidir dónde
deben ejecutarse los procesos para facilitar la adaptabilidad.

Ingeniería de Software Arquitecturas de software
32
3.7 Diseño de software de arquitectura de tiempo real Los métodos y herramientas que se usan para construir otros tipos de sistemas no
sirven para el software de tiempo real:
no son suficientemente fiables.
sólo contemplan el tiempo de respuesta medio, no el peor.
no se garantizan los requisitos temporales.
Las plataformas de desarrollo y ejecución suelen ser diferentes:
es difícil hacer pruebas en la plataforma de ejecución.
es difícil medir los tiempos con precisión.
Niveles de abstracción
Los métodos de diseño de software comprenden una serie de transformaciones
desde los requisitos iniciales hasta el código ejecutable
Normalmente se consideran distintos niveles de abstracción en la descripción de
un sistema:
Especificación de requisitos
Diseño arquitectónico
Diseño detallado
Codificación
Pruebas
Cuanto más precisa sea la notación empleada en cada nivel mejor será la calidad
del sistema final.
Ingeniería de Software Arquitecturas de software
33
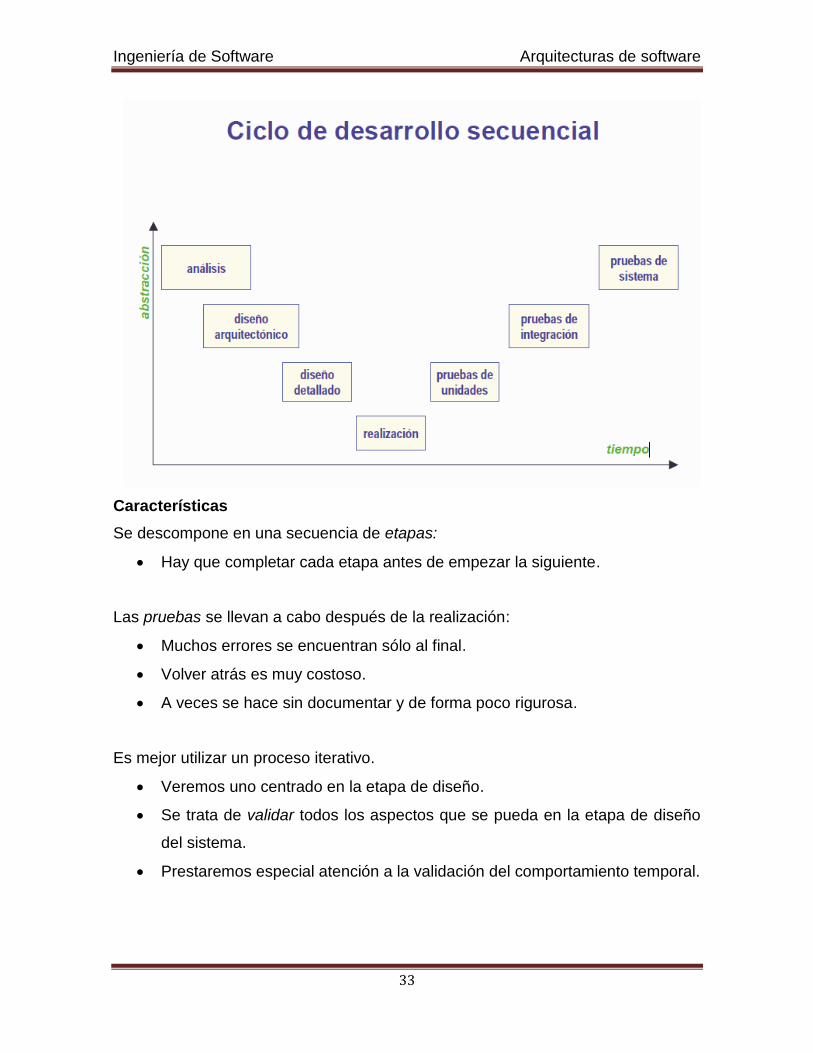
Características
Se descompone en una secuencia de etapas:
Hay que completar cada etapa antes de empezar la siguiente.
Las pruebas se llevan a cabo después de la realización:
Muchos errores se encuentran sólo al final.
Volver atrás es muy costoso.
A veces se hace sin documentar y de forma poco rigurosa.
Es mejor utilizar un proceso iterativo.
Veremos uno centrado en la etapa de diseño.
Se trata de validar todos los aspectos que se pueda en la etapa de diseño
del sistema.
Prestaremos especial atención a la validación del comportamiento temporal.

Ingeniería de Software Arquitecturas de software
34
Bibliografía
Unidad 6 Diseño y Arquitectura de Software
http://radyel.wordpress.com/3/
Ingeniería Del Software
http://ederjacielsantos.blogspot.mx/2013/04/31-descomposicion-modular.html
Libro Roger Pressman- Ingeniería en sistemas
Unidad VI Diseño y arquitectura de Software
http://aniramchaparro.wordpress.com/unidad-vi-karime/
Clase 03: Arquitecturas de Sistemas Distribuidos
https://www.google.com.mx/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=0
CDEQFjAB&url=https%3A%2F%2Fp8.secure.hostingprod.com%2F%40www.miuni
verso.org%2Fssl%2Fgutierrezcasas%2Fefren%2Fuacj%2Fclases%2Fsist_dist%2
Fclase03%2Fclase03.doc&ei=J-aTUfrHHKSMyAGVsYG4DA&usg=AFQjCNHZkq-
7G66uYFkwzF3zMUI0cnqw4g&sig2=UTpS6O17NEmL1J0OuWYq1A&cad=rja


















