
Apuntes Aesi Umh
372
1 Universidad Miguel Hernández Curso MODELADO DEL COMPORTAMIENTO DE SISTEMAS INFORMÁTICOS Y DE COMUNICACIONES Impartido por Ramón Puigjaner MATERIAL DOCENTE Elche, 5 de Noviembre de 2001
-
Upload
hector-angel -
Category
Documents
-
view
92 -
download
0
Transcript of Apuntes Aesi Umh

1
Universidad Miguel Hernández
Curso
MODELADO DEL COMPORTAMIENTO DE SISTEMAS INFORMÁTICOS
Y DE COMUNICACIONES
Impartido por
Ramón Puigjaner
MATERIAL DOCENTE
Elche, 5 de Noviembre de 2001

2
TEORÍA DE COLAS 1. Introducción.........................................................................................................................5
1.1. Presentación general....................................................................................................5 1.2. Clasificación de los procesos estocásticos ..................................................................5
1.2.1. Procesos estacionarios .....................................................................................6 1.2.2. Procesos independientes ..................................................................................7 1.2.3. Procesos de Markov ........................................................................................7 1.2.4. Procesos de nacimiento-muerte .......................................................................7 1.2.5. Procesos semimarkovianos..............................................................................8 1.2.6. Recorridos aleatorios .......................................................................................8 1.2.7. Procesos de renovación ...................................................................................8
2. Procesos de Markov ............................................................................................................9 2.1. Procesos estocásticos y cadenas de Markov ...............................................................9
2.1.1. Cadenas de Markov de tiempo continuo (CMTC) ........................................10 2.1.2. Distribución temporal ....................................................................................11 2.1.3. Clasificación de los estados y distribución en régimen estacionario.............12 2.1.4. Notación matricial .........................................................................................13
2.2. Problemática de las cadenas de Markov ...................................................................14
3. Teoría de colas...................................................................................................................15 3.1. Características de un modelo de colas.......................................................................15 3.2. Notación ....................................................................................................................17 3.3. Variables y relaciones Fundamentales ......................................................................17
3.3.1. Variables fundamentales................................................................................18 3.3.2. Relaciones fundamentales .............................................................................18
3.4. El proceso de Poisson................................................................................................21 3.4.1. Distribución de Poisson.................................................................................21 3.4.2. Distribución exponencial...............................................................................22 3.4.3. Propiedades de los procesos de Poisson........................................................23
3.5. Procesos Nacimiento-Muerte ....................................................................................23 3.6. Colas M/M/m/B/K ....................................................................................................26
3.6.1. Cola M/M/1 ...................................................................................................26 3.6.2. Cola M/M/∞ (infinito número de servidores)................................................29 3.6.3. Cola M/M/m ..................................................................................................30 3.6.4. Llegadas desanimadas. ..................................................................................31 3.6.5. Cola M/M/1/B: Almacenamiento finito.........................................................32 3.6.6. Cola M/M/1//K: Población finita...................................................................33 3.6.7. Cola M/M/∞//K..............................................................................................35 3.6.8. Cola M/M/m/B/K ...........................................................................................36 3.6.9. Conclusión.....................................................................................................37
3.7. Cola M/G/1................................................................................................................38 3.7.1. Deducción por el cliente marcado .................................................................38 3.7.2. Deducción por la función generatriz .............................................................41
3.8. Modelo de Skinner ....................................................................................................45 3.9. Colas con prioridades ................................................................................................45
3.9.1. Colas con prioridades sin interrupción ..........................................................45 3.9.2. Colas con prioridades con interrupción .........................................................47
3.10. Sistemas multi-cola ..................................................................................................49 3.10.1. Modelo exhaustivo ........................................................................................50 3.10.2. Modelo con puerta .........................................................................................51

3
3.10.3. Modelo limitado ............................................................................................52 3.11. Colas con clases de clientes......................................................................................52
3.11.1. Cola con servidor compartido........................................................................52 3.11.2. Cola con servidor interrumpible. ...................................................................53 3.11.3. Cola con estrategia de un servidor por cliente...............................................53 3.11.4. Ley de Cox. ...................................................................................................54
3.12. Colas G/G/1: Método de difusión.............................................................................57 3.12.1. Enfoque basado en el teorema del límite central...........................................57 3.12.2. Enfoque basado en el proceso de retorno instantáneo...................................58
4. Teoría de redes de colas.....................................................................................................67 4.1. Introducción ..............................................................................................................67 4.2. Tipos de redes............................................................................................................67 4.3. Métodos analíticos exactos........................................................................................69
4.3.1. Teorema de BCMP ........................................................................................69 4.3.2. Métodos de cálculo de redes cerradas ...........................................................81
4.4. Métodos aproximados ...............................................................................................94 4.4.1. Método de difusión........................................................................................94 4.4.2. Método de descomposición-agregación ........................................................97 4.4.3. Método de descomposición de Courtois......................................................100 4.4.4. Métodos iterativos .......................................................................................108
6. Simulación.......................................................................................................................116 6.1. Generación de secuencias de números aleatorios ...................................................116
6.1.1. Generadores conguenciales lineales ............................................................117 6.2. Comprobación de las secuencias de números aleatorios.........................................120
6.2.1. Procedimientos de test generales para estudiar datos aleatorios .................120 6.2.2. Procedimientos de test empíricos para estudiar secuencias de números
aleatorios......................................................................................................121 6.2.3. Procedimientos de test teóricos para estudiar datos aleatorios....................128
6.3. Generación de números aleatorios no uniformes ....................................................132 6.3.1. Transoformación por la integral de probabilidad inversa............................133 6.3.2. Composición................................................................................................134 6.3.3. Rechazo-Aceptación....................................................................................136 6.3.4. Caracterización ............................................................................................138 6.3.5. Descomposición ..........................................................................................140 6.3.6. Comparación................................................................................................142
6.4. Organización de los simuladores.............................................................................142 6.4.1. Control del tiempo en un simulador ............................................................143 6.4.2. Estructuras de datos en un simulador ..........................................................143
6.5. Análisis estadístico de la simulación y de sus resultados........................................144 6.5.1. Condiciones iniciales, transitorios y equilibrio ...........................................144 6.5.2. Elección de los tamaños de muestra ............................................................144 6.5.3. Métodos para muestras independientes .......................................................148 6.5.4. Métodos para muestras correladas...............................................................151
6.6. Validación y comprobación de modelos de simulación..........................................157 6.7. Herramientas de construcción de modelos..............................................................158
6.7.1. Modelos de simulación................................................................................158 6.7.2. Lenguajes de modelización .........................................................................158

4
MODELADO DE SISTEMAS
1. Introducción.....................................................................................................................160 1.1. La noción de cliente ................................................................................................160 1.2. La noción de estación de servicio ...........................................................................160 1.3. Recolección de información....................................................................................161
2. Modelado de sistemas Informáticos ................................................................................161 2.1. Modelos individuales de subsistemas .....................................................................161
2.1.1. Tambores o discos de cabezas fijas .............................................................161 2.1.2. Discos ........... ..............................................................................................166 2.1.3. Memorias secundarias de estado sólido.......................................................181 2.1.4. Subsistemas secuenciales ............................................................................185 2.1.5. CPU ....... .....................................................................................................185 2.1.6. Memoria principal .......................................................................................188
2.2. Modelos de sistemas informáticos: El servidor central y variantes ........................194 2.2.1. Sistema transaccional ..................................................................................195 2.2.2. Sistema conversacional................................................................................199
4. Modelado y evaluación de redes .....................................................................................288 4.1. Redes malladas........................................................................................................288
4.1.1. Modelos elementales de sus componentes ..................................................288 4.1.2. Modelos globales.........................................................................................290
4.2. Redes con compartición del medio .........................................................................306 4.2.1. Sistema de polling .......................................................................................306 4.2.2. Técnicas de acceso al azar ...........................................................................307
4.3. Redes de área local ..................................................................................................309 4.3.1. Redes locales CSMA/CD ............................................................................309 4.3.2. Redes locales de paso de testigo (token ring)..............................................322 4.3.3. Comparación de estrategias en redes locales: paso de testigo y
CSMA/CD ...................................................................................................335 4.4. Redes digitales de servicios integrados de banda ancha (ATM).............................335
4.4.1. Caracterización de las fuentes de tráfico .....................................................335 4.4.2. Métricas de la calidad del servicio ..............................................................352 4.4.3 Gestión del tráfico .......................................................................................357 4.4.4. Conmutación de celdas ATM......................................................................372

5
TEORÍA DE COLAS
1. INTRODUCCIÓN 1.1. PRESENTACIÓN GENERAL ¿Qué informático no se ha encontrado alguna vez esperando a que su listado saliera por la impresora ocupada en emitir los interminables resultados de una explotación o de otro programador? ¿Quién que se haya sentado en un terminal para trabajar en tiempo compartido en un ordenador no ha tenido que esperar a que su programa entrara en memoria o utilizara suficientemente la CPU? ¿Qué jefe de explotación no se ha visto en la necesidad de hacer esperar programas que no podían ejecutarse por falta de cintas o discos? Existen, como se ve, numerosas circunstancias en que la evaluación del comportamiento de un sistema informático o de comunicaciones debe efectuarse mediante la construcción de un modelo. Ello será así siempre que no exista alguno de los elementos hardware o software que lo componen, como son los casos de: - Instalación de un nuevo sistema o de reconfiguración (cambio de configuración hardware,
consideración de una carga futura, etc.) de uno existente.
- Implantación de nuevas aplicaciones en un sistema existente.
- Diseño de un nuevo computador.
- Diseño de un sistema de comunicaciones (hardware o protocolos).
- etc.
En todos estos casos los modelos de evaluación de prestaciones pretenden poner de manifiesto los retardos y contenciones que se producen cuando más de un cliente (programa, mensaje, acceso, etc.) pretende hacer uso de un mismo servidor (CPU, línea, disco, etc.). La evolución de estos dispositivos puede asimilarse, en general, a un proceso estocástico sometido a determinadas entradas. Es por ello se que empezará analizando los distintos tipos de procesos estocásticos dependiendo de las relaciones que existen en todo instante entre los sucesivos estados.
1.2. CLASIFICACIÓN DE LOS PROCESOS ESTOCÁSTICOS Se considera que un proceso estocástico es una familia de variables aleatorias X(t), que están indexadas por el parámetro t. Se puede imaginar como una partícula que evoluciona a lo largo del tiempo tomando distintos valores. Su clasificación depende de tres cantidades: - el espacio de estado
- el parámetro índice (normalmente el tiempo)
- las dependencias estadísticas entre las variables aleatorias X(t) para distintos valores del índice t.
El conjunto de posibles valores (o estados) que puede tomar X(t) se denomina su espacio de estado. Si las posiciones que la partícula puede ocupar son finitas y contables, se dirá que se tiene un proceso de estados discretos, al cual también se hará referencia como a una cadena. Por el contrario si las posiciones permitidas de la partícula están sobre un intervalo continuo finito o infinito, entonces se dirá que se tiene un proceso de estado continuo. Se considera ahora el parámetro índice (tiempo). Si los instantes en que se producen los cambios de posición de la partícula son finitos o contables, entonces se dirá que se tiene un

6
proceso de tiempo discreto. Si los cambios de posición se producen en cualquier instante dentro de intervalos finitos o infinitos, entonces se dirá que se tiene un proceso de tiempo continuo. En el primer caso se escribirá con frecuencia Xn en vez de X(t) y se denominará secuencia aleatoria o estocástica en vez de proceso aleatorio o estocástico. Ahora bien el punto realmente diferenciador de los distintos tipos de procesos estocásticos es la relación de la variable Xn o X(t) con los valores anteriores o posteriores. Para ello es preciso especificar la función de distribución conjunta de las variables (o vectores) aleatorias X = [X(t1), X(t2), ...], es decir
FX(x, t) = P[X(t1) ≤ x1, ..., X(tn) ≤ xn]
para toda x = (x1, x2, ..., xn), t = (t1, t2, ..., tn) y n. En cualquier caso es la función FX(x, t) la que describe esta relación entre las variables del proceso estocástico. A continuación se describen algunos tipos caracterizados por distintos tipos de relaciones de dependencia entre las variables aleatorias. La figura 1.1 resume los distintos tipos de procesos estocásticos considerados.
Proceso semi-markovianopij arbitrario
Proceso de Markovpij arbitrario
Proceso denacimiento-muertep
ij para |j - i| > 0
f(∆t) sin memoria
Recorrido aleatoriopij = q( j - i )f(∆t) arbitrario
Proceso derenovaciónqa (1) = 1f(∆t) arbitrario
f(∆t) arbitrario
f(∆t) sin memoria
Figura 1.1.
1.2.1. PROCESOS ESTACIONARIOS Se dirá que un proceso estocástico X(t) es estacionario si FX(x, t) es invariante a los desplazamientos de tiempo para todos los valores de sus argumentos; esto es, dada cualquier constante ∆t, debe cumplirse
FX(x, t + ∆t) = FX(x, t)
donde la notación t + ∆tse define como el vector (t1 + ∆t, t2 + ∆t, ..., tn + ∆t).

7
Una noción asociada, la de estacionaridad en sentido amplio, se identifica con el proceso aleatorio X(t) si solamente el primer y el segundo momentos son independientes de su posición en el eje del tiempo, esto es si E[X(t)] es independiente de t y si E[X(t)X(t + ∆t)] depende solo de ∆t, pero no de t. Se observa que todos los procesos estacionarios lo son en sentido amplio, pero no al revés. Evidentemente, la teoría de los procesos estacionarios es más sencilla que la de los no estacionarios.
1.2.2. PROCESOS INDEPENDIENTES El más sencillo y trivial de los procesos estocásticos es la secuencia aleatoria en que Xn forma un conjunto de variables aleatorias independientes, esto es la función de distribución de probabilidad del proceso estocástico puede descomponerse en producto de factores de cada componente
( ) ( ) ( )∏=
==n
iiiXnnXXX tXfttXXftXf
n1
11,..., ,,...,,,...,,1
En este caso se llevan al extremo las cosas al llamar proceso aleatorio a tal secuencia, puesto que no hay estructura ni dependencia entre las variables aleatorias. En caso de un proceso aleatorio continuo puede definirse y hacerse referencia a él como "ruido blanco" (un ejemplo es la derivada respecto al tiempo del movimiento browniano).
1.2.3. PROCESOS DE MARKOV Constituyen una forma sencilla y útil de dependencia entre las variables aleatorias que forman el proceso estocástico. Un proceso de Markov con un espacio de estado discreto se denomina cadena de Markov. La cadena de Markov de tiempo discreto es la más fácil de conceptualizar y comprender. Un conjunto de variables Xn forma una cadena de Markov si la probabilidad que el nuevo estado sea xn + 1 depende solo del estado actual xn y no de los estados anteriores; es decir la dependencia se extiende hacia atrás solo una unidad de tiempo o bien la historia del proceso que afecta a su futuro queda resumida en su estado actual. En el caso de una cadena de Markov de tiempo discreto, los instantes en que el sistema puede cambiar de estado se pueden asimilar a los enteros 0, 1, 2, ..., n, …. En el caso de cadenas de Markov de tiempo continuo, las transiciones entre estados pueden producirse en cualquier instante. Por lo tanto se está obligado a considerar la variable aleatoria que describe durante cuanto tiempo el sistema permanecerá en su estado (discreto) actual antes que se produzca una transición a otro estado. Puesto que la propiedad de Markov exige que toda la historia pasada se resuma en el estado actual, ello impone una fuerte restricción en la distribución del tiempo de proceso residual que el sistema permanecerá en el estado actual. De hecho, como se verá, se exige que la distribución sea sin memoria, lo cual cumplen la distribución exponencial para tiempo continuo y la geométrica para tiempo discreto. Analíticamente la propiedad de Markov puede escribirse como
P[X(tn + 1) = xn + 1 | X(tn) = xn, X(tn - 1) = xn - 1, ..., X(t1) = x1] = P[X(tn + 1) = xn + 1 | X(tn) = xn]
donde t1 < t2 < ... < tn < tn + 1 y xi está incluida en algún espacio de estado discreto.
1.2.4. PROCESOS DE NACIMIENTO-MUERTE Constituyen una clase muy importante dentro de los procesos de Markov y la condición suplementaria que presentan tanto en tiempo continuo como discreto es que las transiciones se producen sólo entre estados vecinos. Esto es, si se elige el conjunto de los enteros como

8
espacio de estado discreto (sin pérdida de generalidad), entonces el proceso de nacimiento-muerte requiere que si Xn = i, entonces Xn + 1 = i - 1, i ó i + 1 y ningún otro.
1.2.5. PROCESOS SEMIMARKOVIANOS En este caso lo que se hace es relajar la exigencia de falta de memoria en las distribuciones que definían los intervalos entre transiciones de los procesos de Markov haciendo que ahora pueda ser cualquier tipo de distribución. Se observa, sin embargo que en los instantes de transición entre estados, el proceso se comporta exactamente como un proceso de Markov ordinario y se dirá que los procesos semimarkovianos tienen un proceso de Markov incluido en los instantes de transición.
1.2.6. RECORRIDOS ALEATORIOS En el estudio de los procesos estocásticos se encuentran a menudo procesos denominados recorridos aleatorios, que se pueden considerar como el que realiza una partícula moviéndose entre los estados de algún espacio de estado (por ejemplo, discreto). El interés consiste en identificar la situación de la partícula en el espacio de estado. El aspecto sobresaliente de un recorrido aleatorio es que la siguiente posición de la partícula es igual a la precedente más una variable aleatoria extraída de una distribución arbitraria y que no cambia con el estado del proceso. Esto es, se dirá que una secuencia Sn es un recorrido aleatorio (iniciado en el origen) si
Sn = X1 + X2 + ... + Xn para n = 1, 2 , …, n.
donde S0 = 0 y X1, X2, … es una secuencia de variables aleatorias con una distribución común. El índice n cuenta solamente el número de transiciones de estado que se han producido. En cualquier caso un recorrido aleatorio no es más que un caso particular de proceso semimarkoviano. En el caso en que la distribución de Xn sea discreta, se tiene en un recorrido aleatorio de estados discretos en cuyo caso la probabilidad pij de ir del estado i al j depende solo de la diferencia de índices j - i (y que se denominará q(j – i)). Un ejemplo de recorrido aleatorio en tiempo continuo es el movimiento browniano y en tiempo discreto es el del número total de caras obtenido al lanzar una moneda al aire.
1.2.7. PROCESOS DE RENOVACIÓN Los procesos de renovación constituyen una clase particular de los recorridos aleatorios en los que el interés consiste en contar las transiciones que se han producido, más que en saber donde se halla la partícula en un instante cualquiera. Esto es, se considera un eje de tiempo real en el cual se ha situado la secuencia de puntos correspondiendo a los instantes de transición. La distribución de los tiempos entre puntos consecutivos sigue una función arbitraria. Se supone que el proceso empieza en el estado 0 (esto es, X(0) = 0) y que aumenta de una unidad en cada transición; esto es, X(t) es igual al número de transiciones que se han producido en el periodo t. En este sentido es un caso especial de recorrido aleatorio en que q1 = 1 y qi = 0 para i ≠ 1. Por otro lado se puede considerar que la ecuación que describe un proceso de renovación en que Sn es la variable aleatoria que representa el instante en que se produce la n-ésima transición. Como antes la secuencia Xn es un conjunto de variables aleatorias independientes distribuidas idénticamente, donde Xn representa ahora el tiempo entre las transiciones n - 1 y n. Hay que ser cuidadoso con la interpretación de la ecuación que describe un proceso de renovación ya que cuando se aplica a un proceso de renovación describe el

9
instante de la n-ésima transición, mientras que cuando se refiere a un recorrido aleatorio describe el estado del proceso y el tiempo entre transiciones es alguna otra variable aleatoria.
2. PROCESOS DE MARKOV En este capítulo se van a introducir algunos conceptos sobre Procesos de Markov, sin profundizar demasiado en sus aspectos matemáticos. Sin embargo, sí que es interesante su utilización como herramienta para validar los sistemas tolerantes a fallos y para construir modelos de prestaciones de sistemas informáticos y teleinformáticos, y por ello interesa su conocimiento.
2.1. PROCESOS ESTOCÁSTICOS Y CADENAS DE MARKOV Los procesos estocásticos constituyen un área de gran importancia dentro de la metodología estadística, siendo la herramienta fundamental para el análisis de fenómenos aleatorios dinámicos. Es decir, para el estudio de variables que fluctúan aleatoriamente en el tiempo. Sus campos de aplicación abarcan desde la predicción, (en áreas como la economía, la climatología, etc.), al control estadístico de procesos (de gran importancia en la industria) y a la optimización de sistemas aleatorios dinámicos. El estudio de problemas de garantía de funcionamiento y prestaciones de sistemas informáticos requiere unas herramientas analíticas muy potentes. Muchas de estas herramientas tienen sus fundamentos, precisamente, en la teoría de procesos estocásticos y más concretamente en los procesos y cadenas de Markov. Un proceso estocástico es una familia de variables aleatorias X(t), t ≥ T, definidas en un espacio probabilístico, indexadas por el parámetro t, donde t varía dentro de un conjunto de índices T. Los valores que toma la variable aleatoria X(t) se llaman estados, y el conjunto de todos los posibles valores forman el espacio de estados, S, del proceso. Si el espacio de estados de un proceso estocástico es discreto, entonces se llama proceso de estado discreto o cadena. En este caso el espacio de estados suele ser el conjunto de los números naturales N = 0, 1, 2, …, o un subconjunto de él. Alternativamente, si el espacio de estados es continuo, entonces se tiene un proceso de estado continuo. Del mismo modo, si el conjunto de índices t es discreto, entonces se tiene un proceso de parámetro discreto; en caso contrario se tiene un proceso de parámetro continuo, donde normalmente T = [0, ∞). Los procesos estocásticos con espacio de estados discreto y parámetro continuo son los que se usan más frecuentemente en los modelos de prestaciones y de tolerancia a fallos. Por ello en el resto de este apartado sólo se tratará este tipo de procesos estocásticos. Aunque todo lo dicho para éstos es extensible para procesos estocásticos de parámetro discreto. Un proceso de Markov es un proceso estocástico cuyo comportamiento dinámico es tal que las distribuciones de probabilidad para su desarrollo futuro dependen sólo del estado actual y no de cómo el proceso llegó a ese estado. Es decir, para t0 < t1 < t2 < … < tn < t, con t y tr ≥ 0 (r = 0, 1, …, n), su función de distribución de probabilidad condicional satisface la siguiente relación, conocida como la propiedad de Markov:
( ) ( ) ( ) ( )[ ] ( ) ( )[ ]nnnnnn xtXxtXPxtXxtXxtXxtXP =≤====≤ −− |,...,,| 0011
Si se considera que el espacio de estados, S, es discreto (finito o contablemente infinito), entonces el proceso de Markov se conoce como cadena de Markov. Si además se considera que el espacio paramétrico, t, es continuo, entonces se tiene una cadena de Markov de parámetro continuo (CMTC). Esto significa que las transiciones desde un estado dado a otro tienen lugar en cualquier instante de tiempo.

10
Si el comportamiento del proceso no depende del instante de observación, se puede elegir de forma arbitraria el origen del eje de tiempos. Por lo tanto se puede afirmar que
( ) ( )[ ] ( ) ( )[ ]nnnn xXxttXPxtXxtXP =≤−==≤ 0||
Una cadena de Markov se dice que es homogénea si cumple la anterior condición. En este capítulo sólo se tratarán cadenas de Markov homogéneas. Una implicación importante de la propiedad de Markov es que la distribución del tiempo de permanencia en cualquier estado debe carecer de memoria. En realidad, si la evolución futura depende sólo del estado actual, no puede depender de la cantidad de tiempo que el proceso ya ha consumido en ese estado. Esto, emparejado con la observación que para una variable aleatoria continua W la única función de densidad que satisface la propiedad de ausencia de memoria
[ ] [ ]τ≥=≥τ+≥ WPtWtWP |
es la exponencial negativa,
( ) ,0 , ≥= − waewf awW
lleva a la conclusión que los tiempos de permanencia en los estados de una CMTC deben ser variables aleatorias distribuidas exponencialmente.
2.1.1. CADENAS DE MARKOV DE TIEMPO CONTINUO (CMTC) Concretando la propiedad de Markov para tiempo continuo y espacio discreto se obtiene la definición de una CMTC: El proceso estocástico X(t) , t ≥ 0 es una CMTC si cumple la condición:
( ) ( ) ( ) ( )[ ] ( ) ( )[ ] |,...,,| 11001111 nnnnnnnnnn xtXxtXPxtXxtXxtXxtXP ≤≤=≤≤≤≤ ++−−++
para 01 ... ttt nn ≥≥≥+ y todo n ≥ N, todo xk ∈ S, y todas las secuencias t0, t1, …, tn + 1. La expresión de la parte derecha de la ecuación anterior es la probabilidad de transición de la cadena, y denota la probabilidad que el proceso vaya desde el estado xn al estado xn + 1. Se utilizará la siguiente notación:
( ) ( ) ( )[ ]itXjXPtpij ==Θ=Θ |,
para identificar la probabilidad que el proceso esté en el estado j en el instante Θ, si estaba en el estado i en el instante t, suponiendo Θ > t. Cuando Θ = t se puede definir
( ) =
=contrario casoen ,0
si ,1,
jittpij
Si la CMTC es homogénea, las probabilidades de transición sólo dependen de la diferencia τ = Θ - t, por lo que se puede simplificar la notación escribiendo:
( ) ( ) ( )[ ]itXjtXPpij ==τ+=τ |
para indicar la probabilidad que el proceso esté en el estado j después de un intervalo de longitud τ, dado que actualmente está en el estado i. La suma de todos los pij(τ) para todos los posibles estados j en el espacio de estados S vale 1 para todos los valores de τ.

11
2.1.2. DISTRIBUCIÓN TEMPORAL La probabilidad que el proceso se encuentre en un estado i en un instante dado t:
( ) ( )[ ]itXPti ==π
puede calcularse a partir de las probabilidades de transición y de la distribución inicial del proceso. Utilizando el teorema de la probabilidad total, se obtiene:
( ) ( ) ( )∑∈
π=πSj
jjii tpt 0
Por lo tanto, el comportamiento probabilístico del proceso queda determinado conociendo la distribución inicial y las probabilidades de transición. Utilizando la propiedad de Markov, se puede obtener la ecuación de Chapman-Kolmogorov para una CMTC homogénea que relaciona las probabilidades de transición a lo largo del tiempo:
( ) ( ) ( )∑∈
ΘΘ−=Sk
kjikij ptptp
En el caso de tiempo continuo, para obtener las probabilidades de transición es necesario resolver un sistema de ecuaciones diferenciales que se derivan de la ecuación de Chapman-Kolmogorov. Se define:
( )ji
ttp
q ijtij ≠
∆
∆= →∆ para ,lim 0
( )ttp
q jjtjj ∆
−∆= →∆
1lim 0
Puede demostrarse que tales límites existen bajo ciertas condiciones de regularidad. La interpretación intuitiva de estas dos cantidades es la siguiente. Dado que el sistema está en el estado i en algún instante de tiempo t, la probabilidad que se produzca una transición al estado j en un intervalo de longitud ∆t es qij∆t. La tasa con la que el proceso se mueve desde el estado i al estado j es igual a qij. Del mismo modo, -qii∆t es la probabilidad que el proceso se mueva desde el estado i hacia cualquier otro estado en un intervalo de duración ∆t. En consecuencia, -qii es la tasa con la que el proceso abandona el estado i. Se supondrá que qij es finito para todo i,j ∈ S. Obsérvese que:
SiqSj
ij ∈∀=∑∈
,0
De la expresión de pij(t) se puede escribir
( ) ( ) ( ) ( )[ ] ( )ΘΘ−−Θ−∆+=−∆+ ∑∈
kjSk
ikikijij ptpttptpttp
Dividiendo ambos lados por ∆t y tomando el límite para 0→∆t y t→Θ , se obtiene:
( ) ( )∑∈
=Sk
kjikij tpqdt
tdp

12
Esta ecuación se conoce como ecuación posterior de Kolmogorov. Del mismo modo, se puede derivar la ecuación anterior de Kolmogorov:
( ) ( )∑∈
=Sk
ikkjij tpqdt
tdp
Estos resultados, junto con la propiedad que la suma de las probabilidades en todo instante es igual a 1, da un sistema de ecuaciones diferenciales cuya solución proporciona la distribución del proceso sobre el espacio de estados S en un instante t arbitrario:
( ) ( )∑∈
π=π
Sjjji
i tqdt
td
En muchos casos, la solución explícita de este sistema de ecuaciones diferenciales es difícil de obtener. En estos casos se debe recurrir a la integración numérica. A veces, no es necesario obtener la distribución temporal, ya que cuando existe la solución en régimen estacionario, que puede ser útil para muchas aplicaciones prácticas.
2.1.3. CLASIFICACIÓN DE LOS ESTADOS Y DISTRIBUCIÓN EN RÉGIMEN ESTACIONARIO
Las condiciones para la existencia de la distribución en régimen estacionario depende de la estructura de la cadena y de la clasificación de los estados. Se define hj como el instante de la primera visita al estado j, es decir, el instante en que el proceso entra por primera vez en el estado j, después de abandonar el estado actual. Además, se define:
( )[ ]iXhPf jij =∞<= 0| como la probabilidad de visitar el estado j en un tiempo finito partiendo del estado i. Se dice que un estado j es transitorio (o no recurrente) si y sólo si hay una probabilidad positiva de que el proceso no vuelva al estado j después de abandonarlo; es decir, si fjj < 1. Un estado j se dice que es recurrente si y sólo si, partiendo del estado j, el proceso vuelve en un tiempo finito al estado j con probabilidad 1: es decir, si fjj = 1. Un estado i se dice que es absorbente si qij = 0 para todo j ≠ i, por tanto si qii = 1. Un estado j se dice que es alcanzable desde el estado i si para algún t > 0, pij(t) > 0. Un subconjunto A del espacio de estados S se dice que es cerrado si
∑ ∑∈ ∈
=Ai Aj
ijq 0
En este caso pij(t) = 0 para todo i ∈ A, todo Aj ∈ , y todo t > 0. De este modo, los estados de A no son alcanzables desde estados de A . Después de definir las propiedades de los estados individuales, se va a definir una importante propiedad de una cadena de Markov considerada como un todo. Una cadena de Markov se dice que es irreducible si S es cerrado y ningún subconjunto propio de S es cerrado. Es decir, si cada estado de S es alcanzable desde cualquier otro estado. Se definen las probabilidades límite πj, j ∈ S como
( )tjtj π=π ∞→lim

13
Puede demostrarse que para toda CMTC irreducible y homogénea los límites anteriores existen y son independientes de la distribución inicial πj(t), j ∈ S ; por otra parte, cuando existen los límites:
( )0lim =
π∞→ dt
td jt
se obtiene siguiente el sistema de ecuaciones lineales de modo que:
∑∈
=πSj
jjiq 0
Ya que éste es un sistema homogéneo, una posible solución es πi =0 para todo i ∈ S. Si ésta es la única solución del sistema, entonces no existe la distribución estacionaria para la CMTC. Si, en cambio, existen otras soluciones, entonces la única distribución límite de la CMTC se obtiene imponiendo la condición de normalización:
∑∈
=πSi
i 1
En este caso los estados de la CMTC son recurrentes, no nulos y ergódicos, de modo que se dice que la propia cadena es ergódica. Las probabilidades límite de una cadena de Markov ergódica satisfacen la relación
( )tpijtj ∞→=π lim
Las distribución límite de una CMTC ergódica se llama también distribución en equilibrio o en régimen estacionario. El tiempo medio de recurrencia para un estado j, Mj, se define como el tiempo medio transcurrido entre dos instantes sucesivos en los que el proceso entra en el estado j. Puede demostrarse que:
jjjj q
Mπ
=1
2.1.4. NOTACIÓN MATRICIAL Se van expresar en notación matricial algunos de los resultados más importantes introducidos hasta aquí. Se utiliza esta notación principalmente por la comodidad de manejo que proporciona. Se define la matriz de probabilidades de transición P(t) como
( ) ( )[ ] ( ) IPP == 0,tpt ij
y se define π(t) como el vector de probabilidades de estar en cada estado en el instante t
π(t) = π1(t), π2(t), …
La ecuación que describe la evolución del estado del sistema puede escribirse en forma matricial como:
π(t) = π(0)P(t),
y la ecuación de Chapman-Kolmogorov como:

14
P(t) = P(t - Θ)P(Θ)
Se puede, también, definir la matriz:
Q = [qij]
que se denomina tanto generador infinitesimal de la matriz de probabilidades de transición P(t) como matriz de tasas de transición. Las ecuaciones posterior y anterior de Kolmogorov pueden escribir en forma matricial, obteniéndose, respectivamente:
( ) ( )tdt
td QPP=
( ) ( )QPP tdt
td=
Estas ecuaciones admiten la solución general siguiente:
( ) tet QP =
que es más elegante desde un punto de vista formal, pero con la misma dificultad de evaluación. Las ecuaciones diferenciales que describen las probabilidades de estar en determinado estado en un instante t se pueden reescribir como:
( )Qtdtd
ππ
=
Finalmente, la ecuación matricial que define la distribución en régimen estacionario de una CMTC ergódica es:
πQ = 0 donde π = π1, π2, ….
2.2. PROBLEMÁTICA DE LAS CADENAS DE MARKOV El principal problema que presentan las cadenas de Markov es el de su dimensión. Debido a la explosión de estados, los modelos de sistemas complejos se convierten en intratables analíticamente. Se han desarrollado algunas técnicas para reducir la complejidad del problema. La solución más común, como se estudiará en el apartado 4.4.3. consiste en dividir el sistema en un conjunto de subsistemas menores, resolver estos subsistemas separadamente, y combinar estas soluciones parciales para obtener la solución del sistema global. Esta técnica se conoce como descomposición estructural. Una alternativa a ésta es la descomposición funcional, que se puede aplicar cuando los tiempos entre eventos siguen dinámicas de velocidades distintas, que, en algunos casos, pueden llegar a ser varios órdenes de magnitud mayores. Muchos de los modelos que se estudiarán en los apartados que siguen pueden representarse por cadenas de Markov. No obstante, atendiendo a la particularidad de su estructura disponen de métodos que permiten hallar su solución en régimen estacionario con un esfuerzo de cálculo notablemente inferior.

15
3. TEORÍA DE COLAS En los computadores es frecuente encontrar a diversos trabajos compartiendo un número limitado de recursos, tales como la CPU, los discos u otros dispositivos. Generalmente, sólo uno (o unos pocos) de los trabajos puede utilizar el recurso mientras que los demás esperan en cola. La teoría de colas de espera es una herramienta matemática que permite cuantificar el fenómeno de formación de colas. A través de ella se intentará calcular el tiempo que pasa un trabajo en cada una de las colas que se forman en un sistema (y por tanto, el tiempo total que pasa un trabajo dentro del sistema o tiempo de respuesta), la longitud media de estas colas y otra serie de parámetros que ayudarán a determinar las prestaciones del sistema. No es por tanto sorprendente que la teoría de colas sea tan popular entre los que se dedican a evaluar las prestaciones de los sistemas de computación.
3.1. CARACTERÍSTICAS DE UN MODELO DE COLAS Se puede imaginar un grupo de estudiantes de informática esperando en la sala de terminales del centro de cálculo. Existe un número determinado (y limitado) de terminales a disposición de los alumnos. Si cuando llega un estudiante todos los terminales están ocupados, éste pasa a esperar en la cola. En términos de teoría de colas, los estudiantes suelen llamarse clientes1. Para abordar el estudio de la formación de colas de espera, se utilizará un modelo abstracto que se denominará estación de servicio. La estación de servicio está compuesta por un servidor o conjunto de servidores que representan al recurso y una cola de espera, que en cada momento contendrá a aquellos clientes que a su llegada a la estación de servicio encuentran al servidor o servidores ocupados (figura 3.1).
Figura 3.1.
En el ejemplo de los estudiantes, la estación de servicio es el centro de cálculo, los servidores son los terminales y los estudiantes que llegan cuando todos éstos están ocupados forman la cola de espera. Para analizar este sistema se han de que especificar las siguientes características: - Proceso de llegada. Si se denominan t1, t2, … , tj a los instantes en los que se producen las
llegadas de los estudiantes, las variables Tj = tj - tj - 1 representarán los tiempos entre llegadas. El proceso de llegada más simple corresponde al caso T1 = T2 = … = Tj = … = constante, que se denomina proceso de llegadas regulares o determinista. Sin embargo, para muchas aplicaciones se trata de un modelo poco realista y que, además, no tiene un tratamiento matemático sencillo. En general, se supondrá que las Tj forman una secuencia de variables aleatorias idéntica e independientemente distribuidas (IID). El proceso de llegadas que se utilizará con mayor frecuencia es el proceso de Poisson que corresponde al caso en el que los tiempos entre llegadas tienen una distribución exponencial. En algunas ocasiones se utilizan otros procesos, como los que corresponden al caso de tiempos entre llegadas con una distribución de Erlang o hiperexponencial. De hecho hay muchos resultados de la teoría de colas que son válidos para todas las distribuciones del tiempo entre llegadas. En estos casos, se dice que el resultado es válido para una distribución general.
1. En estos temas se utilizarán los términos "cliente'', "trabajo'' o "tarea'' según convenga para hacer referencias
a lo que circula a través de las estaciones de servicio, esperando en la colas y recibiendo servicio en los servidores

16
- Distribución del tiempo de servicio. Se necesita conocer cuál es el tiempo que cada estudiante pasa en un terminal. Esto es lo que se denomina tiempo de servicio. Generalmente se supondrá que el tiempo de servicio es una variable aleatoria IID. La distribución más extensamente utilizada es la exponencial, aunque ocasionalmente se utilizan la de Erlang, la hiperexponencial y la general. De nuevo, un resultado obtenido para una distribución general es válido para todas las distribuciones.
- Número de servidores. Puesto que la sala de terminales puede contener uno o varios terminales, se supondrá que todos los terminales son idénticos y que forman parte del mismo sistema de colas. De esta forma cualquier terminal puede ser asignado a cualquier estudiante.
- Tipo de servidores. Hace referencia al comportamiento de los servidores respecto de los clientes. Pueden, por ejemplo, actuar buscando en la cola inmediatamente después de la salida de un cliente o esperar un tiempo antes de hacerlo y si no encuentran ningún cliente esperando dejar pasar un nuevo intervalo antes de volver a mirar en la cola.
- Capacidad del sistema. Es el máximo número de clientes que pueden permanecer en la estación de servicio: haciendo uso de los servidores o esperando. Esta restricción puede surgir debido a limitaciones de espacio o para evitar la formación de largas colas. Cuando la capacidad del sistema es grande, suponer una capacidad infinita facilita el análisis matemático. Nótese que la capacidad del sistema incluye a los que están recibiendo servicio y a los que están esperando en la cola.
- Tamaño de la población. El número total de clientes que pueden llegar a la estación de servicio es el tamaño de la población. En la mayoría de sistemas reales el tamaño de la población es finito. Sin embargo, la población finita presenta mayor complejidad matemática ya que, en un instante determinado, el número de clientes que ya está en la estación de servicio afecta al número de clientes que potencialmente pueden llegar a la estación. Por tanto, si la población es grande, se facilita el análisis suponiéndola infinita.
- Política de servicio. Es la forma de seleccionar cuál de los clientes que esperan en cola pasará a utilizar un servidor, en el momento que uno de ellos quede libre. Hay varias estrategias:
* First Come, First Served (FCFS) o FIFO, los clientes se sirven en el orden de llegada.
* Last Come, First Served (LCFS) o LIFO, los clientes se sirven en el orden inverso al de llegada.
* Round-Robin (RR), se ofrece una cantidad de servicio fija y pequeña a cada cliente, de forma circular.
* Procesador compartido (Processor Sharing , PS), es el límite de la RR cuando se dedican tiempos de servicio infinitesimalmente pequeños a cada cliente.
* Al azar (Service In Random Order, SIRO), los clientes que esperan en cola se atienden en orden aleatorio.
* Prioridad, para que se pueda aplicar una política prioritaria, debe ser posible distinguir distintas clases de clientes. Se otorga preferencia a unas clases sobre otras. Se puede suponer también que hay una cola para cada prioridad ordenadas según la política correspondiente. Cuando el cliente que llega puede tener prioridad sobre el que está recibiendo servicio (ocurre en la LCFS o cuando tienen distintas prioridades) se deberá indicar si el esquema de prioridades afecta únicamente a los clientes que están en cola o a todos (incluyendo los que reciben servicio), dando lugar a tres modalidades:

17
. No expulsiva, (Non preemptive): los clientes que están en el servidor no son afectados.
. Expulsiva con reanudación, (Preemptive-resume): el esquema de prioridades se extiende a los clientes que están recibiendo servicio. Por lo tanto, si un cliente que llega tiene mayor prioridad que alguno de los que está recibiendo servicio, uno de éstos es desalojado por el recién llegado. Cuando el cliente desalojado llega de nuevo al servidor, reemprende el servicio en el punto donde lo dejó.
. Expulsiva con reinicialización, (Preemptive-restart): como la anterior, pero cuando un cliente desalojado llega de nuevo al servidor debe comenzar su servicio como si nunca antes lo hubiera recibido.
3.2. NOTACIÓN Para especificar un modelo de colas se deberán especificar seis parámetros de los que se han listado en el apartado anterior. Para hacerlo de una forma compacta se suele utilizar una notación abreviada introducida por Kendall. La forma general es la siguiente:
A/S/m [/B/K/DS]
Los tres últimos parámetros, si no se explicitan, toman un valor por defecto, donde, - A es la distribución del tiempo entre llegadas,
- S es la distribución del tiempo de servicio,
- m es el número de servidores,
- B es la capacidad del sistema (valor por defecto: infinito),
- K es el tamaño de la población (valor por defecto: infinito),
- DS es la política de servicio (valor por defecto: FCFS).
Tanto A como S simbolizan distribuciones de probabilidad y se representarán mediante una única letra con el siguiente significado: - M Exponencial (o Markoviana),
- Ek Erlang con parámetro k,
- Hk Hiperexponencial con parámetro k,
- D Determinista,
- G General.
En estas distribuciones se supondrá que las llegadas se producen individualmente y que cada servidor atiende a solo un cliente en cada instante. Pueden darse en la realidad procesos de llegada o de servicio que se produzcan en grupos. En estos casos, el tamaño de estos grupos, si se supone constante, se indica mediante un superíndice. Por ejemplo una llegada de Poisson en grupo se representa por Mx, siendo x el tamaño del grupo. DS representa la política de servicio y suele especificarse por una de la de las siguientes siglas: FCFS, LCFS, PS, … cuyo significado se ha visto en el apartado anterior.
3.3. VARIABLES Y RELACIONES FUNDAMENTALES En apartados posteriores se estudiará con cierto detalle el funcionamiento de distintos tipos de estaciones de servicio. Se revisan aquí algunas relaciones sencillas, pero generales, entre algunas de las variables que caracterizan el comportamiento de un modelo de colas.

18
3.3.1. VARIABLES FUNDAMENTALES Las variables más importantes que se estudiarán para caracterizar el comportamiento de un modelo de colas son: - T, tiempo entre llegadas, es decir, el tiempo que transcurre entre dos llegadas sucesivas. Es
una variable aleatoria.
- λ, frecuencia o tasa media de llegada, igual a 1/E[T]
- S, variable aleatoria que representa el tiempo de servicio de cada trabajo.
- µ, capacidad o tasa media de servicio, igual a 1/E[S] de cada servidor. Es el número medio de trabajos que es capaz de atender un servidor por unidad de tiempo. En un sistema con m servidores la capacidad total de servicio es mµ.
- N, número de trabajos en la estación de servicio (variable aleatoria discreta).
- Nq, número de trabajos en espera de recibir servicio (variable aleatoria discreta). Es un número siempre menor que N ya que no incluye a los trabajos que están recibiendo servicio.
- Ns, número de trabajos recibiendo servicio (variable aleatoria discreta).
- R, tiempo de respuesta del sistema (variable aleatoria). Incluye tanto el tiempo de espera como el tiempo de servicio.
- W, tiempo de espera en cola (variable aleatoria).
3.3.2. RELACIONES FUNDAMENTALES Algunas relaciones simples entre estas variables son: - Condición de estabilidad: Si el número de trabajos en el sistema crece continuamente,
tendiendo a infinito, se dice que el sistema es inestable. Para que el sistema sea estable, la tasa media de llegadas debe ser menor que la tasa media de servicio:
λ < mµ
donde m es el número de servidores. Esta condición de estabilidad no se aplica a sistemas con población y/o capacidad finitas, dado que en estos sistemas el tamaño de la cola no puede crecer indefinidamente.
- Ecuación del número de trabajos: El número de trabajos en el sistema es igual al número de trabajos en la cola más el número de trabajos en el servidor:
N = Nq + Ns
donde N, Nq, Ns son variables aleatorias. Esta relación también se cumple para las medias:
E[N] = E[Nq] + E[Ns]
- Ecuación del tiempo: El tiempo que pasa un trabajo en la estación de servicio es igual a la suma del tiempo de espera en cola más el tiempo de servicio:
R = W + S
Nótese que R, W, S son variables aleatorias y que esta relación se puede aplicar a los valores medios:
E[R] = E[W] + E[S]

19
- Ley de Little: Una de las relaciones más importantes y útiles de la teoría de colas es la ley de Little, que permite relacionar el número de trabajos en un sistema, con el tiempo que pasa un trabajo en el sistema. De una forma general la ley se puede enunciar de la siguiente forma:
Número medio de trabajos en el sistema =
= Frecuencia de llegada × tiempo medio de respuesta.
Esta relación se aplica a todos los sistemas (o partes de un sistema) en los que el número de trabajos que entran es igual al número de trabajos que completan su servicio. Es decir, la única condición para que la relación sea aplicable es que no se cree ningún trabajo en el sistema y no se pierdan trabajos dentro del sistema. Incluso en los sistemas en los que algunos trabajos se pierden debido a su capacidad limitada, la ley puede aplicarse a la parte del sistema compuesta por la cola de espera y el servidor, ya que una vez que un trabajo entra en la cola (o servidor) ya no se pierde. En este caso, se ha que ajustar la tasa de llegada para excluir los trabajos que se pierden antes de entrar en la cola.
A continuación, se propone una justificación simple de la ley de Little. Se monitoriza el sistema durante un intervalo de tiempo T y se registran todas las llegadas y salidas de clientes que se producen en este intervalo. Si T es grande, el número de llegadas puede considerarse igual al número de salidas. Si se denomina I a este número, se tiene entonces
Frecuencia de llegada = Número de llegadas/Tiempo de observación = I/T
Como se ve en la figura 3.2 hay tres modos de mostrar los datos que se acaban de obtener. La figura 3.2 (a) muestra por separado el número total de llegadas y salidas como función del tiempo. Si en cada instante se resta la curva de salidas de la de llegadas, se obtiene el número total de trabajos en el sistema en cada instante (figura 3.2 (b)). Por otra parte, si para cada trabajo se resta su tiempo de llegada del de salida se obtiene la figura 3.2 (c), que muestra el tiempo de permanencia de cada trabajo en el sistema. La área rayada en cada una de las figuras representa el tiempo total que pasan en el sistema el conjunto de todos los trabajos. Luego, las tres áreas deben ser iguales. Si se denomina J a esta área, de la figura 3.2 (c) se tiene:
Tiempo medio pasado en el sistema = J/I
De la figura 3.2 (b)
Número medio de trabajos en el sistema = J/T = I/T x J/I =
= Frecuencia de llegada × Tiempo medio pasado en el sistema.
que es la ley de Little.
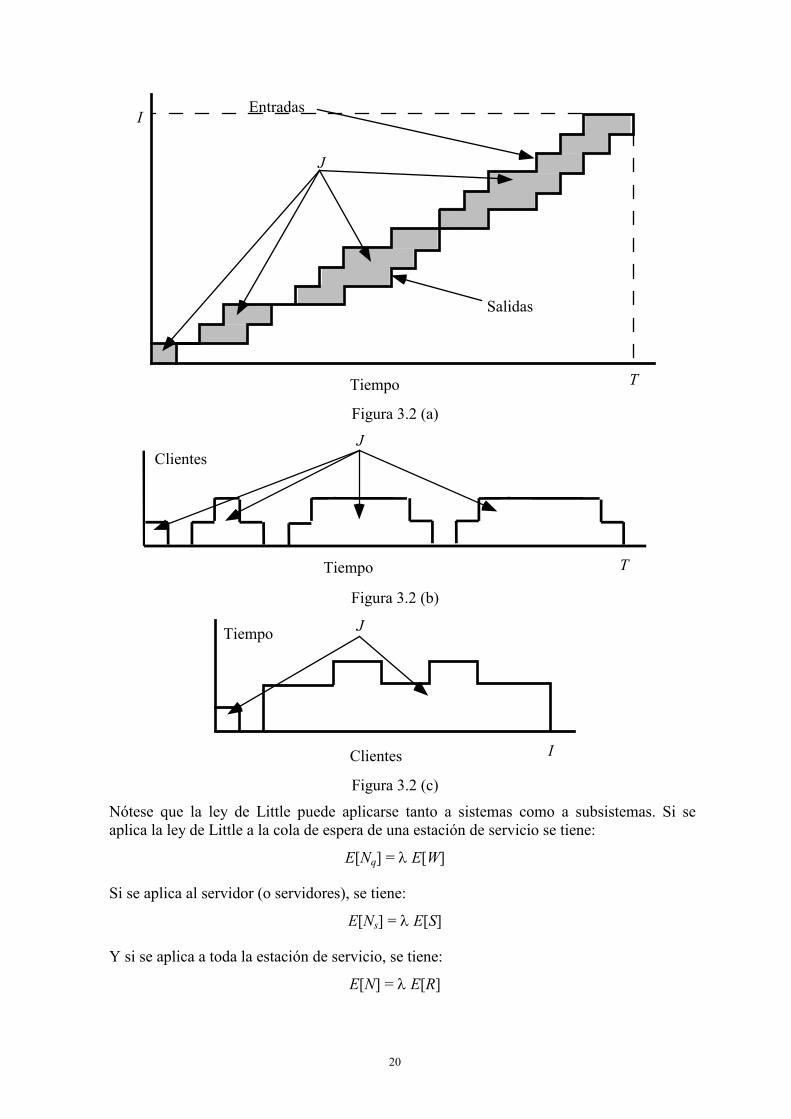
20
J
Entradas
Salidas
Tiempo
I
T
Figura 3.2 (a)
Clientes
Tiempo
J
T Figura 3.2 (b)
Clientes
Tiempo J
I
Figura 3.2 (c)
Nótese que la ley de Little puede aplicarse tanto a sistemas como a subsistemas. Si se aplica la ley de Little a la cola de espera de una estación de servicio se tiene:
E[Nq] = λ E[W]
Si se aplica al servidor (o servidores), se tiene:
E[Ns] = λ E[S]
Y si se aplica a toda la estación de servicio, se tiene:
E[N] = λ E[R]

21
3.4. EL PROCESO DE POISSON El proceso de Poisson es un proceso estocástico de tiempo continuo sobre un espacio de estados discreto. Se suele utilizar para contar el número de sucesos N(t) que ocurren en el intervalo de tiempo [0, t]. El suceso que interesa estudiar aquí es el número de llegadas que se producen a un sistema en el tiempo t. Se dice que N(t), para t ≥ 0 es un proceso de Poisson si se cumplen las cuatro condiciones siguientes: 1. N(0) = 0,
2. El número de llegadas que se producen en intervalos que no se solapan son mutuamente independientes,
3. Para un intervalo de tiempo lo suficiente pequeño [t, t + ∆t] se cumple que:
* la probabilidad de que llegue un cliente es λ∆t + ∅(∆t),
* La probabilidad de que lleguen dos o más clientes es ∅(∆t)
* la probabilidad de que no llegue ningún cliente es 1 - λ∆t + ∅(∆t)
donde ∅(∆t) representa una cantidad que tiende a cero más rápidamente que ∆t, es decir:
( ) 0lim 0 =∆∆∅
→∆ tt
t
4. Las tres probabilidades anteriores dependen de ∆t pero no de t.
Según el punto 3 de la relación anterior, si se elige un ∆t suficientemente pequeño, la probabilidad que en el intervalo [t, t + ∆t] lleguen 2 ó más trabajos puede ser despreciada.
3.4.1. DISTRIBUCIÓN DE POISSON Se va a calcular, ahora, la probabilidad de que lleguen i trabajos en el intervalo [0, t]. Para ello, se supone que el intervalo [0, t] está dividido en m subintervalos iguales de duración ∆t = t/m. Por el punto 2, el hecho de que se produzca una llegada en un subintervalo es independiente de lo que haya ocurrido en los demás. Si m es suficientemente grande, se puede pensar que los intervalos considerados forman una secuencia de Bernoulli con una probabilidad que se produzca una llegada en el intervalo ∆t = t/m igual a
mtp λ=
La probabilidad de más de una llegada por intervalo es despreciable únicamente si ∆t = t/m es muy pequeño. Por tanto, la probabilidad que haya i llegadas será el límite de una distribución binomial cuando ∆t tienda a cero
( ) ( ) ( )( ) ( )( ) imitt tttt
im
tmibtN −→∆→∆ ∆∅+∆λ−∆∅+∆λ
=∆λ= 1lim,,lim 00
Desarrollando esta expresión se obtiene
( ) ( ) ( ) ( ) im
mim
i
mt
mimmm
ittN
−
∞→∞→
λ
−+−−λ
= 1lim1...1lim!

22
de donde
( ) ( ) teittN λ−λ
=!
que es la probabilidad de que se produzcan i llegadas en [0, t] y es la función de densidad de Poisson con parámetro λt. Se trata de una distribución bien conocida, y se sabe que:
E[N(t)]=λt
Var[N(t)]=λt
3.4.2. DISTRIBUCIÓN EXPONENCIAL Una propiedad interesante de la distribución de Poisson es que la distribución del tiempo entre llegadas consecutivas es exponencial Sea T una variable aleatoria que representa el intervalo desde el origen de tiempos (elegido arbitrariamente) al instante en que se produce la primera llegada. Se puede obtener fácilmente la distribución de T, teniendo en cuenta que no se producirán llegadas en el intervalo [0, t] si y solo si T > t. Es decir, Pr[N(t) = 0] = Pr[T>t] donde N(t) representa el número de llegadas en [0, t]. Luego, como se sabe por la distribución de Poisson que
( )[ ] tetN λ−== 0Pr
entonces
[ ] [ ] tetTtT λ−−=>−=≤ 1Pr1Pr
y por tanto
( ) 0 para ,1 ≥−= λ− tetF tT
y
( ) ( )0 para , ≥λ== λ− te
dttdFtf tT
T
Con lo que queda demostrado que para un proceso de llegada de Poisson, el tiempo que transcurre T entre un instante arbitrario y el instante de la primera llegada tiene una distribución exponencial con media 1/λ. Nótese que el origen de tiempos ha sido elegido arbitrariamente. Si se elige como origen el instante de una llegada, entonces T representa el tiempo entre llegadas. En conclusión, en un proceso de Poisson el tiempo entre llegadas tiene una distribución exponencial con valor medio 1/λ y una desviación típica también igual a 1/λ. Es conveniente recordar que la distribución exponencial posee la propiedad de carecer de memoria (propiedad de Markov): Sea ti el instante de la i-ésima llegada. Se supone que han transcurrido t unidades de tiempo antes de que se produzca la siguiente llegada. Sea R la variable aleatoria que representa el tiempo que resta para que se produzca la siguiente llegada, es decir R = T - t, donde T es el tiempo entre llegadas. Para calcular la distribución de R para un valor de t determinado,
[ ] [ ][ ]
[ ][ ]tT
rtTttT
tTrRrR≥
+≤≤=
≥≥≤
=≤Pr
PrPr
|PrPr

23
Desarrollando el numerador queda:
[ ] ( )ttrt
t
x eedxertTt λ−λ−+ λ− −=λ=+≤≤ ∫ 1Pr
y el denominador,
[ ] [ ] ( ) tt eetTtT λ−λ− =−−=≤−=≥ 11Pr1Pr
y, por tanto,
[ ] terR λ−−=≤ 1Pr
de donde se ve que R tiene una distribución exponencial con tasa λ que es la misma que tiene T.
3.4.3. PROPIEDADES DE LOS PROCESOS DE POISSON A continuación, se van a enunciar, sin demostración, otras dos propiedades interesantes de los procesos de Poisson:
3.4.3.1. Superposición de procesos de Poisson Se consideran m fuentes independientes y se supone que cada una de ellas es un proceso de Poisson con tasa λk, para k =1, …, m. Si se combinan estas fuentes en una sola (figura 3.3), se obtiene un nuevo proceso de Poisson con tasa
∑=
λ=λm
kk
1
…λ1
λ2
λm
λ
…
λ1
λ2
λm
λ
p1
p2
pm Figura 3.3. Figura 3.4.
3.4.3.2. Descomposición de un proceso de Poisson Se considera el caso en el que un proceso de Poisson se divide en m vías (figura 3.4). Si la tasa de llegada es λ y la salida por cada una de las ramas se elige independientemente con probabilidad pk, entonces en la k-ésima genera un proceso de Poisson con tasa λpk, para k =1, …, m, y además los m canales son estadísticamente independientes.
3.5. PROCESOS NACIMIENTO-MUERTE Los procesos Nacimiento-Muerte (N-M) son, como se ha visto, un tipo particular de proceso estocástico útil para modelar sistemas en los que los clientes llegan y completan su servicio de uno en uno. El estado del sistema estará representado por la variable aleatoria que corresponde al número de clientes en el mismo, k. Sea un sistema caracterizado por el número k de elementos que hay en él y tal que estos elementos puedan nacer (llegar al sistema) o morir (salir del sistema). Si se denomina Pk(t) la probabilidad de que haya k elementos en el instante t y se considera que en un intervalo

24
suficientemente pequeño sólo puede variar el estado del sistema en un elemento en más o en menos, es decir que para que el instante t + ∆t haya k elementos es preciso que: - O en el instante t hubiera k elementos y no se produjera ningún cambio durante ∆t.
- O en el instante t hubiera k - 1 elementos y se produjera una llegada durante ∆t.
- O en el instante t hubiera k + 1 elementos y se produjera una salida durante ∆t. Además el estado del sistema nunca puede tomar valores negativos, es decir, el mínimo número de elementos que puede haber en el sistema es de cero. Por lo tanto si se admite además que la probabilidad del estado depende del instante t, pero la probabilidad de cambio (nacimiento o muerte) depende sólo del intervalo ∆t, se puede escribir la evolución de la probabilidad del estado para el caso general y para el estado 0, para los que se tiene, respectivamente: - para k > 0
Pk(t + ∆t) = Pk(t) pk,k(∆t) + Pk - 1(t) pk - 1,k(∆t) + Pk + 1(t) pk + 1,k(∆t) + ∅(∆t)
- para k = 0
P0(t + ∆t) = P0(t) p0,0(∆t) + P1(t) p1,0(∆t) + ∅(∆t)
Evidentemente debe cumplirse en todo instante que
( )∑∞
=
=0
1k
k tP
Teniendo en cuenta las características de su comportamiento, los procesos de nacimiento y de muerte se pueden considerar como procesos de Poisson de parámetros dependientes del estado, λk y µk, respectivamente, y, en consecuencia, teniendo en cuenta el desarrollo en serie de la función de probabilidad se puede escribir que: - para k > 0
Pk(t + ∆t) = Pk(t) [1 - λk∆t + ∅(∆t)] [1 - µk∆t + ∅(∆t)] + Pk - 1(t) [λk – 1∆t + ∅(∆t)] + + Pk + 1(t) [µk + 1∆t + ∅(∆t)] + ∅(∆t)
- para k = 0
P0(t + ∆t) = P0(t) [1 - λ0∆t + ∅(∆t)] + P1(t) [µ1∆t + ∅(∆t)] + ∅(∆t) Redisponiendo estas expresiones se obtiene que - para k > 0
( ) ( ) ( ) ( ) ( ) ( ) ( )tttPtPtP
ttPttP
kkkkkkkkk
∆∆∅
+µ+λ+µ+λ−=∆
−∆+++−− 1111
- para k = 0
( ) ( ) ( ) ( ) ( )tttPtP
ttPttP
∆∆∅
+µ+λ−=∆
−∆+1100
00
Pasando el límite cuando ∆t tiende a cero, se obtiene - para k > 0
( ) ( ) ( ) ( ) ( )tPtPtPdt
tdPkkkkkkk
k1111 ++−− µ+λ+µ+λ−=

25
- para k = 0
( ) ( ) ( )tPtPdt
tdP1100
0 µ+λ−=
Este sistema de ecuaciones diferenciales en diferencias representa la dinámica de las probabilidades del sistema. Se denominan ecuaciones de Kolmogorov2. Ahora bien, si se admite que este sistema llega a un régimen estacionario, es decir que las probabilidades son independientes del instante en que se calculan, se tendrá que
Pk(t) = pk , para k ≥ 0 y, por lo tanto
0 = -(λk + µk)pk + λk - 1pk - 1 + µk + 1pk + 1, para k > 0 y
0 = -λ0p0 + µ1p1, para k = 0 Otra forma más sencilla de llegar a estas mismas ecuaciones de régimen estacionario es la que se expone a continuación. Sea un sistema caracterizado por el número k de elementos que hay en el mismo (k ≥ 0). Estos elementos llegan (nacen) al sistema con frecuencia λk que se puede considerar dependiente de k y pueden salir (morir) del sistema con frecuencia µk que se puede considerar también dependiente de k., pero independientes, en ambos casos, del instante en que se producen. Tanto los nacimientos como las muertes sólo pueden producirse de una en una. Se admite, además, que el sistema llega a un estado estacionario donde son conocidas las probabilidades pk de que haya k elementos en el sistema. Evidentemente debe cumplirse que
∑∞
=
=0
1k
kp
y que λ-1 = λ-2 = … = 0 µ0 = µ-1 = … = 0 p-1 = p-2 = ... = 0
Hacia el estado Ek (cuando el sistema contiene k elementos) se produce un flujo de entrada desde los estados Ek + 1 y Ek - 1, que dan una tasa global de llegada al estado Ek de
λk - 1pk - 1 + µk + 1pk + 1 Desde el estado Ek se produce un flujo de salida hacia los estados Ek + 1 y Ek - 1, que dan una tasa global de salida del estado Ek de
(λk + µk)pk Para que el sistema esté en equilibrio ambas tasas deben equilibrarse, es decir, ser iguales, de donde se deduce inmediatamente
λk - 1pk - 1 + µk + 1pk + 1 = (λk + µk)pk a partir de la cual se obtienen inmediatamente las ecuaciones de Kolmogorov en régimen estacionario halladas anteriormente.
2 Según el texto estas ecuaciones se conocen como de Kolmogorov, o de Chapman, o de Kolmoorov-
Chapman, o de Chapman-Kolmogorov

26
Estas ecuaciones, junto con la condición de que la suma de las probabilidades de todos los estados debe ser igual a 1, permiten deducir las probabilidades de los estados. A partir de la ecuación de Kolmogorov en régimen estacionario para k = 0, se puede hallar
1
001 µ
λ= pp
Sustituyendo en la ecuación de Kolmogorov en régimen estacionario para k = 1, se tiene
( ) 22001
00100 ppp µ+λ+
µλ
µ+λ−=
de donde
2
11
21
1002 µ
λ=
µµλλ
= ppp
y, en general,
k
kk
k
i i
ik ppp
µλ
=µλ
= −−
−
= +∏ 1
1
1
0 10
Sustituyendo los valores de pk que se acaban de obtener en la ecuación de la suma de las probabilidades se puede deducir p0
∑∏∞
=
−
= +µλ
+=
1
1
0 1
0
1
1
k
k
i i
i
p
3.6. COLAS M/M/m/B/K Las colas con esta estructura no son más que casos particulares de los procesos de nacimiento-muerte que se acaban de estudiar ya que se trata de sistemas en los que las llegadas al sistema (proceso de nacimiento) y las salidas como consecuencia de la terminación de los servicios (proceso de muerte) son ambos markovianos.
3.6.1. COLA M/M/1 En este tipo de cola, el más sencillo, se supone que: - hay una cola con un sólo servidor
- los tiempos entre llegadas de los clientes están independiente e idénticamente distribuidos con una distribución exponencial cuyo valor medio es 1/λ, que no depende del número de clientes que ya están en el sistema
- los tiempos de servicio de los clientes están independiente e idénticamente distribuidos con una distribución exponencial cuyo valor medio es 1/µ, que no depende del número de clientes que ya están en el sistema
λk = λ, para k = 0, 1, ....
µ k = µ, para k = 1, 2, ....
Las transiciones entre estados se pueden representar tal como muestra la figura 3.5.

27
Aplicando las condiciones de este caso a las soluciones de ecuaciones de Kolmogorov, se encuentra
kk
ik ppp
µλ
=µλ
= ∏−
=0
1
00
y
∑∞
=
µλ
+
=
1
0
1
1
k
kp
La suma del denominador es la de una progresión geométrica infinita que convergerá si es decreciente, es decir si λ es menor que µ y, en este caso,
0λ
µ1
λ
µ2
λ
µk - 1
λ
µk + 1
λ
µk
λ
µ
λ
µ
. . . .
Figura 3.5.
µλ
−=
µλ
−
µλ
+
= 1
11
10p
si se denomina ρ = λ/µ, y se tiene en cuenta que la condición de estabilidad del sistema exige que la capacidad de servicio supere a la frecuencia de llegada, es decir ρ debe estar entre cero y uno, se puede escribir
pk = (1 - ρ)ρk , para k = 0, 1, ...
que es una distribución geométrica. La utilización del servidor viene determinada por la probabilidad que haya algún cliente en servicio, esto es, 1 - p0. Si se substituye p0 por su valor 1 - ρ, se encuentra que la utilización del servidor es ρ. Para calcular el número medio de elementos en el sistema, hay que hacer
( ) ( ) ( ) ( ) =ρρ∂∂
ρρ−=ρρ∂∂
ρρ−=ρρρ−=ρρ−== ∑∑∑∑∑∞
=
∞
=
∞
=
−∞
=
∞
= 111
1
111111
k
k
k
k
k
k
k
k
kk kkkpN
( ) ( )( ) ρ−
ρ=
ρ−ρρ−=
ρ−ρ
ρ∂∂
ρρ−=11
111
1 2
y la varianza
( )( )2
0
22
1 ρ−ρ
=−=σ ∑∞
=kkN pNk

28
Aplicando la ley de Little se puede determinar el tiempo medio de respuesta o de permanencia en el sistema, teniendo en cuenta además que la inversa de la capacidad media de servicio µ es el tiempo medio de servicio s
( ) ρ−=
ρ−µ
=λρ−
ρ=
λ=
11/1
1sNR
Hasta aquí se ha calculado la densidad de probabilidad para el número de trabajos en el sistema, el número medio de trabajos y el tiempo medio que pasan los mismos tanto en el sistema como en la cola. Pero no se ha dicho nada sobre la disciplina de servicio. Sin embargo, si se quiere calcular algo más que valores medios, por ejemplo la distribución de probabilidad de los tiempos de espera o de respuesta, es necesario conocer el orden en que se sirven los trabajos. Cuando llega un cliente a la estación y encuentra k clientes en la misma, si se sigue un política de servicio FCFS, tendrá que esperar durante k + 1 servicios exponenciales antes de salir del sistema (los servicios de los k que ya estaban más el suyo propio).
R = S1 + S2 + … + Sk + Sk + 1
donde Si, para i = 1, 2, … , k + 1 son variables aleatorias idéntica, independiente y exponencialmente distribuidas con valor medio 1/µ. Nótese que por la propiedad de carencia de memoria de la distribución exponencial, no hay necesidad de tener en cuenta el servicio ya recibido por el cliente que ya está en el servidor cuando se produce la llegada. Luego según la descripción que se acaba de ver, el tiempo de respuesta R condicionado a que haya k clientes en la estación tiene una función de densidad de probabilidad (k + 1)-Erlang.
( ) t
kk
R ektkNtf µ−
+µ==
!|
1
por la ley de probabilidad total
( ) [ ] [ ] [ ] =
µλ
−
µλ
µ===≤=≤= ∑ ∫∑
∞
=µ−
+∞
= 00
1
01
!Pr|PrPr
k
kt
x
kk
kR dx
ekxkNkNtRtRtF
( ) =
µλ
−µ=
µλ
−µ=λ
µλ
−µ= ∫∫∫ ∑ µλ−µ−λ−µ−µ− t xt xxt
k
kx dxedxeedx
kxe
0
/1
0011
!1
( )[ ] ( )ttx ee ρ−µ−µλ−µ− −== 10
/1 1
de donde se ve que R tiene distribución exponencial con el valor medio ya calculado:
[ ] ( )ρ−µ=
11RE
Siguiendo un razonamiento análogo al anterior, se puede calcular la distribución del tiempo de espera en la cola
( ) [ ] ( )tR etWtF ρ−µ−ρ−=≤= 11Pr

29
3.6.2. COLA M/M/∞ (INFINITO NÚMERO DE SERVIDORES) Se considera aquí el caso de un sistema que aumenta su capacidad de servicio linealmente con los clientes o como un sistema que siempre tiene un servidor disponible cuando llega un cliente. Evidentemente en el mundo real no existen infinitos servidores, pero existen numerosos casos en que el número de servidores es superior o igual al de clientes, en cuyo caso puede asimilarse a este modelo. En este caso se tiene pues
λk = λ, k = 0, 1, ....
µk = kµ, k = 1, 2, ....
El diagrama de transición de estados es el que muestra la figura 3.6.
0λ
µ
1λ
2µ
2λ
k - 1λ
k + 1λ
kλλ
. . . .
3µ (k-1)µ (k+1)µ (k+2)µkµ Figura 3.6.
Aplicando las condiciones de este caso a las soluciones de ecuaciones de Kolmogorov, se encuentra
( ) !1
1 0
1
00 k
pi
ppkk
ik
µλ
=µ+
λ= ∏
−
=
y
ρ−==
µλ
+
= µλ−
∞
=∑
1
!11
1 /
1
0 e
k
p
k
k
de donde
µλ−
µλ
= /
!e
kp
k
k
para k = 0, 1, 2, ..., que corresponde a una distribución de Poisson de media λ/µ. En consecuencia, el número medio de clientes en el sistema será
N = λ/µ
y el tiempo medio de permanencia, por aplicación de la ley de Little, será
R = 1/µ = s
que, como cabía esperar, coincide con el de servicio, ya que, como se había supuesto que en este sistema siempre había servidor dispuesto a atender al cliente que llegara, los clientes no tienen ninguna espera. Puede demostrarse que los resultados que se acaban de obtener son válidos también para una cola M/G/∞.

30
3.6.3. COLA M/M/m En este caso se supone que la estación de servicio dispone de m servidores (m ≥ 1), cada uno de ellos con una capacidad de servicio µ, que comparten una cola común; por lo tanto:
λk = λ, k = 0, 1, ....
µk = min(kµ, mµ)
de donde
µk = kµ, para 0 ≤ k ≤ m
µk = mµ, para m ≤ k
El diagrama de transición de estados es el que muestra la figura 3.7.
0λ
1λ
2
2λ
m - 1λ λ
mλλ
. . . .
3 (m 1) m m m
m + 1
Figura 3.7.
Debido a la estructura de µk, la aplicación de la ecuación de Kolmogorov debe hacerse por partes; para k menor o igual que m se tiene
( ) !1
1 0
1
00 k
pi
ppkk
ik
µλ
=µ+
λ= ∏
−
=
y para k mayor que m
( ) mk
k
mi
m
ik mm
pmi
pp −
∞
=
−
=
µλ
=µ
λµ+
λ= ∏∏ !
11 0
1
00
Puede demostrarse que la condición de estabilidad es que ρ = λ/(mµ) debe estar comprendido entre cero y uno. De ahí
( ) ( ) 11
00 1
1!!
−−
=
ρ−
ρ+
ρ= ∑
m
k
mk
mm
kmp
de donde se pueden deducir los valores de pk. De esta distribución se puede determinar a fórmula C de Erlang, que da la probabilidad que un cliente al llegar encuentre un servidor libre y que en su momento sirvió para el dimensionamiento de centrales telefónicas. A partir de los resultados anteriores se pueden determinar los valores medios de las magnitudes operacionales (números de clientes en servicio, en la estación y en la cola, tiempos de permanencia en la estación, en la cola y en el servidor), así como sus distribuciones estadísticas, procediendo de forma similar a la usada en la cola M/M/1. En las figuras 3.8 y 3.9 se hallan representados los valores medios de los tiempos de respuesta (en relación con el tiempo de servicio) y de las longitudes de cola, respectivamente.
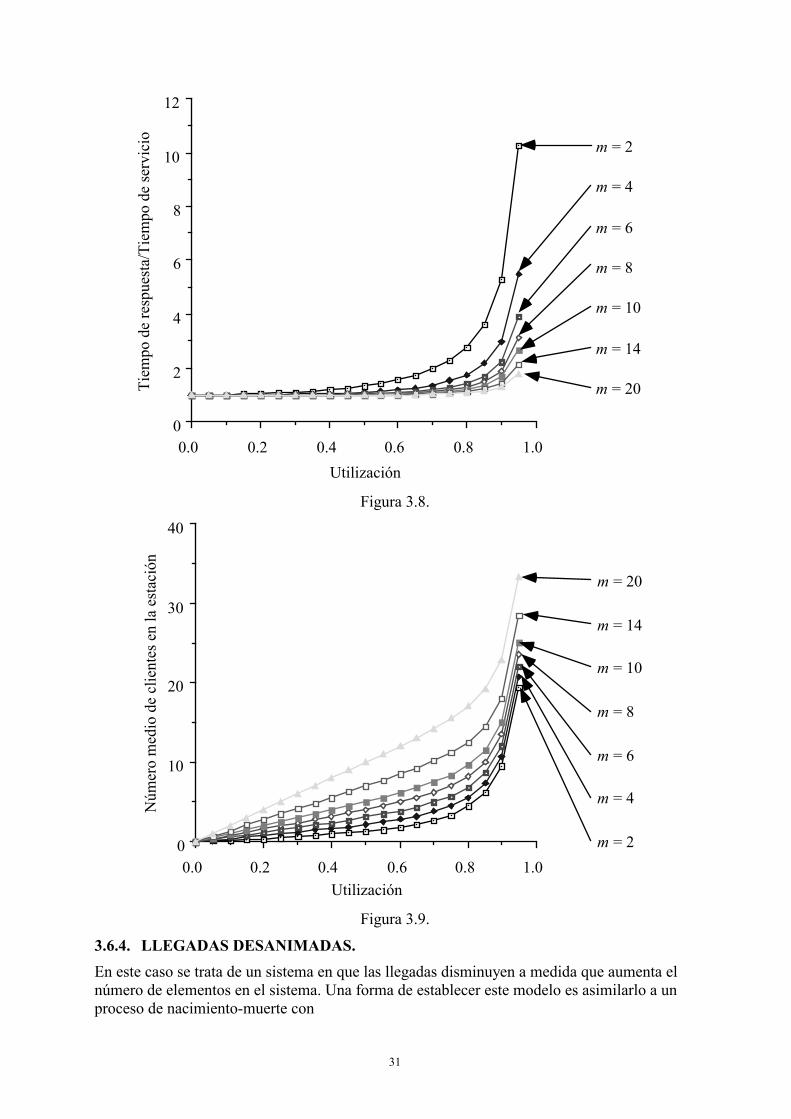
31
0.0 0.2 0.4 0.6 0.8 1.00
2
4
6
8
10
12
m = 2
m = 4
m = 6
m = 8
m = 10
m = 14
m = 20
Utilización
Tiem
po d
e re
spue
sta/
Tiem
po d
e se
rvic
io
Figura 3.8.
.
0.0 0.2 0.4 0.6 0.8 1.00
10
20
30
40
m = 20
m = 14
m = 10
m = 8
m = 6
m = 4
m = 2
Utilización
Núm
ero
med
io d
e cl
ient
es e
n la
est
ació
n
Figura 3.9.
3.6.4. LLEGADAS DESANIMADAS. En este caso se trata de un sistema en que las llegadas disminuyen a medida que aumenta el número de elementos en el sistema. Una forma de establecer este modelo es asimilarlo a un proceso de nacimiento-muerte con

32
λk = λ/(k + 1), para k = 0, 1, ....
µk = µ, para k = 1, 2, ....
El diagrama de transición de estados es el que muestra la figura 3.10.
0
λ
µ1
λ /2
µ2
µk - 1
µk + 1
µk
µµ
. . . .λ /3 λ /(k-1) λ /(k+1) λ /(k+2)λ /k
Figura 3.10.
Aplicando las ecuaciones que dan solución de las ecuaciones de Kolmogorov se tiene
!11
0
1
00 k
pippkk
ik
µλ
=µ+λ
= ∏−
=
expresión idéntica a la obtenida en el apartado 3.6.3. y, por lo tanto, es posible escribir directamente
p0 = e−λ/µ
µλ−
µλ
= /
!e
kp
k
k
3.6.5. COLA M/M/1/B: ALMACENAMIENTO FINITO. Este sistema se caracteriza por que la cola es capaz de contener un numero finito, B, de clientes entre los que reciben servicio y los que están esperando en la cola. Cuando el sistema está lleno, los nuevos clientes que puedan llegar se pierden. De acuerdo con ello se puede asimilar a un proceso de nacimiento-muerte y escribir
λk = λ, para k < B
λk = 0, para k ≥ B
µk = µ, para k = 1, 2, ....
El diagrama de transición de estados es el que muestra la figura 3.11. Aplicando las condiciones de este caso a las soluciones de ecuaciones de Kolmogorov, se encuentra
0λ
µ1
λ
µ2
λ
µB - 1
λ
µB
λ
µ
. . . .
Figura 3.11.

33
Bkpppkk
ik ≤
µλ
=µλ
= ∏−
=
para ,0
1
00
y
pk = 0, k > B
de donde
1
1
0
1
1
1
1+
=
µλ
−
µλ
−=
µλ
+
=
∑BB
k
kp
de donde se pueden obtener fácilmente los valores de pk. De esta distribución se puede determinar a fórmula B de Erlang, que da la probabilidad que un cliente al llegar no encuentre espacio en el sistema y que en su momento sirvió para el dimensionamiento de centrales telefónicas. Como solo caben B clientes en la estación, el sistema alcanza un estado estable para todos los valores de λ y µ. En particular, no es necesario exigir que λ < µ. A partir de los resultados anteriores se pueden determinar los valores medios de las magnitudes operacionales (números de clientes en servicio, en la estación y en la cola, tiempos de permanencia en la estación, en la cola y en el servidor), así como sus distribuciones estadísticas, procediendo de forma similar a la usada en la cola M/M/1. Hay, sin embargo, una diferencia importante y es que mientras en la cola M/M/1 su solución pasaba por la suma de una serie (debido a la suma infinita que aparecía), en este caso la solución puede hallarse siempre numéricamente (aunque en este caso como se trataba de una progresión geométrica se ha podido calcular su valor) puesto que la suma tiene un número finito de términos debido a la limitación de la capacidad.
3.6.6. COLA M/M/1//K: POBLACIÓN FINITA En este caso el número total de posibles clientes, que constituyen la población que se dirige al sistema, es finito e igual a K. Se supondrá que las llegadas serán proporcionales a los clientes que están fuera del sistema. Por lo tanto se puede considerar como un proceso de nacimiento-muerte y escribir
λk = (K - k)λ, para 0 ≤ k ≤ K
λk = 0, para k ≥ K
µk = µ, para k = 1, 2, ....
El diagrama de transición de estados es el que muestra la figura 3.12.
0
Kλ
µ1
µ2
µK - 1
λ
µK
2λ
µ
. . . .(K-1)λ (K-2)λ
Figura 3.12.

34
Aplicando las condiciones de este caso a las soluciones de ecuaciones de Kolmogorov, se encuentra
( )( ) Kk
kKKpiKpp
kk
ik ≤≤
−
µλ
=µ
−λ= ∏
−
=
0 para ,!
!0
1
00
y
pk = 0, para k > K
a partir de las cuales se puede obtener
( )
1
00 !
!−
=
−
µλ
= ∑K
k
k
kKKp
de donde se pueden calcular los valores de pk. La utilización del servidor será
ρ = 1 - p0
Por otra parte, aplicando la ley de Little al servidor se obtiene
µλ
=ρ e
y, por tanto, la tasa media de entrada de clientes a la estación es
λe = (1 - p0)µ
De esta forma y a partir de los valores de las probabilidades, calculadas aquí de nuevo de forma numérica, puesto que al haber la limitación de la población, la suma para determinar p0 vuelve a ser finita, se pueden determinar las restantes magnitudes operacionales como, entre otras, el tiempo medio de respuesta y el número medio de clientes en la estación, que se hallan representados en las figuras 3.13 y 3.14.
35
0.0 0.2 0.4 0.6 0.8 1.00
1
2
3
4
5
6K = 20
K = 14
K = 10
K = 8
K = 6
K = 4
K = 3
K = 2
Tiem
po d
e re
spue
sta/
Tiem
po d
e se
rvic
io
Utilización Figura 3.13.
.
0.0 0.2 0.4 0.6 0.8 1.00
1
2
3
4
5
6
K = 20
K = 14
K = 10
K = 8
K = 6
K = 4
K = 3
K = 2
Utilización
Núm
ero
med
io d
e cl
ient
es e
n la
est
ació
n
Figura 3.14.
3.6.7. COLA M/M/∞//K En este sistema la población, como en el caso anterior es finita e igual a K, pero además existe siempre un canal de servicio para atender a cualquier cliente que llegue al sistema. Es decir se trata de nuevo de un proceso de nacimiento-muerte con las siguientes características:

36
λk = (K - k)λ, para 0 ≤ k ≤ K
λk = 0, para k ≥ K
µk = kµ, para k = 1, 2, ....
El diagrama de transición de estados es el que muestra la figura 3.15.
0
Kλ
µ
12µ
23µ
K - 1
λ
K
2λ. . . .
(K-1)λ (K-2)λ
(K-1)µ Kµ
Figura 3.15.
Aplicando las ecuaciones que dan la solución de la ecuación de Kolmogorov, se tiene
( )( ) Kk
kK
pi
iKppk
k ≤≤
µλ
=µ+
−λ= ∏ 0 para ,
1 00
de donde se puede obtener
K
K
k
k
kK
p
µλ
+
=
µλ
=
−
=∑
1
11
00
así como los valores de las probabilidades de los estados
K
k
k
kK
p
µλ
+
µλ
=
1
y del número medio de clientes en el sistema
µλ
+
µλ
=
µλ
+
µλ
== ∑∑== 11
00
KkK
kkpNK
kK
k
K
kk
3.6.8. COLA M/M/m/B/K Este caso reúne todos los aspectos tratados parcialmente en los apartados anteriores, es decir, m canales de servicio, espacio para B clientes en la cola y población total de K clientes. Evidentemente el número de servidores m ha de ser menor o igual que la capacidad de la cola B, que a su vez ha de ser menor o igual que la población K, ya que de lo contrario las restricciones no tendrían sentido. Por todo ello se tiene que
λk = (K - k)λ, para 0 ≤ k < B

37
λk = 0, para k ≥ B
µk = kµ, para 0 ≤ k ≤ m
µk = mµ, k > m
El diagrama de transición de estados es el que muestra la figura 3.16.
0
Kλ
µ
12µ
23µ
(K-1)λ (K-2)λ
. . . .
. . . .
B-1 B
. . . .
. . . .
m-1 m m+1
(K-m+2)λ
(m-1)µ
(K-m+1)λ
mµ mµ mµ
mµ mµ
(K-B +2)λ (K-B +1)λ
(K-m-1)λ(K-m)λ
Figura 3.16.
Aplicando las ecuaciones que dan la solución de la ecuación de Kolmogorov teniendo en cuenta los intervalos de k, se tiene
( )( ) mk
kK
pi
iKppkk
ik ≤≤
µλ
=µ+
−λ= ∏
−
=
0 para ,1 0
1
00
( )( )
( ) Bkmmmk
kK
pm
iKi
iKpp kmkm
ik ≤≤
µλ
=µ−λ
µ+−λ
= −−
=∏∏ para ,
!!
1 0
1
00
A partir de estas expresiones se puede determinar el valor de p0, que tiene una fórmula bastante complicada y, a continuación, calcular numéricamente los valores de pk que caracterizan el comportamiento del sistema y, a partir de ellos, los de las magnitudes operacionales como el tiempo de respuesta y el número de clientes en el sistema.
3.6.9. CONCLUSIÓN En los casos que se acaban de estudiar se observa que si no hay restricciones ni en la población ni en la capacidad del sistema servidor-cola, el cálculo de la probabilidad p0, a partir de ella, el de las restantes probabilidades de estado y las magnitudes operacionales (número de clientes en el sistema, tiempo medio de respuesta, etc.) exigen la suma de una serie infinita, para llegar a expresiones calculables; se trata pues de un problema analítico. Por el contrario, cuando hay alguna limitación en la población o en la capacidad del sistema, el número de estados es finito y la suma a realizar para el cálculo de p0 lo es también. Se está pues frente a un problema numérico ya que, disponiendo de un elemento de cálculo suficiente, siempre es posible llegar a obtener el resultado.

38
3.7. COLA M/G/1 Las colas de este tipo son las que cumplen las hipótesis siguientes: - Manantial infinito.
- Los intervalos de tiempo entre dos llegadas consecutivas están distribuidos según una ley exponencial de valor medio tm = 1/λ, (λ, número de llegadas por unidad de tiempo), lo cual es equivalente a que las llegadas se produzcan según un proceso aleatorio de Poisson.
- El tiempo de servicio es también una variable aleatoria que puede estar distribuida según cualquier función. El grado de aleatoriedad de la distribución, que será necesario para caracterizarla, viene definido por el coeficiente cuadrático de variación que es la relación entre su varianza y el cuadrado de su media.
2
22
sK s
sσ
=
- El valor medio del tiempo de servicio será s = 1/µ, siendo entonces µ el número medio de clientes que la estación puede atender por unidad de tiempo.
- La disciplina de la cola es FIFO.
- Para que la cola alcance un régimen estacionario estable, y no tienda a una longitud infinita, es preciso que se cumpla la condición de estabilidad que exige que el tiempo medio de servicio sea inferior al tiempo medio entre llegadas o que la capacidad de servicio µ sea superior a la frecuencia de llegada λ.
- Un solo servidor.
En estas circunstancias son aplicables las fórmulas de Khintchin-Pollaczek3, en las que interviene el factor de utilización ρ de la estación de servicio que mantiene la definición de la cola M/M/1, ρ = λ/µ = λs, que representa, como en la cola M/M/1, la probabilidad de que la estación de servicio este ocupada. Las fórmulas de Khintchin-Pollaczeck permiten el cálculo del valor medio del número de clientes y del tiempo de respuesta. La deducción completa de las probabilidades de los distintos estados requiere un tratamiento más complejo, ya que al no ser exponencial la ley de servicio, el comportamiento del proceso depende de su historia anterior.
3.7.1. DEDUCCIÓN POR EL CLIENTE MARCADO Sea un sistema que responde a las especificaciones de una cola M/G/1. Entonces una nueva llegada al sistema encontrará en promedio N clientes en él. De éstos, en promedio, ρ están recibiendo servicio y N - ρ en la cola de espera. Cada uno de los clientes en cola recibirá un servicio promedio de s = 1/µ, como él mismo. Si se representa por R0 el tiempo de servicio restante del cliente que se halla en la estación, o tiempo residual, se puede escribir que el tiempo de respuesta de la nueva llegada será
R = ρR0 + (N - ρ)s + s
Sustituyendo en esta ecuación el tiempo de respuesta a partir de la ley de Little
N /λ = ρR0 + (N - ρ)s + s
3 Según el texto estas fórmulas se conocen como de Khintchin-Pollaczek, o de Pollaczek-Khintchin, o de
Pollaczek, o de Khintchin.

39
y despejando N, se obtiene
ρ−ρ
λ+ρ=10RN
Queda por determinar el tiempo residual R0. Para ello se pueden imaginar los intervalos de servicio consecutivos dispuestos de forma contigua en un eje de tiempos, es decir eliminando los períodos de inactividad del servidor. La secuencia resultante de intervalos independientes e idénticamente distribuidos constituye un proceso de renovación. Los puntos finales de los intervalos de renovación se denominan épocas de renovación. Interesa la variable aleatoria que representa el tiempo entre una observación aleatoria y la siguiente época de renovación; es decir, el tiempo residual del intervalo de renovación. Sean f(x), s y M2 respectivamente la función de densidad de probabilidad, la media y el momento de segundo orden del intervalo de renovación. Sea A un período de tiempo muy largo sobre el que se han dispuesto los intervalos de renovación. Puesto que en promedio habrá A/s intervalos de renovación en el período A, y puesto que un intervalo de renovación es de longitud x con probabilidad f(x)dx, el número medio de intervalos de renovación de longitud x durante el período A es igual a
( )s
dxxAf
Por lo tanto, la porción promedio de A cubierta por intervalos de longitud x es igual a
( )s
dxxAxf
El punto de observación aleatorio, por definición, puede caer con igual probabilidad en cualquier instante de A; por consiguiente, la probabilidad g(x)dx que el intervalo observado de renovación sea de longitud x viene dada por
( ) ( )s
dxxxfdxxg =
de donde se obtiene la longitud media, mr, del intervalo de renovación observado vale
( ) ( )s
Ms
dxxfxxdxxgmr2
0
2
0=== ∫∫
∞∞
Se observa que mr es siempre mayor o igual que s, dándose la igualdad sólo cuando la varianza de los intervalos de renovación es cero. Puesto que el punto de observación es equiprobable sobre todo el intervalo observado, el tiempo residual es igual a
sMmR r
222
0 ==
Substituyendo este resultado en la ecuación en que se calculaba el tiempo de respuesta, se tiene
( )ρ−λ
+ρ=12
22MN

40
de donde se obtiene que el número medio de clientes en la estación de servicio es:
( ) ( ) ( )
σ+
ρ−ρ
+ρ=+ρ−
ρ+ρ= 2
222
2
112
112 s
KN ss
y el tiempo medio de permanencia en la estación de servicio es:
( ) ( ) ( )
σ+
ρ−ρ
+=
+
ρ−ρ
+= 2
22 1
1211
121
ssKsR s
s
Cuando la distribución de tiempos de servicio es exponencial, 12 =sK , estos valores son:
ρ−ρ
=1
N
y
ρ−=
1sR
que coinciden con las ecuaciones halladas en el apartado 3.6.1, como cabía esperar, pues se trata de una cola M/M/1. Estas fórmulas se simplifican también cuando el tiempo de servicio en constante M2 = s2, y por lo tanto 02 =sK .
( )( )ρ−
ρρ−=
122N
y
( )( )ρ−
ρ−=
122 sR
Las fórmulas de Khintchin-Pollaczeck del tiempo de respuesta y del número medio de clientes en el sistema se encuentran representadas en los gráficos de las figuras 3.17 y 3.18.
41
0.0 0.2 0.4 0.6 0.8 1.00
10
20Ks
2 = 1
Ks2 = 0.64
Ks2 = 0.36
Ks2 = 0.16
Ks2 = 0.04
Ks2 = 0
Utilización
Núm
ero
med
io d
e cl
ient
es e
n el
sist
ema
Figura 3.17.
0.0 0.2 0.4 0.6 0.8 1.00
10
20 Ks2 = 1
Ks2 = 0.64
Ks2 = 0.36
Ks2 = 0.16
Ks2 = 0.04
Ks2 = 0
Tiem
po d
e re
spue
sta/
Tiem
po d
e se
rvic
io
Utilización Figura 3.18
3.7.2. DEDUCCIÓN POR LA FUNCIÓN GENERATRIZ
Se consideren los clientes que llegan a una estación según un proceso de Poisson a razón de λ llegadas por unidad de tiempo. El tiempo de servicio del cliente tiene una función de distribución de probabilidad

42
F(t) = Pr[ts ≤ t]
y una función de densidad de probabilidad
f(t) = dF(t)/dt
Se observa el número de clientes en la cola en los instantes de salida de clientes del servidor, es decir en los instantes en que se ha completado el servicio. Dado el número de clientes en el sistema en un instante de salida determinado, el número de clientes en el sistema en instantes de salida futuros depende solo de las nuevas llegadas y de las ocupaciones anteriores. Es decir la sucesión de estados de clientes forma una cadena de Markov incluida. Se supone que el i-ésimo cliente deja el sistema no vacío con ni clientes. En ese instante empieza el servicio del (i + 1)-ésimo cliente. Mientras se ejecuta este servicio, continúan llegando clientes. Si se representa por ai + 1 el número de llegadas durante ese servicio, el estado del sistema en la siguiente salida viene entonces dado por
ni + 1 = ni - 1 + ai + 1, para ni ≥ 1
Si la salida del i-ésimo cliente deja el sistema vacío, la ecuación que describe el proceso es ligeramente diferente. El (i + 1)-ésimo cliente que sale llegó al sistema cuando estaba vacío, por lo que deja detrás de él sólo los clientes que han llegado durante su servicio y por lo tanto se tiene
ni + 1 = ai + 1, para ni = 0
Se observa que en las ecuaciones anteriores, el número de nuevas llegadas es el de las que se producen durante el servicio. La dinámica del estado puede resumirse en la siguiente ecuación
ni + 1 = ni - U(ni) + ai + 1
donde la función U(x) es la función escalón unitario definida como
U(x) = 0, si x ≤ 0 U(x) = 1, si x > 0
Se considera ahora la dinámica del estado, es decir, el número de clientes en el sistema en el instante de la salida. Este estado cambia de un instante de salida a otro con una sola salida y con las nuevas llegadas. No es difícil demostrar que la probabilidad de retorno a cualquier estado en cualquier instante futuro es mayor que cero siempre que la cola sea estable, es decir que el número medio de llegadas en un intervalo de tiempo sea igual al número medio de salidas. Esto sucederá cuando la frecuencia de llegada de clientes durante un servicio sea menor que uno y en ese caso existirá una distribución de probabilidad en régimen permanente. Las ecuaciones anteriores caracterizan completamente la evolución de la cadena de Markov incluida en los instantes de salida. El término aleatorio en esas ecuaciones es el número de llegadas ai. La distribución de probabilidad de esta variable aleatoria determinará completamente las características de la cadena. Nótese que, puesto que ai es el número de llegadas durante un servicio, ambas distribuciones intervienen en su definición. Para una distribución general del tiempo de servicio sólo los instantes de salida son puntos incluidos convenientemente en la cadena de Markov del número de clientes en la cola. Sólo los tiempos de servicio distribuidos exponencialmente tienen la propiedad de falta de

43
memoria. Por lo tanto, para un punto dentro de un tiempo de servicio perteneciente a una distribución cualquiera, el sistema no puede caracterizarse solamente por el número de clientes en el sistema. Es necesario conocer también cuanto tiempo hace que se ha iniciado el servicio. Ello lleva pues a un modelo mucho más complicado. La distribución en régimen permanente puede hallarse empezando por el cálculo de sus valores medios. Calculando la esperanza matemática en ambos miembros de la ecuación de la cadena de Markov incluida se encuentra que existe ese régimen permanente (cuando i tiende a infinito),
lim E[ni + 1] = lim E[ni] = n
y se tiene que
lim E[U(ni)] = lim E[ai + 1]
E[ai + 1] es la esperanza matemática del número de clientes llegados al sistema durante un servicio. Hay dos cantidades aleatorias implicadas en ai + 1, la duración del servicio del cliente y el número de llegadas mientras un cliente recibe servicio. Se calcula ponderando por la duración del servicio del cliente y luego promediando sobre él,
[ ] [ ] ( ) ( ) ( ) sdtttfdtttfdttfttaEaE sii λ=λ=λ=== ∫∫∫∞∞∞
++ 000 11 |
donde s, como en el apartado anterior, es el tiempo medio de servicio de un cliente. Si como es habitual se denomina ρ = λ s, la condición de estabilidad sigue siendo que ρ < 1. Volviendo a la ecuación de la cadena de Markov incluida, el término U(ni) es la función indicador del acontecimiento que el número de clientes en el sistema sea mayor que 0. De acuerdo con ello, se tiene
E[U(ni)] = Pr[más de cero clientes] = 1 - P0
donde P0 es la probabilidad que el sistema esté vacío. La ecuación de la cadena de Markov incluida se transforma entonces en
P0 = 1 - ρ
en que ha desaparecido la dependencia de la i. Una de las técnicas estándar para analizar ecuaciones en diferencias, tales como la de la cadena de Markov incluida, es mediante la función generatriz de probabilidad del estado del sistema que se define como
( ) [ ] [ ]∑∞
=
===ok
ikn
i knzzEzP i Pr
Aplicándola a esa ecuación, se tiene
( ) ( )[ ]11
++−+ = iii anUn
i zEzP
El número de llegadas durante el servicio de un cliente es independiente del número de clientes en el sistema y, por lo tanto, se puede escribir
( ) ( )[ ] [ ]11
+−+ = iii anUn
i zEzEzP

44
Debido a la estacionaridad se puede suprimir la dependencia de i y escribir A(z) = E[za]. El análisis del otro término muestra que
( )[ ] ( ) [ ] [ ]∑∑∞
=
−∞
=
−− ==+==
=
1
10
0
PrPrk
ik
ik
kUknUn knzPknzzE ii
[ ] ( )[ ]01
000
10 PrPr PzzPPknzzP
ki
k −+=
−=+= −
∞
=
− ∑
A partir de las ecuaciones anteriores, se puede escribir
( ) ( )( )[ ] ( )zAPzzPzPi 01
01 Pr −+= −+
Suponiendo que se alcanza el estado estacionario cuando i tiende a infinito, se tiene
lim Pi + 1(z) = lim Pi(z) = P(z)
y utilizando que P0 = 1 - ρ, se tiene
( ) ( )( ) ( )( ) zzA
zAzzP−
−ρ−=
11
Esta función permite encontrar los momentos de la distribución del número de clientes en el sistema. Quitando denominadores y derivando sucesivamente, se tiene
P'(z) [A(z) - z] + P(z) [A'(z) - 1] = (1 - ρ) (-1) A(z) + (1 -ρ) (1 - z) A'(z) =
=P''(z) [A(z) - z] + 2 P'(z) [A'(z) - 1] + P(z) A''(z) = 2 (1 - ρ) (-1) A'(z) + (1 -ρ) (1 - z) A''(z)
Si se hace z = 1, puesto que A(1) = P(1) = 1, se tiene
( ) ( ) ( )( )
( )( )[ ]1'12
1''1'1
1'11'A
AA
APn−
+−ρ−
==
Se ha definido A(z) como la función generatriz de probabilidad del número de llegadas, distribuido según Poisson, durante el tiempo de servicio de un cliente. Si se condicionas por el tiempo de servicio y luego se promedia sobre la densidad del tiempo de servicio, es decir,
( ) [ ] [ ] ( )∫∞
====0
servicio de tiempo| dttftzEzEzA aa
( ) ( ) ( ) ( ) ( )[ ]zFdttfedttfn
etz zt
n
tnn −λ==
λ= ∫∫ ∑
∞ −λ∞ ∞
=
λ−
1!
*
0
1
00
donde F*(s) es la transformada de Laplace de f(t). Esta ecuación expresa la relación entre la transformada de Laplace de la densidad del tiempo de un intervalo aleatorio y la función generatriz de la probabilidad del número de llegadas poissonianas en el intervalo. Diferenciando A(z) con respecto a z y haciendo z = 1, se encuentra
( ) ( ) ρ=λ=λ−== sFzA z 0'|' *1
( ) ( ) 22*2
1 0''|'' MFzA z λ=λ==
donde M2 es el momento de segundo orden del tiempo de servicio. Substituyendo, se tiene

45
( )ρ−λ
+ρ=12
22MN
que es la fórmula de Khintchin-Pollaczeck, idéntica a la obtenida en el apartado 3.7.1.
3.8. MODELO DE SKINNER Se considera el sistema representado en la figura 3.19 en el que las llegadas se producen según un proceso de Poisson de media λ. El servidor atiende un servicio de duración A, donde A es una variable aleatoria con distribución arbitraria FA(t). Después de atender el servicio, el servidor permanece latente, es decir sin ir a explorar la cola en busca de nuevos clientes, durante un tiempo B, donde B es una variable aleatoria, que puede depender de A, y cuya distribución es FB(t). Sea Z la suma de A y B y FZ(t) la función de distribución de Z. Después de un ciclo de servicio y latencia, el servidor inspecciona la cola para ver si hay clientes en ella. Si la cola no está vacía, empieza un nuevo período de servicio. Si la cola está vacía el servidor empieza una nueva latencia C , que es una variable aleatoria independiente de A y B y cuya función de distribución es FC(t).
λ A B C
Figura 3.19.
La principal diferencia del modelo de Skinner con respecto al modelo M/G/1 es que ya no supone la carencia de memoria cuando el sistema está ocioso. Los únicos puntos que cumplen con la propiedad de Markov son los instantes en que el servidor inspecciona la cola. En estas circunstancias, el tiempo medio de respuesta de un servidor de este tipo es
Az
Z
C
C mm
Mm
MR +
λ−λ+=
121
222
donde mA, mZ y mC son los valores medios de las distribuciones de las variables A, Z y C, respectivamente y donde M2Z y M2C son los momentos de segundo orden de las distribuciones de las variables Z y C.
3.9. COLAS CON PRIORIDADES 3.9.1. COLAS CON PRIORIDADES SIN INTERRUPCIÓN Se considera ahora el caso en que el orden de servicio viene fijado por prioridades asignadas externamente. La población de clientes se escinde en un conjunto de C clases distintas, numeradas 1, 2, ... . Este conjunto puede ser finito o infinito. Los índices de clase i tienen prioridad sobre los de clase j, si i < j. Los modelos que se consideran se caracterizan por tener las llegadas al sistema de los clientes de las distintas clases distribuidas según procesos de Poisson independientes de frecuencia λi. El servicio lo suministra una estación con un solo servidor, que atiende a los clientes de la misma clase en orden FIFO. La estación no puede estar ociosa cuando hay clientes en el sistema. Si hay clientes de distintas clases esperando servicio, se sirven primero los de prioridad más alta (índice de clase más bajo).

46
Hay varias posibilidades respecto a la acción a tomar cuando llega un cliente de prioridad más alta que el que está recibiendo servicio en aquel instante. En este modelo se considera que el nuevo cliente espera hasta que se completa el servicio del que está en el servidor. Es la disciplina de prioridad no interruptiva: después de la terminación de cada servicio, se selecciona y sirve hasta su terminación el cliente en espera de mayor prioridad. Los tiempos de servicio de los clientes de clase i tienen una distribución de tipo general de media si = 1/µi y momento de segundo orden M2i. Se representa por ρi = λi/µi = λisi la ocupación que la clase i provoca en el servidor. La condición de estabilidad es que el servidor debe ser capaz de atender a los clientes que llegan, es decir
11
<ρ∑=
C
ii
En estas condiciones se quiere saber en régimen estacionario el número medio Ni de clientes de clase i que hay en el sistema y el tiempo medio de respuesta Ri de los clientes de esta clase. El número medio de clientes de clase i que hay en el servidor recibiendo servicio es ρi y es también la probabilidad que cuando llegue un cliente al sistema halle en el servidor un cliente de clase i. Si hay en servicio un cliente de clase i, el tiempo de servicio restante R0i, es como se ha visto en el apartado 3.7.,
i
ii s
MR
22
0 =
Por consiguiente, el tiempo de espera total R0 provocado por algún cliente que esté recibiendo servicio será
∑∑==
λ=ρ=C
iii
C
i i
ii M
sM
R1
21
20 2
12
Se considera ahora el tiempo de respuesta R1, de los clientes de máxima prioridad. Además de R0, este tiempo de respuesta comprende los tiempos de servicio de todos los clientes que haya en la cola (en promedio N1 - ρ1) cuando llegue al sistema y su propio tiempo de servicio, es decir
R1 = R0 + (N1 - ρ1)s1 + s1
De la ley de Little se tiene que N1 = λ1R1. Substituyendo y despejando R1 se tiene
1
011 1 ρ−
+=R
sR
Para examinar ahora el tiempo de respuesta medio R2 de los clientes de clase 2, conviene hacer la siguiente observación: se supone que un cliente de clase 2, cuando llega y en función de los clientes que hay en espera de clase 1 y de clase 2 tiene que esperar un tiempo T. Todos los clientes de clase 1 que lleguen durante el tiempo T serán servidos antes que él. Puesto que el cliente de clase 1 utiliza el servidor ρ1 por unidad de tiempo, esto causa un retardo adicional de ρ1T. Pero los clientes de clase 1 que lleguen en este período deberán ser servidos

47
provocando un retardo adicional de ρ12T, etc. Es decir, el retardo inicial T del cliente de clase
2 se transforma en
( )1
211 1
...1ρ−
=+ρ+ρ+TT
debido a la llegada de clientes de clase 1. Al llegar, un cliente de clase 2 esta sujeto a los retrasos del cliente en servicio (en promedio R0), de los clientes de clase 1 en la cola (en promedio (N1 - ρ1)s1) y de los clientes de clase 2 en la cola (en promedio (N2 - ρ2)s2). Cada una de estas esperas se transforma por el factor
( )11/1 ρ− a causa de las llegadas de clientes de clase 1. Además hay que considerar el propio tiempo de servicio. La expresión de R2 toma la forma
( ) ( )[ ] 21
22211102 11 ssNsNRR +ρ−
ρ−+ρ−+=
Sustituyendo N1 = λ1R1, donde R1 toma la expresión antes calculada, y N2 = λ2R2, y despejando R2, se obtiene
( )( ) 2211
02 11
sR
R +ρ−ρ−ρ−
=
Se puede ahora escribir una fórmula similar para los clientes de clase j. Si los clientes de las clases 1, 2, ..., j - 1 se mezclan en una sola clase H y se sirven con disciplina FIFO, ello no afectará a los clientes de clase j. La clase H sería la de máxima prioridad y la clase j sería la siguiente. El valor de R0 seguirá siendo el mismo. La utilización de la clase H, ρH, será igual a
ρH = ρ1 + ρ2 + ... + ρj - 1
Aplicando la fórmula de R2 a la clase j, se tiene
( )( ) jj
ii
j
ii
C
iii
jjHH
j sM
sR
R +
ρ−
ρ−
λ=+
ρ−ρ−ρ−=
∑∑
∑
=
−
=
=
1
1
1
12
0
11211
Los números medios de clientes de cada clase se obtienen aplicando la ley de Little, Ni = λiRi.
3.9.2. COLAS CON PRIORIDADES CON INTERRUPCIÓN En este caso si se produce la llegada de un cliente de mayor prioridad que el que está recibiendo servicio, éste queda interrumpido. Según el método de relanzamiento del servicio del cliente interrumpido estos sistemas se pueden clasificar en: - relanzamiento con el tiempo restante: cuando se relanza el servicio del cliente solo ha de
completar el tiempo que le restaba.
- relanzamiento con el mismo tiempo de servicio: cuando se relanza el servicio del cliente se reinicia con el mismo tiempo que cuando fue interrumpido.
- relanzamiento con un tiempo de servicio diferente: cuando se relanza el servicio del cliente se reinicia con un tiempo de servicio distinto del que tenía cuando fue interrumpido.

48
En el primero de estos supuestos, de los dos componentes del tiempo de respuesta que aparecían en las fórmulas del apartado anterior, el tiempo de espera, Wi, y el tiempo de terminación del servicio, hi, es decir desde que se inicia hasta que se termina el servicio, se puede decir que: - Puesto que en caso de haber clientes de menor prioridad recibiendo servicio cuando llega el
cliente marcado, estos clientes son interrumpidos en su servicio, no es necesario considerar los tiempos residuales de servicio de las clases desde la i + 1 hasta la C. Así pues, se puede escribir que:
ρ−
ρ−
λ=
∑∑
∑
=
−
=
=j
ii
j
ii
j
iii
j
MW
1
1
1
12
112
- El tiempo de terminación del servicio, hi, comprende el tiempo de servicio si más los tiempos debidos a las interrupciones debidas a las llegadas de clientes de mayor prioridad (fig. 3.20). Durante hi, se producirán λihi llegadas de clase i, para i = 1, 2, …, i - 1, que ocuparán cada una de ellas el servidor durante si. Por lo tanto se tiene:
Tiempos de interrupción porclientes de mayor prioridad
Tiempo de servicio
Tiempo de terminación
Sin interrupción
Con interrupción
Figura 3.20
∑−
=
λ+=1
1
j
iiijjj hhsh
de donde el tiempo de terminación del servicio vale:
Cjs
h j
ii
jj ,...,2 ,1 para ,
11
1
=ρ−
=
∑−
=
De donde resulta que el tiempo de respuesta para la clase j vale ahora:
+
ρ−
λ
ρ−=
∑
∑
∑=
=−
=
jj
ii
j
iii
j
ii
j sM
R
1
12
1
1121
1
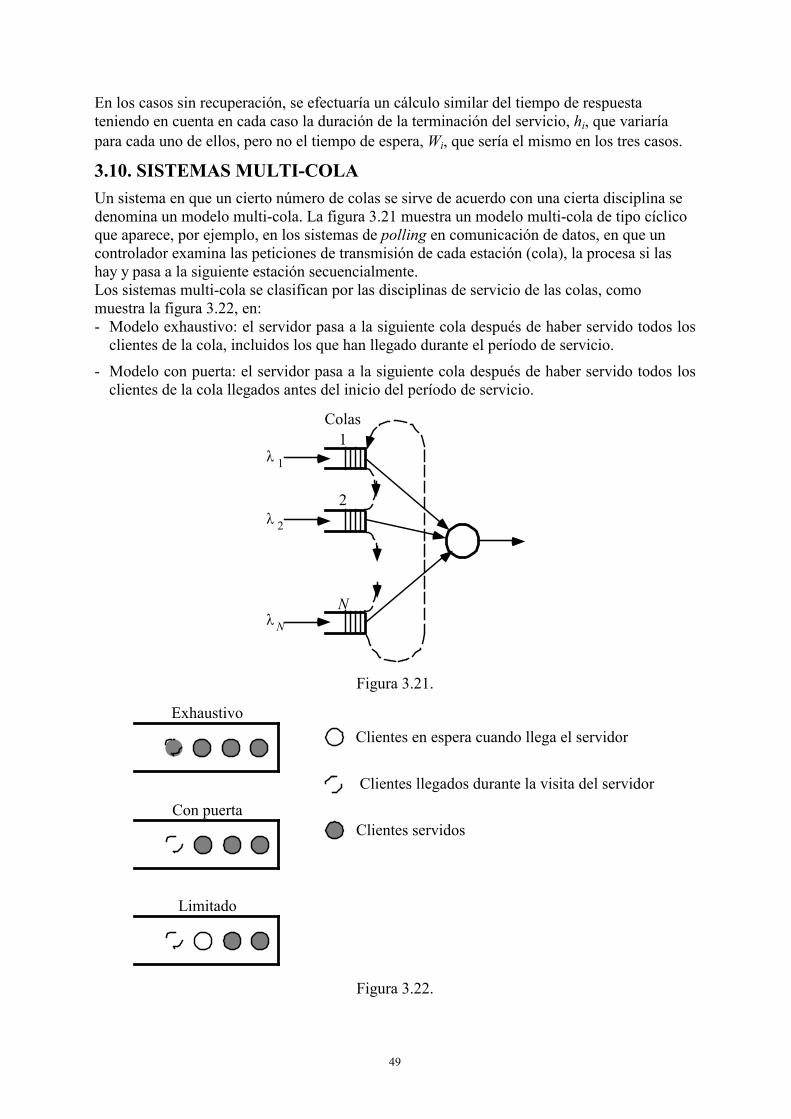
49
En los casos sin recuperación, se efectuaría un cálculo similar del tiempo de respuesta teniendo en cuenta en cada caso la duración de la terminación del servicio, hi, que variaría para cada uno de ellos, pero no el tiempo de espera, Wi, que sería el mismo en los tres casos.
3.10. SISTEMAS MULTI-COLA Un sistema en que un cierto número de colas se sirve de acuerdo con una cierta disciplina se denomina un modelo multi-cola. La figura 3.21 muestra un modelo multi-cola de tipo cíclico que aparece, por ejemplo, en los sistemas de polling en comunicación de datos, en que un controlador examina las peticiones de transmisión de cada estación (cola), la procesa si las hay y pasa a la siguiente estación secuencialmente. Los sistemas multi-cola se clasifican por las disciplinas de servicio de las colas, como muestra la figura 3.22, en: - Modelo exhaustivo: el servidor pasa a la siguiente cola después de haber servido todos los
clientes de la cola, incluidos los que han llegado durante el período de servicio.
- Modelo con puerta: el servidor pasa a la siguiente cola después de haber servido todos los clientes de la cola llegados antes del inicio del período de servicio.
Colas
2
N
1λ 1
λ 2
λ N
Figura 3.21.
Exhaustivo
Con puerta
Limitado
Clientes en espera cuando llega el servidor
Clientes llegados durante la visita del servidor
Clientes servidos
Figura 3.22.

50
- Modelo limitado: el servidor pasa a la siguiente cola después de haber servido como máximo un número determinado de clientes de la cola, incluidos los que han llegado durante el período de servicio.
El tiempo que requiere el servidor para ir de una cola a la siguiente, se denomina tiempo de paso o de movimiento. Si las características del tráfico (frecuencia de llegada, tiempo de servicio, etc.) y el tiempo de paso son idénticos para todas las colas, el modelo se denomina simétrico y, en caso contrario, asimétrico. Para estudiar este modelo se usará la notación siguiente: λi Frecuencia de llegada a la cola i. si Tiempo medio de servicio de la cola i. M2i Momento de segundo orden del tiempo de servicio de la cola i. ui Tiempo medio de paso de la cola i a la siguiente. U2i Momento de segundo orden del tiempo de paso de la cola i a la siguiente. σi Variancia del tiempo de paso de la cola i a la siguiente. El ciclo se define como el intervalo de tiempo desde el instante en que el servidor empieza el servicio en una cola hasta que la visita de nuevo. Si ai es la probabilidad que haya algún cliente en la cola i cuando la visita el servidor y ci es el ciclo medio de esa cola, se tiene entonces:
ai = λi ci
Si hay N colas, el tiempo total de paso es
∑=
=N
iiuc
10
y se deduce que
∑=
+=N
iiii sacc
10
De las ecuaciones anteriores se deduce que
cc
ci ≡ρ−
=0
0
1
donde
∑=
λ=ρN
iii s
10
es la utilización del servidor. Puesto que c0 y ρ0 son independientes de i, también lo es el ciclo medio que se ha denominado c.
3.10.1. MODELO EXHAUSTIVO Se supone que las llegadas son poissonianas y el tiempo de servicio es general para todas las colas. El intervalo desde que el servidor deja la cola hasta que regresa a ella se denomina tiempo inter-visitas. El tiempo medio de espera en la cola i vale

51
( )i
ii
i
iEi
Mv
VW
ρ−λ
+=122
22
donde ρi = λi si es la carga ofrecida por la estación i y vi y V2i son, respectivamente, la media y el momento de segundo orden de tiempo inter-visitas para la cola i. La ecuación anterior puede interpretarse como sigue: el tiempo medio de espera es la suma del tiempo residual inter0visitas y el tiempo medio de espera de una cola de tipo M/G/1. Si C2i es el momento de segundo orden del ciclo de la cola i, la ecuación anterior puede escribirse como
( )c
CW i
iEi 21 2ρ−=
Si el sistema es simétrico, se puede omitir el subíndice i y queda
( )0
0
11
ρ−ρ−=
cv
( ) ( )( )
22
0
2
0
2
2 11
11
vuMNNN
V u +ρ−
λ−+
ρ−ρ−σ
=
( )( )2
0
22
2 11c
cMNC u +
ρ−ρ−λ+σ
=
donde ρ = λs es la carga ofrecida por cada cola. Manipulando las ecuaciones anteriores se obtiene que el tiempo medio de espera vale
( )( )0
202
121
2 ρ−λ+ρ−
+σ
=MNc
uW u
E
3.10.2. MODELO CON PUERTA Con las mismas hipótesis que en el caso anterior respecto de las llegadas y los servicios, se puede escribir que el tiempo medio de espera en la estación i vale
( )c
CW i
Pi 21 2ρ+=
Para el caso simétrico se puede escribir
( )( )2
0
22
2 11c
cMNC u +
ρ−ρ+λ+σ
=
y substituyendo se obtiene el tiempo medio de espera
( )( )0
202
121
2 ρ−λ+ρ+
+σ
=MNc
uW u
P
Conviene observar que la única diferencia con el caso anterior reside en el cambio de un signo en el numerador del segundo sumando.

52
3.10.3. MODELO LIMITADO El análisis de este modelo es bastante complicado. Aquí se presenta solo el resultado para el modelo simétrico con colas de tipo M/G/1 y una limitación de un cliente. Si se marca un cliente y se denomina Qd el número de clientes que llegan a la misma cola durante la permanencia del cliente marcado en el sistema, entonces Qd es igual al número de clientes existentes en la cola después de salir el cliente marcado. Luego, si WL es el tiempo medio de espera, de la fórmula de Little se tiene que
( )sWQ Ld +λ=
Utilizando la función generatriz de la probabilidad conjunta para cada una de las colas, se puede deducir que
( )( )
+λ−
λσ+ρ++λ+
σ+λ=
suNuMN
usQ uu
d 11
22
22
2
Entre las dos ecuaciones anteriores se puede despejar WL y se obtiene
( )( )suN
uMNu
W uuL +λ−
λσ+ρ++λ+
σ=
11
22
22
2
3.11. COLAS CON CLASES DE CLIENTES Se considera una estación M/M/1 con C clases de clientes, en la que λc representa la frecuencia de llegada de la clase c, en la que k = k1 + k2 + … + kc + … + kC es el número total de clientes que hay en la estación, kc el número de clientes de clase c y en la que la capacidad media del servidor para la clase c es µc.
3.11.1. COLA CON SERVIDOR COMPARTIDO. La política de la cola es de servidor compartido, es decir que el tiempo del servidor se lo reparten en quanta de tiempo infinitesimales todos los clientes presentes en el sistema avanzando todos a la misma velocidad. Sea el estado del sistema definido por el vector
( )Ckkkk ..., , , 21=
La distribución de estados en régimen estacionario viene definido por las ecuaciones de equilibrio (similares a las establecidas en la ecuación de Kolmogorov).
( ) =
µ+λ ∑∑
==
C
cc
cC
ccC k
kkkkp
1121 ..., , ,
( ) ( ) ( )∑∑== +
+µ++λ>−=
C
c
ccCc
C
cccCc k
kkkkkpkIkkkkp
121
121 1
1..., ,1..., , ,0..., ,1..., , ,
( ) 0..., , , para 21 ≥Ckkk
La notación I(B) es función del booleano B, de forma que I(B) = 1 si B es cierto y 0 si es falso. Es fácil comprobar por sustitución directa que la solución del sistema anterior que satisface la ecuación de normalización

53
( ) 1..., , , 21 =∑∀k
Ckkkp
para todos los posibles estados, viene dada por
( ) ( ) ∏=
ρρ−=
C
c c
kc
C kkkkkp
c
121 !
!1..., , ,
donde ρc = λc/µc y ρ = ρ1 + ρ2 + … + ρc + … + ρC (para que exista el régimen estacionario preciso que ρ < 1, que es la condición de estabilidad). Nótese que, en lo que concierne el número total de clientes k, la cola con servidor compartido es equivalente a la cola FIFO con factor de utilización ρ , ya que si se suman todas las
( )Ckkkp ..., , , 21 tales que la suma de todas las kc sea igual a k, se obtiene
p(k) = (1 - ρ) ρk
3.11.2. COLA CON SERVIDOR INTERRUMPIBLE. Sea ahora el caso en que la política de la cola sea de servidor interrumpible, gestionándose los clientes interrumpidos por la llegada de nuevos clientes con una pila desde la que se reemprende su ejecución. El estado se define ahora por el vector de longitud variable (c1, c2, …, ck), donde el número de elementos es igual al número de clientes que ha requerido servicio y el i-ésimo elemento es el índice de la clase del cliente que ocupa la i-ésima posición en la pila, siendo el primer cliente el que recibe servicio y estando en espera (interrumpidos) los restantes. Las ecuaciones de equilibrio son
( ) ( ) ( ) ( ) ( )∑∑==
µ+>λ=
>µ+λ
k
jckckc
k
jjk cccpcIccpcIcccp
121121
121 111
,...,,0,...,0,...,,
y su solución, sujeta al cumplimiento de la ecuación de normalización, es
( ) ( )∑=
ρρ−=k
j
ck
icccp1
21 1,...,,
siempre que ρ < 1, y donde el producto toma el valor 1 si el estado es 0 (sistema vacío). Si se desea encontrar la distribución estacionaria del estado agregado del sistema ( )Ckkk ..., , , 21 , se deben sumar todos los vectores que tengan k1 elementos de clase 1, k2 de clase 2,... y kC de clase C, lo cual da
( ) ( ) ∏=
ρρ−=
C
c c
kc
C kkkkkp
c
121 !
!1..., , ,
resultado que coincide con el del apartado anterior.
3.11.3. COLA CON ESTRATEGIA DE UN SERVIDOR POR CLIENTE.
En esta política (que se puede asimilar a una estación de tipo M/M/∞) se requieren tantos servidores como clientes puedan requerir servicio en un instante cualquiera; es decir, tan pronto como llega un cliente se le asigna un servidor durante toda la duración del servicio.

54
En el caso las ecuaciones de equilibrio estacionario son, teniendo en cuenta que la capacidad de servicio es proporcional al número de clientes de cada clase,
( ) =
µ+λ ∑∑
==
C
ccc
C
ccCc kkkkkp
1121 ,..., ..., , ,
( ) ( ) ( ) ( )∑∑==
+µ++λ>−=C
cccCc
C
cccCc kkkkkpkIkkkkp
121
121 1..., ,1..., , ,0..., ,1..., , ,
La solución, cumpliendo con la ecuación de normalización, viene dada por
( ) ∏=
ρ−ρ=
C
c c
kc
C ke
kkkpcc
121 !
..., , ,
Nótese que, aunque estas tres políticas presentan probabilidades en forma de producto, solo en esta última se factoriza completamente en el producto de distribuciones de cada clase de cliente, es decir, en este caso, las variables aleatorias k1, k2, ..., kC son independientes entre sí, mientras que en las políticas de servidor interrumpible y de servidor compartido no lo eran.
3.11.4. LEY DE COX. Se va a definir ahora una familia de distribuciones de probabilidad generales que permitirán relajar la suposición de que el tiempo de servicio requerido esté distribuido exponencialmente. Sea la red de N nodos de la figura 3.23. Nunca puede haber más de un cliente en la red. Los clientes entran en la red por el nodo 1. Después de recibir servicio en el nodo n (con un servicio distribuido exponencialmente con media 1/µn), un cliente deja la red con probabilidad bn, o pasa al nodo (n + 1) con probabilidad an (donde an + bn = 1, para n = 1, 2, …, N - 1). Después del nodo N, el cliente abandona forzosamente la red. Por lo tanto, la probabilidad de que el cliente alcance el nodo n es An = a0 a1 .… an-1 (n = 1, 2, …, N - 1, y a0 = 1) y la de que el cliente visite los nodos 1, 2, …, n y abandone la red es igual a Anbn. Por lo tanto, el tiempo t, que un cliente pasa en la red es, con probabilidad Anbn, la suma de n variables aleatorias independientes y distribuidas exponencialmente. El valor esperado para t es
µ1 µ2 µ3 µNa1
1 - a1 1
a2 a3
1 - a2 1 - a3
aN - 1
Figura 3.23.
[ ] ∑∑ ∑== = µ
=µ
=N
i
iN
n
n
j jnn
AbAtE
1 11 1
1
Sea f(x) la función de densidad de probabilidad de t, y sea F(s) su transformada de Laplace. Puesto que la transformada de Laplace de la función de distribución del tiempo de servicio
del nodo n es n
n
s µ+µ
se puede escribir

55
( ) ∑ ∏= = µ+
µ=
N
n
n
i i
inn s
bAsF1 1
El segundo miembro de esta expresión es una función racional de s, por lo que se puede escribir
( ) ( )( )sQsPsF =
donde P(s) y Q(s) son polinomios. Además, todas las raíces de Q(s) deben ser reales, el grado de Q(s) debe ser mayor que el de P(s) y P(0)/Q(0) = F(0) = 1. Inversamente, cualquier función de s, que satisfaga las condiciones anteriores, puede expresarse en forma de producto
de términos n
n
s µ+µ
, y, por consiguiente, cualquier distribución, cuya transformada de
Laplace sea una función racional de esas características, puede representarse por una red de Cox (figura 3.23) y denominarse distribución de Cox. Los tres modelos pueden revisarse suponiendo, en cada caso, que el tiempo de servicio para los clientes de clase c (c = 1, 2, …, C) tiene una distribución de Cox con parámetros Nc (numero de etapas), 1/µcn (tiempo medio de servicio de la n-ésima etapa, n = 1, 2, …, Nc), acn (probabilidad de seguir hacia la (n + 1)-ésima etapa, n = 0, 1, …, Nc-1, ac0 = 1) y bcn (probabilidad de salir después de la n-ésima etapa, n = 1, 2, …, Nc, bcN = 1). El tiempo medio de servicio de los clientes de clase c es
∑= µ
=µ
cN
n cn
cn
c
A1
1
donde
∏−
=
=1
0
n
icicn aA
es la probabilidad que un cliente de clase c alcance la etapa n de su servicio. Cuando los tiempos de servicio no están distribuidos exponencialmente, el proceso estocástico definido por el número (o vector de números) de clientes en el sistema, no es markoviano y no puede hallarse su distribución en régimen estacionario por medio de las ecuaciones de equilibrio. No obstante, si estas distribuciones son coxianas, puede restaurarse la propiedad markoviano mediante una adecuada redefinición del estado del sistema y el nuevo proceso puede estudiarse de la forma usual. En el caso del servidor de tipo compartido, se define el estado del sistema como un vector de vectores (v1, v2, …, vk), donde
( )ccNccc kkkv ,...,, 21=
es un vector cuyo n-ésimo elemento es el numero de clientes que están en la n--ésima etapa de su servicio. Tal como están definidos los estados del sistema forman un proceso de Markov, ya que todas las etapas están distribuidas exponencialmente. Por consiguiente, se puede escribir un conjunto de ecuaciones de equilibrio para la distribución de (v1, v2, …, vk) en régimen estacionario. Estas ecuaciones tienen en cuenta las transiciones desde un estado hacia afuera y hacia ese estado desde su exterior, debidas a las llegadas de clientes de clase c

56
y debidas a los servicios completados en la etapa n del servicio de clase c (c = 1, 2, …, C; n = 1, 2, …, Nc). La solución de esas ecuaciones, sujeta a la ecuación de normalización, viene dada por
( ) ( ) ∏ ∏= =
µ
λρ−=C
c
N
n
k
cn
cn
cn
kcC
ccn
cA
kkvvp
1 11 !
1!1,...,
donde
∑=
=cN
ncnc kk
1
y
∑ ∑∑= ==
µ
λ=µλ
=ρC
c
N
n cn
cnc
C
c c
cc A
1 11
Si se suman las probabilidades de todos los estados tales que
c
N
ncn kk
c
=∑=1
para c = 1, 2, …, C, se obtiene la distribución del estado del sistema agregado (k1, k2, …, kC), donde sólo se consideran los números de clientes de las distintas clases y no las etapas de servicio, obteniéndose
( ) ( ) ( ) ( ) ∏∏∏ ∑=== =
ρρ−=
µλ
ρ−=
µλ
ρ−=C
c c
kc
C
c
k
c
cC
c
kN
n cn
cnkc
C kk
kk
Ak
kkkkpccc
c
111 121 !
!1!
1!1!
!1,...,,
expresión idéntica a la obtenida en el apartado 3.11.1. En otras palabras, la distribución del vector agregado de estado depende sólo de la media de los tiempos de servicio. Cuando la política es de servidor interrumpible, se define el estado del sistema como el vector de pares [(c1, n1), (c2, n2), …, (ck, nk)], donde k es el número de clientes presentes y (cj, nj) describe el j-ésimo cliente en la pila: cj es la clase y nj la etapa de servicio del cliente. Así definido, el estado forma un proceso de Markov. De forma similar a la anterior se puede obtener la distribución en régimen estacionario, que viene dada por
( ) ( ) ( )[ ] ( )∏ µ
λρ−=
jj
jjj
nc
ncckk
Ancncncp 1,,...,,,, 2211
Agregando todos los estados tales que el índice de clase del primer cliente en la pila sea c1, los del segundo sea c2, etc., da
( ) ( ) ( )∏∏==
ρρ−=µ
λρ−=
k
jc
k
j c
ck j
j
jcccp11
21 11,...,,

57
que es una expresión idéntica a la hallada en 3.11.2. De nuevo, la distribución de ( )Ckkk ,...,, 21 se hace insensible a la forma de la distribución y depende sólo del valor medio del tiempo de servicio de cada clase. Un resultado similar se halla en el caso de la disciplina de un servidor por cliente. Definiendo el estado del sistema por el vector de vectores (v1, v2, …, vC) como en el caso del servidor compartido, se obtiene
( ) ∏∏= =
ρ−
µ
λ=
C
c
N
n
k
cn
cnc
cnC
ccnA
kevvp
1 11 !
1,...,
La agregación lleva a los mismos resultados que los obtenidos en el apartado 3.11.3.
3.12. COLAS G/G/1: MÉTODO DE DIFUSIÓN La aproximación por difusión es un intento de superar las limitaciones de los servidores exponenciales considerando la media y la variancia de las distribuciones de los tiempos de servicio. Se basa en el supuesto que los sistemas casi nunca están vacíos y, como se verá, la calidad de la aproximación realizada es tanto mejor cuanto más próximo de la saturación está el servidor. Se aplica el teorema del límite central para caracterizar las fluctuaciones del número de clientes en el sistema y se sustituye el proceso de valores discretos por un proceso de Markov continuo (el denominado proceso de difusión) con una distribución similar de incrementos infinitesimales. La distribución de probabilidad de este proceso continuo se describe entonces por una ecuación de difusión, que se resuelve con las condiciones de contorno apropiadas.
3.12.1. ENFOQUE BASADO EN EL TEOREMA DEL LÍMITE CENTRAL. Sea el caso de una cola GI/G/1 y se va a proceder a su estudio efectuando las siguientes manipulaciones: - Suposición de distribución normal de las fluctuaciones del número de clientes en el
sistema.
Sea ∆N(t) la variación de la longitud de la cola entre los instantes t y t + ∆. Entonces, para ∆ suficientemente grande, ∆N(t) debe seguir aproximadamente una distribución normal con
E[∆N(t)] = (λ - µ)∆ = β∆
Var[∆N(t)] = (Ka2 λ + Ks
2 µ)∆ = α∆
donde λ es la frecuencia de llegada, µ la capacidad de servicio (o la inversa del tiempo medio de servicio), Ka
2 es el coeficiente cuadrático de variación del tiempo entre llegadas ta, es decir Ka
2 = var(ta)λ2, y Ks2 el coeficiente cuadrático de variación de los tiempos de
servicio ts, es decir Ks2 = var(ts)µ2.
- Sustitución del proceso discreto por un proceso continuo.
Se aproxima el proceso de colas de valores discretos ∆N(t) por un proceso continuo x(t), cuyos cambios incrementales dx(t) están distribuidos normalmente con media βdt y variancia αdt, es decir
dx(t) = βdt + z(t) (αdt)1/2

58
donde z(t) es un proceso gaussiano blanco. Si no se impone ninguna condición de contorno a x(t), entonces x(t) es un movimiento browniano con desplazamiento, que tiene una distribución de probabilidad p(x0, x, t) que satisface
( ) ( ) ( )x
txxpx
txxpt
txxp∂
∂β−
∂∂α
=∂
∂ ,,,,2
,, 02
02
0
donde x0 es el valor inicial y p(x0, x, t)dx = Pr[x ≤ x(t) ≤ x + dt | x(0) = x0]
- Introducción de las condiciones de contorno. La ecuación de difusión se resuelve ahora con la condición de contorno x(t) > 0 (barrera
reflectante) o p(x0, x, t) = 0 para x < 0. Para el caso estacionario, la derivada respecto al tiempo en la ecuación anterior debe ser cero. Entonces la exigencia evidente
( ) 1,,0 0 =∫∞
dxtxxp
lleva a la bien conocida condición de estabilidad β < 0 ó λ < µ y a la condición de contorno
( ) ( ) 0en ,0,,,,
2 00 ==∞β−
∞α xxxpdx
xxdp
Con esta condición de contorno, la solución en régimen permanente de la ecuación de difusión, que se representará, en consecuencia, como p(x), se determina de forma única y es
( ) αβ
αβ
−= /22 exp
- Discretización del proceso de difusión y ajuste para pocos clientes en el sistema. La solución en régimen permanente del proceso de difusión es la anterior distribución
exponencial. El proceso de colas original con valores discretos para el que se interpretó la distribución geométrica cuya variable es el número de clientes en el sistema n con el mismo factor de decremento e-2β/α. Por la misma naturaleza de la suposición básica (el teorema del límite central) no se pueden esperar resultados significativos para pocos clientes en el sistema n. Para distribuciones generales de los tiempos entre llegadas y de servicio, sin embargo, se sabe que la probabilidad de tener la cola vacía es ρ = 1 - λ/µ. Entonces se ajusta la distribución geométrica para n = 0 y se usa αβ−=φ /2e como factor de decremento. Si se representa la distribución aproximada del número de clientes en el sistema, construida de esta forma, por π(n), se obtiene
π(n) = 1 - ρ , si n = 0
π(n) = ρ (1 - φ) φn-1 , si n > 0
3.12.2. ENFOQUE BASADO EN EL PROCESO DE RETORNO INSTANTÁNEO El proceso de difusión que se presenta aquí es una generalización del considerado como estándar. Sea un proceso estocástico X(t), t ≥ 0 (que se usará para aproximar el número de clientes en la cola) que representa la posición de una partícula moviéndose en el intervalo cerrado [0, M] de la recta real. Cuando la partícula se halla en el intervalo abierto ]0, M[, su movimiento está descrito por un proceso de difusión donde α y β son la variancia y la media de la velocidad instantánea de cambio de X(t) y vienen dadas por

59
( ) ( )[ ]t
tXttXEt ∆
−∆+=β →∆ 0lim
( ) ( )[ ][ ] ( ) ( )[ ][ ]t
tXttXEtXttXEt ∆
−∆+−−∆+=α →∆
22
0lim
Cuando la partícula alcanza el límite inferior del intervalo [0, M[ permanece en él durante un período de tiempo h, que es una variable aleatoria, al final del cual "salta" instantáneamente de nuevo al intervalo abierto ]0, M], a un punto cuya posición esta definida por la función de densidad de probabilidad f1(x). Sea fh(r) la función de densidad de probabilidad de h y fh
*(s) su transformada de Laplace cuya forma se puede admitir que es
( ) ( ) ( )∑ ∏∫= =
∞ −
λ+
λ−==
n
i
i
j j
jiih
srh s
abdrrfesf1 1
0
* 1
donde
ai = 1, si i = 1
10y 1 si ,1
1
≤<>= ∏−
=j
i
jji biba
Es decir, se trata de una distribución de Cox. Cuando la partícula alcanza su límite superior en x = M, permanece allí durante un período H cuya función de densidad de probabilidad fH(r) es también de Cox y su transformada de Laplace es
( ) ( ) ( )∑ ∏∫= =
∞ −
µ+
µ−==
m
i
i
j j
jiiH
srH s
ABdrrfesf1 1
0
* 1
donde
Ai = 1, si i = 1
10y 1 si ,1
1
≤<>= ∏−
=j
i
jji BiBA
Al final del período de permanencia en x = M, la partícula retrocede instantáneamente a un punto aleatorio del intervalo ]0, M[ cuya posición está determinada por la función de densidad de probabilidad f2(x). Si se introduce la definición de λ y µ se observa que las medias de h y H son
[ ] 1
1
−
=
λ=λ
= ∑n
i i
iahE
[ ] 1
1
−
=
µ=µ
= ∑m
i i
iAHE
y que las varianzas son

60
[ ] ∑= λ
=n
i i
iahVar
12
[ ] ∑= µ
=m
i i
iAHVar
12
Es fácil ver que el proceso X(t), t ≥ 0 tal como se ha definido no es markoviano ya que, cuando la partícula está en uno de los extremos, el tiempo adicional que permanecerá en él no es independiente del tiempo que ha residido en él hasta el instante presente. Sea f = f(x,t) la función de densidad de probabilidad del proceso estocástico X(t), t ≥ 0 en el intervalo abierto ]0, M] y sean Ax,t y Dx,t los operadores definidos por
2
2
, 21
xf
xf
tffA tx ∂
∂α+
∂∂
β−∂∂
−=
xfffD tx ∂
∂α+β−=
21
,
Además, sea Pi(t), 1 ≤ i ≤ n la probabilidad que la partícula esté en la i-ésima etapa del tiempo de permanencia en el límite inferior en el instante t y Qi(t), 1 ≤ i ≤ M para el límite superior. Con estas hipótesis, las ecuaciones que describen el comportamiento de la partícula son
( ) ( ) ( ) ( ) ( ) ( ) 0111
21
1, =−µ+−λ+ ∑∑==
m
iiii
n
iiiitx xftQBxftPbfA
( ) ( )( ) ( )
≤<λ+λ−=+λ−
=−−− nitPbtP
ifDtPtP
dtd
iiiii
ti 1 si
1 si
111
,011
( ) ( )( ) ( )
≤<µ+µ−=+µ−
=−−− mitQBtQ
ifDtQtQ
dtd
iiiii
tMi 1 si
1 si
111
,11
donde
α
∂∂
+β−= → fx
ffD xt 21lim 0,0
α
∂∂
+β−= → fx
ffD MxtM 21lim,
[ ]( ) [ ]( ) 11 , −− =µ=λ HEhE
Estas ecuaciones son fáciles de interpretar a partir de la siguiente deducción. Sea un subintervalo Ω de ]0, M[. Se puede escribir
+
α
∂∂
+β∂∂
−=∂∂
∫∫ ΩΩdxf
xf
xfdx
t 2
2
21
( ) ( ) ( ) ( ) ( ) ( )∑ ∫∑ ∫=
Ω=
Ω−µ+−λ+
m
iiii
n
iiii dxxftQBdxxftPb
12
11 11

61
que establece que la tasa variación de probabilidad en ω es igual a la tasa de flujo de la probabilidad de masa fuera de Ω (primer sumando del segundo miembro) más la tasa de flujo hacia Ω desde x = 0 y desde x = M (segundo y tercer sumandos). Para las otras dos ecuaciones anteriores se puede escribir (se deduce sólo para P)
( ) ( ) ( ) ( )ttPbtPtttP iiiii 1111 −−− ∆λ+∆λ−=∆+
puesto que los tiempos en las etapas de la ley de Cox están distribuidos exponencialmente; agrupando los términos, dividiendo ambos miembros por ∆t y haciéndolo tender a cero, se obtiene la ecuación deseada para 1 < i ≤ n. Para i = 1 se aplica un procedimiento similar, pero teniendo en cuenta que D0,tf es el flujo de probabilidad de masa fuera del intervalo ]0, M[ hacia el límite inferior y evidentemente en la primera etapa de la ley de Cox en x = 0. Sean P(t) la probabilidad que la partícula esté en el límite inferior en el instante t y Q(t) la probabilidad correspondiente al límite superior
( ) ( ) ( ) ( )∑∑==
==m
ii
n
ii tQtQtPtP
11
Derivando y sustituyendo se tiene
( ) ( ) ( ) fDtPbtPdtd
t
n
iiii ,0
11 +−λ−= ∑
=
( ) ( ) ( ) fDtQBtQdtd
tM
m
iiii ,
11 +−µ−= ∑
=
Los puntos x = 0 y x = M actúan como puntos de absorción. Además debe verificarse que
( ) ( ) 10
=++∫ tQtPfdxM
Si se pasa ahora al estudio de la situación estacionaria se tiene
( ) ( ) ( ) 0, 0 0 =∂
∂==
ttxf
dttdQ
dttdP ii
Sustituyendo se obtiene
tDP ,01
11−λ=
niPb
P ii
iii ≤<
λλ
= −−− 1 111
de donde
fDa
fDbPi
ii
jjii 0
1
10
1
λ=λ= ∏
−
=
−
Por consiguiente
fDPPn
ii 0
1
1
−
=
λ== ∑

62
y de forma similar
fDQQ M
m
ii
1
1
−
=
µ== ∑
Pero
( ) ( ) fDfDbaPbn
iii
n
iiii 0
10
111 =−=−λ ∑∑
==
y
( ) fDQB M
n
iiii =−µ∑
=11
Por lo tanto, el régimen estacionario estará definido por
Axf + λ P f1(x) + µ Q f2(x) = 0
λ P = D0f
µ P = DMf
junto con
( ) ( ) 10
=++∫ tQtPfdxM
Hay que observar que estas relaciones dependen solo de E[h] y de E[H] y son independientes de los momentos de orden superior h y H. Si se aplica el proceso de retorno instantáneo al estudio de una cola G/G/1 como la definida en el apartado anterior estudiada desde el punto de vista del teorema del límite central, se tiene que el intervalo a considerar será [0, ∞[, la función f1(x) = δ(x 1) (función delta de Dirac) ya que solo habrán llegadas individuales. Los parámetros α y β serán
β = λ - µ
α = λ Ka2 + µ Ks
2
Si las llegadas fueran poissonianas se tendría λ = (E[h])-1, pero si no lo es, se considera (E[h])-1= λ' ≠ λ. La aproximación del proceso de retorno unitario de la cola GI/G/1 se representa pues por
( ) 01'21
2
2
=−δλ+α+β− xPdx
fddxdf
fDP 0' =λ
P + f x dx = 10
10
=+ ∫∞
fdxP

63
que da como solución
f(x) = R(e-φ - 1) eφx, para x ≥ 1
f(x) = R(1 - eφx), para 0 ≤ x ≤ 1
donde
22
12sa KK +ρ
ρ−−=φ
µλ
=ρ
λ−µ+λλ
='
'R
La condición de estabilidad exige ρ = λ/µ < 1. Si además se admite λ = λ', lo cual lleva a una cola M/G/1, resulta R = ρ. La longitud media de la cola será
( )
β
α+ρ=
ρ−
+ρ+ρ== ∫
∞
221
1221 22
0
sa KKxfdxL
que es similar a la obtenida de la fórmula de Khitnchin-Pollaczeck
( )( )
ρ−
+ρ+ρ=
121
12s
KPK
L
De hecho si se hace Ka = 1 en la ecuación de L para representar el proceso de llegada de Poisson, se obtiene que el error en la longitud de la cola es
21 2
sKP
KLL
−ρ=−
de forma que el error relativo tiende a cero cuando ρ tiende a uno. Se ha deducido la función de distribución continua de la longitud de la cola GI/G/1 con la aproximación R = ρ. Ahora bien, es necesario devolver su carácter discreto a la longitud de la cola, para lo cual hay varias alternativas. Sea P = 1 - ρ, la primera consiste en hacer
p1(i) = f(i), para i ≥ 1
p1(0) = P
de donde
p1(0) = 1 - ρ
( ) ( ) ( ) 111 ˆˆ1ˆ1ˆ −− ρρ−ρ=ρ−ρρ= iiip
donde φ=ρ eˆ

64
que es idéntica a la obtenida a partir de la aproximación del teorema del límite central. La longitud media de la cola será
( )ρ−
ρ== ∑
∞
= ˆ1111
iiipL
Una segunda discretización consiste en hacer que la probabilidad p2(i) sea la probabilidad correspondiente a la función continua de distribución entre i - 1 e i, es decir,
( ) ρ−= 102p
( )
φ−ρ
−ρ=1ˆ
112p
( ) ( ) ( ) 2 para ,ˆˆ1ˆ
2212 ≥ρρ−
ρφρ
== ∫−idxxfip ii
i
en cuyo caso la longitud media de la cola es
( )
ρ−
+ρ+ρ=
φ
−ρ=12
11122
2sa KK
L
Al comparar estas longitudes L1 y L2 con la obtenida por la fórmula de Khintchin-Pollaczeck para la cola M/G/1 (Ka
2 = 1), que es
( )( )
ρ−
+ρ+ρ=
121
12s
KPK
L
se observa que el error absoluto
2
2
2s
KPK
LLρ
=−
crece con ρ y Ks2. Pero el error relativo (L2 - LKP)/LKP tiene las siguientes propiedades
0lim 20 =
−→ρ
KP
KP
LLL
( )ρ−=−
∞→12lim 2
2
KP
KPK L
LLs
La primera propiedad pone de manifiesto que el error relativo tiende a cero en situaciones de elevada saturación; la segunda establece que cuando Ks
2 crece, el error relativo depende de ρ, pero el factor 2(1 - ρ) hace que los resultados sean inaceptables cuando la utilización es baja. Si se examina ahora el comportamiento de L1 cuando Ks
2 es grande y ρ pequeño, es decir cuando L2 es una mala aproximación, con Ka
2 = 1, se tiene
( ) ( )
ρ−
ρ−
−−
+ρ
ρ−−=ρ 112exp12expˆ
222sss KKK

65
que cuando Ks2
>> 1 >> ρ, da
( )2
121ˆsKρ−
−=ρ
de donde
( )2
1 12 sKLρ−
ρ=
y
( ) ( )[ ] ( )( )ρ−
−ρρ+
ρ≈ρ+−ρ−
ρ−ρ
≈−12
22
2112
221 ssKP KKLL
y por lo tanto
( )ρ−=−
∞→12lim 1
2
KP
KPK L
LL
resultado idéntico al de L2. Si se considera ahora el caso en que 1 - ρ << 1, se tiene entonces
( ) ( ) ( )[ ]32
22 11221121ˆ ρ−∅+
+ρ
ρ−+
+ρρ−
−≈ρss KK
( )( ) ( )[ ]
ρ−∅+
+ρρ−
+ρ−
+ρρ≈ 3
2
2
1 11112 s
s
KK
L
( )[ ]
ρ−∅+
+ρ+
ρ≈− 3
22
1 112 s
sKP KKLL
Por consiguiente
0lim 11 =
−→ρ
KP
KP
LLL
resultado idéntico al de L2, y
( )[ ]31 11lim 2 ρ−∅+ρ
ρ−=
−∞→
KP
KPK L
LL
que es dos veces mejor que el obtenido para L2. De hecho la fórmula de Khintchin-Pollaczeck sugiere una nueva aproximación heurística consistente en hacer
( )( )22
12'sa KK +ρ
ρ−−=φ
de la que se puede deducir

66
( )( )
ρ−
+ρ+ρ=
φ
−ρ=12
1'
11'22
2sa KK
L
que coincide con la longitud de cola LKP cuando Ka2 = 1. La deducción de las probabilidades
de estado se haría mediante la sustitución de ρ por eφ' lo cual equivaldría a hacer que los parámetros de la difusión tomaran los siguientes valores
β = λ - µ
α = λ Ka2 + µ ρ Ks
2 = λ(Ka2 + Ks
2)

67
4. TEORÍA DE REDES DE COLAS 4.1. INTRODUCCIÓN El comportamiento de la mayoría de sistemas informáticos está caracterizado por la presencia de varios puntos de congestión originados por la compartición de diversos recursos. En estos casos es difícil, y a veces demasiado restrictivo, representar el comportamiento del sistema mediante una única estación utilizando los esquemas que se han estudiado en el capítulo anterior. Parece adecuado modelar explícitamente los diferentes puntos de congestión del sistema. El modelo resultante es una red de colas, es decir, un conjunto de estaciones de servicio interconectadas, a través de las cuales circulan los clientes siguiendo un patrón determinista o probabilístico. Formalmente, se puede definir una red de colas como un grafo dirigido cuyos nodos son las estaciones de servicio. Los arcos entre estos nodos indican las transiciones posibles de los clientes entre estaciones de servicio. Los clientes que circulan a través de la red pueden ser de clases diferentes. Los clientes de clases diferentes pueden seguir recorridos distintos a través de la red o solicitar servicios distintos en las estaciones. En general, el estudio de este modelo probabilístico complejo es mucho más difícil que el de una estación de servicio aislada. Existen, sin embargo, muchos casos especiales, caracterizados por ciertas estructuras de interconexión de las estaciones y por diversas distribuciones de los procesos de llegada y de servicio, que han sido analizadas por diferentes autores y se les ha encontrado solución analítica a través de técnicas matemáticas relativamente simples. En los apartados siguientes se estudiarán algunas de estas técnicas.
4.2. TIPOS DE REDES Las redes pueden clasificarse según los tipos de clientes que circulan por sus estaciones en: - Red monoclase: Si en todas las estaciones de la red, los clientes tienen el mismo
(aleatorio) comportamiento, tanto en lo que se refiere a los tiempos de servicio como en lo que atañe al camino que siguen al abandonar la estación, se dice que la red tiene una única clase de clientes. Todos los clientes son (estadísticamente) indistinguibles.
- Red multiclase: En una red con múltiples clases de clientes, los clientes de diferente clase pueden tener diversas características de tiempo de servicio y seguir recorridos distintos a través de la red. Todos los clientes de una misma clase son (estadísticamente) indistinguibles
Las redes también pueden clasificarse según la topología del grafo subyacente en: - Redes abiertas. Están caracterizadas por (figura 4.1):
* la existencia de, al menos, una fuente de clientes
* la existencia de, al menos, un sumidero que absorbe los clientes que salen del sistema
* la posibilidad de encontrar un camino que, a partir de cada nodo, lleve (eventualmente) fuera de la red.
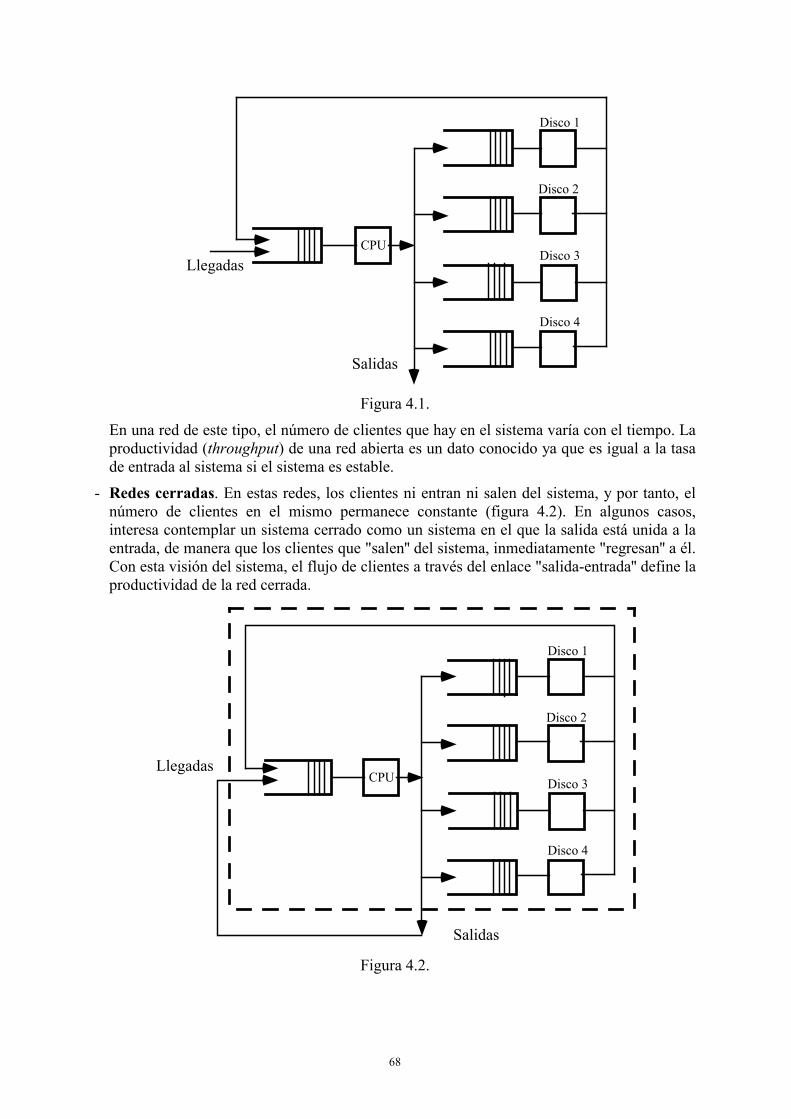
68
CPU
Disco 2
Disco 3
Disco 4
Disco 1
Llegadas
Salidas
Figura 4.1.
En una red de este tipo, el número de clientes que hay en el sistema varía con el tiempo. La productividad (throughput) de una red abierta es un dato conocido ya que es igual a la tasa de entrada al sistema si el sistema es estable.
- Redes cerradas. En estas redes, los clientes ni entran ni salen del sistema, y por tanto, el número de clientes en el mismo permanece constante (figura 4.2). En algunos casos, interesa contemplar un sistema cerrado como un sistema en el que la salida está unida a la entrada, de manera que los clientes que "salen'' del sistema, inmediatamente "regresan'' a él. Con esta visión del sistema, el flujo de clientes a través del enlace "salida-entrada'' define la productividad de la red cerrada.
CPU
Disco 2
Disco 3
Disco 4
Disco 1
Llegadas
Salidas Figura 4.2.

69
- Redes mixtas. En una red con múltiples clases de clientes, es posible que la red sea abierta para un tipo de clientes y cerrada para otro (figura 4.3). Se dice, entonces, que la red es mixta.
Terminales
SubsistemacentralTrabajos transaccionales
Trabajosinteractivos
Figura 4.3.
En resumen, el comportamiento de los clientes dentro de una red está caracterizado por las probabilidades de transición entre estaciones de servicio y la distribución de los tiempos de servicio en cada estación. Para cada estación debe especificarse: el número de servidores, la disciplina de servicio y la capacidad de la estación.
4.3. MÉTODOS ANALÍTICOS EXACTOS Jackson (JACK63) dio la primera forma de tratar redes de colas cerradas con estaciones FIFO y servicio exponencial, que fue ampliada por Gordon y Newell (GORD67). Fueron de forma definitiva Baskett, Chandy, Muntz y Palacios (BASK75), quienes incluyeron en un solo teorema todos los casos susceptibles del mismo tratamiento analítico exacto. Dicho teorema es conocido por el acróstico de sus iniciales: BCMP.
4.3.1. TEOREMA DE BCMP Los sistemas, que considera este teorema, contienen un número arbitrario, pero finito, N, de estaciones de servicio. Hay un número arbitrario, pero finito, C, de clases de clientes distintos, los cuales pueden cambiar de clase cuando pasan de una estación a otra. Dicho con mayor precisión, un cliente de clase c que sale de la estación de servicio i requerirá servicio de la estación j en la clase d con una probabilidad que se indicará por pi,c;j,d. Esta matriz se designará por P = [pi,c;jd]. Un cliente abandona la red (en el caso de ser abierta) con probabilidad
∑∑= =
−=N
j
C
djdicic pp
1 1,0, 1
El par (i,c), asociado a un cliente en una estación, se denomina estado del cliente. El conjunto de estados de los clientes se reparte en uno o más subconjuntos disjuntos (o subcadenas) de la forma siguiente: dos estados del cliente pertenecen a la misma subcadena si hay una probabilidad no nula de que un cliente pueda estar en ambos estados durante su vida en la red. Estas subcadenas se representan por E1, E2, …, EK (K ≥ 1). (Por ejemplo, si los clientes nunca

70
cambian de clase cuando van de una estación a otra, habrá C subcadenas, es decir tantas como clases). Puede ser que algunas subcadenas sean cerradas, con un número constante de clientes en ella, mientras que otras sean abiertas con llegadas y salidas, que hacen que el número de clientes que hay en ellas sea variable. Además, los procesos de llegada externa pueden ser independientes del estado o dependientes del mismo de una forma restringida. Sea S el estado de la red (que se definirá más adelante), y sea M(S) el número de clientes que hay en la red en el estado S y sea M(S, Ek) el número de clientes en la subcadena Ek, cuando la red está en el estado S. Las llegadas externas pueden generarse en una de las dos siguientes formas, que no pueden darse simultáneamente: - por un proceso de Poisson cuya frecuencia instantánea, λ[M(S)], depende del estado del
sistema a través del número de clientes que hay en la red. Una nueva llegada alcanza la estación i en clase c con probabilidad p0,ic. Evidentemente la suma de las p0,ic para todas la i y todas las c debe ser igual a 1.
- por m procesos de Poisson, uno por cada subcadena. La frecuencia instantánea del k-ésimo proceso depende del estado a través del número de clientes que hay en la subcadena Ek. Una nueva llegada a la k-ésima subcadena alcanza la estación i en clase c con probabilidad p0,ic. Evidentemente la suma de las p0,ic para todas la i y todas las c debe ser igual a 1.
Las estaciones de servicio pueden ser de los cuatro tipos siguientes: - Tipo 1. La estación i tiene un solo canal con tiempo de servicio distribuido
exponencialmente, de tiempo medio 1/[µi Fi(mi)], idéntico para todas las clases, siendo mi (mi = mi1 + mi2 + … + miC) el número de clientes en la estación, y la disciplina de la cola, FIFO. Fi(mi) es la velocidad del servidor y satisface Fi(1) = 1 (se pueden simular servidores múltiples haciendo Fi(mi) = min(mi, ni), donde ni es el número máximo de servidores).
- Tipo 2. La estación tiene un solo canal, la disciplina de servicio es de servidor compartido (es decir, cuando hay m clientes en la estación de servicio, cada uno recibe servicio a razón de 1/m de segundo cada segundo) y cada clase de cliente tiene una distribución de tiempos de servicio, que puede ser distinta y arbitraria y debe tener transformada de Laplace racional, o, lo que es lo mismo, su distribución es coxiana. Se admite que el servidor de esta estación tenga una velocidad que sea función del número de clientes que haya en ella Fi(mi).
- Tipo 3. El número de canales en una estación de servicio de este tipo es mayor o igual que el número máximo de clientes que puede haber en la estación en un instante cualquiera y cada clase de cliente tiene una distribución de tiempos de servicio que puede ser distinta y arbitraria y debe tener transformada de Laplace racional, es decir, su distribución coxiana. En una estación de este tipo, que sigue la política de un servidor por cliente, no tiene sentido asignarles velocidad de servicio, ya que cada clase tiene su propia distribución.
- Tipo 4. La estación de servicio de este tipo tiene un solo canal, la disciplina de cola es LIFO con interrupción provocada por el último en llegar y cada clase de cliente tiene una distribución de tiempos de servicio que puede ser distinta y arbitraria y debe tener transformada de Laplace racional, es decir su distribución coxiana, pudiendo el servidor presentar una velocidad de servicio función del número de clientes de la estación Fi(mi).
El estado de la red S está definido por el vector (S1, S2, …, SN), donde cada Si define el estado de la estación i de forma análoga a como se ha visto en 3.10., según el tipo de estación. Aun cuando se sabe que se pueden hacer intervenir las etapas de la estación con distribución de Cox en la definición del estado, desde el punto de vista de la evaluación del comportamiento

71
de sistemas informáticos y teleinformáticos, dicho detalle no es necesario, al no tener normalmente ninguna interpretación física, por lo que el estado de una estación vendrá definido por el vector
Si = (mi1, mi2, …, miC)
La evolución del estado (considerado como una función del tiempo) es un proceso de Markov. Si se está interesado en la distribución en régimen estacionario de las probabilidades de estado p(S) de este proceso de Markov, solo hará falta hallar la solución de las ecuaciones de equilibrio:
( )( ) ( )( )[ ]∑∀
='
a ' de paso de frecuencia' de salida de frecuenciaS
SSSpSSp
satisfaciendo además la ecuación de normalización.
( ) 1=∑∀S
Sp
La existencia de la distribución en régimen estacionario depende de la solución del siguiente sistema de ecuaciones, que refleja el equilibrio del flujo en la red
∑∑= =
+=N
ijd
C
cjdicicjd ppee
1,0
1,
donde p0,jd es la probabilidad de entrada desde el exterior en la estación j de un cliente de clase d. Si la red es abierta este sistema puede resolverse sin ninguna dificultad. Si la red es cerrada, evidentemente todas las p0,jd son nulas y se encuentra un sistema de ecuaciones homogéneo del que hay que hallar una de las infinitas soluciones distinta de la idénticamente nula. De hecho si p0,jd = 0 y pjd,0 = 0, para toda (j,d) de Ek, entonces Ek es cerrada y hay en ella un número fijo de clientes; en caso contrario Ek es abierta.
1
2
p12,22p11,21
p11,11
p21,11p22,12
Figura 4.4.
Para ver la escritura de las ecuaciones de equilibrio y antes de enunciar el teorema de BCMP se van a establecer, como ejemplo, las ecuaciones de equilibrio de sistema de la figura 4.4, donde hay dos clases de clientes. Hay M1 clientes de clase 1 y M2 de clase 2. Todos los tiempos de servicio están exponencialmente distribuidos y 1/µic (i = 1, 2; c = 1, 2) es el tiempo medio de servicio de la clase c en la estación i.

72
Además p12,22 = p21,11 = 1 y p11,11 + p11,21 = 1. Sea mic el número de clientes de clase c en la estación i. Para mayor simplicidad se consideran solamente los estados para los que mic > 0. Las ecuaciones globales serán:
( ) ( )( ) +µ+−++µ++
++− 21,1111112221121121
2221
2122211211 1,1,,1
11
,1,,1 pmmmmmpmm
mmmmmp
( ) ( )( ) +µ+−++µ+ 12122221121111,11111122211211 11,,1,,,, mmmmmppmmmmmp
( ) =µ++
++−+ 22
2221
2222211211 1
11,,1,
mmm
mmmmp
( )
µ
++µ
++µ+µ= 22
2221
2221
2221
211212111122211211 ,,,
mmm
mmm
mmmmmmp
Estas ecuaciones, como puede verse, son similares a las que se establecieron para deducir las ecuaciones de Kolmogorov en el apartado 3.5., pero teniendo en cuenta que, en este caso, la estructura del sistema es más compleja por estar enlazadas varias estaciones y considerar diversas clases de clientes. La solución de estas ecuaciones lleva a determinar la probabilidad del estado como producto de las probabilidades del estado de cada estación. No obstante, el enunciado completo del teorema de BCMP lleva, como ya se ha dicho, a una expresión notablemente más compleja, por lo que se expone aquí sólo las consecuencias que permiten una más fácil comprensión y aplicación. La versión completa permite incluir en el estado la etapa de la estación de Cox en que se encuentra el cliente en las estaciones de servicio no exponencial. En la versión completa de las expresiones que siguen interviene, pues, un elemento más en la definición del estado y un subíndice más en las variables que lo definen. En las condiciones expuestas, el teorema de BCMP establece que:
( ) ( ) ( )∏=
=N
iii SgSd
GSp
1
1
donde - G es la constante de normalización para lograr que la suma de todas las probabilidades de
estado sea igual a 1. Esta constante de normalización puede determinarse sin ningún problema si se trata de un sistema cerrado, pues el número de estados distintos en que puede hallarse el sistema es finito y, por lo tanto, el número de sumandos de la suma de las probabilidades de los distintos estados también lo es. En el caso de una red abierta aparecerá una serie infinita y el valor de G solo podrá hallarse si la serie es sumable, suponiendo que el sistema sea estable (serie convergente).
- d(S) es una función tal que si la red es cerrada vale 1 y si la red es abierta vale
( )( )
∏−
=
λ1
0
SM
i
i
si la frecuencia de llegada depende del número de clientes de la red M(S), o
( )( )
∏ ∏=
−
=
λK
k
ESM
ik
k
i1
1,
0

73
si la frecuencia de llegada a cada subcadena depende del número de clientes que hay en ella.
- Las funciones gi(Si) valen
* si la estación es de tipo 1
( )c
c
m
i
C
c
mic
iciii e
mmSg
µ
= ∏
=
1!
1!1
* si la estación es de tipo 2 ó 4
( )cm
ic
icC
c iciii
em
mSg
µ
= ∏=1 !
1!
* si la estación es de tipo 3
( )cm
ic
icC
c icii
em
Sg
µ
= ∏=1 !
1
Estas expresiones son similares a las halladas en el estudio de las estaciones correspondientes aisladas en el apartado 3.11. Ahora bien, este proceso lleva al conocimiento de las probabilidades de los distintos estados a partir de las cuales es posible determinar magnitudes operacionales tales como la utilización que cada clase de cliente provoca en cada estación, el número medio de elementos de cada clase que hay en cada estación, la productividad medida en número de clientes de cada clase evacuados de cada estación por unidad de tiempo, etc. En caso de tratarse de una red abierta, sólo se podrá determinar la constante de normalización, sin riesgo de error de truncamiento de la suma infinita, cuando esa suma tenga una expresión analítica (la serie sea convergente y sumable). Tal es el caso, por ejemplo, cuando la llegada no depende del estado del sistema y el estado del sistema viene caracterizado simplemente por (m1, m2, …, mN), es decir, por el número total de clientes, mi, que hay en cada estación i. Entonces:
( ) ( ) 4 ó 2 1, tipode esestación la si ,1 imiiimp ρρ−=
( ) 3 tipode esestación la si ,!i
mi
i memp
ii
ρ= ρ−
y donde
1 tipode esestación la si ,1
∑= µ
λ=ρ
C
c i
ici
e
4 ó 3 2, tipode esestación la si ,1
∑= µ
λ=ρ
C
c ic
ici
e
Nótese que la solución de una red de colas abierta solo podrá lograrse si la suma para la deducción de la constante de normalización se presenta en forma de serie sumable; es pues un problema algebraico. Por el contrario, en el caso de una red cerrada, la suma para determinar

74
la constante de normalización es finita y, por lo tanto, puede determinarse calculando todos los sumandos; se trata pues de un problema numérico. No obstante, la utilización práctica de este método, en especial en el caso de redes cerradas, solo aparece cuando se dispone de un software que permita aplicarlo, pues exige un gran número de cálculos. Los algoritmos para efectuarlos reduciendo el número de operaciones a efectuar, se estudian en los apartados siguientes. Sin embargo, antes se va a presentar unos ejemplos calculados a fuerza bruta manual.
4.3.1.1. Ejemplo 1 Sea el ejemplo de la figura 4.5, en que hay un sistema cerrado, con dos clases de clientes y cinco estaciones de servicio, la 1 de tipo 2 (servidor compartido) y las otras cuatro de tipo 1 (FIFO exponencial). En función de las probabilidades de transición, se puede plantear el sistema de ecuaciones homogéneo para determinar las tasas de visita: e11 = e21 + e31 + e41 + e51 e12 = e22 + e32 + e42 + e52 e21 = 0 e11 e22 = e12 e31 = 0.35 e11 e32 = 0 e12 e41 = 0.35 e11 e42 = 0 e12 e51 = 0.3 e11 e52 = 0 e12 de donde e11 = 1; e21 = 0; e31 = 0.35; e41 = 0.35; e51 = 0.3 e12 = 1; e22 = 1; e32 = 0; e42 = 0; e52 = 0 Si se considera, inicialmente, el caso en que hay solo un cliente de clase 2 y ninguno de clase 1, el sistema solo podrá estar en los estados siguientes
S1 = [(0,1),(0,0),(0,0),(0,0),(0,0)]
S2 = [(0,0),(0,1),(0,0),(0,0),(0,0)]
Por lo tanto,
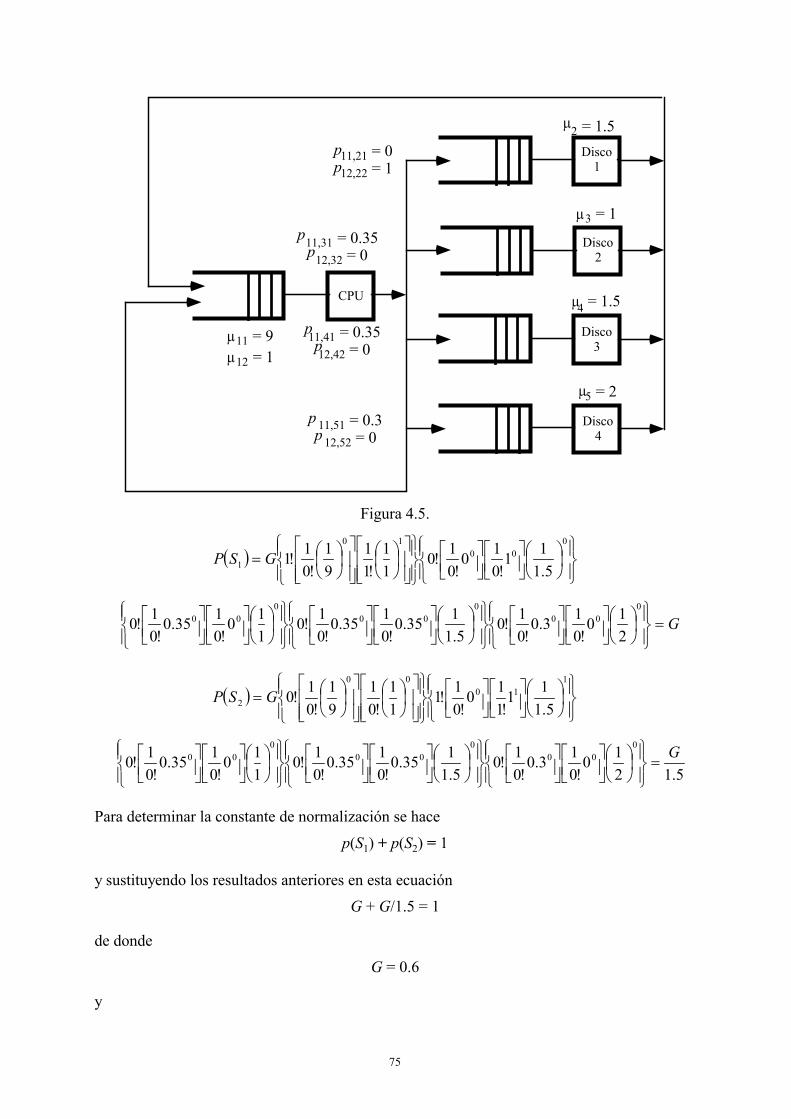
75
CPU
Disco1
Disco2
Disco3
Disco4
µ11 = 9µ12 = 1
p11,21 = 0p12,22 = 1
p11,41 = 0.35p12,42 = 0
p 11,51 = 0.3p 12,52 = 0
p11,31 = 0.35p12,32 = 0
µ2 = 1.5
µ3 = 1
µ4 = 1.5
µ5 = 2
Figura 4.5.
( )
=
000
10
1 5.111
!010
!01!0
11
!11
91
!01!1GSP
G=
000
000
000
210
!013.0
!01!0
5.1135.0
!0135.0
!01!0
110
!0135.0
!01!0
( )
=
110
00
2 5.111
!110
!01!1
11
!01
91
!01!0GSP
5.1210
!013.0
!01!0
5.1135.0
!0135.0
!01!0
110
!0135.0
!01!0
000
000
000 G
=
Para determinar la constante de normalización se hace
p(S1) + p(S2) = 1
y sustituyendo los resultados anteriores en esta ecuación
G + G/1.5 = 1
de donde
G = 0.6
y

76
p(S1) = 0.6 y p(S2) = 0.4
Las magnitudes operacionales que se pueden deducir de estas probabilidades de estado son ρ11 = 0 ρ21 = 0 ρ31 = 0 ρ41 = 0 ρ51 = 0 ρ12 = 0.6 ρ22 = 0.4 ρ32 = 0 ρ42 = 0 ρ52 = 0 ρ1 = 0.6 ρ2 = 0.4 ρ3 = 0 ρ4 = 0 ρ5 = 0 M11 = 0 M21 = 0 M31 = 0 M41 = 0 M51 = 0 M12 = 0.6 M22 = 0.4 M32 = 0 M42 = 0 M52 = 0 M1 = 0.6 M2 = 0.4 M3 = 0 M4 = 0 M5 = 0 X11 = 0 X21 = 0 X31 = 0 X41 = 0 X51 = 0 X12 = 0.6 X22 = 0.4 X32 = 0 X42 = 0 X52 = 0 X1 = 0.6 X2 = 0.4 X3 = 0 X4 = 0 X5 = 0 Si se considera, ahora, el caso en que hay un cliente de cada clase, el sistema solo podrá estar en los siguientes estados
S1 = [(1,1),(0,0),(0,0),(0,0),(0,0)]
S2 = [(0,1),(0,0),(1,0),(0,0),(0,0)]
S3 = [(0,1),(0,0),(0,0),(1,0),(0,0)]
S4 = [(0,1),(0,0),(0,0),(0,0),(1,0)]
S5 = [(1,0),(0,1),(0,0),(0,0),(0,0)]
S6 = [(0,0),(0,1),(1,0),(0,0),(0,0)]
S7 = [(0,0),(0,1),(0,0),(1,0),(0,0)]
S8 = [(0,0),(0,1),(0,0),(0,0),(1,0)]
Por lo tanto, las probabilidades serán (sólo están considerados los factores correspondientes a las estaciones que tienen algún cliente, siendo los demás 1):
( )9
2111111
!11
91
!11!2
11
1GGSP =××××
=
( )20711
110
!0135.0
!01!11
11
!11
91
!01!1
101
10
2GGSP =××
××
=
( )3071
5.110
!0135.0
!11!111
11
!11
91
!01!1
101
10
3GGSP =×
×××
=
( )203
210
!013.0
!11!1111
11
!11
91
!01!1
101
10
4GGSP =
××××
=
( )272111
5.111
!110
!01!1
11
!01
91
!11!1
110
01
5GGSP =×××
=

77
( )30711
110
!0135.0
!11!1
5.111
!110
!01!11
101
110
6GGSP =××
××=
( )4571
5.110
!0135.0
!11!11
5.111
!110
!01!11
101
110
7GGSP =×
××
××=
( )102
10!0
13.0!1
1!1115.1
11!1
10!0
1!111
011
108
GGSP =
×××
××=
Para determinar la constante de normalización
p(S1) + p(S2) + p(S3) + p(S4) + p(S5) + p(S6) + p(S7) + p(S8) = 1
y sustituyendo
11045
7307
272
203
307
207
92
=+++++++GGGGGGGG
de donde
G = 27/41
y
p(S1) = 0.1463 p(S2) = 0.2305 p(S3) = 0.1537 p(S4) = 0.0988
p(S5) = 0.0488 p(S6) = 0.1537 p(S7) = 0.1024 p(S8) = 0.0658
A partir de estas probabilidades de estado pueden calcularse las siguientes magnitudes operacionales ρ11 = 0.122 ρ21 = 0 ρ31 = 0.384 ρ41 = 0.256 ρ51 = 0.165 ρ12 = 0.556 ρ22 = 0.371 ρ32 = 0 ρ42 = 0 ρ52 = 0 ρ1 = 0.678 ρ2 = 0.371 ρ3 = 0.384 ρ4 = 0.256 ρ5= 0.165 M11 = 0.195 M21 = 0 M31 = 0.384 M41 = 0.256 M51 = 0.165 M12 = 0.629 M22 = 0.371 M32 = 0 M42 = 0 M52 = 0 M1 = 0.824 M2 = 0.371 M3 = 0.384 M4 = 0.256 M5 = 0.165 X11 = 1.098 X21 = 0 X31 = 0.384 X41 = 0.384 X51 = 0.329 X12 = 0.556 X22 = 0.556 X32 = 0 X42 = 0 X52 = 0 X1 = 1.654 X2 = 0.556 X3 = 0.384 X4 = 0.384 X5 = 0.329 En la tabla que sigue se exponen los niveles de utilización de las cinco estaciones de servicio cuando hay un cliente de clase 2 y un número variable de clientes de clase 1. M 1 2 3 4 5 ___________________________________________________________________
0 0.6 0.4 0 0 0 1 0.678 0.371 0.384 0.256 0.165 2 0.720 0.352 0.606 0.404 0.260 3 0.744 0.339 0.743 0.495 0.318 4 0.759 0.330 0.831 0.554 0.356 5 0.769 0.324 0.888 0.592 0.381

78
6 0.775 0.321 0.926 0.617 0.397 7 0.779 0.318 0.951 0.634 0.407 Si se deseara conocer otras características del comportamiento del sistema, se podría hacer sin ninguna dificultad a partir de las probabilidades de los distintos estados.
4.3.1.2. Ejemplo 2 Sea el sistema de la figura 4.6 en que se tiene un sistema abierto con dos clases de clientes y trece estaciones de servicio: una CPU (tipo 2) y tres grupos de 4 discos idénticos (tipo 1), con los siguientes datos:
λ1 = 0.05, λ2 = 5
µ11 = 200, µ12 = 300
µ2 = 25
µ3 = 20
µ4 = 15
p11,21 = 0.45, p21,11 = 1
p11,31 = 0.36, p31,11 = 1
p11,41 = 0.18, p41,11 = 1
p12,22 = 0.25, p22,12 = 0.8, p22,11 = 0.2
p12,32 = 0.15, p32,12 = 1
p12,42 = 0.40, p42,12 = 1
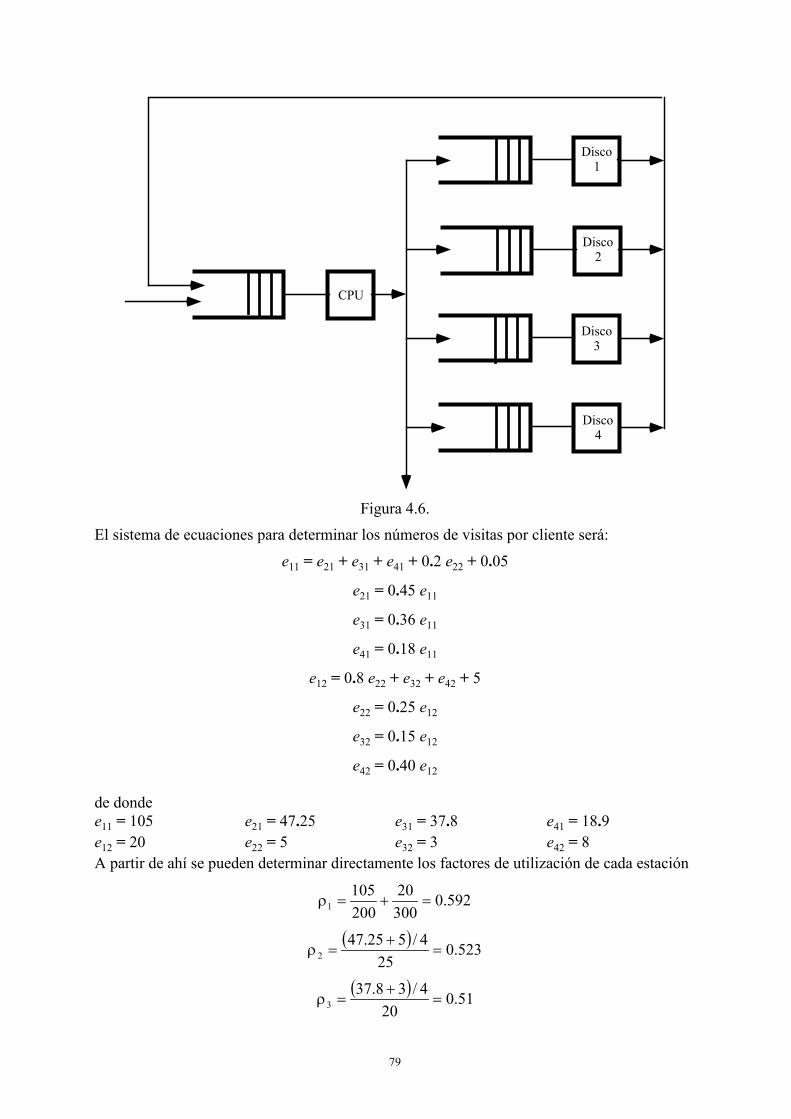
79
CPU
Disco1
Disco2
Disco3
Disco4
Figura 4.6.
El sistema de ecuaciones para determinar los números de visitas por cliente será:
e11 = e21 + e31 + e41 + 0.2 e22 + 0.05
e21 = 0.45 e11
e31 = 0.36 e11
e41 = 0.18 e11
e12 = 0.8 e22 + e32 + e42 + 5
e22 = 0.25 e12
e32 = 0.15 e12
e42 = 0.40 e12
de donde e11 = 105 e21 = 47.25 e31 = 37.8 e41 = 18.9 e12 = 20 e22 = 5 e32 = 3 e42 = 8 A partir de ahí se pueden determinar directamente los factores de utilización de cada estación
592.030020
200105
1 =+=ρ
( ) 523.025
4/525.472 =
+=ρ
( ) 51.020
4/38.373 =
+=ρ

80
( ) 448.015
4/89.184 =
+=ρ
y el número medio de elementos en cada estación
M1 = 0.592/(1 - 0.592) = 1.451
M2 = 0.523/(1 - 0.523) = 1.096
M3 = 0.51/(1 - 0.51) = 1.041
M4 = 0.448/(1 - 0.448) = 0.812
Si se supone, además, que los tiempos de servicio son todos exponenciales, se puede escribir que las utilizaciones provocadas por cada tipo de cliente serán
067.030020 525.0
200105
1211 ==ρ==ρ
050.025
4/5 475.025
4/25.472221 ==ρ==ρ
038.020
4/3 473.020
4/8.373231 ==ρ==ρ
133.015
4/8 315.015 4241 ==ρ==ρ
y los números medios de clientes de cada clase en cada estación
M11 = 0.525/(1 - 0.592) = 1.287 M12 = 0.067/(1 - 0.592) = 0.164
M21 = 0.475/(1 - 0.525) = 0.992 M22 = 0.050/(1 - 0.525) = 0.105
M31 = 0.473/(1 - 0.510) = 0.965 M32 = 0.038/(1 - 0.510) = 0.078
M41 = 0.315/(1 - 0.448) = 0.540 M42 = 0.133/(1 - 0.448) = 0.241
y, por la ley de Little, los tiempos medios de permanencia en cada estación son
mseg 26.12105
10287.1 3
11 =×
=R
mseg 2.820
10164.0 3
12 =×
=R
( ) mseg 9.834/525.47
10096.1 3
2 =+×
=R
( ) mseg 05.1024/88.27
10041.1 3
3 =+×
=R
( ) mseg 19.1214/89.18
10812.0 3
4 =+×
=R
El número medio de visitas a los discos para los clientes de cada clase son

81
( ) 9901.099.0
18.036.045.0118.036.045.0
1 ==++−
++=V
( ) 420.080.0
40.015.025.0140.015.025.0
2 ==++−
++=V
Por lo tanto, los tiempos medios de respuesta para cada clase de cliente son
( ) mseg 72.1085699.018.019.121
99.036.005.102
99.045.09.839926.121991 =
++×+×+=R
( ) mseg 79.44480.040.019.121
80.015.005.102
80.025.09.8342.8142 =
++×+×+=R
4.3.2. MÉTODOS DE CÁLCULO DE REDES CERRADAS Aun cuando el teorema de BCMP contempla un caso notablemente general (clases de clientes, tipos de estaciones, etc.), se va a estudiar con detalle el cálculo de la constante de normalización y de las magnitudes operacionales para una red de características restringidas (sólo estaciones FIFO con servicio exponencial y una sola clase de clientes o red de Jackson) y dar idea de como organizar el cálculo en el caso completo.
4.3.2.1. Algoritmo de Buzen (Redes FIFO exponenciales) Sea una red cerrada con N estaciones de servicio y M clientes, todos de la misma clase. El estado de esta red puede describirse por m = (m1, m2, …, mN), donde mi es el número de clientes en la estación i (m1 + m2 + … + mN = M). Sea pij la probabilidad de que un cliente al salir de la estación i se dirija a la j. Cada estación i está caracterizada por su capacidad de servicio µi, que puede depender del número de clientes que haya en ella, y, cuando así sea, µi(k) representará la capacidad de servicio . Ello permitirá considerar, como ya se ha visto, el caso de estaciones de servicio con varios servidores (multiprocesadores, por ejemplo). En caso de servicio independiente de la carga, si representará el tiempo medio de servicio, que debe ser si = 1/µi. En este caso el teorema de BCMP queda reducido al enunciado por Gordon y Newell y la probabilidad de cada uno de los estados viene dada por
( ) ( ) ( )∏=
=N
iiiN mf
MGmmmp
121
1,...,,
donde
( )( )∏
=
µ=
i
i
m
ki
mi
ii
k
emf
1
si la estación i tiene un servicio dependiente de la carga, o
( ) ( ) ii mi
miiii Xsemf ==
si la estación i tiene un servicio independiente de la carga. Las ei son una solución cualquiera real, positiva y distinta de cero del sistema de ecuaciones

82
NjpeeN
iijij ..., 2, ,1 para ,
1== ∑
=
que aseguran el equilibrio de flujo en cada estación y G(M) es la constante de normalización definida para que la suma de todas las p(m) sea igual a 1. Esto es
( ) ( )( )∑ ∏
∈ =
=NMSm
N
iii mfMG
, 1
donde
( ) ( )
≤<≥== ∑=
NimMmmmmNMS i
N
iiN 0 para ,0y ,|,...,,,
121
Nótese que la suma para determinar G(M) se efectúa sobre todos los posibles estados del sistema, que son
−
−+1
1N
NM
Este número alcanza valores notablemente grandes, incluso para valores modestos de M y N. Así, por ejemplo, para N = 8 y M = 20, el cálculo de G(M) requiere la suma de 888030 términos, cada uno de los cuales consta de ocho factores. Por ello, es prácticamente imposible atacar frontalmente este cálculo, que podría colapsar incluso los más potentes computadores y ello sin tener en cuenta los errores de truncamiento que se introducirían. Atacando el problema inteligentemente, se vera que mediante el algoritmo de Buzen, que se abalizará a continuación, el cálculo de G(M) necesitará sólo N×M sumas y N×M productos. Para deducir este algoritmo es preciso definir una función auxiliar. Sea
( ) ( )( )
∑ ∏∈ =
=nmSm
n
iiin mfmg
, 1
Obsérvese que G(M) = gN(M) y que G(m) = gN(m). Además, para n > 1 y m > 0, se cumple que
( ) ( )( )
( )( )
=
== ∑ ∑ ∏∑ ∏=
=∈ =∈ =
m
kkm
nmSm
n
iii
nmSm
n
iiin
n
mfmfmg0 , 1, 1
( ) ( )( )
( ) ( )∑∑ ∑ ∏=
−= −−∈ =
−=
=
m
knn
m
k nkmSm
n
iiin kmgkfmfkf
01
0 1, 1
que da una forma iterativa de determinar gn(m) a partir de los valores anteriores de esta función. Si, además, la capacidad de servicio es independiente del número de clientes en la estación
fn(k) = (en sn)k = Xnk = Xn fn(k - 1)
Sustituyendo esta ecuación en la anterior y simplificando, se obtiene

83
( ) ( ) ( ) ( ) ( ) ( ) =−+=−= ∑∑=
−−=
−
m
knnn
m
knnn kmgkfmgkmgkfmg
111
01
( ) ( ) ( ) =−−++= ∑−
=−−
1
011 11
m
knnn kmgkfmg
( ) ( ) ( ) ( ) ( )11 1
1
011 −+=−−+= −
−
=−− ∑ mgXmgkmgkfXmg nnn
m
knnnn
Este cálculo recurrente puede inicializarse con
( ) ( )( )
( )( )
( ) m
mSmmSm iii Xmfmfmfmg 11
1,11
1,
1
11 ==== ∑∑ ∏
∈∈ =
para m = 0, 1, …, M, y
gn(0) = 1, para n = 1, 2, …, N
Las relaciones anteriores definen un algoritmo iterativo y su inicialización. Esquemáticamente se trata de completar una tabla de N×M valores, de los que las ecuaciones anteriores definen la primera fila y la primera columna y donde las relaciones antes determinadas permiten irla llenando hasta alcanzar gN(M) = G(M). Las figuras 4.7 y 4.8 muestran como organizar el algoritmo y que sólo es necesario un vector de M posiciones para realizar el cálculo.
Figura 4.7.
En el caso de que el servicio dependa de la carga se debe recurrir directamente a la primera iteración deducida, inicializándola con g1(m) = f1(m) y gn(0) = 1. En este caso el cálculo de la tabla gn(m) requiere el uso de dos vectores (el anterior y el que se está calculando) y cada columna requiere M(M + 1)/2 sumas, M(M + 1)/2 divisiones y
X1 X2 … … Xn - 1 Xn … … XN 0 1 1 … … 1 1 … … 1 1 X1 2 X1
2 3 X1
3 . . . . . .
m - 1 X1m - 1 gn(m - 1)
m X1m gn - 1(m) gn(m) =
gn - 1(m) + Xngn(m - 1)
. .
. .
. . M X1
M gN(M) = = G(M)
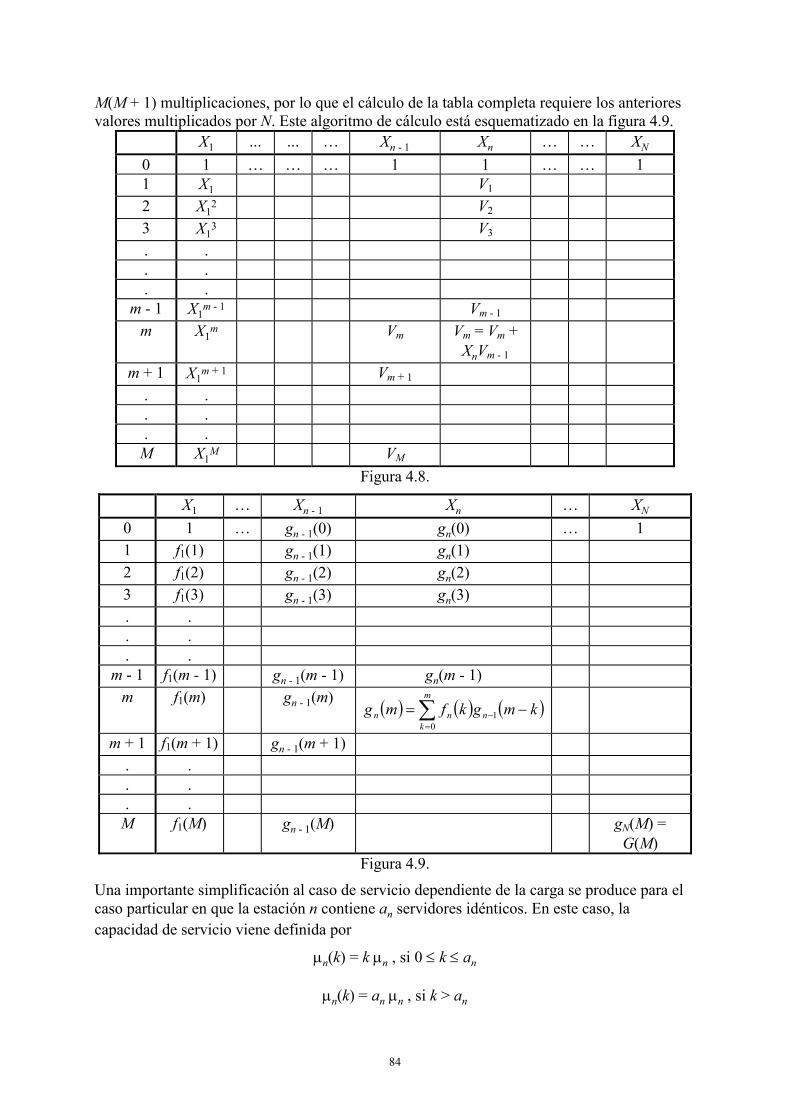
84
M(M + 1) multiplicaciones, por lo que el cálculo de la tabla completa requiere los anteriores valores multiplicados por N. Este algoritmo de cálculo está esquematizado en la figura 4.9.
Figura 4.8.
Figura 4.9.
Una importante simplificación al caso de servicio dependiente de la carga se produce para el caso particular en que la estación n contiene an servidores idénticos. En este caso, la capacidad de servicio viene definida por
µn(k) = k µn , si 0 ≤ k ≤ an
µn(k) = an µn , si k > an
X1 … … … Xn - 1 Xn … … XN 0 1 … … … 1 1 … … 1 1 X1 V1 2 X1
2 V2 3 X1
3 V3 . . . . . .
m - 1 X1m - 1 Vm - 1
m X1m Vm Vm = Vm +
XnVm - 1
m + 1 X1m + 1 Vm + 1
. .
. .
. . M X1
M VM
X1 … Xn - 1 Xn … XN 0 1 … gn - 1(0) gn(0) … 1 1 f1(1) gn - 1(1) gn(1) 2 f1(2) gn - 1(2) gn(2) 3 f1(3) gn - 1(3) gn(3) . . . . . .
m - 1 f1(m - 1) gn - 1(m - 1) gn(m - 1) m f1(m) gn - 1(m) ( ) ( ) ( )∑
=− −=
m
knnn kmgkfmg
01
m + 1 f1(m + 1) gn - 1(m + 1) . . . . . .
M f1(M) gn - 1(M) gN(M) = G(M)

85
donde µn es la capacidad de servicio de cada servidor. En este caso fn(k) tiene la forma
( ) n
kn
n akk
Xkf ≤≤= 0 si ,
!
( ) naknn
kn
n akaaX
kfn
>= − si ,!
que puede escribirse
fn(k) = Xn dn(k)fn'(k - 1), para k ≥ 1
donde
( ) nn akk
kd ≤≤= 0 si ,!
1
( ) nknn
n akaa
kdn
>= − si ,!1
y
fn'(k) = Xnk
Con todo ello se tiene que
( ) ( ) ( ) ( ) ( ) ( ) ( ) =−−+=−= ∑∑=
−−=
−
m
knnnnn
m
knnn kmgkfkdXmgkmgkfmg
111
01 1'
( ) ( ) ( ) ( ) =−−++= ∑−
=−−
1
011 1'1
m
knnnnn kmgkfkdXmg
( ) ( ) ( ) ( ) ( )∑∑−
=−
−
=−− −−+−−
++=
1
1
1
011 111
11 m
aknn
nn
a
knnnn
n
n
kmgkfa
Xkmgkfk
Xmg
Nótese que
( ) ( ) ( ) ( ) ( )∑∑−
=−
−
=− −−+−−=−
1
1
1
01 111111 m
aknn
nn
a
knn
nn
n n
n
kmgkfa
Xkmgkfa
mga
de donde
( ) ( ) ( ) ( ) ( ) =−−
−
++−+= ∑
−
=−−
2
011 11
111
na
knn
nnn
n
nnn kmgkf
akXmg
aX
mgmg
( ) ( ) ( ) ( )
−−
+−−
+−+= ∑−
=−−
2
011 1
11
1na
knn
nn
n
nn kmgkf
kka
mgaX
mg
Esta expresión se reduce a la del caso de servicio independiente de la carga (an = 1) y para an = 2 toma la forma

86
( ) ( ) ( ) ( )[ ]112 11 −+−+= −− mgmg
Xmgmg nn
nnn
4.3.2.2. Distribución marginal del número de clientes en el sistema Se trata de calcular la distribución de las probabilidades de que haya exactamente k clientes en la estación i del sistema. Esta probabilidad puede expresarse, en el caso de servicio independiente de la carga por
( ) ( )( )∑
=∈
==
kmNMSm
Ni
i
mmmpkmP,
21 ,...,,
En vez de calcularla directamente, es útil considerar en primer lugar el cálculo de
( ) ( )( ) ( )( )
===≥ ∑ ∏∑≥
∈ =≥
∈km
NMSm
N
j
mj
kmNMSm
Ni
i
j
i
XMG
mmmpkmP, 1,
211,...,,
( ) ( )
( )( )MG
kMGXXMG
X ki
NkMSm
N
j
mj
ki j −
== ∑ ∏−∈ =, 1
de donde se deduce inmediatamente
( ) ( ) ( ) ( )[ ]1−−−−== kMGXkMGMG
XkmP i
ki
i
Obsérvese que la utilización de la estación i vendrá dada por P(mi ≥ 1) y que valdría, por lo tanto,
( ) ( )( )MG
MGXmP iii11 −
=≥=ρ
En el caso general se tendría que
( ) ( )( ) ( ) ( )
( )
( )( ) ( )
( )∑ ∏∑ ∏∑
=∈
≠=
=∈ =
=∈
====
kmNMSm
N
ijj
jjj
kmNMSm
N
jjj
kmNMSm
Ni
iii
mfMGkf
mfMG
mmmpkmP, 1, 1,
211,...,,
La deducción del algoritmo para calcular la distribución marginal de probabilidad requiere la definición de otra función auxiliar
( ) ( )( )∑ ∏
−=∈
≠=
=
mMmNMSm
N
ijj
jjin
i
mfmg, 1
que puede considerarse como la constante de normalización de una red relacionada con la original, pero sin la estación i y con sólo m clientes. Nótese que
( ) ( )( )
( )( )
( )mgmfmfmg NNMSm
N
jjj
mMmNMSm
N
ijj
jjNN
i
11,
1
1, 1−
−∈
−
=−=
∈≠=
=== ∑ ∏∑ ∏

87
Con esta notación se puede escribir
( ) ( )( ) ( )kMgMGkf
kmP iN
ii −==
Para calcular de forma iterativa la función ( )mg in , se puede tener en cuenta que
( ) ( )( ) ( )∑∑
==
−===M
k
iN
iM
ki kMg
MGkf
kmP00
1
Por lo tanto,
( ) ( ) ( )∑=
−=M
k
iNi kMgkfMG
0
y
( ) ( ) ( ) ( )∑=
−−=M
k
iNi
iN kMgkfMGMg
1
que se pueden calcular iterativamente a partir de
( ) ( ) 100 == Gg iN
4.3.2.3. Productividad
La productividad o λroughput mide el flujo de clientes a través de una estación. Si se denomina λi, el flujo correspondiente en la estación i
( ) ( ) ( )( ) ( ) ( ) ( )
( )( ) ( ) ( )∑∑∑
===
=µ−−
µ=µ−=µ==λ
M
ki
iN
i
i
iM
ki
iN
iM
kiii kkMg
MGkf
ke
kkMgMGkf
kkmP111
1
( ) ( ) ( ) ( ) ( ) ( ) ( )( )MG
MGekMgkfMG
ekMgkf
MGe
i
M
k
iNi
iM
k
iNi
i 1111
01
−=−−=−−= ∑∑
−
==
4.3.2.4. Utilización. Se ha establecido que en el caso de tiempo de servicio independiente de la carga
( )( )
( )( )MG
MGXMG
MGess iiiiii11 −
=−
=λ=ρ
En el caso de tiempo de servicio dependiente de la carga, se debe recurrir a
( ) ( ) ( )( )MG
MgmPkmP
iN
i
M
kii −==−===ρ ∑
=
1011
Si la estación con servicio dependiente de la carga fuera la N, se tendría que, como se ha visto
( ) ( )kgkg NNN 1−=
y por lo tanto

88
( )( )MG
Mg NN
11 −−=ρ
4.3.2.5. Número medio de clientes en el sistema Esta magnitud, cuando hay M clientes en la red, se puede representar por
( ) ( )∑=
==M
kii kmkPMm
1
Para servicio independiente de la carga se tiene
( ) ( ) ( ) ( )( )∑∑∑
===
−=≥===
M
k
ki
M
ki
M
kii MG
kMGXkmPkmkPMm111
de donde se puede deducir
( ) ( )( )
( )( )
( )( ) =
−+
−=
−= ∑∑
==
M
k
kii
M
k
kii MG
kMGXMG
MGXMG
kMGXMm21
1
( ) ( ) ( )( )
( )( ) =
−−−−
+ρ=−−+ρ= ∑∑−
=
−
=
1
1
1
1 1111
M
k
kiii
M
k
ki
ii MG
kMGXMG
MGXkMGXMG
X
( ) ( )[ ]111 −+ρ=−ρ+ρ= MmMm iiiii
En el caso de servicio dependiente de la carga esta magnitud hay que calcularla a partir de su definición.
4.3.2.6. Tiempo medio de respuesta. A partir de la ley de Little aplicada a la estación i se puede establecer que
( ) iii RMm λ=
de donde
( )i
ii
MmR
λ=
En el caso de servicio independiente de la carga resulta
( )[ ]11 −+= MmsR iii
Esta expresión indica que el tiempo de respuesta de una estación es el tiempo de dar servicio del cliente que llega, más el tiempo que tardarán en ser servidos los clientes que el cliente considerado hallará en la cola al llegar y que son los que habría en promedio en la estación si en la red hubiera un cliente menos, precisamente el que está llegando a la estación..
4.3.2.7. Producto de convolución Si en el caso restringido considerado en los apartados anteriores, se plantea el producto de las series de potencias infinitas

89
( ) ( ) ∏ ∑∏=
∞
==
==N
i m
mmi
N
ii
i
ii zXzgzg1 01
definida siempre que converjan las series componentes, gi(z). Entonces g(z) será la función generatriz de la red y los factores gi(z) las funciones generatrices de los nodos. Evidentemente, el coeficiente de zk en g(z) es precisamente la constante de normalización buscada G(M). Este coeficiente es la suma de los términos del tipo
NmN
mm XXX ...2121
uno por cada forma de conseguir que
∑=
=N
ii Mm
1
Sean γi(z) los siguientes productos parciales:
γ1(z) = g1(z), γi(z) = γi - 1(z)gi(z)
y sea Gi(j) el coeficiente de zj en γi(z). El problema es, pues, calcular G(M) = GN(M). Teniendo en cuenta que, en este caso, gi(z) es simplemente una serie geométrica,
( ) ( )zXzg ii −= 1/1 , se pueden escribir las expresiones anteriores
γi(z) = γi - 1(z) + Xi z γi(z)
que implica la siguiente relación de recurrencia para los coeficientes Gi(j):
Gi(j) = Gi - 1(j) + Xi Gi(j - 1)
idéntica, salvando la diferencia de notación, a la obtenida en apartado 4.3.2.1. En el caso de tener distintas clases de clientes es preciso aplicar una convolución multivariada. Si las capacidades de servicio de las estaciones exponenciales son función del número de clientes que hay en la estación y si hay los cuatro tipos de estaciones que prevé el teorema de BCMP, aumentan las dificultades para obtener las relaciones de recurrencia, pero existen y permiten un cálculo más sencillo y directo de la constante de normalización y de las magnitudes operacionales que dependen de ella.
4.3.2.8. Análisis del valor medio El cálculo de las magnitudes operacionales que describen el comportamiento de las redes de colas, tal como ha sido expuesto, requiere, en primer lugar, el cálculo de la constante de normalización y de las probabilidades de estado. Este método, debido a Reiser y Lavenberg, permite el cálculo eficiente de los valores medios de las magnitudes operacionales sin necesidad de pasar ni por el cálculo de las probabilidades de estado ni por el de la constante de normalización. El teorema básico establece que
( ) ( ) ( ) ( )
−−
−
µ+−+= ∑ ci
icicic eMjP
jjeMmsMR ,1111
donde

90
- ( )CMMMM ,...,, 21= es el vector del número total de clientes de cada clase en la red.
- ( )0,...,0,1,0,...,0,0=ce es un vector todo ceros excepto el c-ésimo componente que es un uno.
- ( )MRic es el tiempo medio de respuesta de los clientes de clase c en la estación i cuando en la red hay los clientes de cada clase definidos por el vector (M1, M2, …, MC).
- sic es el tiempo medio de servicio de los clientes de clase c en la estación i.
- ( )ci eMm − es el número medio de clientes en la estación i cuando hay un cliente menos de clase c en la red.
- ( )ci eMjP −− ,1 es la probabilidad que haya j - 1 clientes en la estación i cuando hay un cliente menos de clase c en la red.
- µi(j) es la capacidad de servicio de la estación i en función del número total de clientes j.
Como se ve, es posible tratar incluso el caso en que las capacidades de servicio dependan del estado. Si son constantes, la expresión anterior se simplifica, pudiendo hacerse también extensiones al caso de estaciones de servicio con varios canales. Para estaciones de servicio de tipos 1, 2 y 4 se tiene
( ) ( )[ ]cicic eMmsMR −+= 1
que es similar a la expresión deducida en el apartado 4.3.2.6.; y para estaciones de tipo 3
( ) icic sMR =
Si se denomina Vic el número medio de visitas a la estación i de los clientes de clase c para completar un ciclo y λc la productividad de los clientes de clase c en la estación elegida para contar sus ciclos (en la que evidentemente Vic = 1), las relaciones básicas entre estas magnitudes son
∑=
=λ N
iicic
cc
RV
M
1
iciccic RVm λ=
Este conjunto de relaciones permite calcular el tiempo medio de respuesta de los clientes de clase c en la estación i para una determinada mezcla de clientes en la red cuando se conoce el número medio de clientes en la estación i cuando hay un cliente menos de clase c en la red para todas las estaciones y todas las clases y, luego, el número medio de clientes en cada estación una vez se ha determinado la productividad de cada clase. Por lo tanto, el algoritmo que permitirá efectuar estos cálculos (y que es fácil y directamente programable) puede resumirse como: Paso 1.
( ) imi ∀← ,00

91
Paso 2. Para m1 = 0, 1, …, M1 m2 = 0, 1, …, M2 . . . mC = 0, 1, …, MC Efectuar los pasos del 3 al 5. Paso 3.
( ) ( )[ ]cicic eMmsMR −+← 1 , si la estación es de tipo 1, 2 ó 4; y
( ) icic sMR ← , si la estación es de tipo 3,
para ci ∀∀ y . Paso 4.
iRV
MN
iicic
cc ∀←λ
∑=
para ,
1
Paso 5.
( ) iRVMmC
cicicci ∀λ← ∑
=
para ,1
Ejemplo. Sea el sistema de la figura 4.10. La estación 1 es de tipo 2 y las 2 y 3 de tipo 1. Hay dos clases de clientes cuyas probabilidades de encaminamiento y tiempos medios de servicio son:
Estación clase
11 21 31 12 22 32 sic
11 0 0.5 0.5 0 0 0 1 21 1 0 0 0 0 0 1 31 1 0 0 0 0 0 2 12 0 0 0 0 1 0 2 22 0 0 0 1 0 0 1 31 0 0 0 0 0 0 2
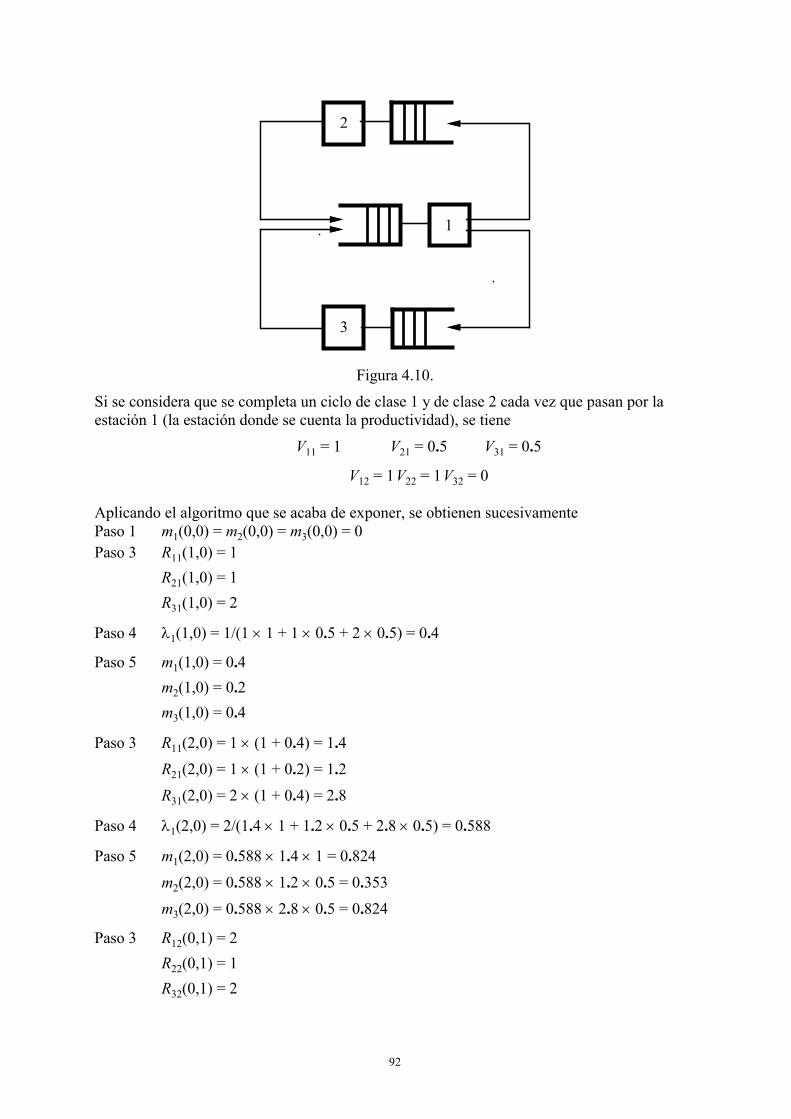
92
1
2
3
Figura 4.10.
Si se considera que se completa un ciclo de clase 1 y de clase 2 cada vez que pasan por la estación 1 (la estación donde se cuenta la productividad), se tiene
V11 = 1 V21 = 0.5 V31 = 0.5
V12 = 1 V22 = 1 V32 = 0
Aplicando el algoritmo que se acaba de exponer, se obtienen sucesivamente Paso 1 m1(0,0) = m2(0,0) = m3(0,0) = 0 Paso 3 R11(1,0) = 1 R21(1,0) = 1 R31(1,0) = 2
Paso 4 λ1(1,0) = 1/(1 × 1 + 1 × 0.5 + 2 × 0.5) = 0.4
Paso 5 m1(1,0) = 0.4 m2(1,0) = 0.2 m3(1,0) = 0.4
Paso 3 R11(2,0) = 1 × (1 + 0.4) = 1.4
R21(2,0) = 1 × (1 + 0.2) = 1.2
R31(2,0) = 2 × (1 + 0.4) = 2.8
Paso 4 λ1(2,0) = 2/(1.4 × 1 + 1.2 × 0.5 + 2.8 × 0.5) = 0.588
Paso 5 m1(2,0) = 0.588 × 1.4 × 1 = 0.824
m2(2,0) = 0.588 × 1.2 × 0.5 = 0.353
m3(2,0) = 0.588 × 2.8 × 0.5 = 0.824
Paso 3 R12(0,1) = 2 R22(0,1) = 1 R32(0,1) = 2

93
Paso 4 λ2(0,1) = 1/(2 × 1 + 1 × 1 + 2 × 0) = 0.333
Paso 5 m1(0,1) = 0.667 m2(0,1) = 0.333 m3(0,1) = 0
Paso 3 R12(0,2) = 2 × (1 + 0.667) = 3.333
R22(0,2) = 1 × (1 + 0.333) = 1.333
R32(0,2) = 2 × (1 + 0) = 2
Paso 4 λ2(0,2) = 2/(3.333 × 1 + 1.333 × 1 + 2 × 0) = 0.429
Paso 5 m1(0,2) = 0.429 × 3.333 × 1 = 1.429
m2(0,2) = 0.429 × 1.333 × 1 = 0.571 m3(0,2) = 0.429 × 2 × 0 = 0
Paso 3 R11(1,1) = 1 × (1 + 0.667) = 1.667
R21(1,1) = 1 × (1 + 0.333) = 1.333
R31(1,1) = 2 × (1 + 0) = 2
R12(1,1) = 2 × (1 + 0.4) = 2.8
R22(1,1) = 1 × (1 + 0.2) = 1.2
R32(1,1) = 2 × (1 + 0.4) = 2.8
Paso 4 λ1(1,1) = 1/(1.667 × 1 + 1.333 × 0.5 + 2 × 0.5) = 0.3
λ2(1,1) = 1/(2.8 × 1 + 1.2 × 1 + 2.8 × 0) = 0.25
Paso 5 m1(1,1) = 0.3 × 1.667 × 1 + 0.25 × 2.8 × 1 = 1.2
m2(1,1) = 0.3 × 1.333 × 0.5 + 0.25 × 1.2 × 1 = 0.5
m3(1,1) = 0.3 × 2 × 0.5 + 0.25 × 2.8 × 0 = 0.3
Paso 3 R11(2,1) = 1 × (1 + 1.2) = 2.2
R21(2,1) = 1 × (1 + 0.5) = 1.5
R31(2,1) = 2 × (1 + 0.3) = 2.6
R12(2,1) = 2 × (1 + 0.824) = 3.647
R22(2,1) = 1 × (1 + 0.353) = 1.353
R32(2,1) = 2 × (1 + 0.824) = 3.647
Paso 4 λ1(2,1) = 2/(2.2 × 1 + 1.5 × 0.5 + 2.6 × 0.5) = 0.471
λ2(2,1) = 1/(3.647 × 1 + 1.353 × 1 + 3.647 × 0) = 0.2
Paso 5 m1(2,1) = 0.471 × 2.2 × 1 + 0.2 × 3.647 × 1 = 1.765
m2(2,1) = 0.471 × 1.5 × 0.5 + 0.2 × 1.353 × 1 = 0.623
m3(2,1) = 0.471 × 2.6 × 0.5 + 0.2 × 3.647 × 0 = 0.612

94
Paso 3 R11(1,2) = 1 × (1 + 1.429) = 2.429
R21(1,2) = 1 × (1 + 0.571) = 1.571
R31(1,2) = 2 × (1 + 0) = 2
R12(1,2) = 2 × (1 + 1.2) = 4.4
R22(1,2) = 1 × (1 + 0.5) = 1.5
R32(1,2) = 2 × (1 + 0.3) = 2.6
Paso 4 λ1(1,2) = 1/(2.429 × 1 + 1.571 × 0.5 + 2 × 0.5) = 0.237
λ2(1,2) = 2/(4.4 × 1 + 1.5 × 1 + 2.6 × 0) = 0.339
Paso 5 m1(1,2) = 0.237 × 2.429 × 1 + 0.339 × 4.4 × 1 = 2.068
m2(1,2) = 0.237 × 1.571 × 0.5 + 0.339 × 1.5 × 1 = 0.695
m3(1,2) = 0.237 × 2 × 0.5 + 0.339 × 2.6 × 0 = 0.237
Paso 3 R11(2,2) = 1 × (1 + 2.068) = 3.068
R21(2,2) = 1 × (1 + 0.695) = 1.695
R31(2,2) = 2 × (1 + 0.237) = 2.474
R12(2,2) = 2 × (1 + 1.765) = 5.530
R22(2,2) = 1 × (1 + 0.623) = 1.623
R32(2,2) = 2 × (1 + 0.612) = 3.224
Paso 4 λ1(2,2) = 2/(3.068 × 1 + 1.695 × 0.5 + 2.474 × 0.5) = 0.388
λ2(2,2) = 2/(5.530 × 1 + 1.623 × 1 + 3.224 × 0) = 0.280
Paso 5 m1(2,2) = 0.388 × 3.068 × 1 + 0.280 × 5.530 × 1 = 2.737
m2(2,2) = 0.388 × 1.695 × 0.5 + 0.280 × 1.623 × 1 = 0.783
m3(2,2) = 0.388 × 2.474 × 0.5 + 0.280 × 3.224 × 0 = 0.480
En este ejemplo queda patente la facilidad de cálculo que aporta este algoritmo.
4.4. MÉTODOS APROXIMADOS Los métodos de tratamiento exacto cubren una pequeña parte de los posibles modelos de sistemas informáticos que se pueden construir y ello a costa de requerir un importante esfuerzo de cálculo. Por ello, han aparecido y siguen apareciendo numerosos métodos de tratamiento analítico que: - o bien permiten tratar modelos no incluidos en el teorema de BCMP
- o bien reducen las necesidades de cálculo que exige el teorema de BCMP
A continuación se exponen en forma resumida los fundamentos de algunos de ellos.
4.4.1. MÉTODO DE DIFUSIÓN Como se vio en el apartado 3.11., la aproximación por difusión es un intento de superar las limitaciones de los servidores con colas FIFO y servicio exponencial, considerando la media y la variancia de las distribuciones de los tiempos de servicio admitiendo, además que las llegadas tampoco sean poissonianas. Sea una red con N estaciones de un solo canal de servicio en que:

95
1. La distribución de tiempos de servicio en cada estación i = 1, 2, …, N tiene una media 1−µ i , donde µi es la capacidad media de servicio, y un coeficiente cuadrático de variación
Ksi2.
2. Los clientes efectúan transiciones instantáneas de la estación i a la j con probabilidad pij, que es independiente del estado del sistema (es decir, el encaminamiento de cada cliente es generado por una cadena de Markov con matriz de transición [p] = [pij]).
3. En el caso de una red abierta, un cliente llega a la red con frecuencia λ0 y el coeficiente cuadrático de variación de los tiempos entre llegadas es K0
2. Un cliente llega a la i-ésima estación con probabilidad p0i y abandona el sistema desde la j-ésima estación con probabilidad pj(N + 1) (por convenio de notación, el manantial se trata como la estación 0 y el sumidero como la N + 1).
La forma de producto de la solución del teorema de BCMP sugiere que el comportamiento de cada estación pueda estudiarse separadamente siempre que se tengan en cuenta las interacciones correspondientes. Es decir se admite que la probabilidad de estado tiene forma de producto de las probabilidades de estado de cada estación en el estado en que se halla el sistema. a. Procesos de llegada y salida Para aplicar la fórmula de las probabilidades en su aproximación de difusión a cada
estación i = 1, 2, .., N, es necesario conocer las características del proceso de llegada λi (frecuencia media de llegada a la estación i) y Kai
2 (coeficiente cuadrático de variación de los tiempos entre llegadas), así como esas mismas características referidas al tiempo de servicio si = µi
-1 y Ksi2.
Para determinar λi y Kai2 es preciso determinar el proceso de salida de la estación i y
luego prestar atención al proceso de llegada que es la suma de los N (N - 1 en las redes cerradas) procesos de salida de las estaciones ponderados por las probabilidades de encaminamiento.
b. Proceso de salida de la estación i.
Durante los períodos de ocupación, la frecuencia de salida es µi y el coeficiente cuadrático de variación Ksi
2. Pero la estación está ocupada con probabilidad ρi solamente (ρi es la utilización de la estación i). En consecuencia, la media y la variancia deben ponderarse con ρi; es decir
Frecuencia media de salida, ρi µi
Variancia de las salidas por unidad de tiempo, ρi Ksi2 µi
c. Proceso de llegada a la estación i. El proceso de llegada es la superposición de los procesos de salida de las estaciones j que
tienen probabilidades de encaminamiento pji distintas de cero. Por consiguiente, la frecuencia de llegada es
∑=
µρ=λN
jjjjii p
1 ó 0

96
Nótese que el índice inferior del sumatorio es j = 0 para las redes abiertas y j = 1 para las cerradas. La expresión del coeficiente cuadrático de variación es
( )[ ]∑=
ρµ+−λ
=1 ó 0
22 111j
jijjjisji
ai ppKK
donde la aproximación efectuada en esta última ecuación se basa en el teorema del límite central.
d. Redes abiertas. Para redes abiertas en régimen estacionario, la frecuencia de llegada a la estación i queda
completamente determinada por la frecuencia de llegada λ0 y las probabilidades de encaminamiento, es decir
λi = λ0 ei
donde ei es el número medio de visitas a la estación i de un cliente durante su estancia en el sistema. Si la cadena de Markov es irreductible, las cantidades ei están determinadas unívocamente por
∑=
+=N
jjijii pepe
10
Con la frecuencia de llegada λi, se obtiene la utilización de la estación i
ρi = eiλ0µi-1
Con estos valores, se puede determinar Kai2 mediante
( )∑=
−−+=N
jijjisjai eepKK
1
1222 11
Conociendo las características de llegada y servicio de la estación se puede determinar la distribución de las longitudes de cola para cada estación mediante cualquiera de los enfoques analizados en el apartado 3.11.
e. Redes cerradas. Los dos problemas básicos que presenta el análisis de redes cerradas son:
- La utilización de la estación ya no puede determinarse fácilmente pues el sistema para determinar las tasas de visita, formado a partir de las probabilidades de encaminamiento, es homogéneo y sus infinitas soluciones serán todas proporcionales entre sí.
- La distribución es sobre una población finita M.
Si r es el factor de proporcionalidad respecto de la solución adecuada al sistema, la utilización de la estación i será, en función de r,
ρi = reiλ0µi-1
No hay forma sencilla de determinar la constante r. Si se supone que por lo menos uno de los parámetros ei/µi es mayor que los otros, entonces la estación con este parámetro es

97
el cuello de botella del sistema. En estas circunstancias, la utilización del cuello de botella tiende a 1 cuando el número de clientes M tiende a infinito. En un sistema cerrado con la estación k como cuello de botella y una población M suficientemente grande, la utilización de una estación se aproxima suficientemente bien por
ρi = eiek-1µi
-1µk
y a partir de ahí se puede seguir aproximadamente un proceso similar al de las redes abiertas.
4.4.2. MÉTODO DE DESCOMPOSICIÓN-AGREGACIÓN Los métodos de descomposición-agregación se caracterizan por tratar de sustituir un grupo de elementos de un sistema por un elemento sintético que reproduzca el comportamiento del conjunto sustituido. En general se busca un grupo de elementos de una red de colas que tengan todos ellos una dinámica parecida y tales que los clientes circulen con gran probabilidad entre ellos y con poca respecto a los externos al conjunto considerado. Entonces se estudia el comportamiento de ese conjunto como un sistema cerrado con un número progresivamente creciente de clientes hasta alcanzar el máximo posible calculándose el tiempo de respuesta o la productividad del conjunto. Este método conocido también como teorema de Norton ya que se inspira en el teorema de ese nombre en teoría de circuitos eléctricos.
4.4.2.1. Caso de una red BCMP con una sola estación no-BCMP Sea una red de colas cerrada que responda a las hipótesis del teorema de BCMP y que tenga una estación viola las citadas hipótesis. Sea una red como la de la figura 4.11 en que la estación 3 sea la que se aparta de las condiciones del teorema de BCMP. Si se supone que en la red hay N clientes y que, por comodidad, solo hay una clase, la red de colas puede analizarse de la forma siguiente: - Paso de descomposición: En est paso se procede a cortocircuitar, es decir a eliminar, la
estación no-BCMP (la 3 en la figura 4.11) sin modificar los flujos de entrada y salida y se analiza la red resultante (figura 4.12) como si esa estación no existiera. Esa red responde ahora a las hipótesis del teorema de BCMP y se puede resolver fácilmente para calcular la productividad a través del cortocircuito. En el caso de la figura 4.12 es igual a la suma de los que van de la estación 1 a la 3, de la estación 2 a la 3 y de la estación 4 a la 3.

98
µ2
p21
p24
p23 p
42
p43
p34
p31
p12
p13
µ3
µ1 µ4
p14
p11
Figura 4.11.
Se calcula esta productividad suponiendo que hay m clientes en la red cortocircuitada (figura 4.12), donde m = 1, 2, ..., M. Esto es, se evalúa la misma red M veces y cada vez se cambia el número de clientes que hay en ella. Sea X(m) la productividad o el flujo a través del cortocircuito cuando hay m clientes en la red.
- Paso de agregación: Ahora, la red de colas original puede reducirse a la estación cortocircuitada (la 3 de la figura 4.11) y otra estación, conocida como la estación compuesta, que representa aproximadamente la red cortocircuitada, como muestra la figura 4.12. La capacidad de servicio de esta estación compuesta es X(m), donde m es el número de clientes que hay en ella, es decir tiene una capacidad de servicio dependiente del estado, manteniendo el número total M de clientes en la red. La red resultante (figura 4.13) tampoco es de BCMP a causa de la estación cortocircuitada (la 3 en este caso). Por lo tanto se ha de analizar este sistema agregado; no obstante teniendo en cuenta su dimensión resulta mucho más simple bien sea por aplicación del algoritmo numérico de las cadenas de Markov, por otro método aproximado o por simulación. Suponiendo, pues, que es posible analizar este sistema de dos estaciones, se pueden obtener las medidas del comportamiento de la estación compuesta y de la estación 3.

99
µ2
p21
p24
p23 p
42
p43
p34
p31
p12
p13
µ1 µ4
p14
p11
Figura 4.12.
µ3
X(m)
Figura 4.13.
Si es posible obtener las distribuciones de las longitudes de cola de la estación 3 y de la estación compuesta, entonces la distribución de la estación 3 es una aproximación de la distribución de la longitud de cola de la estación 3 en la red original. Las distribuciones de las longitudes de cola de las estaciones 1, 2 y 4 pueden obtenerse combinando los resultados obtenidos en el paso de descomposición con la distribución del número de clientes en la cola compuesta obtenida en el paso de agregación. Como ejemplo, se presenta el cálculo para la estación 1. Sea pc(m) la probabilidad que haya m clientes en la estación compuesta, donde m = 1, 2, ..., M, obtenida en el paso de agregación. Además sea q1(m|k) la probabilidad que haya n clientes en la estación 1 cuando hay k clientes en la red compuesta, obtenida en el paso de descomposición para k = 1, 2, ..., M y m = 1, 2, ..., k. Entonces
( ) ( ) ( ) MmkpkmqmqM
kc ..., 2, ,1 para ,|
111 == ∑
=
4.4.2.2. Caso de una red BCMP con una sub-red no-BCMP En este caso se sigue el mismo enfoque, solo que tratando con la sub-red completa.

100
Sea una red de colas en la que una sub-red determinada viola las exigencias del teorema de BCMP (por ejemplo, situaciones en que un cliente sufre un proceso de fork/join, siendo servido por distintas estaciones), como muestra la figura 4.14. Esta situación puede analizarse eliminando la sub-red y analizando la red restante a partir del teorema de BCMP. Como antes, se obtiene la frecuencia con que los clientes entran en la sub-red cortocircuitada en función del número de clientes que hay en ella y se representa la sub-red BCMP como una estación compuesta equivalente con capacidad de servicio dependiente de la carga (figura 4.15).
Red de colas BCMP
Red de colas no-BCMPa cortocircuitar
Figura 4.14.
X(m)
Sub-red no BCMP
Estación compuestaequivalente de la red BCMP
Figura 4.15.
Esta red se debe analizar ahora para obtener medidas del comportamiento de la sub-red no-BCMP mediante técnicas similares a las expuestas en el apartado anterior.
4.4.3. MÉTODO DE DESCOMPOSICIÓN DE COURTOIS Este método, particularmente interesante, propone una técnica sistemática de descomposición. Sea Q una matriz estocástica de orden n que sea casi completamente descomponible en matrices estocásticas QI, I = 1, 2, ..., N, es decir:
Q = Q* + εC
donde

101
=
NNNN
N
N
N
QQQQ
QQQQQQQQQQQQ
Q
..................
...
...
...
321
333231
223221
113121
QI son las submatrices cuadradas de la diagonal principal.
ε es un número pequeño real positivo mucho menor que 1, y, más formalmente, es la máxima suma de los elementos de una fila externos a la submatriz de la diagonal principal y, por lo tanto, la máxima probabilidad de una transición desde un subconjunto de estados a otro subconjunto. Es pues el grado de acoplamiento.
=
*
*3
*2
*1
*
...000...............0...000...000...00
NQ
Q
Q
*IQ son las submatrices estocásticas y cuadradas de la diagonal principal de orden n(I), con
( ) nInN
i=∑
=1
Si es posible efectuar tal descomposición, cada una de las matrices *IQ describirá la dinámica
interna de cada uno de los subsistemas en que se ha descompuesto el sistema global y que están débilmente acoplados con los restantes, ya que la probabilidad de pasar de un subsistema a otro es baja respecto a la de permanecer en el mismo subsistema. La matriz Q tiene un solo valor propio igual a 1. Las matrices *
IQ tienen N valores propios iguales a 1 (uno por cada una de las submatrices de la diagonal principal). Sea λ*(iI) el i-ésimo valor propio de *
IQ en orden de módulo decreciente
λ*(1I) = 1 > |λ*(2I)| > |λ*(3I)| > ....
Cuando 0→ε hay valores propios de Q que tienden a los valores propios de Q*. Sea λ(iI) el valor propio de Q al que tiende λ*(iI) cuando 0→ε . Dicho en otras palabras, Q tiene N - 1 valores propios que son próximos a 1 cuando ε es pequeño. Los vectores propios serán los vectores fila propios ( )Ix 1* a la izquierda de Q* correspondientes a los valores propios λ*(1I) de tal forma que
( ) ( ) ( )III xQx 111 **** λ=
Nótese que
( ) ( )0_______,,0.,,.........0_______,,01* =Ix

102
donde la parte punteada corresponde al vector propio de *IQ . En algunos casos, esa parte
representará solo la parte punteada. ( )1*x es el vector propio fila a la izquierda de Q correspondiente al valor propio λ(iI) = 1. Así
pues se sustituye la solución del sistema
( )[ ] 01* =− IQx
que es un sistema de n ecuaciones con n incógnitas por la solución de N sistemas independientes de n(I) × n(I)
( )[ ] 01 ** =− IQx II
que proporcionarán las probabilidades de estado condicionales a estar en el subsistema I. Las probabilidades de transición del subsistema (conjunto de estados) I al subsistema (conjunto de estados) J se obtienen a partir de
( )( )( )
∑ ∑= =
=
In
i
Jn
jjiIIIJ JI
qxP1 1
* 1
con las cuales se construye la matriz P = [PIJ]. La probabilidad de hallarse en cada uno de los subsistemas (conjuntos de estados) vendrá dada por la solución del sistema
X(1) [P - I] = 0
Finalmente, a partir de estas probabilidades de hallarse en cada uno de los subsistemas (conjuntos de estados), se puede determinar la probabilidad de hallarse en cada uno de los estados
( ) ( ) ( )IiIi xXx 111 *=
Esta aproximación se puede mejorar, si se quiere, multiplicando sucesivamente este vector por la matriz Q o creando una nueva matriz Q* tal que los elementos de cada fila de cada *
IQ vengan incrementados por el ε correspondiente a esa fila distribuido proporcionalmente a las probabilidades de cada uno de los estados del subsistema y rehaciendo el algoritmo que se acaba de exponer. Ejemplo. Sea el sistema cuya matriz estocástica de transición es
0.85 0 0.149 0.0009 0 0.00005 0 0.00005 0.1 0.65 0.249 0 0.0009 0.00005 0 0.00005 0.1 0.8 0.0996 0.0003 0 0 0.0001 0 0 0.0004 0 0.7 0.2995 0 0.0001 0 0.0005 0 0.0004 0.399 0.6 0.0001 0 0 0 0.00005 0 0 0.00005 0.6 0.2499 0.15 0.00003 0 0.00003 0.00004 0 0.1 0.8 0.0999 0 0.00005 0 0 0.00005 0.1999 0.25 0.55 A partir de ella se puede construir la siguiente matriz completamente descomponible

103
0.85 0 0.15 0 0 0 0 0 0.1 0.65 0.25 0 0 0 0 0 0.1 0.8 0.1 0 0 0 0 0 0 0 0 0.7 0.3 0 0 0 0 0 0 0.4 0.6 0 0 0 0 0 0 0 0 0.6 0.25 0.15 0 0 0 0 0 0.1 0.8 0.1 0 0 0 0 0 0.2 0.25 0.55
Para hallar los vectores propios de *1Q se hará *
1x = (a b c)
( ) 0100010001
1.08.01.025.065.01.015.0085.0
=
−cba
de donde
-0.15a + 0.1b + 0.1c = 0
-0.35b + 0.8c = 0
0.15a + 0.25b - 0.9c = 0
que junto con la ecuación
a + b + c = 1
para tener en cuenta que las componentes son probabilidades marginales cuya suma ha de ser 1. Resolviendo se obtiene
( )182609.0417391.04.0*1 =x
Procediendo igualmente en los otros subsistemas se tiene:
( )428571.0571429.0*2 =x
( )203704.0555555.0240741.0*3 =x
Con estos vectores (probabilidades marginales de estado en cada subsistema) se pueden calcular las probabilidades de transición entre subsistemas.
P11 = 0.4(0.85 + 0 + 0.149) + 0.417391(0.1 + 0.65 + 0.249) +
+ 0.182609(0.1 + 0.8 + 0.0996) = 0.99911
P12 = 0.4(0.0009 + 0) + 0.417391(0 + 0.0009) + 0.182609(0.0003 + 0) = 0.00079
etc., hasta llegar a
9999.00000445.00000555.00001.0999286.0000614.00001.000079.099911.0
=P
cuyo vector propio de estado será

104
( ) ( )5.0277427.0222573.01 =X
el cual permite determinar el vector de probabilidad de estado
( ) ( )101852.0277777.012037.011897.015853.0040644.00929.0089029.01 =x
que es el resultado que se deseaba obtener. Finalmente se plantea la cuestión de como obtener la matriz Q a partir de las capacidades de servicio de cada estación. Evidentemente, el sistema debe ser cerrado a fin de que el número de estados sea finito. Si fuera abierto el número de estados posibles tiende a infinito y la técnica que se acaba de exponer resulta inaplicable. Sea un incremento de tiempo δ arbitrario y suficientemente pequeño para que la variación que se pueda producir en él sea como máximo de un cliente, entonces los elementos de cada fila fuera de la diagonal principal serán el producto de la capacidad de servicio de la estación por δ y por la probabilidad de encaminamiento de una estación a otra. El término de la diagonal principal debe ser tal que la suma de los términos de cada fila sea igual a la unidad. Si se denomina Q' a la matriz obtenida como se acaba de exponer, pero haciendo que el término de la diagonal principal haga que la suma de cada fila valga cero, se puede escribir
Q = I + Q'
y para hallar el vector propio correspondiente al valor propio 1
( )[ ] 01 =− QIx
( ) ( )[ ] 0'1 =+− QIIx
( ) 0'1 =Qx
Ahora bien en la matriz Q' el factor ∆ aparece en todos los términos por lo que se pueden dividir todos por él ya que su producto por el valor propio de la matriz Q debe ser igual a cero. Por lo tanto, para los estudios de descomposición se puede construir la matriz Q' simplemente haciendo que los términos de cambio de estado sean el producto de la capacidad de servicio de la estación por la probabilidad de encaminamiento y en la diagonal principal el término adecuado para que la suma de cada fila valga cero. Ejemplo. Sea el sistema de la figura 4.16 en que hay dos clientes en cada una de las dos clases. Establecer la matriz de transición Q o la que se puede utilizar para el cálculo de los valores propios Q'.
3
2
1 0
Figura 4.16.

105
y si se tiene en cuenta, además que p23 = p32 = 0, resulta
4.4.3.1. Análisis del error en el método de descomposición de Courtois El planteo del problema de descomposición de Courtois puede hacerse de la forma siguiente: Se debe obtener el vector q que representa el estado estacionario del proceso de Markov definido por la matriz Q, es decir
q = qQ
con la condición
( ) 1=∑∀n
nq
donde q(n) son las componentes del vector q. Sea un vector d que satisfaga
d = dD
donde D tiene la estructura de k bloques en la diagonal principal. Si se considerara que d es una aproximación de q si
Q = D + εE
2000 1100 0200 1010 0110 0020 1001 0101 0011 0002 2000 * µ0p01 0 µ0p02 0 0 µ0p03 0 0 0 1100 µ1p10 * µ0p01 µ1p12 µ0p02 0 µ1p13 µ0p03 0 0 0200 0 µ1p10 * 0 µ1p12 0 0 µ1p13 0 0 1010 µ2p20 µ2p21 0 * µ0p01 µ0p02 µ2p23 0 µ0p03 0 0110 0 µ2p20 µ2p21 µ1p10 * µ1p12 0 µ2p23 µ1p13 0 0020 0 0 0 µ2p20 µ2p21 * 0 0 µ2p23 0 1001 µ3p30 µ3p31 0 µ3p32 0 0 * µ0p01 µ0p02 µ0p03 0101 0 µ3p30 µ3p31 0 µ3p32 0 µ1p10 * µ1p12 µ1p13 0011 0 0 0 µ3p30 µ3p31 µ3p32 µ2p20 µ2p21 * µ2p23 0002 0 0 0 0 0 0 µ3p30 µ3p31 µ3p32 *
2000 1100 0200 1010 0110 0020 1001 0101 0011 0002 2000 * µ0p01 0 µ0p02 0 0 µ0p03 0 0 0 1100 µ1p10 * µ0p01 µ1p12 µ0p02 0 µ1p13 µ0p03 0 0 0200 0 µ1p10 * 0 µ1p12 0 0 µ1p13 0 0 1010 µ2p20 µ2p21 0 * µ0p01 µ0p02 µ2p23 0 µ0p03 0 0110 0 µ2p20 µ2p21 µ1p10 * µ1p12 0 µ2p23 µ1p13 0 0020 0 0 0 µ2p20 µ2p21 * 0 0 0 0 1001 µ3p30 µ3p31 0 0 0 0 * µ0p01 µ0p02 µ0p03 0101 0 µ3p30 µ3p31 0 0 0 µ1p10 * µ1p12 µ1p13 0011 0 0 0 µ3p30 µ3p31 0 µ2p20 µ2p21 * 0 0002 0 0 0 0 0 0 µ3p30 µ3p31 0 *

106
Debe cumplirse que
q = qQ = qD + εqE
y si se representa por δ el vector de error, es decir
q = d + δ
entonces
d + δ = (d + δ)D + εqE
Ahora bien, por la estructura de las ecuaciones y la condición del vector propio
δ(I - D) = εqE
Por lo tanto, el problema se convierte en buscar k relaciones suplementarias para que las componentes de δ sean pequeñas. Se dice que una matriz estocástica A = a(n, n') es agregable en la partición π si para cualquier n (fila o columna de A), se cumple
( ) ( )∑∑π∈π∈
=ii nn
nnanna''
',''',
Si se cumple, la matriz A se puede agrupar en la matriz estocástica Aπ de dimensión k × k mediante la partición π = (π1, π2, ..., πk) y tal que Aπ = α(i,j), con
( ) ( )∑π∈
=αin
nnaji'
',,
Por ejemplo, si
3/13/13/12/14/14/12/18/38/1
=A
puede agruparse en
3/13/22/12/1
=πA
Volviendo al problema original, si la matriz Q es agrupable en la partición π, Qπ es la matriz estocástica de dimensión k × k, obtenida agrupando Q según π y sea qπ el vector estocástico que satisface
qπ = qπ Qπ
11
=∑=
πk
i
iq
Evidentemente iq π es la probabilidad que el sistema se halle en los estados agrupados en πi, por lo que las condiciones suplementarias que se introducen para resolver d = dD, serán

107
( )∑π∈
π =i
i
nndq
El error de la solución vendrá dado por
δ = δ(Q - εE) + εqE
Si se aproxima por
∑∞
=
ε=δ1i
iia
donde las ai son vectores que deben satisfacer
a1 = a1Q + qE
ai+1 = ai+1Q - aiE, para i ≥ 1
y en primera aproximación
δ = a1ε
En el caso general en que la matriz Q no sea agrupable según π, se puede escribir
UQQ µ+= ˆ
donde: Q es una matriz de la misma dimensión que Q y agrupable según π.
π es una matriz de la misma dimensión que Q
µ es un escalar que cumple las condiciones:
- µ ≤ ε
- los elementos diagonales de Q son positivos
- el valor absoluto de los elementos de π son menores que uno en valor absoluto.
Sea q el vector de probabilidad asociado a Q , es decir,
Qqq ˆˆˆ =
α+= qq ˆ
donde α es el vector de error por aproximar q por q
qUQQqq µ+α+=α+ ˆˆˆˆ
[ ] qUUQqUQ µ+µ−α=µ+α=α ˆ
Si se hace
∑∞
=
µ=α1i
iib

108
Como antes debe cumplirse que
qUQbb += ˆ11
1 para ,ˆ11 ≤−= ++ iUbQbb iii
Si µ es pequeño queda
µ≈α 1b
y la primera aproximación del vector será
q = d + b1µ + εa1
donde
∑∞
=
ε=−1
ˆi
iiadq
determinados como precedentemente.
4.4.4. MÉTODOS ITERATIVOS Dentro de esta familia de métodos se agrupa una amplia variedad de formas de obtener soluciones aproximadas de una red de colas por cálculo iterativo. Existen distintos entornos en los que aplicar estas técnicas, algunos de los cuales se van a revisar a continuación. En general, todos ellos parten de una conjetura razonable que permite establecer la iteración, pero casi en ningún caso no se ha demostrado que la iteración converja, ni que, en caso de converger, esa convergencia se haga sobre un valor próximo al correspondiente a la solución exacta. Aunque estos métodos carezcan de una justificación teórica respecto a su convergencia proporcionan una vía interesante para tratar redes de colas. Distintos métodos con enfoques varios pueden hallarse en (SHUM77), (CHAN75B), (MARI78), (MARI79) y (JACO82).
4.4.4.1. Iteración entre el tratamiento analítico de una red de colas y el tratamiento analítico de una cola
Cuando el tiempo de servicio de una estación no es conocido directamente, pues puede ser función de la carga, puede establecerse una iteración iniciando el cálculo suponiendo el servicio fijo e independiente de la carga y, a medida que se conoce la carga (productividad) por cálculo del modelo cerrado de red de colas, se va recalculando el tiempo de servicio hasta que se logra la convergencia. Tal es el caso, por ejemplo, de un sistema informático representable por un modelo en red de colas cerrada en el que se desea tener en cuenta el efecto de la carga sobre el tiempo de servicio de los discos debido a los conflictos en la utilización de la unidad de control durante la transferencia. Se puede iniciar el cálculo considerando que el tiempo de servicio de los discos es la suma de los correspondientes al movimiento del brazo, a la latencia y a la transferencia. Con este valor se pueden calcular analíticamente las medidas que caracterizan el comportamiento del sistema y en particular la productividad de los discos. Con estos valores se puede calcular el retardo que se produce en la unidad de control, mediante un modelo M/M/1//(número de discos) y que incrementa el tiempo de servicio de los discos. Hecho este cálculo se dispone de una nueva aproximación del tiempo de servicio de los discos que sirve para efectuar un nuevo cálculo de la red cerrada y obtener nuevas

109
productividades de los discos. La iteración continua hasta que el tiempo de servicio de los discos entre dos iteraciones consecutivas varía por debajo de una cota preestablecida.
4.4.4.2. Método de los modelos subordinados Este método iterativo (JACO82) es aplicable a cualquier problema de retención simultánea de recursos que pueda establecerse en forma de un conjunto primario de recursos y un subsistema secundario. El concepto clave del enfoque es el particionamiento de las esperas en dos componentes: - el retardo en la cola debido a la congestión en el subsistema secundario, incluyendo en
tiempo de permanencia en la cola del recurso primario debido a la congestión en el subsistema secundario. Esto es algo sutil: por ejemplo en un subsistema de E/S, este componente debe incluir todos los retardos debidos a la congestión de la unidad de control, incluso el tiempo pasado en la cola del disco en el caso que el cliente que retiene el disco está esperando para acceder a la unidad de control.
- el retardo en la cola debido únicamente a la congestión en el recurso primario, es decir el tiempo pasado en la cola del recurso primario cuando el subsistema secundario no está congestionado. En un subsistema de E/S, por ejemplo, este componente debe constar del tiempo pasado en la cola del disco en el caso que el cliente que retiene el disco está moviendo el brazo (y en espera rotacional también en el caso de posicionamiento angular).
Esta partición de los retardos en las colas no es convencional ya que no corresponde a las colas en que se observaría a los clientes en mediciones sobre el sistema real. Al mismo tiempo es significativa ya que divide los retardos en las colas en la porción que estará afectada por modificaciones del subsistema secundario y la porción que estará afectada por modificaciones en el conjunto primario de recursos. En un subsistema de E/S, por ejemplo, el tiempo de espera en la cola del disco que está bloqueado esperando el acceso a la unidad de control sólo puede disminuirse aumentando la capacidad de la unidad de control. Este método de los modelos subordinados implica la iteración entre dos modelos, cada uno de los cuales estima uno de estos componentes del retardo en la cola. El valor de este retardo (servidor sin espera) se obtiene a partir de las medidas del comportamiento en el otro modelo. El algoritmo consta de los siguientes pasos: 1. Identificar aquellos componentes del sistema total correspondientes al conjunto primario
de recursos P y al subsistema secundario S. Como se ha descrito previamente, un recurso primario es aquél que debe obtenerse antes de usar cualquiera de los recursos del subsistema secundario. El subsistema secundario consta de aquellos recursos obtenidos y usados mientras se retiene el recurso primario. En cada recurso primario i, un cliente tiene una requisición de servicio, posiblemente nulo, de servicio no solapado DNi, durante el cual se retiene este recurso sin intentar obtener servicio del subsistema secundario. En cada recurso j del subsistema secundario, un cliente que retiene el recurso primario i tiene una requisición de servicio solapado DOij, durante el cual se retienen tanto el recurso primario i como el secundario j. Por lo tanto, en cada recurso primario i un cliente tiene la requisición total de servicio:
∑∈
+=Sj
jii DODND
y en cada recurso j del subsistema secundario un cliente tiene una requisición total de servicio:
∑∈
=Pi
ij DOD

110
2. Calcular los siguiente parámetros:
- El tiempo de servicio no solapado del recurso primario DN es el tiempo total que un cliente retiene recursos primarios solamente sin intentar obtener servicio del subsistema secundario
∑∈
=Pi
iDNDN
En el caso de un modelo con factor de multiprogramación limitado, este tiempo sería cero (la competencia entre la CPU y el subsistema de E/S empieza tan pronto como se ha obtenido una partición de memoria). En el caso de un modelo de un subsistema de E/S este tiempo sería el tiempo total que un cliente gasta en el movimiento del brazo (suponiendo que solo se requiere la unidad de control durante la latencia y la transferencia de los datos).
- El tiempo de servicio del subsistema secundario DO es la suma de los tiempos de servicio en los distintos recursos que constituyen el subsistema secundario
∑∈
=Sj
jDDO
En el caso de un modelo con factor de multiprogramación limitado, este tiempo sería la suma de los tiempos de servicio en la CPU y el subsistema de E/S. En el caso de un modelo de un subsistema de E/S, este tiempo sería el tiempo total que un cliente gasta en la latencia y la transferencia de los datos.
3. Analizar el subsistema secundario aislado, para obtener una representación del flujo equivalente. El objetivo de este paso es reflejar el hecho que el subsistema secundario tiene una restricción de población: puesto que el recurso primario debe obtenerse antes de entrar en el subsistema secundario, en el subsistema secundario puede haber tantos clientes como recursos secundarios haya. Se procede de la forma siguiente:
- Crear un modelo aumentado del subsistema secundario que consta de los recursos del subsistema secundario (cada uno con el tiempo de servicio apropiado Dj) junto con un servidor retardo puro cuyo tiempo de servicio es igual al tiempo de servicio no solapado del recurso primario DN.
- Analizar este modelo para cada posible población de clientes, determinando en cada caso la productividad del modelo.
- Usar estas productividades dependientes de la carga para definir un servidor dependiente de la carga. Para longitudes de cola superiores a la población máxima, usar la productividad correspondiente a la máxima.
4. Crear dos modelos de redes de colas para el sistema global. En cada uno de estos modelos, la parte del sistema global en que se produce la retención simultánea de recursos está substituida por dos componentes:
4.1. En el primero de estos modelos, uno de los componentes es un servidor retardo puro actuando de forma subordinada del retardo debido a la congestión del subsistema secundario. El otro de estos componentes es una representación explícita del conjunto de recursos primarios en que cada recurso primario i tiene su tiempo de servicio Di. En el caso del modelo de un sistema con factor de multiprogramación limitado, los recursos primarios se representarían como una estación con tantos servidores como particiones hay en la memoria; el tiempo de

111
servicio de cada servidor es igual a la suma de los tiempos de servicio del cliente en la CPU y el subsistema de E/S. En el caso de un modelo de un subsistema de E/S, los recursos primarios se representarían como estaciones de un servidor correspondientes a los distintos discos; el tiempo de servicio de cada uno sería la suma de los tiempos de movimiento del brazo, de latencia y de transferencia de datos.
4.2. En el segundo de estos modelos, uno de estos componentes es un servidor retardo puro actuando como subordinado de la espera en los recursos primarios cuando los subsistemas secundarios no están congestionados. El otro de estos componentes es el servidor con capacidad de servicio dependiente de la carga definido en el paso 3 y que representa el subsistema secundario aumentado.
5. Iterar entre los dos modelos definidos en el paso 4:
5.1. En el modelo definido en el paso 4.1., hacer cero el tiempo de servicio del servidor retardo puro que actúa como subordinado de la espera debida a la congestión del subsistema secundario.
5.2. Resolver el modelo definido en el paso 4.1. Estimar la espera en el recurso primario sumando para todos los recursos primarios las diferencias entre el promedio de los tiempos de respuesta de los recursos (Ri, medida del comportamiento obtenida mediante el análisis) y sus tiempos de servicio (Di, parámetro del modelo).
5.3. Hacer el tiempo de servicio del servidor retardo puro del modelo definido en el paso 4.2. igual al valor calculado en el paso 5.2. Resolver este modelo. Estimar la espera debida a la congestión en el subsistema secundario restando el tiempo de servicio del servidor dependiente de la carga (su tiempo de residencia con una población de un cliente, que es igual a DN + DO) del tiempo de residencia medio en este servidor (medida del comportamiento obtenida mediante el análisis),
5.4. Comparar el valor que se acaba de calcular con el tiempo de servicio del servidor retardo puro usado en el paso 5.2. Si difieren, substituirlo y volver al paso 5.2.
4.4.4.3. Método de la red auxiliar Este método (CHAN75B) (MARI78) establece la conjetura de iteración pasando a través de las probabilidades marginales asintóticas. Se considera una red cerrada con leyes de servicio generales y tal que: - la matriz de encaminamiento es independiente del estado, y, por lo tanto, constante.
- las N estaciones son tales que
* la disciplina es FIFO,
* la ley de distribución de los tiempos de servicio tiene una transformada de Laplace racional (distribución de Cox).
* el servidor es único.
- los M clientes son de la misma clase.
Se estudia cada estación como una cola λ(m)/K/1. Para cada estación es preciso hallar una sucesión λ(m), para m = 0, 1, ..., M tal que el comportamiento de la estación, calculado de esta forma sea próximo del comportamiento real de la estación en la red. Sea
λ = λ1(0), λ1(1), ..., λ1(M), λ2(0), ..., λN(M)

112
el vector que caracteriza las frecuencias de llegada condicionales a cada estación para el conjunto de la red cerrada. A partir de un vector inicial λ(0) se calcula iterativamente, como muestra la figura 4.17, un vector λ(k) por medio de la red auxiliar con la misma topología, pero con leyes de servicio exponenciales e independientes del número de clientes de cada estación y cuyos valores varían según los resultados cada iteración. Es preciso además tener en cuenta que la frecuencia de llegada a la estación i cuando hay en ella mi clientes, λi(mi) es igual a la frecuencia de salida de la red abierta complementaria (la red completa exceptuando la estación i) cuando en ella hay los M - mi elementos, λi(M - mi). La inicialización se hace suponiendo que el tiempo medio de servicio de cada estación, considerando distribución exponencial, es igual al de la ley de la distribución correspondiente.
Determinación de λ(k) Inicialización de λ(0)
Cálculo de lasprobabilidades
marginales
Comprobacionesde parada
Corrección dela red auxiliar
FINAL
Satisfechas
No satisfechas
(n i)Pi
Figura 4.17.
El cálculo de las λ(k) se efectúa considerando la red cerrada de la misma topología y con servicios exponenciales, mediante las fórmulas deducidas al analizar el algoritmo de Buzen y sus consecuencias.
( ) ( )( ) Mmm
ma ii
iiii ..., 2, ,1 para ,
1=
µµ
=
( ) 0 si ,1 == iii mmA

113
( ) ( ) 0 si ,1
>= ∑=
i
m
jiii mjamA
( )1i
ii
xXµ
=
donde xi es la solución del sistema
∑=
=N
jjjii xpx
1
y pij son las probabilidades de encaminamiento,
( ) ( )( )∑ ∏
∈ =
=nmSm
n
i ii
mi
n mAX
mgi
, 1
( ) ( )( )Mg
mAX
mmmpn
n
i ii
mi
n
i
∏== 1
21 ,..,,
y donde
( ) ( ) ( )∑=
− −=m
kn
n
kn
n kmgkA
Xmg
01
por el algoritmo general de cálculo de la constante de normalización. Si además λi(mi) = λi para mi = 1, 2, ..., M
gn(m) = Xn gn(m - 1) + gn - 1(m)
y por las fórmulas de la productividad, se pueden calcular las frecuencias de llegada a cada estación. A continuación se calculan el número medio de clientes en cada estación y la frecuencia media de llegada, de la forma siguiente
( )∑=
=M
miiii mPmm
11
( ) ( )∑=
λ=λM
miiiii mPm
11
donde Pi(mi) representa la probabilidad que en la estación i haya mi clientes. Hay que recordar que
λi(mi) = λi(M - mi)
por lo que para el cálculo de las frecuencias de llegada en función de la carga a cada estación en cada iteración es preciso considerar la red abierta complementaria de cada estación cuando en aquélla hay los clientes que no están en ésta.

114
Para este cálculo se puede utilizar un algoritmo derivado del de Buzen que se puede encontrar en (MARI78). Una vez se dispone para todas las estaciones del número medio de clientes y de la frecuencia media de llegada, se pasa a la comprobación de parada, consistente en determinar si
MmN
ii =∑
=1
Njp j
N
iiji ..., 2, ,1 para ,
1=λ=λ∑
=
Haciendo
i
ii x
tλ
=
la segunda condición de parada se puede escribir
Njxtpxt jj
N
iijii ..., 2, ,1 para ,
1==∑
=
lo que equivale a comprobar que
t1 = t2 = ... = tN
Sea
∑=
=N
iitN
t1
1
Si se fija una tolerancia δ se puede determinar: - para toda la red si hay un número de clientes excesivo o insuficiente, según que
M
MmN
ii −∑
=1
sea mayor o menor que δ, respectivamente. - para cada estación se calcula si tiene una frecuencia excesiva o insuficiente según que
(ti - t)/t
sea mayor o menor que δ, respectivamente. De esta forma se definen los conjuntos I+ e I- de estaciones con frecuencia excesiva e insuficiente, respectivamente.
Si no hay error de número de clientes y si los conjuntos I+ e I- están vacíos, se considera que los resultados de esta iteración son satisfactorios y se detiene la secuencia de iteraciones. Si no es así, hay que determinar un nuevo vector µ(k + 1) a partir del µ(k) haciendo las modificaciones siguientes: - si el número de clientes es excesivo o insuficiente y los conjuntos I+ e I- están vacíos,
entonces para todas las estaciones (i = 1, 2, ..., N) se hace

115
( ) ( )
y
N
jj
ki
ki
m
M
µ=µ
∑=
+
1
1
- si el número de clientes es admisible y los conjuntos I+ e I- no están vacíos, entonces para todas las estaciones (i = 1, 2, ..., N) se hace
( ) ( )y
iki
ki t
t /11
µ=µ +
- si el número de clientes es excesivo y los conjuntos I+ e I- no están vacíos, entonces para las estaciones con frecuencia insuficiente (i ∈ I-) se hace
( ) ( )y
iki
ki t
t /11
µ=µ +
- si el número de clientes es insuficiente y los conjuntos I+ e I- no están vacíos, entonces para las estaciones con frecuencia excesiva (i ∈ I+) se hace
( ) ( )y
iki
ki t
t /11
µ=µ +
Inicialmente en (CHAN75B) se tomó y = 1. No obstante, para acelerar la convergencia en (MARI78) se propone tomar
y = 1 para leyes exponenciales
y = 2 para leyes hiperexponenciales
y = 1/2 para leyes hipoexponenciales
El objetivo de las modificaciones de µ(k) (prescindiendo de la corrección propuesta en (MARI78)) es: - en las estaciones con flujo insuficiente (I-, t > ti) es lograr que en la siguiente iteración esas
estaciones tengan frecuencias de llegada inferiores. En otras palabras, en el análisis de la red auxiliar en la siguiente iteración, la frecuencia de llegada a las estaciones sin error de flujo insuficiente se hará inferior con lo que se reducirá la longitud media de la cola y el flujo a través de esas estaciones.
- en las estaciones con flujo excesivo (I+, t > ti) sirve, mutatis mutandis, el razonamiento anterior.
- cuando el error está en el número total de elementos se deben reducir todas las frecuencias de llegada si el número de clientes es excesivo con lo que se reducen las longitudes medias de cola y viceversa.

116
6. SIMULACIÓN La simulación es esencialmente una técnica de muestreo estadístico controlado que puede usarse para estudiar sistemas estocásticos complejos cuando los métodos analíticos y/o numéricos no bastan, como sucede frecuentemente en el estudio de sistemas informáticos y teleinformáticos. La simulación consiste en la construcción de un programa que representa el comportamiento dinámico de un sistema estocástico. La ejecución de ese programa permite observar el comportamiento del sistema por un muestreo artificial realizado en el mismo computador en que se ejecuta el programa que representa el sistema. En particular se hará referencia a la simulación de acontecimientos discretos en que los cambios de estado del sistema se producen sólo en puntos de una secuencia creciente de tiempos. La simulación permite, además, mejorar la calidad de los modelos liberándolos de las restricciones impuestas para conseguir un tratamiento analítico o numérico (tipos de distribuciones, encaminamiento aleatorio de los trabajos, etc.). Para alcanzar este objetivo se presentan diversos problemas, comunes a todos los procesos de simulación de sistemas discretos y que, principalmente, son: - la generación de secuencias de números aleatorios
- la organización del mecanismo de simulación
- la extracción de las estadísticas correspondientes a los resultados de la simulación
En cualquier caso, las etapas que hay que seguir en el tratamiento de un problema por experimentación simulada son: - Formulación del modelo de simulación
- Implantación del modelo
- Diseño de los experimentos de simulación
- Validación del modelo de simulación
- Ejecución de los experimentos de simulación y análisis de sus resultados. La mayoría de los proyectos de simulación están casi completamente dominados por las dos primeras fases, puesto que, en general, la construcción de modelos de simulación exige tantos esfuerzos y tiempo (humano y máquina) que muchos investigadores disponen de poco tiempo para validar el simulador, planificar su ejecución eficiente e interpretar correctamente los resultados. No obstante, estos problemas son tanto o más importantes que la construcción del simulador.
6.1. GENERACIÓN DE SECUENCIAS DE NÚMEROS ALEATORIOS Un generador de números aleatorios (o mejor, de números pseudoaleatorios) es un algoritmo que produce secuencias de números que siguen una distribución de probabilidad determinada y que tienen una apariencia de aleatoriedad. El hablar de secuencia de números significa que el algoritmo debe ser capaz de producir muchos números aleatorios de una manera secuencial. Aunque un usuario determinado puede necesitar solo relativamente pocos de tales números, se exige que el algoritmo sea capaz de producir muchos números. El considerar una distribución de probabilidad implica que se puede asociar una probabilidad a la aparición de cada número producido por el algoritmo. Normalmente se considera que la distribución de probabilidad es la uniforme sobre el intervalo ]0, 1[. En general, si se tiene una secuencia de números aleatorios distribuidos uniformemente en ese intervalo, siempre es

117
posible transformarlos mediante la integral de probabilidad inversa para obtener números que tengan la distribución deseada. Con respecto a la apariencia de aleatoriedad puede ser algo sorprendente que la base de la mayoría de los algoritmos más frecuentemente utilizados para la generación de números aleatorios sea una relación de recurrencia determinista en que cada número es una función del precedente. La verdadera aleatoriedad requiere la independencia de los sucesivos números, pero el algoritmo produce una secuencia dependiente. Cuando los parámetros de la relación de recurrencia se eligen cuidadosamente, tales algoritmos para generar números aleatorios uniformes producen secuencias que estadísticamente aparecen como aleatorias. Esta apariencia de aleatoriedad es el origen del término números pseudoaleatorios. Puesto que los resultados de la simulación dependen de forma crítica de una aceptable apariencia de aleatoriedad, es importante que un generador de números aleatorios uniformes cumpla con un amplio proceso de comprobación estadístico.
6.1.1. GENERADORES CONGUENCIALES LINEALES La mayoría de los generadores de números aleatorios uniformes son de este tipo y emplean una relación de recurrencia de la forma:
Xn + 1 = aXn + c (mod m)
donde todas las cantidades son no negativas y se las conoce como: m el módulo, m > 0;
a el multiplicador, 0 < a < m;
c el incremento, 0 ≤ c < m;
X0 el valor inicial, 0 < X0 < m.
La aplicación sucesiva de la ecuación anterior produce una secuencia de enteros Xn = X1, X2, ... considerada como de números aleatorios uniformes distribuidos entre 0 y m - 1. Los números aleatorios uniformes distribuidos en el intervalo ]0, 1[ se obtienen dividiendo los valores anteriores por m, es decir para n = 1, 2, 3, ..., se tiene
Un = Xn/m
Por ejemplo, la secuencia obtenida para m = 10 y X0 = a = c = 7, es
7, 6, 9, 0, 7, 6, 9, 0, . . . .
Como este ejemplo pone de manifiesto, la secuencia no siempre es aleatoria para cualquier elección de m, a, c y X0; los principios para elegir estos números "mágicos" se enunciarán a lo largo de este apartado. Además, en algunos casos será útil considerar b = a - 1 para simplificar alguna de las fórmulas. Evidentemente se considerarán los casos en que a ≥ 2 y b ≥ 1. El ejemplo anterior pone de manifiesto que la secuencia congruencial llega siempre a un bucle, es decir que un determinado ciclo de números se repite sin fin. El ciclo de números que se repite se denomina período. Para que una secuencia sea útil es preciso que el período sea largo. El caso especial de c = 0 merece una mención aparte, puesto que el proceso de generación de números es algo más rápido que cuando c > 0. No obstante la elección de c = 0 acorta el período. Los términos método congruencial multiplicativo y método congruencial mixto se aplican respectivamente a los casos en que c = 0 y c > 0.

118
6.1.1.1. Elección del módulo La elección del módulo m debe hacerse atendiendo a las dos siguientes características: - m debe ser suficientemente grande a fin de permitir que el período también lo sea ya que
nunca será mayor que el módulo.
- la necesidad que la operación (aXn + c ) mod m sea rápida aun cuando la división sea una operación lenta. Para ello es conveniente elegir m de tal forma que sea (en computadores binarios) 2 elevado a la longitud e de la palabra en bits w = 2e, con lo cual el cálculo del resto de la división se transforma en un truncado y el cálculo se efectúa eficientemente. Otra técnica consiste en utilizar como módulo m = w ± 1, normalmente con c = 0. En este caso, después de efectuar el producto aX se tendría el resultado en dos registros; en el primero q (cociente de la división por w) y en el segundo r (resto de la división por w). En consecuencia, en el caso de m = w + 1, se tendría
aX = q(w + 1) + (r - q)
y (aX) mod(w + 1) sería igual a r - q o a r - q + (w + 1) según que r - q ≥ 0 ó r - q < 0, respectivamente. En caso de elegir m = w - 1 se utilizaría una técnica similar.
6.1.1.2. Elección del multiplicador El multiplicador, junto con el módulo, determina la longitud del período y el aspecto aleatorio de los números que lo componen. Así, por ejemplo, si se hace a = c = 1, se obtiene un período máximo con cualquier módulo, pero su aleatoriedad dejará mucho que desear. Por otro lado si m es el producto de diversos primos, el período sólo será máximo para a = 1, pero si m es una potencia elevada de un primo, la elección de a es mucho más amplia. Las condiciones que deben cumplir a y c vienen fijadas por los teoremas que se exponen a continuación. Teorema A. La secuencia congruencial lineal definida por m, a, c y X0 tiene un período máximo m si y solo si 1. c es primo respecto a m;
2. b = a - 1 es un múltiplo de p, para cada p que divida a m;
3. b es un múltiplo de 4, si m es un múltiplo de 4.
En el caso en que c = 0, el teorema que se acaba de exponer pone de manifiesto que nunca podrá alcanzarse la longitud de período máxima, como tampoco debe aparecer nunca el valor Xn = 0, ya que a partir de ese momento la secuencia Xn + 1 = aXn mod m quedaría degenerada. En general, si Xn es múltiplo de d, los sucesivos valores de la secuencia multiplicativa también lo serán. Por lo tanto, Xn deberá ser primo con m para cualquier n, para que la longitud del período sea como máximo el número de enteros entre 0 y m que son primos con m. Si se considera el caso en que m = pe, entonces se tiene Xn + 1 = anX0 mod pe y es evidente que se tiene un período de longitud 1 si a es múltiplo de p, por lo que se tomará a primo con respecto a p. Entonces el período es el menor entero λ tal que X0 = aλX0 mod pe. Cuando a es primo con m, el menor valor de λ, para el cual aλ = 1 mod m, se denomina orden de a módulo m. Cualquiera de tales valores de a que tiene el máximo orden módulo m posible, se denomina un elemento primitivo módulo m. Si λ(m) representa el orden de un elemento primitivo, es decir el máximo orden posible módulo m, puede demostrarse que:
λ(2) = 1, λ(4) = 2, λ(2e) = 2e - 2, si e ≥ 3
λ(pe) = pe - 1 (p - 1), si p > 2

119
( ) ( ) ( )( )tt et
eet
e ppmcmpp λλ=λ ,...,... 1111
Estas observaciones pueden resumirse en el siguiente: Teorema B. El período máximo posible cuando c = 0 es λ(m). Este período se alcanza si: 1. X0 es primo respecto a m;
2. a es un elemento primitivo módulo m.
Nótese que se puede obtener un período de longitud m - 1 si m es primo, que es uno menos que la longitud máxima, por lo que a efectos prácticos es tan largo como se quería. El problema se ha trasladado ahora a conocer si un número es primitivo, para lo cual puede ayudar el siguiente: Teorema C. El número a es un elemento primitivo módulo pe si y solo si: 1. pe = 2, si a es impar; o pe = 4, si a mod 4 = 3; o pe = 8, si a mod 8 = 3, 5, 7; o p = 2, y
4≥e si a mod 8 = 3, 5; ó
2. p es impar, e = 1, a ≠ 0 mod p y a(p - 1)/q ≠ 1 mod p, para cualquier divisor primo q de 1−p ; ó
3. p es impar, e > 1, a satisface la condición 2 y ap - 1 ≠ 1 mod p2.
En el caso común m = 2e, con e ≥ 4, las condiciones anteriores se simplifican a la simple exigencia que a = 3 ó 5 mod 8, lo cual indica que una cuarta parte de los posibles multiplicadores dan un período máximo.
6.1.1.3. El generador de números aleatorios uniformes del sistema 360 Uno de los generadores de números aleatorios más conocido es el implantado en el sistema 360 de IBM con una palabra de 32 bits de los cuales uno está reservado al signo y los restantes al módulo. En consecuencia, la elección obvia es m = 231. Un generador multiplicativo (c = 0) con m = 2k tendrá un período máximo de longitud m/4. Por lo tanto en el sistema 360 de IBM con m = 231, el período máximo es de 231/4 = 229 y la longitud del período puede depender también del valor inicial. Cuando el módulo es primo, el máximo período posible es m - 1. Sucede que (afortunadamente) el mayor primo menor que 231 es 231 - 1 = 2147483647, por lo que eligiendo este valor como módulo, el período será solo una unidad inferior. Se observa que las condiciones que aseguran un período máximo no garantizan necesariamente buenas propiedades estadísticas para el generador, aunque la elección como multiplicador de a = 75 satisface ambas exigencias. Es decir que el generador sería
Xn + 1 = 75Xn mod ( 231 - 1) = 16807 Xn mod (2147483647)
6.1.1.4. Barajado de los generadores congruenciales lineales Con el fin de mejorar la aleatoriedad de la secuencia de números generada, en muchos casos se procede a un barajado de los resultados que adopta, con frecuencia la forma siguiente: - se crea una tabla con 27 = 128 valores procedentes del generador considerado.
- con los siete bits de menor peso del nuevo valor generado considerados como un número binario se direcciona el elemento correspondiente de la tabla anterior.
- el valor que se da como salida es el que ocupaba la posición direccionada en la tabla y es substituido por el valor que se acaba de generar.
- se repiten estos dos últimos pasos tantas veces como sea necesario.

120
Se observa que este esquema de barajado depende de la elección del módulo m. Para un módulo m = 231, los bits de menor peso de la secuencia congruencial no son uniformes y su uso puede perjudicar más que beneficiar. Con un módulo m = 231 - 1 y un multiplicador b = 75, los bits de menor peso son uniformes y se obtienen los resultados deseados.
6.2. COMPROBACIÓN DE LAS SECUENCIAS DE NÚMEROS ALEATORIOS
El objetivo principal es obtener secuencias de números que parezcan aleatorias. Hasta ahora la preocupación ha sido lograr un período suficientemente largo para que, a efectos prácticos, no se produzcan repeticiones. Ello es importante, pero no garantiza que la secuencia sea útil en las aplicaciones que requieran de estas secuencias de números. La teoría estadística proporciona algunas medidas cuantitativas de la aleatoriedad. Literalmente no hay fin en el número de tests que pueden concebirse. Se tratarán algunos tests que se han mostrado útiles, instructivos y adaptados al cálculo automático. Cada secuencia que deba utilizarse debe comprobarse cuidadosamente y así en los apartados que siguen se tratará como llevar a cabo estos tests de una manera correcta. Se distinguen dos tipos de tests: - tests empíricos para los cuales el computador manipula grupos de números de la secuencia
y evalúa algunas magnitudes estadísticas.
- tests teóricos para los cuales se establecen las características de la secuencia usando métodos de la teoría de números basados en la regla de recurrencia utilizada en la formación de la secuencia.
6.2.1. PROCEDIMIENTOS DE TEST GENERALES PARA ESTUDIAR DATOS ALEATORIOS
6.2.1.1. Test de ji cuadrado Este test es tal vez el más conocido de los tests estadísticos y es un método básico que se usa en conexión con muchos otros. Es adecuado para comprobar distribuciones de tipo discreto o, lo que es los mismo, cuando las observaciones que se realizan caen en clases determinadas. En general, una observación puede caer en una entre k categorías. Se considera que se hacen n observaciones independientes en el sentido que el resultado de cada observación no afecta al resultado de ninguna de las demás. Sea pi la probabilidad que cada observación caiga en la categoría i y sea Yi el número de observaciones que realmente caen en la categoría i. Si se forma el estadístico
( )∑=
−=
k
i i
ii
ipipY
V1
2
desarrollando el cuadrado de la diferencia y teniendo en cuenta que
Y1 + Y2 + ... + Yk = n
p1 + p2 + ... + pk = 1
se llega a la expresión
npY
nV
k
i i
i −
= ∑
=1
21
que facilita el cálculo de V.

121
A continuación es preciso plantearse la cuestión de cual es un valor razonable de V. La respuesta está en utilizar una de las tablas de ji cuadrado fijando el nivel de confianza y el número de grados de libertad, que es igual, en primera aproximación, al número de categorías menos el número de relaciones existentes.
6.2.1.2. Test de Kolmogorov-Smirnov Como se acaba de ver, el test de ji cuadrado se aplica a situaciones en que las observaciones caen en un número finito de categorías. No es inusual, sin embargo, considerar cantidades aleatorias que pueden tener infinitos valores. Por ejemplo, un número aleatorio real entre 0 y 1 puede tomar infinitos valores distintos; incluso aunque solo un número finito de ellos puede representarse en un computador y se desea que los valores pseudoaleatorios se comporten esencialmente como si fueran números aleatorios reales. Sea F(x) la función de distribución de probabilidad de la variable aleatoria considerada. Si se hacen n observaciones independientes de una cantidad aleatoria X, obteniendo los valores X1, X2, …, Xn, se puede formar la función de distribución empírica Fn(x), donde
( )n
xXXXxF n
n≤
=son que ,...,, de número 21
que tendrá el aspecto de una escalera irregular. Cuando n crece Fn(x) tiende a ser una aproximación cada vez mejor de F(x). El test de Kolmogorov-Smirnov (test KS) puede usarse cuando F(x) no tiene saltos y se basa en la diferencia entre F(x) y Fn(x). Para hacer el test KS, se forman los siguientes estadísticos
( ) ( )[ ]xFxFnK nxn −= +∞<<∞−+ max
( ) ( )[ ]xFxFnK nxn −= +∞<<∞−− max
Aquí +nK mide la máxima desviación cuando Fn es mayor que F, y −
nK mide la máxima desviación cuando F es mayor que Fn. Puede demostrarse que la desviación tipo de Fn(x) es proporcional a la inversa de la raíz cuadrada de n, por lo que la multiplicación por la raíz cuadrada de n en las ecuaciones anteriores magnifica los estadísticos +
nK y −nK para que esta
desviación tipo sea independiente de n. Como en el test de ji cuadrado se debe consultar en una tabla acerca de los valores +
nK y −nK
para determinar su significación.
6.2.2. PROCEDIMIENTOS DE TEST EMPÍRICOS PARA ESTUDIAR SECUENCIAS DE NÚMEROS ALEATORIOS
En este apartado se expondrán tests específicos que se han aplicado a las secuencias de números aleatorios para investigar su aleatoriedad. Cada test se aplica a la secuencia Un = U0, U1, U2, ... de números reales que se quiere averiguar si son independientes y uniformemente distribuidos entre 0 y 1. Algunos de los tests están diseñados primariamente para secuencias de valores enteros, en vez de reales. Entonces se considerará la secuencia Yn = Y0, Y1, Y2, ... que está definida por la regla Yn = parte entera de (dUn) y donde se supone que la secuencia Yn es de valores independientes y está uniformemente distribuida entre 0 y d - 1.

122
6.2.2.1. Test de equidistribución La primera condición que debe cumplir la secuencia Un es que sus números estén uniformemente distribuidos entre 0 y 1. Hay dos formas de realizar este test: - Usar el test de Kolmogorov-Smirnov con F(x) = x para 0 ≤ x ≤ 1.
- Sea d un número conveniente, por ejemplo 64 ó 128 en un computador binario, y usar la secuencia Yn en lugar de la Un. Para cada entero r, 0 ≤ r ≤ d, contar el número de veces que Yj = r para 0 ≤ j ≤ n, y entonces aplicar el test de ji cuadrado usando k = d y la probabilidad pi = 1/d para cada categoría.
6.2.2.2. Test serial Un criterio más general consiste en querer que pares de números sucesivos estén uniformemente distribuidos de forma independiente. Para realizar este test se cuenta simplemente el número de veces que aparece el par ( )122 , +jj YY = (q, r), para 0 ≤ j ≤ n; Esta cuenta debe hacerse para cada par de enteros (q, r) con
drq ≤≤ ,0 y se aplica el test de ji cuadrado a estas k = d2 categorías con probabilidad 1/d2 en cada categoría. Como en el caso del test de equidistribución, d debe ser un valor adecuado, pero será bastante menor puesto que para que el test de ji cuadrado sea válido es preciso que n sea grande con respecto a k (por ejemplo que n ≥ 5d2). Claramente se puede generalizar este test a triplas, cuádruplas, etc., en vez de pares; sin embargo, entonces el valor de d debe reducirse severamente para evitar tener demasiadas categorías. Cuando se consideran cuádruplas o agrupaciones de orden superior, se pueden usar test menos exactos, como el del póker, que se describirán más adelante. Nótese que es preciso generar 2n números de la secuencia Yn para disponer de n observaciones. Por otro lado, no hay que caer en el error de utilizar los pares (Y0, Y1), (Y1, Y2), …, (Yn - 1, Yn), ya que los pares considerados no serían independientes.
6.2.2.3. Test de las lagunas Este test pretende examinar la longitud de las "lagunas" entre apariciones de Uj en un cierto ámbito. Si a y b son dos números reales con 0 ≤ a, b ≤ 1, se quieren considerar las longitudes de subsecuencias consecutivas Uj, Uj + 1, …, Uj + r donde Uj + r se halla entre a y b pero las otras U no. Esta subsecuencia de r + 1 números de longitud constituye una laguna de longitud r. Para determinar el número de lagunas de cada longitud se podría usar un algoritmo como el siguiente: Algoritmo L. Este algoritmo aplicado a la secuencia para cualquier par de valores a y b, cuenta el número de lagunas de longitudes 0, 1, …, t - 1 y el número de las que son ≥ t, hasta que se hayan examinado n lagunas. L1. [Inicializar] Hacer j = -1, s = 0 y CONT(r) = 0 para 0 ≤ r ≤ t.
L2. [Hacer r igual a 0] Hacer r = 0.
L3. [¿a ≤ Uj ≤ b?] Incrementar j en uno. Si Uj ≥ a y Uj < b, ir al paso L5.
L4. [Incrementar r] Hacer r = r + 1 y volver al paso L3.
L5. [Registrar la longitud de la laguna] Puesto que se ha encontrado una laguna de longitud r, si r ≥ t, incrementar CONT(t) en uno y, en caso contrario, incrementar en uno CONT(r).
L6. [¿Se han encontrado n lagunas?] Incrementar s en uno. Si s < n, volver al paso L2.

123
Después de ejecutar este algoritmo, se aplica el test de ji cuadrado a los k = t + 1 valores de CONT(0), CONT(1), …, CONT(t), usando las siguientes probabilidades:
p0 = p, p1 = p(1 - p), p2 = p(1 - p)2, …, pt - 1 = p(1 - p)t - 1, pt = (1 - p)t
En este caso p = b - a es la probabilidad que a ≤ Uj ≤ b. Los valores de n y t deben elegirse, como de costumbre, para que cada uno de los valores de CONT(r) sea 5 ó más, preferiblemente más. Este test se aplica a menudo con a = 0 ó con b = 1 para omitir una de las comparaciones del paso L3. Los casos especiales en que (a, b) = (0, 0.5) ó (0.5, 1) dan lugar a los tests denominados de las lagunas por encima y por debajo de la media, respectivamente. Nótese finalmente que si la secuencia observada fuera muy poco aleatoria, el algoritmo L podría no tener fin.
6.2.2.4. Test del póker o de las particiones El test del póker clásico considera n grupos de cinco enteros sucesivos (Y5j, Y5j + 1, …, Y5j + 4) para 0 ≤ j < n y observa cual de las siete posibles combinaciones coincide con cada quíntupla:
Todas distintas : abcde
Pareja: aabcd
Doble pareja: aabbc
Trío: aaabc
Fool: aaabb
Póker: aaaab
Repóker: aaaaa
y el test de ji cuadrado se basa en el número de quíntuplas de cada categoría. Es razonable plantearse una versión algo más sencilla de este test para facilitar su programación. Un buen compromiso sería contar simplemente el número de valores distintos en cada grupo de cinco. Se tendrían entonces cinco categorías:
Cinco distintas: Todas distintas
Cuatro distintas: Pareja
Tres distintas: Doble pareja o Trío
Dos distintas: Fool o Póker
Todas iguales: Repóker
En general se pueden considerar n grupos de k números sucesivos y se puede contar el número de k-tuplas con r valores distintos. El test de ji cuadrado se efectúa entonces usando la probabilidad
( ) ( )
+−−=
rk
drdddp kr
1...1

124
de que haya r diferentes. El último factor de la probabilidad es un número de Stirling.
6.2.2.5. Test del coleccionista de cromos Este test está relacionado con el del póker del mismo modo que el de las lagunas lo está con el de la frecuencia. Se usa la secuencia Yn y se observan las longitudes de las secuencias Yj
+ 1, Yj + 2, …, Yj + r requerida para obtener un conjunto completo de enteros entre 0 y d - 1. El algoritmo que sigue expone con precisión como realizar esta cuenta. Algoritmo C. Dada la secuencia de enteros Y0, Y1, ..., con 0 ≤ Yj ≤ d, este algoritmo para el test del coleccionista de cromos cuenta las longitudes de n segmentos consecutivos de colecciones de cromos. Al final CONT(r) es el número de segmentos con longitud r, d ≤ r < t y CONT(t) es el número de segmentos de longitud ≥ t. C1. [Inicializar] Hacer j = -1, s = 0 y CONT(r) = 0 para d ≤ r ≤ t.
C2. [Poner a cero q y r] Hacer q = 0, r = 0 y CROMO(k) = 0 para 0 ≤ k < d.
C3. [Siguiente observación] Incrementar r y j en uno. Si CROMO(Yj) ≠ 0, repetir este paso.
C4. [¿Conjunto completo?] Hacer CROMO(Yj) = 1 y q = q + 1 (La subsecuencia observada hasta ahora contiene q valores distintos; si q = d, se tiene, por consiguiente, un conjunto completo). Si q < d, volver al paso C3.
C5. [Registrar la longitud] Si r ≥ t, incrementar CONT(t) en uno y, en caso contrario incrementar CONT(r) en uno.
C6. [¿Se ha alcanzado n?] Incrementar s en uno. Si s < n volver al paso C2.
El test de ji cuadrado debe aplicarse a CONT(d), CONT(d + 1), …, CONT(t) con k = t - d + 1, después que el algoritmo C haya contado n colecciones completas. Las probabilidades correspondientes son:
trddr
ddp rr <≤
−−
= si 11!
−= − d
rddp tr
1!1
6.2.2.6. Test de la permutación Si se divide la secuencia de entrada en n grupos de t elementos cada uno, esto es (Ujt, Ujt + 1, …, Ujt + t - 1) para 0 ≤ j < n, entonces los elementos de cada grupo pueden tener t! ordenaciones relativas posibles; se cuenta el número de veces que aparece cada ordenación y se aplica el test de ji cuadrado con k = t! y con probabilidad 1/t! para cada ordenación. Por ejemplo, si t = 3, se podrían tener seis categorías, de acuerdo a si U3j < U3j + 1 < U3j + 2, ó U3j < U3j + 2 < U3j + 1, ó U3j + 1 < U3j < U3j + 2, ó U3j + 1 < U3j + 2 < U3j, ó U3j + 2 < U3j < U3j + 1, ó U3j + 2 < U3j + 1 < U3j. Se supone que en este test no puede haber igualdad entre las U, teniendo en cuenta como han sido generadas. Una forma conveniente de realizar el test de la permutación es mediante el siguiente algoritmo. Algoritmo P. Dada una secuencia de elementos distintos (U1, …, Ut), se calcula un entero f(U1, …, Ut) tal que
0 ≤ f(U1, …, Ut) < t!

125
y f(U1, …, Ut) = f(V1, …, Vt) si y solo si (U1, …, Ut) y (V1, …, Vt) tienen la misma ordenación relativa. P1. [Inicializar] Hacer r = t y f = 0. (Durante este algoritmo se tiene 0 ≤ f < t!/r!),
P2. [Encontrar el máximo] Encontrar el máximo de (U1, …, Ur) y suponer que Us es el máximo. Hacer f = rf + s - 1.
P3. [Intercambiar] Intercambiar Ur y Us.
P4. [Decrementar r] Decrementar r en uno. Si r > 1, volver al paso P2.
Obsérvese que la secuencia (U1, …, Ut) quedará clasificada en orden creciente cuando el algoritmo termine. Para demostrar que el resultado f caracteriza de forma unívoca el orden inicial de (U1, …, Ut), obsérvese que el algoritmo P puede funcionar al revés. Para r = 2, 3, …, t, hacer s = f mod r, f = parte entera de f/r e intercambiar Ur y Us. Es fácil ver que esto deshará los efectos de los pasos P2 a P4.; por lo tanto nunca dos permutaciones distintas pueden conducir a un mismo valor de f y al algoritmo P funciona correctamente. La idea subyacente en este algoritmo es una representación numérica con bases mezcladas denominada sistema de numeración factorial donde cada posición tiene un peso proporcional al factorial de la posición y los dígitos pueden variar entre cero y el orden de la posición que ocupa.
6.2.2.7. Test de las monotonías También pueden comprobarse en una secuencia las monotonías ascendentes y descendentes. Esto significa examinar la longitud de las subsecuencias monótonas de la secuencia original, es decir, los segmentos que son crecientes o decrecientes. Como ejemplo de definición precisa de una monotonía, puede considerarse la secuencia de diez números 1 2 9 8 5 3 6 7 0 4 y poniendo una raya vertical entre Xj y Xj + 1 siempre que Xj > Xj + 1, se obtiene
| 1 2 9 | 8 | 5 | 3 6 7 | 0 4 |
que pone de manifiesto las monotonías crecientes: hay una de longitud 3, seguida de dos de longitud 1, seguida de otra de longitud 3 y otra de longitud 2. A diferencia del test de las lagunas y del del coleccionista de cromos (que en muchos otros aspectos son similares a este test), no se debe aplicar el test de ji cuadrado a los datos anteriores, puesto que las monotonías adyacentes no son independientes. Una monotonía larga tiende a ser seguida por una de corta y viceversa. Esta falta de independencia es suficiente para invalidar la aplicación del test de ji cuadrado. En su lugar debe calcularse el siguiente estadístico a partir del número de monotonías de cada longitud que hayan aparecido:
( )[ ] ( )[ ] ijji anbjCONTnbiCONTn
V ∑ −−=1
donde n es la longitud de la secuencia y los coeficientes aij y bi son iguales a

126
=
17286013947611158083865557892789213947611326290470678524523422615111580904707241454281361871809183865678525428140721271391356855789452343618727139180979.9044278922261518091135689.90444.4529
666564636261
565554535251
464544434241
363534333231
262524232221
161514131211
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
( )
=
8401
504029
72919
12011
245
61
654321 bbbbbb
El estadístico V debe tener una distribución de ji cuadrado con seis (no cinco) grados de libertad cuando n es grande (por encima de 4000). El mismo test puede aplicarse a las monotonías descendientes.
6.2.2.8. Test del máximo de t
Sea Vj = max(Utj, Utj + 1, …, Utj + t - 1) para 0 ≤ j < n. Se aplica ahora el test de Kolmogorov-Smirnov a la secuencia V0, V1, …, Vn - 1 con la función de distribución F(x) = xt, con 0 ≤ x ≤ 1. Alternativamente se podría aplicar el test de equidistribución a la secuencia V0
t, V1t, …, Vn - 1
t. Para verificar este test, se debe demostrar que la función de distribución de las Vj es F(x) = xt. La probabilidad que max(U1, U2, …, Ut) ≤ x es la probabilidad que U1 ≤ x y U2 ≤ x y … y Ut ≤ x, que es el producto de las probabilidades individuales, es decir xx…x = xt.
6.2.2.9. Test de las colisiones El test de ji cuadrado solo puede aplicarse cuando se espera un número no trivial de elementos en cada categoría. Pero hay otro tipo de test que puede usarse cuando el número de categorías es mucho mayor que el número de observaciones. Se supone que se tienen m urnas y que se lanzan n bolas al azar a esas urnas cuando m es mucho mayor que n. La mayoría de las bolas caerá en urnas que estaban previamente vacías, pero si una bola cae en una urna que ya contiene al menos una bola se dirá que se produce una colisión. El test de las colisiones cuenta el número de colisiones y un generador pasa este test si no produce ni demasiadas ni demasiado pocas colisiones. Para fijar ideas puede suponerse que m = 220 y n = 214. Entonces cada urna recibirá solo en promedio un sesentaycuatroavo de bola. La probabilidad que una urna dada contenga exactamente k bolas es
( ) knkk mm
kn
p −−− −
= 11
por lo que el número esperado de colisiones por urna es
( ) 0101
11 pmnpkppk
kk
kk
kk +−=−=− ∑∑∑
≥≥≥
Puesto que
( )
∅+
+−=−= −−
321
0 211
mnm
nmnmp n

127
se encuentra que el número total de colisiones que se producen en todas las urnas es ligeramente inferior a n2/(2m ) = 128. Se puede usar el test de las colisiones para evaluar un generador de números aleatorios en un gran número de dimensiones. Por ejemplo, cuando m = 220 y n = 214 se puede comprobar la aleatoriedad en 20 dimensiones de un generador formando vectores de 20 dimensiones Vj = (Y20j, Y20j + 1, …, Y20j + 19) para 0 ≤ j < n. Basta mantener una tabla de m = 220 bits, un bit para cada posible valor de Vj, para determinar las colisiones. Inicialmente todos los bits están a cero; luego para cada Vj, si el valor correspondiente ya está a 1 se registra una colisión, y en caso contrario se pone el bit a 1. Para decidir si se pasa el test, se puede usar la siguiente tabla de puntos de porcentaje cuando m = 220 y n = 214:
colisiones ≤ 101 108 119 126 134 145 153
probabilidad 0.009 0.043 0.244 0.476 0.742 0.946 0.989
La teoría subyacente a estas probabilidades es la misma que se utilizó en el test del póker; la probabilidad de tener c colisiones es la probabilidad que estén ocupadas n - c urnas, es decir
( ) ( )
−
++−−=
cnn
mcnmmmp nc
1...1
6.2.2.10. Test de la correlación serie Se puede calcular el coeficiente de correlación serie que mide la dependencia entre Uj y Uj + 1, que no es más que un caso particular del coeficiente de correlación entre dos secuencias U0, U1, …, Un - 1 y V0, V1, …, Vn - 1, cuya expresión es
−
−
−
=
∑∑∑∑
∑∑∑
−
=
−
=
−
=
−
=
−
=
−
=
−
=
21
0
1
0
2
21
0
1
0
2
1
0
1
0
1
0
n
jj
n
jj
n
jj
n
jj
n
jj
n
jj
n
jjj
VVnUUn
VUVUnC
y en las que se hace Vj = U(j + 1)mod n. El coeficiente de correlación está siempre entre -1 y +1. Cuando es cero o pequeño en valor absoluto, indica que las cantidades Uj y Vj son relativamente independientes una de otra, pero cuando el coeficiente de correlación es ±1 indica una dependencia lineal total. Por consiguiente, es de desear que C esté próximo a cero. De hecho, puesto que U0U1 no es completamente independiente de U1U2, el coeficiente de correlación serie no se espera que sea exactamente cero. Un buen valor de C deberá cumplir
nnnn C σ+µ≤≤σ−µ 22
donde
( )13
11 ,
11
+−
−=σ
−−
=µnnn
nn nn

128
Además en vez de calcular el coeficiente de correlación entre observaciones contiguas, se puede calcular también entre (U0, U1, …, Un - 1) y la secuencia desplazada cíclicamente (Uq, …, Un - 1, U0, …, Uq - 1), con 0 < q < n.
6.2.3. PROCEDIMIENTOS DE TEST TEÓRICOS PARA ESTUDIAR DATOS ALEATORIOS
Aunque es siempre posible comprobar un generador de números aleatorios usando los métodos que se acaban de describir, es, de lejos, mejor disponer de tests a priori, es decir, resultados teóricos que digan anticipadamente la calidad del generador o cuáles pueden ser los resultados de los tests anteriores. Tales resultados dan un conocimiento mucho mejor acerca de los métodos de generación que el que pueden dar los métodos empíricos de test. El desarrollo de esta teoría es particularmente difícil y puede encontrarse con todo detalle en (KNUT81).
6.2.3.1. Test espectral En este apartado se estudiará una forma especialmente importante de comprobar la calidad de los generadores congruenciales lineales de números aleatorios. No solo todos los buenos generadores pasan este test, sino que ninguno de los malos lo pasa. Es desde luego el test más potente conocido y requiere particular atención. Como test teórico que es, considera la totalidad de la secuencia, aunque requerirá de un programa para poder determinar los resultados. Los más importantes criterios de aleatoriedad parecen relacionarse con las propiedades de la distribución conjunta de t elementos consecutivos de la secuencia. Si se tiene una secuencia Un de período m, la idea consiste en analizar en un espacio de t dimensiones el conjunto de la totalidad de los m puntos
(Un, Un + 1, …, Un + t - 1)
Por simplicidad se supone que se tiene una secuencia congruencial lineal (X0, a, c, m) de período máximo m (por lo que c ≠ 0) o que m es primo, c = 0 y el período es de longitud m - 1. En el último caso se añadirá el punto (0, 0, …,0) al conjunto de puntos de tal forma que siempre habrá m puntos en total. Este punto suplementario tiene un efecto despreciable cuando m es grande y hace que la teoría sea mucho más sencilla. En estas condiciones se
puede reescribir la expresión anterior como ( ) ( )( ) ( )( )
<≤− mxxsxssxsx
mt 0|,....,,,1 1 , donde
s(x) = (ax + c) mod m es el sucesor de x. Obsérvese que se está considerando sólo el conjunto de tales puntos en t dimensiones y no el orden en que estos puntos están realmente generados. Pero el orden de generación se refleja en la dependencia entre las componentes de los vectores y el test espectral estudia tales dependencias para varias dimensiones t tratando con la totalidad de los puntos que se pueden llegar a generar. Por ejemplo considérese la representación gráfica de un pequeño caso en 2 y 3 dimensiones, para el generador
s(x) = (137x + 187) mod 256
Desde luego un generador con un período de 256 difícilmente será aleatorio, pero 256 es suficientemente pequeño para poder dibujar el diagrama y ganar alguna comprensión antes de volver a valores de m mayores que sean de interés práctico. Quizá lo más sorprendente del dibujo que se obtendría es que se puede cubrir todos los puntos mediante un número relativamente reducido de rectas paralelas; por descontado hay muchas familias distintas de rectas que cumplen esa condición. Por ejemplo, un conjunto de 20 rectas

129
casi verticales será una solución, del mismo modo que otro conjunto de 21 rectas con una inclinación de casi 30o. Es algo parecido a los campos de producción de árboles. Si se considera el mismo generador en tres dimensiones, se obtienen los 256 puntos en un cubo añadiendo la componente s(s(x)) a cada uno de los 256 puntos (x, s(x)) dispuestos en el plano. Se puede imaginar como una estructura cristalina en tres dimensiones en la que también se pueden descubrir familias de planos que recubren la totalidad de los puntos. Como primera impresión se podría pensar que un comportamiento tan sistemático es tan poco aleatorio que los generadores congruenciales lineales deberían rechazarse. No obstante una reflexión más cuidadosa recordando que m es grande en la práctica, proporciona una mejor visión. La estructura regular es esencialmente el "grano" que se ve cuando se examinan los números aleatorios bajo un microscopio de alto poder. Si se toman números verdaderamente aleatorios entre 0 y 1 y se redondean o trucan a precisión finita de tal forma que todos sean un múltiplo entero de 1/µ, para algún número dado, µ, entonces los puntos de t dimensiones que se obtienen tendrán un carácter extremadamente regular cuando se miren al microscopio. Sea 1/µ2 la distancia máxima entre líneas, tomada sobre todas las familias de rectas paralelas que cubren los puntos (x/m, s(x)/m) en dos dimensiones. Se denominará µ2 la precisión bidimensional del generador de números aleatorios, puesto que los pares de números sucesivos tiene una estructura fina que es esencialmente buena en una parte entre µ2. De forma similar, sea 1/µ3 la distancia máxima entre planos, tomada sobre todas las familias de planos paralelos que cubren todos los puntos (x/m, s(x)/m, s(s(x))/m). Se denominará µ3 precisión tridimensional. La precisión t-dimensional µt será el recíproco de la distancia máxima entre hiperplanos tomados sobre todas las familias de hiperplanos paralelos de t - 1 dimensiones que cubren los puntos (x/m, s(x)/m, …, st - 1(x)/m). La diferencia esencial entre las secuencias periódicas y las verdaderamente aleatorias que se han truncado a múltiplos de 1/µ es que la precisión de las secuencias verdaderamente aleatorias es la misma en todas las dimensiones, mientras que la precisión de las secuencias periódicas disminuye cuando t aumenta. Por lo tanto, puesto que solo hay m puntos en un cubo de t dimensiones cuando m es la longitud del período, no se puede alcanzar una precisión t-dimensional mejor que aproximadamente m1/t. Cuando se considera la independencia de t valores consecutivos, los números aleatorios generados por computador se comportarán en esencia como si se tomaran verdaderos números aleatorios y se truncaran a log µt bits, donde µt disminuye al aumentar t. En la práctica, una precisión variable de este tipo es todo lo que se necesita. No se insiste en que la precisión decadimensional sea 235, en el sentido que todos los (235)10 posibles decatuplos (Un, Un + 1, …, Un + 9) deben ser equiprobables en una máquina de 35 bits; para valores tan grandes de t se quiere que solamente unos pocos bits de mayor peso de (Un, Un + 1, …, Un + t - 1) se comporten como si fueran independientemente aleatorios. Por otra parte, cuando una aplicación necesita una elevada resolución de la secuencia de números aleatorios, las secuencias conguenciales lineales sencillas serán inadecuadas; deberán usarse generadores con períodos más largos incluso aunque solo se genere una pequeña parte del período. Elevar al cuadrado el período esencialmente hará lo mismo con la precisión en dimensiones elevadas, es decir doblará el número efectivo de bits de precisión. El test espectral se basa en los valores de µt para valores pequeños de t, por ejemplo 2 ≤ t ≤ 6. Las dimensiones 2, 3 y 4 parecen ser las más adecuadas para detectar las deficiencias importantes de una secuencia, pero puesto que se considera la totalidad del período parece mejor aumentar en uno o dos la dimensión. Por otra parte, los valores de µt para t ≥ 10 parecen no tener significado práctico.

130
Podría parecer inicialmente que sólo se debe aplicar el test espectral para valores de t convenientemente altos; si el generador pasa el test de tres dimensiones, parece plausible que también lo haga en dos dimensiones, por lo que se puede ahorrar esta prueba. La falacia de este razonamiento se produce porqué se aplican condiciones más estrictas para dimensiones menores. Algunos autores han sugerido usar el mínimo número Nt de rectas, planos o hiperplanos que recubren los puntos en vez de la distancia máxima entre ellos. Sin embargo, este número no parece tan importante ni tiene una interpretación tan clara como el concepto de precisión definido anteriormente. Para determinar las sucesivas precisiones para valores crecientes del número de dimensiones se puede aplicar el algoritmo que se expone a continuación, cuya justificación completa puede hallarse en (KNUT81). Algoritmo S. Este algoritmo determina el valor de
( )mxaaxxxx tt
tt mod0....|....min 121
221 =+++++=µ −
para 2 ≤ t ≤ T, dados a, m y T, donde 0 < a < m y a y m son primos entre sí. Toda la aritmética de este algoritmo se efectúa entre enteros cuyos módulos rara vez exceden m2, excepto en el paso S8; de hecho casi todas las variables enteras serán inferiores a m en valor absoluto durante el cálculo. Cuando se calcula µt para t ≥ 3, el algoritmo trabaja con dos matrices U y V de dimensión t × t, cuyos vectores fila se representarán por Ui = (ui1, …, uit) y Vi = (vi1, …, vit) para 1 δ i ≤ t. Estos vectores satisfacen las condiciones
ui1 + a ui2 + … + at - 1uit = 0 mod m , 1 ≤ i ≤ t
Ui . Vj = δijm , 1 ≤ i, j ≤ t
Hay otros tres vectores auxiliares, X = (x1, …, xt), Y = (y1, …, yt) y Z = (z1, …, zt). Durante la totalidad del algoritmo s representará el menor límite superior de µt
2 que se haya descubierto hasta ese momento y r representará at - 1 mod m. S1. [Inicialización] Hacer h = a, h' = m, p = 1, p' = 0, r = a y s = 1 + a2 (Los primeros pasos
de este algoritmo tratan el caso de t = 2 por un método especial parecido al algoritmo de Euclides; se tiene h - ap = h' - ap' = 0 mod m y hp' - h'p = ±m durante esta fase del cálculo).
S2. [Paso euclídeo] Hacer q = parte entera de h'/h, u = h' - qh, v = p' - qp. Si u2 + v2 < s, hacer s = u2 + v2, h' = h, h = u, p' = p y p = v y repetir el paso S2.
S3. [Cálculo de µ2] Hacer u = u - h y v = v - p; y si u2 + v2 < s, hacer s = u2 + v2, h' = u y p' = v. Entonces la salida es s1/2 = µ2 (Ahora se deben preparar las matrices U y V para que satisfagan las condición antes expuestas en preparación de los cálculos de dimensiones superiores). Sea
−−
=
−−
=hp
hpV
phph
U''
, ''
donde el signo - se elige para V si y solo si p' > 0.
S4. [Incremento de t] Si t = T, el algoritmo termina. (En caso contrario se incrementará t en uno. En este momento U y V son matrices t x t que satisfacen las condiciones antes

131
expuestas y deben ampliarse añadiéndoles unas nuevas fila y columna apropiadas). Hacer t = t + 1 y r = (ar) mod m. Hacer Ut = (-r, 0, 0, …, 0, 1) y hacer uit = 0 para 1 ≤ i < t. Hacer Vt = (0, 0, 0, …, m). Finalmente para 1 ≤ i < t, hacer q = redondeo(vi1r/m), vit = vi1 - qm y Ut = Ut + qUt (Aquí redondeo(x) representa el entero más próximo a x, es decir, (parte entera de (x + 1/2))). Finalmente hacer s = min(s, Ut , Ut), k = t y j = 1.
S5. [Transformación] Para 1 ≤ i ≤ t, hacer las siguientes operaciones: Si i ≠ j y 2|Vi.Vj| > Vj ⋅ Vj, hacer q = redondeo((Vi ⋅ Vj)/( Vj ⋅ Vj)), Vi = Vi - q Vj, Uj = Uj + qUi y k = j. (El hecho de omitir esta transformación cuando 2|Vi ⋅ Vj| es exactamente igual a Vj ⋅ Vj evita que el algoritmo entre en un bucle sin fin).
S6. [Examinar la nueva cota] Si k = j (es decir si la transformación del paso S5 ha hecho algo útil), hacer s = min(s, Uj ⋅ Uj).
S7. [Incrementar j] Si j = t, hacer j = 1; en caso contrario hacer j = j + 1. Ahora si j ≠ k, volver al paso S5 (Si j = k, se ha ido a través de t - 1 ciclos consecutivos sin transformación, por lo que el proceso de transformación está clavado).
S8. [Preparación para la búsqueda] Hacer X = (0, 0, …, 0), Y = (0, 0, …, 0), k = t y
( ) ( ) ( )[ ] tjmsVVz jj ≤≤⋅= 1 para /de entera partede entera parte 2
(Se examinarán todas las X = (x1, …, xt) con |xj| ≤ zj para 1 ≤ j ≤ t. En centenares de aplicaciones de este algoritmo, ni ninguna zj ha resultado ser mayor que 1 ni la búsqueda exhaustiva de los pasos siguientes ha reducido s; sin embargo, tales fenómenos son probablemente posibles en casos fantásticos, especialmente en dimensiones más elevadas. Durante la búsqueda exhaustiva, el vector Y será siempre igual a x1U1 + … + xtUt, de tal forma que f(x1, …, xt) = Y ⋅ Y. Puesto que f(-x1, …, -xt) = f(x1, …, xt), se examinarán sólo vectores cuyo primer componente no nulo sea positivo. El método es el de contar en pasos de uno, considerando (x1, …, xt) como los dígitos de un sistema de numeración equilibrado con bases mezcladas (2z1 + 1, …, 2zt + 1)).
S9. [Avanzar xk] Si xk = zk, ir al paso S11. En caso contrario incrementar xk en 1 y hacer Y = Y + Uk.
S10. [Incrementar k] Hacer k = k + 1. Entonces si k ≤ t, hacer xk = -zk, Y = Y - 2zkUk y repetir el paso S10. Pero si k > t, hacer s = min (s, Y ⋅ Y).
S11. [Decrementar k] Hacer k = k - 1. Si k ≥ 1, volver al paso S9. En caso contrario la salida es µt = s1/2 (la búsqueda exhaustiva ha terminado) y volver al paso S4.
En la práctica este algoritmo se aplica para T = 5 ó 6 y funciona razonablemente bien cuando T = 7 ú 8, pero es terriblemente lento cuando T ≥ 9 ya que la búsqueda exhaustiva tiene a hacer crecer el tiempo proporcionalmente a 3T. Un ejemplo ayudará a clarificar el algoritmo S. Se considera el generador congruencial lineal definido por
m = 1010, a = 3141592621, c = 1, X0 = 0
Seis ciclos del algoritmo euclídeo de los pasos S2 y S3 bastan para demostrar que el mínimo valor distinto de cero de x1
2 + x22 con

132
x1 + 3141592621x2 = 0 mod 1010
se produce para x1 = 67654 y x2 = 226; por lo tanto la precisión bidimensional de este generador es
3748.6765422667654 222 ≈+=µ
Pasando a tres dimensiones, se buscará el valor mínimo de x12 + x2
2 + x32 tal que
x1 + 3141592621x2 + 31415926212x3 = 0 mod 1010
El paso S4 establece las matrices
−
−−=
−
−−=
010000000000013071811346765422625649185694190611191
1335793866019144190611022667654
VU
La primera iteración del paso S5, con q = 1 para i = 2 y q = 4 para i = 3, las cambia en
−−−
−−=
−−
=259674276176762444764
512557737434425826535256491856944190611191
133579386601914419061149721082801
VU
Las siguientes catorce iteraciones del paso S5 tienen (j, q1, q2, q3) = (2, -2, *, 0), (3, 0, 3, *), (1, *, -10, -1), (2, -1, *, -6), (3, -1, 0, *), (1, *, 0, 2), (2, 0, *, -1), (3, 3, 4,*), (1, *, 0, 0), (2, -5, *, 0), (3, 1, 0, *), (1, *, -3, -1), (2, 0, *, 0) y (3, 0, 0, *). Ahora el proceso de transformación está clavado pero las filas de las matrices se han convertido en algo significativamente mas corto:
−−−−
−−=
−−−−
−−=
17077369749816854296159368943810928098712994234601246888874
130983227
918104302227776161479
VU
Los límites buscados (z1, z2, z3) en el paso S8 resultan ser (0, 0, 1), por lo que U3 es la solución más corta de la ecuación y, por lo tanto se tiene
21089.1017130983227 2223 ≈++=µ
6.3. GENERACIÓN DE NÚMEROS ALEATORIOS NO UNIFORMES El problema de generar números aleatorios según alguna distribución no uniforme puede resolverse en principio mediante la distribución inversa de probabilidad como se tratará en el apartado 6.3.1. No obstante, esta integral inversa no siempre puede calcularse o su cálculo puede ser difícil o laborioso, por lo que es interesante disponer de métodos que permitan generar directamente valores distribuidos según una ley de probabilidad determinada y ello de forma exacta, rápida, fácil de implantar y económica en memoria del sistema. Los métodos que pueden utilizarse, aparte el de utilizar la ley de distribución inversa, pueden agruparse en cinco grupos, aunque no totalmente disjuntos, que son: - composición
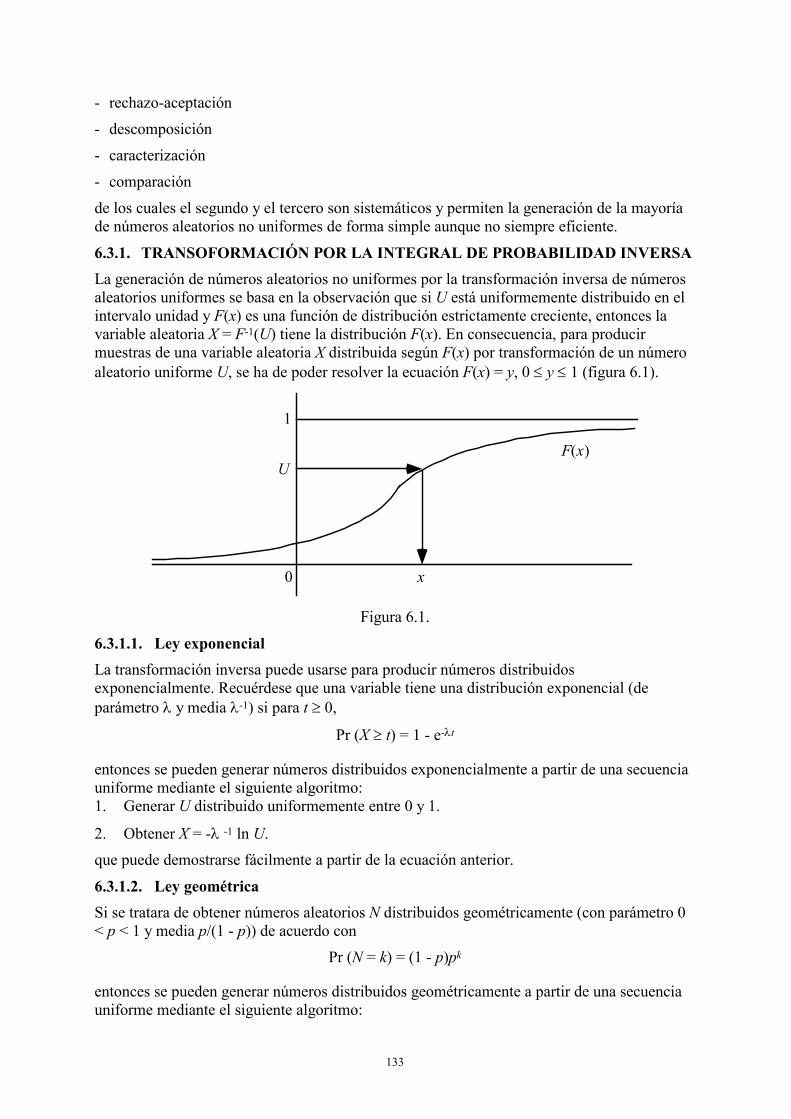
133
- rechazo-aceptación
- descomposición
- caracterización
- comparación
de los cuales el segundo y el tercero son sistemáticos y permiten la generación de la mayoría de números aleatorios no uniformes de forma simple aunque no siempre eficiente.
6.3.1. TRANSOFORMACIÓN POR LA INTEGRAL DE PROBABILIDAD INVERSA La generación de números aleatorios no uniformes por la transformación inversa de números aleatorios uniformes se basa en la observación que si U está uniformemente distribuido en el intervalo unidad y F(x) es una función de distribución estrictamente creciente, entonces la variable aleatoria X = F-1(U) tiene la distribución F(x). En consecuencia, para producir muestras de una variable aleatoria X distribuida según F(x) por transformación de un número aleatorio uniforme U, se ha de poder resolver la ecuación F(x) = y, 0 ≤ y ≤ 1 (figura 6.1).
x
U
0
1
F(x)
Figura 6.1.
6.3.1.1. Ley exponencial La transformación inversa puede usarse para producir números distribuidos exponencialmente. Recuérdese que una variable tiene una distribución exponencial (de parámetro λ y media λ-1) si para t ≥ 0,
Pr (X ≥ t) = 1 - e-λt
entonces se pueden generar números distribuidos exponencialmente a partir de una secuencia uniforme mediante el siguiente algoritmo: 1. Generar U distribuido uniformemente entre 0 y 1.
2. Obtener X = -λ -1 ln U. que puede demostrarse fácilmente a partir de la ecuación anterior.
6.3.1.2. Ley geométrica Si se tratara de obtener números aleatorios N distribuidos geométricamente (con parámetro 0 < p < 1 y media p/(1 - p)) de acuerdo con
Pr (N = k) = (1 - p)pk
entonces se pueden generar números distribuidos geométricamente a partir de una secuencia uniforme mediante el siguiente algoritmo:

134
1. Generar U distribuido uniformemente entre 0 y 1.
2. Obtener
UN ln1−λ−=
que puede demostrarse fácilmente a partir de la ecuación anterior.
6.3.1.3. Ley de Bernouilli Si se tratara de obtener números aleatorios X que pueden tomar los valores 0 y 1 distribuidos según la ley de Bernouilli (con parámetro 0 < p < 1) de acuerdo con
Pr (X = 1) = p y Pr (X = 0) = 1 - p
entonces se pueden generar números distribuidos según una ley de Bernouilli a partir de una secuencia uniforme mediante el siguiente algoritmo: 1. Generar U distribuido uniformemente entre 0 y 1.
2. Obtener X = 1 si U ≤ p y X = 0 si U > p, que puede demostrarse fácilmente a partir de la ecuación anterior. Con este algoritmo el intervalo unidad está partido en subintervalos de longitud p y 1 - p; el subintervalo (en que cae el número aleatorio uniforme) determina el valor de la variable aleatoria de Bernouilli.
6.3.1.4. Ley de Poisson Si se tratara de obtener números aleatorios N distribuidos según una ley de Poisson (con parámetro y media λ > 0) de acuerdo con
Pr (N = k) = e-λ λk/k!
entonces se pueden generar números distribuidos según una ley de Poisson a partir de una secuencia uniforme por el siguiente algoritmo: 1. Generar U distribuido uniformemente entre 0 y 1.
2. Obtener N = 0 si U ≤ e-λ
N = 1 si e-λ< U ≤ e-λ + λ e-λ N = 2 si e-λ+ λ e-λ < U ≤ e-λ + λ e-λ + λ2 e-λ/2
. . . . . . . .
que puede demostrarse fácilmente a partir de la ecuación anterior.
6.3.2. COMPOSICIÓN Las técnicas de composición pueden utilizarse para producir muestras de una variable aleatoria X que tenga una representación como una suma de variables aleatorias independientes con una distribución común, es decir, como X = T1 + T2 + ... + Tn para algún n > 1 donde las Ti son variables aleatorias idénticamente distribuidas.
6.3.2.1. Ley de Erlang
Una variable aleatoria de Erlang X (con parámetro de escala λ > 0 y parámetro de forma integral k > 0) tiene una función de densidad
fX(x) = e-λx λk xk - 1/(k - 1)!

135
concentrada en x ≥ 0. Esta variable aleatoria tiene la representación X = T1 + T2 + ... + Tk, donde las Ti son independientes y están distribuidas exponencialmente con media E[Ti] = λ-1; es decir E[X] = kλ-1 y Var[X] = kλ-2. Entonces se pueden generar números distribuidos según una ley de Erlang a partir de una secuencia uniforme mediante el siguiente algoritmo: 1. Generar U1, U2, ... , Uk mutuamente independientes y distribuidos uniformemente entre 0
y 1.
2. Obtener X = -λ-1 ln(U1U2...Uk), expresión que resulta de la manipulación algebraica de X = T1 + T2 + ... + Tk donde Ti = -λ-1 ln Ui.
6.3.2.2. Ley gamma Se puede usar también la composición para producir muestras de una distribución gamma. Una variable aleatoria gamma (con parámetro de escala λ > 0 y parámetro de forma k > 0) tiene una función de densidad como la que aparece en la ecuación del párrafo anterior con el factorial (k - 1)! sustituido por la función gamma definida para k > 0 por
( ) ∫∞
∞−
−−= dtetkG tk 1
La función gamma interpola los factoriales en el sentido que
( ) ( ) ( ) 0 todapara ,1y ... 2, 1, ,0 para ,!1 >=+Γ==+Γ kkkGkkkk
Como antes E[X] = kλ-1 y Var[X] = kλ-2. La suma de dos variables aleatorias gamma, cada una con parámetro de escala m parámetros de forma k1 y k2, respectivamente, es una variable aleatoria gamma con parámetro de escala m y parámetro de forma k = k1 + k2. Es conveniente generar muestras de distribuciones gamma con parámetro de forma k como la suma de un número aleatorio gamma distribuido con parámetro de forma k1 igual a la parte entera de k y un número aleatorio gamma distribuido con parámetro de forma k2 = k - k1. La generación de este último es bastante difícil y se realiza mediante un programa especial cuidadosamente escrito que puede consultarse en obras especializadas. También puede usarse una técnica de rechazo-aceptación (ver apartado 6.3.3.3.) basada en la observación que la función
( ) ( ) 10 si /1 ≤≤Γ= − xkxxg k
( ) ( ) xkexg x <Γ= − 1 si /
es mayorante de la función de densidad gamma
( ) ( )kxexf kx Γ= −− /1
6.3.2.3. Ley binomial Para ilustrar el uso de la composición para una variable aleatoria discreta se considera la distribución binomial. Para un entero positivo n y 0 < p < 1, la variable aleatoria X tiene una distribución binomial (con media np) si para k = 0, 1, ..., n,
( ) ( ) knk ppkn
kX −−
== 1Pr

136
Pueden obtenerse números aleatorios binomiales observando que X tiene la representación X = λ1 + λ2 + ... + λn, donde las λi son variables aleatorias independientes de Bernouilli, es decir Pr (λi= 1) = p y Pr (λi = 0) = 1 - p para i = 1, 2, ..., n. Ello permite establecer el siguiente algoritmo: Algoritmo G G1. Generar U1, U2, ..., Un mutuamente independientes y uniformemente distribuidos entre
0 y 1.
G2. Para i = 1, 2, ..., n , hacer λi = 1 si Ui ≤ p e Yi = 0 si Ui > p. G3. Obtener X = λ1 + λ2 + ... + λn.
Esta técnica para producir números binomiales es costosa en tiempo de cálculo cuando n es grande y es mejor considerar otros métodos.
6.3.3. RECHAZO-ACEPTACIÓN Al igual que los métodos de descomposición que se describirán en el apartado 6.3.5., los de rechazo-aceptación son una forma sistemática de generar números aleatorios no uniformes. Las técnicas de rechazo-aceptación se usan a menudo en conjunción con técnicas de descomposición y son aplicables tanto a variables aleatorias discretas como continuas. Sea X una variable aleatoria que tenga una función de densidad fX(x) que está acotada y concentrada en un intervalo finito (que se considerará como el intervalo unidad). Es decir para algún α < ∞,
fX(x) ≤ α si 0 ≤ x ≤ 1
y
fX(x) = 0 en caso contrario
Ello permite establecer el siguiente algoritmo: 1. Generar U1 y U2 independientes y uniformemente distribuidos entre 0 y 1.
2. Calcular α-1 fX(U1). Si U2 ≤ α-1 fX(U1), obtener X = U1. En caso contrario rechazar el par U1, U2 y repetir el paso 1.
Se observa que no todos los pares U1, U2 de los números aleatorios uniformes producen una muestra de la variable aleatoria X (figura 6.2). Es fácil demostrar que el algoritmo anterior produce una muestra a partir de la función de densidad fX(x).
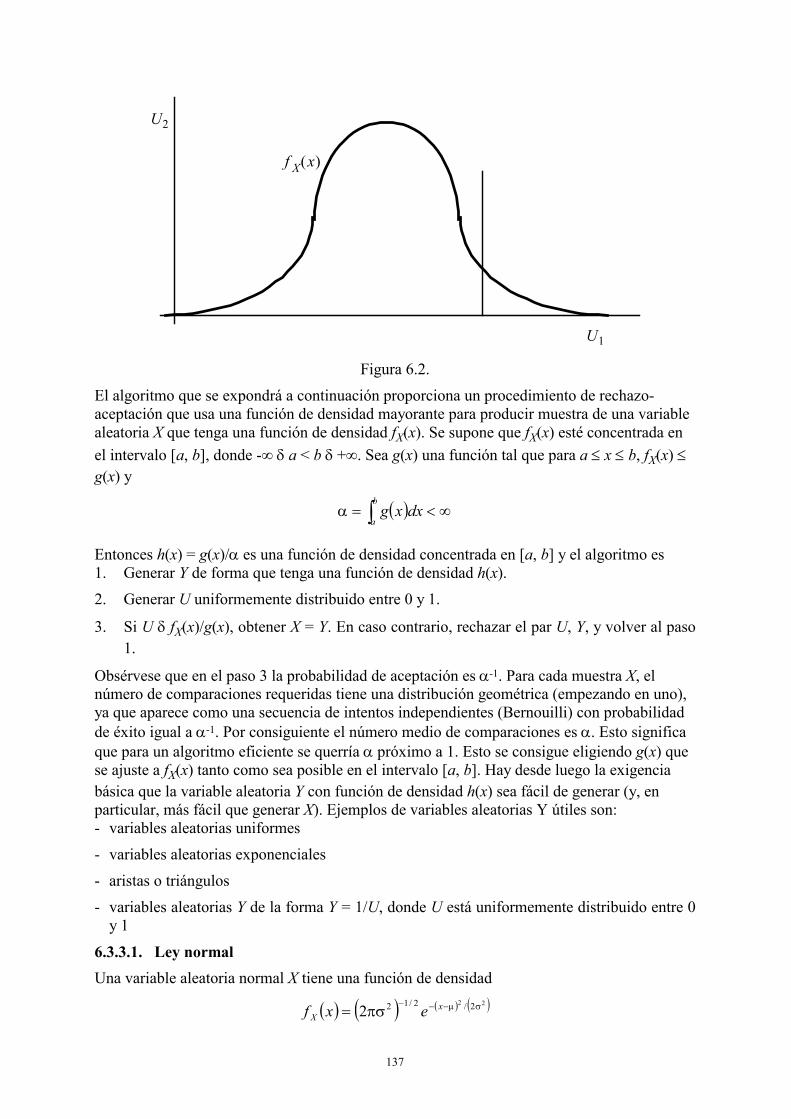
137
U1
U2
f X(x)
Figura 6.2.
El algoritmo que se expondrá a continuación proporciona un procedimiento de rechazo-aceptación que usa una función de densidad mayorante para producir muestra de una variable aleatoria X que tenga una función de densidad fX(x). Se supone que fX(x) esté concentrada en el intervalo [a, b], donde -∞ δ a < b δ +∞. Sea g(x) una función tal que para a ≤ x ≤ b, fX(x) ≤ g(x) y
( ) ∞<=α ∫b
adxxg
Entonces h(x) = g(x)/α es una función de densidad concentrada en [a, b] y el algoritmo es 1. Generar Y de forma que tenga una función de densidad h(x).
2. Generar U uniformemente distribuido entre 0 y 1.
3. Si U δ fX(x)/g(x), obtener X = Y. En caso contrario, rechazar el par U, Y, y volver al paso 1.
Obsérvese que en el paso 3 la probabilidad de aceptación es α-1. Para cada muestra X, el número de comparaciones requeridas tiene una distribución geométrica (empezando en uno), ya que aparece como una secuencia de intentos independientes (Bernouilli) con probabilidad de éxito igual a α-1. Por consiguiente el número medio de comparaciones es α. Esto significa que para un algoritmo eficiente se querría α próximo a 1. Esto se consigue eligiendo g(x) que se ajuste a fX(x) tanto como sea posible en el intervalo [a, b]. Hay desde luego la exigencia básica que la variable aleatoria Y con función de densidad h(x) sea fácil de generar (y, en particular, más fácil que generar X). Ejemplos de variables aleatorias Y útiles son: - variables aleatorias uniformes
- variables aleatorias exponenciales
- aristas o triángulos
- variables aleatorias Y de la forma Y = 1/U, donde U está uniformemente distribuido entre 0 y 1
6.3.3.1. Ley normal Una variable aleatoria normal X tiene una función de densidad
( ) ( ) ( ) ( )22 2/2/122 σµ−−−πσ= x
X exf

138
para -∞ < x < +∞. El algoritmo que se expone a continuación proporciona números aleatorios X normales normalizados (media cero y desviación tipo uno) y usa una técnica de rechazo-aceptación para producir el valor absoluto de un número aleatorio normal; un verdadero número aleatorio normal se obtiene entonces añadiéndole un signo al azar (es decir, + con probabilidad 0.5 y - con la misma probabilidad). 1. Generar U1 y U2 independientes y uniformemente distribuidos entre 0 y 1.
2. Hacer X = -ln U1.
3. Si ( ) 2/12
2−−≤ xeU aceptar X. En caso contrario rechazar el par U1, U2 y repetir el paso 1.
4. Generar un signo al azar (+ ó -), añadirlo a X y entregarlo como resultado.
Esta técnica para generar números aleatorios normales tiene esencialmente una precisión perfecta.
6.3.4. CARACTERIZACIÓN Dada una fuente de números aleatorios uniformes, a veces es posible generar números aleatorios no uniformes aprovechando propiedades características de determinadas distribuciones.
6.3.4.1. Ley de Poisson Se considera la distribución de Poisson y una técnica basada en la propiedad del proceso que los intervalos entre llegadas están distribuidos exponencialmente. Es decir que si los instantes entre acontecimientos sucesivos son X1, X2, ..., para t ≥ 0 y n = 0, 1, 2, ..., se puede escribir que N(t) = n si y solo si X1 + ... + Xn ≤ t y X1 + ... + Xn + 1 > t Esta expresión para t = 1 sugiere un procedimiento para obtener muestras de una variable aleatoria poissoniana con parámetro λ. A partir de números aleatorios mutuamente independientes y uniformemente distribuidos (entre 0 y 1) U1, U2, ..., se pueden obtener números aleatorios exponenciales (de parámetro Y) X1, X2, ..., mediante una transformación logarítmica; cuando se toma N = k, donde k esta definido por la condición conjunta X1 + ... + Xn ≤ 1 y X1 + ... + Xn + 1 > 1. De acuerdo con este esquema se puede hacer:
N = 0 si X1 > 1,
N = 1 si X1 ≤ 1 y X1 + X2 > 1,
N = 2 si X1 + X2 ≤ 1 y X1 + X2 + X3 > 1,
......
Obsérvese que con este esquema puede ser necesario generar más de un número aleatorio uniforme para producir un muestra única de la variable aleatoria poissoniana N. Hay además una observación de cálculo que hacer. El acontecimiento N = k se produce si y solo si X1 + ... + Xk ≤ 1 y X1 + ... + Xk + 1 > 1 y esto último sucede si y solo si U1U2 ... Uk > e-λ y U1U2 ... Uk
+1 ≤ e-λ. Es decir
N = 0 si U1 ≤ e-λ,
N = 1 si U1 > e-λ y U1U2 ≤ e-λ,
N = 2 si U1U2 > e-λ y U1U2U3 ≤ e-λ,
......

139
y calculando una sola vez se evita la necesidad de tomar logaritmos y dividir por λ cada vez que se genera un número aleatorio uniforme U; sin embargo es necesario multiplicar en vez de sumar los números aleatorios uniformes. Este método de generar números aleatorios poissonianos es, por lo general, ligeramente más rápido que el de la transformación inversa, pero requiere más números aleatorios.
6.3.4.2. Ley normal Se considera como otro ejemplo el llamado "método polar" para producir números aleatorios normales. El método polar usa una técnica de rechazo-aceptación basada en el resultado que si dos variables aleatorias normales (media 0, desviación tipo 1) e independientes X1 y X2 se transforman a coordenadas polares R y φ de acuerdo con
R2 = X12 + X2
2 y φ = arctan (X2/X1)
entonces R2 está exponencialmente distribuido (media 2) y φ está uniformemente distribuido (entre 0 y 2π) e independiente de R. Entonces para producir un par de números aleatorios normales estandarizados e independientes, X1 y X2, se puede utilizar el siguiente algoritmo: 1. Generar U1 y U2 independientes y distribuidos uniformemente entre 0 y 1.
2. Hacer V1 = 2U1 - 1 y V2 = 2U2 - 1.
3. Hacer S = V12 + V2
2. Si S ≥ 1, rechazar el par U1, U2 y repetir a partir del paso 1. En caso contrario dar como resultado
X1 = V1[(-2 ln S)/S]1/2 y X2 = V2[(-2 ln S)/S]1/2
Obsérvese que el método polar es exacto, mientras que el procedimiento basado en la obtención numérica de la inversa de la integral de probabilidad normal, no lo es normalmente.
6.3.4.3. Ley beta Las técnicas de caracterización pueden aplicarse también para obtener muestras de la distribución beta. Una variable aleatoria beta X toma valores en el intervalo unidad y tiene una densidad de probabilidad de la forma
fX(x) = xa - 1(1 - x)b - 1/B(a, b) si 0 ≤ x ≤ 1
fX(x) = 0 , en caso contrario
donde a, b > 0. La ecuación B(a, b) es la función beta
( ) ( ) ( ) ( )( )ba
badxxxbaB ba
+ΓΓΓ
=−= ∫ −−1
0
11 1,
La variable aleatoria definida por las ecuaciones anteriores tiene una media igual a a/(a + b) y
una desviación tipo ( )[ ]ba
baab+
−+ 2/11/ . Obsérvese que cuando a = b = 1, la distribución beta
se reduce a la distribución uniforme en el intervalo unidad. La función de densidad beta es una familia de dos parámetros en el intervalo unidad que puede adoptar una gran variedad de formas y es una de las más frecuentemente utilizadas para ajustar datos. El muestreo de la distribución beta se reduce al muestreo de dos distribuciones gamma a causa de que la variable Z1/(Z1 + Z2) tiene una distribución beta con parámetros a y b cuando Z1 y Z2 son variables aleatorias independientes con distribución gamma con parámetro de

140
escala 1 y parámetros de forma a y b, respectivamente. Ello puede implantarse en el siguiente algoritmo: 1. Generar Z1 de forma que siga una distribución gamma con parámetro de escala 1 y
parámetro de forma a.
2. Generar Z2 de forma que siga una distribución gamma con parámetro de escala 1 y parámetro de forma b.
3. Dar como resultado X = Z1/(Z1 + Z2).
También es posible obtener una muestra de variable aleatoria beta usando una técnica de rechazo-aceptación basada en la siguiente caracterización. Se definen Z1 y Z2 de acuerdo con Z1 = U1
1/a y Z2 = U21/b, donde U1 y U2 son variables aleatorias independientes y distribuidas
uniformemente en el intervalo unidad. Entonces puesto que Z1 + Z2 ≤ 1, la variable aleatoria X = Z1/(Z1 + Z2) tiene una distribución beta con parámetros a y b. Todo ello puede implantarse ne le siguiente algoritmo: 1. Generar U1 y U2 independientes y distribuidas uniformemente entre 0 y 1.
2. Hacer Z1 = U11/a y Z2 = U2
1/b
3. Si Z1 + Z2 ≤ 1, dar como resultado X = Z1/(Z1 + Z2); en caso contrario volver al paso 1.
6.3.5. DESCOMPOSICIÓN Se considera ahora una forma sistemática y muy potente de generar números aleatorios no uniformes que es aplicable tanto a distribuciones discretas como continuas. Las técnicas de descomposición (mezcla) se basan en la visualización de muestras de la variable aleatoria especificada X como viniendo de varias poblaciones. La idea esencial es representar la distribución de X como una mezcla lineal convexa de distribuciones de tal forma que la mayor parte de las veces X se realice como una variable simple que sea fácil de generar. Los procedimientos específicos de descomposición son normalmente complejos y a menudo incorporan técnicas de rechazo-aceptación. Sea X una variable aleatoria que tiene una función de densidad fX(x) que puede representarse por
fX(x) = p1f1(x) + ... + pkfk(x)
donde las pi son no negativas y su suma es la unidad y las fi(x) son funciones de densidad de probabilidad. Se define también una variable aleatoria discreta Z de acuerdo con
Pr[Z = j] = pj
para j = 1, 2, ..., k. El algoritmo general adoptaría la forma: 1. Generar Z de forma que siga la distribución discreta definida por la ecuación anterior.
2. Generar y devolver Z de forma que tenga la densidad fZ(x).
Este algoritmo se aplica directamente a las distribuciones mezcla. Por ejemplo la distribución hiperexponencial definida para t ≥ 0 por
[ ] ( ) ( )( )tt epeptX 21 111Pr λ−λ− −−+−=≤
donde 0 < p < 1, λ1, λ2 > 0 y λ1 ≠ λ2.

141
Los métodos actualmente más rápidos para generar números aleatorios normales y exponenciales usan la descomposición. El enfoque es dividir la función de densidad (de la ley normal o exponencial) en una cola y un gran número de rectángulos y cuñas. Para una discusión detallada ver (KNUT81). Hay muchas formas de descomponer una función de densidad especificada. Para seleccionar la descomposición hay que guiarse por consideraciones geométricas. Las funciones de densidad triangulares, es decir correspondientes a U1 + U2, donde U1 y U2 son variables aleatorias uniformes independientes e idénticamente distribuidas se usan frecuentemente en las técnicas de descomposición. También son útiles las cuñas, correspondientes a max(U1, U2), es decir, que tengan por densidad de probabilidad
f(x) = 2x si 0 ≤ x ≤ 1 f(x) = 0 en caso contrario
y min(U1, U2), es decir,
f(x) = 2(1 - x) si 0 ≤ x ≤ 1 f(x) = 0 en caso contrario
6.3.5.1. Ley de Cauchy Aunque la distribución de Cauchy no es de las más frecuentemente utilizadas sirve para ilustrar la descomposición. La variable de Cauchy X tiene la función de densidad
fX(x) = π-1(1 + x2)-1
para -∞ < x < +∞. Lo que se hará, será producir una muestra del valor absoluto de X y luego asignarles el signo. La descomposición de f|X|(x) (figura 6.3) se hará en tres áreas mediante una recta vertical x = a y una horizontal f|X|(x) = f|X|(a). Se denomina región 1 al área entre las rectas horizontal y vertical, región 2 al área por encima de la recta horizontal, y región 3 al área a la derecha de la recta vertical. Se elige a = 1 de tal forma que la región 1 sea lo mayor posible (por lo tanto, muestreada a partir de la distribución uniforme tan a menudo como sea posible). Las áreas de las regiones 1, 2 y 3 son iguales, respectivamente, a p1, p2 y p3 y f1(x), f2(x) y f3(x) son las correspondientes funciones de densidad uniforme, en forma de cuña y en forma de cola larga. Específicamente, para 0 ≤ x < ∞, se representa f|X|(x) por
f|X|(x) = p1f1(x) + p2f2(x) + p3f3(x)
donde
f1(x) = 1 si 0 ≤ x ≤ 1
f1(x) = 0 si x > 1
f2(x) = [(2/π)(1 + x2)-1 - (1/π)]/[(1/2) - (1/π)] si 0 ≤ x ≤ 1
f2(x) = 0 si x > 1
f3(x) = (4/π)(1 + x2)-1 si 0 ≤ x ≤ 1
f3(x) = 0 si x > 1

142
con p1 = 1/π, p2 = (1/2) - (1/π) y p3 = 1/2. Las muestras de la función f1(x) pueden obtenerse directamente y las muestras de la función de densidad de cola f3(x) pueden obtenerse mediante una técnica de rechazo-aceptación eligiendo como función mayorante h(x) = 1/x2 y recordando que esta es la función del recíproco de una variable aleatoria uniformemente distribuida en el intervalo unidad. La función restante en forma de cuña f2(x) se denomina función de densidad "quasi-lineal" para la cual hay una eficiente técnica de rechazo-aceptación. Para más detalles consultar (KNUT81).
6.3.6. COMPARACIÓN Las técnicas que implican generalizaciones del esquema de Von Neumann para producir números aleatorios exponenciales se han desarrollado para ciertos tipos de números aleatorios. La técnica de Von Neumann se basa en comparaciones entre números aleatorios uniformes. En particular, estas técnicas de comparación conducen a un sencillo algoritmo para producir muestras a partir de funciones de densidad de la forma ae-G(x). El procedimiento básico de comparación produce muestras de una variable aleatoria X que tenga una función de densidad de la forma:
( ) ( ) ( )xGb
a
yGX edyexf −
−−
= ∫
1
concentrada en un intervalo fijo [a, b], donde 0 ≤ G(x) ≤ 1. Para cumplir esto, se genera una secuencia de números aleatorios mutuamente independientes T, U1, U2, ..., estando Ui distribuidos uniformemente entre 0 y 1; la función F(t) de distribución de T, se supone que es invertible en el intervalo [a, b] y de tal forma que G(⋅) = F-1(⋅). Con probabilidad 1, ó T < U1 ó hay un entero finito K tal que T ≥ U1 ≥... ≥ UK - 1 < UK. Las secuencias de números T, U1, U2, ..., UK se generan hasta que se encuentra un subíndice de parada impar. Con todo ello se puede construir el siguiente algoritmo: 1. Generar U uniformemente distribuido entre 0 y 1. Hacer X = a + (b - a)U y T = G(X).
2. Generar T, U1, U2, ..., UK, mutuamente independientes y uniformemente distribuidos entre 0 y 1, con K determinado por T ≥ U1 ≥... ≥ UK - 1 < UK (K = 1 si T < U1).
3. Si K es par, rechazar X y repetir 1.
4. Si K es impar, dar X como resultado.
6.4. ORGANIZACIÓN DE LOS SIMULADORES Para estudiar la organización de un simulador, se puede plantear el problema de la simulación de una sencilla cola con un servidor con el siguiente mecanismo: - los clientes que llegan entran en la cola
- espera para recibir el servicio
- servicio
- salida del modelo
Este modelo describe y sincroniza la llegada y el servicio de los clientes. A continuación se verá como se han de tratar los acontecimientos a lo largo del tiempo y que información se ha de guardar del funcionamiento del sistema para que sea fácil representarlo.

143
6.4.1. CONTROL DEL TIEMPO EN UN SIMULADOR Para establecer la temporización y la sincronización de los acontecimientos que se están simulando pueden usarse dos métodos: - temporización síncrona o avance por unidades de tiempo
- temporización asíncrona o avance por acontecimientos
6.4.1.1. Temporización síncrona o avance por unidades de tiempo Con temporización síncrona, el tiempo del modelo de simulación avanza por unidades de tiempo ∆t elegidas de forma apropiada. El estado del sistema se determina entonces determinando que acontecimientos ocurrieron durante la unidad de tiempo transcurrida y estos dos pasos (avance y actualización) se repiten tantas veces como unidades de tiempo se desee simular. ∆t debe elegirse suficientemente pequeño para que durante ese período solo pueda producirse un acontecimiento: o la llegada de un cliente al sistema o su salida. La aparición de estos acontecimientos viene regida por sus leyes de probabilidad, que según sean con o sin memoria exigirán guardar una distinta cantidad de información.
6.4.1.2. Temporización asíncrona o avance por acontecimientos Este tipo de sincronización difiere de la anterior en que el reloj del simulador avanza cada vez de una cantidad variable en lugar de fija. Conceptualmente, el procedimiento de temporización consiste en mantener el sistema funcionando hasta que se produce un acontecimiento, momento en que el simulador establece una pausa momentánea para registrar el cambio en el estado del sistema. Para implantar este concepto, el simulador realmente procede a mantener una lista de acontecimientos o calendario. En el caso del sistema considerado, la lista de acontecimientos consta solamente de dos acontecimientos futuros, es decir, cuando se producirá la siguiente llegada y cuando terminará el servicio del cliente en la estación, si lo hay. Cada vez que se produce la llegada de un cliente o la terminación de un servicio, el simulador determina en primer lugar cuanto tiempo ha de transcurrir hasta el siguiente acontecimiento del mismo tipo y lo suma al valor actual del tiempo del reloj simulado. Esta suma se almacena entonces en la lista de acontecimientos. Para determinar cual será el siguiente acontecimiento el simulador debe buscar el mínimo de los tiempos planificados en el calendario. El método de temporización síncrona puede tener ventajas sobre el de temporización asíncrona si el sistema estudiado contiene actividades altamente periódicas o síncronas, como por ejemplo la simulación del funcionamiento del hardware de un computador a un nivel muy detallado en que el ciclo de la maquina debe elegirse como unidad de tiempo ∆t. No obstante en la mayoría de las situaciones el enfoque de temporización asíncrona es más eficiente en la ejecución de los programas e incluso más fácil de programar en lenguaje de programación convencional. La mayoría de los lenguajes de programación de modelos de simulación adoptan este método.
6.4.2. ESTRUCTURAS DE DATOS EN UN SIMULADOR En un programa de simulación, los cambios del sistema se producen cuando tiene lugar un acontecimiento. El estado del sistema está representado por una colección de objetos relacionados entre sí, tales como los clientes de la cola de espera de un servidor. La relaciones entre los objetos se describen normalmente mediante estructuras de datos tales como listas, colas, pilas, tablas, etc. Un ejemplo típico de tal relación lo constituye la lista de acontecimientos o calendario, cuya complejidad irá incrementándose a medida que aumenten los servidores, los clientes y sus clases.

144
6.5. ANÁLISIS ESTADÍSTICO DE LA SIMULACIÓN Y DE SUS RESULTADOS
6.5.1. CONDICIONES INICIALES, TRANSITORIOS Y EQUILIBRIO En muchos casos, el objetivo de un estudio de simulación es investigar el comportamiento de un sistema simulado en sus condiciones de funcionamiento en régimen estacionario o permanente. Entonces se debe prestar especial atención a las condiciones iniciales y a los períodos transitorios, puesto que el comportamiento del modelo de simulación no será el típico del sistema simulado hasta que el sistema alcance las condiciones del régimen permanente. Por consiguiente, deberá prescindirse de los datos observados durante este período transitorio. En consecuencia, si es posible, se debe iniciar la simulación en un estado que sea representativo de las condiciones de régimen permanente a fin de minimizar la duración de los transitorios no deseados. Determinar si el sistema ha alcanzado sus condiciones de régimen permanente no es muchas veces una cuestión sencilla, ya que este régimen permanente está definido mediante una distribución de probabilidad del estado del sistema y no por un valor determinado de ese estado. Esto es, la noción del transitorio de un sistema estocástico es distinta de la de un sistema determinista (como un circuito eléctrico, por ejemplo), donde el comportamiento transitorio está completamente caracterizado por su respuesta impulsional. Debe reconocerse que el equilibrio es una condición límite que se puede aproximar pero que nunca se alcanza exactamente. No hay un punto determinado de la simulación en que se pueda considerar que a partir de él el sistema está en equilibrio, pero se puede escoger algún punto razonable a partir del cual se esté en condiciones de despreciar el error que se hace al considerar que el sistema está en equilibrio. Desde ahora se hablará de período transitorio en este sentido. El período transitorio es, en general, dependiente de las condiciones iniciales. Por ejemplo, en el caso de una cola, a menudo se inicia la simulación con la cola vacía. Esto es probablemente no demasiado malo en una cola con un solo servidor en que esta condición es equivalente sencillamente a iniciar la simulación al principio de un período de ocupación del servidor. En sistemas más complejos, estas condiciones iniciales representan estados demasiado atípicos del sistema. Iniciar la simulación en estados más típicos acelera la llegada al régimen permanente, pero todavía se ha de estimar el período transitorio y excluir los datos recogidos es este período para no sesgar los resultados con conclusiones preconcebidas. Idealmente se deben seleccionar probabilisticamente las condiciones iniciales, de acuerdo con la distribución en régimen permanente. Pero si se tuviera tal información, no sería necesario realizar la simulación. Por consiguiente, en la práctica la búsqueda de buenas condiciones iniciales debe basarse en algún conocimiento previo del sistema o en los resultados de simulaciones piloto o en estudios previos con modelos susceptibles de tratamiento analítico. La elección de condiciones iniciales razonables puede disminuir el período transitorio pero no puede eliminarlo completamente. Para estimar la duración del transitorio, hay hacer un cierto número de ejecuciones piloto a partir del mismo punto de partida y comparar la distribución observada del estado del sistema en épocas distintas de la simulación. No es preciso decir que para efectuar estas distintas ejecuciones piloto es preciso elegir distintas semillas (seed, valor inicial X0) del generador de números aleatorios para cada una de las ejecuciones.
6.5.2. ELECCIÓN DE LOS TAMAÑOS DE MUESTRA La elección del tamaño de la muestra está claramente entre los factores más importantes de un experimento de simulación. Desafortunadamente, a menudo el analista selecciona el tamaño de la muestra algo arbitrariamente y luego espera que las estimaciones obtenidas sean

145
suficientemente precisas. Tal procedimiento es claramente inapropiado. El procedimiento correcto es efectuar un análisis estadístico para determinar el número de muestras requerido para obtener una precisión determinada.
6.5.2.1. Muestras independientes Se supone que se quiere estimar µ, la media de Y, que es la medida del comportamiento del sistema que se ha elegido. Se supone que las observaciones de esta medida, Y1, Y2, ..., Yn son estadísticamente independientes y están distribuidas normalmente con una media desconocida µ. El intervalo de confianza de la media de las muestras
n
YY
n
ii∑
== 1
puede obtenerse a partir de la variable
( )yy
nYn
YZσµ−
=σ
µ−=
/
que sigue una distribución t de Student con n - 1 grados de libertad y donde la variancia de la muestra viene definida por
( )n
YYn
ii
y
∑=
−=σ 1
2
2
Por consiguiente
( )α−=
≤
σµ−
≤− −α−α 1Pr 1,2/1,2/ ny
n tnYt
Invirtiendo las desigualdades se puede obtener el intervalo de confianza de la estimación µ
α−=
σ+≤µ≤
σ− −α−α 1Pr 1,2/1,2/
n
tY
n
tY ynyn
que queda acotada entre dos variables aleatorias. Se ve pues que, para reducir el intervalo de confianza, el tamaño n de la muestra debe ser suficientemente grande. Además cuando n aumenta (a partir de 30, por ejemplo) la distribución t de Student tiende a una distribución normal con lo que en la expresión anterior hay que reemplazar tα/2; n - 1 por zα/2 ( el parámetro de la ley normal centrada y reducida), con lo que se obtiene
α−=
σ+≤µ≤
σ− αα 1Pr 2/2/
n
zY
n
zY yy
Es decir para un intervalo de nivel de confianza fijado 1 - α, el tamaño requerido de la muestra puede estimarse aproximando la desviación tipo por la sY obtenida de las ejecuciones piloto o de observaciones anteriores.

146
En muchas simulaciones, sin embargo, la hipótesis de normalidad no puede aplicarse a los datos observados. Si las Yi no están distribuidas normalmente, se les puede aplicar alguna transformación g(y), de tal forma que los datos resultantes g(Yi) si lo estén. Transformaciones tales como g(y) = log y o g(y) = y1/2 pueden reducir el efecto de la larga cola de la distribución que a menudo se encuentra en la simulación de un sistema. En muchas situaciones, sin embargo, no es necesario realizar tal transformación. En virtud del teorema límite central, la distribución de media de las muestras tiende a una distribución normal siempre que n sea suficientemente grande, independientemente de la distribución de las Yi, y siempre que la media y la variancia sean finitas. Entonces las fórmulas obtenidas del intervalo de confianza siguen siendo válidas.
6.5.2.2. Muestras correladas Si los datos de salida de una simulación están correlados, las fórmulas anteriores del intervalo de confianza no pueden usarse y se debe introducir algún modelo que reconozca explícitamente la existencia de correlación entre las observaciones. Sea Yi la i-ésima observación recogida en un experimento y si se supone que la secuencia de observaciones Yi define un proceso aleatorio estacionario covariante; esto es, el proceso Yi tiene una media invariante del índice
µ = E[Yi]
y una función de autocovariancia
Rj = E[(Yi - µ) (Yi + j - µ)] < ∞
que solo es función de la diferencia de índices j. Se supone que se tienen n observaciones de la secuencia Yi. La existencia de correlación no afecta a la estimación de la media de la población, µ, cuya mejor estimación es la media de la muestras
n
YY
n
ii∑
== 1
Puede demostrarse que la variancia de la estimación es
[ ]n
nj
n
Rnj
Y
n
jj
n
njj
ρ
−+σ
=
−
=∑∑
+
=
+
+−=
1
1
21
11211
Var
donde σ2 = R0 es la variancia (desconocida) de las Yi, y
0RR j
j =ρ
Haciendo que n tienda a infinito en la expresión de la variancia, se tiene
[ ]( ) cRYnj
jn2Var lim σ== ∑
∞
−∞=∞→
donde

147
∑∑∞
=
∞
−∞=
ρ+=ρ=1
21j
jj
jc
resume el efecto de la correlación sobre la variancia de la media de las muestras; si Yi es una secuencia no correlada, c en la expresión anterior vale 1. En muchos casos se encontrará que su valor es superior a la unidad (por ejemplo cuando la secuencia Yi es el tiempo de espera del i-ésimo cliente). Aunque es posible en teoría, pocas veces se encontrará que c sea inferior a la unidad. Es importante observar que existe una relación entre la variable c de la expresión anterior y el espectro de la secuencia estocástica Yi
( ) ( )( )∫
π
π−λλ
π
=σ
π=
dP
PPc
21
0022
donde
( ) ( )
λ+
π=
π=λ ∑∑
∞
=
∞
−∞=
λ−
10 cos2
21
21
kk
k
ikk kRReRP
es el espectro de la secuencia donde -π ≤ λ ≤ π e 1−=i . Por lo tanto es la transformada de Fourier de la función de autocovariancia y su relación inversa viene dada por
( ) ( ) ( )∫∫π
π−
π
π−
λ− λλλ=λλ= dkPdePR ikk cos
y haciendo k = 0, se obtiene
( )∫π
π−λλ=σ dP2
Volviendo a la expresión de la variancia cuando n es suficientemente grande, se puede escribir
[ ]cnn
cY/
Var22 σ
=σ
=
Es decir, se puede interpretar que n/c representa el tamaño efectivo de muestras independientes cuando el tamaño de las muestras correladas es n. En base al teorema del límite central, se puede demostrar que la media de la muestra está asintóticamente distribuida normalmente
α−=
≤
σ
µ−≤− αα 1
/Pr 2/22/ z
ncYz
Es decir, el intervalo de confianza de µ viene dado por
nczY σ± α 2/

148
Hay que tener presente que, en general, no se conoce el resultado de las expresiones del límite de la variancia ni de c.
6.5.3. MÉTODOS PARA MUESTRAS INDEPENDIENTES Suponiendo que se alcanza el estado estacionario, se puede tratar de obtener resultados del régimen permanente mediante dos distintos enfoques: - de diseño de simulación de forma que se obtengan observaciones estadísticamente
independientes que permitan aplicar los métodos de la estadística clásica al análisis de los resultados obtenidos por la simulación.
- de análisis espectral de los datos correlacionados, utilizando los métodos de análisis de series temporales, estimando directamente los efectos de la correlación.
Dentro de la primera clase hay tres procedimientos clásicos para obtener observaciones estadísticamente independientes (FISH73): - Método de las repeticiones
- Método de las medias de los lotes
- Método regenerativo
6.5.3.1. Método de las repeticiones En este método de las repeticiones se llevan a cabo m ejecuciones independientes del modelo de simulación con n observaciones en cada una. La independencia se consigue utilizando distintas sucesiones de números aleatorios en cada ejecución con el mismo estado inicial. Es decir, se puede considerar que se ha obtenido un conjunto de observaciones Yi
(j) para 1 ≤ i ≤ n y 1 ≤ j ≤ m; es decir, se tienen en total N = mn observaciones. La media de las muestras de la j-ésima repetición será
njn
YY
n
i
ji
j ..., 2, ,1 para 1
)(
)( ==∑
=
La mejor estimación de la media de la población µ será entonces
n
Y
m
YY
m
j
n
i
ij
m
jj ∑∑∑
= == == 1 1
)(
1
y la variancia de la muestra
( )∑=
−−
=σm
j
jy YY
m 1
2)(2
11
Cuando n es suficientemente grande, las medias de cada repetición están aproximadamente
distribuidas normalmente. Entonces la distribución de la variable m
Yy /2σ
µ− puede
aproximarse por una distribución t de Student con m - 1 grados de libertad. Por lo tanto, el intervalo de confianza de µ viene dado por
m
tY ym
21,2/ σ
± −α

149
Además, si m es grande, se puede reemplazar la ley de Student por la normal, con lo que el intervalo de confianza pasará a ser
m
zY y
22/ σ
± α
Comparando las expresiones del intervalo de confianza, se ve que el método de las repeticiones dice que 22
ync σ≈σ . Si el intervalo de confianza no es tan estrecho como se desea, entonces se debe ejecutar la simulación durante un período más largo. Se supone que el intervalo de confianza se quiere que sea ±δ alrededor de la media. Entonces el tamaño de la muestra se estima a partir de las fórmulas anteriores como
nz
cz
N y
2
2/22
2/ˆ
δ
σ≈σ
δ≈ αα
Es decir, el tamaño de muestra requerido para cada una de las m repeticiones viene dado por
mnz
n y
2
2/ˆ
δ
σ≈ α
Por consiguiente, se deberá alargar cada una de las repeticiones para alcanzar el número de observaciones definido en la expresión anterior. Alternativamente, si se mantiene la duración de cada repetición n, un número de repeticiones que será preciso efectuar será
2
2/ˆ
δ
σ≈ α yz
m
El principal inconveniente de este método es que la ejecución de cada repetición requiere un período inicial de estabilización antes de alcanzar el régimen permanente, por lo que se desperdicia mucho tiempo de simulación improductivo.
6.5.3.2. Método de las medias de los lotes (batch means) Este método que es uno de los más utilizados, consiste en llevar a cabo una ejecución de longitud suficientemente larga del modelo dividiendo el conjunto de las observaciones de la ejecución en m lotes de n observaciones en cada lote; dicho de otra forma, se hace que cada período constituya el transitorio del siguiente. Si se elige m suficientemente grande, las observaciones sucesivas no estarán prácticamente correladas. Para que fueran independientes debería cumplirse, además, que estuvieran distribuidas normalmente, aunque se consideran independientes si se da solo la condición de no correlación. Con frecuencia se combina este método con el anterior. La formulación es idéntica a la del método anterior con solo cambiar cada repetición por cada uno de los lotes en que se divide la simulación.
6.5.3.3. Método regenerativo El método regenerativo puede utilizarse si el sistema lo es y se dice que lo es cuando existe una sucesión de puntos, llamados de regeneración, tales que en ellos el modelo se halla cada vez en las mismas condiciones y en cada uno de los cuales lo sucedido hasta aquel instante no

150
influye en lo que sucederá a partir de él. Además, evita todos los problemas de determinación del período transitorio. La ejecución de la simulación se divide entonces en una secuencia de bloques independientes igualmente distribuidos. Los problemas que plantea el método regenerativo son: - determinar si existen puntos de regeneración
- que existiendo puntos de regeneración, el sistema vuelva a ellos con una cierta frecuencia, es decir que el tiempo medio entre estos pasos por él sea finito y suficientemente pequeño.
Las ventajas de este método residen en que la agrupación aleatoria de las observaciones que proporcionan los puntos de regeneración, produce bloques independientes idénticamente distribuidos desde el inicio de la simulación, lo cual permite evitar los problemas de dependencia estadística entre las sucesivas observaciones y de determinación del estado estacionario, todo lo cual permite definir mejores estimadores. El problema de determinar puntos de regeneración se resuelve fácilmente en redes abiertas, donde la red vacía lo es. No obstante en redes cerradas la determinación de dichos puntos de regeneración es un problema del que, en general, sólo se conocen aproximaciones que, además, no incluyen normalmente en su ámbito las redes resultantes de la representación de sistemas informáticos. Sean 0 < E1 < E2 < ... < Ek < ... la sucesión de instantes en que el sistema pasa por puntos de regeneración que por pares consecutivos definirán los procesos regenerativos X(t), t ≥ 0. Si se considera que el sistema evoluciona en un estado estacionario, se podrá escribir, si X es la variable aleatoria que representa X(t) en equilibrio, que
limt → ∞ Pr[X(t) ≤ x] = Pr[X ≤ x]
El valor que se quiere estimar con la simulación es el valor esperado de alguna función f de X
r = E[f(X)]
Se puede considerar que cada ciclo genera un par (Yi, di), donde Yi es la integral de f(X(t)) a lo largo del i-ésimo ciclo y di es la longitud del i-ésimo ciclo. Entonces los pares de variables aleatorias (Y1, d1), (Y2, d2), ..., (Yi, di), ... son independientes e idénticamente distribuidos y
( )( ) [ ][ ]i
i
t
t dEYE
t
duuXfr == ∫ ∞−
∞→lim
Se supone que el simulador pasa por n puntos de regeneración y se calculan las medias y variancias de las Y y las d, así como la covariancia de ambas secuencias; entonces la expresión anterior sugiere que se puede utilizar como estimador r la relación entre las medias de ambas sucesiones, es decir, dYr ˆ/ˆˆ = . Una expresión aproximada del intervalo de confianza puede deducirse usando la normalidad asintótica de la variable Yi - rdi:
ndz
rrnd
zr
σ+≤≤
σ− αα 2/2/ ˆˆ
donde la estimación de la variancia de la variable aleatoria Yi - rdi es 2222 ˆˆ2ˆ dydy rr σ+σ−σ=σ .
El estimador de la expresión de r converge hacia la media de la población r, cuando n tiende a infinito. Para muestras de tamaño finito n, este estimador es sesgado por lo que para

151
muestras pequeñas el método de Jacknife proporciona mejores estimadores puntuales con un intervalo de confianza 2
1,2/ ˆˆ jnj tr σ± −α , siendo
( )∑ ∑∑
∑
∑
∑
= =
≠=
≠=
≠=
≠=
−−−−
=σ
−−=
n
i
n
ijn
ikk
k
n
ikk
k
jn
ikk
k
n
ikk
k
j rd
Y
ndYn
nd
Y
nn
dYr
1 1
2
1
12
1
1
ˆ11
1ˆ 1ˆ
6.5.4. MÉTODOS PARA MUESTRAS CORRELADAS Para los intervalos de confianza cuando las muestras están correladas se han propuesto dos métodos. En el primero se ajusta a la secuencia de salida un modelo autoregresivo de series temporales y en el segundo, se aplican técnicas espectrales.
6.5.4.1. Método autoregresivo
En la práctica, diversos métodos para estimar [ ]nXVar usan aproximaciones. Un método en particular se basa en la suposición que se puede tomar una secuencia de observaciones dependientes X1, …, Xn y transformarla en una secuencia de observaciones independientes e idénticamente distribuidas. Se supone que existe una tal secuencia b0, …, bp tal que
( ) npiXbYp
ssisi ..., ,1 para
0∑
=− +=µ−=
sea una secuencia de variables aleatorias independientes e idénticamente distribuidas de media cero y variancia σ2. En la literatura de series temporales la expresión anterior denota una representación autoregresiva de Xi y p el orden de la autoregresión. Obsérvese que
∑+=
− −=
n
piipn Y
pnY
1
1
tiene variancia σ2/(n - p). Para ver como se relaciona con la [ ]nXVar se puede reescribir la expresión anterior en la forma
( )∑ ∑+= =
−− =
µ−
−=
n
pi
p
ssispn Xb
pnY
1 0
1
( )
µ−+
++
−−µ−
−= ∑∑ ∑∑∑
+−=
−
=
−
=+−==
pbXbXXbXbpn
Xpn
nb n
pniip
p
s
sp
ii
n
sniis
p
ii
1
1
1 1110
1
donde
2 para 0
≥≡ ∑=
pbbp
ss
de tal forma que
( )[ ] 0lim =µ−−−∞→ npnn XbY

152
Por consiguiente
[ ] [ ]2
2
2
VarVar
nbbY
X pnn
σ≈≈ −
La significación y el atractivo de este resultado proviene del hecho que se puede aproximar [ ]nXVar por una función de p, b0, …, bp y σ2 en vez de una media infinita de
autocovariancias. De hecho,
[ ] ( ) ( ) j
p
srsrjsr
p
ssjis
p
rrirjii RbbXbXbEYYE δσ==
µ−µ−= ∑∑∑
=−+
=−+
=−+
2
0,00
donde
≠=
=δ0 si 00 si 1
jj
j
y, por lo tanto,
222
0,
σ=== ∑∑ ∑∞
−∞=
∞
−∞= =−+ VbRbRbb
jj
j
p
srsrjsr
de tal forma que V = σ2/b2 que establece la equivalencia de las aproximaciones realizadas. Es evidente que existen muchas secuencias p, b0, …, bp y σ2 que satisfacen las expresiones anteriores. Para obtener una solución sin pérdida de generalidad se puede definir b0 + 1 y suponer que el objetivo sea la determinación de b1, …, bp que minimiza σ2. Entonces la minimización de la expresión de [ ] jjiiYYE δσ=+
2 para j = 0 conduce a p ecuaciones lineales
prRRb r
p
ssrs ..., ,1 para
1
=−=∑=
−
que determina de forma única b1, …, bp que minimiza, siempre que se conozca R0, …, Rp. Si se sustituyen las autocovariancias de las muestras
( )( )[ ] psXXXXsn
Rsn
insinis ..., ,0 para 1ˆ
1=−−
−= ∑
−
=+
en la ecuación anterior se puede calcular pbb ˆ ..., ,1 ,una estimación única de b1, …, bp,
respectivamente. Es fácil demostrar que pbb ˆ ..., ,1 difiere de la estimación que minimiza
( )∑ ∑∑+= =
−+=
µ−
−=
−
n
pi
p
ssis
n
pii Xb
pnY
pn 1
2
01
2 11
en un cantidad que tiende a cero en probabilidad cuando n crece. Estas estimaciones se denominan estimaciones de mínimos cuadrados lineales de los coeficientes de autoregresión. El cálculo directo de pbb ˆ ..., ,1 a partir de

153
prRRb r
p
ssrs ..., ,1 para ˆˆˆ
1
=−=∑=
−
requiere de la inversión de una matriz. Existe un procedimiento recursivo que evita este paso. Sea jib ,
ˆ una estimación de bj cuando se supone que el orden de la autoregresión p es j. Se puede demostrar que para j = 1, …, i - 1
1,1,1,,1ˆˆˆˆ
+−+++ += jiiiijiji bbbb
i
iii V
Wb −=++ 1,1ˆ
∑=
+−=i
kkikii RbW
01,
ˆˆ
∑=
=i
kkkii RbV
0,
ˆˆ
donde jji bb ˆˆ, = para p = i. Las expresiones anteriores permiten la estimación de los
parámetros autoregresivos de orden progresivamente elevado de una forma sencilla. Para estimar σ2 a partir de las ecuaciones de su definición y del sistema de ecuaciones, cuya solución se ha obviado, se puede llegar a
∑=
=σp
sss Rb
0
2
que se puede estimar por
∑=
=σp
sssii Rb
0,
2 ˆˆ
con 1ˆ, ≡sib .
Para determinar el valor apropiado para el orden de autoregresión p, hay que hacer recurso a un test estadístico. Se supone que se calculan esquemas para i = 0, …, q, donde es un valor grande, considerablemente mayor que el orden autoregresivo anticipado. Entonces si el esquema es de orden 0 ≤ j < q, la distribución de
σ
σ−=− 2
2
ˆˆ
1j
qjq nT
converge en una distribución de ji-cuadrado con q - j grados de libertad cuando n crece. La comprobación para j = 0, 1, … continúa hasta que produce la falta de significación. Una vez se ha determinado p, se estima V = σ2/b2 mediante
2
0,
2
ˆ
ˆˆ
σ=
∑=
p
sspb
V

154
Aunque este enfoque para estimar [ ]nXVar puede parecer cualquier cosa menos directa, una pequeña reflexión muestra que se está transformando implícitamente X1, …, Xn en una secuencia de variables aleatorias asintóticamente no correladas cuya variancia es considerablemente fácil de estimar. Considérese la secuencia
( )∑=
− −=p
snsispi XXbY
0,
ˆˆ
donde iY es una estimación de la verdadera perturbación Yi. Ahora se puede reescribir la ecuación anterior como
( ) ( ) ( )( ) ( )( )[ ]=µ−−−µ−−+µ−−µ−= ∑∑=
−=
−
p
snnspsispn
p
ssisi XbbXbbXbXbY
0,,
0
ˆˆˆ
( ) ( )( ) ( )( )[ ]∑=
− µ−−−µ−−++µ−−=p
snnspsispi XbbXbbXY
0,,
ˆˆ
Mediante un argumento limitativo se puede demostrar que para n suficientemente grande
ii YY ≈ˆ de tal forma que [ ] [ ] jijii YYYE −δσ≈≈ 2ˆ,ˆCovy 0ˆ . Esto es, en muestras grandes se
puede considerar np YY ˆ ..., ,ˆ1+ como no correladas y con media nula. Esto sugiere estimar
[ ]iYVar por
( )( )[ ] ≈−−−
=− ∑∑∑
+=−−
=+=
n
pinkinji
p
kjkpjp
n
pii XXXX
pnbbY
pn 10,,,
1
2 1ˆˆˆ1
npRbRbb p
p
jjjp
p
kjkjkpjp <<σ==≈ ∑∑
==− para ˆˆˆˆˆˆ 2
0,
0,,,
Ahora se sabe que ppp bb ˆ ..., ,ˆ1 y 2ˆ pσ son estimadores consistentes de b0, …, bp y σ2,
respectivamente. Por consiguiente V es un estimador consistente de [ ]nXnV Var = . Sin embargo, no se dispone de ningún cálculo directo de los grados de libertad. Para superar este problema se aproxima la distribución de VV /ˆ por la de una variable de ji-cuadrado. Si X es de χ2(f), entonces E[X] = f y Var[X] = 2f, de tal forma que una forma de calcular el número de grados de libertad es
[ ]( )[ ]XXEf
Var2 2
=
A causa de la consistencia es evidente que
[ ] 2
2ˆlim
bVVEn
σ==∞→
Además, se puede demostrar que
[ ] ( )∑=
−∞→ −=
p
ssn bspbVVn
0
12 24ˆVarlim

155
Entonces se puede calcular el número de grados de libertad como
( )∑=
−= p
ssbsp
nbf
022
En resumen pues, para calcular el intervalo de confianza con muestras correladas mediante el método autoregresivo, la marcha de cálculo es la siguiente: 1. Estimar p, b0, …, bp y σ2.
2. Estimar V.
3. Estimar f.
4. Calcular una estimación del intervalo de µ.
6.5.4.2. Método espectral Examinando la forma
[ ] ∑−
=
−=
1
011Var
n
ssn R
ns
nX
se observa que la razón de convergencia de [ ]nXVar hacia ∑∞
−∞=
=s
sRV tiene como función de
ponderación
nsns
W sn ±±=−= ..., ,1 ,0 para 1)1(,
Si n es suficientemente grande, de tal forma que usar V/n por [ ]nXVar no introduzca prácticamente ningún error, entonces uno puede preguntarse si existen otras funciones de ponderación que permitan la aproximación de V mediante una combinación lineal de un número considerablemente pequeño de covariancias, pero con un error ligeramente mayor. La respuesta es sí. Considérese la expresión más general
nkRWVk
kss
iski ≤= ∑
−=
para )(,
donde )(,iskW está definida de tal forma que garantiza
VRVs
sik == ∑∞
−∞=∞→lim
Puesto que Rs no es conocido en la práctica, las autocovariancias de la forma
( )( )[ ] psXXXXsn
Rsn
insinis ..., ,0 para 1ˆ
1=−−
−= ∑
−
=+

156
deben substituirse en la anterior expresión de Vi. Escribiendo la expresión de las autocovariancias de las muestras como
( )( )[ ] ( )( )[ ] 0 para 1ˆ1
≥µ−µ−µ−µ−−
= ∑−
=+ sXXXX
snR
sn
insinis
se puede demostrar directamente que
[ ] VRRnE ssn −=−∞→ˆlim
[ ] ∑−=
∞→ −=−k
ks
iskiin WVVVnE )(
,ˆlim
de tal forma que
[ ] ∑−=
−−≈k
ks
iskii WVnVVE )(
,1ˆ
Claramente
[ ] VVE ikn =∞→∞→ˆlimlim
siempre que k crezca más lentamente que n. En términos finitos, si k es suficientemente grande de tal forma que Vi → V, entonces
∑−=
−−= k
ks
isk
ii
Wn
VV
)(,
11
ˆˆ
evita el sesgo que introduce el uso de nX en vez de µ y, por consiguiente, es un estimador preferido de V. Al aplicar la estimación espectral, frecuentemente se substituye el divisor n - s en las fórmulas anteriores por n. El efecto es despreciable para n>> k. Como el lector aprecia, el uso de k <<n elimina el cálculo de nk RR ˆ ..., ,ˆ
1+ con el ahorro subsiguiente. Sin embargo, consideraciones de variancia proporcionan una atracción más
importante para iV y iV . Se puede demostrar que para k suficientemente grande
[ ] [ ]
κ+≈=
∑
−=∞→∞→
k
ks
iskiinin WVVnVn 2)(
,2ˆVarlimˆVarlim
donde κ indica una contribución a la variancia debida a la falta de normalidad de X1, …, Xn. La significación de la fórmula anterior proviene del hecho que la suma de la derecha es una función creciente de k. ello implica que una vez que se ha determinado k de tal forma que
VVE i ≈
ˆ , un valor mayor de k mejora la aproximación [ ] VVE i ≈ˆ a expensas de un
incremento de [ ]iVar ˆV . Una vez proporcionada la justificación de buscar funciones de ponderación distintas de )1(
,skW , es preciso analizar las opciones disponibles. Aunque la literatura teórica sobre el análisis espectral sugiere muchas alternativas, sólo dos han emergido como serias competidoras de la

157
primera elección. Esto es, con respecto a consideraciones acerca del error de la aproximación y de la variancia, pretenden dominar otras sugerencias. Una es la función de ponderación de Tukey-Hanning
( ) ≤π+
=contrario casoen 0
s si 'cos15.0)2(,
ksW sk
para s' = s/k. La otra es la función de ponderación de Parzen:
( )
≤<−
≤+−
=contrario casoen 0k/2 si '12
2/ si '6'613
32
)3(, kss
ksssW sk
A título de comparación, se puede demostrar que )2(,skW produce un error de aproximación
menor que en de )3(,skW para un valor dado de k. Sin embargo, la desigualdad se invierte
cuando se consideran las variancias para una k dada. En particular se puede demostrar que
para VVE ≈
2ˆ y VVE ≈
3ˆ ,
nkVV 2
2 75.0ˆVar ≈
nkVV 2
3 539.0ˆVar ≈
donde el término debido a la falta de normalidad se supone κ << k. Además,
kWk
kssk =∑
−=
)2(,
kWk
kssk 75.0)3(
, =∑−=
de tal forma que 2ˆV y 3
ˆV pueden calcularse fácilmente. También puede usarse la fórmula del método autoregresivo para calcular los grados de libertad. Para la función de ponderación de
Tukey-Hanning, kn.f 66722 = , y para la de Parzen,
knf 711.33 = .
6.6. VALIDACIÓN Y COMPROBACIÓN DE MODELOS DE SIMULACIÓN
Una vez se ha construido y verificado el modelo, se desea comprobar la validez o credibilidad del modelo de simulación. Para establecer la inferencia del sistema real a partir de los resultados obtenidos en la simulación, el modelo debe ser una representación razonablemente válida del sistema real. El proceso de validación puede parecer bastante directo en un principio. Pero, en la práctica, es difícil establecer tests de validación concluyentes. En algunos casos, no hay contrapartida existente para alguna de las alternativas simuladas. Tal situación se produce cuando debe diseñarse un sistema completamente nuevo y se utilizan experimentos de simulación para

158
elegir entre alternativas de diseño. Si se dispone del sistema considerado o de uno similar, se obtendría alguna seguridad de la validez demostrando que para una o dos versiones alternativas del sistema simulado y un conjunto de condiciones, el simulador produce resultados que no son inconsistentes con el comportamiento conocido del sistema real. En caso contrario, el modelo es francamente sospechoso. Por otra parte, no se puede hacer ninguna afirmación rotunda acerca de la credibilidad del modelo incluso si el modelo pasa el test bajo ciertas variaciones y conjuntos de condiciones: Hay siempre la incertidumbre asociada con el establecimiento de una conclusión general a partir de un número reducido de pruebas. El tratamiento de esta incertidumbre inherente cae dentro del reino de diseño estadístico y del análisis de experimentos. El nivel de detalle requerido en la validación de un modelo de simulación debe depender de como debe usarse este modelo en la toma de decisiones. En otras palabras, se debe volver al objetivo principal de estudio de simulación y elegir alguna medida del comportamiento que indique si los datos de observación generados por el simulador concuerdan suficientemente con los del sistema real. Si la medida de comportamiento así obtenida es algún valor medio, entonces deben aplicarse las nociones de nivel de significación y de intervalo de confianza para cuantificar la significación estadística de la diferencia entre los efectos reales y los simulados. El análisis de la variancia puede usarse para comprobar la hipótesis que la media de una serie de datos generados por el simulador es igual a la media de los datos observados correspondientes al sistema real. En algunos casos, el criterio de comportamiento no es solo el valor medio de las observaciones, sino su distribución de frecuencias. En este caso se debe acudir a los tests de hipótesis, como los ya vistos de ji cuadrado y de Kolmogorov-Smirnov.
6.7. HERRAMIENTAS DE CONSTRUCCIÓN DE MODELOS 6.7.1. MODELOS DE SIMULACIÓN La construcción de modelos de simulación puede hacerse recurriendo a distintas herramientas, entre las que se pueden citar: - lenguajes de programación convencionales que pueden tener extensiones para la
generación de números aleatorios, el tratamiento de listas, etc., como por ejemplo el GASP como extensión del FORTRAN y el SIMULA como extensión del ALGOL.
- lenguajes de simulación, especialmente diseñados con este objeto, que incorporan a las extensiones citadas en el apartado anterior las de extracción y presentación de resultados; entre otros se pueden citar el GPSS y el SIMSCRIPT.
- paquetes de simulación cerrados orientados generalmente al estudio de sistemas informáticos trabajando en tiempo real; tienen informaciones relacionadas con el comportamiento de los equipos informáticos más frecuentes y hay que indicarles la configuración y describirles adecuadamente la carga. Los casos más típicos de este tipo de herramientas son el SCERT y el CASE.
6.7.2. LENGUAJES DE MODELIZACIÓN La aparición de técnicas analíticas de solución de modelos de sistemas teleinformáticos ha promovido la aparición de un numeroso conjunto de lenguajes de modelización, que basándose con frecuencia en alguna forma de lenguaje de programación estructurado, permiten la construcción y posterior tratamiento de modelos a base de redes de colas. Con frecuencia el método de resolver la red es de tipo analítico (principalmente convolución o análisis del valor medio) aunque también incorporan otros métodos analíticos aproximados y métodos de simulación. Los hay de tipo general que permiten la descripción de las estaciones

159
de servicio y el encaminamiento de los clientes entre ellas, sin estar orientados a ningún tipo específico de sistemas y entre otros se pueden citar los siguientes: - QNAP2
. Desarrollado por el INRIA (Institut Nacional de Recherche en Informatique et Automatique) tiene la forma de un lenguaje estructurado tipo PASCAL, con ciertos tipos de datos predefinidos (QUEUE, CUSTOMER, CLASS, ETC.) permitiendo varios tratamientos analíticos exactos y aproximados, tratamiento por cadenas de Markov y tratamiento por simulación, según las características de la red y el deseo del usuario.
- RESQ.
. Estructurado sobre una base fuertemente interactiva aporta sensiblemente los mismos tratamientos que el anterior (excepto el de las cadenas de Markov). Ha sido desarrollado por IBM basándose en un conjunto de productos anteriores.
- BEST-1.
. Desarrollado de BGS Systems (Buzen y asociados) se orienta al estudio de modelos de sistemas informáticos y redes de comunicación (arquitecturas SNA, etc.). Tal vez es el producto comercial mas popular en su ámbito.
Otros lenguajes, por el contrario, están claramente orientados a un determinado tipo de sistemas, normalmente sistemas de comunicación, sin entrar en el detalle del tipo de modelo subyacente. Entre otros se pueden citar:
- QUARTZ
. desarrollado por el CNET, contiene modelos de distintos sistemas de comunicación con sus protocolos proporcionando los resultados solamente a través de tratamientos numéricos y no de simulación.
- NETWORK
. similar al anterior, su diferencia reside en la posibilidad de estudiar por simulación modelos no tratables numéricamente.

160
MODELADO DE SISTEMAS
1. INTRODUCCIÓN Las distintas herramientas estudiadas (colas, redes de colas, redes de Petri, procesos de Markov, simulación, etc.) pueden usarse para estudiar el comportamiento de un sistema informático o teleinformático poniendo de manifiesto y estimando los retrasos y contenciones que se producen cuando diversos clientes pretenden utilizar el mismo recurso. Las distintas herramientas cubren distintos aspectos del estudio de un sistema. Así la teoría de colas nos permite estudiar separadamente cada uno de los componentes de un sistema pero sin poder tener en cuenta del hecho que un cliente habitualmente sólo puede recibir servicio de un servidor y al estudiar cada dispositivo por separado se pierde de vista el hecho mencionado. Si se desea tener en cuenta el mencionado hecho de la imposibilidad de simultaneidad de uso de diversos recursos por un mismo cliente es preciso pasar a modelos globales. Dichos modelos globales se pueden construir mediante cualquiera de las restantes herramientas. Sin embargo, todas ellas excepto la simulación exigen la adaptación de la realidad a las condiciones específicas exigidas por el método de que se trate. La simulación, al menos teóricamente, no tiene ninguna limitación en cuanto a las características del modelo construido. Este aumento de la precisión del modelo construido tiene como coste unos mayores tiempos de puesta a punto del modelo y de ejecución del mismo. Sin embargo, antes de entrar en la construcción de modelos usando las distintas herramientas citadas conviene fijar ideas en que se entiendo por cliente y por servidor.
1.1. LA NOCIÓN DE CLIENTE Típicamente un cliente puede ser una porción de software en un sistema informático, un paquete de información en un entorno de comunicación por conmutación de paquetes, una llamada telefónica en un entorno de comunicación por conmutación de circuitos, etc. En general, un cliente es una entidad que requiere servicio de uno más dispositivos servidores. Dependiendo del problema, se puede decidir agrupar todos los clientes en una sola clase o en distintas clases. Por ejemplo, tiene sentido considerar una sola clase si todos los clientes se comportan aproximadamente de la misma forma, es decir, tienen similares requerimientos de servicio, similar encaminamiento, y no hay prioridades entre ellos. Sin embargo, si algunos clientes tienen prioridad sobre otros o tienen distintos requerimientos de servicio o distinto encaminamiento, entonces, evidentemente, tiene sentido colocarlos en clases separadas.
1.2. LA NOCIÓN DE ESTACIÓN DE SERVICIO Una estación de servicio esta constituida por un mecanismo de servicio que puede ser un elemento hardware o un fragmento de software o una combinación de los dos. Por ejemplo, se pueden considerar una CPU, un disco, un módulo de memoria, un bus, un enlace de comunicación, un nodo de conmutación, etc. como estaciones de servicio. Cada mecanismo de servicio tiene un buffer (al que se hace referencia como cola), donde los clientes esperan hasta que reciben servicio. En general, la capacidad del buffer es finita, esto es, solo puede acomodar un número finito de clientes. Sin embargo, si un buffer finito es muy grande, entonces puede suponerse que es infinito, ya que a efectos prácticos no hay límite en el número de clientes que puede acomodar. En general, se supondrá que la capacidad de un buffer es infinita a menos que se advierta lo contrario. Además, después de haber identificado las distintas estaciones de servicio que constituyen un sistema, es preciso identificar como están interconectadas, es decir, como pueden desplazarse los clientes entre las distintas estaciones.

161
1.3. RECOLECCIÓN DE INFORMACIÓN Después de haber identificado los clientes y, eventualmente, sus clases, y las estaciones de servicio y su interconexión, es necesario caracterizar la distribución de los tiempos de servicio de cada clase de cliente en cada estación en la que puede recibir servicio, las probabilidades de encaminamiento de los clientes entre las distintas estaciones, y la distribución de los tiempos entre llegadas de los clientes que llegan al sistema procedentes del exterior. En muchos casos, esta información debe recopilarse a partir de datos obtenidos de la monitorización experimental del sistema considerado; en otros casos estos datos están basados en una estimación hecha por personas expertas a partir del comportamiento de sistemas similares. Hay que tener presente que la calidad de los resultados que se obtengan de un modelo depende más de los datos introducidos que de la mayor o menor aproximación del modelo. Dicho en otras palabras, un modelo nunca mejorará la calidad de los datos introducidos, en todo caso la empeorará.
2. MODELADO DE SISTEMAS INFORMÁTICOS 2.1. MODELOS INDIVIDUALES DE SUBSISTEMAS La modelización de sistemas informáticos puede enfocarse estableciendo modelos individuales de cada uno de los subsistemas o bien estableciendo un modelo global de todo el sistema. En este apartado analizaremos los modelos individuales de cada uno de los subsistemas y en el 2.2. los modelos globales. En el volumen primero de esta obra se han analizado un conjunto de modelos de colas que admiten un tratamiento de cálculo sencillo (posible con la ayuda de una calculadora de bolsillo con las cuatro reglas y la raíz cuadrada). En este apartado se estudiará el funcionamiento de distintos dispositivos que componen un sistema informático o teleinformático y se tratará de hallar a cual de los modelos estudiados se asemeja en mayor grado. En algunos casos la correspondencia será directa; en otros, como se verá, será preciso forzar la realidad para hacerla encajar en alguno de los esquemas tipo estudiados que admiten un cálculo sencillo. Es decir, el proceso que se seguirá será el de analizar el funcionamiento del dispositivo considerado, ver a que modelo de colas se adapta mejor y hacer la simplificaciones que convengan para lograr su adaptación; a continuación será conveniente analizar el efecto de las simplificaciones realizadas sobre los resultados obtenidos.
2.1.1. TAMBORES O DISCOS DE CABEZAS FIJAS Estos dispositivos (fig. 2.1)solo permiten tratar una sola entrada-salida simultánea, debido a que la unidad de control y/o el canal solo permiten el paso de una de ellas. Por lo tanto, independientemente del número de ejes de que se disponga, a efectos de su modelización, es equivalente a que se dispusiera de uno solo. El modelo está constituido por una cola que da acceso a la unidad que controla los distintos dispositivos.

162
Disco de cabezas fijas Tambor
Cabezas de lectura-escritura
Figura 2.1.
El número de accesos por unidad de tiempo λ depende de las aplicaciones que se ejecutan en el momento estudiado y, aun cuando, estrictamente, las peticiones se generan a partir de una población finita (trabajos en ejecución), normalmente se puede admitir que las peticiones provienen de una población infinita y, además, que siguen una distribución poissoniana. Otros elementos que intervendrán en la definición del tipo de modelo a utilizar serán: - el contenido de los tambores (archivos de datos o archivo de paginación)
- la política de ordenación de las peticiones de servicio (FIFO o por latencia mínima).
2.1.1.1. Tambores con archivos de datos y disciplina FIFO El tiempo de servicio estará compuesto del tiempo de latencia (tiempo que transcurre desde la adquisición de la unidad de control hasta que el registro a transferir pasa por debajo de la cabeza de lectura-escritura correspondiente) más el tiempo de transferencia (tiempo que tardan en transferirse todos los bits del registro). El tiempo medio de servicio s y la variancia de los tiempos de servicio σs
2 se determinarán teniendo en cuenta las distribuciones del tiempo de latencia y del de transferencia de los registros. Esta situación puede, pues, modelarse sin dificultad mediante una cola M/G/1 y aplicar las fórmulas de Pollaczeck-Khintchin ya que la frecuencia de llegada sigue una distribución de Poisson y el servicio es la suma de dos variables aleatorias, por lo tanto una ley general. Si se denomina RG la longitud media de los registros transferidos, σRG su desviación tipo, medidos ambos en vueltas, λ la frecuencia media de la llegada de peticiones de acceso a los tambores y τ el tiempo de una revolución, sustituyendo en las fórmulas de Pollaczeck-Kintchin se tiene
τ
ρ−
+ρ+
+=
11
211
21 2CRGR
donde el factor de utilización vale
τ
+λ=ρ RG
21
y el coeficiente cuadrático de variación

163
2
2
2
21121
+
σ+=
RGC
RG
teniendo en cuenta que los tiempos de latencia estarán uniformemente distribuidos entre cero y τ el correspondiente a una vuelta y, por lo tanto, su valor medio será τ/2 y su variancia τ2/12.
2.1.1.2. Tambores con archivos de paginación y disciplina FIFO En este caso al tratarse de un archivo de paginación, todos los registros serán de la misma longitud, si al acabar la transferencia de un registro no hay ninguno en espera, no es necesario que el servidor explore continuamente la llegada de una nueva petición ya que, en el mejor de los casos, sólo podrá empezar a servirla cuando se llegue a un entorno de página (fig. 2.2). Por lo tanto parece razonable utilizar un modelo de Skinner donde la variable B vale cero y la C, el tiempo correspondiente a de dejar circular el sector correspondiente a una página, es decir, τ/k, donde k es el número de sectores de una pista.
Figura 2.2
La variable A, correspondiente al tiempo de servicio comprenderá los tiempos de latencia y transferencia. La distribución de los tiempos de latencia será uniforme discreta entre cero y el tiempo correspondiente al giro de una vuelta menos un sector, es decir, k - 1 sectores. Por lo tanto, los momentos del tiempo de servicio A (suma de latencia y transferencia) serán
( )k
kkk
kmA 2110
21 τ+
=τ
+
τ
−+=
( )2
2
2 3211
k
kkM A
τ
++
=
Puesto que todos los registros tienen la misma longitud, el tambor de paginación está en una posición apta para empezar a atender un nuevo acceso inmediatamente después de terminar el anterior y si hay algún acceso pendiente en la cola lo atiende. En el modelo de Skinner esto significa B = 0, de donde FA(t) = FZ(t). Si la cola está vacía inmediatamente después que el tambor acabe de atender una entrada/salida, debe permanecer en latencia durante el tiempo necesario para recorrer un registro antes de que sea necesario volver a examinar la cola. Por lo tanto, en este caso, no es

164
una variable aleatoria, sino que es una constante igual a τ/k, de donde mC = τ/k y M2C = τ2/k2. En consecuencia, sustituyendo y simplificando, el tiempo medio de respuesta será
( )( ) τ
τ+λ−
τ
++λ
++= −
−−
−1
11
1
122111
31
21
k
kkkR
2.1.1.3. Tambores con archivos de paginación y disciplina de latencia mínima (shortest latency time first, SLTF)
En este caso, si la distribución de accesos es uniforme entre los k sectores de todas las pistas, se puede descomponer el proceso de Poisson de llegada en k procesos, dirigidos, cada uno, a uno de los conjuntos de sectores que ocupan la misma posición en todas las pistas, asignándoles un servidor ficticio, que, por turno, se transforma en el servidor real de tal forma que nunca entran en conflicto dos servidores ficticios al tratar de adquirir el servidor real, y gestiona la cola de cada sector en forma FIFO. Entonces cada servidor actúa como un servidor de Skinner que después de cada servicio espera el paso de k - 1 sectores antes de volver a explorar la cola y si la encuentra vacía deja pasar una vuelta completa. Esta política permita una mejora del tiempo de respuesta ya que en muchos casos el que se "cuele" el acceso correspondiente a un sector que se encuentra en la latencia de otro, no perjudica el tiempo de respuesta de este último y mejora apreciablemente el del primero. Aplicando el modelo de Skinner a cada uno de los servidores ficticios que hemos considerado, resulta que todas las variables aleatorias que intervienen se transforman en constantes. A vale τ/k, el tiempo de transferir un registro; B vale (k - 1)τ/k, el tiempo de recorrer los k - 1 sectores de la misma vuelta que es el tiempo que debemos esperar hasta explorar nuevamente la cola; y C vale τ, el tiempo de una vuelta, que debemos esperar para volver a explorar la cola de un sector cuando, al hacerlo, la hallemos vacía. Por lo tanto, mA = τ/k, mZ = mC = τ , M2A = τ2/k2 y M2Z = M2C = τ2, y, en consecuencia sustituyendo y simplificando en el resultado del modelo de Skinner, se tiene
( ) τ
+
ρ−ρ+
= −1
121 kR
donde τλ
=ρk
2.1.1.4. Tambores con archivos de datos y disciplina de latencia mínima El estudio de este caso no permite la aplicación simple de alguno de los modelos estudiados. Para ello debe recurrirse a la simulación o a modelos más sofisticados, como el que resulta de aplicar las hipótesis que la distribución de los tiempos de servicio (latencia más transferencia) es
1 - e-t/(τRG), para 0 < t < τ
1 - e-t/(τRG) e-(t - τ)/(τRG), para t > τ
y que todos los registros son equiprobables, que permite llegar a una expresión aproximada del tiempo de respuesta que es

165
τ
ρ−
ρ+
ρ−ρ
++=23
1368.0
121 RGR
2.1.1.5. Ejemplo En un canal de entrada-salida hay un tambor conectado y gira a 3600 r.p.m. La longitud media de los registros es de 1/5 de vuelta. Los accesos se producen a razón de 60 por segundo. Determinar el tiempo medio de respuesta en las siguientes situaciones: 1. Archivos de datos con una desviación tipo de la longitud de los registros que se puede
estimar en 1/10 de revolución y política FIFO de gestión de la cola.
2. Archivos de paginación y política FIFO de gestión de la cola.
3. Archivos de paginación y política SLTF de gestión de la cola.
Solución De la velocidad de rotación se encuentra que el tiempo necesario para dar una vuelta es
τ = 1/3600 min = 60/3600 = 1/60 s = 1000/60 = 16.67 ms
y las características estadísticas de la latencia rotacional son:
mL = 16.67/2 = 8.33 ms
σL2 = 16.672/12 = 23.24 ms2
1. Las características estadísticas de la llegada son λ = 30 acc/s y las del servicio, suma de las de la latencia más la transferencia, son:
s = 8.33 + 16.67/5 = 11.67 ms
σs2 = (16.67/10)2 + 23.24 = 26.02 ms2
y como el comportamiento se asemeja al de una cola M/G/1, se deben aplicar las fórmulas de Khintchin-Pollaczeck con
ρ = 60 × 11.67/1000 = 0.7
de donde se obtiene el tiempo de respuesta
( ) ms 89.2767.1102.261
7.0127.0167.11 2 =
+
−×+×=R
2. En este caso se debe aplicar el modelo de Skinner con
ms 1067.165215
=×+
== ZA mm
( )22
222 ms 22.12267.1653
21515
=×
++
== ZA MM
mC = 16.67/5 = 3.33 ms

166
M2C = (16.67/5)2 = 11.11 ms2
y sustituyendo en la fórmula del modelo de Skinner, se obtiene el tiempo de respuesta buscado
ms 83.201010
1000601
22.1221000
6021
33.3211.11
=+−
+×
=R
3. En este caso se debe aplicar el modelo de Skinner con
mA = 16.67/5 = 3.33 ms
mZ = mC = 16.67 ms
M2Z = M2C = 16.672 = 277.78 ms2
λ = 60/5 = 12 acc/s
y sustituyendo en la fórmula del modelo de Skinner, se obtiene el tiempo de respuesta buscado
ms 40.1333.333.3
1000121
78.277100012
21
67.16278.277
=+−
+×
=R
2.1.2. DISCOS Se va a considerar en primer lugar un comportamiento básico de una operación de entrada-salida en disco para, después, estudiar variantes sobre él. Esta configuración básica supone que una unidad de control controla un subsistema de discos y está conectada a la memoria central a través de un canal no compartido con otros subsistemas (fig. 2.3).
Memoria
Discos
UC
Figura 2.3.
Así pues, se puede considerar que el proceso de E/S en un disco se descompone básicamente en las siguientes fases representadas en la figura 2.4:

167
LlegadaCola del
discoCola dela UCSK LT TF
UC ocupada
disco ocupado
disco yUC libres
Figura 2.4.
- La petición de acceso generada por algún programa (de aplicación o de sistema) se pone en una cola para acceder al disco correspondiente. La gestión de esta cola por parte del sistema operativo se supondrá que es FIFO.
- El acceso sale de la cola para lanzar el movimiento del brazo (seek) cuando la unidad de control y el disco correspondiente están libres simultáneamente, ocupando durante un tiempo despreciable la unidad de control, ya que se trata de un tiempo de microsegundos de proceso del acceso por la electrónica de la unidad de control frente a los milisegundos de los movimientos mecánicos del disco.
- Una vez acabado el desplazamiento del brazo, el acceso trata de iniciar la transferencia a través de la unidad de control, colocándose en la cola de este dispositivo que se supondrá inicialmente FIFO,.
- Cuando adquiere su servicio, la retiene durante los tiempos de latencia y transferencia.
- Una vez acabada la transferencia se liberan, a la vez, el disco y la unidad de control, que quedan en disposición de atender nuevos accesos.
A continuación se va a exponer un modelo simplificado de fácil tratamiento manual para este funcionamiento. Más adelante se estudiarán otros modelos correspondientes a otras alternativas de funcionamiento de los discos.
2.1.2.1. Discos sin posicionamiento angular y disciplina FIFO en la unidad de control El funcionamiento de un subsistema de discos como el que acabamos de describir en el apartado anterior, está representado exactamente en el diagrama de bloques de colas de la figura 2.5, en la que se aprecian las distintas etapas de la operación de E/S en disco (la cola, el movimiento del brazo, la cola de la unidad de control y el servicio de la unidad de control durante la latencia y la transferencia). La dificultad para construir un modelo exacto del funcionamiento de un subsistema de discos reside en el doble paso de la petición por la unidad de control: primero para dar la orden al disco de mover el brazo y luego para realizar la transferencia una vez el registro pasa por la cabeza de lectura-esritura. La figura 2.6, cuya diferencia reside en considerar que para salir de la cola de acceso al disco (inicio del movimiento del brazo) no es necesario que esté libre la unidad de control o el canal (ambos suponemos que constituyen un todo) y solo es necesario que esté libre el disco representa un modelo simplificado del mismo subsistema. En este caso al pasar las peticiones una sola vez por la unidad de control permite un modelo fácil de construir y tratar. La hipótesis realizada, que la espera suplementaria, debida a que la unidad de control esté ocupada y el disco libre, es pequeña en las circunstancias normales de funcionamiento del subsistema, se verificará más adelante.

168
.
.
.
Disco 1
Disco 2
Disco n
UC
SK1
SK2
SKn
.
.
.
Figura 2.5.
.
.
.
Disco 1
Disco 2
Disco n
UC
SK1
SK2
SKn
Figura 2.6.
El cálculo del tiempo de respuesta con estas hipótesis simplificadoras, se desglosa en las siguientes fases: a) Cálculo para cada archivo i del tiempo medio de ocupación de la unidad de control, que
es igual al tiempo de latencia, Li más el tiempo de transferencia, TFi.
Si admitimos unas hipótesis similares a las del funcionamiento de los tambores con archivos de datos y acceso FIFO, es decir, que los registros pueden empezar en cualquier lugar de la pista y todos tienen un acceso igualmente probable, los tiempos de latencia se podrá considerar que están distribuidos según una ley uniforme entre cero y el tiempo de una vuelta. Por lo tanto, el tiempo medio de latencia corresponde al de media vuelta

169
( 2/τ=iL ) y la variancia al cuadrado del tiempo de una vuelta dividido por doce ( 12/22 τ=σ
iL ).
El tiempo de transferencia se puede considerar igual al tiempo de una vuelta dividido por el número de registros físicos que hay en promedio en una pista o bien puede calcularse a partir la longitud del registro y de la velocidad de transferencia del disco.
b) Determinación del número medio λi de accesos, tanto entradas como salidas, a cada archivo, i, por unidad de tiempo, que depende de las aplicaciones que se ejecuten en ese instante.
c) Cálculo de la ocupación de la unidad de control provocada por cada archivo y que es λi(Li + TFi).
d) Cálculo del factor de utilización de la unidad de control, que es igual a la suma de todos los valores calculados en el apartado anterior.
e) Cálculo del tiempo medio de servicio de la unidad de control, que es el promedio de los valores calculados en el apartado a ponderados por las frecuencias de acceso, calculadas en el apartado b.
f) Cálculo del tiempo medio de espera en la unidad de control, Wuc que es igual al tiempo medio de estancia en el sistema (unidad de control) menos el de servicio. Los cálculos efectuados en los cinco apartados anteriores tienen por objeto proporcionar los datos necesarios para el tratamiento del modelo que se expone en este punto. Hay que tener en cuenta que en este caso, ya que el manantial no es infinito, puesto que esta cola puede tener, como máximo, tantos accesos en conflicto para usar la unidad de control como discos haya en el subsistema, el modelo aplicable sería el M/G/1//ND, donde ND es el número de discos del subsistema, que carece de tratamiento analítico. Como aproximación se puede aplicar un modelo M/G/1 o M/M/1//ND. Para el cálculo de este último modelo podemos emplear las fórmulas adecuadas (apartado 3.3.6. del primer volumen de esta obra) o los gráficos que nos dan ese valor directamente en función de ρuc, de suc y del número de mecanismos de acceso o ejes (clientes en la figura 3.13 del mismo volumen). Las dos aproximaciones propuestas son ambas pesimistas, la primera por considerar una población infinita en vez de finita, y la segunda por considerar una distribución exponencial de los tiempos de servicio con una variancia igual a la media, cuando, normalmente, es inferior a la media, ya que la latencia tiene un desviación tipo inferior a la media y en general todos los registros son de la misma longitud con desviación tipo nula. Por lo tanto, se debe elegir siempre la menos pesimista de ambas, que normalmente es la M/M/1//ND.
g) Cálculo para cada disco j (un archivo puede estar entre varios discos, o, por el contrario, en un disco puede haber varios archivos) de las características del tiempo de servicio, que es igual al tiempo de desplazamiento de brazo, SKj, más el tiempo de espera en la unidad de control, Wuc, más el tiempo de latencia, Lj, más el tiempo de transferencia TFj, que depende de los archivos que haya en el disco
sj = SKj + Wuc + Lj + TFj
El desplazamiento del brazo depende del tipo de accionamiento y de la ocupación y de la situación de los archivos en el disco.

170
Para calcular las características estadísticas del desplazamiento es preciso conocer, además de la situación y de la ocupación de los archivos en el disco, la frecuencia de acceso a cada uno de ellos. Si se admite que sólo hay un archivo que ocupa N cilindros podremos decir que la probabilidad de que se produzca un desplazamiento de n cilindros, si todos son igualmente probables, vale (fig. 2.7):
N
N - 2nn n
Posibilidad de desplazamiento en ambos sentidos
Posibilidad de desplazamiento sólo en un sentido Figura 2.7.
( )2
212212N
nNNN
nNNN
nPn−
=−
+=
El primer sumando representa la probabilidad de que la posición inicial esté entre los n primeros o últimos cilindros y se efectúa un desplazamiento de esa longitud (solo puede ser en un sentido). El segundo representa la probabilidad de un desplazamiento que tenga su posición inicial entre los cilindros n y N - n, en cuyo caso el desplazamiento puede hacerse en los dos sentidos.
En consecuencia el desplazamiento medio valdrá
( )∑∑==
−=
−==
N
n
N
nn N
NN
nNnnPn1
2
21 3
12
y la variancia
( )2
2422
12
22
1
22
1818
312
NNN
NN
NnNnnPn
N
n
N
nnn
−+=
−−
−=−=σ ∑∑
==
Cuando el número de cilindros ocupados por el archivo, N, es grande, estos valores pueden aproximarse por
3Nn =
18
22 Nn =σ
Aun cuando realmente este cálculo debería hacerse con los tiempos necesarios para efectuar estos desplazamientos, normalmente proporciona una aproximación suficiente la transformación en tiempo de los números de cilindros correspondientes al desplazamiento medio y a la desviación tipo, de acuerdo con las curvas que nos relacionan desplazamientos con tiempos (fig. 2.8).

171
Desplazamiento del brazo
Tiempo
Figura 2.8.
El tiempo de espera en la unidad de control tiene un valor medio que ya hemos calculado (párrafo f) y una variancia que se podría calcular a partir de la distribución de probabilidad del número de clientes en ella, pero que, en primera aproximación (la que se efectúa normalmente) se puede considerar igual al cuadrado de la media. Esta aproximación no tiene demasiada influencia ya que, normalmente, este sumando representa un porcentaje pequeño del tiempo de servicio del disco y, además, es una hipótesis normalmente pesimista, ya que la desviación tipo real es inferior a la media que sirve en parte para compensar la hipótesis simplificadora de suponer que si el disco está libre pude lanzarse la operación de E/S independientemente del estado de la unidad de control.
Las características estadísticas del tiempo de latencia ya se han comentado (párrafo 2.1.1.1.) y las del tiempo de transferencia se pueden determinar fácilmente conociendo las de los registros de los archivos que hay en el disco y las frecuencias de acceso de cada uno de ellos. Por lo tanto se puede escribir
∑
∑
∈
∈
λ
λ
+++=
j
j
Dii
Diii
jucjj
FTLWKSs
( )
λ
λ
−λ
λ
+++σ=σ∑
∑
∑
∑
∈
∈
∈
∈
222
222
122
j
j
j
j
j
Dii
Diii
Dii
Diii
jucSKj
FTFTL
W
h) Cálculo, a partir de los datos obtenidos, del factor de utilización de cada disco
∑∈
λ=ρjDi
ijj s
i) Cálculo del tiempo de respuesta de cada disco por aplicación de las fórmulas de Khintchin-Pollaczeck. Se hace, sin embargo, la incorrección de suponer que las llegadas provienen de una población infinita, lo cual no es cierto, puesto que, como máximo, es igual al número de trabajos en ejecución en la unidad central. No obstante, si el nivel de multiprogramación es algo elevado o si se trata de sistemas transaccionales, los resultados acostumbran a ser suficientemente aproximados.

172
j) Al actuar de esta forma no hemos tenido en cuenta, como hemos supuesto, que para salir de la cola que da acceso al disco correspondiente es preciso, no sólo que el disco este libre, sino que también lo ha de estar la unidad de control. Puede añadirse un tiempo que corrija el de respuesta por la espera suplementaria provocada por el tiempo residual de una transferencia, que idéntico al tiempo residual calculado al estudiar las colas M/G/1, y que, por lo tanto multiplicado por la probabilidad que el disco esté libre (1 - ρj), puede hacerse igual a
( )
σ+ρρ−
uc
ucucucj s
s''
'21'1
2
y para ser mas exactos se consideran para cada disco los valores referentes a la unidad de control provocados por los restantes discos, pero no él mismo (por ello se han indicado las variables correspondientes con tilde). No obstante, en la mayoría de los casos, esta corrección tiene poca importancia, a no ser que se alcancen elevados factores de utilización de los discos y la unidad de control.
La interpretación de esta expresión nos dice que la probabilidad de encontrar la unidad de control ocupada y el disco libre es (1 - ρj)ρuc' y el tiempo medio de ocupación será la mitad del tiempo de transferencia en la unidad de control. El término complementario es para tener en cuenta la distribución de los tiempos de transferencia.
Ejemplo: Se considera un subsistema de tres discos donde se hallan los archivos que consulta y actualiza un sistema transaccional de tiempo real. Las transacciones llegan a razón de 30 por segundo. Los discos giran a 3.600 r.p.m. Al archivo A acceden el 60% de las transacciones de las cuales el 25% son de actualización. Hay 10 registros por pista. El disco está lleno en un 50%, lo cual hace que la media y la desviación tipo de los tiempos de desplazamiento de brazo sean 20 ms y 16 ms, respectivamente. Al archivo B acceden el 40% de las transacciones sin actualización. Hay 5 registros por pista. El disco está totalmente lleno por lo que la media y la desviación tipo de los tiempos de desplazamiento de brazo son 30 ms y 24 ms, respectivamente. Al archivo C acceden el 20% de las transacciones que hacen en promedio tres accesos por transacción. Hay 20 registros por pista. El disco está lleno de un 30%, por lo que la media y la desviación tipo de los tiempos de desplazamiento de brazo son 15 ms y 12 ms, respectivamente. Se pretende encontrar los tiempos de respuesta de cada uno de los archivos. Para ello se seguirá la marcha de cálculo que se acaba de proponer. Determinación de las frecuencias de acceso a cada disco:
λA = 30 × 0.6 × 1.25 = 22.5 accesos/s
λB = 30 × 0.4 × 1 = 12 accesos/s
λC = 30 × 0.2 × 3 = 18 accesos/s
Determinación de los tiempos de servicio en la unidad de control de los accesos a cada disco:
L + TFA = 8.33 + 16.67/10 = 10 ms
L + TFB = 8.33 + 16.67/5 = 11.67 ms
L + TFC = 8.33 + 16.67/20 = 9.17 ms

173
Determinación de las utilizaciones en la unidad de control de los accesos a cada disco:
λA (L + TFA) = 22.5 × 10/1000 = 0.225
λB (L + TFB) = 12 × 11.67/1000 = 0.140
λC (L + TFC) = 18 × 9.17/1000 = 0.165
Determinación de la utilización de la unidad de control
ρuc = 0.225 + 0.140 + 0.165 = 0.53
Determinación del tiempo medio de servicio en la unidad de control
suc = (0.225 + 0.140 + 0.165)/(22.5 + 12 + 18) = 0.0101 s
Determinación del tiempo de espera en la unidad de control usando el gráfico de la figura 3.13 del primer volumen de esta obra con ρ = 0.53 y 3 mecanismos de acceso (clientes):
Wuc = (1.45 - 1) × 0.0101 = 0.0045 s
Determinación de los tiempos medios de servicio de cada uno de los discos:
sA = 20 + 4.55 + 10 = 34.55 ms
sB = 30 + 4.55 + 11.67 = 46.22 ms
sC = 15 + 4.55 + 9.17 = 28.72 ms
Determinación de las utilizaciones de cada uno de los discos
ρA = 22.5 × 0.03455 = 0.777
ρB = 12 × 0.04622 = 0.555
ρC = 18 × 0.02872 = 0.517
Determinación de las variancias de los tiempos de servicio de cada uno de los discos:
σA2 = 162 + 4.552 + 16.672/12 + 02 = 299.85 ms2
σB2 = 242 + 4.552 + 16.672/12 + 02 = 619.85 ms2
σC2 = 122 + 4.552 + 16.672/12 + 02 = 187.85 ms2
Determinación de los tiempos de respuesta de cada disco por aplicación delas fórmulas de Khintchin-Pollaczeck:
( ) ms 83.10955.34
85.2991777.012
777.0155.34 2 =
+×
−×+×=AR
( ) ms 28.8322.46
85.6191555.012
555.0122.46 2 =
+×
−×+×=BR

174
( ) ms 70.4772.2885.1871
517.012517.0172.28 2 =
+×
−×+×=CR
Determinación de la corrección debida a la espera suplementaria en la cola de acceso al disco a causa de estar ocupada la unidad de control se calcula como sigue
ρ'A = 0.140 + 0.165 = 0.305
s'A = (12 × 11.67 + 18 × 9.17)/(12 + 18) = 10.17 ms
22
22
22
2 ms 652.2417.101812
1267.1617.918
1267.1667.1112
' =−+
+×+
+×
=σ A
( ) ms 428.021
17.10652.2417.10305.0777.01 2 =×
+××−=∆ A
ρ'B = 0.225 + 0.165 = 0.39
s'B = (22.5 × 10 + 18 × 9.17)/(22.5 + 18) = 9.63 ms
22
22
22
2 ms 317.2363.9185.22
1267.1617.918
1267.16105.22
' =−+
+×+
+×
=σ B
( ) ms 046.121
63.9317.2363.939.0555.01 2 =×
+××−=∆ B
ρ'C = 0.225 + 0.140 = 0.365
s'C = (22.5 × 10 + 12 × 11.67)/(22.5 + 12) = 10.58 ms
22
22
22
2 ms 776.2358.10125.22
1267.1667.1112
1267.16105.22
' =−+
+×+
+×
=σ C
( ) ms 130.121
58.10776.2358.10365.0517.01 2 =×
+××−=∆C
Determinación de los tiempos medios de respuesta corregidos de cada uno de los discos:
R'A = 109.83 + 1.92 = 111.75 ms.
R'B = 83.38 + 2.35 = 85.73 ms.
R'C = 47.70 + 2.34 = 50.04 ms.
2.1.2.2. Discos con posicionamiento angular y cola FIFO. En los discos con posicionamiento angular, la diferencia de funcionamiento estriba en que cuando el brazo se ha posicionado no solicita inmediatamente servicio de la unidad de control, sino que lo hace únicamente cuando el registro sobre el cual debe efectuarse la transferencia llega debajo de la cabeza de lectura-escritura. Si en ese momento encuentra libre la unidad de control la retiene durante el tiempo de efectuarla más, según la tecnología de

175
disco utilizada, el tiempo correspondiente al posicionamiento angular (ángulo entre la señal de aviso de la llegada del registro y el registro propiamente dicho); si la encuentra ocupada, deja pasar una vuelta completa y lo reintenta, sin que el hecho de haber perdido una vuelta le dé ninguna prioridad. Este funcionamiento queda representado en el diagrama de tiempos de la figura 2.9.
LlegadaCola del
disco SK LT TF
UCocupada
disco ocupado
disco yUC libres
PA
Pérdida de tiempopor vueltas perdidas
Figura 2.9.
La marcha de cálculo es muy similar, teniendo en cuenta, sin embargo, las diferencias de funcionamiento. a) Cálculo para cada archivo i del tiempo medio de ocupación de la unidad de control, que
es igual al tiempo medio de posicionamiento angular, PAi, más el de transferencia, TFi.
El tiempo de posicionamiento angular depende de la tecnología de disco utilizada. Si la unidad es inteligente y trabaja con discos sectorizados, puede considerarse prácticamente nulo; pero en caso contrario puede depender del número de marcas grabadas físicamente (mecánicas o magnéticas) en el disco para detectar registros y del número de registros por pista.
b) Idéntico al párrafo 2.1.2.1.b.
c) Cálculo de la ocupación de la unidad de control provocada por el archivo i, que vale en este caso
λi(PAi + TFi )
d) Cálculo del factor de utilización de la unidad de control, ρuc, que es la suma de todos los valores calculados en el párrafo anterior.
e) No es necesario en este caso.
f) En estas circunstancias no se puede hablar propiamente de tiempo de espera, sino de tiempo de retención debido a las vueltas perdidas. Se puede escribir que la probabilidad de no perder vuelta, p0, vale
p0 = 1 - ρuc
y las de perder 1, 2, ..., n vueltas, son, respectivamente
p1 = (1 - ρuc) ρuc
p2 = (1 - ρuc) ρuc2

176
p3 = (1 - ρuc) ρuc3
.
.
.
pn = (1 - ρuc) ρucn
Por lo tanto, las características estadísticas de este tiempo perdido valen
( )∑∑∞
=
∞
= ρ−ρ
τ=ρ−ρτ=τ=00 1
1i uc
ucuc
iuc
iivp iipW
( )( )2
22
0
222
0
222
111
1 uc
uc
uc
uc
iuc
iuc
uc
uc
iivp ipi
ρ−
ρτ=
ρ−
ρ−ρ−ρτ=
ρ−
ρ−τ=σ ∑∑
∞
=
∞
=
g) El tiempo de servicio de cada disco, j, es igual al tiempo de desplazamiento del brazo, más el tiempo de espera (latencia) hasta que llega la marca de posicionamiento angular o el registro, más el tiempo debido a vueltas perdidas, más el tiempo de posicionamiento angular, si lo hay, más el tiempo de transferencia.
sj = SKj + Lj + Wvp + PAj + TFj
Como se conocen las características estadísticas de todos los sumandos, se puede escribir
( )
∑
∑
∈
∈
λ
+λ
+++=
j
j
Dii
Diiii
vpjjj
FTAPWLKSs
( )
( )
λ
λ
−λ
+
−λ
+
+
λ
λ
−λ
λ
+σ++σ=σ
∑
∑
∑
∑
∑
∑
∑
∑
∈
∈
∈
∈
∈
∈
∈
∈
222
min max
22
22
22
12
122
j
j
j
j
j
j
j
j
j
Dii
Diii
Dii
Dii
iii
Dii
Diii
Dii
Diii
vpj
SKj
PAPAPAPA
FTFTL
h) Idéntico al del párrafo 2.1.2.1.h.
i) Idéntico al del párrafo 2.1.2.1.i.
j) Idéntico al del párrafo 2.1.2.1.j.
Un ejemplo del cálculo de este caso se tratará en el apartado 2.1.2.5.
2.1.2.3. Discos con unidad de acceso dual. En numerosos casos cuando una sola unidad de control no puede soportar el tráfico que se provoca sobre los archivos del subsistema, en vez de partirlo en dos subsistemas, se puede colocar una segunda unidad de control sobre el mismo subsistema (fig. 2.10). Para distribuir los accesos entre ambas unidades de control se pueden adoptar diversas políticas, de las

177
cuales la más frecuente es la de considerar las dos unidades de control como una estación de servicio con dos canales.
Discos
UC
UC
Memoria
Figura 2.10.
El cambio que hay que introducir en la marcha de cálculo propuesta en los apartados anteriores consiste sólo en que hace falta considerar que la estación unidad de control tiene dos canales de servicio, si se considera que el acceso a las unidades de control se hace a través de una cola FIFO, por lo que el modelo adecuado sería el M/G/2//M, que no tiene tratamiento analítico. Por ello, como en el caso de una sola unidad de control se pueden efectuar aproximaciones mediante modelos M/G/1 con frecuencia de llegada mitad, M/M/2, si el número de discos es elevado, o, de forma mas exacta, estableciendo un modelo de tipo M/M/2//M (apartado 3.3.6. del primer volumen de esta obra). Si los discos trabajan con posicionamiento angular, si ρuc es la utilización conjunta de las dos unidades de control (y se supone, además, que el sistema operativo distribuye la utilización equitativamente entre ambas unidades), las probabilidades del número de vueltas perdidas son:
22
0 21
21
22
21
ρ
−=
ρ
−ρ
+
ρ
−= ucucucucp
2222
1 221
221
22
21
ρ
ρ
−=
ρ
ρ
−ρ
+
ρ
−= ucucucucucucp
.
.
. n
ucuc
n
ucucucucnp
2222
221
221
22
21
ρ
ρ
−=
ρ
ρ
−ρ
+
ρ
−=
que es idéntica a la del caso de una sola unidad de control pero sustituyendo la utilización por el cuadrado de la mitad de la utilización conjunta de ambas unidades de control. Con esta información se pueden rehacer los cálculos establecidos en los dos apartados anteriores teniendo en cuenta las modificaciones que se acaban de establecer.
2.1.2.4. Variantes de las políticas de posicionamiento de brazo. La ordenación de los accesos antes de iniciar el movimiento de brazo se puede hacer según distintas políticas. Las más frecuentes son las siguientes: - FIFO, que es la que hemos considerado hasta el momento.

178
- Mínimo desplazamiento de brazo (SSTF). Esta política es similar a la de latencia mínima expuesta en el apartado referente a los tambores: El siguiente acceso es siempre el más próximo a la posición actual del brazo. Esta política presenta la desventaja potencial de retrasar mucho algunos accesos, si la carga del disco se hace grande. En otras palabras, si el brazo está en un extremo y la cola de accesos es larga, se corre el riesgo de tardar mucho tiempo en acceder a las posiciones que se hallen en el otro extremo del disco. Es, no obstante, una situación que se observa en raras ocasiones. Desde el punto de vista de las características estadísticas, la virtud de esta política es la de disminuir el tiempo medio y la desventaja de, eventualmente, aumentar la variancia. Desde el punto de vista del consumo de recursos, esta política aumenta el overhead del sistema operativo al tener que insertar cada nuevo acceso en la lista encadenada de accesos, calculando su lugar de inserción en función del cilindro al que va a acceder y de los de los accesos en curso y pendientes.
- SCAN. En esta política el brazo recorre la superficie del disco en un sentido, hacia adelante o hacia atrás, mientras quedan accesos pendientes en el mismo sentido. Cuando no hay más, se invierte el sentido. Con respecto a la política anterior evita los retrasos grandes en los accesos extremos (mejorando la variancia) y disminuye el overhead del sistema operativo a costa de un pequeño empeoramiento del valor medio.
- SCAN de M pasos. En esta política los accesos se agrupan en paquetes de, como máximo, M y sobre cada paquete se aplica la política SCAN. En la actualidad, las unidades de control de discos realizan esta política sin recurrir a ninguna gestión del sistema operativo, que sigue ordenando los accesos en una cola FIFO y transfiriendo paquetes de M accesos a la unidad de control, que es la que realiza la ordenación definitiva de los accesos. En este caso el desplazamiento medio de brazo de cada acceso, si se admite que los accesos se distribuyen uniformemente entre los N cilindros del disco es N/M, que puede traducirse a tiempo mediante la curva correspondiente.
Se han hecho diversos intentos de aproximaciones analíticas para el estudio del comportamientos de estas políticas y aparte, como se ha visto, de la FIFO y de la SCAN de M pasos y teniendo en cuenta la no linealidad del tiempo en función del desplazamiento del brazo del disco, el método más cómodo para este estudio resulta todavía la simulación.
2.1.2.5. Ejemplo Considérese un subsistema de seis discos al que llegan 60 accesos por segundo uniformemente repartidos. Los discos giran a 3600 r.p.m., tienen un tiempo medio de desplazamiento de brazo de 23 ms. y una desviación de tipo de 16 ms. Hay 5 registros por pista trabajando de forma sectorizada, es decir, que cuando hacen uso del dispositivo de posicionamiento angular puede considerarse que no hay ninguna espera entre el aviso y la llegada del registro. Determinar el tiempo medio de respuesta del subsistema en las siguientes hipótesis de trabajo: 1. Una unidad de control con gestión FIFO.
2. Una unidad de control con gestión SLTF.
3. Dos unidades de control con gestión FIFO.
4. Dos unidades de control con gestión SLTF.
Siguiendo las marchas de cálculo expuestas en 2.1.2.1., 2.1.2.2. y 2.1.2.3. se puede hacer: Tiempo medio de una revolución de los discos:
ms 67.163600
1000602 =×
==τ L

179
Tiempo de transferencia de los registros:
ms 33.3567.16
==TF
Utilización de la o las unidades de control:
1. 7.01000
60267.1633.3
=×
+
=ρuc
2. 2.01000
6033.3=
×=ρuc
3. 7.01000
60267.1633.3
=×
+
=ρuc
4. 2.01000
6033.3=
×=ρuc
Tiempo de espera en la unidad de control (casos 1 y 3) o tiempo por vueltas perdidas en la unidad de control (casos 2 y 4): 1. Utilizando el gráfico de la figura 3.13 del primer volumen de esta obra para tratar un
modelo M/M/1//6, se tiene
Wuc = (2.05 - 1) × 11.67 = 12.25 ms
2. El tiempo medio de vueltas perdidas por acceso será de
ms 17.467.162.01
2.0=
−=vpW
y su variancia
( )22
22 ms 81.8667.16
2.012.0
=−
=σvp
3. En este caso hay que proceder a calcular el tiempo de respuesta del conjunto de las dos unidades de control a través de un modelo M/M/2//6 (apartado 3.3.6. del primer volumen de esta obra).
µλ
= 601 pp 2
02 15
µλ
= pp 3
03 30
µλ
= pp
4
04 45
µλ
= pp 5
05 45
µλ
= pp 6
06 5.22
µλ
= pp
de donde, haciendo λ/µ = x, y teniendo en cuenta que la suma de las probabilidades ha de ser igual a la unidad, se tiene
654320 5.2245453015611
xxxxxxp
++++++=

180
La frecuencia media de llegada será
6543210 012345660 ppppppp λ+λ+λ+λ+λ+λ+λ=
Sustituyendo las expresiones de las probabilidades pi, para i = 1, …, 6 en la expresión anterior y dividiéndola por la capacidad de servicio µ, se llega a
65432
65432
5.224545301561459090603067.060
xxxxxxxxxxxx
uc +++++++++++
==ρ=µ
de donde
29.25x6 + 58.5x5 + 58.5x4 + 39x3 + 19.5x2 + 1.8x - 0.7 = 0
que tiene como solución x = 0.13331.
Con ello se puede proceder al cálculo de p0 y las demás probabilidades de estado de esta cola, que son:
p0 = 0.4643085 p1 = 0.3713818 p2 = 0.1237723 p3 = 0.0330002
p4 = 0.0065989 p5 = 0.0008797 p6 = 0.0000586
A partir de ellas se puede calcular el número medio de clientes en las dos unidades de control, que será
N = 0 × 0.4643085 + 1 × 0.3713818 + 2 × 0.1237723 + 3 × 0.0330002 +
+ 4 × 0.0065989 + 5 × 0.0008797 + 6 × 0.0000586 = 0.7490727
y, por aplicación de la ley de Little, el tiempo medio de respuesta será
Ruc = 0.7490727/60 = 0.01249 s = 12.49 ms.
y el de espera en las unidades de control
Wuc = 12.49 - 11.67 = 0.82 ms.
4. El cálculo del tiempo por vueltas perdidas es idéntico al del punto 2 cambiando la utilización de 0.2 por la (0.2/2)2 = 0.01, es decir, que el tiempo medio de vueltas perdidas por acceso será de
ms 17.067.1601.01
01.0=
−=vpW
y su variancia
( )22
22 ms 84.267.16
01.0101.0
=−
=σvp
Las características estadísticas (media y variancia) del tiempo de servicio de cada uno de los discos serán: 1. s = 23 + 12.25 + 8.33 + 3.33 = 46.92 ms
σs2 = 162 + 12.252 + 16.672/12 + 02 = 429.21 ms2

181
2. s = 23 + 8.33 + 4.17 + 3.33 = 38.83 ms
σs2 = 162 + 16.672/12 + 86.81 + 02 = 365.97 ms2
3. s = 23 + 0.82 + 8.33 + 3.33 = 35.48 ms
σs2 = 162 + 0.822 + 16.672/12 + 02 = 279.82 ms2
4. s = 23 + 8.33 + 0.17 + 3.33 = 34.83 ms.
σs2 = 162 + 16.672/12 + 2.84 + 02 = 281.99 ms2
Las utilizaciones respectivas serán
1. 469.01000
92.466
60==ρD
2. 388.01000
83.386
60==ρD
3. 355.01000
48.356
60==ρD
4. 348.01000
83.346
60==ρD
y, por aplicación de las fórmulas de Khintchin-Pollaczeck, se obtiene
1. ( ) ms 69.7192.46
21.4291469.012
469.0192.46 2 =
+
−+=DR
2. ( ) ms 13.5483.3897.3651
388.012388.0183.38 2 =
+
−+=DR
3. ( ) ms 41.4748.35
82.2791355.012
355.0148.35 2 =
+
−+=DR
4. ( ) ms 91.4183.3499.2811
348.012348.0183.34 2 =
+
−+=DR
2.1.3. MEMORIAS SECUNDARIAS DE ESTADO SÓLIDO La sustitución de los discos y tambores con sus componentes electromecánicos, lentos y poco fiables, se viene buscando desde hace largo tiempo. Dos tecnologías, que en un instante determinado parecieron que podían sustituir a los discos y tambores o, por lo menos, llenar el hueco que, en cuanto a capacidad y tiempo de acceso, existe entre aquéllos y la memoria principal, son las burbujas magnéticas y los dispositivos acoplados por carga (Charge Coupled Devices, o CCD). Entre sus principales características se pueden citar
Burbujas magnéticas CCD Tamaño del chip (bits) 16 K 16 K Densidad (bits/pulg2) 106 106
Velocidad de transmisión (MHz) 0.1 2 Tiempo de acceso máximo (ms) 5.14 0.2

182
Sin entrar en el detalle de su funcionamiento que se puede encontrar en la literatura especializada, tanto unas como otros se pueden considerar como memorias rotativas con los períodos de rotación (tiempo de acceso máximo) que aparecen en la tabla anterior. No obstante, al no existir partes mecánicas rotativas a velocidad constante debido a su inercia en discos y tambores, se pueden variar dinámicamente las velocidades de rotación a fin de optimizar el rendimiento. Si se organizan como archivos de datos no se podrá obtener demasiada ventaja de aquella posibilidad. Sin embargo, si se utilizan como archivos de paginación, se puede optimizar su rendimiento de forma inalcanzable en dispositivos mecánicos. Si se considera un dispositivo de burbujas magnéticas organizado como un archivo de paginación con latencia mínima se puede mejorar el rendimiento deteniendo el dispositivo (sin inercia) en un entorno de página. Si se hace esto, el tiempo de respuesta pasa a ser
τ
ρ−
ρ+= −
1211kR
con un ahorro correspondiente al tiempo de media revolución y donde las variables corresponden a la definición dada en el apartado 2.1.1.3. El caso de los CCD es algo más complicado, pues estos dispositivos requieren refrescar continuamente los bits de información contenidos en ellos. Para optimizar su rendimiento se puede efectuar el siguiente análisis. Estos dispositivos están organizados como registros de desplazamiento recirculantes, que tienen frecuencias de reloj máxima y mínima. Ésta viene fijada para evitar la pérdida de información y aquélla por las características de los circuitos de los CCD. Entre estas dos frecuencias se dispone de un margen de maniobra en el que, al no haber ninguna inercia, se puede variar la frecuencia de una forma dinámica. En la exposición que sigue, se supone que se tienen bloques de N posiciones y que en cada registro hay un solo bloque. Las llegadas de nuevas requisiciones al CCD pueden producirse en cualquier instante del período de rotación. Entonces, si el CCD está circulando la información a frecuencia constante mientras está ocioso (con período de revolución T) es evidente que la latencia esperada será de media revolución. Sean tmin y tmax los períodos mínimo y máximo de transmisión de una posición, r = tmax/tmin y f(t) la distancia (en posiciones) a que la posición inicial de la memoria está en el instante t. Entonces L, la latencia media será
( )∫+
=Tu
udxxf
TtL min
Gráficamente L corresponde al área del período ocioso de la figura 2.11 dividida por la longitud T del período.
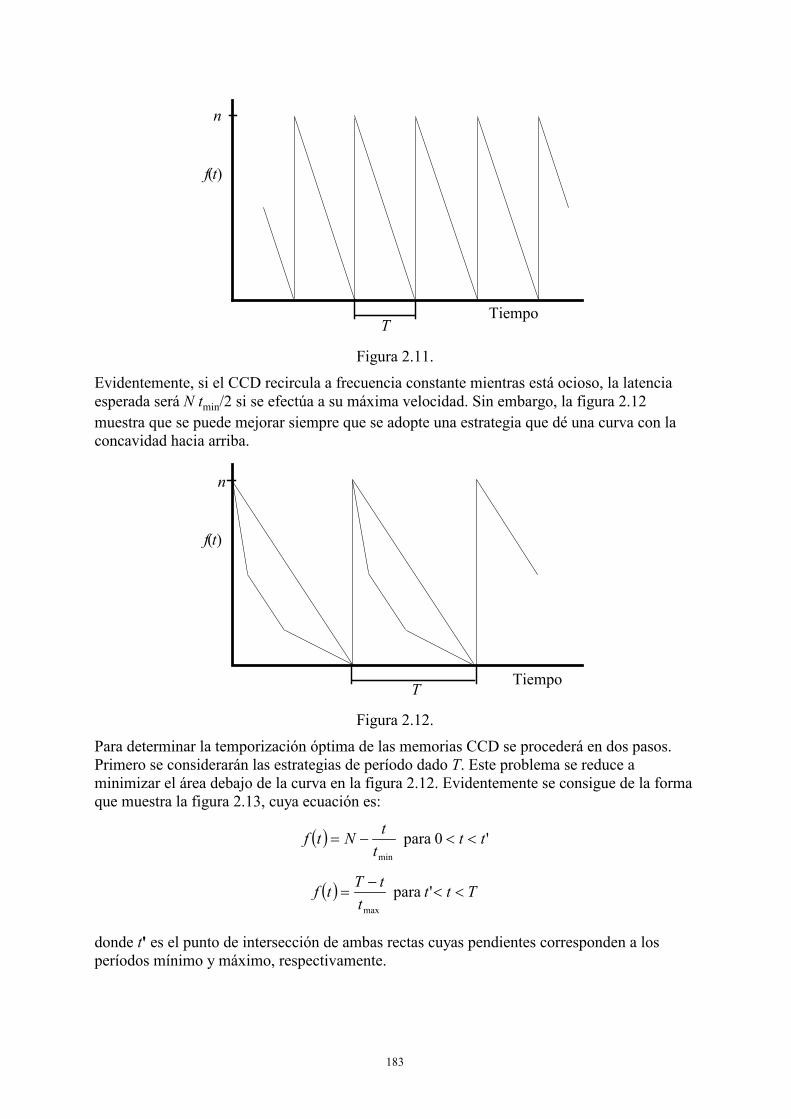
183
TTiempo
n
f(t)
Figura 2.11.
Evidentemente, si el CCD recircula a frecuencia constante mientras está ocioso, la latencia esperada será N tmin/2 si se efectúa a su máxima velocidad. Sin embargo, la figura 2.12 muestra que se puede mejorar siempre que se adopte una estrategia que dé una curva con la concavidad hacia arriba.
T Tiempo
n
f(t)
Figura 2.12.
Para determinar la temporización óptima de las memorias CCD se procederá en dos pasos. Primero se considerarán las estrategias de período dado T. Este problema se reduce a minimizar el área debajo de la curva en la figura 2.12. Evidentemente se consigue de la forma que muestra la figura 2.13, cuya ecuación es:
( ) '0 para min
ttt
tNtf <<−=
( ) Tttt
tTtf <<−
= ' para max
donde t' es el punto de intersección de ambas rectas cuyas pendientes corresponden a los períodos mínimo y máximo, respectivamente.
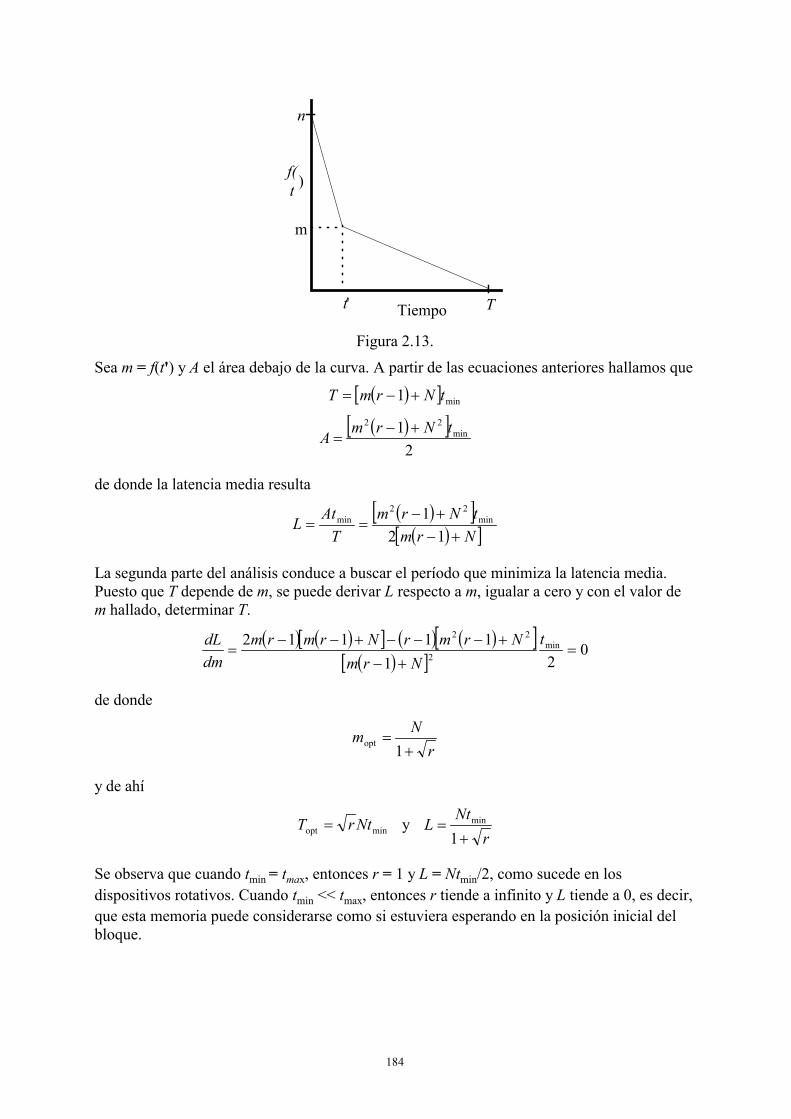
184
Tt'
m
f(t )
n
Tiempo Figura 2.13.
Sea m = f(t') y A el área debajo de la curva. A partir de las ecuaciones anteriores hallamos que
( )[ ] min1 tNrmT +−=
( )[ ]2
1 min22 tNrm
A+−
=
de donde la latencia media resulta
( )[ ]( )[ ]Nrm
tNrmT
AtL+−
+−==
121 min
22min
La segunda parte del análisis conduce a buscar el período que minimiza la latencia media. Puesto que T depende de m, se puede derivar L respecto a m, igualar a cero y con el valor de m hallado, determinar T.
( ) ( )[ ] ( ) ( )[ ]( )[ ]
021
11112 min2
22
=+−
+−−−+−−=
tNrm
NrmrNrmrmdmdL
de donde
rNm
+=
1opt
y de ahí
minopt NtrT = y r
NtL
+=
1min
Se observa que cuando tmin = tmax, entonces r = 1 y L = Ntmin/2, como sucede en los dispositivos rotativos. Cuando tmin << tmax, entonces r tiende a infinito y L tiende a 0, es decir, que esta memoria puede considerarse como si estuviera esperando en la posición inicial del bloque.
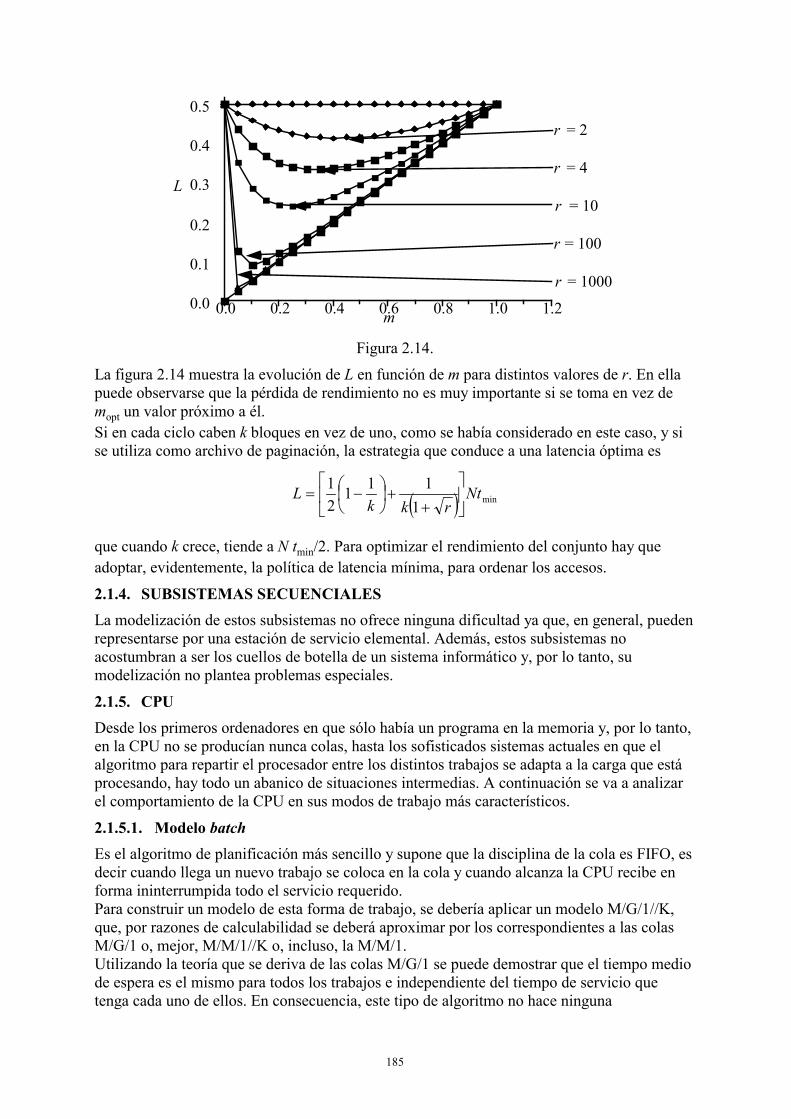
185
0.0 0.2 0.4 0.6 0.8 1.0 1.20.0
0.1
0.2
0.3
0.4
0.5
L
m
r = 2
r = 4
r = 10
r = 100
r = 1000
Figura 2.14.
La figura 2.14 muestra la evolución de L en función de m para distintos valores de r. En ella puede observarse que la pérdida de rendimiento no es muy importante si se toma en vez de mopt un valor próximo a él. Si en cada ciclo caben k bloques en vez de uno, como se había considerado en este caso, y si se utiliza como archivo de paginación, la estrategia que conduce a una latencia óptima es
( ) min1111
21 Nt
rkkL
++
−=
que cuando k crece, tiende a N tmin/2. Para optimizar el rendimiento del conjunto hay que adoptar, evidentemente, la política de latencia mínima, para ordenar los accesos.
2.1.4. SUBSISTEMAS SECUENCIALES La modelización de estos subsistemas no ofrece ninguna dificultad ya que, en general, pueden representarse por una estación de servicio elemental. Además, estos subsistemas no acostumbran a ser los cuellos de botella de un sistema informático y, por lo tanto, su modelización no plantea problemas especiales.
2.1.5. CPU Desde los primeros ordenadores en que sólo había un programa en la memoria y, por lo tanto, en la CPU no se producían nunca colas, hasta los sofisticados sistemas actuales en que el algoritmo para repartir el procesador entre los distintos trabajos se adapta a la carga que está procesando, hay todo un abanico de situaciones intermedias. A continuación se va a analizar el comportamiento de la CPU en sus modos de trabajo más característicos.
2.1.5.1. Modelo batch Es el algoritmo de planificación más sencillo y supone que la disciplina de la cola es FIFO, es decir cuando llega un nuevo trabajo se coloca en la cola y cuando alcanza la CPU recibe en forma ininterrumpida todo el servicio requerido. Para construir un modelo de esta forma de trabajo, se debería aplicar un modelo M/G/1//K, que, por razones de calculabilidad se deberá aproximar por los correspondientes a las colas M/G/1 o, mejor, M/M/1//K o, incluso, la M/M/1. Utilizando la teoría que se deriva de las colas M/G/1 se puede demostrar que el tiempo medio de espera es el mismo para todos los trabajos e independiente del tiempo de servicio que tenga cada uno de ellos. En consecuencia, este tipo de algoritmo no hace ninguna

186
discriminación entre los trabajos según su tiempo de servicio, ya que, en promedio, todos esperan lo mismo. No se adapta, pues, a sistemas que trabajen en tiempo compartido, pero es el que provoca menos overhead por parte del sistema operativo.
2.1.5.2. Modelo del procesador compartido Este modelo, conocido en la literatura anglo-sajona como processor sharing (PS) o round robin (RR), supone que cuando un trabajo sale de la CPU todavía no ha terminado su servicio y vuelve a colocarse en la cola (fig 2.15) con una probabilidad b. Por otra parte la política de asignación de la CPU dice que se asigna a cada trabajo un quantum de tiempo de servicio ininterrumpido q. El objetivo es que si hay n trabajos en la CPU, cada uno de ellos reciba 1/n del tiempo disponible de la CPU por cada unidad de tiempo.
q
b1 - bλ
Figura2.15.
Aunque puede estudiarse su comportamiento, a partir de la cola M/G/1, se va a hacer una deducción algo más larga del tiempo de respuesta, pero que permite comprender mejor el mecanismo de este modelo, aunque simplificando algunas hipótesis. En el apartado 3.10.1. del primer volumen de esta obra hay una exposición y una deducción más correctas de este modelo, pero la exposición que sigue, a pesar de sus deficiencias, es suficientemente interesante. Por ejemplo, hay que tener en cuenta que la probabilidad b no es constante, ya que para un trabajo determinado disminuye a medida que recibe servicio de la CPU. No obstante, se supondrá constante. Se supondrá que la probabilidad de que un trabajo requiera k quanta viene expresada por la distribución geométrica.
Prob (S < kq) = (1 - b) bk - 1
Además se considerará que el estado del sistema viene representado por el número N de trabajos y que la probabilidad del estado N es PN. Se considerará que un trabajo, que requiera k quanta, llega a la CPU y encuentra j trabajos en ella. Se marca este trabajo que pasará k - 1 veces por el camino de retorno antes de salir de la CPU. Una pasada del trabajo marcado se define como el período que empieza cuando llega a la cola y termina cuando sale de la estación de servicio después de recibir un quantum. Sea Ti el tiempo necesario para realizar la i-ésima pasada. Durante la primera pasada, el trabajo marcado tiene j trabajos por delante. Uno de ellos está recibiendo servicio, por lo que abandonará la estación al cabo de aq unidades de tiempo (0 < a < 1). Se puede escribir
Ti = aq + (j - 1)q + q
Las duraciones de las pasadas sucesivas son múltiplos enteros de q. Si hi es la duración media de la i-ésima pasada, medida en número de quanta, el trabajo marcado durante esta pasada tiene hi - 1 trabajos por delante, de los cuales b (hi - 1) volverán a la cola. Obsérvese que este resultado se basa en la suposición de que la probabilidad de que un trabajo requiera un nuevo quantum es independiente de su historia, y concuerda, por consiguiente, con la distribución geométrica de probabilidad y es válida, ya que se supone también que la distribución de tiempos de servicio no tiene tampoco memoria.

187
Durante la i-ésima pasada del trabajo marcado hay en promedio λTi llegadas. Puesto que hi = Ti/q, se tiene para k ≥ 3
Ti + 1 = b (hi - 1) q + λ Ti q + q
o de forma equivalente
( )a
abqTaTi
ii −
−−+=
−−
+ 111
2
22
1
donde
a = λ q + b
Mediante el mismo enfoque se puede escribir
T2 = b j q + λ T1 q + q = λ q T1 + q (1 + b j)
y sustituyendo este valor en la expresión de Ti + 1, se puede expresar el tiempo medio gastado por el trabajo marcado en el modelo, cuando encuentra j trabajos a su llegada.
( ) ( )
ρ−
ρ−+λ
−−
+ρ−−
+==−
=∑ 11
11
11
1
11
bjTa
aqkqTTjtkk
iik
donde b
q−λ
=ρ1
. Obsérvese que ρ es el factor de utilización, puesto que el tiempo medio de
servicio es q/(1 - b). El número medio de trabajos en espera de recibir servicio en la cola viene dado por
( ) ρ−=−=− ∑∑∑∞
=
∞
=
∞
=
NpNppNN
NN
NN
N111
1
La media de aq es ρq/2, puesto que la estación de servicio está ocupada sólo durante una fracción del tiempo igual a ρ. Observando que la longitud de la cola a la llegada del trabajo marcado es j - 1, se puede deducir la expresión de T1.
+
ρ−= 1
21 NqT
Por las fórmulas de Khintchin-Pollaczeck y teniendo en cuenta que la distribución geométrica tiene variancia b, se puede escribir que
( )( )ρ−
+ρ+ρ=
1212 bN
Calculando la media respecto a j de tk(j) se tiene
( ) ( )
ρ−
ρ−+λ
−−
+ρ−−
+==−
∑ 111
11
1
1
1 NbTa
aqkqTjtptk
kjk

188
donde se podrían substituir los valores ya calculados y donde se observaría que si a < 1, tk depende del tiempo de servicio kq de forma que tiende a ser lineal al crecer k, con pendiente 1/(1- ρ) > 1. El tiempo medio de respuesta será
( )∑∞
=
− −=1
1 1k
kk tbbR
Si se hace, además, que el quantum q tienda a cero, como si la CPU procesara simultáneamente todos los trabajos, se tiene que b y a tienden a 1, si ρ se mantiene constante. El número medio de trabajos tiende a ρ/(1 - ρ) y T1 tiende a cero. Con todo ello se obtiene, si
S es el tiempo de servicio de un trabajo, que ( )ρ−
=1
SSR . De esta fórmula se deduce que el
procesador compartido favorece los trabajos con tiempos de ejecución cortos, aunque el tiempo de servicio medio del conjunto de todos los trabajos coincida con el del modelo batch. Una deducción más correcta de estos resultados, como ya hemos dicho, se halla en el apartado 3.10.1. del primer volumen de esta obra.
2.1.5.3. Procesador interrumpible Otro interesante algoritmo de gestión de la CPU es aquél en que el trabajo llegado más recientemente interrumpe, si ha lugar, el servicio de la CPU, desplazando el trabajo, que recibía servicio, a la cabeza de la cola (en realidad es una pila) hasta que o es interrumpido a su vez o termina su servicio (fig. 2.16), en cuyo caso el trabajo en cabeza de la pila reanuda su servicio.
Llegada con interrupción
Programa interrumpido
Programa restauradoPrograma finalizado
Figura 2.16.
En este caso se puede calcular el tiempo de respuesta condicional de un trabajo en una CPU que recibe λ llegadas por unidad de tiempo, que requiera un servicio de duración S , como la suma de su tiempo de servicio más su tiempo de espera. El promedio de este último es sólo el número medio de trabajos λS que le interrumpen por el tiempo medio de respuesta de los trabajos que es Sm/(1 - ρ), lo cual se deduce fácilmente teniendo en cuenta las interrupciones que se producen durante el servicio de los trabajos que han interrumpido al considerado. Por
consiguiente ( )ρ−
λ+=
1mSS
SSR ; pero ρ = λ Sm, de donde ( )ρ−
=1
SSR , que es exactamente el
mismo que en el caso anterior. Una deducción más completa de estos resultados se vio en el apartado 3.10.2. del primer volumen de esta obra.
2.1.6. MEMORIA PRINCIPAL La modelización de la memoria es especialmente importante en el caso de los sistemas de tiempo real e interactivos, mientras que en el caso de los sistemas batch, debido a la menor variabilidad de la ocupación de la memoria a lo largo del tiempo, es más fácil determinar su mapa.

189
Considerando el caso de los sistemas de tiempo real, la primera cuestión que se plantea es qué cantidad de memoria ocupará. En el caso de sistemas que trabajan sin paginación, la determinación de la memoria ocupada por cada programa es trivial y el montador dará esa información. Otro tanto se puede decir del caso en que las particiones de memoria sean fijas. Si las particiones de memoria son dinámicas, entonces el número medio de páginas, que un programa ocupará en memoria, dependerá del algoritmo de sustitución de páginas que se utilice. Uno de los utilizados con mayor frecuencia es el del conjunto de trabajo o working set. Antes de exponer este modelo se recuerda de forma resumida las propiedades de localidad de los programas que son: 1. Durante cualquier intervalo de tiempo, un programa concentra sus referencias de forma
no uniforme sobre sus páginas.
2. La correlación entre las configuraciones de referencias en el pasado inmediato y el futuro inmediato tiende a ser alta y la correlación entre secuencias de referencias no solapadas tiende a cero a medida que la distancia entre ellas aumenta.
3. Tomada en función del tiempo, la frecuencia con que se referencia una página tiende a cambiar lentamente, es decir, es quasi-estacionaria.
Estos principios son una abstracción de, por lo menos, tres fenómenos observados en la práctica. 1. Los programas tienden a usar estructuras de control secuenciales y en bucle y las
referencias a los datos se agrupan en posiciones determinadas durante cortos intervalos de tiempo.
2. Los programadores tienden a concentrar su atención en pequeñas partes de grandes problemas durante períodos moderadamente largos y sencillas alteraciones del algoritmo y de la organización de los datos pueden aumentar este efecto en varios órdenes de magnitud.
3. Se sabe por experiencia que los programas pueden ejecutarse eficientemente incluso cuando sólo un subconjunto de sus páginas está en la memoria principal.
El conjunto de trabajo en un instante dado debe ser, idealmente, las páginas necesarias para la ejecucion durante el próximo intervalo. En ausencia de información sobre las referencias futuras, es necesario estimar la localidad del pasado inmediato. Más formalmente, el conjunto de trabajo W(t, T) en el instante t se define como el subconjunto de las páginas referenciadas en el intervalo del tiempo [t - T + 1, t]. El parámetro T se denomina ventana y debe elegirse de forma que: - Sea suficientemente grande para que la probabilidad de que una página de la localidad
actual salga del conjunto de trabajo actual sea pequeña.
- Sea suficientemente pequeña para que la probabilidad de que haya más de una transición entre localidades contenidas en la ventana sea pequeña.
Si la secuencia de referencias es r1, r2, ..., rt, ..., δ(t, T) = 1, si rt + 1 ∈ W(t, T) y δ(t, T) = 0, en caso contrario. Sea
( ) ( )[ ]TtEtm t ,lim δ= ∞→
donde m(T) representará la probabilidad de fallo de página al hacer una referencia. Es evidente que
W(t + 1, T + 1) = W(t, T) + δ(t, T)

190
Tomando límites en esta expresión, se halla S(T + 1) = S(T) + m(T), donde S(T) representa la talla media del conjunto de trabajo. Ejemplo: Se considera la secuencia de 20 referencias a páginas y se consideran 6 posibles valores de T. Determinar los valores de S(T) y m(T) para T = 1, 2, 3, 4, 5 y 6. 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 T = 1 . 1 . 2 . 3 . 4 . 5 . 2. 1 . 3 3 . 2 . 3 . 4 . 5 . 4 . 5 . 1 1 . 3 . 2 . 5
S(T) = 20/20 = 1 y m(T) = 18/20 = 0.9
T = 2 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 . . 1 . 2 . 3 . 4 . 5 . 2 . 1 . 3 2 . 3 . 4 5 4 . 5 . 1 . 3 . 2
S(T) = 37/20 = 1.85 y m(T) = 15/20 = 0.75
T = 3 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 1 2 3 4 5 2 1 1 3 2 3 4 5 4 5 5 1 3 2 . . . 1 . 2 . 3 . 4 . 5 . 2 . . 2 . 3 . 4 . . . 3
S(T) = 50/20 = 2.50 y m(T) = 15/20 = 0.75
T = 4 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 1 2 3 4 5 2 1 1 3 2 3 4 5 4 5 5 1 3 2 1 2 3 4 5 2 2 1 2 3 3 4 4 5 1 3 . . . . 1 . 2 3 . 4 . 5 . . 2 . . . . 1
S(T) = 62/20 = 3.10 y m(T) = 13/20 = 0.65
T = 5 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 1 2 3 4 5 2 1 1 3 2 3 4 5 4 5 5 1 3 2 1 2 3 4 5 2 2 1 1 2 3 3 3 4 4 5 1 3 1 2 3 4 5 5 2 2 4 5 1 . . . . . 1 . 3 4 . . . . .
S(T) = 71/20 = 3.55 y m(T) = 11/20 = 0.55
T = 6 1 2 3 4 5 2 1 3 3 2 3 4 5 4 5 1 1 3 2 5 1 2 3 4 5 2 1 1 3 2 3 4 5 4 5 5 1 3 2 1 2 3 4 5 2 2 1 1 2 3 3 3 4 4 5 1 3 1 2 3 4 5 5 5 1 2 2 2 3 4 5 1 . . . . . 1 1 3 4 4 . . . . . 4
S(T) = 78/20 = 3.90 y m(T) = 10/20 = 0.50
Este ejemplo muestra con suficiente claridad que, a medida que aumenta la medida de la ventana T, aumenta la talla media del conjunto de trabajo S(T), pero disminuye la frecuencia de fallo de página m(T). No obstante, hay que resaltar que lo único que se pretende poner de manifiesto es el mecanismo para conocer el conjunto de trabajo, pero se ha efectuado a partir de una secuencia de referencias de página lejos de la realidad. Considérese ahora en el caso de sistemas de tiempo real. Ante todo es preciso conocer el tiempo de permanencia de una transacción en memoria, que es igual a la suma de los tiempos de espera en la cola de la CPU, de uso de CPU y de realización de las operaciones de entrada-salida. Este tiempo de presencia influye, evidentemente, en la memoria necesaria y el nivel de multiprogramación. A su vez, éste incide en la determinación de la dimensión de la cola existente en la CPU. Por lo tanto, se está frente a un sistema de ecuaciones cuyo método más

191
simple de solución es el tanteo, máxime si se tiene en cuenta que algunas variables deben ser enteras. Evidentemente, hay que considerar, además, para el estudio de la memoria necesaria, el espacio ocupado por el software fijo (sistema operativo, sistema de base de datos, etc.) Las principales dificultades en el establecimiento de modelos de unidades centrales reside en la obtención de datos suficientemente correctos. Así, respecto a los programas, la longitud de código ejecutado, el tamaño de los programas, y en los sistemas de memoria virtual, el conjunto de trabajo y la frecuencia de fallo de página, y respecto al procesador, el número de instrucciones ejecutadas por unidad de tiempo, no son datos fáciles de obtener. Tal vez la forma más segura, y eso aun para cada caso concreto, es a través de medidas realizadas con monitores sobre sistemas ya existentes. A continuación se expone un sencillo ejemplo de modelo de un conjunto CPU-memoria. Ejemplo: Se dispone de una CPU capaz de ejecutar 5000000 instrucciones por segundo. Este sistema atiende transacciones a razón de 4 por segundo, sabiendo que los accesos de entrada-salida tienen un tiempo medio de respuesta de 75 milisegundos. Determinar la memoria necesaria y el factor de multiprogramación del sistema, sabiendo que las características de las transacciones están resumidas en el cuadro que se expone a continuación.
Al tratarse de un sistema en tiempo real donde todos los trabajos tienen accesos a la CPU de la misma duración aproximada (lo cual es cierto en muchos sistemas reales), podemos utilizar sin demasiada diferencia cualquiera de los modelos de CPU (batch, round robin) antes expuestos. En este caso utilizaremos, concretamente, el modelo batch. Las ráfagas medias de instrucciones que se ejecutarán entre dos accesos consecutivos serán de
T1 800/(5 + 1) = 133.3 instrucciones × 103
T2 900/(6 + 1) = 128.6 instrucciones × 103
T3 1100/(8 + 1) = 122.2 instrucciones × 103
T4 150/(9 + 1) = 150.0 instrucciones × 103
y la ráfaga media es de
310 nesinstruccio 4.13110102095.3275.376
10101502092.1225.3276.1285.3763.123×=
×+×+×+×××+××+××+××
cuyo tiempo medio de ejecución de una ráfaga será de
ms 28.26 s 02628.0500000
104.131 3
==×
El factor de utilización de la CPU es:
( ) 77.0500000100
101500101100209005.328005.37 3
=×
××+×+×+×=ρ
Accesos Ocupación (Kb) Instrucciones × 103 Frecuencia % T1 5 20 800 37.5 T2 6 25 900 32.5 T3 8 40 1100 20.0 T4 9 50 1500 10.0

192
Para determinar el factor de multiprogramación es preciso saber el tiempo de respuesta de la CPU y viceversa. Por lo tanto, para salir del callejón sin salida hay que obtener una primera aproximación de ambos. Admitiendo en primera aproximación y como hipótesis muy pesimista que se puede aplicar a la cola de la CPU un modelo de tipo M/M/1, se tiene
ms 26.11477.01
28.26=
−=R , lo cual da un tiempo medio de espera por ráfaga en la cola de la
CPU de WCPU = 114.26 - 26.28 = 87.98 ms Los tiempos de presencia de cada una de las transacciones serán
ms 88.106275598.876500
8000001 =×+×+=R
ms 86.124575698.877500
9000002 =×+×+=R
ms 82.161175898.879500
11000003 =×+×+=R
ms 80.185475998.8710500
15000004 =×+×+=R
De donde, en primera aproximación, se puede tomar como factor de multiprogramación, el número medio de trabajos en memoria, que se calcula aplicando la ley de Little,
MP = (0.375 × 1.06288 + 0.325 × 1.24586 + 0.2 × 1.61182 + 0.1 × 1.85480) × 4 =
= 5.25 trabajos
que debe redondearse a un entero próximo y que da una idea del orden de magnitud del factor de multiprogramación que puede ser adecuado. Se elige, por ejemplo, 6 y, por lo tanto, se puede establecer para la CPU un modelo de tipo M/M/1//6. Aunque se pueden utilizar los gráficos de la figura 3.13 del primer volumen de esta obra, se va a plantear el cálculo de las probabilidades de los distintos estados.
µλ
= 01 6 pp 2
02 30
µλ
= pp 3
03 120
µλ
= pp
4
04 360
µλ
= pp
5
05 720
µλ
= pp
6
06 720
µλ
= pp
de donde, haciendo λ/µ = x y teniendo en cuenta que la suma de las siete probabilidades ha de ser igual a la unidad, se tiene
654320 72072036012030611
xxxxxxp
++++++=
Por otro lado se puede escribir que la frecuencia media de llegada es el promedio de las frecuencias de llegada dependientes del estado
4 = 6 λ p0 + 5 λ p1 + 4 λ p2 + 3 λ p3 + 2 λ p4 + 1 λ p5 + 0 λ p6

193
y sustituyendo las expresiones de las probabilidades en esta última ecuación, se llega a la ecuación
65432
65432
720720360120306172072036012030677.04
xxxxxxxxxxxx
+++++++++++
==ρ=µ
de donde
165.6x6 + 165.6x5 + 82.8x4 + 27.6x3 + 6.9x2 + 1.38x - 0.77 = 0
y resolviendo se obtiene x = 0.18137, que permite calcular las probabilidades
p0 = 0.230017 p1 = 0.250309 p2 = 0.226993 p3 = 0.164679
p4 = 0.089604 p5 = 0.032503 p6 = 0.005895
lo cual permite calcular el número medio de elementos en el sistema
N = 0 × 0.230017 + 1 × 0.250309 + 2 × 0.226993 + 3 × 0.164679 +
+ 4 × 0.089604 + 5 × 0.032503 + 6 × 0.005895 = 1.754633
y el tiempo medio de respuesta de cada ráfaga en el sistema es, por la ley de Little
( ) ms 85.59 s 05985.041.0102.09325.07375.06
754633.1==
××+×+×+×=R
y, en consecuencia, el tiempo medio de espera por ráfaga será:
WCPU = 59.89 - 26.28 = 33.61 ms
Los tiempos medios de presencia de cada transacción en memoria para su ejecución serán ahora, calculados de forma idéntica a como se ha hecho antes:
R1 = 736.66 ms R2 = 865.27 ms R3 = 1122.49 ms R4 = 1311.10 ms
Ahora bien, para determinar el tiempo de respuesta de una transacción, es decir, desde que una transacción llega al sistema hasta que termina su ejecución, hay que sumar a estos tiempos el tiempo de espera que sufren cuando encuentran ocupados los seis espacios de memoria (factor de multiprogramación) disponibles para la ejecución de las transacciones. Esto puede modelarse mediante una estación con seis canales de servicio, cuyo factor de ocupación y tiempo medio de servicio son respectivamente,
Sm = 0.73666 × 0.375 + 0.86527 × 0.325 + 1.12249 × 0.2 + 1.3111 × 0.1 = 0.91307 s
ρm = 4 × 0.91307/6 = 0.609
y construyendo, por razones de factibilidad, un modelo M/M/6 (cuando realmente debería ser M/G/6) y utilizando, por ejemplo, el gráfico de la figura 3.8 del primer volumen de esta obra, se tiene que el tiempo medio de espera en la cola antes de recibir el servicio es
Wm = (1.1 - 1) × 0.91307 = 0.09131 ms
con lo que los tiempos de respuesta de cada transacción son
R1 = 736.66 + 91.31 = 827.97 ms

194
R2 = 865.27 + 91.31 = 956.58 ms
R3 = 1122.49 + 91.31 = 1213.80 ms
R4 = 1311.10 + 91.31 = 1402.41 ms
La memoria media ocupada será:
M = (0.375 × 0.73666 × 20 + 0.325 × 0.86527 × 25 +
+ 0.2 × 1.12249 × 40 + 0.1 × 1.31110 × 50) × 4 = 112.4 K
aunque la memoria máxima necesaria, que es la que se debe reservar para esta aplicación será:
Mmax = 6 × 50 = 300 K
Repitiendo el cálculo para otros valores del factor de multiprogramación, se pueden resumir los resultados en la siguiente tabla:
Los tiempos están medidos en milisegundos y la ocupación de la memoria en K. Obsérvese que, al ir aumentando el factor de multiprogramación, aumentan el tiempo de ejecución o de presencia de la transacción y la memoria media ocupada pero disminuye en mayor magnitud la cola de entrada en memoria (y, en consecuencia, las áreas tampón para almacenar los mensajes).
2.2. MODELOS DE SISTEMAS INFORMÁTICOS: EL SERVIDOR CENTRAL Y VARIANTES
El modelo del servidor central constituye el esquema básico de red de colas para estudiar las prestaciones de un sistema informático. Puede tomar la forma de una red de colas abierta (figura 2.17) o cerrada (figura 2.18). Su nombre le viene del hecho que la CPU adopta una posición central en el esquema, como puede verse en ambas figuras.
MP 3 4 5 6 7 R1 658 692.68 719.5 736.66 755.75 R2 773.5 813.96 845.25 865.27 887.54 R3 1004.5 1056.75 1096.75 1122.49 1151.13 R4 1183 1240.8 1285.5 1311.1 1345.67 Rm 817.34 859.68 892.42 913.07 936.67 ρm > 1 0.8597 0.7139 0.6089 0.5352 W - 1031.61 249.88 91.34 46.83 M - 105.86 109.86 112.4 115.27
Mmax 450 600 750 900 1050

195
Disco1
Disco2
Disco3
Disco4
CPU
Figura 2.17.
Disco1
Disco2
Disco3
Disco4
CPU
Terminales
Figura 2.18.
En una primera aproximación sólo se considerarán aquellos elementos críticos del sistema informático, la CPU y los discos, y la carga que deben soportar, definida por una llegada de transacciones en un sistema abierto y por un conjunto de terminales en uno cerrado, y se dejará para más adelante la consideración de otros elementos tales como la unidad de control del subsistema de discos, la memoria y su gestión, etc. El tratamiento de modelos de los sistemas informáticos mediante redes de colas exige unos cálculos imposibles de ser realizados a mano (o con la ayuda de una calculadora de bolsillo). Los modelos que se estudiarán estarán escritos en el lenguaje de modelización QNAP2, cuyo resumen y técnicas básicas de utilización pueden encontrarse en el anexo 2 del primer volumen de esta obra.
2.2.1. SISTEMA TRANSACCIONAL Un sistema transaccional es aquel que no tiene ninguna posibilidad de modificar la carga que recibe. Por lo tanto se puede representar tal como muestra la figura 2.17. En este caso se ha

196
supuesto que llegan al sistema dos tipos de transacciones descritas por sus frecuencias de llegada (7 y 3 transacciones por segundo, respectivamente), sus peticiones de consumo de CPU (8.52 y 12 milisegundos, respectivamente) y sus perfiles de accesos a los discos (descritos por las tablas PROF1 y PROF2, respectivamente). Los discos se supondrá que su tiempo de servicio estará compuesto del de desplazamiento de brazo (13, 12, 11 y 10 milisegundos, respectivamente, dependiendo de su grado de ocupación), del de latencia rotacional (8.33 milisegundos, equivalente a media vuelta si se supone que giran a 3600 r.p.m.) y del de transferencia de un bloque (1.67 milisegundos, equivalentes a que en cada pista hubiera 10 bloques). El modelo que se muestra a continuación fuerza las hipótesis con el fin de lograr una red de colas que responda al teorema de BCMP (apartado 4.3.1. del primer volumen de esta obra). Para ello se requiere que las llegadas sigan procesos de Poisson, que la CPU siga una política de procesador compartido y que se represente a los discos por estaciones FIFO con tiempos de servicio con distribución exponencial independiente de la clase. De estas hipótesis todas son bastante razonables excepto la de suponer que los tiempos de servicio de los discos sigan una distribución exponencial; en cualquier caso, esta hipótesis es pesimista, por lo que los resultados representarán una estimación prudente del comportamiento del sistema. Obsérvese que para resolver la red de colas se utiliza el método de convolución, que es exacto. Al resultado estándar que ofrece el lenguaje QNAP2, hay que añadir el cálculo del tiempo de respuesta de cada tipo de transacción. Para ello se aplicará la ley de Little, calculando el número medio de transacciones de cada clase que hay en el sistema (CPU y discos) y dividiéndolo por su frecuencia de llegada respectiva. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),ENTRADA1,ENTRADA2; 2 REAL PROF1(4)=(2,1.5,1,0.5); 3 REAL PROF2(4)=(1.5,2,3,3.5); 4 REAL TR1,TR2; 5 CLASS C1,C2; 6 INTEGER I; 7 /STATION/ NAME=CPU; 8 SCHED=PS; 9 SERVICE(C1)=CST(8.52); 10 SERVICE(C2)=CST(12.); 11 TRANSIT(C1)=DISC,PROF1,OUT,1; 12 TRANSIT(C2)=DISC,PROF2,OUT,1; 13 /STATION/ NAME=DISC; 14 TRANSIT=CPU; 15 /STATION/ NAME=DISC(1); 16 SERVICE=EXP(23.); 17 /STATION/ NAME=DISC(2); 18 SERVICE=EXP(22.); 19 /STATION/ NAME=DISC(3); 20 SERVICE=EXP(21.); 21 /STATION/ NAME=DISC(4); 22 SERVICE=EXP(20.); 23 /STATION/ NAME=ENTRADA1; 24 TYPE=SOURCE; 25 SERVICE=EXP(1000./7.); 26 TRANSIT=CPU,C1; 27 /STATION/ NAME=ENTRADA2; 28 TYPE=SOURCE; 29 SERVICE=EXP(1000./3.); 30 TRANSIT=CPU,C2; 31 /CONTROL/ CLASS=ALL QUEUE; 32 /EXEC/ BEGIN 33 PRINT; 34 SOLVE; 35 TR1:=MCUSTNB(CPU,C1);

197
36 TR2:=MCUSTNB(CPU,C2); 37 FOR I:= 1 STEP 1 UNTIL 4 DO 38 BEGIN 39 TR1:=TR1+MCUSTNB(DISC(I),C1); 40 TR2:=TR2+MCUSTNB(DISC(I),C2); 41 END; 42 TR1:=TR1/MTHRUPUT(ENTRADA1); 43 TR2:=TR2/MTHRUPUT(ENTRADA2); 44 PRINT("RESPONSE TIME OF CLASS C1 =",TR1); 45 PRINT("RESPONSE TIME OF CLASS C2 =",TR2); 46 END; - CONVOLUTION METHOD ("CONVOL") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.05 *0.7538 * 3.062 * 40.83 *0.7500E-01* *(C1 )* 8.520 *0.3578 * 1.454 * 34.61 *0.4200E-01* *(C2 )* 12.00 *0.3960 * 1.609 * 48.75 *0.3300E-01* * * * * * * * * DISC 1 * 23.00 *0.4255 *0.7406 * 40.03 *0.1850E-01* *(C1 )* 23.00 *0.3220 *0.5605 * 40.03 *0.1400E-01* *(C2 )* 23.00 *0.1035 *0.1802 * 40.03 *0.4500E-02* * * * * * * * * DISC 2 * 22.00 *0.3630 *0.5699 * 34.54 *0.1650E-01* *(C1 )* 22.00 *0.2310 *0.3626 * 34.54 *0.1050E-01* *(C2 )* 22.00 *0.1320 *0.2072 * 34.54 *0.6000E-02* * * * * * * * * DISC 3 * 21.00 *0.3360 *0.5060 * 31.63 *0.1600E-01* *(C1 )* 21.00 *0.1470 *0.2214 * 31.63 *0.7000E-02* *(C2 )* 21.00 *0.1890 *0.2846 * 31.63 *0.9000E-02* * * * * * * * * DISC 4 * 20.00 *0.2800 *0.3889 * 27.78 *0.1400E-01* *(C1 )* 20.00 *0.7000E-01*0.9722E-01* 27.78 *0.3500E-02* *(C2 )* 20.00 *0.2100 *0.2917 * 27.78 *0.1050E-01* * * * * * * * * ENTRADA1 * 142.9 * 1.000 * 1.000 * 142.9 *0.7000E-02* * * * * * * * * ENTRADA2 * 333.3 * 1.000 * 1.000 * 333.3 *0.3000E-02* * * * * * * * ******************************************************************* MEMORY USED: 7870 WORDS OF 4 BYTES ( 0.31 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 385.1 RESPONSE TIME OF CLASS C2 = 857.5 47 /END/ Si se quiere mejorar la representación del comportamiento de los discos, es preciso representarlos por una cola FIFO pero con un tiempo de servicio que siga una ley hipoexponencial con una desviación tipo que valga la mitad del valor medio (valor razonable, si se tiene en cuenta que la desviación tipo del tiempo de movimiento de brazo es del orden del 75% del valor medio, que la de la latencia, que sigue una distribución uniforme, es del orden del 60% del tiempo medio y que la de la transferencia vale cero, ya que normalmente todos los bloques son del mismo tamaño. Obsérvese que en este caso para poder utilizar el método aproximado de difusión, es preciso que todas las estaciones sean FIFO, lo cual obliga a que la CPU deje de ser de procesador compartido y ase a serlo. Obsérvese también que los tiempos de respuesta de todas las estaciones y, en consecuencia, los de las transacciones son menores. Ello es debido a que este método tiene en cuenta las desviaciones tipo de los tiempos de servicio de todas las

198
estaciones, mientras que el de convolución sólo tiene en cuenta los valores medios y en este caso las desviaciones tipo son menores que las del caso anterior. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),ENTRADA1,ENTRADA2; 2 REAL PROF1(4)=(2,1.5,1,0.5); 3 REAL PROF2(4)=(1.5,2,3,3.5); 4 REAL TR1,TR2; 5 CLASS C1,C2; 6 INTEGER I; 7 /STATION/ NAME=CPU; 8 SCHED=FIFO; 9 SERVICE(C1)=CST(8.52); 10 SERVICE(C2)=CST(12.); 11 TRANSIT(C1)=DISC,PROF1,OUT,1; 12 TRANSIT(C2)=DISC,PROF2,OUT,1; 13 /STATION/ NAME=DISC; 14 TRANSIT=CPU; 15 /STATION/ NAME=DISC(1); 16 SERVICE=HEXP(23.,0.25); 17 /STATION/ NAME=DISC(2); 18 SERVICE=HEXP(22.,0.25); 19 /STATION/ NAME=DISC(3); 20 SERVICE=HEXP(21.,0.25); 21 /STATION/ NAME=DISC(4); 22 SERVICE=HEXP(20.,0.25); 23 /STATION/ NAME=ENTRADA1; 24 TYPE=SOURCE; 25 SERVICE=EXP(1000./7.); 26 TRANSIT=CPU,C1; 27 /STATION/ NAME=ENTRADA2; 28 TYPE=SOURCE; 29 SERVICE=EXP(1000./3.); 30 TRANSIT=CPU,C2; 31 /CONTROL/ CLASS=ALL QUEUE; 32 /EXEC/ BEGIN 33 PRINT; 34 SOLVE; 35 TR1:=MCUSTNB(CPU,C1); 36 TR2:=MCUSTNB(CPU,C2); 37 FOR I:= 1 STEP 1 UNTIL 4 DO 38 BEGIN 39 TR1:=TR1+MCUSTNB(DISC(I),C1); 40 TR2:=TR2+MCUSTNB(DISC(I),C2); 41 END; 42 TR1:=TR1/MTHRUPUT(ENTRADA1); 43 TR2:=TR2/MTHRUPUT(ENTRADA2); 44 PRINT("RESPONSE TIME OF CLASS C1 =",TR1); 45 PRINT("RESPONSE TIME OF CLASS C2 =",TR2); 46 END; - APPROXIMATE ITERATIV METHOD ("DIFFU") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.05 *0.7538 * 1.823 * 24.31 *0.7500E-01* *(C1 )* 8.520 *0.3578 *0.9568 * 22.78 *0.4200E-01* *(C2 )* 12.00 *0.3960 *0.8666 * 26.26 *0.3300E-01* * * * * * * * * DISC 1 * 23.00 *0.4255 *0.5972 * 32.28 *0.1850E-01* *(C1 )* 23.00 *0.3220 *0.4520 * 32.28 *0.1400E-01* *(C2 )* 23.00 *0.1035 *0.1453 * 32.28 *0.4500E-02* * * * * * * * * DISC 2 * 22.00 *0.3630 *0.4772 * 28.92 *0.1650E-01* *(C1 )* 22.00 *0.2310 *0.3037 * 28.92 *0.1050E-01*

199
*(C2 )* 22.00 *0.1320 *0.1735 * 28.92 *0.6000E-02* * * * * * * * * DISC 3 * 21.00 *0.3360 *0.4301 * 26.88 *0.1600E-01* *(C1 )* 21.00 *0.1470 *0.1882 * 26.88 *0.7000E-02* *(C2 )* 21.00 *0.1890 *0.2420 * 26.88 *0.9000E-02* * * * * * * * * DISC 4 * 20.00 *0.2800 *0.3411 * 24.37 *0.1400E-01* *(C1 )* 20.00 *0.7000E-01*0.8528E-01* 24.37 *0.3500E-02* *(C2 )* 20.00 *0.2100 *0.2558 * 24.37 *0.1050E-01* * * * * * * * * ENTRADA1 * 142.9 * 1.000 * 1.000 * 142.9 *0.7000E-02* * * * * * * * * ENTRADA2 * 333.3 * 1.000 * 1.000 * 333.3 *0.3000E-02* * * * * * * * ******************************************************************* MEMORY USED: 7878 WORDS OF 4 BYTES ( 0.32 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 283.7 RESPONSE TIME OF CLASS C2 = 561.1 47 /END/
2.2.2. SISTEMA CONVERSACIONAL Un sistema conversacional es aquel que recibe sus entradas un cierto tiempo después de haber enviado la respuesta a la petición anterior. Por lo tanto se puede representar tal como muestra la figura 2.18.
2.2.2.1. Terminales con cargas separadas En este caso se ha supuesto que hay conectados al sistema dos tipos de terminales (N1 y N2, respectivamente) que generan peticiones después de sus respectivos tiempos de reflexión (30 y 60 segundos, respectivamente). Estas peticiones solicitan consumos de CPU (8.52 y 12 milisegundos, respectivamente) y están también descritas por sus perfiles de acceso a los discos (descritos por las tablas PROF1 y PROF2, respectivamente). Los discos, como en los ejemplos del apartado anterior, se supondrá que su tiempo de servicio estará compuesto del de desplazamiento de brazo (13, 12, 11 y 10 milisegundos, respectivamente, dependiendo de su grado de ocupación), del de latencia rotacional (8.33 milisegundos, equivalente a media vuelta si se supone que giran a 3600 r.p.m.) y del de transferencia de un bloque (1.67 milisegundos, equivalentes a que en cada pista hubiera 10 bloques). El modelo que se muestra a continuación fuerza las hipótesis con el fin de lograr una red de colas que responda al teorema de BCMP (apartado 4.3.1. del primer volumen de esta obra). Para ello se requiere que la CPU siga una política de procesador compartido y que se represente a los discos por estaciones FIFO con tiempos de servicio con distribución exponencial independiente de la clase. De estas hipótesis todas son bastante razonables excepto la de suponer que los tiempos de servicio de los discos sigan una distribución exponencial; en cualquier caso, esta hipótesis es pesimista, por lo que los resultados representarán una estimación prudente del comportamiento del sistema. Obsérvese que para resolver la red de colas se utiliza el método del análisis del valor medio (MVA), que es exacto. Al resutado estándar que ofrece el lenguaje QNAP2 hay que añadir el cálculo del tiempo de respuesta de cada tipo de transacción, para lo cual se aplicará la ley de Little, calculando el número medio de peticiones de cada clase que hay en el sistema (CPU y discos) y dividiéndolo por su frecuencia de llegada respectiva, que es la de la salida de los terminales. En este caso se ha hecho variar el número de terminales de cada clase entre 100 y 400, por lo que no se incluyen 16 tablas de resultados. Sólo se ha dejado la última y se han dejado los resultados de todas las demás.

200
SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),TERMINAL; 2 REAL PROB1(4)=(2,1.5,1,0.5); 3 REAL PROB2(4)=(1.5,2,3,3.5); 4 REAL TR1,TR2,TTR1,TTR2; 5 CLASS C1,C2; 6 INTEGER I,N1,N2; 7 /STATION/ NAME=CPU; 8 SCHED=PS; 9 SERVICE(C1)=CST(8.52); 10 SERVICE(C2)=CST(12.); 11 TRANSIT(C1)=DISC,PROB1,TERMINAL,1; 12 TRANSIT(C2)=DISC,PROB2,TERMINAL,1; 13 /STATION/ NAME=DISC; 14 TRANSIT=CPU; 15 /STATION/ NAME=DISC(1); 16 SERVICE=EXP(23.); 17 /STATION/ NAME=DISC(2); 18 SERVICE=EXP(22.); 19 /STATION/ NAME=DISC(3); 20 SERVICE=EXP(21.); 21 /STATION/ NAME=DISC(4); 22 SERVICE=EXP(20.); 23 /STATION/ NAME=TERMINAL; 24 TYPE=INFINITE; 25 INIT(C1)=N1; 26 INIT(C2)=N2; 27 SERVICE(C1)=EXP(30000.); 28 SERVICE(C2)=EXP(60000.); 29 TRANSIT=CPU; 30 /CONTROL/ CLASS=ALL QUEUE; 31 /EXEC/ FOR N1:=100 STEP 100 UNTIL 400 DO 32 FOR N2:=100 STEP 100 UNTIL 400 DO 33 BEGIN 34 PRINT; 35 PRINT("NUMERO DE USUARIOS DE CLASE 1 =",N1); 36 PRINT("NUMERO DE USUARIOS DE CLASE 2 =",N2); 37 SOLVE; 38 TR1:=MCUSTNB(CPU,C1); 39 TR2:=MCUSTNB(CPU,C2); 40 FOR I:= 1 STEP 1 UNTIL 4 DO 41 BEGIN 42 TR1:=TR1+MCUSTNB(DISC(I),C1); 43 TR2:=TR2+MCUSTNB(DISC(I),C2); 44 END; 45 TR1:=TR1/MTHRUPUT(TERMINAL,C1); 46 TR2:=TR2/MTHRUPUT(TERMINAL,C2);; 47 TTR1:=(N1-MCUSTNB(TERMINAL,C1))/MTHRUPUT(TERMINAL,C1); 48 TTR2:=(N2-MCUSTNB(TERMINAL,C2))/MTHRUPUT(TERMINAL,C2);; 49 PRINT("RESPONSE TIME OF CLASS C1 =",TR1,TTR1); 50 PRINT("RESPONSE TIME OF CLASS C2 =",TR2,TTR2); 51 END; NUMERO DE USUARIOS DE CLASE 1 = 100 NUMERO DE USUARIOS DE CLASE 2 = 100 RESPONSE TIME OF CLASS C1 = 218.5 218.5 RESPONSE TIME OF CLASS C2 = 469.9 469.9 NUMERO DE USUARIOS DE CLASE 1 = 100 NUMERO DE USUARIOS DE CLASE 2 = 200 RESPONSE TIME OF CLASS C1 = 276.9 276.9 RESPONSE TIME OF CLASS C2 = 617.1 617.1

201
NUMERO DE USUARIOS DE CLASE 1 = 100 NUMERO DE USUARIOS DE CLASE 2 = 300 RESPONSE TIME OF CLASS C1 = 431.6 431.6 RESPONSE TIME OF CLASS C2 = 1013. 1013. NUMERO DE USUARIOS DE CLASE 1 = 100 NUMERO DE USUARIOS DE CLASE 2 = 400 RESPONSE TIME OF CLASS C1 = 1606. 1606. RESPONSE TIME OF CLASS C2 = 4031. 4031. NUMERO DE USUARIOS DE CLASE 1 = 200 NUMERO DE USUARIOS DE CLASE 2 = 100 RESPONSE TIME OF CLASS C1 = 272.1 272.1 RESPONSE TIME OF CLASS C2 = 578.4 578.4 NUMERO DE USUARIOS DE CLASE 1 = 200 NUMERO DE USUARIOS DE CLASE 2 = 200 RESPONSE TIME OF CLASS C1 = 391.5 391.5 RESPONSE TIME OF CLASS C2 = 877.6 877.6 NUMERO DE USUARIOS DE CLASE 1 = 200 NUMERO DE USUARIOS DE CLASE 2 = 300 RESPONSE TIME OF CLASS C1 = 1070. 1070. RESPONSE TIME OF CLASS C2 = 2613. 2613. NUMERO DE USUARIOS DE CLASE 1 = 200 NUMERO DE USUARIOS DE CLASE 2 = 400 RESPONSE TIME OF CLASS C1 = 5532. 5532. RESPONSE TIME OF CLASS C2 = 0.1413E+05 0.1413E+05 NUMERO DE USUARIOS DE CLASE 1 = 300 NUMERO DE USUARIOS DE CLASE 2 = 100 RESPONSE TIME OF CLASS C1 = 371.4 371.4 RESPONSE TIME OF CLASS C2 = 787.5 787.5 NUMERO DE USUARIOS DE CLASE 1 = 300 NUMERO DE USUARIOS DE CLASE 2 = 200 RESPONSE TIME OF CLASS C1 = 780.5 780.5 RESPONSE TIME OF CLASS C2 = 1823. 1823. NUMERO DE USUARIOS DE CLASE 1 = 300 NUMERO DE USUARIOS DE CLASE 2 = 300 RESPONSE TIME OF CLASS C1 = 4471. 4471. RESPONSE TIME OF CLASS C2 = 0.1134E+05 0.1134E+05 NUMERO DE USUARIOS DE CLASE 1 = 300 NUMERO DE USUARIOS DE CLASE 2 = 400 RESPONSE TIME OF CLASS C1 = 9997. 9997.

202
RESPONSE TIME OF CLASS C2 = 0.2563E+05 0.2563E+05 NUMERO DE USUARIOS DE CLASE 1 = 400 NUMERO DE USUARIOS DE CLASE 2 = 100 RESPONSE TIME OF CLASS C1 = 640.4 640.4 RESPONSE TIME OF CLASS C2 = 1398. 1398. NUMERO DE USUARIOS DE CLASE 1 = 400 NUMERO DE USUARIOS DE CLASE 2 = 200 RESPONSE TIME OF CLASS C1 = 3347. 3347. RESPONSE TIME OF CLASS C2 = 8365. 8365. NUMERO DE USUARIOS DE CLASE 1 = 400 NUMERO DE USUARIOS DE CLASE 2 = 300 RESPONSE TIME OF CLASS C1 = 9049. 9049. RESPONSE TIME OF CLASS C2 = 0.2313E+05 0.2313E+05 NUMERO DE USUARIOS DE CLASE 1 = 400 NUMERO DE USUARIOS DE CLASE 2 = 400 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.11 * 1.000 * 281.2 * 2843. *0.9894E-01* *(C1 )* 8.520 *0.4585 * 129.0 * 2397. *0.5381E-01* *(C2 )* 12.00 *0.5415 * 152.3 * 3374. *0.4513E-01* * * * * * * * * DISC 1 * 23.00 *0.5541 * 1.241 * 51.52 *0.2409E-01* *(C1 )* 23.00 *0.4125 *0.9237 * 51.50 *0.1794E-01* *(C2 )* 23.00 *0.1415 *0.3175 * 51.59 *0.6154E-02* * * * * * * * * DISC 2 * 22.00 *0.4765 *0.9099 * 42.01 *0.2166E-01* *(C1 )* 22.00 *0.2960 *0.5650 * 42.00 *0.1345E-01* *(C2 )* 22.00 *0.1805 *0.3449 * 42.03 *0.8205E-02* * * * * * * * * DISC 3 * 21.00 *0.4468 *0.8076 * 37.96 *0.2128E-01* *(C1 )* 21.00 *0.1883 *0.3405 * 37.96 *0.8968E-02* *(C2 )* 21.00 *0.2585 *0.4672 * 37.96 *0.1231E-01* * * * * * * * * DISC 4 * 20.00 *0.3769 *0.6046 * 32.09 *0.1884E-01* *(C1 )* 20.00 *0.8968E-01*0.1440 * 32.10 *0.4484E-02* *(C2 )* 20.00 *0.2872 *0.4607 * 32.08 *0.1436E-01* * * * * * * * * TERMINAL *0.3942E+05*0.0000E+00* 515.2 *0.3942E+05*0.1307E-01* *(C1 )*0.3000E+05*0.0000E+00* 269.1 *0.3000E+05*0.8968E-02* *(C2 )*0.6000E+05*0.0000E+00* 246.2 *0.6000E+05*0.4103E-02* * * * * * * * ******************************************************************* MEMORY USED: 42213 WORDS OF 4 BYTES ( 1.69 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 0.1460E+05 0.1460E+05 RESPONSE TIME OF CLASS C2 = 0.3750E+05 0.3750E+05 52 /END/

203
2.2.2.2. Terminales con cargas compartidas Este caso es idéntico al del apartado anterior con la única diferencia que todos los terminales pueden generar los dos tipos de carga. Se conoce la probabilidad con que se generarán peticiones de los dos tipos de carga (60% y 40%, respectivamente). SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),TERMINAL; 2 REAL PROB1(4)=(2,1.5,1,0.5); 3 REAL PROB2(4)=(1.5,2,3,3.5); 4 REAL TR1,TR2; 5 CLASS C1,C2; 6 INTEGER I,N; 7 /STATION/ NAME=CPU; 8 SCHED=PS; 9 SERVICE(C1)=CST(8.52); 10 SERVICE(C2)=CST(12.); 11 TRANSIT(C1)=DISC,PROB1,TERMINAL,C1,0.6,TERMINAL,C2,0.4; 12 TRANSIT(C2)=DISC,PROB2,TERMINAL,C1,0.6,TERMINAL,C2,0.4; 13 /STATION/ NAME=DISC; 14 TRANSIT=CPU; 15 /STATION/ NAME=DISC(1); 16 SERVICE=EXP(23.); 17 /STATION/ NAME=DISC(2); 18 SERVICE=EXP(22.); 19 /STATION/ NAME=DISC(3); 20 SERVICE=EXP(21.); 21 /STATION/ NAME=DISC(4); 22 SERVICE=EXP(20.); 23 /STATION/ NAME=TERMINAL; 24 TYPE=INFINITE; 25 INIT(C1)=N; 26 SERVICE(C1)=EXP(30000.); 27 SERVICE(C2)=EXP(60000.); 28 TRANSIT=CPU; 29 /CONTROL/ CLASS=ALL QUEUE; 30 /EXEC/ FOR N:=150 STEP 150 UNTIL 750 DO 31 BEGIN 32 PRINT; 33 PRINT("NUMERO DE USUARIOS =",N); 34 SOLVE; 35 TR1:=MCUSTNB(CPU,C1); 36 TR2:=MCUSTNB(CPU,C2); 37 FOR I:= 1 STEP 1 UNTIL 4 DO 38 BEGIN 39 TR1:=TR1+MCUSTNB(DISC(I),C1); 40 TR2:=TR2+MCUSTNB(DISC(I),C2); 41 END; 42 TR1:=TR1/MTHRUPUT(TERMINAL,C1); 43 TR2:=TR2/MTHRUPUT(TERMINAL,C2);; 44 PRINT("RESPONSE TIME OF CLASS C1 =",TR1); 45 PRINT("RESPONSE TIME OF CLASS C2 =",TR2); 46 END; NUMERO DE USUARIOS = 150 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.2960 *0.4189 * 14.76 *0.2837E-01* *(C1 )* 8.520 *0.1088 *0.1539 * 12.06 *0.1277E-01* *(C2 )* 12.00 *0.1873 *0.2650 * 16.98 *0.1560E-01* * * * * * * *
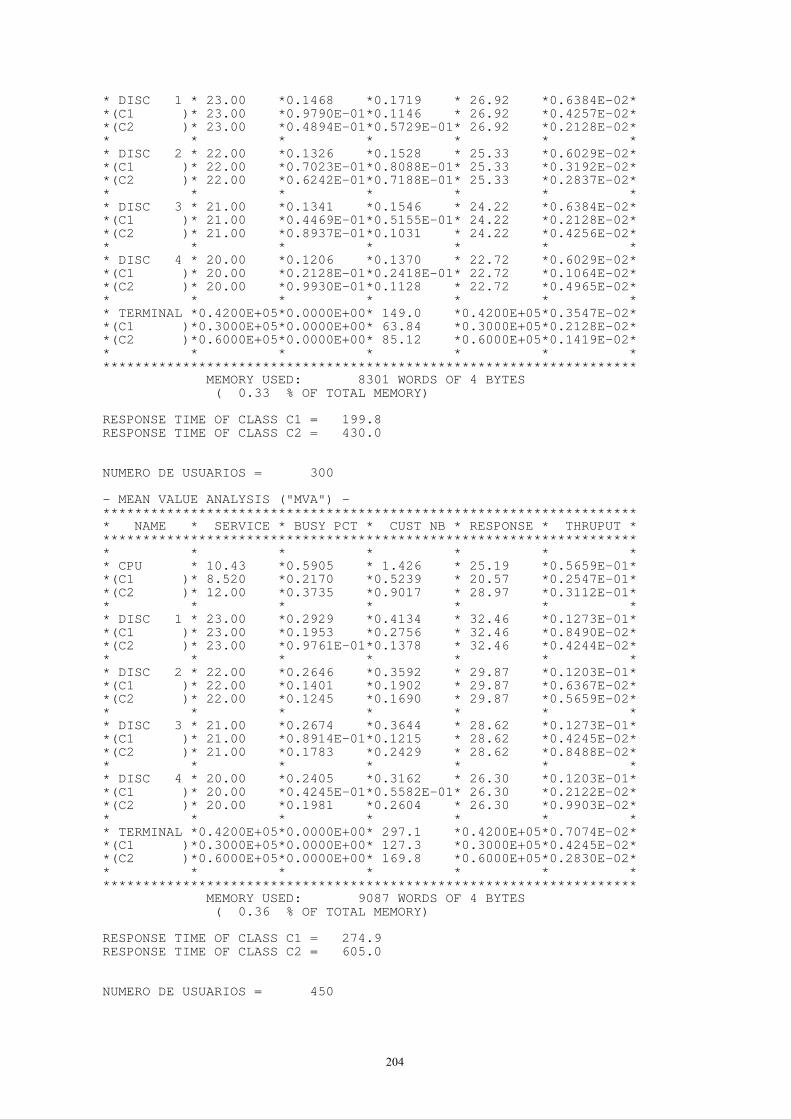
204
* DISC 1 * 23.00 *0.1468 *0.1719 * 26.92 *0.6384E-02* *(C1 )* 23.00 *0.9790E-01*0.1146 * 26.92 *0.4257E-02* *(C2 )* 23.00 *0.4894E-01*0.5729E-01* 26.92 *0.2128E-02* * * * * * * * * DISC 2 * 22.00 *0.1326 *0.1528 * 25.33 *0.6029E-02* *(C1 )* 22.00 *0.7023E-01*0.8088E-01* 25.33 *0.3192E-02* *(C2 )* 22.00 *0.6242E-01*0.7188E-01* 25.33 *0.2837E-02* * * * * * * * * DISC 3 * 21.00 *0.1341 *0.1546 * 24.22 *0.6384E-02* *(C1 )* 21.00 *0.4469E-01*0.5155E-01* 24.22 *0.2128E-02* *(C2 )* 21.00 *0.8937E-01*0.1031 * 24.22 *0.4256E-02* * * * * * * * * DISC 4 * 20.00 *0.1206 *0.1370 * 22.72 *0.6029E-02* *(C1 )* 20.00 *0.2128E-01*0.2418E-01* 22.72 *0.1064E-02* *(C2 )* 20.00 *0.9930E-01*0.1128 * 22.72 *0.4965E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 149.0 *0.4200E+05*0.3547E-02* *(C1 )*0.3000E+05*0.0000E+00* 63.84 *0.3000E+05*0.2128E-02* *(C2 )*0.6000E+05*0.0000E+00* 85.12 *0.6000E+05*0.1419E-02* * * * * * * * ******************************************************************* MEMORY USED: 8301 WORDS OF 4 BYTES ( 0.33 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 199.8 RESPONSE TIME OF CLASS C2 = 430.0 NUMERO DE USUARIOS = 300 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5905 * 1.426 * 25.19 *0.5659E-01* *(C1 )* 8.520 *0.2170 *0.5239 * 20.57 *0.2547E-01* *(C2 )* 12.00 *0.3735 *0.9017 * 28.97 *0.3112E-01* * * * * * * * * DISC 1 * 23.00 *0.2929 *0.4134 * 32.46 *0.1273E-01* *(C1 )* 23.00 *0.1953 *0.2756 * 32.46 *0.8490E-02* *(C2 )* 23.00 *0.9761E-01*0.1378 * 32.46 *0.4244E-02* * * * * * * * * DISC 2 * 22.00 *0.2646 *0.3592 * 29.87 *0.1203E-01* *(C1 )* 22.00 *0.1401 *0.1902 * 29.87 *0.6367E-02* *(C2 )* 22.00 *0.1245 *0.1690 * 29.87 *0.5659E-02* * * * * * * * * DISC 3 * 21.00 *0.2674 *0.3644 * 28.62 *0.1273E-01* *(C1 )* 21.00 *0.8914E-01*0.1215 * 28.62 *0.4245E-02* *(C2 )* 21.00 *0.1783 *0.2429 * 28.62 *0.8488E-02* * * * * * * * * DISC 4 * 20.00 *0.2405 *0.3162 * 26.30 *0.1203E-01* *(C1 )* 20.00 *0.4245E-01*0.5582E-01* 26.30 *0.2122E-02* *(C2 )* 20.00 *0.1981 *0.2604 * 26.30 *0.9903E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 297.1 *0.4200E+05*0.7074E-02* *(C1 )*0.3000E+05*0.0000E+00* 127.3 *0.3000E+05*0.4245E-02* *(C2 )*0.6000E+05*0.0000E+00* 169.8 *0.6000E+05*0.2830E-02* * * * * * * * ******************************************************************* MEMORY USED: 9087 WORDS OF 4 BYTES ( 0.36 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 274.9 RESPONSE TIME OF CLASS C2 = 605.0 NUMERO DE USUARIOS = 450
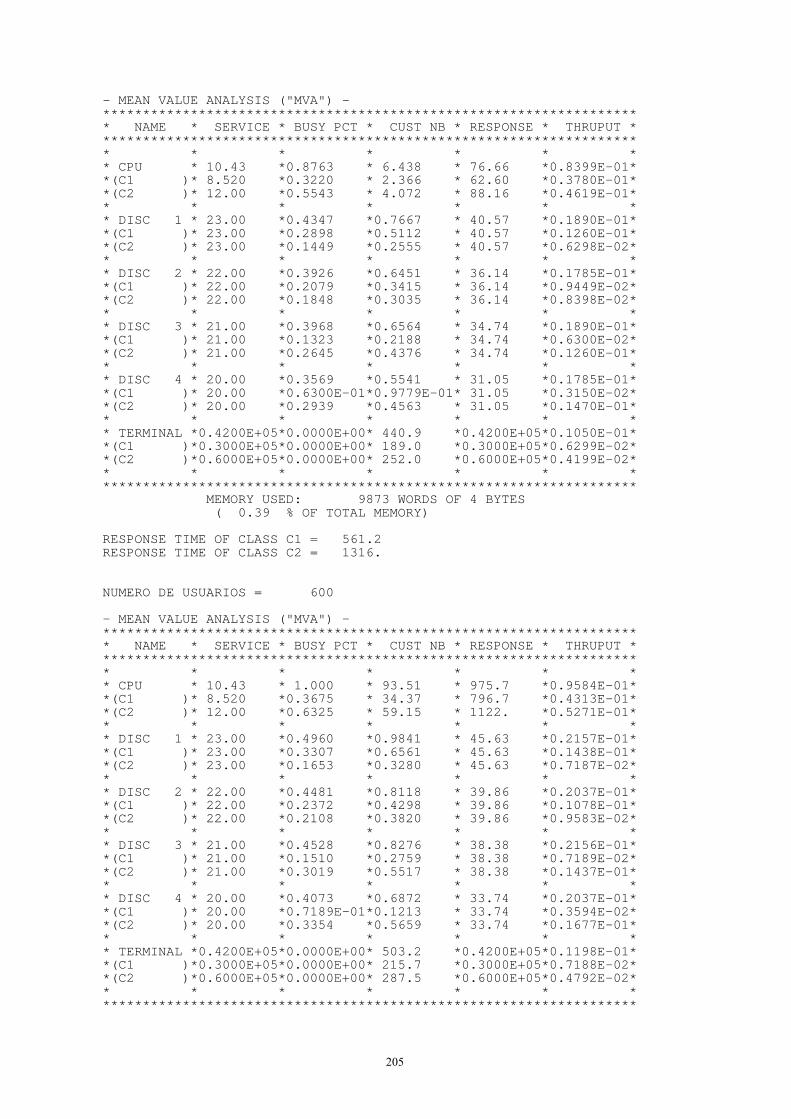
205
- MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8763 * 6.438 * 76.66 *0.8399E-01* *(C1 )* 8.520 *0.3220 * 2.366 * 62.60 *0.3780E-01* *(C2 )* 12.00 *0.5543 * 4.072 * 88.16 *0.4619E-01* * * * * * * * * DISC 1 * 23.00 *0.4347 *0.7667 * 40.57 *0.1890E-01* *(C1 )* 23.00 *0.2898 *0.5112 * 40.57 *0.1260E-01* *(C2 )* 23.00 *0.1449 *0.2555 * 40.57 *0.6298E-02* * * * * * * * * DISC 2 * 22.00 *0.3926 *0.6451 * 36.14 *0.1785E-01* *(C1 )* 22.00 *0.2079 *0.3415 * 36.14 *0.9449E-02* *(C2 )* 22.00 *0.1848 *0.3035 * 36.14 *0.8398E-02* * * * * * * * * DISC 3 * 21.00 *0.3968 *0.6564 * 34.74 *0.1890E-01* *(C1 )* 21.00 *0.1323 *0.2188 * 34.74 *0.6300E-02* *(C2 )* 21.00 *0.2645 *0.4376 * 34.74 *0.1260E-01* * * * * * * * * DISC 4 * 20.00 *0.3569 *0.5541 * 31.05 *0.1785E-01* *(C1 )* 20.00 *0.6300E-01*0.9779E-01* 31.05 *0.3150E-02* *(C2 )* 20.00 *0.2939 *0.4563 * 31.05 *0.1470E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 440.9 *0.4200E+05*0.1050E-01* *(C1 )*0.3000E+05*0.0000E+00* 189.0 *0.3000E+05*0.6299E-02* *(C2 )*0.6000E+05*0.0000E+00* 252.0 *0.6000E+05*0.4199E-02* * * * * * * * ******************************************************************* MEMORY USED: 9873 WORDS OF 4 BYTES ( 0.39 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 561.2 RESPONSE TIME OF CLASS C2 = 1316. NUMERO DE USUARIOS = 600 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 93.51 * 975.7 *0.9584E-01* *(C1 )* 8.520 *0.3675 * 34.37 * 796.7 *0.4313E-01* *(C2 )* 12.00 *0.6325 * 59.15 * 1122. *0.5271E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9841 * 45.63 *0.2157E-01* *(C1 )* 23.00 *0.3307 *0.6561 * 45.63 *0.1438E-01* *(C2 )* 23.00 *0.1653 *0.3280 * 45.63 *0.7187E-02* * * * * * * * * DISC 2 * 22.00 *0.4481 *0.8118 * 39.86 *0.2037E-01* *(C1 )* 22.00 *0.2372 *0.4298 * 39.86 *0.1078E-01* *(C2 )* 22.00 *0.2108 *0.3820 * 39.86 *0.9583E-02* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8276 * 38.38 *0.2156E-01* *(C1 )* 21.00 *0.1510 *0.2759 * 38.38 *0.7189E-02* *(C2 )* 21.00 *0.3019 *0.5517 * 38.38 *0.1437E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6872 * 33.74 *0.2037E-01* *(C1 )* 20.00 *0.7189E-01*0.1213 * 33.74 *0.3594E-02* *(C2 )* 20.00 *0.3354 *0.5659 * 33.74 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * *******************************************************************

206
MEMORY USED: 10659 WORDS OF 4 BYTES ( 0.43 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 4987. RESPONSE TIME OF CLASS C2 = 0.1272E+05 NUMERO DE USUARIOS = 750 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 243.5 * 2541. *0.9584E-01* *(C1 )* 8.520 *0.3675 * 89.49 * 2075. *0.4313E-01* *(C2 )* 12.00 *0.6325 * 154.0 * 2922. *0.5271E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9841 * 45.64 *0.2157E-01* *(C1 )* 23.00 *0.3307 *0.6561 * 45.64 *0.1438E-01* *(C2 )* 23.00 *0.1653 *0.3280 * 45.64 *0.7187E-02* * * * * * * * * DISC 2 * 22.00 *0.4481 *0.8118 * 39.86 *0.2037E-01* *(C1 )* 22.00 *0.2372 *0.4298 * 39.86 *0.1078E-01* *(C2 )* 22.00 *0.2108 *0.3820 * 39.86 *0.9583E-02* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8276 * 38.38 *0.2156E-01* *(C1 )* 21.00 *0.1510 *0.2759 * 38.38 *0.7189E-02* *(C2 )* 21.00 *0.3019 *0.5517 * 38.38 *0.1437E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6872 * 33.74 *0.2037E-01* *(C1 )* 20.00 *0.7189E-01*0.1213 * 33.74 *0.3594E-02* *(C2 )* 20.00 *0.3354 *0.5659 * 33.74 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 11445 WORDS OF 4 BYTES ( 0.46 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 0.1266E+05 RESPONSE TIME OF CLASS C2 = 0.3252E+05 47 /END/
2.2.2.3. Influencia de la unidad de control del subsistema de discos En los apartados anteriores se ha considerado que el tiempo de servicio de los discos era independiente de la carga. Ahora bien el tiempo de servicio de los discos incluye el tiempo necesario para resolver, por parte de la unidad de control, los conflictos que se producen cuando el subsistema de discos comparte un camino común hacia la memoria central del sistema. Para resolver este conflicto se establece un modelo iterativo que empieza suponiendo que el tiempo debido a la solución de los conflictos es nulo, lo cual permite tener una primera estimación del tiempo de servicio de los discos, resolver la red de colas y conocer la productividad de los discos. Esta información permite calcular el citado tiempo de acuerdo con los procedimientos expuestos en el apartado 2.1.2., lo cual permite tener una mejor estimación del tiempo de servicio de los discos. el proceso continua hasta que la diferencia entre dos iteraciones sucesivas es suficientemente pequeña. Se observará en algún caso alguna oscilación en el tiempo de servicio de los discos, lo cual es razonable, ya que inicialmente se parte de un valor del tiempo de servicio de los discos inferior al real, lo cual da una productividad mayor que la real. Esta productividad permite

207
calcular un tiempo para la solución de conflictos que será mayor que el real. Es decir, la convergencia de esta iteración es oscilante. Este método puede aplicarse también a sistemas transaccionales, pero en este caso, no es necesario efectuar ninguna iteración, ya que la productividad de los discos viene determinada por la frecuencia de entrada de transacciones al sistema y, ésta es conocida.
2.2.2.3.1. Con política SLTF En este caso el cálculo del tiempo de resolución de conflictos se efectúa tal como explica el apartado 2.1.2.2. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),TERMINAL; 2 REAL PROB1(4)=(2,1.5,1,0.5); 3 REAL PROB2(4)=(1.5,2,3,3.5); 4 REAL TR1,TR2; 5 REAL SD(4),VP,VPN,LT,TF,VR=3600,TAU,UC, 6 SK(4)=(13.,12.,11.,10.); 7 REAL EPS; 8 CLASS C1,C2; 9 INTEGER I,N; 10 /STATION/ NAME=CPU; 11 SCHED=PS; 12 SERVICE(C1)=CST(8.52); 13 SERVICE(C2)=CST(12.); 14 TRANSIT(C1)=DISC,PROB1,TERMINAL,C1,0.6,TERMINAL,C2,0.4; 15 TRANSIT(C2)=DISC,PROB2,TERMINAL,C1,0.6,TERMINAL,C2,0.4; 16 /STATION/ NAME=DISC; 17 TRANSIT=CPU; 18 /STATION/ NAME=DISC(1); 19 SERVICE=EXP(SD(1)); 20 /STATION/ NAME=DISC(2); 21 SERVICE=EXP(SD(2)); 22 /STATION/ NAME=DISC(3); 23 SERVICE=EXP(SD(3)); 24 /STATION/ NAME=DISC(4); 25 SERVICE=EXP(SD(4)); 26 /STATION/ NAME=TERMINAL; 27 TYPE=INFINITE; 28 INIT(C1)=N; 29 SERVICE(C1)=EXP(30000.); 30 SERVICE(C2)=EXP(60000.); 31 TRANSIT=CPU; 32 /CONTROL/ CLASS=ALL QUEUE; 33 /EXEC/ BEGIN 34 TAU:=60.*1000./VR; 35 TF:=TAU/10.; 36 LT:=TAU/2.; 37 FOR N:=150 STEP 150 UNTIL 750 DO 38 BEGIN 39 PRINT("NUMERO DE USUARIOS =",N); 40 EPS:=1.; 41 VP:=0.; 42 WHILE EPS>=1.E-4 DO 43 BEGIN 44 FOR I:=1 STEP 1 UNTIL 4 DO SD(I):=SK(I)+LT+VP+TF; 45 PRINT; 46 SOLVE; 47 UC:=0.; 48 FOR I:=1 STEP 1 UNTIL 4 DO UC := UC + TF * MTHRUPUT ==> (DISC(I)); 49 VPN:=TAU*UC/(1.-UC); 50 EPS:=ABS(VP-VPN)/VPN; 51 VP:=VPN; 52 END;
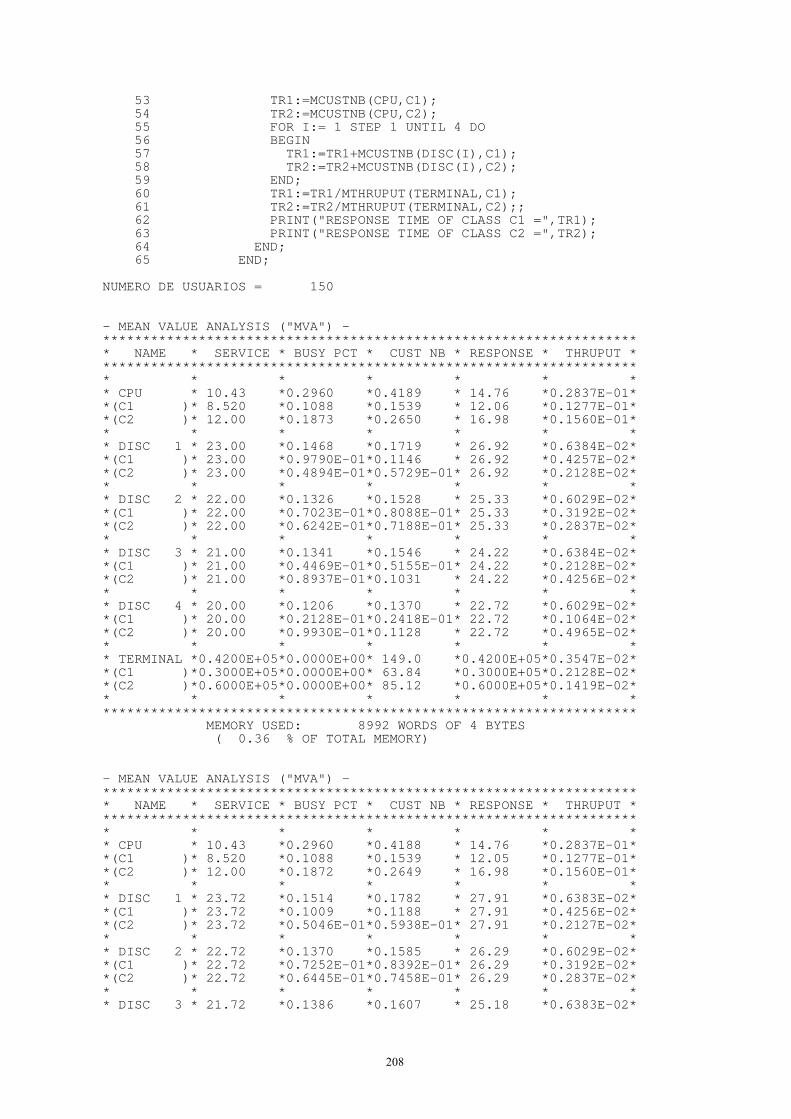
208
53 TR1:=MCUSTNB(CPU,C1); 54 TR2:=MCUSTNB(CPU,C2); 55 FOR I:= 1 STEP 1 UNTIL 4 DO 56 BEGIN 57 TR1:=TR1+MCUSTNB(DISC(I),C1); 58 TR2:=TR2+MCUSTNB(DISC(I),C2); 59 END; 60 TR1:=TR1/MTHRUPUT(TERMINAL,C1); 61 TR2:=TR2/MTHRUPUT(TERMINAL,C2);; 62 PRINT("RESPONSE TIME OF CLASS C1 =",TR1); 63 PRINT("RESPONSE TIME OF CLASS C2 =",TR2); 64 END; 65 END; NUMERO DE USUARIOS = 150 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.2960 *0.4189 * 14.76 *0.2837E-01* *(C1 )* 8.520 *0.1088 *0.1539 * 12.06 *0.1277E-01* *(C2 )* 12.00 *0.1873 *0.2650 * 16.98 *0.1560E-01* * * * * * * * * DISC 1 * 23.00 *0.1468 *0.1719 * 26.92 *0.6384E-02* *(C1 )* 23.00 *0.9790E-01*0.1146 * 26.92 *0.4257E-02* *(C2 )* 23.00 *0.4894E-01*0.5729E-01* 26.92 *0.2128E-02* * * * * * * * * DISC 2 * 22.00 *0.1326 *0.1528 * 25.33 *0.6029E-02* *(C1 )* 22.00 *0.7023E-01*0.8088E-01* 25.33 *0.3192E-02* *(C2 )* 22.00 *0.6242E-01*0.7188E-01* 25.33 *0.2837E-02* * * * * * * * * DISC 3 * 21.00 *0.1341 *0.1546 * 24.22 *0.6384E-02* *(C1 )* 21.00 *0.4469E-01*0.5155E-01* 24.22 *0.2128E-02* *(C2 )* 21.00 *0.8937E-01*0.1031 * 24.22 *0.4256E-02* * * * * * * * * DISC 4 * 20.00 *0.1206 *0.1370 * 22.72 *0.6029E-02* *(C1 )* 20.00 *0.2128E-01*0.2418E-01* 22.72 *0.1064E-02* *(C2 )* 20.00 *0.9930E-01*0.1128 * 22.72 *0.4965E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 149.0 *0.4200E+05*0.3547E-02* *(C1 )*0.3000E+05*0.0000E+00* 63.84 *0.3000E+05*0.2128E-02* *(C2 )*0.6000E+05*0.0000E+00* 85.12 *0.6000E+05*0.1419E-02* * * * * * * * ******************************************************************* MEMORY USED: 8992 WORDS OF 4 BYTES ( 0.36 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.2960 *0.4188 * 14.76 *0.2837E-01* *(C1 )* 8.520 *0.1088 *0.1539 * 12.05 *0.1277E-01* *(C2 )* 12.00 *0.1872 *0.2649 * 16.98 *0.1560E-01* * * * * * * * * DISC 1 * 23.72 *0.1514 *0.1782 * 27.91 *0.6383E-02* *(C1 )* 23.72 *0.1009 *0.1188 * 27.91 *0.4256E-02* *(C2 )* 23.72 *0.5046E-01*0.5938E-01* 27.91 *0.2127E-02* * * * * * * * * DISC 2 * 22.72 *0.1370 *0.1585 * 26.29 *0.6029E-02* *(C1 )* 22.72 *0.7252E-01*0.8392E-01* 26.29 *0.3192E-02* *(C2 )* 22.72 *0.6445E-01*0.7458E-01* 26.29 *0.2837E-02* * * * * * * * * DISC 3 * 21.72 *0.1386 *0.1607 * 25.18 *0.6383E-02*
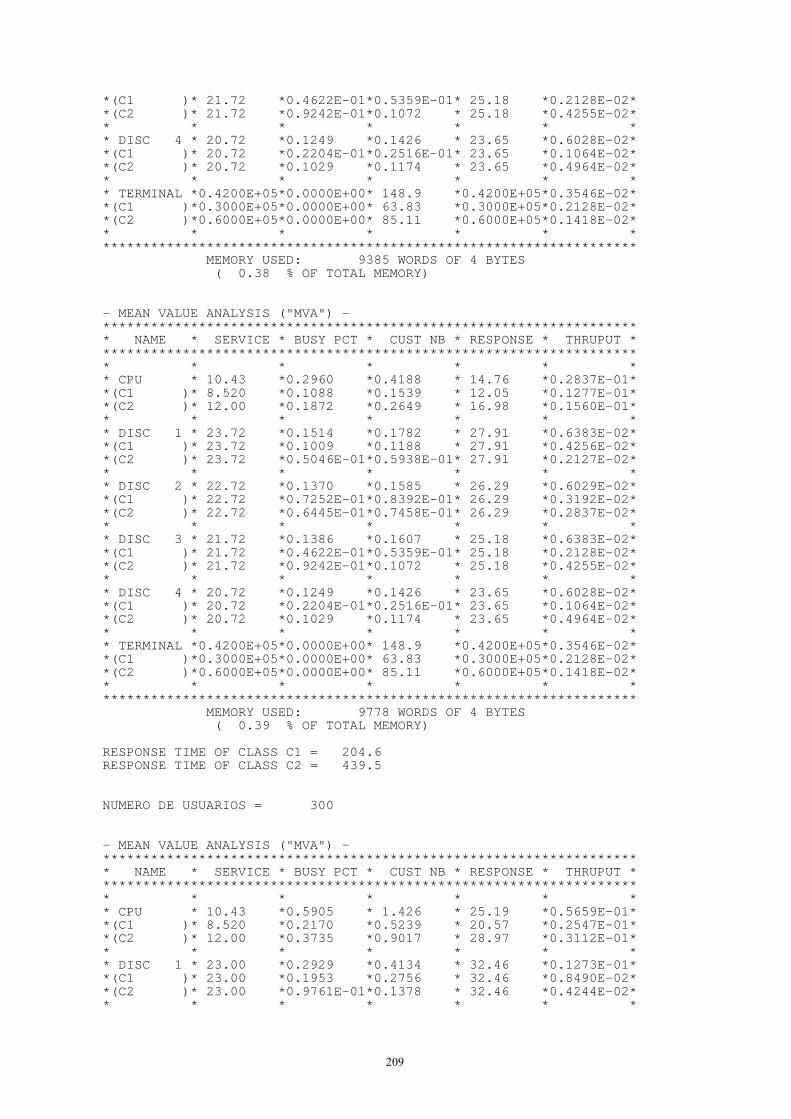
209
*(C1 )* 21.72 *0.4622E-01*0.5359E-01* 25.18 *0.2128E-02* *(C2 )* 21.72 *0.9242E-01*0.1072 * 25.18 *0.4255E-02* * * * * * * * * DISC 4 * 20.72 *0.1249 *0.1426 * 23.65 *0.6028E-02* *(C1 )* 20.72 *0.2204E-01*0.2516E-01* 23.65 *0.1064E-02* *(C2 )* 20.72 *0.1029 *0.1174 * 23.65 *0.4964E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 148.9 *0.4200E+05*0.3546E-02* *(C1 )*0.3000E+05*0.0000E+00* 63.83 *0.3000E+05*0.2128E-02* *(C2 )*0.6000E+05*0.0000E+00* 85.11 *0.6000E+05*0.1418E-02* * * * * * * * ******************************************************************* MEMORY USED: 9385 WORDS OF 4 BYTES ( 0.38 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.2960 *0.4188 * 14.76 *0.2837E-01* *(C1 )* 8.520 *0.1088 *0.1539 * 12.05 *0.1277E-01* *(C2 )* 12.00 *0.1872 *0.2649 * 16.98 *0.1560E-01* * * * * * * * * DISC 1 * 23.72 *0.1514 *0.1782 * 27.91 *0.6383E-02* *(C1 )* 23.72 *0.1009 *0.1188 * 27.91 *0.4256E-02* *(C2 )* 23.72 *0.5046E-01*0.5938E-01* 27.91 *0.2127E-02* * * * * * * * * DISC 2 * 22.72 *0.1370 *0.1585 * 26.29 *0.6029E-02* *(C1 )* 22.72 *0.7252E-01*0.8392E-01* 26.29 *0.3192E-02* *(C2 )* 22.72 *0.6445E-01*0.7458E-01* 26.29 *0.2837E-02* * * * * * * * * DISC 3 * 21.72 *0.1386 *0.1607 * 25.18 *0.6383E-02* *(C1 )* 21.72 *0.4622E-01*0.5359E-01* 25.18 *0.2128E-02* *(C2 )* 21.72 *0.9242E-01*0.1072 * 25.18 *0.4255E-02* * * * * * * * * DISC 4 * 20.72 *0.1249 *0.1426 * 23.65 *0.6028E-02* *(C1 )* 20.72 *0.2204E-01*0.2516E-01* 23.65 *0.1064E-02* *(C2 )* 20.72 *0.1029 *0.1174 * 23.65 *0.4964E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 148.9 *0.4200E+05*0.3546E-02* *(C1 )*0.3000E+05*0.0000E+00* 63.83 *0.3000E+05*0.2128E-02* *(C2 )*0.6000E+05*0.0000E+00* 85.11 *0.6000E+05*0.1418E-02* * * * * * * * ******************************************************************* MEMORY USED: 9778 WORDS OF 4 BYTES ( 0.39 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 204.6 RESPONSE TIME OF CLASS C2 = 439.5 NUMERO DE USUARIOS = 300 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5905 * 1.426 * 25.19 *0.5659E-01* *(C1 )* 8.520 *0.2170 *0.5239 * 20.57 *0.2547E-01* *(C2 )* 12.00 *0.3735 *0.9017 * 28.97 *0.3112E-01* * * * * * * * * DISC 1 * 23.00 *0.2929 *0.4134 * 32.46 *0.1273E-01* *(C1 )* 23.00 *0.1953 *0.2756 * 32.46 *0.8490E-02* *(C2 )* 23.00 *0.9761E-01*0.1378 * 32.46 *0.4244E-02* * * * * * * *
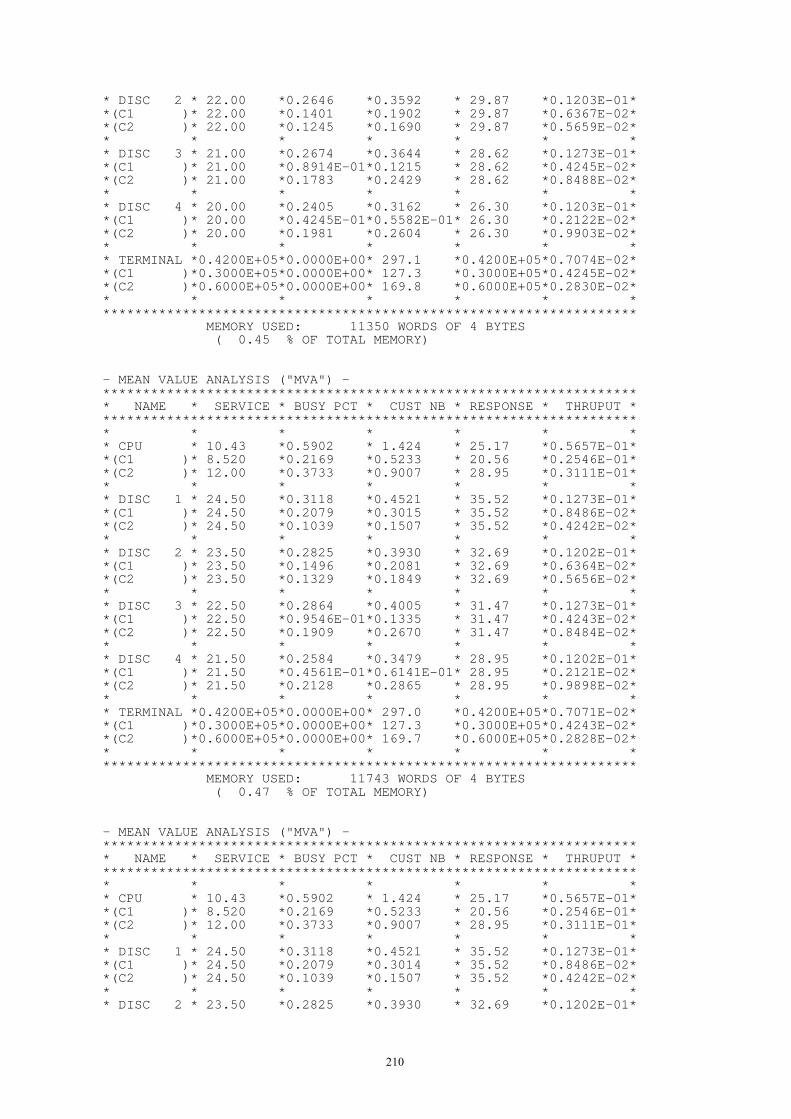
210
* DISC 2 * 22.00 *0.2646 *0.3592 * 29.87 *0.1203E-01* *(C1 )* 22.00 *0.1401 *0.1902 * 29.87 *0.6367E-02* *(C2 )* 22.00 *0.1245 *0.1690 * 29.87 *0.5659E-02* * * * * * * * * DISC 3 * 21.00 *0.2674 *0.3644 * 28.62 *0.1273E-01* *(C1 )* 21.00 *0.8914E-01*0.1215 * 28.62 *0.4245E-02* *(C2 )* 21.00 *0.1783 *0.2429 * 28.62 *0.8488E-02* * * * * * * * * DISC 4 * 20.00 *0.2405 *0.3162 * 26.30 *0.1203E-01* *(C1 )* 20.00 *0.4245E-01*0.5582E-01* 26.30 *0.2122E-02* *(C2 )* 20.00 *0.1981 *0.2604 * 26.30 *0.9903E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 297.1 *0.4200E+05*0.7074E-02* *(C1 )*0.3000E+05*0.0000E+00* 127.3 *0.3000E+05*0.4245E-02* *(C2 )*0.6000E+05*0.0000E+00* 169.8 *0.6000E+05*0.2830E-02* * * * * * * * ******************************************************************* MEMORY USED: 11350 WORDS OF 4 BYTES ( 0.45 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5902 * 1.424 * 25.17 *0.5657E-01* *(C1 )* 8.520 *0.2169 *0.5233 * 20.56 *0.2546E-01* *(C2 )* 12.00 *0.3733 *0.9007 * 28.95 *0.3111E-01* * * * * * * * * DISC 1 * 24.50 *0.3118 *0.4521 * 35.52 *0.1273E-01* *(C1 )* 24.50 *0.2079 *0.3015 * 35.52 *0.8486E-02* *(C2 )* 24.50 *0.1039 *0.1507 * 35.52 *0.4242E-02* * * * * * * * * DISC 2 * 23.50 *0.2825 *0.3930 * 32.69 *0.1202E-01* *(C1 )* 23.50 *0.1496 *0.2081 * 32.69 *0.6364E-02* *(C2 )* 23.50 *0.1329 *0.1849 * 32.69 *0.5656E-02* * * * * * * * * DISC 3 * 22.50 *0.2864 *0.4005 * 31.47 *0.1273E-01* *(C1 )* 22.50 *0.9546E-01*0.1335 * 31.47 *0.4243E-02* *(C2 )* 22.50 *0.1909 *0.2670 * 31.47 *0.8484E-02* * * * * * * * * DISC 4 * 21.50 *0.2584 *0.3479 * 28.95 *0.1202E-01* *(C1 )* 21.50 *0.4561E-01*0.6141E-01* 28.95 *0.2121E-02* *(C2 )* 21.50 *0.2128 *0.2865 * 28.95 *0.9898E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 297.0 *0.4200E+05*0.7071E-02* *(C1 )*0.3000E+05*0.0000E+00* 127.3 *0.3000E+05*0.4243E-02* *(C2 )*0.6000E+05*0.0000E+00* 169.7 *0.6000E+05*0.2828E-02* * * * * * * * ******************************************************************* MEMORY USED: 11743 WORDS OF 4 BYTES ( 0.47 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5902 * 1.424 * 25.17 *0.5657E-01* *(C1 )* 8.520 *0.2169 *0.5233 * 20.56 *0.2546E-01* *(C2 )* 12.00 *0.3733 *0.9007 * 28.95 *0.3111E-01* * * * * * * * * DISC 1 * 24.50 *0.3118 *0.4521 * 35.52 *0.1273E-01* *(C1 )* 24.50 *0.2079 *0.3014 * 35.52 *0.8486E-02* *(C2 )* 24.50 *0.1039 *0.1507 * 35.52 *0.4242E-02* * * * * * * * * DISC 2 * 23.50 *0.2825 *0.3930 * 32.69 *0.1202E-01*
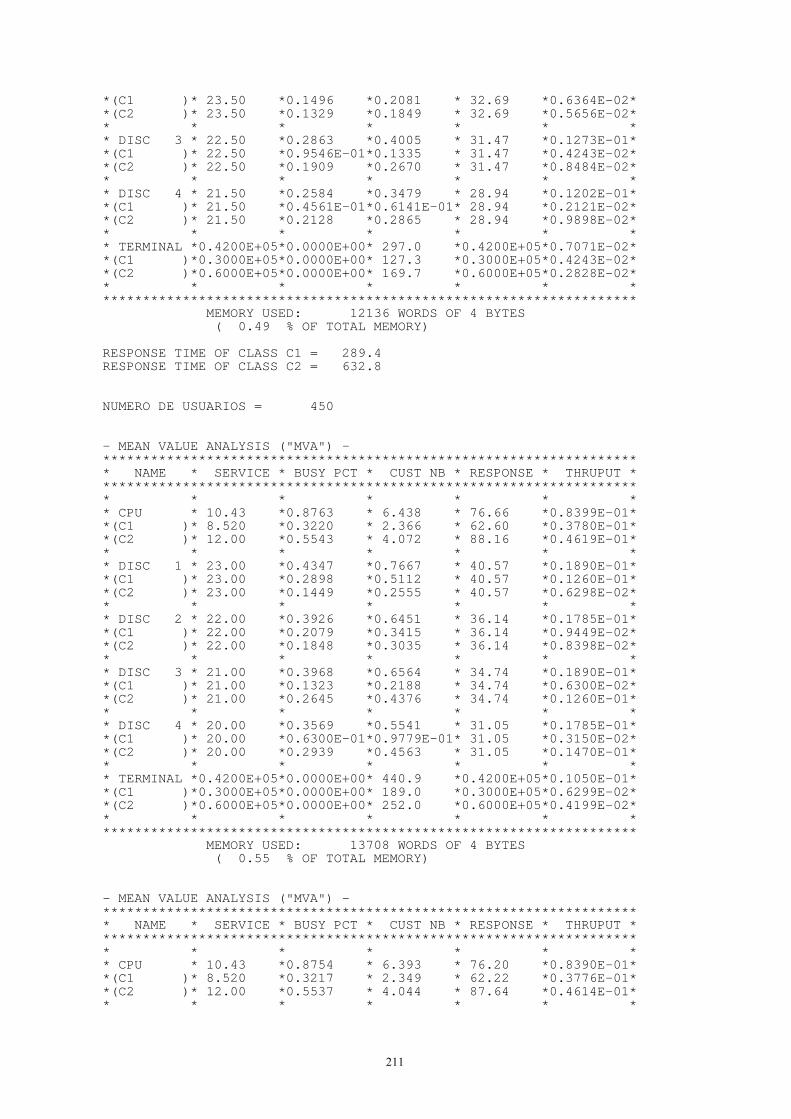
211
*(C1 )* 23.50 *0.1496 *0.2081 * 32.69 *0.6364E-02* *(C2 )* 23.50 *0.1329 *0.1849 * 32.69 *0.5656E-02* * * * * * * * * DISC 3 * 22.50 *0.2863 *0.4005 * 31.47 *0.1273E-01* *(C1 )* 22.50 *0.9546E-01*0.1335 * 31.47 *0.4243E-02* *(C2 )* 22.50 *0.1909 *0.2670 * 31.47 *0.8484E-02* * * * * * * * * DISC 4 * 21.50 *0.2584 *0.3479 * 28.94 *0.1202E-01* *(C1 )* 21.50 *0.4561E-01*0.6141E-01* 28.94 *0.2121E-02* *(C2 )* 21.50 *0.2128 *0.2865 * 28.94 *0.9898E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 297.0 *0.4200E+05*0.7071E-02* *(C1 )*0.3000E+05*0.0000E+00* 127.3 *0.3000E+05*0.4243E-02* *(C2 )*0.6000E+05*0.0000E+00* 169.7 *0.6000E+05*0.2828E-02* * * * * * * * ******************************************************************* MEMORY USED: 12136 WORDS OF 4 BYTES ( 0.49 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 289.4 RESPONSE TIME OF CLASS C2 = 632.8 NUMERO DE USUARIOS = 450 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8763 * 6.438 * 76.66 *0.8399E-01* *(C1 )* 8.520 *0.3220 * 2.366 * 62.60 *0.3780E-01* *(C2 )* 12.00 *0.5543 * 4.072 * 88.16 *0.4619E-01* * * * * * * * * DISC 1 * 23.00 *0.4347 *0.7667 * 40.57 *0.1890E-01* *(C1 )* 23.00 *0.2898 *0.5112 * 40.57 *0.1260E-01* *(C2 )* 23.00 *0.1449 *0.2555 * 40.57 *0.6298E-02* * * * * * * * * DISC 2 * 22.00 *0.3926 *0.6451 * 36.14 *0.1785E-01* *(C1 )* 22.00 *0.2079 *0.3415 * 36.14 *0.9449E-02* *(C2 )* 22.00 *0.1848 *0.3035 * 36.14 *0.8398E-02* * * * * * * * * DISC 3 * 21.00 *0.3968 *0.6564 * 34.74 *0.1890E-01* *(C1 )* 21.00 *0.1323 *0.2188 * 34.74 *0.6300E-02* *(C2 )* 21.00 *0.2645 *0.4376 * 34.74 *0.1260E-01* * * * * * * * * DISC 4 * 20.00 *0.3569 *0.5541 * 31.05 *0.1785E-01* *(C1 )* 20.00 *0.6300E-01*0.9779E-01* 31.05 *0.3150E-02* *(C2 )* 20.00 *0.2939 *0.4563 * 31.05 *0.1470E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 440.9 *0.4200E+05*0.1050E-01* *(C1 )*0.3000E+05*0.0000E+00* 189.0 *0.3000E+05*0.6299E-02* *(C2 )*0.6000E+05*0.0000E+00* 252.0 *0.6000E+05*0.4199E-02* * * * * * * * ******************************************************************* MEMORY USED: 13708 WORDS OF 4 BYTES ( 0.55 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8754 * 6.393 * 76.20 *0.8390E-01* *(C1 )* 8.520 *0.3217 * 2.349 * 62.22 *0.3776E-01* *(C2 )* 12.00 *0.5537 * 4.044 * 87.64 *0.4614E-01* * * * * * * *
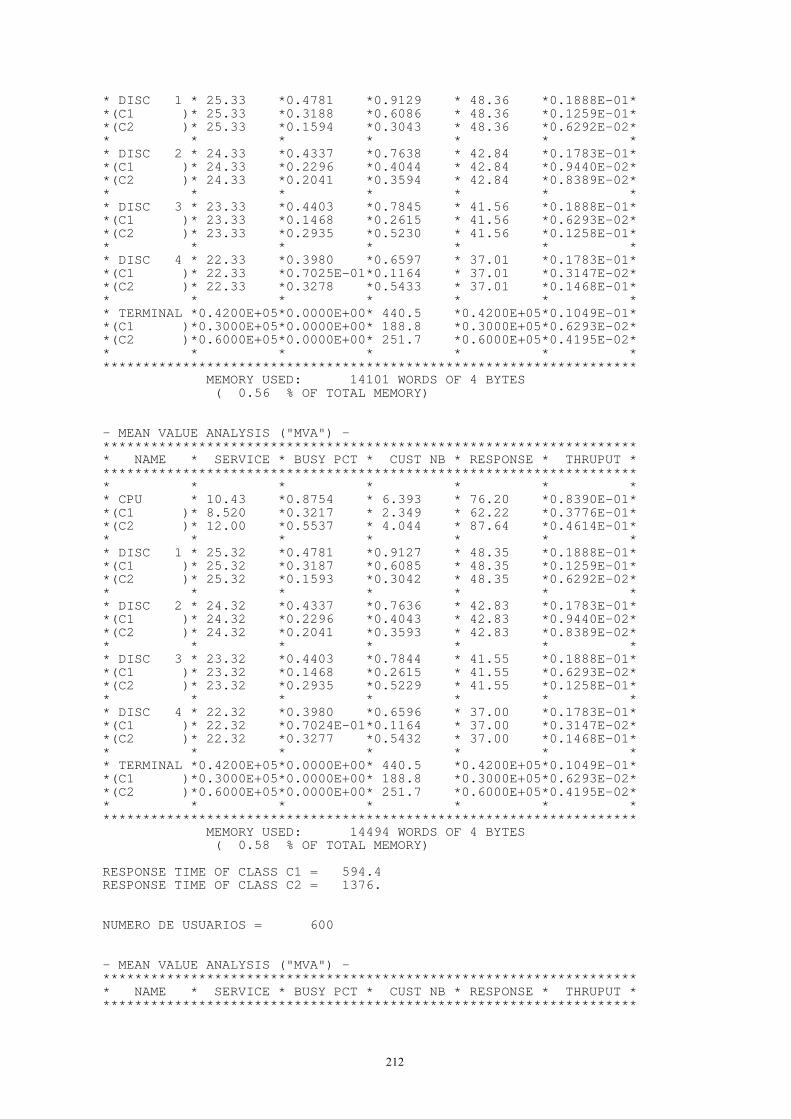
212
* DISC 1 * 25.33 *0.4781 *0.9129 * 48.36 *0.1888E-01* *(C1 )* 25.33 *0.3188 *0.6086 * 48.36 *0.1259E-01* *(C2 )* 25.33 *0.1594 *0.3043 * 48.36 *0.6292E-02* * * * * * * * * DISC 2 * 24.33 *0.4337 *0.7638 * 42.84 *0.1783E-01* *(C1 )* 24.33 *0.2296 *0.4044 * 42.84 *0.9440E-02* *(C2 )* 24.33 *0.2041 *0.3594 * 42.84 *0.8389E-02* * * * * * * * * DISC 3 * 23.33 *0.4403 *0.7845 * 41.56 *0.1888E-01* *(C1 )* 23.33 *0.1468 *0.2615 * 41.56 *0.6293E-02* *(C2 )* 23.33 *0.2935 *0.5230 * 41.56 *0.1258E-01* * * * * * * * * DISC 4 * 22.33 *0.3980 *0.6597 * 37.01 *0.1783E-01* *(C1 )* 22.33 *0.7025E-01*0.1164 * 37.01 *0.3147E-02* *(C2 )* 22.33 *0.3278 *0.5433 * 37.01 *0.1468E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 440.5 *0.4200E+05*0.1049E-01* *(C1 )*0.3000E+05*0.0000E+00* 188.8 *0.3000E+05*0.6293E-02* *(C2 )*0.6000E+05*0.0000E+00* 251.7 *0.6000E+05*0.4195E-02* * * * * * * * ******************************************************************* MEMORY USED: 14101 WORDS OF 4 BYTES ( 0.56 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8754 * 6.393 * 76.20 *0.8390E-01* *(C1 )* 8.520 *0.3217 * 2.349 * 62.22 *0.3776E-01* *(C2 )* 12.00 *0.5537 * 4.044 * 87.64 *0.4614E-01* * * * * * * * * DISC 1 * 25.32 *0.4781 *0.9127 * 48.35 *0.1888E-01* *(C1 )* 25.32 *0.3187 *0.6085 * 48.35 *0.1259E-01* *(C2 )* 25.32 *0.1593 *0.3042 * 48.35 *0.6292E-02* * * * * * * * * DISC 2 * 24.32 *0.4337 *0.7636 * 42.83 *0.1783E-01* *(C1 )* 24.32 *0.2296 *0.4043 * 42.83 *0.9440E-02* *(C2 )* 24.32 *0.2041 *0.3593 * 42.83 *0.8389E-02* * * * * * * * * DISC 3 * 23.32 *0.4403 *0.7844 * 41.55 *0.1888E-01* *(C1 )* 23.32 *0.1468 *0.2615 * 41.55 *0.6293E-02* *(C2 )* 23.32 *0.2935 *0.5229 * 41.55 *0.1258E-01* * * * * * * * * DISC 4 * 22.32 *0.3980 *0.6596 * 37.00 *0.1783E-01* *(C1 )* 22.32 *0.7024E-01*0.1164 * 37.00 *0.3147E-02* *(C2 )* 22.32 *0.3277 *0.5432 * 37.00 *0.1468E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 440.5 *0.4200E+05*0.1049E-01* *(C1 )*0.3000E+05*0.0000E+00* 188.8 *0.3000E+05*0.6293E-02* *(C2 )*0.6000E+05*0.0000E+00* 251.7 *0.6000E+05*0.4195E-02* * * * * * * * ******************************************************************* MEMORY USED: 14494 WORDS OF 4 BYTES ( 0.58 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 594.4 RESPONSE TIME OF CLASS C2 = 1376. NUMERO DE USUARIOS = 600 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * *******************************************************************
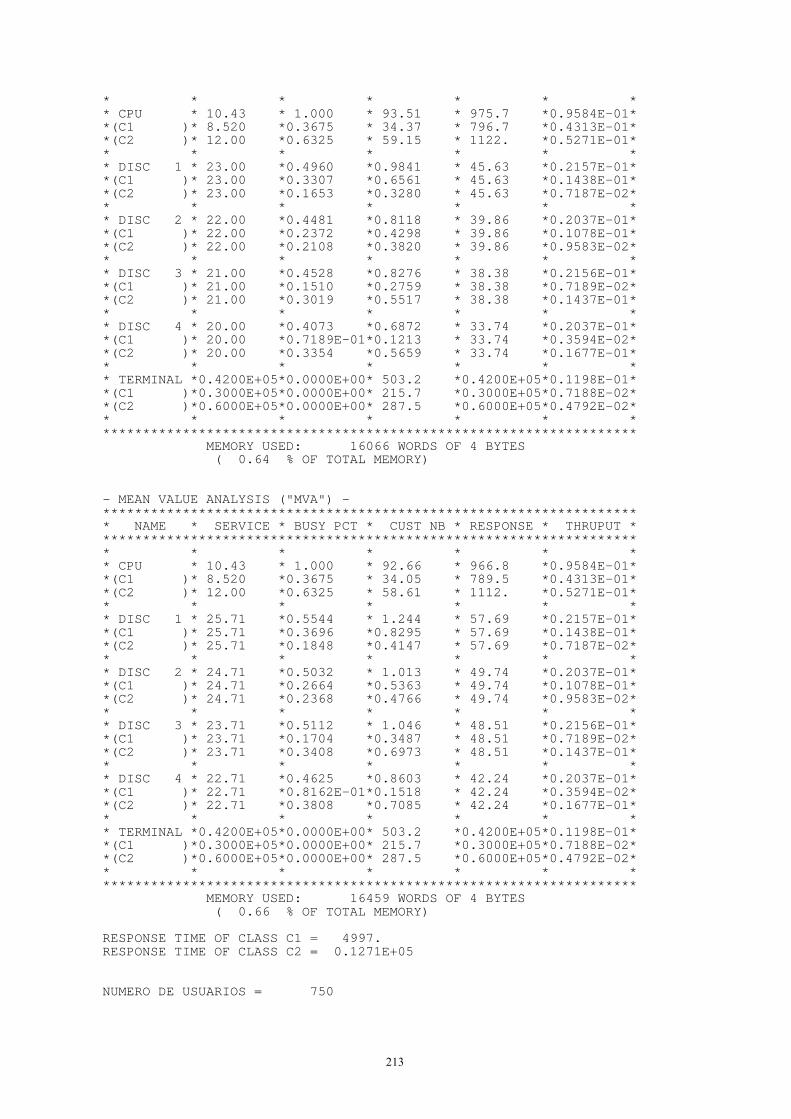
213
* * * * * * * * CPU * 10.43 * 1.000 * 93.51 * 975.7 *0.9584E-01* *(C1 )* 8.520 *0.3675 * 34.37 * 796.7 *0.4313E-01* *(C2 )* 12.00 *0.6325 * 59.15 * 1122. *0.5271E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9841 * 45.63 *0.2157E-01* *(C1 )* 23.00 *0.3307 *0.6561 * 45.63 *0.1438E-01* *(C2 )* 23.00 *0.1653 *0.3280 * 45.63 *0.7187E-02* * * * * * * * * DISC 2 * 22.00 *0.4481 *0.8118 * 39.86 *0.2037E-01* *(C1 )* 22.00 *0.2372 *0.4298 * 39.86 *0.1078E-01* *(C2 )* 22.00 *0.2108 *0.3820 * 39.86 *0.9583E-02* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8276 * 38.38 *0.2156E-01* *(C1 )* 21.00 *0.1510 *0.2759 * 38.38 *0.7189E-02* *(C2 )* 21.00 *0.3019 *0.5517 * 38.38 *0.1437E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6872 * 33.74 *0.2037E-01* *(C1 )* 20.00 *0.7189E-01*0.1213 * 33.74 *0.3594E-02* *(C2 )* 20.00 *0.3354 *0.5659 * 33.74 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 16066 WORDS OF 4 BYTES ( 0.64 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 92.66 * 966.8 *0.9584E-01* *(C1 )* 8.520 *0.3675 * 34.05 * 789.5 *0.4313E-01* *(C2 )* 12.00 *0.6325 * 58.61 * 1112. *0.5271E-01* * * * * * * * * DISC 1 * 25.71 *0.5544 * 1.244 * 57.69 *0.2157E-01* *(C1 )* 25.71 *0.3696 *0.8295 * 57.69 *0.1438E-01* *(C2 )* 25.71 *0.1848 *0.4147 * 57.69 *0.7187E-02* * * * * * * * * DISC 2 * 24.71 *0.5032 * 1.013 * 49.74 *0.2037E-01* *(C1 )* 24.71 *0.2664 *0.5363 * 49.74 *0.1078E-01* *(C2 )* 24.71 *0.2368 *0.4766 * 49.74 *0.9583E-02* * * * * * * * * DISC 3 * 23.71 *0.5112 * 1.046 * 48.51 *0.2156E-01* *(C1 )* 23.71 *0.1704 *0.3487 * 48.51 *0.7189E-02* *(C2 )* 23.71 *0.3408 *0.6973 * 48.51 *0.1437E-01* * * * * * * * * DISC 4 * 22.71 *0.4625 *0.8603 * 42.24 *0.2037E-01* *(C1 )* 22.71 *0.8162E-01*0.1518 * 42.24 *0.3594E-02* *(C2 )* 22.71 *0.3808 *0.7085 * 42.24 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 16459 WORDS OF 4 BYTES ( 0.66 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 4997. RESPONSE TIME OF CLASS C2 = 0.1271E+05 NUMERO DE USUARIOS = 750

214
- MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 243.5 * 2541. *0.9584E-01* *(C1 )* 8.520 *0.3675 * 89.49 * 2075. *0.4313E-01* *(C2 )* 12.00 *0.6325 * 154.0 * 2922. *0.5271E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9841 * 45.64 *0.2157E-01* *(C1 )* 23.00 *0.3307 *0.6561 * 45.64 *0.1438E-01* *(C2 )* 23.00 *0.1653 *0.3280 * 45.64 *0.7187E-02* * * * * * * * * DISC 2 * 22.00 *0.4481 *0.8118 * 39.86 *0.2037E-01* *(C1 )* 22.00 *0.2372 *0.4298 * 39.86 *0.1078E-01* *(C2 )* 22.00 *0.2108 *0.3820 * 39.86 *0.9583E-02* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8276 * 38.38 *0.2156E-01* *(C1 )* 21.00 *0.1510 *0.2759 * 38.38 *0.7189E-02* *(C2 )* 21.00 *0.3019 *0.5517 * 38.38 *0.1437E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6872 * 33.74 *0.2037E-01* *(C1 )* 20.00 *0.7189E-01*0.1213 * 33.74 *0.3594E-02* *(C2 )* 20.00 *0.3354 *0.5659 * 33.74 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 17638 WORDS OF 4 BYTES ( 0.71 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 242.7 * 2532. *0.9584E-01* *(C1 )* 8.520 *0.3675 * 89.18 * 2067. *0.4313E-01* *(C2 )* 12.00 *0.6325 * 153.5 * 2912. *0.5271E-01* * * * * * * * * DISC 1 * 25.71 *0.5544 * 1.244 * 57.69 *0.2157E-01* *(C1 )* 25.71 *0.3696 *0.8295 * 57.69 *0.1438E-01* *(C2 )* 25.71 *0.1848 *0.4147 * 57.69 *0.7187E-02* * * * * * * * * DISC 2 * 24.71 *0.5032 * 1.013 * 49.74 *0.2037E-01* *(C1 )* 24.71 *0.2664 *0.5363 * 49.74 *0.1078E-01* *(C2 )* 24.71 *0.2368 *0.4766 * 49.74 *0.9583E-02* * * * * * * * * DISC 3 * 23.71 *0.5112 * 1.046 * 48.51 *0.2156E-01* *(C1 )* 23.71 *0.1704 *0.3487 * 48.51 *0.7189E-02* *(C2 )* 23.71 *0.3408 *0.6973 * 48.51 *0.1437E-01* * * * * * * * * DISC 4 * 22.71 *0.4625 *0.8603 * 42.24 *0.2037E-01* *(C1 )* 22.71 *0.8162E-01*0.1518 * 42.24 *0.3594E-02* *(C2 )* 22.71 *0.3808 *0.7085 * 42.24 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 18031 WORDS OF 4 BYTES ( 0.72 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 0.1266E+05

215
RESPONSE TIME OF CLASS C2 = 0.3251E+05 66 /END/ Si se desea efectuar el estudio por simulación es necesario reestructurar el modelo reproduciendo los mecanismos de funcionamiento de los discos. En primer lugar se presenta un modelo simplificado prescindiendo de la necesidad que la unidad de control esté libre para poder iniciar el movimiento del brazo. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE INTEGER M; 2 QUEUE CPU,DISC(4),UC,TERMINAL,R(2); 3 REAL PROF1(4)=(2.,3.5,4.5,5.); 4 REAL PROF2(4)=(1.5,3.5,6.5,10.); 5 REAL TR1,TR2; 6 REAL SD(4),TF,VR=3600,TAU,D,SK(4)=(13.,12.,11.,10.); 7 CLASS C1,C2; 8 INTEGER I,N; 9 REF CUSTOMER C; 10 /STATION/ NAME=CPU; 11 SCHED=PS; 12 SERVICE(C1)=BEGIN 13 CST(8.52); 14 D := UNIFORM(0., 6.); 15 FOR I := 1 STEP 1 UNTIL 4 DO 16 IF D <= PROF1(I) THEN TRANSIT(DISC(I)); 17 C:=R(1).FIRST; 18 WHILE C.FATHER <> CUSTOMER DO C:=C.NEXT; 19 TRANSIT(C,OUT); 20 IF D <= 5.6 THEN TRANSIT(TERMINAL,C1) 21 ELSE TRANSIT(TERMINAL,C2); 22 END; 23 SERVICE(C2)=BEGIN 24 CST(12.); 25 D := UNIFORM(0., 11.); 26 FOR I := 1 STEP 1 UNTIL 4 DO 27 IF D <= PROF2(I) THEN TRANSIT(DISC(I)); 28 C:=R(2).FIRST; 29 WHILE C.FATHER <> CUSTOMER DO C:=C.NEXT; 30 TRANSIT(C,OUT); 31 IF D <= 10.6 THEN TRANSIT(TERMINAL,C1) 32 ELSE TRANSIT(TERMINAL,C2); 33 END; 34 /STATION/ NAME=DISC; 35 SERVICE=BEGIN 36 HEXP(SK(M),0.5); 37 UNIFORM(0.,TAU); 38 WHILE UC.NB > 0 DO CST(TAU); 39 TRANSIT(NEW(CUSTOMER),UC); 40 CST(TF); 41 TRANSIT(CPU); 42 END; 43 /STATION/ NAME=UC; 44 SERVICE=BEGIN 45 CST(TF); 46 TRANSIT(OUT); 47 END; 48 /STATION/ NAME=TERMINAL; 49 TYPE=INFINITE; 50 INIT(C1)=6*N/10; 51 INIT(C2)=4*N/10; 52 SERVICE(C1)=BEGIN 53 EXP(30000.); 54 TRANSIT(NEW(CUSTOMER),R(1),C1); 55 END;

216
56 SERVICE(C2)=BEGIN 57 EXP(60000.); 58 TRANSIT(NEW(CUSTOMER),R(2),C2); 59 END; 60 TRANSIT=CPU; 61 /CONTROL/ TMAX=5000000.; 62 CLASS=ALL QUEUE; 63 ACCURACY=R; 64 /EXEC/ BEGIN 65 TAU:=60.*1000./VR; 66 TF:=TAU/10.; 67 FOR I:=1 STEP 1 UNTIL 4 DO DISC(I).M:=I; 68 FOR N:=150 STEP 150 UNTIL 750 DO 69 BEGIN 70 PRINT("NUMERO DE USUARIOS =",N); 71 SIMUL; 72 TR1:=MCUSTNB(CPU,C1); 73 TR2:=MCUSTNB(CPU,C2); 74 FOR I:= 1 STEP 1 UNTIL 4 DO 75 BEGIN 76 TR1:=TR1+MCUSTNB(DISC(I),C1); 77 TR2:=TR2+MCUSTNB(DISC(I),C2); 78 END; 79 TR1:=TR1/MTHRUPUT(TERMINAL,C1); 80 TR2:=TR2/MTHRUPUT(TERMINAL,C2);; 81 PRINT("RESPONSE TIME OF CLASS C1 =",TR1); 82 PRINT("RESPONSE TIME OF CLASS C2 =",TR2); 83 END; 84 END; NUMERO DE USUARIOS = 150 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.40 *0.2929 *0.3778 * 13.43 * 140700* *(C1 )* 8.524 *0.1097 *0.1419 * 11.03 * 64322* *(C2 )* 12.00 *0.1833 *0.2360 * 15.45 * 76378* * * * * * * * * DISC 1 * 23.59 *0.1513 *0.1695 * 26.44 * 32054* *(C1 )* 23.55 *0.1013 *0.1143 * 26.59 * 21501* *(C2 )* 23.68 *0.4998E-01*0.5514E-01* 26.12 * 10553* * * * * * * * * DISC 2 * 22.63 *0.1357 *0.1488 * 24.81 * 29979* *(C1 )* 22.61 *0.7300E-01*0.8078E-01* 25.02 * 16141* *(C2 )* 22.66 *0.6270E-01*0.6799E-01* 24.57 * 13838* * * * * * * * * DISC 3 * 21.58 *0.1363 *0.1489 * 23.59 * 31566* *(C1 )* 21.46 *0.4573E-01*0.5051E-01* 23.71 * 10653* *(C2 )* 21.64 *0.9052E-01*0.9843E-01* 23.53 * 20913* * * * * * * * * DISC 4 * 20.60 *0.1214 *0.1310 * 22.23 * 29478* *(C1 )* 20.66 *0.2225E-01*0.2410E-01* 22.38 * 5383* *(C2 )* 20.59 *0.9920E-01*0.1069 * 22.19 * 24095* * * * * * * * * UC * 1.668 *0.4106E-01*0.4106E-01* 1.668 * 123077* *(C1 )* 1.666 *0.1789E-01*0.1789E-01* 1.666 * 53678* *(C2 )* 1.666 *0.2312E-01*0.2312E-01* 1.666 * 69399* * * * * * * * * TERMINAL *0.4189E+05*0.0000E+00* 149.0 *0.4189E+05* 17623* *(C1 )*0.2976E+05*0.0000E+00* 63.82 *0.2976E+05* 10644* *(C2 )*0.6039E+05*0.0000E+00* 85.20 *0.6039E+05* 6979* * * * * * * * * R 1 *0.0000E+00*0.0000E+00*0.4117 * 193.4 * 10644* * +/- *0.0000E+00*0.0000E+00*0.1394E-01* 5.020 * *

217
*(C1 )*0.0000E+00*0.0000E+00*0.4117 * 193.4 * 10644* * * * * * * * * R 2 *0.0000E+00*0.0000E+00*0.5644 * 404.4 * 6979* * +/- *0.0000E+00*0.0000E+00*0.2017E-01* 13.69 * * *(C2 )*0.0000E+00*0.0000E+00*0.5644 * 404.4 * 6979* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 16756 WORDS OF 4 BYTES ( 0.67 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 193.4 RESPONSE TIME OF CLASS C2 = 404.4 NUMERO DE USUARIOS = 300 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.41 *0.5967 * 1.274 * 22.23 * 286455* *(C1 )* 8.512 *0.2221 *0.4707 * 18.05 * 130344* *(C2 )* 12.00 *0.3747 *0.8029 * 25.72 * 156111* * * * * * * * * DISC 1 * 24.16 *0.3126 *0.4031 * 31.15 * 64704* *(C1 )* 24.19 *0.2107 *0.2749 * 31.57 * 43540* *(C2 )* 24.09 *0.1020 *0.1282 * 30.30 * 21164* * * * * * * * * DISC 2 * 23.21 *0.2849 *0.3525 * 28.72 * 61367* *(C1 )* 23.15 *0.1514 *0.1894 * 28.96 * 32704* *(C2 )* 23.28 *0.1335 *0.1631 * 28.45 * 28663* * * * * * * * * DISC 3 * 22.14 *0.2851 *0.3517 * 27.32 * 64364* *(C1 )* 22.26 *0.9643E-01*0.1204 * 27.79 * 21657* *(C2 )* 22.08 *0.1886 *0.2314 * 27.09 * 42707* * * * * * * * * DISC 4 * 21.17 *0.2562 *0.3067 * 25.33 * 60529* *(C1 )* 21.08 *0.4626E-01*0.5579E-01* 25.42 * 10975* *(C2 )* 21.18 *0.2100 *0.2509 * 25.31 * 49554* * * * * * * * * UC * 1.664 *0.8352E-01*0.8352E-01* 1.664 * 250964* *(C1 )* 1.667 *0.3631E-01*0.3631E-01* 1.667 * 108876* *(C2 )* 1.668 *0.4741E-01*0.4741E-01* 1.668 * 142088* * * * * * * * * TERMINAL *0.4153E+05*0.0000E+00* 297.3 *0.4153E+05* 35492* *(C1 )*0.2996E+05*0.0000E+00* 129.5 *0.2996E+05* 21469* *(C2 )*0.5924E+05*0.0000E+00* 167.8 *0.5924E+05* 14023* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 1.111 * 258.8 * 21468* * +/- *0.0000E+00*0.0000E+00*0.4013E-01* 6.931 * * *(C1 )*0.0000E+00*0.0000E+00* 1.111 * 258.8 * 21468* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 1.576 * 562.1 * 14022* * +/- *0.0000E+00*0.0000E+00*0.5821E-01* 19.61 * * *(C2 )*0.0000E+00*0.0000E+00* 1.576 * 562.1 * 14022* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 23866 WORDS OF 4 BYTES ( 0.95 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 258.8

218
RESPONSE TIME OF CLASS C2 = 562.1 NUMERO DE USUARIOS = 450 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.42 *0.8761 * 5.898 * 70.17 * 420245* *(C1 )* 8.508 *0.3243 * 2.163 * 56.81 * 190333* *(C2 )* 12.00 *0.5518 * 3.736 * 81.25 * 229912* * * * * * * * * DISC 1 * 24.73 *0.4695 *0.7093 * 37.36 * 94930* *(C1 )* 24.76 *0.3144 *0.4810 * 37.87 * 63508* *(C2 )* 24.67 *0.1551 *0.2282 * 36.32 * 31422* * * * * * * * * DISC 2 * 23.75 *0.4240 *0.5972 * 33.45 * 89251* *(C1 )* 23.80 *0.2261 *0.3224 * 33.94 * 47499* *(C2 )* 23.71 *0.1980 *0.2748 * 32.91 * 41752* * * * * * * * * DISC 3 * 22.71 *0.4288 *0.6010 * 31.83 * 94409* *(C1 )* 22.78 *0.1445 *0.2059 * 32.44 * 31730* *(C2 )* 22.67 *0.2842 *0.3951 * 31.52 * 62679* * * * * * * * * DISC 4 * 21.72 *0.3860 *0.5102 * 28.71 * 88864* *(C1 )* 21.77 *0.6898E-01*0.9286E-01* 29.31 * 15841* *(C2 )* 21.71 *0.3170 *0.4173 * 28.57 * 73023* * * * * * * * * UC * 1.666 *0.1224 *0.1224 * 1.666 * 367454* *(C1 )* 1.669 *0.5292E-01*0.5292E-01* 1.669 * 158578* *(C2 )* 1.666 *0.6958E-01*0.6958E-01* 1.666 * 208876* * * * * * * * * TERMINAL *0.4144E+05*0.0000E+00* 441.7 *0.4144E+05* 52801* *(C1 )*0.2989E+05*0.0000E+00* 190.8 *0.2989E+05* 31758* *(C2 )*0.5888E+05*0.0000E+00* 250.9 *0.5888E+05* 21043* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 3.264 * 513.9 * 31754* * +/- *0.0000E+00*0.0000E+00*0.2443 * 41.16 * * *(C1 )*0.0000E+00*0.0000E+00* 3.264 * 513.9 * 31754* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 5.051 * 1200. * 21035* * +/- *0.0000E+00*0.0000E+00*0.4771 * 121.2 * * *(C2 )*0.0000E+00*0.0000E+00* 5.051 * 1200. * 21035* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 31440 WORDS OF 4 BYTES ( 1.26 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 514.0 RESPONSE TIME OF CLASS C2 = 1200. NUMERO DE USUARIOS = 600 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.42 *0.9997 * 88.51 * 923.2 * 479346* *(C1 )* 8.507 *0.3693 * 32.69 * 754.1 * 216721* *(C2 )* 12.00 *0.6304 * 55.82 * 1063. * 262625*
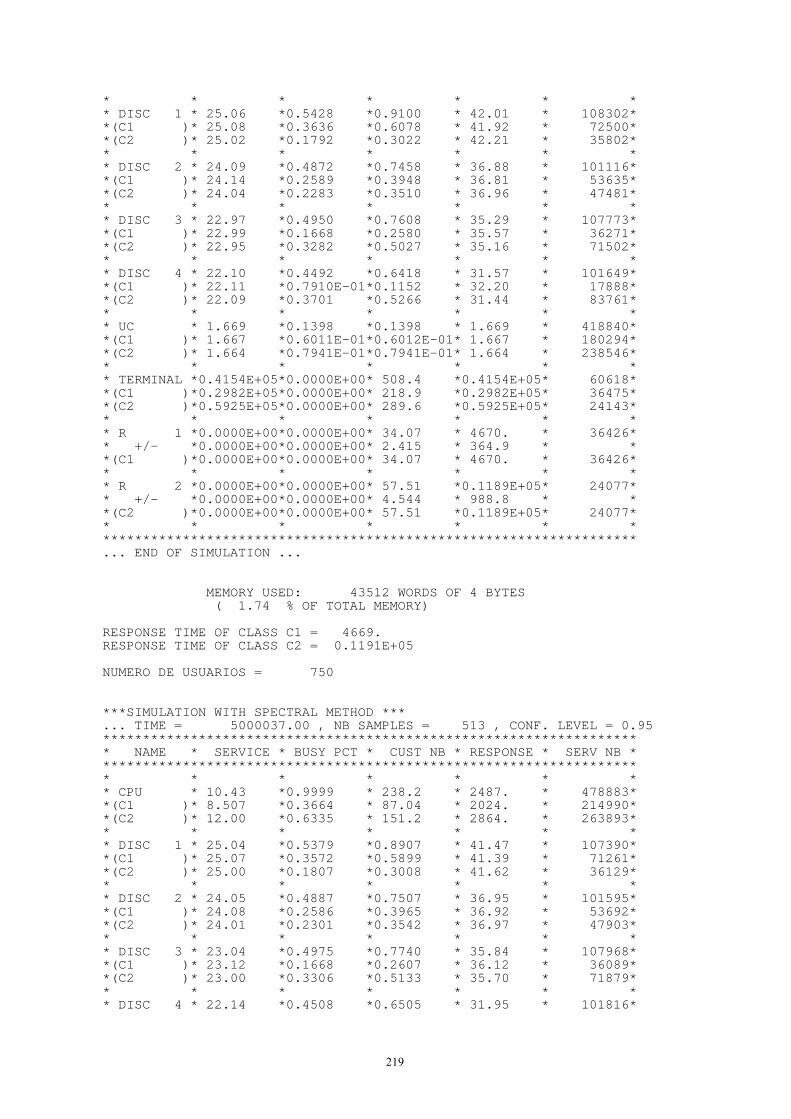
219
* * * * * * * * DISC 1 * 25.06 *0.5428 *0.9100 * 42.01 * 108302* *(C1 )* 25.08 *0.3636 *0.6078 * 41.92 * 72500* *(C2 )* 25.02 *0.1792 *0.3022 * 42.21 * 35802* * * * * * * * * DISC 2 * 24.09 *0.4872 *0.7458 * 36.88 * 101116* *(C1 )* 24.14 *0.2589 *0.3948 * 36.81 * 53635* *(C2 )* 24.04 *0.2283 *0.3510 * 36.96 * 47481* * * * * * * * * DISC 3 * 22.97 *0.4950 *0.7608 * 35.29 * 107773* *(C1 )* 22.99 *0.1668 *0.2580 * 35.57 * 36271* *(C2 )* 22.95 *0.3282 *0.5027 * 35.16 * 71502* * * * * * * * * DISC 4 * 22.10 *0.4492 *0.6418 * 31.57 * 101649* *(C1 )* 22.11 *0.7910E-01*0.1152 * 32.20 * 17888* *(C2 )* 22.09 *0.3701 *0.5266 * 31.44 * 83761* * * * * * * * * UC * 1.669 *0.1398 *0.1398 * 1.669 * 418840* *(C1 )* 1.667 *0.6011E-01*0.6012E-01* 1.667 * 180294* *(C2 )* 1.664 *0.7941E-01*0.7941E-01* 1.664 * 238546* * * * * * * * * TERMINAL *0.4154E+05*0.0000E+00* 508.4 *0.4154E+05* 60618* *(C1 )*0.2982E+05*0.0000E+00* 218.9 *0.2982E+05* 36475* *(C2 )*0.5925E+05*0.0000E+00* 289.6 *0.5925E+05* 24143* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 34.07 * 4670. * 36426* * +/- *0.0000E+00*0.0000E+00* 2.415 * 364.9 * * *(C1 )*0.0000E+00*0.0000E+00* 34.07 * 4670. * 36426* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 57.51 *0.1189E+05* 24077* * +/- *0.0000E+00*0.0000E+00* 4.544 * 988.8 * * *(C2 )*0.0000E+00*0.0000E+00* 57.51 *0.1189E+05* 24077* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 43512 WORDS OF 4 BYTES ( 1.74 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 4669. RESPONSE TIME OF CLASS C2 = 0.1191E+05 NUMERO DE USUARIOS = 750 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9999 * 238.2 * 2487. * 478883* *(C1 )* 8.507 *0.3664 * 87.04 * 2024. * 214990* *(C2 )* 12.00 *0.6335 * 151.2 * 2864. * 263893* * * * * * * * * DISC 1 * 25.04 *0.5379 *0.8907 * 41.47 * 107390* *(C1 )* 25.07 *0.3572 *0.5899 * 41.39 * 71261* *(C2 )* 25.00 *0.1807 *0.3008 * 41.62 * 36129* * * * * * * * * DISC 2 * 24.05 *0.4887 *0.7507 * 36.95 * 101595* *(C1 )* 24.08 *0.2586 *0.3965 * 36.92 * 53692* *(C2 )* 24.01 *0.2301 *0.3542 * 36.97 * 47903* * * * * * * * * DISC 3 * 23.04 *0.4975 *0.7740 * 35.84 * 107968* *(C1 )* 23.12 *0.1668 *0.2607 * 36.12 * 36089* *(C2 )* 23.00 *0.3306 *0.5133 * 35.70 * 71879* * * * * * * * * DISC 4 * 22.14 *0.4508 *0.6505 * 31.95 * 101816*

220
*(C1 )* 22.23 *0.7912E-01*0.1165 * 32.72 * 17799* *(C2 )* 22.12 *0.3717 *0.5341 * 31.78 * 84017* * * * * * * * * UC * 1.669 *0.1398 *0.1398 * 1.669 * 418769* *(C1 )* 1.667 *0.5963E-01*0.5963E-01* 1.667 * 178841* *(C2 )* 1.664 *0.7986E-01*0.7987E-01* 1.664 * 239928* * * * * * * * * TERMINAL *0.4176E+05*0.0000E+00* 508.7 *0.4176E+05* 60366* *(C1 )*0.3033E+05*0.0000E+00* 220.9 *0.3033E+05* 36231* *(C2 )*0.5893E+05*0.0000E+00* 287.8 *0.5893E+05* 24135* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 88.41 *0.1220E+05* 36149* * +/- *0.0000E+00*0.0000E+00* 4.697 * 550.3 * * *(C1 )*0.0000E+00*0.0000E+00* 88.41 *0.1220E+05* 36149* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 152.9 *0.3166E+05* 23964* * +/- *0.0000E+00*0.0000E+00* 5.910 * 1484. * * *(C2 )*0.0000E+00*0.0000E+00* 152.9 *0.3166E+05* 23964* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 57432 WORDS OF 4 BYTES ( 2.30 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 0.1220E+05 RESPONSE TIME OF CLASS C2 = 0.3168E+05 85 /END/ Si quiere refinarse el modelo y desea tenerse en cuenta los retardos que se producen en el inicio del movimiento del brazo debido a que la unidad de control esté ocupada por una transferencia desde otro disco, deben utilizarse un semáforo por disco y otro para la unidad de control, este último de mayor prioridad, que describen y controlan los conflictos de acceso al disco cuando la unidad de control está transfiriendo desde otro disco. Además, se ha desglosado cada disco en dos servidores, QDISC, que representa la espera hasta iniciar el servicio, y DISC, que representa el mecanismo de acceso a la información. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE INTEGER M; 2 QUEUE CPU,QDISC(4),DISC(4),SDISC(4),UC,SUC,TERMINAL,R(2); 3 REAL PROF1(4)=(2.,3.5,4.5,5.); 4 REAL PROF2(4)=(1.5,3.5,6.5,10.); 5 REAL TR1,TR2; 6 REAL SD(4),TF,VR=3600,TAU,D,SK(4)=(13.,12.,11.,10.); 7 CLASS C1,C2; 8 INTEGER I,N; 9 REF CUSTOMER C; 10 /STATION/ NAME=CPU; 11 SCHED=PS; 12 SERVICE(C1)=BEGIN 13 CST(8.52); 14 D := UNIFORM(0., 6.); 15 FOR I := 1 STEP 1 UNTIL 4 DO 16 IF D <= PROF1(I) THEN TRANSIT(QDISC(I)); 17 C:=R(1).FIRST; 18 WHILE C.FATHER <> CUSTOMER DO C:=C.NEXT; 19 TRANSIT(C,OUT); 20 IF D <= 5.6 THEN TRANSIT(TERMINAL,C1) 21 ELSE TRANSIT(TERMINAL,C2); 22 END; 23 SERVICE(C2)=BEGIN 24 CST(12.);

221
25 D := UNIFORM(0., 11.); 26 FOR I := 1 STEP 1 UNTIL 4 DO 27 IF D <= PROF2(I) THEN TRANSIT(QDISC(I)); 28 C:=R(2).FIRST; 29 WHILE C.FATHER <> CUSTOMER DO C:=C.NEXT; 30 TRANSIT(C,OUT); 31 IF D <= 10.6 THEN TRANSIT(TERMINAL,C1) 32 ELSE TRANSIT(TERMINAL,C2); 33 END; 34 /STATION/ NAME=QDISC; 35 SERVICE=BEGIN 36 P(SDISC(M)); 37 P(SUC,2); 38 V(SUC); 39 TRANSIT(DISC(M)); 40 END; 41 /STATION/ NAME=SDISC; 42 TYPE=SEMAPHORE; 43 /STATION/ NAME=DISC; 44 SERVICE=BEGIN 45 HEXP(SK(M),0.5); 46 UNIFORM(0.,TAU); 47 WHILE UC.NB > 0 DO CST(TAU); 48 TRANSIT(NEW(CUSTOMER),UC); 49 CST(TF); 50 V(SDISC(M)); 51 TRANSIT(CPU); 52 END; 53 /STATION/ NAME=UC; 54 SERVICE=BEGIN 55 P(SUC,1); 56 CST(TF); 57 V(SUC); 58 TRANSIT(OUT); 59 END; 60 /STATION/ NAME=SUC; 61 TYPE=SEMAPHORE; 62 /STATION/ NAME=TERMINAL; 63 TYPE=INFINITE; 64 INIT(C1)=6*N/10; 65 INIT(C2)=4*N/10; 66 SERVICE(C1)=BEGIN 67 EXP(30000.); 68 TRANSIT(NEW(CUSTOMER),R(1),C1); 69 END; 70 SERVICE(C2)=BEGIN 71 EXP(60000.); 72 TRANSIT(NEW(CUSTOMER),R(2),C2); 73 END; 74 TRANSIT=CPU; 75 /CONTROL/ TMAX=5000000.; 76 CLASS=ALL QUEUE; 77 ACCURACY=R; 78 /EXEC/ BEGIN 79 TAU:=60.*1000./VR; 80 TF:=TAU/10.; 81 FOR I:=1 STEP 1 UNTIL 4 DO 82 BEGIN 83 DISC(I).M:=I; 84 QDISC(I).M:=I; 85 END; 86 FOR N:=150 STEP 150 UNTIL 750 DO 87 BEGIN 88 PRINT("NUMERO DE USUARIOS =",N); 89 SIMUL; 90 TR1:=MCUSTNB(CPU,C1); 91 TR2:=MCUSTNB(CPU,C2); 92 FOR I:= 1 STEP 1 UNTIL 4 DO 93 BEGIN

222
94 TR1:=TR1+MCUSTNB(DISC(I),C1)+MCUSTNB(QDISC(I),C1); 95 TR2:=TR2+MCUSTNB(DISC(I),C2)+MCUSTNB(QDISC(I),C2); 96 END; 97 TR1:=TR1/MTHRUPUT(TERMINAL,C1); 98 TR2:=TR2/MTHRUPUT(TERMINAL,C2);; 99 PRINT("RESPONSE TIME OF CLASS C1 =",TR1); 100 PRINT("RESPONSE TIME OF CLASS C2 =",TR2); 101 END; 102 END; NUMERO DE USUARIOS = 150 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.42 *0.2963 *0.3868 * 13.60 * 142170* *(C1 )* 8.524 *0.1100 *0.1429 * 11.07 * 64511* *(C2 )* 12.00 *0.1864 *0.2440 * 15.71 * 77659* * * * * * * * * QDISC 1 * 2.565 *0.1653E-01*0.1836E-01* 2.850 * 32221* *(C1 )* 2.694 *0.1167E-01*0.1307E-01* 3.016 * 21660* *(C2 )* 2.300 *0.4857E-02*0.5298E-02* 2.508 * 10561* * * * * * * * * QDISC 2 * 2.071 *0.1260E-01*0.1358E-01* 2.232 * 30424* *(C1 )* 2.149 *0.6964E-02*0.7553E-02* 2.331 * 16204* *(C2 )* 1.983 *0.5639E-02*0.6028E-02* 2.120 * 14220* * * * * * * * * QDISC 3 * 1.936 *0.1232E-01*0.1318E-01* 2.070 * 31829* *(C1 )* 1.986 *0.4214E-02*0.4555E-02* 2.147 * 10606* *(C2 )* 1.910 *0.8109E-02*0.8620E-02* 2.031 * 21223* * * * * * * * * QDISC 4 * 1.749 *0.1049E-01*0.1141E-01* 1.903 * 29985* *(C1 )* 1.751 *0.1874E-02*0.1992E-02* 1.862 * 5351* *(C2 )* 1.748 *0.8614E-02*0.9418E-02* 1.912 * 24634* * * * * * * * * DISC 1 * 23.72 *0.1529 *0.1529 * 23.72 * 32221* *(C1 )* 23.77 *0.1030 *0.1030 * 23.77 * 21660* *(C2 )* 23.62 *0.4989E-01*0.4989E-01* 23.62 * 10561* * * * * * * * * DISC 2 * 22.58 *0.1374 *0.1374 * 22.58 * 30424* *(C1 )* 22.59 *0.7323E-01*0.7322E-01* 22.59 * 16204* *(C2 )* 22.56 *0.6416E-01*0.6416E-01* 22.56 * 14220* * * * * * * * * DISC 3 * 21.66 *0.1379 *0.1379 * 21.66 * 31829* *(C1 )* 21.75 *0.4613E-01*0.4613E-01* 21.75 * 10606* *(C2 )* 21.61 *0.9173E-01*0.9173E-01* 21.61 * 21223* * * * * * * * * DISC 4 * 20.60 *0.1236 *0.1236 * 20.60 * 29985* *(C1 )* 20.52 *0.2196E-01*0.2196E-01* 20.52 * 5351* *(C2 )* 20.62 *0.1016 *0.1016 * 20.62 * 24634* * * * * * * * * SDISC 1 *0.0000E+00*0.0000E+00*0.1638E-01* 15.37 * 5327* *(C1 )*0.0000E+00*0.0000E+00*0.1157E-01* 15.80 * 3663* *(C2 )*0.0000E+00*0.0000E+00*0.4801E-02* 14.43 * 1664* * * * * * * * * SDISC 2 *0.0000E+00*0.0000E+00*0.1247E-01* 14.21 * 4387* *(C1 )*0.0000E+00*0.0000E+00*0.6898E-02* 14.69 * 2347* *(C2 )*0.0000E+00*0.0000E+00*0.5567E-02* 13.65 * 2040* * * * * * * * * SDISC 3 *0.0000E+00*0.0000E+00*0.1217E-01* 13.14 * 4628* *(C1 )*0.0000E+00*0.0000E+00*0.4167E-02* 13.61 * 1531* *(C2 )*0.0000E+00*0.0000E+00*0.7999E-02* 12.91 * 3097* * * * * * * * * SDISC 4 *0.0000E+00*0.0000E+00*0.1034E-01* 12.72 * 4065* *(C1 )*0.0000E+00*0.0000E+00*0.1848E-02* 12.82 * 721*

223
*(C2 )*0.0000E+00*0.0000E+00*0.8492E-02* 12.70 * 3344* * * * * * * * * UC * 1.668 *0.4152E-01*0.4152E-01* 1.668 * 124459* *(C1 )* 1.666 *0.1794E-01*0.1794E-01* 1.666 * 53821* *(C2 )* 1.666 *0.2353E-01*0.2353E-01* 1.666 * 70638* * * * * * * * * SUC *0.0000E+00*0.0000E+00*0.5943E-03*0.7392 * 4020* *(C1 )*0.0000E+00*0.0000E+00*0.2346E-03*0.7307 * 1605* *(C2 )*0.0000E+00*0.0000E+00*0.3597E-03*0.7448 * 2415* * * * * * * * * TERMINAL *0.4170E+05*0.0000E+00* 149.0 *0.4170E+05* 17711* *(C1 )*0.2997E+05*0.0000E+00* 64.44 *0.2997E+05* 10690* *(C2 )*0.5956E+05*0.0000E+00* 84.57 *0.5956E+05* 7021* * * * * * * * * R 1 *0.0000E+00*0.0000E+00*0.4143 * 193.8 * 10690* * +/- *0.0000E+00*0.0000E+00*0.1475E-01* 4.638 * * *(C1 )*0.0000E+00*0.0000E+00*0.4143 * 193.8 * 10690* * * * * * * * * R 2 *0.0000E+00*0.0000E+00*0.5807 * 413.6 * 7021* * +/- *0.0000E+00*0.0000E+00*0.2421E-01* 11.88 * * *(C2 )*0.0000E+00*0.0000E+00*0.5807 * 413.6 * 7021* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 20218 WORDS OF 4 BYTES ( 0.81 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 193.8 RESPONSE TIME OF CLASS C2 = 413.6 NUMERO DE USUARIOS = 300 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.42 *0.5977 * 1.285 * 22.40 * 286758* *(C1 )* 8.512 *0.2214 *0.4725 * 18.18 * 129969* *(C2 )* 12.00 *0.3763 *0.8121 * 25.90 * 156789* * * * * * * * * QDISC 1 * 5.543 *0.7193E-01*0.9080E-01* 6.997 * 64878* *(C1 )* 5.806 *0.5048E-01*0.6421E-01* 7.385 * 43473* *(C2 )* 5.010 *0.2145E-01*0.2659E-01* 6.210 * 21405* * * * * * * * * QDISC 2 * 4.514 *0.5489E-01*0.6611E-01* 5.436 * 60805* *(C1 )* 4.747 *0.3073E-01*0.3717E-01* 5.743 * 32366* *(C2 )* 4.249 *0.2417E-01*0.2894E-01* 5.088 * 28439* * * * * * * * * QDISC 3 * 4.315 *0.5577E-01*0.6725E-01* 5.203 * 64625* *(C1 )* 4.549 *0.1987E-01*0.2408E-01* 5.513 * 21838* *(C2 )* 4.195 *0.3590E-01*0.4318E-01* 5.046 * 42787* * * * * * * * * QDISC 4 * 3.604 *0.4383E-01*0.5092E-01* 4.187 * 60816* *(C1 )* 3.871 *0.8308E-02*0.9644E-02* 4.493 * 10732* *(C2 )* 3.547 *0.3552E-01*0.4128E-01* 4.121 * 50084* * * * * * * * * DISC 1 * 24.12 *0.3130 *0.3130 * 24.12 * 64878* *(C1 )* 24.13 *0.2098 *0.2098 * 24.13 * 43473* *(C2 )* 24.09 *0.1031 *0.1031 * 24.09 * 21405* * * * * * * * * DISC 2 * 23.21 *0.2822 *0.2822 * 23.21 * 60805* *(C1 )* 23.25 *0.1505 *0.1505 * 23.25 * 32366* *(C2 )* 23.16 *0.1317 *0.1317 * 23.16 * 28439* * * * * * * *

224
* DISC 3 * 22.11 *0.2857 *0.2857 * 22.11 * 64625* *(C1 )* 22.07 *0.9638E-01*0.9638E-01* 22.07 * 21838* *(C2 )* 22.13 *0.1894 *0.1894 * 22.13 * 42787* * * * * * * * * DISC 4 * 21.17 *0.2574 *0.2574 * 21.17 * 60816* *(C1 )* 21.10 *0.4529E-01*0.4529E-01* 21.10 * 10732* *(C2 )* 21.18 *0.2121 *0.2121 * 21.18 * 50084* * * * * * * * * SDISC 1 *0.0000E+00*0.0000E+00*0.7141E-01* 17.06 * 20931* *(C1 )*0.0000E+00*0.0000E+00*0.5014E-01* 17.31 * 14480* *(C2 )*0.0000E+00*0.0000E+00*0.2127E-01* 16.48 * 6451* * * * * * * * * SDISC 2 *0.0000E+00*0.0000E+00*0.5438E-01* 15.85 * 17149* *(C1 )*0.0000E+00*0.0000E+00*0.3045E-01* 16.12 * 9448* *(C2 )*0.0000E+00*0.0000E+00*0.2392E-01* 15.53 * 7701* * * * * * * * * SDISC 3 *0.0000E+00*0.0000E+00*0.5522E-01* 14.89 * 18545* *(C1 )*0.0000E+00*0.0000E+00*0.1970E-01* 15.11 * 6519* *(C2 )*0.0000E+00*0.0000E+00*0.3552E-01* 14.77 * 12026* * * * * * * * * SDISC 4 *0.0000E+00*0.0000E+00*0.4330E-01* 13.76 * 15735* *(C1 )*0.0000E+00*0.0000E+00*0.8219E-02* 14.27 * 2879* *(C2 )*0.0000E+00*0.0000E+00*0.3508E-01* 13.65 * 12856* * * * * * * * * UC * 1.664 *0.8357E-01*0.8358E-01* 1.664 * 251124* *(C1 )* 1.667 *0.3615E-01*0.3615E-01* 1.667 * 108409* *(C2 )* 1.668 *0.4762E-01*0.4762E-01* 1.668 * 142715* * * * * * * * * SUC *0.0000E+00*0.0000E+00*0.2103E-02*0.6548 * 16062* *(C1 )*0.0000E+00*0.0000E+00*0.8689E-03*0.6429 * 6757* *(C2 )*0.0000E+00*0.0000E+00*0.1234E-02*0.6633 * 9305* * * * * * * * * TERMINAL *0.4131E+05*0.0000E+00* 297.3 *0.4131E+05* 35634* *(C1 )*0.2966E+05*0.0000E+00* 128.7 *0.2966E+05* 21560* *(C2 )*0.5915E+05*0.0000E+00* 168.6 *0.5915E+05* 14074* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 1.110 * 257.3 * 21560* * +/- *0.0000E+00*0.0000E+00*0.3306E-01* 5.692 * * *(C1 )*0.0000E+00*0.0000E+00* 1.110 * 257.3 * 21560* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 1.588 * 564.3 * 14074* * +/- *0.0000E+00*0.0000E+00*0.6595E-01* 16.94 * * *(C2 )*0.0000E+00*0.0000E+00* 1.588 * 564.3 * 14074* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 29038 WORDS OF 4 BYTES ( 1.16 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 257.3 RESPONSE TIME OF CLASS C2 = 564.3 NUMERO DE USUARIOS = 450 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.42 *0.8704 * 5.643 * 67.61 * 417354* *(C1 )* 8.508 *0.3214 * 2.081 * 55.16 * 188637* *(C2 )* 12.00 *0.5490 * 3.563 * 77.89 * 228717* * * * * * * * * QDISC 1 * 8.642 *0.1626 *0.2378 * 12.64 * 94064* *(C1 )* 8.863 *0.1112 *0.1644 * 13.10 * 62752*

225
*(C2 )* 8.200 *0.5135E-01*0.7341E-01* 11.72 * 31312* * * * * * * * * QDISC 2 * 7.169 *0.1269 *0.1722 * 9.732 * 88491* *(C1 )* 7.393 *0.6968E-01*0.9564E-01* 10.15 * 47131* *(C2 )* 6.913 *0.5719E-01*0.7659E-01* 9.259 * 41360* * * * * * * * * QDISC 3 * 6.858 *0.1284 *0.1738 * 9.280 * 93620* *(C1 )* 7.211 *0.4553E-01*0.6178E-01* 9.785 * 31568* *(C2 )* 6.678 *0.8288E-01*0.1120 * 9.022 * 62052* * * * * * * * * QDISC 4 * 5.607 *0.9957E-01*0.1276 * 7.187 * 88795* *(C1 )* 6.081 *0.1912E-01*0.2456E-01* 7.811 * 15722* *(C2 )* 5.505 *0.8045E-01*0.1031 * 7.052 * 73073* * * * * * * * * DISC 1 * 24.67 *0.4642 *0.4642 * 24.67 * 94064* *(C1 )* 24.67 *0.3096 *0.3096 * 24.67 * 62752* *(C2 )* 24.68 *0.1546 *0.1546 * 24.68 * 31312* * * * * * * * * DISC 2 * 23.76 *0.4205 *0.4205 * 23.76 * 88490* *(C1 )* 23.74 *0.2238 *0.2238 * 23.74 * 47131* *(C2 )* 23.78 *0.1967 *0.1967 * 23.78 * 41359* * * * * * * * * DISC 3 * 22.70 *0.4251 *0.4251 * 22.70 * 93620* *(C1 )* 22.65 *0.1430 *0.1430 * 22.65 * 31568* *(C2 )* 22.73 *0.2821 *0.2821 * 22.73 * 62052* * * * * * * * * DISC 4 * 21.69 *0.3851 *0.3851 * 21.69 * 88795* *(C1 )* 21.78 *0.6850E-01*0.6850E-01* 21.78 * 15722* *(C2 )* 21.67 *0.3166 *0.3166 * 21.67 * 73073* * * * * * * * * SDISC 1 *0.0000E+00*0.0000E+00*0.1618 * 18.74 * 43165* *(C1 )*0.0000E+00*0.0000E+00*0.1107 * 18.82 * 29409* *(C2 )*0.0000E+00*0.0000E+00*0.5106E-01* 18.56 * 13756* * * * * * * * * SDISC 2 *0.0000E+00*0.0000E+00*0.1260 * 17.45 * 36104* *(C1 )*0.0000E+00*0.0000E+00*0.6922E-01* 17.59 * 19676* *(C2 )*0.0000E+00*0.0000E+00*0.5676E-01* 17.27 * 16428* * * * * * * * * SDISC 3 *0.0000E+00*0.0000E+00*0.1275 * 16.56 * 38498* *(C1 )*0.0000E+00*0.0000E+00*0.4523E-01* 16.86 * 13413* *(C2 )*0.0000E+00*0.0000E+00*0.8228E-01* 16.40 * 25085* * * * * * * * * SDISC 4 *0.0000E+00*0.0000E+00*0.9863E-01* 15.25 * 32332* *(C1 )*0.0000E+00*0.0000E+00*0.1895E-01* 15.72 * 6030* *(C2 )*0.0000E+00*0.0000E+00*0.7968E-01* 15.15 * 26302* * * * * * * * * UC * 1.666 *0.1216 *0.1216 * 1.666 * 364969* *(C1 )* 1.669 *0.5245E-01*0.5246E-01* 1.669 * 157173* *(C2 )* 1.666 *0.6922E-01*0.6923E-01* 1.666 * 207796* * * * * * * * * SUC *0.0000E+00*0.0000E+00*0.3560E-02*0.5916 * 30091* *(C1 )*0.0000E+00*0.0000E+00*0.1466E-02*0.5732 * 12788* *(C2 )*0.0000E+00*0.0000E+00*0.2094E-02*0.6052 * 17303* * * * * * * * * TERMINAL *0.4175E+05*0.0000E+00* 442.0 *0.4175E+05* 52386* *(C1 )*0.2980E+05*0.0000E+00* 188.5 *0.2980E+05* 31464* *(C2 )*0.5972E+05*0.0000E+00* 253.4 *0.5972E+05* 20922* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 3.172 * 504.1 * 31464* * +/- *0.0000E+00*0.0000E+00*0.3049 * 44.56 * * *(C1 )*0.0000E+00*0.0000E+00* 3.172 * 504.1 * 31464* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 4.878 * 1166. * 20919* * +/- *0.0000E+00*0.0000E+00*0.4612 * 113.9 * * *(C2 )*0.0000E+00*0.0000E+00* 4.878 * 1166. * 20919* * * * * * * * ******************************************************************* ... END OF SIMULATION ...
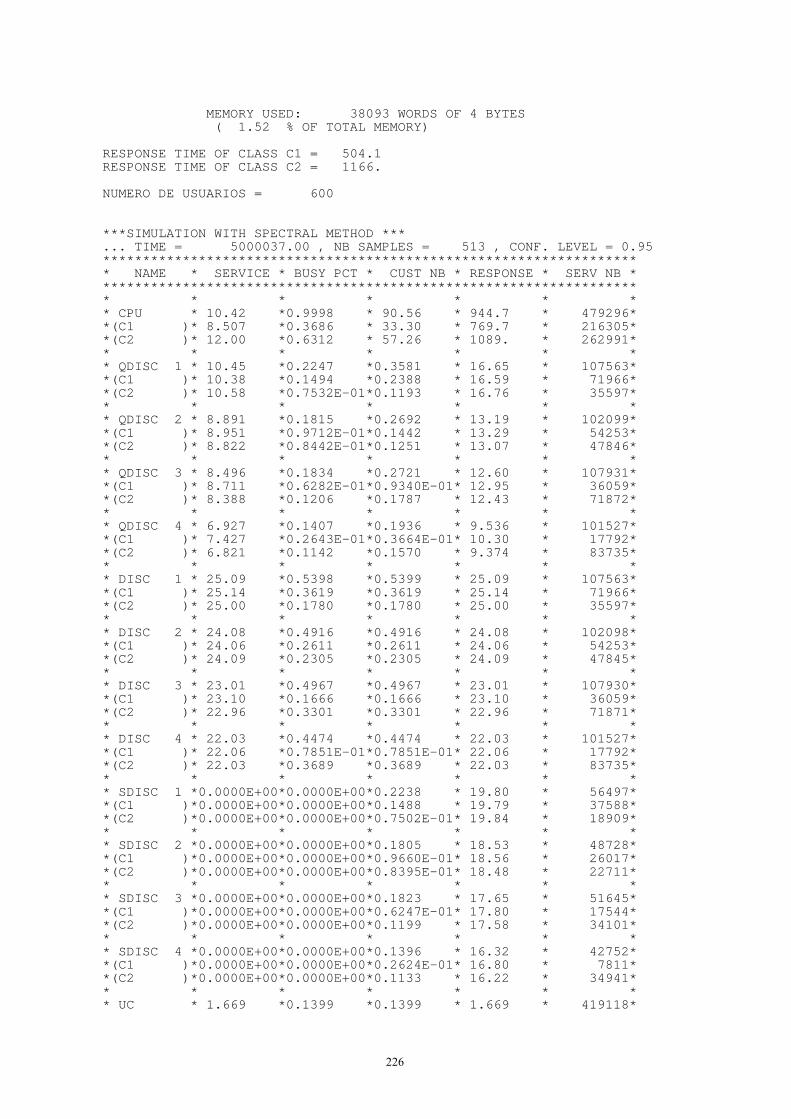
226
MEMORY USED: 38093 WORDS OF 4 BYTES ( 1.52 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 504.1 RESPONSE TIME OF CLASS C2 = 1166. NUMERO DE USUARIOS = 600 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.42 *0.9998 * 90.56 * 944.7 * 479296* *(C1 )* 8.507 *0.3686 * 33.30 * 769.7 * 216305* *(C2 )* 12.00 *0.6312 * 57.26 * 1089. * 262991* * * * * * * * * QDISC 1 * 10.45 *0.2247 *0.3581 * 16.65 * 107563* *(C1 )* 10.38 *0.1494 *0.2388 * 16.59 * 71966* *(C2 )* 10.58 *0.7532E-01*0.1193 * 16.76 * 35597* * * * * * * * * QDISC 2 * 8.891 *0.1815 *0.2692 * 13.19 * 102099* *(C1 )* 8.951 *0.9712E-01*0.1442 * 13.29 * 54253* *(C2 )* 8.822 *0.8442E-01*0.1251 * 13.07 * 47846* * * * * * * * * QDISC 3 * 8.496 *0.1834 *0.2721 * 12.60 * 107931* *(C1 )* 8.711 *0.6282E-01*0.9340E-01* 12.95 * 36059* *(C2 )* 8.388 *0.1206 *0.1787 * 12.43 * 71872* * * * * * * * * QDISC 4 * 6.927 *0.1407 *0.1936 * 9.536 * 101527* *(C1 )* 7.427 *0.2643E-01*0.3664E-01* 10.30 * 17792* *(C2 )* 6.821 *0.1142 *0.1570 * 9.374 * 83735* * * * * * * * * DISC 1 * 25.09 *0.5398 *0.5399 * 25.09 * 107563* *(C1 )* 25.14 *0.3619 *0.3619 * 25.14 * 71966* *(C2 )* 25.00 *0.1780 *0.1780 * 25.00 * 35597* * * * * * * * * DISC 2 * 24.08 *0.4916 *0.4916 * 24.08 * 102098* *(C1 )* 24.06 *0.2611 *0.2611 * 24.06 * 54253* *(C2 )* 24.09 *0.2305 *0.2305 * 24.09 * 47845* * * * * * * * * DISC 3 * 23.01 *0.4967 *0.4967 * 23.01 * 107930* *(C1 )* 23.10 *0.1666 *0.1666 * 23.10 * 36059* *(C2 )* 22.96 *0.3301 *0.3301 * 22.96 * 71871* * * * * * * * * DISC 4 * 22.03 *0.4474 *0.4474 * 22.03 * 101527* *(C1 )* 22.06 *0.7851E-01*0.7851E-01* 22.06 * 17792* *(C2 )* 22.03 *0.3689 *0.3689 * 22.03 * 83735* * * * * * * * * SDISC 1 *0.0000E+00*0.0000E+00*0.2238 * 19.80 * 56497* *(C1 )*0.0000E+00*0.0000E+00*0.1488 * 19.79 * 37588* *(C2 )*0.0000E+00*0.0000E+00*0.7502E-01* 19.84 * 18909* * * * * * * * * SDISC 2 *0.0000E+00*0.0000E+00*0.1805 * 18.53 * 48728* *(C1 )*0.0000E+00*0.0000E+00*0.9660E-01* 18.56 * 26017* *(C2 )*0.0000E+00*0.0000E+00*0.8395E-01* 18.48 * 22711* * * * * * * * * SDISC 3 *0.0000E+00*0.0000E+00*0.1823 * 17.65 * 51645* *(C1 )*0.0000E+00*0.0000E+00*0.6247E-01* 17.80 * 17544* *(C2 )*0.0000E+00*0.0000E+00*0.1199 * 17.58 * 34101* * * * * * * * * SDISC 4 *0.0000E+00*0.0000E+00*0.1396 * 16.32 * 42752* *(C1 )*0.0000E+00*0.0000E+00*0.2624E-01* 16.80 * 7811* *(C2 )*0.0000E+00*0.0000E+00*0.1133 * 16.22 * 34941* * * * * * * * * UC * 1.669 *0.1399 *0.1399 * 1.669 * 419118*
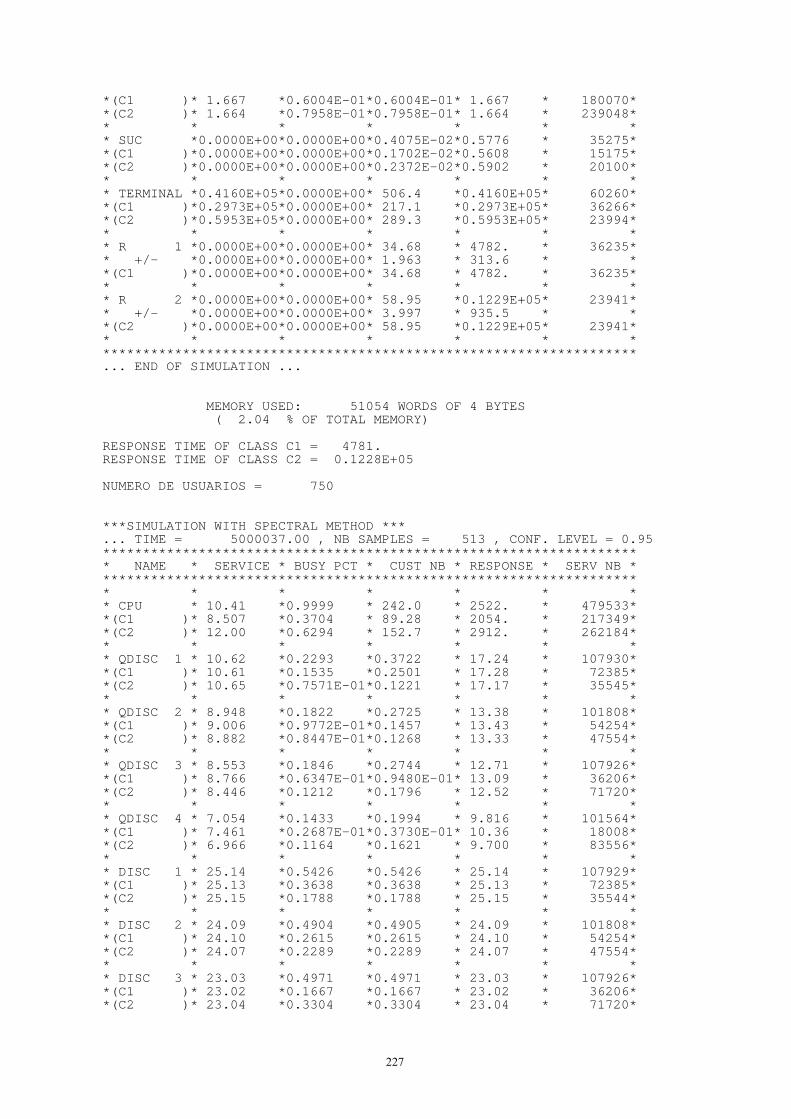
227
*(C1 )* 1.667 *0.6004E-01*0.6004E-01* 1.667 * 180070* *(C2 )* 1.664 *0.7958E-01*0.7958E-01* 1.664 * 239048* * * * * * * * * SUC *0.0000E+00*0.0000E+00*0.4075E-02*0.5776 * 35275* *(C1 )*0.0000E+00*0.0000E+00*0.1702E-02*0.5608 * 15175* *(C2 )*0.0000E+00*0.0000E+00*0.2372E-02*0.5902 * 20100* * * * * * * * * TERMINAL *0.4160E+05*0.0000E+00* 506.4 *0.4160E+05* 60260* *(C1 )*0.2973E+05*0.0000E+00* 217.1 *0.2973E+05* 36266* *(C2 )*0.5953E+05*0.0000E+00* 289.3 *0.5953E+05* 23994* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 34.68 * 4782. * 36235* * +/- *0.0000E+00*0.0000E+00* 1.963 * 313.6 * * *(C1 )*0.0000E+00*0.0000E+00* 34.68 * 4782. * 36235* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 58.95 *0.1229E+05* 23941* * +/- *0.0000E+00*0.0000E+00* 3.997 * 935.5 * * *(C2 )*0.0000E+00*0.0000E+00* 58.95 *0.1229E+05* 23941* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 51054 WORDS OF 4 BYTES ( 2.04 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 4781. RESPONSE TIME OF CLASS C2 = 0.1228E+05 NUMERO DE USUARIOS = 750 ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 5000037.00 , NB SAMPLES = 513 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * CPU * 10.41 *0.9999 * 242.0 * 2522. * 479533* *(C1 )* 8.507 *0.3704 * 89.28 * 2054. * 217349* *(C2 )* 12.00 *0.6294 * 152.7 * 2912. * 262184* * * * * * * * * QDISC 1 * 10.62 *0.2293 *0.3722 * 17.24 * 107930* *(C1 )* 10.61 *0.1535 *0.2501 * 17.28 * 72385* *(C2 )* 10.65 *0.7571E-01*0.1221 * 17.17 * 35545* * * * * * * * * QDISC 2 * 8.948 *0.1822 *0.2725 * 13.38 * 101808* *(C1 )* 9.006 *0.9772E-01*0.1457 * 13.43 * 54254* *(C2 )* 8.882 *0.8447E-01*0.1268 * 13.33 * 47554* * * * * * * * * QDISC 3 * 8.553 *0.1846 *0.2744 * 12.71 * 107926* *(C1 )* 8.766 *0.6347E-01*0.9480E-01* 13.09 * 36206* *(C2 )* 8.446 *0.1212 *0.1796 * 12.52 * 71720* * * * * * * * * QDISC 4 * 7.054 *0.1433 *0.1994 * 9.816 * 101564* *(C1 )* 7.461 *0.2687E-01*0.3730E-01* 10.36 * 18008* *(C2 )* 6.966 *0.1164 *0.1621 * 9.700 * 83556* * * * * * * * * DISC 1 * 25.14 *0.5426 *0.5426 * 25.14 * 107929* *(C1 )* 25.13 *0.3638 *0.3638 * 25.13 * 72385* *(C2 )* 25.15 *0.1788 *0.1788 * 25.15 * 35544* * * * * * * * * DISC 2 * 24.09 *0.4904 *0.4905 * 24.09 * 101808* *(C1 )* 24.10 *0.2615 *0.2615 * 24.10 * 54254* *(C2 )* 24.07 *0.2289 *0.2289 * 24.07 * 47554* * * * * * * * * DISC 3 * 23.03 *0.4971 *0.4971 * 23.03 * 107926* *(C1 )* 23.02 *0.1667 *0.1667 * 23.02 * 36206* *(C2 )* 23.04 *0.3304 *0.3304 * 23.04 * 71720*

228
* * * * * * * * DISC 4 * 22.10 *0.4489 *0.4489 * 22.10 * 101563* *(C1 )* 22.15 *0.7976E-01*0.7977E-01* 22.15 * 18008* *(C2 )* 22.09 *0.3691 *0.3691 * 22.09 * 83555* * * * * * * * * SDISC 1 *0.0000E+00*0.0000E+00*0.2283 * 19.98 * 57139* *(C1 )*0.0000E+00*0.0000E+00*0.1529 * 19.95 * 38328* *(C2 )*0.0000E+00*0.0000E+00*0.7541E-01* 20.04 * 18811* * * * * * * * * SDISC 2 *0.0000E+00*0.0000E+00*0.1812 * 18.61 * 48704* *(C1 )*0.0000E+00*0.0000E+00*0.9721E-01* 18.61 * 26117* *(C2 )*0.0000E+00*0.0000E+00*0.8402E-01* 18.60 * 22587* * * * * * * * * SDISC 3 *0.0000E+00*0.0000E+00*0.1836 * 17.72 * 51820* *(C1 )*0.0000E+00*0.0000E+00*0.6313E-01* 17.78 * 17757* *(C2 )*0.0000E+00*0.0000E+00*0.1205 * 17.69 * 34063* * * * * * * * * SDISC 4 *0.0000E+00*0.0000E+00*0.1422 * 16.48 * 43137* *(C1 )*0.0000E+00*0.0000E+00*0.2669E-01* 16.77 * 7957* *(C2 )*0.0000E+00*0.0000E+00*0.1155 * 16.42 * 35180* * * * * * * * * UC * 1.669 *0.1399 *0.1399 * 1.669 * 419226* *(C1 )* 1.667 *0.6030E-01*0.6030E-01* 1.667 * 180853* *(C2 )* 1.664 *0.7935E-01*0.7935E-01* 1.664 * 238373* * * * * * * * * SUC *0.0000E+00*0.0000E+00*0.3964E-02*0.5706 * 34736* *(C1 )*0.0000E+00*0.0000E+00*0.1650E-02*0.5574 * 14798* *(C2 )*0.0000E+00*0.0000E+00*0.2314E-02*0.5804 * 19938* * * * * * * * * TERMINAL *0.4132E+05*0.0000E+00* 504.9 *0.4132E+05* 60539* *(C1 )*0.2984E+05*0.0000E+00* 219.6 *0.2984E+05* 36583* *(C2 )*0.5886E+05*0.0000E+00* 285.4 *0.5886E+05* 23956* * * * * * * * * R 1 *0.0000E+00*0.0000E+00* 90.68 *0.1240E+05* 36496* * +/- *0.0000E+00*0.0000E+00* 2.499 * 879.9 * * *(C1 )*0.0000E+00*0.0000E+00* 90.68 *0.1240E+05* 36496* * * * * * * * * R 2 *0.0000E+00*0.0000E+00* 154.4 *0.3224E+05* 23809* * +/- *0.0000E+00*0.0000E+00* 5.857 * 1275. * * *(C2 )*0.0000E+00*0.0000E+00* 154.4 *0.3224E+05* 23809* * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 67334 WORDS OF 4 BYTES ( 2.69 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 0.1239E+05 RESPONSE TIME OF CLASS C2 = 0.3222E+05 103 /END/ Puede observarse que los resultados de los tres modelos son muy similares normalmente siempre dentro de los intervalos de confianza. El modelo analítico es ligeramente pesimista en particular para un número reducido de terminales. La diferencia fundamental reside en el tiempo de cálculo que varía de pocos segundos en el modelo analítico a horas en los de simulación.
2.2.2.3.2. Con política FIFO En este caso el cálculo del tiempo de resolución de conflictos se efectúa tal como explica el apartado 2.1.2.1. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986

229
1 /DECLARE/ QUEUE CPU,DISC(4),TERMINAL; 2 REAL PROB1(4)=(2,1.5,1,0.5); 3 REAL PROB2(4)=(1.5,2,3,3.5); 4 REAL TR1,TR2; 5 REAL SD(4),VP,VPN,LT,TF,VR=3600,TAU,UC,TUC,AC,R(0:6), 6 PR(6),X,Y,W,WN,POL,DER,SK(4)=(13.,12.,11.,10.); 7 REAL EPS,DELTA; 8 CLASS C1,C2; 9 INTEGER I,N; 10 /STATION/ NAME=CPU; 11 SCHED=PS; 12 SERVICE(C1)=CST(8.52); 13 SERVICE(C2)=CST(12.); 14 TRANSIT(C1)=DISC,PROB1,TERMINAL,C1,0.6,TERMINAL,C2,0.4; 15 TRANSIT(C2)=DISC,PROB2,TERMINAL,C1,0.6,TERMINAL,C2,0.4; 16 /STATION/ NAME=DISC; 17 TRANSIT=CPU; 18 /STATION/ NAME=DISC(1); 19 SERVICE=EXP(SD(1)); 20 /STATION/ NAME=DISC(2); 21 SERVICE=EXP(SD(2)); 22 /STATION/ NAME=DISC(3); 23 SERVICE=EXP(SD(3)); 24 /STATION/ NAME=DISC(4); 25 SERVICE=EXP(SD(4)); 26 /STATION/ NAME=TERMINAL; 27 TYPE=INFINITE; 28 INIT(C1)=N; 29 SERVICE(C1)=EXP(30000.); 30 SERVICE(C2)=EXP(60000.); 31 TRANSIT=CPU; 32 /CONTROL/ CLASS=ALL QUEUE; 33 /EXEC/ BEGIN 34 TAU:=60.*1000./VR; 35 TF:=TAU/10.; 36 LT:=TAU/2.; 37 FOR N:=150 STEP 150 UNTIL 750 DO 38 BEGIN 39 PRINT("NUMERO DE USUARIOS =",N); 40 EPS := 1.; 41 W := 0.; 42 WHILE ABS(EPS) > 1.E-4 DO 43 BEGIN 44 FOR I := 1 STEP 1 UNTIL 4 DO SD(I) := SK(I) + W + L ==> T + TF; 45 PRINT; 46 SOLVE; 47 UC := 0.; 48 AC := 0.; 49 FOR I := 1 STEP 1 UNTIL 4 DO BEGIN 50 UC := UC + MTHRUPUT(DISC(I))*(LT + TF); 51 AC := AC + MTHRUPUT(DISC(I)); 52 END; 53 TUC := UC/AC; 54 R(0) := 1.; 55 FOR I := 1 STEP 1 UNTIL 4 DO BEGIN 56 R(I) := R(I - 1) * (5 - I); 57 PR(I) := I * R(I); 58 END; 59 R(0) := -UC/(1 - UC); 60 X := 1.; 61 DELTA := 1.; 62 WHILE ABS(DELTA) > 1.E-4 DO BEGIN 63 POL := R(4); 64 DER := PR(4); 65 FOR I := 3 STEP -1 UNTIL 1 DO BEGIN 66 POL := POL * X + R(I); 67 DER := DER * X + PR(I); 68 END;

230
69 POL := POL * X + R(0); 70 Y := X - POL/DER; 71 DELTA := (Y - X)/Y; 72 X := Y; 73 END; 74 R(0) := 1.; 75 FOR I := 1 STEP 1 UNTIL 4 DO BEGIN 76 R(I) := R(I - 1) * (5 - I) * Y; 77 END; 78 POL := 0.; 79 FOR I := 4 STEP -1 UNTIL 0 DO BEGIN 80 POL := POL + R(I); 81 END; 82 POL := 1/POL; 83 DER := 0.; 84 FOR I := 4 STEP -1 UNTIL 0 DO BEGIN 85 R(I) := R(I) * POL; 86 DER := DER + I * R(I); 87 END; 88 WN := DER/AC - TUC; 89 EPS := (W - WN)/WN; 90 W := WN; 91 END; 92 TR1:=MCUSTNB(CPU,C1); 93 TR2:=MCUSTNB(CPU,C2); 94 FOR I:= 1 STEP 1 UNTIL 4 DO 95 BEGIN 96 TR1:=TR1+MCUSTNB(DISC(I),C1); 97 TR2:=TR2+MCUSTNB(DISC(I),C2); 98 END; 99 TR1:=TR1/MTHRUPUT(TERMINAL,C1); 100 TR2:=TR2/MTHRUPUT(TERMINAL,C2);; 101 PRINT("RESPONSE TIME OF CLASS C1 =",TR1); 102 PRINT("RESPONSE TIME OF CLASS C2 =",TR2); 103 END; 104 END; NUMERO DE USUARIOS = 150 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.2960 *0.4189 * 14.76 *0.2837E-01* *(C1 )* 8.520 *0.1088 *0.1539 * 12.06 *0.1277E-01* *(C2 )* 12.00 *0.1873 *0.2650 * 16.98 *0.1560E-01* * * * * * * * * DISC 1 * 23.00 *0.1468 *0.1719 * 26.92 *0.6384E-02* *(C1 )* 23.00 *0.9790E-01*0.1146 * 26.92 *0.4257E-02* *(C2 )* 23.00 *0.4894E-01*0.5729E-01* 26.92 *0.2128E-02* * * * * * * * * DISC 2 * 22.00 *0.1326 *0.1528 * 25.33 *0.6029E-02* *(C1 )* 22.00 *0.7023E-01*0.8088E-01* 25.33 *0.3192E-02* *(C2 )* 22.00 *0.6242E-01*0.7188E-01* 25.33 *0.2837E-02* * * * * * * * * DISC 3 * 21.00 *0.1341 *0.1546 * 24.22 *0.6384E-02* *(C1 )* 21.00 *0.4469E-01*0.5155E-01* 24.22 *0.2128E-02* *(C2 )* 21.00 *0.8937E-01*0.1031 * 24.22 *0.4256E-02* * * * * * * * * DISC 4 * 20.00 *0.1206 *0.1370 * 22.72 *0.6029E-02* *(C1 )* 20.00 *0.2128E-01*0.2418E-01* 22.72 *0.1064E-02* *(C2 )* 20.00 *0.9930E-01*0.1128 * 22.72 *0.4965E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 149.0 *0.4200E+05*0.3547E-02* *(C1 )*0.3000E+05*0.0000E+00* 63.84 *0.3000E+05*0.2128E-02* *(C2 )*0.6000E+05*0.0000E+00* 85.12 *0.6000E+05*0.1419E-02* * * * * * * *
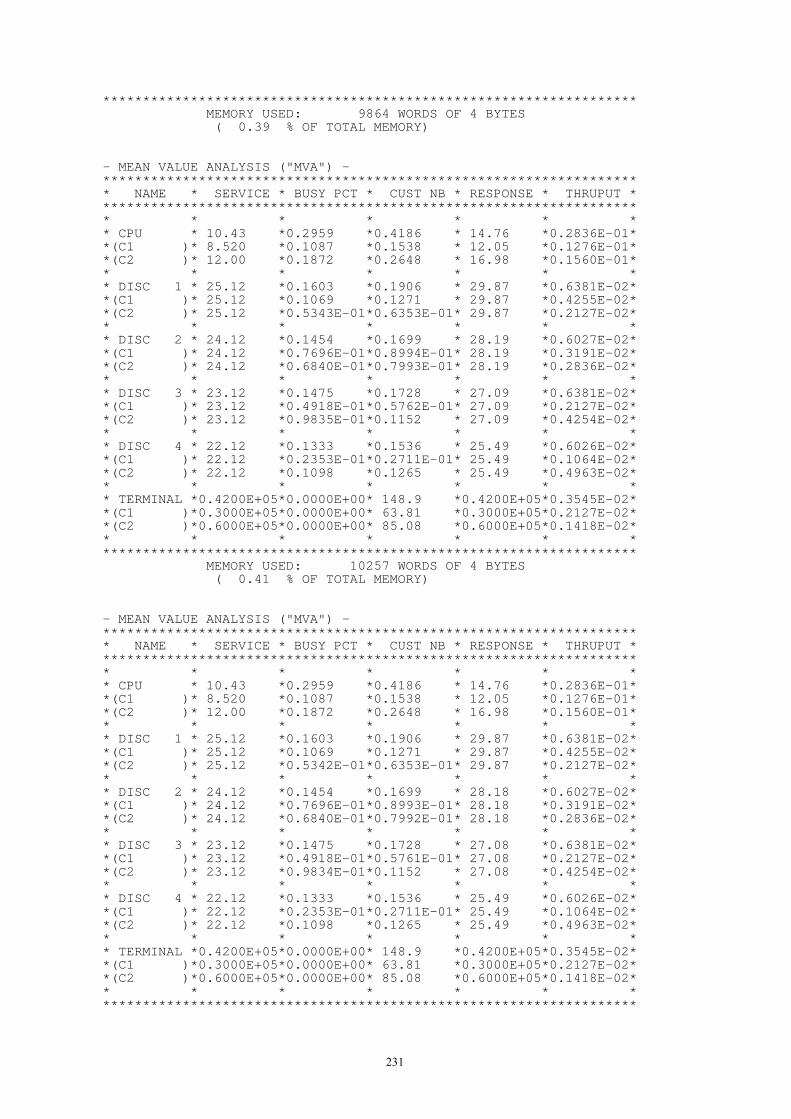
231
******************************************************************* MEMORY USED: 9864 WORDS OF 4 BYTES ( 0.39 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.2959 *0.4186 * 14.76 *0.2836E-01* *(C1 )* 8.520 *0.1087 *0.1538 * 12.05 *0.1276E-01* *(C2 )* 12.00 *0.1872 *0.2648 * 16.98 *0.1560E-01* * * * * * * * * DISC 1 * 25.12 *0.1603 *0.1906 * 29.87 *0.6381E-02* *(C1 )* 25.12 *0.1069 *0.1271 * 29.87 *0.4255E-02* *(C2 )* 25.12 *0.5343E-01*0.6353E-01* 29.87 *0.2127E-02* * * * * * * * * DISC 2 * 24.12 *0.1454 *0.1699 * 28.19 *0.6027E-02* *(C1 )* 24.12 *0.7696E-01*0.8994E-01* 28.19 *0.3191E-02* *(C2 )* 24.12 *0.6840E-01*0.7993E-01* 28.19 *0.2836E-02* * * * * * * * * DISC 3 * 23.12 *0.1475 *0.1728 * 27.09 *0.6381E-02* *(C1 )* 23.12 *0.4918E-01*0.5762E-01* 27.09 *0.2127E-02* *(C2 )* 23.12 *0.9835E-01*0.1152 * 27.09 *0.4254E-02* * * * * * * * * DISC 4 * 22.12 *0.1333 *0.1536 * 25.49 *0.6026E-02* *(C1 )* 22.12 *0.2353E-01*0.2711E-01* 25.49 *0.1064E-02* *(C2 )* 22.12 *0.1098 *0.1265 * 25.49 *0.4963E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 148.9 *0.4200E+05*0.3545E-02* *(C1 )*0.3000E+05*0.0000E+00* 63.81 *0.3000E+05*0.2127E-02* *(C2 )*0.6000E+05*0.0000E+00* 85.08 *0.6000E+05*0.1418E-02* * * * * * * * ******************************************************************* MEMORY USED: 10257 WORDS OF 4 BYTES ( 0.41 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.2959 *0.4186 * 14.76 *0.2836E-01* *(C1 )* 8.520 *0.1087 *0.1538 * 12.05 *0.1276E-01* *(C2 )* 12.00 *0.1872 *0.2648 * 16.98 *0.1560E-01* * * * * * * * * DISC 1 * 25.12 *0.1603 *0.1906 * 29.87 *0.6381E-02* *(C1 )* 25.12 *0.1069 *0.1271 * 29.87 *0.4255E-02* *(C2 )* 25.12 *0.5342E-01*0.6353E-01* 29.87 *0.2127E-02* * * * * * * * * DISC 2 * 24.12 *0.1454 *0.1699 * 28.18 *0.6027E-02* *(C1 )* 24.12 *0.7696E-01*0.8993E-01* 28.18 *0.3191E-02* *(C2 )* 24.12 *0.6840E-01*0.7992E-01* 28.18 *0.2836E-02* * * * * * * * * DISC 3 * 23.12 *0.1475 *0.1728 * 27.08 *0.6381E-02* *(C1 )* 23.12 *0.4918E-01*0.5761E-01* 27.08 *0.2127E-02* *(C2 )* 23.12 *0.9834E-01*0.1152 * 27.08 *0.4254E-02* * * * * * * * * DISC 4 * 22.12 *0.1333 *0.1536 * 25.49 *0.6026E-02* *(C1 )* 22.12 *0.2353E-01*0.2711E-01* 25.49 *0.1064E-02* *(C2 )* 22.12 *0.1098 *0.1265 * 25.49 *0.4963E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 148.9 *0.4200E+05*0.3545E-02* *(C1 )*0.3000E+05*0.0000E+00* 63.81 *0.3000E+05*0.2127E-02* *(C2 )*0.6000E+05*0.0000E+00* 85.08 *0.6000E+05*0.1418E-02* * * * * * * * *******************************************************************
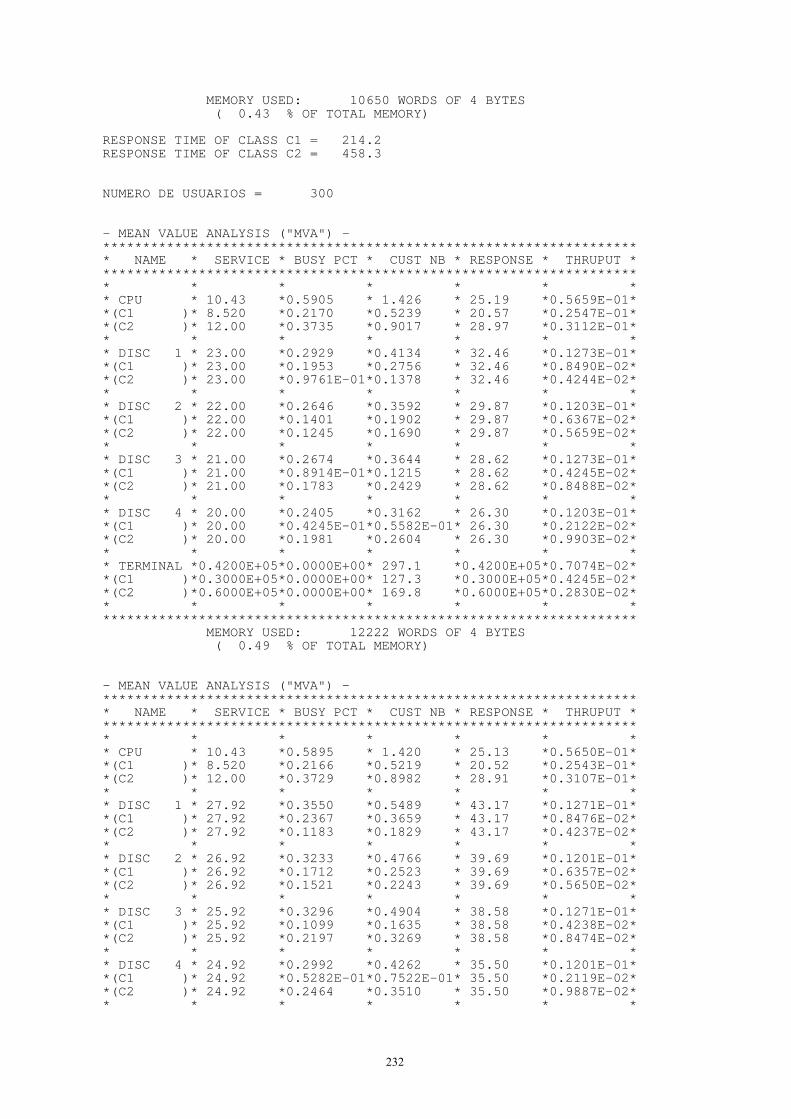
232
MEMORY USED: 10650 WORDS OF 4 BYTES ( 0.43 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 214.2 RESPONSE TIME OF CLASS C2 = 458.3 NUMERO DE USUARIOS = 300 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5905 * 1.426 * 25.19 *0.5659E-01* *(C1 )* 8.520 *0.2170 *0.5239 * 20.57 *0.2547E-01* *(C2 )* 12.00 *0.3735 *0.9017 * 28.97 *0.3112E-01* * * * * * * * * DISC 1 * 23.00 *0.2929 *0.4134 * 32.46 *0.1273E-01* *(C1 )* 23.00 *0.1953 *0.2756 * 32.46 *0.8490E-02* *(C2 )* 23.00 *0.9761E-01*0.1378 * 32.46 *0.4244E-02* * * * * * * * * DISC 2 * 22.00 *0.2646 *0.3592 * 29.87 *0.1203E-01* *(C1 )* 22.00 *0.1401 *0.1902 * 29.87 *0.6367E-02* *(C2 )* 22.00 *0.1245 *0.1690 * 29.87 *0.5659E-02* * * * * * * * * DISC 3 * 21.00 *0.2674 *0.3644 * 28.62 *0.1273E-01* *(C1 )* 21.00 *0.8914E-01*0.1215 * 28.62 *0.4245E-02* *(C2 )* 21.00 *0.1783 *0.2429 * 28.62 *0.8488E-02* * * * * * * * * DISC 4 * 20.00 *0.2405 *0.3162 * 26.30 *0.1203E-01* *(C1 )* 20.00 *0.4245E-01*0.5582E-01* 26.30 *0.2122E-02* *(C2 )* 20.00 *0.1981 *0.2604 * 26.30 *0.9903E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 297.1 *0.4200E+05*0.7074E-02* *(C1 )*0.3000E+05*0.0000E+00* 127.3 *0.3000E+05*0.4245E-02* *(C2 )*0.6000E+05*0.0000E+00* 169.8 *0.6000E+05*0.2830E-02* * * * * * * * ******************************************************************* MEMORY USED: 12222 WORDS OF 4 BYTES ( 0.49 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5895 * 1.420 * 25.13 *0.5650E-01* *(C1 )* 8.520 *0.2166 *0.5219 * 20.52 *0.2543E-01* *(C2 )* 12.00 *0.3729 *0.8982 * 28.91 *0.3107E-01* * * * * * * * * DISC 1 * 27.92 *0.3550 *0.5489 * 43.17 *0.1271E-01* *(C1 )* 27.92 *0.2367 *0.3659 * 43.17 *0.8476E-02* *(C2 )* 27.92 *0.1183 *0.1829 * 43.17 *0.4237E-02* * * * * * * * * DISC 2 * 26.92 *0.3233 *0.4766 * 39.69 *0.1201E-01* *(C1 )* 26.92 *0.1712 *0.2523 * 39.69 *0.6357E-02* *(C2 )* 26.92 *0.1521 *0.2243 * 39.69 *0.5650E-02* * * * * * * * * DISC 3 * 25.92 *0.3296 *0.4904 * 38.58 *0.1271E-01* *(C1 )* 25.92 *0.1099 *0.1635 * 38.58 *0.4238E-02* *(C2 )* 25.92 *0.2197 *0.3269 * 38.58 *0.8474E-02* * * * * * * * * DISC 4 * 24.92 *0.2992 *0.4262 * 35.50 *0.1201E-01* *(C1 )* 24.92 *0.5282E-01*0.7522E-01* 35.50 *0.2119E-02* *(C2 )* 24.92 *0.2464 *0.3510 * 35.50 *0.9887E-02* * * * * * * *
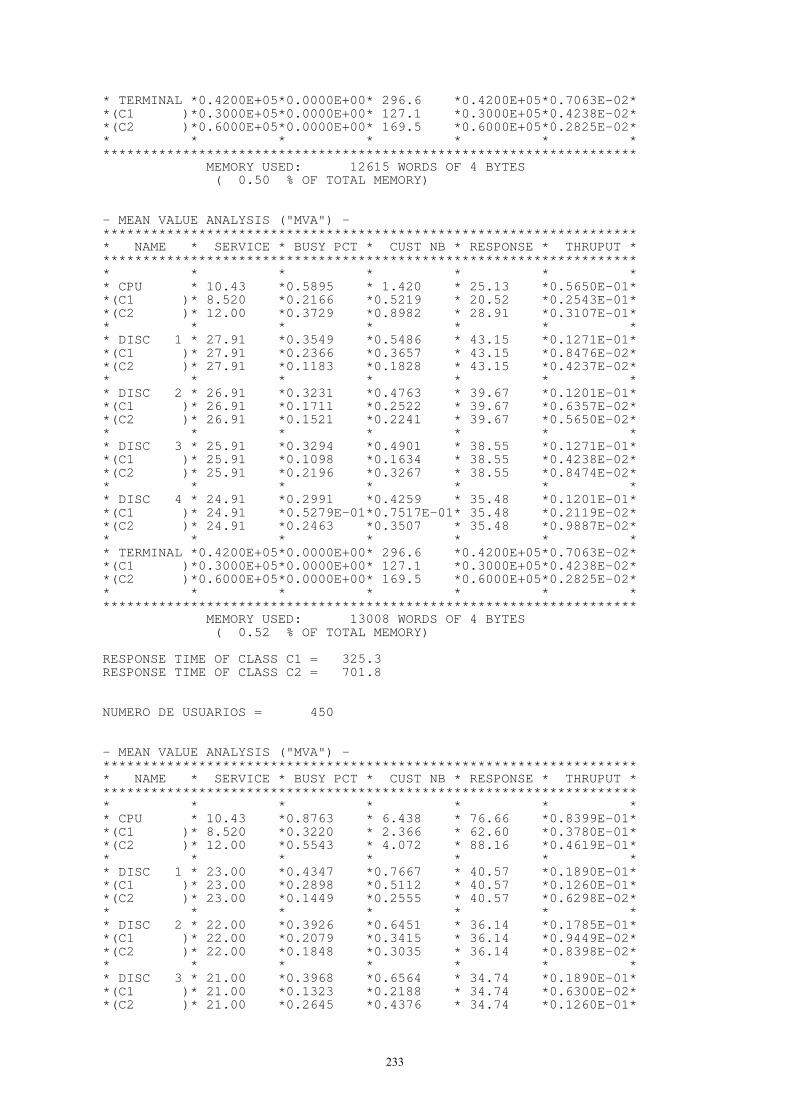
233
* TERMINAL *0.4200E+05*0.0000E+00* 296.6 *0.4200E+05*0.7063E-02* *(C1 )*0.3000E+05*0.0000E+00* 127.1 *0.3000E+05*0.4238E-02* *(C2 )*0.6000E+05*0.0000E+00* 169.5 *0.6000E+05*0.2825E-02* * * * * * * * ******************************************************************* MEMORY USED: 12615 WORDS OF 4 BYTES ( 0.50 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5895 * 1.420 * 25.13 *0.5650E-01* *(C1 )* 8.520 *0.2166 *0.5219 * 20.52 *0.2543E-01* *(C2 )* 12.00 *0.3729 *0.8982 * 28.91 *0.3107E-01* * * * * * * * * DISC 1 * 27.91 *0.3549 *0.5486 * 43.15 *0.1271E-01* *(C1 )* 27.91 *0.2366 *0.3657 * 43.15 *0.8476E-02* *(C2 )* 27.91 *0.1183 *0.1828 * 43.15 *0.4237E-02* * * * * * * * * DISC 2 * 26.91 *0.3231 *0.4763 * 39.67 *0.1201E-01* *(C1 )* 26.91 *0.1711 *0.2522 * 39.67 *0.6357E-02* *(C2 )* 26.91 *0.1521 *0.2241 * 39.67 *0.5650E-02* * * * * * * * * DISC 3 * 25.91 *0.3294 *0.4901 * 38.55 *0.1271E-01* *(C1 )* 25.91 *0.1098 *0.1634 * 38.55 *0.4238E-02* *(C2 )* 25.91 *0.2196 *0.3267 * 38.55 *0.8474E-02* * * * * * * * * DISC 4 * 24.91 *0.2991 *0.4259 * 35.48 *0.1201E-01* *(C1 )* 24.91 *0.5279E-01*0.7517E-01* 35.48 *0.2119E-02* *(C2 )* 24.91 *0.2463 *0.3507 * 35.48 *0.9887E-02* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 296.6 *0.4200E+05*0.7063E-02* *(C1 )*0.3000E+05*0.0000E+00* 127.1 *0.3000E+05*0.4238E-02* *(C2 )*0.6000E+05*0.0000E+00* 169.5 *0.6000E+05*0.2825E-02* * * * * * * * ******************************************************************* MEMORY USED: 13008 WORDS OF 4 BYTES ( 0.52 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 325.3 RESPONSE TIME OF CLASS C2 = 701.8 NUMERO DE USUARIOS = 450 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8763 * 6.438 * 76.66 *0.8399E-01* *(C1 )* 8.520 *0.3220 * 2.366 * 62.60 *0.3780E-01* *(C2 )* 12.00 *0.5543 * 4.072 * 88.16 *0.4619E-01* * * * * * * * * DISC 1 * 23.00 *0.4347 *0.7667 * 40.57 *0.1890E-01* *(C1 )* 23.00 *0.2898 *0.5112 * 40.57 *0.1260E-01* *(C2 )* 23.00 *0.1449 *0.2555 * 40.57 *0.6298E-02* * * * * * * * * DISC 2 * 22.00 *0.3926 *0.6451 * 36.14 *0.1785E-01* *(C1 )* 22.00 *0.2079 *0.3415 * 36.14 *0.9449E-02* *(C2 )* 22.00 *0.1848 *0.3035 * 36.14 *0.8398E-02* * * * * * * * * DISC 3 * 21.00 *0.3968 *0.6564 * 34.74 *0.1890E-01* *(C1 )* 21.00 *0.1323 *0.2188 * 34.74 *0.6300E-02* *(C2 )* 21.00 *0.2645 *0.4376 * 34.74 *0.1260E-01*
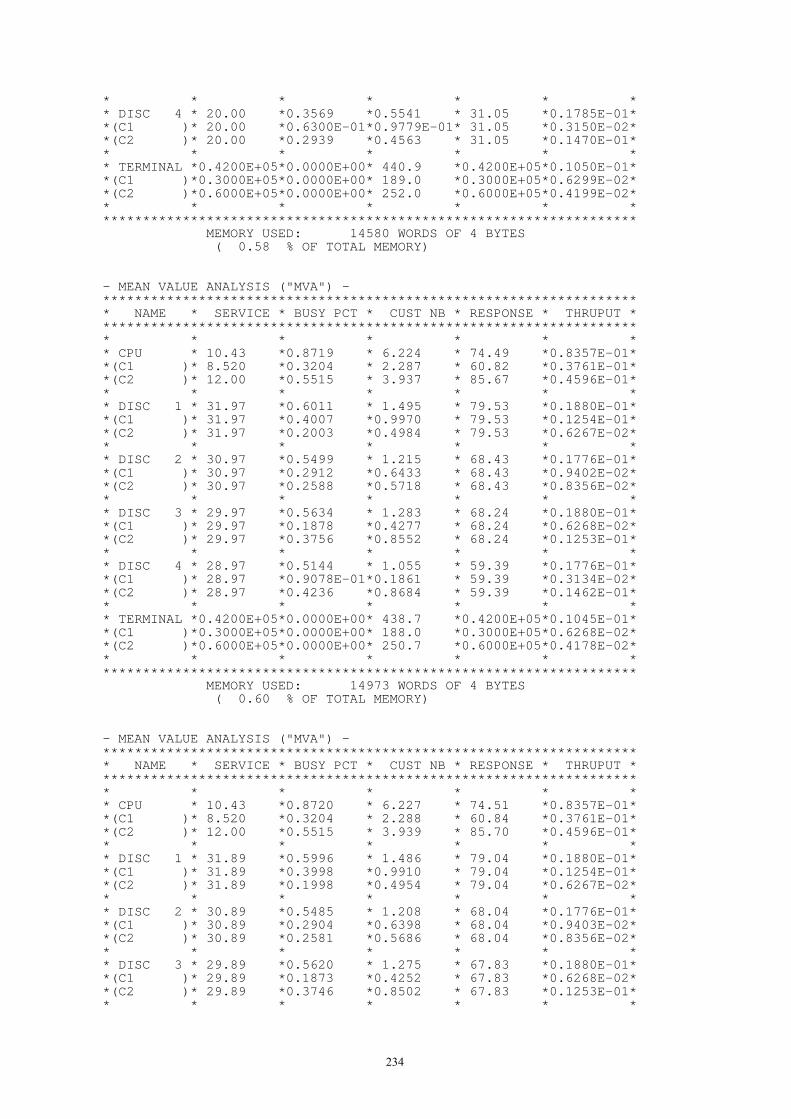
234
* * * * * * * * DISC 4 * 20.00 *0.3569 *0.5541 * 31.05 *0.1785E-01* *(C1 )* 20.00 *0.6300E-01*0.9779E-01* 31.05 *0.3150E-02* *(C2 )* 20.00 *0.2939 *0.4563 * 31.05 *0.1470E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 440.9 *0.4200E+05*0.1050E-01* *(C1 )*0.3000E+05*0.0000E+00* 189.0 *0.3000E+05*0.6299E-02* *(C2 )*0.6000E+05*0.0000E+00* 252.0 *0.6000E+05*0.4199E-02* * * * * * * * ******************************************************************* MEMORY USED: 14580 WORDS OF 4 BYTES ( 0.58 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8719 * 6.224 * 74.49 *0.8357E-01* *(C1 )* 8.520 *0.3204 * 2.287 * 60.82 *0.3761E-01* *(C2 )* 12.00 *0.5515 * 3.937 * 85.67 *0.4596E-01* * * * * * * * * DISC 1 * 31.97 *0.6011 * 1.495 * 79.53 *0.1880E-01* *(C1 )* 31.97 *0.4007 *0.9970 * 79.53 *0.1254E-01* *(C2 )* 31.97 *0.2003 *0.4984 * 79.53 *0.6267E-02* * * * * * * * * DISC 2 * 30.97 *0.5499 * 1.215 * 68.43 *0.1776E-01* *(C1 )* 30.97 *0.2912 *0.6433 * 68.43 *0.9402E-02* *(C2 )* 30.97 *0.2588 *0.5718 * 68.43 *0.8356E-02* * * * * * * * * DISC 3 * 29.97 *0.5634 * 1.283 * 68.24 *0.1880E-01* *(C1 )* 29.97 *0.1878 *0.4277 * 68.24 *0.6268E-02* *(C2 )* 29.97 *0.3756 *0.8552 * 68.24 *0.1253E-01* * * * * * * * * DISC 4 * 28.97 *0.5144 * 1.055 * 59.39 *0.1776E-01* *(C1 )* 28.97 *0.9078E-01*0.1861 * 59.39 *0.3134E-02* *(C2 )* 28.97 *0.4236 *0.8684 * 59.39 *0.1462E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 438.7 *0.4200E+05*0.1045E-01* *(C1 )*0.3000E+05*0.0000E+00* 188.0 *0.3000E+05*0.6268E-02* *(C2 )*0.6000E+05*0.0000E+00* 250.7 *0.6000E+05*0.4178E-02* * * * * * * * ******************************************************************* MEMORY USED: 14973 WORDS OF 4 BYTES ( 0.60 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8720 * 6.227 * 74.51 *0.8357E-01* *(C1 )* 8.520 *0.3204 * 2.288 * 60.84 *0.3761E-01* *(C2 )* 12.00 *0.5515 * 3.939 * 85.70 *0.4596E-01* * * * * * * * * DISC 1 * 31.89 *0.5996 * 1.486 * 79.04 *0.1880E-01* *(C1 )* 31.89 *0.3998 *0.9910 * 79.04 *0.1254E-01* *(C2 )* 31.89 *0.1998 *0.4954 * 79.04 *0.6267E-02* * * * * * * * * DISC 2 * 30.89 *0.5485 * 1.208 * 68.04 *0.1776E-01* *(C1 )* 30.89 *0.2904 *0.6398 * 68.04 *0.9403E-02* *(C2 )* 30.89 *0.2581 *0.5686 * 68.04 *0.8356E-02* * * * * * * * * DISC 3 * 29.89 *0.5620 * 1.275 * 67.83 *0.1880E-01* *(C1 )* 29.89 *0.1873 *0.4252 * 67.83 *0.6268E-02* *(C2 )* 29.89 *0.3746 *0.8502 * 67.83 *0.1253E-01* * * * * * * *
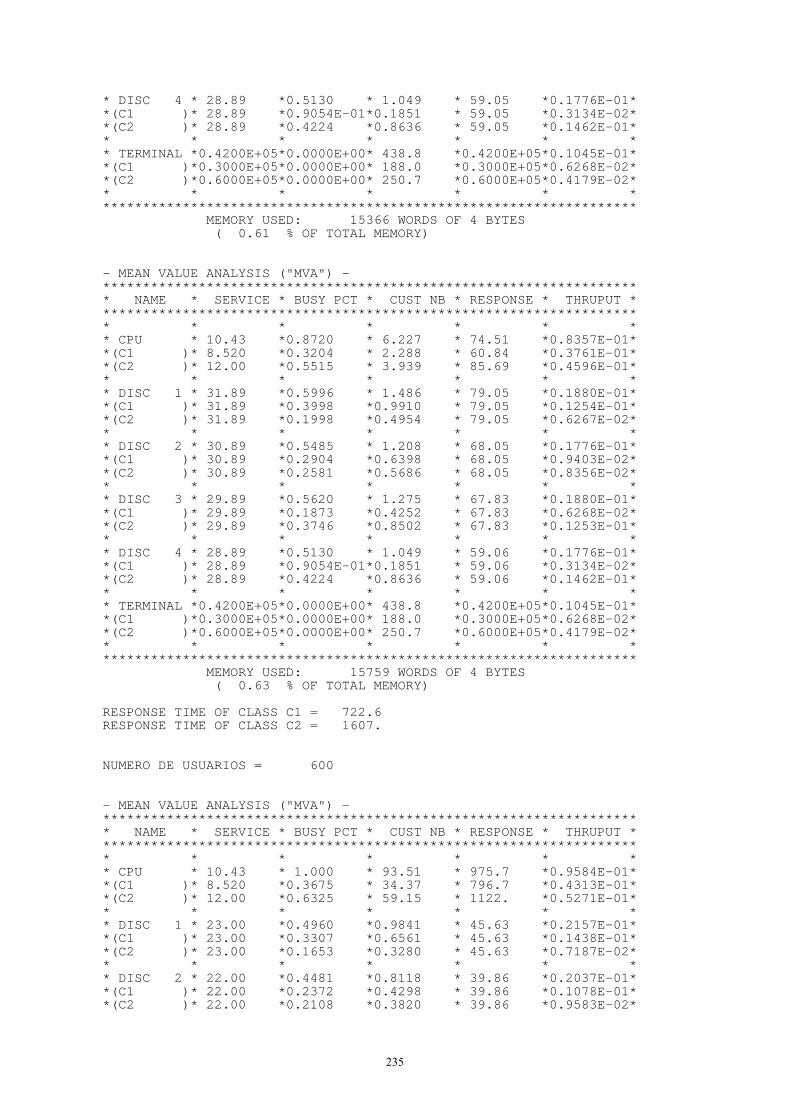
235
* DISC 4 * 28.89 *0.5130 * 1.049 * 59.05 *0.1776E-01* *(C1 )* 28.89 *0.9054E-01*0.1851 * 59.05 *0.3134E-02* *(C2 )* 28.89 *0.4224 *0.8636 * 59.05 *0.1462E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 438.8 *0.4200E+05*0.1045E-01* *(C1 )*0.3000E+05*0.0000E+00* 188.0 *0.3000E+05*0.6268E-02* *(C2 )*0.6000E+05*0.0000E+00* 250.7 *0.6000E+05*0.4179E-02* * * * * * * * ******************************************************************* MEMORY USED: 15366 WORDS OF 4 BYTES ( 0.61 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8720 * 6.227 * 74.51 *0.8357E-01* *(C1 )* 8.520 *0.3204 * 2.288 * 60.84 *0.3761E-01* *(C2 )* 12.00 *0.5515 * 3.939 * 85.69 *0.4596E-01* * * * * * * * * DISC 1 * 31.89 *0.5996 * 1.486 * 79.05 *0.1880E-01* *(C1 )* 31.89 *0.3998 *0.9910 * 79.05 *0.1254E-01* *(C2 )* 31.89 *0.1998 *0.4954 * 79.05 *0.6267E-02* * * * * * * * * DISC 2 * 30.89 *0.5485 * 1.208 * 68.05 *0.1776E-01* *(C1 )* 30.89 *0.2904 *0.6398 * 68.05 *0.9403E-02* *(C2 )* 30.89 *0.2581 *0.5686 * 68.05 *0.8356E-02* * * * * * * * * DISC 3 * 29.89 *0.5620 * 1.275 * 67.83 *0.1880E-01* *(C1 )* 29.89 *0.1873 *0.4252 * 67.83 *0.6268E-02* *(C2 )* 29.89 *0.3746 *0.8502 * 67.83 *0.1253E-01* * * * * * * * * DISC 4 * 28.89 *0.5130 * 1.049 * 59.06 *0.1776E-01* *(C1 )* 28.89 *0.9054E-01*0.1851 * 59.06 *0.3134E-02* *(C2 )* 28.89 *0.4224 *0.8636 * 59.06 *0.1462E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 438.8 *0.4200E+05*0.1045E-01* *(C1 )*0.3000E+05*0.0000E+00* 188.0 *0.3000E+05*0.6268E-02* *(C2 )*0.6000E+05*0.0000E+00* 250.7 *0.6000E+05*0.4179E-02* * * * * * * * ******************************************************************* MEMORY USED: 15759 WORDS OF 4 BYTES ( 0.63 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 722.6 RESPONSE TIME OF CLASS C2 = 1607. NUMERO DE USUARIOS = 600 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 93.51 * 975.7 *0.9584E-01* *(C1 )* 8.520 *0.3675 * 34.37 * 796.7 *0.4313E-01* *(C2 )* 12.00 *0.6325 * 59.15 * 1122. *0.5271E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9841 * 45.63 *0.2157E-01* *(C1 )* 23.00 *0.3307 *0.6561 * 45.63 *0.1438E-01* *(C2 )* 23.00 *0.1653 *0.3280 * 45.63 *0.7187E-02* * * * * * * * * DISC 2 * 22.00 *0.4481 *0.8118 * 39.86 *0.2037E-01* *(C1 )* 22.00 *0.2372 *0.4298 * 39.86 *0.1078E-01* *(C2 )* 22.00 *0.2108 *0.3820 * 39.86 *0.9583E-02*

236
* * * * * * * * DISC 3 * 21.00 *0.4528 *0.8276 * 38.38 *0.2156E-01* *(C1 )* 21.00 *0.1510 *0.2759 * 38.38 *0.7189E-02* *(C2 )* 21.00 *0.3019 *0.5517 * 38.38 *0.1437E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6872 * 33.74 *0.2037E-01* *(C1 )* 20.00 *0.7189E-01*0.1213 * 33.74 *0.3594E-02* *(C2 )* 20.00 *0.3354 *0.5659 * 33.74 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 17724 WORDS OF 4 BYTES ( 0.71 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 87.48 * 912.8 *0.9584E-01* *(C1 )* 8.520 *0.3675 * 32.15 * 745.3 *0.4313E-01* *(C2 )* 12.00 *0.6325 * 55.33 * 1050. *0.5271E-01* * * * * * * * * DISC 1 * 34.68 *0.7479 * 2.966 * 137.5 *0.2156E-01* *(C1 )* 34.68 *0.4986 * 1.977 * 137.5 *0.1438E-01* *(C2 )* 34.68 *0.2493 *0.9884 * 137.5 *0.7187E-02* * * * * * * * * DISC 2 * 33.68 *0.6859 * 2.184 * 107.2 *0.2037E-01* *(C1 )* 33.68 *0.3632 * 1.156 * 107.2 *0.1078E-01* *(C2 )* 33.68 *0.3228 * 1.028 * 107.2 *0.9583E-02* * * * * * * * * DISC 3 * 32.68 *0.7047 * 2.386 * 110.7 *0.2156E-01* *(C1 )* 32.68 *0.2349 *0.7954 * 110.7 *0.7189E-02* *(C2 )* 32.68 *0.4698 * 1.591 * 110.7 *0.1437E-01* * * * * * * * * DISC 4 * 31.68 *0.6451 * 1.818 * 89.27 *0.2037E-01* *(C1 )* 31.68 *0.1139 *0.3209 * 89.27 *0.3594E-02* *(C2 )* 31.68 *0.5313 * 1.497 * 89.27 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 18117 WORDS OF 4 BYTES ( 0.72 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 5063. RESPONSE TIME OF CLASS C2 = 0.1261E+05 NUMERO DE USUARIOS = 750 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 243.5 * 2541. *0.9584E-01* *(C1 )* 8.520 *0.3675 * 89.49 * 2075. *0.4313E-01* *(C2 )* 12.00 *0.6325 * 154.0 * 2922. *0.5271E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9841 * 45.64 *0.2157E-01* *(C1 )* 23.00 *0.3307 *0.6561 * 45.64 *0.1438E-01*
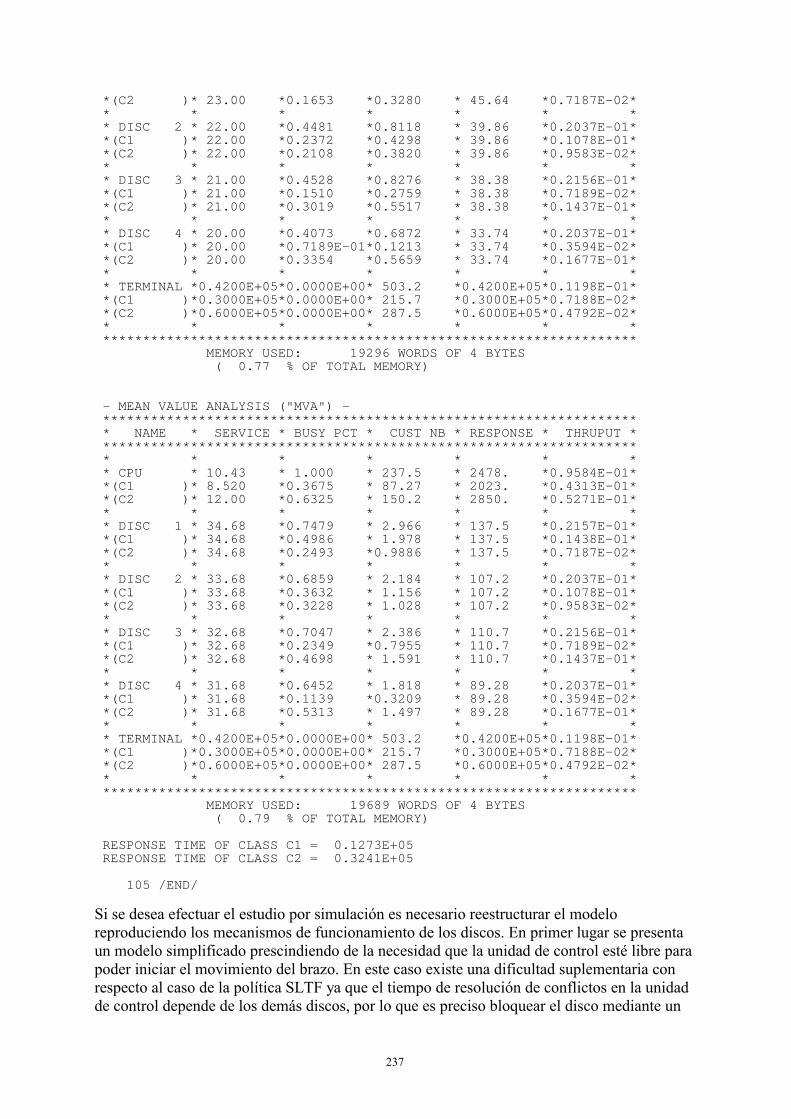
237
*(C2 )* 23.00 *0.1653 *0.3280 * 45.64 *0.7187E-02* * * * * * * * * DISC 2 * 22.00 *0.4481 *0.8118 * 39.86 *0.2037E-01* *(C1 )* 22.00 *0.2372 *0.4298 * 39.86 *0.1078E-01* *(C2 )* 22.00 *0.2108 *0.3820 * 39.86 *0.9583E-02* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8276 * 38.38 *0.2156E-01* *(C1 )* 21.00 *0.1510 *0.2759 * 38.38 *0.7189E-02* *(C2 )* 21.00 *0.3019 *0.5517 * 38.38 *0.1437E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6872 * 33.74 *0.2037E-01* *(C1 )* 20.00 *0.7189E-01*0.1213 * 33.74 *0.3594E-02* *(C2 )* 20.00 *0.3354 *0.5659 * 33.74 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 19296 WORDS OF 4 BYTES ( 0.77 % OF TOTAL MEMORY) - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 237.5 * 2478. *0.9584E-01* *(C1 )* 8.520 *0.3675 * 87.27 * 2023. *0.4313E-01* *(C2 )* 12.00 *0.6325 * 150.2 * 2850. *0.5271E-01* * * * * * * * * DISC 1 * 34.68 *0.7479 * 2.966 * 137.5 *0.2157E-01* *(C1 )* 34.68 *0.4986 * 1.978 * 137.5 *0.1438E-01* *(C2 )* 34.68 *0.2493 *0.9886 * 137.5 *0.7187E-02* * * * * * * * * DISC 2 * 33.68 *0.6859 * 2.184 * 107.2 *0.2037E-01* *(C1 )* 33.68 *0.3632 * 1.156 * 107.2 *0.1078E-01* *(C2 )* 33.68 *0.3228 * 1.028 * 107.2 *0.9583E-02* * * * * * * * * DISC 3 * 32.68 *0.7047 * 2.386 * 110.7 *0.2156E-01* *(C1 )* 32.68 *0.2349 *0.7955 * 110.7 *0.7189E-02* *(C2 )* 32.68 *0.4698 * 1.591 * 110.7 *0.1437E-01* * * * * * * * * DISC 4 * 31.68 *0.6452 * 1.818 * 89.28 *0.2037E-01* *(C1 )* 31.68 *0.1139 *0.3209 * 89.28 *0.3594E-02* *(C2 )* 31.68 *0.5313 * 1.497 * 89.28 *0.1677E-01* * * * * * * * * TERMINAL *0.4200E+05*0.0000E+00* 503.2 *0.4200E+05*0.1198E-01* *(C1 )*0.3000E+05*0.0000E+00* 215.7 *0.3000E+05*0.7188E-02* *(C2 )*0.6000E+05*0.0000E+00* 287.5 *0.6000E+05*0.4792E-02* * * * * * * * ******************************************************************* MEMORY USED: 19689 WORDS OF 4 BYTES ( 0.79 % OF TOTAL MEMORY) RESPONSE TIME OF CLASS C1 = 0.1273E+05 RESPONSE TIME OF CLASS C2 = 0.3241E+05 105 /END/ Si se desea efectuar el estudio por simulación es necesario reestructurar el modelo reproduciendo los mecanismos de funcionamiento de los discos. En primer lugar se presenta un modelo simplificado prescindiendo de la necesidad que la unidad de control esté libre para poder iniciar el movimiento del brazo. En este caso existe una dificultad suplementaria con respecto al caso de la política SLTF ya que el tiempo de resolución de conflictos en la unidad de control depende de los demás discos, por lo que es preciso bloquear el disco mediante un

238
flag desde que el brazo se ha posicionado y se solicita el servicio de la unidad de control hasta que éste ha terminado después de la espera en la cola, la latencia y la transferencia. Si quiere refinarse el modelo y desea tenerse en cuenta, como en el caso anterior y de la misma forma, los retardos que se producen en el inicio del movimiento del brazo debido a que la unidad de control esté ocupada por una transferencia desde otro disco. Puede observarse que los resultados de los tres modelos son muy similares normalmente siempre dentro de los intervalos de confianza. El modelo analítico es ligeramente pesimista en particular para un número reducido de terminales. La diferencia fundamental reside en el tiempo de cálculo que varía de pocos segundos en el modelo analítico a horas en los de simulación.
2.2.2.4. Influencia de la gestión de memoria por un factor de multiprogramación El esquema que representa el funcionamiento de un sistema de este tipo se puede ver en la figura 2.19. En este sistema se gestiona la memoria limitando el número máximo de programas (factor de multiprogramación) que pueden estar en ejecución simultánea en la memoria del sistema. Este sistema no admite ningún tratamiento analítico exacto, por lo que su estudio se realizará por un método analítico aproximado (descomposición-agregación) y por simulación.
2.2.2.4.1. Estudio analítico Para efectuar este estudio analítico se utilizará una adaptación del teorema de Norton para el estudio de sistemas por descomposición-agregación (apartado 4.4.2. del primer volumen de esta obra).
Disco1
Disco2
Disco3
Disco4
CPU
TerminalesGestión dememoria
Figura 2.19.
En la fase de descomposición se estudiará el sistema central (CPU y discos) como un sistema cerrado, como el que muestra la figura 2.20, con un número de programas en ejecución igual a todos los posibles enteros inferiores o iguales al factor de multiprogramación, para determinar su productividad. Aunque se desconoce la frecuencia de llegada de programas de las distintas clases al sistema, se supondrá que llegarán en la proporción especificada (60% y 40%, respectivamente). Esta productividad será la capacidad de servicio equivalente del
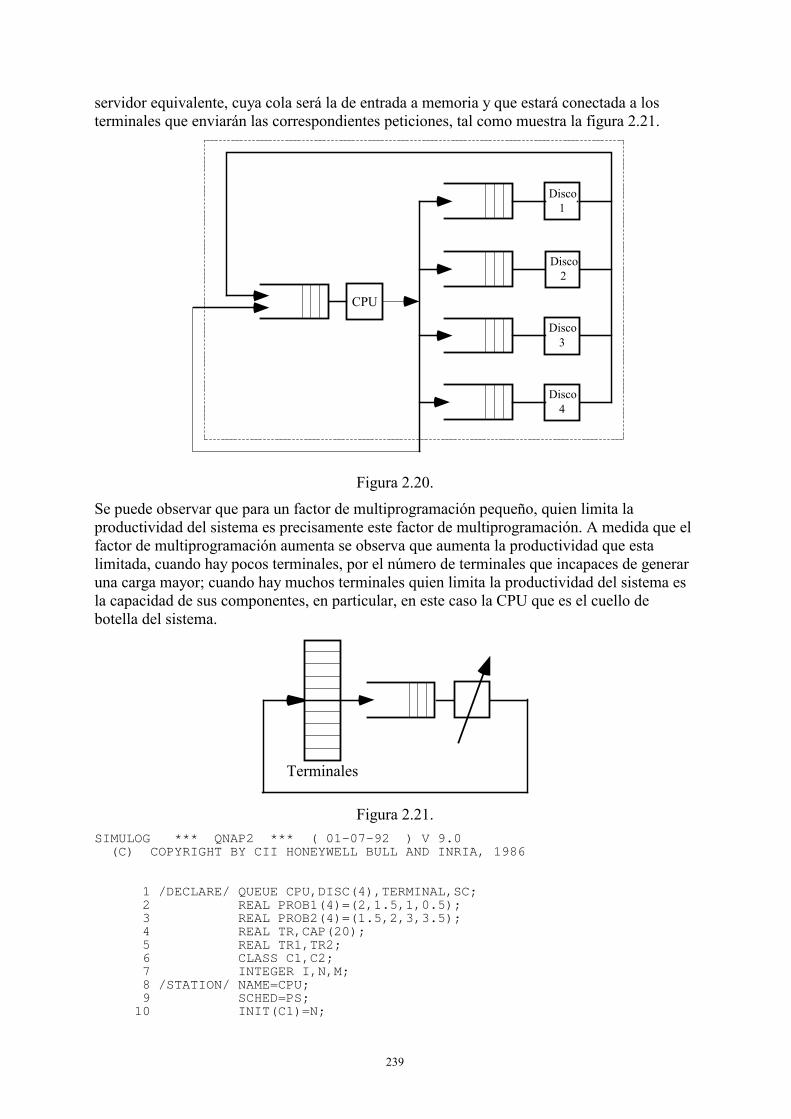
239
servidor equivalente, cuya cola será la de entrada a memoria y que estará conectada a los terminales que enviarán las correspondientes peticiones, tal como muestra la figura 2.21.
Disco1
Disco2
Disco3
Disco4
CPU
Figura 2.20.
Se puede observar que para un factor de multiprogramación pequeño, quien limita la productividad del sistema es precisamente este factor de multiprogramación. A medida que el factor de multiprogramación aumenta se observa que aumenta la productividad que esta limitada, cuando hay pocos terminales, por el número de terminales que incapaces de generar una carga mayor; cuando hay muchos terminales quien limita la productividad del sistema es la capacidad de sus componentes, en particular, en este caso la CPU que es el cuello de botella del sistema.
Terminales
Figura 2.21. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),TERMINAL,SC; 2 REAL PROB1(4)=(2,1.5,1,0.5); 3 REAL PROB2(4)=(1.5,2,3,3.5); 4 REAL TR,CAP(20); 5 REAL TR1,TR2; 6 CLASS C1,C2; 7 INTEGER I,N,M; 8 /STATION/ NAME=CPU; 9 SCHED=PS; 10 INIT(C1)=N;

240
11 SERVICE(C1)=CST(8.52); 12 SERVICE(C2)=CST(12.); 13 TRANSIT(C1)=DISC,PROB1,CPU,C1,0.6,CPU,C2,0.4; 14 TRANSIT(C2)=DISC,PROB2,CPU,C1,0.6,CPU,C2,0.4; 15 /STATION/ NAME=DISC; 16 TRANSIT=CPU; 17 /STATION/ NAME=DISC(1); 18 SERVICE=EXP(23.); 19 /STATION/ NAME=DISC(2); 20 SERVICE=EXP(22.); 21 /STATION/ NAME=DISC(3); 22 SERVICE=EXP(21.); 23 /STATION/ NAME=DISC(4); 24 SERVICE=EXP(20.); 25 /EXEC/ BEGIN 26 NETWORK(CPU,DISC); 27 FOR N := 1 STEP 1 UNTIL 20 DO 28 BEGIN 29 PRINT; 30 PRINT("FACTOR DE MULTIPROGRAMACION =",N); 31 SOLVE; 32 CAP(N) := MTHRUPUT(CPU); 33 FOR I:=1 STEP 1 UNTIL 4 DO CAP(N):=CAP(N)-MTHRUPUT(DI ==> SC(I(); 34 END; 35 FOR N := 1 STEP 1 UNTIL 20 DO PRINT(N,CAP(N)); 36 END; FACTOR DE MULTIPROGRAMACION = 1 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.3566 *0.3566 * 10.43 *0.3418E-01* * * * * * * * * DISC 1 * 23.00 *0.1769 *0.1769 * 23.00 *0.7690E-02* * * * * * * * * DISC 2 * 22.00 *0.1598 *0.1598 * 22.00 *0.7263E-02* * * * * * * * * DISC 3 * 21.00 *0.1615 *0.1615 * 21.00 *0.7690E-02* * * * * * * * * DISC 4 * 20.00 *0.1453 *0.1453 * 20.00 *0.7263E-02* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 2 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.5793 *0.7859 * 14.15 *0.5552E-01* * * * * * * * * DISC 1 * 23.00 *0.2873 *0.3381 * 27.07 *0.1249E-01* * * * * * * * * DISC 2 * 22.00 *0.2596 *0.3010 * 25.52 *0.1180E-01* * * * * * * * * DISC 3 * 21.00 *0.2623 *0.3047 * 24.39 *0.1249E-01* * * * * * * * * DISC 4 * 20.00 *0.2360 *0.2702 * 22.91 *0.1180E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES
241
( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 3 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.7245 * 1.294 * 18.63 *0.6944E-01* * * * * * * * * DISC 1 * 23.00 *0.3593 *0.4808 * 30.78 *0.1562E-01* * * * * * * * * DISC 2 * 22.00 *0.3246 *0.4223 * 28.62 *0.1476E-01* * * * * * * * * DISC 3 * 21.00 *0.3281 *0.4281 * 27.40 *0.1562E-01* * * * * * * * * DISC 4 * 20.00 *0.2951 *0.3749 * 25.40 *0.1476E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 4 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8210 * 1.883 * 23.93 *0.7868E-01* * * * * * * * * DISC 1 * 23.00 *0.4072 *0.6030 * 34.06 *0.1770E-01* * * * * * * * * DISC 2 * 22.00 *0.3678 *0.5232 * 31.29 *0.1672E-01* * * * * * * * * DISC 3 * 21.00 *0.3718 *0.5309 * 29.99 *0.1770E-01* * * * * * * * * DISC 4 * 20.00 *0.3344 *0.4597 * 27.50 *0.1672E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 5 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.8852 * 2.552 * 30.08 *0.8484E-01* * * * * * * * * DISC 1 * 23.00 *0.4390 *0.7037 * 36.87 *0.1909E-01* * * * * * * * * DISC 2 * 22.00 *0.3966 *0.6041 * 33.51 *0.1803E-01* * * * * * * * * DISC 3 * 21.00 *0.4009 *0.6137 * 32.15 *0.1909E-01* * * * * * * * * DISC 4 * 20.00 *0.3606 *0.5263 * 29.19 *0.1803E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 6 - MEAN VALUE ANALYSIS ("MVA") - *******************************************************************
242
* NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9276 * 3.295 * 37.06 *0.8890E-01* * * * * * * * * DISC 1 * 23.00 *0.4601 *0.7838 * 39.19 *0.2000E-01* * * * * * * * * DISC 2 * 22.00 *0.4156 *0.6667 * 35.29 *0.1889E-01* * * * * * * * * DISC 3 * 21.00 *0.4201 *0.6778 * 33.89 *0.2000E-01* * * * * * * * * DISC 4 * 20.00 *0.3778 *0.5767 * 30.53 *0.1889E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 7 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9552 * 4.102 * 44.81 *0.9154E-01* * * * * * * * * DISC 1 * 23.00 *0.4737 *0.8451 * 41.03 *0.2060E-01* * * * * * * * * DISC 2 * 22.00 *0.4280 *0.7133 * 36.67 *0.1945E-01* * * * * * * * * DISC 3 * 21.00 *0.4325 *0.7257 * 35.23 *0.2060E-01* * * * * * * * * DISC 4 * 20.00 *0.3891 *0.6134 * 31.53 *0.1945E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 8 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9728 * 4.964 * 53.24 *0.9323E-01* * * * * * * * * DISC 1 * 23.00 *0.4825 *0.8902 * 42.44 *0.2098E-01* * * * * * * * * DISC 2 * 22.00 *0.4359 *0.7468 * 37.69 *0.1981E-01* * * * * * * * * DISC 3 * 21.00 *0.4405 *0.7602 * 36.24 *0.2098E-01* * * * * * * * * DISC 4 * 20.00 *0.3962 *0.6393 * 32.27 *0.1981E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 9 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9838 * 5.867 * 62.22 *0.9428E-01* * * * * * * * * DISC 1 * 23.00 *0.4879 *0.9223 * 43.47 *0.2121E-01*
243
* * * * * * * * DISC 2 * 22.00 *0.4408 *0.7699 * 38.43 *0.2004E-01* * * * * * * * * DISC 3 * 21.00 *0.4455 *0.7842 * 36.96 *0.2121E-01* * * * * * * * * DISC 4 * 20.00 *0.4007 *0.6569 * 32.79 *0.2004E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 10 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9905 * 6.801 * 71.65 *0.9493E-01* * * * * * * * * DISC 1 * 23.00 *0.4913 *0.9443 * 44.21 *0.2136E-01* * * * * * * * * DISC 2 * 22.00 *0.4438 *0.7855 * 38.94 *0.2017E-01* * * * * * * * * DISC 3 * 21.00 *0.4485 *0.8003 * 37.47 *0.2136E-01* * * * * * * * * DISC 4 * 20.00 *0.4034 *0.6685 * 33.14 *0.2017E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 11 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9945 * 7.759 * 81.40 *0.9532E-01* * * * * * * * * DISC 1 * 23.00 *0.4933 *0.9591 * 44.72 *0.2145E-01* * * * * * * * * DISC 2 * 22.00 *0.4456 *0.7956 * 39.28 *0.2025E-01* * * * * * * * * DISC 3 * 21.00 *0.4504 *0.8108 * 37.81 *0.2145E-01* * * * * * * * * DISC 4 * 20.00 *0.4051 *0.6759 * 33.37 *0.2025E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 12 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9969 * 8.731 * 91.39 *0.9554E-01* * * * * * * * * DISC 1 * 23.00 *0.4944 *0.9686 * 45.06 *0.2150E-01* * * * * * * * * DISC 2 * 22.00 *0.4467 *0.8020 * 39.50 *0.2030E-01* * * * * * * * * DISC 3 * 21.00 *0.4514 *0.8175 * 38.03 *0.2150E-01* * * * * * * * * DISC 4 * 20.00 *0.4061 *0.6805 * 33.52 *0.2030E-01*
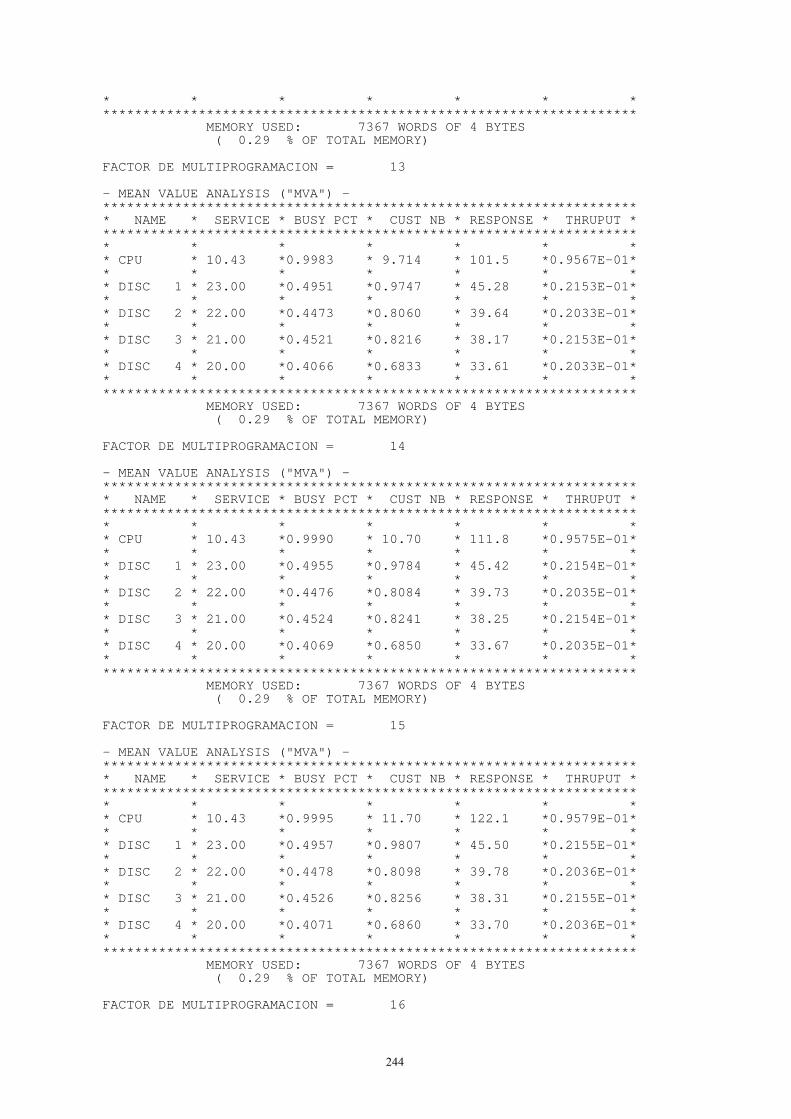
244
* * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 13 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9983 * 9.714 * 101.5 *0.9567E-01* * * * * * * * * DISC 1 * 23.00 *0.4951 *0.9747 * 45.28 *0.2153E-01* * * * * * * * * DISC 2 * 22.00 *0.4473 *0.8060 * 39.64 *0.2033E-01* * * * * * * * * DISC 3 * 21.00 *0.4521 *0.8216 * 38.17 *0.2153E-01* * * * * * * * * DISC 4 * 20.00 *0.4066 *0.6833 * 33.61 *0.2033E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 14 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9990 * 10.70 * 111.8 *0.9575E-01* * * * * * * * * DISC 1 * 23.00 *0.4955 *0.9784 * 45.42 *0.2154E-01* * * * * * * * * DISC 2 * 22.00 *0.4476 *0.8084 * 39.73 *0.2035E-01* * * * * * * * * DISC 3 * 21.00 *0.4524 *0.8241 * 38.25 *0.2154E-01* * * * * * * * * DISC 4 * 20.00 *0.4069 *0.6850 * 33.67 *0.2035E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 15 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9995 * 11.70 * 122.1 *0.9579E-01* * * * * * * * * DISC 1 * 23.00 *0.4957 *0.9807 * 45.50 *0.2155E-01* * * * * * * * * DISC 2 * 22.00 *0.4478 *0.8098 * 39.78 *0.2036E-01* * * * * * * * * DISC 3 * 21.00 *0.4526 *0.8256 * 38.31 *0.2155E-01* * * * * * * * * DISC 4 * 20.00 *0.4071 *0.6860 * 33.70 *0.2036E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 16
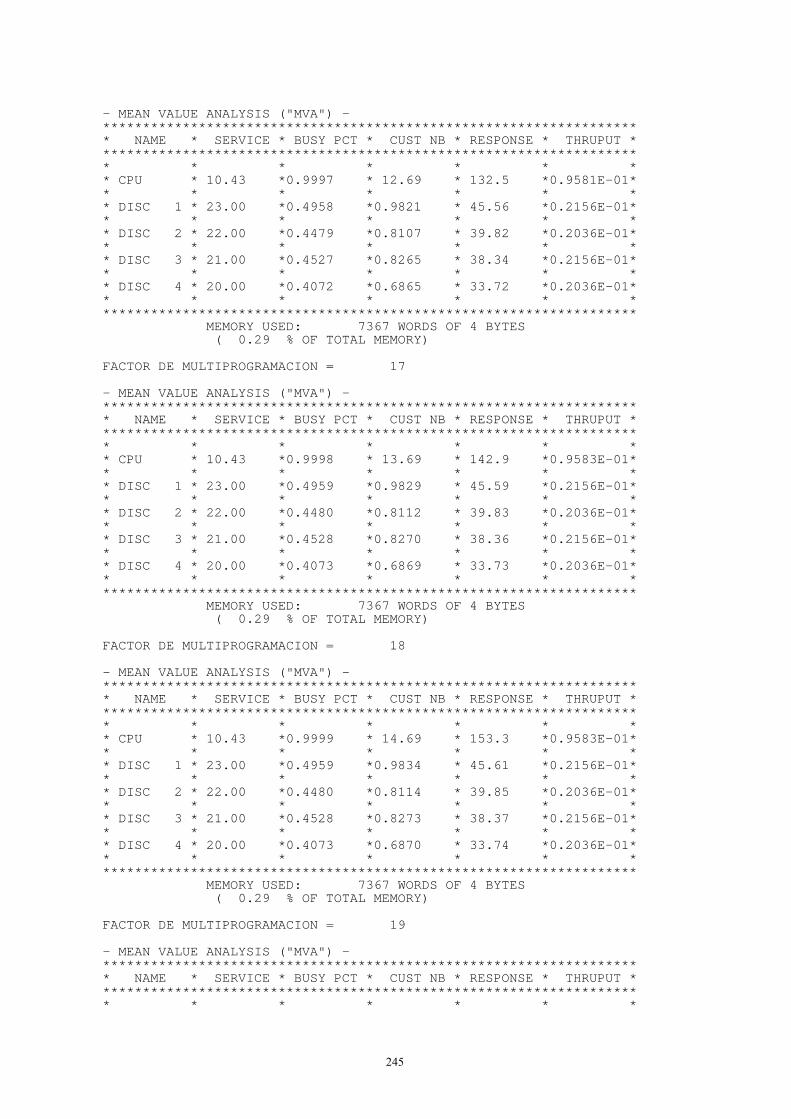
245
- MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9997 * 12.69 * 132.5 *0.9581E-01* * * * * * * * * DISC 1 * 23.00 *0.4958 *0.9821 * 45.56 *0.2156E-01* * * * * * * * * DISC 2 * 22.00 *0.4479 *0.8107 * 39.82 *0.2036E-01* * * * * * * * * DISC 3 * 21.00 *0.4527 *0.8265 * 38.34 *0.2156E-01* * * * * * * * * DISC 4 * 20.00 *0.4072 *0.6865 * 33.72 *0.2036E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 17 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9998 * 13.69 * 142.9 *0.9583E-01* * * * * * * * * DISC 1 * 23.00 *0.4959 *0.9829 * 45.59 *0.2156E-01* * * * * * * * * DISC 2 * 22.00 *0.4480 *0.8112 * 39.83 *0.2036E-01* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8270 * 38.36 *0.2156E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6869 * 33.73 *0.2036E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 18 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 *0.9999 * 14.69 * 153.3 *0.9583E-01* * * * * * * * * DISC 1 * 23.00 *0.4959 *0.9834 * 45.61 *0.2156E-01* * * * * * * * * DISC 2 * 22.00 *0.4480 *0.8114 * 39.85 *0.2036E-01* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8273 * 38.37 *0.2156E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6870 * 33.74 *0.2036E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 19 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * *

246
* CPU * 10.43 * 1.000 * 15.69 * 163.7 *0.9584E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9837 * 45.62 *0.2156E-01* * * * * * * * * DISC 2 * 22.00 *0.4480 *0.8116 * 39.85 *0.2037E-01* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8274 * 38.37 *0.2156E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6871 * 33.74 *0.2037E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 20 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.43 * 1.000 * 16.69 * 174.1 *0.9584E-01* * * * * * * * * DISC 1 * 23.00 *0.4960 *0.9838 * 45.62 *0.2156E-01* * * * * * * * * DISC 2 * 22.00 *0.4480 *0.8117 * 39.85 *0.2037E-01* * * * * * * * * DISC 3 * 21.00 *0.4528 *0.8275 * 38.38 *0.2156E-01* * * * * * * * * DISC 4 * 20.00 *0.4073 *0.6872 * 33.74 *0.2037E-01* * * * * * * * ******************************************************************* MEMORY USED: 7367 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) 1 0.4272E-02 2 0.6940E-02 3 0.8680E-02 4 0.9835E-02 5 0.1060E-01 6 0.1111E-01 7 0.1144E-01 8 0.1165E-01 9 0.1179E-01 10 0.1187E-01 11 0.1191E-01 12 0.1194E-01 13 0.1196E-01 14 0.1197E-01 15 0.1197E-01 16 0.1198E-01 17 0.1198E-01 18 0.1198E-01 19 0.1198E-01 20 0.1198E-01 37 38 /STATION/ NAME=TERMINAL; 39 TYPE=INFINITE; 40 INIT(C1)=N; 41 SERVICE(C1)=EXP(30000.); 42 SERVICE(C2)=EXP(60000.); 43 TRANSIT=SC; 44 /STATION/ NAME=SC; 45 SERVICE=EXP(1.); 46 RATE=CAP(1 STEP 1 UNTIL M); 47 TRANSIT=TERMINAL,C1,0.6,TERMINAL,C2; 48 INIT=N;

247
49 /CONTROL/ OPTION=NRESULT; 50 /EXEC/ BEGIN 51 NETWORK(TERMINAL,SC); 52 PRINT(" TERM FM PRODUCTIVIDAD RESPUESTA"); 53 FOR N := 150 STEP 150 UNTIL 750 DO 54 FOR M := 1 STEP 1 UNTIL 20 DO 55 BEGIN 56 SOLVE; 57 PRINT(N,M,MTHRUPUT(SC),MRESPONSE(SC)); 58 END; 59 END; TERM FM PRODUCTIVIDAD RESPUESTA 150 1 0.4272E-02 0.6333E+05 150 2 0.6940E-02 0.2284E+05 150 3 0.8680E-02 9845. 150 4 0.9792E-02 3956. 150 5 0.1026E-01 1871. 150 6 0.1040E-01 1270. 150 7 0.1045E-01 1051. 150 8 0.1048E-01 956.2 150 9 0.1049E-01 910.4 150 10 0.1049E-01 887.3 150 11 0.1050E-01 875.4 150 12 0.1050E-01 869.3 150 13 0.1050E-01 866.2 150 14 0.1050E-01 864.7 150 15 0.1050E-01 863.9 150 16 0.1050E-01 863.5 150 17 0.1050E-01 863.3 150 18 0.1050E-01 863.2 150 19 0.1050E-01 863.2 150 20 0.1050E-01 863.1 300 1 0.4272E-02 0.1687E+06 300 2 0.6940E-02 0.8768E+05 300 3 0.8680E-02 0.6169E+05 300 4 0.9835E-02 0.4951E+05 300 5 0.1060E-01 0.4287E+05 300 6 0.1111E-01 0.3899E+05 300 7 0.1144E-01 0.3665E+05 300 8 0.1165E-01 0.3523E+05 300 9 0.1179E-01 0.3436E+05 300 10 0.1187E-01 0.3385E+05 300 11 0.1191E-01 0.3354E+05 300 12 0.1194E-01 0.3336E+05 300 13 0.1196E-01 0.3326E+05 300 14 0.1197E-01 0.3320E+05 300 15 0.1197E-01 0.3316E+05 300 16 0.1198E-01 0.3315E+05 300 17 0.1198E-01 0.3314E+05 300 18 0.1198E-01 0.3313E+05 300 19 0.1198E-01 0.3313E+05 300 20 0.1198E-01 0.3313E+05 450 1 0.4272E-02 0.2740E+06 450 2 0.6940E-02 0.1525E+06 450 3 0.8680E-02 0.1135E+06 450 4 0.9835E-02 0.9526E+05 450 5 0.1060E-01 0.8530E+05 450 6 0.1111E-01 0.7948E+05 450 7 0.1144E-01 0.7598E+05 450 8 0.1165E-01 0.7384E+05 450 9 0.1179E-01 0.7255E+05 450 10 0.1187E-01 0.7177E+05 450 11 0.1191E-01 0.7131E+05 450 12 0.1194E-01 0.7104E+05 450 13 0.1196E-01 0.7088E+05 450 14 0.1197E-01 0.7080E+05 450 15 0.1197E-01 0.7075E+05 450 16 0.1198E-01 0.7072E+05

248
450 17 0.1198E-01 0.7070E+05 450 18 0.1198E-01 0.7070E+05 450 19 0.1198E-01 0.7069E+05 450 20 0.1198E-01 0.7069E+05 600 1 0.4272E-02 0.3793E+06 600 2 0.6940E-02 0.2174E+06 600 3 0.8680E-02 0.1654E+06 600 4 0.9835E-02 0.1410E+06 600 5 0.1060E-01 0.1277E+06 600 6 0.1111E-01 0.1200E+06 600 7 0.1144E-01 0.1153E+06 600 8 0.1165E-01 0.1125E+06 600 9 0.1179E-01 0.1107E+06 600 10 0.1187E-01 0.1097E+06 600 11 0.1191E-01 0.1091E+06 600 12 0.1194E-01 0.1087E+06 600 13 0.1196E-01 0.1085E+06 600 14 0.1197E-01 0.1084E+06 600 15 0.1197E-01 0.1083E+06 600 16 0.1198E-01 0.1083E+06 600 17 0.1198E-01 0.1083E+06 600 18 0.1198E-01 0.1083E+06 600 19 0.1198E-01 0.1083E+06 600 20 0.1198E-01 0.1083E+06 750 1 0.4272E-02 0.4847E+06 750 2 0.6940E-02 0.2822E+06 750 3 0.8680E-02 0.2172E+06 750 4 0.9835E-02 0.1868E+06 750 5 0.1060E-01 0.1702E+06 750 6 0.1111E-01 0.1605E+06 750 7 0.1144E-01 0.1546E+06 750 8 0.1165E-01 0.1511E+06 750 9 0.1179E-01 0.1489E+06 750 10 0.1187E-01 0.1476E+06 750 11 0.1191E-01 0.1468E+06 750 12 0.1194E-01 0.1464E+06 750 13 0.1196E-01 0.1461E+06 750 14 0.1197E-01 0.1460E+06 750 15 0.1197E-01 0.1459E+06 750 16 0.1198E-01 0.1459E+06 750 17 0.1198E-01 0.1458E+06 750 18 0.1198E-01 0.1458E+06 750 19 0.1198E-01 0.1458E+06 750 20 0.1198E-01 0.1458E+06 60 /END/ El modelo anterior se ha ignorado el overhead del sistema operativo que se puede simular de forma simple considerando que el consumo de CPU está aumentado por un incremento lineal función del factor de multiprogramación. Podrá observarse que la productividad del sistema aumenta con el factor de multiprogramación hasta alcanzar un máximo (en este caso para un factor de multiprogramación de 8 ó 9) para decrecer a continuación a causa del incremento del overhead. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),TERMINAL,SC; 2 REAL PROB1(4)=(2,1.5,1,0.5); 3 REAL PROB2(4)=(1.5,2,3,3.5); 4 REAL TR,CAP(20); 5 REAL TR1,TR2; 6 CLASS C1,C2; 7 INTEGER I,N,M; 8 /STATION/ NAME=CPU; 9 SCHED=PS; 10 INIT(C1)=N;

249
11 SERVICE(C1)=CST(8.52+0.1*N); 12 SERVICE(C2)=CST(12.+0.1*N); 13 TRANSIT(C1)=DISC,PROB1,CPU,C1,0.6,CPU,C2,0.4; 14 TRANSIT(C2)=DISC,PROB2,CPU,C1,0.6,CPU,C2,0.4; 15 /STATION/ NAME=DISC; 16 TRANSIT=CPU; 17 /STATION/ NAME=DISC(1); 18 SERVICE=EXP(23.); 19 /STATION/ NAME=DISC(2); 20 SERVICE=EXP(22.); 21 /STATION/ NAME=DISC(3); 22 SERVICE=EXP(21.); 23 /STATION/ NAME=DISC(4); 24 SERVICE=EXP(20.); 25 /EXEC/ BEGIN 26 NETWORK(CPU,DISC); 27 FOR N := 1 STEP 1 UNTIL 20 DO 28 BEGIN 29 PRINT; 30 PRINT("FACTOR DE MULTIPROGRAMACION =",N); 31 SOLVE; 32 CAP(N) := MTHRUPUT(CPU); 33 FOR I:=1 STEP 1 UNTIL 4 DO CAP(N):=CAP(N)-MTHRUPUT(DI ==> SC(I)); 34 END; 35 FOR N := 1 STEP 1 UNTIL 20 DO PRINT(N,CAP(N)); 36 END; FACTOR DE MULTIPROGRAMACION = 1 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.53 *0.3588 *0.3588 * 10.53 *0.3406E-01* * * * * * * * * DISC 1 * 23.00 *0.1763 *0.1763 * 23.00 *0.7664E-02* * * * * * * * * DISC 2 * 22.00 *0.1592 *0.1592 * 22.00 *0.7238E-02* * * * * * * * * DISC 3 * 21.00 *0.1609 *0.1609 * 21.00 *0.7664E-02* * * * * * * * * DISC 4 * 20.00 *0.1448 *0.1448 * 20.00 *0.7238E-02* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 2 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.63 *0.5856 *0.7970 * 14.47 *0.5507E-01* * * * * * * * * DISC 1 * 23.00 *0.2850 *0.3350 * 27.04 *0.1239E-01* * * * * * * * * DISC 2 * 22.00 *0.2574 *0.2983 * 25.49 *0.1170E-01* * * * * * * * * DISC 3 * 21.00 *0.2602 *0.3019 * 24.37 *0.1239E-01* * * * * * * * * DISC 4 * 20.00 *0.2340 *0.2678 * 22.89 *0.1170E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES

250
( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 3 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.73 *0.7345 * 1.324 * 19.35 *0.6843E-01* * * * * * * * * DISC 1 * 23.00 *0.3541 *0.4722 * 30.67 *0.1540E-01* * * * * * * * * DISC 2 * 22.00 *0.3199 *0.4149 * 28.53 *0.1454E-01* * * * * * * * * DISC 3 * 21.00 *0.3233 *0.4205 * 27.31 *0.1540E-01* * * * * * * * * DISC 4 * 20.00 *0.2908 *0.3684 * 25.33 *0.1454E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 4 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.83 *0.8334 * 1.945 * 25.28 *0.7692E-01* * * * * * * * * DISC 1 * 23.00 *0.3981 *0.5849 * 33.80 *0.1731E-01* * * * * * * * * DISC 2 * 22.00 *0.3596 *0.5080 * 31.07 *0.1635E-01* * * * * * * * * DISC 3 * 21.00 *0.3635 *0.5154 * 29.78 *0.1731E-01* * * * * * * * * DISC 4 * 20.00 *0.3269 *0.4467 * 27.32 *0.1635E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 5 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 10.93 *0.8984 * 2.659 * 32.37 *0.8216E-01* * * * * * * * * DISC 1 * 23.00 *0.4252 *0.6720 * 36.35 *0.1849E-01* * * * * * * * * DISC 2 * 22.00 *0.3841 *0.5778 * 33.09 *0.1746E-01* * * * * * * * * DISC 3 * 21.00 *0.3882 *0.5868 * 31.74 *0.1849E-01* * * * * * * * * DISC 4 * 20.00 *0.3492 *0.5040 * 28.87 *0.1746E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 6 - MEAN VALUE ANALYSIS ("MVA") - *******************************************************************
251
* NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.03 *0.9401 * 3.459 * 40.61 *0.8520E-01* * * * * * * * * DISC 1 * 23.00 *0.4409 *0.7345 * 38.32 *0.1917E-01* * * * * * * * * DISC 2 * 22.00 *0.3983 *0.6264 * 34.60 *0.1810E-01* * * * * * * * * DISC 3 * 21.00 *0.4026 *0.6367 * 33.21 *0.1917E-01* * * * * * * * * DISC 4 * 20.00 *0.3621 *0.5430 * 29.99 *0.1810E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 7 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.13 *0.9659 * 4.333 * 49.94 *0.8675E-01* * * * * * * * * DISC 1 * 23.00 *0.4490 *0.7752 * 39.71 *0.1952E-01* * * * * * * * * DISC 2 * 22.00 *0.4056 *0.6570 * 35.64 *0.1844E-01* * * * * * * * * DISC 3 * 21.00 *0.4099 *0.6682 * 34.23 *0.1952E-01* * * * * * * * * DISC 4 * 20.00 *0.3687 *0.5669 * 30.75 *0.1844E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 8 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.23 *0.9813 * 5.263 * 60.25 *0.8735E-01* * * * * * * * * DISC 1 * 23.00 *0.4521 *0.7983 * 40.62 *0.1965E-01* * * * * * * * * DISC 2 * 22.00 *0.4084 *0.6736 * 36.29 *0.1856E-01* * * * * * * * * DISC 3 * 21.00 *0.4128 *0.6854 * 34.87 *0.1965E-01* * * * * * * * * DISC 4 * 20.00 *0.3713 *0.5794 * 31.21 *0.1856E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 9 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.33 *0.9902 * 6.236 * 71.38 *0.8736E-01* * * * * * * * * DISC 1 * 23.00 *0.4521 *0.8083 * 41.12 *0.1966E-01*
252
* * * * * * * * DISC 2 * 22.00 *0.4084 *0.6801 * 36.64 *0.1856E-01* * * * * * * * * DISC 3 * 21.00 *0.4128 *0.6922 * 35.21 *0.1966E-01* * * * * * * * * DISC 4 * 20.00 *0.3713 *0.5839 * 31.45 *0.1856E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 10 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.43 *0.9950 * 7.236 * 83.15 *0.8702E-01* * * * * * * * * DISC 1 * 23.00 *0.4503 *0.8093 * 41.33 *0.1958E-01* * * * * * * * * DISC 2 * 22.00 *0.4068 *0.6799 * 36.77 *0.1849E-01* * * * * * * * * DISC 3 * 21.00 *0.4112 *0.6920 * 35.34 *0.1958E-01* * * * * * * * * DISC 4 * 20.00 *0.3698 *0.5831 * 31.53 *0.1849E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 11 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.53 *0.9975 * 8.253 * 95.43 *0.8649E-01* * * * * * * * * DISC 1 * 23.00 *0.4476 *0.8046 * 41.34 *0.1946E-01* * * * * * * * * DISC 2 * 22.00 *0.4043 *0.6755 * 36.76 *0.1838E-01* * * * * * * * * DISC 3 * 21.00 *0.4087 *0.6876 * 35.33 *0.1946E-01* * * * * * * * * DISC 4 * 20.00 *0.3676 *0.5791 * 31.51 *0.1838E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 12 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.63 *0.9988 * 9.281 * 108.1 *0.8585E-01* * * * * * * * * DISC 1 * 23.00 *0.4443 *0.7965 * 41.23 *0.1932E-01* * * * * * * * * DISC 2 * 22.00 *0.4014 *0.6688 * 36.66 *0.1824E-01* * * * * * * * * DISC 3 * 21.00 *0.4057 *0.6807 * 35.24 *0.1932E-01* * * * * * * * * DISC 4 * 20.00 *0.3649 *0.5734 * 31.43 *0.1824E-01*
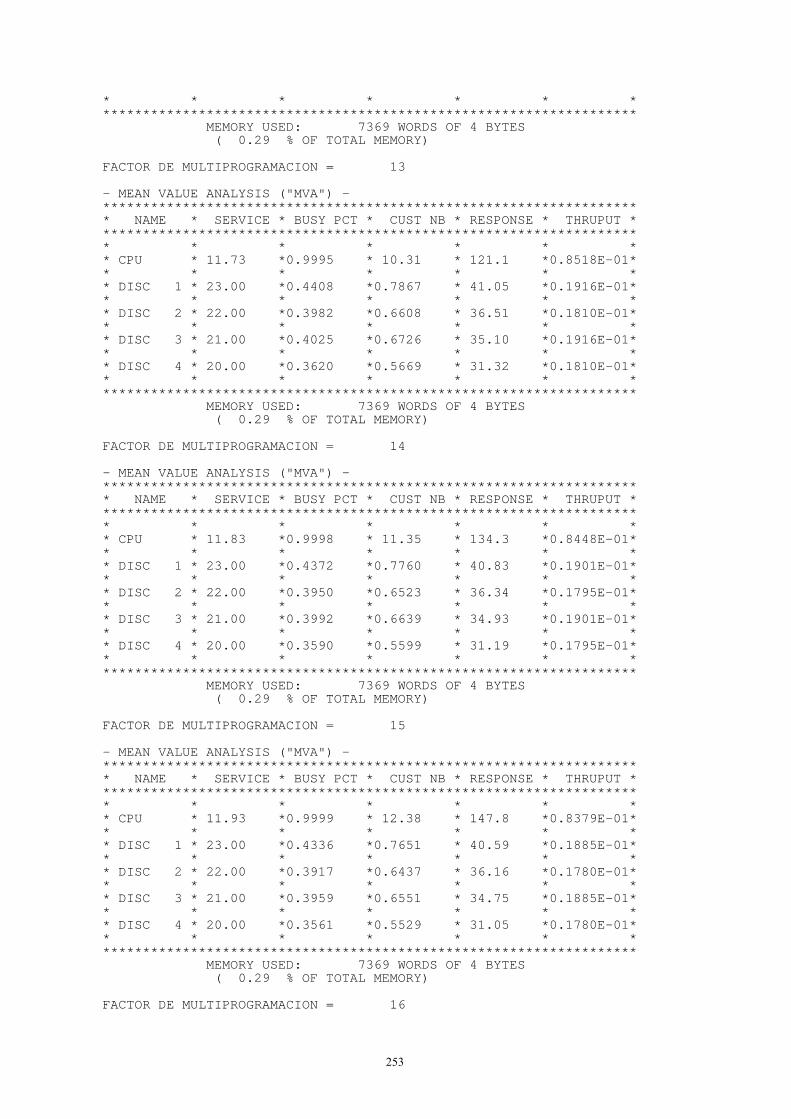
253
* * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 13 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.73 *0.9995 * 10.31 * 121.1 *0.8518E-01* * * * * * * * * DISC 1 * 23.00 *0.4408 *0.7867 * 41.05 *0.1916E-01* * * * * * * * * DISC 2 * 22.00 *0.3982 *0.6608 * 36.51 *0.1810E-01* * * * * * * * * DISC 3 * 21.00 *0.4025 *0.6726 * 35.10 *0.1916E-01* * * * * * * * * DISC 4 * 20.00 *0.3620 *0.5669 * 31.32 *0.1810E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 14 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.83 *0.9998 * 11.35 * 134.3 *0.8448E-01* * * * * * * * * DISC 1 * 23.00 *0.4372 *0.7760 * 40.83 *0.1901E-01* * * * * * * * * DISC 2 * 22.00 *0.3950 *0.6523 * 36.34 *0.1795E-01* * * * * * * * * DISC 3 * 21.00 *0.3992 *0.6639 * 34.93 *0.1901E-01* * * * * * * * * DISC 4 * 20.00 *0.3590 *0.5599 * 31.19 *0.1795E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 15 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 11.93 *0.9999 * 12.38 * 147.8 *0.8379E-01* * * * * * * * * DISC 1 * 23.00 *0.4336 *0.7651 * 40.59 *0.1885E-01* * * * * * * * * DISC 2 * 22.00 *0.3917 *0.6437 * 36.16 *0.1780E-01* * * * * * * * * DISC 3 * 21.00 *0.3959 *0.6551 * 34.75 *0.1885E-01* * * * * * * * * DISC 4 * 20.00 *0.3561 *0.5529 * 31.05 *0.1780E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 16
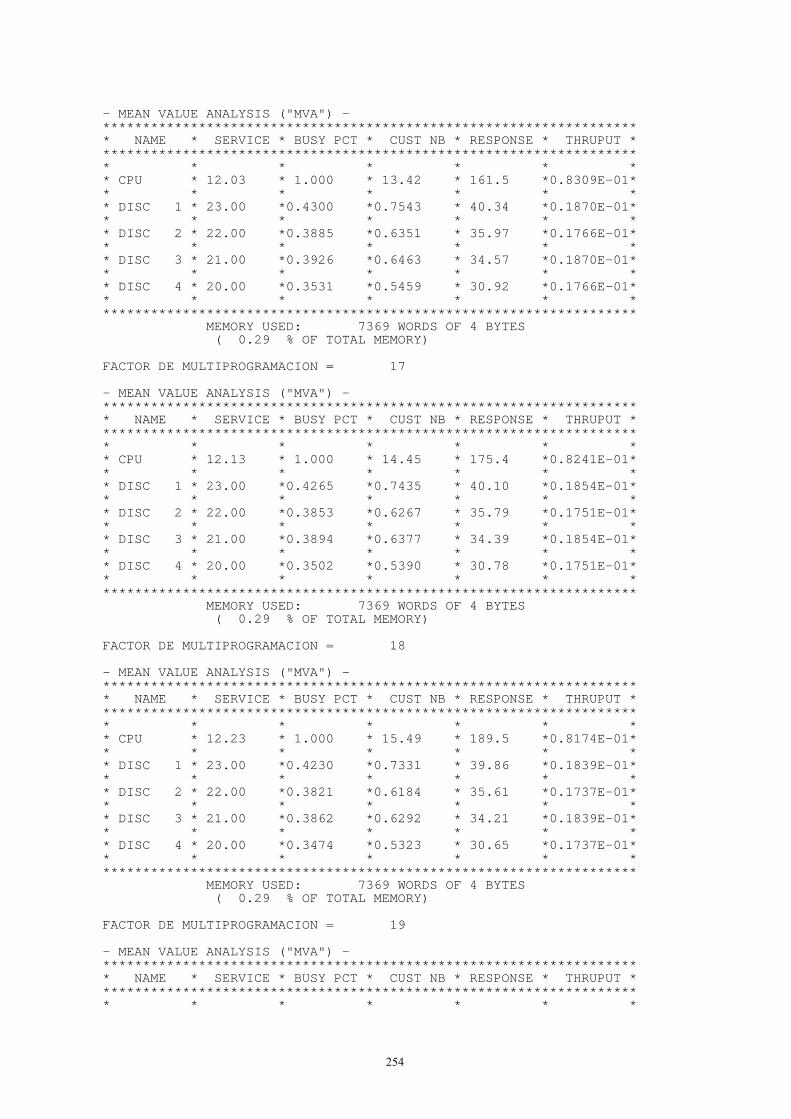
254
- MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 12.03 * 1.000 * 13.42 * 161.5 *0.8309E-01* * * * * * * * * DISC 1 * 23.00 *0.4300 *0.7543 * 40.34 *0.1870E-01* * * * * * * * * DISC 2 * 22.00 *0.3885 *0.6351 * 35.97 *0.1766E-01* * * * * * * * * DISC 3 * 21.00 *0.3926 *0.6463 * 34.57 *0.1870E-01* * * * * * * * * DISC 4 * 20.00 *0.3531 *0.5459 * 30.92 *0.1766E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 17 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 12.13 * 1.000 * 14.45 * 175.4 *0.8241E-01* * * * * * * * * DISC 1 * 23.00 *0.4265 *0.7435 * 40.10 *0.1854E-01* * * * * * * * * DISC 2 * 22.00 *0.3853 *0.6267 * 35.79 *0.1751E-01* * * * * * * * * DISC 3 * 21.00 *0.3894 *0.6377 * 34.39 *0.1854E-01* * * * * * * * * DISC 4 * 20.00 *0.3502 *0.5390 * 30.78 *0.1751E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 18 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 12.23 * 1.000 * 15.49 * 189.5 *0.8174E-01* * * * * * * * * DISC 1 * 23.00 *0.4230 *0.7331 * 39.86 *0.1839E-01* * * * * * * * * DISC 2 * 22.00 *0.3821 *0.6184 * 35.61 *0.1737E-01* * * * * * * * * DISC 3 * 21.00 *0.3862 *0.6292 * 34.21 *0.1839E-01* * * * * * * * * DISC 4 * 20.00 *0.3474 *0.5323 * 30.65 *0.1737E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 19 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * *

255
* CPU * 12.33 * 1.000 * 16.52 * 203.8 *0.8108E-01* * * * * * * * * DISC 1 * 23.00 *0.4196 *0.7229 * 39.63 *0.1824E-01* * * * * * * * * DISC 2 * 22.00 *0.3790 *0.6104 * 35.43 *0.1723E-01* * * * * * * * * DISC 3 * 21.00 *0.3831 *0.6210 * 34.04 *0.1824E-01* * * * * * * * * DISC 4 * 20.00 *0.3446 *0.5257 * 30.51 *0.1723E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 20 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 12.43 * 1.000 * 17.55 * 218.2 *0.8042E-01* * * * * * * * * DISC 1 * 23.00 *0.4162 *0.7129 * 39.40 *0.1810E-01* * * * * * * * * DISC 2 * 22.00 *0.3760 *0.6025 * 35.26 *0.1709E-01* * * * * * * * * DISC 3 * 21.00 *0.3800 *0.6129 * 33.87 *0.1810E-01* * * * * * * * * DISC 4 * 20.00 *0.3418 *0.5193 * 30.39 *0.1709E-01* * * * * * * * ******************************************************************* MEMORY USED: 7369 WORDS OF 4 BYTES ( 0.29 % OF TOTAL MEMORY) 1 0.4258E-02 2 0.6883E-02 3 0.8554E-02 4 0.9616E-02 5 0.1027E-01 6 0.1065E-01 7 0.1084E-01 8 0.1092E-01 9 0.1092E-01 10 0.1088E-01 11 0.1081E-01 12 0.1073E-01 13 0.1065E-01 14 0.1056E-01 15 0.1047E-01 16 0.1039E-01 17 0.1030E-01 18 0.1022E-01 19 0.1013E-01 20 0.1005E-01 37 38 /STATION/ NAME=TERMINAL; 39 TYPE=INFINITE; 40 INIT(C1)=N; 41 SERVICE(C1)=EXP(30000.); 42 SERVICE(C2)=EXP(60000.); 43 TRANSIT=SC; 44 /STATION/ NAME=SC; 45 SERVICE=EXP(1.); 46 RATE=CAP(1 STEP 1 UNTIL M); 47 TRANSIT=TERMINAL,C1,0.6,TERMINAL,C2; 48 INIT=N; 49 /CONTROL/ OPTION=NRESULT;

256
50 /EXEC/ BEGIN 51 NETWORK(TERMINAL,SC); 52 PRINT(" TERM FM PRODUCTIVIDAD"); 53 FOR N := 150 STEP 150 UNTIL 750 DO 54 FOR M := 1 STEP 1 UNTIL 20 DO 55 BEGIN 56 SOLVE; 57 PRINT(N,M,MTHRUPUT(SC)); 58 END; 59 END; TERM FM PRODUCTIVIDAD 150 1 0.4258E-02 150 2 0.6883E-02 150 3 0.8554E-02 150 4 0.9599E-02 150 5 0.1010E-01 150 6 0.1027E-01 150 7 0.1033E-01 150 8 0.1035E-01 150 9 0.1035E-01 150 10 0.1034E-01 150 11 0.1033E-01 150 12 0.1030E-01 150 13 0.1028E-01 150 14 0.1025E-01 150 15 0.1022E-01 150 16 0.1019E-01 150 17 0.1015E-01 150 18 0.1011E-01 150 19 0.1007E-01 150 20 0.1002E-01 300 1 0.4258E-02 300 2 0.6883E-02 300 3 0.8554E-02 300 4 0.9616E-02 300 5 0.1027E-01 300 6 0.1065E-01 300 7 0.1084E-01 300 8 0.1092E-01 300 9 0.1092E-01 300 10 0.1088E-01 300 11 0.1081E-01 300 12 0.1073E-01 300 13 0.1065E-01 300 14 0.1056E-01 300 15 0.1047E-01 300 16 0.1039E-01 300 17 0.1030E-01 300 18 0.1022E-01 300 19 0.1013E-01 300 20 0.1005E-01 450 1 0.4258E-02 450 2 0.6883E-02 450 3 0.8554E-02 450 4 0.9616E-02 450 5 0.1027E-01 450 6 0.1065E-01 450 7 0.1084E-01 450 8 0.1092E-01 450 9 0.1092E-01 450 10 0.1088E-01 450 11 0.1081E-01 450 12 0.1073E-01 450 13 0.1065E-01 450 14 0.1056E-01 450 15 0.1047E-01

257
450 16 0.1039E-01 450 17 0.1030E-01 450 18 0.1022E-01 450 19 0.1013E-01 450 20 0.1005E-01 600 1 0.4258E-02 600 2 0.6883E-02 600 3 0.8554E-02 600 4 0.9616E-02 600 5 0.1027E-01 600 6 0.1065E-01 600 7 0.1084E-01 600 8 0.1092E-01 600 9 0.1092E-01 600 10 0.1088E-01 600 11 0.1081E-01 600 12 0.1073E-01 600 13 0.1065E-01 600 14 0.1056E-01 600 15 0.1047E-01 600 16 0.1039E-01 600 17 0.1030E-01 600 18 0.1022E-01 600 19 0.1013E-01 600 20 0.1005E-01 750 1 0.4258E-02 750 2 0.6883E-02 750 3 0.8554E-02 750 4 0.9616E-02 750 5 0.1027E-01 750 6 0.1065E-01 750 7 0.1084E-01 750 8 0.1092E-01 750 9 0.1092E-01 750 10 0.1088E-01 750 11 0.1081E-01 750 12 0.1073E-01 750 13 0.1065E-01 750 14 0.1056E-01 750 15 0.1047E-01 750 16 0.1039E-01 750 17 0.1030E-01 750 18 0.1022E-01 750 19 0.1013E-01 750 20 0.1005E-01 60 /END/ Un mejor modelo de este sistema teniendo en cuenta el overhead del sistema operativo consiste en representarlo por un cierto número de clientes, proporcional al factor de multiprogramación ya que el overhead depende de él, que consumen accesos a la CPU y a los discos a intervalos aleatorios. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),ESP,TERMINAL,SC; 2 REAL PROB1(4)=(2,1.5,1,0.5); 3 REAL PROB2(4)=(1.5,2,3,3.5); 4 REAL PROBOS(4)=(0.2,0.15,0.1,0.05); 5 REAL TR,CAP(20); 6 REAL TR1,TR2; 7 CLASS C1,C2,OS; 8 INTEGER I,N,M; 9 /STATION/ NAME=CPU; 10 SCHED=PS; 11 INIT(C1)=N;

258
12 SERVICE(C1)=CST(8.52); 13 SERVICE(C2)=CST(12.); 14 SERVICE(OS)=CST(1.+0.1*N); 15 TRANSIT(C1)=DISC,PROB1,CPU,C1,0.6,CPU,C2,0.4; 16 TRANSIT(C2)=DISC,PROB2,CPU,C1,0.6,CPU,C2,0.4; 17 TRANSIT(OS)=DISC,PROBOS,ESP,1; 18 /STATION/ NAME=DISC; 19 TRANSIT=CPU; 20 /STATION/ NAME=DISC(1); 21 SERVICE=EXP(23.); 22 /STATION/ NAME=DISC(2); 23 SERVICE=EXP(22.); 24 /STATION/ NAME=DISC(3); 25 SERVICE=EXP(21.); 26 /STATION/ NAME=DISC(4); 27 SERVICE=EXP(20.); 28 /STATION/ NAME=ESP; 29 INIT(OS)=N; 30 SERVICE=EXP(500./N); 31 TRANSIT=CPU; 32 /CONTROL/ CLASS=ALL QUEUE; 33 /EXEC/ BEGIN 34 NETWORK(CPU,DISC,ESP); 35 FOR N := 1 STEP 1 UNTIL 20 DO 36 BEGIN 37 PRINT; 38 PRINT("FACTOR DE MULTIPROGRAMACION =",N); 39 SOLVE; 40 CAP(N) := MTHRUPUT(CPU,C1)+MTHRUPUT(CPU,C2); 41 FOR I:=1 STEP 1 UNTIL 4 DO CAP(N):=CAP(N)-MTHRUPUT(DI ==> SC(I),C1) 42 -MTHRUPUT(DI ==> SC(I),C2); 43 END; 44 FOR N := 1 STEP 1 UNTIL 20 DO PRINT(N,CAP(N)); 45 END; FACTOR DE MULTIPROGRAMACION = 1 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 9.698 *0.3581 *0.3604 * 9.760 *0.3693E-01* *(C1 )* 8.520 *0.1304 *0.1308 * 8.547 *0.1531E-01* *(C2 )* 12.00 *0.2245 *0.2252 * 12.04 *0.1871E-01* *(OS )* 1.100 *0.3203E-02*0.4346E-02* 1.492 *0.2912E-02* * * * * * * * * DISC 1 * 23.00 *0.1850 *0.1881 * 23.39 *0.8042E-02* *(C1 )* 23.00 *0.1174 *0.1184 * 23.21 *0.5103E-02* *(C2 )* 23.00 *0.5868E-01*0.5921E-01* 23.21 *0.2551E-02* *(OS )* 23.00 *0.8931E-02*0.1051E-01* 27.07 *0.3883E-03* * * * * * * * * DISC 2 * 22.00 *0.1654 *0.1675 * 22.27 *0.7520E-02* *(C1 )* 22.00 *0.8419E-01*0.8473E-01* 22.14 *0.3827E-02* *(C2 )* 22.00 *0.7484E-01*0.7532E-01* 22.14 *0.3402E-02* *(OS )* 22.00 *0.6407E-02*0.7431E-02* 25.52 *0.2912E-03* * * * * * * * * DISC 3 * 21.00 *0.1648 *0.1661 * 21.17 *0.7848E-02* *(C1 )* 21.00 *0.5358E-01*0.5380E-01* 21.09 *0.2551E-02* *(C2 )* 21.00 *0.1072 *0.1076 * 21.09 *0.5103E-02* *(OS )* 21.00 *0.4077E-02*0.4736E-02* 24.39 *0.1942E-03* * * * * * * * * DISC 4 * 20.00 *0.1465 *0.1471 * 20.08 *0.7326E-02* *(C1 )* 20.00 *0.2551E-01*0.2556E-01* 20.04 *0.1276E-02* *(C2 )* 20.00 *0.1191 *0.1193 * 20.04 *0.5953E-02* *(OS )* 20.00 *0.1942E-02*0.2224E-02* 22.91 *0.9708E-04*
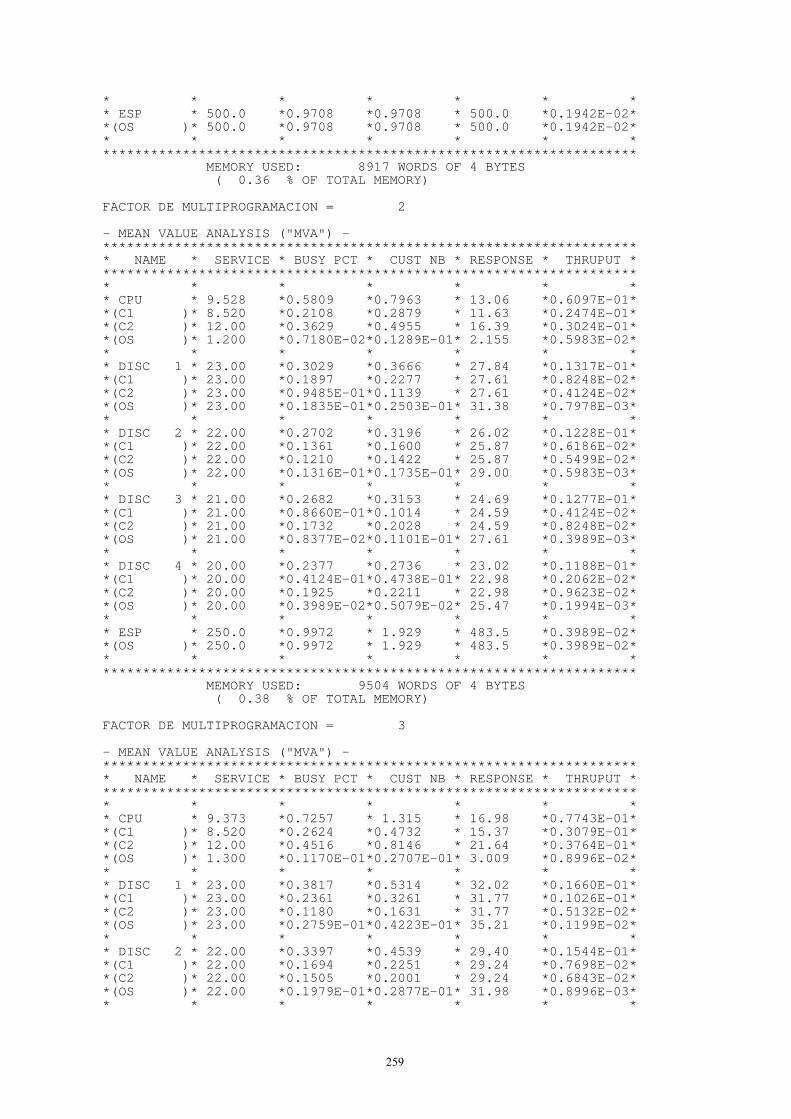
259
* * * * * * * * ESP * 500.0 *0.9708 *0.9708 * 500.0 *0.1942E-02* *(OS )* 500.0 *0.9708 *0.9708 * 500.0 *0.1942E-02* * * * * * * * ******************************************************************* MEMORY USED: 8917 WORDS OF 4 BYTES ( 0.36 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 2 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 9.528 *0.5809 *0.7963 * 13.06 *0.6097E-01* *(C1 )* 8.520 *0.2108 *0.2879 * 11.63 *0.2474E-01* *(C2 )* 12.00 *0.3629 *0.4955 * 16.39 *0.3024E-01* *(OS )* 1.200 *0.7180E-02*0.1289E-01* 2.155 *0.5983E-02* * * * * * * * * DISC 1 * 23.00 *0.3029 *0.3666 * 27.84 *0.1317E-01* *(C1 )* 23.00 *0.1897 *0.2277 * 27.61 *0.8248E-02* *(C2 )* 23.00 *0.9485E-01*0.1139 * 27.61 *0.4124E-02* *(OS )* 23.00 *0.1835E-01*0.2503E-01* 31.38 *0.7978E-03* * * * * * * * * DISC 2 * 22.00 *0.2702 *0.3196 * 26.02 *0.1228E-01* *(C1 )* 22.00 *0.1361 *0.1600 * 25.87 *0.6186E-02* *(C2 )* 22.00 *0.1210 *0.1422 * 25.87 *0.5499E-02* *(OS )* 22.00 *0.1316E-01*0.1735E-01* 29.00 *0.5983E-03* * * * * * * * * DISC 3 * 21.00 *0.2682 *0.3153 * 24.69 *0.1277E-01* *(C1 )* 21.00 *0.8660E-01*0.1014 * 24.59 *0.4124E-02* *(C2 )* 21.00 *0.1732 *0.2028 * 24.59 *0.8248E-02* *(OS )* 21.00 *0.8377E-02*0.1101E-01* 27.61 *0.3989E-03* * * * * * * * * DISC 4 * 20.00 *0.2377 *0.2736 * 23.02 *0.1188E-01* *(C1 )* 20.00 *0.4124E-01*0.4738E-01* 22.98 *0.2062E-02* *(C2 )* 20.00 *0.1925 *0.2211 * 22.98 *0.9623E-02* *(OS )* 20.00 *0.3989E-02*0.5079E-02* 25.47 *0.1994E-03* * * * * * * * * ESP * 250.0 *0.9972 * 1.929 * 483.5 *0.3989E-02* *(OS )* 250.0 *0.9972 * 1.929 * 483.5 *0.3989E-02* * * * * * * * ******************************************************************* MEMORY USED: 9504 WORDS OF 4 BYTES ( 0.38 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 3 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 9.373 *0.7257 * 1.315 * 16.98 *0.7743E-01* *(C1 )* 8.520 *0.2624 *0.4732 * 15.37 *0.3079E-01* *(C2 )* 12.00 *0.4516 *0.8146 * 21.64 *0.3764E-01* *(OS )* 1.300 *0.1170E-01*0.2707E-01* 3.009 *0.8996E-02* * * * * * * * * DISC 1 * 23.00 *0.3817 *0.5314 * 32.02 *0.1660E-01* *(C1 )* 23.00 *0.2361 *0.3261 * 31.77 *0.1026E-01* *(C2 )* 23.00 *0.1180 *0.1631 * 31.77 *0.5132E-02* *(OS )* 23.00 *0.2759E-01*0.4223E-01* 35.21 *0.1199E-02* * * * * * * * * DISC 2 * 22.00 *0.3397 *0.4539 * 29.40 *0.1544E-01* *(C1 )* 22.00 *0.1694 *0.2251 * 29.24 *0.7698E-02* *(C2 )* 22.00 *0.1505 *0.2001 * 29.24 *0.6843E-02* *(OS )* 22.00 *0.1979E-01*0.2877E-01* 31.98 *0.8996E-03* * * * * * * *
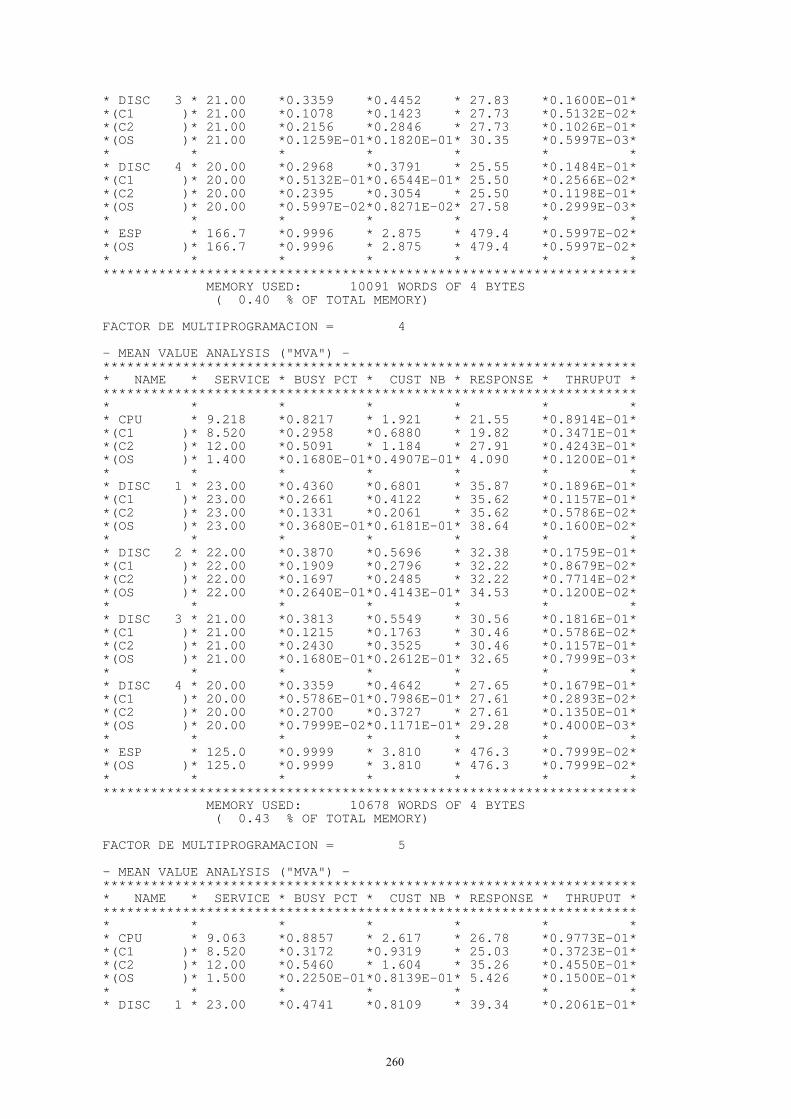
260
* DISC 3 * 21.00 *0.3359 *0.4452 * 27.83 *0.1600E-01* *(C1 )* 21.00 *0.1078 *0.1423 * 27.73 *0.5132E-02* *(C2 )* 21.00 *0.2156 *0.2846 * 27.73 *0.1026E-01* *(OS )* 21.00 *0.1259E-01*0.1820E-01* 30.35 *0.5997E-03* * * * * * * * * DISC 4 * 20.00 *0.2968 *0.3791 * 25.55 *0.1484E-01* *(C1 )* 20.00 *0.5132E-01*0.6544E-01* 25.50 *0.2566E-02* *(C2 )* 20.00 *0.2395 *0.3054 * 25.50 *0.1198E-01* *(OS )* 20.00 *0.5997E-02*0.8271E-02* 27.58 *0.2999E-03* * * * * * * * * ESP * 166.7 *0.9996 * 2.875 * 479.4 *0.5997E-02* *(OS )* 166.7 *0.9996 * 2.875 * 479.4 *0.5997E-02* * * * * * * * ******************************************************************* MEMORY USED: 10091 WORDS OF 4 BYTES ( 0.40 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 4 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 9.218 *0.8217 * 1.921 * 21.55 *0.8914E-01* *(C1 )* 8.520 *0.2958 *0.6880 * 19.82 *0.3471E-01* *(C2 )* 12.00 *0.5091 * 1.184 * 27.91 *0.4243E-01* *(OS )* 1.400 *0.1680E-01*0.4907E-01* 4.090 *0.1200E-01* * * * * * * * * DISC 1 * 23.00 *0.4360 *0.6801 * 35.87 *0.1896E-01* *(C1 )* 23.00 *0.2661 *0.4122 * 35.62 *0.1157E-01* *(C2 )* 23.00 *0.1331 *0.2061 * 35.62 *0.5786E-02* *(OS )* 23.00 *0.3680E-01*0.6181E-01* 38.64 *0.1600E-02* * * * * * * * * DISC 2 * 22.00 *0.3870 *0.5696 * 32.38 *0.1759E-01* *(C1 )* 22.00 *0.1909 *0.2796 * 32.22 *0.8679E-02* *(C2 )* 22.00 *0.1697 *0.2485 * 32.22 *0.7714E-02* *(OS )* 22.00 *0.2640E-01*0.4143E-01* 34.53 *0.1200E-02* * * * * * * * * DISC 3 * 21.00 *0.3813 *0.5549 * 30.56 *0.1816E-01* *(C1 )* 21.00 *0.1215 *0.1763 * 30.46 *0.5786E-02* *(C2 )* 21.00 *0.2430 *0.3525 * 30.46 *0.1157E-01* *(OS )* 21.00 *0.1680E-01*0.2612E-01* 32.65 *0.7999E-03* * * * * * * * * DISC 4 * 20.00 *0.3359 *0.4642 * 27.65 *0.1679E-01* *(C1 )* 20.00 *0.5786E-01*0.7986E-01* 27.61 *0.2893E-02* *(C2 )* 20.00 *0.2700 *0.3727 * 27.61 *0.1350E-01* *(OS )* 20.00 *0.7999E-02*0.1171E-01* 29.28 *0.4000E-03* * * * * * * * * ESP * 125.0 *0.9999 * 3.810 * 476.3 *0.7999E-02* *(OS )* 125.0 *0.9999 * 3.810 * 476.3 *0.7999E-02* * * * * * * * ******************************************************************* MEMORY USED: 10678 WORDS OF 4 BYTES ( 0.43 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 5 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 9.063 *0.8857 * 2.617 * 26.78 *0.9773E-01* *(C1 )* 8.520 *0.3172 *0.9319 * 25.03 *0.3723E-01* *(C2 )* 12.00 *0.5460 * 1.604 * 35.26 *0.4550E-01* *(OS )* 1.500 *0.2250E-01*0.8139E-01* 5.426 *0.1500E-01* * * * * * * * * DISC 1 * 23.00 *0.4741 *0.8109 * 39.34 *0.2061E-01*
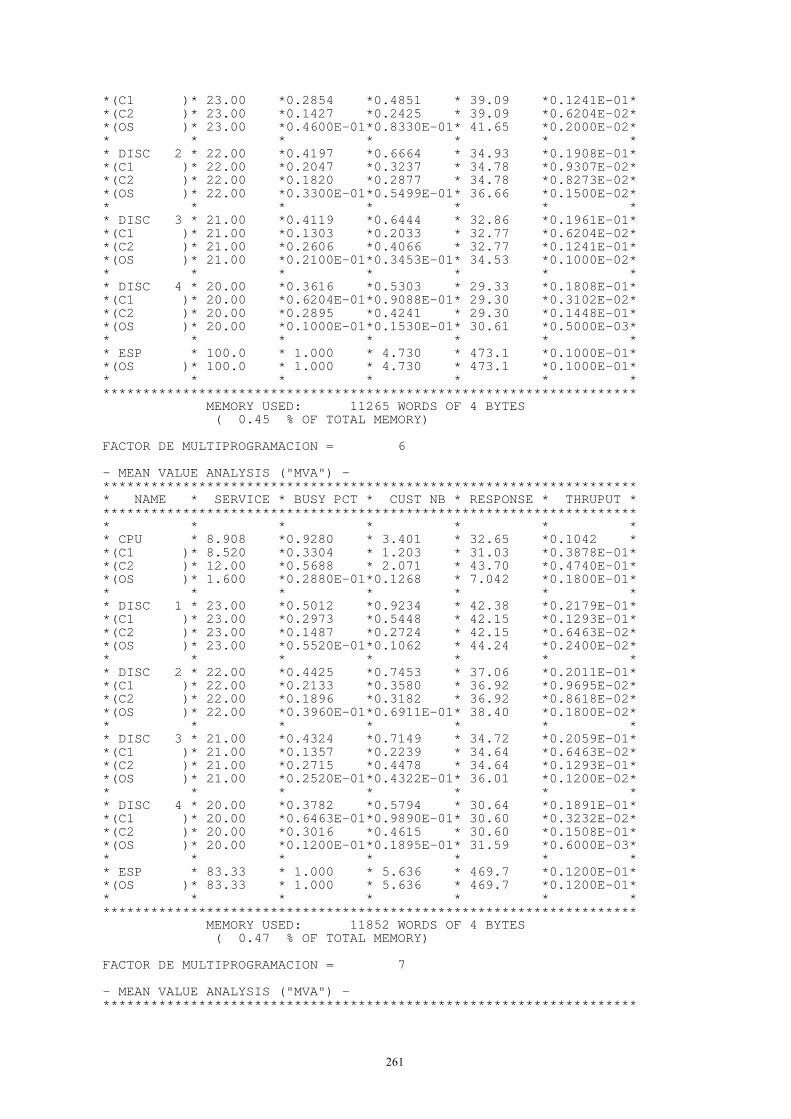
261
*(C1 )* 23.00 *0.2854 *0.4851 * 39.09 *0.1241E-01* *(C2 )* 23.00 *0.1427 *0.2425 * 39.09 *0.6204E-02* *(OS )* 23.00 *0.4600E-01*0.8330E-01* 41.65 *0.2000E-02* * * * * * * * * DISC 2 * 22.00 *0.4197 *0.6664 * 34.93 *0.1908E-01* *(C1 )* 22.00 *0.2047 *0.3237 * 34.78 *0.9307E-02* *(C2 )* 22.00 *0.1820 *0.2877 * 34.78 *0.8273E-02* *(OS )* 22.00 *0.3300E-01*0.5499E-01* 36.66 *0.1500E-02* * * * * * * * * DISC 3 * 21.00 *0.4119 *0.6444 * 32.86 *0.1961E-01* *(C1 )* 21.00 *0.1303 *0.2033 * 32.77 *0.6204E-02* *(C2 )* 21.00 *0.2606 *0.4066 * 32.77 *0.1241E-01* *(OS )* 21.00 *0.2100E-01*0.3453E-01* 34.53 *0.1000E-02* * * * * * * * * DISC 4 * 20.00 *0.3616 *0.5303 * 29.33 *0.1808E-01* *(C1 )* 20.00 *0.6204E-01*0.9088E-01* 29.30 *0.3102E-02* *(C2 )* 20.00 *0.2895 *0.4241 * 29.30 *0.1448E-01* *(OS )* 20.00 *0.1000E-01*0.1530E-01* 30.61 *0.5000E-03* * * * * * * * * ESP * 100.0 * 1.000 * 4.730 * 473.1 *0.1000E-01* *(OS )* 100.0 * 1.000 * 4.730 * 473.1 *0.1000E-01* * * * * * * * ******************************************************************* MEMORY USED: 11265 WORDS OF 4 BYTES ( 0.45 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 6 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 8.908 *0.9280 * 3.401 * 32.65 *0.1042 * *(C1 )* 8.520 *0.3304 * 1.203 * 31.03 *0.3878E-01* *(C2 )* 12.00 *0.5688 * 2.071 * 43.70 *0.4740E-01* *(OS )* 1.600 *0.2880E-01*0.1268 * 7.042 *0.1800E-01* * * * * * * * * DISC 1 * 23.00 *0.5012 *0.9234 * 42.38 *0.2179E-01* *(C1 )* 23.00 *0.2973 *0.5448 * 42.15 *0.1293E-01* *(C2 )* 23.00 *0.1487 *0.2724 * 42.15 *0.6463E-02* *(OS )* 23.00 *0.5520E-01*0.1062 * 44.24 *0.2400E-02* * * * * * * * * DISC 2 * 22.00 *0.4425 *0.7453 * 37.06 *0.2011E-01* *(C1 )* 22.00 *0.2133 *0.3580 * 36.92 *0.9695E-02* *(C2 )* 22.00 *0.1896 *0.3182 * 36.92 *0.8618E-02* *(OS )* 22.00 *0.3960E-01*0.6911E-01* 38.40 *0.1800E-02* * * * * * * * * DISC 3 * 21.00 *0.4324 *0.7149 * 34.72 *0.2059E-01* *(C1 )* 21.00 *0.1357 *0.2239 * 34.64 *0.6463E-02* *(C2 )* 21.00 *0.2715 *0.4478 * 34.64 *0.1293E-01* *(OS )* 21.00 *0.2520E-01*0.4322E-01* 36.01 *0.1200E-02* * * * * * * * * DISC 4 * 20.00 *0.3782 *0.5794 * 30.64 *0.1891E-01* *(C1 )* 20.00 *0.6463E-01*0.9890E-01* 30.60 *0.3232E-02* *(C2 )* 20.00 *0.3016 *0.4615 * 30.60 *0.1508E-01* *(OS )* 20.00 *0.1200E-01*0.1895E-01* 31.59 *0.6000E-03* * * * * * * * * ESP * 83.33 * 1.000 * 5.636 * 469.7 *0.1200E-01* *(OS )* 83.33 * 1.000 * 5.636 * 469.7 *0.1200E-01* * * * * * * * ******************************************************************* MEMORY USED: 11852 WORDS OF 4 BYTES ( 0.47 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 7 - MEAN VALUE ANALYSIS ("MVA") - *******************************************************************
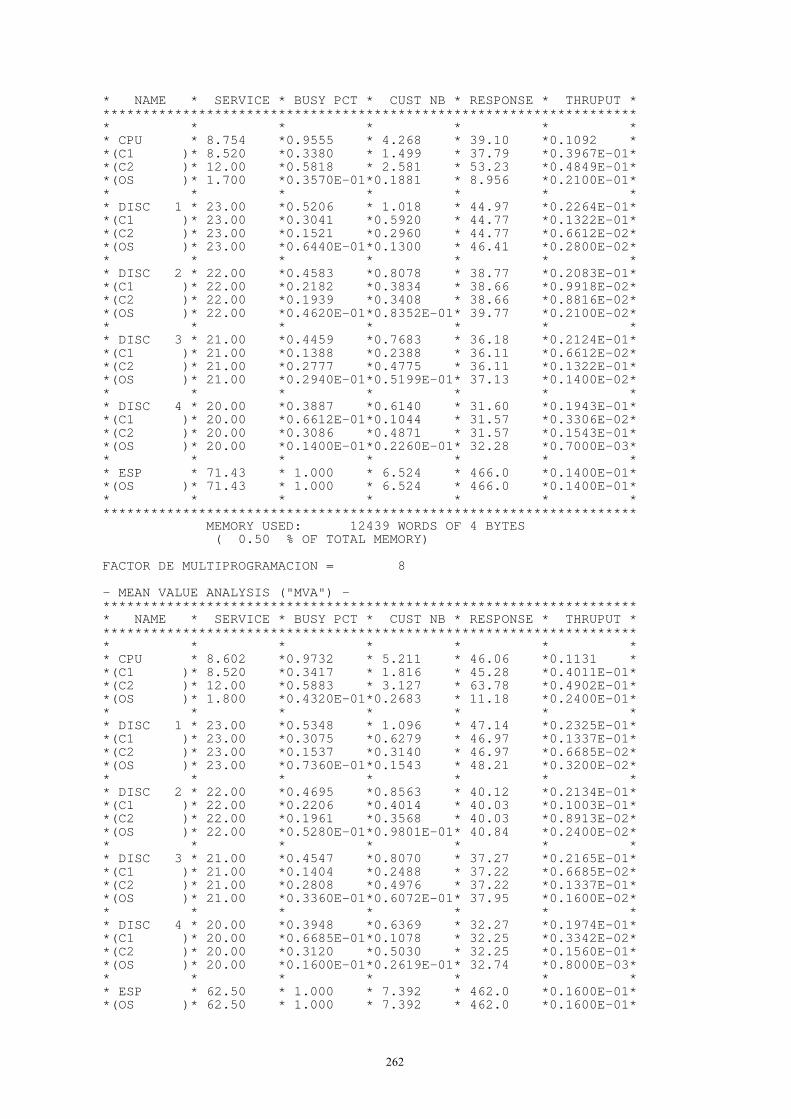
262
* NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 8.754 *0.9555 * 4.268 * 39.10 *0.1092 * *(C1 )* 8.520 *0.3380 * 1.499 * 37.79 *0.3967E-01* *(C2 )* 12.00 *0.5818 * 2.581 * 53.23 *0.4849E-01* *(OS )* 1.700 *0.3570E-01*0.1881 * 8.956 *0.2100E-01* * * * * * * * * DISC 1 * 23.00 *0.5206 * 1.018 * 44.97 *0.2264E-01* *(C1 )* 23.00 *0.3041 *0.5920 * 44.77 *0.1322E-01* *(C2 )* 23.00 *0.1521 *0.2960 * 44.77 *0.6612E-02* *(OS )* 23.00 *0.6440E-01*0.1300 * 46.41 *0.2800E-02* * * * * * * * * DISC 2 * 22.00 *0.4583 *0.8078 * 38.77 *0.2083E-01* *(C1 )* 22.00 *0.2182 *0.3834 * 38.66 *0.9918E-02* *(C2 )* 22.00 *0.1939 *0.3408 * 38.66 *0.8816E-02* *(OS )* 22.00 *0.4620E-01*0.8352E-01* 39.77 *0.2100E-02* * * * * * * * * DISC 3 * 21.00 *0.4459 *0.7683 * 36.18 *0.2124E-01* *(C1 )* 21.00 *0.1388 *0.2388 * 36.11 *0.6612E-02* *(C2 )* 21.00 *0.2777 *0.4775 * 36.11 *0.1322E-01* *(OS )* 21.00 *0.2940E-01*0.5199E-01* 37.13 *0.1400E-02* * * * * * * * * DISC 4 * 20.00 *0.3887 *0.6140 * 31.60 *0.1943E-01* *(C1 )* 20.00 *0.6612E-01*0.1044 * 31.57 *0.3306E-02* *(C2 )* 20.00 *0.3086 *0.4871 * 31.57 *0.1543E-01* *(OS )* 20.00 *0.1400E-01*0.2260E-01* 32.28 *0.7000E-03* * * * * * * * * ESP * 71.43 * 1.000 * 6.524 * 466.0 *0.1400E-01* *(OS )* 71.43 * 1.000 * 6.524 * 466.0 *0.1400E-01* * * * * * * * ******************************************************************* MEMORY USED: 12439 WORDS OF 4 BYTES ( 0.50 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 8 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 8.602 *0.9732 * 5.211 * 46.06 *0.1131 * *(C1 )* 8.520 *0.3417 * 1.816 * 45.28 *0.4011E-01* *(C2 )* 12.00 *0.5883 * 3.127 * 63.78 *0.4902E-01* *(OS )* 1.800 *0.4320E-01*0.2683 * 11.18 *0.2400E-01* * * * * * * * * DISC 1 * 23.00 *0.5348 * 1.096 * 47.14 *0.2325E-01* *(C1 )* 23.00 *0.3075 *0.6279 * 46.97 *0.1337E-01* *(C2 )* 23.00 *0.1537 *0.3140 * 46.97 *0.6685E-02* *(OS )* 23.00 *0.7360E-01*0.1543 * 48.21 *0.3200E-02* * * * * * * * * DISC 2 * 22.00 *0.4695 *0.8563 * 40.12 *0.2134E-01* *(C1 )* 22.00 *0.2206 *0.4014 * 40.03 *0.1003E-01* *(C2 )* 22.00 *0.1961 *0.3568 * 40.03 *0.8913E-02* *(OS )* 22.00 *0.5280E-01*0.9801E-01* 40.84 *0.2400E-02* * * * * * * * * DISC 3 * 21.00 *0.4547 *0.8070 * 37.27 *0.2165E-01* *(C1 )* 21.00 *0.1404 *0.2488 * 37.22 *0.6685E-02* *(C2 )* 21.00 *0.2808 *0.4976 * 37.22 *0.1337E-01* *(OS )* 21.00 *0.3360E-01*0.6072E-01* 37.95 *0.1600E-02* * * * * * * * * DISC 4 * 20.00 *0.3948 *0.6369 * 32.27 *0.1974E-01* *(C1 )* 20.00 *0.6685E-01*0.1078 * 32.25 *0.3342E-02* *(C2 )* 20.00 *0.3120 *0.5030 * 32.25 *0.1560E-01* *(OS )* 20.00 *0.1600E-01*0.2619E-01* 32.74 *0.8000E-03* * * * * * * * * ESP * 62.50 * 1.000 * 7.392 * 462.0 *0.1600E-01* *(OS )* 62.50 * 1.000 * 7.392 * 462.0 *0.1600E-01*
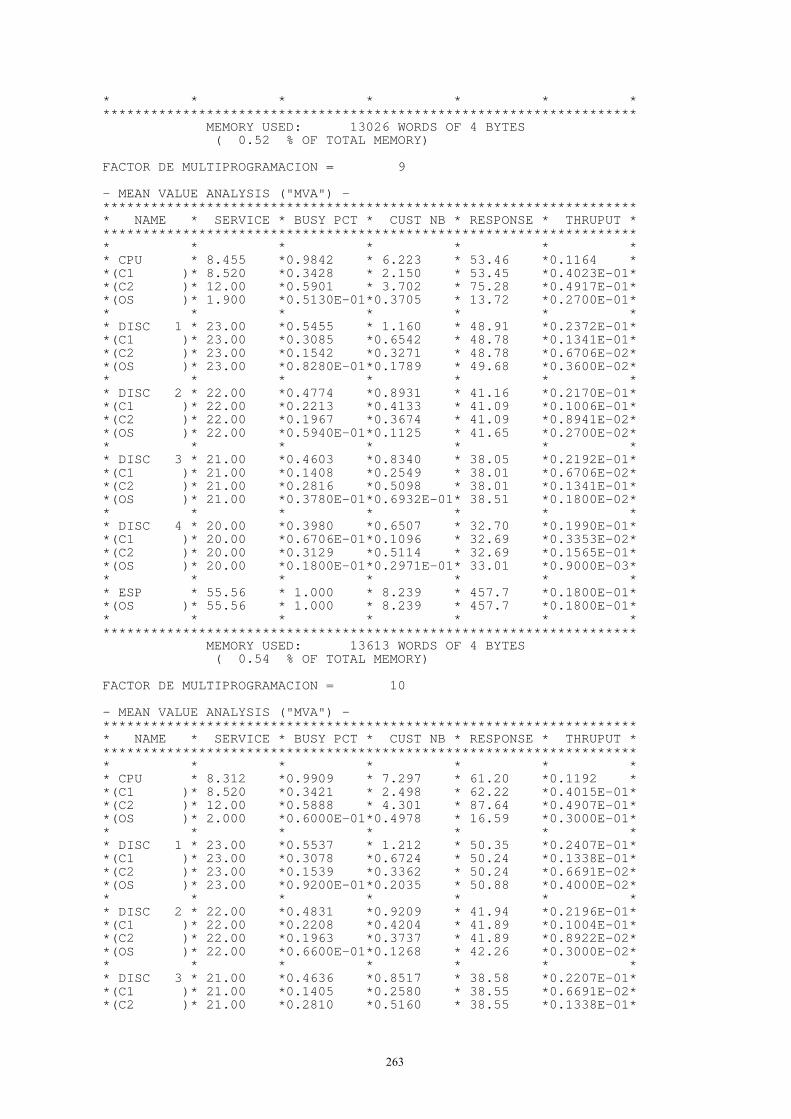
263
* * * * * * * ******************************************************************* MEMORY USED: 13026 WORDS OF 4 BYTES ( 0.52 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 9 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 8.455 *0.9842 * 6.223 * 53.46 *0.1164 * *(C1 )* 8.520 *0.3428 * 2.150 * 53.45 *0.4023E-01* *(C2 )* 12.00 *0.5901 * 3.702 * 75.28 *0.4917E-01* *(OS )* 1.900 *0.5130E-01*0.3705 * 13.72 *0.2700E-01* * * * * * * * * DISC 1 * 23.00 *0.5455 * 1.160 * 48.91 *0.2372E-01* *(C1 )* 23.00 *0.3085 *0.6542 * 48.78 *0.1341E-01* *(C2 )* 23.00 *0.1542 *0.3271 * 48.78 *0.6706E-02* *(OS )* 23.00 *0.8280E-01*0.1789 * 49.68 *0.3600E-02* * * * * * * * * DISC 2 * 22.00 *0.4774 *0.8931 * 41.16 *0.2170E-01* *(C1 )* 22.00 *0.2213 *0.4133 * 41.09 *0.1006E-01* *(C2 )* 22.00 *0.1967 *0.3674 * 41.09 *0.8941E-02* *(OS )* 22.00 *0.5940E-01*0.1125 * 41.65 *0.2700E-02* * * * * * * * * DISC 3 * 21.00 *0.4603 *0.8340 * 38.05 *0.2192E-01* *(C1 )* 21.00 *0.1408 *0.2549 * 38.01 *0.6706E-02* *(C2 )* 21.00 *0.2816 *0.5098 * 38.01 *0.1341E-01* *(OS )* 21.00 *0.3780E-01*0.6932E-01* 38.51 *0.1800E-02* * * * * * * * * DISC 4 * 20.00 *0.3980 *0.6507 * 32.70 *0.1990E-01* *(C1 )* 20.00 *0.6706E-01*0.1096 * 32.69 *0.3353E-02* *(C2 )* 20.00 *0.3129 *0.5114 * 32.69 *0.1565E-01* *(OS )* 20.00 *0.1800E-01*0.2971E-01* 33.01 *0.9000E-03* * * * * * * * * ESP * 55.56 * 1.000 * 8.239 * 457.7 *0.1800E-01* *(OS )* 55.56 * 1.000 * 8.239 * 457.7 *0.1800E-01* * * * * * * * ******************************************************************* MEMORY USED: 13613 WORDS OF 4 BYTES ( 0.54 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 10 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 8.312 *0.9909 * 7.297 * 61.20 *0.1192 * *(C1 )* 8.520 *0.3421 * 2.498 * 62.22 *0.4015E-01* *(C2 )* 12.00 *0.5888 * 4.301 * 87.64 *0.4907E-01* *(OS )* 2.000 *0.6000E-01*0.4978 * 16.59 *0.3000E-01* * * * * * * * * DISC 1 * 23.00 *0.5537 * 1.212 * 50.35 *0.2407E-01* *(C1 )* 23.00 *0.3078 *0.6724 * 50.24 *0.1338E-01* *(C2 )* 23.00 *0.1539 *0.3362 * 50.24 *0.6691E-02* *(OS )* 23.00 *0.9200E-01*0.2035 * 50.88 *0.4000E-02* * * * * * * * * DISC 2 * 22.00 *0.4831 *0.9209 * 41.94 *0.2196E-01* *(C1 )* 22.00 *0.2208 *0.4204 * 41.89 *0.1004E-01* *(C2 )* 22.00 *0.1963 *0.3737 * 41.89 *0.8922E-02* *(OS )* 22.00 *0.6600E-01*0.1268 * 42.26 *0.3000E-02* * * * * * * * * DISC 3 * 21.00 *0.4636 *0.8517 * 38.58 *0.2207E-01* *(C1 )* 21.00 *0.1405 *0.2580 * 38.55 *0.6691E-02* *(C2 )* 21.00 *0.2810 *0.5160 * 38.55 *0.1338E-01*
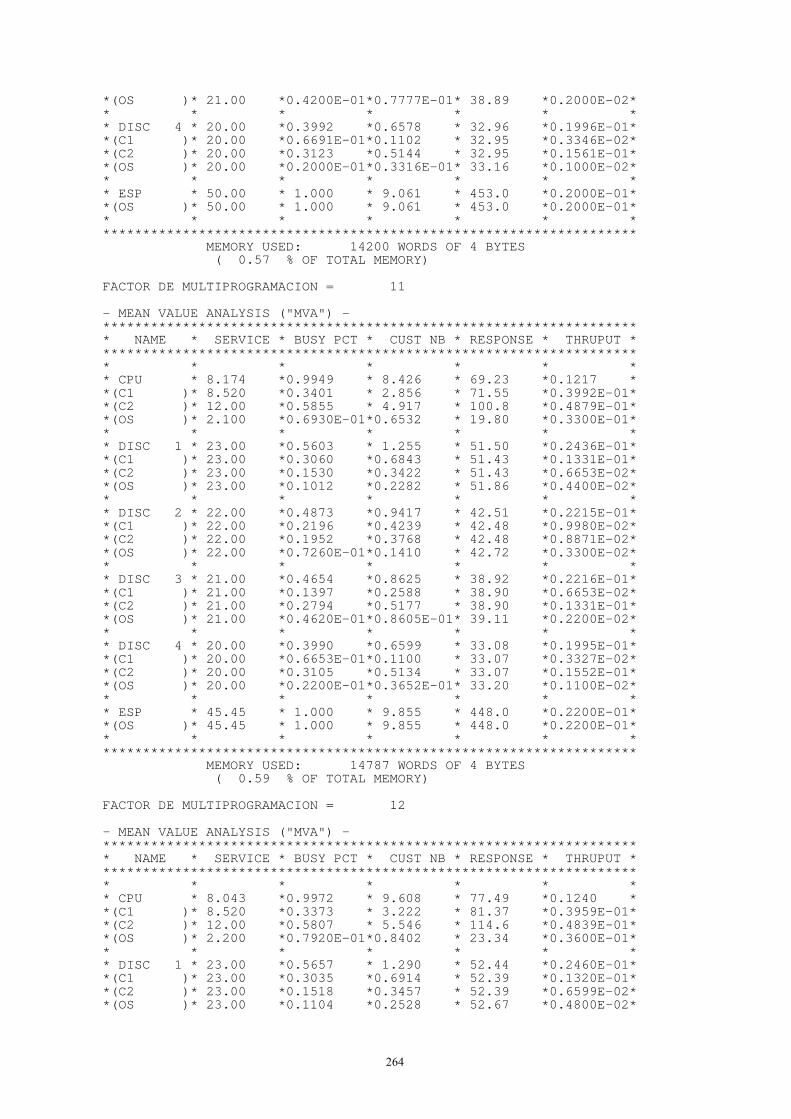
264
*(OS )* 21.00 *0.4200E-01*0.7777E-01* 38.89 *0.2000E-02* * * * * * * * * DISC 4 * 20.00 *0.3992 *0.6578 * 32.96 *0.1996E-01* *(C1 )* 20.00 *0.6691E-01*0.1102 * 32.95 *0.3346E-02* *(C2 )* 20.00 *0.3123 *0.5144 * 32.95 *0.1561E-01* *(OS )* 20.00 *0.2000E-01*0.3316E-01* 33.16 *0.1000E-02* * * * * * * * * ESP * 50.00 * 1.000 * 9.061 * 453.0 *0.2000E-01* *(OS )* 50.00 * 1.000 * 9.061 * 453.0 *0.2000E-01* * * * * * * * ******************************************************************* MEMORY USED: 14200 WORDS OF 4 BYTES ( 0.57 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 11 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 8.174 *0.9949 * 8.426 * 69.23 *0.1217 * *(C1 )* 8.520 *0.3401 * 2.856 * 71.55 *0.3992E-01* *(C2 )* 12.00 *0.5855 * 4.917 * 100.8 *0.4879E-01* *(OS )* 2.100 *0.6930E-01*0.6532 * 19.80 *0.3300E-01* * * * * * * * * DISC 1 * 23.00 *0.5603 * 1.255 * 51.50 *0.2436E-01* *(C1 )* 23.00 *0.3060 *0.6843 * 51.43 *0.1331E-01* *(C2 )* 23.00 *0.1530 *0.3422 * 51.43 *0.6653E-02* *(OS )* 23.00 *0.1012 *0.2282 * 51.86 *0.4400E-02* * * * * * * * * DISC 2 * 22.00 *0.4873 *0.9417 * 42.51 *0.2215E-01* *(C1 )* 22.00 *0.2196 *0.4239 * 42.48 *0.9980E-02* *(C2 )* 22.00 *0.1952 *0.3768 * 42.48 *0.8871E-02* *(OS )* 22.00 *0.7260E-01*0.1410 * 42.72 *0.3300E-02* * * * * * * * * DISC 3 * 21.00 *0.4654 *0.8625 * 38.92 *0.2216E-01* *(C1 )* 21.00 *0.1397 *0.2588 * 38.90 *0.6653E-02* *(C2 )* 21.00 *0.2794 *0.5177 * 38.90 *0.1331E-01* *(OS )* 21.00 *0.4620E-01*0.8605E-01* 39.11 *0.2200E-02* * * * * * * * * DISC 4 * 20.00 *0.3990 *0.6599 * 33.08 *0.1995E-01* *(C1 )* 20.00 *0.6653E-01*0.1100 * 33.07 *0.3327E-02* *(C2 )* 20.00 *0.3105 *0.5134 * 33.07 *0.1552E-01* *(OS )* 20.00 *0.2200E-01*0.3652E-01* 33.20 *0.1100E-02* * * * * * * * * ESP * 45.45 * 1.000 * 9.855 * 448.0 *0.2200E-01* *(OS )* 45.45 * 1.000 * 9.855 * 448.0 *0.2200E-01* * * * * * * * ******************************************************************* MEMORY USED: 14787 WORDS OF 4 BYTES ( 0.59 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 12 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 8.043 *0.9972 * 9.608 * 77.49 *0.1240 * *(C1 )* 8.520 *0.3373 * 3.222 * 81.37 *0.3959E-01* *(C2 )* 12.00 *0.5807 * 5.546 * 114.6 *0.4839E-01* *(OS )* 2.200 *0.7920E-01*0.8402 * 23.34 *0.3600E-01* * * * * * * * * DISC 1 * 23.00 *0.5657 * 1.290 * 52.44 *0.2460E-01* *(C1 )* 23.00 *0.3035 *0.6914 * 52.39 *0.1320E-01* *(C2 )* 23.00 *0.1518 *0.3457 * 52.39 *0.6599E-02* *(OS )* 23.00 *0.1104 *0.2528 * 52.67 *0.4800E-02*
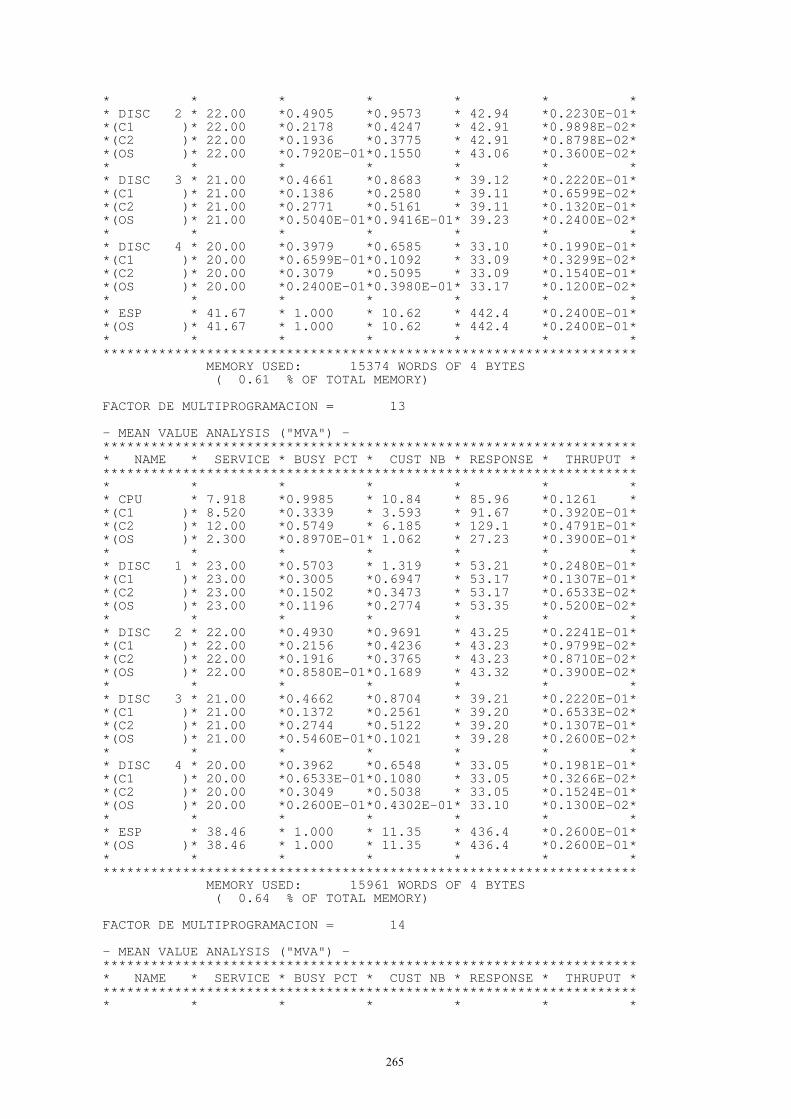
265
* * * * * * * * DISC 2 * 22.00 *0.4905 *0.9573 * 42.94 *0.2230E-01* *(C1 )* 22.00 *0.2178 *0.4247 * 42.91 *0.9898E-02* *(C2 )* 22.00 *0.1936 *0.3775 * 42.91 *0.8798E-02* *(OS )* 22.00 *0.7920E-01*0.1550 * 43.06 *0.3600E-02* * * * * * * * * DISC 3 * 21.00 *0.4661 *0.8683 * 39.12 *0.2220E-01* *(C1 )* 21.00 *0.1386 *0.2580 * 39.11 *0.6599E-02* *(C2 )* 21.00 *0.2771 *0.5161 * 39.11 *0.1320E-01* *(OS )* 21.00 *0.5040E-01*0.9416E-01* 39.23 *0.2400E-02* * * * * * * * * DISC 4 * 20.00 *0.3979 *0.6585 * 33.10 *0.1990E-01* *(C1 )* 20.00 *0.6599E-01*0.1092 * 33.09 *0.3299E-02* *(C2 )* 20.00 *0.3079 *0.5095 * 33.09 *0.1540E-01* *(OS )* 20.00 *0.2400E-01*0.3980E-01* 33.17 *0.1200E-02* * * * * * * * * ESP * 41.67 * 1.000 * 10.62 * 442.4 *0.2400E-01* *(OS )* 41.67 * 1.000 * 10.62 * 442.4 *0.2400E-01* * * * * * * * ******************************************************************* MEMORY USED: 15374 WORDS OF 4 BYTES ( 0.61 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 13 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 7.918 *0.9985 * 10.84 * 85.96 *0.1261 * *(C1 )* 8.520 *0.3339 * 3.593 * 91.67 *0.3920E-01* *(C2 )* 12.00 *0.5749 * 6.185 * 129.1 *0.4791E-01* *(OS )* 2.300 *0.8970E-01* 1.062 * 27.23 *0.3900E-01* * * * * * * * * DISC 1 * 23.00 *0.5703 * 1.319 * 53.21 *0.2480E-01* *(C1 )* 23.00 *0.3005 *0.6947 * 53.17 *0.1307E-01* *(C2 )* 23.00 *0.1502 *0.3473 * 53.17 *0.6533E-02* *(OS )* 23.00 *0.1196 *0.2774 * 53.35 *0.5200E-02* * * * * * * * * DISC 2 * 22.00 *0.4930 *0.9691 * 43.25 *0.2241E-01* *(C1 )* 22.00 *0.2156 *0.4236 * 43.23 *0.9799E-02* *(C2 )* 22.00 *0.1916 *0.3765 * 43.23 *0.8710E-02* *(OS )* 22.00 *0.8580E-01*0.1689 * 43.32 *0.3900E-02* * * * * * * * * DISC 3 * 21.00 *0.4662 *0.8704 * 39.21 *0.2220E-01* *(C1 )* 21.00 *0.1372 *0.2561 * 39.20 *0.6533E-02* *(C2 )* 21.00 *0.2744 *0.5122 * 39.20 *0.1307E-01* *(OS )* 21.00 *0.5460E-01*0.1021 * 39.28 *0.2600E-02* * * * * * * * * DISC 4 * 20.00 *0.3962 *0.6548 * 33.05 *0.1981E-01* *(C1 )* 20.00 *0.6533E-01*0.1080 * 33.05 *0.3266E-02* *(C2 )* 20.00 *0.3049 *0.5038 * 33.05 *0.1524E-01* *(OS )* 20.00 *0.2600E-01*0.4302E-01* 33.10 *0.1300E-02* * * * * * * * * ESP * 38.46 * 1.000 * 11.35 * 436.4 *0.2600E-01* *(OS )* 38.46 * 1.000 * 11.35 * 436.4 *0.2600E-01* * * * * * * * ******************************************************************* MEMORY USED: 15961 WORDS OF 4 BYTES ( 0.64 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 14 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * *
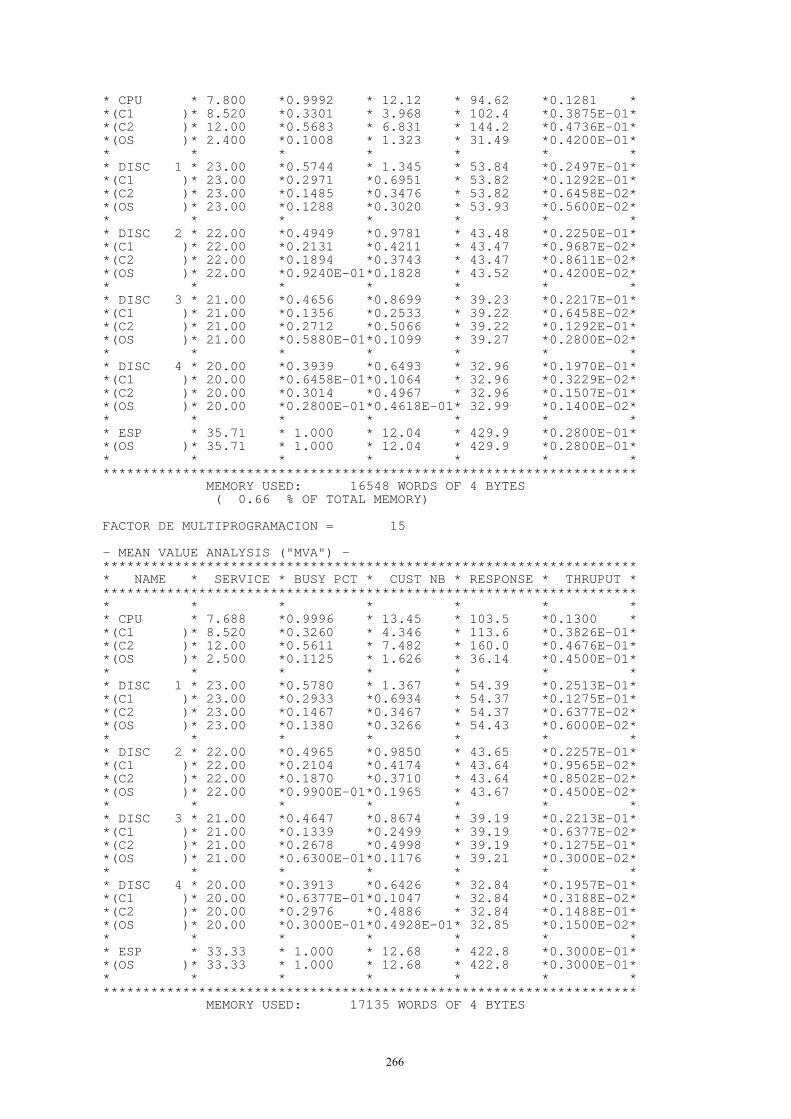
266
* CPU * 7.800 *0.9992 * 12.12 * 94.62 *0.1281 * *(C1 )* 8.520 *0.3301 * 3.968 * 102.4 *0.3875E-01* *(C2 )* 12.00 *0.5683 * 6.831 * 144.2 *0.4736E-01* *(OS )* 2.400 *0.1008 * 1.323 * 31.49 *0.4200E-01* * * * * * * * * DISC 1 * 23.00 *0.5744 * 1.345 * 53.84 *0.2497E-01* *(C1 )* 23.00 *0.2971 *0.6951 * 53.82 *0.1292E-01* *(C2 )* 23.00 *0.1485 *0.3476 * 53.82 *0.6458E-02* *(OS )* 23.00 *0.1288 *0.3020 * 53.93 *0.5600E-02* * * * * * * * * DISC 2 * 22.00 *0.4949 *0.9781 * 43.48 *0.2250E-01* *(C1 )* 22.00 *0.2131 *0.4211 * 43.47 *0.9687E-02* *(C2 )* 22.00 *0.1894 *0.3743 * 43.47 *0.8611E-02* *(OS )* 22.00 *0.9240E-01*0.1828 * 43.52 *0.4200E-02* * * * * * * * * DISC 3 * 21.00 *0.4656 *0.8699 * 39.23 *0.2217E-01* *(C1 )* 21.00 *0.1356 *0.2533 * 39.22 *0.6458E-02* *(C2 )* 21.00 *0.2712 *0.5066 * 39.22 *0.1292E-01* *(OS )* 21.00 *0.5880E-01*0.1099 * 39.27 *0.2800E-02* * * * * * * * * DISC 4 * 20.00 *0.3939 *0.6493 * 32.96 *0.1970E-01* *(C1 )* 20.00 *0.6458E-01*0.1064 * 32.96 *0.3229E-02* *(C2 )* 20.00 *0.3014 *0.4967 * 32.96 *0.1507E-01* *(OS )* 20.00 *0.2800E-01*0.4618E-01* 32.99 *0.1400E-02* * * * * * * * * ESP * 35.71 * 1.000 * 12.04 * 429.9 *0.2800E-01* *(OS )* 35.71 * 1.000 * 12.04 * 429.9 *0.2800E-01* * * * * * * * ******************************************************************* MEMORY USED: 16548 WORDS OF 4 BYTES ( 0.66 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 15 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 7.688 *0.9996 * 13.45 * 103.5 *0.1300 * *(C1 )* 8.520 *0.3260 * 4.346 * 113.6 *0.3826E-01* *(C2 )* 12.00 *0.5611 * 7.482 * 160.0 *0.4676E-01* *(OS )* 2.500 *0.1125 * 1.626 * 36.14 *0.4500E-01* * * * * * * * * DISC 1 * 23.00 *0.5780 * 1.367 * 54.39 *0.2513E-01* *(C1 )* 23.00 *0.2933 *0.6934 * 54.37 *0.1275E-01* *(C2 )* 23.00 *0.1467 *0.3467 * 54.37 *0.6377E-02* *(OS )* 23.00 *0.1380 *0.3266 * 54.43 *0.6000E-02* * * * * * * * * DISC 2 * 22.00 *0.4965 *0.9850 * 43.65 *0.2257E-01* *(C1 )* 22.00 *0.2104 *0.4174 * 43.64 *0.9565E-02* *(C2 )* 22.00 *0.1870 *0.3710 * 43.64 *0.8502E-02* *(OS )* 22.00 *0.9900E-01*0.1965 * 43.67 *0.4500E-02* * * * * * * * * DISC 3 * 21.00 *0.4647 *0.8674 * 39.19 *0.2213E-01* *(C1 )* 21.00 *0.1339 *0.2499 * 39.19 *0.6377E-02* *(C2 )* 21.00 *0.2678 *0.4998 * 39.19 *0.1275E-01* *(OS )* 21.00 *0.6300E-01*0.1176 * 39.21 *0.3000E-02* * * * * * * * * DISC 4 * 20.00 *0.3913 *0.6426 * 32.84 *0.1957E-01* *(C1 )* 20.00 *0.6377E-01*0.1047 * 32.84 *0.3188E-02* *(C2 )* 20.00 *0.2976 *0.4886 * 32.84 *0.1488E-01* *(OS )* 20.00 *0.3000E-01*0.4928E-01* 32.85 *0.1500E-02* * * * * * * * * ESP * 33.33 * 1.000 * 12.68 * 422.8 *0.3000E-01* *(OS )* 33.33 * 1.000 * 12.68 * 422.8 *0.3000E-01* * * * * * * * ******************************************************************* MEMORY USED: 17135 WORDS OF 4 BYTES

267
( 0.69 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 16 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 7.582 *0.9998 * 14.84 * 112.6 *0.1319 * *(C1 )* 8.520 *0.3215 * 4.727 * 125.3 *0.3774E-01* *(C2 )* 12.00 *0.5535 * 8.137 * 176.4 *0.4612E-01* *(OS )* 2.600 *0.1248 * 1.977 * 41.19 *0.4800E-01* * * * * * * * * DISC 1 * 23.00 *0.5812 * 1.386 * 54.85 *0.2527E-01* *(C1 )* 23.00 *0.2893 *0.6899 * 54.84 *0.1258E-01* *(C2 )* 23.00 *0.1447 *0.3449 * 54.84 *0.6290E-02* *(OS )* 23.00 *0.1472 *0.3512 * 54.88 *0.6400E-02* * * * * * * * * DISC 2 * 22.00 *0.4977 *0.9901 * 43.77 *0.2262E-01* *(C1 )* 22.00 *0.2076 *0.4129 * 43.77 *0.9434E-02* *(C2 )* 22.00 *0.1845 *0.3670 * 43.77 *0.8386E-02* *(OS )* 22.00 *0.1056 *0.2102 * 43.78 *0.4800E-02* * * * * * * * * DISC 3 * 21.00 *0.4634 *0.8633 * 39.12 *0.2207E-01* *(C1 )* 21.00 *0.1321 *0.2460 * 39.12 *0.6290E-02* *(C2 )* 21.00 *0.2642 *0.4921 * 39.12 *0.1258E-01* *(OS )* 21.00 *0.6720E-01*0.1252 * 39.13 *0.3200E-02* * * * * * * * * DISC 4 * 20.00 *0.3884 *0.6349 * 32.69 *0.1942E-01* *(C1 )* 20.00 *0.6290E-01*0.1028 * 32.69 *0.3145E-02* *(C2 )* 20.00 *0.2935 *0.4798 * 32.69 *0.1468E-01* *(OS )* 20.00 *0.3200E-01*0.5232E-01* 32.70 *0.1600E-02* * * * * * * * * ESP * 31.25 * 1.000 * 13.28 * 415.1 *0.3200E-01* *(OS )* 31.25 * 1.000 * 13.28 * 415.1 *0.3200E-01* * * * * * * * ******************************************************************* MEMORY USED: 17722 WORDS OF 4 BYTES ( 0.71 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 17 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 7.482 *0.9999 * 16.29 * 121.9 *0.1336 * *(C1 )* 8.520 *0.3168 * 5.110 * 137.4 *0.3719E-01* *(C2 )* 12.00 *0.5454 * 8.796 * 193.5 *0.4545E-01* *(OS )* 2.700 *0.1377 * 2.380 * 46.67 *0.5100E-01* * * * * * * * * DISC 1 * 23.00 *0.5840 * 1.403 * 55.26 *0.2539E-01* *(C1 )* 23.00 *0.2851 *0.6849 * 55.25 *0.1240E-01* *(C2 )* 23.00 *0.1425 *0.3424 * 55.25 *0.6198E-02* *(OS )* 23.00 *0.1564 *0.3759 * 55.27 *0.6800E-02* * * * * * * * * DISC 2 * 22.00 *0.4985 *0.9938 * 43.86 *0.2266E-01* *(C1 )* 22.00 *0.2045 *0.4077 * 43.86 *0.9296E-02* *(C2 )* 22.00 *0.1818 *0.3624 * 43.86 *0.8263E-02* *(OS )* 22.00 *0.1122 *0.2237 * 43.86 *0.5100E-02* * * * * * * * * DISC 3 * 21.00 *0.4618 *0.8580 * 39.01 *0.2199E-01* *(C1 )* 21.00 *0.1301 *0.2418 * 39.01 *0.6198E-02* *(C2 )* 21.00 *0.2603 *0.4836 * 39.01 *0.1240E-01* *(OS )* 21.00 *0.7140E-01*0.1327 * 39.02 *0.3400E-02* * * * * * * * * DISC 4 * 20.00 *0.3852 *0.6264 * 32.53 *0.1926E-01*
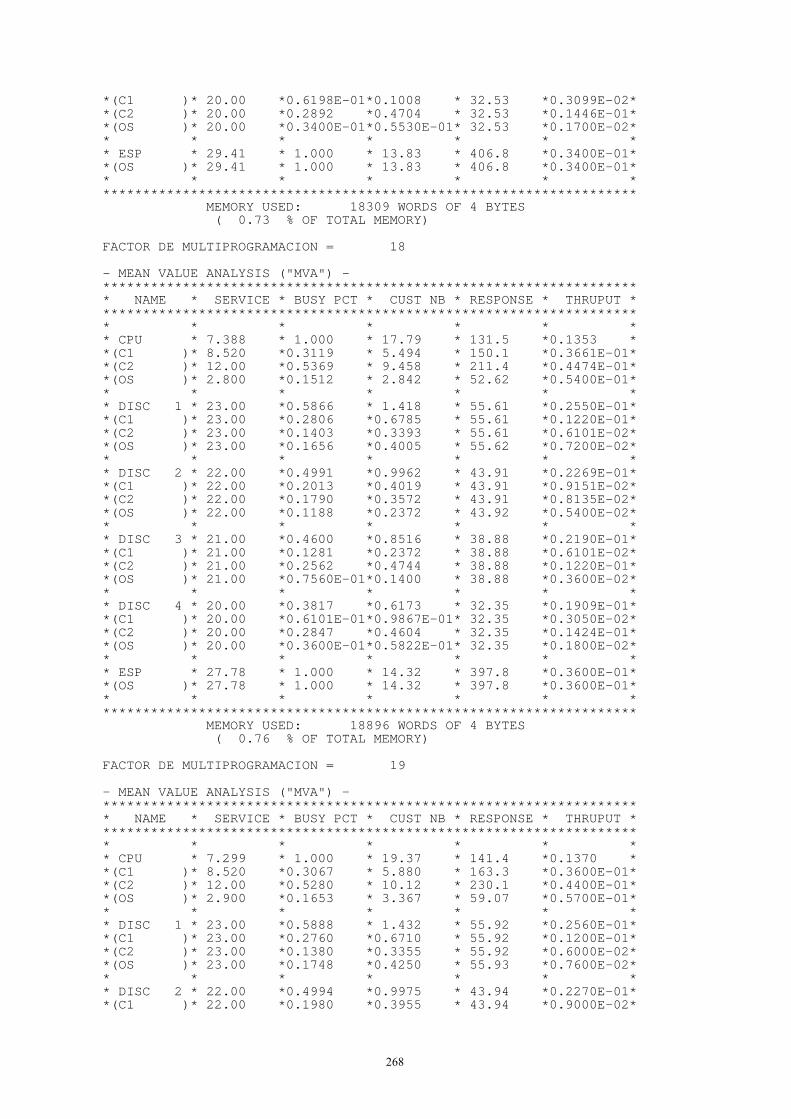
268
*(C1 )* 20.00 *0.6198E-01*0.1008 * 32.53 *0.3099E-02* *(C2 )* 20.00 *0.2892 *0.4704 * 32.53 *0.1446E-01* *(OS )* 20.00 *0.3400E-01*0.5530E-01* 32.53 *0.1700E-02* * * * * * * * * ESP * 29.41 * 1.000 * 13.83 * 406.8 *0.3400E-01* *(OS )* 29.41 * 1.000 * 13.83 * 406.8 *0.3400E-01* * * * * * * * ******************************************************************* MEMORY USED: 18309 WORDS OF 4 BYTES ( 0.73 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 18 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 7.388 * 1.000 * 17.79 * 131.5 *0.1353 * *(C1 )* 8.520 *0.3119 * 5.494 * 150.1 *0.3661E-01* *(C2 )* 12.00 *0.5369 * 9.458 * 211.4 *0.4474E-01* *(OS )* 2.800 *0.1512 * 2.842 * 52.62 *0.5400E-01* * * * * * * * * DISC 1 * 23.00 *0.5866 * 1.418 * 55.61 *0.2550E-01* *(C1 )* 23.00 *0.2806 *0.6785 * 55.61 *0.1220E-01* *(C2 )* 23.00 *0.1403 *0.3393 * 55.61 *0.6101E-02* *(OS )* 23.00 *0.1656 *0.4005 * 55.62 *0.7200E-02* * * * * * * * * DISC 2 * 22.00 *0.4991 *0.9962 * 43.91 *0.2269E-01* *(C1 )* 22.00 *0.2013 *0.4019 * 43.91 *0.9151E-02* *(C2 )* 22.00 *0.1790 *0.3572 * 43.91 *0.8135E-02* *(OS )* 22.00 *0.1188 *0.2372 * 43.92 *0.5400E-02* * * * * * * * * DISC 3 * 21.00 *0.4600 *0.8516 * 38.88 *0.2190E-01* *(C1 )* 21.00 *0.1281 *0.2372 * 38.88 *0.6101E-02* *(C2 )* 21.00 *0.2562 *0.4744 * 38.88 *0.1220E-01* *(OS )* 21.00 *0.7560E-01*0.1400 * 38.88 *0.3600E-02* * * * * * * * * DISC 4 * 20.00 *0.3817 *0.6173 * 32.35 *0.1909E-01* *(C1 )* 20.00 *0.6101E-01*0.9867E-01* 32.35 *0.3050E-02* *(C2 )* 20.00 *0.2847 *0.4604 * 32.35 *0.1424E-01* *(OS )* 20.00 *0.3600E-01*0.5822E-01* 32.35 *0.1800E-02* * * * * * * * * ESP * 27.78 * 1.000 * 14.32 * 397.8 *0.3600E-01* *(OS )* 27.78 * 1.000 * 14.32 * 397.8 *0.3600E-01* * * * * * * * ******************************************************************* MEMORY USED: 18896 WORDS OF 4 BYTES ( 0.76 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 19 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 7.299 * 1.000 * 19.37 * 141.4 *0.1370 * *(C1 )* 8.520 *0.3067 * 5.880 * 163.3 *0.3600E-01* *(C2 )* 12.00 *0.5280 * 10.12 * 230.1 *0.4400E-01* *(OS )* 2.900 *0.1653 * 3.367 * 59.07 *0.5700E-01* * * * * * * * * DISC 1 * 23.00 *0.5888 * 1.432 * 55.92 *0.2560E-01* *(C1 )* 23.00 *0.2760 *0.6710 * 55.92 *0.1200E-01* *(C2 )* 23.00 *0.1380 *0.3355 * 55.92 *0.6000E-02* *(OS )* 23.00 *0.1748 *0.4250 * 55.93 *0.7600E-02* * * * * * * * * DISC 2 * 22.00 *0.4994 *0.9975 * 43.94 *0.2270E-01* *(C1 )* 22.00 *0.1980 *0.3955 * 43.94 *0.9000E-02*
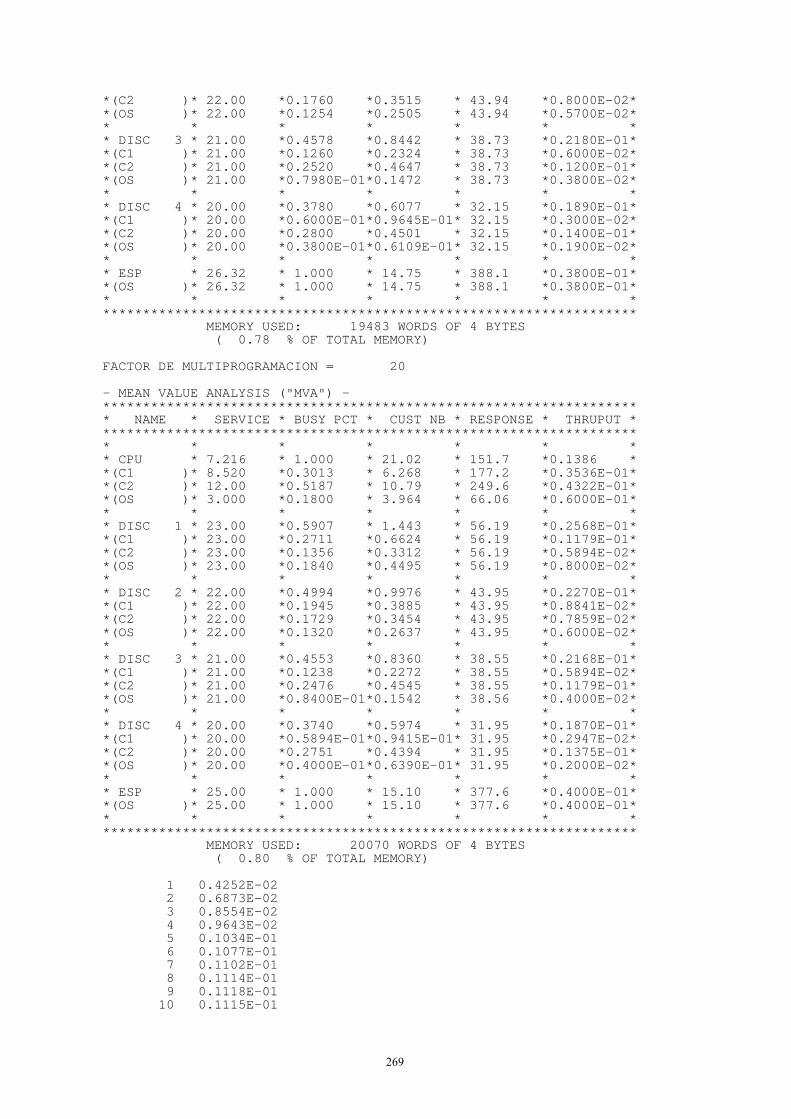
269
*(C2 )* 22.00 *0.1760 *0.3515 * 43.94 *0.8000E-02* *(OS )* 22.00 *0.1254 *0.2505 * 43.94 *0.5700E-02* * * * * * * * * DISC 3 * 21.00 *0.4578 *0.8442 * 38.73 *0.2180E-01* *(C1 )* 21.00 *0.1260 *0.2324 * 38.73 *0.6000E-02* *(C2 )* 21.00 *0.2520 *0.4647 * 38.73 *0.1200E-01* *(OS )* 21.00 *0.7980E-01*0.1472 * 38.73 *0.3800E-02* * * * * * * * * DISC 4 * 20.00 *0.3780 *0.6077 * 32.15 *0.1890E-01* *(C1 )* 20.00 *0.6000E-01*0.9645E-01* 32.15 *0.3000E-02* *(C2 )* 20.00 *0.2800 *0.4501 * 32.15 *0.1400E-01* *(OS )* 20.00 *0.3800E-01*0.6109E-01* 32.15 *0.1900E-02* * * * * * * * * ESP * 26.32 * 1.000 * 14.75 * 388.1 *0.3800E-01* *(OS )* 26.32 * 1.000 * 14.75 * 388.1 *0.3800E-01* * * * * * * * ******************************************************************* MEMORY USED: 19483 WORDS OF 4 BYTES ( 0.78 % OF TOTAL MEMORY) FACTOR DE MULTIPROGRAMACION = 20 - MEAN VALUE ANALYSIS ("MVA") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * CPU * 7.216 * 1.000 * 21.02 * 151.7 *0.1386 * *(C1 )* 8.520 *0.3013 * 6.268 * 177.2 *0.3536E-01* *(C2 )* 12.00 *0.5187 * 10.79 * 249.6 *0.4322E-01* *(OS )* 3.000 *0.1800 * 3.964 * 66.06 *0.6000E-01* * * * * * * * * DISC 1 * 23.00 *0.5907 * 1.443 * 56.19 *0.2568E-01* *(C1 )* 23.00 *0.2711 *0.6624 * 56.19 *0.1179E-01* *(C2 )* 23.00 *0.1356 *0.3312 * 56.19 *0.5894E-02* *(OS )* 23.00 *0.1840 *0.4495 * 56.19 *0.8000E-02* * * * * * * * * DISC 2 * 22.00 *0.4994 *0.9976 * 43.95 *0.2270E-01* *(C1 )* 22.00 *0.1945 *0.3885 * 43.95 *0.8841E-02* *(C2 )* 22.00 *0.1729 *0.3454 * 43.95 *0.7859E-02* *(OS )* 22.00 *0.1320 *0.2637 * 43.95 *0.6000E-02* * * * * * * * * DISC 3 * 21.00 *0.4553 *0.8360 * 38.55 *0.2168E-01* *(C1 )* 21.00 *0.1238 *0.2272 * 38.55 *0.5894E-02* *(C2 )* 21.00 *0.2476 *0.4545 * 38.55 *0.1179E-01* *(OS )* 21.00 *0.8400E-01*0.1542 * 38.56 *0.4000E-02* * * * * * * * * DISC 4 * 20.00 *0.3740 *0.5974 * 31.95 *0.1870E-01* *(C1 )* 20.00 *0.5894E-01*0.9415E-01* 31.95 *0.2947E-02* *(C2 )* 20.00 *0.2751 *0.4394 * 31.95 *0.1375E-01* *(OS )* 20.00 *0.4000E-01*0.6390E-01* 31.95 *0.2000E-02* * * * * * * * * ESP * 25.00 * 1.000 * 15.10 * 377.6 *0.4000E-01* *(OS )* 25.00 * 1.000 * 15.10 * 377.6 *0.4000E-01* * * * * * * * ******************************************************************* MEMORY USED: 20070 WORDS OF 4 BYTES ( 0.80 % OF TOTAL MEMORY) 1 0.4252E-02 2 0.6873E-02 3 0.8554E-02 4 0.9643E-02 5 0.1034E-01 6 0.1077E-01 7 0.1102E-01 8 0.1114E-01 9 0.1118E-01 10 0.1115E-01

270
11 0.1109E-01 12 0.1100E-01 13 0.1089E-01 14 0.1076E-01 15 0.1063E-01 16 0.1048E-01 17 0.1033E-01 18 0.1017E-01 19 0.1000E-01 20 0.9824E-02 46 47 /STATION/ NAME=TERMINAL; 48 TYPE=INFINITE; 49 INIT(C1)=N; 50 SERVICE(C1)=EXP(30000.); 51 SERVICE(C2)=EXP(60000.); 52 TRANSIT=SC; 53 /STATION/ NAME=SC; 54 SERVICE=EXP(1.); 55 RATE=CAP(1 STEP 1 UNTIL M); 56 TRANSIT=TERMINAL,C1,0.6,TERMINAL,C2; 57 /CONTROL/ OPTION=NRESULT; 58 /EXEC/ BEGIN 59 NETWORK(TERMINAL,SC); 60 PRINT(" TERM FM PRODUCTIVIDAD"); 61 FOR N := 150 STEP 150 UNTIL 750 DO 62 FOR M := 1 STEP 1 UNTIL 20 DO 63 BEGIN 64 SOLVE; 65 PRINT(N,M,MTHRUPUT(SC)); 66 END; 67 END; TERM FM PRODUCTIVIDAD 150 1 0.3477E-02 150 2 0.3541E-02 150 3 0.3545E-02 150 4 0.3546E-02 150 20 0.3546E-02 300 1 0.4252E-02 300 2 0.6702E-02 300 3 0.7024E-02 300 4 0.7058E-02 300 5 0.7067E-02 300 6 0.7069E-02 300 7 0.7070E-02 300 8 0.7071E-02 300 20 0.7071E-02 450 1 0.4252E-02 450 2 0.6873E-02 450 3 0.8554E-02 450 4 0.9624E-02 450 5 0.1014E-01 450 6 0.1031E-01 450 7 0.1038E-01 450 8 0.1040E-01 450 9 0.1041E-01 450 10 0.1040E-01 450 11 0.1039E-01 450 12 0.1038E-01 450 13 0.1035E-01 450 14 0.1033E-01 450 15 0.1029E-01 450 16 0.1025E-01

271
450 17 0.1019E-01 450 18 0.1011E-01 450 19 0.1001E-01 450 20 0.9876E-02 600 1 0.4252E-02 600 2 0.6873E-02 600 3 0.8554E-02 600 4 0.9643E-02 600 5 0.1034E-01 600 6 0.1077E-01 600 7 0.1102E-01 600 8 0.1114E-01 600 9 0.1118E-01 600 10 0.1115E-01 600 11 0.1109E-01 600 12 0.1100E-01 600 13 0.1089E-01 600 14 0.1076E-01 600 15 0.1063E-01 600 16 0.1048E-01 600 17 0.1033E-01 600 18 0.1017E-01 600 19 0.1000E-01 600 20 0.9824E-02 750 1 0.4252E-02 750 2 0.6873E-02 750 3 0.8554E-02 750 4 0.9643E-02 750 5 0.1034E-01 750 6 0.1077E-01 750 7 0.1102E-01 750 8 0.1114E-01 750 9 0.1118E-01 750 10 0.1115E-01 750 11 0.1109E-01 750 12 0.1100E-01 750 13 0.1089E-01 750 14 0.1076E-01 750 15 0.1063E-01 750 16 0.1048E-01 750 17 0.1033E-01 750 18 0.1017E-01 750 19 0.1000E-01 750 20 0.9824E-02 68 /END/
2.2.2.4.2. Estudio por simulación Para estudiar este caso por simulación se usa un semáforo con un valor incial igual al factor de multiprogramación que controla la salida de los programas de la cola de entrada en memoria. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE CPU,DISC(4),MEM,SMEM,TERMINAL,R(2); 2 REAL PROF1(4)=(2.,3.5,4.5,5.); 3 REAL PROF2(4)=(1.5,3.5,6.5,10.); 4 REAL TR1,TR2; 5 REAL D; 6 CLASS C1,C2; 7 INTEGER I,N,M; 8 REF CUSTOMER C; 9 /STATION/ NAME=CPU; 10 SCHED=PS; 11 SERVICE(C1)=BEGIN

272
12 CST(8.52); 13 D := UNIFORM(0., 6.); 14 FOR I := 1 STEP 1 UNTIL 4 DO 15 IF D <= PROF1(I) THEN TRANSIT(DISC(I)); 16 C:=R(1).FIRST; 17 WHILE C.FATHER <> CUSTOMER DO C:=C.NEXT; 18 TRANSIT(C,OUT); 19 V(SMEM); 20 IF D <= 5.6 THEN TRANSIT(TERMINAL,C1) 21 ELSE TRANSIT(TERMINAL,C2); 22 END; 23 SERVICE(C2)=BEGIN 24 CST(12.); 25 D := UNIFORM(0., 11.); 26 FOR I := 1 STEP 1 UNTIL 4 DO 27 IF D <= PROF2(I) THEN TRANSIT(DISC(I)); 28 C:=R(2).FIRST; 29 WHILE C.FATHER <> CUSTOMER DO C:=C.NEXT; 30 TRANSIT(C,OUT); 31 V(SMEM); 32 IF D <= 10.6 THEN TRANSIT(TERMINAL,C1) 33 ELSE TRANSIT(TERMINAL,C2); 34 END; 35 /STATION/ NAME=DISC; 36 TRANSIT=CPU; 37 /STATION/ NAME=DISC(1); 38 SERVICE=EXP(23.); 39 /STATION/ NAME=DISC(2); 40 SERVICE=EXP(22.); 41 /STATION/ NAME=DISC(3); 42 SERVICE=EXP(21.); 43 /STATION/ NAME=DISC(4); 44 SERVICE=EXP(20.); 45 /STATION/ NAME=MEM; 46 SERVICE=BEGIN 47 P(SMEM); 48 TRANSIT(CPU); 49 END; 50 /STATION/ NAME=SMEM; 51 TYPE=SEMAPHORE,MULTIPLE(M); 52 /STATION/ NAME=TERMINAL; 53 TYPE=INFINITE; 54 INIT(C1)=6*N/10; 55 INIT(C2)=4*N/10; 56 SERVICE(C1)=BEGIN 57 EXP(30000.); 58 TRANSIT(NEW(CUSTOMER),R(1),C1); 59 END; 60 SERVICE(C2)=BEGIN 61 EXP(60000.); 62 TRANSIT(NEW(CUSTOMER),R(2),C2); 63 END; 64 TRANSIT=MEM; 65 /CONTROL/ TMAX=5000000.; 66 CLASS=ALL QUEUE; 67 ACCURACY=ALL QUEUE,ALL CLASS; 68 OPTION=NRESULT; 69 /EXEC/ BEGIN 70 FOR N:=150 STEP 150 UNTIL 750 DO 71 FOR M:=1 STEP 1 UNTIL 20 DO 72 BEGIN 73 PRINT(" "); 74 PRINT("NUMERO DE USUARIOS =",N); 75 PRINT("FACTOR DE MULTIPROGRAMACION =",M); 76 SIMUL; 77 PRINT("TIEMPO DE RESPUESTA DE LA CLASE C1 =",MRESPONS ==> E(R(1))," +/-"),CRESPONSE(R(1)); 78 PRINT("TIEMPO DE RESPUESTA DE LA CLASE C2 =",MRESPONS ==> E(R(2))," +/-",CRESPONSE(R(2)));

273
79 PRINT("PRODUCTIVIDAD C1 =",MTHRUPUT(TERMINAL,C1)); 80 PRINT("PRODUCTIVIDAD C2 =",MTHRUPUT(TERMINAL,C2)); 81 PRINT("PRODUCTIVIDAD TOTAL =",MTHRUPUT(TERMINAL)); 82 END; 83 END; NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 1 TIEMPO DE RESPUESTA DE LA CLASE C1 = 1203. +/- 132.0 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1368. +/- 145.4 PRODUCTIVIDAD C1 = 0.2059E-02 PRODUCTIVIDAD C2 = 0.1356E-02 PRODUCTIVIDAD TOTAL = 0.3415E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 2 TIEMPO DE RESPUESTA DE LA CLASE C1 = 292.9 +/- 14.44 TIEMPO DE RESPUESTA DE LA CLASE C2 = 499.6 +/- 23.42 PRODUCTIVIDAD C1 = 0.2131E-02 PRODUCTIVIDAD C2 = 0.1380E-02 PRODUCTIVIDAD TOTAL = 0.3511E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 3 TIEMPO DE RESPUESTA DE LA CLASE C1 = 225.9 +/- 6.840 TIEMPO DE RESPUESTA DE LA CLASE C2 = 450.0 +/- 11.90 PRODUCTIVIDAD C1 = 0.2157E-02 PRODUCTIVIDAD C2 = 0.1422E-02 PRODUCTIVIDAD TOTAL = 0.3579E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 4 TIEMPO DE RESPUESTA DE LA CLASE C1 = 207.7 +/- 5.688 TIEMPO DE RESPUESTA DE LA CLASE C2 = 433.0 +/- 10.70 PRODUCTIVIDAD C1 = 0.2121E-02 PRODUCTIVIDAD C2 = 0.1404E-02 PRODUCTIVIDAD TOTAL = 0.3525E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 5 TIEMPO DE RESPUESTA DE LA CLASE C1 = 199.2 +/- 4.684 TIEMPO DE RESPUESTA DE LA CLASE C2 = 435.9 +/- 14.78 PRODUCTIVIDAD C1 = 0.2151E-02 PRODUCTIVIDAD C2 = 0.1396E-02 PRODUCTIVIDAD TOTAL = 0.3548E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 6 TIEMPO DE RESPUESTA DE LA CLASE C1 = 204.1 +/- 5.110 TIEMPO DE RESPUESTA DE LA CLASE C2 = 432.1 +/- 11.13 PRODUCTIVIDAD C1 = 0.2152E-02 PRODUCTIVIDAD C2 = 0.1403E-02 PRODUCTIVIDAD TOTAL = 0.3555E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 7

274
TIEMPO DE RESPUESTA DE LA CLASE C1 = 199.7 +/- 4.501 TIEMPO DE RESPUESTA DE LA CLASE C2 = 421.5 +/- 10.48 PRODUCTIVIDAD C1 = 0.2186E-02 PRODUCTIVIDAD C2 = 0.1417E-02 PRODUCTIVIDAD TOTAL = 0.3603E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 8 TIEMPO DE RESPUESTA DE LA CLASE C1 = 198.5 +/- 4.878 TIEMPO DE RESPUESTA DE LA CLASE C2 = 424.8 +/- 19.15 PRODUCTIVIDAD C1 = 0.2149E-02 PRODUCTIVIDAD C2 = 0.1434E-02 PRODUCTIVIDAD TOTAL = 0.3582E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 9 TIEMPO DE RESPUESTA DE LA CLASE C1 = 198.4 +/- 5.270 TIEMPO DE RESPUESTA DE LA CLASE C2 = 434.7 +/- 11.33 PRODUCTIVIDAD C1 = 0.2136E-02 PRODUCTIVIDAD C2 = 0.1414E-02 PRODUCTIVIDAD TOTAL = 0.3550E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 10 TIEMPO DE RESPUESTA DE LA CLASE C1 = 202.1 +/- 4.602 TIEMPO DE RESPUESTA DE LA CLASE C2 = 431.1 +/- 13.87 PRODUCTIVIDAD C1 = 0.2131E-02 PRODUCTIVIDAD C2 = 0.1416E-02 PRODUCTIVIDAD TOTAL = 0.3547E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 11 TIEMPO DE RESPUESTA DE LA CLASE C1 = 198.6 +/- 4.440 TIEMPO DE RESPUESTA DE LA CLASE C2 = 434.3 +/- 12.54 PRODUCTIVIDAD C1 = 0.2112E-02 PRODUCTIVIDAD C2 = 0.1400E-02 PRODUCTIVIDAD TOTAL = 0.3513E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 12 TIEMPO DE RESPUESTA DE LA CLASE C1 = 198.2 +/- 4.445 TIEMPO DE RESPUESTA DE LA CLASE C2 = 427.3 +/- 10.75 PRODUCTIVIDAD C1 = 0.2130E-02 PRODUCTIVIDAD C2 = 0.1426E-02 PRODUCTIVIDAD TOTAL = 0.3557E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 13 TIEMPO DE RESPUESTA DE LA CLASE C1 = 194.8 +/- 5.251 TIEMPO DE RESPUESTA DE LA CLASE C2 = 426.7 +/- 16.19 PRODUCTIVIDAD C1 = 0.2155E-02 PRODUCTIVIDAD C2 = 0.1410E-02 PRODUCTIVIDAD TOTAL = 0.3564E-02 NUMERO DE USUARIOS = 150

275
FACTOR DE MULTIPROGRAMACION = 14 TIEMPO DE RESPUESTA DE LA CLASE C1 = 198.4 +/- 4.229 TIEMPO DE RESPUESTA DE LA CLASE C2 = 413.1 +/- 12.75 PRODUCTIVIDAD C1 = 0.2165E-02 PRODUCTIVIDAD C2 = 0.1417E-02 PRODUCTIVIDAD TOTAL = 0.3583E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 15 TIEMPO DE RESPUESTA DE LA CLASE C1 = 200.7 +/- 4.384 TIEMPO DE RESPUESTA DE LA CLASE C2 = 420.0 +/- 12.93 PRODUCTIVIDAD C1 = 0.2111E-02 PRODUCTIVIDAD C2 = 0.1419E-02 PRODUCTIVIDAD TOTAL = 0.3530E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 16 TIEMPO DE RESPUESTA DE LA CLASE C1 = 198.6 +/- 4.382 TIEMPO DE RESPUESTA DE LA CLASE C2 = 426.8 +/- 14.29 PRODUCTIVIDAD C1 = 0.2102E-02 PRODUCTIVIDAD C2 = 0.1437E-02 PRODUCTIVIDAD TOTAL = 0.3539E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 17 TIEMPO DE RESPUESTA DE LA CLASE C1 = 195.8 +/- 5.330 TIEMPO DE RESPUESTA DE LA CLASE C2 = 436.9 +/- 13.08 PRODUCTIVIDAD C1 = 0.2144E-02 PRODUCTIVIDAD C2 = 0.1432E-02 PRODUCTIVIDAD TOTAL = 0.3576E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 18 TIEMPO DE RESPUESTA DE LA CLASE C1 = 203.5 +/- 6.075 TIEMPO DE RESPUESTA DE LA CLASE C2 = 428.2 +/- 15.84 PRODUCTIVIDAD C1 = 0.2137E-02 PRODUCTIVIDAD C2 = 0.1424E-02 PRODUCTIVIDAD TOTAL = 0.3561E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 19 TIEMPO DE RESPUESTA DE LA CLASE C1 = 199.3 +/- 4.100 TIEMPO DE RESPUESTA DE LA CLASE C2 = 434.2 +/- 12.39 PRODUCTIVIDAD C1 = 0.2131E-02 PRODUCTIVIDAD C2 = 0.1397E-02 PRODUCTIVIDAD TOTAL = 0.3527E-02 NUMERO DE USUARIOS = 150 FACTOR DE MULTIPROGRAMACION = 20 TIEMPO DE RESPUESTA DE LA CLASE C1 = 199.6 +/- 4.646 TIEMPO DE RESPUESTA DE LA CLASE C2 = 432.3 +/- 13.82 PRODUCTIVIDAD C1 = 0.2145E-02 PRODUCTIVIDAD C2 = 0.1414E-02 PRODUCTIVIDAD TOTAL = 0.3558E-02

276
NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 1 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2751E+05 +/- 1568. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2776E+05 +/- 1421. PRODUCTIVIDAD C1 = 0.2608E-02 PRODUCTIVIDAD C2 = 0.1708E-02 PRODUCTIVIDAD TOTAL = 0.4315E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 2 TIEMPO DE RESPUESTA DE LA CLASE C1 = 2601. +/- 465.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 2856. +/- 457.2 PRODUCTIVIDAD C1 = 0.4017E-02 PRODUCTIVIDAD C2 = 0.2666E-02 PRODUCTIVIDAD TOTAL = 0.6683E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 3 TIEMPO DE RESPUESTA DE LA CLASE C1 = 578.0 +/- 45.58 TIEMPO DE RESPUESTA DE LA CLASE C2 = 844.7 +/- 52.41 PRODUCTIVIDAD C1 = 0.4198E-02 PRODUCTIVIDAD C2 = 0.2805E-02 PRODUCTIVIDAD TOTAL = 0.7003E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 4 TIEMPO DE RESPUESTA DE LA CLASE C1 = 391.3 +/- 16.26 TIEMPO DE RESPUESTA DE LA CLASE C2 = 679.6 +/- 27.13 PRODUCTIVIDAD C1 = 0.4281E-02 PRODUCTIVIDAD C2 = 0.2822E-02 PRODUCTIVIDAD TOTAL = 0.7103E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 5 TIEMPO DE RESPUESTA DE LA CLASE C1 = 313.0 +/- 13.72 TIEMPO DE RESPUESTA DE LA CLASE C2 = 606.7 +/- 33.46 PRODUCTIVIDAD C1 = 0.4260E-02 PRODUCTIVIDAD C2 = 0.2820E-02 PRODUCTIVIDAD TOTAL = 0.7080E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 6 TIEMPO DE RESPUESTA DE LA CLASE C1 = 288.4 +/- 10.66 TIEMPO DE RESPUESTA DE LA CLASE C2 = 591.9 +/- 22.31 PRODUCTIVIDAD C1 = 0.4198E-02 PRODUCTIVIDAD C2 = 0.2873E-02 PRODUCTIVIDAD TOTAL = 0.7071E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 7 TIEMPO DE RESPUESTA DE LA CLASE C1 = 283.4 +/- 9.203 TIEMPO DE RESPUESTA DE LA CLASE C2 = 605.2 +/- 24.34 PRODUCTIVIDAD C1 = 0.4255E-02 PRODUCTIVIDAD C2 = 0.2818E-02 PRODUCTIVIDAD TOTAL = 0.7073E-02

277
NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 8 TIEMPO DE RESPUESTA DE LA CLASE C1 = 284.2 +/- 7.004 TIEMPO DE RESPUESTA DE LA CLASE C2 = 616.8 +/- 16.67 PRODUCTIVIDAD C1 = 0.4240E-02 PRODUCTIVIDAD C2 = 0.2818E-02 PRODUCTIVIDAD TOTAL = 0.7057E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 9 TIEMPO DE RESPUESTA DE LA CLASE C1 = 286.8 +/- 10.44 TIEMPO DE RESPUESTA DE LA CLASE C2 = 631.2 +/- 24.94 PRODUCTIVIDAD C1 = 0.4297E-02 PRODUCTIVIDAD C2 = 0.2829E-02 PRODUCTIVIDAD TOTAL = 0.7126E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 10 TIEMPO DE RESPUESTA DE LA CLASE C1 = 280.1 +/- 6.936 TIEMPO DE RESPUESTA DE LA CLASE C2 = 604.7 +/- 20.48 PRODUCTIVIDAD C1 = 0.4324E-02 PRODUCTIVIDAD C2 = 0.2852E-02 PRODUCTIVIDAD TOTAL = 0.7176E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 11 TIEMPO DE RESPUESTA DE LA CLASE C1 = 277.0 +/- TIEMPO DE RESPUESTA DE LA CLASE C2 = 612.9 +/- PRODUCTIVIDAD C1 = 0.4234E-02 PRODUCTIVIDAD C2 = 0.2850E-02 PRODUCTIVIDAD TOTAL = 0.7085E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 12 TIEMPO DE RESPUESTA DE LA CLASE C1 = 271.8 +/- 8.461 TIEMPO DE RESPUESTA DE LA CLASE C2 = 596.0 +/- 22.32 PRODUCTIVIDAD C1 = 0.4185E-02 PRODUCTIVIDAD C2 = 0.2836E-02 PRODUCTIVIDAD TOTAL = 0.7021E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 13 TIEMPO DE RESPUESTA DE LA CLASE C1 = 275.7 +/- 5.732 TIEMPO DE RESPUESTA DE LA CLASE C2 = 603.1 +/- 21.92 PRODUCTIVIDAD C1 = 0.4220E-02 PRODUCTIVIDAD C2 = 0.2837E-02 PRODUCTIVIDAD TOTAL = 0.7057E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 14 TIEMPO DE RESPUESTA DE LA CLASE C1 = 267.0 +/- 7.359 TIEMPO DE RESPUESTA DE LA CLASE C2 = 584.8 +/- 16.10 PRODUCTIVIDAD C1 = 0.4203E-02 PRODUCTIVIDAD C2 = 0.2837E-02 PRODUCTIVIDAD TOTAL = 0.7040E-02

278
NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 15 TIEMPO DE RESPUESTA DE LA CLASE C1 = 277.2 +/- 8.135 TIEMPO DE RESPUESTA DE LA CLASE C2 = 606.3 +/- 35.44 PRODUCTIVIDAD C1 = 0.4265E-02 PRODUCTIVIDAD C2 = 0.2845E-02 PRODUCTIVIDAD TOTAL = 0.7110E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 16 TIEMPO DE RESPUESTA DE LA CLASE C1 = 273.0 +/- 9.014 TIEMPO DE RESPUESTA DE LA CLASE C2 = 603.3 +/- 34.12 PRODUCTIVIDAD C1 = 0.4334E-02 PRODUCTIVIDAD C2 = 0.2794E-02 PRODUCTIVIDAD TOTAL = 0.7128E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 17 TIEMPO DE RESPUESTA DE LA CLASE C1 = 281.3 +/- 12.82 TIEMPO DE RESPUESTA DE LA CLASE C2 = 637.2 +/- 20.09 PRODUCTIVIDAD C1 = 0.4279E-02 PRODUCTIVIDAD C2 = 0.2819E-02 PRODUCTIVIDAD TOTAL = 0.7098E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 18 TIEMPO DE RESPUESTA DE LA CLASE C1 = 280.6 +/- 14.11 TIEMPO DE RESPUESTA DE LA CLASE C2 = 609.5 +/- 22.24 PRODUCTIVIDAD C1 = 0.4215E-02 PRODUCTIVIDAD C2 = 0.2825E-02 PRODUCTIVIDAD TOTAL = 0.7040E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 19 TIEMPO DE RESPUESTA DE LA CLASE C1 = 274.8 +/- 7.892 TIEMPO DE RESPUESTA DE LA CLASE C2 = 604.3 +/- 20.16 PRODUCTIVIDAD C1 = 0.4210E-02 PRODUCTIVIDAD C2 = 0.2819E-02 PRODUCTIVIDAD TOTAL = 0.7029E-02 NUMERO DE USUARIOS = 300 FACTOR DE MULTIPROGRAMACION = 20 TIEMPO DE RESPUESTA DE LA CLASE C1 = 281.5 +/- 9.702 TIEMPO DE RESPUESTA DE LA CLASE C2 = 618.9 +/- 24.63 PRODUCTIVIDAD C1 = 0.4271E-02 PRODUCTIVIDAD C2 = 0.2792E-02 PRODUCTIVIDAD TOTAL = 0.7063E-02 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 1 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.6185E+05 +/- 4855 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.6237E+05 +/- 2654 PRODUCTIVIDAD C1 = 0.2609E-02 PRODUCTIVIDAD C2 = 0.1728E-02

279
PRODUCTIVIDAD TOTAL = 0.4337E-02 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 2 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2279E+05 +/- 962.2 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2308E+05 +/- 984.3 PRODUCTIVIDAD C1 = 0.4189E-02 PRODUCTIVIDAD C2 = 0.2774E-02 PRODUCTIVIDAD TOTAL = 0.6963E-02 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 3 TIEMPO DE RESPUESTA DE LA CLASE C1 = 9991. +/- 870.6 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.1034E+05 +/- 808.1 PRODUCTIVIDAD C1 = 0.5248E-02 PRODUCTIVIDAD C2 = 0.3437E-02 PRODUCTIVIDAD TOTAL = 0.8684E-02 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 4 TIEMPO DE RESPUESTA DE LA CLASE C1 = 3839. +/- 898.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 4194. +/- 875.7 PRODUCTIVIDAD C1 = 0.5922E-02 PRODUCTIVIDAD C2 = 0.3952E-02 PRODUCTIVIDAD TOTAL = 0.9874E-02 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 5 TIEMPO DE RESPUESTA DE LA CLASE C1 = 1636. +/- 219.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1998. +/- 318.0 PRODUCTIVIDAD C1 = 0.6129E-02 PRODUCTIVIDAD C2 = 0.4144E-02 PRODUCTIVIDAD TOTAL = 0.1027E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 6 TIEMPO DE RESPUESTA DE LA CLASE C1 = 1124. +/- 184.6 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1526. +/- 176.9 PRODUCTIVIDAD C1 = 0.6277E-02 PRODUCTIVIDAD C2 = 0.4115E-02 PRODUCTIVIDAD TOTAL = 0.1039E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 7 TIEMPO DE RESPUESTA DE LA CLASE C1 = 896.3 +/- 127.5 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1354. +/- 152.1 PRODUCTIVIDAD C1 = 0.6296E-02 PRODUCTIVIDAD C2 = 0.4188E-02 PRODUCTIVIDAD TOTAL = 0.1048E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 8 TIEMPO DE RESPUESTA DE LA CLASE C1 = 751.9 +/- 93.14 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1241. +/- 106.9 PRODUCTIVIDAD C1 = 0.6285E-02

280
PRODUCTIVIDAD C2 = 0.4215E-02 PRODUCTIVIDAD TOTAL = 0.1050E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 9 TIEMPO DE RESPUESTA DE LA CLASE C1 = 704.2 +/- 64.31 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1228. +/- 76.14 PRODUCTIVIDAD C1 = 0.6347E-02 PRODUCTIVIDAD C2 = 0.4159E-02 PRODUCTIVIDAD TOTAL = 0.1051E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 10 TIEMPO DE RESPUESTA DE LA CLASE C1 = 681.1 +/- 69.64 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1236. +/- 80.35 PRODUCTIVIDAD C1 = 0.6400E-02 PRODUCTIVIDAD C2 = 0.4167E-02 PRODUCTIVIDAD TOTAL = 0.1057E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 11 TIEMPO DE RESPUESTA DE LA CLASE C1 = 655.5 +/- 62.48 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1253. +/- 96.03 PRODUCTIVIDAD C1 = 0.6347E-02 PRODUCTIVIDAD C2 = 0.4201E-02 PRODUCTIVIDAD TOTAL = 0.1055E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 12 TIEMPO DE RESPUESTA DE LA CLASE C1 = 616.5 +/- 79.11 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1220. +/- 103.6 PRODUCTIVIDAD C1 = 0.6307E-02 PRODUCTIVIDAD C2 = 0.4218E-02 PRODUCTIVIDAD TOTAL = 0.1053E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 13 TIEMPO DE RESPUESTA DE LA CLASE C1 = 599.3 +/- 39.90 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1224. +/- 82.81 PRODUCTIVIDAD C1 = 0.6302E-02 PRODUCTIVIDAD C2 = 0.4206E-02 PRODUCTIVIDAD TOTAL = 0.1051E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 14 TIEMPO DE RESPUESTA DE LA CLASE C1 = 584.5 +/- 51.45 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1215. +/- 64.20 PRODUCTIVIDAD C1 = 0.6252E-02 PRODUCTIVIDAD C2 = 0.4221E-02 PRODUCTIVIDAD TOTAL = 0.1047E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 15 TIEMPO DE RESPUESTA DE LA CLASE C1 = 600.3 +/- 70.83 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1258. +/- 99.84

281
PRODUCTIVIDAD C1 = 0.6335E-02 PRODUCTIVIDAD C2 = 0.4165E-02 PRODUCTIVIDAD TOTAL = 0.1050E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 16 TIEMPO DE RESPUESTA DE LA CLASE C1 = 555.5 +/- 44.20 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1202. +/- 77.31 PRODUCTIVIDAD C1 = 0.6263E-02 PRODUCTIVIDAD C2 = 0.4183E-02 PRODUCTIVIDAD TOTAL = 0.1045E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 17 TIEMPO DE RESPUESTA DE LA CLASE C1 = 573.9 +/- 41.08 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1279. +/- 95.87 PRODUCTIVIDAD C1 = 0.6371E-02 PRODUCTIVIDAD C2 = 0.4173E-02 PRODUCTIVIDAD TOTAL = 0.1054E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 18 TIEMPO DE RESPUESTA DE LA CLASE C1 = 543.5 +/- 33.83 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1188. +/- 75.87 PRODUCTIVIDAD C1 = 0.6273E-02 PRODUCTIVIDAD C2 = 0.4235E-02 PRODUCTIVIDAD TOTAL = 0.1051E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 19 TIEMPO DE RESPUESTA DE LA CLASE C1 = 543.6 +/- 32.13 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1238. +/- 71.38 PRODUCTIVIDAD C1 = 0.6325E-02 PRODUCTIVIDAD C2 = 0.4164E-02 PRODUCTIVIDAD TOTAL = 0.1049E-01 NUMERO DE USUARIOS = 450 FACTOR DE MULTIPROGRAMACION = 20 TIEMPO DE RESPUESTA DE LA CLASE C1 = 586.7 +/- 58.12 TIEMPO DE RESPUESTA DE LA CLASE C2 = 1328. +/- 106.8 PRODUCTIVIDAD C1 = 0.6390E-02 PRODUCTIVIDAD C2 = 0.4183E-02 PRODUCTIVIDAD TOTAL = 0.1057E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 1 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.9447E+05 +/- 7168. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.9517E+05 +/- 3567. PRODUCTIVIDAD C1 = 0.2645E-02 PRODUCTIVIDAD C2 = 0.1755E-02 PRODUCTIVIDAD TOTAL = 0.4401E-02 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 2 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.4248E+05 +/- 2968.

282
TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.4285E+05 +/- 1614. PRODUCTIVIDAD C1 = 0.4230E-02 PRODUCTIVIDAD C2 = 0.2859E-02 PRODUCTIVIDAD TOTAL = 0.7089E-02 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 3 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2682E+05 +/- 2292. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2719E+05 +/-1403. PRODUCTIVIDAD C1 = 0.5229E-02 PRODUCTIVIDAD C2 = 0.3491E-02 PRODUCTIVIDAD TOTAL = 0.8720E-02 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 4 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1891E+05 +/- 1036. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.1924E+05 +/- 920.5 PRODUCTIVIDAD C1 = 0.5956E-02 PRODUCTIVIDAD C2 = 0.3924E-02 PRODUCTIVIDAD TOTAL = 0.9880E-02 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 5 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1479E+05 +/- 1650. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.1525E+05 +/- 1091. PRODUCTIVIDAD C1 = 0.6352E-02 PRODUCTIVIDAD C2 = 0.4238E-02 PRODUCTIVIDAD TOTAL = 0.1059E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 6 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1222E+05 +/- 890.0 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.1273E+05 +/- 868.7 PRODUCTIVIDAD C1 = 0.6643E-02 PRODUCTIVIDAD C2 = 0.4389E-02 PRODUCTIVIDAD TOTAL = 0.1103E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 7 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1015E+05 +/- 835.8 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.1068E+05 +/- 748.9 PRODUCTIVIDAD C1 = 0.6952E-02 PRODUCTIVIDAD C2 = 0.4589E-02 PRODUCTIVIDAD TOTAL = 0.1154E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 8 TIEMPO DE RESPUESTA DE LA CLASE C1 = 8752. +/- 600.0 TIEMPO DE RESPUESTA DE LA CLASE C2 = 9380. +/- 599.8 PRODUCTIVIDAD C1 = 0.7004E-02 PRODUCTIVIDAD C2 = 0.4696E-02 PRODUCTIVIDAD TOTAL = 0.1170E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 9

283
TIEMPO DE RESPUESTA DE LA CLASE C1 = 8497. +/- 781.1 TIEMPO DE RESPUESTA DE LA CLASE C2 = 9185. +/- 766.9 PRODUCTIVIDAD C1 = 0.7105E-02 PRODUCTIVIDAD C2 = 0.4713E-02 PRODUCTIVIDAD TOTAL = 0.1182E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 10 TIEMPO DE RESPUESTA DE LA CLASE C1 = 8157. +/- 626.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 8876. +/- 694.5 PRODUCTIVIDAD C1 = 0.7217E-02 PRODUCTIVIDAD C2 = 0.4761E-02 PRODUCTIVIDAD TOTAL = 0.1198E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 11 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7881. +/- 627.6 TIEMPO DE RESPUESTA DE LA CLASE C2 = 8656. +/- 686.6 PRODUCTIVIDAD C1 = 0.7249E-02 PRODUCTIVIDAD C2 = 0.4778E-02 PRODUCTIVIDAD TOTAL = 0.1203E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 12 TIEMPO DE RESPUESTA DE LA CLASE C1 = 8017. +/- 766.4 TIEMPO DE RESPUESTA DE LA CLASE C2 = 8972. +/- 1068. PRODUCTIVIDAD C1 = 0.7172E-02 PRODUCTIVIDAD C2 = 0.4747E-02 PRODUCTIVIDAD TOTAL = 0.1192E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 13 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7953. +/- 633.5 TIEMPO DE RESPUESTA DE LA CLASE C2 = 8954. +/- 651.3 PRODUCTIVIDAD C1 = 0.7199E-02 PRODUCTIVIDAD C2 = 0.4787E-02 PRODUCTIVIDAD TOTAL = 0.1199E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 14 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7921. +/- 616.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 9025. +/- 622.3 PRODUCTIVIDAD C1 = 0.7162E-02 PRODUCTIVIDAD C2 = 0.4737E-02 PRODUCTIVIDAD TOTAL = 0.1190E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 15 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7250. +/- 681.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 8376. +/- 744.3 PRODUCTIVIDAD C1 = 0.7300E-02 PRODUCTIVIDAD C2 = 0.4812E-02 PRODUCTIVIDAD TOTAL = 0.1211E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 16

284
TIEMPO DE RESPUESTA DE LA CLASE C1 = 7906. +/- 684.2 TIEMPO DE RESPUESTA DE LA CLASE C2 = 9144. +/- 713.4 PRODUCTIVIDAD C1 = 0.7157E-02 PRODUCTIVIDAD C2 = 0.4774E-02 PRODUCTIVIDAD TOTAL = 0.1193E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 17 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7800. +/- 676.0 TIEMPO DE RESPUESTA DE LA CLASE C2 = 9136. +/- 678.3 PRODUCTIVIDAD C1 = 0.7143E-02 PRODUCTIVIDAD C2 = 0.4761E-02 PRODUCTIVIDAD TOTAL = 0.1190E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 18 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7553. +/- 775.8 TIEMPO DE RESPUESTA DE LA CLASE C2 = 8942. +/- 797.9 PRODUCTIVIDAD C1 = 0.7203E-02 PRODUCTIVIDAD C2 = 0.4775E-02 PRODUCTIVIDAD TOTAL = 0.1198E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 19 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7755. +/- 842.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 9259. +/- 946.8 PRODUCTIVIDAD C1 = 0.7248E-02 PRODUCTIVIDAD C2 = 0.4675E-02 PRODUCTIVIDAD TOTAL = 0.1192E-01 NUMERO DE USUARIOS = 600 FACTOR DE MULTIPROGRAMACION = 20 TIEMPO DE RESPUESTA DE LA CLASE C1 = 7899. +/- 560.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 9470. +/- 600.2 PRODUCTIVIDAD C1 = 0.7261E-02 PRODUCTIVIDAD C2 = 0.4726E-02 PRODUCTIVIDAD TOTAL = 0.1199E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 1 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1322E+06 +/- 0.1259+05 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.1334E+06 +/- 8839. PRODUCTIVIDAD C1 = 0.2601E-02 PRODUCTIVIDAD C2 = 0.1731E-02 PRODUCTIVIDAD TOTAL = 0.4331E-02 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 2 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.6394E+05 +/- 4500. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.6452E+05 +/- 2714. PRODUCTIVIDAD C1 = 0.4222E-02 PRODUCTIVIDAD C2 = 0.2859E-02 PRODUCTIVIDAD TOTAL = 0.7081E-02 NUMERO DE USUARIOS = 750

285
FACTOR DE MULTIPROGRAMACION = 3 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.4312E+05 +/- 1890. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.4350E+05 +/- 1487. PRODUCTIVIDAD C1 = 0.5304E-02 PRODUCTIVIDAD C2 = 0.3495E-02 PRODUCTIVIDAD TOTAL = 0.8800E-02 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 4 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.3325E+05 +/- 1250. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.3369E+05 +/- 1043. PRODUCTIVIDAD C1 = 0.5977E-02 PRODUCTIVIDAD C2 = 0.3948E-02 PRODUCTIVIDAD TOTAL = 0.9925E-02 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 5 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2874E+05 +/- 1389. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2926E+05 +/- 947.7 PRODUCTIVIDAD C1 = 0.6390E-02 PRODUCTIVIDAD C2 = 0.4211E-02 PRODUCTIVIDAD TOTAL = 0.1060E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 6 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2514E+05 +/- 1146. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2570E+05 +/- 1045. PRODUCTIVIDAD C1 = 0.6720E-02 PRODUCTIVIDAD C2 = 0.4461E-02 PRODUCTIVIDAD TOTAL = 0.1118E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 7 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2240E+05 +/- 925.9 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2300E+05 +/- 931.1 PRODUCTIVIDAD C1 = 0.6973E-02 PRODUCTIVIDAD C2 = 0.4627E-02 PRODUCTIVIDAD TOTAL = 0.1160E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 8 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2162E+05 +/- 1090. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2226E+05 +/- 989.5 PRODUCTIVIDAD C1 = 0.7116E-02 PRODUCTIVIDAD C2 = 0.4686E-02 PRODUCTIVIDAD TOTAL = 0.1180E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 9 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2042E+05 +/- 1715. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2112E+05 +/- 1136. PRODUCTIVIDAD C1 = 0.7257E-02 PRODUCTIVIDAD C2 = 0.4709E-02 PRODUCTIVIDAD TOTAL = 0.1197E-01

286
NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 10 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2153E+05 +/- 826.5 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2234E+05 +/- 762.9 PRODUCTIVIDAD C1 = 0.7110E-02 PRODUCTIVIDAD C2 = 0.4659E-02 PRODUCTIVIDAD TOTAL = 0.1177E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 11 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.2000E+05 +/- 1023. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2091E+05 +/- 888.7 PRODUCTIVIDAD C1 = 0.7249E-02 PRODUCTIVIDAD C2 = 0.4790E-02 PRODUCTIVIDAD TOTAL = 0.1204E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 12 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1972E+05 +/- 957.1 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2066E+05 +/- 811.5 PRODUCTIVIDAD C1 = 0.7263E-02 PRODUCTIVIDAD C2 = 0.4833E-02 PRODUCTIVIDAD TOTAL = 0.1210E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 13 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1967E+05 +/- 1020. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2068E+05 +/- 1030. PRODUCTIVIDAD C1 = 0.7188E-02 PRODUCTIVIDAD C2 = 0.4824E-02 PRODUCTIVIDAD TOTAL = 0.1201E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 14 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1990E+05 +/- 1096. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2103E+05 +/- 920.0 PRODUCTIVIDAD C1 = 0.7236E-02 PRODUCTIVIDAD C2 = 0.4824E-02 PRODUCTIVIDAD TOTAL = 0.1206E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 15 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1955E+05 +/- 810.2 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2069E+05 +/- 860.1 PRODUCTIVIDAD C1 = 0.7296E-02 PRODUCTIVIDAD C2 = 0.4830E-02 PRODUCTIVIDAD TOTAL = 0.1213E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 16 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1991E+05 +/- 900.6 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2118E+05 +/- 817.7 PRODUCTIVIDAD C1 = 0.7211E-02 PRODUCTIVIDAD C2 = 0.4787E-02 PRODUCTIVIDAD TOTAL = 0.1200E-01

287
NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 17 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1953E+05 +/- 988.3 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2085E+05 +/- 1015. PRODUCTIVIDAD C1 = 0.7271E-02 PRODUCTIVIDAD C2 = 0.4806E-02 PRODUCTIVIDAD TOTAL = 0.1208E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 18 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1958E+05 +/- 1025. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2100E+05 +/- 1373. PRODUCTIVIDAD C1 = 0.7256E-02 PRODUCTIVIDAD C2 = 0.4813E-02 PRODUCTIVIDAD TOTAL = 0.1207E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 19 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1910E+05 +/- 821.2 TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2065E+05 +/- 781.8 PRODUCTIVIDAD C1 = 0.7345E-02 PRODUCTIVIDAD C2 = 0.4811E-02 PRODUCTIVIDAD TOTAL = 0.1216E-01 NUMERO DE USUARIOS = 750 FACTOR DE MULTIPROGRAMACION = 20 TIEMPO DE RESPUESTA DE LA CLASE C1 = 0.1960E+05 +/- 1216. TIEMPO DE RESPUESTA DE LA CLASE C2 = 0.2113E+05 +/- 800.1 PRODUCTIVIDAD C1 = 0.7321E-02 PRODUCTIVIDAD C2 = 0.4792E-02 PRODUCTIVIDAD TOTAL = 0.1211E-01 84 /END/

288
4. MODELADO Y EVALUACIÓN DE REDES Se va a tratar ahora de la aplicación de los modelos de colas estudiados en los capítulos 3 y 4 del primer volumen de esta obra al análisis del comportamiento de algunos esquemas frecuentes de sistemas de transmisión de datos.
4.1. REDES MALLADAS 4.1.1. MODELOS ELEMENTALES DE SUS COMPONENTES
4.1.1.1. Línea punto a punto Una línea punto a punto utilizada para transmitir datos entre dos estaciones con protocolo de tipo stop and wait, se puede asimilar a una estación de servicio con una cola FIFO, que, por razones de simplicidad de cálculo, se admitirá que recibe peticiones de transmisión de mensajes a razón de λ llegadas por segundo con distribución poissoniana y cada uno de los cuales retiene la línea durante el tiempo necesario para el servicio tV. Ahora bien, el tiempo necesario para enviar un mensaje, tT, comprende el tiempo de transmisión del mensaje, tI, más el tiempo de espera para verificar la correcta recepción del mensaje (time out), tout.
tT = tI + tout
Ahora bien el tiempo necesario para asegurar la correcta recepción de un mensaje necesita, además, el tiempo necesario para llevar a cabo las retransmisiones necesarias para lograrlo, que dependerá de la probabilidad p que una transmisión no se realice correctamente. Ello significa que
( )p
ttipptt T
iT
iTV −
=−+= ∑∞
= 11
1
En esta expresión no se tiene en cuenta la posibilidad de tener errores en los mensajes de aceptación (ack). En consecuencia, la productividad máxima, λmax, que se puede obtener de una línea será
ITV atp
tp
t−
=−
==λ111
max
donde el parámetro a = tT/tI ≤ 1, se ha introducido para relacionar la productividad de datos con la longitud del mensaje tI. Si λ es la frecuencia de llegada al transmisor en mensajes por segundo, su productividad normalizada (o utilización) λtI con este protocolo estará acotada por
11<
−≤λ=ρ
aptI
Esta expresión muestra explícitamente la dependencia de la productividad respecto a la probabilidad de error p y a la relación entre el tiempo de transmisión de un mensaje y el tiempo de un ciclo (transmisión más espera). Si el tiempo de espera es despreciable frente al de transmisión el time out también puede serlo y entonces a = 1 y, en consecuencia, la utilización de la línea puede llegar hasta

289
ρ < 1 - p
Si el protocolo en vez de tener una ventana de 1 en el proceso de espera, la tuviera de dimensión N (protocolo go-back-N), se puede considerar en un caso ideal que los mensajes se transmiten de forma continua sin ninguna espera entre ellos ya que no es preciso esperar el mensaje de aceptación. Por lo tanto para calcular el tiempo medio de servicio se puede usar las misma expresión que para el protocolo anterior pero usando el tiempo de transmisión, tI, en vez del correspondiente a un ciclo de transmisión más espera. Es decir, que
( ) ( )
−
−+=−+= ∑
∞
= ppattipptt I
iT
iIV 1
1111
La productividad que provoca la saturación será en este caso
( )[ ]patp
tp
t ITV 11111
max −+−
=−
==λ
y la productividad normalizada estará acotada por
( )paptI 11
1−+
−<λ=ρ
Obsérvese que cuando a tiende a 1 (los tiempos de propagación y proceso despreciables frente al de transmisión) se obtiene un comportamiento similar al del protocolo de espera simple. Determinado el tiempo de servicio, para calcular el tiempo de respuesta del sistema, es decir, el tiempo desde la puesta a disposición del transmisor del mensaje hasta su llegada al receptor se puede adoptar un modelo de tipo M/M/1 o mejor M/G/1. En particular, si se admite que la transmisión se efectúa por paquetes (mensajes de idéntica longitud) y que la tasa de retransmisiones es despreciable, entonces se puede utilizar un modelo M/D/1, donde la D significa determinista, es decir, tiempo de servicio constante, que no es m´ss que un caso particular del modelo M/G/1. Para encontrar el tamaño óptimo del paquete, se empieza considerando la transmisión de un paquete que tiene una longitud de lp bits más un conjunto de lc bits de control. En estas circunstancias, la probabilidad de que al menos un bit llegue con error viene dada por
( ) cpcp llb
llb qpp ++ −=−−= 111
Considerando valores muy pequeños de pb, de tal forma que (lp + lc) pb << 1, entonces se puede considerar que, aproximadamente
p = (lp + lc) pb << 1
En estas condiciones la máxima productividad de datos que se podrá obtener será, suponiendo el protocolo con ventana de N
( )( )[ ]pat
lplD
I
pp 11
1max −+
−=λ=
Haciendo tI = (lp + lc)/C, donde C es la capacidad de transmisión de la línea en bits/segundo, se tiene que la capacidad de transferencia normalizada (o utilización) será

290
( )( )( ) 1
111
≤
+−+
+−
+=
bcp
bcp
cp
p
pllapll
lll
CD
Esta expresión pone de manifiesto la influencia de la longitud del paquete lp, de la de los campos de control lc, y la probabilidad de error de un bit pb. En estas condiciones se puede buscar cual es la longitud de paquete que optimiza la productividad de información; para este cálculo acostumbra a hacerse la aproximación de admitir que el denominador del segundo corchete tiende a 1 y, por lo tanto,
( )
−
−−= 1
1log41
2opt bec
cp pl
ll
Si además lcpb << 1, la expresión anterior se simplifica hasta obtener
b
cp p
ll =opt
4.1.2. MODELOS GLOBALES Si se desea representar el conjunto de la red, es preciso representar cada uno de los componentes de la red mediante una estación de servicio con su cola gestionada de acuerdo con las normas de uso de la línea que establezca el protocolo.
4.1.2.1. Sin considerar el mecanismo de control de tráfico Así, por ejemplo, si se considera la red mallada de la figura 4.1, con las cargas en mensajes por minuto que aparecen en la tabla siguiente: a
de A B C D A 60 80 100 B 75 50 25 C 80 120 40 D 100 150 50
en que cada línea se considera capaz de transmitir simultáneamente en los dos sentidos, cada línea se representará por dos estaciones con sus colas FIFO, que unen en direcciones opuestas los nodos entre los que está conectada la línea. Se supondrá, además, que el encaminamiento entre cada par entrada-salida es fijo, de acuerdo con la siguiente tabla:
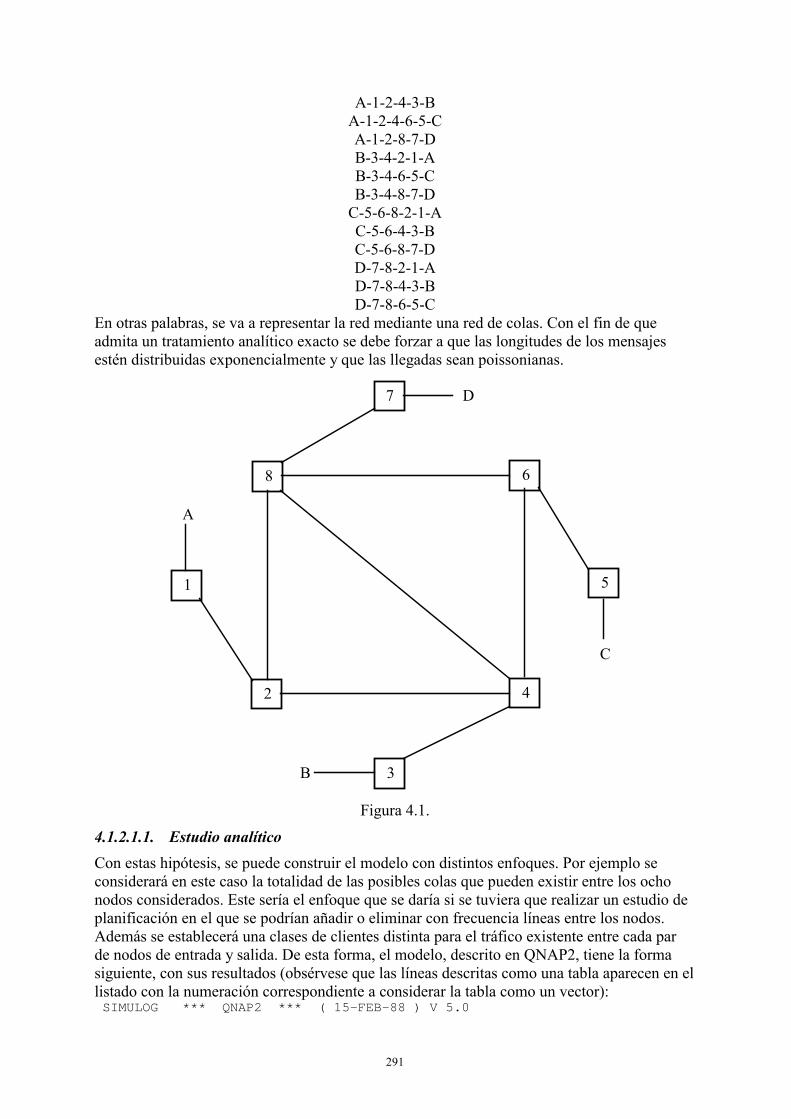
291
A-1-2-4-3-B A-1-2-4-6-5-C A-1-2-8-7-D B-3-4-2-1-A B-3-4-6-5-C B-3-4-8-7-D
C-5-6-8-2-1-A C-5-6-4-3-B C-5-6-8-7-D D-7-8-2-1-A D-7-8-4-3-B D-7-8-6-5-C
En otras palabras, se va a representar la red mediante una red de colas. Con el fin de que admita un tratamiento analítico exacto se debe forzar a que las longitudes de los mensajes estén distribuidas exponencialmente y que las llegadas sean poissonianas.
1
2
3
4
5
6
7
8
A
B
C
D
Figura 4.1.
4.1.2.1.1. Estudio analítico Con estas hipótesis, se puede construir el modelo con distintos enfoques. Por ejemplo se considerará en este caso la totalidad de las posibles colas que pueden existir entre los ocho nodos considerados. Este sería el enfoque que se daría si se tuviera que realizar un estudio de planificación en el que se podrían añadir o eliminar con frecuencia líneas entre los nodos. Además se establecerá una clases de clientes distinta para el tráfico existente entre cada par de nodos de entrada y salida. De esta forma, el modelo, descrito en QNAP2, tiene la forma siguiente, con sus resultados (obsérvese que las líneas descritas como una tabla aparecen en el listado con la numeración correspondiente a considerar la tabla como un vector): SIMULOG *** QNAP2 *** ( 15-FEB-88 ) V 5.0

292
(C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE GEN,LINIA(8,8); 2 REAL TRAB,TRAC,TRAD,TRBA,TRBC,TRBD,TRCA,TRCB,TRCD,TRDA,TRD ==> B,TRDC; 3 INTEGER I; 4 CLASS CLAB,CLAC,CLAD,CLBA,CLBC,CLBD,CLCA,CLCB,CLCD,CLDA,CL ==> DB,CLDC; 5 6 /STATION/ NAME = GEN; 7 TYPE = SOURCE; 8 SERVICE = EXP(60000./930.); 9 TRANSIT = LINIA(1,2),CLAB,60,LINIA(1,2),CLAC,80,LINIA(1,2) ==> ,CLAD,100, 10 LINIA(3,4),CLBA,75,LINIA(3,4),CLBC,50,LINIA(3,4) ==> ,CLBD,25, 11 LINIA(5,6),CLCA,80,LINIA(5,6),CLCB,120,LINIA(5,6 ==> ),CLCD,40, 12 LINIA(7,8),CLDA,100,LINIA(7,8),CLDB,150,LINIA(7, ==> 8),CLDC,50; 13 14 /STATION/ NAME = LINIA; 15 SERVICE = EXP(256.*8./64.); 16 17 /STATION/ NAME = LINIA(1,2); 18 TRANSIT(CLAB) = LINIA(2,4); 19 TRANSIT(CLAC) = LINIA(2,4); 20 TRANSIT(CLAD) = LINIA(2,8); 21 22 /STATION/ NAME = LINIA(2,1); 23 TRANSIT = OUT; 24 25 /STATION/ NAME = LINIA(2,4); 26 TRANSIT(CLAB) = LINIA(4,3); 27 TRANSIT(CLAC) = LINIA(4,6); 28 29 /STATION/ NAME = LINIA(2,8); 30 TRANSIT(CLAD) = LINIA(8,7); 31 32 /STATION/ NAME = LINIA(3,4); 33 TRANSIT(CLBA) = LINIA(4,2); 34 TRANSIT(CLBC) = LINIA(4,6); 35 TRANSIT(CLBD) = LINIA(4,8); 36 37 /STATION/ NAME = LINIA(4,2); 38 TRANSIT(CLBA) = LINIA(2,1); 39 40 /STATION/ NAME = LINIA(4,3); 41 TRANSIT = OUT; 42 43 /STATION/ NAME = LINIA(4,6); 44 TRANSIT(CLAC) = LINIA(6,5); 45 TRANSIT(CLBC) = LINIA(6,5); 46 47 /STATION/ NAME = LINIA(4,8); 48 TRANSIT(CLBD) = LINIA(8,7); 49 50 /STATION/ NAME = LINIA(5,6); 51 TRANSIT(CLCA) = LINIA(6,8); 52 TRANSIT(CLCB) = LINIA(6,4); 53 TRANSIT(CLCD) = LINIA(6,8); 54 55 /STATION/ NAME = LINIA(6,4); 56 TRANSIT(CLCB) = LINIA(4,3); 57 58 /STATION/ NAME = LINIA(6,5); 59 TRANSIT = OUT; 60

293
61 /STATION/ NAME = LINIA(6,8); 62 TRANSIT(CLCA) = LINIA(8,2); 63 TRANSIT(CLCD) = LINIA(8,7); 64 65 /STATION/ NAME = LINIA(7,8); 66 TRANSIT(CLDA) = LINIA(8,2); 67 TRANSIT(CLDB) = LINIA(8,4); 68 TRANSIT(CLDC) = LINIA(8,6); 69 70 /STATION/ NAME = LINIA(8,2); 71 TRANSIT(CLCA) = LINIA(2,1); 72 TRANSIT(CLDA) = LINIA(2,1); 73 74 /STATION/ NAME = LINIA(8,4); 75 TRANSIT(CLDB) = LINIA(4,3); 76 77 /STATION/ NAME = LINIA(8,6); 78 TRANSIT(CLDC) = LINIA(6,5); 79 80 /STATION/ NAME = LINIA(8,7); 81 TRANSIT = OUT; 82 83 /EXEC/ BEGIN 84 NETWORK(GEN, 85 LINIA(1,2),LINIA(2,1),LINIA(2,4),LINIA(2,8), 86 LINIA(3,4),LINIA(4,2),LINIA(4,3),LINIA(4,6), 87 LINIA(4,8),LINIA(5,6),LINIA(6,4),LINIA(6,5), 88 LINIA(6,8),LINIA(7,8),LINIA(8,2),LINIA(8,4), 89 LINIA(8,6),LINIA(8,7)); 90 PRINT; 91 SOLVE; 92 TRAB := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,4))+ 93 MRESPONSE(LINIA(4,3)); 94 TRAC := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,4))+ 95 MRESPONSE(LINIA(4,6))+MRESPONSE(LINIA(6,5)); 96 TRAD := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,8))+ 97 MRESPONSE(LINIA(8,7)); 98 TRBA := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,2))+ 99 MRESPONSE(LINIA(2,1)); 100 TRBC := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,6))+ 101 MRESPONSE(LINIA(6,5)); 102 TRBD := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,8))+ 103 MRESPONSE(LINIA(8,7)); 104 TRCA := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,8))+ 105 MRESPONSE(LINIA(8,2))+MRESPONSE(LINIA(2,1)); 106 TRCB := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,4))+ 107 MRESPONSE(LINIA(4,3)); 108 TRCD := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,8))+ 109 MRESPONSE(LINIA(8,7)); 110 TRDA := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,2))+ 111 MRESPONSE(LINIA(2,1)); 112 TRDB := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,4))+ 113 MRESPONSE(LINIA(4,3)); 114 TRDC := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,6))+ 115 MRESPONSE(LINIA(6,5)); 116 PRINT(TRAB,TRAC,TRAD); 117 PRINT(TRBA,TRBC,TRBD); 118 PRINT(TRCA,TRCB,TRCD); 119 PRINT(TRDA,TRDB,TRDC); 120 END; - CONVOLUTION METHOD ("CONVOL") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * GEN * 64.52 * 1.000 * 1.000 * 64.52 *0.1550E-01* * * * * * * *

294
* LINIA 2 * 32.00 *0.1280 *0.1468 * 36.70 *0.4000E-02* * * * * * * * * LINIA 9 * 32.00 *0.1360 *0.1574 * 37.04 *0.4250E-02* * * * * * * * * LINIA 12 * 32.00 *0.7467E-01*0.8069E-01* 34.58 *0.2333E-02* * * * * * * * * LINIA 16 * 32.00 *0.5333E-01*0.5634E-01* 33.80 *0.1667E-02* * * * * * * * * LINIA 20 * 32.00 *0.8000E-01*0.8696E-01* 34.78 *0.2500E-02* * * * * * * * * LINIA 26 * 32.00 *0.4000E-01*0.4167E-01* 33.33 *0.1250E-02* * * * * * * * * LINIA 27 * 32.00 *0.1760 *0.2136 * 38.83 *0.5500E-02* * * * * * * * * LINIA 30 * 32.00 *0.6933E-01*0.7450E-01* 34.38 *0.2167E-02* * * * * * * * * LINIA 32 * 32.00 *0.1333E-01*0.1351E-01* 32.43 *0.4167E-03* * * * * * * * * LINIA 38 * 32.00 *0.1280 *0.1468 * 36.70 *0.4000E-02* * * * * * * * * LINIA 44 * 32.00 *0.6400E-01*0.6838E-01* 34.19 *0.2000E-02* * * * * * * * * LINIA 45 * 32.00 *0.9600E-01*0.1062 * 35.40 *0.3000E-02* * * * * * * * * LINIA 48 * 32.00 *0.6400E-01*0.6838E-01* 34.19 *0.2000E-02* * * * * * * * * LINIA 56 * 32.00 *0.1600 *0.1905 * 38.10 *0.5000E-02* * * * * * * * * LINIA 58 * 32.00 *0.9600E-01*0.1062 * 35.40 *0.3000E-02* * * * * * * * * LINIA 60 * 32.00 *0.8000E-01*0.8696E-01* 34.78 *0.2500E-02* * * * * * * * * LINIA 62 * 32.00 *0.2667E-01*0.2740E-01* 32.88 *0.8333E-03* * * * * * * * * LINIA 63 * 32.00 *0.8800E-01*0.9649E-01* 35.09 *0.2750E-02* * * * * * * * ******************************************************************* MEMORY USED: 19812 WORDS OF 4 BYTES ( 2.48 % OF TOTAL MEMORY) 110.1 141.1 105.6 105.2 104.6 102.3 143.3 109.7 106.0 110.5 111.7 106.4 121 122 /END/ Si se quisiera estudiar el efecto de la constancia en la longitud de los mensajes transmitidos (lo cual es bastante frecuente, pues las redes transmiten paquetes de longitud constante), no se podrá seguir utilizando el método exacto de convolución y se deberá pasar al aproximado de difusión. La diferencia entre ambos modelos reside exclusivamente en la descripción del tiempo de servicio de las líneas, que de exponencial pasa ahora a ser constante. SIMULOG *** QNAP2 *** ( 15-FEB-88 ) V 5.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE GEN,LINIA(8,8); 2 REAL TRAB,TRAC,TRAD,TRBA,TRBC,TRBD,TRCA,TRCB,TRCD,TRDA,TRD ==> B,TRDC; 3 INTEGER I; 4 CLASS CLAB,CLAC,CLAD,CLBA,CLBC,CLBD,CLCA,CLCB,CLCD,CLDA,CL ==> DB,CLDC; 5 6 /STATION/ NAME = GEN; 7 TYPE = SOURCE; 8 SERVICE = EXP(60000./930.); 9 TRANSIT = LINIA(1,2),CLAB,60,LINIA(1,2),CLAC,80,LINIA(1,2)

295
==> ,CLAD,100, 10 LINIA(3,4),CLBA,75,LINIA(3,4),CLBC,50,LINIA(3,4) ==> ,CLBD,25, 11 LINIA(5,6),CLCA,80,LINIA(5,6),CLCB,120,LINIA(5,6 ==> ),CLCD,40, 12 LINIA(7,8),CLDA,100,LINIA(7,8),CLDB,150,LINIA(7, ==> 8),CLDC,50; 13 14 /STATION/ NAME = LINIA; 15 SERVICE = CST(256.*8./64.); 16 17 /STATION/ NAME = LINIA(1,2); 18 TRANSIT(CLAB) = LINIA(2,4); 19 TRANSIT(CLAC) = LINIA(2,4); 20 TRANSIT(CLAD) = LINIA(2,8); 21 22 /STATION/ NAME = LINIA(2,1); 23 TRANSIT = OUT; 24 25 /STATION/ NAME = LINIA(2,4); 26 TRANSIT(CLAB) = LINIA(4,3); 27 TRANSIT(CLAC) = LINIA(4,6); 28 29 /STATION/ NAME = LINIA(2,8); 30 TRANSIT(CLAD) = LINIA(8,7); 31 32 /STATION/ NAME = LINIA(3,4); 33 TRANSIT(CLBA) = LINIA(4,2); 34 TRANSIT(CLBC) = LINIA(4,6); 35 TRANSIT(CLBD) = LINIA(4,8); 36 37 /STATION/ NAME = LINIA(4,2); 38 TRANSIT(CLBA) = LINIA(2,1); 39 40 /STATION/ NAME = LINIA(4,3); 41 TRANSIT = OUT; 42 43 /STATION/ NAME = LINIA(4,6); 44 TRANSIT(CLAC) = LINIA(6,5); 45 TRANSIT(CLBC) = LINIA(6,5); 46 47 /STATION/ NAME = LINIA(4,8); 48 TRANSIT(CLBD) = LINIA(8,7); 49 50 /STATION/ NAME = LINIA(5,6); 51 TRANSIT(CLCA) = LINIA(6,8); 52 TRANSIT(CLCB) = LINIA(6,4); 53 TRANSIT(CLCD) = LINIA(6,8); 54 55 /STATION/ NAME = LINIA(6,4); 56 TRANSIT(CLCB) = LINIA(4,3); 57 58 /STATION/ NAME = LINIA(6,5); 59 TRANSIT = OUT; 60 61 /STATION/ NAME = LINIA(6,8); 62 TRANSIT(CLCA) = LINIA(8,2); 63 TRANSIT(CLCD) = LINIA(8,7); 64 65 /STATION/ NAME = LINIA(7,8); 66 TRANSIT(CLDA) = LINIA(8,2); 67 TRANSIT(CLDB) = LINIA(8,4); 68 TRANSIT(CLDC) = LINIA(8,6); 69 70 /STATION/ NAME = LINIA(8,2); 71 TRANSIT(CLCA) = LINIA(2,1); 72 TRANSIT(CLDA) = LINIA(2,1); 73 74 /STATION/ NAME = LINIA(8,4);

296
75 TRANSIT(CLDB) = LINIA(4,3); 76 77 /STATION/ NAME = LINIA(8,6); 78 TRANSIT(CLDC) = LINIA(6,5); 79 80 /STATION/ NAME = LINIA(8,7); 81 TRANSIT = OUT; 82 83 /EXEC/ BEGIN 84 NETWORK(GEN, 85 LINIA(1,2),LINIA(2,1),LINIA(2,4),LINIA(2,8), 86 LINIA(3,4),LINIA(4,2),LINIA(4,3),LINIA(4,6), 87 LINIA(4,8),LINIA(5,6),LINIA(6,4),LINIA(6,5), 88 LINIA(6,8),LINIA(7,8),LINIA(8,2),LINIA(8,4), 89 LINIA(8,6),LINIA(8,7)); 90 PRINT; 91 SOLVE; 92 TRAB := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,4))+ 93 MRESPONSE(LINIA(4,3)); 94 TRAC := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,4))+ 95 MRESPONSE(LINIA(4,6))+MRESPONSE(LINIA(6,5)); 96 TRAD := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,8))+ 97 MRESPONSE(LINIA(8,7)); 98 TRBA := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,2))+ 99 MRESPONSE(LINIA(2,1)); 100 TRBC := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,6))+ 101 MRESPONSE(LINIA(6,5)); 102 TRBD := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,8))+ 103 MRESPONSE(LINIA(8,7)); 104 TRCA := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,8))+ 105 MRESPONSE(LINIA(8,2))+MRESPONSE(LINIA(2,1)); 106 TRCB := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,4))+ 107 MRESPONSE(LINIA(4,3)); 108 TRCD := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,8))+ 109 MRESPONSE(LINIA(8,7)); 110 TRDA := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,2))+ 111 MRESPONSE(LINIA(2,1)); 112 TRDB := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,4))+ 113 MRESPONSE(LINIA(4,3)); 114 TRDC := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,6))+ 115 MRESPONSE(LINIA(6,5)); 116 PRINT(TRAB,TRAC,TRAD); 117 PRINT(TRBA,TRBC,TRBD); 118 PRINT(TRCA,TRCB,TRCD); 119 PRINT(TRDA,TRDB,TRDC); 120 END; - APPROXIMATE DIFFUSIONS METHOD ("DIFFU") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * GEN * 64.52 * 1.000 * 1.000 * 64.52 *0.1550E-01* * * * * * * * * LINIA 2 * 32.00 *0.1280 *0.1374 * 34.35 *0.4000E-02* * * * * * * * * LINIA 9 * 32.00 *0.1360 *0.1466 * 34.48 *0.4250E-02* * * * * * * * * LINIA 12 * 32.00 *0.7467E-01*0.7765E-01* 33.28 *0.2333E-02* * * * * * * * * LINIA 16 * 32.00 *0.5333E-01*0.5482E-01* 32.89 *0.1667E-02* * * * * * * * * LINIA 20 * 32.00 *0.8000E-01*0.8348E-01* 33.39 *0.2500E-02* * * * * * * * * LINIA 26 * 32.00 *0.4000E-01*0.4083E-01* 32.66 *0.1250E-02* * * * * * * * * LINIA 27 * 32.00 *0.1760 *0.1945 * 35.37 *0.5500E-02* * * * * * * *

297
* LINIA 30 * 32.00 *0.6933E-01*0.7190E-01* 33.18 *0.2167E-02* * * * * * * * * LINIA 32 * 32.00 *0.1333E-01*0.1342E-01* 32.22 *0.4167E-03* * * * * * * * * LINIA 38 * 32.00 *0.1280 *0.1374 * 34.35 *0.4000E-02* * * * * * * * * LINIA 44 * 32.00 *0.6400E-01*0.6617E-01* 33.08 *0.2000E-02* * * * * * * * * LINIA 45 * 32.00 *0.9600E-01*0.1011 * 33.68 *0.3000E-02* * * * * * * * * LINIA 48 * 32.00 *0.6400E-01*0.6617E-01* 33.08 *0.2000E-02* * * * * * * * * LINIA 56 * 32.00 *0.1600 *0.1752 * 35.05 *0.5000E-02* * * * * * * * * LINIA 58 * 32.00 *0.9600E-01*0.1011 * 33.68 *0.3000E-02* * * * * * * * * LINIA 60 * 32.00 *0.8000E-01*0.8343E-01* 33.37 *0.2500E-02* * * * * * * * * LINIA 62 * 32.00 *0.2667E-01*0.2703E-01* 32.44 *0.8333E-03* * * * * * * * * LINIA 63 * 32.00 *0.8800E-01*0.9222E-01* 33.53 *0.2750E-02* * * * * * * * ******************************************************************* MEMORY USED: 19812 WORDS OF 4 BYTES ( 2.48 % OF TOTAL MEMORY) 103.0 134.5 100.8 100.5 100.3 99.14 135.6 102.8 101.0 103.2 103.8 101.2 121 122 /END/ Obsérvese que al tener una dispersión nula alrededor del valor medio, los tiempos de respuesta calculados son, como era de esperar, más bajos en este caso que en el anterior. El modelo que se acaba de construir es más exacto en este caso que en el anterior, pero su tratamiento es aproximado mientras que en el caso anterior era exacto. Si se quisiera profundizar en la modelización de este sistema, se podría, por ejemplo, tener en cuenta la influencia del proceso de los mensajes (para control de errores y encaminamiento, por ejemplo) en cada nodo, representando los conflictos que se producen en cada uno de ellos. Con esta hipótesis suplementaria, el modelo resultaría, partiendo del caso en que se pretendía un modelo analítico con tratamiento analítico exacto, sería: SIMULOG *** QNAP2 *** ( 15-FEB-88 ) V 5.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE GEN,LINIA(8,8),CPU(8); 2 REAL TRAB,TRAC,TRAD,TRBA,TRBC,TRBD,TRCA,TRCB,TRCD,TRDA,TRD ==> B,TRDC; 3 INTEGER I; 4 CLASS CLAB,CLAC,CLAD,CLBA,CLBC,CLBD,CLCA,CLCB,CLCD,CLDA,CL ==> DB,CLDC; 5 6 /STATION/ NAME = GEN; 7 TYPE = SOURCE; 8 SERVICE = EXP(60000./930.); 9 TRANSIT = CPU(1),CLAB,60,CPU(1),CLAC,80,CPU(1),CLAD,100, 10 CPU(3),CLBA,75,CPU(3),CLBC,50,CPU(3),CLBD,25, 11 CPU(5),CLCA,80,CPU(5),CLCB,120,CPU(5),CLCD,40, 12 CPU(7),CLDA,100,CPU(7),CLDB,150,CPU(7),CLDC,50; 13 14 /STATION/ NAME = LINIA; 15 SERVICE = EXP(256.*8./64.); 16 17 /STATION/ NAME = LINIA(1,2);

298
18 TRANSIT = CPU(2); 19 20 /STATION/ NAME = LINIA(2,1); 21 TRANSIT = CPU(1); 22 23 /STATION/ NAME = LINIA(2,4); 24 TRANSIT = CPU(4); 25 26 /STATION/ NAME = LINIA(2,8); 27 TRANSIT = CPU(8); 28 29 /STATION/ NAME = LINIA(3,4); 30 TRANSIT = CPU(4); 31 32 /STATION/ NAME = LINIA(4,2); 33 TRANSIT = CPU(2); 34 35 /STATION/ NAME = LINIA(4,3); 36 TRANSIT = CPU(3); 37 38 /STATION/ NAME = LINIA(4,6); 39 TRANSIT = CPU(6); 40 41 /STATION/ NAME = LINIA(4,8); 42 TRANSIT = CPU(8); 43 44 /STATION/ NAME = LINIA(5,6); 45 TRANSIT = CPU(6); 46 47 /STATION/ NAME = LINIA(6,5); 48 TRANSIT = CPU(5); 49 50 /STATION/ NAME = LINIA(6,4); 51 TRANSIT = CPU(4); 52 53 /STATION/ NAME = LINIA(6,8); 54 TRANSIT = CPU(8); 55 56 /STATION/ NAME = LINIA(7,8); 57 TRANSIT = CPU(8); 58 59 /STATION/ NAME = LINIA(8,2); 60 TRANSIT = CPU(2); 61 62 /STATION/ NAME = LINIA(8,7); 63 TRANSIT = CPU(7); 64 65 /STATION/ NAME = LINIA(8,6); 66 TRANSIT = CPU(6); 67 68 /STATION/ NAME = LINIA(8,4); 69 TRANSIT = CPU(4); 70 71 /STATION/ NAME = CPU; 72 SERVICE = EXP(1.); 73 74 /STATION/ NAME = CPU(1); 75 TRANSIT(CLAB,CLAC,CLAD) = LINIA(1,2); 76 TRANSIT(CLBA,CLCA,CLDA) = OUT; 77 78 /STATION/ NAME = CPU(2); 79 TRANSIT(CLAB) = LINIA(2,4); 80 TRANSIT(CLAC) = LINIA(2,4); 81 TRANSIT(CLAD) = LINIA(2,8); 82 TRANSIT(CLBA) = LINIA(2,1); 83 TRANSIT(CLCA) = LINIA(2,1); 84 TRANSIT(CLDA) = LINIA(2,1); 85 86 /STATION/ NAME = CPU(3);

299
87 TRANSIT(CLBA,CLBC,CLBD) = LINIA(3,4); 88 TRANSIT(CLAB,CLCB,CLDB) = OUT; 89 90 /STATION/ NAME = CPU(4); 91 TRANSIT(CLAB) = LINIA(4,3); 92 TRANSIT(CLAC) = LINIA(4,6); 93 TRANSIT(CLBA) = LINIA(4,2); 94 TRANSIT(CLBC) = LINIA(4,6); 95 TRANSIT(CLBD) = LINIA(4,8); 96 TRANSIT(CLCB) = LINIA(4,3); 97 TRANSIT(CLDB) = LINIA(4,3); 98 99 /STATION/ NAME = CPU(5); 100 TRANSIT(CLCA,CLCB,CLCD) = LINIA(5,6); 101 TRANSIT(CLAC,CLBC,CLDC) = OUT; 102 103 /STATION/ NAME = CPU(6); 104 TRANSIT(CLAC) = LINIA(6,5); 105 TRANSIT(CLBC) = LINIA(6,5); 106 TRANSIT(CLCA) = LINIA(6,8); 107 TRANSIT(CLCB) = LINIA(6,4); 108 TRANSIT(CLCD) = LINIA(6,8); 109 TRANSIT(CLDC) = LINIA(6,5); 110 111 /STATION/ NAME = CPU(7); 112 TRANSIT(CLDA,CLDB,CLDC) = LINIA(7,8); 113 TRANSIT(CLAD,CLBD,CLCD) = OUT; 114 115 /STATION/ NAME = CPU(8); 116 TRANSIT(CLAD) = LINIA(8,7); 117 TRANSIT(CLBD) = LINIA(8,7); 118 TRANSIT(CLCA) = LINIA(8,2); 119 TRANSIT(CLCD) = LINIA(8,7); 120 TRANSIT(CLDA) = LINIA(8,2); 121 TRANSIT(CLDB) = LINIA(8,4); 122 TRANSIT(CLDC) = LINIA(8,6); 123 124 /CONTROL/ CLASS = ALL QUEUE; 125 /EXEC/ BEGIN 126 NETWORK(GEN, 127 CPU(1 STEP 1 UNTIL 8), 128 LINIA(1,2),LINIA(2,1),LINIA(2,4),LINIA(2,8), 129 LINIA(3,4),LINIA(4,2),LINIA(4,3),LINIA(4,6), 130 LINIA(4,8),LINIA(5,6),LINIA(6,4),LINIA(6,5), 131 LINIA(6,8),LINIA(7,8),LINIA(8,2),LINIA(8,4), 132 LINIA(8,6),LINIA(8,7)); 133 PRINT; 134 SOLVE; 135 TRAB := MRESPONSE(CPU(1))+MRESPONSE(LINIA(1,2))+ 136 MRESPONSE(CPU(2))+MRESPONSE(LINIA(2,4))+ 137 MRESPONSE(CPU(4))+MRESPONSE(LINIA(4,3))+ 138 MRESPONSE(CPU(3)); 139 TRAC := MRESPONSE(CPU(1))+MRESPONSE(LINIA(1,2))+ 140 MRESPONSE(CPU(2))+MRESPONSE(LINIA(2,4))+ 141 MRESPONSE(CPU(4))+MRESPONSE(LINIA(4,6))+ 142 MRESPONSE(CPU(6))+MRESPONSE(LINIA(6,5))+ 143 MRESPONSE(CPU(5)); 144 TRAD := MRESPONSE(CPU(1))+MRESPONSE(LINIA(1,2))+ 145 MRESPONSE(CPU(2))+MRESPONSE(LINIA(2,8))+ 146 MRESPONSE(CPU(8))+MRESPONSE(LINIA(8,7))+ 147 MRESPONSE(CPU(7)); 148 TRBA := MRESPONSE(CPU(3))+MRESPONSE(LINIA(3,4))+ 149 MRESPONSE(CPU(4))+MRESPONSE(LINIA(4,2))+ 150 MRESPONSE(CPU(2))+MRESPONSE(LINIA(2,1))+ 151 MRESPONSE(CPU(1)); 152 TRBC := MRESPONSE(CPU(3))+MRESPONSE(LINIA(3,4))+ 153 MRESPONSE(CPU(4))+MRESPONSE(LINIA(4,6))+ 154 MRESPONSE(CPU(6))+MRESPONSE(LINIA(6,5))+ 155 MRESPONSE(CPU(5));

300
156 TRBD := MRESPONSE(CPU(3))+MRESPONSE(LINIA(3,4))+ 157 MRESPONSE(CPU(4))+MRESPONSE(LINIA(4,8))+ 158 MRESPONSE(CPU(8))+MRESPONSE(LINIA(8,7))+ 159 MRESPONSE(CPU(7)); 160 TRCA := MRESPONSE(CPU(5))+MRESPONSE(LINIA(5,6))+ 161 MRESPONSE(CPU(6))+MRESPONSE(LINIA(6,8))+ 162 MRESPONSE(CPU(8))+MRESPONSE(LINIA(8,2))+ 163 MRESPONSE(CPU(2))+MRESPONSE(LINIA(2,1))+ 164 MRESPONSE(CPU(1)); 165 TRCB := MRESPONSE(CPU(5))+MRESPONSE(LINIA(5,6))+ 166 MRESPONSE(CPU(6))+MRESPONSE(LINIA(6,4))+ 167 MRESPONSE(CPU(4))+MRESPONSE(LINIA(4,3))+ 168 MRESPONSE(CPU(3)); 169 TRCD := MRESPONSE(CPU(5))+MRESPONSE(LINIA(5,6))+ 170 MRESPONSE(CPU(6))+MRESPONSE(LINIA(6,8))+ 171 MRESPONSE(CPU(8))+MRESPONSE(LINIA(8,7))+ 172 MRESPONSE(CPU(7)); 173 TRDA := MRESPONSE(CPU(7))+MRESPONSE(LINIA(7,8))+ 174 MRESPONSE(CPU(8))+MRESPONSE(LINIA(8,2))+ 175 MRESPONSE(CPU(2))+MRESPONSE(LINIA(2,1))+ 176 MRESPONSE(CPU(1)); 177 TRDB := MRESPONSE(CPU(7))+MRESPONSE(LINIA(7,8))+ 178 MRESPONSE(CPU(8))+MRESPONSE(LINIA(8,4))+ 179 MRESPONSE(CPU(4))+MRESPONSE(LINIA(4,3))+ 180 MRESPONSE(CPU(3)); 181 TRDC := MRESPONSE(CPU(7))+MRESPONSE(LINIA(7,8))+ 182 MRESPONSE(CPU(8))+MRESPONSE(LINIA(8,6))+ 183 MRESPONSE(CPU(6))+MRESPONSE(LINIA(6,5))+ 184 MRESPONSE(CPU(5)); 185 PRINT(TRAB,TRAC,TRAD); 186 PRINT(TRBA,TRBC,TRBD); 187 PRINT(TRCA,TRCB,TRCD); 188 PRINT(TRDA,TRDB,TRDC); 189 END; - CONVOLUTION METHOD ("CONVOL") - ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * THRUPUT * ******************************************************************* * * * * * * * * GEN * 64.52 * 1.000 * 1.000 * 64.52 *0.1550E-01* * * * * * * * * LINIA 2 * 32.00 *0.1280 *0.1468 * 36.70 *0.4000E-02* *(CLAB )* 32.00 *0.3200E-01*0.3670E-01* 36.70 *0.1000E-02* *(CLAC )* 32.00 *0.4267E-01*0.4893E-01* 36.70 *0.1333E-02* *(CLAD )* 32.00 *0.5333E-01*0.6116E-01* 36.70 *0.1667E-02* * * * * * * * * LINIA 9 * 32.00 *0.1360 *0.1574 * 37.04 *0.4250E-02* *(CLBA )* 32.00 *0.4000E-01*0.4630E-01* 37.04 *0.1250E-02* *(CLCA )* 32.00 *0.4267E-01*0.4938E-01* 37.04 *0.1333E-02* *(CLDA )* 32.00 *0.5333E-01*0.6173E-01* 37.04 *0.1667E-02* * * * * * * * * LINIA 12 * 32.00 *0.7467E-01*0.8069E-01* 34.58 *0.2333E-02* *(CLAB )* 32.00 *0.3200E-01*0.3458E-01* 34.58 *0.1000E-02* *(CLAC )* 32.00 *0.4267E-01*0.4611E-01* 34.58 *0.1333E-02* * * * * * * * * LINIA 16 * 32.00 *0.5333E-01*0.5634E-01* 33.80 *0.1667E-02* *(CLAD )* 32.00 *0.5333E-01*0.5634E-01* 33.80 *0.1667E-02* * * * * * * * * LINIA 20 * 32.00 *0.8000E-01*0.8696E-01* 34.78 *0.2500E-02* *(CLBA )* 32.00 *0.4000E-01*0.4348E-01* 34.78 *0.1250E-02* *(CLBC )* 32.00 *0.2667E-01*0.2899E-01* 34.78 *0.8333E-03* *(CLBD )* 32.00 *0.1333E-01*0.1449E-01* 34.78 *0.4167E-03* * * * * * * * * LINIA 26 * 32.00 *0.4000E-01*0.4167E-01* 33.33 *0.1250E-02* *(CLBA )* 32.00 *0.4000E-01*0.4167E-01* 33.33 *0.1250E-02* * * * * * * * * LINIA 27 * 32.00 *0.1760 *0.2136 * 38.83 *0.5500E-02*

301
*(CLAB )* 32.00 *0.3200E-01*0.3883E-01* 38.83 *0.1000E-02* *(CLCB )* 32.00 *0.6400E-01*0.7767E-01* 38.83 *0.2000E-02* *(CLDB )* 32.00 *0.8000E-01*0.9709E-01* 38.83 *0.2500E-02* * * * * * * * * LINIA 30 * 32.00 *0.6933E-01*0.7450E-01* 34.38 *0.2167E-02* *(CLAC )* 32.00 *0.4267E-01*0.4585E-01* 34.38 *0.1333E-02* *(CLBC )* 32.00 *0.2667E-01*0.2865E-01* 34.38 *0.8333E-03* * * * * * * * * LINIA 32 * 32.00 *0.1333E-01*0.1351E-01* 32.43 *0.4167E-03* *(CLBD )* 32.00 *0.1333E-01*0.1351E-01* 32.43 *0.4167E-03* * * * * * * * * LINIA 38 * 32.00 *0.1280 *0.1468 * 36.70 *0.4000E-02* *(CLCA )* 32.00 *0.4267E-01*0.4893E-01* 36.70 *0.1333E-02* *(CLCB )* 32.00 *0.6400E-01*0.7339E-01* 36.70 *0.2000E-02* *(CLCD )* 32.00 *0.2133E-01*0.2446E-01* 36.70 *0.6667E-03* * * * * * * * * LINIA 44 * 32.00 *0.6400E-01*0.6838E-01* 34.19 *0.2000E-02* *(CLCB )* 32.00 *0.6400E-01*0.6838E-01* 34.19 *0.2000E-02* * * * * * * * * LINIA 45 * 32.00 *0.9600E-01*0.1062 * 35.40 *0.3000E-02* *(CLAC )* 32.00 *0.4267E-01*0.4720E-01* 35.40 *0.1333E-02* *(CLBC )* 32.00 *0.2667E-01*0.2950E-01* 35.40 *0.8333E-03* *(CLDC )* 32.00 *0.2667E-01*0.2950E-01* 35.40 *0.8333E-03* * * * * * * * * LINIA 48 * 32.00 *0.6400E-01*0.6838E-01* 34.19 *0.2000E-02* *(CLCA )* 32.00 *0.4267E-01*0.4558E-01* 34.19 *0.1333E-02* *(CLCD )* 32.00 *0.2133E-01*0.2279E-01* 34.19 *0.6667E-03* * * * * * * * * LINIA 56 * 32.00 *0.1600 *0.1905 * 38.10 *0.5000E-02* *(CLDA )* 32.00 *0.5333E-01*0.6349E-01* 38.10 *0.1667E-02* *(CLDB )* 32.00 *0.8000E-01*0.9524E-01* 38.10 *0.2500E-02* *(CLDC )* 32.00 *0.2667E-01*0.3175E-01* 38.10 *0.8333E-03* * * * * * * * * LINIA 58 * 32.00 *0.9600E-01*0.1062 * 35.40 *0.3000E-02* *(CLCA )* 32.00 *0.4267E-01*0.4720E-01* 35.40 *0.1333E-02* *(CLDA )* 32.00 *0.5333E-01*0.5900E-01* 35.40 *0.1667E-02* * * * * * * * * LINIA 60 * 32.00 *0.8000E-01*0.8696E-01* 34.78 *0.2500E-02* *(CLDB )* 32.00 *0.8000E-01*0.8696E-01* 34.78 *0.2500E-02* * * * * * * * * LINIA 62 * 32.00 *0.2667E-01*0.2740E-01* 32.88 *0.8333E-03* *(CLDC )* 32.00 *0.2667E-01*0.2740E-01* 32.88 *0.8333E-03* * * * * * * * * LINIA 63 * 32.00 *0.8800E-01*0.9649E-01* 35.09 *0.2750E-02* *(CLAD )* 32.00 *0.5333E-01*0.5848E-01* 35.09 *0.1667E-02* *(CLBD )* 32.00 *0.1333E-01*0.1462E-01* 35.09 *0.4167E-03* *(CLCD )* 32.00 *0.2133E-01*0.2339E-01* 35.09 *0.6667E-03* * * * * * * * * CPU 1 * 1.000 *0.8250E-02*0.8319E-02* 1.008 *0.8250E-02* *(CLAB )* 1.000 *0.1000E-02*0.1008E-02* 1.008 *0.1000E-02* *(CLAC )* 1.000 *0.1333E-02*0.1344E-02* 1.008 *0.1333E-02* *(CLAD )* 1.000 *0.1667E-02*0.1681E-02* 1.008 *0.1667E-02* *(CLBA )* 1.000 *0.1250E-02*0.1260E-02* 1.008 *0.1250E-02* *(CLCA )* 1.000 *0.1333E-02*0.1344E-02* 1.008 *0.1333E-02* *(CLDA )* 1.000 *0.1667E-02*0.1681E-02* 1.008 *0.1667E-02* * * * * * * * * CPU 2 * 1.000 *0.8250E-02*0.8319E-02* 1.008 *0.8250E-02* *(CLAB )* 1.000 *0.1000E-02*0.1008E-02* 1.008 *0.1000E-02* *(CLAC )* 1.000 *0.1333E-02*0.1344E-02* 1.008 *0.1333E-02* *(CLAD )* 1.000 *0.1667E-02*0.1681E-02* 1.008 *0.1667E-02* *(CLBA )* 1.000 *0.1250E-02*0.1260E-02* 1.008 *0.1250E-02* *(CLCA )* 1.000 *0.1333E-02*0.1344E-02* 1.008 *0.1333E-02* *(CLDA )* 1.000 *0.1667E-02*0.1681E-02* 1.008 *0.1667E-02* * * * * * * * * * * * * * * * CPU 3 * 1.000 *0.8000E-02*0.8065E-02* 1.008 *0.8000E-02* *(CLAB )* 1.000 *0.1000E-02*0.1008E-02* 1.008 *0.1000E-02* *(CLBA )* 1.000 *0.1250E-02*0.1260E-02* 1.008 *0.1250E-02* *(CLBC )* 1.000 *0.8333E-03*0.8401E-03* 1.008 *0.8333E-03*

302
*(CLBD )* 1.000 *0.4167E-03*0.4200E-03* 1.008 *0.4167E-03* *(CLCB )* 1.000 *0.2000E-02*0.2016E-02* 1.008 *0.2000E-02* *(CLDB )* 1.000 *0.2500E-02*0.2520E-02* 1.008 *0.2500E-02* * * * * * * * * CPU 4 * 1.000 *0.9333E-02*0.9421E-02* 1.009 *0.9333E-02* *(CLAB )* 1.000 *0.1000E-02*0.1009E-02* 1.009 *0.1000E-02* *(CLAC )* 1.000 *0.1333E-02*0.1346E-02* 1.009 *0.1333E-02* *(CLBA )* 1.000 *0.1250E-02*0.1262E-02* 1.009 *0.1250E-02* *(CLBC )* 1.000 *0.8333E-03*0.8412E-03* 1.009 *0.8333E-03* *(CLBD )* 1.000 *0.4167E-03*0.4206E-03* 1.009 *0.4167E-03* *(CLCB )* 1.000 *0.2000E-02*0.2019E-02* 1.009 *0.2000E-02* *(CLDB )* 1.000 *0.2500E-02*0.2524E-02* 1.009 *0.2500E-02* * * * * * * * * CPU 5 * 1.000 *0.7000E-02*0.7049E-02* 1.007 *0.7000E-02* *(CLAC )* 1.000 *0.1333E-02*0.1343E-02* 1.007 *0.1333E-02* *(CLBC )* 1.000 *0.8333E-03*0.8392E-03* 1.007 *0.8333E-03* *(CLCA )* 1.000 *0.1333E-02*0.1343E-02* 1.007 *0.1333E-02* *(CLCB )* 1.000 *0.2000E-02*0.2014E-02* 1.007 *0.2000E-02* *(CLCD )* 1.000 *0.6667E-03*0.6714E-03* 1.007 *0.6667E-03* *(CLDC )* 1.000 *0.8333E-03*0.8392E-03* 1.007 *0.8333E-03* * * * * * * * * CPU 6 * 1.000 *0.7000E-02*0.7049E-02* 1.007 *0.7000E-02* *(CLAC )* 1.000 *0.1333E-02*0.1343E-02* 1.007 *0.1333E-02* *(CLBC )* 1.000 *0.8333E-03*0.8392E-03* 1.007 *0.8333E-03* *(CLCA )* 1.000 *0.1333E-02*0.1343E-02* 1.007 *0.1333E-02* *(CLCB )* 1.000 *0.2000E-02*0.2014E-02* 1.007 *0.2000E-02* *(CLCD )* 1.000 *0.6667E-03*0.6714E-03* 1.007 *0.6667E-03* *(CLDC )* 1.000 *0.8333E-03*0.8392E-03* 1.007 *0.8333E-03* * * * * * * * * CPU 7 * 1.000 *0.7750E-02*0.7811E-02* 1.008 *0.7750E-02* *(CLAD )* 1.000 *0.1667E-02*0.1680E-02* 1.008 *0.1667E-02* *(CLBD )* 1.000 *0.4167E-03*0.4199E-03* 1.008 *0.4167E-03* *(CLCD )* 1.000 *0.6667E-03*0.6719E-03* 1.008 *0.6667E-03* *(CLDA )* 1.000 *0.1667E-02*0.1680E-02* 1.008 *0.1667E-02* *(CLDB )* 1.000 *0.2500E-02*0.2520E-02* 1.008 *0.2500E-02* *(CLDC )* 1.000 *0.8333E-03*0.8398E-03* 1.008 *0.8333E-03* * * * * * * * * CPU 8 * 1.000 *0.9083E-02*0.9167E-02* 1.009 *0.9083E-02* *(CLAD )* 1.000 *0.1667E-02*0.1682E-02* 1.009 *0.1667E-02* *(CLBD )* 1.000 *0.4167E-03*0.4205E-03* 1.009 *0.4167E-03* *(CLCA )* 1.000 *0.1333E-02*0.1346E-02* 1.009 *0.1333E-02* *(CLCD )* 1.000 *0.6667E-03*0.6728E-03* 1.009 *0.6667E-03* *(CLDA )* 1.000 *0.1667E-02*0.1682E-02* 1.009 *0.1667E-02* *(CLDB )* 1.000 *0.2500E-02*0.2523E-02* 1.009 *0.2500E-02* *(CLDC )* 1.000 *0.8333E-03*0.8410E-03* 1.009 *0.8333E-03* * * * * * * * ******************************************************************* MEMORY USED: 62251 WORDS OF 4 BYTES ( 7.78 % OF TOTAL MEMORY) 114.1 146.1 109.6 109.2 108.6 106.3 148.4 113.8 110.0 114.6 115.7 110.4 190 191 /END/ Obsérvese que en este caso se ha solicitado que los resultados estén desglosados por clases de mensajes.
4.1.2.1.2. Estudio por simulación Si se quisiera rehacer el estudio utilizando la simulación, el modelo resulta simplificado y mucho más próximo a la realidad puesto que los mensajes cuando están al final de la línea, buscan la siguiente línea por consulta en la tabla de encaminamiento (tal como se haría en

303
realidad en el nodo al recibir el mensaje) teniendo en cuenta cual es el destino final del mismo. Ahora bien. su tiempo de cálculo aumenta de manera muy importante. Para comparar la calidad de los resultados, éstos se han calculado mediante el uso de la cola auxiliar destinada a este objetivo y por suma de los tiempos medios de respuesta correspondientes a cada uno de los tramos que constituyen el camino de un tipo de mensajes determinado. Pueden compararse los resultados obtenidos de este modelo con los obtenidos en el modelo de hipótesis equivalentes del apartado anterior. SIMULOG *** QNAP2 *** ( 01-07-92 ) V 9.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE INTEGER J; 2 QUEUE GEN,LINIA(8,8),R(4,4); 3 REAL DIREC(8,4)=(0,2,2,2, 4 1,4,4,8, 5 4,0,4,4, 6 2,3,6,8, 7 6,6,0,6, 8 8,4,5,8, 9 8,8,8,0, 10 2,4,6,7); 11 12 REAL TRAB,TRAC,TRAD,TRBA,TRBC,TRBD,TRCA,TRCB,TRCD,TRDA,TR ==> DB,TRDC; 13 INTEGER OD(12) = ( 60,140,240, 14 315,365,390, 15 470,590,630, 16 730,880,930); 17 INTEGER I,K; 18 CUSTOMER INTEGER ORIG,DESTI; 19 REF CUSTOMER C; 20 /EXEC/ FOR I := 1 STEP 1 UNTIL 8 DO FOR K := 1 STEP 1 UNTIL 8 DO 21 LINIA(I,K).J := K; 22 /STATION/ NAME = GEN; 23 TYPE = SOURCE; 24 SERVICE = BEGIN 25 EXP(60000./930.); 26 I:= RINT(1,930); 27 FOR K := 1 STEP 1 UNTIL 11 DO 28 BEGIN 29 IF I < OD(K) THEN 30 BEGIN 31 ORIG := 1; 32 DESTI := 2; 33 C := NEW(CUSTOMER); 34 TRANSIT(C,R(ORIG,DESTI)); 35 TRANSIT(LINIA(2 * ORIG - 1,2 * ORIG)); 36 END; 37 IF ((I > OD(K)) AND (I <= OD(K + 1))) THEN 38 BEGIN 39 ORIG := K/3 + 1; 40 K := K + 1; 41 DESTI := K - K/3 * 3; 42 IF DESTI = 0 THEN DESTI := 3; 43 IF DESTI >= ORIG THEN DESTI := DESTI + 1; 44 C := NEW(CUSTOMER); 45 TRANSIT(C,R(ORIG,DESTI)); 46 TRANSIT(LINIA(2 * ORIG - 1,2 * ORIG)); 47 END; 48 END; 49 END; 50 51 /STATION/ NAME = LINIA; 52 SERVICE = BEGIN 53 EXP(256.*8./64.);

304
54 I:=DIREC(J,DESTI); 55 IF I=0 THEN 56 BEGIN 57 C := R(ORIG,DESTI).FIRST; 58 WHILE C <> SON DO C := C.NEXT; 59 TRANSIT(C,OUT); 60 TRANSIT (OUT); 61 END; 62 TRANSIT (LINIA(J,I)); 63 END; 64 65 /CONTROL/ TMAX= 300000; 66 ACCURACY= ALL QUEUE; 67 68 /EXEC/ BEGIN 69 PRINT; 70 SIMUL; 71 TRAB := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,4))+ 72 MRESPONSE(LINIA(4,3)); 73 TRAC := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,4))+ 74 MRESPONSE(LINIA(4,6))+MRESPONSE(LINIA(6,5)); 75 TRAD := MRESPONSE(LINIA(1,2))+MRESPONSE(LINIA(2,8))+ 76 MRESPONSE(LINIA(8,7)); 77 TRBA := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,2))+ 78 MRESPONSE(LINIA(2,1)); 79 TRBC := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,6))+ 80 MRESPONSE(LINIA(6,5)); 81 TRBD := MRESPONSE(LINIA(3,4))+MRESPONSE(LINIA(4,8))+ 82 MRESPONSE(LINIA(8,7)); 83 TRCA := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,8))+ 84 MRESPONSE(LINIA(8,2))+MRESPONSE(LINIA(2,1)); 85 TRCD := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,8))+ 86 MRESPONSE(LINIA(8,7)); 87 TRCB := MRESPONSE(LINIA(5,6))+MRESPONSE(LINIA(6,4))+ 88 MRESPONSE(LINIA(4,3)); 89 TRDA := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,2))+ 90 MRESPONSE(LINIA(2,1)); 91 TRDB := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,4))+ 92 MRESPONSE(LINIA(4,3)); 93 TRDC := MRESPONSE(LINIA(7,8))+MRESPONSE(LINIA(8,6))+ 94 MRESPONSE(LINIA(6,5)); 95 PRINT(TRAB,TRAC,TRAD); 96 PRINT(TRBA,TRBC,TRBD); 97 PRINT(TRCA,TRCB,TRCD); 98 PRINT(TRDA,TRDB,TRDC); 99 END; ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 300000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * GEN * 64.03 * 1.000 * 1.000 * 64.03 * 4684* * +/- * 1.829 *0.0000E+00*0.0000E+00* 1.829 * * * * * * * * * * LINIA 2 * 30.88 *0.1246 *0.1477 * 36.61 * 1210* * +/- * 2.017 *0.1055E-01*0.1607E-01* 3.188 * * * * * * * * * * LINIA 9 * 31.34 *0.1347 *0.1531 * 35.63 * 1289* * +/- * 1.999 *0.1170E-01*0.1384E-01* 2.597 * * * * * * * * * * LINIA 12 * 31.07 *0.7519E-01*0.8277E-01* 34.20 * 726* * +/- * 2.504 *0.7059E-02*0.1367E-01* 3.444 * * * * * * * * * * LINIA 16 * 34.91 *0.5632E-01*0.6102E-01* 37.82 * 484* * +/- * 4.215 *0.9778E-02*0.1091E-01* 5.125 * *

305
* * * * * * * * LINIA 20 * 32.59 *0.7801E-01*0.8174E-01* 34.15 * 718* * +/- * 2.378 *0.7146E-02*0.8014E-02* 2.579 * * * * * * * * * * LINIA 26 * 34.57 *0.4171E-01*0.4353E-01* 36.08 * 362* * +/- * 3.707 *0.6404E-02*0.6778E-02* 4.122 * * * * * * * * * * LINIA 27 * 32.92 *0.1857 *0.2277 * 40.37 * 1691* * +/- * 1.851 *0.1625E-01*0.2106E-01* 3.039 * * * * * * * * * * LINIA 30 * 35.30 *0.7448E-01*0.8044E-01* 38.12 * 633* * +/- * 3.819 *0.9264E-02*0.1115E-01* 4.429 * * * * * * * * * * LINIA 32 * 28.69 *0.1243E-01*0.1243E-01* 28.69 * 130* * +/- * 4.742 *0.2918E-02*0.2918E-02* 4.742 * * * * * * * * * * LINIA 38 * 30.73 *0.1345 *0.1547 * 35.35 * 1313* * +/- * 1.734 *0.1065E-01*0.1591E-01* 2.745 * * * * * * * * * * LINIA 44 * 32.35 *0.6922E-01*0.7420E-01* 34.68 * 642* * +/- * 2.659 *0.8011E-02*0.9049E-02* 3.228 * * * * * * * * * * LINIA 45 * 31.92 *0.9321E-01*0.1024 * 35.07 * 876* * +/- * 2.950 *0.8071E-02*0.1099E-01* 3.485 * * * * * * * * * * LINIA 48 * 29.55 *0.6609E-01*0.6892E-01* 30.81 * 671* * +/- * 2.910 *0.6452E-02*0.6856E-02* 2.968 * * * * * * * * * * LINIA 56 * 32.19 *0.1548 *0.1929 * 40.11 * 1443* * +/- * 2.196 *0.1281E-01*0.2053E-01* 3.851 * * * * * * * * * * LINIA 58 * 32.63 *0.1008 *0.1104 * 35.71 * 927* * +/- * 2.415 *0.9855E-02*0.1273E-01* 3.771 * * * * * * * * * * LINIA 60 * 33.53 *0.8171E-01*0.8924E-01* 36.62 * 731* * +/- * 2.046 *0.8194E-02*0.9643E-02* 3.040 * * * * * * * * * * LINIA 62 * 35.31 *0.2860E-01*0.2887E-01* 35.64 * 243* * +/- * 5.058 *0.5594E-02*0.5755E-02* 5.120 * * * * * * * * * * LINIA 63 * 34.11 *0.9402E-01*0.1019 * 36.97 * 827* * +/- * 2.188 *0.8583E-02*0.9742E-02* 2.344 * * * * * * * * * * R 2 *0.0000E+00*0.0000E+00*0.1180 * 110.9 * 319* * +/- *0.0000E+00*0.0000E+00*0.3193E-01* 9.902 * * * * * * * * * * R 3 *0.0000E+00*0.0000E+00*0.1920 * 141.5 * 407* * +/- *0.0000E+00*0.0000E+00*0.2514E-01* 14.12 * * * * * * * * * * R 4 *0.0000E+00*0.0000E+00*0.1836 * 113.8 * 484* * +/- *0.0000E+00*0.0000E+00*0.2303E-01* 8.691 * * * * * * * * * * R 5 *0.0000E+00*0.0000E+00*0.1280 * 106.1 * 362* * +/- *0.0000E+00*0.0000E+00*0.1609E-01* 7.103 * * * * * * * * * * R 7 *0.0000E+00*0.0000E+00*0.8297E-01* 110.1 * 226* * +/- *0.0000E+00*0.0000E+00*0.1289E-01* 9.790 * * * * * * * * * * R 8 *0.0000E+00*0.0000E+00*0.4081E-01* 94.18 * 130* * +/- *0.0000E+00*0.0000E+00*0.7638E-02* 9.646 * * * * * * * * * * R 9 *0.0000E+00*0.0000E+00*0.2082 * 136.4 * 458* * +/- *0.0000E+00*0.0000E+00*0.2374E-01* 6.981 * * * * * * * * * * R 10 *0.0000E+00*0.0000E+00*0.2370 * 110.8 * 642* * +/- *0.0000E+00*0.0000E+00*0.2296E-01* 6.225 * * * * * * * * * * R 12 *0.0000E+00*0.0000E+00*0.7255E-01* 102.2 * 213* * +/- *0.0000E+00*0.0000E+00*0.7541E-02* 7.903 * *

306
* * * * * * * * R 13 *0.0000E+00*0.0000E+00*0.1787 * 114.3 * 469* * +/- *0.0000E+00*0.0000E+00*0.2146E-01* 8.399 * * * * * * * * * * R 14 *0.0000E+00*0.0000E+00*0.2829 * 116.2 * 730* * +/- *0.0000E+00*0.0000E+00*0.3170E-01* 6.388 * * * * * * * * * * R 15 *0.0000E+00*0.0000E+00*0.8914E-01* 110.0 * 243* * +/- *0.0000E+00*0.0000E+00*0.1678E-01* 9.066 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 105146 WORDS OF 4 BYTES ( 4.21 % OF TOTAL MEMORY) 111.2 144.0 111.4 105.9 107.3 99.80 137.5 110.4 103.1 111.4 117.1 110.8 100 101 /END/ Se puede observar la concordancia de los resultados obtenidos por el tratamiento del modelo analítico con los dos obtenidos del modelo de simulación.
4.1.2.2. Considerando el mecanismo de control de tráfico La primera idea que parecería poder usarse para representar el mecanismo de control de flujo por ventana deslizante sería suponer que la cola de entrada fuera de capacidad limitada. No obstante, rápidamente hay que descartar la idea ya que con esta hipótesis los mensajes que llegan al sistema cuando la cola esta llena se pierden, cuando en realidad esperan a que se produzca el retorno del mensaje de confirmación de transmisión correcta de los mensajes enviados.
4.2. REDES CON COMPARTICIÓN DEL MEDIO 4.2.1. SISTEMA DE POLLING Para empezar, se puede considerar el caso del mecanismo de polling circular (roll-call polling) en que el controlador envía por turno mensajes de polling a cada estación remota y cada una de ellas responde al controlador centralizado con los mensajes recibidos desde la última transmisión o con una indicación de no tener mensajes pendientes. Si se considera un sistema con N terminales, donde para la estación i, wi es el tiempo necesario para enviar un mensaje de polling, mi la longitud media de los mensajes (incluyendo los bits de control del mensaje o paquete) medida en tiempo de transmisión por la línea correspondiente, M2i es momento de segundo orden de las longitudes de mensaje y λi es la frecuencia de llegada de mensajes, se puede observar que se está en un caso de servidor multi-cola estudiado en el apartdo 3.10. del primer volumen de esta obra. En este caso, normalmente, el tiempo de propagación puede considerarse prácticamente constante, por lo que su variancia es nula. La fórmula que nos daba el tiempo de espera de los mensajes en la estación para el caso simétrico en el que se supone que todas las estaciones remotas tienen el mismo comportamiento (se puede suprimir el subíndice i) era
( )( )0
20
121
2
2
ρ−λ+ρ±
+σ
=MNc
uW u
donde el signo - corresponde al sistema exhaustivo y el + al sistema con puerta.

307
Al considerarse nula va variancia del tiempo de propagación, se obtiene que
( )( )0
20
121
ρ−λ+ρ±
=MNc
W
Las variables que aparecen se pueden calcular de la forma siguiente c0 = Nw, ρ0 = Nλt y ρ = λt. Finalmente se puede analizar que w,, el tiempo total necesario para enviar un mensaje de polling, depende de tP, tiempo de transmisión de un mensaje de polling, de tS, tiempo de sincronización de un mensaje de polling y de u, tiempo de propagación del mensaje, que depende de la velocidad de propagación de la energía en el medio considerado y de la topología de conexión de las estaciones y es la suma de los tiempos requeridos por las señales para propagarse de ida y vuelta entre cada estación y el controlador; con estas condiciones se puede escribir que
w = tP + tS + u
En el caso de polling en cascada (hub polling) el controlador envía un mensaje de polling a la estación remota más alejada, la cual devuelve los mensajes en espera y envía el mensaje (o indicación con el último mensaje transmitido) de polling a la estación más próxima a ella, la cual repite el mecanismo hasta que el mensaje de polling es devuelto al controlador. Para este esquema de funcionamiento toda la deducción realizada para el polling circular sigue siendo válida a condición de cambiar el valor del tiempo necesario para enviar un mensaje de polling, w, que ahora depende solamente del tiempo de sincronización, tS, y del tiempo de propagación de entre dos estaciones consecutivas, que en un esquema donexión lineal, puede tomarse en primera aproximación como u(1 + N)/(2N). Así pues,
w = tS + u(1 + N)/(2N)
4.2.2. TÉCNICAS DE ACCESO AL AZAR La alternativa a utilizar de forma controlada un medio de comunicación, como era el polling, es utilizar el medio de comunicación de forma aleatoria de tal manera que cada estación transmita cuando quiera, pero estableciendo los mecanismos necesarios para detectar los conflictos y colisiones que se puedan producir y sin que exista ninguna estación central de control, lo que conduce a una arquitectura completamente descentralizada. Los ejemplos clásicos de este tipo de conexión son los referenciados en la literatura como Aloha puro y Aloha ranurado (slotted Aloha) desarrollados a principios de los años setenta en la Universidad de Hawaii (ABRA73).
4.2.2.1. Aloha puro En el Aloha puro cada estación transmite cuando le llega el mensaje, es decir en un instante aleatorio. Como consecuencia de ello dos o más mensajes pueden solaparse en el tiempo provocando una colisión y debe existir algún mecanismo para detectarlas. En el sistema original todos los mensajes se transmitían por radio y una central de recepción era la encargada de detectar las colisiones. En caso de una colisión las estaciones en conflicto intentan retransmitir el mensaje, pero deben decalar sus reintentos aleatoriamente, siguiendo algún algoritmo de resolución de colisiones para evitar que se produzca de nuevo. Si se considera que hay N estaciones que compiten por utilizar el canal, que cada una de las cuales transmite en promedio λ paquetes por segundo que llegan distribuidos según una ley de Poisson. Estos paquetes se pueden considerar de longitud fija m, medida en tiempo, de acuerdo con la capacidad del canal.

308
En estas circunstancias, la utilización ρ del canal por los paquetes llegados al sistema será (equivalente a la intensidad de tráfico)
ρ = Nλm
Ahora bien la frecuencia total de llegada de paquetes de una estación al canal de transmisión, considerando los llegados de nuevo y las retransmisiones, será λ' > λ, que se admitirá que también está distribuida según una ley de Poisson (lo cual es cierto si los tiempos de espera para las retransmisiones son grandes), y con lo que la utilización real del canal será entonces G, que vendrá dado por
G = Nλ'm
Si se considera ahora un paquete típico de m segundos de longitud, sufrirá una colisión con otro paquete si se solapa con él en cualquier punto. Es fácil ver que es necesario un intervalo de 2m segundos sin ningún otro paquete para que no se produzca la colisión (fig. 4.2). A partir de la ley de Poisson se puede escribir que esta probabilidad vale
GmN ee 22 −λ− =
mm
m m
2m
Colisión
Con colisión
Sin colisión
Figura 4.2.
La relación ρ/G representa la fracción de mensajes transmitidos con éxito por el canal y debe ser igual a la probabilidad que se acaba de calcular de que no haya colisión. En consecuencia, se tiene que la expresión de la productividad normalizada (utilización) ρ del Aloha puro es:
ρ = G e-2G
La productividad máxima se puede determinar derivando respecto a G e igualando a cero, de donde se obtiene que G = 0.5 y ρ = 0.5 e-1 = 0.18. Este cálculo pone de manifiesto que la productividad máxima de este sistema está limitada al 18% de la capacidad del canal. Finalmente se pueden a calcular los retardos que se producirán en este sistema. Para determinarlos se debe definir la estrategia de retransmisión cuando se produce una colisión. Si se admite que se procede eligiendo al azar un intervalo múltiplo entero de la longitud m del paquete y generado al azar entre 1 y K y se denominan R el tiempo necesario para detectar una colisión (tiempos de transmisión y de proceso) y E el número medio de retransmisiones por mensaje transmitido, en consecuencia, el tiempo medio D requerido para transmitir un paquete con éxito será

309
+
+++=2
11 KRERmD
El número medio de retransmisiones dependerá del intervalo de retransmisión K. Evidentemente, cuanto mayor sea K tanto menor serán las nuevas colisiones que se producirán hasta llegar a desaparecer esta dependencia. Cuando esto suceda, obviamente se podrá escribir
EG+=
ρ1
y sustituyendo la ecuación de la productividad, se obtiene
E = e2G - 1
4.2.2.2. Aloha ranurado Este sistema es idéntico al anterior solo que existe un reloj centralizado que divide el tiempo en intervalos de longitud m y las transmisiones sólo pueden iniciarse al inicio de cada intervalo. Esto permite que el intervalo durante el cual pueden producirse colisiones quede reducido a m, con lo que la productividad normalizada viene definida por
ρ = Ge-G
que tiene el máximo para G = 1 y esta productividad máxima vale ρ = e-1 = 0.368, el doble del obtenido para el Aloha puro. Finalmente para determinar los retardos que se producirán en este sistema, se puede proceder como en el caso del Aloha puro y admitir el mismo mecanismo de solución de colisiones. De esta forma el tiempo medio D requerido para transmitir un paquete con éxito será
+
++++=2
15.05.1 KRERmD
Respecto al número medio de retransmisiones también se puede escribir
EG+=
ρ1
y sustituyendo la ecuación de la productividad normalizada, se obtiene
E = eG - 1
4.3. REDES DE ÁREA LOCAL En este apartado se estudiarán las redes de área local con políticas CSMA/CD sobre un bus y de circulación de testigo (token passing), respectivamente, para poder proceder finalmente a su comparación.
4.3.1. REDES LOCALES CSMA/CD Visto el bajo rendimiento que puede obtenerse de las estrategias tipo Aloha, que alcanzan como máximo el 36.8% en el caso ranurado con un sincronismo total entre todas las estaciones, se han propuesto numerosas estrategias alternativas con el fin de mejorarlo. Entre

310
otras se puede considerar la familia de protocolos de tipo CSMA/CD (Carrier Sensing Multiple Access/Collission Detection), cuyo ejemplo más representativo es el Ethernet. Las características principales de este procedimiento son: - todas las estaciones pueden "oir" las transmisiones que se producen en el canal;
- una estación puede transmitir si detecta la señal portadora (de ahí la denominación de carrier sensing) que el canal está ocioso;
- puesto que pueden producirse colisiones cuando dos o más estaciones separadas fisicamente al detectar el canal libre inician cada una su transmisión; cuando una estación detecta una colisión (de ahí la denominación de collision detection), transmite una señal especial notificando a las demás estaciones este efecto y aborta su transmisión.
El mecanismo de detectar la portadora y, por lo tanto, de transmitir solamente si se aprecia libre el canal ya es una mejora con respecto al Aloha; y la detección de colisiones abortando el mensaje en vez de continuar con su emisión hasta el final es otra. Se han propuesto numerosas técnicas que difieren principalmente en la gestión de la transmisión cuando se ha detectado la línea ocupada. Por ejemplo, en el esquema p-persistente una estación que detecta el canal ocupado transmite con probabilidad p cuando el canal queda libre y con probabilidad 1 - p difiere la transmisión del intervalo de propagación tp. La forma de determinar p depende de diversas estrategias. Todos los esquemas se refieren a estaciones capaces de detectar el fin de una transmisión tan pronto como ésta ha terminado. Ello requiere que el tiempo de propagación entre extremos tp sea pequeño comparado con el de transmisión del mensaje m. Esta condición se representa normalmente por tener un parámetro a = tp/m << 1. Si el tiempo de propagación se hace demasiado largo (a tendiendo a 1 o mayor), el esquema degenera hacia una simple estrategia Aloha. El bien conocido Ethernet es un protocolo CSMA/CD 1-persistente con una determinación aleatoria de retrasos tipo Aloha cuando se detecta una colisión; ahora bien, este intervalo se dobla cada vez que se produce una nueva colisión hasta alcanzar un valor máximo en cuyo momento la estación comunica a los niveles superiores el fallo de la transmisión.
4.3.1.1. Estudio analítico de la productividad Para empezar se puede estudiar la productividad máxima que se puede obtener de un red de este tipo y después se analizarán los tiempos de respuesta que se pueden obtener.
A B
Dos direcciones
tp Figura 4.3.
Considérese la topología de la figura 4.3 en la que las estaciones tienen conexión pasiva a un bus de dos direcciones. Si se consideran las dos estaciones más alejadas, A y B, para determinar el tiempo necesario para transmitir un mensaje entre ambas, cuyo inverso será la productividad máxima en la peor de las situaciones y se denomina tiempo virtual de transmisión, tv a ese tiempo, que como muestra la figura 4.4 consta de tres componentes: - el tiempo m de transmisión del mensaje

311
- el tiempo tp para detectar la terminación del mensaje
- múltiplo de 2tp unidades de tiempo para resolver las colisiones una vez se hayan detectado.
tiempo para detectar una colisión
intervalo de colisión
tiempo de detección
m. . . .tp 2tp 2tp 2tp
Figura 4.4.
Cuando se produce una colisión se requieren 2Jtp unidades de tiempo para resolverla, donde J representa el número de retransmisiones que se han realizado para resolver la colisión. Este parámetro es comparable al E = G/ρ - 1, que se introdujo al estudiar los sistemas Aloha. El tiempo de transmisión virtual valdrá entonces
tv = m + tp + 2Jtp = m[1 + a(1 + 2J)]
A continuación se debe encontrar el valor de J, que depende de la estrategia de retransmisión y que, para el caso del Ethernet, es función de la duplicación de intervalos. No obstante y para simplificar (aunque con una aproximación suficiente) se puede admitir que la longitud del intervalo de colisión está distribuido geométricamente en unidades de 2tp con parámetro pc. En consecuencia el número medio de retransmisiones será
( ) ck
kcc ppkpJ 11
1
1 =−= ∑∞
=
−
Se ha transformado pues el problema de determinar J en el de hacerlo con pc. Para ello se considera que hay N estaciones en la red tratando de transmitir (N >> 1) y que la probabilidad de que una estación transmita en un intervalo 2tp sea p. La probabilidad de que exactamente una estación transmita y tenga éxito es entonces
pc = n p (1 - p)n - 1
Es fácil encontrar entonces que el valor que maximiza esta expresión es p = 1/N. Usando este valor y haciendo tender N a infinito, se encuentra en el límite que
11
max11lim −
−
∞→ =
−= e
Np
N
Nc
y sustituyendo este valor sucesivamente en las ecuaciones anteriores, se encuentra
( )[ ]eamtv 211 ++=
cuyo inverso nos dará la productividad máxima que es posible obtener y cuyo valor normalizado o utilización será
( ) aeam
44.611
2111
+=
++≤λ=ρ

312
Como ejemplo, para a = 0.1, la máxima utilización posible es del 60%, notablemente superior al máximo alcanzable en el mejor de los casos del Aloha que era del 36.8%.
4.3.1.2. Estudio analítico del tiempo de respuesta Para estudiar el tiempo de respuesta de una red de este tipo, se puede representar el bus de una red CSMA/CD como muestra la figura 4.5 haciendo las siguientes suposiciones: - en cada nodo j, para j = 1, 2, …, n, los mensajes llegan con una frecuencia λj, para los
cuales se fija un tiempo de transmisión m; la cola de cada nodo se supone de capacidad infinita gestionada con disciplina FIFO.
- los nodos están equidistribuidos sobre el bus y el tiempo de propagación entre los nodos i y j (i > j) es τij = tp(i - j)/(n - 1).
- cuando termina la señal portadora, cada nodo retrasa el acceso al bus de un tiempo conocido como tiempo entre tramas (inter-frame gap), que está distribuido exponencialmente con media tgap.
- cuando se produce una colisión cada nodo transmite una señal de detención (jam signal) de longitud tjam para asegurar el final de la operación. El tiempo de retransmisión está distribuido exponencialmente con media µ-1.
1
λ 1m1
2
λ 2m2
j
λ jmj
n
λ nmn
Figura 4.5.
El tiempo medio de respuesta del nodo j, Rj, es la suma de la espera en el nodo, Rqj, más el tiempo de acceso del nodo j, Raj.
Rj = Rqj + Raj
El tiempo de espera en el nodo puede estudiarse mediante una cola M/G/1, es decir,
( ) ( ) jsj
jqj SCR
j
21'12
'+
ρ−
ρ=
donde
Sj = mj + Raj
( )jjjj Sm +λ=ρ '
y 2jsC es el coeficiente cuadrático de variación del tiempo Sj.
La estimación de 2jsC es algo complicada y se puede aproximar por 2
jsC = 1. Entonces se obtiene que el tiempo medio de respuesta vale

313
ajajjj
jjj R
RS
R +λ−ρ−
λ=
1
2
donde ρj = λjmj y solo queda por determinar Raj. Este tiempo puede expresarse por
Raj = p0jtdj + ncjtbj
donde: - p0j es la probabilidad que un mensaje llegue al nodo j cuando está ocioso, es decir, p0j = 1 -
ρj - λjRaj
- tdj es el retraso medio debido a que el bus esté ocupado, es decir
k
m
jk j
kdj m
Mt k
212∑
≠ ρ−ρ
=
- ncj es el número medio de colisiones por unidad de tiempo, es decir
( )cj
bjjcjjcj p
ppppn
−
−+=
11 00
donde pcj es la probabilidad que se produzca una colisión cuando el nodo j transmite un mensaje, es decir,
vj
kjk j
kcj PPp
ρ−ρ−
+ρ−
ρ= ∑
≠ 11
10
con ∑=
ρ=ρn
jj
10 , Pk, probabilidad que se produzca una colisión después de que el nodo j
transmita un mensaje, que vale ( ) ( ) ( )[ ]∏
≠
τ+µ−τ+λ−τλ− −+−=kji
mi
mikk
kkijkk epepepP,
'0
'0
20 11
siendo
<<<<τ<<<<τ
<<<<=τ
jkiikjjikkij
ijkkji
kj
ij
, para,2, para,2
, para,0'
y Pv,probabilidad de se produzca una colisión cuando el nodo j está ocioso, que vale
( )[ ]∏≠
µτ−τλ− −+−=ji
iivijiji epepP 2
02
0 11
- tbj es tiempo medio de la operación de retransmisión, es decir
tbj =tjam + µ-1 + tdj

314
A partir de las fórmulas anteriores se puede determinar Raj por iteración, inicializada con Raj = 0 y, una vez obtenido, Rj.
4.3.1.3. Estudio por simulación Para este estudio se supone que la carga está uniformemente distribuida en su generación y en su destino. Como en casos anteriores, se usará una cola ficticia para determinar el tiempo de respuesta del sistema así como su intervalo de confianza. El interés de este modelo reside en el uso de flags para controlar el uso del canal de comunicación y la retransmisión de los mensajes que han sufrido colisión. Puesto que los lenguajes de modelización no disponen del mecanismo que permite "oir" la transmisión que se acaba de realizar, la modelización se basa en conocimiento del instante en que se efectuó la transmisión precedente y el tiempo de propagación (intervalo dentro del cual una nueva transmisión provocará una colisión). En cuanto a los resultados conviene observar que a medida que aumenta la frecuencia de llegada aumenta el número de colisiones, que se puede determinar por diferencia entre los mensajes generados y los que han salido del canal de comunicación (bus).
4.3.1.3.1. Primer modelo En este modelo simplificado se supone que en el momento de la transmisión, una estación está en un extremo y todas las demás en el otro, es decir, el tiempo de propagación entre estaciones es constante e igual al necesario para que la luz recorra el bus en su totalidad. SIMULOG *** QNAP2 *** ( 15-FEB-88 ) V 5.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE S, EST(8), BUS, R, SF; 2 CUSTOMER INTEGER I; 3 CUSTOMER REAL TSERV, TESP; 4 REAL TARR, SERV, ESP, TEMPS, TPROP, TEMPSC; 5 REF CUSTOMER C,D; 6 LABEL L; 7 FLAG FL, BL; 8 INTEGER CONF = 0; 9 10 /STATION/ NAME = S; 11 TYPE = SOURCE; 12 SERVICE = BEGIN 13 EXP(TARR); 14 I := RINT(1,8); 15 TSERV := EXP(SERV); 16 IF TSERV < 3.*TPROP THEN TSERV := 3.*TPROP; 17 C := NEW(CUSTOMER); 18 TRANSIT(C,R); 19 TRANSIT(EST(I)); 20 END; 21 22 /STATION/ NAME = EST; 23 SERVICE = BEGIN 24 L: IF BUS.NB = 0 THEN 25 BEGIN 26 C := NEW(CUSTOMER); 27 C.TSERV := TSERV; 28 UNSET(FL); 29 UNSET(BL); 30 TEMPS := TIME + TPROP; 31 TRANSIT(C, BUS); 32 WAIT(FL); 33 IF CONF = 0 THEN 34 BEGIN 35 SET(BL);

315
36 TRANSIT(OUT); 37 END; 38 SET(BL); 39 CONF := 0; 40 TESP := EXP(ESP); 41 IF TESP<2.*TPROP THEN TESP := 2. * TPROP; 42 CST(TESP); 43 GOTO L; 44 END; 45 IF (TIME < TEMPS) AND (CONF = 0) THEN 46 BEGIN 47 CONF := 1; 48 D := BUS.FIRST; 49 TEMPSC := TEMPS - TIME; 50 CST(TEMPSC); 51 TRANSIT(D, OUT); 52 SET(FL); 53 TESP := EXP(ESP); 54 IF TESP<2.*TPROP THEN TESP := 2. * TPROP; 55 CST(TESP); 56 GOTO L; 57 END; 58 IF (TIME < TEMPS) AND (CONF = 1) THEN 59 BEGIN 60 TESP := EXP(ESP); 61 IF TESP<2.*TPROP THEN TESP := 2. * TPROP; 62 CST(TESP); 63 GOTO L; 64 END; 65 WAIT(BL); 66 GOTO L; 67 END; 68 69 /STATION/ NAME = BUS; 70 SERVICE = BEGIN 71 CST(TSERV + 2.*TPROP); 72 C := R.FIRST; 73 WHILE C.FATHER <> FATHER DO C := C.NEXT; 74 TRANSIT(C, OUT); 75 SET(FL); 76 TRANSIT(OUT); 77 END; 78 79 /STATION/ NAME = SF; 80 INIT = 1; 81 SERVICE = BEGIN 82 SET(FL); 83 SET(BL); 84 TRANSIT(OUT); 85 END; 86 87 /CONTROL/ TMAX = 100000.; ACCURACY = ALL QUEUE; 88 89 /EXEC/ BEGIN 90 TPROP := 0.01; 91 SERV := 0.8; 92 ESP := 0.1; 93 TEMPS := -TPROP; 94 FOR TARR := 5, 2.5, 1.25 DO SIMUL; 95 END; ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 100000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * *******************************************************************

316
* * * * * * * * S * 5.073 * 1.000 * 1.000 * 5.073 * 19713* * +/- *0.7027E-01*0.0000E+00*0.0000E+00*0.7027E-01* * * * * * * * * * EST 1 *0.9595 *0.2390E-01*0.2459E-01*0.9873 * 2491* * +/- *0.4293E-01*0.1102E-02*0.1180E-02*0.5266E-01* * * * * * * * * * EST 2 *0.9714 *0.2364E-01*0.2425E-01*0.9966 * 2433* * +/- *0.3115E-01*0.1343E-02*0.1491E-02*0.3891E-01* * * * * * * * * * EST 3 *0.9993 *0.2534E-01*0.2609E-01* 1.029 * 2536* * +/- *0.4504E-01*0.1101E-02*0.1159E-02*0.4904E-01* * * * * * * * * * EST 4 *0.9660 *0.2350E-01*0.2407E-01*0.9892 * 2433* * +/- *0.4483E-01*0.1456E-02*0.1518E-02*0.7335E-01* * * * * * * * * * EST 5 *0.9709 *0.2321E-01*0.2356E-01*0.9856 * 2390* * +/- *0.4695E-01*0.1439E-02*0.1497E-02*0.4730E-01* * * * * * * * * * EST 6 *0.9677 *0.2312E-01*0.2366E-01*0.9905 * 2389* * +/- *0.3450E-01*0.9612E-03*0.1328E-02*0.4168E-01* * * * * * * * * * EST 7 *0.9455 *0.2308E-01*0.2367E-01*0.9696 * 2441* * +/- *0.3795E-01*0.1200E-02*0.1322E-02*0.3643E-01* * * * * * * * * * EST 8 *0.9635 *0.2505E-01*0.2576E-01*0.9906 * 2600* * +/- *0.3988E-01*0.1589E-02*0.1727E-02*0.4196E-01* * * * * * * * * * BUS *0.7994 *0.1624 *0.1624 *0.7994 * 20314* * +/- *0.9631E-02*0.2830E-02*0.2830E-02*0.9631E-02* * * * * * * * * * R *0.0000E+00*0.0000E+00*0.1956 *0.9924 * 19713* * +/- *0.0000E+00*0.0000E+00*0.5210E-02*0.2011E-01* * * * * * * * * * SF *0.0000E+00*0.0000E+00*0.0000E+00*0.0000E+00* 1* * +/- *-1.000 *0.0000E+00*0.0000E+00*-1.000 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 20091 WORDS OF 4 BYTES ( 2.51 % OF TOTAL MEMORY) ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 100000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * S * 2.523 * 1.000 * 1.000 * 2.523 * 39639* * +/- *0.3238E-01*0.0000E+00*0.0000E+00*0.3238E-01* * * * * * * * * * EST 1 * 1.190 *0.6058E-01*0.6443E-01* 1.266 * 5091* * +/- *0.3643E-01*0.1890E-02*0.2066E-02*0.4254E-01* * * * * * * * * * EST 2 * 1.189 *0.5951E-01*0.6372E-01* 1.274 * 5003* * +/- *0.3580E-01*0.4234E-02*0.3192E-02*0.4344E-01* * * * * * * * * * EST 3 * 1.174 *0.5754E-01*0.6086E-01* 1.242 * 4901* * +/- *0.4252E-01*0.2450E-02*0.2627E-02*0.4427E-01* * * * * * * * * * EST 4 * 1.191 *0.5883E-01*0.6312E-01* 1.278 * 4937* * +/- *0.3555E-01*0.2305E-02*0.2675E-02*0.4592E-01* * * * * * * * * * EST 5 * 1.198 *0.5927E-01*0.6323E-01* 1.278 * 4949* * +/- *0.4266E-01*0.2633E-02*0.2816E-02*0.4674E-01* *

317
* * * * * * * * EST 6 * 1.185 *0.5835E-01*0.6266E-01* 1.272 * 4926* * +/- *0.3425E-01*0.2123E-02*0.2498E-02*0.4209E-01* * * * * * * * * * EST 7 * 1.181 *0.5895E-01*0.6315E-01* 1.265 * 4993* * +/- *0.3740E-01*0.2661E-02*0.3207E-02*0.5317E-01* * * * * * * * * * EST 8 * 1.182 *0.5717E-01*0.6104E-01* 1.262 * 4837* * +/- *0.3262E-01*0.2484E-02*0.3251E-02*0.4343E-01* * * * * * * * * * BUS *0.7520 *0.3316 *0.3316 *0.7520 * 44091* * +/- *0.1085E-01*0.4436E-02*0.4436E-02*0.1085E-01* * * * * * * * * * R *0.0000E+00*0.0000E+00*0.5022 * 1.267 * 39637* * +/- *0.0000E+00*0.0000E+00*0.1750E-01*0.2458E-01* * * * * * * * * * SF *0.0000E+00*0.0000E+00*0.0000E+00*0.0000E+00* 1* * +/- *-1.000 *0.0000E+00*0.0000E+00*-1.000 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 20364 WORDS OF 4 BYTES ( 2.55 % OF TOTAL MEMORY) ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 100000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * S * 1.257 * 1.000 * 1.000 * 1.257 * 79568* * +/- *0.9795E-02*0.0000E+00*0.0000E+00*0.9795E-02* * * * * * * * * * EST 1 * 2.045 *0.2052 *0.2709 * 2.699 * 10034* * +/- *0.5773E-01*0.8730E-02*0.1612E-01*0.1282 * * * * * * * * * * EST 2 * 2.020 *0.2039 *0.2667 * 2.642 * 10096* * +/- *0.7101E-01*0.8998E-02*0.1768E-01*0.1390 * * * * * * * * * * EST 3 * 2.011 *0.1991 *0.2592 * 2.617 * 9904* * +/- *0.6745E-01*0.8805E-02*0.1469E-01*0.1115 * * * * * * * * * * EST 4 * 2.028 *0.2000 *0.2602 * 2.637 * 9864* * +/- *0.5786E-01*0.6761E-02*0.1179E-01*0.1073 * * * * * * * * * * EST 5 * 2.001 *0.2017 *0.2622 * 2.601 * 10079* * +/- *0.6415E-01*0.6065E-02*0.1510E-01*0.1624 * * * * * * * * * * EST 6 * 2.035 *0.1993 *0.2610 * 2.664 * 9797* * +/- *0.7039E-01*0.8648E-02*0.1688E-01*0.1333 * * * * * * * * * * EST 7 * 2.021 *0.2007 *0.2594 * 2.611 * 9934* * +/- *0.6259E-01*0.7496E-02*0.1742E-01*0.2369 * * * * * * * * * * EST 8 * 2.014 *0.1985 *0.2571 * 2.608 * 9858* * +/- *0.7488E-01*0.7814E-02*0.1403E-01*0.1413 * * * * * * * * * * BUS *0.5523 *0.6622 *0.6622 *0.5523 * 119899* * +/- *0.5897E-02*0.7369E-02*0.7369E-02*0.5897E-02* * * * * * * * * * R *0.0000E+00*0.0000E+00* 2.096 * 2.635 * 79566* * +/- *0.0000E+00*0.0000E+00*0.8279E-01*0.1023 * * * * * * * * * * SF *0.0000E+00*0.0000E+00*0.0000E+00*0.0000E+00* 1* * +/- *-1.000 *0.0000E+00*0.0000E+00*-1.000 * *

318
* * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 21279 WORDS OF 4 BYTES ( 2.66 % OF TOTAL MEMORY) 96 97 /END/
4.3.1.3.2. Segundo modelo Este modelo, más detallado, tiene en cuenta la distancia entre cada par de estaciones a efecto de determinar el tiempo de propagación del mensaje entre ellas se presenta a continuación. En este caso se ha supuesto las estaciones equidistantes sobre el bus. SIMULOG *** QNAP2 *** ( 15-FEB-88 ) V 5.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE REAL POS; 2 QUEUE S, EST(8), BUS, R, SF; 3 CUSTOMER INTEGER I; 4 CUSTOMER REAL TSERV, TESP, TEMPSC; 5 REAL TARR, SERV, ESP, TEMPS, VPROP, TPROP, TCONF; 6 REF CUSTOMER C,D; 7 LABEL L; 8 FLAG FL, BL; 9 INTEGER J, CONF = 0; 10 11 /EXEC/ FOR J := 1 STEP 1 UNTIL 8 DO EST(J).POS := 2.*(J - 1)/7.; 12 13 /STATION/ NAME = S; 14 TYPE = SOURCE; 15 SERVICE = BEGIN 16 EXP(TARR); 17 I := RINT(1,8); 18 TSERV := EXP(SERV); 19 IF TSERV < 3.*TPROP THEN TSERV := 3.*TPROP; 20 D := NEW(CUSTOMER); 21 TRANSIT(D,R); 22 TRANSIT(EST(I)); 23 END; 24 25 /STATION/ NAME = EST; 26 SERVICE = BEGIN 27 L: IF BUS.NB = 0 THEN 28 BEGIN 29 D := NEW(CUSTOMER); 30 D.I := I; 31 D.TSERV := TSERV; 32 UNSET(FL); 33 UNSET(BL); 34 TEMPS := TIME; 35 TRANSIT(D, BUS); 36 WAIT(FL); 37 IF CONF = 0 THEN 38 BEGIN 39 SET(BL); 40 TRANSIT(OUT); 41 END; 42 SET(BL); 43 CONF := 0; 44 TESP := EXP(ESP); 45 IF TESP<2.*TPROP THEN TESP := 2. * TPROP; 46 CST(TESP);

319
47 GOTO L; 48 END; 49 TCONF := TEMPS + 50 ABS(POS-EST(BUS.FIRST.I).POS)/VPRO ==> P; 51 IF (TIME < TCONF) AND (CONF = 0) THEN 52 BEGIN 53 CONF := 1; 54 C := BUS.FIRST; 55 TEMPSC := TCONF - TIME; 56 CST(TEMPSC); 57 TRANSIT(C, OUT); 58 SET(FL); 59 TESP := EXP(ESP); 60 IF TESP<2.*TPROP THEN TESP := 2. * TPROP; 61 CST(TESP); 62 GOTO L; 63 END; 64 TCONF := TEMPS + 65 ABS(POS-EST(BUS.FIRST.I).POS)/VPRO ==> P; 66 IF (TIME < TCONF) AND (CONF = 1) THEN 67 BEGIN 68 TESP := EXP(ESP); 69 IF TESP<2.*TPROP THEN TESP := 2. * TPROP; 70 CST(TESP); 71 GOTO L; 72 END; 73 WAIT(BL); 74 GOTO L; 75 END; 76 77 /STATION/ NAME = BUS; 78 SERVICE = BEGIN 79 CST(TSERV + 2.*TPROP); 80 D := R.FIRST; 81 WHILE D.FATHER <> FATHER DO D := D.NEXT; 82 TRANSIT(D, OUT); 83 SET(FL); 84 TRANSIT(OUT); 85 END; 86 87 /STATION/ NAME = SF; 88 INIT = 1; 89 SERVICE = BEGIN 90 SET(FL); 91 SET(BL); 92 TRANSIT(OUT); 93 END; 94 95 /CONTROL/ TMAX = 100000.; ACCURACY = ALL QUEUE; 96 97 /EXEC/ BEGIN 98 VPROP := 200.; 99 TPROP := 2. / VPROP; 100 SERV := 1000. * 8. * 1000. / 10000000.; 101 ESP := 0.1; 102 TEMPS := -TPROP; 103 FOR TARR := 5., 2.5, 1.25 DO SIMUL; 104 END; ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 100000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * *

320
* S * 5.068 * 1.000 * 1.000 * 5.068 * 19733* * +/- *0.5344E-01*0.0000E+00*0.0000E+00*0.5344E-01* * * * * * * * * * EST 1 *0.9360 *0.2311E-01*0.2379E-01*0.9635 * 2469* * +/- *0.5033E-01*0.1296E-02*0.1320E-02*0.4063E-01* * * * * * * * * * EST 2 *0.9808 *0.2440E-01*0.2500E-01* 1.005 * 2488* * +/- *0.4080E-01*0.1663E-02*0.1820E-02*0.4532E-01* * * * * * * * * * EST 3 *0.9902 *0.2520E-01*0.2585E-01* 1.016 * 2545* * +/- *0.2786E-01*0.1102E-02*0.1162E-02*0.2986E-01* * * * * * * * * * EST 4 *0.9907 *0.2406E-01*0.2470E-01* 1.017 * 2429* * +/- *0.5019E-01*0.1498E-02*0.1643E-02*0.5540E-01* * * * * * * * * * EST 5 *0.9684 *0.2372E-01*0.2421E-01*0.9887 * 2449* * +/- *0.4366E-01*0.1340E-02*0.1452E-02*0.5112E-01* * * * * * * * * * EST 6 *0.9767 *0.2320E-01*0.2373E-01*0.9991 * 2375* * +/- *0.4694E-01*0.1332E-02*0.1313E-02*0.4745E-01* * * * * * * * * * EST 7 *0.9461 *0.2287E-01*0.2357E-01*0.9753 * 2417* * +/- *0.4056E-01*0.1226E-02*0.1296E-02*0.4393E-01* * * * * * * * * * EST 8 *0.9627 *0.2465E-01*0.2556E-01*0.9981 * 2561* * +/- *0.4653E-01*0.1694E-02*0.1838E-02*0.4692E-01* * * * * * * * * * BUS *0.8065 *0.1627 *0.1627 *0.8065 * 20173* * +/- *0.9759E-02*0.2653E-02*0.2653E-02*0.9759E-02* * * * * * * * * * R *0.0000E+00*0.0000E+00*0.1964 *0.9954 * 19733* * +/- *0.0000E+00*0.0000E+00*0.5582E-02*0.2419E-01* * * * * * * * * * SF *0.0000E+00*0.0000E+00*0.0000E+00*0.0000E+00* 1* * +/- *-1.000 *0.0000E+00*0.0000E+00*-1.000 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 20303 WORDS OF 4 BYTES ( 2.54 % OF TOTAL MEMORY) ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 100000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * S * 2.526 * 1.000 * 1.000 * 2.526 * 39581* * +/- *0.2548E-01*0.0000E+00*0.0000E+00*0.2548E-01* * * * * * * * * * EST 1 * 1.158 *0.5923E-01*0.6320E-01* 1.235 * 5116* * +/- *0.3427E-01*0.2213E-02*0.2338E-02*0.4100E-01* * * * * * * * * * EST 2 * 1.165 *0.5716E-01*0.6059E-01* 1.235 * 4905* * +/- *0.3564E-01*0.2838E-02*0.3470E-02*0.3341E-01* * * * * * * * * * EST 3 * 1.169 *0.5670E-01*0.5981E-01* 1.233 * 4850* * +/- *0.3230E-01*0.1764E-02*0.2189E-02*0.3443E-01* * * * * * * * * * EST 4 * 1.149 *0.5730E-01*0.6068E-01* 1.217 * 4985* * +/- *0.3344E-01*0.2136E-02*0.2580E-02*0.2837E-01* * * * * * * * * * EST 5 * 1.172 *0.5659E-01*0.6003E-01* 1.243 * 4830* * +/- *0.3511E-01*0.2234E-02*0.2464E-02*0.4163E-01* * * * * * * * *

321
* EST 6 * 1.152 *0.5751E-01*0.6145E-01* 1.231 * 4992* * +/- *0.3814E-01*0.4050E-02*0.3213E-02*0.4757E-01* * * * * * * * * * EST 7 * 1.137 *0.5757E-01*0.6111E-01* 1.207 * 5063* * +/- *0.3089E-01*0.2267E-02*0.2390E-02*0.3661E-01* * * * * * * * * * EST 8 * 1.168 *0.5655E-01*0.6052E-01* 1.250 * 4840* * +/- *0.3664E-01*0.2391E-02*0.3958E-02*0.5169E-01* * * * * * * * * * BUS *0.7676 *0.3288 *0.3288 *0.7676 * 42839* * +/- *0.1029E-01*0.3980E-02*0.3980E-02*0.1029E-01* * * * * * * * * * R *0.0000E+00*0.0000E+00*0.4874 * 1.231 * 39581* * +/- *0.0000E+00*0.0000E+00*0.1392E-01*0.2546E-01* * * * * * * * * * SF *0.0000E+00*0.0000E+00*0.0000E+00*0.0000E+00* 1* * +/- *-1.000 *0.0000E+00*0.0000E+00*-1.000 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 20494 WORDS OF 4 BYTES ( 2.56 % OF TOTAL MEMORY) ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 100000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * S * 1.262 * 1.000 * 1.000 * 1.262 * 79204* * +/- *0.1006E-01*0.0000E+00*0.0000E+00*0.1006E-01* * * * * * * * * * EST 1 * 2.094 *0.2085 *0.2821 * 2.833 * 9959* * +/- *0.7286E-01*0.7572E-02*0.1523E-01*0.1692 * * * * * * * * * * EST 2 * 1.960 *0.1920 *0.2433 * 2.484 * 9796* * +/- *0.5722E-01*0.6981E-02*0.7738E-02*0.1101 * * * * * * * * * * EST 3 * 1.887 *0.1879 *0.2456 * 2.466 * 9960* * +/- *0.6054E-01*0.7918E-02*0.1728E-01*0.1566 * * * * * * * * * * EST 4 * 1.981 *0.1953 *0.2487 * 2.523 * 9859* * +/- *0.6218E-01*0.7137E-02*0.1469E-01*0.1484 * * * * * * * * * * EST 5 * 1.932 *0.1934 *0.2475 * 2.471 * 10014* * +/- *0.5231E-01*0.7738E-02*0.1554E-01*0.1104 * * * * * * * * * * EST 6 * 1.950 *0.1920 *0.2470 * 2.509 * 9845* * +/- *0.6601E-01*0.8493E-02*0.2069E-01*0.1586 * * * * * * * * * * EST 7 * 1.951 *0.1950 *0.2484 * 2.484 * 9997* * +/- *0.5944E-01*0.6637E-02*0.1218E-01*0.1058 * * * * * * * * * * EST 8 * 2.083 *0.2036 *0.2781 * 2.846 * 9774* * +/- *0.8340E-01*0.9369E-02*0.2129E-01*0.1961 * * * * * * * * * * BUS *0.5861 *0.6600 *0.6600 *0.5861 * 112617* * +/- *0.5736E-02*0.8169E-02*0.8169E-02*0.5736E-02* * * * * * * * * * R *0.0000E+00*0.0000E+00* 2.041 * 2.577 * 79204* * +/- *0.0000E+00*0.0000E+00*0.9304E-01*0.9968E-01* * * * * * * * * * SF *0.0000E+00*0.0000E+00*0.0000E+00*0.0000E+00* 1* * +/- *-1.000 *0.0000E+00*0.0000E+00*-1.000 * * * * * * * * *

322
******************************************************************* ... END OF SIMULATION ... MEMORY USED: 21829 WORDS OF 4 BYTES ( 2.73 % OF TOTAL MEMORY) 105 106 /END/
4.3.2. REDES LOCALES DE PASO DE TESTIGO (TOKEN RING) El funcionamiento de este algoritmo, al menos desde el punto de vista de su comportamiento, es similar al del polling en cascada (hub polling); la diferencia estriba en que no hay ningún controlador central. Todas las estaciones funcionan de forma descentralizada. Todos los mensajes se mueven alrededor de un anillo y son repetidos activamente por cada estación por la que pasan, tal como muestra la figura 4.6. La estación que encuentra su propia dirección como destino, copia el mensaje para enviarlo a los terminales o procesadores conectados a ella, mientras pasa hacia la siguiente estación. La estación que ha emitido el mensaje lo destruye cuando le llega desde el anillo.
Figura 4.6.
La red de paso de testigo es un estándar para las redes de área local basado en un control de acceso de tipo secuencial. En este protocolo, la señal que autoriza la transmisión, denominada testigo o token, circula entre los nodos conectados al anillo. Un nodo que tenga datos a transmitir, atrapa el token libre y lo convierte en ocupado que transporta un mensaje con la dirección de destino. Una vez que el mensaje haya sido recibido por el nodo de destino, el token regresa al nodo origen para indicar la finalización de la transmisión y repetir el proceso si hay aún mensajes a transmitir o enviarlo libre otra vez al anillo. Esto significa que, como máximo, hay un mensaje circulando en el anillo. Hay tres criterios para hacer de nuevo libre el token: - tipo exhaustivo: el token se convierte en libre después de haber transmitido todos los datos,
incluso los recibidos durante la transmisión.
- tipo con puerta: el token se convierte en libre después de haber transmitido los datos que estaban en espera al iniciar la transmisión.
- tipo limitado: el token se convierte en libre después de haber transmitido todos los datos posibles durante un período de tiempo preestablecido o cuando la cola se vacía si el período es más corto.

323
4.3.2.1. Estudio analítico Una red de área local de este tipo puede modelarse tal como muestra la figura 4.7. El token puede considerarse como un servidor simple que se pasea alrededor del anillo para servir a los nodos que tienen datos a transmitir. Se trata pues de modelo multi-cola tal como el que se describe en el apartado 3.10. del primer volumen de esta obra.
j - 1λ j - 1
λ j
λ j + 1
j + 1
j
λ 2
λ 1
λ n
n
1
2
Figura 4.7.
Sea n el número de nodos, y uj y 2juσ , respectivamente, la media y la variancia del tiempo de
paso del nodo j al siguiente. Este tiempo es la suma del tiempo de propagación y del retardo del nodo debido al proceso y al registro de decalaje que existe en él. Sean cj y M2j la media y el momento de segundo orden del tiempo de un ciclo, respectivamente. El tiempo de un ciclo está definido por el que transcurre entre dos pasos consecutivos del token por un nodo.
4.3.2.1.1. Caso simétrico Si el sistema es simétrico y el proceso de llegada es de Poisson, de acuerdo con los resultados obtenidos en el apartado 3.10. del primer volumen de esta obra, el tiempo de respuesta para cualquier nodo vale
( )( )0
202
121
2 ρ−λ+ρ±
+σ
=Mnc
uR u
El signo ± toma el signo - para el caso exhaustivo y el + para el caso con puerta, λ es la frecuencia de llegada del proceso de Poisson a un nodo, m y M2 son, respectivamente, la media y el momento de segundo orden del tiempo de servicio. La utilización del nodo es ρ = λm, ρ0 = nρ es la utilización del servidor rotativo y c0 = nu el tiempo total de latencia en vacío del token.
4.3.2.1.2. Caso asimétrico En este caso aún puede considerarse que el tiempo del ciclo del token cj y viene dado por
cc
c j ≡ρ−
=0
0
1
donde ∑∑==
ρ=ρ=n
jj
n
jjuc
10
10 y . Por lo tanto, de acuerdo con el punto 3.10 del primer
volumen de esta obra, el tiempo medio de respuesta del nodo j viene dado por

324
( )c
MR jc
jj 21 2
ρ±=
donde el signo ± tiene el mismo significado que en el apartado anterior. Esta ecuación tiene el inconveniente que el momento de segundo orden del tiempo de ciclo
jcM 2 requiere una compleja iteración con un importante tiempo de cálculo. Un método aproximado se expone a continuación. El tiempo entre visitas se define como el período que transcurre desde que el token deja el nodo hasta que regresa a él. Sean vj y
jvM 2 , respectivamente, la media y el momento de segundo orden del tiempo entre visitas. Entonces, de acuerdo con el apartado 3.10. del primer volumen de esta obra, se tiene que el tiempo de respuesta del nodo j vale
( )ρ−
λ+=
12222 jj
j
vj
Mv
MR j
El segundo miembro de la igualdad es la suma del tiempo residual entre visitas y el tiempo de respuesta por la cola del nodo, por lo que la fórmula anterior tanto es válida para el caso exhaustivo como para el caso con puerta. Promediando la expresión anterior con ρj se obtiene
( ) ( ) ( )∑∑∑===
ρ±ρρ−
+λρ−
ρ=ρ
n
jjj
n
jjj
n
jjj
cMR
10
0
12
0
0
1
11212
donde el signo ± tiene el sentido ya citado y se supone que 02 =σju . Por otro lado, si se ha
supuesto que cj = c es independiente de j, parece razonable hacerlo también con el momento de segundo orden, es decir cc MM
j 22 = . Con ello a partir de la expresión anterior se puede determinar M2c que se puede sustituir en la expresión del tiempo de respuesta, con lo que se obtiene
( ) ( )
ρ±ρ
λρ+
ρ−
ρ±=
∑
∑
=
=n
jjj
n
jjj
jj
McR
1
120
00 112
1
donde el signo ± toma el signo - para el caso exhaustivo y el signo + para el caso con puerta..
4.3.2.2. Estudio por simulación Cada nodo puede considerarse como la asociación de una cola pasiva en donde espera el mensaje a que llegue el token para ser transmitido y de una segunda estación que representa el nodo conectado al anillo. Esta segunda estación sirve dos tipos de clientes: token y mensajes. En este ejemplo se estudiará una red, en que la carga está uniformemente distribuida en su generación y en su destino. Como en casos anteriores se creará una cola ficticia para determinar el tiempo de respuesta del sistema así como su intervalo de confianza. Se puede observar en estos resultados que a medida que aumenta la frecuencia de llegada (en el modelo, disminuye el tiempo medio entre llegadas) disminuye el número de token que circula por la red y aumenta el número de mensajes.

325
SIMULOG *** QNAP2 *** ( 15-FEB-88 ) V 5.0 (C) COPYRIGHT BY CII HONEYWELL BULL AND INRIA, 1986 1 /DECLARE/ QUEUE INTEGER N, M; 2 QUEUE NUS(8),ESP(8),S,R; 3 INTEGER I; 4 REAL TARR; 5 CUSTOMER REAL TSERV; 6 CUSTOMER INTEGER ORIGEN,DESTI; 7 REF CUSTOMER C,D; 8 FLAG SEM; 9 CLASS TOK,MIS; 10 11 /STATION/ NAME = S; 12 TYPE = SOURCE; 13 SERVICE = BEGIN 14 EXP(TARR); 15 ORIGEN := RINT(1,8); 16 DESTI := RINT(1,7); 17 IF DESTI >= ORIGEN THEN DESTI := DESTI + 1; 18 TSERV := EXP(800.); & microsegons 19 C := NEW(CUSTOMER); 20 TRANSIT(C,R,MIS); 21 TRANSIT(ESP(ORIGEN),MIS); 22 END; 23 24 /STATION/ NAME = NUS; 25 TYPE = MULTIPLE(2); 26 SERVICE(TOK) = BEGIN 27 WHILE ESP(N).NB > 0 DO 28 BEGIN 29 D := ESP(N).FIRST; 30 CST(D.TSERV); 31 TRANSIT(D,NUS(M)); 32 UNSET(SEM); 33 WAIT(SEM); 34 END; 35 CST(20); & microsegons 36 TRANSIT(NUS(M)); 37 END; 38 SERVICE(MIS) = BEGIN 39 IF N = ORIGEN THEN 40 BEGIN 41 SET(SEM); 42 TRANSIT(OUT); 43 END; 44 IF N = DESTI THEN 45 BEGIN 46 C := R.FIRST; 47 WHILE SON <> C DO C := C.NEXT; 48 TRANSIT(C,OUT); 49 END; 50 CST(1.6); & microsegons 51 TRANSIT(NUS(M)); 52 END; 53 54 /STATION/ NAME = NUS(1); 55 INIT(TOK) = 1; 56 57 /CONTROL/ TMAX = 10000000; CLASS = ALL QUEUE; 58 ACCURACY = ALL QUEUE, ALL CLASS; 59 60 /EXEC/ BEGIN 61 FOR I := 1 STEP 1 UNTIL 8 DO 62 BEGIN 63 NUS(I).N := I; 64 ESP(I).N := I; 65 NUS(I).M := I + 1;

326
66 END; 67 NUS(8).M := 1; 68 FOR TARR := 100000, 10000, 5000, 1000, 800 DO 69 BEGIN 70 PRINT; 71 PRINT ("TEMPS ENTRE ARRIBADES ",TARR,"MICROSEG"); 72 SIMUL; 73 END; 74 END; TEMPS ENTRE ARRIBADES 0.1000E+06MICROSEG ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 10000000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * NUS 1 * 20.11 *0.6248E-01*0.1250 * 20.11 * 62141* * +/- *0.1347 *0.3563E-03*0.7126E-03*0.1347 * * *(TOK )* 20.14 *0.6247E-01*0.1249 * 20.14 * 62038* * +/- *0.1349 *0.3569E-03*0.7137E-03*0.1349 * * *(MIS )* 1.398 *0.7199E-05*0.1440E-04* 1.398 * 103* * +/- *-1.000 *0.1365E-05*0.2730E-05*-1.000 * * * * * * * * * * NUS 2 * 20.07 *0.6237E-01*0.1247 * 20.07 * 62140* * +/- *0.8790E-01*0.3143E-03*0.6286E-03*0.8790E-01* * *(TOK )* 20.10 *0.6236E-01*0.1247 * 20.10 * 62037* * +/- *0.8881E-01*0.3151E-03*0.6302E-03*0.8881E-01* * *(MIS )* 1.382 *0.7119E-05*0.1424E-04* 1.382 * 103* * +/- *-1.000 *0.1691E-05*0.3381E-05*-1.000 * * * * * * * * * * NUS 3 * 20.09 *0.6242E-01*0.1248 * 20.09 * 62140* * +/- *0.7185E-01*0.2305E-03*0.4610E-03*0.7185E-01* * *(TOK )* 20.12 *0.6241E-01*0.1248 * 20.12 * 62037* * +/- *0.7276E-01*0.2315E-03*0.4629E-03*0.7276E-01* * *(MIS )* 1.351 *0.6959E-05*0.1392E-04* 1.351 * 103* * +/- *-1.000 *0.1862E-05*0.3724E-05*-1.000 * * * * * * * * * * NUS 4 * 20.08 *0.6239E-01*0.1248 * 20.08 * 62140* * +/- *0.1148 *0.3504E-03*0.7009E-03*0.1148 * * *(TOK )* 20.11 *0.6238E-01*0.1248 * 20.11 * 62037* * +/- *0.1140 *0.3514E-03*0.7028E-03*0.1140 * * *(MIS )* 1.522 *0.7839E-05*0.1568E-04* 1.522 * 103* * +/- *-1.000 *0.1646E-05*0.3292E-05*-1.000 * * * * * * * * * * NUS 5 * 20.19 *0.6274E-01*0.1255 * 20.19 * 62140* * +/- *0.1325 *0.3989E-03*0.7978E-03*0.1325 * * *(TOK )* 20.22 *0.6273E-01*0.1255 * 20.22 * 62037* * +/- *0.1470 *0.3994E-03*0.7988E-03*0.1470 * * *(MIS )* 1.382 *0.7119E-05*0.1424E-04* 1.382 * 103* * +/- *-1.000 *0.1337E-05*0.2674E-05*-1.000 * * * * * * * * * * NUS 6 * 20.11 *0.6249E-01*0.1250 * 20.11 * 62140* * +/- *0.1433 *0.4475E-03*0.8951E-03*0.1433 * * *(TOK )* 20.14 *0.6248E-01*0.1250 * 20.14 * 62037* * +/- *0.1429 *0.4480E-03*0.8960E-03*0.1429 * * *(MIS )* 1.398 *0.7199E-05*0.1440E-04* 1.398 * 103* * +/- *-1.000 *0.1526E-05*0.3053E-05*-1.000 * * * * * * * * * * NUS 7 * 20.11 *0.6249E-01*0.1250 * 20.11 * 62140* * +/- *0.1094 *0.3093E-03*0.6186E-03*0.1094 * * *(TOK )* 20.15 *0.6249E-01*0.1250 * 20.15 * 62037* * +/- *0.9936E-01*0.3094E-03*0.6187E-03*0.9936E-01* * *(MIS )* 1.398 *0.7199E-05*0.1440E-04* 1.398 * 103* * +/- *-1.000 *0.1483E-05*0.2966E-05*-1.000 * * * * * * * * *

327
* NUS 8 * 20.17 *0.6268E-01*0.1254 * 20.17 * 62140* * +/- *0.1637 *0.4324E-03*0.8647E-03*0.1637 * * *(TOK )* 20.20 *0.6267E-01*0.1253 * 20.20 * 62037* * +/- *0.1642 *0.4327E-03*0.8654E-03*0.1642 * * *(MIS )* 1.367 *0.7039E-05*0.1408E-04* 1.367 * 103* * +/- *-1.000 *0.1334E-05*0.2667E-05*-1.000 * * * * * * * * * * ESP 1 *0.0000E+00*0.0000E+00*0.9553E-03* 734.8 * 13* * +/- *-1.000 *0.0000E+00*0.8521E-03*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.9553E-03* 734.8 * 13* * +/- *-1.000 *0.0000E+00*0.8521E-03*-1.000 * * * * * * * * * * ESP 2 *0.0000E+00*0.0000E+00*0.7404E-03* 528.8 * 14* * +/- *-1.000 *0.0000E+00*0.6695E-03*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.7404E-03* 528.8 * 14* * +/- *-1.000 *0.0000E+00*0.6695E-03*-1.000 * * * * * * * * * * ESP 3 *0.0000E+00*0.0000E+00*0.8659E-03* 541.2 * 16* * +/- *-1.000 *0.0000E+00*0.4874E-03*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.8659E-03* 541.2 * 16* * +/- *-1.000 *0.0000E+00*0.4874E-03*-1.000 * * * * * * * * * * ESP 4 *0.0000E+00*0.0000E+00*0.7169E-03* 1434. * 5* * +/- *-1.000 *0.0000E+00*0.6916E-03*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.7169E-03* 1434. * 5* * +/- *-1.000 *0.0000E+00*0.6916E-03*-1.000 * * * * * * * * * * ESP 5 *0.0000E+00*0.0000E+00*0.1484E-02* 1060. * 14* * +/- *-1.000 *0.0000E+00*0.9771E-03*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.1484E-02* 1060. * 14* * +/- *-1.000 *0.0000E+00*0.9771E-03*-1.000 * * * * * * * * * * ESP 6 *0.0000E+00*0.0000E+00*0.9811E-03* 754.7 * 13* * +/- *-1.000 *0.0000E+00*0.9433E-03*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.9811E-03* 754.7 * 13* * +/- *-1.000 *0.0000E+00*0.9433E-03*-1.000 * * * * * * * * * * ESP 7 *0.0000E+00*0.0000E+00*0.9871E-03* 759.3 * 13* * +/- *-1.000 *0.0000E+00*0.6366E-03*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.9871E-03* 759.3 * 13* * +/- *-1.000 *0.0000E+00*0.6366E-03*-1.000 * * * * * * * * * * ESP 8 *0.0000E+00*0.0000E+00*0.1368E-02* 912.0 * 15* * +/- *-1.000 *0.0000E+00*0.1041E-02*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.1368E-02* 912.0 * 15* * +/- *-1.000 *0.0000E+00*0.1041E-02*-1.000 * * * * * * * * * * S *0.9609E+05* 1.000 * 1.000 *0.9609E+05* 103* * +/- *-1.000 *0.0000E+00*0.0000E+00*-1.000 * * * * * * * * * * R *0.0000E+00*0.0000E+00*0.8148E-02* 791.0 * 103* * +/- *-1.000 *0.0000E+00*0.2265E-02*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.8148E-02* 791.0 * 103* * +/- *-1.000 *0.0000E+00*0.2265E-02*-1.000 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 71019 WORDS OF 4 BYTES ( 8.88 % OF TOTAL MEMORY) TEMPS ENTRE ARRIBADES 0.1000E+05MICROSEG ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 10000000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 *******************************************************************
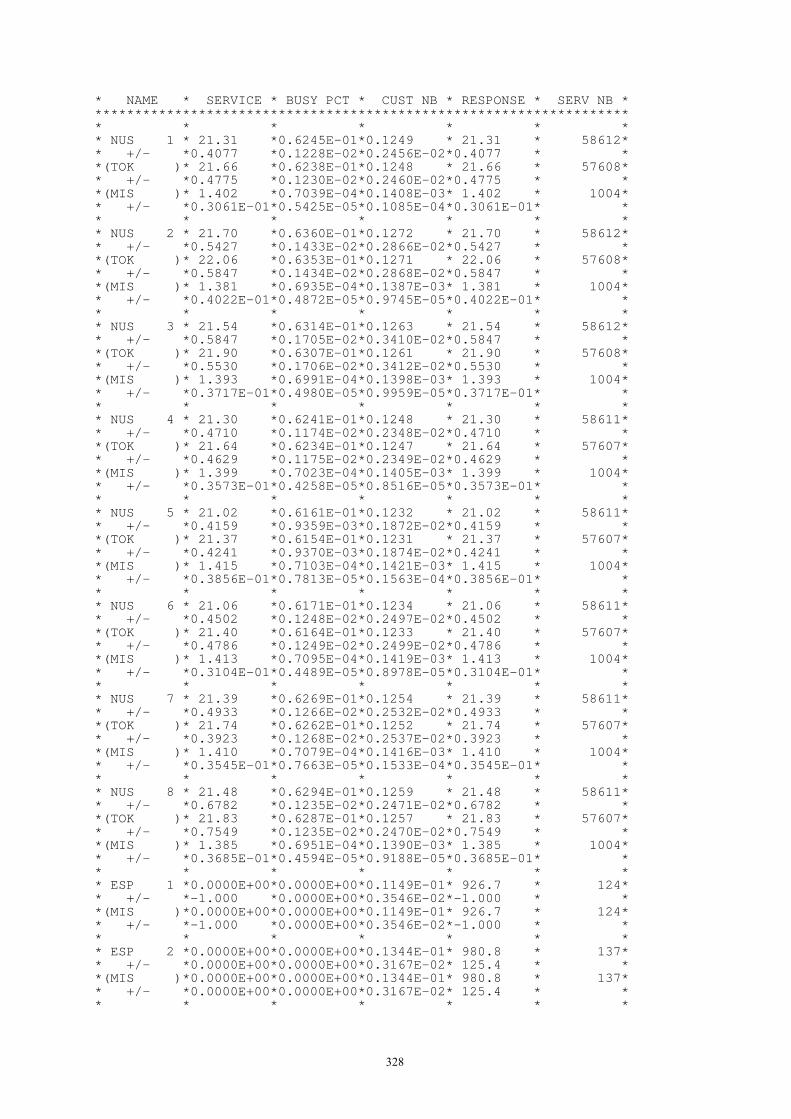
328
* NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * NUS 1 * 21.31 *0.6245E-01*0.1249 * 21.31 * 58612* * +/- *0.4077 *0.1228E-02*0.2456E-02*0.4077 * * *(TOK )* 21.66 *0.6238E-01*0.1248 * 21.66 * 57608* * +/- *0.4775 *0.1230E-02*0.2460E-02*0.4775 * * *(MIS )* 1.402 *0.7039E-04*0.1408E-03* 1.402 * 1004* * +/- *0.3061E-01*0.5425E-05*0.1085E-04*0.3061E-01* * * * * * * * * * NUS 2 * 21.70 *0.6360E-01*0.1272 * 21.70 * 58612* * +/- *0.5427 *0.1433E-02*0.2866E-02*0.5427 * * *(TOK )* 22.06 *0.6353E-01*0.1271 * 22.06 * 57608* * +/- *0.5847 *0.1434E-02*0.2868E-02*0.5847 * * *(MIS )* 1.381 *0.6935E-04*0.1387E-03* 1.381 * 1004* * +/- *0.4022E-01*0.4872E-05*0.9745E-05*0.4022E-01* * * * * * * * * * NUS 3 * 21.54 *0.6314E-01*0.1263 * 21.54 * 58612* * +/- *0.5847 *0.1705E-02*0.3410E-02*0.5847 * * *(TOK )* 21.90 *0.6307E-01*0.1261 * 21.90 * 57608* * +/- *0.5530 *0.1706E-02*0.3412E-02*0.5530 * * *(MIS )* 1.393 *0.6991E-04*0.1398E-03* 1.393 * 1004* * +/- *0.3717E-01*0.4980E-05*0.9959E-05*0.3717E-01* * * * * * * * * * NUS 4 * 21.30 *0.6241E-01*0.1248 * 21.30 * 58611* * +/- *0.4710 *0.1174E-02*0.2348E-02*0.4710 * * *(TOK )* 21.64 *0.6234E-01*0.1247 * 21.64 * 57607* * +/- *0.4629 *0.1175E-02*0.2349E-02*0.4629 * * *(MIS )* 1.399 *0.7023E-04*0.1405E-03* 1.399 * 1004* * +/- *0.3573E-01*0.4258E-05*0.8516E-05*0.3573E-01* * * * * * * * * * NUS 5 * 21.02 *0.6161E-01*0.1232 * 21.02 * 58611* * +/- *0.4159 *0.9359E-03*0.1872E-02*0.4159 * * *(TOK )* 21.37 *0.6154E-01*0.1231 * 21.37 * 57607* * +/- *0.4241 *0.9370E-03*0.1874E-02*0.4241 * * *(MIS )* 1.415 *0.7103E-04*0.1421E-03* 1.415 * 1004* * +/- *0.3856E-01*0.7813E-05*0.1563E-04*0.3856E-01* * * * * * * * * * NUS 6 * 21.06 *0.6171E-01*0.1234 * 21.06 * 58611* * +/- *0.4502 *0.1248E-02*0.2497E-02*0.4502 * * *(TOK )* 21.40 *0.6164E-01*0.1233 * 21.40 * 57607* * +/- *0.4786 *0.1249E-02*0.2499E-02*0.4786 * * *(MIS )* 1.413 *0.7095E-04*0.1419E-03* 1.413 * 1004* * +/- *0.3104E-01*0.4489E-05*0.8978E-05*0.3104E-01* * * * * * * * * * NUS 7 * 21.39 *0.6269E-01*0.1254 * 21.39 * 58611* * +/- *0.4933 *0.1266E-02*0.2532E-02*0.4933 * * *(TOK )* 21.74 *0.6262E-01*0.1252 * 21.74 * 57607* * +/- *0.3923 *0.1268E-02*0.2537E-02*0.3923 * * *(MIS )* 1.410 *0.7079E-04*0.1416E-03* 1.410 * 1004* * +/- *0.3545E-01*0.7663E-05*0.1533E-04*0.3545E-01* * * * * * * * * * NUS 8 * 21.48 *0.6294E-01*0.1259 * 21.48 * 58611* * +/- *0.6782 *0.1235E-02*0.2471E-02*0.6782 * * *(TOK )* 21.83 *0.6287E-01*0.1257 * 21.83 * 57607* * +/- *0.7549 *0.1235E-02*0.2470E-02*0.7549 * * *(MIS )* 1.385 *0.6951E-04*0.1390E-03* 1.385 * 1004* * +/- *0.3685E-01*0.4594E-05*0.9188E-05*0.3685E-01* * * * * * * * * * ESP 1 *0.0000E+00*0.0000E+00*0.1149E-01* 926.7 * 124* * +/- *-1.000 *0.0000E+00*0.3546E-02*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.1149E-01* 926.7 * 124* * +/- *-1.000 *0.0000E+00*0.3546E-02*-1.000 * * * * * * * * * * ESP 2 *0.0000E+00*0.0000E+00*0.1344E-01* 980.8 * 137* * +/- *0.0000E+00*0.0000E+00*0.3167E-02* 125.4 * * *(MIS )*0.0000E+00*0.0000E+00*0.1344E-01* 980.8 * 137* * +/- *0.0000E+00*0.0000E+00*0.3167E-02* 125.4 * * * * * * * * *
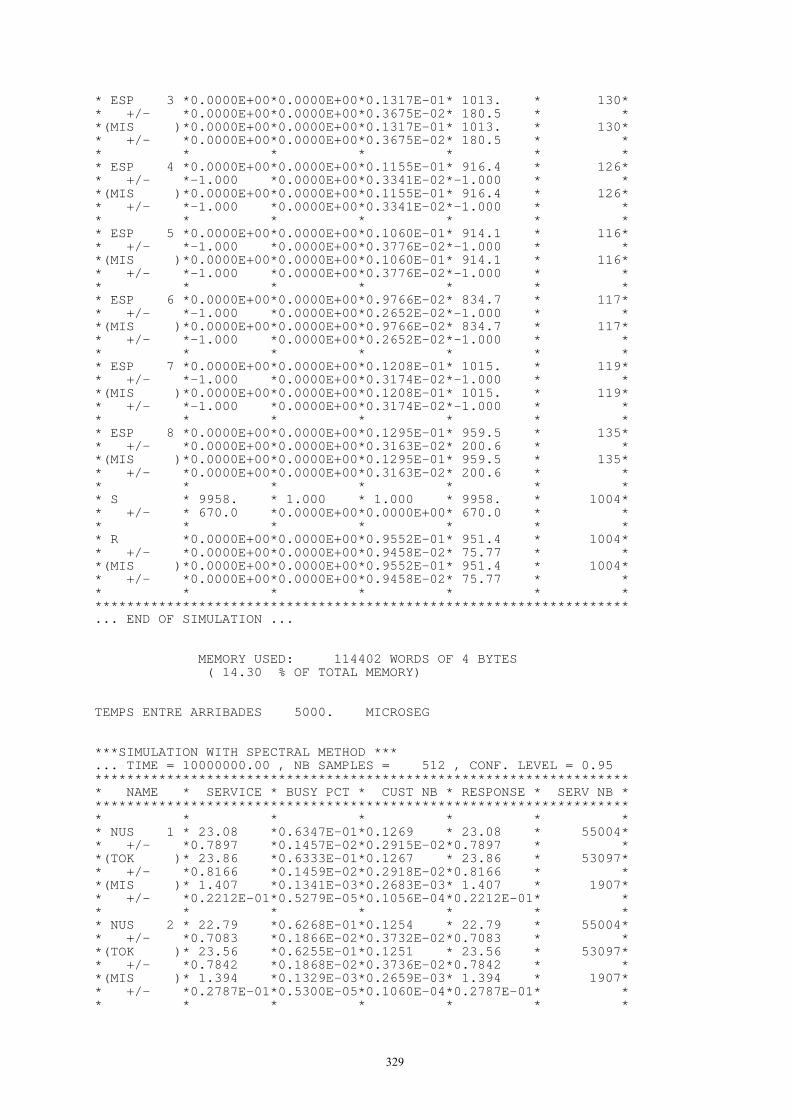
329
* ESP 3 *0.0000E+00*0.0000E+00*0.1317E-01* 1013. * 130* * +/- *0.0000E+00*0.0000E+00*0.3675E-02* 180.5 * * *(MIS )*0.0000E+00*0.0000E+00*0.1317E-01* 1013. * 130* * +/- *0.0000E+00*0.0000E+00*0.3675E-02* 180.5 * * * * * * * * * * ESP 4 *0.0000E+00*0.0000E+00*0.1155E-01* 916.4 * 126* * +/- *-1.000 *0.0000E+00*0.3341E-02*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.1155E-01* 916.4 * 126* * +/- *-1.000 *0.0000E+00*0.3341E-02*-1.000 * * * * * * * * * * ESP 5 *0.0000E+00*0.0000E+00*0.1060E-01* 914.1 * 116* * +/- *-1.000 *0.0000E+00*0.3776E-02*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.1060E-01* 914.1 * 116* * +/- *-1.000 *0.0000E+00*0.3776E-02*-1.000 * * * * * * * * * * ESP 6 *0.0000E+00*0.0000E+00*0.9766E-02* 834.7 * 117* * +/- *-1.000 *0.0000E+00*0.2652E-02*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.9766E-02* 834.7 * 117* * +/- *-1.000 *0.0000E+00*0.2652E-02*-1.000 * * * * * * * * * * ESP 7 *0.0000E+00*0.0000E+00*0.1208E-01* 1015. * 119* * +/- *-1.000 *0.0000E+00*0.3174E-02*-1.000 * * *(MIS )*0.0000E+00*0.0000E+00*0.1208E-01* 1015. * 119* * +/- *-1.000 *0.0000E+00*0.3174E-02*-1.000 * * * * * * * * * * ESP 8 *0.0000E+00*0.0000E+00*0.1295E-01* 959.5 * 135* * +/- *0.0000E+00*0.0000E+00*0.3163E-02* 200.6 * * *(MIS )*0.0000E+00*0.0000E+00*0.1295E-01* 959.5 * 135* * +/- *0.0000E+00*0.0000E+00*0.3163E-02* 200.6 * * * * * * * * * * S * 9958. * 1.000 * 1.000 * 9958. * 1004* * +/- * 670.0 *0.0000E+00*0.0000E+00* 670.0 * * * * * * * * * * R *0.0000E+00*0.0000E+00*0.9552E-01* 951.4 * 1004* * +/- *0.0000E+00*0.0000E+00*0.9458E-02* 75.77 * * *(MIS )*0.0000E+00*0.0000E+00*0.9552E-01* 951.4 * 1004* * +/- *0.0000E+00*0.0000E+00*0.9458E-02* 75.77 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 114402 WORDS OF 4 BYTES ( 14.30 % OF TOTAL MEMORY) TEMPS ENTRE ARRIBADES 5000. MICROSEG ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 10000000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * NUS 1 * 23.08 *0.6347E-01*0.1269 * 23.08 * 55004* * +/- *0.7897 *0.1457E-02*0.2915E-02*0.7897 * * *(TOK )* 23.86 *0.6333E-01*0.1267 * 23.86 * 53097* * +/- *0.8166 *0.1459E-02*0.2918E-02*0.8166 * * *(MIS )* 1.407 *0.1341E-03*0.2683E-03* 1.407 * 1907* * +/- *0.2212E-01*0.5279E-05*0.1056E-04*0.2212E-01* * * * * * * * * * NUS 2 * 22.79 *0.6268E-01*0.1254 * 22.79 * 55004* * +/- *0.7083 *0.1866E-02*0.3732E-02*0.7083 * * *(TOK )* 23.56 *0.6255E-01*0.1251 * 23.56 * 53097* * +/- *0.7842 *0.1868E-02*0.3736E-02*0.7842 * * *(MIS )* 1.394 *0.1329E-03*0.2659E-03* 1.394 * 1907* * +/- *0.2787E-01*0.5300E-05*0.1060E-04*0.2787E-01* * * * * * * * *
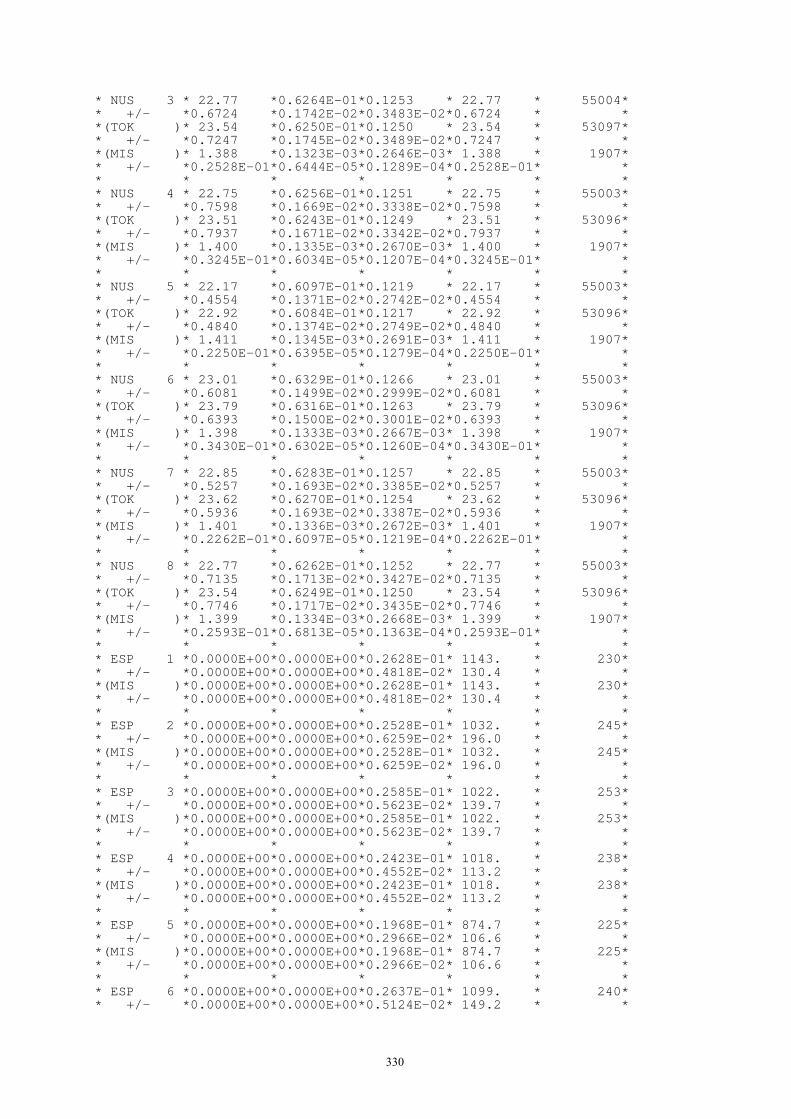
330
* NUS 3 * 22.77 *0.6264E-01*0.1253 * 22.77 * 55004* * +/- *0.6724 *0.1742E-02*0.3483E-02*0.6724 * * *(TOK )* 23.54 *0.6250E-01*0.1250 * 23.54 * 53097* * +/- *0.7247 *0.1745E-02*0.3489E-02*0.7247 * * *(MIS )* 1.388 *0.1323E-03*0.2646E-03* 1.388 * 1907* * +/- *0.2528E-01*0.6444E-05*0.1289E-04*0.2528E-01* * * * * * * * * * NUS 4 * 22.75 *0.6256E-01*0.1251 * 22.75 * 55003* * +/- *0.7598 *0.1669E-02*0.3338E-02*0.7598 * * *(TOK )* 23.51 *0.6243E-01*0.1249 * 23.51 * 53096* * +/- *0.7937 *0.1671E-02*0.3342E-02*0.7937 * * *(MIS )* 1.400 *0.1335E-03*0.2670E-03* 1.400 * 1907* * +/- *0.3245E-01*0.6034E-05*0.1207E-04*0.3245E-01* * * * * * * * * * NUS 5 * 22.17 *0.6097E-01*0.1219 * 22.17 * 55003* * +/- *0.4554 *0.1371E-02*0.2742E-02*0.4554 * * *(TOK )* 22.92 *0.6084E-01*0.1217 * 22.92 * 53096* * +/- *0.4840 *0.1374E-02*0.2749E-02*0.4840 * * *(MIS )* 1.411 *0.1345E-03*0.2691E-03* 1.411 * 1907* * +/- *0.2250E-01*0.6395E-05*0.1279E-04*0.2250E-01* * * * * * * * * * NUS 6 * 23.01 *0.6329E-01*0.1266 * 23.01 * 55003* * +/- *0.6081 *0.1499E-02*0.2999E-02*0.6081 * * *(TOK )* 23.79 *0.6316E-01*0.1263 * 23.79 * 53096* * +/- *0.6393 *0.1500E-02*0.3001E-02*0.6393 * * *(MIS )* 1.398 *0.1333E-03*0.2667E-03* 1.398 * 1907* * +/- *0.3430E-01*0.6302E-05*0.1260E-04*0.3430E-01* * * * * * * * * * NUS 7 * 22.85 *0.6283E-01*0.1257 * 22.85 * 55003* * +/- *0.5257 *0.1693E-02*0.3385E-02*0.5257 * * *(TOK )* 23.62 *0.6270E-01*0.1254 * 23.62 * 53096* * +/- *0.5936 *0.1693E-02*0.3387E-02*0.5936 * * *(MIS )* 1.401 *0.1336E-03*0.2672E-03* 1.401 * 1907* * +/- *0.2262E-01*0.6097E-05*0.1219E-04*0.2262E-01* * * * * * * * * * NUS 8 * 22.77 *0.6262E-01*0.1252 * 22.77 * 55003* * +/- *0.7135 *0.1713E-02*0.3427E-02*0.7135 * * *(TOK )* 23.54 *0.6249E-01*0.1250 * 23.54 * 53096* * +/- *0.7746 *0.1717E-02*0.3435E-02*0.7746 * * *(MIS )* 1.399 *0.1334E-03*0.2668E-03* 1.399 * 1907* * +/- *0.2593E-01*0.6813E-05*0.1363E-04*0.2593E-01* * * * * * * * * * ESP 1 *0.0000E+00*0.0000E+00*0.2628E-01* 1143. * 230* * +/- *0.0000E+00*0.0000E+00*0.4818E-02* 130.4 * * *(MIS )*0.0000E+00*0.0000E+00*0.2628E-01* 1143. * 230* * +/- *0.0000E+00*0.0000E+00*0.4818E-02* 130.4 * * * * * * * * * * ESP 2 *0.0000E+00*0.0000E+00*0.2528E-01* 1032. * 245* * +/- *0.0000E+00*0.0000E+00*0.6259E-02* 196.0 * * *(MIS )*0.0000E+00*0.0000E+00*0.2528E-01* 1032. * 245* * +/- *0.0000E+00*0.0000E+00*0.6259E-02* 196.0 * * * * * * * * * * ESP 3 *0.0000E+00*0.0000E+00*0.2585E-01* 1022. * 253* * +/- *0.0000E+00*0.0000E+00*0.5623E-02* 139.7 * * *(MIS )*0.0000E+00*0.0000E+00*0.2585E-01* 1022. * 253* * +/- *0.0000E+00*0.0000E+00*0.5623E-02* 139.7 * * * * * * * * * * ESP 4 *0.0000E+00*0.0000E+00*0.2423E-01* 1018. * 238* * +/- *0.0000E+00*0.0000E+00*0.4552E-02* 113.2 * * *(MIS )*0.0000E+00*0.0000E+00*0.2423E-01* 1018. * 238* * +/- *0.0000E+00*0.0000E+00*0.4552E-02* 113.2 * * * * * * * * * * ESP 5 *0.0000E+00*0.0000E+00*0.1968E-01* 874.7 * 225* * +/- *0.0000E+00*0.0000E+00*0.2966E-02* 106.6 * * *(MIS )*0.0000E+00*0.0000E+00*0.1968E-01* 874.7 * 225* * +/- *0.0000E+00*0.0000E+00*0.2966E-02* 106.6 * * * * * * * * * * ESP 6 *0.0000E+00*0.0000E+00*0.2637E-01* 1099. * 240* * +/- *0.0000E+00*0.0000E+00*0.5124E-02* 149.2 * *

331
*(MIS )*0.0000E+00*0.0000E+00*0.2637E-01* 1099. * 240* * +/- *0.0000E+00*0.0000E+00*0.5124E-02* 149.2 * * * * * * * * * * ESP 7 *0.0000E+00*0.0000E+00*0.2572E-01* 1085. * 237* * +/- *0.0000E+00*0.0000E+00*0.4317E-02* 147.0 * * *(MIS )*0.0000E+00*0.0000E+00*0.2572E-01* 1085. * 237* * +/- *0.0000E+00*0.0000E+00*0.4317E-02* 147.0 * * * * * * * * * * ESP 8 *0.0000E+00*0.0000E+00*0.2500E-01* 1046. * 239* * +/- *0.0000E+00*0.0000E+00*0.5461E-02* 173.0 * * *(MIS )*0.0000E+00*0.0000E+00*0.2500E-01* 1046. * 239* * +/- *0.0000E+00*0.0000E+00*0.5461E-02* 173.0 * * * * * * * * * * S * 5238. * 1.000 * 1.000 * 5238. * 1907* * +/- * 219.7 *0.0000E+00*0.0000E+00* 219.7 * * * * * * * * * * R *0.0000E+00*0.0000E+00*0.1993 * 1045. * 1907* * +/- *0.0000E+00*0.0000E+00*0.1847E-01* 74.18 * * *(MIS )*0.0000E+00*0.0000E+00*0.1993 * 1045. * 1907* * +/- *0.0000E+00*0.0000E+00*0.1847E-01* 74.18 * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 157613 WORDS OF 4 BYTES ( 19.70 % OF TOTAL MEMORY) TEMPS ENTRE ARRIBADES 1000. MICROSEG ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 10000000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * NUS 1 * 61.63 *0.6358E-01*0.1272 * 61.63 * 20631* * +/- * 6.193 *0.3718E-02*0.7435E-02* 6.193 * * *(TOK )* 119.1 *0.6288E-01*0.1258 * 119.1 * 10562* * +/- * 20.65 *0.3716E-02*0.7433E-02* 20.65 * * *(MIS )* 1.390 *0.6999E-03*0.1400E-02* 1.390 * 10069* * +/- *0.9350E-02*0.1776E-04*0.3552E-04*0.9350E-02* * * * * * * * * * NUS 2 * 63.39 *0.6539E-01*0.1308 * 63.39 * 20631* * +/- * 4.534 *0.3894E-02*0.7787E-02* 4.534 * * *(TOK )* 122.5 *0.6468E-01*0.1294 * 122.5 * 10562* * +/- * 16.47 *0.3904E-02*0.7809E-02* 16.47 * * *(MIS )* 1.396 *0.7026E-03*0.1405E-02* 1.396 * 10069* * +/- *0.1102E-01*0.2228E-04*0.4456E-04*0.1102E-01* * * * * * * * * * NUS 3 * 62.98 *0.6497E-01*0.1299 * 62.98 * 20631* * +/- * 5.727 *0.3575E-02*0.7150E-02* 5.727 * * *(TOK )* 121.7 *0.6427E-01*0.1285 * 121.7 * 10562* * +/- * 29.96 *0.3579E-02*0.7158E-02* 29.96 * * *(MIS )* 1.389 *0.6994E-03*0.1399E-02* 1.389 * 10069* * +/- *0.9545E-02*0.1971E-04*0.3942E-04*0.9545E-02* * * * * * * * * * NUS 4 * 60.30 *0.6220E-01*0.1244 * 60.30 * 20631* * +/- * 5.706 *0.4437E-02*0.8874E-02* 5.706 * * *(TOK )* 116.4 *0.6149E-01*0.1230 * 116.4 * 10562* * +/- * 19.09 *0.4432E-02*0.8865E-02* 19.09 * * *(MIS )* 1.409 *0.7095E-03*0.1419E-02* 1.409 * 10069* * +/- *0.1115E-01*0.2008E-04*0.4017E-04*0.1115E-01* * * * * * * * * * NUS 5 * 60.82 *0.6274E-01*0.1255 * 60.82 * 20631* * +/- * 7.048 *0.4138E-02*0.8275E-02* 7.048 * * *(TOK )* 117.5 *0.6203E-01*0.1241 * 117.5 * 10562*
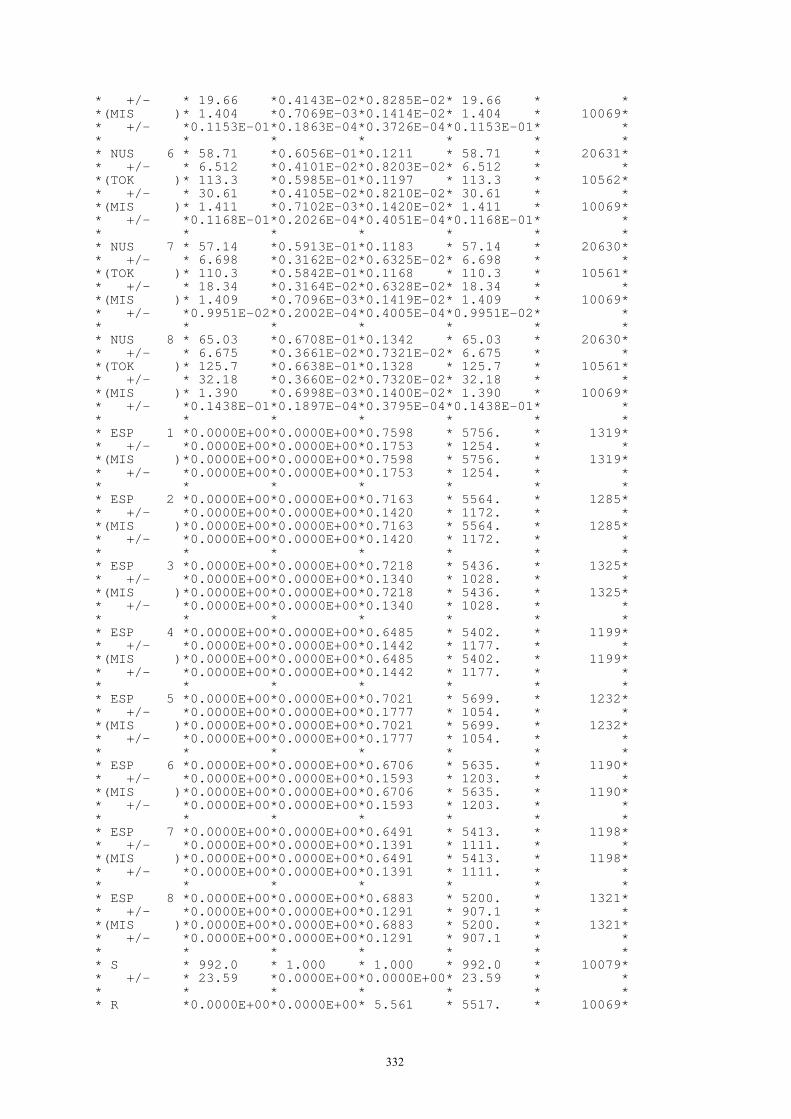
332
* +/- * 19.66 *0.4143E-02*0.8285E-02* 19.66 * * *(MIS )* 1.404 *0.7069E-03*0.1414E-02* 1.404 * 10069* * +/- *0.1153E-01*0.1863E-04*0.3726E-04*0.1153E-01* * * * * * * * * * NUS 6 * 58.71 *0.6056E-01*0.1211 * 58.71 * 20631* * +/- * 6.512 *0.4101E-02*0.8203E-02* 6.512 * * *(TOK )* 113.3 *0.5985E-01*0.1197 * 113.3 * 10562* * +/- * 30.61 *0.4105E-02*0.8210E-02* 30.61 * * *(MIS )* 1.411 *0.7102E-03*0.1420E-02* 1.411 * 10069* * +/- *0.1168E-01*0.2026E-04*0.4051E-04*0.1168E-01* * * * * * * * * * NUS 7 * 57.14 *0.5913E-01*0.1183 * 57.14 * 20630* * +/- * 6.698 *0.3162E-02*0.6325E-02* 6.698 * * *(TOK )* 110.3 *0.5842E-01*0.1168 * 110.3 * 10561* * +/- * 18.34 *0.3164E-02*0.6328E-02* 18.34 * * *(MIS )* 1.409 *0.7096E-03*0.1419E-02* 1.409 * 10069* * +/- *0.9951E-02*0.2002E-04*0.4005E-04*0.9951E-02* * * * * * * * * * NUS 8 * 65.03 *0.6708E-01*0.1342 * 65.03 * 20630* * +/- * 6.675 *0.3661E-02*0.7321E-02* 6.675 * * *(TOK )* 125.7 *0.6638E-01*0.1328 * 125.7 * 10561* * +/- * 32.18 *0.3660E-02*0.7320E-02* 32.18 * * *(MIS )* 1.390 *0.6998E-03*0.1400E-02* 1.390 * 10069* * +/- *0.1438E-01*0.1897E-04*0.3795E-04*0.1438E-01* * * * * * * * * * ESP 1 *0.0000E+00*0.0000E+00*0.7598 * 5756. * 1319* * +/- *0.0000E+00*0.0000E+00*0.1753 * 1254. * * *(MIS )*0.0000E+00*0.0000E+00*0.7598 * 5756. * 1319* * +/- *0.0000E+00*0.0000E+00*0.1753 * 1254. * * * * * * * * * * ESP 2 *0.0000E+00*0.0000E+00*0.7163 * 5564. * 1285* * +/- *0.0000E+00*0.0000E+00*0.1420 * 1172. * * *(MIS )*0.0000E+00*0.0000E+00*0.7163 * 5564. * 1285* * +/- *0.0000E+00*0.0000E+00*0.1420 * 1172. * * * * * * * * * * ESP 3 *0.0000E+00*0.0000E+00*0.7218 * 5436. * 1325* * +/- *0.0000E+00*0.0000E+00*0.1340 * 1028. * * *(MIS )*0.0000E+00*0.0000E+00*0.7218 * 5436. * 1325* * +/- *0.0000E+00*0.0000E+00*0.1340 * 1028. * * * * * * * * * * ESP 4 *0.0000E+00*0.0000E+00*0.6485 * 5402. * 1199* * +/- *0.0000E+00*0.0000E+00*0.1442 * 1177. * * *(MIS )*0.0000E+00*0.0000E+00*0.6485 * 5402. * 1199* * +/- *0.0000E+00*0.0000E+00*0.1442 * 1177. * * * * * * * * * * ESP 5 *0.0000E+00*0.0000E+00*0.7021 * 5699. * 1232* * +/- *0.0000E+00*0.0000E+00*0.1777 * 1054. * * *(MIS )*0.0000E+00*0.0000E+00*0.7021 * 5699. * 1232* * +/- *0.0000E+00*0.0000E+00*0.1777 * 1054. * * * * * * * * * * ESP 6 *0.0000E+00*0.0000E+00*0.6706 * 5635. * 1190* * +/- *0.0000E+00*0.0000E+00*0.1593 * 1203. * * *(MIS )*0.0000E+00*0.0000E+00*0.6706 * 5635. * 1190* * +/- *0.0000E+00*0.0000E+00*0.1593 * 1203. * * * * * * * * * * ESP 7 *0.0000E+00*0.0000E+00*0.6491 * 5413. * 1198* * +/- *0.0000E+00*0.0000E+00*0.1391 * 1111. * * *(MIS )*0.0000E+00*0.0000E+00*0.6491 * 5413. * 1198* * +/- *0.0000E+00*0.0000E+00*0.1391 * 1111. * * * * * * * * * * ESP 8 *0.0000E+00*0.0000E+00*0.6883 * 5200. * 1321* * +/- *0.0000E+00*0.0000E+00*0.1291 * 907.1 * * *(MIS )*0.0000E+00*0.0000E+00*0.6883 * 5200. * 1321* * +/- *0.0000E+00*0.0000E+00*0.1291 * 907.1 * * * * * * * * * * S * 992.0 * 1.000 * 1.000 * 992.0 * 10079* * +/- * 23.59 *0.0000E+00*0.0000E+00* 23.59 * * * * * * * * * * R *0.0000E+00*0.0000E+00* 5.561 * 5517. * 10069*
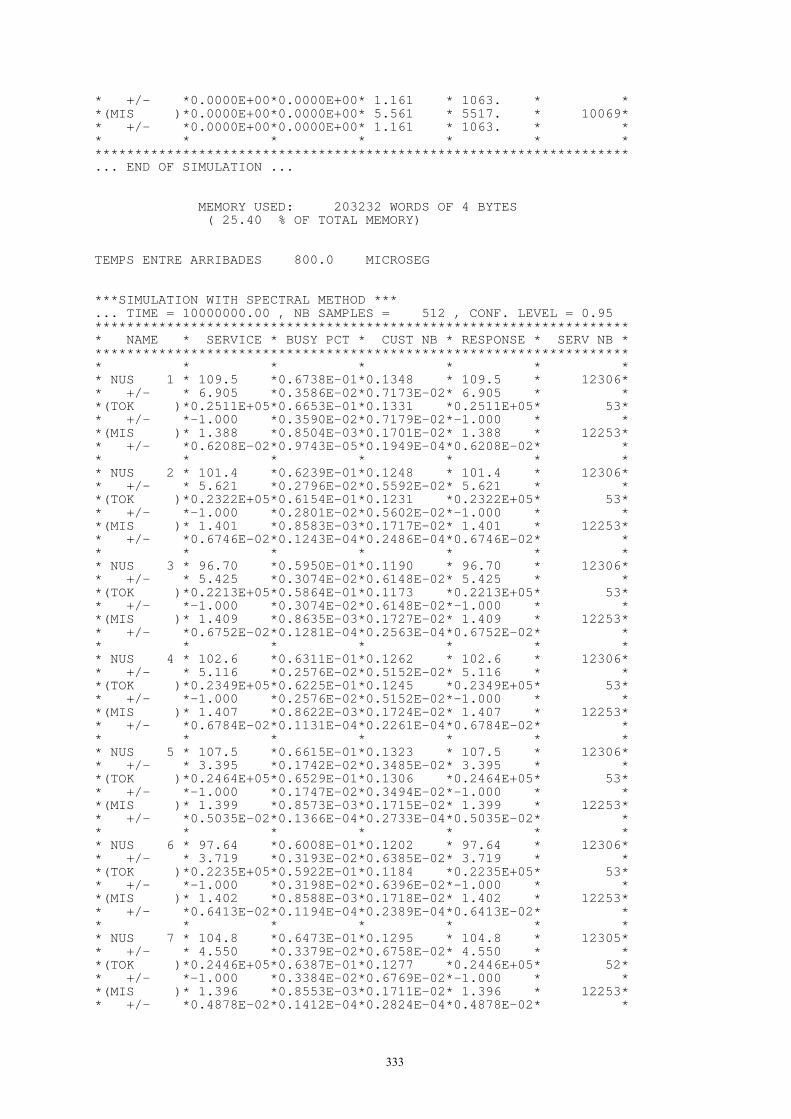
333
* +/- *0.0000E+00*0.0000E+00* 1.161 * 1063. * * *(MIS )*0.0000E+00*0.0000E+00* 5.561 * 5517. * 10069* * +/- *0.0000E+00*0.0000E+00* 1.161 * 1063. * * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 203232 WORDS OF 4 BYTES ( 25.40 % OF TOTAL MEMORY) TEMPS ENTRE ARRIBADES 800.0 MICROSEG ***SIMULATION WITH SPECTRAL METHOD *** ... TIME = 10000000.00 , NB SAMPLES = 512 , CONF. LEVEL = 0.95 ******************************************************************* * NAME * SERVICE * BUSY PCT * CUST NB * RESPONSE * SERV NB * ******************************************************************* * * * * * * * * NUS 1 * 109.5 *0.6738E-01*0.1348 * 109.5 * 12306* * +/- * 6.905 *0.3586E-02*0.7173E-02* 6.905 * * *(TOK )*0.2511E+05*0.6653E-01*0.1331 *0.2511E+05* 53* * +/- *-1.000 *0.3590E-02*0.7179E-02*-1.000 * * *(MIS )* 1.388 *0.8504E-03*0.1701E-02* 1.388 * 12253* * +/- *0.6208E-02*0.9743E-05*0.1949E-04*0.6208E-02* * * * * * * * * * NUS 2 * 101.4 *0.6239E-01*0.1248 * 101.4 * 12306* * +/- * 5.621 *0.2796E-02*0.5592E-02* 5.621 * * *(TOK )*0.2322E+05*0.6154E-01*0.1231 *0.2322E+05* 53* * +/- *-1.000 *0.2801E-02*0.5602E-02*-1.000 * * *(MIS )* 1.401 *0.8583E-03*0.1717E-02* 1.401 * 12253* * +/- *0.6746E-02*0.1243E-04*0.2486E-04*0.6746E-02* * * * * * * * * * NUS 3 * 96.70 *0.5950E-01*0.1190 * 96.70 * 12306* * +/- * 5.425 *0.3074E-02*0.6148E-02* 5.425 * * *(TOK )*0.2213E+05*0.5864E-01*0.1173 *0.2213E+05* 53* * +/- *-1.000 *0.3074E-02*0.6148E-02*-1.000 * * *(MIS )* 1.409 *0.8635E-03*0.1727E-02* 1.409 * 12253* * +/- *0.6752E-02*0.1281E-04*0.2563E-04*0.6752E-02* * * * * * * * * * NUS 4 * 102.6 *0.6311E-01*0.1262 * 102.6 * 12306* * +/- * 5.116 *0.2576E-02*0.5152E-02* 5.116 * * *(TOK )*0.2349E+05*0.6225E-01*0.1245 *0.2349E+05* 53* * +/- *-1.000 *0.2576E-02*0.5152E-02*-1.000 * * *(MIS )* 1.407 *0.8622E-03*0.1724E-02* 1.407 * 12253* * +/- *0.6784E-02*0.1131E-04*0.2261E-04*0.6784E-02* * * * * * * * * * NUS 5 * 107.5 *0.6615E-01*0.1323 * 107.5 * 12306* * +/- * 3.395 *0.1742E-02*0.3485E-02* 3.395 * * *(TOK )*0.2464E+05*0.6529E-01*0.1306 *0.2464E+05* 53* * +/- *-1.000 *0.1747E-02*0.3494E-02*-1.000 * * *(MIS )* 1.399 *0.8573E-03*0.1715E-02* 1.399 * 12253* * +/- *0.5035E-02*0.1366E-04*0.2733E-04*0.5035E-02* * * * * * * * * * NUS 6 * 97.64 *0.6008E-01*0.1202 * 97.64 * 12306* * +/- * 3.719 *0.3193E-02*0.6385E-02* 3.719 * * *(TOK )*0.2235E+05*0.5922E-01*0.1184 *0.2235E+05* 53* * +/- *-1.000 *0.3198E-02*0.6396E-02*-1.000 * * *(MIS )* 1.402 *0.8588E-03*0.1718E-02* 1.402 * 12253* * +/- *0.6413E-02*0.1194E-04*0.2389E-04*0.6413E-02* * * * * * * * * * NUS 7 * 104.8 *0.6473E-01*0.1295 * 104.8 * 12305* * +/- * 4.550 *0.3379E-02*0.6758E-02* 4.550 * * *(TOK )*0.2446E+05*0.6387E-01*0.1277 *0.2446E+05* 52* * +/- *-1.000 *0.3384E-02*0.6769E-02*-1.000 * * *(MIS )* 1.396 *0.8553E-03*0.1711E-02* 1.396 * 12253* * +/- *0.4878E-02*0.1412E-04*0.2824E-04*0.4878E-02* *
334
* * * * * * * * NUS 8 * 103.2 *0.6352E-01*0.1270 * 103.2 * 12305* * +/- * 4.519 *0.2117E-02*0.4234E-02* 4.519 * * *(TOK )*0.2410E+05*0.6266E-01*0.1253 *0.2410E+05* 52* * +/- *-1.000 *0.2115E-02*0.4230E-02*-1.000 * * *(MIS )* 1.396 *0.8551E-03*0.1710E-02* 1.396 * 12253* * +/- *0.5278E-02*0.1169E-04*0.2338E-04*0.5278E-02* * * * * * * * * * ESP 1 *0.0000E+00*0.0000E+00* 20.89 *0.1285E+06* 1622* * +/- *0.0000E+00*0.0000E+00* 2.330 *0.1118E+05* * *(MIS )*0.0000E+00*0.0000E+00* 20.89 *0.1285E+06* 1622* * +/- *0.0000E+00*0.0000E+00* 2.330 *0.1118E+05* * * * * * * * * * ESP 2 *0.0000E+00*0.0000E+00* 19.79 *0.1297E+06* 1523* * +/- *0.0000E+00*0.0000E+00* 2.213 *0.1044E+05* * *(MIS )*0.0000E+00*0.0000E+00* 19.79 *0.1297E+06* 1523* * +/- *0.0000E+00*0.0000E+00* 2.213 *0.1044E+05* * * * * * * * * * ESP 3 *0.0000E+00*0.0000E+00* 18.60 *0.1274E+06* 1458* * +/- *0.0000E+00*0.0000E+00* 1.609 *0.1332E+05* * *(MIS )*0.0000E+00*0.0000E+00* 18.60 *0.1274E+06* 1458* * +/- *0.0000E+00*0.0000E+00* 1.609 *0.1332E+05* * * * * * * * * * ESP 4 *0.0000E+00*0.0000E+00* 18.17 *0.1232E+06* 1474* * +/- *0.0000E+00*0.0000E+00* 1.572 *0.1280E+05* * *(MIS )*0.0000E+00*0.0000E+00* 18.17 *0.1232E+06* 1474* * +/- *0.0000E+00*0.0000E+00* 1.572 *0.1280E+05* * * * * * * * * * ESP 5 *0.0000E+00*0.0000E+00* 19.04 *0.1240E+06* 1535* * +/- *0.0000E+00*0.0000E+00* 2.000 *0.1414E+05* * *(MIS )*0.0000E+00*0.0000E+00* 19.04 *0.1240E+06* 1535* * +/- *0.0000E+00*0.0000E+00* 2.000 *0.1414E+05* * * * * * * * * * ESP 6 *0.0000E+00*0.0000E+00* 19.32 *0.1273E+06* 1517* * +/- *0.0000E+00*0.0000E+00* 2.245 *0.1378E+05* * *(MIS )*0.0000E+00*0.0000E+00* 19.32 *0.1273E+06* 1517* * +/- *0.0000E+00*0.0000E+00* 2.245 *0.1378E+05* * * * * * * * * * ESP 7 *0.0000E+00*0.0000E+00* 20.31 *0.1297E+06* 1561* * +/- *0.0000E+00*0.0000E+00* 1.996 *0.1299E+05* * *(MIS )*0.0000E+00*0.0000E+00* 20.31 *0.1297E+06* 1561* * +/- *0.0000E+00*0.0000E+00* 1.996 *0.1299E+05* * * * * * * * * * ESP 8 *0.0000E+00*0.0000E+00* 19.63 *0.1249E+06* 1563* * +/- *0.0000E+00*0.0000E+00* 1.951 *0.1021E+05* * *(MIS )*0.0000E+00*0.0000E+00* 19.63 *0.1249E+06* 1563* * +/- *0.0000E+00*0.0000E+00* 1.951 *0.1021E+05* * * * * * * * * * S * 811.1 * 1.000 * 1.000 * 811.1 * 12328* * +/- * 14.66 *0.0000E+00*0.0000E+00* 14.66 * * * * * * * * * * R *0.0000E+00*0.0000E+00* 155.7 *0.1269E+06* 12253* * +/- *0.0000E+00*0.0000E+00* 24.78 *0.2250E+05* * *(MIS )*0.0000E+00*0.0000E+00* 155.7 *0.1269E+06* 12253* * +/- *0.0000E+00*0.0000E+00* 24.78 *0.2250E+05* * * * * * * * * ******************************************************************* ... END OF SIMULATION ... MEMORY USED: 264749 WORDS OF 4 BYTES ( 33.09 % OF TOTAL MEMORY) 75 /END/ Para ahorrar tiempo de simulación, es posible parar la rotación del token cuando en la red no quedan mensajes. cuando llega un mensaje, puede calcularse la posición del token y relanzar su rotación.

335
4.3.3. COMPARACIÓN DE ESTRATEGIAS EN REDES LOCALES: PASO DE TESTIGO Y CSMA/CD
Existen numerosos estudios de comparación del comportamiento de redes de área local de tipo de paso de testigo y de tipo CSMA/CD. El resumen de todos ellos podría ser: - las redes de tipo CSMA/CD resultan ventajosas cuando la utilización que se hace de ellas
no es elevada, es decir, cuando el nivel de colisiones es bajo.
- las redes de tipo de paso de testigo resultan ventajosas cuando la utilización que se hace de ellas es elevada, es decir, cuando el overhead provocado por la latencia de las estaciones y la circulación del testigo tienen poco peso frente a la información transmitida.
Ahora bien, en el caso de seleccionar una entre varias redes es preciso recurrir a la definición de la carga estimada y utilizar las ecuaciones descritas en los apartados anteriores para determinar los tiempos de respuesta que se pueden esperar. Este resultado junto con la proyección estimada de la carga en el futuro nos puede proporcionar una referencia interesante a la hora de seleccionar una red de área local para una aplicación determinada.
4.4. REDES DIGITALES DE SERVICIOS INTEGRADOS DE BANDA ANCHA (ATM)
El mundo de los modelos de los sistemas ATM cubre un ámbito extraordinariamente amplio y que está en constante evolución. En este apartado sólo se tratarán algunos aspectos que pueden considerarse básicos en el estudio de las prestaciones que se estima que tendrán estos futuros sistemas. En particular se tratarán los aspectos de la caracterización de las fuentes de tráfico, de las métricas de la calidad del servicio, de la superposición de secuencias de tráfico, de la gestión del tráfico y de la conmutación de celdas ATM. En este apartado sólo se expondrán modelos analíticos ad hoc y no de simulación, ya que estos últimos no aportan ninguna originalidad especial y simplemente consisten en representar los mecanismos de los que se han construido los modelos analíticos. Hay que tener en cuenta, además, que todos los modelos que se puedan construir en la actualidad son sólo estimaciones de realidades que todavía no se conocen.
4.4.1. CARACTERIZACIÓN DE LAS FUENTES DE TRÁFICO Simplificando el problema de las fuentes de tráfico en redes ATM se puede decir que hay dos tipos de fuente: - las de frecuencia de bits constante (constant bit rate, CBR) entre las que se pueden
encontrar la voz (donde aun cuando la generación de sonido no es constante, sí lo es a los efectos de frecuencia de generación de bits ya que se transmiten también los períodos de silencio) y el video codificado a frecuencia de bits constante.
- las de frecuencia de bits variable (variable bit rate, VBR) entre las que se pueden encontrar los paquetes de datos, las imágenes y el video codificado de forma diferencial.
Las fuentes del primer tipo son fáciles de caracterizar ya que simplemente conociendo los bits que se generan por unidad de tiempo y la capacidad de carga útil de las celdas ATM se puede determinar con facilidad la frecuencia de llegada de celdas. En el segundo caso se trata de fuentes que generan a ráfagas. Sin embargo, la definición de rafagueo (burstiness) no es única en la literatura. Entre otras medidas de este concepto se encuentran: - la relación entre las frecuencias de pico y media de generación de bits.

336
- la longitud media de una ráfaga, esto es, el período activo medio en que la fuente genera a la frecuencia de pico.
- el coeficiente cuadrático de variación (relación entre la variancia y el cuadrado de la media) del tiempo entre llegadas consecutivas de celdas.
De ellas la que se ha adoptado como estándar es la primera. La figura 4.8 muestra el rafagueo de algunas aplicaciones que se supone serán típicas de este entorno. Diversos parámetros que se usan frecuentemente para caracterizar fuentes VBR son: - Rp, frecuencia de pico de generación de celdas
- N, número medio de celdas en un período activo
- Ti, tiempo medio entre el inicio de un período activo y el inicio del siguiente período activo
- m, frecuencia media de generación de celdas
- β, rafagueo del tráfico
σ−σσ
σσ−σσσσ−
=
kkk
k
k
Q
. . .....
. . .
. . .
21
2221
1121
1K 10K 100K 1M 10M 100MFrecuencia de pico (bit/s)
1
10
100
1000
Rafagueo
Correomultimedia
Telecon-ferencia
Composiciónde imágenes
Acceso a basesde datos mulimedia
Cálculodistribuido
Visuaizacióninteractiva
Figura 4.8.
Sean a-1 y s-1 respectivamente la duración media de los períodos activo y silente. Sea, además, T el mínimo tiempo entre llegadas de celdas durante el período activo. Entonces, se tiene:
Ti = (a-1 + s-1) Rp = 1/T m = a-1/(a-1 + s-1) β = Rp/m N = a-1/T

337
4.4.1.1. Servicios a CBR Los servicios a CBR generan tráfico a frecuencia constante y pueden describirse simplemente por su frecuencia de pico, que coincide con la media y, por lo tanto su rafagueo es igual a 1. La voz en CBR se codifica mediante la técnica PCM (pulse code modulation) en que se convierte una señal analógica a formato digital representando muestras de la amplitud de la señal original mediante impulsos codificados en binario. La ITU recomienda usar 64 Kb/s para la voz en CBR. A esta frecuencia, la señal analógica se muestrea cada 125 µs y la amplitud de la señal se discretiza en 256 niveles, que requiere que cada trama de PCM tenga 8 bits. En general, la frecuencia de generación será:
Ancho de banda = (bits/muestra) x (muestras/s)
Ejemplos típicos de servicios de este tipo son voz, video y audio con requerimientos de ancho de banda descritos en la tabla 4.1.
Telefonía 64 Estéreo de Hi-fi 1400 Telefax grupo III 14.4 Telefax grupo IV 64 Telefax propietario 1500
Tabla 4.1.
4.4.1.2. Servicios a VBR El tráfico generado por una fuente de este tipo o alterna períodos de actividad y silencio o tiene una frecuencia de generación que varía continuamente. Además, y como consecuencia de ello, el rafagueo es mayor que la unidad y con frecuencia mucho mayor. El problema que ello genera desde el punto de vista de la gestión de la red es que no puede asignarse el ancho de banda en función de la frecuencia de pico ya que provocaría una importante subutilización de la red. Cualquier otro tipo de asignación de ancho de banda exige un control del grado calidad de servicio que se obtenga.
4.4.1.2.1. Servicios de video El video se presenta a los usuarios como una serie de tramas en que el movimiento de la escena se refleja en pequeños cambios entre las tramas visualizadas secuencialmente. Las tramas aparecen en la pantalla a frecuencia constante, 24 ó 30 tramas por segundo, de tal forma que el ojo humano integre las diferencias entre tramas para recuperar la sensación de movimiento. La representación digital de las señales de video requiere la transformación del campo continuo de la imagen en el dominio discreto. Esta transformación es una aplicación de muestras de la imagen continua en un conjunto finito de amplitudes discretas que recubren el ámbito de intensidades de la imagen, de forma similar a como el PCM permitía codificar la voz. La generación que se producirá será pues:
Ancho de banda = (bit/pixel) × (pixel/trama) × (trama/s)
Ejemplos típicos de estos anchos de banda aparecen en la tabla 4.2.
Servicio Ancho de banda (Kb/s)
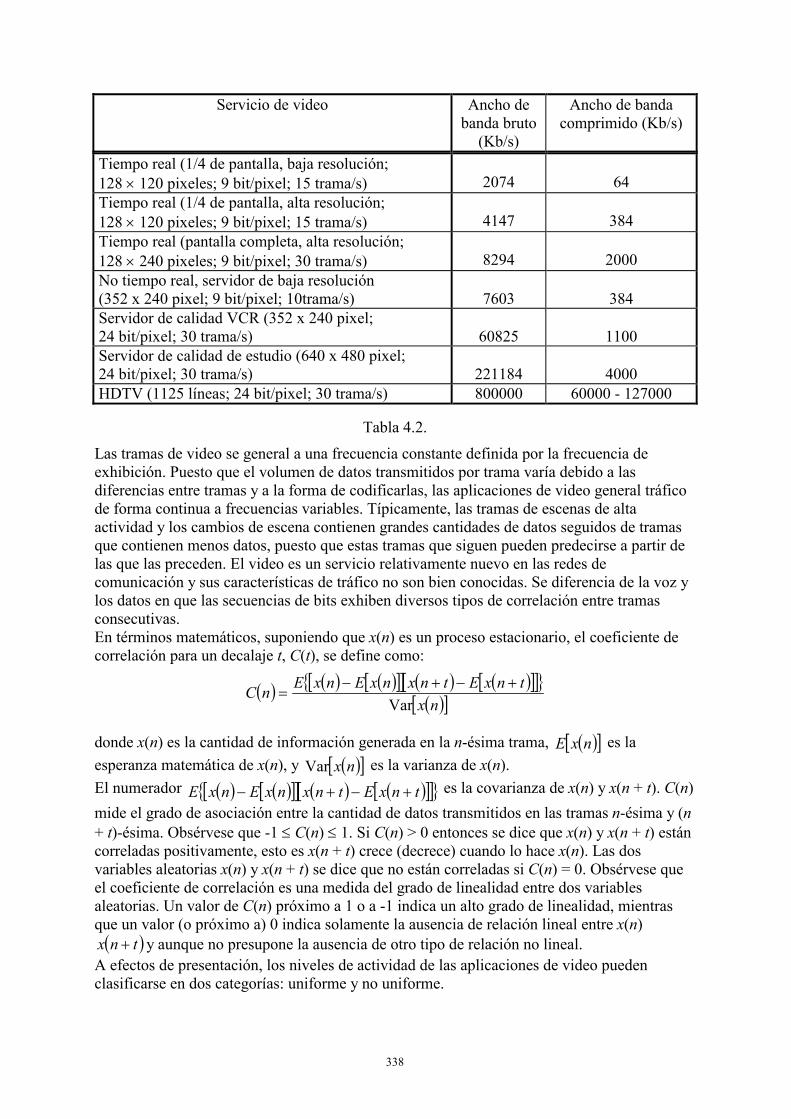
338
Tiempo real (1/4 de pantalla, baja resolución; 128 × 120 pixeles; 9 bit/pixel; 15 trama/s)
2074
64
Tiempo real (1/4 de pantalla, alta resolución; 128 × 120 pixeles; 9 bit/pixel; 15 trama/s)
4147
384
Tiempo real (pantalla completa, alta resolución; 128 × 240 pixeles; 9 bit/pixel; 30 trama/s)
8294
2000
No tiempo real, servidor de baja resolución (352 x 240 pixel; 9 bit/pixel; 10trama/s)
7603
384
Servidor de calidad VCR (352 x 240 pixel; 24 bit/pixel; 30 trama/s)
60825
1100
Servidor de calidad de estudio (640 x 480 pixel; 24 bit/pixel; 30 trama/s)
221184
4000
HDTV (1125 líneas; 24 bit/pixel; 30 trama/s) 800000 60000 - 127000
Tabla 4.2.
Las tramas de video se general a una frecuencia constante definida por la frecuencia de exhibición. Puesto que el volumen de datos transmitidos por trama varía debido a las diferencias entre tramas y a la forma de codificarlas, las aplicaciones de video general tráfico de forma continua a frecuencias variables. Típicamente, las tramas de escenas de alta actividad y los cambios de escena contienen grandes cantidades de datos seguidos de tramas que contienen menos datos, puesto que estas tramas que siguen pueden predecirse a partir de las que las preceden. El video es un servicio relativamente nuevo en las redes de comunicación y sus características de tráfico no son bien conocidas. Se diferencia de la voz y los datos en que las secuencias de bits exhiben diversos tipos de correlación entre tramas consecutivas. En términos matemáticos, suponiendo que x(n) es un proceso estacionario, el coeficiente de correlación para un decalaje t, C(t), se define como:
( ) ( ) ( )[ ][ ] ( ) ( )[ ][ ] ( )[ ]nx
tnxEtnxnxEnxEnCVar
+−+−=
donde x(n) es la cantidad de información generada en la n-ésima trama, ( )[ ]nxE es la esperanza matemática de x(n), y ( )[ ]nxVar es la varianza de x(n). El numerador ( ) ( )[ ][ ] ( ) ( )[ ][ ] tnxEtnxnxEnxE +−+− es la covarianza de x(n) y x(n + t). C(n) mide el grado de asociación entre la cantidad de datos transmitidos en las tramas n-ésima y (n + t)-ésima. Obsérvese que -1 ≤ C(n) ≤ 1. Si C(n) > 0 entonces se dice que x(n) y x(n + t) están correladas positivamente, esto es x(n + t) crece (decrece) cuando lo hace x(n). Las dos variables aleatorias x(n) y x(n + t) se dice que no están correladas si C(n) = 0. Obsérvese que el coeficiente de correlación es una medida del grado de linealidad entre dos variables aleatorias. Un valor de C(n) próximo a 1 o a -1 indica un alto grado de linealidad, mientras que un valor (o próximo a) 0 indica solamente la ausencia de relación lineal entre x(n)
( )tnx + y aunque no presupone la ausencia de otro tipo de relación no lineal. A efectos de presentación, los niveles de actividad de las aplicaciones de video pueden clasificarse en dos categorías: uniforme y no uniforme.
Servicio de video Ancho de banda bruto
(Kb/s)
Ancho de banda comprimido (Kb/s)

339
4.4.1.2.1.1. Escenas de video con nivel de actividad uniforme
En las escenas con nivel actividad uniforme, el cambio en el contenido de información de tramas consecutivas no es significativo. Una aplicación típica es el videoteléfono donde la pantalla muestra una persona hablando. a) Modelo autoregresivo de estado continuo Sea λ(n) la frecuencia de bit de la n-ésima trama. El modelo autoregresivo propuesto por Maglaris et al. estima que la frecuencia de bit de la n-ésima trama a partir de la (n - 1)-ésima es
λ(n) = aλ(n - 1) + bω(n)
donde a y b son constantes y ω(n) es una variable aleatoria gaussiana de media m. La media E(λ) y la autocovarianza de la frecuencia de bit C(n) valen
abmE−
=1
( ) 2
2
1 aabnC
n
−=
que pueden usarse para determinar las dos variables desconocidas a y b a partir de los valores medidos de la media y de la autocovarianza. Este modelo es bastante exacto con respecto de las medidas reales pero no es práctico para usarlo en estudios analíticos de modelos de colas aunque sí lo es en modelos de simulación. b) Modelos markovianos de tiempo continuo y estado discreto Este modelo tratable analíticamente fue también desarrollado por Maglaris et al. Sean P y L respectivamente las frecuencias máxima y mínima de bits generados por la fuente de video. Además, se supone que las posibles frecuencias entre P y L están cuantificadas uniformemente en M niveles de tamaño constante A = (P - L)/M. Considerando cada nivel de cuantificación como un estado, se tiene el estado i correspondiente a una frecuencia λ(i), donde
λ(i) = iA, 0 ≤ i ≤ M
Entonces, la frecuencia real de la fuente es λ(i) + L. Las frecuencias de transición entre los estados del sistema vienen dadas por
( )( )
≤≤−==β
−≤≤+==α−=
contrario casoen 01 ;1y si
10 ;1y si , Miikiji
MiikijiMkjR
La elección de estas frecuencias se basa en la observación que si una fuente de video está en una fase de alta actividad, entonces es más frecuente que pase a una fase de menor actividad que una de mayor. De forma similar, si la fuente está en una fase de baja actividad es más probable que pase a una de mayor actividad que a una de menor. M se elige arbitrariamente; si se toman valores grandes se tendrá una mayor granularidad en la cuantificación de las frecuencias de bits, aumentando, por lo tanto, la precisión del modelo. Sin embargo, cuando M se hace mayor (y por lo tanto el número de estados), la complejidad de los modelos para analizar tal tipo de fuentes también lo hará. Por lo tanto, como es habitual, hay que buscar un equilibrio entre precisión y complejidad. Sea πi la probabilidad en régimen estacionario que el proceso de Markov esté en el estado i, 0 ≤ i ≤ M. πi es la solución del siguiente conjunto de ecuaciones
( ) ( ) 1,,0 ,1 1 −…=βπ+=απ− + MiiiM ii

340
10
=π∑=
M
ii
Es fácil verificar por sustitución que las πi valen
( ) MiiMi
MiMi
i ,,0 ,!!
!…=
β+α
β
β+α
α−
=π−
Las incógnitas A, α y β se estiman igualando la media E[λ], la varianza Var[λ] y la autocovarianza C[gt] del proceso de Markov con los valores medidos usando las siguientes ecuaciones
[ ] ( ) MApiEM
ii =λπ=λ ∑
=0
donde p = α/(α + β),
[ ] [ ] [ ][ ]22Var λ−λ=λ EE
donde [ ]2λE es el momento de segundo orden de la frecuencia de bits,
[ ] ( )ppMA −=λ 1Var 2
[ ] [ ] ( )τβ+α−λ=τ eC Var
c) Modelos markovianos de tiempo y estado discretos Similar al anterior este modelo se define sobre los estados de 0 a M donde el estado i corresponde al nivel discretizado de frecuencia λ(i). En este modelo, el tiempo se discretiza en intervalos de longitud fija siendo cada intervalo igual al de generación de una trama. Al final de cada intervalo, el proceso se mueve del estado i al estado i + 1 con probabilidad αi, o al estado i - 1 con probabilidad βi, o permanece en el estado i con probabilidad γi, de tal forma que αi + βi + γi = 1. Las probabilidades de transición de estado son pues:
( )
==γ≤≤−==β
−≤≤+==α=
si 1 ;1y si
10 ;1y si ,
ikjMiikijMiikij
kjp
i
i
i
Las probabilidades de transición en este modelo han de tener una ordenación similar a las del modelo anterior. Así pues
αi ≥ αi + 1 para 0 ≤ i ≤ M - 1
βi ≥ βi - 1 para 1 ≤ i ≤ M
M se elige arbitrariamente. Para los valores de αi y βi se han propuesto diversos conjuntos, como por ejemplo:
Conjunto I: αi = c(1 - i/M); βi = ci/M; γi = 1 - c
Conjunto II: αi = c1(1 - i/M); βi = c2i/M; γi = 1 - c1 + (c1 - c2)i/M
Conjunto III: αi = c1(i - M)2; βi = c2i2 ; γi = 1 - c1(i - M)2 - c2i2

341
donde c, c1 y c2 son constantes. Ambos modelos markovianos capturan la rápida disminución del coeficiente de correlación de la frecuencia de bits en tramas consecutivas, que decae a partir de pocos centenares de milisegundos. Estos modelos no son adecuados para la modelización de niveles de actividad no uniforme debido a que - las transiciones desde el estado i se permiten sólo a sus estados vecinos i + 1 e i - 1, que
considera solo pequeños cambios en las frecuencias de generación de bits.
- las correlaciones a largo plazo en los cambios de escena que tardan algunos segundos en producirse no pueden ser capturados por estos modelos.
4.4.1.2.1.2. Escenas de video con nivel de actividad no uniforme
En los videos de movimiento, además de la rápida disminución de las correlaciones a corto plazo, hay una lenta disminución de las correlaciones a largo plazo de la cantidad de información generada por trama que se produce en los instantes de cambio de escena. a) Modelo markoviano bidimensional de tiempo continuo Este modelo propuesto por Sen et al es una generalización de los anteriores. Cada dimensión del modelo puede considerarse como una cadena de Markov unidimensional de las tratadas en el apartado anterior. En dos dimensiones es posible modelar las pequeñas fluctuaciones en la frecuencia de generación de bits entre tramas consecutivas para incluir los saltos a mayores o menores frecuencias de generación, pudiendo modelar la correlación en los cambios de escena. Sean Ah y Al los intervalos de cuantificación de la alta y la baja frecuencia, respectivamente. En general se definen N1 + 1 niveles de baja frecuencia y N2 + 1 de alta y sea (i, j) el estado que corresponde a la frecuencia (iAh +jAl), 0 ≤ i ≤ N2, 0 ≤ j ≤ N1. De acuerdo con las pruebas de validación citadas en el apartado anterior, una fuente de video sencilla puede caracterizarse precisamente con N1 = 1, mientras que N2 se elige de forma arbitraria pero suficientemente grande para explorar todas las frecuencias de generación de bit igualmente probables. Como se indicó anteriormente tanto la precisión como la complejidad del modelo crecen cuando N1 lo hace. La figura 4.9 muestra la representación del proceso bidimensional de Markov para una fuente sencilla. Las frecuencias de transición entre los estados de esta cadena de Markov bidimensional se definen de la forma siguiente:
Ah + Al 2Ah + Al
0 N2Ah
N2Ah + Al
(N2 + 1)c
2d
Ah 2Ah
Al
N2c
N2c
(N2 + 1)c c
c
N2d
N2d2dd
d
N1a N1a N1ab b b
Figura 4.9.
( ) ( )
( )
( )
≤≤≤≤==−==≤≤−≤≤==+==−
≤≤≤≤−====−≤≤≤≤+====−
=
122121
1221212
122121
1221211
2211
0 ;1;y 1 ; si 0 ;10;y 1 ; si
1 ;0;1 ;y si 10 ;0;1 ;y si
,,,
NjNijmmikikidNjNijmmikikciN
NjNijmjmikkjbNjNijmjmikkajN
mkmkR

342
Con N1 = 1, los parámetros usados para caracterizar el proceso de Markov en función de los parámetros de la fuente son: 1/d = tiempo medio de permanencia en el nivel alto de actividad;
1/c = tiempo medio de permanencia en el nivel bajo de actividad;
q = fracción de tiempo en el nivel alto de actividad, q = c /(c + d);
γ = relación entre la frecuencia de generación de datos en el nivel alto de actividad y el nivel bajo;
C[0] = varianza;
C[τ] = función de covarianza;
λ = la frecuencia media global de generación de bits.
Entonces, [ ] ( ) 21 10 lAppNC −= , donde p = a /(a + b), [ ] [ ] ( )τ+−=τ baeCC 0 ,
l
hl
pANApAN
1
1 +=γ y
hl qApAN +=λ 1 A partir de datos reales, puede recogerse un conjunto de estadísticas para estimar los valores de q, 1/d, C[0], C[τ], γ y λ. Usando las ecuaciones anteriores pueden determinarse los valores de Ah, Al, a y b para caracterizar completamente el proceso de Markov. b) Proceso de medias móviles autoregresivas (ARMA)
Además de los dos tipos de correlación modelados en las cadenas de Markov bidimensionales, puede suceder que la covarianza de las secuencias de bits de fuentes de video presente otras correlaciones para otros decalajes. El significado de esta correlación se resume de la forma siguiente: - La función de autocovarianza no se desvanece para decalajes k ≠ 0, incluso cuando se
superponen un gran número de fuentes codificadas. Por lo tanto, la suposición que la superposición de un gran número de fuentes se comporta como una secuencia poissoniana no es válida en estos entornos.
- El efecto de la correlación de los procesos de llegada depende de la utilización de la cola. Con niveles de utilización de hasta el 61%, se observa que su efecto es despreciable, mientras que su efecto en el comportamiento de la cola se hace significativo a partir del 76% de utilización. A mayores cargas, se observa además que ligeros cambios en la autocovarianza provoca cambios significativos en el comportamiento de las métricas de prestaciones (retraso y probabilidad de pérdida).
Se propone el modelo ARMA para tener en cuenta estas correlaciones además de capturar las dos ya citadas que se producen en escenas de nivel de actividad no uniforme. Sea Xn la secuencia de variables aleatorias que representan el proceso de llegada de celdas de video. Suponiendo que E[Xn] = E[X0] y que Covarianza(Xn, X0) = Covarianza(Xn + k, Xn) = R(k), la función de autocovarianza R(k) depende sólo del decalaje k. La caracterización de las estadísticas del proceso de llegada de celdas ATM mediante un modelo ARMA es un procedimiento de tres pasos de acuerdo con Grunenfelder et al.: 1. Paso de medida. Se estiman la media, la varianza y la autocovarianza a largo plazo a
partir de la salida de celdas del codificador.
2. Paso de estimación de parámetros. El procedimiento ARMA consta de un filtro de orden finito, un filtro recursivo y una no linealidad sin memoria. Los parámetros del modelo matemático ARMA se estiman a partir de los datos medidos.

343
3. Paso de la función de transferencia. Este paso produce la secuencia de tiempos entre llegadas de celdas tomando en consideración un ruido blanco.
El proceso de llegada ARMA se usa en simulaciones para estimar la función de distribución de probabilidad del retraso en la cola y la media y la varianza del tiempo entre salidas visto por una celda que llega. Sin embargo estos modelos no pueden usarse en modelización analítica.
4.4.1.2.2. Servicios de voz En el apartado 4.4.1.1. se ha visto la caracterización de los servicios de voz codificados por PCM produciendo una secuencia de CBR. Sin embargo, para mejorar la eficiencia de la transmisión sin reducir la calidad de la voz, puede extenderse el PCM al PCM diferencial (DPCM) e incluso al PCM diferencial adaptativo (ADPCM) especificados por la ITU-T. Una fuente de voz alterna períodos de habla (activos) con otros de silencio. En CBR se transmiten tanto los períodos activos como los de silencio, lo que provoca un uso ineficiente de los recursos de la red. Para alcanzar altos niveles de utilización de estos recursos, las fuentes de voz pueden transformarse en fuentes VBR de tal forma que los paquetes se generan sólo cuando la fuente está activa, aumentando, en consecuencia la eficiencia de la transmisión. La transmisión de celdas generadas durante los períodos activos, usando codificación ADPCM, alcanza una relación de compresión superior a 4 sin degradación apreciable en la calidad de la voz. Un período activo de una fuente de voz corresponde a pronunciar un párrafo, mientras que uno de silencio corresponde a la ausencia de voz (pausas para respirar, recopilación de las propias ideas, escucha del interlocutor, etc.). Los períodos de silencio constituyen el 60-65% del tiempo de transmisión de las llamadas de voz en cada dirección. Más específicamente, el promedio de los períodos activo y silente son respectivamente 352 ms y 650 ms, resultados de medición. Además, en una conversación normal, la duración del período activo se ajusta razonablemente bien a una distribución exponencial, mientras que la duración del de silencio se ajusta menos bien. Sin embargo, los modelos de fuentes de voz más frecuentemente usados suponen que tanto el período activo como el de silencio tienen duraciones distribuidas exponencialmente. Se ha hallado que la precisión de los modelos a dos estados con duraciones distribuidas exponencialmente es razonablemente buena si se multiplexan más de 25 fuentes de voz, mientras que el modelo es poco conveniente si el número de fuentes multiplexadas es inferior a 10.
4.4.1.2.2.1. Proceso de Poisson interrumpido (IPP, Interrumped Poisson Process)
El IPP es un proceso de Poisson que alternativamente genera durante un período de tiempo distribuido exponencialmente (período activo) y deja de hacerlo durante otro período de tiempo distribuido también exponencialmente pero con una distribución independiente de la anterior (período de silencio). Durante el período activo, el tiempo entre llegadas de paquetes está distribuido exponencialmente (proceso de Poisson), mientras que no se generan paquetes durante el período de silencio. Como se ha dicho todos los procesos se consideran independientes. Sean 1/σA, 1/σS y λ, respectivamente las duraciones medias de los períodos activo y silente y la frecuencia de generación de paquetes durante el período activo. Entonces, la función de distribución de probabilidad del período activo, Pr[X ≤ t], del período silente, Pr[Y ≤ t], y de los tiempos entre llegadas de paquetes en el período activo, Pr[Z ≤ t], son
[ ] tAetX σ−−=≤ 1Pr , [ ] tSetY σ−−=≤ 1Pr y [ ] tetZ λ−−=≤ 1Pr . Además sean πA y πS, respectivamente, la probabilidad que el proceso de Markov de dos estados se halle en el período activo y silente. Entonces

344
SA
AA σ+σ
σ=π y
SA
SS σ+σ
σ=π
Sea ahora φ(s) la transformada de Laplace de la distribución de los tiempos entre llegadas de paquetes y considérese el proceso de actividad/inactividad justo después de la llegada de un paquete. El tiempo hasta la siguiente llegada es el mínimo de (X, Z). El acontecimiento es una llegada con probabilidad λ/(λ + σA) y es un cambio de un estado activo a un estado silente con probabilidad σA/(λ + σA). Al final del período de silencio, el proceso se repite de nuevo, por lo tanto, se tiene
( ) +
+σ+λ
σ+λσ+λ
λ+σ
σσ+λ
σ+
+σ+λσ+λ
σ+λλ
=φ2
ssss
A
A
AS
S
A
A
A
A
A
…+
+σ+λ
σ+λσ+λ
λ
+σ
σ
σ+λ
σ+
322
ss A
A
AS
S
A
A
y después de algunas manipulaciones
( ) ( )( ) λσ+σ+σ+λ+
+σλ=φ
SAS
S
sss
s 2
Los dos primeros momentos de la distribución de tiempos entre llegadas de paquetes, E[X], y su coeficiente cuadrático de variación c2, son entonces
[ ]S
SAXEλσ
σ+σ=
( )22 2
1SA
Acσ+σ
λσ+=
Una IPP con parámetros (σA, σS, λ) es equivalente a una distribución hiperexponencial de parámetros (p1, µ1, p2, µ2), donde
( ) ( )[ ] 2/121 45.0 ASASA λσ−σ+σ+λ+σ+σ+λ=µ
( ) ( )[ ] 2/122 45.0 ASASA λσ−σ+σ+λ−σ+σ+λ=µ
21
21 µ−µ
µ−λ=p
p2 = 1 – p1
Recíprocamente, el IPP, (σA, σS, λ), equivalente de una distribución hiperexponencial de parámetros (p1, µ1, p2, µ2) es
λ = p1µ1 + p2µ2
( )λ
µ−µ=σ
22121 pp
A

345
λµµ
=σ 21S
A continuación se va a estudiar el problema siguiente: Dados los tres primeros momentos de los tiempos entre llegadas, E[X], E[X2] y E[X3], ¿cuáles son los parámetros de la distribución exponencial (o del IPP) que tienen estos mismos tres momentos? Siempre que
[ ] [ ] [ ] 23 5.1 XEXEXE >
los parámetros (p1, µ1, p2, µ2) vienen determinados de forma única por las ecuaciones
[ ] [ ] [ ][ ] [ ] [ ]322
32
2326
XEXEXEXEXEXEu
−
−=
[ ] [ ][ ] [ ] [ ]322
22
23612
XEXEXEXEXEv
−
−=
( )[ ]2/1221 45.0, vuu −±=µµ
[ ]
µ
−µ−µ
µµ=
121
212
1XEp
p1 = 1 – p2
Si la condición anterior no se cumple, entonces hay un número infinito de formas de seleccionar los parámetros de la distribución hiperexponencial. El siguiente conjunto está sugerido por Marie en el contexto del análisis aproximado de redes de colas.
[ ]XE2
1 =µ
[ ] 221
cXE=µ
( ) 221
12
5.0c
pµ−µµ
=
En estas ecuaciones se supone que el coeficiente cuadrático de variación es mayor o igual que 1, que, como se ha visto es precisamente el caso. Obsérvese que si se usan las fórmulas anteriores para obtener los parámetros de la distribución hiperexponencial (que ajusta sólo los dos primeros momentos), entonces no hay una correspondencia uno a uno entre sus parámetros y el IPP equivalente. En este caso, puede elegirse arbitrariamente uno de los parámetros del IPP. Por ejemplo, puede elegirse λ de tal forma que 1/λ sea el tiempo de transmisión de una celda en el medio.
4.4.1.2.2.1. Proceso de Bernouilli interrumpido (IBP, Interrumped Bernouilli Process)
Este proceso es la versión discreta del IPP. El tiempo está ranurado, con la longitud de cada ranura igual al tiempo de una celda en el medio. Una ranura estará en estado activo o en estado silente. Una ranura en estado activo contiene una celda con probabilidad α y ninguna con probabilidad 1 - α, mientras que no llega ninguna celda en estado silente. Cuando una

346
ranura está en estado activo (independientemente de si contiene celda o no), la siguiente ranura estará también en estado activo con probabilidad p y cambiará a estado silente con probabilidad 1 - p. De modo similar, si una ranura está en estado silente, la siguiente también lo estará con probabilidad q y cambiará a estado activo con probabilidad 1 - q. De acuerdo con todo esto, tanto el período activo, Pr[X = x], como el silente, Pr[Y = y], están distribuidos geométricamente. Esto es
[ ] ( ) 1 ,1Pr 1 ≥−== − xppxX x
[ ] ( ) 1 ,1Pr 1 ≥−== − yqqyY y
con duraciones medias de 1/(1 – p) y 1/(1 – q). De forma similar a la versión continua, la solución de la probabilidades en régimen estacionario de estar el estado activo, πA, y silente, πS son
qpq
A −−−
=π2
1
qpp
S −−−
=π2
1
La media E[X], el coeficiente cuadrático de variación, c2, y el momento de tercer orden, E[X3], de la distribución de los tiempos entre llegadas de celdas de un IBP pueden obtenerse de la transformada en z, φ(z), del IBP y se definen en función de (p, q, α) como sigue
( ) ( )[ ]( )( ) ( )[ ] 1111
12 +α−+−−+α−
−−+α=φ
zpqzqpqpzpzz
( ) ( )qqpXE
−α−−
=1
2
( )( )( )
−−−
+−α+= 1
211 2
2
qpqppc
( ) ( )( ) ( )
( )( ) ( )
( )2
2
3
2
2223 2331
1112
11126
pc
qqq
qXE ρ−+
+
ρα−
+−α
−ρ−α
α−−
ρ−+
ρ−α−
=
donde ρ = 1/E[X] es la probabilidad que una ranura contenga una celda, definida como la utilización de la fuente. Suponiendo que una ranura en un período activo contenga siempre una celda (es decir, α = 1), entonces las expresiones anteriores se reducen a
[ ]q
qpXE−
−−=
12
( )( )( )2
2
21
qpqppc
−−+−
=
[ ] ( )( ) 2
2
23 233
116
pc
qqXE ρ−+
+ρ−
ρ−=

347
Dados los valores de E[X], c2 y E[X3], los parámetros del IBP que ajusta estos momentos no pueden obtenerse de forma directa debido a la complejidad de la expresión de E[X3]. Sin embargo, puede usarse el siguiente algoritmo propuesto por Park y Perros, que proporciona una buena estimación de los parámetros (p, q, α). Sea a el valor absoluto de a. 0. Sea α = ρ; min = 100000.
1. Hacer α = α + ε. Si α ≥ 1, entonces parar el algoritmo. 2. Si las dos condiciones siguientes no se cumplen, entonces volver a 1.
Condición 1: ( ) 0231 22 >ρ−αρ+α−c
Condición 2: ( ) 02231 222 >α+ρ+αρ−α−c
3. Calcular p y q, de acuerdo con
α−α+αρ−αα−ρ−αρ+α
= 22
22
223
ccp
α−α+αρ−αα−α+ρ+αρ−α
= 22
222
2223
ccq
4. Calcular el tercer momento, m3, del IBP con parámetros (p, q, α) mediante las fórmulas anteriores. Si [ ] ε<− 3
3 XEm , entonces parar el algoritmo. En caso contrario, si
[ ]33min XEm −> , entonces salvar los parámetros (p, q, α) y hacer [ ]3
3min XEm −= y volver al paso 1.
El algoritmo busca la mínima diferencia entre el tercer momento de la distribución y del IBP con los parámetros estimados. Si no se usa el tercer momento, entonces es necesario establecer arbitrariamente el valor de uno de los tres parámetros y calcular los otros dos a partir de las ecuaciones de los dos primeros momentos. En particular si se hace α = 1, pueden usarse las fórmulas correspondientes a esta hipótesis para estimar los valores de p y q. En este caso se tiene
( )2
121c
p ρ−−=
( )( )ρ−
ρ−−=
111 pq
4.4.1.2.3. Servicios de datos El término datos se utiliza aquí para indicar cualquier aplicación que use texto codificado, es decir cualquier aplicación que no sea ni voz, ni audio ni video ni imagen. A pesar de que las redes se utilizan desde hace mucho tiempo, las características del tráfico de las fuentes de datos son mal conocidas. La principal dificultad reside en que no hay una conexión de datos típica ya que las hay, como las transferencias de archivos, que transfieren grandes cantidades de datos de forma casi continua durante la duración de la conexión, otras, como el correo electrónico envía solo algunos centenares de bytes. Otras conexiones trabajan de forma conectada mientras que otras lo hacen de forma desconectada. Las aplicaciones interactivas requieren intercambios bidireccionales mientras que la actualización de una base de datos puede usar conexiones unidireccionales. Además, hay que tener en cuenta que las redes ATM se usan para interconectar LANs, es decir, no conecta pares de usuarios, sino los grupos de usuarios conectados a cada LAN. Teniendo en cuenta todas estas dificultades, se tratan a continuación diferentes aplicaciones de datos.
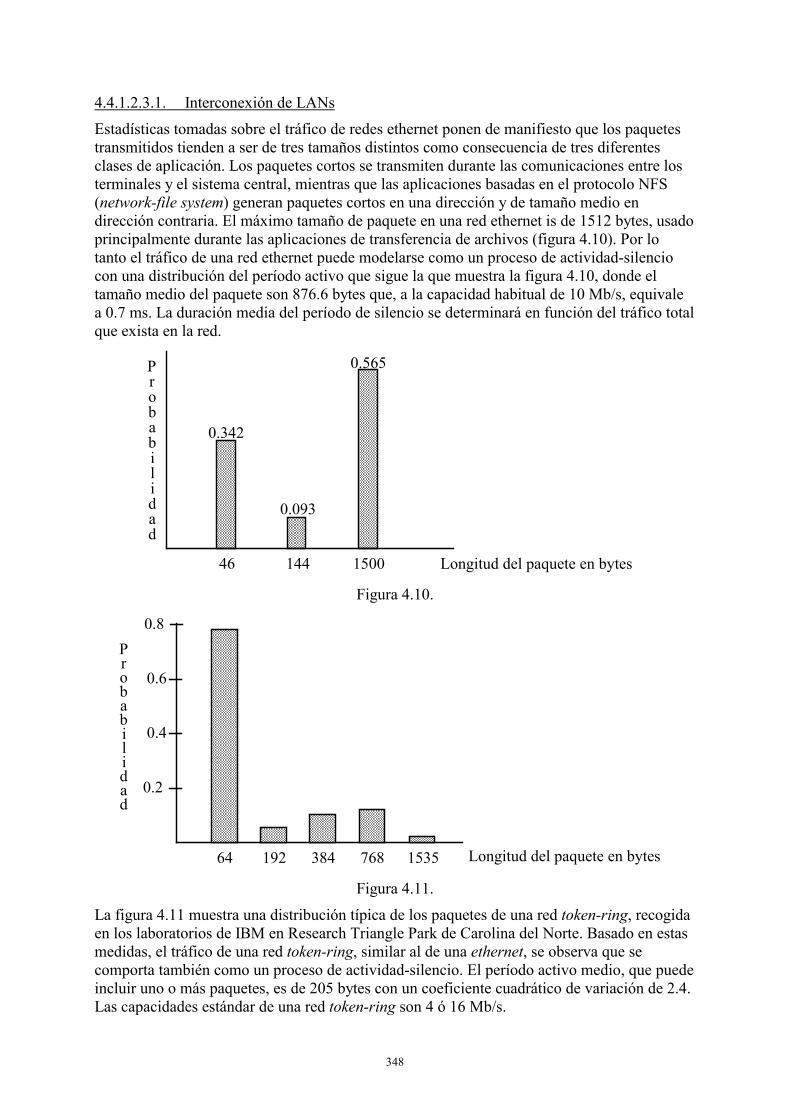
348
4.4.1.2.3.1. Interconexión de LANs
Estadísticas tomadas sobre el tráfico de redes ethernet ponen de manifiesto que los paquetes transmitidos tienden a ser de tres tamaños distintos como consecuencia de tres diferentes clases de aplicación. Los paquetes cortos se transmiten durante las comunicaciones entre los terminales y el sistema central, mientras que las aplicaciones basadas en el protocolo NFS (network-file system) generan paquetes cortos en una dirección y de tamaño medio en dirección contraria. El máximo tamaño de paquete en una red ethernet is de 1512 bytes, usado principalmente durante las aplicaciones de transferencia de archivos (figura 4.10). Por lo tanto el tráfico de una red ethernet puede modelarse como un proceso de actividad-silencio con una distribución del período activo que sigue la que muestra la figura 4.10, donde el tamaño medio del paquete son 876.6 bytes que, a la capacidad habitual de 10 Mb/s, equivale a 0.7 ms. La duración media del período de silencio se determinará en función del tráfico total que exista en la red.
0.342
46
0.093
144
0.565
1500
Probabilidad
Longitud del paquete en bytes Figura 4.10.
Probabilidad
Longitud del paquete en bytes
0.2
0.4
0.6
0.8
64 192 384 768 1535 Figura 4.11.
La figura 4.11 muestra una distribución típica de los paquetes de una red token-ring, recogida en los laboratorios de IBM en Research Triangle Park de Carolina del Norte. Basado en estas medidas, el tráfico de una red token-ring, similar al de una ethernet, se observa que se comporta también como un proceso de actividad-silencio. El período activo medio, que puede incluir uno o más paquetes, es de 205 bytes con un coeficiente cuadrático de variación de 2.4. Las capacidades estándar de una red token-ring son 4 ó 16 Mb/s.
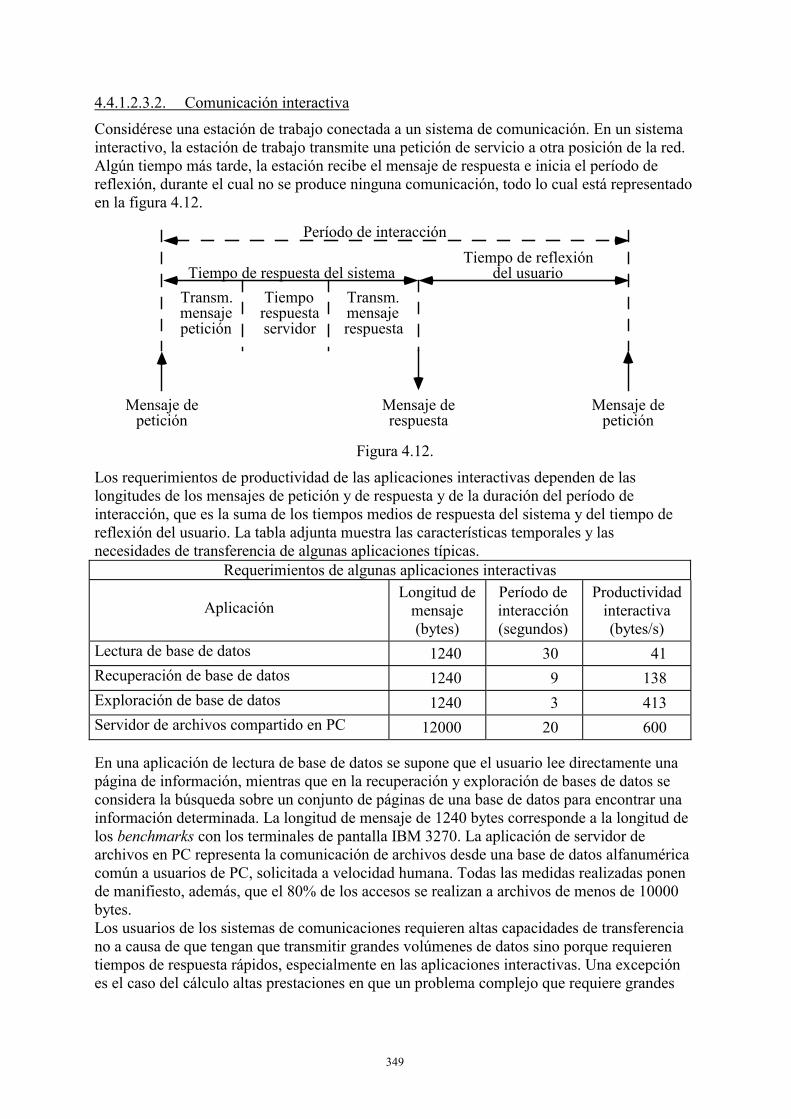
349
4.4.1.2.3.2. Comunicación interactiva
Considérese una estación de trabajo conectada a un sistema de comunicación. En un sistema interactivo, la estación de trabajo transmite una petición de servicio a otra posición de la red. Algún tiempo más tarde, la estación recibe el mensaje de respuesta e inicia el período de reflexión, durante el cual no se produce ninguna comunicación, todo lo cual está representado en la figura 4.12.
Transm.mensajepetición
Transm.mensajerespuesta
Tiemporespuestaservidor
Período de interacción
Tiempo de respuesta del sistemaTiempo de reflexión
del usuario
Mensaje depetición
Mensaje derespuesta
Mensaje depetición
Figura 4.12.
Los requerimientos de productividad de las aplicaciones interactivas dependen de las longitudes de los mensajes de petición y de respuesta y de la duración del período de interacción, que es la suma de los tiempos medios de respuesta del sistema y del tiempo de reflexión del usuario. La tabla adjunta muestra las características temporales y las necesidades de transferencia de algunas aplicaciones típicas.
Requerimientos de algunas aplicaciones interactivas
Aplicación Longitud de
mensaje (bytes)
Período de interacción (segundos)
Productividad interactiva (bytes/s)
Lectura de base de datos 1240 30 41 Recuperación de base de datos 1240 9 138 Exploración de base de datos 1240 3 413 Servidor de archivos compartido en PC 12000 20 600 En una aplicación de lectura de base de datos se supone que el usuario lee directamente una página de información, mientras que en la recuperación y exploración de bases de datos se considera la búsqueda sobre un conjunto de páginas de una base de datos para encontrar una información determinada. La longitud de mensaje de 1240 bytes corresponde a la longitud de los benchmarks con los terminales de pantalla IBM 3270. La aplicación de servidor de archivos en PC representa la comunicación de archivos desde una base de datos alfanumérica común a usuarios de PC, solicitada a velocidad humana. Todas las medidas realizadas ponen de manifiesto, además, que el 80% de los accesos se realizan a archivos de menos de 10000 bytes. Los usuarios de los sistemas de comunicaciones requieren altas capacidades de transferencia no a causa de que tengan que transmitir grandes volúmenes de datos sino porque requieren tiempos de respuesta rápidos, especialmente en las aplicaciones interactivas. Una excepción es el caso del cálculo altas prestaciones en que un problema complejo que requiere grandes

350
tiempos de proceso con grandes volúmenes de datos se resuelve en un conjunto de supercomputadores conectado a través de una red de comunicación de alta velocidad.
4.4.1.2.3.2. Cálculo de altas prestaciones
En el cálculo distribuido, una tarea se divide en un cierto número de partes o subtareas y cada una de ellas se carga en un supercomputador distinto y se ejecutan simultáneamente con el fin de ganar en prestaciones. Durante el cálculo los computadores necesitan intercambiar información para agregar los resultados obtenidos por cada subtarea. La red de comunicación permite a los computadores realizar este intercambio. si la comunicación entre computadores es lenta comparada con su velocidad de cálculo o no puede solaparse con el cálculo, entonces cada computador estará ocioso mientras espera los datos y, por lo tanto, infrautilizado. El tamaño del paquete es un factor importante en la determinación de la productividad de la comunicación. En experimentos realizados con un sistema de entrada salida de un supercomputador Cray modelo D, se observó que la productividad del canal de entrada-salida, cuya capacidad es de 800 Mb/s, era de 280 Mb/s con paquetes de 16 Kbytes. El tamaño del paquete que permitía saturar el enlace era de 256 Kbytes, que es equivalente a una ráfaga de aproximadamente 5600 celdas. Para ilustrar las demandas de gran ancho de banda en aplicaciones de cálculo de altas prestaciones, se presentan a continuación algunos resultados observados en la aplicación de la planificación dinámica de la radioterapia. Los datos en este sistema pasan de un supercomputador Cray a la interfaz de terminal de red a través de un enlace HIPPI. Las estadísticas recogidas se convierten para simular el tráfico en una red ATM. La frecuencia de tráfico indica el tráfico ATM total que llega en un intervalo fijo de N ranuras dividido por la duración del intervalo. Cuando se promedia el tráfico sobre N = 8000 ranuras, la frecuencia de pico se observa que es alrededor de 145 Mb/s, mientras que es igual a 600 Mb/s con N = 200 ranuras. El tráfico, como se esperaba, alterna períodos de actividad y de silencio. Hay solo tres duraciones observadas distintas del período de actividad, correspondientes a paquetes HIPPI de longitudes de 24 bytes, 2264 bytes y de 16 Kbytes, como muestra la figura 4.13.
1.0
0.75
0.5
0.25
020 60 420
Probbility
Active period (cells) Figura 4.13
El número medio de celdas ATM medido es de 372.9, con un coeficiente cuadrático de variación de 0.155. Por consiguiente, estadísticamente el período activo tiene poca variación y puede modelarse mediante una distribución de Erlang con seis fases o mediante una distribución constante. Por otra parte, se observa que el período de silencio tiene un gran coeficiente cuadrático de variación de 83.
351
Estos primeros resultados indican que ni el IPP ni el IBP son candidatos razonables para modelar con precisión el comportamiento de una fuente de datos. Una alternativa es suponer que estos dos modelos markovianos producen buenos resultados y usarlos sin ningún cambio. Alternativamente, pueden desarrollarse nuevos modelos para el tráfico de datos en que la duración de lso períodos de silencio no son exponenciales (o geométricos). sin embargo, puede esperarse que estos modelos sean mucho más complejos que los IPP o IBP y puedan tener un uso limitado (como el ARPA para la modelización de las fuentes de tráfico video).
4.4.1.2.4. Servicios de multimedia El término multimedia se usa para referirse a la representación, almacenamiento, recuperación y diseminación de información procesable expresada en diversos media, tales como texto, voz, video, gráficos, imagen, audio y video, Ejemplos de aplicaciones multimedia incluyen teleconferencia, video en demanda, imágenes médicas, anuncios, etc.
Texto anotado con voz Voz (32 Kb/s) 1 página de texto/30 s (1.24 x (8/30) Kb/s)
32.3
Imágenes de oficina anotadas con voz Voz (32 Kb/s) 1 página/90 s (60 x (8/90) Kb/s)
37.3
Imágenes de alta resolución anotadas con voz Voz (32 Kb/s) 1 imagen/90 s* [(2000 x 2000 x 12)/(10 x 90 x 1000) Kb/s]
85.3
Sonido de calidad CD y sistema de oficina (p. e. biblioteca) Audio (384 Kb/s) 1 imagen/60 s* [(2000 x 2000 x 12)/(10 x 60 x 1000) Kb/s]
392
Teleconferencia compleja Voz (32 Kb/s) Páginas de texto de 1.24 KB/60 s (1.24 x (8/60) Kb/s) Grágicos de 35 KB/60 s (35 x (8/60) Kb/s) 2 imágenes de alta de resolución de 60 KB/60 s 2 ventanas de video de baja calidad (128 Kb/s)
325
Sistema de distribución de video Sonido con calidad CD (1100 Kb/s) Video de calidad VCR (384 Kb/s)
1484
• Nota: Ratio de compresión 10:1; resolución 2000 x 2000; 12 bit/pixel Tabla 4.4.
Las aplicaciones multimedia difieren de las unimedia de diversas maneras. Varias aplicaciones multimedia implican grupos de usuarios y requieren conexiones punto-multipunto o multipunto-multipunto. En general, imponen condiciones estrictas de tiempo real a la red. Puesto que emplean diferentes tipos de media, la mayoría de las aplicaciones multimedia general grandes cantidades de secuencias de bits. La tabla 4.4 muestra las necesidades de ancho de banda de algunas aplicaciones multimedia, de acuerdo con [RUSS93].
Aplicación
Ancho de
Banda (Kb/s)

352
Los servicios multimedia en redes B-ISDN incluyen entro otros aspectos: - Establecimiento de llamadas múltiples
- Control en tiempo real de servicios integrados de tiempo real tales como video, audio y voz
- Sincronización entre grupos de usuarios
- Asignación dinámica de los recursos de la red que tenga en consideración los diferentes de servicio de cada aplicación integrada en el servicio.
- Transferencia multipunto eficiente
- Sincronización de las distintas aplicaciones, como entre video y audio.
4.4.2. MÉTRICAS DE LA CALIDAD DEL SERVICIO
4.4.2.1. Parámetros de control de llamada Hay tres métricas de interés en las redes orientadas a conexión, como las redes ATM: - Retraso de establecimiento de la conexión
- Retraso de liberación de la conexión
- Probabilidad de aceptación de la conexión
4.4.2.1.1. Retraso de establecimiento de la conexión El retraso de establecimiento de la conexión es el intervalo de tiempo entre la transferencia del mensaje de establecimiento de la llamada y la transmisión del mensaje de aceptación de la conexión. No es una métrica específica de ATM y está determinado principalmente por los retrasos en el proceso en los distintos puntos de transferencia de la señal en la red. Suponiendo que los retrasos por proceso en los intercambios ATM son similares a los de la ISDN, el retraso medio de establecimiento debe ser inferior a 4500 ms con el 95% de los valores del retraso inferiores a 8350 ms.
4.4.2.1.2. Retraso de liberación de la conexión El retraso de liberación de la conexión es el intervalo de tiempo entre la transferencia del mensaje de liberación de la conexión y la transmisión del mensaje de aceptación de la liberación. Pueden hacerse unas consideraciones similares a las del caso anterior, por lo que el retraso medio de liberación debe ser inferior a 300 ms con el 95% de los valores del retraso inferiores a 850 ms.
4.4.2.1.3. Probabilidad de aceptación de la conexión La probabilidad de aceptación de la conexión es la proporción de llamadas aceptadas sobre un período de tiempo suficientemente largo. También se la denomina probabilidad de bloqueo, por extensión de este mismo concepto existente en telefonía. Es uno de las más importantes métricas de comportamiento usadas para la asignación de los recursos de la red y también en el dimensionamiento de las redes. Sin embargo, con la introducción del B-ISDN hay una nueva incertidumbre con respecto a las características futuras del tráfico y de los servicios. A pesar de ello se han hecho esfuerzos para estimar los tiempos de conexión y las frecuencias de llamada de las nuevas aplicaciones B-ISDN para su planificación inicial.
4.4.2.2. Parámetros de transferencia de la información Constituyen el conjunto de parámetros requeridos por las aplicaciones y usados por la red para determinar si se puede admitir o no una nueva conexión. Tales parámetros en las redes ATM incluyen:

353
- Tasa de error de bits
- Tasa de pérdida de celdas
- Tasa de inserción de celdas
- Retraso de transferencia
- Variación del retraso de las celdas (jitter)
- Sincronización de objetos relacionados (skew)
4.4.2.2.1. Tasa de error de bits La tasa de error de bits (Bit error ratio, BER) es la relación entre los errores de bit que se han producido en el campo de información y el número total de bits transmitidos en el campo de información. No es una métrica específica de las redes ATM. Comparado con las redes existentes, el BER en ATM se espera que sea mucho menor, debido a la introducción de la tecnología de fibra óptica como medio de transmisión. La tabla 4.5 presenta unas primeras recomendaciones sobre el BER para diversos servicios B-ISDN.
Aplicación Frecuencia de bits BER* BER**
Videoteléfono 2 Mb/s 1 x 10-11 1.3 x 10-6 Videoconferencia 5 Mb/s 10-11 1.8 x 10-6 Distribución de TV 20-50 Mb/s 3 x 10-13 6 x 10-7 MPEG1 1.5 Mb/s 4 x 10-11 2.5 x 10-6 MPEG2 10 Mb/s 6 x 10-12 1.5 x 10-6
• Sin control de error en AAL • Corrección del error de un bit en cada celda y corrección por pérdida de celdas en AAL.
Tabla 4.5.
Suponiendo que los errores en los bits se producen aleatoriamente, la probabilidad que no haya errores en los datos de una celda ATM de 48 bytes (384 bits) en un enlace es
(1 - BER)384
Así, por ejemplo, con BER = 10-6, esta probabilidad es igual a 0.99617, que aumenta a 0.999996 con BER = 10-9.
4.4.2.2.2. Tasa de pérdida de celdas La tasa de pérdida de celdas (Cell loss ratio, CLR) es la relación entre el número de celdas perdidas y el número total de celdas enviadas por un usuario dentro de un intervalo de tiempo especificado. CLR es una métrica especifica de ATM y tiene un impacto significativo en la QoS proporcionada a los usuarios. Todos los AAL, excepto el AAL 5, incluyen números de secuencia de las celdas para detectar en el receptor las celdas perdidas. La tabla 4.6 nos muestra algunos valores fijados como objetivos en aplicaciones típicas. Las celdas se pierden en las redes por dos razones: desbordamiento de la capacidad de los buffers y errores en los bits de la cabecera que pueden detectarse pero no corregirse.

354
Aplicación Frecuencia de bits CLR* CLR**
Videoteléfono (CBR) 0.064-2 Mb/s 10-8 8 x 10-6 Videoteléfono (VBR) 2 Mb/s 10-8 8 x 10-6 Videoconferencia 5 Mb/s 4 x 10-9 5 x 10-6 Distribución de TV 20-50 Mb/s 10-10 8 x 10-7 MPEG1 1.5 Mb/s 10-8 9.5 x 10-6 MPEG2 10 Mb/s 2 x 10-9 4 x 10-6
• Sin control de error en AAL • Corrección del error de un bit en cada celda y corrección por pérdida de celdas en AAL.
Tabla 4.6.
El efecto de las pérdidas de celdas y las acciones que toman las redes ATM sobre las celdas perdidas difieren según los distintos tipos de servicios. Por ejemplo, los servicios de datos requieren valores muy bajos del CLR, mientras que los servicios de voz pueden tolerar pérdidas moderadas de celdas. Para un CLR dado, el tiempo medio entre pérdidas de celdas (average time between cell losses, ATBCL) viene dado por
segundos CLR (Mb/s)ón codificaci de Frecuencia
10853ATCBCL6
×××
=−
En la tabla 4.7 tenemos una muestra de los valores que puede tomar esta variable.
Frecuencia de codificación ATBCL 64 Kb/s 6625 s
1.544 Mb/s 274.6 s 45 Mb/s 9.42 s 155 Mb/s 2.735 s 620 Mb/s 0.684 s
Tabla 4.7. ATBCL para CLR = 10-6
Puesto que las pérdidas de celdas se producen con mayor frecuencia cuando aumenta la velocidad de codificación, se requiere concebir contramedidas extraordinarias en las redes ATM, en particular, para las aplicaciones sensibles a las pérdidas. Los requerimientos de pérdidas de celdas de las aplicaciones son valores promedio y proporcionan sólo una información parcial. Por ejemplo, el tiempo entre pérdidas de celdas con un CLR de 10-6 es igual a 2.735 s en un enlace de 155 Mb/s. El impacto de tener dos pérdidas de celdas consecutivas cada 5.47 s tiene un impacto más significativo sobre la imagen de la calidad comparado con el de una cada 2.735 s. Por lo tanto, estamos en una mejor situación si las pérdidas se distribuyen uniformemente a lo largo de la duración de un servicio de vídeo; por el contrario, en un servicio de transmisión de datos, preferiríamos perder todas las celdas que siguen a una perdida perteneciendo al mismo mensaje, puesto que deberemos retransmitir el mensaje si éste no llega correctamente al receptor.
4.4.2.2.3. Tasa de inserción de celdas La tasa de inserción de celdas (Cell insertion ratio, CIR) es la relación entre las celdas entregadas en una dirección incorrecta y todas las celdas enviadas. Este error se produce cuando no se detecta un error en la cabecera de la celda. Las celdas que llegan sin ser esperadas pueden provocar la pérdida de sincronización en determinados servicios. Además, las celdas mal encaminadas producen un aumento el tráfico

355
en enlaces distintos de los que debía usar la conexión a la que pertenecía la celda. La tabla 4.8 da la lista de algunos valores típicos de la CIR.
Servicio CIR Telefonía 10-3 Transmisión de datos 10-6 Cálculo distribuido 10-6 Sonido Hi Fi 10-7 Control de procesos remotos 10-6
Tabla 4.8.
4.4.2.2.4. Retraso de transferencia El retraso de transferencia (Transfer delay) entre dos puntos de la red se define como el tiempo transcurrido desde que el primer bit abandona el primer punto de observación hasta el instante que el último bit pasa por el segundo punto de observación. Los dos puntos son las dos interfaces en cada nodo terminal si la métrica considerada es el retraso de extremo a extremo. Los diversos factores que componen el retraso en una red ATM son: - Retraso de codificación: El tiempo requerido para convertir una señal no digital en digital.
Depende del algoritmo de codificación y del hardware y el software usado para ello. También se considera como retraso de codificación, por ejemplo, el tiempo de compresión.
- Retraso de paquetización: El tiempo requerido para acumular el número de bits para formar una celda ATM, que depende del tipo de nivel de adaptación usado y del generador de bits. Por ejemplo, voz PCM transmitida usando AAL 1 introduciría un retraso de paquetización de 47 × 8/64 = 5.875 ms, mientras que tomaría solamente 44 × 8/10 = 35.2 µs para llenar una celda en una transmisión vídeo MPEG-II usando AAL 2.
- Retraso de propagación: El tiempo debido a la velocidad de la luz en el medio de transmisión y depende de la distancia entre la fuente y el destino. La tabla 4.9 muestra algunos tiempos de los retrasos de propagación en distintos medios.
- Retraso de transmisión: Antes de poder efectuar ningún proceso, es preciso que los 424 bits de la celda lleguen desde el enlace. El retraso depende de la velocidad del enlace y se hace despreciable a medida que la velocidad de transmisión aumenta. Por ejemplo, una celda en un enlace a 155 Mb/s tarda alrededor de 2.73 µs, pero se reduce a 0.68 µs en un enlace a 622 Mb/s.
Medio de transmisión Retraso de propagación Cable coaxial 4 µs/km Cable de fibra óptica 5 µs/km Cable coaxial submarino 6 µs/km Satélite (14000 Km de altitud) 110 ms Satélite (36000 Km de altitud) 360 ms
Tabla 4.9.
- Retraso de conmutación: El tiempo que tarda la celda en atravesar el conmutador. Depende de la velocidad interna del conmutador y del overhead añadido por el encaminamiento de la celda dentro del conmutador. Por ejemplo, una red Banyan con 256 puertos de enterada (salida) construida con elementos de 2 × 2 requeriría 1 byte de

356
overhead por celda para el autoencaminamiento dentro del conmutador. En un conmutador ATM típico, el tiempo total que necesita para conmutar una celda consta de una consulta a una tabla para determinar el puerto de salida y del tiempo que toma en atravesar el conmutador desde el puerto de entrada al de salida. Este último tiempo, además de la velocidad de los enlaces internos, depende de la técnica de resolución de la contención usada en el tejido de conmutación.
- Retraso en las colas: Los conmutadores ATM pueden tener buffers en los puertos de entrada, o en los de salida, o internos, o en cualquier combinación. Su utilidad se discutirá en el análisis de los conmutadores. Este componente tiene en cuenta los tiempos pasados por las celdas en ellos.
- Retraso por reensamblado: El tiempo para recomponer un mensaje a partir de las celdas que lo componen. Debe efectuarse esta tarea antes de entregar el mensaje a la aplicación. La tabla 4.10 muestra los valores del retraso típico de extremo a extremo para algunos servicios típicos.
Servicio BER CLR Retraso (ms) Transmisión de datos 10-7 10-6 1000 Cálculo distribuido 10-7 10-6 50 Sonido Hi Fi 10-5 10-5 1000 Control de procesos remotos 10-5 10-3 1000
Tabla 4.10.
4.4.2.2.5. Variación del retraso de las celdas (jitter) El retraso de extremo a extremo de la i-ésima celda es D + Wi, donde D es una constante que incluye los retrasos de propagación y transmisión (más la conmutación) y Wi es la componente aleatoria del retraso que aparece por causa de la estancia en los buffers dentro de la red. El tiempo entre llegadas de celdas en el receptor viene dado por
(D + Wi+1) – (D + Wi) = δ
Idealmente, los tiempos entre llegadas de celdas en el receptor son iguales a los tiempos entre salidas de celdas, que es el caso si Wi+1 = Wi. Sin embargo, debido a la aleatoriedad de la red, la variable aleatoria Wi no es constante. La variación del retraso de las celdas (jitter) (Cell delay variation, CDV) tiene varias definiciones, como: - La variancia del retraso de transmisión de la conexión, esto es [ ]( )[ ]2
ii WEWE − .
- La diferencia entre los valores del retraso de tránsito de las celdas de una conexión: Wi+1 - Wi; esto es [ ]wWW ii >−+1Pr .
- Variación instantánea del retraso de tránsito de las celdas respecto de la media; esto es [ ][ ]wWEW ii >−Pr .
La tabla 4.11 presenta el retraso y el jitter de distintos servicios de vídeo.

357
Aplicación Retraso (ms) Jitter (ms) Videoconferencia a 64 Kb/s 300 130 Vídeo NTSC con NTSC a 1.5 Mb/s 5 6.5 Vídeo HDTV a 20 Mb/s 0.8 1 Voz comprimida a 16 Kb/s 30 130 Voz MPEG a 256 Kb/s 7 9.1
Tabla 4.11.
Puede reducirse el jitter mediante el uso adecuado de un buffer, tal como muestra la figura 4.14.
Emisor Receptor
Red
Eliminador dejitter
Figura 4.14.
4.4.2.2.6. Sincronización de objetos relacionados (skew) La sincronización de objetos relacionados (skew) se define como la diferencia en los instantes de presentación de dos objetos relacionados (por ejemplo, las secuencias de vídeo y de audio). La sincronización gruesa representa los retrasos gruesos entre al imagen y el sonido que la acompaña, mientras que el fino representa los retrasos entre el movimiento de los labios y la voz. Sus objetivos en diversas aplicaciones multimedia aparecen en la tabla 4.12.
4.4.3 GESTIÓN DEL TRÁFICO Dentro del concepto de gestión del tráfico se incluyen todas las técnicas de controlar el uso de los recursos de la red para prevenir o corregir que la red se convierta en un cuello de botella.
Aplicación Objetivo del skew
Audio+texto o imagen (sesión en una dirección)
Skew grueso < 1 s
Audio + vídeo
(sesiones multipunto a multipunto)
Skew grueso < 200 ms Skew fino:
Audio en avance del vídeo < 20 ms Vídeo en avance del audio < 120 ms
Teleconferencia compleja audio+vídeo+imagen+texto
Skew grueso < 200 ms Skew fino:
Audio en avance del vídeo < 20 ms Vídeo en avance del audio < 120 ms
Tabla 4.12.
Las redes de conmutación de circuitos y las de conmutación de paquetes tenían mecanismos de gestión del tráfico. Sin embargo, al estar dedicadas a un único tipo de tráfico, estos mecanismos no se pueden exportar directamente a las redes ATM, pensadas para hacer pasar a su través todos los tipos de tráfico, cada uno con características y exigencias de calidad de servicio distintas. Es preciso desarrollar nuevos mecanismos específicos que tengan en cuenta no tan sólo los aspectos citados sino también la velocidad prevista de los enlaces, muy superior a la de las redes precedentes.

358
4.4.3.1. Características particulares de las redes ATM En redes de conmutación de circuitos, a cada conexión se asignaba una cantidad fija de ancho de banda y se proporcionaba una frecuencia constante de transmisión a las entidades comunicantes durante toda la duración de la conexión. En las redes de conmutación de paquetes, el control de tráfico es mucho más complejo debido a la naturaleza aleatoria de las características del tráfico de llegada y a los problemas de contención en los recursos de la red. En estas redes había dos tipos de control de tráfico: - El control de flujo trataba de regular la frecuencia con que el emisor enviaba paquetes. Se
usaban normalmente mecanismos de ventana deslizante.
- El control de congestión trataba de regular el flujo del tráfico en los enlaces de entrada en cada nodo de la red.
Sin embargo, estas dos técnicas no son directamente trasladables a las redes ATM. Algunos de los aspectos que impiden esta traslación son los siguientes: 1. Las diversas fuentes de VBR pueden generar tráfico a frecuencias significativamente
diferentes. Mientras una transmisión de voz genera unos pocos kilobits por segundo, la HDTV puede generar varios megabits por segundo. Además, estas generaciones pueden adoptar formas muy variadas a lo largo del tiempo.
2. Una misma fuente puede generar múltiples tipos de tráfico (voz, datos, imágenes) con diferentes características.
3. Además de las métricas clásicas de comportamiento, como bloqueo de llamadas o pérdida de celdas, las redes ATM han de tener en cuenta el máximo retraso, el jitter y el skew.
4. Los distintos servicios tienen diferentes tipos de exigencias de calidad de servicio en niveles considerablemente variados. El multiplexado de varios tráficos VBR en una misma conexión y también con tráfico CBR complica la posibilidad de predecir el comportamiento de la red para ambos tipos de aplicaciones. Los servicios de tiempo real son especialmente sensibles a la degradación del comportamiento.
5. Las características del tráfico de los distintos servicios todavía no se conocen bien.
6. Puesto que la velocidad de transmisión aumenta (menor tiempo de transmisión), y también lo hace la relación entre la duración de la llamada y el tiempo de transmisión de una celda, se añaden nuevas dimensiones al problema. Debido a los aumentos de la dimensión de la red y de la velocidad de los enlaces, el número de celdas en tránsito en la red se hace mucho mayor. Además los tiempos de propagación grandes comparados con los tiempos de transmisión hacen aumentar el tiempo que pasa desde la aparición de la congestión hasta el momento de su detección por los elementos de control de la red.
7. Las altas velocidades de transmisión limitan el tiempo disponible para el proceso sobre la marcha en los nodos intermedios.
Considerando las altas velocidades de transmisión, el conjunto de algoritmos de control debe ser tan simple como sea posible para permitir sus implantaciones en hardware. Además, es posible que los usuarios no sean capaces de definir con precisión las características de su tráfico. Por lo tanto las técnicas de control no sólo deben usar sencillas caracterizaciones de las fuentes que faciliten a los usuarios un conocimiento intuitivo, sino que también deben ser robustos y minimizar las consecuencias de especificaciones de tráfico poco precisas. Un sistema de control de tráfico puede provocar o la congestión de la red o la infrautilización de los recursos de la red. Un problema añadido es que las redes ATM no sólo deben soportar las

359
aplicaciones actuales sino las emergentes aplicaciones multimedia y también otras ahora inimaginables. Los mecanismos de control de congestión se pueden clasificar en dos categorías: control preventivo y control correctivo. Las técnicas de control preventivo de la congestión tratan de prevenir la congestión tomando las acciones apropiadas antes de que se produzca la congestión. Sin embargo, está admitido que las técnicas de control preventivo no son suficientes para eliminar los problemas de congestión en las redes ATM y que, cuando se produce la congestión, es necesario reaccionar ante el problema. Las técnicas de control reactivo propuestas inician la recuperación a partir del estado congestionado. En un esquema reactivo, la red está monitorizada para detectar la congestión. Cuando se detecta la congestión, se pide a las fuentes de ralentizar o parar su transmisión hasta que se elimine la congestión. El problema principal de los esquemas reactivos es el elevado valor del producto del retraso de propagación por el ancho de banda en las redes ATM, que introduce la posibilidad que para el instante que una fuente recibe una notificación, puede ser demasiado tarde para reaccionar. Las distintas técnicas de control se aplica en distintos momentos. La figura 4.15 muestra diversas técnicas propuestas para las redes ATM y los momentos en que son más efectivas.
4.4.3.2. Provisión de recursos La provisión de recursos es una importante función de gestión de tráfico para las redes existentes. Su papel es proporcionar un aceptable nivel del comportamiento del bloqueo de conexiones. La topología de la red, el número de enlaces y sus anchos de banda y el número de nodos de acceso y de conmutación deben determinarse a partir del conocimiento de los requerimientos de tráfico.

360
Contoladaptivo defrecuencia
Control preventivo Control reactivo
Tiempode celda
Retraso depropagación
Duración dela conexión
Largoplazo Provisión
de recursos
Control de admisiónde llamadas
Encaminamientode llamadas
Codificacióndinámica de
fuentesNegociaciónde parámetrosen la llamada
Ventanasadaptivas
Conformadode tráfico
Marcado delexceso de tráfico
Descartadoselectivo
Verificacióndel tráfico
Figura 4.15.
A medida que el tiempo pasa, el número de usuarios, la cantidad de tráfico generado y los tipos de aplicaciones usadas cambiarán. En consecuencia, la red dimensionada para otras hipótesis debe corregirse y adaptarse a las necesidades actuales; por lo tanto deben añadirse enlaces y nodos, o sustituirlos por otros elementos de mayor capacidad y velocidad. Para ello deben usarse todas las técnicas clásicas usadas en el dimensionamiento de las redes existentes, adaptándolas a las características de las redes B-ISDN. Sin embargo, en ciertos aspectos las redes ATM, al tener un único recurso para asignar, el camino virtual, ciertos aspectos de provisión de recursos quedan simplificados. Recordemos que un camino virtual es una conexión semipermanente con un ancho de banda determinado y prefijado. Dependiendo del tráfico, algún camino virtual puede estar subutilizado mientras que otros, que pueden compartir el mismo enlace físico, están saturados. Esta situación puede tener soluciones a corto plazo. Sin embargo, deben encontrarse soluciones a largo plazo (definición de caminos virtuales, capacidad de los enlaces, etc.). Este es todavía un problema abierto en las redes ATM.
4.4.3.3. Control de admisión de llamadas Cuando se recibe en la red la petición de una nueva conexión, se ejecuta el procedimiento de admisión de llamadas para decidir si se la acepta o la rechaza. Se acepta la llamada si hay recursos suficientes para proporcionar la QoS solicitada por la nueva petición de conexión sin afectar a la QoS proporcionada a las conexiones existentes. En consecuencia, aparece la necesidad de responder a dos cuestiones:
¿Cómo se determina el ancho de banda requerido por la nueva conexión?

361
¿Cómo puede asegurarse que los niveles de servicio requeridos por las conexiones existentes no estarán afectados cuando se multiplexen junto con esta nueva conexión?
Cualquier técnica diseñada para responder a estas dos cuestiones debe ser capaz de funcionar en tiempo real y debe intentar maximizar la utilización de los recursos de la red. El primer paso es determinar el conjunto de parámetros requeridos para describir adecuadamente la actividad de la fuente de tráfico para poder efectuar una predicción precisa de las métricas de interés de la red. Es preciso pues tener una buena descripción del tráfico y de la red. El tráfico ya se ha estudiado. Una red ATM puede modelarse como una colección de colas. Teóricamente no hay ningún problema en encontrar la solución. Sin embargo, es prácticamente imposible resolverlo en tiempo real debido a su dimensión (cientos de colas con miles de fuentes). Debemos pues enfocar el problema mediante descomposición. Para resolver una cola aislada se requiere la caracterización de su secuencia de llegadas, de su capacidad efectiva de su servidor y de la dimensión de buffer. Un enlace i puede modelarse como una cola simple con N secuencias de llegada, un buffer de capacidad K y un tiempo de servicio constante (igual a 53 ´ 8/velocidad del enlace), donde N es el número de conexiones multiplexadas en el nodo i. El análisis de tal cola se hace pronto irrealizable a medida que aumenta el número de secuencias multiplexadas. Por ejemplo, consideremos el caso que cada secuencia esté modelada por un IBP de dos estados. Entonces la obtención de la tasa de pérdidas requerirá la solución de un sistema de 2N(K +1) ecuaciones lineales. Una cola con 10 posiciones en el buffer y 100 fuentes requerirá la solución de un sistema de 11264 ecuaciones lineales. El enfoque típico para vencer esta dificultad consiste en reducir la dimensionalidad del problema por reducción del número de secuencias que llegan a la cola a un valor suficientemente pequeño. Para obtener las medidas de comportamiento deseadas cuando llega una petición de una nueva conexión, la cola puede analizarse con solo dos secuencias de llegada: una correspondiente a la de la nueva conexión y otra representando la superposición de todas las existentes en el momento de la llegada. Dependiendo de como se modele la superposición del tráfico, la dimensionalidad del problema puede reducirse, haciendo, por consiguiente, más factible la solución. Vamos pues a estudiar, antes de entrar en el problema del control de aceptación de llamadas, propiamente dicho, a estudiar la superposición de secuencias de llegada.
4.4.3.3.1. Superposición de procesos de llegada Si todas las secuencias de llegada fueran poissonianas, no habría ningún problema de superposición: el proceso agrupando todas las llegadas seguiría siendo poissoniano. Desgraciadamente, los procesos que describen las secuencias de llegada no lo son, por lo que hay que recurrir a otros tipos de modelos. Suponiendo que el tráfico de la nueva llegada está caracterizado por un IBP de dos estados y que el tráfico existente se representa como un proceso MMBP de k estados, el número de ecuaciones a resolver es de 2k(K + 1). Para k = 2 y K =100, tenemos 404 ecuaciones. Vemos pues que se puede lograr una importante reducción de la dimensionalidad. Existen diversas técnicas, principalmente aproximadas, usadas para superponer secuencias de llegada. Frecuentemente se representan como procesos de Poisson modulados markovianamente (Markov Modulate Poisson Process, MMPP) o como procesos de Bernouilli modulados markovianamente (Markov Modulate Bernouilli Process, MMBP) con un número de estados variable en el proceso de Markov, aunque normalmente se eligen los de dos estados.

362
4.4.3.3.1.1. MMPP
Un MMPP es un proceso de Poisson doblemente estocástico. Las llegadas se producen según un proceso de Poisson con una frecuencia que varía de acuerdo con una cadena de Markov de k estados, independiente del proceso de llegada. Un MMPP se caracteriza por la matriz de frecuencias de transición de la cadena de Markov subyacente y por las frecuencias de llegada. Sea i es estado de la cadena de Markov, ki ,....,1∈ , σij la frecuencia de transición del estado i al estado j, con i ≠ j, y λi la frecuencia de llegada cuando la cadena de Markov está en el estado i, con λi > 0. Definamos
∑≠=
σ=σk
jijiji
;1
En forma matricial tenemos
σ−σσ
σσ−σσσσ−
=
kkk
k
k
Q
. . .....
. . .
. . .
21
2221
1121
λ
λλ
=Λ
k. . .00....0. . .00. . .0
2
1
Suponiendo que Q no depende del tiempo t, el vector de probabilidad en régimen estacionario π de Q es la solución del siguiente sistema de ecuaciones:
1 ;01
=π=π ∑=
k
iiQ
Representemos por Xm el tiempo entre las llegadas (m –1)-ésima y m-ésima. La distribución de Xm depende de los estados del proceso de Markov entre las dos llegadas, digamos entre los estados i y j. Entre los instantes de ambas llegadas, se produce un cierto número de transiciones, geométricamente distribuido, desde el estado i al estado j a través de uno o varios pasos durante los cuales no se produce ninguna llegada. Este período viene finalmente seguido por una transición desde el estado i al estado j en que se produce la llegada cuando el proceso está en el estado j. Sean: - Jm = estado del proceso de Markov en el instante en que se produce la m-ésima llegada.
- Fij(x) = Pr[Jm = j, Xm ≤ x | Jm - 1 = i], m ≥ 2, la probabilidad que el tiempo entre las llegadas (m –1)-ésima y m-ésima sea menor o igual que x, y que el proceso en el estado j cuando se produce la m-ésima llegada dado que la (m –1)-ésima llegada se haya producido cuando el sistema estaba en el estado i. Cuando el instante de origen no corresponde con uno de llegada, hay que definir las probabilidades Pr[J1 = j, X1 ≤ x | J0 = i], es decir, cuando m = 1.
- ( ) ( )[ ]xFxF ij= , i, j = 1, …., k.
Entonces la secuencia ( ) 0 ,, ≥mXJ mm es un proceso markoviano de renovación con matriz de probabilidades de transición F(x), donde
( ) ( ) Λ= ∫ Λ− 0
x uQ duexF
con

363
( ) ( ) Λ−Λ=∞ −1QF
Para obtener los momentos condicionales entre del tiempo entre las llegadas (m –1)-ésima y m-ésima, observemos primero que la transformada de Laplace de F(∞), f*(s), viene dada por
( ) ( )[ ] ( ) Λ−Λ+=−= −1* exp QsIsXEsf
El r-ésimo momento de Xm, rmµ , puede obtenerse entonces de la r-ésima derivada de f*(s), que
vale
( )[ ] ( ) ( ) 1 ,1 ,! 111 ≥≥Λ−ΛΛ−Λ=µ +−−− mrQQr rmrm
De forma similar, la matriz transformada de Laplace conjunta f*(s1, s2, …., sm) de X1, X2, …., Xm, m > 1, viene dada por
( ) ( )[ ]∏∑=
−
=
Λ−Λ+=
−=
m
jj
m
lllm QIsXsEsssf
1
1
121
* exp,....,,
Entonces µ1; m + 1 = E[X1 X m + 1] se obtiene a partir de f*(s1, s2, …., sm):
( ) ( )[ ] ( ) ( ) Λ−ΛΛ−ΛΛ−Λ=µ −+−−−+
21121;1 QQQ
m
m
Entonces el paso r-ésimo de la matriz de correlación E[X1 – E[X1]]E[Xr + 1 – E[Xr + 1]], r ≥ 1, viene dado por
( ) ( )[ ] ( )[ ]( ) Λ−ΛΛ−Λ−Λ−ΛΛ−Λ −−−−− 21112 QQIQQm
Para caracterizar completamente un MMPP, debe definirse el estado inicial del proceso P. Dos posibles definiciones son: - MMPP empieza en un instante arbitrario que es P = πΛ/πλ, donde λ = (λ1, …., λ1)T se
conoce como el entorno estacionario del MMPP
- P es el vector estacionario F(∞), conocido como el intervalo estacionario del MMPP.
Dado el vector de probabilidad inicial P del MMPP, su matriz de transición en el m-ésimo paso, esto es, su probabilidad de estar en el estado j se produzca en el instante m-ésimo con j = 1, 2, …., k, viene dada por
( )[ ]mQP Λ−Λ −1
Los momentos de la distribución de los tiempos entre llegadas y la matriz de coeficientes de correlación se determinan de forma similar. Consideremos el MMPP de dos estados con parámetros Q y Λ, donde
σ−σ
σσ−=
22
11Q
λ
λ=Λ
2
1
00
Sean, además, - Ti = tiempo hasta la siguiente llegada dado que se produce una llegada cuando el proceso
está en el estado i.

364
- ti = tiempo hasta el siguiente acontecimiento dado que se produce una llegada cuando el proceso está en el estado i.
Consideremos el proceso inmediatamente después de que se produzca una llegada en el estado i. Debido a la falta de memoria de la distribución exponencial, el tiempo de permanencia en el estado i está exponencialmente distribuido con media σi. El siguiente acontecimiento es o una llegada o una transición desde el estado i a otro estado, siendo la distribución del tiempo hasta el próximo acontecimiento el mínimo de las dos variables aleatorias. Puesto que los dos acontecimientos están exponencialmente distribuidos con frecuencias σi y λi, el tiempo hasta el siguiente acontecimiento está exponencialmente distribuido con frecuencia (σi + λi). Además, el siguiente acontecimiento será una llegada con probabilidad (en adelante c.p.) λi/(σi + λi) o una transición de estado c.p. σi/(σi + λi). Entonces,
( )( )
λ+σσ+λ+σλ
=11121
11111 / c.p.
/ c.p. Tt
tT
( )( )
λ+σσ+λ+σλ
=22212
22222 / c.p.
/ c.p. Tt
tT
La transformada de Laplace de T1, A1(s), y de T2, A2(s), se obtienen de la forma siguiente,
( ) ( )sAss
sA 211
1
11
11
11
1
11
111 λ+σ
σ+λ+σ
λ+σ+
λ+σλ
+λ+σλ+σ
=
( ) ( )sAss
sA 122
2
22
22
22
2
22
222 λ+σ
σ+λ+σ
λ+σ+
λ+σλ
+λ+σλ+σ
=
Resolviendo
( ) ( )( )( ) 212211
221211 σσ−+λ+σ+λ+σ
+λ+σλ+λσ=
sss
sA
( ) ( )( )( ) 212211
112122 σσ−+λ+σ+λ+σ
+λ+σλ+λσ=
sss
sA
Dados A1(s) y A2(s), y (π1,π2) = (σ1/(σ1 + σ2), σ2/(σ1 + σ2), la transformada de Laplace de la función de distribución de la probabilidad del tiempo entre llegadas incondicional A(s) viene dada por
( ) ( ) ( )
( )( )( )
( )212112
2212112
2121122112
221
212
2211
1
1
λλ+λσ+λσ+λ+λ+λσ+λσ
+
λλ+λσ+λσλσ+λσλσ+λσ
+=π+π=
ss
s
sAsAsA
La media E[T] y el coeficiente cuadrático de variación c2(T) del tiempo entre llegadas de un MMPP de dos estados se obtiene a partir de las dos primeras derivadas de A(s) y son
[ ]1221
21
λσ+λσσ+σ
=TE

365
( ) ( )( )( )2
21121221
221212 2
σ+σλλ+λσ+λσλ−λσσ
=Tc
Además, la correlación con decalaje unitario del tiempo entre celdas C(1) es
( ) [ ]( ) [ ]( )[ ]( )
( )( )( )( )2
211212212
21212111
Var1
σ+σλλ+λσ+λσσσλ−λλλ
=−−
= ++
TcTTETTETE
C rrrr
Observemos que un IPP es un caso particular de MMPP con k = 2 y λ2 = 0. Además, si σ1 = σ2, entonces el MMPP se reduce a un proceso de Poisson con frecuencia λ1. 4.4.3.3.1.2. Superposición de MMPPs
La superposición de MMPPs es otro MMPP. Consideremos N MMPPs, cada uno con parámetros Qi y λi. Entonces la matriz de transición Q y la matriz de frecuencias de llegada Λ del proceso resultante de la superposición son
NNQQQQ Λ⊕⊕Λ⊕Λ=Λ⊕⊕⊕= ....y .... 2121
donde ⊕ es la suma de Kronecker, definida a continuación. Observemos que tanto Q como son matrices de k × k, donde
∏=
=N
iikk
1
La suma de Kronecker de dos matrices Q1 y Q2 se define como sigue:
( ) ( )2121 12QIIQQQ QQ ⊗+⊗=⊕
donde 2 ,1 , =iIiQ , es la matriz identidad del mismo orden que la matriz Qi y ⊗ representa el
producto de Kronecker, que se define para dos matrices C = [cij] y D = [dij] como
=⊗
DcDcDc
DcDcDcDC
nmnn
m
. . .. . .. . .. . .. . .
. . .
21
11211
De forma equivalente, el estado resultante de la superposición de N MMPPs es (i1, i2, …, iN), donde ij representa el j-ésimo MMPP componente. La frecuencia total de llegada en el estado (i1, i2, …, iN) es la suma de las frecuencias de llegada de los procesos componentes, que dependen del estado ij; esto es
( ) ∑=
λ=λN
jiN j
iii1
21 ,...,,
La tasa de transición desde el estado (i1, i2, …, ij = k, … , iN) al estado (i1, i2, …, ij = m, … , iN) viene dado por la frecuencia de paso del estado ij = k al estado ij = m en el j-ésimo MMPP componente. Cuando el número de procesos componentes aumenta, el número de estados del proceso resultante de la superposición crece exponencialmente. Para reducir la complejidad de resolver las colas con un gran número de procesos de llegada, el proceso superpuesto puede aproximarse por un proceso más sencillo que capture las características importantes del

366
proceso original con la mayor precisión posible. El modelo más sencillo que tiene el potencial de aproximar con una precisión razonable un MMPP de un gran número de fases es el MMPP de dos fases definido por cuatro parámetros (λ1, λ2) y (σ1, σ2). Entonces, el problema se reduce a elegir los parámetros del MMPP de dos estados usando cuatro métricas del proceso superpuesto. Por ejemplo, supongamos que se conocen los cuatro primeros momentos del proceso superpuesto. Entonces, usando las ecuaciones de los cuatro primeros momentos del MMPP de dos estados y los valores dados, tenemos un sistema de cuatro ecuaciones con cuatro incógnitas, que puede resolverse para obtener los valores de las incógnitas. Sin embargo, en general, no hay garantía que haya un MMPP que ajuste exactamente los cuatro primeros momentos del proceso superpuesto. Incluso si hay un ajuste exacto, tenemos que tratar un sistema no lineal. Por lo tanto, el ajuste debe hacerse de forma aproximada. Consideremos el proceso que cuenta celdas en que el tiempo entre llegadas está distribuido según un MMPP de dos estados y representemos por M(t) y J(t), respectivamente, el número de celdas llegadas durante (0, t], t > 0, y el estado del MMPP en el instante t, J(t) = 1, 2. Entonces el proceso [M(t), J(t)] tiene como media m, varianza v y momento de tercer orden µ3 del proceso de llegada
21
1221
σ+σλσ+λσ
=m ( )
( )221
212
12
σ+σσσλ−λ
=v 21
312
321
3 σ+σλσ+λσ
=µ
Además, para capturar la correlación de la secuencia de llegadas, sea r(t) la función de covariancia que caracteriza la dependencia entre los tiempos de llegada en dos instantes distintos. La siguiente igualdad es válida para una amplia clase de procesos de Poisson doblemente estocásticos, cuando T tiende a infinito
( )[ ]( )[ ]
( )m
dttr
TmETm ∫
∞
+= 02
1Var
Además, representemos por τ la constante de tiempo definida por
( )∫∞
=τ0
1 dttrv
Entonces, la aproximación exponencial de la covariancia rap(t) = v exp[-t/τ] que ajusta r(0) y la integral de la covariancia es una buena aproximación de r(t) para un amplio conjunto de condiciones. Para un MMPP de dos estados, τ viene dado por
21
1σ+σ
=τ
Entonces, dados m, v, µ3 y τ, los parámetros del MMPP de dos estados se obtienen por
( ) ( )η+τη
=ση+τ
=σ1
1
121
η−=λ
η+=λ
vmvm 21
donde

367
( ) 5.1
332 3
y 42
1v
mmvm −−µ=δδ+−δ+=η
En este ámbito no es necesario construir el proceso superpuesto y obtener los parámetros m, v, µ3 y τ, para obtener los parámetros del MMPP de dos estados. En su lugar, observemos que M(t) es el proceso que cuenta las llegadas y que las secuencias son independientes con parámetros mi, vi, µi3 y τi, i = 1, …, N, tenemos
∑∑∑∑====
τ=τµ=µ==N
ii
iN
ii
N
ii
N
ii v
vvvmm
1133
11
que simplifica el procedimiento.
4.4.3.3.1.3. MMBP
En este proceso el tiempo está discretizado en ranuras de longitud fija. La probabilidad que una ranura contenga una celda es un proceso de Bernouilli con un parámetro que varía de acuerdo con un proceso de Markov de r estados, que es independiente del proceso de llegada. Al final de cada ranura, el proceso de Markov pasa del estado i al estado j c.p. pij o permanece en el estado i c.p. pii, de tal forma que
ripr
jij ..., 2, ,1 ,1
1
==∑=
En el estado i, una ranura contiene una celda c.p. αi y ninguna celda c.p. 1 - αi. Las probabilidades de llegada de las celdas y el proceso de Markov subyacente se suponen independientes entre sí. Un MMBP se caracteriza por la matriz de probabilidad de transición P y la matriz diagonal Λ de probabilidades de llegada:
=
rrrr
r
ppp
pppP
. . .. . .. . .. . .. . .
. . .
21
11211
α
α=Λ
r. . .00. . .. . .. . .. . .
0. . .01
Para determinar la función generatriz T(z) de los tiempos entre llegadas de celdas en un MMBP, representemos por πj la probabilidad en régimen estacionario que el MMBP esté en el estado j, y π = (π1, … , πr) y representemos por bj la probabilidad condicional que el MMBP esté en el estado j si se ha producido la llegada de una celda y b = (b1, , br). Entonces π es la solución del sistema de ecuaciones πP = π y λπ/Λπ=b con ( )T
rαα=λ ,....,1 . T(z) puede obtenerse de forma similar a como se hizo con los MMPP,
( ) ( )[ ] λΛ−−= − PIzPIbzzT 1
de donde a partir de las sucesivas derivadas podríamos obtener los distintos momentos de la distribución. Consideremos ahora el MMBP de dos estados con matriz de probabilidad de transición P y matriz de probabilidades de llegada Λ:
β
α=Λ
−
−=
00
1
1qq
ppP

368
Dado que el proceso de Markov está en el estado 1 (2), permanecerá en el mismo estado en la siguiente ranura c.p. p (q) o cambiará de estado c.p. 1 – p (1 – q). La probabilidad que el MMBP esté en el estado i, πi, es la solución del sistema de ecuaciones
[ ] [ ] 1y ,, 212121 =π+πππ=ππ P
Esto es,
qpp
qpq
−−−
=π−−
−=π
21
21
21
La probabilidad que una ranura contenga una celda (utilización de la fuente) viene dada por
( ) ( )qp
pq−−
β−+α−=βπ+απ=ρ
211
21
A continuación obtenemos la función generatriz de los tiempos entre llegadas de celdas. Sea Ti el intervalo hasta la próxima llegada, si el proceso de Markov está en el estado i y sea T el tiempo entre llegadas de una celda. Consideremos el instante en que se produce una llegada cuando el proceso de Markov está en el estado 1. En la siguiente ranura: - El MMBP puede permanecer en el estado 1 y se produce una llegada, lo cual sucede c.p.
pα - El MMBP puede moverse al estado 2 y se produce una llegada, lo cual sucede c.p. (1 -
p)β
- El MMBP puede permanecer en el estado 1 y no se produce ninguna llegada, lo cual sucede c.p. p(1 - α)
- El MMBP puede moverse al estado 2, y no se produce ninguna llegada, lo cual sucede c.p. (1 - p)(1 - β)
Por lo tanto tenemos
( )( )
( )( )
( )( )
( )( )
β−−+β−+α−+β
=
α−−+α−+
β−+α=
11 c.p. 1 1 c.p. 1
1 c.p. 1Ty
11 c.p. 1 1 c.p. 1
1 c.p. 1
1
22
2
11
qTqT
pTpT
ppT
De donde se obtiene
( ) ( ) ( ) ( )[ ]( )( )( ) ( ) ( )[ ] 111111
1112
2
1 +β−+α−−−+α−β−β−+α+−−αβ−
=zqpzqp
zppzqpzT
( ) ( ) ( ) ( )[ ]( )( )( ) ( ) ( )[ ] 111111
1112
2
2 +β−+α−−−+α−β−α−+β+−−βα−
=zqpzqp
zqqzqpzT
Representemos ahora por a la probabilidad que el MMBP esté en el estado i y que se produzca una llegada. Usando la independencia de las llegadas y el proceso de Markov, tenemos a1 = π1α y a2 = π2β. Entonces, si se produce una llegada, la probabilidad que el MMBP esté en el estado i, bi, es igual a
21
22
21
11
aaa
baa
ab
+=
+=

369
Prescindiendo de forma apropiada de las condiciones en los tiempos entre llegadas T1 y T2, la transformada en z de los tiempos entre llegadas viene dada por
( )01
22
12
2
dzdzdzczc
zT++
+=
( ) ( )( ) ( )( )[ ]222 11111 βα−−+αβ−−−−= pqqpc
( ) ( )[ ]( ) ( )[ ]α−+ββ−β−+αα−= qqpppqc 11111
( )( )( ) ( ) ( )[ ]β−+α−−+β−α−= pqqpd 111112
( ) ( )[ ] ( ) ( )[ ]β−+α−β−+α−−= 11111 qppqd
( ) ( )β−+α−= pqd 110
En general, el k-ésimo momento del tiempo entre llegadas con B = (b1, b2) es igual a
[ ] ( ) eFFIBkTE kkk 1! −−−=
donde e = (1, 1)T y
( ) ( )( )( )( ) ( )
β−α−−
β−−α−=
111111
qqpp
F
La media E[T] y el coeficiente cuadrático de variación c2 del tiempo entre llegadas de celdas se obtienen entonces a partir de las respectivas derivadas de T(z):
[ ] ( ) ( )β−+α−−−
=pq
qpTE11
2
( ) ( )[ ]( ) ( ) ( )
( ) ( )
( ) ( )[ ] ( ) ( )[ ]( )( ) ( ) ( ) ( )[ ]
11112
111112
211
111112
2
2
−−+αβ+β−+α−−−
−+β−+α−β−+α−+
+−−
β−+α−−
−+αβ+β−+α−β−+α−
=
qppqqpqppqqp
qppq
qppqpqc
La autocorrelación del tiempo entre llegadas de un MMBP puede obtenerse de forma similar al de los MMPP. Sea t el intervalo de tiempo entre una ranura determinada cuando el proceso de llegada está en el estado i y la ranura en que se produce la siguiente llegada en el estado j. Entonces
( )( )( )
( )( )( )
( )
β−+−α−+
−α=
−β−+α−+
α=
1 c.p. 1 11 c.p. 1
1 c.p. 1
11 c.p. 1 1 c.p. 1
c.p. 1
21
1121
21
1111
qtqt
qt
ptpt
pt
( )( )
( )( )( )( )( )( )
−β−+−α−+
β=
−β−+α−+−β
= 11 c.p. 1 11 c.p. 1
c.p. 1
11 c.p. 1 1 c.p. 1 1 c.p. 1
22
1222
22
1212
qtqt
qt
ptpt
pt
Sean Sn el estado del proceso de llegada cuando se produce la n-ésima llegada, Tnj el tiempo entre las llegadas (n - 1)-ésima y n-ésima, la cual se produce en el estado j. Definiendo

370
[ ]iSzEA nT
ijnj == −1 |
y usando las definiciones de tij y de Tnj, tenemos
[ ] 2 ,1, , == jizEA ijtij
Entonces,
( ) ( )( )( ) ( )( ) ( )( ) ( ) ( )( )
( )( ) ( ) )(1)(11)(
)(11)(11)(
)(1)(111)(
)(11)(1)(
221221
221212
211121
211111
zqzAzzAqqzzA
zzApzpzAzpzA
zqzAzzAqzqzA
zzApzpzApzzA
β−+−α−+β=
−β−+α−+−β=
β−+−α−+−α=
−β−+α−+α=
Definamos, además,
( ) [ ] ( ) [ ]
( ) ( ) ( )( ) ( ) ( ) ( )
( ) ( ) ( )( )
=
=
=
==== −−−
212
21121
2
1
2221
1211
121211
,,
,
|z,y | 1
zzCzzC
zzCzBzB
zBzAzAzAzA
zA
iSzEzzCjSzEzB nTT
inT
jnnn
Entonces,
( ) ( ) ( )∑=
=2
12121,
jjij zBzAzzC
Viendo que C(z1, z2) = A(z1) B(z2), podemos reescribir
( ) ( )( )( )( ) ( )
( ) ( )( ) ( )
( )( )
β−α−βα
=
β−−−α−−−β−−α−−
qzzqzppz
zAzAzAzA
qzzqzppz
11
11111111
2221
1211
o, de forma equivalente,
( )[ ] ( ) zPzAIzPI Λ=Λ−−
El término P(I - Λ) representa una transición sin llegada, mientras que PΛ representa una transición con llegada. Despejando A(z),
( ) ( )[ ] zPIzPIzA ΛΛ−−= −1
Viendo que Bi(z) = Ai1(z) + Ai2(z),
( ) ( )[ ] ezPIzPIzB ΛΛ−−= −1
De la definición de (z1, z2), tenemos
[ ] ( ) ( )[ ] ( )( )
( )( ) ( )
( )( ) ( ) ( ) ( )21
212
2112221
111
111
,,
21z1
zBzApq
ppq
q
zzCzzC
SPSPzE nnTT nn
−β+−α
−β−β+−α
−α=
=
=== −−
−

371
Entonces
[ ] ( )( ) ( )
( )( ) ( )
( ) ( )
( )( ) ( )
( )( ) ( ) ( )[ ] ( )[ ] ePIPIPIPI
pqp
pqq
zzB
zzA
pqp
pqqTTE
zznn
ΛΛ−−ΛΛ−−
−β+−α
−β−β+−α
−α=
=∂
∂∂
∂
−β+−α
−β−β+−α
−α=
−−
==
−
22
1;12
2
1
11
111
111
111
111
21
De donde la función de autocorrelación del tiempo entre llegadas de celdas sucesivas viene dado por
[ ][ ]
[ ] [ ] [ ][ ]
( ) ( )( )( )( ) ( ) ( ) ( )[ ]222
22
1111
1112111
VarianzaVarianzaCovarianza
−+αβ+−β+−α−−−+−−β−ααβ
=
=−
==ψ −−−
qppqqpcqpqp
TTETETTE
TTT
n
nnnn
n
nn
Observemos que si α = β, el MMBP tiene solo un estado y se convierte en un proceso de Bernouilli. Si o α o β son iguales a cero, entonces el MMBP degenera en un IBP. En ambos casos especiales, la autocorrelación de los tiempos entre llegadas de celdas es igual a cero, que puede validarse fácilmente a partir de la función de autocorrelación con decalaje igual a 1.
4.4.3.3.1.4. Superposición de MMBPs
La superposición de MMBPs es un proceso conmutado de lotes de Bernouilli (Switched Batch Bernouilli Process, SBBP). El tiempo en un SBBP está dividido en ranuras de igual longitud. Las llegadas durante una ranura se producen como un proceso de lotes con una distribución de lotes de la misma longitud que varían según una cadena de Markov de k estados. Por simplicidad de presentación, el proceso superpuesto se discute solamente para la superposición de N MMBPs, cada uno de dos estados y parámetros Pi y Λi. Sea ij el estado del j-ésimo proceso MMBP componente. Entonces el proceso superpuesto tiene 2N estados en que cada estado (i1, i2, …., iN) representa el estado de los N procesos MMBP. En particular, al final de una ranura, cada proceso componente en el estado 1 se mueve al estado 2 c.p. (1 – pi) o permanece en el estado 1 c.p. pi. Las probabilidades respectivas para los procesos componentes que están en el estado 2 son iguales a (1 – qi) y qi, respectivamente. Definamos, además, ( )*
jj iip → como la probabilidad que el j-ésimo proceso componente
esté en el estado *ji , si estaba en el estado i durante la ranura previa, y ( )'iip → como la
probabilidad que el SBBP esté en el estado i’, si estaba en el estado i durante la ranura previa. Entonces,
( ) ( )∏=
→=→N
jjj iipiip
1
*'
Las probabilidades ( )'iip → definen los elementos de la matriz de probabilidades de transición del proceso superpuesto. Para caracterizar completamente el SBBP, sea Bi la variable aleatoria que representa la distribución del tamaño del lote cuando el proceso superpuesto está en el estado i = (i1, i2, …., iN). Sea γ(ij) la probabilidad que se produzca la llegada de una celda en el proceso componente j; γ(ij) = αj si el proceso está en el estado 1 o

372
γ(ij) = βj si está en el estado 2. En los dos extremos, ninguno de los procesos componentes puede generar una celda, esto es, Bi = 0, que se produce c.p.
( )[ ]∏=
γ−N
jji
1
1
o cada proceso componente puede generar una celda, esto es, Bi = N, c.p.
( )∏=
γN
jji
1
Cuando se generan m celdas, m de las N fuentes generan celdas, mientras que no se producen
llegadas de las otras N – m fuentes. Hay ( )!!!
mNmN
− diferentes combinaciones de las m de las
N fuentes generando celdas para que esto suceda. Sea Sl el conjunto de las m-tuplas de índices y S = (1, …, N). Además, sea q ∈ N los índices del proceso componente l que genera celdas, mientras que los que no generan celdas viene dado en N – q. La distribución de probabilidad viene dado ahora por
[ ] ( ) ( )[ ]( )
NliilBl jjsr qSi
jqi
ji ,....,0 ,1Pr =γ−γ== ∑ ∏∏∈ −∈∈
Entonces el proceso superpuesto es un SBBP de 2N estados con una matriz de probabilidad de transición P = [ ( )'iip → ] y una distribución del tamaño del lote Pr[Bi = l] para cada estado i y l = 0, …, N.
4.4.3.3.2. Asignación de ancho de banda
4.4.3.3.3. Algoritmos de admisión de llamadas
4.4.3.4. Conformación del tráfico
4.4.3.5. Detección de infracciones de tráfico
4.4.3.6. Descarte selectivo
4.4.3.7. Mecanismos reactivos de control de la congestión
4.4.4. CONMUTACIÓN DE CELDAS ATM


















