
Apuntes de R 0. Inicio 25/09/2007 20:50:00 · Apuntes de R – 1. Comandos básicos 25/09/2007...
52
Apuntes de R 0. Inicio 25/09/2007 20:50:00 ← 0. R es un lenguaje de programación y cálculo, como MatLab o GNU, cuyos antecesores son los paquete de cálculos estadísticos S, SSPS, S++. R funciona mediante una cónsola y diferentes ventanas donde se presentan las tareas que están siendo ejecutadas en un momento dado. La diferencia principal entre R y los paquetes de la familia S es que los comandos de éstos producen y almacenan buena parte de los cálculos intermedios entre la data y el resultado final deseado; mientras que R únicamente almacena y presenta el resultado final. ← ← 1. El “prompt” o señal de que la cónsola espera un comando de ejecución puede variar según el SO sea UNIX, WINDOWS o MACOS. En estos apuntes escribimos ← > ← para el prompt. Para ejecutar un comando en la cónsola se escribe el nombre del comando y a continuación se pulsa ENTER. Por ejemplo, ← > help + ENTER ← que en adelante escribiremos simplemente ← > help ← es un comando que abre la página de ayuda de R. Esta página web también se puede abrir con del botón de ayuda sobre la barra de herramientas. ← ← 2. Podemos pedir ayuda sobre un comando o paquete particular desde la cónsola de R mediante dos comandos ← > help(tópico o comando preciso) ← > example(comando o paquete preciso) ← ← Por ejemplo ← > help(solve) ← despliega la información sobre el comando solve. Una alternativa es ← > ?solve ← ← 3. Al igual que otros paquetes (como LaTeX), el lenguaje R es sensible a las mayúsculas y signos de puntuación.
Transcript of Apuntes de R 0. Inicio 25/09/2007 20:50:00 · Apuntes de R – 1. Comandos básicos 25/09/2007...

Apuntes de R 0. Inicio 25/09/2007 20:50:00
← 0. R es un lenguaje de programación y cálculo, como MatLab o GNU,
cuyos antecesores son los paquete de cálculos estadísticos S, SSPS, S++. R
funciona mediante una cónsola y diferentes ventanas donde se presentan las
tareas que están siendo ejecutadas en un momento dado. La diferencia
principal entre R y los paquetes de la familia S es que los comandos de éstos
producen y almacenan buena parte de los cálculos intermedios entre la data
y el resultado final deseado; mientras que R únicamente almacena y
presenta el resultado final.
←← 1. El “prompt” o señal de que la cónsola espera un comando de
ejecución puede variar según el SO sea UNIX, WINDOWS o MACOS. En estos
apuntes escribimos
← >
← para el prompt. Para ejecutar un comando en la cónsola se escribe el
nombre del comando y a continuación se pulsa ENTER. Por ejemplo,
← > help + ENTER
← que en adelante escribiremos simplemente
← > help
← es un comando que abre la página de ayuda de R. Esta página web
también se puede abrir con del botón de ayuda sobre la barra de
herramientas.
←← 2. Podemos pedir ayuda sobre un comando o paquete particular desde
la cónsola de R mediante dos comandos
← > help(tópico o comando preciso)
← > example(comando o paquete preciso)
←← Por ejemplo
← > help(solve)
← despliega la información sobre el comando solve. Una alternativa es
← > ?solve
←← 3. Al igual que otros paquetes (como LaTeX), el lenguaje R es sensible
a las mayúsculas y signos de puntuación.

←4. Las variables numéricas, literales o lógicas que están siendo usadas en
memoria, constituyen el “espacio de trabajo” de R. Para chequear desde la
cónsola el espacio de trabajo, se emplea el comando
> objects()
Una alternativa es el comando
> ls()
Para remover alguna o todas las varibles utilizadas se emplea
> rm

Apuntes de R – 1. Comandos básicos 25/09/2007 20:50:00
← 1. Vectores: Probar con los siguientes comandos
← > x<-c(1,2,3)
← asigna el nombre x al vector (1,2,3). Para ver la coordenada j del
vector x se escribe
← > x[j]
← > y<- 1:7
← asigna el nombre y al vector de 7 entradas (1...7). Para hacer vectores
con secuencias no enteras se utiliza el comando sec(). Por ejemplo,
← > z<-seq(1,20,by=.5)
← da 40 entradas de 0,5 en 0,5. Para construir un vector que repita
varias veces las coordenadas se usa la función
← >rep(variable,#repeticiones por variable,#repeticiones por vectores).
← Se puede probar con los siguientes comandos
← > c(x,y,0,y)
← > rep(y,3)
← > rep(y,3,25)
← > c(“a”,”b”)[ rep(c(1,2,2,1), times=4)]
←← 2. Operaciones con vectores
← Las variables vectoriales se operan coordenada a coordenada y por
“múltiplos de entradas”, probar
← > x+y
← > x*y
← > 1/x
← > x+2*y

← > x-3
← Las funciones se aplican coordenada a coordenada, por ejemplo,
← > sin(y)
← > exp(x)
← Las funciones tienen nombres en inglés, exp, sin, cos, ln, sqrt,
etcétera.
← > sum(y)
← da la suma de las 30 entradas de y, sum(x) da 1+2+3=6. Del mismo
modo, > prod(y)
← da el producto de las entradas del vector y.
←← 3. Funciones: Para ver una coordenada de un vector-variable se
utilizan corchetes. x[2] es la segunda coordenada del vector-variable x. De
este modo se pueden utilizar sólo algunas coordenadas o entradas de un
vector-variable. Por ejemplo:
← > q<-1:10
← > q[1:5]
← > exp(-q)[1:5]
←← La raíz cuadrada se puede tomar compleja o real. Si escribimos
← > sqrt(-17)
← obtendremos un NAN (Not Available Number, número no disponible).
Para obtener la raíz compleja debemos escribir
← > sqrt(-17+0i)
←← 4. Definir funciones: Uno puede definir sus propias funciones. Por
ejemplo
← > f<-function(x,y) x/(1+y^2)

← > f(1:10,10:1)
← Como otro ejemplo, una manera de definir el producto escalar entre
dos vectores (de igual longitud) es mediante
← > f<-function(x,y) sum(x*y)/length(x*y)
←←← 5. Graficar: El nombre del número real Pi es “pi”; probar el siguiente
comando
← > u<-seq(0,2*pi,by=0.1)
← > plot(sin(u),cos(u))
← que da como resultado el gráfico de un círculo unitario (ver ficha de
Graficar).
←← 6. Resumen estadístico:
← >Summary(x)
← es el primer comando estadístico de R que veremos en estos apuntes.
Provee un resumen de los estadísticos de la variable aleatoria x, cuartiles,
media, mediana, mínimo y máximo.
←←

Apuntes de R – 2. Graficación (I) 25/09/2007 20:50:00
← 1. El comando básico para graficar es plot(horizontal, vertical) donde
en “horizontal” debe ir una variable independiente y en “vertical” una
variable dependiente. Es decir, este comando plot es para graficación
explícita, no para variables implícitas.
←← Se puede probar con los siguientes comandos
←← > x<-seq(-5,5,by=.01)
← > plot(x,sin(x))
← > plot(x,cos(x),type="l")
←←← > plot(x,exp(x))
← > plot(x,x^2)
← > plot(x,tan(x))
← > plot(x,log(x))
← > plot(x,3*x-1+exp(-x^2))
← > plot(x,3*x-1+1.5*exp(-x^2))
← > plot(x,3*x-1+6*exp(-x^2))
← > plot(x,3*x-1+10*exp(-x^2))
←←← 2. Para graficar es mejor evitar los valores NA (ver ficha de comandos
básicos). Una buena opción es eliminarlos con un comando lógico de
argumento opcional, por ejemplo
←

← > x<-1:30
← > u<-(2*log(x)-3)[(!is.na(x)) & x>.2]
← > plot(x,u)
← Para ver en una tabla los valores de las horizontales y las verticales se
utiliza el comando data.frame(); por ejemplo
← > data.frame(sin(u),cos(u))
← da como resultado una que contiene los 63 pares coordenados de la
gráfica anterior.
←← Para dibujar curvas implícitas en R2, como las cónicas, se suelen
emplear coordenadas polares. Probar la siguiente secuencia de comandos
← > u<-seq(0,2*pi,by=0.1)
← > plot(sin(u),cos(u))
←← Se pueden cambiar los parámetros de un dibujo con
← par(...)
← Algunos parámetros son:
← bg=”...” (back ground) determina el color del fondo
← bty=”...” (box type) determina el gráfico de la caja de coordenadas, los
tipos son "o", "l", "7", "c", "u", or "]". El tipo “n” suprime la
caja.
← cex=... determina la escala numérica del dibujo.
← cex.axis= escala de las letras de los ejes
← cex.lab= escala de las estiquetas de los ejes
← cex.main= escala del texto principal
← cex.sub= escala del subtítulo

← col=”...” color para el dibujo. Del mismo modo hay col.axis, col.lab,
col.main, col.sub.
← fg=”...” (fore ground) color del primer plano de puntos a graficar
← ljoin=”...” (line join) para junta entre líneas, “round”=círculo abierto,
“mitre”=punto ingleteado, “bevel”=biselado
← lty=”...” (line type) tipo de línea, los tipos son “blank” (no pinta las
líneas), “solid" (línea recta continua), "dashed" (segmentada)
"dotted" (punteada) "dotdash"(punto-segmentada), "longdash"
(segmentos más largos).
← lwd=... (line width) grosor de la línea, el argumento es un entero, el
valor por defecto es 1.
← new=TRUE/FALSE parámetro lógico. Si se le asigna el valor TRUE
entonces el próximo gráfico no debería borrar al existente, sino comenzar a
graficar como si el espacio del dibujo estuviese limpio (“nuevo”).
← pty=”...” (point type) el tipo de punto puede ser
←← Por ejemplo,
← par(cex=.4)
← x<-seq(-5,5,by=0.01)
← Col<-c("blue","red","yellow","green","black","magenta")
← for (n in 1:6) {par(col=Col[n])
← plot(x,sin(n*x),type=”l”)
← par(new=TRUE)}
←← Para dibujar una cadena finita de Markov de 100 pasos, con paso
aleatorio entre los puntos equiprobables (+-1,0) y (0,+-1), tenemos el
siguiente algoritmo
←← par(bg="white",col="blue")
← T<-(1/2)*pi*sample(1:4, 100, replace = TRUE, prob =
c(1/4,1/4,1/4,1/4))
← u<-array(0,c(100,2))

← for (n in 1:100) u[n,]<-c(cos(T[n]),sin(T[n]))
← p<-array(0,c(101,2))
← for (n in 2:101) {p[n,]<-p[n-1,]+u[n-1,]}
← plot(p[,1], p[,2])
← polygon(p[,1], p[,2], col= 'pink')
←← Este es un dibujo de segmentos y flechas
← x <- runif(12); y <- rnorm(12)← i <- order(x,y); x <- x[i]; y <- y[i]← plot(x, y, main="arrows(.) and segments(.)")← ## draw arrows from point to point :← s <- seq(length(x)-1)# one shorter than data← arrows(x[s], y[s], x[s+1], y[s+1], col= 1:3)← s <- s[-length(s)]← segments(x[s], y[s], x[s+2], y[s+2], col= 'pink')
←

Apuntes de R – 3. Valores lógicos y literales25/09/2007 20:50:00
← 1. Valores lógicos: son cuatro.
← T=true=cierto,
← F=falso,
← NA=not available=no disponible,
← NAN=not available number=número no disponible,
← Ojo: Los dos últimos no son iguales.
←← 2. Operadores lógico-matemáticos: son ==igualdad exacta, < menor,
> mayor, <= menor o igual, >=mayor o igual, y != para desigual o distinto.
Por ejemplo, si x<-1:10 entonces el comando sin(x)>0 devuelve diez valores
lógicos T F o NA según los valores de las coordenadas de x. El comando
is.na(ln(x)) pregunta, en cada coordenada, si el valor ln(x) no está
disponible. Por ejemplo,
← > z<-c(log(-5:5))
← > y<-z[is.na(z)]
← > w<- z[!is.na(z)]
← > u<-(z+1)[(!is.na(z)) & z>0]
←←← 3. Reemplazar valores NaN:
← Si un vector x tiene coordenadas con el valor NaN, éstas se pueden
reemplazar.
← > x[is.na(x)] <- 0
← Si un vector y tiene coordenadas negativas, éstas se pueden
reemplazar por su valor absoluto. Probar
← > y[y < 0] <- -y[y < 0]
← o bien, la alternativa
← > y <- abs(y)

←← 4. Etiquetas literales: Se pueden poner etiquetas literales a las
variables de los vectores. Probar con los siguientes comandos:
← > etiquetas<-paste(c("pepe","paco","manolo"),1:10,sep=" ")
← > etiquetas
← La salida es
← [1] "pepe 1" "paco 2" "manolo 3" "pepe 4" "paco 5" "manolo 6"
"pepe 7" "paco 8" "manolo 9" "pepe 10"
←← Los valores literales se pueden clasificar a su vez con otras etiquetas
literales. Por ejemplo:
← > names(fruit) <- c("orange", "banana", "apple", "peach")
← > lunch <- fruit[c("apple","orange")]
← > lunch
← apple orange
← 1 5
←

Apuntes de R - 4. Atributos y clases 25/09/2007 20:50:00
← 1. Atributos de un objeto: Las unidades básicas que opera R se llaman
“objetos” y cada objeto tiene atributos asignados.
← Los vectores son objetos con dos atributos: el “modo” y la “longitud”.
Los valores de un vector tienen todos el mismo tipo modo. Hay cuatro
modos de valores/vectores: Lógicos, numéricos, complejos y literales. Se
puede chequear los atributos de un objeto en la cónsola
← > mode(objeto)
← > lenght(objeto)
← > attributes(objeto)
←← 2. Cambio de atributos: Hay comandos para cambiar los atributos de
un objeto. Probar
← > z <- 0:9
← > digits <- as.character(z)
← > d <- as.integer(digits)
←← Incluso un objeto “vacío” debe tener modo, por ejemplo
← > e <- numeric()
← > f <-character()
← Etc. Una vez definido un objeto, el mismo se puede extender
añadiendo coordenadas. Por ejemplo
← > e[3] <- 17
← convierte a e en un vector de longitud 3, cuyas dos primeras
coordenadas son NaN.
← Igualmente se puede recortar la longitud de un vector
← > z <- z[2 * 1:5]
← convierte a z en un objeto de 5 entradas, que guarda las coordenadas
pares del vector anterior (los valores anteriores no son retenidos). Otra
manera de recortar o agrandar vectores es afectar directamente la longitud:
← > length(z) <- 3

←← 3. Clases de objetos: Cada objeto manejado por R tiene una clase, la
cual se puede chequear en cónsola con la función
← > class(objeto)
← Las clase de un objeto puede ser vector, list (lista), array (arreglo),
matrix (matriz), factor y data.frame (tabla de datos que se usa para
graficar); entre otras.

Apuntes de R - 5. Categorizar datos 25/09/2007 20:50:00
← 1. Para categorizar datos se emplean vectores de etiquetas literales y
luego se pueden extraer las distintas etiquetas. Por ejemplo, supongamos
tenemos el vector
←← > hemo<- (8.427885, 8.000042, 11.047349, 8.307965, 8.593702,
8.385527 8.452119, 10.416440, 8.635803, 8.500829, 10.542262,
11.747262, 11.585744, 10.533605, 9.655760, 11.755239, 11.305091,
8.737905, 8.888192, 8.071025, 9.318215, 11.980419, 10.043428,
11.876826, 10.498559, 9.455843, 10.696550, 8.006800, 10.229528,
8.079028)
←← que corresponde a los niveles de hemoglobina de 30 personas, cuyos
sexos y clase económica son respectivamente
←← >
sexo<-c("m","f","f","m","f","m","f","m","m","f","f","f","m","m","f","m","f","m",
"m","f","f","m","m","f","m","m","m","f","f","f")
←← >
clase<-c("F","E","D","E","A","E","C","F","E","F","D","B","B","C","E","F","C","A",
"B","C","D","B","F","E","F","C","D","B","E","F")
←← Para manejar las categorías literales como factores escribimos
← > sexof<-factor(sexo)
← > clasef<-factor(clase)
←← El vecto sexof es el mismo vector sexo, cuyas etiquetas literales ahora
son factores o símbolos, que además han sido contabilizados por “niveles”.
Para ver el número de etiquetas de una categorización se escribe, por
ejemplo
←← > Levels(sexof)
←

← 2. Las categorías convertidas a factores (o etiquetas) sirven para
categorizar los datos y procesarlos según esas etiquetas. Si ahora
quisiéramos conocer las medias de niveles de hemoglobina por sexos,
empleamos el comando tapply() del modo siguiente:
←← > mediahemosex<-tapply(hemo,sexof,mean)
← > mediahemosex
← para ver las medias de la misma data categorizada por clase social
escribimos
←← > mediahemoclase<-tapply(hemo,clasef,mean)
← > mediahemoclase
← El último argumento puede ser cualquier función que se aplique a un
grupo de datos como la media (mean) o la varianza (var). Prueba con
←← > varhemoclase<-tapply(hemo,clasef,var)
← > varhemoclase
←← Uno también puede aplicar funciones construidas por uno mismo, por
ejemplo el error medio estandar de un vector de datos es
← > Ems<- function(z) sqrt(var(z)/length(z))
← > Emshemosex<-tapply(x,sexof,Ems)
← > Emshemosex

Apuntes de R – 6. Estadísticos Básicos (I) 25/09/2007 20:50:00
← 1. Números aleatorios: El comando rnorm(k) provee un vector con k
entradas aleatorias. La distribución de rnorm() es una gaussiana estándar.
Por ejemplo
← > x<-rnorm(100)
← asigna a la letra x un vector de 100 entradas aleatorias. Cada vez que
se ejecuta el comando, cambian los valores de las entradas.
← >summary(x) provee un resumen de los estadísticos elementales de x,
considerada como una V.A. con 100 ocurrencias.
←← 2. Importar datos: Uno puede importar datos de una tabla. Por
ejemplo; consideremos las variables
← x <- 1:20
← > w <- 1 + sqrt(x)/2
← El comando
← > Tabla <- data.frame(x=x, y= x + rnorm(x)*w)
← crea una tabla (data.frame) en la cual la columna y es una nueva
variable que toma los valores de x perturbados por un valor aleatorio que
depende de los valores de w. Esta tabla se almacena completamente en una
nueva variable llamada Tabla. Ahora se pueden importar los datos de esta
tabla para procesar sus estadísticos:
← > fm <- lm(y ~ x, data=Tabla)
← > summary(fm)
← Los valores de los estadísticos que arroja el último comando cambian
cada vez que ejecutamos el bloque de sentencias.
←← Para importar datos de una tabla se emplean tres comandos:
← > system.file(); este comando busca el archivo deseado,
← > file.show; este comando muestra (despliega) la tabla elegida, y
← > read.table; este comando extrae los valores de la tabla para
asignarlos a una nueva variable. Para ver un ejemplo, se puede ejecutar la
siguiente lista de comandos:
←← > filepath <- system.file("data", "morley.tab" , package="datasets")

← Éste es el camino o ubicación del archivo.
← > file.show(filepath)
← Esto despliega la tabla-archivo que se halla en el camino anterior.
← > Tabla<-read.table(filepath)
← Esto extrae los datos de la tabla y los envía a la variable aleatoria
Tabla. Si se quiere ver los archivos de la tabla se puede escribir
← > Tabla
←← A continuación se
← > Tabla$Expt <- factor(Tabla$Expt)
← > Tabla$Run <- factor(Tabla$Run)
← > attach(mm)
← > plot(Expt, Speed, main="Speed of Light Data", xlab="Experiment
No.")
← > frec <- aov(Speed ~ Run + Expt, data=mm)
← > frec0 <- update(frec, . ~ . - Run)
← El gráfico anterior, en efecto, es el de un experimento sobre la
velocidad de la luz...
←← 3. ANOVA: Para realizar el análisis de variabilidad se ejecuta el
comando
← > anova(fm0, fm)
← Para terminar la sesión se escribe
← > detach()
← > rm(frec, frec0)

←← Este es otro ejem. De graficación:
← > detach()
← > rm(fm, fm0)
← > x <- seq(-pi, pi, len=50)
← > y <- x
← > f <- outer(x, y, function(x, y) cos(y)/(1 + x^2))
← > oldpar <- par(no.readonly = TRUE)
← > par(pty="s")
← > contour(x, y, f)
←←← 4. REGRESIÓN: Para ver cómo R realiza una regresión lineal sobre la
variable, ejecuta los siguientes comandos
← > plot(x, y)
← > lrf <- lowess(x, y)
← > lines(x, lrf$y)
← > abline(0, 1, lty=3)
← > abline(coef(fm), col = "red")
←← Para comparar error versus los ajustes,
← > plot(fitted(fm), resid(fm),
← + xlab="Valores ajustados", (los signos + los
pone R
← + ylab="Residuos", automáticamente)
← + main="Residuos vs Ajustes")
←←← La bondad del ajuste depende de cómo la siguiente gráfica se acerca a
la recta bisectriz:
> qqnorm(resid(fm), main="Rankit Plot de Residuos")
←

Apuntes de R – 7. Arreglos y matrices 25/09/2007 20:50:00
← 1. Arreglos: Los arreglos son generalizaciones de vectores. Para
generar arreglos con R se emplea el comando

← > array(obj,tam)
← donde obj=un objeto o lista de datos y tam=tamaño o dimensión del
arreglo en filas x columnas. La sintaxis adecuada de este comando es como
sigue:
←← > x <- array(1:20, dim=c(4,5))
←← asigna al objeto x un arreglo matricial de 4 filas x 5
columnas,en las cuales se disponen los números del 1 al 20.
Uno puede asimismo llamar a las entradas, filas y columnas
del arreglo;
← > x[2,3] llama a la posición (2,3)
← > x[2,] llama a la fila 2
← > x[,3] llama a la columna 3
←← En los índices de los arreglos podemos usar otros arreglos como
argumentos. Probemos con
←← > i <- array(c(1:3,3:1), dim=c(3,2))
← > i
← > x[i]
←← También podemos cambiar los datos de una entrada particular de la
matriz, por ejemplo
←← > x[,1] <- 0
←

← Manda a cero todos los valores de la primera columna.
←← 2. Crear arreglos: Se pueden crear arreglos con listas de datos, he aquí
dos maneras de arreglar un vector de 24 entradas aleatorias:
←← > z<-rnorm(24)
← > Z<-array(z,dim=c(3,2,4))
← > ZB<-array(z,dim=c(6,4))
←← Si la longitud del vector original de datos no coincide con la dimensión
del arreglo, entonces al hacer el arreglo o bien se trunca la lista (si la
dimensión es menor) o bien se vuelve a comenzar la lista (si la dimensión es
mayor).
←← > u<-rnorm(24)
← > v<-1:15
← > U<-array(u,dim=c(5,4))
← > V<-array(v,dim=c(5,4))
←← 3. Operaciones: Las operaciones con arreglos requieren que los
arreglos tengan igual dimensión; probar con
←← > 2*U-1
← > U + V
← > U * V
←

← 4. Producto exterior: Dados dos arreglos A B de dimensiones
respectivas a,b (donde la dimensión de un arreglo es un vector), el producto
exterior de A por B produce un nuevo arreglo de dimensión (a,b) cuyas
entradas se producen coordenada a coordenada. Probar
←← > A<-1:4
← > U %o% A
← > A %o% U
←← Una alternativa para A %o% U es escribir
←← > outer(A,U,*)
←← El último argumento es una función (en este caso el producto usual *),
pero se puede poner cualquier otra función de dos argumentos f(x,y).
Pruébese por ejemplo con
←← > f<-function(x,y) x/(1+y^2)
← > outer(U,A,f)
←← 5. Arreglos traspuestos y permutados: En R hay un comando
←← > aperm(arreglo, perm)
←← que produce una permutación del arreglo según los índices. Si A es un
arreglo de dimensión d, donde a su vez d es un vector de longitud = k; y
pensamos en cualquier permutación de k enteros como un vector s de
longitud k cuyas entradas son precisamente los enteros 1...k; entonces el
comando
←

← > B<-aperm(A,s)
←← produce un nuevo arreglo cuyas entradas satisfacen
← B[s[j[1]],..,s[j[k]]]=A[j[1],..,j[k]] . En particular, el traspuesto de un
arreglo de dos dimensiones (un arreglo “matricial”) A se obtiene mediante el
comando
←← > B <- apero(A, c(2,1))
← Se puede utilizar, en este caso, el comando resumido
← > B <- t(A)
←← 3. Regla de reciclaje de datos:
← i) Toda lista de datos (vector) se lee de izquierda a derecha. Los datos
se vacían de arriba abajo y de izquierda a derecha; es decir, en ORDEN
LEXICOGRÁFICA.
← ii) Todo vector demasiado corto se extiende reciclando sus valores, se
vuelve a leer la lista desde el principio hasta completar la dimensión total del
arreglo.
← iii) Sólo se admiten operaciones entre arreglos con la misma
dimensión.
← Todo vector más largo que una matriz o arreglo sobre el cual opera
genera un error.
←← Esta regla de reciclaje de datos es seguida por R por “defecto”, vale
decir, automáticamente, a menos que se le especifique lo contrario. Para
comprender mejor la manera en que opera dicha regla compárese la manera
de definir las siguientes funciones: Definamos la función
← > f<- function(x,y) sin(x*y)
←← Puesto que el argumento es bilineal, la función f(x,y) es simétrica
(aunque no es bilineal pues la función trigonométrica sin(---) elimina la
linealidad. Esta función (y cualquier otra construida del mismo modo) se
puede emplear para producir matrices simétricas con el comando
← > N<-outer(1:5,1:5,f)
←

← Un error común es pensar que dicha orden es equivalente a
← > M<-array(f(1:5,1:5),dim=c(5,5))
←← Mientras la primera secuencia produce una matriz simétrica, la
segunda produce una matriz que repite la misma columna 5 veces. Una
manera alternativa de obtener la segunda matriz es mediante el comando
← > MB<- array(sin((1:5)^2)),dim=c(5,5))

Apuntes de R –8. Matrices 25/09/2007 20:50:00
← En R las matrices son arreglos 2-dimensionales, es decir, arreglos A
tales que su dimensión d=dim(A) es un vector de longitud 2.
←← 1. Suma: Se hace igual que con los arreglos, A+B es la suma matricial
coordenada a coordenada.
←← 2. Producto: El producto matricial se escribe %*% para distinguirlo del
producto coordenada a coordenada *. Por ejemplo, si X es un vector de
longitud n y A es una matriz cuadrada nxn, entonces X %*% A %*% X es una
forma cuadrática.
←← 3. Trasposición: Como ya se dijo (ver Arreglos), la traspuesta de A se
obtiene con el comando t(A).
←← 4. Diagonal: La diagonal de una matriz A (cuadrada o no), es el vector
que se extrae de los coeficientes de la forma A[j,j]; y se obtiene con el
comando diag(A). Por otra parte, si v es un vector de longitud n; entonces
diag(v) produce una matriz diagonal cuya diagonal es, precisamente, el
vector v.
←← 5. Inversas y sistemas de ecuaciones: La inversa de una matriz
cuadrada A se calcula mediante el comando
←← > solve(A)
←← Sin embargo, el cálculo de inversas matriciales es inestable en R. Dado
un vector b, el sistema Ax=b en R se escribe del modo siguiente
← > x<- A %*% b
←← Para resolver dicho sistema se emplea el comando
← > x<-solve(A,b)
← Este comando es más estable numéricamente que la orden
← > x<-solve(A) %*% b

←← 6. Autovalores: El comando
← > Aut<-eigen(M)
← calcula los autovalores y autovectores de una matriz simétrica M, y los
asigna a un arreglo Aut. El resultado es una lista de dos componentes,
llamados “values” (valores) y “vectors” (vectores).
← > f<-function(x,y) exp(-(x^2)*(y^2))
← > O<-outer(1:10,1:10,f)
← > Aut<-Eigen(O)
←← Para obtener una sola de las componentes, digamos los autovalores,
escribimos
← > Aut$val
← > Aut$vec
←← Otra manera es
← > Autval <- eigen(Sm)$values
←← Para matrices demasiado grandes, si se quiere ahorrar tiempo
evitando que R calcule los autovectores, se puede emplear una variante. Por
ejemplo
← > u<-seq(-10,10,by=.01)
← > P<-outer(u,u,f)
← produce una matriz simétrica de 1000x1000. Aunque R es capaz de
calcular autovalores y autovectores (pruebe eigen(P) si se atreve...) la lista
de retorno es demasiado grande. Una buena alternativa es
← > Autval <- eigen(P, only.values = TRUE)$values
←

← -------------POR TRADUCIR--------------
←← 5.7.5 Least squares fitting and the QR decomposition
←← The function lsfit() returns a list giving results of a least squares fitting
procedure. An assignment such as
←← > ans <- lsfit(X, y)
← gives the results of a least squares fit where y is the vector of
observations and X is the design matrix. See the help facility for more
details, and also for the follow-up function ls.diag() for, among other things,
regression diagnostics. Note that a grand mean term is automatically
included and need not be included explicitly as a column of X. Further note
that you almost always will prefer using lm(.) (see Linear models) to lsfit() for
regression modelling.
←← Another closely related function is qr() and its allies. Consider the
following assignments
←← > Xplus <- qr(X)
← > b <- qr.coef(Xplus, y)
← > fit <- qr.fitted(Xplus, y)
← > res <- qr.resid(Xplus, y)
← These compute the orthogonal projection of y onto the range of X in fit,
the projection onto the orthogonal complement in res and the coefficient
vector for the projection in b, that is, b is essentially the result of the Matlab
`backslash' operator.
←← It is not assumed that X has full column rank. Redundancies will be
discovered and removed as they are found.
←← This alternative is the older, low-level way to perform least squares
calculations. Although still useful in some contexts, it would now generally be
replaced by the statistical models features, as will be discussed in Statistical
models in R.
←

← 5.8 Forming partitioned matrices, cbind() and rbind()
←← As we have already seen informally, matrices can be built up from
other vectors and matrices by the functions cbind() and rbind(). Roughly
cbind() forms matrices by binding together matrices horizontally, or
column-wise, and rbind() vertically, or row-wise.
←← In the assignment
←← > X <- cbind(arg_1, arg_2, arg_3, ...)
← the arguments to cbind() must be either vectors of any length, or
matrices with the same column size, that is the same number of rows. The
result is a matrix with the concatenated arguments arg_1, arg_2, ... forming
the columns.
←← If some of the arguments to cbind() are vectors they may be shorter
than the column size of any matrices present, in which case they are
cyclically extended to match the matrix column size (or the length of the
longest vector if no matrices are given).
←← The function rbind() does the corresponding operation for rows. In this
case any vector argument, possibly cyclically extended, are of course taken
as row vectors.
←← Suppose X1 and X2 have the same number of rows. To combine these
by columns into a matrix X, together with an initial column of 1s we can use
←← > X <- cbind(1, X1, X2)
← The result of rbind() or cbind() always has matrix status. Hence
cbind(x) and rbind(x) are possibly the simplest ways explicitly to allow the
vector x to be treated as a column or row matrix respectively.
←← 5.9 The concatenation function, c(), with arrays
←

← It should be noted that whereas cbind() and rbind() are concatenation
functions that respect dim attributes, the basic c() function does not, but
rather clears numeric objects of all dim and dimnames attributes. This is
occasionally useful in its own right.
←← The official way to coerce an array back to a simple vector object is to
use as.vector()
←← > vec <- as.vector(X)
← However a similar result can be achieved by using c() with just one
argument, simply for this side-effect:
←← > vec <- c(X)
← There are slight differences between the two, but ultimately the choice
between them is largely a matter of style (with the former being preferable).
←← 5.10 Frequency tables from factors
←← Recall that a factor defines a partition into groups. Similarly a pair of
factors defines a two way cross classification, and so on. The function table()
allows frequency tables to be calculated from equal length factors. If there
are k factor arguments, the result is a k-way array of frequencies.
←← Suppose, for example, that statef is a factor giving the state code for
each entry in a data vector. The assignment
←← > statefr <- table(statef)
← gives in statefr a table of frequencies of each state in the sample. The
frequencies are ordered and labelled by the levels attribute of the factor.
This simple case is equivalent to, but more convenient than,
←← > statefr <- tapply(statef, statef, length)
← Further suppose that incomef is a factor giving a suitably defined
“income class” for each entry in the data vector, for example with the cut()
function:
←

← > factor(cut(incomes, breaks = 35+10*(0:7))) -> incomef
← Then to calculate a two-way table of frequencies:
←← > table(incomef,statef)
← statef
← incomef act nsw nt qld sa tas vic wa
← (35,45] 1 1 0 1 0 0 1 0
← (45,55] 1 1 1 1 2 0 1 3
← (55,65] 0 3 1 3 2 2 2 1
← (65,75] 0 1 0 0 0 0 1 0
← Extension to higher-way frequency tables is immediate.

Apuntes de R –9. Listas 25/09/2007 20:50:00
← 1) Qué es una lista? Una lista es una colección de objetos,
categorizados por nombres, llamados “componentes”, que pueden ser
diferentes.
← > Lista <- list(nombre=”Juan”, esposa=”María”,
no.hijos=3,edad.hijos=c(2,4,5))
← Las componentes están numeradas por orden de aparición y se les
llama individualmente
← > Lista[[1]]
← El número de componentes de una lista lo da el comando
← > length(Lista)
← Si uno olvida el número de una componente la puede buscar por su
nombre
← > Lista$esposa
← y las componentes se pueden almacenar en otros vectores
← x<-Lista$edad.hijos
←← 2. Construir una lista: Se hace con el comando
← > Lst <- list(nombre1=objeto_1, ..., nombre_m=objeto_m)
← Si omitimos los nombres, las componentes sólo se pueden especificar
por números. Los objetos asignados a una lista son COPIADOS, de modo que
los originales no son afectados. Una lista puede ser extendida añadiendo
componentes nuevas
← > Lista[5] <- list(matrix=Mat)
← O por concatenación de listas
← ListaABC<-c(lista.A, lista.B, lista.C)

Apuntes de R –10. Archivos de datos 25/09/2007 20:50:00
Una lista de datos es una lista clasificada como “data.frame”. Las listas de
datos tienen restricciones:

• Las componentes son vectores, factores, matrices u otros archivos
de datos.
• Los valores numéricos, lógicos o factores no se alteran. Los valores
literales (caracteres) se CONVIERTEN EN FACTORES.
• Los vectores que forman un archivo de datos (data.frame) tienen la
MISMA LONGITUD y las matrices tienen todas FILAS DE IGUAL
LONGITUD.
←← Una lista cualquiera L1que satisface las propiedades anteriores puede
ser realmacenada o leída como data.frame mediante el comando
← > L2<-As.data.frame(L1)
← Para crear una data.frame se utiliza el comando data.frame. Por ejem,
← > Diario<-data.frame(casa=statef, lote=ingresos, saldo=ingresosf)
←← Añadir y quitar:
← Se pueden añadir listas nuevas a las que se manejan actualmente
mediante el comando
← > attach(cualquier lista vieja)
← Todo lo que ha sido añadido puede luego ser retirado también,
mediante el comando
← > detach(lo que quiera retirar)
←← Para trabajar con archivos de datos (data.frame) es útil tener en
cuenta las siguientes recomendaciones:
• Dado un problema bien definido, junta todas las variables del
problema en una data.frame con un nombre adecuado.
• Al trabajar con un problema de tipo funcional, es mejor dejar la
variable independiente en la posición de la 1ra componente, y la
dependiente en la 2da posición.
• Antes de cerrar un problema, identifica las variables que quieres
conservar en el futuro. Añádelas a la data.frame con asignaciones $
y luego aplica el comando detach(-).
• Borra o remueve todas las cantidades no deseadas del directorio de
trabajo y manténlo limpio de variables temporales, en la medida de
lo posible.
←

←←←←←←←←←
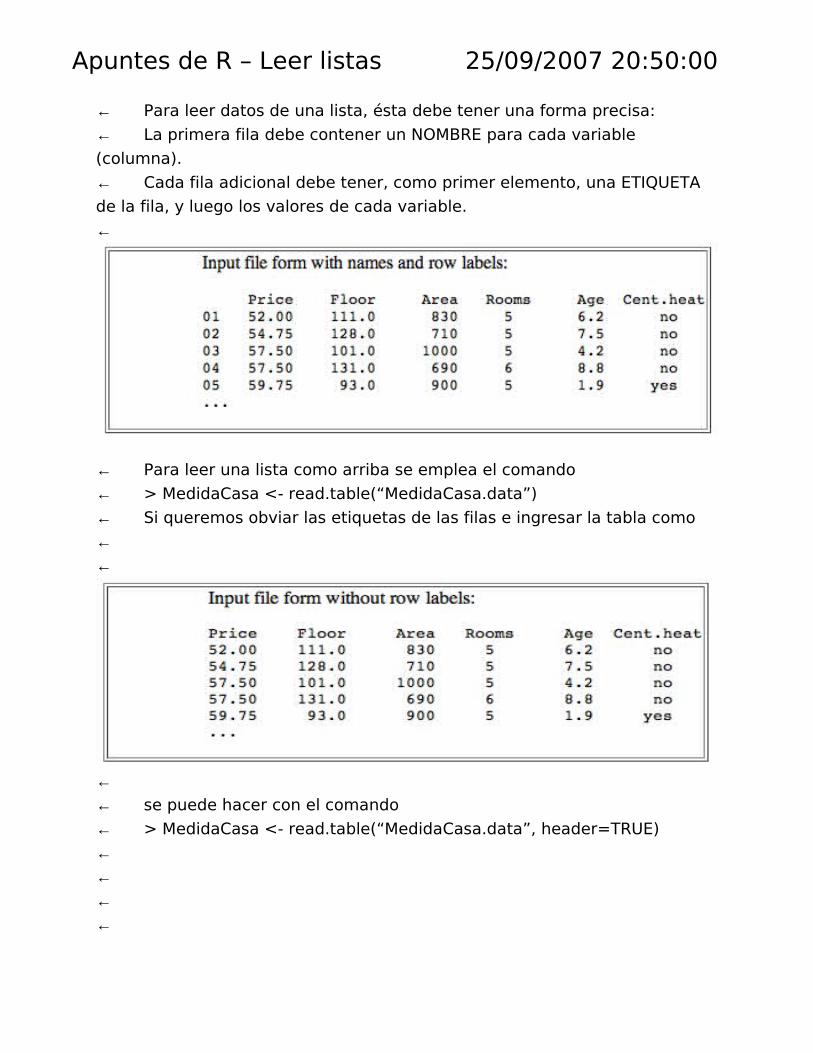
Apuntes de R – Leer listas 25/09/2007 20:50:00
← Para leer datos de una lista, ésta debe tener una forma precisa:
← La primera fila debe contener un NOMBRE para cada variable
(columna).
← Cada fila adicional debe tener, como primer elemento, una ETIQUETA
de la fila, y luego los valores de cada variable.
←
← Para leer una lista como arriba se emplea el comando
← > MedidaCasa <- read.table(“MedidaCasa.data”)
← Si queremos obviar las etiquetas de las filas e ingresar la tabla como
←←
←← se puede hacer con el comando
← > MedidaCasa <- read.table(“MedidaCasa.data”, header=TRUE)
←←←←

←←

Apuntes de R –11. Distribuciones 25/09/2007 20:50:00

25/09/2007 20:50:00

25/09/2007 20:50:00

25/09/2007 20:50:00

25/09/2007 20:50:00
←

25/09/2007 20:50:00

Apuntes de R – Comandos de Ejecución 25/09/2007 20:50:00
← R es un lenguaje de programación y cálculo en el cual toda expresión
(simbólica) es se puede agrupar. Los signos de agrupación en R son los
usuales de Matemáticas: Corchetes [], paréntesis () y llaves {}.
←← 1. Las expresiones o comandos se agrupan con paréntesis o llaves. Los
corchetes se emplean para evaluar coordenadas de vectores o tablas.
←← 2. Cada comando ejecutable devuelve un valor o resultado. El ejemplo
más sencillo de un comando ejecutable es una asignación del tipo x<-1:5; el
resultado en este caso es el valor asignado, que puede ser empleado
ulteriormente.
←← 3. Los comandos se suelen agrupar con llaves del modo
← {expr_1; ...; expr_m}
← El valor de un grupo de expresiones es el resultado de la última
expresión del grupo. Cada grupo de expresiones es, a su vez, una nueva
expresión o comando que puede, a su vez, se incluida entre paréntesis y ser
empleada como parte de una expresión o comando más largo.
←← 4. Ejecución condicional: Es una construcción de la forma
←← > if (expr_1) expr_2 else expr_3
←← donde expr_1 es una expresión de valor lógico simple (no vectorial).
←← Con frecuencia se emplean las abreviaturas &&, || como parte de la
condición. Mientras que los símbolos &, | afectan a vectores (coordenada a
coordenada); los símbolos && y || en cambio afectan a constantes (vectores
de longitud 1) y únicamente evalúan el segundo argumento si es necesario.
←← Una alternativa es el condicional “vectorizado”
←← >ifelse(condition, a, b)

←← que devuelve un vector de la longitud del (vector más largo del)
argumento, con elementos “a[i] if condition[i] is true, otherwise b[i]”.
←← 5. Lazos y ejecución repetida: Se construyen con el comando
←
← > for (N in expr_1) expr_2
←← donde N es la variable contador del lazo, expr_1 es una
expresión/vector (usualmente una secuencia como 1:20), y expr_2 es
usualmente una expresión agrupada cuyas sub-expresiones se escriben en
terminos del contador N. Esta expr_2 es repetidamente evaluada mientras el
contador N corre por la secuencia del vector expr_1.
←← Como ejemplo, supongamos que “ind” es un vector de indicadores de
clase y que queremos producir gráficos separados de y en función de x a lo
largo de las clases. Una posibilidad es emplear el comando “coplot(---)” lo
cual produciría un arreglo de dibujos correspondientes a cada nivel de los
factores/categorías. Otra manera de hacer esto es colocar todos los gráficos
en un “display” como sigue
←← > xc <- split(x, ind)
← > yc <- split(y, ind)
← > for (i in 1:length(yc)) {
← plot(xc[[i]], yc[[i]]);
← abline(lsfit(xc[[i]], yc[[i]]))
← }
←← Notemos que la función “split(---)” produce una lista de vectores
obtenidos mediante la truncación de vectores largos de acuerdo con las
clases especificadas por los factores/categorías. Esta es una función útil,
mayormente empleada junto al comando “boxplots”.
←

← Nota: Los lazos “for(---)” se emplean en R con menos frecuencia que
en lenguajes compilados, pues los lazos que toman un “objeto” dependiendo
de un contador N, en R, se suelen escribir y ejecutar de manera más rápida.
Otras facilidades tipo lazos son
←← > repeat expr
← > while (condition) expr
←← El comando
←← > break
←← se emplea para terminar cualquier lazo, incluso de manera anormal, y
es el único modo de finalizar los lazos que se construyen con el comando
“repeat”. El comando
←← > next
←← se emplea para romper ciclos particulares y saltar al ciclo “siguiente”.
Las secuencias para controlar lazos se suelen construir a través de
funciones.
←← Caminata aleatoria
> m<- readline(“Número de ramas del grafo = ?”) % OJO CON LAS
COMILLAS!!
← > n<- readline(“Número de pasos de la caminata = ?”)
← > M<- as.integer(m)
← > N<- as.integer(n)
← >Arg<-(2*pi/M)*floor(runif(N,0,M))
← >hor<-cos(Arg) % mov. Aleat. Horizontal

← >ver<-sin(Arg) % mov. Aleat. Vertical.
← >C<-0
← >length(C)<-2*(N+1)
← >dim(C)<-c(N+1,2)
← > C[1,1]<-0
← > C[1,2]<-0
← > for (k in 1:N) (C[k+1,1]<-C[k,1]+hor[k])
← > for (k in 1:N) (C[k+2,1]<-C[k,2]+ver[k])
← > plot(C) % pasos aleatorios de la caminata (gráfico de saltos
aleatorios)
← > x<-seq(0,1,by=.01) % variable de las combinaciones convexas
← > u<-0
← > length(u)<-2*(N+1)*length(x)
← >D<-0
← >length(D)<- 2*(N+1)
← >dim(D)<-c(N+1,2)
← >for (k in 1:N) (D[k,]<-C[k+1,])
← > u<-array((1-x)%o%C+x%o%D, dim=c((N+1)*length(x),2))
← > plot(u, type="l", col="magenta") %gráfico de la caminata continua)
←←

25/09/2007 20:50:00

25/09/2007 20:50:00
←

25/09/2007 20:50:00


25/09/2007 20:50:00

25/09/2007 20:50:00
←


















